Decision Trees* von Julia Heise, Philipp Thoms, Hans-Martin Wulfmeyer. *Entscheidungsbäume
|
|
|
- Christina Hochberg
- vor 6 Jahren
- Abrufe
Transkript
1 Decision Trees* von Julia Heise, Philipp Thoms, Hans-Martin Wulfmeyer *Entscheidungsbäume
2 Gliederung 1. Einführung 2. Induktion 3. Beispiel 4. Fazit
3 Einführung 1. Einführung a. Was sind Decision Trees? b. Wo und Wann setzt man sie ein? c. Warum Decision Trees? d. Herausforderungen 2. Induktion 3. Beispiel 4. Fazit
4 Was sind Decision Trees? Instanzen die durch Attribute beschrieben werden als Baum dargestellt gerichtet und nach Aussagekraft der Attribute geordnet Der Baum t sagt die Werte c1,...,cn eines Attributes für die Instanz X voraus t: X -> {c1,...,cn} Regeln für die Zuordnung in Form von if,then Aussagen abgelesen von den Pfaden des Baumes
5 Wo und wann setzt man sie ein? Klassifikation und Regression Bedingungen: Instance Space: Instanzen werden durch Attribute-Werte Paare beschrieben Target Attribute: Sollen zugeordnet werden Target Attribut muss diskret sein klassische Einsatzbeispiele: Test auf Kreditwürdigkeit oder medizinische Diagnosen
6 Warum Decision Trees? Regeln in kürzester Form leicht ablesbar Evaluieren der Attribute läuft bedeutend schneller ab Entscheidungsprozess wird verkürzt

7

8
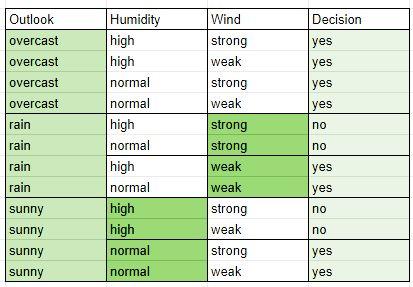
9
 OR (Outlook = Rain AND Wind = Weak) then")
10 Regelbeispiel: if (Outlook = sunny AND Humidity =Normal) OR (Outlook = Overcast ) OR (Outlook = Rain AND Wind = Weak) then Yes
11 Herausforderungen Kann man die Attribute so wählen, dass der Baum möglichst klein ist? Algorithmen um Attribute zu priorisieren Kontinuierliche Attributwerte : Wie viele Bereiche und wie groß? Wie behandelt man Fehler oder fehlende Attributwerte?
12 Induktion 1. Einführung 2. Induktion a. Algorithmen zur Induktion b. Bewertungsmaße zum Splitting 3. Beispiel 4. Fazit
13 Algorithmen zur Induktion ID3 (Iterative Dichotomiser 3) C4.5
14 ID3 Algorithmus (Quinlan, 1979) lernt den Baum von oben nach unten (Top-down) wählt das beste Merkmal zum spalten aus (greedy) beste = Information gain des splits rekursive Anwendung auf Kindknoten
15 ID3 Algorithmus - Pseudocode 1. X das beste Attribute aus allen Attributen 2. X = Spalt -Attribut vom derzeitigen Knoten 3. FÜR ALLE Werte von X erstelle Kindknoten mit zugehörigen Daten 4. Beginne von vorne falls noch Merkmale übrig
16 ID3 Algorithmus - Nachteile lernt meist nur das lokale Optima kann nur mit diskreten Daten arbeiten Problem des Overfitting bzw. Rauschanfälligkeit

17 ID3 Algorithmus - Overfitting
18 ID3 Algorithmus - Overfitting Ansätze Wachsen des Baums ab bestimmter Tiefe stoppen Problem: Wann? Baum induzieren, dann Beschneiden (pruning) des Baums reduced-error pruning post-pruning C4.5 Algorithmus
19 C4.5 "a landmark decision tree program that is probably the machine learning workhorse most widely used in practice to date". - Ian H. Witten; Eibe Frank; Mark A. Hall (2011)
20 C4.5 Algorithmus (Quinlan, 1993) Erweiterung des ID3 Algorithmus löst das Problem des Overfittings behandelt fehlende Attribute in Trainingsbeispielen kann mit kontinuierlichen Werten umgehen
21 C4.5 Algorithmus - Regeln unbekannte Attributwerte: Wahrscheinlichkeit & Gewichtung kontinuierlichen Werte: alle möglichen Splits in Attributwerten erfassen und besten selektieren Post-Pruning (Bottom-Up): Ast im Baum durch Blatt ersetzen wenn erwartete Fehler durch Blatt geringer Ast im Baum durch Teil-Ast ersetzen wenn erwartete Fehler durch Teil-Ast geringer
22 Weitere DT Algorithmen C5.0/See5 kommerzielle & patentgeschützte Weiterentwicklung von C4.5 CART (Classification And Regression Trees) induziert nur binäre Bäume, Gini Index zur Bewertung andere pruning Methode -> cost-complexity model CHAID (chi-square automatic interaction detector) nur diskrete Werte, stoppen des Wachsens ab bestimmter Tiefe
23 Bewertungsmaße Entropie Gini
24 Entropie misst die unreinheit der Menge unserer Beispiele für boolesche Klassifikation: für mehr als zwei Klassen:
25 Entropie - Information Gain beschreibt wie gut ein Merkmal unsere Menge klassifiziert Vergleich der Entropie vor und nach dem Spalten mit Merkmal A genauer beschreibt es die reduzierung der Entropie nach dem Spalten S = Trainingsbeispiele A = ausgewähltes Merkmal/Attribut Values(A) = alle möglichen Werte die A annehmen kann S v = Untermenge von S in der alle Beispiele Merkmal=v haben
26 Information Gain - Gain Ratio normalisiert den Information Gain Probleme: Lösung: nicht definiert wenn der Nenner null ist Gain Ratio favorisiert Attribute mit sehr geringer Entropie Wähle alle Attribute bei denen Information Gain Ø des Information Gain von dieser Menge selektieren wir das beste Attribut anhand des Gain Ratio
27 Gini Impurity misst die homogenität oder Reinheit der Trainingsbeispiele auch als Missklassifikationsrate beschreibbar kleiner = besser P i = relative Häufigkeit der Elemente mit Klasse i J = Menge der möglichen Klassen Gini Impurity Gini Koeffizient
28 Gini Impurity vs Information Gain(Entropie) Gini eher für kontinuierliche Attribute, Entropie eher für diskrete Attribute Unterschied in nur 2% der Fälle im Vergleich Entropie ist etwas langsamer das der Logarithmus berechnet werden muss Ergebnis: macht kaum einen Unterschied welchen wir verwenden
29 Beispiel 1. Einführung 2. Induktion 3. Beispiel 4. Fazit

30 Beispiel PlayTennis mithilfe von ID3
31 Entropy vom Set: Entropy (S)= -9/14*log 2 (9/14) -5/14*log 2 (5/14) = 0.94 Information Gain von Outlook: Gain(S,Outlook) = Entropy(S) - 5/14*Entropy(S Sun ) - 4/14*Entropy(S Rain ) - 5/14*Entropy(S Overcast ) = /14* /14*0-5/14*0,971 Gain(S,Outlook) = 0.246
32 Entropy vom Set: Entropy (S)= -9/14*log 2 (9/14) -5/14*log 2 (5/14) = 0.94 Information Gain: Gain(S, Outlook) = Gain(S, Humidity) = Gain(S, Wind) = Gain(S, Temperature) = Information Gain von Outlook: Gain(S,Outlook) = Entropy(S) - 5/14*Entropy(S Sun ) - 4/14*Entropy(S Rain ) - 5/14*Entropy(S Overcast ) = /14* /14*0-5/14*0,971 Gain(S,Outlook) = 0.246
 =0.97 -(⅗)*0 - (⅖)*0 = 0.97 Gain(S Sun,Temperature) =0.")
