Clustern: Voraussetzungen
|
|
|
- Kevin Weiner
- vor 6 Jahren
- Abrufe
Transkript
1 Clustering Gruppen (Cluster) ähnlicher Elemente bilden Elemente in einem Cluster sollen sich möglichst ähnlich sein, u. den Elementen in anderen Clustern möglichst unähnlich im Gegensatz zu Kategorisierung unüberwacht, d.h. anfangs keine Kategorien vorhanden Kategorienbildung
2 Clustern von Dokumenten Wörtern semantische (distributionelle) Ähnlichkeit syntaktische Ähnlichkeit (Wortarten, z.b. [1]) graphematische Ähnlichkeit Phoneme Morpheme Sätze...
3 Clustern im IR Dokumente explorative Datenanalyse (Text Mining) (semi-)automatisch Kategorienmodell erzeugen Terme Thesaurusgenerierung Suchergebnisse nur Ergebnisliste (cutoff) statt n Dokumente Ergebnisdarstellung Relevance Feedback: nur Terme aus ausgew. großen Clustern hinzufügen
4 Clustern: Voraussetzungen Menge von Elementen Ähnlichkeitsmaß zwischen allen Elementen Vektorähnlichkeit (Kosinus) bei Dokumenten distributionelle Ähnlichkeit bei Phonemen, Morphemen, Wörtern Schwellwert für Ähnlichkeit
5 Dokumente clustern
6 Dokumente clustern
7 Dokumente clustern
8 Dokumente clustern
9 Dokumente clustern
10 Clusteringmethoden Nicht-hierarchisch (flach) erzeugend aktualisierend Hierarchisch agglomerativ (bottom-up) partitionierend (top-down)
11 Clusteringmethoden Nicht-hierarchisch (flach) erzeugend Clique Single Link Star String aktualisierend k-means (Reallocation) EM One Pass Hierarchisch agglomerativ (bottom-up) partitionierend (top-down)
12 Clusteringmethoden Nicht-hierarchisch (flach) erzeugend aktualisierend Hierarchisch agglomerativ (bottom-up) Single Link Complete Linkage Group Average partitionierend (top-down) Wards Methode
13 Clusteringmethoden Hard Clustering jedes Element in genau einem Cluster keine überlappenden Cluster Soft Clustering Elemente können in mehreren Clustern sein Grade der Clusterzugehörigkeit überlappende Cluster
14 Dokumente clustern Voraussetzungen: Menge von n Dokumenten bzw. Dokumentvektoren Ähnlichkeit zwischen allen n Dokumentvektoren n x n Ähnlichkeitsmatrix hoher Rechenaufwand O(n²) gekürzte Dokumentvektoren Ähnlichkeitsschwellwert Relationsmatrix: ähnliche Dokumente = 1, unähnliche = 0 speichern als Adjazenzstruktur n(n-1)/2 Elemente
15 Ähnlichkeitsmatrix
16 Relationsmatrix
17 Nicht-hierarchische Methoden erzeugen neue Cluster Vorteil: Anzahl Cluster muss nicht vorher angegeben werden Laufzeit mindestens O(n²) auf Basis vorhandener Cluster vorhandene Cluster werden aktualisiert Anzahl Cluster muss vorher angegeben werden Laufzeit linear O(n)
18 Nicht-hierarchische Methoden zum Erzeugen neuer Cluster: Clique Single Link Star String
19 Clique Jedes Element jedem anderen Element im Cluster ähnlich Ein Element kann in mehrere Cluster gruppiert werden erzeugt viele kleine Cluster aus untereinander ähnlichen Elementen Cluster enthält nur Prototypen Laufzeit O(n³)
20 Clique-Algorithmus for i = 1 to n do d i in neues Cluster for r = i+1 to n do for k = r to n do if d k zu allen d im akt. Cluster ähnlich then füge d k zu akt. Cluster hinzu lege neues Cluster mit d i an if akt. Cluster enthält nur d i und d i bereits in anderen Clustern then lösche Cluster eliminiere doppelte Cluster oder Untermengen
21 Clique-Cluster
22 Single Link neues Element wird Cluster hinzugefügt, wenn es irgendeinem Element im Cluster ähnlich ist findet verbundene Komponenten (connected components) keine überlappenden Cluster erzeugt niedrige Anzahl großer Cluster zwei Elemente im gleichen Cluster müssen sich nicht unbedingt ähnlich sein alle Elemente fungieren als Prototypen Laufzeit O(n²)
23 Single Link-Algorithmus for i = 1 to n do platziere d i in neues Cluster for r = i+1 to n do for k = r to n do if d k ähnlich zu irgendeinem d im Cluster then füge d k zu Cluster hinzu bilde neues Cluster mit d i, falls noch in keinem Cluster
24 Single Link-Cluster
25 Star neues Element wird ins Cluster aufgenommen, wenn es dem ersten Element im Cluster ähnlich ist bildet überlappende Cluster Clusteranzahl u. -Größe zwischen Clique und Single Link erstes Clusterelement fungiert als Prototyp
26 Star-Algorithmus for i = 1 to n do platziere d i in neues Cluster for r = i+1 to n do for k = r to n do if d k ähnlich zu d i then füge d k zu Cluster hinzu bilde neues Cluster mit d i, falls noch in keinem Cluster
27 Star-Cluster
28 String neues Element muss dem zuletzt hinzugefügten Element ähnlich sein Elemente kettenweise zu Clustern verbinden Ketten sind zyklenfreie Pfade durch Relationsgraphen keine überlappenden Cluster Cluster hängen von der Reihenfolge ab Cluster enthalten nur Prototypen
29 String-Algorithmus for i = 1 to n do platziere d i in neues Cluster for r = i+1 to n do for k = r to n do if d k ähnlich zu d i und d k noch in keinem Cluster then füge d k zu Cluster hinzu d r = d k bilde neues Cluster mit d i, falls noch in keinem Cluster
30 String-Cluster
31 Nicht-hierarchische erzeugende Methoden: Vergleich Clique erzeugt homogenste kleinste Cluster in hoher Zahl Single Link erzeugt wenige große Cluster mit schwacher Ähnlichkeit Star und String liegen zwischen den beiden Extremen überlappende Cluster: Clique, Star disjunkte Cluster: Single Link, String
32 Nicht-hierarchische Methoden auf Basis vorhandener Cluster k-means (Reallocation) One Pass kommen aus ohne vorausberechnete Ähnlichkeitsmatrix Einsatz von Zentroiden geringerer Rechenaufwand Laufzeit O(n) anfängliche Clusterung vorgegeben iterative Revision der Zuordung Dokumente zu Cluster
33 k-means Anzahl der Cluster am Anfang festgelegt werden zufällig erzeugt alle Elemente werden einem Cluster zugeordnet keine Überlappung Einsatz von Zentroiden
34 k-means-algorithmus zufällige Cluster erzeugen wiederholen bis Cluster stabil: Zentroide der Cluster berechnen Ähnlichkeit Dokumente Zentroide berechnen Dokumente den Clustern mit ähnlichsten Zentroiden zuweisen
35 One-Pass-Assignment schnellste Laufzeit: O(n) alle Dokumente werden in einem Durchlauf zugeordnet eignet sich auch für sehr große Dokumentensammlungen es werden aber keine optimalen Cluster gefunden nicht alle Elemente im Cluster sind sich gegenseitig ähnlich Clustering hängt von der Reihenfolge ab
36 One-Pass-Algorithmus Erstes Dokument ins erste Cluster platzieren Wiederholen bis alle Doks zugewiesen: Zentroid des neuen Clusters berechnen Ähnlichkeit des nächsten Terms mit allen Zentroiden berechnen wenn Ähnlichkeit Dokument-Zentroid über Schwellwert: Dokument ins ähnlichste Cluster sonst Dokument in neues Cluster
37 Clusteringmethoden Nicht-hierarchisch (flach) erzeugend aktualisierend Hierarchisch agglomerativ (bottom-up) Single Link Complete Linkage Group Average partitionierend (top-down) Wards Methode
38 Hierarchisches Clustering partitionierend: Wards Methode: Kleinste-Quadrate-Methode in der Praxis schlechte Ergebnisse [4] wird kaum angewandt
39 Hierarchisches Clustering agglomerativ geringerer Rechenaufwand: mit jeder Bildung eines neuen Clusters wird Zahl der Vergleiche eingeschränkt Laufzeit O(n²) erzeugt baumartige Hierarchien
40 Hierarchisches agglomeratives Clustering allgemeiner Algorithmus: wiederhole bis nur noch ein Cluster übrig: finde zwei Cluster mit größter Ähnlichkeit vereine beide Cluster Ähnlichkeit zwischen neuem Cluster und übrigen Clustern neu berechnen
41 Hierarchisches agglomeratives Clustering Ähnlichkeit zwischen zwei Clustern: Single Link: Ähnlichkeit ist maximale Ähnl. zwischen zwei beliebigen Doks aus den Clustern Verbindung durch die beiden ähnlichsten Elemente zweier Cluster Complete Linkage: Ähnlichkeit ist minimale Ähnl. zwischen zwei beliebigen Doks aus den Clustern Group Average: Durchschnittsähnlichkeit aller Doks im Cluster
42 Vergleich hierarchischagglomerativer Methoden Single Link große Cluster schwach ähnliche Elemente nicht alle Elemente sind sich ähnlich bildet auch langgestreckte Cluster Complete Linkage kleine Cluster sehr ähnliche Elemente Group Average wie Complete Linkage
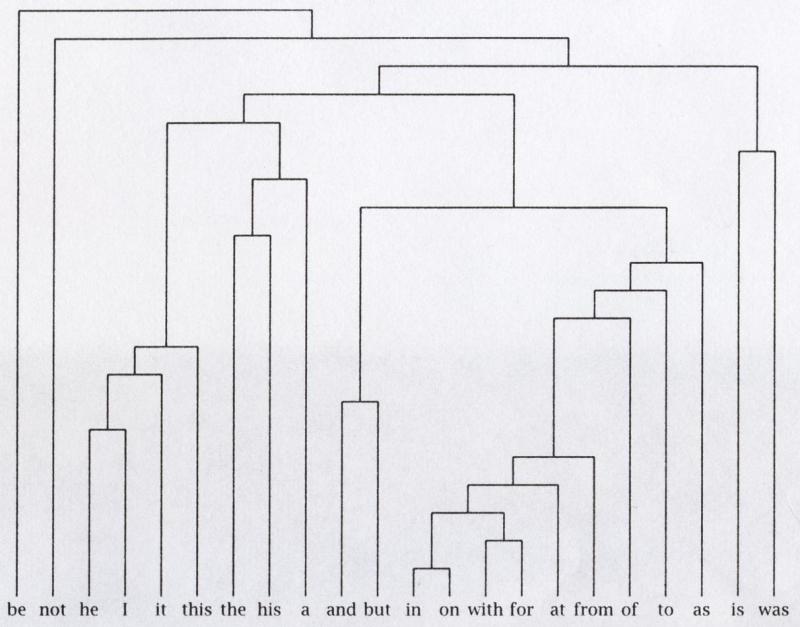
43 Dendrogramm
44 Literaturangaben [1] R. Rapp (1996): Die Berechnung von Assoziationen: Ein korpuslinguistischer Ansatz. Olms Verlag. [2] G. Kowalski (1997): Information Retrieval Systems: Theory and Implementation. Kluwer Academic Publishers. [3] K. Haenelt: Kursfolien: [4] A. Hotho, A. Nürnberger, G. Paass (2005): A brief survey of text mining. In LDV-Forum, 20(1).
