Sprachtechnologie in Suchmaschinen
|
|
|
- Hans Langenberg
- vor 7 Jahren
- Abrufe
Transkript
1 Sprachtechnologie in Suchmaschinen Hauptseminar Suchmaschinen Computerlinguistik Sommersemester 2010 Stefan Langer
2 Suchmaschinen Architektur und Anforderungen
3 3
4 4

5 5
6 6
7 7

8 8
9 9
10 10
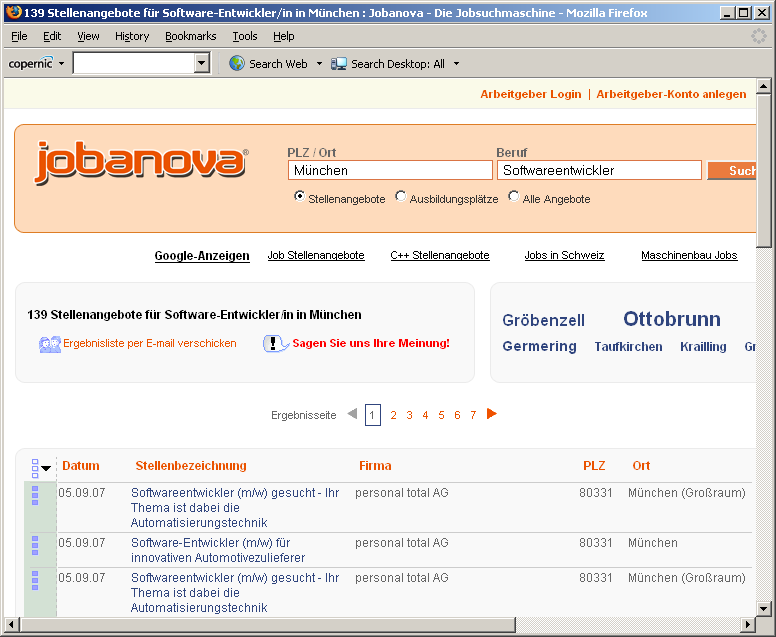
11 Suchmaschinen - Beispiel Nicht zuletzt: Enterprise search d.h. Suche im Intranet von Firmen und anderen Organisationen 11
12 Anforderungen an Suchmaschinen: Recall und Präzision Suchmaschinen Suchmaschinen reichen nicht? Fragen Sie die Menschen des Meta-re-SearchTeams in Wien. Förderung der Suchmaschinen- Technologie und des freien Wissenszugangs Die blinde Kuh Die erste deutschsprachige Suchmaschine für Kinder - gefördert vom Bundesministerium für Familie, Senioren, Frauen und Jugend. Heilige Kuh Wikipedia 1. in der Ethnologie eine aus religiösen sowie aus ökonomischen Gründen als unantastbar erklärte Kuh. In vielen weidewirtschaftlich oder nomadisch geprägten... 12
13 Anforderungen an Suchmaschinen: Ergebnissortierung nach Relevanz Suchmaschinen 1 2 Alle Informationen über Suchmaschinen Mit zahlreichen Illustrationen und Verweisen Das Thema Suchmaschinen interessiert und hier nur am Rande 13
14 Anforderungen an Suchmaschinen: Ergebnisverfeinerung Suchmaschinen Treffer 1 von Enzyklopädische Einträge Alle Informationen über Suchmaschinen Mit zahlreichen Illustrationen und Verweisen Wissenschaftliche Artikel Zeitungsmeldungen 14
15 Übung 1 Wozu verwenden Sie Suchmaschinen? Welche Zusatzfunktionen neben der eigentlichen Suche verwenden Sie? Welche Eigenschaften/Zusatzfunktionen würden Sie sich wünschen? Wo gibt es Ihrer Meinung nach Verbesserungsmöglichkeiten? 15
16 Ergebnisse Übung 1 Wozu verwenden Sie Suchmaschinen? Einkaufen Hotelbuchung, Reiseplanung Preisvergleich Eventsuche Personensuche Routenplanung Medizinische Ratschläge Beantwortung von Fragen (Wolfram Alpha) Bildersuche Rechtschreibprüfung 16
17 Ergebnisse Übung 1 (Teil II) Welche Zusatzfunktionen neben der eigentlichen Suche verwenden Sie? Präfixsuche ( *) Übersetzung Rechtschreibkorrektur Welche Eigenschaften/Zusatzfunktionen würden Sie sich wünschen und wo gibt es Ihrer Meinung nach Verbesserungsmöglichkeiten Mehr Navigatoren Sprache, Disambiguierung Bildsuche (nach Bildinhalten) Reguläre Ausdrücke 17
18 Grobe schematische Architektur einer Suchmaschine Dokument Dokument Dokumente INDEX Dokumentenverarbeitung Anfrageverarbeitung Anfragen 18
19 Anfrageverarbeitung Erkennung von Anfrageeigenschaften (z.b. Sprache) Parsen der Anfrage Linguistische Normalisierung Tokenisierung Buchstaben(sequenzen)normalisierung Rechtschreibkorrektur Morphologische Analyse Stopwortentfernung Hinzufügen von Information (z.b. Synonyme) 19
20 Dokumentenverarbeitung Erkennung von Dokumenteneigenschaften (z.b. Sprachenidentifizierung, Dokumentformat) Konversion in intern verwendetes Dokumentenformat (z.b. XML mit Unicode) Linguistische Normalisierung Tokenisierung Buchstaben(sequenzen)normalisierung Morphologische Analyse Informationsextraktion (z.b. Personennamen) Hinzufügen von Information (z.b. Synonyme) 20
21 Ziel computerlinguistischer Module in Suchmaschinen Verbesserung der Ergebnisqualität Vorauswahl von Ergebnissen Navigation in den Ergebnissen 21
22 Übung 2: Linguistik in Suchmaschinen Was stellen Sie sich unter linguistischen Modulen in Suchmaschinen vor? Welche Module kennen Sie, welche machen Sinn? Wie tragen linguistische Funktionalitäten zur Ergebnisverbesserung bei? Verbesserung der Ergebnisqualität Vorauswahl von Ergebnissen Navigation in den Ergebnissen 22
23 23

24 24
25 Linguistische Module in Suchmaschinen Eine Übersicht Sprachenidentifizierung Tokenisierung Morphologische Analyse Rechtschreibkorrektur Synonyme Informationsextraktion
26 Sprachenidentifizierung Automatische Erkennung der Sprache eines elektronischen Dokuments
27 Sprachenidentifizierung لسانيات من ويكيبيديا الموسوعة الحرة هي العلم الذي للسانيات أو اللغويات يهتم بدراسة اللغات اإلنسانية و دراسة خصائصها و تراكيبها و درجات التشابه و التباين فيما بينها. أما اللغوي هو الشخص الذي.يقوم بهذه الدراسة ]تحرير[ اقرأ أيضا Lingüística La Lingüística és la ciència que estudia totes les manifestacions de la parla humana, és a dir, l'estudi de la llengua en el seu vessant escrit i oral. En un sentit ampli la lingüística és l'estudi de les llengües humanes, analitzant el que tenen en comú i el que les diferencia. Un lingüista és, per tant, una persona que estudia les llengües. Yezhoniezh Ez-ledan e c'heller lâret ez eo ar yezhoniezh studi yezhoù mab-den. Deskrivañ en un doare objektivel ha dielfennañ mont-en-dro ar yezhoù dres ma vezont implijet gant an dud hep en em soursial da varnañ 27
28 Spracherkennung: Wörter oder N-Gramme? sch der ich ein che die... der und die in von den zu für... 28
29 Wörterbuchbasierte Erkennung Daten Wörterbuch mit 100 bis mehreren 1000 Wörter pro Sprache (abhängig vom zu klassifizierenden Dokumenttyp und dem morphologischen System einer Sprache) in einer Zeichensatzkodierung Konversion des Wörterbuchs in alle Zeichensatzkodierungen, die für eine Sprache relevant sind Algorithmus Vergleiche Wörter im Dokument mit Wörtern im Wörterbuch Erkennungswert eines Wortes abhängig von: Ergebnis Worthäufigkeit Eindeutigkeit Länge Erkennung der Dokumentsprache und der Zeichensatzkodierung 29
30 N-Gramm-basierter Ansatz Daten Für jedes Sprach-/Kodierungspaar N-Gramm-Liste mit Häufigkeit Algorithmus Vergleiche N-Gramm-Liste mit N-Grammen aus Dokument Berechne Ähnlichkeit zwischen Trainingsdaten und Dokument (Wahrscheinlichkeit der Zugehörigkeit zur Sprache) Ergebnis Erkennung der Dokumentsprache und der Zeichensatzkodierung 30
31 Sprachenerkennung: Vergleich der Ansätze Wortbasiert Trainingskorpus muss nicht ganz sauber sein, da manuelle Überprüfung möglich N-Gramm-Ansatz Sauberes Trainingskorpus Aufwändiges Training, wenn manuell überprüft Training einfach Nachträgliche Überprüfung und Korrektur unproblematisch Nachträgliche Überprüfung / Revision kaum möglich, außer über Trainingskorpus relative große Datenbasis zur Erkennung kleine Datenbasis Neue Kodierungen einfach zu ergänzen Konversion des Trainingskorpus nötig zur Ergänzung von neuen Kodierungen Nicht für Sprachen ohne durch Leerzeichen markierte Wortgrenzen (Japanisch, Chinesisch... Alle Sprachen 31
32 Recall & Präzision von Modulen zur Sprachenidentifikation Sprache F-Maß en (English) 93,72 es (Spanish) 96,73 de (German) 96,39 fr (French) 95,65 it (Italian) 99,38 ja (Japanese) 98,91 ko (Korean) 100,00 nl (Dutch) 98,01 ru (Russian) 92,16 zh (Chinese) 99,42 32
