Vertiefungsrichtung Marktforschung
|
|
|
- Matilde Fertig
- vor 8 Jahren
- Abrufe
Transkript
 Christian Reinboth Darstellen Explorative Datenanalyse Beschreiben")
1 Vertiefungsrichtung Marktforschung Sommersemester 2006 Dipl.-WiInf.(FH) Christian Reinboth Darstellen Explorative Datenanalyse Beschreiben Erkennen Testen

2 Inhalte: Explorative Datenanalyse Wir unterscheiden in... Deskriptive Statistik (Beschreibung und Visualisierung der Daten) Explorative Statistik (Suchen nach Strukturen und Auffälligkeiten) Induktive Statistik (Testen von Hypothesen und Schätzen von Parametern) Fragestellung: Was ist an der Verteilung eines Merkmals bemerkenswert? Was gehört zur explorativen Datenanalyse? Berechnung statistischer Maßzahlen Darstellung absoluter und relativer Häufigkeiten Visualisierung diskreter und stetiger Variablen Analyse von Ausreißern Analyse fehlender Daten Transformation von Daten Erstellung von Dummy-Variablen Prüfung der Voraussetzungen für weiterführende Analysemethoden

3 Inhalte: Explorative Datenanalyse Zu Beginn einer Datenanalyse... Streudiagramme Lagemaße / Maße der zentralen Tendenz Streudiagramm-Matritzen Das arithmetische Mittel Der Median Ursachen für Ausreißer Die Perzentilwerte Identifikation von Ausreißern Der Modus Leverage-Effekt Umgang mit Ausreißern Streuungsmaße / Dispersionsparameter Ausreißeranalyse Die Spannweite Der Interquartilsabstand Gründe für fehlende Daten Varianz & Standardabweichung Struktur fehlender Daten Umgang mit fehlenden Daten Grafische Darstellungsmöglichkeiten Fehlende Daten Säulen- und Balkendiagramme Kreisdiagramme Prüfung auf Normalverteilung Histogramme Prüfung auf Homoskedastizität Stem-and-Leaf-Plots Prüfung auf Linearität Box-Plots P-P-Diagramme Q-Q-Diagramme Prüfung von Voraussetzungen Arbeit mit Dummy-Variablen

4 Zu Beginn einer Datenanalyse......ist es sinnvoll, einen Überblick über die vorliegenden Daten zu bekommen Darstellung von Lage und Verteilung der Werte gibt es Auffälligkeiten in den Daten? Lagemaße: arithmetisches Mittel, Median, Perzentile, Modus Streumaße: Spannweite, Interquartilsabstand, Varianz, Standardabweichung Grafische Darstellung: Balken-, Kreis-, Stabdiagramm, Stem-and-Leaf, Histogramm, Box-Plot... Lassen sich extrem große oder kleine Werte (Ausreißer) in den Daten identifizieren? Sind außergewöhnliche Umstände oder Fehler die Ursache? Verzerren die Ausreißer die Ergebnisse der Datenanalyse? Ist es möglich, sie aus der weiteren Analyse auszuschließen? Erfüllen die vorliegenden Daten alle Voraussetzungen für weiterführende Analyseverfahren? Liegt eine Normalverteilung vor? Liegt eine Gleichheit der Varianzen vor? (Homoskedastizität) Welche Tests und Untersuchungen in eine solche explorative Datenanalyse gehören, ist nicht definitiv festgelegt Je nach der Art der Daten sowie der nachfolgenden Verfahren sind geeignete Teilelemente auszuwählen

5 Lagemaße: Das arithmetische Mittel Das arithmetische Mittel ist das bekannteste statistische Lagemaß (Standardmittelwert) Es kann nur für metrisch skalierte Daten berechnet werden (Intervallskala, Verhältnisskala) Vorsicht: SPSS berechnet das arithmetische Mittel auch für nichtmetrische Daten (Schulnoten!) Methodenkenntnisse des Anwenders sind daher erforderlich! n Liegen von einem metrischen Merkmal x insgesamt n Werte vor, berechnet sich das arithmetische Mittel durch: x = Die Gesamtsumme aller Abweichungen von arithmetischen Mittel beträgt daher stets Null Das arithmetische Mittel ist nicht robust, d.h. sehr empfindlich gegenüber Ausreißern Beispiel: 1, 2, 3, 4 > ( ) / 4 = 2,5 >>> 1, 2, 3, 50 > ( ) / 4 = 14 1 x n i=1 i
 / 4 = 2,5 >>> 1, 2, 3, 50 > (1+2+3+50) / 4 = 14 1 x n i=1 i")
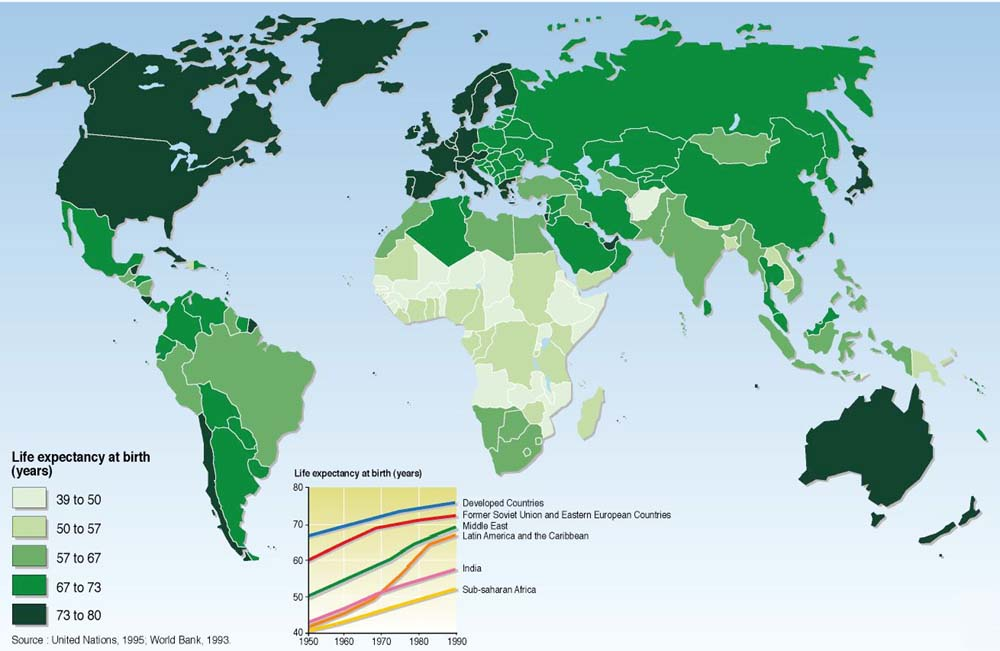
6 Weltweite Lebenserwartung
7 Lagemaße: Der Median Der Median ist der Wert, der in der Mitte der geordneten Verteilung liegt Die Berechnung des Medians setzt mindestens ordinalskalierte Daten voraus Bei einer ungeraden Anzahl an Werten, wird der mittlere Wert gewählt: Bei einer geraden Anzahl an Werten wird das arithmetischen Mittel der beiden zentralen Werte gewählt: Bei klassierten Daten wird der mittlere Fall der zentralen Klasse ermittelt (unter Annahme einer Gleichverteilung) Der Median ist äußerst robust, d.h. er wird von Ausreißern nicht beeinflusst Aus diesem Grund ist er in der Regel aussagekräftiger als das arithmetische Mittel Beispiel: 1, 2, 3, 4, 5 > Median: 3 >>> x med = x n x med = x n x n , 2, 3, 4, 50 > Median: 3

 Der bekannteste Perzentilwert ist das 50%-Perzentil, welches auch als Median bezeichnet wird Häufig verwendet wird auch die Vierteilung des Wertebereichs mit den sogenannten")
8 Lagemaße: Perzentilwerte Perzentilwerte sind Werte, unterhalb derer ein eindeutig definierter Anteil aller Werte liegt Für die Berechnung der Perzentile müssen mindestens ordinalskalierte Daten vorliegen (geordnet) Der bekannteste Perzentilwert ist das 50%-Perzentil, welches auch als Median bezeichnet wird Häufig verwendet wird auch die Vierteilung des Wertebereichs mit den sogenannten Quartilen: 25%-Perzentil (25% aller Werte liegen unterhalb dieses Wertes) 50%-Perzentil, Median (50% aller Werte liegen unter- bzw. oberhalb dieses Wertes) 75%-Perzentil (75% aller Werte liegen unterhalb dieses Wertes) Ebenso wie der Median, sind die Perzentile absolut robust, d.h. von Ausreißern nicht zu beeinflussen
 75%-Perzentil (75% aller Werte liegen unterhalb dieses Wertes) Ebenso wie der Median, sind die Perzentile absolut robust, d.h. von Ausreißern nicht zu beeinflussen")
9 Lagemaße: Der Modus Der Modus (Modalwert) ist der in den vorliegenden Daten am häufigsten auftretende Wert Bei klassierten Daten ist der Modus die Klassenmitte der Klasse mit den meisten Fällen (nur gleichbreite Klassen) Die Berechnung des Modus ist in der Regel nur bei diskreten Daten sinnvoll (Punktwahrscheinlichkeit) Er wird insbesondere für nominalskalierte Merkmale gebildet, da hier kein anderes Lagemaß möglich ist Bei metrisch skalierten Daten können gleichbreite Klassen gebildet und darüber der Modus ermittelt werden Vorteil: Der Modus ist auch ohne Berechnung erkennbar und kann daher in der Praxis schnell bestimmt werden Nachteil: Der Modus kann nur eindeutig interpretiert werden, wenn ein einzelnes, klares Maximum vorliegt Sind mehrere Werte mit gleicher Häufigkeit vertreten, gibt SPSS den in der Häufigkeitstabelle zuoberst stehenden Wert an

10 Lagemaße: Skalenniveaus & Interpretation Lagemaß Minimales Skalenniveau Modalwert Nominalskalenniveau Median / Perzentile Ordinalskalenniveau Arithmetisches Mittel Metrisches Skalenniveau Verhältnis der Lagemaße Verteilungsform x x med x mod x x med x mod x x med x mod Symmetrische Verteilung Linkssteile Verteilung Rechtssteile Verteilung

11 Streuungsmaße: Die Spannweite Die Spannweite ist der Abstand zwischen dem kleinsten (Minimum) und dem größten (Maximum) Wert im Datensatz Die Spannweite ist als Streuungsmaß ungenügend, da sie extrem stark von Ausreißern beeinflusst wird Existieren an beiden Verteilungsrändern Ausreißer, wird die Spannweite nur(!) durch diese bestimmt Beispiel: 1, 2, 3, 4, 5 > Spannweite: 4 >>> 1, 2, 3, 4, 50 > Spannweite: 49

12 Streuungsmaße: Der Interquartilsabstand Der Interquartilsabstand (IQR = Inter Quartile Range) ist der Abstand zwischen dem oberen und dem unteren Quartil Da die beiden Quartile nicht von Ausreißern beeinflusst werden können, ist der IQR deutlich robuster als die Spannweite Aus den Quartilen sowie Minimum und Maximum lässt sich die kompakte 5-Werte-Zusammenfassung bilden Interquartilsabstand

13 Streuungsmaße: Die Varianz Die Varianz (bzw. Standardabweichung) ist das gebräuchlichste Streuungsmaß Sie berechnet sich als Summe der quadrierten Abweichungen der Einzelwerte (Ausgleich negativer und positiver Abweichungen) vom arithmetischen Mittel, geteilt durch die Gesamtzahl aller Werte N 1 X i X 2 N 1 i=1 Bei der Berechnung der Stichproben-Varianz (SPSS) stehen die Freiheitsgrade im Nenner: S 2= Die Varianz wird kleiner, je näher die Einzelwerte am arithmetischen Mittel liegen Sind alle Werte mit dem Mittel identisch (keine Streuung), ergibt sich eine Varianz von Null Bei der Interpretation des Ergebnisses ist zu beachten, dass die quadrierten Werte in die Berechnung eingehen Dies hat zur Folge, dass auch die Varianz in der quadrierten Einheit dimensioniert ist (also z.b. in ² statt in ) Zur besseren Interpretation wird häufig die Standardabweichung als Quadratwurzel der Varianz angegeben
, ergibt sich eine Varianz von Null Bei der Interpretation des Ergebnisses ist zu beachten, dass")
14 Grafische Darstellung univariater Daten Darstellungsformen Diskrete Merkmale Wenig Ausprägungen Stetige Merkmale Viele Ausprägungen Stabdiagramm Stem & Leaf Säulendiagramm Histogramm Balkendiagramm Box-Plot Kreisdiagramm Q-Q-Diagramm

