Anwendung der Business Analytics
|
|
|
- Agnes Martin
- vor 8 Jahren
- Abrufe
Transkript
1 Anwendung der Business Analytics TDWI 2013 München Prof. Dr. Carsten Felden Dipl.-Wirt.-Inf. Claudia Koschtial Technische Universität Bergakademie Freiberg (Sachsen) Institut für Wirtschaftsinformatik Silbermannstraße 2, Freiberg (Sachsen), Deutschland
 Institut für Wirtschaftsinformatik Silbermannstraße 2,")
2 Die Dozenten Univ.-Prof. Dr. Carsten Felden Institut für Wirtschaftsinformatik an der Technischen Universität Bergakademie Freiberg (Sachsen). Geschäftsführer der Marmeladenbaum GmbH ( Gutachter für internationale Journals und eingeladener Sprecher auf internationalen Veranstaltungen im Themengebiet der Business Intelligence. Dipl.-Wirt.-Inf. Claudia Koschtial Institut für Wirtschaftsinformatik an der Technischen Universität Bergakademie Freiberg (Sachsen). Geschäftsführerin der Marmeladenbaum GmbH 2
 Gutachter für internationale Journals und eingeladener Sprecher auf internationalen Veranstaltungen im Themengebiet der")
3 Agenda Einführung und Einordnung Business Analytics Begriffe Analytische Fähigkeiten Hype Cycle Analytischer Prozess Anwendungsfelder und Verfahren Assoziationsanalyse Entscheidungsbaum Neuronale Netze Clusterverfahren Praktischer Teil 3

4 Eine kurze Geschichte der Business Analytics Business Analytics beschreibt den Prozess der so genannten Datenveredelung. Es ist ein strategisches Werkzeug für Entscheidungsträger in Unternehmen. Analyticslösungen kommen branchenübergreifend zum Einsatz. Ziel ist es, Antworten nicht nur auf die Frage: Was war?, sondern auch: Was wird sein? zu finden. [Felden, 2009] 4

5 Vier Typen der analytischen Fähigkeit nach Gartner 5

6 Hype Cycle für Business Intelligence (2007) 6

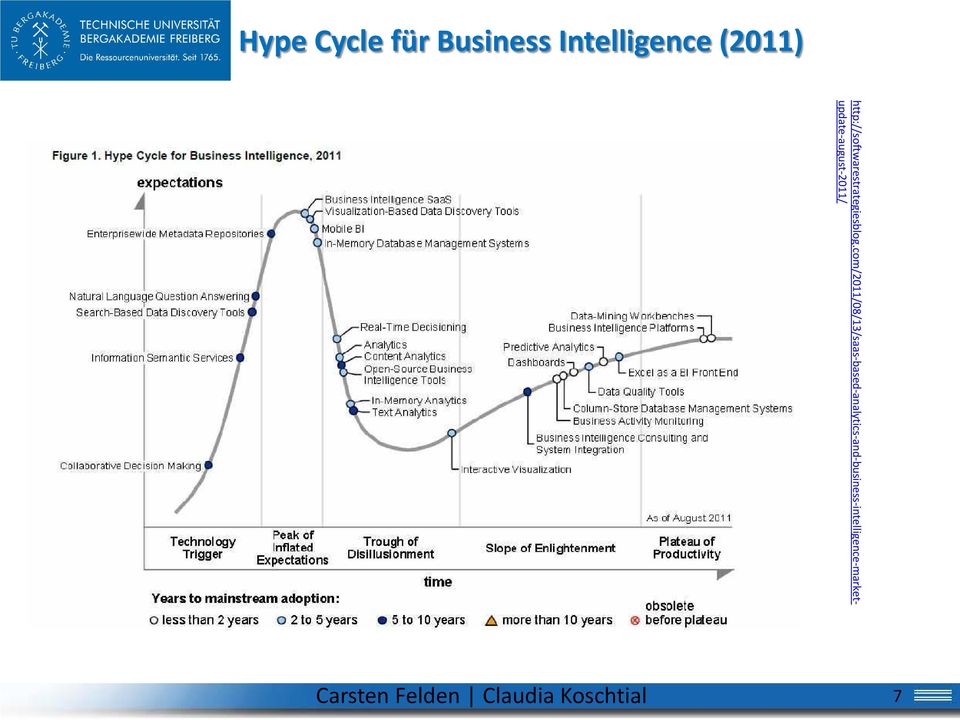
7 Hype Cycle für Business Intelligence (2011) 7
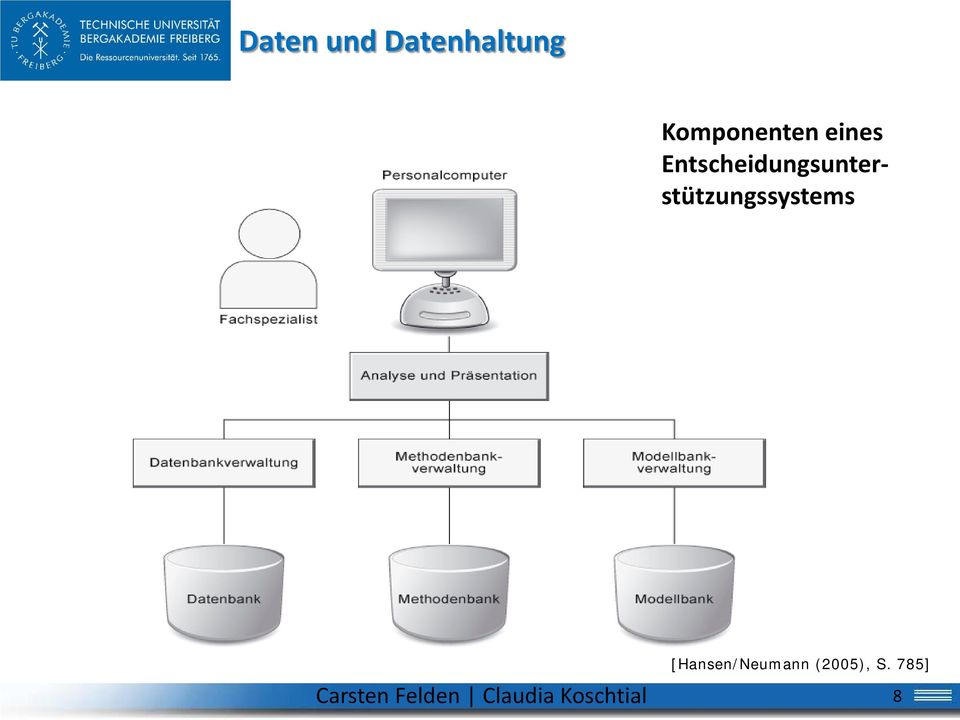
8 Daten und Datenhaltung Komponenten eines Entscheidungsunterstützungssystems [Hansen/Neumann (2005), S. 785] 8
9 Statistische Grundlagen Maschinelles Lernen und Data Mining I Knowledge Discovery in Databases (KDD) beschreibt den.. non-trivial process of identifying valid, novel, potentially useful, and ultimately understandable patterns in data.. [Fayyad et al. 1996] Prozess, umfangreiche Datenbestände implizit vorhandenes Wissen entdecken Knowledge Extraction Data Archaeology Data Analysis 9

10 Statistische Grundlagen Prozessmodelle Knowledge Discovery in Databases I Data Mining Interpretation Wissen Transformation Muster Vorverarbeitung Auswahl Transformierte Daten Vorverarbeitete Daten Datenbank Zieldatenbestand 10

11 Statistische Grundlagen Klassische Aufgabenstellungen Aufgaben Verfahren Klassifikation/ Regression Clusterung Abhängigkeitsanalyse Entscheidungsbäume Künstliche Neuronale Netze Clusterverfahren Assoziationsanalyse 11

12 Statistische Grundlagen Datenbereinigung Name Alter Region Stadt Kinder Meier 56 Sachsen Freiberg 3 Schulz 32 Sachsen Freiberg Yes Muster Sachsen Dresden 2 Müller 18 Sachsen Freiburg 4 fehlende Werte fehlerhafte Werte Redundanz 12

13 Agenda Einführung und Einordnung Business Analytics Begriffe Analytische Fähigkeiten Hype Cycle Analytischer Prozess Anwendungsfelder und Verfahren Assoziationsanalyse Entscheidungsbaum Neuronale Netze Clusterverfahren Praktischer Teil 13

14 Analyse des Kundenverhaltens Assoziationsanalyse Ziel der Assoziationsanalyse ist das Erkennen und Bewerten von gemeinsam auftretenden Datenelementen (Items). Items können Elemente von Mengen oder einzelne Attributwerte von Datensätzen sein. Eine Menge von Items wird als Itemset oder auch Itemmenge bezeichnet. Beispiel: Items in Mengen: Warenkorb {Artikel A, Artikel B} Items im Datensatz: (PLZ=47057,..., Käufergruppe=A) Voraussetzung: Vorhandensein einer Datenbasis bestehend aus einzelnen Transaktionen (z. B. Menge von Kassenbons) 14

15 Analyse des Kundenverhaltens Ergebnisse der Assoziationsanalyse Assoziationsregel: allgemeiner: WENN Item a DANN Item b Kurz: {a} {b} WENN Itemset X DANN Itemset Y Kurz: X Y Beispiel: WENN Artikel a und Artikel b gekauft werden, DANN wird auch Artikel c gekauft. 15

16 Analyse des Kundenverhaltens Einsatzgebiete der Assoziationsanalyse Warenkorbanalyse Gesundheitswesen Banken Telekommunikation Technik Text-Mining Web-Log-Mining Welche Verbundkäufe werden getätigt? Welche Behandlungsmethoden werden nacheinander verwendet? Welche Kunden sind abwanderungsgefährdet? Optimierung von Prozessabläufen bei telefonischen Serviceanforderungen Fehlerentdeckung in Fertigungsprozessen Finden von Begriffszusammenhängen Auffinden von Zugriffsmustern auf Web-Sites 16

17 Analyse des Kundenverhaltens Bewertung von Assoziationsregeln Einfache Regeln: WENN Itemset X DANN Itemset Y Die Aussagekraft der Regeln soll bewertet werden, etwa so: Wird Produkt a gekauft, so wird in 75% der Fälle auch Produkt b gekauft! Dies ist im gesamten Datenbestand bei 10% aller Transaktionen zu beobachten. Diese Größen bezeichnet man als Support und Konfidenz. Zu ihrer Definition benötigt man einen Datenbestand D, der aus einzelnen Transaktionen t 1,..., t n besteht. Also D = {t 1,..., t n } mit D = n (Anzahl der Elemente) 17

18 Analyse des Kundenverhaltens Grundstruktur der Algorithmen 1. Bestimme alle Regeln, deren Support größer oder gleich einer vorgegebenen Schranke (MinSup) ist. 2. Bestimme von diesen Regeln diejenigen, deren Konfidenz größer oder gleich einer vorgegebenen Schranke (MinKonf) ist. Die beiden Schranken MinSup und MinKonf müssen vom Anwender vorgegeben werden. Bekannteste Vertreter: Apriori und Apriori-Tid Algorithmus (Agrawal und Srikant (1994)) 18

19 Analyse des Kundenverhaltens Erweiterungen der Assoziationsanalyse Taxonomien Ziel: Betrachtung von Zusatzwissen (Strukturen) in der Menge der Items Taxonomie: Getränke alkoholische Getränke nicht-alkoholische Getränke Backwaren Bier Wein Spirituosen Kaffee Saft Milch Zucker Mehl Ergebnis: Neue, verallgemeinerte Regeln auf Basis der Taxonomie. 19

20 Neukundengewinnung Data Mining im Beziehungslebenszyklus 20

21 Neukundengewinnung Entscheidungsbaumverfahren Ziel der Anwendung von Entscheidungsbaumverfahren ist die Erzeugung eines Modells, durch welches unbekannte Datenobjekte bestimmten vorgegebenen Klassen zugeordnet werden können. Diese Zuordnung geschieht anhand von Regeln, die durch einen Klassifikationsbaum dargestellt werden können. Beispiel Einteilung von Datensätzen, die Angaben über Kunden enthalten, so dass damit die Käufergruppe erkannt werden kann, in die der Kunde voraussichtlich gehört. Voraussetzung: Datenbestand bei dem für jeden Datensatz die zugehörige Klasse bereits bekannt ist. 21
22 Neukundengewinnung Grundstruktur der Algorithmen zum Entscheidungsbaumverfahren Der Gesamtdatenbestand wird in eine Trainingsmenge und eine Testmenge aufgeteilt. Dann wird die Trainingsmenge sukzessive aufgeteilt, so dass daraus homogenere Gruppen von Datensätzen bezüglich der Klassifikationsvariablen entstehen. Die Aufteilung der Datenmengen kann durch einen Baum dargestellt werden, in dem jeder Knoten eine Datenmenge indiziert, dem ein Homogenitätsmaß zugeordnet wird. Erreicht dieses Homogenitätsmaß einen vorgegebenen Wert, so wird der Knoten einer bestimmten Klasse zugeordnet. 22
23 Neukundengewinnung Allgemeiner Aufbau eines Entscheidungsbaum Datensätze gesamt: 1000 kreditwürdig: 500 nicht-kreditwürdig: 500 Attribut A erfüllt Bedingung K 1 Attribut A erfüllt nicht Bedingung K 1 Datensätze gesamt: 700 kreditwürdig: 480 nicht-kreditwürdig: 220 Datensätze gesamt: 300 kreditwürdig: 20 nicht-kreditwürdig: 280 Attribut B erfüllt Bedingung K 2 Attribut B erfüllt nicht Bedingung K 2 Datensätze gesamt: 400 kreditwürdig: 390 nicht-kreditwürdig: 10 Datensätze gesamt: 300 kreditwürdig: 90 nicht-kreditwürdig:
24 Neukundengewinnung Modellevaluation Overfitting Empirische Studien zeigen, dass eine Verbesserung der Fehlklassifikationsquote auf der Trainingsmenge zunächst einhergeht mit einer Verbesserung auf der Testmenge. Ab einem gewissen Punkt steigt die Fehlklassifikationsquote auf der Testmenge dann wieder an. Dieses Phänomen bezeichnet man als Overfitting. Mögliche Gründe prinzipielles Problem fehlerhafte Testdaten (noise) geringe Aussagekraft der Regeln bei zu kleiner Datenbasis 24
25 Neukundengewinnung Neuronale Netze Bei der Erstellung Künstlicher Neuronaler Netze wird versucht, die Arbeitsweise des menschlichen Gehirns nachzubilden. Ein Netz besteht aus künstlichen Neuronen und deren Verknüpfungen. Wesentliches Merkmal der Netze ist ihre Lernfähigkeit. 25
26 Neukundengewinnung McCulloch-Pitts-Neuron Gesamtinput: ergibt sich als gewichtete Summe der Eingangssignale (Inputwerte) x 1,, x j,, x n Aktivierung: Die Aktivierung des Neurons geschieht über die Aktivierungsfunktion f, deren Wert von der Differenz aus Gesamtinput und Schwellenwert θ abhängt. Je nach Aktivierung entsteht ein Outputwert y. 26
27 Neukundengewinnung Vorwärts gerichtete Neuronale Netze Multilayer-Perzeptron Das Multilayer-Perzeptron (MLP) ist ein Spezialfall eines vorwärts gerichteten KNNs, das zur Klassifikation eingesetzt werden kann. Es können drei Schichttypen differenziert werden: Inputschicht, Versteckte Schicht, Outputschicht. Es sind nur Neuronen verschiedener Schichten miteinander verbunden. Die Outputwerte vorgelagerter Neuronen werden über gewichtete Verbindungen an nachgelagerte Neuronen gesendet. Beim vorwärts gerichteten Netz werden Impulse nur in eine Richtung weitergegeben, es gibt keine Schleifen. 27
28 Neukundengewinnung Beispiel Multilayer-Perzeptron 28
29 Neukundengewinnung Lernparadigmen Überwachtes Lernen (supervised learning) Klassifizierung [z.b. Back-Propagation] Bestärkendes Lernen (reinforcement learning) Unüberwachtes Lernen (unsupervised learning) Clusterung [z.b. Self-Organizing-Maps] 29
30 Neukundengewinnung Back-Propagation Die Werte eines Datensatzes werden in die Neuronen der Inputschicht eingegeben. Anschließend über die Neuronen und deren Verbindungen weitergeleitet, bis ein Wert in der Outputschicht erzeugt wurde, der die durch das Netz berechnete Klasse des Datensatzes angibt. (Forward Pass) Dieser Wert wird mit der tatsächlichen Klassenzugehörigkeit verglichen. (Fehlerbestimmung) Bei einer Abweichung von Soll - und Ist -Wert werden ausgehend von den Outputneuronen die zugehörigen Verbindungsgewichte sowie die Verbindungsgewichte der Neuronen vorgelagerter Schichten derart geändert, dass die Abweichung minimiert wird. (Backward Pass) 30
31 Neukundengewinnung Kritische Betrachtung Vorteile Vorwärts gerichtete Künstliche Neuronale Netze können sehr gute Ergebnisse bei der Klassifikation und Prognose erzeugen. Die offene Struktur macht das Modell sehr flexibel. Nachteile Es werden keine expliziten Regeln angegeben. Das Adaptieren der Gewichte geschieht mitunter sehr langsam. Netzstruktur & Gewichtsinitialisierung sind nicht vorgegeben. 31
32 Cluster-Verfahren Idee der Cluster-Verfahren 32
33 Cluster-Verfahren Anwendungsbeispiele Kundensegmentierung Welche Kundenprofile existieren? (Analyse von Kundenattributen) Kaufverhalten Welche Gruppen bzgl. des Kaufverhaltens bestehen? (Analyse von Kaufähnlichkeiten) Technik Finden ähnlicher Oberflächen Text-Mining Finden ähnlicher Texte Web-Log-Mining Auffinden von Benutzergruppen auf Web- Sites 33
34 Cluster-Verfahren Ähnlichkeitsmaße vs. Distanzmaße Um die Ähnlichkeit zweier Datensätze zu bestimmen, werden oftmals geometrische Distanzmaße d herangezogen. Es gilt: kleine Distanz große Ähnlichkeit große Distanz kleine Ähnlichkeit Dabei ist für die Anwendbarkeit der Maße zu beachten, welche Definitionsbereiche die Attribute haben. Unterschieden werden muss zwischen numerischen und nominalen Attributen. 34
35 Cluster-Verfahren Distanzfunktion zweier Datensätze mit nominalen Merkmalen Gegeben seien zwei Datensätze, die Objekte anhand von n nominalen Merkmalen unterscheiden x = (x1, x2,..., xn) und y = (y1, y2,..., yn) Distanz: Anzahl der Attribute, deren Ausprägungen nicht übereinstimmen. Ähnlichkeit: Anzahl der Attribute, deren Ausprägungen übereinstimmen x = (blau, hoch, dick, süß, Mainz) y = (grün, hoch, dick, süß, Essen) d(x, y) = 2 sim(x, y) = 3 35
36 Cluster-Verfahren Dendrogramm zur Darstellung hierarchischer Verfahren 1 2 1, 2 3 3,4 1, 2, 3, 4, 5 4 3, 4, 5 5 agglomerative Methode divisive Methode Schritt 36
37 Cluster-Verfahren Single-Linkage Complete-Linkage Average-Linkage x x x x o o x x x x 37
38 Cluster-Verfahren Algorithmus für ein agglomeratives Verfahren Erstelle die Distanzmatrix. Bilde einen neuen Cluster aus den zwei Objekten bzw. Clustern, die den geringsten Abstand zueinander haben. Bestimme die Distanz zwischen dem neuen Cluster und allen anderen Objekten bzw. Clustern. Wiederhole ab Schritt 2, bis sich alle Objekte in einem einzigen Cluster befinden. 38
39 Cluster-Verfahren Partitionierendes Cluster-Verfahren k-means Wähle K Objekte zufällig als initiale Clustercentroide. Ordne die Objekte jeweils dem Cluster zu, zu dessen Centroid der geringste Abstand vom Objekt besteht. Bestimme in den Clustern die aktuellen Centroide. Prüfe, ob alle Objekte den Clustern mit dem geringsten Abstand zum Centroiden zugeordnet sind, wenn nein, springe zu 2. Problem: Abhängigkeit von der Auswahl der initialen Centroide und der Reihenfolge der Werte. 39
40 Text Mining Das Data Mining, als eine Phase im KDD-Prozess, dient der Erkenntnisgewinnung aus umfangreichen Datenbeständen, wobei diese auf Grundlage strukturierter Daten durchgeführt wird. Die Methoden des Data Mining wurden nicht entwickelt, um unstrukturierte Daten zu verarbeiten. Liegen Textdokumente als Basis zur inhaltlichen Entdeckung bisher unbekannter Informationen vor, wird daher das Text Mining angewendet. Im Gegensatz zum Data Mining sind die durch das Text Mining aufgespürten, unbekannten Informationen nicht für jeden unbekannt. Der Autor des Dokumentes kannte die Information und legte sie schriftlich nieder. Wichtig ist, dass die ermittelten Informationen für den Rezipienten neu sind. 40
41 Text Mining Das Vektormodell, oft auch als algebraisches Modell bezeichnet, erzeugt einen Vektor im mehrdimensionalen Raum. Jeder Deskriptor eines Index stellt eine Dimension dieses Vektors dar. Dieser spannt einen Dokumentenraum auf. Hierbei wird die Termhäufigkeit als Stärke der Ausprägung einer Dimension genutzt und durch den Begriff Gewicht ausgedrückt. 41
42 Text Mining Dokument Vektor Mr Brown, the former Agriculture Secretary, told the BBC he would be prepared to oppose the government on the issue of variable fees. He is among the Labour backbenchers and several former ministers who fear the fees may deter students from poorer backgrounds from going to the best institutions. They claim the variable rate charged for different courses could cause a "two-tier" system agriculture market government freedom fees students rate system country policy Dimension Gewicht d j freq ij t i 42
43 Text Mining und Intelligente Software Agenten Das Probabilistische Modell integriert die Beziehungen der Deskriptoren in die Bewertung und geht nicht von der Annahme der Unabhängigkeit zwischen den Deskriptoren aus. Im Ergebnis werden Wahrscheinlichkeiten ermittelt, welche die Relevanz von Dokumenten für den Nutzer aufzeigen. Um Aussagen über die Wahrscheinlichkeit treffen zu können, ist zumindest für eine Teilmenge der Dokumente die Relevanz zu bestimmen. 43
