Herausforderung Multikern-Systeme
|
|
|
- Felix Beutel
- vor 8 Jahren
- Abrufe
Transkript
1 Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Herausforderung Multikern-Systeme Walter F. Tichy

2 Wir erleben gerade eine Umwälzung der Informatik Von Anfang an war die Informatik geprägt vom sequenziellen Rechner. Parallelität war nur in Nischen präsent: Numerisches Rechnen Betriebssysteme, Datenbanken Parallelität auf Instruktionsebene Mit Mehrkern-Chips wird Parallelität flächendeckend zur Verfügung stehen. Es ist bereits schwierig, einen Rechner mit nur einem Prozessor zu kaufen. 2

3 Einige wichtige Parallelrechner Atanasoff-Berry-Rechner von 1942 Erster digitaler, elektronischer Rechner. Vor ENIAC! (1946) 30 parallele Addierer/ Subtrahierer 3

4 Einige wichtige Parallelrechner Atanasoff-Berry-Computer erster, digitaler, elektronischer Rechner (1942) Eniac ist von 1946 Zuses Rechner von 1941 war elektromechanisch War bereits parallel! Konnte 30 Additionen/ Subtraktionen gleichzeitig ausführen. 4

5 Einige wichtige Parallelrechner Illiac-IV: SIMD, verteilter Speicher Nur ein Exemplar gebaut: Prozessoren Schnellster Rechner bis

6 Wichtige Parallelrechner Cray-1 Vektorrechner gemeinsamer Speicher Vektorregister mit 64 Elementen Vektorinstruktionen implementiert mit Fließbändern. Erstmals geliefert 1976 Damals der zweitschnellste Rechner nach Illiac-VI 6

7 Wichtige Parallelrechner CM-1 Connection Machine SIMD-Rechner, verteilter Speicher Prozessoren (1-Bit) Hyperkubus als Verbindungsnetz Erstmals geliefert 1986 Erster massiv paralleler Rechner 7

8 Wichtige Parallelrechner Rechnerbündel (Cluster Computers) Standard PCs verbunden mit Standard-Netzen MIMD-Rechner mit verteiltem Speicher Kostenvorteile durch Komponenten aus dem Massenmarkt Heute die schnellsten Rechner Siehe top500.org Nasa Avalon mit 140 Alpha Knoten,

9 Ihr Laptop ein Parallelrechner? Preise Juni
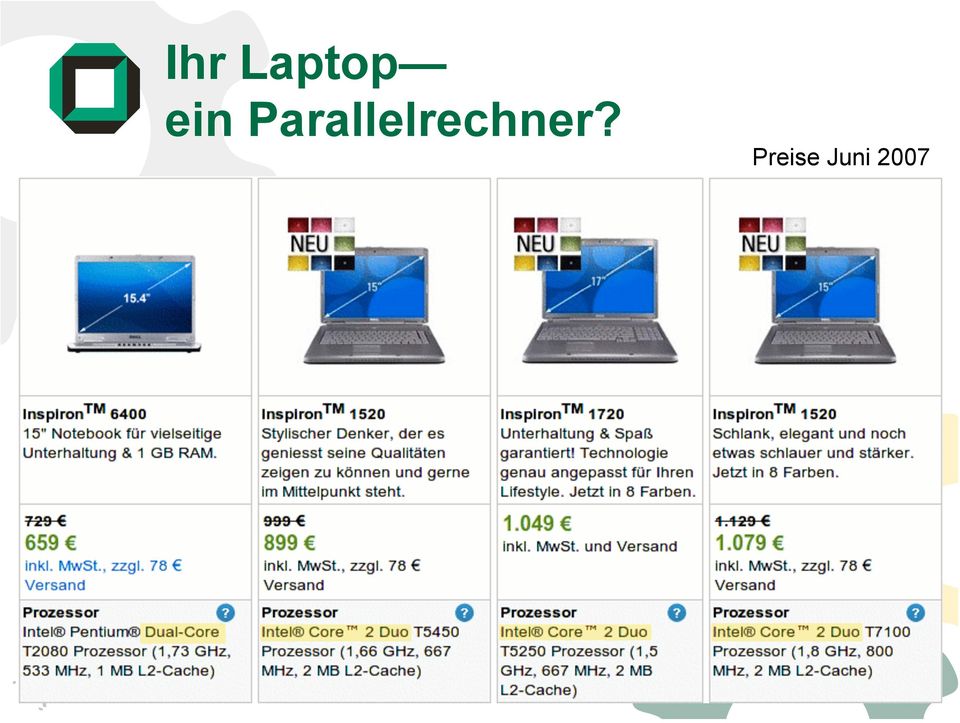
10 Intel Dunnington 6 Prozessoren auf einem Chip 3 x 2 Xeon Prozessoren (nicht HWmehrfädig) 2,6 GHz 130 W 45nm Technik Lieferbar

11 Sun Niagara 2: 8 Prozessoren auf 3,42 cm 2 8 Sparc Prozessoren 8 HW-Fäden pro Prozessor 8x9 Kreuzschiene 1,4 GHz 75 W 65nm Technik Lieferbar 2007 Erste Version

12 Aber der Rekord ist das nicht Fast unbemerkt hat Cisco bereits 2005 ein Paket-Vermittlungs-Chip gebaut. 12

13 Cisco Metro: 192 Prozessoren auf 3,24 cm 2 0,5 mm 2 pro Prozessor 16 Gruppen zu je 12 Prozessoren (192 insgesamt) 192 Tenselica Prozessoren 10 Gips 250 MHz 35W 130nm Technik (2005) Bei aktueller 45 nm Technik wäre Raum für das Achtfache an Prozessoren 13

14 Nvidia GeForce 8 Graphics Processing Unit Prozessor, 1,35 GHz, 32-Bit FPU, 1024 Register 128 Prozessoren insgesamt, jeder mit 96 Fäden in HW Insgesamt HW-Fäden! SIMD 16 KB 14

15 Was ist passiert? 15
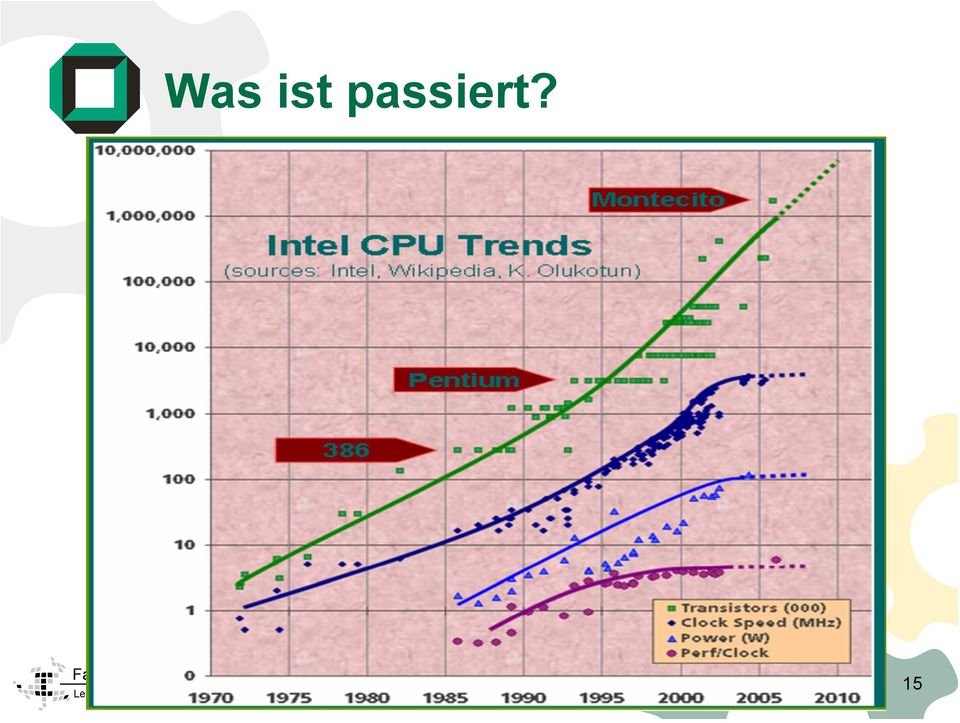
16 Moore sche Regel, neue Version Verdopplung der Anzahl Prozessoren pro Chip mit jeder Chip-Generation, bei etwa gleicher Taktfrequenz Parallelrechner werden in naher Zukunft flächendeckend zur Verfügung stehen. 16

17 Was tun mit all den Kernen? Wer braucht 100 Prozessoren für M/S Word? Mangel an Vorstellungskraft, Informatik-Ausbildung? Gesucht werden überzeugende Anwendungen, die Hunderte von Prozessoren gebrauchen können. Wovon könnten alle Nutzer von PCs, eingebetteten Systemen und Mobiltelefonen profitieren? 17

18 Automatischer Protokollführer Tragbare Geräte kooperieren bei Besprechung: protokollieren Aussagen identifzieren Sprecher, übersetzen, kondensieren suchen Gewünschtes 18

