Parallele Rechnerarchitekturen. Bisher behandelte: Vorlesung 7 (theoretische Grundkonzepte) Nun konkrete Ausprägungen
|
|
|
- Walther Kohler
- vor 7 Jahren
- Abrufe
Transkript
1 Parallele Rechnerarchitekturen Bisher behandelte: Vorlesung 7 (theoretische Grundkonzepte) Nun konkrete Ausprägungen
2 Pipelining Beispiel aus dem realen Leben (;-)) Wäschewaschen in WG Füllen der Waschmaschine mit schmutziger Wäsche Umfüllen der gewaschenen Wäsche in den Trockner nach dem Trocknen Wäsche zusammenlegen Nach dem Zusammenlegen einen Mitbewohner bitte, Wäsche in den Schrank zu legen
3 Pipelining (2) Zeit Aufgaben
4 Pipelining (2) Zeit Aufgaben (4 Bew.) Wäschewaschen sequentiell Wäschewaschen mit Pipelining
5 Pipelining (3) Zentrale Steuerschleife eines von-neumann-rechners: Fetch Execute von-neumann-rechner: entweder Lesen eines Befehls (fetch) oder Ausführen eines Befehls (execute)
6 Pipelining (4) Realer Mikroprozessor (z.b. I8086): ADD AX,disp[BX][SI]; AX := AX + MEM(disp + [BX] + [SI]) Detaillierung:
7 1 Lesen des aktuellen Befehls IR := MEM(IP); 2 Dekodieren des geholten Befehls Um welchen Befehl handelt es sich, Länge des Befehls 3 Inkrement des Befehlszählers IP := IP + Befehlslänge; Berechnen der Adresse des Speicheroperanden Eff_Adr := disp + [BX] + [SI]; 4 Lesen der Operanden OP1 := AX; OP2 := MEM (Eff_Adr); 5 6 Ausführen der Operation RES := Op1 + Op2; Schreiben des Ergebnisses AX := RES;
8 Pipelining (5) Realer Mikroprozessor (z.b. I8086): ADD AX,disp[BX][SI]; AX := AX + MEM(disp + [BX] + [SI]) Für jede der 6 Phasen gibt es spezielle Hardware, die brachliegt, wenn nicht gerade die jeweilige Phase ausgeführt wird. Ausweg: zeitlich überlappte Ausführung der Befehle (Pipelining)
9 Pipelining (6) Phase: Annahme: jede Phase benötigt gleich viel Zeit i i+1 i+2 i i+1 i+2 i+3 i i+1 i+2 i+3 i+4 i i+1 i+2 i+3 i+4 i+5 i i+1 i+2 i+3 i+4 i+5 i+6 i i+1 i+2 i+3 i+4 i+5 i+6 i+7 t t+1 t+2 t+3 t+4 t+5 t+6 t+7 Zeit
10 Pipelining (7) Konkretisierung: Beispiel MIPS-Befehlssatz (siehe auch Patterson/Hennessy: Rechnerorganistionund Entwurf, Heidelberg, Spektrum 2005) load word (lw) store word (sw) add (add) subtract (sub) and (and) or (or) set less then (slt) branch on equal (beq)
11 Pipelining (8) Konkretisierung: load word (lw) store word (sw) add (add) subtract (sub) and (and) or (or) set less then (slt) branch on equal (beq) Klasse Befehl hol. Register les. ALU-Op. Dat.zgr. Register schr. Gesamt lw 200ps 100 ps 200 ps 200 ps 100ps 800 ps sw 200ps 100 ps 200 ps 200 ps 700 ps R-Format (add,..) 200 ps 100 ps 200 ps 100 ps 600 ps beq 200 ps 100 ps 200 ps 500 ps
12 Pipelining (9) Befehlsausführung lw sequentiell Zeit lw $1, 100($0) lw $2, 200($0) lw $3, 300($0) H R A D R H R A D R H R A D R H Befehl holen R Registerzugriff A ALU Zugriff D Datenzugriff
13 Pipelining (10) Befehlsausführung lw mit Pipelining Zeit lw $1, 100($0) lw $2, 200($0) lw $3, 300($0) H R A D R H R A D R H R A D R H Befehl holen R Registerzugriff (lesen 2. Hälfte, schreiben 1. Hälfte des Taktzyklus) A ALU Zugriff D Datenzugriff
14 Hemmnisse: Strukturkonflikte Datenkonflikte Steuerkonflikt Pipelining (11)
15 Pipelining (12) Hemmnisse: Strukturkonflikte Ein Ereignis, bei dem ein Befehl nicht im vorgesehenen Taktzyklus ausgeführt werden kann, da die Hardware die Befehlskombination nicht unterstützt, die zum Ausführen im angegebenen Taktzyklus festgelegt wurde. Beispiel Wäschewaschen: es gibt keine separate Waschmaschine und keinen separaten Trockner, sondern ein Waschmaschinen- Trockner-Kombigerät
16 Pipelining (13) Hemmnisse: Datenkonflikte Ein Ereignis, bei dem ein Befehl nicht im vorgesehenen Taktzyklus ausgeführt werden kann, weil Daten zum Ausführen des Befehls noch nicht verfügbar sind. Beispiel Wäschewaschen: Sie stellen bei Zusammenlegen fest, dass eine Socke fehlt. Mögliche Strategie: Sie gehen in Ihr Zimmer und suchen nach der Socke. Dann muss das Zusammenlegen getrockneter Wäsche und das Trocknen gewaschener Wäsche warten.
17 Pipelining (14) Hemmnisse: Datenkonflikte Datenkonflikt aufgrund der Abhängigkeit eines Befehls von einem früher begonnenen Befehl Beispiel: add $s0, $t0, $t1 sub $t2, $s0, $t3 sub-befehl benötigt als Eingabeoperand Ergebnis des add- Befehls Bubbles (Wartetakte, Pipelineleerlauf)
18 Pipelining (15) Hemmnisse: Datenkonflikte Gegenmaßnahme: Forwarding oder Bypassing: Fehlende Datenelemente aus internen Pufferspeichern add $s0,$t0,$t1 IF ID EX MEM WB 5 Pipelinestufen: IF Instruction Fetch (Befehl holen) ID Instruction Decode (Register lesen) EX Execute (Ausführungsstufe) MEM Memory Access (Speicherzugriff) WB Write Back (Register schreiben) blau hinterlegt: Befehl benutzt die betreffende Pielinestufe
19 Pipelining (16) Hemmnisse: Datenkonflikte Gegenmaßnahme: Forwarding oder Bypassing: Fehlende Datenelemente aus internen Pufferspeichern add $s0,$t0,$t1 IF ID EX MEM WB sub $s2,$s0,$t3 IF ID EX MEM WB
20 Pipelining (17) Hemmnisse: Datenkonflikte Gegenmaßnahme: Forwarding oder Bypassing: Problem: R-Befehl verwendet direkt Daten aus Ladebefehl lw $s0,20($t1) IF ID EX MEM WB Bubble Bubble Bubble Bubble Bubble sub $s2,$s0,$t3 IF ID EX MEM WB
21 Pipelining (18) Hemmnisse: Datenkonflikte A = B + E; C = B + F; MIPS-Code: (alle Variablen im Speicher, Offset mit Register $t0 adressierbar) lw $t1, 0($t0) lw $t2, 4($t0) add $t3, $t1, $t2 sw $t3, 12($t0) lw $t4, 8($t0) add $t5, $t1,$t4 sw $t5, 16($t0)
22 Pipelining (19) Hemmnisse: Datenkonflikte A = B + E; C = B + F; MIPS-Code: (alle Variablen im Speicher, Offset mit Register $t0 adressierbar) lw $t1, 0($t0) lw $t2, 4($t0) add $t3, $t1, $t2 Konflikt, wegen lw --> R-Befehl --> Bubble sw $t3, 12($t0) lw $t4, 8($t0) add $t5, $t1,$t4 Konflikt, wegen lw --> R-Befehl --> Bubble sw $t5, 16($t0)
23 Pipelining (20) Hemmnisse: Datenkonflikte A = B + E; C = B + F; Umordnung: lw $t1, 0($t0) lw $t2, 4($t0) lw $t4, 8($t0) add $t3, $t1, $t2 sw $t3, 12($t0) add $t5, $t1,$t4 sw $t5, 16($t0)
24 Pipelining (21) Hemmnisse: Steuerkonflikt: Ein Ereignis, bei dem der gewünschte Befehl nicht im gewünschten Taktzyklus ausgeführt werden kann, weil der Befehl, der geholt wurde, nicht der ist, der benötigt wird. im Computer: Entscheidungsbefehl Adresse des zeitlich zunächst auszuführenden Befehls ist erst nach Abarbeitung des Entscheidungsbefehls bekannt!