44 Text Mining und Intelligente Software Agenten Beispiele: Entscheidungsbaum; Support Vector Machines; Rocchio Algorithmus; k-nn Algorithmus; Multilayer Perceptron; HyperPipes. 44
45 Text Mining Zulässigkeit beschränkt auf deutsche Zeichen Anwendung einer Stoppwortliste Eliminierung bei einer Wortlänge < 3 Eliminierung bei Termfrequenz #1 pro Text Anwendung von Wortstämmen Eliminierung der oberen 5 Prozent der Verteilungskurve Anzahl der verbleibenden Worte Nr Prozent Sonderzeichen
46 Text Mining 80, , ,0000 SVM 65,0000 Voted Perceptron k-nn (k=1) J48 60, , ,0000 naive Bayes HyperPipes AdaBoost M1 SimpleLogistic MLP Rocchio 45, ,
47 Agenda Einführung und Einordnung Business Analytics Begriffe Analytische Fähigkeiten Hype Cycle Analytischer Prozess Anwendungsfelder und Verfahren Assoziationsanalyse Entscheidungsbaum Neuronale Netze Clusterverfahren Praktischer Teil 47
48 Fragen? 48
Begriffsbestimmung CRISP-DM-Modell Betriebswirtschaftliche Einsatzgebiete des Data Mining Web Mining und Text Mining
 Gliederung 1. Einführung 2. Grundlagen Data Mining Begriffsbestimmung CRISP-DM-Modell Betriebswirtschaftliche Einsatzgebiete des Data Mining Web Mining und Text Mining 3. Ausgewählte Methoden des Data
Gliederung 1. Einführung 2. Grundlagen Data Mining Begriffsbestimmung CRISP-DM-Modell Betriebswirtschaftliche Einsatzgebiete des Data Mining Web Mining und Text Mining 3. Ausgewählte Methoden des Data
Anwendung der Predictive Analytics
 TDWI Konferenz mit BARC@TDWI Track 2014 München, 23. 25. Juni 2014 Anwendung der Predictive Analytics Prof. Dr. Carsten Felden Dipl. Wirt. Inf. Claudia Koschtial Technische Universität Bergakademie Freiberg
TDWI Konferenz mit BARC@TDWI Track 2014 München, 23. 25. Juni 2014 Anwendung der Predictive Analytics Prof. Dr. Carsten Felden Dipl. Wirt. Inf. Claudia Koschtial Technische Universität Bergakademie Freiberg
Management Support Systeme
 Management Support Systeme WS 24-25 4.-6. Uhr PD Dr. Peter Gluchowski Folie Gliederung MSS WS 4/5. Einführung Management Support Systeme: Informationssysteme zur Unterstützung betrieblicher Fach- und Führungskräfte
Management Support Systeme WS 24-25 4.-6. Uhr PD Dr. Peter Gluchowski Folie Gliederung MSS WS 4/5. Einführung Management Support Systeme: Informationssysteme zur Unterstützung betrieblicher Fach- und Führungskräfte
Anwendungen der Business Analytics TDWI 2011 München 112. Europäische TDWI Konferenz
 Anwendungen der Business Analytics TDWI 2011 München 112. Europäische TDWI Konferenz Dipl.- Wirt.-Inf. Claudia Koschtial Univ.-Prof. Dr. Carsten Felden E-Mail: carsten.felden@bwl.tu-freiberg.de Die Dozenten
Anwendungen der Business Analytics TDWI 2011 München 112. Europäische TDWI Konferenz Dipl.- Wirt.-Inf. Claudia Koschtial Univ.-Prof. Dr. Carsten Felden E-Mail: carsten.felden@bwl.tu-freiberg.de Die Dozenten
Ermittlung von Assoziationsregeln aus großen Datenmengen. Zielsetzung
 Ermittlung von Assoziationsregeln aus großen Datenmengen Zielsetzung Entscheidungsträger verwenden heutzutage immer häufiger moderne Technologien zur Lösung betriebswirtschaftlicher Problemstellungen.
Ermittlung von Assoziationsregeln aus großen Datenmengen Zielsetzung Entscheidungsträger verwenden heutzutage immer häufiger moderne Technologien zur Lösung betriebswirtschaftlicher Problemstellungen.
DISKUSSIONSBEITRÄGE DER FAKULTÄT FÜR BETRIEBSWIRTSCHAFTSLEHRE MERCATOR SCHOOL OF MANAGEMENT UNIVERSITÄT DUISBURG-ESSEN. Nr. 374
 DISKUSSIONSBEITRÄGE DER FAKULTÄT FÜR BETRIEBSWIRTSCHAFTSLEHRE MERCATOR SCHOOL OF MANAGEMENT UNIVERSITÄT DUISBURG-ESSEN Nr. 374 Eignung von Verfahren der Mustererkennung im Process Mining Sabrina Kohne
DISKUSSIONSBEITRÄGE DER FAKULTÄT FÜR BETRIEBSWIRTSCHAFTSLEHRE MERCATOR SCHOOL OF MANAGEMENT UNIVERSITÄT DUISBURG-ESSEN Nr. 374 Eignung von Verfahren der Mustererkennung im Process Mining Sabrina Kohne
Voraussetzung wieder: Datenraum mit Instanzen, mehrere Attribute - kein ausgezeichnetes Zielattribut, keine vorgegebenen Klassen
 7. Clusteranalyse (= Häufungsanalyse; Clustering-Verfahren) wird der multivariaten Statistik zugeordnet Voraussetzung wieder: Datenraum mit Instanzen, mehrere Attribute - kein ausgezeichnetes Zielattribut,
7. Clusteranalyse (= Häufungsanalyse; Clustering-Verfahren) wird der multivariaten Statistik zugeordnet Voraussetzung wieder: Datenraum mit Instanzen, mehrere Attribute - kein ausgezeichnetes Zielattribut,
Data Mining Anwendungen und Techniken
 Data Mining Anwendungen und Techniken Knut Hinkelmann DFKI GmbH Entdecken von Wissen in banken Wissen Unternehmen sammeln ungeheure mengen enthalten wettbewerbsrelevantes Wissen Ziel: Entdecken dieses
Data Mining Anwendungen und Techniken Knut Hinkelmann DFKI GmbH Entdecken von Wissen in banken Wissen Unternehmen sammeln ungeheure mengen enthalten wettbewerbsrelevantes Wissen Ziel: Entdecken dieses
Zeichen bei Zahlen entschlüsseln
 Zeichen bei Zahlen entschlüsseln In diesem Kapitel... Verwendung des Zahlenstrahls Absolut richtige Bestimmung von absoluten Werten Operationen bei Zahlen mit Vorzeichen: Addieren, Subtrahieren, Multiplizieren
Zeichen bei Zahlen entschlüsseln In diesem Kapitel... Verwendung des Zahlenstrahls Absolut richtige Bestimmung von absoluten Werten Operationen bei Zahlen mit Vorzeichen: Addieren, Subtrahieren, Multiplizieren
Anmerkungen zur Übergangsprüfung
 DM11 Slide 1 Anmerkungen zur Übergangsprüfung Aufgabeneingrenzung Aufgaben des folgenden Typs werden wegen ihres Schwierigkeitsgrads oder wegen eines ungeeigneten fachlichen Schwerpunkts in der Übergangsprüfung
DM11 Slide 1 Anmerkungen zur Übergangsprüfung Aufgabeneingrenzung Aufgaben des folgenden Typs werden wegen ihres Schwierigkeitsgrads oder wegen eines ungeeigneten fachlichen Schwerpunkts in der Übergangsprüfung
Exploration und Klassifikation von BigData
 Exploration und Klassifikation von BigData Inhalt Einführung Daten Data Mining: Vorbereitungen Clustering Konvexe Hülle Fragen Google: Riesige Datenmengen (2009: Prozessieren von 24 Petabytes pro Tag)
Exploration und Klassifikation von BigData Inhalt Einführung Daten Data Mining: Vorbereitungen Clustering Konvexe Hülle Fragen Google: Riesige Datenmengen (2009: Prozessieren von 24 Petabytes pro Tag)
4. Jeder Knoten hat höchstens zwei Kinder, ein linkes und ein rechtes.
 Binäre Bäume Definition: Ein binärer Baum T besteht aus einer Menge von Knoten, die durch eine Vater-Kind-Beziehung wie folgt strukturiert ist: 1. Es gibt genau einen hervorgehobenen Knoten r T, die Wurzel
Binäre Bäume Definition: Ein binärer Baum T besteht aus einer Menge von Knoten, die durch eine Vater-Kind-Beziehung wie folgt strukturiert ist: 1. Es gibt genau einen hervorgehobenen Knoten r T, die Wurzel
Data Mining und Knowledge Discovery in Databases
 Data Mining und Knowledge Discovery in Databases Begriffsabgrenzungen... Phasen der KDD...3 3 Datenvorverarbeitung...4 3. Datenproblematik...4 3. Möglichkeiten der Datenvorverarbeitung...4 4 Data Mining
Data Mining und Knowledge Discovery in Databases Begriffsabgrenzungen... Phasen der KDD...3 3 Datenvorverarbeitung...4 3. Datenproblematik...4 3. Möglichkeiten der Datenvorverarbeitung...4 4 Data Mining
Unterrichtsmaterialien in digitaler und in gedruckter Form. Auszug aus: Übungsbuch für den Grundkurs mit Tipps und Lösungen: Analysis
 Unterrichtsmaterialien in digitaler und in gedruckter Form Auszug aus: Übungsbuch für den Grundkurs mit Tipps und Lösungen: Analysis Das komplette Material finden Sie hier: Download bei School-Scout.de
Unterrichtsmaterialien in digitaler und in gedruckter Form Auszug aus: Übungsbuch für den Grundkurs mit Tipps und Lösungen: Analysis Das komplette Material finden Sie hier: Download bei School-Scout.de
2 Evaluierung von Retrievalsystemen
 2. Evaluierung von Retrievalsystemen Relevanz 2 Evaluierung von Retrievalsystemen Die Evaluierung von Verfahren und Systemen spielt im IR eine wichtige Rolle. Gemäß der Richtlinien für IR der GI gilt es,...
2. Evaluierung von Retrievalsystemen Relevanz 2 Evaluierung von Retrievalsystemen Die Evaluierung von Verfahren und Systemen spielt im IR eine wichtige Rolle. Gemäß der Richtlinien für IR der GI gilt es,...
Neuronale Netze (I) Biologisches Neuronales Netz
 Biologisches Neuronales Netz") Neuronale Netze (I) Biologisches Neuronales Netz Im menschlichen Gehirn ist ein Neuron mit bis zu 20.000 anderen Neuronen verbunden. Milliarden von Neuronen beteiligen sich simultan an der Verarbeitung
Neuronale Netze (I) Biologisches Neuronales Netz Im menschlichen Gehirn ist ein Neuron mit bis zu 20.000 anderen Neuronen verbunden. Milliarden von Neuronen beteiligen sich simultan an der Verarbeitung
6. Bayes-Klassifikation. (Schukat-Talamazzini 2002)
") 6. Bayes-Klassifikation (Schukat-Talamazzini 2002) (Böhm 2003) (Klawonn 2004) Der Satz von Bayes: Beweis: Klassifikation mittels des Satzes von Bayes (Klawonn 2004) Allgemeine Definition: Davon zu unterscheiden
6. Bayes-Klassifikation (Schukat-Talamazzini 2002) (Böhm 2003) (Klawonn 2004) Der Satz von Bayes: Beweis: Klassifikation mittels des Satzes von Bayes (Klawonn 2004) Allgemeine Definition: Davon zu unterscheiden
Seminar Business Intelligence Teil II. Data Mining & Knowledge Discovery
 Seminar Business Intelligence Teil II Data Mining & Knowledge Discovery Was ist Data Mining? Sabine Queckbörner Was ist Data Mining? Data Mining Was ist Data Mining? Nach welchen Mustern wird gesucht?
Seminar Business Intelligence Teil II Data Mining & Knowledge Discovery Was ist Data Mining? Sabine Queckbörner Was ist Data Mining? Data Mining Was ist Data Mining? Nach welchen Mustern wird gesucht?
Data Mining und maschinelles Lernen
 Data Mining und maschinelles Lernen Einführung und Anwendung mit WEKA Caren Brinckmann 16. August 2000 http://www.coli.uni-sb.de/~cabr/vortraege/ml.pdf http://www.cs.waikato.ac.nz/ml/weka/ Inhalt Einführung:
Data Mining und maschinelles Lernen Einführung und Anwendung mit WEKA Caren Brinckmann 16. August 2000 http://www.coli.uni-sb.de/~cabr/vortraege/ml.pdf http://www.cs.waikato.ac.nz/ml/weka/ Inhalt Einführung:
Vorlesungsplan. Von Naïve Bayes zu Bayesischen Netzwerk- Klassifikatoren. Naïve Bayes. Bayesische Netzwerke
 Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Lineargleichungssysteme: Additions-/ Subtraktionsverfahren
 Lineargleichungssysteme: Additions-/ Subtraktionsverfahren W. Kippels 22. Februar 2014 Inhaltsverzeichnis 1 Einleitung 2 2 Lineargleichungssysteme zweiten Grades 2 3 Lineargleichungssysteme höheren als
Lineargleichungssysteme: Additions-/ Subtraktionsverfahren W. Kippels 22. Februar 2014 Inhaltsverzeichnis 1 Einleitung 2 2 Lineargleichungssysteme zweiten Grades 2 3 Lineargleichungssysteme höheren als
Mining High-Speed Data Streams
 Mining High-Speed Data Streams Pedro Domingos & Geoff Hulten Departement of Computer Science & Engineering University of Washington Datum : 212006 Seminar: Maschinelles Lernen und symbolische Ansätze Vortragender:
Mining High-Speed Data Streams Pedro Domingos & Geoff Hulten Departement of Computer Science & Engineering University of Washington Datum : 212006 Seminar: Maschinelles Lernen und symbolische Ansätze Vortragender:
Zahlenwinkel: Forscherkarte 1. alleine. Zahlenwinkel: Forschertipp 1
 Zahlenwinkel: Forscherkarte 1 alleine Tipp 1 Lege die Ziffern von 1 bis 9 so in den Zahlenwinkel, dass jeder Arm des Zahlenwinkels zusammengezählt das gleiche Ergebnis ergibt! Finde möglichst viele verschiedene
Zahlenwinkel: Forscherkarte 1 alleine Tipp 1 Lege die Ziffern von 1 bis 9 so in den Zahlenwinkel, dass jeder Arm des Zahlenwinkels zusammengezählt das gleiche Ergebnis ergibt! Finde möglichst viele verschiedene
1. Man schreibe die folgenden Aussagen jeweils in einen normalen Satz um. Zum Beispiel kann man die Aussage:
 Zählen und Zahlbereiche Übungsblatt 1 1. Man schreibe die folgenden Aussagen jeweils in einen normalen Satz um. Zum Beispiel kann man die Aussage: Für alle m, n N gilt m + n = n + m. in den Satz umschreiben:
Zählen und Zahlbereiche Übungsblatt 1 1. Man schreibe die folgenden Aussagen jeweils in einen normalen Satz um. Zum Beispiel kann man die Aussage: Für alle m, n N gilt m + n = n + m. in den Satz umschreiben:
Mean Time Between Failures (MTBF)
") Mean Time Between Failures (MTBF) Hintergrundinformation zur MTBF Was steht hier? Die Mean Time Between Failure (MTBF) ist ein statistischer Mittelwert für den störungsfreien Betrieb eines elektronischen
Mean Time Between Failures (MTBF) Hintergrundinformation zur MTBF Was steht hier? Die Mean Time Between Failure (MTBF) ist ein statistischer Mittelwert für den störungsfreien Betrieb eines elektronischen
Tiefgreifende Prozessverbesserung und Wissensmanagement durch Data Mining
 Tiefgreifende Prozessverbesserung und Wissensmanagement durch Data Mining Ausgangssituation Kaizen Data Mining ISO 9001 Wenn andere Methoden an ihre Grenzen stoßen Es gibt unzählige Methoden, die Abläufe
Tiefgreifende Prozessverbesserung und Wissensmanagement durch Data Mining Ausgangssituation Kaizen Data Mining ISO 9001 Wenn andere Methoden an ihre Grenzen stoßen Es gibt unzählige Methoden, die Abläufe
Willkommen zur Vorlesung Statistik
 Willkommen zur Vorlesung Statistik Thema dieser Vorlesung: Varianzanalyse Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften Prof. Dr. Wolfgang
Willkommen zur Vorlesung Statistik Thema dieser Vorlesung: Varianzanalyse Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften Prof. Dr. Wolfgang
Würfelt man dabei je genau 10 - mal eine 1, 2, 3, 4, 5 und 6, so beträgt die Anzahl. der verschiedenen Reihenfolgen, in denen man dies tun kann, 60!.
 040304 Übung 9a Analysis, Abschnitt 4, Folie 8 Die Wahrscheinlichkeit, dass bei n - maliger Durchführung eines Zufallexperiments ein Ereignis A ( mit Wahrscheinlichkeit p p ( A ) ) für eine beliebige Anzahl
040304 Übung 9a Analysis, Abschnitt 4, Folie 8 Die Wahrscheinlichkeit, dass bei n - maliger Durchführung eines Zufallexperiments ein Ereignis A ( mit Wahrscheinlichkeit p p ( A ) ) für eine beliebige Anzahl
Das große ElterngeldPlus 1x1. Alles über das ElterngeldPlus. Wer kann ElterngeldPlus beantragen? ElterngeldPlus verstehen ein paar einleitende Fakten
 Das große x -4 Alles über das Wer kann beantragen? Generell kann jeder beantragen! Eltern (Mütter UND Väter), die schon während ihrer Elternzeit wieder in Teilzeit arbeiten möchten. Eltern, die während
Das große x -4 Alles über das Wer kann beantragen? Generell kann jeder beantragen! Eltern (Mütter UND Väter), die schon während ihrer Elternzeit wieder in Teilzeit arbeiten möchten. Eltern, die während
Business Analytics im E-Commerce
 Business Analytics im E-Commerce Kunde, Kontext und sein Verhalten verstehen für personalisierte Kundenansprache Janusz Michalewicz CEO Über die Firma Crehler Erstellung von Onlineshops Analyse von Transaktionsdaten
Business Analytics im E-Commerce Kunde, Kontext und sein Verhalten verstehen für personalisierte Kundenansprache Janusz Michalewicz CEO Über die Firma Crehler Erstellung von Onlineshops Analyse von Transaktionsdaten
Data Mining mit der SEMMA Methodik. Reinhard Strüby, SAS Institute Stephanie Freese, Herlitz PBS AG
 Data Mining mit der SEMMA Methodik Reinhard Strüby, SAS Institute Stephanie Freese, Herlitz PBS AG Data Mining Data Mining: Prozeß der Selektion, Exploration und Modellierung großer Datenmengen, um Information
Data Mining mit der SEMMA Methodik Reinhard Strüby, SAS Institute Stephanie Freese, Herlitz PBS AG Data Mining Data Mining: Prozeß der Selektion, Exploration und Modellierung großer Datenmengen, um Information
Clustering Seminar für Statistik
 Clustering Markus Kalisch 03.12.2014 1 Ziel von Clustering Finde Gruppen, sodas Elemente innerhalb der gleichen Gruppe möglichst ähnlich sind und Elemente von verschiedenen Gruppen möglichst verschieden
Clustering Markus Kalisch 03.12.2014 1 Ziel von Clustering Finde Gruppen, sodas Elemente innerhalb der gleichen Gruppe möglichst ähnlich sind und Elemente von verschiedenen Gruppen möglichst verschieden
Ablaufbeschreibung für das neu Aufsetzen von Firebird und Interbase Datenbanken mit der IBOConsole
 Lavid-F.I.S. Ablaufbeschreibung für das neu Aufsetzen von Firebird und Interbase Datenbanken mit der Lavid Software GmbH Dauner Straße 12, D-41236 Mönchengladbach http://www.lavid-software.net Support:
Lavid-F.I.S. Ablaufbeschreibung für das neu Aufsetzen von Firebird und Interbase Datenbanken mit der Lavid Software GmbH Dauner Straße 12, D-41236 Mönchengladbach http://www.lavid-software.net Support:
Lavid-F.I.S. Ablaufbeschreibung für. Arbeitszeiterfassung. Lavid-F.I.S.
 Lavid-F.I.S. Ablaufbeschreibung für Dauner Str. 12, D-41236 Mönchengladbach, Tel. 02166-97022-0, Fax -15, Email: info@lavid-software.net 1. Inhalt 1. Inhalt... 2 2. Verwendbar für... 3 3. Aufgabe... 3
Lavid-F.I.S. Ablaufbeschreibung für Dauner Str. 12, D-41236 Mönchengladbach, Tel. 02166-97022-0, Fax -15, Email: info@lavid-software.net 1. Inhalt 1. Inhalt... 2 2. Verwendbar für... 3 3. Aufgabe... 3
Prozessbewertung und -verbesserung nach ITIL im Kontext des betrieblichen Informationsmanagements. von Stephanie Wilke am 14.08.08
 Prozessbewertung und -verbesserung nach ITIL im Kontext des betrieblichen Informationsmanagements von Stephanie Wilke am 14.08.08 Überblick Einleitung Was ist ITIL? Gegenüberstellung der Prozesse Neuer
Prozessbewertung und -verbesserung nach ITIL im Kontext des betrieblichen Informationsmanagements von Stephanie Wilke am 14.08.08 Überblick Einleitung Was ist ITIL? Gegenüberstellung der Prozesse Neuer
Um zusammenfassende Berichte zu erstellen, gehen Sie folgendermaßen vor:
 Ergebnisreport: mehrere Lehrveranstaltungen zusammenfassen 1 1. Ordner anlegen In der Rolle des Berichterstellers (siehe EvaSys-Editor links oben) können zusammenfassende Ergebnisberichte über mehrere
Ergebnisreport: mehrere Lehrveranstaltungen zusammenfassen 1 1. Ordner anlegen In der Rolle des Berichterstellers (siehe EvaSys-Editor links oben) können zusammenfassende Ergebnisberichte über mehrere
15.3 Bedingte Wahrscheinlichkeit und Unabhängigkeit
 5.3 Bedingte Wahrscheinlichkeit und Unabhängigkeit Einführendes Beispiel ( Erhöhung der Sicherheit bei Flugreisen ) Die statistische Wahrscheinlichkeit, dass während eines Fluges ein Sprengsatz an Bord
5.3 Bedingte Wahrscheinlichkeit und Unabhängigkeit Einführendes Beispiel ( Erhöhung der Sicherheit bei Flugreisen ) Die statistische Wahrscheinlichkeit, dass während eines Fluges ein Sprengsatz an Bord
Semestralklausur zur Vorlesung. Web Mining. Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7.
 Semestralklausur zur Vorlesung Web Mining Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7. 2004 Name: Vorname: Matrikelnummer: Fachrichtung: Punkte: (1).... (2)....
Semestralklausur zur Vorlesung Web Mining Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7. 2004 Name: Vorname: Matrikelnummer: Fachrichtung: Punkte: (1).... (2)....
4. Lernen von Entscheidungsbäumen. Klassifikation mit Entscheidungsbäumen. Entscheidungsbaum
 4. Lernen von Entscheidungsbäumen Klassifikation mit Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch /Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse zugeordnet werden.
4. Lernen von Entscheidungsbäumen Klassifikation mit Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch /Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse zugeordnet werden.
Künstliche Intelligenz Maschinelles Lernen
 Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert Sommersemester 2009 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen
Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert Sommersemester 2009 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen
QM: Prüfen -1- KN16.08.2010
 QM: Prüfen -1- KN16.08.2010 2.4 Prüfen 2.4.1 Begriffe, Definitionen Ein wesentlicher Bestandteil der Qualitätssicherung ist das Prüfen. Sie wird aber nicht wie früher nach der Fertigung durch einen Prüfer,
QM: Prüfen -1- KN16.08.2010 2.4 Prüfen 2.4.1 Begriffe, Definitionen Ein wesentlicher Bestandteil der Qualitätssicherung ist das Prüfen. Sie wird aber nicht wie früher nach der Fertigung durch einen Prüfer,
Theoretische Grundlagen der Informatik WS 09/10
 Theoretische Grundlagen der Informatik WS 09/10 - Tutorium 6 - Michael Kirsten und Kai Wallisch Sitzung 13 02.02.2010 Inhaltsverzeichnis 1 Formeln zur Berechnung Aufgabe 1 2 Hamming-Distanz Aufgabe 2 3
Theoretische Grundlagen der Informatik WS 09/10 - Tutorium 6 - Michael Kirsten und Kai Wallisch Sitzung 13 02.02.2010 Inhaltsverzeichnis 1 Formeln zur Berechnung Aufgabe 1 2 Hamming-Distanz Aufgabe 2 3
Fachbericht zum Thema: Anforderungen an ein Datenbanksystem
 Fachbericht zum Thema: Anforderungen an ein Datenbanksystem von André Franken 1 Inhaltsverzeichnis 1 Inhaltsverzeichnis 1 2 Einführung 2 2.1 Gründe für den Einsatz von DB-Systemen 2 2.2 Definition: Datenbank
Fachbericht zum Thema: Anforderungen an ein Datenbanksystem von André Franken 1 Inhaltsverzeichnis 1 Inhaltsverzeichnis 1 2 Einführung 2 2.1 Gründe für den Einsatz von DB-Systemen 2 2.2 Definition: Datenbank
Entscheidungsbaumverfahren
 Entscheidungsbaumverfahren Allgemeine Beschreibung Der Entscheidungsbaum ist die Darstellung einer Entscheidungsregel, anhand derer Objekte in Klassen eingeteilt werden. Die Klassifizierung erfolgt durch
Entscheidungsbaumverfahren Allgemeine Beschreibung Der Entscheidungsbaum ist die Darstellung einer Entscheidungsregel, anhand derer Objekte in Klassen eingeteilt werden. Die Klassifizierung erfolgt durch
WEKA A Machine Learning Interface for Data Mining
 WEKA A Machine Learning Interface for Data Mining Frank Eibe, Mark Hall, Geoffrey Holmes, Richard Kirkby, Bernhard Pfahringer, Ian H. Witten Reinhard Klaus Losse Künstliche Intelligenz II WS 2009/2010
WEKA A Machine Learning Interface for Data Mining Frank Eibe, Mark Hall, Geoffrey Holmes, Richard Kirkby, Bernhard Pfahringer, Ian H. Witten Reinhard Klaus Losse Künstliche Intelligenz II WS 2009/2010
kleines keyword brevier Keywords sind das Salz in der Suppe des Online Marketing Gordian Hense
 Keywords sind das Salz in der Suppe des Online Marketing Keywords - Das Salz in der Suppe des Online Marketing Keyword Arten Weitgehend passende Keywords, passende Wortgruppe, genau passende Wortgruppe
Keywords sind das Salz in der Suppe des Online Marketing Keywords - Das Salz in der Suppe des Online Marketing Keyword Arten Weitgehend passende Keywords, passende Wortgruppe, genau passende Wortgruppe
360 - Der Weg zum gläsernen Unternehmen mit QlikView am Beispiel Einkauf
 360 - Der Weg zum gläsernen Unternehmen mit QlikView am Beispiel Einkauf Von der Entstehung bis heute 1996 als EDV Beratung Saller gegründet, seit 2010 BI4U GmbH Firmensitz ist Unterschleißheim (bei München)
360 - Der Weg zum gläsernen Unternehmen mit QlikView am Beispiel Einkauf Von der Entstehung bis heute 1996 als EDV Beratung Saller gegründet, seit 2010 BI4U GmbH Firmensitz ist Unterschleißheim (bei München)
PPC und Data Mining. Seminar aus Informatik LV-911.039. Michael Brugger. Fachbereich der Angewandten Informatik Universität Salzburg. 28.
 PPC und Data Mining Seminar aus Informatik LV-911.039 Michael Brugger Fachbereich der Angewandten Informatik Universität Salzburg 28. Mai 2010 M. Brugger () PPC und Data Mining 28. Mai 2010 1 / 14 Inhalt
PPC und Data Mining Seminar aus Informatik LV-911.039 Michael Brugger Fachbereich der Angewandten Informatik Universität Salzburg 28. Mai 2010 M. Brugger () PPC und Data Mining 28. Mai 2010 1 / 14 Inhalt
14. Minimale Schichtdicken von PEEK und PPS im Schlauchreckprozeß und im Rheotensversuch
 14. Minimale Schichtdicken von PEEK und PPS im Schlauchreckprozeß und im Rheotensversuch Analog zu den Untersuchungen an LDPE in Kap. 6 war zu untersuchen, ob auch für die Hochtemperatur-Thermoplaste aus
14. Minimale Schichtdicken von PEEK und PPS im Schlauchreckprozeß und im Rheotensversuch Analog zu den Untersuchungen an LDPE in Kap. 6 war zu untersuchen, ob auch für die Hochtemperatur-Thermoplaste aus
Übungen zur Softwaretechnik
 Technische Universität München Fakultät für Informatik Lehrstuhl IV: Software & Systems Engineering Markus Pister, Dr. Bernhard Rumpe WS 2002/2003 Lösungsblatt 9 17. Dezember 2002 www4.in.tum.de/~rumpe/se
Technische Universität München Fakultät für Informatik Lehrstuhl IV: Software & Systems Engineering Markus Pister, Dr. Bernhard Rumpe WS 2002/2003 Lösungsblatt 9 17. Dezember 2002 www4.in.tum.de/~rumpe/se
Dokumentation zum Spielserver der Software Challenge
 Dokumentation zum Spielserver der Software Challenge 10.08.2011 Inhaltsverzeichnis: Programmoberfläche... 2 Ein neues Spiel erstellen... 2 Spielfeldoberfläche... 4 Spielwiederholung laden... 5 Testdurchläufe...
Dokumentation zum Spielserver der Software Challenge 10.08.2011 Inhaltsverzeichnis: Programmoberfläche... 2 Ein neues Spiel erstellen... 2 Spielfeldoberfläche... 4 Spielwiederholung laden... 5 Testdurchläufe...
Leseauszug DGQ-Band 14-26
 Leseauszug DGQ-Band 14-26 Einleitung Dieser Band liefert einen Ansatz zur Einführung von Prozessmanagement in kleinen und mittleren Organisationen (KMO) 1. Die Erfolgskriterien für eine Einführung werden
Leseauszug DGQ-Band 14-26 Einleitung Dieser Band liefert einen Ansatz zur Einführung von Prozessmanagement in kleinen und mittleren Organisationen (KMO) 1. Die Erfolgskriterien für eine Einführung werden
Lineare Gleichungssysteme
 Brückenkurs Mathematik TU Dresden 2015 Lineare Gleichungssysteme Schwerpunkte: Modellbildung geometrische Interpretation Lösungsmethoden Prof. Dr. F. Schuricht TU Dresden, Fachbereich Mathematik auf der
Brückenkurs Mathematik TU Dresden 2015 Lineare Gleichungssysteme Schwerpunkte: Modellbildung geometrische Interpretation Lösungsmethoden Prof. Dr. F. Schuricht TU Dresden, Fachbereich Mathematik auf der
TEXTKLASSIFIKATION. WS 2011/12 Computerlinguistik I Deasy Sukarya & Tania Bellini
 TEXTKLASSIFIKATION WS 2011/12 Computerlinguistik I Deasy Sukarya & Tania Bellini GLIEDERUNG 1. Allgemeines Was ist Textklassifikation? 2. Aufbau eines Textklassifikationssystems 3. Arten von Textklassifikationssystemen
TEXTKLASSIFIKATION WS 2011/12 Computerlinguistik I Deasy Sukarya & Tania Bellini GLIEDERUNG 1. Allgemeines Was ist Textklassifikation? 2. Aufbau eines Textklassifikationssystems 3. Arten von Textklassifikationssystemen
robotron*e count robotron*e sales robotron*e collect Anmeldung Webkomponente Anwenderdokumentation Version: 2.0 Stand: 28.05.2014
 robotron*e count robotron*e sales robotron*e collect Anwenderdokumentation Version: 2.0 Stand: 28.05.2014 Seite 2 von 5 Alle Rechte dieser Dokumentation unterliegen dem deutschen Urheberrecht. Die Vervielfältigung,
robotron*e count robotron*e sales robotron*e collect Anwenderdokumentation Version: 2.0 Stand: 28.05.2014 Seite 2 von 5 Alle Rechte dieser Dokumentation unterliegen dem deutschen Urheberrecht. Die Vervielfältigung,
7. Übung - Datenbanken
 7. Übung - Datenbanken Informatik I für Verkehrsingenieure Aufgaben inkl. Beispiellösungen 1. Aufgabe: DBS a Was ist die Kernaufgabe von Datenbanksystemen? b Beschreiben Sie kurz die Abstraktionsebenen
7. Übung - Datenbanken Informatik I für Verkehrsingenieure Aufgaben inkl. Beispiellösungen 1. Aufgabe: DBS a Was ist die Kernaufgabe von Datenbanksystemen? b Beschreiben Sie kurz die Abstraktionsebenen
26. GIL Jahrestagung
 GeorgAugustUniversität Göttingen 26. GIL Jahrestagung Einsatz von künstlichen Neuronalen Netzen im Informationsmanagement der Land und Ernährungswirtschaft: Ein empirischer Methodenvergleich Holger Schulze,
GeorgAugustUniversität Göttingen 26. GIL Jahrestagung Einsatz von künstlichen Neuronalen Netzen im Informationsmanagement der Land und Ernährungswirtschaft: Ein empirischer Methodenvergleich Holger Schulze,
In diesem Tutorial lernen Sie, wie Sie einen Termin erfassen und verschiedene Einstellungen zu einem Termin vornehmen können.
 Tutorial: Wie erfasse ich einen Termin? In diesem Tutorial lernen Sie, wie Sie einen Termin erfassen und verschiedene Einstellungen zu einem Termin vornehmen können. Neben den allgemeinen Angaben zu einem
Tutorial: Wie erfasse ich einen Termin? In diesem Tutorial lernen Sie, wie Sie einen Termin erfassen und verschiedene Einstellungen zu einem Termin vornehmen können. Neben den allgemeinen Angaben zu einem
Unterrichtsmaterialien in digitaler und in gedruckter Form. Auszug aus:
 Unterrichtsmaterialien in digitaler und in gedruckter Form Auszug aus: If-clauses - conditional sentences - Nie mehr Probleme mit Satzbau im Englischen! Das komplette Material finden Sie hier: School-Scout.de
Unterrichtsmaterialien in digitaler und in gedruckter Form Auszug aus: If-clauses - conditional sentences - Nie mehr Probleme mit Satzbau im Englischen! Das komplette Material finden Sie hier: School-Scout.de
Data Mining: Einige Grundlagen aus der Stochastik
 Data Mining: Einige Grundlagen aus der Stochastik Hagen Knaf Studiengang Angewandte Mathematik Hochschule RheinMain 21. Oktober 2015 Vorwort Das vorliegende Skript enthält eine Zusammenfassung verschiedener
Data Mining: Einige Grundlagen aus der Stochastik Hagen Knaf Studiengang Angewandte Mathematik Hochschule RheinMain 21. Oktober 2015 Vorwort Das vorliegende Skript enthält eine Zusammenfassung verschiedener
teischl.com Software Design & Services e.u. office@teischl.com www.teischl.com/booknkeep www.facebook.com/booknkeep
 teischl.com Software Design & Services e.u. office@teischl.com www.teischl.com/booknkeep www.facebook.com/booknkeep 1. Erstellen Sie ein neues Rechnungsformular Mit book n keep können Sie nun Ihre eigenen
teischl.com Software Design & Services e.u. office@teischl.com www.teischl.com/booknkeep www.facebook.com/booknkeep 1. Erstellen Sie ein neues Rechnungsformular Mit book n keep können Sie nun Ihre eigenen
Dokumentation für die software für zahnärzte der procedia GmbH Onlinedokumentation
 Dokumentation für die software für zahnärzte der procedia GmbH Onlinedokumentation (Bei Abweichungen, die bspw. durch technischen Fortschritt entstehen können, ziehen Sie bitte immer das aktuelle Handbuch
Dokumentation für die software für zahnärzte der procedia GmbH Onlinedokumentation (Bei Abweichungen, die bspw. durch technischen Fortschritt entstehen können, ziehen Sie bitte immer das aktuelle Handbuch
Mitarbeiterbefragung als PE- und OE-Instrument
 Mitarbeiterbefragung als PE- und OE-Instrument 1. Was nützt die Mitarbeiterbefragung? Eine Mitarbeiterbefragung hat den Sinn, die Sichtweisen der im Unternehmen tätigen Menschen zu erkennen und für die
Mitarbeiterbefragung als PE- und OE-Instrument 1. Was nützt die Mitarbeiterbefragung? Eine Mitarbeiterbefragung hat den Sinn, die Sichtweisen der im Unternehmen tätigen Menschen zu erkennen und für die
Im Folgenden wird Ihnen an einem Beispiel erklärt, wie Sie Excel-Anlagen und Excel-Vorlagen erstellen können.
 Excel-Schnittstelle Im Folgenden wird Ihnen an einem Beispiel erklärt, wie Sie Excel-Anlagen und Excel-Vorlagen erstellen können. Voraussetzung: Microsoft Office Excel ab Version 2000 Zum verwendeten Beispiel:
Excel-Schnittstelle Im Folgenden wird Ihnen an einem Beispiel erklärt, wie Sie Excel-Anlagen und Excel-Vorlagen erstellen können. Voraussetzung: Microsoft Office Excel ab Version 2000 Zum verwendeten Beispiel:
Erstellen einer digitalen Signatur für Adobe-Formulare
 Erstellen einer digitalen Signatur für Adobe-Formulare (Hubert Straub 24.07.13) Die beiden Probleme beim Versenden digitaler Dokumente sind einmal die Prüfung der Authentizität des Absenders (was meist
Erstellen einer digitalen Signatur für Adobe-Formulare (Hubert Straub 24.07.13) Die beiden Probleme beim Versenden digitaler Dokumente sind einmal die Prüfung der Authentizität des Absenders (was meist
Programmiersprachen und Übersetzer
 Programmiersprachen und Übersetzer Sommersemester 2010 19. April 2010 Theoretische Grundlagen Problem Wie kann man eine unendliche Menge von (syntaktisch) korrekten Programmen definieren? Lösung Wie auch
Programmiersprachen und Übersetzer Sommersemester 2010 19. April 2010 Theoretische Grundlagen Problem Wie kann man eine unendliche Menge von (syntaktisch) korrekten Programmen definieren? Lösung Wie auch
Was meinen die Leute eigentlich mit: Grexit?
 Was meinen die Leute eigentlich mit: Grexit? Grexit sind eigentlich 2 Wörter. 1. Griechenland 2. Exit Exit ist ein englisches Wort. Es bedeutet: Ausgang. Aber was haben diese 2 Sachen mit-einander zu tun?
Was meinen die Leute eigentlich mit: Grexit? Grexit sind eigentlich 2 Wörter. 1. Griechenland 2. Exit Exit ist ein englisches Wort. Es bedeutet: Ausgang. Aber was haben diese 2 Sachen mit-einander zu tun?
Basis und Dimension. Als nächstes wollen wir die wichtigen Begriffe Erzeugendensystem und Basis eines Vektorraums definieren.
 Basis und Dimension Als nächstes wollen wir die wichtigen Begriffe Erzeugendensystem und Basis eines Vektorraums definieren. Definition. Sei V ein K-Vektorraum und (v i ) i I eine Familie von Vektoren
Basis und Dimension Als nächstes wollen wir die wichtigen Begriffe Erzeugendensystem und Basis eines Vektorraums definieren. Definition. Sei V ein K-Vektorraum und (v i ) i I eine Familie von Vektoren
SFirm32 Umstellung FTAM EBICS
 SFirm32 Umstellung FTAM EBICS Für die Umstellung des Übertragungsverfahrens FTAM auf EBICS sind folgende Voraussetzungen erforderlich: + Gültige FTAM-Freischaltung bei der Naspa ist vorhanden + Elektronische
SFirm32 Umstellung FTAM EBICS Für die Umstellung des Übertragungsverfahrens FTAM auf EBICS sind folgende Voraussetzungen erforderlich: + Gültige FTAM-Freischaltung bei der Naspa ist vorhanden + Elektronische
Vorgehensweise bei Lastschriftverfahren
 Vorgehensweise bei Lastschriftverfahren Voraussetzung hierfür sind nötige Einstellungen im ControlCenter. Sie finden dort unter Punkt 29 die Möglichkeit bis zu drei Banken für das Lastschriftverfahren
Vorgehensweise bei Lastschriftverfahren Voraussetzung hierfür sind nötige Einstellungen im ControlCenter. Sie finden dort unter Punkt 29 die Möglichkeit bis zu drei Banken für das Lastschriftverfahren
Was bisher geschah. Lernen: überwachtes Lernen. biologisches Vorbild neuronaler Netze: unüberwachtes Lernen
 Was bisher geschah Lernen: überwachtes Lernen korrigierendes Lernen bestärkendes Lernen unüberwachtes Lernen biologisches Vorbild neuronaler Netze: Neuron (Zellkörper, Synapsen, Axon) und Funktionsweise
Was bisher geschah Lernen: überwachtes Lernen korrigierendes Lernen bestärkendes Lernen unüberwachtes Lernen biologisches Vorbild neuronaler Netze: Neuron (Zellkörper, Synapsen, Axon) und Funktionsweise
Ihre Interessentendatensätze bei inobroker. 1. Interessentendatensätze
 Ihre Interessentendatensätze bei inobroker Wenn Sie oder Ihre Kunden die Prozesse von inobroker nutzen, werden Interessentendatensätze erzeugt. Diese können Sie direkt über inobroker bearbeiten oder mit
Ihre Interessentendatensätze bei inobroker Wenn Sie oder Ihre Kunden die Prozesse von inobroker nutzen, werden Interessentendatensätze erzeugt. Diese können Sie direkt über inobroker bearbeiten oder mit
Quadratische Gleichungen
 Quadratische Gleichungen Aufgabe: Versuche eine Lösung zu den folgenden Zahlenrätseln zu finden:.) Verdoppelt man das Quadrat einer Zahl und addiert, so erhält man 00..) Addiert man zum Quadrat einer Zahl
Quadratische Gleichungen Aufgabe: Versuche eine Lösung zu den folgenden Zahlenrätseln zu finden:.) Verdoppelt man das Quadrat einer Zahl und addiert, so erhält man 00..) Addiert man zum Quadrat einer Zahl
Grundlagen verteilter Systeme
 Universität Augsburg Insitut für Informatik Prof. Dr. Bernhard Bauer Wolf Fischer Christian Saad Wintersemester 08/09 Übungsblatt 3 12.11.08 Grundlagen verteilter Systeme Lösungsvorschlag Aufgabe 1: a)
Universität Augsburg Insitut für Informatik Prof. Dr. Bernhard Bauer Wolf Fischer Christian Saad Wintersemester 08/09 Übungsblatt 3 12.11.08 Grundlagen verteilter Systeme Lösungsvorschlag Aufgabe 1: a)
Fibonacci Retracements und Extensions im Trading
 Fibonacci Retracements und Extensions im Trading Einführung Im 12. Jahrhundert wurde von dem italienischem Mathematiker Leonardo da Pisa die Fibonacci Zahlenfolge entdeckt. Diese Zahlenreihe bestimmt ein
Fibonacci Retracements und Extensions im Trading Einführung Im 12. Jahrhundert wurde von dem italienischem Mathematiker Leonardo da Pisa die Fibonacci Zahlenfolge entdeckt. Diese Zahlenreihe bestimmt ein
Grundbegriffe der Informatik
 Grundbegriffe der Informatik Einheit 15: Reguläre Ausdrücke und rechtslineare Grammatiken Thomas Worsch Universität Karlsruhe, Fakultät für Informatik Wintersemester 2008/2009 1/25 Was kann man mit endlichen
Grundbegriffe der Informatik Einheit 15: Reguläre Ausdrücke und rechtslineare Grammatiken Thomas Worsch Universität Karlsruhe, Fakultät für Informatik Wintersemester 2008/2009 1/25 Was kann man mit endlichen
Transparente Hausverwaltung Marketingschmäh oder doch: eine neue Dimension der Dienstleistung?
 Transparente Hausverwaltung Marketingschmäh oder doch: eine neue Dimension der Dienstleistung? INTERNET Geschäftsführer Biletti Immobilien GmbH 24/7 WEB Server Frankgasse 2, 1090 Wien E-mail: udo.weinberger@weinberger-biletti.at
Transparente Hausverwaltung Marketingschmäh oder doch: eine neue Dimension der Dienstleistung? INTERNET Geschäftsführer Biletti Immobilien GmbH 24/7 WEB Server Frankgasse 2, 1090 Wien E-mail: udo.weinberger@weinberger-biletti.at
FlowFact Alle Versionen
 Training FlowFact Alle Versionen Stand: 29.09.2005 Rechnung schreiben Einführung Wie Sie inzwischen wissen, können die unterschiedlichsten Daten über verknüpfte Fenster miteinander verbunden werden. Für
Training FlowFact Alle Versionen Stand: 29.09.2005 Rechnung schreiben Einführung Wie Sie inzwischen wissen, können die unterschiedlichsten Daten über verknüpfte Fenster miteinander verbunden werden. Für
Software Engineering. Sommersemester 2012, Dr. Andreas Metzger
 Software Engineering (Übungsblatt 2) Sommersemester 2012, Dr. Andreas Metzger Übungsblatt-Themen: Prinzip, Technik, Methode und Werkzeug; Arten von Wartung; Modularität (Kohäsion/ Kopplung); Inkrementelle
Software Engineering (Übungsblatt 2) Sommersemester 2012, Dr. Andreas Metzger Übungsblatt-Themen: Prinzip, Technik, Methode und Werkzeug; Arten von Wartung; Modularität (Kohäsion/ Kopplung); Inkrementelle
Bedienungsanleitung für den Online-Shop
 Hier sind die Produktgruppen zu finden. Zur Produktgruppe gibt es eine Besonderheit: - Seite 1 von 18 - Zuerst wählen Sie einen Drucker-Hersteller aus. Dann wählen Sie das entsprechende Drucker- Modell
Hier sind die Produktgruppen zu finden. Zur Produktgruppe gibt es eine Besonderheit: - Seite 1 von 18 - Zuerst wählen Sie einen Drucker-Hersteller aus. Dann wählen Sie das entsprechende Drucker- Modell
Wie Sie beliebig viele PINs, die nur aus Ziffern bestehen dürfen, mit einem beliebigen Kennwort verschlüsseln: Schritt 1
 Wie Sie beliebig viele PINs, die nur aus Ziffern bestehen dürfen, mit einem beliebigen Kennwort verschlüsseln: Schritt 1 Zunächst einmal: Keine Angst, die Beschreibung des Verfahrens sieht komplizierter
Wie Sie beliebig viele PINs, die nur aus Ziffern bestehen dürfen, mit einem beliebigen Kennwort verschlüsseln: Schritt 1 Zunächst einmal: Keine Angst, die Beschreibung des Verfahrens sieht komplizierter
Zusatzmodul Lagerverwaltung
 P.A.P.A. die kaufmännische Softwarelösung Zusatzmodul Inhalt Einleitung... 2 Definieren der Lager... 3 Zuteilen des Lagerorts... 3 Einzelartikel... 4 Drucken... 4 Zusammenfassung... 5 Es gelten ausschließlich
P.A.P.A. die kaufmännische Softwarelösung Zusatzmodul Inhalt Einleitung... 2 Definieren der Lager... 3 Zuteilen des Lagerorts... 3 Einzelartikel... 4 Drucken... 4 Zusammenfassung... 5 Es gelten ausschließlich
Handbuch ECDL 2003 Basic Modul 5: Datenbank Grundlagen von relationalen Datenbanken
 Handbuch ECDL 2003 Basic Modul 5: Datenbank Grundlagen von relationalen Datenbanken Dateiname: ecdl5_01_00_documentation_standard.doc Speicherdatum: 14.02.2005 ECDL 2003 Basic Modul 5 Datenbank - Grundlagen
Handbuch ECDL 2003 Basic Modul 5: Datenbank Grundlagen von relationalen Datenbanken Dateiname: ecdl5_01_00_documentation_standard.doc Speicherdatum: 14.02.2005 ECDL 2003 Basic Modul 5 Datenbank - Grundlagen
Lichtbrechung an Linsen
 Sammellinsen Lichtbrechung an Linsen Fällt ein paralleles Lichtbündel auf eine Sammellinse, so werden die Lichtstrahlen so gebrochen, dass sie durch einen Brennpunkt der Linse verlaufen. Der Abstand zwischen
Sammellinsen Lichtbrechung an Linsen Fällt ein paralleles Lichtbündel auf eine Sammellinse, so werden die Lichtstrahlen so gebrochen, dass sie durch einen Brennpunkt der Linse verlaufen. Der Abstand zwischen
50. Mathematik-Olympiade 2. Stufe (Regionalrunde) Klasse 11 13. 501322 Lösung 10 Punkte
 Klasse 11 13. 501322 Lösung 10 Punkte") 50. Mathematik-Olympiade. Stufe (Regionalrunde) Klasse 3 Lösungen c 00 Aufgabenausschuss des Mathematik-Olympiaden e.v. www.mathematik-olympiaden.de. Alle Rechte vorbehalten. 503 Lösung 0 Punkte Es seien
50. Mathematik-Olympiade. Stufe (Regionalrunde) Klasse 3 Lösungen c 00 Aufgabenausschuss des Mathematik-Olympiaden e.v. www.mathematik-olympiaden.de. Alle Rechte vorbehalten. 503 Lösung 0 Punkte Es seien
Retouren im Online-Handel Verbraucherbefragung
 www.pwc.de Retouren im Online-Handel Verbraucherbefragung November 2013 Hintergrund der Analyse Ab 1. Juni 2014 dürfen Online-Händler für die Bearbeitung von Retouren auch dann eine Gebühr verlangen, wenn
www.pwc.de Retouren im Online-Handel Verbraucherbefragung November 2013 Hintergrund der Analyse Ab 1. Juni 2014 dürfen Online-Händler für die Bearbeitung von Retouren auch dann eine Gebühr verlangen, wenn
Downloadfehler in DEHSt-VPSMail. Workaround zum Umgang mit einem Downloadfehler
 Downloadfehler in DEHSt-VPSMail Workaround zum Umgang mit einem Downloadfehler Downloadfehler bremen online services GmbH & Co. KG Seite 2 Inhaltsverzeichnis Vorwort...3 1 Fehlermeldung...4 2 Fehlerbeseitigung...5
Downloadfehler in DEHSt-VPSMail Workaround zum Umgang mit einem Downloadfehler Downloadfehler bremen online services GmbH & Co. KG Seite 2 Inhaltsverzeichnis Vorwort...3 1 Fehlermeldung...4 2 Fehlerbeseitigung...5
Additional Cycle Index (ACIX) Thomas Theuerzeit
 Thomas Theuerzeit") Additional Cycle Index (ACIX) Thomas Theuerzeit Der nachfolgende Artikel über den ACIX stammt vom Entwickler des Indikators Thomas Theuerzeit. Weitere Informationen über Projekte von Thomas Theuerzeit
Additional Cycle Index (ACIX) Thomas Theuerzeit Der nachfolgende Artikel über den ACIX stammt vom Entwickler des Indikators Thomas Theuerzeit. Weitere Informationen über Projekte von Thomas Theuerzeit
Tutorial: Homogenitätstest
 Tutorial: Homogenitätstest Eine Bank möchte die Kreditwürdigkeit potenzieller Kreditnehmer abschätzen. Einerseits lebt die Bank ja von der Vergabe von Krediten, andererseits verursachen Problemkredite
Tutorial: Homogenitätstest Eine Bank möchte die Kreditwürdigkeit potenzieller Kreditnehmer abschätzen. Einerseits lebt die Bank ja von der Vergabe von Krediten, andererseits verursachen Problemkredite
OECD Programme for International Student Assessment PISA 2000. Lösungen der Beispielaufgaben aus dem Mathematiktest. Deutschland
 OECD Programme for International Student Assessment Deutschland PISA 2000 Lösungen der Beispielaufgaben aus dem Mathematiktest Beispielaufgaben PISA-Hauptstudie 2000 Seite 3 UNIT ÄPFEL Beispielaufgaben
OECD Programme for International Student Assessment Deutschland PISA 2000 Lösungen der Beispielaufgaben aus dem Mathematiktest Beispielaufgaben PISA-Hauptstudie 2000 Seite 3 UNIT ÄPFEL Beispielaufgaben
XT Großhandelsangebote
 XT GROßHANDELSANGEBOTE XT Großhandelsangebote Die neuen XT- Großhandelsangebote bieten Ihnen eine große Anzahl an Vereinfachungen und Verbesserungen, z.b. Großhandelsangebote werden zum Stichtag automatisch
XT GROßHANDELSANGEBOTE XT Großhandelsangebote Die neuen XT- Großhandelsangebote bieten Ihnen eine große Anzahl an Vereinfachungen und Verbesserungen, z.b. Großhandelsangebote werden zum Stichtag automatisch
Repräsentative Umfrage zur Beratungsqualität im deutschen Einzelhandel (Auszug)
") Porsche Consulting Exzellent handeln Repräsentative Umfrage zur Beratungsqualität im deutschen Einzelhandel (Auszug) Oktober 2013 Inhalt Randdaten der Studie Untersuchungsziel der Studie Ergebnisse der
Porsche Consulting Exzellent handeln Repräsentative Umfrage zur Beratungsqualität im deutschen Einzelhandel (Auszug) Oktober 2013 Inhalt Randdaten der Studie Untersuchungsziel der Studie Ergebnisse der
Vorlesung Text und Data Mining S9 Text Clustering. Hans Hermann Weber Univ. Erlangen, Informatik
 Vorlesung Text und Data Mining S9 Text Clustering Hans Hermann Weber Univ. Erlangen, Informatik Document Clustering Überblick 1 Es gibt (sehr viele) verschiedene Verfahren für das Bilden von Gruppen Bei
Vorlesung Text und Data Mining S9 Text Clustering Hans Hermann Weber Univ. Erlangen, Informatik Document Clustering Überblick 1 Es gibt (sehr viele) verschiedene Verfahren für das Bilden von Gruppen Bei
Mathematik. UND/ODER Verknüpfung. Ungleichungen. Betrag. Intervall. Umgebung
 Mathematik UND/ODER Verknüpfung Ungleichungen Betrag Intervall Umgebung Stefan Gärtner 004 Gr Mathematik UND/ODER Seite UND Verknüpfung Kommentar Aussage Symbolform Die Aussagen Hans kann schwimmen p und
Mathematik UND/ODER Verknüpfung Ungleichungen Betrag Intervall Umgebung Stefan Gärtner 004 Gr Mathematik UND/ODER Seite UND Verknüpfung Kommentar Aussage Symbolform Die Aussagen Hans kann schwimmen p und
Speicher in der Cloud
 Speicher in der Cloud Kostenbremse, Sicherheitsrisiko oder Basis für die unternehmensweite Kollaboration? von Cornelius Höchel-Winter 2013 ComConsult Research GmbH, Aachen 3 SYNCHRONISATION TEUFELSZEUG
Speicher in der Cloud Kostenbremse, Sicherheitsrisiko oder Basis für die unternehmensweite Kollaboration? von Cornelius Höchel-Winter 2013 ComConsult Research GmbH, Aachen 3 SYNCHRONISATION TEUFELSZEUG
Lernende Suchmaschinen
 Lernende Suchmaschinen Qingchui Zhu PG 520 - Intelligence Service (WiSe 07 / SoSe 08) Verzeichnis 1 Einleitung Problemstellung und Zielsetzung 2 Was ist eine lernende Suchmaschine? Begriffsdefinition 3
Lernende Suchmaschinen Qingchui Zhu PG 520 - Intelligence Service (WiSe 07 / SoSe 08) Verzeichnis 1 Einleitung Problemstellung und Zielsetzung 2 Was ist eine lernende Suchmaschine? Begriffsdefinition 3
Institut für Computational Engineering ICE. N ä h e r d ra n a m S ys t e m d e r Te c h n i k d e r Z u ku n f t. w w w. n t b.
 Institut für Computational Engineering ICE N ä h e r d ra n a m S ys t e m d e r Te c h n i k d e r Z u ku n f t w w w. n t b. c h Rechnen Sie mit uns Foto: ESA Das Institut für Computational Engineering
Institut für Computational Engineering ICE N ä h e r d ra n a m S ys t e m d e r Te c h n i k d e r Z u ku n f t w w w. n t b. c h Rechnen Sie mit uns Foto: ESA Das Institut für Computational Engineering
Data Mining (ehem. Entscheidungsunterstützungssysteme)
") Data Mining (ehem. Entscheidungsunterstützungssysteme) Melanie Pfoh Anja Tetzner Christian Schieder Übung WS 2014/15 AGENDA TEIL 1 Aufgabe 1 (Wiederholung OPAL / Vorlesungsinhalte) ENTSCHEIDUNG UND ENTSCHEIDUNGSTHEORIE
Data Mining (ehem. Entscheidungsunterstützungssysteme) Melanie Pfoh Anja Tetzner Christian Schieder Übung WS 2014/15 AGENDA TEIL 1 Aufgabe 1 (Wiederholung OPAL / Vorlesungsinhalte) ENTSCHEIDUNG UND ENTSCHEIDUNGSTHEORIE
Häufige Item-Mengen: die Schlüssel-Idee. Vorlesungsplan. Apriori Algorithmus. Methoden zur Verbessung der Effizienz von Apriori
 Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,