Message-Passing: Einführung
|
|
|
- Karin Meyer
- vor 5 Jahren
- Abrufe
Transkript
1 Message-Passing: Einführung Architecture of Parallel Computer Systems WS15/16 JSimon 1 Punkt zu Punkt Senden und Empfangen Message-Passing Mechanismus Erzeugung von Prozessen Übertragung einer Nachricht zwischen den Prozessen durch send() und recv() Funktionen Prozess 1 Object x; send (&x, 2); Datentransfer Prozess 2 Object y; recv (&y, 1); Architecture of Parallel Computer Systems WS15/16 JSimon 2 1
2 Message Passing Interface (MPI) Bibliothek (C, C++, Fortran) für den Austausch von Nachrichten zwischen Prozessen Prozesse werden statisch allokiert und mit 0,,N-1 nummeriert Jeder Prozess startet das gleiche Programm (Single Program Multiple Data - SPMD) Stellt Funktionen und Datentypen beginnend mit MPI_ bereit (logische) Topologie ist eine Clique Jeder Prozessor kann direkt mit jedem anderen kommunizieren Kommunikatoren regeln die Kommunikation zwischen den Prozessen Jeder Prozess gehört zu mindestens einem Kommunikator Jede Nachricht wird in einem Kommunikator transportiert Kommunikatoren können beliebig neu erzeugt werden Architecture of Parallel Computer Systems WS15/16 JSimon 3 MPI Versionen Version 10: (1994) 129 MPI-Funktionen, C und Fortran77 Version 11 Spezifikation verfeinert Version 12 Weitere Eindeutigkeiten Version 20: (1997) Mehr Funktionalitäten, 193 weitere Funktionen Dynamische Generierung von Prozessen, Einseitige Kommunikation, MPI-Funktionen für I/O C++ und Fortran90 Version 30: (ab 2013) nicht blockierende kollektive Funktionen, Remote Memory Access, nicht blockierende parallele File I/O Architecture of Parallel Computer Systems WS15/16 JSimon 4 2
3 SPMD Ausführungsmodell Single Program Multiple Data (SPMD) lässt sich aber auch erweitern: #include <mpih> main (int argc, char *argv[]) { MPI_Init(&argc, &argv); MPI_Comm_rank(MPI_COMM_WORLD, & myrank); /* find process rank */ if (myrank == 0) master(); else worker(); MPI_Finalize(); } Dabei sind master() und worker() Funktionen die durch einen Master- und ggf mehrere Worker-Prozesse ausgeführt werden sollen Architecture of Parallel Computer Systems WS15/16 JSimon 5 Basisroutinen MPI_Init(int *,char ***); Startet MPI Muss erste MPI-Routine sein, die aufgerufen wird MPI_Finalize(); Beendet MPI und schließt die Kommunikationskanäle MPI_Comm_rank( MPI_Comm, int *) Rückgabe: Eigene Prozessnummer innerhalb Des Kommunikators Menge von MPI-Prozessen, die Nachrichten austauschen können MPI_COMM_WORLD enthält alle Prozesse MPI_Comm_size( MPI_Comm, int *) Rückgabe: Anzahl der Prozesse innerhalb Des Kommunikators Architecture of Parallel Computer Systems WS15/16 JSimon 6 3
4 Basisroutinen MPI_Send(void *, int, MPI_Datatype, int, int, MPI_Comm); Zeiger auf Message- s Tab Ziel- Tag so Message länge pro- Im Speicher zess(or) MPI_Datatype C-Datentyp MPI_CHAR char MPI_SHORT short MPI_INT int MPI_LONG long MPI_UNSIGNED_CHAR (unsigned) char MPI_UNSIGNED_SHORT unsogned short MPI_UNSIGNED unsigned int MPI_UNSIGNED_LONG unsigned long MPI_FLOAT float MPI_DOUBLE double MPI_DOUBLE_LONG long double MPI_BYTE - MPI_PACKED - Architecture of Parallel Computer Systems WS15/16 JSimon 7 Basisroutinen MPI_Recv(void *, int, MPI_Datatype, int, int, MPI_Comm, MPI_Status*); Zeiger auf Buffer- s Tab Tag so Status der Message größe Sender Empfangs- Im Speicher operation MPI_ANY_SOURCE + MPI_ANY_TAG sind Wildcarts Tag und Communicator des MPI_Send und MPI_Recv müssen übereinstimmen MPI_Status enthält ua: status MPI_SOURCE (Sender der Nachricht) status MPI_TAG (Message-Tag) status MPI_ERROR (0, falls kein Fehler) MPI_Send/MPI_Recv blockiert (eventuell!) Architecture of Parallel Computer Systems WS15/16 JSimon 8 4
5 MPI für Java Objekt-orientiertes Java-Interface für MPI entwickelt im HPJava Projekt mpijava 12 unterstützt MPI 11 (zb MPICH) import mpi*; public class MPI_HelloWorld { public static void main(string[] args) { Systemoutprintln( Hello, world ); } } Ausführung javac MPI_HelloWorldjava prunjava 4 MPI_HelloWorld openmpi unterstützt ebenfalls Java Architecture of Parallel Computer Systems WS15/16 JSimon 9 Further MPI bindings MPI for Python and more Common LISP Ruby Perl Caml Common Language Infrastructure (CLI) Architecture of Parallel Computer Systems WS15/16 JSimon 10 5
6 Kommunikationsmethoden buffernd / nicht buffernd Nachricht wird (beim Sender) zwischengespeichert synchron / nicht synchron Programmflusskontrolle wird nicht zurückgegeben, bis die zu sendende Nachricht angekommen ist blockierend / nicht blockierend Programmflusskontrolle wird nicht zurückgegeben, bis die zu sendende Nachricht gesichert ist (entweder beim Empfänger oder in einem Systembuffer) User-Speicher ist nach Rückkehr wieder frei nutzbar Architecture of Parallel Computer Systems WS15/16 JSimon 11 Send Kommunikationsmodi (1) Standard Mode Send passendes Recv muss nicht vor Send ausgeführt werden Größe des Buffers nicht im MPI-Standard definiert Falls Buffer genutzt, kann das Send beendet werden bevor das passende Recv erreicht ist Buffered Mode Send kann vor dem passenden Recv starten und beenden Speicher für Buffer muss explizit allokiert werden MPI_Buffer_attach() Synchronous Mode Send und Recv können beliebig starten, beenden aber gemeinsam Ready Mode Send kann nur starten, wenn passendes Recv bereits erreicht wurde Ansonsten kommt eine Fehlermeldung Architecture of Parallel Computer Systems WS15/16 JSimon 12 6
7 Send Kommunikationsmodi (2) Alle vier Modi können mit einem blocking oder nonblocking Send kombiniert werden Nur der Standardmodus ist für das blocking und nonblocking Recv möglich Jeder Send Typ kann mit jedem Recv Typ matchen Architecture of Parallel Computer Systems WS15/16 JSimon 13 Beispiel: Blockierendes Senden Blockierendes Senden eines Werts x von MPI-Prozess 0 zu MPI-Prozess 1 int myrank; int msgtag = 4711; int x; MPI_Comm_rank (MPI_COMM_WORLD, & myrank); /* get process rank */ if (myrank == 0) MPI_Send (&x, 1, MPI_INT, 1, msgtag, MPI_COMM_WORLD); else if (myrank == 1) { int status; int x; MPI_Recv (&x, 1, MPI_INT, 0, msgtag, MPI_COMM_WORLD, status); } Architecture of Parallel Computer Systems WS15/16 JSimon 14 7
8 Non-Blocking Routinen Non-blocking Send: MPI_Isend(buf, count, datatype, dest, tag, comm, request) Kommt sofort zurück, obwohl die zu versendenden Daten noch nicht geändert werden dürfen Non-blocking Receive: MPI_Irecv(buf, count, datatype, dest, tag, comm, request) Kommt sofort zurück, obwohl ggf noch keine Daten vorliegen Beendigung durch MPI_Wait() und MPI_Test() erkennen MPI_Waits() wartet bis Operation beendet ist MPI_Test() kommt sofort mit dem Zustand der Send- / Recv-routine (beendet bzw nicht-beendet) zurück Dafür muss der request Parameter verwendet werden Architecture of Parallel Computer Systems WS15/16 JSimon 15 Beispiel: Nichtblockierendes Senden Nichtblockierendes Senden eines Werts x von MPI- Prozess 0 zu MPI-Prozess 1, wobei MPI-Prozess 0 mit Ausführung unmittelbar fortfahren kann int myrank; int msgtag = 4711; MPI_Comm_rank (MPI_COMM_WORLD, & myrank); /* find process rank */ if (myrank == 0) { int status; int x; MPI_Isend (&x, 1, MPI_INT, 1, msgtag, MPI_COMM_WORLD, req1); compute(); MPI_Wait (req1, status); } else if (myrank == 1) { int status; int x; MPI_Recv (&x, 1, MPI_INT, 0, msgtag, MPI_COMM_WORLD, status); } Architecture of Parallel Computer Systems WS15/16 JSimon 16 8
