GPU-Computing im Rahmen der Vorlesung Hochleistungsrechnen
|
|
|
- Heike Baumgartner
- vor 8 Jahren
- Abrufe
Transkript
1 GPU-Computing im Rahmen der Vorlesung Hochleistungsrechnen Universität Hamburg Scientific Visualization and Parallel Processing

2 Übersicht Hintergrund und Entwicklung von GPGPU Programmierumgebungen & Werkzeuge (CUDA) Programmierbeispiel (Matrix-Matrix Multiplikation) Einsatz von GPUs im Hochleistungsrechnen Referenzen Foliensatz basiert auf einer Vorlage von Prof. Dr. Ludwig, viele Beispiele und Graphiken aus [4] entnommen 2

3 Was ist Rendering User-Specified 3-D Coordinates (floating pt.) (3.7, 0.9, 8.3) Screen Coordinates (integer) (273, 407) Pixels with correct color (4.1, 0.5, 2.7) (3.5, 0.4, 6.1) (240, 390) (298, 396) Geometry Processing Rasterization Transformation und Beleuchtung Flächenfüllung und Texturierung Quelle (mod.): A. Lastra (UNC) 3
 (240, 390) (298, 396) Geometry Processing Rasterization Transformation und")
4 Hintergrund Bis 2000 bei Graphikkarten fixed function pipeline Transform & Lighting Engine (Geforce256, 99/00) 4

5 General Purpose Graphics Programming Programmierung auf Basis der Graphik Pipeline Datenarrays in Texturen Filter als Fragment Shader Stream Programming 5

6 GPGPU Beispiel DSP 6

7 Weiterentwicklung Nutzung der GPU als Parallelprozessor Vorangetrieben durch Universitäten und Forschung Weiterhin alles Graphik basiert (OpenGL) Entwicklung von Hochsprachen: Cg C for Graphics HLSL High Level Shading Language GLSL OpenGL Shading Language BrookGPU Stream Programming 7

8 GLSL Beispiel Programmierbare Vertex-Shader und Pixel-Shader ( fragment shader ) sind seit OpenGL 2.0 (2004) standardisiert: GLSL (OpenGL Shading Language) Literatur: R. J. Rost, B. Licea-Kange: OpenGL Shading Language, Addison-Wesley, 2010 SAXPY (Single-precision Alpha X Plus Y) in C in GLSL (fragment shader) float saxpy ( float2 coords : TEXCOORD0, uniform sampler2d texturey, uniform sampler2d texturex, uniform float alpha ) : COLOR { float x = x_orig[i]; float x = tex2d(texturex,coords); float y = y_orig[i]; float y = tex2d(texturey,coords); y_new[i] = y + alpha * x; float result = y + alpha * x; return result; } Operationen erfordern Iteration: Operationen werden beim Zeichnen eines for-schleife (serielle Ausführung) texturierten Rechtecks parallel ausgeführt 8
![texturey, uniform sampler2d texturex, uniform float alpha ) : COLOR { float x = x_orig[i]; float x = tex2d(texturex,coords); float y = y_orig[i]; float y = tex2d(texturey,coords); y_new[i] = y](/docs-images/43/7627631/images/page_8.jpg "+ alpha * x; float result = y + alpha * x; return result; } Operationen erfordern Iteration: Operationen werden beim Zeichnen eines for-schleife (serielle Ausführung) texturierten Rechtecks")
9 GPU Programmierung Heute Unified Shading Architecture Unified Hardware (Processors) Verschiedene Entwicklungsumgebungen Nvidia CUDA AMD Stream Brook GPU / Brook+ Rapid Mind Platform PGI Accelerator Compiler Suite Middleware und Support Bibliotheken Mathematik Bibliotheken (lineare Algebra) 9

10 CUDA Konzept Compute Unified Device Architecture Unified Hardware (Processors) and Software Erste Grafikkarte verfügbar seit Ende 2006 Dedicated Many-Core Co-Prozessor Programmier Model: SIMD SIMT (Single-Instruction Multiple-Thread) Single instruction Multiple instruction Single data SISD MISD Keine Graphik API mehr Multiple data SIMD MIMD Highlevel Entwicklung in C/C++, Fortran, 10

11 CUDA Werkzeuge CUDA Toolkit / SDK Treiber, SDK, Compiler, Beispiele Profiler, Occupancy Calculator, Debugger Unterstützt werden: C/C++, FORTRAN, OpenCL, DirectCompute Bibliotheken CUBLAS (Basic Linear Algebra Subprograms) CUFFT (Fourier Transformation, Basis: fftw) CUDPP (Data Parallel Primitives), THRUST (STL) Entwicklungsumgebungen Visual Studio + NEXUS (Parallel Nsight) 11
, THRUST (STL) Entwicklungsumgebungen Visual Studio + NEXUS")
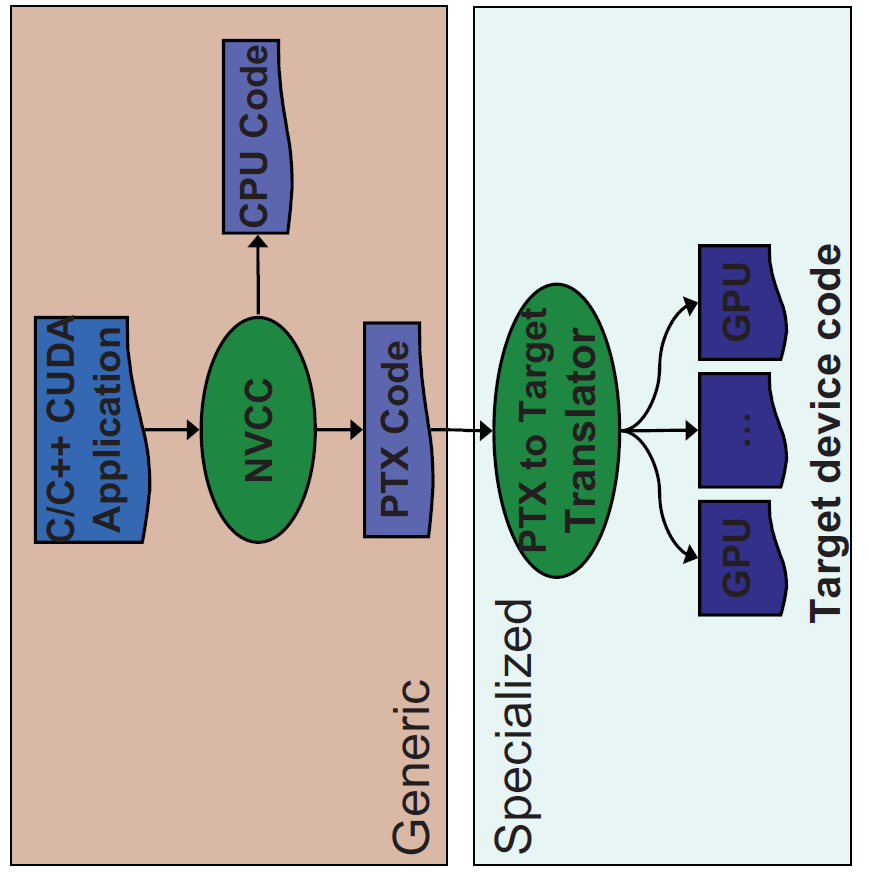
12 Codegenerierung 12

13 GF100 Architektur (Fermi) 13


 Concurrent Thread Execution IEEE 754-2008 (FMA) ECC")
14 Streaming Multiprozessor 16 Streaming Multiprozessoren 32 CUDA Kerne FP / INT Unit 16 Load / Store Units 64k shared memory / L1 Cache 4 Special Function Units (SFU) (sin, cos, sqr, ) Concurrent Thread Execution IEEE (FMA) ECC Speicher 14
 Concurrent Thread Execution IEEE 754-2008 (FMA) ECC")

15 Vergleich G80 / GT200 / GF100 15


16 Vergleich Fermi / Keppler 16

17 Thread (1,0) Thread (1,1) Thread (1,2) Thread (0,0) Thread (1,0) Thread (2,0) CUDA Programming Model Threads, Blocks and Grids Block (0,0) Grid Block (0,0) Block (0,1) Block (1,0) Block (1,1) 17
 Block (0,1) Block (1,0) Block (1,1)")
18 Time CUDA Programming Model Typical CUDA workflow Allocate memory in device DRAM Copy initial data to device Process data by one or more kernel calls Copy back results to host DRAM Free allocated device DRAM Host Kernel 1 Kernel 2 Device Grid 1 Grid 2 18


19 CUDA Threads 19
20 CUDA Programming Model Memory Model Private local memory Per thread Registers or in global memory Shared memory Shared by all threads within a block On-Chip Global memory Accessible by all threads Persistent across kernel calls Special memory: Constant memory (cached) Texture memory (cached) Block Grid 20
 Texture memory")
21 CUDA Hardware Architecture Warps Threads are organised into warps Warp consists of 32 Threads (on current hardware) Divergent threads only occur within warps Switching between warps comes at no cost, because all threads have their own set of registers Care needs to be taken when accessing shared or global memory by threads of a warp Time SM multithreaded instruction scheduler warp 6 instruction 23 warp 10 instruction 6 warp 1 instruction warp 6 instruction 24 warp 1 instruction 14 Taken from NVIDIA 21
22 Requires specific problem type: Enough data parallelism Enough data to work on Enough computation per data element Often data transfer between host and device DRAM is limiting factor Keep data on GPU Fine tuning is done on a very low programming level Need to understand hardware GPU hardware is simpler than CPU Hard to maintain Limitations of CUDA 22

