Ranking Functions im Web: PageRank & HITS
|
|
|
- Birgit Lang
- vor 6 Jahren
- Abrufe
Transkript
1 im Web: PageRank & HITS 28. Januar 2013 Universität Heidelberg Institut für Computerlinguistik Information Retrieval




2




3
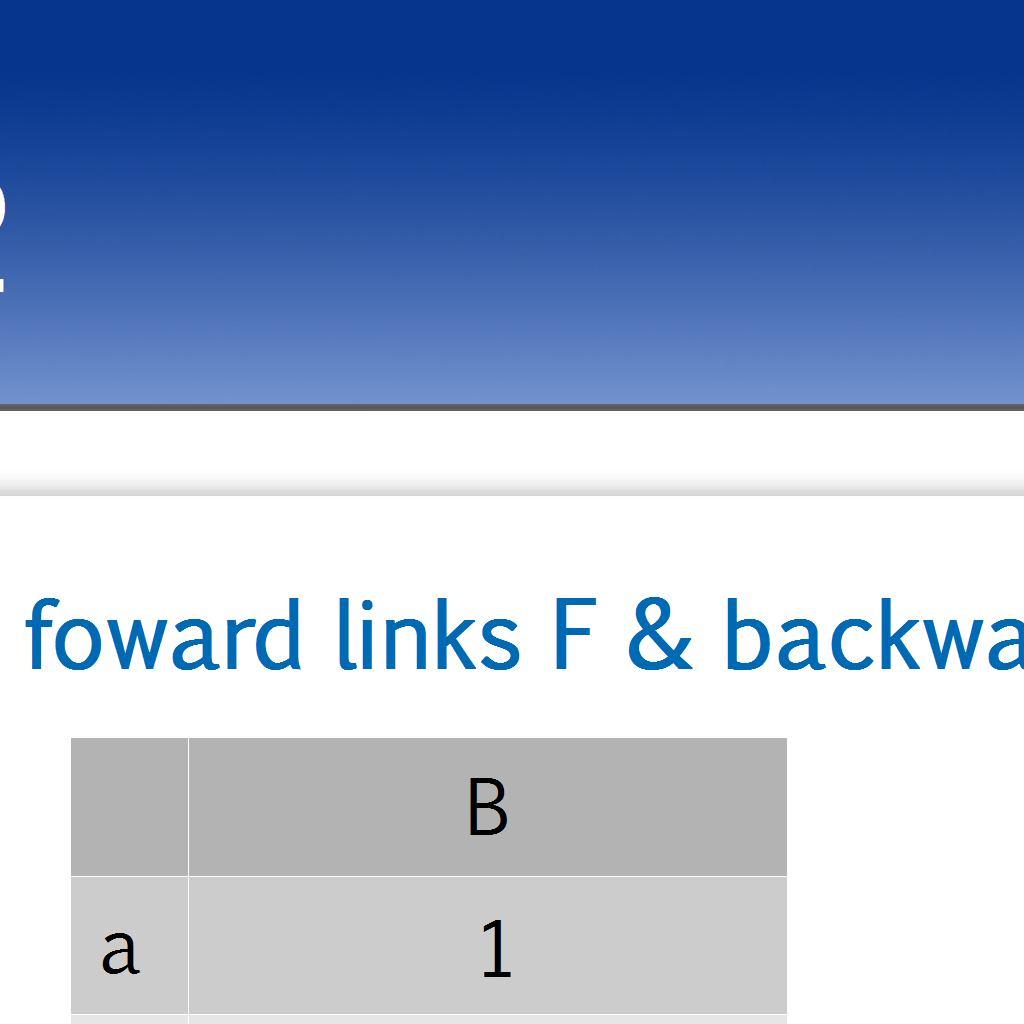
4 4 / 30 Idee PageRank Entstehung: Larry Page & Sergey Brin, 1998, genutzt von Google Annahme: Eine wichtige Seite ist eine Seite mit vielen backlinks Problem: Lässt sich leicht manipulieren Jeder Backlink hat das gleiche Gewicht Erweiterung: Die Backlinks werden danach gewichtet, welchen Rang ihre Ausgangsseite hat Formel: R = car Mit u,v: Webseiten c: Konstante R(u): PageRank der Seite u B: Menge aller backlinks N: Anzahl von forward links

5
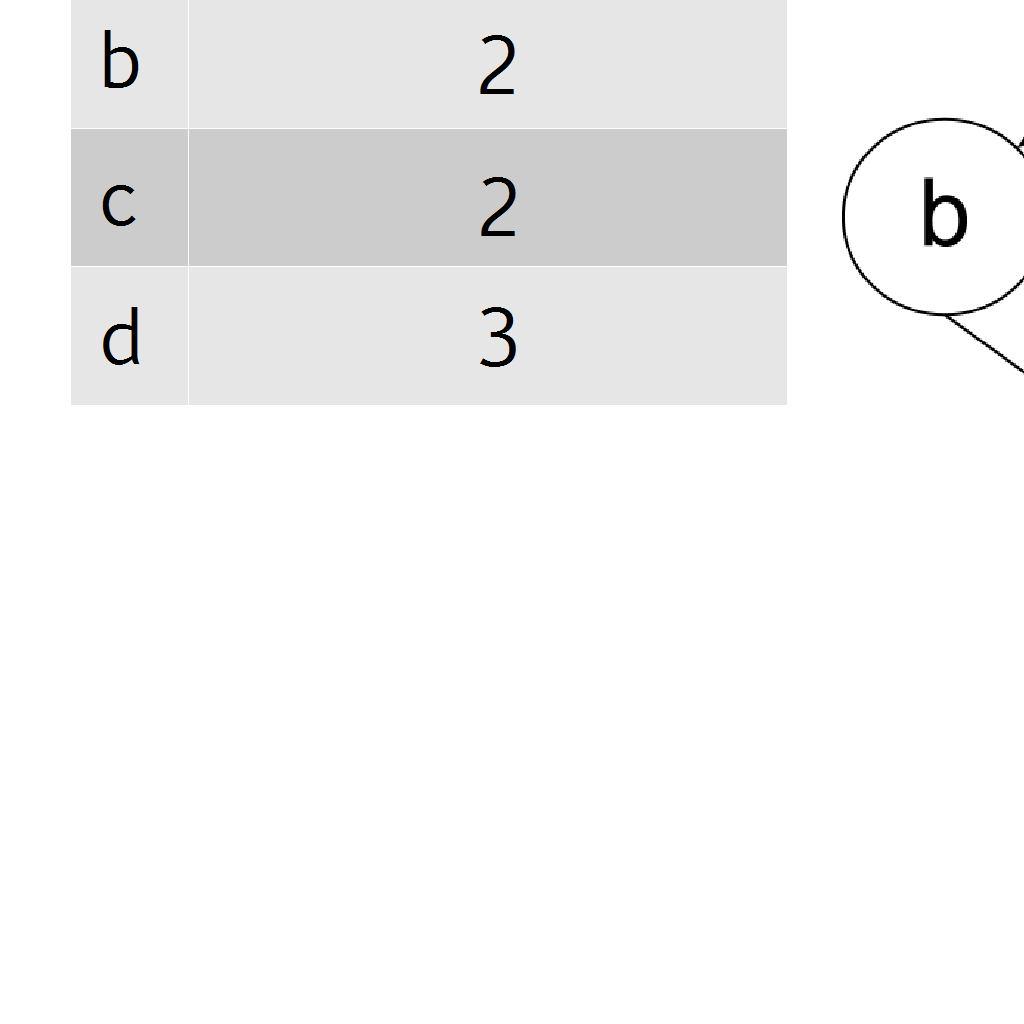
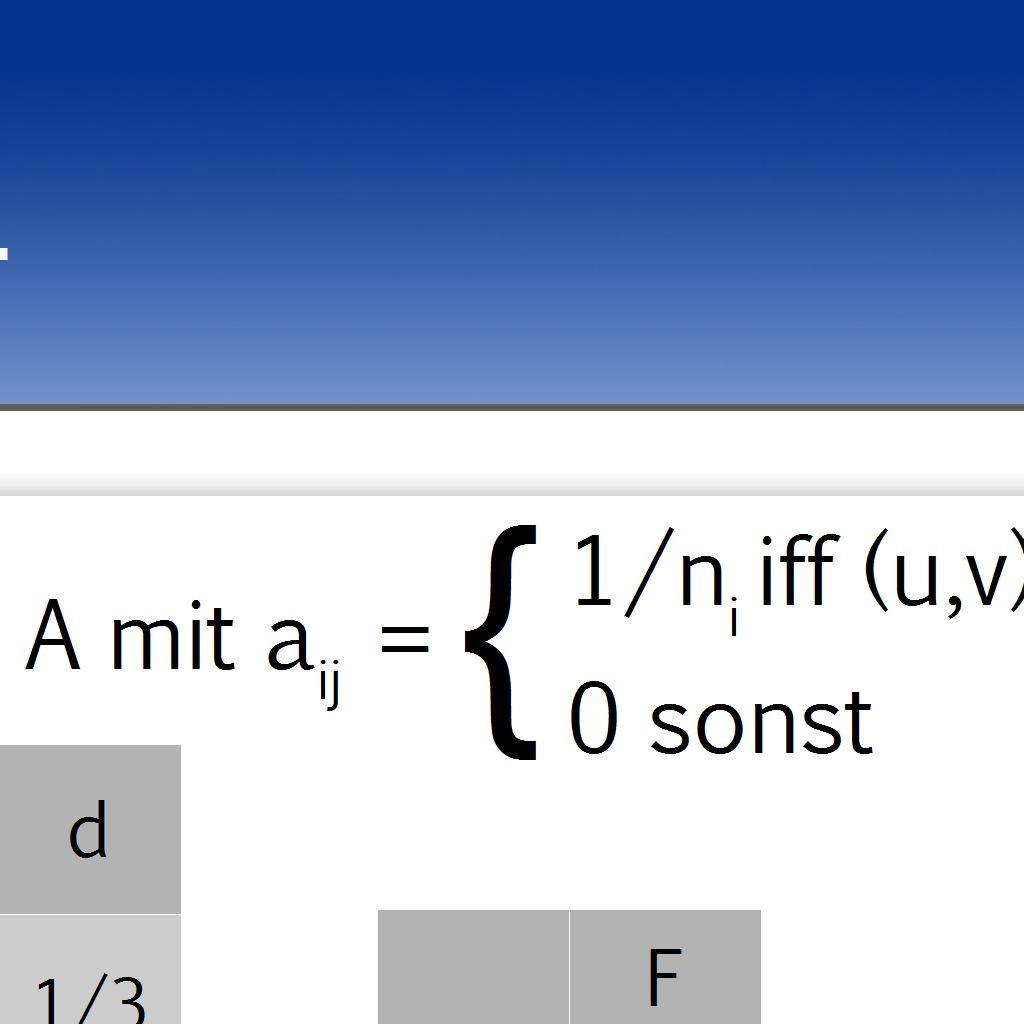
6 6 / 30 Berechnung PageRank Darstellung des Graphen: Adjazenzmatrix A mit a ij = 1/n i iff (u,v) E { 0 sonst mit n i = Anzahl forward Links von Seite i Optionen: Eigenproblem lösen Power Iteration Wahrscheinlichkeit: AR = cr a ij kann als Wahrscheinlichkeit verstanden werden, dass Surfer zufällig von Seite i auf Seite j klickt Alle Links auf einer Seite haben die gleiche Wahrscheinlichkeit
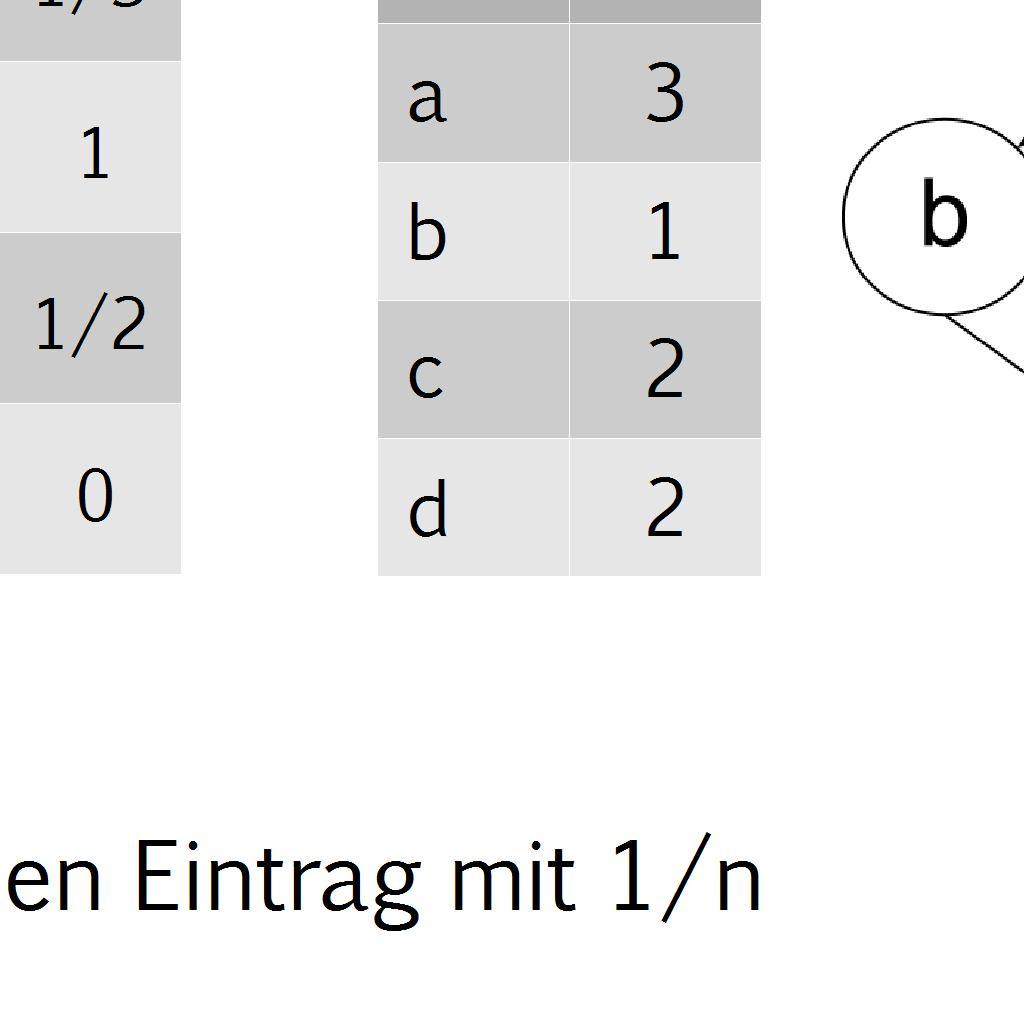
7 7 / 30 Berechnung PageRank Probleme mit A: Eine Reihe hat nur 0 Einträge (dann keine Wahrscheinlichkeit) Setze 1/n mit n = Anzahl der Spalten in A /der Webseiten A ist reduzierbar (Rank Sink) A' = α A + (1-α) E mit e ij = 1/n & α ist Konzentrationsparameter Pseudocode für Power Iteration: Setze π T 0 = et /n Until convergence do π T k+1 = α πt k A + (1- α)e π j : Vektor mit allen PageRanks nach j Iterationen π Komponente i des Vektors j ist der Pagerank der Seite i
8

9


10
11 11 / 30 Schritt 5 5: Multipliziere Konzentrationsparameter α = 0.9 mit jedem Eintrag der Matrix A a b c d a b c d a b c 0 0 1/2 1/3 1/3 1/ /2 * 0.9 a b c d 0 1/2 1/2 0 d
12 Schritt 6 & 7 12 / 30 E 6: Erstelle Helfermatrix E mit e ij = 1/n a b c d a b c d a b c * 0.1 a b c d d : Multipliziere 1 - α = 0.1 mit jedem Eintrag der Matrix
13 Schritt 8 13 / 30 8: Addiere A+E a b c d a b c d a b c d a a a b b = b c c c d d d
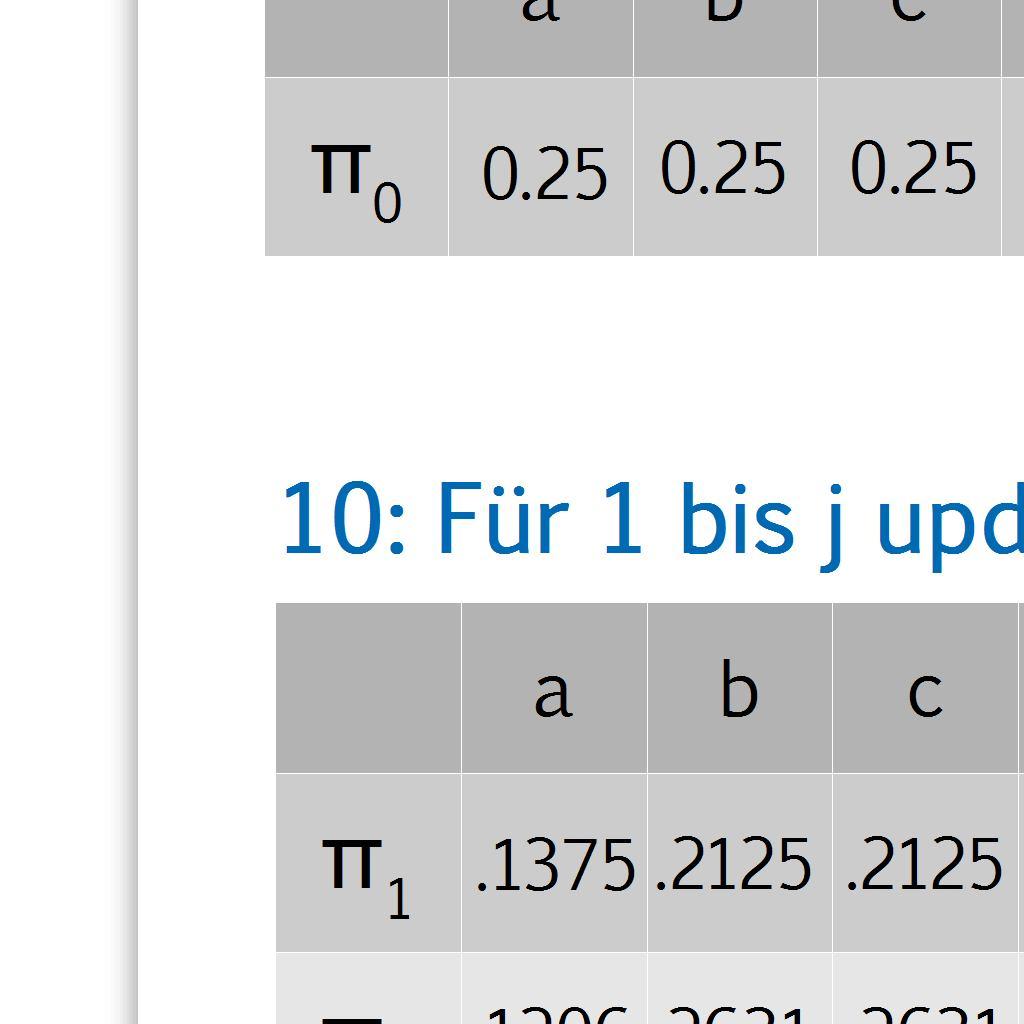
14 Schritt 9 & / 30 9: Initalisiere PageRank Vektor π 0 mit 1/n in jeder Komponete a a b c d a b c d b π c d : Für 1 bis j update π durch π T = k+1 πt X k π 1 π 2 a b c d a b c d π j d b c a



15
16 16 / 30 Laufzeit & Konvergenz PageRank Konvergenz Konvergiert immer, da Matrix reduzierbar Schnelligkeit der Konvergenz ist abhängig von α Laufzeit Initialisierung: mehrere Tage Nach query: nur ein look-up
17 17 / 30 Vor- & Nachteile PageRank Vorteil Query unabhängig Schnelle Auswertung nach Anfrage Schwer zu manipulieren Funktioniert offenbar sehr gut, da Erfolgsrezept von Google Nachteil Query unabhängig Topic Drift möglich PageRank muss mit anderem Maß kombiniert werden Hohe Initialisierungskosten
18 18 / 30 Idee HITS Hyperlink Induced Topic Search Entstehung: Jon Kleinberg, 1997 Autoritätsseite: vertrauenswürdige Seite Hubs: Seite, die auf viele Autoritätsseiten verlinkt Ziel: ggb. Query σ, was sind die Autoritätsseiten zu σ? Annahme: Suche in allen Seiten, die σ enthalten (Menge Q σ )
19 19 / 30 Idee HITS Problem: Q σ zu groß Q σ enthält Autoritätsseite nicht möchte Menge S σ mit: vielen relevanten Seiten Klein (fast) alle Authoritätsseiten Erstelle S σ : Nehme t besten Seiten aus Q σ (Menge R σ ) Füge alle Seiten hinzu, auf die ein Link aus R σ zeigt, aber maximal d viele