19 Inhalt-basierte Bildsuche Anfrage per Beispiel Relevanz- Rückkopplung Ähnlichkeits - Metrik Kandidaten Endergebnis Tausende Bilder Angepasst an Charakteristiken persönlicher Bildbanken: Bilder nicht gekennzeichnet Viele Bilder von wenigen Personen Komplexe Bilder mit Personen, Objekten, Orten, Ereignissen 19

20 Wozu die Rechenleistung einsetzen? Intuitive Schnittstellen, mit Bild- und Sprachverarbeitung Vorausschauende Anwendungen, die ahnen, was der Benutzer will Eingehende Modellierung des Benutzers und der Umgebung Berechnungen, die heute zu langsam sind Erhöhung der Zuverlässigkeit 20

21 Was ist das Problem bei der Software? Für den Erfolg müssen Parallelisierung, Produktivität und Qualität gleichzeitig gemeistert werden. Parallelisierung nur bei Beschleunigung interessant SW-Produktivität und Qualität dürfen nicht schlechter werden! Sprachen, Debugger, Analysewerkzeuge sind unzureichend für Parallelität (Thread Goto?) Die meisten Programmierer sind unzureichend auf Parallelität vorbereitet. 21
22 Beispiel: Analyse von Massenspektrogrammen Massenspektrogramme C 21 H 31 N 5 O 2 Wirkstoff Laden der Spektrogramme Laden eines Wirkstoffes n... Mehrstufiges Algorithmen-Fließband: Suchen von Metaboliten in den Spektrogrammen Parallelisierungspotential Desktop-Applikation Ergebnis: Zeitabhängige Darstellung der Metaboliten 22
23 Mehrschichtige Parallelisierung mit Entwurfs-Mustern 23
24 Auto-Tuning Problem: Bestimme alle leistungsrelevanten Parameter in allen Ebenen um globales Leistungsoptimum zu finden. Parameterwerte abhängig von HW und SW (z.b. Anzahl Kerne, Ebenen, Anzahl Fließband- Stufen, Fließband-Struktur, Größe der Datenpartitionen) Einstellung per Hand zu aufwendig 24
25 Auto-Tuning (2) Lösung: Automatischer Parameter-Optimierer Als Bibliothek, die einfach in eine Anwendung integrierbar ist Nimmt Laufzeit-Stichproben, um den Parameterraum zu reduzieren (kann i.d.r. nicht alles durchprobieren) Leistungsunterschiede zwischen bester und schlechtester Konfiguration bei der Massenspektrogramm-Analyse: approx. 40% Gesamtbeschleunigung mit Paralleliseriung und Auto-Tuning: 2.9 Tested on 8-core machine (2x Intel Xeon E5320 Quad-Core at 1,86 GHz/core) 25
26 Erfahrungen mit Parallelisierung nicht-numerischer Anwendungen Am Beispiel BZip2 Kompressionsprogramm Vielfach im täglichen Gebrauch Ca 8000 Zeilen, quelloffen Im Wettbewerb parallelisiert 4 Teams von je zwei Personen gegeneinander 3 Monate Training in OpenMP und Posix-Fäden Wettbewerb dauerte 3 Wochen (Abschlussarbeit) 26
27 Beschleunigung Gewinner erreichte 10-fachen Beschleunigung auf Sun Niagara T1 (acht Prozessoren, 32 HW-Fäden). 27
28 Was hat funktioniert? Massive Umstrukturierung war erforderlich Teams, die hier wenig investierten, hatten keinen Erfolg. Die Gewinner parallelisierten erst am Tag vor der Abgabe; die übrigen Zeit von 3 Wochen wurde nur dazu benutzt, das Programm für die Parallelisierung vorzubereiten. Viele Abhängigkeiten, Seiteneffekte und Optimierungen für den sequentiellen Ablauf mussten beseitigt werden, bevor überhaupt Parallelisierung möglich war. 28
29 Was hat nicht funktioniert? Parallelisierungskonstrukte nach und nach hinzu zu fügen hat bei keinem Team funktioniert. Nur den Laufzeit-kritischen Pfad zu parallelisieren reichte nicht. Feingranulare Parallelisierung innerer Schleifen hat keine nennenswerte Beschleunigung erzielt. Parallelisierte Einheiten müssen größere Arbeitsabschnitte umfassen. Algorithmen waren so spezielle, dass geeignete, parallelisierte Bibliotheksroutinen kaum zu Fakultät erwarten für Informatik sind. 29
30 Parallelisierung ist keine Geheimkunst Arbeite nach Plan! Herumprobieren reicht nicht. Entwickle Hypothesen und Abschätzungen, wo Parallelisierung am meisten Gewinn bringen könnte! Beachte mehrere Parallelisierungsebenen! Benutze Parallelisierungsmuster! Auftraggeber/Auftragnehmer, Fließband, Gebietszerlegung, Erzeuger/Verbraucher. Verzweifle nicht bei der Restrukturierung! Ärmel hochkrempeln und anfangen! 30
31 Forschungsthemen Parallele Softwaretechnik Bessere Programmiersprachen zum direkten Ausdruck paralleler Abläufe Parallele Entwurfsmuster und Architekturen Parallele Algorithmen und Bibliotheken Robustheit, Suche von Parallelisierungsfehlern Leistungsvorhersagen für parallele Architekturen Werkzeuge zur Restrukturierung und Parallelisierung Neue Anwendungsklassen U.v.a.m. 31
32 Schluss Zukünftige Leistungssteigerungen nur über Parallelität Ziel: Beschleunigung von Anwendungen bei gleichbleibender Produktivität, Qualität während sich die Anzahl der Prozessorkerne pro Chip alle zwei Jahre verdoppelt. Viele der Grundlagen der Informatik müssen neu überdacht werden. Reinventing Computing 32
33 International Workshop Multicore Software Engineering, Mai 2009, Vancouver. GI-Arbeitskreis Software Engineering für parallele Systeme (SEPAS) Auf geht s! Gehn mas an! Let s go! 33
Di 7.4. Herausforderung Mehrkern-Systeme. Walter Tichy. January 26-30, 2009, Munich, Germany ICM - International Congress Centre Munich
 Di 7.4 January 26-30, 2009, Munich, Germany ICM - International Congress Centre Munich Herausforderung Mehrkern-Systeme Walter Tichy Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Herausforderung
Di 7.4 January 26-30, 2009, Munich, Germany ICM - International Congress Centre Munich Herausforderung Mehrkern-Systeme Walter Tichy Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Herausforderung
Herausforderung Multikern-Systeme
 Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Herausforderung Multikern-Systeme Walter F. Tichy Wir erleben gerade eine Umwälzung der Informatik Von Anfang an war die Informatik geprägt
Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Herausforderung Multikern-Systeme Walter F. Tichy Wir erleben gerade eine Umwälzung der Informatik Von Anfang an war die Informatik geprägt
Herausforderung Multikern-Systeme
 Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Herausforderung Multikern-Systeme Walter F. Tichy Wir erleben gerade eine Umwälzung der Informatik Von Anfang an war die Informatik geprägt
Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Herausforderung Multikern-Systeme Walter F. Tichy Wir erleben gerade eine Umwälzung der Informatik Von Anfang an war die Informatik geprägt
Bereit für die Multicore-Revolution?
 Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Bereit für die Multicore-Revolution? Walter F. Tichy Wir erleben gerade eine Umwälzung der Informatik Von Anfang an war die Informatik geprägt
Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Bereit für die Multicore-Revolution? Walter F. Tichy Wir erleben gerade eine Umwälzung der Informatik Von Anfang an war die Informatik geprägt
Kapitel 4 Grundlagen zur Parallelverarbeitung
 Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Kapitel 4 Grundlagen zur Parallelverarbeitung SWT I Sommersemester 2009 Prof. Dr. Walter F. Tichy Dipl.-Inform. David J. Meder Warum Parallelverarbeitung?
Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Kapitel 4 Grundlagen zur Parallelverarbeitung SWT I Sommersemester 2009 Prof. Dr. Walter F. Tichy Dipl.-Inform. David J. Meder Warum Parallelverarbeitung?
Hochleistungsrechnen für Wissenschaft und Wirtschaft im internationalen Verbund