23 Beispiel: Matrix-Matrix Multiplikation 2 quadratische Matrizen der Größe Width 23
24 Main Function 24

25 Matrix-Matrix Multiplikation 25
26 CUDA Implementierung 26

27 Exkurs: CUDA Device Memory Model 27

28 Exkurs: Speicher Management 28

29 Exkurs: Datentransfer Host Device 29
30 CUDA Implementierung 30
31 CUDA Kernel 31
32 Aufruf des Kernels 32
33 Optimierung Optimierung ist enorm wichtig! Maximierung der Auslastung (Occupancy): Speicherdurchsatz (Bandbreite) Anweisungsdurchsatz Auslastung Beispiel: Speicher Optimierung Transfer zwischen Host Device Speichertypen (global, shared, constant) Coalesced vs. non-coalesced Zugriff 33
34 OpenCL Compute Language für CPUs und GPUs Offener Standard für heterogene Umgebungen Khronos Group (Apple) OpenCL 1.0 ( ) OpenGL and OpenCL share Resources OpenCL is designed to efficiently share with OpenGL Textures, Buffer Objects and Renderbuffers Data is shared, not copied 34

35 OpenCL Context 35
36 OpenCL Beispiel // OpenCL Objects cl_device_id device; cl_context context; cl_command_queue queue; cl_program program; cl_kernel kernel; cl_mem buffer; // Setup OpenCL clgetdeviceids(null, CL_DEVICE_TYPE_DEFAULT, 1, &device, NULL); context = clcreatecontext(null, 1, &device, NULL, NULL, NULL); queue = clcreatecommandqueue(context, device, (cl_command_queue_properties)0, NULL); // Setup Buffer buffer = clcreatebuffer(context, CL_MEM_COPY_HOST_PTR, sizeof(cl_float)*10240, data, NULL); 36
37 OpenCL Beispiel cont. // Build the kernel program = clcreateprogramwithsource(context, 1, (const char**)&source, NULL, NULL); clbuildprogram(program, 0, NULL, NULL, NULL, NULL); kernel = clcreatekernel(program, "calcsin", NULL); // Execute the kernel clsetkernelarg(kernel, 0, sizeof(buffer), &buffer); size_t global_dimensions[] = {LENGTH,0,0}; clenqueuendrangekernel(queue, kernel, 1, NULL, global_dimensions, NULL, 0, NULL, NULL); // Read back the results clenqueuereadbuffer(queue, buffer, CL_TRUE, 0, sizeof(cl_float)*length, data, 0, NULL, NULL); // Clean up 37
38 Top100 (11/2012) Einsatz von GPUs im HPC 50 Systeme mit Nvidia/Tesla 3 System mit ATI (22) Einsatzgebiete: Astronomie und Astrophysik Biologie, Chemie Finanzwirtschaft 38
39 GPU Cluster in der Top100 (11/2012) Titan (Top500 Platz 1) R R (TFlops) max peak max peak Cray XK7, Opteron C 2.200GHz, Cray Gemini interconnect, NVIDIA K20x Tianhe-1a (Top500 Platz 8) R R (TFlops) NUDT TH MPP, X Ghz 6C, Nvidia GF104 39