33 Tokenisierung & Normalisierung
34 Tokenisierung Aufteilen eines Textes in indizierbare Token Recht trivial für westliche Sprachen; schwierig für Chinesisch, Japanisch, Thai
35 Normalisierung Groß- Kleinschreibung Akzente é e Umlaute ä a / ae (asiatische) Schriftzeichen in voller Breite/halber Breite ロ ロ Entsprechend auch lateinische Schriftzeichen im asiatischen Kontext Andere Zeichen Scharfes ß u.ä. Ohm-Zeichen, Angström-Zeichen 35
36 Morphologische Analyse Grundformenreduzierung Kompositasegmentierung
37 Grundformenreduzierung & Verwandtes shop shops kauppa NOM SG kauppa-ko NOM SG KO kauppa-kin NOM SG KIN kauppa-kaan NOM SG KAAN kauppa-han NOM SG HAN kauppa-pa NOM SG PA kauppa-ko-han NOM SG KO HAN kauppa-pa-han NOM SG PA HAN kauppa-pa-s NOM SG PA S kauppa-ko-s NOM SG KO S kauppa-kin-ko NOM SG KIN KO kauppa-kaan-ko NOM SG KAAN KO kauppa-kin-ko-han NOM SG KIN KO HAN kauppa-ni NOM SG SG1 kauppa-ni-ko NOM SG SG1 KO kauppa-ni-kin NOM SG SG1 KIN kauppa-ni-kaan NOM SG SG1 KAAN kauppa-ni-han NOM SG SG1 HAN kauppa-ni-pa NOM SG SG1 PA kauppa-ni-ko-han NOM SG SG1 KO HAN kauppa-ni-pa-han NOM SG SG1 PA HAN kauppa-ni-pa-s NOM SG SG1 PA S kauppa-ni-ko-s NOM SG SG1 KO S kauppa-ni-kin-ko NOM SG SG1 KIN KO kauppa-ni-kaan-ko NOM SG SG1 KAAN KO kauppa-ni-kin-ko-han NOM SG SG1 KIN KO HAN ETC ETC 37
38 Yandex 38
39 Grundformenreduzierung Stemming Wörterbuchbasiert Wörterbuch + Regeln Dokumenten Suchmaschinen Rahmen Dokumenten:Dokument Suchmaschinen: Suchmaschine Rahmen:Rahmen Dokumenten:Dokument+en Suchmaschinen: Suchmaschine+n Rahmen:Rahmen+ Computers Merkels Computers:Computer Merkels:? Computers:Computer+s Merkels:Merkel+s 39
40 Lemmatisierung durch Expansion von Dokumententermen mit Lemmatisierung Document haus Lemmatizer haus Index Lemmas field: haus hauses häuser häusern Query häuser haus, hauses, häuser, häusern Normal field: haus ohne Alle Wortformen der Wörter im Dokument werden in den Index geschrieben. Die Sprache der Anfrage muss nicht bekannt sein 40
41 Lemmatisierung durch Reduktion Document maisons Lemmatizer (French) maisons maison Index Lemmas field: maison - Normal field: maisons Mit Lemmatisierung Lemmatizer maison maison Query maison ohne Wörter in Anfrage und Dokument werden auf die Grundform(en) reduziert. Dazu muss die Sprache der Anfrage bekannt sein 41
42 Lemmatisierung durch Anfrageexpansion Index Mit Lemmatisierung Document maisons Lemmatizer (French) NO ACTION maisons (lemma field not set) Lemmatizer maison maisons, maison Query maison ohne Lemmatisierung 42
43 Nominalkompositanalyse Blumen versand Internet such maschine Fuchs schwanz Bahn hof Tisch fuß ball 43
44 Synonyme
45 Übung 3 Was sind Synonyme? Was für Typen von bedeutungsähnlichen sprachlichen Einheiten, die in Suchmaschinen relevant sein könnten, gibt es außerdem? Welche Optionen gibt es, um Synonyme in die Suche einzubeziehen?
46 Synonyme und Verwandtes: Ergebnisse der Übung I Synonyme sind sprachliche Ausdrücke, die ohne Bedeutungsveränderung austauschbar sind. Z.B. Zündholz/Streichholz Synonyme in Suchmaschinen: sollten gleichbedeutende Ausdrücke zu gleichen Suchergebnissen führen 46
47 Synonyme und Verwandtes: Ergebnisse der Übung II Andere Bedeutungsähnlichkeiten: - Alle Sinnrelationen: Hyponymie, Hyperonymie, Meronymie/Holonymie - Abkürzungen und Akronyme (z.b. UNO United Nations Organisation) - Paraphrasen - Übersetzungen - Umschreibungen - Komposita Kompositatteile - Technische Umsetzung von Synonymexpansion: - Expansion der Anfrage - Expansion der Terme im Dokument ( Synonyme im Index) - Andere Einsatzmöglichkeiten: Zur Disambiguierung von Anfragen 47
48 Rechtschreibkorrektur
49 Rechtschreibkorrektur Vergleiche Anfrageterme mit bekannten Termen: Mauresegler Mauersegler Merkel Mergel Voraussetzung: Abstandsmaß zwischen Termen Algorithmus zum schnellen Abgleich zwischen Lexikon und Anfrageterm Zusätzlich: Erstellung des Lexikons auf Basis der indizierten Terme Phrasen-Rechtschreibkorrektur Britnay Speers Britney Spears
50 Rechtschreibkorrektur: Verwandtes Phonetische Korrektur Phonetische Suche 50
51 Stopwörter
52 Stoppwörter und Stoppphrasen Wo finde ich Informationen über Eric Rohmer Eric Rohmer und Godard 52
53 Informationsextraktion Extraktion von Eigennamen und weitergehende Ansätze
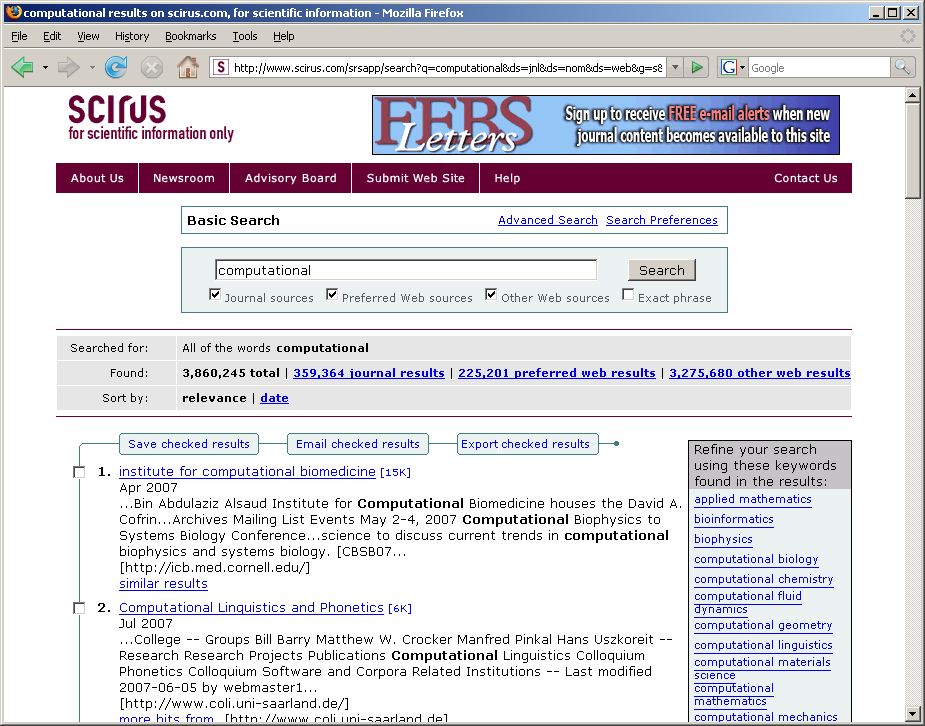
54 Informationsextraktion 54
55 Henrik Johan Ibsen (* 20. März 1828 in Skien/Norwegen; 23. Mai 1906 in Kristiania, damaliger Name von Oslo) war ein norwegischer Schriftsteller, der für den Naturalismus in Deutschland und Norwegen bedeutend war... 55
56 SUUCH.DE Ibsen Geburtstag Suuchen 1024 Treffer Zusammenfassung Henrik Ibsen wurde am 20. März 1828 in Skien/Norwegen geboren. Quellen: wikipedia.de ; lexikon.meyers.de; Treffer 1: Wikipedia... Auch ausgereifte Suchmaschinen wie Google setzen Computerlinguistik ein (ein Sprachtechnologieprodukt der Firma Canoo, Basel)
57 Maschinelle Übersetzung
58 Maschinelle Übersetzung in Suchmaschinen Mögliche Strategien Übersetzung der Originaldokumente und Indizierung der übersetzten Dokumente Langsame Dokumentenverarbeitung Übersetzung des Index Ambiguität, wenn Kontext nicht berücksichtigt Übersetzung der angezeigten Dokumenteninhalte, evt. kombiniert mit der Übersetzung des gesamten Dokuments wenn ausgewählt verlangsamte Ergebnisverarbeitung Übersetzung der Anfragen Hier zeigt sich besonders stark das Problem der Ambiguität 58
59 Klassifikation und Clustering 59
60 Klassifizierung Zuweisung zu vordefinierten Kategorien Dokumentenklassifizierung Erfordert vordefinierte, saubere Kategorien und Trainingsdokumente oder Auswahl exemplarischer Dokumente durch den Benutzer Mögliche Dimensionen: Inhaltliche Themenbereiche Disziplinen Dokumententypen (z.b. wiss. Artikel, Zeitungsartikel, Adresssammlung) Anfrageklassifizierung 60
61 Clustering Bildung von ad-hoc-klassen durch Zusammenfassung ähnlicher Dokumente Meist Ergebnisclustering auf Basis des Dokumentenvektors 61
62 Nächstes Thema: An Introduction to Information Retrieval, Kapitel 1 Ganz lesen bis nächste Woche, bitte. 62
63 Übung (Gruppenarbeit, min.) Sie haben ein Korpus mit 5 Millionen Nur-Text-Dokumenten und einer Gesamtgröße von ca 10 GB (auf einer lokal zugänglichen Maschine). Sie haben mit einem Team von 3 Leuten 3 Tage Zeit eine Anwendung zu entwickeln die es erlaubt: 1. möglichst schnell alle Dokumente zu finden, in denen ein bestimmter Term auftaucht 2. Alle Dokumente zu finden, in denen ein Term nicht auftaucht 3. Alle möglichen Kombinationen aus mehreren Termen die im Dokument enthalten sind bzw. nicht enthalten sind Machen Sie einen Plan. 63