9 Kollektive Kommunikation Kommunikation innerhalb einer Gruppe aus Prozessen keine Message-Tags nutzbar Broadcast- und Scatter-Routinen MPI_Bcast() - Broadcast from root to all other processes MPI_Gather() - Gather values for group of processes MPI_Scatter() - Scatters buffer in parts to group of processes MPI_Alltoall() - Sends data from all processes to all processes MPI_Reduce() - Combine values on all processes to single value MPI_Reduce_Scatter() - Combine values and scatter results MPI_Scan() - Compute prefix reductions of data on processes Architecture of Parallel Computer Systems WS15/16 JSimon 17 Kollektive Kommunikation Vorher Nachher root B MPI_BCAST B B B B root A B C D MPI_SCATTER A B C D A B C D MPI_GATHER root A B C D A B C D A B C D MPI_ALLGATHER A B C D A B C D A B C D A B C D A B C D A B C D A B C D E F G H I J K L M N O P MPI_ALLTOALL A B C D E F G H I J K L M N O P A E I M B F J N C G K O D H L P RANK Architecture of Parallel Computer Systems WS15/16 JSimon 18 9
10 Beispiel: MPI_Gather Beachte, dass MPI_Gather von allen Prozessen inkl Root aufgerufen werden muss! int data[10]; (* data to be gathered from processes */ MPI_Comm_rank (MPI_COMM_WORLD, & myrank); /* find process rank */ if (myrank == 0) { MPI_Comm_Size(MPI_COMM_WORLD, &grp_size); buf = (int*)malloc(grp_size*10*sizeof(int)); /* allocate memory /* } MPI_Gather (data, 10, MPI_INT, buf, grp_size*10, MPI_INT, 0, MPI_COM_WORLD); Architecture of Parallel Computer Systems WS15/16 JSimon 19 Einseitige Kommunikation Verfügbar ab MPI Version 2 Remote Memory Access, put + get Operationen Initialisierungen MPI_Alloc_mem(), MPI_Free_mem() MPI_Win_create(), MPI_Win_free() Kommunikationsroutine MPI_Put() MPI_Get() MPI_Accumulate() Synchronizationen MPI_Win_fence() MPI_Win_post(), MPI_Win_start(), MPI_Win_complete(), MPI_Win_wait() MPI_Win_lock(), MPI_Win_unlock() Architecture of Parallel Computer Systems WS15/16 JSimon 20 10
11 Message-Passing-Modell Pro s: Programmierer kontrolliert die Daten- und Arbeitsverteilung Eindeutigkeit der Lokalität Con s: Relativ hoher Kommunikationsaufwand bei kleinen Nachrichten Korrektheit der Programme schwer zu überprüfen Beispiel: Message Passing Interface (MPI) Architecture of Parallel Computer Systems WS15/16 JSimon 21 Shared-Memory-Modell Pro s: Einfache Befehle Lesen / Schreiben des entfernten Speichers durch Bilden eines Ausdrucks bzw einfache Wertzuweisung Programmierwerkzeuge vorhanden Con s: Manipulation von gemeinsam genutzten Speicherzellen erfordern meistens doch explizite Synchronisation Keine Eindeutigkeit der Lokalität Beispiele: OpenMP, POSIX Threads Architecture of Parallel Computer Systems WS15/16 JSimon 22 11
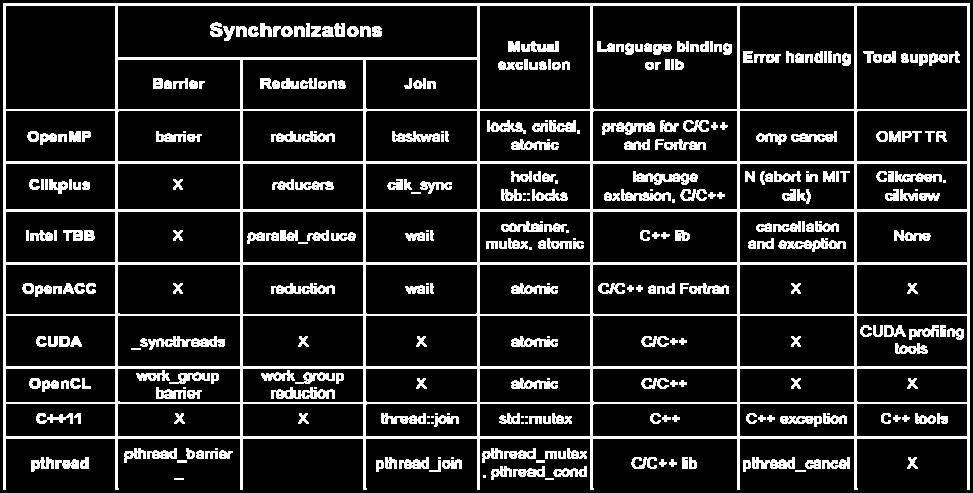
12 Hybrides Modell: Shared Mem + Message Passing Network Process Thread Address space Beispiele: POSIX Threads innerhalb der Knoten und MPI zwischen Knoten OpenMP für Intra- und MPI für Inter-Knoten-Kommunikation Architecture of Parallel Computer Systems WS15/16 JSimon 23 Hybride Programmierung processes message passing MPI threading shared memory OpenMP Pthreads Domain decomposition accelerated operations SIMD MIC GPU FPGA Libraries CUDA OpenCL OpenACC Architecture of Parallel Computer Systems WS15/16 JSimon 24 12

13 OpenCL Open Computing Language parallel execution on single or multiple processors for heterogeneous platforms of CPUs, GPUs, and other processors Desktop and handheld profiles works with graphics APIs such as OpenGL based on a proposal by Apple Inc supported processors: Intel, AMD, Nvidia, and ARM work in progress: FPGA Design Goals Data- and task-parallel compute model based on C99 language Implements a relaxed consistency shared memory model with multiple distinct address spaces OpenCL 20 Device partitioning, separate compilation and linking, Enhanced image support, Built-in kernels, DirectX functionality Architecture of Parallel Computer Systems WS15/16 JSimon 25 OpenCL Implements a relaxed consistency shared memory model Multiple distinct address spaces Address space can be collapsed depending on the device s memory subsystem Address qualifiers private local constant / global Example: global float4 *p; Built-in Data Types Scalar and vector data types Pointers Data-type conversion functions Image type (2D/3D) Architecture of Parallel Computer Systems WS15/16 JSimon 26 13
14 OpenACC Open Accelerator High level gateway to lower level CUDA GPU programming language accelerate C and FORTRAN code directives identifies parallel regions Initially developed by PGI, Cray, Nvidia supported processors: AMD, NVIDIA, Intel? Design Goals No modification or adaption of programs to use accelerators OpenACC compiler First compilers from Cray, PGI, and CAPS GCC ab Version 5 (offloading to Nvidia targets) Architecture of Parallel Computer Systems WS15/16 JSimon 27 MPI + X X = OpenMP, Pthreads, spezielle Bibliotheken Pros Reduzierung der Anzahl an MPI-Prozesse dadurch ggf bessere Skalierung Weniger Overhead für die Zwischenspeicherungen von Daten Schnellere Synchronisation innerhalb (Unter-) Gruppen Cons Zwei unterschiedliche Programmierparadigmen Portabilität könnte problematisch sein Architecture of Parallel Computer Systems WS15/16 JSimon 28 14
")

 JSimon")
15 Heterogeneous and Many-Core Programming (1) Architecture of Parallel Computer Systems WS15/16 JSimon 29 Heterogeneous and Many-Core Programming (2) Architecture of Parallel Computer Systems WS15/16 JSimon 30 15
16 Partitioned Global Address SPACE PGAS parallel programming model Global memory address space that is logically partitioned A portion of the memory is local to each process or thread Combines advantages of SPMD programming for distributed memory systems with data referencing semantics of shared memory systems Variables and arrays can be shared or local Thread can use references to its local variables and all shared variables Thread has fast access to its local variables and its portion of shared variables Higher latencies to remote portions of shared variables node 0 loc[] node 1 node m s[ ] s[] s[] local address space global address space Architecture of Parallel Computer Systems WS15/16 JSimon 31 Implementations of PGAS PGAS fits well to the communication hierarchy of hybrid architectures Communication network, shared memory nodes Affinity of threads to parts of the global memory effects the efficiency of program execution Languages Unified Parallel C Co-array Fortran Titanium Fortress Chapel X10 Architecture of Parallel Computer Systems WS15/16 JSimon 32 16
17 Abstraktionsebenen der Programmierung Programmiersprache PGAS Pthreads OpenMP MPI Threads Shared-Memory Message-Passing verteiltes Shared-Memory MPP Cluster SMP CC-NUMA Cray-Link 3d-Netz IB MyriNet Ethernet Architecture of Parallel Computer Systems WS15/16 JSimon 33 17
OpenMP Data Scope Clauses
 OpenMP Data Scope Clauses private (list) erklärt die Variablen in der Liste list zu privaten Variablen der einzelnen Threads des Teams shared (list) erklärt die Variablen in der Liste list zu gemeinsamen