40 GPU Cluster MPI zur Kommunikation der Knoten untereinande Sehr gute Auslastung und Effizienz/Strom Verhältnis Schwierig: Umsetzung und Optimierung 40
41 FORTRAN und CUDA FORTRAN noch weit verbreitet (z.b. Klimaforschung) CUBLAS, CUFFT (NVIDIA) CUDA implementation of BLAS routines with Fortran API F2C-ACC (NOAA Earth System Research Laboratory) Generates C or CUDA output from Fortran95 input HMPP Workbench (CAPS Enterprise) Directive-based source-to-source compiler PGI Compiler Suite Directive-based Compiler 41
 = 0.0 do j = 1,n2 c(i,k) = c(i,k) + a(i,j) * b(j,k) enddo enddo enddo!")
42 PGI Accelerator Compiler Fortran CUDA Beispiel OpenMP-like implicit programming model for X64+GPU-systems!$acc region do k = 1,n1 do i = 1,n3 c(i,k) = 0.0 do j = 1,n2 c(i,k) = c(i,k) + a(i,j) * b(j,k) enddo enddo enddo!$acc end region Example 42
 subroutine ksaxpy( n, a, x, y ) real, dimension(*) :: x,y real, value :: a integer, value :: n, i i = (blockidx%x-1) * blockdim%x + threadidx%x if( i <= n ) y(i)")
43 Fortran CUDA Beispiel PGI CUDA Fortran Compiler! Kernel definition attributes(global) subroutine ksaxpy( n, a, x, y ) real, dimension(*) :: x,y real, value :: a integer, value :: n, i i = (blockidx%x-1) * blockdim%x + threadidx%x if( i <= n ) y(i) = a * x(i) + y(i) end subroutine! Host subroutine subroutine solve( n, a, x, y ) real, device, dimension(*) :: x, y real :: a integer :: n! call the kernel call ksaxpy<<<n/64, 64>>>( n, a, x, y ) end subroutine Example 43
44 GPU-Computing am RRZ/SVPP Arbeitsgruppe: Scientific Visualization and Parallel Processing der Informatik GPU-Cluster: 96 CPU-Cores und 24 Nvidia Tesla M2070Q verteilt auf 8 Knoten DDN Storage mit 60 TB RAW Kapazität ausschließlich zur Entwicklung und Erprobung, kein produktiver Betrieb Forschung: Entwicklung von Verfahren zur Visualisierung wissenschaftlicher Daten Lehre: Vorlesung Datenvisualisierung und GPU-Computing von Prof. Dr.-Ing. Olbrich im Sommersemester 44
45 Zusammenfassung Stetig steigende Entwicklung seit 2000 Beschleunigt seit Einführung von CUDA (2007) IEEE Unterstützung / ECC Speicher Für FORTRAN Source2Source Compiler Optimierung ist enorm wichtig Alternativen zu CUDA: OpenCL Intel s Knights Family OpenACC C++ AMP 45
46 Referenzen [1] [2] [3] [4] Programming Massively Parallel Processors: A Hands-On Approach, Kirk & Hwu [5] Cuda by Example: An Introduction to General-Purpose GPU Programming, Sanders & Kandrot [6] GPU Computing Gems, Hwu 46
GPU-Computing. Michael Vetter
 GPU-Computing Universität Hamburg Scientific Visualization and Parallel Processing @ Informatik Climate Visualization Laboratory @ Clisap/CEN Übersicht Hintergrund und Entwicklung von GPGPU Programmierumgebungen
GPU-Computing Universität Hamburg Scientific Visualization and Parallel Processing @ Informatik Climate Visualization Laboratory @ Clisap/CEN Übersicht Hintergrund und Entwicklung von GPGPU Programmierumgebungen
Hochleistungsrechnen Grafikkartenprogrammierung. Prof. Dr. Thomas Ludwig Universität Hamburg Informatik Wissenschaftliches Rechnen
 Hochleistungsrechnen Grafikkartenprogrammierung Prof. Dr. Thomas Ludwig Universität Hamburg Informatik Wissenschaftliches Rechnen Übersicht Hintergrund und Entwicklung von GPGPU Programmierumgebungen &
Hochleistungsrechnen Grafikkartenprogrammierung Prof. Dr. Thomas Ludwig Universität Hamburg Informatik Wissenschaftliches Rechnen Übersicht Hintergrund und Entwicklung von GPGPU Programmierumgebungen &
CUDA. Moritz Wild, Jan-Hugo Lupp. Seminar Multi-Core Architectures and Programming. Friedrich-Alexander-Universität Erlangen-Nürnberg
 CUDA Seminar Multi-Core Architectures and Programming 1 Übersicht Einleitung Architektur Programmierung 2 Einleitung Computations on GPU 2003 Probleme Hohe Kenntnisse der Grafikprogrammierung nötig Unterschiedliche
CUDA Seminar Multi-Core Architectures and Programming 1 Übersicht Einleitung Architektur Programmierung 2 Einleitung Computations on GPU 2003 Probleme Hohe Kenntnisse der Grafikprogrammierung nötig Unterschiedliche
Compute Unified Device Architecture CUDA
 Compute Unified Device Architecture 06. Februar 2012 1 / 13 Gliederung 2 / 13 : Compute Unified Device Architecture entwickelt von Nvidia Corporation spezifiziert Software- und Hardwareeigenschaften Ziel:
Compute Unified Device Architecture 06. Februar 2012 1 / 13 Gliederung 2 / 13 : Compute Unified Device Architecture entwickelt von Nvidia Corporation spezifiziert Software- und Hardwareeigenschaften Ziel:
Masterpraktikum Scientific Computing
 Masterpraktikum Scientific Computing High-Performance Computing Thomas Auckenthaler Wolfgang Eckhardt Technische Universität München, Germany Outline Entwicklung General Purpose GPU Programming (GPGPU)
Masterpraktikum Scientific Computing High-Performance Computing Thomas Auckenthaler Wolfgang Eckhardt Technische Universität München, Germany Outline Entwicklung General Purpose GPU Programming (GPGPU)
GPGPU mit NVIDIA CUDA
 01.07.12 GPGPU mit NVIDIA CUDA General-Purpose on Formatvorlagecomputing des Graphics Processing durch Units Untertitelmasters mit KlickenCompute bearbeiten NVIDIA Unified Device Architecture Gliederung
01.07.12 GPGPU mit NVIDIA CUDA General-Purpose on Formatvorlagecomputing des Graphics Processing durch Units Untertitelmasters mit KlickenCompute bearbeiten NVIDIA Unified Device Architecture Gliederung
General Purpose Computation on GPUs
 General Purpose Computation on GPUs Matthias Schneider, Robert Grimm Universität Erlangen-Nürnberg {matthias.schneider, robert.grimm}@informatik.stud.uni-erlangen.de M. Schneider, R. Grimm 1 Übersicht
General Purpose Computation on GPUs Matthias Schneider, Robert Grimm Universität Erlangen-Nürnberg {matthias.schneider, robert.grimm}@informatik.stud.uni-erlangen.de M. Schneider, R. Grimm 1 Übersicht
Masterpraktikum Scientific Computing
 Masterpraktikum Scientific Computing High-Performance Computing Thomas Auckenthaler Wolfgang Eckhardt Prof. Dr. Michael Bader Technische Universität München, Germany Outline Organisatorisches Entwicklung
Masterpraktikum Scientific Computing High-Performance Computing Thomas Auckenthaler Wolfgang Eckhardt Prof. Dr. Michael Bader Technische Universität München, Germany Outline Organisatorisches Entwicklung
Programmierbeispiele und Implementierung. Name: Michel Steuwer E-Mail: michel.steuwer@wwu.de
 > Programmierbeispiele und Implementierung Name: Michel Steuwer E-Mail: michel.steuwer@wwu.de 2 > Übersicht > Matrix Vektor Multiplikation > Mandelbrotmenge / Apfelmännchen berechnen > Kantendetektion
> Programmierbeispiele und Implementierung Name: Michel Steuwer E-Mail: michel.steuwer@wwu.de 2 > Übersicht > Matrix Vektor Multiplikation > Mandelbrotmenge / Apfelmännchen berechnen > Kantendetektion
GPGPU-Programmierung
 12 GPGPU-Programmierung 2013/04/25 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken ist im Allgemeinen nicht erlaubt. Motivation (1) General Purpose Computing on
12 GPGPU-Programmierung 2013/04/25 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken ist im Allgemeinen nicht erlaubt. Motivation (1) General Purpose Computing on
Proseminar. GPU-Computing Cuda vs. OpenCL. SS 2013 Alexander Stepanov
 Proseminar GPU-Computing Cuda vs. OpenCL SS 2013 Alexander Stepanov Inhaltsverzeichnis 1. Einführung: Warum GPU Computing? CPU vs. GPU GPU Architektur 2. CUDA Architektur Beispiel Matrix Multiplikation
Proseminar GPU-Computing Cuda vs. OpenCL SS 2013 Alexander Stepanov Inhaltsverzeichnis 1. Einführung: Warum GPU Computing? CPU vs. GPU GPU Architektur 2. CUDA Architektur Beispiel Matrix Multiplikation
CUDA. Axel Jena, Jürgen Pröll. Multi-Core Architectures and Programming. Friedrich-Alexander-Universität Erlangen-Nürnberg Axel Jena, Jürgen Pröll 1
 CUDA Axel Jena, Jürgen Pröll Multi-Core Architectures and Programming Axel Jena, Jürgen Pröll 1 Warum Tesla? Traditionelle Graphikkarten Getrennte Prozessoren für Vertex- / Pixelberechnungen - Nachteil:
CUDA Axel Jena, Jürgen Pröll Multi-Core Architectures and Programming Axel Jena, Jürgen Pröll 1 Warum Tesla? Traditionelle Graphikkarten Getrennte Prozessoren für Vertex- / Pixelberechnungen - Nachteil:
Seminar GPU-Programmierung/Parallelverarbeitung
 Seite iv Literaturverzeichnis 1) Bengel, G.; et al.: Masterkurs Parallele und Verteilte Systeme. Vieweg + Teubner, Wiesbaden, 2008. 2) Breshears, C.: The Art of Concurrency - A Thread Monkey's Guide to
Seite iv Literaturverzeichnis 1) Bengel, G.; et al.: Masterkurs Parallele und Verteilte Systeme. Vieweg + Teubner, Wiesbaden, 2008. 2) Breshears, C.: The Art of Concurrency - A Thread Monkey's Guide to