64 IR - Grundlagen Texte durchsuchen: mit grep dies stößt bei größeren Textmengen schnell an die Grenzen des Machbaren Mithilfe eines Indizes: Invertierte Dateien (inverted index) Grundidee der Implementierung: Hash oder Trie (aber Indizes von großen Suchmaschinen sind noch wesentlich optimierter) 64
65 Invertierter Index Zerlegung des Dokuments in Terme Zuordnung von Termen zu Dokument-Ids Dokument 1 Schöne Frauen gehören nach Cannes wie die Aschewolke an den isländischen Himmel Dokument 2 Index schöne.d1 frauen.d1. himmel.d1/d2 wasser.d2 Fliegen.d2 Getrocknetes Wasser, das vom Himmel fällt und Tiere ohne Flügel, die trotzdem fliegen können? 65
66 Implementierung eines invertierten Indexes Zu Übungszwecken: - Verwenden Sie eine in Ihrer Programmiersprache verfügbare Datenstruktur, die schnelles Nachschlagen von Termen (und Zuordnung zu Werten erlaubt) - Z.B. Hash, Trie, (Dictionary) 66
67 Retrieval mit boolschen Ausdrücken Verknüpfung von Suchtermen mit UND/ODER/NICHT Dokumenten-Ids für jede Teilquery Bilde Schnittmengen (UND) /Differenzmengen (NICHT) / bzw. Vereinigungsmengen (ODER) Effiziente Algorithmen verfügbar S. Abschnitt 1.3 im IR-Buch 67
68 Wie misst man die Qualität einer Suchmaschine: Trefferquote (Recall) und Genauigkeit (Precision) F A A F D 68
69 F-measure Fmeasure = 2xprecisionxrecall / precision+recall (Harmonisches Mittel zwischen Precision und Recall) 69
70 Übung (10 min) Welche IR-Szenarien kann mit einfachen boolschen Ausdrücken (UND/ODER/NICHT) auf einfachen Termen nicht ohne weiteres lösen? Wie sehen Lösungsmöglichkeiten aus? 70
71 Ergebnisse der Übung Welche IR-Szenarien lassen sich mit einfacher boolscher Suche nicht lösen: Ranking Termnähe (Phrasen, Terme die nahe beieinander stehen) Berücksichtung der Dokumentengröße und Termhäufigkeit Wichtigkeit eines Dokuments Dokumentenstrukur/Position des Suchterms im Dokument Vektor-Ähnlichkeitsmaße 71
72 Suche von Termfolgen und Nähe im durchsuchten Dokument AND(Rot,Grün) SEQUENZ(Rot,Grün) NAH(Rot,Grün) 72
73 Ranking 73
Sprachtechnologie in Suchmaschinen
 Sprachtechnologie in Suchmaschinen Masterseminar Computerlinguistik Sommersemester 2014 Stefan Langer stefan.langer@cis.uni-muenchen.de Suchmaschinen Beispiele Übung 1 Wozu verwenden Sie Suchmaschinen?
Sprachtechnologie in Suchmaschinen Masterseminar Computerlinguistik Sommersemester 2014 Stefan Langer stefan.langer@cis.uni-muenchen.de Suchmaschinen Beispiele Übung 1 Wozu verwenden Sie Suchmaschinen?
SPRACHTECHNOLOGIE IN SUCHMASCHINEN IR-GRUNDLAGEN
 SPRACHTECHNOLOGIE IN SUCHMASCHINEN IR-GRUNDLAGEN HAUPTSEMINAR SUCHMASCHINEN COMPUTERLINGUISTIK SOMMERSEMESTER 2016 STEFAN LANGER STEFAN.LANGER@CIS.UNI -MUENCHEN.DE Übung (Gruppenarbeit, 10-15 min.) Sie
SPRACHTECHNOLOGIE IN SUCHMASCHINEN IR-GRUNDLAGEN HAUPTSEMINAR SUCHMASCHINEN COMPUTERLINGUISTIK SOMMERSEMESTER 2016 STEFAN LANGER STEFAN.LANGER@CIS.UNI -MUENCHEN.DE Übung (Gruppenarbeit, 10-15 min.) Sie
Sprachtechnologie in Suchmaschinen
 Sprachtechnologie in Suchmaschinen Masterseminar Computerlinguistik Sommersemester 2016 Stefan Langer stefan.langer@cis.uni-muenchen.de Suchmaschinen Beispiele Info zum Seminar Kontakt Stefan Langer stefan.langer@cis.uni-muenchen.de
Sprachtechnologie in Suchmaschinen Masterseminar Computerlinguistik Sommersemester 2016 Stefan Langer stefan.langer@cis.uni-muenchen.de Suchmaschinen Beispiele Info zum Seminar Kontakt Stefan Langer stefan.langer@cis.uni-muenchen.de
Lemmatisierung und Stemming in Suchmaschinen
 Lemmatisierung und Stemming in Suchmaschinen Hauptseminar Suchmaschinen Computerlinguistik Sommersemester 2016 Stefan Langer stefan.langer@cis.uni-muenchen.de Trefferquote (Recall) und Genauigkeit (Precision)
Lemmatisierung und Stemming in Suchmaschinen Hauptseminar Suchmaschinen Computerlinguistik Sommersemester 2016 Stefan Langer stefan.langer@cis.uni-muenchen.de Trefferquote (Recall) und Genauigkeit (Precision)
Lemmatisierung und Stemming in Suchmaschinen
 Lemmatisierung und Stemming in Suchmaschinen Hauptseminar Suchmaschinen Computerlinguistik Sommersemester 2014 Stefan Langer stefan.langer@cis.uni-muenchen.de Trefferquote (Recall) und Genauigkeit (Precision)
Lemmatisierung und Stemming in Suchmaschinen Hauptseminar Suchmaschinen Computerlinguistik Sommersemester 2014 Stefan Langer stefan.langer@cis.uni-muenchen.de Trefferquote (Recall) und Genauigkeit (Precision)
INFORMATIONSEXTRAKTION IN SUCHMASCHINEN
 INFORMATIONSEXTRAKTION IN SUCHMASCHINEN S E M I N A R S U C H M A S C H I N E N S O M M E R S E M ESTER 2014 S T E FA N L A N G E R, C I S, U N I V E R S I TÄT M Ü N C H E N Schematische Architektur einer
INFORMATIONSEXTRAKTION IN SUCHMASCHINEN S E M I N A R S U C H M A S C H I N E N S O M M E R S E M ESTER 2014 S T E FA N L A N G E R, C I S, U N I V E R S I TÄT M Ü N C H E N Schematische Architektur einer
SPRACHENIDENTIFIZIERUNG SEMINAR: KLASSIFIKATION DOZENT: STEFAN LANGER CIS, UNIVERSITÄT MÜNCHEN WINTERSEMESTER 2016
 SPRACHENIDENTIFIZIERUNG SEMINAR: KLASSIFIKATION DOZENT: STEFAN LANGER CIS, UNIVERSITÄT MÜNCHEN WINTERSEMESTER 2016 Wozu Sprachen- und Kodierungserkennung Interne Verarbeitung Kodierungserkennung um überhaupt
SPRACHENIDENTIFIZIERUNG SEMINAR: KLASSIFIKATION DOZENT: STEFAN LANGER CIS, UNIVERSITÄT MÜNCHEN WINTERSEMESTER 2016 Wozu Sprachen- und Kodierungserkennung Interne Verarbeitung Kodierungserkennung um überhaupt
Tokenisierung und Lemmatisierung in Suchmaschinen
 Tokenisierung und Lemmatisierung in Suchmaschinen Hauptseminar Suchmaschinen Computerlinguistik Sommersemester 2010 Stefan Langer stefan.langer@cis.uni-muenchen.de Übung: Tokenisierung (5 min) Was ist
Tokenisierung und Lemmatisierung in Suchmaschinen Hauptseminar Suchmaschinen Computerlinguistik Sommersemester 2010 Stefan Langer stefan.langer@cis.uni-muenchen.de Übung: Tokenisierung (5 min) Was ist
SPRACHENIDENTIFIZIERUNG
 SPRACHENIDENTIFIZIERUNG S E M I N A R : K L A S S I F I K AT I O N D OZ E N T: S T E FA N L A N G E R C I S, U N I V E R S I TÄT M Ü N C H E N W I N T E R S E M ES T E R 2013 Sprachenindentifizierung Automatische
SPRACHENIDENTIFIZIERUNG S E M I N A R : K L A S S I F I K AT I O N D OZ E N T: S T E FA N L A N G E R C I S, U N I V E R S I TÄT M Ü N C H E N W I N T E R S E M ES T E R 2013 Sprachenindentifizierung Automatische
BLATT 1. Dieser Test soll mir helfen, Ihre Vorkenntnisse richtig einzuschätzen und die Seminarinhalte entsprechend anzupassen.
