Bio Data Management. Kapitel 7 Annotationen
|
|
|
- Viktor Lorentz
- vor 6 Jahren
- Abrufe
Transkript
1 Bio Data Management Kapitel 7 Annotationen Wersemester 2014/15 Dr. Anika Groß Universität Leipzig, Institut für Informatik, Abteilung Datenbanken
2 Vorläufiges Inhaltsverzeichnis 1. Motivation und Grundlagen 2. Bio-Datenbanken 3. Datenmodelle und Anfragesprachen 4. Modellierung von Bio-Datenbanken 5. Sequenzierung und Alignments 6. Genexpressionsanalyse 7. Annotationen 8. Datenegration: Ansätze und Systeme 9. Schema- und Ontologiematching 10. Versionierung von Datenbeständen WS 2014/15, Universität Leipzig, Anika Groß 2
3 Informationsflut in den Lebenswissenschaften Zehntausende Gene und gen-regulatorische Elemente (in versch. Spezies) Zahlreiche Interaktionen in komplexen molekularen Netzwerken Millionen von Publikationen... Zuordnung Hattori A, Tsujimoto M.: Processing of antigenic peptides by aminopeptidases. Biol Pharm Bull., 2004 der Funktionen, Prozesse, Interaktionen zu biologischen Objekten der enthaltenen Themen zu Publikationen... Nutzen maschinenverstehbarer Annotationen WS 2014/15, Universität Leipzig, Anika Groß 3
4 Annotationen in den Lebenswissenschaften Annotationen dienen der semantischen Beschreibung der Eigenschaften von (biologischen) Objekten Zur Erfassung von Metadaten Möglichst einheitlicher Gebrauch der domänenspezifischen Begriffe Assoziationen eines zu beschreibenden Objekts zu den Begriffen eines Vokabulars bzw. den Konzepten einer Ontologie Zunächst: Was ist eine Ontologie??? WS 2014/15, Universität Leipzig, Anika Groß 4
5 Ontologien Begriff in Philosophie Informatik An ontology is an explicit specification of a conceptualization. (T. R. Gruber, 1993) Erweiterung: An ontology is an explicit, formal specification of a shared conceptualization in a domain of erest. Ausschnitt NCI Thesaurus Ausschnitt Gene Ontology (GO) Anatomic Structure, System, or Substance Biological Process Body Part Organ Tissue Growth Signaling Kidney Lung Skin Cell growth Organ growth Left Lung Right Lung heart growth lung growth WS 2014/15, Universität Leipzig, Anika Groß 5
6 Repräsentation von Bio-Ontologien [Term] id: MA: name: heart relationship: part_of MA: ! cardiovascular system relationship: part_of MA: ! heart/pericardium OBO = Open Biomedical Ontologies <owl:class rdf:about=" <rdfs:label xml:lang="en">heart</rdfs:label> <oboinowl:hasobonamespace>adult_mouse_anatomy.gxd</oboinowl:hasobonamespace> <rdfs:subclassof> <owl:restriction> <owl:onproperty> <owl:objectproperty rdf:about=" </owl:onproperty> <owl:somevaluesfrom rdf:resource=" </owl:restriction> </rdfs:subclassof> <rdfs:subclassof> OWL = Web Ontology Language <owl:restriction> <owl:onproperty> <owl:objectproperty rdf:about=" </owl:onproperty> <owl:somevaluesfrom rdf:resource=" </owl:restriction> </rdfs:subclassof> </owl:class>< WS 2014/15, Universität Leipzig, Anika Groß 6

7 Ontologietypen O.Lassila, D. McGuinness: The Role of Frame-Based Representation on the Semantic Web. Stanford Knowledge Systems Laboratory, WS 2014/15, Universität Leipzig, Anika Groß 7


8 Ontologie-Editoren protege.stanford.edu WS 2014/15, Universität Leipzig, Anika Groß 8



9 Ontologie-Browser bioportal.bioontology.org WS 2014/15, Universität Leipzig, Anika Groß 9

10 Weit verbreitete Anwendung der Gene Ontology WS 2014/15, Universität Leipzig, Anika Groß 10



11 Arten von Annotationen - Biologische Objekte (Gene, Proteine, ) - Pathways, Netzwerke -... Experiment- Annotation MIAME, MGED... Annotation biologischer Objekte / Pathways GO, KEGG,... Annotation von Publikationen (indexing) MeSH, GO,... Annotation von klinischen Dokumenten ICD, SNOMED, LOINC,... MIAME MGED KEGG MeSH ICD SNOMED LOINC NCIT Minimum Information About a Microarray Experiment Microarray Gene Expression Data Kyoto Encyclopedia of Genes and Genomes Medical Subject Headings International Classification of Diseases Systematized Nomenclature of Medicine Clinical Terms Logical Observation Identifiers Names and Codes NCI (National Cancer Institute) Thesaurus WS 2014/15, Universität Leipzig, Anika Groß 11
12 Annotationsmodell Ontologie O 1 = (C, R) Ontologie O 2 = (C, R) Annotation-Mapping (S, O 1, A) Instanzquelle S = I Annotation-Mapping (S, O 2, A) C R I A Menge von Konzepten Menge von Relationen Menge von Instanzen Menge von Annotationen / Korrepondenzen Annotation a=(i,c), aa, ii, cc, object_id - concept_id WS 2014/15, Universität Leipzig, Anika Groß 12

13 Beispiel: GO-Annotationen Assoziation eines Proteins zu einem/r bestimmten biologischen Prozess / zellulären Komponente / molekularen Funktion Component: is egral to membrane TAP1 Process: peptide transport Function: protein heterodimerization activity GO-Konzept is egral to membrane - Details Accession GO: Name is egral to membrane Definition Penetrating at least one phospholipid bilayer of a membrane. [...] Synonym transmembrane is_obsolete false WS 2014/15, Universität Leipzig, Anika Groß 13
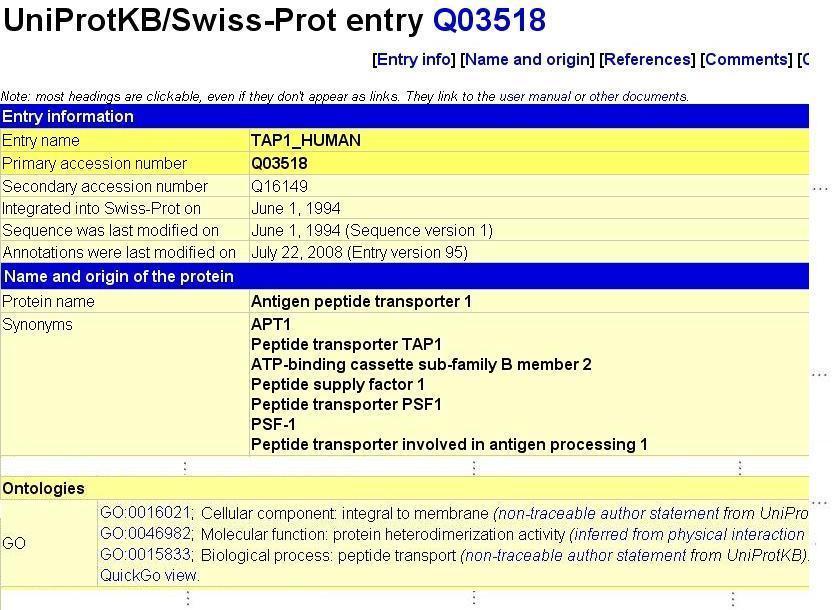
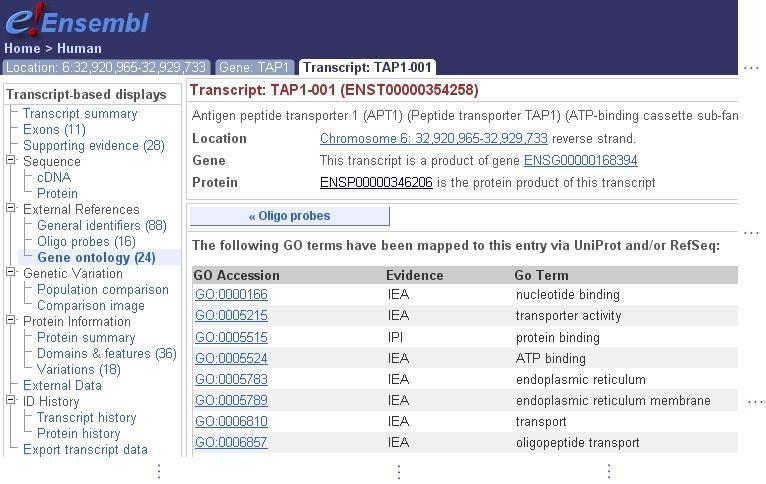
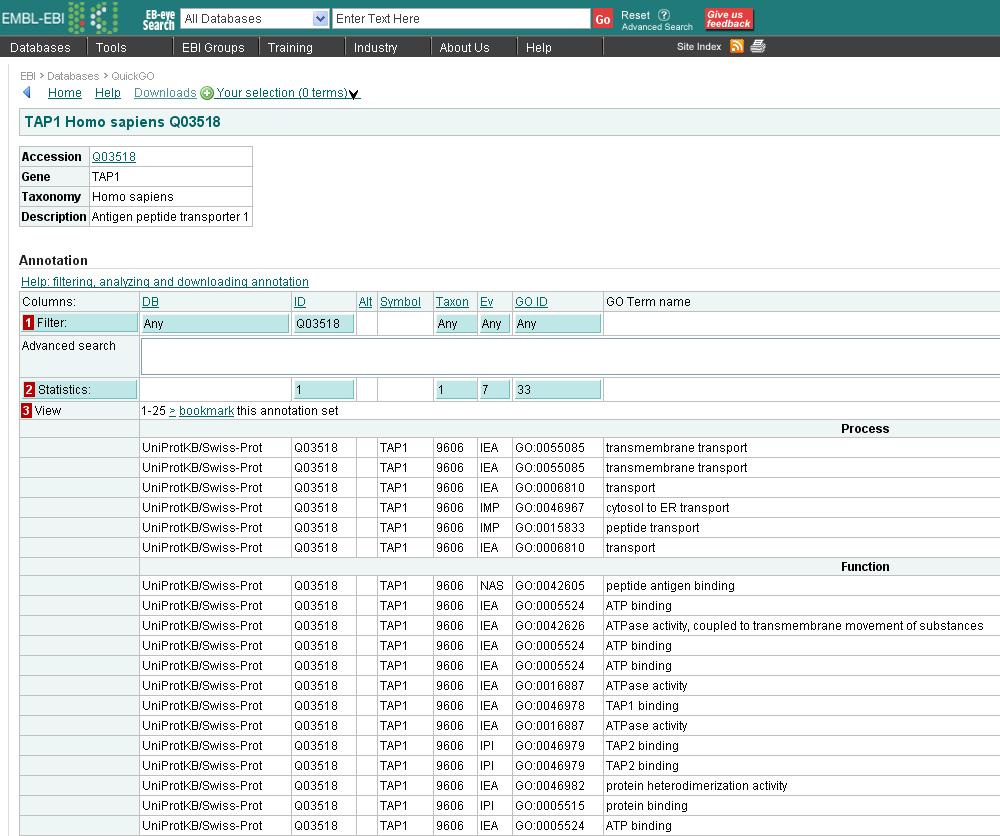
14 Beispiel: GO-Annotationen WS 2014/15, Universität Leipzig, Anika Groß 14


15 Beispiel: MeSH-Annotationen MeSH = Medical Subject Headings WS 2014/15, Universität Leipzig, Anika Groß 15
16 Repräsentation von Annotationen Nicht normalisiert, z.b. CSV-Dateien von GOA Entry-Modell, z.b. Entry-Modell von SwissProt Normalisiert, ER, z.b. MySQL-DB von Ensembl GOA db db_object_id db_object_symbol qualifier go_id db_reference Evidence EC_with aspect db_object_name synonym db_object_type tax_id ins_date assigned_by - UniProtKB - Q TAP1_HUMAN - - GO: GOA:spkw GO_REF: IEA - SP_KW:KW F - Antigen peptide transporter 1 - TAP1, ABCB2, PSF1, RING4, Y3: Antigen peptide transporter 1, IPI Protein - taxon: UniProtKB WS 2014/15, Universität Leipzig, Anika Groß 16
17 Repräsentation von Annotationen SwissProt WS 2014/15, Universität Leipzig, Anika Groß 17
18 WS 2014/15, Universität Leipzig, Anika Groß 18 Ensembl Repräsentation von Annotationen Gene gene_id Type varchar analysis_id seq_region_id seq_region_start seq_region_end seq_region_strand tiny display_xref_id gene_stable_id gene_id stable_id varchar version transcript transcript_id gene_id seq_region_id seq_region_start seq_region_end seq_region_strand tiny display_xref_id translation translation_id transcript_id seq_start start_exon_id seq_end end_exon_id n 1 object_xref object_xref_id ensembl_id ensembl_object _type Translation, Gene, Transcript xref_id xref xref_id external_db_id dbprimary_acc varchar display_label varchar version varchar description varchar external_db external_db_id dbname varchar release varchar status KNOWN, PRED, ORTH, go_xref object_xref_id linkage_type IC, IDA, IEA, IEP, IGI, IMP, IPI, n 1..n 1
19 Erweitertes Annotationsmodell Ontologie O 1 = (C, R) Ontologie O 2 = (C, R) Qualitätstaxonomien Q = (Q 1,,Q m ) Annotation-Mapping (S, O 1, Q, A) Annotation-Mapping (S, O 2, Q, A) Instanzquelle S = I Speichern zusätzlicher Korrespondenz-Informationen Verweis auf Qualitätstaxonomie(n) Annotation aa, a=(i,c,{q}) concept_id object_id {qual_term} z.b. Annotationsherkunft (provenance) Evidence Codes Andere: Curator, Methode, Datum, Quelle... WS 2014/15, Universität Leipzig, Anika Groß 19
20 Herkunft von GO-Annotationen - Evidence Codes Herkunft/Ursprung von Annotationen: engl. provenance Evidence Code (EC) * gibt an, woher die Annotation zu einem bestimmten Term stammt z.b. durch welche Art von Experiment oder Analyse wurde die Information nachgewiesen Repräsentation durch Taxonomie kann als Qualitätsmerkmal genutzt werden, Zuverlässigkeit (engl. reliability) All ECs Manually assigned (man man) Automatically assigned (auto auto) Obsolete (obs obs) Experimental (exp exp) Author Statement (auth auth) Curator Statement (cur ( cur) Computational Analysis (comp ( comp) EXP TAS NAS IC ND RCA IGC ISS IEA NR IDA IPI IMP IGI IEP High reliability ISO ISA ISM * L ow reliability WS 2014/15, Universität Leipzig, Anika Groß 20
21 Methoden der automatischen Annotation Ziel: Vorschlagsgenerierung (Verifikation notwendig!) IEA (Inferred from Electronic Annotation): automatische Zuordnung, kein Curator; automatische Berechnung oder Übertragung von Annotationen ISS (Inferred from Sequence or Structural Similarity): sequenzbasierte Analyse, Zuordnung nach manueller Bewertung Methoden Sequenzähnlichkeit, Homologie-Mappings Funktionale Gruppen (funktional ähnliche Proteine, InterPro) Keyword-Mappings (SwissProt, Enzyme Codes) Text-Mining: Automatische Extraktion von Annotationen aus Publikationen WS 2014/15, Universität Leipzig, Anika Groß 21
22 Text Mining zur Automatischen Annotation Text Mining: Automatisierter Prozess zur Analyse natürlicher Sprache in Texten 1) Auffinden relevanter Dokumente (Information Retrieval (IR)) z.b. alle Artikel zu einem Protein, alle neuen Artikel (letzter Monat/letztes Jahr/ ), Suche in Literaturdatenbank (z.b. Pubmed) Query auf indexierten Texten Einbeziehen von Textstatistiken z.b. inverse Dokumenthäufigkeit (Inverse document frequency) Gesamtanzahl an Dokumenten in DB IDF t =log Anzahl der Dokumente mit dem Term t WS 2014/15, Universität Leipzig, Anika Groß 22
23 Text Mining zur Automatischen Annotation 2) Auffinden biologisch bedeutsamer semantischer Strukturen in Texten (Information Extraction (IE)) a) Tagging biologischer Entitäten b) Erkennen von Beziehungen Named Entity Recognition (NER): Erkennen von Entitäten (Proteine, Gene, Krankheiten, Funktionen, Prozesse ) in Texten z.b. erwähnt als Genesymbol/ID/Accession, Name, Synonym, Stemming (Identifizieren des Wortstamms) POS (Part of speech): Identifizieren der Wortart (z.b. Substantiv, Verb, Adjektiv, ) Verwenden von domänenspezifischen Wörterbüchern, Ontologien, Identifikation von Mustern, Nutzen regelbasierter Ansätze, maschinelles Lernen (SVM, HMM, Entscheidungsbaum, ) Abb: WS 2014/15, Universität Leipzig, Anika Groß 23
24 Nutzen / Anwendungen von Annotationen Strukturiertes Erfassen von Wissen statt natürlicher Sprache (einheitliche Begriffswelt, maschinenverstehbar) Erleichterte Suche & Navigation Ermittlung signifikanter über-/unterrepräsentierter GO-Terme in einer Menge von biologischen Objekten Unterstützung von Text-Mining / Natural Language Processing Ontology Matching (z.b. instanzbasiertes Matchen von GO Subontologien, GOPubmed ) Weitere Anwendung MeSH: 2 Mengen von Publikationen aus untersch. Jahren mit MeSH Annotationen Ermittlung der Hype -Themen Nutzen in klinischen Studien Beschreibung der Experimente strukturierte Erfassung der Phänotypen von Teilnehmern (kurzfristig) Therapie-Vorschlagsgenerierung (langfristig) WS 2014/15, Universität Leipzig, Anika Groß 24
25 Applikation: GO-Pubmed Klassifikation von PubMed-Artikeln / Abstracts unter Verwendung von GO- und MeSH-Kategorien WS 2014/15, Universität Leipzig, Anika Groß 25
26 Applikation: Term Enrichment Auch: Funktionale Analysen, functional profiling Ermittlung signifikant über-/unterrepräsentierter GO-Terme in einer Menge von biologischen Objekten im Vergleich zu einer Hergrundmenge (z.b. alle Gene einer Spezies) Automatische Zuordnung biologischer Funktionen in sehr großen Datensätzen Daten stammen z.b. aus Microarray Experimenten zur Genexpression, positiven Selektion von Arten (Evolutionsanalysen), Hypergeometrische Verteilung, Wilcoxon Rank Test, Binomialverteilung... Tools: GO::Termfinder, FUNC, FatiGO WS 2014/15, Universität Leipzig, Anika Groß 26
27 Applikation: Term Enrichment Eingabe Liste von Genen/Proteinen mit GAV (z.b. Expressionslevel) Gene GAV* CTSR4 1 CA151 0 TNR1B 0 RPB4 1 MOGS 0 Menge von Annotationen Gene CTSR4 Concept GO: ( ion channel activity) CTSR4 GO: ( ion transport) CTSR4 GO: ( membrane) CTSR4 GO: ( egral to membrane) Ontologie (z.b. Gene Ontology) Term Enrichment (statistischer Signifikanztest) Ausgabe Liste von Ontologiekonzepten mit Signifikanzwert bzgl. der untersuchten Gene/Proteine (z.b. Liste von Funktionen und Prozessen aus GO mit FWER) Concept FWER** GO: (olfactory receptor activity) 0 GO: (egral to membrane) 0 GO: (rinsic to membrane) 0 GO: (membrane part) 0 GO: (membrane) GO: (cell surface receptor linked signal transduction) GO: (neurophysiological process) GO: (organismal physiological process) GO: (response to stimulus) GO: (signal transducer activity) * GAV = Gene-Associated WS 2014/15, Variable, Universität ** Leipzig, FWER = Family Anika Wise Groß Error Rate 27
28 Hypergeometrischer Test Berechne den pvalue für jedes Konzept C (signifikant: pvalue 0.05) pvalue C 1 a i=0 AN A i n i N n * Interessant = Gene mit einer bestimmten Eigenschaft, z.b. differentiell exprimiert, positiv selektiert, Annotationen des Konzepts C A - annotierte Gene zu Konzept C a - annotierte eressante Gene * von C N - alle Gene n - alle eressanten Gene a A A-a Binomialkoeffizient N Gene n N Gene N-n WS 2014/15, Universität Leipzig, Anika Groß 28
29 Term Enrichment - Beispiel i 3 i i=0 7 3 p = 0.03 A = 3 a = 3 N = 7 n = 3 c2 c1 g5 g6 g7 c3 g7 g1 g6 g2 g1 g5 g4 g3 g4 g3 g6 g2 A = 7 a = 3 N = 7 n = 3 A = 5 a = 1 N = 7 n = 3 p = 1 p = 0.14 A = 3 a = 1 N = 7 n = 3 c4 c5 g1 g2 g6 g2 g3 A = 2 a = 0 N = 7 n = 3 p = 0.51 p = 0.29 g g Gene mit der eressanten Eigenschaft Gene ohne die eressante Eigenschaft g1 g2 g3 g4 g5 g6 g7 WS 2014/15, Universität Leipzig, Anika Groß 29
30 GO Slim-Terme Abgespeckte Versionen der GO Subontologien, enthalten eine Untermenge der GO Terme Geben einen Überblick zum Ontologieinhalt Keine Details aus feingranularen Termen Beispiel: GO: immune system process Nutzen: Zusammenfassung der Resultate, wenn eine weitgefasste Klassifikation der Genproduktfunktion notwendig ist GO-Annotation eines Genoms, Microarray, cdna Sammlung Entsprechend der Bedürfnisse durch Nutzer selbst erstellt, z.b. spezifisch für bestimmte Spezies oder für bestimmte Bereiche der Ontologie GO stellt generische, nicht spezies-spezifische GO Slim-Terme zur Verfügung (~150) Außerdem stehen Modellorganismen-spezifische Slim-Terme zur Verfügung WS 2014/15, Universität Leipzig, Anika Groß 30
31 Annotationsmodell mit Versionierung ontology X i = (C i, R i, t i ) annotation mapping (S k, X i, Q, A) X i+1 Y j+1... quality taxonomies Q = (Q 1,,Q m ) instance source S k = (I k, t k ) S k+1 ontology Y j = (C j, R j, t j ) annotation mapping (S k, Y j, Q, A) O v = (C v, R v, t v ) v - Versionsnummer t release timestamp WS 2014/15, Universität Leipzig, Anika Groß 31
32 Evolutionsanalyse von Annotationen* Vergleich von zwei großen Datenquellen im Zeitraum März 2004 Dezember 2008 GO Annotationen für humane Proteine Analyse der Annotationshäufigkeit in bestimmten Evidence-Gruppen über die Zeit / Versionshistorie Ensembl v 31 v 52 Swiss-Prot v 47 v 56 * Groß, A.; Hartung, M.; Kirsten, T.; Rahm, E.: Estimating the Quality of Ontology-based Annotations by Considering Evolutionary Changes, Proc. 6th Data Integration in the Life Sciences (DILS) Conf., 2009 WS 2014/15, Universität Leipzig, Anika Groß 32
33 # annotations Quantitative Analyse über die Zeit (Ensembl) Manuelle vs. automatische Annotationen 0 man auto version 78% von 265,000 automatisch zugeordnet Auch Löschungen von Annotationen treten auf Nur manuelle Annotationen auth exp comp cur version 22% manuelle Annotationen WS 2014/15, Universität Leipzig, Anika Groß 33

34 Fragen? WS 2014/15, Universität Leipzig, Anika Groß 34
Ontologie-Management Kapitel 3: Anwendungen
 Ontologie-Management Kapitel 3: Anwendungen Wintersemester 2013/14 Anika Groß Universität Leipzig, Institut für Informatik Abteilung Datenbanken http://dbs.uni-leipzig.de Die Folien zur Vorlesung Ontologie
Ontologie-Management Kapitel 3: Anwendungen Wintersemester 2013/14 Anika Groß Universität Leipzig, Institut für Informatik Abteilung Datenbanken http://dbs.uni-leipzig.de Die Folien zur Vorlesung Ontologie
Ontologie-Management
 Ontologie-Management Problemseminar WS 2008/09 http://dbs.uni-leipzig.de 1 Ontologiebegriff Philosophie Informatik Die Ontologie ist eine philosophische An Disziplin, ontology die is sich an (primär) explicit,
Ontologie-Management Problemseminar WS 2008/09 http://dbs.uni-leipzig.de 1 Ontologiebegriff Philosophie Informatik Die Ontologie ist eine philosophische An Disziplin, ontology die is sich an (primär) explicit,
Ontologien und Ontologiesprachen
 Ontologien und Ontologiesprachen Semantische Datenintegration SoSe2005 Uni Bremen Yu Zhao Gliederung 1. Was ist Ontologie 2. Anwendungsgebiete 3. Ontologiesprachen 4. Entwicklung von Ontologien 5. Zusammenfassung
Ontologien und Ontologiesprachen Semantische Datenintegration SoSe2005 Uni Bremen Yu Zhao Gliederung 1. Was ist Ontologie 2. Anwendungsgebiete 3. Ontologiesprachen 4. Entwicklung von Ontologien 5. Zusammenfassung
Ontologie-Management Kapitel 1: Einführung
 Ontologie-Management Kapitel 1: Einführung Dr. Michael Hartung Wintersemester 2012/13 Universität Leipzig Institut für Informatik http://dbs.uni-leipzig.de Inhalt Begriffsdefinition(en) Klassifikation
Ontologie-Management Kapitel 1: Einführung Dr. Michael Hartung Wintersemester 2012/13 Universität Leipzig Institut für Informatik http://dbs.uni-leipzig.de Inhalt Begriffsdefinition(en) Klassifikation
Diplomarbeit: GOMMA: Eine Plattform zur flexiblen Verwaltung und Analyse von Ontologie Mappings in der Bio-/Medizininformatik
 Diplomarbeit: GOMMA: Eine Plattform zur flexiblen Verwaltung und Analyse von Ontologie Mappings in der Bio-/Medizininformatik Bearbeiter: Shuangqing He Betreuer: Toralf Kirsten, Michael Hartung Universität
Diplomarbeit: GOMMA: Eine Plattform zur flexiblen Verwaltung und Analyse von Ontologie Mappings in der Bio-/Medizininformatik Bearbeiter: Shuangqing He Betreuer: Toralf Kirsten, Michael Hartung Universität
Medical Data Models Ein offenes Repository Medizinscher Formulare
 Ein offenes Repository Medizinscher Formulare auf Basis von CDISC ODM German CDISC User Group Leverkusen, 26. Februar 2013 Dr. Bernhard Breil 2 Inhalt Medizinische Dokumentation Probleme Forschungsfrage
Ein offenes Repository Medizinscher Formulare auf Basis von CDISC ODM German CDISC User Group Leverkusen, 26. Februar 2013 Dr. Bernhard Breil 2 Inhalt Medizinische Dokumentation Probleme Forschungsfrage
Semantische Suche und Visualisierung von biomedizinischen Relationsdaten
 Semantische Suche und Visualisierung von biomedizinischen Relationsdaten Johannes Hellrich Jena University Language & Information Engineering Lab Friedrich-Schiller-Universität Jena Tagung der Computerlinguistik-Studierenden,
Semantische Suche und Visualisierung von biomedizinischen Relationsdaten Johannes Hellrich Jena University Language & Information Engineering Lab Friedrich-Schiller-Universität Jena Tagung der Computerlinguistik-Studierenden,
Expressionsdatenanalyse. Vorlesung Einführung in die Bioinformatik - Expressionsdatenanalyse
 Expressionsdatenanalyse U. Scholz & M. Lange Folie #6-1 Grundidee U. Scholz & M. Lange Folie #6-2 Ergebnis der Experimente I U. Scholz & M. Lange Folie #6-3 Genexpression U. Scholz & M. Lange Folie #6-4
Expressionsdatenanalyse U. Scholz & M. Lange Folie #6-1 Grundidee U. Scholz & M. Lange Folie #6-2 Ergebnis der Experimente I U. Scholz & M. Lange Folie #6-3 Genexpression U. Scholz & M. Lange Folie #6-4
Medical Data Models Ein offenes Repository Medizinscher Formulare
 Ein offenes Repository Medizinscher Formulare Metadatenmanagement in der patientenorientierten Forschung Berlin, 18. Dezember 2012 Dr. Bernhard Breil 2 Inhalt Medizinische Dokumentation Probleme Forschungsfrage
Ein offenes Repository Medizinscher Formulare Metadatenmanagement in der patientenorientierten Forschung Berlin, 18. Dezember 2012 Dr. Bernhard Breil 2 Inhalt Medizinische Dokumentation Probleme Forschungsfrage
WMS Block: Management von Wissen in Dokumentenform PART: Text Mining. Myra Spiliopoulou
 WMS Block: Management von Wissen in nform PART: Text Mining Myra Spiliopoulou WIE ERFASSEN UND VERWALTEN WIR EXPLIZITES WISSEN? 1. Wie strukturieren wir Wissen in nform? 2. Wie verwalten wir nsammlungen?
WMS Block: Management von Wissen in nform PART: Text Mining Myra Spiliopoulou WIE ERFASSEN UND VERWALTEN WIR EXPLIZITES WISSEN? 1. Wie strukturieren wir Wissen in nform? 2. Wie verwalten wir nsammlungen?
YAGO YAGO. A semantic knowledge base. Paul Boeck. Humboldt Universität zu Berlin Institut für Informatik. Dezember 2012 1/19
 1/19 A semantic knowledge base Paul Boeck Humboldt Universität zu Berlin Institut für Informatik Dezember 2012 2/19 Übersicht 1 Einführung 2 Das Modell Struktur Semantik 3 Das System 4 Anwendung 3/19 Einführung
1/19 A semantic knowledge base Paul Boeck Humboldt Universität zu Berlin Institut für Informatik Dezember 2012 2/19 Übersicht 1 Einführung 2 Das Modell Struktur Semantik 3 Das System 4 Anwendung 3/19 Einführung
Medizinische Nomenklaturen
 Medizinische Nomenklaturen Einführung Nomenklaturen Wissenschaftliches Beziehungssystem Sammlung von Namen, die nach bestimmten Regeln gebildet wurden Systematische Zusammenstellung von Deskriptoren (Bezeichnungen,
Medizinische Nomenklaturen Einführung Nomenklaturen Wissenschaftliches Beziehungssystem Sammlung von Namen, die nach bestimmten Regeln gebildet wurden Systematische Zusammenstellung von Deskriptoren (Bezeichnungen,
VL Algorithmische BioInformatik (19710) WS2013/2014 Woche 16 - Mittwoch. Annkatrin Bressin Freie Universität Berlin
 WS2013/2014 Woche 16 - Mittwoch. Annkatrin Bressin Freie Universität Berlin") VL Algorithmische BioInformatik (19710) WS2013/2014 Woche 16 - Mittwoch Annkatrin Bressin Freie Universität Berlin Vorlesungsthemen Part 1: Background Basics (4) 1. The Nucleic Acid World 2. Protein Structure
VL Algorithmische BioInformatik (19710) WS2013/2014 Woche 16 - Mittwoch Annkatrin Bressin Freie Universität Berlin Vorlesungsthemen Part 1: Background Basics (4) 1. The Nucleic Acid World 2. Protein Structure
SAS CONTEXTUAL ANALYSIS IN ACTION ERFAHRUNGEN AUS EINEM EIN SELBSTVERSUCH
 SAS CONTEXTUAL ANALYSIS IN ACTION ERFAHRUNGEN AUS EINEM EIN SELBSTVERSUCH GERHARD SVOLBA COMPETENCE CENTER ANALYTICS WIEN, 17. NOVEMBER 2015 SAS CONTEXTUAL ANALYSIS 14.1 EIN BLICK IN DIE PRODUKTBESCHREIBUNG
SAS CONTEXTUAL ANALYSIS IN ACTION ERFAHRUNGEN AUS EINEM EIN SELBSTVERSUCH GERHARD SVOLBA COMPETENCE CENTER ANALYTICS WIEN, 17. NOVEMBER 2015 SAS CONTEXTUAL ANALYSIS 14.1 EIN BLICK IN DIE PRODUKTBESCHREIBUNG
Datenmodelle im Kontext von Europeana. Stefanie Rühle (SUB Göttingen)
") Datenmodelle im Kontext von Europeana Stefanie Rühle (SUB Göttingen) Übersicht Datenmodelle RDF DCAM ORE SKOS FRBR CIDOC CRM Datenmodelle "Datenmodellierung bezeichnet Verfahren in der Informatik zur formalen
Datenmodelle im Kontext von Europeana Stefanie Rühle (SUB Göttingen) Übersicht Datenmodelle RDF DCAM ORE SKOS FRBR CIDOC CRM Datenmodelle "Datenmodellierung bezeichnet Verfahren in der Informatik zur formalen
Medizinische Dokumentation. Wiederholung, Taxonomien, Ontologien, Terminologien
 Medizinische Dokumentation Wiederholung, Taxonomien, Ontologien, Terminologien 1 Syntaktische Interoperabilität Zwei Datensätze gleichen Inhalts, aber unterschiedlicher Struktur (Syntaktik) Moser Gerda
Medizinische Dokumentation Wiederholung, Taxonomien, Ontologien, Terminologien 1 Syntaktische Interoperabilität Zwei Datensätze gleichen Inhalts, aber unterschiedlicher Struktur (Syntaktik) Moser Gerda
Personalisierung. Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung. Data Mining.
 Personalisierung Personalisierung Thomas Mandl Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung Klassifikation Die Nutzer werden in vorab bestimmte Klassen/Nutzerprofilen
Personalisierung Personalisierung Thomas Mandl Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung Klassifikation Die Nutzer werden in vorab bestimmte Klassen/Nutzerprofilen
Semantic Web Technologies I
 Semantic Web Technologies I Lehrveranstaltung im WS11/12 Dr. Elena Simperl PD Dr. Sebastian Rudolph M. Sc. Anees ul Mehdi Ontology Engineering Dr. Elena Simperl XML und URIs Einführung in RDF RDF Schema
Semantic Web Technologies I Lehrveranstaltung im WS11/12 Dr. Elena Simperl PD Dr. Sebastian Rudolph M. Sc. Anees ul Mehdi Ontology Engineering Dr. Elena Simperl XML und URIs Einführung in RDF RDF Schema
Semantic Web. RDF, RDFS, OWL, and Ontology Engineering. F. Abel, N. Henze, and D. Krause 17.12.2009. IVS Semantic Web Group
 Semantic Web RDF, RDFS, OWL, and Ontology Engineering F. Abel, N. Henze, and D. Krause IVS Semantic Web Group 17.12.2009 Exercise 1: RDFS OWL Erstellen Sie mit Hilfe von RDF Schema und OWL eine Ontologie
Semantic Web RDF, RDFS, OWL, and Ontology Engineering F. Abel, N. Henze, and D. Krause IVS Semantic Web Group 17.12.2009 Exercise 1: RDFS OWL Erstellen Sie mit Hilfe von RDF Schema und OWL eine Ontologie
OWL und Protégé. Seminar A.I. Tools Matthias Loskyll 14.12.2006
 OWL und Protégé Seminar A.I. Tools Matthias Loskyll 14.12.2006 Überblick Einführung OWL Eigenschaften Sprachbeschreibung Übersicht Protégé Beschreibung des Tools Demo Zusammenfassung 2 Einführung Google?
OWL und Protégé Seminar A.I. Tools Matthias Loskyll 14.12.2006 Überblick Einführung OWL Eigenschaften Sprachbeschreibung Übersicht Protégé Beschreibung des Tools Demo Zusammenfassung 2 Einführung Google?
MOL.504 Analyse von DNA- und Proteinsequenzen. Datenbanken & Informationssysteme
 MOL.504 Analyse von DNA- und Proteinsequenzen Datenbanken & Informationssysteme Inhaltsübersicht Informationsysteme National Center for Biotechnology Information (NCBI) The European Bioinformatics Institute
MOL.504 Analyse von DNA- und Proteinsequenzen Datenbanken & Informationssysteme Inhaltsübersicht Informationsysteme National Center for Biotechnology Information (NCBI) The European Bioinformatics Institute
Präsentation des Dissertationsvorhabens Erste Schritte. Carola Carstens Hildesheim, 15. Oktober 2007
 Präsentation des Dissertationsvorhabens Erste Schritte Carola Carstens Hildesheim, 15. Oktober 2007 Überblick Rahmenbedingungen Institut Thematische Interessen Erste Schritte Erfassung des State of the
Präsentation des Dissertationsvorhabens Erste Schritte Carola Carstens Hildesheim, 15. Oktober 2007 Überblick Rahmenbedingungen Institut Thematische Interessen Erste Schritte Erfassung des State of the
Metadaten für die Informationsversorgung von morgen: Kooperativ erstellen - gemeinsam nutzen
 Metadaten für die Informationsversorgung von morgen: Kooperativ erstellen - gemeinsam nutzen Was sind Metadaten? Metadaten sind strukturierte Daten über Daten. Sie dienen der Beschreibung von Informationsressourcen.
Metadaten für die Informationsversorgung von morgen: Kooperativ erstellen - gemeinsam nutzen Was sind Metadaten? Metadaten sind strukturierte Daten über Daten. Sie dienen der Beschreibung von Informationsressourcen.
Terminologie-Extraktion: Beispiel
 Terminologie-Extraktion: Beispiel The major risks of long-term cardiotoxicity relate to treatment prior to the BMT, in particular, anthracyclines, ablative-dose Cytoxan (ie, dose > 150 mg/ kg), chest [radiation
Terminologie-Extraktion: Beispiel The major risks of long-term cardiotoxicity relate to treatment prior to the BMT, in particular, anthracyclines, ablative-dose Cytoxan (ie, dose > 150 mg/ kg), chest [radiation
Opinion Mining in der Marktforschung
 Opinion Mining in der Marktforschung von andreas.boehnke@stud.uni-bamberg.de S. 1 Überblick I. Motivation Opinion Mining II. Grundlagen des Text Mining III. Grundlagen des Opinion Mining IV. Opinion Mining
Opinion Mining in der Marktforschung von andreas.boehnke@stud.uni-bamberg.de S. 1 Überblick I. Motivation Opinion Mining II. Grundlagen des Text Mining III. Grundlagen des Opinion Mining IV. Opinion Mining
Rollen in GFO und HL7-RIM
 n in GFO und HL7-RIM Frank Loebe Forschungsgruppe Ontologien in der Medizin (Onto-Med) Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig frank.loebe@imise.uni-leipzig.de
n in GFO und HL7-RIM Frank Loebe Forschungsgruppe Ontologien in der Medizin (Onto-Med) Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig frank.loebe@imise.uni-leipzig.de
3. Ontologien und Wissensbasen
 Ontologien Ontologien stellen mittlerweile die Basis für viele innovative wissensbasierte Systeme dar: 3. Ontologien und Wissensbasen ecommerce/elearning Knowledge Management Informationsextraktion/Data-mining
Ontologien Ontologien stellen mittlerweile die Basis für viele innovative wissensbasierte Systeme dar: 3. Ontologien und Wissensbasen ecommerce/elearning Knowledge Management Informationsextraktion/Data-mining
INFORMATIONSEXTRAKTION IN SUCHMASCHINEN
 INFORMATIONSEXTRAKTION IN SUCHMASCHINEN S E M I N A R S U C H M A S C H I N E N S O M M E R S E M ESTER 2014 S T E FA N L A N G E R, C I S, U N I V E R S I TÄT M Ü N C H E N Schematische Architektur einer
INFORMATIONSEXTRAKTION IN SUCHMASCHINEN S E M I N A R S U C H M A S C H I N E N S O M M E R S E M ESTER 2014 S T E FA N L A N G E R, C I S, U N I V E R S I TÄT M Ü N C H E N Schematische Architektur einer
IHE und kontrollierte Vokabulare Erfahrungen aus der Praxis Robert Lorenz Pansoma GmbH
 IHE und kontrollierte Vokabulare Erfahrungen aus der Praxis Robert Lorenz Pansoma GmbH Dezember 2015 WER Pansoma GmbH Sitz in Korneuburg, NÖ Tochterunternehmen in Horn, NÖ Beratung und Software in der
IHE und kontrollierte Vokabulare Erfahrungen aus der Praxis Robert Lorenz Pansoma GmbH Dezember 2015 WER Pansoma GmbH Sitz in Korneuburg, NÖ Tochterunternehmen in Horn, NÖ Beratung und Software in der
Was sind Ontologie-Editoren?
 Was sind Ontologie-Editoren? Kurzeinführung Protégé Sonja von Mach und Jessica Otte Gliederung Ontologie Editoren- allgemein warum nutzen wofür nutzen Probleme Marktlage Einführung in die praktische Arbeit
Was sind Ontologie-Editoren? Kurzeinführung Protégé Sonja von Mach und Jessica Otte Gliederung Ontologie Editoren- allgemein warum nutzen wofür nutzen Probleme Marktlage Einführung in die praktische Arbeit
3.5 OWL: WEB Ontology Language (1)
") 3.5 OWL: WEB Ontology Language (1) 3.5.1 OWL-Syntax (Teil 1) A) Namensräume / RDF-Tag: Die OWL-Syntax basiert auf XML, XML-Schema, RDF und RDFS. Daher sind die zugehörigen Namensräume am Anfang des Quelltextes
3.5 OWL: WEB Ontology Language (1) 3.5.1 OWL-Syntax (Teil 1) A) Namensräume / RDF-Tag: Die OWL-Syntax basiert auf XML, XML-Schema, RDF und RDFS. Daher sind die zugehörigen Namensräume am Anfang des Quelltextes
Seminar Informationsintegration und Informationsqualität. Dragan Sunjka. 30. Juni 2006
 Seminar Informationsintegration und Informationsqualität TU Kaiserslautern 30. Juni 2006 Gliederung Autonomie Verteilung führt zu Autonomie... Intra-Organisation: historisch Inter-Organisation: Internet
Seminar Informationsintegration und Informationsqualität TU Kaiserslautern 30. Juni 2006 Gliederung Autonomie Verteilung führt zu Autonomie... Intra-Organisation: historisch Inter-Organisation: Internet
Ausgangsposition. Aspekte der Texttechnologie. Aspekte der Texttechnologie. Susanne J. Jekat Zürcher Hochschule Winterthur E-mail: jes@zhwin.
 Aspekte der Texttechnologie Susanne J. Jekat Zürcher Hochschule Winterthur E-mail: jes@zhwin.ch Aspekte der Texttechnologie Thema 5 Semantic Web Termine: 24. Mai 2007 Lernfrage: Was ist das Semantic Web
Aspekte der Texttechnologie Susanne J. Jekat Zürcher Hochschule Winterthur E-mail: jes@zhwin.ch Aspekte der Texttechnologie Thema 5 Semantic Web Termine: 24. Mai 2007 Lernfrage: Was ist das Semantic Web
Wissen aus unstrukturierten natürlichsprachlichen
 ZKI Tagung AK Supercomputing, 19.-20. Okt. 2015 Wissen aus unstrukturierten natürlichsprachlichen Daten Sprachtechnologie und Textanalytik in the large Udo Hahn Jena University Language & Information Engineering
ZKI Tagung AK Supercomputing, 19.-20. Okt. 2015 Wissen aus unstrukturierten natürlichsprachlichen Daten Sprachtechnologie und Textanalytik in the large Udo Hahn Jena University Language & Information Engineering
Industrie 4.0 und Smart Data
 Industrie 4.0 und Smart Data Herausforderungen für die IT-Infrastruktur bei der Auswertung großer heterogener Datenmengen Richard Göbel Inhalt Industrie 4.0 - Was ist das? Was ist neu? Herausforderungen
Industrie 4.0 und Smart Data Herausforderungen für die IT-Infrastruktur bei der Auswertung großer heterogener Datenmengen Richard Göbel Inhalt Industrie 4.0 - Was ist das? Was ist neu? Herausforderungen
Vorlesung Maschinelles Lernen
 Vorlesung Maschinelles Lernen LACE Katharina Morik LS 8 Künstliche Intelligenz Fakultät für Informatik Technische Universität Dortmund 28.1.2014 1 von 71 Gliederung 1 Organisation von Sammlungen Web 2.0
Vorlesung Maschinelles Lernen LACE Katharina Morik LS 8 Künstliche Intelligenz Fakultät für Informatik Technische Universität Dortmund 28.1.2014 1 von 71 Gliederung 1 Organisation von Sammlungen Web 2.0
Benutzerhandbuch Publikationsumgebung
 Terminologieserver Benutzerhandbuch Publikationsumgebung Bedienung der öffentlichen Weboberfläche Datum: 06.12.2013 Version: 1.1 Inhaltsverzeichnis 1. Einleitung 3 1.1. Zweck und Zielgruppe des Dokuments
Terminologieserver Benutzerhandbuch Publikationsumgebung Bedienung der öffentlichen Weboberfläche Datum: 06.12.2013 Version: 1.1 Inhaltsverzeichnis 1. Einleitung 3 1.1. Zweck und Zielgruppe des Dokuments
Information Workbench Linked Data-Anwendungen im Unternehmen. Leipziger Semantic Web Tag, 5.5.2011 Peter Haase, fluid Operations
 Information Workbench Linked Data-Anwendungen im Unternehmen Leipziger Semantic Web Tag, 5.5.2011 Peter Haase, fluid Operations Agenda Linked Data im Unternehmen Herausforderungen Die Information Workbench
Information Workbench Linked Data-Anwendungen im Unternehmen Leipziger Semantic Web Tag, 5.5.2011 Peter Haase, fluid Operations Agenda Linked Data im Unternehmen Herausforderungen Die Information Workbench
Text Mining und Textzusammenfassung. Jürgen Kirkovits Doris Rongitsch Daniela Wagenhofer
 Text Mining und Textzusammenfassung Jürgen Kirkovits Doris Rongitsch Daniela Wagenhofer Übersicht 1. Definition 2. Prozessablauf 3. Textzusammenfassung 4. Praxisbeispiel Definition Text Mining is the art
Text Mining und Textzusammenfassung Jürgen Kirkovits Doris Rongitsch Daniela Wagenhofer Übersicht 1. Definition 2. Prozessablauf 3. Textzusammenfassung 4. Praxisbeispiel Definition Text Mining is the art
PG-402 Wissensmanagement: Ontologiebasierte Wissensextraktion
 PG-402 Wissensmanagement: Ontologiebasierte Wissensextraktion WS2001/2002 Klaus Unterstein 20.10.2001 PG-402 Wissensmanagement: Ontologiebasierte Wissensextraktion 1 Verlauf Begriffsklärung Ontologiebasierte
PG-402 Wissensmanagement: Ontologiebasierte Wissensextraktion WS2001/2002 Klaus Unterstein 20.10.2001 PG-402 Wissensmanagement: Ontologiebasierte Wissensextraktion 1 Verlauf Begriffsklärung Ontologiebasierte
unter Verwendung von Folien von Herrn Prof. Dr. Flensburg, von Laudon/Laudon/Schoder und von Frau Prof. Dr. Schuhbauer
 Knowledge Management Wissensmanagement 0. Produktionsfaktoren 1. Data Information Knowledge 2. Knowledge representation Wissensdarstellung 3. Interfaces to artificial intelligence 4. Knowledge management
Knowledge Management Wissensmanagement 0. Produktionsfaktoren 1. Data Information Knowledge 2. Knowledge representation Wissensdarstellung 3. Interfaces to artificial intelligence 4. Knowledge management
Kapitel IR:I. I. Einführung. Retrieval-Szenarien Begriffsbildung Einordnung Information Retrieval
 Kapitel IR:I I. Einführung Retrieval-Szenarien Begriffsbildung Einordnung Information Retrieval IR:I-1 Introduction STEIN 2005-2010 Retrieval-Szenarien Liefere Dokumente, die die Terme «Information» und
Kapitel IR:I I. Einführung Retrieval-Szenarien Begriffsbildung Einordnung Information Retrieval IR:I-1 Introduction STEIN 2005-2010 Retrieval-Szenarien Liefere Dokumente, die die Terme «Information» und
Molekularbiologische Datenbanken
 Molekularbiologische Datenbanken Übungen Sommersemester 2004 Silke Trißl Prof. Ulf Leser Wissensmanagement in der Bioinformatik Organisatorisches Mittwoch 11 13 Uhr, RUD26 0'313 Mi, 05. Mai 2004 entfällt
Molekularbiologische Datenbanken Übungen Sommersemester 2004 Silke Trißl Prof. Ulf Leser Wissensmanagement in der Bioinformatik Organisatorisches Mittwoch 11 13 Uhr, RUD26 0'313 Mi, 05. Mai 2004 entfällt
HEALTH Institut für Biomedizin und Gesundheitswissenschaften
 HEALTH Institut für Biomedizin und Gesundheitswissenschaften Konzept zur Verbesserung eines klinischen Information Retrieval Systems unter Verwendung von Apache UIMA und medizinischen Ontologien Georg
HEALTH Institut für Biomedizin und Gesundheitswissenschaften Konzept zur Verbesserung eines klinischen Information Retrieval Systems unter Verwendung von Apache UIMA und medizinischen Ontologien Georg
Semantische Datenintegration: von der Theorie zur Anwendung
 Semantische Datenintegration: von der Theorie zur Anwendung Prof. Dr. Heiner Stuckenschmidt Institut für Enterprise Systems Name und Datum www.uni-mannheim.de Seite 1 Teil I: Grundlagen Das Problem der
Semantische Datenintegration: von der Theorie zur Anwendung Prof. Dr. Heiner Stuckenschmidt Institut für Enterprise Systems Name und Datum www.uni-mannheim.de Seite 1 Teil I: Grundlagen Das Problem der
Unterstützt HL7 die interdisziplinäre Zusammenarbeit?
 Effiziente und wirtschaftliche Gesundheitsversorgung von heute und morgen nur mit Medizinischer Dokumentation und Medizinischer Informatik, Medizinischer Biometrie und Epidemiologie 5. bis 9. September
Effiziente und wirtschaftliche Gesundheitsversorgung von heute und morgen nur mit Medizinischer Dokumentation und Medizinischer Informatik, Medizinischer Biometrie und Epidemiologie 5. bis 9. September
Ontology Development For A Pharmacogenetics Knowledge Base
 DIANE E. OLIVER, DANIEL L. RUBIN, JOSHUA M. STUART, MICHAEL HEWITT, TERI E. KLEIN, RUSS B. ALTMAN Stanford University School of Medicine Stanford Medical Informatics Ontology Development For A Pharmacogenetics
DIANE E. OLIVER, DANIEL L. RUBIN, JOSHUA M. STUART, MICHAEL HEWITT, TERI E. KLEIN, RUSS B. ALTMAN Stanford University School of Medicine Stanford Medical Informatics Ontology Development For A Pharmacogenetics
Ein Portal für Medizinische Formulare. Martin Dugas dugas@uni-muenster.de
 Ein Portal für Medizinische Formulare Martin Dugas dugas@uni-muenster.de Agenda Kurzvorstellung IMI Hintergrund und Problemstellung MDM-Portal für Medizinische Formulare Diskussion: Freier Zugang zu medizinischen
Ein Portal für Medizinische Formulare Martin Dugas dugas@uni-muenster.de Agenda Kurzvorstellung IMI Hintergrund und Problemstellung MDM-Portal für Medizinische Formulare Diskussion: Freier Zugang zu medizinischen
Referat Ontologieevaluation. Gliederung THEORIE. 1) Prozess der Ontologieentwicklung. 2) Warum werden Ontologien evaluiert?
 Prozess der Ontologieentwicklung. 2) Warum werden Ontologien evaluiert?") Referat Ontologieevaluation Gliederung THEORIE 1) Prozess der Ontologieentwicklung 2) Warum werden Ontologien evaluiert? 3) Ansätze der Ontologieevaluation 3.1) Level der Evaluation 3.1.1) Vokabular und
Referat Ontologieevaluation Gliederung THEORIE 1) Prozess der Ontologieentwicklung 2) Warum werden Ontologien evaluiert? 3) Ansätze der Ontologieevaluation 3.1) Level der Evaluation 3.1.1) Vokabular und
Seminar Textmining SS 2015 Grundlagen des Maschinellen Lernens
 Seminar Textmining SS 2015 Grundlagen des Maschinellen Lernens Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 17.04.2015 Entscheidungsprobleme beim Textmining
Seminar Textmining SS 2015 Grundlagen des Maschinellen Lernens Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 17.04.2015 Entscheidungsprobleme beim Textmining
Semantik in Suchmaschinen Beispiele. Karin Haenelt 7.12.2014
 Semantik in Suchmaschinen Beispiele Karin Haenelt 7.12.2014 Inhalt Google Knowledge Graph Freebase schema.org 2 Google Knowledge Graph Zuordnung von Suchtermen zu Weltentitäten Darstellung von Zusammenhängen
Semantik in Suchmaschinen Beispiele Karin Haenelt 7.12.2014 Inhalt Google Knowledge Graph Freebase schema.org 2 Google Knowledge Graph Zuordnung von Suchtermen zu Weltentitäten Darstellung von Zusammenhängen
Semantische Reputationsinteroperabilität
 Semantische sinteroperabilität Adrian Paschke (CSW) und Rehab Alnemr (HPI) Corporate Semantic Web Workshop, Xinnovations 2010, 14. September 2010, Berlin Agenda Motivation Unternehmensreputation Probleme
Semantische sinteroperabilität Adrian Paschke (CSW) und Rehab Alnemr (HPI) Corporate Semantic Web Workshop, Xinnovations 2010, 14. September 2010, Berlin Agenda Motivation Unternehmensreputation Probleme
Untersuchung von DNA Methylierungsprofilen mit Hilfe veröffentlichter Genexpressionsignaturen
 Untersuchung von DNA Methylierungsprofilen mit Hilfe veröffentlichter Genexpressionsignaturen Christian Ruckert Universität Münster 7. September 2010 Inhalt 1 Einleitung 2 Daten und Methoden 3 Ergebnisse
Untersuchung von DNA Methylierungsprofilen mit Hilfe veröffentlichter Genexpressionsignaturen Christian Ruckert Universität Münster 7. September 2010 Inhalt 1 Einleitung 2 Daten und Methoden 3 Ergebnisse
Inaugural-Dissertation. Philosophie
 Ontology On Demand Vollautomatische Ontologieerstellung aus deutschen Texten mithilfe moderner Textmining-Prozesse Inaugural-Dissertation zur Erlangung des Grades eines Doktors der Philosophie in der Fakultät
Ontology On Demand Vollautomatische Ontologieerstellung aus deutschen Texten mithilfe moderner Textmining-Prozesse Inaugural-Dissertation zur Erlangung des Grades eines Doktors der Philosophie in der Fakultät
Eine semantische Suchmaschine in der Biomedizin
 Eine semantische Suchmaschine in der Biomedizin Jena University Language and Information Engineering Lab Anne Schneider Friedrich-Schiller-Universität Jena Einstieg Großes Wachstum von Daten im Bereich
Eine semantische Suchmaschine in der Biomedizin Jena University Language and Information Engineering Lab Anne Schneider Friedrich-Schiller-Universität Jena Einstieg Großes Wachstum von Daten im Bereich
Einführung. Arbeitsgruppe. Proseminar Corporate Semantic Web. Prof. Dr. Adrian Paschke
 Arbeitsgruppe Proseminar Corporate Semantic Web Einführung Prof. Dr. Adrian Paschke Arbeitsgruppe Corporate Semantic Web (AG-CSW) Institut für Informatik, Freie Universität Berlin paschke@inf.fu-berlin.de
Arbeitsgruppe Proseminar Corporate Semantic Web Einführung Prof. Dr. Adrian Paschke Arbeitsgruppe Corporate Semantic Web (AG-CSW) Institut für Informatik, Freie Universität Berlin paschke@inf.fu-berlin.de
semantische Informationssysteme
 "Finden" nicht "Suchen" Fakultät TI Department Informatik AW1, Master, SS 2008 Gliederung 1 Motivation 2 Semantic Web 3 Ontologien 4 Zusammenfassung Gliederung 1 Motivation die perfekte Informationsplattform
"Finden" nicht "Suchen" Fakultät TI Department Informatik AW1, Master, SS 2008 Gliederung 1 Motivation 2 Semantic Web 3 Ontologien 4 Zusammenfassung Gliederung 1 Motivation die perfekte Informationsplattform
Ontologien & Enterprise Ontology
 Ontologien & Enterprise Ontology Dietmar Gombotz, 0426481 Information Management Seminar WS 2005, TU Wien Agenda Was ist eine Ontologie Warum brauchen wir Ontologien Formale Sprachen zur Beschreibung von
Ontologien & Enterprise Ontology Dietmar Gombotz, 0426481 Information Management Seminar WS 2005, TU Wien Agenda Was ist eine Ontologie Warum brauchen wir Ontologien Formale Sprachen zur Beschreibung von
Semantic Web Technologies I! Lehrveranstaltung im WS10/11! Dr. Andreas Harth! Dr. Sebastian Rudolph!
 Semantic Web Technologies I! Lehrveranstaltung im WS10/11! Dr. Andreas Harth! Dr. Sebastian Rudolph! www.semantic-web-grundlagen.de Ontology Engineering! Dr. Sebastian Rudolph! Semantic Web Architecture
Semantic Web Technologies I! Lehrveranstaltung im WS10/11! Dr. Andreas Harth! Dr. Sebastian Rudolph! www.semantic-web-grundlagen.de Ontology Engineering! Dr. Sebastian Rudolph! Semantic Web Architecture
AWMF Delegiertenkonferenz
 AWMF Delegiertenkonferenz Frankfurt, 15. November 2014 11. Revision der ICD Ulrich Vogel Deutsches Institut für Medizinische Dokumentation und Information (DIMDI) Im Geschäftsbereich des 11. Revision der
AWMF Delegiertenkonferenz Frankfurt, 15. November 2014 11. Revision der ICD Ulrich Vogel Deutsches Institut für Medizinische Dokumentation und Information (DIMDI) Im Geschäftsbereich des 11. Revision der
Molekularbiologische Datenbanken
 Molekularbiologische Datenbanken Übungen Aufgabe 2 Silke Trißl Ulf Leser Wissensmanagement in der Bioinformatik Microarray oder Expressionsanalyse Gleiche Erbinformation in der Zelle (Genom), aber viele
Molekularbiologische Datenbanken Übungen Aufgabe 2 Silke Trißl Ulf Leser Wissensmanagement in der Bioinformatik Microarray oder Expressionsanalyse Gleiche Erbinformation in der Zelle (Genom), aber viele
SKOS-MED. Ein Vokabular zur Integration biomedizinischer Terminologien. Motivation
 SKOS-MED Ein Vokabular zur Integration biomedizinischer Terminologien Motivation Datenerhebung in Forschung: hohe Datenqualität, semantische Interoperabilität, Wiederverwendung Viele ausgereifte biomedizinische
SKOS-MED Ein Vokabular zur Integration biomedizinischer Terminologien Motivation Datenerhebung in Forschung: hohe Datenqualität, semantische Interoperabilität, Wiederverwendung Viele ausgereifte biomedizinische
Ärzte bekommen etwas für die Daten, die sie eingeben neue Möglichkeiten der Analytik für Kliniken und Forschungseinrichtungen mit SAP HANA Dr.
 Ärzte bekommen etwas für die Daten, die sie eingeben neue Möglichkeiten der Analytik für Kliniken und Forschungseinrichtungen mit SAP HANA Dr. Bernhard Escherich, SAP Ärzte geben eine Fülle von Daten ein,
Ärzte bekommen etwas für die Daten, die sie eingeben neue Möglichkeiten der Analytik für Kliniken und Forschungseinrichtungen mit SAP HANA Dr. Bernhard Escherich, SAP Ärzte geben eine Fülle von Daten ein,
Literatursuche in Med-Datenbanken
 Literatursuche in Med-Datenbanken Heide Lingard Abteilung Allgemein- und Familienmedizin,, MUW Donausymposium Krems 7 Oktober 2006 Welche Datenbank Medline PubMed Scopus Science Citation Index (SCI) Journal
Literatursuche in Med-Datenbanken Heide Lingard Abteilung Allgemein- und Familienmedizin,, MUW Donausymposium Krems 7 Oktober 2006 Welche Datenbank Medline PubMed Scopus Science Citation Index (SCI) Journal
XDOC Extraktion, Repräsentation und Auswertung von Informationen
 XDOC Extraktion, Repräsentation und Auswertung von Informationen Manuela Kunze Otto-von-Guericke Universität Magdeburg Fakultät für Informatik Institut für Wissens- und Sprachverarbeitung Gliederung Ausgangspunkt
XDOC Extraktion, Repräsentation und Auswertung von Informationen Manuela Kunze Otto-von-Guericke Universität Magdeburg Fakultät für Informatik Institut für Wissens- und Sprachverarbeitung Gliederung Ausgangspunkt
Dr. Christian Stein Ontologie-Design Die nächste Generation des Web für sich nutzen lernen
 Technische Universität Braunschweig Humboldt-Universität zu Berlin Projekt iglos Dr. Christian Stein Ontologie-Design Die nächste Generation des Web für sich nutzen lernen Dr. Christian Stein (christian.stein@hu-berlin.de)
Technische Universität Braunschweig Humboldt-Universität zu Berlin Projekt iglos Dr. Christian Stein Ontologie-Design Die nächste Generation des Web für sich nutzen lernen Dr. Christian Stein (christian.stein@hu-berlin.de)
Die Bedeutung kontrollierter Vokabulare für Fachabteilungslösungen
 Die Bedeutung kontrollierter Vokabulare für Fachabteilungslösungen 12. Fachtagung "Praxis der Informationsverarbeitung in Krankenhaus und Versorgungsnetzen" (KIS2007) Ludwigshafen, 20. Juni 2007 Josef
Die Bedeutung kontrollierter Vokabulare für Fachabteilungslösungen 12. Fachtagung "Praxis der Informationsverarbeitung in Krankenhaus und Versorgungsnetzen" (KIS2007) Ludwigshafen, 20. Juni 2007 Josef
Automatische Analyse pra klinischer Forschungsergebnisse
 Universität Bielefeld 15. Mai 2014 Automatische Analyse pra klinischer Forschungsergebnisse zur Auswahl Erfolg versprechender klinischer Studien und individualisierter Therapien Roman Klinger, Philipp
Universität Bielefeld 15. Mai 2014 Automatische Analyse pra klinischer Forschungsergebnisse zur Auswahl Erfolg versprechender klinischer Studien und individualisierter Therapien Roman Klinger, Philipp
Semantic Web. www.geo-spirit.org. Metadata extraction
 Semantic Web www.geo-spirit.org WP 6 WP 3 Metadata extraction Ontologies Semantic Web Tim Berners Lee Was wäre, wenn der Computer den Inhalt einer Seite aus dem World Wide Web nicht nur anzeigen, sondern
Semantic Web www.geo-spirit.org WP 6 WP 3 Metadata extraction Ontologies Semantic Web Tim Berners Lee Was wäre, wenn der Computer den Inhalt einer Seite aus dem World Wide Web nicht nur anzeigen, sondern
Bericht BTI7311: Informatik Seminar Was sind Ontologien?
 Bericht BTI7311: Informatik Seminar Was sind Ontologien? Inhaltsverzeichnis 1 Ontologien...3 1.1 Ontologien in der Philosophie...3 1.2 Ontologien in der Psychologie...3 1.3 Ontologien in der Informatik...3
Bericht BTI7311: Informatik Seminar Was sind Ontologien? Inhaltsverzeichnis 1 Ontologien...3 1.1 Ontologien in der Philosophie...3 1.2 Ontologien in der Psychologie...3 1.3 Ontologien in der Informatik...3
Exposé zur Studienarbeit. 04. August 2010
 Exposé zur Studienarbeit Relevanzranking in Lucene im biomedizinischen Kontext Christoph Jacob Betreuer: Phillipe Thomas, Prof. Dr. Ulf Leser 04. August 2010 1. Motivation Sucht und ihr werdet finden dieses
Exposé zur Studienarbeit Relevanzranking in Lucene im biomedizinischen Kontext Christoph Jacob Betreuer: Phillipe Thomas, Prof. Dr. Ulf Leser 04. August 2010 1. Motivation Sucht und ihr werdet finden dieses
Data Lakes: Lösung oder neue Herausforderung für Data-Integration
 Data Lakes: Lösung oder neue Herausforderung für Big-Data Data-Integration Integration? PD Dr. Christoph Quix Fraunhofer-Institut für Angewandte Informationstechnik FIT Life Science Informatics Abteilungsleiter
Data Lakes: Lösung oder neue Herausforderung für Big-Data Data-Integration Integration? PD Dr. Christoph Quix Fraunhofer-Institut für Angewandte Informationstechnik FIT Life Science Informatics Abteilungsleiter
Exploring the knowledge in Semi Structured Data Sets with Rich Queries
 Exploring the knowledge in Semi Structured Data Sets with Rich Queries Jürgen Umbrich Sebastian Blohm Institut AIFB, Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 www.kit.ed Overview
Exploring the knowledge in Semi Structured Data Sets with Rich Queries Jürgen Umbrich Sebastian Blohm Institut AIFB, Universität Karlsruhe (TH) Forschungsuniversität gegründet 1825 www.kit.ed Overview
Text-Mining: Einführung
 Text-Mining: Einführung Claes Neuefeind Fabian Steeg 22. April 2010 Organisatorisches Was ist Text-Mining? Definitionen Anwendungsbeispiele Textuelle Daten Aufgaben u. Teilbereiche Literatur Kontakt Sprechstunde:
Text-Mining: Einführung Claes Neuefeind Fabian Steeg 22. April 2010 Organisatorisches Was ist Text-Mining? Definitionen Anwendungsbeispiele Textuelle Daten Aufgaben u. Teilbereiche Literatur Kontakt Sprechstunde:
Swetlana Stickhof. Universität Heidelberg 03.02.2013
 Modellierung einer Testdokumentation mit Suchfunktionen in Semantic MediaWiki und Implementierung einer Jira-Anbindung als Semantic MediaWiki Extension Universität Heidelberg 03.02.2013 1 Inhalt Motivation
Modellierung einer Testdokumentation mit Suchfunktionen in Semantic MediaWiki und Implementierung einer Jira-Anbindung als Semantic MediaWiki Extension Universität Heidelberg 03.02.2013 1 Inhalt Motivation
Semantic Web Praktikum..und andere Praktika... WS 2004/05
 Semantic Web Praktikum..und andere Praktika... WS 2004/05 Robert Baumgartner, Jürgen Dorn, Georg Gottlob, Marcus Herzog KFK Semantic Web Kernfachkombination Wirtschaftsinformatik Vertiefendes Wahlfach
Semantic Web Praktikum..und andere Praktika... WS 2004/05 Robert Baumgartner, Jürgen Dorn, Georg Gottlob, Marcus Herzog KFK Semantic Web Kernfachkombination Wirtschaftsinformatik Vertiefendes Wahlfach
Museumsdaten in Portalen --------------------------------------
 Museumsdaten in Portalen -------------------------------------- Die Vernetzungsstandards museumdat und museumvok 1 2 Ausgangssituation: Aus völlig heterogenen Datenbeständen in den Museen Es gibt nicht
Museumsdaten in Portalen -------------------------------------- Die Vernetzungsstandards museumdat und museumvok 1 2 Ausgangssituation: Aus völlig heterogenen Datenbeständen in den Museen Es gibt nicht
Inhaltsverzeichnis. Kurzfassung. Abstract
 Inhaltsverzeichnis Kurzfassung Abstract Inhaltsverzeichnis iii v vii 1 Einleitung 1 1.1 Problemstellung und Einordnung der Arbeit 1 1.2 Lösungsansatz 7 L3 Verwandte Arbeiten S 1.3.1 Datenbank-Suchmaschmen
Inhaltsverzeichnis Kurzfassung Abstract Inhaltsverzeichnis iii v vii 1 Einleitung 1 1.1 Problemstellung und Einordnung der Arbeit 1 1.2 Lösungsansatz 7 L3 Verwandte Arbeiten S 1.3.1 Datenbank-Suchmaschmen
EXTRAKTION UND KLASSIFIKATION VON BEWERTETEN PRODUKTFEATURES AUF WEBSEITEN
 EXTRAKTION UND KLASSIFIKATION VON BEWERTETEN PRODUKTFEATURES AUF WEBSEITEN T-SYSTEMS MULTIMEDIA SOLUTIONS GMBH, 16. FEBRUAR 2012 1. Schlüsselworte Semantic Web, Opinion Mining, Sentiment Analysis, Stimmungsanalyse,
EXTRAKTION UND KLASSIFIKATION VON BEWERTETEN PRODUKTFEATURES AUF WEBSEITEN T-SYSTEMS MULTIMEDIA SOLUTIONS GMBH, 16. FEBRUAR 2012 1. Schlüsselworte Semantic Web, Opinion Mining, Sentiment Analysis, Stimmungsanalyse,
Die On-line Präsenz des Tourismusverbands Innsbruck und seine Feriendörfer. Univ.-Prof. Dr. Dieter Fensel STI Innsbruck, University of Innsbruck
 Die On-line Präsenz des Tourismusverbands Innsbruck und seine Feriendörfer Univ.-Prof. Dr. Dieter Fensel STI Innsbruck, University of Innsbruck Copyright 2008 STI INNSBRUCK www.sti-innsbruck.at 1 Der Hotelier
Die On-line Präsenz des Tourismusverbands Innsbruck und seine Feriendörfer Univ.-Prof. Dr. Dieter Fensel STI Innsbruck, University of Innsbruck Copyright 2008 STI INNSBRUCK www.sti-innsbruck.at 1 Der Hotelier
Übung II. Einführung, Teil 1. Arbeiten mit Ensembl
 Übung II Einführung, Teil 1 Arbeiten mit Ensembl Ensembl Genome Browser (Bereitstellung von Vielzeller Genomen) Projekt wurde 1999 initiiert Projektpartner EMBL European Bioinformatics Institute (EBI)
Übung II Einführung, Teil 1 Arbeiten mit Ensembl Ensembl Genome Browser (Bereitstellung von Vielzeller Genomen) Projekt wurde 1999 initiiert Projektpartner EMBL European Bioinformatics Institute (EBI)
Bioinformatik Statistik und Analyse mit R 22.05.2009-1 -
 Bioinformatik Statistik und Analyse mit R 22.05.2009-1 - Definition: Bioinformatik Die Bioinformatik http://de.wikipedia.org/wiki/bioinformatik (englisch bioinformatics, auch computational biology) ist
Bioinformatik Statistik und Analyse mit R 22.05.2009-1 - Definition: Bioinformatik Die Bioinformatik http://de.wikipedia.org/wiki/bioinformatik (englisch bioinformatics, auch computational biology) ist
Library of Labs Application Profile (LiLa AP)
") Evaluierung und Zertifizierung von datenprofilen Teil II Application Profile (LiLa AP) Claus Spiecker Universitätsbibliothek Stuttgart Co-funded by the Community programme econtentplus 4. Leipziger Kongress
Evaluierung und Zertifizierung von datenprofilen Teil II Application Profile (LiLa AP) Claus Spiecker Universitätsbibliothek Stuttgart Co-funded by the Community programme econtentplus 4. Leipziger Kongress
Semantic-Web-Sprachen XML, RDF (und RDFS), OWL
, OWL") Semantic-Web-Sprachen XML, RDF (und RDFS), OWL PTI 991 Wissensmanagementsystemen Dozent: Prof. Sybilla Schwarz 1 Agenda Problem Semantisches Web Semantische Sprache XML RDF RDFS OWL Zusammenfassung 2 Problem
Semantic-Web-Sprachen XML, RDF (und RDFS), OWL PTI 991 Wissensmanagementsystemen Dozent: Prof. Sybilla Schwarz 1 Agenda Problem Semantisches Web Semantische Sprache XML RDF RDFS OWL Zusammenfassung 2 Problem
Detecting Near Duplicates for Web Crawling
 Detecting Near Duplicates for Web Crawling Gurmeet Singh Manku et al., WWW 2007* * 16th international conference on World Wide Web Detecting Near Duplicates for Web Crawling Finde near duplicates in großen
Detecting Near Duplicates for Web Crawling Gurmeet Singh Manku et al., WWW 2007* * 16th international conference on World Wide Web Detecting Near Duplicates for Web Crawling Finde near duplicates in großen
InterPro & SP-ML. Syntax und Verwendung der Beschreibungssprache XML Ausarbeitung im Seminar XML in der Bioinformatik.
 InterPro & SP-ML Syntax und Verwendung der Beschreibungssprache XML Ausarbeitung im Seminar XML in der Bioinformatik Stefan Albaum 18. Dezember 2002 Inhaltsverzeichnis 1 SPTr-XML 2 1.1 SWISS-PROT...........................
InterPro & SP-ML Syntax und Verwendung der Beschreibungssprache XML Ausarbeitung im Seminar XML in der Bioinformatik Stefan Albaum 18. Dezember 2002 Inhaltsverzeichnis 1 SPTr-XML 2 1.1 SWISS-PROT...........................
Vorbesprechung Seminar Biomedical Informatics
 Vorbesprechung Martin Dugas und Xiaoyi Jiang Institut für Informatik Sommersemester 2016 Organisation Vorlage: Englischsprachige Publikation Vortrag: ca. 30min + 15min Diskussion, Blockseminar Anfang/Mitte
Vorbesprechung Martin Dugas und Xiaoyi Jiang Institut für Informatik Sommersemester 2016 Organisation Vorlage: Englischsprachige Publikation Vortrag: ca. 30min + 15min Diskussion, Blockseminar Anfang/Mitte
Extraktion von Metadaten als Basis für eine semantische Integration heterogener Informationssysteme
 Extraktion von Metadaten als Basis für eine semantische Integration heterogener Informationssysteme Liane Haak, Axel Hahn Abteilung Wirtschaftsinformatik Carl von Ossietzky Universität Oldenburg Fakultät
Extraktion von Metadaten als Basis für eine semantische Integration heterogener Informationssysteme Liane Haak, Axel Hahn Abteilung Wirtschaftsinformatik Carl von Ossietzky Universität Oldenburg Fakultät
Information Retrieval
 Information Retrieval Norbert Fuhr 12. April 2010 Einführung 1 IR in Beispielen 2 Was ist IR? 3 Dimensionen des IR 4 Daten Information Wissen 5 Rahmenarchitektur für IR-Systeme IR in Beispielen IR-Aufgaben
Information Retrieval Norbert Fuhr 12. April 2010 Einführung 1 IR in Beispielen 2 Was ist IR? 3 Dimensionen des IR 4 Daten Information Wissen 5 Rahmenarchitektur für IR-Systeme IR in Beispielen IR-Aufgaben
The integration of business intelligence and knowledge management
 The integration of business intelligence and knowledge management Seminar: Business Intelligence Ketevan Karbelashvili Master IE, 3. Semester Universität Konstanz Inhalt Knowledge Management Business intelligence
The integration of business intelligence and knowledge management Seminar: Business Intelligence Ketevan Karbelashvili Master IE, 3. Semester Universität Konstanz Inhalt Knowledge Management Business intelligence
Informationsextraktion aus radiologischen Befundberichten
 Informationsextraktion aus radiologischen Befundberichten Philipp Daumke, Soeren Holste, Sarah Ambroz, Michael Poprat, Kai Simon, Dirk Marwede, Elmar Kotter Partner» Anbieter von Textanalyse-Software für
Informationsextraktion aus radiologischen Befundberichten Philipp Daumke, Soeren Holste, Sarah Ambroz, Michael Poprat, Kai Simon, Dirk Marwede, Elmar Kotter Partner» Anbieter von Textanalyse-Software für
ENTWURF, ERRICHTUNG, BETRIEB VON DATENNETZEN
 ENTWURF, ERRICHTUNG, BETRIEB VON DATENNETZEN Dr. Manfred Siegl m.siegl @ citem.at N E T Z M A N A G E M E N T Was erwartest Du vom Netz? Das es immer gut funktioniert. In Wirklichkeit sind wir alle abhängig
ENTWURF, ERRICHTUNG, BETRIEB VON DATENNETZEN Dr. Manfred Siegl m.siegl @ citem.at N E T Z M A N A G E M E N T Was erwartest Du vom Netz? Das es immer gut funktioniert. In Wirklichkeit sind wir alle abhängig
Ein Ansatz für eine Ontologie-basierte Verbindung von IT Monitoring und IT Governance
 Ein Ansatz für eine Ontologie-basierte Verbindung von IT Monitoring und IT Governance MITA 2014 23.09.2014 Andreas Textor andreas.textor@hs-rm.de Hochschule RheinMain Labor für Verteilte Systeme Fachbereich
Ein Ansatz für eine Ontologie-basierte Verbindung von IT Monitoring und IT Governance MITA 2014 23.09.2014 Andreas Textor andreas.textor@hs-rm.de Hochschule RheinMain Labor für Verteilte Systeme Fachbereich
INEX. INitiative for the Evaluation of XML Retrieval. Sebastian Rassmann, Christian Michele
 INEX INitiative for the Evaluation of XML Retrieval Was ist INEX? 2002 gestartete Evaluierungsinitiative Evaluierung von Retrievalmethoden für XML Dokumente Berücksichtigt die hierarchische Dokumentstruktur
INEX INitiative for the Evaluation of XML Retrieval Was ist INEX? 2002 gestartete Evaluierungsinitiative Evaluierung von Retrievalmethoden für XML Dokumente Berücksichtigt die hierarchische Dokumentstruktur
Linked Open Data (LOD) im Enterprise 2.0. Florian Kondert COO, Business Development
 im Enterprise 2.0. Florian Kondert COO, Business Development") Linked Open Data (LOD) im Enterprise 2.0 Florian Kondert COO, Business Development Über die SWC 21 Experten Semantische Technologien für Enterprise Systeme Thesaurus- & Metadaten Management Text Extraction
Linked Open Data (LOD) im Enterprise 2.0 Florian Kondert COO, Business Development Über die SWC 21 Experten Semantische Technologien für Enterprise Systeme Thesaurus- & Metadaten Management Text Extraction
1. Einführung. Datenbanken Grundlagen
 1. Einführung Datenbanken Grundlagen Wo finden wir Datenbanken? Was sind Datenbanken/ Datenbankensysteme(DBS)? A collection of related data items mit folgenden Eigenschaften: Eine Datebank repräsentiert
1. Einführung Datenbanken Grundlagen Wo finden wir Datenbanken? Was sind Datenbanken/ Datenbankensysteme(DBS)? A collection of related data items mit folgenden Eigenschaften: Eine Datebank repräsentiert
ITIL Prozese in APEX am Beispiel des Vodafone FCH
 ITIL Prozese in APEX am Beispiel des Vodafone FCH Tobias Strohmeyer Düsseldorf, 10.06.2015 MT AG Kurzporträt Stefan Witwicki Ratingen, 2015 GESCHÄFTSFORM HAUPTSITZ INHABERGEFÜHRTE AG RATINGEN GRÜNDUNGSJAHR
ITIL Prozese in APEX am Beispiel des Vodafone FCH Tobias Strohmeyer Düsseldorf, 10.06.2015 MT AG Kurzporträt Stefan Witwicki Ratingen, 2015 GESCHÄFTSFORM HAUPTSITZ INHABERGEFÜHRTE AG RATINGEN GRÜNDUNGSJAHR
Semantic Web Services
 Semantic Web Services Daniel Fischer TU Chemnitz - WS 2011/12 1 Gliederung (1) Web Services (2) Semantic Web Services: Motivation (3) Ontologien (4) Technologien 1. WSDL 2. SA-WSDL 3. WSMF / WSMO 4. OWL-S
Semantic Web Services Daniel Fischer TU Chemnitz - WS 2011/12 1 Gliederung (1) Web Services (2) Semantic Web Services: Motivation (3) Ontologien (4) Technologien 1. WSDL 2. SA-WSDL 3. WSMF / WSMO 4. OWL-S