Einführung in Maschinelles Lernen zur Datenanalyse
|
|
|
- Bertold Bruhn
- vor 6 Jahren
- Abrufe
Transkript

1 Einführung in Maschinelles Lernen zur Datenanalyse Prof. Dr. Ing. Morris Riedel School of Engineering and Natural Sciences, University of Iceland Research Group Leader, Juelich Supercomputing Centre, Germany Smart Data Innovation Lab, Leitung Community Medizin TUTORIAL TEIL 1 Grundlagen und Überblick 13. Oktober 2016 Karlsruhe
2 Gliederung 2/ 59
3 Gliederung des Tutorials 1. Grundlagen und Überblick 2. Klassifikation von Daten in Anwendungen Das Tutorial ist nur ein kleiner Ausschnitt an Grundlagen und Skills die ein normaler Universitätskurs vermittelt und kann daher nicht die volle Breite des maschinellen Lernens zeigen 3/ 59

4 Gliederung Teil 1 Grundlagen und Überblick Grundlagen Motivation Überblick der Methoden Einfaches Anwendungsbeispiel Entscheidungsgrenze & Lineare Separabilität Einfaches Perceptron Lernmodell Lernen aus Daten Systematischer Prozess des Lernens Prädiktive and Deskriptive Aufgaben Verschiedene Lernansätze Terminologien & Datensätze Modell Evaluation und Phasen 4/ 59
5 Grundlagen 5/ 59

6 Motivation Deutliche Zunahme in Datensammlungen und Größe der Speichertechnologien Extrahieren von sinnvollen Informationen wird zunehmend ein Problem in den Datenmengen Traditionelle Techniken zur Datenanalyse können oft nicht mehr benutzt werden (bspw. zu wenig Hauptspeicher, mehr Rechenkraft, etc.) Maschinelles Lernen / Data Mining sind Technologien die traditionelle Methoden der Datenanalyse mit Algorithmen verbinden und für große Datenmengen sinnvoll sind Maschinelles Lernen / Data Mining zieht automatisch nützliche Informationen aus Datenmengen heraus und sollte einem systematischen Prozess folgen modifiziert von [1] Introduction to Data Mining Maschinelles Lernen & Data Mining sowie Nutzung von Statistik Traditionalle Ansätze wie Algorithmen oder Methoden trotzdem sinnvoll Bswp. Reduzierung von Daten zu Smart Data ( hohe Informationsdichte ) 6/ 59
7 Maschinelles Lernen Voraussetzungen und Überblick 1. Irgendein Muster existiert in den Daten 2. Es existiert keine mathematische Formel 3. Daten sind vorhanden Idee Lernen von Daten ist auch in vielen anderen Disziplinen wichtig Bspw. signal processing, data mining, etc. Herausforderung: Komplexe Daten Maschinelles Lernen ist ein breiter Expertenbereich und reicht von abtrakter Theorie bis zur extremen Praxis (Klare Algorithmen bis zu Faustregeln ) Data Mining Data Science Machine Learning Applied Statistics 7/ 59

 [2] PANGAEA data collection [3] UCI Machine Learning")
8 Beispiele Datensammlungen Datensammlung der Erd und Umweltwissenschaften Eher starker Unterschied zu UCI machine learning repository Beispielen (Echte wissenschaftliche Datensätze) (Beispiele zum Lernen und Vergleichen) [2] PANGAEA data collection [3] UCI Machine Learning Repository 8/ 59
9 Überblick der Methoden Maschinelles Lernen kann man grob in drei Bereiche einteilen die sich Klassifikation, Clustering und Regression nennen weitere Techniken dienen der Datenauswahl und Datenänderung Klassifikation Clustering Regression? Gruppen existieren Neuer Datenpunkt in welcher Gruppe? Keine Gruppen existieren Erzeuge Gruppen durch Daten die ähnlich sind Identifizierung einer Linie und Trends in den Datensätzen Der konkrete Fokus in diesem Tutorial ist die Klassifikation mit einem bekannten Algorithmus 9/ 59
?")

10 Einfaches Anwendungsbeispiel: Klassifikation einer Blume (1) Problem Understanding Phase (Welcher Blumentyp ist das?)? (Typ der Blume IRIS Setosa ) Gruppen existieren Neuer Datenpunkt in welcher Gruppe? [4] Image sources: Species Iris Group of North America Database, (Typ der Blume IRIS Virginica ) 10 / 59
![Das Maschinelle Lernen Problem (Typ der Blume IRIS Setosa ) (Typ der Blume IRIS Virginica ) [4] Image](/docs-images/68/59286678/images/11-1.jpg "sources: Species Iris Group of North America Database, www.signa.")