 Eingangtest (anonym) BLATT 1 Dieser Test soll mir helfen, Ihre Vorkenntnisse richtig einzuschätzen und die Seminarinhalte entsprechend anzupassen. 1) Was ist ein Zeichensatz (character set) und was eine
Eingangtest (anonym) BLATT 1 Dieser Test soll mir helfen, Ihre Vorkenntnisse richtig einzuschätzen und die Seminarinhalte entsprechend anzupassen. 1) Was ist ein Zeichensatz (character set) und was eine
SPRACHENIDENTIFIZIERUNG
 SPRACHENIDENTIFIZIERUNG S E M I N A R : S U C H M A S C H I N E N D OZ E N T: S T E FA N L A N G E R C I S, U N I V E R S I TÄT M Ü N C H E N S O M M E R S E M ES T E R 2015 Wozu Sprachen- und Kodierungserkennung
SPRACHENIDENTIFIZIERUNG S E M I N A R : S U C H M A S C H I N E N D OZ E N T: S T E FA N L A N G E R C I S, U N I V E R S I TÄT M Ü N C H E N S O M M E R S E M ES T E R 2015 Wozu Sprachen- und Kodierungserkennung
Information Retrieval. Peter Kolb
 Information Retrieval Peter Kolb Semesterplan Einführung Boolesches Retrievalmodell Volltextsuche, invertierter Index Boolesche Logik und Mengen Vektorraummodell Evaluation im IR Term- und Dokumentrepräsentation
Information Retrieval Peter Kolb Semesterplan Einführung Boolesches Retrievalmodell Volltextsuche, invertierter Index Boolesche Logik und Mengen Vektorraummodell Evaluation im IR Term- und Dokumentrepräsentation
Was ist ein Korpus. Zitat aus: Carstensen et al. Computerlinguistik und Sprachtechnologie: Eine Einführung. Kap. 4.2, Textkorpora
 Was ist ein Korpus Korpora sind Sammlungen linguistisch aufbereitete(r) Texte in geschriebener oder gesprochener Sprache, die elektronisch gespeichert vorliegen. Zitat aus: Carstensen et al. Computerlinguistik
Was ist ein Korpus Korpora sind Sammlungen linguistisch aufbereitete(r) Texte in geschriebener oder gesprochener Sprache, die elektronisch gespeichert vorliegen. Zitat aus: Carstensen et al. Computerlinguistik
Seminar Text- und Datamining Textmining-Grundlagen Erste Schritte mit NLTK
 Seminar Text- und Datamining Textmining-Grundlagen Erste Schritte mit NLTK Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 08.05.2014 Gliederung 1 Vorverarbeitung
Seminar Text- und Datamining Textmining-Grundlagen Erste Schritte mit NLTK Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 08.05.2014 Gliederung 1 Vorverarbeitung
Lucene eine Demo. Sebastian Marius Kirsch 9. Februar 2006
 Lucene eine Demo Sebastian Marius Kirsch skirsch@luusa.org 9. Februar 2006 Text Retrieval wie funktioniert das? Aufgabe: Finde zu Stichwörtern die passenden Dokumente Sortiere sie nach Relevanz zur Suchanfrage.
Lucene eine Demo Sebastian Marius Kirsch skirsch@luusa.org 9. Februar 2006 Text Retrieval wie funktioniert das? Aufgabe: Finde zu Stichwörtern die passenden Dokumente Sortiere sie nach Relevanz zur Suchanfrage.
Was ist Statistik? Wozu dienen statistische Methoden?
 25. APRIL 2002: BLATT 1 Übersicht Was ist Statistik? Wozu dienen statistische Methoden? Was ist maschinelle Sprachverarbeitung? Welche Rolle spielen statistische Methoden in verschiedenen Teilbereichen
25. APRIL 2002: BLATT 1 Übersicht Was ist Statistik? Wozu dienen statistische Methoden? Was ist maschinelle Sprachverarbeitung? Welche Rolle spielen statistische Methoden in verschiedenen Teilbereichen
Information Retrieval. Domenico Strigari Dominik Wißkirchen
 Information Retrieval Domenico Strigari Dominik Wißkirchen 2009-12-22 Definition Information retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies
Information Retrieval Domenico Strigari Dominik Wißkirchen 2009-12-22 Definition Information retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies
Bücher und Artikel zum Thema
 Materialsammlung zur Implementierung von Information Retrieval Systemen Karin Haenelt 11.12.2005/11.12.2004/06.12.2003/10.11.2002 1 Bücher und Artikel zum Thema Frakes/Baeza-Yates, 1992 Baeza-Yates/Ribeiro-Neto,
Materialsammlung zur Implementierung von Information Retrieval Systemen Karin Haenelt 11.12.2005/11.12.2004/06.12.2003/10.11.2002 1 Bücher und Artikel zum Thema Frakes/Baeza-Yates, 1992 Baeza-Yates/Ribeiro-Neto,
Materialsammlung zur Implementierung von Information Retrieval Systemen
 Materialsammlung zur Implementierung von Information Retrieval Systemen Karin Haenelt 11.12.2005/11.12.2004/06.12.2003/10.11.2002 1 Bücher und Artikel zum Thema Frakes/Baeza-Yates, 1992 Baeza-Yates/Ribeiro-Neto,
Materialsammlung zur Implementierung von Information Retrieval Systemen Karin Haenelt 11.12.2005/11.12.2004/06.12.2003/10.11.2002 1 Bücher und Artikel zum Thema Frakes/Baeza-Yates, 1992 Baeza-Yates/Ribeiro-Neto,
Suchmaschinen. Anwendung RN Semester 7. Christian Koczur
 Suchmaschinen Anwendung RN Semester 7 Christian Koczur Inhaltsverzeichnis 1. Historischer Hintergrund 2. Information Retrieval 3. Architektur einer Suchmaschine 4. Ranking von Webseiten 5. Quellenangabe
Suchmaschinen Anwendung RN Semester 7 Christian Koczur Inhaltsverzeichnis 1. Historischer Hintergrund 2. Information Retrieval 3. Architektur einer Suchmaschine 4. Ranking von Webseiten 5. Quellenangabe
SEMINAR KLASSIFIKATION & CLUSTERING STATISTISCHE GRUNDLAGEN. Stefan Langer WINTERSEMESTER 2014/15.
 SEMINAR KLASSIFIKATION & CLUSTERING WINTERSEMESTER 2014/15 STATISTISCHE GRUNDLAGEN Stefan Langer stefan.langer@cis.uni-muenchen.de Frequenz & Häufigkeit: Übersicht Absolute Häufigkeit Relative Häufigkeit
SEMINAR KLASSIFIKATION & CLUSTERING WINTERSEMESTER 2014/15 STATISTISCHE GRUNDLAGEN Stefan Langer stefan.langer@cis.uni-muenchen.de Frequenz & Häufigkeit: Übersicht Absolute Häufigkeit Relative Häufigkeit
Erkennung fremdsprachiger Ausdrücke im Text
 Erkennung fremdsprachiger Ausdrücke im Text Jekaterina Siilivask Betreuer: Dr. Helmut Schmid Centrum für Informations- und Sprachbearbeiting Ludwig- Maximilians- Universität München 19.05.2014 Jekaterina
Erkennung fremdsprachiger Ausdrücke im Text Jekaterina Siilivask Betreuer: Dr. Helmut Schmid Centrum für Informations- und Sprachbearbeiting Ludwig- Maximilians- Universität München 19.05.2014 Jekaterina
Volltextsuche und Text Mining
 Volltextsuche und Text Mining Seminar: Einfuehrung in die Computerlinguistik Dozentin: Wiebke Petersen by Rafael Cieslik 2oo5-Jan-2o 1 Gliederung 1. Volltextsuche 1. Zweck 2. Prinzip 1. Index 2. Retrieval
Volltextsuche und Text Mining Seminar: Einfuehrung in die Computerlinguistik Dozentin: Wiebke Petersen by Rafael Cieslik 2oo5-Jan-2o 1 Gliederung 1. Volltextsuche 1. Zweck 2. Prinzip 1. Index 2. Retrieval
Übersicht. Volltextindex Boolesches Retrieval Termoperationen Indexieren mit Apache Lucene
 Übersicht Volltextindex Boolesches Retrieval Termoperationen Indexieren mit Apache Lucene 5.0.07 1 IR-System Peter Kolb 5.0.07 Volltextindex Dokumentenmenge durchsuchbar machen Suche nach Wörtern Volltextindex:
Übersicht Volltextindex Boolesches Retrieval Termoperationen Indexieren mit Apache Lucene 5.0.07 1 IR-System Peter Kolb 5.0.07 Volltextindex Dokumentenmenge durchsuchbar machen Suche nach Wörtern Volltextindex:
Computerlinguistische Grundlagen. Jürgen Hermes Wintersemester 17/18 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln
 Computerlinguistische Grundlagen Jürgen Hermes Wintersemester 17/18 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Was ist Computerlinguistik? Definition Anwendungen Fragestellung
Computerlinguistische Grundlagen Jürgen Hermes Wintersemester 17/18 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Was ist Computerlinguistik? Definition Anwendungen Fragestellung
Studienprojekt TaxoSearch Spezifikation
 Studienprojekt TaxoSearch Spezifikation Semantisch gestützte Suche im Internet Lehrstuhl für Computerlinguistik Ruprecht-Karls-Universität Heidelberg WS 2002-2003 vorgestellt von Thorsten Beinhorn, Vesna
Studienprojekt TaxoSearch Spezifikation Semantisch gestützte Suche im Internet Lehrstuhl für Computerlinguistik Ruprecht-Karls-Universität Heidelberg WS 2002-2003 vorgestellt von Thorsten Beinhorn, Vesna
! Die Idee Kombination von Informatik und einem anderen Fach
 Computerlinguistik Integriertes Anwendungsfach im B.Sc.Studiengang Department Informatik / Universität Hamburg! Wie funktioniert das integrierte Anwendungsfach Computerlinguistik (organisatorisch)?! Beziehungen
Computerlinguistik Integriertes Anwendungsfach im B.Sc.Studiengang Department Informatik / Universität Hamburg! Wie funktioniert das integrierte Anwendungsfach Computerlinguistik (organisatorisch)?! Beziehungen
Übersicht. Grundidee des Indexing Lucene Wichtige Methoden und Klassen Lucene Indizierungsbeispiele Lucene Suchbeispiele Lucene QueryParser Syntax
