Einführung Nichtparametrische Verfahren. Ereignisanalyse. Marcel Noack. 7. Mai 2008
|
|
|
- Linda Maurer
- vor 6 Jahren
- Abrufe
Transkript
1 7. Mai 2008
2 Inhaltsverzeichnis 1 Mathematische Grundlagen Der Datensatz 2
3 Zusammenhänge Mathematische Grundlagen Der Datensatz F (t) + S(t) = 1
4 Zusammenhänge Mathematische Grundlagen Der Datensatz F (t) + S(t) = 1 P (T t) + P (T t) = P (Ω) = 1
5 Zusammenhänge Mathematische Grundlagen Der Datensatz F (t) + S(t) = 1 P (T t) + P (T t) = P (Ω) = 1 t 0 f(u)du + t f(u)du = 0 f(u)du = 1
 &")
6 Mathematische Grundlagen Der Datensatz Verteilungsfunktion F (t) & Survivalfunktion S(t)
7 Mathematische Grundlagen Der Datensatz Verteilungsfunktion F (t) & Survivalfunktion S(t)
8 Variablen Mathematische Grundlagen Der Datensatz Variable id noj tstart tfin sex ti tb te tmar pres presn edu Beschreibung Identifiziert jede einzelne Befragungsperson im Datensatz Laufende Nummer der Jobepisode Anfangszeit der Jobepisode in Monaten seit Beginn des Jahrhunderts (1=1900) Endzeit der Jobepisode in Monaten seit Beginn des Jahrhunderts Geschlecht: 1=Männer, 2=Frauen Interviewzeitpunkt in Monaten seit Beginn des Jahrhunderts Geburtsdatum Eintritt in den Arbeitsmarkt in Monaten seit Beginn des Jahrhunderts Eintritt in die Ehe in Monaten seit Beginn des Jahrhunderts, 0 wenn unverheiratet Prestigewert des Jobs Prestigewert des darauf folgenden Jobs, -1 falls kein weiterer Job Höchster Bildungsabschluss vor Eintritt in den Arbeitsmarkt in Jahren
9 Beispiel: 1. Fall Mathematische Grundlagen Der Datensatz list id noj tstart tfin sex ti tb te tmar pres presn edu in 1/9, sepby(id)

10 Beispiel: 1. Fall Mathematische Grundlagen Der Datensatz list id noj tstart tfin sex ti tb te tmar pres presn edu in 1/9, sepby(id)
11 Arbeitsvariablen Mathematische Grundlagen Der Datensatz Erstellung der Variable des für destination :
12 Arbeitsvariablen Mathematische Grundlagen Der Datensatz Erstellung der Variable des für destination : des misst, ob eine Episode mit einem Ereignis endet oder eine Rechtszensierung vorliegt
13 Arbeitsvariablen Mathematische Grundlagen Der Datensatz Erstellung der Variable des für destination : des misst, ob eine Episode mit einem Ereignis endet oder eine Rechtszensierung vorliegt Rechtszensiert, wenn tfin=ti; Episode beendet, wenn tfin ~= ti.
14 Arbeitsvariablen Mathematische Grundlagen Der Datensatz Erstellung der Variable des für destination : des misst, ob eine Episode mit einem Ereignis endet oder eine Rechtszensierung vorliegt Rechtszensiert, wenn tfin=ti; Episode beendet, wenn tfin ~= ti.
15 Arbeitsvariablen Mathematische Grundlagen Der Datensatz Erstellung der Variable des für destination : des misst, ob eine Episode mit einem Ereignis endet oder eine Rechtszensierung vorliegt Rechtszensiert, wenn tfin=ti; Episode beendet, wenn tfin ~= ti. Erstellung der Variablen tf für finish time :
16 Arbeitsvariablen Mathematische Grundlagen Der Datensatz Erstellung der Variable des für destination : des misst, ob eine Episode mit einem Ereignis endet oder eine Rechtszensierung vorliegt Rechtszensiert, wenn tfin=ti; Episode beendet, wenn tfin ~= ti. Erstellung der Variablen tf für finish time : Bildet die Differenz aus den Variablen tfin und tstart.
17 Arbeitsvariablen Mathematische Grundlagen Der Datensatz Erstellung der Variable des für destination : des misst, ob eine Episode mit einem Ereignis endet oder eine Rechtszensierung vorliegt Rechtszensiert, wenn tfin=ti; Episode beendet, wenn tfin ~= ti. Erstellung der Variablen tf für finish time : Bildet die Differenz aus den Variablen tfin und tstart. Auf diese Weise wird die Verweildauer in einer Jobepisode für jede Befragungsperson in Monaten gemessen.
18 Arbeitsvariablen Mathematische Grundlagen Der Datensatz Erstellung der Variable des für destination : des misst, ob eine Episode mit einem Ereignis endet oder eine Rechtszensierung vorliegt Rechtszensiert, wenn tfin=ti; Episode beendet, wenn tfin ~= ti. Erstellung der Variablen tf für finish time : Bildet die Differenz aus den Variablen tfin und tstart. Auf diese Weise wird die Verweildauer in einer Jobepisode für jede Befragungsperson in Monaten gemessen. destination & finish time gen des = tfin ~= ti
19 Arbeitsvariablen Mathematische Grundlagen Der Datensatz Erstellung der Variable des für destination : des misst, ob eine Episode mit einem Ereignis endet oder eine Rechtszensierung vorliegt Rechtszensiert, wenn tfin=ti; Episode beendet, wenn tfin ~= ti. Erstellung der Variablen tf für finish time : Bildet die Differenz aus den Variablen tfin und tstart. Auf diese Weise wird die Verweildauer in einer Jobepisode für jede Befragungsperson in Monaten gemessen. destination & finish time gen des = tfin ~= ti gen tf = tfin - tstart + 1
20 sind Verfahren, bei denen keine Annahmen über die Verteilung der Wartezeit gemacht wird.
21 sind Verfahren, bei denen keine Annahmen über die Verteilung der Wartezeit gemacht wird. Hierzu zählen die Life-Table-Methode ( Sterbetafelschätzung ) als auch die Kaplan-Meier-Schätzung (Product-Limit Estimation).
22 sind Verfahren, bei denen keine Annahmen über die Verteilung der Wartezeit gemacht wird. Hierzu zählen die Life-Table-Methode ( Sterbetafelschätzung ) als auch die Kaplan-Meier-Schätzung (Product-Limit Estimation). Die Life-Table Methode hat ihren Ursprung in der Demographie und zählt zu den bekanntesten und lange Zeit beliebtesten Methoden der.
23 sind Verfahren, bei denen keine Annahmen über die Verteilung der Wartezeit gemacht wird. Hierzu zählen die Life-Table-Methode ( Sterbetafelschätzung ) als auch die Kaplan-Meier-Schätzung (Product-Limit Estimation). Die Life-Table Methode hat ihren Ursprung in der Demographie und zählt zu den bekanntesten und lange Zeit beliebtesten Methoden der. Der wesentlicher Unterschied zwischen diesen beiden nichtparametrischen explorativen Verfahren ist, dass die Sterbetafel-Schätzung für gruppierte Wartezeiten und die Produkt-Limit-Schätzung für exakte Wartezeiten konzipiert ist.
24 Life Table Methode: Verweildauer in Intervallen Wie bereits erwähnt, sind bei der Life-Table Methode keine Annahmen über die Verteilung von T notwendig.
25 Life Table Methode: Verweildauer in Intervallen Wie bereits erwähnt, sind bei der Life-Table Methode keine Annahmen über die Verteilung von T notwendig. Errechnet werden die Survivorfunktionen zu Beginn des jeweiligen Intervalls sowie für jedes Intervall die Dichte- und Hazardfunktion (und deren Standardfehler).
26 Life Table Methode: Verweildauer in Intervallen Wie bereits erwähnt, sind bei der Life-Table Methode keine Annahmen über die Verteilung von T notwendig. Errechnet werden die Survivorfunktionen zu Beginn des jeweiligen Intervalls sowie für jedes Intervall die Dichte- und Hazardfunktion (und deren Standardfehler). Nachteile dieser Methode sind, dass diskrete Zeitintervalle nötig sind und dass sie eine grosse Anzahl an events benötigt, um reliable zu sein.
27 Life Table Methode: Verweildauer in Intervallen Wie bereits erwähnt, sind bei der Life-Table Methode keine Annahmen über die Verteilung von T notwendig. Errechnet werden die Survivorfunktionen zu Beginn des jeweiligen Intervalls sowie für jedes Intervall die Dichte- und Hazardfunktion (und deren Standardfehler). Nachteile dieser Methode sind, dass diskrete Zeitintervalle nötig sind und dass sie eine grosse Anzahl an events benötigt, um reliable zu sein. Um die diskreten Intervalle zu erhalten, wird die Zeitachse punktweise aufgesplittet.
28 Life Table Methode: Verweildauer in Intervallen Wie bereits erwähnt, sind bei der Life-Table Methode keine Annahmen über die Verteilung von T notwendig. Errechnet werden die Survivorfunktionen zu Beginn des jeweiligen Intervalls sowie für jedes Intervall die Dichte- und Hazardfunktion (und deren Standardfehler). Nachteile dieser Methode sind, dass diskrete Zeitintervalle nötig sind und dass sie eine grosse Anzahl an events benötigt, um reliable zu sein. Um die diskreten Intervalle zu erhalten, wird die Zeitachse punktweise aufgesplittet.
29 Life Table Methode: Notation
30 Life Table Methode: Notation Mit der Konvention: τ L+1 = existieren L Intervalle, von denen jedes die linke Grenze beinhaltet, aber nicht die Rechte.
31 Life Table Methode: Notation Mit der Konvention: τ L+1 = existieren L Intervalle, von denen jedes die linke Grenze beinhaltet, aber nicht die Rechte. I l = {t τ l T τ l+1 }, l = 1,, L
32 Life Table Methode: Notation Mit der Konvention: τ L+1 = existieren L Intervalle, von denen jedes die linke Grenze beinhaltet, aber nicht die Rechte. I l = {t τ l T τ l+1 }, l = 1,, L Terminologie:
33 Life Table Methode: Notation Mit der Konvention: τ L+1 = existieren L Intervalle, von denen jedes die linke Grenze beinhaltet, aber nicht die Rechte. I l = {t τ l T τ l+1 }, l = 1,, L Terminologie: N l Zahl der Fälle, die in Intervall I l eintreten.