33 Overcast ist eindeutig Information gain muss für Sun und Rain neu berechnet werden Bsp. für den linken Ast: S Sun = {D1,D2,D8,D9,D11} Gain(S Sun,Humidity) =0.97 -(⅗)*0 - (⅖)*0 = 0.97 Gain(S Sun,Temperature) = (⅖) *0 - (⅖)*1 - (⅕)*0 = 0.57 Gain(S Sun,Wind) =0.97 -(⅖)*1 - (⅗)*0.981 = 0.019

34 fertiger Baum wenn: Alle Attribute abgelaufen festes Ergebnis (Entropy = 0)
35 Fazit 1. Einführung 2. Induktion 3. Beispiel 4. Fazit
36 Fazit Vorteile Regeln werden einfach abgeleitet Robust, sowohl gegenüber Fehlern in der Klassifikation im Training, als auch bei fehlerhaften Attributwerten Kann einfach zu Random Forest erweitert werden Nachteile Keine gute Klassifizierung für kontinuierliche Targetfunktionen Kontinuierliche Attribute erhöhen den Rechenaufwand stark Kann sehr groß werden Beschneidung ist notwendig Kann an Overfitting leiden
37 Danke für die Aufmerksamkeit! Seht ihr den Wald vor lauter Bäumen nicht mehr, oder habt ihr alles verstanden?
38 Quellen Machine Learning - A Guide to Current Research (1986) Tom Mitchell et. al. Induction of Decision Trees (1985) J.R. Quinlan A comparative study of decision tree ID3 and C4.5 (2014) Badr Hssina et. al. Top 10 algorithms in data mining (2008) Wu, X., Kumar, V., Ross Quinlan, J. et al. Theoretical Comparison between the Gini Index and Information Gain Criteria (2004) Laura Elena Raileanu, Kilian Stoffel
Decision Tree Learning
 Decision Tree Learning Computational Linguistics Universität des Saarlandes Sommersemester 2011 28.04.2011 Entscheidungsbäume Repräsentation von Regeln als Entscheidungsbaum (1) Wann spielt Max Tennis?
Decision Tree Learning Computational Linguistics Universität des Saarlandes Sommersemester 2011 28.04.2011 Entscheidungsbäume Repräsentation von Regeln als Entscheidungsbaum (1) Wann spielt Max Tennis?
Entscheidungsbäume. Minh-Khanh Do Erlangen,
 Entscheidungsbäume Minh-Khanh Do Erlangen, 11.07.2013 Übersicht Allgemeines Konzept Konstruktion Attributwahl Probleme Random forest E-Mail Filter Erlangen, 11.07.2013 Minh-Khanh Do Entscheidungsbäume
Entscheidungsbäume Minh-Khanh Do Erlangen, 11.07.2013 Übersicht Allgemeines Konzept Konstruktion Attributwahl Probleme Random forest E-Mail Filter Erlangen, 11.07.2013 Minh-Khanh Do Entscheidungsbäume
Maschinelles Lernen: Symbolische Ansätze
 Maschinelles Lernen: Symbolische Ansätze Musterlösung für das 7. Übungsblatt Aufgabe 1 Gegeben sei folgende Beispielmenge: Day Outlook Temperature Humidity Wind PlayTennis D1? Hot High Weak No D2 Sunny
Maschinelles Lernen: Symbolische Ansätze Musterlösung für das 7. Übungsblatt Aufgabe 1 Gegeben sei folgende Beispielmenge: Day Outlook Temperature Humidity Wind PlayTennis D1? Hot High Weak No D2 Sunny
Entscheidungsbäume aus großen Datenbanken: SLIQ
 Entscheidungsbäume aus großen Datenbanken: SLIQ C4.5 iteriert häufig über die Trainingsmenge Wie häufig? Wenn die Trainingsmenge nicht in den Hauptspeicher passt, wird das Swapping unpraktikabel! SLIQ:
Entscheidungsbäume aus großen Datenbanken: SLIQ C4.5 iteriert häufig über die Trainingsmenge Wie häufig? Wenn die Trainingsmenge nicht in den Hauptspeicher passt, wird das Swapping unpraktikabel! SLIQ:
Entscheidungsbaum-Lernen: Übersicht
 Entscheidungsbaum-Lernen: Übersicht Entscheidungsbäume als Repräsentationsformalismus Semantik: Klassifikation Lernen von Entscheidungsbäumen vollst. Suche vs. TDIDT Tests, Ausdrucksfähigkeit Maße: Information
Entscheidungsbaum-Lernen: Übersicht Entscheidungsbäume als Repräsentationsformalismus Semantik: Klassifikation Lernen von Entscheidungsbäumen vollst. Suche vs. TDIDT Tests, Ausdrucksfähigkeit Maße: Information
3. Entscheidungsbäume. Verfahren zum Begriffslernen (Klassifikation) Beispiel: weiteres Beispiel: (aus Böhm 2003) (aus Morik 2002)
 Beispiel: weiteres Beispiel: (aus Böhm 2003) (aus Morik 2002)") 3. Entscheidungsbäume Verfahren zum Begriffslernen (Klassifikation) Beispiel: weiteres Beispiel: (aus Böhm 2003) (aus Morik 2002) (aus Wilhelm 2001) Beispiel: (aus Böhm 2003) Wann sind Entscheidungsbäume
3. Entscheidungsbäume Verfahren zum Begriffslernen (Klassifikation) Beispiel: weiteres Beispiel: (aus Böhm 2003) (aus Morik 2002) (aus Wilhelm 2001) Beispiel: (aus Böhm 2003) Wann sind Entscheidungsbäume
Data Mining und Text Mining Einführung. S2 Einfache Regellerner
 Data Mining und Text Mining Einführung S2 Einfache Regellerner Hans Hermann Weber Univ. Erlangen, Informatik 8 Wintersemester 2003 hans.hermann.weber@gmx.de Inhalt Einiges über Regeln und Bäume R1 ein
Data Mining und Text Mining Einführung S2 Einfache Regellerner Hans Hermann Weber Univ. Erlangen, Informatik 8 Wintersemester 2003 hans.hermann.weber@gmx.de Inhalt Einiges über Regeln und Bäume R1 ein
Maschinelles Lernen Entscheidungsbäume
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen Entscheidungsbäume Paul Prasse Entscheidungsbäume Eine von vielen Anwendungen: Kreditrisiken Kredit - Sicherheiten
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen Entscheidungsbäume Paul Prasse Entscheidungsbäume Eine von vielen Anwendungen: Kreditrisiken Kredit - Sicherheiten
Lernen von Entscheidungsbäumen. Volker Tresp Summer 2014
 Lernen von Entscheidungsbäumen Volker Tresp Summer 2014 1 Anforderungen an Methoden zum Datamining Schnelle Verarbeitung großer Datenmengen Leichter Umgang mit hochdimensionalen Daten Das Lernergebnis
Lernen von Entscheidungsbäumen Volker Tresp Summer 2014 1 Anforderungen an Methoden zum Datamining Schnelle Verarbeitung großer Datenmengen Leichter Umgang mit hochdimensionalen Daten Das Lernergebnis
Analytics Entscheidungsbäume
 Analytics Entscheidungsbäume Professional IT Master Prof. Dr. Ingo Claßen Hochschule für Technik und Wirtschaft Berlin Regression Klassifikation Quellen Regression Beispiel Baseball-Gehälter Gehalt: gering
Analytics Entscheidungsbäume Professional IT Master Prof. Dr. Ingo Claßen Hochschule für Technik und Wirtschaft Berlin Regression Klassifikation Quellen Regression Beispiel Baseball-Gehälter Gehalt: gering
Splitting. Impurity. c 1. c 2. c 3. c 4
 Splitting Impurity Sei D(t) eine Menge von Lernbeispielen, in der X(t) auf die Klassen C = {c 1, c 2, c 3, c 4 } verteilt ist. Illustration von zwei möglichen Splits: c 1 c 2 c 3 c 4 ML: III-29 Decision
Splitting Impurity Sei D(t) eine Menge von Lernbeispielen, in der X(t) auf die Klassen C = {c 1, c 2, c 3, c 4 } verteilt ist. Illustration von zwei möglichen Splits: c 1 c 2 c 3 c 4 ML: III-29 Decision
Maschinelles Lernen: Symbolische Ansätze
 Maschinelles Lernen: Symbolische Ansätze Wintersemester 2009/2010 Musterlösung für das 9. Übungsblatt Aufgabe 1: Decision Trees Gegeben sei folgende Beispielmenge: Age Education Married Income Credit?
