Professionelle Entwicklungstools auf PC s und HPC Clustern
|
|
|
- Elizabeth Grosser
- vor 5 Jahren
- Abrufe
Transkript

1 Competence in High Performance Computing Professionelle Entwicklungstools auf PC s und HPC Clustern Mario Deilmann <mario.deilmann@pallas.com> DECUS Symposium, Bonn 8. April 2003 Pallas GmbH Hermülheimer Straße 10 D Brühl, Germany info@pallas.com
2 Informationen zur Person Name: Mario Deilmann Firma: Pallas Aufgabe: Technischen Support & Produktplanung Ausbildung: Diplom-Ingenieur (Maschinenbau) Dissertation (Direkte Numerische Simulation) 26. DECUS Symposium Folie: 2
3 Agenda Sinn und Zweck von professionellen Entwicklungstools Kurze Übersicht über die verschiedenen Ansätze zur Optimierung Serielle Optimierung Serielle Performance Analyse Parallele Programmentwicklung und Optimierung Paralleler Debugger MPI Performance Analyse OpenMP Performance Analyse Hybride Tools 26. DECUS Symposium Folie: 3
4 Think of the tremendous human tragedy of time and energy a lot of scientists have lost trying to use (massive) parallel machines. Henry Burkhardt (deposed CEO of Kendall Square Research ) 26. DECUS Symposium Folie: 4
5 Welchen Nutzen haben prof. Entwicklungstools Entwicklungszyklus wird effizienter Systemressourcen werden optimal genutzt Programmlaufzeit wird kürzer d.h. Performance wird größer Es werden mehr Probleme in der gleichen Zeit gelöst bei geringeren Ressourcen Markteinführung wird verkürzt Welche Verbesserung sind notwendig und wie groß der tatsächliche Gewinn der Änderungen an der Applikation (speed up) Man spart Zeit und Geld! 26. DECUS Symposium Folie: 5
6 Wer profitiert von Performance Gewinnen Öl- und Gasindustrie: Seismische Analyse Forschung: Gewöhnliche, partielle Differentialgleichungen IT: Data Mining Pharmazeutischen Industrie: Wirkstoffdesign Meteorologie: Wettervorhersage Automobileindustrie: Crash Simulation Chemieindustrie: Simulation molekulardynamischer Prozesse Luftfahrtindustrie: Simulation im Windkanal Finanzbereich: Risikoanalysen Lange Programm-Laufzeit und große Datenmengen 26. DECUS Symposium Folie: 6
7 Welche Tools gibt es Optimierende Compiler beschleunigen die Ausführungszeit (Parallele) Linker verkürzen den Build-Zyklus Debugger verkürzen entscheidend die Fehlersuche Profiler können ermitteln welche Zeit in welchem Programmteil verbracht wurde Spezielle Bibliotheken ermögliche den Zugriff auf hoch optimierte plattformunabhängige Routinen (BLAS, LAPACK, FFT, JPEG, MPEG,...) Performance Analysetools liefern Informationen über Lastverteilung und Performance Engpässe 26. DECUS Symposium Folie: 7
8 Applikation Entwicklungsphase Auswahl von Algorithmen und Datenstrukturen Nicht optimierter serieller Code Serielle Codeoptimierung Optimierter serieller Code Optimierter paralleler Code Parallele Codeoptimierung 26. DECUS Symposium Folie: 8
9 Programm Zyklus / Einsatz von Werkzeugen Bibliotheken C/C++ Compiler Fortran Compiler UPC (Parallel C) Performance Analyse Thread Analyse MPI/OpenMP Analyse Source Code Compile Link Execute Output Paralleler/Inkrementeller Linker Debugger 26. DECUS Symposium Folie: 9
10 Serielle Code-Optimierung 26. DECUS Symposium Folie: 10
11 Basis Performance- nicht optimierter Code Simulation einer bewegten Wasseroberfläche 26. DECUS Symposium Folie: 11
12 Compiler Optimierungen Vektorisierung Code-Transformation (Schleifen) Spekulations-Analyse Daten / Programm Code in den Cache laden Explizite Parallelisierung Inter Prozedur Analyse Umstrukturierung des Programmcodes auf Basis verschiedenerer Programm-Module Profile Feedback Analyse Umstrukturierung des Programmcodes auf Basis repräsentativer Programmläufe Luafzeit [s] Matrixmultiplikation - Sun Blade 1000 noopt O1 O2 O3 O4 Optimierung -x 26. DECUS Symposium Folie: 12



13 Serieller Debugger 26. DECUS Symposium Folie: 13

14 Profiler Routine Anzahl der Aufrufe Quellcodeinformationen Laufzeit 26. DECUS Symposium Folie: 14


15 Profiler Statistisches Sampling Prozessor Counter DLL s, Threads 26. DECUS Symposium Folie: 15
16 Profiler - Tuning Assistent Quellcode Hinweis 26. DECUS Symposium Folie: 16
17 Optimierungszyklus - optimierter serieller Code 9x schneller Wenig Änderungen am Quellcode 7x 9x Performance Bibliotheken 4x 1x Standard Compiler Performance Bibliotheken Standard Compiler Opt. Compiler Opt. Compiler 26. DECUS Symposium Folie: 17

18 Parallele Code-Optimierung 26. DECUS Symposium Folie: 18
19 Parallele Programmiermodelle!$omp parallel Multithreading: Parallelität auf Instruktionslevel call MPI_INIT(!$ompierr do) OpenMP: call MPI_COMM_RANK( Parallelität do j = auf 1, MPI_COMM_WORLD, p Schleifen- und myid, Tasksebene ierr ) call MPI_COMM_SIZE( do i = MPI_COMM_WORLD, 1, m numprocs, ierr ) MPI: Parallelität print *, "Process auf ", myid, c(i,j) Kommunikationsebene = " of 0.0", numprocs, " is alive" c send b to each enddo other process Hybride do Modelle: 25 i = 1,bcols enddo MPI + OpenMP / MPI + (Auto)Threading call MPI_BCAST(b(1,i), do i = mbrows, MPI_DOUBLE_PRECISION, master, & MPI_COMM_WORLD,!$omp do ierr) 25 continue do ii = 1, n arow(ii) = a(i,ii) c send a row of a enddo to each other process; tag with row number do 40 i!$omp = 1,numprocs-1 do do 30 j = 1,acols do j = 1, p buffer(j) = a(i,j) do k = 1, n 30 continue c(i,j) = c(i,j) + arow(k) * b(k,j) call MPI_SEND(buffer, enddo acols, MPI_DOUBLE_PRECISION, i, & i, MPI_COMM_WORLD, enddo ierr) numsent = enddo numsent+1!$omp end parallel Bei der Lösung von Problemen auf parallelen Maschinen bedarf es neuer Ansätze und Werkzeuge 26. DECUS Symposium Folie: 19
20 Gegenüberstellung: Performance - Aufwand Programm Performance OpenMP Debugger MPI MPI OpenMP Entwicklung/Testen Aufwand bei der Entwicklung 26. DECUS Symposium Folie: 20

21 Fall Studie - LS-DYNA (OpenMP) Speed-UP CPUs 3D: Elemente 1 CPU Zeit = Sekunden 2 CPU Zeit = Sekunden 4 CPU Zeit = Sekunden Quad Xeon LS-DYNA ist ein Finite Element Programm für Crash- Simulationen Ca. 750,000 Zeilen Fortran und C Quellcode 1.74x speed up auf 2 CPUs, 2.74x speed up auf 4 CPUs 26. DECUS Symposium Folie: 21


22 Fall Studie Verbrennungssimulation (MPI) CPUs 1 Mio. Elemente 2D: 1000 x 1000 Cray T3E 1CPU 100 Stunden 100CPUs 1,5 Stunden NSCORE Programm zur Direkten numerischen Simulation von Verbrennungsvorgängen 350x speed up auf 512 CPUs 26. DECUS Symposium Folie: 22

23 Parallele Programmentwicklung 26. DECUS Symposium Folie: 23

24 Paralleler Debugger 26. DECUS Symposium Folie: 24
25 Anforderungen an einen parallelen Debugger Eigenschaften eines seriellen command line Debuggers plus Graphische User Interface Dynamischer call tree (grafisch) Darstellung der Nachrichten-Kommunikation (grafisch) Übersichtliche Darstellung paralleler Prozesse (> 100 threads) Unterstützung verschiedener paralleler Programmierparadigmen Kontrollstrukturen zur Synchronisation paralleler Prozesse Automatische Start aller beteiligten Prozesse 26. DECUS Symposium Folie: 25


26 Debugger Features Debug-Aktionen Breakpoint Evaluationpoint Watchpoint Daten Management Darstellung Statistiken Visualisierung Änderungen während des Programmlaufs 26. DECUS Symposium Folie: 26

27 Grafische Darstellung des call tree s Dynamisch Darstellung des Programmablaufs Potentielle Konflikte können visualisiert werden Kontrolle und Abhängigkeiten des Programmablaufs 26. DECUS Symposium Folie: 27

28 Dedizierte Kontrolle der einzelnen Prozesse Kontrolle einzelner Threads und Ablaufkontrolle auf Threadlevel Beliebige Gruppierung von Threads und Prozessen Dynamische Gruppierung von Threads und Prozessen Definition von Ablaufkriterien für Prozessgruppen breakpoints barrier 26. DECUS Symposium Folie: 28


29 Visualisierung der Kommunikation Darstellung der Nachrichtenwege zu einem definierten Zeitpunkt Inter-Prozess Kommunikation Visualisierung von Kommunikations- Problemen (hängende, unerwartet Nachrichten) 26. DECUS Symposium Folie: 29

