Lineare Klassifikatoren
|
|
|
- Minna Schreiber
- vor 5 Jahren
- Abrufe
Transkript
1 Lineare Klassifikatoren Mustererkennung und Klassifikation, Vorlesung No. 8 1 M. O. Franz falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001.
2 Übersicht 1 Nächste-Nachbarn- und lineare Klassifikation 2 Klassifikation in hochdimensionalen Problemen 3 Lineare Klassifikation
3 Übersicht 1 Nächste-Nachbarn- und lineare Klassifikation 2 Klassifikation in hochdimensionalen Problemen 3 Lineare Klassifikation

4 Durch Nächste-Nachbar-Regel erzeugtes Voronoi-Mosaik
5 k-nächste-nachbarn-regel Offensichtliche Erweiterung: k-nächste-nachbarn-regel Entscheide immer für die Klasse ω i der Mehrheit aller Prototypen innerhalb der k-nächste-nachbarn-zelle. Im Limit unendlich vieler Daten führt die k-nächste-nachbarn- Regel auf kleinere Fehlerraten als die Nächste-Nachbar-Regel. Die Schätzungen sind robuster (wegen Mehrheitswahl), aber glätten über eine größere Umgebung.
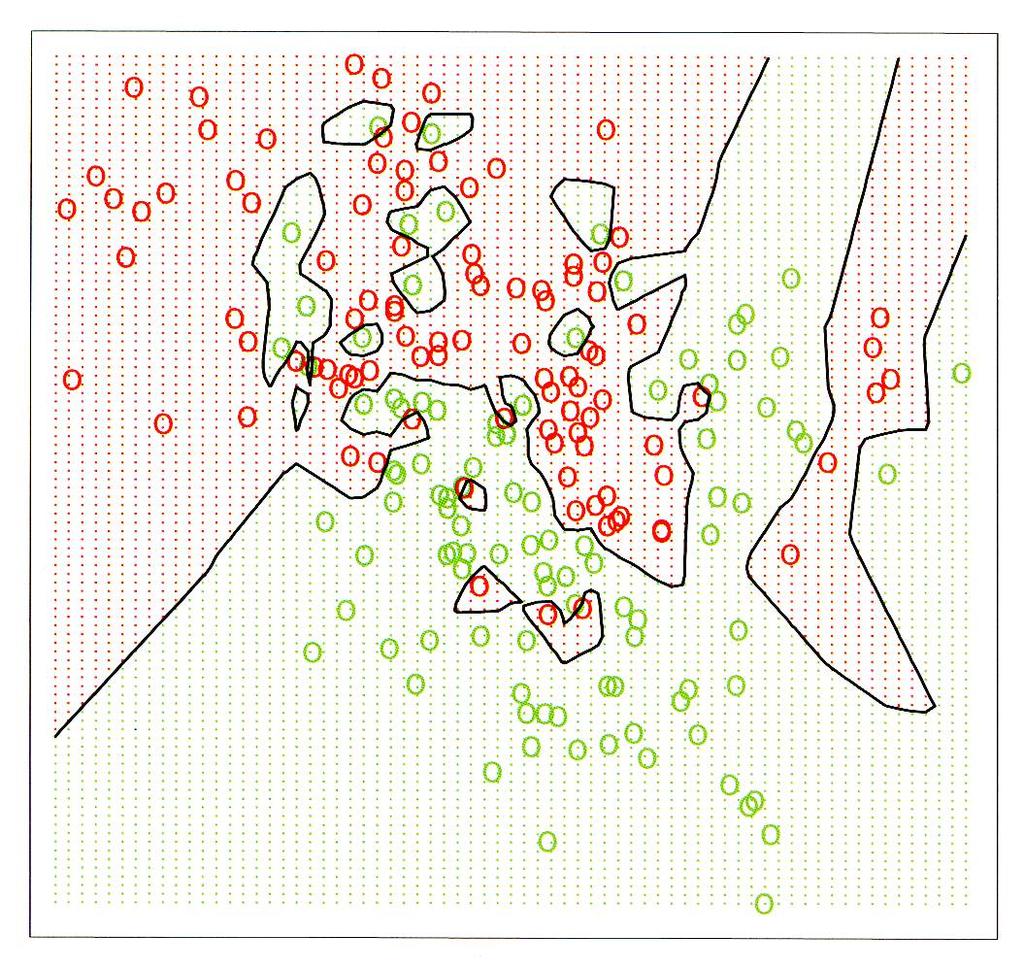
6 Beispiel: 1-Nächster-Nachbar-Klassifikator [Hastie et al., 2001]

7 Beispiel: 15-Nächste-Nachbarn-Klassifikator [Hastie et al., 2001]

8 Beispiel: Linearer Klassifikator [Hastie et al., 2001]

9 Beispiel: Bayes-Klassifikator [Hastie et al., 2001]
10 Beispiel: Fehlerraten [Hastie et al., 2001]
11 Vergleich Nächste-Nachbarn / lineare Klassifikatoren Lineare Entscheidungsgrenzen sind glatt und relativ stabil anzufitten, aber sie basieren auf der (anscheinend) einschränkenden Annahme der linearen Trennbarkeit hoher Bias, geringe Varianz. NN-Klassifikatoren machen beinahe keine einschränkenden Annahmen über die Verteilung, aber die Entscheidungsgrenzen hängen sehr stark vom jeweiligen Trainingsdatensatz ab geringer Bias, hohe Varianz. Lineare Klassifikatoren eignen sich besonders für breite, identisch oder isotrop gaußverteilte Klassen, NN für Mischungen vieler schmaler Verteilungen.
12 Übersicht 1 Nächste-Nachbarn- und lineare Klassifikation 2 Klassifikation in hochdimensionalen Problemen 3 Lineare Klassifikation
13 Fluch der Dimensionalität Fluch der Dimensionalität: Die Komplexität von Funktionen mit mehreren Variablen kann exponentiell mit der Dimension wachsen, d.h. die Schätzung einer solchen Funktion erfordert ebenfalls exponentiell viele Daten. Anzahl w der Würfel x 2 x2 Volumen der Seitenlänge L steigt mit der Dimension d x1 bei gleicher Kantenlänge l wie D = 1 x 1 D = 2 x 1 x3 D = 3 [Bishop, 2006] w = L (hier w = 3 d ) l Die Anzahl Datenpunkte für NN mit gleicher Auflösung skaliert ebenso! d
14 Beispiel: Fluch der Dimensionalität (2) [Hastie et al., 2001]
15 Beispiel: Fluch der Dimensionalität (3) volume fraction Welcher Volumenanteil einer d-dimensionalen Kugel mit Radius 1 liegt in der Schale von 1 ɛ und 1? Volumen der Kugel: Anteil: V(r) = Kr d V(1) V(1 ɛ) V(1) = 1 (1 ɛ) d [Bishop, 2006] In hochdimensionalen Räumen ist das Volumen einer Kugel in einer dünnen Schale an der Oberfläche konzentriert!
16 Klassifikation in hochdimensionalen Räumen Durch den Fluch der Dimensionalität funktionieren nichtparametrische Methoden wie NN oder Kerndichteschätzer nur bei geringer Dimensionalität. Klassifikation in hochdimensionalen Räumen erfordert Vorwissen. Reale Daten lassen sich dennoch oft klassifizieren, obwohl sie hochdimensional sind, weil sie oft nur einen niedrigdimensionalen Unterraum besetzen, lokale Glattheitseigenschaften aufweisen (d.h. kleine Änderungen am Input führen auch zu kleinen Änderungen des Ergebnisses). Lineare Klassifikatoren nutzen Vorwissen über solche lokale Glattheitseigenschaften der Klassenverteilungen.
17 Übersicht 1 Nächste-Nachbarn- und lineare Klassifikation 2 Klassifikation in hochdimensionalen Problemen 3 Lineare Klassifikation
18 Lineare Diskriminantenfunktionen Lineare Diskriminantenfunktion: g(x) = w x + w 0 mit dem Gewichtsvektor w und Bias oder Schwellwert w 0.
19 Lineare Entscheidungsgrenzen Entscheidungsregel: Entscheide für Klasse ω 1 für g(x) > 0, für ω 2 für g(x) < 0, keine Entscheidung für g(x) = 0. Die Gleichung g(x) = 0 definiert eine Entscheidungsfläche, die Punkte von ω 1 und ω 2 trennt. Da g(x) linear ist, ist die Entscheidungsfläche eine Hyperebene. Für 2 Punkte x 1 und x 2 auf der Hyperebene H gilt w x 1 + w 0 = w x 2 + w 0 bzw. w (x 1 x 2 ) = 0. d.h. der Gewichtsvektor w ist der Normalenvektor der Hyperebene H. H teilt den Merkmalsraum in 2 Halbräume: R 1 für ω 1 bzw. g(x) > 0 (d.h. w zeigt Richtung R 1, positive Seite), R 2 für ω 2 bzw. g(x) < 0 (negative Seite).
