Multivariate Verfahren
|
|
|
- David Arnold
- vor 6 Jahren
- Abrufe
Transkript
1 Selbstkontrollarbeit 1 Multivariate Verfahren Musterlösung

2 Aufgabe 1 (40 Punkte) Auf der dem Kurs beigelegten CD finden Sie im Unterverzeichnis Daten/Excel/ die Datei zahlen.xlsx. Alternativ können Sie die Datei hier downloaden. 1.1 Lesen Sie die Datei in SPSS ein. Berücksichtigen Sie, dass in der Exceltabelle keine Variablennamen enthalten sind! (3 P.) 1


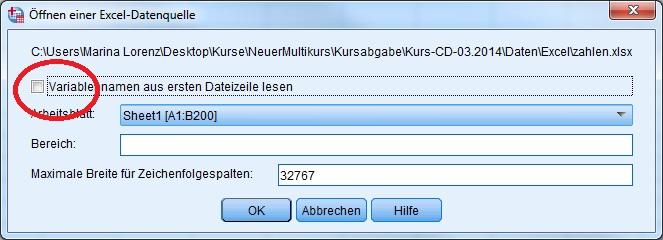
3 Hinweise zum Erzeugen der Lösung: 2

4 1.2 Lassen Sie sich die Mittelwerte, Kovarianzen und Korrelationen ausgeben! (3 P.) Hinweise zum Erzeugen der Lösung: 3




5 1.3 Plotten Sie außerdem Histogramme der einzelnen Variablen mit Normalverteilungskurve. Sprechen die Grafiken für oder gegen eine univariate Normalverteilung der beiden Variablen? Begründen Sie Ihre Antwort. (4 P.) Die Grafiken sprechen bei beiden Variablen für eine Normalverteilung, da das Histogramm im Großen und Ganzen an der Normalverteilungskurve liegt. 4


 Da beide Randverteilungen normalverteilt sind, kann man annehmen, dass die Daten bivariat (oder")
6 Hinweise zum Erzeugen der Lösung: 1.4 Gehen Sie jetzt von einer univariaten Normalverteilung der Variablen aus. Welcher bivariaten Verteilung gehören die Daten an? Geben Sie die Maximum-Likelihood-Schätzer für die Verteilungsparameter an (gerundet auf zwei Nachkommastellen)! (6 P.) Da beide Randverteilungen normalverteilt sind, kann man annehmen, dass die Daten bivariat (oder multivariat) normalverteilt sind. Die Schätzer für die Parameter lassen sich aus den SPSS Outputs entnehmen: ˆµ = [ ], ˆΣ = N 1 N S = [ ] = [ 0.87 ]
7 1.5 Bestimmen Sie zur Erzeugung weiterer Zufallszahlen die Cholesky-Wurzel der Kovarianzmatrix. Nehmen Sie an, dass z 1 = 0.51 und z 2 = 0.23 zwei Realisierungen von unabhängigen, standard-normalverteilten Zufallszahlen sind, und generieren sie daraus eine bivariate Zufallszahl mit der von Ihnen in Teilaufgabe 1.4 bestimmten Verteilung! (12 P.) ρ = 0.675, σ 1 = 0.93, σ 2 = 1.97 µ 1 = 0.98 µ 2 = 0.99 [ ] [ ] [ ] σ Γ = 0 σ 2 ρ = 1 ρ x 1 = µ 1 + Γ 11 z 1 + Γ 12 z 2 = 0.51 x 2 = µ 2 + Γ 21 z 1 + Γ 22 z 2 = Nehmen Sie an, dass die Daten, die Sie in SPSS eingelesen haben, eine Realisation des Zufallsvektors x sind, und verwenden Sie Ihre Ergebnisse aus Teilaufgabe 1.4. Bestimmen Sie den Erwartungswert und die Kovarianzmatrix der Transformation y = Ax + c mit A = [ ] [ ] E[x] =, Var[x] = [ ] 4.05 E[y] = AE[x] + c = 4.98 [ ] Var[y] = AVar[x]A = [ ] und c = [ 6 3 ]. (8 P.) 1.7 Ist die Korrelation zum 5%-Niveau signifikant von 0 verschieden? Begründen Sie Ihre Antwort. (2 P.) Ja, die Korrelation ist zum 5%-Niveau signifikant von 0 verschieden. Die Korrelation ist sogar zum 1%-Niveau signifikant, daher gilt es für größere α-werte ebenso; entsprechend ist der p Wert bei Wenn die Variable 1 einen hohen Wert annimmt, ist dann die Variable 2 eher groß oder eher klein? Begründen Sie Ihre Antwort. (2 P.) Tendenziell ist die Variable 2 dann ebenfalls groß, da die Korrelation mit ρ = recht hoch ist. 6
8 Aufgabe 2 (26 Punkte) Betrachten Sie bitte den SPSS-Output in Abb Wie lautet der Mittelwertsvektor x und die Stichproben-Kovarianzmatrix der Variablen Selfreportedhealth und LifeSatisfaction (gerundet auf 3 Kommastellen)? (2 P.) Mittelwertsvektor x = [6.447, 6, 347], [ ] Stichproben-Kovarianzmatrix S = Prüfen Sie die Nullhypothese µ = [7, 7] für die beiden Variablen (α = 0.05). (12 P.) Die Hotelling T 2 -Statistik lautet: T 2 = N( x µ 0 ) S 1 ( x µ 0 ) T 2 (p, N 1) [ ] Es gilt: S 1 =, N = 34, p = 2, α = 0.05, β 0 = [7, 7], x β 0 = [ 0.553, 0.653]. Man findet T 2 = Der Testwert T 2 muß mit einem Faktor multipliziert werden, damit die F -Verteilung benutzt werden kann. N p (N 1)p T 2 := T 2 = F (p, N p) F (1 α, p, N p) = Damit wird H 0 : µ = [7, 7] beibehalten. 7
9 Abbildung 1: SPSS-Output zu Aufgabe 2 8
10 2.3 Betrachten Sie nun alle 3 Variablen. Welche der Korrelationen unterscheiden sich signifikant von 0 unter Einhaltung eines simultanen Signifikanzniveaus von α α = 0.01? Verwenden Sie ein adjustiertes Signifikanzniveau für die Einzeltests. (4 P.) Adjustiert man die Einzeltests, so legt man ein Signifikanzniveau α/3 = 0.01/3 = für die Einzeltests zugrunde. Die p-werte aus der Korrelationstabelle sind größer als dieser Wert, bis auf p(selfreportedhealth, LifeSatisfaction) = (die Korrelation ist 0.681). 2.4 Führen Sie einen Test der Hypothese P = I durch, der das Signifikanzniveau α = α = 0.01 exakt einhält. Vergleichen Sie mit Teilaufgabe 2.3 und dem SPSS-Output. (8 P.) Die Teststatistik für den multivariaten Test H 0 : P = I ist T = N log det R die für große N χ 2 -verteilt ist mit df = p(p+1)/2 p = p(p 1)/2 Freiheitsgraden. Es gilt N = 34, p = 3 und somit df = 3. Damit ergibt sich det R = (siehe Output) und T = Das χ(0.99, 3)-Quantil ist Damit wird H 0 : P = I abgelehnt. In Teilaufgabe 2.3 wurde mit Bonferroni-Adjustierung ebenfalls H 0 abgelehnt. Da es sich hierbei um eine konservative Testprozedur handelt (also α α), hätte es passieren können, daß in 2.4 (exakte Einhaltung des Signifikanzniveaus) die H 0 abgelehnt wird, jedoch in 2.3 beibehalten wird. Der SPSS-Output ergibt einen etwas anderen Testwert (22.129). Offenbar wurde der korrigierte Wert N = N (2p + 11)/6 = und somit T = berechnet (Rundungsfehler, da nur 3 Kommastellen). 9
11 Abbildung 2: SPSS-Output zu Aufgabe 3 Aufgabe 3 (34 Punkte) Prüfen Sie anhand eines linearen Prognosemodells, ob die Variablen Selfreportedhealth und Air pollution einen statistisch bedeutsamen Einfluß auf die Variable LifeSatisfaction ausüben. Hilfsgrößen: (X X) 1 = , X y = Weitere Hilfsgrößen entnehmen Sie bitte den Outputs (Abb. 2). 10
12 3.1 Schätzen Sie die Parameter β und σ 2 eines multiplen Regressionsmodells. (6 P.) Abbildung 3: SPSS-Output zu Afg. 3 Die Regressionsparameter sind ˆβ = (X X) 1 X y = = (die von SPSS berechnete Lösung (Abb. 3) ist etwas anders, da man (X X) 1 mit mehr als 4 Kommastellen angeben müßte). Die Schätzung von σ 2 entnimmt man dem SPSS-Output: ˆσ 2 = mean square residual = (MQR im Skript). 3.2 Berechnen Sie die geschätzte Kovarianzmatrix von ˆβ und die Korrelation der Schätzer von β 0, β 1, β 2. (8 P.) Die geschätzte Kovarianzmatrix von ˆβ und die Korrelation der Schätzer von β 0, β 1, β 2 lauten Var(ˆβ) = ˆσ 2 (X X) 1 = , Ĉorr(ˆβ) =