OpenMP Data Scope Clauses private (list) erklärt die Variablen in der Liste list zu privaten Variablen der einzelnen Threads des Teams shared (list) erklärt die Variablen in der Liste list zu gemeinsamen
Das Message Passing Paradigma (1)
") Das Message Passing Paradigma (1) Das Message Passing Paradigma (2) Sehr flexibel, universell, hoch effizient Programm kann logisch in beliebig viele Prozesse aufgeteilt werden Prozesse können unterschiedlichen
Das Message Passing Paradigma (1) Das Message Passing Paradigma (2) Sehr flexibel, universell, hoch effizient Programm kann logisch in beliebig viele Prozesse aufgeteilt werden Prozesse können unterschiedlichen
Kurzübersicht über die wichtigsten MPI-Befehle
 Kurzübersicht über die wichtigsten MPI-Befehle Hans Joachim Pflug Rechen- und Kommunkationszentrum der RWTH Aachen Inhalt MPI_Init / MPI_Finalize...2 MPI_Comm_size / MPI_Comm_rank...3 MPI_Send / MPI_Recv...4
Kurzübersicht über die wichtigsten MPI-Befehle Hans Joachim Pflug Rechen- und Kommunkationszentrum der RWTH Aachen Inhalt MPI_Init / MPI_Finalize...2 MPI_Comm_size / MPI_Comm_rank...3 MPI_Send / MPI_Recv...4
Message-Passing: Einführung
 Message-Passing: Einführung Vorlesung: Architektur Paralleler Rechnersysteme WS14/15 J.Simon 1 Punkt zu Punkt Senden und Empfangen Message-Passing Mechanismus Erzeugung von Prozessen. Übertragung einer
Message-Passing: Einführung Vorlesung: Architektur Paralleler Rechnersysteme WS14/15 J.Simon 1 Punkt zu Punkt Senden und Empfangen Message-Passing Mechanismus Erzeugung von Prozessen. Übertragung einer
4.4. MPI Message Passing Interface
 4.4. MPI Message Passing Interface Ferienakademie 2009 Franz Diebold Agenda 1. Einführung, Motivation 2. Kommunikationsmodell 3. Punkt-Zu-Punkt-Kommunikation 4. Globale Kommunikation 5. Vergleich MPI und
4.4. MPI Message Passing Interface Ferienakademie 2009 Franz Diebold Agenda 1. Einführung, Motivation 2. Kommunikationsmodell 3. Punkt-Zu-Punkt-Kommunikation 4. Globale Kommunikation 5. Vergleich MPI und
Exkurs: Paralleles Rechnen
 Münster Exkurs: Paralleles Rechnen Münster Exkurs: Paralleles Rechnen 2 /21 Konzepte für Parallelrechner P P P C C C Gemeinsamer Speicher Verteilter Speicher Verbindungsnetzwerk Speicher M, Münster Exkurs:
Münster Exkurs: Paralleles Rechnen Münster Exkurs: Paralleles Rechnen 2 /21 Konzepte für Parallelrechner P P P C C C Gemeinsamer Speicher Verteilter Speicher Verbindungsnetzwerk Speicher M, Münster Exkurs:
Paralleles Rechnen: MPI
 Münster Paralleles Rechnen: MPI 11.12.2015 Top 500 Münster Paralleles Rechnen: MPI 2 /23 32 Großrechner in Deutschland unter den Top 500 davon 5 Systeme unter den Top 50 8 Hazel Hen (HLRS Stuttgart) 11
Münster Paralleles Rechnen: MPI 11.12.2015 Top 500 Münster Paralleles Rechnen: MPI 2 /23 32 Großrechner in Deutschland unter den Top 500 davon 5 Systeme unter den Top 50 8 Hazel Hen (HLRS Stuttgart) 11
Message-Passing: Einführung
 Message-Passing: Einführung Vorlesung: Architektur Paralleler Rechnersysteme WS09/10 J.Simon 1 Punkt zu Punkt Senden und Empfangen Message-Passing Mechanismus Erzeugung von Prozessen. Übertragung einer
Message-Passing: Einführung Vorlesung: Architektur Paralleler Rechnersysteme WS09/10 J.Simon 1 Punkt zu Punkt Senden und Empfangen Message-Passing Mechanismus Erzeugung von Prozessen. Übertragung einer
Parallele Programmierung
 Parallele Programmierung PThreads OpenMP MPI Übung: Architektur Paralleler Rechnersysteme WS08/09 J.Simon 1 PThread Programmierung Übung: Architektur Paralleler Rechnersysteme WS08/09 J.Simon 2 1 PThreads
Parallele Programmierung PThreads OpenMP MPI Übung: Architektur Paralleler Rechnersysteme WS08/09 J.Simon 1 PThread Programmierung Übung: Architektur Paralleler Rechnersysteme WS08/09 J.Simon 2 1 PThreads
Modelle der Parallelverarbeitung
 Modelle der Parallelverarbeitung Modelle der Parallelverarbeitung 12. Message Passing Interface Thomas Worsch Fakultät für Informatik Karlsruher Institut für Technologie Sommersemester 2017 1 / 36 Überblick
Modelle der Parallelverarbeitung Modelle der Parallelverarbeitung 12. Message Passing Interface Thomas Worsch Fakultät für Informatik Karlsruher Institut für Technologie Sommersemester 2017 1 / 36 Überblick
MPI Message Passing Interface. Matus Dobrotka Jan Lietz
 MPI Message Passing Interface Matus Dobrotka Jan Lietz 25.5.2016 MPI Ein Standard, der den Nachrichtenaustausch bei parallelen Berechnungen auf verteilten Computersystemen beschreibt MPI-Applikation mehrere
MPI Message Passing Interface Matus Dobrotka Jan Lietz 25.5.2016 MPI Ein Standard, der den Nachrichtenaustausch bei parallelen Berechnungen auf verteilten Computersystemen beschreibt MPI-Applikation mehrere
Praktikum: Paralleles Programmieren für Geowissenschaftler
 Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart hermann.lenhart@zmaw.de MPI Einführung I: Einführung Nachrichtenaustausch mit MPI MPI point-to-point communication
Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart hermann.lenhart@zmaw.de MPI Einführung I: Einführung Nachrichtenaustausch mit MPI MPI point-to-point communication
Einführung in das parallele Programmieren mit MPI und Java
 Einführung in das parallele Programmieren mit und Java Seite 1 Übersicht Parallele Prozesse und Erste Schritte mit Kollektive Kommunikation Weitere Möglichkeiten Seite 2 Literatur (1) Homepage des 2-Forums
Einführung in das parallele Programmieren mit und Java Seite 1 Übersicht Parallele Prozesse und Erste Schritte mit Kollektive Kommunikation Weitere Möglichkeiten Seite 2 Literatur (1) Homepage des 2-Forums
Parallel Programming: Message-Passing-Interface
 Vorlesung Rechnerarchitektur 2 Seite 71 MPI-Einführung Parallel Programming: Voraussetzungen im Source-Code für ein MPI Programm: mpi.h includen Die Kommandozeilenparameter des Programms müssen an MPI_Init
Vorlesung Rechnerarchitektur 2 Seite 71 MPI-Einführung Parallel Programming: Voraussetzungen im Source-Code für ein MPI Programm: mpi.h includen Die Kommandozeilenparameter des Programms müssen an MPI_Init
Praktikum: Paralleles Programmieren für Geowissenschaftler
 Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart, Nathanael Hübbe hermann.lenhart@zmaw.de MPI Einführung I: Hardware Voraussetzung zur Parallelen Programmierung
Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart, Nathanael Hübbe hermann.lenhart@zmaw.de MPI Einführung I: Hardware Voraussetzung zur Parallelen Programmierung
Trend der letzten Jahre in der Parallelrechentechnik
 4.1 Einführung Trend der letzten 10-15 Jahre in der Parallelrechentechnik weg von den spezialisierten Superrechner-Plattformen hin zu kostengünstigeren Allzwecksystemen, die aus lose gekoppelten einzelnen
4.1 Einführung Trend der letzten 10-15 Jahre in der Parallelrechentechnik weg von den spezialisierten Superrechner-Plattformen hin zu kostengünstigeren Allzwecksystemen, die aus lose gekoppelten einzelnen
Computergrundlagen Moderne Rechnerarchitekturen
 Computergrundlagen Moderne Rechnerarchitekturen Axel Arnold Institut für Computerphysik Universität Stuttgart Wintersemester 2010/11 Aufbau eines modernen Computers DDR3- Speicher Prozessor Prozessor PEG