15 Grafik: Säulen- und Balkendiagramme Säulen- und Balkendiagramme eigenen sich primär für diskrete Merkmale mit einer geringen Anzahl an Ausprägungen Stetige Merkmale müssen vor der Darstellung klassiert werden, damit diese interpretierbar wird SPSS ermöglicht die grafische Darstellung sowohl der absoluten als auch der relativen Häufigkeiten im Diagramm


16 Grafik: Kreisdiagramme Ebenso wie Säulen- und Balkendiagramme sind Kreisdiagramme primär für diskrete Merkmalsverteilungen geeignet Bei stetigen Merkmalen ist eine Klassierung für die grafische Darstellung unbedingt erforderlich

17 Grafik: Histogramme Ein Histogramm stellt die Häufigkeitsverteilung der Werte einer intervallskalierten Variablen dar Dabei wird von nach der Größe geordneten Daten ausgegangen, die in n Klassen aufgeteilt werden, welche theoretisch nicht die gleiche Breite besitzen müssen (SPSS erstellt Histogramme stets mit gleichbreiten Klassen) Über jeder Klasse wird ein Rechteck konstruiert, dessen Flächeninhalt sich proportional zur absoluten bzw. relativen Häufigkeit der jeweiligen Klasse verhält (je nach Anlage des Histogramms) Die Form der Darstellung eignet sich primär für stetige Merkmale mit einer großen Anzahl an Ausprägungen Bei der Erstellung von Histogrammen mit SPSS ist zu beachten, dass maximal 21 Klassen gebildet werden können Außerdem kann eine Normalverteilungskurve in das Histogramm eingeblendet werden, aus der abgelesen werden kann, wie eine Normalverteilung bei Daten mit gleichem Mittelwert und gleicher Streuung aussehen würde (Voraussetzungsprüfung)
 Die Form der Darstellung eignet sich primär für stetige Merkmale mit einer großen Anzahl an Ausprägungen Bei der")
18 Grafik: Stem-and-Leaf-Plots Stem-and-Leaf-Plots (Stamm-Blatt-Diagramme) eignen sich ebenfalls zur Darstellung stetiger Merkmale Der große Vorteil gegenüber jeder anderen grafischen Darstellungsform ist, dass die Originaldaten (bis zu einer gewissen Genauigkeit) noch aus dem Diagramm abgelesen werden können Das Diagramm ist ähnlich aufgebaut wie ein seitlich gekipptes Histogramm, d.h. flächenproportional Der Stamm besteht in der Regel aus der ersten Ziffer, die Blätter aus der jeweils folgenden (Rundungen) Sehr große oder sehr kleine Zahlen können auf- bzw. abgerundet oder als Extremwerte ausgewiesen werden Stem-and-Leaf-Plots können auch genutzt werden, um zwei Verteilungen miteinander zu vergleichen Extremes Stem width: Each leaf: 10 1 case(s) Datensatz A Datensatz B Extremes Stem width: Each leaf: Extremes 10 1 case(s)
 Sehr große oder sehr kleine Zahlen können auf- bzw.")
19 Grafik: Box-Plots Box-Plots bieten einen direkten Verteilungsüberblick und eignen sich insbesondere zum Verteilungsvergleich Sie stellen sowohl Lage als auch Streuung der Verteilung dar und dienen zudem der Identifikation von Ausreißern * Extremer Wert Ausreißer Größter nicht-extremer Wert Oberes Quartil 7 IQR 4 IQR Median IQR Unteres Quartil Kleinster nicht-extremer Wert 42 Ausreißer

20 Grafik: Box-Plots Aus der Lage des Medians innerhalb eines Box-Plots läßt sich die Form der Verteilung ablesen Symmetrische Verteilung Linkssteile Verteilung Rechtssteile Verteilung

21 Grafik: Box-Plots Sollen mehrere Verteilungen bzw. mehrere überschneidungsfreie Gruppen (beispielsweise männliche und weibliche Angestellte) innerhalb einer Verteilung miteinander verglichen werden, lassen sich Box-Plots nebeneinander darstellen Weitergehende Vergleiche sind über gruppierte Box-Plots möglich, d.h. es erfolgt eine Aufteilung anhand mehr als nur eines Merkmals (beispielsweise anhand des Geschlechts und des Minderheitenstatus, wodurch sich vier Gruppen ergeben)
22 Grafik: P-P-Diagramme Ein P-P-Diagramm trägt die kumulierten Häufigkeiten der beobachteten Werte gegen die zu erwartenden kumulierten Häufigkeiten einer Vergleichsverteilung ab in der Regel einer Normalverteilung (möglich sind aber auch andere) Je stärker sich die Verteilung der Stichprobenwerte und die Vergleichsverteilung ähneln, desto stärker stimmen die empirischen mit den erwarteten kumulierten Häufigkeiten überein, erkennbar am diagonalen Verlauf des Diagramms Bei einer perfekten Übereinstimmung von tatsächlicher und theoretischer Verteilung (in der Praxis nicht zu erwarten) liegen sämtliche Punkte auf der eingezeichneten Diagonalen
23 Grafik: Trendbereinigte P-P-Diagramme Zusätzlich zum P-P-Diagramm kann auch ein trendbereinigtes P-P-Diagramm ausgegeben werden, bei dem die beobachteten kumulierten Häufigkeiten nicht mit den erwarteten kumulierten Häufigkeiten, sondern mit den Abweichungen der beobachteten von den erwarteten kumulierten Häufigkeiten dargestellt werden
24 Grafik: Q-Q-Diagramme Q-Q-Diagramme dienen wie P-P-Diagramme dem visuellen Vergleich einer vorliegenden Verteilung mit einer Referenzverteilung beispielsweise zur Überprüfung der Voraussetzung einer Normalverteilung Im Gegensatz zum P-P-Diagramm werden im Q-Q-Diagramm nicht beobachtete und erwartete kumulierte Häufigkeiten gegenübergestellt, sondern die direkt beobachteten und erwarteten Werte Wie im P-P-Diagramm kennzeichnen auch im Q-Q-Diagramm Abweichungen der Punkte vom Verlauf der diagonalen Abweichungen der beobachteten von den erwarteten Werten ein Indiz dafür, dass die beobachteten Merkmalswerte der Referenzverteilung nicht genügen
25 Grafik: Trendbereinigte Q-Q-Diagramme Zusätzlich zum Q-Q-Diagramm kann wie auch beim P-P-Diagramm ein trendbereinigtes Q-Q-Diagramm ausgegeben werden, bei dem die beobachteten Werte nicht mit den erwarteten Werten, sondern mit den Abweichungen der beobachteten von den erwarteten Werten dargestellt werden
26 Grafische Darstellung multivariater Daten Darstellungsformen Bivariate Darstellung Mehr als zwei Variablen 2-D-Streudiagramm Profildiagramme 3-D-Streudiagramm Streudiagramm-Matrix Andrew's Fourier Chernoff-Gesichter
27 Grafik: Streudiagramme Streudiagramme stellen die gemeinsame Verteilung der Werte zweier Variablen (bzw. dreier Variablen in einem 3-D-Streudiagramm) dar, indem die entsprechenden Werte beider Variablen gegeneinander abgetragen werden Die Lage und Verteilung der Wertepaare ermöglicht Rückschlüsse auf mögliche Zusammenhänge Beispiel: Treten in der Tendenz große Werte der einen Variablen gepaart mit großen Werten der anderen Variablen auf, so kann ein positiver Zusammenhang vermutet werden (beispielsweise bei Werbeausgaben und Verkaufszahlen) Ein gefundener Zusammenhang kann nicht in eine bestimmte Richtung interpretiert werden, d.h. aus der Grafik ist nicht abzulesen, ob Variable A Variable B beeinflusst oder umgekehrt, bzw. ob ein Scheinzusammenhang besteht