34 Life Table Methode: Notation Mit der Konvention: τ L+1 = existieren L Intervalle, von denen jedes die linke Grenze beinhaltet, aber nicht die Rechte. I l = {t τ l T τ l+1 }, l = 1,, L Terminologie: N l Zahl der Fälle, die in Intervall I l eintreten. E l Zahl der Ereignisse / Übergänge im Intervall I l,ausfälle
35 Life Table Methode: Notation Mit der Konvention: τ L+1 = existieren L Intervalle, von denen jedes die linke Grenze beinhaltet, aber nicht die Rechte. I l = {t τ l T τ l+1 }, l = 1,, L Terminologie: N l Zahl der Fälle, die in Intervall I l eintreten. E l Zahl der Ereignisse / Übergänge im Intervall I l,ausfälle Z l Zahl der Zensierungen im intervall I l
36 Life Table Methode: Notation Mit der Konvention: τ L+1 = existieren L Intervalle, von denen jedes die linke Grenze beinhaltet, aber nicht die Rechte. I l = {t τ l T τ l+1 }, l = 1,, L Terminologie: N l Zahl der Fälle, die in Intervall I l eintreten. E l Zahl der Ereignisse / Übergänge im Intervall I l,ausfälle Z l Zahl der Zensierungen im intervall I l R l Risk Set / Risikomenge im Intervall I l,noch lebende
37 Life Table Methode: Notation Mit der Konvention: τ L+1 = existieren L Intervalle, von denen jedes die linke Grenze beinhaltet, aber nicht die Rechte. I l = {t τ l T τ l+1 }, l = 1,, L Terminologie: N l Zahl der Fälle, die in Intervall I l eintreten. E l Zahl der Ereignisse / Übergänge im Intervall I l,ausfälle Z l Zahl der Zensierungen im intervall I l R l Risk Set / Risikomenge im Intervall I l,noch lebende R l Zahl der Elemente in R l
38 Life Table Methode: Grundidee Rekursive Bestimmung von N l. Es gilt für das erste Intervall: N 1 = N
39 Life Table Methode: Grundidee Rekursive Bestimmung von N l. Es gilt für das erste Intervall: N 1 = N Für das zweite Intervall: N 2 = N 1 E 1 Z 1 usw.
40 Life Table Methode: Grundidee Rekursive Bestimmung von N l. Es gilt für das erste Intervall: N 1 = N Für das zweite Intervall: N 2 = N 1 E 1 Z 1 usw. Zur Berechnung der Risikomenge sind nun Annahmen über die Verteilung der zensierten Fälle während des Intervalls zu machen.
41 Life Table Methode: Grundidee Rekursive Bestimmung von N l. Es gilt für das erste Intervall: N 1 = N Für das zweite Intervall: N 2 = N 1 E 1 Z 1 usw. Zur Berechnung der Risikomenge sind nun Annahmen über die Verteilung der zensierten Fälle während des Intervalls zu machen. Üblicherweise wird angenommen, dass die Zensierungen gleichmäßig über das gesamte Intervall verteilt sind.
42 Life Table Methode: Grundidee Rekursive Bestimmung von N l. Es gilt für das erste Intervall: N 1 = N Für das zweite Intervall: N 2 = N 1 E 1 Z 1 usw. Zur Berechnung der Risikomenge sind nun Annahmen über die Verteilung der zensierten Fälle während des Intervalls zu machen. Üblicherweise wird angenommen, dass die Zensierungen gleichmäßig über das gesamte Intervall verteilt sind. R l = N l 1 2 Z l
43 : Stata Der Befehl, um Sterbetafeln in Stata zu berechnen lautet ltable.
44 : Stata Der Befehl, um Sterbetafeln in Stata zu berechnen lautet ltable. Einen Überblick könne wir uns mit help ltable verschaffen.
45 : Stata Der Befehl, um Sterbetafeln in Stata zu berechnen lautet ltable. Einen Überblick könne wir uns mit help ltable verschaffen. Der Befehl ltable tf des, intervals(30) su f h zerlegt die Zeit in 30-Monats-Intervalle und führt zu 3 Tabellen. Die Optionen führen zu folgendem Output:
46 : Stata Der Befehl, um Sterbetafeln in Stata zu berechnen lautet ltable. Einen Überblick könne wir uns mit help ltable verschaffen. Der Befehl ltable tf des, intervals(30) su f h zerlegt die Zeit in 30-Monats-Intervalle und führt zu 3 Tabellen. Die Optionen führen zu folgendem Output: su survival: Verteilungsfunktion der Überlebenswahrscheinlichkeiten
47 : Stata Der Befehl, um Sterbetafeln in Stata zu berechnen lautet ltable. Einen Überblick könne wir uns mit help ltable verschaffen. Der Befehl ltable tf des, intervals(30) su f h zerlegt die Zeit in 30-Monats-Intervalle und führt zu 3 Tabellen. Die Optionen führen zu folgendem Output: su survival: Verteilungsfunktion der Überlebenswahrscheinlichkeiten f failure: Dichtefunktion
48 : Stata Der Befehl, um Sterbetafeln in Stata zu berechnen lautet ltable. Einen Überblick könne wir uns mit help ltable verschaffen. Der Befehl ltable tf des, intervals(30) su f h zerlegt die Zeit in 30-Monats-Intervalle und führt zu 3 Tabellen. Die Optionen führen zu folgendem Output: su survival: Verteilungsfunktion der Überlebenswahrscheinlichkeiten f failure: Dichtefunktion h hazard: Risikofunktion
49 : Stata Der Befehl, um Sterbetafeln in Stata zu berechnen lautet ltable. Einen Überblick könne wir uns mit help ltable verschaffen. Der Befehl ltable tf des, intervals(30) su f h zerlegt die Zeit in 30-Monats-Intervalle und führt zu 3 Tabellen. Die Optionen führen zu folgendem Output: su survival: Verteilungsfunktion der Überlebenswahrscheinlichkeiten f failure: Dichtefunktion h hazard: Risikofunktion Da Sterbetafeln recht unübersichtlich sein können, bietet es sich an, die in ihnen enthaltene Information graphisch darzustellen.

50 Survival
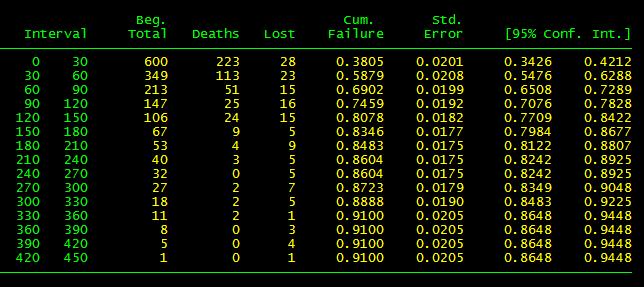
51 Failure

52 Hazard
")
53 ltable tf des, intervals(30) gr
")
54 ltable tf des, intervals(30) by(sex) gr
 by(sex)")
55 ltable tf des, intervals(30) by(sex) gr overlay
56 ltable tf des, intervals(30) by(sex) gr overlay ci

57 Graph Editor
58 Der Unterschied zu der Life-Table Methode ist die direkte Verwendung der Wartezeiten.
59 Der Unterschied zu der Life-Table Methode ist die direkte Verwendung der Wartezeiten. Es ist also unnötig, eine Zusammenfassung der Zeit in Intervallen vorzunehmen.
60 Der Unterschied zu der Life-Table Methode ist die direkte Verwendung der Wartezeiten. Es ist also unnötig, eine Zusammenfassung der Zeit in Intervallen vorzunehmen. Statt dessen wird die Risikomenge für jeden Zeitpunkt, an dem ein Ereignis statt findet, berechnet.
61 Der Unterschied zu der Life-Table Methode ist die direkte Verwendung der Wartezeiten. Es ist also unnötig, eine Zusammenfassung der Zeit in Intervallen vorzunehmen. Statt dessen wird die Risikomenge für jeden Zeitpunkt, an dem ein Ereignis statt findet, berechnet. Eine Sortierung der Zeitpunkte mit Ereignissen ist erforderlich: τ 1 < τ 2 < τ 3 < < τ L
62 Der Unterschied zu der Life-Table Methode ist die direkte Verwendung der Wartezeiten. Es ist also unnötig, eine Zusammenfassung der Zeit in Intervallen vorzunehmen. Statt dessen wird die Risikomenge für jeden Zeitpunkt, an dem ein Ereignis statt findet, berechnet. Eine Sortierung der Zeitpunkte mit Ereignissen ist erforderlich: τ 1 < τ 2 < τ 3 < < τ L wobei τ 1 den Zeitpunkt bezeichnet, an dem das erste Ereignis stattfindet, τ 2 den Zeitpunkt, an dem das zweite Ereignis staffindet, und so weiter.
63 : Notation E l Zahl der Episoden mit Ereignissen zum Zeitpunkt τ l. Es gilt: τ 0 = 0 Hierbei handelt es sich um die Anzahl der Personen, die in diesem Intervall ausfallen
64 : Notation E l Zahl der Episoden mit Ereignissen zum Zeitpunkt τ l. Es gilt: τ 0 = 0 Hierbei handelt es sich um die Anzahl der Personen, die in diesem Intervall ausfallen Z l Zahl der Zensierugen im Intervall τ l 1 t < τ l. Dies bedeutet, dass wenn Zensierung und Ereigniss zum selben Zeitpunkt stattfinden wird angenommen, dass die Zensierung etwas später statt findet.
65 : Notation E l Zahl der Episoden mit Ereignissen zum Zeitpunkt τ l. Es gilt: τ 0 = 0 Hierbei handelt es sich um die Anzahl der Personen, die in diesem Intervall ausfallen Z l Zahl der Zensierugen im Intervall τ l 1 t < τ l. Dies bedeutet, dass wenn Zensierung und Ereigniss zum selben Zeitpunkt stattfinden wird angenommen, dass die Zensierung etwas später statt findet. R l Risikomenge zum Zeitpunkt τ l, d.h.: mit einer Startzeit t Start < t l und einer Endzeit t Ende t l. Also die Personen die noch leben
66 : Notation E l Zahl der Episoden mit Ereignissen zum Zeitpunkt τ l. Es gilt: τ 0 = 0 Hierbei handelt es sich um die Anzahl der Personen, die in diesem Intervall ausfallen Z l Zahl der Zensierugen im Intervall τ l 1 t < τ l. Dies bedeutet, dass wenn Zensierung und Ereigniss zum selben Zeitpunkt stattfinden wird angenommen, dass die Zensierung etwas später statt findet. R l Risikomenge zum Zeitpunkt τ l, d.h.: mit einer Startzeit t Start < t l und einer Endzeit t Ende t l. Also die Personen die noch leben Es gilt für einen Zeitpunkt mit Ereignis: q l = E l R l p l = 1 q l = 1 E l R l
67 Product-Limit-Estimator Der Product-Limit-Estimator für S(t) ist definiert als: Ŝ(t) = p 1 p 2 p 3 p l 1 = p l = 1 E l R l l:τ l <t l:τ l <t
68 Product-Limit-Estimator Der Product-Limit-Estimator für S(t) ist definiert als: Ŝ(t) = p 1 p 2 p 3 p l 1 = p l = 1 E l R l l:τ l <t l:τ l <t Ŝ(t) = (1 q 0 ) (1 q 1 ) (1 q 2 ) (1 q 3 )
69 Product-Limit-Estimator Der Product-Limit-Estimator für S(t) ist definiert als: Ŝ(t) = p 1 p 2 p 3 p l 1 = p l = 1 E l R l Ŝ(t) = l:τ l <t l:τ l <t Ŝ(t) = (1 q 0 ) (1 q 1 ) (1 q 2 ) (1 q 3 ) ( 1 E ) ( 0 1 E ) ( 1 1 E ) ( 2 1 E ) 3 R 0 R 1 R 2 R 3
70 Product-Limit-Estimator Der Product-Limit-Estimator für S(t) ist definiert als: Ŝ(t) = p 1 p 2 p 3 p l 1 = p l = 1 E l R l wobei: Ŝ(t) = Ŝ(t) = l:τ l <t l:τ l <t Ŝ(t) = (1 q 0 ) (1 q 1 ) (1 q 2 ) (1 q 3 ) ( 1 E ) ( 0 1 E ) ( 1 1 E ) ( 2 1 E ) 3 R 0 R 1 R 2 R 3 ( 1 0 ) ( 1 1 ) ( 1 1 ) ( 1 1 ) ( 1 2 ) ( 1 1 )
71 Product-Limit-Estimator Der Product-Limit-Estimator für S(t) ist definiert als: Ŝ(t) = p 1 p 2 p 3 p l 1 = p l = 1 E l R l wobei: Ŝ(t) = Ŝ(t) = l:τ l <t l:τ l <t Ŝ(t) = (1 q 0 ) (1 q 1 ) (1 q 2 ) (1 q 3 ) ( 1 E ) ( 0 1 E ) ( 1 1 E ) ( 2 1 E ) 3 R 0 R 1 R 2 R 3 ( 1 0 ) ( 1 1 ) ( 1 1 ) ( 1 1 ) ( 1 2 ) ( 1 1 ) Ŝ(t) = 1 0, 992 0, , , , 99167
72 in Stata Um eine Kaplan-Meier Schätzung in Stata durchzuführen müssen wir Stata ein paar Angaben mitteilen.