13 3.3 Prüfen Sie, ob die Regressoren zur Erklärung der abhängigen Variable beitragen (α = 0.05). (4 P.) Dem SPSS-Output entnimmt man die F -Statistik = MQE/MQR. Der p-wert ist 0.000, sodaß auf einem Niveau von α = 0.05 die H 0 : β 1 = β 2 = 0 abgelehnt wird (p < α). 3.4 Prüfen Sie die einzelnen Regressions-Parameter auf Signifikanz (α = 0.05). Warum müssen dabei die einzelnen Signifikanz-Niveaus auf α/3 adjustiert werden? Was hat dies für das simultane Signifikanz-Niveau zur Folge? (8 P.) Der Diagonale von Var(ˆβ) entnimmt man die quadrierten Standardfehler der Parameterschätzungen, d.h. s 2 j = {2.191, 0.021, 0.032}, s i = {1.480, 0.145, 0.179}. Daraus ergeben sich die t-werte t i = ˆβ i /s i = {0.932, 5.519, 0.591} (auch hier wirken sich die wenigen Stellen in (X X) 1 stark aus; vgl. Abb. 2). Die quadrierten Standardfehler sind χ 2 (N q 1)-verteilt (N = 34, q = 2, N q 1 = 31), somit ergibt sich eine t(n q 1)- Verteilung von ˆβ i /s i. Deren Quantile sind t(1 α/2, N q 1) = 2.04, adjustierte Werte t(1 α/(2 3), N q 1) = Damit wird H 01 : β 1 = 0 abgelehnt. Dies entspricht dem SPSS-Output (p = 0.000). Auch nach einer Bonferroni-Adjustierung wird H 01 abgelehnt. Das simultane Signifikanz-Niveau von 5% wird also auch für den Test H 0 = H 00 H 01 H 02 : β 0 = β 1 = β 2 = 0 eingehalten. 3.5 Berechnen Sie den Determinationskoeffizienten und interpretieren Sie den Wert. (2 P.) Der Determinationskoeffizient ist R 2 = Daher wird 46.4% der Varianz von LifeSatisfaction durch Selfreportedhealth und Air pollution erklärt. 12
14 3.6 Ein Land hat auf den unabhängigen Variablen die Werte Selfreportedhealth = 6.1 und Air pollution = 7.0. Prognostizieren Sie die Variable LifeSatisfaction und berechnen Sie ein 95%-Prognoseintervall. (6 P.) Die individuelle Prognose der Variable LifeSatisfaction ist ŷ 0 = x ˆβ 0 = [1, 6.1, 7] = Die Prognosefehler lauten t ˆσ 1 + x 0(X X) 1 x 0 = mit N = 34, q = 2, α = 0.05, t = t(1 α/2, N q 1) = 2.04, ˆσ = = Das 95%-Prognoseintervall ist also 7.001±
Multivariate Verfahren
 Selbstkontrollarbeit 1 Multivariate Verfahren Diese Selbstkontrollarbeit bezieht sich auf die Kapitel 1 bis 4 der Kurseinheit 1 (Multivariate Statistik) des Kurses Multivariate Verfahren (883). Hinweise:
Selbstkontrollarbeit 1 Multivariate Verfahren Diese Selbstkontrollarbeit bezieht sich auf die Kapitel 1 bis 4 der Kurseinheit 1 (Multivariate Statistik) des Kurses Multivariate Verfahren (883). Hinweise:
Musterlösung. Modulklausur Multivariate Verfahren
 Musterlösung Modulklausur 31821 Multivariate Verfahren 25. September 2015 Aufgabe 1 (15 Punkte) Kennzeichnen Sie die folgenden Aussagen zur Regressionsanalyse mit R für richtig oder F für falsch. F Wenn
Musterlösung Modulklausur 31821 Multivariate Verfahren 25. September 2015 Aufgabe 1 (15 Punkte) Kennzeichnen Sie die folgenden Aussagen zur Regressionsanalyse mit R für richtig oder F für falsch. F Wenn
Lösung Übungsblatt 5
 Lösung Übungsblatt 5 5. Januar 05 Aufgabe. Die sogenannte Halb-Normalverteilung spielt eine wichtige Rolle bei der statistischen Analyse von Ineffizienzen von Produktionseinheiten. In Abhängigkeit von
Lösung Übungsblatt 5 5. Januar 05 Aufgabe. Die sogenannte Halb-Normalverteilung spielt eine wichtige Rolle bei der statistischen Analyse von Ineffizienzen von Produktionseinheiten. In Abhängigkeit von
1 Wahrscheinlichkeitsrechnung. 2 Zufallsvariablen und ihre Verteilung. 3 Statistische Inferenz. 4 Intervallschätzung. 5 Hypothesentests.
 0 Einführung 1 Wahrscheinlichkeitsrechnung 2 Zufallsvariablen und ihre Verteilung 3 Statistische Inferenz 4 Intervallschätzung 5 Hypothesentests 6 Regression Lineare Regressionsmodelle Deskriptive Statistik:
0 Einführung 1 Wahrscheinlichkeitsrechnung 2 Zufallsvariablen und ihre Verteilung 3 Statistische Inferenz 4 Intervallschätzung 5 Hypothesentests 6 Regression Lineare Regressionsmodelle Deskriptive Statistik:
Statistik II. IV. Hypothesentests. Martin Huber
 Statistik II IV. Hypothesentests Martin Huber 1 / 22 Übersicht Weitere Hypothesentests in der Statistik 1-Stichproben-Mittelwert-Tests 1-Stichproben-Varianz-Tests 2-Stichproben-Tests Kolmogorov-Smirnov-Test
Statistik II IV. Hypothesentests Martin Huber 1 / 22 Übersicht Weitere Hypothesentests in der Statistik 1-Stichproben-Mittelwert-Tests 1-Stichproben-Varianz-Tests 2-Stichproben-Tests Kolmogorov-Smirnov-Test
Das (multiple) Bestimmtheitsmaß R 2. Beispiel: Ausgaben in Abhängigkeit vom Einkommen (I) Parameterschätzer im einfachen linearen Regressionsmodell
 Bestimmtheitsmaß R 2. Beispiel: Ausgaben in Abhängigkeit vom Einkommen (I) Parameterschätzer im einfachen linearen Regressionsmodell") 1 Lineare Regression Parameterschätzung 13 Im einfachen linearen Regressionsmodell sind also neben σ ) insbesondere β 1 und β Parameter, deren Schätzung für die Quantifizierung des linearen Zusammenhangs
1 Lineare Regression Parameterschätzung 13 Im einfachen linearen Regressionsmodell sind also neben σ ) insbesondere β 1 und β Parameter, deren Schätzung für die Quantifizierung des linearen Zusammenhangs
Musterlösung. Modulklausur Multivariate Verfahren
 Musterlösung Modulklausur 31821 Multivariate Verfahren 27. März 2015 Aufgabe 1 Kennzeichnen Sie die folgenden Aussagen über die beiden Zufallsvektoren ([ ] [ ]) ([ ] [ ]) 2 1 0 1 25 2 x 1 N, x 3 0 1 2
Musterlösung Modulklausur 31821 Multivariate Verfahren 27. März 2015 Aufgabe 1 Kennzeichnen Sie die folgenden Aussagen über die beiden Zufallsvektoren ([ ] [ ]) ([ ] [ ]) 2 1 0 1 25 2 x 1 N, x 3 0 1 2
0 sonst. a) Wie lautet die Randwahrscheinlichkeitsfunktion von Y? 0.5 y = 1
 Wie lautet die Randwahrscheinlichkeitsfunktion von Y? 0.5 y = 1") Aufgabe 1 (2 + 2 + 2 + 1 Punkte) Gegeben sei folgende gemeinsame Wahrscheinlichkeitsfunktion f(x, y) = P (X = x, Y = y) der Zufallsvariablen X und Y : 0.2 x = 1, y = 1 0.3 x = 2, y = 1 f(x, y) = 0.45 x
Aufgabe 1 (2 + 2 + 2 + 1 Punkte) Gegeben sei folgende gemeinsame Wahrscheinlichkeitsfunktion f(x, y) = P (X = x, Y = y) der Zufallsvariablen X und Y : 0.2 x = 1, y = 1 0.3 x = 2, y = 1 f(x, y) = 0.45 x
Prognoseintervalle für y 0 gegeben x 0
 10 Lineare Regression Punkt- und Intervallprognosen 10.5 Prognoseintervalle für y 0 gegeben x 0 Intervallprognosen für y 0 zur Vertrauenswahrscheinlichkeit 1 α erhält man also analog zu den Intervallprognosen