30 MPI Performance Analyse 26. DECUS Symposium Folie: 30
31 Anforderungen an ein Performance Analysetool Analyse von MPI und User Routinen des optimierten Programms Statistische Analyse von Programm und Kommunikation Darstellung der Lastverteilung Einfache und schnelle Handhabung Filtermöglichkeiten (Prozesse, Nachrichten, kollektive and MPI I/O Operationen) Geringen Einfluss auf die Applikations-Performance 26. DECUS Symposium Folie: 31

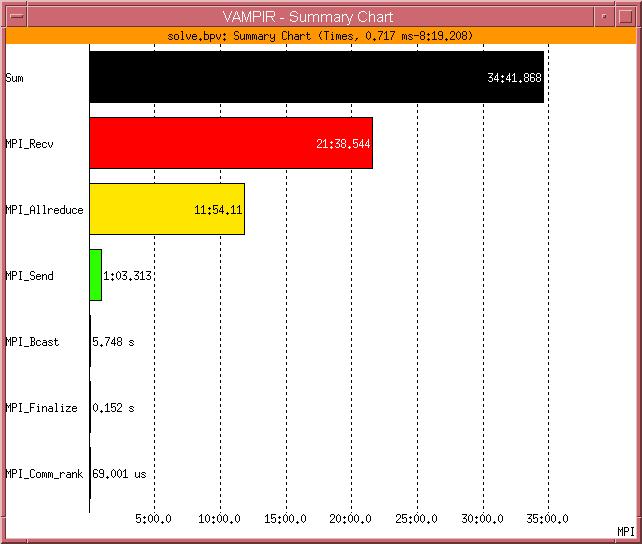
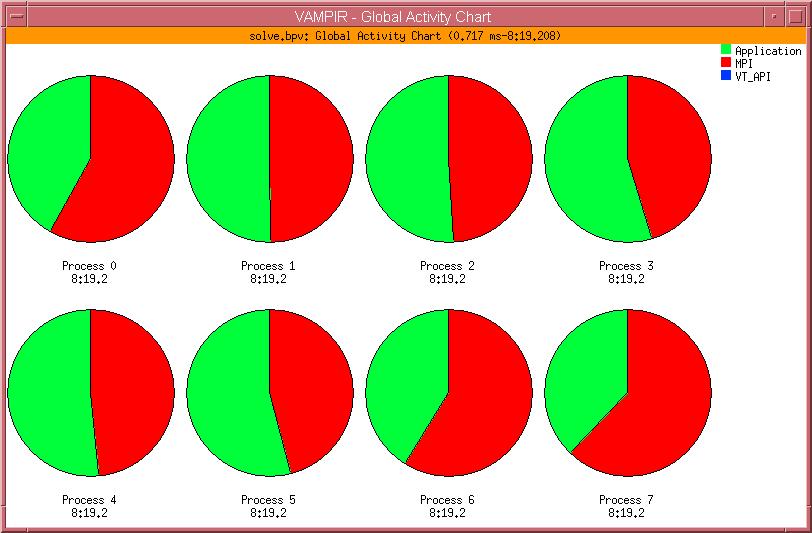
32 Statistik des Programmablaufs 26. DECUS Symposium Folie: 32




33 Detail Information Nachricht gesendet Nachricht empfangen Nachrichten- Linie Zusätzliche Details 26. DECUS Symposium Folie: 33

34 Fall Studie - LM LM (Lokal Modell) ist das Programm des Deutschen Wetterdienstes (DWD) für die Wettervorhersage im Skalenbereich von 1-10 km. Untersucht wurden : Einfluss von Prozessorgitter zu Knotengitter Aufteilung Überlappung von I/O und Berechnung 26. DECUS Symposium Folie: 34
35 Trace LM - Test Fall auf 224 Prozessoren Input Output 20 Zeitschritte 26. DECUS Symposium Folie: 35
36 LM - Laufzeit Phase Input Dauer beim Start von LM : 45 s Zeitschritte Dauer ca. 2.3 s Auswertung der Kommunikation Performance Datenverteilung: Prozess Knoten Aufteilung Output Dauer ca. 20 s beim Start Ca. 20 s nach jedem Zeitschritt 26. DECUS Symposium Folie: 36


37 LM Zeitschritt Analyse Ein Zeitschritt Statistik über alle Prozesse 26. DECUS Symposium Folie: 37

38 LM Knotenmapping Analyse Kommunikation zwischen den Prozessen Kommunikation zwischen den SMP Knoten 26. DECUS Symposium Folie: 38
39 LM Zeitschritt Analyse MPI Kommunikation beträgt ca. 16% der Laufzeit Lastverteilung ist gut (geringer Kommunikationsoverhead) Kommunikations-Matrix Typische 2 D Nachbarkommunikation Zuviel off node Kommunikation Lösungsansatz: Verbessertes Mapping durch Inner-Knoten- Kommunikation (shared memory statt interconnect) 26. DECUS Symposium Folie: 39


40 Verbesserung des Prozessor Mappings Ursprüngliches Knotenmapping Verbessertes Knotenmapping 26. DECUS Symposium Folie: 40

41 Analyse der Output Phase Alle Prozesse senden an Prozess DECUS Symposium Folie: 41
42 Analyse der Output Phase Das Schreiben des Output blockiert alle Prozesse und benötigt soviel Zeit wie 8 Zeitschritte Der gesamte Output ist somit über Prozess 0 serialisiert Lösungsansatz: Verwendung eines dedizierten I/O Knotens Jeder Prozess sendet seine Output Daten an den I/O Knoten und rechnet weiter Der I/O Knoten führt die Festplattenzugriffe durch während die Berechnung weiter geht 26. DECUS Symposium Folie: 42


43 Analyse der Output Phase I/O Knoten Überlagerung Berechnung- I/O 26. DECUS Symposium Folie: 43


44 OpenMP Analyse 26. DECUS Symposium Folie: 44
45 Anforderungen an ein OpenMP Analysetool OpenMP Performance Probleme Probleme bei der Lastverteilung Synchronisation Probleme Darstellung folgender Faktoren Effektiver speed up Ausführungszeitaufteilung (Parallel, Seriell, Overhead) Vergleich verschiedene Programmläufe Anzahl der verwendeten Threads wird einfach über ein Umgebungsvariable getriggert! 26. DECUS Symposium Folie: 45

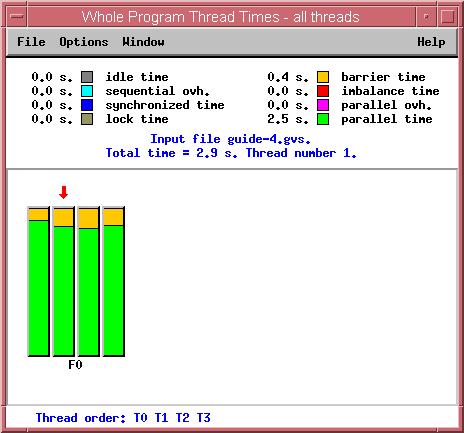
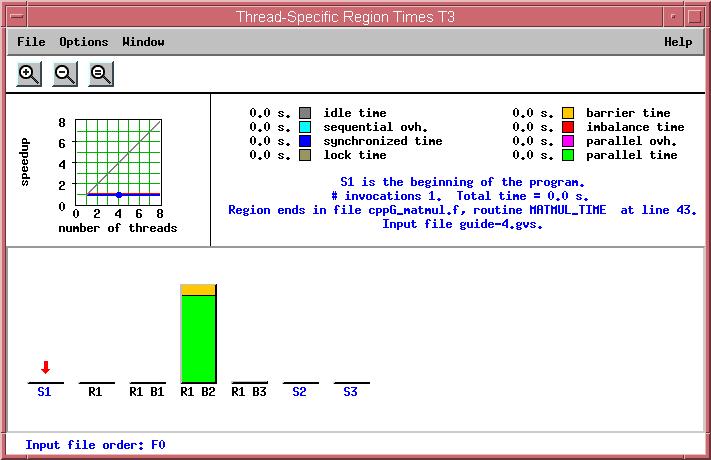

46 OpenMP Beispiel - Matrixmultiplikation Information pro Thread Statistik (Bereich/Gesamt) 26. DECUS Symposium Folie: 46
 26.")
47 OpenMP Beispiel - Matrixmultiplikation Vergleich idealer-tatsächlicher Performance speed up Identifizierung von bottlenecks (barriers, locks, seq. time) 26. DECUS Symposium Folie: 47
 26.")
48 Thread Analyse parallele Probleme Synchronisationsprobleme (memory leaks) 26. DECUS Symposium Folie: 48



49 Thread Analyse - deadlock 26. DECUS Symposium Folie: 49


50 Basis Performance nicht optimierter Code 26. DECUS Symposium Folie: 50
51 Optimierter serieller Code 9x schneller Wenig Änderungen am Quellcode 7x 9x Performance Bibliotheken 4x 1x Standard Compiler Performance Bibliotheken Standard Compiler Opt. Compiler Opt. Compiler 26. DECUS Symposium Folie: 51
52 Optimierter paralleler Code - OpenMP 15x schneller Mittlere Änderungen am Quellcode 13x Performance Bibliotheken Wenig Änderungen am Quellcode 7x 9x Performance Bibliotheken OpenMP Threading OpenMP Threading 4x 1x Standard Compiler Performance Bibliotheken Standard Compiler Opt. Compiler Opt. Compiler Opt. Compiler Opt. Compiler 26. DECUS Symposium Folie: 52