11 Das Maschinelle Lernen Problem (Typ der Blume IRIS Setosa ) (Typ der Blume IRIS Virginica ) [4] Image sources: Species Iris Group of North America Database, Lernproblem: Ein prädiktiver Task Automatisiert herausfinden ob es sich um den Blumentyp Setosa oder Virginica handelt Binäres / Zwei-Klassen Klassifikationsproblem Welche Attribute in den Daten helfen hier? (Welcher Blumentyp ist das?) 11 / 59

12 Prüfung der Anwendbarkeit von Maschinellen Lernen 1. Irgendein Muster existiert in den Daten Wir glauben an ein Muster mit petal length & petal width die den Typ beschreiben 2. Es existiert keine mathematische Formel So gut wir momentan wissen scheint es dafür keine exakte Formel zu geben 3. Daten sind vorhanden Datenkollektion aus UCI Datensatz Iris 150 labelled samples (aka Datenpunkte ) Balanciert: 50 samples / Klasse (2) Data Understanding Phase [6] UCI Machine Learning Repository Iris Dataset (vier Attribute in den Daten für jedes Sample im Datensatz) (ein Klassenlabel für jedes Sample im Datensatz) [5] Image source: Wikipedia, Sepal sepal length in cm sepal width in cm petal length in cm petal width in cm Klasse: Iris Setosa, oder Iris Versicolour, oder Iris Virginica 12 / 59

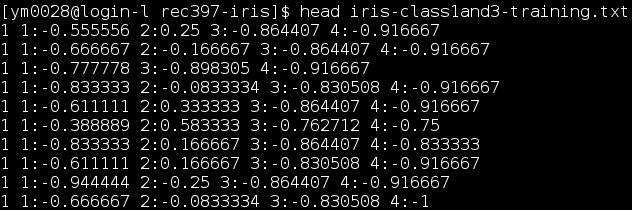
13 Datensatz Iris 13 / 59
14 Übungen Datenexploration 14 / 59
15 Verstehen der Daten Prüfung von Metadaten Zuerst: Check metadata wenn vorhanden Beispiel: Downloaded iris.names beinhaltet Metadaten (Metadaten fehlen oft in Praxis leider) (Subject, title, or context) (author, source, or creator) (number of samples, instances) (attribute information) (detailed attribute information) (detailed attribute information) [6] UCI Machine Learning Repository Iris Dataset 15 / 59
, Excel in Windows, etc. Bspw.")
 (vier Attribute in den Daten für jedes Sample im Datensatz) (ein Klassenlabel für jedes Sample im Datensatz) sepal length in cm sepal width in")
16 Verstehen der Daten Tabellenansicht Oft sinnvoll: Prüfung der Daten in Tabellenansicht ( Auszug ) Bspw. Nutzung GUI Rattle (Bibliothek von R), Excel in Windows, etc. Bspw. Prüfung ob erste Zeile header information ist oder ein Sample (Achtung erstes Sample wird hier als Header genommen, das resultiert in nur 149 data Samples statt 150) (vier Attribute in den Daten für jedes Sample im Datensatz) (ein Klassenlabel für jedes Sample im Datensatz) sepal length in cm sepal width in cm petal length in cm petal width in cm Klasse: Iris Setosa, oder Iris Versicolour, oder Iris Virginica [7] Rattle Library for R 16 / 59