73 in Stata Um eine Kaplan-Meier Schätzung in Stata durchzuführen müssen wir Stata ein paar Angaben mitteilen. Als Ereignisdaten deklarieren stset tf, f(des)

74 in Stata Um eine Kaplan-Meier Schätzung in Stata durchzuführen müssen wir Stata ein paar Angaben mitteilen. Als Ereignisdaten deklarieren stset tf, f(des)

75 Ereignisdatensatz definieren Definieren über stset, Informationen durch stdes und stsum.

76 Schätzung Der Stata Befehl für die Kaplan-Meier Schätzung lautet sts list

77 sts graph

78 sts graph, by(sex)
79 Signifikanztests Die Teststatistiken folgen nährungsweise einer χ 2 -Verteilung.
80 Signifikanztests Die Teststatistiken folgen nährungsweise einer χ 2 -Verteilung. H 0 geht davon aus, dass keine Unterschiede zwischen den Subgruppen bestehen.
81 Signifikanztests Die Teststatistiken folgen nährungsweise einer χ 2 -Verteilung. H 0 geht davon aus, dass keine Unterschiede zwischen den Subgruppen bestehen. H 1 nimmt an, dass sich die Überlebensfunktionen unterscheiden.
82 Signifikanztests Die Teststatistiken folgen nährungsweise einer χ 2 -Verteilung. H 0 geht davon aus, dass keine Unterschiede zwischen den Subgruppen bestehen. H 1 nimmt an, dass sich die Überlebensfunktionen unterscheiden. Log-Rank Test(Savage) : sts test varlist, logrank
83 Signifikanztests Die Teststatistiken folgen nährungsweise einer χ 2 -Verteilung. H 0 geht davon aus, dass keine Unterschiede zwischen den Subgruppen bestehen. H 1 nimmt an, dass sich die Überlebensfunktionen unterscheiden. Log-Rank Test(Savage) : sts test varlist, logrank Wilcoxon Test (Breslow) : sts test varlist, wilcoxon
84 Signifikanztests Die Teststatistiken folgen nährungsweise einer χ 2 -Verteilung. H 0 geht davon aus, dass keine Unterschiede zwischen den Subgruppen bestehen. H 1 nimmt an, dass sich die Überlebensfunktionen unterscheiden. Log-Rank Test(Savage) : sts test varlist, logrank Wilcoxon Test (Breslow) : sts test varlist, wilcoxon Tarone-Ware Test : sts test varlist, tware
85 Signifikanztests Die Teststatistiken folgen nährungsweise einer χ 2 -Verteilung. H 0 geht davon aus, dass keine Unterschiede zwischen den Subgruppen bestehen. H 1 nimmt an, dass sich die Überlebensfunktionen unterscheiden. Log-Rank Test(Savage) : sts test varlist, logrank Wilcoxon Test (Breslow) : sts test varlist, wilcoxon Tarone-Ware Test : sts test varlist, tware Peto-Peto-Prentice Test : sts test varlist, peto
86 Signifikanztests Die Teststatistiken folgen nährungsweise einer χ 2 -Verteilung. H 0 geht davon aus, dass keine Unterschiede zwischen den Subgruppen bestehen. H 1 nimmt an, dass sich die Überlebensfunktionen unterscheiden. Log-Rank Test(Savage) : sts test varlist, logrank Wilcoxon Test (Breslow) : sts test varlist, wilcoxon Tarone-Ware Test : sts test varlist, tware Peto-Peto-Prentice Test : sts test varlist, peto Fleming-Harrington Test : sts test varlist, fh()
87 Signifikanztests Die Teststatistiken folgen nährungsweise einer χ 2 -Verteilung. H 0 geht davon aus, dass keine Unterschiede zwischen den Subgruppen bestehen. H 1 nimmt an, dass sich die Überlebensfunktionen unterscheiden. Log-Rank Test(Savage) : sts test varlist, logrank Wilcoxon Test (Breslow) : sts test varlist, wilcoxon Tarone-Ware Test : sts test varlist, tware Peto-Peto-Prentice Test : sts test varlist, peto Fleming-Harrington Test : sts test varlist, fh() Cox Test : sts test varlist, cox
Berechnung des LOG-RANK-Tests bei Überlebenskurven
 Statistik 1 Berechnung des LOG-RANK-Tests bei Überlebenskurven Hans-Dieter Spies inventiv Health Germany GmbH Brandenburger Weg 3 60437 Frankfurt hd.spies@t-online.de Zusammenfassung Mit Hilfe von Überlebenskurven
Statistik 1 Berechnung des LOG-RANK-Tests bei Überlebenskurven Hans-Dieter Spies inventiv Health Germany GmbH Brandenburger Weg 3 60437 Frankfurt hd.spies@t-online.de Zusammenfassung Mit Hilfe von Überlebenskurven
Diagnose und Prognose: Kurzfassung 4
 Diagnose und Prognose: Kurzfassung 4 Ziele der 4. Vorlesung Inhaltliche Verbindung zwischen inhaltlicher Statistisches Konzept / Problemstellung Problemstellung und statistischem statistische Methode Konzept/Methode
Diagnose und Prognose: Kurzfassung 4 Ziele der 4. Vorlesung Inhaltliche Verbindung zwischen inhaltlicher Statistisches Konzept / Problemstellung Problemstellung und statistischem statistische Methode Konzept/Methode
Formelsammlung zur Vorlesung Lebensdaueranalyse
 Lebensdauer- und Ereignisanalyse WiSe 9/ Michael Höhle Formelsammlung zur Vorlesung Lebensdaueranalyse erstellt von Susanne Konrath Einführung. Hazardrate und Survivalfunktion T stetig mit Verteilungsfunktion
Lebensdauer- und Ereignisanalyse WiSe 9/ Michael Höhle Formelsammlung zur Vorlesung Lebensdaueranalyse erstellt von Susanne Konrath Einführung. Hazardrate und Survivalfunktion T stetig mit Verteilungsfunktion
Ereignisanalyse. Petra Stein / Marcel Noack
 Ereignisanalyse Petra Stein / Marcel Noack 12. Juli 2007 Inhaltsverzeichnis 1 Einleitung 3 2 Grundlagen 6 2.1 Regression für Längschnittdaten?................ 6 2.2 Unterscheidungen: A vs. B....................
Ereignisanalyse Petra Stein / Marcel Noack 12. Juli 2007 Inhaltsverzeichnis 1 Einleitung 3 2 Grundlagen 6 2.1 Regression für Längschnittdaten?................ 6 2.2 Unterscheidungen: A vs. B....................
Übungsaufgaben, Statistik 1
 Übungsaufgaben, Statistik 1 Kapitel 3: Wahrscheinlichkeiten [ 4 ] 3. Übungswoche Der Spiegel berichtet in Heft 29/2007 von folgender Umfrage vom 3. und 4. Juli 2007:,, Immer wieder werden der Dalai Lama
Übungsaufgaben, Statistik 1 Kapitel 3: Wahrscheinlichkeiten [ 4 ] 3. Übungswoche Der Spiegel berichtet in Heft 29/2007 von folgender Umfrage vom 3. und 4. Juli 2007:,, Immer wieder werden der Dalai Lama
Kaplan-Meier-Schätzer
 Kaplan-Meier-Schätzer Ausgangssituation Zwei naive Ansätze zur Schätzung der Survivalfunktion Unverzerrte Schätzung der Survivalfunktion Der Kaplan-Meier-Schätzer Standardfehler und Konfidenzintervall
Kaplan-Meier-Schätzer Ausgangssituation Zwei naive Ansätze zur Schätzung der Survivalfunktion Unverzerrte Schätzung der Survivalfunktion Der Kaplan-Meier-Schätzer Standardfehler und Konfidenzintervall
Grundzüge der Ereignisdatenanalyse
 Grundzüge der Ereignisdatenanalyse Regressionsmodelle Sommersemester 2009 Regressionsmodelle Event History Analysis (1/48) Übersicht Wiederholung Exponential- und Weibull-Modell Weitere Modelle Regressionsmodelle
Grundzüge der Ereignisdatenanalyse Regressionsmodelle Sommersemester 2009 Regressionsmodelle Event History Analysis (1/48) Übersicht Wiederholung Exponential- und Weibull-Modell Weitere Modelle Regressionsmodelle
Übersicht. VL Forschungsmethoden. Ereignisdatenanalyse
 VL Forschungsmethoden Ereignisdatenanalyse 1 2 3 4 5 Übersicht VL Forschungsmethoden Event Data (1/45) Harold Macmillan, PM 1957-1963 The greatest challenge in politics: events, my dear boy, events Was
VL Forschungsmethoden Ereignisdatenanalyse 1 2 3 4 5 Übersicht VL Forschungsmethoden Event Data (1/45) Harold Macmillan, PM 1957-1963 The greatest challenge in politics: events, my dear boy, events Was
Statistische Analyse von Ereigniszeiten
 Statistische Analyse von Survival Analysis VO Biostatistik im WS 2006/2007 1 2 3 : Leukemiedaten (unzensiert) 33 Patienten mit Leukemie; Zielvariable Überlebenszeit. Alle Patienten verstorben und Überlebenszeit
Statistische Analyse von Survival Analysis VO Biostatistik im WS 2006/2007 1 2 3 : Leukemiedaten (unzensiert) 33 Patienten mit Leukemie; Zielvariable Überlebenszeit. Alle Patienten verstorben und Überlebenszeit
Stetige Verteilungen. A: Beispiele Beispiel 1: a) In den folgenden Abbildungen sind die Dichtefunktionen von drei bekannten Verteilungen graphisch
 In den folgenden Abbildungen sind die Dichtefunktionen von drei bekannten Verteilungen graphisch") 6 Stetige Verteilungen 1 Kapitel 6: Stetige Verteilungen A: Beispiele Beispiel 1: a) In den folgenden Abbildungen sind die Dichtefunktionen von drei bekannten Verteilungen graphisch dargestellt. 0.2 6
6 Stetige Verteilungen 1 Kapitel 6: Stetige Verteilungen A: Beispiele Beispiel 1: a) In den folgenden Abbildungen sind die Dichtefunktionen von drei bekannten Verteilungen graphisch dargestellt. 0.2 6
Survival Analysis. Rene.Boeheim@jku.at. December 2008
 Survival Analysis René Böheim Rene.Boeheim@jku.at December 2008 Basierend auf Cleves, Gould, and Gutierrez (2004), An Introduction to Survival Analysis using Stata, Revised Edition, Stata Press, Texas.
