Paralleles Höchstleistungsrechnen
|
|
|
- Maike Koenig
- vor 5 Jahren
- Abrufe
Transkript
1 Paralleles Höchstleistungsrechnen Peter Bastian Interdisziplinäres Zentrum für Wissenschaftliches Rechnen Universität Heidelberg Im Neuenheimer Feld 368 D Heidelberg 5. November 2008
2
3 Inhaltsverzeichnis Inhaltsverzeichnis 1 Motivation Organisatorisches Motivation Einige Beispielanwendungen Superrechner Inhalt der Vorlesung Rundgang Parametrisierte Prozesse Parallele Summenberechnung Lokalisieren Nachrichtenaustausch Sequentielle Rechnerarchitektur Performance AMD Opteron Prozessor Kommunikationsnetzwerke Synchronisationsmechanismen bei gemeinsamen Speicher Hardware Locks Barrieren Semaphore Philosophenproblem Leser-Schreiber-Problem PThreads Allgemeines Thread Management Synchronisation Threads und Objektorientierung Ausklang
4 Inhaltsverzeichnis 4
5 1 Motivation 1.1 Organisatorisches Vorlesung Dozent Peter Bastian zu finden in: INF 368, Raum Vorlesung Di 9-11 in 368/532, Do 9-11 in 350/U014 Skript, Folien (falls verfügbar), Übungsaufgaben: de/phlr.html Übung Leiter: Christian Engwer findet statt im CIP-Pool des IWR, Otto-Meierhof-Zentrum Zeit: Noch zu vereinbaren! Anmeldung zur Übung Schein auf Übungsaufgaben Bachelor/Master: mündliche Prüfung (bzw. Klausur bei großem Andrang) Voraussetzung für die Teilnahme an der mündlichen Prüfung/Klausur: 50% der Übungsaufgaben C/C++ Kentnisse erforderlich 1.2 Motivation Warum parallel Rechnen? Nebenläufigkeit Abarbeitung mehrerer Prozesse auf einem Prozessor Multi-Tasking Betriebssysteme seit den 60er Jahren Bedienung mehrerer Geräte und Benutzer Ziel: Steigerung der Auslastung Hyperthreading : Nutze Wartezeiten des Prozessors Mehrere Dinge gleichzeitig : Web-Browser, Desktop Koordinationsproblematik tritt bereits hier auf Verteilte Anwendungen 5

6 1 Motivation Datenbasis ist inhärent verteilt: betriebswirtschaftliche Software, Warenfluß in großen Unternehmen Hier wichtig: plattformübergreifende Kommunikation, Client-Server Architekturen Auch wichtig: Sicherheit, VPN, etc. (behandeln wir nicht) High Performance Computing Treibt Rechnerentwicklung seit Anfang 1940er Anwendungen: mathematische Modellierung und numerische Simulation ungestillter Hunger nach Rechenzeit: Modellfehler detailliertere Physik Approximationsfehler mehr Freiheitsgrade Grand Challenges: Kosmologie, z. B. Galaxiendynamik Proteinfaltung Erdbebenvorhersage Klimaentwicklung ASCI Program (Advanced Simulation and Computing) Programm amerikanischer Parallelrechner seit 1992, Funding 2004: 200 Mio US-$ DoE, 87 Mio US-$ NSF Earth Simulator (Japan) Juni 2002 bis Juni 2004 der leistungsfähigste Computer der Welt Kosten: 350 bis 500 Mio US-$ Folie (und die folgenden) von J. Dongarra 6
7 1.2 Motivation Earth Simulator Architecture Earth Simulator Gebäude 7
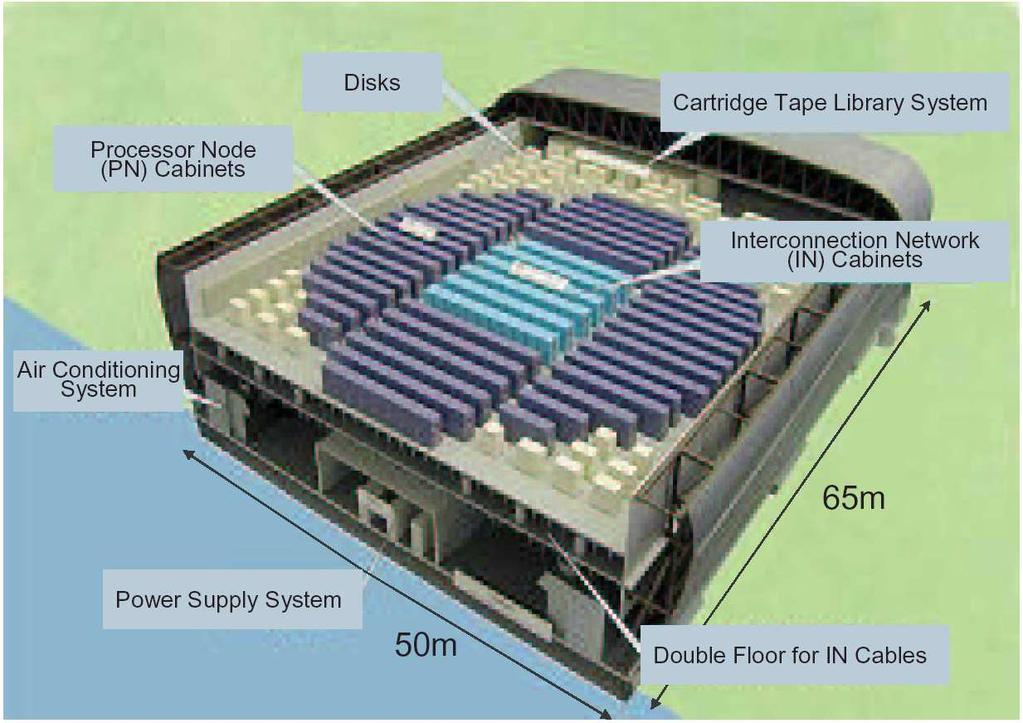
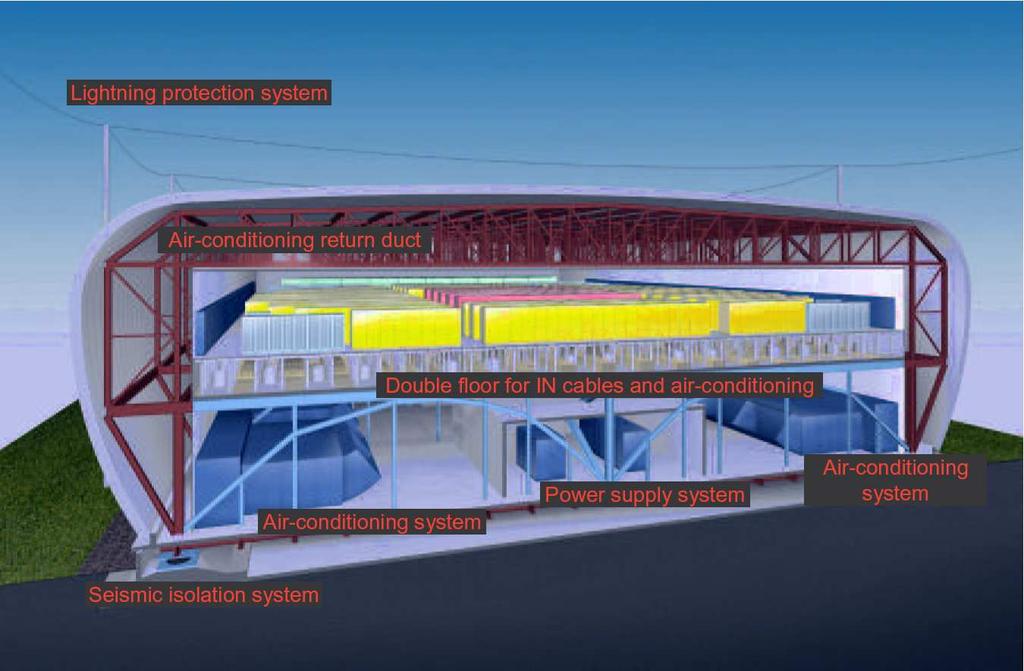
8 1 Motivation Earth Simulator Gebäude 8

9 1.2 Motivation... die Kabel... die Kabel 9


10 1 Motivation... und ein Kraftwerk Terascale Simulation Facility 10



11 1.3 Einige Beispielanwendungen Lawrence Livermore National Laboratory BlueGene/L Prozessoren, 478 TFLOPS seit Einige Beispielanwendungen Couplex Benchmark far field 3000 m near field 6 m 0.9 m 5 m 15 m seal container gallery 50 m repository Couplex1, Couplex2 Couplex Transport Model Flow equation: u = f in Ω, u = K H 11
12 1 Motivation Transport equations i = silica, 135 Cs, 238 Pu, 242 Pu, 234 U, 238 U: ( ) Ci Rω t + λc i + j i = q(c 1,...,C n ) in Ω, Processes: Convection-dispersion (Scheidegger) j i = uc i D(u) C i Radioactive decay 238 Pu 234 U, 242 Pu 238 U Precipitation: 238 Pu, 242 Pu, 234 U, 238 U as disolved components and (immobile) solid phase Couplex 2 [Micromole/yr] 4e e-10 3e e-10 2e e-10 1e-10 5e-11 0 U234 Host to Outside -5e e+06 2e+06 3e+06 4e+06 5e+06 6e+06 Time [yr] 1622 vertices vertices vertices vertices P Unbekannte Par. Rechenzeit [h] Seq. Rechenzeit [h] (Gemeinsame Arbeit mit Stefan Lang) Dichteströmung brine, 1200 kg/m3 perturbation water, 1000 kg/m3 periodic boundary conditions 12
g), (C) = C b + (1 C) 0 in Ω Transport equation: (ΦC) t + j + q = 0, j = Cu D C Elliptic flow equation coupled to parabolic/hyperbolic transport equation Cell centered finite")

13 1.3 Einige Beispielanwendungen Salzstock, Ozean, Atmosphäre, Sterninneres, Erdmantel, Kaffeetasse Density driven flow in Porous Media Flow equation (Bussinesq approximation): u = f, u = K µ ( p (C)g), (C) = C b + (1 C) 0 in Ω Transport equation: (ΦC) t + j + q = 0, j = Cu D C Elliptic flow equation coupled to parabolic/hyperbolic transport equation Cell centered finite volume discretization, second order Godunov scheme for convective terms Cell centered multigrid method Decoupled solution scheme Simulation Results Comparison of two-dimensional and three-dimensional simulation 2d 3d Simulation Data Grid size: , about 9000 time steps Solves linear system with unknowns per time step (requires 30 seconds on 384 processors) 13



 Visualisierung großer Datenmengen ist ein Problem Alle")

14 1 Motivation Data produced per time step: 3.2 GByte in binary float Data produced by whole simulation: 29 TByte Visualization requires intelligent ways of data reduction and/or parallelized visualization tools In addition I/O capabilities of HELICS should be improved in the future Fault-tolerance might become an issue Virtuelles Labor Verändere physikalische Parameter (links wenig Diffusion, rechts viel Diffusion) Visualisierung großer Datenmengen ist ein Problem Alle Komponenten einer Simulation müssen parallel bearbeitet werden In-Situ Reinigungsverfahren 100 m Pumpbrunnen 400 m Schadstoff Boden mit variabler Durchlässigkeit Förderbrunnen 14

15 1.3 Einige Beispielanwendungen 3D Transport in Heterogenem Medium Zellenzentrierte Finite-Volumen Verfahren (CCMG, HOG) Zellen, time steps (Transparenz) Parallele Rechnung auf 384 Prozessoren Numerische Strömungsberechnung p, C 15
16 1 Motivation Pro Zelle: Phys. Größen wie Druck, Temperatur, Konzentration Je mehr Zellen desto genauer das Ergebnis Lokale Datenabhängigkeiten (Differentiation!) Beschleunigung ideal festes Problem wachsendes Problem Beschleunigung Prozessoren Gegebenes Problem immer schneller rechnen Mit mehr Prozessoren immer größere Probleme rechnen 1.4 Superrechner Was ist ein Superrechner? Gerät Jahr $ Takt [MHz] MBytes MFLOPS CDC M $ Cray 1A M $ Cray X-MP/ M $ C ASCI Red Pentium Core 2 XE QX > X-MP/48: P=4, C90: P=16, ASCI Red: P=9152 PC von heute = Superrechner von gestern 16
17 1.4 Superrechner Entwicklung Einzelprozessoren in den 90ern 1 Entwicklung Multiprozessoren 2 HELICS Entwicklung seit den 90er Jahren: Cluster Computer 1 Culler/Singh, Parallel Computer Architecture. 2 Culler/Singh, Parallel Computer Architecture. 17

18 1 Motivation Aufbau aus Standardbauteilen Aktuelle Entwicklung Multicore Prozessoren Coprozessoren Cell, Clearspeed General Purpose GPU-Computing Petaflop Computer: Gleitkommaoperationen pro Sekunde erreicht im Juni 2008 der IBM Roadrunner Cores, Opteron mit Cell Coprozessoren Giga, Terra, Peta,... Verdopplung der Rechenleistung alle 13.5 Monate. Liste einiger berühmter Computer: Name Zeit Prozessoren Rechenoperationen/s CDC Cray ASCI Red IBM Roadrunner General Purpose GPU-Computing 18
19 1.5 Inhalt der Vorlesung Quelle: NVIDIA Effiziente Algorithmen Schnelle Rechner sind nicht alles! Rechenzeiten zur (approximativen) Lösung spezieller linearer Gleichungssysteme: (für einen Rechner mit 1 GFLOP/s) N Gauß ( 2 3 N3 ) Mehrgitter (100N) s 10 4 s s 10 3 s Tage 10 2 s Jahre 0.1 s Jahre 1 s Parallelisierung kann einem ineffizienten Verfahren nicht helfen! Schnelle Rechner und schnelle Algorithmen 1.5 Inhalt der Vorlesung Inhalt der Vorlesung 19
20 1 Motivation I Hardware Prozessorentwicklung, Pipelining, SIMD, MIMD, Caches, Cachekonsistenz, Multicore Verbindungsnetzwerke Grafikprozessoren II Programmierung gemeinsamer Speicher: Locks, Semaphore PThreads, OpenMP verteilter Speicher: MPI-I, MPI-II RPC, Corba CUDA Illustration mittels N-Körper-Problem III Algorithmen Bewertung von Algorithmen, prinzipielles Vorgehen, Lastverteilung dichtbesetzte Matrizen dünnbesetzte Gleichungssysteme Sortieren, N-Körper-Problem Links Vorlesung ASCI Program Seymour Cray TOP 500 Supercomputer Sites 20
21 2 Rundgang 2.1 Parametrisierte Prozesse Parametrisieren von Prozessen Single Program Multiple Date (SPMD). Erlaubt Formulierung skalierbarer Algorithmen. parallel many-process-scalar-product const int N; // Problemgröße const int P; // Anzahl Prozesse double x[n], y[n]; // Vektoren double s = 0; // Resultat process Π [int p 0,..., P 1] int i; double ss = 0; for (i = N p/p; i < N (p + 1)/P; i++) ss += x[i]*y[i]; [s = s + ss]; // Hier warten dann doch wieder alle 2.2 Parallele Summenberechnung Parallele Summenberechnung 000 s 0 + s 1 + s 2 + s s 0 + s s 0 s s 2 + s s 2 s si s 4 + s 5 + s 6 + s s 4 + s s 4 s s 6 + s s 6 s 7 21
22 2 Rundgang Implementierung Parallele Summe parallel parallel-sum-scalar-product const int d = 4; const int N = 100; // Problemgröße const int P = 2 d ; // Anzahl Prozesse double x[n], y[n]; // Vektoren double s[p] = 0[P]; // Resultat int flag[p] = 0[P]; // Prozess p ist fertig process Π [int p 0,..., P 1] int i, r, m, k; for (i = N p/p; i < N (p + 1)/P; i++) s[p]+ = x[i] y[i]; for (i = 0; i < d; i++) [ ( i r = p & 2 )]; k // lösche letzten i + 1 bits k=0 m = r 2 i ; // setze Bit i if (p == m) flag[m]=1; if (p == r) while (!flag[m]); // Bedingungssynchronisation s[p] = s[p] + s[m]; 2.3 Lokalisieren Lokalisieren der Vektoren parallel local-data-scalar-product const int P, N; double s = 0; 22
23 2.4 Nachrichtenaustausch process Π [ int p 0,...,P 1] double x[n/p + 1], y[n/p + 1]; // Lokaler Ausschnitt der Vektoren int i; double ss=0; for (i = 0,i < (p + 1) N/P p N/P;i++) ss = ss + x[i] y[i]; [s = s + ss; ] 2.4 Nachrichtenaustausch Summenberechnung mit Nachrichtenaustausch parallel message-passing-scalar-product const int d, P= 2 d, N; // Konstanten! process Π [int p 0,...,P 1] double x[n/p], y[n/p];// Lokaler Ausschnitt der Vektoren int i, r, m; double s = 0, ss; for (i = 0,i < (p + 1) N/P p N/P;i++) s = s + x[i] y[i]; for (i = 0,i < d,i++) // d Schritte [ ( i r = p & 2 )]; k k=0 m = r 2 i ; if (p == m) send(π r,s); if (p == r) receive(π m,ss); s = s + ss; 23