 Hochleistungsrechnen für Wissenschaft und Wirtschaft im internationalen Verbund Prof. Dr. rer. nat. Christian Schröder Dipl.-Ing. Thomas Hilbig, Dipl.-Ing. Gerhard Hartmann Fachbereich Elektrotechnik und
Hochleistungsrechnen für Wissenschaft und Wirtschaft im internationalen Verbund Prof. Dr. rer. nat. Christian Schröder Dipl.-Ing. Thomas Hilbig, Dipl.-Ing. Gerhard Hartmann Fachbereich Elektrotechnik und
Installation OMNIKEY 3121 USB
 Installation OMNIKEY 3121 USB Vorbereitungen Installation PC/SC Treiber CT-API Treiber Einstellungen in Starke Praxis Testen des Kartenlesegeräts Vorbereitungen Bevor Sie Änderungen am System vornehmen,
Installation OMNIKEY 3121 USB Vorbereitungen Installation PC/SC Treiber CT-API Treiber Einstellungen in Starke Praxis Testen des Kartenlesegeräts Vorbereitungen Bevor Sie Änderungen am System vornehmen,
OpenMP am Beispiel der Matrizenmultiplikation
 OpenMP am Beispiel der Matrizenmultiplikation David J. Meder, Dr. Victor Pankratius IPD Tichy Lehrstuhl für Programmiersysteme KIT die Kooperation von Forschungszentrum Karlsruhe GmbH und Universität Karlsruhe
OpenMP am Beispiel der Matrizenmultiplikation David J. Meder, Dr. Victor Pankratius IPD Tichy Lehrstuhl für Programmiersysteme KIT die Kooperation von Forschungszentrum Karlsruhe GmbH und Universität Karlsruhe
Zeichen bei Zahlen entschlüsseln
 Zeichen bei Zahlen entschlüsseln In diesem Kapitel... Verwendung des Zahlenstrahls Absolut richtige Bestimmung von absoluten Werten Operationen bei Zahlen mit Vorzeichen: Addieren, Subtrahieren, Multiplizieren
Zeichen bei Zahlen entschlüsseln In diesem Kapitel... Verwendung des Zahlenstrahls Absolut richtige Bestimmung von absoluten Werten Operationen bei Zahlen mit Vorzeichen: Addieren, Subtrahieren, Multiplizieren
Mikrocontroller Grundlagen. Markus Koch April 2011
 Mikrocontroller Grundlagen Markus Koch April 2011 Übersicht Was ist ein Mikrocontroller Aufbau (CPU/RAM/ROM/Takt/Peripherie) Unterschied zum Mikroprozessor Unterschiede der Controllerarten Unterschiede
Mikrocontroller Grundlagen Markus Koch April 2011 Übersicht Was ist ein Mikrocontroller Aufbau (CPU/RAM/ROM/Takt/Peripherie) Unterschied zum Mikroprozessor Unterschiede der Controllerarten Unterschiede
Übersicht. Nebenläufige Programmierung. Praxis und Semantik. Einleitung. Sequentielle und nebenläufige Programmierung. Warum ist. interessant?
 Übersicht Aktuelle Themen zu Informatik der Systeme: Nebenläufige Programmierung: Praxis und Semantik Einleitung 1 2 der nebenläufigen Programmierung WS 2011/12 Stand der Folien: 18. Oktober 2011 1 TIDS
Übersicht Aktuelle Themen zu Informatik der Systeme: Nebenläufige Programmierung: Praxis und Semantik Einleitung 1 2 der nebenläufigen Programmierung WS 2011/12 Stand der Folien: 18. Oktober 2011 1 TIDS
Windows Server 2008 (R2): Anwendungsplattform
: Anwendungsplattform") Mag. Christian Zahler, Stand: August 2011 13 14 Mag. Christian Zahler, Stand: August 2011 Mag. Christian Zahler, Stand: August 2011 15 1.5.2 Remotedesktop-Webverbindung Windows Server 2008 (R2): Anwendungsplattform
Mag. Christian Zahler, Stand: August 2011 13 14 Mag. Christian Zahler, Stand: August 2011 Mag. Christian Zahler, Stand: August 2011 15 1.5.2 Remotedesktop-Webverbindung Windows Server 2008 (R2): Anwendungsplattform
AGROPLUS Buchhaltung. Daten-Server und Sicherheitskopie. Version vom 21.10.2013b
 AGROPLUS Buchhaltung Daten-Server und Sicherheitskopie Version vom 21.10.2013b 3a) Der Daten-Server Modus und der Tresor Der Daten-Server ist eine Betriebsart welche dem Nutzer eine grosse Flexibilität
AGROPLUS Buchhaltung Daten-Server und Sicherheitskopie Version vom 21.10.2013b 3a) Der Daten-Server Modus und der Tresor Der Daten-Server ist eine Betriebsart welche dem Nutzer eine grosse Flexibilität
Dr. Kraus & Partner Ihr Angebot zu Konfliktmanagement
 Dr. Kraus & Partner Ihr Angebot zu Konfliktmanagement Sämtliche Zeichnungen und Karikaturen dieser Präsentation sind urheberrechtlich geschützt und dürfen nur mit schriftlicher Genehmigung seitens Dr.
Dr. Kraus & Partner Ihr Angebot zu Konfliktmanagement Sämtliche Zeichnungen und Karikaturen dieser Präsentation sind urheberrechtlich geschützt und dürfen nur mit schriftlicher Genehmigung seitens Dr.
Professionelle Seminare im Bereich MS-Office
 Der Name BEREICH.VERSCHIEBEN() ist etwas unglücklich gewählt. Man kann mit der Funktion Bereiche zwar verschieben, man kann Bereiche aber auch verkleinern oder vergrößern. Besser wäre es, die Funktion
Der Name BEREICH.VERSCHIEBEN() ist etwas unglücklich gewählt. Man kann mit der Funktion Bereiche zwar verschieben, man kann Bereiche aber auch verkleinern oder vergrößern. Besser wäre es, die Funktion
Excel beschleunigen mit dem mit Windows HPC Server 2008 R2
 Excel beschleunigen mit dem mit Windows HPC Server 2008 R2 Steffen Krause Technical Evangelist Microsoft Deutschland GmbH http://blogs.technet.com/steffenk Haftungsausschluss Microsoft kann für die Richtigkeit
Excel beschleunigen mit dem mit Windows HPC Server 2008 R2 Steffen Krause Technical Evangelist Microsoft Deutschland GmbH http://blogs.technet.com/steffenk Haftungsausschluss Microsoft kann für die Richtigkeit
Formular»Fragenkatalog BIM-Server«
 Formular»Fragenkatalog BIM-Server«Um Ihnen so schnell wie möglich zu helfen, benötigen wir Ihre Mithilfe. Nur Sie vor Ort kennen Ihr Problem, und Ihre Installationsumgebung. Bitte füllen Sie dieses Dokument
Formular»Fragenkatalog BIM-Server«Um Ihnen so schnell wie möglich zu helfen, benötigen wir Ihre Mithilfe. Nur Sie vor Ort kennen Ihr Problem, und Ihre Installationsumgebung. Bitte füllen Sie dieses Dokument
Anleitung zum Extranet-Portal des BBZ Solothurn-Grenchen
 Anleitung zum Extranet-Portal des BBZ Solothurn-Grenchen Inhalt Anleitung zum Extranet-Portal des BBZ Solothurn-Grenchen 2.2 Installation von Office 2013 auf Ihrem privaten PC 2.3 Arbeiten mit den Microsoft
Anleitung zum Extranet-Portal des BBZ Solothurn-Grenchen Inhalt Anleitung zum Extranet-Portal des BBZ Solothurn-Grenchen 2.2 Installation von Office 2013 auf Ihrem privaten PC 2.3 Arbeiten mit den Microsoft
Updatehinweise für die Version forma 5.5.5
 Updatehinweise für die Version forma 5.5.5 Seit der Version forma 5.5.0 aus 2012 gibt es nur noch eine Office-Version und keine StandAlone-Version mehr. Wenn Sie noch mit der alten Version forma 5.0.x
Updatehinweise für die Version forma 5.5.5 Seit der Version forma 5.5.0 aus 2012 gibt es nur noch eine Office-Version und keine StandAlone-Version mehr. Wenn Sie noch mit der alten Version forma 5.0.x
Konzepte der Informatik
 Konzepte der Informatik Vorkurs Informatik zum WS 2011/2012 26.09. - 30.09.2011 17.10. - 21.10.2011 Dr. Werner Struckmann / Christoph Peltz Stark angelehnt an Kapitel 1 aus "Abenteuer Informatik" von Jens
Konzepte der Informatik Vorkurs Informatik zum WS 2011/2012 26.09. - 30.09.2011 17.10. - 21.10.2011 Dr. Werner Struckmann / Christoph Peltz Stark angelehnt an Kapitel 1 aus "Abenteuer Informatik" von Jens
SWT II Projekt. Chat - Anwendung. Pflichtenheft 2000 SWT
 SWT II Projekt Chat - Anwendung Pflichtenheft 2000 SWT i Versionen Datum Version Beschreibung Autor 3.11.2000 1.0 erste Version Dietmar Matthes ii Inhaltsverzeichnis 1. ZWECK... 1 1.1. RAHMEN... 1 1.2.
SWT II Projekt Chat - Anwendung Pflichtenheft 2000 SWT i Versionen Datum Version Beschreibung Autor 3.11.2000 1.0 erste Version Dietmar Matthes ii Inhaltsverzeichnis 1. ZWECK... 1 1.1. RAHMEN... 1 1.2.
