Entwicklung einer KI für Skat. Hauptseminar Erwin Lang
|
|
|
- Axel Hauer
- vor 6 Jahren
- Abrufe
Transkript
1 Entwicklung einer KI für Skat Hauptseminar Erwin Lang
2 Inhalt Skat Forschung Eigene Arbeit Risikoanalyse
3 Skat Entwickelte sich Anfang des 19. Jahrhunderts Kartenspiel mit Blatt aus 32 Karten 3 Spieler Trick-taking game Hauptsächlich in Deutschland verbreitet Ähnlichkeit zu Bridge
4 Skat [Bildquelle:
5 Skat Unvollständige Informationen Zufall Diverse Spielvarianten Immenser Zustandsraum Spielphasen Spieler-rollen
6 Forschung Skatspieler Kermit Vollständige Umsetzung Vereint diverse Ansätze Supervised Learning Modell Tree Search Selektion und Inferenz [ijcai2009]
7 Forschung Imperfekte Information Testdaten Approximationsfunktion Perfekte Information Herleiten von Welten Suche [ijcai2009]
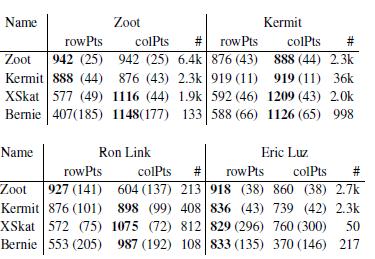
8 Forschung [ijcai2009]
9 Forschung Abstraction Selection Reinforcement Learning Idee: Auswahl und Wechsel eines Modells Viele Durchläufe => feine Abstraktion Wenige Durchläufe => grobe Abstraktion [vanseijen2014]
10 Forschung Markov Prozess wird vorausgesetzt (S,A,P,R,γ) Abstraktion z.b. durch Features Wechseln von Abstraktion wird als interne Aktion modelliert Lernproblem [vanseijen2014]
11 Forschung [vanseijen2014]
12 Forschung AlphaGo Spielt Go auf Expertenlevel Kombiniert neuronale Netze mit RL Lerndaten [silver et al., 2016]
13 Forschung [silver et al., 2016]

14 Forschung [silver et al., 2016]
15 Wo stehe ich? Skat mit aktuellen Ansätzen
16 Eigene Arbeit Vision Neuartigen Ansatz für Skat finden Umsetzung einer KI für das vollständige Spiel Entwicklung eines aussagekräftigen Testszenarios Stand Grundprojekt abgeschlossen
17 Eigene Arbeit Infrastruktur für Implementierung Recherche von Ansätzen Implementierung Vergleich

18
19 Eigene Arbeit Support Vector Machines Alpha Beta Pruning Temporal Difference Learning Monte Carlo Ansätze

20 Eigene Arbeit
21 Eigene Arbeit [Browne und Powley 2012]
22 Eigene Arbeit Implementierung in eingeschränktem Szenario Kein Reizen Nur der Alleinspieler wird simuliert Spielvarianten werden nicht explizit betrachtet
23 Eigene Arbeit 90 Tests für jeden Ansatz mit wachsender Simulationszahl Alle Ansätze besser als zufälliges Spielen Monte Carlo Reinforcement Learning lieferte die besten Ergebnisse
24 Eigene Arbeit Analytische Arbeit Formale Bewertung von Methoden Modell Laufzeit Kombinierbarkeit Praktische Umsetzung Ggf. Referenzimplementierung
25 Eigene Arbeit Grundlagen Skat formal beschreiben Analyse Entwurf auf Basis des Hauptprojekts
26 Eigene Arbeit Realisierung Test Testszenario Tests durchführen
27 Risikoanalyse Zeitliche Rahmen wird gesprengt Kein guter Ansatz wird gefunden Performance erlaubt keine umfangreichen Tests Fehler in der Umsetzung führen zu falschen/schlechten Ergebnissen Ansatz stellt sich als nicht gut heraus
28 Quellen [ijcai2009] Buro, M.; Long, J. R.; Furtak, T. & Sturtevant, N. R. (2009), Improving State Evaluation, Inference, and Search in Trick-Based Card Games., in Craig Boutilier, ed., 'IJCAI', pp [vanseijen2014] van Seijen, H.; Whiteson, S. & Kester, L. J. H. M. (2014), 'Efficient Abstraction Selection in Reinforcement Learning.', Computational Intelligence 30 (4), [silver et al., 2016] Mastering the game of Go with deep neural networks and tree search Nature, Vol. 529, No (27 January 2016), pp , doi: /nature16961 by David Silver, Aja Huang, Chris J. Maddison, et al.
29 Quellen [Sutton und Barto 1998] Sutton, Richard S. ; Barto, Andrew G.: Introduction to Reinforcement Learning. 1st. Cambridge, MA, USA : MIT Press, ISBN [Browne und Powley 2012] Browne, Cb ; Powley, Edward: A survey of monte carlo tree search methods. In: Intelligence and AI 4 (2012), Nr. 1, S URL arnumber= ISSN X [Hearst 1998] Hearst, Marti A.: Support Vector Machines. In: IEEE Intelligent Systems 13 (1998), Juli, Nr. 4, S URL ISSN [Knuth und Moore 1975] Knuth, Donald E. ; Moore, Ronald W.: An Analysis of Alpha-Beta Pruning. In: Artif. Intell. 6 (1975), Nr. 4, S URL
Reinforcement-Learning
 Reinforcement-Learning Vortrag von: Fabien Lapok Betreuer: Prof. Dr. Meisel 1 Agenda Motivation Überblick und Probleme von RL Aktuelle Forschung Mein Vorgehen Konferenzen und Quellen 2 Reinforcement Learning
Reinforcement-Learning Vortrag von: Fabien Lapok Betreuer: Prof. Dr. Meisel 1 Agenda Motivation Überblick und Probleme von RL Aktuelle Forschung Mein Vorgehen Konferenzen und Quellen 2 Reinforcement Learning
Hauptseminar: Skat-KI auf Basis von Monte Carlo Tree Search
 Hauptseminar: Skat-KI auf Basis von Monte Carlo Tree Search Erwin Lang Haw Hamburg 1 Einleitung In dieser Ausarbeitung wird die bisherige Arbeit bezüglich einer künstlichen Intelligenz für das Kartenspiel
Hauptseminar: Skat-KI auf Basis von Monte Carlo Tree Search Erwin Lang Haw Hamburg 1 Einleitung In dieser Ausarbeitung wird die bisherige Arbeit bezüglich einer künstlichen Intelligenz für das Kartenspiel
Backgammon. Tobias Krönke. Technische Universität Darmstadt Fachbereich Informatik Fachgebiet Knowledge Engineering
 Technische Universität Darmstadt Fachbereich Informatik Fachgebiet Knowledge Engineering Seminar zu Knowledge Engineering und Lernen in Spielen, 2010 Gliederung Gliederung Startaufstellung Abbildung: GNU
Technische Universität Darmstadt Fachbereich Informatik Fachgebiet Knowledge Engineering Seminar zu Knowledge Engineering und Lernen in Spielen, 2010 Gliederung Gliederung Startaufstellung Abbildung: GNU
Intelligente Systeme
 Intelligente Systeme Spiele Prof. Dr. R. Kruse C. Braune {rudolf.kruse,christian,braune}@ovgu.de Institut für Intelligente Kooperierende Systeme Fakultät für Informatik Otto-von-Guericke Universität Magdeburg
Intelligente Systeme Spiele Prof. Dr. R. Kruse C. Braune {rudolf.kruse,christian,braune}@ovgu.de Institut für Intelligente Kooperierende Systeme Fakultät für Informatik Otto-von-Guericke Universität Magdeburg
Reinforcement Learning
 Reinforcement Learning Viktor Seifert Seminar: Knowledge Engineering und Lernen in Spielen SS06 Prof. Johannes Fürnkranz Übersicht 1. Definition 2. Allgemeiner Lösungsansatz 3. Temporal Difference Learning
Reinforcement Learning Viktor Seifert Seminar: Knowledge Engineering und Lernen in Spielen SS06 Prof. Johannes Fürnkranz Übersicht 1. Definition 2. Allgemeiner Lösungsansatz 3. Temporal Difference Learning
Handlungsplanung und Allgemeines Spiel Ausblick: GDL-II. Peter Kissmann
