Institut für Informatik Lehrstuhl Maschinelles Lernen. Uwe Dick
|
|
|
- Martin Dieter
- vor 6 Jahren
- Abrufe
Transkript

1 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning 2 Uwe Dick
2 Funktionsapproximation Modellierung Value Iteration Least-Squares-Methoden Gradienten-Methoden Policy Iteration Least-Squares-Methoden Gradienten-Methoden Gade e e Policy Gradient Actor-Critic-Methoden




3 Funktionsapproximation Darstellen der Value Function als parametrisierte Funktion aus dem Funktionsraum F mit Parametervektor µ. Vorhersageproblem: Finde Parametervektor µ, so dass V ¼, bzw. Q ¼ am besten approximiert wird. Scheffer/S Sawade/Dick, Masch hinelles Lernen 2
4 Funktionsapproximation Generatives Modell Annahme: Es kann jederzeit aus P und R gesamplet werden. Nicht aber P(s s,a) abgefragt werden. Das Reinforcement Learning Problem: Beispiele <s t, a t, R t, s t+1 > aus Interaktion mit der Umgebung. Mögliche Annahme: Interaktion folgt der zu lernenden Policy On-policy-Verteilung von Zuständen ¹(s).
5 Batch Reinforcement Learning Episode gesamplet nach ¼ b Zum Trainingszeitpunkt nur Zugang g zu dieser einen Episode. Scheffer/S Sawade/Dick, Maschinelles Lernen 2
6 Approximate Policy Iteration Initialisiere Policy pi Iteriere Approximate Policy Evaluation Finde ˆQ, eine Approximation von Q durch Interaktion fester Trainingsmenge Policy Improvement Finde, so dass ˆ 1 arg max Qsa t a (, ), für alle a t 1
7 Approximate Policy Iteration Falls Samples von Q ¼ (sa) (s,a) bekannt, lerne Q ¼ vom Trainingssample mit Hilfe einer überwachten Regressionsmethode. Problem: Oft off-policy, d.h. Trainingsbeispiele werden beobachtet während einer Verhaltenspolicy gefolgt wird. Sample Selection Bias (Unterschiedliche Trainingund Testverteilungen p(s,a))
8 Approximate Policy Evaluation Idee: Minimiere den quadratischen Abstand zwischen Q und TQ. Mean Squared Bellman Error Leider ist TQ nicht notwendigerweise in F. Besser: Minimiere Mean Squared Projected Bellman Error
9 Bellman-Residuen-Minimierung Temporal Difference Methode. Bellman-Gleichung als Fixpunkt-Gleichung. Linke Seite als Fehler interpretieren: Bellman Residuum. ¹ stationäre Verteilung von Zuständen. Empirisch:
10 Bellman-Residuen-Minimierung Problem: Schätzer nicht erwartungstreu. Denn Es folgt: Scheffer/S Sawade/Dick, Maschinelles Le ernen 2
11 Bellman-Residuen-Minimierung Aber für gilt: Es gilt aber für Erwartungswerte über Zufallsvariablen X: Scheffer/S Sawade/Dick, Maschinelles Le ernen 2
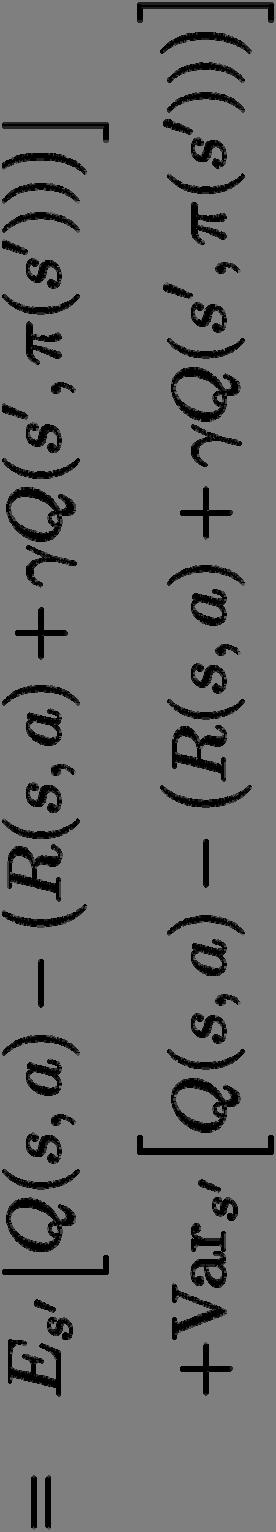
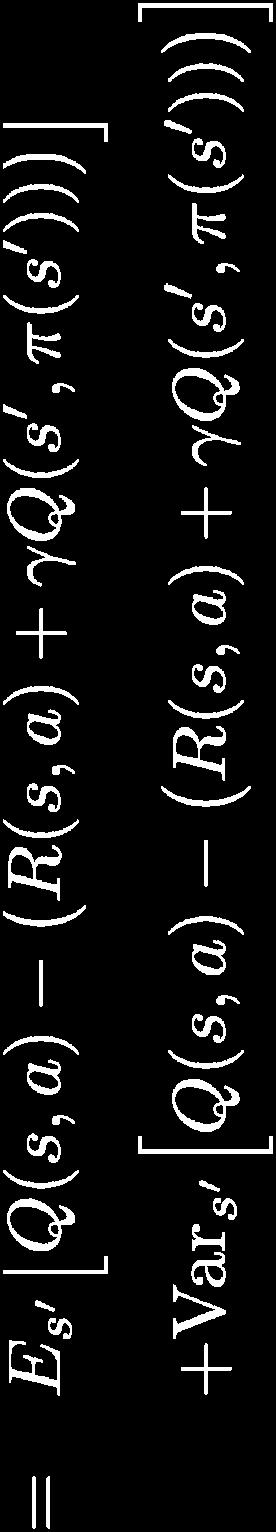


12 Bellman-Residuen-Minimierung Anwendung auf inneren Erwartungswert: Aber: Schätzung aus Samples ist Scheffer/S Sawade/Dick, Maschinelles Le ernen 2
13 Bellman-Residuen-Minimierung Alternative Herleitung für BRM mit Funktionsapproximation. Optimierungskriterium J ( ) E [ Qˆ ( s, a ; ) ( R ( s, a ) E [ Qˆ( s, a ; )])] s, a t t t t s t 1 t 1 t E E s 2 s [ [ t( ) t] ] t Gradient 1 J J ( ) 2 E [ ( ) Qˆ ( s, a ; )] s, s t t t t t1 t1 E [ E [ ( ) s ] E [ Qˆ ( s, a ; ) s ]] st st1 t t st1 t1 t1 t
14 Bellman-Residuen-Minimierung Daher müssen eigentlich immer zwei unabhängige Nachfolgezustände gezogen werden, um erwartungstreue Schätzung zu bekommen Unpraktisch und oft unrealistisch Stattdessen wurde vorgeschlagen, einfach nur ein Sample zu nehmen und die Updates damit zu machen. Damit konvergiert der Algorithmus allerdings nicht mehr gegen den Fixpunkt von
15 Residual Gradient Die neue Lösung nennt man Residual Gradient (RG) Lösung I.A. schlechtere Lösung als genaue BRM Aber dafür kann ein stochastischer echter Gradient berechnet werden (allerdings nicht für das ursprünglich gewünschte Optimierungskriterium) (Kommt später)
16 BRM Vorschlag: [Antos et. al. 07] Erwartungstreue durch Einführung einer Hilfsfunktion h2f. Scheffer/S Sawade/Dick, Maschinelles Lernen 2
17 Least-Squares Temporal Difference Q ist aus Funktionsraum F. T ¼ Q aber nicht notwendigerweise. LSTD minimiert den quadratischen Abstand zwischen Q und der Projektion von T ¼ Q auf F. Unbiased. LSTD oft bessere Ergebnisse. Scheffer/S Sawade/Dick, Maschinelles Le ernen 2
18 Fitted Policy Evaluation mit Samples Q = 0. Ziehe N Samples s,a aus ¹(s),p(a). Ziehe R und Nachfolgezustand s entsprechend Modell. Iteriere: Mit diesen Samples <s, a, R, s > wird ein Bellman- Update-Schritt durchgeführt: Q (, s a) R(, s a) Q ( s', ( s')) k1 M i1 Dann least-squares Fitting: M Qˆ ( s, a) argmin Q ( s, a ) f( s, a ) k1 k1 i i i i f i 1 k
19 Projected Bellman Equation Lineare Approximation der Q-Funktion ˆ(, ; ) T Qsa (, sa ) Fixpunkt der Bellman Gleichung Projektion: Least-Squares Definiere Q r p π SA SA SA x S Q( ij) Q( s, a ) r( ij) R( s, a ) i i p( ij,') i P( s s, a ) j j i' i j Q T Q S x S A π j i (, i', ij ) ( a s ), falls i i',sonst 0
20 Projected Bellman Equation Lineare Approximation, also Q= π Definiere T(Q)=r+ pπq Dann Mit T ( ) Q T π (Q) 1 T T, T pπ, z T r kann als Lösung von berechnet werden. z
21 LSTD-Q Gegeben eine Menge von n Samples ( s, a, s ') Gegeben eine Menge von n Samples 0, 0, z For i=1...n ( s, a ) ( s, a ) T i i 1 i i i i ( s, a ) ( s', ( s' )) T i i1 i i i i zi zi 1 ( si, ai) ri Löse nach ˆ 1 ˆ 1 ˆ 1 n n n n n n z i i i
22 LSPE-Q Gegeben eine Menge von n Samples ( s, a, s ') Gegeben eine Menge von n Samples 0, 0, z For i=1...n T ( s, a ) ( s, a ) i i1 i i i i ( s, a ) ( s', ( s' )) T i i1 i i i i i i i zi zi 1 ( si, ai) ri h 1 h 1 1 1( 1) wobei 1 z i i i ˆ i i i i i i i i i n
23 Konvergenz n Für konvergieren beide Lösungen gegen i h die Lösung der projected Bellman Gleichung i. Konvergenz für beide Algorithmen bewiesen, falls Samples nach h gesamplet wurden. Intuitiv dadurch, dass n, n, zn z n n n Aber h darf nicht deterministisch sein. Es kann also z.b. eine e-greedy Policy verwendet werden. ˆ h
24 Least-Squares-Methoden LSPE-Q ist ein inkrementeller Algorithmus, kann also als online On-Policy Methode verwendet werden und z.b. von einer guten Startlösung ˆ h 0 profitieren. LSTD-Q auf der anderen Seite berechnet die Lösung in einem Schritt, was bessere Stabilität im Vergleich zu LSPE bedeuten kann, falls sich die Policy h während der Evaluierung ändert.