Maschinelles Lernen: Symbolische Ansätze Wintersemester 2009/2010 Musterlösung für das 9. Übungsblatt Aufgabe 1: Decision Trees Gegeben sei folgende Beispielmenge: Age Education Married Income Credit?
Mathematische Grundlagen III
 Mathematische Grundlagen III Maschinelles Lernen II: Klassifikation mit Entscheidungsbäumen Vera Demberg Universität des Saarlandes 12. Juli 2012 Vera Demberg (UdS) Mathe III 12. Juli 2012 1 / 38 Einleitung
Mathematische Grundlagen III Maschinelles Lernen II: Klassifikation mit Entscheidungsbäumen Vera Demberg Universität des Saarlandes 12. Juli 2012 Vera Demberg (UdS) Mathe III 12. Juli 2012 1 / 38 Einleitung
Maschinelles Lernen: Symbolische Ansätze. Wintersemester 2013/2014 Musterlösung für das 7. Übungsblatt
 Maschinelles Lernen: Symbolische Ansätze Wintersemester 2013/2014 Musterlösung für das 7. Übungsblatt 1 Aufgabe 1 Nearest Neighbour Gegeben sei folgende Beispielmenge: Day Outlook Temperature Humidity
Maschinelles Lernen: Symbolische Ansätze Wintersemester 2013/2014 Musterlösung für das 7. Übungsblatt 1 Aufgabe 1 Nearest Neighbour Gegeben sei folgende Beispielmenge: Day Outlook Temperature Humidity
Data Mining und Maschinelles Lernen Lösungsvorschlag für das 7. Übungsblatt
 Data Mining und Maschinelles Lernen Lösungsvorschlag für das 7. Übungsblatt Knowledge Engineering Group Data Mining und Maschinelles Lernen Lösungsvorschlag 7. Übungsblatt 1 Aufgabe 1a) Auffüllen von Attributen
Data Mining und Maschinelles Lernen Lösungsvorschlag für das 7. Übungsblatt Knowledge Engineering Group Data Mining und Maschinelles Lernen Lösungsvorschlag 7. Übungsblatt 1 Aufgabe 1a) Auffüllen von Attributen
Induktion von Entscheidungsbäumen
 Induktion von Entscheidungsbäumen Christian Borgelt Institut für Wissens- und Sprachverarbeitung Otto-von-Guericke-Universität Magdeburg Universitätsplatz 2, 39106 Magdeburg E-mail: borgelt@iws.cs.uni-magdeburg.de
Induktion von Entscheidungsbäumen Christian Borgelt Institut für Wissens- und Sprachverarbeitung Otto-von-Guericke-Universität Magdeburg Universitätsplatz 2, 39106 Magdeburg E-mail: borgelt@iws.cs.uni-magdeburg.de
Vorlesungsplan. Von Naïve Bayes zu Bayesischen Netzwerk- Klassifikatoren. Naïve Bayes. Bayesische Netzwerke
 Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Moderne Methoden der KI: Maschinelles Lernen
 Moderne Methoden der KI: Maschinelles Lernen Prof. Dr.Hans-Dieter Burkhard Vorlesung Entscheidungsbäume Darstellung durch Regeln ID3 / C4.5 Bevorzugung kleiner Hypothesen Overfitting Entscheidungsbäume
Moderne Methoden der KI: Maschinelles Lernen Prof. Dr.Hans-Dieter Burkhard Vorlesung Entscheidungsbäume Darstellung durch Regeln ID3 / C4.5 Bevorzugung kleiner Hypothesen Overfitting Entscheidungsbäume
INTELLIGENTE DATENANALYSE IN MATLAB. Überwachtes Lernen: Entscheidungsbäume
 INTELLIGENTE DATENANALYSE IN MATLAB Überwachtes Lernen: Entscheidungsbäume Literatur Stuart Russell und Peter Norvig: Artificial Intelligence. Andrew W. Moore: http://www.autonlab.org/tutorials. 2 Überblick
INTELLIGENTE DATENANALYSE IN MATLAB Überwachtes Lernen: Entscheidungsbäume Literatur Stuart Russell und Peter Norvig: Artificial Intelligence. Andrew W. Moore: http://www.autonlab.org/tutorials. 2 Überblick
Prädiktion und Klassifikation mit
 Prädiktion und Klassifikation mit Random Forest Prof. Dr. T. Nouri Nouri@acm.org Technical University NW-Switzerland /35 Übersicht a. Probleme mit Decision Tree b. Der Random Forests RF c. Implementation
Prädiktion und Klassifikation mit Random Forest Prof. Dr. T. Nouri Nouri@acm.org Technical University NW-Switzerland /35 Übersicht a. Probleme mit Decision Tree b. Der Random Forests RF c. Implementation
3.3 Nächste-Nachbarn-Klassifikatoren
 3.3 Nächste-Nachbarn-Klassifikatoren Schrauben Nägel Klammern Neues Objekt Instanzbasiertes Lernen (instance based learning) Einfachster Nächste-Nachbar-Klassifikator: Zuordnung zu der Klasse des nächsten
3.3 Nächste-Nachbarn-Klassifikatoren Schrauben Nägel Klammern Neues Objekt Instanzbasiertes Lernen (instance based learning) Einfachster Nächste-Nachbar-Klassifikator: Zuordnung zu der Klasse des nächsten
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Entscheidungsbäume
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Entscheidungsbäume Christoph Sawade/Niels Landwehr Jules Rasetaharison, Tobias Scheffer Entscheidungsbäume Eine von vielen Anwendungen:
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Entscheidungsbäume Christoph Sawade/Niels Landwehr Jules Rasetaharison, Tobias Scheffer Entscheidungsbäume Eine von vielen Anwendungen:
Kapitel ML: III. III. Entscheidungsbäume. Repräsentation und Konstruktion Impurity-Funktionen Entscheidungsbaumalgorithmen Pruning
 Kapitel ML: III III. Entscheidungsbäume Repräsentation und Konstruktion Impurity-Funktionen Entscheidungsbaumalgorithmen Pruning ML: III-1 Decision Trees c STEIN/LETTMANN 2005-2011 Spezifikation von Klassifikationsproblemen
Kapitel ML: III III. Entscheidungsbäume Repräsentation und Konstruktion Impurity-Funktionen Entscheidungsbaumalgorithmen Pruning ML: III-1 Decision Trees c STEIN/LETTMANN 2005-2011 Spezifikation von Klassifikationsproblemen
Entscheidungsbaum-Lernen: Übersicht
 Entscheidungsbaum-Lernen: Übersicht Entscheidungsbäume Repräsentationsformalismus Tests Semantik: Klassifikation Ausdrucksfähigkeit Lernen von Entscheidungsbäumen Szenario vollst. Suche vs. TDIDT Maße:
Entscheidungsbaum-Lernen: Übersicht Entscheidungsbäume Repräsentationsformalismus Tests Semantik: Klassifikation Ausdrucksfähigkeit Lernen von Entscheidungsbäumen Szenario vollst. Suche vs. TDIDT Maße:
2. Lernen von Entscheidungsbäumen
 2. Lernen von Entscheidungsbäumen Entscheidungsbäume 2. Lernen von Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse
2. Lernen von Entscheidungsbäumen Entscheidungsbäume 2. Lernen von Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse
Symbolisches Lernen. Proseminar Kognitive Robotik. Johannes Klein. Technische Universität München. June 22, 2012
 Symbolisches Lernen Proseminar Kognitive Robotik Johannes Klein Technische Universität München June 22, 2012 1/18 Einleitung Lernverfahren Entscheidungsbaum ID3 Diskussion Inhalt Übersicht Symbolisches
Symbolisches Lernen Proseminar Kognitive Robotik Johannes Klein Technische Universität München June 22, 2012 1/18 Einleitung Lernverfahren Entscheidungsbaum ID3 Diskussion Inhalt Übersicht Symbolisches
Modellierung. Entscheidungsbäume, ume, Boosting, Metalerner, Random Forest. Wolfgang Konen Fachhochschule Köln Oktober 2007.
 Modellierung Entscheidungsbäume, ume, Boosting, Metalerner, Random Forest Wolfgang Konen Fachhochschule Köln Oktober 2007 W. Konen DMC WS2007 Seite - 1 W. Konen DMC WS2007 Seite - 2 Inhalt Typen der Modellierung
Modellierung Entscheidungsbäume, ume, Boosting, Metalerner, Random Forest Wolfgang Konen Fachhochschule Köln Oktober 2007 W. Konen DMC WS2007 Seite - 1 W. Konen DMC WS2007 Seite - 2 Inhalt Typen der Modellierung
Maschinelles Lernen: Symbolische Ansätze
 Maschinelles Lernen: Symbolische Ansätze Wintersemester 2008/2009 Musterlösung für das 7. Übungsblatt Aufgabe 1: Evaluierung und Kosten Gegeben sei ein Datensatz mit 300 Beispielen, davon 2 /3 positiv
Maschinelles Lernen: Symbolische Ansätze Wintersemester 2008/2009 Musterlösung für das 7. Übungsblatt Aufgabe 1: Evaluierung und Kosten Gegeben sei ein Datensatz mit 300 Beispielen, davon 2 /3 positiv
Mathias Krüger / Seminar Datamining
 Entscheidungsbäume mit SLIQ und SPRINT Mathias Krüger Institut für Informatik FernUniversität Hagen 4.7.2008 / Seminar Datamining Gliederung Einleitung Klassifikationsproblem Entscheidungsbäume SLIQ (
Entscheidungsbäume mit SLIQ und SPRINT Mathias Krüger Institut für Informatik FernUniversität Hagen 4.7.2008 / Seminar Datamining Gliederung Einleitung Klassifikationsproblem Entscheidungsbäume SLIQ (
4. Lernen von Entscheidungsbäumen
 4. Lernen von Entscheidungsbäumen Entscheidungsbäume 4. Lernen von Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse
4. Lernen von Entscheidungsbäumen Entscheidungsbäume 4. Lernen von Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse
Einführung in die Methoden der Künstlichen Intelligenz
 www.is.cs.uni-fra ankfurt.de Einführung in die Methoden der Künstlichen Intelligenz Vorlesung 8 Entscheidungsbaumlernen 2 19. Mai 2009 Ingo J. Timm, René Schumann Übersicht 1. Einführung 2. Grundlegende
www.is.cs.uni-fra ankfurt.de Einführung in die Methoden der Künstlichen Intelligenz Vorlesung 8 Entscheidungsbaumlernen 2 19. Mai 2009 Ingo J. Timm, René Schumann Übersicht 1. Einführung 2. Grundlegende
Begriffsbestimmung CRISP-DM-Modell Betriebswirtschaftliche Einsatzgebiete des Data Mining Web Mining und Text Mining
 Gliederung 1. Einführung 2. Grundlagen Data Mining Begriffsbestimmung CRISP-DM-Modell Betriebswirtschaftliche Einsatzgebiete des Data Mining Web Mining und Text Mining 3. Ausgewählte Methoden des Data
Gliederung 1. Einführung 2. Grundlagen Data Mining Begriffsbestimmung CRISP-DM-Modell Betriebswirtschaftliche Einsatzgebiete des Data Mining Web Mining und Text Mining 3. Ausgewählte Methoden des Data
Industrie Chance oder Risiko? Martin Botteck Prof. Dr.-Ing. Kommunikationsdienste und -anwendungen
 Industrie 4.0 - Chance oder Risiko? Martin Botteck Prof. Dr.-Ing. Kommunikationsdienste und -anwendungen Industrielle Revolution, Version 4.0 Der Kongress im Jahr 2015: Worum geht es überhaupt? Kongress
Industrie 4.0 - Chance oder Risiko? Martin Botteck Prof. Dr.-Ing. Kommunikationsdienste und -anwendungen Industrielle Revolution, Version 4.0 Der Kongress im Jahr 2015: Worum geht es überhaupt? Kongress
5 BINÄRE ENTSCHEIDUNGS- DIAGRAMME (BDDS)
") 5 BINÄRE ENTSCHEIDUNGS- DIAGRAMME (BDDS) Sommersemester 2009 Dr. Carsten Sinz, Universität Karlsruhe Datenstruktur BDD 2 1986 von R. Bryant vorgeschlagen zur Darstellung von aussagenlogischen Formeln (genauer:
5 BINÄRE ENTSCHEIDUNGS- DIAGRAMME (BDDS) Sommersemester 2009 Dr. Carsten Sinz, Universität Karlsruhe Datenstruktur BDD 2 1986 von R. Bryant vorgeschlagen zur Darstellung von aussagenlogischen Formeln (genauer:
Einführung. Einführung in die Methoden der Künstlichen Intelligenz. Maschinelles Lernen. Lernen und Agenten. Beispiele
 Einführung Einführung in die Methoden der Künstlichen Intelligenz Maschinelles Lernen Dr. David Sabel WS 2012/13 Direkte Programmierung eines intelligenten Agenten nicht möglich (bisher) Daher benötigt:
Einführung Einführung in die Methoden der Künstlichen Intelligenz Maschinelles Lernen Dr. David Sabel WS 2012/13 Direkte Programmierung eines intelligenten Agenten nicht möglich (bisher) Daher benötigt:
Algorithmische Modelle als neues Paradigma
 Algorithmische Modelle als neues Paradigma Axel Schwer Seminar über Philosophische Grundlagen der Statistik, WS 2010/11 Betreuer: Prof. Dr. Thomas Augustin München, den 28. Januar 2011 1 / 29 LEO BREIMAN
Algorithmische Modelle als neues Paradigma Axel Schwer Seminar über Philosophische Grundlagen der Statistik, WS 2010/11 Betreuer: Prof. Dr. Thomas Augustin München, den 28. Januar 2011 1 / 29 LEO BREIMAN
Data Mining auf Datenströmen Andreas M. Weiner
 Technische Universität Kaiserslautern Fachbereich Informatik Lehrgebiet Datenverwaltungssysteme Integriertes Seminar Datenbanken und Informationssysteme Sommersemester 2005 Thema: Data Streams Andreas
Technische Universität Kaiserslautern Fachbereich Informatik Lehrgebiet Datenverwaltungssysteme Integriertes Seminar Datenbanken und Informationssysteme Sommersemester 2005 Thema: Data Streams Andreas
Künstliche Intelligenz Maschinelles Lernen
 Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert Sommersemester 2009 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen
Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert Sommersemester 2009 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen
11. Übung Knowledge Discovery
 Prof. Dr. Gerd Stumme, Robert Jäsche Fachgebiet Wissensverarbeitung. Übung Knowledge Discovery.7.7 Sommersemester 7 Informationsgewinn Im folgenden betrachten wir die Menge von n rainingsobjeten, mit den
Prof. Dr. Gerd Stumme, Robert Jäsche Fachgebiet Wissensverarbeitung. Übung Knowledge Discovery.7.7 Sommersemester 7 Informationsgewinn Im folgenden betrachten wir die Menge von n rainingsobjeten, mit den
Entscheidungsbäume. Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Entscheidungsbäume Christoph Sawade /Niels Landwehr/Paul Prasse Silvia Makowski Tobias Scheffer Entscheidungsbäume Eine von vielen
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Entscheidungsbäume Christoph Sawade /Niels Landwehr/Paul Prasse Silvia Makowski Tobias Scheffer Entscheidungsbäume Eine von vielen
Seminarvortrag zum Thema maschinelles Lernen I - Entscheidungsbäume. von Lars-Peter Meyer. im Seminar Methoden wissensbasierter Systeme
 Seminarvortrag zum Thema maschinelles Lernen I - Entscheidungsbäume von Lars-Peter Meyer im Seminar Methoden wissensbasierter Systeme bei Prof. Brewka im WS 2007/08 Übersicht Überblick maschinelles Lernen
Seminarvortrag zum Thema maschinelles Lernen I - Entscheidungsbäume von Lars-Peter Meyer im Seminar Methoden wissensbasierter Systeme bei Prof. Brewka im WS 2007/08 Übersicht Überblick maschinelles Lernen
Motivation. Themenblock: Klassifikation. Binäre Entscheidungsbäume. Ansätze. Praktikum: Data Warehousing und Data Mining.
 Motivation Themenblock: Klassifikation Praktikum: Data Warehousing und Data Mining Ziel Item hat mehrere Attribute Anhand von n Attributen wird (n+)-tes vorhergesagt. Zusätzliches Attribut erst später
Motivation Themenblock: Klassifikation Praktikum: Data Warehousing und Data Mining Ziel Item hat mehrere Attribute Anhand von n Attributen wird (n+)-tes vorhergesagt. Zusätzliches Attribut erst später
Methoden der Datenanalyse AI-basierte Decision Support Systeme WS 2006/07
 Regression Trees Methoden der Datenanalyse AI-basierte Decision Support Systeme WS 2006/07 Ao.Univ.Prof. Dr. Marcus Hudec marcus.hudec@univie.ac.at Institut für Scientific Computing, Universität Wien 2
Regression Trees Methoden der Datenanalyse AI-basierte Decision Support Systeme WS 2006/07 Ao.Univ.Prof. Dr. Marcus Hudec marcus.hudec@univie.ac.at Institut für Scientific Computing, Universität Wien 2
Induktion von Assoziationsregeln. Stefan Mandl
 Induktion von Assoziationsregeln Stefan Mandl Inhalt Was sind Assoziationsregeln? Qualitätsbewertung Algorithmus Was sind Assoziationsregeln? Assoziationsregeln Assoziationsregeln beschreiben Korrelationen
Induktion von Assoziationsregeln Stefan Mandl Inhalt Was sind Assoziationsregeln? Qualitätsbewertung Algorithmus Was sind Assoziationsregeln? Assoziationsregeln Assoziationsregeln beschreiben Korrelationen
Vorlesung Wissensentdeckung
 Vorlesung Wissensentdeckung Additive Modelle Katharina Morik, Weihs 2.6.2015 1 von 33 Gliederung 1 Merkmalsauswahl Gütemaße und Fehlerabschätzung 2 von 33 Ausgangspunkt: Funktionsapproximation Die bisher
Vorlesung Wissensentdeckung Additive Modelle Katharina Morik, Weihs 2.6.2015 1 von 33 Gliederung 1 Merkmalsauswahl Gütemaße und Fehlerabschätzung 2 von 33 Ausgangspunkt: Funktionsapproximation Die bisher
4 Induktion von Regeln
 4 Induktion von egeln Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- aare beschrieben sind. Jedes Objekt kann einer Klasse zugeordnet werden. Ein Entscheidungsbaum liefert eine Entscheidung
4 Induktion von egeln Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- aare beschrieben sind. Jedes Objekt kann einer Klasse zugeordnet werden. Ein Entscheidungsbaum liefert eine Entscheidung
Data Mining - Wiederholung
 Data Mining - Wiederholung Norbert Fuhr 18. Januar 2006 Problemstellungen Problemstellungen Daten vs. Information Def. Data Mining Arten von strukturellen Beschreibungen Regeln (Klassifikation, Assoziations-)
Data Mining - Wiederholung Norbert Fuhr 18. Januar 2006 Problemstellungen Problemstellungen Daten vs. Information Def. Data Mining Arten von strukturellen Beschreibungen Regeln (Klassifikation, Assoziations-)
Maschinelles Lernen Entscheidungsbäume
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen Entscheidungsbäume Christoph Sawade /Niels Landwehr/Paul Prasse Dominik Lahmann Tobias Scheffer Entscheidungsbäume
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen Entscheidungsbäume Christoph Sawade /Niels Landwehr/Paul Prasse Dominik Lahmann Tobias Scheffer Entscheidungsbäume
Vorlesung Wissensentdeckung
 Gliederung Vorlesung Wissensentdeckung Additive Modelle Katharina Morik, Weihs 1 Merkmalsauswahl Gütemaße und Fehlerabschätzung.6.015 1 von 33 von 33 Ausgangspunkt: Funktionsapproximation Aufteilen der
Gliederung Vorlesung Wissensentdeckung Additive Modelle Katharina Morik, Weihs 1 Merkmalsauswahl Gütemaße und Fehlerabschätzung.6.015 1 von 33 von 33 Ausgangspunkt: Funktionsapproximation Aufteilen der
Theorie des maschinellen Lernens
 Theorie des maschinellen Lernens Hans U. Simon 16. Juni 017 18 Entscheidungsbäume Ein Entscheidungsbaum T stellt eine Voraussagefunktion h T : X Y dar. Stellen wir uns der Einfachheit halber einen binären
Theorie des maschinellen Lernens Hans U. Simon 16. Juni 017 18 Entscheidungsbäume Ein Entscheidungsbaum T stellt eine Voraussagefunktion h T : X Y dar. Stellen wir uns der Einfachheit halber einen binären
Bayes sches Lernen: Übersicht
 Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 10: Naive Bayes (V. 1.0)
Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 10: Naive Bayes (V. 1.0)
Data Warehousing und Data Mining
 Data Warehousing und Data Mining Klassifikation Ulf Leser Wissensmanagement in der Bioinformatik Inhalt dieser Vorlesung Einführung Problemstellung Evaluation Overfitting knn Klassifikator Naive-Bayes
Data Warehousing und Data Mining Klassifikation Ulf Leser Wissensmanagement in der Bioinformatik Inhalt dieser Vorlesung Einführung Problemstellung Evaluation Overfitting knn Klassifikator Naive-Bayes
Grundzüge DS & Alg (WS14/15) Lösungsvorschlag zu Aufgabenblatt 3. Aufgabe 1. (a) nicht-heap (b) Heap 25. (c) Beinahe-Heap 9.
 Lösungsvorschlag zu Aufgabenblatt 3. Aufgabe 1. (a) nicht-heap (b) Heap 25. (c) Beinahe-Heap 9.") Lösungsvorschlag zu Aufgabenblatt Aufgabe 1 (a) nicht-heap 1 1 5 5 1 1 (b) Heap 5 1 1 14 5 10 4 (c) Beinahe-Heap 1 1 4 1 10 Heapify 1. Iteration. Iteration. Iteration 1 1 1 1 1 1 10 4 1 10 4 1 10 4 1 1
Lösungsvorschlag zu Aufgabenblatt Aufgabe 1 (a) nicht-heap 1 1 5 5 1 1 (b) Heap 5 1 1 14 5 10 4 (c) Beinahe-Heap 1 1 4 1 10 Heapify 1. Iteration. Iteration. Iteration 1 1 1 1 1 1 10 4 1 10 4 1 10 4 1 1
Kapitel ML:IV (Fortsetzung)
") Kapitel ML:IV (Fortsetzung) IV. Statistische Lernverfahren Wahrscheinlichkeitsrechnung Bayes-Klassifikation Maximum-a-Posteriori-Hypothesen ML:IV-18 Statistical Learning c STEIN 2005-2011 Satz 3 (Bayes)
Kapitel ML:IV (Fortsetzung) IV. Statistische Lernverfahren Wahrscheinlichkeitsrechnung Bayes-Klassifikation Maximum-a-Posteriori-Hypothesen ML:IV-18 Statistical Learning c STEIN 2005-2011 Satz 3 (Bayes)
Vortragsthema. Thema: Klassifikation. Klassifikation. OS Data Mining SS10 Madeleine Weiand 1
 Vortragsthema Klassifikation OS Data Mining SS0 Madeleine Weiand Agenda Agenda I III Begriff Klassifikation Abgrenzung Anforderungen Anwendungsgebiete Dimensionsreduktion Umsetzung in Software Vergleich
Vortragsthema Klassifikation OS Data Mining SS0 Madeleine Weiand Agenda Agenda I III Begriff Klassifikation Abgrenzung Anforderungen Anwendungsgebiete Dimensionsreduktion Umsetzung in Software Vergleich
Methoden der Datenanalyse AI-basierte Decision Support Systeme WS 2006/07
 Classification Methoden der Datenanalyse AI-basierte Decision Support Systeme WS 2006/07 Ao.Univ.Prof. Dr. Marcus Hudec marcus.hudec@univie.ac.at Institut für Scientific Computing, Universität Wien 2 Classification
Classification Methoden der Datenanalyse AI-basierte Decision Support Systeme WS 2006/07 Ao.Univ.Prof. Dr. Marcus Hudec marcus.hudec@univie.ac.at Institut für Scientific Computing, Universität Wien 2 Classification
Künstliche Intelligenz Maschinelles Lernen
 Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert WS 2009/2010 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen Unüberwachtes
Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert WS 2009/2010 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen Unüberwachtes
4. Lernen von Entscheidungsbäumen. Klassifikation mit Entscheidungsbäumen. Entscheidungsbaum
 4. Lernen von Entscheidungsbäumen Klassifikation mit Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch /Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse zugeordnet werden.
4. Lernen von Entscheidungsbäumen Klassifikation mit Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch /Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse zugeordnet werden.
Binary Decision Diagrams
 Hauptseminar Model Checking Binary Decision Diagrams Kristofer Treutwein 23.4.22 Grundlagen Normalformen Als kanonische Darstellungsform für boolesche Terme gibt es verschiedene Normalformen, u.a. die
Hauptseminar Model Checking Binary Decision Diagrams Kristofer Treutwein 23.4.22 Grundlagen Normalformen Als kanonische Darstellungsform für boolesche Terme gibt es verschiedene Normalformen, u.a. die
Vorlesung. Machine Learning - Entscheidungsbäume
 Vorlesung Machine Learning - Entscheidungsbäume Vorlesung Machine Learning - Entscheidungsbäume http://de.wikipedia.org/wiki/datei:deu_tutorial_-_hochladen_von_bildern_neu%2bcommons.svg http://www.rulequest.com/personal/
Vorlesung Machine Learning - Entscheidungsbäume Vorlesung Machine Learning - Entscheidungsbäume http://de.wikipedia.org/wiki/datei:deu_tutorial_-_hochladen_von_bildern_neu%2bcommons.svg http://www.rulequest.com/personal/
Mathematische Grundlagen III
 Mathematische Grundlagen III Maschinelles Lernen III: Clustering Vera Demberg Universität des Saarlandes 7. Juli 202 Vera Demberg (UdS) Mathe III 7. Juli 202 / 35 Clustering vs. Klassifikation In den letzten
Mathematische Grundlagen III Maschinelles Lernen III: Clustering Vera Demberg Universität des Saarlandes 7. Juli 202 Vera Demberg (UdS) Mathe III 7. Juli 202 / 35 Clustering vs. Klassifikation In den letzten
Lernen von Klassifikationen
 Lernen von Klassifikationen Gegeben: Trainingsbeispiele: Paare der Form (x i, f(x i )) Gesucht: Funktion f, die die Trainingsbeispiele klassifiziert. (a): Lernen mit Trainingsdaten (b): Genauigkeitsüberprüfung
Lernen von Klassifikationen Gegeben: Trainingsbeispiele: Paare der Form (x i, f(x i )) Gesucht: Funktion f, die die Trainingsbeispiele klassifiziert. (a): Lernen mit Trainingsdaten (b): Genauigkeitsüberprüfung
Entscheidungsbaum-Lernen. im Proseminar Maschinelles Lernen
 Entscheidungsbaum-Lernen im Proseminar Maschinelles Lernen Wintersemester 2003/2004 2. Dezember 2003 Gliederung: 1 Einleitung 1.1 Was sind Entscheidungsbäume? 1.2 Was ist Entscheidungsbaumlernen ( Decision
Entscheidungsbaum-Lernen im Proseminar Maschinelles Lernen Wintersemester 2003/2004 2. Dezember 2003 Gliederung: 1 Einleitung 1.1 Was sind Entscheidungsbäume? 1.2 Was ist Entscheidungsbaumlernen ( Decision
Theoretische Informatik 1
 Theoretische Informatik 1 Teil 12 Bernhard Nessler Institut für Grundlagen der Informationsverabeitung TU Graz SS 2007 Übersicht 1 Maschinelles Lernen Definition Lernen 2 agnostic -learning Definition
Theoretische Informatik 1 Teil 12 Bernhard Nessler Institut für Grundlagen der Informationsverabeitung TU Graz SS 2007 Übersicht 1 Maschinelles Lernen Definition Lernen 2 agnostic -learning Definition
Algorithmen und Datenstrukturen
 Algorithmen und Datenstrukturen Wintersemester 2012/13 26. Vorlesung Greedy- und Approximationsalgorithmen Prof. Dr. Alexander Wolff Lehrstuhl für Informatik I Operations Research Optimierung für Wirtschaftsabläufe:
Algorithmen und Datenstrukturen Wintersemester 2012/13 26. Vorlesung Greedy- und Approximationsalgorithmen Prof. Dr. Alexander Wolff Lehrstuhl für Informatik I Operations Research Optimierung für Wirtschaftsabläufe:
Naive Bayes für Regressionsprobleme
 Naive Bayes für Regressionsprobleme Vorhersage numerischer Werte mit dem Naive Bayes Algorithmus Nils Knappmeier Fachgebiet Knowledge Engineering Fachbereich Informatik Technische Universität Darmstadt
Naive Bayes für Regressionsprobleme Vorhersage numerischer Werte mit dem Naive Bayes Algorithmus Nils Knappmeier Fachgebiet Knowledge Engineering Fachbereich Informatik Technische Universität Darmstadt
x 2 x 1 x 3 5.1 Lernen mit Entscheidungsbäumen
 5.1 Lernen mit Entscheidungsbäumen Falls zum Beispiel A = {gelb, rot, blau} R 2 und B = {0, 1}, so definiert der folgende Entscheidungsbaum eine Hypothese H : A B (wobei der Attributvektor aus A mit x
5.1 Lernen mit Entscheidungsbäumen Falls zum Beispiel A = {gelb, rot, blau} R 2 und B = {0, 1}, so definiert der folgende Entscheidungsbaum eine Hypothese H : A B (wobei der Attributvektor aus A mit x
Einführung in die Methoden der Künstlichen Intelligenz. Maschinelles Lernen
 Einführung in die Methoden der Künstlichen Intelligenz Maschinelles Lernen Dr. David Sabel WS 2012/13 Stand der Folien: 14. Februar 2013 Einführung Direkte Programmierung eines intelligenten Agenten nicht
Einführung in die Methoden der Künstlichen Intelligenz Maschinelles Lernen Dr. David Sabel WS 2012/13 Stand der Folien: 14. Februar 2013 Einführung Direkte Programmierung eines intelligenten Agenten nicht
Proseminar Data Mining. Entscheidungsbäume. von. Alexander M. Bielesch SS 2000 Universität Ulm
 Proseminar Data Mining Entscheidungsbäume von Alexander M. Bielesch alexander.bielesch@informatik.uni-ulm.de SS 2000 Universität Ulm 0 Inhaltsübersicht 0 Inhaltsübersicht...i 1 Entscheidungsbäume...1 1.1
Proseminar Data Mining Entscheidungsbäume von Alexander M. Bielesch alexander.bielesch@informatik.uni-ulm.de SS 2000 Universität Ulm 0 Inhaltsübersicht 0 Inhaltsübersicht...i 1 Entscheidungsbäume...1 1.1
Vorlesung. Data und Web Mining. Kurzinformation zur. Univ.-Prof. Dr. Ralph Bergmann. Lehrstuhl für Wirtschaftsinformatik II
 Kurzinformation zur Vorlesung Data und Web Mining Univ.-Prof. Dr. Ralph Bergmann www.wi2.uni-trier.de - I - 1 - Die Ausgangssituation (1) Unternehmen und Organisationen haben enorme Datenmengen angesammelt
Kurzinformation zur Vorlesung Data und Web Mining Univ.-Prof. Dr. Ralph Bergmann www.wi2.uni-trier.de - I - 1 - Die Ausgangssituation (1) Unternehmen und Organisationen haben enorme Datenmengen angesammelt
Modellierung mit künstlicher Intelligenz
 Samuel Kost kosts@mailbox.tu-freiberg.de Institut für Numerische Mathematik und Optimierung Modellierung mit künstlicher Intelligenz Ein Überblick über existierende Methoden des maschinellen Lernens 13.
Samuel Kost kosts@mailbox.tu-freiberg.de Institut für Numerische Mathematik und Optimierung Modellierung mit künstlicher Intelligenz Ein Überblick über existierende Methoden des maschinellen Lernens 13.
Logistische Regression
 Logistische Regression Markus Kalisch 30.09.2014 1 Big Picture: Statistisches Lernen Supervised Learning (X,Y) Unsupervised Learning X VL 7, 11, 12 Regression Y kontinuierlich VL 1, 2, 4, 5, 6 Klassifikation
Logistische Regression Markus Kalisch 30.09.2014 1 Big Picture: Statistisches Lernen Supervised Learning (X,Y) Unsupervised Learning X VL 7, 11, 12 Regression Y kontinuierlich VL 1, 2, 4, 5, 6 Klassifikation
WEKA A Machine Learning Interface for Data Mining
 WEKA A Machine Learning Interface for Data Mining Frank Eibe, Mark Hall, Geoffrey Holmes, Richard Kirkby, Bernhard Pfahringer, Ian H. Witten Reinhard Klaus Losse Künstliche Intelligenz II WS 2009/2010
WEKA A Machine Learning Interface for Data Mining Frank Eibe, Mark Hall, Geoffrey Holmes, Richard Kirkby, Bernhard Pfahringer, Ian H. Witten Reinhard Klaus Losse Künstliche Intelligenz II WS 2009/2010
Übungsblatt LV Künstliche Intelligenz, Data Mining (1), 2014
, 2014") Übungsblatt LV Künstliche Intelligenz, Data Mining (1), 2014 Aufgabe 1. Data Mining a) Mit welchen Aufgabenstellungen befasst sich Data Mining? b) Was versteht man unter Transparenz einer Wissensrepräsentation?
Übungsblatt LV Künstliche Intelligenz, Data Mining (1), 2014 Aufgabe 1. Data Mining a) Mit welchen Aufgabenstellungen befasst sich Data Mining? b) Was versteht man unter Transparenz einer Wissensrepräsentation?
Maschinelles Lernen: Symbolische Ansätze
 Maschinelles Lernen: Symbolische Ansätze Wintersemester 2008/2009 Musterlösung für das 5. Übungsblatt Aufgabe 1: Covering-Algorithmus und Coverage-Space Visualisieren Sie den Ablauf des Covering-Algorithmus
Maschinelles Lernen: Symbolische Ansätze Wintersemester 2008/2009 Musterlösung für das 5. Übungsblatt Aufgabe 1: Covering-Algorithmus und Coverage-Space Visualisieren Sie den Ablauf des Covering-Algorithmus
Vorhersagequalität zufälliger Baumstrukturen
 Vorhersagequalität zufälliger Baumstrukturen Vorhersagequalität zufälliger Baumstrukturen Bachelor-Thesis von Alexander Heinz März 20 Fachbereich Informatik Fachgebiet Knowledge Engineering Betreuer &
Vorhersagequalität zufälliger Baumstrukturen Vorhersagequalität zufälliger Baumstrukturen Bachelor-Thesis von Alexander Heinz März 20 Fachbereich Informatik Fachgebiet Knowledge Engineering Betreuer &
Bayes sches Lernen: Übersicht
 Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 5: Naive Bayes + IBL (V.
Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 5: Naive Bayes + IBL (V.
Übungen zur Vorlesung Datenstrukturen und Algorithmen SS 2006 Blatt 13
 Übungen zur Vorlesung Datenstrukturen und Algorithmen SS 2006 Blatt 13 Sven Grothklags University of Paderborn 10. Juli 2006 Sven Grothklags (University of Paderborn) DuA Übungsblatt 13 10. Juli 2006 1
Übungen zur Vorlesung Datenstrukturen und Algorithmen SS 2006 Blatt 13 Sven Grothklags University of Paderborn 10. Juli 2006 Sven Grothklags (University of Paderborn) DuA Übungsblatt 13 10. Juli 2006 1
Kapitel ML: III (Fortsetzung)
") Kapitel ML: III (Fortsetzung) III. Entscheidungsbäume Repräsentation und Konstruktion Impurity-Funktionen Entscheidungsbaumalgorithmen Pruning ML: III-87 Decision Trees c STEIN/LETTMANN 2005-2011 Missklassifikationskosten
Kapitel ML: III (Fortsetzung) III. Entscheidungsbäume Repräsentation und Konstruktion Impurity-Funktionen Entscheidungsbaumalgorithmen Pruning ML: III-87 Decision Trees c STEIN/LETTMANN 2005-2011 Missklassifikationskosten
> Parallele Systeme Übung: 4. Übungsblatt Philipp Kegel Wintersemester 2012/2013. Parallele und Verteilte Systeme, Institut für Informatik
 > Parallele Systeme Übung: 4. Übungsblatt Philipp Kegel Wintersemester 2012/2013 Parallele und Verteilte Systeme, Institut für Informatik Inhaltsverzeichnis 2 1 Besprechung des 4. Übungsblattes Aufgabe
> Parallele Systeme Übung: 4. Übungsblatt Philipp Kegel Wintersemester 2012/2013 Parallele und Verteilte Systeme, Institut für Informatik Inhaltsverzeichnis 2 1 Besprechung des 4. Übungsblattes Aufgabe
Vorlesung 04.12.2006: Binäre Entscheidungsdiagramme (BDDs) Dr. Carsten Sinz
 Dr. Carsten Sinz") Vorlesung 04.12.2006: Binäre Entscheidungsdiagramme (BDDs) Dr. Carsten Sinz Datenstruktur BDD 1986 von R. Bryant vorgeschlagen zur Darstellung von aussagenlogischen Formeln (genauer: Booleschen Funktionen)
Vorlesung 04.12.2006: Binäre Entscheidungsdiagramme (BDDs) Dr. Carsten Sinz Datenstruktur BDD 1986 von R. Bryant vorgeschlagen zur Darstellung von aussagenlogischen Formeln (genauer: Booleschen Funktionen)
Exponentiation: das Problem Gegeben: (multiplikative) Halbgruppe (H, ), Element a H, n N Aufgabe: berechne das Element
 Halbgruppe (H, ), Element a H, n N Aufgabe: berechne das Element") Problemstellung Banale smethode : das Problem Gegeben: (multiplikative) Halbgruppe (H, ), Element a H, n N Aufgabe: berechne das Element a n = } a a a {{ a } H n (schreiben ab jetzt a n statt a n ) Hinweis:
Problemstellung Banale smethode : das Problem Gegeben: (multiplikative) Halbgruppe (H, ), Element a H, n N Aufgabe: berechne das Element a n = } a a a {{ a } H n (schreiben ab jetzt a n statt a n ) Hinweis:
Pareto optimale lineare Klassifikation
 Seminar aus Maschinellem Lernen Pareto optimale lineare Klassifikation Vesselina Poulkova Betreuer: Eneldo Loza Mencía Gliederung 1. Einleitung 2. Pareto optimale lineare Klassifizierer 3. Generelle Voraussetzung
Seminar aus Maschinellem Lernen Pareto optimale lineare Klassifikation Vesselina Poulkova Betreuer: Eneldo Loza Mencía Gliederung 1. Einleitung 2. Pareto optimale lineare Klassifizierer 3. Generelle Voraussetzung
Algorithmen und Datenstrukturen
 1 Algorithmen und Datenstrukturen Wintersemester 01/13 6. Vorlesung Prioritäten setzen Prof. Dr. Alexander Wolff Lehrstuhl für Informatik I Guten Morgen! Tipps für unseren ersten Test am 0. November: Lesen
1 Algorithmen und Datenstrukturen Wintersemester 01/13 6. Vorlesung Prioritäten setzen Prof. Dr. Alexander Wolff Lehrstuhl für Informatik I Guten Morgen! Tipps für unseren ersten Test am 0. November: Lesen
Mining High-Speed Data Streams
 Mining High-Speed Data Streams Pedro Domingos & Geoff Hulten Departement of Computer Science & Engineering University of Washington Datum : 212006 Seminar: Maschinelles Lernen und symbolische Ansätze Vortragender:
Mining High-Speed Data Streams Pedro Domingos & Geoff Hulten Departement of Computer Science & Engineering University of Washington Datum : 212006 Seminar: Maschinelles Lernen und symbolische Ansätze Vortragender:
Trainieren und Visualisieren eines Entscheidungsbaums
 D3kjd3Di38lk323nnm Kapitel 6 KAPITEL 6 Entscheidungsbäume Wie SVMs sind auch Entscheidungsbäume sehr flexible Machine-Learning-Algorithmen, die sich sowohl für Klassifikations- als auch Regressionsaufgaben
D3kjd3Di38lk323nnm Kapitel 6 KAPITEL 6 Entscheidungsbäume Wie SVMs sind auch Entscheidungsbäume sehr flexible Machine-Learning-Algorithmen, die sich sowohl für Klassifikations- als auch Regressionsaufgaben
Der Alpha-Beta-Algorithmus
 Der Alpha-Beta-Algorithmus Maria Hartmann 19. Mai 2017 1 Einführung Wir wollen für bestimmte Spiele algorithmisch die optimale Spielstrategie finden, also die Strategie, die für den betrachteten Spieler
Der Alpha-Beta-Algorithmus Maria Hartmann 19. Mai 2017 1 Einführung Wir wollen für bestimmte Spiele algorithmisch die optimale Spielstrategie finden, also die Strategie, die für den betrachteten Spieler
3. Lernen von Entscheidungsbäumen
 3. Lernen von Entscheidungsbäumen Entscheidungsbäume 3. Lernen von Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse
3. Lernen von Entscheidungsbäumen Entscheidungsbäume 3. Lernen von Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse
Einführung in das Maschinelle Lernen I
 Einführung in das Maschinelle Lernen I Vorlesung Computerlinguistische Techniken Alexander Koller 26. Januar 2015 Maschinelles Lernen Maschinelles Lernen (Machine Learning): äußerst aktiver und für CL
Einführung in das Maschinelle Lernen I Vorlesung Computerlinguistische Techniken Alexander Koller 26. Januar 2015 Maschinelles Lernen Maschinelles Lernen (Machine Learning): äußerst aktiver und für CL
Learning to Optimize Mobile Robot Navigation Based on HTN Plans
 Learning to Optimize Mobile Robot Navigation Based on HTN Plans lernen Betreuer: Freek Stulp Hauptseminar Intelligente Autonome Systeme (WiSe 2004/05) Forschungs- und Lehreinheit Informatik IX 8. Dezember
Learning to Optimize Mobile Robot Navigation Based on HTN Plans lernen Betreuer: Freek Stulp Hauptseminar Intelligente Autonome Systeme (WiSe 2004/05) Forschungs- und Lehreinheit Informatik IX 8. Dezember
Konzepte der AI: Maschinelles Lernen
 Konzepte der AI: Maschinelles Lernen Nysret Musliu, Wolfgang Slany Abteilung für Datenbanken und Artificial Intelligence Institut für Informationssysteme, TU-Wien Übersicht Was ist Lernen? Wozu maschinelles
Konzepte der AI: Maschinelles Lernen Nysret Musliu, Wolfgang Slany Abteilung für Datenbanken und Artificial Intelligence Institut für Informationssysteme, TU-Wien Übersicht Was ist Lernen? Wozu maschinelles
Projekt Maschinelles Lernen WS 06/07
 Projekt Maschinelles Lernen WS 06/07 1. Auswahl der Daten 2. Evaluierung 3. Noise und Pruning 4. Regel-Lernen 5. ROC-Kurven 6. Pre-Processing 7. Entdecken von Assoziationsregeln 8. Ensemble-Lernen 9. Wettbewerb
Projekt Maschinelles Lernen WS 06/07 1. Auswahl der Daten 2. Evaluierung 3. Noise und Pruning 4. Regel-Lernen 5. ROC-Kurven 6. Pre-Processing 7. Entdecken von Assoziationsregeln 8. Ensemble-Lernen 9. Wettbewerb
Wünschenswerte Eigenschaft von Suchbäumen mit n Knoten: Suchen, Einfügen, Löschen auch im schlechtesten Fall O(log n)
") .6 Ausgeglichene Mehrweg-Suchbäume Wünschenswerte Eigenschaft von Suchbäumen mit n Knoten: Suchen, Einfügen, Löschen auch im schlechtesten Fall O(log n) Methoden: lokale Transformationen (AVL-Baum) Stochastische
.6 Ausgeglichene Mehrweg-Suchbäume Wünschenswerte Eigenschaft von Suchbäumen mit n Knoten: Suchen, Einfügen, Löschen auch im schlechtesten Fall O(log n) Methoden: lokale Transformationen (AVL-Baum) Stochastische
Reinforcement Learning
 Reinforcement Learning 1. Allgemein Reinforcement Learning 2. Neuronales Netz als Bewertungsfunktion 3. Neuronales Netz als Reinforcement Learning Nils-Olaf Bösch 1 Allgemein Reinforcement Learning Unterschied
Reinforcement Learning 1. Allgemein Reinforcement Learning 2. Neuronales Netz als Bewertungsfunktion 3. Neuronales Netz als Reinforcement Learning Nils-Olaf Bösch 1 Allgemein Reinforcement Learning Unterschied
Business Intelligence & Machine Learning
 AUSFÜLLHILFE: BEWEGEN SIE DEN MAUSZEIGER ÜBER DIE ÜBERSCHRIFTEN. AUSFÜHRLICHE HINWEISE: LEITFADEN MODULBESCHREIBUNG Business Intelligence & Machine Learning Kennnummer Workload Credits/LP Studiensemester
AUSFÜLLHILFE: BEWEGEN SIE DEN MAUSZEIGER ÜBER DIE ÜBERSCHRIFTEN. AUSFÜHRLICHE HINWEISE: LEITFADEN MODULBESCHREIBUNG Business Intelligence & Machine Learning Kennnummer Workload Credits/LP Studiensemester
Repetitive Strukturen
 Repetitive Strukturen Andreas Liebig Philipp Muigg ökhan Ibis Repetitive Strukturen, (z.b. sich wiederholende Strings), haben eine große Bedeutung in verschiedenen Anwendungen, wie z.b. Molekularbiologie,
Repetitive Strukturen Andreas Liebig Philipp Muigg ökhan Ibis Repetitive Strukturen, (z.b. sich wiederholende Strings), haben eine große Bedeutung in verschiedenen Anwendungen, wie z.b. Molekularbiologie,
Künstliche Intelligenz
 Künstliche Intelligenz Data Mining Approaches for Instrusion Detection Espen Jervidalo WS05/06 KI - WS05/06 - Espen Jervidalo 1 Overview Motivation Ziel IDS (Intrusion Detection System) HIDS NIDS Data
Künstliche Intelligenz Data Mining Approaches for Instrusion Detection Espen Jervidalo WS05/06 KI - WS05/06 - Espen Jervidalo 1 Overview Motivation Ziel IDS (Intrusion Detection System) HIDS NIDS Data
a) Fügen Sie die Zahlen 39, 38, 37 und 36 in folgenden (2, 3)-Baum ein:
 Fügen Sie die Zahlen 39, 38, 37 und 36 in folgenden (2, 3)-Baum ein:") 1 Aufgabe 8.1 (P) (2, 3)-Baum a) Fügen Sie die Zahlen 39, 38, 37 und 36 in folgenden (2, 3)-Baum ein: Zeichnen Sie, was in jedem Schritt passiert. b) Löschen Sie die Zahlen 65, 70 und 100 aus folgendem
1 Aufgabe 8.1 (P) (2, 3)-Baum a) Fügen Sie die Zahlen 39, 38, 37 und 36 in folgenden (2, 3)-Baum ein: Zeichnen Sie, was in jedem Schritt passiert. b) Löschen Sie die Zahlen 65, 70 und 100 aus folgendem
CBLOCK: An Automatic Blocking Mechanism for Large-Scale De-duplication Tasks. Cathleen Ramson, Stefan Lehmann LSDD SS 2013 25.04.
 CBLOCK: An Automatic Blocking Mechanism for Large-Scale De-duplication Tasks Cathleen Ramson, Stefan Lehmann LSDD SS 2013 25.04.2013 Gliederung 2 Motivation Ziel Algorithmen Zusammenfassung Bewertung Motivation
CBLOCK: An Automatic Blocking Mechanism for Large-Scale De-duplication Tasks Cathleen Ramson, Stefan Lehmann LSDD SS 2013 25.04.2013 Gliederung 2 Motivation Ziel Algorithmen Zusammenfassung Bewertung Motivation