 = w x + w 0 = w x p + w 0 r w w w = r w oder r = g(x) w Abstand zum Ursprung: g(x) = w 0 r 0 = w 0 / w.")
20 Abstand zur Entscheidungsebene Die Diskriminantenfunktion g(x) mißt die Distanz von x zu H: x = x p + r w w Da g(x p ) = 0 bzw. w x p = w 0, ist g(x) = w x + w 0 = w x p + w 0 r w w w = r w oder r = g(x) w Abstand zum Ursprung: g(x) = w 0 r 0 = w 0 / w.

21 Polychotomien (1) One-vs.-All-Architektur:
22 Polychotomien (2) One-vs.-One-Architektur:
23 Polychotomien: Lineare Maschinen Für c Klassen werden c lineare Diskriminantenfunktionen g i (x) = w i x + w 0i benutzt. Entscheidung für ω i, wenn g i (x) > g j (x) für alle j i.
24 Entscheidungsgrenzen in linearen Maschinen Zwei angrenzende Entscheidungsregionen R i und R j werden durch einen Abschnitt H ij einer Hyperebene getrennt: g i (x) = g j (x) bzw. (w i w j ) x + (w i0 w j0 ) = 0, d.h. der Normalenvektor von H ij ist (w i w j ), der (vorzeichenbehaftete) Abstand von x zu H ij ist (g i (x) g j (x))/ w i w j. Jede Entscheidungsregion ist einfach zusammenhängend. Lineare Maschinen sind daher besonders für Probleme mit unimodalen A-posteriori-Verteilungene geeignet. Aber: Es gibt multimodale Probleme, bei denen lineare Diskriminanten hervorragend abschneiden, und unimodale Probleme, bei denen sie schlecht funktionieren (s. Gauß)
25 Erweiterte Merkmalsvektoren d g(x) = w 0 + w i x i = i=1 d w i x i i=0 Erweiterter Merkmalsvektor: 1 x 1 ] y =. x d = [ 1 x Einführung einer zusätzlichen konstanten Koordinate x 0 = 1 vereinfacht Notation. Erweiterter Gewichtsvektor: w 0 w 1 [ ] a =.. = w0 w w d
k-nächste-nachbarn-schätzung
 k-nächste-nachbarn-schätzung Mustererkennung und Klassifikation, Vorlesung No. 7 1 M. O. Franz 29.11.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht
k-nächste-nachbarn-schätzung Mustererkennung und Klassifikation, Vorlesung No. 7 1 M. O. Franz 29.11.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht
Nichtlineare Klassifikatoren
 Nichtlineare Klassifikatoren Mustererkennung und Klassifikation, Vorlesung No. 11 1 M. O. Franz 12.01.2008 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht
Nichtlineare Klassifikatoren Mustererkennung und Klassifikation, Vorlesung No. 11 1 M. O. Franz 12.01.2008 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht
Linear nichtseparable Probleme
 Linear nichtseparable Probleme Mustererkennung und Klassifikation, Vorlesung No. 10 1 M. O. Franz 20.12.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht
Linear nichtseparable Probleme Mustererkennung und Klassifikation, Vorlesung No. 10 1 M. O. Franz 20.12.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht
Überblick. Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung
 Grundlagen Überblick Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes-Klassifikator
Grundlagen Überblick Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes-Klassifikator
Signalentdeckungstheorie, Dichteschätzung
 Signalentdeckungstheorie, Dichteschätzung Mustererkennung und Klassifikation, Vorlesung No. 6 1 M. O. Franz 15.11.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001.
Signalentdeckungstheorie, Dichteschätzung Mustererkennung und Klassifikation, Vorlesung No. 6 1 M. O. Franz 15.11.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001.
Überblick. Überblick. Bayessche Entscheidungsregel. A-posteriori-Wahrscheinlichkeit (Beispiel) Wiederholung: Bayes-Klassifikator
 Wiederholung: Bayes-Klassifikator") Überblick Grundlagen Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes-Klassifikator
Überblick Grundlagen Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes-Klassifikator
Überblick. Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung
 Grundlagen Überblick Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes- Entscheidungsfunktionen
Grundlagen Überblick Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes- Entscheidungsfunktionen
Wenn PCA in der Gesichtserkennung eingesetzt wird heißen die Eigenvektoren oft: Eigenfaces
 EFME-Zusammenfassusng WS11 Kurze Fragen: Wenn PCA in der Gesichtserkennung eingesetzt wird heißen die Eigenvektoren oft: Eigenfaces Unter welcher Bedingung konvergiert der Online Perceptron Algorithmus?
EFME-Zusammenfassusng WS11 Kurze Fragen: Wenn PCA in der Gesichtserkennung eingesetzt wird heißen die Eigenvektoren oft: Eigenfaces Unter welcher Bedingung konvergiert der Online Perceptron Algorithmus?
Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 2016
 Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 1 M. Sperber (matthias.sperber@kit.edu) S. Nguyen (thai.nguyen@kit.edu) Übungsblatt 3 Maschinelles Lernen und Klassifikation Abgabe online
Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 1 M. Sperber (matthias.sperber@kit.edu) S. Nguyen (thai.nguyen@kit.edu) Übungsblatt 3 Maschinelles Lernen und Klassifikation Abgabe online
Mustererkennung. Support Vector Machines. R. Neubecker, WS 2018 / Support Vector Machines
 Mustererkennung R. Neubecker, WS 018 / 019 (SVM) kommen aus der statistischen Lerntheorie gehören zu den optimalen Klassifikatoren = SVMs minimieren nicht nur den Trainingsfehler, sondern auch den (voraussichtlichen)
Mustererkennung R. Neubecker, WS 018 / 019 (SVM) kommen aus der statistischen Lerntheorie gehören zu den optimalen Klassifikatoren = SVMs minimieren nicht nur den Trainingsfehler, sondern auch den (voraussichtlichen)
Syntaktische und Statistische Mustererkennung. Bernhard Jung
 Syntaktische und Statistische Mustererkennung VO 1.0 840.040 (UE 1.0 840.041) Bernhard Jung bernhard@jung.name http://bernhard.jung.name/vussme/ 1 Rückblick Entscheidungstheorie Bayes'sche Klassifikation
Syntaktische und Statistische Mustererkennung VO 1.0 840.040 (UE 1.0 840.041) Bernhard Jung bernhard@jung.name http://bernhard.jung.name/vussme/ 1 Rückblick Entscheidungstheorie Bayes'sche Klassifikation
EFME Aufsätze ( Wörter) Der Aufbau von Entscheidungsbäumen...1
 Der Aufbau von Entscheidungsbäumen...1") EFME Aufsätze (150 200 Wörter) Der Aufbau von Entscheidungsbäumen...1 PCA in der Gesichtserkennung... 2 Bias, Varianz und Generalisierungsfähigkeit... 3 Parametrische und nicht-parametrische Lernverfahren:
EFME Aufsätze (150 200 Wörter) Der Aufbau von Entscheidungsbäumen...1 PCA in der Gesichtserkennung... 2 Bias, Varianz und Generalisierungsfähigkeit... 3 Parametrische und nicht-parametrische Lernverfahren:
Mustererkennung. Bayes-Klassifikator. R. Neubecker, WS 2016 / Bayes-Klassifikator
 Mustererkennung Bayes-Klassifikator R. Neubecker, WS 2016 / 2017 Bayes-Klassifikator 2 Kontext Ziel: Optimaler Klassifikator ( = minimaler Klassifikationsfehler), basierend auf Wahrscheinlichkeitsverteilungen
Mustererkennung Bayes-Klassifikator R. Neubecker, WS 2016 / 2017 Bayes-Klassifikator 2 Kontext Ziel: Optimaler Klassifikator ( = minimaler Klassifikationsfehler), basierend auf Wahrscheinlichkeitsverteilungen
Alois Fichtl, Julius Vogelbacher 10. Juni Voronoi und Johnson-Mehl Mosaike
 Alois Fichtl, Julius Vogelbacher 10. Juni 2008 Voronoi und Johnson-Mehl Mosaike Seite 2 Voronoi- und Johnson-Mehl-Mosaike Alois Fichtl, Julius Vogelbacher 10. Juni 2008 Inhaltsverzeichnis Einführung Mosaike
Alois Fichtl, Julius Vogelbacher 10. Juni 2008 Voronoi und Johnson-Mehl Mosaike Seite 2 Voronoi- und Johnson-Mehl-Mosaike Alois Fichtl, Julius Vogelbacher 10. Juni 2008 Inhaltsverzeichnis Einführung Mosaike
Unüberwachtes Lernen
 Unüberwachtes Lernen Mustererkennung und Klassifikation, Vorlesung No. 12 M. O. Franz 17.01.2008 Übersicht 1 Hauptkomponentenanalyse 2 Nichtlineare Hauptkomponentenanalyse 3 K-Means-Clustering Übersicht
Unüberwachtes Lernen Mustererkennung und Klassifikation, Vorlesung No. 12 M. O. Franz 17.01.2008 Übersicht 1 Hauptkomponentenanalyse 2 Nichtlineare Hauptkomponentenanalyse 3 K-Means-Clustering Übersicht
Vorlesung 2. Maschinenlernen: Klassische Ansätze I
 Vorlesung 2 Maschinenlernen: Klassische Ansätze I Martin Giese Martin.giese@tuebingen.mpg.de Übersicht! Statistische Formulierung des überwachten Lernproblems! Einfache Klassifikatoren! Regression I. Statistiche
Vorlesung 2 Maschinenlernen: Klassische Ansätze I Martin Giese Martin.giese@tuebingen.mpg.de Übersicht! Statistische Formulierung des überwachten Lernproblems! Einfache Klassifikatoren! Regression I. Statistiche
Andere Methoden zur Klassikation und Objekterkennung
 Andere Methoden zur Klassikation und Objekterkennung Heike Zierau 05. Juni 2007 1. Einführung 2. Prototypmethoden K-means Clustering Gaussian Mixture Gaussian Mixture vs. K-means Clustering 3. nächste-nachbarn
Andere Methoden zur Klassikation und Objekterkennung Heike Zierau 05. Juni 2007 1. Einführung 2. Prototypmethoden K-means Clustering Gaussian Mixture Gaussian Mixture vs. K-means Clustering 3. nächste-nachbarn
1 Einleitung Definitionen, Begriffe Grundsätzliche Vorgehensweise... 3
 Inhaltsverzeichnis 1 Einleitung 1 1.1 Definitionen, Begriffe........................... 1 1.2 Grundsätzliche Vorgehensweise.................... 3 2 Intuitive Klassifikation 6 2.1 Abstandsmessung zur Klassifikation..................
Inhaltsverzeichnis 1 Einleitung 1 1.1 Definitionen, Begriffe........................... 1 1.2 Grundsätzliche Vorgehensweise.................... 3 2 Intuitive Klassifikation 6 2.1 Abstandsmessung zur Klassifikation..................
Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester Lösungsblatt 3 Maschinelles Lernen und Klassifikation
 Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester M. Sperber (matthias.sperber@kit.edu) S. Nguyen (thai.nguyen@kit.edu) Lösungsblatt 3 Maschinelles Lernen und Klassifikation Aufgabe : Zufallsexperiment
Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester M. Sperber (matthias.sperber@kit.edu) S. Nguyen (thai.nguyen@kit.edu) Lösungsblatt 3 Maschinelles Lernen und Klassifikation Aufgabe : Zufallsexperiment
One-class Support Vector Machines
 One-class Support Vector Machines Seminar Wissensbasierte Systeme Dietrich Derksen 3. Januar 204 Motivation One-class Support Vector Machines: Detektion von Ausreißern (Systemfehlererkennung) Klassifikation
One-class Support Vector Machines Seminar Wissensbasierte Systeme Dietrich Derksen 3. Januar 204 Motivation One-class Support Vector Machines: Detektion von Ausreißern (Systemfehlererkennung) Klassifikation
Das Modell: Nichtlineare Merkmalsextraktion (Preprozessing) + Lineare Klassifikation
 + Lineare Klassifikation") Das Modell: Nichtlineare Merkmalsextraktion (Preprozessing) + Lineare Klassifikation Hochdimensionaler Eingaberaum {0,1} Z S quadratisch aufgemalt (zwecks besserer Visualisierung) als Retina bestehend
Das Modell: Nichtlineare Merkmalsextraktion (Preprozessing) + Lineare Klassifikation Hochdimensionaler Eingaberaum {0,1} Z S quadratisch aufgemalt (zwecks besserer Visualisierung) als Retina bestehend
Vorlesung Wissensentdeckung
 Vorlesung Wissensentdeckung Stützvektormethode Katharina Morik, Uwe Ligges 10.6.2010 1 von 40 Gliederung 1 Hinführungen zur SVM 2 Maximum Margin Methode Lagrange-Optimierung 3 Weich trennende SVM 2 von
Vorlesung Wissensentdeckung Stützvektormethode Katharina Morik, Uwe Ligges 10.6.2010 1 von 40 Gliederung 1 Hinführungen zur SVM 2 Maximum Margin Methode Lagrange-Optimierung 3 Weich trennende SVM 2 von
Vorlesung Wissensentdeckung
 Gliederung Vorlesung Wissensentdeckung Stützvektormethode 1 Hinführungen zur SVM Katharina Morik, Claus Weihs 26.5.2009 2 Maximum Margin Methode Lagrange-Optimierung 3 Weich trennende SVM 1 von 40 2 von
Gliederung Vorlesung Wissensentdeckung Stützvektormethode 1 Hinführungen zur SVM Katharina Morik, Claus Weihs 26.5.2009 2 Maximum Margin Methode Lagrange-Optimierung 3 Weich trennende SVM 1 von 40 2 von
( ) ( ) < b k, 1 k n} (2) < x k
 ( ) < b k, 1 k n} (2) < x k") Technische Universität Dortmund Fakultät für Mathematik Proseminar Analysis Prof. Dr. Röger Benjamin Czyszczon Satz von Heine Borel Gliederung 1. Zellen und offene Überdeckungen 2. Satz von Heine Borel
Technische Universität Dortmund Fakultät für Mathematik Proseminar Analysis Prof. Dr. Röger Benjamin Czyszczon Satz von Heine Borel Gliederung 1. Zellen und offene Überdeckungen 2. Satz von Heine Borel
Mustererkennung und Klassifikation
 Mustererkennung und Klassifikation WS 2007/2008 Fakultät Informatik Technische Informatik Prof. Dr. Matthias Franz mfranz@htwg-konstanz.de www-home.htwg-konstanz.de/~mfranz/heim.html Grundlagen Überblick
Mustererkennung und Klassifikation WS 2007/2008 Fakultät Informatik Technische Informatik Prof. Dr. Matthias Franz mfranz@htwg-konstanz.de www-home.htwg-konstanz.de/~mfranz/heim.html Grundlagen Überblick
Übungen zur Linearen Algebra 1
 Übungen zur Linearen Algebra 1 Wintersemester 014/015 Universität Heidelberg - IWR Prof. Dr. Guido Kanschat Dr. Dörte Beigel Philipp Siehr Blatt 7 Abgabetermin: Freitag, 05.1.014, 11 Uhr Aufgabe 7.1 (Vektorräume
Übungen zur Linearen Algebra 1 Wintersemester 014/015 Universität Heidelberg - IWR Prof. Dr. Guido Kanschat Dr. Dörte Beigel Philipp Siehr Blatt 7 Abgabetermin: Freitag, 05.1.014, 11 Uhr Aufgabe 7.1 (Vektorräume
Zulassungstest zur Physik II für Chemiker
 SoSe 2016 Zulassungstest zur Physik II für Chemiker 03.08.16 Name: Matrikelnummer: T1 T2 T3 T4 T5 T6 T7 T8 T9 T10 T TOT.../4.../4.../4.../4.../4.../4.../4.../4.../4.../4.../40 R1 R2 R3 R4 R TOT.../6.../6.../6.../6.../24