28 Grafik: Streudiagramm-Matrix Liegt ein multivariater Fall vor, d.h. sollen für mehrere Variablenpaare jeweils gemeinsame Verteilungen dargestellt werden, ist statt einer Reihe bivariater Streudiagramme ein gemeinsames Streudiagramm in Form einer Matrix sinnvoll Eine Streudiagramm-Matrix erlaubt den schnellen Überblick über die Vielzahl aller denkbaren Paarverteilungen und gestattet das rasche Auffinden symmetrischer oder anderweitig auffälliger Einzel-Streudiagramme Jedes Streudiagramm taucht zweimal in der Matrix auf (einmal oberhalb und einmal unterhalb der Hauptdiagonalen), wobei die jeweiligen Achsen der Diagramme miteinander vertauscht sind (Gehalt <> Anfangsgehalt; Anfangsgehalt <> Gehalt)
29 Ausreißeranalyse: Einführung Bei einem Ausreißer handelt es sich um einen gemessenen oder erhobenen Wert,der nicht den Erwartungen entspricht bzw. nicht zu den restlichen Werten der Verteilung passt Es existiert keine klare Definition darüber, wann ein Wert als Ausreißer bezeichnet werden kann- beim Box-Plot z.b. werden alle Werte außerhalb des dreifachen IQR-Bereichs um den Median als Ausreißer klassifiziert Es gibt drei mögliche Ursachen für das Auftreten eines Ausreißers: Der Ausreißer kennzeichnet einen außergewöhnlichen Wert, beispielsweise eine einzelne aus dem Rahmen fallende Beobachtung (der einzige befragte Millionär), die sich aber erklären lässt mitunter können solche Ausreißer auch ein Hinweis darauf sein, dass die Befragung falsch angelegt wurde und daher nicht repräsentativ ist Der Ausreißer kennzeichnet einen korrekt erfassten außergewöhnlichen Wert, für den es keinerlei Erklärung gibt Generell ist zwischen normalen Ausreißen und multivariaten Ausreißern zu unterscheiden: Der Ausreißer wurde durch einen verfahrenstechnischen Fehler verursacht, beispielsweise einen Fehler bei der Dateneingabe, beim Codieren der Daten oder einen technischen Ausfall bei der Datenerfassung bzw. -speicherung Normaler Ausreißer = außergewöhnlich großer oder kleiner Wert (persönliches Einkommen im Millionenbereich) Multivariarer Ausreißer = für sich betrachtet im normalen Bereich liegende Einzelwerte, die in ihrer Kombination quer durch die Variablen einen einzigartigen Fall ergeben (86jährige Frau mit Internetanschluss) Die entscheidende Frage der Ausreißeranalyse lautet: Werden die Ausreißer beibehalten oder verworfen?
30 Ausreißeranalyse: Identifikation Wie lassen sich Ausreißer erkennen? Identifikation von Ausreißern über die Extremwerttabelle Grafische Identifikation von Ausreißern im Streudiagramm Unterscheidung in Ausreißer und extreme Werte im Box-Plot
31 Ausreißeranalyse: Leverage-Effekt Auswirkung eines Ausreißers auf den Verlauf einer lineare Regressionsgerade Einzelne Ausreißer können die Regressionsgerade zu sich hinziehen und das Ergebnis einer linearen Regressionsanalyse erheblich beeinflussen
32 Ausreißeranalyse: Umgang Wie ist nun mit den gefundenen Ausreißern umzugehen? Generell gibt es drei Möglichkeiten: Ausschluss aus der Analyse Eingang in die Analyse Kennzeichnung als fehlende Werte Verschiedene Überlegungen sind für die Entscheidung von Bedeutung: Wie ist das Auftreten der Ausreißer zu erklären? Handelt es sich um Eingabefehler und ist es möglich, diese zu bereinigen? Was sagen die Werte über Anlage und Durchführung der Erhebung aus? Welche Auswirkungen haben die Ausreißer auf die Ergebnisse der Datenanalyse? Beeinflussen sie beispielsweise den Verlauf der Regressionsgraden? (Leverage-Effekt) Werden die Analyseergebnisse so stark verzerrt, dass die Ausreißer entfernt werden müssen? Welcher Datenverlust entsteht, wenn die Ausreißer aus dem Datensatz entfernt werden?
33 Fehlende Daten: Einführung Unter fehlenden Daten sind einzelne fehlende Werte zu verstehen Typische fehlende Werte bei Personenbefragungen: Angaben zum Einkommen Angaben zum eigenen Körper Angaben zum Sexualverhalten Fehlende Werte sind ein Problem, wenn ein Zusammenhang zwischen der Wahrscheinlichkeit des Fehlens und einem anderen Sachverhalt zu vermuten ist, die Verteilung der fehlenden Werte also nicht zufällig ist Beispiel: Kommt es bei der Frage nach dem Einkommen tendenziell eher zu Auskunftsverweigerungen bei Personen mit niedrigem Einkommen, so wird dies das erhobene Durchschnittseinkommen verzerren Bei der Untersuchung fehlender Daten ist daher vor allem zu klären: Fehlen so viele Werte, dass eine sinnvolle Auswertung des Datensatzes unmöglich ist? Sind die fehlenden Werte zufällig im Datensatz gestreut oder lässt sich ein Muster identifizieren? Generell bieten sich drei Möglichkeiten des Umgangs mit fehlenden Daten an: Es werden ausschließlich die vollständigen Fälle zur weiteren Auswertung zugelassen Einzelne Fälle oder einzelne Variablen werden von der weiteren Auswertung ausgeschlossen Die fehlenden Werte werden induktiv oder statistisch ersetzt
34 Fehlende Daten: Ursachen Das Fehlen von Daten kann auf vier Ursachen zurückgeführt werden: Dateneingabefehler (z.b. Buchstaben in einem Zahlenfeld) Codierungs- und Übertragungsfehler während Eingabe oder Speicherung Ungenaue Datenfelder bei der Erhebung (z.b. Studienrichtung bei einer Befragung von Nicht-Akademikern) Aktionen des Befragten, beispielsweise Vergessen der Angaben, widersinnige Angaben (höchster Schulabschluss ist die Mittlere Reife, trotzdem wurde eine Abiturnote eingetragen), Nichtauskunftsfähigkeit oder bewusste Entscheidung eine bestimmte Frage nicht zu beantworten (Einkommen, Körper, Sexualverhalten...) Fehlende Werte sind bei der Arbeit mit empirischen Daten keine Ausnahme, sondern die Regel Die Wahrscheinlichkeit für das Auftreten fehlender Werte steigt im Allgemeinen mit der Größe des Datensatzes Bei der Analyse langer Zeitreihen, z.b. der Auswertung der Niederschlagsmengen der letzten 200 Jahre, werden aufgrund von Katastrophen, Krieg oder anderen Gründen immer wieder einzelne Werte nicht erfasst worden sein Gerade in der sozialwissenschaftlichen Forschung und bei der Marktforschung im Zuge der Befragung von hunderten oder tausenden Personen kommt es aufgrund verschiedenster Ursachen häufig zu Einzelausfällen Mit fehlenden Daten ist bei jeder marktforscherischen Untersuchung zu rechnen! Das Problem der fehlenden Daten sollte vom Marktforscher nicht einfach ignoriert werden!
35 Fehlende Daten: Zufälligkeitsgrade Man unterscheidet in drei Zufälligkeitsgrade bezüglich des Auftretens fehlender Daten: MCAR, MAR und NRM Der Zufälligkeitsgrad entscheidet, ob fehlende Werte ausgeschlossen oder ersetzt werden können MCAR = missing completely at random Fehlende Werte treten vollkommen zufällig auf Die Wahrscheinlichkeit des Fehlen eines Wertes steht nicht in Zusammenhang mit anderen Größen MAR = missing at random Es ist kein Zusammenhang zwischen dem Auftreten von fehlenden Werten der Variable Y und der Variable Y selbst (niedrige Einkommen werden tendenziell nicht angegeben) oder eine Korrelation mit einer anderen Variable X (Frauen sind tendenziell weniger bereit, Auskünfte über ihr Körpergewicht zu machen) feststellbar Das Auftreten von fehlenden Werten steht (teilweise) in Zusammenhang mit einer anderen erhobenen Variablen Es ist kein Zusammenhang zwischen dem Auftreten von fehlenden Werten der Variable Y und der Variable Y selbst feststellbar, aber eine (schwache) Korrelation des Auftretens von fehlenden Y-Werten mit einer anderen Variable X NRM = nonrandom missing Das Auftreten von fehlenden Werten folgt klaren Gesetzmäßigkeiten, Zufälligkeit ist auszuschließen Es kann entweder ein Zusammenhang zwischen dem Auftreten von fehlenden Werten der Variable Y und der Variable Y selbst oder mit einer anderen Variable X oder auch beides vorliegen, d.h. das Auftreten eines fehlenden Wertes kann vollständig durch eine andere Variable oder die Variable selbst erklärt werden
36 Fehlende Daten: Umgang Welche der drei Methoden angewandt werden kann, hängt wesentlich vom Zufälligkeitsgrad ab CCA = complete case approach Es werden ausschließlich vollständige Fälle für die weitere Analyse verwendet Alle Fälle mit auch nur einem fehlenden Wert werden aus dem Datensatz entfernt Die Methode kann nur bei zufällig fehlenden Daten (MCAR) angewendet werden Günstig ist sie bei einer großen Stichprobe, da die gelöschten Fälle hier unkritisch sind Ausschluss von Fällen oder Variablen Ziel ist die Verringerung des Gesamtanteils fehlender Werte Abwägen zwischen dem Datenverlust und der Reduktion der Probleme durch fehlende Werte Günstigste Methode für nicht zufällig auftretende fehlende Werte (MAR, NRM) Der Ausschluss von Fällen kann fallweise oder paarweise erfolgen Ersetzen fehlender Werte Grundidee: metrische Daten (ausschließlich!) lassen sich ersetzen, wenn Regelmäßigkeiten erkennbar sind Möglich ist der Ersatz über verschiedene induktive (nichtmathematische) und statistische (mathematische) Verfahren Die Gefahr besteht darin, dass man den Datensatz für vollständig hält bzw. durch die Ersetzungen verzerrt
37 Fehlende Daten: Ausschlussverfahren Fallweiser Ausschluss: Fehlt ein einzelner Wert, wird der komplette Fall von der weiteren Analyse ausgeschlossen Vorteil: bestimmte Arten von Asymmetrien werden vermieden, da keine Teilfälle in die Analyse eingehen Nachteil: relevantes Datenmaterial geht verloren, der Stichprobenumfang sinkt mit jedem Ausschluss Paarweiser Ausschluss: Fehlen einzelne Werte, wird mit den restlichen Werten des Falles weitergearbeitet Vorteil: alle Fälle bleiben erhalten, der Stichprobenumfang verändert sich nicht Nachteil: bei multivariaten Analysen bilden u.u. unterschiedlich große Datensätze die Berechnungsgrundlage Um Fälle zu vermeiden, bei denen auf unterschiedlich große Datensätze zurückgegriffen und gleichzeitig verglichen wird, ist der fallweise Ausschluss das weitaus häufiger verwendete Ausschlussverfahren
38 Fehlende Daten: Ersatzwertverfahren Induktive Verfahren: Die fehlenden Werte werden auf der Basis von Informationen ersetzt, die über die Stichprobe vorliegen Nachbeobachtungen: zusätzliche Beobachtungen / Befragungen werden angestellt (Repräsentativität?) Externe Konstanten: konstanter Wert aus externer Quelle oder früherer Studie wird ersatzweise verwendet Statistische Verfahren: Metrische fehlende Werte können aus der Stichprobe geschätzt werden (Voraussetzung ist MCAR) Mittelwertersatz: ein fehlender Wert einer Variable wird durch den Mittelwert dieser Variablen ersetzt Formen des Mittelwertersatzes: Mittel / Median der Nachbarpunkte, Zeitreihen-Mittelwert & lineare Interpolation Vorteil: die Verfahren sind leicht anzuwenden, benötigt werden lediglich die entsprechenden Mittelwerte Nachteil: die Varianz, die Verteilung der Daten und eventuelle Korrelationen werden verzerrt Linearer Trend: ein fehlender Wert einer Variablen wird durch den linearen Trendwert für diese Variable ersetzt Voraussetzung: für die gültigen Werte lässt sich ein sinnvoller linearer Trend ermitteln Fehlende Werte können dann durch die Werte der Trendgraden an der betreffenden Stelle ersetzt werden Nachteil: der lineare Trend in den Variablen wird verstärkt, die Varianz der Verteilung verringert sich
39 Normalverteilungsprüfung: Einführung 2 Die Gauß- oder Normalverteilung ist die wichtigste kontinuierliche Wahrscheinlichkeitsverteilung Die zugehörige Dichtefunktion ist als Gaußsche Glockenkurve bekannt Eigenschaften: 1 f x = e 2 Dichtefunktion ist glockenförmig und symmetrisch Erwartungswert, Median und Modus sind gleich Zufallsvariable hat eine unendliche Spannweite Viele statistische Verfahren setzen die Normalverteilung der Daten in der Grundgesamtheit voraus Es ist daher häufig zu prüfen, ob von einer solchen Verteilung ausgegangen werden kann (auch näherungsweise) Erwartungswert Median Modus 1 x 2
40 Normalverteilungsprüfung: Dichtefunktion

41 Normalverteilungsprüfung: Histogramm Grafische Analyse mit Histogramm und überlagerter Normalverteilungskurve Die Balken des Histogramms spiegeln die Breite der Wertebereiche wieder da zudem für leere Wertebereiche ein Freiraum ausgegeben wird, kommt im Histogramm die gesamte empirische Verteilung der Variablen zum Ausdruck Dies ermöglicht den direkten Vergleich mit einer eingezeichneten theoretischen Verteilung, wie beispielsweise der Normalverteilung Der Grad der Abweichung einer Normalverteilung lässt sich auch anhand verschiedener Maßzahlen wie Exzeß (Kurtosis) und Schiefe bestimmen
42 Normalverteilungsprüfung: Q-Q Grafische Analyse mit Q-Q-Diagramm und trendbereinigtem Q-Q-Diagramm
43 Normalverteilungsprüfung: K-S-A Die Prüfung auf Vorliegen einer Normalverteilung kann auch mit einem Anpassungstests erfolgen In SPSS lässt sich dazu beispielsweise der Kolmogorov-Smirnov-Anpassungstest nutzen Der Test arbeitet mit der kumulierten empirischen und der kumulierten erwarteten Referenzverteilung Die maximale Differenz zwischen beiden Verteilungen wird zur Berechnung der Prüfgröße Z nach Kolmogorov-Smirnov verwendet, mit der dann aus einer Tabelle der für einen Stichprobenumfang n kritische Wert für die maximale Differenz bei einem gegebenen Signifikanzniveau abgelesen werden kann Nullhypothese H0 des SPSS-Tests: die Werte der untersuchten Variablen sind normalverteilt Berechnet wird die Wahrscheinlichkeit, mit der das Zurückweisen dieser Hypothese falsch ist (Signifikanzwert) Je größer diese Wahrscheinlichkeit ausfällt, desto eher ist von einer Normalverteilung der Werte auszugehen Im nebenstehenden Beispiel eines Kolmogorov-Smirnov-Tests fällt der Signifikanzwert mit 0,00 so niedrig aus, dass die Annahme der Normalverteilung zurückzuweisen ist Bei der Interpretation ist zu beachten, dass es sich um einen Test auf perfekte Normalverteilung handelt Anzuraten ist daher die Kombination mit einem der grafischen Prüfverfahren
 Gleichheit der Varianzen = Homoskedastizität Ungleichheit der Varianzen = Hetroskedastizität Mit dem Signifikanztest nach Levene wird die Nullhypothese H0 überprüft, dass die")
44 Homoskedastizitätsprüfung: Levene-Test Viele statistische Verfahren setzen voraus, dass die Varianzen innerhalb verschiedener Fallgruppen gleich sind (beispielsweise Signifikanztests und Mittelwertvergleiche) Gleichheit der Varianzen = Homoskedastizität Ungleichheit der Varianzen = Hetroskedastizität Mit dem Signifikanztest nach Levene wird die Nullhypothese H0 überprüft, dass die Varianzen in der Grundgesamtheit in allen Gruppen homogen (gleich) sind Der Test arbeitet mit dem F-Wert als statistischem Prüfmaß mit bekannter Verteilung Es wird getestet, mit welcher Wahrscheinlichkeit die beobachteten Abweichungen in den Varianzen auftreten können, wenn in der Grundgesamtheit absolute Varianzgleichheit herrscht Diese Wahrscheinlichkeit wird als Testergebnis ausgewiesen Eine geringe Wahrscheinlichkeit weist auf eine Varianzungleichheit hin
45 Grafische Homoskedastizitätsprüfung Eine grafische Prüfung auf Homoskedastizität kann mit Streudiagrammen oder Boxplots durchgeführt werden Hierbei ist auf die unterschiedlichen Streuungen und die Höhe des Medians zu achten