Grafikkarten-Architektur
 > Grafikkarten-Architektur Parallele Strukturen in der GPU Name: Sebastian Albers E-Mail: s.albers@wwu.de 2 > Inhalt > CPU und GPU im Vergleich > Rendering-Pipeline > Shader > GPGPU > Nvidia Tesla-Architektur
> Grafikkarten-Architektur Parallele Strukturen in der GPU Name: Sebastian Albers E-Mail: s.albers@wwu.de 2 > Inhalt > CPU und GPU im Vergleich > Rendering-Pipeline > Shader > GPGPU > Nvidia Tesla-Architektur
GPU-Programmierung: OpenCL
 Seminar: Multicore Programmierung Sommerstemester 2009 04.06.2009 Inhaltsverzeichnis 1 GPU-Programmierung von Grafikkarten von GPU-Computing 2 Architektur Spracheigenschaften Vergleich mit CUDA Beispiel
Seminar: Multicore Programmierung Sommerstemester 2009 04.06.2009 Inhaltsverzeichnis 1 GPU-Programmierung von Grafikkarten von GPU-Computing 2 Architektur Spracheigenschaften Vergleich mit CUDA Beispiel
GPGPU WITH OPENCL. Praktikum Parallele Rechnerarchitekturen, 2015w Franz Richter-Gottfried
 GPGPU WITH OPENCL Praktikum Parallele Rechnerarchitekturen, 2015w Franz Richter-Gottfried INFRASTRUCTURE Enqueue interactive job srun --gres --pty bash Graphics cards available for tesla_k20,
GPGPU WITH OPENCL Praktikum Parallele Rechnerarchitekturen, 2015w Franz Richter-Gottfried INFRASTRUCTURE Enqueue interactive job srun --gres --pty bash Graphics cards available for tesla_k20,
GPGPU-Programmierung
 12 GPGPU-Programmierung 2014/04/29 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken ist im Allgemeinen nicht erlaubt. Motivation (1) General Purpose Computing on
12 GPGPU-Programmierung 2014/04/29 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken ist im Allgemeinen nicht erlaubt. Motivation (1) General Purpose Computing on
Eine kurze Geschichte der Grafikkarten
 3.1 Einführung Eine kurze Geschichte der Grafikkarten ursprünglich: Graphics Card steuert Monitor an Mitte 80er: Grafikkarten mit 2D-Beschleunigung angelehnt an Arcade- und Home-Computer frühe 90er: erste
3.1 Einführung Eine kurze Geschichte der Grafikkarten ursprünglich: Graphics Card steuert Monitor an Mitte 80er: Grafikkarten mit 2D-Beschleunigung angelehnt an Arcade- und Home-Computer frühe 90er: erste
Stream Processing und High- Level GPGPU Sprachen
 Stream Processing und High- Level GPGPU Sprachen Seminar Programmierung von Grafikkarten Jens Breitbart Problem 5000% 4000% 3000% 2000% Rechenleistung: +71% pro Jahr Bandbreite: +25% pro Jahr Zugriffszeit:
Stream Processing und High- Level GPGPU Sprachen Seminar Programmierung von Grafikkarten Jens Breitbart Problem 5000% 4000% 3000% 2000% Rechenleistung: +71% pro Jahr Bandbreite: +25% pro Jahr Zugriffszeit:
OpenCL. OpenCL. Boris Totev, Cornelius Knap
 OpenCL OpenCL 1 OpenCL Gliederung Entstehungsgeschichte von OpenCL Was, warum und überhaupt wieso OpenCL CUDA, OpenGL und OpenCL GPUs OpenCL Objekte Work-Units OpenCL Adressbereiche OpenCL API Codebeispiel
OpenCL OpenCL 1 OpenCL Gliederung Entstehungsgeschichte von OpenCL Was, warum und überhaupt wieso OpenCL CUDA, OpenGL und OpenCL GPUs OpenCL Objekte Work-Units OpenCL Adressbereiche OpenCL API Codebeispiel
RST-Labor WS06/07 GPGPU. General Purpose Computation On Graphics Processing Units. (Grafikkarten-Programmierung) Von: Marc Blunck
 Von: Marc Blunck") RST-Labor WS06/07 GPGPU General Purpose Computation On Graphics Processing Units (Grafikkarten-Programmierung) Von: Marc Blunck Ablauf Einführung GPGPU Die GPU GPU Architektur Die Programmierung Programme
RST-Labor WS06/07 GPGPU General Purpose Computation On Graphics Processing Units (Grafikkarten-Programmierung) Von: Marc Blunck Ablauf Einführung GPGPU Die GPU GPU Architektur Die Programmierung Programme
Parallele Programmierung mit GPUs
 Parallele Programmierung mit GPUs Jutta Fitzek Vortrag im Rahmen des Moduls Parallele Programmierung, WS12/13, h_da Agenda GPUs: Historie GPU Programmierung Konzepte Codebeispiel Generelle Tipps & Tricks
Parallele Programmierung mit GPUs Jutta Fitzek Vortrag im Rahmen des Moduls Parallele Programmierung, WS12/13, h_da Agenda GPUs: Historie GPU Programmierung Konzepte Codebeispiel Generelle Tipps & Tricks
GPGPU-Architekturen CUDA Programmiermodell Beispielprogramm. Einführung CUDA. Ralf Seidler. Friedrich-Alexander-Universität Erlangen-Nürnberg
 Einführung CUDA Friedrich-Alexander-Universität Erlangen-Nürnberg PrakParRA, 18.11.2010 Outline 1 GPGPU-Architekturen 2 CUDA Programmiermodell 3 Beispielprogramm Outlook 1 GPGPU-Architekturen 2 CUDA Programmiermodell
Einführung CUDA Friedrich-Alexander-Universität Erlangen-Nürnberg PrakParRA, 18.11.2010 Outline 1 GPGPU-Architekturen 2 CUDA Programmiermodell 3 Beispielprogramm Outlook 1 GPGPU-Architekturen 2 CUDA Programmiermodell
Praxiseinheit: Realisierung einer hardwarebeschleunigten Disparitätenberechnung zur automatischen Auswertung von Stereobildern
 Praxiseinheit: Realisierung einer hardwarebeschleunigten Disparitätenberechnung zur automatischen Auswertung von Stereobildern Institut für Betriebssysteme und Rechnerverbund TU Braunschweig 25.10., 26.10.
Praxiseinheit: Realisierung einer hardwarebeschleunigten Disparitätenberechnung zur automatischen Auswertung von Stereobildern Institut für Betriebssysteme und Rechnerverbund TU Braunschweig 25.10., 26.10.
Computer Graphics Shader
 Computer Graphics Shader Sven Janusch Inhalt Fixed Function Pipeline Programmable Pipeline Implementierung Applikation Beispiel Sven Janusch 2 Fixed Function Pipeline T&L Pipeline (Transformation and Lighting)
Computer Graphics Shader Sven Janusch Inhalt Fixed Function Pipeline Programmable Pipeline Implementierung Applikation Beispiel Sven Janusch 2 Fixed Function Pipeline T&L Pipeline (Transformation and Lighting)
Einführung. GPU-Versuch. Andreas Schäfer Friedrich-Alexander-Universität Erlangen-Nürnberg
 GPU-Versuch andreas.schaefer@cs.fau.de Friedrich-Alexander-Universität Erlangen-Nürnberg Praktikum Parallele Rechnerarchitekturen SS2014 Outline 1 Einführung 2 Outlook 1 Einführung 2 Eine kurze Geschichte
GPU-Versuch andreas.schaefer@cs.fau.de Friedrich-Alexander-Universität Erlangen-Nürnberg Praktikum Parallele Rechnerarchitekturen SS2014 Outline 1 Einführung 2 Outlook 1 Einführung 2 Eine kurze Geschichte
GPGPU-Programming. Constantin Timm Informatik 12 TU Dortmund 2012/04/09. technische universität dortmund. fakultät für informatik informatik 12
 12 GPGPU-Programming Constantin Timm Informatik 12 TU Dortmund 2012/04/09 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken ist im Allgemeinen nicht erlaubt. Motivation
12 GPGPU-Programming Constantin Timm Informatik 12 TU Dortmund 2012/04/09 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken ist im Allgemeinen nicht erlaubt. Motivation
Ein kleiner Einblick in die Welt der Supercomputer. Christian Krohn 07.12.2010 1
 Ein kleiner Einblick in die Welt der Supercomputer Christian Krohn 07.12.2010 1 Vorschub: FLOPS Entwicklung der Supercomputer Funktionsweisen von Supercomputern Zukunftsvisionen 2 Ein Top10 Supercomputer
Ein kleiner Einblick in die Welt der Supercomputer Christian Krohn 07.12.2010 1 Vorschub: FLOPS Entwicklung der Supercomputer Funktionsweisen von Supercomputern Zukunftsvisionen 2 Ein Top10 Supercomputer
Rheinisch-Westfälische Technische Hochschule Aachen. Seminararbeit
 Rheinisch-Westfälische Technische Hochschule Aachen Seminararbeit Analyse von General Purpose Computation on Graphics Processing Units Bibliotheken in Bezug auf GPU-Hersteller. Gregori Kerber Matrikelnummer
Rheinisch-Westfälische Technische Hochschule Aachen Seminararbeit Analyse von General Purpose Computation on Graphics Processing Units Bibliotheken in Bezug auf GPU-Hersteller. Gregori Kerber Matrikelnummer
Multicore-Architekturen
 Universität Erlangen- Nürnberg Technische Universität München Universität Stuttgart Multicore-Architekturen Vortrag im Rahmen der Ferienakademie 2009 Kurs 1: Programmierkonzepte für Multi-Core Rechner
Universität Erlangen- Nürnberg Technische Universität München Universität Stuttgart Multicore-Architekturen Vortrag im Rahmen der Ferienakademie 2009 Kurs 1: Programmierkonzepte für Multi-Core Rechner
Ferienakademie Erik Muttersbach
 Ferienakademie 2009 - Erik Muttersbach 1. Einführung 2. Kernels, Threads, Blocks 3. CUDA Execution Model 4. Software Stack 5. Die CUDA Runtime API 6. Speichertypen/ Zugriff 7. Profiling und Optimierung
Ferienakademie 2009 - Erik Muttersbach 1. Einführung 2. Kernels, Threads, Blocks 3. CUDA Execution Model 4. Software Stack 5. Die CUDA Runtime API 6. Speichertypen/ Zugriff 7. Profiling und Optimierung