SoSe 2016 Zulassungstest zur Physik II für Chemiker 03.08.16 Name: Matrikelnummer: T1 T2 T3 T4 T5 T6 T7 T8 T9 T10 T TOT.../4.../4.../4.../4.../4.../4.../4.../4.../4.../4.../40 R1 R2 R3 R4 R TOT.../6.../6.../6.../6.../24
Pareto optimale lineare Klassifikation
 Seminar aus Maschinellem Lernen Pareto optimale lineare Klassifikation Vesselina Poulkova Betreuer: Eneldo Loza Mencía Gliederung 1. Einleitung 2. Pareto optimale lineare Klassifizierer 3. Generelle Voraussetzung
Seminar aus Maschinellem Lernen Pareto optimale lineare Klassifikation Vesselina Poulkova Betreuer: Eneldo Loza Mencía Gliederung 1. Einleitung 2. Pareto optimale lineare Klassifizierer 3. Generelle Voraussetzung
Principal Component Analysis (PCA)
") Principal Component Analysis (PCA) Motivation: Klassifikation mit der PCA Berechnung der Hauptkomponenten Theoretische Hintergründe Anwendungsbeispiel: Klassifikation von Gesichtern Weiterführende Bemerkungen
Principal Component Analysis (PCA) Motivation: Klassifikation mit der PCA Berechnung der Hauptkomponenten Theoretische Hintergründe Anwendungsbeispiel: Klassifikation von Gesichtern Weiterführende Bemerkungen
Methoden zur Cluster - Analyse
 Kapitel 4 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität Leipzig Machine learning in bioinformatics
Kapitel 4 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität Leipzig Machine learning in bioinformatics
Vorlesung Maschinelles Lernen
 Vorlesung Maschinelles Lernen Stützvektormethode Katharina Morik LS 8 Informatik 8.11.2011 1 von 38 Gliederung 1 2 Lagrange-Optimierung 2 von 38 Übersicht über die Stützvektormethode (SVM) Eigenschaften
Vorlesung Maschinelles Lernen Stützvektormethode Katharina Morik LS 8 Informatik 8.11.2011 1 von 38 Gliederung 1 2 Lagrange-Optimierung 2 von 38 Übersicht über die Stützvektormethode (SVM) Eigenschaften
Funktionslernen. 5. Klassifikation. 5.6 Support Vector Maschines (SVM) Reale Beispiele. Beispiel: Funktionenlernen
 Reale Beispiele. Beispiel: Funktionenlernen") 5. Klassifikation 5.6 Support Vector Maschines (SVM) übernommen von Stefan Rüping, Katharina Morik, Universität Dortmund Vorlesung Maschinelles Lernen und Data Mining, WS 2002/03 und Katharina Morik, Claus
5. Klassifikation 5.6 Support Vector Maschines (SVM) übernommen von Stefan Rüping, Katharina Morik, Universität Dortmund Vorlesung Maschinelles Lernen und Data Mining, WS 2002/03 und Katharina Morik, Claus
Vorlesung Maschinelles Lernen
 Vorlesung Maschinelles Lernen Stützvektormethode Katharina Morik LS 8 Informatik Technische Universität Dortmund 12.11.2013 1 von 39 Gliederung 1 Hinführungen zur SVM 2 Maximum Margin Methode Lagrange-Optimierung
Vorlesung Maschinelles Lernen Stützvektormethode Katharina Morik LS 8 Informatik Technische Universität Dortmund 12.11.2013 1 von 39 Gliederung 1 Hinführungen zur SVM 2 Maximum Margin Methode Lagrange-Optimierung
Support Vector Machines (SVM)
") Universität Ulm 12. Juni 2007 Inhalt 1 2 3 Grundlegende Idee Der Kern-Trick 4 5 Multi-Klassen-Einteilung Vor- und Nachteile der SVM 1 2 3 Grundlegende Idee Der Kern-Trick 4 5 Multi-Klassen-Einteilung Vor-
Universität Ulm 12. Juni 2007 Inhalt 1 2 3 Grundlegende Idee Der Kern-Trick 4 5 Multi-Klassen-Einteilung Vor- und Nachteile der SVM 1 2 3 Grundlegende Idee Der Kern-Trick 4 5 Multi-Klassen-Einteilung Vor-
Filter. Industrielle Bildverarbeitung, Vorlesung No M. O. Franz
 Filter Industrielle Bildverarbeitung, Vorlesung No. 5 1 M. O. Franz 07.11.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Burger & Burge, 2005. Übersicht 1 Lineare Filter 2 Formale
Filter Industrielle Bildverarbeitung, Vorlesung No. 5 1 M. O. Franz 07.11.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Burger & Burge, 2005. Übersicht 1 Lineare Filter 2 Formale
. TRENNENDE HYPEREBENEN
 VORLESUNG ÜBER KONVEXITÄT Daniel Plaumann Universität Konstanz Wintersemester /.. HYPEREBENEN De nition.. Es sei V ein reeller Vektorraum. Eine lineare Abbildung ℓ V R heißt lineares Funktional auf V.
VORLESUNG ÜBER KONVEXITÄT Daniel Plaumann Universität Konstanz Wintersemester /.. HYPEREBENEN De nition.. Es sei V ein reeller Vektorraum. Eine lineare Abbildung ℓ V R heißt lineares Funktional auf V.
Decision-Tree-Klassifikator
 D3kjd3Di38lk323nnm Decision-Tree-Klassifikator Decision Trees haben einige Vorteile gegenüber den beiden schon beschriebenen Klassifikationsmethoden. Man benötigt in der Regel keine so aufwendige Vorverarbeitung
D3kjd3Di38lk323nnm Decision-Tree-Klassifikator Decision Trees haben einige Vorteile gegenüber den beiden schon beschriebenen Klassifikationsmethoden. Man benötigt in der Regel keine so aufwendige Vorverarbeitung
Serie 3. z = f(x, y) = 9 (x 2) 2 (y 3) 2 z 2 = 9 (x 2) 2 (y 3) 2, z 0 9 = (x 2) 2 + (y 3) 2 + z 2, z 0.
 = 9 (x 2) 2 (y 3) 2 z 2 = 9 (x 2) 2 (y 3) 2, z 0 9 = (x 2) 2 + (y 3) 2 + z 2, z 0.") Analysis D-BAUG Dr Cornelia Busch FS 2016 Serie 3 1 a) Zeigen Sie, dass der Graph von f(x, y) = 9 (x 2) 2 (y 3) 2 eine Halbkugel beschreibt und bestimmen Sie ihren Radius und ihr Zentrum z = f(x, y) =
Analysis D-BAUG Dr Cornelia Busch FS 2016 Serie 3 1 a) Zeigen Sie, dass der Graph von f(x, y) = 9 (x 2) 2 (y 3) 2 eine Halbkugel beschreibt und bestimmen Sie ihren Radius und ihr Zentrum z = f(x, y) =
102 KAPITEL 14. FLÄCHEN
 102 KAPITEL 14. FLÄCHEN Definition 14.3.1 (Kurve) Es sei M eine k-dimensionale Untermannigfaltigkeit des R n. Eine C 1 - Kurve γ : ( a, a) R n mit γ(( a, a)) M heißt Kurve auf M durch x 0 = γ(0). Definition
102 KAPITEL 14. FLÄCHEN Definition 14.3.1 (Kurve) Es sei M eine k-dimensionale Untermannigfaltigkeit des R n. Eine C 1 - Kurve γ : ( a, a) R n mit γ(( a, a)) M heißt Kurve auf M durch x 0 = γ(0). Definition
Proseminar HS Ebene algebraische Kurven Vortrag I.6. Duale Kurven. David Bürge 4. November 2010
 Proseminar HS 010 - Ebene algebraische Kurven Vortrag I.6 Duale Kurven David Bürge 4. November 010 1 1 1 1 Eine nierenförmige Kleinsche Quartik und ihre duale Kurve in R INHALTSVERZEICHNIS Inhaltsverzeichnis
Proseminar HS 010 - Ebene algebraische Kurven Vortrag I.6 Duale Kurven David Bürge 4. November 010 1 1 1 1 Eine nierenförmige Kleinsche Quartik und ihre duale Kurve in R INHALTSVERZEICHNIS Inhaltsverzeichnis
Vorlesung Wissensentdeckung
 Vorlesung Wissensentdeckung Stützvektormethode Katharina Morik, Uwe Ligges 23.5.2013 1 von 48 Gliederung 1 Geometrie linearer Modelle: Hyperebenen Einführung von Schölkopf/Smola 2 Lagrange-Optimierung
Vorlesung Wissensentdeckung Stützvektormethode Katharina Morik, Uwe Ligges 23.5.2013 1 von 48 Gliederung 1 Geometrie linearer Modelle: Hyperebenen Einführung von Schölkopf/Smola 2 Lagrange-Optimierung
Automatic segmentation for dental operation planning. Diplomarbeit. Nguyen The Duy