Text Mining. Peter Kolb 25.6.2012
 Text Mining Peter Kolb 25.6.2012 Übersicht Big Data Information Retrieval vs. Text Mining Anwendungen Dokumentenähnlichkeit Termähnlichkeit Merkmalsauswahl und -Gewichtung Kategorisierung Clustering Big
Text Mining Peter Kolb 25.6.2012 Übersicht Big Data Information Retrieval vs. Text Mining Anwendungen Dokumentenähnlichkeit Termähnlichkeit Merkmalsauswahl und -Gewichtung Kategorisierung Clustering Big
Vorlesung Text und Data Mining S9 Text Clustering. Hans Hermann Weber Univ. Erlangen, Informatik
 Vorlesung Text und Data Mining S9 Text Clustering Hans Hermann Weber Univ. Erlangen, Informatik Document Clustering Überblick 1 Es gibt (sehr viele) verschiedene Verfahren für das Bilden von Gruppen Bei
Vorlesung Text und Data Mining S9 Text Clustering Hans Hermann Weber Univ. Erlangen, Informatik Document Clustering Überblick 1 Es gibt (sehr viele) verschiedene Verfahren für das Bilden von Gruppen Bei
Voraussetzung wieder: Datenraum mit Instanzen, mehrere Attribute - kein ausgezeichnetes Zielattribut, keine vorgegebenen Klassen
 7. Clusteranalyse (= Häufungsanalyse; Clustering-Verfahren) wird der multivariaten Statistik zugeordnet Voraussetzung wieder: Datenraum mit Instanzen, mehrere Attribute - kein ausgezeichnetes Zielattribut,
7. Clusteranalyse (= Häufungsanalyse; Clustering-Verfahren) wird der multivariaten Statistik zugeordnet Voraussetzung wieder: Datenraum mit Instanzen, mehrere Attribute - kein ausgezeichnetes Zielattribut,
Clustering von Dokumenten (k-means, HCL)
") Clustering von Dokumenten (k-means, HCL) Jonas Wolz Universität Ulm Zusammenfassung Ein Überblick über das Clustering von Dokumenten. Außerdem werden zwei dafür verwendete Algorithmen vorgestellt (k-means
Clustering von Dokumenten (k-means, HCL) Jonas Wolz Universität Ulm Zusammenfassung Ein Überblick über das Clustering von Dokumenten. Außerdem werden zwei dafür verwendete Algorithmen vorgestellt (k-means
Data Mining und Knowledge Discovery in Databases
 Data Mining und Knowledge Discovery in Databases Begriffsabgrenzungen... Phasen der KDD...3 3 Datenvorverarbeitung...4 3. Datenproblematik...4 3. Möglichkeiten der Datenvorverarbeitung...4 4 Data Mining
Data Mining und Knowledge Discovery in Databases Begriffsabgrenzungen... Phasen der KDD...3 3 Datenvorverarbeitung...4 3. Datenproblematik...4 3. Möglichkeiten der Datenvorverarbeitung...4 4 Data Mining
Clustering Seminar für Statistik
 Clustering Markus Kalisch 03.12.2014 1 Ziel von Clustering Finde Gruppen, sodas Elemente innerhalb der gleichen Gruppe möglichst ähnlich sind und Elemente von verschiedenen Gruppen möglichst verschieden
Clustering Markus Kalisch 03.12.2014 1 Ziel von Clustering Finde Gruppen, sodas Elemente innerhalb der gleichen Gruppe möglichst ähnlich sind und Elemente von verschiedenen Gruppen möglichst verschieden
Seminar zum Thema Künstliche Intelligenz:
 Wolfgang Ginolas Seminar zum Thema Künstliche Intelligenz: Clusteranalyse Wolfgang Ginolas 11.5.2005 Wolfgang Ginolas 1 Beispiel Was ist eine Clusteranalyse Ein einfacher Algorithmus 2 bei verschieden
Wolfgang Ginolas Seminar zum Thema Künstliche Intelligenz: Clusteranalyse Wolfgang Ginolas 11.5.2005 Wolfgang Ginolas 1 Beispiel Was ist eine Clusteranalyse Ein einfacher Algorithmus 2 bei verschieden
4 Greedy-Algorithmen (gierige Algorithmen)
") Greedy-Algorithmen (gierige Algorithmen) Greedy-Algorithmen werden oft für die exakte oder approximative Lösung von Optimierungsproblemen verwendet. Typischerweise konstruiert ein Greedy-Algorithmus eine
Greedy-Algorithmen (gierige Algorithmen) Greedy-Algorithmen werden oft für die exakte oder approximative Lösung von Optimierungsproblemen verwendet. Typischerweise konstruiert ein Greedy-Algorithmus eine
Einführung in das Data Mining Clustering / Clusteranalyse
 Einführung in das Data Mining Clustering / Clusteranalyse Sascha Szott Fachgebiet Informationssysteme HPI Potsdam 21. Mai 2008 Teil I Einführung Clustering / Clusteranalyse Ausgangspunkt: Menge O von Objekten
Einführung in das Data Mining Clustering / Clusteranalyse Sascha Szott Fachgebiet Informationssysteme HPI Potsdam 21. Mai 2008 Teil I Einführung Clustering / Clusteranalyse Ausgangspunkt: Menge O von Objekten
generiere aus Textdokumenten zunächst Metadaten, wende Data Mining - Techniken dann nur auf diese an
 9. Text- und Web-Mining Text Mining: Anwendung von Data Mining - Verfahren auf große Mengen von Online-Textdokumenten Web Mining: Anwendung von Data Mining - Verfahren auf Dokumente aus dem WWW oder auf
9. Text- und Web-Mining Text Mining: Anwendung von Data Mining - Verfahren auf große Mengen von Online-Textdokumenten Web Mining: Anwendung von Data Mining - Verfahren auf Dokumente aus dem WWW oder auf
Anfrage Erweiterung 03.11.2011 Jan Schrader
 Anfrage Erweiterung 03.11.2011 Jan Schrader Vocabulary Mismatch Problem Anfrage und Dokument passen nicht zusammen obwohl Dokument zur Anfrage relevant Grund: Synonymproblem verschiedene Menschen benennen
Anfrage Erweiterung 03.11.2011 Jan Schrader Vocabulary Mismatch Problem Anfrage und Dokument passen nicht zusammen obwohl Dokument zur Anfrage relevant Grund: Synonymproblem verschiedene Menschen benennen
17.1.2014 Einführung in die Programmierung Laborübung bei Korcan Y. Kirkici. 12.Übung 13.1. bis 17.1.2014
 17.1.2014 Einführung in die Programmierung Laborübung bei Korcan Y. Kirkici 12.Übung 13.1. bis 17.1.2014 1 BEFRAGUNG http://1.bp.blogspot.com/- waaowrew9gc/tuhgqro4u_i/aaaaaaaaaey/3xhl 4Va2SOQ/s1600/crying%2Bmeme.png
17.1.2014 Einführung in die Programmierung Laborübung bei Korcan Y. Kirkici 12.Übung 13.1. bis 17.1.2014 1 BEFRAGUNG http://1.bp.blogspot.com/- waaowrew9gc/tuhgqro4u_i/aaaaaaaaaey/3xhl 4Va2SOQ/s1600/crying%2Bmeme.png
Text Mining und CRM. Hans Hermann Weber Univ. Erlangen IMMD 8, den 12.09.03
 Text Mining und CRM Hans Hermann Weber Univ. Erlangen IMMD 8, den 12.09.03 Was ist Textmining Unstrukturierte Daten (Text) anreichern mit Strukturinformation: Metadaten hinzufügen Struktur (Segmentinformation)
Text Mining und CRM Hans Hermann Weber Univ. Erlangen IMMD 8, den 12.09.03 Was ist Textmining Unstrukturierte Daten (Text) anreichern mit Strukturinformation: Metadaten hinzufügen Struktur (Segmentinformation)
Data Mining - Clustering. Sven Elvers
 Agenda Data Mining Clustering Aktuelle Arbeiten Thesis Outline 2 Agenda Data Mining Clustering Aktuelle Arbeiten Thesis Outline 3 Data Mining Entdecken versteckter Informationen, Muster und Zusammenhänge