Seminar Game Development Game Computer Graphics. Einleitung
 Einleitung Gliederung OpenGL Realismus Material Beleuchtung Schatten Echtzeit Daten verringern Grafik Hardware Beispiel CryEngine 2 Kristian Keßler OpenGL Was ist OpenGL? Grafik API plattform- und programmiersprachenunabhängig
Einleitung Gliederung OpenGL Realismus Material Beleuchtung Schatten Echtzeit Daten verringern Grafik Hardware Beispiel CryEngine 2 Kristian Keßler OpenGL Was ist OpenGL? Grafik API plattform- und programmiersprachenunabhängig
Grundlagen von CUDA, Sprachtypische Elemente
 Grundlagen von CUDA, Sprachtypische Elemente Stefan Maskanitz 03.07.2009 CUDA Grundlagen 1 Übersicht 1. Einleitung 2. Spracheigenschaften a. s, Blocks und Grids b. Speicherorganistion c. Fehlerbehandlung
Grundlagen von CUDA, Sprachtypische Elemente Stefan Maskanitz 03.07.2009 CUDA Grundlagen 1 Übersicht 1. Einleitung 2. Spracheigenschaften a. s, Blocks und Grids b. Speicherorganistion c. Fehlerbehandlung
Parallele Algorithmen mit OpenCL. Universität Osnabrück, Henning Wenke, 2013-05-08
 Parallele Algorithmen mit OpenCL Universität Osnabrück, Henning Wenke, 2013-05-08 Aufräumen Ressourcen in umgekehrter Abhängigkeitsreihenfolge freigeben Objekte haben Reference-Count (RC), initial 1 clrelease
Parallele Algorithmen mit OpenCL Universität Osnabrück, Henning Wenke, 2013-05-08 Aufräumen Ressourcen in umgekehrter Abhängigkeitsreihenfolge freigeben Objekte haben Reference-Count (RC), initial 1 clrelease
Thema: Hardware-Shader
 Seminar Grafikprogrammierung Thema: Hardware-Shader Christian Bauer 03.07.08 Überblick Entwicklung Die Shader im Detail Programmierung GPGPU Zusammenfassung & Ausblick 1/19 Entwicklung (1) Früher: Berechnung
Seminar Grafikprogrammierung Thema: Hardware-Shader Christian Bauer 03.07.08 Überblick Entwicklung Die Shader im Detail Programmierung GPGPU Zusammenfassung & Ausblick 1/19 Entwicklung (1) Früher: Berechnung
GPGPU Basiskonzepte. von Marc Kirchhoff GPGPU Basiskonzepte 1
 GPGPU Basiskonzepte von Marc Kirchhoff 29.05.2006 GPGPU Basiskonzepte 1 Inhalt Warum GPGPU Streams, Kernels und Prozessoren Datenstrukturen Algorithmen 29.05.2006 GPGPU Basiskonzepte 2 Warum GPGPU? Performance
GPGPU Basiskonzepte von Marc Kirchhoff 29.05.2006 GPGPU Basiskonzepte 1 Inhalt Warum GPGPU Streams, Kernels und Prozessoren Datenstrukturen Algorithmen 29.05.2006 GPGPU Basiskonzepte 2 Warum GPGPU? Performance
Physikalische Berechnungen mit General Purpose Graphics Processing Units (GPGPUs)
") Fakultätsname XYZ Fachrichtung XYZ Institutsname XYZ, Professur XYZ Physikalische Berechnungen mit General Purpose Graphics Processing Units (GPGPUs) im Rahmen des Proseminars Technische Informatik Juni
Fakultätsname XYZ Fachrichtung XYZ Institutsname XYZ, Professur XYZ Physikalische Berechnungen mit General Purpose Graphics Processing Units (GPGPUs) im Rahmen des Proseminars Technische Informatik Juni
Yilmaz, Tolga MatNr: Mesaud, Elias MatNr:
 Yilmaz, Tolga MatNr: 157317 Mesaud, Elias MatNr: 151386 1. Aufbau und Funktionsweise einer Grafikkarte 2. CPU vs. GPU 3. Software 4. Beispielprogramme Kompilierung und Vorführung 5. Wo wird Cuda heutzutage
Yilmaz, Tolga MatNr: 157317 Mesaud, Elias MatNr: 151386 1. Aufbau und Funktionsweise einer Grafikkarte 2. CPU vs. GPU 3. Software 4. Beispielprogramme Kompilierung und Vorführung 5. Wo wird Cuda heutzutage
Computergrafik Universität Osnabrück, Henning Wenke,
 Computergrafik Universität Osnabrück, Henning Wenke, 2012-06-25 Kapitel XV: Parallele Algorithmen mit OpenCL 15.1 Parallele Programmierung Quellen: V.a. Wikipedia. Leistungsdaten unter Vorbehalt. Bitte
Computergrafik Universität Osnabrück, Henning Wenke, 2012-06-25 Kapitel XV: Parallele Algorithmen mit OpenCL 15.1 Parallele Programmierung Quellen: V.a. Wikipedia. Leistungsdaten unter Vorbehalt. Bitte
Gliederung. Was ist CUDA? CPU GPU/GPGPU CUDA Anwendungsbereiche Wirtschaftlichkeit Beispielvideo
 Gliederung Was ist CUDA? CPU GPU/GPGPU CUDA Anwendungsbereiche Wirtschaftlichkeit Beispielvideo Was ist CUDA? Nvidia CUDA ist eine von NvidiaGPGPU-Technologie, die es Programmierern erlaubt, Programmteile
Gliederung Was ist CUDA? CPU GPU/GPGPU CUDA Anwendungsbereiche Wirtschaftlichkeit Beispielvideo Was ist CUDA? Nvidia CUDA ist eine von NvidiaGPGPU-Technologie, die es Programmierern erlaubt, Programmteile
PGI Accelerator Model
 PGI Accelerator Model Philip Höhlein, Nils Werner Supervision: R. Membarth, P. Kutzer, F. Hannig Hardware-Software-Co-Design Universität Erlangen-Nürnberg Philip Höhlein, Nils Werner 1 Übersicht Motivation
PGI Accelerator Model Philip Höhlein, Nils Werner Supervision: R. Membarth, P. Kutzer, F. Hannig Hardware-Software-Co-Design Universität Erlangen-Nürnberg Philip Höhlein, Nils Werner 1 Übersicht Motivation
Interaktive Globale Beleuchtung nach dem Antiradiance-Verfahren mittels der Open Computing Language (OpenCL)
") Interaktive Globale Beleuchtung nach dem Antiradiance-Verfahren mittels der Open Computing Language (OpenCL) Verteidigung der Belegarbeit Andreas Stahl Zielstellung Globales Beleuchtungsverfahren für die
Interaktive Globale Beleuchtung nach dem Antiradiance-Verfahren mittels der Open Computing Language (OpenCL) Verteidigung der Belegarbeit Andreas Stahl Zielstellung Globales Beleuchtungsverfahren für die
The Modular Structure of Complex Systems. 30.06.2004 Seminar SoftwareArchitektur Fabian Schultz
 The Modular Structure of Complex Systems 1 Modularisierung Vorteile Organisation Mehrere unabhängig Teams können gleichzeitig arbeiten Flexibilität Änderung einzelner Module Verständlichkeit Nachteile
The Modular Structure of Complex Systems 1 Modularisierung Vorteile Organisation Mehrere unabhängig Teams können gleichzeitig arbeiten Flexibilität Änderung einzelner Module Verständlichkeit Nachteile
OpenCL. Multi-Core Architectures and Programming (Seminar) Apelt, Nicolas / Zöllner, Christian
 Apelt, Nicolas / Zöllner, Christian") OpenCL Multi-Core Architectures and Programming (Seminar) Apelt, Nicolas / Zöllner, Christian Hardware-Software-Co-Design Universität Erlangen-Nürnberg Apelt, Nicolas / Zöllner, Christian 1 Was ist OpenCL?
OpenCL Multi-Core Architectures and Programming (Seminar) Apelt, Nicolas / Zöllner, Christian Hardware-Software-Co-Design Universität Erlangen-Nürnberg Apelt, Nicolas / Zöllner, Christian 1 Was ist OpenCL?
GPU Programmierung. Thorsten Grosch
 Thorsten Grosch Willkommen zur ersten Vorlesung! g Heute Organisatorisches Vorstellung von Team und Vorlesung Historischer Rückblick zu GPUs 2 Das Team Vorlesung Jun.-Prof. Thorsten Grosch AG Computervisualistik
Thorsten Grosch Willkommen zur ersten Vorlesung! g Heute Organisatorisches Vorstellung von Team und Vorlesung Historischer Rückblick zu GPUs 2 Das Team Vorlesung Jun.-Prof. Thorsten Grosch AG Computervisualistik
Motivation (GP)GPU CUDA Zusammenfassung. CUDA und Python. Christian Wilms. Integriertes Seminar Projekt Bildverarbeitung
GPU CUDA Zusammenfassung. CUDA und Python. Christian Wilms. Integriertes Seminar Projekt Bildverarbeitung") CUDA und Python Christian Wilms Integriertes Seminar Projekt Bildverarbeitung Universität Hamburg WiSe 2013/14 12. Dezember 2013 Christian CUDA und Python 1 Gliederung 1 Motivation 2 (GP)GPU 3 CUDA 4 Zusammenfassung
CUDA und Python Christian Wilms Integriertes Seminar Projekt Bildverarbeitung Universität Hamburg WiSe 2013/14 12. Dezember 2013 Christian CUDA und Python 1 Gliederung 1 Motivation 2 (GP)GPU 3 CUDA 4 Zusammenfassung
Tag der Umweltmeteorologie 12.05.2015. Michael Kunz
 Tag der Umweltmeteorologie 12.05.2015 Michael Kunz Beschleunigung von Ausbreitungsmodellen durch Portierung auf Grafikkarten Einleitung Das GRAL/GRAMM-System Cuda-GRAL Ergebnisse Vergleich der Modellergebnisse
Tag der Umweltmeteorologie 12.05.2015 Michael Kunz Beschleunigung von Ausbreitungsmodellen durch Portierung auf Grafikkarten Einleitung Das GRAL/GRAMM-System Cuda-GRAL Ergebnisse Vergleich der Modellergebnisse
Spezialprozessoren zur Übernahme Grafik-spezifischer Aufgaben, vorrangig der Bildschirmausgabe
 Grafikprozessoren Spezialprozessoren zur Übernahme Grafik-spezifischer Aufgaben, vorrangig der Bildschirmausgabe 2D: Berechnung der Bildes aus einfachen Grafikprimitiven 3D: Bildaufbau aus räumlicher Beschreibung
Grafikprozessoren Spezialprozessoren zur Übernahme Grafik-spezifischer Aufgaben, vorrangig der Bildschirmausgabe 2D: Berechnung der Bildes aus einfachen Grafikprimitiven 3D: Bildaufbau aus räumlicher Beschreibung
Grafiktreiber im Linuxkernel - die Außenseiter -