25 Gradientenbasierte Policy Evaluation Eine andere Möglichkeit von (online) Policy Evaluation sind gradientenbasierte Methoden. 1 2 ˆ t 1 t t Q ( st, at) Q( st, at; t) 2 (, ) ˆ(, ; ) ˆ t t Q st at Q st at Q( st, at; t) Q ( s ist unbekannt. Deshalb wird es t, at) approximiert durch eine stochastische Approximation eines Bellman Updates (1 Sample) Rsa (, ) Qs ˆ ( ', a')
26 TD(0) Daraus ergibt sich die Update-Regel für TD(0): ˆ ˆ ˆ t1 t t Rs ( t, at) Qs ( t 1, at 1; ) Qs ( t, at; ) Qs ( t, at; t) Spezialfall lineare Funktionsapproximation T T t 1 t t R( st, at) ( st 1, at 1) t ( st, at) t( st, at) Auch hier gilt wieder, dass die Policy nicht deterministisch sein darf. Aber: Kein Sample eines echten Gradienten!
27 Gradientenbasierte Policy Evaluation Echter Echter Gradient ist Residual Gradient E s, s t t t t t 1 [ ( ) Qˆ ( s, a ; )] E [ E [ ( ) s ] E [ Qˆ ( s, a ; ) s ]] st st1 t t st1 t1 t1 t Empirischer Gradient (1 Sample) T T Rs ( t, at) ( st 1, at 1) t ( st, at) t T ( ( s, a ) ( s, a )) t1 t1 t t
28 Konvergenz Konvergenz für TD(0) ist unter bestimmten Annahmen und einem On-Policy-Sample-Prozess bewiesen. Wie immer muss zum On-Policy Lernen eine stochastische Policy verwendet werden. Um eine (möglichst) deterministische Policy zu lernen, wird oft z.b. das Epsilon einer epsilon- greedy Policy nach und nach immer kleiner gewählt. Leider ist für sehr kleine Epsilon die Konvergenz nicht mehr gewährleistet!
29 Konvergenz Residual Gradient hat bessere Konvergenzeigenschaften, vor allen Dingen dadurch, dass ein echter Gradient verwendet wird. Für Off-Policy TD(0) Policy Evaluation kann i.a. keine Konvergenz gezeigt werden. (Kann aber trotzdem konvergieren)
30 Off-Policy Policy Evaluation Off-Policy Policy Evaluation bedeutet, dass die Samples ( st, at, st 1) nach einer Verhaltenspolicy b gezogen g (generiert) werden, man aber die Value Function von einer anderen Policy lernen möchte. b ist i.a. stochastisch, um zu gewährleisten, dass alle Zustands-Aktions-Paare gesehen werden. Realisierung abhängig von Falls deterministisch, Realisierung durch Subsampling Falls stochastisch, Realisierung durch Importance Sampling
31 Off-Policy Policy Evaluation Subsampling: Verwerfe alle Beispiele ( st, at, st 1), die nicht zur Policy passen Importance Sampling: Umgewichten der Beispiele im Update. Z.B. TD(0): E[ ( ) ] E[ ( ) ] t t t t t t ( s, a ) t ( s, a ) t b t t TD(0) mit Importance Sampling: t 1 t t t t ( ) ( s t, a t )
32 Scheffer/Sawade/Dick, Maschinelles Lernen 2 Divergenz von Q-Learning
33 Off-Policy Policy Evaluation Neue Algorithmen, die auch Konvergenz unter Off- Policy-Lernen garantieren. Z.B. GTD Algorithmus. (Gradient TD) Idee: Neues Optimierungskriterium: Minimiere die L2-Norm des TD(0)-Updates. T E[ ( ) ] E[ ( ) ] t t t t Da das Update als der Fehler der derzeigen Lösung angesehen werden kann, macht die Minimierung intuitiv Sinn.
34 GTD-Algorithmus Der Gradient kann folgendermaßen berechnet werden: E[ ( ) ] E[ ( ) ] E[ ( ) ] E[ ( ) ] T T T E[( ' ) ] E[ ( ) ] Bei Approximation basierend auf Samples (für Stochastic Gradient) wird nur einer der beiden Erwartungswerte direkt gesamplet. T ( ) u T t1 t t t t t t u u ( u ) t1 t t t t t
35 Policy Improvement Falls A endlich und klein, kann die greedy Policy berechnet werden. Ansonsten muss sie approximiert werden. Man kann z.b. auch die Policy als eine Funktion von Zustand auf optimale Aktion lernen, etwa indem man das (approximative) max auf Samplemenge bestimmt und damit lernt.
36 Approximative PI Theoretische Garantien Konvergenz von Approximativen Policy Iteration Algorithmen ist i.a. nicht beweisbar. Man kann aber Suboptimalitätsschranken angeben, abhängig ggvon den maximalen Fehlern bei Policy Evaluation und Policy Improvement. Scheffer/S Sawade/Dick, Masch hinelles Lernen 2
37 Approximative PI Theoretische Garantien Ist der Fehler bei der Policy Evaluation beschränkt mit ˆ ˆ t Q Q Q ˆ t Q Q Und der Fehler der Policy Improvement mit ˆt ˆ ˆt ˆ ˆt T ( Q ) T( Q ) Dann kann der gesamte Fehler mit lim sup t beschränkt werden ˆ ˆ 2 t * Q Q 2 (1 ) Q
38 FA für Reinforcement Learning Online Updates: Anpassen von µ t nach jeder Interaktion <s t, a t, R t, s t+1 >. Qˆ (; ) t Qˆ(; ) Gradientenabstieg: Q t * t Q t
39 FA für Reinforcement Learning Spezialfall: lineare Methoden. ˆ(; ) T Q t Gradientenabstieg: 1 2 ˆ t1 t t (, ) (, ; ) 2 Q st at Q st at t (, ) ˆ(, ; ) ˆ t t Q st at Q st at Q( st, at; t) (, ) ˆ t t Q st at Q( st, at; ) ( st, at)
40 FA für Reinforcement Learning Value Function V ¼ unbekannt. Ersetze mit Schätzung. Monte-Carlo: Erwartungstreue Schätzung von V ¼. Konvergenz zu lokalem Optimum. (Unter Bedingungen g für t t) Temporal Difference (TD(0)): Gebiaste Schätzung. keine Konvergenz zu lokalem Optimum beweisbar.
41 Approximative Value Iteration Analog zu Approximativer Policy Evaluation: Finde Fixpunkt von Bellman Gleichung für das Kontrollproblem. QT Q Bei parametrischer Approximation mit Parametervektor T Q( )
42 Approximative Value Iteration Der Bellman-Operator ist definiert als TQ ( )( sa, ) Rsa (, ) max E[ Qs ( ', a)] Und die Projektion wird realisiert durch Least- Squares-Approximation ( Q) min f F Q f a 2 2 s'
![Fitted Value Iteration mit Samples [Szepesvári & Munos 05] V = 0.](/docs-images/77/76314149/images/43-4.jpg "Ziehe N Zustände s aus ¹(s).")
.")
43 Fitted Value Iteration mit Samples [Szepesvári & Munos 05] V = 0. Ziehe N Zustände s aus ¹(s). Für jedes s und a2a, Ziehe M Nachfolgezustände s aus P( s,a) und Rewards R(s,a). Iteriere: Mit diesen Samples <s, a, R, s > wird ein Bellman- Update-Schritt durchgeführt: Dann least-squares Fitting:
44 Scheffer/Sawade/Dick, Maschinelles Lernen 2 Fehlerabschätzung
45 Approximatives Q-Learning Lineare Parametrisierung der Q-Funktion Iterationsschritt: 1 * ˆ t1 t t Q st at Q st at t (, ) (, ; ) 2 Analog zu TD(0) wird das unbekannte Q * ( st, at ) approximiert mit einem Bellman-Update (, ) (, ) [max ˆ(, ; )] * Q st at R st at Es Q st 1 a t t1 2
46 Approximatives Q-Learning Wieder stochastische Gradient-Methode, es wird also der Erwartungswert durch stochastische Samples approximiert ˆ ˆ ˆ t1 t t Rs ( t, at) max Qs ( t1, a; t) Qs ( t, at; t) Qs ( t, at; t) a T T t t Rs ( t, at) max ( st 1, a) t ( st, at) t ( st, at) a Unter bestimmen Voraussetzungen kann man die Konvergenz von Q-Learning beweisen, allerdings müssen dafür Einschränkungen für Art der Policy oder der Featurevektoren gemacht werden.