Computergrundlagen Moderne Rechnerarchitekturen Axel Arnold Institut für Computerphysik Universität Stuttgart Wintersemester 2010/11 Aufbau eines modernen Computers DDR3- Speicher Prozessor Prozessor PEG
OpenCL. Programmiersprachen im Multicore-Zeitalter. Tim Wiersdörfer
 OpenCL Programmiersprachen im Multicore-Zeitalter Tim Wiersdörfer Inhaltsverzeichnis 1. Was ist OpenCL 2. Entwicklung von OpenCL 3. OpenCL Modelle 1. Plattform-Modell 2. Ausführungs-Modell 3. Speicher-Modell
OpenCL Programmiersprachen im Multicore-Zeitalter Tim Wiersdörfer Inhaltsverzeichnis 1. Was ist OpenCL 2. Entwicklung von OpenCL 3. OpenCL Modelle 1. Plattform-Modell 2. Ausführungs-Modell 3. Speicher-Modell
Exkurs: Paralleles Rechnen
 Münster Exkurs: Paralleles Rechnen December 2, 2013 , Münster Exkurs: Paralleles Rechnen 2 /27 Warum parallel Rechnen? Westf alische Wilhelms-Universit at M unster Exkurs: Paralleles Rechnen 2 /27 JUQUEEN,
Münster Exkurs: Paralleles Rechnen December 2, 2013 , Münster Exkurs: Paralleles Rechnen 2 /27 Warum parallel Rechnen? Westf alische Wilhelms-Universit at M unster Exkurs: Paralleles Rechnen 2 /27 JUQUEEN,
Vorlesung Parallelrechner und Parallelprogrammierung, SoSe 2016
 Paralleles Programmieren mit OpenMP und MPI Einführung in MPI Vorlesung Parallelrechner und Parallelprogrammierung, SoSe 2016 Steinbuch Centre for Computing Hartmut Häfner, Steinbuch Centre for Computing
Paralleles Programmieren mit OpenMP und MPI Einführung in MPI Vorlesung Parallelrechner und Parallelprogrammierung, SoSe 2016 Steinbuch Centre for Computing Hartmut Häfner, Steinbuch Centre for Computing
Konzepte der parallelen Programmierung
 Fakultät Informatik, Institut für Technische Informatik, Professur Rechnerarchitektur Konzepte der parallelen Programmierung Parallele Programmiermodelle Nöthnitzer Straße 46 Raum 1029 Tel. +49 351-463
Fakultät Informatik, Institut für Technische Informatik, Professur Rechnerarchitektur Konzepte der parallelen Programmierung Parallele Programmiermodelle Nöthnitzer Straße 46 Raum 1029 Tel. +49 351-463
Computergrundlagen Moderne Rechnerarchitekturen
 Aufbau eines modernen Computers Computergrundlagen Moderne Rechnerarchitekturen Axel Arnold Institut für Computerphysik Universität Stuttgart DDR3- Speicher Prozessor Prozessor PEG Graphikkarte(n) weitere
Aufbau eines modernen Computers Computergrundlagen Moderne Rechnerarchitekturen Axel Arnold Institut für Computerphysik Universität Stuttgart DDR3- Speicher Prozessor Prozessor PEG Graphikkarte(n) weitere
Projektseminar Parallele Programmierung
 HTW Dresden WS 2017/2018 Organisatorisches Praktikum, 4 SWS Do. 15:10-18:30 Uhr, Z136c, 2 Doppelstunden Labor Z 136c ist Donnerstag 15:10-18:30 reserviert, gemeinsam mit anderen Projektseminaren Selbständige
HTW Dresden WS 2017/2018 Organisatorisches Praktikum, 4 SWS Do. 15:10-18:30 Uhr, Z136c, 2 Doppelstunden Labor Z 136c ist Donnerstag 15:10-18:30 reserviert, gemeinsam mit anderen Projektseminaren Selbständige
Multi- und Many-Core
 Multi- und Many-Core Benjamin Warnke Arbeitsbereich Wissenschaftliches Rechnen Fachbereich Informatik Fakultät für Mathematik, Informatik und Naturwissenschaften Universität Hamburg 2016-12-15 Benjamin
Multi- und Many-Core Benjamin Warnke Arbeitsbereich Wissenschaftliches Rechnen Fachbereich Informatik Fakultät für Mathematik, Informatik und Naturwissenschaften Universität Hamburg 2016-12-15 Benjamin
Message Passing Interface: MPI
 Message Passing Interface: MPI Geschichte: Erster MPI Standard Etwa 60 Personen, von 40 Institutionen (29-30 April 1992) MPI 1 im November 1993 MPI 1.1 im Juni 1995 MPI 1.2 Juli 1997 (Nur Ergänzung zu
Message Passing Interface: MPI Geschichte: Erster MPI Standard Etwa 60 Personen, von 40 Institutionen (29-30 April 1992) MPI 1 im November 1993 MPI 1.1 im Juni 1995 MPI 1.2 Juli 1997 (Nur Ergänzung zu
Programmierung von Parallelrechnern
 Programmierung von Parallelrechnern Speichermodelle Gemeinsamer Speicher Verteilter Speicher Programmiermethoden Speichergekoppelt Nachrichtengekoppelt Programmierkonzepte Annotierung sequentieller Programme
Programmierung von Parallelrechnern Speichermodelle Gemeinsamer Speicher Verteilter Speicher Programmiermethoden Speichergekoppelt Nachrichtengekoppelt Programmierkonzepte Annotierung sequentieller Programme
MPI: Message passing interface
 MPI: Message passing interface Es werden mehrere Prozesse gestartet, die das gleiche Programm abarbeiten. Diese Prozesse können auf dem gleichen Knoten oder verschiedenen Knoten eines Clusters von Rechnern
MPI: Message passing interface Es werden mehrere Prozesse gestartet, die das gleiche Programm abarbeiten. Diese Prozesse können auf dem gleichen Knoten oder verschiedenen Knoten eines Clusters von Rechnern
Architektur paralleler Rechnersysteme - Effiziente HPC Systeme -
 Architektur paralleler Rechnersysteme - Effiziente HPC Systeme - WS 13/14 Nr. L.079.05722 Master-Studiengang Informatik, V2/Ü1 www.uni-paderborn.de/pc2 Vorlesung: Architektur Paralleler Rechnersysteme
Architektur paralleler Rechnersysteme - Effiziente HPC Systeme - WS 13/14 Nr. L.079.05722 Master-Studiengang Informatik, V2/Ü1 www.uni-paderborn.de/pc2 Vorlesung: Architektur Paralleler Rechnersysteme
Praktikum: Paralleles Programmieren für Geowissenschaftler
 Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart, Enno Zieckler hermann.lenhart@informatik.uni-hamburg.de MPI Kommunikation: Das wichtigste Kriterium für
Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart, Enno Zieckler hermann.lenhart@informatik.uni-hamburg.de MPI Kommunikation: Das wichtigste Kriterium für
Praktikum: Paralleles Programmieren für Geowissenschaftler
 Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart, Ulrich Körner, Nathanael Hübbe hermann.lenhart@zmaw.de MPI Einführung III: Kommunikation Standard = blockierende
Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart, Ulrich Körner, Nathanael Hübbe hermann.lenhart@zmaw.de MPI Einführung III: Kommunikation Standard = blockierende
Praktikum: Paralleles Programmieren für Geowissenschaftler
 Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart, Nathanael Hübbe hermann.lenhart@informatik.uni-hamburg.de MPI Kommunikation: Das wichtigste Kriterium für
Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart, Nathanael Hübbe hermann.lenhart@informatik.uni-hamburg.de MPI Kommunikation: Das wichtigste Kriterium für
Parallele Algorithmen SoSe 2016
 Hochschule Harz FB Automatisierung und Informatik 3. Labor: MPI Parallele Algorithmen SoSe 2016 Thema: MPI-Programmierung im Cluster mit globalen Kommunikationsoperationen: 1 Versuchsziele Einen Cluster
Hochschule Harz FB Automatisierung und Informatik 3. Labor: MPI Parallele Algorithmen SoSe 2016 Thema: MPI-Programmierung im Cluster mit globalen Kommunikationsoperationen: 1 Versuchsziele Einen Cluster
Projektseminar Parallele Programmierung
 HTW Dresden WS 2016/2017 Organisatorisches Praktikum, 4 SWS Do. 15:10-18:30 Uhr, Z136c, 2 Doppelstunden Labor Z 136c ist Montag und Donnerstag 15:10-18:30 reserviert, gemeinsam mit anderen Projektseminaren
HTW Dresden WS 2016/2017 Organisatorisches Praktikum, 4 SWS Do. 15:10-18:30 Uhr, Z136c, 2 Doppelstunden Labor Z 136c ist Montag und Donnerstag 15:10-18:30 reserviert, gemeinsam mit anderen Projektseminaren
MPI-2 Die Zukunft des Message Passing?