 Automatic segmentation for dental operation planning Diplomarbeit Nguyen The Duy 24.02.2012 Motivation Quelle: bestbudapestdentist.com Aufgabenstellung Segmentierung des Oberkiefers (Maxilla) Detektion
Automatic segmentation for dental operation planning Diplomarbeit Nguyen The Duy 24.02.2012 Motivation Quelle: bestbudapestdentist.com Aufgabenstellung Segmentierung des Oberkiefers (Maxilla) Detektion
Eigenfaces vs. Fisherfaces: Recognition Using Class Specific Linear Projection
 Eigenfaces vs. Fisherfaces: Recognition Using Class Specific Linear Projection P. Belhumeur, J. Hespanha, D. Kriegman IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 19, No. 7, July
Eigenfaces vs. Fisherfaces: Recognition Using Class Specific Linear Projection P. Belhumeur, J. Hespanha, D. Kriegman IEEE Transactions on Pattern Analysis and Machine Intelligence, Vol. 19, No. 7, July
Sei ω eine symplektische Struktur auf U 2n. Satz 12. In einer Umgebung eines beliebigen Punktes x gibt es
 Satz von Darboux Sei ω eine symplektische Struktur auf U 2n. Satz 12. In einer Umgebung eines beliebigen Punktes x gibt es Koordinaten (x 1,..., x n, p 1,..., p n ), sodass ω = n i=1 dp i dx i. Ferner
Satz von Darboux Sei ω eine symplektische Struktur auf U 2n. Satz 12. In einer Umgebung eines beliebigen Punktes x gibt es Koordinaten (x 1,..., x n, p 1,..., p n ), sodass ω = n i=1 dp i dx i. Ferner
Support Vector Machines, Kernels
 Support Vector Machines, Kernels Katja Kunze 13.01.04 19.03.2004 1 Inhalt: Grundlagen/Allgemeines Lineare Trennung/Separation - Maximum Margin Hyperplane - Soft Margin SVM Kernels Praktische Anwendungen
Support Vector Machines, Kernels Katja Kunze 13.01.04 19.03.2004 1 Inhalt: Grundlagen/Allgemeines Lineare Trennung/Separation - Maximum Margin Hyperplane - Soft Margin SVM Kernels Praktische Anwendungen
Lineare Methoden zur Klassifizierung
 Lineare Methoden zur Klassifizierung Kapitel 3 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität
Lineare Methoden zur Klassifizierung Kapitel 3 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität
Inhalt der Vorlesung. 1 Einführung 2 Konvexe Mengen 3 Konvexe Funktionen 4 Konvexe Optimierung 5 Lösungsverfahren (6 Anwendungen)
") Inhalt der Vorlesung 1 Einführung 2 Konvexe Mengen 3 Konvexe Funktionen 4 Konvexe Optimierung 5 Lösungsverfahren (6 Anwendungen) 1 S-M. Grad - Optimierung II / Universität Leipzig, SS2018 Beispiel 1.1
Inhalt der Vorlesung 1 Einführung 2 Konvexe Mengen 3 Konvexe Funktionen 4 Konvexe Optimierung 5 Lösungsverfahren (6 Anwendungen) 1 S-M. Grad - Optimierung II / Universität Leipzig, SS2018 Beispiel 1.1
Klassische Klassifikationsalgorithmen
 Klassische Klassifikationsalgorithmen Einführung in die Wissensverarbeitung 2 VO 708.560+ 1 UE 442.072 SS 2013 Institut für Signalverarbeitung und Sprachkommunikation TU Graz Inffeldgasse 12/1 www.spsc.tugraz.at
Klassische Klassifikationsalgorithmen Einführung in die Wissensverarbeitung 2 VO 708.560+ 1 UE 442.072 SS 2013 Institut für Signalverarbeitung und Sprachkommunikation TU Graz Inffeldgasse 12/1 www.spsc.tugraz.at
Einführung R. Neubecker, WS 2018 / 2019
 Mustererkennung Einführung R. Neubecker, WS 2018 / 2019 1 Übersicht Hyperebenen-Mathematik Anmerkungen Zusammenfassung Mustererkennung (Pattern recognition) Mustererkennung ist die Fähigkeit, in einer
Mustererkennung Einführung R. Neubecker, WS 2018 / 2019 1 Übersicht Hyperebenen-Mathematik Anmerkungen Zusammenfassung Mustererkennung (Pattern recognition) Mustererkennung ist die Fähigkeit, in einer
Übungen zur Ingenieur-Mathematik III WS 2012/13 Blatt
 Übungen zur Ingenieur-Mathematik III WS 2012/13 Blatt 9 19.12.2012 Aufgabe 35: Thema: Differenzierbarkeit a) Was bedeutet für eine Funktion f : R n R, dass f an der Stelle x 0 R n differenzierbar ist?
Übungen zur Ingenieur-Mathematik III WS 2012/13 Blatt 9 19.12.2012 Aufgabe 35: Thema: Differenzierbarkeit a) Was bedeutet für eine Funktion f : R n R, dass f an der Stelle x 0 R n differenzierbar ist?
Tangentialebene. Sei f eine stetig differenzierbare Funktion und p = (p 1,..., p n ) die Koordinaten eines Punktes P auf der durch
 die Koordinaten eines Punktes P auf der durch") Tangentialebene Sei f eine stetig differenzierbare Funktion und p = (p 1,..., p n ) die Koordinaten eines Punktes P auf der durch implizit definierten Fläche. f (x 1,..., x n ) = c Tangentialebene 1-1
Tangentialebene Sei f eine stetig differenzierbare Funktion und p = (p 1,..., p n ) die Koordinaten eines Punktes P auf der durch implizit definierten Fläche. f (x 1,..., x n ) = c Tangentialebene 1-1
3.3 Nächste-Nachbarn-Klassifikatoren
 3.3 Nächste-Nachbarn-Klassifikatoren Schrauben Nägel Klammern Neues Objekt Instanzbasiertes Lernen (instance based learning) Einfachster Nächste-Nachbar-Klassifikator: Zuordnung zu der Klasse des nächsten
3.3 Nächste-Nachbarn-Klassifikatoren Schrauben Nägel Klammern Neues Objekt Instanzbasiertes Lernen (instance based learning) Einfachster Nächste-Nachbar-Klassifikator: Zuordnung zu der Klasse des nächsten
12. Flächenrekonstruktion aus 3D-Punktwolken und generalisierte Voronoi-Diagramme
 12. Flächenrekonstruktion aus 3D-Punktwolken und generalisierte Voronoi-Diagramme (Einfache) Voronoi-Diagramme: Motivation: gegeben: Raum R, darin Menge S von Objekten Frage nach Zerlegung von R in "Einflusszonen"
12. Flächenrekonstruktion aus 3D-Punktwolken und generalisierte Voronoi-Diagramme (Einfache) Voronoi-Diagramme: Motivation: gegeben: Raum R, darin Menge S von Objekten Frage nach Zerlegung von R in "Einflusszonen"
Kapitel 8. Neuronale Netze
 Kapitel 8 Neuronale Netze Ansätze zum Entwurf eines Klassifikators Es gibt zwei prinzipiell unterschiedliche Ansätze zum Entwurf eines Klassifikators:. Statistische parametrische Modellierung der Klassenverteilungen,
Kapitel 8 Neuronale Netze Ansätze zum Entwurf eines Klassifikators Es gibt zwei prinzipiell unterschiedliche Ansätze zum Entwurf eines Klassifikators:. Statistische parametrische Modellierung der Klassenverteilungen,
Instanzenbasiertes Lernen: Übersicht
 Instanzenbasiertes Lernen: Übersicht k-nearest Neighbor Lokal gewichtete Regression Fallbasiertes Schließen Lernen: Lazy oder Eager Teil 11: IBL (V. 1.0) 1 c G. Grieser Instanzenbasiertes Lernen Idee:
Instanzenbasiertes Lernen: Übersicht k-nearest Neighbor Lokal gewichtete Regression Fallbasiertes Schließen Lernen: Lazy oder Eager Teil 11: IBL (V. 1.0) 1 c G. Grieser Instanzenbasiertes Lernen Idee:
Übungen zu Theoretische Physik II
 Physikalisches Institut Übungsblatt 8 Universität Bonn 08.2.206 Theoretische Physik WS 6/7 Übungen zu Theoretische Physik II Prof. Dr. Hartmut Monien, Christoph Liyanage, Manuel Krauß Abgabe: spätestens
