Neuronale Netze. Volker Tresp
|
|
|
- Hansl Ritter
- vor 7 Jahren
- Abrufe
Transkript
1 Neuronale Netze Volker Tresp 1
2 Einführung Der Entwurf eines guten Klassifikators/Regressionsmodells hängt entscheidend von geeigneten Basisfunktion en ab Manchmal sind geeignete Basisfunktionen (Merkmalsextraktoren) anwendungsspezifisch nahe liegend Generische Basisfunktionen wie Polynome, RBFs haben das Problem, dass die benötigte Anzahl mit der Eingangsdimension rapide ansteigt ( Fluch der Dimension ) Es sollte doch möglich sein, geeignete Basisfunktionen zu erlernen Dies ist genau die Grundidee hinter Neuronalen Netzen Bei Neuronalen Netzen kommen ganz spezielle Basisfunktionen zum Einsatz: sigmoide Basisfunktionen 2
3 Neuronale Netze: wesentliche Vorteile Neuronale Netze sind universelle Approximatoren: jede stetige Funktion kann beliebig genau approximiert werden (mit genügend vielen sigmoiden Basisfunktionen) Entscheidender Vorteil Neuronaler Netze: mit wenigen Basisfunktionen einen sehr guten Fit zu erreichen bei gleichzeitiger hervorragender Generalisierungseigenschaften Besondere Approximationseigenschaften Neuronaler Netze in hohen Dimensionen 3
4 Flexiblere Modelle: Neuronale Netze Auch bei einem Neuronalen Netz besteht der Ausgang (bzw. die Aktivierungsfunktion h(x) im Falle eines Perzeptrons) aus der linear-gewichteten Summation von Basisfunktionen ŷ i = f(x i ) = H 1 h=0 w h sig(x i, v h ) Beachte, dass neben den Ausgangsgewichten w das Neuronale Netz auch innere Gewichte v h enthält 4
5 Neuronale Basisfunktionen Spezielle Form der Basisfunktionen z i = sig(x i, v h ) = sig mit sig(in) = M 1 1 j=0 1 + exp( in) Adaption der inneren Parameter v h,j der Basisfunktionen! v h,j x i,j 5
6 Harte und weiche (sigmoide) Übertragungsfunktion Zunächst wird die Aktivierungsfunktion als gewichtete Summe der Eingangsgrößen x i berechnet zu h(x i ) = M 1 j=0 w j x i,j (beachte: x i,0 = 1 ist ein konstanter Eingang, so dass w 0 dem Bias entspricht) Das sigmoide Neuron unterscheidet sich vom Perzeptron durch die Übertragungsfunktion Perceptron : ŷ i = sign(h(x i )) SigmoidesNeuron : ŷ i = sig(h(x i )) 6

7 Transferfunktion 7
8 Charakteristische Hyperebene Definiere die Hyperebene Identisch mit: sig M 1 j=0 M 1 j=0 v h,j x i,j = 0.5 v h,j x i,j = 0 Teppich über einer Stufe 8

9 Architektur eines Neuronalen Netzes 9
10 Varianten Will man einen binären Klassifikator lernen, dann wendet man manchmal die sigmoide Transferfunktion auch auf das Ausgabeneuron an und berechnet als Ausgang ŷ i = f(x i ) = sig(z i, w) Bei Problemen mit mehr Klassen, führt man mehrere Ausgangsneuronen ein. Zum Beispiel, um die K Ziffern zu klassifizieren ŷ i,k = f k (x i ) = sig(z i, w k ) k = 1, 2,..., K und man entscheidet sich für die Klasse l, so dass l = arg max k (ŷ i,k ) Das vorgestellte Neuronale Netz wird Multi Layer Perceptron (MLP) genannt 10

11 Architektur eines Neuronalen Netzes mit mehreren Ausgängen 11
12 Lernen mit mehreren sigmoiden Ausgängen Ziel ist wieder die Minimierung des quadratischen Fehlers über alle Ausgänge cost(w, v) = N K (y i,k f k (x i, w, v)) 2 i=1 k=1 Die least squares Lösung für v kann nicht geschlossen formuliert werden Typischerweise werden sowohl w als auch v durch Gradientenabstieg optimiert 12
13 Adaption der Ausgangsgewichte Für die Gradienten der Kostenfunktion nach den Ausgangsgewichten ergibt sich für Muster i: cost(x i, w, v) w k,h = 2δ i,k z i,h wobei δ i,k = sig (z i, w k )(y i,k f k (x i, w, v)) das zurückpropagierte Fehlersignal ist (error backpropagation). Entsprechende beim ADALINE ergibt sich für den musterbasierter Gradientenabstieg: w k,h w k,h + ηδ i,k z i,h 13
14 Ableitung der sigmoiden Übertragungsfunktion nach dem Argument Es lässt sich hierbei elegant schreiben sig (in) = exp( in) = sig(in)(1 sig(in)) (1 + exp( in)) 2 14
15 Adaption der Eingangsgewichte Für die Gradienten der Kostenfunktion nach den Eingangsgewichten ergibt sich für Muster i: cost(x i, w, v) v h,j = 2δ i,h x i,j wobei der zurückpropagierte Fehler ist K δ i,h = sig (x i, v h ) w k,h δ i,k k=1 Entsprechende beim ADALINE ergibt sich für den musterbasierter Gradientenabstieg: v h,j v h,j + ηδ i,h x i,j 15
16 Musterbasiertes Lernen Iteriere über alle Trainingsdaten sei x i der aktuelle Datenpunkt x i wird angelegt und man berechnet z i, y i (Vorwärtspropagation ) Durch Fehler-Rückpropagation (error backpropagation) werden die δ i,h, δ i,k berechnet Adaptiere w k,h w k,h + ηδ i,k z i,h Alle Operationen lokal: biologisch plausibel v h,j v h,j + ηδ i,h x i,j 16
17 Neuronales Netz und Überanpassung Im Vergleich zu konventionellen statistischen Modellen hat ein Neuronales Netz sehr viele freie Parameter, was zu Überanpassung führen kann Die beiden gebräuchlichsten Methoden damit umzugehen sind Regularisierung und Stopped-Training Wir diskutieren zunächst Regularisierung 17
18 Neuronale Netze: Regularisierung Wir führen Regularisierungsterme ein und erhalten cost pen (w, v) = N K i=1 k=1 M φ 1 (y i,k f k (x i, w, v) 2 +λ 1 h=0 w 2 h +λ 2 H 1 h=0 M j=0 v 2 h,j Die Adaptionsregeln ändern sich zu (mit weight decay term) w k,h w k,h + η ( δ i,k z i,h λ 1 w k,h ) v h,j v h,j + η ( δ i,h x i,j λ 2 v h,j ) 18
19 Künstliches Beispiel Daten von zwei Klassen (rote, grüne Kringel) werden generiert Die Klassen überlappen Die optimale Klassifikationsgrenze ist gestrichelt gezeigt Beim Neuronalen Netz ohne Regularisierung sieht man Überanpassung (stetige Kurve) 19

20
21 Künstliches Beispiel mit Regularisierung Mit Regularisierung (λ 1 = λ 2 = 0.2) werden die wahren Klassengrenzen besser getroffen Der Trainingsfehler ist beim unregularisierten Netz kleiner, der Testfehler ist allerdings beim regularisierten Netz kleiner! 20
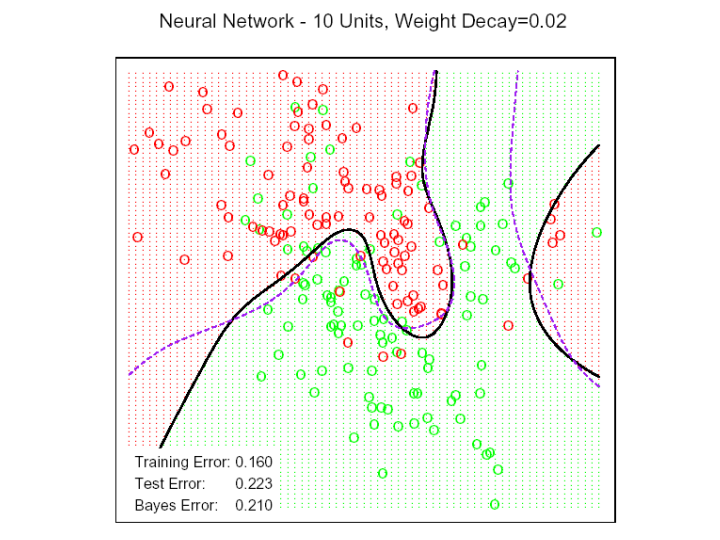
22
23 Optimaler Regularisierungsparameter Der Regularisierungsparameter wird zwischen 0 und 0.15 variiert Die vertikale Axe zeigt den Testfehler für viele unabhängige Experimente Der beste Testfehler wird bei einem Regularisierungsparameter von 0.07 erzielt Die Variation im Testfehler wird mit größerem Regularisierungsparameter geringer 21
24

25 Erkennung handgeschriebener Ziffern 22
26 Erkennung handgeschriebener Ziffern mit Neuronalen Netzen Im Beispiel hier: grauwertige Bilder; 320 Ziffern im Trainingssatz, 160 Ziffern im Testsatz Net-1: Keine versteckte Schicht: entspricht in etwa 10 Perzeptrons, eines für jede Ziffer Net-2: Eine versteckte Schicht mit 12 Knoten; voll-vernetzt (normales Neuronales Netz mit einer versteckten Schicht) 23
27
28 Neuronale Netze mit lokaler Verbindungsstruktur: Net-3 Bei weiteren Varianten wurde die Komplexität anwendungsspezifisch eingeschränkt Net-3: Zwei versteckte Schichten mit lokaler Verbindungsstruktur: orientiert an den lokalen rezeptiven Feldern im Gehirn Jedes der 8 8 Neuronen in der ersten versteckten Schicht ist nur mit 3 3 Eingangsneuronen verbunden aus einem rezeptivem Feld verbunden In der zweiten versteckten Schicht ist jedes der 4 4 Neuronen mit 5 5 Neuronen der ersten versteckten Schicht verbunden Net-3 hat weniger als 50% der Gewichte als Net-2 aber mehr Neuronen 24
29
30 Neuronale Netze mit Weight-Sharing (Net-4) Net-4: Zwei versteckte Schichten mit lokaler Verbindungsstruktur und weight-sharing Alle rezeptiven Felder im linken 8 8 Block haben die gleichen Gewichte; ebenso alle rezeptiven Felder im rechten 8 8 Block Der 4 4 Block in der zweiten versteckten Schicht wie zuvor 25
31
32 Neuronale Netze mit Weight-Sharing (Net-5) Net-5: Zwei versteckte Schichten mit lokaler Verbindungsstruktur und zwei Ebenen von weight-sharing 26
33
34 Lernkurven Ein Trainingsepoch bezeichnet den einmaligen Durchgang durch alle Daten Die nächste Abbildung zeigt die Performanz auf Testdaten Net-1: Man sieht die Überanpassung mit zunehmenden Trainingsiterationen Net-5: Zeigt die besten Resultate und zeigt keine Überanpassung 27
35
36 Statistiken Net-5 hat die beste Performanz. Die Anzahl der freien Parameter (1060) ist viel geringer als die Anzahl der Parameter (5194) 28
37 Regularisierung mit Stopped-Training In der nächsten Abbildung sieht man typische Verläufe für Trainingssatz und Testsatz als Funktion der Trainingsiterationen Wie zu erwarten nimmt der Trainingsfehler mit der Trainingszeit stetig ab Wie zu erwarten nimmt zunächst der Testfehler ebenso ab; etwas überraschend gibt es ein Minimum und der Testfehler nimmt dann wieder zu Erklärung: Im Laufe des Trainings nehmen die Freiheitsgrade im Neuronalen Netz zu; wenn zu viele Freiheitsgrade zur Verfügung stehen, sieht man Überanpassung Man kann ein Neuronales Netz dadurch sinnvoll regularisieren, in dem man das Training rechtzeitig beendet (Regularisierung durch Stopped-Training) 29
38

39
40 Optimierung der Lernrate η Die Konvergenz kann durch die Größe von η beeinflusst werden In der nächsten Abbildung sieht man, dass wenn die Lernrate zu klein gewählt wird, es sehr lange dauern kann, bis das Optimum erreicht wird Wird die Lernrate zu gross gewählt, sieht an oszillatorisches Verhalten oder sogar instabiles Verhalten 30
41
42 Zusammenfassung Neuronale Netze sind sehr leistungsfähig mit hoher Performanz Das Training ist aufwendig, aber man kann mit einiger Berechtigung sagen, dass das Neuronale Netz tatsächlich etwas lernt, nämlich die optimale Repräsentation der Eingangsdaten in der versteckten Schicht Die Vorhersage ist schnell berechenbar Neuronale Netze sind universelle Approximatoren Neuronale Netze besitzen sehr gute Approximationseigenschaften Nachteil: das Training hat etwas von einer Kunst; eine Reihe von Größen müssen bestimmt werden (Anzahl der versteckten Knoten, Lernraten, Regularisierungsparameter,...) Nachteil: Ein trainiertes Netz stellt ein lokales Optimum dar; Nicht-Eindeutigkeit der Lösung 31
43 Aber: In einem neueren Benchmarktest hat ein (Bayes sches) Neuronales Netz alle konkurrierenden Ansätze geschlagen!
44 Zeitreihenmodellierung Die nächste Abbildung zeigt eine Finanzdatenzeitreihe (DAX) Andere Zeitreihen von Interesse: Energiepreise, Stromverbrauch, Gasverbrauch,... 32
45
46 Neuronale Netze in der Zeitreihenmodellierung Sei x t, t = 1, 2,... die zeitdiskrete Zeitreihe von Interesse (Beispiel: DAX) Sei u t, t = 1, 2,... eine weitere Zeitreihe, die Informationen über x t liefert (Beispiel: Dow Jones) Der Einfachheit halber nehmen wir an, dass x t und u t skalar sind; Ziel ist die Vorhersage des nächsten Werts der Zeitreihe Wir nehmen ein System an der Form x t = f(x t 1,..., x t Mx, u t 1,..., u t Mu ) + ɛ t mit i.i.d. Zufallszahlen ɛ t, t = 1, 2,.... Diese modellieren unbekannte Störgrößen 33
47 Neuronale Netze in der Zeitreihenmodellierung (2) Wir modellieren durch ein Neuronales Netz f(x t 1,..., x t Mx, u t 1,..., u t Mu ) f NN (x t 1,..., x t Mx, u t 1,..., u t Mu ) und erhalten als Kostenfunktion cost = N (x t f NN (x t 1,..., x t Mx, u t 1,..., u t Mu )) 2 t=1 Das Neuronale Netz kann nun wie zuvor mit Backpropagation trainiert werden Das beschriebene Modell ist ein NARX Modell: Nonlinear Auto Regressive Model with external inputs. Andere Bezeichnung: TDNN (time-delay neural network) 34
48 Rekurrente Neuronale Netze Wenn x t nicht direkt gemessen werden kann, sondern nur verrauschte Messungen zur Verfügung stehen (Verallgemeinerung des linearen Kalman Filters), reicht einfaches Backpropagation nicht mehr aus, sondern man muss komplexere Lernverfahren verwenden: Backpropagation through time (BPTT) Real-Time Recurrent Learning (RTRL) Dynamic Backpropagation 35
49 APPENDIX 36
50 Appendix: Approximationsgenauigkeit Neuronaler Netze Dies ist der entscheidende Punkt: wie viele innere Knoten sind notwendig, um eine vorgegebene Approximationsgenauigkeit zu erreichen? Die Anzahle der inneren Knoten, die benötigt werden, um eine vorgegebene Approximationsgenauigkeit zu erreichen, hängt von der Komplexität der zu approximierenden Funktion ab. Barron führt für das Maß der Komplexität der zu approximierenden Funktion f(x) die Größe C f ein, welche definiert ist als R d w f(w) dw = C f, wobei f(w) die Fouriertransformation von f(x) ist. C f bestraft im Besonderen hohe Frequenzanteile. Die Aufgabe des Neuronalen Netzes ist es, eine Funktion f(x) mit Komplexitätsmaß C f zu approximieren. 37
51 Der Eingangsvektor x ist aus R d, das Neuronale Netz besitzt n innere Knoten und die Netzapproximation bezeichnen wir mit f n (x) Wir definieren als Approximationsfehler AF den mittleren quadratischen Fehler zwischen f(x) und f n (x) AF = (f(x) f n (x)) 2 µ(dx). B r (1) µ ist ein beliebiges Wahrscheinlichkeitsmaß auf der Kugel B r = {x : x r} mit Radius r > 0 Barron hat nun gezeigt, dass für jede Funktion, für welche C f endlich ist und für jedes n 1 ein Neuronales Netz mit einer inneren Schicht existiert, so dass für den nach letzten Gleichung definierten Approximationsfehler AF Neur gilt AF Neur (2rC f) 2. (2) n Dieses überraschende Resultat zeigt, dass die Anzahl der inneren Knoten unabhängig von der Dimension d des Eingangsraumes ist.
52 Man beachte, dass für konventionelle Approximatoren mit festen Basisfunktionen der Approximationsfehler AF kon exponentiell mit der Dimension ansteigt : AF kon (1/n) 2/d. Für gewisse Funktionenklassen kann C f exponentiell schnell mit der Dimension anwachsen, und es wäre somit nicht viel gewonnen. Barron zeigt jedoch, dass C f für große Klassen von Funktionen nur recht langsam mit der Dimension (z.b. proportional) wächst. Quellen: Tresp, V. (1995). Die besonderen Eigenschaften Neuronaler Netze bei der Approximation von Funktionen. Künstliche Intelligenz, Nr. 4. A. Barron. Universal Approximation Bounds for Superpositions of a Sigmoidal Function. IEEE Trans. Information Theory, Vol. 39, Nr. 3, Seite , Mai 1993.
Neuronale Netze. Volker Tresp
 Neuronale Netze Volker Tresp 1 Einführung Der Entwurf eines guten Klassifikators/Regressionsmodells hängt entscheidend von geeigneten Basisfunktion en ab Manchmal sind geeignete Basisfunktionen (Merkmalsextraktoren)
Neuronale Netze Volker Tresp 1 Einführung Der Entwurf eines guten Klassifikators/Regressionsmodells hängt entscheidend von geeigneten Basisfunktion en ab Manchmal sind geeignete Basisfunktionen (Merkmalsextraktoren)
Basisfunktionen. und Neuronale Netze. Volker Tresp
 Basisfunktionen und Neuronale Netze Volker Tresp 1 I am an AI optimist. We ve got a lot of work in machine learning, which is sort of the polite term for AI nowadays because it got so broad that it s not
Basisfunktionen und Neuronale Netze Volker Tresp 1 I am an AI optimist. We ve got a lot of work in machine learning, which is sort of the polite term for AI nowadays because it got so broad that it s not
Lineare Regression. Volker Tresp
 Lineare Regression Volker Tresp 1 Die Lernmaschine: Das lineare Modell / ADALINE Wie beim Perzeptron wird zunächst die Aktivierungsfunktion gewichtete Summe der Eingangsgrößen x i berechnet zu h i = M
Lineare Regression Volker Tresp 1 Die Lernmaschine: Das lineare Modell / ADALINE Wie beim Perzeptron wird zunächst die Aktivierungsfunktion gewichtete Summe der Eingangsgrößen x i berechnet zu h i = M
Die Datenmatrix für Überwachtes Lernen
 Die Datenmatrix für Überwachtes Lernen X j j-te Eingangsvariable X = (X 0,..., X M 1 ) T Vektor von Eingangsvariablen M Anzahl der Eingangsvariablen N Anzahl der Datenpunkte Y Ausgangsvariable x i = (x
Die Datenmatrix für Überwachtes Lernen X j j-te Eingangsvariable X = (X 0,..., X M 1 ) T Vektor von Eingangsvariablen M Anzahl der Eingangsvariablen N Anzahl der Datenpunkte Y Ausgangsvariable x i = (x
Optimal-trennende Hyperebenen und die Support Vector Machine. Volker Tresp
 Optimal-trennende Hyperebenen und die Support Vector Machine Volker Tresp 1 (Vapnik s) Optimal-trennende Hyperebenen (Optimal Separating Hyperplanes) Wir betrachten wieder einen linearen Klassifikator
Optimal-trennende Hyperebenen und die Support Vector Machine Volker Tresp 1 (Vapnik s) Optimal-trennende Hyperebenen (Optimal Separating Hyperplanes) Wir betrachten wieder einen linearen Klassifikator
6.4 Neuronale Netze zur Verarbeitung von Zeitreihen
 6.4 Neuronale Netze zur Verarbeitung von Zeitreihen Aufgabe: Erlernen einer Zeitreihe x(t + 1) = f(x(t), x(t 1), x(t 2),...) Idee: Verzögerungskette am Eingang eines neuronalen Netzwerks, z.b. eines m-h-1
6.4 Neuronale Netze zur Verarbeitung von Zeitreihen Aufgabe: Erlernen einer Zeitreihe x(t + 1) = f(x(t), x(t 1), x(t 2),...) Idee: Verzögerungskette am Eingang eines neuronalen Netzwerks, z.b. eines m-h-1
Mustererkennung: Neuronale Netze. D. Schlesinger ()Mustererkennung: Neuronale Netze 1 / 12
Mustererkennung: Neuronale Netze 1 / 12") Mustererkennung: Neuronale Netze D. Schlesinger ()Mustererkennung: Neuronale Netze 1 / 12 Feed-Forward Netze y 1 y 2 y m...... x 1 x 2 x n Output Schicht i max... Zwischenschicht i... Zwischenschicht 1
Mustererkennung: Neuronale Netze D. Schlesinger ()Mustererkennung: Neuronale Netze 1 / 12 Feed-Forward Netze y 1 y 2 y m...... x 1 x 2 x n Output Schicht i max... Zwischenschicht i... Zwischenschicht 1
Hannah Wester Juan Jose Gonzalez
 Neuronale Netze Supervised Learning Proseminar Kognitive Robotik (SS12) Hannah Wester Juan Jose Gonzalez Kurze Einführung Warum braucht man Neuronale Netze und insbesondere Supervised Learning? Das Perzeptron
Neuronale Netze Supervised Learning Proseminar Kognitive Robotik (SS12) Hannah Wester Juan Jose Gonzalez Kurze Einführung Warum braucht man Neuronale Netze und insbesondere Supervised Learning? Das Perzeptron
Neuronale Netze in der Phonetik: Feed-Forward Netze. Pfitzinger, Reichel IPSK, LMU München {hpt 14.
 Neuronale Netze in der Phonetik: Feed-Forward Netze Pfitzinger, Reichel IPSK, LMU München {hpt reichelu}@phonetik.uni-muenchen.de 14. Juli 2006 Inhalt Typisierung nach Aktivierungsfunktion Lernen in einschichtigen
Neuronale Netze in der Phonetik: Feed-Forward Netze Pfitzinger, Reichel IPSK, LMU München {hpt reichelu}@phonetik.uni-muenchen.de 14. Juli 2006 Inhalt Typisierung nach Aktivierungsfunktion Lernen in einschichtigen
Wissensentdeckung in Datenbanken
 Wissensentdeckung in Datenbanken Deep Learning (II) Nico Piatkowski und Uwe Ligges Informatik Künstliche Intelligenz 25.07.2017 1 von 14 Überblick Faltungsnetze Dropout Autoencoder Generative Adversarial
Wissensentdeckung in Datenbanken Deep Learning (II) Nico Piatkowski und Uwe Ligges Informatik Künstliche Intelligenz 25.07.2017 1 von 14 Überblick Faltungsnetze Dropout Autoencoder Generative Adversarial
Grundlagen zu neuronalen Netzen. Kristina Tesch
 Grundlagen zu neuronalen Netzen Kristina Tesch 03.05.2018 Gliederung 1. Funktionsprinzip von neuronalen Netzen 2. Das XOR-Beispiel 3. Training des neuronalen Netzes 4. Weitere Aspekte Kristina Tesch Grundlagen
Grundlagen zu neuronalen Netzen Kristina Tesch 03.05.2018 Gliederung 1. Funktionsprinzip von neuronalen Netzen 2. Das XOR-Beispiel 3. Training des neuronalen Netzes 4. Weitere Aspekte Kristina Tesch Grundlagen
Neuronale Netze. Anna Wallner. 15. Mai 2007
 5. Mai 2007 Inhalt : Motivation Grundlagen Beispiel: XOR Netze mit einer verdeckten Schicht Anpassung des Netzes mit Backpropagation Probleme Beispiel: Klassifikation handgeschriebener Ziffern Rekurrente
5. Mai 2007 Inhalt : Motivation Grundlagen Beispiel: XOR Netze mit einer verdeckten Schicht Anpassung des Netzes mit Backpropagation Probleme Beispiel: Klassifikation handgeschriebener Ziffern Rekurrente
Künstliche Neuronale Netze
 Inhalt (Biologische) Neuronale Netze Schwellenwertelemente Allgemein Neuronale Netze Mehrschichtiges Perzeptron Weitere Arten Neuronaler Netze 2 Neuronale Netze Bestehend aus vielen Neuronen(menschliches
Inhalt (Biologische) Neuronale Netze Schwellenwertelemente Allgemein Neuronale Netze Mehrschichtiges Perzeptron Weitere Arten Neuronaler Netze 2 Neuronale Netze Bestehend aus vielen Neuronen(menschliches
Lineare Klassifikatoren. Volker Tresp
 Lineare Klassifikatoren Volker Tresp 1 Einführung Lineare Klassifikatoren trennen Klassen durch eine lineare Hyperebene (genauer: affine Menge) In hochdimensionalen Problemen trennt schon eine lineare
Lineare Klassifikatoren Volker Tresp 1 Einführung Lineare Klassifikatoren trennen Klassen durch eine lineare Hyperebene (genauer: affine Menge) In hochdimensionalen Problemen trennt schon eine lineare
Klassifikationsverfahren und Neuronale Netze
 Klassifikationsverfahren und Neuronale Netze Hauptseminar - Methoden der experimentellen Teilchenphysik Thomas Keck 9.12.2011 KIT Universität des Landes Baden-Württemberg und nationales Forschungszentrum
Klassifikationsverfahren und Neuronale Netze Hauptseminar - Methoden der experimentellen Teilchenphysik Thomas Keck 9.12.2011 KIT Universität des Landes Baden-Württemberg und nationales Forschungszentrum
Wir haben in den vorherigen Kapiteln verschiedene Verfahren zur Regression und Klassifikation kennengelernt (z.b. lineare Regression, SVMs)
") 6. Neuronale Netze Motivation Wir haben in den vorherigen Kapiteln verschiedene Verfahren zur Regression und Klassifikation kennengelernt (z.b. lineare Regression, SVMs) Abstrakt betrachtet sind alle diese
6. Neuronale Netze Motivation Wir haben in den vorherigen Kapiteln verschiedene Verfahren zur Regression und Klassifikation kennengelernt (z.b. lineare Regression, SVMs) Abstrakt betrachtet sind alle diese
Praktische Optimierung
 Wintersemester 27/8 Praktische Optimierung (Vorlesung) Prof. Dr. Günter Rudolph Fakultät für Informatik Lehrstuhl für Algorithm Engineering Metamodellierung Inhalt Multilayer-Perceptron (MLP) Radiale Basisfunktionsnetze
Wintersemester 27/8 Praktische Optimierung (Vorlesung) Prof. Dr. Günter Rudolph Fakultät für Informatik Lehrstuhl für Algorithm Engineering Metamodellierung Inhalt Multilayer-Perceptron (MLP) Radiale Basisfunktionsnetze
Das Perzeptron. Volker Tresp
 Das Perzeptron Volker Tresp 1 Einführung Das Perzeptron war eines der ersten ernstzunehmenden Lernmaschinen Die wichtigsten Elemente Sammlung und Vorverarbeitung der Trainingsdaten Wahl einer Klasse von
Das Perzeptron Volker Tresp 1 Einführung Das Perzeptron war eines der ersten ernstzunehmenden Lernmaschinen Die wichtigsten Elemente Sammlung und Vorverarbeitung der Trainingsdaten Wahl einer Klasse von
Nichtlineare Klassifikatoren
 Nichtlineare Klassifikatoren Mustererkennung und Klassifikation, Vorlesung No. 11 1 M. O. Franz 12.01.2008 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht
Nichtlineare Klassifikatoren Mustererkennung und Klassifikation, Vorlesung No. 11 1 M. O. Franz 12.01.2008 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht
Neural Networks: Architectures and Applications for NLP
 Neural Networks: Architectures and Applications for NLP Session 02 Julia Kreutzer 8. November 2016 Institut für Computerlinguistik, Heidelberg 1 Overview 1. Recap 2. Backpropagation 3. Ausblick 2 Recap
Neural Networks: Architectures and Applications for NLP Session 02 Julia Kreutzer 8. November 2016 Institut für Computerlinguistik, Heidelberg 1 Overview 1. Recap 2. Backpropagation 3. Ausblick 2 Recap
Thema 3: Radiale Basisfunktionen und RBF- Netze
 Proseminar: Machine Learning 10 Juli 2006 Thema 3: Radiale Basisfunktionen und RBF- Netze Barbara Rakitsch Zusammenfassung: Aufgabe dieses Vortrags war es, die Grundlagen der RBF-Netze darzustellen 1 Einführung
Proseminar: Machine Learning 10 Juli 2006 Thema 3: Radiale Basisfunktionen und RBF- Netze Barbara Rakitsch Zusammenfassung: Aufgabe dieses Vortrags war es, die Grundlagen der RBF-Netze darzustellen 1 Einführung
Konzepte der AI Neuronale Netze
 Konzepte der AI Neuronale Netze Franz Wotawa Institut für Informationssysteme, Database and Artificial Intelligence Group, Technische Universität Wien Email: wotawa@dbai.tuwien.ac.at Was sind Neuronale
Konzepte der AI Neuronale Netze Franz Wotawa Institut für Informationssysteme, Database and Artificial Intelligence Group, Technische Universität Wien Email: wotawa@dbai.tuwien.ac.at Was sind Neuronale
Wissensentdeckung in Datenbanken
 Wissensentdeckung in Datenbanken Deep Learning Nico Piatkowski und Uwe Ligges Informatik Künstliche Intelligenz 20.07.2017 1 von 11 Überblick Künstliche Neuronale Netze Motivation Formales Modell Aktivierungsfunktionen
Wissensentdeckung in Datenbanken Deep Learning Nico Piatkowski und Uwe Ligges Informatik Künstliche Intelligenz 20.07.2017 1 von 11 Überblick Künstliche Neuronale Netze Motivation Formales Modell Aktivierungsfunktionen
RL und Funktionsapproximation
 RL und Funktionsapproximation Bisher sind haben wir die Funktionen V oder Q als Tabellen gespeichert. Im Allgemeinen sind die Zustandsräume und die Zahl der möglichen Aktionen sehr groß. Deshalb besteht
RL und Funktionsapproximation Bisher sind haben wir die Funktionen V oder Q als Tabellen gespeichert. Im Allgemeinen sind die Zustandsräume und die Zahl der möglichen Aktionen sehr groß. Deshalb besteht
Neuronale Netze. Gehirn: ca Neuronen. stark vernetzt. Schaltzeit ca. 1 ms (relativ langsam, vgl. Prozessor)
") 29 Neuronale Netze Gehirn: ca. 10 11 Neuronen stark vernetzt Schaltzeit ca. 1 ms (relativ langsam, vgl. Prozessor) Mustererkennung in 0.1s 100 Schritte Regel 30 Was ist ein künstl. neuronales Netz? Ein
29 Neuronale Netze Gehirn: ca. 10 11 Neuronen stark vernetzt Schaltzeit ca. 1 ms (relativ langsam, vgl. Prozessor) Mustererkennung in 0.1s 100 Schritte Regel 30 Was ist ein künstl. neuronales Netz? Ein
Neuronale Netze. Christian Böhm.
 Ludwig Maximilians Universität München Institut für Informatik Forschungsgruppe Data Mining in der Medizin Neuronale Netze Christian Böhm http://dmm.dbs.ifi.lmu.de/dbs 1 Lehrbuch zur Vorlesung Lehrbuch
Ludwig Maximilians Universität München Institut für Informatik Forschungsgruppe Data Mining in der Medizin Neuronale Netze Christian Böhm http://dmm.dbs.ifi.lmu.de/dbs 1 Lehrbuch zur Vorlesung Lehrbuch
Adaptive Systeme. Mehrere Neuronen, Assoziative Speicher und Mustererkennung. Prof. Dr. rer. nat. Nikolaus Wulff
 Adaptive Systeme Mehrere Neuronen, Assoziative Speicher und Mustererkennung Prof. Dr. rer. nat. Nikolaus Wulff Modell eines Neuron x x 2 x 3. y y= k = n w k x k x n Die n binären Eingangssignale x k {,}
Adaptive Systeme Mehrere Neuronen, Assoziative Speicher und Mustererkennung Prof. Dr. rer. nat. Nikolaus Wulff Modell eines Neuron x x 2 x 3. y y= k = n w k x k x n Die n binären Eingangssignale x k {,}
Weitere Untersuchungen hinsichtlich der Anwendung von KNN für Solvency 2. Tom Schelthoff
 Weitere Untersuchungen hinsichtlich der Anwendung von KNN für Solvency 2 Tom Schelthoff 30.11.2018 Inhaltsverzeichnis Deep Learning Seed-Stabilität Regularisierung Early Stopping Dropout Batch Normalization
Weitere Untersuchungen hinsichtlich der Anwendung von KNN für Solvency 2 Tom Schelthoff 30.11.2018 Inhaltsverzeichnis Deep Learning Seed-Stabilität Regularisierung Early Stopping Dropout Batch Normalization
kurze Wiederholung der letzten Stunde: Neuronale Netze Dipl.-Inform. Martin Lösch (0721) Dipl.-Inform.
 Dipl.-Inform.") kurze Wiederholung der letzten Stunde: Neuronale Netze martin.loesch@kit.edu (0721) 608 45944 Labor Wissensrepräsentation Aufgaben der letzten Stunde Übersicht Neuronale Netze Motivation Perzeptron Multilayer
kurze Wiederholung der letzten Stunde: Neuronale Netze martin.loesch@kit.edu (0721) 608 45944 Labor Wissensrepräsentation Aufgaben der letzten Stunde Übersicht Neuronale Netze Motivation Perzeptron Multilayer
Rekurrente / rückgekoppelte neuronale Netzwerke
 Rekurrente / rückgekoppelte neuronale Netzwerke Forschungsseminar Deep Learning 2018 Universität Leipzig 12.01.2018 Vortragender: Andreas Haselhuhn Neuronale Netzwerke Neuron besteht aus: Eingängen Summenfunktion
Rekurrente / rückgekoppelte neuronale Netzwerke Forschungsseminar Deep Learning 2018 Universität Leipzig 12.01.2018 Vortragender: Andreas Haselhuhn Neuronale Netzwerke Neuron besteht aus: Eingängen Summenfunktion
Technische Universität Berlin Fakultät IV Elektrotechnik und Informatik. 8. Aufgabenblatt
 Technische Universität Berlin Fakultät IV Elektrotechnik und Informatik Künstliche Intelligenz: Grundlagen und Anwendungen Albayrak, Fricke (AOT) Oer, Thiel (KI) Wintersemester 2014 / 2015 8. Aufgabenblatt
Technische Universität Berlin Fakultät IV Elektrotechnik und Informatik Künstliche Intelligenz: Grundlagen und Anwendungen Albayrak, Fricke (AOT) Oer, Thiel (KI) Wintersemester 2014 / 2015 8. Aufgabenblatt
Der Backpropagation-Algorithmus als Beispiel für Lernalgorithmen künstlicher neuronaler Netze Reinhard Eck 1
 Der Backpropagation-Algorithmus als Beispiel für Lernalgorithmen künstlicher neuronaler Netze 2.04.2006 Reinhard Eck Was reizt Informatiker an neuronalen Netzen? Wie funktionieren Gehirne höherer Lebewesen?
Der Backpropagation-Algorithmus als Beispiel für Lernalgorithmen künstlicher neuronaler Netze 2.04.2006 Reinhard Eck Was reizt Informatiker an neuronalen Netzen? Wie funktionieren Gehirne höherer Lebewesen?
(hoffentlich kurze) Einführung: Neuronale Netze. Dipl.-Inform. Martin Lösch. (0721) Dipl.-Inform.
 Einführung: Neuronale Netze. Dipl.-Inform. Martin Lösch. (0721) Dipl.-Inform.") (hoffentlich kurze) Einführung: martin.loesch@kit.edu (0721) 608 45944 Überblick Einführung Perzeptron Multi-layer Feedforward Neural Network MLNN in der Anwendung 2 EINFÜHRUNG 3 Gehirn des Menschen Vorbild
(hoffentlich kurze) Einführung: martin.loesch@kit.edu (0721) 608 45944 Überblick Einführung Perzeptron Multi-layer Feedforward Neural Network MLNN in der Anwendung 2 EINFÜHRUNG 3 Gehirn des Menschen Vorbild
Studiengang Simulation Technology
 1. Institut für Theoretische Physik Studiengang Simulation Technology Bachelorarbeit Selbstoptimierende Neuronale Netze zur Klassifizierung von Reaktanden und Produkten in der Reaktionsdynamik Erstprüfer
1. Institut für Theoretische Physik Studiengang Simulation Technology Bachelorarbeit Selbstoptimierende Neuronale Netze zur Klassifizierung von Reaktanden und Produkten in der Reaktionsdynamik Erstprüfer
kurze Wiederholung der letzten Stunde: Neuronale Netze Dipl.-Inform. Martin Lösch (0721) Dipl.-Inform.
 Dipl.-Inform.") kurze Wiederholung der letzten Stunde: Neuronale Netze martin.loesch@kit.edu (0721) 608 45944 Labor Wissensrepräsentation Neuronale Netze Motivation Perzeptron Übersicht Multilayer Neural Networks Grundlagen
kurze Wiederholung der letzten Stunde: Neuronale Netze martin.loesch@kit.edu (0721) 608 45944 Labor Wissensrepräsentation Neuronale Netze Motivation Perzeptron Übersicht Multilayer Neural Networks Grundlagen
Symbolumwandlung der Kernfunktionen
 91 Symbolumwandlung der Kernfunktionen Positiv definierte, konvexe Kernfunktionen können als Fuzzy-Mengen betrachtet werden. z.b.: µ B (x) = 1 1 + ( x 50 10 ) 2 92 ZF-Funktionen 1 1 0-5 0 5 (a) 1 0-5 0
91 Symbolumwandlung der Kernfunktionen Positiv definierte, konvexe Kernfunktionen können als Fuzzy-Mengen betrachtet werden. z.b.: µ B (x) = 1 1 + ( x 50 10 ) 2 92 ZF-Funktionen 1 1 0-5 0 5 (a) 1 0-5 0
Automatische Spracherkennung
 Automatische Spracherkennung 3 Vertiefung: Drei wichtige Algorithmen Teil 3 Soweit vorhanden ist der jeweils englische Fachbegriff, so wie er in der Fachliteratur verwendet wird, in Klammern angegeben.
Automatische Spracherkennung 3 Vertiefung: Drei wichtige Algorithmen Teil 3 Soweit vorhanden ist der jeweils englische Fachbegriff, so wie er in der Fachliteratur verwendet wird, in Klammern angegeben.
Künstliche neuronale Netze
 Künstliche neuronale Netze Eigenschaften neuronaler Netze: hohe Arbeitsgeschwindigkeit durch Parallelität, Funktionsfähigkeit auch nach Ausfall von Teilen des Netzes, Lernfähigkeit, Möglichkeit zur Generalisierung
Künstliche neuronale Netze Eigenschaften neuronaler Netze: hohe Arbeitsgeschwindigkeit durch Parallelität, Funktionsfähigkeit auch nach Ausfall von Teilen des Netzes, Lernfähigkeit, Möglichkeit zur Generalisierung
Modell Komplexität und Generalisierung
 Modell Komplexität und Generalisierung Christian Herta November, 2013 1 von 41 Christian Herta Bias-Variance Lernziele Konzepte des maschinellen Lernens Targetfunktion Overtting, Undertting Generalisierung
Modell Komplexität und Generalisierung Christian Herta November, 2013 1 von 41 Christian Herta Bias-Variance Lernziele Konzepte des maschinellen Lernens Targetfunktion Overtting, Undertting Generalisierung
Was bisher geschah Künstliche Neuronen: Mathematisches Modell und Funktionen: Eingabe-, Aktivierungs- Ausgabefunktion Boolesche oder reelle Ein-und
 Was bisher geschah Künstliche Neuronen: Mathematisches Modell und Funktionen: Eingabe-, Aktivierungs- Ausgabefunktion Boolesche oder reelle Ein-und Ausgaben Aktivierungsfunktionen: Schwellwertfunktion
Was bisher geschah Künstliche Neuronen: Mathematisches Modell und Funktionen: Eingabe-, Aktivierungs- Ausgabefunktion Boolesche oder reelle Ein-und Ausgaben Aktivierungsfunktionen: Schwellwertfunktion
6.2 Feed-Forward Netze
 6.2 Feed-Forward Netze Wir haben gesehen, dass wir mit neuronalen Netzen bestehend aus einer oder mehreren Schichten von Perzeptren beispielsweise logische Funktionen darstellen können Nun betrachten wir
6.2 Feed-Forward Netze Wir haben gesehen, dass wir mit neuronalen Netzen bestehend aus einer oder mehreren Schichten von Perzeptren beispielsweise logische Funktionen darstellen können Nun betrachten wir
Analyse komplexer Szenen mit Hilfe von Convolutional Neural Networks
 Analyse komplexer Szenen mit Hilfe von Convolutional Anwendungen 1 Vitalij Stepanov HAW-Hamburg 24 November 2011 2 Inhalt Motivation Alternativen Problemstellung Anforderungen Lösungsansätze Zielsetzung
Analyse komplexer Szenen mit Hilfe von Convolutional Anwendungen 1 Vitalij Stepanov HAW-Hamburg 24 November 2011 2 Inhalt Motivation Alternativen Problemstellung Anforderungen Lösungsansätze Zielsetzung
Rekurrente Neuronale Netze
 Rekurrente Neuronale Netze Gregor Mitscha-Baude May 9, 2016 Motivation Standard neuronales Netz: Fixe Dimensionen von Input und Output! Motivation In viele Anwendungen variable Input/Output-Länge. Spracherkennung
Rekurrente Neuronale Netze Gregor Mitscha-Baude May 9, 2016 Motivation Standard neuronales Netz: Fixe Dimensionen von Input und Output! Motivation In viele Anwendungen variable Input/Output-Länge. Spracherkennung
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Hypothesenbewertung
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hypothesenbewertung Christoph Sawade/Niels Landwehr Dominik Lahmann Tobias Scheffer Überblick Hypothesenbewertung, Risikoschätzung
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hypothesenbewertung Christoph Sawade/Niels Landwehr Dominik Lahmann Tobias Scheffer Überblick Hypothesenbewertung, Risikoschätzung
Wir haben in den vorherigen Kapiteln verschiedene Verfahren zur Regression und Klassifikation kennengelernt (z.b. lineare Regression, SVMs)
") 6. Neuronale Netze Motivation Wir haben in den vorherigen Kapiteln verschiedene Verfahren zur Regression und Klassifikation kennengelernt (z.b. lineare Regression, SVMs) Abstrakt betrachtet sind alle diese
6. Neuronale Netze Motivation Wir haben in den vorherigen Kapiteln verschiedene Verfahren zur Regression und Klassifikation kennengelernt (z.b. lineare Regression, SVMs) Abstrakt betrachtet sind alle diese
Neuronale Netze (Konnektionismus) Einführung in die KI. Beispiel-Aufgabe: Schrifterkennung. Biologisches Vorbild. Neuronale Netze.
 Einführung in die KI. Beispiel-Aufgabe: Schrifterkennung. Biologisches Vorbild. Neuronale Netze.") Einführung in die KI Prof. Dr. sc. Hans-Dieter Burkhard Vorlesung (Konnektionismus) sind biologisch motiviert können diskrete, reell-wertige und Vektor-wertige Funktionen berechnen Informationsspeicherung
Einführung in die KI Prof. Dr. sc. Hans-Dieter Burkhard Vorlesung (Konnektionismus) sind biologisch motiviert können diskrete, reell-wertige und Vektor-wertige Funktionen berechnen Informationsspeicherung
Maschinelles Lernen: Neuronale Netze. Ideen der Informatik
 Maschinelles Lernen: Neuronale Netze Ideen der Informatik Kurt Mehlhorn Adrian Neumann 16. Januar 2014 Übersicht Biologische Inspiration Stand der Kunst in Objekterkennung auf Bildern Künstliche Neuronale
Maschinelles Lernen: Neuronale Netze Ideen der Informatik Kurt Mehlhorn Adrian Neumann 16. Januar 2014 Übersicht Biologische Inspiration Stand der Kunst in Objekterkennung auf Bildern Künstliche Neuronale
Neuronale. Netze. Henrik Voigt. Neuronale. Netze in der Biologie Aufbau Funktion. Neuronale. Aufbau Netzarten und Topologien
 in der Seminar Literaturarbeit und Präsentation 17.01.2019 in der Was können leisten und was nicht? Entschlüsseln von Texten??? Bilderkennung??? in der in der Quelle: justetf.com Quelle: zeit.de Spracherkennung???
in der Seminar Literaturarbeit und Präsentation 17.01.2019 in der Was können leisten und was nicht? Entschlüsseln von Texten??? Bilderkennung??? in der in der Quelle: justetf.com Quelle: zeit.de Spracherkennung???
Praktikum Computational Intelligence 2 Ulrich Lehmann, Johannes Brenig, Michael Schneider
 Praktikum Computational Intelligence 2 Ulrich Lehmann, Johannes Brenig, Michael Schneider Versuch: Training eines Künstlich Neuronalen Netzes (KNN) zur Approximation einer Kennlinie in JavaNNS 28.01.2008
Praktikum Computational Intelligence 2 Ulrich Lehmann, Johannes Brenig, Michael Schneider Versuch: Training eines Künstlich Neuronalen Netzes (KNN) zur Approximation einer Kennlinie in JavaNNS 28.01.2008
Neuronale Netze (Konnektionismus)
") Einführung in die KI Prof. Dr. sc. Hans-Dieter Burkhard Daniel Göhring Vorlesung (Konnektionismus) sind biologisch motiviert können diskrete, reell-wertige und Vektor-wertige Funktionen berechnen Informationsspeicherung
Einführung in die KI Prof. Dr. sc. Hans-Dieter Burkhard Daniel Göhring Vorlesung (Konnektionismus) sind biologisch motiviert können diskrete, reell-wertige und Vektor-wertige Funktionen berechnen Informationsspeicherung
Martin Stetter WS 03/04, 2 SWS. VL: Dienstags 8:30-10 Uhr
 Statistische und neuronale Lernverfahren Martin Stetter WS 03/04, 2 SWS VL: Dienstags 8:30-0 Uhr PD Dr. Martin Stetter, Siemens AG Statistische und neuronale Lernverfahren Behandelte Themen 0. Motivation
Statistische und neuronale Lernverfahren Martin Stetter WS 03/04, 2 SWS VL: Dienstags 8:30-0 Uhr PD Dr. Martin Stetter, Siemens AG Statistische und neuronale Lernverfahren Behandelte Themen 0. Motivation
B-Spline-Kurve und -Basisfunktionen
 48 B-Spline-Kurve und -Basisfunktionen Eine B-Spline-Kurve der Ordnung k ist ein stückweise aus B-Splines (Basisfunktion) zusammengesetztes Polynom vom Grad (k 1), das an den Segmentübergängen im allgemeinen
48 B-Spline-Kurve und -Basisfunktionen Eine B-Spline-Kurve der Ordnung k ist ein stückweise aus B-Splines (Basisfunktion) zusammengesetztes Polynom vom Grad (k 1), das an den Segmentübergängen im allgemeinen
Einführung in die Neuroinformatik Lösungen zum 5. Aufgabenblatt
 Einführung in die Neuroinformatik Lösungen zum 5. Aufgabenblatt 7. Aufgabe : Summe {} Man sieht leicht ein, dass ein einzelnes Perzeptron mit Gewichten c, c 2, c 3 und Schwelle θ das Problem nicht lösen
Einführung in die Neuroinformatik Lösungen zum 5. Aufgabenblatt 7. Aufgabe : Summe {} Man sieht leicht ein, dass ein einzelnes Perzeptron mit Gewichten c, c 2, c 3 und Schwelle θ das Problem nicht lösen
Neuro-Info Notizen. Markus Klemm.net WS 2016/2017. Inhaltsverzeichnis. 1 Hebbsche Lernregel. 1 Hebbsche Lernregel Fälle Lernrate...
 Neuro-Info Notizen Marus Klemm.net WS 6/7 Inhaltsverzeichnis Hebbsche Lernregel. Fälle........................................ Lernrate..................................... Neural Gas. Algorithmus.....................................
Neuro-Info Notizen Marus Klemm.net WS 6/7 Inhaltsverzeichnis Hebbsche Lernregel. Fälle........................................ Lernrate..................................... Neural Gas. Algorithmus.....................................
Lineare Klassifikatoren. Volker Tresp
 Lineare Klassifikatoren Volker Tresp 1 Klassifikatoren Klassifikation ist die zentrale Aufgabe in der Mustererkennung Sensoren liefern mir Informationen über ein Objekt Zu welcher Klasse gehört das Objekt:
Lineare Klassifikatoren Volker Tresp 1 Klassifikatoren Klassifikation ist die zentrale Aufgabe in der Mustererkennung Sensoren liefern mir Informationen über ein Objekt Zu welcher Klasse gehört das Objekt:
Training von RBF-Netzen. Rudolf Kruse Neuronale Netze 134
 Training von RBF-Netzen Rudolf Kruse Neuronale Netze 34 Radiale-Basisfunktionen-Netze: Initialisierung SeiL fixed ={l,...,l m } eine feste Lernaufgabe, bestehend ausmtrainingsbeispielenl=ı l,o l. Einfaches
Training von RBF-Netzen Rudolf Kruse Neuronale Netze 34 Radiale-Basisfunktionen-Netze: Initialisierung SeiL fixed ={l,...,l m } eine feste Lernaufgabe, bestehend ausmtrainingsbeispielenl=ı l,o l. Einfaches
Das Modell: Nichtlineare Merkmalsextraktion (Preprozessing) + Lineare Klassifikation
 + Lineare Klassifikation") Das Modell: Nichtlineare Merkmalsextraktion (Preprozessing) + Lineare Klassifikation Hochdimensionaler Eingaberaum {0,1} Z S quadratisch aufgemalt (zwecks besserer Visualisierung) als Retina bestehend
Das Modell: Nichtlineare Merkmalsextraktion (Preprozessing) + Lineare Klassifikation Hochdimensionaler Eingaberaum {0,1} Z S quadratisch aufgemalt (zwecks besserer Visualisierung) als Retina bestehend
Teil III: Wissensrepräsentation und Inferenz. Kap.5: Neuronale Netze
 Vorlesung Künstliche Intelligenz Wintersemester 2008/09 Teil III: Wissensrepräsentation und Inferenz Kap.5: Neuronale Netze Dieses Kapitel basiert auf Material von Andreas Hotho Mehr Details sind in der
Vorlesung Künstliche Intelligenz Wintersemester 2008/09 Teil III: Wissensrepräsentation und Inferenz Kap.5: Neuronale Netze Dieses Kapitel basiert auf Material von Andreas Hotho Mehr Details sind in der
Andreas Scherer. Neuronale Netze. Grundlagen und Anwendungen. vieweg
 Andreas Scherer Neuronale Netze Grundlagen und Anwendungen vieweg Inhaltsverzeichnis Vorwort 1 1 Einführung 3 1.1 Was ist ein neuronales Netz? 3 1.2 Eigenschaften neuronaler Netze 5 1.2.1 Allgemeine Merkmale
Andreas Scherer Neuronale Netze Grundlagen und Anwendungen vieweg Inhaltsverzeichnis Vorwort 1 1 Einführung 3 1.1 Was ist ein neuronales Netz? 3 1.2 Eigenschaften neuronaler Netze 5 1.2.1 Allgemeine Merkmale
Maschinelles Lernen Vorlesung
 Maschinelles Lernen Vorlesung SVM Kernfunktionen, Regularisierung Katharina Morik 15.11.2011 1 von 39 Gliederung 1 Weich trennende SVM 2 Kernfunktionen 3 Bias und Varianz bei SVM 2 von 39 SVM mit Ausnahmen
Maschinelles Lernen Vorlesung SVM Kernfunktionen, Regularisierung Katharina Morik 15.11.2011 1 von 39 Gliederung 1 Weich trennende SVM 2 Kernfunktionen 3 Bias und Varianz bei SVM 2 von 39 SVM mit Ausnahmen
Technische Universität. Fakultät für Informatik
 Technische Universität München Fakultät für Informatik Forschungs- und Lehreinheit Informatik VI Neuronale Netze - Supervised Learning Probleme des Backpropagation-Algorithmus und Alternativen Seminar
Technische Universität München Fakultät für Informatik Forschungs- und Lehreinheit Informatik VI Neuronale Netze - Supervised Learning Probleme des Backpropagation-Algorithmus und Alternativen Seminar
Klassifizierungsverfahren und neuronale Netze Hauptseminar - Methoden der experimentellen Teilchenphysik
 Hauptseminar WS 2011/2012 Klassifizierungsverfahren und neuronale Netze Hauptseminar - Methoden der experimentellen Teilchenphysik Thomas Keck t.keck@online.de Karlsruher Institut für Technologie, 09.12.2011
Hauptseminar WS 2011/2012 Klassifizierungsverfahren und neuronale Netze Hauptseminar - Methoden der experimentellen Teilchenphysik Thomas Keck t.keck@online.de Karlsruher Institut für Technologie, 09.12.2011
Neuronale Netze. Einführung i.d. Wissensverarbeitung 2 VO UE SS Institut für Signalverarbeitung und Sprachkommunikation
 Neuronale Netze Einführung in die Wissensverarbeitung 2 VO 708.560+ 1 UE 442.072 SS 2013 Institut für Signalverarbeitung und Sprachkommunikation TU Graz Inffeldgasse 12/1 www.spsc.tugraz.at Institut für
Neuronale Netze Einführung in die Wissensverarbeitung 2 VO 708.560+ 1 UE 442.072 SS 2013 Institut für Signalverarbeitung und Sprachkommunikation TU Graz Inffeldgasse 12/1 www.spsc.tugraz.at Institut für
Wärmebedarfsprognose für Einfamilienhaushalte auf Basis von Künstlichen Neuronalen Netzen
 Wärmebedarfsprognose für Einfamilienhaushalte auf Basis von Künstlichen Neuronalen Netzen Internationale Energiewirtschaftstagung Wien - 12.02.2015 Maike Hasselmann, Simon Döing Einführung Wärmeversorgungsanlagen
Wärmebedarfsprognose für Einfamilienhaushalte auf Basis von Künstlichen Neuronalen Netzen Internationale Energiewirtschaftstagung Wien - 12.02.2015 Maike Hasselmann, Simon Döing Einführung Wärmeversorgungsanlagen
Maschinelles Lernen: Neuronale Netze. Ideen der Informatik Kurt Mehlhorn
 Maschinelles Lernen: Neuronale Netze Ideen der Informatik Kurt Mehlhorn 16. Januar 2014, überarbeitet am 20. Januar 2017 Übersicht Stand der Kunst: Bilderverstehen, Go spielen Was ist ein Bild in Rohform?
Maschinelles Lernen: Neuronale Netze Ideen der Informatik Kurt Mehlhorn 16. Januar 2014, überarbeitet am 20. Januar 2017 Übersicht Stand der Kunst: Bilderverstehen, Go spielen Was ist ein Bild in Rohform?
Perzeptronen. Katrin Dust, Felix Oppermann Universität Oldenburg, FK II - Department für Informatik Vortrag im Rahmen des Proseminars 2004
 Perzeptronen Katrin Dust, Felix Oppermann Universität Oldenburg, FK II - Department für Informatik Vortrag im Rahmen des Proseminars 2004 1/25 Gliederung Vorbilder Neuron McCulloch-Pitts-Netze Perzeptron
Perzeptronen Katrin Dust, Felix Oppermann Universität Oldenburg, FK II - Department für Informatik Vortrag im Rahmen des Proseminars 2004 1/25 Gliederung Vorbilder Neuron McCulloch-Pitts-Netze Perzeptron
Reinforcement Learning
 Reinforcement Learning 1. Allgemein Reinforcement Learning 2. Neuronales Netz als Bewertungsfunktion 3. Neuronales Netz als Reinforcement Learning Nils-Olaf Bösch 1 Allgemein Reinforcement Learning Unterschied
Reinforcement Learning 1. Allgemein Reinforcement Learning 2. Neuronales Netz als Bewertungsfunktion 3. Neuronales Netz als Reinforcement Learning Nils-Olaf Bösch 1 Allgemein Reinforcement Learning Unterschied
Einfaches Framework für Neuronale Netze
 Einfaches Framework für Neuronale Netze Christian Silberbauer, IW7, 2007-01-23 Inhaltsverzeichnis 1. Einführung...1 2. Funktionsumfang...1 3. Implementierung...2 4. Erweiterbarkeit des Frameworks...2 5.
Einfaches Framework für Neuronale Netze Christian Silberbauer, IW7, 2007-01-23 Inhaltsverzeichnis 1. Einführung...1 2. Funktionsumfang...1 3. Implementierung...2 4. Erweiterbarkeit des Frameworks...2 5.
Radiale-Basisfunktionen-Netze. Rudolf Kruse Neuronale Netze 120
 Radiale-Basisfunktionen-Netze Rudolf Kruse Neuronale Netze 2 Radiale-Basisfunktionen-Netze Eigenschaften von Radiale-Basisfunktionen-Netzen (RBF-Netzen) RBF-Netze sind streng geschichtete, vorwärtsbetriebene
Radiale-Basisfunktionen-Netze Rudolf Kruse Neuronale Netze 2 Radiale-Basisfunktionen-Netze Eigenschaften von Radiale-Basisfunktionen-Netzen (RBF-Netzen) RBF-Netze sind streng geschichtete, vorwärtsbetriebene
Ausgleichsproblem. Definition (1.0.3)
") Ausgleichsproblem Definition (1.0.3) Gegeben sind n Wertepaare (x i, y i ), i = 1,..., n mit x i x j für i j. Gesucht ist eine stetige Funktion f, die die Wertepaare bestmöglich annähert, d.h. dass möglichst
Ausgleichsproblem Definition (1.0.3) Gegeben sind n Wertepaare (x i, y i ), i = 1,..., n mit x i x j für i j. Gesucht ist eine stetige Funktion f, die die Wertepaare bestmöglich annähert, d.h. dass möglichst
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Modellevaluierung. Niels Landwehr
 Universität Potsdam Institut für Informatik ehrstuhl Maschinelles ernen Modellevaluierung Niels andwehr ernen und Vorhersage Klassifikation, Regression: ernproblem Eingabe: Trainingsdaten Ausgabe: Modell
Universität Potsdam Institut für Informatik ehrstuhl Maschinelles ernen Modellevaluierung Niels andwehr ernen und Vorhersage Klassifikation, Regression: ernproblem Eingabe: Trainingsdaten Ausgabe: Modell
Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 2016
 Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 1 M. Sperber (matthias.sperber@kit.edu) S. Nguyen (thai.nguyen@kit.edu) Übungsblatt 3 Maschinelles Lernen und Klassifikation Abgabe online
Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 1 M. Sperber (matthias.sperber@kit.edu) S. Nguyen (thai.nguyen@kit.edu) Übungsblatt 3 Maschinelles Lernen und Klassifikation Abgabe online
Ridge Regression und Kernalized Support Vector Machines : Einführung und Vergleich an einem Anwendungsbeispiel
 Ridge Regression und Kernalized Support Vector Machines : Einführung und Vergleich an einem Anwendungsbeispiel Dr. Dominik Grimm Probelehrveranstaltung Fakultät für Informatik und Mathematik Hochschule
Ridge Regression und Kernalized Support Vector Machines : Einführung und Vergleich an einem Anwendungsbeispiel Dr. Dominik Grimm Probelehrveranstaltung Fakultät für Informatik und Mathematik Hochschule
Adaptive Systeme. Neuronale Netze: Neuronen, Perzeptron und Adaline. Prof. Dr. rer. nat. Nikolaus Wulff
 Adaptive Systeme Neuronale Netze: Neuronen, Perzeptron und Adaline Prof. Dr. rer. nat. Nikolaus Wulff Neuronale Netze Das (menschliche) Gehirn ist ein Musterbeispiel für ein adaptives System, dass sich
Adaptive Systeme Neuronale Netze: Neuronen, Perzeptron und Adaline Prof. Dr. rer. nat. Nikolaus Wulff Neuronale Netze Das (menschliche) Gehirn ist ein Musterbeispiel für ein adaptives System, dass sich
Neuronale Netze (I) Biologisches Neuronales Netz
 Biologisches Neuronales Netz") Neuronale Netze (I) Biologisches Neuronales Netz Im menschlichen Gehirn ist ein Neuron mit bis zu 20.000 anderen Neuronen verbunden. Milliarden von Neuronen beteiligen sich simultan an der Verarbeitung
Neuronale Netze (I) Biologisches Neuronales Netz Im menschlichen Gehirn ist ein Neuron mit bis zu 20.000 anderen Neuronen verbunden. Milliarden von Neuronen beteiligen sich simultan an der Verarbeitung
Computational Intelligence 1 / 20. Computational Intelligence Künstliche Neuronale Netze Perzeptron 3 / 20
 Gliederung / Künstliche Neuronale Netze Perzeptron Einschränkungen Netze von Perzeptonen Perzeptron-Lernen Perzeptron Künstliche Neuronale Netze Perzeptron 3 / Der Psychologe und Informatiker Frank Rosenblatt
Gliederung / Künstliche Neuronale Netze Perzeptron Einschränkungen Netze von Perzeptonen Perzeptron-Lernen Perzeptron Künstliche Neuronale Netze Perzeptron 3 / Der Psychologe und Informatiker Frank Rosenblatt
Maschinelles Lernen: Neuronale Netze. Ideen der Informatik Kurt Mehlhorn
 Maschinelles Lernen: Neuronale Netze Ideen der Informatik Kurt Mehlhorn 16. Januar 2014, überarbeitet am 20. Januar 2017 Übersicht Stand der Kunst: Bilderverstehen, Go spielen Was ist ein Bild in Rohform?
Maschinelles Lernen: Neuronale Netze Ideen der Informatik Kurt Mehlhorn 16. Januar 2014, überarbeitet am 20. Januar 2017 Übersicht Stand der Kunst: Bilderverstehen, Go spielen Was ist ein Bild in Rohform?
Statistical Learning
 Statistical Learning M. Gruber KW 42 Rev.1 1 Neuronale Netze Wir folgen [1], Lec 10. Beginnen wir mit einem Beispiel. Beispiel 1 Wir konstruieren einen Klassifikator auf der Menge, dessen Wirkung man in
Statistical Learning M. Gruber KW 42 Rev.1 1 Neuronale Netze Wir folgen [1], Lec 10. Beginnen wir mit einem Beispiel. Beispiel 1 Wir konstruieren einen Klassifikator auf der Menge, dessen Wirkung man in
Einführung in die Computerlinguistik
 Einführung in die Computerlinguistik Neuronale Netze WS 2014/2015 Vera Demberg Neuronale Netze Was ist das? Einer der größten Fortschritte in der Sprachverarbeitung und Bildverarbeitung der letzten Jahre:
Einführung in die Computerlinguistik Neuronale Netze WS 2014/2015 Vera Demberg Neuronale Netze Was ist das? Einer der größten Fortschritte in der Sprachverarbeitung und Bildverarbeitung der letzten Jahre:
Interpolation und Approximation von Funktionen
 Kapitel 6 Interpolation und Approximation von Funktionen Bei ökonomischen Anwendungen tritt oft das Problem auf, dass eine analytisch nicht verwendbare (oder auch unbekannte) Funktion f durch eine numerisch
Kapitel 6 Interpolation und Approximation von Funktionen Bei ökonomischen Anwendungen tritt oft das Problem auf, dass eine analytisch nicht verwendbare (oder auch unbekannte) Funktion f durch eine numerisch
Systemtheorie. Vorlesung 6: Lösung linearer Differentialgleichungen. Fakultät für Elektro- und Informationstechnik, Manfred Strohrmann
 Systemtheorie Vorlesung 6: Lösung linearer Differentialgleichungen Fakultät für Elektro- und Informationstechnik, Manfred Strohrmann Einführung Viele technischen Anwendungen lassen sich zumindest näherungsweise
Systemtheorie Vorlesung 6: Lösung linearer Differentialgleichungen Fakultät für Elektro- und Informationstechnik, Manfred Strohrmann Einführung Viele technischen Anwendungen lassen sich zumindest näherungsweise
Linear nichtseparable Probleme
 Linear nichtseparable Probleme Mustererkennung und Klassifikation, Vorlesung No. 10 1 M. O. Franz 20.12.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht
Linear nichtseparable Probleme Mustererkennung und Klassifikation, Vorlesung No. 10 1 M. O. Franz 20.12.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht
Einführung in Support Vector Machines (SVMs)
") Einführung in (SVM) Januar 31, 2011 Einführung in (SVMs) Table of contents Motivation Einführung in (SVMs) Outline Motivation Vektorrepräsentation Klassifikation Motivation Einführung in (SVMs) Vektorrepräsentation
Einführung in (SVM) Januar 31, 2011 Einführung in (SVMs) Table of contents Motivation Einführung in (SVMs) Outline Motivation Vektorrepräsentation Klassifikation Motivation Einführung in (SVMs) Vektorrepräsentation
Computational Intelligence I Künstliche Neuronale Netze
 Computational Intelligence I Künstliche Neuronale Nete Universität Dortmund, Informatik I Otto-Hahn-Str. 6, 44227 Dortmund lars.hildebrand@uni-dortmund.de Inhalt der Vorlesung 0. Organisatorisches & Vorbemerkungen.
Computational Intelligence I Künstliche Neuronale Nete Universität Dortmund, Informatik I Otto-Hahn-Str. 6, 44227 Dortmund lars.hildebrand@uni-dortmund.de Inhalt der Vorlesung 0. Organisatorisches & Vorbemerkungen.
5. Lernregeln für neuronale Netze
 5. Lernregeln für neuronale Netze 1. Allgemeine Lokale Lernregeln 2. Lernregeln aus Zielfunktionen: Optimierung durch Gradientenverfahren 3. Beispiel: Überwachtes Lernen im Einschicht-Netz Schwenker NI1
5. Lernregeln für neuronale Netze 1. Allgemeine Lokale Lernregeln 2. Lernregeln aus Zielfunktionen: Optimierung durch Gradientenverfahren 3. Beispiel: Überwachtes Lernen im Einschicht-Netz Schwenker NI1
Grundlagen neuronaler Netzwerke
 AUFBAU DES NEURONALEN NETZWERKS Enrico Biermann enrico@cs.tu-berlin.de) WS 00/03 Timo Glaser timog@cs.tu-berlin.de) 0.. 003 Marco Kunze makunze@cs.tu-berlin.de) Sebastian Nowozin nowozin@cs.tu-berlin.de)
AUFBAU DES NEURONALEN NETZWERKS Enrico Biermann enrico@cs.tu-berlin.de) WS 00/03 Timo Glaser timog@cs.tu-berlin.de) 0.. 003 Marco Kunze makunze@cs.tu-berlin.de) Sebastian Nowozin nowozin@cs.tu-berlin.de)
Frequentisten und Bayesianer. Volker Tresp
 Frequentisten und Bayesianer Volker Tresp 1 Frequentisten 2 Die W-Verteilung eines Datenmusters Nehmen wir an, dass die wahre Abhängigkeit linear ist, wir jedoch nur verrauschte Daten zur Verfügung haben
Frequentisten und Bayesianer Volker Tresp 1 Frequentisten 2 Die W-Verteilung eines Datenmusters Nehmen wir an, dass die wahre Abhängigkeit linear ist, wir jedoch nur verrauschte Daten zur Verfügung haben
Neuronale Netze mit mehreren Schichten
 Neuronale Netze mit mehreren Schichten Lehrstuhl für Künstliche Intelligenz Institut für Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg (Lehrstuhl Informatik 8) Neuronale Netze mit mehreren
Neuronale Netze mit mehreren Schichten Lehrstuhl für Künstliche Intelligenz Institut für Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg (Lehrstuhl Informatik 8) Neuronale Netze mit mehreren
Einige überwachte Lernverfahren. Perzeptron, Mehrschicht-Perzeptronen und die Backpropagation-Lernregel
 Einige überwachte Lernverfahren Perzeptron, Mehrschicht-Perzeptronen und die Backpropagation-Lernregel Funktionsweise eines künstlichen Neurons x w k Neuron k x 2 w 2k net k f y k x n- w n-,k x n w n,k
Einige überwachte Lernverfahren Perzeptron, Mehrschicht-Perzeptronen und die Backpropagation-Lernregel Funktionsweise eines künstlichen Neurons x w k Neuron k x 2 w 2k net k f y k x n- w n-,k x n w n,k
5 Interpolation und Approximation
 5 Interpolation und Approximation Problemstellung: Es soll eine Funktion f(x) approximiert werden, von der die Funktionswerte nur an diskreten Stellen bekannt sind. 5. Das Interpolationspolynom y y = P(x)
5 Interpolation und Approximation Problemstellung: Es soll eine Funktion f(x) approximiert werden, von der die Funktionswerte nur an diskreten Stellen bekannt sind. 5. Das Interpolationspolynom y y = P(x)
Der Sprung in die Zukunft! Einführung in neuronale Netzwerke
 Der Sprung in die Zukunft! Einführung in neuronale Netzwerke Inhalt 1. Warum auf einmal doch? 2. Welche Einsatzgebiete gibt es? 3. Was sind neuronale Netze und wie funktionieren sie? 4. Wie lernen neuronale
Der Sprung in die Zukunft! Einführung in neuronale Netzwerke Inhalt 1. Warum auf einmal doch? 2. Welche Einsatzgebiete gibt es? 3. Was sind neuronale Netze und wie funktionieren sie? 4. Wie lernen neuronale
Mustererkennung. Support Vector Machines. R. Neubecker, WS 2018 / Support Vector Machines
 Mustererkennung R. Neubecker, WS 018 / 019 (SVM) kommen aus der statistischen Lerntheorie gehören zu den optimalen Klassifikatoren = SVMs minimieren nicht nur den Trainingsfehler, sondern auch den (voraussichtlichen)
Mustererkennung R. Neubecker, WS 018 / 019 (SVM) kommen aus der statistischen Lerntheorie gehören zu den optimalen Klassifikatoren = SVMs minimieren nicht nur den Trainingsfehler, sondern auch den (voraussichtlichen)
Seminar K nowledge Engineering und L ernen in Spielen
 K nowledge Engineering und Lernen in Spielen Neural Networks Seminar K nowledge Engineering und L ernen in Spielen Stefan Heinje 1 Inhalt Neuronale Netze im Gehirn Umsetzung Lernen durch Backpropagation
K nowledge Engineering und Lernen in Spielen Neural Networks Seminar K nowledge Engineering und L ernen in Spielen Stefan Heinje 1 Inhalt Neuronale Netze im Gehirn Umsetzung Lernen durch Backpropagation
Künstliche Neuronale Netze
 Fakultät Informatik, Institut für Technische Informatik, Professur für VLSI-Entwurfssysteme, Diagnostik und Architektur Künstliche Neuronale Netze Hauptseminar Martin Knöfel Dresden, 16.11.2017 Gliederung
Fakultät Informatik, Institut für Technische Informatik, Professur für VLSI-Entwurfssysteme, Diagnostik und Architektur Künstliche Neuronale Netze Hauptseminar Martin Knöfel Dresden, 16.11.2017 Gliederung
Universität des Saarlandes
 Universität des Saarlandes FR 6.2 Informatik Prof. Dr. Kurt Mehlhorn Dr. Antonios Antoniadis André Nusser WiSe 2017/18 Übungen zu Ideen der Informatik http://www.mpi-inf.mpg.de/departments/algorithms-complexity/teaching/winter17/ideen/
Universität des Saarlandes FR 6.2 Informatik Prof. Dr. Kurt Mehlhorn Dr. Antonios Antoniadis André Nusser WiSe 2017/18 Übungen zu Ideen der Informatik http://www.mpi-inf.mpg.de/departments/algorithms-complexity/teaching/winter17/ideen/
So lösen Sie das multivariate lineare Regressionsproblem von Christian Herta
 Multivariate Lineare Regression Christian Herta Oktober, 2013 1 von 34 Christian Herta Multivariate Lineare Regression Lernziele Multivariate Lineare Regression Konzepte des Maschinellen Lernens: Kostenfunktion
Multivariate Lineare Regression Christian Herta Oktober, 2013 1 von 34 Christian Herta Multivariate Lineare Regression Lernziele Multivariate Lineare Regression Konzepte des Maschinellen Lernens: Kostenfunktion
Konvergenz von Hopfield-Netzen
 Matthias Jauernig 1. August 2006 Zusammenfassung Die nachfolgende Betrachtung bezieht sich auf das diskrete Hopfield-Netz und hat das Ziel, die Konvergenz des Verfahrens zu zeigen. Leider wird dieser Beweis
Matthias Jauernig 1. August 2006 Zusammenfassung Die nachfolgende Betrachtung bezieht sich auf das diskrete Hopfield-Netz und hat das Ziel, die Konvergenz des Verfahrens zu zeigen. Leider wird dieser Beweis