 Seminar WS 03/04 MPI-2 Die Zukunft des Message Passing? LS Rechnerarchitektur Sven Stork Übersicht 1) Einführung 2) Parallel I/O 3) RMA 4) DPM 5) Zusammenfassung Einführung Einführung Was ist MPI? Ein
Seminar WS 03/04 MPI-2 Die Zukunft des Message Passing? LS Rechnerarchitektur Sven Stork Übersicht 1) Einführung 2) Parallel I/O 3) RMA 4) DPM 5) Zusammenfassung Einführung Einführung Was ist MPI? Ein
CUDA. Moritz Wild, Jan-Hugo Lupp. Seminar Multi-Core Architectures and Programming. Friedrich-Alexander-Universität Erlangen-Nürnberg
 CUDA Seminar Multi-Core Architectures and Programming 1 Übersicht Einleitung Architektur Programmierung 2 Einleitung Computations on GPU 2003 Probleme Hohe Kenntnisse der Grafikprogrammierung nötig Unterschiedliche
CUDA Seminar Multi-Core Architectures and Programming 1 Übersicht Einleitung Architektur Programmierung 2 Einleitung Computations on GPU 2003 Probleme Hohe Kenntnisse der Grafikprogrammierung nötig Unterschiedliche
Parallelverarbeitung
 Parallelverarbeitung WS 2015/16 Universität Siegen rolanda.dwismuellera@duni-siegena.de Tel.: 0271/740-4050, Büro: H-B 8404 Stand: 18. Januar 2016 Betriebssysteme / verteilte Systeme Parallelverarbeitung
Parallelverarbeitung WS 2015/16 Universität Siegen rolanda.dwismuellera@duni-siegena.de Tel.: 0271/740-4050, Büro: H-B 8404 Stand: 18. Januar 2016 Betriebssysteme / verteilte Systeme Parallelverarbeitung
MPI Prozessgruppen, Topologien, kollektive Kommunikation
 MPI Prozessgruppen, Topologien, kollektive Kommunikation Parallelrechner Sommersemester 2004 tome@informatik.tu-chemnitz.de Inhalt Prozessgruppen und der Communicator Kollektive Kommunikation Prozess Topologien
MPI Prozessgruppen, Topologien, kollektive Kommunikation Parallelrechner Sommersemester 2004 tome@informatik.tu-chemnitz.de Inhalt Prozessgruppen und der Communicator Kollektive Kommunikation Prozess Topologien
OpenMP - Geschichte. 1997: OpenMP Version 1.0 für Fortran
 OpenMP - Geschichte 1997: OpenMP Version 1.0 für Fortran Standard für f r die Shared-Memory Memory-Programmierung inzwischen für f r alle namhaften SMP-Rechner verfügbar wird im techn.-wiss. Rechnen die
OpenMP - Geschichte 1997: OpenMP Version 1.0 für Fortran Standard für f r die Shared-Memory Memory-Programmierung inzwischen für f r alle namhaften SMP-Rechner verfügbar wird im techn.-wiss. Rechnen die
de facto Standard für nachrichten-basierte Programmierung für FORTRAN, C und C++ =>
 7. MPI Message Passing Interface de facto Standard für nachrichten-basierte Programmierung für FORTRAN, C und C++ => www.mpi-forum.de MPI Programmiermodell SPMD- Programmstruktur 6 Basisfunktionen: MPI_Init
7. MPI Message Passing Interface de facto Standard für nachrichten-basierte Programmierung für FORTRAN, C und C++ => www.mpi-forum.de MPI Programmiermodell SPMD- Programmstruktur 6 Basisfunktionen: MPI_Init
Parallele Programmierung mit MPI
 Parallele Programmierung mit MPI Marc-Oliver Straub entstanden aus: Parallele Programmierung mit MPI - ein Praktikum Warum Parallelprogrammierung große numerische Probleme (Simulation) optische Bildverarbeitung
Parallele Programmierung mit MPI Marc-Oliver Straub entstanden aus: Parallele Programmierung mit MPI - ein Praktikum Warum Parallelprogrammierung große numerische Probleme (Simulation) optische Bildverarbeitung
Praktikum: Paralleles Programmieren für Geowissenschaftler
 Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart hermann.lenhart@informatik.uni-hamburg.de MPI Einführung II: Send/Receive Syntax Broadcast Reduce Operation
Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart hermann.lenhart@informatik.uni-hamburg.de MPI Einführung II: Send/Receive Syntax Broadcast Reduce Operation
Parallel Processing in a Nutshell OpenMP & MPI kurz vorgestellt
 Parallel Processing in a Nutshell & kurz vorgestellt 16. Juni 2009 1 / 29 1 Das Problem 2 2 / 29 1 Das Problem 2 3 2 / 29 1 Das Problem 2 3 4 2 / 29 1 Das Problem 2 3 4 2 / 29 Multi-Core Prozessoren halten
Parallel Processing in a Nutshell & kurz vorgestellt 16. Juni 2009 1 / 29 1 Das Problem 2 2 / 29 1 Das Problem 2 3 2 / 29 1 Das Problem 2 3 4 2 / 29 1 Das Problem 2 3 4 2 / 29 Multi-Core Prozessoren halten
Simulation der MPI collective operations im PIOsimHD
 Uni Hamburg WR - Informatik 04.04.2012 Simulation der MPI collective operations im PIOsimHD 1 Artur Thiessen Informatik Bachelor Matrikelnummer: 5944906 7thiesse@informatik.uni-hamburg.de Inhaltsverzeichnis
Uni Hamburg WR - Informatik 04.04.2012 Simulation der MPI collective operations im PIOsimHD 1 Artur Thiessen Informatik Bachelor Matrikelnummer: 5944906 7thiesse@informatik.uni-hamburg.de Inhaltsverzeichnis
OpenCL. OpenCL. Boris Totev, Cornelius Knap
 OpenCL OpenCL 1 OpenCL Gliederung Entstehungsgeschichte von OpenCL Was, warum und überhaupt wieso OpenCL CUDA, OpenGL und OpenCL GPUs OpenCL Objekte Work-Units OpenCL Adressbereiche OpenCL API Codebeispiel
OpenCL OpenCL 1 OpenCL Gliederung Entstehungsgeschichte von OpenCL Was, warum und überhaupt wieso OpenCL CUDA, OpenGL und OpenCL GPUs OpenCL Objekte Work-Units OpenCL Adressbereiche OpenCL API Codebeispiel
Einführung in C. EDV1-04C-Einführung 1
 Einführung in C 1 Helmut Erlenkötter C Programmieren von Anfang an Rowohlt Taschenbuch Verlag ISBN 3-4993 499-60074-9 19,90 DM http://www.erlenkoetter.de Walter Herglotz Das Einsteigerseminar C++ bhv Verlags
Einführung in C 1 Helmut Erlenkötter C Programmieren von Anfang an Rowohlt Taschenbuch Verlag ISBN 3-4993 499-60074-9 19,90 DM http://www.erlenkoetter.de Walter Herglotz Das Einsteigerseminar C++ bhv Verlags
Vorlesung Betriebssysteme II
 1 / 15 Vorlesung Betriebssysteme II Thema 3: IPC Robert Baumgartl 20. April 2015 2 / 15 Message Passing (Nachrichtenaustausch) Prinzip 2 grundlegende Operationen: send(), receive() notwendig, wenn kein
1 / 15 Vorlesung Betriebssysteme II Thema 3: IPC Robert Baumgartl 20. April 2015 2 / 15 Message Passing (Nachrichtenaustausch) Prinzip 2 grundlegende Operationen: send(), receive() notwendig, wenn kein
Parallele Algorithmen mit OpenCL. Universität Osnabrück, Henning Wenke,
 Parallele Algorithmen mit OpenCL Universität Osnabrück, Henning Wenke, 2013-04-17 Kapitel I OpenCL Einführung Allgemeines Open Compute Language: API für einheitliche parallele Programmierung heterogener
Parallele Algorithmen mit OpenCL Universität Osnabrück, Henning Wenke, 2013-04-17 Kapitel I OpenCL Einführung Allgemeines Open Compute Language: API für einheitliche parallele Programmierung heterogener
Memory Models Frederik Zipp
 Memory Models Frederik Zipp Seminar: Programmiersprachen für Parallele Programmierung (SS 2010) Fakultät für Informatik - IPD SNELTING LEHRSTUHL PROGRAMMIERPARADIGMEN 1
Memory Models Frederik Zipp Seminar: Programmiersprachen für Parallele Programmierung (SS 2010) Fakultät für Informatik - IPD SNELTING LEHRSTUHL PROGRAMMIERPARADIGMEN 1
Ressourcenmanagement in Netzwerken SS06 Vorl. 12,
 Ressourcenmanagement in Netzwerken SS06 Vorl. 12, 30.6.06 Friedhelm Meyer auf der Heide Name hinzufügen 1 Prüfungstermine Dienstag, 18.7. Montag, 21. 8. und Freitag, 22.9. Bitte melden sie sich bis zum
Ressourcenmanagement in Netzwerken SS06 Vorl. 12, 30.6.06 Friedhelm Meyer auf der Heide Name hinzufügen 1 Prüfungstermine Dienstag, 18.7. Montag, 21. 8. und Freitag, 22.9. Bitte melden sie sich bis zum
Einige Grundlagen zu OpenMP
 Einige Grundlagen zu OpenMP Stephanie Friedhoff, Martin Lanser Mathematisches Institut Universität zu Köln 22. Juni 2016 Überblick Was ist OpenMP? Basics Das OpenMP fork-join-modell Kompilieren und Ausführen
Einige Grundlagen zu OpenMP Stephanie Friedhoff, Martin Lanser Mathematisches Institut Universität zu Köln 22. Juni 2016 Überblick Was ist OpenMP? Basics Das OpenMP fork-join-modell Kompilieren und Ausführen
Multicomputer ohne gemeinsamen Speicher 73
 Multicomputer ohne gemeinsamen Speicher 73 CPU RAM CPU RAM Netzwerk CPU RAM CPU RAM CPU RAM Multicomputer bestehen aus einzelnen Rechnern mit eigenem Speicher, die über ein Netzwerk miteinander verbunden
Multicomputer ohne gemeinsamen Speicher 73 CPU RAM CPU RAM Netzwerk CPU RAM CPU RAM CPU RAM Multicomputer bestehen aus einzelnen Rechnern mit eigenem Speicher, die über ein Netzwerk miteinander verbunden
Praktikum: Paralleles Programmieren für Geowissenschaftler
 Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart, Nathanael Hübbe MPI Kollektive Operationen Neben Point-to-Point Kommunikation mittels Send & Recv verfügt
Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart, Nathanael Hübbe MPI Kollektive Operationen Neben Point-to-Point Kommunikation mittels Send & Recv verfügt
Grundlagen zu MPI. Martin Lanser Mathematisches Institut Universität zu Köln. October 24, 2017
 Grundlagen zu MPI Martin Lanser Mathematisches Institut Universität zu Köln October 24, 2017 Überblick Einige Grundlagen Punkt-zu-Punkt Kommunikation Globale Kommunikation Kommunikation plus Berechnung
Grundlagen zu MPI Martin Lanser Mathematisches Institut Universität zu Köln October 24, 2017 Überblick Einige Grundlagen Punkt-zu-Punkt Kommunikation Globale Kommunikation Kommunikation plus Berechnung
Programmieren mit MPI
 Programmieren mit MPI MPI steht für: Message Passing Interface Standard. Spezifiziert die Schnittstelle einer Bibliothek für Nachrichtentausch. Standardisierung durch ein Gremium, in dem: Hersteller v.