Physikalisches Institut Übungsblatt 8 Universität Bonn 08.2.206 Theoretische Physik WS 6/7 Übungen zu Theoretische Physik II Prof. Dr. Hartmut Monien, Christoph Liyanage, Manuel Krauß Abgabe: spätestens
KAPITEL VIII. Elektrostatik. VIII.1 Elektrisches Potential. VIII.1.1 Skalarpotential. VIII.1.2 Poisson-Gleichung
 KAPITEL III Elektrostatik Hier fehlt die obligatorische Einleitung... Im stationären Fall vereinfachen sich die Maxwell Gauß und die Maxwell Faraday-Gleichungen für die elektrische Feldstärke E( r) die
KAPITEL III Elektrostatik Hier fehlt die obligatorische Einleitung... Im stationären Fall vereinfachen sich die Maxwell Gauß und die Maxwell Faraday-Gleichungen für die elektrische Feldstärke E( r) die
Lineare Klassifikatoren
 Universität Potsdam Institut für Informatik Lehrstuhl Lineare Klassifikatoren Christoph Sawade, Blaine Nelson, Tobias Scheffer Inhalt Klassifikationsproblem Bayes sche Klassenentscheidung Lineare Klassifikator,
Universität Potsdam Institut für Informatik Lehrstuhl Lineare Klassifikatoren Christoph Sawade, Blaine Nelson, Tobias Scheffer Inhalt Klassifikationsproblem Bayes sche Klassenentscheidung Lineare Klassifikator,
3.4 Kombinatorische Äquivalenz und Dualität von Polytopen
 222 Diskrete Geometrie (Version 3) 12. Januar 2012 c Rudolf Scharlau 3.4 Kombinatorische Äquivalenz und Dualität von Polytopen Dieser Abschnitt baut auf den beiden vorigen auf, indem er weiterhin den Seitenverband
222 Diskrete Geometrie (Version 3) 12. Januar 2012 c Rudolf Scharlau 3.4 Kombinatorische Äquivalenz und Dualität von Polytopen Dieser Abschnitt baut auf den beiden vorigen auf, indem er weiterhin den Seitenverband
6 Methoden zur Lösung des elektrostatischen Randwertproblems
 6 Methoden zur Lösung des elektrostatischen Randwertproblems Die generelle Strategie zur Lösung des elektrostatischen Randwertproblems umfaßt zwei Schritte: 1. Finde eine spezielle Lösung der Poisson-Gleichung
6 Methoden zur Lösung des elektrostatischen Randwertproblems Die generelle Strategie zur Lösung des elektrostatischen Randwertproblems umfaßt zwei Schritte: 1. Finde eine spezielle Lösung der Poisson-Gleichung
Extremalprobleme mit Nebenbedingungen
 Extremalprobleme mit Nebenbedingungen In diesem Abschnitt untersuchen wir Probleme der folgenden Form: g(x 0 ) = inf{g(x) : x Ω, f(x) = 0}, (x 0 Ω, f(x 0 ) = 0). (1) Hierbei sind Ω eine offene Menge des
Extremalprobleme mit Nebenbedingungen In diesem Abschnitt untersuchen wir Probleme der folgenden Form: g(x 0 ) = inf{g(x) : x Ω, f(x) = 0}, (x 0 Ω, f(x 0 ) = 0). (1) Hierbei sind Ω eine offene Menge des
Übungen zur Vorlesung Grundlagen der Bilderzeugung und Bildanalyse (Mustererkennung) WS 05/06. Musterlösung 11
 WS 05/06. Musterlösung 11") ALBERT-LUDWIGS-UNIVERSITÄT FREIBURG INSTITUT FÜR INFORMATIK Lehrstuhl für Mustererkennung und Bildverarbeitung Prof. Dr.-Ing. Hans Burkhardt Georges-Köhler-Allee Geb. 05, Zi 0-09 D-790 Freiburg Tel. 076-03
ALBERT-LUDWIGS-UNIVERSITÄT FREIBURG INSTITUT FÜR INFORMATIK Lehrstuhl für Mustererkennung und Bildverarbeitung Prof. Dr.-Ing. Hans Burkhardt Georges-Köhler-Allee Geb. 05, Zi 0-09 D-790 Freiburg Tel. 076-03
Wahrscheinlichkeitsrechnung und Statistik für Biologen Diskriminanzanalyse
 Wahrscheinlichkeitsrechnung und Statistik für Biologen Diskriminanzanalyse Noémie Becker & Dirk Metzler http://evol.bio.lmu.de/_statgen 3. Juli 2013 Übersicht 1 Ruf des Kleinspechts 2 Modell Vorgehen der
Wahrscheinlichkeitsrechnung und Statistik für Biologen Diskriminanzanalyse Noémie Becker & Dirk Metzler http://evol.bio.lmu.de/_statgen 3. Juli 2013 Übersicht 1 Ruf des Kleinspechts 2 Modell Vorgehen der
Textmining Klassifikation von Texten Teil 2: Im Vektorraummodell
 Textmining Klassifikation von Texten Teil 2: Im Vektorraummodell Dept. Informatik 8 (Künstliche Intelligenz) Friedrich-Alexander-Universität Erlangen-Nürnberg (Informatik 8) Klassifikation von Texten Teil
Textmining Klassifikation von Texten Teil 2: Im Vektorraummodell Dept. Informatik 8 (Künstliche Intelligenz) Friedrich-Alexander-Universität Erlangen-Nürnberg (Informatik 8) Klassifikation von Texten Teil
Mathematik II für Studierende der Informatik (Analysis und lineare Algebra) im Sommersemester 2018
 im Sommersemester 2018") (Analysis und lineare Algebra) im Sommersemester 2018 15. April 2018 1/46 Die Dimension eines Vektorraums Satz 2.27 (Basisergänzungssatz) Sei V ein Vektorraum über einem Körper K. Weiter seien v 1,...,
(Analysis und lineare Algebra) im Sommersemester 2018 15. April 2018 1/46 Die Dimension eines Vektorraums Satz 2.27 (Basisergänzungssatz) Sei V ein Vektorraum über einem Körper K. Weiter seien v 1,...,
Ferienkurs - Experimentalphysik 2 - Übungsblatt - Lösungen
 Technische Universität München Department of Physics Ferienkurs - Experimentalphysik 2 - Übungsblatt - Lösungen Montag Daniel Jost Datum 2/8/212 Aufgabe 1: (a) Betrachten Sie eine Ladung, die im Ursprung
Technische Universität München Department of Physics Ferienkurs - Experimentalphysik 2 - Übungsblatt - Lösungen Montag Daniel Jost Datum 2/8/212 Aufgabe 1: (a) Betrachten Sie eine Ladung, die im Ursprung
Morphologische Filter
 Morphologische Filter Industrielle Bildverarbeitung, Vorlesung No. 8 1 M. O. Franz 28.11.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Burger & Burge, 2005. Übersicht 1 Morphologische
Morphologische Filter Industrielle Bildverarbeitung, Vorlesung No. 8 1 M. O. Franz 28.11.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Burger & Burge, 2005. Übersicht 1 Morphologische
Projektive Räume und Unterräume
 Projektive Räume und Unterräume Erik Slawski Proseminar Analytische Geometrie bei Prof. Dr. Werner Seiler und Marcus Hausdorf Wintersemester 2007/2008 Fachbereich 17 Mathematik Universität Kassel Inhaltsverzeichnis
Projektive Räume und Unterräume Erik Slawski Proseminar Analytische Geometrie bei Prof. Dr. Werner Seiler und Marcus Hausdorf Wintersemester 2007/2008 Fachbereich 17 Mathematik Universität Kassel Inhaltsverzeichnis
Optimierung. Vorlesung 02
 Optimierung Vorlesung 02 LPs in kanonischer Form Für i = 1,, m und j = 1,, d seien c j, b i und a ij reele Zahlen. Gesucht wird eine Belegung der Variablen x 1,, x d, so das die Zielfunktion d c j x j
Optimierung Vorlesung 02 LPs in kanonischer Form Für i = 1,, m und j = 1,, d seien c j, b i und a ij reele Zahlen. Gesucht wird eine Belegung der Variablen x 1,, x d, so das die Zielfunktion d c j x j
Neuronale Netzwerke: Feed-forward versus recurrent (d.h. feed-back )
") Neuronale Netzwerke: Feed-forward versus recurrent (d.h. feed-back ) A: Schrittweise vorwärts-gerichtete Abbildung: Eingangssignal (Input) r in Ausgansgsignal (Output) r out Überwachtes Lernen (wie z.b.