Anleitung zur Nutzung des SharePort Utility
 Anleitung zur Nutzung des SharePort Utility Um die am USB Port des Routers angeschlossenen Geräte wie Drucker, Speicherstick oder Festplatte am Rechner zu nutzen, muss das SharePort Utility auf jedem Rechner
Anleitung zur Nutzung des SharePort Utility Um die am USB Port des Routers angeschlossenen Geräte wie Drucker, Speicherstick oder Festplatte am Rechner zu nutzen, muss das SharePort Utility auf jedem Rechner
Einführung in die Systemprogrammierung
 Einführung in die Systemprogrammierung Speedup: Grundlagen der Performanz Prof. Dr. Christoph Reichenbach Fachbereich 12 / Institut für Informatik 30. April 2015 Eine Aufgabe aus der Praxis Gegeben ein
Einführung in die Systemprogrammierung Speedup: Grundlagen der Performanz Prof. Dr. Christoph Reichenbach Fachbereich 12 / Institut für Informatik 30. April 2015 Eine Aufgabe aus der Praxis Gegeben ein
Fotos in Tobii Communicator verwenden
 Fotos in Tobii Communicator verwenden Hier wird beschrieben wie man Fotos in Tobii Communicator verwenden kann und was man zur Nutzung beachten sollte. Fotonutzung in Tobii Communicator In einigen Fällen
Fotos in Tobii Communicator verwenden Hier wird beschrieben wie man Fotos in Tobii Communicator verwenden kann und was man zur Nutzung beachten sollte. Fotonutzung in Tobii Communicator In einigen Fällen
A1 Desktop Security Installationshilfe. Symantec Endpoint Protection 12.1 für Windows/Mac
 A Desktop Security Installationshilfe Symantec Endpoint Protection. für Windows/Mac Inhalt. Systemvoraussetzung & Vorbereitung S. Download der Client Software (Windows) S. 4 Installation am Computer (Windows)
A Desktop Security Installationshilfe Symantec Endpoint Protection. für Windows/Mac Inhalt. Systemvoraussetzung & Vorbereitung S. Download der Client Software (Windows) S. 4 Installation am Computer (Windows)
Updateanleitung für SFirm 3.1
 Updateanleitung für SFirm 3.1 Vorab einige Informationen über das bevorstehende Update Bei der neuen Version 3.1 von SFirm handelt es sich um eine eigenständige Installation, beide Versionen sind komplett
Updateanleitung für SFirm 3.1 Vorab einige Informationen über das bevorstehende Update Bei der neuen Version 3.1 von SFirm handelt es sich um eine eigenständige Installation, beide Versionen sind komplett
Datenübernahme easyjob 3.0 zu easyjob 4.0
 Datenübernahme easyjob 3.0 zu easyjob 4.0 Einführung...3 Systemanforderung easyjob 4.0...3 Vorgehensweise zur Umstellung zu easyjob 4.0...4 Installation easyjob 4.0 auf dem Server und Arbeitsstationen...4
Datenübernahme easyjob 3.0 zu easyjob 4.0 Einführung...3 Systemanforderung easyjob 4.0...3 Vorgehensweise zur Umstellung zu easyjob 4.0...4 Installation easyjob 4.0 auf dem Server und Arbeitsstationen...4
LabView7Express Gerätesteuerung über LAN in einer Client-Serverkonfiguration. 1. Steuerung eines VI über LAN
 LabView7Express Gerätesteuerung über LAN in einer Client-Serverkonfiguration Arbeitsblatt und Demonstration A. Rost 1. Steuerung eines VI über LAN Eine Möglichkeit zur Steuerung virtueller Instrumente
LabView7Express Gerätesteuerung über LAN in einer Client-Serverkonfiguration Arbeitsblatt und Demonstration A. Rost 1. Steuerung eines VI über LAN Eine Möglichkeit zur Steuerung virtueller Instrumente
In 12 Schritten zum mobilen PC mit Paragon Drive Copy 11 und Microsoft Windows Virtual PC
 PARAGON Technologie GmbH, Systemprogrammierung Heinrich-von-Stephan-Str. 5c 79100 Freiburg, Germany Tel. +49 (0) 761 59018201 Fax +49 (0) 761 59018130 Internet www.paragon-software.com Email sales@paragon-software.com
PARAGON Technologie GmbH, Systemprogrammierung Heinrich-von-Stephan-Str. 5c 79100 Freiburg, Germany Tel. +49 (0) 761 59018201 Fax +49 (0) 761 59018130 Internet www.paragon-software.com Email sales@paragon-software.com
Tipps und Tricks zu Netop Vision und Vision Pro
 Tipps und Tricks zu Netop Vision und Vision Pro Anwendungen auf Schülercomputer freigeben und starten Netop Vision ermöglicht Ihnen, Anwendungen und Dateien auf allen Schülercomputern gleichzeitig zu starten.
Tipps und Tricks zu Netop Vision und Vision Pro Anwendungen auf Schülercomputer freigeben und starten Netop Vision ermöglicht Ihnen, Anwendungen und Dateien auf allen Schülercomputern gleichzeitig zu starten.
Ihr IT-Administrator oder unser Support wird Ihnen im Zweifelsfall gerne weiterhelfen.
 Dieses Dokument beschreibt die nötigen Schritte für den Umstieg des von AMS.4 eingesetzten Firebird-Datenbankservers auf die Version 2.5. Beachten Sie dabei, dass diese Schritte nur bei einer Server-Installation
Dieses Dokument beschreibt die nötigen Schritte für den Umstieg des von AMS.4 eingesetzten Firebird-Datenbankservers auf die Version 2.5. Beachten Sie dabei, dass diese Schritte nur bei einer Server-Installation
Installationsanleitung dateiagent Pro
 Installationsanleitung dateiagent Pro Sehr geehrter Kunde, mit dieser Anleitung möchten wir Ihnen die Installation des dateiagent Pro so einfach wie möglich gestalten. Es ist jedoch eine Softwareinstallation
Installationsanleitung dateiagent Pro Sehr geehrter Kunde, mit dieser Anleitung möchten wir Ihnen die Installation des dateiagent Pro so einfach wie möglich gestalten. Es ist jedoch eine Softwareinstallation
Java Script für die Nutzung unseres Online-Bestellsystems
 Es erreichen uns immer wieder Anfragen bzgl. Java Script in Bezug auf unser Online-Bestell-System und unser Homepage. Mit dieser Anleitung möchten wir Ihnen einige Informationen, und Erklärungen geben,
Es erreichen uns immer wieder Anfragen bzgl. Java Script in Bezug auf unser Online-Bestell-System und unser Homepage. Mit dieser Anleitung möchten wir Ihnen einige Informationen, und Erklärungen geben,
Überprüfung der digital signierten E-Rechnung
 Überprüfung der digital signierten E-Rechnung Aufgrund des BMF-Erlasses vom Juli 2005 (BMF-010219/0183-IV/9/2005) gelten ab 01.01.2006 nur noch jene elektronischen Rechnungen als vorsteuerabzugspflichtig,
Überprüfung der digital signierten E-Rechnung Aufgrund des BMF-Erlasses vom Juli 2005 (BMF-010219/0183-IV/9/2005) gelten ab 01.01.2006 nur noch jene elektronischen Rechnungen als vorsteuerabzugspflichtig,
Handbuch für Lehrer. Wie Sie bettermarks im Mathe- Unterricht einsetzen können
 Handbuch für Lehrer Wie Sie bettermarks im Mathe- Unterricht einsetzen können Schulbuch, Arbeitsheft, Test- und Whiteboard- Tool Einsatzmöglichkeiten Schulbuch bettermarks bietet Themen- Einstiege, Übungen
Handbuch für Lehrer Wie Sie bettermarks im Mathe- Unterricht einsetzen können Schulbuch, Arbeitsheft, Test- und Whiteboard- Tool Einsatzmöglichkeiten Schulbuch bettermarks bietet Themen- Einstiege, Übungen
2. Einrichtung der ODBC-Schnittstelle aus orgamax (für 32-bit-Anwendungen)
") 1. Einführung: Über den ODBC-Zugriff können Sie bestimmte Daten aus Ihren orgamax-mandanten in anderen Anwendungen (beispielsweise Microsoft Excel oder Microsoft Access) einlesen. Dies bietet sich beispielsweise
1. Einführung: Über den ODBC-Zugriff können Sie bestimmte Daten aus Ihren orgamax-mandanten in anderen Anwendungen (beispielsweise Microsoft Excel oder Microsoft Access) einlesen. Dies bietet sich beispielsweise
Ein kleiner Einblick in die Welt der Supercomputer. Christian Krohn 07.12.2010 1