Agenda Data Mining Clustering Aktuelle Arbeiten Thesis Outline 2 Agenda Data Mining Clustering Aktuelle Arbeiten Thesis Outline 3 Data Mining Entdecken versteckter Informationen, Muster und Zusammenhänge
Die Clusteranalyse 24.06.2009. Clusteranalyse. Grundidee Mögliche Anwendungsgebiete gg Vorgehensweise Beispiele. methodenlehre ll Clusteranalyse
 Clusteranalyse Thomas Schäfer SS 2009 1 Die Clusteranalyse Grundidee Mögliche Anwendungsgebiete gg Vorgehensweise Beispiele Thomas Schäfer SS 2009 2 1 Die Clusteranalyse Grundidee: Eine heterogene Gesamtheit
Clusteranalyse Thomas Schäfer SS 2009 1 Die Clusteranalyse Grundidee Mögliche Anwendungsgebiete gg Vorgehensweise Beispiele Thomas Schäfer SS 2009 2 1 Die Clusteranalyse Grundidee: Eine heterogene Gesamtheit
1 Hochverfügbarkeit. 1.1 Einführung. 1.2 Network Load Balancing (NLB) Quelle: Microsoft. Hochverfügbarkeit
 Quelle: Microsoft. Hochverfügbarkeit") 1 Hochverfügbarkeit Lernziele: Network Load Balancing (NLB) Failover-Servercluster Verwalten der Failover Cluster Rolle Arbeiten mit virtuellen Maschinen Prüfungsanforderungen von Microsoft: Configure
1 Hochverfügbarkeit Lernziele: Network Load Balancing (NLB) Failover-Servercluster Verwalten der Failover Cluster Rolle Arbeiten mit virtuellen Maschinen Prüfungsanforderungen von Microsoft: Configure
Seminar Komplexe Objekte in Datenbanken
 Seminar Komplexe Objekte in Datenbanken OPTICS: Ordering Points To Identify the Clustering Structure Lehrstuhl für Informatik IX - Univ.-Prof. Dr. Thomas Seidl, RWTH-Aachen http://www-i9.informatik.rwth-aachen.de
Seminar Komplexe Objekte in Datenbanken OPTICS: Ordering Points To Identify the Clustering Structure Lehrstuhl für Informatik IX - Univ.-Prof. Dr. Thomas Seidl, RWTH-Aachen http://www-i9.informatik.rwth-aachen.de
Clustering mit dem K-Means-Algorithmus (Ein Experiment)
") Clustering mit dem K-Means- (Ein Experiment) Andreas Runk 7. März 2013 Index 1 2 3 4 5 Andreas Runk Clustering mit dem K-Means- 2/40 Ziele: des K-Means Finde/erstelle geeignetes Testcorpus möglichst gute
Clustering mit dem K-Means- (Ein Experiment) Andreas Runk 7. März 2013 Index 1 2 3 4 5 Andreas Runk Clustering mit dem K-Means- 2/40 Ziele: des K-Means Finde/erstelle geeignetes Testcorpus möglichst gute
Suche in Spielbäumen Spielbäume Minimax Algorithmus Alpha-Beta Suche. Suche in Spielbäumen. KI SS2011: Suche in Spielbäumen 1/20
 Suche in Spielbäumen Suche in Spielbäumen KI SS2011: Suche in Spielbäumen 1/20 Spiele in der KI Suche in Spielbäumen Spielbäume Minimax Algorithmus Alpha-Beta Suche Einschränkung von Spielen auf: 2 Spieler:
Suche in Spielbäumen Suche in Spielbäumen KI SS2011: Suche in Spielbäumen 1/20 Spiele in der KI Suche in Spielbäumen Spielbäume Minimax Algorithmus Alpha-Beta Suche Einschränkung von Spielen auf: 2 Spieler:
Eine vorprozessierte Variante von Scatter/Gather
 Universität Duisburg-Essen, Standort Duisburg Institut für Informatik und interaktive Systeme Fachgebiet Informationssysteme Ausarbeitung zum Blockseminar Invisible Web Eine vorprozessierte Variante von
Universität Duisburg-Essen, Standort Duisburg Institut für Informatik und interaktive Systeme Fachgebiet Informationssysteme Ausarbeitung zum Blockseminar Invisible Web Eine vorprozessierte Variante von
Alignment-Verfahren zum Vergleich biologischer Sequenzen
 zum Vergleich biologischer Sequenzen Hans-Joachim Böckenhauer Dennis Komm Volkshochschule Zürich. April Ein biologisches Problem Fragestellung Finde eine Methode zum Vergleich von DNA-Molekülen oder Proteinen
zum Vergleich biologischer Sequenzen Hans-Joachim Böckenhauer Dennis Komm Volkshochschule Zürich. April Ein biologisches Problem Fragestellung Finde eine Methode zum Vergleich von DNA-Molekülen oder Proteinen
Literatur. Dominating Set (DS) Dominating Sets in Sensornetzen. Problem Minimum Dominating Set (MDS)
 Dominating Sets in Sensornetzen. Problem Minimum Dominating Set (MDS)") Dominating Set 59 Literatur Dominating Set Grundlagen 60 Dominating Set (DS) M. V. Marathe, H. Breu, H.B. Hunt III, S. S. Ravi, and D. J. Rosenkrantz: Simple Heuristics for Unit Disk Graphs. Networks 25,
Dominating Set 59 Literatur Dominating Set Grundlagen 60 Dominating Set (DS) M. V. Marathe, H. Breu, H.B. Hunt III, S. S. Ravi, and D. J. Rosenkrantz: Simple Heuristics for Unit Disk Graphs. Networks 25,
Nexis Analyser. Die ersten Schritte. Analyse durchführen. Anmeldung: www.lexisnexis.com/de/nexis
 Übersicht: Der Nexis Analyser hilft Ihnen, die Trends Ihrer Suche zu analysieren. Passen Sie Ihre Grafiken individuell an und laden Sie diese ganz einfach herunter eine Vielzahl an Formaten steht Ihnen
Übersicht: Der Nexis Analyser hilft Ihnen, die Trends Ihrer Suche zu analysieren. Passen Sie Ihre Grafiken individuell an und laden Sie diese ganz einfach herunter eine Vielzahl an Formaten steht Ihnen
Häufige Item-Mengen: die Schlüssel-Idee. Vorlesungsplan. Apriori Algorithmus. Methoden zur Verbessung der Effizienz von Apriori
 Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Kapitel 4: Dynamische Datenstrukturen. Algorithmen und Datenstrukturen WS 2012/13. Prof. Dr. Sándor Fekete
 Kapitel 4: Dynamische Datenstrukturen Algorithmen und Datenstrukturen WS 2012/13 Prof. Dr. Sándor Fekete 4.4 Binäre Suche Aufgabenstellung: Rate eine Zahl zwischen 100 und 114! Algorithmus 4.1 INPUT: OUTPUT:
Kapitel 4: Dynamische Datenstrukturen Algorithmen und Datenstrukturen WS 2012/13 Prof. Dr. Sándor Fekete 4.4 Binäre Suche Aufgabenstellung: Rate eine Zahl zwischen 100 und 114! Algorithmus 4.1 INPUT: OUTPUT:
13. Binäre Suchbäume
 1. Binäre Suchbäume Binäre Suchbäume realiesieren Wörterbücher. Sie unterstützen die Operationen 1. Einfügen (Insert) 2. Entfernen (Delete). Suchen (Search) 4. Maximum/Minimum-Suche 5. Vorgänger (Predecessor),
1. Binäre Suchbäume Binäre Suchbäume realiesieren Wörterbücher. Sie unterstützen die Operationen 1. Einfügen (Insert) 2. Entfernen (Delete). Suchen (Search) 4. Maximum/Minimum-Suche 5. Vorgänger (Predecessor),
Data Mining-Modelle und -Algorithmen
 Data Mining-Modelle und -Algorithmen Data Mining-Modelle und -Algorithmen Data Mining ist ein Prozess, bei dem mehrere Komponenten i n- teragieren. Sie greifen auf Datenquellen, um diese zum Training,
Data Mining-Modelle und -Algorithmen Data Mining-Modelle und -Algorithmen Data Mining ist ein Prozess, bei dem mehrere Komponenten i n- teragieren. Sie greifen auf Datenquellen, um diese zum Training,
Kurs 1613 Einführung in die imperative Programmierung
 Aufgabe 1 Gegeben sei die Prozedur BubbleSort: procedure BubbleSort(var iofeld:tfeld); { var hilf:integer; i:tindex; j:tindex; vertauscht:boolean; i:=1; repeat vertauscht := false; for j := 1 to N - i