 Grafiktreiber im Linuxkernel - die Außenseiter - Creative Commons by-nc-nd Grundlagen Was ist eine Grafikkarte? Grundlagen Was ist eine Grafikkarte? Ausgabelogik Grundlagen Was ist eine Grafikkarte? Ausgabelogik
Grafiktreiber im Linuxkernel - die Außenseiter - Creative Commons by-nc-nd Grundlagen Was ist eine Grafikkarte? Grundlagen Was ist eine Grafikkarte? Ausgabelogik Grundlagen Was ist eine Grafikkarte? Ausgabelogik
OpenCL Implementierung von OpenCV Funktionen
 Multi-Core Architectures and Programming OpenCL Implementierung von OpenCV Funktionen julian.mueller@e-technik.stud.uni-erlangen.de Hardware/Software Co-Design August 18, 2011 1 Table of content 1 OpenCL
Multi-Core Architectures and Programming OpenCL Implementierung von OpenCV Funktionen julian.mueller@e-technik.stud.uni-erlangen.de Hardware/Software Co-Design August 18, 2011 1 Table of content 1 OpenCL
Rapide An Event-Based Architecture Definition Language
 Rapide An Event-Based Architecture Definition Language Ralf Bettentrup Seminar: Architekturbeschreibungssprachen Wozu Rapide? Computer mit Modem Provider Broker Client Broker PC Prov 1 Client 1 RS-232
Rapide An Event-Based Architecture Definition Language Ralf Bettentrup Seminar: Architekturbeschreibungssprachen Wozu Rapide? Computer mit Modem Provider Broker Client Broker PC Prov 1 Client 1 RS-232
Aktuelle Trends und Herausforderungen in der Finite-Elemente-Simulation
 Aktuelle Trends und Herausforderungen in der Finite-Elemente-Simulation Kai Diethelm GNS Gesellschaft für numerische Simulation mbh Braunschweig engineering software development Folie 1 Überblick Vorstellung
Aktuelle Trends und Herausforderungen in der Finite-Elemente-Simulation Kai Diethelm GNS Gesellschaft für numerische Simulation mbh Braunschweig engineering software development Folie 1 Überblick Vorstellung
Raytracing in GA mittels OpenACC. Michael Burger, M.Sc. FG Scientific Computing TU Darmstadt
 Raytracing in GA mittels OpenACC Michael Burger, M.Sc. FG Scientific Computing TU Darmstadt michael.burger@sc.tu-darmstadt.de 05.11.12 FB Computer Science Scientific Computing Michael Burger 1 / 33 Agenda
Raytracing in GA mittels OpenACC Michael Burger, M.Sc. FG Scientific Computing TU Darmstadt michael.burger@sc.tu-darmstadt.de 05.11.12 FB Computer Science Scientific Computing Michael Burger 1 / 33 Agenda
GPGPU-Architekturen CUDA Programmiermodell Beispielprogramm Organiosatorisches. Tutorial CUDA. Ralf Seidler
 Friedrich-Alexander-Universität Erlangen-Nürnberg 05.10.2010 Outline 1 GPGPU-Architekturen 2 CUDA Programmiermodell 3 Beispielprogramm 4 Organiosatorisches Outlook 1 GPGPU-Architekturen 2 CUDA Programmiermodell
Friedrich-Alexander-Universität Erlangen-Nürnberg 05.10.2010 Outline 1 GPGPU-Architekturen 2 CUDA Programmiermodell 3 Beispielprogramm 4 Organiosatorisches Outlook 1 GPGPU-Architekturen 2 CUDA Programmiermodell
SS08, LS12, Friedrich-Alexander-Universität Erlangen Florian Hänel, Frederic Pollmann HS Multicore Architectures and Programming GPU EVOLUTION
 SS08, LS12, Friedrich-Alexander-Universität Erlangen Florian Hänel, Frederic Pollmann HS Multicore Architectures and Programming GPU EVOLUTION (until Geforce 7 Series) 1 ÜBERSICHT Grafikpipeline Verlagerung
SS08, LS12, Friedrich-Alexander-Universität Erlangen Florian Hänel, Frederic Pollmann HS Multicore Architectures and Programming GPU EVOLUTION (until Geforce 7 Series) 1 ÜBERSICHT Grafikpipeline Verlagerung
OpenCL. Programmiersprachen im Multicore-Zeitalter. Tim Wiersdörfer
 OpenCL Programmiersprachen im Multicore-Zeitalter Tim Wiersdörfer Inhaltsverzeichnis 1. Was ist OpenCL 2. Entwicklung von OpenCL 3. OpenCL Modelle 1. Plattform-Modell 2. Ausführungs-Modell 3. Speicher-Modell
OpenCL Programmiersprachen im Multicore-Zeitalter Tim Wiersdörfer Inhaltsverzeichnis 1. Was ist OpenCL 2. Entwicklung von OpenCL 3. OpenCL Modelle 1. Plattform-Modell 2. Ausführungs-Modell 3. Speicher-Modell
Cell and Larrabee Microarchitecture
 Cell and Larrabee Microarchitecture Benjamin Grund Dominik Wolfert Universität Erlangen-Nürnberg 1 Übersicht Einleitung Herkömmliche Prozessorarchitekturen Motivation für Entwicklung neuer Architekturen
Cell and Larrabee Microarchitecture Benjamin Grund Dominik Wolfert Universität Erlangen-Nürnberg 1 Übersicht Einleitung Herkömmliche Prozessorarchitekturen Motivation für Entwicklung neuer Architekturen
OpenGL. (Open Graphic Library)
") OpenGL (Open Graphic Library) Agenda Was ist OpenGL eigentlich? Geschichte Vor- und Nachteile Arbeitsweise glscene OpenGL per Hand Debugging Trend Was ist OpenGL eigentlich? OpenGL ist eine Spezifikation
OpenGL (Open Graphic Library) Agenda Was ist OpenGL eigentlich? Geschichte Vor- und Nachteile Arbeitsweise glscene OpenGL per Hand Debugging Trend Was ist OpenGL eigentlich? OpenGL ist eine Spezifikation
Staff. Tim Conrad. Zeitplan. Blockseminar: Verteiltes Rechnen und Parallelprogrammierung. Sommer Semester 2013. Tim Conrad
 Blockseminar: Verteiltes Rechnen und Parallelprogrammierung Sommer Semester 2013 Tim Conrad Staff Tim Conrad AG Computational Proteomics email: conrad@math.fu-berlin.de Telefon: 838-51445 Büro: Raum 138,
Blockseminar: Verteiltes Rechnen und Parallelprogrammierung Sommer Semester 2013 Tim Conrad Staff Tim Conrad AG Computational Proteomics email: conrad@math.fu-berlin.de Telefon: 838-51445 Büro: Raum 138,
Numerik und Rechnen. Martin Heide & Dominik Holler. 12. Juni 2006
 12. Juni 2006 Bibliothek für Lineare Algebra GPGPU-Programming: Low-Level High-Level Bibliothek Bibliothek für Lineare Algebra Gliederung 1 Bibliothek für Lineare Algebra 2 Skalare Bibliothek für Lineare
12. Juni 2006 Bibliothek für Lineare Algebra GPGPU-Programming: Low-Level High-Level Bibliothek Bibliothek für Lineare Algebra Gliederung 1 Bibliothek für Lineare Algebra 2 Skalare Bibliothek für Lineare
CUDA. (Compute Unified Device Architecture) Thomas Trost. May 31 th 2016
 Thomas Trost. May 31 th 2016") CUDA (Compute Unified Device Architecture) Thomas Trost May 31 th 2016 Introduction and Overview platform and API for parallel computing on GPUs by NVIDIA relatively straightforward general purpose use
CUDA (Compute Unified Device Architecture) Thomas Trost May 31 th 2016 Introduction and Overview platform and API for parallel computing on GPUs by NVIDIA relatively straightforward general purpose use
GPGPUs am Jülich Supercomputing Centre
 GPGPUs am Jülich Supercomputing Centre 20. April 2012 Jochen Kreutz Jülich Supercomputing Centre (JSC) Teil des Forschungszentrums Jülich und des Institute for Advanced Simulation (IAS) betreibt Supercomputer
GPGPUs am Jülich Supercomputing Centre 20. April 2012 Jochen Kreutz Jülich Supercomputing Centre (JSC) Teil des Forschungszentrums Jülich und des Institute for Advanced Simulation (IAS) betreibt Supercomputer
Ansätze 4. GPU. Echtzeit- Raytracing. Polygon- Rendering. Computerspiele Sommer (c) 2013, Peter Sturm, Universität Trier 1
 2013, Peter Sturm, Universität Trier 1") 4. GPU Ansätze Echtzeit- Raytracing Modell und Materialeigenschaften auf Raytracer Kontinuierliche Darstellung Polygon- Rendering CPU wählt darzustellende Polygone aus Render Pipeline (c) 2013, Peter Sturm,
4. GPU Ansätze Echtzeit- Raytracing Modell und Materialeigenschaften auf Raytracer Kontinuierliche Darstellung Polygon- Rendering CPU wählt darzustellende Polygone aus Render Pipeline (c) 2013, Peter Sturm,
Softwareprojekt Spieleentwicklung
 Softwareprojekt Spieleentwicklung Prototyp I (2D) Prototyp II (3D) Softwareprojekt 12.04. 19.04. 26.04. 03.05. 31.05. Meilenstein I 28.06. Meilenstein II Prof. Holger Theisel, Tobias Günther, OvGU Magdeburg
Softwareprojekt Spieleentwicklung Prototyp I (2D) Prototyp II (3D) Softwareprojekt 12.04. 19.04. 26.04. 03.05. 31.05. Meilenstein I 28.06. Meilenstein II Prof. Holger Theisel, Tobias Günther, OvGU Magdeburg
Vorstellung SimpliVity. Tristan P. Andres Senior IT Consultant
 Vorstellung SimpliVity Tristan P. Andres Senior IT Consultant Agenda Wer ist SimpliVity Was ist SimpliVity Wie funktioniert SimpliVity Vergleiche vsan, vflash Read Cache und SimpliVity Gegründet im Jahr
Vorstellung SimpliVity Tristan P. Andres Senior IT Consultant Agenda Wer ist SimpliVity Was ist SimpliVity Wie funktioniert SimpliVity Vergleiche vsan, vflash Read Cache und SimpliVity Gegründet im Jahr
SimpliVity. Hyper Converged Infrastruktur. we do IT better
 SimpliVity Hyper Converged Infrastruktur we do IT better Agenda Wer ist SimpliVity Was ist SimpliVity Wie funktioniert SimpliVity Live-Demo Wer ist Simplivity Gegründet: 2009 Mission: Simplify IT Infrastructure