 Ein kleiner Einblick in die Welt der Supercomputer Christian Krohn 07.12.2010 1 Vorschub: FLOPS Entwicklung der Supercomputer Funktionsweisen von Supercomputern Zukunftsvisionen 2 Ein Top10 Supercomputer
Ein kleiner Einblick in die Welt der Supercomputer Christian Krohn 07.12.2010 1 Vorschub: FLOPS Entwicklung der Supercomputer Funktionsweisen von Supercomputern Zukunftsvisionen 2 Ein Top10 Supercomputer
OUTSOURCING ADVISOR. Analyse von SW-Anwendungen und IT-Dienstleistungen auf ihre Global Sourcing Eignung. Bewertung von Dienstleistern und Standorten
 Outsourcing Advisor Bewerten Sie Ihre Unternehmensanwendungen auf Global Sourcing Eignung, Wirtschaftlichkeit und wählen Sie den idealen Dienstleister aus. OUTSOURCING ADVISOR Der Outsourcing Advisor ist
Outsourcing Advisor Bewerten Sie Ihre Unternehmensanwendungen auf Global Sourcing Eignung, Wirtschaftlichkeit und wählen Sie den idealen Dienstleister aus. OUTSOURCING ADVISOR Der Outsourcing Advisor ist
Zahlen und das Hüten von Geheimnissen (G. Wiese, 23. April 2009)
") Zahlen und das Hüten von Geheimnissen (G. Wiese, 23. April 2009) Probleme unseres Alltags E-Mails lesen: Niemand außer mir soll meine Mails lesen! Geld abheben mit der EC-Karte: Niemand außer mir soll
Zahlen und das Hüten von Geheimnissen (G. Wiese, 23. April 2009) Probleme unseres Alltags E-Mails lesen: Niemand außer mir soll meine Mails lesen! Geld abheben mit der EC-Karte: Niemand außer mir soll
Terminabgleich mit Mobiltelefonen
 Terminabgleich mit Mobiltelefonen Sie können Termine- und Aufgaben aus unserem Kalender, sowie die Adressdaten aus dem Hauptprogramm mit Ihrem Mobiltelefon abgleichen. MS Outlook dient dabei als Schnittstelle
Terminabgleich mit Mobiltelefonen Sie können Termine- und Aufgaben aus unserem Kalender, sowie die Adressdaten aus dem Hauptprogramm mit Ihrem Mobiltelefon abgleichen. MS Outlook dient dabei als Schnittstelle
Lineargleichungssysteme: Additions-/ Subtraktionsverfahren
 Lineargleichungssysteme: Additions-/ Subtraktionsverfahren W. Kippels 22. Februar 2014 Inhaltsverzeichnis 1 Einleitung 2 2 Lineargleichungssysteme zweiten Grades 2 3 Lineargleichungssysteme höheren als
Lineargleichungssysteme: Additions-/ Subtraktionsverfahren W. Kippels 22. Februar 2014 Inhaltsverzeichnis 1 Einleitung 2 2 Lineargleichungssysteme zweiten Grades 2 3 Lineargleichungssysteme höheren als
Wichtige Hinweise zu den neuen Orientierungshilfen der Architekten-/Objektplanerverträge
 Wichtige Hinweise zu den neuen Orientierungshilfen der Architekten-/Objektplanerverträge Ab der Version forma 5.5 handelt es sich bei den Orientierungshilfen der Architekten-/Objektplanerverträge nicht
Wichtige Hinweise zu den neuen Orientierungshilfen der Architekten-/Objektplanerverträge Ab der Version forma 5.5 handelt es sich bei den Orientierungshilfen der Architekten-/Objektplanerverträge nicht
Übungen zur Softwaretechnik
 Technische Universität München Fakultät für Informatik Lehrstuhl IV: Software & Systems Engineering Markus Pister, Dr. Bernhard Rumpe WS 2002/2003 Lösungsblatt 9 17. Dezember 2002 www4.in.tum.de/~rumpe/se
Technische Universität München Fakultät für Informatik Lehrstuhl IV: Software & Systems Engineering Markus Pister, Dr. Bernhard Rumpe WS 2002/2003 Lösungsblatt 9 17. Dezember 2002 www4.in.tum.de/~rumpe/se
Auslesen der Fahrtdaten wiederholen Schritt für Schritt erklärt (Funktion Abfrage zur Datensicherung erstellen )
") + twinline GmbH + Am Heidekrug 28 + D-16727 Velten Auslesen der Fahrtdaten wiederholen Schritt für Schritt erklärt (Funktion Abfrage zur Datensicherung erstellen ) Der gewöhnliche Auslesevorgang der aktuellen
+ twinline GmbH + Am Heidekrug 28 + D-16727 Velten Auslesen der Fahrtdaten wiederholen Schritt für Schritt erklärt (Funktion Abfrage zur Datensicherung erstellen ) Der gewöhnliche Auslesevorgang der aktuellen
Installationsanleitung
 Installationsanleitung zu @Schule.rlp (2015) Inhaltsverzeichnis Inhaltsverzeichnis... 1 Voraussetzungen... 2 vorbereitende Aufgaben... 3 Installation @Schule.rlp (2015):... 3 Installation Java SE Runtime
Installationsanleitung zu @Schule.rlp (2015) Inhaltsverzeichnis Inhaltsverzeichnis... 1 Voraussetzungen... 2 vorbereitende Aufgaben... 3 Installation @Schule.rlp (2015):... 3 Installation Java SE Runtime
Task: Nmap Skripte ausführen
 Task: Nmap Skripte ausführen Inhalt Einfache Netzwerkscans mit NSE Ausführen des Scans Anpassung der Parameter Einleitung Copyright 2009-2015 Greenbone Networks GmbH Herkunft und aktuellste Version dieses
Task: Nmap Skripte ausführen Inhalt Einfache Netzwerkscans mit NSE Ausführen des Scans Anpassung der Parameter Einleitung Copyright 2009-2015 Greenbone Networks GmbH Herkunft und aktuellste Version dieses
Lizenzen auschecken. Was ist zu tun?
 Use case Lizenzen auschecken Ihr Unternehmen hat eine Netzwerk-Commuterlizenz mit beispielsweise 4 Lizenzen. Am Freitag wollen Sie Ihren Laptop mit nach Hause nehmen, um dort am Wochenende weiter zu arbeiten.
Use case Lizenzen auschecken Ihr Unternehmen hat eine Netzwerk-Commuterlizenz mit beispielsweise 4 Lizenzen. Am Freitag wollen Sie Ihren Laptop mit nach Hause nehmen, um dort am Wochenende weiter zu arbeiten.
4D Server v12 64-bit Version BETA VERSION
 4D Server v12 64-bit Version BETA VERSION 4D Server v12 unterstützt jetzt das Windows 64-bit Betriebssystem. Hauptvorteil der 64-bit Technologie ist die rundum verbesserte Performance der Anwendungen und
4D Server v12 64-bit Version BETA VERSION 4D Server v12 unterstützt jetzt das Windows 64-bit Betriebssystem. Hauptvorteil der 64-bit Technologie ist die rundum verbesserte Performance der Anwendungen und
2. Installation unter Windows 8.1 mit Internetexplorer 11.0
 1. Allgemeines Der Zugang zum Landesnetz stellt folgende Anforderungen an die Software: Betriebssystem: Windows 7 32- / 64-bit Windows 8.1 64-bit Windows Server 2K8 R2 Webbrowser: Microsoft Internet Explorer
1. Allgemeines Der Zugang zum Landesnetz stellt folgende Anforderungen an die Software: Betriebssystem: Windows 7 32- / 64-bit Windows 8.1 64-bit Windows Server 2K8 R2 Webbrowser: Microsoft Internet Explorer
Avira Management Console 2.6.1 Optimierung für großes Netzwerk. Kurzanleitung
 Avira Management Console 2.6.1 Optimierung für großes Netzwerk Kurzanleitung Inhaltsverzeichnis 1. Einleitung... 3 2. Aktivieren des Pull-Modus für den AMC Agent... 3 3. Ereignisse des AMC Agent festlegen...
Avira Management Console 2.6.1 Optimierung für großes Netzwerk Kurzanleitung Inhaltsverzeichnis 1. Einleitung... 3 2. Aktivieren des Pull-Modus für den AMC Agent... 3 3. Ereignisse des AMC Agent festlegen...
Kommunikations-Management
 Tutorial: Wie kann ich E-Mails schreiben? Im vorliegenden Tutorial lernen Sie, wie Sie in myfactory E-Mails schreiben können. In myfactory können Sie jederzeit schnell und einfach E-Mails verfassen egal
Tutorial: Wie kann ich E-Mails schreiben? Im vorliegenden Tutorial lernen Sie, wie Sie in myfactory E-Mails schreiben können. In myfactory können Sie jederzeit schnell und einfach E-Mails verfassen egal
Das große ElterngeldPlus 1x1. Alles über das ElterngeldPlus. Wer kann ElterngeldPlus beantragen? ElterngeldPlus verstehen ein paar einleitende Fakten
 Das große x -4 Alles über das Wer kann beantragen? Generell kann jeder beantragen! Eltern (Mütter UND Väter), die schon während ihrer Elternzeit wieder in Teilzeit arbeiten möchten. Eltern, die während
Das große x -4 Alles über das Wer kann beantragen? Generell kann jeder beantragen! Eltern (Mütter UND Väter), die schon während ihrer Elternzeit wieder in Teilzeit arbeiten möchten. Eltern, die während
Facharbeit Informatik. Thema:
 Facharbeit Informatik Thema: Rechneraufbau Mit Locad 2002 1 Inhaltsangabe Inhalt: Seite: 1. Einleitung 3 2. Inbetriebnahme der Schaltung 3 3. Eingabe 4 4. CPU 5 5. RAM/HDD 8 6. Ausgabe 10 7. Auf einer
Facharbeit Informatik Thema: Rechneraufbau Mit Locad 2002 1 Inhaltsangabe Inhalt: Seite: 1. Einleitung 3 2. Inbetriebnahme der Schaltung 3 3. Eingabe 4 4. CPU 5 5. RAM/HDD 8 6. Ausgabe 10 7. Auf einer
SJ OFFICE - Update 3.0
 SJ OFFICE - Update 3.0 Das Update auf die vorherige Version 2.0 kostet netto Euro 75,00 für die erste Lizenz. Das Update für weitere Lizenzen kostet jeweils netto Euro 18,75 (25%). inkl. Programmsupport
SJ OFFICE - Update 3.0 Das Update auf die vorherige Version 2.0 kostet netto Euro 75,00 für die erste Lizenz. Das Update für weitere Lizenzen kostet jeweils netto Euro 18,75 (25%). inkl. Programmsupport
1. Bearbeite Host Netzgruppen
 1. Bearbeite Host Netzgruppen Eine "Host Netzgruppe" (von jetzt an Netzgruppe) kann mit einer Gästeliste, wenn Sie jemand zu einer Party einladen, verglichen werden. Sie haben eine Gästeliste erstellt
1. Bearbeite Host Netzgruppen Eine "Host Netzgruppe" (von jetzt an Netzgruppe) kann mit einer Gästeliste, wenn Sie jemand zu einer Party einladen, verglichen werden. Sie haben eine Gästeliste erstellt
PRAKTISCHE BEISPIELE FÜR SCHREIBTISCHARBEIT. Unterpunkt 2.5
 PRAKTISCHE BEISPIELE FÜR SCHREIBTISCHARBEIT Unterpunkt 2.5 Um die beruflichen Fähigkeiten einer Person mit Schwerbehinderung bei Schreibtischtätigkeiten, zu beurteilen ist es wesentlich, in der simulierten
PRAKTISCHE BEISPIELE FÜR SCHREIBTISCHARBEIT Unterpunkt 2.5 Um die beruflichen Fähigkeiten einer Person mit Schwerbehinderung bei Schreibtischtätigkeiten, zu beurteilen ist es wesentlich, in der simulierten
Installation SPSS Netzwerkversion (Mac)
") Installation SPSS Netzwerkversion (Mac) (V1, 2.7.2014) Vor der Installation Schritt 1 Lesen Sie bitte diesen Text und die folgende Anleitung gründlich! Unnötigen Nachfragen verzögern bei derartigen Massengeschäften
Installation SPSS Netzwerkversion (Mac) (V1, 2.7.2014) Vor der Installation Schritt 1 Lesen Sie bitte diesen Text und die folgende Anleitung gründlich! Unnötigen Nachfragen verzögern bei derartigen Massengeschäften
Online Newsletter III
 Online Newsletter III Hallo zusammen! Aus aktuellem Anlass wurde ein neuer Newsletter fällig. Die wichtigste Neuerung betrifft unseren Webshop mit dem Namen ehbshop! Am Montag 17.10.11 wurde die Testphase
Online Newsletter III Hallo zusammen! Aus aktuellem Anlass wurde ein neuer Newsletter fällig. Die wichtigste Neuerung betrifft unseren Webshop mit dem Namen ehbshop! Am Montag 17.10.11 wurde die Testphase
PQ Explorer. Netzübergreifende Power Quality Analyse. Copyright by Enetech 2000-2010 www.enetech.de Alle Rechte vorbehalten. ros@enetech.
 1 PQ Explorer Netzübergreifende Power Quality Analyse 2 Ortsunabhängige Analyse: so einfach, wie noch nie PQ-Explorer ist ein Instrument, das die Kontrolle und Überwachung von Energieversorgungsnetzen
1 PQ Explorer Netzübergreifende Power Quality Analyse 2 Ortsunabhängige Analyse: so einfach, wie noch nie PQ-Explorer ist ein Instrument, das die Kontrolle und Überwachung von Energieversorgungsnetzen
Festigkeit von FDM-3D-Druckteilen
 Festigkeit von FDM-3D-Druckteilen Häufig werden bei 3D-Druck-Filamenten die Kunststoff-Festigkeit und physikalischen Eigenschaften diskutiert ohne die Einflüsse der Geometrie und der Verschweißung der
Festigkeit von FDM-3D-Druckteilen Häufig werden bei 3D-Druck-Filamenten die Kunststoff-Festigkeit und physikalischen Eigenschaften diskutiert ohne die Einflüsse der Geometrie und der Verschweißung der
Windows 10 > Fragen über Fragen
 www.computeria-olten.ch Monatstreff für Menschen ab 50 Merkblatt 103 Windows 10 > Fragen über Fragen Was ist das? Muss ich dieses Upgrade machen? Was bringt mir das neue Programm? Wie / wann muss ich es
www.computeria-olten.ch Monatstreff für Menschen ab 50 Merkblatt 103 Windows 10 > Fragen über Fragen Was ist das? Muss ich dieses Upgrade machen? Was bringt mir das neue Programm? Wie / wann muss ich es
2 Die Terminaldienste Prüfungsanforderungen von Microsoft: Lernziele:
 2 Die Terminaldienste Prüfungsanforderungen von Microsoft: Configuring Terminal Services o Configure Windows Server 2008 Terminal Services RemoteApp (TS RemoteApp) o Configure Terminal Services Gateway
2 Die Terminaldienste Prüfungsanforderungen von Microsoft: Configuring Terminal Services o Configure Windows Server 2008 Terminal Services RemoteApp (TS RemoteApp) o Configure Terminal Services Gateway
E-Mail-Inhalte an cobra übergeben
 E-Mail-Inhalte an cobra übergeben Sie bieten ihren potentiellen oder schon bestehenden Kunden über ihre Website die Möglichkeit, per Bestellformular verschiedene Infomaterialien in Papierform abzurufen?
E-Mail-Inhalte an cobra übergeben Sie bieten ihren potentiellen oder schon bestehenden Kunden über ihre Website die Möglichkeit, per Bestellformular verschiedene Infomaterialien in Papierform abzurufen?
Daten Sichern mit dem QNAP NetBak Replicator 4.0
 Daten Sichern mit dem QNAP NetBak Replicator 4.0 Was ist NetBak Replicator: Der NetBak Replicator ist ein Backup-Programm von QNAP für Windows, mit dem sich eine Sicherung von Daten in die Giri-Cloud vornehmen
Daten Sichern mit dem QNAP NetBak Replicator 4.0 Was ist NetBak Replicator: Der NetBak Replicator ist ein Backup-Programm von QNAP für Windows, mit dem sich eine Sicherung von Daten in die Giri-Cloud vornehmen
Anbindung LMS an Siemens S7. Information
 Datum: 18.09.2003 Status: Autor: Datei: Lieferzustand Rödenbeck Dokument1 Versio n Änderung Name Datum 1.0 Erstellt TC 18.09.03 Seite 1 von 1 Inhalt 1 Allgemein...3 2 Komponenten...3 3 Visualisierung...4
Datum: 18.09.2003 Status: Autor: Datei: Lieferzustand Rödenbeck Dokument1 Versio n Änderung Name Datum 1.0 Erstellt TC 18.09.03 Seite 1 von 1 Inhalt 1 Allgemein...3 2 Komponenten...3 3 Visualisierung...4
Unterrichtsmaterialien in digitaler und in gedruckter Form. Auszug aus: Portfolio: "Die Ratten" von Gerhart Hauptmann
 Unterrichtsmaterialien in digitaler und in gedruckter Form Auszug aus: Portfolio: "Die Ratten" von Gerhart Hauptmann Das komplette Material finden Sie hier: Download bei School-Scout.de Titel: man zum
Unterrichtsmaterialien in digitaler und in gedruckter Form Auszug aus: Portfolio: "Die Ratten" von Gerhart Hauptmann Das komplette Material finden Sie hier: Download bei School-Scout.de Titel: man zum
Folgende Einstellungen sind notwendig, damit die Kommunikation zwischen Server und Client funktioniert:
 Firewall für Lexware professional konfigurieren Inhaltsverzeichnis: 1. Allgemein... 1 2. Einstellungen... 1 3. Windows XP SP2 und Windows 2003 Server SP1 Firewall...1 4. Bitdefender 9... 5 5. Norton Personal
Firewall für Lexware professional konfigurieren Inhaltsverzeichnis: 1. Allgemein... 1 2. Einstellungen... 1 3. Windows XP SP2 und Windows 2003 Server SP1 Firewall...1 4. Bitdefender 9... 5 5. Norton Personal
Kurze Anleitung zum Guthaben-Aufladen bei. www.blau.de
 Kurze Anleitung zum Guthaben-Aufladen bei www.blau.de Seite 1 von 8 Inhaltsverzeichnis 1 blau.de aufrufen... 3 2 Ihr Konto bei blau.de... 4 2.1 Aufladen über das Internet... 5 2.2 Aufladen direkt am Mobiltelefon
Kurze Anleitung zum Guthaben-Aufladen bei www.blau.de Seite 1 von 8 Inhaltsverzeichnis 1 blau.de aufrufen... 3 2 Ihr Konto bei blau.de... 4 2.1 Aufladen über das Internet... 5 2.2 Aufladen direkt am Mobiltelefon
SafeRun-Modus: Die Sichere Umgebung für die Ausführung von Programmen
 SafeRun-Modus: Die Sichere Umgebung für die Ausführung von Programmen Um die maximale Sicherheit für das Betriebssystem und Ihre persönlichen Daten zu gewährleisten, können Sie Programme von Drittherstellern
SafeRun-Modus: Die Sichere Umgebung für die Ausführung von Programmen Um die maximale Sicherheit für das Betriebssystem und Ihre persönlichen Daten zu gewährleisten, können Sie Programme von Drittherstellern
ACDSee Pro 2. ACDSee Pro 2 Tutorials: Übertragung von Fotos (+ Datenbank) auf einen anderen Computer. Über Metadaten und die Datenbank
 auf einen anderen Computer. Über Metadaten und die Datenbank") Tutorials: Übertragung von Fotos (+ ) auf einen anderen Computer Export der In dieser Lektion erfahren Sie, wie Sie am effektivsten Fotos von einem Computer auf einen anderen übertragen. Wenn Sie Ihre
Tutorials: Übertragung von Fotos (+ ) auf einen anderen Computer Export der In dieser Lektion erfahren Sie, wie Sie am effektivsten Fotos von einem Computer auf einen anderen übertragen. Wenn Sie Ihre
Technische Voraussetzungen und Kompatibilitätsliste GemDat/Rubin
 Technische Voraussetzungen und Kompatibilitätsliste GemDat/Rubin Zielgruppe Kunde und GemDat Informatik AG Freigabedatum 5. April 20 Version 1.43 Status Freigegeben Copyright 20 by GemDat Informatik AG
Technische Voraussetzungen und Kompatibilitätsliste GemDat/Rubin Zielgruppe Kunde und GemDat Informatik AG Freigabedatum 5. April 20 Version 1.43 Status Freigegeben Copyright 20 by GemDat Informatik AG
Bilder zum Upload verkleinern
 Seite 1 von 9 Bilder zum Upload verkleinern Teil 1: Maße der Bilder verändern Um Bilder in ihren Abmessungen zu verkleinern benutze ich die Freeware Irfan View. Die Software biete zwar noch einiges mehr
Seite 1 von 9 Bilder zum Upload verkleinern Teil 1: Maße der Bilder verändern Um Bilder in ihren Abmessungen zu verkleinern benutze ich die Freeware Irfan View. Die Software biete zwar noch einiges mehr
Internet online Update (Internet Explorer)
") Um Ihr Consoir Beta immer schnell und umkompliziert auf den aktuellsten Stand zu bringen, bieten wir allen Kunden ein Internet Update an. Öffnen Sie Ihren Internetexplorer und gehen auf unsere Internetseite:
Um Ihr Consoir Beta immer schnell und umkompliziert auf den aktuellsten Stand zu bringen, bieten wir allen Kunden ein Internet Update an. Öffnen Sie Ihren Internetexplorer und gehen auf unsere Internetseite:
Neuerungen PRIMUS 2014
 SEPA Der Zahlungsverkehr wird europäisch Ist Ihr Unternehmen fit für SEPA? Mit PRIMUS 2014 sind Sie auf SEPA vorbereitet. SEPA betrifft auch Sie. Spätestens ab August 2014 gibt es vor der Single European
SEPA Der Zahlungsverkehr wird europäisch Ist Ihr Unternehmen fit für SEPA? Mit PRIMUS 2014 sind Sie auf SEPA vorbereitet. SEPA betrifft auch Sie. Spätestens ab August 2014 gibt es vor der Single European
Rillsoft Project - Installation der Software
 Rillsoft Project - Installation der Software Dieser Leitfaden in 6 Schritten soll Sie schrittweise durch die Erst-Installation von Rillsoft Project führen. Beachten Sie bitte im Vorfeld die nachstehenden
Rillsoft Project - Installation der Software Dieser Leitfaden in 6 Schritten soll Sie schrittweise durch die Erst-Installation von Rillsoft Project führen. Beachten Sie bitte im Vorfeld die nachstehenden
Grundlagen der Informatik
 Mag. Christian Gürtler Programmierung Grundlagen der Informatik 2011 Inhaltsverzeichnis I. Allgemeines 3 1. Zahlensysteme 4 1.1. ganze Zahlen...................................... 4 1.1.1. Umrechnungen.................................
Mag. Christian Gürtler Programmierung Grundlagen der Informatik 2011 Inhaltsverzeichnis I. Allgemeines 3 1. Zahlensysteme 4 1.1. ganze Zahlen...................................... 4 1.1.1. Umrechnungen.................................
ALEMÃO. Text 1. Lernen, lernen, lernen
 ALEMÃO Text 1 Lernen, lernen, lernen Der Mai ist für viele deutsche Jugendliche keine schöne Zeit. Denn dann müssen sie in vielen Bundesländern die Abiturprüfungen schreiben. Das heiβt: lernen, lernen,
ALEMÃO Text 1 Lernen, lernen, lernen Der Mai ist für viele deutsche Jugendliche keine schöne Zeit. Denn dann müssen sie in vielen Bundesländern die Abiturprüfungen schreiben. Das heiβt: lernen, lernen,
Grundfunktionen und Bedienung
 Kapitel 13 Mit der App Health ist eine neue Anwendung in ios 8 enthalten, die von vorangegangenen Betriebssystemen bislang nicht geboten wurde. Health fungiert dabei als Aggregator für die Daten von Fitness-
Kapitel 13 Mit der App Health ist eine neue Anwendung in ios 8 enthalten, die von vorangegangenen Betriebssystemen bislang nicht geboten wurde. Health fungiert dabei als Aggregator für die Daten von Fitness-
2. Die eigenen Benutzerdaten aus orgamax müssen bekannt sein
 Einrichtung von orgamax-mobil Um die App orgamax Heute auf Ihrem Smartphone nutzen zu können, ist eine einmalige Einrichtung auf Ihrem orgamax Rechner (bei Einzelplatz) oder Ihrem orgamax Server (Mehrplatz)
Einrichtung von orgamax-mobil Um die App orgamax Heute auf Ihrem Smartphone nutzen zu können, ist eine einmalige Einrichtung auf Ihrem orgamax Rechner (bei Einzelplatz) oder Ihrem orgamax Server (Mehrplatz)
Persönliches Adressbuch
 Persönliches Adressbuch Persönliches Adressbuch Seite 1 Persönliches Adressbuch Seite 2 Inhaltsverzeichnis 1. WICHTIGE INFORMATIONEN ZUR BEDIENUNG VON CUMULUS 4 2. ALLGEMEINE INFORMATIONEN ZUM PERSÖNLICHEN
Persönliches Adressbuch Persönliches Adressbuch Seite 1 Persönliches Adressbuch Seite 2 Inhaltsverzeichnis 1. WICHTIGE INFORMATIONEN ZUR BEDIENUNG VON CUMULUS 4 2. ALLGEMEINE INFORMATIONEN ZUM PERSÖNLICHEN
Cambridge ESOL BULATS Online FAQs Konfiguration des Internet Explorers
 Cambridge ESOL BULATS Online FAQs Konfiguration des Internet Explorers Page 1 of 7 Version 1.2 Inhalt 1.1 Einführung... 3 1.2 Vertrauenswürdige Sites... 4 1.3 Pop-up Blocker... 5 1.4 Zugriff auf die lokale
Cambridge ESOL BULATS Online FAQs Konfiguration des Internet Explorers Page 1 of 7 Version 1.2 Inhalt 1.1 Einführung... 3 1.2 Vertrauenswürdige Sites... 4 1.3 Pop-up Blocker... 5 1.4 Zugriff auf die lokale
Unsere Produkte. Wir automatisieren Ihren Waren- und Informationsfluss. Wir unterstützen Ihren Verkaufsaußendienst.
 Die clevere Auftragserfassung Unsere Produkte Das smarte Lagerverwaltungssystem Die Warenwirtschaft für den Handel Wir unterstützen Ihren Verkaufsaußendienst. Wir automatisieren Ihren Waren- und Informationsfluss.
Die clevere Auftragserfassung Unsere Produkte Das smarte Lagerverwaltungssystem Die Warenwirtschaft für den Handel Wir unterstützen Ihren Verkaufsaußendienst. Wir automatisieren Ihren Waren- und Informationsfluss.
Einrichten eines Postfachs mit Outlook Express / Outlook bis Version 2000
 Folgende Anleitung beschreibt, wie Sie ein bestehendes Postfach in Outlook Express, bzw. Microsoft Outlook bis Version 2000 einrichten können. 1. Öffnen Sie im Menü die Punkte Extras und anschließend Konten
Folgende Anleitung beschreibt, wie Sie ein bestehendes Postfach in Outlook Express, bzw. Microsoft Outlook bis Version 2000 einrichten können. 1. Öffnen Sie im Menü die Punkte Extras und anschließend Konten
Inhalt. 1 Einleitung AUTOMATISCHE DATENSICHERUNG AUF EINEN CLOUDSPEICHER
 AUTOMATISCHE DATENSICHERUNG AUF EINEN CLOUDSPEICHER Inhalt 1 Einleitung... 1 2 Einrichtung der Aufgabe für die automatische Sicherung... 2 2.1 Die Aufgabenplanung... 2 2.2 Der erste Testlauf... 9 3 Problembehebung...
AUTOMATISCHE DATENSICHERUNG AUF EINEN CLOUDSPEICHER Inhalt 1 Einleitung... 1 2 Einrichtung der Aufgabe für die automatische Sicherung... 2 2.1 Die Aufgabenplanung... 2 2.2 Der erste Testlauf... 9 3 Problembehebung...
GITS Steckbriefe 1.9 - Tutorial
 Allgemeines Die Steckbriefkomponente basiert auf der CONTACTS XTD Komponente von Kurt Banfi, welche erheblich modifiziert bzw. angepasst wurde. Zuerst war nur eine kleine Änderung der Komponente für ein
Allgemeines Die Steckbriefkomponente basiert auf der CONTACTS XTD Komponente von Kurt Banfi, welche erheblich modifiziert bzw. angepasst wurde. Zuerst war nur eine kleine Änderung der Komponente für ein
Anleitung zur Installation und Nutzung des Sony PRS-T1 ebook Readers
 Anleitung zur Installation und Nutzung des Sony PRS-T1 ebook Readers Der neue Sony PRS-T1 ebook-reader ist nicht mehr mit dem Programm Adobe Digital Editions zu bedienen. Es sind daher einige Schritte
Anleitung zur Installation und Nutzung des Sony PRS-T1 ebook Readers Der neue Sony PRS-T1 ebook-reader ist nicht mehr mit dem Programm Adobe Digital Editions zu bedienen. Es sind daher einige Schritte
Stammdaten Auftragserfassung Produktionsbearbeitung Bestellwesen Cloud Computing
 Stammdaten Auftragserfassung Produktionsbearbeitung Bestellwesen Cloud Computing Finanzbuchhaltung Wenn Sie Fragen haben, dann rufen Sie uns an, wir helfen Ihnen gerne weiter - mit Ihrem Wartungsvertrag
Stammdaten Auftragserfassung Produktionsbearbeitung Bestellwesen Cloud Computing Finanzbuchhaltung Wenn Sie Fragen haben, dann rufen Sie uns an, wir helfen Ihnen gerne weiter - mit Ihrem Wartungsvertrag
Anleitung zur Installation und Nutzung des Sony PRS-T1 ebook Readers
 Anleitung zur Installation und Nutzung des Sony PRS-T1 ebook Readers Der neue Sony PRS-T1 ebook-reader ist nicht mehr mit dem Programm Adobe Digital Editions zu bedienen. Es sind daher einige Schritte
Anleitung zur Installation und Nutzung des Sony PRS-T1 ebook Readers Der neue Sony PRS-T1 ebook-reader ist nicht mehr mit dem Programm Adobe Digital Editions zu bedienen. Es sind daher einige Schritte
Installation und Inbetriebnahme von SolidWorks
 Inhaltsverzeichnis FAKULTÄT FÜR INGENIEURWISSENSCHAFTEN I Prof. Dr.-Ing. Frank Lobeck Installation und Inbetriebnahme von SolidWorks Inhaltsverzeichnis Inhaltsverzeichnis... I 1. Einleitung... 1 2. Installation...
Inhaltsverzeichnis FAKULTÄT FÜR INGENIEURWISSENSCHAFTEN I Prof. Dr.-Ing. Frank Lobeck Installation und Inbetriebnahme von SolidWorks Inhaltsverzeichnis Inhaltsverzeichnis... I 1. Einleitung... 1 2. Installation...
AZK 1- Freistil. Der Dialog "Arbeitszeitkonten" Grundsätzliches zum Dialog "Arbeitszeitkonten"
 AZK 1- Freistil Nur bei Bedarf werden dafür gekennzeichnete Lohnbestandteile (Stundenzahl und Stundensatz) zwischen dem aktuellen Bruttolohnjournal und dem AZK ausgetauscht. Das Ansparen und das Auszahlen
AZK 1- Freistil Nur bei Bedarf werden dafür gekennzeichnete Lohnbestandteile (Stundenzahl und Stundensatz) zwischen dem aktuellen Bruttolohnjournal und dem AZK ausgetauscht. Das Ansparen und das Auszahlen
EOS Utility WLAN Installation
 EOS Utility WLAN Installation Kameramodelle: EOS-1D X (WFT-E6), EOS-1D C (WFT-E6), EOS-1Ds Mark III (WFT-E2(II), EOS-1D Mark IV (WFT-E2(II), EOS 1D Mark III (WFT-E2(II), EOS 5D Mark III (WFT-E7), EOS 5D
EOS Utility WLAN Installation Kameramodelle: EOS-1D X (WFT-E6), EOS-1D C (WFT-E6), EOS-1Ds Mark III (WFT-E2(II), EOS-1D Mark IV (WFT-E2(II), EOS 1D Mark III (WFT-E2(II), EOS 5D Mark III (WFT-E7), EOS 5D
SharePoint Demonstration
 SharePoint Demonstration Was zeigt die Demonstration? Diese Demonstration soll den modernen Zugriff auf Daten und Informationen veranschaulichen und zeigen welche Vorteile sich dadurch in der Zusammenarbeit
SharePoint Demonstration Was zeigt die Demonstration? Diese Demonstration soll den modernen Zugriff auf Daten und Informationen veranschaulichen und zeigen welche Vorteile sich dadurch in der Zusammenarbeit
Checkliste für die Behebung des Problems, wenn der PC Garmin USB GPS-Geräte nicht erkennt.
 TITEL: Checkliste für die Behebung des Problems, wenn der PC Garmin USB GPS-Geräte nicht erkennt. BEREICH(E): GPS-Tracks.com ERSTELLT VON: Christian Steiner STATUS: Release 1.0 DATUM: 10. September 2006
TITEL: Checkliste für die Behebung des Problems, wenn der PC Garmin USB GPS-Geräte nicht erkennt. BEREICH(E): GPS-Tracks.com ERSTELLT VON: Christian Steiner STATUS: Release 1.0 DATUM: 10. September 2006
Installationsanleitung Maschinenkonfiguration und PP s. Release: VISI 21 Autor: Anja Gerlach Datum: 18. Dezember 2012 Update: 18.
 Installationsanleitung Maschinenkonfiguration und PP s Release: VISI 21 Autor: Anja Gerlach Datum: 18. Dezember 2012 Update: 18.Februar 2015 Inhaltsverzeichnis 1 Einbinden der Postprozessoren... 3 1.1
Installationsanleitung Maschinenkonfiguration und PP s Release: VISI 21 Autor: Anja Gerlach Datum: 18. Dezember 2012 Update: 18.Februar 2015 Inhaltsverzeichnis 1 Einbinden der Postprozessoren... 3 1.1
Flyer, Sharepics usw. mit LibreOffice oder OpenOffice erstellen
 Flyer, Sharepics usw. mit LibreOffice oder OpenOffice erstellen Wir wollen, dass ihr einfach für eure Ideen und Vorschläge werben könnt. Egal ob in ausgedruckten Flyern, oder in sozialen Netzwerken und
Flyer, Sharepics usw. mit LibreOffice oder OpenOffice erstellen Wir wollen, dass ihr einfach für eure Ideen und Vorschläge werben könnt. Egal ob in ausgedruckten Flyern, oder in sozialen Netzwerken und
Rechnung wählen Lernstandserfassung
 Rechnungen verstehen Richtige F1 Rechnung wählen Lernstandserfassung 1. Wie rechnen Sie? Höhe eines Personenwagens Schätzen Sie die Höhe des Gebäudes. Schätzen Sie die Grundfläche des Gebäudes. Schätzen
Rechnungen verstehen Richtige F1 Rechnung wählen Lernstandserfassung 1. Wie rechnen Sie? Höhe eines Personenwagens Schätzen Sie die Höhe des Gebäudes. Schätzen Sie die Grundfläche des Gebäudes. Schätzen
Daten verarbeiten. Binärzahlen
 Daten verarbeiten Binärzahlen In Digitalrechnern werden (fast) ausschließlich nur Binärzahlen eingesetzt. Das Binärzahlensystem ist das Stellenwertsystem mit der geringsten Anzahl von Ziffern. Es kennt
Daten verarbeiten Binärzahlen In Digitalrechnern werden (fast) ausschließlich nur Binärzahlen eingesetzt. Das Binärzahlensystem ist das Stellenwertsystem mit der geringsten Anzahl von Ziffern. Es kennt
10.05.2007 Universität Potsdam ZEIK - Zentrale Einrichtung für Informationsverarbeitung und Kommunikation
 10.05.2007 Universität Potsdam ZEIK - Zentrale Einrichtung für Informationsverarbeitung und Kommunikation Konfigurationsanleitungen MS Windows Server Update Services (WSUS) - Konfiguration Inhalt: 1. Konfiguration
10.05.2007 Universität Potsdam ZEIK - Zentrale Einrichtung für Informationsverarbeitung und Kommunikation Konfigurationsanleitungen MS Windows Server Update Services (WSUS) - Konfiguration Inhalt: 1. Konfiguration