20 20 / 30 Berechnung HITS Gewichte: Jede Seite p hat ein Autoritätsgewicht x p und ein Hubgewicht y p Formeln: Die Gewichte x und y für alle Seiten werden abwechselnd berechnet (1) (2) Initialisierung: Pseudocode: Until convergence do { Matrix A mit a ij = 1 iff (q,p) E Update (1) 0 sonst Update (2) x & y mit 1 in allen Komponenten Normalisiere x und y


21
22
23
24 Schritt 3: Iteration 1 24 / 30 3: Iteration 1 Update x x a b a b c d Update y c y d Normalisiere x und y x 18 x y 90 y
25 Schritt 3: Iteration 2 25 / 30 3: Iteration 2 Update x x a b a b c d Update y c y d Normalisiere x und y x x x y y y
26
27 27 / 30 Laufzeit & Konvergenz HITS Konvergenz Konvergiert immer, aber Laufzeit abhängig von Initialvektor Laufzeit Keine Intialisierungskosten Bei jeder Query: Menge S σ & Graph G erstellen Gewichte berechnen: Power Method
28 28 / 30 Vor- & Nachteile HITS Vorteile: Duales ranking Erstellt ein kleines, lösbares Problem Nachteile Query-abhängig Hub Wert kann leicht beeinflust werden Autoritätswert kann durch Werbung beeinflust werden Topic drift
29 29 / 30 Vergleich PageRank & HITS PageRank HITS Manipulierbar? Ja, aber erschwert Ja, der Hub Score Laufzeit? Initialisierung Nach einer Query Kombination mit anderem Maß nötig? mehrere Tage Nur ein look-up Ja Keine Power Method Nein Topic drift möglich? Ja Ja Query unabhängig Ja Nein Konvergiert? Immer Ergebnis kann u.u. Falsch sein
30 References 30 / 30 Papers & Internet Pages Lawrence Page, Sergey Brin, Rajeev Motwani und Terry Winograd The PageRank Citation Ranking: Bringing Order to the Web. Technical Report. Stanford InfoLab. Jon M. Kleinberg Authoritative sources in a hyperlinked environment. In Journal of the ACM. Amy N. Langeville, Carl D. Meyer (2005). A Survey of Eigenvector Methods of Web Information Retrieval. In SIAM Review. Franz Embacher (o.j.) Von Graphen, Genen und dem WWW. [ ] Ian Rogers The Google Pagerank Algorithm and How It Works [ ] Google Inc Google Toolbar. [ ] Patent Page, Lawrence Method for node ranking in a linked database. US Patent 1998, No [ ] Pictures [ ]
31 PageRank: Beispiel Input: Ein Graph G=(V,E) mit V = {1, 2, 3, 4} und E={(a,b), (a,c), (a,d), (b,d), (c,a), (c,d), (d,b), (d,c)} Schritt 10: Iteration ( ) = (a b c d) a = = b = = c = = d = = Iteration ( ) = (a b c d) a = = b = = c = = d = =
32 HITS: Beispiel Input: Ein Graph G=(V,E) mit V = {1, 2, 3, 4} und E={(a,b), (a,c), (a,d), (b,d), (c,a), (c,d), (d,b), (d,c)} Schritt 3: Iteration 1 x = (a b c d) mit a = 1 b = 1+1 = 2 c = 1+1 = 2 d = = 3 y = (a b c d) mit a = = 7 b = 3 = 3 c = 1+3 = 4 d = 2+2 = x = 1² + 2² + 2² + 3² = 18 y = 7² + 3² + 4² + 4² = 90 1 x = (a b c d) mit a = 18 = b = 18 = c = 18 = d = 18 = y = (a b c d) mit a = 90 = b = 90 = c = 90 = d = 90 =
33 Iteration 2 x = (a b c d) mit a = b = = c = = d = = y = (a b c d) mit a = = b = c = = d = = x = ² ² ² ² = = y = ² ² ² ² = = x = (a b c d) mit a = = b = = c = = d = = y = (a b c d) mit a = b = c = d = = = = =
PG520 - Webpageranking
 12. Oktober 2007 Webpageranking - Quellen The PageRank citation ranking: Bringing order to the Web; Page, Brin etal. Technical report, 1998. A Unified Probabilistic Framework for Web Page Scoring Systems;
12. Oktober 2007 Webpageranking - Quellen The PageRank citation ranking: Bringing order to the Web; Page, Brin etal. Technical report, 1998. A Unified Probabilistic Framework for Web Page Scoring Systems;
Diskrete Modellierung
 Diskrete Modellierung Wintersemester 2013/14 Prof. Dr. Isolde Adler Letzte Vorlesung: Korrespondenz zwischen der Page-Rank-Eigenschaft und Eigenvektoren zum Eigenwert 1 der Page-Rank-Matrix Markov-Ketten