53 Optimierte parallel Performance 15x schneller 26. DECUS Symposium Folie: 53

54 Hybride Modelle 26. DECUS Symposium Folie: 54


55 MPI OpenMP Analyse expandieren 26. DECUS Symposium Folie: 55

56 MPI+OpenMP verschiedene Programmläufe 26. DECUS Symposium Folie: 56


57 Einsatzgebiet der Werkzeuge SMP PC ASCI-Q 30 Teraflop System HP SMP System 2-4 CPUs 4 GB Hauptspeicher 100 GB Festplattenspeicher 374 * 32-way GS320 System Alpha CPUs 12 TB Hauptspeicher 600 TB Festplattenspeicher 26. DECUS Symposium Folie: 57

58 Folie: 1 58 Vielen Dank für Ihre Aufmerksamkeit Pallas GmbH Hermülheimer Straße 10 D Brühl, Germany info@pallas.com
Praktikum: Paralleles Programmieren für Geowissenschaftler
 Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart hermann.lenhart@zmaw.de MPI Einführung I: Einführung Nachrichtenaustausch mit MPI MPI point-to-point communication
Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart hermann.lenhart@zmaw.de MPI Einführung I: Einführung Nachrichtenaustausch mit MPI MPI point-to-point communication
Praktikum: Paralleles Programmieren für Geowissenschaftler
 Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart, Nathanael Hübbe hermann.lenhart@zmaw.de MPI Einführung I: Hardware Voraussetzung zur Parallelen Programmierung
Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart, Nathanael Hübbe hermann.lenhart@zmaw.de MPI Einführung I: Hardware Voraussetzung zur Parallelen Programmierung
OpenMP - Geschichte. 1997: OpenMP Version 1.0 für Fortran
 OpenMP - Geschichte 1997: OpenMP Version 1.0 für Fortran Standard für f r die Shared-Memory Memory-Programmierung inzwischen für f r alle namhaften SMP-Rechner verfügbar wird im techn.-wiss. Rechnen die
OpenMP - Geschichte 1997: OpenMP Version 1.0 für Fortran Standard für f r die Shared-Memory Memory-Programmierung inzwischen für f r alle namhaften SMP-Rechner verfügbar wird im techn.-wiss. Rechnen die
C-to-CUDA-Compiler. Johannes Kölsch. October 29, 2012
 October 29, 2012 Inhaltsverzeichnis 1 2 3 4 5 6 Motivation Motivation CUDA bietet extreme Leistung für parallelisierbare Programme Kompliziert zu programmieren, da multi-level parallel und explizit verwalteter
October 29, 2012 Inhaltsverzeichnis 1 2 3 4 5 6 Motivation Motivation CUDA bietet extreme Leistung für parallelisierbare Programme Kompliziert zu programmieren, da multi-level parallel und explizit verwalteter
Parallel Computing. Einsatzmöglichkeiten und Grenzen. Prof. Dr. Nikolaus Wulff
 Parallel Computing Einsatzmöglichkeiten und Grenzen Prof. Dr. Nikolaus Wulff Parallel Architekturen Flynn'sche Klassifizierung: SISD: single Instruction, single Data Klassisches von-neumann sequentielles
Parallel Computing Einsatzmöglichkeiten und Grenzen Prof. Dr. Nikolaus Wulff Parallel Architekturen Flynn'sche Klassifizierung: SISD: single Instruction, single Data Klassisches von-neumann sequentielles
Intel Cluster Studio. Michael Burger FG Scientific Computing TU Darmstadt michael.burger@sc.tu-darmstadt.de
 Intel Cluster Studio Michael Burger FG Scientific Computing TU Darmstadt michael.burger@sc.tu-darmstadt.de 19.03.13 FB Computer Science Scientific Computing Michael Burger 1 / 30 Agenda Was ist das Intel
Intel Cluster Studio Michael Burger FG Scientific Computing TU Darmstadt michael.burger@sc.tu-darmstadt.de 19.03.13 FB Computer Science Scientific Computing Michael Burger 1 / 30 Agenda Was ist das Intel
Nebenläufige Programme mit Python
 Nebenläufige Programme mit Python PyCon DE 2012 Stefan Schwarzer, SSchwarzer.com info@sschwarzer.com Leipzig, Deutschland, 2012-10-30 Nebenläufige Programme mit Python Stefan Schwarzer, info@sschwarzer.com
Nebenläufige Programme mit Python PyCon DE 2012 Stefan Schwarzer, SSchwarzer.com info@sschwarzer.com Leipzig, Deutschland, 2012-10-30 Nebenläufige Programme mit Python Stefan Schwarzer, info@sschwarzer.com
Was ist ein Profiler?
 Profiling Was ist ein Profiler? (Theorie) Invasives Profiling Nichtinvasives Profiling Profiling in der Praxis gprof, gcov OProfile valgrind/callgrind Intel VTune Was ist ein Profiler? Analyse des Laufzeitverhaltens
Profiling Was ist ein Profiler? (Theorie) Invasives Profiling Nichtinvasives Profiling Profiling in der Praxis gprof, gcov OProfile valgrind/callgrind Intel VTune Was ist ein Profiler? Analyse des Laufzeitverhaltens
Multi- und Many-Core
 Multi- und Many-Core Benjamin Warnke Arbeitsbereich Wissenschaftliches Rechnen Fachbereich Informatik Fakultät für Mathematik, Informatik und Naturwissenschaften Universität Hamburg 2016-12-15 Benjamin
Multi- und Many-Core Benjamin Warnke Arbeitsbereich Wissenschaftliches Rechnen Fachbereich Informatik Fakultät für Mathematik, Informatik und Naturwissenschaften Universität Hamburg 2016-12-15 Benjamin
Praktikum: Paralleles Programmieren für Geowissenschaftler
 Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart & Enno Zickler hermann.lenhart@zmaw.de OpenMP Allgemeine Einführung I OpenMP Merkmale: OpenMP ist keine Programmiersprache!
Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart & Enno Zickler hermann.lenhart@zmaw.de OpenMP Allgemeine Einführung I OpenMP Merkmale: OpenMP ist keine Programmiersprache!
Automatische Parallelisierung
 MPI und OpenMP in HPC Anwendungen findet man immer häufiger auch den gemeinsamen Einsatz von MPI und OpenMP: OpenMP wird zur thread-parallelen Implementierung des Codes auf einem einzelnen Rechenknoten
MPI und OpenMP in HPC Anwendungen findet man immer häufiger auch den gemeinsamen Einsatz von MPI und OpenMP: OpenMP wird zur thread-parallelen Implementierung des Codes auf einem einzelnen Rechenknoten
Höchstleistungsrechnen in der Cloud
 Höchstleistungsrechnen in der Cloud Michael Gienger Höchstleistungsrechenzentrum Stuttgart Stuttgart, 13.11.2018 :: :: :: Agenda Hintergrund Höchstleistungsrechnen Cloud Computing Motivation Integration
Höchstleistungsrechnen in der Cloud Michael Gienger Höchstleistungsrechenzentrum Stuttgart Stuttgart, 13.11.2018 :: :: :: Agenda Hintergrund Höchstleistungsrechnen Cloud Computing Motivation Integration
Einige Grundlagen zu OpenMP
 Einige Grundlagen zu OpenMP Stephanie Friedhoff, Martin Lanser Mathematisches Institut Universität zu Köln 22. Juni 2016 Überblick Was ist OpenMP? Basics Das OpenMP fork-join-modell Kompilieren und Ausführen
Einige Grundlagen zu OpenMP Stephanie Friedhoff, Martin Lanser Mathematisches Institut Universität zu Köln 22. Juni 2016 Überblick Was ist OpenMP? Basics Das OpenMP fork-join-modell Kompilieren und Ausführen
Parallel Computing. Einsatzmöglichkeiten und Grenzen. Prof. Dr. Nikolaus Wulff
 Parallel Computing Einsatzmöglichkeiten und Grenzen Prof. Dr. Nikolaus Wulff Vorüberlegungen Wann ist paralleles Rechnen sinnvoll? Wenn die Performance/Geschwindigkeit steigt. Wenn sich größere Probleme
Parallel Computing Einsatzmöglichkeiten und Grenzen Prof. Dr. Nikolaus Wulff Vorüberlegungen Wann ist paralleles Rechnen sinnvoll? Wenn die Performance/Geschwindigkeit steigt. Wenn sich größere Probleme
Schnelle modulare Synthese auf Mehrkern-Architekturen. GPN7 So, Jürgen Reuter
 Schnelle modulare Synthese auf Mehrkern-Architekturen GPN7 So, 06.07.2008 Jürgen Reuter Ausgangspunkt: SoundPaint Integriere Entwurf von Klängen & Komposition Ziel: Ausdrucksvollere elektronische Musik
Schnelle modulare Synthese auf Mehrkern-Architekturen GPN7 So, 06.07.2008 Jürgen Reuter Ausgangspunkt: SoundPaint Integriere Entwurf von Klängen & Komposition Ziel: Ausdrucksvollere elektronische Musik
2 Rechnerarchitekturen
 2 Rechnerarchitekturen Rechnerarchitekturen Flynns Klassifikation Flynnsche Klassifikation (Flynn sche Taxonomie) 1966 entwickelt, einfaches Modell, bis heute genutzt Beschränkung der Beschreibung auf
2 Rechnerarchitekturen Rechnerarchitekturen Flynns Klassifikation Flynnsche Klassifikation (Flynn sche Taxonomie) 1966 entwickelt, einfaches Modell, bis heute genutzt Beschränkung der Beschreibung auf