Survival Analysis René Böheim Rene.Boeheim@jku.at December 2008 Basierend auf Cleves, Gould, and Gutierrez (2004), An Introduction to Survival Analysis using Stata, Revised Edition, Stata Press, Texas.
I. Zahlen, Rechenregeln & Kombinatorik
 XIV. Wiederholung Seite 1 I. Zahlen, Rechenregeln & Kombinatorik 1 Zahlentypen 2 Rechenregeln Brüche, Wurzeln & Potenzen, Logarithmen 3 Prozentrechnung 4 Kombinatorik Möglichkeiten, k Elemente anzuordnen
XIV. Wiederholung Seite 1 I. Zahlen, Rechenregeln & Kombinatorik 1 Zahlentypen 2 Rechenregeln Brüche, Wurzeln & Potenzen, Logarithmen 3 Prozentrechnung 4 Kombinatorik Möglichkeiten, k Elemente anzuordnen
Zufallsvariablen [random variable]
![Zufallsvariablen [random variable]](/thumbs/52/29710821.jpg "Zufallsvariablen [random variable]") Zufallsvariablen [random variable] Eine Zufallsvariable (Zufallsgröße) X beschreibt (kodiert) die Versuchsausgänge ω Ω mit Hilfe von Zahlen, d.h. X ist eine Funktion X : Ω R ω X(ω) Zufallsvariablen werden
Zufallsvariablen [random variable] Eine Zufallsvariable (Zufallsgröße) X beschreibt (kodiert) die Versuchsausgänge ω Ω mit Hilfe von Zahlen, d.h. X ist eine Funktion X : Ω R ω X(ω) Zufallsvariablen werden
Nicht-parametrische Statistik Eine kleine Einführung
 Nicht-parametrische Statistik Eine kleine Einführung Überblick Anwendung nicht-parametrischer Statistik Behandelte Tests Mann-Whitney U Test Kolmogorov-Smirnov Test Wilcoxon Test Binomialtest Chi-squared
Nicht-parametrische Statistik Eine kleine Einführung Überblick Anwendung nicht-parametrischer Statistik Behandelte Tests Mann-Whitney U Test Kolmogorov-Smirnov Test Wilcoxon Test Binomialtest Chi-squared
Anpassungstests VORGEHENSWEISE
 Anpassungstests Anpassungstests prüfen, wie sehr sich ein bestimmter Datensatz einer erwarteten Verteilung anpasst bzw. von dieser abweicht. Nach der Erläuterung der Funktionsweise sind je ein Beispiel
Anpassungstests Anpassungstests prüfen, wie sehr sich ein bestimmter Datensatz einer erwarteten Verteilung anpasst bzw. von dieser abweicht. Nach der Erläuterung der Funktionsweise sind je ein Beispiel
Aufgaben zu Kapitel 5:
 Aufgaben zu Kapitel 5: Aufgabe 1: Ein Wissenschaftler untersucht, in wie weit die Reaktionszeit auf bestimmte Stimuli durch finanzielle Belohnung zu steigern ist. Er möchte vier Bedingungen vergleichen:
Aufgaben zu Kapitel 5: Aufgabe 1: Ein Wissenschaftler untersucht, in wie weit die Reaktionszeit auf bestimmte Stimuli durch finanzielle Belohnung zu steigern ist. Er möchte vier Bedingungen vergleichen:
Schätzung des Lifetime Values von Spendern mit Hilfe der Überlebensanalyse
 Schätzung Lifetime Values von Spenn mit Hilfe Überlebensanalyse Einführung in das Verfahren am Beispiel Einzugsgenehmigung Überlebensanalysen o Ereignisdatenanalysen behandeln das Problem, mit welcher
Schätzung Lifetime Values von Spenn mit Hilfe Überlebensanalyse Einführung in das Verfahren am Beispiel Einzugsgenehmigung Überlebensanalysen o Ereignisdatenanalysen behandeln das Problem, mit welcher
Einführung in die Survival-Analyse (Modul: Methoden II)
") Einführung in die Survival-Analyse (Modul: Methoden II) ROLAND RAU Universität Rostock, Sommersemester 2013 14. Mai 2013 c Roland Rau Survival-Analyse 06. Sitzung 1 / 23 Hinweis: Interview mit Prof. Matthias
Einführung in die Survival-Analyse (Modul: Methoden II) ROLAND RAU Universität Rostock, Sommersemester 2013 14. Mai 2013 c Roland Rau Survival-Analyse 06. Sitzung 1 / 23 Hinweis: Interview mit Prof. Matthias
Einführung in die Induktive Statistik: Testen von Hypothesen
 Einführung in die Induktive Statistik: Testen von Hypothesen Jan Gertheiss LMU München Sommersemester 2011 Vielen Dank an Christian Heumann für das Überlassen von TEX-Code! Testen: Einführung und Konzepte
Einführung in die Induktive Statistik: Testen von Hypothesen Jan Gertheiss LMU München Sommersemester 2011 Vielen Dank an Christian Heumann für das Überlassen von TEX-Code! Testen: Einführung und Konzepte
Konfidenzintervalle Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Anteilswert Differenzen von Erwartungswert Anteilswert
 Konfidenzintervalle Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Anteilswert Differenzen von Erwartungswert Anteilswert Beispiel für Konfidenzintervall Im Prinzip haben wir
Konfidenzintervalle Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Anteilswert Differenzen von Erwartungswert Anteilswert Beispiel für Konfidenzintervall Im Prinzip haben wir
Übung zu Empirische Ökonomie für Fortgeschrittene SS 2009
 Übung zu Empirische Ökonomie für Fortgeschrittene Steen Elstner, Klaus Wohlrabe, Steen Henzel SS 9 1 Wichtige Verteilungen Die Normalverteilung Eine stetige Zufallsvariable mit der Wahrscheinlichkeitsdichte
Übung zu Empirische Ökonomie für Fortgeschrittene Steen Elstner, Klaus Wohlrabe, Steen Henzel SS 9 1 Wichtige Verteilungen Die Normalverteilung Eine stetige Zufallsvariable mit der Wahrscheinlichkeitsdichte
Survival Analysis (Modul: Lebensdaueranalyse)
") Survival Analysis (Modul: Lebensdaueranalyse) ROLAND RAU Universität Rostock, Sommersemester 2015 05. Mai 2015 c Roland Rau Survival Analysis 1 / 18 Zensierung & Trunkierung: Nicht vollständig beobachtete
Survival Analysis (Modul: Lebensdaueranalyse) ROLAND RAU Universität Rostock, Sommersemester 2015 05. Mai 2015 c Roland Rau Survival Analysis 1 / 18 Zensierung & Trunkierung: Nicht vollständig beobachtete
Testen von Hypothesen:
 Testen von Hypothesen: Ein Beispiel: Eine Firma produziert Reifen. In der Entwicklungsabteilung wurde ein neues Modell entwickelt, das wesentlich ruhiger läuft. Vor der Markteinführung muss aber auch noch
Testen von Hypothesen: Ein Beispiel: Eine Firma produziert Reifen. In der Entwicklungsabteilung wurde ein neues Modell entwickelt, das wesentlich ruhiger läuft. Vor der Markteinführung muss aber auch noch
Kapitel 3. Zufallsvariable. Wahrscheinlichkeitsfunktion, Dichte und Verteilungsfunktion. Erwartungswert, Varianz und Standardabweichung
 Kapitel 3 Zufallsvariable Josef Leydold c 2006 Mathematische Methoden III Zufallsvariable 1 / 43 Lernziele Diskrete und stetige Zufallsvariable Wahrscheinlichkeitsfunktion, Dichte und Verteilungsfunktion
Kapitel 3 Zufallsvariable Josef Leydold c 2006 Mathematische Methoden III Zufallsvariable 1 / 43 Lernziele Diskrete und stetige Zufallsvariable Wahrscheinlichkeitsfunktion, Dichte und Verteilungsfunktion
Einfache statistische Auswertungen mit dem Programm SPSS
 Einfache statistische Auswertungen mit dem Programm SPSS Datensatz: fiktive_daten.sav Dipl. Päd. Anne Haßelkus Dr. Dorothea Dette-Hagenmeyer 11/2011 Überblick 1 Deskriptive Statistiken; Mittelwert berechnen...
Einfache statistische Auswertungen mit dem Programm SPSS Datensatz: fiktive_daten.sav Dipl. Päd. Anne Haßelkus Dr. Dorothea Dette-Hagenmeyer 11/2011 Überblick 1 Deskriptive Statistiken; Mittelwert berechnen...
8. Keine Normalverteilung der Störgrößen (Verletzung der B4-Annahme)
") 8. Keine Normalverteilung der Störgrößen (Verletzung der B4-Annahme) Annahme B4: Die Störgrößen u i sind normalverteilt, d.h. u i N(0, σ 2 ) Beispiel: [I] Neoklassisches Solow-Wachstumsmodell Annahme einer
8. Keine Normalverteilung der Störgrößen (Verletzung der B4-Annahme) Annahme B4: Die Störgrößen u i sind normalverteilt, d.h. u i N(0, σ 2 ) Beispiel: [I] Neoklassisches Solow-Wachstumsmodell Annahme einer
A: Beispiele Beispiel 1: Zwei Zufallsvariablen X und Y besitzen die beiden folgenden Wahrscheinlichkeitsfunktionen:
 5 Diskrete Verteilungen 1 Kapitel 5: Diskrete Verteilungen A: Beispiele Beispiel 1: Zwei Zufallsvariablen X und Y besitzen die beiden folgenden Wahrscheinlichkeitsfunktionen: 5 0.6 x 0.4 5 x (i) P x (x)
5 Diskrete Verteilungen 1 Kapitel 5: Diskrete Verteilungen A: Beispiele Beispiel 1: Zwei Zufallsvariablen X und Y besitzen die beiden folgenden Wahrscheinlichkeitsfunktionen: 5 0.6 x 0.4 5 x (i) P x (x)
Laden des Datensatzes und erstellen eines Survival-Objektes. Laden des Datensatzes und Data Cleaning
 Laden des Datensatzes und erstellen eines Survival-Objektes Laden des Datensatzes und Data Cleaning Das Laden des Datensatzes sollte wenig Schwierigkeiten verursachen. Nachdem Sie mittels setwd("c:/sommer2015/survival")
Laden des Datensatzes und erstellen eines Survival-Objektes Laden des Datensatzes und Data Cleaning Das Laden des Datensatzes sollte wenig Schwierigkeiten verursachen. Nachdem Sie mittels setwd("c:/sommer2015/survival")
Mathematik für Biologen
 Mathematik für Biologen Prof. Dr. Rüdiger W. Braun Heinrich-Heine-Universität Düsseldorf 19. Januar 2011 1 Nichtparametrische Tests Ordinalskalierte Daten 2 Test für ein Merkmal mit nur zwei Ausprägungen
Mathematik für Biologen Prof. Dr. Rüdiger W. Braun Heinrich-Heine-Universität Düsseldorf 19. Januar 2011 1 Nichtparametrische Tests Ordinalskalierte Daten 2 Test für ein Merkmal mit nur zwei Ausprägungen
Verteilungsmodelle. Verteilungsfunktion und Dichte von T
 Verteilungsmodelle Verteilungsfunktion und Dichte von T Survivalfunktion von T Hazardrate von T Beziehungen zwischen F(t), S(t), f(t) und h(t) Vorüberlegung zu Lebensdauerverteilungen Die Exponentialverteilung
Verteilungsmodelle Verteilungsfunktion und Dichte von T Survivalfunktion von T Hazardrate von T Beziehungen zwischen F(t), S(t), f(t) und h(t) Vorüberlegung zu Lebensdauerverteilungen Die Exponentialverteilung
Kapitel 12 Stetige Zufallsvariablen Dichtefunktion und Verteilungsfunktion. stetig. Verteilungsfunktion
 Kapitel 12 Stetige Zufallsvariablen 12.1. Dichtefunktion und Verteilungsfunktion stetig Verteilungsfunktion Trägermenge T, also die Menge der möglichen Realisationen, ist durch ein Intervall gegeben Häufig
Kapitel 12 Stetige Zufallsvariablen 12.1. Dichtefunktion und Verteilungsfunktion stetig Verteilungsfunktion Trägermenge T, also die Menge der möglichen Realisationen, ist durch ein Intervall gegeben Häufig
Statistische Thermodynamik I Lösungen zur Serie 1
 Statistische Thermodynamik I Lösungen zur Serie Zufallsvariablen, Wahrscheinlichkeitsverteilungen 4. März 2. Zwei Lektoren lesen ein Buch. Lektor A findet 2 Druckfehler, Lektor B nur 5. Von den gefundenen
Statistische Thermodynamik I Lösungen zur Serie Zufallsvariablen, Wahrscheinlichkeitsverteilungen 4. März 2. Zwei Lektoren lesen ein Buch. Lektor A findet 2 Druckfehler, Lektor B nur 5. Von den gefundenen
Übung Statistik I Statistik mit Stata SS07-21.05.2007 6. Grafiken und Wiederholung
 Übung Statistik I Statistik mit Stata SS07-21.05.2007 6. Grafiken und Wiederholung Andrea Kummerer (M.A.) Oec R. I-53 Sprechstunde: Di. 15-16 Uhr Andrea.Kummerer@sowi.uni-goettingen.de Statistik mit Stata
Übung Statistik I Statistik mit Stata SS07-21.05.2007 6. Grafiken und Wiederholung Andrea Kummerer (M.A.) Oec R. I-53 Sprechstunde: Di. 15-16 Uhr Andrea.Kummerer@sowi.uni-goettingen.de Statistik mit Stata
Statistische Tests zu ausgewählten Problemen
 Einführung in die statistische Testtheorie Statistische Tests zu ausgewählten Problemen Teil 4: Nichtparametrische Tests Statistische Testtheorie IV Einführung Beschränkung auf nichtparametrische Testverfahren
Einführung in die statistische Testtheorie Statistische Tests zu ausgewählten Problemen Teil 4: Nichtparametrische Tests Statistische Testtheorie IV Einführung Beschränkung auf nichtparametrische Testverfahren
Analyse von Querschnittsdaten. Signifikanztests I Basics
 Analyse von Querschnittsdaten Signifikanztests I Basics Warum geht es in den folgenden Sitzungen? Kontinuierliche Variablen Generalisierung kategoriale Variablen Datum 13.10.2004 20.10.2004 27.10.2004
Analyse von Querschnittsdaten Signifikanztests I Basics Warum geht es in den folgenden Sitzungen? Kontinuierliche Variablen Generalisierung kategoriale Variablen Datum 13.10.2004 20.10.2004 27.10.2004
Hochschule Bremerhaven Medizintechnik Mathcad Kapitel 6
 6. Diagramme mit Mathcad In diesem Kapitel geht es um andere, als X Y Diagramme. 6.. Kreisdiagramme. Schritt: Die darzustellende Funktion muß zunächst als Funktion definiert werden, zum Beispiel f(x):=
6. Diagramme mit Mathcad In diesem Kapitel geht es um andere, als X Y Diagramme. 6.. Kreisdiagramme. Schritt: Die darzustellende Funktion muß zunächst als Funktion definiert werden, zum Beispiel f(x):=
Übung Statistik I Statistik mit Stata SS Probeklausur, Wiederholungen und Übungen
 Übung Statistik I Statistik mit Stata SS07 11.06.2007 8. Probeklausur, Wiederholungen und Übungen Andrea Kummerer (M.A.) Oec R. I-53 Sprechstunde: n.v. Andrea.Kummerer@sowi.uni-goettingen.de Statistik
Übung Statistik I Statistik mit Stata SS07 11.06.2007 8. Probeklausur, Wiederholungen und Übungen Andrea Kummerer (M.A.) Oec R. I-53 Sprechstunde: n.v. Andrea.Kummerer@sowi.uni-goettingen.de Statistik
Klausur zu Methoden der Statistik I (mit Kurzlösung) Wintersemester 2007/2008. Aufgabe 1
 Wintersemester 2007/2008. Aufgabe 1") Lehrstuhl für Statistik und Ökonometrie der Otto-Friedrich-Universität Bamberg Prof. Dr. Susanne Rässler Klausur zu Methoden der Statistik I (mit Kurzlösung) Wintersemester 2007/2008 Aufgabe 1 Ihnen liegt
Lehrstuhl für Statistik und Ökonometrie der Otto-Friedrich-Universität Bamberg Prof. Dr. Susanne Rässler Klausur zu Methoden der Statistik I (mit Kurzlösung) Wintersemester 2007/2008 Aufgabe 1 Ihnen liegt
Lebensdauer eines x-jährigen
 Lebensdauer eines x-jährigen Sabrina Scheriau 20. November 2007, Graz 1 INHALTSVERZEICHNIS 2 Inhaltsverzeichnis 1 Einleitung 3 2 Sterbewahrscheinlichkeiten 4 2.1 Definition und Ermittlung....................
Lebensdauer eines x-jährigen Sabrina Scheriau 20. November 2007, Graz 1 INHALTSVERZEICHNIS 2 Inhaltsverzeichnis 1 Einleitung 3 2 Sterbewahrscheinlichkeiten 4 2.1 Definition und Ermittlung....................
Tumorregister München
 Tumorregister München Inzidenz und Mortalität Auswahlmatrix Homepage English P-NET: Neuroendokr. Pankreastu. Survival Diagnosejahr 1998-14 Patienten 368 Erkrankungen 368 Fälle in Auswertung 292 Erstellungsdatum
Tumorregister München Inzidenz und Mortalität Auswahlmatrix Homepage English P-NET: Neuroendokr. Pankreastu. Survival Diagnosejahr 1998-14 Patienten 368 Erkrankungen 368 Fälle in Auswertung 292 Erstellungsdatum
13. Übungswoche. Kapitel 12: Varianzanalyse (Fortsetzung)
") 1 13. Übungswoche Kapitel 12: Varianzanalyse (Fortsetzung) [ 3 ] Im Vorkurs Mathematik für Wirtschafstwissenschaftler vor Beginn des Sommersemesters 2009 wurde am Anfang und am Ende ein Test geschrieben,
1 13. Übungswoche Kapitel 12: Varianzanalyse (Fortsetzung) [ 3 ] Im Vorkurs Mathematik für Wirtschafstwissenschaftler vor Beginn des Sommersemesters 2009 wurde am Anfang und am Ende ein Test geschrieben,
Einige Statistische Tests für den Ein- Zwei- und k-stichprobenfall (Nach Sachs, Stat. Meth.)
") ue biostatistik: nichtparametrische testverfahren / ergänzung 1/6 h. Lettner / physik Statistische Testverfahren Einige Statistische Tests für den Ein- Zwei- und k-stichprobenfall (Nach Sachs, Stat. Meth.)
ue biostatistik: nichtparametrische testverfahren / ergänzung 1/6 h. Lettner / physik Statistische Testverfahren Einige Statistische Tests für den Ein- Zwei- und k-stichprobenfall (Nach Sachs, Stat. Meth.)
[ 1 ] Welche der folgenden Aussagen sind WAHR? Kreuzen Sie sie an.
![[ 1 ] Welche der folgenden Aussagen sind WAHR? Kreuzen Sie sie an.](/thumbs/52/30312207.jpg "[ 1 ] Welche der folgenden Aussagen sind WAHR? Kreuzen Sie sie an.") 13 Zeitreihenanalyse 1 Kapitel 13: Zeitreihenanalyse A: Übungsaufgaben: [ 1 ] 1 a a) Nach der Formel x t+i berechnet man einen ein f achen gleitenden Durchschnitt. 2a + 1 i= a b) Die Residuale berechnet
13 Zeitreihenanalyse 1 Kapitel 13: Zeitreihenanalyse A: Übungsaufgaben: [ 1 ] 1 a a) Nach der Formel x t+i berechnet man einen ein f achen gleitenden Durchschnitt. 2a + 1 i= a b) Die Residuale berechnet
Tutorial: Vergleich von Anteilen
 Tutorial: Vergleich von Anteilen Die Sicherung des Pensionssystems ist in vielen Ländern ein heikles Thema. Noch stärker als der Streit, wer wann welche Pension beziehen können soll, tobt ein Streit, welche
Tutorial: Vergleich von Anteilen Die Sicherung des Pensionssystems ist in vielen Ländern ein heikles Thema. Noch stärker als der Streit, wer wann welche Pension beziehen können soll, tobt ein Streit, welche
Simulation von Zufallsversuchen mit dem Voyage 200
 Simulation von Zufallsversuchen mit dem Voyage 00 Guido Herweyers KHBO Campus Oostende K.U.Leuven 1. Entenjagd Zehn Jäger, alle perfekte Schützen, lauern vor einem Feld auf Enten. Bald landen dort 10 Enten.
Simulation von Zufallsversuchen mit dem Voyage 00 Guido Herweyers KHBO Campus Oostende K.U.Leuven 1. Entenjagd Zehn Jäger, alle perfekte Schützen, lauern vor einem Feld auf Enten. Bald landen dort 10 Enten.
Klausur Stochastik und Statistik 31. Juli 2012
 Klausur Stochastik und Statistik 31. Juli 2012 Prof. Dr. Matthias Schmid Institut für Statistik, LMU München Wichtig: ˆ Überprüfen Sie, ob Ihr Klausurexemplar vollständig ist. Die Klausur besteht aus fünf
Klausur Stochastik und Statistik 31. Juli 2012 Prof. Dr. Matthias Schmid Institut für Statistik, LMU München Wichtig: ˆ Überprüfen Sie, ob Ihr Klausurexemplar vollständig ist. Die Klausur besteht aus fünf
Kapitel 8 Einführung der Integralrechnung über Flächenmaße
 8. Flächenmaße 8.1 Flächenmaßfunktionen zu nicht negativen Randfunktionen Wir wenden uns einem auf den ersten Blick neuen Thema zu, der Ermittlung des Flächenmaßes A von Flächen A, die vom nicht unterhalb
8. Flächenmaße 8.1 Flächenmaßfunktionen zu nicht negativen Randfunktionen Wir wenden uns einem auf den ersten Blick neuen Thema zu, der Ermittlung des Flächenmaßes A von Flächen A, die vom nicht unterhalb
Survival Analysis (Modul: Lebensdaueranalyse)
") Survival Analysis (Modul: Lebensdaueranalyse) ROLAND RAU Universität Rostock, Sommersemester 2015 12. Mai 2015 c Roland Rau Survival Analysis 1 / 24 Hausaufgabe 1 Schreiben Sie die Log-Likelihood Gleichung
Survival Analysis (Modul: Lebensdaueranalyse) ROLAND RAU Universität Rostock, Sommersemester 2015 12. Mai 2015 c Roland Rau Survival Analysis 1 / 24 Hausaufgabe 1 Schreiben Sie die Log-Likelihood Gleichung
1 Dichte- und Verteilungsfunktion
 Tutorium Yannick Schrör Klausurvorbereitungsaufgaben Statistik Lösungen Yannick.Schroer@rub.de 9.2.26 ID /455 Dichte- und Verteilungsfunktion Ein tüchtiger Professor lässt jährlich 2 Bücher drucken. Die
Tutorium Yannick Schrör Klausurvorbereitungsaufgaben Statistik Lösungen Yannick.Schroer@rub.de 9.2.26 ID /455 Dichte- und Verteilungsfunktion Ein tüchtiger Professor lässt jährlich 2 Bücher drucken. Die
Ein- und Zweistichprobentests
 (c) Projekt Neue Statistik 2003 - Lernmodul: Ein- Zweistichprobentests Ein- Zweistichprobentests Worum geht es in diesem Modul? Wiederholung: allgemeines Ablaufschema eines Tests Allgemeine Voraussetzungen
(c) Projekt Neue Statistik 2003 - Lernmodul: Ein- Zweistichprobentests Ein- Zweistichprobentests Worum geht es in diesem Modul? Wiederholung: allgemeines Ablaufschema eines Tests Allgemeine Voraussetzungen
Mathematik für Biologen
 Mathematik für Biologen Prof. Dr. Rüdiger W. Braun Heinrich-Heine-Universität Düsseldorf 10. November 2010 1 Bedingte Wahrscheinlichkeit Satz von der totalen Wahrscheinlichkeit Bayessche Formel 2 Grundprinzipien
Mathematik für Biologen Prof. Dr. Rüdiger W. Braun Heinrich-Heine-Universität Düsseldorf 10. November 2010 1 Bedingte Wahrscheinlichkeit Satz von der totalen Wahrscheinlichkeit Bayessche Formel 2 Grundprinzipien
Empirische Analysen mit dem SOEP
 Empirische Analysen mit dem SOEP Methodisches Lineare Regressionsanalyse & Logit/Probit Modelle Kurs im Wintersemester 2007/08 Dipl.-Volksw. Paul Böhm Dipl.-Volksw. Dominik Hanglberger Dipl.-Volksw. Rafael
Empirische Analysen mit dem SOEP Methodisches Lineare Regressionsanalyse & Logit/Probit Modelle Kurs im Wintersemester 2007/08 Dipl.-Volksw. Paul Böhm Dipl.-Volksw. Dominik Hanglberger Dipl.-Volksw. Rafael
Biometrie und Methodik (Statistik) - WiSem08/09 Probeklausur 1
 - WiSem08/09 Probeklausur 1") Biometrie und Methodik (Statistik) - WiSem08/09 Probeklausur 1 Aufgabe 1 (10 Punkte). 10 Schüler der zehnten Klasse unterziehen sich zur Vorbereitung auf die Abschlussprüfung einem Mathematiktrainingsprogramm.
Biometrie und Methodik (Statistik) - WiSem08/09 Probeklausur 1 Aufgabe 1 (10 Punkte). 10 Schüler der zehnten Klasse unterziehen sich zur Vorbereitung auf die Abschlussprüfung einem Mathematiktrainingsprogramm.
Übungen (HS-2010): Urteilsfehler. Autor: Siegfried Macho
: Urteilsfehler. Autor: Siegfried Macho") Übungen (HS-2010): Urteilsfehler Autor: Siegfried Macho Inhaltsverzeichnis i Inhaltsverzeichnis 1. Übungen zu Kapitel 2 1 Übungen zu Kontingenz- und Kausalurteile 1 Übung 1-1: 1. Übungen zu Kapitel 2 Gegeben:
Übungen (HS-2010): Urteilsfehler Autor: Siegfried Macho Inhaltsverzeichnis i Inhaltsverzeichnis 1. Übungen zu Kapitel 2 1 Übungen zu Kontingenz- und Kausalurteile 1 Übung 1-1: 1. Übungen zu Kapitel 2 Gegeben:
Kapitel 8. Einfache Regression. Anpassen des linearen Regressionsmodells, OLS. Eigenschaften der Schätzer für das Modell
 Kapitel 8 Einfache Regression Josef Leydold c 2006 Mathematische Methoden VIII Einfache Regression 1 / 21 Lernziele Lineares Regressionsmodell Anpassen des linearen Regressionsmodells, OLS Eigenschaften
Kapitel 8 Einfache Regression Josef Leydold c 2006 Mathematische Methoden VIII Einfache Regression 1 / 21 Lernziele Lineares Regressionsmodell Anpassen des linearen Regressionsmodells, OLS Eigenschaften
Statistik II: Signifikanztests /1
 Medien Institut : Signifikanztests /1 Dr. Andreas Vlašić Medien Institut (0621) 52 67 44 vlasic@medien-institut.de Gliederung 1. Noch einmal: Grundlagen des Signifikanztests 2. Der chi 2 -Test 3. Der t-test
Medien Institut : Signifikanztests /1 Dr. Andreas Vlašić Medien Institut (0621) 52 67 44 vlasic@medien-institut.de Gliederung 1. Noch einmal: Grundlagen des Signifikanztests 2. Der chi 2 -Test 3. Der t-test
Monte Carlo Methoden in Kreditrisiko-Management
 Monte Carlo Methoden in Kreditrisiko-Management P Kreditportfolio bestehend aus m Krediten; Verlustfunktion L = n i=1 L i; Die Verluste L i sind unabhängig bedingt durch einen Vektor Z von ökonomischen
Monte Carlo Methoden in Kreditrisiko-Management P Kreditportfolio bestehend aus m Krediten; Verlustfunktion L = n i=1 L i; Die Verluste L i sind unabhängig bedingt durch einen Vektor Z von ökonomischen
Survival Analysis (Modul: Lebensdaueranalyse)
") Survival Analysis (Modul: Lebensdaueranalyse) ROLAND RAU Universität Rostock, Sommersemester 2015 19. Mai 2015 Roland Rau Survival Analysis 1 / 26 Nächste & übernächste Woche Nächste Woche: Projektwoche
Survival Analysis (Modul: Lebensdaueranalyse) ROLAND RAU Universität Rostock, Sommersemester 2015 19. Mai 2015 Roland Rau Survival Analysis 1 / 26 Nächste & übernächste Woche Nächste Woche: Projektwoche
Zufallsgrößen. Vorlesung Statistik für KW 29.04.2008 Helmut Küchenhoff
 Zufallsgrößen 2.5 Zufallsgrößen 2.5.1 Verteilungsfunktion einer Zufallsgröße 2.5.2 Wahrscheinlichkeits- und Dichtefunktion Wahrscheinlichkeitsfunktion einer diskreten Zufallsgröße Dichtefunktion einer
Zufallsgrößen 2.5 Zufallsgrößen 2.5.1 Verteilungsfunktion einer Zufallsgröße 2.5.2 Wahrscheinlichkeits- und Dichtefunktion Wahrscheinlichkeitsfunktion einer diskreten Zufallsgröße Dichtefunktion einer
Biometrieübung 5 Spezielle Verteilungen. 1. Anzahl von weiblichen Mäusen in Würfen von jeweils 4 Mäusen
 Biometrieübung 5 (Spezielle Verteilungen) - Aufgabe Biometrieübung 5 Spezielle Verteilungen Aufgabe 1. Anzahl von weiblichen Mäusen in Würfen von jeweils 4 Mäusen Anzahl weiblicher Mäuse (k) Anzahl Würfe
Biometrieübung 5 (Spezielle Verteilungen) - Aufgabe Biometrieübung 5 Spezielle Verteilungen Aufgabe 1. Anzahl von weiblichen Mäusen in Würfen von jeweils 4 Mäusen Anzahl weiblicher Mäuse (k) Anzahl Würfe
Stochastik und Statistik für Ingenieure Vorlesung 4
 Prof. Dr. Hans-Jörg Starkloff TU Bergakademie Freiberg Institut für Stochastik Stochastik und Statistik für Ingenieure Vorlesung 4 30. Oktober 2012 Quantile einer stetigen Zufallsgröße Die reelle Zahl
Prof. Dr. Hans-Jörg Starkloff TU Bergakademie Freiberg Institut für Stochastik Stochastik und Statistik für Ingenieure Vorlesung 4 30. Oktober 2012 Quantile einer stetigen Zufallsgröße Die reelle Zahl
5.8 Anpassungstests. W. Kössler (IfI HU Berlin) Werkzeuge der empirischen Forschung 389 / 419
 Werkzeuge der empirischen Forschung 389 / 419") 5.8 8.1 Einführung empirische Verteilungsfunktion 8.2 EDF- Kolmogorov-Smirnov-Test Anderson-Darling-Test Cramer-von Mises-Test 8.3 Anpassungstest auf Normalverteilung - Shapiro-Wilk-Test 8.4. auf weitere
5.8 8.1 Einführung empirische Verteilungsfunktion 8.2 EDF- Kolmogorov-Smirnov-Test Anderson-Darling-Test Cramer-von Mises-Test 8.3 Anpassungstest auf Normalverteilung - Shapiro-Wilk-Test 8.4. auf weitere
Forschungsstatistik I
 Prof. Dr. G. Meinhardt. Stock, Taubertsberg R. 0-0 (Persike) R. 0-1 (Meinhardt) Sprechstunde jederzeit nach Vereinbarung Forschungsstatistik I Dr. Malte Persike persike@uni-mainz.de http://psymet0.sowi.uni-mainz.de/
Prof. Dr. G. Meinhardt. Stock, Taubertsberg R. 0-0 (Persike) R. 0-1 (Meinhardt) Sprechstunde jederzeit nach Vereinbarung Forschungsstatistik I Dr. Malte Persike persike@uni-mainz.de http://psymet0.sowi.uni-mainz.de/
Computergestützte Methoden. Master of Science Prof. Dr. G. H. Franke WS 07/08
 Computergestützte Methoden Master of Science Prof. Dr. G. H. Franke WS 07/08 1 Seminarübersicht 1. Einführung 2. Recherchen mit Datenbanken 3. Erstellung eines Datenfeldes 4. Skalenniveau und Skalierung
Computergestützte Methoden Master of Science Prof. Dr. G. H. Franke WS 07/08 1 Seminarübersicht 1. Einführung 2. Recherchen mit Datenbanken 3. Erstellung eines Datenfeldes 4. Skalenniveau und Skalierung
Christian FG Schendera. Regressionsanalyse. mit SPSS. 2. korrigierte und aktualisierte Auflage DE GRUYTER OLDENBOURG
 Christian FG Schendera Regressionsanalyse mit SPSS 2. korrigierte und aktualisierte Auflage DE GRUYTER OLDENBOURG Inhalt Vorworte V 1 Korrelation 1 1.1 Einführung 1 1.2 Erste Voraussetzung: Das Skalenniveau
Christian FG Schendera Regressionsanalyse mit SPSS 2. korrigierte und aktualisierte Auflage DE GRUYTER OLDENBOURG Inhalt Vorworte V 1 Korrelation 1 1.1 Einführung 1 1.2 Erste Voraussetzung: Das Skalenniveau
Statistik II. Statistische Tests. Statistik II
 Statistik II Statistische Tests Statistik II - 12.5.2006 1 Test auf Anteilswert: Binomialtest Sei eine Stichprobe unabhängig, identisch verteilter ZV (i.i.d.). Teile diese Stichprobe in zwei Teilmengen
Statistik II Statistische Tests Statistik II - 12.5.2006 1 Test auf Anteilswert: Binomialtest Sei eine Stichprobe unabhängig, identisch verteilter ZV (i.i.d.). Teile diese Stichprobe in zwei Teilmengen
Vorwort Zufallsvariable X, Erwartungswert E(X), Varianz V(X) 1.1 Zufallsvariable oder Zufallsgröße Erwartungswert und Varianz...
, Varianz V(X) 1.1 Zufallsvariable oder Zufallsgröße Erwartungswert und Varianz...") Inhaltsverzeichnis Vorwort... 2 Zum Einstieg... 3 1 Zufallsvariable X, Erwartungswert E(X), Varianz V(X) 1.1 Zufallsvariable oder Zufallsgröße... 5 1.2 Erwartungswert und Varianz... 7 2 Wahrscheinlichkeitsverteilungen
Inhaltsverzeichnis Vorwort... 2 Zum Einstieg... 3 1 Zufallsvariable X, Erwartungswert E(X), Varianz V(X) 1.1 Zufallsvariable oder Zufallsgröße... 5 1.2 Erwartungswert und Varianz... 7 2 Wahrscheinlichkeitsverteilungen
Kategoriale Daten. Johannes Hain. Lehrstuhl für Mathematik VIII Statistik 1/17
 Johannes Hain Lehrstuhl für Mathematik VIII Statistik 1/17 Übersicht Besitzen die Daten, die statistisch ausgewertet werden sollen, kategoriales Skalenniveau, unterscheidet man die folgenden Szenarien:
Johannes Hain Lehrstuhl für Mathematik VIII Statistik 1/17 Übersicht Besitzen die Daten, die statistisch ausgewertet werden sollen, kategoriales Skalenniveau, unterscheidet man die folgenden Szenarien:
Mathematische und statistische Methoden II
 Statistik & Methodenlehre e e Prof. Dr. G. Meinhardt 6. Stock, Wallstr. 3 (Raum 06-206) Sprechstunde jederzeit nach Vereinbarung und nach der Vorlesung. Mathematische und statistische Methoden II Dr. Malte
Statistik & Methodenlehre e e Prof. Dr. G. Meinhardt 6. Stock, Wallstr. 3 (Raum 06-206) Sprechstunde jederzeit nach Vereinbarung und nach der Vorlesung. Mathematische und statistische Methoden II Dr. Malte
Tumorregister München
 Tumorregister München Inzidenz und Mortalität Auswahlmatrix Homepage English ICD- C92: Myeloische Leukämie Survival Diagnosejahr 1988-1997 1998-14 Patienten 436 3 653 Erkrankungen 436 3 667 Fälle in Auswertung
Tumorregister München Inzidenz und Mortalität Auswahlmatrix Homepage English ICD- C92: Myeloische Leukämie Survival Diagnosejahr 1988-1997 1998-14 Patienten 436 3 653 Erkrankungen 436 3 667 Fälle in Auswertung
Zweiseitiger Test für den unbekannten Mittelwert µ einer Normalverteilung bei unbekannter Varianz
 Grundlage: Zweiseitiger Test für den unbekannten Mittelwert µ einer Normalverteilung bei unbekannter Varianz Die Testvariable T = X µ 0 S/ n genügt der t-verteilung mit n 1 Freiheitsgraden. Auf der Basis
Grundlage: Zweiseitiger Test für den unbekannten Mittelwert µ einer Normalverteilung bei unbekannter Varianz Die Testvariable T = X µ 0 S/ n genügt der t-verteilung mit n 1 Freiheitsgraden. Auf der Basis
Tumorregister München
 Tumorregister München Inzidenz und Mortalität Auswahlmatrix Homepage English ICD-1 C91.: Akute lymphat. Leukämie Survival Diagnosejahr 1988-1997 1998-14 Patienten 179 752 Erkrankungen 179 752 Fälle in
Tumorregister München Inzidenz und Mortalität Auswahlmatrix Homepage English ICD-1 C91.: Akute lymphat. Leukämie Survival Diagnosejahr 1988-1997 1998-14 Patienten 179 752 Erkrankungen 179 752 Fälle in
3 Bedingte Wahrscheinlichkeit, Unabhängigkeit
 3 Bedingte Wahrscheinlichkeit, Unabhängigkeit Bisher : (Ω, A, P) zur Beschreibung eines Zufallsexperiments Jetzt : Zusatzinformation über den Ausgang des Experiments, etwa (das Ereignis) B ist eingetreten.
3 Bedingte Wahrscheinlichkeit, Unabhängigkeit Bisher : (Ω, A, P) zur Beschreibung eines Zufallsexperiments Jetzt : Zusatzinformation über den Ausgang des Experiments, etwa (das Ereignis) B ist eingetreten.
Nonparametric estimation of the probability of default 1
 probability of default 1 probability of default 2 probability of default 3 Fixierte Studienzeit Fixierter Anteil an Toten (z.b. 80%) Fixierte Beobachtungsz. A B C D E 10 20 30 A B C D E 10 20 35 A B C
probability of default 1 probability of default 2 probability of default 3 Fixierte Studienzeit Fixierter Anteil an Toten (z.b. 80%) Fixierte Beobachtungsz. A B C D E 10 20 30 A B C D E 10 20 35 A B C
Willkommen zur Vorlesung Statistik (Master)
") Willkommen zur Vorlesung Statistik (Master) Thema dieser Vorlesung: Verteilungsfreie Verfahren Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften
Willkommen zur Vorlesung Statistik (Master) Thema dieser Vorlesung: Verteilungsfreie Verfahren Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften
Kommentierter SPSS-Ausdruck zur logistischen Regression
 Daten: POK V AG 3 (POKV_AG3_V07.SAV) Kommentierter SPSS-Ausdruck zur logistischen Regression Fragestellung: Welchen Einfluss hat die Fachnähe und das Geschlecht auf die interpersonale Attraktion einer
Daten: POK V AG 3 (POKV_AG3_V07.SAV) Kommentierter SPSS-Ausdruck zur logistischen Regression Fragestellung: Welchen Einfluss hat die Fachnähe und das Geschlecht auf die interpersonale Attraktion einer
Tumorregister München
 Tumorregister München Inzidenz und Mortalität Auswahlmatrix Homepage English ICD-1 C9: Plasmozytom Survival Diagnosejahr 1988-1997 1998-14 Patienten 445 3 754 Erkrankungen 445 3 757 Fälle in Auswertung
Tumorregister München Inzidenz und Mortalität Auswahlmatrix Homepage English ICD-1 C9: Plasmozytom Survival Diagnosejahr 1988-1997 1998-14 Patienten 445 3 754 Erkrankungen 445 3 757 Fälle in Auswertung
Definition 2.1 Der Erwartungswert einer diskreten Zufallsvariablen mit Wahrscheinlichkeitsfunktion
 Kapitel 2 Erwartungswert 2.1 Erwartungswert einer Zufallsvariablen Definition 2.1 Der Erwartungswert einer diskreten Zufallsvariablen mit Wahrscheinlichkeitsfunktion È ist definiert als Ü ÜÈ Üµ Für spätere
Kapitel 2 Erwartungswert 2.1 Erwartungswert einer Zufallsvariablen Definition 2.1 Der Erwartungswert einer diskreten Zufallsvariablen mit Wahrscheinlichkeitsfunktion È ist definiert als Ü ÜÈ Üµ Für spätere
Hypothesen: Fehler 1. und 2. Art, Power eines statistischen Tests
 ue biostatistik: hypothesen, fehler 1. und. art, power 1/8 h. lettner / physik Hypothesen: Fehler 1. und. Art, Power eines statistischen Tests Die äußerst wichtige Tabelle über die Zusammenhänge zwischen
ue biostatistik: hypothesen, fehler 1. und. art, power 1/8 h. lettner / physik Hypothesen: Fehler 1. und. Art, Power eines statistischen Tests Die äußerst wichtige Tabelle über die Zusammenhänge zwischen
EIN AUSWERTUNGSTOOL FÜR DIE EXPLORATIVE ANALYSE VON ÜBERLEBENSZEITEN
 114 1. Konferenz der SAS-Benutzer in Forschung und Entwicklung, Humboldt-Universität zu Berlin, 20./21.02.1997 EIN AUSWERTUNGSTOOL FÜR DIE EXPLORATIVE ANALYSE VON ÜBERLEBENSZEITEN Hans-Peter Altenburg
114 1. Konferenz der SAS-Benutzer in Forschung und Entwicklung, Humboldt-Universität zu Berlin, 20./21.02.1997 EIN AUSWERTUNGSTOOL FÜR DIE EXPLORATIVE ANALYSE VON ÜBERLEBENSZEITEN Hans-Peter Altenburg
Rentenbeginn und Lebenserwartung
 Rentenbeginn und Lebenserwartung Sebastian Jeworutzki 23.04.2009 Sebastian Jeworutzki Rentenbeginn und Lebenserwartung 1/31 Gliederung 1 Einleitung 2 Informationen zum SOEP 3 Das Kalendarium des SOEP Das
Rentenbeginn und Lebenserwartung Sebastian Jeworutzki 23.04.2009 Sebastian Jeworutzki Rentenbeginn und Lebenserwartung 1/31 Gliederung 1 Einleitung 2 Informationen zum SOEP 3 Das Kalendarium des SOEP Das
Statistischer Rückschluss und Testen von Hypothesen
 Statistischer Rückschluss und Testen von Hypothesen Statistischer Rückschluss Lerne von der Stichprobe über Verhältnisse in der Grundgesamtheit Grundgesamtheit Statistischer Rückschluss lerne aus Analyse
Statistischer Rückschluss und Testen von Hypothesen Statistischer Rückschluss Lerne von der Stichprobe über Verhältnisse in der Grundgesamtheit Grundgesamtheit Statistischer Rückschluss lerne aus Analyse
Seminar zur Energiewirtschaft:
 Seminar zur Energiewirtschaft: Ermittlung der Zahlungsbereitschaft für erneuerbare Energien bzw. bessere Umwelt Vladimir Udalov 1 Modelle mit diskreten abhängigen Variablen 2 - Ausgangssituation Eine Dummy-Variable
Seminar zur Energiewirtschaft: Ermittlung der Zahlungsbereitschaft für erneuerbare Energien bzw. bessere Umwelt Vladimir Udalov 1 Modelle mit diskreten abhängigen Variablen 2 - Ausgangssituation Eine Dummy-Variable
Frailty Models in Survival Analysis
 Aus dem Institut für Medizinische Epidemiologie, Biometrie und Informatik (Direktor: Prof. Dr. Johannes Haerting) Frailty Models in Survival Analysis Habilitation zur Erlangung des akademischen Grades
Aus dem Institut für Medizinische Epidemiologie, Biometrie und Informatik (Direktor: Prof. Dr. Johannes Haerting) Frailty Models in Survival Analysis Habilitation zur Erlangung des akademischen Grades
4.2 Grundlagen der Testtheorie
 4.2 Grundlagen der Testtheorie Januar 2009 HS MD-SDL(FH) Prof. Dr. GH Franke Kapitel 5 Vertiefung: Reliabilität Kapitel 5 Vertiefung: Reliabilität 5.1 Definition Die Reliabilität eines Tests beschreibt
4.2 Grundlagen der Testtheorie Januar 2009 HS MD-SDL(FH) Prof. Dr. GH Franke Kapitel 5 Vertiefung: Reliabilität Kapitel 5 Vertiefung: Reliabilität 5.1 Definition Die Reliabilität eines Tests beschreibt
Bivariate Zusammenhänge
 Bivariate Zusammenhänge Tabellenanalyse: Kreuztabellierung und Kontingenzanalyse Philosophische Fakultät Institut für Soziologie Berufsverläufe und Berufserfolg von Hochschulabsolventen Dozent: Mike Kühne
Bivariate Zusammenhänge Tabellenanalyse: Kreuztabellierung und Kontingenzanalyse Philosophische Fakultät Institut für Soziologie Berufsverläufe und Berufserfolg von Hochschulabsolventen Dozent: Mike Kühne
Algorithmen und Datenstrukturen
 Algorithmen und Datenstrukturen Dipl. Inform. Andreas Wilkens 1 Organisatorisches Freitag, 05. Mai 2006: keine Vorlesung! aber Praktikum von 08.00 11.30 Uhr (Gruppen E, F, G, H; Vortestat für Prototyp)
Algorithmen und Datenstrukturen Dipl. Inform. Andreas Wilkens 1 Organisatorisches Freitag, 05. Mai 2006: keine Vorlesung! aber Praktikum von 08.00 11.30 Uhr (Gruppen E, F, G, H; Vortestat für Prototyp)
SPSS V Gruppenvergleiche ( 2 Gruppen) abhängige (verbundene) Stichproben
 abhängige (verbundene) Stichproben") SPSS V Gruppenvergleiche ( 2 Gruppen) abhängige (verbundene) Stichproben ÜBERSICHT: Testverfahren bei abhängigen (verbundenen) Stichproben parametrisch nicht-parametrisch 2 Gruppen t-test bei verbundenen
SPSS V Gruppenvergleiche ( 2 Gruppen) abhängige (verbundene) Stichproben ÜBERSICHT: Testverfahren bei abhängigen (verbundenen) Stichproben parametrisch nicht-parametrisch 2 Gruppen t-test bei verbundenen
Survival Analysis (Modul: Lebensdaueranalyse)
") Survival Analysis (Modul: Lebensdaueranalyse) ROLAND RAU Universität Rostock, Sommersemester 2014 22. April 2014 c Roland Rau Survival Analysis 1 / 23 Erinnerung: Prüfungsmodalitäten Nr. Termine evtl.
Survival Analysis (Modul: Lebensdaueranalyse) ROLAND RAU Universität Rostock, Sommersemester 2014 22. April 2014 c Roland Rau Survival Analysis 1 / 23 Erinnerung: Prüfungsmodalitäten Nr. Termine evtl.
Inhaltsverzeichnis. Vorwort
 V Vorwort XI 1 Zum Gebrauch dieses Buches 1 1.1 Einführung 1 1.2 Der Text in den Kapiteln 1 1.3 Was Sie bei auftretenden Problemen tun sollten 2 1.4 Wichtig zu wissen 3 1.5 Zahlenbeispiele im Text 3 1.6
V Vorwort XI 1 Zum Gebrauch dieses Buches 1 1.1 Einführung 1 1.2 Der Text in den Kapiteln 1 1.3 Was Sie bei auftretenden Problemen tun sollten 2 1.4 Wichtig zu wissen 3 1.5 Zahlenbeispiele im Text 3 1.6
Mathematische und statistische Methoden I
 Prof. Dr. G. Meinhardt 6. Stock, Wallstr. 3 (Raum 06-206) Sprechstunde jederzeit nach Vereinbarung und nach der Vorlesung. Mathematische und statistische Methoden I Dr. Malte Persike persike@uni-mainz.de
Prof. Dr. G. Meinhardt 6. Stock, Wallstr. 3 (Raum 06-206) Sprechstunde jederzeit nach Vereinbarung und nach der Vorlesung. Mathematische und statistische Methoden I Dr. Malte Persike persike@uni-mainz.de
4 Diskrete Wahrscheinlichkeitsverteilungen
 4 Diskrete Wahrscheinlichkeitsverteilungen 4.1 Wahrscheinlichkeitsräume, Ereignisse und Unabhängigkeit Definition: Ein diskreter Wahrscheinlichkeitsraum ist ein Paar (Ω, Pr), wobei Ω eine endliche oder
4 Diskrete Wahrscheinlichkeitsverteilungen 4.1 Wahrscheinlichkeitsräume, Ereignisse und Unabhängigkeit Definition: Ein diskreter Wahrscheinlichkeitsraum ist ein Paar (Ω, Pr), wobei Ω eine endliche oder
Standardisierte Vorgehensweisen und Regeln zur Gewährleistung von: Eindeutigkeit Schlussfolgerungen aus empirischen Befunden sind nur dann zwingend
 Standardisierte Vorgehensweisen und Regeln zur Gewährleistung von: Eindeutigkeit Schlussfolgerungen aus empirischen Befunden sind nur dann zwingend oder eindeutig, wenn keine alternativen Interpretationsmöglichkeiten
Standardisierte Vorgehensweisen und Regeln zur Gewährleistung von: Eindeutigkeit Schlussfolgerungen aus empirischen Befunden sind nur dann zwingend oder eindeutig, wenn keine alternativen Interpretationsmöglichkeiten
Kursthemen 12. Sitzung. Spezielle Verteilungen: Warteprozesse. Spezielle Verteilungen: Warteprozesse
 Kursthemen 12. Sitzung Folie I - 12-1 Spezielle Verteilungen: Warteprozesse Spezielle Verteilungen: Warteprozesse A) Die Geometrische Verteilung (Folien 2 bis 7) A) Die Geometrische Verteilung (Folien
Kursthemen 12. Sitzung Folie I - 12-1 Spezielle Verteilungen: Warteprozesse Spezielle Verteilungen: Warteprozesse A) Die Geometrische Verteilung (Folien 2 bis 7) A) Die Geometrische Verteilung (Folien
Ereignisanalyse. Sterbetafel-Methode Kaplan-Meier-Verfahren Cox-Regression. Kurt Holm. Almo Statistik-System
 Ereignisanalyse Sterbetafel-Methode Kaplan-Meier-Verfahren Cox-Regression Kurt Holm Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2013 1 Im Text wird häufig auf das
Ereignisanalyse Sterbetafel-Methode Kaplan-Meier-Verfahren Cox-Regression Kurt Holm Almo Statistik-System www.almo-statistik.de holm@almo-statistik.de kurt.holm@jku.at 2013 1 Im Text wird häufig auf das
Chi-Quadrat Verfahren
 Chi-Quadrat Verfahren Chi-Quadrat Verfahren werden bei nominalskalierten Daten verwendet. Die einzige Information, die wir bei Nominalskalenniveau zur Verfügung haben, sind Häufigkeiten. Die Quintessenz
Chi-Quadrat Verfahren Chi-Quadrat Verfahren werden bei nominalskalierten Daten verwendet. Die einzige Information, die wir bei Nominalskalenniveau zur Verfügung haben, sind Häufigkeiten. Die Quintessenz
Kaplan-Meier und Nelson-Aalen Schätzer II Konsistenz und Vertrauensintervall
 Kaplan-Meier und Nelson-Aalen Schätzer II Konsistenz und Vertrauensintervall Christian Reichlin Michael Stadelmann 29. Mai 26 Statistik-Seminar bei Frau Prof. Dr. Sara van de Geer, Herrn Dr. Prof. Barbour,
Kaplan-Meier und Nelson-Aalen Schätzer II Konsistenz und Vertrauensintervall Christian Reichlin Michael Stadelmann 29. Mai 26 Statistik-Seminar bei Frau Prof. Dr. Sara van de Geer, Herrn Dr. Prof. Barbour,
Mathematische und statistische Methoden II
 Sprechstunde jederzeit nach Vereinbarung und nach der Vorlesung Wallstr. 3, 6. Stock, Raum 06-206 Mathematische und statistische Methoden II Dr. Malte Persike persike@uni-mainz.de lordsofthebortz.de lordsofthebortz.de/g+
Sprechstunde jederzeit nach Vereinbarung und nach der Vorlesung Wallstr. 3, 6. Stock, Raum 06-206 Mathematische und statistische Methoden II Dr. Malte Persike persike@uni-mainz.de lordsofthebortz.de lordsofthebortz.de/g+
1 Grundprinzipien statistischer Schlußweisen
 Grundprinzipien statistischer Schlußweisen - - Grundprinzipien statistischer Schlußweisen Für die Analyse zufallsbehafteter Eingabegrößen und Leistungsparameter in diskreten Systemen durch Computersimulation
Grundprinzipien statistischer Schlußweisen - - Grundprinzipien statistischer Schlußweisen Für die Analyse zufallsbehafteter Eingabegrößen und Leistungsparameter in diskreten Systemen durch Computersimulation