Diskrete Modellierung Wintersemester 2013/14 Prof. Dr. Isolde Adler Letzte Vorlesung: Korrespondenz zwischen der Page-Rank-Eigenschaft und Eigenvektoren zum Eigenwert 1 der Page-Rank-Matrix Markov-Ketten
Wie Google Webseiten bewertet. François Bry
 Wie Google Webseiten bewertet François Bry Heu6ge Vorlesung 1. Einleitung 2. Graphen und Matrizen 3. Erste Idee: Ranking als Eigenvektor 4. Fragen: Exisi6ert der Eigenvektor? Usw. 5. Zweite Idee: Die Google
Wie Google Webseiten bewertet François Bry Heu6ge Vorlesung 1. Einleitung 2. Graphen und Matrizen 3. Erste Idee: Ranking als Eigenvektor 4. Fragen: Exisi6ert der Eigenvektor? Usw. 5. Zweite Idee: Die Google
5. Vorlesung. Das Ranking Problem PageRank HITS (Hubs & Authorities) Markov Ketten und Random Walks PageRank und HITS Berechnung
 Markov Ketten und Random Walks PageRank und HITS Berechnung") 5. Vorlesung Das Ranking Problem PageRank HITS (Hubs & Authorities) Markov Ketten und Random Walks PageRank und HITS Berechnung Seite 120 The Ranking Problem Eingabe: D: Dokumentkollektion Q: Anfrageraum
5. Vorlesung Das Ranking Problem PageRank HITS (Hubs & Authorities) Markov Ketten und Random Walks PageRank und HITS Berechnung Seite 120 The Ranking Problem Eingabe: D: Dokumentkollektion Q: Anfrageraum
Detecting Near Duplicates for Web Crawling
 Detecting Near Duplicates for Web Crawling Gurmeet Singh Manku et al., WWW 2007* * 16th international conference on World Wide Web Detecting Near Duplicates for Web Crawling Finde near duplicates in großen
Detecting Near Duplicates for Web Crawling Gurmeet Singh Manku et al., WWW 2007* * 16th international conference on World Wide Web Detecting Near Duplicates for Web Crawling Finde near duplicates in großen
Google s PageRank. Eine Anwendung von Matrizen und Markovketten. Vortrag im Rahmen der Lehrerfortbildung an der TU Clausthal 23.
 Google s PageRank Eine Anwendung von Matrizen und Markovketten Vortrag im Rahmen der Lehrerfortbildung an der TU Clausthal 23. September 2009 Dr. Werner Sandmann Institut für Mathematik Technische Universität
Google s PageRank Eine Anwendung von Matrizen und Markovketten Vortrag im Rahmen der Lehrerfortbildung an der TU Clausthal 23. September 2009 Dr. Werner Sandmann Institut für Mathematik Technische Universität
Die treffende Auswahl anbieten: Im Internet (Referat 3a)
") www.zeix.com Die treffende Auswahl anbieten: Im Internet (Referat 3a) Fachtagung: Suchfunktionen im Web Zürich, 26. Oktober 2006 Jürg Stuker, namics Gregor Urech, Zeix Bern, Frankfurt, Hamburg, München,
www.zeix.com Die treffende Auswahl anbieten: Im Internet (Referat 3a) Fachtagung: Suchfunktionen im Web Zürich, 26. Oktober 2006 Jürg Stuker, namics Gregor Urech, Zeix Bern, Frankfurt, Hamburg, München,
Ohne Mathematik undenkbar!
 Die tägliche - Suche: Ohne Mathematik undenkbar! Dipl.-Wirt.Math. Jan Maruhn FB IV - Mathematik Universität Trier 29. März 2006 29. März 2006 Seite 1 Gliederung Einleitung und Motivation Das Internet als
Die tägliche - Suche: Ohne Mathematik undenkbar! Dipl.-Wirt.Math. Jan Maruhn FB IV - Mathematik Universität Trier 29. März 2006 29. März 2006 Seite 1 Gliederung Einleitung und Motivation Das Internet als
PageRank-Algorithmus
 Proseminar Algorithms and Data Structures Gliederung Gliederung 1 Einführung 2 PageRank 3 Eziente Berechnung 4 Zusammenfassung Motivation Motivation Wir wollen eine Suchmaschine bauen, die das Web durchsucht.
Proseminar Algorithms and Data Structures Gliederung Gliederung 1 Einführung 2 PageRank 3 Eziente Berechnung 4 Zusammenfassung Motivation Motivation Wir wollen eine Suchmaschine bauen, die das Web durchsucht.
5. Suchmaschinen Herausforderungen beim Web Information Retrieval. Herausforderungen beim Web Information Retrieval. Architektur von Suchmaschinen
 5. Suchmaschinen Herausforderungen beim Web Information Retrieval 5. Suchmaschinen 5. Suchmaschinen Herausforderungen beim Web Information Retrieval Verweisstrukturen haben eine wichtige Bedeutung Spamming
5. Suchmaschinen Herausforderungen beim Web Information Retrieval 5. Suchmaschinen 5. Suchmaschinen Herausforderungen beim Web Information Retrieval Verweisstrukturen haben eine wichtige Bedeutung Spamming
Vorlesung Information Retrieval Wintersemester 04/05
 Vorlesung Information Retrieval Wintersemester 04/05 14. Dezember 2004 Institut für Informatik III Universität Bonn Tel. 02 28 / 73-45 31 Fax 02 28 / 73-43 82 jw@informatik.uni-bonn.de 0 Themenübersicht
Vorlesung Information Retrieval Wintersemester 04/05 14. Dezember 2004 Institut für Informatik III Universität Bonn Tel. 02 28 / 73-45 31 Fax 02 28 / 73-43 82 jw@informatik.uni-bonn.de 0 Themenübersicht
Hyperlink Induced Topic Search (HITS)
") Erweiterungen des Ekaterina Tikhoncheva Seminar Information Retrieval Universität Heidelberg 19.01.2014 Agenda Einführung Erweiterungen des 1 Einführung 2 3 Schritt 1 Schritt 2 Konvergenz 4 5 Erweiterungen
Erweiterungen des Ekaterina Tikhoncheva Seminar Information Retrieval Universität Heidelberg 19.01.2014 Agenda Einführung Erweiterungen des 1 Einführung 2 3 Schritt 1 Schritt 2 Konvergenz 4 5 Erweiterungen
Suchmaschinenalgorithmen. Vortrag von: Thomas Müller
 Suchmaschinenalgorithmen Vortrag von: Thomas Müller Kurze Geschichte Erste Suchmaschine für Hypertexte am CERN Erste www-suchmaschine World Wide Web Wanderer 1993 Bis 1996: 2 mal jährlich Durchlauf 1994:
Suchmaschinenalgorithmen Vortrag von: Thomas Müller Kurze Geschichte Erste Suchmaschine für Hypertexte am CERN Erste www-suchmaschine World Wide Web Wanderer 1993 Bis 1996: 2 mal jährlich Durchlauf 1994:
Websuche. Einflussfaktor (Impact Factor) Bibliographische Kopplung. Bibliometrik: Zitatanalyse. Linkanalyse
 Bibliographische Kopplung. Bibliometrik: Zitatanalyse. Linkanalyse") Einflussfaktor (Imact Factor) Websuche Linkanalyse Von Garfield in 1972 entwickelt, um die Bedeutung (Qualität, Einfluss) von wissenschaftlichen Zeitschriften zu messen. Maß dafür, wie oft Artikel einer
Einflussfaktor (Imact Factor) Websuche Linkanalyse Von Garfield in 1972 entwickelt, um die Bedeutung (Qualität, Einfluss) von wissenschaftlichen Zeitschriften zu messen. Maß dafür, wie oft Artikel einer
Ranking: Google und CiteSeer
 Konrad-Zuse-Zentrum für Informationstechnik Berlin Takustraße 7 D-14195 Berlin-Dahlem Germany ZARA KANAEVA Ranking: Google und CiteSeer ZIB-Report 04-55 (Dezember 2004) Zusammenfassung Im Rahmen des klassischen
Konrad-Zuse-Zentrum für Informationstechnik Berlin Takustraße 7 D-14195 Berlin-Dahlem Germany ZARA KANAEVA Ranking: Google und CiteSeer ZIB-Report 04-55 (Dezember 2004) Zusammenfassung Im Rahmen des klassischen
Die treffende Auswahl anbieten: Im Intranet (Referat 3b)
") www.zeix.com Die treffende Auswahl anbieten: Im Intranet (Referat 3b) Fachtagung: Suchfunktionen im Web Zürich, 26. Oktober 2006 Marco Hassler, namics Jacqueline Badran, Zeix Bern, Frankfurt, Hamburg,
www.zeix.com Die treffende Auswahl anbieten: Im Intranet (Referat 3b) Fachtagung: Suchfunktionen im Web Zürich, 26. Oktober 2006 Marco Hassler, namics Jacqueline Badran, Zeix Bern, Frankfurt, Hamburg,
5. Suchmaschinen Herausforderungen beim Web Information Retrieval. 5. Suchmaschinen. Herausforderungen beim Web Information Retrieval
 5. Suchmaschinen Herausforderungen beim Web Information Retrieval 5. Suchmaschinen Herausforderungen beim Web Information Retrieval Architektur von Suchmaschinen Spezielle Bewertungsfunktionen Information
5. Suchmaschinen Herausforderungen beim Web Information Retrieval 5. Suchmaschinen Herausforderungen beim Web Information Retrieval Architektur von Suchmaschinen Spezielle Bewertungsfunktionen Information
Web Information Retrieval. Web Information Retrieval. Informationssuche im Web Typen von Web-Suche (nach Andrei Broder) Das World Wide Web
 Das World Wide Web") Web Information Retrieval Web Information Retrieval Ingo Frommholz / Norbert Fuhr 30. Januar 2012 Informationssuche im Web Browsing und Suche Beispiel einer Web-Suchmaschine: Google Hypertext und Web IR
Web Information Retrieval Web Information Retrieval Ingo Frommholz / Norbert Fuhr 30. Januar 2012 Informationssuche im Web Browsing und Suche Beispiel einer Web-Suchmaschine: Google Hypertext und Web IR
Die Suchmaschine Google
 Seminar: Algorithmen für das WWW Die Suchmaschine Google Volker C. Schöch Institut für Informatik Freie Universität Berlin vschoech@inf.fu-berlin.de 19. Juni 2001 Zusammenfassung Google ist die erste Suchmaschine,
Seminar: Algorithmen für das WWW Die Suchmaschine Google Volker C. Schöch Institut für Informatik Freie Universität Berlin vschoech@inf.fu-berlin.de 19. Juni 2001 Zusammenfassung Google ist die erste Suchmaschine,
Web Algorithmen. Ranking. Dr. Michael Brinkmeier. Technische Universität Ilmenau Institut für Theoretische Informatik. Wintersemester 2008/09
 Web Algorithmen Ranking Dr. Michael Brinkmeier Technische Universität Ilmenau Institut für Theoretische Informatik Wintersemester 2008/09 M.Brinkmeier (TU Ilmenau) Web Algorithmen Wintersemester 2008/09
Web Algorithmen Ranking Dr. Michael Brinkmeier Technische Universität Ilmenau Institut für Theoretische Informatik Wintersemester 2008/09 M.Brinkmeier (TU Ilmenau) Web Algorithmen Wintersemester 2008/09
Suchmaschinen und Markov-Ketten 1 / 42
 Suchmaschinen und Markov-Ketten 1 / 42 Zielstellung 1 Wir geben einen kurzen Überblick über die Arbeitsweise von Suchmaschinen für das Internet. Eine Suchmaschine erwartet als Eingabe ein Stichwort oder
Suchmaschinen und Markov-Ketten 1 / 42 Zielstellung 1 Wir geben einen kurzen Überblick über die Arbeitsweise von Suchmaschinen für das Internet. Eine Suchmaschine erwartet als Eingabe ein Stichwort oder
Seminar über Algorithmen
 Seminar über Algorithmen Authoritative Sources in a Hyperlinked Environment Intro & Motivation!... 3 Motivation!... 3 Introduction!... 3 Queries!... 3 Problems!... 3 Subgraph of WWW!... 4 Internet as a
Seminar über Algorithmen Authoritative Sources in a Hyperlinked Environment Intro & Motivation!... 3 Motivation!... 3 Introduction!... 3 Queries!... 3 Problems!... 3 Subgraph of WWW!... 4 Internet as a
Quelle. Thematische Verteilungen. Worum geht es? Wiederholung. Link-Analyse: HITS. Link-Analyse: PageRank. Link-Analyse: PageRank. Link-Analyse: HITS
 Hauptseminar Web Information Retrieval Quelle Thematische Verteilungen 07.05.2003 Daniel Harbig Chakrabati, Soumen; Joshi, Mukul; Punera, Kunal; Pennock, David (2002): The Structure of Broad Topics on
Hauptseminar Web Information Retrieval Quelle Thematische Verteilungen 07.05.2003 Daniel Harbig Chakrabati, Soumen; Joshi, Mukul; Punera, Kunal; Pennock, David (2002): The Structure of Broad Topics on
Suchmaschinenoptimierung (SEO)
") Suchmaschinenoptimierung (SEO) SOMEXCLOUD Social Media Akademie Marco Schlauri Webrepublic AG 11.06.2014 About Me SEO Consultant Webrepublic AG Agentur für Online Marketing und Digitale Strategie Location:
Suchmaschinenoptimierung (SEO) SOMEXCLOUD Social Media Akademie Marco Schlauri Webrepublic AG 11.06.2014 About Me SEO Consultant Webrepublic AG Agentur für Online Marketing und Digitale Strategie Location:
Suchmaschinen: Für einen sich rasant ändernden Suchraum gigantischer Größe sind Anfragen ohne merkliche Reaktionszeit zu beantworten.
 Die Größe des Netzes Schätzungen gehen weit auseinander: Über eine Milliarde im Gebrauch befindliche IP-Adressen Zwischen 20 Milliarden und einer Billion indizierte Webseiten. Ungefähr 200 Millionen Websites
Die Größe des Netzes Schätzungen gehen weit auseinander: Über eine Milliarde im Gebrauch befindliche IP-Adressen Zwischen 20 Milliarden und einer Billion indizierte Webseiten. Ungefähr 200 Millionen Websites
Veranstalter: Lehrstuhl DBIS - Prof. Georg Lausen Betreuer: Thomas Hornung, Michael Schmidt 21.10.2008
 Veranstalter: Lehrstuhl DBIS - Prof. Georg Lausen Betreuer: Thomas Hornung, Michael Schmidt 21.10.2008 Laut Studienordnung Master/Diplom: 16ECTS/15KP Entspricht: 480 Semesterstunden = 34h/Woche pp p.p.
Veranstalter: Lehrstuhl DBIS - Prof. Georg Lausen Betreuer: Thomas Hornung, Michael Schmidt 21.10.2008 Laut Studienordnung Master/Diplom: 16ECTS/15KP Entspricht: 480 Semesterstunden = 34h/Woche pp p.p.
Alles nur Google? Das Innenleben der Suchmaschinen
 Alles nur Google? Das Innenleben der Suchmaschinen Prof. Dr. Klaus Meyer-Wegener Friedrich-Alexander-Universität Technische Fakultät Institut für Informatik 1. Das World-wide Web (WWW) oft auch "Internet"
Alles nur Google? Das Innenleben der Suchmaschinen Prof. Dr. Klaus Meyer-Wegener Friedrich-Alexander-Universität Technische Fakultät Institut für Informatik 1. Das World-wide Web (WWW) oft auch "Internet"
Web-Suche. Einflussfaktor (Impact Factor) Bibliographische Kopplung. Bibliometrik: Zitat-Analyse. Link-Analyse
 Bibliographische Kopplung. Bibliometrik: Zitat-Analyse. Link-Analyse") Einflussfaktor (Impact Factor) Web-Suche Link-Analyse Von Garfield in 1972 entwickelt, um die Bedeutung (Qualität, Einfluss) von wissenschaftlichen Zeitschriften zu messen. Maß dafür, wie oft Artikel einer
Einflussfaktor (Impact Factor) Web-Suche Link-Analyse Von Garfield in 1972 entwickelt, um die Bedeutung (Qualität, Einfluss) von wissenschaftlichen Zeitschriften zu messen. Maß dafür, wie oft Artikel einer
16. All Pairs Shortest Path (ASPS)
") . All Pairs Shortest Path (ASPS) All Pairs Shortest Path (APSP): Eingabe: Gewichteter Graph G=(V,E) Ausgabe: Für jedes Paar von Knoten u,v V die Distanz von u nach v sowie einen kürzesten Weg a b c d e
. All Pairs Shortest Path (ASPS) All Pairs Shortest Path (APSP): Eingabe: Gewichteter Graph G=(V,E) Ausgabe: Für jedes Paar von Knoten u,v V die Distanz von u nach v sowie einen kürzesten Weg a b c d e
Generierung von sozialen Netzwerken. Steffen Brauer WiSe 2011/12 HAW Hamburg
 Generierung von sozialen Netzwerken Steffen Brauer WiSe 2011/12 HAW Hamburg Agenda Motivation Soziale Netzwerke Modelle Metriken Forschungsumfeld Ausblick 2 Motivation Wo gibt es Netzwerke? Computernetzwerke
Generierung von sozialen Netzwerken Steffen Brauer WiSe 2011/12 HAW Hamburg Agenda Motivation Soziale Netzwerke Modelle Metriken Forschungsumfeld Ausblick 2 Motivation Wo gibt es Netzwerke? Computernetzwerke
Link Analysis and Web Search Jan Benedikt Führer
 Link Analysis and Web Search Jan Benedikt Führer 16. Januar 2011 DKE TUD Jan Benedikt Führer 1 Gliederung Motivation Link-Analyse mit Hubs und Authorities PageRank Anwendung innerhalb des WWW Anwendungen
Link Analysis and Web Search Jan Benedikt Führer 16. Januar 2011 DKE TUD Jan Benedikt Führer 1 Gliederung Motivation Link-Analyse mit Hubs und Authorities PageRank Anwendung innerhalb des WWW Anwendungen
Web Information Retrieval. Zwischendiskussion. Überblick. Meta-Suchmaschinen und Fusion (auch Rank Aggregation) Fusion
 Fusion") Web Information Retrieval Hauptseminar Sommersemester 2003 Thomas Mandl Überblick Mehrsprachigkeit Multimedialität Heterogenität Qualität, semantisch, technisch Struktur Links HTML Struktur Technologische
Web Information Retrieval Hauptseminar Sommersemester 2003 Thomas Mandl Überblick Mehrsprachigkeit Multimedialität Heterogenität Qualität, semantisch, technisch Struktur Links HTML Struktur Technologische
Algorithmische Methoden der Netzwerkanalyse
 Algorithmische Methoden der Netzwerkanalyse Marco Gaertler 9. Dezember, 2008 1/ 15 Abstandszentralitäten 2/ 15 Distanzsummen auf Bäumen Lemma Sei T = (V, E) ein ungerichteter Baum und T s = (V S, E s )
Algorithmische Methoden der Netzwerkanalyse Marco Gaertler 9. Dezember, 2008 1/ 15 Abstandszentralitäten 2/ 15 Distanzsummen auf Bäumen Lemma Sei T = (V, E) ein ungerichteter Baum und T s = (V S, E s )
eco Kompetenzgruppe Online Marketing SEO nach Panda, Penguin & Co.: Warum Social Search die Lösung sein muss Michael Fritz, 18.06.
 eco Kompetenzgruppe Online Marketing SEO nach Panda, Penguin & Co.: Warum Social Search die Lösung sein muss Michael Fritz, 18.06.2012 Searchmetrics GmbH 2012 Über mich Michael Fritz Online Marketing /
eco Kompetenzgruppe Online Marketing SEO nach Panda, Penguin & Co.: Warum Social Search die Lösung sein muss Michael Fritz, 18.06.2012 Searchmetrics GmbH 2012 Über mich Michael Fritz Online Marketing /
Ontologie-basiertes Web Mining
 Ontologie-basiertes Web Mining Marc Ehrig 1, Jens Hartmann 1, Christoph chmitz 2 1 Institut AIFB, Universität Karlsruhe, 76128 Karlsruhe {ehrig,hartmann}@aifb.uni-karlsruhe.de 2 FG Wissensverarbeitung,
Ontologie-basiertes Web Mining Marc Ehrig 1, Jens Hartmann 1, Christoph chmitz 2 1 Institut AIFB, Universität Karlsruhe, 76128 Karlsruhe {ehrig,hartmann}@aifb.uni-karlsruhe.de 2 FG Wissensverarbeitung,
Übungsaufgaben mit Lösungsvorschlägen
 Otto-Friedrich-Universität Bamberg Lehrstuhl für Medieninformatik Prof. Dr. Andreas Henrich Dipl. Wirtsch.Inf. Daniel Blank Einführung in das Information Retrieval, 8. Mai 2008 Veranstaltung für die Berufsakademie
Otto-Friedrich-Universität Bamberg Lehrstuhl für Medieninformatik Prof. Dr. Andreas Henrich Dipl. Wirtsch.Inf. Daniel Blank Einführung in das Information Retrieval, 8. Mai 2008 Veranstaltung für die Berufsakademie
Suchmaschinen. Anwendung RN Semester 7. Christian Koczur
 Suchmaschinen Anwendung RN Semester 7 Christian Koczur Inhaltsverzeichnis 1. Historischer Hintergrund 2. Information Retrieval 3. Architektur einer Suchmaschine 4. Ranking von Webseiten 5. Quellenangabe
Suchmaschinen Anwendung RN Semester 7 Christian Koczur Inhaltsverzeichnis 1. Historischer Hintergrund 2. Information Retrieval 3. Architektur einer Suchmaschine 4. Ranking von Webseiten 5. Quellenangabe
PageRank-Algorithmus
 PageRank-Algorithmus Benedikt Wolters Matr.-Nr. 300037 31. Januar 2012 Proseminar Algorithms and Data Structures WS 2011/12 Lehrstuhl für Informatik 2, RWTH Aachen Betreuer: Dipl.-Inform. Haidi Yue 1 1
PageRank-Algorithmus Benedikt Wolters Matr.-Nr. 300037 31. Januar 2012 Proseminar Algorithms and Data Structures WS 2011/12 Lehrstuhl für Informatik 2, RWTH Aachen Betreuer: Dipl.-Inform. Haidi Yue 1 1
9. IR im Web. bei Anfragen im Web gibt es eine Reihe von zusätzlichen Problemen, die gelöst werden
 IR im Web 9. IR im Web bei Anfragen im Web gibt es eine Reihe von zusätzlichen Problemen, die gelöst werden müssen Einführung in Information Retrieval 394 Probleme verteilte Daten: Daten sind auf vielen
IR im Web 9. IR im Web bei Anfragen im Web gibt es eine Reihe von zusätzlichen Problemen, die gelöst werden müssen Einführung in Information Retrieval 394 Probleme verteilte Daten: Daten sind auf vielen
Vorlesung 3 MINIMALE SPANNBÄUME
 Vorlesung 3 MINIMALE SPANNBÄUME 72 Aufgabe! Szenario: Sie arbeiten für eine Firma, die ein Neubaugebiet ans Netz (Wasser, Strom oder Kabel oder...) anschließt! Ziel: Alle Haushalte ans Netz bringen, dabei
Vorlesung 3 MINIMALE SPANNBÄUME 72 Aufgabe! Szenario: Sie arbeiten für eine Firma, die ein Neubaugebiet ans Netz (Wasser, Strom oder Kabel oder...) anschließt! Ziel: Alle Haushalte ans Netz bringen, dabei
Erfahrungen, Einblicke, Experimente
 Detaillierter Blick in eine Link-Datenbank Erfahrungen, Einblicke, Experimente 03/13/10 Überblick Erfahrungen mit dem Link-Graph der Suchmaschine Neomo Link-Datenbank Link-Algorithmen in Theorie und Praxis
Detaillierter Blick in eine Link-Datenbank Erfahrungen, Einblicke, Experimente 03/13/10 Überblick Erfahrungen mit dem Link-Graph der Suchmaschine Neomo Link-Datenbank Link-Algorithmen in Theorie und Praxis
Graphenalgorithmen und lineare Algebra Hand in Hand Vorlesung für den Bereich Diplom/Master Informatik
 Vorlesung für den Bereich Diplom/Master Informatik Dozent: Juniorprof. Dr. Henning Meyerhenke PARALLELES RECHNEN INSTITUT FÜR THEORETISCHE INFORMATIK, FAKULTÄT FÜR INFORMATIK KIT Universität des Landes
Vorlesung für den Bereich Diplom/Master Informatik Dozent: Juniorprof. Dr. Henning Meyerhenke PARALLELES RECHNEN INSTITUT FÜR THEORETISCHE INFORMATIK, FAKULTÄT FÜR INFORMATIK KIT Universität des Landes
Die Mathematik hinter Google. Übersicht. Was leistet eine Suchmaschine? Michael Eisermann. www.igt.uni-stuttgart.de/eiserm/popularisation/#tag2012
 Die Mathematik hinter Google Michael Eisermann Institut für Geometrie und Topologie, Universität Stuttgart Tag der Wissenschaft, 0. Juni 0 Sehr geehrte Damen und Herren, ich begrüße Sie! Mein Name ist
Die Mathematik hinter Google Michael Eisermann Institut für Geometrie und Topologie, Universität Stuttgart Tag der Wissenschaft, 0. Juni 0 Sehr geehrte Damen und Herren, ich begrüße Sie! Mein Name ist
26 Mathematik im Blickpunkt
 26 Mathematik im Blickpunkt Über Suchmaschinen und Datenbanken Mit dem Siegeszug des Web ist der größte Informationsspeicher in der Geschichte der Menschheit entstanden. Suchmaschinen und Datenbanken ermöglichen
26 Mathematik im Blickpunkt Über Suchmaschinen und Datenbanken Mit dem Siegeszug des Web ist der größte Informationsspeicher in der Geschichte der Menschheit entstanden. Suchmaschinen und Datenbanken ermöglichen
Semestralklausur zur Vorlesung. Web Mining. Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7.
 Semestralklausur zur Vorlesung Web Mining Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7. 2004 Name: Vorname: Matrikelnummer: Fachrichtung: Punkte: (1).... (2)....
Semestralklausur zur Vorlesung Web Mining Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7. 2004 Name: Vorname: Matrikelnummer: Fachrichtung: Punkte: (1).... (2)....
Wie Web 2.0 und Suche zusammenwachsen. Prof. Dr. Dirk Lewandowski dirk.lewandowski@haw-hamburg.de
 Wie Web 2.0 und Suche zusammenwachsen Prof. Dr. Dirk Lewandowski dirk.lewandowski@haw-hamburg.de Web search: Always different, always the same AltaVista 1996 1 http://web.archive.org/web/19961023234631/http://altavista.digital.com/
Wie Web 2.0 und Suche zusammenwachsen Prof. Dr. Dirk Lewandowski dirk.lewandowski@haw-hamburg.de Web search: Always different, always the same AltaVista 1996 1 http://web.archive.org/web/19961023234631/http://altavista.digital.com/
Übungsaufgaben. Aufgabe 1 Internetsuchmaschinen. Einführung in das Information Retrieval, 8. Mai 2008 Veranstaltung für die Berufsakademie Karlsruhe
 Otto-Friedrich-Universität Bamberg Lehrstuhl für Medieninformatik Prof. Dr. Andreas Henrich Dipl. Wirtsch.Inf. Daniel Blank Einführung in das Information Retrieval, 8. Mai 2008 Veranstaltung für die Berufsakademie
Otto-Friedrich-Universität Bamberg Lehrstuhl für Medieninformatik Prof. Dr. Andreas Henrich Dipl. Wirtsch.Inf. Daniel Blank Einführung in das Information Retrieval, 8. Mai 2008 Veranstaltung für die Berufsakademie
Gesucht und gefunden wie geht s?
 Gesucht und gefunden wie geht s? Osnabrück, den 31. März 2014 Falk Neubert, M.Sc. Wissenschaftlicher Mitarbeiter im Fach BWL/Management Support und Wirtschaftsinformatik / Universität Osnabrück Mitglied
Gesucht und gefunden wie geht s? Osnabrück, den 31. März 2014 Falk Neubert, M.Sc. Wissenschaftlicher Mitarbeiter im Fach BWL/Management Support und Wirtschaftsinformatik / Universität Osnabrück Mitglied
Suchmaschinenwerbung: Sponsored Links als Geschäftsmodell der Suchwerkzeuge
 Chang Kaiser Suchmaschinenwerbung: Sponsored Links als Geschäftsmodell der Suchwerkzeuge Mit einer Fallstudie über chinesische Suchdienste Verlag Dr. Kovac Hamburg 2010 Inhalt Abbildungsverzeichnis 11
Chang Kaiser Suchmaschinenwerbung: Sponsored Links als Geschäftsmodell der Suchwerkzeuge Mit einer Fallstudie über chinesische Suchdienste Verlag Dr. Kovac Hamburg 2010 Inhalt Abbildungsverzeichnis 11
Suchmaschinen Grundlagen. Thomas Grabowski
 Suchmaschinen Grundlagen Thomas Grabowski 1 / 45 Überblick 1. Einleitung 2. Suchmaschinen Architektur 3. Crawling-Prozess 4. Storage 5. Indexing 6. Ranking 2 / 45 1. Einleitung Der Webgraph unterliegt
Suchmaschinen Grundlagen Thomas Grabowski 1 / 45 Überblick 1. Einleitung 2. Suchmaschinen Architektur 3. Crawling-Prozess 4. Storage 5. Indexing 6. Ranking 2 / 45 1. Einleitung Der Webgraph unterliegt
1 Marketingplan Teil 3
 Der vierte Teil ist in folgende Unterpunkte gegliedert: 1. Marketingplan Teil 3 2. Ranking Analyse 3. Doorways 4. Page Rank 5. Verlinkung 6. Popularitätssteigerung 7. Vorschau auf den fünften Teil 1 Marketingplan
Der vierte Teil ist in folgende Unterpunkte gegliedert: 1. Marketingplan Teil 3 2. Ranking Analyse 3. Doorways 4. Page Rank 5. Verlinkung 6. Popularitätssteigerung 7. Vorschau auf den fünften Teil 1 Marketingplan
SEO - Suchmaschinenoptimierung
 SEO - Suchmaschinenoptimierung 2-tägiges SEO-Intensiv-Seminar: Mit Suchmaschinenoptimierung (SEO) zum Erfolg im Web! Beschreibung SEO (Suchmaschinenoptimierung) ist ein kritischer Erfolgsfaktor für Websites
SEO - Suchmaschinenoptimierung 2-tägiges SEO-Intensiv-Seminar: Mit Suchmaschinenoptimierung (SEO) zum Erfolg im Web! Beschreibung SEO (Suchmaschinenoptimierung) ist ein kritischer Erfolgsfaktor für Websites
Links und Anchortexte
 Links und Anchortexte Matthias Bargel, Claudia Ebner, Malgorzata Jaskulska-Piechota, Elke Pürzer 20. Juni 2007 Hauptseminar Informationsextraktion aus Webseiten CIS, SS 2007 Begriffe Link Als Hyperlink,
Links und Anchortexte Matthias Bargel, Claudia Ebner, Malgorzata Jaskulska-Piechota, Elke Pürzer 20. Juni 2007 Hauptseminar Informationsextraktion aus Webseiten CIS, SS 2007 Begriffe Link Als Hyperlink,
Datenstrukturen und Algorithmen SS07
 Datenstrukturen und Algorithmen SS07 Datum: 27.6.2007 Michael Belfrage mbe@student.ethz.ch belfrage.net/eth Programm von Heute Online Algorithmen Update von Listen Move to Front (MTF) Transpose Approximationen
Datenstrukturen und Algorithmen SS07 Datum: 27.6.2007 Michael Belfrage mbe@student.ethz.ch belfrage.net/eth Programm von Heute Online Algorithmen Update von Listen Move to Front (MTF) Transpose Approximationen
Kurze Einführung in Web Data Mining
 Kurze Einführung in Web Data Mining Yeong Su Lee Centrum für Informations- und Sprachverarbeitung (CIS), LMU 17.10.2007 Kurze Einführung in Web Data Mining 1 Überblick Was ist Web? Kurze Geschichte von
Kurze Einführung in Web Data Mining Yeong Su Lee Centrum für Informations- und Sprachverarbeitung (CIS), LMU 17.10.2007 Kurze Einführung in Web Data Mining 1 Überblick Was ist Web? Kurze Geschichte von
HMC WEB INDEX. Erste große Deutschland Studie. Wie fit sind die Clubs im online marketing? www.webindex.hmc-germany.com.
 21.11.2013 HMC WEB INDEX Erste große Deutschland Studie. Wie fit sind die Clubs im online marketing? www.webindex.hmc-germany.com Ansprechpartner Dirk Kemmerling Geschäftsführer HMC Germany HMC Health
21.11.2013 HMC WEB INDEX Erste große Deutschland Studie. Wie fit sind die Clubs im online marketing? www.webindex.hmc-germany.com Ansprechpartner Dirk Kemmerling Geschäftsführer HMC Germany HMC Health
P2P - Projekt. 1. Die gleiche Aufgabe zwei Herangehensweisen 2. Voraussetzungen. 3. Automatische Semantische Konvergenz
 P2P - Projekt 1. Die gleiche Aufgabe zwei Herangehensweisen 2. Voraussetzungen 1. Natürlicher Suchalgorithmus 2. Small Worlds 3. Automatische Semantische Konvergenz 1. Netzwerkerstellung 2. Suche 1. Die
P2P - Projekt 1. Die gleiche Aufgabe zwei Herangehensweisen 2. Voraussetzungen 1. Natürlicher Suchalgorithmus 2. Small Worlds 3. Automatische Semantische Konvergenz 1. Netzwerkerstellung 2. Suche 1. Die
Textdokument-Suche auf dem Rechner Implementierungsprojekt
 Textdokument-Suche auf dem Rechner Implementierungsprojekt Referent: Oliver Petra Seminar: Information Retrieval Institut für Computerlinguistik Ruprecht-Karls-Universität Heidelberg 19.01.2015 Überblick
Textdokument-Suche auf dem Rechner Implementierungsprojekt Referent: Oliver Petra Seminar: Information Retrieval Institut für Computerlinguistik Ruprecht-Karls-Universität Heidelberg 19.01.2015 Überblick
Web Data Mining. Alexander Hinneburg Sommersemester 2007
 Web Data Mining Alexander Hinneburg Sommersemester 2007 Termine Vorlesung Mi. 10:00-11:30 Raum?? Übung Mi. 11:45-13:15 Raum?? Klausuren Mittwoch, 23. Mai Donnerstag, 12. Juli Buch Bing Liu: Web Data Mining
Web Data Mining Alexander Hinneburg Sommersemester 2007 Termine Vorlesung Mi. 10:00-11:30 Raum?? Übung Mi. 11:45-13:15 Raum?? Klausuren Mittwoch, 23. Mai Donnerstag, 12. Juli Buch Bing Liu: Web Data Mining
Numerisches Programmieren
 Technische Universität München SoSe 213 Institut für Informatik Prof. Dr. Thomas Huckle Dipl.-Inf. Christoph Riesinger Dipl.-Math. Jürgen Bräckle Numerisches Programmieren 2. Programmieraufgabe: Lineare
Technische Universität München SoSe 213 Institut für Informatik Prof. Dr. Thomas Huckle Dipl.-Inf. Christoph Riesinger Dipl.-Math. Jürgen Bräckle Numerisches Programmieren 2. Programmieraufgabe: Lineare
Suchmaschinenoptimierung. Dr. Lars Göhler
 Suchmaschinenoptimierung Dr. Lars Göhler Suchmaschinenoptimierung search engine optimization (seo) optimiert Websites so, dass sie mit Suchmaschinen gefunden werden erhöht den Wert einer Website ist überlebenswichtig
Suchmaschinenoptimierung Dr. Lars Göhler Suchmaschinenoptimierung search engine optimization (seo) optimiert Websites so, dass sie mit Suchmaschinen gefunden werden erhöht den Wert einer Website ist überlebenswichtig
Bewertung von linktopologischen Verfahren als bestimmender Ranking-Faktor bei WWW- Suchmaschinen
 Bewertung von linktopologischen Verfahren als bestimmender Ranking-Faktor bei WWW- Suchmaschinen DIRK LEWANDOWSKI Heinrich-Heine-Universität Düsseldorf Institut für Sprache und Information, Abt. Informationswissenschaft
Bewertung von linktopologischen Verfahren als bestimmender Ranking-Faktor bei WWW- Suchmaschinen DIRK LEWANDOWSKI Heinrich-Heine-Universität Düsseldorf Institut für Sprache und Information, Abt. Informationswissenschaft
Einführung in die Internetrecherche
 Hellmut Riediger Recherchieren: Grundsätze und Grundbegriffe Einführung in die Internetrecherche Geschichte, Struktur und Allgemeines Zürcher Fachhochschule 1 Geschichte: Internet, WWW, Google 1969 Gründung
Hellmut Riediger Recherchieren: Grundsätze und Grundbegriffe Einführung in die Internetrecherche Geschichte, Struktur und Allgemeines Zürcher Fachhochschule 1 Geschichte: Internet, WWW, Google 1969 Gründung

Im Web gefunden werden
 Existenz 2013 Bad Tölz Im Web gefunden werden Suchmaschinen-Marketing von SEA bis SEO Franz-Rudolf Borsch 1 Die kommenden 45min 1. 2. Sie sind nicht alleine Herkunft der Besucher 3. Suchmaschinen locken
Existenz 2013 Bad Tölz Im Web gefunden werden Suchmaschinen-Marketing von SEA bis SEO Franz-Rudolf Borsch 1 Die kommenden 45min 1. 2. Sie sind nicht alleine Herkunft der Besucher 3. Suchmaschinen locken
Musterlösungen zur Linearen Algebra II Blatt 5
 Musterlösungen zur Linearen Algebra II Blatt 5 Aufgabe. Man betrachte die Matrix A := über dem Körper R und über dem Körper F und bestimme jeweils die Jordan- Normalform. Beweis. Das charakteristische
Musterlösungen zur Linearen Algebra II Blatt 5 Aufgabe. Man betrachte die Matrix A := über dem Körper R und über dem Körper F und bestimme jeweils die Jordan- Normalform. Beweis. Das charakteristische
SEO 2 - SUCHMASCHINENOPTIMIERUNG. Profitable Keywords finden
 SEO 2 - SUCHMASCHINENOPTIMIERUNG Profitable Keywords finden SUCHMASCHINENOPTIMIERUNG SEO ON-PAGE Alle Maßnahmen, zur besseren Auffindbarkeit Ihrer Website in den Suchmaschinen, die Sie selbst auf Ihrer
SEO 2 - SUCHMASCHINENOPTIMIERUNG Profitable Keywords finden SUCHMASCHINENOPTIMIERUNG SEO ON-PAGE Alle Maßnahmen, zur besseren Auffindbarkeit Ihrer Website in den Suchmaschinen, die Sie selbst auf Ihrer
Web Data Management Systeme
 Web Data Management Systeme Seminar: Web-Qualitätsmanagement Arne Frenkel Agenda Einführung Suchsysteme Suchmaschinen & Meta-Suchmaschinen W3QS WebSQL WebLog Information Integration Systems Ariadne TSIMMIS
Web Data Management Systeme Seminar: Web-Qualitätsmanagement Arne Frenkel Agenda Einführung Suchsysteme Suchmaschinen & Meta-Suchmaschinen W3QS WebSQL WebLog Information Integration Systems Ariadne TSIMMIS
Information Retrieval Modelle und neue Technologien. Prof. Dr. Wolfgang Riggert FDH Flensburg
 Information Retrieval Modelle und neue Technologien Prof. Dr. Wolfgang Riggert FDH Flensburg Gliederung IR-Modelle Suchmaschinen Beispiel: Google Neue Technologien Retrievalmodell - allgemein Ein Retrievalmodell
Information Retrieval Modelle und neue Technologien Prof. Dr. Wolfgang Riggert FDH Flensburg Gliederung IR-Modelle Suchmaschinen Beispiel: Google Neue Technologien Retrievalmodell - allgemein Ein Retrievalmodell
Erfolgreich suchen im Internet
 Erfolgreich suchen im Internet Steffen-Peter Ballstaedt 05.10.2015 Statistik Weltweit: etwa 1 Milliarde Websites BRD: 15 Millionen Websites Das Internet verdoppelt sich alle 5,32 Jahre Die häufigste Aktivität
Erfolgreich suchen im Internet Steffen-Peter Ballstaedt 05.10.2015 Statistik Weltweit: etwa 1 Milliarde Websites BRD: 15 Millionen Websites Das Internet verdoppelt sich alle 5,32 Jahre Die häufigste Aktivität
Bitte schreiben Sie sich in die Mailingliste der Vorlesung ein! Den Link finden Sie auf der Vorlesungshomepage.
 Mailingliste Bitte schreiben Sie sich in die Mailingliste der Vorlesung ein! Den Link finden Sie auf der Vorlesungshomepage. ZUR ERINNERUNG Regulärer Stundenplan Freitag, 14-16 Uhr: Vorlesung, ExWi A6
Mailingliste Bitte schreiben Sie sich in die Mailingliste der Vorlesung ein! Den Link finden Sie auf der Vorlesungshomepage. ZUR ERINNERUNG Regulärer Stundenplan Freitag, 14-16 Uhr: Vorlesung, ExWi A6
Inhaltsverzeichnis 18.11.2011
 Inhaltsverzeichnis Zur besseren Übersicht haben wir die Inhalte auf mehrere Arbeitsblätter aufgeteilt. Dieses Inhaltsverzeichnis dient der Übersicht. Die Namen für die Arbeitsblätter unterliegen einer
Inhaltsverzeichnis Zur besseren Übersicht haben wir die Inhalte auf mehrere Arbeitsblätter aufgeteilt. Dieses Inhaltsverzeichnis dient der Übersicht. Die Namen für die Arbeitsblätter unterliegen einer
BILDUNG. FREUDE INKLUSIVE. Webkonzeption III - Der Internetauftritt. Suchmaschinenoptimierung. BFI Wien, 03.06.2014
 BILDUNG. FREUDE INKLUSIVE. Webkonzeption III - Der Internetauftritt Suchmaschinenoptimierung BFI Wien, 03.06.2014 1 Zeitplan Das haben wir heute vor 08:30h bis 9:45h Grundlagen der Suchmaschinenoptimierung
BILDUNG. FREUDE INKLUSIVE. Webkonzeption III - Der Internetauftritt Suchmaschinenoptimierung BFI Wien, 03.06.2014 1 Zeitplan Das haben wir heute vor 08:30h bis 9:45h Grundlagen der Suchmaschinenoptimierung
WebSearchBench: Ein Open Source Baukasten für Internet Suchmaschinen der nächsten Generation. Christoph Lindemann
 WebSearchBench: Ein Open Source Baukasten für Internet Suchmaschinen der nächsten Generation Christoph Lindemann Universität Dortmund Informatik IV -Rechnersysteme und Leistungsbewertung- August-Schmidt-Str.
WebSearchBench: Ein Open Source Baukasten für Internet Suchmaschinen der nächsten Generation Christoph Lindemann Universität Dortmund Informatik IV -Rechnersysteme und Leistungsbewertung- August-Schmidt-Str.
Vorlesung Information Retrieval Wintersemester 04/05
 Vorlesung Information Retrieval Wintersemester 04/05 20. Januar 2005 Institut für Informatik III Universität Bonn Tel. 02 28 / 73-45 31 Fax 02 28 / 73-43 82 jw@informatik.uni-bonn.de 0 Themenübersicht
Vorlesung Information Retrieval Wintersemester 04/05 20. Januar 2005 Institut für Informatik III Universität Bonn Tel. 02 28 / 73-45 31 Fax 02 28 / 73-43 82 jw@informatik.uni-bonn.de 0 Themenübersicht
Deep Web. Timo Mika Gläßer
 Deep Web Timo Mika Gläßer Inhaltsverzeichnis Deep Web Was ist das? Beispiele aus dem Deep Web PubMed AllMusic Statistiken zu Surface/Shallow und Deep Web Auffinden von potentiellen Quellen ([BC04], [WM04],
Deep Web Timo Mika Gläßer Inhaltsverzeichnis Deep Web Was ist das? Beispiele aus dem Deep Web PubMed AllMusic Statistiken zu Surface/Shallow und Deep Web Auffinden von potentiellen Quellen ([BC04], [WM04],
Schnelle und konsistente Stoffwertberechnung mit Spline Interpolation Arbeiten innerhalb der IAPWS Task Group "CFD Steam Property Formulation"
 M. Kunick, H. J. Kretzschmar Hochschule Zittau/Görlitz, Fachgebiet Technische Thermodynamik, Zittau Schnelle und konsistente Stoffwertberechnung mit Spline Interpolation Arbeiten innerhalb der IAPWS Task
M. Kunick, H. J. Kretzschmar Hochschule Zittau/Görlitz, Fachgebiet Technische Thermodynamik, Zittau Schnelle und konsistente Stoffwertberechnung mit Spline Interpolation Arbeiten innerhalb der IAPWS Task
Bewertung von linktopologischen Verfahren als bestimmender Ranking-Faktor bei WWW- Suchmaschinen
 Bewertung von linktopologischen Verfahren als bestimmender Ranking-Faktor bei WWW- Suchmaschinen DIRK LEWANDOWSKI Heinrich-Heine-Universität Düsseldorf Institut für Sprache und Information, Abt. Informationswissenschaft
Bewertung von linktopologischen Verfahren als bestimmender Ranking-Faktor bei WWW- Suchmaschinen DIRK LEWANDOWSKI Heinrich-Heine-Universität Düsseldorf Institut für Sprache und Information, Abt. Informationswissenschaft
Adolf Berner Deutschland GmbH shop.berner.eu
 Modell Klimaservicestation Mobil Klimaservicestation Pkw/Lkw Klimaservicestation AC1234-7 Klimaservicestation AC1234-8 ACS 611 /ACS 511 Adolf Berner Deutschland Adolf Berner Deutschland Adolf Berner Deutschland
Modell Klimaservicestation Mobil Klimaservicestation Pkw/Lkw Klimaservicestation AC1234-7 Klimaservicestation AC1234-8 ACS 611 /ACS 511 Adolf Berner Deutschland Adolf Berner Deutschland Adolf Berner Deutschland
Personalisierung. Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung. Data Mining.
 Personalisierung Personalisierung Thomas Mandl Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung Klassifikation Die Nutzer werden in vorab bestimmte Klassen/Nutzerprofilen
Personalisierung Personalisierung Thomas Mandl Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung Klassifikation Die Nutzer werden in vorab bestimmte Klassen/Nutzerprofilen
!"#$"%&'()*$+()',!-+.'/',
*$+()',!-+.'/',") Soziotechnische Informationssysteme 5. Facebook, Google+ u.ä. Inhalte Historisches Relevanz Relevante Technologien Anwendungsarchitekturen 4(5,12316,7'.'0,!.80/6,9*$:'0+$.;.,&0$'0, 3, Historisches Facebook
Soziotechnische Informationssysteme 5. Facebook, Google+ u.ä. Inhalte Historisches Relevanz Relevante Technologien Anwendungsarchitekturen 4(5,12316,7'.'0,!.80/6,9*$:'0+$.;.,&0$'0, 3, Historisches Facebook
Deep Web Suchen wir was man finden könnte?
 Deep Web Suchen wir was man finden könnte? Dr. Dirk Lewandowski dirk.lewandowski@uni-duesseldorf.de www.durchdenken.de/lewandowski Gliederung Die Bedeutung des Deep Web Die Größe des Deep Web Strategien
Deep Web Suchen wir was man finden könnte? Dr. Dirk Lewandowski dirk.lewandowski@uni-duesseldorf.de www.durchdenken.de/lewandowski Gliederung Die Bedeutung des Deep Web Die Größe des Deep Web Strategien
Industrie- und Handelskammer Stuttgart
 Industrie- und Handelskammer Stuttgart SUCHMASCHINEN-OPTIMIERUNG die vorderen Plätze bei Google, Yahoo & Co 1. Über Beyond Media 2. Erste Schritte 3. freundliche 4. Arbeitsweise 5. Bewertungsmethoden 6.
Industrie- und Handelskammer Stuttgart SUCHMASCHINEN-OPTIMIERUNG die vorderen Plätze bei Google, Yahoo & Co 1. Über Beyond Media 2. Erste Schritte 3. freundliche 4. Arbeitsweise 5. Bewertungsmethoden 6.
Advanced Encryption Standard. Copyright Stefan Dahler 20. Februar 2010 Version 2.0
 Advanced Encryption Standard Copyright Stefan Dahler 20. Februar 2010 Version 2.0 Vorwort Diese Präsentation erläutert den Algorithmus AES auf einfachste Art. Mit Hilfe des Wissenschaftlichen Rechners
Advanced Encryption Standard Copyright Stefan Dahler 20. Februar 2010 Version 2.0 Vorwort Diese Präsentation erläutert den Algorithmus AES auf einfachste Art. Mit Hilfe des Wissenschaftlichen Rechners
Algorithmen für Routenplanung 11. Vorlesung, Sommersemester 2012 Daniel Delling 6. Juni 2012
 Algorithmen für Routenplanung 11. Vorlesung, Sommersemester 2012 Daniel Delling 6. Juni 2012 MICROSOFT RESEARCH SILICON VALLEY KIT Universität des Landes Baden-Württemberg und nationales Großforschungszentrum
Algorithmen für Routenplanung 11. Vorlesung, Sommersemester 2012 Daniel Delling 6. Juni 2012 MICROSOFT RESEARCH SILICON VALLEY KIT Universität des Landes Baden-Württemberg und nationales Großforschungszentrum
Ethik für Webdesigner und Webagenten (Felix Stoll)
") Ethik für Webdesigner und Webagenten (Felix Stoll) Ein Vortrag im Proseminar Ethische Aspekte der Informationsverarbeitung 1. Ethik im Internet (allgemein) 2. Ethik des Webdesigners 3. Webagenten (Suchmaschinen)
Ethik für Webdesigner und Webagenten (Felix Stoll) Ein Vortrag im Proseminar Ethische Aspekte der Informationsverarbeitung 1. Ethik im Internet (allgemein) 2. Ethik des Webdesigners 3. Webagenten (Suchmaschinen)
Planen mit mathematischen Modellen 00844: Computergestützte Optimierung. Autor: Dr. Heinz Peter Reidmacher
 Planen mit mathematischen Modellen 00844: Computergestützte Optimierung Leseprobe Autor: Dr. Heinz Peter Reidmacher 11 - Portefeuilleanalyse 61 11 Portefeuilleanalyse 11.1 Das Markowitz Modell Die Portefeuilleanalyse
Planen mit mathematischen Modellen 00844: Computergestützte Optimierung Leseprobe Autor: Dr. Heinz Peter Reidmacher 11 - Portefeuilleanalyse 61 11 Portefeuilleanalyse 11.1 Das Markowitz Modell Die Portefeuilleanalyse
Kürzeste Wege in Graphen. Maurice Duvigneau Otto-von-Guericke Universität Fakultät für Informatik
 Kürzeste Wege in Graphen Maurice Duvigneau Otto-von-Guericke Universität Fakultät für Informatik Gliederung Einleitung Definitionen Algorithmus von Dijkstra Bellmann-Ford Algorithmus Floyd-Warshall Algorithmus
Kürzeste Wege in Graphen Maurice Duvigneau Otto-von-Guericke Universität Fakultät für Informatik Gliederung Einleitung Definitionen Algorithmus von Dijkstra Bellmann-Ford Algorithmus Floyd-Warshall Algorithmus
Literaturverzeichnis. Zeitschriftenartikel. Onlinedokumente
 Literaturverzeichnis Zeitschriftenartikel Puscher Frank (2008) Erfolg durch Sichtbarkeit: Suchmaschinen-Werbung lohnt sich auch für kleinere Unternehmen. In: c t 03/08, S 88 90. Hannover: Heise Zeitschriften
Literaturverzeichnis Zeitschriftenartikel Puscher Frank (2008) Erfolg durch Sichtbarkeit: Suchmaschinen-Werbung lohnt sich auch für kleinere Unternehmen. In: c t 03/08, S 88 90. Hannover: Heise Zeitschriften
Algorithmen II Vorlesung am 15.11.2012
 Algorithmen II Vorlesung am 15.11.2012 Kreisbasen, Matroide & Algorithmen INSTITUT FÜR THEORETISCHE INFORMATIK PROF. DR. DOROTHEA WAGNER KIT Universität des Landes Baden-Württemberg und Algorithmen nationales
Algorithmen II Vorlesung am 15.11.2012 Kreisbasen, Matroide & Algorithmen INSTITUT FÜR THEORETISCHE INFORMATIK PROF. DR. DOROTHEA WAGNER KIT Universität des Landes Baden-Württemberg und Algorithmen nationales
Praxiswissen Suchmaschinenoptimierung
 Praxiswissen Suchmaschinenoptimierung Eine Einleitung in die wichtigsten Grundlagen für eine bessere Platzierung in Suchmaschinen Wer in der digitalen Welt auf sich aufmerksam machen will, sollte sich
Praxiswissen Suchmaschinenoptimierung Eine Einleitung in die wichtigsten Grundlagen für eine bessere Platzierung in Suchmaschinen Wer in der digitalen Welt auf sich aufmerksam machen will, sollte sich
Vergleich von Methoden zur Rekonstruktion von genregulatorischen Netzwerken (GRN)
") Exposé zur Bachelorarbeit: Vergleich von Methoden zur Rekonstruktion von genregulatorischen Netzwerken (GRN) Fakultät: Informatik, Humboldt-Universität zu Berlin Lijuan Shi 09.05.2013 Betreuer: Prof. Dr.
Exposé zur Bachelorarbeit: Vergleich von Methoden zur Rekonstruktion von genregulatorischen Netzwerken (GRN) Fakultät: Informatik, Humboldt-Universität zu Berlin Lijuan Shi 09.05.2013 Betreuer: Prof. Dr.
2 Evaluierung von Retrievalsystemen
 2. Evaluierung von Retrievalsystemen Relevanz 2 Evaluierung von Retrievalsystemen Die Evaluierung von Verfahren und Systemen spielt im IR eine wichtige Rolle. Gemäß der Richtlinien für IR der GI gilt es,...
2. Evaluierung von Retrievalsystemen Relevanz 2 Evaluierung von Retrievalsystemen Die Evaluierung von Verfahren und Systemen spielt im IR eine wichtige Rolle. Gemäß der Richtlinien für IR der GI gilt es,...
Black-Hat Search Engine Optimization (SEO) Practices for Websites
 Practices for Websites") Beispielbild Black-Hat Search Engine Optimization (SEO) Practices for Websites Damla Durmaz - 29. Januar. 2009 Proseminar Technisch Informatik Leitung: Georg Wittenburg Betreuer: Norman Dziengel Fachbereich
Beispielbild Black-Hat Search Engine Optimization (SEO) Practices for Websites Damla Durmaz - 29. Januar. 2009 Proseminar Technisch Informatik Leitung: Georg Wittenburg Betreuer: Norman Dziengel Fachbereich
Mathematik ist überall. Prof. Dr. Roland Speicher Universität des Saarlandes
 Mathematik ist überall Prof. Dr. Roland Speicher Universität des Saarlandes Ziele meines Vortrages Mathematik ist schön Mathematik ist wichtig Mathematiker werden überall benötigt Mathematiker werden
Mathematik ist überall Prof. Dr. Roland Speicher Universität des Saarlandes Ziele meines Vortrages Mathematik ist schön Mathematik ist wichtig Mathematiker werden überall benötigt Mathematiker werden
WHITE PAPER. Presseportal Report 2011: Kostenlose Presseportale im Vergleich
 Presseportal Report 2011: Kostenlose Presseportale im Vergleich Es gibt inzwischen eine Vielzahl von Presseportalen, über die Pressemitteilungen im Internet veröffentlicht werden können, viele davon sind
Presseportal Report 2011: Kostenlose Presseportale im Vergleich Es gibt inzwischen eine Vielzahl von Presseportalen, über die Pressemitteilungen im Internet veröffentlicht werden können, viele davon sind