Evaluation. Einleitung. Implementierung Integration. Zusammenfassung Ausblick
 Christopher Schleiden Bachelor Kolloquium 15.09.2009 Einleitung Evaluation Implementierung Integration Zusammenfassung Ausblick Einleitung laperf Lineare Algebra Bibliothek für C++ Möglichkeit zur Integration
Christopher Schleiden Bachelor Kolloquium 15.09.2009 Einleitung Evaluation Implementierung Integration Zusammenfassung Ausblick Einleitung laperf Lineare Algebra Bibliothek für C++ Möglichkeit zur Integration
Schneller als Hadoop?
 Schneller als Hadoop? Einführung in Spark Cluster Computing 19.11.2013 Dirk Reinemann 1 Agenda 1. Einführung 2. Motivation 3. Infrastruktur 4. Performance 5. Ausblick 19.11.2013 Dirk Reinemann 2 EINFÜHRUNG
Schneller als Hadoop? Einführung in Spark Cluster Computing 19.11.2013 Dirk Reinemann 1 Agenda 1. Einführung 2. Motivation 3. Infrastruktur 4. Performance 5. Ausblick 19.11.2013 Dirk Reinemann 2 EINFÜHRUNG
Mehrprozessorarchitekturen
 Mehrprozessorarchitekturen (SMP, UMA/NUMA, Cluster) Arian Bär 12.07.2004 12.07.2004 Arian Bär 1 Gliederung 1. Einleitung 2. Symmetrische Multiprozessoren (SMP) Allgemeines Architektur 3. Speicherarchitekturen
Mehrprozessorarchitekturen (SMP, UMA/NUMA, Cluster) Arian Bär 12.07.2004 12.07.2004 Arian Bär 1 Gliederung 1. Einleitung 2. Symmetrische Multiprozessoren (SMP) Allgemeines Architektur 3. Speicherarchitekturen
Memory Models Frederik Zipp
 Memory Models Frederik Zipp Seminar: Programmiersprachen für Parallele Programmierung (SS 2010) Fakultät für Informatik - IPD SNELTING LEHRSTUHL PROGRAMMIERPARADIGMEN 1
Memory Models Frederik Zipp Seminar: Programmiersprachen für Parallele Programmierung (SS 2010) Fakultät für Informatik - IPD SNELTING LEHRSTUHL PROGRAMMIERPARADIGMEN 1
OpenMP. Viktor Styrbul
 OpenMP Viktor Styrbul Inhaltsverzeichnis Was ist OpenMP Warum Parallelisierung Geschichte Merkmale von OpenMP OpenMP-fähige Compiler OpenMP Ausführungsmodell Kernelemente von OpenMP Zusammenfassung Was
OpenMP Viktor Styrbul Inhaltsverzeichnis Was ist OpenMP Warum Parallelisierung Geschichte Merkmale von OpenMP OpenMP-fähige Compiler OpenMP Ausführungsmodell Kernelemente von OpenMP Zusammenfassung Was
Computergrundlagen Moderne Rechnerarchitekturen
 Computergrundlagen Moderne Rechnerarchitekturen Axel Arnold Institut für Computerphysik Universität Stuttgart Wintersemester 2010/11 Aufbau eines modernen Computers DDR3- Speicher Prozessor Prozessor PEG
Computergrundlagen Moderne Rechnerarchitekturen Axel Arnold Institut für Computerphysik Universität Stuttgart Wintersemester 2010/11 Aufbau eines modernen Computers DDR3- Speicher Prozessor Prozessor PEG
Praktikum: Paralleles Programmieren für Geowissenschaftler
 Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart, Tim Jammer & Jannek Squar Dr. HermannJ. Lenhart hermann.lenhart@informatik.unihamburg.de MPI Einführung
Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart, Tim Jammer & Jannek Squar Dr. HermannJ. Lenhart hermann.lenhart@informatik.unihamburg.de MPI Einführung
Die deutsche Windows HPC Benutzergruppe
 Christian Terboven, Dieter an Mey {terboven, anmey}@rz.rwth aachen.de Rechen und Kommunikationszentrum RWTH Aachen Windows HPC Server Launch 16. Oktober, Frankfurt am Main Agenda o Hochleistungsrechnen
Christian Terboven, Dieter an Mey {terboven, anmey}@rz.rwth aachen.de Rechen und Kommunikationszentrum RWTH Aachen Windows HPC Server Launch 16. Oktober, Frankfurt am Main Agenda o Hochleistungsrechnen
Inhaltsverzeichnis. Visualisierung von Ausführungstraces. 1. Motivation. 2. Anwendungsfelder. 3. Visualisierungstools. 4.
 DIMO MALESHKOV Leiter: Dr.-Ing. Andreas Kerren Universität Kaiserslautern Inhaltsverzeichnis 1. Motivation 2. Anwendungsfelder 3. Visualisierungstools 4. Zusammenfassung 2/25 Inhaltsverzeichnis 1. Motivation
DIMO MALESHKOV Leiter: Dr.-Ing. Andreas Kerren Universität Kaiserslautern Inhaltsverzeichnis 1. Motivation 2. Anwendungsfelder 3. Visualisierungstools 4. Zusammenfassung 2/25 Inhaltsverzeichnis 1. Motivation
Hochleistungsrechnen mit Windows Verifikations- und Analyseprogramme Christian Terboven Rechen- und Kommunikationszentrum RWTH Aachen
 Hochleistungsrechnen mit Windows Verifikations- und Analyseprogramme hristian Terboven Rechen- und Kommunikationszentrum RWTH Aachen 1 Hochleistungsrechnen mit Windows enter omputing and ommunication Agenda
Hochleistungsrechnen mit Windows Verifikations- und Analyseprogramme hristian Terboven Rechen- und Kommunikationszentrum RWTH Aachen 1 Hochleistungsrechnen mit Windows enter omputing and ommunication Agenda
Konzepte der parallelen Programmierung
 Fakultät Informatik, Institut für Technische Informatik, Professur Rechnerarchitektur Konzepte der parallelen Programmierung Parallele Programmiermodelle Nöthnitzer Straße 46 Raum 1029 Tel. +49 351-463
Fakultät Informatik, Institut für Technische Informatik, Professur Rechnerarchitektur Konzepte der parallelen Programmierung Parallele Programmiermodelle Nöthnitzer Straße 46 Raum 1029 Tel. +49 351-463
Vorstellung der SUN Rock-Architektur
 Fakultät Informatik Institut für Technische Informatik, Professur für VLSI-Entwurfssysteme, Diagnostik und Architektur Vorstellung der SUN Rock-Architektur Hauptseminar Ronald Rist Dresden, 14.01.2009
Fakultät Informatik Institut für Technische Informatik, Professur für VLSI-Entwurfssysteme, Diagnostik und Architektur Vorstellung der SUN Rock-Architektur Hauptseminar Ronald Rist Dresden, 14.01.2009
Erste Erfahrungen mit Installation und Betrieb
 Erste Erfahrungen mit Installation und Betrieb von OpenHPC 14.10.2016 Holger Angenent Röntgenstr. 7-13, 48149 Münster 2 > Problemstellung Jeder neue Cluster kam bisher mit neuem Clustermanagement Einarbeitungszeit
Erste Erfahrungen mit Installation und Betrieb von OpenHPC 14.10.2016 Holger Angenent Röntgenstr. 7-13, 48149 Münster 2 > Problemstellung Jeder neue Cluster kam bisher mit neuem Clustermanagement Einarbeitungszeit
Profiling in Python. Seminar: Effiziente Programmierung. Jan Pohlmann. November Jan Pohlmann Profiling in Python November / 32
 Profiling in Python Seminar: Effiziente Programmierung Jan Pohlmann November 2017 Jan Pohlmann Profiling in Python November 2017 1 / 32 Gliederung 1 Grundlagen Profiling Was ist das Ziele und Herausforderungen
Profiling in Python Seminar: Effiziente Programmierung Jan Pohlmann November 2017 Jan Pohlmann Profiling in Python November 2017 1 / 32 Gliederung 1 Grundlagen Profiling Was ist das Ziele und Herausforderungen
Beschreiben Sie die Eigenschaften der verschiedenen Rechnertypen an Hand:
 Hochschule Harz FB Automatisierung/Informatik Fachprüfung: Parallele Algorithmen (Musterklausur) Alle Hilfsmittel sind zugelassen! 1. Aufgabe Beschreiben Sie die Eigenschaften der verschiedenen Rechnertypen
Hochschule Harz FB Automatisierung/Informatik Fachprüfung: Parallele Algorithmen (Musterklausur) Alle Hilfsmittel sind zugelassen! 1. Aufgabe Beschreiben Sie die Eigenschaften der verschiedenen Rechnertypen
Performance Engineering: Forschung und Dienstleistung für HPC-Kunden. Dirk Schmidl
 Performance Engineering: Forschung und Dienstleistung für HPC-Kunden Hardware Komplexität GPU KNL MPI L U S T R E SMP Claix NVMe HOME Storage OPA Die Komplexität moderner HPC Systeme erfordert Optimierung
Performance Engineering: Forschung und Dienstleistung für HPC-Kunden Hardware Komplexität GPU KNL MPI L U S T R E SMP Claix NVMe HOME Storage OPA Die Komplexität moderner HPC Systeme erfordert Optimierung
Praktikum: Paralleles Programmieren für Geowissenschaftler
 Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart, Enno Zieckler hermann.lenhart@informatik.uni-hamburg.de MPI Kommunikation: Das wichtigste Kriterium für
Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart, Enno Zieckler hermann.lenhart@informatik.uni-hamburg.de MPI Kommunikation: Das wichtigste Kriterium für