46 Linearitätsprüfung Die Prüfung auf Linearität kann sowohl grafisch als auch statistisch erfolgen Grafische Prüfung: Auswertung von Streudiagrammen oder Scatterplots Statistische Prüfung: Analyse der Residuen oder Regressionsanalyse
47 Arbeit mit Dummy-Variablen Für viele Analyseverfahren wird ein metrisches Skalenniveau vorausgesetzt (z.b. Multiple Regression) Sollen nominalskalierte Daten in ein solches Verfahren einfließen, müssen Dummy-Variablen gebildet werden Dummy-Variablen sind binäre Variablen, die nur die Werte 0 und 1 annehmen können Eine dichotome Variable lässt sich durch Transformation in eine Dummy-Variable überführen 0 = Ausprägung liegt nicht vor 1 = Ausprägung liegt vor Beispiel: Untersuchung der Einflüsse von Verpackungseigenschaften auf das Kaufverhalten Dummy-Variable q1 nimmt für rote Verpackungen den Wert 1, für nicht-rote Verpackungen den Wert 0 an Analog dazu lässt sich auch eine Dummy-Variable q2 für die Farbe Gelb und q3 für die Farbe Grün definieren Existieren nur diese drei Verpackungsfarben kann auf q3 aber verzichtet werden, da: Wenn q1 = 0 und q2 = 0 muss q3 = 1 gelten Drei Farben lassen sich daher über nur zwei Dummy-Variablen beschreiben Generelle Regel: Eine nominale Variable mit n Ausprägungen lässt sich in n-1 Dummy-Variablen abbilden
48 Gibt es noch Fragen?
90-minütige Klausur Statistik für Studierende der Kommunikationswissenschaft
 Prof. Dr. Helmut Küchenhoff SS08 90-minütige Klausur Statistik für Studierende der Kommunikationswissenschaft am 22.7.2008 Anmerkungen Überprüfen Sie bitte sofort, ob Ihre Angabe vollständig ist. Sie sollte
Prof. Dr. Helmut Küchenhoff SS08 90-minütige Klausur Statistik für Studierende der Kommunikationswissenschaft am 22.7.2008 Anmerkungen Überprüfen Sie bitte sofort, ob Ihre Angabe vollständig ist. Sie sollte
Lösungen zu Janssen/Laatz, Statistische Datenanalyse mit SPSS 1
 LÖSUNG 3A Lösungen zu Janssen/Laatz, Statistische Datenanalyse mit SPSS 1 Mit den Berechnungsfunktionen LG10(?) und SQRT(?) in "Transformieren", "Berechnen" können logarithmierte Werte sowie die Quadratwurzel
LÖSUNG 3A Lösungen zu Janssen/Laatz, Statistische Datenanalyse mit SPSS 1 Mit den Berechnungsfunktionen LG10(?) und SQRT(?) in "Transformieren", "Berechnen" können logarithmierte Werte sowie die Quadratwurzel
4. Erstellen von Klassen
 Statistik mit Tabellenkalkulation 4. Erstellen von Klassen Mit einem einfachen Befehl lässt sich eine Liste von Zahlen auf die Häufigkeit der einzelnen Werte untersuchen. Verwenden Sie dazu den Befehl
Statistik mit Tabellenkalkulation 4. Erstellen von Klassen Mit einem einfachen Befehl lässt sich eine Liste von Zahlen auf die Häufigkeit der einzelnen Werte untersuchen. Verwenden Sie dazu den Befehl
1,11 1,12 1,13 1,14 1,15 1,16 1,17 1,17 1,17 1,18
 3. Deskriptive Statistik Ziel der deskriptiven (beschreibenden) Statistik (explorativen Datenanalyse) ist die übersichtliche Darstellung der wesentlichen in den erhobenen Daten enthaltene Informationen
3. Deskriptive Statistik Ziel der deskriptiven (beschreibenden) Statistik (explorativen Datenanalyse) ist die übersichtliche Darstellung der wesentlichen in den erhobenen Daten enthaltene Informationen
2. Deskriptive Statistik 2.1. Häufigkeitstabellen, Histogramme, empirische Verteilungsfunktionen
 4. Datenanalyse und Modellbildung Deskriptive Statistik 2-1 2. Deskriptive Statistik 2.1. Häufigkeitstabellen, Histogramme, empirische Verteilungsfunktionen Für die Auswertung einer Messreihe, die in Form
4. Datenanalyse und Modellbildung Deskriptive Statistik 2-1 2. Deskriptive Statistik 2.1. Häufigkeitstabellen, Histogramme, empirische Verteilungsfunktionen Für die Auswertung einer Messreihe, die in Form
Grundlagen der Inferenzstatistik
 Grundlagen der Inferenzstatistik (Induktive Statistik oder schließende Statistik) Dr. Winfried Zinn 1 Deskriptive Statistik versus Inferenzstatistik Die Deskriptive Statistik stellt Kenngrößen zur Verfügung,
Grundlagen der Inferenzstatistik (Induktive Statistik oder schließende Statistik) Dr. Winfried Zinn 1 Deskriptive Statistik versus Inferenzstatistik Die Deskriptive Statistik stellt Kenngrößen zur Verfügung,
Auswertung mit dem Statistikprogramm SPSS: 30.11.05
 Auswertung mit dem Statistikprogramm SPSS: 30.11.05 Seite 1 Einführung SPSS Was ist eine Fragestellung? Beispiel Welche statistische Prozedur gehört zu welcher Hypothese? Statistische Berechnungen mit
Auswertung mit dem Statistikprogramm SPSS: 30.11.05 Seite 1 Einführung SPSS Was ist eine Fragestellung? Beispiel Welche statistische Prozedur gehört zu welcher Hypothese? Statistische Berechnungen mit
Standardisierung von Daten Darstellung von Daten in Texten, Tabellen und Abbildungen. Standardisierung von Daten
 DAS THEMA: TABELLEN UND ABBILDUNGEN Standardisierung von Daten Darstellung von Daten in Texten, Tabellen und Abbildungen Standardisierung von Daten z-standardisierung Standardnormalverteilung 1 DIE Z-STANDARDISIERUNG
DAS THEMA: TABELLEN UND ABBILDUNGEN Standardisierung von Daten Darstellung von Daten in Texten, Tabellen und Abbildungen Standardisierung von Daten z-standardisierung Standardnormalverteilung 1 DIE Z-STANDARDISIERUNG
Franz Kronthaler. Statistik angewandt. Datenanalyse ist (k)eine Kunst. Excel Edition. ^ Springer Spektrum
eine Kunst. Excel Edition. ^ Springer Spektrum") Franz Kronthaler Statistik angewandt Datenanalyse ist (k)eine Kunst Excel Edition ^ Springer Spektrum Inhaltsverzeichnis Teil I Basiswissen und Werkzeuge, um Statistik anzuwenden 1 Statistik ist Spaß 3
Franz Kronthaler Statistik angewandt Datenanalyse ist (k)eine Kunst Excel Edition ^ Springer Spektrum Inhaltsverzeichnis Teil I Basiswissen und Werkzeuge, um Statistik anzuwenden 1 Statistik ist Spaß 3
Box-and-Whisker Plot -0,2 0,8 1,8 2,8 3,8 4,8
 . Aufgabe: Für zwei verschiedene Aktien wurde der relative Kurszuwachs (in % beobachtet. Aus den jeweils 20 Quartaldaten ergaben sich die folgenden Box-Plots. Box-and-Whisker Plot Aktie Aktie 2-0,2 0,8,8
. Aufgabe: Für zwei verschiedene Aktien wurde der relative Kurszuwachs (in % beobachtet. Aus den jeweils 20 Quartaldaten ergaben sich die folgenden Box-Plots. Box-and-Whisker Plot Aktie Aktie 2-0,2 0,8,8
Willkommen zur Vorlesung Statistik
 Willkommen zur Vorlesung Statistik Thema dieser Vorlesung: Varianzanalyse Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften Prof. Dr. Wolfgang
Willkommen zur Vorlesung Statistik Thema dieser Vorlesung: Varianzanalyse Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften Prof. Dr. Wolfgang
Universität Bonn 28. Juli 2010 Fachbereich Rechts- und Wirtschaftswissenschaften Statistische Abteilung Prof. Dr. A. Kneip. KLAUSUR Statistik B
 Universität Bonn 28. Juli 2010 Fachbereich Rechts- und Wirtschaftswissenschaften Statistische Abteilung Prof. Dr. A. Kneip Sommersemester 2010 KLAUSUR Statistik B Hinweise zur Bearbeitung: Bei allen Teilaufgaben
Universität Bonn 28. Juli 2010 Fachbereich Rechts- und Wirtschaftswissenschaften Statistische Abteilung Prof. Dr. A. Kneip Sommersemester 2010 KLAUSUR Statistik B Hinweise zur Bearbeitung: Bei allen Teilaufgaben
1 Darstellen von Daten
 1 Darstellen von Daten BesucherInnenzahlen der Bühnen Graz in der Spielzeit 2010/11 1 Opernhaus 156283 Hauptbühne 65055 Probebühne 7063 Ebene 3 2422 Next Liberty 26800 Säulen- bzw. Balkendiagramm erstellen
1 Darstellen von Daten BesucherInnenzahlen der Bühnen Graz in der Spielzeit 2010/11 1 Opernhaus 156283 Hauptbühne 65055 Probebühne 7063 Ebene 3 2422 Next Liberty 26800 Säulen- bzw. Balkendiagramm erstellen
Korrelation (II) Korrelation und Kausalität
 Korrelation und Kausalität") Korrelation (II) Korrelation und Kausalität Situation: Seien X, Y zwei metrisch skalierte Merkmale mit Ausprägungen (x 1, x 2,..., x n ) bzw. (y 1, y 2,..., y n ). D.h. für jede i = 1, 2,..., n bezeichnen
Korrelation (II) Korrelation und Kausalität Situation: Seien X, Y zwei metrisch skalierte Merkmale mit Ausprägungen (x 1, x 2,..., x n ) bzw. (y 1, y 2,..., y n ). D.h. für jede i = 1, 2,..., n bezeichnen
Auswertung und Darstellung wissenschaftlicher Daten (1)
") Auswertung und Darstellung wissenschaftlicher Daten () Mag. Dr. Andrea Payrhuber Zwei Schritte der Auswertung. Deskriptive Darstellung aller Daten 2. analytische Darstellung (Gruppenvergleiche) SPSS-Andrea
Auswertung und Darstellung wissenschaftlicher Daten () Mag. Dr. Andrea Payrhuber Zwei Schritte der Auswertung. Deskriptive Darstellung aller Daten 2. analytische Darstellung (Gruppenvergleiche) SPSS-Andrea
Grundlagen der Datenanalyse am Beispiel von SPSS
 Grundlagen der Datenanalyse am Beispiel von SPSS Einführung Dipl. - Psych. Fabian Hölzenbein hoelzenbein@psychologie.uni-freiburg.de Einführung Organisatorisches Was ist Empirie? Was ist Statistik? Dateneingabe
Grundlagen der Datenanalyse am Beispiel von SPSS Einführung Dipl. - Psych. Fabian Hölzenbein hoelzenbein@psychologie.uni-freiburg.de Einführung Organisatorisches Was ist Empirie? Was ist Statistik? Dateneingabe
Güte von Tests. die Wahrscheinlichkeit für den Fehler 2. Art bei der Testentscheidung, nämlich. falsch ist. Darauf haben wir bereits im Kapitel über
 Güte von s Grundlegendes zum Konzept der Güte Ableitung der Gütefunktion des Gauss im Einstichprobenproblem Grafische Darstellung der Gütefunktionen des Gauss im Einstichprobenproblem Ableitung der Gütefunktion
Güte von s Grundlegendes zum Konzept der Güte Ableitung der Gütefunktion des Gauss im Einstichprobenproblem Grafische Darstellung der Gütefunktionen des Gauss im Einstichprobenproblem Ableitung der Gütefunktion
Stichprobenauslegung. für stetige und binäre Datentypen