Aufgabe 1 Gegeben sei die Prozedur BubbleSort: procedure BubbleSort(var iofeld:tfeld); { var hilf:integer; i:tindex; j:tindex; vertauscht:boolean; i:=1; repeat vertauscht := false; for j := 1 to N - i
Vorlesung Algorithmische Geometrie. Streckenschnitte. Martin Nöllenburg 19.04.2011
 Vorlesung Algorithmische Geometrie LEHRSTUHL FÜR ALGORITHMIK I INSTITUT FÜR THEORETISCHE INFORMATIK FAKULTÄT FÜR INFORMATIK Martin Nöllenburg 19.04.2011 Überlagern von Kartenebenen Beispiel: Gegeben zwei
Vorlesung Algorithmische Geometrie LEHRSTUHL FÜR ALGORITHMIK I INSTITUT FÜR THEORETISCHE INFORMATIK FAKULTÄT FÜR INFORMATIK Martin Nöllenburg 19.04.2011 Überlagern von Kartenebenen Beispiel: Gegeben zwei
FACHARBEIT. Grundlagen der Gestaltung von Facharbeiten. Fach: Schule: Schüler: Fachlehrer: Jahrgangsstufe 12 Schuljahr:
 FACHARBEIT Grundlagen der Gestaltung von Facharbeiten Fach: Schule: Schüler: Fachlehrer: Jahrgangsstufe 12 Schuljahr: 2 Inhaltsverzeichnis INHALTSVERZEICHNIS... 2 1 GRUNDLAGEN DER GESTALTUNG VON FACHARBEITEN...
FACHARBEIT Grundlagen der Gestaltung von Facharbeiten Fach: Schule: Schüler: Fachlehrer: Jahrgangsstufe 12 Schuljahr: 2 Inhaltsverzeichnis INHALTSVERZEICHNIS... 2 1 GRUNDLAGEN DER GESTALTUNG VON FACHARBEITEN...
Programmierkurs: Delphi: Einstieg
 Seite 1 von 6 Programmierkurs: Delphi: Einstieg Aus Wikibooks Inhaltsverzeichnis 1 Einstieg Einstieg Was ist Delphi Borland Delphi ist eine RAD-Programmierumgebung von Borland. Sie basiert auf der Programmiersprache
Seite 1 von 6 Programmierkurs: Delphi: Einstieg Aus Wikibooks Inhaltsverzeichnis 1 Einstieg Einstieg Was ist Delphi Borland Delphi ist eine RAD-Programmierumgebung von Borland. Sie basiert auf der Programmiersprache
5.2 Das All-Pairs-Shortest-Paths-Problem (APSP-Problem) Kürzeste Wege zwischen allen Knoten. Eingabe: Gerichteter Graph G =(V, E, c)
 Kürzeste Wege zwischen allen Knoten. Eingabe: Gerichteter Graph G =(V, E, c)") 5.2 Das All-Pairs-Shortest-Paths-Problem (APSP-Problem) Kürzeste Wege zwischen allen Knoten. Eingabe: Gerichteter Graph G =(V, E, c) mit V = {1,...,n} und E {(v, w) 1 apple v, w apple n, v 6= w}. c : E!
5.2 Das All-Pairs-Shortest-Paths-Problem (APSP-Problem) Kürzeste Wege zwischen allen Knoten. Eingabe: Gerichteter Graph G =(V, E, c) mit V = {1,...,n} und E {(v, w) 1 apple v, w apple n, v 6= w}. c : E!
2015 conject all rights reserved
 2015 conject all rights reserved Inhaltsverzeichnis 1. Einleitung... 3 2. Schritte für Anpassung des Planmanagements... 5 3. Kategoriewerte ergänzen... 5 4. Blockwerte in den Blockdateien ergänzen... 6
2015 conject all rights reserved Inhaltsverzeichnis 1. Einleitung... 3 2. Schritte für Anpassung des Planmanagements... 5 3. Kategoriewerte ergänzen... 5 4. Blockwerte in den Blockdateien ergänzen... 6
Schritt für Schritt Anleitung zum Erstellen einer Android-App zum Ein- und Ausschalten einer LED
 Schritt für Schritt Anleitung zum Erstellen einer Android-App zum Ein- und Ausschalten einer LED Mit Google Chrome nach MIT App Inventor suchen. In den Suchergebnissen (siehe unten) auf
Schritt für Schritt Anleitung zum Erstellen einer Android-App zum Ein- und Ausschalten einer LED Mit Google Chrome nach MIT App Inventor suchen. In den Suchergebnissen (siehe unten) auf
Zitieren mit Write-N-Cite 4 (Anleitung für Windows)
") Zitieren mit Write-N-Cite 4 (Anleitung für Windows) Eine Installationsanleitung für Write-N-Cite 4 finden Sie unter http://www.ulb.uni-muenster.de/literaturverwaltung/refworks/write-n-cite.html. Schritt
Zitieren mit Write-N-Cite 4 (Anleitung für Windows) Eine Installationsanleitung für Write-N-Cite 4 finden Sie unter http://www.ulb.uni-muenster.de/literaturverwaltung/refworks/write-n-cite.html. Schritt
Beheben von verlorenen Verknüpfungen 20.06.2005
 Vor folgender Situation ist sicher jeder Solid Edge-Anwender beim Öffnen von Baugruppen oder Drafts schon einmal gestanden: Die Ursache dafür kann sein: Die Dateien wurden über den Explorer umbenannt:
Vor folgender Situation ist sicher jeder Solid Edge-Anwender beim Öffnen von Baugruppen oder Drafts schon einmal gestanden: Die Ursache dafür kann sein: Die Dateien wurden über den Explorer umbenannt:
Datenstruktur, die viele Operationen dynamischer Mengen unterstützt
 Algorithmen und Datenstrukturen 265 10 Binäre Suchbäume Suchbäume Datenstruktur, die viele Operationen dynamischer Mengen unterstützt Kann als Wörterbuch, aber auch zu mehr eingesetzt werden (Prioritätsschlange)
Algorithmen und Datenstrukturen 265 10 Binäre Suchbäume Suchbäume Datenstruktur, die viele Operationen dynamischer Mengen unterstützt Kann als Wörterbuch, aber auch zu mehr eingesetzt werden (Prioritätsschlange)
Vorlesung Suchmaschinen Semesterklausur Wintersemester 2013/14
 Universität Augsburg, Institut für Informatik Wintersemester 2013/14 Prof. Dr. W. Kießling 10. Oktober 2013 F. Wenzel, D. Köppl Suchmaschinen Vorlesung Suchmaschinen Semesterklausur Wintersemester 2013/14
Universität Augsburg, Institut für Informatik Wintersemester 2013/14 Prof. Dr. W. Kießling 10. Oktober 2013 F. Wenzel, D. Köppl Suchmaschinen Vorlesung Suchmaschinen Semesterklausur Wintersemester 2013/14
Informatik II Greedy-Algorithmen
 7/7/06 lausthal Erinnerung: Dynamische Programmierung Informatik II reedy-algorithmen. Zachmann lausthal University, ermany zach@in.tu-clausthal.de Zusammenfassung der grundlegenden Idee: Optimale Sub-Struktur:
7/7/06 lausthal Erinnerung: Dynamische Programmierung Informatik II reedy-algorithmen. Zachmann lausthal University, ermany zach@in.tu-clausthal.de Zusammenfassung der grundlegenden Idee: Optimale Sub-Struktur:
VBA-Programmierung: Zusammenfassung
 VBA-Programmierung: Zusammenfassung Programmiersprachen (Definition, Einordnung VBA) Softwareentwicklung-Phasen: 1. Spezifikation 2. Entwurf 3. Implementierung Datentypen (einfach, zusammengesetzt) Programmablaufsteuerung
VBA-Programmierung: Zusammenfassung Programmiersprachen (Definition, Einordnung VBA) Softwareentwicklung-Phasen: 1. Spezifikation 2. Entwurf 3. Implementierung Datentypen (einfach, zusammengesetzt) Programmablaufsteuerung
 orgexterndoc31 Inhaltsverzeichnis Einleitung... 1 Installation... 3 Grundinstallation... 3 Installation pro Arbeitsplatz... 6 Lizenzierung... 7 Benutzung Einzeldokument... 9 1. Möglichkeit:... 9 2. Möglichkeit...
orgexterndoc31 Inhaltsverzeichnis Einleitung... 1 Installation... 3 Grundinstallation... 3 Installation pro Arbeitsplatz... 6 Lizenzierung... 7 Benutzung Einzeldokument... 9 1. Möglichkeit:... 9 2. Möglichkeit...
