Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Sprachtechnologie. Tobias Scheffer Paul Prasse Michael Großhans
|
|
|
- Minna Kramer
- vor 5 Jahren
- Abrufe
Transkript

1 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Sprachtechnologie Tobias Scheffer Paul Prasse Michael Großhans
2 Organisation Vorlesung/Übung, praktische Informatik. 4 SWS. 6 Leistungspunkte Übung: Mo 14:00-15:30 Vorlesung : Mo 12:00-13:30 Raum:
3 Organisation Zielgruppen: Diplom, Bachelor. Master. 3
4 Organisation Webseite: Institut für Informatik > Professuren > Informatik/Maschinelles Lernen > Folien: Vorlesung Sprachtechnologie Am Tag nach der Vorlesung auf der Webseite. Übungen: Eine Woche im voraus auf der Webseite. 4
5 Organisation Übungsaufgaben: Am Tag nach der Vorlesung im Netz. Werden in der darauffolgenden Übung besprochen. Sie können für einzelne Aufgaben votieren. Sie müssen für 2/3 der Aufgaben des Semesters votieren, um die Prüfung ablegen zu können. Sie rechnen votierte Aufgaben vor. Erste Übung: Mündliche Prüfung am Ende des Semesters. 5
6 Literatur Folienkopien auf der Webseite Statistische Sprachverarbeitung: Manning & Schütze: Foundations of Statistical Natural Language Processing. MIT Press Spracherkennung: The HTK Book, im Internet verfügbar. Speech Recognition Toolkit Huang, Acero und Hon: Spoken Language Processing. Prentice Hall. Information Retrieval: Manning, Raghavan, Schütze: Introduction to Information Retrieval. Cambridge University Press. 6
7 Inhalt Verarbeitung geschriebener und gesprochener natürlicher Sprache. Sprachmodelle Spracherkennung Spracherzeugung Klassifikation Übersetzung Themenmodelle Informationsextraktion Suche 7


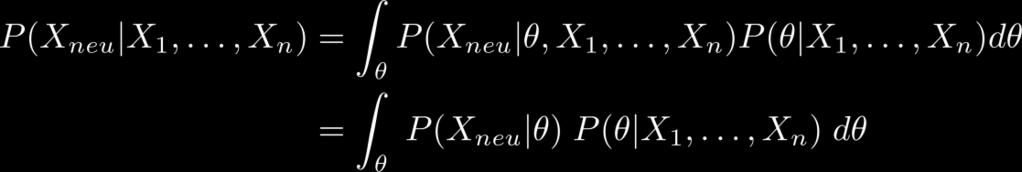


8 Mathematische Grundlagen 8
9 Statistische Sprachmodelle Elementares Werkzeug für Spracherkennung, Rechtschreibkorrektur, Auto-Complete, Übersetzung, Wahrscheinlichkeit einer Abfolge von Wörtern. Ich pflücke Beeren vs. Ich pflücke Bären. P( w,..., w ) P( w ) P( w w )... P( w w,..., w ) 1 T T T 1 1 P( w ) P( w w )... P( w w, w ) N T T 1 T N 1 P w w w P w w w T (,..., ) (,.. 9 ) i i 1 1 i i 1 i N 1
10 Statistische Sprachmodelle Grammatik, Akzeptor, Parser: Menge der Sätze einer Sprache. Als Mechanismus für Verarbeitung natürlicher Sprache nicht geeignet. Sprache hat keine scharfen Ränder, fast alles ist möglich. Statistisches Sprachmodell, statistische Inferenz. Wahrscheinlichkeit eines Satzes. Wahrscheinlichste Interpretation. 10
 P( X ) P( X X Jede Variable X i nur von Vorgänger X i-1 abhängig. Markov-Modell: Probabilistischer endlicher Automat, Folge der Zustände ist Markov-Kette. n 1,.")
11 Markov-Prozesse X 1,..., X n : Zufallsvariablen. Allgemein gilt: P( X Zufallsvariablen bilden eine Markovkette, gdw: n P( X,..., X ) P( X ) P( X X Jede Variable X i nur von Vorgänger X i-1 abhängig. Markov-Modell: Probabilistischer endlicher Automat, Folge der Zustände ist Markov-Kette. n 1,..., X n) P( X1) P( X i X i 1,..., X1) i 2 1 n 1 i i 1) i 2 (Andrei Markov, ) 11
12 Hidden-Markov-Modell Akustisches Modell für Spracherkennung. Zustände emittieren Beobachtungen O t (mit Wahrscheinlichkeit b i (O t )). b 3 ( Äähhh... ) = Neues Thema [ ] "(keine Fragen)" "(r/f Antwort)" "Äähhh..." [.95 ] b = % 90% 5% 1 2 Kapiert 3 Nicht kapiert 90% 1% 15% 80% [.9 ] 1 b = 0.1 4% 4% 1% 4 Richtige Antwort 5 Falsche Antwort [ 0 ] b = 1 0 [ 0 ] b =
13 Part-of-Speech Tagging, Parsing j ( ) j p, q) P( w1 ( p 1), N pq, w( q 1 m G) Outside NP Die N große braune j j ( p, q) P( w N, G) pq Inside pq N N Kiste 13

14 Named Entity Recognition 14
15 Übersetzung 15
16 Vektorraummodell Repräsentation von Texten. Textklassifikation, Clusteranalyse, Textähnlichkeit, Suche. Zytoplasma... Aaron 90 Aar 90 Aal Im Vek torraummodell entspricht jeder Text ge nau e inem Pu nkt im Rau m. Die Wort - r ei he nfol ge bl ei bt d a be i un b e rü c k - sichtigt. 16

17 Textklassifikation, Informationsextraktion 17

18 Themenmodelle Zuordnung Themen Wörter eines Dokuments Organisation von Dokumentensammlung anhand enthaltener Themen Probabilistisches Modell: LDA 18
19 Indexstrukturen Schnelle Suche in großen Textsammlungen This is a text. A text has many words. Words are made from letters. Terme Vorkommen Letters 60 Made 50 Many 28 Text 11, 19 words 33, 40 Letters: 60 Made: 50 l d a m n Many: 28 t Text: 11,19 w Words:33,40 19
 Textanalyse und Signalerzeugung 1 Signal ) P( Signal w1,..., wt ) P( w1,.")