SimpliVity Hyper Converged Infrastruktur we do IT better Agenda Wer ist SimpliVity Was ist SimpliVity Wie funktioniert SimpliVity Live-Demo Wer ist Simplivity Gegründet: 2009 Mission: Simplify IT Infrastructure
Multicore Herausforderungen an das Software-Engineering. Prof. Dr.-Ing. Michael Uelschen Hochschule Osnabrück 15.09.2010
 Multicore Herausforderungen an das Software-Engineering Prof. Dr.-Ing. Michael Uelschen Hochschule Osnabrück 15.09.2010 Inhalt _ Motivation _ Herausforderung 1: Hardware _ Herausforderung 2: Software-Partitionierung
Multicore Herausforderungen an das Software-Engineering Prof. Dr.-Ing. Michael Uelschen Hochschule Osnabrück 15.09.2010 Inhalt _ Motivation _ Herausforderung 1: Hardware _ Herausforderung 2: Software-Partitionierung
arlanis Software AG SOA Architektonische und technische Grundlagen Andreas Holubek
 arlanis Software AG SOA Architektonische und technische Grundlagen Andreas Holubek Speaker Andreas Holubek VP Engineering andreas.holubek@arlanis.com arlanis Software AG, D-14467 Potsdam 2009, arlanis
arlanis Software AG SOA Architektonische und technische Grundlagen Andreas Holubek Speaker Andreas Holubek VP Engineering andreas.holubek@arlanis.com arlanis Software AG, D-14467 Potsdam 2009, arlanis
Aktuelle Grafikleistungen
 Aktuelle Grafikleistungen Alexander Hötzendorfer Universität Ulm 03. Juli 2007 Inhalt Übersicht Aktuelle Techniken HDR-Lighting Tessellation Aufbau der Rendering-Pipeline Shader Vertex-Shader Geometry-Shader
Aktuelle Grafikleistungen Alexander Hötzendorfer Universität Ulm 03. Juli 2007 Inhalt Übersicht Aktuelle Techniken HDR-Lighting Tessellation Aufbau der Rendering-Pipeline Shader Vertex-Shader Geometry-Shader
Paralleler Cuckoo-Filter. Seminar: Implementierungstechniken für Hauptspeicherdatenbanksysteme Jeremias Neth München, 21.
 Paralleler Cuckoo-Filter Seminar: Implementierungstechniken für Hauptspeicherdatenbanksysteme Jeremias Neth München, 21. November 2017 1 Paralleler Cuckoo-Filter Cuckoo-Hashtabelle Serieller Cuckoo-Filter
Paralleler Cuckoo-Filter Seminar: Implementierungstechniken für Hauptspeicherdatenbanksysteme Jeremias Neth München, 21. November 2017 1 Paralleler Cuckoo-Filter Cuckoo-Hashtabelle Serieller Cuckoo-Filter
2 Rechnerarchitekturen
 2 Rechnerarchitekturen Rechnerarchitekturen Flynns Klassifikation Flynnsche Klassifikation (Flynn sche Taxonomie) 1966 entwickelt, einfaches Modell, bis heute genutzt Beschränkung der Beschreibung auf
2 Rechnerarchitekturen Rechnerarchitekturen Flynns Klassifikation Flynnsche Klassifikation (Flynn sche Taxonomie) 1966 entwickelt, einfaches Modell, bis heute genutzt Beschränkung der Beschreibung auf
Architektur und Programmierung von Grafik- und Koprozessoren
 Architektur und Programmierung von Grafik- und Koprozessoren General Purpose Programmierung auf Grafikprozessoren Stefan Zellmann Lehrstuhl für Informatik, Universität zu Köln SS2018 Host Interface Ausführungszeit
Architektur und Programmierung von Grafik- und Koprozessoren General Purpose Programmierung auf Grafikprozessoren Stefan Zellmann Lehrstuhl für Informatik, Universität zu Köln SS2018 Host Interface Ausführungszeit
FPGA Beschleuniger. Your Name. Armin Jeyrani Mamegani Your Organization (Line #2)
") FPGA Beschleuniger 15.12.2008 Armin Jeyrani Mamegani Your Name HAW Hamburg Your Title Department Your Organization Informatik (Line #1) Your Organization (Line #2) Einleitung Wiederholung aus AW1: Handy
FPGA Beschleuniger 15.12.2008 Armin Jeyrani Mamegani Your Name HAW Hamburg Your Title Department Your Organization Informatik (Line #1) Your Organization (Line #2) Einleitung Wiederholung aus AW1: Handy
Moderne parallele Rechnerarchitekturen
 Seminar im WS0708 Moderne parallele Rechnerarchitekturen Prof. Sergei Gorlatch Dipl.-Inf. Maraike Schellmann schellmann@uni-muenster.de Einsteinstr. 62, Raum 710, Tel. 83-32744 Dipl.-Inf. Philipp Kegel
Seminar im WS0708 Moderne parallele Rechnerarchitekturen Prof. Sergei Gorlatch Dipl.-Inf. Maraike Schellmann schellmann@uni-muenster.de Einsteinstr. 62, Raum 710, Tel. 83-32744 Dipl.-Inf. Philipp Kegel
Video Line Array Highest Resolution CCTV
 Schille Informationssysteme GmbH Video Line Array Highest Resolution CCTV SiDOC20120817-001 Disadvantages of high resolution cameras High costs Low frame rates Failure results in large surveillance gaps
Schille Informationssysteme GmbH Video Line Array Highest Resolution CCTV SiDOC20120817-001 Disadvantages of high resolution cameras High costs Low frame rates Failure results in large surveillance gaps
 Übersicht 1. Anzeigegeräte 2. Framebuffer 3. Grundlagen 3D Computergrafik 4. Polygongrafik, Z-Buffer 5. Texture-Mapping/Shading 6. GPU 7. Programmierbare Shader 1 LCD/TFT Technik Rotation der Licht-Polarisationsebene
Übersicht 1. Anzeigegeräte 2. Framebuffer 3. Grundlagen 3D Computergrafik 4. Polygongrafik, Z-Buffer 5. Texture-Mapping/Shading 6. GPU 7. Programmierbare Shader 1 LCD/TFT Technik Rotation der Licht-Polarisationsebene
Johann Wolfgang Goethe-Universität
 Flynn sche Klassifikation SISD (single instruction, single data stream): IS IS CU PU DS MM Mono (Mikro-)prozessoren CU: Control Unit SM: Shared Memory PU: Processor Unit IS: Instruction Stream MM: Memory
Flynn sche Klassifikation SISD (single instruction, single data stream): IS IS CU PU DS MM Mono (Mikro-)prozessoren CU: Control Unit SM: Shared Memory PU: Processor Unit IS: Instruction Stream MM: Memory
MULTICORE- UND GPGPU- ARCHITEKTUREN
 MULTICORE- UND GPGPU- ARCHITEKTUREN Korbinian Pauli - 17. November 2011 Seminar Multicore Programmierung, WS11, Universität Passau 2 Einleitung Klassisches Problem der Informatik: riesige Datenmenge! Volkszählung
MULTICORE- UND GPGPU- ARCHITEKTUREN Korbinian Pauli - 17. November 2011 Seminar Multicore Programmierung, WS11, Universität Passau 2 Einleitung Klassisches Problem der Informatik: riesige Datenmenge! Volkszählung
Introduction Workshop 11th 12th November 2013
 Introduction Workshop 11th 12th November 2013 Lecture I: Hardware and Applications Dr. Andreas Wolf Gruppenleiter Hochleistungsrechnen Hochschulrechenzentrum Overview Current and next System Hardware Sections
Introduction Workshop 11th 12th November 2013 Lecture I: Hardware and Applications Dr. Andreas Wolf Gruppenleiter Hochleistungsrechnen Hochschulrechenzentrum Overview Current and next System Hardware Sections
> High-Level Programmierung heterogener paralleler Systeme
 > High-Level Programmierung heterogener paralleler Systeme Projektseminar im SoSe 2012 Prof. Sergei Gorlatch, Michel Steuwer, Tim Humernbrum AG Parallele und Verteilte Systeme, Westfälische Wilhelms-Universität
> High-Level Programmierung heterogener paralleler Systeme Projektseminar im SoSe 2012 Prof. Sergei Gorlatch, Michel Steuwer, Tim Humernbrum AG Parallele und Verteilte Systeme, Westfälische Wilhelms-Universität
Intel Cluster Studio. Michael Burger FG Scientific Computing TU Darmstadt michael.burger@sc.tu-darmstadt.de
 Intel Cluster Studio Michael Burger FG Scientific Computing TU Darmstadt michael.burger@sc.tu-darmstadt.de 19.03.13 FB Computer Science Scientific Computing Michael Burger 1 / 30 Agenda Was ist das Intel
Intel Cluster Studio Michael Burger FG Scientific Computing TU Darmstadt michael.burger@sc.tu-darmstadt.de 19.03.13 FB Computer Science Scientific Computing Michael Burger 1 / 30 Agenda Was ist das Intel
C C. Hochleistungsrechnen (HPC) auf dem Windows Compute Cluster des RZ der RWTH Aachen. 1 WinHPC 2006 - Einführung Center. 31.
 auf dem Windows Compute Cluster des RZ der RWTH Aachen. 1 WinHPC 2006 - Einführung Center. 31.") Hochleistungsrechnen (HP) auf dem Windows ompute luster des RZ der RWTH Aachen 31. Mai 2006 hristian Terboven Dieter an Mey {terboven anmey}@rz.rwth-aachen.de 1 WinHP 2006 - Einführung enter SunFire V40z
Hochleistungsrechnen (HP) auf dem Windows ompute luster des RZ der RWTH Aachen 31. Mai 2006 hristian Terboven Dieter an Mey {terboven anmey}@rz.rwth-aachen.de 1 WinHP 2006 - Einführung enter SunFire V40z
Exascale Computing. = Exascale braucht Manycore-Hardware...und was für Software??? 46/58
 Exascale Computing Die FLOP/s-Tabelle: Name Faktor erreicht heute Giga 10 9 1976 CPU-Kern Tera 10 12 1997 Graphikkarte (GPU) Peta 10 15 2009 Supercomputer Exa 10 18 2020(?) Der gegenwärtig schnellste Rechner
Exascale Computing Die FLOP/s-Tabelle: Name Faktor erreicht heute Giga 10 9 1976 CPU-Kern Tera 10 12 1997 Graphikkarte (GPU) Peta 10 15 2009 Supercomputer Exa 10 18 2020(?) Der gegenwärtig schnellste Rechner
