Kapitel 1: Einführung, Normalisierung, Differentielle Gene, Multiples Testen. Kapitel 2: Clustering und Klassifikation
|
|
|
- Stephan Stieber
- vor 8 Jahren
- Abrufe
Transkript
1 Vorlesung MicroarrayDatenanalyse Kapitel1:Einführung,Normalisierung, DifferentielleGene,MultiplesTesten Kapitel2:ClusteringundKlassifikation

2 WassindDNA Microarrays? mrna Protein DNA

3 WassindDNA Microarrays? MicroarrayssindTechnologieplattformenzur MessungderAktivitäteinergroßenAnzahlvon Genen. DabeiwerdenihreProdukte(meistmRNA) quantifiziert. HierzuwerdenDNASequenzenverwendet,dieauf eineroberfläche(jenachplattformverschiedene) immobilisiertwerden. Vorlesung:MicroarrayDatenanalyse Kapitel1
 quantifiziert.")
4 WassindDNA Microarrays?...Microarrays...MessungderAktivitätvonGenen (...mrna). WelcheanderenMethodenkennenSie,die dieseszielverfolgen? Vorlesung:MicroarrayDatenanalyse Kapitel1

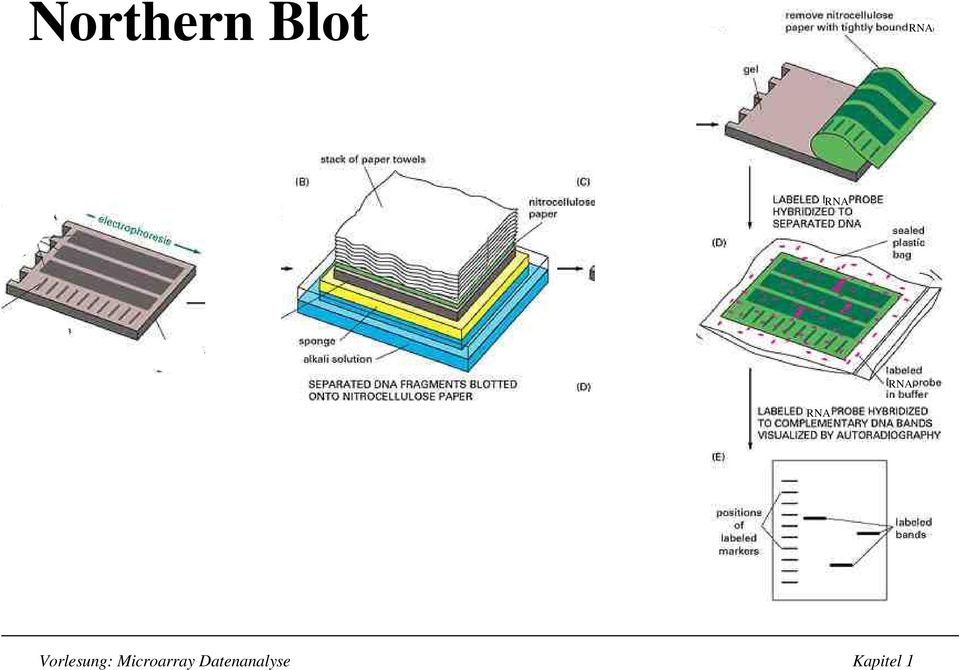
5 NorthernBlot RNA RNA RNA RNA Vorlesung:MicroarrayDatenanalyse Kapitel1
6 RT PCR RNA cdna 5 RNA 3 cdna dsdna Vorlesung:MicroarrayDatenanalyse DaRNAdurchPCRnicht direktamplifiziertwerden kann,mußsiezunächstin cdnaumgeschrieben werden(revers transkribiert,rt) ZurQuantifizierungsind zweiansätzemöglich: 1Internerendogener Standard(zB Housekeepinggene) 2KompetitiveRTPCR: ZugabevonsogMimic Fragmenten,dieder Reaktionzugegeben werdenundzusammen mitdereigentlichen Zielsequenzamplifiziert werden Kapitel1

7 SAGE=SerialAnalysisofGeneExpression Zellenisolieren mrnaisolierenundcdnasynthetisieren TranskriptmitAnchorEnzymschneiden Taggen LigierenderTags Sequenzierung Quantifizierung Vorlesung:MicroarrayDatenanalyse Kapitel1

8 WOZU? klassischesbeispiel: krankgesund Tumor(Niere) NormaleNiere RNA Präparation MESSUNG?! wasunterscheidet Tumor von Normal? Vorlesung:MicroarrayDatenanalyse Kapitel1

9 WOMIT? Plattformen Filter Vorlesung:MicroarrayDatenanalyse Glas chips Affymetrix Kapitel1

10 Plattformen Filter 1991 Lennon&Lehrach,1991 Vorlesung:MicroarrayDatenanalyse Glas chips 1995 StanfordUniversity, Schenaetal,1995 Affymetrix 1996 Lockhardtetal,1996 Kapitel2

11 Plattformen NylonFilter eineprobe radioaktivessignal vielespotsmöglich großefläche/lokaleeffekte Überstrahlen nureineprobeprohybri disierungsvorgang Vorlesung:MicroarrayDatenanalyse GlasTräger roteundgrüneprobe FloureszenzSignal bis~20000spotsmöglich gleichzeitigeshybridisieren vonprobeundkontrolle (rot/grün) Chip eineprobebestehendaus 16 20Wdh.undzugehörigen Mismatches kommerziellerchip gutereproduzierbaredaten nureineprobeprohybri disierungsvorgang Kapitel1

12 Grundprinzip u q Se 1 z en e u q e S 2 z n q e S n z n e u RNA cdnas oder Oligos Vorlesung:MicroarrayDatenanalyse Probe1 Probe2 Kapitel1

13 Grundprinzip Filter Vorlesung:MicroarrayDatenanalyse Glas chips Affymetrix Kapitel2 Kapitel1

14 Grundannahme DasgemesseneSignalspiegelt(nachgeeigneter Aufreinigung )grundsätzlichdiemengernainder Probewider Vorlesung:MicroarrayDatenanalyse Kapitel2 Kapitel1

15 VerarbeitungvonMicroarrayDaten: Biologie Diagnostik Therapie...? Experiment Design Experiment (Microarray)! Bildverarbeitung Rohe Intensitätswerte Biologische Verifikation Normalisierung ExpressionsLevel Analyse:Clustering;ClassDiscovery;Klassifikation;DifferentielleGene;... Vorlesung:MicroarrayDatenanalyse Kapitel1

16 WelcheNormalisierungsMethodengibtes? BenutzerdefinierteSets GesamterDatensatz Housekeeping(?!) InterneKontrollenetc Nützlichbei MostGenesUnchanged Settings Nützlichbei MostGenesChanged Settings Skalierungs methoden Mean Median Shorth Zscore Vorlesung:MicroarrayDatenanalyse Regressions methoden Transformations methoden gesamt linear/polynomial local linear/polynomial qspline Varianz Stabilisierung AnalysisofVariance/ MLbasedmethods Verteilungs basiert ANOVA Quantil Normalisierung Kapitel1

17 Beobachtung VarianzdergemessenenIntensitäthängtvonder absolutenintensitätab FuerjedenSpotk, wurdedievarianz(rk Gk)²/2gegendasMittel (Rk+Gk)/2geplottet. DieroteLiniezeigtden movingaverage Vorlesung:MicroarrayDatenanalyse Kapitel1

18 FehlerModellNotation i=1,...,dproben i k k=1, ngene Vorlesung:MicroarrayDatenanalyse Kapitel1

19 FehlerModell Vorlesung:MicroarrayDatenanalyse Kapitel1

20 i

21 i Yik = (ai + ε ik ) + (bi bk exp(ηik )) xik Yik ai ε ik + bi bk exp(ηik ) xik = bi bi Yik ai = (ε ik / bi ) + (bk xik ) exp(ηik ) bi ν ik mik
22 Beispiel:Fehler Modell RockeandDurbin(J.Comput.Biol.2001): η Yk = α + β k e + ν Yk:GemesseneIntensitätdesGensk k:wahresexpressionslevelvongenk :offset η,ν:multiplikativer/additiverfehler, Unabhängig,normalverteilt BeigrossenExpressionswertenbkistdermultiplikative Fehlerbesondersdominant. Fuerkleineb kistderadditivefehlerdominant.
23 ηki : N (0, σ ) 2 η Yik ai = ν ki + mki exp(ηik ) bi ν ki : N (0, σ 2ν ) E (Yik ) = ai + bi mik E (exp(ηki )) Var (Yik ) = Var (ν ki bi ) + Var (bi mki exp(ηki )) = c' b m +b σ 2 η 2 i 2 ki 2 i c ' = Var (exp(ηki )) 2 η 2 ν = c ( E (Yki ) ai ) + b σ 2 η 2 cη2 = c 'η2 / E 2 (exp(ηik )) 2 i 2 ν
24 Darausergibtsich var( E (Yik )) = c ( E (Yik ) a ) + b 2 2 NuntransformieredieDaten,sodassman konstantevarianzerhält,dienichtvommittelwert abhängt 2
25 Varianz StabilisierendeTransformation SeiYudieFamilievonzufälligenVariablenmit: EYu=u,VarYu=v(u).DefinieredieTransformation x h (x ) = 1 v(u ) du Varh(Yu) unabhängigvonu
26 Varianz StabilisierendeTransformation ar sinh( x) = log( x + x 2 + 1)
27 Die verallgemeinertelog Transformation f(x)=log(x) hs(x)=arsinh(x/s) intensity ( arsinh(x ) = log x + x2 + 1 ) W.Huberetal., ISMB2002 D.Rocke&B. Durbin,ISMB2002
28 Variancestabilizingtransform ations x f (x ) = 1 v(u ) v (u ) u 2 f log u 1.)constantCV( m ultiplicative ) 2.)offset du v (u ) (u + u0 )2 3.)additiveandm ultiplicative f log(u + u0 ) u + u0 v (u ) (u + u0 ) + s f arsinh s 2 2
29 RobusteParam eterschätzung Yki ai arsinh = µ k + ε ki, bi ε ki : N (0,c 2 ) Robustem axim um likelihoodschätzung M= { { a }, { b }, c, { µ } } i i k
30 VerarbeitungvonMicroarrayDaten: Biologie Diagnostik Therapie...? Experiment Design Experiment (Microarray)! Bildverarbeitung Rohe Intensitätswerte Biologische Verifikation Normalisierung ExpressionsLevel Analyse:Clustering;ClassDiscovery;Klassifikation;DifferentielleGene;... Vorlesung:MicroarrayDatenanalyse Kapitel1
31 DifferentielleGenefinden Patients,Samples,Timepoints... Genes Twocell/tissue/diseasetypes: wild type/mutant control/treated diseasea/diseaseb responding/nonresponding etc.etc... Foreverysample(cellline/patient)wehavethe expressionlevelsofthousandsofgenesand theinformationwhetheritisaorb
32 Logratio Isathree foldinducedgenemoretrust worthythanatwo foldinducedgene? Productintensity(logscale)
33 A B Conclusion:Inadditiontothe differencesingeneexpressionyou alsohaveavitalinterestinits variability...thisinformationis neededtoobtainmeaningfullists ofgenes A B
34 StandardDeviationandStandard Error StandardDeviation(SD):Variabilityofthe measurement StandardError(SE):Variabilityofthemeanof severalmeasurements nreplications NormalDistributedData:
35 Questions: Whichgenesaredifferentiallyexpressed? >Ranking Aretheseresults significant? >StatisticalAnalysis Thatmeans:Istheprobabilitysufficiently smallthattheresultis bychance?
36 Ranking: Problem:Produceanorderedlistof differentiallyexpressedgenesstarting withthemostupregulatedgeneand endingwiththemostdownregulated gene Rankingmeansfindingtherightgenes drawingourattentiontothem Inmanyapplicationsitisthemost importantstep
37 RankingisnotTesting Ranking:Findingtherightgenes Testing:Decidingwhethergenesare significant Thereismorethenonewaytorank Thereismorethenonewaytotest Thecriteriaforwhichrankingisbestis differentfromthecriteriawhichtestis best powerisoftennoargument
38 Ranking:OrderGenesduetoamountoffold change/score >maybesomethatarenotdifferential inreality(falsepositive) Genecandidate1 Genecandidate2 Genecandidate3 Genecandidate4 Genecandidate5 Genecandidate6 Genecandidate7 Genecandidate8 Genecandidate9 Gene... Orderduetosomescore, Intuitively:Foldchange 1st:mostdifferential, 2nd:secondmostdiff...
39 Testing:FindGenesduetoamountoffold change/scorewhicharesignificants.t.thereareless than5%falsepositives >maybeyoumisssome (FalseNegatives) Genecandidate1 Genecandidate2 Genecandidate3 Genecandidate4 Genecandidate5 Genecandidate6 Genecandidate7 Genecandidate8 Genecandidate9 Gene... Orderduetosomescore, Intuitively:Foldchange 1st:mostdifferential, 2nd:secondmostdiff...
40 Whichgeneismoredifferentially expressed?
41 RankingisScoring Youneedtoscoredifferential geneexpression Differentscoresleadtodifferent rankings Whatscoresarethere?

42 T Score Idea:Takevariancesintoaccount Change:lowChange:highChange:high Variance:highVariance:lowVariance:high
43 Change: HIGH Variance: SMALL Change: SMALL Variance: HIGH Thuge T~0
44 Change: HIGH Variance: HIGH Change: SMALL Variance: SMALL T? T?
45 TScore Ttest Pvalue BerechneTScoresfürein zufälligesexperiment ErstelleeinHistogrammderTscores undmarkieredie5%höchstenund niedrigsten(rot) BerechneTScorefürGenxund zeichnediesenein(grün) WiegroßistdieWahrscheinlichkeit,mindestenssoextremwiedergrüne Pfeilzusein?
46 T TestPROBLEMS Therearemanygenes( >tests)butonly fewrepetitions isusing s asestimategood? ifmeasuredvarianceissmallt becomeseasilyverylarge Therefore:formicroarrayitisreasonable touseamodfiedversionofthettest
47 FudgeFactors: Youneedtoestimatethevariancefromdata Youmightunderestimateaalreadysmallvariance (constantlyexpressedgenes) ThedenominatorinTbecomesreallysmall Constantlyexpressedgenesshowupontopofthelist Correction:Addaconstantfudgefactors0 RegularizedT score >Limma >SAM >Twilight
48 SAM:SignificanceAnalysisforMicroarrays X1 X 2 d (i ) = s (i ) + s0 s (i ) = a( ( xm (i ) X 1 ) + ( xn (i ) X 2 ) 2 m n 1/ n1 + 1/ n2 a= n1 + n2 2 2
49 MoreScores: WilcoxonScore(robust) PAUcScore(separation) pairedt Score(pairedData) F Score(morethen2conditions) Correlationtoareferencegene etcetc
50 Differentscoresgivedifferent rankings Krankheit1vsKrankheit2 (Golubetal.)
51 WhichScoreisthebest one? Thatdependsonyour problem...
52 NextQuestion: Ok,Ichoseascoreandfoundasetof candidategenes CanItrusttheobservedexpression differences? StatisticalAnalysis
53 P Values Everyoneknowsthatthep valuemust bebelow isaholynumberbothinmedicine andbiology...whatelseshouldyouknowaboutp values
54 Rumors Ifthegeneisnotdifferentially expressedthep valueishigh Ifthegeneisdifferentiallyexpressed thep valuesislow Boththesestatementsarewrong!
55 Reminder:TypeIandTypeIIERROR H1 Alternative Hypothesis: NOTH0 H0 NullHypothesis: GeneNOT differential Positive: Negative: rejectedh0(differentialgene) acceptedh0
56 Reminder:TypeIandTypeIIERROR H0H1
57 ThebasicIdeabehindp values: WeobserveascoreS=1.27 Canthisbejustarandomfluctuation? Assume:Itisarandomfluctuation =Thegeneisnotdifferentially expressed =Thenullhypothesisholds Theorygivesusthedistributionofthe scoreunderthisassumption P Value:Probabilitythatarandom scoreisequalorhighertos=1.27 inabsolutevalue(twosidedtest)
58 Permutationsandempiricalp values
59 Ifageneisnotdifferentiallyexpressed: Thep valueisarandomnumberbetween0and 1! Itisunlikelythatsuchanumberis below0.05(5%probability)
60 Ifageneisdifferentiallyexpressed: Thep valuehasnomeaning,sinceitwas computedundertheassumptionthatthegeneis notdifferentiallyexpressed. Wehopethatitissmallsincethescore ishigh,butthereisabsolutelyno theoreticalsupportforthis
61 Testingonlyonegene: Ifthegeneisnotdifferentially expressedasmallp valueisunlikely, henceweshouldbesurprisedbythis observation. Ifwemakeitarulethatwediscardthegeneif thep valuesisabove0.05,itisunlikelythata randomscorewillpassthisfilter
62 Multipletestingwithonlynon inducedgenes 1gene 10genes 30,000genes
63 TheMultipleTestingProblem P valuesarerandomnumbersbetween0and1.foronlyone suchnumberitisunlikelytofallinthissmallinterval,butifwe have30.000suchnumbersmanywillbeinthere.
64 Wetestmhypotheses truehypotheses rejectedhypotheses H0H1 TRUE FALSE Acctepted Rejected Error=falsepositive Error=falsenegative Error=falsepositive Error=falsenegative
65 FWER=Family wiseerrorrate: ProbabilityofatleastoneType1 error(falsepositive)among theaccepted(significant)genes H0H1 FALSE TRUE Accepted Rejected
66 FDR=FalseDiscoveryRate ExpectednumberofType1 errors(falsepositives)amongrejected hypotheses H0H1 FALSE TRUE Accepted Rejected with if if
67 Controllingthefamilywiseerrorrate (FWER) Ifwewanttoavoidrandomnumbersinthisinterval weneedtomakeitsmaller.themorenumbers,the smaller.for30.000numbersverysmall. Thisstrategyiscalled:Controllingthefamilywise errorrate
68 HowtocontroltheFWER? Note,thatadjustingtheintervalbordercanalsobe donebyadjustingthep valuesandleavingthecutoff at0.05. Therearemanywaystoadjustp valuesformultiple testing: Bonferroni: Better:WestfallandYoung
69 Inmicroarraystudiescontrollingthe FWERisnotagoodidea...Itistoo conservative. Adifferenttypeoferrormeasure becamemorepopular TheFalseDiscoveryRate Whatistheidea?
70 TheFDR Scoregenesandrankthem Chooseacutoff Looselyspeaking:TheFDRisthe bestguessforthenumberof falsepositivegenesthatscore abovethecutoff
71 Theconfusingliterature: Therearemanydifferentdefinitionsofthefalse discoveryrateintheliterature: Original:Benjamini Hochberg PositiveFDR ConditionalFDR LocalFDR Thereisalsoafundamentaldifferencebetween controllingandestimatingafdr
72 Inmicroarrayanalysisitbecame populartouseestimatedfdrs Differencestop values: TheFDRreferstoalistofgenes.Thep value referstoasinglegene. Thep valueisbasedontheassumptionthatthe geneisnotdifferentiallyexpressed,thefdr makesnosuchassumption. P valuesneedtobecorrectedformultiplicity, FDRsnot!
73 Anotherdifferenceinconcept: Ifa4xchangehasasmallp value,thismeansthat4xchange istoohightoberandomfluctuation Conclusion:4xchangeissignificant Ifalistof150geneswith4xchangeormorehasasmall estimatedfdrthismeansthatwehavemoregenesonthis levelthanwouldbeexpectedbychance. Conclusion:4xchangecanbenoise,but150genesonthat levelaretoomanytobeexplainedjustbyrandomfluctuation. InFWERAnalysisthefoldchange4xissignificant,inFDR Analysisitisthenumber150thatissignificant.
74 Histogramsofthep valuesofall genesonthearray
75 FWER:Verticalcutoff FDR:Horizontalcutoff
Was sind MICROARRAYS? Microarrays sind Technologieplattformen zur Messung der Aktivität einer großen Anzahl von Genen.
 MICROARRAYS Was sind Microarrays? Welche Technologieplattformen gibt es? Beispiel: Rot-Grün Chip Wie wird ein Chip hergestellt (Film)? Welche Fragen kann man mit Chips beantworten? Datenfluß: Experiment-Design
MICROARRAYS Was sind Microarrays? Welche Technologieplattformen gibt es? Beispiel: Rot-Grün Chip Wie wird ein Chip hergestellt (Film)? Welche Fragen kann man mit Chips beantworten? Datenfluß: Experiment-Design
Statistische Analyse von hochdimensionalen Daten in der Bioinformatik
 Statistische Analyse von hochdimensionalen Daten in der Bioinformatik Florian Frommlet Institut für medizinische Statistik, Medizinische Universität Wien Wien, November 2013 Einführung DNA Molekül Zwei
Statistische Analyse von hochdimensionalen Daten in der Bioinformatik Florian Frommlet Institut für medizinische Statistik, Medizinische Universität Wien Wien, November 2013 Einführung DNA Molekül Zwei
Bioinformatik Statistik und Analyse mit R 22.05.2009-1 -
 Bioinformatik Statistik und Analyse mit R 22.05.2009-1 - Definition: Bioinformatik Die Bioinformatik http://de.wikipedia.org/wiki/bioinformatik (englisch bioinformatics, auch computational biology) ist
Bioinformatik Statistik und Analyse mit R 22.05.2009-1 - Definition: Bioinformatik Die Bioinformatik http://de.wikipedia.org/wiki/bioinformatik (englisch bioinformatics, auch computational biology) ist
Statistische Analyse von hochdimensionalen Daten in der Bioinformatik
 Statistische Analyse von hochdimensionalen Daten in der Bioinformatik Florian Frommlet Institut für medizinische Statistik, Medizinische Universität Wien Wien, Jänner 2015 Einführung DNA Molekül Zwei komplementäre
Statistische Analyse von hochdimensionalen Daten in der Bioinformatik Florian Frommlet Institut für medizinische Statistik, Medizinische Universität Wien Wien, Jänner 2015 Einführung DNA Molekül Zwei komplementäre
Einführung in die Bioinformatik
 Einführung in die Bioinformatik Kay Nieselt SS 011 9. It s hip to chip - von Microarrays zu personalisierter Medizin WSI/ZBIT, Eberhard Karls Universität Tübingen Das menschliche Genom (.000.000.000 Basenpaare)
Einführung in die Bioinformatik Kay Nieselt SS 011 9. It s hip to chip - von Microarrays zu personalisierter Medizin WSI/ZBIT, Eberhard Karls Universität Tübingen Das menschliche Genom (.000.000.000 Basenpaare)
Transcriptomics: Analysis of Microarrays
 Transcriptomics: Analysis of Microarrays Dion Whitehead dion@uni-muenster.de Division of Bioinformatics, Westfälische Wilhelms Universität Münster Microarrays Vorlesungsüberblick : 1. Überblick von Microarray
Transcriptomics: Analysis of Microarrays Dion Whitehead dion@uni-muenster.de Division of Bioinformatics, Westfälische Wilhelms Universität Münster Microarrays Vorlesungsüberblick : 1. Überblick von Microarray
Testing in Microarray Experiments, StatisticalScience(18), Seiten
, Seiten") 261 Literatur: I Lehmann & Romano, Kapitel 9 I Dudoit, Sha er & Boldrick (2003): Multiple Hypothesis Testing in Microarray Experiments, StatisticalScience(18), Seiten 71-103 Problem: Eine endliche Menge
261 Literatur: I Lehmann & Romano, Kapitel 9 I Dudoit, Sha er & Boldrick (2003): Multiple Hypothesis Testing in Microarray Experiments, StatisticalScience(18), Seiten 71-103 Problem: Eine endliche Menge