17 Vorbereiten der Daten Korrigierter Header (3) Data Preparation Phase (korrigierter Header, resultiert in 150 data Samples) (Korrektur des Headers ist nicht immer notwendig, oder kann z.b. automatisiert werden, bspw. Rattle) 17 / 59
 Zur Erinnerung: Unser konkretes Lernproblem Automatisiert herausfinden ob es sich um den Blumentyp Setosa oder Virginica handelt")
18 Vorbereiten der Daten Entfernung der Dritten Klasse Daten Vorbereitung der Daten für unser konkretes Problem In der Praxis braucht man nicht alle Daten im Datensatz zur Problemlösung Bspw. Nutzung von Sampling Strategien (achten sie auf Klassenbalance) Zur Erinnerung: Unser konkretes Lernproblem Automatisiert herausfinden ob es sich um den Blumentyp Setosa oder Virginica handelt Binäres / Zwei-Klassen Klassifikationsproblem (Drei Klassen Problem N = 150 Samples enthält auch Iris Versicolour) (Zwei Klassen Problem N = 100 Samples enthält nicht mehr Iris Versicolour) (Entfernen der Versicolour Klasse samples aus dem Datensatz) 18 / 59
19 Vorbereiten der Daten Feature Selektion Vorbereitung der Daten für unser konkretes Problem In der Praxis braucht man nicht alle Daten im Datensatz zur Problemlösung Bspw. Nutzung von Feature Selektion (bspw. Entfernung von Attributen) Zur Erinnerung: Unser angenommenes Muster in den Daten Wir glauben an ein Muster mit petal length & petal width die den Typ beschreiben sepal length in cm sepal width in cm petal length in cm petal width in cm Klasse: Iris Setosa, oder Iris Versicolour, oder Iris Virginica (N = 100 samples mit 4 Attributen und 1 class label) petal length in cm petal width in cm Klasse: Iris Setosa, oder Iris Versicolour, oder Iris Virginica (N = 100 samples mit 2 Attributen und 1 class label) 19 / 59
20 Vorbereiten der Daten: Grafische Darstellung petal width (in cm) Dataset (Zur Erinnerung: Wir glauben an ein Muster mit petal length & petal width die den Typ beschreiben) (Attribute mit d=2) (x1 ist petal length, x2 ist petal width) Dataset (N = 100 samples) 0.5 (Und die class labels?) petal length (in cm) 20 / 59
21 Vorbereiten der Daten: Klassen Labels petal width (in cm) Iris-setosa Iris-virginica 1 (N = 100 samples) (Das ist noch kein maschinelles Lernen) petal length (in cm) 21 / 59
22 Lineare Separabilität & Lineare Entscheidungsgrenze petal width (in cm) ? (4) Modelling Phase Die Daten sind linear separabel (nicht oft in Praxis) Eine Linie wird eine Entscheidungsgrenze ob ein neuer Punkt rot oder grün wird Iris-setosa Iris-virginica 1 (N = 100 samples) (Entscheidungsgrenze, aber wie genau erstellt? Maschinelles Lernen) petal length (in cm) 22 / 59
23 Entscheidungsgrenze & Mathematische Notation Resultate aus erster Datensichtung Linie kann zwischen Klassen erstellt werden in linear separabelen Daten Alle Datenpunkte der Iris-setosa sind unterhalt dieser Linie Alle Datenpunkte der Iris-virginica sind oberhalb dieser Linie Mathematische Notation Input: (Attribute der Blumen, bei uns nur zwei hier) Output: class +1 (Iris-virginica) or class -1 (Iris-setosa) (Entscheidungsgrenze) Iris-virginica wenn Iris-setosa wenn (w i und threshold kennen wir noch nicht) (Kompakte Notation) 23 / 59
24 Entscheidungsgrenze & Entscheidungsraum Beispiel (Entscheidungslinie) (Gleichung der Linie) modified from [13] An Introduction to Statistical Learning (Alle Punkte X i auf dieser Linie erfüllen die Gleichung) 24 / 59
![Einfaches Lineares Lernmodell Das Perceptron Analogie des menschlichen Lernens [8] F.](/docs-images/68/59286678/images/25-0.jpg "Rosenblatt, 1957 Menschliches Gehirn hat Nervenzellen die sich Neuronen nennen Es lernt durch die Änderung der Stärken von Neuronenverbindungen (w i ) durch wiederholte Stimulation deselben Impulses")
25 Einfaches Lineares Lernmodell Das Perceptron Analogie des menschlichen Lernens [8] F. Rosenblatt, 1957 Menschliches Gehirn hat Nervenzellen die sich Neuronen nennen Es lernt durch die Änderung der Stärken von Neuronenverbindungen (w i ) durch wiederholte Stimulation deselben Impulses (aka Trainingsphase ) Trainieren eines Perceptron Lernmodells ändert die Gewichte w i Solange bis die input-output Beziehung in den Trainingsdaten stimmt (Trainingsdaten) (modelliert als bias Term) (Aktivierungs -funktion, +1 or -1) (Das Signal) d (Dimension der Features) (repräsentiert den Threshold) 25 / 59
 Mehr als nur die gewichtete Summe der Inputs")
 +1) (bspw. Sample #6, Summe ist negativ (-0.")
26 Perceptron Beispiel einer Boolean Funktion (Trainingsdaten) (trainingsphase) Output node Interpretation (trainiertes Perceptron Modell) Mehr als nur die gewichtete Summe der Inputs threshold (aka bias) Aktivierungsfunktion sign (weighted sum): nimmt Zeichen der Summe (bspw. Sample #3, Summe ist positiv (0.2) +1) (bspw. Sample #6, Summe ist negativ (-0.1) -1) 26 / 59