 Indizierung Lucene Übersicht Grundidee des Indexing Lucene Wichtige Methoden und Klassen Lucene Indizierungsbeispiele Lucene Suchbeispiele Lucene QueryParser Syntax Grundideen und Ziel des Indexing Effizientes
Indizierung Lucene Übersicht Grundidee des Indexing Lucene Wichtige Methoden und Klassen Lucene Indizierungsbeispiele Lucene Suchbeispiele Lucene QueryParser Syntax Grundideen und Ziel des Indexing Effizientes
Thema: Prototypische Implementierung des Vektormodells
 Ruprecht-Karls-Universität Heidelberg Seminar für Computerlinguistik Hauptseminar: Information Retrieval WS 06/07 Thema: Prototypische Implementierung des Vektormodells Sascha Orf Carina Silberer Cäcilia
Ruprecht-Karls-Universität Heidelberg Seminar für Computerlinguistik Hauptseminar: Information Retrieval WS 06/07 Thema: Prototypische Implementierung des Vektormodells Sascha Orf Carina Silberer Cäcilia
NLP im Information Retrieval
 NLP im Information Retrieval Tokenisierung Stoppwortlisten Stemming, Morphologische Analyse, Kompositazerlegung Flaches Parsing: Phrasen, Mehrwortlexeme N-Gramme Lesartendisambiguierung Thesauri, Semantische
NLP im Information Retrieval Tokenisierung Stoppwortlisten Stemming, Morphologische Analyse, Kompositazerlegung Flaches Parsing: Phrasen, Mehrwortlexeme N-Gramme Lesartendisambiguierung Thesauri, Semantische
Kapitel IR:II. II. Grundlagen des Information Retrieval. Retrieval-Evaluierung Indexterme
 Kapitel IR:II II. Grundlagen des Information Retrieval Retrieval-Evaluierung Indexterme IR:II-1 Basics STEIN 2005-2010 Batch-Mode-Retrieval einmaliges Absetzen einer Anfrage; nur eine Antwort wird geliefert
Kapitel IR:II II. Grundlagen des Information Retrieval Retrieval-Evaluierung Indexterme IR:II-1 Basics STEIN 2005-2010 Batch-Mode-Retrieval einmaliges Absetzen einer Anfrage; nur eine Antwort wird geliefert
Vortrag im Rahmen der Vorlesung Data Warehouse Dozentin: Prof. Dr. Frey-Luxemburger WS 2011/2012. Referent: Florian Kalisch (GR09)
") Vortrag im Rahmen der Vorlesung Data Warehouse Dozentin: Prof. Dr. Frey-Luxemburger WS 2011/2012 Referent: Florian Kalisch (GR09) Rückblick Aktueller Status Einführung in Text-Mining Der Text-Mining Prozess
Vortrag im Rahmen der Vorlesung Data Warehouse Dozentin: Prof. Dr. Frey-Luxemburger WS 2011/2012 Referent: Florian Kalisch (GR09) Rückblick Aktueller Status Einführung in Text-Mining Der Text-Mining Prozess
dacore Datenbanksysteme AG Neue Konzepte zur Optimierung der Auslastungsplanung und Big Data im Informationsmanagement
 dacore Datenbanksysteme AG Neue Konzepte zur Optimierung der Auslastungsplanung und Big Data im Informationsmanagement dacore Datenbanksysteme AG Neue Konzepte zur Optimierung der Auslastungsplanung Die
dacore Datenbanksysteme AG Neue Konzepte zur Optimierung der Auslastungsplanung und Big Data im Informationsmanagement dacore Datenbanksysteme AG Neue Konzepte zur Optimierung der Auslastungsplanung Die
IR Seminar SoSe 2012 Martin Leinberger
 IR Seminar SoSe 2012 Martin Leinberger Suchmaschinen stellen Ergebnisse häppchenweise dar Google: 10 Ergebnisse auf der ersten Seite Mehr Ergebnisse gibt es nur auf Nachfrage Nutzer geht selten auf zweite
IR Seminar SoSe 2012 Martin Leinberger Suchmaschinen stellen Ergebnisse häppchenweise dar Google: 10 Ergebnisse auf der ersten Seite Mehr Ergebnisse gibt es nur auf Nachfrage Nutzer geht selten auf zweite
Proseminar Linguistische Annotation
 Proseminar Linguistische Annotation Ines Rehbein und Josef Ruppenhofer SS 2010 Ines Rehbein und Josef Ruppenhofer (SS10) Linguistische Annotation April 2010 1 / 22 Seminarplan I. Linguistische Annotation
Proseminar Linguistische Annotation Ines Rehbein und Josef Ruppenhofer SS 2010 Ines Rehbein und Josef Ruppenhofer (SS10) Linguistische Annotation April 2010 1 / 22 Seminarplan I. Linguistische Annotation
Praktikum Information Retrieval Wochen 12: Suchmaschine
 Praktikum Information Retrieval Wochen 12: Suchmaschine Matthias Jordan 7. November 18. November 2011 Lösungen: Upload bis 18. November 2011 Aktuelle Informationen, Ansprechpartner, Material und Upload
Praktikum Information Retrieval Wochen 12: Suchmaschine Matthias Jordan 7. November 18. November 2011 Lösungen: Upload bis 18. November 2011 Aktuelle Informationen, Ansprechpartner, Material und Upload
Information-Retrieval: Evaluation
 Information-Retrieval: Evaluation Claes Neuefeind Fabian Steeg 17. Dezember 2009 Themen des Seminars Boolesches Retrieval-Modell (IIR 1) Datenstrukturen (IIR 2) Tolerantes Retrieval (IIR 3) Vektorraum-Modell
Information-Retrieval: Evaluation Claes Neuefeind Fabian Steeg 17. Dezember 2009 Themen des Seminars Boolesches Retrieval-Modell (IIR 1) Datenstrukturen (IIR 2) Tolerantes Retrieval (IIR 3) Vektorraum-Modell
Informationsextraktion. Christoph Wiewiorski Patrick Hommers
 Informationsextraktion Christoph Wiewiorski Patrick Hommers 1 Informationsextraktion(IE) - Einführung Ziel: Domänenspezifische Informationen aus freiem Text gezielt aufspüren und strukturieren Gleichzeitig
Informationsextraktion Christoph Wiewiorski Patrick Hommers 1 Informationsextraktion(IE) - Einführung Ziel: Domänenspezifische Informationen aus freiem Text gezielt aufspüren und strukturieren Gleichzeitig
Information-Retrieval: Unscharfe Suche
 Information-Retrieval: Unscharfe Suche Claes Neuefeind Fabian Steeg 19. November 2009 Themen des Seminars Boolesches Retrieval-Modell (IIR 1) Datenstrukturen (IIR 2) Tolerantes Retrieval (IIR 3) Vektorraum-Modell
Information-Retrieval: Unscharfe Suche Claes Neuefeind Fabian Steeg 19. November 2009 Themen des Seminars Boolesches Retrieval-Modell (IIR 1) Datenstrukturen (IIR 2) Tolerantes Retrieval (IIR 3) Vektorraum-Modell
Apache Solr. Apache Solr. ALD:HS WiSe 2011/2012. Einleitung. Features. Implementation. Verwaltung. Benutzung
 Universität zu Köln Sprachliche Informationsverarbeitung Hauptseminar: Angewandte linguistische Datenverarbeitung Dozent: Prof. Dr. Jürgen Rolshoven Referent: Patrick Pelinski 1 Gliederung Beschreibung,
Universität zu Köln Sprachliche Informationsverarbeitung Hauptseminar: Angewandte linguistische Datenverarbeitung Dozent: Prof. Dr. Jürgen Rolshoven Referent: Patrick Pelinski 1 Gliederung Beschreibung,
Automatische Rekonstruktion und Spezifizierung von Attributnamen in Webtabellen
 Automatische Rekonstruktion und Spezifizierung von Attributnamen in Webtabellen Mark Reinke Bachelorarbeit TU Dresden 17. Februar 2014 Webtabellen Warum sind Webtabellen von Bedeutung? Sie können relationale
Automatische Rekonstruktion und Spezifizierung von Attributnamen in Webtabellen Mark Reinke Bachelorarbeit TU Dresden 17. Februar 2014 Webtabellen Warum sind Webtabellen von Bedeutung? Sie können relationale
UNIVERSITÄT DES SAARLANDES PfflLOSOPHISCHE FAKULTÄT HI EMPIRISCHE HUMANWISSENSCHAFTEN
 UNIVERSITÄT DES SAARLANDES PfflLOSOPHISCHE FAKULTÄT HI EMPIRISCHE HUMANWISSENSCHAFTEN Automatische Klassifizierung von deutschsprachigen elektronischen Katalogen der Elektroindustrie nach dem Elektrotechnischen
UNIVERSITÄT DES SAARLANDES PfflLOSOPHISCHE FAKULTÄT HI EMPIRISCHE HUMANWISSENSCHAFTEN Automatische Klassifizierung von deutschsprachigen elektronischen Katalogen der Elektroindustrie nach dem Elektrotechnischen
Griesbaum, Heuwing, Ruppenhofer, Werner (Hrsg.) HiER Proceedings des 8. Hildesheimer Evaluierungsund Retrievalworkshop
 HiER Proceedings des 8. Hildesheimer Evaluierungsund Retrievalworkshop") Griesbaum, Heuwing, Ruppenhofer, Werner (Hrsg.) HiER 2013 Proceedings des 8. Hildesheimer Evaluierungsund Retrievalworkshop Hildesheim, 25. 26. April 2013 J. Griesbaum, B. Heuwing, J. Ruppenhofer, K. Werner
Griesbaum, Heuwing, Ruppenhofer, Werner (Hrsg.) HiER 2013 Proceedings des 8. Hildesheimer Evaluierungsund Retrievalworkshop Hildesheim, 25. 26. April 2013 J. Griesbaum, B. Heuwing, J. Ruppenhofer, K. Werner
4. Webbasierte Recherche
 4. Webbasierte Recherche In diesem Kapitel lernen Sie, was Suchmaschinen sind, und wie Sie sie verwenden können. Am Beispiel von Google werden Sie Suchanfragen formulieren lernen und die erweiterte Suche
4. Webbasierte Recherche In diesem Kapitel lernen Sie, was Suchmaschinen sind, und wie Sie sie verwenden können. Am Beispiel von Google werden Sie Suchanfragen formulieren lernen und die erweiterte Suche
Maschinelle Sprachverarbeitung: Part-of-Speech-Tagging
 HUMBOLDT-UNIVERSITÄT ZU BERLIN Institut für Informatik Lehrstuhl Wissensmanagement Maschinelle Sprachverarbeitung: Part-of-Speech-Tagging Tobias Scheffer Ulf Brefeld POS-Tagging Zuordnung der Wortart von
