Einführung in die Computerlinguistik
|
|
|
- Rosa Brodbeck
- vor 6 Jahren
- Abrufe
Transkript
1 Einführung in die Computerlinguistik Spracherkennung und Hidden Markov Modelle Dozentin: Wiebke Petersen WS 2004/2005 Wiebke Petersen Einführung in die Computerlinguistik WS 04/05
2 Spracherkennung
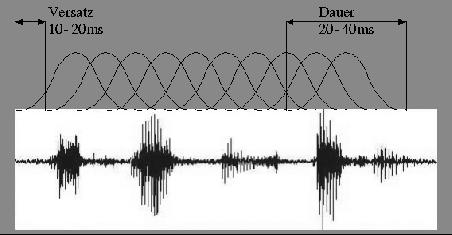
3 Merkmalsextraktion 4
 und den diskret (2) gesprochenen Satz")
4 Frequenzdiagramme (Beispiele) Die Abbildung zeigt den Unterschied der Frequenzdiagramme für den kontinuierlich (1) und den diskret (2) gesprochenen Satz "Die Sonne lacht".
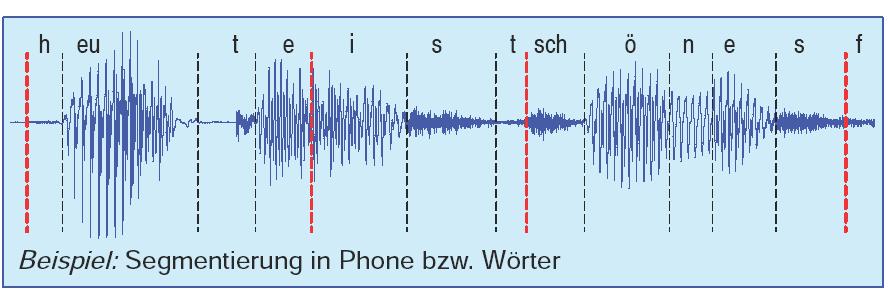
5 Frequenzdiagramme (Segmentierungsproblem)
6

7 Hidden Markov Modell HMM für 'haben'
8 9 Karin Haenelt, Hidden Markov-Modelle, Markov-Kette Definition 3 Eine Markov-Kette ist ein spezieller stochastischer Prozess, bei dem zu jedem Zeitpunkt die Wahrscheinlichkeiten aller zukünftigen Zustände nur vom momentanen Zustand abhängen (= Markov-Eigenschaft) d.h. es gilt: ) ( ),..., ( t t t t t t t t x X x X P x X x X x X x X P = = = = = = = Brants, 1999: 30
9 Hidden Markov-Modell: Beispiel in einem Text lassen sich nur die Ausgaben (= produzierte Wörter) beobachten (visible) die Sequenz von Zuständen (= Wortarten), die die Wörter ausgeben, (Satzmuster) lässt sich nicht beobachten (hidden) mehrere Sequenzen können dieselbe Ausgabe erzeugen: nomn auxv part wir werden geschickt nomn kopv adje wir werden geschickt.3 x.2 x.4 x.3 x.2 x.4 = Karin Haenelt, Hidden Markov-Modelle, x.2 x.3 x.5 x.2 x.2 =
10 Ein Hidden Markov-Modell Übergangsmatrix Emissionsmatrix Startwahr scheinlich keit X t X t+1 o t π Adje AuxV KopV Nomn Part geschickt werden wir... Adje AuxV KopV Nomn Part Karin Haenelt, Hidden Markov-Modelle,
11 Hidden Markov-Modell: Gewinnung der Daten Übersicht Annotation eines Corpus Auszählung der Sequenzen Umrechnung der Häufigkeiten in prozentuale Anteile Karin Haenelt, Hidden Markov-Modelle,
12 Hidden Markov-Modell: Gewinnung der Daten (1) Annotation eines Corpus Auszählung der Sequenzen Umrechnung der Häufigkeiten in prozentuale Anteile Wir nomn werden auxv geschickt part. Wir nomn werden kopv geschickt adje Karin Haenelt, Hidden Markov-Modelle,
13 Hidden Markov-Modell: Gewinnung der Daten (2) Annotation eines Corpus Auszählung der Sequenzen Umrechnung der Häufigkeiten in prozentuale Anteile Adje AuxV KopV Nomn Part geschickt werden wir. Adje AuxV KopV Nomn Part Karin Haenelt, Hidden Markov-Modelle,
14 Hidden Markov-Modell: Gewinnung der Daten (3) Annotation eines Corpus Auszählung der Sequenzen Umrechnung der Häufigkeiten in prozentuale Anteile Adje AuxV KopV Nomn Part geschickt werden wir. Adje AuxV KopV Nomn Part Karin Haenelt, Hidden Markov-Modelle,
15 Drei grundlegende Aufgaben, die mit HMMs bearbeitet werden 1. Dekodierung: Wahrscheinlichkeit einer Beobachtung finden brute force Forward-Algorithmus / Backward-Algorithmus 2. Beste Pfad-Sequenz finden brute force Viterbi-Algorithmus 3. Training: Aufbau des besten Modells aus Trainingsdaten Karin Haenelt, Hidden Markov-Modelle, Manning/Schütze, 2000: 325
16 A1: Wahrscheinlichkeit einer Beobachtung finden gegeben gesucht eine Sequenz von Beobachtungen O=(wir,werden,geschickt) ein Modell Adje AuxV KopV Nomn Part g schickt werden wir.. Adje AuxV KopV Nomn Part die Wahrscheinlichkeit P( wir, werden, geschickt µ ) P( O µ ) O = ( o1,..., ot) µ = ( A, B, Π) π Karin Haenelt, Hidden Markov-Modelle,
17 A1: Wahrscheinlichkeit einer Beobachtung finden Lösungsweg 1: brute force Für alle möglichen Zustandsfolgen - Berechnung der Wahrscheinlichkeit der Beobachtungen - Summierung der Wahrscheinlichkeiten P( O µ ) = X = X P ( O X, µ ) P( X µ ) 1... X t+ 1 π X 1 T 1 Π a X X b X t t + 1 X t= 1 t t + 1 o t Karin Haenelt, Hidden Markov-Modelle, state transition symbol emission 27 Manning/Schütze, 2000: 326
18 A1: Wahrscheinlichkeit einer Beobachtung finden Lösungsweg 1: brute force: Beispiel P( O µ ) = X 1... X t+ 1 π X 1 T 1 Π a X X b t t + 1 X X t= 1 t t + 1 o t Beispiel für state emission HMM P(wir,werden,geschickt Adje Adje Adje, µ) + P(wir,werden,geschickt Adje Adje AuxV, µ) + + P(wir,werden,geschickt Nomn AuxV Part, µ) + + P(wir,werden,geschickt Nomn KopV Adje, µ) + + P(wir,werden,geschickt Part Part Part, µ) = Karin Haenelt, Hidden Markov-Modelle, =0.0.3 x.2 x.4 x.3 x.2 x.4 = x.2 x.3 x.5 x.2 x.2 = =0.0 =
19 HMM [Aufgabe]: Beste Pfadsequenz finden gegeben gesucht eine Sequenz von Beobachtungen O=(wir,werden,geschickt) ein Modell die wahrscheinlichste Pfadsequenz P( wir, werden, geschickt µ ) O = ( o1,..., ot) µ = ( A, B, Π) Adje AuxV KopV Nomn Part g schickt werden wir.. Adje AuxV KopV Nomn Part π arg x max P( O µ ) Karin Haenelt, Viterbi-Algorithmus
20 HMM [Aufgabe]: Beste Pfadsequenz finden Modellvariante: mit Startsymbol statt mit Tabelle der Startwahrscheinlichkeiten) Adje Adje.2 AuxV.2 KopV.2 Nomn.1 Part.3.3 AuxV KopV Nomn Part g schickt werden wir Karin Haenelt, Viterbi-Algorithmus
21 Karin Haenelt, Viterbi-Algorithmus Ineffiziente Lösung 1 wir Adje werden Adje geschickt Adje 2 geschickt AuxV 3 geschickt KopV 4 geschickt Nom 5 geschickt Part 6 werden AuxV geschickt Adje 7 geschickt AuxV wir Nomn werden AuxV geschickt Part 86 wir Nomn werden KopV geschickt Adje wir Part werden Part geschickt Part Für 3 Beobachtungen und 5 Kategorien 5 3 Schritte
22 Beispiel ineffiziente Suche der besten Lösung P(Adje Adje Adje wir,werden,geschickt, µ) P(Adje Adje AuxV wir,werden,geschickt, µ) P(Nomn AuxV Part wir,werden,geschickt, µ) P(Nomn KopV Adje wir,werden,geschickt, µ) P(Part Part Part wir,werden,geschickt, µ) =0.0.3 x.2 x.4 x.3 x.2 x.4 = x.2 x.3 x.5 x.2 x.2 = = Karin Haenelt, Viterbi-Algorithmus
23 Viterbi-Lösung Kompakte Darstellung der Pfade als Gitter (Trellis) Wiederverwendung partieller Ergebnisse statt Neuberechnung Speichert für jeden Zeitpunkt t die Wahrscheinlichkeit des wahrscheinlichsten Pfades, der zu einem Knoten führt den Vorgängerknoten auf diesem Pfad. wir Adje wir AuxV wir KopV wir Nomn wir Part Karin Haenelt, Viterbi-Algorithmus werden Adje werden AuxV werden KopV werden Nomn werden Part geschickt Adje geschickt AuxV geschickt KopV geschickt Nomn geschickt Part
24 Daten 1: Wahrscheinlichkeit des wahrscheinlichsten Pfades. wir Adje 0 wir AuxV 0 wir KopV 0 wir Nomn0.06 wir Part 0 werden Adje 0 werden AuxV werden KopV werden Nomn0 werden Part 0 geschickt Adje geschickt AuxV 0 geschickt KopV 0 geschickt Nomn0 geschickt Part wir Nomn Knoten >0 Wahrscheinlichkeit des wahrscheinlichsten Pfades 0 unwahrscheinlicher Pfad Karin Haenelt, Viterbi-Algorithmus
25 Daten 2: Vorgängerknoten auf wahrscheinlichstem Pfad. wir Adje 0 wir AuxV 0 wir KopV 0 wir Nomn wir Part 0 werden Adje 0 werden AuxV Nomn werden KopV Nomn werden Nomn0 werden Part 0 geschickt Adje KopV geschickt AuxV 0 geschickt KopV 0 geschickt Nomn0 geschickt Part AuxV wir Nomn Knoten Vorgänger-Knoten auf wahrscheinlichstem Pfad 0 Vorgänger-Knoten auf wahrscheinlichstem Pfad bei P(X i ) = 0 (= unwahrscheinlicher Pfad) Karin Haenelt, Viterbi-Algorithmus
26 Daten 1 und 2: Übersicht. wir Adje 0 wir AuxV 0 wir KopV 0 wir Nomn0.06 wir Part 0 werden Adje 0 werden AuxV werden KopV werden Nomn0 werden Part 0 geschickt Adje geschickt AuxV 0 geschickt KopV 0 geschickt Nomn0 geschickt Part wir Adje 0 wir AuxV 0 wir KopV 0 wir Nomn wir Part Karin Haenelt, Viterbi-Algorithmus werden Adje 0 werden AuxV Nomn werden KopV Nomn werden Nomn0 werden Part 0 geschickt Adje KopV geschickt AuxV 0 geschickt KopV 0 geschickt Nomn0 geschickt Part AuxV
27 Tracing (1): Initialisierung Setzen der Startknoten für Verfolgung - Wahrscheinlichkeit der wahrscheinlichsten Pfade - Vorgängerknoten auf den wahrscheinlichsten Pfaden Karin Haenelt, Viterbi-Algorithmus
28 Tracing (2): 1. Iteration. wir Adje 0 wir AuxV 0 wir KopV 0 wir Nomn0.06 wir Part 0 Funktion δ Berechnung der Wahrscheinlichkeit des wahrscheinlichsten Pfades. wir Adje 0 wir AuxV 0 wir KopV 0 wir Nomn wir Part Karin Haenelt, Viterbi-Algorithmus Funktion ψ Ermittlung des Vorgängerknotens auf dem wahrscheinlichsten Pfad
29 Tracing (3): 2. Iteration. wir Nomn0.06 werden Adje 0 werden AuxV werden KopV werden Nomn0 werden Part 0. wir Nomn werden Adje 0 werden AuxV Nomn werden KopV Nomn werden Nomn0 werden Part Karin Haenelt, Viterbi-Algorithmus
30 Tracing (4): 3. Iteration. wir Nomn0.06 werden Adje 0 werden AuxV werden KopV werden Nomn0 werden Part 0 geschickt Adje geschickt AuxV 0 geschickt KopV 0 geschickt Nomn0 geschickt Part wir Nomn werden Adje 0 werden AuxV Nomn werden KopV Nomn werden Nomn0 werden Part 0 geschickt Adje KopV geschickt AuxV 0 geschickt KopV 0 geschickt Nomn0 geschickt Part AuxV Karin Haenelt, Viterbi-Algorithmus
31 Tracing (5): Terminierung und Pfadausgabe. wir Nomn0.06 werden Adje 0 werden AuxV werden KopV werden Nomn0 werden Part 0 geschickt Adje geschickt AuxV 0 geschickt KopV 0 geschickt Nomn0 geschickt Part wir Nomn werden Adje 0 werden AuxV Nomn werden KopV Nomn werden Nomn0 werden Part 0 geschickt Adje KopV geschickt AuxV 0 geschickt KopV 0 geschickt Nomn0 geschickt Part AuxV Karin Haenelt, Viterbi-Algorithmus
Hidden Markov Models
 Hidden Markov Models Kursfolien Karin Haenelt 09.05002 1 Letzte Änderung 18.07002 Hidden Markov Models Besondere Form eines probabilistischen endlichen Automaten Weit verbreitet in der statistischen Sprachverarbeitung
Hidden Markov Models Kursfolien Karin Haenelt 09.05002 1 Letzte Änderung 18.07002 Hidden Markov Models Besondere Form eines probabilistischen endlichen Automaten Weit verbreitet in der statistischen Sprachverarbeitung
Hidden Markov Models (HMM) Karin Haenelt
 Karin Haenelt") Hidden Markov Models (HMM) Karin Haenelt 16.5.2009 1 Inhalt Einführung Theoretische Basis Elementares Zufallsereignis Stochastischer Prozess (Folge von elementaren Zufallsereignissen) Markow-Kette (Stochastischer
Hidden Markov Models (HMM) Karin Haenelt 16.5.2009 1 Inhalt Einführung Theoretische Basis Elementares Zufallsereignis Stochastischer Prozess (Folge von elementaren Zufallsereignissen) Markow-Kette (Stochastischer
Der Viterbi-Algorithmus.
 Der Viterbi-Algorithmus. Eine Erläuterung der formalen Spezifikation am Beispiel des Part-of-Speech Tagging. Kursskript Karin Haenelt, 9..7 (.5.) Einleitung In diesem Skript wird der Viterbi-Algorithmus
Der Viterbi-Algorithmus. Eine Erläuterung der formalen Spezifikation am Beispiel des Part-of-Speech Tagging. Kursskript Karin Haenelt, 9..7 (.5.) Einleitung In diesem Skript wird der Viterbi-Algorithmus
Tagging mit Hidden Markov Models und Viterbi-Algorithmus
 Tagging mit Hidden Markov Models und Viterbi-Algorithmus Annelen Brunner, Stephanie Schuldes, Nicola Kaiser, Olga Mordvinova HS Parsing SoSe 2003 PD Dr. Karin Haenelt Inhalt Ziel des Seminarprojekts Theorie:
Tagging mit Hidden Markov Models und Viterbi-Algorithmus Annelen Brunner, Stephanie Schuldes, Nicola Kaiser, Olga Mordvinova HS Parsing SoSe 2003 PD Dr. Karin Haenelt Inhalt Ziel des Seminarprojekts Theorie:
Hidden Markov Modelle
 Hidden Markov Modelle in der Sprachverarbeitung Paul Gabriel paul@pogo.franken.de Seminar Sprachdialogsysteme: Hidden Markov Modelle p.1/3 Überblick Merkmalsvektoren Stochastischer Prozess Markov-Ketten
Hidden Markov Modelle in der Sprachverarbeitung Paul Gabriel paul@pogo.franken.de Seminar Sprachdialogsysteme: Hidden Markov Modelle p.1/3 Überblick Merkmalsvektoren Stochastischer Prozess Markov-Ketten
Tutoriums-Paper zu Hidden Markov Models
 Tutoriums-Paper zu Hidden Markov Models Mario Mohr February 1, 2015 Contents 1 Das Modell 1 2 Der Forward-Algorithmus 2 2.1 Wahrscheinlichkeiten von Beobachtungsketten........................ 4 2.2 Filtering.............................................
Tutoriums-Paper zu Hidden Markov Models Mario Mohr February 1, 2015 Contents 1 Das Modell 1 2 Der Forward-Algorithmus 2 2.1 Wahrscheinlichkeiten von Beobachtungsketten........................ 4 2.2 Filtering.............................................
Hidden Markov Models
 Hidden Markov Models Nikolas Dörfler 21.11.2003 1 Einleitung Hauptseminar Machine Learning Nicht alle Vorgänge laufen stehts in einer festen deterministischen Reihenfolge ab und sind somit relativ einfach
Hidden Markov Models Nikolas Dörfler 21.11.2003 1 Einleitung Hauptseminar Machine Learning Nicht alle Vorgänge laufen stehts in einer festen deterministischen Reihenfolge ab und sind somit relativ einfach
Grundbegriffe der Wahrscheinlichkeitstheorie. Karin Haenelt
 Grundbegriffe der Wahrscheinlichkeitstheorie Karin Haenelt 1 Inhalt Wahrscheinlichkeitsraum Bedingte Wahrscheinlichkeit Abhängige und unabhängige Ereignisse Stochastischer Prozess Markow-Kette 2 Wahrscheinlichkeitsraum
Grundbegriffe der Wahrscheinlichkeitstheorie Karin Haenelt 1 Inhalt Wahrscheinlichkeitsraum Bedingte Wahrscheinlichkeit Abhängige und unabhängige Ereignisse Stochastischer Prozess Markow-Kette 2 Wahrscheinlichkeitsraum
Hidden Markov Model (HMM)
") Hidden Markov Model (HMM) Kapitel 1 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität Leipzig
Hidden Markov Model (HMM) Kapitel 1 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität Leipzig
Zusammenfassung Tutorien der Woche ALDABI
 Zusammenfassung Tutorien der Woche 27.-31. 01. 2014 ALDABI Markov-Ketten: Viele Ereignisse schon in unserem Alltag beeinflussen sich gegenseitig, können also als Ablauf oder Kette von Ereignissen gesehen
Zusammenfassung Tutorien der Woche 27.-31. 01. 2014 ALDABI Markov-Ketten: Viele Ereignisse schon in unserem Alltag beeinflussen sich gegenseitig, können also als Ablauf oder Kette von Ereignissen gesehen
Friedrich-Alexander-Universität Professur für Computerlinguistik. Nguyen Ai Huong
 Part-of-Speech Tagging Friedrich-Alexander-Universität Professur für Computerlinguistik Nguyen Ai Huong 15.12.2011 Part-of-speech tagging Bestimmung von Wortform (part of speech) für jedes Wort in einem
Part-of-Speech Tagging Friedrich-Alexander-Universität Professur für Computerlinguistik Nguyen Ai Huong 15.12.2011 Part-of-speech tagging Bestimmung von Wortform (part of speech) für jedes Wort in einem
Part-Of-Speech-Tagging mit Viterbi Algorithmus
 Part-Of-Speech-Tagging mit Viterbi Algorithmus HS Endliche Automaten Inna Nickel, Julia Konstantinova 19.07.2010 1 / 21 Gliederung 1 Motivation 2 Theoretische Grundlagen Hidden Markov Model Viterbi Algorithmus
Part-Of-Speech-Tagging mit Viterbi Algorithmus HS Endliche Automaten Inna Nickel, Julia Konstantinova 19.07.2010 1 / 21 Gliederung 1 Motivation 2 Theoretische Grundlagen Hidden Markov Model Viterbi Algorithmus
Hidden-Markov-Modelle
 Proseminar: Machine-Learning Hidden-Markov-Modelle Benjamin Martin Zusammenfassung 1953 stellten Watson und Crick ihr DNA-Modell vor. Damit öffnete sich für Genforscher ein riesiges Gebiet, das bisher
Proseminar: Machine-Learning Hidden-Markov-Modelle Benjamin Martin Zusammenfassung 1953 stellten Watson und Crick ihr DNA-Modell vor. Damit öffnete sich für Genforscher ein riesiges Gebiet, das bisher
Part-of-Speech Tagging. Stephanie Schuldes
 Part-of-Speech Tagging Stephanie Schuldes 05.06.2003 PS Erschließen von großen Textmengen Geißler/Holler SoSe 2003 Motivation Ziel: vollständiges Parsing und Verstehen natürlicher Sprache Herantasten durch
Part-of-Speech Tagging Stephanie Schuldes 05.06.2003 PS Erschließen von großen Textmengen Geißler/Holler SoSe 2003 Motivation Ziel: vollständiges Parsing und Verstehen natürlicher Sprache Herantasten durch
Signalverarbeitung 2. Volker Stahl - 1 -
 - 1 - Hidden Markov Modelle - 2 - Idee Zu klassifizierende Merkmalvektorfolge wurde von einem (unbekannten) System erzeugt. Nutze Referenzmerkmalvektorfolgen um ein Modell Des erzeugenden Systems zu bauen
- 1 - Hidden Markov Modelle - 2 - Idee Zu klassifizierende Merkmalvektorfolge wurde von einem (unbekannten) System erzeugt. Nutze Referenzmerkmalvektorfolgen um ein Modell Des erzeugenden Systems zu bauen
HMM/KNN zur Spracherkennung
 HMM/KNN zur Spracherkennung Andreas Hallerbach 18. Januar 2005 Universität Ulm Fakultät für Informatik Abteilung Neuroinformatik Hauptseminar Neuroinformatik WS 04/05 Spracherkennung Zusammenfassung Die
HMM/KNN zur Spracherkennung Andreas Hallerbach 18. Januar 2005 Universität Ulm Fakultät für Informatik Abteilung Neuroinformatik Hauptseminar Neuroinformatik WS 04/05 Spracherkennung Zusammenfassung Die
3. Übung zur Vorlesung NLP Analyse des Wissensrohstoffes Text im Sommersemester 2008 mit Musterlösungen
 3. Übung zur Vorlesung NLP Analyse des Wissensrohstoffes Text im Sommersemester 2008 mit Musterlösungen Dr. Andreas Hotho, Dipl.-Inform. Dominik Benz, Wi.-Inf. Beate Krause 14. Mai 2008 1 Kollokationen
3. Übung zur Vorlesung NLP Analyse des Wissensrohstoffes Text im Sommersemester 2008 mit Musterlösungen Dr. Andreas Hotho, Dipl.-Inform. Dominik Benz, Wi.-Inf. Beate Krause 14. Mai 2008 1 Kollokationen
Zentralübung Diskrete Wahrscheinlichkeitstheorie (zur Vorlesung Prof. Esparza)
") SS 2013 Zentralübung Diskrete Wahrscheinlichkeitstheorie (zur Vorlesung Prof. Esparza) Dr. Werner Meixner Fakultät für Informatik TU München http://www14.in.tum.de/lehre/2013ss/dwt/uebung/ 10. Mai 2013
SS 2013 Zentralübung Diskrete Wahrscheinlichkeitstheorie (zur Vorlesung Prof. Esparza) Dr. Werner Meixner Fakultät für Informatik TU München http://www14.in.tum.de/lehre/2013ss/dwt/uebung/ 10. Mai 2013
Operationen auf endlichen Automaten und Transduktoren
 Operationen auf endlichen Automaten und Transduktoren Kursfolien Karin Haenelt 1 Notationskonventionen L reguläre Sprache A endlicher Automat DEA deterministischer endlicher Automat NEA nichtdeterministischer
Operationen auf endlichen Automaten und Transduktoren Kursfolien Karin Haenelt 1 Notationskonventionen L reguläre Sprache A endlicher Automat DEA deterministischer endlicher Automat NEA nichtdeterministischer
Probabilistische kontextfreie Grammatiken
 Mathematische Grundlagen III Probabilistische kontextfreie Grammatiken 14 Juni 2011 1/26 Ambiguität beim Parsing Wörter können verschiedene Bedeutungen haben und mehr als einer Wortkategorien angehören
Mathematische Grundlagen III Probabilistische kontextfreie Grammatiken 14 Juni 2011 1/26 Ambiguität beim Parsing Wörter können verschiedene Bedeutungen haben und mehr als einer Wortkategorien angehören
Bayes sche Klassifikatoren. Uwe Reichel IPS, LMU München 16. Juli 2008
 Bayes sche Klassifikatoren Uwe Reichel IPS, LMU München reichelu@phonetik.uni-muenchen.de 16. Juli 2008 Inhalt Einleitung Grundlagen der Wahrscheinlichkeitsrechnung Noisy-Channel-Modell Bayes sche Klassifikation
Bayes sche Klassifikatoren Uwe Reichel IPS, LMU München reichelu@phonetik.uni-muenchen.de 16. Juli 2008 Inhalt Einleitung Grundlagen der Wahrscheinlichkeitsrechnung Noisy-Channel-Modell Bayes sche Klassifikation
Suche. Sebastian Stüker
 Institut für Anthropomatik Suche Sebastian Stüker 11.01.2010 Interactive Systems Labs X.Huang/Acero/Hon, Spoken Language Processing : Kapitel 12,13 Konferenzartikel: Hagen Soltau, Florian Metze, Christian
Institut für Anthropomatik Suche Sebastian Stüker 11.01.2010 Interactive Systems Labs X.Huang/Acero/Hon, Spoken Language Processing : Kapitel 12,13 Konferenzartikel: Hagen Soltau, Florian Metze, Christian
Software Engineering Ergänzung zur Vorlesung
 Ergänzung zur Vorlesung Prof. Dr. Markus Müller-Olm WS 2008 2009 2.6.1 Endliche und reguläre Sprachen Endliche und reguläre Sprache: fundamental in vielen Bereichen der Informatik: theorie Formale Sprachen
Ergänzung zur Vorlesung Prof. Dr. Markus Müller-Olm WS 2008 2009 2.6.1 Endliche und reguläre Sprachen Endliche und reguläre Sprache: fundamental in vielen Bereichen der Informatik: theorie Formale Sprachen
Maschinelle Sprachverarbeitung: Part-of-Speech-Tagging
 HUMBOLDT-UNIVERSITÄT ZU BERLIN Institut für Informatik Lehrstuhl Wissensmanagement Maschinelle Sprachverarbeitung: Part-of-Speech-Tagging Tobias Scheffer Ulf Brefeld POS-Tagging Zuordnung der Wortart von
HUMBOLDT-UNIVERSITÄT ZU BERLIN Institut für Informatik Lehrstuhl Wissensmanagement Maschinelle Sprachverarbeitung: Part-of-Speech-Tagging Tobias Scheffer Ulf Brefeld POS-Tagging Zuordnung der Wortart von
Domenico Strigari, Byambasuren Terbish, Bilal Erkin
 Hidden Markov Modelle Domenico Strigari, Byambasuren Terbish, Bilal Erkin Hidden Markov Modelle (HMM) i. Geschichte ii. Markovkette iii. Wahrscheinlichkeitsgrundlagen iv. HMM Theorie v. Spracherkennung
Hidden Markov Modelle Domenico Strigari, Byambasuren Terbish, Bilal Erkin Hidden Markov Modelle (HMM) i. Geschichte ii. Markovkette iii. Wahrscheinlichkeitsgrundlagen iv. HMM Theorie v. Spracherkennung
Angewandte Stochastik
 Angewandte Stochastik Dr. C.J. Luchsinger 13 Allgemeine Theorie zu Markov-Prozessen (stetige Zeit, diskreter Zustandsraum) Literatur Kapitel 13 * Grimmett & Stirzaker: Kapitel 6.9 Wie am Schluss von Kapitel
Angewandte Stochastik Dr. C.J. Luchsinger 13 Allgemeine Theorie zu Markov-Prozessen (stetige Zeit, diskreter Zustandsraum) Literatur Kapitel 13 * Grimmett & Stirzaker: Kapitel 6.9 Wie am Schluss von Kapitel
Einführung in die Computerlinguistik
 Einführung in die Computerlinguistik Merkmalstrukturen und Unifikation Dozentin: Wiebke Petersen WS 2004/2005 Wiebke Petersen Formale Komplexität natürlicher Sprachen WS 03/04 Universität Potsdam Institut
Einführung in die Computerlinguistik Merkmalstrukturen und Unifikation Dozentin: Wiebke Petersen WS 2004/2005 Wiebke Petersen Formale Komplexität natürlicher Sprachen WS 03/04 Universität Potsdam Institut
Hidden Markov Model ein Beispiel
 Hidden Markov Model ein Beispiel Gegeben: Folge von Beobachtungen O = o 1,..., o n = nass, nass, trocken, nass, trocken Menge möglicher Systemzustände: Z = {Sonne, Regen} Beobachtungswahrscheinlichkeiten:
Hidden Markov Model ein Beispiel Gegeben: Folge von Beobachtungen O = o 1,..., o n = nass, nass, trocken, nass, trocken Menge möglicher Systemzustände: Z = {Sonne, Regen} Beobachtungswahrscheinlichkeiten:
Einführung in die Computerlinguistik
 Einführung in die Computerlinguistik HMM POS-Tagging Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 20 POS Tags (1) Jurafsky and Martin (2009) POS = part-of-speech Tags sind morphosyntaktische
Einführung in die Computerlinguistik HMM POS-Tagging Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 20 POS Tags (1) Jurafsky and Martin (2009) POS = part-of-speech Tags sind morphosyntaktische
Stochastik Praktikum Markov Chain Monte Carlo Methoden
 Stochastik Praktikum Markov Chain Monte Carlo Methoden Humboldt-Universität zu Berlin 14.10.2010 Problemstellung Wie kann eine Zufallsstichprobe am Computer simuliert werden, deren Verteilung aus einem
Stochastik Praktikum Markov Chain Monte Carlo Methoden Humboldt-Universität zu Berlin 14.10.2010 Problemstellung Wie kann eine Zufallsstichprobe am Computer simuliert werden, deren Verteilung aus einem
Matrizen. Nicht nur eine Matrix, sondern viele 0,5 0,2 0,3 A 0,2 0,7 0,1
 Nicht nur eine Matrix, sondern viele Matrizen 0,5 0,2 0,3 A 0,2 0,7 0,1 015 0,15 0,75 075 0,1 01 aber keine Matrize und auch keine Matratzen 1 Wie beschreibt man Prozesse? Makov-Modell Modell Markov- Prozess
Nicht nur eine Matrix, sondern viele Matrizen 0,5 0,2 0,3 A 0,2 0,7 0,1 015 0,15 0,75 075 0,1 01 aber keine Matrize und auch keine Matratzen 1 Wie beschreibt man Prozesse? Makov-Modell Modell Markov- Prozess




Elementare Begriffe der Wahrscheinlichkeitstheorie für die Sprachverarbeitung
 Elementare Begriffe der Wahrscheinlichkeitstheorie für die Sprachverarbeitung Kursfolien Karin Haenelt 1 Übersicht Wahrscheinlichkeitsfunktion P Wahrscheinlichkeit und bedingte Wahrscheinlichkeit Bayes-Formeln
Elementare Begriffe der Wahrscheinlichkeitstheorie für die Sprachverarbeitung Kursfolien Karin Haenelt 1 Übersicht Wahrscheinlichkeitsfunktion P Wahrscheinlichkeit und bedingte Wahrscheinlichkeit Bayes-Formeln
2. Woche Eindeutige Entschlüsselbarleit, Sätze von Kraft und McMillan, Huffmancodierung
 2 Woche Eindeutige Entschlüsselbarleit, Sätze von Kraft und McMillan, Huffmancodierung 2 Woche: Eindeutige Entschlüsselbarleit, Sätze von Kraft und McMillan, Huffmancodierung 24/ 44 Zwei Beispiele a 0
2 Woche Eindeutige Entschlüsselbarleit, Sätze von Kraft und McMillan, Huffmancodierung 2 Woche: Eindeutige Entschlüsselbarleit, Sätze von Kraft und McMillan, Huffmancodierung 24/ 44 Zwei Beispiele a 0
W-Rechnung und Statistik für Ingenieure Übung 11
 W-Rechnung und Statistik für Ingenieure Übung 11 Aufgabe 1 Ein Fahrzeugpark enthält 6 Fahrzeuge. Jedes Fahrzeug hat die Wahrscheinlichkeit p = 0.1 (bzw. p = 0.3), dass es kaputt geht. Pro Tag kann nur
W-Rechnung und Statistik für Ingenieure Übung 11 Aufgabe 1 Ein Fahrzeugpark enthält 6 Fahrzeuge. Jedes Fahrzeug hat die Wahrscheinlichkeit p = 0.1 (bzw. p = 0.3), dass es kaputt geht. Pro Tag kann nur
Wissensrepräsentation
 Wissensrepräsentation Vorlesung Sommersemester 2008 8. Sitzung Dozent Nino Simunic M.A. Computerlinguistik, Campus DU (Fortsetzung LC-/Chart-Parsing) Statistische Verfahren in der KI Impliziert Maschinelles
Wissensrepräsentation Vorlesung Sommersemester 2008 8. Sitzung Dozent Nino Simunic M.A. Computerlinguistik, Campus DU (Fortsetzung LC-/Chart-Parsing) Statistische Verfahren in der KI Impliziert Maschinelles
Bedingt unabhängige Zufallsvariablen
 7. Markov-Ketten 7. Definition und Eigenschaften von Markov-Ketten Benannt nach Andrei A. Markov [856-9] Einige Stichworte: Markov-Ketten Definition Eigenschaften Konvergenz Hidden Markov Modelle Sei X
7. Markov-Ketten 7. Definition und Eigenschaften von Markov-Ketten Benannt nach Andrei A. Markov [856-9] Einige Stichworte: Markov-Ketten Definition Eigenschaften Konvergenz Hidden Markov Modelle Sei X
Endliche Markov-Ketten - eine Übersicht
 Endliche Markov-Ketten - eine Übersicht Diese Übersicht über endliche Markov-Ketten basiert auf dem Buch Monte Carlo- Algorithmen von Müller-Gronbach et. al. und dient als Sammlung von Definitionen und
Endliche Markov-Ketten - eine Übersicht Diese Übersicht über endliche Markov-Ketten basiert auf dem Buch Monte Carlo- Algorithmen von Müller-Gronbach et. al. und dient als Sammlung von Definitionen und
Endliche Automaten. Grundlagen: Alphabet, Zeichenreihe, Sprache. Karin Haenelt
 Endliche Automaten Grundlagen: Alphabet, Zeichenreihe, Sprache Karin Haenelt 1 Alphabet, Zeichenreihe und Sprache Alphabet unzerlegbare Einzelzeichen Verwendung: als Eingabe- und Ausgabezeichen eines endlichen
Endliche Automaten Grundlagen: Alphabet, Zeichenreihe, Sprache Karin Haenelt 1 Alphabet, Zeichenreihe und Sprache Alphabet unzerlegbare Einzelzeichen Verwendung: als Eingabe- und Ausgabezeichen eines endlichen
Mathematische Grundlagen der Computerlinguistik III: Statistische Methoden Probeklausur
 Mathematische Grundlagen der Computerlinguistik III: Statistische Methoden Probeklausur Crocker/Demberg/Staudte Sommersemester 2014 17.07.2014 1. Sie haben 90 Minuten Zeit zur Bearbeitung der Aufgaben.
Mathematische Grundlagen der Computerlinguistik III: Statistische Methoden Probeklausur Crocker/Demberg/Staudte Sommersemester 2014 17.07.2014 1. Sie haben 90 Minuten Zeit zur Bearbeitung der Aufgaben.
Markov-Ketten Proseminar: Das virtuelle Labor Ariane Wietschke
 Markov-Ketten Proseminar: Das virtuelle Labor Ariane Wietschke 28.01.2004 28.01.04 Ariane Wietschke - Markov-Ketten 1 Übersicht 1. Herleitung der Definition 2. Komponenten von Markov-Ketten 3. Arten von
Markov-Ketten Proseminar: Das virtuelle Labor Ariane Wietschke 28.01.2004 28.01.04 Ariane Wietschke - Markov-Ketten 1 Übersicht 1. Herleitung der Definition 2. Komponenten von Markov-Ketten 3. Arten von
Aufabe 7: Baum-Welch Algorithmus
 Effiziente Algorithmen VU Ausarbeitung Aufabe 7: Baum-Welch Algorithmus Florian Fest, Matr. Nr.0125496 baskit@generationfun.at Claudia Hermann, Matr. Nr.0125532 e0125532@stud4.tuwien.ac.at Matteo Savio,
Effiziente Algorithmen VU Ausarbeitung Aufabe 7: Baum-Welch Algorithmus Florian Fest, Matr. Nr.0125496 baskit@generationfun.at Claudia Hermann, Matr. Nr.0125532 e0125532@stud4.tuwien.ac.at Matteo Savio,
Hidden Markov Models in Anwendungen
 Hidden Markov Models in Anwendungen Dr. Vera Demberg Universität des Saarlandes 31. Mai 2012 Vera Demberg (UdS) HMM Anwendungen 31. Mai 2012 1 / 26 Hidden Markov Modelle in der Computerlinguistik Table
Hidden Markov Models in Anwendungen Dr. Vera Demberg Universität des Saarlandes 31. Mai 2012 Vera Demberg (UdS) HMM Anwendungen 31. Mai 2012 1 / 26 Hidden Markov Modelle in der Computerlinguistik Table
16. November 2011 Zentralitätsmaße. H. Meyerhenke: Algorithmische Methoden zur Netzwerkanalyse 87
 16. November 2011 Zentralitätsmaße H. Meyerhenke: Algorithmische Methoden zur Netzwerkanalyse 87 Darstellung in spektraler Form Zentralität genügt Ax = κ 1 x (Herleitung s. Tafel), daher ist x der Eigenvektor
16. November 2011 Zentralitätsmaße H. Meyerhenke: Algorithmische Methoden zur Netzwerkanalyse 87 Darstellung in spektraler Form Zentralität genügt Ax = κ 1 x (Herleitung s. Tafel), daher ist x der Eigenvektor
Wortdekodierung. Vorlesungsunterlagen Speech Communication 2, SS Franz Pernkopf/Erhard Rank
 Wortdekodierung Vorlesungsunterlagen Speech Communication 2, SS 2004 Franz Pernkopf/Erhard Rank Institute of Signal Processing and Speech Communication University of Technology Graz Inffeldgasse 16c, 8010
Wortdekodierung Vorlesungsunterlagen Speech Communication 2, SS 2004 Franz Pernkopf/Erhard Rank Institute of Signal Processing and Speech Communication University of Technology Graz Inffeldgasse 16c, 8010
1 Part-of-Speech Tagging
 2. Übung zur Vorlesung NLP Analyse des Wissensrohstoes Text im Sommersemester 2008 Dr. Andreas Hotho, Dipl.-Inform. Dominik Benz, Wi.-Inf. Beate Krause 28. Mai 2008 1 Part-of-Speech Tagging 1.1 Grundlagen
2. Übung zur Vorlesung NLP Analyse des Wissensrohstoes Text im Sommersemester 2008 Dr. Andreas Hotho, Dipl.-Inform. Dominik Benz, Wi.-Inf. Beate Krause 28. Mai 2008 1 Part-of-Speech Tagging 1.1 Grundlagen
Wann sind Codes eindeutig entschlüsselbar?
 Wann sind Codes eindeutig entschlüsselbar? Definition Suffix Sei C ein Code. Ein Folge s {0, 1} heißt Suffix in C falls 1 c i, c j C : c i = c j s oder 2 c C und einen Suffix s in C: s = cs oder 3 c C
Wann sind Codes eindeutig entschlüsselbar? Definition Suffix Sei C ein Code. Ein Folge s {0, 1} heißt Suffix in C falls 1 c i, c j C : c i = c j s oder 2 c C und einen Suffix s in C: s = cs oder 3 c C
Statistische Verfahren:
 Statistische Verfahren: Hidden-Markov-Modelle für Multiples Alignment Stochastic Context-Free Grammars (SCFGs) für RNA-Multiples Alignment Übersicht 1 1. Hidden-Markov-Models (HMM) für Multiples Alignment
Statistische Verfahren: Hidden-Markov-Modelle für Multiples Alignment Stochastic Context-Free Grammars (SCFGs) für RNA-Multiples Alignment Übersicht 1 1. Hidden-Markov-Models (HMM) für Multiples Alignment
Reranking. Parse Reranking. Helmut Schmid. Institut für maschinelle Sprachverarbeitung Universität Stuttgart
 Institut für maschinelle Sprachverarbeitung Universität Stuttgart schmid@ims.uni-stuttgart.de Die Folien basieren teilweise auf Folien von Mark Johnson. Koordinationen Problem: PCFGs können nicht alle
Institut für maschinelle Sprachverarbeitung Universität Stuttgart schmid@ims.uni-stuttgart.de Die Folien basieren teilweise auf Folien von Mark Johnson. Koordinationen Problem: PCFGs können nicht alle
Machine Translation with Inferred Stochastic Finite-State Transducers
 Machine Translation with Inferred Stochastic Finite-State Transducers von Klaus Suttner HS: Endliche Automaten Dozentin: Karin Haenelt Seminar für Computerlinguistik Universität Heidelberg 29.06.09 Finite-state
Machine Translation with Inferred Stochastic Finite-State Transducers von Klaus Suttner HS: Endliche Automaten Dozentin: Karin Haenelt Seminar für Computerlinguistik Universität Heidelberg 29.06.09 Finite-state
Kürzeste und Schnellste Wege
 Kürzeste und Schnellste Wege Wie funktionieren Navis? André Nusser (Folien inspiriert von Kurt Mehlhorn) Struktur Straßennetzwerke Naiver Algorithmus Dijkstras Algorithmus Transitknoten Nachbemerkungen
Kürzeste und Schnellste Wege Wie funktionieren Navis? André Nusser (Folien inspiriert von Kurt Mehlhorn) Struktur Straßennetzwerke Naiver Algorithmus Dijkstras Algorithmus Transitknoten Nachbemerkungen
Einführung in die Computerlinguistik POS-Tagging
 Einführung in die Computerlinguistik POS-Tagging Laura Heinrich-Heine-Universität Düsseldorf Sommersemester 2013 POS Tags (1) POS = part-of-speech Tags sind morphosyntaktische Kategorien von Wortformen.
Einführung in die Computerlinguistik POS-Tagging Laura Heinrich-Heine-Universität Düsseldorf Sommersemester 2013 POS Tags (1) POS = part-of-speech Tags sind morphosyntaktische Kategorien von Wortformen.
Zeitstetige Markov-Prozesse: Einführung und Beispiele
 Zeitstetige Markov-Prozesse: Einführung und Beispiele Simone Wielart 08.12.10 Inhalt Q-Matrizen und ihre Exponentiale Inhalt Q-Matrizen und ihre Exponentiale Zeitstetige stochastische Prozesse Inhalt Q-Matrizen
Zeitstetige Markov-Prozesse: Einführung und Beispiele Simone Wielart 08.12.10 Inhalt Q-Matrizen und ihre Exponentiale Inhalt Q-Matrizen und ihre Exponentiale Zeitstetige stochastische Prozesse Inhalt Q-Matrizen
8. Reinforcement Learning
 8. Reinforcement Learning Einführung 8. Reinforcement Learning Wie können Agenten ohne Trainingsbeispiele lernen? Auch kennt der Agent zu Beginn nicht die Auswirkungen seiner Handlungen. Stattdessen erhält
8. Reinforcement Learning Einführung 8. Reinforcement Learning Wie können Agenten ohne Trainingsbeispiele lernen? Auch kennt der Agent zu Beginn nicht die Auswirkungen seiner Handlungen. Stattdessen erhält
Einführung in die Theorie der Markov-Ketten. Jens Schomaker
 Einführung in die Theorie der Markov-Ketten Jens Schomaker Markov-Ketten Zur Motivation der Einführung von Markov-Ketten betrachte folgendes Beispiel: 1.1 Beispiel Wir wollen die folgende Situation mathematisch
Einführung in die Theorie der Markov-Ketten Jens Schomaker Markov-Ketten Zur Motivation der Einführung von Markov-Ketten betrachte folgendes Beispiel: 1.1 Beispiel Wir wollen die folgende Situation mathematisch
3. Prozesse mit kontinuierlicher Zeit
 3. Prozesse mit kontinuierlicher Zeit 3.1 Einführung Wir betrachten nun Markov-Ketten (X(t)) t R +. 0 Wie beim Übergang von der geometrischen zur Exponentialverteilung können wir uns auch hier einen Grenzprozess
3. Prozesse mit kontinuierlicher Zeit 3.1 Einführung Wir betrachten nun Markov-Ketten (X(t)) t R +. 0 Wie beim Übergang von der geometrischen zur Exponentialverteilung können wir uns auch hier einen Grenzprozess
BZQ II: Stochastikpraktikum
 BZQ II: Stochastikpraktikum Block 5: Markov-Chain-Monte-Carlo-Verfahren Randolf Altmeyer February 1, 2017 Überblick 1 Monte-Carlo-Methoden, Zufallszahlen, statistische Tests 2 Nichtparametrische Methoden
BZQ II: Stochastikpraktikum Block 5: Markov-Chain-Monte-Carlo-Verfahren Randolf Altmeyer February 1, 2017 Überblick 1 Monte-Carlo-Methoden, Zufallszahlen, statistische Tests 2 Nichtparametrische Methoden
Lösungen zu Übungsblatt 10 Höhere Mathematik Master KI Diskrete Zufallsgrößen/Markov-Ketten
 Lösungen zu Übungsblatt 0 Höhere Mathematik Master KI Hinweise: Die Aufgaben - beziehen sich auf das Thema Diskrete Zufallsgrößen, Ihre Verteilungen und Erwartungswerte. Siehe dazu auch das auf der Homepage
Lösungen zu Übungsblatt 0 Höhere Mathematik Master KI Hinweise: Die Aufgaben - beziehen sich auf das Thema Diskrete Zufallsgrößen, Ihre Verteilungen und Erwartungswerte. Siehe dazu auch das auf der Homepage
Einführung in die Computerlinguistik
 Einführung in die Computerlinguistik Statistische Verfahren in der lexikalischen Semantik WS 2/22 Manfred Pinkal Beispiel: Adjektive im Wahrig-Korpus Frequenzen in einem kleinen Teilkorpus: n groß - -
Einführung in die Computerlinguistik Statistische Verfahren in der lexikalischen Semantik WS 2/22 Manfred Pinkal Beispiel: Adjektive im Wahrig-Korpus Frequenzen in einem kleinen Teilkorpus: n groß - -
Algorithmen auf Sequenzen Paarweiser Sequenzvergleich: Alignments
 Algorithmen auf Sequenzen Paarweiser Sequenzvergleich: Alignments Sven Rahmann Genominformatik Universitätsklinikum Essen Universität Duisburg-Essen Universitätsallianz Ruhr Einführung Bisher: Berechnung
Algorithmen auf Sequenzen Paarweiser Sequenzvergleich: Alignments Sven Rahmann Genominformatik Universitätsklinikum Essen Universität Duisburg-Essen Universitätsallianz Ruhr Einführung Bisher: Berechnung
Multiple Alignments. Vorlesung Einführung in die Angewandte Bioinformatik Prof. Dr. Sven Rahmann. Webseite zur Vorlesung
 Multiple Alignments Vorlesung Einführung in die Angewandte Bioinformatik Prof. Dr. Sven Rahmann Webseite zur Vorlesung http://bioinfo.wikidot.com/ Sprechstunde Mo 16-17 in OH14, R214 Sven.Rahmann -at-
Multiple Alignments Vorlesung Einführung in die Angewandte Bioinformatik Prof. Dr. Sven Rahmann Webseite zur Vorlesung http://bioinfo.wikidot.com/ Sprechstunde Mo 16-17 in OH14, R214 Sven.Rahmann -at-
DWT 2.3 Ankunftswahrscheinlichkeiten und Übergangszeiten 400/467 Ernst W. Mayr
 2. Ankunftswahrscheinlichkeiten und Übergangszeiten Bei der Analyse von Markov-Ketten treten oftmals Fragestellungen auf, die sich auf zwei bestimmte Zustände i und j beziehen: Wie wahrscheinlich ist es,
2. Ankunftswahrscheinlichkeiten und Übergangszeiten Bei der Analyse von Markov-Ketten treten oftmals Fragestellungen auf, die sich auf zwei bestimmte Zustände i und j beziehen: Wie wahrscheinlich ist es,
Einführung in die Computerlinguistik
 Einführung in die Computerlinguistik Statistische Modellierung I WS 2010/2011 Manfred Pinkal Wortartinformation Wortartinformation ist eine wichtige Voraussetzung für die syntaktische Analyse. Woher kommt
Einführung in die Computerlinguistik Statistische Modellierung I WS 2010/2011 Manfred Pinkal Wortartinformation Wortartinformation ist eine wichtige Voraussetzung für die syntaktische Analyse. Woher kommt
Einführung in Markoff-Ketten
 Einführung in Markoff-Ketten von Peter Pfaffelhuber Version: 6. Juli 200 Inhaltsverzeichnis 0 Vorbemerkung Grundlegendes 2 Stationäre Verteilungen 6 3 Markoff-Ketten-Konvergenzsatz 8 0 Vorbemerkung Die
Einführung in Markoff-Ketten von Peter Pfaffelhuber Version: 6. Juli 200 Inhaltsverzeichnis 0 Vorbemerkung Grundlegendes 2 Stationäre Verteilungen 6 3 Markoff-Ketten-Konvergenzsatz 8 0 Vorbemerkung Die
Wintersemester 2004/ Februar 2005
 Lehrstuhl für Praktische Informatik III Norman May B6, 29, Raum C0.05 68131 Mannheim Telefon: (0621) 181 2517 Email: norman@pi3.informatik.uni-mannheim.de Matthias Brantner B6, 29, Raum C0.05 68131 Mannheim
Lehrstuhl für Praktische Informatik III Norman May B6, 29, Raum C0.05 68131 Mannheim Telefon: (0621) 181 2517 Email: norman@pi3.informatik.uni-mannheim.de Matthias Brantner B6, 29, Raum C0.05 68131 Mannheim
1. Was ist eine Wahrscheinlichkeit P(A)?
?") 1. Was ist eine Wahrscheinlichkeit P(A)? Als Wahrscheinlichkeit verwenden wir ein Maß, welches die gleichen Eigenschaften wie die relative Häufigkeit h n () besitzt, aber nicht zufallsbehaftet ist. Jan
1. Was ist eine Wahrscheinlichkeit P(A)? Als Wahrscheinlichkeit verwenden wir ein Maß, welches die gleichen Eigenschaften wie die relative Häufigkeit h n () besitzt, aber nicht zufallsbehaftet ist. Jan
{ } Markov Ketten { ( ) ( ) } ( ) X Zeitdiskret Wertdiskret (diskrete Zustände) Markov Kette N ter Ordnung: Statistische Aussagen über den
 ( ) } ( ) X Zeitdiskret Wertdiskret (diskrete Zustände) Markov Kette N ter Ordnung: Statistische Aussagen über den") Markov Ketten Markov Ketten X i Stochastischer Prozess X Zeitdiskret Wertdiskret (diskrete Zustände) Markov Kette N ter Ordnung: Statistische Aussagen üer den aktuellenzustand können auf der Basisder Kenntnis
Markov Ketten Markov Ketten X i Stochastischer Prozess X Zeitdiskret Wertdiskret (diskrete Zustände) Markov Kette N ter Ordnung: Statistische Aussagen üer den aktuellenzustand können auf der Basisder Kenntnis
Einführung in die Computerlinguistik Berechenbarkeit, Entscheidbarkeit, Halteproblem
 Einführung in die Computerlinguistik Berechenbarkeit, Entscheidbarkeit, Halteproblem Dozentin: Wiebke Petersen 14.1.2009 Wiebke Petersen Einführung CL (WiSe 09/10) 1 Hinweis zu den Folien Der Text dieser
Einführung in die Computerlinguistik Berechenbarkeit, Entscheidbarkeit, Halteproblem Dozentin: Wiebke Petersen 14.1.2009 Wiebke Petersen Einführung CL (WiSe 09/10) 1 Hinweis zu den Folien Der Text dieser
WS 2008/09. Diskrete Strukturen
 WS 2008/09 Diskrete Strukturen Prof. Dr. J. Esparza Lehrstuhl für Grundlagen der Softwarezuverlässigkeit und theoretische Informatik Fakultät für Informatik Technische Universität München http://www7.in.tum.de/um/courses/ds/ws0809
WS 2008/09 Diskrete Strukturen Prof. Dr. J. Esparza Lehrstuhl für Grundlagen der Softwarezuverlässigkeit und theoretische Informatik Fakultät für Informatik Technische Universität München http://www7.in.tum.de/um/courses/ds/ws0809
Einführung in die Statistik für Wirtschaftswissenschaftler für Betriebswirtschaft und Internationales Management
 Einführung in die Statistik für Wirtschaftswissenschaftler für Betriebswirtschaft und Internationales Management Sommersemester 2013 Hochschule Augsburg Unabhängigkeit von Ereignissen A, B unabhängig:
Einführung in die Statistik für Wirtschaftswissenschaftler für Betriebswirtschaft und Internationales Management Sommersemester 2013 Hochschule Augsburg Unabhängigkeit von Ereignissen A, B unabhängig:
Automatische Spracherkennung
 Ernst Günter Schukat-Talamazzini Automatische Spracherkennung Grundlagen, statistische Modelle und effiziente Algorithmen Technische Universität Darmetadt FACHBEREICH INFORMATIK BIBLIOTHEK MH Invsntar-Nr.:
Ernst Günter Schukat-Talamazzini Automatische Spracherkennung Grundlagen, statistische Modelle und effiziente Algorithmen Technische Universität Darmetadt FACHBEREICH INFORMATIK BIBLIOTHEK MH Invsntar-Nr.:
Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 2016
 Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 1 M. Sperber (matthias.sperber@kit.edu) S. Nguyen (thai.nguyen@kit.edu) Übungsblatt 3 Maschinelles Lernen und Klassifikation Abgabe online
Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 1 M. Sperber (matthias.sperber@kit.edu) S. Nguyen (thai.nguyen@kit.edu) Übungsblatt 3 Maschinelles Lernen und Klassifikation Abgabe online
Reasoning and decision-making under uncertainty
 Reasoning and decision-making under uncertainty 9. Vorlesung Actions, interventions and complex decisions Sebastian Ptock AG Sociable Agents Rückblick: Decision-Making A decision leads to states with values,
Reasoning and decision-making under uncertainty 9. Vorlesung Actions, interventions and complex decisions Sebastian Ptock AG Sociable Agents Rückblick: Decision-Making A decision leads to states with values,
Einführung in die (induktive) Statistik
 Statistik") Einführung in die (induktive) Statistik Typische Fragestellung der Statistik: Auf Grund einer Problemmodellierung sind wir interessiert an: Zufallsexperiment beschrieben durch ZV X. Problem: Verteilung
Einführung in die (induktive) Statistik Typische Fragestellung der Statistik: Auf Grund einer Problemmodellierung sind wir interessiert an: Zufallsexperiment beschrieben durch ZV X. Problem: Verteilung
Parsing Übersicht und Kurskonzept
 Parsing Übersicht und Kurskonzept Kursfolien Karin Haenelt 01.04.2003 1 Übersetzung Verkehr, Auto Wohnen Sprachverarbeitung Pragmatik Textualität Semantik Syntax Morphologie Informationsanalyse Sprachanalyse
Parsing Übersicht und Kurskonzept Kursfolien Karin Haenelt 01.04.2003 1 Übersetzung Verkehr, Auto Wohnen Sprachverarbeitung Pragmatik Textualität Semantik Syntax Morphologie Informationsanalyse Sprachanalyse
Mathematik für Naturwissenschaften, Teil 2
 Lösungsvorschläge für die Aufgaben zur Vorlesung Mathematik für Naturwissenschaften, Teil Zusatzblatt SS 09 Dr. J. Schürmann keine Abgabe Aufgabe : Eine Familie habe fünf Kinder. Wir nehmen an, dass die
Lösungsvorschläge für die Aufgaben zur Vorlesung Mathematik für Naturwissenschaften, Teil Zusatzblatt SS 09 Dr. J. Schürmann keine Abgabe Aufgabe : Eine Familie habe fünf Kinder. Wir nehmen an, dass die
Modell zur Einflussanalyse Ein Modell zur Einflussanalyse von Methodenänderungen in Entwicklungsprozessen
 Modell zur Einflussanalyse Ein Modell zur Einflussanalyse von Methodenänderungen in Entwicklungsprozessen Roland Koppe, Stefan Häusler, Axel Hahn 2 Übersicht Einleitung und Motivation Ansatz und Methodik
Modell zur Einflussanalyse Ein Modell zur Einflussanalyse von Methodenänderungen in Entwicklungsprozessen Roland Koppe, Stefan Häusler, Axel Hahn 2 Übersicht Einleitung und Motivation Ansatz und Methodik
Turing Maschine. Thorsten Timmer. SS 2005 Proseminar Beschreibungskomplexität bei Prof. D. Wotschke. Turing Maschine SS 2005 p.
 Thorsten Timmer SS 2005 Proseminar Beschreibungskomplexität bei Prof. D. Wotschke Turing Maschine SS 2005 p. 1/35 Inhalt Einführung Formale Definition Berechenbare Sprachen und Funktionen Berechnung ganzzahliger
Thorsten Timmer SS 2005 Proseminar Beschreibungskomplexität bei Prof. D. Wotschke Turing Maschine SS 2005 p. 1/35 Inhalt Einführung Formale Definition Berechenbare Sprachen und Funktionen Berechnung ganzzahliger
Einführung in die Computerlinguistik
 Einführung in die Computerlinguistik Statistische Verfahren in der lexikalischen Semantik Evaluation Annotation eines Goldstandard : Testkorpus mit der relevanten Zielinformation (z.b. Wortart) Automatische
Einführung in die Computerlinguistik Statistische Verfahren in der lexikalischen Semantik Evaluation Annotation eines Goldstandard : Testkorpus mit der relevanten Zielinformation (z.b. Wortart) Automatische
Willkommen zur Vorlesung Statistik (Master)
") Willkommen zur Vorlesung Statistik (Master) Thema dieser Vorlesung: Verteilung diskreter Zufallsvariablen Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften
Willkommen zur Vorlesung Statistik (Master) Thema dieser Vorlesung: Verteilung diskreter Zufallsvariablen Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften
Übungen zu Rechnerkommunikation
 Übungen zu Rechnerkommunikation Wintersemester 00/0 Übung 6 Mykola Protsenko, Jürgen Eckert PD. Dr.-Ing. Falko Dressler Friedrich-Alexander d Universität Erlangen-Nürnberg Informatik 7 (Rechnernetze und
Übungen zu Rechnerkommunikation Wintersemester 00/0 Übung 6 Mykola Protsenko, Jürgen Eckert PD. Dr.-Ing. Falko Dressler Friedrich-Alexander d Universität Erlangen-Nürnberg Informatik 7 (Rechnernetze und
DynaTraffic Modelle und mathematische Prognosen. Simulation der Verteilung des Verkehrs mit Hilfe von Markov-Ketten
 DynaTraffic Modelle und mathematische Prognosen Simulation der Verteilung des Verkehrs mit Hilfe von Markov-Ketten Worum geht es? Modelle von Verkehrssituationen Graphen: Kanten, Knoten Matrixdarstellung
DynaTraffic Modelle und mathematische Prognosen Simulation der Verteilung des Verkehrs mit Hilfe von Markov-Ketten Worum geht es? Modelle von Verkehrssituationen Graphen: Kanten, Knoten Matrixdarstellung
5 Interpolation und Approximation
 5 Interpolation und Approximation Problemstellung: Es soll eine Funktion f(x) approximiert werden, von der die Funktionswerte nur an diskreten Stellen bekannt sind. 5. Das Interpolationspolynom y y = P(x)
5 Interpolation und Approximation Problemstellung: Es soll eine Funktion f(x) approximiert werden, von der die Funktionswerte nur an diskreten Stellen bekannt sind. 5. Das Interpolationspolynom y y = P(x)
Algorithmische Bioinformatik
 Algorithmische Bioinformatik Hidden-Markov-Modelle Viterbi - Algorithmus Ulf Leser Wissensmanagement in der Bioinformatik Inhalt der Vorlesung Hidden Markov Modelle Baum, L. E. and Petrie, T. (1966). "Statistical
Algorithmische Bioinformatik Hidden-Markov-Modelle Viterbi - Algorithmus Ulf Leser Wissensmanagement in der Bioinformatik Inhalt der Vorlesung Hidden Markov Modelle Baum, L. E. and Petrie, T. (1966). "Statistical
Brownsche Bewegung. M. Gruber SS 2016, KW 11. Zusammenfassung
 Brownsche Bewegung M. Gruber SS 2016, KW 11 Zusammenfassung Stochastische Prozesse, Pfade; Definition der Brownschen Bewegung; Eigenschaften der Brownschen Bewegung: Kovarianz, Stationarität, Selbstähnlichkeit;
Brownsche Bewegung M. Gruber SS 2016, KW 11 Zusammenfassung Stochastische Prozesse, Pfade; Definition der Brownschen Bewegung; Eigenschaften der Brownschen Bewegung: Kovarianz, Stationarität, Selbstähnlichkeit;
Sachrechnen/Größen WS 14/15-
 Kapitel Daten & Wahrscheinlichkeit 3.1 Kombinatorische Grundlagen 3.2 Kombinatorik & Wahrscheinlichkeit in der Grundschule 3.3 Daten Darstellen 3.1 Kombinatorische Grundlagen Verschiedene Bereiche der
Kapitel Daten & Wahrscheinlichkeit 3.1 Kombinatorische Grundlagen 3.2 Kombinatorik & Wahrscheinlichkeit in der Grundschule 3.3 Daten Darstellen 3.1 Kombinatorische Grundlagen Verschiedene Bereiche der
Kapitel 9: Informationstheorie. 2. Entropie
 ZHAW, NT, FS2008, Rumc, Kapitel 9: 2-1 Kapitel 9: Informationstheorie 2. Entropie Inhaltsverzeichnis 2.1. INFORATIONSQUELLEN...2 2.2. INFORATIONSGEHALT...3 2.3. INIALE ANZAHL BINÄRE FRAGEN...5 2.4. ENTROPIE
ZHAW, NT, FS2008, Rumc, Kapitel 9: 2-1 Kapitel 9: Informationstheorie 2. Entropie Inhaltsverzeichnis 2.1. INFORATIONSQUELLEN...2 2.2. INFORATIONSGEHALT...3 2.3. INIALE ANZAHL BINÄRE FRAGEN...5 2.4. ENTROPIE
ETWR Teil B. Spezielle Wahrscheinlichkeitsverteilungen (stetig)
") ETWR Teil B 2 Ziele Bisher (eindimensionale, mehrdimensionale) Zufallsvariablen besprochen Lageparameter von Zufallsvariablen besprochen Übertragung des gelernten auf diskrete Verteilungen Ziel des Kapitels
ETWR Teil B 2 Ziele Bisher (eindimensionale, mehrdimensionale) Zufallsvariablen besprochen Lageparameter von Zufallsvariablen besprochen Übertragung des gelernten auf diskrete Verteilungen Ziel des Kapitels
11. Übung Algorithmen I
 Timo Bingmann, Christian Schulz INSTITUT FÜR THEORETISCHE INFORMATIK, PROF. SANDERS KIT Timo Universität Bingmann, des LandesChristian Baden-Württemberg Schulz und nationales Forschungszentrum in der Helmholtz-Gemeinschaft
Timo Bingmann, Christian Schulz INSTITUT FÜR THEORETISCHE INFORMATIK, PROF. SANDERS KIT Timo Universität Bingmann, des LandesChristian Baden-Württemberg Schulz und nationales Forschungszentrum in der Helmholtz-Gemeinschaft
15.5 Stetige Zufallsvariablen
 5.5 Stetige Zufallsvariablen Es gibt auch Zufallsvariable, bei denen jedes Elementarereignis die Wahrscheinlich keit hat. Beispiel: Lebensdauer eines radioaktiven Atoms Die Lebensdauer eines radioaktiven
5.5 Stetige Zufallsvariablen Es gibt auch Zufallsvariable, bei denen jedes Elementarereignis die Wahrscheinlich keit hat. Beispiel: Lebensdauer eines radioaktiven Atoms Die Lebensdauer eines radioaktiven
Bayes sche Netze: Konstruktion, Inferenz, Lernen und Kausalität. Volker Tresp
 Bayes sche Netze: Konstruktion, Inferenz, Lernen und Kausalität Volker Tresp 1 Einführung Bisher haben wir uns fast ausschließich mit überwachtem Lernen beschäftigt: Ziel war es, eine (oder mehr als eine)
Bayes sche Netze: Konstruktion, Inferenz, Lernen und Kausalität Volker Tresp 1 Einführung Bisher haben wir uns fast ausschließich mit überwachtem Lernen beschäftigt: Ziel war es, eine (oder mehr als eine)
Modellbildung und Simulation
 Modellbildung und Simulation Wintersemester 2007/2008 Klaus Kasper Praktikum Mittwochs: 10:15 13:30 (Y) Start: 24.10.2007 Ort: D15/202 Donnerstags: 14:15 17:30 (X) Start: 25.10.2007 Ort: D15/102 Zulassungsvoraussetzung
Modellbildung und Simulation Wintersemester 2007/2008 Klaus Kasper Praktikum Mittwochs: 10:15 13:30 (Y) Start: 24.10.2007 Ort: D15/202 Donnerstags: 14:15 17:30 (X) Start: 25.10.2007 Ort: D15/102 Zulassungsvoraussetzung
Spracherkennung und Sprachsynthese
 Spracherkennung und Sprachsynthese Einführung in die Computerlinguistik Sommersemester 2012 Peter Kolb Spracherkennung / -synthese Spracherkennung (automatic speech recognition, ASR) Sprachsynthese (text-to-speech,
Spracherkennung und Sprachsynthese Einführung in die Computerlinguistik Sommersemester 2012 Peter Kolb Spracherkennung / -synthese Spracherkennung (automatic speech recognition, ASR) Sprachsynthese (text-to-speech,
Definition 2.1 Der Erwartungswert einer diskreten Zufallsvariablen mit Wahrscheinlichkeitsfunktion
 Kapitel 2 Erwartungswert 2.1 Erwartungswert einer Zufallsvariablen Definition 2.1 Der Erwartungswert einer diskreten Zufallsvariablen mit Wahrscheinlichkeitsfunktion È ist definiert als Ü ÜÈ Üµ Für spätere
Kapitel 2 Erwartungswert 2.1 Erwartungswert einer Zufallsvariablen Definition 2.1 Der Erwartungswert einer diskreten Zufallsvariablen mit Wahrscheinlichkeitsfunktion È ist definiert als Ü ÜÈ Üµ Für spätere
Praktikum Maschinelle Übersetzung Lexikon and Word Alignment
 Praktikum Maschinelle Übersetzung Lexikon and Word Alignment Um die Aufgaben auszuführen, können Sie ihre Daten in folgendem Verzeichnis speichern: /project/smtstud/ss10/systems/username/ Wir werden zunächst
Praktikum Maschinelle Übersetzung Lexikon and Word Alignment Um die Aufgaben auszuführen, können Sie ihre Daten in folgendem Verzeichnis speichern: /project/smtstud/ss10/systems/username/ Wir werden zunächst
Methoden der Biosignalverarbeitung
 Vorlesung SS 2012 Methoden der Biosignalverarbeitung Generatives und Diskriminatives Training Dipl. Math. Michael Wand Prof. Dr. Tanja Schultz 1 / 95 Generatives und Diskriminatives Training Mit dieser
Vorlesung SS 2012 Methoden der Biosignalverarbeitung Generatives und Diskriminatives Training Dipl. Math. Michael Wand Prof. Dr. Tanja Schultz 1 / 95 Generatives und Diskriminatives Training Mit dieser
Einführung in die Computerlinguistik deterministische und nichtdeterministische endliche Automaten
 Einführung in die Computerlinguistik deterministische und nichtdeterministische endliche Automaten Dozentin: Wiebke Petersen Foliensatz 4 Wiebke Petersen Einführung CL 1 Äquivalenz von endlichen Automaten
Einführung in die Computerlinguistik deterministische und nichtdeterministische endliche Automaten Dozentin: Wiebke Petersen Foliensatz 4 Wiebke Petersen Einführung CL 1 Äquivalenz von endlichen Automaten