Entscheidungsbäume. Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen
|
|
|
- Axel Pfaff
- vor 7 Jahren
- Abrufe
Transkript

1 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Entscheidungsbäume Christoph Sawade /Niels Landwehr/Paul Prasse Silvia Makowski Tobias Scheffer
2 Entscheidungsbäume Eine von vielen Anwendungen: Kreditrisiken nein abgelehnt nein Kredit - Sicherheiten > 2 x verfügbares Einkommen? ja nein Arbeitslos? ja angenommen ja Länger als 3 Monate beschäftigt? abgelehnt Ja Schufa-Auskunft positiv? nein nein angenommen abgelehnt Kredit - Sicherheiten > 5 x verfügbares Einkommen? nein Student? ja ja abgelehnt abgelehnt 2
3 Entscheidungsbäume Einfach zu interpretieren. Liefern Klassifikation plus Begründung. Abgelehnt, weil weniger als 3 Monate beschäftigt und Kredit-Sicherheiten < 2 x verfügbares Einkommen. Können aus Beispielen gelernt werden. Einfacher Lernalgorithmus. Effizient, skalierbar. Klassifikations- und Regressionsbäume. Klassifikations-, Regressions-, Modellbäume häufig Komponenten komplexer (z.b. Risiko-)Modelle. 3
4 Klassifikation Eingabe: Instanz (Objekt) x X. Instanzen sind durch Vektoren von Attributen repräsentiert. Eine Instanz ist eine Belegung der Attribute. Instanzen werden auch als Merkmalsvektoren bezeichnet. x x x 1 m Ausgabe: Klasse y Y; endliche Menge Y. z.b {akzeptiert, abgelehnt}; {Spam, Nicht-Spam}. Klasse wird auch als Zielattribut bezeichnet. 4
5 Klassifikationslernen Eingabe: Trainingsdaten. Ausgabe: Klassifikator. L x i ( x, y1),...,( x x x, y 1 N N i1 im ) f : X Y Z.B. Entscheidungsbaum: Pfad entlang der Kanten zu einem Blatt liefert Klassifikation 5
6 Regression Eingabe: Instanz (Objekt) x X. Instanzen sind durch Vektoren (fett gedruckt) von Attributen (kursiv) repräsentiert. Eine Instanz ist eine Belegung der Attribute. Ausgabe: Funktionswert y Y; kontinuierlicher Wert. Lernproblem: kontinuierliche Trainingsdaten. L z.b. ( x, y1),...,( x, y 1 N N ( x 1,3.5),...,(, 2.8) x N ) 6
7 Andere Lernprobleme Im Laufe des Semesters werden wir noch andere Problemstellungen kennen lernen. Z.B. ordinale Regression. Präferenzlernen, Instanzen in die richtige Reihenfolge bringen. Z.B. Sequenzlernen. Eingabe: Sequenz (z.b. Folge von Wörtern) Ausgabe: Sequenz (z.b. Folge semantischer Tags). Z.B. Strukturlernen. Eingabe: Sequenz, Baum, Graph (z.b. Text, Web). Ausgabe: Baum, Graph (z.b. Parsbaum, Klassifikation von Webseiten). 7
8 Entscheidungsbäume Testknoten: Testen, ob der Wert eines Attributs eine Bedingung erfüllen; bedingte Verzweigung in einen Ast. Terminalknoten: Liefern einen Wert als Ausgabe. nein abgelehnt nein Kredit - Sicherheiten > 2 x verfügbares Einkommen? ja nein Arbeitslos? ja angenommen ja Länger als 3 Monate beschäftigt? abgelehnt Ja Schufa-Auskunft positiv? nein nein angenommen abgelehnt Kredit - Sicherheiten > 5 x verfügbares Einkommen? nein Student? ja ja abgelehnt abgelehnt 8
9 Entscheidungsbäume Entscheidungsbäume können logische Operationen repräsentieren, wie:,, XOR A B C D E nein abgelehnt nein Kredit - Sicherheiten > 2 x verfügbares Einkommen? ja nein Arbeitslos? ja angenommen ja Länger als 3 Monate beschäftigt? abgelehnt Ja Schufa-Auskunft positiv? nein nein angenommen abgelehnt Kredit - Sicherheiten > 5 x verfügbares Einkommen? nein Student? ja ja abgelehnt abgelehnt 9
10 Anwendung von Entscheidungsbäumen Testknoten: führe Test aus, wähle passende Verzweigung, rekursiver Aufruf. Terminalknoten: liefere Wert als Klasse zurück. nein abgelehnt nein Kredit - Sicherheiten > 2 x verfügbares Einkommen? ja nein Arbeitslos? ja angenommen ja Länger als 3 Monate beschäftigt? abgelehnt Ja Schufa-Auskunft positiv? nein nein angenommen abgelehnt Kredit - Sicherheiten > 5 x verfügbares Einkommen? nein Student? ja ja abgelehnt abgelehnt 10
11 Anwendung von Entscheidungsbäumen Entscheidungsbäume sinnvoll, wenn: Instanzen durch Attribut-Werte-Paare beschrieben werden. Zielattribut hat einen diskreten Wertebereicht. Bei Erweiterung auf Modellbäume auch kontinuierlicherer Wertebereich möglich. Interpretierbarkeit der Vorhersage gewünscht ist. Anwendungsgebiete: Medizinische Diagnose Kreditwürdigkeit 11
12 Lernen von Entscheidungsbäumen Tag Aussicht Temperatur Luftfeuchtigkeit Wind Tennis? 1 sonnig heiß hoch schwach nein 2 sonnig heiß hoch stark nein 3 bedeckt heiß hoch schwach ja 4 Regen mild hoch schwach ja 5 Regen kühl normal schwach ja 6 Regen kühl normal stark nein 7 bedeckt kühl normal stark ja 8 sonnig mild hoch schwach nein 9 sonnig kühl normal schwach ja 10 Regen mild normal schwach ja Finde Entscheidungsbaum, der zumindest für die Trainingsdaten die richtige Klasse liefert. Trivialer Weg: Erzeuge einen Baum, der lediglich die Trainingsdaten reproduziert. 12
13 Lernen von Entscheidungsbäumen Tag Aussicht Temperatur Wind Tennis? 1 sonnig heiß schwach nein 2 sonnig heiß stark nein 3 bedeckt heiß schwach ja 4 bedeckt kühl stark ja 5 bedeckt kühl schwach ja sonnig Aussicht bedeckt Temp. Temp. heiß kühl heiß kühl Wind Wind Wind Wind schwach stark schwach stark schwach schwach stark stark nein nein?? ja? ja ja 13
14 Lernen von Entscheidungsbäumen Eleganter Weg: Unter den Bäumen, die mit den Trainingsdaten konsistent sind, wähle einen möglichst kleinen Baum (möglichst wenige Knoten). Kleine Bäume sind gut, weil: sie leichter zu interpretieren sind; sie in vielen Fällen besser generalisieren. Es gibt mehr Beispiele pro Blattknoten. Die Klassenentscheidungen in den Blättern stützen sich so auf mehr Beispiele. 14
15 Vollständige Suche nach kleinstem Baum Wie viele Entscheidungsbäume gibt es? Angenommen m binäre Attribute, zwei Klassen. Komplexität einer vollständigen Suche nach kleinstem Baum? 15
16 Lernen von Entscheidungsbäumen Greedy-Algorithmus, der einen kleinen Baum (statt des kleinsten Baumes) findet, dafür aber polynomiell in Anzahl der Attribute ist. Idee für Algorithmus? 16
17 Top-Down Konstruktion Solange die Trainingsdaten nicht perfekt klassifiziert sind: Wähle das beste Attribut A, um die Trainingsdaten zu separieren. Erzeuge für jeden Wert des Attributs A einen neuen Nachfolgeknoten und weise die Trainingsdaten dem so entstandenen Baum zu. Problem: Welches Attribut ist das beste? [29 +, 35 -] ja x 1 x 2 nein [29 +, 35 -] ja nein [21+, 5 -] [8+, 30 -] [18+, 33 -] [11+, 2 -] 17
18 Entropie Entropie = Maß für Unsicherheit. S ist Menge von Trainingsdaten. p + ist Anteil von positiven Beispielen in S. p ist Anteil von negativen Beispielen in S. Entropie misst die Unsicherheit in S: H S = p + log 2 p + p log 2 p 18
19 Entropie H S = Erwartete Anzahl von Bits, die benötigt werden, um die Zielklasse von zufällig gezogenen Beispielen aus der Menge S zu kodieren. Optimaler, kürzester Kode Entropie einer Zufallsvariable y: H y = p y = v log 2 p(y = v) v Empirische Entropie Zufallsvariable y auf Daten L: H L, y = p L y = v log 2 p L y = v v 19
20 Bedingte Entropie Bedingte Entropie von Zufallsvariable y gegeben Ereignis x=v: Empirische bedingte Entropie auf Daten L: 20 ' 2 ) ' ( )log ' ( ) ( ) ( v v x v x v y p v x v y p v x y H y H ' 2 ) ' ( ˆ )log ' ( ˆ ), ( ), ( v L L v x v x v y p v x v y p v x y L H y L H
21 Information Gain Entropie der Klassenvariable: Unsicherheit über korrekte Klassifikation. Transinformation eines Attributes ( Information Gain ). Verringerung der Entropie der Klassenvariable nach Test des Wertes des Attributes. Empirische Transinformation auf Daten L: IG( x) H( y) p( x v) H ( y) v xv IG ˆ, y) ( L, x) H( L, y) p v L( x v) H( L xv 21
22 Beispiel Beispiele IG = 0,05 IG = 0,46 IG = 0,05 x 1 : Kredit > 3 x Einkommen? H L, y) pˆ ( y v)log pˆ ( y v) ( v L x 2 : Länger als 3 Monate beschäftigt? IG ˆ, y) ( L, x) H( L, y) p v L( x v) H( L xv L x 3 : Student? 1 Ja Ja Nein Ja 2 Ja Nein Nein Nein 3 Nein Ja Ja Ja 4 Nein Nein Ja Nein 5 Nein Ja Nein Ja 6 Nein Nein Nein Ja y: Kredit zurückgezahlt? 22