6 Produktqualität Systeme: Integrationstest [sehr stark gekürzt]
![6 Produktqualität Systeme: Integrationstest [sehr stark gekürzt]](/thumbs/27/12066220.jpg "6 Produktqualität Systeme: Integrationstest [sehr stark gekürzt]") 1 Software-Qualitätssicherung 2 Integrationsstrategien big bang 6 Produktqualität Systeme: Integrationstest [sehr stark gekürzt] nicht-inkrementell geschäftsprozeßorientiert Prof. Dr. Helmut Balzert Lehrstuhl
1 Software-Qualitätssicherung 2 Integrationsstrategien big bang 6 Produktqualität Systeme: Integrationstest [sehr stark gekürzt] nicht-inkrementell geschäftsprozeßorientiert Prof. Dr. Helmut Balzert Lehrstuhl
Clusteranalyse. Clusteranalyse. Fragestellung und Aufgaben. Abgrenzung Clusteranalyse - Diskriminanzanalyse. Rohdatenmatrix und Distanzmatrix
 TECHNISCHE UNIVERSITÄT MÜNCHEN-WEIHENSTEPHAN MATHEMATIK UND STATISTIK INFORMATIONS- UND DOKUMENTATIONSZENTRUM R. Biometrische und Ökonometrische Methoden II SS 00 Fragestellung und Aufgaben Abgrenzung
TECHNISCHE UNIVERSITÄT MÜNCHEN-WEIHENSTEPHAN MATHEMATIK UND STATISTIK INFORMATIONS- UND DOKUMENTATIONSZENTRUM R. Biometrische und Ökonometrische Methoden II SS 00 Fragestellung und Aufgaben Abgrenzung
PND Tool Quellcodegenerierung
 PND Tool Quellcodegenerierung Handbuch Autor: Heiko Weiß Inhaltsverzeichnis 1 Allgemeines 3 2 Systemanforderungen 3 3 Anforderungen an ein Petrinetz 3 4 Bibliotheken 3 5 Petrinetzdatei und Bibliothek laden
PND Tool Quellcodegenerierung Handbuch Autor: Heiko Weiß Inhaltsverzeichnis 1 Allgemeines 3 2 Systemanforderungen 3 3 Anforderungen an ein Petrinetz 3 4 Bibliotheken 3 5 Petrinetzdatei und Bibliothek laden
Sortieralgorithmen. Inhalt: InsertionSort BubbleSort QuickSort. Marco Block
 Inhalt: InsertionSort BubbleSort QuickSort Block M.: "Java-Intensivkurs - In 14 Tagen lernen Projekte erfolgreich zu realisieren", Springer-Verlag 2007 InsertionSort I Das Problem unsortierte Daten in
Inhalt: InsertionSort BubbleSort QuickSort Block M.: "Java-Intensivkurs - In 14 Tagen lernen Projekte erfolgreich zu realisieren", Springer-Verlag 2007 InsertionSort I Das Problem unsortierte Daten in
Exploration und Klassifikation von BigData
 Exploration und Klassifikation von BigData Inhalt Einführung Daten Data Mining: Vorbereitungen Clustering Konvexe Hülle Fragen Google: Riesige Datenmengen (2009: Prozessieren von 24 Petabytes pro Tag)
Exploration und Klassifikation von BigData Inhalt Einführung Daten Data Mining: Vorbereitungen Clustering Konvexe Hülle Fragen Google: Riesige Datenmengen (2009: Prozessieren von 24 Petabytes pro Tag)
Wiederholung ADT Menge Ziel: Verwaltung (Finden, Einfügen, Entfernen) einer Menge von Elementen
 einer Menge von Elementen") Was bisher geschah abstrakter Datentyp : Signatur Σ und Axiome Φ z.b. ADT Menge zur Verwaltung (Finden, Einfügen, Entfernen) mehrerer Elemente desselben Typs Spezifikation einer Schnittstelle Konkreter
Was bisher geschah abstrakter Datentyp : Signatur Σ und Axiome Φ z.b. ADT Menge zur Verwaltung (Finden, Einfügen, Entfernen) mehrerer Elemente desselben Typs Spezifikation einer Schnittstelle Konkreter
HEUTE. Datenstrukturen im Computer. Datenstrukturen. Rekursion. Feedback Evaluation. abstrakte Datenstrukturen
 9.2.5 HUT 9.2.5 3 atenstrukturen im omputer atenstrukturen ie beiden fundamentalen atenstrukturen in der Praxis sind rray und Liste Rekursion Feedback valuation rray Zugriff: schnell Umordnung: langsam
9.2.5 HUT 9.2.5 3 atenstrukturen im omputer atenstrukturen ie beiden fundamentalen atenstrukturen in der Praxis sind rray und Liste Rekursion Feedback valuation rray Zugriff: schnell Umordnung: langsam
Programmierung 2. Dynamische Programmierung. Sebastian Hack. Klaas Boesche. Sommersemester 2012. hack@cs.uni-saarland.de. boesche@cs.uni-saarland.
 1 Programmierung 2 Dynamische Programmierung Sebastian Hack hack@cs.uni-saarland.de Klaas Boesche boesche@cs.uni-saarland.de Sommersemester 2012 2 Übersicht Stammt aus den Zeiten als mit Programmierung
1 Programmierung 2 Dynamische Programmierung Sebastian Hack hack@cs.uni-saarland.de Klaas Boesche boesche@cs.uni-saarland.de Sommersemester 2012 2 Übersicht Stammt aus den Zeiten als mit Programmierung
Suchen und Sortieren Sortieren. Heaps
 Suchen und Heaps (Folie 245, Seite 63 im Skript) 3 7 21 10 17 31 49 28 14 35 24 42 38 Definition Ein Heap ist ein Binärbaum, der die Heapeigenschaft hat (Kinder sind größer als der Vater), bis auf die
Suchen und Heaps (Folie 245, Seite 63 im Skript) 3 7 21 10 17 31 49 28 14 35 24 42 38 Definition Ein Heap ist ein Binärbaum, der die Heapeigenschaft hat (Kinder sind größer als der Vater), bis auf die
Grundlagen der Informatik. Prof. Dr. Stefan Enderle NTA Isny
 Grundlagen der Informatik Prof. Dr. Stefan Enderle NTA Isny 2 Datenstrukturen 2.1 Einführung Syntax: Definition einer formalen Grammatik, um Regeln einer formalen Sprache (Programmiersprache) festzulegen.
Grundlagen der Informatik Prof. Dr. Stefan Enderle NTA Isny 2 Datenstrukturen 2.1 Einführung Syntax: Definition einer formalen Grammatik, um Regeln einer formalen Sprache (Programmiersprache) festzulegen.
Christian Zietzsch / Norman Zänker. Text Mining. und dessen Implementierung. Diplomica Verlag
 Christian Zietzsch / Norman Zänker Text Mining und dessen Implementierung Diplomica Verlag Christian Zietzsch, Norman Zänker Text Mining und dessen Implementierung ISBN: 978-3-8428-0970-3 Herstellung:
Christian Zietzsch / Norman Zänker Text Mining und dessen Implementierung Diplomica Verlag Christian Zietzsch, Norman Zänker Text Mining und dessen Implementierung ISBN: 978-3-8428-0970-3 Herstellung:
Kompakte Graphmodelle handgezeichneter Bilder
 Kompakte Graphmodelle handgezeichneter Bilder Einbeziehung in Authentizierung und Bilderkennung Inhaltsverzeichnis Seminar Mustererkennung WS 006/07 Autor: Stefan Lohs 1 Einleitung 1 Das graphische Modell.1
Kompakte Graphmodelle handgezeichneter Bilder Einbeziehung in Authentizierung und Bilderkennung Inhaltsverzeichnis Seminar Mustererkennung WS 006/07 Autor: Stefan Lohs 1 Einleitung 1 Das graphische Modell.1
Innovator 11 classix. Java Reverse Engineering. HowTo. Ralph Schönleber. www.mid.de
 Innovator 11 classix Java Reverse Engineering Ralph Schönleber HowTo www.mid.de Mit Innovator Java Reverse Engineering durchführen Inhaltsverzeichnis Voraussetzungen... 2 Java Reverse Engineering... 2
Innovator 11 classix Java Reverse Engineering Ralph Schönleber HowTo www.mid.de Mit Innovator Java Reverse Engineering durchführen Inhaltsverzeichnis Voraussetzungen... 2 Java Reverse Engineering... 2
Large-Scale Image Search
 Large-Scale Image Search Visuelle Bildsuche in sehr großen Bildsammlungen Media Mining I Multimedia Computing, Universität Augsburg Rainer.Lienhart@informatik.uni-augsburg.de www.multimedia-computing.{de,org}
Large-Scale Image Search Visuelle Bildsuche in sehr großen Bildsammlungen Media Mining I Multimedia Computing, Universität Augsburg Rainer.Lienhart@informatik.uni-augsburg.de www.multimedia-computing.{de,org}
Modbus-Master-Treiber
 Modbus-Master-Treiber 1. Einleitung MODBUS ist ein offenes serielles Kommunikationsprotokoll, das auf einer Master/Slave Architektur basiert. Dabei greift der MODBUS-Master (Touch Panel PC) auf die fest
Modbus-Master-Treiber 1. Einleitung MODBUS ist ein offenes serielles Kommunikationsprotokoll, das auf einer Master/Slave Architektur basiert. Dabei greift der MODBUS-Master (Touch Panel PC) auf die fest
Importieren und Exportieren von Inhalt
 Importieren und Exportieren von Inhalt Willkommen bei Corel DESIGNER, dem umfassenden vektorbasierten Zeichenprogramm zur Erstellung technischer Grafiken. In diesem Tutorial importieren Sie eine AutoCAD
Importieren und Exportieren von Inhalt Willkommen bei Corel DESIGNER, dem umfassenden vektorbasierten Zeichenprogramm zur Erstellung technischer Grafiken. In diesem Tutorial importieren Sie eine AutoCAD
Monte Carlo Methoden
 Monte Carlo Methoden im Verstärkungslernen [Spink] Bryan Spink 2003 Ketill Gunnarsson [ ketill@inf.fu-berlin.de ], Seminar zum Verstärkungslernen, Freie Universität Berlin [ www.inf.fu-berlin.de ] Einleitung
Monte Carlo Methoden im Verstärkungslernen [Spink] Bryan Spink 2003 Ketill Gunnarsson [ ketill@inf.fu-berlin.de ], Seminar zum Verstärkungslernen, Freie Universität Berlin [ www.inf.fu-berlin.de ] Einleitung
Cliquen in Graphen Mathematische Grundlagen und der Bron-Kerbosch-Algorithmus. Karin Haenelt 24.11.2012
 Cliquen in Graphen Mathematische Grundlagen und der Bron-Kerbosch-Algorithmus Karin Haenelt 24.11.2012 Themen Einführung einige Clustering-Algorithmen Clique-Algorithmus Graphentheoretische Definition:
Cliquen in Graphen Mathematische Grundlagen und der Bron-Kerbosch-Algorithmus Karin Haenelt 24.11.2012 Themen Einführung einige Clustering-Algorithmen Clique-Algorithmus Graphentheoretische Definition:
datenfabrik.phone Telefonnummern mit den SQL Server Integration Services validieren www.datenfabrik.com
 datenfabrik.phone Telefonnummern mit den SQL Server Integration Services validieren Erstellen eines neuen SSIS Projektes. Wählen Sie das Template Integration Services Project aus.. Geben Sie einen Namen
datenfabrik.phone Telefonnummern mit den SQL Server Integration Services validieren Erstellen eines neuen SSIS Projektes. Wählen Sie das Template Integration Services Project aus.. Geben Sie einen Namen
Das Briefträgerproblem
 Das Briefträgerproblem Paul Tabatabai 30. Dezember 2011 Inhaltsverzeichnis 1 Problemstellung und Modellierung 2 1.1 Problem................................ 2 1.2 Modellierung.............................
Das Briefträgerproblem Paul Tabatabai 30. Dezember 2011 Inhaltsverzeichnis 1 Problemstellung und Modellierung 2 1.1 Problem................................ 2 1.2 Modellierung.............................
Erweiterung für Premium Auszeichnung
 Anforderungen Beliebige Inhalte sollen im System als Premium Inhalt gekennzeichnet werden können Premium Inhalte sollen weiterhin für unberechtigte Benutzer sichtbar sein, allerdings nur ein bestimmter
Anforderungen Beliebige Inhalte sollen im System als Premium Inhalt gekennzeichnet werden können Premium Inhalte sollen weiterhin für unberechtigte Benutzer sichtbar sein, allerdings nur ein bestimmter
Textdokument-Suche auf dem Rechner Implementierungsprojekt
 Textdokument-Suche auf dem Rechner Implementierungsprojekt Referent: Oliver Petra Seminar: Information Retrieval Institut für Computerlinguistik Ruprecht-Karls-Universität Heidelberg 19.01.2015 Überblick
Textdokument-Suche auf dem Rechner Implementierungsprojekt Referent: Oliver Petra Seminar: Information Retrieval Institut für Computerlinguistik Ruprecht-Karls-Universität Heidelberg 19.01.2015 Überblick
Das Studiengangsinformationssystem (SGIS)
") Das Studiengangsinformationssystem (SGIS) Hinweise für Studiengangsverantwortliche und Typo3-Redakteure Version 1.a Mai 2015 Kontakt: Christian Birringer, Referat 1.4 - Allgemeine Studienberatung und Career
Das Studiengangsinformationssystem (SGIS) Hinweise für Studiengangsverantwortliche und Typo3-Redakteure Version 1.a Mai 2015 Kontakt: Christian Birringer, Referat 1.4 - Allgemeine Studienberatung und Career
22. Algorithmus der Woche Partnerschaftsvermittlung Drum prüfe, wer sich ewig bindet
 22. Algorithmus der Woche Partnerschaftsvermittlung Drum prüfe, wer sich ewig bindet Autor Volker Claus, Universität Stuttgart Volker Diekert, Universität Stuttgart Holger Petersen, Universität Stuttgart
22. Algorithmus der Woche Partnerschaftsvermittlung Drum prüfe, wer sich ewig bindet Autor Volker Claus, Universität Stuttgart Volker Diekert, Universität Stuttgart Holger Petersen, Universität Stuttgart
3.1 Konstruktion von minimalen Spannbäumen Es gibt zwei Prinzipien für die Konstruktion von minimalen Spannbäumen (Tarjan): blaue Regel rote Regel
: blaue Regel rote Regel") 3.1 Konstruktion von minimalen Spannbäumen Es gibt zwei Prinzipien für die Konstruktion von minimalen Spannbäumen (Tarjan): blaue Regel rote Regel EADS 3.1 Konstruktion von minimalen Spannbäumen 16/36
3.1 Konstruktion von minimalen Spannbäumen Es gibt zwei Prinzipien für die Konstruktion von minimalen Spannbäumen (Tarjan): blaue Regel rote Regel EADS 3.1 Konstruktion von minimalen Spannbäumen 16/36
Künstliche Intelligenz Maschinelles Lernen
 Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert Sommersemester 2009 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen
Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert Sommersemester 2009 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen
Datenbankanwendung. Prof. Dr.-Ing. Sebastian Michel TU Kaiserslautern. Wintersemester 2014/15. smichel@cs.uni-kl.de
 Datenbankanwendung Wintersemester 2014/15 Prof. Dr.-Ing. Sebastian Michel TU Kaiserslautern smichel@cs.uni-kl.de Wiederholung: Anfragegraph Anfragen dieses Typs können als Graph dargestellt werden: Der
Datenbankanwendung Wintersemester 2014/15 Prof. Dr.-Ing. Sebastian Michel TU Kaiserslautern smichel@cs.uni-kl.de Wiederholung: Anfragegraph Anfragen dieses Typs können als Graph dargestellt werden: Der
"Alles, was einen Wert zurueckliefert, ist ein Ausdruck." Konstanten, Variablen, "Formeln" oder auch Methoden koennen Werte zurueckgeben.
 Ausdruecke "Alles, was einen Wert zurueckliefert, ist ein Ausdruck." Konstanten, Variablen, "Formeln" oder auch Methoden koennen Werte zurueckgeben. Im Gegensatz zu Anweisungen; die geben keinen Wert zurueck.
Ausdruecke "Alles, was einen Wert zurueckliefert, ist ein Ausdruck." Konstanten, Variablen, "Formeln" oder auch Methoden koennen Werte zurueckgeben. Im Gegensatz zu Anweisungen; die geben keinen Wert zurueck.
Aufgabenstellung und Zielsetzung
 Aufgabenstellung und Zielsetzung In diesem Szenario werden Sie eine Bestellung, vorliegend im XML-Format, über einen Web-Client per HTTP zum XI- System senden. Dort wird die XML-Datei mittels eines HTTP-Interfaces
Aufgabenstellung und Zielsetzung In diesem Szenario werden Sie eine Bestellung, vorliegend im XML-Format, über einen Web-Client per HTTP zum XI- System senden. Dort wird die XML-Datei mittels eines HTTP-Interfaces
8 Diskrete Optimierung
 8 Diskrete Optimierung Definition 8.1. Ein Graph G ist ein Paar (V (G), E(G)) besteh aus einer lichen Menge V (G) von Knoten (oder Ecken) und einer Menge E(G) ( ) V (G) 2 von Kanten. Die Ordnung n(g) von
8 Diskrete Optimierung Definition 8.1. Ein Graph G ist ein Paar (V (G), E(G)) besteh aus einer lichen Menge V (G) von Knoten (oder Ecken) und einer Menge E(G) ( ) V (G) 2 von Kanten. Die Ordnung n(g) von
Datenstrukturen und Algorithmen
 Datenstrukturen und Algorithmen VO 708.031 Bäume robert.legenstein@igi.tugraz.at 1 Inhalt der Vorlesung 1. Motivation, Einführung, Grundlagen 2. Algorithmische Grundprinzipien 3. Sortierverfahren 4. Halden
Datenstrukturen und Algorithmen VO 708.031 Bäume robert.legenstein@igi.tugraz.at 1 Inhalt der Vorlesung 1. Motivation, Einführung, Grundlagen 2. Algorithmische Grundprinzipien 3. Sortierverfahren 4. Halden
Im Folgenden wird Ihnen an einem Beispiel erklärt, wie Sie Excel-Anlagen und Excel-Vorlagen erstellen können.
 Excel-Schnittstelle Im Folgenden wird Ihnen an einem Beispiel erklärt, wie Sie Excel-Anlagen und Excel-Vorlagen erstellen können. Voraussetzung: Microsoft Office Excel ab Version 2000 Zum verwendeten Beispiel:
Excel-Schnittstelle Im Folgenden wird Ihnen an einem Beispiel erklärt, wie Sie Excel-Anlagen und Excel-Vorlagen erstellen können. Voraussetzung: Microsoft Office Excel ab Version 2000 Zum verwendeten Beispiel:
Anmerkungen zur Übergangsprüfung
 DM11 Slide 1 Anmerkungen zur Übergangsprüfung Aufgabeneingrenzung Aufgaben des folgenden Typs werden wegen ihres Schwierigkeitsgrads oder wegen eines ungeeigneten fachlichen Schwerpunkts in der Übergangsprüfung
DM11 Slide 1 Anmerkungen zur Übergangsprüfung Aufgabeneingrenzung Aufgaben des folgenden Typs werden wegen ihres Schwierigkeitsgrads oder wegen eines ungeeigneten fachlichen Schwerpunkts in der Übergangsprüfung
Theoretische Grundlagen der Informatik
 Theoretische Grundlagen der Informatik Vorlesung am 12.01.2012 INSTITUT FÜR THEORETISCHE 0 KIT 12.01.2012 Universität des Dorothea Landes Baden-Württemberg Wagner - Theoretische und Grundlagen der Informatik
Theoretische Grundlagen der Informatik Vorlesung am 12.01.2012 INSTITUT FÜR THEORETISCHE 0 KIT 12.01.2012 Universität des Dorothea Landes Baden-Württemberg Wagner - Theoretische und Grundlagen der Informatik
Alerts für Microsoft CRM 4.0
 Alerts für Microsoft CRM 4.0 Benutzerhandbuch Der Inhalt des Dokuments ist Änderungen vorbehalten. Microsoft und Microsoft CRM sind registrierte Markenzeichen von Microsoft Inc. Alle weiteren erwähnten
Alerts für Microsoft CRM 4.0 Benutzerhandbuch Der Inhalt des Dokuments ist Änderungen vorbehalten. Microsoft und Microsoft CRM sind registrierte Markenzeichen von Microsoft Inc. Alle weiteren erwähnten
Babeș-Bolyai Universität Cluj Napoca Fakultät für Mathematik und Informatik Grundlagen der Programmierung MLG5005. Paradigmen im Algorithmenentwurf
 Babeș-Bolyai Universität Cluj Napoca Fakultät für Mathematik und Informatik Grundlagen der Programmierung MLG5005 Paradigmen im Algorithmenentwurf Problemlösen Problem definieren Algorithmus entwerfen
Babeș-Bolyai Universität Cluj Napoca Fakultät für Mathematik und Informatik Grundlagen der Programmierung MLG5005 Paradigmen im Algorithmenentwurf Problemlösen Problem definieren Algorithmus entwerfen
NOTENVERWALTUNG UND VIELES MEHR INHALT
 Anleitung INHALT 1. ÜBERSICHT... 4 2. SCHULE ANLEGEN... 5 3. SCHÜLER ANLEGEN... 9 4. NOTENSCHEMAS... 15 5. KURSE... 17 6. KALENDER... 19 7. BEURTEILUNGEN... 21 8. ANWESENHEITEN... 27 9. ZEUGNISSE... 29
Anleitung INHALT 1. ÜBERSICHT... 4 2. SCHULE ANLEGEN... 5 3. SCHÜLER ANLEGEN... 9 4. NOTENSCHEMAS... 15 5. KURSE... 17 6. KALENDER... 19 7. BEURTEILUNGEN... 21 8. ANWESENHEITEN... 27 9. ZEUGNISSE... 29
Algorithmen II Vorlesung am 15.11.2012
 Algorithmen II Vorlesung am 15.11.2012 Kreisbasen, Matroide & Algorithmen INSTITUT FÜR THEORETISCHE INFORMATIK PROF. DR. DOROTHEA WAGNER KIT Universität des Landes Baden-Württemberg und Algorithmen nationales
Algorithmen II Vorlesung am 15.11.2012 Kreisbasen, Matroide & Algorithmen INSTITUT FÜR THEORETISCHE INFORMATIK PROF. DR. DOROTHEA WAGNER KIT Universität des Landes Baden-Württemberg und Algorithmen nationales
EndNote Web. Quick Reference Card THOMSON SCIENTIFIC
 THOMSON SCIENTIFIC EndNote Web Quick Reference Card Web ist ein webbasierter Service, der Studenten und Forschern beim Verfassen wissenschaftlicher Arbeiten behilflich ist. ISI Web of Knowledge, EndNote
THOMSON SCIENTIFIC EndNote Web Quick Reference Card Web ist ein webbasierter Service, der Studenten und Forschern beim Verfassen wissenschaftlicher Arbeiten behilflich ist. ISI Web of Knowledge, EndNote
Imagic IMS Client und Office 2007-Zusammenarbeit
 Imagic IMS Client und Office 2007-Zusammenarbeit Das Programm Imagic ims Client v ist zu finden über: Start -> Alle Programme -> Imagic ims Client v anklicken. Im Ordner Office 2007 v finden Sie PowerPoint
Imagic IMS Client und Office 2007-Zusammenarbeit Das Programm Imagic ims Client v ist zu finden über: Start -> Alle Programme -> Imagic ims Client v anklicken. Im Ordner Office 2007 v finden Sie PowerPoint
Anleitung zum Erstellen von Moodle-Quizfragen in Word
 Anleitung zum Erstellen von Moodle-Quizfragen in Word Die Vorlagedateien Speichern Sie die.zip Datei an den gewünschten Ort und entpacken Sie diese. In dem neuen Ordner befinden sich nun folgende Dateien:
Anleitung zum Erstellen von Moodle-Quizfragen in Word Die Vorlagedateien Speichern Sie die.zip Datei an den gewünschten Ort und entpacken Sie diese. In dem neuen Ordner befinden sich nun folgende Dateien:
Praktikum Software Engineering
 Praktikum Software Engineering Verwendung von Enterprise Architect Pascal Weber, David Kulicke KIT Universität des Landes Baden-Württemberg und nationales Forschungszentrum in der Helmholtz-Gemeinschaft
Praktikum Software Engineering Verwendung von Enterprise Architect Pascal Weber, David Kulicke KIT Universität des Landes Baden-Württemberg und nationales Forschungszentrum in der Helmholtz-Gemeinschaft
BINGO! Ein fokussierender Crawler zur Generierung personalisierter Ontologien
 BINGO! Ein fokussierender Crawler zur Generierung personalisierter Ontologien Martin Theobald Stefan Siersdorfer,, Sergej Sizov Universität des Saarlandes Lehrstuhl für Datenbanken und Informationssysteme
BINGO! Ein fokussierender Crawler zur Generierung personalisierter Ontologien Martin Theobald Stefan Siersdorfer,, Sergej Sizov Universität des Saarlandes Lehrstuhl für Datenbanken und Informationssysteme
Flexibilität im Prozess mit Oracle Business Rules 11g
 Flexibilität im Prozess mit Oracle Business Rules 11g Michael Stapf ORACLE Deutschland GmbH Frankfurt Schlüsselworte: Geschäftsregeln, Business Rules, Rules Engine, BPEL Process Manager, SOA Suite 11g,
Flexibilität im Prozess mit Oracle Business Rules 11g Michael Stapf ORACLE Deutschland GmbH Frankfurt Schlüsselworte: Geschäftsregeln, Business Rules, Rules Engine, BPEL Process Manager, SOA Suite 11g,
Tutorial: Fotobuch gestalten und für die Ausgabe vorbereiten
 Tutorial: und für die Ausgabe vorbereiten Formulare mit ausgefeiltem Layout CD-ROM Die Beispieldatei finden Sie auf der CD-ROM im Ordner»Arbeitsdateien\ Tutorial\Fotobuch«. In den Zeiten der Digitalfotografie
Tutorial: und für die Ausgabe vorbereiten Formulare mit ausgefeiltem Layout CD-ROM Die Beispieldatei finden Sie auf der CD-ROM im Ordner»Arbeitsdateien\ Tutorial\Fotobuch«. In den Zeiten der Digitalfotografie
Faktura. IT.S FAIR Faktura. Handbuch. Dauner Str.12, D-41236 Mönchengladbach, Hotline: 0900/1 296 607 (1,30 /Min)
") IT.S FAIR Faktura Handbuch Dauner Str.12, D-41236 Mönchengladbach, Hotline: 0900/1 296 607 (1,30 /Min) 1. Inhalt 1. Inhalt... 2 2. Wie lege ich einen Kontakt an?... 3 3. Wie erstelle ich eine Aktion für
IT.S FAIR Faktura Handbuch Dauner Str.12, D-41236 Mönchengladbach, Hotline: 0900/1 296 607 (1,30 /Min) 1. Inhalt 1. Inhalt... 2 2. Wie lege ich einen Kontakt an?... 3 3. Wie erstelle ich eine Aktion für
4. Lernen von Entscheidungsbäumen. Klassifikation mit Entscheidungsbäumen. Entscheidungsbaum
 4. Lernen von Entscheidungsbäumen Klassifikation mit Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch /Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse zugeordnet werden.