Beispielvortrag: HPCG auf Intel Haswell-EP
 Beispielvortrag: HPCG auf Intel Haswell-EP Johannes Hofmann 1 Seminarvortrag Architekturen von Multi- und Vielkern-Prozessoren Erlangen, 19.4.2016 1 Computer Architecture, University Erlangen-Nuremberg
Beispielvortrag: HPCG auf Intel Haswell-EP Johannes Hofmann 1 Seminarvortrag Architekturen von Multi- und Vielkern-Prozessoren Erlangen, 19.4.2016 1 Computer Architecture, University Erlangen-Nuremberg
Nutzung paralleler Prozesse bei der Umweltsimulation
 Nutzung paralleler Prozesse bei der Umweltsimulation RALF Wieland rwieland@zalf.de ZALF/LSA Nutzung paralleler Prozesse bei der Umweltsimulation p. 1 Warum parallele Prozesse? Die Steigerung der Taktfrequenz
Nutzung paralleler Prozesse bei der Umweltsimulation RALF Wieland rwieland@zalf.de ZALF/LSA Nutzung paralleler Prozesse bei der Umweltsimulation p. 1 Warum parallele Prozesse? Die Steigerung der Taktfrequenz
Grundlagen in LabWindows TM /CVI
 Grundlagen in LabWindows TM /CVI Einführung in die ereignisorientierte ANSI-C-Programmierumgebung LabWindows TM /CVI Jan Wagner Applications Engineer National Instruments Germany GmbH Agenda Einführung
Grundlagen in LabWindows TM /CVI Einführung in die ereignisorientierte ANSI-C-Programmierumgebung LabWindows TM /CVI Jan Wagner Applications Engineer National Instruments Germany GmbH Agenda Einführung
Parallele Programmierung mit OpenMP
 Parallele Programmierung mit OpenMP - Eine kurze Einführung - 11.06.2003 RRZN Kolloquium SS 2003 1 Gliederung 1. Grundlagen 2. Programmiermodell 3. Sprachkonstrukte 4. Vergleich MPI und OpenMP 11.06.2003
Parallele Programmierung mit OpenMP - Eine kurze Einführung - 11.06.2003 RRZN Kolloquium SS 2003 1 Gliederung 1. Grundlagen 2. Programmiermodell 3. Sprachkonstrukte 4. Vergleich MPI und OpenMP 11.06.2003
Vorlesung Betriebssysteme II
 1 / 15 Vorlesung Betriebssysteme II Thema 3: IPC Robert Baumgartl 20. April 2015 2 / 15 Message Passing (Nachrichtenaustausch) Prinzip 2 grundlegende Operationen: send(), receive() notwendig, wenn kein
1 / 15 Vorlesung Betriebssysteme II Thema 3: IPC Robert Baumgartl 20. April 2015 2 / 15 Message Passing (Nachrichtenaustausch) Prinzip 2 grundlegende Operationen: send(), receive() notwendig, wenn kein
PRIP-Preis. Effizientes Object Tracking durch Programmierung von Mehrkernprozessoren und Grafikkarten
 Masterarbeit @ PRIP-Preis Effizientes Object Tracking durch Programmierung von Mehrkernprozessoren und Grafikkarten Michael Rauter Pattern Recognition and Image Processing Group Institute of Computer Aided
Masterarbeit @ PRIP-Preis Effizientes Object Tracking durch Programmierung von Mehrkernprozessoren und Grafikkarten Michael Rauter Pattern Recognition and Image Processing Group Institute of Computer Aided
FPGA Systementwurf. Rosbeh Etemadi. Paderborn University. 29. Mai 2007
 Paderborn Center for Parallel l Computing Paderborn University 29. Mai 2007 Übersicht 1. FPGAs 2. Entwicklungssprache VHDL 3. Matlab/Simulink 4. Entwicklungssprache Handel-C 5. Fazit Übersicht FPGAs 1.
Paderborn Center for Parallel l Computing Paderborn University 29. Mai 2007 Übersicht 1. FPGAs 2. Entwicklungssprache VHDL 3. Matlab/Simulink 4. Entwicklungssprache Handel-C 5. Fazit Übersicht FPGAs 1.
Programmieren in Haskell Debugging
 Programmieren in Haskell Debugging Peter Steffen Universität Bielefeld Technische Fakultät 30.01.2009 1 Programmieren in Haskell Debugger Definition laut Wikipedia: Ein Debugger (von engl. bug im Sinne
Programmieren in Haskell Debugging Peter Steffen Universität Bielefeld Technische Fakultät 30.01.2009 1 Programmieren in Haskell Debugger Definition laut Wikipedia: Ein Debugger (von engl. bug im Sinne
Computergrundlagen Moderne Rechnerarchitekturen
 Aufbau eines modernen Computers Computergrundlagen Moderne Rechnerarchitekturen Axel Arnold Institut für Computerphysik Universität Stuttgart DDR3- Speicher Prozessor Prozessor PEG Graphikkarte(n) weitere
Aufbau eines modernen Computers Computergrundlagen Moderne Rechnerarchitekturen Axel Arnold Institut für Computerphysik Universität Stuttgart DDR3- Speicher Prozessor Prozessor PEG Graphikkarte(n) weitere
Master-Thread führt Programm aus, bis durch die Direktive
 OpenMP seit 1998 Standard (www.openmp.org) für die Shared-Memory Programmierung; (Prä-)Compiler für viele Systeme kommerziell oder frei (z.b. Omni von phase.hpcc.jp/omni) verfügbar Idee: automatische Generierung
OpenMP seit 1998 Standard (www.openmp.org) für die Shared-Memory Programmierung; (Prä-)Compiler für viele Systeme kommerziell oder frei (z.b. Omni von phase.hpcc.jp/omni) verfügbar Idee: automatische Generierung
Rechnerarchitektur SS 2013
 Rechnerarchitektur SS 2013 Parallel Random Access Machine (PRAM) Michael Engel TU Dortmund, Fakultät für Informatik Teilweise basierend auf Material von Gernot A. Fink und R. Yahyapour 6. Juni 2013 Parallel
Rechnerarchitektur SS 2013 Parallel Random Access Machine (PRAM) Michael Engel TU Dortmund, Fakultät für Informatik Teilweise basierend auf Material von Gernot A. Fink und R. Yahyapour 6. Juni 2013 Parallel
Verkürzung von Entwurfszeiten
 Verkürzung von Entwurfszeiten durch Matlab-basiertes HPC R. Fink, S. Pawletta Übersicht aktuelle Situation im ingenieurtechnischen Bereich Multi-SCEs als Konzept zur Verkürzung von Entwurfszeiten Realisierung
Verkürzung von Entwurfszeiten durch Matlab-basiertes HPC R. Fink, S. Pawletta Übersicht aktuelle Situation im ingenieurtechnischen Bereich Multi-SCEs als Konzept zur Verkürzung von Entwurfszeiten Realisierung
Leistungsanalyse von Rechnersystemen
 Zentrum für Informationsdienste und Hochleistungsrechnen (ZIH) Leistungsanalyse von Rechnersystemen Auf Ein-/Ausgabe spezialisierte Benchmarks Zellescher Weg 12 Willers-Bau A109 Tel. +49 351-463 - 32424
Zentrum für Informationsdienste und Hochleistungsrechnen (ZIH) Leistungsanalyse von Rechnersystemen Auf Ein-/Ausgabe spezialisierte Benchmarks Zellescher Weg 12 Willers-Bau A109 Tel. +49 351-463 - 32424
Vorlesung Hochleistungsrechnen SS 2010 (c) Thomas Ludwig 447
 Thomas Ludwig 447") Siehe: http://en.wikipedia.org/wiki/debugging Vorlesung Hochleistungsrechnen SS 2010 (c) Thomas Ludwig 447 Vorlesung Hochleistungsrechnen SS 2010 (c) Thomas Ludwig 448 Siehe: http://en.wikipedia.org/wiki/legacy_code
Siehe: http://en.wikipedia.org/wiki/debugging Vorlesung Hochleistungsrechnen SS 2010 (c) Thomas Ludwig 447 Vorlesung Hochleistungsrechnen SS 2010 (c) Thomas Ludwig 448 Siehe: http://en.wikipedia.org/wiki/legacy_code
Simulation der instationären Strömung in einem Diffusionsofen mit Wärmestrahlung
 Simulation der instationären Strömung in einem Diffusionsofen mit Wärmestrahlung R. Kessler DLR-AS-CASE Simulation der instationären Strömung in einem Diffusionsofen mit Wärmestrahlung Slide 1 > HPC 2009
Simulation der instationären Strömung in einem Diffusionsofen mit Wärmestrahlung R. Kessler DLR-AS-CASE Simulation der instationären Strömung in einem Diffusionsofen mit Wärmestrahlung Slide 1 > HPC 2009
Seminarvortrag: Direktivenbasierte Programmierung von Beschleunigern mit OpenMP 4.5 und OpenACC 2.5 im Vergleich
 Seminarvortrag: Direktivenbasierte Programmierung von Beschleunigern mit Direktivenbasierte Programmierung von Beschleunigern mit Agenda Einführung / Motivation Überblick zu OpenMP und OpenACC Asynchronität
Seminarvortrag: Direktivenbasierte Programmierung von Beschleunigern mit Direktivenbasierte Programmierung von Beschleunigern mit Agenda Einführung / Motivation Überblick zu OpenMP und OpenACC Asynchronität
magnitude Erste Erfahrungen mit dem neuen HPC-System der UDE
 magnitude Erste Erfahrungen mit dem neuen HPC-System der UDE ZKI-AK Supercomputing Holger Gollan Agenda Die Universität Duisburg-Essen (UDE) Das Zentrum für Informations- und Mediendienste (ZIM Das Center
magnitude Erste Erfahrungen mit dem neuen HPC-System der UDE ZKI-AK Supercomputing Holger Gollan Agenda Die Universität Duisburg-Essen (UDE) Das Zentrum für Informations- und Mediendienste (ZIM Das Center
Centre of Excellence for High Performance Computing Erlangen Kompetenzgruppe für Supercomputer und Technisch-Wissenschaftliche Simulation
 1 Centre of Excellence for High Performance Computing Erlangen Kompetenzgruppe für Supercomputer und Technisch-Wissenschaftliche Simulation Dr. G. Wellein, Regionales Rechenzentrum Erlangen Supercomputer
1 Centre of Excellence for High Performance Computing Erlangen Kompetenzgruppe für Supercomputer und Technisch-Wissenschaftliche Simulation Dr. G. Wellein, Regionales Rechenzentrum Erlangen Supercomputer
Das HLRN-System. Peter Endebrock, RRZN Hannover
 Das HLRN-System Peter Endebrock, RRZN Hannover vorweg (1) Heute Vorträge im Dreierpack: Peter Endebrock: Das HLRN-System Gerd Brand: MPI Simone Knief: OpenMP Peter Endebrock, RRZN Hannover, Kolloquium,
Das HLRN-System Peter Endebrock, RRZN Hannover vorweg (1) Heute Vorträge im Dreierpack: Peter Endebrock: Das HLRN-System Gerd Brand: MPI Simone Knief: OpenMP Peter Endebrock, RRZN Hannover, Kolloquium,
Parallel Regions und Work-Sharing Konstrukte
 Parallel Regions und Work-Sharing Konstrukte Um eine Parallelisierung von größeren Programmabschnitten, als es einzelne Schleifen sind, zu ermöglichen, stellt OpenMP als allgemeinstes Konzept die Parallel
Parallel Regions und Work-Sharing Konstrukte Um eine Parallelisierung von größeren Programmabschnitten, als es einzelne Schleifen sind, zu ermöglichen, stellt OpenMP als allgemeinstes Konzept die Parallel
Microsoft Azure Deutschland ist jetzt verfügbar -
 Einordnung und Überblick Data Scientist Operationalisierung IT-Abteilung Anwendungsentwickler Der Data Scientist agil Tool seiner Wahl möglichst wenig Zeit Skalierung Code für die Operationalisierung Der
Einordnung und Überblick Data Scientist Operationalisierung IT-Abteilung Anwendungsentwickler Der Data Scientist agil Tool seiner Wahl möglichst wenig Zeit Skalierung Code für die Operationalisierung Der
Oracle Bare Metal Cloud Service
 Oracle Bare Metal Cloud Service Ein Überblick Marcus Schröder Master Principal Sales Consultant Business Unit Core & Cloud Technologies November, 2017 2 Safe Harbor Statement The following is intended
Oracle Bare Metal Cloud Service Ein Überblick Marcus Schröder Master Principal Sales Consultant Business Unit Core & Cloud Technologies November, 2017 2 Safe Harbor Statement The following is intended
Tuning des Weblogic /Oracle Fusion Middleware 11g. Jan-Peter Timmermann Principal Consultant PITSS
 Tuning des Weblogic /Oracle Fusion Middleware 11g Jan-Peter Timmermann Principal Consultant PITSS 1 Agenda Bei jeder Installation wiederkehrende Fragen WievielForms Server braucheich Agenda WievielRAM
Tuning des Weblogic /Oracle Fusion Middleware 11g Jan-Peter Timmermann Principal Consultant PITSS 1 Agenda Bei jeder Installation wiederkehrende Fragen WievielForms Server braucheich Agenda WievielRAM
Konzepte und Methoden der Systemsoftware. Aufgabe 1: Polling vs Interrupts. SoSe bis P
 SoSe 2014 Konzepte und Methoden der Systemsoftware Universität Paderborn Fachgebiet Rechnernetze Präsenzübung 3(Musterlösung) 2014-05-05 bis 2014-05-09 Aufgabe 1: Polling vs Interrupts (a) Erläutern Sie
SoSe 2014 Konzepte und Methoden der Systemsoftware Universität Paderborn Fachgebiet Rechnernetze Präsenzübung 3(Musterlösung) 2014-05-05 bis 2014-05-09 Aufgabe 1: Polling vs Interrupts (a) Erläutern Sie
news 12 / 2010 Aktionsrabatt
 news 12 / 2010 Inhalt Editorial 2 HPC-Entwicklertag am 14.2. in Köln 2 Intel Inspector XE 3 Intel Cluster Studio 4,5 Intel VTune Amplifier XE 6,7 10% Dezemberaktion, Upgrades 7 Aktionspreisliste Dezember
news 12 / 2010 Inhalt Editorial 2 HPC-Entwicklertag am 14.2. in Köln 2 Intel Inspector XE 3 Intel Cluster Studio 4,5 Intel VTune Amplifier XE 6,7 10% Dezemberaktion, Upgrades 7 Aktionspreisliste Dezember
PostgreSQL auf vielen CPUs. Hans-Jürgen Schönig Hans-Jürgen Schönig
 PostgreSQL auf vielen CPUs Ansätze zur Skalierung PostgreSQL auf einer CPU Traditionell läuft eine Query auf nur einer CPU Historisch gesehen war das kein Problem Mittlerweile ist das ein großes Problem
PostgreSQL auf vielen CPUs Ansätze zur Skalierung PostgreSQL auf einer CPU Traditionell läuft eine Query auf nur einer CPU Historisch gesehen war das kein Problem Mittlerweile ist das ein großes Problem
Hochleistungsrechnen Hybride Parallele Programmierung. Prof. Dr. Thomas Ludwig Universität Hamburg Informatik Wissenschaftliches Rechnen
 Hochleistungsrechnen Hybride Parallele Programmierung Prof. Dr. Thomas Ludwig Universität Hamburg Informatik Wissenschaftliches Rechnen Inhaltsübersicht Einleitung und Motivation Programmiermodelle für
Hochleistungsrechnen Hybride Parallele Programmierung Prof. Dr. Thomas Ludwig Universität Hamburg Informatik Wissenschaftliches Rechnen Inhaltsübersicht Einleitung und Motivation Programmiermodelle für
PARADOM. Parallele Algorithmische Differentiation in OpenModelica für energietechnische Simulationen und Optimierungen.
 Zentrum für Informationsdienste und Hochleistungsrechnen TU Dresden PARADOM Parallele Algorithmische Differentiation in OpenModelica für energietechnische Simulationen und Optimierungen Martin Flehmig
Zentrum für Informationsdienste und Hochleistungsrechnen TU Dresden PARADOM Parallele Algorithmische Differentiation in OpenModelica für energietechnische Simulationen und Optimierungen Martin Flehmig
Michael Stumpen Grid Computing. Prof. Dr. Fuhr SS04 Kommunikation. Wide-Area Implementation of the Message Passing Interface
 Michael Stumpen 740261 Grid Computing Prof. Dr. Fuhr SS04 Kommunikation Wide-Area Implementation of the Message Passing Interface 1. Einleitung Idee zu Grid Computing entstand Anfang der 70er Zunehmendes
Michael Stumpen 740261 Grid Computing Prof. Dr. Fuhr SS04 Kommunikation Wide-Area Implementation of the Message Passing Interface 1. Einleitung Idee zu Grid Computing entstand Anfang der 70er Zunehmendes
www.hocomputer.de - info@hocomputer.de - Tel: (+49) / 0221 / 76 20 86
 / 0221 / 76 20 86") news 2 / 205 Nur bis 22. Dezember 0 % Sonderrabatt Details auf Seite 8 Cluster Edition named User Die komplette Dokumentation. www.hocomputer.de - info@hocomputer.de - Tel: (+49) / 022 / 76 20 86 205 h.o.-computer
news 2 / 205 Nur bis 22. Dezember 0 % Sonderrabatt Details auf Seite 8 Cluster Edition named User Die komplette Dokumentation. www.hocomputer.de - info@hocomputer.de - Tel: (+49) / 022 / 76 20 86 205 h.o.-computer
Kommunikationsmodelle
 Kommunikationsmodelle Dr. Victor Pankratius David J. Meder IPD Tichy Lehrstuhl für Programmiersysteme KIT die Kooperation von Forschungszentrum Karlsruhe GmbH und Universität Karlsruhe (TH) Grundlegende
Kommunikationsmodelle Dr. Victor Pankratius David J. Meder IPD Tichy Lehrstuhl für Programmiersysteme KIT die Kooperation von Forschungszentrum Karlsruhe GmbH und Universität Karlsruhe (TH) Grundlegende
Seminar - Multicore Programmierung
 1 / 35 Seminar - Multicore Programmierung Performanz Max Binder Fakultät für Informatik und Mathematik Universität Passau 10. Februar 2011 2 / 35 Inhaltsverzeichnis 1 Einleitung Hinführung Definition Entwicklung
1 / 35 Seminar - Multicore Programmierung Performanz Max Binder Fakultät für Informatik und Mathematik Universität Passau 10. Februar 2011 2 / 35 Inhaltsverzeichnis 1 Einleitung Hinführung Definition Entwicklung
HP IT-Symposium
 www.decus.de 1 HP User Society / DECUS IT-Symposium 2006 Mehr Hardware oder RAC? Markus.Michalewicz@oracle.com BU Database Technologies ORACLE Deutschland GmbH Grundannahmen Jedes Performance-Problem lässt
www.decus.de 1 HP User Society / DECUS IT-Symposium 2006 Mehr Hardware oder RAC? Markus.Michalewicz@oracle.com BU Database Technologies ORACLE Deutschland GmbH Grundannahmen Jedes Performance-Problem lässt
Allgemeine Speed-Up Formel. Gesetz von Gustafson-Barsis
 5 Leistungsanalyse Parallelrechner Allgemeine Speed-Up Formel Amdahlsche Gesetz Gesetz von Gustafson-Barsis Karp-Flatt Maß 1 5.1 Allgemeine Speed-Up Formel Allgemeine Speed-Up Formel Speedup = Sequentielle
5 Leistungsanalyse Parallelrechner Allgemeine Speed-Up Formel Amdahlsche Gesetz Gesetz von Gustafson-Barsis Karp-Flatt Maß 1 5.1 Allgemeine Speed-Up Formel Allgemeine Speed-Up Formel Speedup = Sequentielle
Lehrstuhl für Datenverarbeitung. Technische Universität München. Leistungskurs C++ Multithreading
 Leistungskurs C++ Multithreading Threading mit Qt Plattformübergreifende Thread-Klasse Sehr einfach zu benutzen Leider etwas schlecht dokumentiert Leistungskurs C++ 2 QThread Plattformübergreifende Thread-Klasse
Leistungskurs C++ Multithreading Threading mit Qt Plattformübergreifende Thread-Klasse Sehr einfach zu benutzen Leider etwas schlecht dokumentiert Leistungskurs C++ 2 QThread Plattformübergreifende Thread-Klasse
Compute Unified Device Architecture CUDA
 Compute Unified Device Architecture 06. Februar 2012 1 / 13 Gliederung 2 / 13 : Compute Unified Device Architecture entwickelt von Nvidia Corporation spezifiziert Software- und Hardwareeigenschaften Ziel:
Compute Unified Device Architecture 06. Februar 2012 1 / 13 Gliederung 2 / 13 : Compute Unified Device Architecture entwickelt von Nvidia Corporation spezifiziert Software- und Hardwareeigenschaften Ziel:
Wissenschaftliches Rechnen im SoSe 2015 Dr. J. Kunkel, Hans Ole Hatzel Abgabe:
 Universität Hamburg Übungsblatt 2 zum Praktikum Department Informatik Paralleles Programmieren Wissenschaftliches Rechnen im SoSe 2015 Dr. J. Kunkel, Hans Ole Hatzel 06.05.2015 1 Vertiefung von C-Kentnissen
Universität Hamburg Übungsblatt 2 zum Praktikum Department Informatik Paralleles Programmieren Wissenschaftliches Rechnen im SoSe 2015 Dr. J. Kunkel, Hans Ole Hatzel 06.05.2015 1 Vertiefung von C-Kentnissen
Hochleistungsrechnen in Darmstadt: Der Lichtenberg- Hochleistungsrechner. Dr. Andreas Wolf. Gruppenleiter Hochleistungsrechnen Hochschulrechenzentrum
 Hochleistungsrechnen in Darmstadt: Der Lichtenberg- Hochleistungsrechner Dr. Andreas Wolf Gruppenleiter Hochleistungsrechnen Hochschulrechenzentrum Überblick Randbedingungen der HPC Beschaffung an der
Hochleistungsrechnen in Darmstadt: Der Lichtenberg- Hochleistungsrechner Dr. Andreas Wolf Gruppenleiter Hochleistungsrechnen Hochschulrechenzentrum Überblick Randbedingungen der HPC Beschaffung an der
SSPO User Meeting 2016 R1/R2. SSPO Systems Solutions & Process Optimization Inh. Pishrow Shali. SSPO Inh. Pishrow Shali
 SSPO User Meeting 2016 R1/R2 SSPO Systems Solutions & Process Optimization Inh. Pishrow Shali SSPO Inh. Pishrow Shali http://www.ss-po.de WorkPlan User Meeting Herzlich Willkommen Wir begrüßen Sie zu unserem
SSPO User Meeting 2016 R1/R2 SSPO Systems Solutions & Process Optimization Inh. Pishrow Shali SSPO Inh. Pishrow Shali http://www.ss-po.de WorkPlan User Meeting Herzlich Willkommen Wir begrüßen Sie zu unserem
Trend der letzten Jahre in der Parallelrechentechnik
 4.1 Einführung Trend der letzten 10-15 Jahre in der Parallelrechentechnik weg von den spezialisierten Superrechner-Plattformen hin zu kostengünstigeren Allzwecksystemen, die aus lose gekoppelten einzelnen
4.1 Einführung Trend der letzten 10-15 Jahre in der Parallelrechentechnik weg von den spezialisierten Superrechner-Plattformen hin zu kostengünstigeren Allzwecksystemen, die aus lose gekoppelten einzelnen
Praktikum: Paralleles Programmieren für Geowissenschaftler
 Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart & Tim Jammer Dr. HermannJ. Lenhart hermann.lenhart@informatik.unihamburg.de MPI Einführung III: ScatterV/
Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart & Tim Jammer Dr. HermannJ. Lenhart hermann.lenhart@informatik.unihamburg.de MPI Einführung III: ScatterV/
Leistungs- und Geschwindigkeitssteigerung. Dipl.-Ing. Sebastian F. Kleinau Applikationsingenieur
 Leistungs- und Geschwindigkeitssteigerung von LabVIEW-Projekten Dipl.-Ing. Sebastian F. Kleinau Applikationsingenieur Agenda 1. Einführung 2. Hilfreiche Werkzeuge zur Codeanalyse 3. Benchmarks für LabVIEW-VIs
Leistungs- und Geschwindigkeitssteigerung von LabVIEW-Projekten Dipl.-Ing. Sebastian F. Kleinau Applikationsingenieur Agenda 1. Einführung 2. Hilfreiche Werkzeuge zur Codeanalyse 3. Benchmarks für LabVIEW-VIs
Praktikum: Paralleles Programmieren für Geowissenschaftler
 Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart, Ulrich Körner, Nathanael Hübbe hermann.lenhart@zmaw.de OpenMP Einführung I: Allgemeine Einführung Prozesse
Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart, Ulrich Körner, Nathanael Hübbe hermann.lenhart@zmaw.de OpenMP Einführung I: Allgemeine Einführung Prozesse
Tutorium Softwaretechnik I
 Tutorium Softwaretechnik I Moritz Klammler 11. Juli 2017 Fakultät für Informatik, IPD Tichy Titelfoto: Copyright (C) 2010 Multimotyl CC BY-SA 3.0 1 11. Juli 2017 Moritz Klammler - Tutorium Softwaretechnik
Tutorium Softwaretechnik I Moritz Klammler 11. Juli 2017 Fakultät für Informatik, IPD Tichy Titelfoto: Copyright (C) 2010 Multimotyl CC BY-SA 3.0 1 11. Juli 2017 Moritz Klammler - Tutorium Softwaretechnik
Partitionierung von rechenintensiven Aufgaben zwischen FPGA und CPUs
 Partitionierung von rechenintensiven Aufgaben zwischen FPGA und CPUs Embedded Computing Conference 2017 Tobias Welti, Dr. M. Rosenthal High Performance Embedded Platforms ZHAW Institute of Embedded Systems
Partitionierung von rechenintensiven Aufgaben zwischen FPGA und CPUs Embedded Computing Conference 2017 Tobias Welti, Dr. M. Rosenthal High Performance Embedded Platforms ZHAW Institute of Embedded Systems
Games with Cellular Automata auf Parallelen Rechnerarchitekturen
 Bachelor Games with Cellular Automata auf Parallelen en ( ) Dipl.-Inf. Marc Reichenbach Prof. Dietmar Fey Ziel des s Paralleles Rechnen Keine akademische Nische mehr Vielmehr Allgemeingut für den Beruf
Bachelor Games with Cellular Automata auf Parallelen en ( ) Dipl.-Inf. Marc Reichenbach Prof. Dietmar Fey Ziel des s Paralleles Rechnen Keine akademische Nische mehr Vielmehr Allgemeingut für den Beruf
Matlab. Alexandra Mehlhase & Felix Böckelmann. 26. Juni Analysetechniken in der Softwaretechnik Technische Universität Berlin SS 2008
 Was ist /Simulink Modellierung mit Modellierung mit /Simulink Vergleich -Modelica Analysetechniken in der Softwaretechnik Technische Universität Berlin SS 2008 26. Juni 2008 Inhaltsverzeichnis Was ist
Was ist /Simulink Modellierung mit Modellierung mit /Simulink Vergleich -Modelica Analysetechniken in der Softwaretechnik Technische Universität Berlin SS 2008 26. Juni 2008 Inhaltsverzeichnis Was ist
Computeranwendung in der Chemie Informatik für Chemiker(innen) 3. Software
 3. Software") Computeranwendung in der Chemie Informatik für Chemiker(innen) 3. Software Jens Döbler 2003 "Computer in der Chemie", WS 2003-04, Humboldt-Universität VL3 Folie 1 Grundlagen Software steuert Computersysteme
Computeranwendung in der Chemie Informatik für Chemiker(innen) 3. Software Jens Döbler 2003 "Computer in der Chemie", WS 2003-04, Humboldt-Universität VL3 Folie 1 Grundlagen Software steuert Computersysteme
Praktikum: Paralleles Programmieren für Geowissenschaftler
 Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart & Felix Hoffmann hermann.lenhart@informatik.uni-hamburg.de MPI Einführung III Scatterv / Gatherv Programmbeispiele
Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart & Felix Hoffmann hermann.lenhart@informatik.uni-hamburg.de MPI Einführung III Scatterv / Gatherv Programmbeispiele
Lehrstuhl für Datenverarbeitung. Technische Universität München. Leistungskurs C++ Multithreading
 Leistungskurs C++ Multithreading Threading mit Qt Plattformübergreifende Thread-Klasse Sehr einfach zu benutzen Leider etwas schlecht dokumentiert Leistungskurs C++ 2 QThread Plattformübergreifende Thread-Klasse
Leistungskurs C++ Multithreading Threading mit Qt Plattformübergreifende Thread-Klasse Sehr einfach zu benutzen Leider etwas schlecht dokumentiert Leistungskurs C++ 2 QThread Plattformübergreifende Thread-Klasse
Universität Karlsruhe (TH)
") Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 OpenMP-Programmierung Teil III Multikern-Praktikum Wintersemester 06-07 Inhalt Was ist OpenMP? Parallele Regionen Konstrukte zur Arbeitsteilung
Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 OpenMP-Programmierung Teil III Multikern-Praktikum Wintersemester 06-07 Inhalt Was ist OpenMP? Parallele Regionen Konstrukte zur Arbeitsteilung
h.o.-computer news 20 Jahre ho-computer Die Party geht weiter Jubiläumsrabatt auf alle Intel-Softwareprodukte bis zum 20. Dezember
 h.o.-computer news ho-computer Entwicklertag Paralleles Programmieren im Kölner Schokoladenmuseum Intel Parallel Studio Promotion Intel Compiler Suite Pakete & Lizenzmodelle Inhalt Editorial 2 ho-computer
h.o.-computer news ho-computer Entwicklertag Paralleles Programmieren im Kölner Schokoladenmuseum Intel Parallel Studio Promotion Intel Compiler Suite Pakete & Lizenzmodelle Inhalt Editorial 2 ho-computer
Lehrstuhl für Datenverarbeitung. Technische Universität München. Leistungskurs C++ Multithreading
 Leistungskurs C++ Multithreading Zeitplan 16.10. Vorlesung 23.10. Vorlesung, Gruppeneinteilung 30.10. Vorlesung, HA1 06.11. Vorlesung, HA2 13.11. Vorlesung entfällt wegen SVV 20.11. Präsentation Vorprojekt
Leistungskurs C++ Multithreading Zeitplan 16.10. Vorlesung 23.10. Vorlesung, Gruppeneinteilung 30.10. Vorlesung, HA1 06.11. Vorlesung, HA2 13.11. Vorlesung entfällt wegen SVV 20.11. Präsentation Vorprojekt
Multi-threaded Programming with Cilk
 Multi-threaded Programming with Cilk Hobli Taffame Institut für Informatik Ruprecht-Karls Universität Heidelberg 3. Juli 2013 1 / 27 Inhaltsverzeichnis 1 Einleitung Warum Multithreading? Ziele 2 Was ist
Multi-threaded Programming with Cilk Hobli Taffame Institut für Informatik Ruprecht-Karls Universität Heidelberg 3. Juli 2013 1 / 27 Inhaltsverzeichnis 1 Einleitung Warum Multithreading? Ziele 2 Was ist
Ausblick auf den HLRN III - die neue HPC Ressource für Norddeutschland
 Ausblick auf den HLRN III - die neue HPC Ressource für Norddeutschland Holger Naundorf RRZN Leibniz Universität IT Services Schloßwender Straße 5 30159 Hannover naundorf@rrzn.uni-hannover.de 14. März 2013
Ausblick auf den HLRN III - die neue HPC Ressource für Norddeutschland Holger Naundorf RRZN Leibniz Universität IT Services Schloßwender Straße 5 30159 Hannover naundorf@rrzn.uni-hannover.de 14. März 2013
Matrix Transposition mit gaspi_read_notify. Vanessa End HPCN Workshop 11. Mai 2016
 Matrix Transposition mit gaspi_read_notify Vanessa End HPCN Workshop 11. Mai 2016 Überblick Motivation Matrix Transposition GASPI Matrix Transposition in GASPI Zusammenfassung und Ausblick 2 Motivation
Matrix Transposition mit gaspi_read_notify Vanessa End HPCN Workshop 11. Mai 2016 Überblick Motivation Matrix Transposition GASPI Matrix Transposition in GASPI Zusammenfassung und Ausblick 2 Motivation
Optimierungen der Lattice Boltzmann Methode auf x86-64 basierten Architekturen
 Optimierungen der Lattice Boltzmann Methode auf x86-64 basierten Architekturen J. Treibig, S. Hausmann, U. Ruede 15.09.05 / ASIM 2005 - Erlangen Gliederung 1 Einleitung Motivation Grundlagen 2 Optimierungen
Optimierungen der Lattice Boltzmann Methode auf x86-64 basierten Architekturen J. Treibig, S. Hausmann, U. Ruede 15.09.05 / ASIM 2005 - Erlangen Gliederung 1 Einleitung Motivation Grundlagen 2 Optimierungen
Programmierkurs für Chemiker in Fortran Sommersemester 2013
 Programmierkurs für Chemiker in Fortran Sommersemester 2013 Roland Mitric Lehrstuhl für theoretische Chemie Institut für theoretische und physikalische Chemie Emil-Fischer-Str. 42 / Raum 01.008 roland.mitric@uni-wuerzburg.de
Programmierkurs für Chemiker in Fortran Sommersemester 2013 Roland Mitric Lehrstuhl für theoretische Chemie Institut für theoretische und physikalische Chemie Emil-Fischer-Str. 42 / Raum 01.008 roland.mitric@uni-wuerzburg.de
Praktikum: Paralleles Programmieren für Geowissenschaftler
 Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart hermann.lenhart@informatik.uni-hamburg.de MPI Einführung II: Send/Receive Syntax Broadcast Reduce Operation
Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart hermann.lenhart@informatik.uni-hamburg.de MPI Einführung II: Send/Receive Syntax Broadcast Reduce Operation
Praktikum: Paralleles Programmieren für Geowissenschaftler
 Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart & Enno Zickler Dr. HermannJ. Lenhart hermann.lenhart@informatik.unihamburg.de MPI Einführung II: Kollektive
Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart & Enno Zickler Dr. HermannJ. Lenhart hermann.lenhart@informatik.unihamburg.de MPI Einführung II: Kollektive
Intel Thread Checker
 Kurs 1: Ferienakademie 2009 26. September 2009 Gliederung Gliederung Was macht der Thread Checker und warum? Historisches Alternativen Was macht der Thread Checker und warum? Historisches Alternativen
Kurs 1: Ferienakademie 2009 26. September 2009 Gliederung Gliederung Was macht der Thread Checker und warum? Historisches Alternativen Was macht der Thread Checker und warum? Historisches Alternativen
ODA Erfahrungen und Neuigkeiten
 ODA Erfahrungen und Neuigkeiten Dierk Lenz 25. Oktober 2017 Köln Oracle Database Appliance (ODA) Mitglied der Familie der Oracle Engineered Systems, d.h.: Hardware und Software (Betriebssystem, Datenbank)
ODA Erfahrungen und Neuigkeiten Dierk Lenz 25. Oktober 2017 Köln Oracle Database Appliance (ODA) Mitglied der Familie der Oracle Engineered Systems, d.h.: Hardware und Software (Betriebssystem, Datenbank)
PostgreSQL in großen Installationen
 PostgreSQL in großen Installationen Cybertec Schönig & Schönig GmbH Hans-Jürgen Schönig Wieso PostgreSQL? - Die fortschrittlichste Open Source Database - Lizenzpolitik: wirkliche Freiheit - Stabilität,
PostgreSQL in großen Installationen Cybertec Schönig & Schönig GmbH Hans-Jürgen Schönig Wieso PostgreSQL? - Die fortschrittlichste Open Source Database - Lizenzpolitik: wirkliche Freiheit - Stabilität,
T-Systems SfR - HPCN Workshop
 HPC System Design und die Auswirkungen auf die Anwendungsperformance Thomas Alrutz HPC & escience Solutions & Innovations - Scientific & Technical ICT T-Systems Solutions for Research GmbH T-Systems SfR
HPC System Design und die Auswirkungen auf die Anwendungsperformance Thomas Alrutz HPC & escience Solutions & Innovations - Scientific & Technical ICT T-Systems Solutions for Research GmbH T-Systems SfR
Aktuelle RTOS-Entwicklungen aus der Forschung
 Aktuelle RTOS-Entwicklungen aus der Forschung Lennart Downar Seminar Fehlertoleranz und Echtzeit 16. Februar 2016 Aktuelle RTOS-Entwicklungen aus der Forschung Lennart Downar 1/28 Übersicht 1 Einführung
Aktuelle RTOS-Entwicklungen aus der Forschung Lennart Downar Seminar Fehlertoleranz und Echtzeit 16. Februar 2016 Aktuelle RTOS-Entwicklungen aus der Forschung Lennart Downar 1/28 Übersicht 1 Einführung
Cilk Sprache für Parallelprogrammierung. IPD Snelting, Lehrstuhl für Programmierparadigmen
 Cilk Sprache für Parallelprogrammierung IPD Snelting, Lehrstuhl für Programmierparadigmen David Soria Parra Geschichte Geschichte Entwickelt 1994 am MIT Laboratory for Computer Science Cilk 1: Continuations
Cilk Sprache für Parallelprogrammierung IPD Snelting, Lehrstuhl für Programmierparadigmen David Soria Parra Geschichte Geschichte Entwickelt 1994 am MIT Laboratory for Computer Science Cilk 1: Continuations