20 Spracherkennung und -erzeugung Spracherkennung: Akustisches Modell + Sprachmodell arg max ( w,..., w 1 arg max ) ( w,..., w 1 T P( w,..., w T ) Textanalyse und Signalerzeugung 1 Signal ) P( Signal w1,..., wt ) P( w1,..., wt ) Akustisches Modell Sprachmodell Anwendung: Sprachportale T Zustand 1 P[ Zustand 1] 10% 90% Zustand 2 5% 1 Zustand % 1% 15% 80% 4% 4% 1% Zustand 4 Zustand 5 20
21 Websuche Crawling: Welche URL wann besuchen? Endlos-URLs, dynamische Seiteninhalte. Aktualisierungshäufigkeiten und Zeitpunkte. Identische Seiten. Link-Spam. Relevanz-Ranking: Analyse der Linkstruktur. 21
22 Fragen? (diese Woche noch keine Übungsaufgaben, nächste Woche noch keine Übung) Erster Übungstermin:
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Tobias Scheffer, Tom Vanck, Paul Prasse
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Sprachtechnologie Tobias Scheffer, Tom Vanck, Paul Prasse Organisation Vorlesung/Übung, praktische Informatik. 4 SWS. Termin: Montags,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Sprachtechnologie Tobias Scheffer, Tom Vanck, Paul Prasse Organisation Vorlesung/Übung, praktische Informatik. 4 SWS. Termin: Montags,
Information Retrieval, Vektorraummodell
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Information Retrieval, Vektorraummodell Tobias Scheffer Paul Prasse Michael Großhans Uwe Dick Information Retrieval Konstruktion
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Information Retrieval, Vektorraummodell Tobias Scheffer Paul Prasse Michael Großhans Uwe Dick Information Retrieval Konstruktion
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Niels Landwehr, Jules Rasetaharison, Christoph Sawade, Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen Niels Landwehr, Jules Rasetaharison, Christoph Sawade, Tobias Scheffer Organisation Vorlesung/Übung, praktische
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen Niels Landwehr, Jules Rasetaharison, Christoph Sawade, Tobias Scheffer Organisation Vorlesung/Übung, praktische
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Maschinelles Lernen. Tobias Scheffer Michael Brückner
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen Tobias Scheffer Michael Brückner Organisation Vorlesung/Übung, praktische Informatik. 4 SWS. Übung: Mo 10:00-11:30
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen Tobias Scheffer Michael Brückner Organisation Vorlesung/Übung, praktische Informatik. 4 SWS. Übung: Mo 10:00-11:30
Hidden-Markov-Modelle
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hidden-Markov-Modelle Tobias Scheffer Thomas Vanck Hidden-Markov-Modelle: Wozu? Spracherkennung: Akustisches Modell. Geschriebene
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hidden-Markov-Modelle Tobias Scheffer Thomas Vanck Hidden-Markov-Modelle: Wozu? Spracherkennung: Akustisches Modell. Geschriebene
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Maschinelles Lernen
 Universität Potsdam Institut für Informatik Lehrstuhl Niels Landwehr, Silvia Makowski, Christoph Sawade, Tobias Scheffer Organisation Vorlesung/Übung, praktische Informatik. 4 SWS. Übung: Di 10:00-11:30
Universität Potsdam Institut für Informatik Lehrstuhl Niels Landwehr, Silvia Makowski, Christoph Sawade, Tobias Scheffer Organisation Vorlesung/Übung, praktische Informatik. 4 SWS. Übung: Di 10:00-11:30
Statistische Sprachmodelle
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Statistische Sprachmodelle Tobias Scheffer Thomas Vanck Statistische Sprachmodelle Welche Sätze sind Elemente einer Sprache (durch
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Statistische Sprachmodelle Tobias Scheffer Thomas Vanck Statistische Sprachmodelle Welche Sätze sind Elemente einer Sprache (durch
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Zusammenfassung. Tobias Scheffer Paul Prasse Michael Großhans Uwe Dick
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Zusammenfassung Tobias Scheffer Paul Prasse Michael Großhans Uwe Dick Statistische Sprachmodelle Wie wahrscheinlich ist ein bestimmter
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Zusammenfassung Tobias Scheffer Paul Prasse Michael Großhans Uwe Dick Statistische Sprachmodelle Wie wahrscheinlich ist ein bestimmter
Einführung in die Computerlinguistik
 Einführung in die Computerlinguistik Einführung Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2018 1 / 14 Anwendungen der Computerlinguistik Carstensen et al. (2010); Jurafsky and Martin
Einführung in die Computerlinguistik Einführung Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2018 1 / 14 Anwendungen der Computerlinguistik Carstensen et al. (2010); Jurafsky and Martin
Hidden Markov Models
 Hidden Markov Models Kursfolien Karin Haenelt 09.05002 1 Letzte Änderung 18.07002 Hidden Markov Models Besondere Form eines probabilistischen endlichen Automaten Weit verbreitet in der statistischen Sprachverarbeitung
Hidden Markov Models Kursfolien Karin Haenelt 09.05002 1 Letzte Änderung 18.07002 Hidden Markov Models Besondere Form eines probabilistischen endlichen Automaten Weit verbreitet in der statistischen Sprachverarbeitung
Information Retrieval,
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Information Retrieval, Vektorraummodell Tobias Scheffer Uwe Dick Peter Haider Paul Prasse Information Retrieval Konstruktion von
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Information Retrieval, Vektorraummodell Tobias Scheffer Uwe Dick Peter Haider Paul Prasse Information Retrieval Konstruktion von
Kontextfreie Grammatiken
 Kontextfreie Grammatiken Vorlesung Computerlinguistische Techniken Alexander Koller 16. Oktober 2015 Übersicht Worum geht es in dieser Vorlesung? Übungen und Abschlussprojekt Kontextfreie Grammatiken Computerlinguistische
Kontextfreie Grammatiken Vorlesung Computerlinguistische Techniken Alexander Koller 16. Oktober 2015 Übersicht Worum geht es in dieser Vorlesung? Übungen und Abschlussprojekt Kontextfreie Grammatiken Computerlinguistische
Maschinelles Lernen II
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen II Niels Landwehr Organisation Vorlesung/Übung 4 SWS. Ort: 3.01.2.31. Termin: Vorlesung: Dienstag, 10:00-11:30.
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen II Niels Landwehr Organisation Vorlesung/Übung 4 SWS. Ort: 3.01.2.31. Termin: Vorlesung: Dienstag, 10:00-11:30.
Vorbesprechung Mathe III
 Vorbesprechung Mathe III Dr. Vera Demberg, Prof. Dr. Enrico Lieblang (HTW) Universität des Saarlandes April 19th, 2012 Vera Demberg (UdS) Vorbesprechung Mathe III April 19th, 2012 1 / 20 Formalien Pflichtveranstaltung
Vorbesprechung Mathe III Dr. Vera Demberg, Prof. Dr. Enrico Lieblang (HTW) Universität des Saarlandes April 19th, 2012 Vera Demberg (UdS) Vorbesprechung Mathe III April 19th, 2012 1 / 20 Formalien Pflichtveranstaltung
Maschinelle Sprachverarbeitung: N-Gramm-Modelle
 HUMBOLD-UNIVERSIÄ ZU BERLIN Institut für Informatik Lehrstuhl Wissensmanagement Maschinelle Sprachverarbeitung: N-Gramm-Modelle obias Scheffer, Ulf Brefeld Statistische Sprachmodelle Welche Sätze sind
HUMBOLD-UNIVERSIÄ ZU BERLIN Institut für Informatik Lehrstuhl Wissensmanagement Maschinelle Sprachverarbeitung: N-Gramm-Modelle obias Scheffer, Ulf Brefeld Statistische Sprachmodelle Welche Sätze sind
NLP - Analyse des Wissensrohstoffs Text
 NLP - Analyse des Wissensrohstoffs Text Dr. Andreas Hotho Dominik Benz Beate Krause Sommersemester 2008 Folie: 1 Organisatorisches Vorlesung Beginn: 8. April 2008 Dienstag 10.15 h - 11.45 h, in Raum 1607
NLP - Analyse des Wissensrohstoffs Text Dr. Andreas Hotho Dominik Benz Beate Krause Sommersemester 2008 Folie: 1 Organisatorisches Vorlesung Beginn: 8. April 2008 Dienstag 10.15 h - 11.45 h, in Raum 1607
NLP - Analyse des Wissensrohstoffs Text
 NLP - Analyse des Wissensrohstoffs Text Vorlesung Beginn: 8. April 2008 Dienstag 10.15 h - 11.45 h, in Raum 1607 oder 0443 Übungen Dr. Andreas Hotho Dominik Benz Beate Krause Sommersemester 2008 Beginn:
NLP - Analyse des Wissensrohstoffs Text Vorlesung Beginn: 8. April 2008 Dienstag 10.15 h - 11.45 h, in Raum 1607 oder 0443 Übungen Dr. Andreas Hotho Dominik Benz Beate Krause Sommersemester 2008 Beginn:
Natürlichsprachliche Systeme I Materialien zur Vorlesung
 Natürlichsprachliche Systeme I Materialien zur Vorlesung D. Rösner Institut für Wissens- und Sprachverarbeitung Fakultät für Informatik Otto-von-Guericke Universität Magdeburg WS 2010/11, 19. Oktober 2010,
Natürlichsprachliche Systeme I Materialien zur Vorlesung D. Rösner Institut für Wissens- und Sprachverarbeitung Fakultät für Informatik Otto-von-Guericke Universität Magdeburg WS 2010/11, 19. Oktober 2010,
Der Viterbi-Algorithmus im Part-of-Speech Tagging
 Der Viterbi-Algorithmus im Part-of-Speech Tagging Kursfolien Karin Haenelt 1 Themen Zweck des Viterbi-Algorithmus Hidden Markov Model Formale Spezifikation Beispiel Arc Emission Model State Emission Model
Der Viterbi-Algorithmus im Part-of-Speech Tagging Kursfolien Karin Haenelt 1 Themen Zweck des Viterbi-Algorithmus Hidden Markov Model Formale Spezifikation Beispiel Arc Emission Model State Emission Model
Softwareprojektpraktikum Maschinelle Übersetzung
 Softwareprojektpraktikum Maschinelle Übersetzung Jan-Thorsten Peter, Andreas Guta, Jan Rosendahl max.bleu@i6.informatik.rwth-aachen.de 5. Mai 2017 Human Language Technology and Pattern Recognition Lehrstuhl
Softwareprojektpraktikum Maschinelle Übersetzung Jan-Thorsten Peter, Andreas Guta, Jan Rosendahl max.bleu@i6.informatik.rwth-aachen.de 5. Mai 2017 Human Language Technology and Pattern Recognition Lehrstuhl
Was ist Statistik? Wozu dienen statistische Methoden?
 25. APRIL 2002: BLATT 1 Übersicht Was ist Statistik? Wozu dienen statistische Methoden? Was ist maschinelle Sprachverarbeitung? Welche Rolle spielen statistische Methoden in verschiedenen Teilbereichen
25. APRIL 2002: BLATT 1 Übersicht Was ist Statistik? Wozu dienen statistische Methoden? Was ist maschinelle Sprachverarbeitung? Welche Rolle spielen statistische Methoden in verschiedenen Teilbereichen
Wortdekodierung. Vorlesungsunterlagen Speech Communication 2, SS Franz Pernkopf/Erhard Rank
 Wortdekodierung Vorlesungsunterlagen Speech Communication 2, SS 2004 Franz Pernkopf/Erhard Rank Institute of Signal Processing and Speech Communication University of Technology Graz Inffeldgasse 16c, 8010
Wortdekodierung Vorlesungsunterlagen Speech Communication 2, SS 2004 Franz Pernkopf/Erhard Rank Institute of Signal Processing and Speech Communication University of Technology Graz Inffeldgasse 16c, 8010
Kapitel 2: Spracherkennung Automatisches Verstehen gesprochener Sprache
 Automatisches Verstehen gesprochener Sprache. Spracherkennung Martin Hacker Bernd Ludwig Günther Görz Professur für Künstliche Intelligenz Department Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg
Automatisches Verstehen gesprochener Sprache. Spracherkennung Martin Hacker Bernd Ludwig Günther Görz Professur für Künstliche Intelligenz Department Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg
Hidden Markov Models (HMM)
") Hidden Markov Models (HMM) Kursfolien Karin Haenelt 1 Themen Definitionen Stochastischer Prozess Markow Kette (Visible) Markov Model Hidden Markov Model Aufgaben, die mit HMMs bearbeitet werden Algorithmen
Hidden Markov Models (HMM) Kursfolien Karin Haenelt 1 Themen Definitionen Stochastischer Prozess Markow Kette (Visible) Markov Model Hidden Markov Model Aufgaben, die mit HMMs bearbeitet werden Algorithmen
xii Inhaltsverzeichnis Generalisierung Typisierte Merkmalsstrukturen Literaturhinweis
 Inhaltsverzeichnis 1 Computerlinguistik Was ist das? 1 1.1 Aspekte der Computerlinguistik.................. 1 1.1.1 Computerlinguistik: Die Wissenschaft........... 2 1.1.2 Computerlinguistik und ihre Nachbardisziplinen.....
Inhaltsverzeichnis 1 Computerlinguistik Was ist das? 1 1.1 Aspekte der Computerlinguistik.................. 1 1.1.1 Computerlinguistik: Die Wissenschaft........... 2 1.1.2 Computerlinguistik und ihre Nachbardisziplinen.....
Rückblick. Aufteilung in Dokumente anwendungsabhängig. Tokenisierung und Normalisierung sprachabhängig
 3. IR-Modelle Rückblick Aufteilung in Dokumente anwendungsabhängig Tokenisierung und Normalisierung sprachabhängig Gesetz von Zipf sagt aus, dass einige Wörter sehr häufig vorkommen; Stoppwörter können
3. IR-Modelle Rückblick Aufteilung in Dokumente anwendungsabhängig Tokenisierung und Normalisierung sprachabhängig Gesetz von Zipf sagt aus, dass einige Wörter sehr häufig vorkommen; Stoppwörter können
Maschinelle Sprachverarbeitung: Part-of-Speech-Tagging
 HUMBOLDT-UNIVERSITÄT ZU BERLIN Institut für Informatik Lehrstuhl Wissensmanagement Maschinelle Sprachverarbeitung: Part-of-Speech-Tagging Tobias Scheffer Ulf Brefeld POS-Tagging Zuordnung der Wortart von
HUMBOLDT-UNIVERSITÄT ZU BERLIN Institut für Informatik Lehrstuhl Wissensmanagement Maschinelle Sprachverarbeitung: Part-of-Speech-Tagging Tobias Scheffer Ulf Brefeld POS-Tagging Zuordnung der Wortart von
Inhaltsverzeichnis. Bibliografische Informationen digitalisiert durch
 Inhaltsverzeichnis 1 Computerlinguistik - Was ist das? 1 1.1 Aspekte der Computerlinguistik 1 1.1.1 Computer linguistik: Die Wissenschaft 2 1.1.2 Computerlinguistik und ihre Nachbardisziplinen 3 1.1.3
Inhaltsverzeichnis 1 Computerlinguistik - Was ist das? 1 1.1 Aspekte der Computerlinguistik 1 1.1.1 Computer linguistik: Die Wissenschaft 2 1.1.2 Computerlinguistik und ihre Nachbardisziplinen 3 1.1.3
! Die Idee Kombination von Informatik und einem anderen Fach
 Computerlinguistik Integriertes Anwendungsfach im B.Sc.Studiengang Department Informatik / Universität Hamburg! Wie funktioniert das integrierte Anwendungsfach Computerlinguistik (organisatorisch)?! Beziehungen
Computerlinguistik Integriertes Anwendungsfach im B.Sc.Studiengang Department Informatik / Universität Hamburg! Wie funktioniert das integrierte Anwendungsfach Computerlinguistik (organisatorisch)?! Beziehungen
Projektgruppe. Text Labeling mit Sequenzmodellen
 Projektgruppe Enes Yigitbas Text Labeling mit Sequenzmodellen 4. Juni 2010 Motivation Möglichkeit der effizienten Verarbeitung von riesigen Datenmengen In vielen Bereichen erwünschte automatisierte Aufgabe:
Projektgruppe Enes Yigitbas Text Labeling mit Sequenzmodellen 4. Juni 2010 Motivation Möglichkeit der effizienten Verarbeitung von riesigen Datenmengen In vielen Bereichen erwünschte automatisierte Aufgabe:
Elementare Begriffe der Wahrscheinlichkeitstheorie für die Sprachverarbeitung
 Elementare Begriffe der Wahrscheinlichkeitstheorie für die Sprachverarbeitung Kursfolien Karin Haenelt 1 Übersicht Wahrscheinlichkeitsfunktion P Wahrscheinlichkeit und bedingte Wahrscheinlichkeit Bayes-Formeln
Elementare Begriffe der Wahrscheinlichkeitstheorie für die Sprachverarbeitung Kursfolien Karin Haenelt 1 Übersicht Wahrscheinlichkeitsfunktion P Wahrscheinlichkeit und bedingte Wahrscheinlichkeit Bayes-Formeln
Anwendungen der KI / SoSe 2018
 Anwendungen der KI / SoSe 2018 Organisatorisches Prof. Dr. Adrian Ulges Angewandte Informatik / Medieninformatik / Wirtschaftsinformatik / ITS Fachbereich DSCM Hochschule RheinMain KursWebsite: www.ulges.de
Anwendungen der KI / SoSe 2018 Organisatorisches Prof. Dr. Adrian Ulges Angewandte Informatik / Medieninformatik / Wirtschaftsinformatik / ITS Fachbereich DSCM Hochschule RheinMain KursWebsite: www.ulges.de
INTELLIGENTE DATENANALYSE IN MATLAB. Einführungsveranstaltung
 INTELLIGENTE DATENANALYSE IN MATLAB Einführungsveranstaltung Überblick Organisation. Literatur. Inhalt und Ziele der Vorlesung. Beispiele aus der Praxis. 2 Organisation Vorlesung/Übung + Projektarbeit.