 Stichprobenauslegung für stetige und binäre Datentypen Roadmap zu Stichproben Hypothese über das interessierende Merkmal aufstellen Stichprobe entnehmen Beobachtete Messwerte abbilden Schluss von der Beobachtung
Stichprobenauslegung für stetige und binäre Datentypen Roadmap zu Stichproben Hypothese über das interessierende Merkmal aufstellen Stichprobe entnehmen Beobachtete Messwerte abbilden Schluss von der Beobachtung
Aufgabe 1: Nehmen Sie Stellung zu den folgenden Behauptungen (richtig/falsch mit stichwortartiger Begründung).
.") Aufgabe 1: Nehmen Sie Stellung zu den folgenden Behauptungen (richtig/falsch mit stichwortartiger Begründung). a) Die Anzahl der voneinander verschiedenen Beobachtungswerte eines statistischen Merkmals
Aufgabe 1: Nehmen Sie Stellung zu den folgenden Behauptungen (richtig/falsch mit stichwortartiger Begründung). a) Die Anzahl der voneinander verschiedenen Beobachtungswerte eines statistischen Merkmals
Profil A 49,3 48,2 50,7 50,9 49,8 48,7 49,6 50,1 Profil B 51,8 49,6 53,2 51,1 51,1 53,4 50,7 50 51,5 51,7 48,8
 1. Aufgabe: Eine Reifenfirma hat für Winterreifen unterschiedliche Profile entwickelt. Bei jeweils gleicher Geschwindigkeit und auch sonst gleichen Bedingungen wurden die Bremswirkungen gemessen. Die gemessenen
1. Aufgabe: Eine Reifenfirma hat für Winterreifen unterschiedliche Profile entwickelt. Bei jeweils gleicher Geschwindigkeit und auch sonst gleichen Bedingungen wurden die Bremswirkungen gemessen. Die gemessenen
Teil II: Einführung in die Statistik
 Teil II: Einführung in die Statistik (50 Punkte) Bitte beantworten Sie ALLE Fragen. Es handelt sich um multiple choice Fragen. Sie müssen die exakte Antwortmöglichkeit angeben, um die volle Punktzahl zu
Teil II: Einführung in die Statistik (50 Punkte) Bitte beantworten Sie ALLE Fragen. Es handelt sich um multiple choice Fragen. Sie müssen die exakte Antwortmöglichkeit angeben, um die volle Punktzahl zu
Einfache statistische Auswertungen mit dem Programm SPSS
 Einfache statistische Auswertungen mit dem Programm SPSS Datensatz: fiktive_daten.sav Dipl. Päd. Anne Haßelkus Dr. Dorothea Dette-Hagenmeyer 11/2011 Überblick 1 Deskriptive Statistiken; Mittelwert berechnen...
Einfache statistische Auswertungen mit dem Programm SPSS Datensatz: fiktive_daten.sav Dipl. Päd. Anne Haßelkus Dr. Dorothea Dette-Hagenmeyer 11/2011 Überblick 1 Deskriptive Statistiken; Mittelwert berechnen...
Einfache statistische Auswertungen mit dem TI-Nspire
 1. Neues Dokument und darin eine neue Seite anlegen Als Typ 6: Lists & Spreadsheet wählen. Darin die Messwerte in einer Spalte erfassen. Dies ergibt die Urliste. Wenn mehrere Messwerte vorliegen, die diejenigen,
1. Neues Dokument und darin eine neue Seite anlegen Als Typ 6: Lists & Spreadsheet wählen. Darin die Messwerte in einer Spalte erfassen. Dies ergibt die Urliste. Wenn mehrere Messwerte vorliegen, die diejenigen,
V 2 B, C, D Drinks. Möglicher Lösungsweg a) Gleichungssystem: 300x + 400 y = 520 300x + 500y = 597,5 2x3 Matrix: Energydrink 0,7 Mineralwasser 0,775,
 Gleichungssystem: 300x + 400 y = 520 300x + 500y = 597,5 2x3 Matrix: Energydrink 0,7 Mineralwasser 0,775,") Aufgabenpool für angewandte Mathematik / 1. Jahrgang V B, C, D Drinks Ein gastronomischer Betrieb kauft 300 Dosen Energydrinks (0,3 l) und 400 Liter Flaschen Mineralwasser und zahlt dafür 50, Euro. Einen
Aufgabenpool für angewandte Mathematik / 1. Jahrgang V B, C, D Drinks Ein gastronomischer Betrieb kauft 300 Dosen Energydrinks (0,3 l) und 400 Liter Flaschen Mineralwasser und zahlt dafür 50, Euro. Einen
Statistische Auswertung:
 Statistische Auswertung: Die erhobenen Daten mittels der selbst erstellten Tests (Surfaufgaben) Statistics Punkte aus dem Punkte aus Surftheorietest Punkte aus dem dem und dem Surftheorietest max.14p.
Statistische Auswertung: Die erhobenen Daten mittels der selbst erstellten Tests (Surfaufgaben) Statistics Punkte aus dem Punkte aus Surftheorietest Punkte aus dem dem und dem Surftheorietest max.14p.
Klausur zu Methoden der Statistik I (mit Kurzlösung) Wintersemester 2007/2008. Aufgabe 1
 Wintersemester 2007/2008. Aufgabe 1") Lehrstuhl für Statistik und Ökonometrie der Otto-Friedrich-Universität Bamberg Prof. Dr. Susanne Rässler Klausur zu Methoden der Statistik I (mit Kurzlösung) Wintersemester 2007/2008 Aufgabe 1 Ihnen liegt
Lehrstuhl für Statistik und Ökonometrie der Otto-Friedrich-Universität Bamberg Prof. Dr. Susanne Rässler Klausur zu Methoden der Statistik I (mit Kurzlösung) Wintersemester 2007/2008 Aufgabe 1 Ihnen liegt
Auswerten mit Excel. Viele Video-Tutorials auf Youtube z.b. http://www.youtube.com/watch?v=vuuky6xxjro
 Auswerten mit Excel Viele Video-Tutorials auf Youtube z.b. http://www.youtube.com/watch?v=vuuky6xxjro 1. Pivot-Tabellen erstellen: In der Datenmaske in eine beliebige Zelle klicken Registerkarte Einfügen
Auswerten mit Excel Viele Video-Tutorials auf Youtube z.b. http://www.youtube.com/watch?v=vuuky6xxjro 1. Pivot-Tabellen erstellen: In der Datenmaske in eine beliebige Zelle klicken Registerkarte Einfügen
Primzahlen und RSA-Verschlüsselung
 Primzahlen und RSA-Verschlüsselung Michael Fütterer und Jonathan Zachhuber 1 Einiges zu Primzahlen Ein paar Definitionen: Wir bezeichnen mit Z die Menge der positiven und negativen ganzen Zahlen, also
Primzahlen und RSA-Verschlüsselung Michael Fütterer und Jonathan Zachhuber 1 Einiges zu Primzahlen Ein paar Definitionen: Wir bezeichnen mit Z die Menge der positiven und negativen ganzen Zahlen, also
Einfache Varianzanalyse für abhängige
 Einfache Varianzanalyse für abhängige Stichproben Wie beim t-test gibt es auch bei der VA eine Alternative für abhängige Stichproben. Anmerkung: Was man unter abhängigen Stichproben versteht und wie diese
Einfache Varianzanalyse für abhängige Stichproben Wie beim t-test gibt es auch bei der VA eine Alternative für abhängige Stichproben. Anmerkung: Was man unter abhängigen Stichproben versteht und wie diese
- Beschreibung der Stichprobe(n-Häufigkeitsverteilung) <- Ermittlung deskriptiver Maßzahlen (Mittelungsmaße, Variationsmaße, Formparameter)
 <- Ermittlung deskriptiver Maßzahlen (Mittelungsmaße, Variationsmaße, Formparameter)")
Bachelorabschlussseminar Dipl.-Kfm. Daniel Cracau
 1 Einführung in die statistische Datenanalyse Bachelorabschlussseminar Dipl.-Kfm. Daniel Cracau 2 Gliederung 1.Grundlagen 2.Nicht-parametrische Tests a. Mann-Whitney-Wilcoxon-U Test b. Wilcoxon-Signed-Rank
1 Einführung in die statistische Datenanalyse Bachelorabschlussseminar Dipl.-Kfm. Daniel Cracau 2 Gliederung 1.Grundlagen 2.Nicht-parametrische Tests a. Mann-Whitney-Wilcoxon-U Test b. Wilcoxon-Signed-Rank
Lineargleichungssysteme: Additions-/ Subtraktionsverfahren
 Lineargleichungssysteme: Additions-/ Subtraktionsverfahren W. Kippels 22. Februar 2014 Inhaltsverzeichnis 1 Einleitung 2 2 Lineargleichungssysteme zweiten Grades 2 3 Lineargleichungssysteme höheren als
Lineargleichungssysteme: Additions-/ Subtraktionsverfahren W. Kippels 22. Februar 2014 Inhaltsverzeichnis 1 Einleitung 2 2 Lineargleichungssysteme zweiten Grades 2 3 Lineargleichungssysteme höheren als
Felix Klug SS 2011. 2. Tutorium Deskriptive Statistik
 2. Tutorium Deskriptive Statistik Felix Klug SS 2011 Skalenniveus Weitere Beispiele für Skalenniveus (Entnommen aus Wiederholungsblatt 1.): Skalenniveu Nominalskala Ordinalskala Intervallskala Verhältnisskala
2. Tutorium Deskriptive Statistik Felix Klug SS 2011 Skalenniveus Weitere Beispiele für Skalenniveus (Entnommen aus Wiederholungsblatt 1.): Skalenniveu Nominalskala Ordinalskala Intervallskala Verhältnisskala
Univariates Chi-Quadrat-Verfahren für ein dichotomes Merkmal und eine Messwiederholung: Test nach McNemar
 Univariates Chi-Quadrat-Verfahren für ein dichotomes Merkmal und eine Messwiederholung: Test nach McNemar Inhaltsverzeichnis Univariates Chi-Quadrat-Verfahren für ein dichotomes Merkmal und eine Messwiederholung:
Univariates Chi-Quadrat-Verfahren für ein dichotomes Merkmal und eine Messwiederholung: Test nach McNemar Inhaltsverzeichnis Univariates Chi-Quadrat-Verfahren für ein dichotomes Merkmal und eine Messwiederholung:
Dieses erste Kreisdiagramm, bezieht sich auf das gesamte Testergebnis der kompletten 182 getesteten Personen. Ergebnis
 Datenanalyse Auswertung Der Kern unseres Projektes liegt ganz klar bei der Fragestellung, ob es möglich ist, Biere von und geschmacklich auseinander halten zu können. Anhand der folgenden Grafiken, sollte
Datenanalyse Auswertung Der Kern unseres Projektes liegt ganz klar bei der Fragestellung, ob es möglich ist, Biere von und geschmacklich auseinander halten zu können. Anhand der folgenden Grafiken, sollte
9. Schätzen und Testen bei unbekannter Varianz
 9. Schätzen und Testen bei unbekannter Varianz Dr. Antje Kiesel Institut für Angewandte Mathematik WS 2011/2012 Schätzen und Testen bei unbekannter Varianz Wenn wir die Standardabweichung σ nicht kennen,
9. Schätzen und Testen bei unbekannter Varianz Dr. Antje Kiesel Institut für Angewandte Mathematik WS 2011/2012 Schätzen und Testen bei unbekannter Varianz Wenn wir die Standardabweichung σ nicht kennen,
Anhand des bereits hergeleiteten Models erstellen wir nun mit der Formel
 Ausarbeitung zum Proseminar Finanzmathematische Modelle und Simulationen bei Raphael Kruse und Prof. Dr. Wolf-Jürgen Beyn zum Thema Simulation des Anlagenpreismodels von Simon Uphus im WS 09/10 Zusammenfassung
Ausarbeitung zum Proseminar Finanzmathematische Modelle und Simulationen bei Raphael Kruse und Prof. Dr. Wolf-Jürgen Beyn zum Thema Simulation des Anlagenpreismodels von Simon Uphus im WS 09/10 Zusammenfassung
Modul 1 STATISTIK Eine erste Einführung
 Kassel Modul 1 STATISTIK Eine erste Einführung 2009 Alphadi - www.alphadi.de Copyright Die Informa@onen in diesem Produkt werden ohne Rücksicht auf einen eventuellen Patentschutz veröffentlicht. Warennamen
Kassel Modul 1 STATISTIK Eine erste Einführung 2009 Alphadi - www.alphadi.de Copyright Die Informa@onen in diesem Produkt werden ohne Rücksicht auf einen eventuellen Patentschutz veröffentlicht. Warennamen
QM: Prüfen -1- KN16.08.2010
 QM: Prüfen -1- KN16.08.2010 2.4 Prüfen 2.4.1 Begriffe, Definitionen Ein wesentlicher Bestandteil der Qualitätssicherung ist das Prüfen. Sie wird aber nicht wie früher nach der Fertigung durch einen Prüfer,
QM: Prüfen -1- KN16.08.2010 2.4 Prüfen 2.4.1 Begriffe, Definitionen Ein wesentlicher Bestandteil der Qualitätssicherung ist das Prüfen. Sie wird aber nicht wie früher nach der Fertigung durch einen Prüfer,
Evaluation der Normalverteilungsannahme
 Evaluation der Normalverteilungsannahme. Überprüfung der Normalverteilungsannahme im SPSS P. Wilhelm; HS SPSS bietet verschiedene Möglichkeiten, um Verteilungsannahmen zu überprüfen. Angefordert werden
Evaluation der Normalverteilungsannahme. Überprüfung der Normalverteilungsannahme im SPSS P. Wilhelm; HS SPSS bietet verschiedene Möglichkeiten, um Verteilungsannahmen zu überprüfen. Angefordert werden
Analog zu Aufgabe 16.1 werden die Daten durch folgenden Befehl eingelesen: > kredit<-read.table("c:\\compaufg\\kredit.
 Lösung 16.3 Analog zu Aufgabe 16.1 werden die Daten durch folgenden Befehl eingelesen: > kredit
Lösung 16.3 Analog zu Aufgabe 16.1 werden die Daten durch folgenden Befehl eingelesen: > kredit
Statistik II für Betriebswirte Vorlesung 2
 PD Dr. Frank Heyde TU Bergakademie Freiberg Institut für Stochastik Statistik II für Betriebswirte Vorlesung 2 21. Oktober 2014 Verbundene Stichproben Liegen zwei Stichproben vor, deren Werte einander
PD Dr. Frank Heyde TU Bergakademie Freiberg Institut für Stochastik Statistik II für Betriebswirte Vorlesung 2 21. Oktober 2014 Verbundene Stichproben Liegen zwei Stichproben vor, deren Werte einander
geben. Die Wahrscheinlichkeit von 100% ist hier demnach nur der Gehen wir einmal davon aus, dass die von uns angenommenen
 geben. Die Wahrscheinlichkeit von 100% ist hier demnach nur der Vollständigkeit halber aufgeführt. Gehen wir einmal davon aus, dass die von uns angenommenen 70% im Beispiel exakt berechnet sind. Was würde
geben. Die Wahrscheinlichkeit von 100% ist hier demnach nur der Vollständigkeit halber aufgeführt. Gehen wir einmal davon aus, dass die von uns angenommenen 70% im Beispiel exakt berechnet sind. Was würde
Melanie Kaspar, Prof. Dr. B. Grabowski 1
 7. Hypothesentests Ausgangssituation: Man muss sich zwischen 2 Möglichkeiten (=Hypothesen) entscheiden. Diese Entscheidung soll mit Hilfe von Beobachtungen ( Stichprobe ) getroffen werden. Die Hypothesen
7. Hypothesentests Ausgangssituation: Man muss sich zwischen 2 Möglichkeiten (=Hypothesen) entscheiden. Diese Entscheidung soll mit Hilfe von Beobachtungen ( Stichprobe ) getroffen werden. Die Hypothesen
Varianzanalyse (ANOVA: analysis of variance)
") Varianzanalyse (AOVA: analysis of variance) Einfaktorielle VA Auf der Basis von zwei Stichproben wird bezüglich der Gleichheit der Mittelwerte getestet. Variablen müssen Variablen nur nominalskaliert sein.
Varianzanalyse (AOVA: analysis of variance) Einfaktorielle VA Auf der Basis von zwei Stichproben wird bezüglich der Gleichheit der Mittelwerte getestet. Variablen müssen Variablen nur nominalskaliert sein.
Expertenrunde Gruppe 1: Wiederholungsgruppe EXCEL (Datenerfassung, Darstellungsformen, Verwertung)
") Epertenrunde Gruppe 1: Wiederholungsgruppe EXCEL (Datenerfassung, Darstellungsformen, Verwertung) Im Folgenden wird mit Hilfe des Programms EXEL, Version 007, der Firma Microsoft gearbeitet. Die meisten
Epertenrunde Gruppe 1: Wiederholungsgruppe EXCEL (Datenerfassung, Darstellungsformen, Verwertung) Im Folgenden wird mit Hilfe des Programms EXEL, Version 007, der Firma Microsoft gearbeitet. Die meisten
Tutorial: Homogenitätstest
 Tutorial: Homogenitätstest Eine Bank möchte die Kreditwürdigkeit potenzieller Kreditnehmer abschätzen. Einerseits lebt die Bank ja von der Vergabe von Krediten, andererseits verursachen Problemkredite
Tutorial: Homogenitätstest Eine Bank möchte die Kreditwürdigkeit potenzieller Kreditnehmer abschätzen. Einerseits lebt die Bank ja von der Vergabe von Krediten, andererseits verursachen Problemkredite
Das große ElterngeldPlus 1x1. Alles über das ElterngeldPlus. Wer kann ElterngeldPlus beantragen? ElterngeldPlus verstehen ein paar einleitende Fakten
 Das große x -4 Alles über das Wer kann beantragen? Generell kann jeder beantragen! Eltern (Mütter UND Väter), die schon während ihrer Elternzeit wieder in Teilzeit arbeiten möchten. Eltern, die während
Das große x -4 Alles über das Wer kann beantragen? Generell kann jeder beantragen! Eltern (Mütter UND Väter), die schon während ihrer Elternzeit wieder in Teilzeit arbeiten möchten. Eltern, die während
Überblick über die Verfahren für Ordinaldaten
 Verfahren zur Analyse ordinalskalierten Daten 1 Überblick über die Verfahren für Ordinaldaten Unterschiede bei unabhängigen Stichproben Test U Test nach Mann & Whitney H Test nach Kruskal & Wallis parametrische
Verfahren zur Analyse ordinalskalierten Daten 1 Überblick über die Verfahren für Ordinaldaten Unterschiede bei unabhängigen Stichproben Test U Test nach Mann & Whitney H Test nach Kruskal & Wallis parametrische
1.3 Die Beurteilung von Testleistungen
 1.3 Die Beurteilung von Testleistungen Um das Testergebnis einer Vp zu interpretieren und daraus diagnostische Urteile ableiten zu können, benötigen wir einen Vergleichsmaßstab. Im Falle des klassischen
1.3 Die Beurteilung von Testleistungen Um das Testergebnis einer Vp zu interpretieren und daraus diagnostische Urteile ableiten zu können, benötigen wir einen Vergleichsmaßstab. Im Falle des klassischen
Statistik mit Excel. für Praktiker: Statistiken aufbereiten und präsentieren HORST-DIETER RADKE
 Statistik mit Excel für Praktiker: Statistiken aufbereiten und präsentieren HORST-DIETER RADKE INHALTS- VERZEICHNIS Vorwort 13 Schreiben Sie uns! 15 1 Statistische Untersuchungen 17 Wozu Statistik? 18
Statistik mit Excel für Praktiker: Statistiken aufbereiten und präsentieren HORST-DIETER RADKE INHALTS- VERZEICHNIS Vorwort 13 Schreiben Sie uns! 15 1 Statistische Untersuchungen 17 Wozu Statistik? 18
Fortgeschrittene Statistik Logistische Regression
 Fortgeschrittene Statistik Logistische Regression O D D S, O D D S - R A T I O, L O G I T T R A N S F O R M A T I O N, I N T E R P R E T A T I O N V O N K O E F F I Z I E N T E N, L O G I S T I S C H E
Fortgeschrittene Statistik Logistische Regression O D D S, O D D S - R A T I O, L O G I T T R A N S F O R M A T I O N, I N T E R P R E T A T I O N V O N K O E F F I Z I E N T E N, L O G I S T I S C H E
Uli Greßler. Qualitätsmanagement. Überwachung der Produkt- und Prozessqualität. Arbeitsheft. 2. Auflage. Bestellnummer 04796
 Uli Greßler Qualitätsmanagement Überwachung der Produt- und Prozessqualität Arbeitsheft 2. Auflage Bestellnummer 04796 Haben Sie Anregungen oder Kritipunte zu diesem Produt? Dann senden Sie eine E-Mail
Uli Greßler Qualitätsmanagement Überwachung der Produt- und Prozessqualität Arbeitsheft 2. Auflage Bestellnummer 04796 Haben Sie Anregungen oder Kritipunte zu diesem Produt? Dann senden Sie eine E-Mail
Übung 5 : G = Wärmeflussdichte [Watt/m 2 ] c = spezifische Wärmekapazität k = Wärmeleitfähigkeit = *p*c = Wärmediffusität
![Übung 5 : G = Wärmeflussdichte [Watt/m 2 ] c = spezifische Wärmekapazität k = Wärmeleitfähigkeit = *p*c = Wärmediffusität](/thumbs/26/9283097.jpg "Übung 5 : G = Wärmeflussdichte [Watt/m 2 ] c = spezifische Wärmekapazität k = Wärmeleitfähigkeit = *p*c = Wärmediffusität") Übung 5 : Theorie : In einem Boden finden immer Temperaturausgleichsprozesse statt. Der Wärmestrom läßt sich in eine vertikale und horizontale Komponente einteilen. Wir betrachten hier den Wärmestrom in
Übung 5 : Theorie : In einem Boden finden immer Temperaturausgleichsprozesse statt. Der Wärmestrom läßt sich in eine vertikale und horizontale Komponente einteilen. Wir betrachten hier den Wärmestrom in
Gibt es einen Geschmacksunterschied zwischen Coca Cola und Cola Zero?
 Gibt es einen Geschmacksunterschied zwischen Coca Cola und Cola Zero? Manche sagen: Ja, manche sagen: Nein Wie soll man das objektiv feststellen? Kann man Geschmack objektiv messen? - Geschmack ist subjektiv
Gibt es einen Geschmacksunterschied zwischen Coca Cola und Cola Zero? Manche sagen: Ja, manche sagen: Nein Wie soll man das objektiv feststellen? Kann man Geschmack objektiv messen? - Geschmack ist subjektiv
Dokumentation. estat Version 2.0
 Dokumentation estat Version 2.0 Installation Die Datei estat.xla in beliebiges Verzeichnis speichern. Im Menü Extras AddIns... Durchsuchen die Datei estat.xla auswählen. Danach das Auswahlhäkchen beim
Dokumentation estat Version 2.0 Installation Die Datei estat.xla in beliebiges Verzeichnis speichern. Im Menü Extras AddIns... Durchsuchen die Datei estat.xla auswählen. Danach das Auswahlhäkchen beim
Zusammenhänge zwischen metrischen Merkmalen
 Zusammenhänge zwischen metrischen Merkmalen Darstellung des Zusammenhangs, Korrelation und Regression Daten liegen zu zwei metrischen Merkmalen vor: Datenpaare (x i, y i ), i = 1,..., n Beispiel: x: Anzahl
Zusammenhänge zwischen metrischen Merkmalen Darstellung des Zusammenhangs, Korrelation und Regression Daten liegen zu zwei metrischen Merkmalen vor: Datenpaare (x i, y i ), i = 1,..., n Beispiel: x: Anzahl
Stellen Sie bitte den Cursor in die Spalte B2 und rufen die Funktion Sverweis auf. Es öffnet sich folgendes Dialogfenster
 Es gibt in Excel unter anderem die so genannten Suchfunktionen / Matrixfunktionen Damit können Sie Werte innerhalb eines bestimmten Bereichs suchen. Als Beispiel möchte ich die Funktion Sverweis zeigen.
Es gibt in Excel unter anderem die so genannten Suchfunktionen / Matrixfunktionen Damit können Sie Werte innerhalb eines bestimmten Bereichs suchen. Als Beispiel möchte ich die Funktion Sverweis zeigen.
Korrelation. Übungsbeispiel 1. Übungsbeispiel 4. Übungsbeispiel 2. Übungsbeispiel 3. Korrel.dtp Seite 1
 Korrelation Die Korrelationsanalyse zeigt Zusammenhänge auf und macht Vorhersagen möglich Was ist Korrelation? Was sagt die Korrelationszahl aus? Wie geht man vor? Korrelation ist eine eindeutige Beziehung
Korrelation Die Korrelationsanalyse zeigt Zusammenhänge auf und macht Vorhersagen möglich Was ist Korrelation? Was sagt die Korrelationszahl aus? Wie geht man vor? Korrelation ist eine eindeutige Beziehung
STATISTIK. Erinnere dich
 Thema Nr.20 STATISTIK Erinnere dich Die Stichprobe Drei Schüler haben folgende Noten geschrieben : Johann : 4 6 18 7 17 12 12 18 Barbara : 13 13 12 10 12 3 14 12 14 15 Julia : 15 9 14 13 10 12 12 11 10
Thema Nr.20 STATISTIK Erinnere dich Die Stichprobe Drei Schüler haben folgende Noten geschrieben : Johann : 4 6 18 7 17 12 12 18 Barbara : 13 13 12 10 12 3 14 12 14 15 Julia : 15 9 14 13 10 12 12 11 10
Statistik mit Excel. für Praktiker: Statistiken aufbereiten und präsentieren HORST-DIETER RADKE. Markt+Technik
 Statistik mit Excel für Praktiker: Statistiken aufbereiten und präsentieren HORST-DIETER RADKE Markt+Technik Vorwort Schreiben Sie uns! 13 15 Statistische Untersuchungen 17 Wozu Statistik? 18 Wirtschaftliche
Statistik mit Excel für Praktiker: Statistiken aufbereiten und präsentieren HORST-DIETER RADKE Markt+Technik Vorwort Schreiben Sie uns! 13 15 Statistische Untersuchungen 17 Wozu Statistik? 18 Wirtschaftliche
Einführung in statistische Analysen
 Einführung in statistische Analysen Andreas Thams Econ Boot Camp 2008 Wozu braucht man Statistik? Statistik begegnet uns jeden Tag... Weihnachten macht Deutschen Einkaufslaune. Im Advent überkommt die
Einführung in statistische Analysen Andreas Thams Econ Boot Camp 2008 Wozu braucht man Statistik? Statistik begegnet uns jeden Tag... Weihnachten macht Deutschen Einkaufslaune. Im Advent überkommt die
Ein möglicher Unterrichtsgang
 Ein möglicher Unterrichtsgang. Wiederholung: Bernoulli Experiment und Binomialverteilung Da der sichere Umgang mit der Binomialverteilung, auch der Umgang mit dem GTR und den Diagrammen, eine notwendige
Ein möglicher Unterrichtsgang. Wiederholung: Bernoulli Experiment und Binomialverteilung Da der sichere Umgang mit der Binomialverteilung, auch der Umgang mit dem GTR und den Diagrammen, eine notwendige
Korrelation - Regression. Berghold, IMI
 Korrelation - Regression Zusammenhang zwischen Variablen Bivariate Datenanalyse - Zusammenhang zwischen 2 stetigen Variablen Korrelation Einfaches lineares Regressionsmodell 1. Schritt: Erstellung eines
Korrelation - Regression Zusammenhang zwischen Variablen Bivariate Datenanalyse - Zusammenhang zwischen 2 stetigen Variablen Korrelation Einfaches lineares Regressionsmodell 1. Schritt: Erstellung eines
Tipp III: Leiten Sie eine immer direkt anwendbare Formel her zur Berechnung der sogenannten "bedingten Wahrscheinlichkeit".
 Mathematik- Unterrichts- Einheiten- Datei e. V. Klasse 9 12 04/2015 Diabetes-Test Infos: www.mued.de Blutspenden werden auf Diabetes untersucht, das mit 8 % in der Bevölkerung verbreitet ist. Dabei werden
Mathematik- Unterrichts- Einheiten- Datei e. V. Klasse 9 12 04/2015 Diabetes-Test Infos: www.mued.de Blutspenden werden auf Diabetes untersucht, das mit 8 % in der Bevölkerung verbreitet ist. Dabei werden
Business Value Launch 2006
 Quantitative Methoden Inferenzstatistik alea iacta est 11.04.2008 Prof. Dr. Walter Hussy und David Tobinski UDE.EDUcation College im Rahmen des dokforums Universität Duisburg-Essen Inferenzstatistik Erläuterung
Quantitative Methoden Inferenzstatistik alea iacta est 11.04.2008 Prof. Dr. Walter Hussy und David Tobinski UDE.EDUcation College im Rahmen des dokforums Universität Duisburg-Essen Inferenzstatistik Erläuterung
Name (in Druckbuchstaben): Matrikelnummer: Unterschrift:
: Matrikelnummer: Unterschrift:") 20-minütige Klausur zur Vorlesung Lineare Modelle im Sommersemester 20 PD Dr. Christian Heumann Ludwig-Maximilians-Universität München, Institut für Statistik 2. Oktober 20, 4:5 6:5 Uhr Überprüfen Sie
20-minütige Klausur zur Vorlesung Lineare Modelle im Sommersemester 20 PD Dr. Christian Heumann Ludwig-Maximilians-Universität München, Institut für Statistik 2. Oktober 20, 4:5 6:5 Uhr Überprüfen Sie
Füllmenge. Füllmenge. Füllmenge. Füllmenge. Mean = 500,0029 Std. Dev. = 3,96016 N = 10.000. 485,00 490,00 495,00 500,00 505,00 510,00 515,00 Füllmenge
 2.4 Stetige Zufallsvariable Beispiel. Abfüllung von 500 Gramm Packungen einer bestimmten Ware auf einer automatischen Abfüllanlage. Die Zufallsvariable X beschreibe die Füllmenge einer zufällig ausgewählten
2.4 Stetige Zufallsvariable Beispiel. Abfüllung von 500 Gramm Packungen einer bestimmten Ware auf einer automatischen Abfüllanlage. Die Zufallsvariable X beschreibe die Füllmenge einer zufällig ausgewählten
Kontingenzkoeffizient (nach Pearson)
") Assoziationsmaß für zwei nominale Merkmale misst die Unabhängigkeit zweier Merkmale gibt keine Richtung eines Zusammenhanges an 46 o jl beobachtete Häufigkeiten der Kombination von Merkmalsausprägungen
Assoziationsmaß für zwei nominale Merkmale misst die Unabhängigkeit zweier Merkmale gibt keine Richtung eines Zusammenhanges an 46 o jl beobachtete Häufigkeiten der Kombination von Merkmalsausprägungen
Statistische Thermodynamik I Lösungen zur Serie 1
 Statistische Thermodynamik I Lösungen zur Serie Zufallsvariablen, Wahrscheinlichkeitsverteilungen 4. März 2. Zwei Lektoren lesen ein Buch. Lektor A findet 2 Druckfehler, Lektor B nur 5. Von den gefundenen
Statistische Thermodynamik I Lösungen zur Serie Zufallsvariablen, Wahrscheinlichkeitsverteilungen 4. März 2. Zwei Lektoren lesen ein Buch. Lektor A findet 2 Druckfehler, Lektor B nur 5. Von den gefundenen
Prüfung eines Datenbestandes
 Prüfung eines Datenbestandes auf Abweichungen einzelner Zahlen vom erwarteten mathematisch-statistischen Verhalten, die nicht mit einem Zufall erklärbar sind (Prüfung auf Manipulationen des Datenbestandes)
Prüfung eines Datenbestandes auf Abweichungen einzelner Zahlen vom erwarteten mathematisch-statistischen Verhalten, die nicht mit einem Zufall erklärbar sind (Prüfung auf Manipulationen des Datenbestandes)
Statistik II für Betriebswirte Vorlesung 3
 PD Dr. Frank Heyde TU Bergakademie Freiberg Institut für Stochastik Statistik II für Betriebswirte Vorlesung 3 5. November 2013 Beispiel: Aktiensplit (Aczel & Sounderpandan, Aufg. 14-28) Ein Börsenanalyst
PD Dr. Frank Heyde TU Bergakademie Freiberg Institut für Stochastik Statistik II für Betriebswirte Vorlesung 3 5. November 2013 Beispiel: Aktiensplit (Aczel & Sounderpandan, Aufg. 14-28) Ein Börsenanalyst
Binäre abhängige Variablen
 Binäre abhängige Variablen Thushyanthan Baskaran thushyanthan.baskaran@awi.uni-heidelberg.de Alfred Weber Institut Ruprecht Karls Universität Heidelberg Einführung Oft wollen wir qualitative Variablen
Binäre abhängige Variablen Thushyanthan Baskaran thushyanthan.baskaran@awi.uni-heidelberg.de Alfred Weber Institut Ruprecht Karls Universität Heidelberg Einführung Oft wollen wir qualitative Variablen
4. Jeder Knoten hat höchstens zwei Kinder, ein linkes und ein rechtes.
 Binäre Bäume Definition: Ein binärer Baum T besteht aus einer Menge von Knoten, die durch eine Vater-Kind-Beziehung wie folgt strukturiert ist: 1. Es gibt genau einen hervorgehobenen Knoten r T, die Wurzel
Binäre Bäume Definition: Ein binärer Baum T besteht aus einer Menge von Knoten, die durch eine Vater-Kind-Beziehung wie folgt strukturiert ist: 1. Es gibt genau einen hervorgehobenen Knoten r T, die Wurzel
50. Mathematik-Olympiade 2. Stufe (Regionalrunde) Klasse 11 13. 501322 Lösung 10 Punkte
 Klasse 11 13. 501322 Lösung 10 Punkte") 50. Mathematik-Olympiade. Stufe (Regionalrunde) Klasse 3 Lösungen c 00 Aufgabenausschuss des Mathematik-Olympiaden e.v. www.mathematik-olympiaden.de. Alle Rechte vorbehalten. 503 Lösung 0 Punkte Es seien
50. Mathematik-Olympiade. Stufe (Regionalrunde) Klasse 3 Lösungen c 00 Aufgabenausschuss des Mathematik-Olympiaden e.v. www.mathematik-olympiaden.de. Alle Rechte vorbehalten. 503 Lösung 0 Punkte Es seien
Zeichen bei Zahlen entschlüsseln
 Zeichen bei Zahlen entschlüsseln In diesem Kapitel... Verwendung des Zahlenstrahls Absolut richtige Bestimmung von absoluten Werten Operationen bei Zahlen mit Vorzeichen: Addieren, Subtrahieren, Multiplizieren
Zeichen bei Zahlen entschlüsseln In diesem Kapitel... Verwendung des Zahlenstrahls Absolut richtige Bestimmung von absoluten Werten Operationen bei Zahlen mit Vorzeichen: Addieren, Subtrahieren, Multiplizieren
Austausch- bzw. Übergangsprozesse und Gleichgewichtsverteilungen
 Austausch- bzw. Übergangsrozesse und Gleichgewichtsverteilungen Wir betrachten ein System mit verschiedenen Zuständen, zwischen denen ein Austausch stattfinden kann. Etwa soziale Schichten in einer Gesellschaft:
Austausch- bzw. Übergangsrozesse und Gleichgewichtsverteilungen Wir betrachten ein System mit verschiedenen Zuständen, zwischen denen ein Austausch stattfinden kann. Etwa soziale Schichten in einer Gesellschaft:
Deskription, Statistische Testverfahren und Regression. Seminar: Planung und Auswertung klinischer und experimenteller Studien
