Rechnerstrukturen: VO, WS 2012/13 Teil 2 Kapitel 5 Kapitel 7
|
|
|
- Georg Frei
- vor 8 Jahren
- Abrufe
Transkript
1 Rechnerstrukturen: VO, WS 2012/13 Teil 2 Kapitel 5 Kapitel 7 Diese Ausarbeitung habe ich mithilfe der Vorlesungsfolien sowie der deutschen Fassung des Buches Computer Organization And Design von David A. Patterson und John L. Hennessy gemacht. Sie ist zwar sehr umfangreich, sollte aber meiner Meinung nach alle wichtigen Themen der Vorlesung behandeln. Trotzdem sind Fehler und Unvollständigkeiten möglich. Da ich die meisten Informationen aus dem Buch habe, bin ich aber zuversichtlich, dass das meiste stimmen sollte ;-) Allerdings habe ich nicht alles von den Folien ausgearbeitet. Vernachlässigt werden in dieser Ausarbeitung unter anderem Graphiken bzw. deren Erklärung (vgl. dazu besonders die Folien oder auch das Buch) Rechenbeispiele (vgl. dazu besonders die Folien oder auch das Buch) Kapitel 4 habe ich nicht vollständig ausgearbeitet (in diesem Kapitel befinden sich in den Folien auch einige Graphiken dazu also auch Folien + Buch vergleichen) Weitere Unvollständigkeiten sind möglich. Ich habe mit dieser Ausarbeitung jedenfalls für die Prüfung bei Prof. Grünbacher gelernt und eine Zwei bekommen :-) Autorin: Quellen: Michaela e @student.tuwien.ac.at Rechnerorganisation und Rechnerentwurf: Die Hardware/Software-Schnittstelle von David A. Patterson und John L. Hennessy Folien von Prof. Herbert Grünbacher 1
 Allerdings habe ich nicht alles von den Folien ausgearbeitet.")
2 Chapter 5: Large and Fast Exploiting Memory Hierarchy Es gibt unterschiedliche Arten von Speichern: Static Random Access Memory (SRAM) o 0.5ns 2.5ns, $2000 $5000 per GB Dynamic Random Access Memory (DRAM) o 50ns 70ns, $20 $75 per GB Magnetic disk o 5ms 20ms, $0.20 $2 per GB Die Memory-Hierarchie Die Speicherhierarchie ist eine Struktur, die mehrere Speicherebenen verwendet; je größer die Distanz zur CPU wird, desto größer werden die Speicher und desto länger ist die Zugriffszeit. Man sollte das Prinzip der Lokalität ausnutzen, um dem User so viel Speicher wie verfügbar ist in der billigsten Technologie mit der Geschwindigkeit der schnellsten Technologie zur Verfügung zu stellen. 2

3 Geographische Distanzen (Vergleichsbeispiel aus dem Alltag) Das Prinzip der Lokalität Programme greifen zu einem bestimmten Zeitpunkt immer nur auf einen kleinen Teil ihres Adressraums zu. Anhand verschiedener Aspekte von Lokalität lassen sich Vermutungen aufstellen, welche Adressbereiche vermutlich (häufig, bald wieder, etc.) adressiert werden. Temporäre Lokalität (Temporal locality) o Items, die erst kürzlich adressiert wurden, werden wahrscheinlich bald wieder adressiert werden o z.b. Instructions in einer Schleife, induction variables (Variablen, die um einen fixen Wert erhöht oder gesenkt werden Räumliche Lokalität (Spatial locality) o Items, die nahe zu solchen liegen, die erst kürzlich adressiert wurden, werden wahrscheinlich auch bald adressiert o z.b. sequentieller Instruction Zugriff, Array-Daten Das Prinzip der Lokalität kann nun folgendermaßen vorteilhaft genutzt werden: eine Memory-Hierarchie aufbauen auf der Disk muss alles gespeichert werden die Items, auf die erst kürzlich zugegriffen wurde (und alle naheliegenden) werden von der Disk in den kleineren DRAM Memory kopiert Main memory die Items, deren Zugriff am wenigstens weit zurückliegt (und alle naheliegenden) werden vom DRAM in den kleineren SRAM Memory kopiert Cache memory (direkt bei der CPU) Ein Block (auch Zeile genannt) ist die kleinste Informationseinheit, die in der zweistufigen Hierarchie vorhanden oder nicht vorhanden sein kann. Ein Block kann aus mehreren Words bestehen. Wenn die Daten, auf die zugegriffen werden soll, im oberen Level vorhanden sind, spricht man von einem Hit. Die Hit Rate ist dabei die Trefferrate, also der Anteil der 3

4 Speicherzugriffe, bei denen der gesuchte Block in einer Ebene der Speicherhierarchie (z.b. in einem Cache) gefunden wird. (Hit Ratio = hits / accesses; ratio = Verhältnis, Anteil) Wenn die Daten, auf die zugegriffen werden soll, nicht vorhanden sind, spricht man von einem Miss. Die Miss Rate ist dabei die Fehlzugriffsrate, also der Anteil an Speicherzugriffen, bei denen der gesuchte Block nicht innerhalb einer Ebene der Speicherhierarchie gefunden wird. (Miss Ratio = misses / accesses = 1 hit ratio) Hat ein Miss stattgefunden, muss der gesuchte Block aus einem unteren Level in das höhere kopiert werden. Dann kann auf die Daten im höheren Level zugegriffen werden. Unter Hit Time (Zugriffszeit) versteht man die Zeit für den Zugriff auf eine Ebene der Speicherhierarchie, einschließlich der Zeit, die benötigt wird, um festzustellen, ob der Zugriff ein Treffer oder ein Fehlzugriff ist. Unter Miss Penalty (Fehlzugriffsaufwand) versteht man die Zeit, die benötigt wird, um einen Block von einer unteren Ebene in eine höhere Ebene der Speicherhierarchie zu laden. Diese beinhaltet die Zeit für die Übertragung und das Einfügen des Blocks in die höhere Ebene, auf der der Fehlzugriff stattgefunden hat, sowie die Zeit für den Zugriff auf den block durch den Prozessor. Der Cache Memory Der Cache Memory ist jener Level in der Speicherhierarchie, der der CPU am nächsten ist. 4
 Hat ein Miss stattgefunden, muss der gesuchte Block aus einem unteren Level in das höhere kopiert werden.")
5 Direct Mapped Cache (Direkt abgebildeter Cache) Beim mapped cache wird jede Speicheradresse auf genau eine Position im Cache abgebildet. Die Adresse bestimmt dabei die Stelle im Cache. (Block Adresse) modulo (Anzahl der Blocks im Cache Die Anzahl der Blöcke ist ein Vielfaches von 2. Die untersten log 2 Bits werden für die Bestimmung der Adresse verwendet. d.h. ein 8-Blöcke großer Cache verwendet z.b. die untersten 3 Bits der Adresse. Doch wie weiß man jetzt, welcher Block wirklich an einer bestimmten Cache Position gespeichert ist? Anhand der Adresse kennen wir ja nur die untersten Bits. Um eine Lösung für dieses Problem zu finden, wir der Cache um eine Menge von Tags erweitert. Ein Tag ist ein Feld in einer Tabelle, die für eine Ebene der Speicherhierarchie verwendet wird. Dieses Feld enthält die Adressinformation, die man benötigt, um zu erkennen, ob der zugehörige Block in der entsprechenden Hierarchieebene einem angeforderten Wort entspricht. In diesem Fall enthalten die Tags die notwendige Adressinformationen, um zu erkennen, ob ein Wort im Cache dem angeforderten Wort entspricht. Der Tag muss nur den oberen Teil der Adresse enthalten, der den Bits entspricht, die nicht als Index für den Cache verwendet werden. Zusätzlich gibt es noch das Valid Bit (auch Gültigkeits-Bit). Das ist ein Feld in den Tabellen einer Speicherhierarchie, das angibt, ob der zugehörige Block gültige Daten enthält. Ist das Valid Bit = 1, bedeutet das, dass gültige Daten in diesem Block gespeichert sind. Ist es 0, sind keine gültigen Daten gespeichert. Der Default-Wert für dieses Bit ist 0. 5

6 Ein Cache Beispiel 8-Blocks, 1 Word pro Block, direct mapped Initial State (Anfangszustand) > > > 6

7 Beispiel: Large Block Size (Beispiel auch im Buch, S. 455, deutsche Version) Überlegungen zur Block-Größe Größere Blöcke sollten die Miss Rate verringern. Grund dafür ist die räumliche Lokalität (spatial locality) da die Blöcke größer sind, kann auch mehr Information in den Cache geladen werden. Allerdings führen große Blöcke dazu, dass weniger von ihnen im Cache Platz haben. Es kommt es zu einem stärkeren Wettbewerb und somit steigt die Miss Rate (in einem fixed size cache). Weiters steigt durch eine größere Blockgröße auch die Miss Penalty (Dauer, bis ein Block auch einer unteren Ebene nachgeladen wird und dann vom Prozessor verwendet werden kann). Grund dafür ist, dass das Laden größerer Blöcke natürlich länger dauert. Dieser negative Effekt könnte die Vorteile einer durch größere Blöcke reduzierten Miss Rate überwiegen. Cache Misses Findet ein Cache Hit statt, kann die CPU normal ihre Arbeit fortsetzen. Kommt es jedoch zu einem Cache Miss, muss die CPU Pipeline gestallt (abgedrosselt) werden. Der Block muss vom nächsten Level der Hierarchie geholt werden (fetch). Nach einem Instruction Cache Miss muss der Instruction Fetch erneut gestartet werden. Nach einem Data Cache Miss muss der Datenzugriff abgeschlossen werden. Schreibverfahren Daten, die im Cache existieren, sind natürlich auch in den Ebenen darunter gespeichert. Wenn nun Information im Cache verändert wird (on data-write hit), gibt es unterschiedliche Möglichkeiten, diese Information auch in den unteren Levels auf den aktuellen Stand zu bringen, damit der Cache und der Memory nicht inkonsistent sind. 7
.")
8 Write-Through Bei einem Write-Through wird immer, wenn Information im Cache verändert wird, auch der Memory upgedated. Der Nachteil daran ist allerdings, dass Schreibzugriffe dadurch länger dauern. Eine Lösung dafür ist ein sogenannter write buffer. Dieser ist ein FIFO (first in first out) Puffer, der die Daten aufnimmt, die drauf warten, dass sie in den Speicher geschrieben werden. Die CPU kann sofort ihre Arbeit fortsetzen, die Daten werden aus dem write buffer nach und nach in den Speicher geschrieben. Zu einem Stall kommt es nur dann, wenn der write buffer bereits voll ist. Write(Copy)-Back Eine Alternative zur Write-Through-Technik ist Write(Copy)-Back. Dabei wird bei einem data-write hit nur der Block im Cache upgedated. Zusätzlich wird vermerkt, ob der Block verändert wurde (man sagt auch, der Blick ist dirty). In diesem Zusammenhang gibt es das dirty bit. Ist dieses gesetzt, also 1, zeigt es an, dass ein Block verändert wurde. Die veränderte Information wird erst dann in den Memory übernommen, wenn ein solcher dirty Block ausgetauscht wird. Auch hier kann ein write buffer verwendet werden. Dieser macht es möglich, dass der Block, der den dirty block ersetzt, zuerst gelesen werden kann. Write Allocation Wenn es zu einem write miss kommt, ist (in einem write-through Cache) die übliche Methode, einen Block im Cache zu reservieren. Das wird auch als write allocate bezeichnet. Der Block wird aus dem Speicher geladen, und dann wird der entsprechende Teil des Blocks überschrieben. Eine alternative Strategie ist es, den Teil des Bocks im Speicher zu aktualisieren, ihn aber nicht in den Cache zu stellen, auch als no write allocate bezeichnet. Die Motivvation für diese Schemata ist die Beobachtung, dass Programme manchmal ganze Datenblöcke schreiben, bevor sie diese lesen (z.b. bei der Initialisierung). Für einen write-back Cache ist es komplizierter, da hier Information im Cache verändert worden sein kann. Dadurch könnte es passieren, dass wir einen Block überschreiben, der nicht auf der nächst niedrigeren Speicherebene gesichert ist. Design des Speichersystems zur Unterstützung von Caches Cache-Fehlzugriffe werden aus dem Hauptspeicher bedient, der aus DRAM-Bausteinen aufgebaut ist. Es ist zwar schwierig, die Latenz (Verzögerung; latent: unsichtbar, versteckt, unterschwellig) zu reduzieren, die anfällt, bis das erste Wort aus dem Speicher geholt wird, aber die Miss Penalty (Fehlzugriffsaufwand) kann reduziert werden, in dem die Bandbreite vom Speicher zum Cache erhöht wird. Dadurch kann man größere Blöcke verwenden und trotzdem einen geringeren Fehlzugriffsaufwand haben. 8
-Back Eine Alternative zur Write-Through-Technik ist Write(Copy)-Back. Dabei wird bei einem data-write hit nur der Block im Cache upgedated.")
9 Cache Leistung messen und verbessern Die CPU Time setzt sich aus verschiedenen Komponenten zusammen. aus den Programm Execution Cycles (Zyklen zur Programmausführung) o hier ist die hit time inkludiert aus den Memory Stall Cycles (Zyklen bei einer Verzögerung im Speicher) o die Stalls entstehen vor allem durch Cache Misses Für die Performance spielt auch die Hit Time eine wichtige Rolle. Die Average Memory Access Time (AMAT) lässt sich folgendermaßen berechnen: Associative Caches Bei assoziativen Caches lassen sich verschiedene Arten unterscheiden: Fully associative o ein Block kann hier an jeder belieben Position im Speicher platziert werden o wird ein Block gesucht, müssen auch alle Einträge durchsucht werden o ein Comparator für jeden Cache-Eintrag ist notwendig, was allerdings teuer ist n-way set associative o jedes Set im Cache enthält n Einträge o Die Blocknummer bestimmt, welches Set gewählt wird (Block Number) modulo (Anzahl der Sets im Cache) o Um einen Eintrag zu finden, müssen alle Einträge in einem Set durchsucht werden o es werden n Comparators benötigt, was weniger teuer ist Höhere Assoziativität verringert die Miss Rate. but with diminishing (vermindert) returns 9
 lässt sich folgendermaßen berechnen: Associative Caches Bei assoziativen Caches lassen sich verschiedene Arten unterscheiden: Fully associative o ein Block kann")