Einführung in die Angewandte Bioinformatik: Analyse und Design von DNA Microarrays
 Einführung in die Angewandte Bioinformatik: Analyse und Design von DNA Microarrays 08.07.2010 Prof. Dr. Sven Rahmann 1 Transcript Omics (Genexpressionsanalyse) Zum Verständnis von lebenden Organismen untersucht
Einführung in die Angewandte Bioinformatik: Analyse und Design von DNA Microarrays 08.07.2010 Prof. Dr. Sven Rahmann 1 Transcript Omics (Genexpressionsanalyse) Zum Verständnis von lebenden Organismen untersucht
Molekularbiologische Datenbanken
 Molekularbiologische Datenbanken ESTs und cdnas Microarrays Ulf Leser Wissensmanagement in der Bioinformatik Sequenzierung Methode nach Sanger Verarbeitungsschritte Base Calling Assembly Finishing Ulf
Molekularbiologische Datenbanken ESTs und cdnas Microarrays Ulf Leser Wissensmanagement in der Bioinformatik Sequenzierung Methode nach Sanger Verarbeitungsschritte Base Calling Assembly Finishing Ulf
AlgoBio WS 16/17 Differenzielle Genexpression. Annalisa Marsico
 AlgoBio WS 16/17 Differenzielle Genexpression Annalisa Marsico 04.01.2017 Pipeline für die Mikroarray-Analyse Bildanalyse Hintergrundkorrektur Normalisierung Vorverarbeitung Zusammenfassung Quantifizierung
AlgoBio WS 16/17 Differenzielle Genexpression Annalisa Marsico 04.01.2017 Pipeline für die Mikroarray-Analyse Bildanalyse Hintergrundkorrektur Normalisierung Vorverarbeitung Zusammenfassung Quantifizierung
Medizinische Fakultät Auswertestrategien von Microarrays Einführung
 Medizinische Fakultät Auswertestrategien von Microarrays Einführung PD Dr. Knut Krohn IZKF Leipzig Dr. Markus Eszlinger Med. Klinik III Forschungslabor DNA RNA Hintergrund Charakteristisches Muster der
Medizinische Fakultät Auswertestrategien von Microarrays Einführung PD Dr. Knut Krohn IZKF Leipzig Dr. Markus Eszlinger Med. Klinik III Forschungslabor DNA RNA Hintergrund Charakteristisches Muster der
Eine Einführung in R: Hochdimensionale Daten: n << p
 Eine Einführung in R: Hochdimensionale Daten: n
Eine Einführung in R: Hochdimensionale Daten: n
Grundlagen der Bioinformatik Übung 5: Microarray Analysis. Yvonne Lichtblau
 Grundlagen der Bioinformatik Übung 5: Microarray Analysis Yvonne Lichtblau Vorstellung Lösungen Übung 4 Yvonne Lichtblau: Grundlagen der Bioinformatik, Sommer Semester 2017 2 Lösungen vorstellen - Übung
Grundlagen der Bioinformatik Übung 5: Microarray Analysis Yvonne Lichtblau Vorstellung Lösungen Übung 4 Yvonne Lichtblau: Grundlagen der Bioinformatik, Sommer Semester 2017 2 Lösungen vorstellen - Übung
AlgoBio WS 16/17 Genexpressionanalyse. Annalisa Marsico
 AlgoBio WS 16/17 Genexpressionanalyse Annalisa Marsico 14.12.2016 Die Mikroarray-Revolution Mikroarrays messen die Genexpression Warum ist es wichtig, die Genexpression zu messen? Die Vielfalt der Zellen
AlgoBio WS 16/17 Genexpressionanalyse Annalisa Marsico 14.12.2016 Die Mikroarray-Revolution Mikroarrays messen die Genexpression Warum ist es wichtig, die Genexpression zu messen? Die Vielfalt der Zellen
Inhalt Genexpression Microarrays E-Northern
 Inhalt Genexpression Microarrays E-Northern Genexpression Übersicht Definition Proteinbiosynthese Ablauf Transkription Translation Transport Expressionskontrolle Genexpression: Definition Realisierung
Inhalt Genexpression Microarrays E-Northern Genexpression Übersicht Definition Proteinbiosynthese Ablauf Transkription Translation Transport Expressionskontrolle Genexpression: Definition Realisierung
Einführung in die Bioinformatik
 Einführung in die Bioinformatik Kay Nieselt SS 01 8. It s hip to chip - von Microarrays zu personalisierter Medizin WSI/ZBIT, Eberhard Karls Universität Tübingen Das menschliche Genom (~.000.000.000 Basenpaare)
Einführung in die Bioinformatik Kay Nieselt SS 01 8. It s hip to chip - von Microarrays zu personalisierter Medizin WSI/ZBIT, Eberhard Karls Universität Tübingen Das menschliche Genom (~.000.000.000 Basenpaare)
Grundlagen der Bioinformatik Übung 6: Microarray Analysis. Yvonne Lichtblau
 Grundlagen der Bioinformatik Übung 6: Microarray Analysis Yvonne Lichtblau Vorstellung Lösungen Übung 4/Übung 5 Yvonne Lichtblau: Grundlagen der Bioinformatik, Sommer Semester 2016 2 Lösungen vorstellen
Grundlagen der Bioinformatik Übung 6: Microarray Analysis Yvonne Lichtblau Vorstellung Lösungen Übung 4/Übung 5 Yvonne Lichtblau: Grundlagen der Bioinformatik, Sommer Semester 2016 2 Lösungen vorstellen
Die Varianzanalyse ohne Messwiederholung. Jonathan Harrington. Bi8e noch einmal datasets.zip laden
 Die Varianzanalyse ohne Messwiederholung Jonathan Harrington Bi8e noch einmal datasets.zip laden Variablen, Faktoren, Stufen Eine Varianzanalyse ist die Erweiterung von einem t- test t- test oder ANOVA
Die Varianzanalyse ohne Messwiederholung Jonathan Harrington Bi8e noch einmal datasets.zip laden Variablen, Faktoren, Stufen Eine Varianzanalyse ist die Erweiterung von einem t- test t- test oder ANOVA
Einführung in die Angewandte Bioinformatik: Analyse und Design von DNA Microarrays
 Einführung in die Angewandte Bioinformatik: Analyse und Design von DNA Microarrays 09.07.2009 Prof. Dr. Sven Rahmann 1 Transcript Omics (Genexpressionsanalyse) Zum Verständnis von lebenden Organismen untersucht
Einführung in die Angewandte Bioinformatik: Analyse und Design von DNA Microarrays 09.07.2009 Prof. Dr. Sven Rahmann 1 Transcript Omics (Genexpressionsanalyse) Zum Verständnis von lebenden Organismen untersucht
Versuchsplanung SoSe 2015 R - Lösung zu Übung 1 am 24.04.2015 Autor: Ludwig Bothmann
 Versuchsplanung SoSe 2015 R - Lösung zu Übung 1 am 24.04.2015 Autor: Ludwig Bothmann Contents Aufgabe 1 1 b) Schätzer................................................. 3 c) Residuenquadratsummen........................................
Versuchsplanung SoSe 2015 R - Lösung zu Übung 1 am 24.04.2015 Autor: Ludwig Bothmann Contents Aufgabe 1 1 b) Schätzer................................................. 3 c) Residuenquadratsummen........................................
Vorlesung: Biostatistische Methoden
 Vorlesung: Biostatistische Methoden Einführung in die Analyse von Microarray Daten Erzeugen der Daten Messmodell Ulrich Mansmann, Manuela Hummel IBE, Institut für Statistik, LMU Warum Microarrays? Fortschritte
Vorlesung: Biostatistische Methoden Einführung in die Analyse von Microarray Daten Erzeugen der Daten Messmodell Ulrich Mansmann, Manuela Hummel IBE, Institut für Statistik, LMU Warum Microarrays? Fortschritte
BioChip-Microarrays: Grundlagenforschung und Chancen für die Krankheitsdiagnostik
 BioChip-Microarrays: Grundlagenforschung und Chancen für die Krankheitsdiagnostik Ruprecht Kuner Abteilung Molekulare Genomanalyse DKFZ Heidelberg Vortragsübersicht Folie 1 1. Was ist ein Biochip / Microarray?
BioChip-Microarrays: Grundlagenforschung und Chancen für die Krankheitsdiagnostik Ruprecht Kuner Abteilung Molekulare Genomanalyse DKFZ Heidelberg Vortragsübersicht Folie 1 1. Was ist ein Biochip / Microarray?
Datenauswertung von Microarrays Genexpressionsanalyse
 Datenauswertung von Microarrays Genexpressionsanalyse Stefan Röpcke Berlin, 29. 6. 2004 Auf der zweiten Folie ist das Merkblatt eingefügt. Am Ende finden Sie noch weitere Folien (aus anderen Vorträgen).
Datenauswertung von Microarrays Genexpressionsanalyse Stefan Röpcke Berlin, 29. 6. 2004 Auf der zweiten Folie ist das Merkblatt eingefügt. Am Ende finden Sie noch weitere Folien (aus anderen Vorträgen).
Trennungsverfahren Techniken (in der Biologie)
") Trennungsverfahren Techniken (in der Biologie)? Biomoleküle können getrennt werden aufgrund ihrer - chemischen Eigenschaften: Ladung, Löslichkeit, Wechselwirkung mit spezifischen Reagenzen, Molmasse -
Trennungsverfahren Techniken (in der Biologie)? Biomoleküle können getrennt werden aufgrund ihrer - chemischen Eigenschaften: Ladung, Löslichkeit, Wechselwirkung mit spezifischen Reagenzen, Molmasse -
Wichtige Themen aus der Vorlesung Bioinformatik II SS 2014
 Universität des Saarlandes FR 6.2 Informatik Prof. Dr. Hans-Peter Lenhof M. Sc. Daniel Stöckel M. Sc. Patrick Trampert M. Sc. Lara Schneider Wichtige Themen aus der Vorlesung Bioinformatik II SS 2014 Hinweis:
Universität des Saarlandes FR 6.2 Informatik Prof. Dr. Hans-Peter Lenhof M. Sc. Daniel Stöckel M. Sc. Patrick Trampert M. Sc. Lara Schneider Wichtige Themen aus der Vorlesung Bioinformatik II SS 2014 Hinweis:
Lösung zu Kapitel 11: Beispiel 1
 Lösung zu Kapitel 11: Beispiel 1 Eine Untersuchung bei 253 Personen zur Kundenzufriedenheit mit einer Einzelhandelskette im Südosten der USA enthält Variablen mit sozialstatistischen Daten der befragten
Lösung zu Kapitel 11: Beispiel 1 Eine Untersuchung bei 253 Personen zur Kundenzufriedenheit mit einer Einzelhandelskette im Südosten der USA enthält Variablen mit sozialstatistischen Daten der befragten
Leistungskatalog. Core Facilities. Juli 2014. Seite 1 von 6
 Leistungskatalog Core Facilities Juli 2014 Seite 1 von 6 Inhalt 1 Core Facilities... 3 1.1 Core Facility: Genomics für Globale Genanalysen... 3 1.1.1 Next Generation Sequencing - DNA... 3 1.1.2 Next Generation
Leistungskatalog Core Facilities Juli 2014 Seite 1 von 6 Inhalt 1 Core Facilities... 3 1.1 Core Facility: Genomics für Globale Genanalysen... 3 1.1.1 Next Generation Sequencing - DNA... 3 1.1.2 Next Generation
BioChip-Microarrays: Grundlagenforschung und Chancen für die Krankheitsdiagnostik
 BioChip-Microarrays: Grundlagenforschung und Chancen für die Krankheitsdiagnostik Ruprecht Kuner Abteilung Molekulare Genomanalyse DKFZ Heidelberg Vortragsübersicht Folie 1 1. Was ist ein Biochip? 2. Zielmoleküle
BioChip-Microarrays: Grundlagenforschung und Chancen für die Krankheitsdiagnostik Ruprecht Kuner Abteilung Molekulare Genomanalyse DKFZ Heidelberg Vortragsübersicht Folie 1 1. Was ist ein Biochip? 2. Zielmoleküle
(Repeated-measures ANOVA) path = "Verzeichnis wo Sie anova1 gespeichert haben" attach(paste(path, "anova1", sep="/"))
 path = Verzeichnis wo Sie anova1 gespeichert haben attach(paste(path, anova1, sep=/))") Varianzanalyse mit Messwiederholungen (Repeated-measures ANOVA) Jonathan Harrington Befehle: anova2.txt path = "Verzeichnis wo Sie anova1 gespeichert haben" attach(paste(path, "anova1", sep="/")) Messwiederholungen:
Varianzanalyse mit Messwiederholungen (Repeated-measures ANOVA) Jonathan Harrington Befehle: anova2.txt path = "Verzeichnis wo Sie anova1 gespeichert haben" attach(paste(path, "anova1", sep="/")) Messwiederholungen:
Methoden & Tools für die Expressionsdatenanalyse. Vorlesung Einführung in die Bioinformatik - Expressionsdatenanalyse U. Scholz & M.
 Methoden & Tools für die Expressionsdatenanalyse U. Scholz & M. Lange Folie #7-1 Vorgehensmodell Expressionsdatenverarbeitung Bildanalyse Normalisierung/Filterung Datenauswertung U. Scholz & M. Lange Folie
Methoden & Tools für die Expressionsdatenanalyse U. Scholz & M. Lange Folie #7-1 Vorgehensmodell Expressionsdatenverarbeitung Bildanalyse Normalisierung/Filterung Datenauswertung U. Scholz & M. Lange Folie
Biostatistik, WS 2015/2016 Der zwei-stichproben-t-test
 1/29 Biostatistik, WS 2015/2016 Der zwei-stichproben-t-test (t-test für ungepaarte Stichproben) Matthias Birkner http://www.staff.uni-mainz.de/birkner/biostatistik1516/ 11.12.2015 2/29 Inhalt 1 t-test
1/29 Biostatistik, WS 2015/2016 Der zwei-stichproben-t-test (t-test für ungepaarte Stichproben) Matthias Birkner http://www.staff.uni-mainz.de/birkner/biostatistik1516/ 11.12.2015 2/29 Inhalt 1 t-test
Abkürzungsverzeichnis. 1. Einleitung 1. 2. Material und Methoden 8
 Inhaltsverzeichnis I Abkürzungsverzeichnis VI 1. Einleitung 1 1.1 Stabilisierung von Makromolekülen 1 1.2 Natürliche Umgebungen von Proteinen 4 1.3 Künstliche Umgebungen von Proteinen 5 1.4 Ziel der vorliegenden
Inhaltsverzeichnis I Abkürzungsverzeichnis VI 1. Einleitung 1 1.1 Stabilisierung von Makromolekülen 1 1.2 Natürliche Umgebungen von Proteinen 4 1.3 Künstliche Umgebungen von Proteinen 5 1.4 Ziel der vorliegenden
Genexpressionsregulation
 Genexpressionsregulation Genexpressionsregulation Different tissue types 1 2 3 4 5 6 7 8 Taken from Caron et al., 2001 Verschiedene Ebenen der Genexpressionsregulation Epigenetic mechanisms Transkriptionskontrolle
Genexpressionsregulation Genexpressionsregulation Different tissue types 1 2 3 4 5 6 7 8 Taken from Caron et al., 2001 Verschiedene Ebenen der Genexpressionsregulation Epigenetic mechanisms Transkriptionskontrolle
Statistische Verfahren für Hochdurchsatztechniken am Beispiel von Microarrays
 Statistische Verfahren für Hochdurchsatztechniken am Beispiel von Microarrays Anita Höland Institut für Medizinische Informatik, AG Med. Statistik Institut für Medizinische Mikrobiologie Institute for
Statistische Verfahren für Hochdurchsatztechniken am Beispiel von Microarrays Anita Höland Institut für Medizinische Informatik, AG Med. Statistik Institut für Medizinische Mikrobiologie Institute for
Motivation. Wilcoxon-Rangsummentest oder Mann-Whitney U-Test. Wilcoxon Rangsummen-Test Voraussetzungen. Bemerkungen
 Universität Karlsruhe (TH) Forschungsuniversität gegründet 825 Wilcoxon-Rangsummentest oder Mann-Whitney U-Test Motivation In Experimenten ist die Datenmenge oft klein Daten sind nicht normalverteilt Dann
Universität Karlsruhe (TH) Forschungsuniversität gegründet 825 Wilcoxon-Rangsummentest oder Mann-Whitney U-Test Motivation In Experimenten ist die Datenmenge oft klein Daten sind nicht normalverteilt Dann
Eine wunderbare Reise durch die Laborwelten.
 Eine wunderbare Reise durch die Laborwelten. DNA-Chip-Technologie in der Molekularbiologie medi Zentrum für medizinische Bildung Biomedizinische Analytik Max-Daetwyler-Platz 2 3014 Bern Tel. 031 537 32
Eine wunderbare Reise durch die Laborwelten. DNA-Chip-Technologie in der Molekularbiologie medi Zentrum für medizinische Bildung Biomedizinische Analytik Max-Daetwyler-Platz 2 3014 Bern Tel. 031 537 32
Hypothesentests mit R Ashkan Taassob Andreas Reisch 21.04.09 1
 Hypothesentests mit R Ashkan Taassob Andreas Reisch 21.04.09 1 Inhalt Programmiersprache R Syntax Umgang mit Dateien Tests t Test F Test Wilcoxon Test 2 Test Zusammenfassung 2 Programmiersprache R Programmiersprache
Hypothesentests mit R Ashkan Taassob Andreas Reisch 21.04.09 1 Inhalt Programmiersprache R Syntax Umgang mit Dateien Tests t Test F Test Wilcoxon Test 2 Test Zusammenfassung 2 Programmiersprache R Programmiersprache
Einführung in die Bioinformatik
 Einführung in die Bioinformatik Kay Nieselt SS 0 6. It s hip to chip - von Microarrays zu personalisierter Medizin WSI/ZBIT, Eberhard Karls Universität Tübingen Das menschliche Genom (~.000.000.000 Basenpaare)
Einführung in die Bioinformatik Kay Nieselt SS 0 6. It s hip to chip - von Microarrays zu personalisierter Medizin WSI/ZBIT, Eberhard Karls Universität Tübingen Das menschliche Genom (~.000.000.000 Basenpaare)
Statistische Auswertung der Daten von Blatt 13
 Statistische Auswertung der Daten von Blatt 13 Problemstellung 1 Graphische Darstellung der Daten 1 Diskussion der Normalverteilung 3 Mittelwerte und deren Konfidenzbereiche 3 Signifikanz der Behandlung
Statistische Auswertung der Daten von Blatt 13 Problemstellung 1 Graphische Darstellung der Daten 1 Diskussion der Normalverteilung 3 Mittelwerte und deren Konfidenzbereiche 3 Signifikanz der Behandlung
Umgang mit und Ersetzen von fehlenden Werten bei multivariaten Analysen
 Umgang mit und Ersetzen von fehlenden Werten bei multivariaten Analysen Warum überhaupt Gedanken machen? Was fehlt, ist doch weg, oder? Allgegenwärtiges Problem in psychologischer Forschung Bringt Fehlerquellen
Umgang mit und Ersetzen von fehlenden Werten bei multivariaten Analysen Warum überhaupt Gedanken machen? Was fehlt, ist doch weg, oder? Allgegenwärtiges Problem in psychologischer Forschung Bringt Fehlerquellen
FRAGESTUNDE WS 2016/17 QM 2. Dr. Christian Schwarz 1
 FRAGESTUNDE Dr. Christian Schwarz 1 #2 - Allgemein Q: Müssen wir den Standard Error händisch berechnen können? R: Nein. Q: Hat das Monte Carlo Experiment irgendeine Bedeutung für uns im Hinblick auf die
FRAGESTUNDE Dr. Christian Schwarz 1 #2 - Allgemein Q: Müssen wir den Standard Error händisch berechnen können? R: Nein. Q: Hat das Monte Carlo Experiment irgendeine Bedeutung für uns im Hinblick auf die
Neue DNA Sequenzierungstechnologien im Überblick
 Neue DNA Sequenzierungstechnologien im Überblick Dr. Bernd Timmermann Next Generation Sequencing Core Facility Max Planck Institute for Molecular Genetics Berlin, Germany Max-Planck-Gesellschaft 80 Institute
Neue DNA Sequenzierungstechnologien im Überblick Dr. Bernd Timmermann Next Generation Sequencing Core Facility Max Planck Institute for Molecular Genetics Berlin, Germany Max-Planck-Gesellschaft 80 Institute
Eine Einführung in R: Statistische Tests
 Eine Einführung in R: Statistische Tests Bernd Klaus, Verena Zuber Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.uni-leipzig.de/ zuber/teaching/ws12/r-kurs/
Eine Einführung in R: Statistische Tests Bernd Klaus, Verena Zuber Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.uni-leipzig.de/ zuber/teaching/ws12/r-kurs/
Die Paten)erbarkeit von Gensequenzen - von Biomarkern. Prof. Dr. iur. Dr. rer. pol. Jürgen Ensthaler, TU Berlin
erbarkeit von Gensequenzen - von Biomarkern. Prof. Dr. iur. Dr. rer. pol. Jürgen Ensthaler, TU Berlin") Die Paten)erbarkeit von Gensequenzen - von Biomarkern Prof. Dr. iur. Dr. rer. pol. Jürgen Ensthaler, TU Berlin Was sind Biomarker? Defini)on: Ø Es gibt noch keine einheitliche Defini)on für Biomarker.
Die Paten)erbarkeit von Gensequenzen - von Biomarkern Prof. Dr. iur. Dr. rer. pol. Jürgen Ensthaler, TU Berlin Was sind Biomarker? Defini)on: Ø Es gibt noch keine einheitliche Defini)on für Biomarker.
Protokoll Praktikum für Humanbiologie Studenten
 Protokoll Praktikum für Humanbiologie Studenten Teil A: Charakterisierung der Auswirkungen von γ Interferon auf die Protein und mrna Mengen in humanen A549 Lungenepithelzellen. Studentenaufgaben Tag 1
Protokoll Praktikum für Humanbiologie Studenten Teil A: Charakterisierung der Auswirkungen von γ Interferon auf die Protein und mrna Mengen in humanen A549 Lungenepithelzellen. Studentenaufgaben Tag 1
Syntax. Ausgabe *Ü12. *1. corr it25 with alter li_re kontakt.
 Syntax *Ü2. *. corr it25 with alter li_re kontakt. *2. regression var=it25 alter li_re kontakt/statistics /dependent=it25 /enter. regression var=it25 li_re kontakt/statistics /dependent=it25 /enter. *3.
Syntax *Ü2. *. corr it25 with alter li_re kontakt. *2. regression var=it25 alter li_re kontakt/statistics /dependent=it25 /enter. regression var=it25 li_re kontakt/statistics /dependent=it25 /enter. *3.
Affymetrix Evaluierung
 technische universität Affymetrix Evaluierung Evaluation mit Benchmark Datensätzen Datensätze Spike-in Datensatz von Affymetrix (59 x HGU95A) 16 Gene wurden in 14 Konzentration kontrolliert einer Probe
technische universität Affymetrix Evaluierung Evaluation mit Benchmark Datensätzen Datensätze Spike-in Datensatz von Affymetrix (59 x HGU95A) 16 Gene wurden in 14 Konzentration kontrolliert einer Probe
R-WORKSHOP II. Inferenzstatistik. Johannes Pfeffer
 R-WORKSHOP II Inferenzstatistik Johannes Pfeffer Dresden, 25.1.2011 01 Outline Lösung der Übungsaufgabe Selbstdefinierte Funktionen Inferenzstatistik t-test Kruskal-Wallis Test Übungsaufgabe TU Dresden,
R-WORKSHOP II Inferenzstatistik Johannes Pfeffer Dresden, 25.1.2011 01 Outline Lösung der Übungsaufgabe Selbstdefinierte Funktionen Inferenzstatistik t-test Kruskal-Wallis Test Übungsaufgabe TU Dresden,
Auswertung mit dem Statistikprogramm SPSS: 30.11.05
 Auswertung mit dem Statistikprogramm SPSS: 30.11.05 Seite 1 Einführung SPSS Was ist eine Fragestellung? Beispiel Welche statistische Prozedur gehört zu welcher Hypothese? Statistische Berechnungen mit
Auswertung mit dem Statistikprogramm SPSS: 30.11.05 Seite 1 Einführung SPSS Was ist eine Fragestellung? Beispiel Welche statistische Prozedur gehört zu welcher Hypothese? Statistische Berechnungen mit
Clustering. Clustering:
 Clustering Clustering: Gruppierung und Einteilung einer Datenmenge nach ähnlichen Merkmalen Unüberwachte Klassifizierung (Neuronale Netze- Terminologie) Distanzkriterium: Ein Datenvektor ist zu anderen
Clustering Clustering: Gruppierung und Einteilung einer Datenmenge nach ähnlichen Merkmalen Unüberwachte Klassifizierung (Neuronale Netze- Terminologie) Distanzkriterium: Ein Datenvektor ist zu anderen
Center for Biotechnology, Bielefeld
 Andreas Albersmeier CeBiTec Bielefeld 3. Life Science Conference Analytik Jena Jena 14.05.2014 Center for Biotechnology, Bielefeld sketchup.google.com Genomik Transkriptomik Proteomics Metabolomics Genom
Andreas Albersmeier CeBiTec Bielefeld 3. Life Science Conference Analytik Jena Jena 14.05.2014 Center for Biotechnology, Bielefeld sketchup.google.com Genomik Transkriptomik Proteomics Metabolomics Genom
Biologie I/B: Klassische und molekulare Genetik, molekulare Grundlagen der Entwicklung Theoretische Übungen SS 2014
 Biologie I/B: Klassische und molekulare Genetik, molekulare Grundlagen der Entwicklung Theoretische Übungen SS 2014 Fragen für die Übungsstunde 8 (14.07-18.07.) 1) Von der DNA-Sequenz zum Protein Sie können
Biologie I/B: Klassische und molekulare Genetik, molekulare Grundlagen der Entwicklung Theoretische Übungen SS 2014 Fragen für die Übungsstunde 8 (14.07-18.07.) 1) Von der DNA-Sequenz zum Protein Sie können
Sequenziertechnologien
 Sequenziertechnologien Folien teilweise von G. Thallinger übernommen 11 Entwicklung der Sequenziertechnologie First Generation 1977 Sanger Sequenzierung (GOLD Standard) Second Generation 2005 454 Sequencing
Sequenziertechnologien Folien teilweise von G. Thallinger übernommen 11 Entwicklung der Sequenziertechnologie First Generation 1977 Sanger Sequenzierung (GOLD Standard) Second Generation 2005 454 Sequencing
Biometrische und Ökonometrische Methoden II Lösungen 2
 TECHNISCHE UNIVERSITÄT MÜNCHEN - WEIHENSTEPHAN SS 01 MATHEMATIK UND STATISTIK, INFORMATIONS- UND DOKUMENTATIONSZENTRUM Biometrische und Ökonometrische Methoden II Lösungen 2 1. a) Zunächst wird die Tafel
TECHNISCHE UNIVERSITÄT MÜNCHEN - WEIHENSTEPHAN SS 01 MATHEMATIK UND STATISTIK, INFORMATIONS- UND DOKUMENTATIONSZENTRUM Biometrische und Ökonometrische Methoden II Lösungen 2 1. a) Zunächst wird die Tafel
Statistics, Data Analysis, and Simulation SS 2015
 Mainz, June 11, 2015 Statistics, Data Analysis, and Simulation SS 2015 08.128.730 Statistik, Datenanalyse und Simulation Dr. Michael O. Distler Dr. Michael O. Distler
Mainz, June 11, 2015 Statistics, Data Analysis, and Simulation SS 2015 08.128.730 Statistik, Datenanalyse und Simulation Dr. Michael O. Distler Dr. Michael O. Distler
Dr. A. Yassouridis Max-Planck-Institut für Psychiatrie AG: Statistik
 Statistische Analyse von Genexpress ions daten Dr. A. Yassouridis Max-Planck-Institut für Psychiatrie AG: Statistik Die exakten Wissenschaften Die schönste Forschungsaufgabe in einer Wissenschaft ist,
Statistische Analyse von Genexpress ions daten Dr. A. Yassouridis Max-Planck-Institut für Psychiatrie AG: Statistik Die exakten Wissenschaften Die schönste Forschungsaufgabe in einer Wissenschaft ist,
1 Einleitung... 1. 1.4 Glucoserepression...3. 1.8 Zielsetzung... 24. 2 Material und Methoden... 25
 Inhaltsverzeichnis 1 Einleitung... 1 1.1 Zuckerstoffwechsel von Saccharomyces cerevisiae... 1 1.2 Glucoseinaktivierung... 2 1.3 Glucoseinduzierter gezielter mrna-abbau... 3 1.4 Glucoserepression...3 1.5
Inhaltsverzeichnis 1 Einleitung... 1 1.1 Zuckerstoffwechsel von Saccharomyces cerevisiae... 1 1.2 Glucoseinaktivierung... 2 1.3 Glucoseinduzierter gezielter mrna-abbau... 3 1.4 Glucoserepression...3 1.5
Klausur zu Methoden der Statistik II (mit Kurzlösung) Wintersemester 2008/2009. Aufgabe 1
 Wintersemester 2008/2009. Aufgabe 1") Lehrstuhl für Statistik und Ökonometrie der Otto-Friedrich-Universität Bamberg Prof. Dr. Susanne Rässler Klausur zu Methoden der Statistik II (mit Kurzlösung) Wintersemester 2008/2009 Aufgabe 1 Im Rahmen
Lehrstuhl für Statistik und Ökonometrie der Otto-Friedrich-Universität Bamberg Prof. Dr. Susanne Rässler Klausur zu Methoden der Statistik II (mit Kurzlösung) Wintersemester 2008/2009 Aufgabe 1 Im Rahmen
Statistische Inferenz
 Statistische Inferenz Prinzip der statistischen Inferenz Datensätze = Stichproben aus einer Gesamtpopulation (meistens) Beispiel : Messung der Körpertemperatur von 106 gesunden Individuen man vermutet,
Statistische Inferenz Prinzip der statistischen Inferenz Datensätze = Stichproben aus einer Gesamtpopulation (meistens) Beispiel : Messung der Körpertemperatur von 106 gesunden Individuen man vermutet,
ANalysis Of VAriance (ANOVA) 1/2
 1/2") ANalysis Of VAriance (ANOVA) 1/2 Markus Kalisch 16.10.2014 1 ANOVA - Idee ANOVA 1: Zwei Medikamente zur Blutdrucksenkung und Placebo (Faktor). Gibt es einen sign. Unterschied in der Wirkung (kontinuierlich)?
ANalysis Of VAriance (ANOVA) 1/2 Markus Kalisch 16.10.2014 1 ANOVA - Idee ANOVA 1: Zwei Medikamente zur Blutdrucksenkung und Placebo (Faktor). Gibt es einen sign. Unterschied in der Wirkung (kontinuierlich)?
Varianzanalyse mit Messwiederholungen (Repeated- measures (ANOVA) BiFe noch einmal datasets.zip laden
 BiFe noch einmal datasets.zip laden") Varianzanalyse mit Messwiederholungen (Repeated- measures (ANOVA) Jonathan Harrington Befehle: anova2.txt BiFe noch einmal datasets.zip laden sowie install.packages("ez") library(ez) Messwiederholungen:
Varianzanalyse mit Messwiederholungen (Repeated- measures (ANOVA) Jonathan Harrington Befehle: anova2.txt BiFe noch einmal datasets.zip laden sowie install.packages("ez") library(ez) Messwiederholungen:
Workflow- basiertes Data Mining in der Bioinformatik
 05/ 04/ 06 mine- IT: Workflow- basiertes Data Mining in der Bioinformatik Theoretical Bioinformatics Hintergrund Medizinische Bioinformatik: Forschungsbereich an der Schnitt stelle zwischen Molekularbiologie
05/ 04/ 06 mine- IT: Workflow- basiertes Data Mining in der Bioinformatik Theoretical Bioinformatics Hintergrund Medizinische Bioinformatik: Forschungsbereich an der Schnitt stelle zwischen Molekularbiologie
Varianzanalyse * (1) Varianzanalyse (2)
 Varianzanalyse (2)") Varianzanalyse * (1) Einfaktorielle Varianzanalyse (I) Die Varianzanalyse (ANOVA = ANalysis Of VAriance) wird benutzt, um Unterschiede zwischen Mittelwerten von drei oder mehr Stichproben auf Signifikanz
Varianzanalyse * (1) Einfaktorielle Varianzanalyse (I) Die Varianzanalyse (ANOVA = ANalysis Of VAriance) wird benutzt, um Unterschiede zwischen Mittelwerten von drei oder mehr Stichproben auf Signifikanz
Etablierung einer. Homemade - PCR
 Etablierung einer Homemade - PCR Anja Schöpflin Institut für Pathologie Universitätsklinikum Freiburg Überblick: Anwendungsgebiete der PCR Anforderungen an Primer Auswahl geeigneter Primer / Primerdesign
Etablierung einer Homemade - PCR Anja Schöpflin Institut für Pathologie Universitätsklinikum Freiburg Überblick: Anwendungsgebiete der PCR Anforderungen an Primer Auswahl geeigneter Primer / Primerdesign
Medizinische Informatik Homepage: http://www.meduniwien.ac.at/msi/einf_i_d_med_inf
 Bakkalaureat-Studium Medizinische Informatik Kooperation Einführung in die Medizinische Informatik Homepage: http://www.meduniwien.ac.at/msi/einf_i_d_med_inf Besondere Einrichtung für Medizinische Statistik
Bakkalaureat-Studium Medizinische Informatik Kooperation Einführung in die Medizinische Informatik Homepage: http://www.meduniwien.ac.at/msi/einf_i_d_med_inf Besondere Einrichtung für Medizinische Statistik
Modellierung biologischer. Christian Maidorfer Thomas Zwifl (Seminar aus Informatik)
") Modellierung biologischer Prozesse Christian Maidorfer Thomas Zwifl (Seminar aus Informatik) Überblick Einführung Arten von Modellen Die stochastische Pi-Maschine Warum Modelle Die Biologie konzentriert
Modellierung biologischer Prozesse Christian Maidorfer Thomas Zwifl (Seminar aus Informatik) Überblick Einführung Arten von Modellen Die stochastische Pi-Maschine Warum Modelle Die Biologie konzentriert
Teil XI. Hypothesentests für zwei Stichproben. Woche 9: Hypothesentests für zwei Stichproben. Lernziele. Beispiel: Monoaminooxidase und Schizophrenie
 Woche 9: Hypothesentests für zwei Stichproben Patric Müller Teil XI Hypothesentests für zwei Stichproben ETHZ WBL 17/19, 26.06.2017 Wahrscheinlichkeit und Statistik Patric
Woche 9: Hypothesentests für zwei Stichproben Patric Müller Teil XI Hypothesentests für zwei Stichproben ETHZ WBL 17/19, 26.06.2017 Wahrscheinlichkeit und Statistik Patric
Proportions Tests. Proportions Test können in zwei Fällen benutzt werden. Vergleich von beobachteten vs. erwarteten Proportionen
 Proportions-Tests Proportions Tests Proportions Test können in zwei Fällen benutzt werden Vergleich von beobachteten vs. erwarteten Proportionen Test der Unabhängigkeit von 2 Faktoren kann auch zum Vergleich
Proportions-Tests Proportions Tests Proportions Test können in zwei Fällen benutzt werden Vergleich von beobachteten vs. erwarteten Proportionen Test der Unabhängigkeit von 2 Faktoren kann auch zum Vergleich
Molekularbiologische Datenbanken
 Molekularbiologische Datenbanken Übungen Aufgabe 2 Silke Trißl Ulf Leser Wissensmanagement in der Bioinformatik Microarray oder Expressionsanalyse Gleiche Erbinformation in der Zelle (Genom), aber viele
Molekularbiologische Datenbanken Übungen Aufgabe 2 Silke Trißl Ulf Leser Wissensmanagement in der Bioinformatik Microarray oder Expressionsanalyse Gleiche Erbinformation in der Zelle (Genom), aber viele
Milenia Hybridetect. Detection of DNA and Protein
 Milenia Hybridetect Detection of DNA and Protein Firmenprofil und Produkte Milenia Biotec GmbH ist im Jahr 2000 gegründet worden. Die Firma entwickelt, produziert, vermarktet und verkauft diagnostische
Milenia Hybridetect Detection of DNA and Protein Firmenprofil und Produkte Milenia Biotec GmbH ist im Jahr 2000 gegründet worden. Die Firma entwickelt, produziert, vermarktet und verkauft diagnostische
Statistik II Wahrscheinlichkeitsrechnung und induktive Statistik Erste Klausur zum Sommersemester 2005 26. Juli 2005
 Statistik II Wahrscheinlichkeitsrechnung und induktive Statistik Erste Klausur zum Sommersemester 2005 26. Juli 2005 Aufgabe 1: Grundzüge der Wahrscheinlichkeitsrechnung 19 P. Als Manager eines großen
Statistik II Wahrscheinlichkeitsrechnung und induktive Statistik Erste Klausur zum Sommersemester 2005 26. Juli 2005 Aufgabe 1: Grundzüge der Wahrscheinlichkeitsrechnung 19 P. Als Manager eines großen
PD Dr. med. Christian Meisel Site Leader Oncology & Head Translational Medicine Roche Pharma Research and Early Development, Penzberg
 Personalisierte Medizin - Status und Zukunft PD Dr. med. Christian Meisel Site Leader Oncology & Head Translational Medicine Roche Pharma Research and Early Development, Penzberg Personalisierte Medizin
Personalisierte Medizin - Status und Zukunft PD Dr. med. Christian Meisel Site Leader Oncology & Head Translational Medicine Roche Pharma Research and Early Development, Penzberg Personalisierte Medizin
1. Erklären Sie den Unterschied zwischen einem einseitigen und zweiseitigen Hypothesentest.
 Statistik II Übung 3: Hypothesentests Diese Übung beschäftigt sich mit der Anwendung diverser Hypothesentests (zum Beispiel zum Vergleich der Mittelwerte und Verteilungen zweier Stichproben). Verwenden
Statistik II Übung 3: Hypothesentests Diese Übung beschäftigt sich mit der Anwendung diverser Hypothesentests (zum Beispiel zum Vergleich der Mittelwerte und Verteilungen zweier Stichproben). Verwenden
Inhaltsverzeichnis. 1 Einleitung... 1
 Inhaltsverzeichnis 1 Einleitung... 1 1.1 G-Protein-gekoppelte Rezeptoren... 3 1.1.1 Klassifizierung und Struktur von G-Protein-gekoppelten Rezeptoren... 6 1.1.2 Purinerge Rezeptoren... 12 1.1.3 Pharmazeutische
Inhaltsverzeichnis 1 Einleitung... 1 1.1 G-Protein-gekoppelte Rezeptoren... 3 1.1.1 Klassifizierung und Struktur von G-Protein-gekoppelten Rezeptoren... 6 1.1.2 Purinerge Rezeptoren... 12 1.1.3 Pharmazeutische
Molekulare Systeme 2 Zellulärer Metabolismus
 Molekulare Systeme Zellulärer Metabolismus Dr. Jochen Forberg Institut für Medizinische Informatik, Statistik und Epidemiologie Kinetik des zellulären Stoffwechsels Der zelluläre Stoffwechsel ist ein komplexes
Molekulare Systeme Zellulärer Metabolismus Dr. Jochen Forberg Institut für Medizinische Informatik, Statistik und Epidemiologie Kinetik des zellulären Stoffwechsels Der zelluläre Stoffwechsel ist ein komplexes
9. Schätzen und Testen bei unbekannter Varianz
 9. Schätzen und Testen bei unbekannter Varianz Dr. Antje Kiesel Institut für Angewandte Mathematik WS 2011/2012 Schätzen und Testen bei unbekannter Varianz Wenn wir die Standardabweichung σ nicht kennen,
9. Schätzen und Testen bei unbekannter Varianz Dr. Antje Kiesel Institut für Angewandte Mathematik WS 2011/2012 Schätzen und Testen bei unbekannter Varianz Wenn wir die Standardabweichung σ nicht kennen,
Untersuchung der differentiellen Genexpression mit DNA-Microarrays bei Akuter Lymphoblastischer Leukämie im Vergleich mit normalen B-Lymphozyten
 Untersuchung der differentiellen Genexpression mit DNA-Microarrays bei Akuter Lymphoblastischer Leukämie im Vergleich mit normalen B-Lymphozyten Dissertation zur Erlangung des akademischen Grades doctor
Untersuchung der differentiellen Genexpression mit DNA-Microarrays bei Akuter Lymphoblastischer Leukämie im Vergleich mit normalen B-Lymphozyten Dissertation zur Erlangung des akademischen Grades doctor
X =, y In welcher Annahme unterscheidet sich die einfache KQ Methode von der ML Methode?
 Aufgabe 1 (25 Punkte) Zur Schätzung der Produktionsfunktion des Unternehmens WV wird ein lineares Regressionsmodell der Form angenommen. Dabei ist y t = β 1 + x t2 β 2 + e t, t = 1,..., T (1) y t : x t2
Aufgabe 1 (25 Punkte) Zur Schätzung der Produktionsfunktion des Unternehmens WV wird ein lineares Regressionsmodell der Form angenommen. Dabei ist y t = β 1 + x t2 β 2 + e t, t = 1,..., T (1) y t : x t2
Rekonstruktion biologischer Netzwerke (mit probabilistischen Methoden) Einführung 11.10.2010
 Einführung 11.10.2010") Rekonstruktion biologischer Netzwerke (mit probabilistischen Methoden) Einführung 11.10.2010 Prof. Dr. Sven Rahmann 1 Team Prof. Dr. Sven Rahmann Zeit Mo 10-12; Do 8:30-10 Ort OH14, R104 Alle Informationen
Rekonstruktion biologischer Netzwerke (mit probabilistischen Methoden) Einführung 11.10.2010 Prof. Dr. Sven Rahmann 1 Team Prof. Dr. Sven Rahmann Zeit Mo 10-12; Do 8:30-10 Ort OH14, R104 Alle Informationen
Inhalt. 3 Das Werkzeug... 47 3.1 Restriktionsenzyme... 47 3.2 Gele... 58 3.2.1 Agarosegele... 58
 Inhalt 1 Was ist denn Molekularbiologie, bitteschön?...................... 1 1.1 Das Substrat der Molekularbiologie, oder: Molli-World für Anfänger.... 2 1.2 Was brauche ich zum Arbeiten?..................................
Inhalt 1 Was ist denn Molekularbiologie, bitteschön?...................... 1 1.1 Das Substrat der Molekularbiologie, oder: Molli-World für Anfänger.... 2 1.2 Was brauche ich zum Arbeiten?..................................
Einführung in die Genexpressionsplattform des IVM
 Einführung in die Genexpressionsplattform des IVM 1. Prinzip und wichtige Termini 2. RNA Präparation und Qualitätskontrolle 3. Datenauswertung 4. Kosten 5. Protokolle 6. Informationen für Kooperationspartner
Einführung in die Genexpressionsplattform des IVM 1. Prinzip und wichtige Termini 2. RNA Präparation und Qualitätskontrolle 3. Datenauswertung 4. Kosten 5. Protokolle 6. Informationen für Kooperationspartner
Entwicklung und Validierung von multiplex real-time RT-PCR assays in der Virusdiagnostik
 Entwicklung und Validierung von multiplex real-time RT-PCR assays in der Virusdiagnostik Bernd Hoffmann, Klaus R. Depner, Horst Schirrmeier & Martin Beer Friedrich-Loeffler-Institut Greifswald-Insel Riems