INTELLIGENTE DATENANALYSE IN MATLAB Einführungsveranstaltung Überblick Organisation. Literatur. Inhalt und Ziele der Vorlesung. Beispiele aus der Praxis. 2 Organisation Vorlesung/Übung + Projektarbeit.
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. NLP-Pipeline. Tobias Scheffer Paul Prasse Michael Großhans
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen NLP-Pipeline Tobias Scheffer Paul Prasse Michael Großhans NLP- (Natural Language Processing-) Pipeline Folge von Verarbeitungsschritten
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen NLP-Pipeline Tobias Scheffer Paul Prasse Michael Großhans NLP- (Natural Language Processing-) Pipeline Folge von Verarbeitungsschritten
Part-Of-Speech-Tagging mit Viterbi Algorithmus
 Part-Of-Speech-Tagging mit Viterbi Algorithmus HS Endliche Automaten Inna Nickel, Julia Konstantinova 19.07.2010 1 / 21 Gliederung 1 Motivation 2 Theoretische Grundlagen Hidden Markov Model Viterbi Algorithmus
Part-Of-Speech-Tagging mit Viterbi Algorithmus HS Endliche Automaten Inna Nickel, Julia Konstantinova 19.07.2010 1 / 21 Gliederung 1 Motivation 2 Theoretische Grundlagen Hidden Markov Model Viterbi Algorithmus
Rückblick. Aufteilung in Dokumente anwendungsabhängig. Tokenisierung und Normalisierung sprachabhängig
 3. IR-Modelle Rückblick Aufteilung in Dokumente anwendungsabhängig Tokenisierung und Normalisierung sprachabhängig Gesetz von Zipf sagt aus, dass einige Wörter sehr häufig vorkommen; Stoppwörter können
3. IR-Modelle Rückblick Aufteilung in Dokumente anwendungsabhängig Tokenisierung und Normalisierung sprachabhängig Gesetz von Zipf sagt aus, dass einige Wörter sehr häufig vorkommen; Stoppwörter können
Einführung in die maschinelle Sprachverarbeitung
 Einführung in die maschinelle Sprachverarbeitung Michaela Geierhos CIS Centrum für Informations- und Sprachverarbeitung Ludwig-Maximilians-Universität München 17. April 2007 17.04.2007 Statistische Methoden
Einführung in die maschinelle Sprachverarbeitung Michaela Geierhos CIS Centrum für Informations- und Sprachverarbeitung Ludwig-Maximilians-Universität München 17. April 2007 17.04.2007 Statistische Methoden
Tagging mit Hidden Markov Models und Viterbi-Algorithmus
 Tagging mit Hidden Markov Models und Viterbi-Algorithmus Annelen Brunner, Stephanie Schuldes, Nicola Kaiser, Olga Mordvinova HS Parsing SoSe 2003 PD Dr. Karin Haenelt Inhalt Ziel des Seminarprojekts Theorie:
Tagging mit Hidden Markov Models und Viterbi-Algorithmus Annelen Brunner, Stephanie Schuldes, Nicola Kaiser, Olga Mordvinova HS Parsing SoSe 2003 PD Dr. Karin Haenelt Inhalt Ziel des Seminarprojekts Theorie:
Friedrich-Alexander-Universität Professur für Computerlinguistik. Nguyen Ai Huong
 Part-of-Speech Tagging Friedrich-Alexander-Universität Professur für Computerlinguistik Nguyen Ai Huong 15.12.2011 Part-of-speech tagging Bestimmung von Wortform (part of speech) für jedes Wort in einem
Part-of-Speech Tagging Friedrich-Alexander-Universität Professur für Computerlinguistik Nguyen Ai Huong 15.12.2011 Part-of-speech tagging Bestimmung von Wortform (part of speech) für jedes Wort in einem
Der VITERBI-Algorithmus
 Der VITERBI-Algorithmus Hauptseminar Parsing Sommersemester 2002 Lehrstuhl für Computerlinguistik Universität Heidelberg Thorsten Beinhorn http://janus.cl.uni-heidelberg.de/~beinhorn 2 Inhalt Ziel des
Der VITERBI-Algorithmus Hauptseminar Parsing Sommersemester 2002 Lehrstuhl für Computerlinguistik Universität Heidelberg Thorsten Beinhorn http://janus.cl.uni-heidelberg.de/~beinhorn 2 Inhalt Ziel des
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. NLP-Pipeline. Tobias Scheffer Peter Haider Paul Prasse
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen NLP-Pipeline Tobias Scheffer Peter Haider Paul Prasse NLP-Pipeline Folge von Verarbeitungsschritten für Informationsextraktion,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen NLP-Pipeline Tobias Scheffer Peter Haider Paul Prasse NLP-Pipeline Folge von Verarbeitungsschritten für Informationsextraktion,
Einführung in die Computerlinguistik
 Einführung in die Computerlinguistik Neuronale Netze WS 2014/2015 Vera Demberg Neuronale Netze Was ist das? Einer der größten Fortschritte in der Sprachverarbeitung und Bildverarbeitung der letzten Jahre:
Einführung in die Computerlinguistik Neuronale Netze WS 2014/2015 Vera Demberg Neuronale Netze Was ist das? Einer der größten Fortschritte in der Sprachverarbeitung und Bildverarbeitung der letzten Jahre:
Einführung in die maschinelle Sprachverarbeitung
 Einführung in die maschinelle Sprachverarbeitung Michaela Geierhos CIS Centrum für Informations- und Sprachverarbeitung Ludwig-Maximilians-Universität München 17. April 2007 17.04.2007 Statistische Methoden
Einführung in die maschinelle Sprachverarbeitung Michaela Geierhos CIS Centrum für Informations- und Sprachverarbeitung Ludwig-Maximilians-Universität München 17. April 2007 17.04.2007 Statistische Methoden
Grundlagen und Definitionen
 Grundlagen und Definitionen Wissensmanagement VO 340088 Bartholomäus Wloka https://www.adaptemy.com Maschinelle Sprachverarbeitung Breites Spektrum an Methoden der Computerverarbeitung von Sprache. Kann
Grundlagen und Definitionen Wissensmanagement VO 340088 Bartholomäus Wloka https://www.adaptemy.com Maschinelle Sprachverarbeitung Breites Spektrum an Methoden der Computerverarbeitung von Sprache. Kann
Einführung in die Computerlinguistik
 Einführung in die Computerlinguistik Statistische Grundlagen Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 21 Diskrete Wahrscheinlichkeitsräume (1) Carstensen et al. (2010), Abschnitt
Einführung in die Computerlinguistik Statistische Grundlagen Laura Kallmeyer Heinrich-Heine-Universität Düsseldorf Summer 2016 1 / 21 Diskrete Wahrscheinlichkeitsräume (1) Carstensen et al. (2010), Abschnitt
Latente Dirichlet-Allokation
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Latente Dirichlet-Allokation Tobias Scheffer Peter Haider Paul Prasse Themenmodellierung Themenmodellierung (Topic modeling) liefert
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Latente Dirichlet-Allokation Tobias Scheffer Peter Haider Paul Prasse Themenmodellierung Themenmodellierung (Topic modeling) liefert
Text-Mining: Klassifikation I - Naive Bayes vs. Rocchio
 Text-Mining: Klassifikation I - Naive Bayes vs. Rocchio Claes Neuefeind Fabian Steeg 17. Juni 2010 Klassifikation im Text-Mining Klassifikation Textkategorisierung Naive Bayes Beispielrechnung Rocchio
Text-Mining: Klassifikation I - Naive Bayes vs. Rocchio Claes Neuefeind Fabian Steeg 17. Juni 2010 Klassifikation im Text-Mining Klassifikation Textkategorisierung Naive Bayes Beispielrechnung Rocchio
Vorlesung Modellierung nebenläufiger Systeme Sommersemester 2014 Universität Duisburg-Essen
 Vorlesung Modellierung nebenläufiger Systeme Sommersemester 2014 Universität Duisburg-Essen Barbara König Übungsleitung: Sebastian Küpper Barbara König Vorlesung Modellierung nebenläufiger Systeme 1 Das
Vorlesung Modellierung nebenläufiger Systeme Sommersemester 2014 Universität Duisburg-Essen Barbara König Übungsleitung: Sebastian Küpper Barbara König Vorlesung Modellierung nebenläufiger Systeme 1 Das
Indexieren und Suchen
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Indexieren und Suchen Tobias Scheffer Index-Datenstrukturen, Suchalgorithmen Invertierte Indizes Suffix-Bäume und -Arrays Signaturdateien
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Indexieren und Suchen Tobias Scheffer Index-Datenstrukturen, Suchalgorithmen Invertierte Indizes Suffix-Bäume und -Arrays Signaturdateien
INTELLIGENTE DATENANALYSE IN MATLAB
 INTELLIGENTE DATENANALYSE IN MATLAB Einführungsveranstaltung Überblick Organisation Literatur Inhalt und Ziele der Vorlesung Beispiele aus der Praxis 2 Organisation Vorlesung/Übung + Projektarbeit. 4 Semesterwochenstunden.
INTELLIGENTE DATENANALYSE IN MATLAB Einführungsveranstaltung Überblick Organisation Literatur Inhalt und Ziele der Vorlesung Beispiele aus der Praxis 2 Organisation Vorlesung/Übung + Projektarbeit. 4 Semesterwochenstunden.
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. NLP-Pipeline. Tobias Scheffer Peter Haider Uwe Dick Paul Prasse
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen NLP-Pipeline Tobias Scheffer Peter Haider Uwe Dick Paul Prasse NLP-Pipeline Folge von Verarbeitungsschritten für Informationsextraktion,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen NLP-Pipeline Tobias Scheffer Peter Haider Uwe Dick Paul Prasse NLP-Pipeline Folge von Verarbeitungsschritten für Informationsextraktion,
Boole sches Retrieval als frühes, aber immer noch verbreitetes IR-Modell mit zahlreichen Erweiterungen
 Rückblick Boole sches Retrieval als frühes, aber immer noch verbreitetes IR-Modell mit zahlreichen Erweiterungen Vektorraummodell stellt Anfrage und Dokumente als Vektoren in gemeinsamen Vektorraum dar
Rückblick Boole sches Retrieval als frühes, aber immer noch verbreitetes IR-Modell mit zahlreichen Erweiterungen Vektorraummodell stellt Anfrage und Dokumente als Vektoren in gemeinsamen Vektorraum dar
Einführung in die Computerlinguistik Überblick
 Einführung in die Computerlinguistik Überblick Hinrich Schütze & Robert Zangenfeind Centrum für Informations- und Sprachverarbeitung, LMU München 2015-10-12 Schütze & Zangenfeind: Überblick 1 / 19 Was
Einführung in die Computerlinguistik Überblick Hinrich Schütze & Robert Zangenfeind Centrum für Informations- und Sprachverarbeitung, LMU München 2015-10-12 Schütze & Zangenfeind: Überblick 1 / 19 Was
Statistische Sprachmodelle
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Statistische Sprachmodelle obias Scheffer Paul Prasse Michael Großhans Uwe Dick Statistische Sprachmodelle Welche Sätze sind Elemente
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Statistische Sprachmodelle obias Scheffer Paul Prasse Michael Großhans Uwe Dick Statistische Sprachmodelle Welche Sätze sind Elemente
Statistische Verfahren in der Computerlinguistik
 Statistische Verfahren in der Computerlinguistik Zweiter Teil Einführung in die Computerlinguistik Sommersemester 2009 Übersicht Statistische vs. symbolische Verfahren in der CL Statistik beschreibende
Statistische Verfahren in der Computerlinguistik Zweiter Teil Einführung in die Computerlinguistik Sommersemester 2009 Übersicht Statistische vs. symbolische Verfahren in der CL Statistik beschreibende
Mathematisch-algorithmische Grundlagen für Big Data
 Mathematisch-algorithmische Grundlagen für Big Data Numerische Algorithmen für Datenanalyse und Optimierung Prof. Dr. Peter Becker Fachbereich Informatik Hochschule Bonn-Rhein-Sieg Sommersemester 2017
Mathematisch-algorithmische Grundlagen für Big Data Numerische Algorithmen für Datenanalyse und Optimierung Prof. Dr. Peter Becker Fachbereich Informatik Hochschule Bonn-Rhein-Sieg Sommersemester 2017
Named Entity Recognition (NER)
") Named Entity Recognition (NER) Katharina Stein 01/12/2017 Named Entity Recognition 1 Inhalt Named Entity Recognition Was ist Named Entity Recognition? Bedeutung für Natural Language Processing Herausforderungen
Named Entity Recognition (NER) Katharina Stein 01/12/2017 Named Entity Recognition 1 Inhalt Named Entity Recognition Was ist Named Entity Recognition? Bedeutung für Natural Language Processing Herausforderungen
Studienfach Linguistische Informatik. 1 Modulbezeichnung Grundlagen der Computerlinguistik I 7,5 ECTS
 1 Modulbezeichnung Grundlagen der Computerlinguistik I 7,5 ECTS 2 Lehrveranstaltungen VL Grundlagen der Computerlinguistik 1 (2 SWS) UE Grundlagen der Computerlinguistik 1 (2 SWS) UE Arbeitstechniken der
1 Modulbezeichnung Grundlagen der Computerlinguistik I 7,5 ECTS 2 Lehrveranstaltungen VL Grundlagen der Computerlinguistik 1 (2 SWS) UE Grundlagen der Computerlinguistik 1 (2 SWS) UE Arbeitstechniken der
LI07: Hidden Markov Modelle und Part-of-Speech Tagging
 LI07: Hidden Markov Modelle und Part-of-Speech Tagging sumalvico@informatik.uni-leipzig.de 18. Mai 2017 Wiederholung: Statistisches Sprachmodell Ein statistisches Sprachmodell besteht allgemein aus: einer
LI07: Hidden Markov Modelle und Part-of-Speech Tagging sumalvico@informatik.uni-leipzig.de 18. Mai 2017 Wiederholung: Statistisches Sprachmodell Ein statistisches Sprachmodell besteht allgemein aus: einer
12. Vorlesung. Statistische Sprachmodelle für Information Retrieval
 12. Vorlesung Statistische Sprachmodelle für Information Retrieval Allgemeiner Ansatz Unigram Modell Beziehung zum Vektorraummodell mit TF-IDF Gewichten Statistische Spachmodelle zur Glättung Idee von
12. Vorlesung Statistische Sprachmodelle für Information Retrieval Allgemeiner Ansatz Unigram Modell Beziehung zum Vektorraummodell mit TF-IDF Gewichten Statistische Spachmodelle zur Glättung Idee von
Part-of-Speech Tagging. Stephanie Schuldes
 Part-of-Speech Tagging Stephanie Schuldes 05.06.2003 PS Erschließen von großen Textmengen Geißler/Holler SoSe 2003 Motivation Ziel: vollständiges Parsing und Verstehen natürlicher Sprache Herantasten durch
Part-of-Speech Tagging Stephanie Schuldes 05.06.2003 PS Erschließen von großen Textmengen Geißler/Holler SoSe 2003 Motivation Ziel: vollständiges Parsing und Verstehen natürlicher Sprache Herantasten durch
Vorlesung Formale Aspekte der Software-Sicherheit und Kryptographie Sommersemester 2015 Universität Duisburg-Essen
 Vorlesung Formale Aspekte der Software-Sicherheit und Kryptographie Sommersemester 2015 Universität Duisburg-Essen Prof. Barbara König Übungsleitung: Sebastian Küpper Barbara König Form. Asp. der Software-Sicherheit
Vorlesung Formale Aspekte der Software-Sicherheit und Kryptographie Sommersemester 2015 Universität Duisburg-Essen Prof. Barbara König Übungsleitung: Sebastian Küpper Barbara König Form. Asp. der Software-Sicherheit
Hidden Markov Models in Anwendungen
 Hidden Markov Models in Anwendungen Prof Dr. Matthew Crocker Universität des Saarlandes 18. Juni 2015 Matthew Crocker (UdS) HMM Anwendungen 18. Juni 2015 1 / 26 Hidden Markov Modelle in der Computerlinguistik
Hidden Markov Models in Anwendungen Prof Dr. Matthew Crocker Universität des Saarlandes 18. Juni 2015 Matthew Crocker (UdS) HMM Anwendungen 18. Juni 2015 1 / 26 Hidden Markov Modelle in der Computerlinguistik
Formale Systeme. Prof. P.H. Schmitt. Winter 2007/2008. Fakultät für Informatik Universität Karlsruhe (TH) Voraussetzungen
 Voraussetzungen") Formale Systeme Prof. P.H. Schmitt Fakultät für Informatik Universität Karlsruhe (TH) Winter 2007/2008 Prof. P.H. Schmitt Formale Systeme Winter 2007/2008 1 / 12 Übungen und Tutorien Es gibt wöchentliche
Formale Systeme Prof. P.H. Schmitt Fakultät für Informatik Universität Karlsruhe (TH) Winter 2007/2008 Prof. P.H. Schmitt Formale Systeme Winter 2007/2008 1 / 12 Übungen und Tutorien Es gibt wöchentliche
Institut für Informatik Lehrstuhl Maschinelles Lernen
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen NLP-PipelinePipeline Tobias Scheffer Peter Haider Uwe Dick Paul Prasse NLP-Pipeline Folge von Verarbeitungsschritten für Informationsextraktion,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen NLP-PipelinePipeline Tobias Scheffer Peter Haider Uwe Dick Paul Prasse NLP-Pipeline Folge von Verarbeitungsschritten für Informationsextraktion,
Anhang III: Modulhandbuch
 Anhang III: Modulhandbuch Das Modulhandbuch wird gemäß 1 Abs. (1) der Satzung der Technischen Universität Darmstadt zur Regelung der Bekanntmachung von Satzungen der Technischen Universität Darmstadt vom
Anhang III: Modulhandbuch Das Modulhandbuch wird gemäß 1 Abs. (1) der Satzung der Technischen Universität Darmstadt zur Regelung der Bekanntmachung von Satzungen der Technischen Universität Darmstadt vom
LDA-based Document Model for Adhoc-Retrieval
 Martin Luther Universität Halle-Wittenberg 30. März 2007 Inhaltsverzeichnis 1 2 plsi Clusterbasiertes Retrieval 3 Latent Dirichlet Allocation LDA-basiertes Retrieval Komplexität 4 Feineinstellung Parameter
Martin Luther Universität Halle-Wittenberg 30. März 2007 Inhaltsverzeichnis 1 2 plsi Clusterbasiertes Retrieval 3 Latent Dirichlet Allocation LDA-basiertes Retrieval Komplexität 4 Feineinstellung Parameter
NLP Eigenschaften von Text
 NLP Eigenschaften von Text Dr. Andreas Hotho Dominik Benz Beate Krause Sommersemester 2008 Folie: 1 Übersicht Einführung Eigenschaften von Text Words I: Satzgrenzenerkennung, Tokenization, Kollokationen
NLP Eigenschaften von Text Dr. Andreas Hotho Dominik Benz Beate Krause Sommersemester 2008 Folie: 1 Übersicht Einführung Eigenschaften von Text Words I: Satzgrenzenerkennung, Tokenization, Kollokationen
Probabilistic Ranking Principle besagt, dass Rangfolge gemäß dieser Wahrscheinlichkeiten optimal ist
 Rückblick Probabilistisches IR bestimmt die Wahrscheinlichkeit, dass ein Dokument d zur Anfrage q relevant ist Probabilistic Ranking Principle besagt, dass Rangfolge gemäß dieser Wahrscheinlichkeiten optimal
Rückblick Probabilistisches IR bestimmt die Wahrscheinlichkeit, dass ein Dokument d zur Anfrage q relevant ist Probabilistic Ranking Principle besagt, dass Rangfolge gemäß dieser Wahrscheinlichkeiten optimal
Datenbanken & Informationssysteme (WS 2016/2017)
") Datenbanken & Informationssysteme (WS 2016/2017) Klaus Berberich (klaus.berberich@htwsaar.de) Wolfgang Braun (wolfgang.braun@htwsaar.de) 0. Organisatorisches Dozenten Klaus Berberich (klaus.berberich@htwsaar.de)
Datenbanken & Informationssysteme (WS 2016/2017) Klaus Berberich (klaus.berberich@htwsaar.de) Wolfgang Braun (wolfgang.braun@htwsaar.de) 0. Organisatorisches Dozenten Klaus Berberich (klaus.berberich@htwsaar.de)
Grundlagen der Programmiersprachen
 GPS-0-1 Grundlagen der Programmiersprachen Prof. Dr. Uwe Kastens Sommersemester 2016 Vorlesung Grundlagen der Programmiersprachen SS 2016 / Folie 001 Anfang Begrüßung Ziele GPS-0-2 Die Vorlesung soll Studierende
GPS-0-1 Grundlagen der Programmiersprachen Prof. Dr. Uwe Kastens Sommersemester 2016 Vorlesung Grundlagen der Programmiersprachen SS 2016 / Folie 001 Anfang Begrüßung Ziele GPS-0-2 Die Vorlesung soll Studierende
Die Geschichte der Sprachverarbeitung ist eine Geschichte voller Mißverständnisse WS 2011/2012
 Die Geschichte der Sprachverarbeitung ist eine Geschichte voller Mißverständnisse WS 2011/2012 Christian Kölbl Universität Augsburg, Lehrprofessur für Informatik 25. Oktober 2011 HAL 9000 - Zukunftsmusik
Die Geschichte der Sprachverarbeitung ist eine Geschichte voller Mißverständnisse WS 2011/2012 Christian Kölbl Universität Augsburg, Lehrprofessur für Informatik 25. Oktober 2011 HAL 9000 - Zukunftsmusik
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Sprachportale Tobias Scheffer Motivation Es gibt, grob geschätzt: 1.15 Md Mrd. 15Mrd 1.5 Mrd. 668 Mio. Die wenigsten Computer verfügen
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Sprachportale Tobias Scheffer Motivation Es gibt, grob geschätzt: 1.15 Md Mrd. 15Mrd 1.5 Mrd. 668 Mio. Die wenigsten Computer verfügen
Informatikgrundlagen (WS 2016/2017)
") Informatikgrundlagen (WS 2016/2017) Klaus Berberich (klaus.berberich@htwsaar.de) Wolfgang Braun (wolfgang.braun@htwsaar.de) 0. Organisatorisches Dozenten Klaus Berberich (klaus.berberich@htwsaar.de) Sprechstunde
Informatikgrundlagen (WS 2016/2017) Klaus Berberich (klaus.berberich@htwsaar.de) Wolfgang Braun (wolfgang.braun@htwsaar.de) 0. Organisatorisches Dozenten Klaus Berberich (klaus.berberich@htwsaar.de) Sprechstunde
Einführung in die Computerlinguistik Statistische Grundlagen
 Diskrete Wahrscheinlichkeitsräume (1) Einführung in die Computerlinguistik Statistische Grundlagen Laura Heinrich-Heine-Universität Düsseldorf Wintersemester 2011/2012 In vielen Bereichen der CL kommt
Diskrete Wahrscheinlichkeitsräume (1) Einführung in die Computerlinguistik Statistische Grundlagen Laura Heinrich-Heine-Universität Düsseldorf Wintersemester 2011/2012 In vielen Bereichen der CL kommt
Text-Mining: Einführung
 Text-Mining: Einführung Claes Neuefeind Fabian Steeg 22. April 2010 Organisatorisches Was ist Text-Mining? Definitionen Anwendungsbeispiele Textuelle Daten Aufgaben u. Teilbereiche Literatur Kontakt Sprechstunde:
Text-Mining: Einführung Claes Neuefeind Fabian Steeg 22. April 2010 Organisatorisches Was ist Text-Mining? Definitionen Anwendungsbeispiele Textuelle Daten Aufgaben u. Teilbereiche Literatur Kontakt Sprechstunde:
Randomisierte Algorithmen
 Randomisierte Algorithmen Randomisierte Algorithmen 1. Einleitung Thomas Worsch Fakultät für Informatik Karlsruher Institut für Technologie Wintersemester 2018/2019 1 / 21 Organisatorisches Überblick Organisatorisches
Randomisierte Algorithmen Randomisierte Algorithmen 1. Einleitung Thomas Worsch Fakultät für Informatik Karlsruher Institut für Technologie Wintersemester 2018/2019 1 / 21 Organisatorisches Überblick Organisatorisches
Vorlesung Künstliche Intelligenz Wintersemester 2009/10
 Vorlesung Künstliche Intelligenz Wintersemester 2009/10 Prof. Dr. Gerd Stumme Dipl.-Inform. Björn-Elmar Macek Vorlesung Dienstag, 10:15 11:45 Uhr, Raum 0443 Beginn: 20.10.2009 Vorlesung Mittwoch 14:00
Vorlesung Künstliche Intelligenz Wintersemester 2009/10 Prof. Dr. Gerd Stumme Dipl.-Inform. Björn-Elmar Macek Vorlesung Dienstag, 10:15 11:45 Uhr, Raum 0443 Beginn: 20.10.2009 Vorlesung Mittwoch 14:00
Grundlagen der Künstlichen Intelligenz
 KI Wintersemester 2013/2014 Grundlagen der Künstlichen Intelligenz Marc Toussaint Machine Learning & Robotics Lab Universität Stuttgart marc.toussaint@informatik.uni-stuttgart.de http://ipvs.informatik.uni-stuttgart.de/mlr/marc/
KI Wintersemester 2013/2014 Grundlagen der Künstlichen Intelligenz Marc Toussaint Machine Learning & Robotics Lab Universität Stuttgart marc.toussaint@informatik.uni-stuttgart.de http://ipvs.informatik.uni-stuttgart.de/mlr/marc/
1/19. Kern-Methoden zur Extraktion von Informationen. Sebastian Marius Kirsch Back Close
 1/19 Kern-Methoden zur Extraktion von Informationen Sebastian Marius Kirsch skirsch@moebius.inka.de 2/19 Gliederung 1. Verfahren zur Extraktion von Informationen 2. Extraktion von Beziehungen 3. Maschinelles
1/19 Kern-Methoden zur Extraktion von Informationen Sebastian Marius Kirsch skirsch@moebius.inka.de 2/19 Gliederung 1. Verfahren zur Extraktion von Informationen 2. Extraktion von Beziehungen 3. Maschinelles
Verteilte Betriebssysteme
 Vorlesung Wintersemester 2003/2004 [CS 6930] 1 Einleitung 1 1 Dozent Prof. Dr.-Ing. Franz J. Hauck bteilung Verteilte Systeme (Prof. Dr. P. Schulthess) E-mail: hauck@informatik.uni-ulm.de Sprechstunde:
Vorlesung Wintersemester 2003/2004 [CS 6930] 1 Einleitung 1 1 Dozent Prof. Dr.-Ing. Franz J. Hauck bteilung Verteilte Systeme (Prof. Dr. P. Schulthess) E-mail: hauck@informatik.uni-ulm.de Sprechstunde:
Lehrstuhl für Mustererkennung
 Lehrstuhl für Mustererkennung Wintersemester 2017/18 Prof. Dr.-Ing. Andreas Maier 21.10.2017 Lehrstuhl für Informatik 5 (Mustererkennung) Friedrich-Alexander-Universität Erlangen-Nürnberg Lehrstuhl für
Lehrstuhl für Mustererkennung Wintersemester 2017/18 Prof. Dr.-Ing. Andreas Maier 21.10.2017 Lehrstuhl für Informatik 5 (Mustererkennung) Friedrich-Alexander-Universität Erlangen-Nürnberg Lehrstuhl für
Grundbegriffe der Wahrscheinlichkeitstheorie. Karin Haenelt
 Grundbegriffe der Wahrscheinlichkeitstheorie Karin Haenelt 1 Inhalt Wahrscheinlichkeitsraum Bedingte Wahrscheinlichkeit Abhängige und unabhängige Ereignisse Stochastischer Prozess Markow-Kette 2 Wahrscheinlichkeitsraum
Grundbegriffe der Wahrscheinlichkeitstheorie Karin Haenelt 1 Inhalt Wahrscheinlichkeitsraum Bedingte Wahrscheinlichkeit Abhängige und unabhängige Ereignisse Stochastischer Prozess Markow-Kette 2 Wahrscheinlichkeitsraum
Maschinelle Sprachverarbeitung: Probabilistische, kontextfreie Grammatiken
 HUMBOLDT-UNIVERSITÄT ZU BERLIN Institut für Informatik Lehrstuhl Wissensmanagement Maschinelle Sprachverarbeitung: Probabilistische, kontextfreie Grammatiken Tobias Scheffer Ulf Brefeld Sprachmodelle N-Gramm-Modell:
HUMBOLDT-UNIVERSITÄT ZU BERLIN Institut für Informatik Lehrstuhl Wissensmanagement Maschinelle Sprachverarbeitung: Probabilistische, kontextfreie Grammatiken Tobias Scheffer Ulf Brefeld Sprachmodelle N-Gramm-Modell:
Spracherkennung. Gliederung:
 Spracherkennung Gliederung: - Einführung - Geschichte - Spracherkennung - Einteilungen - Aufbau und Funktion - Hidden Markov Modelle (HMM) - HMM bei der Spracherkennung - Probleme - Einsatzgebiete und
Spracherkennung Gliederung: - Einführung - Geschichte - Spracherkennung - Einteilungen - Aufbau und Funktion - Hidden Markov Modelle (HMM) - HMM bei der Spracherkennung - Probleme - Einsatzgebiete und
Natural Language Processing
 Natural Language Processing Kapitel 1: Einführung Prof. Dr. Johannes Maucher HdM MIB Version 1.7 13.10.2017 Prof. Dr. Johannes Maucher (HdM MIB) NLP Kapitel 1: Einführung Version 1.7 13.10.2017 1 / 30
Natural Language Processing Kapitel 1: Einführung Prof. Dr. Johannes Maucher HdM MIB Version 1.7 13.10.2017 Prof. Dr. Johannes Maucher (HdM MIB) NLP Kapitel 1: Einführung Version 1.7 13.10.2017 1 / 30
Einführung in das Natural Language Toolkit
 Einführung in das Natural Language Toolkit Markus Ackermann Abteilung für Automatische Sprachverarbeitung (Universität Leipzig) 11. Mai 2011 Kurzeinführung nützliche
Einführung in das Natural Language Toolkit Markus Ackermann Abteilung für Automatische Sprachverarbeitung (Universität Leipzig) 11. Mai 2011 Kurzeinführung nützliche
Hidden Markov Models in Anwendungen
 Hidden Markov Models in Anwendungen Dr. Vera Demberg Universität des Saarlandes 31. Mai 2012 Vera Demberg (UdS) HMM Anwendungen 31. Mai 2012 1 / 26 Hidden Markov Modelle in der Computerlinguistik Table
Hidden Markov Models in Anwendungen Dr. Vera Demberg Universität des Saarlandes 31. Mai 2012 Vera Demberg (UdS) HMM Anwendungen 31. Mai 2012 1 / 26 Hidden Markov Modelle in der Computerlinguistik Table
Information Retrieval. Peter Kolb
 Information Retrieval Peter Kolb Semesterplan Einführung Boolesches Retrievalmodell Volltextsuche, invertierter Index Boolesche Logik und Mengen Vektorraummodell Evaluation im IR Term- und Dokumentrepräsentation
Information Retrieval Peter Kolb Semesterplan Einführung Boolesches Retrievalmodell Volltextsuche, invertierter Index Boolesche Logik und Mengen Vektorraummodell Evaluation im IR Term- und Dokumentrepräsentation
Inhalt. 6.1 Motivation. 6.2 Klassifikation. 6.3 Clusteranalyse. 6.4 Asszoziationsanalyse. Datenbanken & Informationssysteme / Kapitel 6: Data Mining
 6. Data Mining Inhalt 6.1 Motivation 6.2 Klassifikation 6.3 Clusteranalyse 6.4 Asszoziationsanalyse 2 6.1 Motivation Data Mining and Knowledge Discovery zielt darauf ab, verwertbare Erkenntnisse (actionable
6. Data Mining Inhalt 6.1 Motivation 6.2 Klassifikation 6.3 Clusteranalyse 6.4 Asszoziationsanalyse 2 6.1 Motivation Data Mining and Knowledge Discovery zielt darauf ab, verwertbare Erkenntnisse (actionable
Hidden Markov Model (HMM)
") Hidden Markov Model (HMM) Kapitel 1 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität Leipzig
Hidden Markov Model (HMM) Kapitel 1 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität Leipzig
Einführung in die Computerlinguistik Vorbesprechung
 Einführung in die Computerlinguistik Vorbesprechung Dozentin: Wiebke Petersen Wiebke Petersen Einführung CL (Vorbesprechung) 1 Willkommen in Ihrer vermutlich ersten CL-Veranstaltung Titel: Einführung in
Einführung in die Computerlinguistik Vorbesprechung Dozentin: Wiebke Petersen Wiebke Petersen Einführung CL (Vorbesprechung) 1 Willkommen in Ihrer vermutlich ersten CL-Veranstaltung Titel: Einführung in
Algorithmen und Datenstrukturen in der Bioinformatik
 Algorithmen und Datenstrukturen in der Bioinformatik Vorlesung von Dr. Gunnar Klau Wintersemester 2005/2006, FU Berlin gunnar@math.fu-berlin.de http://www.math.fu-berlin.de/~gunnar 1 Aus dem Vorlesungsverzeichnis:
Algorithmen und Datenstrukturen in der Bioinformatik Vorlesung von Dr. Gunnar Klau Wintersemester 2005/2006, FU Berlin gunnar@math.fu-berlin.de http://www.math.fu-berlin.de/~gunnar 1 Aus dem Vorlesungsverzeichnis:
Elementare Wahrscheinlichkeitslehre
 Elementare Wahrscheinlichkeitslehre Vorlesung Computerlinguistische Techniken Alexander Koller 13. November 2015 CL-Techniken: Ziele Ziel 1: Wie kann man die Struktur sprachlicher Ausdrücke berechnen?
Elementare Wahrscheinlichkeitslehre Vorlesung Computerlinguistische Techniken Alexander Koller 13. November 2015 CL-Techniken: Ziele Ziel 1: Wie kann man die Struktur sprachlicher Ausdrücke berechnen?
Übersicht über 1. Vorlesungsabschnitt Form und Darstellung von Informationen
 Einführung in die Informatik für Hörer aller Fakultäten Prof. Jürgen Wolff von Gudenberg (JWG) Prof. Frank Puppe (FP) Prof. Dietmar Seipel (DS) Vorlesung (Mo & Mi 13:30-15:00 im Zuse-Hörsaal): FP: Form
Einführung in die Informatik für Hörer aller Fakultäten Prof. Jürgen Wolff von Gudenberg (JWG) Prof. Frank Puppe (FP) Prof. Dietmar Seipel (DS) Vorlesung (Mo & Mi 13:30-15:00 im Zuse-Hörsaal): FP: Form
Parsing mit NLTK. Parsing mit NLTK. Parsing mit NLTK. Parsing mit NLTK. Beispiel: eine kleine kontextfreie Grammatik (cf. [BKL09], Ch. 8.
![Parsing mit NLTK. Parsing mit NLTK. Parsing mit NLTK. Parsing mit NLTK. Beispiel: eine kleine kontextfreie Grammatik (cf. [BKL09], Ch. 8.](/thumbs/39/18970986.jpg "Parsing mit NLTK. Parsing mit NLTK. Parsing mit NLTK. Parsing mit NLTK. Beispiel: eine kleine kontextfreie Grammatik (cf. [BKL09], Ch. 8.") Gliederung Natürlichsprachliche Systeme I D. Rösner Institut für Wissens- und Sprachverarbeitung Fakultät für Informatik Otto-von-Guericke Universität Magdeburg 1 WS 2011/12, 26. Oktober 2011, c 2010-2012
Gliederung Natürlichsprachliche Systeme I D. Rösner Institut für Wissens- und Sprachverarbeitung Fakultät für Informatik Otto-von-Guericke Universität Magdeburg 1 WS 2011/12, 26. Oktober 2011, c 2010-2012
Textmining Klassifikation von Texten Teil 1: Naive Bayes
 Textmining Klassifikation von Texten Teil 1: Naive Bayes Dept. Informatik 8 (Künstliche Intelligenz) Friedrich-Alexander-Universität Erlangen-Nürnberg (Informatik 8) Klassifikation von Texten 1: Naive
Textmining Klassifikation von Texten Teil 1: Naive Bayes Dept. Informatik 8 (Künstliche Intelligenz) Friedrich-Alexander-Universität Erlangen-Nürnberg (Informatik 8) Klassifikation von Texten 1: Naive