 Handlungsplanung und Allgemeines Spiel Ausblick: GDL-II Peter Kissmann Themen Allgemeines Spiel Einführung Game Desciption Language (GDL) Spielen allgemeiner Spiele Evaluationsfunktionen im allgemeinen
Handlungsplanung und Allgemeines Spiel Ausblick: GDL-II Peter Kissmann Themen Allgemeines Spiel Einführung Game Desciption Language (GDL) Spielen allgemeiner Spiele Evaluationsfunktionen im allgemeinen
Data Mining Künstliche Neuronale Netze vs. Entscheidungsbäume
 Data Mining Künstliche Neuronale Netze vs. Entscheidungsbäume Grundseminar HAW Master Informatik 18.04.2017 Inhaltsübersicht Data Mining & Begriffswelt des Data Mining Klassifikation & Klassifikatoren
Data Mining Künstliche Neuronale Netze vs. Entscheidungsbäume Grundseminar HAW Master Informatik 18.04.2017 Inhaltsübersicht Data Mining & Begriffswelt des Data Mining Klassifikation & Klassifikatoren
Monte Carlo Methoden
 Monte Carlo Methoden im Verstärkungslernen [Spink] Bryan Spink 2003 Ketill Gunnarsson [ ketill@inf.fu-berlin.de ], Seminar zum Verstärkungslernen, Freie Universität Berlin [ www.inf.fu-berlin.de ] Einleitung
Monte Carlo Methoden im Verstärkungslernen [Spink] Bryan Spink 2003 Ketill Gunnarsson [ ketill@inf.fu-berlin.de ], Seminar zum Verstärkungslernen, Freie Universität Berlin [ www.inf.fu-berlin.de ] Einleitung
Reinforcement Learning
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning Uwe Dick Inhalt Problemstellungen Beispiele Markov Decision Processes Planen vollständige MDPs Lernen unbekannte
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning Uwe Dick Inhalt Problemstellungen Beispiele Markov Decision Processes Planen vollständige MDPs Lernen unbekannte
Selected Topics in Machine Learning and Reverse Engineering
 Selected Topics in Machine Learning and Reverse Engineering Dozenten: Prof. Dr. Fabian Theis Email: theis@ma.tum.de Prof. Dr. Oliver Junge Raum: 02.08.040? Tel.: +49 (89) 289 17987, Email: junge@ma.tum.de
Selected Topics in Machine Learning and Reverse Engineering Dozenten: Prof. Dr. Fabian Theis Email: theis@ma.tum.de Prof. Dr. Oliver Junge Raum: 02.08.040? Tel.: +49 (89) 289 17987, Email: junge@ma.tum.de
Erkennung von Kontext aus Sensordaten in einer intelligenten Wohnung
 Erkennung von Kontext aus Sensordaten in einer intelligenten Wohnung Jens Ellenberg 12.01.2011 Jens Ellenberg 1 Inhalt Motivation Ziel der Arbeit Vorarbeiten Architektur Vorgehen Zusammenfassung Literatur
Erkennung von Kontext aus Sensordaten in einer intelligenten Wohnung Jens Ellenberg 12.01.2011 Jens Ellenberg 1 Inhalt Motivation Ziel der Arbeit Vorarbeiten Architektur Vorgehen Zusammenfassung Literatur
Seminar aus maschinellem Lernen MCTS und UCT
 Seminar aus maschinellem Lernen MCTS und UCT 26. November 2014 TU Darmstadt FB 20 Patrick Bitz 1 Übersicht Historisches zu MCTS MCTS UCT Eigenschaften von MCTS Zusammenfassung 26. November 2014 TU Darmstadt
Seminar aus maschinellem Lernen MCTS und UCT 26. November 2014 TU Darmstadt FB 20 Patrick Bitz 1 Übersicht Historisches zu MCTS MCTS UCT Eigenschaften von MCTS Zusammenfassung 26. November 2014 TU Darmstadt
Fachgruppe Statistik, Risikoanalyse & Computing. STAT672 Data Mining. Sommersemester 2007. Prof. Dr. R. D. Reiß
 Fachgruppe Statistik, Risikoanalyse & Computing STAT672 Data Mining Sommersemester 2007 Prof. Dr. R. D. Reiß Überblick Data Mining Begrifflichkeit Unter Data Mining versteht man die Computergestützte Suche
Fachgruppe Statistik, Risikoanalyse & Computing STAT672 Data Mining Sommersemester 2007 Prof. Dr. R. D. Reiß Überblick Data Mining Begrifflichkeit Unter Data Mining versteht man die Computergestützte Suche
Samuel's Checkers Program
 Samuel's Checkers Program Seminar: Knowledge Engineering und Lernen in Spielen 29.06.2004 Ge Hyun Nam Überblick Einleitung Basis Dame-Programm Maschinelles Lernen Auswendiglernen Verallgemeinerndes Lernen
Samuel's Checkers Program Seminar: Knowledge Engineering und Lernen in Spielen 29.06.2004 Ge Hyun Nam Überblick Einleitung Basis Dame-Programm Maschinelles Lernen Auswendiglernen Verallgemeinerndes Lernen
AI in Computer Games. Übersicht. Motivation. Vorteile der Spielumgebung. Techniken. Anforderungen
 Übersicht AI in Computer Games Motivation Vorteile der Spielumgebung Techniken Anwendungen Zusammenfassung Motivation Vorteile der Spielumgebung Modellierung glaubwürdiger Agenten Implementierung menschlicher
Übersicht AI in Computer Games Motivation Vorteile der Spielumgebung Techniken Anwendungen Zusammenfassung Motivation Vorteile der Spielumgebung Modellierung glaubwürdiger Agenten Implementierung menschlicher
«Cyborgs, Innovation und Digitalisierung» Pascal Kaufmann, Founder & CEO Starmind
 «Cyborgs, Innovation und Digitalisierung» Pascal Kaufmann, Founder & CEO Starmind Northwestern University und ETH Zürich Chicago Medical School, 2001 Visueller Input Motorischer Output Die Vernetzung von
«Cyborgs, Innovation und Digitalisierung» Pascal Kaufmann, Founder & CEO Starmind Northwestern University und ETH Zürich Chicago Medical School, 2001 Visueller Input Motorischer Output Die Vernetzung von
Seminar Künstliche Intelligenz WS 2013/14 Grundlagen des Maschinellen Lernens
 Seminar Künstliche Intelligenz WS 2013/14 Grundlagen des Maschinellen Lernens Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 19.12.2013 Allgemeine Problemstellung
Seminar Künstliche Intelligenz WS 2013/14 Grundlagen des Maschinellen Lernens Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 19.12.2013 Allgemeine Problemstellung
Reinforcement Learning
 Effiziente Darstellung von Daten Reinforcement Learning 02. Juli 2004 Jan Schlößin Einordnung Was ist Reinforcement Learning? Einführung - Prinzip der Agent Eigenschaften das Ziel Q-Learning warum Q-Learning
Effiziente Darstellung von Daten Reinforcement Learning 02. Juli 2004 Jan Schlößin Einordnung Was ist Reinforcement Learning? Einführung - Prinzip der Agent Eigenschaften das Ziel Q-Learning warum Q-Learning
High Level-Synthese eines Keypoint-Detection- Algorithmus für FPGAs
 Fakultät Informatik, Institut für Technische Informatik, Professur für VLSI-Entwurfssysteme, Diagnostik und Architektur Belegarbeit High Level-Synthese eines Keypoint-Detection- Algorithmus für FPGAs Max
Fakultät Informatik, Institut für Technische Informatik, Professur für VLSI-Entwurfssysteme, Diagnostik und Architektur Belegarbeit High Level-Synthese eines Keypoint-Detection- Algorithmus für FPGAs Max
Seminar Serious Games FT Vorbesprechung
 Seminar Serious Games FT 2016 Vorbesprechung Agenda 1. Rahmenbedingungen 2. Themenbereiche 3. Zeitplanung Rahmenbedingungen Seminarmodul Bachelor (Modul 1025 bzw. 1044): Workload gesamt: 90 h -> Präsenzzeit:
Seminar Serious Games FT 2016 Vorbesprechung Agenda 1. Rahmenbedingungen 2. Themenbereiche 3. Zeitplanung Rahmenbedingungen Seminarmodul Bachelor (Modul 1025 bzw. 1044): Workload gesamt: 90 h -> Präsenzzeit:
Bridge. Das Spiel (contract bridge) Probleme. Ginsberg's Intelligent Bridge (GIB) Vergleich: Bridge Baron. Übersicht
 Probleme. Ginsberg's Intelligent Bridge (GIB) Vergleich: Bridge Baron. Übersicht") Das Spiel (contract bridge) Probleme Ginsberg's Intelligent Bridge (GIB) Vergleich: Bridge Baron Übersicht 1 1529 England Bridge Ende 19. Jh. USA, England, Frankreich, Russland, Türkei, Ägypten 1925 Contract
Das Spiel (contract bridge) Probleme Ginsberg's Intelligent Bridge (GIB) Vergleich: Bridge Baron Übersicht 1 1529 England Bridge Ende 19. Jh. USA, England, Frankreich, Russland, Türkei, Ägypten 1925 Contract
General Game Playing
 General Game Playing Martin Günther mguenthe@uos.de 17. Juni 2010 1 / 31 1997: Deep Blue schlägt Kasparov Motivation: warum General Game Playing? AAAI General Game Playing Competition 2 / 31 Motivation:
General Game Playing Martin Günther mguenthe@uos.de 17. Juni 2010 1 / 31 1997: Deep Blue schlägt Kasparov Motivation: warum General Game Playing? AAAI General Game Playing Competition 2 / 31 Motivation:
Optimierendes Lernen (Reinforcement Learning) - Adaptive Verfahren für dynamische Optimierungsprobleme. VE 1: Einführung
 - Adaptive Verfahren für dynamische Optimierungsprobleme. VE 1: Einführung") Optimierendes Lernen (Reinforcement Learning) - Adaptive Verfahren für dynamische Optimierungsprobleme VE 1: Einführung Prof. Dr. Martin Riedmiller Machine Learning Lab Albert-Ludwigs-Universitaet Freiburg
Optimierendes Lernen (Reinforcement Learning) - Adaptive Verfahren für dynamische Optimierungsprobleme VE 1: Einführung Prof. Dr. Martin Riedmiller Machine Learning Lab Albert-Ludwigs-Universitaet Freiburg
Arbeitsgruppe Neuroinformatik
 Arbeitsgruppe Neuroinformatik Prof. Dr. Martin Riedmiller Martin.Riedmiller@uos.de Martin Riedmiller, Univ. Osnabrück, Martin.Riedmiller@uos.de Arbeitsgruppe Neuroinformatik 1 Leitmotiv Zukünftige Computerprogramme
Arbeitsgruppe Neuroinformatik Prof. Dr. Martin Riedmiller Martin.Riedmiller@uos.de Martin Riedmiller, Univ. Osnabrück, Martin.Riedmiller@uos.de Arbeitsgruppe Neuroinformatik 1 Leitmotiv Zukünftige Computerprogramme
Business Intelligence & Machine Learning
 AUSFÜLLHILFE: BEWEGEN SIE DEN MAUSZEIGER ÜBER DIE ÜBERSCHRIFTEN. AUSFÜHRLICHE HINWEISE: LEITFADEN MODULBESCHREIBUNG Business Intelligence & Machine Learning Kennnummer Workload Credits/LP Studiensemester
AUSFÜLLHILFE: BEWEGEN SIE DEN MAUSZEIGER ÜBER DIE ÜBERSCHRIFTEN. AUSFÜHRLICHE HINWEISE: LEITFADEN MODULBESCHREIBUNG Business Intelligence & Machine Learning Kennnummer Workload Credits/LP Studiensemester
Kapitel ML: I. I. Einführung. Beispiele für Lernaufgaben Spezifikation von Lernproblemen
 Kapitel ML: I I. Einführung Beispiele für Lernaufgaben Spezifikation von Lernproblemen ML: I-8 Introduction c STEIN/LETTMANN 2005-2010 Beispiele für Lernaufgaben Autoeinkaufsberater Welche Kriterien liegen
Kapitel ML: I I. Einführung Beispiele für Lernaufgaben Spezifikation von Lernproblemen ML: I-8 Introduction c STEIN/LETTMANN 2005-2010 Beispiele für Lernaufgaben Autoeinkaufsberater Welche Kriterien liegen
Künstliche Intelligenz
 1. Juni, 2017 Künstliche Intelligenz Stand der Forschung, Aktuelle Probleme & Herausforderungen Prof. Dr. Roland Kwitt Fachbereich Computerwissenschaften Universität Salzburg Übersicht Begrifflichkeiten
1. Juni, 2017 Künstliche Intelligenz Stand der Forschung, Aktuelle Probleme & Herausforderungen Prof. Dr. Roland Kwitt Fachbereich Computerwissenschaften Universität Salzburg Übersicht Begrifflichkeiten
Institut für Künstliche Intelligenz
 Institut für Künstliche Intelligenz Prof. Sebstaian Rudolph --- Computational Logic Prof. Steffen Hölldobler --- Wissensverarbeitung Prof. Ivo F. Sbalzarini --- Wissenschaftliches Rechnen für Systembiologie
Institut für Künstliche Intelligenz Prof. Sebstaian Rudolph --- Computational Logic Prof. Steffen Hölldobler --- Wissensverarbeitung Prof. Ivo F. Sbalzarini --- Wissenschaftliches Rechnen für Systembiologie
Einsatz von Reinforcement Learning in der Modellfahrzeugnavigation
 Einsatz von Reinforcement Learning in der Modellfahrzeugnavigation von Manuel Trittel Informatik HAW Hamburg Vortrag im Rahmen der Veranstaltung AW1 im Masterstudiengang, 02.12.2008 der Anwendung Themeneinordnung
Einsatz von Reinforcement Learning in der Modellfahrzeugnavigation von Manuel Trittel Informatik HAW Hamburg Vortrag im Rahmen der Veranstaltung AW1 im Masterstudiengang, 02.12.2008 der Anwendung Themeneinordnung
Machinelles Lernen. «Eine kleine Einführung» BSI Business Systems Integration AG
 Machinelles Lernen «Eine kleine Einführung» @ZimMatthias Matthias Zimmermann BSI Business Systems Integration AG «Welcher Unterschied besteht zum Deep Blue Schachcomputer vor 20 Jahren?» AlphaGo Hardware
Machinelles Lernen «Eine kleine Einführung» @ZimMatthias Matthias Zimmermann BSI Business Systems Integration AG «Welcher Unterschied besteht zum Deep Blue Schachcomputer vor 20 Jahren?» AlphaGo Hardware
Adaptives maschinelles Lernen
 Vortrag: Adaptives maschinelles Lernen Eric Winter Universität Koblenz-Landau Fachbereich Informatik - Institut für Softwaretechnik Seminar Software-Adaptivität - Sommersemester 2011 ericwinter@uni-koblenz.de
Vortrag: Adaptives maschinelles Lernen Eric Winter Universität Koblenz-Landau Fachbereich Informatik - Institut für Softwaretechnik Seminar Software-Adaptivität - Sommersemester 2011 ericwinter@uni-koblenz.de
Einführung in die Bioinformatik: Lernen mit Kernen
 Einführung in die Bioinformatik: Lernen mit Kernen Dr. Karsten Borgwardt Forschungsgruppe für Maschinelles Lernen und Bioinformatik Max-Planck-Institut für Intelligente Systeme & Max-Planck-Institut für
Einführung in die Bioinformatik: Lernen mit Kernen Dr. Karsten Borgwardt Forschungsgruppe für Maschinelles Lernen und Bioinformatik Max-Planck-Institut für Intelligente Systeme & Max-Planck-Institut für
Neural Networks: Architectures and Applications for NLP
 Neural Networks: Architectures and Applications for NLP Session 00: Organisatorisches Julia Kreutzer & Julian Hitschler 25. Oktober 2016 Institut für Computerlinguistik, Heidelberg 1 Überblick 1. Vorstellung
Neural Networks: Architectures and Applications for NLP Session 00: Organisatorisches Julia Kreutzer & Julian Hitschler 25. Oktober 2016 Institut für Computerlinguistik, Heidelberg 1 Überblick 1. Vorstellung
Spieltheorie: UCT. Stefan Edelkamp
 Spieltheorie: UCT Stefan Edelkamp Monte Carlo Simulation Alternative zu Minimax-Algorithmen mit Alpha-Beta Pruning: zufällige Spielabläufe (Simulationen) laufen und ermessen den Wert eines Spieles. Erfolgreich
Spieltheorie: UCT Stefan Edelkamp Monte Carlo Simulation Alternative zu Minimax-Algorithmen mit Alpha-Beta Pruning: zufällige Spielabläufe (Simulationen) laufen und ermessen den Wert eines Spieles. Erfolgreich
Konzepte der AI. Unsicheres Schließen
 Konzepte der AI Unsicheres Schließen http://www.dbai.tuwien.ac.at/education/aikonzepte/ Wolfgang Slany Institut für Informationssysteme, Technische Universität Wien mailto: wsi@dbai.tuwien.ac.at, http://www.dbai.tuwien.ac.at/staff/slany/
Konzepte der AI Unsicheres Schließen http://www.dbai.tuwien.ac.at/education/aikonzepte/ Wolfgang Slany Institut für Informationssysteme, Technische Universität Wien mailto: wsi@dbai.tuwien.ac.at, http://www.dbai.tuwien.ac.at/staff/slany/
Einführung in die Methoden der Künstlichen Intelligenz
 Einführung in die Methoden der Künstlichen Intelligenz --- Vorlesung vom 17.4.2007 --- Sommersemester 2007 Prof. Dr. Ingo J. Timm, Andreas D. Lattner Professur für Wirtschaftsinformatik und Simulation
Einführung in die Methoden der Künstlichen Intelligenz --- Vorlesung vom 17.4.2007 --- Sommersemester 2007 Prof. Dr. Ingo J. Timm, Andreas D. Lattner Professur für Wirtschaftsinformatik und Simulation
Artificial Intelligence. Deep Learning Neuronale Netze
 Artificial Intelligence Deep Learning Neuronale Netze REVOLUTION Lernende Maschinen Mit lernenden Maschinen/Deep Learning erleben wir aktuell eine Revolution in der Informationsverarbeitung. Neue Methoden
Artificial Intelligence Deep Learning Neuronale Netze REVOLUTION Lernende Maschinen Mit lernenden Maschinen/Deep Learning erleben wir aktuell eine Revolution in der Informationsverarbeitung. Neue Methoden
Seminar A - Spieltheorie und Multiagent Reinforcement Learning in Team Spielen
 Seminar A - Spieltheorie und Multiagent Reinforcement Learning in Team Spielen Michael Groß mdgrosse@sbox.tugraz.at 20. Januar 2003 0-0 Matrixspiel Matrix Game, Strategic Game, Spiel in strategischer Form.
Seminar A - Spieltheorie und Multiagent Reinforcement Learning in Team Spielen Michael Groß mdgrosse@sbox.tugraz.at 20. Januar 2003 0-0 Matrixspiel Matrix Game, Strategic Game, Spiel in strategischer Form.
Reinforcement Learning
 Reinforcement Learning 1. Allgemein Reinforcement Learning 2. Neuronales Netz als Bewertungsfunktion 3. Neuronales Netz als Reinforcement Learning Nils-Olaf Bösch 1 Allgemein Reinforcement Learning Unterschied
Reinforcement Learning 1. Allgemein Reinforcement Learning 2. Neuronales Netz als Bewertungsfunktion 3. Neuronales Netz als Reinforcement Learning Nils-Olaf Bösch 1 Allgemein Reinforcement Learning Unterschied
(hoffentlich kurze) Einführung: Neuronale Netze. Dipl.-Inform. Martin Lösch. (0721) Dipl.-Inform.
 Einführung: Neuronale Netze. Dipl.-Inform. Martin Lösch. (0721) Dipl.-Inform.") (hoffentlich kurze) Einführung: martin.loesch@kit.edu (0721) 608 45944 Überblick Einführung Perzeptron Multi-layer Feedforward Neural Network MLNN in der Anwendung 2 EINFÜHRUNG 3 Gehirn des Menschen Vorbild
(hoffentlich kurze) Einführung: martin.loesch@kit.edu (0721) 608 45944 Überblick Einführung Perzeptron Multi-layer Feedforward Neural Network MLNN in der Anwendung 2 EINFÜHRUNG 3 Gehirn des Menschen Vorbild
1.1 Was ist KI? 1.1 Was ist KI? Grundlagen der Künstlichen Intelligenz. 1.2 Menschlich handeln. 1.3 Menschlich denken. 1.
 Grundlagen der Künstlichen Intelligenz 20. Februar 2015 1. Einführung: Was ist Künstliche Intelligenz? Grundlagen der Künstlichen Intelligenz 1. Einführung: Was ist Künstliche Intelligenz? Malte Helmert
Grundlagen der Künstlichen Intelligenz 20. Februar 2015 1. Einführung: Was ist Künstliche Intelligenz? Grundlagen der Künstlichen Intelligenz 1. Einführung: Was ist Künstliche Intelligenz? Malte Helmert
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz 1. Einführung: Was ist Künstliche Intelligenz? Malte Helmert Universität Basel 20. Februar 2015 Einführung: Überblick Kapitelüberblick Einführung: 1. Was ist Künstliche
Grundlagen der Künstlichen Intelligenz 1. Einführung: Was ist Künstliche Intelligenz? Malte Helmert Universität Basel 20. Februar 2015 Einführung: Überblick Kapitelüberblick Einführung: 1. Was ist Künstliche
Kybernetik Einführung
 Kybernetik Einführung Mohamed Oubbati Institut für Neuroinformatik Tel.: (+49) 731 / 50 24153 mohamed.oubbati@uni-ulm.de 24. 04. 2012 Einführung Was ist Kybernetik? Der Begriff Kybernetik wurde im 1948
Kybernetik Einführung Mohamed Oubbati Institut für Neuroinformatik Tel.: (+49) 731 / 50 24153 mohamed.oubbati@uni-ulm.de 24. 04. 2012 Einführung Was ist Kybernetik? Der Begriff Kybernetik wurde im 1948
Inpainting. Jane Dienemann Benjamin Vorwerk. Seminar Computational Photography Dozent: Prof. Dr.-Ing.Eisert Sommersemester 2010
 Inpainting Jane Dienemann Benjamin Vorwerk Seminar Computational Photography Dozent: Prof. Dr.-Ing.Eisert Sommersemester 2010 1 Übersicht I. Der Begriff Inpainting II. Die Geschichte der Bildbearbeitung
Inpainting Jane Dienemann Benjamin Vorwerk Seminar Computational Photography Dozent: Prof. Dr.-Ing.Eisert Sommersemester 2010 1 Übersicht I. Der Begriff Inpainting II. Die Geschichte der Bildbearbeitung
Website. Vorlesung Statistisches Lernen. Dozenten. Termine. Einheit 1: Einführung
 Website Vorlesung Statistisches Lernen Einheit 1: Einführung Dr. rer. nat. Christine Pausch Institut für Medizinische Informatik, Statistik und Epidemiologie Universität Leipzig (Aktuelle) Informationen
Website Vorlesung Statistisches Lernen Einheit 1: Einführung Dr. rer. nat. Christine Pausch Institut für Medizinische Informatik, Statistik und Epidemiologie Universität Leipzig (Aktuelle) Informationen
Vorlesung Statistisches Lernen
 Vorlesung Statistisches Lernen Einheit 1: Einführung Dr. rer. nat. Christine Pausch Institut für Medizinische Informatik, Statistik und Epidemiologie Universität Leipzig WS 2014/2015 1 / 20 Organisatorisches
Vorlesung Statistisches Lernen Einheit 1: Einführung Dr. rer. nat. Christine Pausch Institut für Medizinische Informatik, Statistik und Epidemiologie Universität Leipzig WS 2014/2015 1 / 20 Organisatorisches
kurze Wiederholung der letzten Stunde: Neuronale Netze Dipl.-Inform. Martin Lösch (0721) Dipl.-Inform.
 Dipl.-Inform.") kurze Wiederholung der letzten Stunde: Neuronale Netze martin.loesch@kit.edu (0721) 608 45944 Labor Wissensrepräsentation Übersicht Neuronale Netze Motivation Perzeptron Grundlagen für praktische Übungen
kurze Wiederholung der letzten Stunde: Neuronale Netze martin.loesch@kit.edu (0721) 608 45944 Labor Wissensrepräsentation Übersicht Neuronale Netze Motivation Perzeptron Grundlagen für praktische Übungen
Entwicklung einer Entscheidungssystematik für Data- Mining-Verfahren zur Erhöhung der Planungsgüte in der Produktion
 Entwicklung einer Entscheidungssystematik für Data- Mining-Verfahren zur Erhöhung der Planungsgüte in der Produktion Vortrag Seminararbeit David Pogorzelski Aachen, 22.01.2015 Agenda 1 2 3 4 5 Ziel der
Entwicklung einer Entscheidungssystematik für Data- Mining-Verfahren zur Erhöhung der Planungsgüte in der Produktion Vortrag Seminararbeit David Pogorzelski Aachen, 22.01.2015 Agenda 1 2 3 4 5 Ziel der
Machine Learning Spielen allgemeiner Spiele. Stefan Edelkamp
 Machine Learning Spielen allgemeiner Spiele Stefan Edelkamp Themen Allgemeines Spiel Einführung Game Desciption Language (GDL) Spielen allgemeiner Spiele Heuristiken im allgemeinen Spiel und Verbesserungen
Machine Learning Spielen allgemeiner Spiele Stefan Edelkamp Themen Allgemeines Spiel Einführung Game Desciption Language (GDL) Spielen allgemeiner Spiele Heuristiken im allgemeinen Spiel und Verbesserungen
Grundlagen der Künstlichen Intelligenz
 KI Wintersemester 2013/2014 Grundlagen der Künstlichen Intelligenz Marc Toussaint Machine Learning & Robotics Lab Universität Stuttgart marc.toussaint@informatik.uni-stuttgart.de http://ipvs.informatik.uni-stuttgart.de/mlr/marc/
KI Wintersemester 2013/2014 Grundlagen der Künstlichen Intelligenz Marc Toussaint Machine Learning & Robotics Lab Universität Stuttgart marc.toussaint@informatik.uni-stuttgart.de http://ipvs.informatik.uni-stuttgart.de/mlr/marc/
RL und Funktionsapproximation
 RL und Funktionsapproximation Bisher sind haben wir die Funktionen V oder Q als Tabellen gespeichert. Im Allgemeinen sind die Zustandsräume und die Zahl der möglichen Aktionen sehr groß. Deshalb besteht
RL und Funktionsapproximation Bisher sind haben wir die Funktionen V oder Q als Tabellen gespeichert. Im Allgemeinen sind die Zustandsräume und die Zahl der möglichen Aktionen sehr groß. Deshalb besteht
kurze Wiederholung der letzten Stunde: Neuronale Netze Dipl.-Inform. Martin Lösch (0721) Dipl.-Inform.
 Dipl.-Inform.") kurze Wiederholung der letzten Stunde: Neuronale Netze martin.loesch@kit.edu (0721) 608 45944 Labor Wissensrepräsentation Aufgaben der letzten Stunde Übersicht Neuronale Netze Motivation Perzeptron Multilayer
kurze Wiederholung der letzten Stunde: Neuronale Netze martin.loesch@kit.edu (0721) 608 45944 Labor Wissensrepräsentation Aufgaben der letzten Stunde Übersicht Neuronale Netze Motivation Perzeptron Multilayer
3. Das Reinforcement Lernproblem
 3. Das Reinforcement Lernproblem 1. Agierender Agent in der Umgebung 2. Discounted Rewards 3. Markov Eigenschaft des Zustandssignals 4. Markov sche Entscheidung 5. Werte-Funktionen und Bellman sche Optimalität
3. Das Reinforcement Lernproblem 1. Agierender Agent in der Umgebung 2. Discounted Rewards 3. Markov Eigenschaft des Zustandssignals 4. Markov sche Entscheidung 5. Werte-Funktionen und Bellman sche Optimalität
Mustererkennung und Klassifikation
 Mustererkennung und Klassifikation WS 2007/2008 Fakultät Informatik Technische Informatik Prof. Dr. Matthias Franz mfranz@htwg-konstanz.de www-home.htwg-konstanz.de/~mfranz/heim.html Grundlagen Überblick
Mustererkennung und Klassifikation WS 2007/2008 Fakultät Informatik Technische Informatik Prof. Dr. Matthias Franz mfranz@htwg-konstanz.de www-home.htwg-konstanz.de/~mfranz/heim.html Grundlagen Überblick
Reinforcement Learning 2
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning 2 Uwe Dick Inhalt Erinnerung: Bellman-Gleichungen, Bellman-Operatoren Policy Iteration Sehr große oder kontinuierliche
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning 2 Uwe Dick Inhalt Erinnerung: Bellman-Gleichungen, Bellman-Operatoren Policy Iteration Sehr große oder kontinuierliche
Text-Mining: Einführung
 Text-Mining: Einführung Claes Neuefeind Fabian Steeg 22. April 2010 Organisatorisches Was ist Text-Mining? Definitionen Anwendungsbeispiele Textuelle Daten Aufgaben u. Teilbereiche Literatur Kontakt Sprechstunde:
Text-Mining: Einführung Claes Neuefeind Fabian Steeg 22. April 2010 Organisatorisches Was ist Text-Mining? Definitionen Anwendungsbeispiele Textuelle Daten Aufgaben u. Teilbereiche Literatur Kontakt Sprechstunde:
Künstliche Neuronale Netze
 Fakultät Informatik, Institut für Technische Informatik, Professur für VLSI-Entwurfssysteme, Diagnostik und Architektur Künstliche Neuronale Netze Hauptseminar Martin Knöfel Dresden, 16.11.2017 Gliederung
Fakultät Informatik, Institut für Technische Informatik, Professur für VLSI-Entwurfssysteme, Diagnostik und Architektur Künstliche Neuronale Netze Hauptseminar Martin Knöfel Dresden, 16.11.2017 Gliederung
Testfallgenerierung aus Statecharts und Interaktionsdiagrammen
 Testfallgenerierung aus Statecharts und Interaktionsdiagrammen Dehla Sokenou TU Berlin Softwaretechnik Motivation Warum Testen mit Hilfe von UML? UML verbreitete Spezifikationssprache in der Objektorientierung
Testfallgenerierung aus Statecharts und Interaktionsdiagrammen Dehla Sokenou TU Berlin Softwaretechnik Motivation Warum Testen mit Hilfe von UML? UML verbreitete Spezifikationssprache in der Objektorientierung
Thinking Machine. Idee. Die Thinking Machine Visualisierung versucht, die Denkprozesse eines Schachcomputers sichtbar zu machen
 Thinking Machine (http://www.turbulence.org/spotlight/thinking/) Idee Die Thinking Machine Visualisierung versucht, die Denkprozesse eines Schachcomputers sichtbar zu machen Sie wurde von Martin Wattenberg
Thinking Machine (http://www.turbulence.org/spotlight/thinking/) Idee Die Thinking Machine Visualisierung versucht, die Denkprozesse eines Schachcomputers sichtbar zu machen Sie wurde von Martin Wattenberg
Proposal zur Masterarbeit. Kombination der neuroevolutionären Methoden EANT mit Q-Learning und CMA-ES
 Proposal zur Masterarbeit Kombination der neuroevolutionären Methoden EANT mit Q-Learning und CMA-ES Tchando Kongue Einleitung Neuroevolutionäre Algorithmen sind Methoden, die durch die Benutzung von genetischen
Proposal zur Masterarbeit Kombination der neuroevolutionären Methoden EANT mit Q-Learning und CMA-ES Tchando Kongue Einleitung Neuroevolutionäre Algorithmen sind Methoden, die durch die Benutzung von genetischen
Einführung in die Künstliche Intelligenz
 Einführung in die Künstliche Intelligenz Vorlesung WS 2004/05 Joachim Hertzberg, Andreas Nüchter (Übungen) Institut für Informatik Abteilung Wissensbasierte Systeme 1 Web-Seite Organisatorisches http://www.inf.uos.de/hertzberg/lehre/2004_ws/vorlesung_ki-intro/ki_ws04.html
Einführung in die Künstliche Intelligenz Vorlesung WS 2004/05 Joachim Hertzberg, Andreas Nüchter (Übungen) Institut für Informatik Abteilung Wissensbasierte Systeme 1 Web-Seite Organisatorisches http://www.inf.uos.de/hertzberg/lehre/2004_ws/vorlesung_ki-intro/ki_ws04.html
Markov-Ketten-Monte-Carlo-Verfahren
 Markov-Ketten-Monte-Carlo-Verfahren Anton Klimovsky 21. Juli 2014 Strichprobenerzeugung aus einer Verteilung (das Samplen). Markov- Ketten-Monte-Carlo-Verfahren. Metropolis-Hastings-Algorithmus. Gibbs-Sampler.
Markov-Ketten-Monte-Carlo-Verfahren Anton Klimovsky 21. Juli 2014 Strichprobenerzeugung aus einer Verteilung (das Samplen). Markov- Ketten-Monte-Carlo-Verfahren. Metropolis-Hastings-Algorithmus. Gibbs-Sampler.
Monte Carlo Methoden
 Monte Carlo Methoden Lernverfahren zur Berechnung von Wertefunktionen und Policies werden vorgestellt. Vollständige Kenntnis der Dynamik wird nicht vorausgesetzt (im Gegensatz zu den Verfahren der DP).
Monte Carlo Methoden Lernverfahren zur Berechnung von Wertefunktionen und Policies werden vorgestellt. Vollständige Kenntnis der Dynamik wird nicht vorausgesetzt (im Gegensatz zu den Verfahren der DP).
Grundlagen Neuronaler Netze
 Grundlagen Neuronaler Netze Proseminar Data Mining Julian Schmitz Fakultät für Informatik Technische Universität München Email: ga97wuy@mytum.de Zusammenfassung Diese Ausarbeitung will sich als hilfreiches
Grundlagen Neuronaler Netze Proseminar Data Mining Julian Schmitz Fakultät für Informatik Technische Universität München Email: ga97wuy@mytum.de Zusammenfassung Diese Ausarbeitung will sich als hilfreiches
Übersicht. 5. Spiele. I Künstliche Intelligenz II Problemlösen 3. Problemlösen durch Suche 4. Informierte Suchmethoden
 Übersicht I Künstliche Intelligenz II Problemlösen 3. Problemlösen durch Suche 4. Informierte Suchmethoden 5. Spiele III Wissen und Schlußfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen VI
Übersicht I Künstliche Intelligenz II Problemlösen 3. Problemlösen durch Suche 4. Informierte Suchmethoden 5. Spiele III Wissen und Schlußfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen VI
5. Lokale Suchverfahren. Beispiel TSP: k-change Nachbarschaft. Nachbarschaft. k-opt Algorithmus
 5. Lokale Suchverfahren Lokale Suche 5. Lokale Suchverfahren Beispiel TSP: k-change Nachbarschaft Optimale Lösungen können oft nicht effizient ermittelt werden. Heuristiken liefern zwar zulässige Lösungen,
5. Lokale Suchverfahren Lokale Suche 5. Lokale Suchverfahren Beispiel TSP: k-change Nachbarschaft Optimale Lösungen können oft nicht effizient ermittelt werden. Heuristiken liefern zwar zulässige Lösungen,
INTELLIGENTE DATENANALYSE IN MATLAB. Überwachtes Lernen: Entscheidungsbäume
 INTELLIGENTE DATENANALYSE IN MATLAB Überwachtes Lernen: Entscheidungsbäume Literatur Stuart Russell und Peter Norvig: Artificial Intelligence. Andrew W. Moore: http://www.autonlab.org/tutorials. 2 Überblick
INTELLIGENTE DATENANALYSE IN MATLAB Überwachtes Lernen: Entscheidungsbäume Literatur Stuart Russell und Peter Norvig: Artificial Intelligence. Andrew W. Moore: http://www.autonlab.org/tutorials. 2 Überblick
Praktikum Algorithmen-Entwurf (Teil 7)
") Praktikum Algorithmen-Entwurf (Teil 7) 28.11.2005 1 1 Vier gewinnt Die Spielregeln von Vier Gewinnt sind sehr einfach: Das Spielfeld besteht aus 7 Spalten und 6 Reihen. Jeder Spieler erhält zu Beginn des
Praktikum Algorithmen-Entwurf (Teil 7) 28.11.2005 1 1 Vier gewinnt Die Spielregeln von Vier Gewinnt sind sehr einfach: Das Spielfeld besteht aus 7 Spalten und 6 Reihen. Jeder Spieler erhält zu Beginn des
Simulation von Zinsentwicklungen und Bewertung von gängigen Finanzprodukten
 Simulation von Zinsentwicklungen und Bewertung von gängigen Finanzprodukten Andreas Eichler Institut für Finanzmathematik Johannes Kepler Universität Linz 1. Februar 2010 1 / 7 Gliederung 1 Was ist Finanzmathematik
Simulation von Zinsentwicklungen und Bewertung von gängigen Finanzprodukten Andreas Eichler Institut für Finanzmathematik Johannes Kepler Universität Linz 1. Februar 2010 1 / 7 Gliederung 1 Was ist Finanzmathematik
Multivariate Pattern Analysis. Jan Mehnert, Christoph Korn
 Multivariate Pattern Analysis Jan Mehnert, Christoph Korn Übersicht 1. Motivation 2. Features 3. Klassifizierung 4. Statistik 5. Annahmen & Design 6. Similarity 7. Beispiel Grenzen & Probleme der klassischen
Multivariate Pattern Analysis Jan Mehnert, Christoph Korn Übersicht 1. Motivation 2. Features 3. Klassifizierung 4. Statistik 5. Annahmen & Design 6. Similarity 7. Beispiel Grenzen & Probleme der klassischen
Oberflächennahe und ferne Gestenerkennung mittels 3D-Sensorik
 Oberflächennahe und ferne Gestenerkennung mittels 3D-Sensorik 26.10.2016 Gliederung Gesten für Mensch-Maschine Interaktion Anwendungsszenario Interaktive Projektionssitzkiste Herausforderungen Lösungsansatz
Oberflächennahe und ferne Gestenerkennung mittels 3D-Sensorik 26.10.2016 Gliederung Gesten für Mensch-Maschine Interaktion Anwendungsszenario Interaktive Projektionssitzkiste Herausforderungen Lösungsansatz
Künstliche Intelligenz - Optimierungsprobleme - Suche in Spielbäumen
 Künstliche Intelligenz - Optimierungsprobleme - Suche in Spielbäumen Stephan Schwiebert WS 2009/2010 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Optimierungsprobleme
Künstliche Intelligenz - Optimierungsprobleme - Suche in Spielbäumen Stephan Schwiebert WS 2009/2010 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Optimierungsprobleme
Sentiment Analysis (SA) Robert Bärhold & Mario Sänger Text Analytics WS 2012/13 Prof. Leser
 Robert Bärhold & Mario Sänger Text Analytics WS 2012/13 Prof. Leser") Sentiment Analysis (SA) Robert Bärhold & Mario Sänger Text Analytics WS 2012/13 Prof. Leser Gliederung Einleitung Problemstellungen Ansätze & Herangehensweisen Anwendungsbeispiele Zusammenfassung 2 Gliederung
Sentiment Analysis (SA) Robert Bärhold & Mario Sänger Text Analytics WS 2012/13 Prof. Leser Gliederung Einleitung Problemstellungen Ansätze & Herangehensweisen Anwendungsbeispiele Zusammenfassung 2 Gliederung
Deduktives Lernen Explanation-Based Learning
 Deduktives Lernen Explanation-Based Learning Algorithmus grundlegende Idee anhand eines Beispiels Eigenschaften von EBL Utility Problem Implementierung als PROLOG Meta-Interpreter Operationalisierung 1
Deduktives Lernen Explanation-Based Learning Algorithmus grundlegende Idee anhand eines Beispiels Eigenschaften von EBL Utility Problem Implementierung als PROLOG Meta-Interpreter Operationalisierung 1
Reinforcement Learning für Brettspiele: Der Temporal Difference Algorithmus
 e-print http://www.gm.fh-koeln.de/ciopwebpub/kone15a.d/tr-tdgame.pdf, Februar 2015 Reinforcement Learning für Brettspiele: Der Temporal Difference Algorithmus Wolfgang Konen Institut für Informatik, Fakultät
e-print http://www.gm.fh-koeln.de/ciopwebpub/kone15a.d/tr-tdgame.pdf, Februar 2015 Reinforcement Learning für Brettspiele: Der Temporal Difference Algorithmus Wolfgang Konen Institut für Informatik, Fakultät
Modulliste. für den Bachelorstudiengang. Wirtschaftsinformatik. an der Otto-von-Guericke-Universität Magdeburg Fakultät für Informatik
 Modulliste für den Bachelorstudiengang Wirtschaftsinformatik an der Otto-von-Guericke-Universität Magdeburg Fakultät für Informatik vom Sommersemester 2017 Der Bachelorstudiengang Wirtschaftsinformatik
Modulliste für den Bachelorstudiengang Wirtschaftsinformatik an der Otto-von-Guericke-Universität Magdeburg Fakultät für Informatik vom Sommersemester 2017 Der Bachelorstudiengang Wirtschaftsinformatik
Validation Model Selection Kreuz-Validierung Handlungsanweisungen. Validation. Oktober, von 20 Validation
 Validation Oktober, 2013 1 von 20 Validation Lernziele Konzepte des maschinellen Lernens Validierungsdaten Model Selection Kreuz-Validierung (Cross Validation) 2 von 20 Validation Outline 1 Validation
Validation Oktober, 2013 1 von 20 Validation Lernziele Konzepte des maschinellen Lernens Validierungsdaten Model Selection Kreuz-Validierung (Cross Validation) 2 von 20 Validation Outline 1 Validation
Diskrete Strukturen WS 2010/11. Ernst W. Mayr. Wintersemester 2010/11. Fakultät für Informatik TU München
 WS 2010/11 Diskrete Strukturen Ernst W. Mayr Fakultät für Informatik TU München http://www14.in.tum.de/lehre/2010ws/ds/ Wintersemester 2010/11 Diskrete Strukturen Kapitel 0 Organisatorisches Vorlesungen:
WS 2010/11 Diskrete Strukturen Ernst W. Mayr Fakultät für Informatik TU München http://www14.in.tum.de/lehre/2010ws/ds/ Wintersemester 2010/11 Diskrete Strukturen Kapitel 0 Organisatorisches Vorlesungen:
Konzepte der AI: Maschinelles Lernen
 Konzepte der AI: Maschinelles Lernen Nysret Musliu, Wolfgang Slany Abteilung für Datenbanken und Artificial Intelligence Institut für Informationssysteme, TU-Wien Übersicht Was ist Lernen? Wozu maschinelles
Konzepte der AI: Maschinelles Lernen Nysret Musliu, Wolfgang Slany Abteilung für Datenbanken und Artificial Intelligence Institut für Informationssysteme, TU-Wien Übersicht Was ist Lernen? Wozu maschinelles
Formale Verifikation von Software. 10. Juli 2013
 Formale Verifikation von Software 10. Juli 2013 Überblick Wann ist formale Softwareverifikation sinnvoll? Welche Techniken gibt es? Was ist Model Checking und wie kann man es zur Verifikation einsetzen?
Formale Verifikation von Software 10. Juli 2013 Überblick Wann ist formale Softwareverifikation sinnvoll? Welche Techniken gibt es? Was ist Model Checking und wie kann man es zur Verifikation einsetzen?
Knowledge Engineering und Lernen in Spielen. Thema: Opening Book Learning von: Thomas Widjaja
 Knowledge Engineering und Lernen in Spielen Thema: Opening Book Learning von: Thomas Widjaja Gliederung Allgemeines Drei Beispielverfahren zum Anpassen eines Opening Books Deep Blue Logistello (Michael
Knowledge Engineering und Lernen in Spielen Thema: Opening Book Learning von: Thomas Widjaja Gliederung Allgemeines Drei Beispielverfahren zum Anpassen eines Opening Books Deep Blue Logistello (Michael
Theoretische Informatik 1
 Theoretische Informatik 1 Boltzmann Maschine David Kappel Institut für Grundlagen der Informationsverarbeitung TU Graz SS 2014 Übersicht Boltzmann Maschine Neuronale Netzwerke Die Boltzmann Maschine Gibbs
Theoretische Informatik 1 Boltzmann Maschine David Kappel Institut für Grundlagen der Informationsverarbeitung TU Graz SS 2014 Übersicht Boltzmann Maschine Neuronale Netzwerke Die Boltzmann Maschine Gibbs
ERSTELLUNG EINES KONZEPTS ZUM TESTEN DER PERFORMANCE VON JAVA CODE MIT HILFE DER FRAMEWORKS JUNIT UND TESTNG
 ERSTELLUNG EINES KONZEPTS ZUM TESTEN DER PERFORMANCE VON JAVA CODE MIT HILFE DER FRAMEWORKS JUNIT UND TESTNG VORTRAG ZUR SEMINARARBEIT JOHANNES WALLFAHRER 20. JANUAR 2016 Inhalt 1. Einleitung 2. Was ist
ERSTELLUNG EINES KONZEPTS ZUM TESTEN DER PERFORMANCE VON JAVA CODE MIT HILFE DER FRAMEWORKS JUNIT UND TESTNG VORTRAG ZUR SEMINARARBEIT JOHANNES WALLFAHRER 20. JANUAR 2016 Inhalt 1. Einleitung 2. Was ist
Real-time MCTS (4.7) Seminar aus maschinellem Lernen
 Seminar aus maschinellem Lernen") Real-time MCTS (4.7) Seminar aus maschinellem Lernen 20.01.2015 Real-time MCTS David Kaufmann 1 Übersicht Real-time MCTS Was ist das? Beispiele für MCTS in Spielen Tron Ms. Pac-Man 20.01.2015 Real-time
Real-time MCTS (4.7) Seminar aus maschinellem Lernen 20.01.2015 Real-time MCTS David Kaufmann 1 Übersicht Real-time MCTS Was ist das? Beispiele für MCTS in Spielen Tron Ms. Pac-Man 20.01.2015 Real-time
SE Biologisch motivierte Lernverfahren
 SE Biologisch motivierte Lernverfahren Matthias Kubisch kubisch@informatik.hu-berlin.de Labor für Neurorobotik Institut für Informatik Humboldt-Universität zu Berlin 11. April 2012 1 / 18 Übersicht 1 Themen
SE Biologisch motivierte Lernverfahren Matthias Kubisch kubisch@informatik.hu-berlin.de Labor für Neurorobotik Institut für Informatik Humboldt-Universität zu Berlin 11. April 2012 1 / 18 Übersicht 1 Themen
TD-Gammon. Michael Zilske
 TD-Gammon Michael Zilske zilske@inf.fu-berlin.de TD-Gammon Ein Backgammon-Spieler von Gerald Tesauro (Erste Version: 1991) TD-Gammon Ein Neuronales Netz, das immer wieder gegen sich selbst spielt und dadurch
TD-Gammon Michael Zilske zilske@inf.fu-berlin.de TD-Gammon Ein Backgammon-Spieler von Gerald Tesauro (Erste Version: 1991) TD-Gammon Ein Neuronales Netz, das immer wieder gegen sich selbst spielt und dadurch
Seminar über aktuelle Forschungsthemen in der Algorithmik, Dozent Prof. Dr. Alt;
 Seminar über aktuelle Forschungsthemen in der Algorithmik, Dozent Prof. Dr. Alt Referent Matthias Rost 1 Einleitung Definitionen Maximaler Dynamischer Fluss Algorithmus von Ford-Fulkerson Techniken zur
Seminar über aktuelle Forschungsthemen in der Algorithmik, Dozent Prof. Dr. Alt Referent Matthias Rost 1 Einleitung Definitionen Maximaler Dynamischer Fluss Algorithmus von Ford-Fulkerson Techniken zur
Einführung in die Methoden der Künstlichen Intelligenz. Klausurvorbereitung Überblick, Fragen,...
 Einführung in die Methoden der Künstlichen Intelligenz Klausurvorbereitung Überblick, Fragen,... PD Dr. David Sabel SoSe 2014 Stand der Folien: 18. Juli 2014 Klausur Termin: Donnerstag 31. Juli um 9.15h
Einführung in die Methoden der Künstlichen Intelligenz Klausurvorbereitung Überblick, Fragen,... PD Dr. David Sabel SoSe 2014 Stand der Folien: 18. Juli 2014 Klausur Termin: Donnerstag 31. Juli um 9.15h
Intelligente Klassifizierung von technischen Inhalten. Automatisierung und Anwendungspotenziale
 Intelligente Klassifizierung von technischen Inhalten Automatisierung und Anwendungspotenziale Künstliche Intelligenz Machine Learning Deep Learning 1950 1980 2010 Abgeleitet von: https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/
Intelligente Klassifizierung von technischen Inhalten Automatisierung und Anwendungspotenziale Künstliche Intelligenz Machine Learning Deep Learning 1950 1980 2010 Abgeleitet von: https://blogs.nvidia.com/blog/2016/07/29/whats-difference-artificial-intelligence-machine-learning-deep-learning-ai/
Temporal Difference Learning
 Temporal Difference Learning Das Temporal Difference (TD) Lernen ist eine bedeutende Entwicklung im Reinforcement Lernen. Im TD Lernen werden Ideen der Monte Carlo (MC) und dynamische Programmierung (DP)
Temporal Difference Learning Das Temporal Difference (TD) Lernen ist eine bedeutende Entwicklung im Reinforcement Lernen. Im TD Lernen werden Ideen der Monte Carlo (MC) und dynamische Programmierung (DP)
Neue Trends und neue Möglichkeiten der datengetriebenen Versorgungsforschung
 Neue Trends und neue Möglichkeiten der datengetriebenen Versorgungsforschung Hamburg 16.11.2016 Nmedia Fotolia Fraunhofer-Institut für Intelligente Analyseund Informationssysteme Fraunhofer IAIS - Wir
Neue Trends und neue Möglichkeiten der datengetriebenen Versorgungsforschung Hamburg 16.11.2016 Nmedia Fotolia Fraunhofer-Institut für Intelligente Analyseund Informationssysteme Fraunhofer IAIS - Wir
Prozessoptimierung im Krankenhausbereich. Ursula-Änna Schmidt. Verlag Dr. Kovac
 Ursula-Änna Schmidt Prozessoptimierung im Krankenhausbereich Logistische Abläufe mit Schwerpunkt Radiologie und deren Verbesserungspotenziale Verlag Dr. Kovac Hamburg 2011 ^ Abbildungsverzeichnis XI Tabellenverzeichnis
Ursula-Änna Schmidt Prozessoptimierung im Krankenhausbereich Logistische Abläufe mit Schwerpunkt Radiologie und deren Verbesserungspotenziale Verlag Dr. Kovac Hamburg 2011 ^ Abbildungsverzeichnis XI Tabellenverzeichnis
1. Lernen von Konzepten
 1. Lernen von Konzepten Definition des Lernens 1. Lernen von Konzepten Lernziele: Definitionen des maschinellen Lernens kennen, Klassifikationen des maschinellen Lernens kennen, Das Prinzip des induktiven
1. Lernen von Konzepten Definition des Lernens 1. Lernen von Konzepten Lernziele: Definitionen des maschinellen Lernens kennen, Klassifikationen des maschinellen Lernens kennen, Das Prinzip des induktiven
Kapitel III Selektieren und Sortieren
 Kapitel III Selektieren und Sortieren 1. Einleitung Gegeben: Menge S von n Elementen aus einem total geordneten Universum U, i N, 1 i n. Gesucht: i-kleinstes Element in S. Die Fälle i = 1 bzw. i = n entsprechen
Kapitel III Selektieren und Sortieren 1. Einleitung Gegeben: Menge S von n Elementen aus einem total geordneten Universum U, i N, 1 i n. Gesucht: i-kleinstes Element in S. Die Fälle i = 1 bzw. i = n entsprechen
Software vergleichen. Andrea Herrmann AndreaHerrmann3@gmx.de. 25.11.2011 Fachgruppentreffen RE
 Software vergleichen Andrea Herrmann AndreaHerrmann3@gmx.de 25.11.2011 Fachgruppentreffen RE Übersicht 1. Motivation 2. Stand der Forschung 3. Gap-Analyse versus Delta-Analyse 4. Grafischer Vergleich 5.
Software vergleichen Andrea Herrmann AndreaHerrmann3@gmx.de 25.11.2011 Fachgruppentreffen RE Übersicht 1. Motivation 2. Stand der Forschung 3. Gap-Analyse versus Delta-Analyse 4. Grafischer Vergleich 5.
Dekonvolution von Omnikamerabildern
 1 / 23 Dekonvolution von Omnikamerabildern Tobias Börtitz, Hermann Lorenz, Lutz Krätzer, Josef Söntgen Betreuer: Richard Schmidt HTW Dresden, Deutschland Abschluß Präsentation 15. Februar 2012 2 / 23 1
1 / 23 Dekonvolution von Omnikamerabildern Tobias Börtitz, Hermann Lorenz, Lutz Krätzer, Josef Söntgen Betreuer: Richard Schmidt HTW Dresden, Deutschland Abschluß Präsentation 15. Februar 2012 2 / 23 1
Projektpraktikum MultimediaGrid
 Projektpraktikum MultimediaGrid WS 2005/06 Carsten Saathoff Bernhard Tausch Agenda Motivation Aufgaben Zeitplan Vortragsthemen Auswahl des Managements Motivation Grid Wikipedia: Grid computing offers a
Projektpraktikum MultimediaGrid WS 2005/06 Carsten Saathoff Bernhard Tausch Agenda Motivation Aufgaben Zeitplan Vortragsthemen Auswahl des Managements Motivation Grid Wikipedia: Grid computing offers a
Intelligente Algorithmen Einführung in die Technologie
 Intelligente Algorithmen Einführung in die Technologie Dr. KIT Universität des Landes Baden-Württemberg und nationales Forschungszentrum in der Helmholtz-Gemeinschaft www.kit.edu Natürlich sprachliche
Intelligente Algorithmen Einführung in die Technologie Dr. KIT Universität des Landes Baden-Württemberg und nationales Forschungszentrum in der Helmholtz-Gemeinschaft www.kit.edu Natürlich sprachliche
Spiele als Suchproblem
 Spiele als Suchproblem betrachten Spiele für zwei Personen, diese sind abwechselnd am Zug Spiel endet in einem aus einer Menge möglicher Terminalzustände deterministische, im Prinzip zugängliche Umgebung
Spiele als Suchproblem betrachten Spiele für zwei Personen, diese sind abwechselnd am Zug Spiel endet in einem aus einer Menge möglicher Terminalzustände deterministische, im Prinzip zugängliche Umgebung