HUMBOLDT-UNIVERSITÄT ZU BERLIN Institut für Informatik Lehrstuhl Wissensmanagement Maschinelle Sprachverarbeitung: Part-of-Speech-Tagging Tobias Scheffer Ulf Brefeld POS-Tagging Zuordnung der Wortart von
Christoph Broschinski, <broschinski@uni bielefeld.de>
 Normalisierung von Lizenzinformationen in OAI Metadaten: Ein Beitrag zur Verbesserung der Open Access Statusanzeige in wissenschaftlichen Suchmaschinen Christoph Broschinski,
Normalisierung von Lizenzinformationen in OAI Metadaten: Ein Beitrag zur Verbesserung der Open Access Statusanzeige in wissenschaftlichen Suchmaschinen Christoph Broschinski,
Inverted Files for Text Search Engines
 Inverted Files for Text Search Engines Justin Zobel, Alistair Moffat PG 520 Intelligence Service Emel Günal 1 Inhalt Einführung Index - Inverted Files - Indexkonstruktion - Indexverwaltung Optimierung
Inverted Files for Text Search Engines Justin Zobel, Alistair Moffat PG 520 Intelligence Service Emel Günal 1 Inhalt Einführung Index - Inverted Files - Indexkonstruktion - Indexverwaltung Optimierung
xii Inhaltsverzeichnis Generalisierung Typisierte Merkmalsstrukturen Literaturhinweis
 Inhaltsverzeichnis 1 Computerlinguistik Was ist das? 1 1.1 Aspekte der Computerlinguistik.................. 1 1.1.1 Computerlinguistik: Die Wissenschaft........... 2 1.1.2 Computerlinguistik und ihre Nachbardisziplinen.....
Inhaltsverzeichnis 1 Computerlinguistik Was ist das? 1 1.1 Aspekte der Computerlinguistik.................. 1 1.1.1 Computerlinguistik: Die Wissenschaft........... 2 1.1.2 Computerlinguistik und ihre Nachbardisziplinen.....
Klassifikation von Textabschnitten
 Klassifikation von Textabschnitten Am Beispiel von Stellenanzeigen (JASC - Job Ads Section Classifier) Gliederung 1. Einführung: Zu welchem Zweck machen wir das? 2. Klassifikation ein kurzer Überblick
Klassifikation von Textabschnitten Am Beispiel von Stellenanzeigen (JASC - Job Ads Section Classifier) Gliederung 1. Einführung: Zu welchem Zweck machen wir das? 2. Klassifikation ein kurzer Überblick
Neue Erkenntnisse aus unstrukturierten Daten gewinnen
 Neue Erkenntnisse aus unstrukturierten Daten gewinnen Univ.-Prof. Dr. Josef Küng Institut für anwendungsorientierte Wissensverarbeitung (FAW) Johannes Kepler Universität Linz In Zusammenarbeit mit Mag.
Neue Erkenntnisse aus unstrukturierten Daten gewinnen Univ.-Prof. Dr. Josef Küng Institut für anwendungsorientierte Wissensverarbeitung (FAW) Johannes Kepler Universität Linz In Zusammenarbeit mit Mag.
Inhaltsverzeichnis. Bibliografische Informationen digitalisiert durch
 Inhaltsverzeichnis 1 Computerlinguistik - Was ist das? 1 1.1 Aspekte der Computerlinguistik 1 1.1.1 Computer linguistik: Die Wissenschaft 2 1.1.2 Computerlinguistik und ihre Nachbardisziplinen 3 1.1.3
Inhaltsverzeichnis 1 Computerlinguistik - Was ist das? 1 1.1 Aspekte der Computerlinguistik 1 1.1.1 Computer linguistik: Die Wissenschaft 2 1.1.2 Computerlinguistik und ihre Nachbardisziplinen 3 1.1.3
Ivana Daskalovska. Willkommen zur Übung Einführung in die Computerlinguistik. Sarah Bosch,
 Ivana Daskalovska Willkommen zur Übung Einführung in die Computerlinguistik Kontakt: ivana.bt.mk@gmail.com Betreff: EICL Wiederholung Aufgabe 1 Was ist Computerlinguistik? 4 Was ist Computerlinguistik?
Ivana Daskalovska Willkommen zur Übung Einführung in die Computerlinguistik Kontakt: ivana.bt.mk@gmail.com Betreff: EICL Wiederholung Aufgabe 1 Was ist Computerlinguistik? 4 Was ist Computerlinguistik?
Rückblick. Aufteilung in Dokumente anwendungsabhängig. Tokenisierung und Normalisierung sprachabhängig
 3. IR-Modelle Rückblick Aufteilung in Dokumente anwendungsabhängig Tokenisierung und Normalisierung sprachabhängig Gesetz von Zipf sagt aus, dass einige Wörter sehr häufig vorkommen; Stoppwörter können
3. IR-Modelle Rückblick Aufteilung in Dokumente anwendungsabhängig Tokenisierung und Normalisierung sprachabhängig Gesetz von Zipf sagt aus, dass einige Wörter sehr häufig vorkommen; Stoppwörter können
2.4 Effiziente Datenstrukturen
 2.4 Effiziente Datenstrukturen Effizienz des Systems bezeichnet den sparsamer Umgang mit Systemressourcen und die Skalierbarkeit auch über große Kollektionen. Charakteristische Werte für Effizienz sind
2.4 Effiziente Datenstrukturen Effizienz des Systems bezeichnet den sparsamer Umgang mit Systemressourcen und die Skalierbarkeit auch über große Kollektionen. Charakteristische Werte für Effizienz sind
Maschinelle Sprachverarbeitung
 Maschinelle Sprachverarbeitung Übung Aufgabe 4: Regelbasiertes Named Entity Recognition Mario Sänger Informationsextraktionsworkflow Mario Sänger: Maschinelle Sprachverarbeitung - Übung, Wintersemester
Maschinelle Sprachverarbeitung Übung Aufgabe 4: Regelbasiertes Named Entity Recognition Mario Sänger Informationsextraktionsworkflow Mario Sänger: Maschinelle Sprachverarbeitung - Übung, Wintersemester
DATENBLATT LINGUISTIK PLUGIN für Elasticsearch
 LINGUISTIK PLUGIN für Elasticsearch Morphologische Analyse für die Texterschließung und -aufbereitung Lieferumfang IntraFind liefert ein komplettes Softwarepaket als Plugin für Elasticsearch (einsetzbar
LINGUISTIK PLUGIN für Elasticsearch Morphologische Analyse für die Texterschließung und -aufbereitung Lieferumfang IntraFind liefert ein komplettes Softwarepaket als Plugin für Elasticsearch (einsetzbar
Text-Mining: Klassifikation I - Naive Bayes vs. Rocchio
 Text-Mining: Klassifikation I - Naive Bayes vs. Rocchio Claes Neuefeind Fabian Steeg 17. Juni 2010 Klassifikation im Text-Mining Klassifikation Textkategorisierung Naive Bayes Beispielrechnung Rocchio
Text-Mining: Klassifikation I - Naive Bayes vs. Rocchio Claes Neuefeind Fabian Steeg 17. Juni 2010 Klassifikation im Text-Mining Klassifikation Textkategorisierung Naive Bayes Beispielrechnung Rocchio
Vorlesung Information Retrieval Wintersemester 04/05
 Vorlesung Information Retrieval Wintersemester 04/05 14. Oktober 2004 Institut für Informatik III Universität Bonn Tel. 02 28 / 73-45 31 Fax 02 28 / 73-43 82 jw@informatik.uni-bonn.de 1 Themenübersicht
Vorlesung Information Retrieval Wintersemester 04/05 14. Oktober 2004 Institut für Informatik III Universität Bonn Tel. 02 28 / 73-45 31 Fax 02 28 / 73-43 82 jw@informatik.uni-bonn.de 1 Themenübersicht
Rückblick. Aufteilung in Dokumente anwendungsabhängig. Tokenisierung und Normalisierung sprachabhängig
 3. IR-Modelle Rückblick Aufteilung in Dokumente anwendungsabhängig Tokenisierung und Normalisierung sprachabhängig Gesetz von Zipf sagt aus, dass einige Wörter sehr häufig vorkommen; Stoppwörter können
3. IR-Modelle Rückblick Aufteilung in Dokumente anwendungsabhängig Tokenisierung und Normalisierung sprachabhängig Gesetz von Zipf sagt aus, dass einige Wörter sehr häufig vorkommen; Stoppwörter können
Centrum für Informations- und Sprachverarbeitung. Dr. M. Hadersbeck, Digitale Editionen, BAdW München
 # 1 Digitale Editionen und Auszeichnungssprachen Computerlinguistische FinderApps mit Facsimile-Reader Wittgenstein s Nachlass: WiTTFind Goethe s Faust: GoetheFind Hadersbeck M. et. al. Centrum für Informations-
# 1 Digitale Editionen und Auszeichnungssprachen Computerlinguistische FinderApps mit Facsimile-Reader Wittgenstein s Nachlass: WiTTFind Goethe s Faust: GoetheFind Hadersbeck M. et. al. Centrum für Informations-
Information Retrieval, Vektorraummodell
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Information Retrieval, Vektorraummodell Tobias Scheffer Paul Prasse Michael Großhans Uwe Dick Information Retrieval Konstruktion
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Information Retrieval, Vektorraummodell Tobias Scheffer Paul Prasse Michael Großhans Uwe Dick Information Retrieval Konstruktion
Indexieren und Suchen
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Indexieren und Suchen Tobias Scheffer Index-Datenstrukturen, Suchalgorithmen Invertierte Indizes Suffix-Bäume und -Arrays Signaturdateien
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Indexieren und Suchen Tobias Scheffer Index-Datenstrukturen, Suchalgorithmen Invertierte Indizes Suffix-Bäume und -Arrays Signaturdateien
Information Retrieval und Question Answering
 und Question Answering Kai Kugler 19. November 2009 Auffinden von relevantem Wissen Die Relevanz der aufzufindenden Information ist abhängig vom... aktuellen Wissen des Benutzers dem aktuellen Problem
und Question Answering Kai Kugler 19. November 2009 Auffinden von relevantem Wissen Die Relevanz der aufzufindenden Information ist abhängig vom... aktuellen Wissen des Benutzers dem aktuellen Problem
Advanced Topics in Databases The Anatomy of a Large-Scale Hypertextual Web Search Engine
 Advanced Topics in Databases The Anatomy of a Large-Scale Hypertextual Web Search Engine Hasso-Plattner-Institut Potsdam Fachgebiet Informationssysteme Markus Güntert WS 2008/2009 20.01.2009 1 The Anatomy
Advanced Topics in Databases The Anatomy of a Large-Scale Hypertextual Web Search Engine Hasso-Plattner-Institut Potsdam Fachgebiet Informationssysteme Markus Güntert WS 2008/2009 20.01.2009 1 The Anatomy
Ivana Daskalovska. Willkommen zur Übung Einführung in die Computerlinguistik. Morphologie. Sarah Bosch,
 Ivana Daskalovska Willkommen zur Übung Einführung in die Computerlinguistik Morphologie Wiederholung Aufgabe 1 Was ist Morphologie, Morphem? 3 Aufgabe 1 Was ist Morphologie, Morphem? Teildisziplin der
Ivana Daskalovska Willkommen zur Übung Einführung in die Computerlinguistik Morphologie Wiederholung Aufgabe 1 Was ist Morphologie, Morphem? 3 Aufgabe 1 Was ist Morphologie, Morphem? Teildisziplin der
Supervised Learning Algorithmus für Stellenanzeigenklassifikation und Jobdeskriptoren Gewinnung
 Informatik Pawel Broda Supervised Learning Algorithmus für Stellenanzeigenklassifikation und Jobdeskriptoren Gewinnung Diplomarbeit Ludwig Maximilian Universität zu München Centrum für Informations- und
Informatik Pawel Broda Supervised Learning Algorithmus für Stellenanzeigenklassifikation und Jobdeskriptoren Gewinnung Diplomarbeit Ludwig Maximilian Universität zu München Centrum für Informations- und
1. Statistik und Computerlinguistik
 03. JULI 2006: BLATT 1 1. Statistik und Computerlinguistik 1.1. Allgemeines Nachfolgend zur Einführung eine kurze Übersicht über die Rolle der Statistik in der Computerlinguistik - bezogen auf die einzelnen
03. JULI 2006: BLATT 1 1. Statistik und Computerlinguistik 1.1. Allgemeines Nachfolgend zur Einführung eine kurze Übersicht über die Rolle der Statistik in der Computerlinguistik - bezogen auf die einzelnen
Automatische Textzusammenfasung
 Automatische Textzusammenfasung Katja Diederichs Francisco Mondaca Simon Ritter PS Computerlinguistische Grundlagen I - Jürgen Hermes - WS 09/10 Uni Köln Gliederung 1) Einleitung & Überblick 2) Ansätze
Automatische Textzusammenfasung Katja Diederichs Francisco Mondaca Simon Ritter PS Computerlinguistische Grundlagen I - Jürgen Hermes - WS 09/10 Uni Köln Gliederung 1) Einleitung & Überblick 2) Ansätze
Indexierung der HBZ-Verbunddaten mit FAST Data Search
 Indexierung der HBZ-Verbunddaten mit FAST Data Search 8. InetBib-Tagung 2004 Bonn, 5.11.2004 Dr. Peter Kostädt, HBZ NRW Dr. Peter Kostädt, HBZ NRW 1 Katalog Suchmaschine "Saubere" Daten Feldbezogene Suche
Indexierung der HBZ-Verbunddaten mit FAST Data Search 8. InetBib-Tagung 2004 Bonn, 5.11.2004 Dr. Peter Kostädt, HBZ NRW Dr. Peter Kostädt, HBZ NRW 1 Katalog Suchmaschine "Saubere" Daten Feldbezogene Suche
GI-Fachgruppentreffen RE Weak-Words und ihre Auswirkung auf die Qualität von Anforderungsdokumenten. Jennifer Krisch Daimler AG
 GI-Fachgruppentreffen RE Weak-Words und ihre Auswirkung auf die Qualität von Anforderungsdokumenten Jennifer Krisch Daimler AG Inhalte 1 Motivation 2 Was sind Weak-Words? 3 Vorgehen bei der Analyse 4 Evaluation
GI-Fachgruppentreffen RE Weak-Words und ihre Auswirkung auf die Qualität von Anforderungsdokumenten Jennifer Krisch Daimler AG Inhalte 1 Motivation 2 Was sind Weak-Words? 3 Vorgehen bei der Analyse 4 Evaluation
Mathematische Grundlagen der Computerlinguistik III: Statistische Methoden Probeklausur
 Mathematische Grundlagen der Computerlinguistik III: Statistische Methoden Probeklausur Crocker/Demberg/Staudte Sommersemester 2014 17.07.2014 1. Sie haben 90 Minuten Zeit zur Bearbeitung der Aufgaben.
Mathematische Grundlagen der Computerlinguistik III: Statistische Methoden Probeklausur Crocker/Demberg/Staudte Sommersemester 2014 17.07.2014 1. Sie haben 90 Minuten Zeit zur Bearbeitung der Aufgaben.
Exposé zur Studienarbeit. 04. August 2010
 Exposé zur Studienarbeit Relevanzranking in Lucene im biomedizinischen Kontext Christoph Jacob Betreuer: Phillipe Thomas, Prof. Dr. Ulf Leser 04. August 2010 1. Motivation Sucht und ihr werdet finden dieses
Exposé zur Studienarbeit Relevanzranking in Lucene im biomedizinischen Kontext Christoph Jacob Betreuer: Phillipe Thomas, Prof. Dr. Ulf Leser 04. August 2010 1. Motivation Sucht und ihr werdet finden dieses
Blockseminar Einführung in die Korpuslinguistik Seminarleitung: Yvonne Krämer, M.A. Das Korpus. und seine Aufbereitung
 Blockseminar Einführung in die Korpuslinguistik Seminarleitung: Yvonne Krämer, M.A. Das Korpus und seine Aufbereitung Bestandteile eines Korpus sind i.d.r.: Primärdaten Metadaten Annotationen Annotationen
Blockseminar Einführung in die Korpuslinguistik Seminarleitung: Yvonne Krämer, M.A. Das Korpus und seine Aufbereitung Bestandteile eines Korpus sind i.d.r.: Primärdaten Metadaten Annotationen Annotationen
Computerlinguistische Grundlagen. Jürgen Hermes Sommersemester 17 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln
 Computerlinguistische Grundlagen Jürgen Hermes Sommersemester 17 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Computerlinguistik: Schnittstellen Computerlinguistik aus
Computerlinguistische Grundlagen Jürgen Hermes Sommersemester 17 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Computerlinguistik: Schnittstellen Computerlinguistik aus
Stemming. OS Einblicke in die Computerlinguistik Felix Hain HTWK Leipzig
 Stemming OS Einblicke in die Computerlinguistik Felix Hain 12.06.2014 HTWK Leipzig Gliederung Motivation Der Begriff Stemming Potentielle Probleme Stemming-Algorithmen Ansätze Porter-Stemmer-Algorithmus
Stemming OS Einblicke in die Computerlinguistik Felix Hain 12.06.2014 HTWK Leipzig Gliederung Motivation Der Begriff Stemming Potentielle Probleme Stemming-Algorithmen Ansätze Porter-Stemmer-Algorithmus
Opinion Mining Herausforderungen und Anwendung in der Politik
 Opinion Mining Herausforderungen und Anwendung in der Politik 28.09.2011 Umut Yilmaz Inhaltsübersicht 1. Einführung 2. Grundlagen 3. Anwendung in der Politik 4. Anwendungsbeispiel 5. Fazit 2 1. Einführung
Opinion Mining Herausforderungen und Anwendung in der Politik 28.09.2011 Umut Yilmaz Inhaltsübersicht 1. Einführung 2. Grundlagen 3. Anwendung in der Politik 4. Anwendungsbeispiel 5. Fazit 2 1. Einführung
Korrekturprogramme. Von Emine Senol & Gihan S. El Hosami
 Korrekturprogramme Von Emine Senol & Gihan S. El Hosami Einleitung Millionen von Texten werden mit dem Computern täglich erfasst Fehler schleichen sich ein Korrekturprogramme helfen diese zu finden zu
Korrekturprogramme Von Emine Senol & Gihan S. El Hosami Einleitung Millionen von Texten werden mit dem Computern täglich erfasst Fehler schleichen sich ein Korrekturprogramme helfen diese zu finden zu
Search Engine Evaluation. Franziska Häger, Lutz Gericke
 Search Engine Evaluation Franziska Häger, Lutz Gericke 23.07.2009 Ansätze 2 Tägliche Abfragen mit geringer Ergebnismenge Evaluation von Precision und Recall Revisionsabfrage aus Suchmaschinen-Caches Bestimmung
Search Engine Evaluation Franziska Häger, Lutz Gericke 23.07.2009 Ansätze 2 Tägliche Abfragen mit geringer Ergebnismenge Evaluation von Precision und Recall Revisionsabfrage aus Suchmaschinen-Caches Bestimmung
Prototypische Komponenten eines Information Retrieval Systems: Vektormodell
 Prototypische Komponenten eines Information Retrieval Systems: Vektormodell Implementierung & Präsentation: Stefan Schmidt (Uni Mannheim) Kontakt: powder@gmx.de Seminar: Information Retrieval WS2002/2003
Prototypische Komponenten eines Information Retrieval Systems: Vektormodell Implementierung & Präsentation: Stefan Schmidt (Uni Mannheim) Kontakt: powder@gmx.de Seminar: Information Retrieval WS2002/2003
Language Identification XXL
 Ruprecht-Karls Universität Heidelberg Seminar für Computerlinguistik Software Projekt WS 2009/10 Language Identification XXL Referenten: Galina Sigwarth, Maria Semenchuk, George Kakish, Ulzhan Kadirbayeva
Ruprecht-Karls Universität Heidelberg Seminar für Computerlinguistik Software Projekt WS 2009/10 Language Identification XXL Referenten: Galina Sigwarth, Maria Semenchuk, George Kakish, Ulzhan Kadirbayeva
Identifikation der Sprache eines elektronischen Dokumentes oder eines Dokumentausschnitts (z.b. eines Abschnitts).