24 2 Rundgang 24
25 3 Sequentielle Rechnerarchitektur 3.1 Performance Matrixmultiplikation, Pentium IV 2.4 GHz Matrix mal Matrix naive, P IV 2.4 icc tiled M=20, P IV 2.4 icc tiled M=20, P IV 2.4 gcc 1000 MFLOPS N Matrixmultiplikation, Core 2 Duo 2.4 GHz 25
26 3 Sequentielle Rechnerarchitektur 2500 Matrix mal Matrix, T61p, Pointer-Version tiled Core 2 Duo 2,5 GHz, g naive Core 2 Duo 2,5 GHz, g MFLOPS N 3.2 AMD Opteron Prozessor Hammer Architektur Generation 8, 2001 eingeführt 26

27 3.2 AMD Opteron Prozessor Barcelona QuadCore, Generation 10h,

28 3 Sequentielle Rechnerarchitektur Barcelona Core 28

29 3.2 AMD Opteron Prozessor Barcelona Details L1 Cache 64K Instruktionen, 64K Daten. Cache line 64 Bytes. 2 Wege assoziativ, write-allocate, writeback, least-recently-used. MOESI. L2 Cache Victim cache: enthält nur Blöcke, die aus dem L1 cache verdrängt wurden. Größe implementierungsabhängig. L3 Cache non-inclusive: Daten sind entweder im L1 oder L3. Victim Cache, d.h. aus dem L2 verdrängte Blöcke landen hier. Heuristische Sharing-Erkennung. Superskalar Instruktionsdekodierung, Integer units, FP units, address generation jeweils dreifach (3 OPS pro Zyklus). 29

30 3 Sequentielle Rechnerarchitektur Out of order execution, branch prediction. Pipelining: 12 Stufen integer, 17 Stufen floating-point (Hammer). Integrierter Speichercontroller, 128 Bit breit. HyperTransport: Kohärenter Zugriff auf entfernten Speicher. 3.3 Kommunikationsnetzwerke Opteron/Xeon Vergleich Netzwerktopologien I (a) (b) (c) (d) (e) (f) (a) full connected, (b) star, (c) array (d) hypercube, (e) torus, (f) folded torus Hypercube: der Dimension d hat 2 d Prozessoren. Prozessor p ist mit q verbunden wenn sich deren Binärdarstellungen in genau einem Bit unterscheiden. 30
31 3.3 Kommunikationsnetzwerke Netzwerkknoten: Früher (vor 1990) war das der Prozessor selbst, heute sind es dedizierte Kommunikationsprozessoren Netzwerktopologien II Kennzahlen: Topologie k D l B Sym P(P 1) ( Volle Verb. P 1 1 P ) ja Hypercube d d d P P 2 2 ja 2D-Torus 4 2 r 2 2P 2r ja 2D-Feld 4 2(r 1) 2P 2r r nein Ring 2 P 2 P 2 ja Binärer Baum 3 2(h 1) P 1 1 nein d = log 2 P, P = r r, h = log 2 P Store & Forward Routing Store-and-forward routing: Nachricht der Länge n wird in Pakete der Länge N zerlegt. Pipelining auf Paketebene: Paket wird aber vollständig im NK gespeichert NK0 NK1 NK2 NK$d 1$ NK$d$ M M Store & Forward Routing Übertragung eines Paketes: 31
32 3 Sequentielle Rechnerarchitektur Quelle Ziel Routing Routing Routing Zeit Store & Forward Routing Laufzeit: ( n ) t SF (n, N, d) = t s + d(t h + Nt b ) + N 1 (t h + Nt b ) ( = t s + t h d + n ) N 1 + t b (n + N(d 1)). t s : Zeit, die auf Quell und Zielrechner vergeht bis das Netzwerk mit der Nachrichenübertragung beauftragt wird, bzw. bis der empfangende Prozess benachrichtigt wird. Dies ist der Softwareanteil des Protokolls. t h : Zeit die benötigt wird um das erste Byte einer Nachricht von einem Netzwerkknoten zum anderen zu übertragen (engl. node latency, hop time). t b : Zeit für die Übertragung eines Byte von Netzwerkknoten zu Netzwerkknoten. d: Hops bis zum Ziel. Cut-Through Routing Cut-through routing oder wormhole routing: Pakete werden nicht zwischengespeichert, jedes Wort (sog. flit) wird sofort an nächsten Netzwerkknoten weitergeleitet Übertragung eines Paketes: 32
33 3.3 Kommunikationsnetzwerke Quelle Ziel Routing 0 1 Routing 0 Routing Zeit Laufzeit: t CT (n, N, d) = t s + t h d + t b n Zeit für kurze Nachricht (n = N): t CT = t s + dt h + Nt b. Wegen dt h t s (Hardware!) quasi entfernungsunabhängig Deadlock In paketvermittelnden Netzwerken besteht die Gefahr des store-and-forward deadlock: D an A C an D an B A an C B Deadlock Zusammen mit cut-through routing: 33
34 3 Sequentielle Rechnerarchitektur Verklemmungsfreies dimension routing. Beispiel 2D-Gitter: Zerlege Netzwerk in +x, x, +y und y Netzwerke mit jeweils eigenen Puffern. Nachricht läuft erst in Zeile, dann in Spalte. 34
35 4 Synchronisationsmechanismen bei gemeinsamen Speicher 4.1 Hardware Locks Hardware-OPs Verschiedene Lock Algorithmen erfordern Speicherkonsistenz. Hoher extra Aufwand erforderlich, um Speicherkonsistenz zu garantieren. Verfahren sind nicht portabel und erfordern genaue Kenntnis der Architektur. Spezielle Hardware Operationen vereinfachen die Konstruktion von Locks und garantieren die erforderliche Speicherkonsistenz. Übersicht der Hardware-OPs Klassische OPs test-and-set: (atomar) lese Speicherstelle und schreibe 1 rein. atomic-swap: (atomar) tausche Speicherstelle mit Register. fetch-and-increment: (atomar) lese Speicherstelle und schreibe Wert+1 zurück. Andere OPs compare-and-swap (atomar) vertausche load-linked / store-conditional (atomar) lese test-and-set / TAS-Lock Lock baut auf dem atomaren Befehl test-and-set auf. bool test-and-set(bool * target) bool state = *target; *target = true; return state; parallel TAS- Lock bool lock = false process Π [int p 0,...,P 1] while (1) while test-and-set(&lock); %\only<3>\large\structure cache misses %\ textit kritischer Abschnitt;% lock = false; %\ textit unkritischer Abschnitt;% 35
36 4 Synchronisationsmechanismen bei gemeinsamen Speicher TTAS-Lock Verbesserung des TAS-Lock, welche die cache misses reduziert. parallel TTAS-Lock // t e s t and test and set bool lock = false process Π [int p 0,...,P 1] while (1) while (1) if (lock == false) if (test-and-set(&lock)) break; %\ textit kritischer Abschnitt;% lock = false; %\ textit unkritischer Abschnitt;% Exponential Backoff Verbesserung des TTAS-Lock. Der erneute Versuch das Lock zu bekommen wird etwas verzögrt. Die Verzögerung wurde zufällig gewählt. Die obere Zufallsgrenze verdoppelt sich nach jedem weiteren Fehlversuch. parallel ExpBackoff- Lock bool lock = false; process Π [int p 0,...,P 1] while (1) while (1) if (lock == false) if (test-and-set(&lock)) break; else delay [mindelay, maxdelay]; sleep(delay); 36
37 4.1 Hardware Locks maxdelay*=2; %\ textit kritischer Abschnitt;% lock = false; %\ textit unkritischer Abschnitt;% atomic-swap tauscht den Inhalt einer Speicherstelle und eines Registers. atomic-swap kann mehr als test-and-set. TYPE atomic-swap(type * target, TYPE value) TYPE tmp = *target; *target = value; return tmp; test-and-set mit Hilfe von atomic-swap: bool test-and-set(bool * target) return atomic-swap(target, true); fetch-and-increment TYPE fetch-and-increment(type * target) TYPE value = *target; *target = value + 1; return value; Lock basierend auf fetch-and-increment parallel FAI-Lock // naiv implementation int ticketnumber, turn; process Π [int p 0,...,P 1] while (1) int myturn = fetch-and-increment(ticketnumber); while (turn!= myturn); 37
38 4 Synchronisationsmechanismen bei gemeinsamen Speicher %\ textit kritischer Abschnitt;% fetch-and-increment(turn); %\ textit unkritischer Abschnitt;% compare-and-swap Wird in Prozessoren von Intel, AMD und Sun verwendet. bool compare-and-swap(type * target, TYPE expect, TYPE value) TYPE tmp = *target; if (tmp == expect) *target = value; return true; else return false; load-linked / store-conditional Wird in echten RISC Prozessoren verwendet, z.b. ARM, Alpha, MIPS, PowerPC. LL liest von einer Speicheradresse. Ein späteres SC versucht einen neuen Wert in dieser Adresse zu speichern. SC ist erfolgreich, wenn der Wert der Adresse seit dem LL nicht verändert wurde. Wenn der Wert an der Adresse zwischenzeitlich geändert wurde, selbst wenn er jetzt wieder den ursprünglichen Wert hat, schlägt SC fehl. 4.2 Barrieren Erster Entwurf einer Barriere parallel barrier-1 const int P=8; int count=0; 38
39 4.2 Barrieren int release=0; process Π [int p 0,..., P 1] while (1) Berechnung; CSenter; if (count==0) release=0; count=count+1; CSexit; if (count==p) count=0; release=1; else while (release==0) ; // Eintritt // Zurücksetzen // Zähler erhöhen // Verlassen // letzter löscht // und gibt frei // warten Barriere mit Richtungsumkehr parallel sense-reversing-barrier const int P=8; int count=0; int release=0; process Π [int p 0,..., P 1] int local_sense = release; while (1) Berechnung; local_sense = 1-local_sense;// Richtung wechseln CSenter; // Eintritt count=count+1; // Zähler erhöhen CSexit; // Verlassen if (count==p) count=0; // letzter löscht release=local_sense; // und gibt frei else while (release local_sense) ; 39
40 4 Synchronisationsmechanismen bei gemeinsamen Speicher Barriere mit Baum parallel tree-barrier const int d = 4; const int P = 2 d ; int arrived[p]=0,...,0; int continue[p]=0,...,0; process Π [int p 0,..., P 1] int i, r, m, k; while (1) Berechnung; for (i = 0; i < d; i++) // aufwärts [ ( i r = p & 2 )]; k // Bits 0 bis i löschen k=0 m = r 2 i ; // Bit i setzen if (p == m) arrived[m]=1; if (p == r) while( arrived[m]) ; // warte arrived[m]=0; for (i = d 1; i 0; i ) // abwärts [ ( i r = p & 2 )]; k // Bits 0 bis i löschen k=0 m = r 2 i ; if (p == m) while( continue[m]) ; continue[m]=0; if (p == r) continue[m]=1; 40
41 4.3 Semaphore Barriere mit rekursiver Verdopplung parallel recursive-doubling-barrier const int d = 4; const int P = 2 d ; int arrived[d][p]=0[p d]; process Π [int p 0,..., P 1] int i, q; while (1) Berechnung; for (i = 0; i < d; i++) q = p 2 i ; while (arrived[i][p]) ; arrived[i][p]=1; while ( arrived[i][q]) ; arrived[i][q]=0; // alle Stufen // Bit i umschalten 4.3 Semaphore m/n/1 Erzeuger-Verbraucher-Problem parallel prod-con-nm1 const int m = 3, n = 5; Semaphore empty=1; Semaphore full=0; T buf ; // freier Pufferplatz // abgelegter Auftrag // der Puffer process P [int i 0,..., m 1] 41
42 4 Synchronisationsmechanismen bei gemeinsamen Speicher while (1) Erzeuge Auftrag t; P(empty); buf = t; V(full); // Ist Puffer frei? // speichere Auftrag // Auftrag abgelegt process C [int j 0,..., n 1] while (1) P(full); // Ist Auftrag da? t = buf ; // entferne Auftrag V(empty); // Puffer ist frei Bearbeite Auftrag t; 1/1/k Erzeuger-Verbraucher-Problem parallel prod-con-11k const int k = 20; Semaphore empty=k; Semaphore full=0; T buf [k]; int front=0; int rear=0; // zählt freie Pufferplätze // zählt abgelegte Aufträge // der Puffer // neuester Auftrag // ältester Auftrag process P while (1) Erzeuge Auftrag t; P(empty); // Ist Puffer frei? buf [front] = t; // speichere Auftrag front = (front+1) mod k;// nächster freier Platz V(full); // Auftrag abgelegt 42
43 4.3 Semaphore process C while (1) P(full); // Ist Auftrag da? t = buf [rear]; // entferne Auftrag rear = (rear+1) mod k; // nächster Auftrag V(empty); // Puffer ist frei Bearbeite Auftrag t; m/n/k Erzeuger-Verbraucher-Problem parallel prod-con-mnk const int k = 20, m = 3, n = 6; Semaphore empty=k; // zählt freie Pufferplätze Semaphore full=0; // zählt abgelegte Aufträge T buf [k]; // der Puffer int front=0; // neuester Auftrag int rear=0; // ältester Auftrag Semaphore mutexp=1; // Zugriff der Erzeuger Semaphore mutexc=1; // Zugriff der Verbraucher process P [int i 0,..., m 1] while (1) Erzeuge Auftrag t; P(empty); // Ist Puffer frei? P(mutexP); // manipuliere Puffer buf [front] = t; // speichere Auftrag front = (front+1) mod k;// nächster freier Platz V(mutexP); // fertig mit Puffer V(full); // Auftrag abgelegt process C [int j 0,..., n 1] 43
44 4 Synchronisationsmechanismen bei gemeinsamen Speicher while (1) P(full); // Ist Auftrag da? P(mutexC); // manipuliere Puffer t = buf [rear]; // entferne Auftrag rear = (rear+1) mod k; // nächster Auftrag V(mutexC); // fertig mit Puffer V(empty); // Puffer ist frei Bearbeite Auftrag t; 4.4 Philosophenproblem Die speisenden Philosophen: Naive Lösung parallel philosphers 1 const int P = 5; // Anzahl Philosophen Semaphore forks[p] = 1 [P] ; // Gabeln process Philosopher [int p 0,..., P 1] while (1) Denke; P(fork[p]); // rechte Gabel P(fork[(p + 1) mod P]); // linke Gabel Esse; V(fork[p]); // rechte Gabel V(fork[(p + 1) mod P]); // linke Gabel Die speisenden Philosophen: Faire Lösung parallel philosphers 2 const int P = 5; // Anzahl Philosophen 44
45 4.5 Leser-Schreiber-Problem const int think =0, hungry=1, eat=2; Semaphore mutex =1; Semaphore s[p] = 0 [P] ; // essender Philosoph int state[p] = think [P] ; // Zustand process Philosopher [int p 0,..., P 1] void test (int i) int r=(i + P 1) mod P, l=(i + 1) mod P; if (state[i]==hungry state[l] eat state[r] eat) state[i] = eat; V(s[i]); while (1) Denke; P(mutex); state[p] = hungry; test(p); V(mutex); P(s[p]); // Gabeln nehmen Esse; P(mutex); state[p] = think; test((p + P 1) mod P); test((p + 1) mod P); V(mutex); // Gabeln weglegen 4.5 Leser-Schreiber-Problem Leser-Schreiber-Problem: Naive Lösung 45
46 4 Synchronisationsmechanismen bei gemeinsamen Speicher parallel readers writers 1 const int m = 8, n = 4; Semaphore rw=1; Semaphore mutexr=1; int nr=0; // Anzahl Leser und Schreiber // Zugriff auf Datenbank // Anzahl Leser absichern // Anzahl zugreifender Leser process Reader [int i 0,..., m 1] while (1) P(mutexR); // Zugriff Leserzähler nr = nr+1; // Ein Leser mehr if (nr==1) P(rw); // Erster wartet auf DB V(mutexR); // nächster Leser kann rein lese Datenbank; P(mutexR); nr = nr-1; if (nr==0) V(rw); V(mutexR); process Writer [int j 0,..., n 1] while (1) P(rw); schreibe Datenbank; V(rw); // Zugriff Leserzähler // Ein Leser weniger // Letzter gibt DB frei // nächster Leser kann rein // Zugriff auf DB // gebe DB frei Leser-Schreiber-Problem: Faire Lösung parallel readers writers 2 const int m = 8, n = 4; int nr =0, nw =0, dr =0, dw =0; Semaphore e=1; Semaphore r=0; // Anzahl Leser und Schreiber // Zustand // Zugriff auf Warteschlange // Verzögern der Leser 46
47 4.5 Leser-Schreiber-Problem Semaphore w=0; const int reader =1, writer =2; int buf [n + m]; int front=0, rear=0; // Verzögern der Schreiber // Marken // Wer wartet? // Zeiger int wake_up (void) if (nw==0 dr>0 buf [rear]==reader) dr = dr-1; rear = (rear +1) mod (n + m); V(r); return 1; // darf genau einer ausführen // habe einen Leser geweckt if (nw==0 nr==0 dw>0 buf [rear]==writer) dw = dw-1; rear = (rear +1) mod (n + m); V(w); return 1; return 0; // habe einen Schreiber geweckt // habe keinen geweckt process Reader [int i 0,..., m 1] while (1) P(e); // will Zustand verändern if(nw>0 dw>0) buf [front] = reader; // in Warteschlange front = (front+1) mod (n + m); dr = dr+1; V(e); // Zustand freigeben P(r); // warte bis Leser dran sind // hier ist e = 0! nr = nr+1; // hier ist nur einer if (wake_up()==0) // kann einer geweckt werden? V(e); // nein, setze e = 1 lese Datenbank; P(e); // will Zustand verändern nr = nr-1; if (wake_up()==0) // kann einer geweckt werden? V(e); // nein, setze e = 1 47
48 4 Synchronisationsmechanismen bei gemeinsamen Speicher process Writer [int j 0,..., n 1] while (1) P(e); // will Zustand verändern if(nr>0 nw>0) buf [front] = writer; // in Warteschlange front = (front+1) mod (n + m); dw = dw+1; V(e); P(w); nw = nw+1; V(e); // Zustand freigeben // warte bis an der Reihe // hier ist e = 0! // hier ist nur einer // hier braucht keiner geweckt werden schreibe Datenbank; // exklusiver Zugriff P(e); // will Zustand verändern nw = nw-1; if (wake_up()==0) // kann einer geweckt werden? V(e); // nein, setze e = 1 48
49 5 PThreads 5.1 Allgemeines Prozesse und Threads Ein Unix-Prozess hat IDs (process,user,group) Umgebungsvariablen Verzeichnis Programmcode Register, Stack, Heap Dateideskriptoren, Signale message queues, pipes, shared memory Segmente Shared libraries Jeder Prozess besitzt seinen eigenen Adressraum Threads existieren innerhalb eines Prozesses Threads teilen sich einen Adressraum Ein Thread besteht aus ID Stack pointer Register Scheduling Eigenschaften Signale Erzeugungs- und Umschaltzeiten sind kürzer Parallele Funktion Pthreads Jeder Hersteller hatte eine eigene Implementierung von Threads oder light weight processes 1995: IEEE POSIX c Standard (es gibt mehrere drafts ) Standard Dokument ist kostenpflichtig Definiert Threads in portabler Weise Besteht aus C Datentypen und Funktionen Header file pthread.h Bibliotheksname nicht genormt. In Linux -lpthread Übersetzen in Linux: gcc <file> -lpthread Pthreads Übersicht Alle Namen beginnen mit pthread_ pthread_ Thread Verwaltung und sonstige Routinen pthread_attr_ Thread Attributobjekte pthread_mutex_ Alles was mit Mutexvariablen zu tun hat pthread_mutex_attr_ Attribute für Mutexvariablen pthread_cond_ Bedingungsvariablen (condition variables) pthread_cond_attr_ Attribute für Bedingungsvariablen 49
50 5 PThreads 5.2 Thread Management Erzeugen von Threads pthread_t : Datentyp für einen Thread. Opaquer Typ: Datentyp wird in der Bibliothek definiert und wird von deren Funktionen bearbeitet. Inhalt ist implementierungsabhängig. int pthread_create(thread,attr,start_routine,arg) : Startet die Funktion start_routine als Thread. thread : Zeiger auf eine pthread_t Struktur. Dient zum identifizieren des Threads. attr : Threadattribute besprechen wir unten. Default ist NULL. start_routine Zeiger auf eine Funktion vom Typ void* func (void*); arg : void*-zeiger der der Funktion als Argument mitgegeben wird. Rückgabewert größer Null zeigt Fehler an. Threads können weitere Threads starten, maximale Zahl von Threads ist implementierungsabhängig Beenden von Threads Es gibt folgende Möglichkeiten einen Thread zu beenden: Der Thread beendet seine start_routine() Der Thread ruft pthread_exit() Der Thread wird von einem anderen Thread mittels pthread_cancel() beendet Der Prozess wird durch exit() oder durch das Ender der main()-funktion beendet pthread_exit(void* status) Beendet den rufenden Thread. Zeiger wird gespeichert und kann mit pthread_join (s.u.) abgefragt werden (Rückgabe von Ergebnissen). Falls main() diese Routine ruft so laufen existierende Threads weiter und der Prozess wird nicht beendet. Schließt keine geöffneten Dateien! Warten auf Threads Peer Modell: Mehrere gleichberechtigte Threads bearbeiten eine Aufgabe. Programm wird beendet wenn alle Threads fertig sind Erfordert Warten eines Threads bis alle anderen beendet sind Dies ist eine Form der Synchronisation int pthread_join(pthread_t thread, void **status); Wartet bis der angegebene Thread sich beendet Der Thread kann mittel pthread_exit() einen void*-zeiger zurückgeben, Gibt man NULL als Statusparameter, so verzichtet man auf den Rückgabewert 50
51 5.2 Thread Management Thread Management Beispiel #include <pthread.h> /* for threads */ void* prod (int *i) /* Producer thread */ int count=0; while (count<100000) count++; void* con (int *j) /* Consumer thread */ int count=0; while (count< ) count++; int main (int argc, char *argv[]) /* main program */ pthread_t thread_p, thread_c; int i,j; i = 1; pthread_create(&thread_p,null,(void*(*)(void*)) prod,(void *) &i); j = 1; pthread_create(&thread_c, NULL,(void*(*)(void*)) con, (void *) &j); pthread_join(thread_p, NULL); pthread_join(thread_c, NULL); return(0); Übergeben von Argumenten Übergeben von mehreren Argumenten erfordert Definition eines eigenen Datentyps: struct argtype int rank; int a,b; double c;; struct argtype args[p]; pthread_t threads[p]; for (i=0; i<p; i++) args[i].rank=i; args[i].a=... pthread_create(threads+i,null,(void*(*)(void*)) prod, (void *)args+i); Folgendes Beispiel enthält zwei Fehler: pthread_t threads[p]; for (i=0; i<p; i++) pthread_create(threads+i,null,(void*(*)(void*)) prod,&i); Inhalt von i ist möglicherweise verändert bevor Thread liest Falls i eine Stackvariable ist exisitiert diese möglicherweise nicht mehr Thread Identifiers pthread_t pthread_self(void); Liefert die eigene Thread-ID 51
52 5 PThreads int pthread_equal(pthread_t t1, pthread_t t2); Liefert wahr (Wert>0) falls die zwei IDs identisch sind Konzept des opaque data type Join/Detach Ein Thread im Zustand PTHREAD_CREATE_JOINABLE gibt seine Resourcen erst frei, wenn pthread_join ausgeführt wird. Ein Thread im Zustand PTHREAD_CREATE_DETACHED gibt seine Resourcen frei sobald er beendet wird. In diesem Fall ist pthread_join nicht erlaubt. Default ist PTHREAD_CREATE_JOINABLE, das implementieren aber nicht alle Bibliotheken. Deshalb besser: pthread_attr_t attr; pthread_attr_init(&attr); pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE); int rc = pthread_create(&t,&attr,(void*(*)(void*))func,null);... pthread_join(&t,null); pthread_attr_destroy(&attr); Gibt Beispiel für die Verwendung von Attributen 5.3 Synchronisation Mutex Variablen Mutex Variablen realisieren den wechselseitigen Ausschluss innerhalb der Pthreads Bibliothek Erzeugen und initialisieren einer Mutex Variable pthread_mutex_t mutex; pthread_mutex_init(&mutex,null); Mutex Variable ist nach Initialisierung im Zustand frei Eintritt in den kritischen Abschnitt: pthread_mutex_lock(&mutex); Diese Funktion blockiert solange bis man drin ist. Verlasse kritischen Abschnitt pthread_mutex_unlock(&mutex); Gebe Resourcen der Mutex Variable wieder frei pthread_mutex_destroy(&mutex); 52
53 5.3 Synchronisation Bedingungsvariablen Bedingungsvariablen erlauben das inaktive Warten eines Prozesses bis eine gewisse Bedingung eingetreten ist Einfachstes Beispiel: Flaggenvariablen (siehe Beispiel unten) Zu einer Bedingungssynchronisation gehören drei Dinge: Eine Variable vom Typ pthread_cond_t, die das inaktive Warten realisiert Eine Variable vom Typ pthread_mutex_t, die den wechselseitigen Ausschluss beim Ändern der Bedingung realisiert Eine globale Variable, deren Wert die Berechnung der Bedingung erlaubt Erzeugen/Löschen int pthread_cond_init(pthread_cond_t *cond, pthread_condattr_t *attr); initialisiert eine Bedingungsvariable Im einfachsten Fall: pthread_cond_init(&cond,null) int pthread_cond_destroy(pthread_cond_t *cond); gibt die Resourcen einer Bedingungsvariablen wieder frei Wait int pthread_cond_wait(pthread_cond_t *cond,pthread_mutex_t *mutex); blockiert den aufrufenden Thread bis für die Bedingungsvariable die Funktion pthread_signal() aufgerufen wird Beim Aufruf von pthread_wait() muss der Thread auch im Besitz des Locks sein pthread_wait() verlässt das Lock und wartet auf das Signal in atomarer Weise Nach der Rückkehr aus pthread_wait() ist der Thread wieder im Besitz des Locks Nach Rückkehr muss die Bedingung nicht unbeding erfüllt sein Mit einer Bedingungsvariablen sollte man nur genau ein Lock verwenden Signal int pthread_cond_signal(pthread_cond_t *cond); Weckt einen Prozess der auf der Bedingungsvariablen ein pthread_wait() ausgeführt hat. Falls keiner wartet hat die Funktion keinen Effekt. Beim Aufruf sollte der Prozess im Besitz des zugehörigen Locks sein Nach dem Aufruf sollte das Lock freigegeben werden. Erst die Freigabe des Locks erlaubt es dem wartenden Prozess aus der pthread_wait() Funktion zurückzukehren int pthread_cond_broadcast(pthread_cond_t *cond); weckt alle Threads die auf der Bedingungsvariablen ein pthread_wait() ausgeführt haben. Diese bewerben sich dann um das Lock. 53
54 5 PThreads Beispiel I #include<stdio.h> #include<pthread.h> /* for threads */ int arrived_flag=0,continue_flag=0; pthread_mutex_t arrived_mutex, continue_mutex; pthread_cond_t arrived_cond, continue_cond; pthread_attr_t attr; int main (int argc, char *argv[]) pthread_t thread_p, thread_c; pthread_mutex_init(&arrived_mutex,null); pthread_cond_init(&arrived_cond,null); pthread_mutex_init(&continue_mutex,null); pthread_cond_init(&continue_cond,null); Beispiel II pthread_attr_init(&attr); pthread_attr_setdetachstate(&attr, PTHREAD_CREATE_JOINABLE); pthread_create(&thread_p,&attr,(void*(*)(void*)) prod,null); pthread_create(&thread_c,&attr,(void*(*)(void*)) con,null); pthread_join(thread_p, NULL); pthread_join(thread_c, NULL); pthread_attr_destroy(&attr); pthread_cond_destroy(&arrived_cond); pthread_mutex_destroy(&arrived_mutex); pthread_cond_destroy(&continue_cond); pthread_mutex_destroy(&continue_mutex); return(0); Beispiel III void prod (void* p) /* Producer thread */ int i; for (i=0; i<100; i++) printf("ping\n"); pthread_mutex_lock(&arrived_mutex); 54
55 5.4 Threads und Objektorientierung arrived_flag = 1; pthread_cond_signal(&arrived_cond); pthread_mutex_unlock(&arrived_mutex); pthread_mutex_lock(&continue_mutex); while (continue_flag==0) pthread_cond_wait(&continue_cond,&continue_mutex); continue_flag = 0; pthread_mutex_unlock(&continue_mutex); Beispiel IV void con (void* p) /* Consumer thread */ int i; for (i=0; i<100; i++) pthread_mutex_lock(&arrived_mutex); while (arrived_flag==0) pthread_cond_wait(&arrived_cond,&arrived_mutex); arrived_flag = 0; pthread_mutex_unlock(&arrived_mutex); printf("pong\n"); pthread_mutex_lock(&continue_mutex); continue_flag = 1; pthread_cond_signal(&continue_cond); pthread_mutex_unlock(&continue_mutex); 5.4 Threads und Objektorientierung Threads und OO Offensichtlich sind Pthreads relativ unpraktisch zu programmieren Mutexes, Bedingungsvariablen, Flags und Semaphore sollten objektorientiert realisiert werden. Umständliche init/destroy Aufrufe können in Konstruktoren/Destruktoren versteckt werden Threads werden in Aktive Objekte umgesetzt Ein Aktives Objekt läuft unabhängig von anderen Objekten Thread Tools 55
56 5 PThreads #include<iostream> #include" basicthread. hh" #include" threadpool. hh" #include"mutex.hh" #include"barrier.hh" #include" flag. hh" TT: : Mutex lock ; TT: : Flag flag ; TT: : Barrier barrier (10); class Minimalistic : public TT: : BasicThread public : virtual void run () flag. wait ( ) ; lock. lock ( ) ; std : : cout << "thread running" << std : : endl ; lock. unlock ( ) ; ; class SelfStartingWithArgs : public TT: : BasicThread public : SelfStartingWithArgs ( int i ) : rank ( i ) this >start ( ) ; ~SelfStartingWithArgs () this >stop ( ) ; virtual void run () lock. lock ( ) ; std : : cout << "thread " << rank << " running" << std : : endl ; lock. unlock ( ) ; flag. signal ( ) ; private : int rank ; ; c l a s s PoolElement : public TT: : ThreadPoolElement<PoolElement> public : virtual void run () barrier. sync ( ) ; std : : cout << "array thread " << this >context. i () << " of " << this >context. s i z e () << std : : endl ; 56
57 5.5 Ausklang ; const PoolElement& next = this >context. thread ( this >context. i () %this >context. s i z e ( ) ) ; int main ( int argc, char argv [ ] ) Minimalistic a ; a. start ( ) ; SelfStartingWithArgs b ( 5 ) ; TT: : ThreadPool<PoolElement> c (10); c. start ( ) ; a. stop ( ) ; c. stop ( ) ; 5.5 Ausklang Thread Safety Darunter versteht man ob eine Funktion/Bibliothek von mehreren Threads gleichzeitig genutzt werden kann. Eine Funktion ist reentrant falls sie von mehreren Threads gleichzeitig gerufen werden kann. Eine Funktionen, die keine globalen Variablen benutzt ist reentrant Das Laufzeitsystem muss gemeinsam benutzte Resourcen (z.b. den Stack) unter wechselseitigem Ausschluss bearbeiten Der GNU C Compiler muss beim Übersetzen mit einem geeigneten Thread-Modell konfiguriert werden. Mit gcc -v erfährt man das Thread-Modell STL: Allokieren ist threadsicher, Zugriff mehrerer Threads auf einen Container muss vom Benutzer abgesichert werden. Links 1 PThreads tutorial vom LLNL 2 Noch ein Tutorial html 57
58 5 PThreads 58
PThreads. Pthreads. Jeder Hersteller hatte eine eigene Implementierung von Threads oder light weight processes
 PThreads Prozesse und Threads Ein Unix-Prozess hat IDs (process,user,group) Umgebungsvariablen Verzeichnis Programmcode Register, Stack, Heap Dateideskriptoren, Signale message queues, pipes, shared memory
PThreads Prozesse und Threads Ein Unix-Prozess hat IDs (process,user,group) Umgebungsvariablen Verzeichnis Programmcode Register, Stack, Heap Dateideskriptoren, Signale message queues, pipes, shared memory
Paralleles Höchstleistungsrechnen Einführung
 1/40 Paralleles Höchstleistungsrechnen Einführung Peter Bastian Interdisziplinäres Zentrum für Wissenschaftliches Rechnen Universität Heidelberg Im Neuenheimer Feld 368 D-69120 Heidelberg email: Peter.Bastian@iwr.uni-heidelberg.de
1/40 Paralleles Höchstleistungsrechnen Einführung Peter Bastian Interdisziplinäres Zentrum für Wissenschaftliches Rechnen Universität Heidelberg Im Neuenheimer Feld 368 D-69120 Heidelberg email: Peter.Bastian@iwr.uni-heidelberg.de
Parallele Programmiermodelle II
 Parallele Programmiermodelle II Stefan Lang Interdisziplinäres Zentrum für Wissenschaftliches Rechnen Universität Heidelberg INF 368, Raum 532 D-69120 Heidelberg phone: 06221/54-8264 email: Stefan.Lang@iwr.uni-heidelberg.de
Parallele Programmiermodelle II Stefan Lang Interdisziplinäres Zentrum für Wissenschaftliches Rechnen Universität Heidelberg INF 368, Raum 532 D-69120 Heidelberg phone: 06221/54-8264 email: Stefan.Lang@iwr.uni-heidelberg.de
Prozesse und Threads. wissen leben WWU Münster
 Münster Multi Threading in C++ 1 /19 Prozesse und Threads Ein Unix-Prozess hat IDs (process,user,group) Umgebungsvariablen Verzeichnis Programmcode Register, Stack, Heap Dateideskriptoren, Signale message
Münster Multi Threading in C++ 1 /19 Prozesse und Threads Ein Unix-Prozess hat IDs (process,user,group) Umgebungsvariablen Verzeichnis Programmcode Register, Stack, Heap Dateideskriptoren, Signale message
Softwaresysteme I Übungen Jürgen Kleinöder Universität Erlangen-Nürnberg Informatik 4, 2007 U9.fm
 U9 9. Übung U9 9. Übung U9-1 Überblick Besprechung Aufgabe 6 (printdir) Posix-Threads U9.1 U9-2 Motivation von Threads U9-2 Motivation von Threads UNIX-Prozesskonzept: eine Ausführungsumgebung (virtueller
U9 9. Übung U9 9. Übung U9-1 Überblick Besprechung Aufgabe 6 (printdir) Posix-Threads U9.1 U9-2 Motivation von Threads U9-2 Motivation von Threads UNIX-Prozesskonzept: eine Ausführungsumgebung (virtueller
U9-3 Vergleich von Thread-Konzepten. U9-2 Motivation von Threads. U9-3 Vergleich von Thread-Konzepten (2) U9-1 Überblick
 U9-1 Überblick") U9 9. Übung U9 9. Übung U9-1 Überblick Besprechung Aufgabe 6 (printdir) Posix-Threads U9.1 User-Level Threads: Federgewichtige Prozesse Realisierung von Threads auf Anwendungsebene innerhalb eines Prozesses
U9 9. Übung U9 9. Übung U9-1 Überblick Besprechung Aufgabe 6 (printdir) Posix-Threads U9.1 User-Level Threads: Federgewichtige Prozesse Realisierung von Threads auf Anwendungsebene innerhalb eines Prozesses
I 7. Übung. I-1 Überblick. Besprechung Aufgabe 5 (mysh) Online-Evaluation. Posix Threads. Ü SoS I I.1
 Online-Evaluation. Posix Threads. Ü SoS I I.1") I 7. Übung I 7. Übung I-1 Überblick Besprechung Aufgabe 5 (mysh) Online-Evaluation Posix Threads I.1 I-2 Evaluation I-2 Evaluation Online-Evaluation von Vorlesung und Übung SOS zwei TANs, zwei Fragebogen
I 7. Übung I 7. Übung I-1 Überblick Besprechung Aufgabe 5 (mysh) Online-Evaluation Posix Threads I.1 I-2 Evaluation I-2 Evaluation Online-Evaluation von Vorlesung und Übung SOS zwei TANs, zwei Fragebogen
POSIX-Threads. Aufgabe 9 SP - Ü U10.1
 U10 10. Übung U10 10. Übung POSIX-Threads Aufgabe 9 U10.1 U10-1 Motivation von Threads U10-1 Motivation von Threads UNIX-Prozesskonzept: eine Ausführungsumgebung (virtueller Adressraum, Rechte, Priorität,...)
U10 10. Übung U10 10. Übung POSIX-Threads Aufgabe 9 U10.1 U10-1 Motivation von Threads U10-1 Motivation von Threads UNIX-Prozesskonzept: eine Ausführungsumgebung (virtueller Adressraum, Rechte, Priorität,...)
Threads Einführung. Zustände von Threads
 Threads Einführung Parallelität : Zerlegung von Problemstellungen in Teilaufgaben, die parallelel ausgeführt werden können (einfachere Strukturen, eventuell schneller, Voraussetzung für Mehrprozessorarchitekturen)
Threads Einführung Parallelität : Zerlegung von Problemstellungen in Teilaufgaben, die parallelel ausgeführt werden können (einfachere Strukturen, eventuell schneller, Voraussetzung für Mehrprozessorarchitekturen)
Pthreads. David Klaftenegger. Seminar: Multicore Programmierung Sommersemester
 Seminar: Multicore Programmierung Sommersemester 2009 16.07.2009 Inhaltsverzeichnis 1 Speichermodell 2 3 Implementierungsvielfalt Prioritätsinversion 4 Threads Speichermodell Was sind Threads innerhalb
Seminar: Multicore Programmierung Sommersemester 2009 16.07.2009 Inhaltsverzeichnis 1 Speichermodell 2 3 Implementierungsvielfalt Prioritätsinversion 4 Threads Speichermodell Was sind Threads innerhalb
U8-1 Motivation von Threads. U8-2 Vergleich von Thread-Konzepten. U8-2 Vergleich von Thread-Konzepten (2) Motivation
 Motivation") U8 POSIX-Threads U8 POSIX-Threads U8-1 Motivation von Threads U8-1 Motivation von Threads Motivation Thread-Konzepte UNIX-Prozesskonzept: eine Ausführungsumgebung (virtueller Adressraum, Rechte, Priorität,...)
U8 POSIX-Threads U8 POSIX-Threads U8-1 Motivation von Threads U8-1 Motivation von Threads Motivation Thread-Konzepte UNIX-Prozesskonzept: eine Ausführungsumgebung (virtueller Adressraum, Rechte, Priorität,...)
Shared-Memory Programmiermodelle
 Shared-Memory Programmiermodelle mehrere, unabhängige Programmsegmente greifen direkt auf gemeinsame Variablen ( shared variables ) zu Prozeßmodell gemäß fork/join Prinzip, z.b. in Unix: fork: Erzeugung
Shared-Memory Programmiermodelle mehrere, unabhängige Programmsegmente greifen direkt auf gemeinsame Variablen ( shared variables ) zu Prozeßmodell gemäß fork/join Prinzip, z.b. in Unix: fork: Erzeugung
U8 POSIX-Threads U8 POSIX-Threads
 U8 POSIX-Threads U8 POSIX-Threads Motivation Thread-Konzepte pthread-api pthread-koordinierung U8.1 U8-1 Motivation von Threads U8-1 Motivation von Threads UNIX-Prozesskonzept: eine Ausführungsumgebung
U8 POSIX-Threads U8 POSIX-Threads Motivation Thread-Konzepte pthread-api pthread-koordinierung U8.1 U8-1 Motivation von Threads U8-1 Motivation von Threads UNIX-Prozesskonzept: eine Ausführungsumgebung
Betriebssysteme. Vorlesung im Herbstsemester 2010 Universität Mannheim. Kapitel 6: Speicherbasierte Prozessinteraktion
 Betriebssysteme Vorlesung im Herbstsemester 2010 Universität Mannheim Kapitel 6: Speicherbasierte Prozessinteraktion Felix C. Freiling Lehrstuhl für Praktische Informatik 1 Universität Mannheim Vorlesung
Betriebssysteme Vorlesung im Herbstsemester 2010 Universität Mannheim Kapitel 6: Speicherbasierte Prozessinteraktion Felix C. Freiling Lehrstuhl für Praktische Informatik 1 Universität Mannheim Vorlesung
Tafelübung zu BS 2. Threadsynchronisation
 Tafelübung zu BS 2. Threadsynchronisation Olaf Spinczyk Arbeitsgruppe Eingebettete Systemsoftware Lehrstuhl für Informatik 12 TU Dortmund olaf.spinczyk@tu-dortmund.de http://ess.cs.uni-dortmund.de/~os/
Tafelübung zu BS 2. Threadsynchronisation Olaf Spinczyk Arbeitsgruppe Eingebettete Systemsoftware Lehrstuhl für Informatik 12 TU Dortmund olaf.spinczyk@tu-dortmund.de http://ess.cs.uni-dortmund.de/~os/
Threads. Foliensatz 8: Threads Folie 1. Hans-Georg Eßer, TH Nürnberg Systemprogrammierung, Sommersemester 2015
 Sep 19 14:20:18 amd64 sshd[20494]: Accepted rsa for esser from ::ffff:87.234.201.207 port 61557 Sep 19 14:27:41 amd64 syslog-ng[7653]: STATS: dropped 0 Sep 20 01:00:01 amd64 /usr/sbin/cron[29278]: (root)
Sep 19 14:20:18 amd64 sshd[20494]: Accepted rsa for esser from ::ffff:87.234.201.207 port 61557 Sep 19 14:27:41 amd64 syslog-ng[7653]: STATS: dropped 0 Sep 20 01:00:01 amd64 /usr/sbin/cron[29278]: (root)
Tafelübung zu BS 2. Threadsynchronisation
 Tafelübung zu BS 2. Threadsynchronisation Olaf Spinczyk Arbeitsgruppe Eingebettete Systemsoftware Lehrstuhl für Informatik 12 TU Dortmund olaf.spinczyk@tu-dortmund.de http://ess.cs.uni-dortmund.de/~os/
Tafelübung zu BS 2. Threadsynchronisation Olaf Spinczyk Arbeitsgruppe Eingebettete Systemsoftware Lehrstuhl für Informatik 12 TU Dortmund olaf.spinczyk@tu-dortmund.de http://ess.cs.uni-dortmund.de/~os/
Computergrundlagen Moderne Rechnerarchitekturen
 Computergrundlagen Moderne Rechnerarchitekturen Axel Arnold Institut für Computerphysik Universität Stuttgart Wintersemester 2010/11 Aufbau eines modernen Computers DDR3- Speicher Prozessor Prozessor PEG
Computergrundlagen Moderne Rechnerarchitekturen Axel Arnold Institut für Computerphysik Universität Stuttgart Wintersemester 2010/11 Aufbau eines modernen Computers DDR3- Speicher Prozessor Prozessor PEG
Computergrundlagen Moderne Rechnerarchitekturen
 Aufbau eines modernen Computers Computergrundlagen Moderne Rechnerarchitekturen Axel Arnold Institut für Computerphysik Universität Stuttgart DDR3- Speicher Prozessor Prozessor PEG Graphikkarte(n) weitere
Aufbau eines modernen Computers Computergrundlagen Moderne Rechnerarchitekturen Axel Arnold Institut für Computerphysik Universität Stuttgart DDR3- Speicher Prozessor Prozessor PEG Graphikkarte(n) weitere
Distributed Memory Computer (DMC)
") Distributed Memory Computer (DMC) verteilter Speicher: jeder Prozessor kann nur auf seinen lokalen Speicher zugreifen Kopplung mehrerer Prozessoren über E/A-Schnittstellen und Verbindungsnetzwerk, nicht
Distributed Memory Computer (DMC) verteilter Speicher: jeder Prozessor kann nur auf seinen lokalen Speicher zugreifen Kopplung mehrerer Prozessoren über E/A-Schnittstellen und Verbindungsnetzwerk, nicht
Homogene Multi-Core-Prozessor-Architekturen
 Homogene Multi-Core-Prozessor-Architekturen Praktikum Parallele Rechnerarchitekturen Stefan Potyra Lehrstuhl für Informatik 3 (Rechnerarchitektur) Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2009
Homogene Multi-Core-Prozessor-Architekturen Praktikum Parallele Rechnerarchitekturen Stefan Potyra Lehrstuhl für Informatik 3 (Rechnerarchitektur) Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2009
Tafelübung zu BS 2. Threadsynchronisation
 Tafelübung zu BS 2. Threadsynchronisation Olaf Spinczyk Arbeitsgruppe Eingebettete Systemsoftware Lehrstuhl für Informatik 12 TU Dortmund olaf.spinczyk@tu-dortmund.de http://ess.cs.uni-dortmund.de/~os/
Tafelübung zu BS 2. Threadsynchronisation Olaf Spinczyk Arbeitsgruppe Eingebettete Systemsoftware Lehrstuhl für Informatik 12 TU Dortmund olaf.spinczyk@tu-dortmund.de http://ess.cs.uni-dortmund.de/~os/
Concurrency and Processes of Pthreads
 Concurrency and Processes of Pthreads Pthreads Pthreads is a POSIX standard for describing a thread model, it specifies the API and the semantics of the calls. POSIX: Portable Operating System Interface
Concurrency and Processes of Pthreads Pthreads Pthreads is a POSIX standard for describing a thread model, it specifies the API and the semantics of the calls. POSIX: Portable Operating System Interface
Wissenschaftliches Rechen
 Wissenschaftliches Rechen Paralleles Höchstleistungsrechnen Christian Engwer Uni Münster April 5, 2011 Christian Engwer (Uni Münster) Wissenschaftliches Rechen April 5, 2011 1 / 20 Organisatorisches Vorlesung
Wissenschaftliches Rechen Paralleles Höchstleistungsrechnen Christian Engwer Uni Münster April 5, 2011 Christian Engwer (Uni Münster) Wissenschaftliches Rechen April 5, 2011 1 / 20 Organisatorisches Vorlesung
Verteilte Systeme Teil 2
 Distributed Computing HS 2012 Prof. Dr. Roger Wattenhofer, Dr. Thomas Locher C. Decker, B. Keller, S. Welten Prüfung Verteilte Systeme Teil 2 Freitag, 8. Februar 2013 9:00 12:00 Die Anzahl Punkte pro Teilaufgabe
Distributed Computing HS 2012 Prof. Dr. Roger Wattenhofer, Dr. Thomas Locher C. Decker, B. Keller, S. Welten Prüfung Verteilte Systeme Teil 2 Freitag, 8. Februar 2013 9:00 12:00 Die Anzahl Punkte pro Teilaufgabe
Exkurs: Paralleles Rechnen
 Münster Exkurs: Paralleles Rechnen Münster Exkurs: Paralleles Rechnen 2 /21 Konzepte für Parallelrechner P P P C C C Gemeinsamer Speicher Verteilter Speicher Verbindungsnetzwerk Speicher M, Münster Exkurs:
Münster Exkurs: Paralleles Rechnen Münster Exkurs: Paralleles Rechnen 2 /21 Konzepte für Parallelrechner P P P C C C Gemeinsamer Speicher Verteilter Speicher Verbindungsnetzwerk Speicher M, Münster Exkurs:
Übungen zu Systemprogrammierung 1
 Übungen zu Systemprogrammierung 1 Ü5 Threads und Koordinierung Sommersemester 2018 Christian Eichler, Jürgen Kleinöder Lehrstuhl für Informatik 4 Friedrich-Alexander-Universität Erlangen-Nürnberg Lehrstuhl
Übungen zu Systemprogrammierung 1 Ü5 Threads und Koordinierung Sommersemester 2018 Christian Eichler, Jürgen Kleinöder Lehrstuhl für Informatik 4 Friedrich-Alexander-Universität Erlangen-Nürnberg Lehrstuhl
Parallele Rechnerarchitektur II
 Parallele Rechnerarchitektur II Stefan Lang Interdisziplinäres Zentrum für Wissenschaftliches Rechnen Universität Heidelberg INF 368, Raum 532 D-692 Heidelberg phone: 622/54-8264 email: Stefan.Lang@iwr.uni-heidelberg.de
Parallele Rechnerarchitektur II Stefan Lang Interdisziplinäres Zentrum für Wissenschaftliches Rechnen Universität Heidelberg INF 368, Raum 532 D-692 Heidelberg phone: 622/54-8264 email: Stefan.Lang@iwr.uni-heidelberg.de
Übungen zu Systemprogrammierung 1 (SP1)
") Übungen zu Systemprogrammierung 1 (SP1) Ü5 Threads und Koordinierung Andreas Ziegler, Stefan Reif, Jürgen Kleinöder Lehrstuhl für Informatik 4 Verteilte Systeme und Betriebssysteme Friedrich-Alexander-Universität
Übungen zu Systemprogrammierung 1 (SP1) Ü5 Threads und Koordinierung Andreas Ziegler, Stefan Reif, Jürgen Kleinöder Lehrstuhl für Informatik 4 Verteilte Systeme und Betriebssysteme Friedrich-Alexander-Universität
Programmiertechnik. Teil 4. C++ Funktionen: Prototypen Overloading Parameter. C++ Funktionen: Eigenschaften
 Programmiertechnik Teil 4 C++ Funktionen: Prototypen Overloading Parameter C++ Funktionen: Eigenschaften Funktionen (Unterprogramme, Prozeduren) fassen Folgen von Anweisungen zusammen, die immer wieder
Programmiertechnik Teil 4 C++ Funktionen: Prototypen Overloading Parameter C++ Funktionen: Eigenschaften Funktionen (Unterprogramme, Prozeduren) fassen Folgen von Anweisungen zusammen, die immer wieder
Inhalt. Übungen zu Systemnahe Programmierung in C (SPiC) Inhalt. Motivation
 Inhalt. Motivation") Übungen zu Systemnahe Programmierung in C (SPiC) Sebastian Maier (Lehrstuhl Informatik 4) Übung 0 Inhalt vs. Prozesse POSIX Stoppuhr Sommersemester 206 Lehrstuhl Informatik 4 Übungen zu SPiC (SS 206) 2
Übungen zu Systemnahe Programmierung in C (SPiC) Sebastian Maier (Lehrstuhl Informatik 4) Übung 0 Inhalt vs. Prozesse POSIX Stoppuhr Sommersemester 206 Lehrstuhl Informatik 4 Übungen zu SPiC (SS 206) 2
Übungen zu Systemprogrammierung 1 (SP1)
") Übungen zu Systemprogrammierung 1 (SP1) Ü7 Threads und Koordinierung Jens Schedel, Christoph Erhardt, Jürgen Kleinöder Lehrstuhl für Informatik 4 Verteilte Systeme und Betriebssysteme Friedrich-Alexander-Universität
Übungen zu Systemprogrammierung 1 (SP1) Ü7 Threads und Koordinierung Jens Schedel, Christoph Erhardt, Jürgen Kleinöder Lehrstuhl für Informatik 4 Verteilte Systeme und Betriebssysteme Friedrich-Alexander-Universität
Evaluation. Einleitung. Implementierung Integration. Zusammenfassung Ausblick
 Christopher Schleiden Bachelor Kolloquium 15.09.2009 Einleitung Evaluation Implementierung Integration Zusammenfassung Ausblick Einleitung laperf Lineare Algebra Bibliothek für C++ Möglichkeit zur Integration
Christopher Schleiden Bachelor Kolloquium 15.09.2009 Einleitung Evaluation Implementierung Integration Zusammenfassung Ausblick Einleitung laperf Lineare Algebra Bibliothek für C++ Möglichkeit zur Integration
Markus Klußmann, Amjad Saadeh Institut für Informatik. Pthreads. von Markus Klußmann und Amjad Saadeh. Pthreads
 Markus Klußmann, Amjad Saadeh Institut für Informatik Pthreads von Markus Klußmann und Amjad Saadeh Pthreads Inhalt - Was sind Threads? - Prozess vs. Thread - Kurzer Überblick POSIX - Threads im Betriebssystem
Markus Klußmann, Amjad Saadeh Institut für Informatik Pthreads von Markus Klußmann und Amjad Saadeh Pthreads Inhalt - Was sind Threads? - Prozess vs. Thread - Kurzer Überblick POSIX - Threads im Betriebssystem
Kapitel 5. Parallelverarbeitung. Formen der Parallelität
 Kapitel 5 Parallelverarbeitung é Formen der Parallelität é Klassifikation von parallelen Rechnerarchitekturen é Exkurs über Verbindungsstrukturen Bernd Becker Technische Informatik I Formen der Parallelität
Kapitel 5 Parallelverarbeitung é Formen der Parallelität é Klassifikation von parallelen Rechnerarchitekturen é Exkurs über Verbindungsstrukturen Bernd Becker Technische Informatik I Formen der Parallelität
Übungen zu Systemnahe Programmierung in C (SPiC) Sommersemester 2018
 Sommersemester 2018") Übungen zu Systemnahe Programmierung in C (SPiC) Sommersemester 2018 Übung 10 Benedict Herzog Sebastian Maier Lehrstuhl für Informatik 4 Friedrich-Alexander-Universität Erlangen-Nürnberg Lehrstuhl für
Übungen zu Systemnahe Programmierung in C (SPiC) Sommersemester 2018 Übung 10 Benedict Herzog Sebastian Maier Lehrstuhl für Informatik 4 Friedrich-Alexander-Universität Erlangen-Nürnberg Lehrstuhl für
Übungen zu Systemnahe Programmierung in C (SPiC)
") Übungen zu Systemnahe Programmierung in C (SPiC) Sebastian Maier (Lehrstuhl Informatik 4) Übung 10 Sommersemester 2016 Inhalt Threads Motivation Threads vs. Prozesse Kritische Abschnitte Speedup & Amdahl
Übungen zu Systemnahe Programmierung in C (SPiC) Sebastian Maier (Lehrstuhl Informatik 4) Übung 10 Sommersemester 2016 Inhalt Threads Motivation Threads vs. Prozesse Kritische Abschnitte Speedup & Amdahl
Übungen zu Systemnahe Programmierung in C (SPiC) Inhalt. Sebastian Maier (Lehrstuhl Informatik 4) Übung 10. Sommersemester 2016
 Inhalt. Sebastian Maier (Lehrstuhl Informatik 4) Übung 10. Sommersemester 2016") Übungen zu Systemnahe Programmierung in C (SPiC) Sebastian Maier (Lehrstuhl Informatik 4) Übung 10 Sommersemester 2016 Inhalt Motivation vs. Prozesse Kritische Abschnitte Speedup & Amdahl s Gesetz POSIX
Übungen zu Systemnahe Programmierung in C (SPiC) Sebastian Maier (Lehrstuhl Informatik 4) Übung 10 Sommersemester 2016 Inhalt Motivation vs. Prozesse Kritische Abschnitte Speedup & Amdahl s Gesetz POSIX
Aufgabe 9: recgrep rekursive, parallele Suche (letzte Aufgabe)
") U6 6. Übung (Mathematik / Technomathematik) U6 6. Übung (Mathematik / Technomathematik) Besprechung Aufgabe 4 (halde) Besprechung Aufgabe 5 (crawl) Besprechung der Mini-Klausur POSIX-Threads Motivation
U6 6. Übung (Mathematik / Technomathematik) U6 6. Übung (Mathematik / Technomathematik) Besprechung Aufgabe 4 (halde) Besprechung Aufgabe 5 (crawl) Besprechung der Mini-Klausur POSIX-Threads Motivation
Betriebssysteme Teil 11: Interprozess-Kommunikation
 Betriebssysteme Teil 11: Interprozess-Kommunikation 19.12.15 1 Übersicht Grundbegriffe Shared Memory Pipelines Messages Ports Sockets 2 Grundbegriffe Interprocess-Kommunikation = Austausch von Daten über
Betriebssysteme Teil 11: Interprozess-Kommunikation 19.12.15 1 Übersicht Grundbegriffe Shared Memory Pipelines Messages Ports Sockets 2 Grundbegriffe Interprocess-Kommunikation = Austausch von Daten über
Informatik I (D-MAVT)
") Informatik I (D-MAVT) Übungsstunde 8, 22.4.2009 simonmayer@student.ethz.ch ETH Zürich Aufgabe 1: Pointer & Structs Schauen wir s uns an! Aufgabe 2: Grossteils gut gemacht! Dynamische Arrays! Sortieren:
Informatik I (D-MAVT) Übungsstunde 8, 22.4.2009 simonmayer@student.ethz.ch ETH Zürich Aufgabe 1: Pointer & Structs Schauen wir s uns an! Aufgabe 2: Grossteils gut gemacht! Dynamische Arrays! Sortieren:
OpenCL. Programmiersprachen im Multicore-Zeitalter. Tim Wiersdörfer
 OpenCL Programmiersprachen im Multicore-Zeitalter Tim Wiersdörfer Inhaltsverzeichnis 1. Was ist OpenCL 2. Entwicklung von OpenCL 3. OpenCL Modelle 1. Plattform-Modell 2. Ausführungs-Modell 3. Speicher-Modell
OpenCL Programmiersprachen im Multicore-Zeitalter Tim Wiersdörfer Inhaltsverzeichnis 1. Was ist OpenCL 2. Entwicklung von OpenCL 3. OpenCL Modelle 1. Plattform-Modell 2. Ausführungs-Modell 3. Speicher-Modell
Ein kleiner Einblick in die Welt der Supercomputer. Christian Krohn 07.12.2010 1
 Ein kleiner Einblick in die Welt der Supercomputer Christian Krohn 07.12.2010 1 Vorschub: FLOPS Entwicklung der Supercomputer Funktionsweisen von Supercomputern Zukunftsvisionen 2 Ein Top10 Supercomputer
Ein kleiner Einblick in die Welt der Supercomputer Christian Krohn 07.12.2010 1 Vorschub: FLOPS Entwicklung der Supercomputer Funktionsweisen von Supercomputern Zukunftsvisionen 2 Ein Top10 Supercomputer
Paralleles Rechnen: MPI
 Münster Paralleles Rechnen: MPI 11.12.2015 Top 500 Münster Paralleles Rechnen: MPI 2 /23 32 Großrechner in Deutschland unter den Top 500 davon 5 Systeme unter den Top 50 8 Hazel Hen (HLRS Stuttgart) 11
Münster Paralleles Rechnen: MPI 11.12.2015 Top 500 Münster Paralleles Rechnen: MPI 2 /23 32 Großrechner in Deutschland unter den Top 500 davon 5 Systeme unter den Top 50 8 Hazel Hen (HLRS Stuttgart) 11
Angewandte Mathematik und Programmierung
 Angewandte Mathematik und Programmierung Einführung in das Konzept der objektorientierten Anwendungen zu mathematischen Rechnens WS 2013/14 Operatoren Operatoren führen Aktionen mit Operanden aus. Der
Angewandte Mathematik und Programmierung Einführung in das Konzept der objektorientierten Anwendungen zu mathematischen Rechnens WS 2013/14 Operatoren Operatoren führen Aktionen mit Operanden aus. Der
Besprechung Aufgabe 1: Prozesse verwalten Fortsetzung Grundlagen C-Programmierung Aufgabe 2: Threadsynchronisation
 Betriebssysteme Tafelübung 2. Thread-Synchronisation http://ess.cs.tu-dortmund.de/de/teaching/ss2016/bs/ Olaf Spinczyk olaf.spinczyk@tu-dortmund.de http://ess.cs.tu-dortmund.de/~os AG Eingebettete Systemsoftware
Betriebssysteme Tafelübung 2. Thread-Synchronisation http://ess.cs.tu-dortmund.de/de/teaching/ss2016/bs/ Olaf Spinczyk olaf.spinczyk@tu-dortmund.de http://ess.cs.tu-dortmund.de/~os AG Eingebettete Systemsoftware
Betriebssysteme. Tafelübung 2. Thread-Synchronisation. Olaf Spinczyk.
 Betriebssysteme Tafelübung 2. Thread-Synchronisation http://ess.cs.tu-dortmund.de/de/teaching/ss2016/bs/ Olaf Spinczyk olaf.spinczyk@tu-dortmund.de http://ess.cs.tu-dortmund.de/~os AG Eingebettete Systemsoftware
Betriebssysteme Tafelübung 2. Thread-Synchronisation http://ess.cs.tu-dortmund.de/de/teaching/ss2016/bs/ Olaf Spinczyk olaf.spinczyk@tu-dortmund.de http://ess.cs.tu-dortmund.de/~os AG Eingebettete Systemsoftware
Threads. Netzwerk - Programmierung. Alexander Sczyrba Jan Krüger
 Netzwerk - Programmierung Threads Alexander Sczyrba asczyrba@cebitec.uni-bielefeld.de Jan Krüger jkrueger@cebitec.uni-bielefeld.de Übersicht Probleme mit fork Threads Perl threads API Shared Data Mutexes
Netzwerk - Programmierung Threads Alexander Sczyrba asczyrba@cebitec.uni-bielefeld.de Jan Krüger jkrueger@cebitec.uni-bielefeld.de Übersicht Probleme mit fork Threads Perl threads API Shared Data Mutexes
Compute Unified Device Architecture CUDA
 Compute Unified Device Architecture 06. Februar 2012 1 / 13 Gliederung 2 / 13 : Compute Unified Device Architecture entwickelt von Nvidia Corporation spezifiziert Software- und Hardwareeigenschaften Ziel:
Compute Unified Device Architecture 06. Februar 2012 1 / 13 Gliederung 2 / 13 : Compute Unified Device Architecture entwickelt von Nvidia Corporation spezifiziert Software- und Hardwareeigenschaften Ziel:
Offenbar hängt das Ergebnis nur von der Summe der beiden Argumente ab...
 0 1 2 0 2 1 1 2 0 2 1 0 Offenbar hängt das Ergebnis nur von der Summe der beiden Argumente ab... 0 1 2 0 1 2 1 1 3 2 2 3 212 Um solche Tabellen leicht implementieren zu können, stellt Java das switch-statement
0 1 2 0 2 1 1 2 0 2 1 0 Offenbar hängt das Ergebnis nur von der Summe der beiden Argumente ab... 0 1 2 0 1 2 1 1 3 2 2 3 212 Um solche Tabellen leicht implementieren zu können, stellt Java das switch-statement
Spielst du noch oder rechnest du schon?
 Spielst du noch oder rechnest du schon? Mit Spielkonsole und Co. zum Supercomputer der Zukunft Fachbereich Elektrotechnik und Informationstechnik Fachhochschule Bielefeld University of Applied Sciences
Spielst du noch oder rechnest du schon? Mit Spielkonsole und Co. zum Supercomputer der Zukunft Fachbereich Elektrotechnik und Informationstechnik Fachhochschule Bielefeld University of Applied Sciences
Vorlesung Betriebssysteme I
 1 / 22 Vorlesung Betriebssysteme I Thema 8: Threads (Aktivitäten, die zweite) Robert Baumgartl 25. Januar 2018 Threads (Leichtgewichtsprozesse) 2 / 22 Prozess = Container für Ressourcen + (ein) identifizierbarer
1 / 22 Vorlesung Betriebssysteme I Thema 8: Threads (Aktivitäten, die zweite) Robert Baumgartl 25. Januar 2018 Threads (Leichtgewichtsprozesse) 2 / 22 Prozess = Container für Ressourcen + (ein) identifizierbarer
Inhaltsverzeichnis. Carsten Vogt. Nebenläufige Programmierung. Ein Arbeitsbuch mit UNIX/Linux und Java ISBN:
 Inhaltsverzeichnis Carsten Vogt Nebenläufige Programmierung Ein Arbeitsbuch mit UNIX/Linux und Java ISBN: 978-3-446-42755-6 Weitere Informationen oder Bestellungen unter http://www.hanser.de/978-3-446-42755-6
Inhaltsverzeichnis Carsten Vogt Nebenläufige Programmierung Ein Arbeitsbuch mit UNIX/Linux und Java ISBN: 978-3-446-42755-6 Weitere Informationen oder Bestellungen unter http://www.hanser.de/978-3-446-42755-6
CUDA. Moritz Wild, Jan-Hugo Lupp. Seminar Multi-Core Architectures and Programming. Friedrich-Alexander-Universität Erlangen-Nürnberg
 CUDA Seminar Multi-Core Architectures and Programming 1 Übersicht Einleitung Architektur Programmierung 2 Einleitung Computations on GPU 2003 Probleme Hohe Kenntnisse der Grafikprogrammierung nötig Unterschiedliche
CUDA Seminar Multi-Core Architectures and Programming 1 Übersicht Einleitung Architektur Programmierung 2 Einleitung Computations on GPU 2003 Probleme Hohe Kenntnisse der Grafikprogrammierung nötig Unterschiedliche
Kapitel 1 Parallele Modelle Wie rechnet man parallel?
 PRAM- PRAM- DAG- R UND R Coles und Kapitel 1 Wie rechnet man parallel? Vorlesung Theorie Paralleler und Verteilter Systeme vom 11. April 2008 der Das DAG- Das PRAM- Das werkmodell Institut für Theoretische
PRAM- PRAM- DAG- R UND R Coles und Kapitel 1 Wie rechnet man parallel? Vorlesung Theorie Paralleler und Verteilter Systeme vom 11. April 2008 der Das DAG- Das PRAM- Das werkmodell Institut für Theoretische
leave: mov flag, 0 ; 0 in flag speichern: Lock freigeben ret
 Sep 19 14:20:18 amd64 sshd[20494]: Accepted rsa for esser from ::ffff:87.234.201.207 port 61557 Sep 19 14:27:41 amd64 syslog-ng[7653]: STATS: dropped 0 Sep 20 01:00:01 amd64 /usr/sbin/cron[29278]: (root)
Sep 19 14:20:18 amd64 sshd[20494]: Accepted rsa for esser from ::ffff:87.234.201.207 port 61557 Sep 19 14:27:41 amd64 syslog-ng[7653]: STATS: dropped 0 Sep 20 01:00:01 amd64 /usr/sbin/cron[29278]: (root)
Besprechung Aufgabe 5 (crawl) POSIX-Threads. Problem: UNIX-Prozesskonzept ist für viele heutige Anwendungen unzureichend
 POSIX-Threads. Problem: UNIX-Prozesskonzept ist für viele heutige Anwendungen unzureichend") U7 6. Übung U7 6. Übung U7-1 Motivation von Threads U7-1 Motivation von Threads Besprechung Aufgabe 5 (crawl) OSIX-Threads Motivation Thread-Konzepte pthread-ai Koordinierung UNIX-rozesskonzept: eine Ausführungsumgebung
U7 6. Übung U7 6. Übung U7-1 Motivation von Threads U7-1 Motivation von Threads Besprechung Aufgabe 5 (crawl) OSIX-Threads Motivation Thread-Konzepte pthread-ai Koordinierung UNIX-rozesskonzept: eine Ausführungsumgebung
7 Laufzeit-Speicherverwaltung
 7.1 Grundlagen Bevor wir die Code-Generierung betrachten, müssen wir uns Gedanken über zur Laufzeit des zu generierenden Programms notwendige Aktivitäten zur Zuordnung und Freigabe von Speicherplatz machen.
7.1 Grundlagen Bevor wir die Code-Generierung betrachten, müssen wir uns Gedanken über zur Laufzeit des zu generierenden Programms notwendige Aktivitäten zur Zuordnung und Freigabe von Speicherplatz machen.
Systeme 1: Architektur
 slide 1 Vorlesung Systeme 1: Architektur Prof. Dr. Ulrich Ultes-Nitsche Forschungsgruppe Departement für Informatik Universität Freiburg slide 2 Prüfung 18. Februar 2004 8h00-11h40 13h00-18h20 20 Minuten
slide 1 Vorlesung Systeme 1: Architektur Prof. Dr. Ulrich Ultes-Nitsche Forschungsgruppe Departement für Informatik Universität Freiburg slide 2 Prüfung 18. Februar 2004 8h00-11h40 13h00-18h20 20 Minuten
Klausur: Informatik I am 06. Februar 2009 Gruppe: D Dirk Seeber, h_da, Fb Informatik. Nachname: Vorname: Matr.-Nr.: Punkte:
 Seite 1 von 10 Hiermit bestätige ich, dass ich die Übungsleistungen als Voraussetzung für diese Klausur in folgender Übung erfüllt habe. Jahr: Übungsleiter: Unterschrift: 1. Aufgabe ( / 12 Pkt.) Was liefert
Seite 1 von 10 Hiermit bestätige ich, dass ich die Übungsleistungen als Voraussetzung für diese Klausur in folgender Übung erfüllt habe. Jahr: Übungsleiter: Unterschrift: 1. Aufgabe ( / 12 Pkt.) Was liefert
Klausur: Grundlagen der Informatik I, am 06. Februar 2009 Gruppe: A Dirk Seeber, h_da, Fb Informatik. Nachname: Vorname: Matr.-Nr.
 Seite 1 von 9 Hiermit bestätige ich, dass ich die Übungsleistungen als Voraussetzung für diese Klausur in folgender Übung erfüllt habe. Jahr: Übungsleiter: Unterschrift: 1. Aufgabe ( / 12 Pkt.) Was liefert
Seite 1 von 9 Hiermit bestätige ich, dass ich die Übungsleistungen als Voraussetzung für diese Klausur in folgender Übung erfüllt habe. Jahr: Übungsleiter: Unterschrift: 1. Aufgabe ( / 12 Pkt.) Was liefert
U6-1 Organisatories. U6-2 Motivation von Threads. U6-3 Vergleich von Thread-Konzepten. Organisatorisches
 U6 6. Übung U6 6. Übung U6-1 Organisatories U6-1 Organisatories Organisatorisches Zusätzliche Tafelübung zur S1-Klaurvorbereitung Besprechung Aufgabe 5 (crawl) OSIX-Threads Motivation Thread-Konzepte am
U6 6. Übung U6 6. Übung U6-1 Organisatories U6-1 Organisatories Organisatorisches Zusätzliche Tafelübung zur S1-Klaurvorbereitung Besprechung Aufgabe 5 (crawl) OSIX-Threads Motivation Thread-Konzepte am
Klausur: Grundlagen der Informatik I, am 06. Februar 2009 Dirk Seeber, h_da, Fb Informatik. Nachname: Vorname: Matr.-Nr.: Punkte:
 Seite 1 von 10 Hiermit bestätige ich, dass ich die Übungsleistungen als Voraussetzung für diese Klausur in folgender Übung erfüllt habe. Jahr: Übungsleiter: Unterschrift: 1. Aufgabe ( / 10 Pkt.) a) Wer
Seite 1 von 10 Hiermit bestätige ich, dass ich die Übungsleistungen als Voraussetzung für diese Klausur in folgender Übung erfüllt habe. Jahr: Übungsleiter: Unterschrift: 1. Aufgabe ( / 10 Pkt.) a) Wer
Single- und Multitasking
 Single- und Multitasking Peter B. Ladkin ladkin@rvs.uni-bielefeld.de Peter B. Ladkin Command Interpreter (ComInt) läuft wartet auf Tastatur-Eingabe "liest" (parst) die Eingabe (für Prog-Name) Macht "Lookup"
Single- und Multitasking Peter B. Ladkin ladkin@rvs.uni-bielefeld.de Peter B. Ladkin Command Interpreter (ComInt) läuft wartet auf Tastatur-Eingabe "liest" (parst) die Eingabe (für Prog-Name) Macht "Lookup"
e) Welche Aussage zu Speicherzuteilungsverfahren ist falsch?
 Welche Aussage zu Speicherzuteilungsverfahren ist falsch?") Aufgabe 1: (1) Bei den Multiple-Choice-Fragen ist jeweils nur eine richtige Antwort eindeutig anzukreuzen. Auf die richtige Antwort gibt es die angegebene Punktzahl. Wollen Sie eine Multiple-Choice-Antwort
Aufgabe 1: (1) Bei den Multiple-Choice-Fragen ist jeweils nur eine richtige Antwort eindeutig anzukreuzen. Auf die richtige Antwort gibt es die angegebene Punktzahl. Wollen Sie eine Multiple-Choice-Antwort
Advanced Programming in C
 Advanced Programming in C Pointer und Listen Institut für Numerische Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Oktober 2013 Überblick 1 Variablen vs. Pointer - Statischer und dynamischer
Advanced Programming in C Pointer und Listen Institut für Numerische Simulation Rheinische Friedrich-Wilhelms-Universität Bonn Oktober 2013 Überblick 1 Variablen vs. Pointer - Statischer und dynamischer
Optimierungen der Lattice Boltzmann Methode auf x86-64 basierten Architekturen
 Optimierungen der Lattice Boltzmann Methode auf x86-64 basierten Architekturen J. Treibig, S. Hausmann, U. Ruede 15.09.05 / ASIM 2005 - Erlangen Gliederung 1 Einleitung Motivation Grundlagen 2 Optimierungen
Optimierungen der Lattice Boltzmann Methode auf x86-64 basierten Architekturen J. Treibig, S. Hausmann, U. Ruede 15.09.05 / ASIM 2005 - Erlangen Gliederung 1 Einleitung Motivation Grundlagen 2 Optimierungen
Praxiseinheit: Realisierung einer hardwarebeschleunigten Disparitätenberechnung zur automatischen Auswertung von Stereobildern
 Praxiseinheit: Realisierung einer hardwarebeschleunigten Disparitätenberechnung zur automatischen Auswertung von Stereobildern Institut für Betriebssysteme und Rechnerverbund TU Braunschweig 25.10., 26.10.
Praxiseinheit: Realisierung einer hardwarebeschleunigten Disparitätenberechnung zur automatischen Auswertung von Stereobildern Institut für Betriebssysteme und Rechnerverbund TU Braunschweig 25.10., 26.10.
Linux Prinzipien und Programmierung
 Linux Prinzipien und Programmierung Dr. Klaus Höppner Hochschule Darmstadt Sommersemester 2014 1 / 28 Kritische Bereiche bei Threads Deadlocks Conditions/Semaphore 2 / 28 Beispiel aus der letzten Vorlesung
Linux Prinzipien und Programmierung Dr. Klaus Höppner Hochschule Darmstadt Sommersemester 2014 1 / 28 Kritische Bereiche bei Threads Deadlocks Conditions/Semaphore 2 / 28 Beispiel aus der letzten Vorlesung
Hochleistungsrechnen auf dem PC
 Hochleistungsrechnen auf dem PC Steffen Börm Christian-Albrechts-Universität zu Kiel Ringvorlesung Informatik, 26. Juni 2014 S. Börm (CAU Kiel) Hochleistungsrechnen auf dem PC 26. Juni 2014 1 / 33 Übersicht
Hochleistungsrechnen auf dem PC Steffen Börm Christian-Albrechts-Universität zu Kiel Ringvorlesung Informatik, 26. Juni 2014 S. Börm (CAU Kiel) Hochleistungsrechnen auf dem PC 26. Juni 2014 1 / 33 Übersicht
Memory Models Frederik Zipp
 Memory Models Frederik Zipp Seminar: Programmiersprachen für Parallele Programmierung (SS 2010) Fakultät für Informatik - IPD SNELTING LEHRSTUHL PROGRAMMIERPARADIGMEN 1
Memory Models Frederik Zipp Seminar: Programmiersprachen für Parallele Programmierung (SS 2010) Fakultät für Informatik - IPD SNELTING LEHRSTUHL PROGRAMMIERPARADIGMEN 1
Parallel Computing. Einsatzmöglichkeiten und Grenzen. Prof. Dr. Nikolaus Wulff
 Parallel Computing Einsatzmöglichkeiten und Grenzen Prof. Dr. Nikolaus Wulff Parallel Architekturen Flynn'sche Klassifizierung: SISD: single Instruction, single Data Klassisches von-neumann sequentielles
Parallel Computing Einsatzmöglichkeiten und Grenzen Prof. Dr. Nikolaus Wulff Parallel Architekturen Flynn'sche Klassifizierung: SISD: single Instruction, single Data Klassisches von-neumann sequentielles
Informatik für Mathematiker und Physiker Woche 7. David Sommer
 Informatik für Mathematiker und Physiker Woche 7 David Sommer David Sommer 30. Oktober 2018 1 Heute: 1. Repetition Floats 2. References 3. Vectors 4. Characters David Sommer 30. Oktober 2018 2 Übungen
Informatik für Mathematiker und Physiker Woche 7 David Sommer David Sommer 30. Oktober 2018 1 Heute: 1. Repetition Floats 2. References 3. Vectors 4. Characters David Sommer 30. Oktober 2018 2 Übungen
Systeme I: Betriebssysteme Kapitel 4 Prozesse. Wolfram Burgard
 Systeme I: Betriebssysteme Kapitel 4 Prozesse Wolfram Burgard Version 18.11.2015 1 Inhalt Vorlesung Aufbau einfacher Rechner Überblick: Aufgabe, Historische Entwicklung, unterschiedliche Arten von Betriebssystemen
Systeme I: Betriebssysteme Kapitel 4 Prozesse Wolfram Burgard Version 18.11.2015 1 Inhalt Vorlesung Aufbau einfacher Rechner Überblick: Aufgabe, Historische Entwicklung, unterschiedliche Arten von Betriebssystemen
Cache Blöcke und Offsets
 Cache Blöcke und Offsets Ein Cache Eintrag speichert in der Regel gleich mehrere im Speicher aufeinander folgende Bytes. Grund: räumliche Lokalität wird wie folgt besser ausgenutzt: Bei Cache Miss gleich
Cache Blöcke und Offsets Ein Cache Eintrag speichert in der Regel gleich mehrere im Speicher aufeinander folgende Bytes. Grund: räumliche Lokalität wird wie folgt besser ausgenutzt: Bei Cache Miss gleich
Algorithmen und Datenstrukturen
 Algorithmen und Datenstrukturen Dipl. Inform. Andreas Wilkens aw@awilkens.com Überblick Grundlagen Definitionen Eigene Entwicklungen Datenstrukturen Elementare Datentypen Abstrakte Datentypen Elementare
Algorithmen und Datenstrukturen Dipl. Inform. Andreas Wilkens aw@awilkens.com Überblick Grundlagen Definitionen Eigene Entwicklungen Datenstrukturen Elementare Datentypen Abstrakte Datentypen Elementare
Aufgabenblatt 6 Musterlösung
 Prof. Dr. rer. nat. Roland Wismüller Aufgabenblatt 6 Musterlösung Vorlesung Betriebssysteme I Wintersemester 2018/19 Aufgabe 1: Implementierung von Threads (Bearbeitung zu Hause) Der größte Vorteil ist
Prof. Dr. rer. nat. Roland Wismüller Aufgabenblatt 6 Musterlösung Vorlesung Betriebssysteme I Wintersemester 2018/19 Aufgabe 1: Implementierung von Threads (Bearbeitung zu Hause) Der größte Vorteil ist
Übung zur Vorlesung Wissenschaftliches Rechnen Sommersemester 2012 Auffrischung zur Programmierung in C++, 2. Teil
 MÜNSTER Übung zur Vorlesung Wissenschaftliches Rechnen Sommersemester 2012 Auffrischung zur Programmierung in C++ 2. Teil 18. April 2012 Organisatorisches MÜNSTER Übung zur Vorlesung Wissenschaftliches
MÜNSTER Übung zur Vorlesung Wissenschaftliches Rechnen Sommersemester 2012 Auffrischung zur Programmierung in C++ 2. Teil 18. April 2012 Organisatorisches MÜNSTER Übung zur Vorlesung Wissenschaftliches
Java Concurrency Utilities
 Java Concurrency Utilities Java unterstützt seit Java 1.0 Multithreading Java unterstützt das Monitorkonzept mittels der Schlüsselworte synchronized und volatile sowie den java.lang.object Methoden wait(),
Java Concurrency Utilities Java unterstützt seit Java 1.0 Multithreading Java unterstützt das Monitorkonzept mittels der Schlüsselworte synchronized und volatile sowie den java.lang.object Methoden wait(),
2. Der ParaNut-Prozessor "Parallel and more than just another CPU core"
 2. Der ParaNut-Prozessor "Parallel and more than just another CPU core" Neuer, konfigurierbarer Prozessor Parallelität auf Daten- (SIMD) und Thread-Ebene Hohe Skalierbarkeit mit einer Architektur neues
2. Der ParaNut-Prozessor "Parallel and more than just another CPU core" Neuer, konfigurierbarer Prozessor Parallelität auf Daten- (SIMD) und Thread-Ebene Hohe Skalierbarkeit mit einer Architektur neues
parallele Prozesse auf sequenziellen Prozessoren Ein Process ist ein typisches Programm, mit eigenem Addressraum im Speicher.
 Threads parallele Prozesse auf sequenziellen Prozessoren Prozesse und Threads Es gibt zwei unterschiedliche Programme: Ein Process ist ein typisches Programm, mit eigenem Addressraum im Speicher. Ein Thread
Threads parallele Prozesse auf sequenziellen Prozessoren Prozesse und Threads Es gibt zwei unterschiedliche Programme: Ein Process ist ein typisches Programm, mit eigenem Addressraum im Speicher. Ein Thread
Praxis der Programmierung
 Dynamische Datentypen Institut für Informatik und Computational Science Universität Potsdam Henning Bordihn Einige Folien gehen auf A. Terzibaschian zurück. 1 Dynamische Datentypen 2 Dynamische Datentypen
Dynamische Datentypen Institut für Informatik und Computational Science Universität Potsdam Henning Bordihn Einige Folien gehen auf A. Terzibaschian zurück. 1 Dynamische Datentypen 2 Dynamische Datentypen
Repetitorium Programmieren I + II
 Repetitorium Programmieren I + II Stephan Gimbel Johanna Mensik Michael Roth 6. März 2012 Agenda 1 Operatoren 2 Datentypen Gleitpunkt Zahl Typkonvertierung 3 Strommanipulatoren 4 Bedingungen if-else switch-case
Repetitorium Programmieren I + II Stephan Gimbel Johanna Mensik Michael Roth 6. März 2012 Agenda 1 Operatoren 2 Datentypen Gleitpunkt Zahl Typkonvertierung 3 Strommanipulatoren 4 Bedingungen if-else switch-case
32 Bit Konstanten und Adressierung. Grundlagen der Rechnerarchitektur Assembler 78
 32 Bit Konstanten und Adressierung Grundlagen der Rechnerarchitektur Assembler 78 Immediate kann nur 16 Bit lang sein Erinnerung: Laden einer Konstante in ein Register addi $t0, $zero, 200 Als Maschinen
32 Bit Konstanten und Adressierung Grundlagen der Rechnerarchitektur Assembler 78 Immediate kann nur 16 Bit lang sein Erinnerung: Laden einer Konstante in ein Register addi $t0, $zero, 200 Als Maschinen
Softwaretechnik 1 Übung 5
 Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Softwaretechnik 1 Übung 5 2.7.29 Aufgabe 1a) Zeichnen Sie die komplette Vererbungshierarchie der Klasse BufferedOutputStream als UML- Klassendiagramm.
Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 Softwaretechnik 1 Übung 5 2.7.29 Aufgabe 1a) Zeichnen Sie die komplette Vererbungshierarchie der Klasse BufferedOutputStream als UML- Klassendiagramm.
Multiprozessoren. Dr.-Ing. Volkmar Sieh. Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg SS 2011
 Multiprozessoren Dr.-Ing. Volkmar Sieh Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg SS 2011 Multiprozessoren 1/29 2011-06-16 Multiprozessoren Leistungsfähigkeit
Multiprozessoren Dr.-Ing. Volkmar Sieh Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg SS 2011 Multiprozessoren 1/29 2011-06-16 Multiprozessoren Leistungsfähigkeit
Anwendung (2. Versuch:-) Entkopplung der Locks
 Entkopplung der Locks") Gut gemeint aber leider fehlerhaft... Jeder Producer benötigt zwei Locks gleichzeitig, um zu produzieren: 1. dasjenige für den Puffer; 2. dasjenige für einen Semaphor. Musser fürden Semaphor einwait()
Gut gemeint aber leider fehlerhaft... Jeder Producer benötigt zwei Locks gleichzeitig, um zu produzieren: 1. dasjenige für den Puffer; 2. dasjenige für einen Semaphor. Musser fürden Semaphor einwait()
Cell and Larrabee Microarchitecture
 Cell and Larrabee Microarchitecture Benjamin Grund Dominik Wolfert Universität Erlangen-Nürnberg 1 Übersicht Einleitung Herkömmliche Prozessorarchitekturen Motivation für Entwicklung neuer Architekturen
Cell and Larrabee Microarchitecture Benjamin Grund Dominik Wolfert Universität Erlangen-Nürnberg 1 Übersicht Einleitung Herkömmliche Prozessorarchitekturen Motivation für Entwicklung neuer Architekturen
Quiz. Gegeben sei ein 16KB Cache mit 32 Byte Blockgröße. Wie verteilen sich die Bits einer 32 Bit Adresse auf: Tag Index Byte Offset.
 Quiz Gegeben sei ein 16KB Cache mit 32 Byte Blockgröße. Wie verteilen sich die Bits einer 32 Bit Adresse auf: Tag Index Byte Offset 32 Bit Adresse 31 3 29... 2 1 SS 212 Grundlagen der Rechnerarchitektur
Quiz Gegeben sei ein 16KB Cache mit 32 Byte Blockgröße. Wie verteilen sich die Bits einer 32 Bit Adresse auf: Tag Index Byte Offset 32 Bit Adresse 31 3 29... 2 1 SS 212 Grundlagen der Rechnerarchitektur
Datenstrukturen und Algorithmen
 1 Datenstrukturen und Algorithmen Übung 13 FS 2018 Programm von heute 2 1 Feedback letzte Übung 2 Wiederholung Theorie 3 Nächste Übung 1. Feedback letzte Übung 3 Aufgabe 12.3: Summe eines Vektors void
1 Datenstrukturen und Algorithmen Übung 13 FS 2018 Programm von heute 2 1 Feedback letzte Übung 2 Wiederholung Theorie 3 Nächste Übung 1. Feedback letzte Übung 3 Aufgabe 12.3: Summe eines Vektors void
#define N 5 // Anzahl der Philosophen. while (TRUE) { // Der Philosoph denkt
 { // Der Philosoph denkt") Sep 19 14:20:18 amd64 sshd[20494]: Accepted rsa for esser from ::ffff:87.234.201.207 port 61557 Sep 19 14:27:41 amd64 syslog-ng[7653]: STATS: dropped 0 Sep 20 01:00:01 amd64 /usr/sbin/cron[29278]: (root)
Sep 19 14:20:18 amd64 sshd[20494]: Accepted rsa for esser from ::ffff:87.234.201.207 port 61557 Sep 19 14:27:41 amd64 syslog-ng[7653]: STATS: dropped 0 Sep 20 01:00:01 amd64 /usr/sbin/cron[29278]: (root)
Info B VL 17: Deadlocks
 Info B VL 17: Deadlocks Objektorientiere Programmierung in Java 2003 Ute Schmid (Vorlesung) Elmar Ludwig (Übung) FB Mathematik/Informatik, Universität Osnabrück Info B VL 17: Deadlocks p.327 Conditional
Info B VL 17: Deadlocks Objektorientiere Programmierung in Java 2003 Ute Schmid (Vorlesung) Elmar Ludwig (Übung) FB Mathematik/Informatik, Universität Osnabrück Info B VL 17: Deadlocks p.327 Conditional
Betriebssysteme Übung 2. Tutorium System Calls & Multiprogramming
 Betriebssysteme Übung 2. Tutorium System Calls & Multiprogramming Task Wiederholung 1 System SysCalls (1) Wozu? Sicherheit Stabilität Erfordert verschiedene modes of execution: user mode privileged mode
Betriebssysteme Übung 2. Tutorium System Calls & Multiprogramming Task Wiederholung 1 System SysCalls (1) Wozu? Sicherheit Stabilität Erfordert verschiedene modes of execution: user mode privileged mode
Klausur: Grundlagen der Informatik I, am 27. März 2009 Gruppe: F Dirk Seeber, h_da, Fb Informatik. Nachname: Vorname: Matr.-Nr.
 Seite 1 von 9 Hiermit bestätige ich, dass ich die Übungsleistungen als Voraussetzung für diese Klausur in folgender Übung erfüllt habe. Jahr: Übungsleiter: Unterschrift: 1. Aufgabe ( / 15 Pkt.) Was liefert
Seite 1 von 9 Hiermit bestätige ich, dass ich die Übungsleistungen als Voraussetzung für diese Klausur in folgender Übung erfüllt habe. Jahr: Übungsleiter: Unterschrift: 1. Aufgabe ( / 15 Pkt.) Was liefert
Echtzeitbetriebssysteme (am Beispiel QNX) Dr. Stefan Enderle HS Esslingen
 Dr. Stefan Enderle HS Esslingen") Echtzeitbetriebssysteme (am Beispiel QNX) Dr. Stefan Enderle HS Esslingen 3. QNX Neutrino Microkernel 3.1 Einführung Der Neutrino-Kernel (Betriebssystemkern) implementiert (nur) die wichtigsten Teile des
Echtzeitbetriebssysteme (am Beispiel QNX) Dr. Stefan Enderle HS Esslingen 3. QNX Neutrino Microkernel 3.1 Einführung Der Neutrino-Kernel (Betriebssystemkern) implementiert (nur) die wichtigsten Teile des