Neuronale Netzwerke: Feed-forward versus recurrent (d.h. feed-back ) A: Schrittweise vorwärts-gerichtete Abbildung: Eingangssignal (Input) r in Ausgansgsignal (Output) r out Überwachtes Lernen (wie z.b.
Lineare Klassifikationsmethoden
 Verena Krieg Fakultät für Mathematik und Wirtschaftswissenschaften 08. Mai 2007 Inhaltsverzeichnis 1. Einführung 2. Lineare Regression 3. Lineare Diskriminanzanalyse 4. Logistische Regression 4.1 Berechnung
Verena Krieg Fakultät für Mathematik und Wirtschaftswissenschaften 08. Mai 2007 Inhaltsverzeichnis 1. Einführung 2. Lineare Regression 3. Lineare Diskriminanzanalyse 4. Logistische Regression 4.1 Berechnung
Geometrie. Ingo Blechschmidt. 4. März 2007
 Geometrie Ingo Blechschmidt 4. März 2007 Inhaltsverzeichnis 1 Geometrie 2 1.1 Geraden.......................... 2 1.1.1 Ursprungsgeraden in der x 1 x 2 -Ebene.... 2 1.1.2 Ursprungsgeraden im Raum..........
Geometrie Ingo Blechschmidt 4. März 2007 Inhaltsverzeichnis 1 Geometrie 2 1.1 Geraden.......................... 2 1.1.1 Ursprungsgeraden in der x 1 x 2 -Ebene.... 2 1.1.2 Ursprungsgeraden im Raum..........
Berufsmaturitätsprüfung 2013 Mathematik
 GIBB Gewerblich-Industrielle Berufsschule Bern Berufsmaturitätsschule Berufsmaturitätsprüfung 2013 Mathematik Zeit: Hilfsmittel: Hinweise: Punkte: 180 Minuten Formel- und Tabellensammlung ohne gelöste
GIBB Gewerblich-Industrielle Berufsschule Bern Berufsmaturitätsschule Berufsmaturitätsprüfung 2013 Mathematik Zeit: Hilfsmittel: Hinweise: Punkte: 180 Minuten Formel- und Tabellensammlung ohne gelöste
Lösungen zu Prüfung Lineare Algebra I/II für D-MAVT
 Prof. N. Hungerbühler ETH Zürich, Sommer 4 Lösungen zu Prüfung Lineare Algebra I/II für D-MAVT. [ Punkte] Hinweise zur Bewertung: Jede Aussage ist entweder wahr oder falsch; machen Sie ein Kreuzchen in
Prof. N. Hungerbühler ETH Zürich, Sommer 4 Lösungen zu Prüfung Lineare Algebra I/II für D-MAVT. [ Punkte] Hinweise zur Bewertung: Jede Aussage ist entweder wahr oder falsch; machen Sie ein Kreuzchen in
Übungen zu Partielle Differentialgleichungen, WS 2016
 Übungen zu Partielle Differentialgleichungen, WS 2016 Ulisse Stefanelli 16. Januar 2017 1 Beispiele 1. Betrachten Sie die Beispiele von nichtlinearen PDG und Systemen, die wir im Kurs diskutiert haben,
Übungen zu Partielle Differentialgleichungen, WS 2016 Ulisse Stefanelli 16. Januar 2017 1 Beispiele 1. Betrachten Sie die Beispiele von nichtlinearen PDG und Systemen, die wir im Kurs diskutiert haben,
Frequentisten und Bayesianer. Volker Tresp
 Frequentisten und Bayesianer Volker Tresp 1 Frequentisten 2 Die W-Verteilung eines Datenmusters Nehmen wir an, dass die wahre Abhängigkeit linear ist, wir jedoch nur verrauschte Daten zur Verfügung haben
Frequentisten und Bayesianer Volker Tresp 1 Frequentisten 2 Die W-Verteilung eines Datenmusters Nehmen wir an, dass die wahre Abhängigkeit linear ist, wir jedoch nur verrauschte Daten zur Verfügung haben
Beispiele. Strecke A R 1 (genauso für R d ):
:") Definition 6.1.1 (fraktale Dimension). Sei A R d beschränkt und für ε > 0 sei N A (ε) die minimale Anzahl der d-dimensionalen Kugeln vom Radius ε, mit denen A überdeckt werden kann. Die fraktale Dimension
Definition 6.1.1 (fraktale Dimension). Sei A R d beschränkt und für ε > 0 sei N A (ε) die minimale Anzahl der d-dimensionalen Kugeln vom Radius ε, mit denen A überdeckt werden kann. Die fraktale Dimension
Mustererkennung: Neuronale Netze. D. Schlesinger ()Mustererkennung: Neuronale Netze 1 / 12
Mustererkennung: Neuronale Netze 1 / 12") Mustererkennung: Neuronale Netze D. Schlesinger ()Mustererkennung: Neuronale Netze 1 / 12 Feed-Forward Netze y 1 y 2 y m...... x 1 x 2 x n Output Schicht i max... Zwischenschicht i... Zwischenschicht 1
Mustererkennung: Neuronale Netze D. Schlesinger ()Mustererkennung: Neuronale Netze 1 / 12 Feed-Forward Netze y 1 y 2 y m...... x 1 x 2 x n Output Schicht i max... Zwischenschicht i... Zwischenschicht 1
1 Verteilungsfunktionen, Zufallsvariable etc.
 4. Test M3 ET 27 6.6.27 4. Dezember 27 Regelung für den.ten Übungstest:. Wer bei den Professoren Dirschmid, Blümlinger, Vogl oder Langer die UE aus Mathematik 2 gemacht hat, sollte dort die WTH und Statistik
4. Test M3 ET 27 6.6.27 4. Dezember 27 Regelung für den.ten Übungstest:. Wer bei den Professoren Dirschmid, Blümlinger, Vogl oder Langer die UE aus Mathematik 2 gemacht hat, sollte dort die WTH und Statistik
Mathematik 1 für Wirtschaftsinformatik
 für Wirtschaftsinformatik Wintersemester 2012/13 Hochschule Augsburg Spezialfälle und Rechenregeln Spezialfälle der Matrixmultiplikation A = (m n)-matrix, B = (n m)-matrix es existiert A B und B A A quadratisch
für Wirtschaftsinformatik Wintersemester 2012/13 Hochschule Augsburg Spezialfälle und Rechenregeln Spezialfälle der Matrixmultiplikation A = (m n)-matrix, B = (n m)-matrix es existiert A B und B A A quadratisch
Physik-Department. Ferienkurs zur Experimentalphysik 2 - Aufgaben
 Physik-Department Ferienkurs zur Experimentalphysik 2 - Aufgaben Daniel Jost 26/08/13 Technische Universität München Aufgabe 1 Gegeben seien drei Ladungen q 1 = q, q 2 = q und q 3 = q, die sich an den
Physik-Department Ferienkurs zur Experimentalphysik 2 - Aufgaben Daniel Jost 26/08/13 Technische Universität München Aufgabe 1 Gegeben seien drei Ladungen q 1 = q, q 2 = q und q 3 = q, die sich an den
Fluch der Dimensionen
 Kapitel 6 Fazit Die Auswertung der verschiedenen Datensätze hat gezeigt, dass der klassische Random Forest in den meisten Fällen dem Boosting und Lasso-Verfahren bei der Klassifizierung von binären Daten
Kapitel 6 Fazit Die Auswertung der verschiedenen Datensätze hat gezeigt, dass der klassische Random Forest in den meisten Fällen dem Boosting und Lasso-Verfahren bei der Klassifizierung von binären Daten
Anorganische Chemie III
 Seminar zur Vorlesung Anorganische Chemie III Wintersemester 2015/16 Christoph Wölper Institut für Anorganische Chemie der Universität Duisburg-Essen Wiederholung Was bisher geschah # hexagonale Strukturtypen
Seminar zur Vorlesung Anorganische Chemie III Wintersemester 2015/16 Christoph Wölper Institut für Anorganische Chemie der Universität Duisburg-Essen Wiederholung Was bisher geschah # hexagonale Strukturtypen
Wie können Computer lernen?