47 Approximative Value Iteration Konvergenz-Beweise von Value Iteration basieren i.a. auf der Beweisbarkeit der Nichtexpansionseigenschaften der Projektion und der Funktionsapproximation, damit ( T Q )( ) ( T Q )( ') ' D.h., es muss gelten: und Q( ) Q( ') ' ( Q) ( Q') QQ'
48 Approximative Value Iteration Q ( ) Q ( ') ' kann garantiert werden, indem die Featurevektoren normalisiert N werden. 1 i1 Projektion schwieriger zu zeigen. i Scheffer/S Sawade/Dick, Masch hinelles Lernen 2
49 Approximatives SARSA On-Policy-Methode für das Kontrollproblem ˆ ˆ ˆ t1 t t Rs ( t, at) Qs ( t 1, at 1; t) Qs ( t, at; ) t Qs ( t, at; t) T T Rs (, a ) ( s, a ) ( s, a ) t t t t t1 t1 t t t t ( s t, a t) Konvergenz kann unter vernünftigen Annahmen bewiesen werden. Allerdings gilt die Konvergenz grob gesagt nur, falls nicht zu klare Entscheidungen getroffen werden (z.b. nur bei großem Epsilon in Epsilon-Greedy)
50 TD( ) Updateregel: TD( ) Update: 0 1 interpoliert zwischen 1-step und MC. Scheffer/Sawade/Dick, Masch hinelles Le ernen 2
51 Eligibility Traces Algorithmische Sicht auf TD( ) Einführung eines zusätzlichen Speichers e(s) für jeden Zustand s2s. Nach Beobachtung <s t,a t,r t,s t+1 >, berechne Update für alle Zustände Scheffer/S Sawade/Dick, Maschinelles Le ernen 2
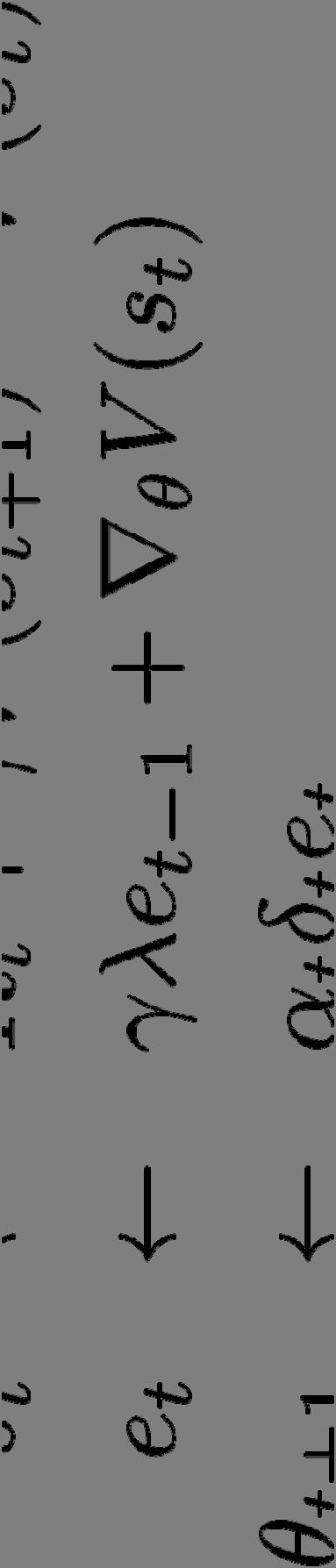





52 FA für Reinforcement Learning TD( ) Eligibility traces: Lineare Methode: Konvergenzgarantie nur für on-policy. Fehlerabschätzung:
 (On-Policy)")

53 SARSA( ) Kontrollproblem: SARSA( ) (On-Policy) Off-policy kann divergieren. Scheffer/S Sawade/Dick, Maschinelles Le ernen 2
54 Scheffer/Sawade/Dick, Maschinelles Lernen 2 SARSA( )
55 Scheffer/Sawade/Dick, Maschinelles Lernen 2 SARSA( )
56 Policy Gradient Lernen einer stochastischen Policy. Die Policy wird explizit repräsentiert, z.b. als Gibbs Verteilung Lerne, so dass minimiert wird Idee: (stochastische) Gradientenmethode
57 Policy Gradient Frage: Wie wird der Gradient berechnet? Antwort: Policy Gradient Theorem Definiere zeitlich discounted Zustandswahrscheinlichkeit Dann
58 Policy Gradient Theorem Es gilt: Policy Gradient Theorem: Sei L definiert wie oben. Dann gilt für den Gradienten D.h. der Gradient berechnet sich auf Grund der gleichen erwarteten Zustandsverteilung und der Value Function
59 Policy Gradient: Log-Trick Der Gradient kann umgeschrieben werden mit Hilfe des log-tricks Daraus folgt für den empirischen Gradienten d.h. der Gradient wird ohne Bias approximiert, wenn die Samples aus der On-Policy Verteilung stammen.
60 Policy Gradient: Baseline Um die Varianz des Gradienten klein zu halten, wird oft eine Baseline in den Gradienten eingefügt Die Baseline verändert nicht den Erwartungswert, denn da Empirischer Gradient:
61 Actor-Critic Um den Gradienten zu berechnen, brauchen wir die Value Function Q Z.B. möglich über MC Andere Möglichkeit: Approximieren der Value Function mit Hilfe z.b. einer linearen Funktion Werden der Actor (die Policy) und der Critic (die Value Function) beide gelernt, spricht man von ACtor-Critic-Methoden
62 Literatur [Auer et al. 02 ]: P.Auer, N.Cesa-Bianchi and P.Fischer: Finite time analysis of the multiarmed bandit problem. Machine Learning 47, [Kearns et al. 02]: M.J. Kearns, Y. Mansour, A.Y. Ng: A sparse sampling algorithm for near-optimal planning in large Markov decision processes. Machine Learning 49: [Kocsis & Szepesvári 06]: L. Kocsis and Cs. Szepesvári: Bandit based Monte- Carlo planning. ECML, [Rust 97]: J. Rust, 1997, Using randomization to break the curse of dimensionality, Econometrica, 65: , [Szepesvári & Munos 05]: Cs. Szepesvári and R. Munos: Finite time bounds for sampling based fitted value iteration, ICML, [Antos et. al. 07]: A. Antos, Cs. Szepesvari and R. Munos: Learning nearoptimal policies with Bellman-residual minimization based fitted policy iteration and a single sample path, Machine Learning Journal, 2007
Reinforcement Learning 2
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning 2 Uwe Dick Inhalt Erinnerung: Bellman-Gleichungen, Bellman-Operatoren Policy Iteration Sehr große oder kontinuierliche
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning 2 Uwe Dick Inhalt Erinnerung: Bellman-Gleichungen, Bellman-Operatoren Policy Iteration Sehr große oder kontinuierliche
Reinforcement Learning
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning Uwe Dick Inhalt Problemstellungen Beispiele Markov Decision Processes Planen vollständige MDPs Lernen unbekannte
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning Uwe Dick Inhalt Problemstellungen Beispiele Markov Decision Processes Planen vollständige MDPs Lernen unbekannte
Monte Carlo Methoden
 Monte Carlo Methoden Lernverfahren zur Berechnung von Wertefunktionen und Policies werden vorgestellt. Vollständige Kenntnis der Dynamik wird nicht vorausgesetzt (im Gegensatz zu den Verfahren der DP).
Monte Carlo Methoden Lernverfahren zur Berechnung von Wertefunktionen und Policies werden vorgestellt. Vollständige Kenntnis der Dynamik wird nicht vorausgesetzt (im Gegensatz zu den Verfahren der DP).
Reinforcement Learning
 Reinforcement Learning 1. Allgemein Reinforcement Learning 2. Neuronales Netz als Bewertungsfunktion 3. Neuronales Netz als Reinforcement Learning Nils-Olaf Bösch 1 Allgemein Reinforcement Learning Unterschied
Reinforcement Learning 1. Allgemein Reinforcement Learning 2. Neuronales Netz als Bewertungsfunktion 3. Neuronales Netz als Reinforcement Learning Nils-Olaf Bösch 1 Allgemein Reinforcement Learning Unterschied
RL und Funktionsapproximation
 RL und Funktionsapproximation Bisher sind haben wir die Funktionen V oder Q als Tabellen gespeichert. Im Allgemeinen sind die Zustandsräume und die Zahl der möglichen Aktionen sehr groß. Deshalb besteht
RL und Funktionsapproximation Bisher sind haben wir die Funktionen V oder Q als Tabellen gespeichert. Im Allgemeinen sind die Zustandsräume und die Zahl der möglichen Aktionen sehr groß. Deshalb besteht
Clusteranalyse: Gauß sche Mischmodelle
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse: Gauß sche Mischmodelle iels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse: Gauß sche Mischmodelle iels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Temporal Difference Learning
 Temporal Difference Learning Das Temporal Difference (TD) Lernen ist eine bedeutende Entwicklung im Reinforcement Lernen. Im TD Lernen werden Ideen der Monte Carlo (MC) und dynamische Programmierung (DP)
Temporal Difference Learning Das Temporal Difference (TD) Lernen ist eine bedeutende Entwicklung im Reinforcement Lernen. Im TD Lernen werden Ideen der Monte Carlo (MC) und dynamische Programmierung (DP)
8. Reinforcement Learning
 8. Reinforcement Learning Einführung 8. Reinforcement Learning Wie können Agenten ohne Trainingsbeispiele lernen? Auch kennt der Agent zu Beginn nicht die Auswirkungen seiner Handlungen. Stattdessen erhält
8. Reinforcement Learning Einführung 8. Reinforcement Learning Wie können Agenten ohne Trainingsbeispiele lernen? Auch kennt der Agent zu Beginn nicht die Auswirkungen seiner Handlungen. Stattdessen erhält
3. Das Reinforcement Lernproblem
 3. Das Reinforcement Lernproblem 1. Agierender Agent in der Umgebung 2. Discounted Rewards 3. Markov Eigenschaft des Zustandssignals 4. Markov sche Entscheidung 5. Werte-Funktionen und Bellman sche Optimalität
3. Das Reinforcement Lernproblem 1. Agierender Agent in der Umgebung 2. Discounted Rewards 3. Markov Eigenschaft des Zustandssignals 4. Markov sche Entscheidung 5. Werte-Funktionen und Bellman sche Optimalität
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Clusteranalyse. Tobias Scheffer Thomas Vanck
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Thomas Vanck Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Thomas Vanck Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Theorie Parameterschätzung Ausblick. Schätzung. Raimar Sandner. Studentenseminar "Statistische Methoden in der Physik"
 Studentenseminar "Statistische Methoden in der Physik" Gliederung 1 2 3 Worum geht es hier? Gliederung 1 2 3 Stichproben Gegeben eine Beobachtungsreihe x = (x 1, x 2,..., x n ): Realisierung der n-dimensionalen
Studentenseminar "Statistische Methoden in der Physik" Gliederung 1 2 3 Worum geht es hier? Gliederung 1 2 3 Stichproben Gegeben eine Beobachtungsreihe x = (x 1, x 2,..., x n ): Realisierung der n-dimensionalen
2. Beispiel: n-armiger Bandit
 2. Beispiel: n-armiger Bandit 1. Das Problem des n-armigen Banditen 2. Methoden zur Berechung von Wert-Funktionen 3. Softmax-Auswahl von Aktionen 4. Inkrementelle Schätzverfahren 5. Nichtstationärer n-armiger
2. Beispiel: n-armiger Bandit 1. Das Problem des n-armigen Banditen 2. Methoden zur Berechung von Wert-Funktionen 3. Softmax-Auswahl von Aktionen 4. Inkrementelle Schätzverfahren 5. Nichtstationärer n-armiger
V π (s) ist der Erwartungswert, der bei Start in s und Arbeit gemäß π insgesamt erreicht wird:
 ist der Erwartungswert, der bei Start in s und Arbeit gemäß π insgesamt erreicht wird:") Moderne Methoden der KI: Maschinelles Lernen Prof. Dr. sc. Hans-Dieter Burkhard Vorlesung Sommer-Semester 2007 Verstärkungs-Lernen (Reinforcement Learning) Literatur: R.S.Sutton, A.G.Barto Reinforcement
Moderne Methoden der KI: Maschinelles Lernen Prof. Dr. sc. Hans-Dieter Burkhard Vorlesung Sommer-Semester 2007 Verstärkungs-Lernen (Reinforcement Learning) Literatur: R.S.Sutton, A.G.Barto Reinforcement
BZQ II: Stochastikpraktikum
 BZQ II: Stochastikpraktikum Block 3: Lineares Modell, Klassifikation, PCA Randolf Altmeyer January 9, 2017 Überblick 1 Monte-Carlo-Methoden, Zufallszahlen, statistische Tests 2 Nichtparametrische Methoden
BZQ II: Stochastikpraktikum Block 3: Lineares Modell, Klassifikation, PCA Randolf Altmeyer January 9, 2017 Überblick 1 Monte-Carlo-Methoden, Zufallszahlen, statistische Tests 2 Nichtparametrische Methoden
Der Metropolis-Hastings Algorithmus
 Der Algorithmus Michael Höhle Department of Statistics University of Munich Numerical Methods for Bayesian Inference WiSe2006/07 Course 30 October 2006 Markov-Chain Monte-Carlo Verfahren Übersicht 1 Einführung
Der Algorithmus Michael Höhle Department of Statistics University of Munich Numerical Methods for Bayesian Inference WiSe2006/07 Course 30 October 2006 Markov-Chain Monte-Carlo Verfahren Übersicht 1 Einführung
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Zusammenfassung. Niels Landwehr, Uwe Dick, Matthias Bussas
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Zusammenfassung Niels Landwehr, Uwe Dick, Matthias Bussas Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Zusammenfassung Niels Landwehr, Uwe Dick, Matthias Bussas Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen
Newton-Verfahren zur gleichungsbeschränkten Optimierung. 1 Gleichungsbeschränkte Optimierungsprobleme
 Newton-Verfahren zur gleichungsbeschränkten Optimierung Armin Farmani Anosheh (afarmani@mail.uni-mannheim.de) 3.Mai 2016 1 Gleichungsbeschränkte Optimierungsprobleme Einleitung In diesem Vortrag geht es
Newton-Verfahren zur gleichungsbeschränkten Optimierung Armin Farmani Anosheh (afarmani@mail.uni-mannheim.de) 3.Mai 2016 1 Gleichungsbeschränkte Optimierungsprobleme Einleitung In diesem Vortrag geht es
Parameterschätzung. Kapitel 14. Modell Es sei {P θ θ Θ}, Θ R m eine Familie von Verteilungen auf χ (sog. Stichprobenraum),
,") Kapitel 14 Parameterschätzung Modell Es sei {P θ θ Θ}, Θ R m eine Familie von Verteilungen auf χ (sog. Stichprobenraum), = ( 1,..., n ) sei eine Realisierung der Zufallsstichprobe X = (X 1,..., X n ) zu
Kapitel 14 Parameterschätzung Modell Es sei {P θ θ Θ}, Θ R m eine Familie von Verteilungen auf χ (sog. Stichprobenraum), = ( 1,..., n ) sei eine Realisierung der Zufallsstichprobe X = (X 1,..., X n ) zu
Lineare Regression. Volker Tresp
 Lineare Regression Volker Tresp 1 Die Lernmaschine: Das lineare Modell / ADALINE Wie beim Perzeptron wird zunächst die Aktivierungsfunktion gewichtete Summe der Eingangsgrößen x i berechnet zu h i = M
Lineare Regression Volker Tresp 1 Die Lernmaschine: Das lineare Modell / ADALINE Wie beim Perzeptron wird zunächst die Aktivierungsfunktion gewichtete Summe der Eingangsgrößen x i berechnet zu h i = M
Gibbs sampling. Sebastian Pado. October 30, Seien X die Trainingdaten, y ein Testdatenpunkt, π die Parameter des Modells
 Gibbs sampling Sebastian Pado October 30, 2012 1 Bayessche Vorhersage Seien X die Trainingdaten, y ein Testdatenpunkt, π die Parameter des Modells Uns interessiert P (y X), wobei wir über das Modell marginalisieren
Gibbs sampling Sebastian Pado October 30, 2012 1 Bayessche Vorhersage Seien X die Trainingdaten, y ein Testdatenpunkt, π die Parameter des Modells Uns interessiert P (y X), wobei wir über das Modell marginalisieren
Das Trust-Region-Verfahren
 Das Trust-Region-Verfahren Nadine Erath 13. Mai 2013... ist eine Methode der Nichtlinearen Optimierung Ziel ist es, das Minimum der Funktion f : R n R zu bestimmen. 1 Prinzip 1. Ersetzen f(x) durch ein
Das Trust-Region-Verfahren Nadine Erath 13. Mai 2013... ist eine Methode der Nichtlinearen Optimierung Ziel ist es, das Minimum der Funktion f : R n R zu bestimmen. 1 Prinzip 1. Ersetzen f(x) durch ein
Übersicht. Künstliche Intelligenz: 21. Verstärkungslernen Frank Puppe 1
 Übersicht I Künstliche Intelligenz II Problemlösen III Wissen und Schlussfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen VI Lernen 18. Lernen aus Beobachtungen 19. Wissen beim Lernen 20. Statistische
Übersicht I Künstliche Intelligenz II Problemlösen III Wissen und Schlussfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen VI Lernen 18. Lernen aus Beobachtungen 19. Wissen beim Lernen 20. Statistische
Grundgesamtheit und Stichprobe
 Grundgesamtheit und Stichprobe Definition 1 Die Menge der Untersuchungseinheiten {U 1,U 2,...,U N } heißt Grundgesamtheit. Die Anzahl N der Einheiten ist der Umfang der Grundgesamtheit. Jeder Einheit U
Grundgesamtheit und Stichprobe Definition 1 Die Menge der Untersuchungseinheiten {U 1,U 2,...,U N } heißt Grundgesamtheit. Die Anzahl N der Einheiten ist der Umfang der Grundgesamtheit. Jeder Einheit U
Dynamische Systeme und Zeitreihenanalyse // Multivariate Normalverteilung und ML Schätzung 11 p.2/38
 Dynamische Systeme und Zeitreihenanalyse Multivariate Normalverteilung und ML Schätzung Kapitel 11 Statistik und Mathematik WU Wien Michael Hauser Dynamische Systeme und Zeitreihenanalyse // Multivariate
Dynamische Systeme und Zeitreihenanalyse Multivariate Normalverteilung und ML Schätzung Kapitel 11 Statistik und Mathematik WU Wien Michael Hauser Dynamische Systeme und Zeitreihenanalyse // Multivariate
Lineare Regression. Christian Herta. Oktober, Problemstellung Kostenfunktion Gradientenabstiegsverfahren
 Lineare Regression Christian Herta Oktober, 2013 1 von 33 Christian Herta Lineare Regression Lernziele Lineare Regression Konzepte des Maschinellen Lernens: Lernen mittels Trainingsmenge Kostenfunktion
Lineare Regression Christian Herta Oktober, 2013 1 von 33 Christian Herta Lineare Regression Lernziele Lineare Regression Konzepte des Maschinellen Lernens: Lernen mittels Trainingsmenge Kostenfunktion
Schwache Konvergenz. Ivan Lecei. 18. Juni Institut für Stochastik
 Institut für Stochastik 18. Juni 2013 Inhalt 1 2 3 4 5 Nach ZGWS konvergiert für n F n (x) = P{ X 1+...+X n np npq x} gegen F(x) = 1 2π x e 1 2 u2 du, wenn die X i unabhängig und bernoulliverteilt sind
Institut für Stochastik 18. Juni 2013 Inhalt 1 2 3 4 5 Nach ZGWS konvergiert für n F n (x) = P{ X 1+...+X n np npq x} gegen F(x) = 1 2π x e 1 2 u2 du, wenn die X i unabhängig und bernoulliverteilt sind
Theoretische Informatik 1
 Theoretische Informatik 1 Teil 12 Bernhard Nessler Institut für Grundlagen der Informationsverabeitung TU Graz SS 2007 Übersicht 1 Maschinelles Lernen Definition Lernen 2 agnostic -learning Definition
Theoretische Informatik 1 Teil 12 Bernhard Nessler Institut für Grundlagen der Informationsverabeitung TU Graz SS 2007 Übersicht 1 Maschinelles Lernen Definition Lernen 2 agnostic -learning Definition
4 Statistik der Extremwertverteilungen
 In diesem Kapitel beschäftigen wir uns mit statistischen Anwendungen der Extremwerttheorie. Wir werden zwei verschiedene Zugänge zur Modellierung von Extremwerten betrachten. Der erste Zugang basiert auf
In diesem Kapitel beschäftigen wir uns mit statistischen Anwendungen der Extremwerttheorie. Wir werden zwei verschiedene Zugänge zur Modellierung von Extremwerten betrachten. Der erste Zugang basiert auf
Grundgesamtheit und Stichprobe
 Grundgesamtheit und Stichprobe Definition 1 Die Menge der Untersuchungseinheiten {U 1,U 2,...,U N } heißt Grundgesamtheit. Die Anzahl N der Einheiten ist der Umfang der Grundgesamtheit. Jeder Einheit U
Grundgesamtheit und Stichprobe Definition 1 Die Menge der Untersuchungseinheiten {U 1,U 2,...,U N } heißt Grundgesamtheit. Die Anzahl N der Einheiten ist der Umfang der Grundgesamtheit. Jeder Einheit U
Einsatz von Reinforcement Learning in der Modellfahrzeugnavigation
 Einsatz von Reinforcement Learning in der Modellfahrzeugnavigation von Manuel Trittel Informatik HAW Hamburg Vortrag im Rahmen der Veranstaltung AW1 im Masterstudiengang, 02.12.2008 der Anwendung Themeneinordnung
Einsatz von Reinforcement Learning in der Modellfahrzeugnavigation von Manuel Trittel Informatik HAW Hamburg Vortrag im Rahmen der Veranstaltung AW1 im Masterstudiengang, 02.12.2008 der Anwendung Themeneinordnung
Einfache lineare Modelle mit Statistik-Software R Beispiel (Ausgaben in Abhängigkeit vom Einkommen)
") 3 Einfache lineare Regression Einfache lineare Modelle mit R 36 Einfache lineare Modelle mit Statistik-Software R Beispiel (Ausgaben in Abhängigkeit vom Einkommen) > summary(lm(y~x)) Call: lm(formula =
3 Einfache lineare Regression Einfache lineare Modelle mit R 36 Einfache lineare Modelle mit Statistik-Software R Beispiel (Ausgaben in Abhängigkeit vom Einkommen) > summary(lm(y~x)) Call: lm(formula =
Optimierung. Optimierung. Vorlesung 2 Optimierung ohne Nebenbedingungen Gradientenverfahren. 2013 Thomas Brox, Fabian Kuhn
 Optimierung Vorlesung 2 Optimierung ohne Nebenbedingungen Gradientenverfahren 1 Minimierung ohne Nebenbedingung Ein Optimierungsproblem besteht aus einer zulässigen Menge und einer Zielfunktion Minimum
Optimierung Vorlesung 2 Optimierung ohne Nebenbedingungen Gradientenverfahren 1 Minimierung ohne Nebenbedingung Ein Optimierungsproblem besteht aus einer zulässigen Menge und einer Zielfunktion Minimum
DWT 2.3 Ankunftswahrscheinlichkeiten und Übergangszeiten 400/467 Ernst W. Mayr
 2. Ankunftswahrscheinlichkeiten und Übergangszeiten Bei der Analyse von Markov-Ketten treten oftmals Fragestellungen auf, die sich auf zwei bestimmte Zustände i und j beziehen: Wie wahrscheinlich ist es,
2. Ankunftswahrscheinlichkeiten und Übergangszeiten Bei der Analyse von Markov-Ketten treten oftmals Fragestellungen auf, die sich auf zwei bestimmte Zustände i und j beziehen: Wie wahrscheinlich ist es,
Endliche Markov-Ketten - eine Übersicht
 Endliche Markov-Ketten - eine Übersicht Diese Übersicht über endliche Markov-Ketten basiert auf dem Buch Monte Carlo- Algorithmen von Müller-Gronbach et. al. und dient als Sammlung von Definitionen und
Endliche Markov-Ketten - eine Übersicht Diese Übersicht über endliche Markov-Ketten basiert auf dem Buch Monte Carlo- Algorithmen von Müller-Gronbach et. al. und dient als Sammlung von Definitionen und
Übung V Lineares Regressionsmodell
 Universität Ulm 89069 Ulm Germany Dipl.-WiWi Michael Alpert Institut für Wirtschaftspolitik Fakultät für Mathematik und Wirtschaftswissenschaften Ludwig-Erhard-Stiftungsprofessur Sommersemester 2007 Übung
Universität Ulm 89069 Ulm Germany Dipl.-WiWi Michael Alpert Institut für Wirtschaftspolitik Fakultät für Mathematik und Wirtschaftswissenschaften Ludwig-Erhard-Stiftungsprofessur Sommersemester 2007 Übung
Die Datenmatrix für Überwachtes Lernen
 Die Datenmatrix für Überwachtes Lernen X j j-te Eingangsvariable X = (X 0,..., X M 1 ) T Vektor von Eingangsvariablen M Anzahl der Eingangsvariablen N Anzahl der Datenpunkte Y Ausgangsvariable x i = (x
Die Datenmatrix für Überwachtes Lernen X j j-te Eingangsvariable X = (X 0,..., X M 1 ) T Vektor von Eingangsvariablen M Anzahl der Eingangsvariablen N Anzahl der Datenpunkte Y Ausgangsvariable x i = (x
Stochastik Praktikum Markov Chain Monte Carlo Methoden
 Stochastik Praktikum Markov Chain Monte Carlo Methoden Humboldt-Universität zu Berlin 14.10.2010 Problemstellung Wie kann eine Zufallsstichprobe am Computer simuliert werden, deren Verteilung aus einem
Stochastik Praktikum Markov Chain Monte Carlo Methoden Humboldt-Universität zu Berlin 14.10.2010 Problemstellung Wie kann eine Zufallsstichprobe am Computer simuliert werden, deren Verteilung aus einem
Reinforcement Learning
 Effiziente Darstellung von Daten Reinforcement Learning 02. Juli 2004 Jan Schlößin Einordnung Was ist Reinforcement Learning? Einführung - Prinzip der Agent Eigenschaften das Ziel Q-Learning warum Q-Learning
Effiziente Darstellung von Daten Reinforcement Learning 02. Juli 2004 Jan Schlößin Einordnung Was ist Reinforcement Learning? Einführung - Prinzip der Agent Eigenschaften das Ziel Q-Learning warum Q-Learning
Statistik II. Regressionsanalyse. Statistik II
 Statistik II Regressionsanalyse Statistik II - 23.06.2006 1 Einfachregression Annahmen an die Störterme : 1. sind unabhängige Realisationen der Zufallsvariable, d.h. i.i.d. (unabh.-identisch verteilt)
Statistik II Regressionsanalyse Statistik II - 23.06.2006 1 Einfachregression Annahmen an die Störterme : 1. sind unabhängige Realisationen der Zufallsvariable, d.h. i.i.d. (unabh.-identisch verteilt)
Konvergenz im quadratischen Mittel und die Parsevelsche Gleichung
 Konvergenz im quadratischen Mittel und die Parsevelsche Gleichung Skript zum Vortrag im Proseminar Analysis bei Dr. Gerhard Mülich Christian Maaß 6.Mai 8 Im letzten Vortrag haben wir gesehen, dass das
Konvergenz im quadratischen Mittel und die Parsevelsche Gleichung Skript zum Vortrag im Proseminar Analysis bei Dr. Gerhard Mülich Christian Maaß 6.Mai 8 Im letzten Vortrag haben wir gesehen, dass das
Latente Dirichlet-Allokation
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Latente Dirichlet-Allokation Tobias Scheffer Peter Haider Paul Prasse Themenmodellierung Themenmodellierung (Topic modeling) liefert
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Latente Dirichlet-Allokation Tobias Scheffer Peter Haider Paul Prasse Themenmodellierung Themenmodellierung (Topic modeling) liefert
Algorithmische Methoden zur Netzwerkanalyse
 Algorithmische Methoden zur Netzwerkanalyse Prof. Dr. Henning Meyerhenke Institut für Theoretische Informatik 1 KIT Henning Die Forschungsuniversität Meyerhenke, in der Institut für Theoretische Informatik
Algorithmische Methoden zur Netzwerkanalyse Prof. Dr. Henning Meyerhenke Institut für Theoretische Informatik 1 KIT Henning Die Forschungsuniversität Meyerhenke, in der Institut für Theoretische Informatik
Nichtlineare Gleichungssysteme
 Nichtlineare Gleichungssysteme Jetzt: Numerische Behandlung nichtlinearer GS f 1 (x 1,..., x n ) =0. f n (x 1,..., x n ) =0 oder kurz f(x) = 0 mit f : R n R n Bemerkung: Neben dem direkten Entstehen bei
Nichtlineare Gleichungssysteme Jetzt: Numerische Behandlung nichtlinearer GS f 1 (x 1,..., x n ) =0. f n (x 1,..., x n ) =0 oder kurz f(x) = 0 mit f : R n R n Bemerkung: Neben dem direkten Entstehen bei
Statistik für Punktprozesse. Seminar Stochastische Geometrie und ihre Anwendungen WS 2009/2010
 Statistik für Punktprozesse Seminar Stochastische Geometrie und ihre Anwendungen WS 009/00 Inhalt I. Fragestellung / Problematik II. Ansätze für a) die Schätzung der Intensität b) ein Testverfahren auf
Statistik für Punktprozesse Seminar Stochastische Geometrie und ihre Anwendungen WS 009/00 Inhalt I. Fragestellung / Problematik II. Ansätze für a) die Schätzung der Intensität b) ein Testverfahren auf
Resampling. in»statistische Methoden in der Physik« Referent: Alex Ortner. Studenten-Seminar Sommersemester 2007
 Resampling in»statistische Methoden in der Physik«Referent: Studenten-Seminar Sommersemester 2007 Gliederung 1 Resampling Prinzip Einleitung Resampling Methoden 2 3 4 Einleitung intuitv Resampling Prinzip
Resampling in»statistische Methoden in der Physik«Referent: Studenten-Seminar Sommersemester 2007 Gliederung 1 Resampling Prinzip Einleitung Resampling Methoden 2 3 4 Einleitung intuitv Resampling Prinzip
2. Stochastische ökonometrische Modelle. - Modelle der ökonomischen Theorie an der Wirklichkeit überprüfen
 .1. Stochastische ökonometrische Modelle.1 Einführung Ziele: - Modelle der ökonomischen Theorie an der Wirklichkeit überprüfen - Numerische Konkretisierung ökonomischer Modelle und deren Analse. . Variierende
.1. Stochastische ökonometrische Modelle.1 Einführung Ziele: - Modelle der ökonomischen Theorie an der Wirklichkeit überprüfen - Numerische Konkretisierung ökonomischer Modelle und deren Analse. . Variierende
Teil VIII. Zentraler Grenzwertsatz und Vertrauensintervalle. Woche 6: Zentraler Grenzwertsatz und Vertrauensintervalle. Lernziele. Typische Situation
 Woche 6: Zentraler Grenzwertsatz und Vertrauensintervalle Patric Müller ETHZ Teil VIII Zentraler Grenzwertsatz und Vertrauensintervalle WBL 17/19, 29.05.2017 Wahrscheinlichkeit
Woche 6: Zentraler Grenzwertsatz und Vertrauensintervalle Patric Müller ETHZ Teil VIII Zentraler Grenzwertsatz und Vertrauensintervalle WBL 17/19, 29.05.2017 Wahrscheinlichkeit
Exponentialabbildung für Matrizen und Systeme von Differentialgleichungen
 Proseminar Lineare Algebra SS10 Exponentialabbildung für Matrizen und Systeme von Differentialgleichungen Simon Strahlegger Heinrich-Heine-Universität Betreuung: Prof. Dr. Oleg Bogopolski Inhaltsverzeichnis:
Proseminar Lineare Algebra SS10 Exponentialabbildung für Matrizen und Systeme von Differentialgleichungen Simon Strahlegger Heinrich-Heine-Universität Betreuung: Prof. Dr. Oleg Bogopolski Inhaltsverzeichnis:
Die Maximum-Likelihood-Methode
 Vorlesung: Computergestützte Datenauswertung Die Maximum-Likelihood-Methode Günter Quast Fakultät für Physik Institut für Experimentelle Kernphysik SS '17 KIT Die Forschungsuniversität in der Helmholtz-Gemeinschaft
Vorlesung: Computergestützte Datenauswertung Die Maximum-Likelihood-Methode Günter Quast Fakultät für Physik Institut für Experimentelle Kernphysik SS '17 KIT Die Forschungsuniversität in der Helmholtz-Gemeinschaft
Monte Carlo Methoden
 Monte Carlo Methoden im Verstärkungslernen [Spink] Bryan Spink 2003 Ketill Gunnarsson [ ketill@inf.fu-berlin.de ], Seminar zum Verstärkungslernen, Freie Universität Berlin [ www.inf.fu-berlin.de ] Einleitung
Monte Carlo Methoden im Verstärkungslernen [Spink] Bryan Spink 2003 Ketill Gunnarsson [ ketill@inf.fu-berlin.de ], Seminar zum Verstärkungslernen, Freie Universität Berlin [ www.inf.fu-berlin.de ] Einleitung
Methoden zur Cluster - Analyse
 Kapitel 4 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität Leipzig Machine learning in bioinformatics
Kapitel 4 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität Leipzig Machine learning in bioinformatics
Das (multiple) Bestimmtheitsmaß R 2. Beispiel: Ausgaben in Abhängigkeit vom Einkommen (I) Parameterschätzer im einfachen linearen Regressionsmodell
 Bestimmtheitsmaß R 2. Beispiel: Ausgaben in Abhängigkeit vom Einkommen (I) Parameterschätzer im einfachen linearen Regressionsmodell") 1 Lineare Regression Parameterschätzung 13 Im einfachen linearen Regressionsmodell sind also neben σ ) insbesondere β 1 und β Parameter, deren Schätzung für die Quantifizierung des linearen Zusammenhangs
1 Lineare Regression Parameterschätzung 13 Im einfachen linearen Regressionsmodell sind also neben σ ) insbesondere β 1 und β Parameter, deren Schätzung für die Quantifizierung des linearen Zusammenhangs
Reinforcement Learning
 Reinforcement Learning Friedhelm Schwenker Institut für Neuroinformatik Vorlesung/Übung: (V) Di 14-16 Uhr, (Ü) Do 12.30-14.00 jeweils im Raum O27/121 Übungsaufgaben sind schriftlich zu bearbeiten (Schein
Reinforcement Learning Friedhelm Schwenker Institut für Neuroinformatik Vorlesung/Übung: (V) Di 14-16 Uhr, (Ü) Do 12.30-14.00 jeweils im Raum O27/121 Übungsaufgaben sind schriftlich zu bearbeiten (Schein
1 Beispiel zur Methode der kleinsten Quadrate
 1 Beispiel zur Methode der kleinsten Quadrate 1.1 Daten des Beispiels t x y x*y x 2 ŷ ˆɛ ˆɛ 2 1 1 3 3 1 2 1 1 2 2 3 6 4 3.5-0.5 0.25 3 3 4 12 9 5-1 1 4 4 6 24 16 6.5-0.5 0.25 5 5 9 45 25 8 1 1 Σ 15 25
1 Beispiel zur Methode der kleinsten Quadrate 1.1 Daten des Beispiels t x y x*y x 2 ŷ ˆɛ ˆɛ 2 1 1 3 3 1 2 1 1 2 2 3 6 4 3.5-0.5 0.25 3 3 4 12 9 5-1 1 4 4 6 24 16 6.5-0.5 0.25 5 5 9 45 25 8 1 1 Σ 15 25
Einführung in die Maximum Likelihood Methodik
 in die Maximum Likelihood Methodik Thushyanthan Baskaran thushyanthan.baskaran@awi.uni-heidelberg.de Alfred Weber Institut Ruprecht Karls Universität Heidelberg Gliederung 1 2 3 4 2 / 31 Maximum Likelihood
in die Maximum Likelihood Methodik Thushyanthan Baskaran thushyanthan.baskaran@awi.uni-heidelberg.de Alfred Weber Institut Ruprecht Karls Universität Heidelberg Gliederung 1 2 3 4 2 / 31 Maximum Likelihood
3.4 Asymptotische Evaluierung von Sch atzer Konsistenz Konsistenz Definition 3.4.1: konsistente Folge von Sch atzer
 3.4 Asymptotische Evaluierung von Schätzer 3.4.1 Konsistenz Bis jetzt haben wir Kriterien basierend auf endlichen Stichproben betrachtet. Konsistenz ist ein asymptotisches Kriterium (n ) und bezieht sich
3.4 Asymptotische Evaluierung von Schätzer 3.4.1 Konsistenz Bis jetzt haben wir Kriterien basierend auf endlichen Stichproben betrachtet. Konsistenz ist ein asymptotisches Kriterium (n ) und bezieht sich
Brownsche Bewegung. M. Gruber SS 2016, KW 11. Zusammenfassung
 Brownsche Bewegung M. Gruber SS 2016, KW 11 Zusammenfassung Stochastische Prozesse, Pfade; Definition der Brownschen Bewegung; Eigenschaften der Brownschen Bewegung: Kovarianz, Stationarität, Selbstähnlichkeit;
Brownsche Bewegung M. Gruber SS 2016, KW 11 Zusammenfassung Stochastische Prozesse, Pfade; Definition der Brownschen Bewegung; Eigenschaften der Brownschen Bewegung: Kovarianz, Stationarität, Selbstähnlichkeit;
Übersicht. 20. Verstärkungslernen
 Übersicht I Künstliche Intelligenz II Problemlösen III Wissen und Schlußfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen VI Lernen 18. Lernen aus Beobachtungen 19. Lernen in neuronalen & Bayes
Übersicht I Künstliche Intelligenz II Problemlösen III Wissen und Schlußfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen VI Lernen 18. Lernen aus Beobachtungen 19. Lernen in neuronalen & Bayes
Optimierung für Nichtmathematiker
 Optimierung für Nichtmathematiker Prof. Dr. R. Herzog WS/ / Inhaltsübersicht 3Einführung in die freie Optimierung 4Orakel und Modellfunktionen 5Optimalitätsbedingungen der freien Optimierung 6Das Newton-Verfahren
Optimierung für Nichtmathematiker Prof. Dr. R. Herzog WS/ / Inhaltsübersicht 3Einführung in die freie Optimierung 4Orakel und Modellfunktionen 5Optimalitätsbedingungen der freien Optimierung 6Das Newton-Verfahren
Nichtlineare Gleichungen
 Nichtlineare Gleichungen Ein wichtiges Problem in der Praxis ist die Bestimmung einer Lösung ξ der Gleichung f(x) =, () d.h. das Aufsuchen einer Nullstelle ξ einer (nicht notwendig linearen) Funktion f.
Nichtlineare Gleichungen Ein wichtiges Problem in der Praxis ist die Bestimmung einer Lösung ξ der Gleichung f(x) =, () d.h. das Aufsuchen einer Nullstelle ξ einer (nicht notwendig linearen) Funktion f.
Theoretische Informatik 1
 Theoretische Informatik 1 Boltzmann Maschine David Kappel Institut für Grundlagen der Informationsverarbeitung TU Graz SS 2014 Übersicht Boltzmann Maschine Neuronale Netzwerke Die Boltzmann Maschine Gibbs
Theoretische Informatik 1 Boltzmann Maschine David Kappel Institut für Grundlagen der Informationsverarbeitung TU Graz SS 2014 Übersicht Boltzmann Maschine Neuronale Netzwerke Die Boltzmann Maschine Gibbs
7. Stochastische Prozesse und Zeitreihenmodelle
 7. Stochastische Prozesse und Zeitreihenmodelle Regelmäßigkeiten in der Entwicklung einer Zeitreihe, um auf zukünftige Entwicklung zu schließen Verwendung zu Prognosezwecken Univariate Zeitreihenanalyse
7. Stochastische Prozesse und Zeitreihenmodelle Regelmäßigkeiten in der Entwicklung einer Zeitreihe, um auf zukünftige Entwicklung zu schließen Verwendung zu Prognosezwecken Univariate Zeitreihenanalyse
Finite Elemente. Dr. S.-J. Kimmerle Institut für Mathematik und Rechneranwendung Fakultät für Luft- und Raumfahrttechnik Wintertrimester 2015
 Dr. S.-J. Kimmerle Institut für Mathematik und Rechneranwendung Fakultät für Luft- und Raumfahrttechnik Wintertrimester 5 Aufgabe 8 (Speichertechniken) Finite Elemente Übung 5 a) Stellen Sie die Matrix
Dr. S.-J. Kimmerle Institut für Mathematik und Rechneranwendung Fakultät für Luft- und Raumfahrttechnik Wintertrimester 5 Aufgabe 8 (Speichertechniken) Finite Elemente Übung 5 a) Stellen Sie die Matrix
Vorlesung 3: Schätzverfahren
 Vorlesung 3: Schätzverfahren 1. Beispiel: General Social Survey 1978 2. Auswahl einer Zufallsstichprobe und Illustration des Stichprobenfehlers 3. Stichprobenverteilung eines Regressionskoeffizienten 4.
Vorlesung 3: Schätzverfahren 1. Beispiel: General Social Survey 1978 2. Auswahl einer Zufallsstichprobe und Illustration des Stichprobenfehlers 3. Stichprobenverteilung eines Regressionskoeffizienten 4.
Statistik II SoSe 2006 immer von 8:00-9:30 Uhr
 Statistik II SoSe 2006 immer von 8:00-9:30 Uhr Was machen wir in der Vorlesung? Testen und Lineares Modell Was machen wir zu Beginn: Wir wiederholen und vertiefen einige Teile aus der Statistik I: Konvergenzarten
Statistik II SoSe 2006 immer von 8:00-9:30 Uhr Was machen wir in der Vorlesung? Testen und Lineares Modell Was machen wir zu Beginn: Wir wiederholen und vertiefen einige Teile aus der Statistik I: Konvergenzarten
Kurs Empirische Wirtschaftsforschung
 Kurs Empirische Wirtschaftsforschung 5. Bivariates Regressionsmodell 1 Martin Halla Institut für Volkswirtschaftslehre Johannes Kepler Universität Linz 1 Lehrbuch: Bauer/Fertig/Schmidt (2009), Empirische
Kurs Empirische Wirtschaftsforschung 5. Bivariates Regressionsmodell 1 Martin Halla Institut für Volkswirtschaftslehre Johannes Kepler Universität Linz 1 Lehrbuch: Bauer/Fertig/Schmidt (2009), Empirische
Bootstrap-Methoden zur Ermittlung kritischer Werte für asymptotische FWER-Kontrolle
 Bootstrap-Methoden zur Ermittlung kritischer Werte für asymptotische FWER-Kontrolle [Dudoit, van der Laan, Pollard: Multiple Testing. Part I Single-Step Procedures for Control of General Type-I-Error Rates]
Bootstrap-Methoden zur Ermittlung kritischer Werte für asymptotische FWER-Kontrolle [Dudoit, van der Laan, Pollard: Multiple Testing. Part I Single-Step Procedures for Control of General Type-I-Error Rates]
Einführung in Quasi-Monte Carlo Verfahren
 Einführung in Quasi- Markus Zahrnhofer 3. Mai 2007 Markus Zahrnhofer () Einführung in Quasi- 3. Mai 2007 1 / 27 Inhalt der Präsentation 1 Motivierendes Beispiel 2 Einführung 3 quasi- Allgemeines Diskrepanz
Einführung in Quasi- Markus Zahrnhofer 3. Mai 2007 Markus Zahrnhofer () Einführung in Quasi- 3. Mai 2007 1 / 27 Inhalt der Präsentation 1 Motivierendes Beispiel 2 Einführung 3 quasi- Allgemeines Diskrepanz
Sparse Hauptkomponentenanalyse
 Sparse Referent: Thomas Klein-Heßling LMU München 20. Januar 2017 1 / 36 1 Einführung 2 3 4 5 2 / 36 Einführung Ziel: vorhandene Datenmenge verstehen Daten komprimieren Bei der Sparse (SPCA) handelt es
Sparse Referent: Thomas Klein-Heßling LMU München 20. Januar 2017 1 / 36 1 Einführung 2 3 4 5 2 / 36 Einführung Ziel: vorhandene Datenmenge verstehen Daten komprimieren Bei der Sparse (SPCA) handelt es
KAPITEL 1. Einleitung
 KAPITEL 1 Einleitung Wir beschäftigen uns in dieser Vorlesung mit Verfahren aus der Numerischen linearen Algebra und insbesondere dem sogenannten Mehrgitterverfahren zur Lösung linearer Gleichungssysteme
KAPITEL 1 Einleitung Wir beschäftigen uns in dieser Vorlesung mit Verfahren aus der Numerischen linearen Algebra und insbesondere dem sogenannten Mehrgitterverfahren zur Lösung linearer Gleichungssysteme
Pr[X t+1 = k] = Pr[X t+1 = k X t = i] Pr[X t = i], also. (q t+1 ) k = p ik (q t ) i, bzw. in Matrixschreibweise. q t+1 = q t P.
![Pr[X t+1 = k] = Pr[X t+1 = k X t = i] Pr[X t = i], also. (q t+1 ) k = p ik (q t ) i, bzw. in Matrixschreibweise. q t+1 = q t P.](/thumbs/64/51976840.jpg "Pr[X t+1 = k] = Pr[X t+1 = k X t = i] Pr[X t = i], also. (q t+1 ) k = p ik (q t ) i, bzw. in Matrixschreibweise. q t+1 = q t P.") 2.2 Berechnung von Übergangswahrscheinlichkeiten Wir beschreiben die Situation zum Zeitpunkt t durch einen Zustandsvektor q t (den wir als Zeilenvektor schreiben). Die i-te Komponente (q t ) i bezeichnet
2.2 Berechnung von Übergangswahrscheinlichkeiten Wir beschreiben die Situation zum Zeitpunkt t durch einen Zustandsvektor q t (den wir als Zeilenvektor schreiben). Die i-te Komponente (q t ) i bezeichnet
Brownsche Bewegung. M. Gruber. 20. März 2015, Rev.1. Zusammenfassung
 Brownsche Bewegung M. Gruber 20. März 2015, Rev.1 Zusammenfassung Stochastische Prozesse, Pfade; Definition der Brownschen Bewegung; Eigenschaften der Brownschen Bewegung: Kovarianz, Stationarität, Selbstähnlichkeit;
Brownsche Bewegung M. Gruber 20. März 2015, Rev.1 Zusammenfassung Stochastische Prozesse, Pfade; Definition der Brownschen Bewegung; Eigenschaften der Brownschen Bewegung: Kovarianz, Stationarität, Selbstähnlichkeit;
5 Interpolation und Approximation
 5 Interpolation und Approximation Problemstellung: Es soll eine Funktion f(x) approximiert werden, von der die Funktionswerte nur an diskreten Stellen bekannt sind. 5. Das Interpolationspolynom y y = P(x)
5 Interpolation und Approximation Problemstellung: Es soll eine Funktion f(x) approximiert werden, von der die Funktionswerte nur an diskreten Stellen bekannt sind. 5. Das Interpolationspolynom y y = P(x)
Spieltheorie: UCT. Stefan Edelkamp
 Spieltheorie: UCT Stefan Edelkamp Monte Carlo Simulation Alternative zu Minimax-Algorithmen mit Alpha-Beta Pruning: zufällige Spielabläufe (Simulationen) laufen und ermessen den Wert eines Spieles. Erfolgreich
Spieltheorie: UCT Stefan Edelkamp Monte Carlo Simulation Alternative zu Minimax-Algorithmen mit Alpha-Beta Pruning: zufällige Spielabläufe (Simulationen) laufen und ermessen den Wert eines Spieles. Erfolgreich
Theoretische Grundlagen der Informatik
 Theoretische Grundlagen der Informatik Vorlesung am 7. Dezember 2017 INSTITUT FÜR THEORETISCHE 0 07.12.2017 Dorothea Wagner - Theoretische Grundlagen der Informatik INSTITUT FÜR THEORETISCHE KIT Die Forschungsuniversität
Theoretische Grundlagen der Informatik Vorlesung am 7. Dezember 2017 INSTITUT FÜR THEORETISCHE 0 07.12.2017 Dorothea Wagner - Theoretische Grundlagen der Informatik INSTITUT FÜR THEORETISCHE KIT Die Forschungsuniversität
x, y 2 f(x)g(x) dµ(x). Es ist leicht nachzuprüfen, dass die x 2 setzen. Dann liefert (5.1) n=1 x ny n bzw. f, g = Ω
g(x) dµ(x). Es ist leicht nachzuprüfen, dass die x 2 setzen. Dann liefert (5.1) n=1 x ny n bzw. f, g = Ω") 5. Hilberträume Definition 5.1. Sei H ein komplexer Vektorraum. Eine Abbildung, : H H C heißt Skalarprodukt (oder inneres Produkt) auf H, wenn für alle x, y, z H, α C 1) x, x 0 und x, x = 0 x = 0; ) x,
5. Hilberträume Definition 5.1. Sei H ein komplexer Vektorraum. Eine Abbildung, : H H C heißt Skalarprodukt (oder inneres Produkt) auf H, wenn für alle x, y, z H, α C 1) x, x 0 und x, x = 0 x = 0; ) x,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Clusteranalyse. Christoph Sawade/Niels Landwehr/Tobias Scheffer
 Universität Potsdam Institut für Informati Lehrstuhl Maschinelles Lernen Clusteranalyse Christoph Sawade/iels Landwehr/Tobias Scheffer Überblic Problemstellung/Motivation Deterministischer Ansatz: K-Means
Universität Potsdam Institut für Informati Lehrstuhl Maschinelles Lernen Clusteranalyse Christoph Sawade/iels Landwehr/Tobias Scheffer Überblic Problemstellung/Motivation Deterministischer Ansatz: K-Means
Konvexe Optimierungsprobleme
 von: Veronika Kühl 1 Konvexe Optimierungsprobleme Betrachtet werden Probleme der Form (P) min x C f(x) wobei f : C R eine auf C konvexe, aber nicht notwendigerweise differenzierbare Funktion ist. Ziel
von: Veronika Kühl 1 Konvexe Optimierungsprobleme Betrachtet werden Probleme der Form (P) min x C f(x) wobei f : C R eine auf C konvexe, aber nicht notwendigerweise differenzierbare Funktion ist. Ziel
Statistik. R. Frühwirth. Statistik. VO Februar R. Frühwirth Statistik 1/536
 fru@hephy.oeaw.ac.at VO 142.090 http://tinyurl.com/tu142090 Februar 2010 1/536 Übersicht über die Vorlesung Teil 1: Deskriptive Teil 2: Wahrscheinlichkeitsrechnung Teil 3: Zufallsvariable Teil 4: Parameterschätzung
fru@hephy.oeaw.ac.at VO 142.090 http://tinyurl.com/tu142090 Februar 2010 1/536 Übersicht über die Vorlesung Teil 1: Deskriptive Teil 2: Wahrscheinlichkeitsrechnung Teil 3: Zufallsvariable Teil 4: Parameterschätzung
Bayes sches Lernen: Übersicht
 Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 10: Naive Bayes (V. 1.0)
Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 10: Naive Bayes (V. 1.0)
Reinforcement Learning
 Reinforcement Learning Viktor Seifert Seminar: Knowledge Engineering und Lernen in Spielen SS06 Prof. Johannes Fürnkranz Übersicht 1. Definition 2. Allgemeiner Lösungsansatz 3. Temporal Difference Learning
Reinforcement Learning Viktor Seifert Seminar: Knowledge Engineering und Lernen in Spielen SS06 Prof. Johannes Fürnkranz Übersicht 1. Definition 2. Allgemeiner Lösungsansatz 3. Temporal Difference Learning
Adaptives maschinelles Lernen
 Vortrag: Adaptives maschinelles Lernen Eric Winter Universität Koblenz-Landau Fachbereich Informatik - Institut für Softwaretechnik Seminar Software-Adaptivität - Sommersemester 2011 ericwinter@uni-koblenz.de
Vortrag: Adaptives maschinelles Lernen Eric Winter Universität Koblenz-Landau Fachbereich Informatik - Institut für Softwaretechnik Seminar Software-Adaptivität - Sommersemester 2011 ericwinter@uni-koblenz.de
Frequentistische Statistik und Bayessche Statistik. Volker Tresp
 Frequentistische Statistik und Bayessche Statistik Volker Tresp 1 Frequentistische Statistik 2 Herangehensweise Die Naturwissenschaft versucht es, der Natur Gesetzmäßigkeiten zu entringen: F = ma Gesetze
Frequentistische Statistik und Bayessche Statistik Volker Tresp 1 Frequentistische Statistik 2 Herangehensweise Die Naturwissenschaft versucht es, der Natur Gesetzmäßigkeiten zu entringen: F = ma Gesetze
Wahrscheinlichkeitstheorie 2
 Wahrscheinlichkeitstheorie 2 Caroline Sporleder Computational Linguistics Universität des Saarlandes Sommersemester 2011 19.05.2011 Caroline Sporleder Wahrscheinlichkeitstheorie 2 (1) Wiederholung (1):
Wahrscheinlichkeitstheorie 2 Caroline Sporleder Computational Linguistics Universität des Saarlandes Sommersemester 2011 19.05.2011 Caroline Sporleder Wahrscheinlichkeitstheorie 2 (1) Wiederholung (1):
TD-Gammon. Michael Zilske
 TD-Gammon Michael Zilske zilske@inf.fu-berlin.de TD-Gammon Ein Backgammon-Spieler von Gerald Tesauro (Erste Version: 1991) TD-Gammon Ein Neuronales Netz, das immer wieder gegen sich selbst spielt und dadurch
TD-Gammon Michael Zilske zilske@inf.fu-berlin.de TD-Gammon Ein Backgammon-Spieler von Gerald Tesauro (Erste Version: 1991) TD-Gammon Ein Neuronales Netz, das immer wieder gegen sich selbst spielt und dadurch
Beispiele. Grundlagen. Kompakte Operatoren. Regularisierungsoperatoren
 Beispiele Grundlagen Kompakte Operatoren Regularisierungsoperatoren Transportgleichung Dierenzieren ( nx ) (f δ n ) (x) = f (x) + n cos, x [0, 1], δ Regularisierung!! Inverse Wärmeleitung Durc f (f δ n
Beispiele Grundlagen Kompakte Operatoren Regularisierungsoperatoren Transportgleichung Dierenzieren ( nx ) (f δ n ) (x) = f (x) + n cos, x [0, 1], δ Regularisierung!! Inverse Wärmeleitung Durc f (f δ n
KAPITEL 5. Erwartungswert
 KAPITEL 5 Erwartungswert Wir betrachten einen diskreten Wahrscheinlichkeitsraum (Ω, P) und eine Zufallsvariable X : Ω R auf diesem Wahrscheinlichkeitsraum. Die Grundmenge Ω hat also nur endlich oder abzählbar
KAPITEL 5 Erwartungswert Wir betrachten einen diskreten Wahrscheinlichkeitsraum (Ω, P) und eine Zufallsvariable X : Ω R auf diesem Wahrscheinlichkeitsraum. Die Grundmenge Ω hat also nur endlich oder abzählbar
Technische Universität München. Aufgaben Mittwoch SS 2012
 Technische Universität München Andreas Wörfel Ferienkurs Analysis 2 für Physiker Aufgaben Mittwoch SS 2012 Aufgabe 1 Äquivalente Aussagen für Stetigkeit( ) Beweisen Sie folgenden Satz: Seien X und Y metrische
Technische Universität München Andreas Wörfel Ferienkurs Analysis 2 für Physiker Aufgaben Mittwoch SS 2012 Aufgabe 1 Äquivalente Aussagen für Stetigkeit( ) Beweisen Sie folgenden Satz: Seien X und Y metrische
Statistik II. Weitere Statistische Tests. Statistik II
 Statistik II Weitere Statistische Tests Statistik II - 19.5.2006 1 Überblick Bisher wurden die Test immer anhand einer Stichprobe durchgeführt Jetzt wollen wir die statistischen Eigenschaften von zwei
Statistik II Weitere Statistische Tests Statistik II - 19.5.2006 1 Überblick Bisher wurden die Test immer anhand einer Stichprobe durchgeführt Jetzt wollen wir die statistischen Eigenschaften von zwei
Optimierung für Nichtmathematiker
 Optimierung für Nichtmathematiker Prof. Dr. R. Herzog WS2/ / Inhaltsübersicht 3Einführung in die freie Optimierung 4Orakel und Modellfunktionen 5Optimalitätsbedingungen der freien Optimierung 6Das Newton-Verfahren
Optimierung für Nichtmathematiker Prof. Dr. R. Herzog WS2/ / Inhaltsübersicht 3Einführung in die freie Optimierung 4Orakel und Modellfunktionen 5Optimalitätsbedingungen der freien Optimierung 6Das Newton-Verfahren
6.8 Newton Verfahren und Varianten
 6. Numerische Optimierung 6.8 Newton Verfahren und Varianten In den vorherigen Kapiteln haben wir grundlegende Gradienten-basierte Verfahren kennen gelernt, die man zur numerischen Optimierung von (unbeschränkten)
6. Numerische Optimierung 6.8 Newton Verfahren und Varianten In den vorherigen Kapiteln haben wir grundlegende Gradienten-basierte Verfahren kennen gelernt, die man zur numerischen Optimierung von (unbeschränkten)
Korollar 116 (Grenzwertsatz von de Moivre)
") Ein wichtiger Spezialfall das Zentralen Grenzwertsatzes besteht darin, dass die auftretenden Zufallsgrößen Bernoulli-verteilt sind. Korollar 116 (Grenzwertsatz von de Moivre) X 1,..., X n seien unabhängige
Ein wichtiger Spezialfall das Zentralen Grenzwertsatzes besteht darin, dass die auftretenden Zufallsgrößen Bernoulli-verteilt sind. Korollar 116 (Grenzwertsatz von de Moivre) X 1,..., X n seien unabhängige
Der CG-Algorithmus (Zusammenfassung)
") Der CG-Algorithmus (Zusammenfassung) Michael Karow Juli 2008 1 Zweck, Herkunft, Terminologie des CG-Algorithmus Zweck: Numerische Berechnung der Lösung x des linearen Gleichungssystems Ax = b für eine
Der CG-Algorithmus (Zusammenfassung) Michael Karow Juli 2008 1 Zweck, Herkunft, Terminologie des CG-Algorithmus Zweck: Numerische Berechnung der Lösung x des linearen Gleichungssystems Ax = b für eine
Numerische Verfahren zur Lösung der Monge-Ampère-Gleichung, Teil II
 für zur Lösung der Monge-Ampère-Gleichung, Teil II Andreas Platen Institut für Geometrie und Praktische Mathematik RWTH Aachen Seminar zur Approximationstheorie im Wintersemester 2009/2010 1 / 27 Gliederung
für zur Lösung der Monge-Ampère-Gleichung, Teil II Andreas Platen Institut für Geometrie und Praktische Mathematik RWTH Aachen Seminar zur Approximationstheorie im Wintersemester 2009/2010 1 / 27 Gliederung
Innere-Punkt-Methoden
 Innere-Punkt-Methoden Johannes Stemick 26.01.2010 Johannes Stemick () Innere-Punkt-Methoden 26.01.2010 1 / 28 Übersicht 1 Lineare Optimierung 2 Innere-Punkt-Methoden Path-following methods Potential reduction
Innere-Punkt-Methoden Johannes Stemick 26.01.2010 Johannes Stemick () Innere-Punkt-Methoden 26.01.2010 1 / 28 Übersicht 1 Lineare Optimierung 2 Innere-Punkt-Methoden Path-following methods Potential reduction
Statistisches Testen
 Statistisches Testen Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Differenzen Anteilswert Chi-Quadrat Tests Gleichheit von Varianzen Prinzip des Statistischen Tests Konfidenzintervall
Statistisches Testen Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Differenzen Anteilswert Chi-Quadrat Tests Gleichheit von Varianzen Prinzip des Statistischen Tests Konfidenzintervall
Simulationsmethoden in der Bayes-Statistik
 Simulationsmethoden in der Bayes-Statistik Hansruedi Künsch Seminar für Statistik, ETH Zürich 6. Juni 2012 Inhalt Warum Simulation? Modellspezifikation Markovketten Monte Carlo Simulation im Raum der Sprungfunktionen
Simulationsmethoden in der Bayes-Statistik Hansruedi Künsch Seminar für Statistik, ETH Zürich 6. Juni 2012 Inhalt Warum Simulation? Modellspezifikation Markovketten Monte Carlo Simulation im Raum der Sprungfunktionen
Nichtlineare Gleichungssysteme
 Kapitel 5 Nichtlineare Gleichungssysteme 51 Einführung Wir betrachten in diesem Kapitel Verfahren zur Lösung von nichtlinearen Gleichungssystemen Nichtlineares Gleichungssystem: Gesucht ist eine Lösung
Kapitel 5 Nichtlineare Gleichungssysteme 51 Einführung Wir betrachten in diesem Kapitel Verfahren zur Lösung von nichtlinearen Gleichungssystemen Nichtlineares Gleichungssystem: Gesucht ist eine Lösung
Statistik und Wahrscheinlichkeitsrechnung
 Statistik und Wahrscheinlichkeitsrechnung Dr. Jochen Köhler 1 Inhalt der heutigen Vorlesung Statistik und Wahrscheinlichkeitsrechnung Zusammenfassung der vorherigen Vorlesung Übersicht über Schätzung und
Statistik und Wahrscheinlichkeitsrechnung Dr. Jochen Köhler 1 Inhalt der heutigen Vorlesung Statistik und Wahrscheinlichkeitsrechnung Zusammenfassung der vorherigen Vorlesung Übersicht über Schätzung und
Kapitel 5 KONVERGENZ
 Kapitel 5 KONVERGENZ Fassung vom 21. April 2002 Claude Portenier ANALYSIS 75 5.1 Metrische Räume 5.1 Metrische Räume DEFINITION 1 Sei X eine Menge. Eine Abbildung d : X X! R + heißt Metrik oder Distanz
Kapitel 5 KONVERGENZ Fassung vom 21. April 2002 Claude Portenier ANALYSIS 75 5.1 Metrische Räume 5.1 Metrische Räume DEFINITION 1 Sei X eine Menge. Eine Abbildung d : X X! R + heißt Metrik oder Distanz