25 Pipelining (22) Hemmnisse: Steuerkonflikt: Strategien Pipeline anhalten. add $s0,20($t1) IF ID EX MEM WB beq $1, $2, 40 IF ID EX MEM WB Bubble Bubble Bubble Bubble Bubble sub $s2,$s0,$t3 IF ID EX MEM WB
26 Pipelining (23) Hemmnisse: Steuerkonflikt: Strategien Sprungvorhersage add $s4,$5,$t6 IF ID EX MEM WB add $s4,$5,$t6 IF ID EX MEM WB beq $1, $2, 40 IF ID EX MEM WB beq $1, $2, 40 IF ID EX MEM WB lw $3,300($s0) IF ID EX MEM WB BubbleBubbleBubbleBubbleBubble or $7,$8,$9 IF ID EX MEM W 400 ps
27 Vektorrechner Motivation/Hintergrund: in wissenschaftlich-technischen Berechnungen haben Vektoren und Matrizen eine zentrale Bedeutung: Abbildung von Vektoren auf eindimensionale, von Matrizen auf zweidimensionale Felder von reellen Zahlen Beispiel (C/C++) double vector[4]; double matrix[4][4];
28 Vektorrechner (2) Verknüpfung zweier Vektorelemente: Addition zweier Vektoren x und y wird zurückgeführt auf die Addition von Elementen mit gleichen Indizes: for ( i= 0; i < 4; i++) z[i] = x[i] + y[i]; oder nach Aufrollen der Schleife (dies ist eine gängige Aktion bei Optimierungsfunktionen des Compilers: z[0] = x[0] + y[0];... z[3] = x[3] + y[3];
29 Vektorrechner (3) Die Datenflussanalyse der Anweisungen z[0] = x[0] + y[0];... z[3] = x[3] + y[3]; zeigt, dass zwischen diesen Anweisungen keinerlei Abhängigkeiten bestehen. Sie sind also maximal parallel ausführbar. Voraussetzung (siehe Schlussfolgerung 4 aus Kapitel Datenflussanalyse): Register für mehrere (hier 3 * 4) reelle Zahlen mehrere (hier 4) Gleitkommaaddierer
30 Vektorrechner (4) x[0] x[1] x[2] x[3] y[0] y[1] y[2] y[3] z[0] z[1] z[2] z[3]
31 Vektorrechner (5) Probleme: Registerbreite und Anzahl der Gleitkommaverarbeitungseinheiten ist endlich wenn Dimension der Vektoren größer ist als die zur Verfügung stehenden Registerbreiten, muss in normalen Architekturen auf die maximale Parallelität verzichtet werden in Vektorrechnern existiert eine spezielle (aber kostspielige) Speicherorganisation, die die Behandlung solcher Fälle wirkungsvoll unterstützt.
32 Vektorrechner (6) des weiteren existieren spezielle Vektorbefehle (auf Maschinenbefehlsniveau), mit denen man mehrstellige Verknüpfungen formuliert (siehe Programmiersprache APL) meist existiert auch zusätzlich Pipelining
33 Vektorrechner (7) Vektorprozessoren werden vor allem im High- Performance-Computing (HPC) genutzt. Beispiele: Cray-Supercomputer (nutzten Vektorprozessoren) der über mehrere Jahre hinweg leistungsfähigste Computer der Welt, der Earth Simulator, arbeitet mit Vektorprozessoren von NEC.
34 Vektorrechner (8) Weitere Anbieter von Vektorrechnern Convex Computer Corporation, z.b. mit der C38xx-Serie, die GaAs-Technologie einsetzte Fujitsu Siemens Computers mit ihrer VPP-Serie.
35 Superskalare und andere Techniken Einführung Vektorrechner: Zusammenfassung mehrerer gleichartiger Befehle zu einem mehrstelligen Befehl (Vektorbefehl) Zusammenfassung mehrere parallel abarbeitbarer unterschiedlicher Befehle nicht möglich Voraussetzung dafür: zusätzliche Ressourcen superskalare Architekturen Siehe
36 Superskalare und andere Techniken (2) Was bedeutet superskalar? Prozessor muss in der Lage sein, mehrere Befehle gleichzeitig pro Takt zu laden Branches dürfen möglichst nicht zur Behinderung des Befehlsflusses führen (durch Sprungvorhersage) Datenabhängigkeiten treten hier in erhöhtem Maße auf und müssen beherrschbar sein Um echte Datenabhängigkeiten auflösen zu können, ist Out-of-Order Ausführung mit anschließenden Sortierung notwendig
37 Superskalare und andere Technologien (3) Superskalararchitektur Befehlsstrom (Instruction Stream) Instruction window (hier 4 Befehle) Scheduling Buffer Buffer Buffer Buffer FK FK GK GK Registerfile
38 Superskalare und andere Techniken (4) Anzahl parallel ausführbarer Befehle ist begrenzt durch: Befehlsfolge selbst (Datenflussanalyse!) Anzahl vorhandener Ausführungseinheiten Beispiel: die Befehlsfolge bestehe nur aus unabhängigen Festkommabefehlen, der Superskalarrechner besitze 2 FK- und 2 GK-Einheiten und kann damit potentiell 4 Befehle parallel ausführen. Hier kann er aber stets nur 2 Befehle parallel ausführen.
39 Superskalare und andere Techniken (5) Wenn die Befehlsfolge aus unabhängigen FK- und GK-Befehlen besteht, dann kann der Rechner 4 Befehle gleichzeitig ausführen, aber nur dann, wenn die Befehlsfolge geeignet vorsortiert wird. Sie muss aus 4er- Paketen aus je 2 FK und 2 GK-Befehlen bestehen. Diese Vorsortierug müsste der Compiler realisieren, der damit Kenntnisse über die Zielarchitektur verfügen müsste (statisches Scheduling)
40 Superskalare und andere Techniken (6) in einem typischen Superskalarprozessor kann die Hardware ein bis acht Befehle pro Takt aussenden Die Befehle müssen unabhängig sein und bestimmte issue criteria erfüllen die Hardware entscheidet zur Laufzeit dynamisch über das Mehrfachaussenden (multiple issue) von Befehlen
41 Superskalare und andere Techniken (7) die variierende Zahl ausgesendeter Befehle wird typisch nach erweiterten Tomasulo-Techniken (mit out-of-order execution) dynamisch scheduled
42 Tomasulo-Algorithmus Der Tomasulo-Algorithmus verfolgt das Ziel, die Ausführung von Befehlen fortzusetzen, selbst wenn Datenabhängigkeiten vorliegen. Read-after-write-Hazards (RAW) (Prozessor verfolgt, wann ein Operand zur Verfügung steht) Write-after-write- (WAW) und Write-after-read- Hazards (WAR) (relevante Registerinhalte beim Decodieren eines Befehls werden in speziellen Reservation Stations gesichert und so vor vorzeitigem Überschreiben geschützt)
43 Tomasulo-Algorithmus Komponenten: Functional Units (FU): Prozessorbausteine, die logisch/arithmetische Berechnungen ausführen. Es gibt hiervon meist mehrere; sie unterscheiden sich in der Art der Operationen, welche sie ausführen können (floating point, integer, load/store, etc.). Bei modernen Prozessoren ist fünf eine typische Zahl für die Anzahl an FUs.
44 Tomasulo-Algorithmus Reservation Stations (RS): Diese implementieren Register Renaming und werden wie temporäre Register behandelt. Für jede FU gibt es zwei bis acht Reservation Stations. Eine Reservation Station enthält die auszuführende Operation, zwei Felder für die Werte der Operanden und zwei Felder für die Herkunft der Operanden, falls sie zum aktuellen Zeitpunkt noch nicht zur Verfügung stehen bzw. noch nicht gültig sind.
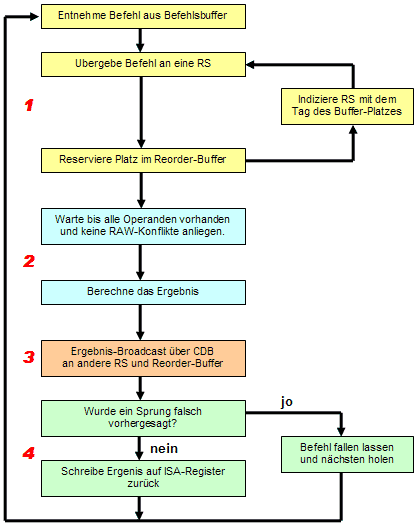
45 Tomasulo-Algorithmus Fetch and Decode Holt Instruktionen in einen Befehlscache. Die Decode-Unit holt sich einen Teil der Befehle und versucht mehrere gleichzeitig zu decodieren (In- Order). Dabei wird versucht Sprünge vorher zusagen.
46 Tomasulo-Algorithmus Dispatch and Issue holt dekodierte Befehle aus Befehlspuffer und übergibt sie In-Order an die Reservation Stations der Execute Units, sobald alle Operanden verfügbar sind (Issue). Solange im Reorder Buffer Platz ist, reserviert sie ein Feld für diesen Befehl mit Hilfe des Tags und gibt dieses an die RS weiter. Wenn nicht wartet sie, bis ein Platz frei wird. (Dispatch Phase)
47 Tomasulo-Algorithmus Execution Führt Befehle auf den Schattenregistern aus, um Data Hazards zu meiden. Befehle werden in den Reorder-Buffer geschrieben und Out-Of-Order ausgeführt, solange es keine RAW-Konflikte gibt. Nach Beenden eines Befehls wird Ergebnis an alle RS gebroadcastet, so dass wartende Befehle fortfahren können. (Write result)
48 Tomasulo-Algorithmus Commit Die Commit/Completion oder Retire Einheit schreibt die Ergebnisse aus den Renaming Registern in die echten ISA Register zurück, nachdem sie geprüft hat, ob abhängige vorangehende Befehle ihre Ergebnisse geliefert haben und keine falsche Sprungvorhersage eingetreten war.
49 Tomasulo-Algorithmus

50 Tomasulo-Algorithmus
51 Superskalare und andere Techniken (7) Compilerscheduling (static) kann unterstützend angewendet werden, ist jedoch nicht unbedingt notwendig Programme für verschiedene Implementierungen einer Superskalararchitektur können objektkodekompatibel sein Im Vergleich zu VLIW-Prozessoren ist die Steuerlogik um ein Vielfaches komplexer.
52 Superskalare und andere Techniken (7) Konsequente Weiterentwicklung dieses Denkansatzes LIW (long instruction word) bzw. VLIW (very long instruction word) Architekturen Bestehen aus langen Befehlsworten, die eine Kettung parallel ausführbarer konventioneller Maschinenbefehle darstellen. Compiler muss ausführen: Vorsortierung Scheduling (Zuordnung zu den Ausführungseinheiten), da die Stellung im VLIW- Befehl den Ausführungseinheiten fest zugeordnet ist.