Jörn Loviscach Hochschule Bremen
 Programmierbare Hardware-Shader Jörn Loviscach Hochschule Bremen Überblick Vertex- und Pixel-Shader Anwendungsbeispiele fx-dateien Anwendungsbeispiele Zusammenfassung Puffer Vertex- und Pixel-Shader Hardware-Renderpipeline
Programmierbare Hardware-Shader Jörn Loviscach Hochschule Bremen Überblick Vertex- und Pixel-Shader Anwendungsbeispiele fx-dateien Anwendungsbeispiele Zusammenfassung Puffer Vertex- und Pixel-Shader Hardware-Renderpipeline
M b o i b l i e l e S a S l a e l s e s f or o S A S P P E R E P P m i m t i S b y a b s a e s e U nw n ir i ed e d P l P a l t a for o m
 Mobile Sales for SAP ERP mit Sybase Unwired Platform Jordi Candel Agenda msc mobile Sybase Unwired Platform Mobile Sales for SAP ERP Referenz Simba Dickie Group Fragen und Antworten Über msc mobile Montreal
Mobile Sales for SAP ERP mit Sybase Unwired Platform Jordi Candel Agenda msc mobile Sybase Unwired Platform Mobile Sales for SAP ERP Referenz Simba Dickie Group Fragen und Antworten Über msc mobile Montreal
Volumenrendering mit CUDA
 Volumenrendering mit CUDA Arbeitsgruppe Visualisierung und Computergrafik http://viscg.uni-muenster.de Überblick Volumenrendering allgemein Raycasting-Algorithmus Volumen-Raycasting mit CUDA Optimierung
Volumenrendering mit CUDA Arbeitsgruppe Visualisierung und Computergrafik http://viscg.uni-muenster.de Überblick Volumenrendering allgemein Raycasting-Algorithmus Volumen-Raycasting mit CUDA Optimierung
Implementation of a Framework Component for Processing Tasks within Threads on the Application Level
 Implementation of a Framework Component for Processing Tasks within Threads on the Application Level Deutsches Krebsforschungszentrum, for Processing Task within Threads on the Application Level Motivation
Implementation of a Framework Component for Processing Tasks within Threads on the Application Level Deutsches Krebsforschungszentrum, for Processing Task within Threads on the Application Level Motivation
1 Einleitung. 2 Parallelisierbarkeit von. Architektur
 Beschleunigung von Aufgaben der parallelen Bildverarbeitung durch Benutzung von NVIDIA-Grafikkarten mit der Compute Unified Device Architecture (CUDA) Roman Glebov roman@glebov.de Abstract Diese Arbeit
Beschleunigung von Aufgaben der parallelen Bildverarbeitung durch Benutzung von NVIDIA-Grafikkarten mit der Compute Unified Device Architecture (CUDA) Roman Glebov roman@glebov.de Abstract Diese Arbeit
Untersuchung und Vorstellung moderner Grafikchiparchitekturen
 Fakultät Informatik, Institut für Technische Informatik, Professur für VLSI-Entwurfssysteme, Diagnostik und Architektur Untersuchung und Vorstellung moderner Grafikchiparchitekturen Hauptseminar Technische
Fakultät Informatik, Institut für Technische Informatik, Professur für VLSI-Entwurfssysteme, Diagnostik und Architektur Untersuchung und Vorstellung moderner Grafikchiparchitekturen Hauptseminar Technische
Visualisierung paralleler bzw. verteilter Programme
 Seminar Visualisierung in Informatik und Naturwissenschaften im SS 1999 Visualisierung paralleler bzw. verteilter Programme Holger Dewes Gliederung Zum Begriff Motivation PARADE Beispiel 1: Thread basierte
Seminar Visualisierung in Informatik und Naturwissenschaften im SS 1999 Visualisierung paralleler bzw. verteilter Programme Holger Dewes Gliederung Zum Begriff Motivation PARADE Beispiel 1: Thread basierte
Software Engineering für moderne parallele Plattformen 9. GPGPUs: Grafikkarten als Parallelrechner
 Software Engineering für moderne parallele Plattformen 9. GPGPUs: Grafikkarten als Parallelrechner Dipl.-Inform. Korbinian Molitorisz M. Sc. Luis Manuel Carril Rodriguez KIT Universität des Landes Baden-Württemberg
Software Engineering für moderne parallele Plattformen 9. GPGPUs: Grafikkarten als Parallelrechner Dipl.-Inform. Korbinian Molitorisz M. Sc. Luis Manuel Carril Rodriguez KIT Universität des Landes Baden-Württemberg
GPUs. Arbeitsbereich Wissenschaftliches Rechnen Fachbereich Informatik Fakultät für Mathematik, Informatik und Naturwissenschaften Universität Hamburg
 GPUs Arbeitsbereich Wissenschaftliches Rechnen Fachbereich Informatik Fakultät für Mathematik, Informatik und Naturwissenschaften Universität Hamburg Vorgelegt von: Johannes Coym E-Mail-Adresse: 4coym@informatik.uni-hamburg.de
GPUs Arbeitsbereich Wissenschaftliches Rechnen Fachbereich Informatik Fakultät für Mathematik, Informatik und Naturwissenschaften Universität Hamburg Vorgelegt von: Johannes Coym E-Mail-Adresse: 4coym@informatik.uni-hamburg.de
Tuning des Weblogic /Oracle Fusion Middleware 11g. Jan-Peter Timmermann Principal Consultant PITSS
 Tuning des Weblogic /Oracle Fusion Middleware 11g Jan-Peter Timmermann Principal Consultant PITSS 1 Agenda Bei jeder Installation wiederkehrende Fragen WievielForms Server braucheich Agenda WievielRAM
Tuning des Weblogic /Oracle Fusion Middleware 11g Jan-Peter Timmermann Principal Consultant PITSS 1 Agenda Bei jeder Installation wiederkehrende Fragen WievielForms Server braucheich Agenda WievielRAM
MPI-Programmierung unter Windows mit MPICH2. Installieren von MPICH2, Übersetzen, Ausführen und Debuggen von MPI-Programmen. Christian Terboven
 MPI-Programmierung unter Windows mit MPIH2 Installieren von MPIH2, Übersetzen, Ausführen und Debuggen von MPI-Programmen hristian Terboven Rechen- und Kommunikationszentrum RWTH Aachen 1 02/2007 luster-installationsworkshop
MPI-Programmierung unter Windows mit MPIH2 Installieren von MPIH2, Übersetzen, Ausführen und Debuggen von MPI-Programmen hristian Terboven Rechen- und Kommunikationszentrum RWTH Aachen 1 02/2007 luster-installationsworkshop
Wiederholung. Vorlesung GPU Programmierung Thorsten Grosch
 Wiederholung Vorlesung Thorsten Grosch Klausur 2 Zeitstunden (26.7., 8:30 10:30 Uhr, G29/307) Keine Hilfsmittel Kein Bleistift / Rotstift verwenden 3 Aufgabentypen Wissensfragen zur Vorlesung (ca. 1/3)
Wiederholung Vorlesung Thorsten Grosch Klausur 2 Zeitstunden (26.7., 8:30 10:30 Uhr, G29/307) Keine Hilfsmittel Kein Bleistift / Rotstift verwenden 3 Aufgabentypen Wissensfragen zur Vorlesung (ca. 1/3)
Proseminar Rechnerarchitekturen. Parallelcomputer: Multiprozessorsysteme
 wwwnet-texde Proseminar Rechnerarchitekturen Parallelcomputer: Multiprozessorsysteme Stefan Schumacher, , PGP Key http://wwwnet-texde/uni Id: mps-folientex,v
wwwnet-texde Proseminar Rechnerarchitekturen Parallelcomputer: Multiprozessorsysteme Stefan Schumacher, , PGP Key http://wwwnet-texde/uni Id: mps-folientex,v
Seminar Parallele Rechnerarchitekturen SS04 \ SIMD Implementierung aktueller Prozessoren 2 (Dominik Tamm) \ Inhalt. Seite 1
 \ Inhalt. Seite 1") \ Inhalt Seite 1 \ Inhalt SIMD Kurze Rekapitulation 3Dnow! (AMD) AltiVec (PowerPC) Quellen Seite 2 \ Wir erinnern uns: Nach Flynn s Taxonomie kann man jeden Computer In eine von vier Kategorien einteilen:
\ Inhalt Seite 1 \ Inhalt SIMD Kurze Rekapitulation 3Dnow! (AMD) AltiVec (PowerPC) Quellen Seite 2 \ Wir erinnern uns: Nach Flynn s Taxonomie kann man jeden Computer In eine von vier Kategorien einteilen:
OpenCL. Seminar Programmiersprachen im Multicore-Zeitalter Universität Siegen Tim Wiersdörfer tim.wiersdoerfer@student.uni-siegen.
 OpenCL Seminar Programmiersprachen im Multicore-Zeitalter Universität Siegen Tim Wiersdörfer tim.wiersdoerfer@student.uni-siegen.de Abstract: In diesem Dokument wird ein grundlegender Einblick in das relativ
OpenCL Seminar Programmiersprachen im Multicore-Zeitalter Universität Siegen Tim Wiersdörfer tim.wiersdoerfer@student.uni-siegen.de Abstract: In diesem Dokument wird ein grundlegender Einblick in das relativ
Parallele Algorithmen mit OpenCL. Universität Osnabrück, Henning Wenke,
 Parallele Algorithmen mit OpenCL Universität Osnabrück, Henning Wenke, 2013-05-29 Kapitel Parallelität [1]: Parallel Programming (Rauber, Rünger, 2007) [2]: Algorithms Sequential & Parallel A Unified Approach
Parallele Algorithmen mit OpenCL Universität Osnabrück, Henning Wenke, 2013-05-29 Kapitel Parallelität [1]: Parallel Programming (Rauber, Rünger, 2007) [2]: Algorithms Sequential & Parallel A Unified Approach
GPU Programmierung. Thorsten Grosch
 Thorsten Grosch Willkommen zur ersten Vorlesung! g Heute Organisatorisches Vorstellung von Team und Vorlesung Historischer Rückblick zu GPUs 2 Das Team Vorlesung Jun.-Prof. Thorsten Grosch AG Computervisualistik
Thorsten Grosch Willkommen zur ersten Vorlesung! g Heute Organisatorisches Vorstellung von Team und Vorlesung Historischer Rückblick zu GPUs 2 Das Team Vorlesung Jun.-Prof. Thorsten Grosch AG Computervisualistik