 Deskription, Statistische Testverfahren und Regression Seminar: Planung und Auswertung klinischer und experimenteller Studien Deskriptive Statistik Deskriptive Statistik: beschreibende Statistik, empirische
Deskription, Statistische Testverfahren und Regression Seminar: Planung und Auswertung klinischer und experimenteller Studien Deskriptive Statistik Deskriptive Statistik: beschreibende Statistik, empirische
Lineare Funktionen. 1 Proportionale Funktionen 3 1.1 Definition... 3 1.2 Eigenschaften... 3. 2 Steigungsdreieck 3
 Lineare Funktionen Inhaltsverzeichnis 1 Proportionale Funktionen 3 1.1 Definition............................... 3 1.2 Eigenschaften............................. 3 2 Steigungsdreieck 3 3 Lineare Funktionen
Lineare Funktionen Inhaltsverzeichnis 1 Proportionale Funktionen 3 1.1 Definition............................... 3 1.2 Eigenschaften............................. 3 2 Steigungsdreieck 3 3 Lineare Funktionen
Statistik I für Betriebswirte Vorlesung 2
 Statistik I für Betriebswirte Vorlesung 2 PD Dr. Frank Heyde TU Bergakademie Freiberg Institut für Stochastik 16. April 2015 PD Dr. Frank Heyde Statistik I für Betriebswirte Vorlesung 2 1 ii) empirische
Statistik I für Betriebswirte Vorlesung 2 PD Dr. Frank Heyde TU Bergakademie Freiberg Institut für Stochastik 16. April 2015 PD Dr. Frank Heyde Statistik I für Betriebswirte Vorlesung 2 1 ii) empirische
Professionelle Seminare im Bereich MS-Office
 Der Name BEREICH.VERSCHIEBEN() ist etwas unglücklich gewählt. Man kann mit der Funktion Bereiche zwar verschieben, man kann Bereiche aber auch verkleinern oder vergrößern. Besser wäre es, die Funktion
Der Name BEREICH.VERSCHIEBEN() ist etwas unglücklich gewählt. Man kann mit der Funktion Bereiche zwar verschieben, man kann Bereiche aber auch verkleinern oder vergrößern. Besser wäre es, die Funktion
Statistik II Wahrscheinlichkeitsrechnung und induktive Statistik Erste Klausur zum Sommersemester 2005 26. Juli 2005
 Statistik II Wahrscheinlichkeitsrechnung und induktive Statistik Erste Klausur zum Sommersemester 2005 26. Juli 2005 Aufgabe 1: Grundzüge der Wahrscheinlichkeitsrechnung 19 P. Als Manager eines großen
Statistik II Wahrscheinlichkeitsrechnung und induktive Statistik Erste Klausur zum Sommersemester 2005 26. Juli 2005 Aufgabe 1: Grundzüge der Wahrscheinlichkeitsrechnung 19 P. Als Manager eines großen
5 Zusammenhangsmaße, Korrelation und Regression
 5 Zusammenhangsmaße, Korrelation und Regression 5.1 Zusammenhangsmaße und Korrelation Aufgabe 5.1 In einem Hauptstudiumsseminar des Lehrstuhls für Wirtschafts- und Sozialstatistik machten die Teilnehmer
5 Zusammenhangsmaße, Korrelation und Regression 5.1 Zusammenhangsmaße und Korrelation Aufgabe 5.1 In einem Hauptstudiumsseminar des Lehrstuhls für Wirtschafts- und Sozialstatistik machten die Teilnehmer
Verteilungsmodelle. Verteilungsfunktion und Dichte von T
 Verteilungsmodelle Verteilungsfunktion und Dichte von T Survivalfunktion von T Hazardrate von T Beziehungen zwischen F(t), S(t), f(t) und h(t) Vorüberlegung zu Lebensdauerverteilungen Die Exponentialverteilung
Verteilungsmodelle Verteilungsfunktion und Dichte von T Survivalfunktion von T Hazardrate von T Beziehungen zwischen F(t), S(t), f(t) und h(t) Vorüberlegung zu Lebensdauerverteilungen Die Exponentialverteilung
Lineare Gleichungssysteme
 Lineare Gleichungssysteme 1 Zwei Gleichungen mit zwei Unbekannten Es kommt häufig vor, dass man nicht mit einer Variablen alleine auskommt, um ein Problem zu lösen. Das folgende Beispiel soll dies verdeutlichen
Lineare Gleichungssysteme 1 Zwei Gleichungen mit zwei Unbekannten Es kommt häufig vor, dass man nicht mit einer Variablen alleine auskommt, um ein Problem zu lösen. Das folgende Beispiel soll dies verdeutlichen
Würfelt man dabei je genau 10 - mal eine 1, 2, 3, 4, 5 und 6, so beträgt die Anzahl. der verschiedenen Reihenfolgen, in denen man dies tun kann, 60!.
 040304 Übung 9a Analysis, Abschnitt 4, Folie 8 Die Wahrscheinlichkeit, dass bei n - maliger Durchführung eines Zufallexperiments ein Ereignis A ( mit Wahrscheinlichkeit p p ( A ) ) für eine beliebige Anzahl
040304 Übung 9a Analysis, Abschnitt 4, Folie 8 Die Wahrscheinlichkeit, dass bei n - maliger Durchführung eines Zufallexperiments ein Ereignis A ( mit Wahrscheinlichkeit p p ( A ) ) für eine beliebige Anzahl
Kapitel 13 Häufigkeitstabellen
 Kapitel 13 Häufigkeitstabellen Die gesammelten und erfaßten Daten erscheinen in der Datendatei zunächst als unübersichtliche Liste von Werten. In dieser Form sind die Daten jedoch wenig aussagekräftig
Kapitel 13 Häufigkeitstabellen Die gesammelten und erfaßten Daten erscheinen in der Datendatei zunächst als unübersichtliche Liste von Werten. In dieser Form sind die Daten jedoch wenig aussagekräftig
Vermögensbildung: Sparen und Wertsteigerung bei Immobilien liegen vorn
 An die Redaktionen von Presse, Funk und Fernsehen 32 02. 09. 2002 Vermögensbildung: Sparen und Wertsteigerung bei Immobilien liegen vorn Das aktive Sparen ist nach wie vor die wichtigste Einflussgröße
An die Redaktionen von Presse, Funk und Fernsehen 32 02. 09. 2002 Vermögensbildung: Sparen und Wertsteigerung bei Immobilien liegen vorn Das aktive Sparen ist nach wie vor die wichtigste Einflussgröße
Zahlenwinkel: Forscherkarte 1. alleine. Zahlenwinkel: Forschertipp 1
 Zahlenwinkel: Forscherkarte 1 alleine Tipp 1 Lege die Ziffern von 1 bis 9 so in den Zahlenwinkel, dass jeder Arm des Zahlenwinkels zusammengezählt das gleiche Ergebnis ergibt! Finde möglichst viele verschiedene
Zahlenwinkel: Forscherkarte 1 alleine Tipp 1 Lege die Ziffern von 1 bis 9 so in den Zahlenwinkel, dass jeder Arm des Zahlenwinkels zusammengezählt das gleiche Ergebnis ergibt! Finde möglichst viele verschiedene
R ist freie Software und kann von der Website. www.r-project.org
 R R ist freie Software und kann von der Website heruntergeladen werden. www.r-project.org Nach dem Herunterladen und der Installation von R kann man R durch Doppelklicken auf das R-Symbol starten. R wird
R R ist freie Software und kann von der Website heruntergeladen werden. www.r-project.org Nach dem Herunterladen und der Installation von R kann man R durch Doppelklicken auf das R-Symbol starten. R wird
Unterrichtsmaterialien in digitaler und in gedruckter Form. Auszug aus: Übungsbuch für den Grundkurs mit Tipps und Lösungen: Analysis
 Unterrichtsmaterialien in digitaler und in gedruckter Form Auszug aus: Übungsbuch für den Grundkurs mit Tipps und Lösungen: Analysis Das komplette Material finden Sie hier: Download bei School-Scout.de
Unterrichtsmaterialien in digitaler und in gedruckter Form Auszug aus: Übungsbuch für den Grundkurs mit Tipps und Lösungen: Analysis Das komplette Material finden Sie hier: Download bei School-Scout.de
METHODENLEHRE I WS 2013/14 THOMAS SCHÄFER
 METHODENLEHRE I WS 2013/14 THOMAS SCHÄFER DAS THEMA: INFERENZSTATISTIK IV INFERENZSTATISTISCHE AUSSAGEN FÜR ZUSAMMENHÄNGE UND UNTERSCHIEDE Inferenzstatistik für Zusammenhänge Inferenzstatistik für Unterschiede
METHODENLEHRE I WS 2013/14 THOMAS SCHÄFER DAS THEMA: INFERENZSTATISTIK IV INFERENZSTATISTISCHE AUSSAGEN FÜR ZUSAMMENHÄNGE UND UNTERSCHIEDE Inferenzstatistik für Zusammenhänge Inferenzstatistik für Unterschiede
Quantilsschätzung als Werkzeug zur VaR-Berechnung
 Quantilsschätzung als Werkzeug zur VaR-Berechnung Ralf Lister, Aktuar, lister@actuarial-files.com Zusammenfassung: Zwei Fälle werden betrachtet und die jeweiligen VaR-Werte errechnet. Im ersten Fall wird
Quantilsschätzung als Werkzeug zur VaR-Berechnung Ralf Lister, Aktuar, lister@actuarial-files.com Zusammenfassung: Zwei Fälle werden betrachtet und die jeweiligen VaR-Werte errechnet. Im ersten Fall wird
Intrinsisch motivierte Mitarbeiter als Erfolgsfaktor für das Ideenmanagement: Eine empirische Untersuchung
 Intrinsisch motivierte Mitarbeiter als Erfolgsfaktor für das Ideenmanagement: Eine empirische Untersuchung Bearbeitet von Martina Sümnig Erstauflage 2015. Taschenbuch. 176 S. Paperback ISBN 978 3 95485
Intrinsisch motivierte Mitarbeiter als Erfolgsfaktor für das Ideenmanagement: Eine empirische Untersuchung Bearbeitet von Martina Sümnig Erstauflage 2015. Taschenbuch. 176 S. Paperback ISBN 978 3 95485
Sowohl die Malstreifen als auch die Neperschen Streifen können auch in anderen Stellenwertsystemen verwendet werden.
 Multiplikation Die schriftliche Multiplikation ist etwas schwieriger als die Addition. Zum einen setzt sie das kleine Einmaleins voraus, zum anderen sind die Überträge, die zu merken sind und häufig in
Multiplikation Die schriftliche Multiplikation ist etwas schwieriger als die Addition. Zum einen setzt sie das kleine Einmaleins voraus, zum anderen sind die Überträge, die zu merken sind und häufig in
1. Einführung und statistische Grundbegriffe. Grundsätzlich unterscheidet man zwei Bedeutungen des Begriffs Statistik:
 . Einführung und statistische Grundbegriffe Grundsätzlich unterscheidet man zwei Bedeutungen des Begriffs Statistik: Quantitative Information Graphische oder tabellarische Darstellung von Datenmaterial
. Einführung und statistische Grundbegriffe Grundsätzlich unterscheidet man zwei Bedeutungen des Begriffs Statistik: Quantitative Information Graphische oder tabellarische Darstellung von Datenmaterial
Fachhochschule Düsseldorf Wintersemester 2008/09
 Fachhochschule Düsseldorf Wintersemester 2008/09 Teilfachprüfung Statistik im Studiengang Wirtschaft Prüfungsdatum: 26.01.2009 Prüfer: Prof. Dr. H. Peters, Diplom-Vw. Lothar Schmeink Prüfungsform: 2-stündige
Fachhochschule Düsseldorf Wintersemester 2008/09 Teilfachprüfung Statistik im Studiengang Wirtschaft Prüfungsdatum: 26.01.2009 Prüfer: Prof. Dr. H. Peters, Diplom-Vw. Lothar Schmeink Prüfungsform: 2-stündige