53 Superskalare und andere Technologien (9) VLIW-Architektur Befehlsstrom (Instruction Stream) Instructionregister 1VLIW- Befehl mit 4 Funktionen Buffer Buffer Buffer Buffer FK FK GK GK Registerfile
54 Superskalare und andere Technologien (10) ein VLIW-Prozessor sendet eine fest vordefinierte Anzahl von Befehlen aus, die als ein großer Befehl oder als ein festes Befehlspaket zusammen gefasst worden sind Der Compiler muss dazu ein solches Paket im Voraus (statisch) nach Möglichkeit zusammenstellen; notfalls sind NOP's einzuarbeiten (Kodeexpansion) Die Zuordnung der Befehle zu den einzelnen Ausführungseinheiten wird vom Compiler (statisch) vorgenommen. Er muss die Architektur genau kennen.
55 Superskalare und andere Technologien (11) Die Schedulinganalyse kann vergleichsweise zur Superskalararchitektur ein größeres Analysefenster (quai instruction window) bilden und diesbezüglich besser optimieren Da kein dynamisches Scheduling verwendet wird, entfällt ensprechend komplexe Steuerlogik sowie Schedulingoverhead.
56 Superskalare und andere Techniken (12) Zusammenfassung: 1 Lesen des aktuellen Befehls 2 Dekodieren des geholten Befehls Inkrementieren des Befehlszählers Berechnen der Adresse des Speicheroperanden Lesen der Operanden 3 Ausführen der Operation 4 Schreiben des Ergebnisses
57 Superskalare und andere Techniken (13) Pipeline (4 stufig): 1. Befehl 2. Befehl 3. Befehl 4. Befehl 5. Befehl 6. Befehl 7. Befehl 8. Befehl 9. Befehl
58 Superskalare und andere Techniken (14) Superskalar,(3 unabhängige Ausführungseinheiten, ohne Pipelining): 1. Befehl 2. Befehl 3. Befehl Befehl 5. Befehl 6. Befehl Befehl 8. Befehl 9. Befehl
59 Superskalare und andere Techniken (15) Superskalar,(3 unabhängige Ausführungseinheiten, mit Pipelining): 1. Befehl 2. Befehl 3. Befehl 4. Befehl 5. Befehl 6. Befehl 7. Befehl 8. Befehl 9. Befehl
60 Superskalare und andere Techniken (16) VLIW,(3 unabhängige Ausführungseinheiten, ohne Pipelining): 1. Befehl 2. Befehl 3. Befehl Befehl 5. Befehl 6. Befehl Befehl 8. Befehl 9. Befehl
61 Superskalare und andere Techniken (17) VLIW,(3 unabhängige Ausführungseinheiten, mit Pipelining): 1. Befehl 2. Befehl 3. Befehl 4. Befehl 5. Befehl 6. Befehl 7. Befehl 8. Befehl 9. Befehl
JR - RA - SS02 Kap
 3.1 Elementare Datentypen, Operationen und ihre Realisierung (siehe 2.1) 3.2 Mikroprogrammierung 3.3 Einfache Implementierung von MIPS 3.4 Pipelining 3.5 Superskalare Befehlsausführung JR - RA - SS02 Kap.
3.1 Elementare Datentypen, Operationen und ihre Realisierung (siehe 2.1) 3.2 Mikroprogrammierung 3.3 Einfache Implementierung von MIPS 3.4 Pipelining 3.5 Superskalare Befehlsausführung JR - RA - SS02 Kap.
JR - RA - SS02 Kap
 3.1 Elementare Datentypen, Operationen und ihre Realisierung (siehe 2.1) 3.2 Mikroprogrammierung 3.3 Einfache Implementierung von MIPS 3.4 Pipelining 3.5 Superskalare Befehlsausführung JR - RA - SS02 Kap.
3.1 Elementare Datentypen, Operationen und ihre Realisierung (siehe 2.1) 3.2 Mikroprogrammierung 3.3 Einfache Implementierung von MIPS 3.4 Pipelining 3.5 Superskalare Befehlsausführung JR - RA - SS02 Kap.
Technische Informatik 1 Übung 8 Instruktionsparallelität (Rechenübung) Andreas Tretter 8./9. Dezember Bitte immer eine Reihe freilassen
 Andreas Tretter 8./9. Dezember Bitte immer eine Reihe freilassen") Technische Informatik 1 Übung 8 Instruktionsparallelität (Rechenübung) Andreas Tretter 8./9. Dezember 2016 Bitte immer eine Reihe freilassen Ziele der Übung Verschiedene Arten von Instruktionsparallelität
Technische Informatik 1 Übung 8 Instruktionsparallelität (Rechenübung) Andreas Tretter 8./9. Dezember 2016 Bitte immer eine Reihe freilassen Ziele der Übung Verschiedene Arten von Instruktionsparallelität
Beispiele von Branch Delay Slot Schedules
 Beispiele von Branch Delay Slot Schedules Bildquelle: David A. Patterson und John L. Hennessy, Computer Organization and Design, Fourth Edition, 2012 Grundlagen der Rechnerarchitektur Prozessor 97 Weniger
Beispiele von Branch Delay Slot Schedules Bildquelle: David A. Patterson und John L. Hennessy, Computer Organization and Design, Fourth Edition, 2012 Grundlagen der Rechnerarchitektur Prozessor 97 Weniger
Datenpfad einer einfachen MIPS CPU
 Datenpfad einer einfachen MIPS CPU Zugriff auf den Datenspeicher Grundlagen der Rechnerarchitektur Prozessor 19 Betrachten nun Load und Store Word Erinnerung, Instruktionen lw und sw sind vom I Typ Format:
Datenpfad einer einfachen MIPS CPU Zugriff auf den Datenspeicher Grundlagen der Rechnerarchitektur Prozessor 19 Betrachten nun Load und Store Word Erinnerung, Instruktionen lw und sw sind vom I Typ Format:
Datenpfad einer einfachen MIPS CPU
 Datenpfad einer einfachen MIPS CPU Zugriff auf den Datenspeicher Grundlagen der Rechnerarchitektur Prozessor 19 Betrachten nun Load und Store Word Erinnerung, Instruktionen lw und sw sind vom I Typ Format:
Datenpfad einer einfachen MIPS CPU Zugriff auf den Datenspeicher Grundlagen der Rechnerarchitektur Prozessor 19 Betrachten nun Load und Store Word Erinnerung, Instruktionen lw und sw sind vom I Typ Format:
Rechnerarchitektur. Marián Vajteršic und Helmut A. Mayer
 Rechnerarchitektur Marián Vajteršic und Helmut A. Mayer Fachbereich Computerwissenschaften Universität Salzburg marian@cosy.sbg.ac.at und helmut@cosy.sbg.ac.at Tel.: 8044-6344 und 8044-6315 30. Mai 2017
Rechnerarchitektur Marián Vajteršic und Helmut A. Mayer Fachbereich Computerwissenschaften Universität Salzburg marian@cosy.sbg.ac.at und helmut@cosy.sbg.ac.at Tel.: 8044-6344 und 8044-6315 30. Mai 2017
Rechnerarchitektur (RA)
") 2 Rechnerarchitektur (RA) Sommersemester 27 Pipelines Jian-Jia Chen Informatik 2 http://ls2-www.cs.tu.de/daes/ 27/5/3 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken
2 Rechnerarchitektur (RA) Sommersemester 27 Pipelines Jian-Jia Chen Informatik 2 http://ls2-www.cs.tu.de/daes/ 27/5/3 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken
Rechnerarchitektur (RA)
") 2 Rechnerarchitektur (RA) Sommersemester 26 Pipelines Jian-Jia Chen Informatik 2 http://ls2-www.cs.tu.de/daes/ 26/5/25 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken
2 Rechnerarchitektur (RA) Sommersemester 26 Pipelines Jian-Jia Chen Informatik 2 http://ls2-www.cs.tu.de/daes/ 26/5/25 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken
Datenpfad einer einfachen MIPS CPU
 Datenpfad einer einfachen MIPS CPU Die Branch Instruktion beq Grundlagen der Rechnerarchitektur Prozessor 13 Betrachten nun Branch Instruktion beq Erinnerung, Branch Instruktionen beq ist vom I Typ Format:
Datenpfad einer einfachen MIPS CPU Die Branch Instruktion beq Grundlagen der Rechnerarchitektur Prozessor 13 Betrachten nun Branch Instruktion beq Erinnerung, Branch Instruktionen beq ist vom I Typ Format:
Lehrveranstaltung: PR Rechnerorganisation Blatt 8. Thomas Aichholzer
 Aufgabe 8.1 Ausnahmen (Exceptions) a. Erklären Sie den Begriff Exception. b. Welche Arten von Exceptions kennen Sie? Wie werden sie ausgelöst und welche Auswirkungen auf den ablaufenden Code ergeben sich
Aufgabe 8.1 Ausnahmen (Exceptions) a. Erklären Sie den Begriff Exception. b. Welche Arten von Exceptions kennen Sie? Wie werden sie ausgelöst und welche Auswirkungen auf den ablaufenden Code ergeben sich
Grundlagen der Informationsverarbeitung:
 Grundlagen der Informationsverarbeitung: Parallelität auf Instruktionsebene Prof. Dr.-Ing. habil. Ulrike Lucke Durchgeführt von Prof. Dr. rer. nat. habil. Mario Schölzel Maximaler Raum für Titelbild (wenn
Grundlagen der Informationsverarbeitung: Parallelität auf Instruktionsebene Prof. Dr.-Ing. habil. Ulrike Lucke Durchgeführt von Prof. Dr. rer. nat. habil. Mario Schölzel Maximaler Raum für Titelbild (wenn
Tutorium Rechnerorganisation
 Woche 8 Tutorien 3 und 4 zur Vorlesung Rechnerorganisation 1 Christian A. Mandery: KIT Universität des Landes Baden-Württemberg und nationales Grossforschungszentrum in der Helmholtz-Gemeinschaft www.kit.edu
Woche 8 Tutorien 3 und 4 zur Vorlesung Rechnerorganisation 1 Christian A. Mandery: KIT Universität des Landes Baden-Württemberg und nationales Grossforschungszentrum in der Helmholtz-Gemeinschaft www.kit.edu
Das Prinzip an einem alltäglichen Beispiel
 3.2 Pipelining Ziel: Performanzsteigerung é Prinzip der Fließbandverarbeitung é Probleme bei Fließbandverarbeitung BB TI I 3.2/1 Das Prinzip an einem alltäglichen Beispiel é Sie kommen aus dem Urlaub und
3.2 Pipelining Ziel: Performanzsteigerung é Prinzip der Fließbandverarbeitung é Probleme bei Fließbandverarbeitung BB TI I 3.2/1 Das Prinzip an einem alltäglichen Beispiel é Sie kommen aus dem Urlaub und
Pipelining. Die Pipelining Idee. Grundlagen der Rechnerarchitektur Prozessor 45
 Pipelining Die Pipelining Idee Grundlagen der Rechnerarchitektur Prozessor 45 Single Cycle Performance Annahme die einzelnen Abschnitte des MIPS Instruktionszyklus benötigen folgende Ausführungszeiten:
Pipelining Die Pipelining Idee Grundlagen der Rechnerarchitektur Prozessor 45 Single Cycle Performance Annahme die einzelnen Abschnitte des MIPS Instruktionszyklus benötigen folgende Ausführungszeiten:
Allgemeine Lösung mittels Hazard Detection Unit
 Allgemeine Lösung mittels Hazard Detection Unit Bildquelle: David A. Patterson und John L. Hennessy, Computer Organization and Design, Fourth Edition, 2012 Grundlagen der Rechnerarchitektur Prozessor 83
Allgemeine Lösung mittels Hazard Detection Unit Bildquelle: David A. Patterson und John L. Hennessy, Computer Organization and Design, Fourth Edition, 2012 Grundlagen der Rechnerarchitektur Prozessor 83
CPU. Dr.-Ing. Volkmar Sieh. Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg SS 2011
 CPU Dr.-Ing. Volkmar Sieh Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg SS 2011 CPU 1/62 2012-02-29 CPU Übersicht: Pipeline-Aufbau Pipeline- Hazards CPU
CPU Dr.-Ing. Volkmar Sieh Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg SS 2011 CPU 1/62 2012-02-29 CPU Übersicht: Pipeline-Aufbau Pipeline- Hazards CPU
Was ist die Performance Ratio?
 Was ist die Performance Ratio? Wie eben gezeigt wäre für k Pipeline Stufen und eine große Zahl an ausgeführten Instruktionen die Performance Ratio gleich k, wenn jede Pipeline Stufe dieselbe Zeit beanspruchen
Was ist die Performance Ratio? Wie eben gezeigt wäre für k Pipeline Stufen und eine große Zahl an ausgeführten Instruktionen die Performance Ratio gleich k, wenn jede Pipeline Stufe dieselbe Zeit beanspruchen
Rechnerarchitektur SS TU Dortmund
 Rechnerarchitektur SS 2016 Exercises: Scoreboarding and Tomasulo s Algorithm Jian-Jia Chen TU Dortmund to be discussed on June, 14, 2016 Jian-Jia Chen (TU Dortmund) 1 / 8 Scoreboardings Im nächste Folien
Rechnerarchitektur SS 2016 Exercises: Scoreboarding and Tomasulo s Algorithm Jian-Jia Chen TU Dortmund to be discussed on June, 14, 2016 Jian-Jia Chen (TU Dortmund) 1 / 8 Scoreboardings Im nächste Folien
Grundlagen der Rechnerarchitektur
 Grundlagen der Rechnerarchitektur Prozessor Übersicht Datenpfad Control Pipelining Data Hazards Control Hazards Multiple Issue Grundlagen der Rechnerarchitektur Prozessor 2 Datenpfad einer einfachen MIPS
Grundlagen der Rechnerarchitektur Prozessor Übersicht Datenpfad Control Pipelining Data Hazards Control Hazards Multiple Issue Grundlagen der Rechnerarchitektur Prozessor 2 Datenpfad einer einfachen MIPS
Technische Informatik I - HS 18
 Institut für Technische Informatik und Kommunikationsnetze Prof. L. Thiele Technische Informatik I - HS 18 Übung 7 Datum : 22.-23. November 2018 Pipelining Aufgabe 1: Taktrate / Latenz In dieser Aufgabe
Institut für Technische Informatik und Kommunikationsnetze Prof. L. Thiele Technische Informatik I - HS 18 Übung 7 Datum : 22.-23. November 2018 Pipelining Aufgabe 1: Taktrate / Latenz In dieser Aufgabe
Prozessorarchitektur. Dynamische Ablaufplanung. M. Schölzel
 Prozessorarchitektur Dynamische Ablaufplanung M. Schölzel Inhalt HW-Architekturen zur Implementierung dynamischer Ablaufplanung: Scoreboard Tomasulo-Algorithmus Inhalt HW-Architekturen zur Implementierung
Prozessorarchitektur Dynamische Ablaufplanung M. Schölzel Inhalt HW-Architekturen zur Implementierung dynamischer Ablaufplanung: Scoreboard Tomasulo-Algorithmus Inhalt HW-Architekturen zur Implementierung
Datenpfad einer einfachen MIPS CPU
 Datenpfad einer einfachen MIPS CPU Die Branch Instruktion beq Grundlagen der Rechnerarchitektur Prozessor 13 Betrachten nun Branch Instruktion beq Erinnerung, Branch Instruktionen beq ist vom I Typ Format:
Datenpfad einer einfachen MIPS CPU Die Branch Instruktion beq Grundlagen der Rechnerarchitektur Prozessor 13 Betrachten nun Branch Instruktion beq Erinnerung, Branch Instruktionen beq ist vom I Typ Format:
Compiler für f r Eingebettete Systeme (CfES)
") Compiler für f r Eingebettete Systeme (CfES) Sommersemester 2009 Dr. Heiko Falk Technische Universität Dortmund Lehrstuhl Informatik 12 Entwurfsautomatisierung für Eingebettete Systeme Kapitel 9 Ausblick
Compiler für f r Eingebettete Systeme (CfES) Sommersemester 2009 Dr. Heiko Falk Technische Universität Dortmund Lehrstuhl Informatik 12 Entwurfsautomatisierung für Eingebettete Systeme Kapitel 9 Ausblick
Hochschule Düsseldorf University of Applied Sciences HSD RISC &CISC
 HSD RISC &CISC CISC - Complex Instruction Set Computer - Annahme: größerer Befehlssatz und komplexere Befehlen höhere Leistungsfähigkeit - Möglichst wenige Zeilen verwendet, um Aufgaben auszuführen - Großer
HSD RISC &CISC CISC - Complex Instruction Set Computer - Annahme: größerer Befehlssatz und komplexere Befehlen höhere Leistungsfähigkeit - Möglichst wenige Zeilen verwendet, um Aufgaben auszuführen - Großer
Technische Informatik 1 Übung 6 Pipelining (Rechenübung) Andreas Tretter 24./25. November 2016
 Andreas Tretter 24./25. November 2016") Technische Informatik 1 Übung 6 Pipelining (Rechenübung) Andreas Tretter 24./25. November 2016 Aufgabe 1: Taktrate / Latenz TI1 - Übung 6: Pipelining Einzeltakt-Architektur TI1 - Übung 6: Pipelining Pipelining-Architektur
Technische Informatik 1 Übung 6 Pipelining (Rechenübung) Andreas Tretter 24./25. November 2016 Aufgabe 1: Taktrate / Latenz TI1 - Übung 6: Pipelining Einzeltakt-Architektur TI1 - Übung 6: Pipelining Pipelining-Architektur
Teil 2: Rechnerorganisation
 Teil 2: Rechnerorganisation Inhalt: Zahlendarstellungen Rechnerarithmetik schrittweiser Entwurf eines hypothetischen Prozessors mit Daten-, Adreß- und Kontrollpfad Speicherorganisation Mikroprogrammierung
Teil 2: Rechnerorganisation Inhalt: Zahlendarstellungen Rechnerarithmetik schrittweiser Entwurf eines hypothetischen Prozessors mit Daten-, Adreß- und Kontrollpfad Speicherorganisation Mikroprogrammierung
Name: Vorname: Matr.-Nr.: 4. a) RISC-Architekturen müssen zur Decodierung von Maschinenbefehlen stets ein mikroprogrammierbares Steuerwerk verwenden.
 RISC-Architekturen müssen zur Decodierung von Maschinenbefehlen stets ein mikroprogrammierbares Steuerwerk verwenden.") Name: Vorname: Matr.-Nr.: 4 Aufgabe 1 (8 Punkte) Entscheiden Sie, welche der folgenden Aussagen zum Thema CISC/RISC-Prinzipien korrekt sind. a) RISC-Architekturen müssen zur Decodierung von Maschinenbefehlen
Name: Vorname: Matr.-Nr.: 4 Aufgabe 1 (8 Punkte) Entscheiden Sie, welche der folgenden Aussagen zum Thema CISC/RISC-Prinzipien korrekt sind. a) RISC-Architekturen müssen zur Decodierung von Maschinenbefehlen
Technische Informatik 1 Übung 7 Pipelining (Rechenübung) Balz Maag 22./23. November 2018
 Balz Maag 22./23. November 2018") Technische Informatik 1 Übung 7 Pipelining (Rechenübung) Balz Maag 22./23. November 2018 Aufgabe 1: Taktrate / Latenz Einzeltakt-Architektur Pipelining-Architektur Pipelining-Architektur 15 15 120 ps 15
Technische Informatik 1 Übung 7 Pipelining (Rechenübung) Balz Maag 22./23. November 2018 Aufgabe 1: Taktrate / Latenz Einzeltakt-Architektur Pipelining-Architektur Pipelining-Architektur 15 15 120 ps 15
Technische Informatik 1 - HS 2016
 Institut für Technische Informatik und Kommunikationsnetze Prof. L. Thiele Technische Informatik 1 - HS 2016 Lösungsvorschläge für Übung 6 Datum: 24. 25. 11. 2016 Pipelining 1 Taktrate / Latenz In dieser
Institut für Technische Informatik und Kommunikationsnetze Prof. L. Thiele Technische Informatik 1 - HS 2016 Lösungsvorschläge für Übung 6 Datum: 24. 25. 11. 2016 Pipelining 1 Taktrate / Latenz In dieser
Technische Informatik 1 - HS 2016
 Institut für Technische Informatik und Kommunikationsnetze Prof. L. Thiele Technische Informatik 1 - HS 2016 Lösungsvorschläge für Übung 8 Datum: 8. 9. 12. 2016 1 Instruktionsparallelität VLIW Gegeben
Institut für Technische Informatik und Kommunikationsnetze Prof. L. Thiele Technische Informatik 1 - HS 2016 Lösungsvorschläge für Übung 8 Datum: 8. 9. 12. 2016 1 Instruktionsparallelität VLIW Gegeben
Technische Informatik 1 - HS 2017
 Institut für Technische Informatik und Kommunikationsnetze Prof. L. Thiele Technische Informatik 1 - HS 2017 Übung 8 Datum: 30. 11. 1. 12. 2017 In dieser Übung soll mit Hilfe des Simulators WinMIPS64 die
Institut für Technische Informatik und Kommunikationsnetze Prof. L. Thiele Technische Informatik 1 - HS 2017 Übung 8 Datum: 30. 11. 1. 12. 2017 In dieser Übung soll mit Hilfe des Simulators WinMIPS64 die
Besprechung des 5. Übungsblattes Parallelität innerhalb der CPU Pipelining
 Themen heute Besprechung des 5. Übungsblattes Parallelität innerhalb der CPU Pipelining Organisatorisches Wie schon in den vorhergehenden Tutorien erwähnt, ist Mehrfachabgabe, außer bei Programmieraufgaben,
Themen heute Besprechung des 5. Übungsblattes Parallelität innerhalb der CPU Pipelining Organisatorisches Wie schon in den vorhergehenden Tutorien erwähnt, ist Mehrfachabgabe, außer bei Programmieraufgaben,
Kap.3 Mikroarchitektur. Prozessoren, interne Sicht
 Kap.3 Mikroarchitektur Prozessoren, interne Sicht 1 3.1 Elementare Datentypen, Operationen und ihre Realisierung (siehe 2.1) 3.2 Mikroprogrammierung 3.3 Einfache Implementierung von MIPS 3.4 Pipelining
Kap.3 Mikroarchitektur Prozessoren, interne Sicht 1 3.1 Elementare Datentypen, Operationen und ihre Realisierung (siehe 2.1) 3.2 Mikroprogrammierung 3.3 Einfache Implementierung von MIPS 3.4 Pipelining
Auch hier wieder. Control. RegDst Branch MemRead MemtoReg ALUOp MemWrite ALUSrc RegWrite. Instruction[31 26] (also: das Opcode Field der Instruktion)
![Auch hier wieder. Control. RegDst Branch MemRead MemtoReg ALUOp MemWrite ALUSrc RegWrite. Instruction[31 26] (also: das Opcode Field der Instruktion)](/thumbs/53/31325432.jpg "Auch hier wieder. Control. RegDst Branch MemRead MemtoReg ALUOp MemWrite ALUSrc RegWrite. Instruction[31 26] (also: das Opcode Field der Instruktion)") Auch hier wieder Aus voriger Wahrheitstabelle lässt sich mechanisch eine kombinatorische Schaltung generieren, die wir im Folgenden mit dem Control Symbol abstrakt darstellen. Instruction[31 26] (also:
Auch hier wieder Aus voriger Wahrheitstabelle lässt sich mechanisch eine kombinatorische Schaltung generieren, die wir im Folgenden mit dem Control Symbol abstrakt darstellen. Instruction[31 26] (also:
Struktur der CPU (1) Die Adress- und Datenpfad der CPU: Befehl holen. Vorlesung Rechnerarchitektur und Rechnertechnik SS Memory Adress Register
 Die Adress- und Datenpfad der CPU: Befehl holen. Vorlesung Rechnerarchitektur und Rechnertechnik SS Memory Adress Register") Struktur der CPU (1) Die Adress- und Datenpfad der CPU: Prog. Counter Memory Adress Register Befehl holen Incrementer Main store Instruction register Op-code Address Memory Buffer Register CU Clock Control
Struktur der CPU (1) Die Adress- und Datenpfad der CPU: Prog. Counter Memory Adress Register Befehl holen Incrementer Main store Instruction register Op-code Address Memory Buffer Register CU Clock Control
Prozessorarchitektur. Sprungvorhersage. M. Schölzel
 Prozessorarchitektur Sprungvorhersage M. Schölzel Inhalt Sprungvorhersage statische Methoden dynamische Methoden Problem Fetch-Phase Befehlswarteschlange Speicher b? Neue Adresse für noch nicht bekannt
Prozessorarchitektur Sprungvorhersage M. Schölzel Inhalt Sprungvorhersage statische Methoden dynamische Methoden Problem Fetch-Phase Befehlswarteschlange Speicher b? Neue Adresse für noch nicht bekannt
Kap.3 Mikroarchitektur. Prozessoren, interne Sicht
 Kap.3 Mikroarchitektur Prozessoren, interne Sicht 3.1 Elementare Datentypen, Operationen und ihre Realisierung (siehe 2.1) 3.2 Mikroprogrammierung 3.3 Einfache Implementierung von MIPS 3.4 Pipelining Implementierung
Kap.3 Mikroarchitektur Prozessoren, interne Sicht 3.1 Elementare Datentypen, Operationen und ihre Realisierung (siehe 2.1) 3.2 Mikroprogrammierung 3.3 Einfache Implementierung von MIPS 3.4 Pipelining Implementierung
Übungen zu Grundlagen der Rechnerarchitektur und -organisation: Bonusaufgaben Übung 8 und Präsenzaufgaben Übung 9
 Übungen zu Grundlagen der Rechnerarchitektur und -organisation: Bonusaufgaben Übung 8 und Präsenzaufgaben Übung 9 Dominik Schoenwetter Erlangen, 30. Juni 2014 Lehrstuhl für Informatik 3 (Rechnerarchitektur)
Übungen zu Grundlagen der Rechnerarchitektur und -organisation: Bonusaufgaben Übung 8 und Präsenzaufgaben Übung 9 Dominik Schoenwetter Erlangen, 30. Juni 2014 Lehrstuhl für Informatik 3 (Rechnerarchitektur)
Data Hazards. Grundlagen der Rechnerarchitektur Prozessor 74
 Data Hazards Grundlagen der Rechnerarchitektur Prozessor 74 Motivation Ist die Pipelined Ausführung immer ohne Probleme möglich? Beispiel: sub $2, $1, $3 and $12, $2, $5 or $13, $6, $2 add $14, $2, $2
Data Hazards Grundlagen der Rechnerarchitektur Prozessor 74 Motivation Ist die Pipelined Ausführung immer ohne Probleme möglich? Beispiel: sub $2, $1, $3 and $12, $2, $5 or $13, $6, $2 add $14, $2, $2
Pipelining for DLX 560 Prozessor. Pipelining : implementation-technique. Pipelining makes CPUs fast. pipe stages
 Pipelining for DLX 560 Prozessor Pipelining : implementation-technique Pipelining makes CPUs fast. pipe stages As many instructions as possible in one unit of time 1 Pipelining can - Reduce CPI - Reduce
Pipelining for DLX 560 Prozessor Pipelining : implementation-technique Pipelining makes CPUs fast. pipe stages As many instructions as possible in one unit of time 1 Pipelining can - Reduce CPI - Reduce
Datenpfaderweiterung Der Single Cycle Datenpfad des MIPS Prozessors soll um die Instruktion min $t0, $t1, $t2 erweitert werden, welche den kleineren
 Datenpfaderweiterung Der Single Cycle Datenpfad des MIPS Prozessors soll um die Instruktion min $t0, $t1, $t2 erweitert werden, welche den kleineren der beiden Registerwerte $t1 und $t2 in einem Zielregister
Datenpfaderweiterung Der Single Cycle Datenpfad des MIPS Prozessors soll um die Instruktion min $t0, $t1, $t2 erweitert werden, welche den kleineren der beiden Registerwerte $t1 und $t2 in einem Zielregister
Dynamisches Scheduling
 12 Dynamisches Scheduling Peter Marwedel Informatik 12 TU Dortmund 2012/05/07 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken ist im Allgemeinen nicht erlaubt.
12 Dynamisches Scheduling Peter Marwedel Informatik 12 TU Dortmund 2012/05/07 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken ist im Allgemeinen nicht erlaubt.
Umstellung auf neue Pipeline
 new_pipe Umstellung auf neue Pipeline»» Umstellung auf neue Pipeline Core mit 2 Port Registerfile In dieser Konfiguration wird am Registerfile ein Phasensplitting durchgeführt, um in jedem Takt 2 Register
new_pipe Umstellung auf neue Pipeline»» Umstellung auf neue Pipeline Core mit 2 Port Registerfile In dieser Konfiguration wird am Registerfile ein Phasensplitting durchgeführt, um in jedem Takt 2 Register
Von-Neumann-Architektur
 Von-Neumann-Architektur Bisher wichtig: Konstruktionsprinzip des Rechenwerkes und Leitwerkes. Neu: Größerer Arbeitsspeicher Ein- und Ausgabewerk (Peripherie) Rechenwerk (ALU) Steuerwerk (CU) Speicher...ppppp...dddddd..
Von-Neumann-Architektur Bisher wichtig: Konstruktionsprinzip des Rechenwerkes und Leitwerkes. Neu: Größerer Arbeitsspeicher Ein- und Ausgabewerk (Peripherie) Rechenwerk (ALU) Steuerwerk (CU) Speicher...ppppp...dddddd..
nutzt heute Diese Prinzipien werden wir im Kapitel 3 behandelt Lehrstuhl für Informatik 3 - D. Fey Vorlesung GRa - SS
 3.1 Einführung (1) Nahezu jeder Prozessor in einem Desktop-Rechner (der auf oder unter dem Tisch steht) und in einem Server- Rechner (auf dem man sich von der Ferne einloggt und dort rechnet) nutzt heute
3.1 Einführung (1) Nahezu jeder Prozessor in einem Desktop-Rechner (der auf oder unter dem Tisch steht) und in einem Server- Rechner (auf dem man sich von der Ferne einloggt und dort rechnet) nutzt heute
Neue Prozessor-Architekturen für Desktop-PC
 Neue Prozessor-Architekturen für Desktop-PC Bernd Däne Technische Universität Ilmenau Fakultät I/A - Institut TTI Postfach 100565, D-98684 Ilmenau Tel. 0-3677-69-1433 bdaene@theoinf.tu-ilmenau.de http://www.theoinf.tu-ilmenau.de/ra1/
Neue Prozessor-Architekturen für Desktop-PC Bernd Däne Technische Universität Ilmenau Fakultät I/A - Institut TTI Postfach 100565, D-98684 Ilmenau Tel. 0-3677-69-1433 bdaene@theoinf.tu-ilmenau.de http://www.theoinf.tu-ilmenau.de/ra1/
DIGITALE SCHALTUNGEN II
 DIGITALE SCHALTUNGEN II 3. Sequentielle Schaltkreise 3.1 Vergleich kombinatorische sequentielle Schaltkreise 3.2 Binäre Speicherelemente 3.2.1 RS Flipflop 3.2.2 Getaktetes RS Flipflop 3.2.3 D Flipflop
DIGITALE SCHALTUNGEN II 3. Sequentielle Schaltkreise 3.1 Vergleich kombinatorische sequentielle Schaltkreise 3.2 Binäre Speicherelemente 3.2.1 RS Flipflop 3.2.2 Getaktetes RS Flipflop 3.2.3 D Flipflop
Technische Informatik - Eine Einführung
 Martin-Luther-Universität Halle-Wittenberg Fachbereich Mathematik und Informatik Lehrstuhl für Technische Informatik Prof. P. Molitor Technische Informatik - Eine Einführung Rechnerarchitektur Aufgabe
Martin-Luther-Universität Halle-Wittenberg Fachbereich Mathematik und Informatik Lehrstuhl für Technische Informatik Prof. P. Molitor Technische Informatik - Eine Einführung Rechnerarchitektur Aufgabe
Teil 1: Prozessorstrukturen
 Teil 1: Prozessorstrukturen Inhalt: Mikroprogrammierung Assemblerprogrammierung Motorola 6809: ein einfacher 8-Bit Mikroprozessor Mikrocontroller Koprozessoren CISC- und RISC-Prozessoren Intel Pentium
Teil 1: Prozessorstrukturen Inhalt: Mikroprogrammierung Assemblerprogrammierung Motorola 6809: ein einfacher 8-Bit Mikroprozessor Mikrocontroller Koprozessoren CISC- und RISC-Prozessoren Intel Pentium
ARM: Befehlssatz (Forts.)
") ARM: Befehlssatz (Forts.) Befehl SWI zum Auslösen eines Software-Interrupts: Instruktionsformat: Ausführung von SWI überführt CPU in den supervisor mode (nach Retten des PC in r14_svc und des CPSR in SPSR_svc)
ARM: Befehlssatz (Forts.) Befehl SWI zum Auslösen eines Software-Interrupts: Instruktionsformat: Ausführung von SWI überführt CPU in den supervisor mode (nach Retten des PC in r14_svc und des CPSR in SPSR_svc)
ARM: Befehlssatz (Forts.)
") ARM: Befehlssatz (Forts.) Befehl SWI zum Auslösen eines Software-Interrupts: Instruktionsformat: Ausführung von SWI überführt CPU in den supervisor mode (nach Retten des PC in r14_svc und des CPSR in SPSR_svc)
ARM: Befehlssatz (Forts.) Befehl SWI zum Auslösen eines Software-Interrupts: Instruktionsformat: Ausführung von SWI überführt CPU in den supervisor mode (nach Retten des PC in r14_svc und des CPSR in SPSR_svc)
Systeme 1: Architektur
 slide 1 Vorlesung Systeme 1: Architektur Prof. Dr. Ulrich Ultes-Nitsche Forschungsgruppe Departement für Informatik Universität Freiburg slide 2 Prüfung 18. Februar 2004 8h00-11h40 13h00-18h20 20 Minuten
slide 1 Vorlesung Systeme 1: Architektur Prof. Dr. Ulrich Ultes-Nitsche Forschungsgruppe Departement für Informatik Universität Freiburg slide 2 Prüfung 18. Februar 2004 8h00-11h40 13h00-18h20 20 Minuten
Technische Informatik 1
 Technische Informatik 1 5 Prozessor Pipelineimplementierung Lothar Thiele Computer Engineering and Networks Laboratory Pipelining Definition 5 2 Definition Pipelining (Fliessbandverarbeitung) ist eine
Technische Informatik 1 5 Prozessor Pipelineimplementierung Lothar Thiele Computer Engineering and Networks Laboratory Pipelining Definition 5 2 Definition Pipelining (Fliessbandverarbeitung) ist eine
Grundlagen der Rechnerarchitektur. MIPS Assembler
 Grundlagen der Rechnerarchitektur MIPS Assembler Übersicht Arithmetik, Register und Speicherzugriff Darstellung von Instruktionen Logische Operationen Weitere Arithmetik Branches und Jumps Prozeduren 32
Grundlagen der Rechnerarchitektur MIPS Assembler Übersicht Arithmetik, Register und Speicherzugriff Darstellung von Instruktionen Logische Operationen Weitere Arithmetik Branches und Jumps Prozeduren 32
Vorlesung Rechnerarchitektur. Einführung
 Vorlesung Rechnerarchitektur Einführung Themen der Vorlesung Die Vorlesung entwickelt an Hand von zwei Beispielen wichtige Prinzipien der Prozessorarchitektur und der Speicherarchitektur: MU0 Arm Speicher
Vorlesung Rechnerarchitektur Einführung Themen der Vorlesung Die Vorlesung entwickelt an Hand von zwei Beispielen wichtige Prinzipien der Prozessorarchitektur und der Speicherarchitektur: MU0 Arm Speicher
Instruktionen pro Takt
 (c) Peter Sturm, Universität Trier (u.a.) 1 Instruktionen pro Takt 500 MIPS (Dhrystone) Taktfrequenz 450 400 350 300 250 200 150 100 50 0 8086 80286 80386 80486 Pentium Pentium Pro Die-Größen: Intel Vorlesung
(c) Peter Sturm, Universität Trier (u.a.) 1 Instruktionen pro Takt 500 MIPS (Dhrystone) Taktfrequenz 450 400 350 300 250 200 150 100 50 0 8086 80286 80386 80486 Pentium Pentium Pro Die-Größen: Intel Vorlesung
Arithmetik, Register und Speicherzugriff. Grundlagen der Rechnerarchitektur Assembler 9
 Arithmetik, Register und Speicherzugriff Grundlagen der Rechnerarchitektur Assembler 9 Arithmetik und Zuweisungen Einfache Arithmetik mit Zuweisung C Programm: a = b + c; d = a e; MIPS Instruktionen: Komplexere
Arithmetik, Register und Speicherzugriff Grundlagen der Rechnerarchitektur Assembler 9 Arithmetik und Zuweisungen Einfache Arithmetik mit Zuweisung C Programm: a = b + c; d = a e; MIPS Instruktionen: Komplexere
IT-Infrastruktur ITIS-D' WS 2014/15. Hans-Georg Eßer Dipl.-Math., Dipl.-Inform. Foliensatz D': Rechnerstrukturen, Teil 2 (Pipelining) v1.
 v1.") ITIS-D' IT-Infrastruktur WS 2014/15 Hans-Georg Eßer Dipl.-Math., Dipl.-Inform. Foliensatz D': Rechnerstrukturen, Teil 2 (Pipelining) v1.0, 2014/11/13 13.11.2014 IT-Infrastruktur, WS 2014/15, Hans-Georg
ITIS-D' IT-Infrastruktur WS 2014/15 Hans-Georg Eßer Dipl.-Math., Dipl.-Inform. Foliensatz D': Rechnerstrukturen, Teil 2 (Pipelining) v1.0, 2014/11/13 13.11.2014 IT-Infrastruktur, WS 2014/15, Hans-Georg
Programmierung Paralleler Prozesse
 Vorlesung Programmierung Paralleler Prozesse Prof. Dr. Klaus Hering Sommersemester 2007 HTWK Leipzig, FB IMN Sortierproblem Gegeben: Menge M mit einer Ordnungsrelation (etwa Menge der reellen Zahlen) Folge
Vorlesung Programmierung Paralleler Prozesse Prof. Dr. Klaus Hering Sommersemester 2007 HTWK Leipzig, FB IMN Sortierproblem Gegeben: Menge M mit einer Ordnungsrelation (etwa Menge der reellen Zahlen) Folge
Assembler am Beispiel der MIPS Architektur
 Assembler am Beispiel der MIPS Architektur Frühere Einsatzgebiete MIPS Silicon Graphics Unix Workstations (z. B. SGI Indigo2) Silicon Graphics Unix Server (z. B. SGI Origin2000) DEC Workstations (z.b.
Assembler am Beispiel der MIPS Architektur Frühere Einsatzgebiete MIPS Silicon Graphics Unix Workstations (z. B. SGI Indigo2) Silicon Graphics Unix Server (z. B. SGI Origin2000) DEC Workstations (z.b.
Tutorium Rechnerorganisation
 Woche 7 Tutorien 3 und 4 zur Vorlesung Rechnerorganisation 1 Christian A. Mandery: KIT Universität des Landes Baden-Württemberg und nationales Grossforschungszentrum in der Helmholtz-Gemeinschaft www.kit.edu
Woche 7 Tutorien 3 und 4 zur Vorlesung Rechnerorganisation 1 Christian A. Mandery: KIT Universität des Landes Baden-Württemberg und nationales Grossforschungszentrum in der Helmholtz-Gemeinschaft www.kit.edu
Arbeitsfolien - Teil 4 CISC und RISC
 Vorlesung Informationstechnische Systeme zur Signal- und Wissensverarbeitung PD Dr.-Ing. Gerhard Staude Arbeitsfolien - Teil 4 CISC und RISC Institut für Informationstechnik Fakultät für Elektrotechnik
Vorlesung Informationstechnische Systeme zur Signal- und Wissensverarbeitung PD Dr.-Ing. Gerhard Staude Arbeitsfolien - Teil 4 CISC und RISC Institut für Informationstechnik Fakultät für Elektrotechnik
Informatik 12 Kapitel 3 - Funktionsweise eines Rechners
 Fachschaft Informatik Informatik 12 Kapitel 3 - Funktionsweise eines Rechners Michael Steinhuber König-Karlmann-Gymnasium Altötting 9. Februar 2017 Folie 1/36 Inhaltsverzeichnis I 1 Komponenten eines PCs
Fachschaft Informatik Informatik 12 Kapitel 3 - Funktionsweise eines Rechners Michael Steinhuber König-Karlmann-Gymnasium Altötting 9. Februar 2017 Folie 1/36 Inhaltsverzeichnis I 1 Komponenten eines PCs
9. Fließbandverarbeitung
 9. Fließbandverarbeitung Nachteile der Mikroprogrammierung Von CISC zu RISC Fließbandverarbeitung Pipeline-Hazards Behandlung von Daten- und Kontroll-Hazards 334 Nachteile mikroprogrammierter CPUs Zusätzliche
9. Fließbandverarbeitung Nachteile der Mikroprogrammierung Von CISC zu RISC Fließbandverarbeitung Pipeline-Hazards Behandlung von Daten- und Kontroll-Hazards 334 Nachteile mikroprogrammierter CPUs Zusätzliche
RISC-Prozessoren (1)
") RISC-Prozessoren (1) 1) 8 Befehlsklassen und ihre mittlere Ausführungshäufigkeit (Fairclough): Zuweisung bzw. Datenbewegung 45,28% Programmablauf 28,73% Arithmetik 10,75% Vergleich 5,92% Logik 3,91% Shift
RISC-Prozessoren (1) 1) 8 Befehlsklassen und ihre mittlere Ausführungshäufigkeit (Fairclough): Zuweisung bzw. Datenbewegung 45,28% Programmablauf 28,73% Arithmetik 10,75% Vergleich 5,92% Logik 3,91% Shift
4. Mikroprogrammierung (Firmware)
") 4. Mikroprogrammierung (Firmware) 4. Ein Mikroprogramm-gesteuerter Computer 4.2 Mikroprogramm-Beispiel: Multiplikation 4.3 Interpretation von Maschinenbefehlen durch ein Mikroprogramm 4. Mikroprogrammierung
4. Mikroprogrammierung (Firmware) 4. Ein Mikroprogramm-gesteuerter Computer 4.2 Mikroprogramm-Beispiel: Multiplikation 4.3 Interpretation von Maschinenbefehlen durch ein Mikroprogramm 4. Mikroprogrammierung
, 2015W Übungsgruppen: Mo., Mi.,
 VU Technische Grundlagen der Informatik Übung 6: Befehlssatz, Pipelining 183.59, 2015W Übungsgruppen: Mo., 1.12. Mi., 16.12.2015 Aufgabe 1: Stack Funktionsweise Erläutern Sie die Funktionsweise eines Stacks
VU Technische Grundlagen der Informatik Übung 6: Befehlssatz, Pipelining 183.59, 2015W Übungsgruppen: Mo., 1.12. Mi., 16.12.2015 Aufgabe 1: Stack Funktionsweise Erläutern Sie die Funktionsweise eines Stacks
Kontrollpfad der hypothetischen CPU
 Kontrollpfad der hypothetischen CPU fast alle Algorithmen benötigen FOR- oder WHILE-Schleifen und IF.. ELSE Verzweigungen Kontrollfluß ist datenabhängig CCR speichert Statussignale N,Z, V,C der letzten
Kontrollpfad der hypothetischen CPU fast alle Algorithmen benötigen FOR- oder WHILE-Schleifen und IF.. ELSE Verzweigungen Kontrollfluß ist datenabhängig CCR speichert Statussignale N,Z, V,C der letzten
9.1. Aufbau einer Befehlspipeline
 Kapitel 9 - Befehlspipelining Seite 191 Kapitel 9 Befehlspipelining 9.1. Aufbau einer Befehlspipeline Ein typischer Befehl in einer Maschine mit einem RISC-artigen Befehlssatz besteht aus den Operationen:
Kapitel 9 - Befehlspipelining Seite 191 Kapitel 9 Befehlspipelining 9.1. Aufbau einer Befehlspipeline Ein typischer Befehl in einer Maschine mit einem RISC-artigen Befehlssatz besteht aus den Operationen:
Prozessorarchitektur. Kapitel 1 - Wiederholung. M. Schölzel
 Prozessorarchitektur Kapitel - Wiederholung M. Schölzel Wiederholung Kombinatorische Logik: Ausgaben hängen funktional von den Eingaben ab. x x 2 x 3 z z = f (x,,x n ) z 2 z m = f m (x,,x n ) Sequentielle
Prozessorarchitektur Kapitel - Wiederholung M. Schölzel Wiederholung Kombinatorische Logik: Ausgaben hängen funktional von den Eingaben ab. x x 2 x 3 z z = f (x,,x n ) z 2 z m = f m (x,,x n ) Sequentielle
Kontrollpfad der hypothetischen CPU
 Kontrollpfad der hypothetischen CPU fast alle Algorithmen benötigen FOR- oder WHILE-Schleifen und IF.. ELSE Verzweigungen Kontrollfluß ist datenabhängig CCR speichert Statussignale N,Z, V,C der letzten
Kontrollpfad der hypothetischen CPU fast alle Algorithmen benötigen FOR- oder WHILE-Schleifen und IF.. ELSE Verzweigungen Kontrollfluß ist datenabhängig CCR speichert Statussignale N,Z, V,C der letzten
, WS2013 Übungsgruppen: Di., Fr.,
 VU Technische Grundlagen der Informatik Übung : Stack, Pipelining., WS20 Übungsgruppen: Di., 0.01. Fr.,.01.201 Aufgabe 1: Stack - Funktionsweise Erläutern Sie die Funktionsweise eines Stacks bzw. Kellerspeichers
VU Technische Grundlagen der Informatik Übung : Stack, Pipelining., WS20 Übungsgruppen: Di., 0.01. Fr.,.01.201 Aufgabe 1: Stack - Funktionsweise Erläutern Sie die Funktionsweise eines Stacks bzw. Kellerspeichers
SUB $2,$5,10 Zeile 1 LDO $5,$0,2*8 Zeile 2 OR $1,$2,$3 Zeile 3 SRU $1,$5,$1 Zeile 4.
 33 7 Pipelining Gegeben ist der folgende Ausschnitt aus einer MMIX Codesequenz: SUB $2,$5, Zeile LDO $5,$,2* Zeile 2 OR $,$2,$3 Zeile 3 SRU $,$5,$ Zeile 4 Zeile und 3 wg b) Geben Sie alle auftretenden
33 7 Pipelining Gegeben ist der folgende Ausschnitt aus einer MMIX Codesequenz: SUB $2,$5, Zeile LDO $5,$,2* Zeile 2 OR $,$2,$3 Zeile 3 SRU $,$5,$ Zeile 4 Zeile und 3 wg b) Geben Sie alle auftretenden
RO II Übungen ohne Lösungen V20
 H. Richter 05.04.2017 RO II Übungen ohne Lösungen V20 Übung 1: Gesamtpunktzahl [76] (76P) 1 Aufgabe: Superskalarität [22] 1.) Worin besteht der Unterschied zwischen einem skalaren Prozessor und einem superskalaren
H. Richter 05.04.2017 RO II Übungen ohne Lösungen V20 Übung 1: Gesamtpunktzahl [76] (76P) 1 Aufgabe: Superskalarität [22] 1.) Worin besteht der Unterschied zwischen einem skalaren Prozessor und einem superskalaren
Johann Wolfgang Goethe-Universität
 Flynn sche Klassifikation SISD (single instruction, single data stream): IS IS CU PU DS MM Mono (Mikro-)prozessoren CU: Control Unit SM: Shared Memory PU: Processor Unit IS: Instruction Stream MM: Memory
Flynn sche Klassifikation SISD (single instruction, single data stream): IS IS CU PU DS MM Mono (Mikro-)prozessoren CU: Control Unit SM: Shared Memory PU: Processor Unit IS: Instruction Stream MM: Memory
Institut für Informatik Prof. Dr. D. Hogrefe Dipl.-Inf. R. Soltwisch, Dipl.-Inform. M. Ebner, Prof. Dr. D. Hogrefe Informatik II - SS 04.
 Kontrollstrukturen Informatik II SS 2004 Teil 4: Assembler Programmierung Sprünge (bedingte und unbedingte) If-then-else, Case Loop (n Durchläufe) While (Abbruchbedingung) Institut für Informatik Prof.
Kontrollstrukturen Informatik II SS 2004 Teil 4: Assembler Programmierung Sprünge (bedingte und unbedingte) If-then-else, Case Loop (n Durchläufe) While (Abbruchbedingung) Institut für Informatik Prof.
Rechnerarchitekturen und Mikrosystemtechnik lectures/2008ws/vorlesung/ram
 64-613 RAM 64-613 Rechnerarchitekturen und Mikrosystemtechnik http://tams-www.informatik.uni-hamburg.de/ lectures/2008ws/vorlesung/ram Andreas Mäder Fakultät für Mathematik, Informatik und Naturwissenschaften
64-613 RAM 64-613 Rechnerarchitekturen und Mikrosystemtechnik http://tams-www.informatik.uni-hamburg.de/ lectures/2008ws/vorlesung/ram Andreas Mäder Fakultät für Mathematik, Informatik und Naturwissenschaften
Prinzipieller Aufbau und Funktionsweise eines Prozessors
 Prinzipieller Aufbau und Funktionsweise eines Prozessors [Technische Informatik Eine Einführung] Univ.- Lehrstuhl für Technische Informatik Institut für Informatik Martin-Luther-Universität Halle-Wittenberg
Prinzipieller Aufbau und Funktionsweise eines Prozessors [Technische Informatik Eine Einführung] Univ.- Lehrstuhl für Technische Informatik Institut für Informatik Martin-Luther-Universität Halle-Wittenberg
32 Bit Konstanten und Adressierung. Grundlagen der Rechnerarchitektur Assembler 78
 32 Bit Konstanten und Adressierung Grundlagen der Rechnerarchitektur Assembler 78 Immediate kann nur 16 Bit lang sein Erinnerung: Laden einer Konstante in ein Register addi $t0, $zero, 200 Als Maschinen
32 Bit Konstanten und Adressierung Grundlagen der Rechnerarchitektur Assembler 78 Immediate kann nur 16 Bit lang sein Erinnerung: Laden einer Konstante in ein Register addi $t0, $zero, 200 Als Maschinen
Digitaltechnik und Rechnerstrukturen. 2. Entwurf eines einfachen Prozessors
 Digitaltechnik und Rechnerstrukturen 2. Entwurf eines einfachen Prozessors 1 Rechnerorganisation Prozessor Speicher Eingabe Steuereinheit Instruktionen Cachespeicher Datenpfad Daten Hauptspeicher Ausgabe
Digitaltechnik und Rechnerstrukturen 2. Entwurf eines einfachen Prozessors 1 Rechnerorganisation Prozessor Speicher Eingabe Steuereinheit Instruktionen Cachespeicher Datenpfad Daten Hauptspeicher Ausgabe
Rechnerarchitektur WS 2003/2004. Klaus Waldschmidt. Teil 11. Hardwaresystemarchitekturen - Superskalarität
 Rechnerarchitektur Vorlesungsbegleitende Unterlagen WS 2003/2004 Klaus Waldschmidt Teil 11 Hardwaresystemarchitekturen - Superskalarität Seite 1 Hardwaresystemarchitekturen HSA moderner Mikroprozessoren
Rechnerarchitektur Vorlesungsbegleitende Unterlagen WS 2003/2004 Klaus Waldschmidt Teil 11 Hardwaresystemarchitekturen - Superskalarität Seite 1 Hardwaresystemarchitekturen HSA moderner Mikroprozessoren
Rechnerstrukturen 1: Der Sehr Einfache Computer
 Inhaltsverzeichnis 1: Der Sehr Einfache Computer 1 Komponenten.................................... 1 Arbeitsweise..................................... 1 Instruktionen....................................
Inhaltsverzeichnis 1: Der Sehr Einfache Computer 1 Komponenten.................................... 1 Arbeitsweise..................................... 1 Instruktionen....................................
Der von Neumann Computer
 Der von Neumann Computer Grundlagen moderner Computer Technologie 1 Der moderne Computer ein weites Spektrum Typ Preis Anwendungsbeispiel embeded Computer 10-20 $ in Autos, Uhren,... Spielcomputer 100-200$
Der von Neumann Computer Grundlagen moderner Computer Technologie 1 Der moderne Computer ein weites Spektrum Typ Preis Anwendungsbeispiel embeded Computer 10-20 $ in Autos, Uhren,... Spielcomputer 100-200$
 TECHNISCHE HOCHSCHULE NÜRNBERG GEORG SIMON OHM Die Mikroprogrammebene eines Rechners Das Abarbeiten eines Arbeitszyklus eines einzelnen Befehls besteht selbst wieder aus verschiedenen Schritten, z.b. Befehl
TECHNISCHE HOCHSCHULE NÜRNBERG GEORG SIMON OHM Die Mikroprogrammebene eines Rechners Das Abarbeiten eines Arbeitszyklus eines einzelnen Befehls besteht selbst wieder aus verschiedenen Schritten, z.b. Befehl
Technische Informatik I - HS 18
 Institut für Technische Informatik und Kommunikationsnetze Prof. L. Thiele Technische Informatik I - HS 8 Musterlösung zu Übung 5 Datum : 8.-9. November 8 Aufgabe : MIPS Architektur Das auf der nächsten
Institut für Technische Informatik und Kommunikationsnetze Prof. L. Thiele Technische Informatik I - HS 8 Musterlösung zu Übung 5 Datum : 8.-9. November 8 Aufgabe : MIPS Architektur Das auf der nächsten
4. Übung - Rechnerarchitektur/Betriebssysteme
 4. Übung - Rechnerarchitektur/Betriebssysteme 1. Aufgabe: Caching Informatik I für Verkehrsingenieure Aufgaben inkl. Beispiellösungen a) Was ist ein Cache? Wann kommt Caching zum Einsatz? b) Welchen Vorteil
4. Übung - Rechnerarchitektur/Betriebssysteme 1. Aufgabe: Caching Informatik I für Verkehrsingenieure Aufgaben inkl. Beispiellösungen a) Was ist ein Cache? Wann kommt Caching zum Einsatz? b) Welchen Vorteil
Grundlagen der Rechnerarchitektur. Prozessor
 Grundlagen der Rechnerarchitektur Prozessor Übersicht Datenpfad Control Pipelining Data Hazards Control Hazards Multiple Issue Grundlagen der Rechnerarchitektur Prozessor 2 Datenpfad einer einfachen MIPS
Grundlagen der Rechnerarchitektur Prozessor Übersicht Datenpfad Control Pipelining Data Hazards Control Hazards Multiple Issue Grundlagen der Rechnerarchitektur Prozessor 2 Datenpfad einer einfachen MIPS
Grundlagen der Rechnerarchitektur. Prozessor
 Grundlagen der Rechnerarchitektur Prozessor Übersicht Datenpfad Control Pipelining Data Hazards Control Hazards Multiple Issue Grundlagen der Rechnerarchitektur Prozessor 2 Datenpfad einer einfachen MIPS
Grundlagen der Rechnerarchitektur Prozessor Übersicht Datenpfad Control Pipelining Data Hazards Control Hazards Multiple Issue Grundlagen der Rechnerarchitektur Prozessor 2 Datenpfad einer einfachen MIPS
2. Computer (Hardware) K. Bothe, Institut für Informatik, HU Berlin, GdP, WS 2015/16
 K. Bothe, Institut für Informatik, HU Berlin, GdP, WS 2015/16") 2. Computer (Hardware) K. Bothe, Institut für Informatik, HU Berlin, GdP, WS 2015/16 Version: 14. Okt. 2015 Computeraufbau: nur ein Überblick Genauer: Modul Digitale Systeme (2. Semester) Jetzt: Grundverständnis
2. Computer (Hardware) K. Bothe, Institut für Informatik, HU Berlin, GdP, WS 2015/16 Version: 14. Okt. 2015 Computeraufbau: nur ein Überblick Genauer: Modul Digitale Systeme (2. Semester) Jetzt: Grundverständnis
1 Rechnerstrukturen 1: Der Sehr Einfache Computer
 David Neugebauer, Informationsverarbeitung - Universität zu Köln, Seminar BIT I Inhaltsverzeichnis 1 Rechnerstrukturen 1: Der Sehr Einfache Computer 1 1.1 Komponenten................................. 1
David Neugebauer, Informationsverarbeitung - Universität zu Köln, Seminar BIT I Inhaltsverzeichnis 1 Rechnerstrukturen 1: Der Sehr Einfache Computer 1 1.1 Komponenten................................. 1