Programmieren mit MPI MPI steht für: Message Passing Interface Standard. Spezifiziert die Schnittstelle einer Bibliothek für Nachrichtentausch. Standardisierung durch ein Gremium, in dem: Hersteller v.
GPU-Programmierung: OpenCL
 Seminar: Multicore Programmierung Sommerstemester 2009 04.06.2009 Inhaltsverzeichnis 1 GPU-Programmierung von Grafikkarten von GPU-Computing 2 Architektur Spracheigenschaften Vergleich mit CUDA Beispiel
Seminar: Multicore Programmierung Sommerstemester 2009 04.06.2009 Inhaltsverzeichnis 1 GPU-Programmierung von Grafikkarten von GPU-Computing 2 Architektur Spracheigenschaften Vergleich mit CUDA Beispiel
Paralleles Programmieren mit MPI und OpenMP
 Paralleles Programmieren mit MPI und OpenMP Vorlesung «Algorithmen für das wissenschaftliche Rechnen» 6.5.2002 Olaf Schenk, Michael Hagemann 6.5.2002 Algorithmen des wissenschaftlichen Rechnens 1 Organisatorisches
Paralleles Programmieren mit MPI und OpenMP Vorlesung «Algorithmen für das wissenschaftliche Rechnen» 6.5.2002 Olaf Schenk, Michael Hagemann 6.5.2002 Algorithmen des wissenschaftlichen Rechnens 1 Organisatorisches
GPGPU mit NVIDIA CUDA
 01.07.12 GPGPU mit NVIDIA CUDA General-Purpose on Formatvorlagecomputing des Graphics Processing durch Units Untertitelmasters mit KlickenCompute bearbeiten NVIDIA Unified Device Architecture Gliederung
01.07.12 GPGPU mit NVIDIA CUDA General-Purpose on Formatvorlagecomputing des Graphics Processing durch Units Untertitelmasters mit KlickenCompute bearbeiten NVIDIA Unified Device Architecture Gliederung
Seminarvortrag: Direktivenbasierte Programmierung von Beschleunigern mit OpenMP 4.5 und OpenACC 2.5 im Vergleich
 Seminarvortrag: Direktivenbasierte Programmierung von Beschleunigern mit Direktivenbasierte Programmierung von Beschleunigern mit Agenda Einführung / Motivation Überblick zu OpenMP und OpenACC Asynchronität
Seminarvortrag: Direktivenbasierte Programmierung von Beschleunigern mit Direktivenbasierte Programmierung von Beschleunigern mit Agenda Einführung / Motivation Überblick zu OpenMP und OpenACC Asynchronität
Parallelisierung der Matrixmultiplikation
 Ein Beispiel für parallele Algorithmen Ivo Hedtke hedtke@math.uni-jena.de www.minet.uni-jena.de/~hedtke/ ehem. Hiwi am Lehrstuhl für Wissenschaftliches Rechnen (Prof. Dr. Zumbusch) Institut für Angewandte
Ein Beispiel für parallele Algorithmen Ivo Hedtke hedtke@math.uni-jena.de www.minet.uni-jena.de/~hedtke/ ehem. Hiwi am Lehrstuhl für Wissenschaftliches Rechnen (Prof. Dr. Zumbusch) Institut für Angewandte
> High-Level Programmierung heterogener paralleler Systeme
 > High-Level Programmierung heterogener paralleler Systeme Projektseminar im SoSe 2012 Prof. Sergei Gorlatch, Michel Steuwer, Tim Humernbrum AG Parallele und Verteilte Systeme, Westfälische Wilhelms-Universität
> High-Level Programmierung heterogener paralleler Systeme Projektseminar im SoSe 2012 Prof. Sergei Gorlatch, Michel Steuwer, Tim Humernbrum AG Parallele und Verteilte Systeme, Westfälische Wilhelms-Universität
Einführung in die Parallelprogrammierung MPI Teil 1: Einführung in MPI
 Einführung in die Parallelprogrammierung MPI Teil 1: Einführung in MPI Annika Hagemeier Jülich Supercomputing Centre (JSC) Forschungszentrum Jülich Inhalt Was ist MPI? MPI Historie Programmiermodell Kommunikationsmodell
Einführung in die Parallelprogrammierung MPI Teil 1: Einführung in MPI Annika Hagemeier Jülich Supercomputing Centre (JSC) Forschungszentrum Jülich Inhalt Was ist MPI? MPI Historie Programmiermodell Kommunikationsmodell
Raytracing in GA mittels OpenACC. Michael Burger, M.Sc. FG Scientific Computing TU Darmstadt
 Raytracing in GA mittels OpenACC Michael Burger, M.Sc. FG Scientific Computing TU Darmstadt michael.burger@sc.tu-darmstadt.de 05.11.12 FB Computer Science Scientific Computing Michael Burger 1 / 33 Agenda
Raytracing in GA mittels OpenACC Michael Burger, M.Sc. FG Scientific Computing TU Darmstadt michael.burger@sc.tu-darmstadt.de 05.11.12 FB Computer Science Scientific Computing Michael Burger 1 / 33 Agenda
Parallele Programmierung mit MPI im Überblick
 Parallele Programmierung mit MPI im Überblick Dieter an Mey e-mail: anmey@rz.rwth-aachen.de 1 Parallelisierung im Überblick Parallelisierung mit OpenMP und MPI an einigen einfachen Beispielen Rechenarchitekturen
Parallele Programmierung mit MPI im Überblick Dieter an Mey e-mail: anmey@rz.rwth-aachen.de 1 Parallelisierung im Überblick Parallelisierung mit OpenMP und MPI an einigen einfachen Beispielen Rechenarchitekturen
Multicomputer ohne gemeinsamen Speicher 170
 Multicomputer ohne gemeinsamen Speicher 170 CPU RAM CPU RAM Netzwerk CPU RAM CPU RAM CPU RAM Multicomputer bestehen aus einzelnen Rechnern mit eigenem Speicher, die über ein Netzwerk miteinander verbunden
Multicomputer ohne gemeinsamen Speicher 170 CPU RAM CPU RAM Netzwerk CPU RAM CPU RAM CPU RAM Multicomputer bestehen aus einzelnen Rechnern mit eigenem Speicher, die über ein Netzwerk miteinander verbunden
Der Goopax Compiler GPU-Programmierung in C++ ZKI AK-Supercomputing, Münster, 27.03.2014, Ingo Josopait
 Der Goopax Compiler GPU-Programmierung in C++ AMD R9 290X: 5.6 TFLOPS (SP MulAdd) Programmierung ~10000 Threads Entwicklungsumgebungen Entwicklungsumgebungen CUDA, OpenCL Compiler: kernel GPU Maschinencode
Der Goopax Compiler GPU-Programmierung in C++ AMD R9 290X: 5.6 TFLOPS (SP MulAdd) Programmierung ~10000 Threads Entwicklungsumgebungen Entwicklungsumgebungen CUDA, OpenCL Compiler: kernel GPU Maschinencode
Mehrprozessorarchitekturen
 Mehrprozessorarchitekturen (SMP, UMA/NUMA, Cluster) Arian Bär 12.07.2004 12.07.2004 Arian Bär 1 Gliederung 1. Einleitung 2. Symmetrische Multiprozessoren (SMP) Allgemeines Architektur 3. Speicherarchitekturen
Mehrprozessorarchitekturen (SMP, UMA/NUMA, Cluster) Arian Bär 12.07.2004 12.07.2004 Arian Bär 1 Gliederung 1. Einleitung 2. Symmetrische Multiprozessoren (SMP) Allgemeines Architektur 3. Speicherarchitekturen
Programmiertechnik. Teil 4. C++ Funktionen: Prototypen Overloading Parameter. C++ Funktionen: Eigenschaften
 Programmiertechnik Teil 4 C++ Funktionen: Prototypen Overloading Parameter C++ Funktionen: Eigenschaften Funktionen (Unterprogramme, Prozeduren) fassen Folgen von Anweisungen zusammen, die immer wieder
Programmiertechnik Teil 4 C++ Funktionen: Prototypen Overloading Parameter C++ Funktionen: Eigenschaften Funktionen (Unterprogramme, Prozeduren) fassen Folgen von Anweisungen zusammen, die immer wieder
2 MPI MESSAGE-PASSING INTERFACE
 2-1 2 MPI MESSAGE-PASSING INTERFACE 2.1 IMPLEMENTIERUNGEN VON MPI Mittlerweile gibt es eine Vielzahl an Implementierungen des Message-Passing Interfaces. Sowohl freie (GNU GPL) also auch kommerziell nutzbare
2-1 2 MPI MESSAGE-PASSING INTERFACE 2.1 IMPLEMENTIERUNGEN VON MPI Mittlerweile gibt es eine Vielzahl an Implementierungen des Message-Passing Interfaces. Sowohl freie (GNU GPL) also auch kommerziell nutzbare
H.1 FORMI: An RMI Extension for Adaptive Applications H.1 FORMI: An RMI Extension for Adaptive Applications
 Motivation The ed-object Approach Java RMI ed Objects in Java RMI Conclusions Universität Erlangen-Nürnberg Informatik 4, 2007 H-Formi-.fm 2007-12-14 13.11 H.1 1 Motivation Distributed object-oriented
Motivation The ed-object Approach Java RMI ed Objects in Java RMI Conclusions Universität Erlangen-Nürnberg Informatik 4, 2007 H-Formi-.fm 2007-12-14 13.11 H.1 1 Motivation Distributed object-oriented
Parallele und Verteilte Algorithmen, Sommer 2007 Software zu den Übungen
 PHILIPPS-UNIVERSITÄT MARBURG Fachbereich Mathematik und Informatik Prof. Dr. R. Loogen J.Berthold D-35032 Marburg Hans Meerwein Straße Lahnberge 23.April 2007 Übungen zu Parallele und Verteilte Algorithmen,
PHILIPPS-UNIVERSITÄT MARBURG Fachbereich Mathematik und Informatik Prof. Dr. R. Loogen J.Berthold D-35032 Marburg Hans Meerwein Straße Lahnberge 23.April 2007 Übungen zu Parallele und Verteilte Algorithmen,
Vorlesung Parallelrechner und Parallelprogrammierung, SoSe 2016
 Paralleles Programmieren mit OpenMP und MPI MPI-Übungsaufgaben Vorlesung Parallelrechner und Parallelprogrammierung, SoSe 2016 Hartmut Steinbuch Häfner, Centre Steinbuch for Computing Centre for Computing
Paralleles Programmieren mit OpenMP und MPI MPI-Übungsaufgaben Vorlesung Parallelrechner und Parallelprogrammierung, SoSe 2016 Hartmut Steinbuch Häfner, Centre Steinbuch for Computing Centre for Computing
Distributed-Memory Programmiermodelle II
 Distributed-emory Programmiermodelle II Stefan Lang Interdisziplinäres Zentrum für Wissenschaftliches Rechnen Universität Heidelberg INF 368, Raum 532 D-69120 Heidelberg phone: 06221/54-8264 email: Stefan.Lang@iwr.uni-heidelberg.de
Distributed-emory Programmiermodelle II Stefan Lang Interdisziplinäres Zentrum für Wissenschaftliches Rechnen Universität Heidelberg INF 368, Raum 532 D-69120 Heidelberg phone: 06221/54-8264 email: Stefan.Lang@iwr.uni-heidelberg.de
Hochleistungsrechnen Hybride Parallele Programmierung. Prof. Dr. Thomas Ludwig Universität Hamburg Informatik Wissenschaftliches Rechnen
 Hochleistungsrechnen Hybride Parallele Programmierung Prof. Dr. Thomas Ludwig Universität Hamburg Informatik Wissenschaftliches Rechnen Inhaltsübersicht Einleitung und Motivation Programmiermodelle für
Hochleistungsrechnen Hybride Parallele Programmierung Prof. Dr. Thomas Ludwig Universität Hamburg Informatik Wissenschaftliches Rechnen Inhaltsübersicht Einleitung und Motivation Programmiermodelle für
Praktikum Parallele Programmierung. Travelling Salesman Problem (TSP)
") UNIVERSITÄT HAMBURG FACHBEREICH INFORMATIK Praktikum Parallele Programmierung Travelling Salesman Problem (TSP) von Ihar Aleinikau Olesja Aleinikau & Timo Dahlbüdding 1. Problemstellung Aufgabe des TSP
UNIVERSITÄT HAMBURG FACHBEREICH INFORMATIK Praktikum Parallele Programmierung Travelling Salesman Problem (TSP) von Ihar Aleinikau Olesja Aleinikau & Timo Dahlbüdding 1. Problemstellung Aufgabe des TSP
Wie kann man es verhindern das Rad immer wieder erneut erfinden zu müssen?
 Generic Programming without Generics from JAVA5 Motivation Wie kann man es verhindern das Rad immer wieder erneut erfinden zu müssen? Ein Bespiel: sie haben bereits eine Klasse zur Multiplikation von Matrizen
Generic Programming without Generics from JAVA5 Motivation Wie kann man es verhindern das Rad immer wieder erneut erfinden zu müssen? Ein Bespiel: sie haben bereits eine Klasse zur Multiplikation von Matrizen
PThreads. Pthreads. Jeder Hersteller hatte eine eigene Implementierung von Threads oder light weight processes
 PThreads Prozesse und Threads Ein Unix-Prozess hat IDs (process,user,group) Umgebungsvariablen Verzeichnis Programmcode Register, Stack, Heap Dateideskriptoren, Signale message queues, pipes, shared memory
PThreads Prozesse und Threads Ein Unix-Prozess hat IDs (process,user,group) Umgebungsvariablen Verzeichnis Programmcode Register, Stack, Heap Dateideskriptoren, Signale message queues, pipes, shared memory
Einführung Sprachfeatures Hinweise, Tipps und Styleguide Informationen. Einführung in C. Patrick Schulz
 Patrick Schulz patrick.schulz@paec-media.de 29.04.2013 1 Einführung Einführung 2 3 4 Quellen 1 Einführung Einführung 2 3 4 Quellen Hello World in Java Einführung 1 public class hello_ world 2 { 3 public
Patrick Schulz patrick.schulz@paec-media.de 29.04.2013 1 Einführung Einführung 2 3 4 Quellen 1 Einführung Einführung 2 3 4 Quellen Hello World in Java Einführung 1 public class hello_ world 2 { 3 public
GPGPU-Programmierung
 12 GPGPU-Programmierung 2013/04/25 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken ist im Allgemeinen nicht erlaubt. Motivation (1) General Purpose Computing on
12 GPGPU-Programmierung 2013/04/25 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken ist im Allgemeinen nicht erlaubt. Motivation (1) General Purpose Computing on
Cilk Sprache für Parallelprogrammierung. IPD Snelting, Lehrstuhl für Programmierparadigmen
 Cilk Sprache für Parallelprogrammierung IPD Snelting, Lehrstuhl für Programmierparadigmen David Soria Parra Geschichte Geschichte Entwickelt 1994 am MIT Laboratory for Computer Science Cilk 1: Continuations
Cilk Sprache für Parallelprogrammierung IPD Snelting, Lehrstuhl für Programmierparadigmen David Soria Parra Geschichte Geschichte Entwickelt 1994 am MIT Laboratory for Computer Science Cilk 1: Continuations
Einführung. GPU-Versuch. Andreas Schäfer Friedrich-Alexander-Universität Erlangen-Nürnberg
 GPU-Versuch andreas.schaefer@cs.fau.de Friedrich-Alexander-Universität Erlangen-Nürnberg Praktikum Parallele Rechnerarchitekturen SS2014 Outline 1 Einführung 2 Outlook 1 Einführung 2 Eine kurze Geschichte
GPU-Versuch andreas.schaefer@cs.fau.de Friedrich-Alexander-Universität Erlangen-Nürnberg Praktikum Parallele Rechnerarchitekturen SS2014 Outline 1 Einführung 2 Outlook 1 Einführung 2 Eine kurze Geschichte
Beschreiben Sie die Eigenschaften der verschiedenen Rechnertypen an Hand:
 Hochschule Harz FB Automatisierung/Informatik Fachprüfung: Parallele Algorithmen (Musterklausur) Alle Hilfsmittel sind zugelassen! 1. Aufgabe Beschreiben Sie die Eigenschaften der verschiedenen Rechnertypen
Hochschule Harz FB Automatisierung/Informatik Fachprüfung: Parallele Algorithmen (Musterklausur) Alle Hilfsmittel sind zugelassen! 1. Aufgabe Beschreiben Sie die Eigenschaften der verschiedenen Rechnertypen
Abstrakte C-Maschine und Stack
 Abstrakte C-Maschine und Stack Julian Tobergte Proseminar C- Grundlagen und Konzepte, 2013 2013-06-21 1 / 25 Gliederung 1 Abstrakte Maschine 2 Stack 3 in C 4 Optional 5 Zusammenfassung 6 Quellen 2 / 25
Abstrakte C-Maschine und Stack Julian Tobergte Proseminar C- Grundlagen und Konzepte, 2013 2013-06-21 1 / 25 Gliederung 1 Abstrakte Maschine 2 Stack 3 in C 4 Optional 5 Zusammenfassung 6 Quellen 2 / 25
ROOT Tutorial für HEPHY@CERN. D. Liko
 ROOT Tutorial für HEPHY@CERN D. Liko Was ist ROOT? Am CERN entwickeltes Tool zur Analyse von Daten Funktionalität in vielen Bereichen Objekte C++ Skriptsprachen Was kann ROOT Verschiedene Aspekte C++ as
ROOT Tutorial für HEPHY@CERN D. Liko Was ist ROOT? Am CERN entwickeltes Tool zur Analyse von Daten Funktionalität in vielen Bereichen Objekte C++ Skriptsprachen Was kann ROOT Verschiedene Aspekte C++ as
Distributed Computing Group
 JAVA TUTORIAL Distributed Computing Group Vernetzte Systeme - SS 06 Übersicht Warum Java? Interoperabilität grosse und gut dokumentierte Library weit verbreitet Syntax sehr nahe an C Erfahrung: Java wird
JAVA TUTORIAL Distributed Computing Group Vernetzte Systeme - SS 06 Übersicht Warum Java? Interoperabilität grosse und gut dokumentierte Library weit verbreitet Syntax sehr nahe an C Erfahrung: Java wird
Compute Unified Device Architecture CUDA
 Compute Unified Device Architecture 06. Februar 2012 1 / 13 Gliederung 2 / 13 : Compute Unified Device Architecture entwickelt von Nvidia Corporation spezifiziert Software- und Hardwareeigenschaften Ziel:
Compute Unified Device Architecture 06. Februar 2012 1 / 13 Gliederung 2 / 13 : Compute Unified Device Architecture entwickelt von Nvidia Corporation spezifiziert Software- und Hardwareeigenschaften Ziel:
Aufbau einer MPI-Nachricht 292
 Aufbau einer MPI-Nachricht 292 int MPI_Send(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm); MPI-Nachrichten bestehen aus einem Header und der zu versendenden Datenstruktur
Aufbau einer MPI-Nachricht 292 int MPI_Send(void* buf, int count, MPI_Datatype datatype, int dest, int tag, MPI_Comm comm); MPI-Nachrichten bestehen aus einem Header und der zu versendenden Datenstruktur
OpenCL. Multi-Core Architectures and Programming (Seminar) Apelt, Nicolas / Zöllner, Christian
 Apelt, Nicolas / Zöllner, Christian") OpenCL Multi-Core Architectures and Programming (Seminar) Apelt, Nicolas / Zöllner, Christian Hardware-Software-Co-Design Universität Erlangen-Nürnberg Apelt, Nicolas / Zöllner, Christian 1 Was ist OpenCL?
OpenCL Multi-Core Architectures and Programming (Seminar) Apelt, Nicolas / Zöllner, Christian Hardware-Software-Co-Design Universität Erlangen-Nürnberg Apelt, Nicolas / Zöllner, Christian 1 Was ist OpenCL?
Pthreads. David Klaftenegger. Seminar: Multicore Programmierung Sommersemester
 Seminar: Multicore Programmierung Sommersemester 2009 16.07.2009 Inhaltsverzeichnis 1 Speichermodell 2 3 Implementierungsvielfalt Prioritätsinversion 4 Threads Speichermodell Was sind Threads innerhalb
Seminar: Multicore Programmierung Sommersemester 2009 16.07.2009 Inhaltsverzeichnis 1 Speichermodell 2 3 Implementierungsvielfalt Prioritätsinversion 4 Threads Speichermodell Was sind Threads innerhalb
Institut für Programmierung und Reaktive Systeme. Java 2. Markus Reschke
 Java 2 Markus Reschke 07.10.2014 Datentypen Was wird gespeichert? Wie wird es gespeichert? Was kann man mit Werten eines Datentyps machen (Operationen, Methoden)? Welche Werte gehören zum Datentyp? Wie
Java 2 Markus Reschke 07.10.2014 Datentypen Was wird gespeichert? Wie wird es gespeichert? Was kann man mit Werten eines Datentyps machen (Operationen, Methoden)? Welche Werte gehören zum Datentyp? Wie
Angewandte Mathematik und Programmierung
 Angewandte Mathematik und Programmierung Einführung in das Konzept der objektorientierten Anwendungen zu mathematischen Rechnens WS 2013/14 Operatoren Operatoren führen Aktionen mit Operanden aus. Der
Angewandte Mathematik und Programmierung Einführung in das Konzept der objektorientierten Anwendungen zu mathematischen Rechnens WS 2013/14 Operatoren Operatoren führen Aktionen mit Operanden aus. Der
GPGPU-Programmierung
 12 GPGPU-Programmierung 2014/04/29 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken ist im Allgemeinen nicht erlaubt. Motivation (1) General Purpose Computing on
12 GPGPU-Programmierung 2014/04/29 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken ist im Allgemeinen nicht erlaubt. Motivation (1) General Purpose Computing on
Erste Java-Programme (Scopes und Rekursion)
") Lehrstuhl Bioinformatik Konstantin Pelz Erste Java-Programme (Scopes und Rekursion) Tutorium Bioinformatik (WS 18/19) Konstantin: Konstantin.pelz@campus.lmu.de Homepage: https://bioinformatik-muenchen.com/studium/propaedeutikumprogrammierung-in-der-bioinformatik/
Lehrstuhl Bioinformatik Konstantin Pelz Erste Java-Programme (Scopes und Rekursion) Tutorium Bioinformatik (WS 18/19) Konstantin: Konstantin.pelz@campus.lmu.de Homepage: https://bioinformatik-muenchen.com/studium/propaedeutikumprogrammierung-in-der-bioinformatik/
Computergrafik Universität Osnabrück, Henning Wenke,
 Computergrafik Universität Osnabrück, Henning Wenke, 2012-06-25 Kapitel XV: Parallele Algorithmen mit OpenCL 15.1 Parallele Programmierung Quellen: V.a. Wikipedia. Leistungsdaten unter Vorbehalt. Bitte
Computergrafik Universität Osnabrück, Henning Wenke, 2012-06-25 Kapitel XV: Parallele Algorithmen mit OpenCL 15.1 Parallele Programmierung Quellen: V.a. Wikipedia. Leistungsdaten unter Vorbehalt. Bitte
Rechnerarchitektur SS 2013
 Rechnerarchitektur SS 2013 Verbindungsnetze Michael Engel TU Dortmund, Fakultät für Informatik Teilweise basierend auf Material von Gernot A. Fink und R. Yahyapour 2. Juli 2013 Leistungsbewertung von Kommunikationsmechanismen
Rechnerarchitektur SS 2013 Verbindungsnetze Michael Engel TU Dortmund, Fakultät für Informatik Teilweise basierend auf Material von Gernot A. Fink und R. Yahyapour 2. Juli 2013 Leistungsbewertung von Kommunikationsmechanismen
OpenMP. Viktor Styrbul
 OpenMP Viktor Styrbul Inhaltsverzeichnis Was ist OpenMP Warum Parallelisierung Geschichte Merkmale von OpenMP OpenMP-fähige Compiler OpenMP Ausführungsmodell Kernelemente von OpenMP Zusammenfassung Was
OpenMP Viktor Styrbul Inhaltsverzeichnis Was ist OpenMP Warum Parallelisierung Geschichte Merkmale von OpenMP OpenMP-fähige Compiler OpenMP Ausführungsmodell Kernelemente von OpenMP Zusammenfassung Was
Message Passing Interface (MPI)
") Westfälische Wilhelms-Universität Münster Ausarbeitung Message Passing Interface (MPI) Im Rahmen des Seminars Parallele und Verteilte Programmierung Julian Pascal Werra Themensteller: Prof. Dr. Herbert
Westfälische Wilhelms-Universität Münster Ausarbeitung Message Passing Interface (MPI) Im Rahmen des Seminars Parallele und Verteilte Programmierung Julian Pascal Werra Themensteller: Prof. Dr. Herbert
Praktikum: Paralleles Programmieren für Geowissenschaftler
 Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart & Enno Zickler Dr. HermannJ. Lenhart hermann.lenhart@informatik.unihamburg.de MPI Einführung II: Kollektive
Praktikum: Paralleles Programmieren für Geowissenschaftler Prof. Thomas Ludwig, Hermann Lenhart & Enno Zickler Dr. HermannJ. Lenhart hermann.lenhart@informatik.unihamburg.de MPI Einführung II: Kollektive
Woche 6. Cedric Tompkin. April 11, Cedric Tompkin Woche 6 April 11, / 29
 Woche 6 Cedric Tompkin April 11, 2018 Cedric Tompkin Woche 6 April 11, 2018 1 / 29 Figure: Mehr Comics Cedric Tompkin Woche 6 April 11, 2018 2 / 29 Learning Objectives Dir kennst Return-by-value und Return-by-reference.
Woche 6 Cedric Tompkin April 11, 2018 Cedric Tompkin Woche 6 April 11, 2018 1 / 29 Figure: Mehr Comics Cedric Tompkin Woche 6 April 11, 2018 2 / 29 Learning Objectives Dir kennst Return-by-value und Return-by-reference.
JAVA BASICS. 2. Primitive Datentypen. 1. Warum Java? a) Boolean (logische Werte wahr & falsch)
 Boolean (logische Werte wahr & falsch)") JAVA BASICS 2. Primitive Datentypen 1. Warum Java? weit verbreitet einfach und (relativ) sicher keine Pointer (?) keine gotos kein Präprozessor keine globalen Variablen garbage collection objekt-orientiert
JAVA BASICS 2. Primitive Datentypen 1. Warum Java? weit verbreitet einfach und (relativ) sicher keine Pointer (?) keine gotos kein Präprozessor keine globalen Variablen garbage collection objekt-orientiert