Entwicklung und Validierung von multiplex real-time RT-PCR assays in der Virusdiagnostik Bernd Hoffmann, Klaus R. Depner, Horst Schirrmeier & Martin Beer Friedrich-Loeffler-Institut Greifswald-Insel Riems
Vorlesung Einführung in die Bioinformatik
 Vorlesung Einführung in die Bioinformatik Dr. Astrid Junker 23.06.2014 Kirsten/Groß, VL Biodatenbanken, Universität Leipzig Was ist Genexpression? wie die genetische Information eines Gens (Abschnitt der
Vorlesung Einführung in die Bioinformatik Dr. Astrid Junker 23.06.2014 Kirsten/Groß, VL Biodatenbanken, Universität Leipzig Was ist Genexpression? wie die genetische Information eines Gens (Abschnitt der
Multiple Regression Mais-NP Zweidimensionale lineare Regression Data Display Dreidimensionale lineare Regression Multiple Regression
 Multiple Regression! Zweidimensionale lineare Regression Modell Bestimmung der Regressionsebene Multiples Bestimmtheitsmaß Test des Bestimmtheitsmaßes Vertrauensintervalle für die Koeffizienten Test des
Multiple Regression! Zweidimensionale lineare Regression Modell Bestimmung der Regressionsebene Multiples Bestimmtheitsmaß Test des Bestimmtheitsmaßes Vertrauensintervalle für die Koeffizienten Test des
Statistische Auswertung:
 Statistische Auswertung: Die erhobenen Daten mittels der selbst erstellten Tests (Surfaufgaben) Statistics Punkte aus dem Punkte aus Surftheorietest Punkte aus dem dem und dem Surftheorietest max.14p.
Statistische Auswertung: Die erhobenen Daten mittels der selbst erstellten Tests (Surfaufgaben) Statistics Punkte aus dem Punkte aus Surftheorietest Punkte aus dem dem und dem Surftheorietest max.14p.
# Befehl für den Lilliefors-Test
 1/5 Matthias Rudolf & Diana Vogel R-Kurs Graduiertenakademie September 2017 Loesungsskript: Tests 1a library(nortest) 1b lillie.test Befehl für den Lilliefors-Test 2a, Datensatz "Schachbeispiel einlesen"
1/5 Matthias Rudolf & Diana Vogel R-Kurs Graduiertenakademie September 2017 Loesungsskript: Tests 1a library(nortest) 1b lillie.test Befehl für den Lilliefors-Test 2a, Datensatz "Schachbeispiel einlesen"
Abkürzungsverzeichnis... 7. Inhaltsverzeichnis... 11. Abbildungsverzeichnis... 17. 1 Einleitung... 21 1.1 Proteomik... 21 1.1.1 Proteom...
 Inhaltsverzeichnis Abkürzungsverzeichnis... 7 Inhaltsverzeichnis... 11 Abbildungsverzeichnis... 17 1 Einleitung... 21 1.1 Proteomik... 21 1.1.1 Proteom... 21 1.1.2 Protein-Protein Interaktionen allgemein...
Inhaltsverzeichnis Abkürzungsverzeichnis... 7 Inhaltsverzeichnis... 11 Abbildungsverzeichnis... 17 1 Einleitung... 21 1.1 Proteomik... 21 1.1.1 Proteom... 21 1.1.2 Protein-Protein Interaktionen allgemein...
Verbesserte Basenpaarung bei DNA-Analysen
 Powered by Seiten-Adresse: https://www.gesundheitsindustriebw.de/de/fachbeitrag/aktuell/verbesserte-basenpaarungbei-dna-analysen/ Verbesserte Basenpaarung bei DNA-Analysen Ein Team aus der Organischen
Powered by Seiten-Adresse: https://www.gesundheitsindustriebw.de/de/fachbeitrag/aktuell/verbesserte-basenpaarungbei-dna-analysen/ Verbesserte Basenpaarung bei DNA-Analysen Ein Team aus der Organischen
Lineare Modelle in R: Einweg-Varianzanalyse
 Lineare Modelle in R: Einweg-Varianzanalyse Achim Zeileis 2009-02-20 1 Datenaufbereitung Wie schon in der Vorlesung wollen wir hier zur Illustration der Einweg-Analyse die logarithmierten Ausgaben der
Lineare Modelle in R: Einweg-Varianzanalyse Achim Zeileis 2009-02-20 1 Datenaufbereitung Wie schon in der Vorlesung wollen wir hier zur Illustration der Einweg-Analyse die logarithmierten Ausgaben der
Probeklausur EW II. Für jede der folgenden Antworten können je 2 Punkte erzielt werden!
 Probeklausur EW II Bitte schreiben Sie Ihre Antworten in die Antwortfelder bzw. markieren Sie die zutreffenden Antworten deutlich in den dafür vorgesehenen Kästchen. Wenn Sie bei einer Aufgabe eine nicht-zutreffende
Probeklausur EW II Bitte schreiben Sie Ihre Antworten in die Antwortfelder bzw. markieren Sie die zutreffenden Antworten deutlich in den dafür vorgesehenen Kästchen. Wenn Sie bei einer Aufgabe eine nicht-zutreffende
Messunsicherheiten in der vektoriellen Netzwerkanalyse
 Messunsicherheiten in der vektoriellen Netzwerkanalyse Matthias Hübler 277. PTB-Seminar Berechnung der Messunsicherheit Empfehlungen für die Praxis Berlin, 11./12. März 2014 Motivation und Überblick zum
Messunsicherheiten in der vektoriellen Netzwerkanalyse Matthias Hübler 277. PTB-Seminar Berechnung der Messunsicherheit Empfehlungen für die Praxis Berlin, 11./12. März 2014 Motivation und Überblick zum
Expressionsdatenanalyse. Vorlesung Einführung in die Bioinformatik - Expressionsdatenanalyse
 Expressionsdatenanalyse U. Scholz & M. Lange Folie #6-1 Grundidee U. Scholz & M. Lange Folie #6-2 Ergebnis der Experimente I U. Scholz & M. Lange Folie #6-3 Genexpression U. Scholz & M. Lange Folie #6-4
Expressionsdatenanalyse U. Scholz & M. Lange Folie #6-1 Grundidee U. Scholz & M. Lange Folie #6-2 Ergebnis der Experimente I U. Scholz & M. Lange Folie #6-3 Genexpression U. Scholz & M. Lange Folie #6-4
DNA-Chip. Seminar Bioanalytik WS 2011/12 Lisa Kaiser
 DNA-Chip Seminar Bioanalytik WS 2011/12 Lisa Kaiser 1. Einführung Warum DNA-Chip? - Enormer Anstieg der Datenmenge Notwendigkeit eines Hochdurchsatz-Systems - Microarrays sollen schnelle und umfassende
DNA-Chip Seminar Bioanalytik WS 2011/12 Lisa Kaiser 1. Einführung Warum DNA-Chip? - Enormer Anstieg der Datenmenge Notwendigkeit eines Hochdurchsatz-Systems - Microarrays sollen schnelle und umfassende
Formelsammlung für das Modul. Statistik 2. Bachelor. Sven Garbade
 Version 2015 Formelsammlung für das Modul Statistik 2 Bachelor Sven Garbade Prof. Dr. phil. Dipl.-Psych. Sven Garbade Fakultät für Angewandte Psychologie SRH Hochschule Heidelberg sven.garbade@hochschule-heidelberg.de
Version 2015 Formelsammlung für das Modul Statistik 2 Bachelor Sven Garbade Prof. Dr. phil. Dipl.-Psych. Sven Garbade Fakultät für Angewandte Psychologie SRH Hochschule Heidelberg sven.garbade@hochschule-heidelberg.de
Einfluss von Hypoxie auf die Interaktion von Leukämieblasten mit Knochenmark-Stromazellen
 Dr. rer. nat. Jasmin Wellbrock und Prof. Dr. Walter Fiedler Projektbericht an die Alfred & Angelika Gutermuth Stiftung Einfluss von Hypoxie auf die Interaktion von Leukämieblasten mit Knochenmark-Stromazellen
Dr. rer. nat. Jasmin Wellbrock und Prof. Dr. Walter Fiedler Projektbericht an die Alfred & Angelika Gutermuth Stiftung Einfluss von Hypoxie auf die Interaktion von Leukämieblasten mit Knochenmark-Stromazellen
Grundlagen der Klonierung. Analytische Methoden der Biologie SS09 7 Klonierung und Gentechnik. Modul
 Restriktion und Ligation: Restriktion und Ligation: Grundlagen der Klonierung Modul 2303-021 1 Restriktion und Ligation Verknüpfung von Fragmenten unterschiedlicher DNA Herkunft Restriktion und Ligation
Restriktion und Ligation: Restriktion und Ligation: Grundlagen der Klonierung Modul 2303-021 1 Restriktion und Ligation Verknüpfung von Fragmenten unterschiedlicher DNA Herkunft Restriktion und Ligation
Eine computergestützte Einführung mit
 Thomas Cleff Deskriptive Statistik und Explorative Datenanalyse Eine computergestützte Einführung mit Excel, SPSS und STATA 3., überarbeitete und erweiterte Auflage ^ Springer Inhaltsverzeichnis 1 Statistik
Thomas Cleff Deskriptive Statistik und Explorative Datenanalyse Eine computergestützte Einführung mit Excel, SPSS und STATA 3., überarbeitete und erweiterte Auflage ^ Springer Inhaltsverzeichnis 1 Statistik
Transgene Organismen
 Transgene Organismen Themenübersicht 1) Einführung 2) Komplementäre DNA (cdna) 3) Vektoren 4) Einschleusung von Genen in Eukaryontenzellen 5) Ausmaß der Genexpression 6) Genausschaltung (Gen-Knockout)
Transgene Organismen Themenübersicht 1) Einführung 2) Komplementäre DNA (cdna) 3) Vektoren 4) Einschleusung von Genen in Eukaryontenzellen 5) Ausmaß der Genexpression 6) Genausschaltung (Gen-Knockout)
Überblick über die Tests
 Anhang A Überblick über die Tests A.1 Ein-Stichproben-Tests A.1.1 Tests auf Verteilungsannahmen ˆ Shapiro-Wilk-Test Situation: Test auf Normalverteilung H 0 : X N(µ, σ 2 ) H 1 : X nicht normalverteilt
Anhang A Überblick über die Tests A.1 Ein-Stichproben-Tests A.1.1 Tests auf Verteilungsannahmen ˆ Shapiro-Wilk-Test Situation: Test auf Normalverteilung H 0 : X N(µ, σ 2 ) H 1 : X nicht normalverteilt
Fragestellungen. Ist das Gewicht von Männern und Frauen signifikant unterschiedlich? (2-sample test)
") Hypothesen Tests Fragestellungen stab.glu 82 97 92 93 90 94 92 75 87 89 hdl 56 24 37 12 28 69 41 44 49 40 ratio 3.60 6.90 6.20 6.50 8.90 3.60 4.80 5.20 3.60 6.60 glyhb 4.31 4.44 4.64 4.63 7.72 4.81 4.84
Hypothesen Tests Fragestellungen stab.glu 82 97 92 93 90 94 92 75 87 89 hdl 56 24 37 12 28 69 41 44 49 40 ratio 3.60 6.90 6.20 6.50 8.90 3.60 4.80 5.20 3.60 6.60 glyhb 4.31 4.44 4.64 4.63 7.72 4.81 4.84