23 Beispiel II IG L, x = Erwartete Reduktion der Unsicherheit durch den Split an Attribut x. Welcher Split ist besser? [29 +, 35 -] ja x 1 x 2 nein H y, L = log log = 0,99 [29 +, 35 -] IG L, x 1 = 0, H L x1=ja,y H L x1=nein,y = 0,26 IG L, x 2 = 0, H L x2=ja,y H L x2=nein,y = 0,11 ja nein [21+, 5 -] [8+, 30 -] [18+, 33 -] [11+, 2 -] 23
24 Information Gain / Info Gain Ratio Motivation: Vorhersage ob ein Student die Prüfung besteht. Wie hoch ist der Info Gain des Attributes Matrikelnummer? Informationsgehalt des Tests ist riesig. 24
25 Information Gain / Info Gain Ratio Motivation: Vorhersage ob ein Student die Prüfung besteht. Wie hoch ist der Info Gain des Attributes Matrikelnummer? Informationsgehalt des Tests ist riesig. Idee: Informationsgehalt des Tests bestrafen. IG( L, x) GainRatio ( L, x) SplitInfo ( L, x) SplitInfo ( L, x) v L xv log L 2 L xv L 25
26 Beispiel: Info Gain Ratio Welcher Split ist besser? [2+, 2-] 1 2 [1+, 0-] [1+, 0 -] IG L, x 1 = 1 x [0+, 1-] [0+, 1-] SplitInfo L, x 1 = log = 2 GainRatio L, x 1 = 0,5 [2+, 2-] ja x 2 nein [2+, 1 -] [1+, 0 -] IG L, x 2 = ,92 = 0,68 SplitInfo L, x 2 = 3 4 log log = 0,81 GainRatio L, x 2 = 0,84 26
27 Algorithmus ID3 Voraussetzung: Klassifikationslernen, Alle Attribute haben festen, diskreten Wertebereich. Idee: rekursiver Algorithmus. Wähle das Attribut, welches die Unsicherheit bzgl. der Zielklasse maximal verringert. Dann rekursiver Aufruf für alle Werte des gewählten Attributs. Solange, bis in einem Zweig nur noch Beispiele derselben Klasse sind. Originalreferenz: J.R. Quinlan: Induction of Decision Trees
28 Algorithmus ID3 Eingabe: L ( x1, y1),...,( xn, y ), verfügbar= ( x N 1,..., x m ) Wenn alle Bsp in L dieselbe Klasse y haben, dann gib Terminalknoten mit Klasse y zurück. Wenn verfügbar=leer, Gib Terminalknoten mit häufigster Klasse in L zurück. Sonst konstruiere Testknoten: Bestimme bestes Attribut x arg max IG( L, x ) v j * x verfügbar i Für alle Werte dieses Attributs: Teile Trainingsmenge, Lj (xk, yk ) L xk* v j Rekursion: Zweig für Wert v = ID3 (, verfügbar \ x ). j i L j * 28
29 Algorithmus ID3: Beispiel Beispiele Eingabe: L ( x1, y1),...,( xn, y ), verfügbar= ( x N 1,..., x m ) Wenn alle Bsp in L dieselbe Klasse y haben, dann gib Terminalknoten mit Klasse y zurück. Wenn verfügbar=leer, Gib Terminalknoten mit häufigster Klasse in L zurück. Sonst konstruiere Testknoten: Bestimme bestes Attribut x* arg max x verfügbar IG( L, xi ) i Für alle Werte dieses Attributs: v j x 1 : Kredit > 3 x Einkommen? Teile Trainingsmenge, Lj (xk, yk ) L xk* v j Rekursion: Zweig für Wert v = ID3 (, verfügbar \ x ). j x 2 : Länger als 3 Monate beschäftigt? L j * x 3 : Student? 1 Ja Ja Nein Ja 2 Ja Nein Nein Nein 3 Nein Ja Ja Ja 4 Nein Nein Ja Nein 5 Nein Ja Nein Ja 6 Nein Nein Nein Ja y: Kredit zurückgezahlt? 29
30 Kontinuierliche Attribute ID3 wählt Attribute mit größtem Informationsgehalt aus und bildet dann einen Zweig für jeden Wert dieses Attributes. Geht nur für diskrete Attribute. Attribute wie Größe, Einkommen, Entfernung haben unendlich viele Werte. Idee? 30
31 Kontinuierliche Attribute Idee: Binäre Entscheidungsbäume, -Tests. Problem: unendlich viele Werte für binäre Tests Idee: nur endlich viele Werte kommen in Trainingsdaten vor. Beispiel: Kontinuierliches Attribut hat folgende Werte: 0,2; 0,4; 0,7; 0,9 Mögliche Splits: 0,2; 0,4; 0,7; 0,9 Andere Möglichkeiten: Attribute in einen diskreten Wertebereich abbilden. 31
32 Algorithmus C4.5 Weiterentwicklung von ID3 Verbesserungen: auch kontinuierliche Attribute behandelt Trainingsdaten mit fehlenden Attributwerten behandelt Attribute mit Kosten Pruning Nicht der letzte Stand: siehe C5.0 Originalreferenz: J.R. Quinlan: C4.5: Programs for Machine Learning
33 Algorithmus C4.5 Eingabe: L ( x1, y1),...,( xn, yn ). Wenn alle Bsp in L dieselbe Klasse y haben, dann gib Terminalknoten mit Klasse y zurück. Wenn alle Instanzen identisch sind: Gib Terminalknoten mit häufigster Klasse in L zurück. Sonst konstruiere besten Testknoten, iteriere dazu über alle Attribute. Diskrete Attribute: wie ID3. Kontinuierliche Attribute: [ in x* v* ] arg max Attribute, Werte v L IG( L,[ xi v]) Wenn bestes Attribut diskret, Rekursion wie ID3. Wenn bestes Attribut kontinuierlich, teile Trainingsmenge: L ( x, y ) L x v links k k k* *, L rechts xk, yk ) L Rekursion: linker Zweig= 4.5( Llinks ) x i ( x v * 4 rechts C, rechter Zweig= C.5( L ) k* 33
34 Information Gain für kontinuierliche Attribute Information Gain eines Tests [ x v] : Empirischer Information Gain: IG([ x v]) H( y) p([ x v]) H xv] ( y) p([ x v]) H[ xv] ( [ y IG( L,[ x v]) H( L, y) pˆ ([ ]) (, ) ˆ L x v H L [ xv] y pl([ x v]) H( L [ xv], y) ) 34
35 C4.5: Beispiel x 1 0,7 0,5 0,5 1 1,5 x 2 t nein t ja x 2 0,5 x 2 1,5 x 1 0,5 x 1 0,6 t f t f x 1 0,7 t ja f f f nein nein ja 35
36 Pruning Problem: Blattknoten, die nur von einem (oder sehr wenigen) Beispielen gestützt werden, liefern häufig keine gute Klassifikation. Pruning: Entfernen von Testknoten, die Blätter mit weniger als einer Mindestzahl von Beispielen erzeugen. Dadurch entstehen Blattknoten, die dann mit der am häufigsten auftretenden Klasse beschriftet werden. 36
37 Pruning mit Schwellwert Für alle Blattknoten: Wenn weniger als r Trainingsbeispiele in den Blattknoten fallen Entferne darüberliegenden Testknoten. Erzeuge neuen Blattknoten, sage Mehrheitsklasse vorher. Regularisierungsparameter r. Einstellung mit Cross Validation. 37
38 Reduced Error Pruning Aufteilen der Trainingsdaten in Trainingsmenge und Pruningmenge. Nach dem Aufbau des Baumes mit der Trainingsmenge: Versuche, zwei Blattknoten durch Löschen eines Tests zusammenzulegen, Solange dadurch die Fehlerrate auf der Pruningmenge verringert wird. 38
39 Umwandlung von Bäumen in Regeln Pfad durch den Baum: Bedingung der Regel Klasse: Schlussfolgerung Pruning von Regeln: Probiere aus, welche Bedingungen weggelassen werden können, ohne dass die Fehlerrate dadurch steigt. 39

40 Umwandlung von Bäumen in Regeln Ausblick sonnig bewölkt regnerisch Luftfeuchtigkeit hoch normal stark schwach Nein Ja R 1 = Wenn Ausblick = sonnig Ja Nein Wind Ja Luftfeuctigkeit = oc, dann kein Tennis spielen R 2 = Wenn Ausblick = sonnig Luftfeuctigkeit = normal, dann Tennis spielen R 3 = Wenn Ausblick = bewölkt, dann Tennis spielen R 4 = Wenn Ausblick = regnerisc Wind = stark, dann kein Tennis spielen R 6 = Wenn Ausblick = regnerisc Wind = scwac, dann Tennis spielen 40
41 Induktiver Bias von Entscheidungsbäumen Version Space: Raum aller Hypothesen, die mit den Daten konsistent sind. Hypothesen im Version Space unterscheiden sich in ihrer Klassifikation neuer Daten. Welche Hypothese ist die Richtige? Induktiver Bias: Bevorzugung einer bestimmten Hypothese im Version Space. Jeder Lernalgorithmus, der nur eine Hypothese zurückliefert muss einen induktiven Bias haben. Induktiver Bias von ID3: kleine Bäume werden bevorzugt. 41
42 Entscheidungsbäume aus großen Datenbanken: SLIQ C4.5 iteriert häufig über die Trainingsmenge (wie häufig?) Wenn die Trainingsmenge nicht in den Hauptspeicher passt, wird das Swapping unpraktikabel! SLIQ: Vorsortieren der Werte für jedes Attribut Baum breadth-first aufbauen, nicht depth-first. Originalreferenz: M. Mehta et. al.: SLIQ: A Fast Scalable Classifier for Data Mining
43 SLIQ: Gini Index Um besten Split zu bestimmen, verwendet SLIQ nicht den Information Gain, sondern den Gini-Index. Für eine Trainingsmenge L mit n unterschiedlichen Klassen: Gini L = 1 p j 2 j=1 n Nach einem binären Split der Menge L in die Mengen L 1 und L 2 ergibt sich: Gini split L = L 1 L Gini L 1 + L 2 L 2 Gini(L 2 ) Gini-Index verhält sich ähnlich wie Information Gain. 43
44 SLIQ - Algorithmus 1. Starte Vorsortieren der Beispiele 2. Solange Abbruchkriterium noch nicht erreicht ist 1. Für alle Attribute 1. Lege für alle Knoten ein Klassenhistogramm an. 2. Starte Evaluierung der Splits 2. Wähle Split 3. Aktualisiere Entscheidungsbaum; für jeden neuen Knoten aktualisiere Klassenliste (Knoten) 44
45 SLIQ (1. Teilschritt) Vorsortieren der Beispiele 1. Für jedes Attribut: Lege eine Attributliste mit den Spalten Wert, Beispiel-ID und Klasse an. 2. Lege eine Klassenliste mit den Spalten Beispiel-ID, Klasse und Knoten an. 3. Iteriere über alle Trainingsbeispiele Für alle Attribute Füge Attributwert, Beispiel-ID und Klasse sortiert (nach Attributwert) in alle Listen ein. Füge die Beispiel-ID, die Klasse und den Knoten (1) nach Beispiel-ID sortiert in die Klassenliste ein. 45
46 SLIQ: Beispiel 46
47 SLIQ: Beispiel 47
48 SLIQ 1. Starte Vorsortieren der Beispiele 2. Solange Abbruchkriterium noch nicht erreicht ist 1. Für alle Attribute 1. Lege für alle Knoten ein Klassenhistogramm an. 2. Starte Evaluierung der Splits 2. Wähle Split 3. Aktualisiere Entscheidungsbaum; für jeden neuen Knoten aktualisiere Klassenliste (Knoten) 48
49 SLIQ (2. Teilschritt) Evaluiere Splits 1. Für alle Knoten, für alle Attribute 1. Lege ein Histogramm an (für alle Klassen speichert das Histogramm die Anzahl der Beispiele vor und nach dem Split). 2. Für alle Attribute x 1. Für jeden Wert v (traversiere Attributliste für A) 1. Finde entsprechenden Eintrag in der Klassenliste (liefert Klasse und Knoten). 2. Aktualisiere Histogramm für den Knoten. 3. Bewerte den Split (falls Maximum, merken!) 49
50 SLIQ: Beispiel 50
51 SLIQ 1. Starte Vorsortieren der Beispiele 2. Solange Abbruchkriterium noch nicht erreicht ist 1. Für alle Attribute 1. Lege für alle Knoten ein Klassenhistogramm an. 2. Starte Evaluierung der Splits 2. Wähle Split 3. Aktualisiere Entscheidungsbaum; für jeden neuen Knoten aktualisiere Klassenliste (Knoten) 51
52 SLIQ (3. Teilschritt) Aktualisiere Klassenliste (Knoten) 1. Traversiere Attributliste des im Knoten verwendeten Attributs. 2. Für alle Einträge (Wert, ID) 3. Finde passenden Eintrag (ID, Klasse, Knoten) in der Klassenliste. 4. Wende Split-Kriterium an, ermittle neuen Knoten. 5. Ersetze Klassenlisteneintrag durch (ID, Klasse, neuer Knoten). 52
53 SLIQ: Beispiel 53
54 SLIQ: Datenstrukturen Datenstrukturen im Speicher Ausgelagerte Datenstrukturen Datenstrukturen in Datenbank 54
55 SLIQ- Pruning Minimum Description Length (MDL): Bestes Modell für einen gegebenen Datensatz minimiert Summe aus Länge der im Modell kodierten Daten plus Länge des Modells. cost M, D = cost D M + cost M cost M = Kosten des Modells (Länge). Wie groß ist der Entscheidungsbaum. cost D M = Kosten, die Daten durch das Modell zu beschreiben. Wie viele Klassifikationsfehler entstehen. 55
56 Pruning MDL Beispiel I Angenommen: 16 binäre Attribute und 3 Klassen cost M, D = cost D M + cost M Kosten für die Kodierung eines internen Knotens: log 2 (m) = log 2 16 = 4 Kosten für die Kodierung eines Blattes: log 2 (k) = log 2 (3) = 2 Kosten für die Kodierung eines Klassifikationsfehlers bei n Trainingsdaten: log 2 (n) 7 Fehler C 1 C 2 C 3 56
57 Pruning MDL Beispiel II Welcher Baum ist besser? 7 Fehler Baum 1: Baum 2: C 1 C 1 C 2 C 3 Interne Knoten Blätter Fehler 4 Fehler C 2 C 1 C 2 Kosten für Baum 1: log 2 n = log 2 n Kosten für Baum 2: log 2 n = log 2 n Wenn n < 16, dann ist Baum 1 besser. Wenn n > 16, dann ist Baum 2 besser. C 3 57
58 SLIQ Eigenschaften Laufzeit für die Initialisierung (Vorsortierung): O n log n für jedes Attribut Großteil der Daten muss nicht im Hauptspeicher gehalten werden. Gute Skalierbarkeit. Wenn Klassenliste nicht mehr in Hauptspeicher passt funktioniert SLIQ nicht mehr. Alternative: SPRINT Kann numerische und diskrete Attribute verarbeiten. Parallelisierbarkeit des Verfahrens. 58
59 Regressionsbäume ID3, C4.5, SLIQ: Lösen Klassifikationsproblem. Ziel: niedrige Fehlerrate + kleine Bäume Attribute können kontinuierlich sein (außer bei ID3), aber Vorhersage ist diskret. Regression: Vorhersage kontinuierlicher Werte. Ziel: niedrige Fehlerquadrate + einfaches Modell. Methoden, die wir jetzt gleich ansehen: Regressionsbäume, Lineare Regression, Modellbäume. m SSE ( y j 1 j f ( x j )) 2 59
60 Regressionsbäume Eingabe: L ( x1, y1),...,( xn, yn ), kontinuierliche y. Gesucht: f : X Y Algorithmus CART Wurde gleichzeitig, unabhängig von C4.5 entwickelt. Terminalknoten enthalten kontinuierlichen Wert. Algorithmus wie C4.5. Für Klassifikation leicht anderes Kriterium (Gini statt IG), kaum Unterschied. Information Gain (und Gini) funktionieren nur für Klassifikation. Split-Kriterium für Regression? Originalreferenz: L. Breiman et. al.: Classification and Regression Trees
61 Regressionsbäume Ziel: niedrige Fehlerquadrate (SSE) + kleiner Baum. Beispiele L kommen im aktuellen Knoten an. SSE im aktuellen Knoten: Mit welchem Test soll gesplittet werden? Kriterium für Testknoten [ x v] : SSE - Red( L,[ x v]) SSE SSE-Reduktion durch Test. Stop-Kriterium: L SSE L [ xv] Führe keinen neuen Split ein, wenn SSE nicht um Mindestbetrag reduziert wird. Erzeuge dann Terminalknoten mit Mittelwert m aus L. SSE L SSE ( x, y) L L [ xv] ( y y) 2 1 mit y L ( x, y) L y 61
62 CART- Beispiel Welcher Split ist besser? L = [2,3,4,10,11,12] SSE L = 100 ja x 1 x 2 L = [2,3,4,10,11,12] nein ja nein L 1 = [2,3] L 2 =[4,10,11,12] L 1 =[2,4,10] L 2 =[3,11,12] SSE L 1 = 0,5 SSE L 2 = 38,75 SSE L 1 = 34,67 SSE L 2 = 48,67 62
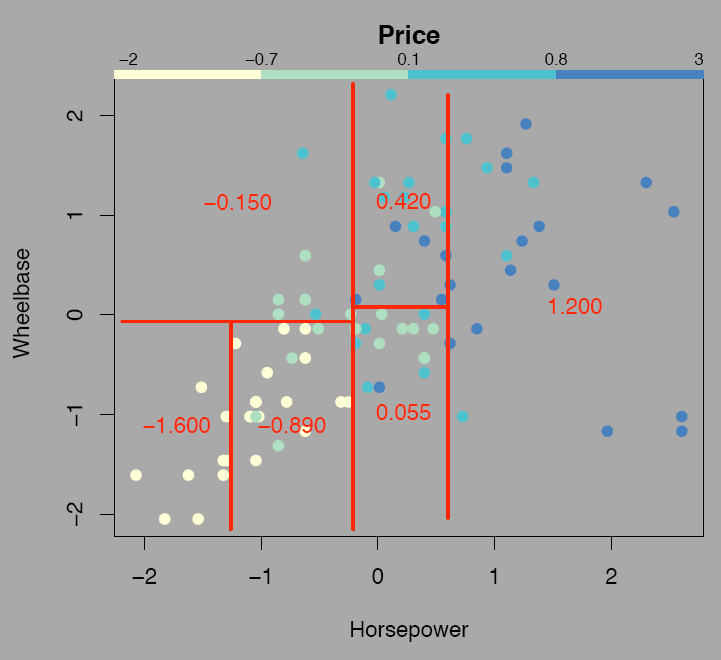
63 Regressionsbäume 63
64 Lineare Regression Regressionsbäume: konstante Vorhersage in jedem Blattknoten. Lineare Regression: Globales Modell einer linearen Abhängigkeit zwischen x und y. Standardverfahren. Für sich genommen nützlich und Voraussetzung für Modellbäume. 64
65 Lineare Regression Eingabe: L ( x, y1),...,( x, y 1 m m Gesucht: lineares Modell ) T f ( x) w x c Normalenvektor Residuen Punkte auf der Regressionsgeraden stehen senkrecht auf Normalenvektor. 65
66 Lineare Regression Eingabe: Gesucht: lineares Modell Vereinfachung zum besseren Verständnis der Herleitung: nur eine Dimension. f ( x) w L T ( x, y1),...,( x x c, y 1 N N Gesucht: Parameter w und c, die SSE minimieren. SSE Ableiten, Ableitung auf null setzen (wie in der Schule). ) T f ( x) w x c 66
67 Lineare Regression, eindimensional SSE SSE c N j1 N 2 ( y f ( x )) ( y ( wx j1 j j1 j j1 j N j1 2( y wx c)( 1) 0 N y wx Nc 0 c* y wx j N j j j j c)) 2 y j wx j c 2 67
68 Lineare Regression, eindimensional SSE SSE w N j1 j1 j1 j1 2 ( y f ( x )) ( y ( wx j ( y wx c*) N j j j1 j j1 2 N j1 w ( y wx y wx) N j j N 2 j 2 j c)) 2( y wx y wx)( x x) 0 w* j j j N ( y y )( xx ) N w j ( x x ) j j c = y + wx 2 68
69 Lineare Regression Eingabe: Gesucht: lineares Modell kleiner Trick: c kann weg, dafür eine zusätzliche Dimension. 69 ), ),...,(, ( 1 1 N N y y L x x f c x w x T ) ( ' ' )... ( ) ( T T x w x w x m m m m x x c w w c x x w w c f
70 Lineare Regression Fehlerquadrate: Gesucht: Parameter w und c, die SSE minimieren. Ableiten, Ableitung auf null setzen (wie in der Schule). Inverse existiert nicht immer Regularisierungsterm addieren (Ridge Regression). 70 ) ( ) ( )) ( ( )) ( ( T 1 2 T 1 2 Xw y Xw y x w x N j j j N j j j y f y SSE y X X X w x w w T 1 T 1 2 T ) ( 0 )) ( ( N j j y j SSE
71 Ridge Regression Ziel: Summe aus Fehlerquadraten und Regularisierungsterm minimieren: w = arg min w y Xw T y Xw + λw T w λ ist Regularisierungsparameter. Gesucht: Parameter w, der Summe aus Fehlerquadrate und Regularisierungsterm minimiert. Lösung: Ableiten und 0 setzen: w = X T X + λi 1 X T y 71
72 Modellbäume Entscheidungsbaum, aber lineares Regressionsmodell in Blattknoten
73 Modellbäume Entscheidungsbaum, aber lineares Regressionsmodell in Blattknoten. ja ja x <.9 x <.5 x < 1.1 nein nein nein
74 Modellbäume: Aufbau neuer Testknoten Führe lineare Regression über alle Beispiele aus, die den aktuellen Knoten erreichen. Bestimme SSE. Iteriere über alle möglichen Tests (wie C4.5). Führe lineare Regressionen für Teilmengen der Beispiele im linken Zweig aus, bestimme SSE links. Führe lineare Regressionen für Teilmengen der Beispiele im rechten Zweig aus, bestimme SSE rechts. Wähle Test mit größtem SSE- SSE links - SSE rechts. Stop-Kriterium: Wenn SSE nicht um Mindestbetrag reduziert wird, führe keinen neuen Test ein. 74
75 Fehlende Attributwerte Problem: Trainingsdaten mit fehlenden Attributwerten. Was, wenn Attribut A getestet wird, für das nicht für jedes Beispiel ein Attributwert existiert? Trainingsbeispiel bekommt Attributwert, der unter allen Beispielen im Knoten n am häufigsten für A vorkommt. Trainingsbeispiel bekommt Attributwert, den die meisten Beispiele mit der gleichen Klassifikation haben. 75
76 Attribute mit Kosten Beispiel: medizinische Diagnose Bluttest kostet mehr als Pulsmessung Fragestellung: Wie kann man einen mit den Trainingsdaten konsistenten Baum mit geringen Kosten lernen? Antwort: Ersetzte Information Gain durch: Tan and Schlimmer (1990): Nunez (1988): IG 2 (L,x) Cost(A) 2 IG L,x 1 Cost A +1 w Parameter w 0,1 steuert den Einfluss der Kosten. 76
77 Entscheidungsbaum - Vorteile Einfach zu interpretieren. Können effizient aus vielen Beispielen gelernt werden. SLIQ, SPRINT Viele Anwendungen. Hohe Genauigkeit. 77
78 Entscheidungsbaum - Nachteile Nicht robust gegenüber Rauschen Tendenz zum Overfitting Instabil 78
79 Bootstrapping Einfache Resampling-Methode. Erzeugt viele Varianten einer Trainingsmenge L. Bootstrap Algorithmus: Wiederhole M mal: Generiere ein Sample L k der Größe n von L: Wiederholtes gleichverteiltes Ziehen mit Zurücklegen von Beispielen. Berechne Modell θ k für L k Gib die Bootstrap-Werte zurück: θ = (θ 1,, θ k ) 79
80 Bootstrapping - Beispiel x = 3,12 0 1,57 19,67 0,22 2,20, x = 4,46 x = x = x = 1,57 0,22 19,67 0 0,22 3,12 0 2,20 19,67 2,20 2, ,22 3,12 1,57 3,12 2,20 0,22, x = 4,13, x = 4,64, x = 1,74 80
81 Bagging Bagging = Bootstrap aggregating Bagging Algorithmus: Wiederhole M mal: Bestimme Bootstrap-Sample L k von L. Bestimme Vorhersagemodell für L k Kombiniere die M gelernten Vorhersagemodelle: Klassifikationsprobleme: Voting Regressionsprobleme: Mittelwertbildung Originalreferenz: L.Breiman: Bagging Predictors z.b. Modellbaum 81
82 Random Forests Wiederhole: Ziehe zufällig mit Zurücklegen n Beispiele aus der Trainingsmenge Wähle zufällig m < m Merkmale Lerne Entscheidungsbaum (ohne Pruning) Klassifikation: Maximum über alle Bäume (Voting) Regression: Mittelwert über alle Bäume Originalreferenz: L. Breiman: Random Forests Bootstrap 82
83 Zusammenfassung Entscheidungsbäume Klassifikation : Vorhersage diskreter Werte. Diskrete Attribute: ID3. Kontinuierliche Attribute: C4.5. Skalierbar für große Datenbanken: SLIQ, SPRINT. Regression: Vorhersage kontinuierlicher Werte. Regressionsbäume: konstante Werte in Blättern. Modellbäume: lineare Modelle in den Blättern. 83
Entscheidungsbäume aus großen Datenbanken: SLIQ
 Entscheidungsbäume aus großen Datenbanken: SLIQ C4.5 iteriert häufig über die Trainingsmenge Wie häufig? Wenn die Trainingsmenge nicht in den Hauptspeicher passt, wird das Swapping unpraktikabel! SLIQ:
Entscheidungsbäume aus großen Datenbanken: SLIQ C4.5 iteriert häufig über die Trainingsmenge Wie häufig? Wenn die Trainingsmenge nicht in den Hauptspeicher passt, wird das Swapping unpraktikabel! SLIQ:
Erstes Mathe-Tutorium am Themen können gewählt werden unter:
 Mathe-Tutorium Erstes Mathe-Tutorium am 07.05. Themen können gewählt werden unter: https://docs.google.com/forms/d/1lyfgke7skvql cgzspjt4mkirnrgnrfpkkn3j2vqos/iewform 1 Uniersität Potsdam Institut für
Mathe-Tutorium Erstes Mathe-Tutorium am 07.05. Themen können gewählt werden unter: https://docs.google.com/forms/d/1lyfgke7skvql cgzspjt4mkirnrgnrfpkkn3j2vqos/iewform 1 Uniersität Potsdam Institut für
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Entscheidungsbäume
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Entscheidungsbäume Christoph Sawade/Niels Landwehr Jules Rasetaharison, Tobias Scheffer Entscheidungsbäume Eine von vielen Anwendungen:
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Entscheidungsbäume Christoph Sawade/Niels Landwehr Jules Rasetaharison, Tobias Scheffer Entscheidungsbäume Eine von vielen Anwendungen:
Maschinelles Lernen Entscheidungsbäume
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen Entscheidungsbäume Paul Prasse Entscheidungsbäume Eine von vielen Anwendungen: Kreditrisiken Kredit - Sicherheiten
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen Entscheidungsbäume Paul Prasse Entscheidungsbäume Eine von vielen Anwendungen: Kreditrisiken Kredit - Sicherheiten
Maschinelles Lernen Entscheidungsbäume
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen Entscheidungsbäume Christoph Sawade /Niels Landwehr/Paul Prasse Dominik Lahmann Tobias Scheffer Entscheidungsbäume
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen Entscheidungsbäume Christoph Sawade /Niels Landwehr/Paul Prasse Dominik Lahmann Tobias Scheffer Entscheidungsbäume
INTELLIGENTE DATENANALYSE IN MATLAB. Überwachtes Lernen: Entscheidungsbäume
 INTELLIGENTE DATENANALYSE IN MATLAB Überwachtes Lernen: Entscheidungsbäume Literatur Stuart Russell und Peter Norvig: Artificial Intelligence. Andrew W. Moore: http://www.autonlab.org/tutorials. 2 Überblick
INTELLIGENTE DATENANALYSE IN MATLAB Überwachtes Lernen: Entscheidungsbäume Literatur Stuart Russell und Peter Norvig: Artificial Intelligence. Andrew W. Moore: http://www.autonlab.org/tutorials. 2 Überblick
INTELLIGENTE DATENANALYSE IN MATLAB
 INTELLIGENTE DATENANALYSE IN MATLAB Überwachtes Lernen: Entscheidungsbäume Literatur Stuart Russell und Peter Norvig: Artificial i Intelligence. Andrew W. Moore: http://www.autonlab.org/tutorials. 2 Überblick
INTELLIGENTE DATENANALYSE IN MATLAB Überwachtes Lernen: Entscheidungsbäume Literatur Stuart Russell und Peter Norvig: Artificial i Intelligence. Andrew W. Moore: http://www.autonlab.org/tutorials. 2 Überblick
Decision Trees* von Julia Heise, Philipp Thoms, Hans-Martin Wulfmeyer. *Entscheidungsbäume
 Decision Trees* von Julia Heise, Philipp Thoms, Hans-Martin Wulfmeyer *Entscheidungsbäume Gliederung 1. Einführung 2. Induktion 3. Beispiel 4. Fazit Einführung 1. Einführung a. Was sind Decision Trees?
Decision Trees* von Julia Heise, Philipp Thoms, Hans-Martin Wulfmeyer *Entscheidungsbäume Gliederung 1. Einführung 2. Induktion 3. Beispiel 4. Fazit Einführung 1. Einführung a. Was sind Decision Trees?
3.3 Nächste-Nachbarn-Klassifikatoren
 3.3 Nächste-Nachbarn-Klassifikatoren Schrauben Nägel Klammern Neues Objekt Instanzbasiertes Lernen (instance based learning) Einfachster Nächste-Nachbar-Klassifikator: Zuordnung zu der Klasse des nächsten
3.3 Nächste-Nachbarn-Klassifikatoren Schrauben Nägel Klammern Neues Objekt Instanzbasiertes Lernen (instance based learning) Einfachster Nächste-Nachbar-Klassifikator: Zuordnung zu der Klasse des nächsten
Decision Tree Learning
 Decision Tree Learning Computational Linguistics Universität des Saarlandes Sommersemester 2011 28.04.2011 Entscheidungsbäume Repräsentation von Regeln als Entscheidungsbaum (1) Wann spielt Max Tennis?
Decision Tree Learning Computational Linguistics Universität des Saarlandes Sommersemester 2011 28.04.2011 Entscheidungsbäume Repräsentation von Regeln als Entscheidungsbaum (1) Wann spielt Max Tennis?
Entscheidungsbäume. Minh-Khanh Do Erlangen,
 Entscheidungsbäume Minh-Khanh Do Erlangen, 11.07.2013 Übersicht Allgemeines Konzept Konstruktion Attributwahl Probleme Random forest E-Mail Filter Erlangen, 11.07.2013 Minh-Khanh Do Entscheidungsbäume
Entscheidungsbäume Minh-Khanh Do Erlangen, 11.07.2013 Übersicht Allgemeines Konzept Konstruktion Attributwahl Probleme Random forest E-Mail Filter Erlangen, 11.07.2013 Minh-Khanh Do Entscheidungsbäume
Vergleich von SVM und Regel- und Entscheidungsbaum-Lernern
 Vergleich von SVM und Regel- und Entscheidungsbaum-Lernern Chahine Abid Bachelor Arbeit Betreuer: Prof. Johannes Fürnkranz Frederik Janssen 28. November 2013 Fachbereich Informatik Fachgebiet Knowledge
Vergleich von SVM und Regel- und Entscheidungsbaum-Lernern Chahine Abid Bachelor Arbeit Betreuer: Prof. Johannes Fürnkranz Frederik Janssen 28. November 2013 Fachbereich Informatik Fachgebiet Knowledge
Mathias Krüger / Seminar Datamining
 Entscheidungsbäume mit SLIQ und SPRINT Mathias Krüger Institut für Informatik FernUniversität Hagen 4.7.2008 / Seminar Datamining Gliederung Einleitung Klassifikationsproblem Entscheidungsbäume SLIQ (
Entscheidungsbäume mit SLIQ und SPRINT Mathias Krüger Institut für Informatik FernUniversität Hagen 4.7.2008 / Seminar Datamining Gliederung Einleitung Klassifikationsproblem Entscheidungsbäume SLIQ (
fuzzy-entscheidungsbäume
 fuzzy-entscheidungsbäume klassische Entscheidungsbaumverfahren fuzzy Entscheidungsbaumverfahren Entscheidungsbäume Was ist ein guter Mietwagen für einen Familienurlaub auf Kreta? 27. März 23 Sebastian
fuzzy-entscheidungsbäume klassische Entscheidungsbaumverfahren fuzzy Entscheidungsbaumverfahren Entscheidungsbäume Was ist ein guter Mietwagen für einen Familienurlaub auf Kreta? 27. März 23 Sebastian
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Modellevaluierung. Niels Landwehr
 Universität Potsdam Institut für Informatik ehrstuhl Maschinelles ernen Modellevaluierung Niels andwehr ernen und Vorhersage Klassifikation, Regression: ernproblem Eingabe: Trainingsdaten Ausgabe: Modell
Universität Potsdam Institut für Informatik ehrstuhl Maschinelles ernen Modellevaluierung Niels andwehr ernen und Vorhersage Klassifikation, Regression: ernproblem Eingabe: Trainingsdaten Ausgabe: Modell
Klassische Klassifikationsalgorithmen
 Klassische Klassifikationsalgorithmen Einführung in die Wissensverarbeitung 2 VO 708.560+ 1 UE 442.072 SS 2013 Institut für Signalverarbeitung und Sprachkommunikation TU Graz Inffeldgasse 12/1 www.spsc.tugraz.at
Klassische Klassifikationsalgorithmen Einführung in die Wissensverarbeitung 2 VO 708.560+ 1 UE 442.072 SS 2013 Institut für Signalverarbeitung und Sprachkommunikation TU Graz Inffeldgasse 12/1 www.spsc.tugraz.at
Klassische Klassifikationsalgorithmen
 Klassische Klassifikationsalgorithmen Einführung in die Wissensverarbeitung 2 VO 708.560+ 1 UE 442.072 SS 2012 Institut für Signalverarbeitung und Sprachkommunikation TU Graz Inffeldgasse 12/1 www.spsc.tugraz.at
Klassische Klassifikationsalgorithmen Einführung in die Wissensverarbeitung 2 VO 708.560+ 1 UE 442.072 SS 2012 Institut für Signalverarbeitung und Sprachkommunikation TU Graz Inffeldgasse 12/1 www.spsc.tugraz.at
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Maschinelles Lernen
 Universität Potsdam Institut für Informatik Lehrstuhl Niels Landwehr, Silvia Makowski, Christoph Sawade, Tobias Scheffer Organisation Vorlesung/Übung, praktische Informatik. 4 SWS. Übung: Di 10:00-11:30
Universität Potsdam Institut für Informatik Lehrstuhl Niels Landwehr, Silvia Makowski, Christoph Sawade, Tobias Scheffer Organisation Vorlesung/Übung, praktische Informatik. 4 SWS. Übung: Di 10:00-11:30
Entscheidungsbaum-Lernen: Übersicht
 Entscheidungsbaum-Lernen: Übersicht Entscheidungsbäume als Repräsentationsformalismus Semantik: Klassifikation Lernen von Entscheidungsbäumen vollst. Suche vs. TDIDT Tests, Ausdrucksfähigkeit Maße: Information
Entscheidungsbaum-Lernen: Übersicht Entscheidungsbäume als Repräsentationsformalismus Semantik: Klassifikation Lernen von Entscheidungsbäumen vollst. Suche vs. TDIDT Tests, Ausdrucksfähigkeit Maße: Information
4. Lernen von Entscheidungsbäumen
 4. Lernen von Entscheidungsbäumen Entscheidungsbäume 4. Lernen von Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse
4. Lernen von Entscheidungsbäumen Entscheidungsbäume 4. Lernen von Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Hypothesenbewertung
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hypothesenbewertung Christoph Sawade/Niels Landwehr Dominik Lahmann Tobias Scheffer Überblick Hypothesenbewertung, Risikoschätzung
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hypothesenbewertung Christoph Sawade/Niels Landwehr Dominik Lahmann Tobias Scheffer Überblick Hypothesenbewertung, Risikoschätzung
Rückblick. Entscheidungsunterstützende Systeme / Kapitel 4: Klassifikation
 Rückblick k-nächste Nachbarn als distanzbasiertes Verfahren zur Klassifikation benötigt sinnvolles Distanzmaß und weist vorher unbekanntem Datenpunkt dann die häufigste Klasse seiner k nächsten Nachbarn
Rückblick k-nächste Nachbarn als distanzbasiertes Verfahren zur Klassifikation benötigt sinnvolles Distanzmaß und weist vorher unbekanntem Datenpunkt dann die häufigste Klasse seiner k nächsten Nachbarn
Bayes sches Lernen: Übersicht
 Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 10: Naive Bayes (V. 1.0)
Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 10: Naive Bayes (V. 1.0)
Maschinelles Lernen: Symbolische Ansätze
 Maschinelles Lernen: Symbolische Ansätze Musterlösung für das 7. Übungsblatt Aufgabe 1 Gegeben sei folgende Beispielmenge: Day Outlook Temperature Humidity Wind PlayTennis D1? Hot High Weak No D2 Sunny
Maschinelles Lernen: Symbolische Ansätze Musterlösung für das 7. Übungsblatt Aufgabe 1 Gegeben sei folgende Beispielmenge: Day Outlook Temperature Humidity Wind PlayTennis D1? Hot High Weak No D2 Sunny
Modellierung. Entscheidungsbäume, ume, Boosting, Metalerner, Random Forest. Wolfgang Konen Fachhochschule Köln Oktober 2007.
 Modellierung Entscheidungsbäume, ume, Boosting, Metalerner, Random Forest Wolfgang Konen Fachhochschule Köln Oktober 2007 W. Konen DMC WS2007 Seite - 1 W. Konen DMC WS2007 Seite - 2 Inhalt Typen der Modellierung
Modellierung Entscheidungsbäume, ume, Boosting, Metalerner, Random Forest Wolfgang Konen Fachhochschule Köln Oktober 2007 W. Konen DMC WS2007 Seite - 1 W. Konen DMC WS2007 Seite - 2 Inhalt Typen der Modellierung
Lernen von Entscheidungsbäumen. Volker Tresp Summer 2014
 Lernen von Entscheidungsbäumen Volker Tresp Summer 2014 1 Anforderungen an Methoden zum Datamining Schnelle Verarbeitung großer Datenmengen Leichter Umgang mit hochdimensionalen Daten Das Lernergebnis
Lernen von Entscheidungsbäumen Volker Tresp Summer 2014 1 Anforderungen an Methoden zum Datamining Schnelle Verarbeitung großer Datenmengen Leichter Umgang mit hochdimensionalen Daten Das Lernergebnis
Bayes Klassifikatoren M E T H O D E N D E S D A T A M I N I N G F A B I A N G R E U E L
 Bayes Klassifikatoren M E T H O D E N D E S D A T A M I N I N G F A B I A N G R E U E L Inhalt Grundlagen aus der Wahrscheinlichkeitsrechnung Hypothesenwahl Optimale Bayes Klassifikator Naiver Bayes Klassifikator
Bayes Klassifikatoren M E T H O D E N D E S D A T A M I N I N G F A B I A N G R E U E L Inhalt Grundlagen aus der Wahrscheinlichkeitsrechnung Hypothesenwahl Optimale Bayes Klassifikator Naiver Bayes Klassifikator
Moderne Methoden der KI: Maschinelles Lernen
 Moderne Methoden der KI: Maschinelles Lernen Prof. Dr.Hans-Dieter Burkhard Vorlesung Entscheidungsbäume Darstellung durch Regeln ID3 / C4.5 Bevorzugung kleiner Hypothesen Overfitting Entscheidungsbäume
Moderne Methoden der KI: Maschinelles Lernen Prof. Dr.Hans-Dieter Burkhard Vorlesung Entscheidungsbäume Darstellung durch Regeln ID3 / C4.5 Bevorzugung kleiner Hypothesen Overfitting Entscheidungsbäume
Bayes sches Lernen: Übersicht
 Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 5: Naive Bayes + IBL (V.
Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 5: Naive Bayes + IBL (V.
3. Entscheidungsbäume. Verfahren zum Begriffslernen (Klassifikation) Beispiel: weiteres Beispiel: (aus Böhm 2003) (aus Morik 2002)
 Beispiel: weiteres Beispiel: (aus Böhm 2003) (aus Morik 2002)") 3. Entscheidungsbäume Verfahren zum Begriffslernen (Klassifikation) Beispiel: weiteres Beispiel: (aus Böhm 2003) (aus Morik 2002) (aus Wilhelm 2001) Beispiel: (aus Böhm 2003) Wann sind Entscheidungsbäume
3. Entscheidungsbäume Verfahren zum Begriffslernen (Klassifikation) Beispiel: weiteres Beispiel: (aus Böhm 2003) (aus Morik 2002) (aus Wilhelm 2001) Beispiel: (aus Böhm 2003) Wann sind Entscheidungsbäume
Vorlesungsplan. Von Naïve Bayes zu Bayesischen Netzwerk- Klassifikatoren. Naïve Bayes. Bayesische Netzwerke
 Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Kapitel 4: Data Mining DATABASE SYSTEMS GROUP. Überblick. 4.1 Einleitung. 4.2 Clustering. 4.3 Klassifikation
 Überblick 4.1 Einleitung 4.2 Clustering 4.3 Klassifikation 1 Klassifikationsproblem Gegeben: eine Menge O D von Objekten o = (o 1,..., o d ) O mit Attributen A i, 1 i d eine Menge von Klassen C = {c 1,...,c
Überblick 4.1 Einleitung 4.2 Clustering 4.3 Klassifikation 1 Klassifikationsproblem Gegeben: eine Menge O D von Objekten o = (o 1,..., o d ) O mit Attributen A i, 1 i d eine Menge von Klassen C = {c 1,...,c
Moderne Methoden der KI: Maschinelles Lernen
 Moderne Methoden der KI: Maschinelles Lernen Prof. Dr.Hans-Dieter Burkhard Vorlesung Sommer-Semester 2008 Konzept-Lernen Konzept-Lernen Lernen als Suche Inductive Bias Konzept-Lernen: Problemstellung Ausgangspunkt:
Moderne Methoden der KI: Maschinelles Lernen Prof. Dr.Hans-Dieter Burkhard Vorlesung Sommer-Semester 2008 Konzept-Lernen Konzept-Lernen Lernen als Suche Inductive Bias Konzept-Lernen: Problemstellung Ausgangspunkt:
Lineare Regression. Volker Tresp
 Lineare Regression Volker Tresp 1 Die Lernmaschine: Das lineare Modell / ADALINE Wie beim Perzeptron wird zunächst die Aktivierungsfunktion gewichtete Summe der Eingangsgrößen x i berechnet zu h i = M
Lineare Regression Volker Tresp 1 Die Lernmaschine: Das lineare Modell / ADALINE Wie beim Perzeptron wird zunächst die Aktivierungsfunktion gewichtete Summe der Eingangsgrößen x i berechnet zu h i = M
INTELLIGENTE DATENANALYSE IN MATLAB. Zusammenfassung
 INTELLIGENTE DATENANALYSE IN MATLAB Zusammenfassung Überwachtes Lernen Gegeben: Trainingsdaten mit bekannten Zielattributen (gelabelte Daten). Eingabe: Instanz (Objekt, Beispiel, Datenpunkt, Merkmalsvektor)
INTELLIGENTE DATENANALYSE IN MATLAB Zusammenfassung Überwachtes Lernen Gegeben: Trainingsdaten mit bekannten Zielattributen (gelabelte Daten). Eingabe: Instanz (Objekt, Beispiel, Datenpunkt, Merkmalsvektor)
Maschinelles Lernen: Symbolische Ansätze
 Maschinelles Lernen: Symbolische Ansätze Musterlösung für das 6. Übungsblatt Aufgabe 1 Gegeben sei eine Beispielmenge mit folgenden Eigenschaften: Jedes Beispiel ist durch 10 nominale Attribute A 1,...,
Maschinelles Lernen: Symbolische Ansätze Musterlösung für das 6. Übungsblatt Aufgabe 1 Gegeben sei eine Beispielmenge mit folgenden Eigenschaften: Jedes Beispiel ist durch 10 nominale Attribute A 1,...,
Theorie des maschinellen Lernens
 Theorie des maschinellen Lernens Hans U. Simon 16. Juni 017 18 Entscheidungsbäume Ein Entscheidungsbaum T stellt eine Voraussagefunktion h T : X Y dar. Stellen wir uns der Einfachheit halber einen binären
Theorie des maschinellen Lernens Hans U. Simon 16. Juni 017 18 Entscheidungsbäume Ein Entscheidungsbaum T stellt eine Voraussagefunktion h T : X Y dar. Stellen wir uns der Einfachheit halber einen binären
Maschinelles Lernen: Symbolische Ansätze
 Maschinelles Lernen: Symbolische Ansätze Wintersemester 2009/2010 Musterlösung für das 9. Übungsblatt Aufgabe 1: Decision Trees Gegeben sei folgende Beispielmenge: Age Education Married Income Credit?
Maschinelles Lernen: Symbolische Ansätze Wintersemester 2009/2010 Musterlösung für das 9. Übungsblatt Aufgabe 1: Decision Trees Gegeben sei folgende Beispielmenge: Age Education Married Income Credit?
Bayessche Lineare Regression
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Baessche Lineare Regression Niels Landwehr Überblick Baessche Lernproblemstellung. Einführendes Beispiel: Münzwurfexperimente.
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Baessche Lineare Regression Niels Landwehr Überblick Baessche Lernproblemstellung. Einführendes Beispiel: Münzwurfexperimente.
5.4 Nächste-Nachbarn-Klassifikatoren
 5.4 Nächste-Nachbarn-Klassifikatoren Schrauben Nägel Klammern Neues Objekt Instanzbasiertes Lernen (instance based learning) Einfacher Nächster-Nachbar-Klassifikator: Zuordnung zu der Klasse des nächsten
5.4 Nächste-Nachbarn-Klassifikatoren Schrauben Nägel Klammern Neues Objekt Instanzbasiertes Lernen (instance based learning) Einfacher Nächster-Nachbar-Klassifikator: Zuordnung zu der Klasse des nächsten
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Niels Landwehr, Jules Rasetaharison, Christoph Sawade, Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen Niels Landwehr, Jules Rasetaharison, Christoph Sawade, Tobias Scheffer Organisation Vorlesung/Übung, praktische
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen Niels Landwehr, Jules Rasetaharison, Christoph Sawade, Tobias Scheffer Organisation Vorlesung/Übung, praktische
2. Lernen von Entscheidungsbäumen
 2. Lernen von Entscheidungsbäumen Entscheidungsbäume 2. Lernen von Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse
2. Lernen von Entscheidungsbäumen Entscheidungsbäume 2. Lernen von Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse
Modelle, Daten, Lernprobleme
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Modelle, Daten, Lernprobleme Tobias Scheffer Überblick Arten von Lernproblemen: Überwachtes Lernen (Klassifikation, Regression,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Modelle, Daten, Lernprobleme Tobias Scheffer Überblick Arten von Lernproblemen: Überwachtes Lernen (Klassifikation, Regression,
Reranking. Parse Reranking. Helmut Schmid. Institut für maschinelle Sprachverarbeitung Universität Stuttgart
 Institut für maschinelle Sprachverarbeitung Universität Stuttgart schmid@ims.uni-stuttgart.de Die Folien basieren teilweise auf Folien von Mark Johnson. Koordinationen Problem: PCFGs können nicht alle
Institut für maschinelle Sprachverarbeitung Universität Stuttgart schmid@ims.uni-stuttgart.de Die Folien basieren teilweise auf Folien von Mark Johnson. Koordinationen Problem: PCFGs können nicht alle
Modelle, Daten, Lernprobleme
 Universität Potsdam Institut für Informatik Lehrstuhl Modelle, Daten, Lernprobleme Tobias Scheffer Überblick Arten von Lernproblemen: Überwachtes Lernen (Klassifikation, Regression, ordinale Regression,
Universität Potsdam Institut für Informatik Lehrstuhl Modelle, Daten, Lernprobleme Tobias Scheffer Überblick Arten von Lernproblemen: Überwachtes Lernen (Klassifikation, Regression, ordinale Regression,
Algorithmen und Datenstrukturen 2
 Algorithmen und Datenstrukturen 2 Lerneinheit 3: Greedy Algorithmen Prof. Dr. Christoph Karg Studiengang Informatik Hochschule Aalen Sommersemester 2016 10.5.2016 Einleitung Einleitung Diese Lerneinheit
Algorithmen und Datenstrukturen 2 Lerneinheit 3: Greedy Algorithmen Prof. Dr. Christoph Karg Studiengang Informatik Hochschule Aalen Sommersemester 2016 10.5.2016 Einleitung Einleitung Diese Lerneinheit
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Hypothesenbewertung. Tobias Scheffer Michael Brückner
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hypothesenbewertung Tobias Scheffer Michael Brückner Hypothesenbewertung Ziel: gute Vorhersagen treffen. Bayesian model averaging,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hypothesenbewertung Tobias Scheffer Michael Brückner Hypothesenbewertung Ziel: gute Vorhersagen treffen. Bayesian model averaging,
Künstliche Intelligenz Maschinelles Lernen
 Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert Sommersemester 2009 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen
Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert Sommersemester 2009 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen
8. A & D - Heapsort. Werden sehen, wie wir durch geschicktes Organsieren von Daten effiziente Algorithmen entwerfen können.
 8. A & D - Heapsort Werden sehen, wie wir durch geschicktes Organsieren von Daten effiziente Algorithmen entwerfen können. Genauer werden wir immer wieder benötigte Operationen durch Datenstrukturen unterstützen.
8. A & D - Heapsort Werden sehen, wie wir durch geschicktes Organsieren von Daten effiziente Algorithmen entwerfen können. Genauer werden wir immer wieder benötigte Operationen durch Datenstrukturen unterstützen.
Hidden-Markov-Modelle
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hidden-Markov-Modelle Tobias Scheffer Thomas Vanck Hidden-Markov-Modelle: Wozu? Spracherkennung: Akustisches Modell. Geschriebene
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hidden-Markov-Modelle Tobias Scheffer Thomas Vanck Hidden-Markov-Modelle: Wozu? Spracherkennung: Akustisches Modell. Geschriebene
Folien zu Data Mining von I. H. Witten und E. Frank. übersetzt von N. Fuhr
 Folien zu Data Mining von I. H. Witten und E. Frank übersetzt von N. Fuhr Von Naivem Bayes zu Bayes'schen Netzwerken Naiver Bayes Annahme: Attribute bedingt unabhängig bei gegebener Klasse Stimmt in der
Folien zu Data Mining von I. H. Witten und E. Frank übersetzt von N. Fuhr Von Naivem Bayes zu Bayes'schen Netzwerken Naiver Bayes Annahme: Attribute bedingt unabhängig bei gegebener Klasse Stimmt in der
Kapitel 5: Ensemble Techniken
 Ludwig Maximilians Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Skript zur Vorlesung Knowledge Discovery in Databases II im Sommersemester 2009 Kapitel 5:
Ludwig Maximilians Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Skript zur Vorlesung Knowledge Discovery in Databases II im Sommersemester 2009 Kapitel 5:
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Sprachtechnologie. Tobias Scheffer Thomas Vanck
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Sprachtechnologie Tobias Scheffer Thomas Vanck Statistik & Maschinelles Lernen Statistik: Deskriptive Statistik: Beschreibung (Tabellen,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Sprachtechnologie Tobias Scheffer Thomas Vanck Statistik & Maschinelles Lernen Statistik: Deskriptive Statistik: Beschreibung (Tabellen,
Data Mining - Wiederholung
 Data Mining - Wiederholung Norbert Fuhr 18. Januar 2006 Problemstellungen Problemstellungen Daten vs. Information Def. Data Mining Arten von strukturellen Beschreibungen Regeln (Klassifikation, Assoziations-)
Data Mining - Wiederholung Norbert Fuhr 18. Januar 2006 Problemstellungen Problemstellungen Daten vs. Information Def. Data Mining Arten von strukturellen Beschreibungen Regeln (Klassifikation, Assoziations-)
Decision-Tree-Klassifikator
 D3kjd3Di38lk323nnm Decision-Tree-Klassifikator Decision Trees haben einige Vorteile gegenüber den beiden schon beschriebenen Klassifikationsmethoden. Man benötigt in der Regel keine so aufwendige Vorverarbeitung
D3kjd3Di38lk323nnm Decision-Tree-Klassifikator Decision Trees haben einige Vorteile gegenüber den beiden schon beschriebenen Klassifikationsmethoden. Man benötigt in der Regel keine so aufwendige Vorverarbeitung
Pairwise Naive Bayes Classifier
 Pairwise Naive Bayes Classifier Jan-Nikolas Sulzmann 1 1 nik.sulzmann@gmx.de Fachbereich Knowledge Engineering Technische Universität Darmstadt Gliederung 1 Ziel dieser Arbeit 2 Naive Bayes Klassifizierer
Pairwise Naive Bayes Classifier Jan-Nikolas Sulzmann 1 1 nik.sulzmann@gmx.de Fachbereich Knowledge Engineering Technische Universität Darmstadt Gliederung 1 Ziel dieser Arbeit 2 Naive Bayes Klassifizierer
3.5 Entscheidungsbaum- Klassifikatoren. Motivation. finden explizites Wissen Entscheidungsbäume sind für die meisten Benutzer verständlich
 3.5 Entscheidungsbaum- Klassifikatoren Motivation ID Alter Autotyp Risiko 1 23 Familie hoch 2 17 Sport hoch 3 43 Sport hoch 4 68 Familie niedrig 5 32 LKW niedrig Autotyp = LKW LKW Risikoklasse = niedrig
3.5 Entscheidungsbaum- Klassifikatoren Motivation ID Alter Autotyp Risiko 1 23 Familie hoch 2 17 Sport hoch 3 43 Sport hoch 4 68 Familie niedrig 5 32 LKW niedrig Autotyp = LKW LKW Risikoklasse = niedrig
INTELLIGENTE DATENANALYSE IN MATLAB. Evaluation & Exploitation von Modellen
 INTELLIGENTE DATENANALYSE IN MATLAB Evaluation & Exploitation von Modellen Überblick Schritte der Datenanalyse: Datenvorverarbeitung Problemanalyse Problemlösung Anwendung der Lösung Aggregation und Selektion
INTELLIGENTE DATENANALYSE IN MATLAB Evaluation & Exploitation von Modellen Überblick Schritte der Datenanalyse: Datenvorverarbeitung Problemanalyse Problemlösung Anwendung der Lösung Aggregation und Selektion
Wann sind Codes eindeutig entschlüsselbar?
 Wann sind Codes eindeutig entschlüsselbar? Definition Suffix Sei C ein Code. Ein Folge s {0, 1} heißt Suffix in C falls 1 c i, c j C : c i = c j s oder 2 c C und einen Suffix s in C: s = cs oder 3 c C
Wann sind Codes eindeutig entschlüsselbar? Definition Suffix Sei C ein Code. Ein Folge s {0, 1} heißt Suffix in C falls 1 c i, c j C : c i = c j s oder 2 c C und einen Suffix s in C: s = cs oder 3 c C
INTELLIGENTE DATENANALYSE IN MATLAB. Evaluation & Exploitation von Modellen
 INTELLIGENTE DATENANALYSE IN MATLAB Evaluation & Exploitation von Modellen Überblick Schritte der Datenanalyse: Datenvorverarbeitung Problemanalyse Problemlösung Anwendung der Lösung Aggregation und Selektion
INTELLIGENTE DATENANALYSE IN MATLAB Evaluation & Exploitation von Modellen Überblick Schritte der Datenanalyse: Datenvorverarbeitung Problemanalyse Problemlösung Anwendung der Lösung Aggregation und Selektion
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Bayes sches Lernen. Niels Landwehr
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayes sches Lernen Niels Landwehr Überblick Grundkonzepte des Bayes schen Lernens Wahrscheinlichstes Modell gegeben Daten Münzwürfe
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayes sches Lernen Niels Landwehr Überblick Grundkonzepte des Bayes schen Lernens Wahrscheinlichstes Modell gegeben Daten Münzwürfe
19. Dynamic Programming I
 495 19. Dynamic Programming I Fibonacci, Längste aufsteigende Teilfolge, längste gemeinsame Teilfolge, Editierdistanz, Matrixkettenmultiplikation, Matrixmultiplikation nach Strassen [Ottman/Widmayer, Kap.
495 19. Dynamic Programming I Fibonacci, Längste aufsteigende Teilfolge, längste gemeinsame Teilfolge, Editierdistanz, Matrixkettenmultiplikation, Matrixmultiplikation nach Strassen [Ottman/Widmayer, Kap.
Analytics Entscheidungsbäume
 Analytics Entscheidungsbäume Professional IT Master Prof. Dr. Ingo Claßen Hochschule für Technik und Wirtschaft Berlin Regression Klassifikation Quellen Regression Beispiel Baseball-Gehälter Gehalt: gering
Analytics Entscheidungsbäume Professional IT Master Prof. Dr. Ingo Claßen Hochschule für Technik und Wirtschaft Berlin Regression Klassifikation Quellen Regression Beispiel Baseball-Gehälter Gehalt: gering
Algorithmen II Vorlesung am
 Algorithmen II Vorlesung am..03 Randomisierte Algorithmen INSTITUT FÜR THEORETISCHE INFORMATIK PROF. DR. DOROTHEA WAGNER KIT Universität des Landes Baden-Württemberg und Algorithmen nationales Forschungszentrum
Algorithmen II Vorlesung am..03 Randomisierte Algorithmen INSTITUT FÜR THEORETISCHE INFORMATIK PROF. DR. DOROTHEA WAGNER KIT Universität des Landes Baden-Württemberg und Algorithmen nationales Forschungszentrum
Classification and Regression Trees. Markus Müller
 Classification and Regression Trees Markus Müller Gliederung Lernen Entscheidungsbäume Induktives Lernen von Bäumen ID3 Algorithmus Einfluß der Beispielmenge auf den Baum Möglichkeiten zur Verbesserung
Classification and Regression Trees Markus Müller Gliederung Lernen Entscheidungsbäume Induktives Lernen von Bäumen ID3 Algorithmus Einfluß der Beispielmenge auf den Baum Möglichkeiten zur Verbesserung
Maschinelles Lernen: Symbolische Ansätze
 Klausur zur Vorlesung Maschinelles Lernen: Symbolische Ansätze Prof. J. Fürnkranz Technische Universität Darmstadt Wintersemester 2014/15 Termin: 17. 2. 2015 Name: Vorname: Matrikelnummer: Fachrichtung:
Klausur zur Vorlesung Maschinelles Lernen: Symbolische Ansätze Prof. J. Fürnkranz Technische Universität Darmstadt Wintersemester 2014/15 Termin: 17. 2. 2015 Name: Vorname: Matrikelnummer: Fachrichtung:
Motivation. Themenblock: Klassifikation. Binäre Entscheidungsbäume. Ansätze. Praktikum: Data Warehousing und Data Mining.
 Motivation Themenblock: Klassifikation Praktikum: Data Warehousing und Data Mining Ziel Item hat mehrere Attribute Anhand von n Attributen wird (n+)-tes vorhergesagt. Zusätzliches Attribut erst später
Motivation Themenblock: Klassifikation Praktikum: Data Warehousing und Data Mining Ziel Item hat mehrere Attribute Anhand von n Attributen wird (n+)-tes vorhergesagt. Zusätzliches Attribut erst später
Ringvorlesung interdisziplinäre, angewandte Mathematik: Maschinelles Lernen
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Ringvorlesung interdisziplinäre, angewandte Mathematik: Maschinelles Lernen Niels Landwehr, Paul Prasse, Termine VL Dienstag 12:15-13:45,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Ringvorlesung interdisziplinäre, angewandte Mathematik: Maschinelles Lernen Niels Landwehr, Paul Prasse, Termine VL Dienstag 12:15-13:45,
Methoden der Datenanalyse AI-basierte Decision Support Systeme WS 2006/07
 Regression Trees Methoden der Datenanalyse AI-basierte Decision Support Systeme WS 2006/07 Ao.Univ.Prof. Dr. Marcus Hudec marcus.hudec@univie.ac.at Institut für Scientific Computing, Universität Wien 2
Regression Trees Methoden der Datenanalyse AI-basierte Decision Support Systeme WS 2006/07 Ao.Univ.Prof. Dr. Marcus Hudec marcus.hudec@univie.ac.at Institut für Scientific Computing, Universität Wien 2
Induktion von Entscheidungsbäumen
 Induktion von Entscheidungsbäumen Christian Borgelt Institut für Wissens- und Sprachverarbeitung Otto-von-Guericke-Universität Magdeburg Universitätsplatz 2, 39106 Magdeburg E-mail: borgelt@iws.cs.uni-magdeburg.de
Induktion von Entscheidungsbäumen Christian Borgelt Institut für Wissens- und Sprachverarbeitung Otto-von-Guericke-Universität Magdeburg Universitätsplatz 2, 39106 Magdeburg E-mail: borgelt@iws.cs.uni-magdeburg.de
19. Dynamic Programming I
 495 19. Dynamic Programming I Fibonacci, Längste aufsteigende Teilfolge, längste gemeinsame Teilfolge, Editierdistanz, Matrixkettenmultiplikation, Matrixmultiplikation nach Strassen [Ottman/Widmayer, Kap.
495 19. Dynamic Programming I Fibonacci, Längste aufsteigende Teilfolge, längste gemeinsame Teilfolge, Editierdistanz, Matrixkettenmultiplikation, Matrixmultiplikation nach Strassen [Ottman/Widmayer, Kap.
Informatik-Seminar Thema 6: Bäume
 Informatik-Seminar 2003 - Thema 6: Bäume Robin Brandt 14. November 2003 1 Robin Brandt Informatik-Seminar 2003 - Thema 6: Bäume Übersicht Definition Eigenschaften Operationen Idee Beispiel Datendefinition
Informatik-Seminar 2003 - Thema 6: Bäume Robin Brandt 14. November 2003 1 Robin Brandt Informatik-Seminar 2003 - Thema 6: Bäume Übersicht Definition Eigenschaften Operationen Idee Beispiel Datendefinition
Vorlesung Wissensentdeckung
 Vorlesung Wissensentdeckung Additive Modelle Katharina Morik, Weihs 2.6.2015 1 von 33 Gliederung 1 Merkmalsauswahl Gütemaße und Fehlerabschätzung 2 von 33 Ausgangspunkt: Funktionsapproximation Die bisher
Vorlesung Wissensentdeckung Additive Modelle Katharina Morik, Weihs 2.6.2015 1 von 33 Gliederung 1 Merkmalsauswahl Gütemaße und Fehlerabschätzung 2 von 33 Ausgangspunkt: Funktionsapproximation Die bisher
4 Induktion von Regeln
 4 Induktion von egeln Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- aare beschrieben sind. Jedes Objekt kann einer Klasse zugeordnet werden. Ein Entscheidungsbaum liefert eine Entscheidung
4 Induktion von egeln Gegeben sei eine Menge von Objekten, die durch Attribut/Wert- aare beschrieben sind. Jedes Objekt kann einer Klasse zugeordnet werden. Ein Entscheidungsbaum liefert eine Entscheidung
Einführung in das Maschinelle Lernen I
 Einführung in das Maschinelle Lernen I Vorlesung Computerlinguistische Techniken Alexander Koller 26. Januar 2015 Maschinelles Lernen Maschinelles Lernen (Machine Learning): äußerst aktiver und für CL
Einführung in das Maschinelle Lernen I Vorlesung Computerlinguistische Techniken Alexander Koller 26. Januar 2015 Maschinelles Lernen Maschinelles Lernen (Machine Learning): äußerst aktiver und für CL
4. Lernen von Entscheidungsbäumen. Klassifikation mit Entscheidungsbäumen. Entscheidungsbaum
 4. Lernen von Entscheidungsbäumen Klassifikation mit Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch /Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse zugeordnet werden.
4. Lernen von Entscheidungsbäumen Klassifikation mit Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch /Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse zugeordnet werden.
Data Mining und Text Mining Einführung. S2 Einfache Regellerner
 Data Mining und Text Mining Einführung S2 Einfache Regellerner Hans Hermann Weber Univ. Erlangen, Informatik 8 Wintersemester 2003 hans.hermann.weber@gmx.de Inhalt Einiges über Regeln und Bäume R1 ein
Data Mining und Text Mining Einführung S2 Einfache Regellerner Hans Hermann Weber Univ. Erlangen, Informatik 8 Wintersemester 2003 hans.hermann.weber@gmx.de Inhalt Einiges über Regeln und Bäume R1 ein
BZQ II: Stochastikpraktikum
 BZQ II: Stochastikpraktikum Block 3: Lineares Modell, Klassifikation, PCA Randolf Altmeyer January 9, 2017 Überblick 1 Monte-Carlo-Methoden, Zufallszahlen, statistische Tests 2 Nichtparametrische Methoden
BZQ II: Stochastikpraktikum Block 3: Lineares Modell, Klassifikation, PCA Randolf Altmeyer January 9, 2017 Überblick 1 Monte-Carlo-Methoden, Zufallszahlen, statistische Tests 2 Nichtparametrische Methoden
Mehrwegbäume Motivation
 Mehrwegbäume Motivation Wir haben gute Strukturen (AVL-Bäume) kennen gelernt, die die Anzahl der Operationen begrenzen Was ist, wenn der Baum zu groß für den Hauptspeicher ist? Externe Datenspeicherung
Mehrwegbäume Motivation Wir haben gute Strukturen (AVL-Bäume) kennen gelernt, die die Anzahl der Operationen begrenzen Was ist, wenn der Baum zu groß für den Hauptspeicher ist? Externe Datenspeicherung
Effizienter Planaritätstest Vorlesung am
 Effizienter Planaritätstest Vorlesung am 23.04.2014 INSTITUT FÜR THEORETISCHE INFORMATIK PROF. DR. DOROTHEA WAGNER Satz Gegebenen einen Graphen G = (V, E) mit n Kanten und m Knoten, kann in O(n + m) Zeit
Effizienter Planaritätstest Vorlesung am 23.04.2014 INSTITUT FÜR THEORETISCHE INFORMATIK PROF. DR. DOROTHEA WAGNER Satz Gegebenen einen Graphen G = (V, E) mit n Kanten und m Knoten, kann in O(n + m) Zeit
Maschinelles Lernen: Symbolische Ansätze
 Maschinelles Lernen: Symbolische Ansätze Wintersemester 2009/2010 Musterlösung für das 1. Übungsblatt Aufgabe 1: Anwendungsszenario Überlegen Sie sich ein neues Szenario des klassifizierenden Lernens (kein
Maschinelles Lernen: Symbolische Ansätze Wintersemester 2009/2010 Musterlösung für das 1. Übungsblatt Aufgabe 1: Anwendungsszenario Überlegen Sie sich ein neues Szenario des klassifizierenden Lernens (kein
Kapitel 10. Maschinelles Lernen Lineare Regression. Welche Gerade? Problemstellung. Th. Jahn. Sommersemester 2017
 10.1 Sommersemester 2017 Problemstellung Welche Gerade? Gegeben sind folgende Messungen: Masse (kg) 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 Kraft (N) 1.6 2.2 3.2 3.0 4.9 5.7 7.1 7.3 8.1 Annahme: Es gibt eine Funktion
10.1 Sommersemester 2017 Problemstellung Welche Gerade? Gegeben sind folgende Messungen: Masse (kg) 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 Kraft (N) 1.6 2.2 3.2 3.0 4.9 5.7 7.1 7.3 8.1 Annahme: Es gibt eine Funktion
Data Mining und maschinelles Lernen
 Data Mining und maschinelles Lernen Einführung und Anwendung mit WEKA Caren Brinckmann 16. August 2000 http://www.coli.uni-sb.de/~cabr/vortraege/ml.pdf http://www.cs.waikato.ac.nz/ml/weka/ Inhalt Einführung:
Data Mining und maschinelles Lernen Einführung und Anwendung mit WEKA Caren Brinckmann 16. August 2000 http://www.coli.uni-sb.de/~cabr/vortraege/ml.pdf http://www.cs.waikato.ac.nz/ml/weka/ Inhalt Einführung:
Vorlesung Wissensentdeckung
 Gliederung Vorlesung Wissensentdeckung Additive Modelle Katharina Morik, Weihs 1 Merkmalsauswahl Gütemaße und Fehlerabschätzung.6.015 1 von 33 von 33 Ausgangspunkt: Funktionsapproximation Aufteilen der
Gliederung Vorlesung Wissensentdeckung Additive Modelle Katharina Morik, Weihs 1 Merkmalsauswahl Gütemaße und Fehlerabschätzung.6.015 1 von 33 von 33 Ausgangspunkt: Funktionsapproximation Aufteilen der
Vorlesung Digitale Bildverarbeitung Sommersemester 2013
 Vorlesung Digitale Bildverarbeitung Sommersemester 2013 Sebastian Houben (Marc Schlipsing) Institut für Neuroinformatik Inhalt Crash-Course in Machine Learning Klassifikationsverfahren Grundsätzliches
Vorlesung Digitale Bildverarbeitung Sommersemester 2013 Sebastian Houben (Marc Schlipsing) Institut für Neuroinformatik Inhalt Crash-Course in Machine Learning Klassifikationsverfahren Grundsätzliches
5. Klassifikation. 5.1 Einleitung. 5.1 Der Prozess der Klassifikation. 5.1 Einleitung. Inhalt dieses Kapitels. Das Klassifikationsproblem
 5. Klassifikation Inhalt dieses Kapitels 5.1 Einleitung Das Klassifikationsproblem, Bewertung von Klassifikatoren 5.2 Bayes-Klassifikatoren Optimaler Bayes-Klassifikator, Naiver Bayes-Klassifikator, Anwendungen
5. Klassifikation Inhalt dieses Kapitels 5.1 Einleitung Das Klassifikationsproblem, Bewertung von Klassifikatoren 5.2 Bayes-Klassifikatoren Optimaler Bayes-Klassifikator, Naiver Bayes-Klassifikator, Anwendungen
5. Klassifikation. Inhalt dieses Kapitels. Das Klassifikationsproblem, Bewertung von Klassifikatoren
 5.1 Einleitung 5. Klassifikation Inhalt dieses Kapitels Das Klassifikationsproblem, Bewertung von Klassifikatoren 5.2 Bayes-Klassifikatoren Optimaler Bayes-Klassifikator, Naiver Bayes-Klassifikator, Anwendungen
5.1 Einleitung 5. Klassifikation Inhalt dieses Kapitels Das Klassifikationsproblem, Bewertung von Klassifikatoren 5.2 Bayes-Klassifikatoren Optimaler Bayes-Klassifikator, Naiver Bayes-Klassifikator, Anwendungen
5.1 Einleitung. 5. Klassifikation. 5.1 Einleitung. 5.1 Der Prozess der Klassifikation. Inhalt dieses Kapitels. Beispiel. Konstruktion des Modells
 5.1 Einleitung 5. Klassifikation Inhalt dieses Kapitels Das Klassifikationsproblem, Bewertung von Klassifikatoren 5.2 Bayes-Klassifikatoren Optimaler Bayes-Klassifikator, Naiver Bayes-Klassifikator, Anwendungen
5.1 Einleitung 5. Klassifikation Inhalt dieses Kapitels Das Klassifikationsproblem, Bewertung von Klassifikatoren 5.2 Bayes-Klassifikatoren Optimaler Bayes-Klassifikator, Naiver Bayes-Klassifikator, Anwendungen
Algorithmen und Komplexität Lösungsvorschlag zu Übungsblatt 8
 ETH Zürich Institut für Theoretische Informatik Prof. Dr. Angelika Steger Florian Meier, Ralph Keusch HS 2017 Algorithmen und Komplexität Lösungsvorschlag zu Übungsblatt 8 Lösungsvorschlag zu Aufgabe 1
ETH Zürich Institut für Theoretische Informatik Prof. Dr. Angelika Steger Florian Meier, Ralph Keusch HS 2017 Algorithmen und Komplexität Lösungsvorschlag zu Übungsblatt 8 Lösungsvorschlag zu Aufgabe 1
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Clusteranalyse. Tobias Scheffer Thomas Vanck
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Thomas Vanck Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Thomas Vanck Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Data Mining auf Datenströmen Andreas M. Weiner
 Technische Universität Kaiserslautern Fachbereich Informatik Lehrgebiet Datenverwaltungssysteme Integriertes Seminar Datenbanken und Informationssysteme Sommersemester 2005 Thema: Data Streams Andreas
Technische Universität Kaiserslautern Fachbereich Informatik Lehrgebiet Datenverwaltungssysteme Integriertes Seminar Datenbanken und Informationssysteme Sommersemester 2005 Thema: Data Streams Andreas
Von schwachen zu starken Lernern
 Von schwachen zu starken Lernern Wir nehmen an, dass ein schwacher Lernalgorithmus L mit vielen Beispielen, aber großem Fehler ε = 1 2 θ gegeben ist. - Wie lässt sich der Verallgemeinerungsfehler ε von
Von schwachen zu starken Lernern Wir nehmen an, dass ein schwacher Lernalgorithmus L mit vielen Beispielen, aber großem Fehler ε = 1 2 θ gegeben ist. - Wie lässt sich der Verallgemeinerungsfehler ε von
Künstliche Intelligenz Maschinelles Lernen
 Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert WS 2009/2010 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen Unüberwachtes
Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert WS 2009/2010 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen Unüberwachtes
Übersicht. Definition Daten Problemklassen Fehlerfunktionen
 Übersicht 1 Maschinelle Lernverfahren Definition Daten Problemklassen Fehlerfunktionen 2 Entwickeln von maschinellen Lernverfahren Aufteilung der Daten Underfitting und Overfitting Erkennen Regularisierung
Übersicht 1 Maschinelle Lernverfahren Definition Daten Problemklassen Fehlerfunktionen 2 Entwickeln von maschinellen Lernverfahren Aufteilung der Daten Underfitting und Overfitting Erkennen Regularisierung
Überblick. Grundkonzepte des Bayes schen Lernens. Wahrscheinlichstes Modell gegeben Daten Münzwürfe Lineare Regression Logistische Regression
 Überblic Grundonepte des Bayes schen Lernens Wahrscheinlichstes Modell gegeben Daten Münwürfe Lineare Regression Logistische Regression Bayes sche Vorhersage Münwürfe Lineare Regression 14 Modell für Münwürfe
Überblic Grundonepte des Bayes schen Lernens Wahrscheinlichstes Modell gegeben Daten Münwürfe Lineare Regression Logistische Regression Bayes sche Vorhersage Münwürfe Lineare Regression 14 Modell für Münwürfe
Programm heute. Algorithmen und Datenstrukturen (für ET/IT) Suchen. Lineare Suche. Such-Algorithmen. Sommersemester Dr.
 Suchen. Lineare Suche. Such-Algorithmen. Sommersemester Dr.") Programm heute Algorithmen und Datenstrukturen (für ET/IT) Sommersemester 0 Dr. Tobias Lasser Computer Aided Medical Procedures Technische Universität München Fortgeschrittene Datenstrukturen Such-Algorithmen
Programm heute Algorithmen und Datenstrukturen (für ET/IT) Sommersemester 0 Dr. Tobias Lasser Computer Aided Medical Procedures Technische Universität München Fortgeschrittene Datenstrukturen Such-Algorithmen
Die Datenmatrix für Überwachtes Lernen
 Die Datenmatrix für Überwachtes Lernen X j j-te Eingangsvariable X = (X 0,..., X M 1 ) T Vektor von Eingangsvariablen M Anzahl der Eingangsvariablen N Anzahl der Datenpunkte Y Ausgangsvariable x i = (x
Die Datenmatrix für Überwachtes Lernen X j j-te Eingangsvariable X = (X 0,..., X M 1 ) T Vektor von Eingangsvariablen M Anzahl der Eingangsvariablen N Anzahl der Datenpunkte Y Ausgangsvariable x i = (x