10 Lineare Regression Punkt- und Intervallprognosen 10.5 Prognoseintervalle für y 0 gegeben x 0 Intervallprognosen für y 0 zur Vertrauenswahrscheinlichkeit 1 α erhält man also analog zu den Intervallprognosen
Kapitel 8. Einfache Regression. Anpassen des linearen Regressionsmodells, OLS. Eigenschaften der Schätzer für das Modell
 Kapitel 8 Einfache Regression Josef Leydold c 2006 Mathematische Methoden VIII Einfache Regression 1 / 21 Lernziele Lineares Regressionsmodell Anpassen des linearen Regressionsmodells, OLS Eigenschaften
Kapitel 8 Einfache Regression Josef Leydold c 2006 Mathematische Methoden VIII Einfache Regression 1 / 21 Lernziele Lineares Regressionsmodell Anpassen des linearen Regressionsmodells, OLS Eigenschaften
Demokurs. Modul Vertiefung der Wirtschaftsmathematik Vertiefung der Statistik
 Demokurs Modul 3741 Vertiefung der Wirtschaftsmathematik und Statistik Kurs 41 Vertiefung der Statistik 15. Juli 010 Seite: 14 KAPITEL 4. ZUSAMMENHANGSANALYSE gegeben, wobei die Stichproben(ko)varianzen
Demokurs Modul 3741 Vertiefung der Wirtschaftsmathematik und Statistik Kurs 41 Vertiefung der Statistik 15. Juli 010 Seite: 14 KAPITEL 4. ZUSAMMENHANGSANALYSE gegeben, wobei die Stichproben(ko)varianzen
4.1. Verteilungsannahmen des Fehlers. 4. Statistik im multiplen Regressionsmodell Verteilungsannahmen des Fehlers
 4. Statistik im multiplen Regressionsmodell In diesem Kapitel wird im Abschnitt 4.1 zusätzlich zu den schon bekannten Standardannahmen noch die Annahme von normalverteilten Residuen hinzugefügt. Auf Basis
4. Statistik im multiplen Regressionsmodell In diesem Kapitel wird im Abschnitt 4.1 zusätzlich zu den schon bekannten Standardannahmen noch die Annahme von normalverteilten Residuen hinzugefügt. Auf Basis
Statistik II. IV. Hypothesentests. Martin Huber
 Statistik II IV. Hypothesentests Martin Huber 1 / 41 Übersicht Struktur eines Hypothesentests Stichprobenverteilung t-test: Einzelner-Parameter-Test F-Test: Multiple lineare Restriktionen 2 / 41 Struktur
Statistik II IV. Hypothesentests Martin Huber 1 / 41 Übersicht Struktur eines Hypothesentests Stichprobenverteilung t-test: Einzelner-Parameter-Test F-Test: Multiple lineare Restriktionen 2 / 41 Struktur
Inferenz im multiplen Regressionsmodell
 1 / 29 Inferenz im multiplen Regressionsmodell Kapitel 4, Teil 1 Ökonometrie I Michael Hauser 2 / 29 Inhalt Annahme normalverteilter Fehler Stichprobenverteilung des OLS Schätzers t-test und Konfidenzintervall
1 / 29 Inferenz im multiplen Regressionsmodell Kapitel 4, Teil 1 Ökonometrie I Michael Hauser 2 / 29 Inhalt Annahme normalverteilter Fehler Stichprobenverteilung des OLS Schätzers t-test und Konfidenzintervall
Vorlesung: Statistik II für Wirtschaftswissenschaft
 Vorlesung: Statistik II für Wirtschaftswissenschaft Prof. Dr. Helmut Küchenhoff Institut für Statistik, LMU München Sommersemester 2017 6 Genzwertsätze Einführung 1 Wahrscheinlichkeit: Definition und Interpretation
Vorlesung: Statistik II für Wirtschaftswissenschaft Prof. Dr. Helmut Küchenhoff Institut für Statistik, LMU München Sommersemester 2017 6 Genzwertsätze Einführung 1 Wahrscheinlichkeit: Definition und Interpretation
4 Statistik normalverteilter Daten
 4 Statistik normalverteilter Daten 4.1 Eine Stichprobe a Die drei Grundfragen. Die schliessende Statistik bildet die Brücke zwischen den Wahrscheinlichkeitsmodellen, die unser Denken strukturieren, und
4 Statistik normalverteilter Daten 4.1 Eine Stichprobe a Die drei Grundfragen. Die schliessende Statistik bildet die Brücke zwischen den Wahrscheinlichkeitsmodellen, die unser Denken strukturieren, und
Modulklausur Multivariate Verfahren
 Name, Vorname Matrikelnummer Modulklausur 31821 Multivariate Verfahren Datum Punkte Note Termin: 28. März 2014, 9.00-11.00 Uhr Erstprüfer: Univ.-Prof. Dr. H. Singer Hinweise zur Bearbeitung der Modulklausur
Name, Vorname Matrikelnummer Modulklausur 31821 Multivariate Verfahren Datum Punkte Note Termin: 28. März 2014, 9.00-11.00 Uhr Erstprüfer: Univ.-Prof. Dr. H. Singer Hinweise zur Bearbeitung der Modulklausur
Statistik. R. Frühwirth. Statistik. VO Februar R. Frühwirth Statistik 1/536
 fru@hephy.oeaw.ac.at VO 142.090 http://tinyurl.com/tu142090 Februar 2010 1/536 Übersicht über die Vorlesung Teil 1: Deskriptive Teil 2: Wahrscheinlichkeitsrechnung Teil 3: Zufallsvariable Teil 4: Parameterschätzung
fru@hephy.oeaw.ac.at VO 142.090 http://tinyurl.com/tu142090 Februar 2010 1/536 Übersicht über die Vorlesung Teil 1: Deskriptive Teil 2: Wahrscheinlichkeitsrechnung Teil 3: Zufallsvariable Teil 4: Parameterschätzung
Kapitel 7. Regression und Korrelation. 7.1 Das Regressionsproblem
 Kapitel 7 Regression und Korrelation Ein Regressionsproblem behandelt die Verteilung einer Variablen, wenn mindestens eine andere gewisse Werte in nicht zufälliger Art annimmt. Ein Korrelationsproblem
Kapitel 7 Regression und Korrelation Ein Regressionsproblem behandelt die Verteilung einer Variablen, wenn mindestens eine andere gewisse Werte in nicht zufälliger Art annimmt. Ein Korrelationsproblem
Multivariate Verfahren
 Selbstkontrollarbeit 2 Multivariate Verfahren Diese Selbstkontrollarbeit bezieht sich auf die Kapitel 5 bis 8 der Kurseinheit 1 (Multivariate Statistik) des Kurses Multivariate Verfahren (883). Hinweise:
Selbstkontrollarbeit 2 Multivariate Verfahren Diese Selbstkontrollarbeit bezieht sich auf die Kapitel 5 bis 8 der Kurseinheit 1 (Multivariate Statistik) des Kurses Multivariate Verfahren (883). Hinweise:
Teil XII. Einfache Lineare Regression. Woche 10: Lineare Regression. Lernziele. Zusammenfassung. Patric Müller
 Woche 10: Lineare Regression Patric Müller Teil XII Einfache Lineare Regression ETHZ WBL 17/19, 03.07.2017 Wahrscheinlichkeit und Statistik Patric Müller WBL 2017 Wahrscheinlichkeit
Woche 10: Lineare Regression Patric Müller Teil XII Einfache Lineare Regression ETHZ WBL 17/19, 03.07.2017 Wahrscheinlichkeit und Statistik Patric Müller WBL 2017 Wahrscheinlichkeit
Schriftliche Prüfung (90 Minuten)
") Dr. M. Kalisch Prüfung Statistik I Winter 2016 Schriftliche Prüfung (90 Minuten) Bemerkungen: Erlaubte Hilfsmittel: 10 hand- oder maschinengeschriebene A4 Seiten (=5 Blätter). Taschenrechner ohne Kommunikationsmöglichkeit.
Dr. M. Kalisch Prüfung Statistik I Winter 2016 Schriftliche Prüfung (90 Minuten) Bemerkungen: Erlaubte Hilfsmittel: 10 hand- oder maschinengeschriebene A4 Seiten (=5 Blätter). Taschenrechner ohne Kommunikationsmöglichkeit.
Schätzen und Testen von Populationsparametern im linearen Regressionsmodell PE ΣO
 Schätzen und Testen von Populationsparametern im linearen Regressionsmodell PE ΣO 4. Dezember 2001 Generalisierung der aus Stichprobendaten berechneten Regressionsgeraden Voraussetzungen für die Generalisierung
Schätzen und Testen von Populationsparametern im linearen Regressionsmodell PE ΣO 4. Dezember 2001 Generalisierung der aus Stichprobendaten berechneten Regressionsgeraden Voraussetzungen für die Generalisierung
Allgemein zu Hypothesentests: Teststatistik. OLS-Inferenz (Small Sample) Allgemein zu Hypothesentests
 Allgemein zu Hypothesentests") OLS-Inferenz (Small Sample) K.H. Schild 3. Mai 017 Allgemein zu Hypothesentests: Teststatistik Konstruktion eines Hypothesentests erfolgt meistens über eine Teststatistik Eine Teststatistik T ist eine
OLS-Inferenz (Small Sample) K.H. Schild 3. Mai 017 Allgemein zu Hypothesentests: Teststatistik Konstruktion eines Hypothesentests erfolgt meistens über eine Teststatistik Eine Teststatistik T ist eine
Klausur zur Vorlesung Statistik III für Studenten mit Wahlfach Statistik. 7. Februar 2008
 L. Fahrmeir, G. Walter Department für Statistik Bitte für die Korrektur freilassen! Aufgabe 3 4 Punkte Klausur zur Vorlesung Statistik III für Studenten mit Wahlfach Statistik 7. Februar 8 Hinweise:. Überprüfen
L. Fahrmeir, G. Walter Department für Statistik Bitte für die Korrektur freilassen! Aufgabe 3 4 Punkte Klausur zur Vorlesung Statistik III für Studenten mit Wahlfach Statistik 7. Februar 8 Hinweise:. Überprüfen
Übung V Lineares Regressionsmodell
 Universität Ulm 89069 Ulm Germany Dipl.-WiWi Michael Alpert Institut für Wirtschaftspolitik Fakultät für Mathematik und Wirtschaftswissenschaften Ludwig-Erhard-Stiftungsprofessur Sommersemester 2007 Übung
Universität Ulm 89069 Ulm Germany Dipl.-WiWi Michael Alpert Institut für Wirtschaftspolitik Fakultät für Mathematik und Wirtschaftswissenschaften Ludwig-Erhard-Stiftungsprofessur Sommersemester 2007 Übung
Tests einzelner linearer Hypothesen I
 4 Multiple lineare Regression Tests einzelner linearer Hypothesen 4.5 Tests einzelner linearer Hypothesen I Neben Tests für einzelne Regressionsparameter sind auch Tests (und Konfidenzintervalle) für Linearkombinationen
4 Multiple lineare Regression Tests einzelner linearer Hypothesen 4.5 Tests einzelner linearer Hypothesen I Neben Tests für einzelne Regressionsparameter sind auch Tests (und Konfidenzintervalle) für Linearkombinationen
Statistik II Übung 4: Skalierung und asymptotische Eigenschaften
 Statistik II Übung 4: Skalierung und asymptotische Eigenschaften Diese Übung beschäftigt sich mit der Skalierung von Variablen in Regressionsanalysen und mit asymptotischen Eigenschaften von OLS. Verwenden
Statistik II Übung 4: Skalierung und asymptotische Eigenschaften Diese Übung beschäftigt sich mit der Skalierung von Variablen in Regressionsanalysen und mit asymptotischen Eigenschaften von OLS. Verwenden
Einfache lineare Modelle mit Statistik-Software R Beispiel (Ausgaben in Abhängigkeit vom Einkommen)
") 3 Einfache lineare Regression Einfache lineare Modelle mit R 36 Einfache lineare Modelle mit Statistik-Software R Beispiel (Ausgaben in Abhängigkeit vom Einkommen) > summary(lm(y~x)) Call: lm(formula =
3 Einfache lineare Regression Einfache lineare Modelle mit R 36 Einfache lineare Modelle mit Statistik-Software R Beispiel (Ausgaben in Abhängigkeit vom Einkommen) > summary(lm(y~x)) Call: lm(formula =
Statistikpraktikum. Carsten Rezny. Sommersemester Institut für angewandte Mathematik Universität Bonn
 Statistikpraktikum Carsten Rezny Institut für angewandte Mathematik Universität Bonn Sommersemester 2014 Mehrdimensionale Datensätze: Multivariate Statistik Multivariate Statistik Mehrdimensionale Datensätze:
Statistikpraktikum Carsten Rezny Institut für angewandte Mathematik Universität Bonn Sommersemester 2014 Mehrdimensionale Datensätze: Multivariate Statistik Multivariate Statistik Mehrdimensionale Datensätze:
Regression und Korrelation
 Kapitel 7 Regression und Korrelation Ein Regressionsproblem behandeltdie VerteilungeinerVariablen, wenn mindestens eine andere gewisse Werte in nicht zufälliger Art annimmt. Ein Korrelationsproblem dagegen
Kapitel 7 Regression und Korrelation Ein Regressionsproblem behandeltdie VerteilungeinerVariablen, wenn mindestens eine andere gewisse Werte in nicht zufälliger Art annimmt. Ein Korrelationsproblem dagegen
Dr. M. Kalisch. Statistik (für Biol./Pharm. Wiss.) Winter Musterlösung
 Winter Musterlösung") Dr. M. Kalisch. Statistik (für Biol./Pharm. Wiss.) Winter 2014 Musterlösung 1. (11 Punkte) a) Für welchen Parameter ist X ein geeigneter Schätzer? X ist ein geeigneter Schätzer für den Erwartungswert µ
Dr. M. Kalisch. Statistik (für Biol./Pharm. Wiss.) Winter 2014 Musterlösung 1. (11 Punkte) a) Für welchen Parameter ist X ein geeigneter Schätzer? X ist ein geeigneter Schätzer für den Erwartungswert µ
2.Tutorium Multivariate Verfahren
 2.Tutorium Multivariate Verfahren - Multivariate Verteilungen - Hannah Busen: 27.04.2015 und 04.05.2015 Nicole Schüller: 28.04.2015 und 05.05.2015 Institut für Statistik, LMU München 1 / 21 Gliederung
2.Tutorium Multivariate Verfahren - Multivariate Verteilungen - Hannah Busen: 27.04.2015 und 04.05.2015 Nicole Schüller: 28.04.2015 und 05.05.2015 Institut für Statistik, LMU München 1 / 21 Gliederung
Konfidenzintervalle Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Anteilswert Differenzen von Erwartungswert Anteilswert
 Konfidenzintervalle Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Anteilswert Differenzen von Erwartungswert Anteilswert Beispiel für Konfidenzintervall Im Prinzip haben wir
Konfidenzintervalle Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Anteilswert Differenzen von Erwartungswert Anteilswert Beispiel für Konfidenzintervall Im Prinzip haben wir
Multivariate Verfahren
 Selbstkontrollarbeit 2 Multivariate Verfahren Musterlösung Aufgabe 1 (28 Punkte) Der Marketing-Leiter einer Lebensmittelherstellers möchte herausfinden, mit welchem Richtpreis eine neue Joghurt-Marke auf
Selbstkontrollarbeit 2 Multivariate Verfahren Musterlösung Aufgabe 1 (28 Punkte) Der Marketing-Leiter einer Lebensmittelherstellers möchte herausfinden, mit welchem Richtpreis eine neue Joghurt-Marke auf
3 Grundlagen statistischer Tests (Kap. 8 IS)
") 3 Grundlagen statistischer Tests (Kap. 8 IS) 3.1 Beispiel zum Hypothesentest Beispiel: Betrachtet wird eine Abfüllanlage für Mineralwasser mit dem Sollgewicht µ 0 = 1000g und bekannter Standardabweichung
3 Grundlagen statistischer Tests (Kap. 8 IS) 3.1 Beispiel zum Hypothesentest Beispiel: Betrachtet wird eine Abfüllanlage für Mineralwasser mit dem Sollgewicht µ 0 = 1000g und bekannter Standardabweichung
Aufgabensammlung (Nicht-MC-Aufgaben) Klausur Ökonometrie SS ( = 57 Punkte)
 Klausur Ökonometrie SS ( = 57 Punkte)") Aufgabe 3 (9 + 5 + 7 + 7 + 3 + 9 + 7 + 10 = 57 Punkte) Hinweis: Beachten Sie die Tabellen mit Quantilen am Ende der Aufgabenstellung! Zu Beginn der Studienjahre 2011 und 2012 wurden Studienanfänger an
Aufgabe 3 (9 + 5 + 7 + 7 + 3 + 9 + 7 + 10 = 57 Punkte) Hinweis: Beachten Sie die Tabellen mit Quantilen am Ende der Aufgabenstellung! Zu Beginn der Studienjahre 2011 und 2012 wurden Studienanfänger an
Statistisches Testen
 Statistisches Testen Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Differenzen Anteilswert Chi-Quadrat Tests Gleichheit von Varianzen Prinzip des Statistischen Tests Konfidenzintervall
Statistisches Testen Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Differenzen Anteilswert Chi-Quadrat Tests Gleichheit von Varianzen Prinzip des Statistischen Tests Konfidenzintervall
Prüfung aus Wahrscheinlichkeitstheorie und Statistik MASCHINENBAU 2002
 Prüfung aus Wahrscheinlichkeitstheorie und Statistik MASCHINENBAU 2002 1. Ein Chemiestudent hat ein Set von 10 Gefäßen vor sich stehen, von denen vier mit Salpetersäure Stoff A), vier mit Glyzerin Stoff
Prüfung aus Wahrscheinlichkeitstheorie und Statistik MASCHINENBAU 2002 1. Ein Chemiestudent hat ein Set von 10 Gefäßen vor sich stehen, von denen vier mit Salpetersäure Stoff A), vier mit Glyzerin Stoff
B. Regressionsanalyse [progdat.sav]
![B. Regressionsanalyse [progdat.sav]](/thumbs/71/64345557.jpg "B. Regressionsanalyse [progdat.sav]") SPSS-PC-ÜBUNG Seite 9 B. Regressionsanalyse [progdat.sav] Ein Unternehmen möchte den zukünftigen Absatz in Abhängigkeit von den Werbeausgaben und der Anzahl der Filialen prognostizieren. Dazu wurden über
SPSS-PC-ÜBUNG Seite 9 B. Regressionsanalyse [progdat.sav] Ein Unternehmen möchte den zukünftigen Absatz in Abhängigkeit von den Werbeausgaben und der Anzahl der Filialen prognostizieren. Dazu wurden über
3. Das einfache lineare Regressionsmodell
 3. Das einfache lineare Regressionsmodell Ökonometrie: (I) Anwendung statistischer Methoden in der empirischen Forschung in den Wirtschaftswissenschaften Konfrontation ökonomischer Theorien mit Fakten
3. Das einfache lineare Regressionsmodell Ökonometrie: (I) Anwendung statistischer Methoden in der empirischen Forschung in den Wirtschaftswissenschaften Konfrontation ökonomischer Theorien mit Fakten
Einfaktorielle Varianzanalyse
 Kapitel 16 Einfaktorielle Varianzanalyse Im Zweistichprobenproblem vergleichen wir zwei Verfahren miteinander. Nun wollen wir mehr als zwei Verfahren betrachten, wobei wir unverbunden vorgehen. Beispiel
Kapitel 16 Einfaktorielle Varianzanalyse Im Zweistichprobenproblem vergleichen wir zwei Verfahren miteinander. Nun wollen wir mehr als zwei Verfahren betrachten, wobei wir unverbunden vorgehen. Beispiel
FERNUNIVERSITÄT IN HAGEN WIRTSCHAFTSWISSENSCHAFT
 FERNUNIVERSITÄT IN HAGEN FAKULTÄT WIRTSCHAFTSWISSENSCHAFT Lehrstuhl für Betriebswirtschaftslehre, insb. Quantitative Methoden und Wirtschaftsmathematik Univ.-Prof. Dr. A. Kleine Lehrstuhl für Angewandte
FERNUNIVERSITÄT IN HAGEN FAKULTÄT WIRTSCHAFTSWISSENSCHAFT Lehrstuhl für Betriebswirtschaftslehre, insb. Quantitative Methoden und Wirtschaftsmathematik Univ.-Prof. Dr. A. Kleine Lehrstuhl für Angewandte
Statistik und Wahrscheinlichkeitsrechnung
 Statistik und Wahrscheinlichkeitsrechnung Dr. Jochen Köhler 1 Inhalt der heutigen Vorlesung Statistik und Wahrscheinlichkeitsrechnung Zusammenfassung der vorherigen Vorlesung Übersicht über Schätzung und
Statistik und Wahrscheinlichkeitsrechnung Dr. Jochen Köhler 1 Inhalt der heutigen Vorlesung Statistik und Wahrscheinlichkeitsrechnung Zusammenfassung der vorherigen Vorlesung Übersicht über Schätzung und
y t = 30, 2. Benutzen Sie die Beobachtungen bis einschließlich 2002, um den Koeffizientenvektor β mit der KQ-Methode zu schätzen.
 Aufgabe 1 (25 Punkte Zur Schätzung des Werbe-Effekts in einem Getränke-Unternehmen wird das folgende lineare Modell aufgestellt: Dabei ist y t = β 1 + x t2 β 2 + e t. y t : x t2 : Umsatz aus Getränkeverkauf
Aufgabe 1 (25 Punkte Zur Schätzung des Werbe-Effekts in einem Getränke-Unternehmen wird das folgende lineare Modell aufgestellt: Dabei ist y t = β 1 + x t2 β 2 + e t. y t : x t2 : Umsatz aus Getränkeverkauf
Kurs Empirische Wirtschaftsforschung
 Kurs Empirische Wirtschaftsforschung 5. Bivariates Regressionsmodell 1 Martin Halla Institut für Volkswirtschaftslehre Johannes Kepler Universität Linz 1 Lehrbuch: Bauer/Fertig/Schmidt (2009), Empirische
Kurs Empirische Wirtschaftsforschung 5. Bivariates Regressionsmodell 1 Martin Halla Institut für Volkswirtschaftslehre Johannes Kepler Universität Linz 1 Lehrbuch: Bauer/Fertig/Schmidt (2009), Empirische
30. März Ruhr-Universität Bochum. Methodenlehre II, SS Prof. Dr. Holger Dette
 Ruhr-Universität Bochum 30. März 2011 1 / 46 Methodenlehre II NA 3/73 Telefon: 0234 322 8284 Email: holger.dette@rub.de Internet: www.ruhr-uni-bochum.de/mathematik3/index.html Vorlesung: Montag, 8.30 10.00
Ruhr-Universität Bochum 30. März 2011 1 / 46 Methodenlehre II NA 3/73 Telefon: 0234 322 8284 Email: holger.dette@rub.de Internet: www.ruhr-uni-bochum.de/mathematik3/index.html Vorlesung: Montag, 8.30 10.00
Schriftliche Prüfung (90 Minuten)
") Dr. M. Kalisch Probeprüfung Statistik 1 Sommer 2014 Schriftliche Prüfung (90 Minuten) Bemerkungen: Alle schriftlichen Hilfsmittel und ein Taschenrechner sind erlaubt. Mobiltelefone sind auszuschalten!
Dr. M. Kalisch Probeprüfung Statistik 1 Sommer 2014 Schriftliche Prüfung (90 Minuten) Bemerkungen: Alle schriftlichen Hilfsmittel und ein Taschenrechner sind erlaubt. Mobiltelefone sind auszuschalten!
1 Beispiel zur Methode der kleinsten Quadrate
 1 Beispiel zur Methode der kleinsten Quadrate 1.1 Daten des Beispiels t x y x*y x 2 ŷ ˆɛ ˆɛ 2 1 1 3 3 1 2 1 1 2 2 3 6 4 3.5-0.5 0.25 3 3 4 12 9 5-1 1 4 4 6 24 16 6.5-0.5 0.25 5 5 9 45 25 8 1 1 Σ 15 25
1 Beispiel zur Methode der kleinsten Quadrate 1.1 Daten des Beispiels t x y x*y x 2 ŷ ˆɛ ˆɛ 2 1 1 3 3 1 2 1 1 2 2 3 6 4 3.5-0.5 0.25 3 3 4 12 9 5-1 1 4 4 6 24 16 6.5-0.5 0.25 5 5 9 45 25 8 1 1 Σ 15 25
FERNUNIVERSITÄT IN HAGEN WIRTSCHAFTSWISSENSCHAFT
 FERNUNIVERSITÄT IN HAGEN FAKULTÄT WIRTSCHAFTSWISSENSCHAFT Lehrstuhl für Betriebswirtschaftslehre, insb. Quantitative Methoden und Wirtschaftsmathematik Univ.-Prof. Dr. A. Kleine Lehrstuhl für Angewandte
FERNUNIVERSITÄT IN HAGEN FAKULTÄT WIRTSCHAFTSWISSENSCHAFT Lehrstuhl für Betriebswirtschaftslehre, insb. Quantitative Methoden und Wirtschaftsmathematik Univ.-Prof. Dr. A. Kleine Lehrstuhl für Angewandte
Formelsammlung für das Modul. Statistik 2. Bachelor. Sven Garbade
 Version 2015 Formelsammlung für das Modul Statistik 2 Bachelor Sven Garbade Prof. Dr. phil. Dipl.-Psych. Sven Garbade Fakultät für Angewandte Psychologie SRH Hochschule Heidelberg sven.garbade@hochschule-heidelberg.de
Version 2015 Formelsammlung für das Modul Statistik 2 Bachelor Sven Garbade Prof. Dr. phil. Dipl.-Psych. Sven Garbade Fakultät für Angewandte Psychologie SRH Hochschule Heidelberg sven.garbade@hochschule-heidelberg.de
5. Spezielle stetige Verteilungen
 5. Spezielle stetige Verteilungen 5.1 Stetige Gleichverteilung Eine Zufallsvariable X folgt einer stetigen Gleichverteilung mit den Parametern a und b, wenn für die Dichtefunktion von X gilt: f x = 1 für
5. Spezielle stetige Verteilungen 5.1 Stetige Gleichverteilung Eine Zufallsvariable X folgt einer stetigen Gleichverteilung mit den Parametern a und b, wenn für die Dichtefunktion von X gilt: f x = 1 für
Multivariate Verfahren
 Multivariate Verfahren Oliver Muthmann 31. Mai 2007 Gliederung 1 Einführung 2 Varianzanalyse (MANOVA) 3 Regressionsanalyse 4 Faktorenanalyse Hauptkomponentenanalyse 5 Clusteranalyse 6 Zusammenfassung Komplexe
Multivariate Verfahren Oliver Muthmann 31. Mai 2007 Gliederung 1 Einführung 2 Varianzanalyse (MANOVA) 3 Regressionsanalyse 4 Faktorenanalyse Hauptkomponentenanalyse 5 Clusteranalyse 6 Zusammenfassung Komplexe
Übung Methodenlehre II, SS 2010
 nlehre II nlehre II, Anwendungsbeispiel 1 Ruhr-Universität Bochum 15. Juni 2010 1 / 21 Quelle nlehre II Mobbing und Persönlichkeit: Unterschiede in grundlegenden Persönlichkeitsdimensionen zwischen Betroffenen
nlehre II nlehre II, Anwendungsbeispiel 1 Ruhr-Universität Bochum 15. Juni 2010 1 / 21 Quelle nlehre II Mobbing und Persönlichkeit: Unterschiede in grundlegenden Persönlichkeitsdimensionen zwischen Betroffenen
Wichtige Definitionen und Aussagen
 Wichtige Definitionen und Aussagen Zufallsexperiment, Ergebnis, Ereignis: Unter einem Zufallsexperiment verstehen wir einen Vorgang, dessen Ausgänge sich nicht vorhersagen lassen Die möglichen Ausgänge
Wichtige Definitionen und Aussagen Zufallsexperiment, Ergebnis, Ereignis: Unter einem Zufallsexperiment verstehen wir einen Vorgang, dessen Ausgänge sich nicht vorhersagen lassen Die möglichen Ausgänge
Institut für Statistik und Mathematische Wirtschaftstheorie Universität Augsburg. PROGNOSE II - Vertiefung Aufgaben und Lösungen Sommersemester 2004
 Institut für Statistik und Mathematische Wirtschaftstheorie Universität Augsburg PROGNOSE II - Vertiefung Aufgaben und Lösungen Sommersemester 2004 Aufgabe 1 U t bedeute weißes Rauschen und B den Backshift
Institut für Statistik und Mathematische Wirtschaftstheorie Universität Augsburg PROGNOSE II - Vertiefung Aufgaben und Lösungen Sommersemester 2004 Aufgabe 1 U t bedeute weißes Rauschen und B den Backshift
13. Lösung weitere Übungsaufgaben Statistik II WiSe 2016/2017
 13. Lösung weitere Übungsaufgaben Statistik II WiSe 2016/2017 1. Aufgabe: Für 25 der größten Flughäfen wurde die Anzahl der abgefertigten Passagiere in den Jahren 2009 und 2012 erfasst. Aus den Daten (Anzahl
13. Lösung weitere Übungsaufgaben Statistik II WiSe 2016/2017 1. Aufgabe: Für 25 der größten Flughäfen wurde die Anzahl der abgefertigten Passagiere in den Jahren 2009 und 2012 erfasst. Aus den Daten (Anzahl
Klassifikation von Signifikanztests
 Klassifikation von Signifikanztests nach Verteilungsannahmen: verteilungsabhängige = parametrische Tests verteilungsunabhängige = nichtparametrische Tests Bei parametrischen Tests werden im Modell Voraussetzungen
Klassifikation von Signifikanztests nach Verteilungsannahmen: verteilungsabhängige = parametrische Tests verteilungsunabhängige = nichtparametrische Tests Bei parametrischen Tests werden im Modell Voraussetzungen
Aufgabenstellung und Ergebnisse zur. Bachelor-Prüfung Schließende Statistik Wintersemester 2017/18. Dr. Martin Becker
 Aufgabenstellung und Ergebnisse zur Bachelor-Prüfung Schließende Statistik Wintersemester 2017/18 Dr. Martin Becker Hinweise für die Klausurteilnehmer Die Klausur besteht aus insgesamt 9 Aufgaben. Prüfen
Aufgabenstellung und Ergebnisse zur Bachelor-Prüfung Schließende Statistik Wintersemester 2017/18 Dr. Martin Becker Hinweise für die Klausurteilnehmer Die Klausur besteht aus insgesamt 9 Aufgaben. Prüfen
Zusammenfassung: Einfache lineare Regression I
 4 Multiple lineare Regression Multiples lineares Modell 41 Zusammenfassung: Einfache lineare Regression I Bisher: Annahme der Gültigkeit eines einfachen linearen Modells y i = β 0 + β 1 x i + u i, i {1,,
4 Multiple lineare Regression Multiples lineares Modell 41 Zusammenfassung: Einfache lineare Regression I Bisher: Annahme der Gültigkeit eines einfachen linearen Modells y i = β 0 + β 1 x i + u i, i {1,,
Mikro-Ökonometrie: Small Sample Inferenz mit OLS
 Mikro-Ökonometrie: Small Sample Inferenz mit OLS 1. November 014 Mikro-Ökonometrie: Small Sample Inferenz mit OLS Folie Zusammenfassung wichtiger Ergebnisse des letzten Kapitels (I) Unter den ersten vier
Mikro-Ökonometrie: Small Sample Inferenz mit OLS 1. November 014 Mikro-Ökonometrie: Small Sample Inferenz mit OLS Folie Zusammenfassung wichtiger Ergebnisse des letzten Kapitels (I) Unter den ersten vier
Schriftliche Prüfung (90 Minuten)
") Dr. M. Kalisch Prüfung Statistik I Winter 2015 Schriftliche Prüfung (90 Minuten) Bemerkungen: Alle schriftlichen Hilfsmittel und ein Taschenrechner sind erlaubt. Mobiltelefone sind auszuschalten! Die Prüfung
Dr. M. Kalisch Prüfung Statistik I Winter 2015 Schriftliche Prüfung (90 Minuten) Bemerkungen: Alle schriftlichen Hilfsmittel und ein Taschenrechner sind erlaubt. Mobiltelefone sind auszuschalten! Die Prüfung
Vorlesung: Lineare Modelle
 Vorlesung: Lineare Modelle Prof Dr Helmut Küchenhoff Institut für Statistik, LMU München SoSe 2014 5 Metrische Einflußgrößen: Polynomiale Regression, Trigonometrische Polynome, Regressionssplines, Transformationen
Vorlesung: Lineare Modelle Prof Dr Helmut Küchenhoff Institut für Statistik, LMU München SoSe 2014 5 Metrische Einflußgrößen: Polynomiale Regression, Trigonometrische Polynome, Regressionssplines, Transformationen
Statistik II. II. Univariates lineares Regressionsmodell. Martin Huber 1 / 20
 Statistik II II. Univariates lineares Regressionsmodell Martin Huber 1 / 20 Übersicht Definitionen (Wooldridge 2.1) Schätzmethode - Kleinste Quadrate Schätzer / Ordinary Least Squares (Wooldridge 2.2)
Statistik II II. Univariates lineares Regressionsmodell Martin Huber 1 / 20 Übersicht Definitionen (Wooldridge 2.1) Schätzmethode - Kleinste Quadrate Schätzer / Ordinary Least Squares (Wooldridge 2.2)
4. Das multiple lineare Regressionsmodell
 4. Das multiple lineare Regressionsmodell Bisher: 1 endogene Variable y wurde zurückgeführt auf 1 exogene Variable x (einfaches lineares Regressionsmodell) Jetzt: Endogenes y wird regressiert auf mehrere
4. Das multiple lineare Regressionsmodell Bisher: 1 endogene Variable y wurde zurückgeführt auf 1 exogene Variable x (einfaches lineares Regressionsmodell) Jetzt: Endogenes y wird regressiert auf mehrere
8. Keine Normalverteilung der Störgrößen (Verletzung der B4-Annahme)
") 8. Keine Normalverteilung der Störgrößen (Verletzung der B4-Annahme) Annahme B4: Die Störgrößen u i sind normalverteilt, d.h. u i N(0, σ 2 ) Beispiel: [I] Neoklassisches Solow-Wachstumsmodell Annahme einer
8. Keine Normalverteilung der Störgrößen (Verletzung der B4-Annahme) Annahme B4: Die Störgrößen u i sind normalverteilt, d.h. u i N(0, σ 2 ) Beispiel: [I] Neoklassisches Solow-Wachstumsmodell Annahme einer
Biomathematik für Mediziner, Klausur WS 1999/2000 Seite 1
 Biomathematik für Mediziner, Klausur WS 1999/2000 Seite 1 Aufgabe 1: Wieviele der folgenden Variablen sind quantitativ stetig? Schulnoten, Familienstand, Religion, Steuerklasse, Alter, Reaktionszeit, Fahrzeit,
Biomathematik für Mediziner, Klausur WS 1999/2000 Seite 1 Aufgabe 1: Wieviele der folgenden Variablen sind quantitativ stetig? Schulnoten, Familienstand, Religion, Steuerklasse, Alter, Reaktionszeit, Fahrzeit,
1. Lösungen zu Kapitel 7
 1. Lösungen zu Kapitel 7 Übungsaufgabe 7.1 Um zu testen ob die Störterme ε i eine konstante Varianz haben, sprich die Homogenitätsannahme erfüllt ist, sind der Breusch-Pagan-Test und der White- Test zwei
1. Lösungen zu Kapitel 7 Übungsaufgabe 7.1 Um zu testen ob die Störterme ε i eine konstante Varianz haben, sprich die Homogenitätsannahme erfüllt ist, sind der Breusch-Pagan-Test und der White- Test zwei
Schriftliche Prüfung (2 Stunden)
") Prüfung Statistik Winter 2013 Schriftliche Prüfung (2 Stunden) Bemerkungen: Alle schriftlichen Hilfsmittel und ein Taschenrechner sind erlaubt. Mobiltelefone sind auszuschalten! Lesen Sie zuerst alle Aufgaben
Prüfung Statistik Winter 2013 Schriftliche Prüfung (2 Stunden) Bemerkungen: Alle schriftlichen Hilfsmittel und ein Taschenrechner sind erlaubt. Mobiltelefone sind auszuschalten! Lesen Sie zuerst alle Aufgaben
Übung zur Empirischen Wirtschaftsforschung V. Das Lineare Regressionsmodell
 Universität Ulm 89069 Ulm Germany Dipl.-WiWi Christian Peukert Institut für Wirtschaftspolitik Fakultät für Mathematik und Wirtschaftswissenschaften Ludwig-Erhard-Stiftungsprofessur Sommersemester 2010
Universität Ulm 89069 Ulm Germany Dipl.-WiWi Christian Peukert Institut für Wirtschaftspolitik Fakultät für Mathematik und Wirtschaftswissenschaften Ludwig-Erhard-Stiftungsprofessur Sommersemester 2010
Schriftliche Prüfung (2 Stunden)
") Dr. L. Meier Statistik und Wahrscheinlichkeitsrechnung Sommer 2015 Schriftliche Prüfung (2 Stunden) Bemerkungen: Erlaubte Hilfsmittel: 10 hand- oder maschinengeschriebene A4 Seiten (=5 Blätter). Taschenrechner
Dr. L. Meier Statistik und Wahrscheinlichkeitsrechnung Sommer 2015 Schriftliche Prüfung (2 Stunden) Bemerkungen: Erlaubte Hilfsmittel: 10 hand- oder maschinengeschriebene A4 Seiten (=5 Blätter). Taschenrechner
Aufgabe 1 (8= Punkte) 13 Studenten haben die folgenden Noten (ganze Zahl) in der Statistikklausur erhalten:
 13 Studenten haben die folgenden Noten (ganze Zahl) in der Statistikklausur erhalten:") Aufgabe 1 (8=2+2+2+2 Punkte) 13 Studenten haben die folgenden Noten (ganze Zahl) in der Statistikklausur erhalten: Die Zufallsvariable X bezeichne die Note. 1443533523253. a) Wie groß ist h(x 5)? Kreuzen
Aufgabe 1 (8=2+2+2+2 Punkte) 13 Studenten haben die folgenden Noten (ganze Zahl) in der Statistikklausur erhalten: Die Zufallsvariable X bezeichne die Note. 1443533523253. a) Wie groß ist h(x 5)? Kreuzen
X =, y In welcher Annahme unterscheidet sich die einfache KQ Methode von der ML Methode?
 Aufgabe 1 (25 Punkte) Zur Schätzung der Produktionsfunktion des Unternehmens WV wird ein lineares Regressionsmodell der Form angenommen. Dabei ist y t = β 1 + x t2 β 2 + e t, t = 1,..., T (1) y t : x t2
Aufgabe 1 (25 Punkte) Zur Schätzung der Produktionsfunktion des Unternehmens WV wird ein lineares Regressionsmodell der Form angenommen. Dabei ist y t = β 1 + x t2 β 2 + e t, t = 1,..., T (1) y t : x t2
Kapitel XII - Gleichmäßig beste unverfälschte Tests und Tests zur Normalverteilung
 Institut für Volkswirtschaftslehre (ECON) Lehrstuhl für Ökonometrie und Statistik Kapitel XII - Gleichmäßig beste unverfälschte Tests und Tests zur Normalverteilung Induktive Statistik Prof. Dr. W.-D.
Institut für Volkswirtschaftslehre (ECON) Lehrstuhl für Ökonometrie und Statistik Kapitel XII - Gleichmäßig beste unverfälschte Tests und Tests zur Normalverteilung Induktive Statistik Prof. Dr. W.-D.
Einige Konzepte aus der Wahrscheinlichkeitstheorie (Wiederh.)
") Einige Konzepte aus der Wahrscheinlichkeitstheorie (Wiederh.) 1 Zusammenfassung Bedingte Verteilung: P (y x) = P (x, y) P (x) mit P (x) > 0 Produktsatz P (x, y) = P (x y)p (y) = P (y x)p (x) Kettenregel
Einige Konzepte aus der Wahrscheinlichkeitstheorie (Wiederh.) 1 Zusammenfassung Bedingte Verteilung: P (y x) = P (x, y) P (x) mit P (x) > 0 Produktsatz P (x, y) = P (x y)p (y) = P (y x)p (x) Kettenregel
Übungsblätter zu Methoden der Empirischen Sozialforschung IV: Regressionsanalyse. Lösungsblatt zu Nr. 2
 Martin-Luther-Universität Halle-Wittenberg Institut für Soziologie Dr. Wolfgang Langer 1 Übungsblätter zu Methoden der Empirischen Sozialforschung IV: Regressionsanalyse Lösungsblatt zu Nr. 2 1. a) Je
Martin-Luther-Universität Halle-Wittenberg Institut für Soziologie Dr. Wolfgang Langer 1 Übungsblätter zu Methoden der Empirischen Sozialforschung IV: Regressionsanalyse Lösungsblatt zu Nr. 2 1. a) Je
Wahrscheinlichkeitsrechnung und Statistik für Biologen Wiederholung: Verteilungen
 Wahrscheinlichkeitsrechnung und Statistik für Biologen Wiederholung: Verteilungen Noémie Becker & Dirk Metzler 31. Mai 2016 Inhaltsverzeichnis 1 Binomialverteilung 1 2 Normalverteilung 2 3 T-Verteilung
Wahrscheinlichkeitsrechnung und Statistik für Biologen Wiederholung: Verteilungen Noémie Becker & Dirk Metzler 31. Mai 2016 Inhaltsverzeichnis 1 Binomialverteilung 1 2 Normalverteilung 2 3 T-Verteilung
Statistik II Übung 3: Hypothesentests
 Statistik II Übung 3: Hypothesentests Diese Übung beschäftigt sich mit der Anwendung diverser Hypothesentests (zum Beispiel zum Vergleich der Mittelwerte und Verteilungen zweier Stichproben). Verwenden
Statistik II Übung 3: Hypothesentests Diese Übung beschäftigt sich mit der Anwendung diverser Hypothesentests (zum Beispiel zum Vergleich der Mittelwerte und Verteilungen zweier Stichproben). Verwenden
Zufallsvariablen. Diskret. Stetig. Verteilung der Stichprobenkennzahlen. Binomial Hypergeometrisch Poisson. Normal Lognormal Exponential
 Zufallsvariablen Diskret Binomial Hypergeometrisch Poisson Stetig Normal Lognormal Exponential Verteilung der Stichprobenkennzahlen Stetige Zufallsvariable Verteilungsfunktion: Dichtefunktion: Integralrechnung:
Zufallsvariablen Diskret Binomial Hypergeometrisch Poisson Stetig Normal Lognormal Exponential Verteilung der Stichprobenkennzahlen Stetige Zufallsvariable Verteilungsfunktion: Dichtefunktion: Integralrechnung:
Einführung in die Induktive Statistik: Testen von Hypothesen
 Einführung in die Induktive Statistik: Testen von Hypothesen Jan Gertheiss LMU München Sommersemester 2011 Vielen Dank an Christian Heumann für das Überlassen von TEX-Code! Testen: Einführung und Konzepte
Einführung in die Induktive Statistik: Testen von Hypothesen Jan Gertheiss LMU München Sommersemester 2011 Vielen Dank an Christian Heumann für das Überlassen von TEX-Code! Testen: Einführung und Konzepte
Eigene MC-Fragen SPSS. 1. Zutreffend auf die Datenerfassung und Datenaufbereitung in SPSS ist
 Eigene MC-Fragen SPSS 1. Zutreffend auf die Datenerfassung und Datenaufbereitung in SPSS ist [a] In der Variablenansicht werden für die betrachteten Merkmale SPSS Variablen definiert. [b] Das Daten-Editor-Fenster
Eigene MC-Fragen SPSS 1. Zutreffend auf die Datenerfassung und Datenaufbereitung in SPSS ist [a] In der Variablenansicht werden für die betrachteten Merkmale SPSS Variablen definiert. [b] Das Daten-Editor-Fenster
3. Gemeinsame und bedingte Verteilung, stochastische Unabhängigkeit
 3. Gemeinsame und bedingte Verteilung, stochastische Unabhängigkeit Lernziele dieses Kapitels: Mehrdimensionale Zufallsvariablen (Zufallsvektoren) (Verteilung, Kenngrößen) Abhängigkeitsstrukturen Multivariate
3. Gemeinsame und bedingte Verteilung, stochastische Unabhängigkeit Lernziele dieses Kapitels: Mehrdimensionale Zufallsvariablen (Zufallsvektoren) (Verteilung, Kenngrößen) Abhängigkeitsstrukturen Multivariate
Wahrscheinlichkeitsrechnung und Statistik für Biologen Spezielle Verteilungen
 Wahrscheinlichkeitsrechnung und Statistik für Biologen Spezielle Verteilungen Noémie Becker & Dirk Metzler http://evol.bio.lmu.de/_statgen 7. Juni 2013 1 Binomialverteilung 2 Normalverteilung 3 T-Verteilung
Wahrscheinlichkeitsrechnung und Statistik für Biologen Spezielle Verteilungen Noémie Becker & Dirk Metzler http://evol.bio.lmu.de/_statgen 7. Juni 2013 1 Binomialverteilung 2 Normalverteilung 3 T-Verteilung
ML-Schätzung. Likelihood Quotienten-Test. Zusammenhang Reparametrisierung und Modell unter linearer Restriktion. Es gilt: β = Bγ + d (3.
 Reparametrisierung des Modells Gegeben sei das Modell (2.1) mit (2.5) unter der linearen Restriktion Aβ = c mit A R a p, rg(a) = a, c R a. Wir betrachten die lineare Restriktion als Gleichungssystem. Die
Reparametrisierung des Modells Gegeben sei das Modell (2.1) mit (2.5) unter der linearen Restriktion Aβ = c mit A R a p, rg(a) = a, c R a. Wir betrachten die lineare Restriktion als Gleichungssystem. Die
Prüfung aus Wahrscheinlichkeitstheorie und Statistik MASCHINENBAU 2003
 Prüfung aus Wahrscheinlichkeitstheorie und Statistik MASCHINENBAU 2003. Eine seltene Krankheit trete mit Wahrscheinlichkeit : 0000 auf. Die bedingte Wahrscheinlichkeit, dass ein bei einem Erkrankten durchgeführter
Prüfung aus Wahrscheinlichkeitstheorie und Statistik MASCHINENBAU 2003. Eine seltene Krankheit trete mit Wahrscheinlichkeit : 0000 auf. Die bedingte Wahrscheinlichkeit, dass ein bei einem Erkrankten durchgeführter
Auswertung und Lösung
 Dieses Quiz soll Ihnen helfen, Kapitel 4.6 und 4.7 besser zu verstehen. Auswertung und Lösung Abgaben: 59 / 265 Maximal erreichte Punktzahl: 8 Minimal erreichte Punktzahl: 0 Durchschnitt: 4.78 1 Frage
Dieses Quiz soll Ihnen helfen, Kapitel 4.6 und 4.7 besser zu verstehen. Auswertung und Lösung Abgaben: 59 / 265 Maximal erreichte Punktzahl: 8 Minimal erreichte Punktzahl: 0 Durchschnitt: 4.78 1 Frage
Einleitung. Statistik. Bsp: Ertrag Weizen. 6.1 Einfache Varianzanalyse
 Einleitung Statistik Institut für angewandte Statistik & EDV Universität für Bodenkultur Wien Der Begriff Varianzanalyse (analysis of variance, ANOVA) taucht an vielen Stellen in der Statistik mit unterschiedlichen
Einleitung Statistik Institut für angewandte Statistik & EDV Universität für Bodenkultur Wien Der Begriff Varianzanalyse (analysis of variance, ANOVA) taucht an vielen Stellen in der Statistik mit unterschiedlichen
Willkommen zur Vorlesung Statistik (Master)
") Willkommen zur Vorlesung Statistik (Master) Thema dieser Vorlesung: Verteilungen stetiger Zufallsvariablen Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften
Willkommen zur Vorlesung Statistik (Master) Thema dieser Vorlesung: Verteilungen stetiger Zufallsvariablen Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften
Regression ein kleiner Rückblick. Methodenseminar Dozent: Uwe Altmann Alexandra Kuhn, Melanie Spate
 Regression ein kleiner Rückblick Methodenseminar Dozent: Uwe Altmann Alexandra Kuhn, Melanie Spate 05.11.2009 Gliederung 1. Stochastische Abhängigkeit 2. Definition Zufallsvariable 3. Kennwerte 3.1 für
Regression ein kleiner Rückblick Methodenseminar Dozent: Uwe Altmann Alexandra Kuhn, Melanie Spate 05.11.2009 Gliederung 1. Stochastische Abhängigkeit 2. Definition Zufallsvariable 3. Kennwerte 3.1 für
Kapitel 3. Inferenz bei OLS-Schätzung I (small sample, unter GM1,..., GM6)
") 8 SMALL SAMPLE INFERENZ DER OLS-SCHÄTZUNG Damit wir die Verteilung von t (und anderen Teststatistiken) exakt angeben können, benötigen wir Verteilungsannahmen über die Störterme; Kapitel 3 Inferenz bei
8 SMALL SAMPLE INFERENZ DER OLS-SCHÄTZUNG Damit wir die Verteilung von t (und anderen Teststatistiken) exakt angeben können, benötigen wir Verteilungsannahmen über die Störterme; Kapitel 3 Inferenz bei
Die Familie der χ 2 (n)-verteilungen
-verteilungen") Die Familie der χ (n)-verteilungen Sind Z 1,..., Z m für m 1 unabhängig identisch standardnormalverteilte Zufallsvariablen, so genügt die Summe der quadrierten Zufallsvariablen χ := m Z i = Z 1 +... +
Die Familie der χ (n)-verteilungen Sind Z 1,..., Z m für m 1 unabhängig identisch standardnormalverteilte Zufallsvariablen, so genügt die Summe der quadrierten Zufallsvariablen χ := m Z i = Z 1 +... +
5. Seminar Statistik
 Sandra Schlick Seite 1 5. Seminar 5. Seminar Statistik 30 Kurztest 4 45 Testen von Hypothesen inkl. Übungen 45 Test- und Prüfverfahren inkl. Übungen 45 Repetitorium und Prüfungsvorbereitung 15 Kursevaluation
Sandra Schlick Seite 1 5. Seminar 5. Seminar Statistik 30 Kurztest 4 45 Testen von Hypothesen inkl. Übungen 45 Test- und Prüfverfahren inkl. Übungen 45 Repetitorium und Prüfungsvorbereitung 15 Kursevaluation
Sie wissen noch, dass 18.99% der Surfer, die kein Smartphone haben, pro Monat weniger als 20 Stunden das Internet nutzen, d.h. f(y 1 X 2 ) =
 =") Aufgabe 1 In einer Umfrage wird der Besitz eines Smartphones (Merkmal X) und die Nutzungsdauer des Internets pro Monat (Merkmal Y ) untersucht. Merkmal X hat zwei Ausprägungen: X 1 : Besitz und X 2 : Nichtbesitz.
Aufgabe 1 In einer Umfrage wird der Besitz eines Smartphones (Merkmal X) und die Nutzungsdauer des Internets pro Monat (Merkmal Y ) untersucht. Merkmal X hat zwei Ausprägungen: X 1 : Besitz und X 2 : Nichtbesitz.
Dr. W. Kuhlisch Dresden, Institut für Mathematische Stochastik
 Dr. W. Kuhlisch Dresden, 12. 08. 2014 Institut für Mathematische Stochastik Klausur Statistik für Studierende der Fachrichtungen Hydrologie und Altlasten/Abwasser zugelassene Hilfsmittel: Taschenrechner
Dr. W. Kuhlisch Dresden, 12. 08. 2014 Institut für Mathematische Stochastik Klausur Statistik für Studierende der Fachrichtungen Hydrologie und Altlasten/Abwasser zugelassene Hilfsmittel: Taschenrechner
Schriftliche Prüfung (120 Minuten)
") Dr. D. Stekhoven Prüfung Mathematik IV Winter 2016 Schriftliche Prüfung (120 Minuten) Bemerkungen: Erlaubte Hilfsmittel: 10 hand- oder maschinengeschriebene A4 Seiten (=5 Blätter). Taschenrechner ohne
Dr. D. Stekhoven Prüfung Mathematik IV Winter 2016 Schriftliche Prüfung (120 Minuten) Bemerkungen: Erlaubte Hilfsmittel: 10 hand- oder maschinengeschriebene A4 Seiten (=5 Blätter). Taschenrechner ohne
Forschungsstatistik I
 Psychologie Prof. Dr. G. Meinhardt 6. Stock, TB II R. 06-206 (Persike) R. 06-321 (Meinhardt) Sprechstunde jederzeit nach Vereinbarung Forschungsstatistik I Dr. Malte Persike persike@uni-mainz.de http://psymet03.sowi.uni-mainz.de/
Psychologie Prof. Dr. G. Meinhardt 6. Stock, TB II R. 06-206 (Persike) R. 06-321 (Meinhardt) Sprechstunde jederzeit nach Vereinbarung Forschungsstatistik I Dr. Malte Persike persike@uni-mainz.de http://psymet03.sowi.uni-mainz.de/
Stochastik (BSc D-MAVT / BSc D-MATH / BSc D-MATL)
") Prof. Dr. M. Maathuis ETH Zürich Winter 2010 Stochastik (BSc D-MAVT / BSc D-MATH / BSc D-MATL) Schreiben Sie für Aufgabe 2-4 stets alle Zwischenschritte und -rechnungen sowie Begründungen auf. Aufgabe
Prof. Dr. M. Maathuis ETH Zürich Winter 2010 Stochastik (BSc D-MAVT / BSc D-MATH / BSc D-MATL) Schreiben Sie für Aufgabe 2-4 stets alle Zwischenschritte und -rechnungen sowie Begründungen auf. Aufgabe
Mathematische und statistische Methoden II
 Methodenlehre e e Prof. Dr. G. Meinhardt 6. Stock, Wallstr. 3 (Raum 06-06) Sprechstunde jederzeit nach Vereinbarung und nach der Vorlesung. Mathematische und statistische Methoden II Dr. Malte Persike
Methodenlehre e e Prof. Dr. G. Meinhardt 6. Stock, Wallstr. 3 (Raum 06-06) Sprechstunde jederzeit nach Vereinbarung und nach der Vorlesung. Mathematische und statistische Methoden II Dr. Malte Persike
Mathematische Statistik Aufgaben zum Üben. Schätzer
 Prof. Dr. Z. Kabluchko Wintersemester 2016/17 Philipp Godland 14. November 2016 Mathematische Statistik Aufgaben zum Üben Keine Abgabe Aufgabe 1 Schätzer Es seien X 1,..., X n unabhängige und identisch
Prof. Dr. Z. Kabluchko Wintersemester 2016/17 Philipp Godland 14. November 2016 Mathematische Statistik Aufgaben zum Üben Keine Abgabe Aufgabe 1 Schätzer Es seien X 1,..., X n unabhängige und identisch
8. Februar 2007. 5. Bei Unterschleif gilt die Klausur als nicht bestanden und es erfolgt eine Meldung an das Prüfungsamt.
 L. Fahrmeir, C. Belitz Department für Statistik Bitte für die Korrektur freilassen! Aufgabe 1 2 3 4 Punkte Klausur zur Vorlesung Statistik III für Studenten mit Wahlfach Statistik 8. Februar 2007 Hinweise:
L. Fahrmeir, C. Belitz Department für Statistik Bitte für die Korrektur freilassen! Aufgabe 1 2 3 4 Punkte Klausur zur Vorlesung Statistik III für Studenten mit Wahlfach Statistik 8. Februar 2007 Hinweise: