1. Computer und neuronale Netze
|
|
|
- Katrin Breiner
- vor 6 Jahren
- Abrufe
Transkript
1 1. Computer und neuronale Netze 1. Was ist die Neuroinformatik? 2. Aufgaben für neuronale Systeme 3. Computer vs. neuronale Netze NI1 1
2 Neuroinformatik ist die Wissenschaft, die sich mit der Informationsverarbeitung in neuronalen Systemen (biologischen und künstlichen) befasst. Neuroinformatik Neurowissenschaften Informatik Neurobiologie Neurophysiologie Neuroanatomie Information Automatik Mathematik Psychologie Kognitionswissenschaften Neuronale Systeme Informationsverarbeitung NI1 2
3 Aufgaben für neuronale Systeme Für welche Aufgabenstellungen sind neuronale Systeme geeignet? Visuelle Erkennung: Erkennung von Objekten, Gesichtern, Handschriftzeichen. Akustische Erkennung: Erkennung von kontinuierlich gesprochener Sprache, die Identifizierung eines Sprechers. Autonome Systeme: Lokalisation im Raum, Ausweichen von Hindernissen, Planung von Wegen. Arithmetik: Berechnung von , π = 3, (Mathematische) Beweise: Gibt es natürliche Zahlen x, y und z, so dass die Gleichung x n + y n = z n für natürliche Zahlen n > 2 erfüllt ist? NI1 3
4 Computer wenige aber komplexe Prozessoren niedriger Vernetzungsgrad 10 1 Taktfrequenz liegt im GHz-Bereich Neuronale Systeme viele einfache Neuronen, z. B. im menschlichen Gehirn hoher Vernetzungsgrad Synapsen pro Neuron wenige hundert Spikes pro Sekunde kaum fehlertolerant fehlertolerant (fuzzy, verrauschte oder wiedersprüchliche Daten) nicht robust; Störung führen meist zum Ausfall explizite Programmierung Trennung von Programmen und Daten robust bzw. stetig; Störung bedeutet kein Totalausfall, sondern eingeschränkte Funktionalität lernen durch Beispiele Keine Trennung; die Synapsenstärke beeinflußt die Neuronenaktivität und umgekehrt NI1 4
5 2. Biologische Grundlagen neuronaler Netze 1. Gehirn 2. Neuron 3. Synapse 4. Neuronale Dynamik NI1 5
. Großhirnrinde und Kleinhirn sind gezeigt.")
6 Menschliches Gehirn Ansicht eines menschlichen Gehirns (von links-hinten). Großhirnrinde und Kleinhirn sind gezeigt. NI1 6
 des Großhirns bei")
7 Gehirne einiger Tiere Fortschreitende Vergrößerung (bzgl. des Volumens und der Einfaltungen) des Großhirns bei Wirbeltieren. NI1 7

; Sternzellen (H-M).")
8 Links: Seitenansicht der linken Gehirnhemisphäre beim Menschen. Die Oberfläche ist stark gefaltet; verschiedene Felder mit ihrer Spezialisierung auf Teilaufgaben sind abgegrenzt. Rechts: Schnitt durch die Hirnrinde einer Katze. Pyramidenzellen (A-G); Sternzellen (H-M). Etwa 1% der Nervenzellen sind durch spezielle Färbungstechniken gezeigt. Menschliches Gehirn: Neuronen. NI1 8

9 Somatosensorische und motorische Hirnrinde NI1 9
10 Schichtenstruktur der Großhirnrinde. Es sind verschiedene neuronale Strukturen gezeigt: Neuronen mit Nervenfasern(links) Verteilung der Zellkörper (Mitte). Organisation der Nervenfasern (rechts). NI1 10
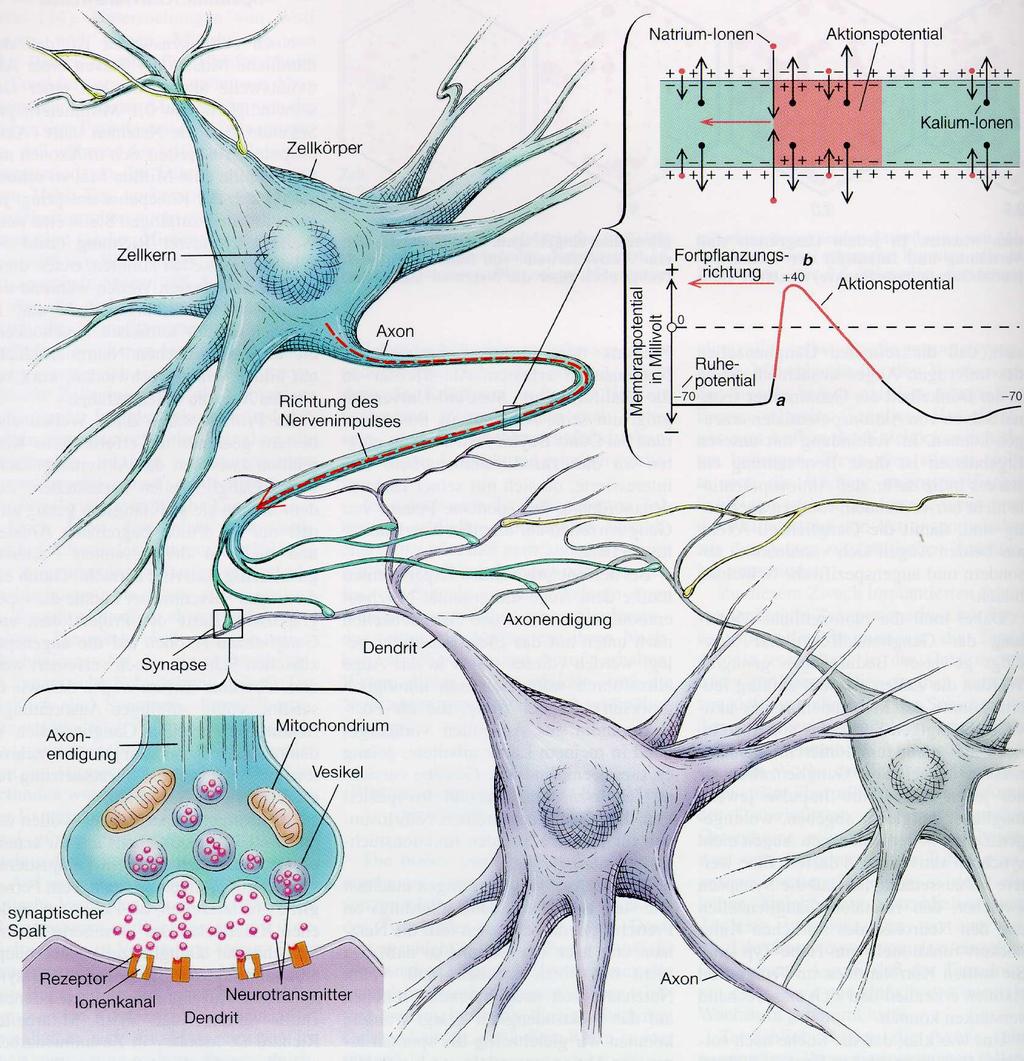
 breitet sich ausgehend vom Zellkörper (genauer vom Axonhügel) über das gesamte Axon bis in die axonalen Endigungen aus.")
11 Neuron (schematisch dargestellt) Anatomische Teilstrukturen eines Neurons: Zellkörper (Soma) Dendrit Axon Der Nervenimpuls (Spike oder Aktionspotential) breitet sich ausgehend vom Zellkörper (genauer vom Axonhügel) über das gesamte Axon bis in die axonalen Endigungen aus. NI1 11

12 Oben: Zellkörper mit einem stark verzweigten Dendriten(baum). An den Verästelungen des Dendriten befinden sich eine Vielzahl von Kontaktstellen, sogenannten Synapsen, von vorgeschalteten Neuronen. Unten: Synaptische Kopplung zweier Neuronen. In der präsynaptischen Membran (axonales Endknöpfchen) befindet sich der Neurotransmitter in den synaptischen Bläschen. NI1 12
 verschlossene Ionenkanäle sind gezeigt.")
13 Zellmembran Sematische Darstellung einer Axonmembran. Offene und durch Tore (gates) verschlossene Ionenkanäle sind gezeigt. Ionen befinden außerhalb und innerhalb der Membran. NI1 13
 sind (in der Mehrzahl) durch gates verschlossen; Natriumionen befinden sich hauptsächlich außerhalb der Zelle.")
14 Die häufigsten Ionenkanaltypen in der Axonmembran: Kaliumkanäle (oben) gehören (in der Mehrzahl) zum offenen Typ; Kaliumionen sind vor allem innerhalb der Zelle. Natriumkanäle (Mitte) sind (in der Mehrzahl) durch gates verschlossen; Natriumionen befinden sich hauptsächlich außerhalb der Zelle. Chloridkanäle (unten) sind (in der Mehrzahl) offen; Chloridionen sind überwiegend außerhalb der Zelle. Chloridionen gibt es deutlich weniger als Kalium- oder Natriumionen. NI1 14

15 Potential an der Zellmembran Messungen des Ruhepotentials an der Zellmembran a Ruhepotential (hier bei -75mV) zwischen dem Inneren und dem Äußeren der Zelle. b kein Potential im Extrazellulärraum c kein Potental im Intrazellulärraum d Einstechen einer Mikroelektrode in die Zelle zur Zeit t 1. Potential fällt sprunghaft auf das Ruhepotential ab. NI1 15

16 Aktionspotential an der Zellmembran Phasen des Aktionspotentials 1. Ruhepotential. 2. Spannungsgesteuerte Natrium- und (wenige) Kaliumkanäle springen auf (durch synaptische Erregung). Positive Natriumionen strömen massiv in die Zelle ein. 3. Natriumionen strömen weiter ein. 4. Natriumkanäle schließen sich. Kaliumkanäle bleiben offen. 5. Positive Kaliumionen strömen durch die offenen Kaliumkanäle weiter aus, ebenso positive Natriumionen (durch die Natriumkanäle vom offen Typ). 6. Kaliumkanäle schließen sich wieder. 7. Ruhepotential wieder erreicht. NI1 16

17 Aktionspotential - Ausbreitung 1. Aktionspotential (AP) wird am Axonhügel ausgelöst. 2. Fortpflanzung des APs mit konstanter Amplitude. 3. Verzweigung des APs am Ende des Axons, sogenannter axonaler Baum. 4. Ausschüttung von Neurotransmitter in den Synapsen. NI1 17
. Neuronen sind getrennt. Synaptischen Spalt sehr klein (einige Nanometer).")
18 Aufbau einer Synapse Präsynaptische Membran (axonales Endknöpfchen des vor der Synapse liegenden Neurons) mit synaptischen Bläschen. Neurotransmitter befindet sich in den synaptischen Bläschen. Postsynaptische Membran (Dendrit des nachfolgenden Neurons). Neuronen sind getrennt. Synaptischen Spalt sehr klein (einige Nanometer). Übertragung des Aktionspotential auf die nachgeschaltete Zelle erfolgt durch Ausschüttung von Neurotransmitter in den synaptischen Spalt. Diese chemische Synapsen kommen vor allem in Wirbeltiergehirnen vor. NI1 18

19 Synaptische Übertragung Oben: Elektronenmikroskopische Aufnahme einer Synapse bei der Ausschüttung von Neurotransmitter. Unten: Sematische Darstellung der Neurotransmitterausschüttung. NI1 19
.")
20 Erregende/Exzitatorische Synapse Aktionspotential erreicht Axonendigung Exizatorischer Neurotransmitter bewirkt das kurzzeitige Öffnen von Natriumkanälen, so dass im Bereich der Synapse, positiv gelandenen Natriumionen in die Zelle einströmen. Dadurch erhöht sich die positive Ladung innerhalb der Zelle. Änderung des Potentials der postsynaptischen Zelle (es wird etwas positiver). EPSP = exzitatorisches postsynaptisches Potential NI1 20
.")
21 Hemmende/Inhibitorische Synapse Aktionspotential erreicht Axonendigung Inhibitorischer Neurotransmitter bewirkt, dass negativ geladene Cloridionen im Bereich der Synapse in die Zelle einströmen können. Dadurch erhöht sich die negative Ladung innerhalb der Zelle. Änderung des Potentials der postsynaptischen Zelle (es wird etwas negativer). IPSP = inhibitorisches postsynaptisches Potential NI1 21
, die ungefähr gleichzeitig die Zelle erreichen (zeitliche Summation der EPSPs), können die Zelle so stark erregen, dass die Feuerschwelle")
22 Räumlich-Zeitliche Summation am Zellkörper Durch einzelne EPSPs werden keine Aktionspotentiale ausgelöst. Viele EPSPs (räumliche Summation der EPSPs über die Synapsen), die ungefähr gleichzeitig die Zelle erreichen (zeitliche Summation der EPSPs), können die Zelle so stark erregen, dass die Feuerschwelle (hier -60mV) erreicht wird. Mit dem Erreichen der Feuerschwelle werden Natriumkanäle geöffnet und ein Aktionsspotential (Spike) ausgelöst. NI1 22

23 Zyklus der neuronalen Dynamik a Ausbreitung des Aktionspotentials auf dem Axon b Synaptische Übertragung c Räumlich-Zeitliche der Eingaben Summation d Auslösung des Aktionspotentials NI1 23

24 Längenverhältnisse im Nervensystem NI1 24
25 Zusammenfassung Warum überhaupt Neuroinformatik? Anatomischer Aufbau: Gehirn, Neuron, Synapse, Aktionspotential Funktionalität der Zellmembran Synaptische Übertragung Zyklus der Neuronale Dynamik NI1 25
26 3. Neuronenmodelle 1. Einleitung zur Modellierung 2. Hodgkin-Huxley-Modell 3. Grundmodell in kontinuierlicher und diskreter Zeit 4. Transferfunktionen (Kennlinien) für Neuronen 5. Neuronenmodelle in Anwendungen NI1 26
27 Modellierung neuronaler Netze Neuronenmodell sollte die neurophysioligischen Vorgänge der neuronalen Verarbeitung repräsentieren. Verknüpfungsstruktur definiert die Neuronenverbindungen im Netzwerk. Die Verbindungsstruktur soll adaptiv sein. Eingänge und Ausgänge für das (Sub)-Netzwerk über die es mit anderen (Sub)-Netzen. Wir unterscheiden grob: Modellierung der neuronalen Dynamik = zeitliche Änderung der neuronalen Aktivierungen. Modellierung der synaptischen Dynamik = Änderung der synaptischen Verbindungsstärken (Kapitel 5). NI1 27
28 Neuronale Verarbeitung: Zusammenfassung 1. Neuronale Netze bestehen aus vielen Einzelbausteinen den Neuronen, die untereinander über Synapsen verbunden sind. 2. Neuronen senden über ihre Axon Aktionspotentiale/Spikes aus. 3. Neuronen sammeln an ihrem Zellkörper und Dendriten eingehende Aktionspotentiale (EPSPs und IPSPs) über ihre Synapsen auf. Man spricht von einer räumlich-zeitlichen Integration/Summation. 4. Überschreitet die am Dendriten integrierte Aktivität den Feuerschwellwert oder kurz Schwellwert, so erzeugt das Neuron ein Aktionspotential (Spike). Man sagt: Das Neuron feuert oder es ist im on-zustand. 5. Bleibt die am Dendriten integrierte Aktivität unter dem Schwellwert, so erzeugt das Neuron kein Aktionspotential (Spike). Man sagt: Das Neuron ist still oder es ist im off-zustand. NI1 28
29 NI1 29
30 Das Hodgkin-Huxley-Modell Von A.L. Hodgkin und A.F. Huxley wurde 1952 wohl das erste Neuronenmodell vorgeschlagen. Grundlage des Hodgkin-Huxley-Modells waren neurophysiologischen Experimenten an der Zellmembran des Riesenaxons des Tintenfisches. Ergebnisse zum Ruhepotential und zur Entstehung und Weiterleitung des Aktionspotential gehen auf diese Experimente zurück. Das Hodgkin-Huxley-Modell enthält die wichtigsten elektrophysiologischen Charakteristika (Ströme der Natrium-, Kalium- und Cloridionen) von Zellmembranen und ist in der Lage Aktionspotentiale darzustellen. Modell ist für große Netzwerke nicht gut geeignet, da es zu aufwendig. NI1 30
31 Hodgkin-Huxley-Modell: Schaltbild Außen 1 G K 1 1 G L G Na C V E - E E + K L Na Innen Ersatzschaltbild für Axonmembran Kalium-, Natrium- und Cloridionenströme werden modelliert. Spannungsabhängiger Membranwiderstand als einstellbarer Widerstand Membrankapazität durch Kondensator NI1 31
32 Hodgkin-Huxley-Modell: Gleichungen Gesamtmembranstrom ist Summe der drei beteiligten Ionenströme und der Strom der die Membran auflädt. Membranpotentials V ist durch Differentialgleichung beschrieben: C dv dt = I ext I Ionen I ext ein externer Strom und I Ionen die Summe der drei beteiligten Ionenströme I K (Kalium), I Na (Natrium) und I L (Leckstrom hauptsächlich Cloridionen) : I Ionen := G K (V E K ) + G }{{} Na (V E Na ) + G }{{} L (V E L ) }{{} I K I Na I L. NI1 32
33 C m die Kapazität der Zellmembran G K := g K n 4 die Leitfähigkeit der Zellmembran für Kaliumionen, wobei g K die Konstante ist, welche die maximal mögliche Leitfähigkeit der Zellmembran für Kaliumionen festlegt G Na := g Na m 3 h die Leitfähigkeit der Zellmembran für Natriumionen, wobei g Na die Konstante ist, welche die maximal mögliche Leitfähigkeit der Zellmembran für Natriumionen festlegt G L := g L = konst die Leckleitfähigkeit der übrigen Ionentypen E K das Gleichgewichtspotential der Kaliumionen E Na das Gleichgewichtspotential der Natriumionen E L das Gleichgewichtspotential der übrigen Ionentypen NI1 33
34 Die Funktionen n, m und h sind DGLs vom Typ dx dt = α i(v )(1 x(t)) β i (V )x(t). α i, β i, i = n, m, h, hängen vom Membranpotential V ab α n (V ) = 0.01(10.0 V ) exp 10.0 V β n (V ) = exp ( V 80.0 α m (V ) = 0.1(25.0 V ) exp 25.0 V β m (V ) = 4.0 exp ( V ) 18.0 α h (V ) = 0.07 exp ( V ) β h (V ) = exp 30.0 V ) NI1 34
35 Hodgkin-Huxley-Modell: Simulation injection current: 8uA 40 membran potential [mv] Analytische Lösung dieses gekoppelten nichtlinearen DGL-Systems ist nicht möglich. Numerische Näherungsverfahren sind notwendig. Hier wurde das einfachste Näherungsverfahren verwendet (Polygonzugverfahren nach Euler) time [msec] NI1 35
36 injection current: 10uA membran potential [mv] Ruhepotential liegt hier bei etwa -70mV Aktionspoteniale bis zu 30mV Hyperpolarisationsphase (Potential < Ruhepotential). Spikedauer ca. 1msec, somit maximale theoretische Spikefrequenz 1000Hz. Hier Inter-Spike-Intervall größer als 10msec, somit ist Spikefrequenz kleiner als 100Hz time [msec] NI1 36
37 firing rate [Hz] Bis zu einer Erregungsschwelle keine Aktionspotentiale. Linearer Anstieg der Feuerrate auf mittlerem Erregungsniveau Sättigung der Feuerrate für hohe Erregungsniveaus injection current [ua] NI1 37
38 Kontinuierliches Grundmodell Keine Modellierung der verschiedenen Ionenkanäle, deshalb sind Spikes nicht mehr modellierbar, sondern müssen explizit (durch eine Funktion) modelliert werden. Neuron ist durch 2 Modellgleichungen beschrieben. 1. DGL für die Beschreibung des dendritischen Membranpotentials u j (t). 2. Axonales Membranpotential durch Funktionsauswertung y j (t) = f(u j (t)). Synaptische Kopplungen werden durch reelle Zahlen c ij modelliert: exzitatorische Kopplung c ij > 0; inhibitorische Kopplung c ij < 0. Räumlich/Zeitliche Integration erfolgt durch Summation der eingehenden Aktionspotentiale (nach Gewichtung mit den synapischen Kopplungsstärken) NI1 38
39 In einem neuronalen Netz mit n Neuronen lauten die Modellgleichungen: n τ u j (t) = u j (t) + x j (t) + c ij y i (t ij ) y j (t) = f j (u j (t)) } i=1 {{ } =:e j (t) τ > 0 Zeitkonstante u j (t) dendritisches Potential des j-ten Neurons u j (t) die (zeitliche) Ableitung von u j. x j (t) externen Input des Neurons j. c ij synaptische Kopplungsstärke von Neuron i zum Neuron j; i.a. ist c ij c ji. ij Laufzeit eines Aktionspotentials von Neuron i zum Neuron j. y j (t) axonales Potential des j-ten Neurons. f j Transferfunktion des j-ten Neurons; häufig ist f j = f für alle Neuronen j = 1..., n und f eine nichtlineare Funktion. NI1 39
40 Diskretes Grundmodell Auch dieses DGL-System ist nicht mehr analytisch lösbar (nur falls f linear und ij = 0). Näherungslösung durch Diskretisierung der Zeit Annäherung: u j (t) (u j (t + t) u j (t))/ t Einsetzen der Näherung in die DGL liefert: τ t (u j(t + t) u j (t)) = u j (t) + e j (t) hier ist ϱ := t τ, 0 < ϱ 1 u j (t + t) = (1 ϱ) u j (t) + ϱ e j (t), y j (t) = f(u j (t)) NI1 40
41 Transferfunktionen I 1. Die lineare Funktion f(x) := x. Ein Neuron mit dieser Transferfunktion heißt lineares Neuron. 2. Die Funktion f(x) := H(x θ) mit der Heaviside-Funktion H. Die Heaviside-Funktion H nimmt für x 0 den Wert H(x) = 1 und für x < 0 den Wert H(x) = 0 an. 3. Die beschränkte stückweise lineare Funktionen: 0 x < 0 f(x) = x x [0, 1] 1 x > 1 (1) 4. Die Funktion f(x) := F β (x) mit F β (x) = 1/(1 + exp( βx)), wobei β > 0 ist. Die Funktion F ist die aus der statistischen Mechanik bekannte Fermi- Funktion. NI1 41
42 Kodierung der Neuronenausgabe Das axonale Potential bei den Modellneuronen mit den Transferfunktionen 2.)-4.) liegt im Wertebereich [0, 1]. Bei einige Modellierungsansätzen (z.b. Hopfield-Netzwerke) wird der Wertebereich der Neuronenausgabe (axonalen Potential) als [ 1, 1] angenommen. Eine Transformation G(x) := 2F (ax + b) 1, mit a > 0 und b R, macht aus einer Transferfunktion F mit Wertebereich [0, 1] eine Transferfunktion mit Wertebereich [ 1, 1]. Wichtige Beispiele: Für a = 1 und b = 0, so wird durch obige Transformation aus der Heaviside-Funktion die Vorzeichen-Funktion. Für a = 1/2 und b = 0, so wird aus der Fermi-Funktion die Tangens- Hyperbolikus-Funktion. NI1 42
43 Heaviside-Funktion Signum-Funktion. NI1 43
44 Begrenzte lineare Funktion Sym. begrenzte lineare Funktion. NI1 44
45 Fermi-Funktion, β = Hyperbolischer Tangens, γ = 1. NI1 45
46 Neuronenmodelle in Anwendungen Gewichtsvektor c Eingabe x Vereinfachtes Neuonenmodell Neuronen ohne Gedächtnis, d.h. ϱ = 1. f Signallaufzeiten werden vernachlässigt, d.h. ij = 0 y Ausgabe NI1 46
47 Beispiele I Betrachtet wird jeweils ein Neuron mit dem synaptischen Gewichtsvektor c R n und dem Eingabevektor x R n : Lineares Neuron y = x, c + θ = n x i c i + θ i=1 Schwellwertneuron { 1 x, c θ y = 0 sonst Kontinuierliches nichtlineares Neuron y = f( x, c + θ), f(s) = exp( s) NI1 47
48 Beispiele II Die Neuronenmodelle basierten bisher auf der Berechnung der gewichteten Summe zwischen einem Vektor x und dem synaptischen Gewichtsvektor c (dies ist das Skalarprodukt x, c ). In der Praxis sind auch distanzberechnende Neuronenmodelle gebräuchlich, wir werden diese später bei den Netzen zur Approximation und Klassifikation, sowie bei den Netzen zur neuronalen Clusteranalyse genauer kennenlernen. Distanzberechnendes Neuron y = x c 2 Radial symmetrisches Neuron y = h( x c 2 ), h(r) = exp( r2 2σ 2) NI1 48
49 4. Neuronale Architekturen Rückgekoppelte neuronale Netzwerke Vorwärtsgekoppelte neuronale Netzwerke Geschichtete neuronale Netze NI1 49
50 Rückgekoppelte Netze Bei rückgekoppelten neuronalen Netzwerken (recurrent/feedback neural networks) sind die Neuonen beliebig miteinander verbunden. Potentiell ist jedes Neuron mit jedem anderen Neuron verbunden. Kopplungsmatrix C R n2 hat keine spezielle Struktur. 1 2 n f f f NI1 50
51 Vorwärtsgekoppelte neuronale Netze Bei den vorwärtsgekoppelten neuronalen Netzen ist der Informationsverarbeitungsfluss streng vorwärts gerichtet, und zwar von den Eingabeneuronen zu den Ausgabeneuronen Die Verarbeitung erfolgt sequentiell durch mehrere Neuronen bzw. Neuronenschichten. Der Verbindungsgraph der Neuronen, repräsentiert durch die Kopplungsmatrix C, ist zyklenfrei. In Anwendungen, sind die geschichteten Netze oder layered neural networks von besonderer Bedeutung. NI1 51
52 Geschichtete neuronale Netze Neuronen der Eingabeschicht propagieren (sensorische) Eingaben in das Netz, diese führen keine neuronalen Berechnungen durch. Deshalb wird diese Schicht meist auch nicht mitgezählt (wie bei Bool schen Schaltnetzen). Man kann sie auch als 0-te Neuronenschicht bezeichnen. Die Neuronen in der Schicht k erhalten ihre Eingaben von Neuronen der Schicht k 1 und geben ihre Berechnung an die Neuronen der Schicht k + 1 weiter. Diese Schichten nennen wir Zwischenschicht oder versteckte Schichte oder hidden layer. Die Neuronen ohne Nachfolgeneuron bilden die Ausgabeschicht. NI1 52
53 Darstellung von Mehrschicht-Netzen In der Literatur findet man zahlreiche Darstellungsformen von neuronalen Netzwerken. Sehr verbreitet ist die Graph-Notation mit einer Knoten- und Kantenmenge. Knoten entsprechen den Neuronen und die synaptischen Kopplungen sind als Kanten dargestellt. C 1 C 2 Eingabe schicht Zwischen schicht Ausgabe schicht NI1 53
54 1 2 Eingabe n+1 n+m Eingabe C 1 n f f f n+m+1 n+m+p C 2 f f f Ausgabe Ausgabe Schematische Darstellung von Einzelneuronen (links) mit den synaptischen Kopplungen (dargestellt als ). Die Neurondarstellung besteht aus dem Dendriten (Rechteck) mit den synaptischen Kopplungen c ij, dem Zellkörper (Halbkreis) mit der Transferfunktion f, und dem Axon (ausgehender Pfeil). Entlang der Pfeile werden reelle Zahlen prozessiert. NI1 54
55 In der linken Abbildung ist ein Netz mit N := n + m + p Neuronen gezeigt: n Neuronen in der Eingabeschicht (diese werden als Eingabe-Neuonen nicht weiter betrachtet, da sie keine neuronale Berechung durchführen). m Neuronen in der Zwischenschicht p Neuronen in der Ausgabeschicht In der rechten Abbildung sind die synaptischen Kopplungen als Matrizen zusammengefasst. Die neuronale Transferfunktion f ist hier als vektorwertige Funktion zu interpretieren. Entlang der Pfeile werden nun Vektoren R n, R m bzw. R p prozessiert. Die Kopplungsmatrix C R N 2 des Gesamtnetzes hat die Form C = 0 C C 2 mit C 1 R n R m und C 2 R m R p NI1 55
56 5. Lernregeln für neuronale Netze 1. Allgemeine Lokale Lernregeln 2. Lernregeln aus Zielfunktionen: Optimierung durch Gradientenverfahren 3. Beispiel: Überwachtes Lernen im Einschicht-Netz NI1 56
57 Einleitung Unter Lernen versteht man den Erwerb neuen Wissens, unter Gedächtnis die Fähigkeit, dieses Wissen so zu lernen, dass es wiederfindbar ist. Mechanismen neuronalen Lernens sind deutlich weniger erforscht als die neurophysiolgischen Vorgänge bei der neuronalen Dynamik (Ruhepotential, Aktionspotential, Ionen-Kanäle, etc). Mögliche Formen des neuronalen Lernens: Änderung der Neuronenzahl Änderung der Verbindungsstruktur/Verbindungsstärken NI1 57
58 Lernen durch Änderung der Synapsenstärken Die Änderung der Synapsenstärken lässt sich durch Differntialgleichungen bzw. Differenzengleichungen (Iterationsgleichungen) beschreiben. Analog zur Beschreibung der neuronalen Dynamik (kontinuierliche und diskrete Zeit). Änderung der synaptischen Kopplungen vollzieht sich langsamer, als die Änderung der neuronalen Zustände. Dies ist beispielsweise durch verschiedene Zeitkonstanten in den Differntialgleichungen modellierbar. NI1 58
59 Aufwand in einem Netz mit n Neuronen: Für die neuronale Dynamik: Je Neuron wird das dendritsche Potential x j (t), in Abhängigkeit der axonalen Potentiale y i (t ij ) aller n Neuronen, berechnet. Schließlich wird das axonale Potential y j (t) = f(x j (t)) bestimmt. Wenn man für die Funktionsauswertung konstanten Aufwand (Funktion als Tabelle gespeichert) annimmt, so sind n 2 Multiplikationen auszuführen. Für die synaptische Dynamik: Setzt man pro Synapse eine DGl an, so sind insgesamt schon O(n 2 ) Operationen durchzuführen, selbst wenn der Aufwand pro Synapse konstant ist. NI1 59
60 Allgemeine Lokale Lernregel Änderung einer synaptischen Kopplung c ij soll durch lokal vorhandene Größen bestimmt werden. Globale Netzwerkzustände sollen dabei nicht berücksichtigt werden (biologisch nicht plausibel und großer Aufwand) i j c ij modifizierbare Synapse Verbindung von Neuron i zum Neuron j f f NI1 60
61 Allgemeine lokale Lernregel als Differenzengleichung: c ij (t) = c ij (t) c ij (t 1) = v(t)c ij (t) + l(t) ( y i (t) ac ij (t) b )( δ j (t) c ) Hierbei sind: c ij (t) := c ij (t) c ij (t t); (meist t = 1) v(t) 0 eine Vergessensrate. In Anwendungen typischerweise v(t) = 0. l(t) 0 eine Lernrate. Gebräuchlich ist l(t) > 0 und l(t) monoton gegen 0 fallend. a, b, c 0 Konstanten. Häufig a = b = c = 0. δ j (t) wird durch das Lernverfahren bestimmt. Wir unterscheiden unüberwachtes und überwachtes Lernen (unsupervised and supervised learning). NI1 61
62 Unüberwachtes Lernen Im unüberwachten Lernen ist δ j (t) = u j (t) (dendritisches Potential) oder δ j (t) = y j (t) (axonales Potential) also beispielsweise c ij (t) = l(t)y i (t)y j (t) Dieses ist eine sehr bekannte Lernregel. Sie wird zu Ehren von Donald Hebb auch Hebb sche Lernregel genannt. Postulat von Hebb (1949): Wenn das Axon der Zelle A nahe genug ist, um eine Zelle B zu erregen, geschieht ein Wachstumsprozess in einer oder in beiden Zellen, so dass die Effizenz von A, als eine auf B feuernde Zelle wächst. NI1 62
63 Überwachtes Lernen j c i j Ausgabe y j des j-ten Neurons. Eingabe y i Lehrersignal T j des j-ten Neurons. Die Ausgabe y i beeinflusst auch die Neuronenausgabe y j (durch c ij ). T j Lehrersignal Idee: Ausgabe y j soll durch Änderung der synaptischen Kopplungs- Ausgabe y j stärke c ij auf das Lehrersignal T j geregelt werden. NI1 63
64 Delta Lernregel Im überwachten Lernen ist δ j (t) = T j y j (t) also erhalten wir etwa c ij (t) = l(t)y i (t) ( T j (t) y j (t) ) hierbei ist T j (t) ein externes Lehrersignal bzw. Sollwert für das Neuron j zur Zeit t. Lernregeln dieser Art, die einen Vergleich zwischen einem Lehrersignal und der Neuronenausgabe, berechnen werden Delta-Regeln genannt. Viele gebräuchliche Lernregeln sind von diesem Typ! Die bekannteste ist die Perzeptron-Lernregel. Sehr viele Lernregeln sind lokal. Wir werden allerdings auch später nichtlokale Lernregeln kennenlernen, beispielsweise unüberwachte Lernregeln zur Berechnung der Hauptkomponenten. Später mehr dazu! NI1 64
65 Beispiel: Nichtlineares kontinuierliches Neuron mit der Ausgabe n y j = f( c ij y i ), u j = i=1 n c ij y i i=1 f differenzierbare monoton wachsend, z.b. Fermifunktion f(x) = 1 1+e x. Die Änderung der Ausgabe von y j bei der Delta-Lernregel: y neu j y j = f( n i=1 c neu ij y i ) f( n c ij y i ) i=1 = f (z) (u neu j u j ) z (u neu j, u j ) = f (z) (c neu ij c ij )y i = l f (z) (T j y j ) y 2 i Also: y neu j = y j + ly 2 i f (z)(t j y j ), wobei ly 2 i f (z) > 0. NI1 65
66 Fallunterscheidungen bei der Delta-Regel: T j = y j, dann bleiben c ij und y j unverändert. y j > T j, also T j y j < 0, dann ist c ij < 0, also yj neu y j < 0, dh. yj neu y j < T j, also T j y j > 0, dann ist c ij > 0, also yj neu y j > 0, dh. yj neu < y j > y j Falls die Lernrate l > 0 klein ist, so ist nach einem Lernschritt mit der Delta- Lernregel der Fehler T y kleiner geworden. Die Delta-Regel zeigt das geforderte Verhalten, nämlich den Fehler zwischen Lehrersignal und Netzausgabe zu minimieren. Wie können nun Lernregeln systematisch hergeleitet werden? NI1 66
67 Konstruktion von Lernregeln Wir gehen nun davon aus, dass uns eine Menge von Eingabesignalen(vektoren) vorliegt, zu denen ebenfalls Sollausgaben/Lehrersignale definiert sind. Wir betrachten überwachte Lernverfahren, hier ist das Ziel dadurch definert, dass die Netzausgabe jeweils dem Lehrersignal möglichst nahe kommen soll! Sei also eine Trainingsmenge gegeben durch Ein-Ausgabepaare: T = {(x µ, T µ ) x µ R d, T µ R n ; µ = 1,..., M} Gesucht ist nun ein neuronales Netz, repräsentiert durch seine Kopplungsmatrix C, so dass für alle Netzausgaben y µ gilt: T µ y µ. Die spezielle Architektur, Anzahl der Neuronen, Anzahl der Schichten, etc braucht an dieser Stelle noch nicht festgelegt zu werden. NI1 67
68 Zielfunktionen T µ y µ muss präzisiert werden. Unterschied von T µ und y µ messen wir durch Normen/Abstandsfunktionen: T µ y µ p := ( n T µ i y µ i p) 1 p i=1 hierbei ist p 1. Für p = 2 erhalten wir die Euklidischen Abstand. Bekannte Abstandsfunktionen sind mit p = 1 die Manhattan Norm/Abstand und für p = die Maximum-Norm/Abstand gegeben durch : T µ y µ := max{ T µ i y µ i i = 1,..., n} Andere Abstandsfunktionen sind auch möglich! NI1 68
69 Wir werden den quadrierten Euklidischen Abstand verwenden, definiert durch T µ y µ 2 2 := n (T µ i y µ i )2 i=1 Die Netzausgabe y ist eine Funktion der Kopplungsmatrix C, also y = y C. Um die Netzausgaben den Sollausgaben anzupassen, soll nun die Kopplungsmatrix C adaptiert werden. Gesucht ist die Kopplungsmatrix C, welche den Unterschied zwischen den Netzausgaben und den Lehrersignalen minimiert. Unterschied wird durch eine Zielfunktion oder Fehlerfunktion E : R r R gemessen. r ist die Zahl der Parameter in der Kopplungsmatrix C. NI1 69
70 Optimierung von Zielfunktionen Sei nun eine reellwertige Zielfunktion E(C), E : R r R gegeben. Gesucht ist nun die Kopplungsmatrix C R r welche E minimiert, d.h. E(C ) E(C) für alle C R r C heißt das globale Minimum der Funktion E. In den meisten Fällen kann C nicht analytisch berechnet werden, man muss sich mit einem suboptimalen lokalen Minimum zufrieden geben. Zur Bestimmung lokaler Minima gibt es nicht immer analytische Verfahren. Gesucht sind numerische Näherungsverfahren zur Berechnung lokaler Minima. Das einfachst numerische Verfahren zur Berechnung lokaler Optima ist das Gradientenverfahren. Voraussetzung: E ist differenzierbar. NI1 70
71 Zunächst sei r = 1. Dann führt die folgende Strategie in ein lokales Minimum der Funktion E : R R: 1. Setze t=0 und wähle einen Startwert C(t). 2. Falls E (C(t)) > 0, dann C(t + 1) < C(t) 3. Falls E (C(t)) < 0, dann C(t + 1) > C(t) Algorithmisch präziser: 1. Setze t = 0. Wähle Schrittweite l > 0, Startwert C(0) und ɛ > 0: 2. Iterierte die Vorschrift für t = 0, 1,... bis C < ɛ: C(t + 1) = C(t) l E (C(t)) NI1 71
72 Für mehrdimensionale Funktionen E : R r R wird der Gradient grade(c) statt der Ableitung E (C) benutzt also 1. Setze t = 0. Wähle Schrittweite l > 0, Startwert C(0) und ɛ > 0: 2. Iterierte die Vorschrift für t = 0, 1,... bis C < ɛ: C(t + 1) = C(t) l grade(c(t)) Zur Erinnerung für f : R r R wird der Gradient gradf(x) definiert durch gradf(x) = ( x 1 f(x),..., x r f(x)) R r Probleme bei Gradienten-Verfahren: Konvergenz gegen lokales Minimum ist langsam; selbst Konvergenz nicht gesichert. l > 0 ist ein Parameter, der die Größe der Korrektur/Anpassung (von C) bestimmt. NI1 72
73 Lernregel für einschichtiges Netz Sei also eine Trainingsmenge gegeben durch T = {(x µ, T µ ) x µ R d, T µ R n ; µ = 1,..., M} Das neuronale Netz bestehe aus einer einzelnen Schicht (Eingabeschicht nicht mitgezählt) bestehend aus n nichtlinearen Neuronen. Berechnungen der Neuronen j = 1,..., n bei Eingabe von x µ R d : 1. u µ j = x, c j = d i=1 xµ i c ij 2. Netzausgaben: y µ j = f(uµ j ) = f ( d i=1 xµ i c ij Definition der Zielfunktion E(C) := E(c 1,..., c n ): ) E(C) = M T µ y µ 2 = µ=1 M n (T µ j yµ j )2 min µ=1 j=1 NI1 73
74 Lernregel als Gradienten-Verfahren: 1. grad E(C) = E(c 1,..., c n ) ausrechnen (Kettenregel zweimal anwenden) (hier für ein einzelnes Gewicht c ij ) : c ij E(C) = M 2 (T µ j yµ j ) ( f (u µ j )) xµ i. µ=1 2. Ableitung in die allgemeine Formel einsetzen (hier für ein einzelnes Gewicht c ij ): c ij (t + 1) := c ij (t + 1) + 2l(t) M (T µ j yµ j )f (u µ j )xµ i µ=1 NI1 74
75 Dies ist eine Batch-Modus-Lernregel, da der gesamte Trainingsdatensatz T benutzt wird um einen Änderung der Matrix C durchzuführen. Die zugehörige inkrementelle Lernregel hat die Form c ij (t + 1) := c ij (t + 1) + 2l(t)(T µ j yµ j )f (u µ j )xµ i Hier werden die Gewichtsanpassungen der c ij durch Einzelmuster herbeigeführt. In beiden Fällen muss der gesamte Trainingsdatensatz mehrfach benutzt werden, bis die berechnete Gewichtsanpassung unter einer a priori definierten Schranke ɛ bleibt. Inkrementelle Lernregeln erfordern nur die Hälfte des Speicherplatzes als die zugehörigen Batch-Modus-Lernregeln (die Einzeländerungen müssen bei Batch-Modus-Lernregeln zunächst aufsummiert werden bevor der eigentliche Anpassungsschritt durchgeführt wird). NI1 75
76 6. Überwachtes Lernen in KNN 1. Einleitung 2. Perzeptron 3. Mehrschichtnetze 4. Netze zum Lernen von Zeitreihen 5. Radiale Basisfunktionsnetze 6. Konstruktive Netze NI1 76
77 6.1 Einleitung Ein KNN soll eine beliebige Abbildung T : X Y lernen, d.h. zu jedem Muster x µ X soll die zugehörige Netzausgabe y µ Y möglichst gleich T µ := T (x µ ) sein Eingabevektoren: x X mit X R m X Z m X {0, 1} m Ausgabevektoren: y Y mit Y {0, 1} n oder Y Z n (Klassifikation) Y R n (Approximation oder Regression) resultierendes Netz hat m Eingabeknoten und n Ausgabeneuronen NI1 77
78 Ziel: Parameter des KNN sind derart einzustellen, dass Fehler R[T ] = T (x) y dp (x, y) X minimiert wird (erwartete Fehler). Probleme: Wahrscheinlichkeitsverteilung P (x, y) auf X Y ist unbekannt. Ansatz: Minimierung des empirischen Fehlers Auswahl einer Trainingsmenge/Stichprobe mit M Vektorpaaren (x 1, T 1 ),..., (x M, T M ) und Einstellung der Netzparameter, so dass der Trainingsfehler R emp [T ] = 1 M M T µ y µ µ=1 minimiert wird (empirischer Fehler). Problem: Fähigkeit des Netzes zur Generalisierung NI1 78
79 Exkurs: McCulloch-Pitts Neuron Struktur eines Neurons (McCulloch and Pitts, 1943): x 1 w = 1 Funktionalität: m u = x i w i = x w = x, w i=1 x x 2 3 u θ y y = { 1 für u θ 0 für sonst x m w = 1 mit x {0, 1} m, w { 1, 1} m, θ Z Satz: Jede beliebige logische Funktion ist mit Netzen aus McCulloch-Pitts Neuronen realisierbar. Lernen ist nicht möglich! NI1 79
80 6.2 Perzeptron Struktur eines Perzeptrons (Rosenblatt 1958): x 1 w 1 Funktionalität: m u = x i w i = x w = x, w i=1 x x 2 3 w 2 w 3 u θ y y = { 1 für u θ 0 für sonst x m w m mit x, w R m und θ R äquivalente Formulierung mit Bias b := θ: m { 1 für u 0 u = x i w i + b = x w + b, y = 0 für sonst i=1 NI1 80
81 gelegentlich wird der Bias b = θ auch als Gewicht w 0 eines weiteren (konstanten) Eingangs x 0 = 1 angesehen: m { 1 für u 0 u = x i w i = x w, y = 0 für sonst i=0 Für m = 2 beschreibt die Gleichung x w = 0 eine Gerade, die die Menge aller Punkte x = (x 1, x 2 ) R 2 in zwei Halbräume P und N teilt: w w1 w2 = (, ) x 2 P x w > 0 N x w < 0 x 1 NI1 81
82 Idee des Perzeptron Lernalgorithmus Lernproblem: X 1 enthält alle x mit f(x) = 1 X 0 enthält alle x mit f(x) = 0 Existiert Gewichtsvektor w mit x w 0 für alle x X 1 und x w < 0 für alle x X 0? Lernschritt: falls (x w 0 und x X 1 ) oder (x w < 0 und x X 0 ) : w(t + 1) = w(t) falls x w < 0 und x X 1 : w(t + 1) = w(t) + x falls x w 0 und x X 0 : w(t + 1) = w(t) x Veranschaulichung für x 1, x 2 X 0 und x 3, x 4 X 1 bei θ = 0: w(3) w(1) x w(0) 4 x 3 x x 1 2 NI1 82
83 einfachere Formulierung der Perzeptron-Lernregel: Sei T {0, 1} der Wert des Lehrersignals (Sollausgabe) für das Eingabemuster x, dann kann Fehler δ am Ausgang des Perzeptrons angegeben werden: δ = (T y) Hiermit lassen sich alle 3 Fälle des Lernschritts einheitlich beschreiben: w(t + 1) = w(t) + δx = w(t) + (T y)x oft wird eine zusätzliche Lernrate η > 0 verwendet: w(t + 1) = w(t) + ηδx = w(t) + η(t y)x NI1 83
84 Lernalgorithmus für Perzeptron: Gegeben: 1 Neuron mit Schwellwert θ R, m Gewichte w i R, i = 1,..., m Menge T mit von M Mustern x µ R m mit Lehrersignalen T µ {0, 1} Schritt 1: Initialisierung Setze w i (0), i = 1,..., m und θ(0) beliebig Schritt 2: Aktivierung Wähle Muster x µ X mit T µ {0, 1} und berechne u = x µ w θ Schritt 3: Ausgabe Setze y = 1 für u 0 bzw. y = 0 für u < 0 Berechne Differenz δ = T µ y NI1 84
85 Schritt 4: Lernen Adaptiere Gewichte: w i (t + 1) = w i (t) + η δx µ i Adaptiere Schwellwert: θ(t + 1) = θ(t) η δ (bei Standard Perzeptron-Lernregel: η = 1) Schritt 5: Ende Solange es in T noch Muster mit δ 0 gibt, gehe zurück zu Schritt 2 Satz zur Konvergenz des Perzeptron Lernalgorithmus: (Minsky und Papert, 1969) Ist das Klassifikationsproblem linear separierbar, dann findet der Perzeptron Lernalgorithmus nach endlicher Anzahl von Lernschritten eine Lösung. NI1 85
86 Konvergenzbeweis des Perzeptron Lernalgorithmus: Annahmen und Vereinfachungen: 1. Es gibt einen Lösungsvektor w mit w = 1, der X 0 und X 1 absolut linear separiert 2. Für alle x X 0 setze x = x Für alle x X = X 0 X 1 gilt: w x > 0 3. Alle Vektoren x X sind normiert: x = 1 4. Gewichtsvektor w(t) hat x X falsch klassifiziert Betrachte cos τ = w w(t + 1) w w(t + 1) = w w(t + 1) w(t + 1) NI1 86
87 Zähler: w w(t + 1) = w (w(t) + x) = w w(t) + w x w w(t) + δ w w(0) + (t + 1)δ Nenner: w(t + 1) 2 = (w(t) + x) (w(t) + x) = w(t) 2 + 2w(t)x + x 2 w(t) 2 + x 2 w(t) w(0) 2 + (t + 1) Einsetzen liefert: cos τ w w(0) + (t + 1)δ w(0) 2 + (t + 1) t ist endlich, da stets gilt: cos τ 1 NI1 87

: 1) Fehlerfläche der")
88 Fehlerflächen Eine Visualisierung des Fehlers am Ausgang eines Perzeptrons in Abhängigkeit von den Gewichten bezeichnet man als Fehlerfläche. Beispiele (für m = 2 Eingänge, θ = 1): 1) Fehlerfläche der Funktion OR 2) Fehlerfläche der Funktion XOR NI1 88
89 Bemerkungen zum Perzeptron Liegt statt eines Klassifikationsproblems mit zwei Klassen ein Klassifikationsproblem mit n Klassen vor, so werden i.a. n Perzeptronen verwendet. Hierbei lernt Perzeptron i, die Muster der Klasse i von den Mustern aller anderen Klassen j i zu trennen. Anteil linear separierbarer Probleme sinkt bei Erhöhung der Eingabedimensionalität m Beispiel: linear separierbare Boole sche Funktionen mit m Variablen m Anzahl linear separierbarer Fkt. Anteil 2 14 (von 16) 87.5% (von 256) 40.6% (von 65536) 2.7% Lösung: mehrschichtige Netze aus Perzeptronen... NI1 89
90 6.3 Mehrschichtiges Perzeptron (MLP) Idee: Lernen mittels Gradientenabstieg (erfordert jedoch eine differenzierbare Transferfunktion Verwendung der sigmoiden Funktion f(x) = 1/(1 + exp( βx)) anstatt der Schwellwertfunktion!) Aufbau eines zweischichtigen MLP mit sigmoiden Neuronen: x Berechnung der Netzausgabe y (2) : u (1) i = m k=1 y (1) i = f(u (1) h u (2) j = i=1 x k w (1) ki θ (1) i i ) y (2) j = f(u (2) j ) y (1) i w (2) ij θ (2) j y W W u (2) (2) (1) (2) u y (1) (1) w w (1) ki (2) ij NI1 90
91 Lernen im mehrschichtigen Perzeptron Quadratischer Fehler am Netzausgang: für Muster µ: E µ = T µ y µ 2 = m (T µj y µj ) 2 j=1 für alle Muster: E = M E µ = p T µ y µ 2 = M m (T µj y µj ) 2 µ=1 µ=1 µ=1 j=1 mit: m : Anzahl Neuronen der Ausgabeschicht M : Anzahl Muster in der Trainingsmenge T µj : Sollwert für Neuron j bei Muster µ y µj : Ausgabe von Neuron j bei Muster µ NI1 91

92 Beispiel einer Fehlerfläche und eines Gradientenabstiegs: Startpunkt E häufig Abstieg in lokale Minima! w 2 w 1 NI1 92
93 Herleitung der Error Backpropagation Lernregel Für Gewichte w ij = w (2) ij der Ausgabeschicht gilt: E µ w ij = = w ij T y (2) 2 (T j w y(2) ) 2 = j ij = 2(T j y (2) j ) j w ij f( ĩ w ij (T j y (2) j ) 2 y (1) ĩ wĩj ) } {{ } u (2) j = 2(T j y (2) j ) f (u (2) j ) y (1) i = 2 y (1) i δ (2) j wobei δ (2) j = (T j y (2) j ) f (u (2) j ) den Fehler von Neuron j der Ausgabeschicht für ein Muster bezeichnet NI1 93
94 Resultierende Lernregeln für Gewichte w ij = w (2) ij der Ausgabeschicht: im Online-Modus: (d.h. Anpassung der Gewichte nach der Präsentation eines einzelnen Musters µ) w ij = w ij η E µ = w ij + η y (1) i δ (2) j w ij im Batch-Modus: (d.h. Anpassung der Gewichte erst nach der Präsentation aller Muster µ) w ij = w ij η E w ij = w ij + η µ y (1) µi δ (2) µj NI1 94
95 Für Gewichte w ki = w (1) ki der versteckten Schicht gilt: E µ w ki = E µ y (1) i = 2 j = 2 j = 2 j y (1) i w ki = (T j y (2) j ) y (1) i y (1) i (T j y (2) j ) 2 y (1) i j f( ĩ (T j y (2) j ) f (u (2) j ) }{{} δ (2) j y (1) ĩ w (2) ĩj } {{ } u (2) j w (2) ) w ki ij f (u (1) i ) x k δ (2) j w (2) ij f (u (1) i )x k = 2 x k δ (1) i x k w ki f( k w ki }{{} u (1) i ) wobei δ (1) i = δ (2) j w (2) ij f (u (1) i ) den Fehler von Neuron i der versteckten j Schicht für ein Muster bezeichnet NI1 95
96 Resultierende Lernregeln für Gewichte w ki = w (1) ki der versteckten Schicht: im Online-Modus: (d.h. Anpassung der Gewichte nach der Präsentation eines einzelnen Musters µ) w ki = w ki η E µ = w ki + η x k δ (1) j w ki im Batch-Modus: (d.h. Anpassung der Gewichte erst nach der Präsentation aller Muster µ) w ki = w ki η E w ki = w ki + η µ x µk δ (1) µi NI1 96
97 Error Backpropagation Lernalgorithmus (Online) für MLP Gegeben: Zweischichtiges m-h-n MLP Menge T mit M Musterpaaren (x, T) mit Eingabemustern x = (x 1,..., x m ) X und zugehörigen Lehresignalen T = (T 1,..., T n ) Y Schritt 1: Initialisierung Setze alle w (1) ki, w(2) ij, θ(1) i und θ (2) j für k = 1,..., m, i = 1,..., h, j = 1,..., n auf kleine zufällige Werte Schritt 2: Berechnung der Netzausgabe y (2) (Vorwärtsphase) Wähle nächstes Muster x T und berechne: u (1) i = m k=1 u (2) j = h i=1 x k w (1) ki θ (1) i und y (1) i = f(u (1) i ) für i = 1,..., h y (1) i w (2) ij θ (2) j und y (2) j = f(u (2) j ) für j = 1,..., n NI1 97
98 Schritt 3: Bestimmung des Fehlers am Netzausgang Berechne δ (2) j = (T j y (2) j ) f (u (2) j ) für j = 1,..., n Schritt 4: Fehlerrückvermittlung (Rückwärtsphase) Berechne δ (1) i = w (2) ij δ(2) j f (u (1) i ) für i = 1,..., h j Schritt 5: Lernen Adaptiere Gewichte: w (2) ij = w (2) ij + η y (1) i δ (2) j w (1) ki = w (1) ki + η x k δ (1) i Adaptiere Schwellwerte: θ (2) j = θ (2) j ηδ (2) j θ (1) i = θ (1) i ηδ (1) i für k = 1,..., m, i = 1,..., h, j = 1,..., n NI1 98
99 Schritt 6: Ende Epoche Solange noch weitere Muster x T zu Schritt 2 vorhanden, gehe zurück Schritt 7: Ende Training Berechne Fehler E = M T µ y µ 2 µ=1 Solange E > ɛ und max. Anzahl Iterationen noch nicht überschritten, gehe zurück zu Schritt 2 Bemerkung: Error Backpropagation Lernalgorithmus kann auch für MLPs mit beliebig vielen Schichten verallgemeinert werden! NI1 99
100 Bemerkungen zum MLP mit Error Backpropgation Schwellwerte θ j wurden in Herleitung wegelassen; Lernregel resultiert aus Betrachtung von θ j als ein mit dem konstanten Eingang x 0 = 1 verbundenes Gewicht w 0j = θ j. einige sigmoide Funktionen und ihre Ableitungen: logistische Funktion: f(x) = 1/(1 + e x ) mit Ableitung f (x) = e x /(1 + e x ) 2 = f(x)(1 f(x)) Fermi-Funktion: f(x) = 1/(1 + e βx ) mit Ableitung f (x) = βe x /(1 + e βx ) 2 = βf(x)(1 f(x)) Tangens hyperbolicus: f(x) = tanh(x) = (e x e x )/(e x + e x ) mit Ableitung f (x) = 1/ cosh 2 (x) = 4/(e x + e x ) 2 die Ausgangsneuronen eines MLP dürfen auch lineare Neuronen sein: f(x) = x, f (x) = 1 sinnvoll bei Einsatz eines MLP zur Approximation! NI1 100

101 mögliche Trajektorie bei Batch-Lernen: mögliche Trajektorie bei Online-Lernen: NI1 101
102 NETtalk als historische Anwendung von Backpropagation Architektur des MLP: Aufgabe: Lernens der Aussprache einfacher englischer Sätze [Sejnowski, Rosenberg 1986] Zahl korrekt ausgesprochener Worte: NI1 102
103 Sätze zur Repräsentierbarkeit mit einem MLP Zweischichtiges MLP mit sigmoiden Neuronen kann jede stetige Funktion [0, 1] n [0, 1] m beliebig genau approximieren [Cybenko 89]. Korollar: Zweischichtiges MLP kann jede stetige Entscheidungsgrenze zwischen zwei Klassen beliebig genau approximieren. Zweischichtiges MLP mit sigmoiden Neuronen in der verdeckten Schicht und linearen Neuronen in der Ausgangsschicht kann jede stetige Funktion mit I n R m auf einem kompakten Intervall I n R n beliebig genau approximieren [Funahashi 89]. Zweischichtiges MLP mit linearen Ausgansneuronen kann jede stetige Funktion mit I n R m auf einem kompakten Intervall I n R n beliebig genau approximieren, wenn die Transferfunktionen in der verdeckten Schicht beschränkt, stetig und nicht konstant sind [Hornik 91]. NI1 103
104 Probleme von MLP und Error Backpropagation 1. allgemeine Probleme eines Gradientenabstiegs: a) Erreichen lokaler Minima b) Flaches Plateau in der Fehlerfläche c) Oszillationen d) Überspringen guter Minima 2. kritische Wahl einer Lernrate η 3. kritische Wahl der Anzahl Neuronen h in der verdeckten Schicht 4. Sättigung (im Sättigungsbereich der sigmoiden Transferfunktion gilt für Neuron j: f (x j ) 0) 5. hohe Symmetrie 6. gute zufällige Initialisierung aller Gewichte w ij nötig (typisch w ij [ 2 m, 2 m ] bei einem MLP mit m Eingabeknoten) NI1 104
105 Veranschaulichung von Problem 1: (für eindimensionale Fehlerfläche; aus: [Zell 1994]) NI1 105
106 Error Backpropagation mit Momentumterm Idee: Berücksichtigung von Gewichtsänderung aus Schritt t 1 in Schritt t Einführung eines Momentumterms (Rumelhart 1986): w ij (t) = η E(t) w ij + α w ij (t 1) = η y i δ j + α w ij (t 1) mit Momentumfaktor 0 α < 1 zwei Fälle: E(t 1) a) sgn( w ij (t 1)) = sgn( ) = sgn( E(t) ) Beschleunigung w ij w ij E(t 1) b) sgn( w ij (t 1)) = sgn( w ij ) sgn( E(t) w ij ) Stabilisierung NI1 106
107 Einsetzen liefert: w ij (t) = η E(t) + α w ij (t 1) w ij = η E(t) ( ) E(t 1) + α η + α w ij (t 2) w ij w ij = η E(t) ( ) E(t 1) E(t 2) + α η ηα w ij w ij w ij =... = η t k=0 k E(t k) α w ij effektive Lernrate für t im Fall a): η eff = η α k = k=0 η (1 α) NI1 107
108 mögliche Trajektorie ohne Momentumterm: (a) kleine Lernrate (b) große Lernrate mögliche Trajektorie mit Momentumterm: (a) kleine Lernrate (b) große Lernrate NI1 108
109 Quickprop Idee: Annäherung der Fehlerfunktion durch Parabel E Lernregel (Fahlman 1989): t-1 w ij (t) = β ij (t) w ij (t 1) mit β ij (t) = und S ij (t) = E w ij (t) S ij (t) S ij (t 1) S ij (t) S = w E t+1 w(t+1) t w(t) w(t-1) w viele Sonderfälle (s. [Zell94]): S(t-1) für t = 0 oder w ij (t 1) = 0 gilt Backpropagation Lernregel S(t) für β ij (t) > β max gilt Lernregel w ij (t) = β max w ij (t 1) S(t+1)=0 w(t) w(t-1) w NI1 109
110 Super Self Adapting Backprop (SuperSAB) Idee: gewichtsspezifische, adaptierbare Lernraten η ij SuperSAB Lernregel (Tollenaere 1990): w ij (t + 1) = w ij (t) η ij (t) E w ij (t) mit η ij (0) = η start η + η ij (t 1) η ij (t) = η η ij (t 1) η ij (t 1) falls falls sonst E (t 1) E (t) > 0 w ij w ij E (t 1) E (t) < 0 w ij w ij Typische Wahl der Parameter: η + = , η = Verwendung nur im Batch-Lernmodus! NI1 110
111 Resilient Backpropagation (RPROP) Problem aller bisher betrachteter Lernalgorithmen für MLPs: w E w d.h. auf flachen Plateaus der Fehlerfläche ist w sehr klein; auf steilen Flanken der Fehlerfläche ist w sehr groß Idee : w sgn E w RPROP Lernregel (Riedmiller, Braun 1993): w ij (t + 1) = w ij (t) η ij (t)sgn E(t) w ij (Vgl. dazu SuperSAB) NI1 111
112 Wahl von η ij (t): (wie beim SuperSAB) η ij (t) = η + η ij (t 1) falls η η ij (t 1) falls η ij (t 1) sonst E (t 1) E (t) > 0 w ij w ij E (t 1) E (t) < 0 w ij w ij Es muß stets gelten: 0 < η < 1 < η + Typische Wahl der Parameter: η + = 1.2 η = 0.5 η(0) = 0.1 (Startwert für alle Lernraten η ij ) η max = 1.0 (Beschränkung der Lernraten nach oben) η min = 10 6 (Beschränkung der Lernraten nach unten) Verwendung nur im Batch-Lernmodus! NI1 112
113 6.4 Neuronale Netze zur Verarbeitung von Zeitreihen Aufgabe: Erlernen einer Zeitreihe x(t + 1) = f(x(t), x(t 1), x(t 2),...) Idee: Verzögerungskette am Eingang eines neuronalen Netzwerks, z.b. eines m-h-1 MLPs: x(t) z 1 x(t) x(t 1) z 1 x(t 2) x(t+1) z 1 x(t m) MLP NI1 113
114 Training und Prognose von ˆx = f(x(t 1),..., x(t m)): x(t) z 1 z 1 x(t 1) x(t 2) x(t) Σ + x(t) z 1 z 1 Schalter x(t 1) x(t 2) x(t) z 1 x(t m) NN z 1 x(t m) trainiertes NN Probleme: m ist fester Architekturparameter, zwei gleiche Teilfolgen bewirken unabhängig vom Kontext immer die gleiche Ausgabe NI1 114
115 Architekturen partiell rekurrenter Netze Jordan Netzwerk [Jordan 1986]: y(t) x(t) s(t) NI1 115
116 Elman Netzwerk [Elman 1990]: y(t) c ij s(t+1) x(t) w ki v ki s(t) Vorteile des Elman-Netzwerks: interne Repräsentation einer Sequenz ist unabhängig von der Ausgabe y, Zahl der Kontextzellen ist unabhängig von der Ausgabedimension! NI1 116
117 Training eines partiell rekurrenten Netzes Möglichkeit A: Modifikation eines Lernverfahrens für nichtrekurrente Netze (z.b. Error Backpropagation, RPROP, Quickprop) Algorithmus (für Elman-Netzwerk): Seien w ki und v ki die Gewichte von Eingabeknoten u k bzw. Kontextknoten s k zum verdeckten Neuron i und c ij die Gewichte der zweiten Netzwerkschicht 1) Setze t = t 0, initialisiere Kontextzellen s(t 0 ) = 0 2) Berechne w ki (t), v ki (t) und c ij (t) gemäß Lernregel für eine Eingabe x(t) mit Sollwert T(t) ohne Beachtung rekurrenter Verbindungen 3) Setze t = t + 1, aktualisiere die Ausgabe s(t) der Kontextzellen und gehe zu 2) Eigenschaften: Fehler von y(t) = f(x(t)) wird minimiert, keine Klassifikation von Sequenzen möglich. NI1 117
118 Möglichkeit B: Verwendung eines Lernverfahrens für rekurrente Netze (z.b. BPTT [Rumelhart 86], RTRL [Willliams 89]) Idee von BPTT ( Backpropagation Through Time ): Entfaltung des Netzwerks in der Zeit! Gradientenabstieg zur Minimierung von E = t max t=t 0 E(t) mit E(t) = { T(t) y(t) falls T(t) zum Zeitpunkt t vorliegt 0 sonst Eigenschaften: Fehler von y(t max ) = f(x(t 0 ),..., x(t max )) wird minimiert, auch Klassifikation von Sequenzen variabler Länge möglich! NI1 118
119 BPTT Algorithmus für Elman Netzwerk Gegeben sei ein (m + h) h n Elman Netzwerk mit: w ki : Gewichte von Eingabeknoten u k zum verdeckten Neuron i v ki : Gewichte von Kontextknoten s k zum verdeckten Neuron i c ij : Gewichte vom verdeckten Neuron i zum Ausgabeneuron j : Fehler am Ausgabeneuron j δ (y) j δ (s) i : Fehler am verdeckten Neuron i Lineare Ausgabeneuronen j = 1,..., n : Annahme: für t = t max gilt: für t < t max gilt: E(t) = 0 für t t max δ (y) j (t) = T j (t) y j (t) c ij = s i (t + 1) δ (y) j (t) δ (y) j (t) = 0 c ij = 0 NI1 119
120 Sigmoide verdeckte Neuronen i = 1,..., h : n für t = t max δ (s) i (t) = c ij δ (y) j (t) s i(t + 1) für t 0 t < t max j=1 v ki (t) = s k (t) δ (s) i (t) w ki (t) = x k (t) δ (s) i (t) δ (s) i (t) = h k=1 v ki (t) = s k (t) δ (s) i (t) w ki (t) = x k (t) δ (s) i (t) v ki δ (s) k (t + 1) s i(t + 1) Resultierende Lernregeln: t max t max c ij = c ij + η 1 c ij, w ki = w ki + η 2 w ki (t), v ki = v ki + η 2 v ki (t) t=t 0 t=t 0 NI1 120
121 6.5 Radiale Basisfunktionen Motivation: Es wird eine Lösung für das folgende Interpolationsproblem gesucht: Gegeben sei eine Menge M = {(x µ, T µ ) : µ = 1,..., p} mit x µ R m und T µ R n. Gibt es eine Funktion g : R m R n mit g(x µ ) = T µ µ = 1,..., p? Idee: Annäherung von g durch eine Linearkombination von p Funktionen h ν (x) = h( x ν x ) mit (beliebig oft differenzierbarer) radialsymmetrischer Funktion h : R + R + Das Interpolationsproblem hat (hier für n = 1) die Form p p g(x µ ) = w ν h ν (x µ ) = w ν h( x ν x µ ) µ = 1,..., p ν=1 ν=1 NI1 121
122 w ν können analytisch bestimmen werden: p g(x µ ) = w ν h( x ν x µ ) = T µ, µ = 1,..., p. ν=1 In Matrixnotation gilt: Hw = T mit H := (H µν ) und H µν := h µ (x ν ) Falls H invertierbar ist, so gilt: w = H 1 T, mit den Vektoren w = (w 1,... w p ) t und T = (T 1,..., t p ) t. einige radialsymmetrische Basisfunktionen (mit r = x x µ ): Gauss-Funktion: h(r) = exp( r2 2σ2) mit σ 0 Inverse multiquadratische Funktionen: 1 h(r) = mit c 0 und α > 0 (r 2 + c 2 ) α Multiquadratische Funktionen: h(r) = (r 2 + c 2 ) β mit c 0 und 0 < β 1 NI1 122
123 Radiales Basisfunktionen-Netzwerk (RBF) Aufbau eines m-h-n RBF-Netzwerks: m Eingabeknoten h RBF-Neuronen n lineare Neuronen C x c ki Berechnung der Netzausgabe z: m u i = (x k c ki ) 2 = x c i k=1 u y W w ij y i = h(u i ) h z j = y i w ij [ + bias j ] z i=1 NI1 123
124 Herleitung der Lernregel für RBF-Netzwerk Es soll eine auf Gradientenabstieg basierende Lernregel für das RBF- Netzwerk hergeleitet werden. Für die Gewichte w ij der Ausgabeschicht gilt: E µ w ij = = w ij T z 2 (T j z j ) 2 w ij = 2(T j z j ) j = 2 y i δ j w ij ĩ yĩwĩj wobei δ j = (T j z j ) den Fehler von Neuron j der Ausgabeschicht für ein Muster bezeichnet NI1 124
125 resultierende Lernregeln für Gewichte w ij der Ausgabeschicht: im Online-Modus: w ij = w ij η 1 E µ w ij = w ij + η 1 y i δ j [bias j = bias j η 1 E µ w ij = bias j + η 1 δ j ] im Batch-Modus: w ij = w ij η 1 [bias j = bias j η 1 E = w ij + η 1 w ij µ y µ i δµ j E = bias j + η 1 w ij µ δ µ j ] NI1 125
126 Für Gewichte c ki der Eingabeschicht gilt: E µ c ki = E µ y i = 2 j = 2 j = 2 j y i c ki (T j z j ) y i (T j z j ) w ij h (u i ) ĩ yĩ wĩj c ki h(u i ) c ki (x k c ki ) 2 (T j z j ) w ij h (u i ) 1 2u i ( 2) (x k c ki ) k = 2 j δ j w ij h (u i ) 1 u i (x k c ki ) Speziell für h(u) = e u2 /2σ 2 = e u2s ergibt sich: E µ c ki = 2 j = 4 j (T j z j ) w ij e u2 i s 2s(x k c ki ) δ j w ij y i s (x k c ki ) NI1 126
127 resultierende Lernregeln für Gewichte c ki der Eingabeschicht bei Verwendung der radialen Basisfunktion h(u) = e u2 /2σ 2 = e u2s : im Online-Modus: c ki = c ki η 2 E µ c ki = c ki + η 2 (x k c ki ) y i s j δ j w ij im Batch-Modus: E c ki = c ki η 2 = c ki + η 2 (x µ k c c ki) y µ i s ki µ j δ µ j w ij NI1 127
128 Lernalgorithmus (online) für RBF-Netzwerk Gegeben: m-h-n RBF-Netzwerk verwendete radiale Basisfunktion: y = h(u) = e u2 /2σ 2 := e u2 s Menge von p gelabelten Mustern (x µ, T µ ) R m R n Schritt 1: Initialisierung Setze w ij für i = 1,..., h, j = 1,..., n auf kleine Zufallswerte und wähle c ki für k = 1,..., m, i = 1,..., h derart, dass die Daten im Eingaberaum überdecken Schritt 2: Berechnung der Netzausgabe z Wähle nächstes gelabeltes Musterpaar (x, T) und berechne: u 2 i = m (x k c ki ) 2 für i = 1,..., h k=1 NI1 128
129 y i = e u2 i /2σ2 = e u2 i s für i = 1,..., h h z j = y i w ij für j = 1,..., n i=1 Schritt 3: Bestimmung des Fehlers am Netzausgang Berechne δ j = (T j z j ) für j = 1,..., n Schritt 4: Lernen Adaptiere Gewichte: w ij = w ij + η 1 y i δ j c ki = c ki + η 2 (x k c ki ) y i s für k = 1,..., m, i = 1,..., h, j = 1,..., n n δ j w ij j=1 Schritt 5: Ende Falls Endekriterium nicht erfüllt, gehe zurück zu 2 NI1 129
130 Bemerkungen zum RBF-Netzwerk Anzahl der RBF-Neuronen ist kleiner als Anzahl Trainingsmuster Vektor c i wird auch als Prototyp bzw. Zentrum bezeichnet Initialisierung der Gewichte c ki z.b. durch äquidistante Verteilung in einem Intervall [min,max] m durch Clusteranalyse (vgl. Kapitel 8) Verhalten des RBF-Netzwerks stark abhängig von der Wahl eines guten Wertes für σ bzw. s z.b.: σ [d min, 2 d min ] (mit d min = kleinster Abstand zwischen zwei Zentren) Parameter σ i bzw. s i kann auch für jedes RBF-Neuron i individuell gewählt und adaptiert werden ( Übung) Adaption von c ki, w ij und σ i bzw. s i ist simultan oder sequentiell möglich! NI1 130
131 Approximation einer verrauschten Funktion mit RBF-Netz: (mit 5 RBF-Neuronen bei σ = 10, mit σ = 0.4, σ = 0.08) NI1 131
132 Unterschiede MLP und RBF bei Klassifikation: MLP: Trennung durch Hyperebenen RBF: Hyperkugeln umfassen Punkte einer Klasse bei MLP ist Repräsentation in verdeckter Schicht verteilt, bei RBF lokal Initialisierung der Gewichte bei MLP zufällig, bei RBF datenabhängig MLP und RBF können Funktionen beliebig genau approximieren i.a. schnellere Konvergenz mit RBF bei guter Initialisierung NI1 132
133 6.6 Konstruktive Lernverfahren Problem: In allen bisherigen neuronalen Netzmodellen wird die Architektur vor Start des Lernverfahrens festgelegt während des Trainings ist keine Anpassung der Architektur an das zu lernende Problem möglich. Idee: Man startet mit einem kleinen neuronalen Netzwerk und fügt während des Trainings bei Bedarf noch weitere Neuronen oder Neuronenschichten hinzu. Beispiele: 1. Upstart Algorithmus (konstruiert Binärbaum aus Perzeptronen) 2. Cascade Correlation (konstruiert pyramidenartige Architektur aus sigmoiden Neuronen) NI1 133
134 Upstart Algorithmus [Frean 1990] rekursiver Algorithmus zum Erlernen beliebiger binärer Abbildungen mit Schwellwertneuronen: upstart(t 0, T 1 ) { trainiere ein Perzeptron Z mit T 0 T 1 wenn mind. 1 Muster aus T 0 falsch klassifiziert wird: bilde T0 T 0 generiere neues Perzeptron X trainiere X mit upstart(t 1, T0 ) wenn mind. 1 Muster aus T 1 falsch klassifiziert wird: bilde T1 T 1 generiere neues Perzeptron Y trainiere Y mit upstart(t 0, T1 ) berechne MAX= max µ i w ix (µ) i von Z verbinde X mit Z durch w < MAX und Y mit Z durch w > MAX } mit: T 0, T 1 Trainingsmenge für Ausgabe 0 bzw. 1 T0 1 Menge falsch klassifizierter Muster aus T 0 bzw. T 1 NI1 134
135 Cascade Correlation Motivation : bei großem Fehler am Ausgang für ein Muster A werden alle Gewichte adaptiert aufgrund fehlender Absprache zwischen den Neuronen der verdeckten Schicht kann Fehler für ein Muster B wachsen ( moving target problem ) Idee : Gewichte v ij eines jedes verdeckten Neurons j werden separat trainiert, indem die Korrelation zwischen der Ausgabe des Neurons und dem Fehler maximiert wird anschließend werden die Gewichte v ij von Neuron j eingefroren Hinzufügen weiterer verdeckter Neuronen (als Kandidatenzellen bezeichnet), bis Fehler am Ausgang ausreichend klein ist automatische Bestimmung einer guten Topologie! NI1 135
136 Cascade Correlation Architektur [Fahlman 90]: n sigmoide oder lineare Neuronen (enthalten θ ) k z sigmoide Neuronen (Kandidatenzellen, enthalten θ j ) j y j m Eingabe knoten 1 2 V W x Ziel: Maximierung der Korrelation S j = k p (y pj y j )(δ pk δ k ) mit y pj Ausgabe der Kandidatenzelle j für Muster p y j mittlere Ausgabe der Kandidatenzelle j δ pk Fehler der Ausgangszelle k für Muster p mittlerer Fehler der Ausgangszelle k δ k NI1 136
137 Für Eingangsgewichte v ij der j-ten Kandidatenzelle gilt: S j v ij = k = k = k = k = k (y pj y j )(δ pk δ k ) v ij p σ k (y pj y j )(δ pk δ k ) v p ij σ k y pj (δ pk δ k ) v p ij σ k f( I pi v ij )(δ pk δ k ) v p ij i σ k f (x pj )I pi (δ pk δ k ) p mit σ k = sgn( p (y pj y j )(δ pk δ k )) I pi = { upi für externen Eingang i für Kandidatenzelle i < j y pi NI1 137
138 Lernalgorithmus für Cascade Correlation Schritt 1: Trainiere die Gewichte w ik und θ k der Ausgangsknoten mit einem geeigneten Algorithmus: - Perzeptron-Lernalgorithmus oder - Delta-Lernregel: w ik = u i (T k y k )f (x k ) - Quickprop-Verfahren bis Fehler E am Netzausgang nicht weiter sinkt Schritt 2: - Stop, wenn Fehler E ausreichend klein - Ansonsten generiere eine neue Kandidatenzelle j und initialisiere v ij zufällig NI1 138
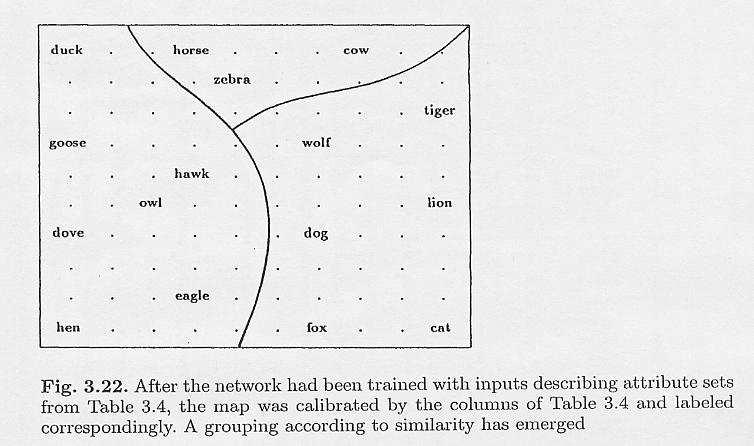
139 Schritt 3: Bestimme Gewichte v ij und θ j der Kandidatenzelle j derart, daß Korrelation S j maximiert wird. Adaptiere hierzu v ij und θ j durch Gradientenaufstieg gemäß v ij = v ij + η σ k f (x pj )I pi (δ pk δ k ) k p θ j = θ j + η σ k f (x pj )(δ pk δ k ) k p bis Korrelation S j nicht weiter steigt Schritt 4: Friere alle Gewichte v ij und θ j der Kandidatenzelle j ein Schritt 5: Gehe nach (1) NI1 139
140 7. Unüberwachte Lernverfahren 1. Neuronale Merkmalskarten 2. Explorative Datenanalyse 3. Methoden zur Datenreduktion der Datenpunkte 4. Methoden zur Merkmalsreduktion der Merkmale NI1 140
141 7.1 Neuronale Merkmalskarten Neuron Schichten der Großhirnrinde Kortikale Säulenarchitektur Laterale Hemmung Karten im Kortex NI1 141
, sowie eine schematische Skizze eines Neurons")
142 Neuron Zur Erinnerung: Lichtmikroskopische Aufnahme eines Neurons (linke) (Golgi-Färbung) und eine elektromikroskopische Aufnahme eines Zellkörpers (rechts oben), sowie eine schematische Skizze eines Neurons (rechts unten). NI1 142
143 Schichten der Großhirnrinde Schichtenstruktur (6 Schichten) der Großhirnrinde (Kortex): Neuronen mit Dendriten und Axonen durch Golgi-Färbung sichtbar(links). Nissl-Färbung: Nur die Zellkörper der Neuronen sind sichtbar(mitte). Weigert-Färbung: Sichtbar sind die Nervenfasern (rechts). NI1 143

144 Kortikale Säulenarchitektur I Der Kortex weist eine sechsschichtige horizontale Gliederung auf, insbesondere durch verschiedene Zelltypen. Verbindungsstrukur vertikal und horizontal; Verbindungen von Pyramidenzellen in Schicht 5 liegen etwa 0,3 bis 0,5 mm um die vertikale Achse, was eine zylindrische Geometrie kortikaler Informationsverarbeitungsmodule nahelegt. Ungeklärt ist, ob es sich bei den kortikalen Säulen sogar um konkrete anatomische Strukturen oder um abstrakte (momentane) funktionelle Struktur handelt. Die unmittelbaren Nachbarn eines Neurons bilden eine funktionelle Einheit. Nachbarneuronen werden leicht erregt. Weiter entfernt liegende Neuronen werden über Interneuronen inhibiert, man spricht von lateraler Inhibition. NI1 144

145 Kortikale Säulenarchitektur II Prinzip der kortikalen Säulen: Hierbei sind eigentlich nicht einzelne Neurone gemeint, auch wenn die kortikalen Säulen in der Simulation so aufgefasst werden. Der gesamte Kortex zeigt diese Säulenarchitektur. NI1 145

146 Laterale Inhibition Center-Surround-Architektur. Jedes Neuron ist mit jedem anderen verbunden. Verbindungen zu benachbarten Neuronen sind exzitatorisch, weiter entfernt liegende Neuronen werden inhibiert. Oben: Querschnitt durch diese Aktivierung. Mitte: Zweidimensionale Darstellung der Aktivierung. Wegen der Form wird sie auch mexican hat function genannt. Unten: Schematische Anordung der kortikalen Säulen. Die laterale Inhibition bewirkt, dass das Neuron welches bei einer Eingabe am stärksten aktiviert wird, letztlich nur selbst aktiv bleibt: The winner takes it all In der Simulation wird das Neuron bestimmt, das durch eine Eingabe am stärksten aktiviert wurde: Winner detection. NI1 146
.")
 enthält Neuronen, die Töne nach der Frequenz sortiert")
147 Karten im Kortex Abbildung oben: Motorischer (links) und sensorischer Kortex (rechts). Abbildung unten: Der auditorische Kortex (genauer das Areal A1) enthält Neuronen, die Töne nach der Frequenz sortiert kartenförmig repräsentieren. NI1 147
.")

148 Abbildung oben: Sensorische Repräsentation der Körperoberfläche bei Hasen (links), Katzen (Mitte) und Affen (rechts). Körper ist proportional zur Größe der ihn repräsentierenden Großhirnrinde gezeigt. Abbildung unten: Auditorischer Kortex der Fledermaus ist schematisch dargestellt (links). Die Verteilung der von den Neuronen repäsentierten Frequenzen ist dargestellt (rechts oben). Für Frequenzen um 61 khz ist etwa die Hälfte der Neuronen sensitiv. Signale in diesem Frequenzbereich nutzt die Fledermaus um aus der Tonhöheverschiebung des reflektierten Signals die Relativgeschwnidigkeit eines Objektes und dem Tier selbst zu bestimmen. Ergebnis einer Computersimulation (rechts unten). NI1 148
149 7.2 Explorative Datenanalyse 1 2 i d 1 2 Probleme Viele Datenpunkte. p p-th data point Hohe Dimension des Merkmalsraumes. Datenpunkte zu Beginn der Analyse möglicherweise nicht vollständig bekannt. M Keine Lehrersignale. i-th feature vector NI1 149
150 7.3 Methoden zur Reduktion der Datenpunkte Zielsetzung Kompetitive Netze, Distanz oder Skalarprodukt Selbstorganisierende Merkmalskarten Einfache kompetitive Netze und k-means Clusteranalyse ART-Netzwerke Verwandte Verfahren: Lernende Vektorquantisierung (LVQ) NI1 150
151 Zielsetzung Es soll eine Repräsentation der Eingabedaten bestimmt werden. Nicht Einzeldaten, sondern prototypische Repräsentationen sollen berechnet werden (Datenreduktion). Ähnliche Daten sollen durch einen Prototypen repäsentiert werden. Regionen mit hoher Datendichte sollen duch mehrere Prototypen repräsentiert sein. Durch spezielle neuronale Netze sollen sich Kartenstrukturen ergeben, d.h. benachbarte Neuronen (Prototypen) auf der Karte sollen durch ähnliche Eingaben aktiviert werden. NI1 151
152 Kompetitives neuronales Netz weight matrix C input x x C output j = argmin x - c k k argmin NI1 152
153 Distanz vs Skalarprodukt zur Gewinnerdetektion Die Euklidische Norm ist durch das Skalarprodukt im R n definiert: x 2 = x, x Für den Abstand zweier Punkte x, y R n gilt demnach: x y 2 2 = x y, x y = x, x 2 x, y + y, y = x x, y + y 2 2 Für die Gewinnersuche bei der Eingabe x unter den Neuronen, gegeben durch Gewichtsvektoren c 1,..., c k und c i 2 = 1 mit i = 1,..., k gilt dann offenbar: j = argmax i x, c i j = argmin i x c i 2 NI1 153
154 Kohonen s Selbstorganisierende Karte Feature Space 2D Grid with Neighbourhood Function Projection Prototypes Zielsetzung beim SOM-Lernen Berechnung von Prototypen im Merkmalsraum, also c i R d, die die gegebenen Daten x R d gut repräsentieren. Nachbarschaftserhaltende Abbildung der Prototypen c i R d auf Gitterpositionen g i auf ein Gitter im R 2 (1D oder 3D Gitter sind auch gebräuchlich). NI1 154
155 Kohonen Lernregel: c j = l t N t (g j, g j ) (x c j ) j ist der Gewinner N t (g j, g j ) eine Nachbarschaftsfunktion. g j die Gitterposition des j-ten Neurons l t und σ t trainingszeitabhängige Lernraten bzw. Nachbarschaftsweitenparameter, die bei wachsender Trainingszeit gegen 0 konvergieren. Beispiel: N t (g j, g j ) = exp( g j g j 2 /2σ 2 t ) NI1 155
156 Kohonen Lernalgorithmus Input: X = {x 1,..., x M } R d 1. Wähle r, s N, eine Clusterzahl k = rs N, eine Lernrate l t > 0, eine Nachbarschaftsfunktion N und max. Lernepochenzahl N. Setze t = Initialisiere Prototypen c 1,..., c k R d (k d Matrix C) 3. Jeder Prototypen c i auf genau eine Gitterposition g i {1,..., r} {1,..., s}. 4. repeat Wähle x X und t = t + 1 j = argmin i x c i (winner detection) for all j: c j = c j + l t N t (g j, g j )(x c j ) (update) 5. until t N NI1 156

157 SOM-Beispiele NI1 157
158 NI1 158
159 2 Data and original map 1 Sequential training after 300 steps NI1 159
160 Kompetitives Lernen (Euklidische Distanz) Input: X = {x 1,..., x M } R d 1. Wähle Clusterzahl k N, eine Lernrate l t > 0 und N. Setze t = Initialisiere Prototypen c 1,..., c k R d (k d Matrix C) 3. repeat Wähle x X und t = t + 1 j = argmin j x c j (winner detection) c j = c j + l t (x c j ) (winner update) 4. until t N NI1 160
161 k-means Clusteranalyse Datenpunkt x R d wird dem nächsten Clusterzentrum c j zugeordnet: j = argmin j x c j. Anpassung des Clusterzentrums: c j = 1 C j + 1 (x c j ) Zum Vergleich beim Kompetitiven Lernen c j = l t (x c j ) l t > 0 eine Folge von Lernraten mit t l t = und t l2 t <. Beispiel: l t = 1/t. NI1 161
162 Beispiel: Kompetitives Lernen NI1 162
163 ART-Netzwerke Adaptive-Resonanz-Theorie (ART) entwickelt von Stephen Grossberg und Gail Carpenter Hier nur ART1 Architektur Erweiterungen: ART 2, ART 3, FuzzyART, ARTMAP ART-Netze sind kompetitive Netze Besonderheit: ART-Netze sind wachsende Netze, d.h. die Zahl der Neuronen kann während des Trainings wachsen (aber nach oben beschränkt); ein Neuron kann allerdings nicht wieder gelöscht werden. Spezialität bei den ART 1 Netzen: Die Eingabedaten und die Gewichtsvektoren (Prototypen) sind binäre Vektoren. NI1 163
164 ART1 Lernen : Idee Inputvektoren und Prototypen {0, 1} d. Es wird höchstens der Gewichtsvektor des Gewinnerneurons c j adaptiert. Ist die Ähnlichkeit zwischen Inputvektor x und c j zu gering, so definiert x einen neuen Prototypen und der Gewinnerprototyp c j bleibt unverändert. Die Ähnlichkeit wird durch das Skalarprodukt x c j = x, c j gemessen. Schranke für die Mindestähnlichkeit wird durch den sogenannten Vigilanzparameter gemessen. Ist die Ähnlichkeit groß genug, so wird c j durch komponentenweises AND von x und c j adaptiert. Maximale Zahl von Neuronen wird vorgegeben. Aus dieser Grundidee lassen sich viele mögliche Algorithmen ableiten. NI1 164
165 ART1 : Bezeichnungen x µ {0, 1} d die Eingabevektoren µ = 1,..., M c i {0, 1} d die Gewichtsvektoren der Neuronen (Prototypen) 1 = (1, 1,..., 1) {0, 1} d der Eins-Vektor mit d Einsen. k Anzahl der maximal möglichen Neuronen. x 1 = d i=1 x i die l 1 -Norm (= Anzahl der Einsen). ϱ [0, 1] der Vigilanzparameter. NI1 165
166 ART1 : Algorithmus 1. Wähle k N und ϱ [0, 1]. 2. Setze c i = 1 für alle i = 1,..., k. 3. WHILE noch ein Muster x vorhanden DO Lies x und setze I := {1,..., k} REPEAT j = argmax j I x, c j / c j 1 (winner detection) I = I \ {j } UNTIL I = x, c j ϱ x 1 4. END IF x, c j ϱ x 1 THEN c j = x c j (winner update) ELSE keine Bearbeitung von x NI1 166
167 Verwandte Verfahren : LVQ Lernende Vektorquantisierung (LVQ) sind überwachte Lernverfahren zur Musterklassifikation. LVQ-Verfahren sind heuristische kompetitive Lernverfahren; entwickelt von Teuvo Kohonen Euklidische Distanz zur Berechnung der Ähnlichkeit/Gewinnerermittlung. Es wird nur LVQ1 vorgestellt. Erweiterungen: LVQ2 und LVQ3 (ggf. Adaptation des 2. Gewinners); OLVQ-Verfahren (neuronenspezifische Lernraten). NI1 167
168 LVQ1 : Algorithmus Input: X = {(x 1, y 1 ),..., (x M, y M )} R d Ω hierbei ist Ω = {1,..., L} eine endliche Menge von Klassen(-Labels). 1. Wähle Prototypenzahl k N, eine Lernrate l t > 0 und N. Setze t = Initialisiere Prototypen c 1,..., c k R d. 3. Bestimme für jeden Protypen c i die Klasse ω i Ω. 4. repeat Wähle Paar (x, y) X und setze t := t + 1 j = argmin i x c i (winner detection + class from nearest neighbor) if ω j y then = 1 else = 1 (correct classification result?) c j = c j + l t (x c j ) (winner update) 5. until t N NI1 168
169 8.4 Methoden zur Reduktion der Merkmale Zielsetzung Hauptachsentransformation (lineare Merkmalstransformation) Neuronale Hauptachsentransformation (Oja und Sanger Netze) NI1 169
170 Zielsetzung 1 2 p M 1 2 i d i-th feature vector p-th data point Einfache kompetitive Netze wie ART, adaptive k-means Clusteranalyse und auch LVQ-Netze führen eine Reduktion der Datenpunkte auf einige wenige repräsentative Prototypen (diese ergeben sich durch lineare Kombination von Datenpunkten) durch. Kohonen s SOM: Reduktion der Datenpunkte auf Prototypen und gleichzeitig Visualisierung der Prototypen durch nichtlineare nachbarschaftserhaltende Projektion. Nun gesucht Reduktion der Datenpunkte auf repräsentative Merkmale, die sich möglichst durch lineare Kombination der vorhandenen Merkmale ergeben. NI1 170
171 Beispieldaten 30 data Variation der Daten in Richtung der beiden definierten Merkmale x 1 und x 2 ist etwa gleich groß. In Richtung des Vektors v 1 = (1, 1) ist die Variation der Daten sehr groß. Orthogonal dazu, in Richtung v 2 = (1, 1) ist sie dagegen deutlich geringer. NI1 171
172 Hauptachsen Offensichtlich sind Merkmale in denen die Daten überhaupt nicht variieren bedeutungslos. Gesucht ist nun ein Orthonormalsystem (v i ) l i=1 im Rd mit (l d), das die Daten mit möglichst kleinem Rekonstruktionsfehler (bzgl. der quadrierten Euklidischen Norm) bei festem (l < d) erklärt. Dies sind die sogenannten Hauptachsen. 1. Hauptachse beschreibt den Vektor v 1 R d mit der größten Variation 2. Hauptachse den Vektor v 2 R d mit der zweitgrößten Variation der senkrecht auf v 1 steht. l. Hauptachse ist der Vektor v l R d, v l senkrecht auf V l 1 = lin{v 1,..., v l 1 } und die Datenpunkte x µ r mit x µ = x µ r +v, v lin{v l } haben in Richtung v l die stärkste Variation. NI1 172
173 Hauptachsentransformation Gegeben sei eine Datenmenge mit M Punkten x µ R d, als M d Datenmatrix X. Die einzelnen Merkmale (sind die Spaltenvektoren in der Datenmatrix X) haben den Mittelwert 0. Sonst durchführen. Für einen Vektor v R d und x µ X ist v, x µ = d i=1 v i x µ i von x µ auf v. die Projektion Für alle Datenpunkte X ist Xv der Vektor mit den Datenprojektionen. Es sei nun (v i ) d i=1 ein Orthonormalsystem in Rd. Sei nun l < d. Für x R d gilt dann hierbei ist α i = x, v i. x = α } 1 v 1 + {{... + α l v } l +α l+1 v l α d v d =: x NI1 173
174 Dann ist der Fehler zwischen x und x d e l (x) := x x 2 2 = α j v j 2 2 j=l+1 Gesucht wird ein System {v i }, so dass e l möglichst klein ist: e l (x µ ) = µ d α µ j v j, d α µ j v j = µ d (α µ j )2 min µ j=l+1 j=l+1 j=l+1 Dabei ist (α µ j )2 (α µ j )2 = α µ j αµ j = (vt jx µ )((x µ ) t v j ) = v t j(x µ (x µ ) t )v j NI1 174
175 Mitteln über alle Muster liefert: 1 M d vj(x t µ (x µ ) t )v j = µ j=l+1 d j=l+1 v t j 1 (x µ (x µ ) t ) M µ }{{} =:R v j R ist die Korrelationsmatrix der Datenmenge X. Es ist damit folgendes Problem zu lösen: d j=l+1 v t jrv j min Ohne Randbedingungen an die v j ist eine Minimierung nicht möglich. Normierung der v t j v j = v j 2 = 1 als Nebenbedingung. Minimierung unter Nebenbedingungen (Siehe auch Analysis 2 (multidimensionale Analysis), speziell die Anwendungen zum Satz über implizite NI1 175
176 Funktionen) führt auf die Minimierung der Funktion ϕ(v l+1,..., v d ) = d j=l+1 v t jrv j d j=l+1 λ j (v t jv j 1) mit Lagrange Multiplikatoren λ j R. Differenzieren von ϕ nach v j und Nullsetzen liefert: ϕ v j = 2Rv j 2λv j = 0 Dies führt direkt auf die Matrixgleichungen Rv j = λ j v j j = l + 1,..., d Das gesuchte System (v j ) d j=1 sind also die Eigenvektoren von R. NI1 176
177 R ist symmetrisch und nichtnegativ definit, dh. alle Eigenwerte λ j sind reell und nichtnegativ, ferner sind die Eigenvektoren v j orthogonal, wegen der Nebenbedingungen sogar orthonormal. Vorgehensweise in der Praxis: Merkmale auf Mittelwert = 0 transformieren; Kovarianzmatrix C = X t X berechnen Eigenwerte λ 1,..., λ d und Eigenvektoren v 1,..., v d (die Hauptachsen) von C bestimmen Daten X auf die d d Hauptachsen projezieren, d.h. X = X V mit V = (v 1, v 2,..., v d ). Die Spalten von V sind also die Eigenvektoren v i. Dies ergibt eine Datenmatrix X mit M Zeilen (Anzahl der Datenpunkte) und d Merkmalen. NI1 177
178 Hauptachsentransformierte Beispieldaten PCA transformierte Datenpunkte, Mittelwert: 1.09e e 16, Standardabweichung: PCA Komponente PCA Komponente NI1 178
179 Neuronale PCA - Oja-Lernregel Lineares Neuonenmodell mit Oja-Lernregel Eingabe x Gewichtsvektor c Lineare Verrechnung der Eingabe x und dem Gewichtsvektor c y = x, c = n x i c i i=1 Lernregel nach Oja c = l t (yx y 2 c) = l t y(x yc) y=xc Ausgabe Satz von Oja (1985): Gewichtsvektor c konvergiert gegen die 1. Hauptachse v 1 (bis auf Normierung), hierbei muss gelten: l t 0 bei t, t l t = und t l2 t <. NI1 179
180 Neuronale PCA - Sanger-Lernregel Verallgemeinerung auf d d lineare Neuronen mit d Gewichtsvektor c j. Die Ausgabe des j-ten Neurons ist dabei: y j = x, c j Lernregel nach Sanger c ij = l t y j (x i j y k c ik ) k=1 Satz von Sanger (1989): c l konvergiert gegen die Hauptachsen v l (bis auf Normierung). Es muss gelten l t 0 bei t, t l t = und t l2 t <. NI1 180
181 Sanger-Transformierte Beispieldaten 4 ermittelte Datenpunkte, Mittelwert: , Standardabweichung: PCA Komponente PCA Komponente NI1 181
182 8. Neuronale Assoziativspeicher 1. Architektur und Musterspeicherung 2. Hetero-Assoziation 3. Auto-Assoziation 4. Bidirektionale NAMS 5. Hopfield-Netze NI1 182
183 Architektur Eingabe x θ θ θ θ θ Ausgabe y NI1 183
184 Musterspeicherung M binäre Musterpaare (x µ, T µ ) (µ = 1,..., M) werden gespeichert durch Hebb-Lernregeln c ij = c ij = M x µ i T µ j µ=1 M x µ i T µ j µ=1 binäre Hebbregel additive Hebbregel Auslesen des Antwortmusters zur Eingabe x µ { 1 i y j = xµ i c ij θ := x µ 0 sonst NI1 184
185 A: B: Input x Output y θ θ θ θ θ NI1 185
186 A: B: Input x Output y θ θ θ θ θ NI1 186
187 A: B: Input x Output y θ = NI1 187
188 Hetero-Assoziation Muster {(x µ, T µ ) : µ = 1,..., M}, x µ {0, 1} m k, T µ {0, 1} n l, p := k m, q = l n Lernregel: c ij = M µ=1 xµ i T µ j Retrieval: z j = 1 [x C θ] dabei ist θ = k Fehler: f 0 = p[z j = 0 T j = 1] = 0 und f 1 = p[z j = 1 T j = 0] = (1 p 0 ) k = pm = k = ln f 1 ln(1 p 0 ) (2) Dabei ist p 0 = p[c ij = 0] = (1 pq) M e Mpq = M = ln p 0 pq (3) Das Retrieval ist sehr genau, wenn f 1 δ q mit δ < 1. δ: Gütekriterium NI1 188
189 Kapazität bei Hetero-Assoziation Falls δ klein, dann ist die Information über das Ausgabemuster T µ : I µ n ( q log 2 q (1 q) log 2 (1 q)) nq log 2 q Relative Speicherkapazität: C = M I µ m n = I µ ln p 0 pqmn = ln p 0 ln(1 p 0 ) nq log qn ln f 2 q 1 Maximieren nach p 0 : = p 0 = 1 2 und damit C max = (ln 2)2 log 2 q ln q + ln δ = ln 2 ln q ln q + ln δ ln 2 Der Limes wird erreicht für q 0 und δ 0, aber δ langsamer, so dass ln δ ln q 0. Für große Matrizen ist C ln 2 bei kleinem δ > 0 erreichbar, wenn q sehr klein gewählt wird. = Spärlichkeit. NI1 189
190 Autoassoziativer Speicher Hetero-Assoziation: x T (pattern mapping) Auto-Assoziation: x = T (pattern completion) Für Auto-Assoziation iteratives Retrieval durch Rückkopplung der Netzausgabe: 1 2 n f f f NI1 190
191 Speichern und Retrieval Muster {(x µ ) : µ = 1,..., M}, x µ {0, 1} m k,, p := k m. Lernregel: c ij = M µ=1 xµ i xµ j Retrieval: z t+1 j Abbruch: z t z t+1 für t > 1 = 1 [zt C θ t ] dabei θ = z t, t = 1 und θ t = k Fehler: f 0 = p[z j = 0 x j = 1] = 0 und f 1 = p[z j = 1 T j = 0] = (1 p 0 ) k = pm = k = ln f 1 ln(1 p 0 ) (4) Dabei ist p 0 = p[c ij = 0] = (1 p 2 ) M e Mp2 = M = ln p 0 p 2 (5) Das Retrieval ist sehr genau, wenn f 1 δ p mit δ < 1. δ: Gütekriterium NI1 191
192 bits/synapse number of iterations number of stored patterns Speicherkapazität und mittlere Iterationszeit Autoassoziation mit n=2048 Neuronen Additive (unterbrochene Linie) und binäre (durchgezogene Linie) Hebb-Regel. 1-Schritt- ( ), 2-Schritt- ( ), und Fixpunkt- Retrieval ( ) Resultate Höhere Speicherkapazität mit binärer Hebbregel! 3) not- Nur wenige Iterationsschritte ( wendig NI1 192 number of stored patterns
193 number of stored patterns error ratio number of neurons Fehlerwahrscheinlichkeit und Musterzahl Näherungsrechung für 1-Schritt- und 2- Schritt-Retrieval (durchgezogene Linien) Experimentelle Ergebnisse für 1-Schritt- ( ), 2-Schritt- ( ) Fixpunkt-Retrieval ( ) Resultate Fehlerwahrscheinlichkeit ist klein (für große Netze 0) Auslesegüte wird durch iteratives Retrieval verbessert NI1 193 number of neurons
194 Bidirektionaler Assoziativspeicher Muster {(x µ, T µ ) : µ = 1,..., M}, x µ {0, 1} m k, p := k m, q = l n. Lernregel:c ij = M µ=1 xµ i xµ j Retrieval: z 2t+1 j = 1 [z 2t C θ 2t ] mit θ 1 = z 1, t = 1 und θ t = k z 2t j = 1 [C z 2t 1 θ 2t 1 ] mit θ t = k Abbruch: z t z t+2 für t 2 NI1 194
195 Hopfield-Netze Autoassoziationsnetzwerk für Muster x µ { 1, 1}, µ = 1,..., M Hopfield-Lernregel c ij = M x µ i xµ j und c ii = 0 µ=1 Aus der Lernregel folgt: Matrix C ist symmetrisch! Die Muster sind nicht spärlich kodiert, sondern prob[x µ i = 1] = prob[xµ i = 1] = 1/2 Iteratives Retrieval mit asynchronem Neuronen-Update: NI1 195
196 x 0 sei das Startmuster Wähle ein Neuron und berechne seinen neuen Zustand! x t+1 i = sgn ( x t C ) Satz: Für jeden Startwerte x 0 gibt es einen Fixpunkt x mit x = lim x t t Beweis: Das Funktional (Lijapunov-Funktion) H(C) = i monoton fallend (und nach unten beschränkt). j x ic ij x j ist Hopfield-Satz gilt für allgemeine symmetrische Matrizen C mit c ii = 0 (ohne Lernen). Die Fixpunkte x können nicht gelernte Muster sein! NI1 196
197 9. KNN in der Praxis Integration eines KNN in eine Anwendung: Schritte der Vorverarbeitung (Auswahl): A) problemspezifische Transformationen B) lineare Transformationen C) Berücksichtigung von Invarianzen D) Dimensionsreduktion E) Beseitigung von Mängeln in Daten input data preprocessing neural network Schritte der Auswertung (Auswahl): A) Bestimmung des Fehlers B) Bestimmung der Klassifikationsrate C) Aufstellen einer Verwechslungsmatrix postprocessing / evaluation output data teach data error accuracy NI1 197
198 9.1 Vorverarbeitung A) problemspezifische Transformationen: Kodierung, z.b. Umwandlung abstrakter, symbolischer oder unscharfer Eingaben in Vektoren aus binären bzw. reellen Zahlen Segmentierung kontinuierlicher Signale B) lineare Transformationen: Normierung: ū i = 1 P P u (µ) i, σi 2 = 1 P 1 µ=1 P µ=1 (u (µ) i ū i ) 2 ũ (µ) i = u(µ) i σ i ū i sinnvoll i.a. bei unterschiedlichen Wertebereichen in den Dimensionen symmetrische Wertebereiche sind für viele neuronale Netzmodelle vorteilhaft! NI1 198
199 C) Berücksichtigung von Invarianzen: Netzausgabe soll invariant sein bzgl. räumlicher oder zeitlicher Verschiebung, Skalierung, Rotation der Eingangsdaten Lösungsmöglichkeiten: 1) Berücksichtigung im Trainingsdatensatz, z.b. durch Replikation jedes Musters in vielen Varianten (ggf. auch künstlich erzeugt) Trainingsdatensatz kann sehr groß werden! 2) Vorverarbeitung durch geeignete Transformationen, z.b. Fourier- Transformation 3) Extraktion invarianter Merkmale, z.b. durch Bestimmung von Momenten (statistische Parameter, die aus den Daten extrahiert werden) Beispiel: Man erhält translationsinvariante Merkmale aus einem Bild B(x, y) durch Berechnung der Zentral-Momente µ pq = x y (x x c) p (y y c ) q B(x, y) mit Schwerpunkt: x c = m 10 /m 00, y c = m 01 /m 00 und Momenten (p + q)-ter Ordnung: m pq = x y xp y q B(x, y) hoher Rechenaufwand erforderlich! NI1 199
200 D) Dimensionsreduktion: Fortlassen irrelevanter Datendimensionen Merkmalkombination: Zusammenfassen mehrerer Datendimensionen z.b. durch eine geeignete Linearkombination Merkmalselektion: 1) Festlegen eines Auswahlkriteriums z.b. ist ein Merkmal oder eine Menge von Merkmalen besser, wenn nach Training eines neuronalen Klassifikators eine geringere Fehlklassifikationsrate erreicht wird 2) Algorithmische Suche nach einer guten Untermenge von k aus d Merkmalen: z.b. durch vollständige Suche, Heuristiken, Branch & Bound,... d! (insgesamt (d k)!k! Möglichkeiten) sehr hoher Rechenaufwand! Hauptachsentransformation (PCA), ggf. auch neuronal mit Lernregel nach Sanger NI1 200
201 E) Beseitigung von Mängeln in Daten Ausreißer 1) Entfernen aus Datensatz (da sie einen zu hohen Einfluss auf Gewichte beim Training haben) 2) Verwendung anderer Fehlerfunktionen ( andere Lernregel) (z.b. E R = µ y t R mit R < 2) Rauschen oder andere Störungen 1) lokale Glättungsoperationen (z.b. Mittelwert-, Median-, oder Gauß- Filter) 2) frequenzabhängiges Filter (z.b. Bandpass, Gabor-Filter) Fehlender Wert in i-ter Dimension bei einem Musterverktor u (ν) ; 1) Entfernen von Muster u (ν) aus Datensatz 2) Einsetzen von Mittelwert u (ν) i = 1 P 1 µ ν u(µ) i 3) Ermitteln von u (ν) i durch Interpolation NI1 201
202 Beispiel 1: Erkennung handgeschriebener Ziffern Schritte der Vorverarbeitung:... NI1 202


203 Beispiel 2: Verifikation von Fingerabdrücken Schritte der Vorverarbeitung:... NI1 203
 NI1 204")
204 Beispiel 3: Sprecher-Verifikation/Identifikation (aus W. Hess, Grundlagen der Sprachsignalverarbeitung) NI1 204
205 Schritte der Vorverarbeitung: problemspezifische Schritte: Abtastung und Quantisierung, Segmentierung des Signals, Einteilung in überlappende Fenster von ca. 10ms bis 30ms Länge unter Anwendung einer Hamming-Fensterfunktion Beseitigung von Störungen: Filtern (z.b. Bandpass) zur Unterdrückung von Rauschen oder Hintergrundgeräuschen Extraktion zeitinvarianter Merkmale: 1. Bestimmung der Signalenergie in einem Fenster 2. Berechnung der Kurzzeitspektren mittels diskreter Fourier-Transformation, Bestimmung der Grund- und Formantfrequenzen 3. Berechnung von LPC-Koeffizienten ( Linear Predictive Coding, Betrachtung eines Signalwertes s(t) = k w k s(t k) als Linearkombination aus früheren Signalwerten) Praktikum im Sommersemester 2006 NI1 205
206 9.2 Auswertung A) Bestimmung des Fehlers: P bisher nur SSE (Sum of Squared Errors): E SSE = (y (µ) t (µ) ) 2 µ=1 besser ist MSE (Mean-Square Error): E MSE = E/P oder RMSE (Root Mean-Square Error): E RMSE = E MSE B) Bestimmung der Gewinnerklasse k aus Netzausgabe y: Maximumsbestimmung: k = argmax k {y k } Umrechnung der Netzausgaben in Wahrscheinlichkeiten für Klassenzugehörigkeiten Berücksichtigung einer Toleranz TOL (typisch TOL=0.2 oder TOL=0.5): Es muß ein k geben mit: y k 1 TOL und für alle k k muß gelten: y k < TOL NI1 206
207 Beispiel: Ausgabevektoren y (µ) für verschiedene Muster u (µ) nach Training eines Klassifikationsproblems auf einem RBF-Netzwerk u 1 u D y y 1 M NI1 207
208 C) Bestimmung der Klassifikationsrate ACC (Accuracy): ACC = 1 P P α(y (µ), t (µ) ) µ=1 mit (bei Maximumsbestimmung, k 2) { 1 falls k α(y (µ), t (µ) ) = = argmax k {y k } und t k = 1 0 sonst oder (bei Verwendung einer Toleranz) { 1 falls α(y (µ), t (µ) tk y ) = k < TOL für alle k 0 sonst D) Überprüfung oder Weiterverarbeitung der Netzausgabe anhand von Kontextwissen E) Aufstellen einer Verwechslungsmatrix V : V i,j gibt an, wie oft ein Muster der Klasse i vom Klassifikator einer falschen Klasse j zugeordnet wurde; Diagonale enthält richtige Klassifikationen NI1 208
")
209 Beispiel: Verwechslungsmatrix bei einer Klassifikation handgeschriebener Ziffern (1000 Trainingsmuster je Klasse) NI1 209
5. Lernregeln für neuronale Netze
 5. Lernregeln für neuronale Netze 1. Allgemeine Lokale Lernregeln 2. Lernregeln aus Zielfunktionen: Optimierung durch Gradientenverfahren 3. Beispiel: Überwachtes Lernen im Einschicht-Netz Schwenker NI1
5. Lernregeln für neuronale Netze 1. Allgemeine Lokale Lernregeln 2. Lernregeln aus Zielfunktionen: Optimierung durch Gradientenverfahren 3. Beispiel: Überwachtes Lernen im Einschicht-Netz Schwenker NI1
3. Neuronenmodelle. 1. Einleitung zur Modellierung. 2. Hodgkin-Huxley-Modell. 3. Grundmodell in kontinuierlicher und diskreter Zeit
 3. Neuronenmodelle 1. Einleitung zur Modellierung 2. Hodgkin-Huxley-Modell 3. Grundmodell in kontinuierlicher und diskreter Zeit 4. Transferfunktionen (Kennlinien) für Neuronen 5. Neuronenmodelle in Anwendungen
3. Neuronenmodelle 1. Einleitung zur Modellierung 2. Hodgkin-Huxley-Modell 3. Grundmodell in kontinuierlicher und diskreter Zeit 4. Transferfunktionen (Kennlinien) für Neuronen 5. Neuronenmodelle in Anwendungen
Neuroinformatik I. Günther Palm Friedhelm Schwenker Abteilung Neuroinformatik
 Neuroinformatik I Günther Palm Friedhelm Schwenker Abteilung Neuroinformatik Vorlesung: Do 10-12 Uhr Raum H21 / Übung: Fr 12-14 Raum 121 und 122 Übungsaufgaben sind schriftlich zu bearbeiten (Schein bei
Neuroinformatik I Günther Palm Friedhelm Schwenker Abteilung Neuroinformatik Vorlesung: Do 10-12 Uhr Raum H21 / Übung: Fr 12-14 Raum 121 und 122 Übungsaufgaben sind schriftlich zu bearbeiten (Schein bei
Einführung in die Neuroinformatik (vormals Neuroinformatik I) WiSe 10/11
 WiSe 10/11") Einführung in die Neuroinformatik (vormals Neuroinformatik I) WiSe 10/11 Günther Palm und Friedhelm Schwenker Institut für Neuroinformatik Universität Ulm Organisation im WS 10/11 Vorlesung: Mi 12-14 Uhr
Einführung in die Neuroinformatik (vormals Neuroinformatik I) WiSe 10/11 Günther Palm und Friedhelm Schwenker Institut für Neuroinformatik Universität Ulm Organisation im WS 10/11 Vorlesung: Mi 12-14 Uhr
Hannah Wester Juan Jose Gonzalez
 Neuronale Netze Supervised Learning Proseminar Kognitive Robotik (SS12) Hannah Wester Juan Jose Gonzalez Kurze Einführung Warum braucht man Neuronale Netze und insbesondere Supervised Learning? Das Perzeptron
Neuronale Netze Supervised Learning Proseminar Kognitive Robotik (SS12) Hannah Wester Juan Jose Gonzalez Kurze Einführung Warum braucht man Neuronale Netze und insbesondere Supervised Learning? Das Perzeptron
Computational Intelligence 1 / 20. Computational Intelligence Künstliche Neuronale Netze Perzeptron 3 / 20
 Gliederung / Künstliche Neuronale Netze Perzeptron Einschränkungen Netze von Perzeptonen Perzeptron-Lernen Perzeptron Künstliche Neuronale Netze Perzeptron 3 / Der Psychologe und Informatiker Frank Rosenblatt
Gliederung / Künstliche Neuronale Netze Perzeptron Einschränkungen Netze von Perzeptonen Perzeptron-Lernen Perzeptron Künstliche Neuronale Netze Perzeptron 3 / Der Psychologe und Informatiker Frank Rosenblatt
Künstliche neuronale Netze
 Künstliche neuronale Netze Eigenschaften neuronaler Netze: hohe Arbeitsgeschwindigkeit durch Parallelität, Funktionsfähigkeit auch nach Ausfall von Teilen des Netzes, Lernfähigkeit, Möglichkeit zur Generalisierung
Künstliche neuronale Netze Eigenschaften neuronaler Netze: hohe Arbeitsgeschwindigkeit durch Parallelität, Funktionsfähigkeit auch nach Ausfall von Teilen des Netzes, Lernfähigkeit, Möglichkeit zur Generalisierung
Neuronale Netze (Konnektionismus) Einführung in die KI. Beispiel-Aufgabe: Schrifterkennung. Biologisches Vorbild. Neuronale Netze.
 Einführung in die KI. Beispiel-Aufgabe: Schrifterkennung. Biologisches Vorbild. Neuronale Netze.") Einführung in die KI Prof. Dr. sc. Hans-Dieter Burkhard Vorlesung (Konnektionismus) sind biologisch motiviert können diskrete, reell-wertige und Vektor-wertige Funktionen berechnen Informationsspeicherung
Einführung in die KI Prof. Dr. sc. Hans-Dieter Burkhard Vorlesung (Konnektionismus) sind biologisch motiviert können diskrete, reell-wertige und Vektor-wertige Funktionen berechnen Informationsspeicherung
Neuronale Netze mit mehreren Schichten
 Neuronale Netze mit mehreren Schichten Lehrstuhl für Künstliche Intelligenz Institut für Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg (Lehrstuhl Informatik 8) Neuronale Netze mit mehreren
Neuronale Netze mit mehreren Schichten Lehrstuhl für Künstliche Intelligenz Institut für Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg (Lehrstuhl Informatik 8) Neuronale Netze mit mehreren
Neuronale Netze. Gehirn: ca Neuronen. stark vernetzt. Schaltzeit ca. 1 ms (relativ langsam, vgl. Prozessor)
") 29 Neuronale Netze Gehirn: ca. 10 11 Neuronen stark vernetzt Schaltzeit ca. 1 ms (relativ langsam, vgl. Prozessor) Mustererkennung in 0.1s 100 Schritte Regel 30 Was ist ein künstl. neuronales Netz? Ein
29 Neuronale Netze Gehirn: ca. 10 11 Neuronen stark vernetzt Schaltzeit ca. 1 ms (relativ langsam, vgl. Prozessor) Mustererkennung in 0.1s 100 Schritte Regel 30 Was ist ein künstl. neuronales Netz? Ein
Aufbau und Beschreibung Neuronaler Netzwerke
 Aufbau und Beschreibung r 1 Inhalt Biologisches Vorbild Mathematisches Modell Grundmodelle 2 Biologisches Vorbild Das Neuron Grundkomponenten: Zellkörper (Soma) Zellkern (Nukleus) Dendriten Nervenfaser
Aufbau und Beschreibung r 1 Inhalt Biologisches Vorbild Mathematisches Modell Grundmodelle 2 Biologisches Vorbild Das Neuron Grundkomponenten: Zellkörper (Soma) Zellkern (Nukleus) Dendriten Nervenfaser
(hoffentlich kurze) Einführung: Neuronale Netze. Dipl.-Inform. Martin Lösch. (0721) Dipl.-Inform.
 Einführung: Neuronale Netze. Dipl.-Inform. Martin Lösch. (0721) Dipl.-Inform.") (hoffentlich kurze) Einführung: martin.loesch@kit.edu (0721) 608 45944 Überblick Einführung Perzeptron Multi-layer Feedforward Neural Network MLNN in der Anwendung 2 EINFÜHRUNG 3 Gehirn des Menschen Vorbild
(hoffentlich kurze) Einführung: martin.loesch@kit.edu (0721) 608 45944 Überblick Einführung Perzeptron Multi-layer Feedforward Neural Network MLNN in der Anwendung 2 EINFÜHRUNG 3 Gehirn des Menschen Vorbild
Was bisher geschah Künstliche Neuronen: Mathematisches Modell und Funktionen: Eingabe-, Aktivierungs- Ausgabefunktion Boolesche oder reelle Ein-und
 Was bisher geschah Künstliche Neuronen: Mathematisches Modell und Funktionen: Eingabe-, Aktivierungs- Ausgabefunktion Boolesche oder reelle Ein-und Ausgaben Aktivierungsfunktionen: Schwellwertfunktion
Was bisher geschah Künstliche Neuronen: Mathematisches Modell und Funktionen: Eingabe-, Aktivierungs- Ausgabefunktion Boolesche oder reelle Ein-und Ausgaben Aktivierungsfunktionen: Schwellwertfunktion
Einführung in neuronale Netze
 Einführung in neuronale Netze Florian Wenzel Neurorobotik Institut für Informatik Humboldt-Universität zu Berlin 1. Mai 2012 1 / 20 Überblick 1 Motivation 2 Das Neuron 3 Aufbau des Netzes 4 Neuronale Netze
Einführung in neuronale Netze Florian Wenzel Neurorobotik Institut für Informatik Humboldt-Universität zu Berlin 1. Mai 2012 1 / 20 Überblick 1 Motivation 2 Das Neuron 3 Aufbau des Netzes 4 Neuronale Netze
Nichtlineare Gleichungssysteme
 Kapitel 5 Nichtlineare Gleichungssysteme 51 Einführung Wir betrachten in diesem Kapitel Verfahren zur Lösung von nichtlinearen Gleichungssystemen Nichtlineares Gleichungssystem: Gesucht ist eine Lösung
Kapitel 5 Nichtlineare Gleichungssysteme 51 Einführung Wir betrachten in diesem Kapitel Verfahren zur Lösung von nichtlinearen Gleichungssystemen Nichtlineares Gleichungssystem: Gesucht ist eine Lösung
Neuronale Netze. Anna Wallner. 15. Mai 2007
 5. Mai 2007 Inhalt : Motivation Grundlagen Beispiel: XOR Netze mit einer verdeckten Schicht Anpassung des Netzes mit Backpropagation Probleme Beispiel: Klassifikation handgeschriebener Ziffern Rekurrente
5. Mai 2007 Inhalt : Motivation Grundlagen Beispiel: XOR Netze mit einer verdeckten Schicht Anpassung des Netzes mit Backpropagation Probleme Beispiel: Klassifikation handgeschriebener Ziffern Rekurrente
Andreas Scherer. Neuronale Netze. Grundlagen und Anwendungen. vieweg
 Andreas Scherer Neuronale Netze Grundlagen und Anwendungen vieweg Inhaltsverzeichnis Vorwort 1 1 Einführung 3 1.1 Was ist ein neuronales Netz? 3 1.2 Eigenschaften neuronaler Netze 5 1.2.1 Allgemeine Merkmale
Andreas Scherer Neuronale Netze Grundlagen und Anwendungen vieweg Inhaltsverzeichnis Vorwort 1 1 Einführung 3 1.1 Was ist ein neuronales Netz? 3 1.2 Eigenschaften neuronaler Netze 5 1.2.1 Allgemeine Merkmale
auch: Konnektionismus; subsymbolische Wissensverarbeitung
 10. Künstliche Neuronale Netze auch: Konnektionismus; subsymbolische Wissensverarbeitung informationsverarbeitende Systeme, bestehen aus meist großer Zahl einfacher Einheiten (Neuronen, Zellen) einfache
10. Künstliche Neuronale Netze auch: Konnektionismus; subsymbolische Wissensverarbeitung informationsverarbeitende Systeme, bestehen aus meist großer Zahl einfacher Einheiten (Neuronen, Zellen) einfache
Neuronale Netze. Maschinelles Lernen. Michael Baumann. Universität Paderborn. Forschungsgruppe Wissensbasierte Systeme Prof. Dr.
 Neuronale Netze Maschinelles Lernen Michael Baumann Universität Paderborn Forschungsgruppe Wissensbasierte Systeme Prof. Dr. Kleine Büning WS 2011/2012 Was ist ein neuronales Netz? eigentlich: künstliches
Neuronale Netze Maschinelles Lernen Michael Baumann Universität Paderborn Forschungsgruppe Wissensbasierte Systeme Prof. Dr. Kleine Büning WS 2011/2012 Was ist ein neuronales Netz? eigentlich: künstliches
Neuronale Netze in der Phonetik: Grundlagen. Pfitzinger, Reichel IPSK, LMU München {hpt 24.
 Neuronale Netze in der Phonetik: Grundlagen Pfitzinger, Reichel IPSK, LMU München {hpt reichelu}@phonetik.uni-muenchen.de 24. Mai 2006 Inhalt Einführung Maschinelles Lernen Lernparadigmen Maschinelles
Neuronale Netze in der Phonetik: Grundlagen Pfitzinger, Reichel IPSK, LMU München {hpt reichelu}@phonetik.uni-muenchen.de 24. Mai 2006 Inhalt Einführung Maschinelles Lernen Lernparadigmen Maschinelles
Maschinelles Lernen: Neuronale Netze. Ideen der Informatik
 Maschinelles Lernen: Neuronale Netze Ideen der Informatik Kurt Mehlhorn Adrian Neumann 16. Januar 2014 Übersicht Biologische Inspiration Stand der Kunst in Objekterkennung auf Bildern Künstliche Neuronale
Maschinelles Lernen: Neuronale Netze Ideen der Informatik Kurt Mehlhorn Adrian Neumann 16. Januar 2014 Übersicht Biologische Inspiration Stand der Kunst in Objekterkennung auf Bildern Künstliche Neuronale
Gliederung. Biologische Motivation Künstliche neuronale Netzwerke. Anwendungsbeispiele Zusammenfassung. Das Perzeptron
 Neuronale Netzwerke Gliederung Biologische Motivation Künstliche neuronale Netzwerke Das Perzeptron Aufbau Lernen und Verallgemeinern Anwendung Testergebnis Anwendungsbeispiele Zusammenfassung Biologische
Neuronale Netzwerke Gliederung Biologische Motivation Künstliche neuronale Netzwerke Das Perzeptron Aufbau Lernen und Verallgemeinern Anwendung Testergebnis Anwendungsbeispiele Zusammenfassung Biologische
Softcomputing Biologische Prinzipien in der Informatik. Neuronale Netze. Dipl. Math. Maria Oelinger Dipl. Inform. Gabriele Vierhuff IF TIF 08 2003
 Softcomputing Biologische Prinzipien in der Informatik Neuronale Netze Dipl. Math. Maria Oelinger Dipl. Inform. Gabriele Vierhuff IF TIF 08 2003 Überblick Motivation Biologische Grundlagen und ihre Umsetzung
Softcomputing Biologische Prinzipien in der Informatik Neuronale Netze Dipl. Math. Maria Oelinger Dipl. Inform. Gabriele Vierhuff IF TIF 08 2003 Überblick Motivation Biologische Grundlagen und ihre Umsetzung
Maschinelles Lernen: Neuronale Netze. Ideen der Informatik Kurt Mehlhorn
 Maschinelles Lernen: Neuronale Netze Ideen der Informatik Kurt Mehlhorn 16. Januar 2014 Übersicht Stand der Kunst im Bilderverstehen: Klassifizieren und Suchen Was ist ein Bild in Rohform? Biologische
Maschinelles Lernen: Neuronale Netze Ideen der Informatik Kurt Mehlhorn 16. Januar 2014 Übersicht Stand der Kunst im Bilderverstehen: Klassifizieren und Suchen Was ist ein Bild in Rohform? Biologische
Backpropagation. feedforward Netze
 Backpropagation Netze ohne Rückkopplung, überwachtes Lernen, Gradientenabstieg, Delta-Regel Datenstrom (Propagation) Input Layer hidden Layer hidden Layer Output Layer Daten Input Fehler Berechnung Fehlerstrom
Backpropagation Netze ohne Rückkopplung, überwachtes Lernen, Gradientenabstieg, Delta-Regel Datenstrom (Propagation) Input Layer hidden Layer hidden Layer Output Layer Daten Input Fehler Berechnung Fehlerstrom
Optimierung. Optimierung. Vorlesung 2 Optimierung ohne Nebenbedingungen Gradientenverfahren. 2013 Thomas Brox, Fabian Kuhn
 Optimierung Vorlesung 2 Optimierung ohne Nebenbedingungen Gradientenverfahren 1 Minimierung ohne Nebenbedingung Ein Optimierungsproblem besteht aus einer zulässigen Menge und einer Zielfunktion Minimum
Optimierung Vorlesung 2 Optimierung ohne Nebenbedingungen Gradientenverfahren 1 Minimierung ohne Nebenbedingung Ein Optimierungsproblem besteht aus einer zulässigen Menge und einer Zielfunktion Minimum
Was bisher geschah. Lernen: überwachtes Lernen. biologisches Vorbild neuronaler Netze: unüberwachtes Lernen
 Was bisher geschah Lernen: überwachtes Lernen korrigierendes Lernen bestärkendes Lernen unüberwachtes Lernen biologisches Vorbild neuronaler Netze: Neuron (Zellkörper, Synapsen, Axon) und Funktionsweise
Was bisher geschah Lernen: überwachtes Lernen korrigierendes Lernen bestärkendes Lernen unüberwachtes Lernen biologisches Vorbild neuronaler Netze: Neuron (Zellkörper, Synapsen, Axon) und Funktionsweise
Neuronale Netze. Einführung i.d. Wissensverarbeitung 2 VO UE SS Institut für Signalverarbeitung und Sprachkommunikation
 Neuronale Netze Einführung in die Wissensverarbeitung 2 VO 708.560+ 1 UE 442.072 SS 2012 Institut für Signalverarbeitung und Sprachkommunikation TU Graz Inffeldgasse 12/1 www.spsc.tugraz.at Institut für
Neuronale Netze Einführung in die Wissensverarbeitung 2 VO 708.560+ 1 UE 442.072 SS 2012 Institut für Signalverarbeitung und Sprachkommunikation TU Graz Inffeldgasse 12/1 www.spsc.tugraz.at Institut für
Lernverfahren von Künstlichen Neuronalen Netzwerken
 Lernverfahren von Künstlichen Neuronalen Netzwerken Untersuchung und Vergleich der bekanntesten Lernverfahren und eine Übersicht über Anwendung und Forschung im Bereich der künstlichen neuronalen Netzen.
Lernverfahren von Künstlichen Neuronalen Netzwerken Untersuchung und Vergleich der bekanntesten Lernverfahren und eine Übersicht über Anwendung und Forschung im Bereich der künstlichen neuronalen Netzen.
Kohonennetze Selbstorganisierende Karten
 Kohonennetze Selbstorganisierende Karten Julian Rith, Simon Regnet, Falk Kniffka Seminar: Umgebungsexploration und Wegeplanung mit Robotern Kohonennetze: Neuronale Netze In Dendriten werden die ankommenden
Kohonennetze Selbstorganisierende Karten Julian Rith, Simon Regnet, Falk Kniffka Seminar: Umgebungsexploration und Wegeplanung mit Robotern Kohonennetze: Neuronale Netze In Dendriten werden die ankommenden
Grundlagen Neuronaler Netze
 Grundlagen Neuronaler Netze Neuronen, Aktivierung, Output, Netzstruktur, Lernziele, Training, Grundstruktur Der Begriff neuronales Netz(-werk) steht immer für künstliche neuronale Netzwerke, wenn nicht
Grundlagen Neuronaler Netze Neuronen, Aktivierung, Output, Netzstruktur, Lernziele, Training, Grundstruktur Der Begriff neuronales Netz(-werk) steht immer für künstliche neuronale Netzwerke, wenn nicht
18 Höhere Ableitungen und Taylorformel
 8 HÖHERE ABLEITUNGEN UND TAYLORFORMEL 98 8 Höhere Ableitungen und Taylorformel Definition. Sei f : D R eine Funktion, a D. Falls f in einer Umgebung von a (geschnitten mit D) differenzierbar und f in a
8 HÖHERE ABLEITUNGEN UND TAYLORFORMEL 98 8 Höhere Ableitungen und Taylorformel Definition. Sei f : D R eine Funktion, a D. Falls f in einer Umgebung von a (geschnitten mit D) differenzierbar und f in a
Was sind Neuronale Netze?
 Neuronale Netze Universität zu Köln SS 2010 Seminar: Künstliche Intelligenz II Dozent: Stephan Schwiebert Referenten: Aida Moradi, Anne Fleischer Datum: 23. 06. 2010 Was sind Neuronale Netze? ein Netzwerk
Neuronale Netze Universität zu Köln SS 2010 Seminar: Künstliche Intelligenz II Dozent: Stephan Schwiebert Referenten: Aida Moradi, Anne Fleischer Datum: 23. 06. 2010 Was sind Neuronale Netze? ein Netzwerk
Neuronale Netze. Einführung i.d. Wissensverarbeitung 2 VO UE SS Institut für Signalverarbeitung und Sprachkommunikation
 Neuronale Netze Einführung in die Wissensverarbeitung 2 VO 708.560+ 1 UE 442.072 SS 2013 Institut für Signalverarbeitung und Sprachkommunikation TU Graz Inffeldgasse 12/1 www.spsc.tugraz.at Institut für
Neuronale Netze Einführung in die Wissensverarbeitung 2 VO 708.560+ 1 UE 442.072 SS 2013 Institut für Signalverarbeitung und Sprachkommunikation TU Graz Inffeldgasse 12/1 www.spsc.tugraz.at Institut für
Erregungsübertragung an Synapsen. 1. Einleitung. 2. Schnelle synaptische Erregung. Biopsychologie WiSe Erregungsübertragung an Synapsen
 Erregungsübertragung an Synapsen 1. Einleitung 2. Schnelle synaptische Übertragung 3. Schnelle synaptische Hemmung chemische 4. Desaktivierung der synaptischen Übertragung Synapsen 5. Rezeptoren 6. Langsame
Erregungsübertragung an Synapsen 1. Einleitung 2. Schnelle synaptische Übertragung 3. Schnelle synaptische Hemmung chemische 4. Desaktivierung der synaptischen Übertragung Synapsen 5. Rezeptoren 6. Langsame
3 Optimierung mehrdimensionaler Funktionen f : R n R
 3 Optimierung mehrdimensionaler Funktionen f : R n R 31 Optimierung ohne Nebenbedingungen Optimierung heißt eigentlich: Wir suchen ein x R n so, dass f(x ) f(x) für alle x R n (dann heißt x globales Minimum)
3 Optimierung mehrdimensionaler Funktionen f : R n R 31 Optimierung ohne Nebenbedingungen Optimierung heißt eigentlich: Wir suchen ein x R n so, dass f(x ) f(x) für alle x R n (dann heißt x globales Minimum)
Natürliche und künstliche neuronale Netze
 Kapitel 2 Natürliche und künstliche neuronale Netze 2.1 Informationsverarbeitung im Gehirn In diesem Abschnitt soll ein sehr knapper und durchaus unvollständiger Überblick gegeben werden, um den Bezug
Kapitel 2 Natürliche und künstliche neuronale Netze 2.1 Informationsverarbeitung im Gehirn In diesem Abschnitt soll ein sehr knapper und durchaus unvollständiger Überblick gegeben werden, um den Bezug
Kapitel LF: IV. IV. Neuronale Netze
 Kapitel LF: IV IV. Neuronale Netze Perzeptron-Lernalgorithmus Gradientenabstiegmethode Multilayer-Perzeptrons und ackpropagation Self-Organizing Feature Maps Neuronales Gas LF: IV-39 Machine Learning c
Kapitel LF: IV IV. Neuronale Netze Perzeptron-Lernalgorithmus Gradientenabstiegmethode Multilayer-Perzeptrons und ackpropagation Self-Organizing Feature Maps Neuronales Gas LF: IV-39 Machine Learning c
f(x, y) = 0 Anschaulich bedeutet das, dass der im Rechteck I J = {(x, y) x I, y J}
 = 0 Anschaulich bedeutet das, dass der im Rechteck I J = {(x, y) x I, y J}") 9 Der Satz über implizite Funktionen 41 9 Der Satz über implizite Funktionen Wir haben bisher Funktionen g( von einer reellen Variablen immer durch Formelausdrücke g( dargestellt Der Zusammenhang zwischen
9 Der Satz über implizite Funktionen 41 9 Der Satz über implizite Funktionen Wir haben bisher Funktionen g( von einer reellen Variablen immer durch Formelausdrücke g( dargestellt Der Zusammenhang zwischen
9 Optimierung mehrdimensionaler reeller Funktionen f : R n R
 9 Optimierung mehrdimensionaler reeller Funktionen f : R n R 91 Optimierung ohne Nebenbedingungen Ein Optimum zu suchen heißt, den größten oder den kleinsten Wert zu suchen Wir suchen also ein x R n, sodass
9 Optimierung mehrdimensionaler reeller Funktionen f : R n R 91 Optimierung ohne Nebenbedingungen Ein Optimum zu suchen heißt, den größten oder den kleinsten Wert zu suchen Wir suchen also ein x R n, sodass
Kapitel LF: IV. Multilayer-Perzeptrons und Backpropagation. Multilayer-Perzeptrons und Backpropagation. LF: IV Machine Learning c STEIN 2005-06
 Kapitel LF: IV IV. Neuronale Netze Perzeptron-Lernalgorithmus Gradientenabstiegmethode Multilayer-Perzeptrons und ackpropagation Self-Organizing Feature Maps Neuronales Gas 39 Multilayer-Perzeptrons und
Kapitel LF: IV IV. Neuronale Netze Perzeptron-Lernalgorithmus Gradientenabstiegmethode Multilayer-Perzeptrons und ackpropagation Self-Organizing Feature Maps Neuronales Gas 39 Multilayer-Perzeptrons und
Neuronale Kodierung sensorischer Reize. Computational Neuroscience Jutta Kretzberg
 Neuronale Kodierung sensorischer Reize Computational Neuroscience 30.10.2006 Jutta Kretzberg (Vorläufiges) Vorlesungsprogramm 23.10.06!! Motivation 30.10.06!! Neuronale Kodierung sensorischer Reize 06.11.06!!
Neuronale Kodierung sensorischer Reize Computational Neuroscience 30.10.2006 Jutta Kretzberg (Vorläufiges) Vorlesungsprogramm 23.10.06!! Motivation 30.10.06!! Neuronale Kodierung sensorischer Reize 06.11.06!!
Der Begriff der konvexen Menge ist bereits aus Definition 1.4, Teil I, bekannt.
 Kapitel 3 Konvexität 3.1 Konvexe Mengen Der Begriff der konvexen Menge ist bereits aus Definition 1.4, Teil I, bekannt. Definition 3.1 Konvexer Kegel. Eine Menge Ω R n heißt konvexer Kegel, wenn mit x
Kapitel 3 Konvexität 3.1 Konvexe Mengen Der Begriff der konvexen Menge ist bereits aus Definition 1.4, Teil I, bekannt. Definition 3.1 Konvexer Kegel. Eine Menge Ω R n heißt konvexer Kegel, wenn mit x
Mathematik II für Studierende der Informatik. Wirtschaftsinformatik (Analysis und lineare Algebra) im Sommersemester 2016
 im Sommersemester 2016") und Wirtschaftsinformatik (Analysis und lineare Algebra) im Sommersemester 2016 5. Juni 2016 Definition 5.21 Ist a R, a > 0 und a 1, so bezeichnet man die Umkehrfunktion der Exponentialfunktion x a x als
und Wirtschaftsinformatik (Analysis und lineare Algebra) im Sommersemester 2016 5. Juni 2016 Definition 5.21 Ist a R, a > 0 und a 1, so bezeichnet man die Umkehrfunktion der Exponentialfunktion x a x als
GRUNDLEGENDE MODELLE. Caroline Herbek
 GRUNDLEGENDE MODELLE Caroline Herbek Lineares Wachstum Charakteristikum: konstante absolute Zunahme d einer Größe N t in einem Zeitschritt Differenzengleichung: N t -N t-1 =d => N t = N t-1 +d (Rekursion)
GRUNDLEGENDE MODELLE Caroline Herbek Lineares Wachstum Charakteristikum: konstante absolute Zunahme d einer Größe N t in einem Zeitschritt Differenzengleichung: N t -N t-1 =d => N t = N t-1 +d (Rekursion)
Neuronale Netze (Konnektionismus)
") Einführung in die KI Prof. Dr. sc. Hans-Dieter Burkhard Vorlesung (Konnektionismus) sind biologisch motiviert können diskrete, reell-wertige und Vektor-wertige Funktionen berechnen, Einsatz z.b. für Klassifizierungsaufgaben
Einführung in die KI Prof. Dr. sc. Hans-Dieter Burkhard Vorlesung (Konnektionismus) sind biologisch motiviert können diskrete, reell-wertige und Vektor-wertige Funktionen berechnen, Einsatz z.b. für Klassifizierungsaufgaben
BK07_Vorlesung Physiologie. 05. November 2012
 BK07_Vorlesung Physiologie 05. November 2012 Stichpunkte zur Vorlesung 1 Aktionspotenziale = Spikes Im erregbaren Gewebe werden Informationen in Form von Aktions-potenzialen (Spikes) übertragen Aktionspotenziale
BK07_Vorlesung Physiologie 05. November 2012 Stichpunkte zur Vorlesung 1 Aktionspotenziale = Spikes Im erregbaren Gewebe werden Informationen in Form von Aktions-potenzialen (Spikes) übertragen Aktionspotenziale
Simulation neuronaler Netzwerke mit TIKAPP
 Überblick Michael Hanke Sebastian Krüger Institut für Psychologie Martin-Luther-Universität Halle-Wittenberg Forschungskolloquium, SS 2004 Überblick Fragen 1 Was sind neuronale Netze? 2 Was ist TIKAPP?
Überblick Michael Hanke Sebastian Krüger Institut für Psychologie Martin-Luther-Universität Halle-Wittenberg Forschungskolloquium, SS 2004 Überblick Fragen 1 Was sind neuronale Netze? 2 Was ist TIKAPP?
Künstliche neuronale Netze
 Künstliche neuronale Netze Sibylle Schwarz Westsächsische Hochschule Zwickau Dr. Friedrichs-Ring 2a, RII 263 http://wwwstud.fh-zwickau.de/~sibsc/ sibylle.schwarz@fh-zwickau.de SS 2011 1 Softcomputing Einsatz
Künstliche neuronale Netze Sibylle Schwarz Westsächsische Hochschule Zwickau Dr. Friedrichs-Ring 2a, RII 263 http://wwwstud.fh-zwickau.de/~sibsc/ sibylle.schwarz@fh-zwickau.de SS 2011 1 Softcomputing Einsatz
Nichtlineare Gleichungssysteme
 Kapitel 2 Nichtlineare Gleichungssysteme Problem: Für vorgegebene Abbildung f : D R n R n finde R n mit oder ausführlicher f() = 0 (21) f 1 ( 1,, n ) = 0, f n ( 1,, n ) = 0 Einerseits führt die mathematische
Kapitel 2 Nichtlineare Gleichungssysteme Problem: Für vorgegebene Abbildung f : D R n R n finde R n mit oder ausführlicher f() = 0 (21) f 1 ( 1,, n ) = 0, f n ( 1,, n ) = 0 Einerseits führt die mathematische
Lösungen zu den Hausaufgaben zur Analysis II
 Christian Fenske Lösungen zu den Hausaufgaben zur Analysis II Blatt 6 1. Seien 0 < b < a und (a) M = {(x, y, z) R 3 x 2 + y 4 + z 4 = 1}. (b) M = {(x, y, z) R 3 x 3 + y 3 + z 3 = 3}. (c) M = {((a+b sin
Christian Fenske Lösungen zu den Hausaufgaben zur Analysis II Blatt 6 1. Seien 0 < b < a und (a) M = {(x, y, z) R 3 x 2 + y 4 + z 4 = 1}. (b) M = {(x, y, z) R 3 x 3 + y 3 + z 3 = 3}. (c) M = {((a+b sin
Einführung in Neuronale Netze
 Einführung in Neuronale Netze Thomas Ruland Contents 1 Das menschliche Gehirn - Höchstleistungen im täglichen Leben 2 2 Die Hardware 2 2.1 Das Neuron 2 2.2 Nachahmung in der Computertechnik: Das künstliche
Einführung in Neuronale Netze Thomas Ruland Contents 1 Das menschliche Gehirn - Höchstleistungen im täglichen Leben 2 2 Die Hardware 2 2.1 Das Neuron 2 2.2 Nachahmung in der Computertechnik: Das künstliche
Eine kleine Einführung in neuronale Netze
 Eine kleine Einführung in neuronale Netze Tobias Knuth November 2013 1.2 Mensch und Maschine 1 Inhaltsverzeichnis 1 Grundlagen neuronaler Netze 1 1.1 Kopieren vom biologischen Vorbild...... 1 1.2 Mensch
Eine kleine Einführung in neuronale Netze Tobias Knuth November 2013 1.2 Mensch und Maschine 1 Inhaltsverzeichnis 1 Grundlagen neuronaler Netze 1 1.1 Kopieren vom biologischen Vorbild...... 1 1.2 Mensch
Facharbeit. Ratsgymnasium Bielefeld Schuljahr 2004/2005. aus dem Fach Biologie. Thema: Künstliche neuronale Netze
 Ratsgymnasium Bielefeld Schuljahr 2004/2005 Facharbeit aus dem Fach Biologie Thema: Künstliche neuronale Netze Verfasser: Joa Ebert Leistungskurs: Biologie Kursleiter: Herr Bökamp Abgabetermin: 25.02.2005
Ratsgymnasium Bielefeld Schuljahr 2004/2005 Facharbeit aus dem Fach Biologie Thema: Künstliche neuronale Netze Verfasser: Joa Ebert Leistungskurs: Biologie Kursleiter: Herr Bökamp Abgabetermin: 25.02.2005
Rekurrente Neuronale Netze. Rudolf Kruse Neuronale Netze 227
 Rekurrente Neuronale Netze Rudolf Kruse Neuronale Netze 227 Rekurrente Netze: Abkühlungsgesetz Ein Körper der Temperaturϑ wird in eine Umgebung der Temperaturϑ A eingebracht. Die Abkühlung/Aufheizung des
Rekurrente Neuronale Netze Rudolf Kruse Neuronale Netze 227 Rekurrente Netze: Abkühlungsgesetz Ein Körper der Temperaturϑ wird in eine Umgebung der Temperaturϑ A eingebracht. Die Abkühlung/Aufheizung des
(künstliche) Neuronale Netze. (c) Till Hänisch 2003,2015, DHBW Heidenheim
 Neuronale Netze. (c) Till Hänisch 2003,2015, DHBW Heidenheim") (künstliche) Neuronale Netze (c) Till Hänisch 2003,2015, DHBW Heidenheim Literatur zusätzlich zum Lit. Verz. Michael Negnevitsky, Artificial Intelligence, Addison Wesley 2002 Aufbau des Gehirns Säugetiergehirn,
(künstliche) Neuronale Netze (c) Till Hänisch 2003,2015, DHBW Heidenheim Literatur zusätzlich zum Lit. Verz. Michael Negnevitsky, Artificial Intelligence, Addison Wesley 2002 Aufbau des Gehirns Säugetiergehirn,
Neuronale Netze. Volker Tresp
 Neuronale Netze Volker Tresp 1 Einführung Der Entwurf eines guten Klassifikators/Regressionsmodells hängt entscheidend von geeigneten Basisfunktion en ab Manchmal sind geeignete Basisfunktionen (Merkmalsextraktoren)
Neuronale Netze Volker Tresp 1 Einführung Der Entwurf eines guten Klassifikators/Regressionsmodells hängt entscheidend von geeigneten Basisfunktion en ab Manchmal sind geeignete Basisfunktionen (Merkmalsextraktoren)
f(x) f(x 0 ) lokales Maximum x U : gilt, so heißt x 0 isoliertes lokales Minimum lokales Minimum Ferner nennen wir x 0 Extremum.
 f(x 0 ) lokales Maximum x U : gilt, so heißt x 0 isoliertes lokales Minimum lokales Minimum Ferner nennen wir x 0 Extremum.") Fabian Kohler Karolina Stoiber Ferienkurs Analsis für Phsiker SS 4 A Extrema In diesem Abschnitt sollen Extremwerte von Funktionen f : D R n R diskutiert werden. Auch hier gibt es viele Ähnlichkeiten mit
Fabian Kohler Karolina Stoiber Ferienkurs Analsis für Phsiker SS 4 A Extrema In diesem Abschnitt sollen Extremwerte von Funktionen f : D R n R diskutiert werden. Auch hier gibt es viele Ähnlichkeiten mit
abiweb NEUROBIOLOGIE 17. März 2015 Webinar zur Abiturvorbereitung
 abiweb NEUROBIOLOGIE 17. März 2015 Webinar zur Abiturvorbereitung Bau Nervenzelle Neuron (Nervenzelle) Dentrit Zellkörper Axon Synapse Gliazelle (Isolierung) Bau Nervenzelle Bau Nervenzelle Neurobiologie
abiweb NEUROBIOLOGIE 17. März 2015 Webinar zur Abiturvorbereitung Bau Nervenzelle Neuron (Nervenzelle) Dentrit Zellkörper Axon Synapse Gliazelle (Isolierung) Bau Nervenzelle Bau Nervenzelle Neurobiologie
(künstliche) Neuronale Netze. (c) Till Hänisch 2003, BA Heidenheim
 Neuronale Netze. (c) Till Hänisch 2003, BA Heidenheim") (künstliche) Neuronale Netze (c) Till Hänisch 2003, BA Heidenheim Literatur zusätzlich zum Lit. Verz. Michael Negnevitsky, Artificial Intelligence, Addison Wesley 2002 Warum? Manche Probleme (z.b. Klassifikation)
(künstliche) Neuronale Netze (c) Till Hänisch 2003, BA Heidenheim Literatur zusätzlich zum Lit. Verz. Michael Negnevitsky, Artificial Intelligence, Addison Wesley 2002 Warum? Manche Probleme (z.b. Klassifikation)
Rückblick auf die letzte Vorlesung. Bemerkung
 Bemerkung 1) Die Bedingung grad f (x 0 ) = 0 T definiert gewöhnlich ein nichtlineares Gleichungssystem zur Berechnung von x = x 0, wobei n Gleichungen für n Unbekannte gegeben sind. 2) Die Punkte x 0 D
Bemerkung 1) Die Bedingung grad f (x 0 ) = 0 T definiert gewöhnlich ein nichtlineares Gleichungssystem zur Berechnung von x = x 0, wobei n Gleichungen für n Unbekannte gegeben sind. 2) Die Punkte x 0 D
Machine Learning - Maschinen besser als das menschliche Gehirn?
 Machine Learning - Maschinen besser als das menschliche Gehirn? Seminar Big Data Science Tobias Stähle 23. Mai 2014 KIT Universität des Landes Baden-Württemberg und nationales Forschungszentrum in der
Machine Learning - Maschinen besser als das menschliche Gehirn? Seminar Big Data Science Tobias Stähle 23. Mai 2014 KIT Universität des Landes Baden-Württemberg und nationales Forschungszentrum in der
8 Extremwerte reellwertiger Funktionen
 8 Extremwerte reellwertiger Funktionen 34 8 Extremwerte reellwertiger Funktionen Wir wollen nun auch Extremwerte reellwertiger Funktionen untersuchen. Definition Es sei U R n eine offene Menge, f : U R
8 Extremwerte reellwertiger Funktionen 34 8 Extremwerte reellwertiger Funktionen Wir wollen nun auch Extremwerte reellwertiger Funktionen untersuchen. Definition Es sei U R n eine offene Menge, f : U R
Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 2016
 Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 1 M. Sperber (matthias.sperber@kit.edu) S. Nguyen (thai.nguyen@kit.edu) Übungsblatt 3 Maschinelles Lernen und Klassifikation Abgabe online
Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 1 M. Sperber (matthias.sperber@kit.edu) S. Nguyen (thai.nguyen@kit.edu) Übungsblatt 3 Maschinelles Lernen und Klassifikation Abgabe online
Implementationsaspekte
 Implementationsaspekte Überlegungen zur Programmierung Neuronaler Netzwerke Implementationsprinzipien Trennung der Aspekte: Datenhaltung numerische Eigenschaften der Objekte Funktionalität Methoden der
Implementationsaspekte Überlegungen zur Programmierung Neuronaler Netzwerke Implementationsprinzipien Trennung der Aspekte: Datenhaltung numerische Eigenschaften der Objekte Funktionalität Methoden der
Schematische Übersicht über das Nervensystem eines Vertebraten
 Schematische Übersicht über das Nervensystem eines Vertebraten Die Integration des sensorischen Eingangs und motorischen Ausgangs erfolgt weder stereotyp noch linear; sie ist vielmehr durch eine kontinuierliche
Schematische Übersicht über das Nervensystem eines Vertebraten Die Integration des sensorischen Eingangs und motorischen Ausgangs erfolgt weder stereotyp noch linear; sie ist vielmehr durch eine kontinuierliche
ε δ Definition der Stetigkeit.
 ε δ Definition der Stetigkeit. Beweis a) b): Annahme: ε > 0 : δ > 0 : x δ D : x δ x 0 < δ f (x δ f (x 0 ) ε Die Wahl δ = 1 n (n N) generiert eine Folge (x n) n N, x n D mit x n x 0 < 1 n f (x n ) f (x
ε δ Definition der Stetigkeit. Beweis a) b): Annahme: ε > 0 : δ > 0 : x δ D : x δ x 0 < δ f (x δ f (x 0 ) ε Die Wahl δ = 1 n (n N) generiert eine Folge (x n) n N, x n D mit x n x 0 < 1 n f (x n ) f (x
Technische Universität München Zentrum Mathematik. Übungsblatt 4
 Technische Universität München Zentrum Mathematik Mathematik (Elektrotechnik) Prof. Dr. Anusch Taraz Dr. Michael Ritter Übungsblatt 4 Hausaufgaben Aufgabe 4. Gegeben sei die Funktion f : D R mit f(x) :=
Technische Universität München Zentrum Mathematik Mathematik (Elektrotechnik) Prof. Dr. Anusch Taraz Dr. Michael Ritter Übungsblatt 4 Hausaufgaben Aufgabe 4. Gegeben sei die Funktion f : D R mit f(x) :=
Neuronale Netze. Seminar aus Algorithmik Stefan Craß,
 Neuronale Netze Seminar aus Algorithmik Stefan Craß, 325656 Inhalt Theoretisches Modell Grundlagen Lernansätze Hopfield-Netze Kohonen-Netze Zusammenfassung 2 Inhalt Theoretisches Modell Grundlagen Lernansätze
Neuronale Netze Seminar aus Algorithmik Stefan Craß, 325656 Inhalt Theoretisches Modell Grundlagen Lernansätze Hopfield-Netze Kohonen-Netze Zusammenfassung 2 Inhalt Theoretisches Modell Grundlagen Lernansätze
Exkurs Modelle und Algorithmen
 Exkurs Modelle und Algorithmen Ansatz künstlich neuronaler Netze (KNN) Versuch, die Wirkungsweise menschlicher Gehirnzellen nachzubilden dabei wird auf formale mathematische Beschreibungen und Algorithmen
Exkurs Modelle und Algorithmen Ansatz künstlich neuronaler Netze (KNN) Versuch, die Wirkungsweise menschlicher Gehirnzellen nachzubilden dabei wird auf formale mathematische Beschreibungen und Algorithmen
Analysis I. 4. Beispielklausur mit Lösungen
 Fachbereich Mathematik/Informatik Prof. Dr. H. Brenner Analysis I 4. Beispielklausur mit en Aufgabe 1. Definiere die folgenden (kursiv gedruckten) Begriffe. (1) Eine bijektive Abbildung f: M N. () Ein
Fachbereich Mathematik/Informatik Prof. Dr. H. Brenner Analysis I 4. Beispielklausur mit en Aufgabe 1. Definiere die folgenden (kursiv gedruckten) Begriffe. (1) Eine bijektive Abbildung f: M N. () Ein
Reinforcement Learning
 Reinforcement Learning 1. Allgemein Reinforcement Learning 2. Neuronales Netz als Bewertungsfunktion 3. Neuronales Netz als Reinforcement Learning Nils-Olaf Bösch 1 Allgemein Reinforcement Learning Unterschied
Reinforcement Learning 1. Allgemein Reinforcement Learning 2. Neuronales Netz als Bewertungsfunktion 3. Neuronales Netz als Reinforcement Learning Nils-Olaf Bösch 1 Allgemein Reinforcement Learning Unterschied
Computational Intelligence I Künstliche Neuronale Netze
 Computational Intelligence I Künstliche Neuronale Nete Universität Dortmund, Informatik I Otto-Hahn-Str. 6, 44227 Dortmund lars.hildebrand@uni-dortmund.de Inhalt der Vorlesung 0. Organisatorisches & Vorbemerkungen.
Computational Intelligence I Künstliche Neuronale Nete Universität Dortmund, Informatik I Otto-Hahn-Str. 6, 44227 Dortmund lars.hildebrand@uni-dortmund.de Inhalt der Vorlesung 0. Organisatorisches & Vorbemerkungen.
Numerische Ableitung
 Numerische Ableitung Die Ableitung kann angenähert werden durch den Differentenquotient: f (x) f(x + h) f(x) h oder f(x + h) f(x h) 2h für h > 0, aber h 0. Beim numerischen Rechnen ist folgendes zu beachten:
Numerische Ableitung Die Ableitung kann angenähert werden durch den Differentenquotient: f (x) f(x + h) f(x) h oder f(x + h) f(x h) 2h für h > 0, aber h 0. Beim numerischen Rechnen ist folgendes zu beachten:
Gewöhnliche Dierentialgleichungen
 Gewöhnliche Dierentialgleichungen sind Gleichungen, die eine Funktion mit ihren Ableitungen verknüpfen. Denition Eine explizite Dierentialgleichung (DGL) nter Ordnung für die reelle Funktion t x(t) hat
Gewöhnliche Dierentialgleichungen sind Gleichungen, die eine Funktion mit ihren Ableitungen verknüpfen. Denition Eine explizite Dierentialgleichung (DGL) nter Ordnung für die reelle Funktion t x(t) hat
Der CG-Algorithmus (Zusammenfassung)
") Der CG-Algorithmus (Zusammenfassung) Michael Karow Juli 2008 1 Zweck, Herkunft, Terminologie des CG-Algorithmus Zweck: Numerische Berechnung der Lösung x des linearen Gleichungssystems Ax = b für eine
Der CG-Algorithmus (Zusammenfassung) Michael Karow Juli 2008 1 Zweck, Herkunft, Terminologie des CG-Algorithmus Zweck: Numerische Berechnung der Lösung x des linearen Gleichungssystems Ax = b für eine
Simulation Neuronaler Netze. Eine praxisorientierte Einführung. Matthias Haun. Mit 44 Bildern, 23 Tabellen und 136 Literatursteilen.
 Simulation Neuronaler Netze Eine praxisorientierte Einführung Matthias Haun Mit 44 Bildern, 23 Tabellen und 136 Literatursteilen expert Inhaltsverzeichnis 1 Einleitung 1.1 Über das Projekt 1 1.2 Über das
Simulation Neuronaler Netze Eine praxisorientierte Einführung Matthias Haun Mit 44 Bildern, 23 Tabellen und 136 Literatursteilen expert Inhaltsverzeichnis 1 Einleitung 1.1 Über das Projekt 1 1.2 Über das
Inhaltsverzeichnis. Vorwort Kapitel 1 Einführung, I: Algebra Kapitel 2 Einführung, II: Gleichungen... 57
 Vorwort... 13 Vorwort zur 3. deutschen Auflage... 17 Kapitel 1 Einführung, I: Algebra... 19 1.1 Die reellen Zahlen... 20 1.2 Ganzzahlige Potenzen... 23 1.3 Regeln der Algebra... 29 1.4 Brüche... 34 1.5
Vorwort... 13 Vorwort zur 3. deutschen Auflage... 17 Kapitel 1 Einführung, I: Algebra... 19 1.1 Die reellen Zahlen... 20 1.2 Ganzzahlige Potenzen... 23 1.3 Regeln der Algebra... 29 1.4 Brüche... 34 1.5
1 Singulärwertzerlegung und Pseudoinverse
 Singulärwertzerlegung und Pseudoinverse Singulärwertzerlegung A sei eine Matrix mit n Spalten und m Zeilen. Zunächst sei n m. Bilde B = A A. Dies ist eine n n-matrix. Berechne die Eigenwerte von B. Diese
Singulärwertzerlegung und Pseudoinverse Singulärwertzerlegung A sei eine Matrix mit n Spalten und m Zeilen. Zunächst sei n m. Bilde B = A A. Dies ist eine n n-matrix. Berechne die Eigenwerte von B. Diese
Anwendungen der Differentialrechnung
 KAPITEL 5 Anwendungen der Differentialrechnung 5.1 Maxima und Minima einer Funktion......................... 80 5.2 Mittelwertsatz.................................... 82 5.3 Kurvendiskussion..................................
KAPITEL 5 Anwendungen der Differentialrechnung 5.1 Maxima und Minima einer Funktion......................... 80 5.2 Mittelwertsatz.................................... 82 5.3 Kurvendiskussion..................................
Membranen und Potentiale
 Membranen und Potentiale 1. Einleitung 2. Zellmembran 3. Ionenkanäle 4. Ruhepotential 5. Aktionspotential 6. Methode: Patch-Clamp-Technik Quelle: Thompson Kap. 3, (Pinel Kap. 3) 2. ZELLMEMBRAN Abbildung
Membranen und Potentiale 1. Einleitung 2. Zellmembran 3. Ionenkanäle 4. Ruhepotential 5. Aktionspotential 6. Methode: Patch-Clamp-Technik Quelle: Thompson Kap. 3, (Pinel Kap. 3) 2. ZELLMEMBRAN Abbildung
Kapitel 16 : Differentialrechnung
 Kapitel 16 : Differentialrechnung 16.1 Die Ableitung einer Funktion 16.2 Ableitungsregeln 16.3 Mittelwertsätze und Extrema 16.4 Approximation durch Taylor-Polynome 16.5 Zur iterativen Lösung von Gleichungen
Kapitel 16 : Differentialrechnung 16.1 Die Ableitung einer Funktion 16.2 Ableitungsregeln 16.3 Mittelwertsätze und Extrema 16.4 Approximation durch Taylor-Polynome 16.5 Zur iterativen Lösung von Gleichungen
Dierentialgleichungen 2. Ordnung
 Dierentialgleichungen 2. Ordnung haben die allgemeine Form x = F (x, x, t. Wir beschränken uns hier auf zwei Spezialfälle, in denen sich eine Lösung analytisch bestimmen lässt: 1. reduzible Dierentialgleichungen:
Dierentialgleichungen 2. Ordnung haben die allgemeine Form x = F (x, x, t. Wir beschränken uns hier auf zwei Spezialfälle, in denen sich eine Lösung analytisch bestimmen lässt: 1. reduzible Dierentialgleichungen:
Mathematik-Tutorium für Maschinenbauer II: Differentialgleichungen und Vektorfelder
 DGL Schwingung Physikalische Felder Mathematik-Tutorium für Maschinenbauer II: Differentialgleichungen und Vektorfelder Johannes Wiedersich 23. April 2008 http://www.e13.physik.tu-muenchen.de/wiedersich/
DGL Schwingung Physikalische Felder Mathematik-Tutorium für Maschinenbauer II: Differentialgleichungen und Vektorfelder Johannes Wiedersich 23. April 2008 http://www.e13.physik.tu-muenchen.de/wiedersich/
Das Perzeptron. Künstliche neuronale Netze. Sebastian Otte. 1 Grundlegendes. 2 Perzeptron Modell
 Fachbereich Design Informatik Medien Studiengang Master Informatik Künstliche neuronale Netze Das Perzeptron Sebastian Otte Dezember 2009 1 Grundlegendes Als Perzeptron bezeichnet man eine Form von künstlichen
Fachbereich Design Informatik Medien Studiengang Master Informatik Künstliche neuronale Netze Das Perzeptron Sebastian Otte Dezember 2009 1 Grundlegendes Als Perzeptron bezeichnet man eine Form von künstlichen
Wissensbasierte Systeme
 Analytisch lösbare Optimierungsaufgaben Das Chaos-Spiel gründet auf der folgenden Vorschrift: Man startet von einem beliebigen Punkt aus geht auf einer Verbindung mit einem von drei zufällig gewählten
Analytisch lösbare Optimierungsaufgaben Das Chaos-Spiel gründet auf der folgenden Vorschrift: Man startet von einem beliebigen Punkt aus geht auf einer Verbindung mit einem von drei zufällig gewählten
Normalengleichungen. Für eine beliebige m n Matrix A erfüllt jede Lösung x des Ausgleichsproblems Ax b min die Normalengleichungen A t Ax = A t b,
 Normalengleichungen Für eine beliebige m n Matrix A erfüllt jede Lösung x des Ausgleichsproblems Ax b min die Normalengleichungen A t Ax = A t b, Normalengleichungen 1-1 Normalengleichungen Für eine beliebige
Normalengleichungen Für eine beliebige m n Matrix A erfüllt jede Lösung x des Ausgleichsproblems Ax b min die Normalengleichungen A t Ax = A t b, Normalengleichungen 1-1 Normalengleichungen Für eine beliebige
Praktikum Computational Intelligence 2 Ulrich Lehmann, Johannes Brenig, Michael Schneider
 Praktikum Computational Intelligence 2 Ulrich Lehmann, Johannes Brenig, Michael Schneider Versuch: Training des XOR-Problems mit einem Künstlichen Neuronalen Netz (KNN) in JavaNNS 11.04.2011 2_CI2_Deckblatt_XORbinaer_JNNS_2
Praktikum Computational Intelligence 2 Ulrich Lehmann, Johannes Brenig, Michael Schneider Versuch: Training des XOR-Problems mit einem Künstlichen Neuronalen Netz (KNN) in JavaNNS 11.04.2011 2_CI2_Deckblatt_XORbinaer_JNNS_2
Technische Universität. Fakultät für Informatik
 Technische Universität München Fakultät für Informatik Forschungs- und Lehreinheit Informatik VI Neuronale Netze - Supervised Learning Proseminar Kognitive Robotik (SS12) Hannah Wester Betreuer: Dr. Florian
Technische Universität München Fakultät für Informatik Forschungs- und Lehreinheit Informatik VI Neuronale Netze - Supervised Learning Proseminar Kognitive Robotik (SS12) Hannah Wester Betreuer: Dr. Florian
Zentrales Nervensystem
 Zentrales Nervensystem Funktionelle Neuroanatomie (Struktur und Aufbau des Nervensystems) Neurophysiologie (Ruhe- und Aktionspotenial, synaptische Übertragung) Fakten und Zahlen (funktionelle Auswirkungen)
Zentrales Nervensystem Funktionelle Neuroanatomie (Struktur und Aufbau des Nervensystems) Neurophysiologie (Ruhe- und Aktionspotenial, synaptische Übertragung) Fakten und Zahlen (funktionelle Auswirkungen)
Computer Vision: Kalman Filter
 Computer Vision: Kalman Filter D. Schlesinger TUD/INF/KI/IS D. Schlesinger () Computer Vision: Kalman Filter 1 / 8 Bayesscher Filter Ein Objekt kann sich in einem Zustand x X befinden. Zum Zeitpunkt i
Computer Vision: Kalman Filter D. Schlesinger TUD/INF/KI/IS D. Schlesinger () Computer Vision: Kalman Filter 1 / 8 Bayesscher Filter Ein Objekt kann sich in einem Zustand x X befinden. Zum Zeitpunkt i
Grundlagen Künstlicher Neuronaler Netze
 FernUniversität in Hagen Fachbereich Elektrotechnik und Informationstechnik Lehrgebiet Informationstechnik Seminar Computational Intelligence in der Prozessautomatisierung 7. Juli 2003 Grundlagen Künstlicher
FernUniversität in Hagen Fachbereich Elektrotechnik und Informationstechnik Lehrgebiet Informationstechnik Seminar Computational Intelligence in der Prozessautomatisierung 7. Juli 2003 Grundlagen Künstlicher
3. Das Reinforcement Lernproblem
 3. Das Reinforcement Lernproblem 1. Agierender Agent in der Umgebung 2. Discounted Rewards 3. Markov Eigenschaft des Zustandssignals 4. Markov sche Entscheidung 5. Werte-Funktionen und Bellman sche Optimalität
3. Das Reinforcement Lernproblem 1. Agierender Agent in der Umgebung 2. Discounted Rewards 3. Markov Eigenschaft des Zustandssignals 4. Markov sche Entscheidung 5. Werte-Funktionen und Bellman sche Optimalität
 Abbildungen Schandry, 2006 Quelle: www.ich-bin-einradfahrer.de Abbildungen Schandry, 2006 Informationsvermittlung im Körper Pioniere der Neurowissenschaften: Santiago Ramón y Cajal (1852-1934) Camillo
Abbildungen Schandry, 2006 Quelle: www.ich-bin-einradfahrer.de Abbildungen Schandry, 2006 Informationsvermittlung im Körper Pioniere der Neurowissenschaften: Santiago Ramón y Cajal (1852-1934) Camillo
Einführung in Neuronale Netze
 Wintersemester 2005/2006 VO 181.138 Einführung in die Artificial Intelligence Einführung in Neuronale Netze Oliver Frölich Abteilung für Datenbanken und Artificial Intelligence Institut für Informationssysteme
Wintersemester 2005/2006 VO 181.138 Einführung in die Artificial Intelligence Einführung in Neuronale Netze Oliver Frölich Abteilung für Datenbanken und Artificial Intelligence Institut für Informationssysteme
Mathematik Übungsblatt - Lösung. b) x=2
 x=2") Hochschule Regensburg Fakultät Informatik/Mathematik Christoph Böhm Sommersemester 204 Technische Informatik Bachelor IT2 Vorlesung Mathematik 2 Mathematik 2 4. Übungsblatt - Lösung Differentialrechnung
Hochschule Regensburg Fakultät Informatik/Mathematik Christoph Böhm Sommersemester 204 Technische Informatik Bachelor IT2 Vorlesung Mathematik 2 Mathematik 2 4. Übungsblatt - Lösung Differentialrechnung
55 Lokale Extrema unter Nebenbedingungen
 55 Lokale Extrema unter Nebenbedingungen Sei f : O R mit O R n differenzierbar. Notwendige Bescheinigung für ein lokales Extremum in p 0 ist dann die Bedingung f = 0 (siehe 52.4 und 49.14). Ist nun F :
55 Lokale Extrema unter Nebenbedingungen Sei f : O R mit O R n differenzierbar. Notwendige Bescheinigung für ein lokales Extremum in p 0 ist dann die Bedingung f = 0 (siehe 52.4 und 49.14). Ist nun F :
Elemente der Analysis II
 Elemente der Analysis II Kapitel 5: Differentialrechnung im R n Informationen zur Vorlesung: http://www.mathematik.uni-trier.de/ wengenroth/ J. Wengenroth () 17. Juni 2009 1 / 31 5.1 Erinnerung Kapitel
Elemente der Analysis II Kapitel 5: Differentialrechnung im R n Informationen zur Vorlesung: http://www.mathematik.uni-trier.de/ wengenroth/ J. Wengenroth () 17. Juni 2009 1 / 31 5.1 Erinnerung Kapitel
Newton-Verfahren zur gleichungsbeschränkten Optimierung. 1 Gleichungsbeschränkte Optimierungsprobleme
 Newton-Verfahren zur gleichungsbeschränkten Optimierung Armin Farmani Anosheh (afarmani@mail.uni-mannheim.de) 3.Mai 2016 1 Gleichungsbeschränkte Optimierungsprobleme Einleitung In diesem Vortrag geht es
Newton-Verfahren zur gleichungsbeschränkten Optimierung Armin Farmani Anosheh (afarmani@mail.uni-mannheim.de) 3.Mai 2016 1 Gleichungsbeschränkte Optimierungsprobleme Einleitung In diesem Vortrag geht es
Selbstorganisierende Karten
 Selbstorganisierende Karten Yacin Bessas yb1@informatik.uni-ulm.de Proseminar Neuronale Netze 1 Einleitung 1.1 Kurzüberblick Die Selbstorganisierenden Karten, auch Self-Organizing (Feature) Maps, Kohonen-
Selbstorganisierende Karten Yacin Bessas yb1@informatik.uni-ulm.de Proseminar Neuronale Netze 1 Einleitung 1.1 Kurzüberblick Die Selbstorganisierenden Karten, auch Self-Organizing (Feature) Maps, Kohonen-