10 Beispiel für einen assoziativen Cache 10
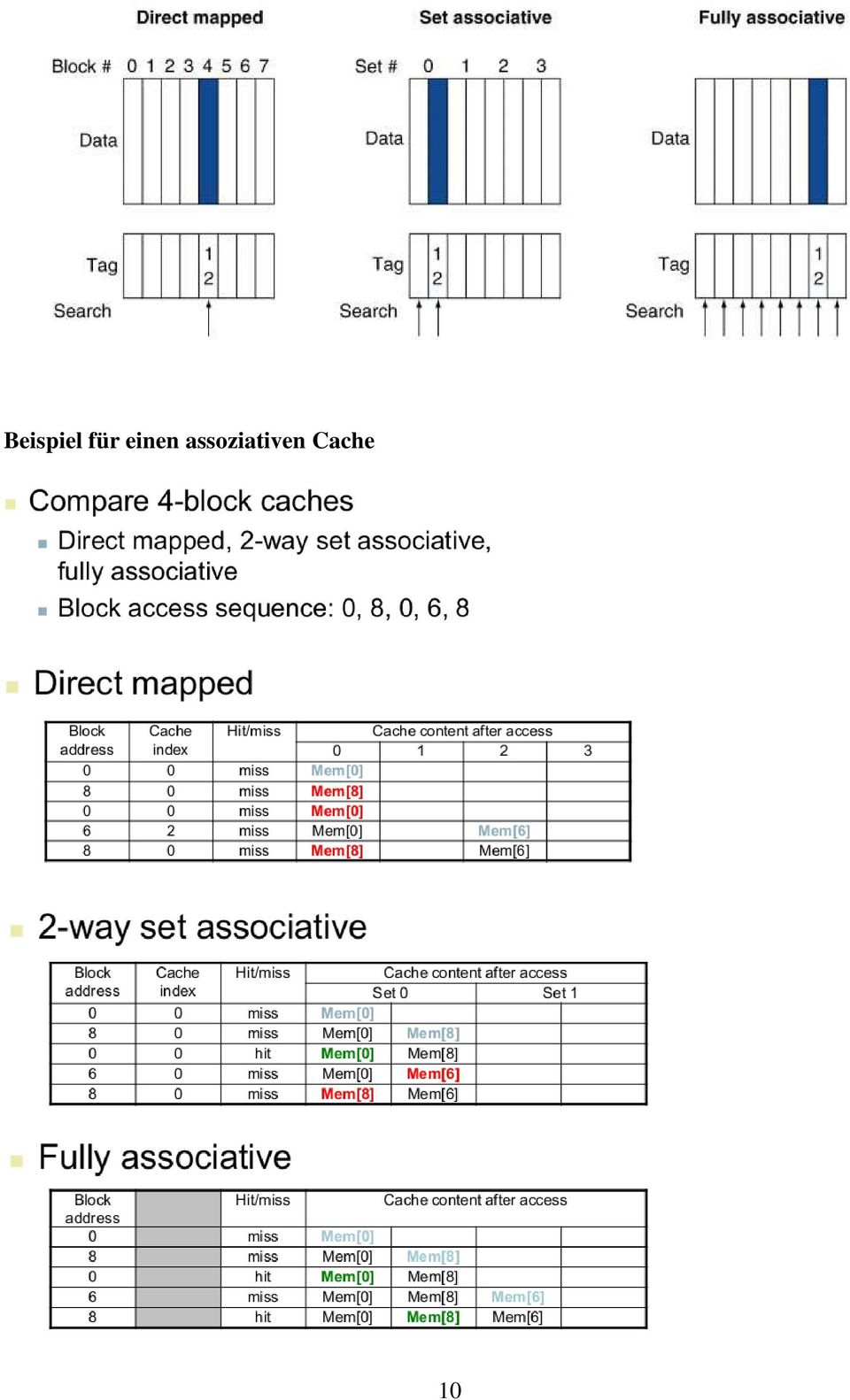
11 Replacement (Austausch) Richtlinien Im Direct Mapped Cache gibt es keine Auswahl, welcher Block ausgetauscht werden soll, da jeder Block nur an eine ganze bestimmte Position im Cache geladen werden kann. Im Set Associative Cache werden ungültige (non-valid) Einträge bevorzugt, falls es solche gibt. Ansonsten wird aus den Einträgen in einem Set ausgewählt. Ein Prinzip der Auswahl kann das Least-recently used Prinzip (LRU) sein. Dabei wird jener Block gewählt, auf den für die längste Zeit nicht mehr zugegriffen wurde. Ein weiteres Prinzip ist das Random Prinzip. Dabei wird ein beliebiger Block zum Austausch ausgewählt. Die Performance ist hierbei bei hoher Assoziativität die gleiche wie mit dem LRU Prinzip. Multilevel Caches Unter Multilevel Caches versteht man eine Speicherhierarchie mit mehreren Cache-Ebenen (statt der Verwendung nur eines Caches und eines Hauptspeichers). Um die Lücke zwischen den schnellen Taktraten moderner Prozessoren und der relativ langen Zugriffszeit auf DRAMs weiter zu schließen, unterstützen viele Mikroprozessoren eine zusätzliche Cache-Ebene. Dieser Cache auf zweiter Ebene, der sich normalerweise auf demselben Chip befindet, wird herangezogen, wenn im primären Cacche ein Fehlzugriff erfolgt. Wenn dieser sekundäre Cache die gewünschten Daten enthält, ist der Fehlzugriffsaufwand für den primären Cache im Wesentlichen die Zugriffszeit des sekundären Caches, was sehr viel kleiner sein kann als die Zugriffszeit auf den Hauptspeicher. Enthalten weder der primäre noch der sekundäre Cache die Daten, ist ein Hauptspeicherzugriff erforderlich und es entsteht ein höherer Fehlgriffsaufwand (miss penalty). Die beiden Caches unterscheiden sich. Der Primary Cache, der direkt bei der CPU ist, ist kleiner als ein gewöhnlicher Cache, dafür aber schneller. Die L-1 Block Size ist auch kleiner als die L-2 Block Size. Der Level-2 Cache (sekundärer Cache) soll bei Misses im primären Cache Vorteile bringen. Er ist größer als ein normaler Cache, dafür langsamer als der primäre Cache. Allerdings ist er immer noch schneller als der Hauptspeicher. Tritt auch im Level-2- Cache ein Miss auf, muss sich der Hauptspeicher darum kümmern. Manche Systeme haben sogar einen L-3 Cache. Die Cache-Struktur mit zwei Ebenen erlaubt, dass sich der Entwurf des primären Caches auf die Minimierung der Trefferzeit konzentriert, um einen kürzeren Taktzyklus oder weniger Pipeline-Stufen zu erzielen. Der Entwurf des sekundären Caches hingegen konzentriert sich auf die Miss Rat, um die Miss Penalty für lange Speicherzugriffe zu reduzieren. Der Fehlerzugriffsaufwand wird durch den sekundären Cache für den primären Cache deutlich reduziert. 11

12 Virtual Memory Der Hauptspeicher fungiert sozusagen als Cache für den Sekundärspeicher (die Disk). Programme teilen sich den Hauptspeicher. Dabei steht jedem Programm ein privater sogenannter virtueller Adressraum zur Verfügung, der häufig verwendeten Code und häufig verwendete Daten des Programms speichert. Jeder Adressraum jedes Programms muss vor fremden Zugriffen geschützt sein. Der Adressraum eines Programms teilt sich in sogenannte Pages auf, die alle eine fixe Größe haben. Die Start-Position jeder Page (im Main Memory oder im Secondary Memory) ist in der Page Table des Programms enthalten. Durch eine Kombination aus Hardware und Software kann eine virtuelle Adresse in eine physische Adresse übersetzt werden. Jede Anfrage an den Hauptspeicher benötigt also erst eine Übersetzung der Adresse vom virtuellen Adressraum in den physischen Adressraum. Ein Miss im virtuellen Memory wird page fault genannt. Page Fault Penalty Wenn es zu einem Page Fault kommt, muss die Page von der Disk geholt werden. Das benötigt Millionen von Clock Cycles und wird vom Betriebssystem gehandhabt. Man kann versuchen, die Page Fault Rate zu minimieren, indem man Fully Associative Placement im Speicher verwendet sowie gute Replacement Algorithmen verwendet. Page Tables Die Page Table speichert Informationen über die Platzierung von Pages. Sie ist ein Array von Einträgen, die über die virtuelle Page-Nummer indiziert werden. Das Page Table Register in der CPU zeigt auf die Page Table im virtuellen Speicher. Wenn die Page im Hauptspeicher präsent ist, wird die physische Page Nummer im Page Table Eintrag gespeichert. Zusätzlich gibt es noch ein Status Bit (referenced, dirty,...). Ein Reference Bit (auch Verwendungsbit) ist ein Feld, das gesetzt wird, wenn auf eine Seite zugegriffen wird, und das für die Implementierung des LRU-Algorithmus oder andere Austauschschemata verwendet wird. 12
 ist in der Page Table des Programms enthalten.")
13 Wenn eine Page im Hauptspeicher nicht präsent ist, wird im Page Table Eintrag auf eine Stelle im Swap Space auf der Disk referenziert. Wenn das Gültigkeit-Bit für eine virtuelle Page nicht gesetzt ist, tritt beim Zugriff ein Page Fault auf. Das Betriebssystem übernimmt daraufhin den Prozessor und muss nun die Page in der nächsten Ebene der Hierarchie finden (das ist normalerweise die Festplatte). Dann muss es entscheiden, wo die angeforderte Page im Hauptspeicher abgelegt werden soll. Die virtuelle Adresse allein lässt nicht unmittelbar erkenne, wo sich die Page auf der Festplatte befindet. Also müssen die Positionen der virtuellen Speicherseiten auf der Festplatte in unserem virtuellen Speichersystem verwaltet werden. Weil wir nicht im Voraus wissen, wann eine Seite im Speicher ersetzt wird, reserviert das Betriebssystem normalerweise bei der Prozesserzeugen für alle Seiten des Prozesses einen Platz auf der Festplatte. Dieser Platz auf der Festplatte wird als Swap Space (Austauschspeicher) bezeichnet. Zu diesem Zeitpunkt wird auch eine Datenstruktur angelegt, in der aufgezeichnet wird, wo auf der Festplatte die einzelnen virtuellen Pages abgelegt sind. Diese Datenstruktur kann Teil der Page Table sein, aber auch eine zusätzliche Datenstruktur die auf dieselbe Weise indiziert wird wie die Page Table. Das Betriebssystem erzeugt auch eine Datenstruktur, die verwaltet, welche Prozesse und welche virtuellen Adressen die verschiedenen physikalischen Seiten verwenden. Wenn ein Page Fault auftritt und alle Pages im Hauptspeicher genutzt werden, muss das Betriebssystem entscheiden, welche Pages ausgetauscht werden soll. Um Page Faults zu minimieren, versucht das Betriebssystem eine Page auszuwählen, die vermutlich nicht in nächster Zukunft gebraucht wird (LRU Austauschschema). Replacement und Writes Um die Page Fault Rate zu reduzieren, sollen vorzugsweise Pages ersetzt werden, die in letzter Zeit nicht oft gebraucht wurden. Das heißt, man soll dem LRU (Last Recently Used) Prinzip folgen. Um zu kennzeichnen, dass auf eine Page zugegriffen wird, gibt es das Reference Bit, das bei einem Zugriff auf die Page auf 1 gesetzt wird. Dieses Bit wird regelmäßig wieder auf 0 gesetzt durch das Betriebssystem. Eine Page, die ein Reference Bit = 0 hat, wurde in letzter Zeit nicht verwendet. Schreiben auf die Disk benötigt Millionen an Cycles. Write through ist dabei sehr unpraktisch. Daher wird Write Back verwendet. Im Page Table Entry wird das dirty bit auf 1 gesetzt, wenn eine Page geschrieben wurde. Schnelle Translation unter Verwendung einer TLB (Translation Lookaside Buffer) Weil die Page Tables im Hauptspeicher untergebracht sind, kann jeder Speicherzugriff durch ein Programm wenigstens doppelt so lang dauern: Ein Speicherzugriff, um die physikalische Adresse zu ermitteln, und ein zweiter, um die Daten zu erhalten. Der Schlüssel für die Verbesserung der Zugriffsleistung ist, die Lokalität des Zgriffs auf die Page Table zu nutzen. Wenn eine Übersetzung für eine virtuelle Page Number verwendet wird, wird sie vielleicht in naher Zukunft schon wieder genutzt (aufgrund der räumlichen und temporären Lokalität). Deshalb enthalten die meisten modernen Prozessoren einen speziellen 13

14 Cache, der die zuletzt verwendeten Übersetzungen enthält. Dieser spezielle Adressübersetzungs-Cache wird üblicherweise Translation-Lookaside Buffer bezeichnet. TLB Misses Wenn sich die Page bei einem TLB Miss im Hauptspeicher befindet, wird der Page Table Eintrag geladen und es erfolgt ein erneuter Versuch. Wenn sich die Page bei einem TLB Miss nicht im Speicher befindet (page fault!), muss sich das Betriebssystem darum kümmern. Die Page muss geladen werden und anschließend die Page Table upgedated. Dann muss die Instruction neu gestartet werden. Memory Protection Es kann sein, dass unterschiedliche Tasks Teile ihres virtuellen Adressraums teilen. Allerdings ist dabei ein Schutz erforderlich, dass es zu keinen Fehlern kommt. Dabei wird die Unterstützung des Betriebssystems benötigt. Für diesen Schutz durch das Betriebssystem wird Hardware Support bereitgestellt. Privilegierter Supervisor Modus (auch genannt: Kernel Modus) Privilegierte Instructions Auf Page Table und andere Statusinformationen kann nur im Supervisor Modus zugegriffen werden System Call Exception 14

15 Quellen für Misses Compulsory Misses (zwangsmäßige Misses, auch genannt: cold start misses) o der erste Zugriff auf einen Block Capacity Misses (Kapazitäts-Misses) o entstehen durch die begrenzte Cache-Größe Blöcke müssen immer wieder ersetzt werden o zu einem solchen Miss kommt es, wenn ein Block ersetzt wurde, der nun wieder gebraucht wird Conflict Misses (Konflikt Misses, auch genannt: Collision/Kollisions-Misses) o diese treten in einem non-fully associative Cache auf o entstehen durch den Wettbewerb, der bei den Einträgen in einem Set besteht o dieser Miss tritt in einem fully associative Cache nicht auf bei der selben Totalgröße 15

16 Chapter 6: Storage and Other I/O Topics I/O Geräte können nach unterschiedlichen Kriterien charakterisiert werden: Verhalten: Input (nur lesen), Output (nur schreiben, kann nicht gelesen werden), Speicherung (Storage; kann mehrfach gelesen und normalerweise auch mehrfach geschrieben werden) Partner: Mensch oder Maschine; stellt entweder Daten als Eingabe bereit oder möchte Daten von der Ausgabe lesen Data rate: Bytes/Sekunde, Transfer/Sekunde die höchste Geschwindigkeit, mit der Daten zwischen Ein-/Ausgabe-Gerät und dem Hauptspeicher oder dem Prozessor übertragen werden können Bei I/O Systemen ist die Systemstabilität bzw. Zuverlässigkeit sehr wichtig, ganz besonders für Speichergeräte. Auch über die Leistung machen wir uns Gedanken. Hier betrachten wir folgende Aspekte: Latency (die Response Time bzw. Antwortzeit) Throughput (Bandwidth) Bei Desktops und Embedded Systems ist man vor allem an einer guten Response Time interessiert sowie an einer Vielfalt an Geräten Bei Servern ist man vor allem am Durchsatz (Throughput) interessiert sowie an der Erweiterbarkeit der Geräte Maßgrößen für Systemstatibiltät/Zuverlässigkeit (Dependability) Ein wichtiger Aspekt bei der Dependability ist die Reliability (ebenfalls mit Zuverlässigkeit, Verlässlichkeit, Funktionssicherheit zu übersetzen). Ein Maß für die Reliability oder eben Zuverlässigkeit ist die Mean Time To Failure (MTTF). Damit ist die mittlere Zeit bis zum Ausfall eines Systems gemeint. Dienstunterbrechungen (Service Interruptions) werden als die mittlere Zeit bis zur Reparatur (Mean Time To Repair, MTTR) angegeben. Die mittlere Zeit zwischen Ausfällen wird Mean Time Between Failures (MTBF) genannt und ist einfach o die Summe aus MTTF + MTTR = MTBF Availability (Verfügbarkeit) ist ebenfalls ein Maß für die Dependability (im Buch übersetzt mit Dienst-Bereitstellung), im Hinblick auf den Wechsle zwischen den beiden Zuständen der Bereitstellung und der Unterbrechung. Die Verfügbarkeit lässt sich folgendermaßen berechnen: o MTTF / (MTTF + MTTR) 16

17 Um die Availability zu verbessern, kann man folgendes tun: die Mean Time To Failure (MTTF) erhöhen - Fehlervermeidung, Fehlertoleranz, Fehler-Forecasting die Mean Time To Repair (MTTR) reduzieren - fortgeschrittene Tools und Prozesse für Diagnose und Reparatur Magnetic Disks Eine Disk ist ein nicht-flüchtiger (non-volatile), rotierender magnetischer Speicher und wird auch Festplatte genannt. Man kann sich eine Festplatte als rotierende Scheibe mit magnetischer Oberfläche vorstellen, die einen beweglichen Lese-/Schreibkopf für den Zugriff auf diese Scheibe verwendet. Da der Festplattenspeicher nicht flüchtig ist, bleiben die Daten auch erhalten, wenn der Strom abgeschaltet wird. Eine Festplatte besteht aus mehreren Platten, die jeweils zwei beschreibbare Oberflächen aufweisen. Jede Oberfläche ist in konzentrische Kreise unterteilt, die sogenannten Tracks (Spuren). Davon gibt es ca bis pro Oberfläche. Jeder Track wiederum ist in Sektoren unterteilt, die die eigentliche Information aufnehmen. Pro Track gibt es ca. 100 bis 500 Sektoren. Zum Lesen und Schreiben müssen die Lese-/Schreibköpfe bewegt werden, sodass sie sich über der richtigen Position befinden. Die Lese-/Schreibköpfe der Festplatte sind miteinander verbunden, wodurch sie sich zusammen bewegen können, sodass jeder Kopf auf jeder Oberfläche über demselben Track steht. Die Tracks auf allen Oberflächen, die sich an einer bestimmten Position unter den Köpfen befinden, werden als Zylinder bezeichnet. Um auf Daten zuzugreifen, muss das Betriebssystem die Festplatte in drei Schritten ansteuern. Bevor es jedoch zu Schritt 1 kommt, kann es noch zu einer Warteverzögerung (queuing delay) kommen, wenn andere Zugriffe noch nicht erledigt wurden. Schritt 1: der Lese-/Schreibkopf wird über den richtigen Track gestellt. Diese Operation wird als Seek (Kopf-Positionierung) bezeichnet, und die Zeit für die Positionierung als Seek Time (Suchzeit). Schritt 2: Nun muss darauf gewartet werden, dass sich der richtige Sektor unter dem Lese-/Schreibkopf befindet. Die Zeit bis dahin wird als Rotation Latency (Umdrehungslatenz oder Umdrehungsverzögerung) bezeichnet. Schritt 3: Nun muss der gefundene Bitblock übertragen werden. Die Zeit, die dafür benötigt wird, nennen wir Transferrate. Ein Festplattencontroller übernimmt normalerweise die Steuerung der Festplatte sowie der Übertragung zwischen Festplatte und Speicher. Somit kommt bei der Festplattenzugriffszeit noch die Controllerzeit hinzu, das ist jener Aufwand, der durch den I/O-Zugriff des Controllers entsteht. In jedem Sektor ist folgende Information gespeichert: die Sektor ID die Daten (512 Bytes, 4096 Bytes proposed = vorhaben, vorschlagen?) Error Correction Code (ECC) 17

18 o wird verwendet, um Defekte und Recording Errors zu verbergen Synchronisationsfelder und Gaps Locality (Lokalität) und OS scheduling (Betriebssystem bestimmt, wann welcher Prozess wie lang und wann drankommen darf) führt zu kleineren durchschnittlichen Suchzeiten (seek times). Flash Storage Ein Flash Speicher ist ein nicht-flüchtiger (non-volatile) semiconductor (in eine Richtung leitend) Speicher. Er ist 100x 1000x schneller als eine Festplatte, außerdem kleiner, braucht weniger Strom und ist robuster. Allerdings ist er viel teuerer, kostet also mehr $/GB (liegt preislich ungefähr zwischen Disk und DRAM). Es gibt verschiedene Typen von Flash Speichern: NOR Flash: eine Bitzelle ist hier wie ein NOR Gatter o es findet ein Random Lese-/Schreibzugriff statt o wird für den Instruction Memory in eingebetteten Systemen verwendet NAND Flash: eine Bitzelle ist hier wie ein NAND Gatter o dichter (mehr Bits/Area), aber Block-at-a-time Zugriff o billiger pro GB o wird für USB Keys, Media Storage, etc. verwendet Flash Bits verbrauchen mit der Zeit (ca. nach 1000en von Zugriffen) - nicht geeignet für direkten RAM oder Disk Replacement - Lösung ist hier Wear Leveling (Verschleißausgleich): Daten von Blöcken, die schon häufig geschrieben wurden, werden auf weniger frequentierte Blöcke neu abgebildet. Verbindungen von Prozessoren, Speicher und I/O Devices In einem Computersystem müssen die verschiedenen Untersysteme Schnittstellen zueinander haben. Der Speicher und der Prozessor müssen miteinander kommunizieren können, ebenso wieder Prozessor und die I/O Geräte. Jahrelang wurde dafür ein Bus verwendet. Das ist eine gemeinsam genutzte Kommunikationsverbindung, die verschiedene Verdrahtungen verwendet, um mehrere Untersysteme zu verbinden. Die wichtigsten Vorteile des Busaufbaus sind seine Vielseitigkeit und die geringen Kosten. Da es nur ein einziges Verbindungsschema gibt, können neue Geräte leicht hinzugeführt werden. Ein Nachteil ist jedoch, dass ein Bus einen Kommunikationsengpass erzeugt, der unter Umständen den maximalen Ein-/Ausgabe-Durchsatz einschränkt. Eine Alternative sind high-speed serielle Verbindungen mit Switches (ähnlich einem Netzwerk). Es gibt unterschiedliche Typen von Bussen. 18

19 Processor-Memory Bus Ein Bus, der Prozessor und Speicher verbindet, und der kurz ist, im Allgemeinen hohe Geschwindigkeit aufweist und an das Speichersystem angepasst ist, um eine maximale Bandbreite zwischen Speicher und Prozessor zu bieten. I/O Bus Dieser Bus ist länger und erlaubt mehrere Verbindungen. Er ist mit dem Processor-Memory Bus über eine Brücke verbunden. Weitere Informationen zu Bussen: Data Lines Die Data Lines übertragen Adressen und Daten. Control Lines Die Control Lines geben Datentypen and und synchronisieren die Transaktionen (können z.b. Steuern, wann etwas übertragen wird, also damit die Geschwindigkeit der Übertragung, indem sie den Takt vorgeben; können auch die Richtung vorgeben, wie die Übertragung erfolgen sein; können angeben, ob das Senden erlaubt ist oder nicht; u.ä.) Synchroner Bus Ein Bus, der einen Takt in den Steuerleitungen (Control Lines) und ein diesem Takt entsprechendes, festes Kommunikationsprotokoll verwendet. Asynchroner Bus Verwendet statt eines Taktes ein Handshake-Protokoll für die Koordination der Benutzung; kann viele unterschiedliche Geräte mit unterschiedlichen Geschwindigkeiten bedienen. Handshake-Protokoll Eine Folge von Schritten für die Koordination asynchroner Busübertragungen, wobei der Sender und der Empfänger nur dann zum nächsten Schritt weitergehen, wenn beide Teilnehmer einig sind, dass der aktuelle Schritt abgeschlossen ist. I/O Management Input/Output wird durch das Betriebsystem ausgehandelt. Da viele Programme I/O Ressourcen teilen, wird Schutz (protection) und Scheduling (Ablaufplanung) benötigt. Weiters können I/O asynchrone Interrupts erzeugen (ähnlich wie Exceptions). Das Programmieren bei I/O ist sehr kniffelig. Daher stellt das Betriebssystem den Programmen Abstraktionen zur Verfügung. Es gibt eine eigene I/O Controller Hardware, die I/O Geräte managet. Diese sorgt für den Transfer von Daten von bzw. zu einem Gerät und synchronisiert die Operationen mit der Software. Weiters gibt es bestimmte Arten von Registern: Command Register o sorgen dafür, dass das Gerät etwas macht 19

20 Status Register o Machen deutlich, was das Gerät tut oder zeigen das Auftreten von Fehlern an Data Register o Write: transferieren Daten zu einem Gerät o Read: transferieren Daten von einem Gerät Um einem I/O Gerät einen Befehl zu geben, muss der Prozessor in der Lage sein, das Gerät anzusprechen und ein oder mehrere Befehlswörter zu übermitteln. Für die Addressierung des Geräts gibt es zwei Methoden: memory-mapped I/O (speicherabgebildete Ein-/Ausgsabe) und gerichtete I/O Anweisungen. Memory-mapped I/O, darunter versteht man ein Ein-/Ausgabe-Schema, wobei Teile des Adressraums den verschiedenen I/O Geräten zugeordnet werden und Lese- und Schreiboperationen für diese Adressen als Befehle für das jeweilige Ein-/Ausgabe-Gerät interpretiert werden. Es kann auch eigene Instructions geben, um I/O Register anzusprechen. (vgl. Foliensatz 6, Folie 20) Polling Beim Polling wird regelmäßig der Status eines I/O Geräts abgefragt, um festzustellen, wann das Gerät wieder bedient werden muss. Dabei werden die I/O Status Register gecheckt. Wenn das Gerät fertig ist, kann eine Operation ausgeführt werden. Wenn ein Fehler aufgetreten ist, muss eine entsprechende Aktion gesetzt werden. In kleinen oder low-performance Real Time Embedded Systems ist Polling üblich (vorhersehbares Timing und niedrige Hardware Kosten sind hierfür die Gründe). In anderen Systemen würde Polling jedoch nur unnötige CPU Zeit benötigen. Interrupts Die Interrupt-gesteuerte Ein-/Ausgabe ist ein I/O Schema, das Interrupts verwendet, um dem Prozessor anzuzeigen, dass ein I/O Gerät Aufmerksamkeit benötigt. Das Ganze funktioniert folgendermaßen: Wenn ein Gerät fertig ist oder ein Fehler auftritt, unterbricht der Controller die CPU. Ein Interrupt ist dabei wie eine Exception. Solche Interrupts sind nicht mit der Ausführung von Instructions synchronisiert. Der Interrupt ist keinem Befehl zugeordnet, daher verhindert er nicht, dass dieser vollständig ausgeführt wird. Die Steuereinheit des Prozessors muss vor dem Starten einer neuen Befehlsausführung also prüfen, ob ein I/O Interrupt ansteht. Wenn ein Interrupt auftritt, muss natürlich auch die Information übermittelt werden, welches Gerät in ausgelöst hat, also dessen Identität. Häufig gibt die Ursacheninformation Auskunft darüber, welches Gerät den Interrupt ausgelöst hat. Interrupts können unterschiedliche Prioritäten haben. Geräte, die dringender Aufmerksamkeit benötigen, bekommen somit eine höhere Priorität als andere. Solche Interrupts können dann den Handler für Interrupts mit niedrigerer Priorität wiederum unterbrechen. 20

21 I/O Data Transfer Bei Polling und interrupt-driven I/O o Diese Übertragungen lassen dem Prozessor die Aufgabe, die Daten zu verschieben und die Übertragung zu verwalten. Der Prozessor kann genutzt werden, um Daten zwischen einem Gerät und einem Speicher basierend auf Polling zu übertragen. Der Prozessor lädt Daten aus I/O-Geräteregistern in prozessorinterne Register und legt sie anschließend im Speicher ab. Alternativ kann die Übertragung von Daten interrupt-gesteuert sein. o Hier liegt das Interesse vor allem darin, die Kosten für den Geräte-Controller und die Schnittstelle gering zu halten und nicht, eine Übertragung mit hoher Bandbreite zu realisieren. Direkter Speicherzugriff (DMA, direct memory access) o Ein Mechanismus, der einem Geräte-Controller die Möglichkeit gibt, Daten direkt zum oder vom Speicher zu übertragen, ohne dass der Prozessor daran beteiligt ist. o Dieser Mechanismus nimmt die Last vom Prozessor und überlässt es dem Geräte-Controller, Daten direkt zum oder vom Speicher zu übertragen, ohne dass der Prozessor daran beteiligt ist. DMA wird mit einem speziellen Controller implementiert, sodass die Übertragung wirklich prozessorunabhängig ist. Der DMA-Controller wird zum Bus Master und leitet die Leseund Schreiboperationen zwischen sich und dem Speicher weiter. (Ein Bus Master ist eine Einheit auf dem Bus, die Bus-Anforderungen initiieren kann). Das OS stellt eine Startadresse im Memory zur Verfügung der I/O Controller transferiert eigenständig vom/zum Speicher bei Fertigstellung oder einem Fehler unterbricht der Controller den Prozessor DMA/Cache Interaction Wenn ein I/O System DMA unterstützt, hat dies Auswirkungen auf das Speichersystem und den Prozessor. Ohne DMA kommen alle Zugriffe auf das Speichersystem vom Prozessor und gehen über die Adressübersetzung und die Caches, als hätte der Prozessor die Speicheranforderung erzeugt. Mit DMA gibt es einen anderen Weg zum Speichersystem der nicht durch den Adressübersetzungsmechanismus oder die Cache-Hierarchie verläuft. Dieser Unterschied führt zu Problemen. Wenn DMA in einen Memory Block schreibt, der auch gecached ist, ist die gecachte Kopie nicht mehr aktuell (sie wird stale = veraltet, abgenutzt, verbraucht). Wenn ein write-back Cache einen dirty block hat und DMA einen Memory Block liest, werden veraltete (stale) Daten gelesen daher muss die Cache Kohärenz gewährleistet werden: o flush blocks from cache if they will be used for DMA (flush = durchspülen; Blöcke werden aus dem Cache genommen oder ersetzt (?) wenn sie für DMA verwendet werden) o andere Möglichkeit: Memory Locations für I/O verwenden, die nicht gecached werden können 21
22 DMA/VM (Virtual Memory) Interaction Sollte DMA in einem virtuellen Speichersystem mit virtuellen oder mit physikalischen Adressen arbeiten? Das Problem bei virtuellen Adressen ist, dass die DMA-Einheit die virtuellen Adressen in physikalische Adressen übersetzen muss. Da Speicherpositionen, an die übertragen wird, im virtuellen Speicher nicht unbedingt fortlaufend sind, müssten bei der Verwendung physikalischer Adressen alle DMA-Übertragungen auf eine Seite beschränkt werden. Um DMA-Übertragungen hier zu ermöglichen, die Seitengrenzen überschreiten, muss man DMA mit virtuellen Adressen arbeiten lassen. Die DMA-Einheit hat in einem solchen System eine kleine Anzahl von Abbildungseinträgen, die die Abbildung von virtuellen auf physische Adressen für eine Übertragung bereitstellen. Die DMA-Einheit muss sich nicht um die Position der an der Übertragung beteiligten Seiten kümmern. Eine weitere Technik des OS ist es, die DMA-Übertragungen in eine Folge von Übertragungen zu zerlegen, die alle auf eine einzige physikalische Seite begrenzt sind. Die Übertragungen werden dann verkettet und weitergegeben; die gesamte Folge muss verarbeitet werden. Während eine Übertragung stattfindet, darf keine Seite neu zugeordnet werden, die an der Übertragung beteiligt ist. I/O Performance messen I/O Performance hängt ab von: o Hardware: CPU, Memory, Controllers, Buses o Software: OS, Database Management System, Application o Workload (Arbeitslast): request rates (Anfragerate) und patterns (Muster) Das Design eines I/O Systems muss einen Ausgleich finden zwischen Response Time und Throuhput o das Ausmaß an Throughput kann oft über eingeschränkte Response Time beeinflusst werden Amdahl s Law Das Amdahlsche Gesetz (benannt 1967 nach Gene Amdahl) ist ein Modell in der Informatik über die Beschleunigung von Programmen durch parallele Ausführung. Nach Amdahl wird der Geschwindigkeitszuwachs vor allem durch den sequentiellen Anteil des Problems beschränkt, da sich dessen Ausführungszeit durch Parallelisierung nicht verringern lässt. Don t neglect (vernachlässigen) I/O performance as parallelism increases compute performance. 22
23 RAID RAID steht für Redundant Array of Inexpensive (Independent) Disks. Gemeint ist eine Anordnung von Festplatten, wobei ein Feld kleiner und billiger Festplatten verwendet wird, um sowohl die Leistung als auch die Zuverlässigkeit zu erhöhen. Es werden also anstelle einer großen Disk mehrere kleine Disks verwendet. Der Parallelismus erhöht die Performance. Zusätzlich gibt es eine bzw. mehrere Extra-Disks für redundantes Datenspeichern (redundant = überflüssig, oder: mehrfach vorhanden sein). Damit Festplattenausfälle (bei mehreren Festplatten) ohne Informationsverlust kompensiert (= entschädigt, gedeckt) werden können, wurde Redundanz eingeführt. Die Zuverlässigkeit wird erschwinglicher, wenn man ein redundantes Feld billiger Festplatten verwendet. Das führte eben zu den RAIDs. Diese stellen ein störfalltolerantes (fault tolerant) Speichersystem dar. Es gibt unterschiedliche Arten von RAIDs. RAID 0 In diesem Fall ist RAID mehr oder weniger eine Fehlbenennung, da es hier keine Redundanz gibt. ES werden jedoch Daten über mehrere Festplatten verteilt, was auch Striping genannt wird. Dabei erhält die Software den Eindruck, mit einer einzigen großen Festplatte zu arbeiten, was die Speicherverwaltung vereinfacht. Außerdem wird dadurch die Verarbeitungsleistung für größere Zugriffe verbessert, weil der Zugriff auf viele Festplatten gleichzeitig geschehen kann. Dadurch wird die Performance verbessert. RAID 1 (Mirroring) Als Spiegeln (mirroring) wird das Schreiben von identischen Daten auf mehrere Festplatten bezeichnet, um die Datenverfügbarkeit zu erhöhen. RAID 1 verwendet doppelt so viele Festplatten wie RAID 0. Immer, wenn Daten auf eine Festplatte geschrieben werden, werden sie gleichzeitig auch auf eine weitere redundante Festplatte geschrieben, sodass es immer zwei Kopien der Information gibt. Wenn eine Festplatte ausfällt, wechselt das System einfach zu der Spiegelplatte und liest den dort abgelegten Inhalt, um die gewünschte Information zu erhalten. Das Spiegeln ist die teuerste RAID-Lösung, weil dafür die meisten Festplatten erforderlich sind es werden N + N Festplatten benötigt. RAID 2 RAID 2 besitzt N + E Disks. Es nutzt ein Fehlererkennungs- und Fehlerkorrekturschema, das häufig für Speicher verwendet wird. Die Daten werden auf Bitlevel über N Disks gesplittet. Ein E-bit Error Correction Code (ECC) wird generiert. Allerdings wird RAID 2 nicht mehr verwendet. Es ist zu komplex. RAID 3: Bit-Interleaved Parity RAID 3 besitzt N + 1 Disks. Statt eine vollständige Kopie der Originaldaten für jede Festplatte anzulegen, brauchen wir nur genügend redundante Informationen, um bei einem Ausfall die verlorenen Informationen wiederherzustellen. Lese- oder Schreiboperationen gehen an alle Festplatten in der Gruppe, und es wird eine zusätzliche Festplatte verwendet, die 23
24 die Prüfinformation für den Fehlerfall enthält. RAID 3 ist beliebt für Anwendungen mit großen Datenmengen, beispielsweise Multimediaanwendungen und numerische Programme. Hier wird das Prinzip der bitweisen verschränkten (interleaved; ineinander verschachtelt) Parität (Gleichheit) verwendet. Ein Paritätsbit ergibt sich einfach als die Summe modulo 2, was gleicht durch eine XOR-Verknüpfung der zu Prüfungen Bits implementiert werden kann. Die redundanten Festplatten enthält die Paritätsbits über die Daten der anderen Festplatten. Wenn eine Festplatte ausfällt, können deren Dateninhalte durch eine XOR-Verknüpfung der Bits aus den funktionsfähigen Festplatten und der paritätsfestplatte wieder erstellt werden. Lesezugriff: alle Disks lesen Schreibzugriff: alle Disk updaten und Parität generieren Bei einem Fehler: Parität verwenden, um fehlende Daten wieder herzustellen nicht weit verbreitet RAID 4: Block-Interleaved Parity RAID 4 besitzt N + 1 Disks. Hier wird die Parität als Blöcke gespeichert und einer Menge von Datenblöcken zugeordnet. Lesezugriff: es wird nur die Disk gelesen, die den geforderten Block enthält Schreibzugriff: es wird nur die Disk gelesen, die den veränderten Block enthält, und die Parity Disk Bei einem Fehler: Parität verwenden, um fehlende Daten wieder herzustellen nicht weit verbreitet 24

25 RAID 5: Distributed Parity RAID 5 besitzt N + 1 Disks. Es ist ähnlich wie RAID 4, allerdings sind die Parity Blocks über Disk verteilt. Das verhindert, dass die Parity Disk zu einem Bottleneck wird. Schreiboperationen können parallel stattfinden, solange sich die Paritätsblöcke auf unterschiedlichen Festplatten befinden. weit verbreitet RAID 6: P + Q Redundanz RAID 6 besitzt N + 2 Disks. Wenn eine einzelne Fehlerkorrektur nicht ausreicht, kann die Parität verallgemeinert werden, sodass eine zweite Berechnung über die Daten erfolgt und eine weitere Prüfplatte benötigt wird. Dieser zweite Prüfblock erlaubt die Wiederherstellung nach einem zweiten Ausfall. Die Fehlertoleranz ist durch mehr Redundanz größer. RAID Zusammenfassung: RAID kann die Performance und Verfügbarkeit verbessern. Server Computer Es ist immer weiter verbreitet, dass Applikationen auf Servern laufen (Web Search, Office Apps, Virtual Worlds, etc.). Dafür werden sehr große Daten-Center-Server benötigt: viele Prozessoren, Netzwerkverbindungen, massive Speicher. Allerdings gibt es Platz- und Leistungseinschränkungen. 25
26 Chapter 7: Multicores, Multiprocessors und Clusters Eine Idee ist es, leistungsfähige Computer einfach durch das Zusammenschalten von kleineren Computern zu schaffen. Das soll die Performance erhöhen. Diese Vision ist der Ursprung der Multiprozessoren. Multiprozessoren sind parallele Prozessoren mit einem einzigen, gemeinsam genutzten Adressraum. Sie müssen skalierbar sein (d.h. man kann eine unterschiedliche Anzahl von ihnen einsetzen). Hardware und Software werden so entsprechend entworfen, dass sie mit einer variablen Anzahl von Prozessoren eingesetzt werden können. Multiprozessoren führen auch zu einer effizienteren Leistungsnutzung, da große, ineffiziente Prozessoren durch kleinere, effizientere ersetzt werden. Dieser Austausch kann eine bessere Leistung pro Watt oder pro Joule bieten. Die Skalierbarkeit von Software führt dazu, dass Multiprozessoren den Betrieb auch bei defekter Hardware noch aufrecht erhalten können, d.h. wenn in einem Multiprozessor mit n Prozessoren ein Prozessor ausfällt, läuft das System mit n-1 Prozessoren weiter. Damit können Multiprozessoren auch die Verfügbarkeit verbessern. Unter Job-Level oder Prozess-Level Parallelismus (Parallelität auf Aufgaben- bzw. Prozessebene) versteht man den Einsatz mehrerer Prozessoren zur gleichzeitigen Ausführung voneinander unabhängiger Programme. Das bietet einen hohen Throughput für diese Programme. Unter einem parallel processing program (parallel arbeitendes Programm) versteht man ein einzelnes Programm, das auf mehreren Prozessoren gleichzeitig ausgeführt werden kann. Unter einem Multicore Microprocessor (Multikernprozessor) versteht man einen Mikroprozessor, der mehrere Prozessoren (so genannte Kerne oder Cores) in einer einzigen Schaltung beinhaltet. Unter einem Cluster versteht man mehrere Rechner, die über ein lokales Netzwerk (LAN) miteinander verbunden sind, und die sich wie ein einziger großer Multiprozessor verhalten. Nebenläufige Software kann auf serieller Hardware ausgeführt werden sowie auf paralleler Hardware. Ebenso kann sequentielle Software sowohl auf serieller als auch auf paralleler Hardware ausgeführt werden. Software sequenziell nebenläufig Hardware seriell parallel Matrixmultiplikation in MatLab, aufgesetzt auf einen Intel Pentium 4 Matrixmultiplikation in MatLab, aufgesetzt auf einem Intel Xeon e5345 (Clovertown) Windows Vista, aufgesetzt auf einem Intel Pentium 4 Windows Vista, aufgesetzt auf einem Intel Xeon e5345 (Clovertown) 26
27 Es gibt keine klare Vorstellung davon, wie man am besten für Multiprozessoren programmieren sollte. Ein einziger Core kann aufgrund der Power Wall jedenfalls nicht weiter skaliert werden. Die Schwierigkeit beim Parallelismus ist nicht die Hardware, sondern dass zu wenige wichtige Anwendungsprogramme für die Ausführung auf Multiprozessoren umgeschrieben wurden. Es ist schwierig, Software zu schreiben, die mehrere Prozessoren nutzt, um eine Aufgabe schneller zu machen, und das Ganze wird noch schlimmer, wenn die Anzahl der Prozessoren zunimmt. Der Grund, warum es so schwierig ist: Mit einem parallelen Programm muss man auf einem Multiprozessor gute Leistung und Kosteneffizienz erzielen, da man sonst gleich einen Einzelprozessor verwenden könnte, weil das für die Programmierung einfacher ist. Tatsächlich können Entwurfstechniken für Einzelprozessoren die Parallelität auf der Befehlsebenen nutzen, ohne dass der Programmierer eingreifen muss. Das reduziert die Bereitschaft, Programme extra umzuschreiben. Um mehrere Prozessoren erfolgreich zu nutzen, muss die Aufgabe in gleich große Teile zerlegt werden, damit kein untätiges Warten entsteht. Auch soll nicht zu viel Zeit auf Kommunikation untereinander verwendet werden (vgl. Reporterbeispiel im Buch mehrere Reporter sollen an einem Artikel arbeiten). Wichtig ist es also, sich um Folgendes zu kümmern bzw. zu beachten und eine Lösung dafür zu finden: - Scheduling (Ablaufplanung) - Lastausgleich - für Synchronisierung aufgewendete Zeit - Zusatzaufwand für Kommunikation Forschungen seit 1960 Es wurde nach der geeigneten Computersprache gesucht, um Programme auf Multiprozessoren auszurichten. Dabei gab es verschiedene Entwicklungen, aber keine schaffte es so schnell, effizient und flexibel wie die traditionellen sequentiellen Sprachen. An einem richtigen Hardware Design für diese Problemstellung ist bis jetzt jeder gescheitert. Weiters gibt es Forschungen im Bereich von Software, die sequentielle Programme automatisch parallelisieren sollen. Fortschritte Es ist leichter ein Programm zu parallelisieren, das mehrere Benutzer bewältigt, die dieselbe Aufgabe ausführen, als ein Programm, dass eine komplizierte Aufgabe eines einzelnen Benutzers bewältigen muss inherent (innewohnend) task-level parallelism Computergraphiken (animierte Videos, Special-Effects): individuelle Szenen, die parallel berechnet werden. Die GPU (Graphic Processing Unit) beinhaltet dafür hunderte von Prozessoren, wobei jeder einen kleinen Teil des Renderings eines Images meistert data-level parallelism Zu data-level parallelism zählt auch Scientific Computing (wissenschaftliches Computing) so wie Wetter, Crash Simulationen, etc. 27
28 Paralleles Programmieren Parallele Software ist ein Problem, da man wirklich eine signifikante Performance- Verbesserung erzielen muss. Ansonsten könnte man einfach einen schnelleren Uniprocessor ( nur ein Prozessor) verwenden, da dafür leichter zu programmieren ist. Folgende Schwierigkeiten bestehen: - Aufteilung, Lastenausgleich - Koordination, Synchronisation - Zeitaufwand (bzw. Overhead) durch Kommunikation - Sequentielle Abhängigkeiten Amdahl s Law Strong Scaling (Starke Skalierung), darunter versteht man die auf einem Multiprozessor erzielte Beschleunigung ohne Vergrößerung der Aufgabenstellung. Weak Scaling (Schwache Skalierung), darunter versteht man die auf einem Multiprozessor erzielte Beschleunigung bei proportional zur Anzahl der Prozessoren erfolgte Vergrößerung der Aufgabenstellung. Die Erzielung einer Beschleunigung auf einem Multiprozessor bei fester Aufgabengröße ist schwieriger, als eine gute Beschleunigung zu erzielen, wenn man die Dimension der Aufgabenstellung vergrößert. Dazu ein paar Beispiele: 28
29 (Annahme ist, dass die Last über die Prozessoren gut ausbalanciert werden kann) (Annahme ist, dass die Last balanciert wurde) Shared Memory Unter SMP (Shared Memory Multiprocessor, Multiprozessor mit gemeinsam genutztem Speicher) versteht man einen Multiprozessor mit einem einzigen Adressraum, was einer impliziten (innewohnend) Kommunikation mit Laden und Speichern entspricht. 29
30 Allen Prozessoren wird also nur ein einziger physikalischer Adressraum zur Verfügung gestellt. Prozessoren kommunizieren über gemeinsam genutzte Variablen im Speicher, wobei alle Prozessoren in der Lage sind, ladend und speichern auf alle Speicherpositionen zuzugreifen. Da parallel arbeitende Prozessoren Daten normalerweise gemeinsam nutzen, müssen sie sich bei der Arbeit an solchen Daten auch koordinieren. Andernfalls könnte ein Prozessor anfangen, mit den Daten zu arbeiten, bevor ein anderer damit fertig ist. Diese Koordination wird als Synchronisierung bezeichnet. Wenn die gemeinsame Nutzung durch einen einigen Adressraum unterstützt wird, muss es separate Mechanismen für die Synchronisierung geben. Ein Ansatz verwendet sogenannte Locks (Sperren) für eine gemeinsam genutzte Variable. Es kann jeweils nur ein Prozessor auf diesen Lock zugreifen, und andere Prozessoren, die auf die gemeinsam genutzten Daten zugreifen sollen, müssen warten, bis der erste Prozessor den Lock für die Variable aufhebt. Bei der Speicherzugriffszeit unterscheidet man zwischen UMA-Multiprozessoren und NUMA-Multiprozessoren. Bei UMA-Multiprozessoren (Uniform Memory Access) wird für den Zugriff auf den Hauptspeicher für alle Prozessoren gleich viel Zeit benötigt, unabhängig davon, auf welches Wort zugegriffen wird. NUMA-Multiprozessoren stehen dann für Non- Uniform Memory Access. Ihre Programmierung ist sehr viel schwieriger, dafür können sie größer ausgelegt werden und sie können eine geringere Latenz (Laufzeit eines Signals in einem technischen System) zum nahe gelegenen Speicher haben. Message Passing Der alternative Ansatz, einen Adressraum gemeinsam zu nutzen, ist, dass jeder Prozessor seinen eigenen privaten physischen Adressraum hat. Dieser alternative Multiprozessor muss über einen expliziten Nachrichtenaustausch erfolgen, womit traditionell auch solche Computer bezeichnet werden. Unter Nachrichtenaustausch versteht man hier die Kommunikation zwischen mehreren Prozessoren durch das explizite Senden und Empfangen von Informationen. Es werden Routinen zum Senden und Empfangen von Nachrichten benötigt. Eine Routine zum Senden von Nachrichten wird von einem Prozessor genutzt, um eine Nachricht an einen anderen Prozessor weiterzugeben. Eine Routine zum Empfangen von Nachrichten wird von einem Prozessor genutzt, um Nachrichten von einem anderen Prozessor entgegenzunehmen. Die Koordination ist in den Nachrichtenaustausch eingebunden. Ein Prozessor weiß, wann eine Nachricht gesendet wird, und der empfangende Prozessor weiß, wann eine Nachricht ankommt. Wenn der Sender eine Bestätigung benötigt, dass die Nachricht angekommen ist, kann der empfangende Prozessor eine Bestätigungsnachricht zurück an den Sender schicken. 30
Die allerwichtigsten Raid Systeme
 Die allerwichtigsten Raid Systeme Michael Dienert 4. Mai 2009 Vorbemerkung Dieser Artikel gibt eine knappe Übersicht über die wichtigsten RAID Systeme. Inhaltsverzeichnis 1 Die Abkürzung RAID 2 1.1 Fehlerraten
Die allerwichtigsten Raid Systeme Michael Dienert 4. Mai 2009 Vorbemerkung Dieser Artikel gibt eine knappe Übersicht über die wichtigsten RAID Systeme. Inhaltsverzeichnis 1 Die Abkürzung RAID 2 1.1 Fehlerraten
Einführung in die technische Informatik
 Einführung in die technische Informatik Christopher Kruegel chris@auto.tuwien.ac.at http://www.auto.tuwien.ac.at/~chris Betriebssysteme Aufgaben Management von Ressourcen Präsentation einer einheitlichen
Einführung in die technische Informatik Christopher Kruegel chris@auto.tuwien.ac.at http://www.auto.tuwien.ac.at/~chris Betriebssysteme Aufgaben Management von Ressourcen Präsentation einer einheitlichen
Virtueller Speicher. SS 2012 Grundlagen der Rechnerarchitektur Speicher 44
 Virtueller Speicher SS 2012 Grundlagen der Rechnerarchitektur Speicher 44 Die Idee Virtuelle Adressen Prozess 1 Speicherblock 0 Speicherblock 1 Speicherblock 2 Speicherblock 3 Speicherblock 4 Speicherblock
Virtueller Speicher SS 2012 Grundlagen der Rechnerarchitektur Speicher 44 Die Idee Virtuelle Adressen Prozess 1 Speicherblock 0 Speicherblock 1 Speicherblock 2 Speicherblock 3 Speicherblock 4 Speicherblock
Lizenzierung von System Center 2012
 Lizenzierung von System Center 2012 Mit den Microsoft System Center-Produkten lassen sich Endgeräte wie Server, Clients und mobile Geräte mit unterschiedlichen Betriebssystemen verwalten. Verwalten im
Lizenzierung von System Center 2012 Mit den Microsoft System Center-Produkten lassen sich Endgeräte wie Server, Clients und mobile Geräte mit unterschiedlichen Betriebssystemen verwalten. Verwalten im
Grundlagen verteilter Systeme
 Universität Augsburg Insitut für Informatik Prof. Dr. Bernhard Bauer Wolf Fischer Christian Saad Wintersemester 08/09 Übungsblatt 3 12.11.08 Grundlagen verteilter Systeme Lösungsvorschlag Aufgabe 1: a)
Universität Augsburg Insitut für Informatik Prof. Dr. Bernhard Bauer Wolf Fischer Christian Saad Wintersemester 08/09 Übungsblatt 3 12.11.08 Grundlagen verteilter Systeme Lösungsvorschlag Aufgabe 1: a)
Grundlagen der Rechnerarchitektur
 Grundlagen der Rechnerarchitektur Ein und Ausgabe Übersicht Grundbegriffe Hard Disks und Flash RAM Zugriff auf IO Geräte RAID Systeme SS 2012 Grundlagen der Rechnerarchitektur Ein und Ausgabe 2 Grundbegriffe
Grundlagen der Rechnerarchitektur Ein und Ausgabe Übersicht Grundbegriffe Hard Disks und Flash RAM Zugriff auf IO Geräte RAID Systeme SS 2012 Grundlagen der Rechnerarchitektur Ein und Ausgabe 2 Grundbegriffe
Fachbericht zum Thema: Anforderungen an ein Datenbanksystem
 Fachbericht zum Thema: Anforderungen an ein Datenbanksystem von André Franken 1 Inhaltsverzeichnis 1 Inhaltsverzeichnis 1 2 Einführung 2 2.1 Gründe für den Einsatz von DB-Systemen 2 2.2 Definition: Datenbank
Fachbericht zum Thema: Anforderungen an ein Datenbanksystem von André Franken 1 Inhaltsverzeichnis 1 Inhaltsverzeichnis 1 2 Einführung 2 2.1 Gründe für den Einsatz von DB-Systemen 2 2.2 Definition: Datenbank
Eigene Dokumente, Fotos, Bilder etc. sichern
 Eigene Dokumente, Fotos, Bilder etc. sichern Solange alles am PC rund läuft, macht man sich keine Gedanken darüber, dass bei einem Computer auch mal ein technischer Defekt auftreten könnte. Aber Grundsätzliches
Eigene Dokumente, Fotos, Bilder etc. sichern Solange alles am PC rund läuft, macht man sich keine Gedanken darüber, dass bei einem Computer auch mal ein technischer Defekt auftreten könnte. Aber Grundsätzliches
Quiz. Gegeben sei ein 16KB Cache mit 32 Byte Blockgröße. Wie verteilen sich die Bits einer 32 Bit Adresse auf: Tag Index Byte Offset.
 Quiz Gegeben sei ein 16KB Cache mit 32 Byte Blockgröße. Wie verteilen sich die Bits einer 32 Bit Adresse auf: Tag Index Byte Offset 32 Bit Adresse 31 3 29... 2 1 SS 212 Grundlagen der Rechnerarchitektur
Quiz Gegeben sei ein 16KB Cache mit 32 Byte Blockgröße. Wie verteilen sich die Bits einer 32 Bit Adresse auf: Tag Index Byte Offset 32 Bit Adresse 31 3 29... 2 1 SS 212 Grundlagen der Rechnerarchitektur
4D Server v12 64-bit Version BETA VERSION
 4D Server v12 64-bit Version BETA VERSION 4D Server v12 unterstützt jetzt das Windows 64-bit Betriebssystem. Hauptvorteil der 64-bit Technologie ist die rundum verbesserte Performance der Anwendungen und
4D Server v12 64-bit Version BETA VERSION 4D Server v12 unterstützt jetzt das Windows 64-bit Betriebssystem. Hauptvorteil der 64-bit Technologie ist die rundum verbesserte Performance der Anwendungen und
NAS 251 Einführung in RAID
 NAS 251 Einführung in RAID Ein Speicher-Volume mit RAID einrichten A S U S T O R - K o l l e g Kursziele Nach Abschluss dieses Kurses sollten Sie: 1. Ü ber ein grundlegendes Verständnis von RAID und seinen
NAS 251 Einführung in RAID Ein Speicher-Volume mit RAID einrichten A S U S T O R - K o l l e g Kursziele Nach Abschluss dieses Kurses sollten Sie: 1. Ü ber ein grundlegendes Verständnis von RAID und seinen
20. Algorithmus der Woche Online-Algorithmen: Was ist es wert, die Zukunft zu kennen? Das Ski-Problem
 20. Algorithmus der Woche Online-Algorithmen: Was ist es wert, die Zukunft zu kennen? Das Ski-Problem Autor Susanne Albers, Universität Freiburg Swen Schmelzer, Universität Freiburg In diesem Jahr möchte
20. Algorithmus der Woche Online-Algorithmen: Was ist es wert, die Zukunft zu kennen? Das Ski-Problem Autor Susanne Albers, Universität Freiburg Swen Schmelzer, Universität Freiburg In diesem Jahr möchte
3 Windows als Storage-Zentrale
 3 Windows als Storage-Zentrale Windows als zentrale Datenspeichereinheit punktet gegenüber anderen Lösungen vor allem bei der Integration in vorhandene Unternehmensnetze sowie bei der Administration. Dabei
3 Windows als Storage-Zentrale Windows als zentrale Datenspeichereinheit punktet gegenüber anderen Lösungen vor allem bei der Integration in vorhandene Unternehmensnetze sowie bei der Administration. Dabei
IBM Software Demos Tivoli Provisioning Manager for OS Deployment
 Für viele Unternehmen steht ein Wechsel zu Microsoft Windows Vista an. Doch auch für gut vorbereitete Unternehmen ist der Übergang zu einem neuen Betriebssystem stets ein Wagnis. ist eine benutzerfreundliche,
Für viele Unternehmen steht ein Wechsel zu Microsoft Windows Vista an. Doch auch für gut vorbereitete Unternehmen ist der Übergang zu einem neuen Betriebssystem stets ein Wagnis. ist eine benutzerfreundliche,
Handbuch B4000+ Preset Manager
 Handbuch B4000+ Preset Manager B4000+ authentic organ modeller Version 0.6 FERROFISH advanced audio applications Einleitung Mit der Software B4000+ Preset Manager können Sie Ihre in der B4000+ erstellten
Handbuch B4000+ Preset Manager B4000+ authentic organ modeller Version 0.6 FERROFISH advanced audio applications Einleitung Mit der Software B4000+ Preset Manager können Sie Ihre in der B4000+ erstellten
OPERATIONEN AUF EINER DATENBANK
 Einführung 1 OPERATIONEN AUF EINER DATENBANK Ein Benutzer stellt eine Anfrage: Die Benutzer einer Datenbank können meist sowohl interaktiv als auch über Anwendungen Anfragen an eine Datenbank stellen:
Einführung 1 OPERATIONEN AUF EINER DATENBANK Ein Benutzer stellt eine Anfrage: Die Benutzer einer Datenbank können meist sowohl interaktiv als auch über Anwendungen Anfragen an eine Datenbank stellen:
Lineargleichungssysteme: Additions-/ Subtraktionsverfahren
 Lineargleichungssysteme: Additions-/ Subtraktionsverfahren W. Kippels 22. Februar 2014 Inhaltsverzeichnis 1 Einleitung 2 2 Lineargleichungssysteme zweiten Grades 2 3 Lineargleichungssysteme höheren als
Lineargleichungssysteme: Additions-/ Subtraktionsverfahren W. Kippels 22. Februar 2014 Inhaltsverzeichnis 1 Einleitung 2 2 Lineargleichungssysteme zweiten Grades 2 3 Lineargleichungssysteme höheren als
Anleitung zur Nutzung des SharePort Utility
 Anleitung zur Nutzung des SharePort Utility Um die am USB Port des Routers angeschlossenen Geräte wie Drucker, Speicherstick oder Festplatte am Rechner zu nutzen, muss das SharePort Utility auf jedem Rechner
Anleitung zur Nutzung des SharePort Utility Um die am USB Port des Routers angeschlossenen Geräte wie Drucker, Speicherstick oder Festplatte am Rechner zu nutzen, muss das SharePort Utility auf jedem Rechner
Betriebssysteme. Dipl.-Ing.(FH) Volker Schepper
 Volker Schepper") Speicherverwaltung Real Mode Nach jedem starten eines PC befindet sich jeder x86 (8086, 80386, Pentium, AMD) CPU im sogenannten Real Mode. Datenregister (16Bit) Adressregister (20Bit) Dadurch lassen sich
Speicherverwaltung Real Mode Nach jedem starten eines PC befindet sich jeder x86 (8086, 80386, Pentium, AMD) CPU im sogenannten Real Mode. Datenregister (16Bit) Adressregister (20Bit) Dadurch lassen sich
Cache Grundlagen. Schreibender Cache Zugriff. SS 2012 Grundlagen der Rechnerarchitektur Speicher 22
 Cache Grundlagen Schreibender Cache Zugriff SS 212 Grundlagen der Rechnerarchitektur Speicher 22 Eine einfache Strategie Schreibt man nur in den Cache, werden Cache und darunter liegender Speicher inkonsistent.
Cache Grundlagen Schreibender Cache Zugriff SS 212 Grundlagen der Rechnerarchitektur Speicher 22 Eine einfache Strategie Schreibt man nur in den Cache, werden Cache und darunter liegender Speicher inkonsistent.
Einrichtung des Cisco VPN Clients (IPSEC) in Windows7
 in Windows7") Einrichtung des Cisco VPN Clients (IPSEC) in Windows7 Diese Verbindung muss einmalig eingerichtet werden und wird benötigt, um den Zugriff vom privaten Rechner oder der Workstation im Home Office über
Einrichtung des Cisco VPN Clients (IPSEC) in Windows7 Diese Verbindung muss einmalig eingerichtet werden und wird benötigt, um den Zugriff vom privaten Rechner oder der Workstation im Home Office über
Grundlagen der Rechnerarchitektur. Speicher
 Grundlagen der Rechnerarchitektur Speicher Übersicht Speicherhierarchie Cache Grundlagen Verbessern der Cache Performance Virtueller Speicher SS 2012 Grundlagen der Rechnerarchitektur Speicher 2 Speicherhierarchie
Grundlagen der Rechnerarchitektur Speicher Übersicht Speicherhierarchie Cache Grundlagen Verbessern der Cache Performance Virtueller Speicher SS 2012 Grundlagen der Rechnerarchitektur Speicher 2 Speicherhierarchie
Stellen Sie bitte den Cursor in die Spalte B2 und rufen die Funktion Sverweis auf. Es öffnet sich folgendes Dialogfenster
 Es gibt in Excel unter anderem die so genannten Suchfunktionen / Matrixfunktionen Damit können Sie Werte innerhalb eines bestimmten Bereichs suchen. Als Beispiel möchte ich die Funktion Sverweis zeigen.
Es gibt in Excel unter anderem die so genannten Suchfunktionen / Matrixfunktionen Damit können Sie Werte innerhalb eines bestimmten Bereichs suchen. Als Beispiel möchte ich die Funktion Sverweis zeigen.
Wie groß ist die Page Table?
 Wie groß ist die Page Table? Im vorigen (typischen) Beispiel verwenden wir 20 Bits zum indizieren der Page Table. Typischerweise spendiert man 32 Bits pro Tabellen Zeile (im Vorigen Beispiel brauchten
Wie groß ist die Page Table? Im vorigen (typischen) Beispiel verwenden wir 20 Bits zum indizieren der Page Table. Typischerweise spendiert man 32 Bits pro Tabellen Zeile (im Vorigen Beispiel brauchten
Datensicherung. Beschreibung der Datensicherung
 Datensicherung Mit dem Datensicherungsprogramm können Sie Ihre persönlichen Daten problemlos Sichern. Es ist möglich eine komplette Datensicherung durchzuführen, aber auch nur die neuen und geänderten
Datensicherung Mit dem Datensicherungsprogramm können Sie Ihre persönlichen Daten problemlos Sichern. Es ist möglich eine komplette Datensicherung durchzuführen, aber auch nur die neuen und geänderten
EasyWk DAS Schwimmwettkampfprogramm
 EasyWk DAS Schwimmwettkampfprogramm Arbeiten mit OMEGA ARES 21 EasyWk - DAS Schwimmwettkampfprogramm 1 Einleitung Diese Präsentation dient zur Darstellung der Zusammenarbeit zwischen EasyWk und der Zeitmessanlage
EasyWk DAS Schwimmwettkampfprogramm Arbeiten mit OMEGA ARES 21 EasyWk - DAS Schwimmwettkampfprogramm 1 Einleitung Diese Präsentation dient zur Darstellung der Zusammenarbeit zwischen EasyWk und der Zeitmessanlage
Grundlagen der Rechnerarchitektur
 Grundlagen der Rechnerarchitektur Speicher Übersicht Speicherhierarchie Cache Grundlagen Verbessern der Cache Performance Virtueller Speicher SS 2012 Grundlagen der Rechnerarchitektur Speicher 2 Speicherhierarchie
Grundlagen der Rechnerarchitektur Speicher Übersicht Speicherhierarchie Cache Grundlagen Verbessern der Cache Performance Virtueller Speicher SS 2012 Grundlagen der Rechnerarchitektur Speicher 2 Speicherhierarchie
Partitionieren in Vista und Windows 7/8
 Partitionieren in Vista und Windows 7/8 Windows Vista und Windows 7 können von Haus aus Festplatten partitionieren. Doch die Funktion ist etwas schwer zu entdecken, denn sie heißt "Volume verkleinern".
Partitionieren in Vista und Windows 7/8 Windows Vista und Windows 7 können von Haus aus Festplatten partitionieren. Doch die Funktion ist etwas schwer zu entdecken, denn sie heißt "Volume verkleinern".
RAID. Name: Artur Neumann
 Name: Inhaltsverzeichnis 1 Was ist RAID 3 1.1 RAID-Level... 3 2 Wozu RAID 3 3 Wie werden RAID Gruppen verwaltet 3 3.1 Software RAID... 3 3.2 Hardware RAID... 4 4 Die Verschiedenen RAID-Level 4 4.1 RAID
Name: Inhaltsverzeichnis 1 Was ist RAID 3 1.1 RAID-Level... 3 2 Wozu RAID 3 3 Wie werden RAID Gruppen verwaltet 3 3.1 Software RAID... 3 3.2 Hardware RAID... 4 4 Die Verschiedenen RAID-Level 4 4.1 RAID
In 15 einfachen Schritten zum mobilen PC mit Paragon Drive Copy 10 und Microsoft Windows Virtual PC
 PARAGON Technologie GmbH, Systemprogrammierung Heinrich-von-Stephan-Str. 5c 79100 Freiburg, Germany Tel. +49 (0) 761 59018201 Fax +49 (0) 761 59018130 Internet www.paragon-software.com Email sales@paragon-software.com
PARAGON Technologie GmbH, Systemprogrammierung Heinrich-von-Stephan-Str. 5c 79100 Freiburg, Germany Tel. +49 (0) 761 59018201 Fax +49 (0) 761 59018130 Internet www.paragon-software.com Email sales@paragon-software.com
Konzepte von Betriebssystemkomponenten Disk-Caches und Dateizugriff
 Konzepte von Betriebssystemkomponenten Disk-Caches und Dateizugriff von Athanasia Kaisa Grundzüge eines Zwischenspeichers Verschiedene Arten von Zwischenspeicher Plattenzwischenspeicher in LINUX Dateizugriff
Konzepte von Betriebssystemkomponenten Disk-Caches und Dateizugriff von Athanasia Kaisa Grundzüge eines Zwischenspeichers Verschiedene Arten von Zwischenspeicher Plattenzwischenspeicher in LINUX Dateizugriff
Primzahlen und RSA-Verschlüsselung
 Primzahlen und RSA-Verschlüsselung Michael Fütterer und Jonathan Zachhuber 1 Einiges zu Primzahlen Ein paar Definitionen: Wir bezeichnen mit Z die Menge der positiven und negativen ganzen Zahlen, also
Primzahlen und RSA-Verschlüsselung Michael Fütterer und Jonathan Zachhuber 1 Einiges zu Primzahlen Ein paar Definitionen: Wir bezeichnen mit Z die Menge der positiven und negativen ganzen Zahlen, also
Schreiben von Pages. Schreiben einer Page in den Swap Space ist sehr teuer (kostet millionen von CPU Zyklen).
.") Schreiben von Pages Schreiben einer Page in den Swap Space ist sehr teuer (kostet millionen von CPU Zyklen). Write Through Strategie (siehe Abschnitt über Caching) ist hier somit nicht sinnvoll. Eine sinnvolle
Schreiben von Pages Schreiben einer Page in den Swap Space ist sehr teuer (kostet millionen von CPU Zyklen). Write Through Strategie (siehe Abschnitt über Caching) ist hier somit nicht sinnvoll. Eine sinnvolle
Lizenzen auschecken. Was ist zu tun?
 Use case Lizenzen auschecken Ihr Unternehmen hat eine Netzwerk-Commuterlizenz mit beispielsweise 4 Lizenzen. Am Freitag wollen Sie Ihren Laptop mit nach Hause nehmen, um dort am Wochenende weiter zu arbeiten.
Use case Lizenzen auschecken Ihr Unternehmen hat eine Netzwerk-Commuterlizenz mit beispielsweise 4 Lizenzen. Am Freitag wollen Sie Ihren Laptop mit nach Hause nehmen, um dort am Wochenende weiter zu arbeiten.
Wichtige Hinweise zu den neuen Orientierungshilfen der Architekten-/Objektplanerverträge
 Wichtige Hinweise zu den neuen Orientierungshilfen der Architekten-/Objektplanerverträge Ab der Version forma 5.5 handelt es sich bei den Orientierungshilfen der Architekten-/Objektplanerverträge nicht
Wichtige Hinweise zu den neuen Orientierungshilfen der Architekten-/Objektplanerverträge Ab der Version forma 5.5 handelt es sich bei den Orientierungshilfen der Architekten-/Objektplanerverträge nicht
Von Bits, Bytes und Raid
 Von Bits, Bytes und Raid Eine Schnuppervorlesung zum Kennenlernen eines Datenspeichers um Bits und Bytes zu unterscheiden um Raid-Festplattensysteme zu verstehen Inhalt Speicherzellen sind elektronische
Von Bits, Bytes und Raid Eine Schnuppervorlesung zum Kennenlernen eines Datenspeichers um Bits und Bytes zu unterscheiden um Raid-Festplattensysteme zu verstehen Inhalt Speicherzellen sind elektronische
Mikrocontroller Grundlagen. Markus Koch April 2011
 Mikrocontroller Grundlagen Markus Koch April 2011 Übersicht Was ist ein Mikrocontroller Aufbau (CPU/RAM/ROM/Takt/Peripherie) Unterschied zum Mikroprozessor Unterschiede der Controllerarten Unterschiede
Mikrocontroller Grundlagen Markus Koch April 2011 Übersicht Was ist ein Mikrocontroller Aufbau (CPU/RAM/ROM/Takt/Peripherie) Unterschied zum Mikroprozessor Unterschiede der Controllerarten Unterschiede
Formular»Fragenkatalog BIM-Server«
 Formular»Fragenkatalog BIM-Server«Um Ihnen so schnell wie möglich zu helfen, benötigen wir Ihre Mithilfe. Nur Sie vor Ort kennen Ihr Problem, und Ihre Installationsumgebung. Bitte füllen Sie dieses Dokument
Formular»Fragenkatalog BIM-Server«Um Ihnen so schnell wie möglich zu helfen, benötigen wir Ihre Mithilfe. Nur Sie vor Ort kennen Ihr Problem, und Ihre Installationsumgebung. Bitte füllen Sie dieses Dokument
Professionelle Seminare im Bereich MS-Office
 Der Name BEREICH.VERSCHIEBEN() ist etwas unglücklich gewählt. Man kann mit der Funktion Bereiche zwar verschieben, man kann Bereiche aber auch verkleinern oder vergrößern. Besser wäre es, die Funktion
Der Name BEREICH.VERSCHIEBEN() ist etwas unglücklich gewählt. Man kann mit der Funktion Bereiche zwar verschieben, man kann Bereiche aber auch verkleinern oder vergrößern. Besser wäre es, die Funktion
Wie halte ich Ordnung auf meiner Festplatte?
 Wie halte ich Ordnung auf meiner Festplatte? Was hältst du von folgender Ordnung? Du hast zu Hause einen Schrank. Alles was dir im Wege ist, Zeitungen, Briefe, schmutzige Wäsche, Essensreste, Küchenabfälle,
Wie halte ich Ordnung auf meiner Festplatte? Was hältst du von folgender Ordnung? Du hast zu Hause einen Schrank. Alles was dir im Wege ist, Zeitungen, Briefe, schmutzige Wäsche, Essensreste, Küchenabfälle,
Teil VIII Von Neumann Rechner 1
 Teil VIII Von Neumann Rechner 1 Grundlegende Architektur Zentraleinheit: Central Processing Unit (CPU) Ausführen von Befehlen und Ablaufsteuerung Speicher: Memory Ablage von Daten und Programmen Read Only
Teil VIII Von Neumann Rechner 1 Grundlegende Architektur Zentraleinheit: Central Processing Unit (CPU) Ausführen von Befehlen und Ablaufsteuerung Speicher: Memory Ablage von Daten und Programmen Read Only
TeamSpeak3 Einrichten
 TeamSpeak3 Einrichten Version 1.0.3 24. April 2012 StreamPlus UG Es ist untersagt dieses Dokument ohne eine schriftliche Genehmigung der StreamPlus UG vollständig oder auszugsweise zu reproduzieren, vervielfältigen
TeamSpeak3 Einrichten Version 1.0.3 24. April 2012 StreamPlus UG Es ist untersagt dieses Dokument ohne eine schriftliche Genehmigung der StreamPlus UG vollständig oder auszugsweise zu reproduzieren, vervielfältigen
Spotlight 5 Gründe für die Sicherung auf NAS-Geräten
 Spotlight 5 Gründe für die Sicherung auf NAS-Geräten NovaStor Inhaltsverzeichnis Skalierbar. Von klein bis komplex.... 3 Kein jonglieren mehr mit Wechselmedien... 3 Zentralisiertes Backup... 4 Datensicherheit,
Spotlight 5 Gründe für die Sicherung auf NAS-Geräten NovaStor Inhaltsverzeichnis Skalierbar. Von klein bis komplex.... 3 Kein jonglieren mehr mit Wechselmedien... 3 Zentralisiertes Backup... 4 Datensicherheit,
Verwendung des Terminalservers der MUG
 Verwendung des Terminalservers der MUG Inhalt Allgemeines... 1 Installation des ICA-Client... 1 An- und Abmeldung... 4 Datentransfer vom/zum Terminalserver... 5 Allgemeines Die Medizinische Universität
Verwendung des Terminalservers der MUG Inhalt Allgemeines... 1 Installation des ICA-Client... 1 An- und Abmeldung... 4 Datentransfer vom/zum Terminalserver... 5 Allgemeines Die Medizinische Universität
Updatehinweise für die Version forma 5.5.5
 Updatehinweise für die Version forma 5.5.5 Seit der Version forma 5.5.0 aus 2012 gibt es nur noch eine Office-Version und keine StandAlone-Version mehr. Wenn Sie noch mit der alten Version forma 5.0.x
Updatehinweise für die Version forma 5.5.5 Seit der Version forma 5.5.0 aus 2012 gibt es nur noch eine Office-Version und keine StandAlone-Version mehr. Wenn Sie noch mit der alten Version forma 5.0.x
Inhalt. 1 Einleitung AUTOMATISCHE DATENSICHERUNG AUF EINEN CLOUDSPEICHER
 AUTOMATISCHE DATENSICHERUNG AUF EINEN CLOUDSPEICHER Inhalt 1 Einleitung... 1 2 Einrichtung der Aufgabe für die automatische Sicherung... 2 2.1 Die Aufgabenplanung... 2 2.2 Der erste Testlauf... 9 3 Problembehebung...
AUTOMATISCHE DATENSICHERUNG AUF EINEN CLOUDSPEICHER Inhalt 1 Einleitung... 1 2 Einrichtung der Aufgabe für die automatische Sicherung... 2 2.1 Die Aufgabenplanung... 2 2.2 Der erste Testlauf... 9 3 Problembehebung...
disk2vhd Wie sichere ich meine Daten von Windows XP? Vorwort 1 Sichern der Festplatte 2
 disk2vhd Wie sichere ich meine Daten von Windows XP? Inhalt Thema Seite Vorwort 1 Sichern der Festplatte 2 Einbinden der Sicherung als Laufwerk für Windows Vista & Windows 7 3 Einbinden der Sicherung als
disk2vhd Wie sichere ich meine Daten von Windows XP? Inhalt Thema Seite Vorwort 1 Sichern der Festplatte 2 Einbinden der Sicherung als Laufwerk für Windows Vista & Windows 7 3 Einbinden der Sicherung als
Anleitung über den Umgang mit Schildern
 Anleitung über den Umgang mit Schildern -Vorwort -Wo bekommt man Schilder? -Wo und wie speichert man die Schilder? -Wie füge ich die Schilder in meinen Track ein? -Welche Bauteile kann man noch für Schilder
Anleitung über den Umgang mit Schildern -Vorwort -Wo bekommt man Schilder? -Wo und wie speichert man die Schilder? -Wie füge ich die Schilder in meinen Track ein? -Welche Bauteile kann man noch für Schilder
Installation und Inbetriebnahme von SolidWorks
 Inhaltsverzeichnis FAKULTÄT FÜR INGENIEURWISSENSCHAFTEN I Prof. Dr.-Ing. Frank Lobeck Installation und Inbetriebnahme von SolidWorks Inhaltsverzeichnis Inhaltsverzeichnis... I 1. Einleitung... 1 2. Installation...
Inhaltsverzeichnis FAKULTÄT FÜR INGENIEURWISSENSCHAFTEN I Prof. Dr.-Ing. Frank Lobeck Installation und Inbetriebnahme von SolidWorks Inhaltsverzeichnis Inhaltsverzeichnis... I 1. Einleitung... 1 2. Installation...
L10N-Manager 3. Netzwerktreffen der Hochschulübersetzer/i nnen Mannheim 10. Mai 2016
 L10N-Manager 3. Netzwerktreffen der Hochschulübersetzer/i nnen Mannheim 10. Mai 2016 Referentin: Dr. Kelly Neudorfer Universität Hohenheim Was wir jetzt besprechen werden ist eine Frage, mit denen viele
L10N-Manager 3. Netzwerktreffen der Hochschulübersetzer/i nnen Mannheim 10. Mai 2016 Referentin: Dr. Kelly Neudorfer Universität Hohenheim Was wir jetzt besprechen werden ist eine Frage, mit denen viele
Nach der Anmeldung im Backend Bereich landen Sie im Kontrollzentrum, welches so aussieht:
 Beiträge erstellen in Joomla Nach der Anmeldung im Backend Bereich landen Sie im Kontrollzentrum, welches so aussieht: Abbildung 1 - Kontrollzentrum Von hier aus kann man zu verschiedene Einstellungen
Beiträge erstellen in Joomla Nach der Anmeldung im Backend Bereich landen Sie im Kontrollzentrum, welches so aussieht: Abbildung 1 - Kontrollzentrum Von hier aus kann man zu verschiedene Einstellungen
Lizenzierung von Windows Server 2012
 Lizenzierung von Windows Server 2012 Das Lizenzmodell von Windows Server 2012 Datacenter und Standard besteht aus zwei Komponenten: Prozessorlizenzen zur Lizenzierung der Serversoftware und CALs zur Lizenzierung
Lizenzierung von Windows Server 2012 Das Lizenzmodell von Windows Server 2012 Datacenter und Standard besteht aus zwei Komponenten: Prozessorlizenzen zur Lizenzierung der Serversoftware und CALs zur Lizenzierung
Leitfaden zur ersten Nutzung der R FOM Portable-Version für Windows (Version 1.0)
") Leitfaden zur ersten Nutzung der R FOM Portable-Version für Windows (Version 1.0) Peter Koos 03. Dezember 2015 0 Inhaltsverzeichnis 1 Voraussetzung... 3 2 Hintergrundinformationen... 3 2.1 Installationsarten...
Leitfaden zur ersten Nutzung der R FOM Portable-Version für Windows (Version 1.0) Peter Koos 03. Dezember 2015 0 Inhaltsverzeichnis 1 Voraussetzung... 3 2 Hintergrundinformationen... 3 2.1 Installationsarten...
Lassen Sie sich dieses sensationelle Projekt Schritt für Schritt erklären:
 Lassen Sie sich dieses sensationelle Projekt Schritt für Schritt erklären: Gold Line International Ltd. Seite 1 STELLEN SIE SICH VOR: Jeder Mensch auf der Erde gibt Ihnen 1,- Dollar Das wäre nicht schwer
Lassen Sie sich dieses sensationelle Projekt Schritt für Schritt erklären: Gold Line International Ltd. Seite 1 STELLEN SIE SICH VOR: Jeder Mensch auf der Erde gibt Ihnen 1,- Dollar Das wäre nicht schwer
2. Word-Dokumente verwalten
 2. Word-Dokumente verwalten In dieser Lektion lernen Sie... Word-Dokumente speichern und öffnen Neue Dokumente erstellen Dateiformate Was Sie für diese Lektion wissen sollten: Die Arbeitsumgebung von Word
2. Word-Dokumente verwalten In dieser Lektion lernen Sie... Word-Dokumente speichern und öffnen Neue Dokumente erstellen Dateiformate Was Sie für diese Lektion wissen sollten: Die Arbeitsumgebung von Word
Dropbox Schnellstart. Was ist Dropbox? Eignet sich Dropbox für mich?
 Dropbox Schnellstart Was ist Dropbox? Dropbox ist eine Software, die alle deine Computer über einen einzigen Ordner verknüpft. Dropbox bietet die einfachste Art, Dateien online zu sichern und zwischen
Dropbox Schnellstart Was ist Dropbox? Dropbox ist eine Software, die alle deine Computer über einen einzigen Ordner verknüpft. Dropbox bietet die einfachste Art, Dateien online zu sichern und zwischen
In 12 Schritten zum mobilen PC mit Paragon Drive Copy 11 und Microsoft Windows Virtual PC
 PARAGON Technologie GmbH, Systemprogrammierung Heinrich-von-Stephan-Str. 5c 79100 Freiburg, Germany Tel. +49 (0) 761 59018201 Fax +49 (0) 761 59018130 Internet www.paragon-software.com Email sales@paragon-software.com
PARAGON Technologie GmbH, Systemprogrammierung Heinrich-von-Stephan-Str. 5c 79100 Freiburg, Germany Tel. +49 (0) 761 59018201 Fax +49 (0) 761 59018130 Internet www.paragon-software.com Email sales@paragon-software.com
Konfiguration VLAN's. Konfiguration VLAN's IACBOX.COM. Version 2.0.1 Deutsch 01.07.2014
 Konfiguration VLAN's Version 2.0.1 Deutsch 01.07.2014 In diesem HOWTO wird die Konfiguration der VLAN's für das Surf-LAN der IAC-BOX beschrieben. Konfiguration VLAN's TITEL Inhaltsverzeichnis Inhaltsverzeichnis...
Konfiguration VLAN's Version 2.0.1 Deutsch 01.07.2014 In diesem HOWTO wird die Konfiguration der VLAN's für das Surf-LAN der IAC-BOX beschrieben. Konfiguration VLAN's TITEL Inhaltsverzeichnis Inhaltsverzeichnis...
DOKUMENTATION VOGELZUCHT 2015 PLUS
 DOKUMENTATION VOGELZUCHT 2015 PLUS Vogelzucht2015 App für Geräte mit Android Betriebssystemen Läuft nur in Zusammenhang mit einer Vollversion vogelzucht2015 auf einem PC. Zusammenfassung: a. Mit der APP
DOKUMENTATION VOGELZUCHT 2015 PLUS Vogelzucht2015 App für Geräte mit Android Betriebssystemen Läuft nur in Zusammenhang mit einer Vollversion vogelzucht2015 auf einem PC. Zusammenfassung: a. Mit der APP
Tapps mit XP-Mode unter Windows 7 64 bit (V2.0)
") Tapps mit XP-Mode unter Windows 7 64 bit (V2.0) 1 Einleitung... 2 2 Download und Installation... 3 2.1 Installation von WindowsXPMode_de-de.exe... 4 2.2 Installation von Windows6.1-KB958559-x64.msu...
Tapps mit XP-Mode unter Windows 7 64 bit (V2.0) 1 Einleitung... 2 2 Download und Installation... 3 2.1 Installation von WindowsXPMode_de-de.exe... 4 2.2 Installation von Windows6.1-KB958559-x64.msu...
Systeme 1. Kapitel 6. Nebenläufigkeit und wechselseitiger Ausschluss
 Systeme 1 Kapitel 6 Nebenläufigkeit und wechselseitiger Ausschluss Threads Die Adressräume verschiedener Prozesse sind getrennt und geschützt gegen den Zugriff anderer Prozesse. Threads sind leichtgewichtige
Systeme 1 Kapitel 6 Nebenläufigkeit und wechselseitiger Ausschluss Threads Die Adressräume verschiedener Prozesse sind getrennt und geschützt gegen den Zugriff anderer Prozesse. Threads sind leichtgewichtige
Memeo Instant Backup Kurzleitfaden. Schritt 1: Richten Sie Ihr kostenloses Memeo-Konto ein
 Einleitung Memeo Instant Backup ist eine einfache Backup-Lösung für eine komplexe digitale Welt. Durch automatisch und fortlaufende Sicherung Ihrer wertvollen Dateien auf Ihrem Laufwerk C:, schützt Memeo
Einleitung Memeo Instant Backup ist eine einfache Backup-Lösung für eine komplexe digitale Welt. Durch automatisch und fortlaufende Sicherung Ihrer wertvollen Dateien auf Ihrem Laufwerk C:, schützt Memeo
Kara-Programmierung AUFGABENSTELLUNG LERNPARCOURS. Abb. 1: Programmfenster. Welt neu erstellen; öffnen; erneut öffnen; speichern; speichern unter
 Kara-Programmierung AUFGABENSTELLUNG LERNPARCOURS Abb. 1: Programmfenster Welt neu erstellen; öffnen; erneut öffnen; speichern; speichern unter Programmfenster anzeigen Einstellungen öffnen Kara direkt
Kara-Programmierung AUFGABENSTELLUNG LERNPARCOURS Abb. 1: Programmfenster Welt neu erstellen; öffnen; erneut öffnen; speichern; speichern unter Programmfenster anzeigen Einstellungen öffnen Kara direkt
Albert HAYR Linux, IT and Open Source Expert and Solution Architect. Open Source professionell einsetzen
 Open Source professionell einsetzen 1 Mein Background Ich bin überzeugt von Open Source. Ich verwende fast nur Open Source privat und beruflich. Ich arbeite seit mehr als 10 Jahren mit Linux und Open Source.
Open Source professionell einsetzen 1 Mein Background Ich bin überzeugt von Open Source. Ich verwende fast nur Open Source privat und beruflich. Ich arbeite seit mehr als 10 Jahren mit Linux und Open Source.
Lizenzierung von SharePoint Server 2013
 Lizenzierung von SharePoint Server 2013 Das Lizenzmodell von SharePoint Server 2013 besteht aus zwei Komponenten: Serverlizenzen zur Lizenzierung der Serversoftware und CALs zur Lizenzierung der Zugriffe
Lizenzierung von SharePoint Server 2013 Das Lizenzmodell von SharePoint Server 2013 besteht aus zwei Komponenten: Serverlizenzen zur Lizenzierung der Serversoftware und CALs zur Lizenzierung der Zugriffe
Handbuch Fischertechnik-Einzelteiltabelle V3.7.3
 Handbuch Fischertechnik-Einzelteiltabelle V3.7.3 von Markus Mack Stand: Samstag, 17. April 2004 Inhaltsverzeichnis 1. Systemvorraussetzungen...3 2. Installation und Start...3 3. Anpassen der Tabelle...3
Handbuch Fischertechnik-Einzelteiltabelle V3.7.3 von Markus Mack Stand: Samstag, 17. April 2004 Inhaltsverzeichnis 1. Systemvorraussetzungen...3 2. Installation und Start...3 3. Anpassen der Tabelle...3
In diesem Tutorial lernen Sie, wie Sie einen Termin erfassen und verschiedene Einstellungen zu einem Termin vornehmen können.
 Tutorial: Wie erfasse ich einen Termin? In diesem Tutorial lernen Sie, wie Sie einen Termin erfassen und verschiedene Einstellungen zu einem Termin vornehmen können. Neben den allgemeinen Angaben zu einem
Tutorial: Wie erfasse ich einen Termin? In diesem Tutorial lernen Sie, wie Sie einen Termin erfassen und verschiedene Einstellungen zu einem Termin vornehmen können. Neben den allgemeinen Angaben zu einem
40-Tage-Wunder- Kurs. Umarme, was Du nicht ändern kannst.
 40-Tage-Wunder- Kurs Umarme, was Du nicht ändern kannst. Das sagt Wikipedia: Als Wunder (griechisch thauma) gilt umgangssprachlich ein Ereignis, dessen Zustandekommen man sich nicht erklären kann, so dass
40-Tage-Wunder- Kurs Umarme, was Du nicht ändern kannst. Das sagt Wikipedia: Als Wunder (griechisch thauma) gilt umgangssprachlich ein Ereignis, dessen Zustandekommen man sich nicht erklären kann, so dass
Er musste so eingerichtet werden, dass das D-Laufwerk auf das E-Laufwerk gespiegelt
 Inhaltsverzeichnis Aufgabe... 1 Allgemein... 1 Active Directory... 1 Konfiguration... 2 Benutzer erstellen... 3 Eigenes Verzeichnis erstellen... 3 Benutzerkonto erstellen... 3 Profil einrichten... 5 Berechtigungen
Inhaltsverzeichnis Aufgabe... 1 Allgemein... 1 Active Directory... 1 Konfiguration... 2 Benutzer erstellen... 3 Eigenes Verzeichnis erstellen... 3 Benutzerkonto erstellen... 3 Profil einrichten... 5 Berechtigungen
iphone-kontakte zu Exchange übertragen
 iphone-kontakte zu Exchange übertragen Übertragen von iphone-kontakten in ein Exchange Postfach Zunächst muss das iphone an den Rechner, an dem es üblicherweise synchronisiert wird, angeschlossen werden.
iphone-kontakte zu Exchange übertragen Übertragen von iphone-kontakten in ein Exchange Postfach Zunächst muss das iphone an den Rechner, an dem es üblicherweise synchronisiert wird, angeschlossen werden.
Kommunikations-Management
 Tutorial: Wie kann ich E-Mails schreiben? Im vorliegenden Tutorial lernen Sie, wie Sie in myfactory E-Mails schreiben können. In myfactory können Sie jederzeit schnell und einfach E-Mails verfassen egal
Tutorial: Wie kann ich E-Mails schreiben? Im vorliegenden Tutorial lernen Sie, wie Sie in myfactory E-Mails schreiben können. In myfactory können Sie jederzeit schnell und einfach E-Mails verfassen egal
Schritt-Schritt-Anleitung zum mobilen PC mit Paragon Drive Copy 10 und VMware Player
 PARAGON Technologie GmbH, Systemprogrammierung Heinrich-von-Stephan-Str. 5c 79100 Freiburg, Germany Tel. +49 (0) 761 59018201 Fax +49 (0) 761 59018130 Internet www.paragon-software.com Email sales@paragon-software.com
PARAGON Technologie GmbH, Systemprogrammierung Heinrich-von-Stephan-Str. 5c 79100 Freiburg, Germany Tel. +49 (0) 761 59018201 Fax +49 (0) 761 59018130 Internet www.paragon-software.com Email sales@paragon-software.com
SILBER SURFER. PC-Treffen der Arbeiterwohlfahrt, Ortsverein Sehnde. PC Internet / Cloud. Leitfaden zur Schulung
 Reiner Luck Bismarckstrasse 6 31319 Sehnde SILBER SURFER PC-Treffen der Arbeiterwohlfahrt, Ortsverein Sehnde PC Internet / Cloud Leitfaden zur Schulung erstellt Datum Version Reiner Luck 13.03.12 1.0 PC
Reiner Luck Bismarckstrasse 6 31319 Sehnde SILBER SURFER PC-Treffen der Arbeiterwohlfahrt, Ortsverein Sehnde PC Internet / Cloud Leitfaden zur Schulung erstellt Datum Version Reiner Luck 13.03.12 1.0 PC
Whitepaper. Produkt: combit Relationship Manager / address manager. Dateiabgleich im Netzwerk über Offlinedateien
 combit GmbH Untere Laube 30 78462 Konstanz Whitepaper Produkt: combit Relationship Manager / address manager Dateiabgleich im Netzwerk über Offlinedateien Dateiabgleich im Netzwerk über Offlinedateien
combit GmbH Untere Laube 30 78462 Konstanz Whitepaper Produkt: combit Relationship Manager / address manager Dateiabgleich im Netzwerk über Offlinedateien Dateiabgleich im Netzwerk über Offlinedateien
.htaccess HOWTO. zum Schutz von Dateien und Verzeichnissen mittels Passwortabfrage
 .htaccess HOWTO zum Schutz von Dateien und Verzeichnissen mittels Passwortabfrage Stand: 21.06.2015 Inhaltsverzeichnis 1. Vorwort...3 2. Verwendung...4 2.1 Allgemeines...4 2.1 Das Aussehen der.htaccess
.htaccess HOWTO zum Schutz von Dateien und Verzeichnissen mittels Passwortabfrage Stand: 21.06.2015 Inhaltsverzeichnis 1. Vorwort...3 2. Verwendung...4 2.1 Allgemeines...4 2.1 Das Aussehen der.htaccess
Zeichen bei Zahlen entschlüsseln
 Zeichen bei Zahlen entschlüsseln In diesem Kapitel... Verwendung des Zahlenstrahls Absolut richtige Bestimmung von absoluten Werten Operationen bei Zahlen mit Vorzeichen: Addieren, Subtrahieren, Multiplizieren
Zeichen bei Zahlen entschlüsseln In diesem Kapitel... Verwendung des Zahlenstrahls Absolut richtige Bestimmung von absoluten Werten Operationen bei Zahlen mit Vorzeichen: Addieren, Subtrahieren, Multiplizieren
Erklärung zum Internet-Bestellschein
 Erklärung zum Internet-Bestellschein Herzlich Willkommen bei Modellbahnbau Reinhardt. Auf den nächsten Seiten wird Ihnen mit hilfreichen Bildern erklärt, wie Sie den Internet-Bestellschein ausfüllen und
Erklärung zum Internet-Bestellschein Herzlich Willkommen bei Modellbahnbau Reinhardt. Auf den nächsten Seiten wird Ihnen mit hilfreichen Bildern erklärt, wie Sie den Internet-Bestellschein ausfüllen und
Novell Client. Anleitung. zur Verfügung gestellt durch: ZID Dezentrale Systeme. Februar 2015. ZID Dezentrale Systeme
 Novell Client Anleitung zur Verfügung gestellt durch: ZID Dezentrale Systeme Februar 2015 Seite 2 von 8 Mit der Einführung von Windows 7 hat sich die Novell-Anmeldung sehr stark verändert. Der Novell Client
Novell Client Anleitung zur Verfügung gestellt durch: ZID Dezentrale Systeme Februar 2015 Seite 2 von 8 Mit der Einführung von Windows 7 hat sich die Novell-Anmeldung sehr stark verändert. Der Novell Client
Das Persönliche Budget in verständlicher Sprache
 Das Persönliche Budget in verständlicher Sprache Das Persönliche Budget mehr Selbstbestimmung, mehr Selbstständigkeit, mehr Selbstbewusstsein! Dieser Text soll den behinderten Menschen in Westfalen-Lippe,
Das Persönliche Budget in verständlicher Sprache Das Persönliche Budget mehr Selbstbestimmung, mehr Selbstständigkeit, mehr Selbstbewusstsein! Dieser Text soll den behinderten Menschen in Westfalen-Lippe,
IntelliRestore Seedload und Notfallwiederherstellung
 IntelliRestore Datensicherung IntelliRestore Seedload und Notfallwiederherstellung Daten. Sichern. Online Vorwort Auch größere Datenmengen lassen sich für gewöhnlich schnell über den IntelliRestore SoftwareClient
IntelliRestore Datensicherung IntelliRestore Seedload und Notfallwiederherstellung Daten. Sichern. Online Vorwort Auch größere Datenmengen lassen sich für gewöhnlich schnell über den IntelliRestore SoftwareClient
Übersicht. Nebenläufige Programmierung. Praxis und Semantik. Einleitung. Sequentielle und nebenläufige Programmierung. Warum ist. interessant?
 Übersicht Aktuelle Themen zu Informatik der Systeme: Nebenläufige Programmierung: Praxis und Semantik Einleitung 1 2 der nebenläufigen Programmierung WS 2011/12 Stand der Folien: 18. Oktober 2011 1 TIDS
Übersicht Aktuelle Themen zu Informatik der Systeme: Nebenläufige Programmierung: Praxis und Semantik Einleitung 1 2 der nebenläufigen Programmierung WS 2011/12 Stand der Folien: 18. Oktober 2011 1 TIDS
Eine Einführung in die Installation und Nutzung von cygwin
 Eine Einführung in die Installation und Nutzung von cygwin 1 1. Woher bekomme ich cygwin? Cygwin ist im Internet auf http://www.cygwin.com/ zu finden. Dort lädt man sich die setup.exe in ein beliebiges
Eine Einführung in die Installation und Nutzung von cygwin 1 1. Woher bekomme ich cygwin? Cygwin ist im Internet auf http://www.cygwin.com/ zu finden. Dort lädt man sich die setup.exe in ein beliebiges
Registrierung am Elterninformationssysytem: ClaXss Infoline
 elektronisches ElternInformationsSystem (EIS) Klicken Sie auf das Logo oder geben Sie in Ihrem Browser folgende Adresse ein: https://kommunalersprien.schule-eltern.info/infoline/claxss Diese Anleitung
elektronisches ElternInformationsSystem (EIS) Klicken Sie auf das Logo oder geben Sie in Ihrem Browser folgende Adresse ein: https://kommunalersprien.schule-eltern.info/infoline/claxss Diese Anleitung
Universität Bielefeld Technische Fakultät AG Rechnernetze und verteilte Systeme. Vorlesung 4: Memory. Wintersemester 2001/2002. Peter B.
 Universität Bielefeld Technische Fakultät AG Rechnernetze und verteilte Systeme Vorlesung 4: Memory Peter B. Ladkin Address Translation Die Adressen, die das CPU benutzt, sind nicht identisch mit den Adressen,
Universität Bielefeld Technische Fakultät AG Rechnernetze und verteilte Systeme Vorlesung 4: Memory Peter B. Ladkin Address Translation Die Adressen, die das CPU benutzt, sind nicht identisch mit den Adressen,
icloud nicht neu, aber doch irgendwie anders
 Kapitel 6 In diesem Kapitel zeigen wir Ihnen, welche Dienste die icloud beim Abgleich von Dateien und Informationen anbietet. Sie lernen icloud Drive kennen, den Fotostream, den icloud-schlüsselbund und
Kapitel 6 In diesem Kapitel zeigen wir Ihnen, welche Dienste die icloud beim Abgleich von Dateien und Informationen anbietet. Sie lernen icloud Drive kennen, den Fotostream, den icloud-schlüsselbund und
Stundenerfassung Version 1.8 Anleitung Arbeiten mit Replikaten
 Stundenerfassung Version 1.8 Anleitung Arbeiten mit Replikaten 2008 netcadservice GmbH netcadservice GmbH Augustinerstraße 3 D-83395 Freilassing Dieses Programm ist urheberrechtlich geschützt. Eine Weitergabe
Stundenerfassung Version 1.8 Anleitung Arbeiten mit Replikaten 2008 netcadservice GmbH netcadservice GmbH Augustinerstraße 3 D-83395 Freilassing Dieses Programm ist urheberrechtlich geschützt. Eine Weitergabe
Kapitel 6 Anfragebearbeitung
 LUDWIG- MAXIMILIANS- UNIVERSITY MUNICH DEPARTMENT INSTITUTE FOR INFORMATICS DATABASE Skript zur Vorlesung: Datenbanksysteme II Sommersemester 2014 Kapitel 6 Anfragebearbeitung Vorlesung: PD Dr. Peer Kröger
LUDWIG- MAXIMILIANS- UNIVERSITY MUNICH DEPARTMENT INSTITUTE FOR INFORMATICS DATABASE Skript zur Vorlesung: Datenbanksysteme II Sommersemester 2014 Kapitel 6 Anfragebearbeitung Vorlesung: PD Dr. Peer Kröger
Mediumwechsel - VR-NetWorld Software
 Mediumwechsel - VR-NetWorld Software Die personalisierte VR-NetWorld-Card wird mit einem festen Laufzeitende ausgeliefert. Am Ende der Laufzeit müssen Sie die bestehende VR-NetWorld-Card gegen eine neue
Mediumwechsel - VR-NetWorld Software Die personalisierte VR-NetWorld-Card wird mit einem festen Laufzeitende ausgeliefert. Am Ende der Laufzeit müssen Sie die bestehende VR-NetWorld-Card gegen eine neue
Betriebssysteme K_Kap11C: Diskquota, Raid
 Betriebssysteme K_Kap11C: Diskquota, Raid 1 Diskquota Mehrbenutzer-BS brauchen einen Mechanismus zur Einhaltung der Plattenkontingente (disk quotas) Quota-Tabelle enthält Kontingenteinträge aller Benutzer
Betriebssysteme K_Kap11C: Diskquota, Raid 1 Diskquota Mehrbenutzer-BS brauchen einen Mechanismus zur Einhaltung der Plattenkontingente (disk quotas) Quota-Tabelle enthält Kontingenteinträge aller Benutzer
Backup-Server einrichten
 Einsteiger Fortgeschrittene Profis markus.meinl@m-quest.ch Version.0 Voraussetzungen für diesen Workshop. Die M-Quest Suite 2005-M oder höher ist auf diesem Rechner installiert 2. Das Produkt M-Lock ist
Einsteiger Fortgeschrittene Profis markus.meinl@m-quest.ch Version.0 Voraussetzungen für diesen Workshop. Die M-Quest Suite 2005-M oder höher ist auf diesem Rechner installiert 2. Das Produkt M-Lock ist
S/W mit PhotoLine. Inhaltsverzeichnis. PhotoLine
 PhotoLine S/W mit PhotoLine Erstellt mit Version 16.11 Ich liebe Schwarzweiß-Bilder und schaue mir neidisch die Meisterwerke an, die andere Fotografen zustande bringen. Schon lange versuche ich, auch so
PhotoLine S/W mit PhotoLine Erstellt mit Version 16.11 Ich liebe Schwarzweiß-Bilder und schaue mir neidisch die Meisterwerke an, die andere Fotografen zustande bringen. Schon lange versuche ich, auch so
RS-Flip Flop, D-Flip Flop, J-K-Flip Flop, Zählschaltungen
 Elektronik Praktikum / Digitaler Teil Name: Jens Wiechula, Philipp Fischer Leitung: Prof. Dr. U. Lynen Protokoll: Philipp Fischer Versuch: 3 Datum: 24.06.01 RS-Flip Flop, D-Flip Flop, J-K-Flip Flop, Zählschaltungen
Elektronik Praktikum / Digitaler Teil Name: Jens Wiechula, Philipp Fischer Leitung: Prof. Dr. U. Lynen Protokoll: Philipp Fischer Versuch: 3 Datum: 24.06.01 RS-Flip Flop, D-Flip Flop, J-K-Flip Flop, Zählschaltungen
Outlook-Daten komplett sichern
 Outlook-Daten komplett sichern Komplettsicherung beinhaltet alle Daten wie auch Kontakte und Kalender eines Benutzers. Zu diesem Zweck öffnen wir OUTLOOK und wählen Datei -> Optionen und weiter geht es
Outlook-Daten komplett sichern Komplettsicherung beinhaltet alle Daten wie auch Kontakte und Kalender eines Benutzers. Zu diesem Zweck öffnen wir OUTLOOK und wählen Datei -> Optionen und weiter geht es
32-Bit Microcontroller based, passive and intelligent UHF RFID Gen2 Tag. Zürcher Fachhochschule
 32-Bit Microcontroller based, passive and intelligent UHF RFID Gen2 Tag Inhalt Vorgeschichte Was wurde erreicht Hardware Energy Micro Microcontroller µctag Plattform EPC Gen2 Tag Standard Protokoll-Vorgaben
32-Bit Microcontroller based, passive and intelligent UHF RFID Gen2 Tag Inhalt Vorgeschichte Was wurde erreicht Hardware Energy Micro Microcontroller µctag Plattform EPC Gen2 Tag Standard Protokoll-Vorgaben
SAP Memory Tuning. Erfahrungsbericht Fritz Egger GmbH & Co OG. Datenbanken sind unsere Welt www.dbmasters.at
 SAP Memory Tuning Erfahrungsbericht Fritz Egger GmbH & Co OG Wie alles begann Wir haben bei Egger schon öfter auch im SAP Bereich Analysen und Tuning durchgeführt. Im Jan 2014 hatten wir einen Workshop
SAP Memory Tuning Erfahrungsbericht Fritz Egger GmbH & Co OG Wie alles begann Wir haben bei Egger schon öfter auch im SAP Bereich Analysen und Tuning durchgeführt. Im Jan 2014 hatten wir einen Workshop
Verwendung des IDS Backup Systems unter Windows 2000
 Verwendung des IDS Backup Systems unter Windows 2000 1. Download der Software Netbackup2000 Unter der Adresse http://www.ids-mannheim.de/zdv/lokal/dienste/backup finden Sie die Software Netbackup2000.
Verwendung des IDS Backup Systems unter Windows 2000 1. Download der Software Netbackup2000 Unter der Adresse http://www.ids-mannheim.de/zdv/lokal/dienste/backup finden Sie die Software Netbackup2000.
Arbeiten mit dem neuen WU Fileshare unter Windows 7
 Arbeiten mit dem neuen WU Fileshare unter Windows 7 Mit dem neuen WU Fileshare bieten Ihnen die IT-Services einen flexibleren und einfacheren Zugriff auf Ihre Dateien unabhängig davon, ob Sie sich im Büro
Arbeiten mit dem neuen WU Fileshare unter Windows 7 Mit dem neuen WU Fileshare bieten Ihnen die IT-Services einen flexibleren und einfacheren Zugriff auf Ihre Dateien unabhängig davon, ob Sie sich im Büro
Mediumwechsel - VR-NetWorld Software
 Mediumwechsel - VR-NetWorld Software Die personalisierte VR-BankCard mit HBCI wird mit einem festen Laufzeitende ausgeliefert. Am Ende der Laufzeit müssen Sie die bestehende VR-BankCard gegen eine neue
Mediumwechsel - VR-NetWorld Software Die personalisierte VR-BankCard mit HBCI wird mit einem festen Laufzeitende ausgeliefert. Am Ende der Laufzeit müssen Sie die bestehende VR-BankCard gegen eine neue