4. Lernen von Entscheidungsbäumen Klassifikation mit Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch /Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse zugeordnet werden.
2. Lernen von Entscheidungsbäumen
 2. Lernen von Entscheidungsbäumen Entscheidungsbäume 2. Lernen von Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse
2. Lernen von Entscheidungsbäumen Entscheidungsbäume 2. Lernen von Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse
Kapiteltests zum Leitprogramm Binäre Suchbäume
 Kapiteltests zum Leitprogramm Binäre Suchbäume Björn Steffen Timur Erdag überarbeitet von Christina Class Binäre Suchbäume Kapiteltests für das ETH-Leitprogramm Adressaten und Institutionen Das Leitprogramm
Kapiteltests zum Leitprogramm Binäre Suchbäume Björn Steffen Timur Erdag überarbeitet von Christina Class Binäre Suchbäume Kapiteltests für das ETH-Leitprogramm Adressaten und Institutionen Das Leitprogramm
Data Mining und Text Mining Einführung. S2 Einfache Regellerner
 Data Mining und Text Mining Einführung S2 Einfache Regellerner Hans Hermann Weber Univ. Erlangen, Informatik 8 Wintersemester 2003 hans.hermann.weber@gmx.de Inhalt Einiges über Regeln und Bäume R1 ein
Data Mining und Text Mining Einführung S2 Einfache Regellerner Hans Hermann Weber Univ. Erlangen, Informatik 8 Wintersemester 2003 hans.hermann.weber@gmx.de Inhalt Einiges über Regeln und Bäume R1 ein
T5 Die Einsatzplanung inkl. Urlaub und Feiertagen
 T5 Die Einsatzplanung inkl. Urlaub und Feiertagen Als nächstes wollen wir uns das Thema Einsatzplanung betrachten. Ziel hierbei ist es sicherzustellen, dass die zugeordneten Mitarbeiter in dem vorgegebenen
T5 Die Einsatzplanung inkl. Urlaub und Feiertagen Als nächstes wollen wir uns das Thema Einsatzplanung betrachten. Ziel hierbei ist es sicherzustellen, dass die zugeordneten Mitarbeiter in dem vorgegebenen
Personalisierung. Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung. Data Mining.
 Personalisierung Personalisierung Thomas Mandl Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung Klassifikation Die Nutzer werden in vorab bestimmte Klassen/Nutzerprofilen
Personalisierung Personalisierung Thomas Mandl Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung Klassifikation Die Nutzer werden in vorab bestimmte Klassen/Nutzerprofilen
Programmieren für mobile Endgeräte SS 2013/2014. Dozenten: Patrick Förster, Michael Hasseler
 Programmieren für mobile Endgeräte SS 2013/2014 Programmieren für mobile Endgeräte 2 Informationen aus der Datenbank lesen Klasse SQLiteDatabase enthält die Methode query(..) 1. Parameter: Tabellenname
Programmieren für mobile Endgeräte SS 2013/2014 Programmieren für mobile Endgeräte 2 Informationen aus der Datenbank lesen Klasse SQLiteDatabase enthält die Methode query(..) 1. Parameter: Tabellenname
Wie Google Webseiten bewertet. François Bry
 Wie Google Webseiten bewertet François Bry Heu6ge Vorlesung 1. Einleitung 2. Graphen und Matrizen 3. Erste Idee: Ranking als Eigenvektor 4. Fragen: Exisi6ert der Eigenvektor? Usw. 5. Zweite Idee: Die Google
Wie Google Webseiten bewertet François Bry Heu6ge Vorlesung 1. Einleitung 2. Graphen und Matrizen 3. Erste Idee: Ranking als Eigenvektor 4. Fragen: Exisi6ert der Eigenvektor? Usw. 5. Zweite Idee: Die Google
Heuristische Suche. Auswahl initialer Lösung. Auswahl nächster Lösung (basierend auf voriger) Such-Strategie. Qualitätsbetrachtung
 Such-Strategie. Qualitätsbetrachtung") Heuristische Suche Die meisten Heuristiken basieren auf iterativer Suche bestehend aus folgenden Elementen: Auswahl einer initialen (vorläufigen) Lösung (z.b. eine Sequenz) Betrachtung der Qualität der
Heuristische Suche Die meisten Heuristiken basieren auf iterativer Suche bestehend aus folgenden Elementen: Auswahl einer initialen (vorläufigen) Lösung (z.b. eine Sequenz) Betrachtung der Qualität der
S=[n] Menge von Veranstaltungen J S kompatibel mit maximaler Größe J
![S=[n] Menge von Veranstaltungen J S kompatibel mit maximaler Größe J](/thumbs/26/8373971.jpg "S=[n] Menge von Veranstaltungen J S kompatibel mit maximaler Größe J") Greedy-Strategie Definition Paradigma Greedy Der Greedy-Ansatz verwendet die Strategie 1 Top-down Auswahl: Bestimme in jedem Schritt eine lokal optimale Lösung, so dass man eine global optimale Lösung
Greedy-Strategie Definition Paradigma Greedy Der Greedy-Ansatz verwendet die Strategie 1 Top-down Auswahl: Bestimme in jedem Schritt eine lokal optimale Lösung, so dass man eine global optimale Lösung
Konfiguration einer Sparkassen-Chipkarte in StarMoney
 Konfiguration einer Sparkassen-Chipkarte in StarMoney In dieser Anleitung möchten wir Ihnen die Kontoeinrichtung in StarMoney anhand einer vorliegenden Sparkassen-Chipkarte erklären. Die Screenshots in
Konfiguration einer Sparkassen-Chipkarte in StarMoney In dieser Anleitung möchten wir Ihnen die Kontoeinrichtung in StarMoney anhand einer vorliegenden Sparkassen-Chipkarte erklären. Die Screenshots in
Eine Baumstruktur sei folgendermaßen definiert. Eine Baumstruktur mit Grundtyp Element ist entweder
 Programmieren in PASCAL Bäume 1 1. Baumstrukturen Eine Baumstruktur sei folgendermaßen definiert. Eine Baumstruktur mit Grundtyp Element ist entweder 1. die leere Struktur oder 2. ein Knoten vom Typ Element
Programmieren in PASCAL Bäume 1 1. Baumstrukturen Eine Baumstruktur sei folgendermaßen definiert. Eine Baumstruktur mit Grundtyp Element ist entweder 1. die leere Struktur oder 2. ein Knoten vom Typ Element
Gibt es verschiedene Arten unendlich? Dieter Wolke
 Gibt es verschiedene Arten unendlich? Dieter Wolke 1 Zuerst zum Gebrauch des Wortes unendlich Es wird in der Mathematik in zwei unterschiedlichen Bedeutungen benutzt Erstens im Zusammenhang mit Funktionen
Gibt es verschiedene Arten unendlich? Dieter Wolke 1 Zuerst zum Gebrauch des Wortes unendlich Es wird in der Mathematik in zwei unterschiedlichen Bedeutungen benutzt Erstens im Zusammenhang mit Funktionen