 Wie können Computer lernen? Ringvorlesung Perspektiven der Informatik, 18.2.2008 Prof. Jun. Matthias Hein Department of Computer Science, Saarland University, Saarbrücken, Germany Inferenz I Wie lernen
Wie können Computer lernen? Ringvorlesung Perspektiven der Informatik, 18.2.2008 Prof. Jun. Matthias Hein Department of Computer Science, Saarland University, Saarbrücken, Germany Inferenz I Wie lernen
Klassifikation von Daten Einleitung
 Klassifikation von Daten Einleitung Lehrstuhl für Künstliche Intelligenz Institut für Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg (Lehrstuhl Informatik 8) Klassifikation von Daten Einleitung
Klassifikation von Daten Einleitung Lehrstuhl für Künstliche Intelligenz Institut für Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg (Lehrstuhl Informatik 8) Klassifikation von Daten Einleitung
Least Absolute Shrinkage And Seletion Operator (LASSO)
") Least Absolute Shrinkage And Seletion Operator (LASSO) Peter von Rohr 20 März 2017 Lineare Modell und Least Squares Als Ausgangspunkt haben wir das Lineare Modell und Least Squares y = Xβ + ɛ (1) ˆβ =
Least Absolute Shrinkage And Seletion Operator (LASSO) Peter von Rohr 20 März 2017 Lineare Modell und Least Squares Als Ausgangspunkt haben wir das Lineare Modell und Least Squares y = Xβ + ɛ (1) ˆβ =
5.4 Nächste-Nachbarn-Klassifikatoren
 5.4 Nächste-Nachbarn-Klassifikatoren Schrauben Nägel Klammern Neues Objekt Instanzbasiertes Lernen (instance based learning) Einfacher Nächster-Nachbar-Klassifikator: Zuordnung zu der Klasse des nächsten
5.4 Nächste-Nachbarn-Klassifikatoren Schrauben Nägel Klammern Neues Objekt Instanzbasiertes Lernen (instance based learning) Einfacher Nächster-Nachbar-Klassifikator: Zuordnung zu der Klasse des nächsten
Klassische Klassifikationsalgorithmen
 Klassische Klassifikationsalgorithmen Einführung in die Wissensverarbeitung 2 VO 708.560+ 1 UE 442.072 SS 2012 Institut für Signalverarbeitung und Sprachkommunikation TU Graz Inffeldgasse 12/1 www.spsc.tugraz.at
Klassische Klassifikationsalgorithmen Einführung in die Wissensverarbeitung 2 VO 708.560+ 1 UE 442.072 SS 2012 Institut für Signalverarbeitung und Sprachkommunikation TU Graz Inffeldgasse 12/1 www.spsc.tugraz.at
26. Der Gaußsche Integralsatz
 6 26. Der Gaußsche Integralsatz Im Folgenden sei eine k-dimensionale Untermannigfaltigkeit des R n und a 2. 26.1. Tangentialvektoren. Ein Vektor v 2 R n heißt Tangentialvektor an in a, falls es eine stetig
6 26. Der Gaußsche Integralsatz Im Folgenden sei eine k-dimensionale Untermannigfaltigkeit des R n und a 2. 26.1. Tangentialvektoren. Ein Vektor v 2 R n heißt Tangentialvektor an in a, falls es eine stetig
Kugelfunktionen und Kugelflächenfunktionen
 Kugelfunktionen und Kugelflächenfunktionen Wir beschreiben jetzt die Konstruktion von Orthonormalsystemen, die insbesondere in der Geophysik bedeutsam sind, wenn Effekte auf der Erdoberfläche, der Erdkugel
Kugelfunktionen und Kugelflächenfunktionen Wir beschreiben jetzt die Konstruktion von Orthonormalsystemen, die insbesondere in der Geophysik bedeutsam sind, wenn Effekte auf der Erdoberfläche, der Erdkugel
1 = z = y + e. Nabla ist ein Vektor, der als Komponenten keine Zahlen sondern Differentiationsbefehle
 Anmerkung zur Notation Im folgenden werden folgende Ausdrücke äquivalent benutzt: r = x y = x 1 x 2 z x 3 1 Der Vektoroperator Definition: := e x x + e y y + e z z = x y z. Nabla ist ein Vektor, der als
Anmerkung zur Notation Im folgenden werden folgende Ausdrücke äquivalent benutzt: r = x y = x 1 x 2 z x 3 1 Der Vektoroperator Definition: := e x x + e y y + e z z = x y z. Nabla ist ein Vektor, der als
Triangulierungen von Punktmengen und Polyedern
 Triangulierungen von Punktmengen und Polyedern Vorlesung im Sommersemester 2000 Technische Universität Berlin Jörg Rambau 17.05.2000 Sekundärpolytop und 6 bistellare Operationen In diesem Kapitel werden
Triangulierungen von Punktmengen und Polyedern Vorlesung im Sommersemester 2000 Technische Universität Berlin Jörg Rambau 17.05.2000 Sekundärpolytop und 6 bistellare Operationen In diesem Kapitel werden
5. Gitter, Gradienten, Interpolation Gitter. (Rezk-Salama, o.j.)
") 5. Gitter, Gradienten, Interpolation 5.1. Gitter (Rezk-Salama, o.j.) Gitterklassifikation: (Bartz 2005) (Rezk-Salama, o.j.) (Bartz 2005) (Rezk-Salama, o.j.) Allgemeine Gitterstrukturen: (Rezk-Salama, o.j.)
5. Gitter, Gradienten, Interpolation 5.1. Gitter (Rezk-Salama, o.j.) Gitterklassifikation: (Bartz 2005) (Rezk-Salama, o.j.) (Bartz 2005) (Rezk-Salama, o.j.) Allgemeine Gitterstrukturen: (Rezk-Salama, o.j.)
Syntaktische und Statistische Mustererkennung. Bernhard Jung
 Syntaktische und Statistische Mustererkennung VO 1.0 840.040 (UE 1.0 840.041) Bernhard Jung bernhard@jung.name http://bernhard.jung.name/vussme/ 1 Rückblick Distanzmaße, Metriken, Pattern Matching Entscheidungstabellen,
Syntaktische und Statistische Mustererkennung VO 1.0 840.040 (UE 1.0 840.041) Bernhard Jung bernhard@jung.name http://bernhard.jung.name/vussme/ 1 Rückblick Distanzmaße, Metriken, Pattern Matching Entscheidungstabellen,
Proseminar über multimediale Lineare Algebra und Analytische Geometrie
 Proseminar über multimediale Lineare Algebra und Analytische Geometrie Aufgabensteller: Dr. M. Kaplan Josef Lichtinger Montag, 1. Dezember 008 Proseminar WS0809 Inhaltsverzeichnis 1 Aufgabenstellung 3
Proseminar über multimediale Lineare Algebra und Analytische Geometrie Aufgabensteller: Dr. M. Kaplan Josef Lichtinger Montag, 1. Dezember 008 Proseminar WS0809 Inhaltsverzeichnis 1 Aufgabenstellung 3
Differentialgeometrie II (Flächentheorie) WS
 WS") Differentialgeometrie II (Flächentheorie) WS 2013-2014 Lektion 9 18. Dezember 2013 c Daria Apushkinskaya 2013 () Flächentheorie: Lektion 9 18. Dezember 2013 1 / 17 9. Einführung in der innere Geometrie
Differentialgeometrie II (Flächentheorie) WS 2013-2014 Lektion 9 18. Dezember 2013 c Daria Apushkinskaya 2013 () Flächentheorie: Lektion 9 18. Dezember 2013 1 / 17 9. Einführung in der innere Geometrie
Vorlesung Digitale Bildverarbeitung Sommersemester 2013
 Vorlesung Digitale Bildverarbeitung Sommersemester 2013 Sebastian Houben (Marc Schlipsing) Institut für Neuroinformatik Inhalt Crash-Course in Machine Learning Klassifikationsverfahren Grundsätzliches
Vorlesung Digitale Bildverarbeitung Sommersemester 2013 Sebastian Houben (Marc Schlipsing) Institut für Neuroinformatik Inhalt Crash-Course in Machine Learning Klassifikationsverfahren Grundsätzliches
Elektromagnetische Felder und Wellen
 Elektromagnetische Felder und Wellen Name: Vorname: Matrikelnummer: Aufgabe 1: Aufgabe 2: Aufgabe 3: Aufgabe 4: Aufgabe 5: Aufgabe 6: Aufgabe 7: Aufgabe 8: Aufgabe 9: Aufgabe 10: Aufgabe 11: Aufgabe 12:
Elektromagnetische Felder und Wellen Name: Vorname: Matrikelnummer: Aufgabe 1: Aufgabe 2: Aufgabe 3: Aufgabe 4: Aufgabe 5: Aufgabe 6: Aufgabe 7: Aufgabe 8: Aufgabe 9: Aufgabe 10: Aufgabe 11: Aufgabe 12: