Clustering. Methods Course: Gene Expression Data Analysis -Day Four. Rainer Spang
|
|
|
- Heike Michaela Roth
- vor 6 Jahren
- Abrufe
Transkript
1 Clustering Methods Course: Gene Expression Data Analysis -Day Four Rainer Spang

2 Eine Krankheit Drei alternative Therapien
3 Klinische Studie Im Mittel 75% 55% 35% Erfolg
4 Drei Subtypen der Krankheit A B C
5 A B C 100% 60% 65% 40% 40% 85% 10% 90% 5%
6 100% A 90% 91,7% B 85% C
7 Fazit Der Therapieerfolg ist angestiegen durch eine verbesserte Diagnose 91,7% 75% Ohne daß eine neue Therapie entwickelt wurde
8 Clustering Ziel: Gruppiere ähnliche Objekte in das gleiche Cluster und unähnliche Objekte in unterschiedliche Cluster Daten Clustering
9 Cluster von Genen Finde koregulierte Gene Funktionale Klassifikation von Genen Fasse Variablen ähnlichen Informationsgehalts zusammen Dimensionsreduktion Borrowing Information across Genes
10 Cluster von Arrays? Suchen nach a priori unbekannten Gruppierungen der Arrays Pathologie Beispiel: Arrays = Genexpressiosnprofile von Patienten Cluster = Potentielle Subentitäten einer Krankheit Kein Clustering-Problem: Rekonstruktion bekannter Gruppierungen der Arrays Diagnostik
11 Leukämie Chiaretti et al. (2004) Gene expression profile of adult T-cell acute lymphocytic leukemia identities distinct subsets of patients with different response to therapy and survival. Blood 103(7):2771-8
12 Analyse von Methoden vs. Analyse von Daten Hat man a priori gelabelte Daten, wie die B und T-ALL im Chiaretti Datensatz so ist man in einer Situation überwachten Lernens, und sollte die dafür vorhandenen Methoden einsetzen. Nichtsdestotrotz kann man das Verhalten von Clusteringverfahren in diesen Situationen analysieren Finden sie die Struktur wieder?
13 Clustering - Die Zutaten Zwei Dinge bestimmen das Ergebnis: Distanzmaß: Quantifizierung der (Un-)Ähnlichkeit der Objekte Cluster-Algorithmus: Verfahren, dass die Gruppierung basierend auf dem gewählten Distanzmaß durchführt
14 Der euklidische Abstand Expressionsprofile x = (x 1,, x n ), y = (y 1,, y n ) d E ( x, y) n i 1 ( x i y i 2 ) Die Luftlinie zwischen zwei Punkten Das Quadrat macht den Abstand sensibel gegen Ausreißer
 d M ( x, y) n i 1 x i y i.")
15 Die Manhattan-Distanz Abstand, wenn nur parallel zu den Koordinatenachsen gelaufen werden darf (wie in den Straßen von Manhattan) d M ( x, y) n i 1 x i y i. Ausreißer fallen weniger ins Gewicht
 ( ) ( ) )( ( 1 ), ( 1 2 1 2 1 i i i i i i i C y y x x y y x x y x d Die Pearson Korrelation beschreibt die")
16 Die Pearson-Korrelation. ) ( ) ( ) )( ( 1 ), ( i i i i i i i C y y x x y y x x y x d Die Pearson Korrelation beschreibt die lineare Abhängigkeit zweier Profile d c (x, y)= d c (ax+b, y), a > 0 Sie vergleicht den Verlauf
17 Beispiel: Clustering von Zeitreihen steep up: x1=(2,4,5,6) up: x2=(2/4,4/4,5/4,6/4) down: x3=(6/4,4/4,3/4,2/4) change: x4=(2.5,3.5,4.5,1)
18 Euklidischer Abstand Matrix of pairwise distances
19 Manhatten-Distanz Matrix of pairwise distances
20 Korrelations-Abstand Matrix of pairwise distances Aus d(x,y)=0 folgt nicht x=y Keine Metrik
21 Normalisierte Abstands-Skalen steep up up down change steep up up down change Euklid. Manh. Korr. Alle Distanzen wurden auf das Interval [0,10] normalisiert und gerundet
22 Standardeinheiten Transformiere die Daten auf Standardeinheiten x x ˆ ˆ Dann ergeben euklidische Distanz und Korrelation proportionale Abstände C 1 2 d ( x, x ) 2 nd ( x, x ) E
23 Cluster-Algorithmen Die Algorithmen sind Verfahren, die die Daten in Gruppen einteilen Sie bauen dabei auf den Distanzmaßen auf Wir diskutieren: Hierachichal Clustering K-Means-Clustering Partitioning around Medoids

24 Hierarchisches Clustern Zu Anfang bildet jedes Profil ein Cluster mit einem Element Berechne alle Abstände zwischen Profilen Suche das Paar mit dem kleinsten Abstand Vereinige es zu einem neuen Cluster Berechne die Abstände zwischen dem neuen Cluster und allen anderen Wiederhole bis nur noch 1 Cluster übrig bleibt.

25 Abstand zwischen Clustern Bisher hatten wir nur Abstandsmasse auf einzelnen Punkten diskutiert Beim hierarchischen Clustering werden aber auch Abstände von Clustern zu Punkten benötigt Wie werden diese definiert?
 Der Mittelwert der Abstände (average linkage) Das Maximum der Abstände (complete")
26 Linkage Berechne die Distanzen von allen Profilen in Cluster 1 zu allen Profilen in Cluster 2 Der Abstand der Cluster zu einander ist dann: Das Minimum der Abstände (single linkage) Der Mittelwert der Abstände (average linkage) Das Maximum der Abstände (complete linkage)
27 Dendrogramm Wenn zwei Cluster zusammengelegt werden, werden sie im Dendrogramm durch eine Klammer verbunden Die Höhe der Klammer entspricht dem Abstand der Cluster
28 Dendrogramm Das Dendrogramm wird oft über eine Heatmap geplotted Dazu müssen die Profile geordnet werden Beachte: Das Dendrogramm legt die Ordnung nicht eindeutig fest Man kann an allen Verzweigungen spiegeln Hierarchie ist nicht gleich Ordnung

29 Heatmap der Distanzen Die Distanzen der Cluster sind im Dendrogramm durch die Höhen der Äste repräsentiert Es gibt n(n-1)/2 Distanzen, aber nur n-1 Asthöhen Information geht verloren Alternativ kann man die Distanzen aller Profile in einer Heatmap darstellen Diese ist nur übersichtlich wenn die Profile günstig geordnet sind Dazu kann man wiederum das Dendrogramm verwenden
30 Hierarchien von Clusterings Der Algorithmus produzierte ein Dendrogramm aber noch kein Clustering Das Dendrogramm kann auf verschiedenen Levels geschnitten werden Jeder Schnitt definiert ein Clustering Der orange Schnitt generiert die drei Cluster (G1,G6,G5), (G2,G3), (G4) Der blaue Schnitt generiert vier Cluster (G1,G6),(G5), (G2,G3), (G4) Es entsteht eine Hierarchie von Clusterings
31 Euklidischer Abstand
32 Manhattan-Distanz
33 Korrelations-Abstand
34 Akute Lymphoblastische Leukämie bei Kinder Golub et al. Science 1999 aber das war kein Clustering-Problem, da die Subentitäten AML und ALL schon a priori bekannt waren
35 K-Means Clustering Die Anzahl K der Cluster muss gewählt werden Suche H Punkte zufällig aus, dies sind die ersten Zentroide Ordne jeden Punkt dem nächst gelegenen Zentroid zu
36 Iteration x x x x x x Bestimme die Zentroide der so entstandenen Cluster und ordne die Punkte wiederum dem nächstgelegenen Zentroid zu Iteriere bis alle Punkte im gleichen Cluster bleiben
37 Optimales Clustering Wir haben K-means Clustering als Algorithmus eingeführt Man kann es auch als ein Optimierungproblem definieren: Ordne die Profile den K-Clustern so zu, dass die folgende Funktion optimiert wird: K 1 W ( C) de ( xi, x j ) 2 k 1 C( i) C( j) k Der Algorithmus ist eine Heuristik zur Minimerung dieser Funktion Natürlich ist das Clustering nur optimal relativ zu dieser Objective Function Mann kann auch andere Objective Functions wählen und erhält andere Clusterings 2
38 Partioning around Medoids PAM Robustere Variante des K-Means Algorithmus durch eine andere Objective Funktion Die Cluster werden nicht durch Zentroide, sondern durch prototypische Datenpunkte (Medoide) repräsentiert Ziel ist es den Abstand zum nächsten Medoid über alle Punkte gleichzeitig zu minimieren Minimiert wird also die Objective Function
39 PAM Algorithmus Initialisierung: Suche zufällig K Prototypen (Medoide) Iteriere bis zur Konvergenz Swapping: Für alle Paare (i,j) bei denen i ein Medoid und j kein Medoid ist: Berechne den Unterschied in der Objective Funktion, der entstünde wenn man j zum Medoid an Stelle von i machte Führe das Swapping durch, wenn es günstig ist
40 Wie viele Cluster sind in den Daten? Für jeden Datenpunkt können wir die Silhouette s(i) berechnen: a(i) := Mittler Abstand von Punkt i zu allen Punkten im gleichen Cluster b(i) := min C d(i,c), wobei d(i,c) der mittlere Abstand von Punkt i zu allen Punkten in Cluster C ist. Das Minimum wird über alle Cluster in denen Punkt i nicht liegt genommen Bestes Konkurenzcluster - s(i) nahe 1 : Profil ist im richtigen Cluster s(i) nahe -1: Profil ist im falschen Cluster s(i) nahe 0: Profil kann sich nicht entscheiden
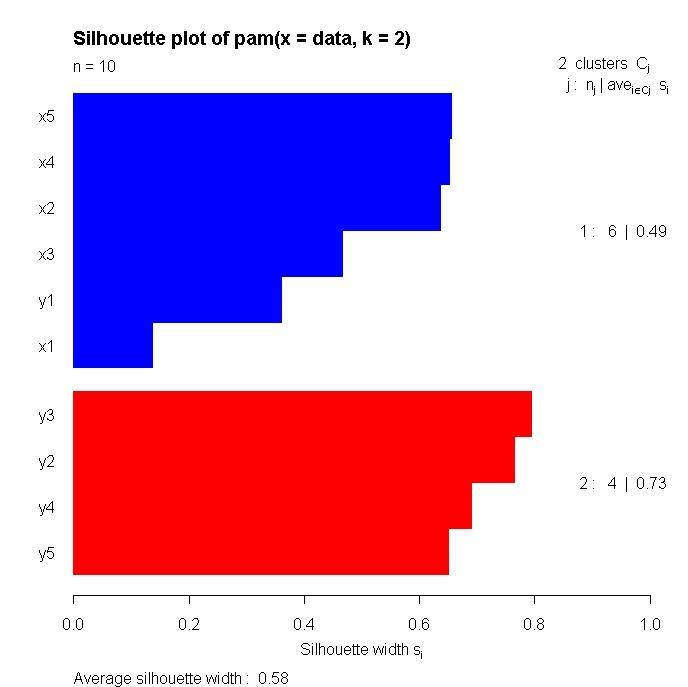
41 Silhouette Plot
42 Silhouette Plot In diesem Cluster gibt es Profile mit kleinem Silhouetten Score Alle Profile in diesem Cluster haben einen hohen Silhouetten Score T-cell Leukemia Chiaretti et al., 2004 Gibt es in Wirklichkeit drei Cluster in den Daten?
43 Silhouette Plot Nein! Die Aufteilung des oberen Clusters in zwei Cluster verschlechtert den Silhouetten Plot T-cell Leukemia Chiaretti et al., 2004
44 Kein Clustering Problem Sie wollen zu einem Referenzprofil die Profile suchen, die ihm am ähnlichsten sind Falscher Ansatz: Sie clustern alle Profile und schauen sich die Profile an, die im selben Cluster wie ihr Referenzprofil liegen Was man bekommt Was man gerne hätte
45 Screening Problem Sie wollen zu einem Referenzprofil die Profile suchen, die ihm am ähnlichsten sind Richtiger Ansatz: Sie berechnen die Abstände aller Profile zum Referenzprofil und sehen sich die Profile mit kleinstem Abstand an Clustering Screening
46 Self Fulfilling Prophecy Sie besitzen a priori label 2 Gruppen von Profilen - Wählen differentiell exprimierte Gene aus Clustern die Daten nur unter Einschluss dieser Gene Beobachten, dass die a priori Gruppen zusammen clustern Interpretieren dies als Bestätigung der a priori label Die Gruppen clustern unter umständen nur wegen der Genauswahl zusammen Zufällige Daten hätten dies auch getan
47 Self Fulfilling Prophecy Randomisierte Labels Clustering mit supervidierter Genselektion Ohne Genselektion
48 Nicht supervidierte Geneselektion Der Microarray hält Gene Nicht alle diese Gene zeigen sinnvolle Clustering Struktur Hybridisierungs-Artefakte produzieren oft kleine Veränderungen in allen Genen Normalisierung kann diese nicht immer eliminieren In den Distanzmaßen summieren sie sich auf Ansatz: Benutze nur stark variierende Gene zum Clustering
49 Clustering mit allen Genen B- und T-cell ALL Chiaretti et al., 2004
50 Clustering mit den Top 100 variabelsten Genen B- und T-cell ALL Chiaretti et al., 2004
51 Genselektion Gene 2 Gene 4 Problem: Unterschiedliche Gene induzieren ein unterschiedliches Clustering

52 Lymphome Gene und Profile von verschiedenen Lymphomen und lymphoiden Zellinen wurden geclustert Globales Clustering: Die bekannten Lymphom Entitäten bilden Cluster aus Genselktion: Der orange Block von Genen Clustert einen Teil der DLBCL Lymphome mit Keimzentrumszellinien und einen anderen Teil mit aktivierten B-Zellen Alizadeh et al Nature 2000
53 Acknowledgement Für diese Vorlesung habe ich Folien, Graphiken und Ideen ausgeliehen bei: Jörg Rahnenführer Tobias Müller Anja v. Heydebreck
Clustering Seminar für Statistik
 Clustering Markus Kalisch 03.12.2014 1 Ziel von Clustering Finde Gruppen, sodas Elemente innerhalb der gleichen Gruppe möglichst ähnlich sind und Elemente von verschiedenen Gruppen möglichst verschieden
Clustering Markus Kalisch 03.12.2014 1 Ziel von Clustering Finde Gruppen, sodas Elemente innerhalb der gleichen Gruppe möglichst ähnlich sind und Elemente von verschiedenen Gruppen möglichst verschieden
Eine Einführung in R: Hochdimensionale Daten: n << p Teil II
 Eine Einführung in R: Hochdimensionale Daten: n
Eine Einführung in R: Hochdimensionale Daten: n
Robuste Clusterverfahren für Microarrays: Bildanalyse und Tumorklassifikation
 Robuste Clusterverfahren für Microarrays: Bildanalyse und Tumorklassifikation Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany
Robuste Clusterverfahren für Microarrays: Bildanalyse und Tumorklassifikation Jörg Rahnenführer Computational Biology and Applied Algorithmics Max Planck Institute for Informatics D-66123 Saarbrücken Germany
Statistische Verfahren für das Data Mining in einem Industrieprojekt
 Statistische Verfahren für das Data Mining in einem Industrieprojekt Thorsten Dickhaus Forschungszentrum Jülich GmbH Zentralinstitut für Angewandte Mathematik Telefon: 02461/61-4193 E-Mail: th.dickhaus@fz-juelich.de
Statistische Verfahren für das Data Mining in einem Industrieprojekt Thorsten Dickhaus Forschungszentrum Jülich GmbH Zentralinstitut für Angewandte Mathematik Telefon: 02461/61-4193 E-Mail: th.dickhaus@fz-juelich.de
Die Clusteranalyse 24.06.2009. Clusteranalyse. Grundidee Mögliche Anwendungsgebiete gg Vorgehensweise Beispiele. methodenlehre ll Clusteranalyse
 Clusteranalyse Thomas Schäfer SS 2009 1 Die Clusteranalyse Grundidee Mögliche Anwendungsgebiete gg Vorgehensweise Beispiele Thomas Schäfer SS 2009 2 1 Die Clusteranalyse Grundidee: Eine heterogene Gesamtheit
Clusteranalyse Thomas Schäfer SS 2009 1 Die Clusteranalyse Grundidee Mögliche Anwendungsgebiete gg Vorgehensweise Beispiele Thomas Schäfer SS 2009 2 1 Die Clusteranalyse Grundidee: Eine heterogene Gesamtheit
Data Mining und Knowledge Discovery in Databases
 Data Mining und Knowledge Discovery in Databases Begriffsabgrenzungen... Phasen der KDD...3 3 Datenvorverarbeitung...4 3. Datenproblematik...4 3. Möglichkeiten der Datenvorverarbeitung...4 4 Data Mining
Data Mining und Knowledge Discovery in Databases Begriffsabgrenzungen... Phasen der KDD...3 3 Datenvorverarbeitung...4 3. Datenproblematik...4 3. Möglichkeiten der Datenvorverarbeitung...4 4 Data Mining
Einführung in die Bioinformatik
 Einführung in die Bioinformatik Kay Nieselt SS 01 8. It s hip to chip - von Microarrays zu personalisierter Medizin WSI/ZBIT, Eberhard Karls Universität Tübingen Das menschliche Genom (~.000.000.000 Basenpaare)
Einführung in die Bioinformatik Kay Nieselt SS 01 8. It s hip to chip - von Microarrays zu personalisierter Medizin WSI/ZBIT, Eberhard Karls Universität Tübingen Das menschliche Genom (~.000.000.000 Basenpaare)
Einführung in die Bioinformatik
 Einführung in die Bioinformatik Kay Nieselt SS 011 9. It s hip to chip - von Microarrays zu personalisierter Medizin WSI/ZBIT, Eberhard Karls Universität Tübingen Das menschliche Genom (.000.000.000 Basenpaare)
Einführung in die Bioinformatik Kay Nieselt SS 011 9. It s hip to chip - von Microarrays zu personalisierter Medizin WSI/ZBIT, Eberhard Karls Universität Tübingen Das menschliche Genom (.000.000.000 Basenpaare)
Multivariate Statistik
 Hermann Singer Multivariate Statistik 1 Auflage 15 Oktober 2012 Seite: 12 KAPITEL 1 FALLSTUDIEN Abbildung 12: Logistische Regression: Geschätzte Wahrscheinlichkeit für schlechte und gute Kredite (rot/blau)
Hermann Singer Multivariate Statistik 1 Auflage 15 Oktober 2012 Seite: 12 KAPITEL 1 FALLSTUDIEN Abbildung 12: Logistische Regression: Geschätzte Wahrscheinlichkeit für schlechte und gute Kredite (rot/blau)
Clusteranalyse. Clusteranalyse. Fragestellung und Aufgaben. Abgrenzung Clusteranalyse - Diskriminanzanalyse. Rohdatenmatrix und Distanzmatrix
 TECHNISCHE UNIVERSITÄT MÜNCHEN-WEIHENSTEPHAN MATHEMATIK UND STATISTIK INFORMATIONS- UND DOKUMENTATIONSZENTRUM R. Biometrische und Ökonometrische Methoden II SS 00 Fragestellung und Aufgaben Abgrenzung
TECHNISCHE UNIVERSITÄT MÜNCHEN-WEIHENSTEPHAN MATHEMATIK UND STATISTIK INFORMATIONS- UND DOKUMENTATIONSZENTRUM R. Biometrische und Ökonometrische Methoden II SS 00 Fragestellung und Aufgaben Abgrenzung
Vorlesung Text und Data Mining S9 Text Clustering. Hans Hermann Weber Univ. Erlangen, Informatik
 Vorlesung Text und Data Mining S9 Text Clustering Hans Hermann Weber Univ. Erlangen, Informatik Document Clustering Überblick 1 Es gibt (sehr viele) verschiedene Verfahren für das Bilden von Gruppen Bei
Vorlesung Text und Data Mining S9 Text Clustering Hans Hermann Weber Univ. Erlangen, Informatik Document Clustering Überblick 1 Es gibt (sehr viele) verschiedene Verfahren für das Bilden von Gruppen Bei
Voraussetzung wieder: Datenraum mit Instanzen, mehrere Attribute - kein ausgezeichnetes Zielattribut, keine vorgegebenen Klassen
 7. Clusteranalyse (= Häufungsanalyse; Clustering-Verfahren) wird der multivariaten Statistik zugeordnet Voraussetzung wieder: Datenraum mit Instanzen, mehrere Attribute - kein ausgezeichnetes Zielattribut,
7. Clusteranalyse (= Häufungsanalyse; Clustering-Verfahren) wird der multivariaten Statistik zugeordnet Voraussetzung wieder: Datenraum mit Instanzen, mehrere Attribute - kein ausgezeichnetes Zielattribut,
Einführung in das Data Mining Clustering / Clusteranalyse
 Einführung in das Data Mining Clustering / Clusteranalyse Sascha Szott Fachgebiet Informationssysteme HPI Potsdam 21. Mai 2008 Teil I Einführung Clustering / Clusteranalyse Ausgangspunkt: Menge O von Objekten
Einführung in das Data Mining Clustering / Clusteranalyse Sascha Szott Fachgebiet Informationssysteme HPI Potsdam 21. Mai 2008 Teil I Einführung Clustering / Clusteranalyse Ausgangspunkt: Menge O von Objekten
Visualisierung hochdimensionaler Daten. Hauptseminar SS11 Michael Kircher
 Hauptseminar SS11 Inhalt Einführung zu hochdimensionalen Daten Visualisierungsmöglichkeiten dimensionale Teilmengen dimensionale Schachtelung Achsenumgestaltung Algorithmen zur Dimensionsreduktion Zusammenfassung
Hauptseminar SS11 Inhalt Einführung zu hochdimensionalen Daten Visualisierungsmöglichkeiten dimensionale Teilmengen dimensionale Schachtelung Achsenumgestaltung Algorithmen zur Dimensionsreduktion Zusammenfassung
GMDS-Tagung 2006 Bioinformatik 1. Assessing the stability of unsupervised learning results in small-sample-size problems
 GMDS-Tagung 2006 Bioinformatik 1 Assessing the stability of unsupervised learning results in small-sample-size problems Ulrich Möller Email: Ulrich.Moeller@hki-jena.de Leibniz Institute for Natural Product
GMDS-Tagung 2006 Bioinformatik 1 Assessing the stability of unsupervised learning results in small-sample-size problems Ulrich Möller Email: Ulrich.Moeller@hki-jena.de Leibniz Institute for Natural Product
Termin3 Klassifikation multispektraler Daten unüberwachte Verfahren
 Ziel Termin3 Klassifikation multispektraler Daten unüberwachte Verfahren Einteilung (=Klassifikation) der Pixel eines multispektralen Datensatzes in eine endliche Anzahl von Klassen. Es sollen dabei versucht
Ziel Termin3 Klassifikation multispektraler Daten unüberwachte Verfahren Einteilung (=Klassifikation) der Pixel eines multispektralen Datensatzes in eine endliche Anzahl von Klassen. Es sollen dabei versucht
Workshop Aktuelle Entwicklungen bei der Auswertung von Fernerkundungsdaten für forstliche Aufgabenstellungen
 Workshop Aktuelle Entwicklungen bei der Auswertung von Fernerkundungsdaten für forstliche Aufgabenstellungen Schätzung von Holzvorräten und Baumartenanteilen mittels Wahrscheinlichkeitsmodellen Haruth
Workshop Aktuelle Entwicklungen bei der Auswertung von Fernerkundungsdaten für forstliche Aufgabenstellungen Schätzung von Holzvorräten und Baumartenanteilen mittels Wahrscheinlichkeitsmodellen Haruth
Data Warehousing und Data Mining
 Data Warehousing und Data Mining Clustering Ulf Leser Wissensmanagement in der Bioinformatik Inhalt dieser Vorlesung Einführung Clustergüte Ähnlichkeiten Clustermitte Hierarchisches Clustering Partitionierendes
Data Warehousing und Data Mining Clustering Ulf Leser Wissensmanagement in der Bioinformatik Inhalt dieser Vorlesung Einführung Clustergüte Ähnlichkeiten Clustermitte Hierarchisches Clustering Partitionierendes
Seminar zum Thema Künstliche Intelligenz:
 Wolfgang Ginolas Seminar zum Thema Künstliche Intelligenz: Clusteranalyse Wolfgang Ginolas 11.5.2005 Wolfgang Ginolas 1 Beispiel Was ist eine Clusteranalyse Ein einfacher Algorithmus 2 bei verschieden
Wolfgang Ginolas Seminar zum Thema Künstliche Intelligenz: Clusteranalyse Wolfgang Ginolas 11.5.2005 Wolfgang Ginolas 1 Beispiel Was ist eine Clusteranalyse Ein einfacher Algorithmus 2 bei verschieden
VL Algorithmische BioInformatik (19710) WS2013/2014 Woche 16 - Mittwoch. Annkatrin Bressin Freie Universität Berlin
 WS2013/2014 Woche 16 - Mittwoch. Annkatrin Bressin Freie Universität Berlin") VL Algorithmische BioInformatik (19710) WS2013/2014 Woche 16 - Mittwoch Annkatrin Bressin Freie Universität Berlin Vorlesungsthemen Part 1: Background Basics (4) 1. The Nucleic Acid World 2. Protein Structure
VL Algorithmische BioInformatik (19710) WS2013/2014 Woche 16 - Mittwoch Annkatrin Bressin Freie Universität Berlin Vorlesungsthemen Part 1: Background Basics (4) 1. The Nucleic Acid World 2. Protein Structure
CLARANS. Semesterprojekt im Fach Wissensexktraktion / Data Mining, Hochschule Wismar, Studiengang Multimedia Engineering, Sommersemester 2013
 CLARANS Semesterprojekt im Fach Wissensexktraktion / Data Mining, Hochschule Wismar, Studiengang Multimedia Engineering, Sommersemester 2013 Daniel Schmidt Mohamed Ibrahim Sven Lautenschläger Inhaltsverzeichnis
CLARANS Semesterprojekt im Fach Wissensexktraktion / Data Mining, Hochschule Wismar, Studiengang Multimedia Engineering, Sommersemester 2013 Daniel Schmidt Mohamed Ibrahim Sven Lautenschläger Inhaltsverzeichnis
Exploration und Klassifikation von BigData
 Exploration und Klassifikation von BigData Inhalt Einführung Daten Data Mining: Vorbereitungen Clustering Konvexe Hülle Fragen Google: Riesige Datenmengen (2009: Prozessieren von 24 Petabytes pro Tag)
Exploration und Klassifikation von BigData Inhalt Einführung Daten Data Mining: Vorbereitungen Clustering Konvexe Hülle Fragen Google: Riesige Datenmengen (2009: Prozessieren von 24 Petabytes pro Tag)
Gliederung. Bachelorseminar: Graphiken in R Visualisierung Kategorialer Daten. Einführung. Visualisierung von zweidimensionalen Kontingenztafeln
 Gliederung Bachelorseinar: Graphiken in R Visualisierung Kategorialer Daten Matthias Mitterayer betreut durch Sebastian Kaiser Einführung Institut für Statistik, LMU München 13. Januar 2011 Fazit Visualisierung
Gliederung Bachelorseinar: Graphiken in R Visualisierung Kategorialer Daten Matthias Mitterayer betreut durch Sebastian Kaiser Einführung Institut für Statistik, LMU München 13. Januar 2011 Fazit Visualisierung
Vorlesung Algorithmische Geometrie. Streckenschnitte. Martin Nöllenburg 19.04.2011
 Vorlesung Algorithmische Geometrie LEHRSTUHL FÜR ALGORITHMIK I INSTITUT FÜR THEORETISCHE INFORMATIK FAKULTÄT FÜR INFORMATIK Martin Nöllenburg 19.04.2011 Überlagern von Kartenebenen Beispiel: Gegeben zwei
Vorlesung Algorithmische Geometrie LEHRSTUHL FÜR ALGORITHMIK I INSTITUT FÜR THEORETISCHE INFORMATIK FAKULTÄT FÜR INFORMATIK Martin Nöllenburg 19.04.2011 Überlagern von Kartenebenen Beispiel: Gegeben zwei
Kernel, Perceptron, Regression. Erich Schubert, Arthur Zimek. 2014-07-20 KDD Übung
 Kernel, Perceptron, Regression Erich Schubert, Arthur Zimek Ludwig-Maximilians-Universität München 2014-07-20 KDD Übung Kernel-Fukctionen Kernel kann mehrdeutig sein! Unterscheidet zwischen: Kernel function
Kernel, Perceptron, Regression Erich Schubert, Arthur Zimek Ludwig-Maximilians-Universität München 2014-07-20 KDD Übung Kernel-Fukctionen Kernel kann mehrdeutig sein! Unterscheidet zwischen: Kernel function
Einführung in die Cluster-Analyse mit SAS
 Einführung in die Cluster-Analyse mit SAS Benutzertreffen am URZ Carina Ortseifen 4. Juli 2003 Inhalt 1. Clusteranalyse im allgemeinen Definition, Distanzmaße, Gruppierung, Kriterien 2. Clusteranalyse
Einführung in die Cluster-Analyse mit SAS Benutzertreffen am URZ Carina Ortseifen 4. Juli 2003 Inhalt 1. Clusteranalyse im allgemeinen Definition, Distanzmaße, Gruppierung, Kriterien 2. Clusteranalyse
Statistik und Wahrscheinlichkeitsrechnung
 Statistik und Wahrscheinlichkeitsrechnung Übung 2 28.02.2008 1 Inhalt der heutigen Übung Beschreibende Statistik Gemeinsames Lösen der Übungsaufgaben 2.1: Häufigkeitsverteilung 2.2: Tukey Boxplot 25:Korrelation
Statistik und Wahrscheinlichkeitsrechnung Übung 2 28.02.2008 1 Inhalt der heutigen Übung Beschreibende Statistik Gemeinsames Lösen der Übungsaufgaben 2.1: Häufigkeitsverteilung 2.2: Tukey Boxplot 25:Korrelation
Produktentwicklung damit sollten Sie rechnen
 Produktentwicklung damit sollten Sie rechnen 0. Zusammenfassung Wer Produktentwicklung betreiben will, muss in erster Linie sehr viel lesen: Dokumente aus unterschiedlichsten Quellen und in vielen Formaten.
Produktentwicklung damit sollten Sie rechnen 0. Zusammenfassung Wer Produktentwicklung betreiben will, muss in erster Linie sehr viel lesen: Dokumente aus unterschiedlichsten Quellen und in vielen Formaten.
a) Zeichnen Sie in das nebenstehende Streudiagramm mit Lineal eine Regressionsgerade ein, die Sie für passend halten.
 Zeichnen Sie in das nebenstehende Streudiagramm mit Lineal eine Regressionsgerade ein, die Sie für passend halten.") Statistik für Kommunikationswissenschaftler Wintersemester 2009/200 Vorlesung Prof. Dr. Helmut Küchenhoff Übung Cornelia Oberhauser, Monia Mahling, Juliane Manitz Thema 4 Homepage zur Veranstaltung: http://www.statistik.lmu.de/~helmut/kw09.html
Statistik für Kommunikationswissenschaftler Wintersemester 2009/200 Vorlesung Prof. Dr. Helmut Küchenhoff Übung Cornelia Oberhauser, Monia Mahling, Juliane Manitz Thema 4 Homepage zur Veranstaltung: http://www.statistik.lmu.de/~helmut/kw09.html
Data Mining als Arbeitsprozess
 Data Mining als Arbeitsprozess Hagen Knaf Studiengang Angewandte Mathematik Hochschule RheinMain 31. Dezember 2015 In Unternehmen werden umfangreichere Aktivitäten oder Projekte im Bereich des Data Mining
Data Mining als Arbeitsprozess Hagen Knaf Studiengang Angewandte Mathematik Hochschule RheinMain 31. Dezember 2015 In Unternehmen werden umfangreichere Aktivitäten oder Projekte im Bereich des Data Mining
Zusammenhänge zwischen metrischen Merkmalen
 Zusammenhänge zwischen metrischen Merkmalen Darstellung des Zusammenhangs, Korrelation und Regression Daten liegen zu zwei metrischen Merkmalen vor: Datenpaare (x i, y i ), i = 1,..., n Beispiel: x: Anzahl
Zusammenhänge zwischen metrischen Merkmalen Darstellung des Zusammenhangs, Korrelation und Regression Daten liegen zu zwei metrischen Merkmalen vor: Datenpaare (x i, y i ), i = 1,..., n Beispiel: x: Anzahl
Rekonstruktion 3D-Datensätze
 Rekonstruktion 3D-Datensätze Messung von 2D Projektionsdaten von einer 3D Aktivitätsverteilung Bekannt sind: räumliche Anordnung der Detektoren/Projektionsflächen ->Ziel: Bestimmung der 3D-Aktivitätsverteilung
Rekonstruktion 3D-Datensätze Messung von 2D Projektionsdaten von einer 3D Aktivitätsverteilung Bekannt sind: räumliche Anordnung der Detektoren/Projektionsflächen ->Ziel: Bestimmung der 3D-Aktivitätsverteilung
Die DOE-Funktionen im Assistenten führen Benutzer durch einen sequenziellen Prozess zum Entwerfen und Analysieren eines oder mehrerer Experimente, in
 Dieses White Paper ist Teil einer Reihe von Veröffentlichungen, welche die Forschungsarbeiten der Minitab-Statistiker erläutern, in deren Rahmen die im Assistenten der Minitab 17 Statistical Software verwendeten
Dieses White Paper ist Teil einer Reihe von Veröffentlichungen, welche die Forschungsarbeiten der Minitab-Statistiker erläutern, in deren Rahmen die im Assistenten der Minitab 17 Statistical Software verwendeten
Data Mining - Clustering. Sven Elvers
 Agenda Data Mining Clustering Aktuelle Arbeiten Thesis Outline 2 Agenda Data Mining Clustering Aktuelle Arbeiten Thesis Outline 3 Data Mining Entdecken versteckter Informationen, Muster und Zusammenhänge
Agenda Data Mining Clustering Aktuelle Arbeiten Thesis Outline 2 Agenda Data Mining Clustering Aktuelle Arbeiten Thesis Outline 3 Data Mining Entdecken versteckter Informationen, Muster und Zusammenhänge
Seminar Komplexe Objekte in Datenbanken
 Seminar Komplexe Objekte in Datenbanken OPTICS: Ordering Points To Identify the Clustering Structure Lehrstuhl für Informatik IX - Univ.-Prof. Dr. Thomas Seidl, RWTH-Aachen http://www-i9.informatik.rwth-aachen.de
Seminar Komplexe Objekte in Datenbanken OPTICS: Ordering Points To Identify the Clustering Structure Lehrstuhl für Informatik IX - Univ.-Prof. Dr. Thomas Seidl, RWTH-Aachen http://www-i9.informatik.rwth-aachen.de
Elemente der Analysis II
 Elemente der Analysis II Kapitel 3: Lineare Abbildungen und Gleichungssysteme Informationen zur Vorlesung: http://www.mathematik.uni-trier.de/ wengenroth/ J. Wengenroth () 15. Mai 2009 1 / 35 3.1 Beispiel
Elemente der Analysis II Kapitel 3: Lineare Abbildungen und Gleichungssysteme Informationen zur Vorlesung: http://www.mathematik.uni-trier.de/ wengenroth/ J. Wengenroth () 15. Mai 2009 1 / 35 3.1 Beispiel
StatStream : Statistical Monitoring of Thousands of Data Streams in Real Time Yunyue Zhu,Dennis Sasha. Vorgetragen von Matthias Altmann
 StatStream : Statistical Monitoring of Thousands of Data Streams in Real Time Yunyue Zhu,Dennis Sasha Vorgetragen von Matthias Altmann Mehrfache Datenströme Beispiel Luft und Raumfahrttechnik: Space Shuttle
StatStream : Statistical Monitoring of Thousands of Data Streams in Real Time Yunyue Zhu,Dennis Sasha Vorgetragen von Matthias Altmann Mehrfache Datenströme Beispiel Luft und Raumfahrttechnik: Space Shuttle
Die Stammzellhierarchie akuter Leukämien des Kindesalters
 Die Stammzellhierarchie akuter Leukämien des Kindesalters - biologische Grundlagen und klinische Implikationen - Priv.-Doz. Dr. med. Josef Vormoor Klinik und Poliklinik für Kinderheilkunde - Pädiatrische
Die Stammzellhierarchie akuter Leukämien des Kindesalters - biologische Grundlagen und klinische Implikationen - Priv.-Doz. Dr. med. Josef Vormoor Klinik und Poliklinik für Kinderheilkunde - Pädiatrische
Häufigkeitstabellen. Balken- oder Kreisdiagramme. kritischer Wert für χ2-test. Kontingenztafeln
 Häufigkeitstabellen Menüpunkt Data PivotTable Report (bzw. entsprechendes Icon): wähle Data Range (Zellen, die die Daten enthalten + Zelle mit Variablenname) wähle kategoriale Variable für Spalten- oder
Häufigkeitstabellen Menüpunkt Data PivotTable Report (bzw. entsprechendes Icon): wähle Data Range (Zellen, die die Daten enthalten + Zelle mit Variablenname) wähle kategoriale Variable für Spalten- oder
Versuchsplanung. Inhalt. Grundlagen. Faktor-Effekt. Allgemeine faktorielle Versuchspläne. Zweiwertige faktorielle Versuchspläne
 Inhalt Versuchsplanung Faktorielle Versuchspläne Dr. Tobias Kiesling Allgemeine faktorielle Versuchspläne Faktorielle Versuchspläne mit zwei Faktoren Erweiterungen Zweiwertige
Inhalt Versuchsplanung Faktorielle Versuchspläne Dr. Tobias Kiesling Allgemeine faktorielle Versuchspläne Faktorielle Versuchspläne mit zwei Faktoren Erweiterungen Zweiwertige
Cluster #4 stellt sich (was) vor...
 vor...") Cluster #4 stellt sich (was) vor... Ausgangssituation Der Cluster Experimental Therapy & Drug Resistance vertritt ein zentrales Thema Schwerpunkt an der Schnittfläche zwischen experimenteller und klinischer
Cluster #4 stellt sich (was) vor... Ausgangssituation Der Cluster Experimental Therapy & Drug Resistance vertritt ein zentrales Thema Schwerpunkt an der Schnittfläche zwischen experimenteller und klinischer
BERGISCHE UNIVERSITÄT WUPPERTAL FB B: SCHUMPETER SCHOOL OF BUSINESS AND ECONOMICS
 Name: Vorname: Matrikel-Nr.: BERGISCHE UNIVERSITÄT WUPPERTAL FB B: SCHUMPETER SCHOOL OF BUSINESS AND ECONOMICS Prüfungsgebiet: MWiWi 1.6 Logistik- und Informationsmanagement Wirtschaftsinformatik Modul
Name: Vorname: Matrikel-Nr.: BERGISCHE UNIVERSITÄT WUPPERTAL FB B: SCHUMPETER SCHOOL OF BUSINESS AND ECONOMICS Prüfungsgebiet: MWiWi 1.6 Logistik- und Informationsmanagement Wirtschaftsinformatik Modul
Korrelation - Regression. Berghold, IMI
 Korrelation - Regression Zusammenhang zwischen Variablen Bivariate Datenanalyse - Zusammenhang zwischen 2 stetigen Variablen Korrelation Einfaches lineares Regressionsmodell 1. Schritt: Erstellung eines
Korrelation - Regression Zusammenhang zwischen Variablen Bivariate Datenanalyse - Zusammenhang zwischen 2 stetigen Variablen Korrelation Einfaches lineares Regressionsmodell 1. Schritt: Erstellung eines
Planen mit mathematischen Modellen 00844: Computergestützte Optimierung. Autor: Dr. Heinz Peter Reidmacher
 Planen mit mathematischen Modellen 00844: Computergestützte Optimierung Leseprobe Autor: Dr. Heinz Peter Reidmacher 11 - Portefeuilleanalyse 61 11 Portefeuilleanalyse 11.1 Das Markowitz Modell Die Portefeuilleanalyse
Planen mit mathematischen Modellen 00844: Computergestützte Optimierung Leseprobe Autor: Dr. Heinz Peter Reidmacher 11 - Portefeuilleanalyse 61 11 Portefeuilleanalyse 11.1 Das Markowitz Modell Die Portefeuilleanalyse
Datenbankanwendung. Prof. Dr.-Ing. Sebastian Michel TU Kaiserslautern. Wintersemester 2014/15. smichel@cs.uni-kl.de
 Datenbankanwendung Wintersemester 2014/15 Prof. Dr.-Ing. Sebastian Michel TU Kaiserslautern smichel@cs.uni-kl.de Wiederholung: Anfragegraph Anfragen dieses Typs können als Graph dargestellt werden: Der
Datenbankanwendung Wintersemester 2014/15 Prof. Dr.-Ing. Sebastian Michel TU Kaiserslautern smichel@cs.uni-kl.de Wiederholung: Anfragegraph Anfragen dieses Typs können als Graph dargestellt werden: Der
V 2 B, C, D Drinks. Möglicher Lösungsweg a) Gleichungssystem: 300x + 400 y = 520 300x + 500y = 597,5 2x3 Matrix: Energydrink 0,7 Mineralwasser 0,775,
 Gleichungssystem: 300x + 400 y = 520 300x + 500y = 597,5 2x3 Matrix: Energydrink 0,7 Mineralwasser 0,775,") Aufgabenpool für angewandte Mathematik / 1. Jahrgang V B, C, D Drinks Ein gastronomischer Betrieb kauft 300 Dosen Energydrinks (0,3 l) und 400 Liter Flaschen Mineralwasser und zahlt dafür 50, Euro. Einen
Aufgabenpool für angewandte Mathematik / 1. Jahrgang V B, C, D Drinks Ein gastronomischer Betrieb kauft 300 Dosen Energydrinks (0,3 l) und 400 Liter Flaschen Mineralwasser und zahlt dafür 50, Euro. Einen
90-minütige Klausur Statistik für Studierende der Kommunikationswissenschaft
 Prof. Dr. Helmut Küchenhoff SS08 90-minütige Klausur Statistik für Studierende der Kommunikationswissenschaft am 22.7.2008 Anmerkungen Überprüfen Sie bitte sofort, ob Ihre Angabe vollständig ist. Sie sollte
Prof. Dr. Helmut Küchenhoff SS08 90-minütige Klausur Statistik für Studierende der Kommunikationswissenschaft am 22.7.2008 Anmerkungen Überprüfen Sie bitte sofort, ob Ihre Angabe vollständig ist. Sie sollte
Methoden zur Visualisierung von Ergebnissen aus Optimierungs- und DOE-Studien
 Methoden zur Visualisierung von Ergebnissen aus Optimierungs- und DOE-Studien Katharina Witowski katharina.witowski@dynamore.de Übersicht Beispiel Allgemeines zum LS-OPT Viewer Visualisierung von Simulationsergebnissen
Methoden zur Visualisierung von Ergebnissen aus Optimierungs- und DOE-Studien Katharina Witowski katharina.witowski@dynamore.de Übersicht Beispiel Allgemeines zum LS-OPT Viewer Visualisierung von Simulationsergebnissen
Bioinformatik Statistik und Analyse mit R 22.05.2009-1 -
 Bioinformatik Statistik und Analyse mit R 22.05.2009-1 - Definition: Bioinformatik Die Bioinformatik http://de.wikipedia.org/wiki/bioinformatik (englisch bioinformatics, auch computational biology) ist
Bioinformatik Statistik und Analyse mit R 22.05.2009-1 - Definition: Bioinformatik Die Bioinformatik http://de.wikipedia.org/wiki/bioinformatik (englisch bioinformatics, auch computational biology) ist
Entscheidungsunterstützende Systeme
 Entscheidungsunterstützende Systeme (WS 015/016) Klaus Berberich (klaus.berberich@htwsaar.de) Rainer Lenz (rainer.lenz@htwsaar.de) 0. Organisatorisches Dozenten Klaus Berberich (klaus.berberich@htwsaar.de)
Entscheidungsunterstützende Systeme (WS 015/016) Klaus Berberich (klaus.berberich@htwsaar.de) Rainer Lenz (rainer.lenz@htwsaar.de) 0. Organisatorisches Dozenten Klaus Berberich (klaus.berberich@htwsaar.de)
fh management, communication & it Constantin von Craushaar fh-management, communication & it Statistik Angewandte Statistik
 fh management, communication & it Folie 1 Angewandte Statistik Übersicht Semester 1 Einführung ins SPSS Auswertung im SPSS anhand eines einfachen Beispieles Häufigkeitsauswertungen Grafiken Datenmanipulationen
fh management, communication & it Folie 1 Angewandte Statistik Übersicht Semester 1 Einführung ins SPSS Auswertung im SPSS anhand eines einfachen Beispieles Häufigkeitsauswertungen Grafiken Datenmanipulationen
Kapitel 4: Data Mining
 LUDWIG- MAXIMILIANS- UNIVERSITY MUNICH DEPARTMENT INSTITUTE FOR INFORMATICS Skript zur Vorlesung: Einführung in die Informatik: Systeme und Anwendungen Sommersemester 2013 Kapitel 4: Data Mining i Vorlesung:
LUDWIG- MAXIMILIANS- UNIVERSITY MUNICH DEPARTMENT INSTITUTE FOR INFORMATICS Skript zur Vorlesung: Einführung in die Informatik: Systeme und Anwendungen Sommersemester 2013 Kapitel 4: Data Mining i Vorlesung:
Eine vorprozessierte Variante von Scatter/Gather
 Universität Duisburg-Essen, Standort Duisburg Institut für Informatik und interaktive Systeme Fachgebiet Informationssysteme Ausarbeitung zum Blockseminar Invisible Web Eine vorprozessierte Variante von
Universität Duisburg-Essen, Standort Duisburg Institut für Informatik und interaktive Systeme Fachgebiet Informationssysteme Ausarbeitung zum Blockseminar Invisible Web Eine vorprozessierte Variante von
Neue Wege zur Reduktion der Antibiotikaverordnung bei Atemwegsinfektionen.
 Neue Wege zur Reduktion der Antibiotikaverordnung bei Atemwegsinfektionen. Reduktion der Antibiotikaverordnungen bei akuten Atemwegserkrankungen 1. Basis für rationale Antibiotikaverordnungen: Leitlinien
Neue Wege zur Reduktion der Antibiotikaverordnung bei Atemwegsinfektionen. Reduktion der Antibiotikaverordnungen bei akuten Atemwegserkrankungen 1. Basis für rationale Antibiotikaverordnungen: Leitlinien
Computer Vision: 3D-Geometrie. D. Schlesinger () Computer Vision: 3D-Geometrie 1 / 17
 Computer Vision: 3D-Geometrie 1 / 17") Computer Vision: 3D-Geometrie D. Schlesinger () Computer Vision: 3D-Geometrie 1 / 17 Lochkamera Modell C Projektionszentrum, Optische Achse, Bildebene, P Hauptpunkt (optische Achse kreuzt die Bildebene),
Computer Vision: 3D-Geometrie D. Schlesinger () Computer Vision: 3D-Geometrie 1 / 17 Lochkamera Modell C Projektionszentrum, Optische Achse, Bildebene, P Hauptpunkt (optische Achse kreuzt die Bildebene),
mi-rna, zirkulierende DNA
 Erbsubstanz: Grundlagen und Klinik mi-rna, zirkulierende DNA 26.11.2010 Ingolf Juhasz-Böss Homburg / Saar Klinische Erfahrungen zirkulierende mirna erstmals 2008 im Serum von B-Zell Lymphomen beschrieben
Erbsubstanz: Grundlagen und Klinik mi-rna, zirkulierende DNA 26.11.2010 Ingolf Juhasz-Böss Homburg / Saar Klinische Erfahrungen zirkulierende mirna erstmals 2008 im Serum von B-Zell Lymphomen beschrieben
6. Künstliche Intelligenz
 6.1. Turing-Test 6.2. Lernen In diesem Abschnitt besprechen wir wie man an Hand von Beispielen lernt, Objekte zu erkennen und verschiedene Dinge voneinander zu unterscheiden. Diese sogenannte Mustererkennung
6.1. Turing-Test 6.2. Lernen In diesem Abschnitt besprechen wir wie man an Hand von Beispielen lernt, Objekte zu erkennen und verschiedene Dinge voneinander zu unterscheiden. Diese sogenannte Mustererkennung
Visualisierung und Vergleich der Clusterverfahren anhand von QEBS-Daten
 Bachelorarbeit Visualisierung und Vergleich der Clusterverfahren anhand von QEBS-Daten zur Erlangung des Grades Bachelor of Science von Sophia Hendriks (Matrikelnummer: 182984) Studiengang Statistik eingereicht
Bachelorarbeit Visualisierung und Vergleich der Clusterverfahren anhand von QEBS-Daten zur Erlangung des Grades Bachelor of Science von Sophia Hendriks (Matrikelnummer: 182984) Studiengang Statistik eingereicht
Mustererkennung in Energieverbrauchsdaten
 Mustererkennung in Energieverbrauchsdaten Ein Modul für die Energiemanagement-Software IngSoft InterWatt Karsten Reese & Dr. Roberto Monetti Mustererkennung in Energieverbrauchsdaten, 22. März 2015 Folie
Mustererkennung in Energieverbrauchsdaten Ein Modul für die Energiemanagement-Software IngSoft InterWatt Karsten Reese & Dr. Roberto Monetti Mustererkennung in Energieverbrauchsdaten, 22. März 2015 Folie
Teil II. Nichtlineare Optimierung
 Teil II Nichtlineare Optimierung 60 Kapitel 1 Einleitung In diesem Abschnitt wird die Optimierung von Funktionen min {f(x)} x Ω betrachtet, wobei Ω R n eine abgeschlossene Menge und f : Ω R eine gegebene
Teil II Nichtlineare Optimierung 60 Kapitel 1 Einleitung In diesem Abschnitt wird die Optimierung von Funktionen min {f(x)} x Ω betrachtet, wobei Ω R n eine abgeschlossene Menge und f : Ω R eine gegebene
SUDOKU - Strategien zur Lösung
 SUDOKU Strategien v. /00 SUDOKU - Strategien zur Lösung. Naked Single (Eindeutiger Wert)? "Es gibt nur einen einzigen Wert, der hier stehen kann". Sind alle anderen Werte bis auf einen für eine Zelle unmöglich,
SUDOKU Strategien v. /00 SUDOKU - Strategien zur Lösung. Naked Single (Eindeutiger Wert)? "Es gibt nur einen einzigen Wert, der hier stehen kann". Sind alle anderen Werte bis auf einen für eine Zelle unmöglich,
Clustering mit dem K-Means-Algorithmus (Ein Experiment)
") Clustering mit dem K-Means- (Ein Experiment) Andreas Runk 7. März 2013 Index 1 2 3 4 5 Andreas Runk Clustering mit dem K-Means- 2/40 Ziele: des K-Means Finde/erstelle geeignetes Testcorpus möglichst gute
Clustering mit dem K-Means- (Ein Experiment) Andreas Runk 7. März 2013 Index 1 2 3 4 5 Andreas Runk Clustering mit dem K-Means- 2/40 Ziele: des K-Means Finde/erstelle geeignetes Testcorpus möglichst gute
Diagrammtypen. 8. Dezember 2012
 Diagrammtypen 8. Dezember 212 DIAGRAMME AUSWAHLMATRIX Zur einfachen Bestimmung eines geeigneten Diagrammtypen sollten Sie sich nach dem Sammeln und Eingeben der Daten fragen, welche Aussage ihr Diagramm
Diagrammtypen 8. Dezember 212 DIAGRAMME AUSWAHLMATRIX Zur einfachen Bestimmung eines geeigneten Diagrammtypen sollten Sie sich nach dem Sammeln und Eingeben der Daten fragen, welche Aussage ihr Diagramm
MATHEMATISCHE ANALYSE VON ALGORITHMEN
 MATHEMATISCHE ANALYSE VON ALGORITHMEN Michael Drmota Institut für Diskrete Mathematik und Geometrie, TU Wien michael.drmota@tuwien.ac.at www.dmg.tuwien.ac.at/drmota/ Ringvorlesung SS 2008, TU Wien Algorithmus
MATHEMATISCHE ANALYSE VON ALGORITHMEN Michael Drmota Institut für Diskrete Mathematik und Geometrie, TU Wien michael.drmota@tuwien.ac.at www.dmg.tuwien.ac.at/drmota/ Ringvorlesung SS 2008, TU Wien Algorithmus
Seminar Visual Analytics and Visual Data Mining
 Seminar Visual Analytics and Visual Data Mining Dozenten:, AG Visual Computing Steffen Oeltze, AG Visualisierung Organisatorisches Seminar für Diplom und Bachelor-Studenten (max. 18) (leider nicht für
Seminar Visual Analytics and Visual Data Mining Dozenten:, AG Visual Computing Steffen Oeltze, AG Visualisierung Organisatorisches Seminar für Diplom und Bachelor-Studenten (max. 18) (leider nicht für
Proseminar - Data Mining
 Proseminar - Data Mining SCCS, Fakultät für Informatik Technische Universität München SS 2014, SS 2014 1 Data Mining: Beispiele (1) Hausnummererkennung (Klassifikation) Source: http://arxiv.org/abs/1312.6082,
Proseminar - Data Mining SCCS, Fakultät für Informatik Technische Universität München SS 2014, SS 2014 1 Data Mining: Beispiele (1) Hausnummererkennung (Klassifikation) Source: http://arxiv.org/abs/1312.6082,
Identifizierung und Schutz von Waldbeständen mit vorrangiger Bedeutung für den Erhalt der Biodiversität
 Identifizierung und Schutz von Waldbeständen mit vorrangiger Bedeutung für den Erhalt der Biodiversität Ergebnisse der Habitatmodellierung und der systematischer Schutzgebietsplanung Flintbek, den 16.
Identifizierung und Schutz von Waldbeständen mit vorrangiger Bedeutung für den Erhalt der Biodiversität Ergebnisse der Habitatmodellierung und der systematischer Schutzgebietsplanung Flintbek, den 16.
Personalisierung. Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung. Data Mining.
 Personalisierung Personalisierung Thomas Mandl Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung Klassifikation Die Nutzer werden in vorab bestimmte Klassen/Nutzerprofilen
Personalisierung Personalisierung Thomas Mandl Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung Klassifikation Die Nutzer werden in vorab bestimmte Klassen/Nutzerprofilen
Large-Scale Image Search
 Large-Scale Image Search Visuelle Bildsuche in sehr großen Bildsammlungen Media Mining I Multimedia Computing, Universität Augsburg Rainer.Lienhart@informatik.uni-augsburg.de www.multimedia-computing.{de,org}
Large-Scale Image Search Visuelle Bildsuche in sehr großen Bildsammlungen Media Mining I Multimedia Computing, Universität Augsburg Rainer.Lienhart@informatik.uni-augsburg.de www.multimedia-computing.{de,org}
Data-Mining: Ausgewählte Verfahren und Werkzeuge
 Fakultät Informatik Institut für Angewandte Informatik Lehrstuhl Technische Informationssysteme Data-Mining: Ausgewählte Verfahren und Vortragender: Jia Mu Betreuer: Dipl.-Inf. Denis Stein Dresden, den
Fakultät Informatik Institut für Angewandte Informatik Lehrstuhl Technische Informationssysteme Data-Mining: Ausgewählte Verfahren und Vortragender: Jia Mu Betreuer: Dipl.-Inf. Denis Stein Dresden, den
Unsupervised Kernel Regression
 9. Mai 26 Inhalt Nichtlineare Dimensionsreduktion mittels UKR (Unüberwachte KernRegression, 25) Anknüpfungspunkte Datamining I: PCA + Hauptkurven Benötigte Zutaten Klassische Kernregression Kerndichteschätzung
9. Mai 26 Inhalt Nichtlineare Dimensionsreduktion mittels UKR (Unüberwachte KernRegression, 25) Anknüpfungspunkte Datamining I: PCA + Hauptkurven Benötigte Zutaten Klassische Kernregression Kerndichteschätzung
Einfache Statistiken in Excel
 Einfache Statistiken in Excel Dipl.-Volkswirtin Anna Miller Bergische Universität Wuppertal Schumpeter School of Business and Economics Lehrstuhl für Internationale Wirtschaft und Regionalökonomik Raum
Einfache Statistiken in Excel Dipl.-Volkswirtin Anna Miller Bergische Universität Wuppertal Schumpeter School of Business and Economics Lehrstuhl für Internationale Wirtschaft und Regionalökonomik Raum
Maschinelles Lernen: Neuronale Netze. Ideen der Informatik Kurt Mehlhorn
 Maschinelles Lernen: Neuronale Netze Ideen der Informatik Kurt Mehlhorn 16. Januar 2014 Übersicht Stand der Kunst im Bilderverstehen: Klassifizieren und Suchen Was ist ein Bild in Rohform? Biologische
Maschinelles Lernen: Neuronale Netze Ideen der Informatik Kurt Mehlhorn 16. Januar 2014 Übersicht Stand der Kunst im Bilderverstehen: Klassifizieren und Suchen Was ist ein Bild in Rohform? Biologische
Funktionaler Zusammenhang. Lehrplan Realschule
 Funktionaler Bildungsstandards Lehrplan Realschule Die Schülerinnen und Schüler nutzen Funktionen als Mittel zur Beschreibung quantitativer Zusammenhänge, erkennen und beschreiben funktionale Zusammenhänge
Funktionaler Bildungsstandards Lehrplan Realschule Die Schülerinnen und Schüler nutzen Funktionen als Mittel zur Beschreibung quantitativer Zusammenhänge, erkennen und beschreiben funktionale Zusammenhänge
Lineare Modelle in R: Einweg-Varianzanalyse
 Lineare Modelle in R: Einweg-Varianzanalyse Achim Zeileis 2009-02-20 1 Datenaufbereitung Wie schon in der Vorlesung wollen wir hier zur Illustration der Einweg-Analyse die logarithmierten Ausgaben der
Lineare Modelle in R: Einweg-Varianzanalyse Achim Zeileis 2009-02-20 1 Datenaufbereitung Wie schon in der Vorlesung wollen wir hier zur Illustration der Einweg-Analyse die logarithmierten Ausgaben der
Anfrage Erweiterung 03.11.2011 Jan Schrader
 Anfrage Erweiterung 03.11.2011 Jan Schrader Vocabulary Mismatch Problem Anfrage und Dokument passen nicht zusammen obwohl Dokument zur Anfrage relevant Grund: Synonymproblem verschiedene Menschen benennen
Anfrage Erweiterung 03.11.2011 Jan Schrader Vocabulary Mismatch Problem Anfrage und Dokument passen nicht zusammen obwohl Dokument zur Anfrage relevant Grund: Synonymproblem verschiedene Menschen benennen
Entscheidungsbäume. Definition Entscheidungsbaum. Frage: Gibt es einen Sortieralgorithmus mit o(n log n) Vergleichen?
 Vergleichen?") Entscheidungsbäume Frage: Gibt es einen Sortieralgorithmus mit o(n log n) Vergleichen? Definition Entscheidungsbaum Sei T ein Binärbaum und A = {a 1,..., a n } eine zu sortierenden Menge. T ist ein Entscheidungsbaum
Entscheidungsbäume Frage: Gibt es einen Sortieralgorithmus mit o(n log n) Vergleichen? Definition Entscheidungsbaum Sei T ein Binärbaum und A = {a 1,..., a n } eine zu sortierenden Menge. T ist ein Entscheidungsbaum
Clustering algorithms (Overview)
") Seminar Algorithmen zum Wirkstoffdesign Clustering algorithms (Overview) Matthias Zschunke 14. Dezember 2003 Zusammenfassung Aufgaben wie Genomics, Proteomics oder auch die Suche nach neuen pharmakophoren
Seminar Algorithmen zum Wirkstoffdesign Clustering algorithms (Overview) Matthias Zschunke 14. Dezember 2003 Zusammenfassung Aufgaben wie Genomics, Proteomics oder auch die Suche nach neuen pharmakophoren
Eine Kurzanleitung zu Mathematica
 MOSES Projekt, GL, Juni 2003 Eine Kurzanleitung zu Mathematica Wir geben im Folgenden eine sehr kurze Einführung in die Möglichkeiten, die das Computer Algebra System Mathematica bietet. Diese Datei selbst
MOSES Projekt, GL, Juni 2003 Eine Kurzanleitung zu Mathematica Wir geben im Folgenden eine sehr kurze Einführung in die Möglichkeiten, die das Computer Algebra System Mathematica bietet. Diese Datei selbst
8. Clusterbildung, Klassifikation und Mustererkennung
 8. Clusterbildung, Klassifikation und Mustererkennung Begriffsklärung (nach Voss & Süße 1991): Objekt: wird in diesem Kapitel mit einem zugeordneten Merkmalstupel (x 1,..., x M ) identifiziert (Merkmalsextraktion
8. Clusterbildung, Klassifikation und Mustererkennung Begriffsklärung (nach Voss & Süße 1991): Objekt: wird in diesem Kapitel mit einem zugeordneten Merkmalstupel (x 1,..., x M ) identifiziert (Merkmalsextraktion
Motivation. Themenblock: Klassifikation. Binäre Entscheidungsbäume. Ansätze. Praktikum: Data Warehousing und Data Mining.
 Motivation Themenblock: Klassifikation Praktikum: Data Warehousing und Data Mining Ziel Item hat mehrere Attribute Anhand von n Attributen wird (n+)-tes vorhergesagt. Zusätzliches Attribut erst später
Motivation Themenblock: Klassifikation Praktikum: Data Warehousing und Data Mining Ziel Item hat mehrere Attribute Anhand von n Attributen wird (n+)-tes vorhergesagt. Zusätzliches Attribut erst später
Cluster-Analyse Ziel: Anwendungsbereiche: Nutzen: Bezug zur Statistik: Bezug zu maschinellem Lernen:
 Cluster-Analyse Ziel: Analyse von Daten ohne Klassenzugehörigkeit (mit Klassen siehe Klassifikation). Objekte werden so zu Clustern zusammengefasst, dass innerhalb eines Clusters die Objekte möglichst
Cluster-Analyse Ziel: Analyse von Daten ohne Klassenzugehörigkeit (mit Klassen siehe Klassifikation). Objekte werden so zu Clustern zusammengefasst, dass innerhalb eines Clusters die Objekte möglichst
Morphologie auf Binärbildern
 Morphologie auf Binärbildern WS07 5.1 Konen, Zielke WS07 5.2 Konen, Zielke Motivation Aufgabe: Objekte zählen Probleme: "Salt-&-Pepper"-Rauschen erzeugt falsche Objekte Verschmelzen richtiger Objekte durch
Morphologie auf Binärbildern WS07 5.1 Konen, Zielke WS07 5.2 Konen, Zielke Motivation Aufgabe: Objekte zählen Probleme: "Salt-&-Pepper"-Rauschen erzeugt falsche Objekte Verschmelzen richtiger Objekte durch
FAKTORIELLE VERSUCHSPLÄNE. Andreas Handl
 FAKTORIELLE VERSUCHSPLÄNE Andreas Handl 1 Inhaltsverzeichnis 1 Versuchsplanung 4 2 Einfaktorielle Varianzanalyse 6 2.1 DieAnnahmen... 6 2.2 Die ANOVA-Tabelle und der F -Test... 6 2.3 Versuche mit zwei
FAKTORIELLE VERSUCHSPLÄNE Andreas Handl 1 Inhaltsverzeichnis 1 Versuchsplanung 4 2 Einfaktorielle Varianzanalyse 6 2.1 DieAnnahmen... 6 2.2 Die ANOVA-Tabelle und der F -Test... 6 2.3 Versuche mit zwei
Proseminar Künstliche Intelligenz
 Proseminar Künstliche Intelligenz Data-Mining Tobias Loose Roy Thieme 20. Dezember 2011 1 / 51 Inhaltsverzeichnis 1 Einleitung 2 Empfehlungen Metriken Dinge Empfehlen 3 Clusteranalyse Hierarchische Clusteranalyse
Proseminar Künstliche Intelligenz Data-Mining Tobias Loose Roy Thieme 20. Dezember 2011 1 / 51 Inhaltsverzeichnis 1 Einleitung 2 Empfehlungen Metriken Dinge Empfehlen 3 Clusteranalyse Hierarchische Clusteranalyse
Datenerfassung und Datenmanagement
 Datenerfassung und Datenmanagement Statistische Auswertungssysteme sind heute eine aus der angewandten Statistik nicht mehr wegzudenkende Hilfe. Dies gilt insbesondere für folgende Aufgabenbereiche: -
Datenerfassung und Datenmanagement Statistische Auswertungssysteme sind heute eine aus der angewandten Statistik nicht mehr wegzudenkende Hilfe. Dies gilt insbesondere für folgende Aufgabenbereiche: -
Algorithms for Regression and Classification
 Fakultät für Informatik Effiziente Algorithmen und Komplexitätstheorie Algorithms for Regression and Classification Robust Regression and Genetic Association Studies Robin Nunkesser Fakultät für Informatik
Fakultät für Informatik Effiziente Algorithmen und Komplexitätstheorie Algorithms for Regression and Classification Robust Regression and Genetic Association Studies Robin Nunkesser Fakultät für Informatik
Studiendesign und Statistik: Interpretation publizierter klinischer Daten
 Studiendesign und Statistik: Interpretation publizierter klinischer Daten Dr. Antje Jahn Institut für Medizinische Biometrie, Epidemiologie und Informatik Universitätsmedizin Mainz Hämatologie im Wandel,
Studiendesign und Statistik: Interpretation publizierter klinischer Daten Dr. Antje Jahn Institut für Medizinische Biometrie, Epidemiologie und Informatik Universitätsmedizin Mainz Hämatologie im Wandel,
4. Diskussion. 4.1. Polymerase-Kettenreaktion
 59 4. Diskussion Bei der Therapie maligner Tumoren stellt die Entwicklung von Kreuzresistenz gegen Zytostatika ein ernstzunehmendes Hindernis dar. Im wesentlich verantwortlich für die so genannte Multidrug
59 4. Diskussion Bei der Therapie maligner Tumoren stellt die Entwicklung von Kreuzresistenz gegen Zytostatika ein ernstzunehmendes Hindernis dar. Im wesentlich verantwortlich für die so genannte Multidrug
Linearer Zusammenhang von Datenreihen
 Linearer Zusammenhang von Datenreihen Vielen Problemen liegen (möglicherweise) lineare Zusammenhänge zugrunde: Mein Internetanbieter verlangt eine Grundgebühr und rechnet minutenweise ab Ich bestelle ein
Linearer Zusammenhang von Datenreihen Vielen Problemen liegen (möglicherweise) lineare Zusammenhänge zugrunde: Mein Internetanbieter verlangt eine Grundgebühr und rechnet minutenweise ab Ich bestelle ein
CBLOCK: An Automatic Blocking Mechanism for Large-Scale De-duplication Tasks. Cathleen Ramson, Stefan Lehmann LSDD SS 2013 25.04.
 CBLOCK: An Automatic Blocking Mechanism for Large-Scale De-duplication Tasks Cathleen Ramson, Stefan Lehmann LSDD SS 2013 25.04.2013 Gliederung 2 Motivation Ziel Algorithmen Zusammenfassung Bewertung Motivation
CBLOCK: An Automatic Blocking Mechanism for Large-Scale De-duplication Tasks Cathleen Ramson, Stefan Lehmann LSDD SS 2013 25.04.2013 Gliederung 2 Motivation Ziel Algorithmen Zusammenfassung Bewertung Motivation
Conjoint Measurement:
 Conjoint Measurement: Eine Erfolgsgeschichte Das Ganze ist mehr als die Summe seiner Teile Leonhard Kehl Paul Green & Vithala Rao (1971) De-Kompositionelle Messung von Präferenzstrukturen aus Gesamt-Urteilen:
Conjoint Measurement: Eine Erfolgsgeschichte Das Ganze ist mehr als die Summe seiner Teile Leonhard Kehl Paul Green & Vithala Rao (1971) De-Kompositionelle Messung von Präferenzstrukturen aus Gesamt-Urteilen:
Weitere Fragestellungen im Zusammenhang mit einer linearen Einfachregression
 Weitere Fragestellungen im Zusammenhang mit einer linearen Einfachregression Speziell im Zusammenhang mit der Ablehnung der Globalhypothese werden bei einer linearen Einfachregression weitere Fragestellungen
Weitere Fragestellungen im Zusammenhang mit einer linearen Einfachregression Speziell im Zusammenhang mit der Ablehnung der Globalhypothese werden bei einer linearen Einfachregression weitere Fragestellungen
Greater occipital nerve block using local anaesthetics alone or with triamcinolone for transformed migraine: a randomised comparative study
 Greater occipital nerve block using local anaesthetics alone or with triamcinolone for transformed migraine: a randomised comparative study A. Ashkenazi, R. Matro, J.W. Shaw, M.A. Abbas, S.D. Silberstein
Greater occipital nerve block using local anaesthetics alone or with triamcinolone for transformed migraine: a randomised comparative study A. Ashkenazi, R. Matro, J.W. Shaw, M.A. Abbas, S.D. Silberstein
Verwendung von OO-Metriken zur Vorhersage
 Verwendung von OO-Metriken zur Vorhersage Tobias Angermayr Übersicht 1. Definitionen 2. Gründe, Anforderungen, Ziele 3. Die CK-Metriken 4. Beobachtungen 5. Studie 6. Zusammenfassung Folie 2 Definitionen
Verwendung von OO-Metriken zur Vorhersage Tobias Angermayr Übersicht 1. Definitionen 2. Gründe, Anforderungen, Ziele 3. Die CK-Metriken 4. Beobachtungen 5. Studie 6. Zusammenfassung Folie 2 Definitionen
Untersuchung der Zusammenhänge zwischen der gebauten Struktur einer Stadt und der
 Ein agentenbasiertes t Simulationsmodell ll zur Untersuchung der Zusammenhänge zwischen der gebauten Struktur einer Stadt und der sozialen Organisation ihrer Bevölkerung Reinhard König, Informatik in der
Ein agentenbasiertes t Simulationsmodell ll zur Untersuchung der Zusammenhänge zwischen der gebauten Struktur einer Stadt und der sozialen Organisation ihrer Bevölkerung Reinhard König, Informatik in der
Die Kinder-Krebs-Initiative Buchholz, Holm-Seppensen (KKI) fördert die Erforschung von Lymphomen und Leukämien bei Kindern
 fördert die Erforschung von Lymphomen und Leukämien bei Kindern") Die Kinder-Krebs-Initiative Buchholz, Holm-Seppensen (KKI) fördert die Erforschung von Lymphomen und Leukämien bei Kindern Krebserkrankungen bei Kindern in Deutschland Wie aus dem Report des Deutschen
Die Kinder-Krebs-Initiative Buchholz, Holm-Seppensen (KKI) fördert die Erforschung von Lymphomen und Leukämien bei Kindern Krebserkrankungen bei Kindern in Deutschland Wie aus dem Report des Deutschen
Einfache statistische Auswertungen mit dem Programm SPSS
 Einfache statistische Auswertungen mit dem Programm SPSS Datensatz: fiktive_daten.sav Dipl. Päd. Anne Haßelkus Dr. Dorothea Dette-Hagenmeyer 11/2011 Überblick 1 Deskriptive Statistiken; Mittelwert berechnen...
Einfache statistische Auswertungen mit dem Programm SPSS Datensatz: fiktive_daten.sav Dipl. Päd. Anne Haßelkus Dr. Dorothea Dette-Hagenmeyer 11/2011 Überblick 1 Deskriptive Statistiken; Mittelwert berechnen...