.") BLATT 1 1 Sprachenidentifizierung: Zielsetzung und Anwendungen 1.1 Allgemeine Zielsetzung Identifikation der Sprache eines elektronischen Dokumentes oder eines Dokumentausschnitts (z.b. eines Abschnitts).
BLATT 1 1 Sprachenidentifizierung: Zielsetzung und Anwendungen 1.1 Allgemeine Zielsetzung Identifikation der Sprache eines elektronischen Dokumentes oder eines Dokumentausschnitts (z.b. eines Abschnitts).
Sharon Goldwater & David McClosky. Sarah Hartmann Advanced Topics in Statistical Machine Translation
 Sharon Goldwater & David McClosky Sarah Hartmann 13.01.2015 Advanced Topics in Statistical Machine Translation Einführung Modelle Experimente Diskussion 2 Einführung Das Problem Der Lösungsvorschlag Modelle
Sharon Goldwater & David McClosky Sarah Hartmann 13.01.2015 Advanced Topics in Statistical Machine Translation Einführung Modelle Experimente Diskussion 2 Einführung Das Problem Der Lösungsvorschlag Modelle
Installationsanleitung NX 10
 Installationsanleitung NX 10 Vorbereitung Mindestanforderungen für zertifizierte Betriebssysteme Die folgenden Betriebssysteme sind zertifiziert und die Mindestanforderung für NX 10. Neuere Versionen und
Installationsanleitung NX 10 Vorbereitung Mindestanforderungen für zertifizierte Betriebssysteme Die folgenden Betriebssysteme sind zertifiziert und die Mindestanforderung für NX 10. Neuere Versionen und
3. Vorlesung. Skip-Pointer Komprimierung der Postings Speicherung des Dictionarys Kontext-Anfragen. Seite 55
 3. Vorlesung Skip-Pointer Komprimierung der Postings Speicherung des Dictionarys Kontext-Anfragen Seite 55 Wiederholung, Invertierte Liste Anfrage mit zwei Termen (logisches UND) Merge-Operation durchläuft
3. Vorlesung Skip-Pointer Komprimierung der Postings Speicherung des Dictionarys Kontext-Anfragen Seite 55 Wiederholung, Invertierte Liste Anfrage mit zwei Termen (logisches UND) Merge-Operation durchläuft
8. Mai Humboldt-Universität zu Berlin. LingPipe. Mark Kibanov und Maik Lange. Index. Allgemeine Infos. Features
 Humboldt-Universität zu Berlin 8. Mai 2008 1 2 logistic regression 3 Benutzer 4 Fazit 5 Quellen Was ist? is a suite of Java libraries for the linguistic analysis of human. Was ist? is a suite of Java libraries
Humboldt-Universität zu Berlin 8. Mai 2008 1 2 logistic regression 3 Benutzer 4 Fazit 5 Quellen Was ist? is a suite of Java libraries for the linguistic analysis of human. Was ist? is a suite of Java libraries
Semantische Suche in Zeitungsartikeln
 6. Oktober 2011 1 2 3 4 5 6 Motivation Ziel Teilaufgaben Im Internet finden sich viele Nachrichtenseiten Für die Suche auf diesen Seiten wird meißt Volltextsuche verwendet Suche nach Vorkommen der Suchbegriffe
6. Oktober 2011 1 2 3 4 5 6 Motivation Ziel Teilaufgaben Im Internet finden sich viele Nachrichtenseiten Für die Suche auf diesen Seiten wird meißt Volltextsuche verwendet Suche nach Vorkommen der Suchbegriffe
Space Usage Rules. Neele Halbur, Helge Spieker InformatiCup 2015 19. März 2015
 Space Usage Rules? InformatiCup 2015 1 Agenda 1. Vorstellung des Teams 2. Entwicklungsprozess und Umsetzung 3. Verbesserung der Strategien 4. Auswertung der Strategien 5. Ausblick 6. Fazit 2 Vorstellung
Space Usage Rules? InformatiCup 2015 1 Agenda 1. Vorstellung des Teams 2. Entwicklungsprozess und Umsetzung 3. Verbesserung der Strategien 4. Auswertung der Strategien 5. Ausblick 6. Fazit 2 Vorstellung
Einführung in die maschinelle Sprachverarbeitung
 Einführung in die maschinelle Sprachverarbeitung Michaela Geierhos CIS Centrum für Informations- und Sprachverarbeitung Ludwig-Maximilians-Universität München 17. April 2007 17.04.2007 Statistische Methoden
Einführung in die maschinelle Sprachverarbeitung Michaela Geierhos CIS Centrum für Informations- und Sprachverarbeitung Ludwig-Maximilians-Universität München 17. April 2007 17.04.2007 Statistische Methoden
Einführung in die maschinelle Sprachverarbeitung
 Einführung in die maschinelle Sprachverarbeitung Michaela Geierhos CIS Centrum für Informations- und Sprachverarbeitung Ludwig-Maximilians-Universität München 17. April 2007 17.04.2007 Statistische Methoden
Einführung in die maschinelle Sprachverarbeitung Michaela Geierhos CIS Centrum für Informations- und Sprachverarbeitung Ludwig-Maximilians-Universität München 17. April 2007 17.04.2007 Statistische Methoden
Bachelorarbeit Erkennung von Fließtext in PDF-Dokumenten
 Bachelorarbeit Erkennung von Fließtext in PDF-Dokumenten 16.08.2016 David Spisla Albert Ludwigs Universität Freiburg Technische Fakultät Institut für Informatik Gliederung Motivation Schwierigkeiten bei
Bachelorarbeit Erkennung von Fließtext in PDF-Dokumenten 16.08.2016 David Spisla Albert Ludwigs Universität Freiburg Technische Fakultät Institut für Informatik Gliederung Motivation Schwierigkeiten bei
Anwendung von Vektormodell und boolschem Modell in Kombination
 Anwendung von Vektormodell und boolschem Modell in Kombination Julia Kreutzer Seminar Information Retrieval Institut für Computerlinguistik Universität Heidelberg 12.01.2015 Motivation Welche Filme sind
Anwendung von Vektormodell und boolschem Modell in Kombination Julia Kreutzer Seminar Information Retrieval Institut für Computerlinguistik Universität Heidelberg 12.01.2015 Motivation Welche Filme sind
Semestralklausur zur Vorlesung. Web Mining. Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7.
 Semestralklausur zur Vorlesung Web Mining Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7. 2004 Name: Vorname: Matrikelnummer: Fachrichtung: Punkte: (1).... (2)....
Semestralklausur zur Vorlesung Web Mining Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7. 2004 Name: Vorname: Matrikelnummer: Fachrichtung: Punkte: (1).... (2)....
Text Mining und Textzusammenfassung. Jürgen Kirkovits Doris Rongitsch Daniela Wagenhofer
 Text Mining und Textzusammenfassung Jürgen Kirkovits Doris Rongitsch Daniela Wagenhofer Übersicht 1. Definition 2. Prozessablauf 3. Textzusammenfassung 4. Praxisbeispiel Definition Text Mining is the art
Text Mining und Textzusammenfassung Jürgen Kirkovits Doris Rongitsch Daniela Wagenhofer Übersicht 1. Definition 2. Prozessablauf 3. Textzusammenfassung 4. Praxisbeispiel Definition Text Mining is the art