 [8] F.")
 (Jeder grüne Bereich und blaue Bereich sind Regionen des gleichen Klassenlabels bestimmt durch das Vorzeichen der Funktion) (Rote Parameters korrespondieren zu der")
27 Zusammenfassung Perceptron & Hypothesis Set h(x) Wann: Bei einem linearen Klassifikationsproblem Ziel: lernen eines Werts (+1/-1) über/unter einem bestimmen threshold Klassen label wird vereinfacht: Iris-setosa = -1 and Iris-virginica = +1 Input: (Attribute in einem Datensatz) [8] F. Rosenblatt, 1957 Lineare Formel (nimm Attribute und gebe Ihnen verschiedenene Gewichte ) Alle gelernten Formels sind tatsächlich unterschiedliche Hypothesen (Parameters die eine Hypothese von der anderen unterscheiden) (Jeder grüne Bereich und blaue Bereich sind Regionen des gleichen Klassenlabels bestimmt durch das Vorzeichen der Funktion) (Rote Parameters korrespondieren zu der roten Linie in der Grafik) (Frage bleibt: We wird nun wirklich w i gelernt und der threshold?) 27 / 59
 Entscheidungsgrenze:")
 Möglich durch Vereinfachungen denn wir lernen auch den threshold: w i (Vektor")
![notation, Nutzung T = transpose) (equivalenz dotproduct Notation) [9] Rosenblatt, 1958 (All](/docs-images/68/59286678/images/28-4.jpg "Notationen sind equivalent und resultieren in einem Skalar von diesem Skalar nutzen wir dann das")
28 Perceptron Lernalgorithmus Vektor W Verstehen Wann: Wenn wir glauben es gibt ein lineares Muster in Daten Annahme: Linear separable Daten (Algorithmus konvergiert) Entscheidungsgrenze: perpendicular vector w i fixes orientation of the line (Punkte auf der Entscheidungsgrenze halten Gleichung ein) Möglich durch Vereinfachungen denn wir lernen auch den threshold: w i (Vektor notation, Nutzung T = transpose) (equivalenz dotproduct Notation) [9] Rosenblatt, 1958 (All Notationen sind equivalent und resultieren in einem Skalar von diesem Skalar nutzen wir dann das Vorzeichen) 28 / 59
29 Verstehen des Dot Product Beispiel & Interpretation Dot product Zwei Vektoren sind gegeben Multiplikation der Vektorkomponenten Hinzufügen des resultierenden Produkts Einfaches Beispiel: Wichtig: Dot product zweier Vektoren ist tatsächlich ein Skalar! (ein Skalar!) Projektioneigenschaft eines Dot product (vereinfacht) Orthogonale Projektion von Vektor in Richtung von Vektor (Projektion) Normalisierung durch Länge Vektor 29 / 59
30 Perceptron Lernalgorithmus Lernschritte Iterative Methode nutzt labelled Datensatz (ein Punkt wird jedesmal gewählt) 1. Wählen einen falsch klassifizierten Punkt wo gilt das: y = +1 w + yx (a) w x 2. Update des weight Vektors: (a) (b) Addieren eines Vektors oder Subtrahieren eines Vektors (y n ist entweder +1 oder -1) Algorithmus konvergiert wenn es keine falsch klassifizierten Punkte gibt (konvergiert also nur wenn linear separable Daten existieren) (b) y = -1 w yx w x 30 / 59
31 [Video] Perceptron Lernalgorithmus [10] PLA Video 31 / 59
32 Lernen aus Daten 32 / 59
 Data Understanding; (3) Data Preparation; (4) Modeling; (5) Evaluation; (6) Deployment (Lernen von Daten passiert hier) Lessons Learned aus der Praxis Man bewegt sich")
33 Systematischer Prozess Systematische Datenanalyse orientiert am Standard Prozess Cross-Industry Standard Process for Data Mining (CRISP-DM) A data mining project is guided by these six phases: (1) Problem Understanding; (2) Data Understanding; (3) Data Preparation; (4) Modeling; (5) Evaluation; (6) Deployment (Lernen von Daten passiert hier) Lessons Learned aus der Praxis Man bewegt sich zwischen den Phasen immer hin und her [11] C. Shearer, CRISP-DM model, Journal Data Warehousing, 5:13 33 / 59
34 Maschinelles Lernen und Data Mining Anwendungen Maschinelles Lernen kann man in zwei Kategorien einteilen: Prediktive & Deskriptive Aufgaben Prädiktive Aufgaben [1] Introduction to Data Mining Sagt Wert eines Attributs vorher basiert auf Werten anderer Attribute Target/dependent variable: Attribut zur Vorhersage Explanatory/independent variables: Attribute für Entscheidungen genutzt E.g. Vorhersage des Typs einer Blumer basierend auf Charakteristiken Deskriptive Tasks Beschreibt Muster die die Beziehungen in Daten zusammenfassen Muster können sein Korrelationen, Trends, Trajektorien, Anomalien Oft eher beschreibend und braucht oft eine Art von Post-processing E.g. Kreditkartenmißbrauch anhand untypischer Transaktionen 34 / 59
 0 0 1 2 3 4 5 6 7 8 petal length (in cm) [4] Image sources: Species Iris Group of North America Database, www.signa.org 35 / 59")
35 Prädiktive Aufgabe: Erkenne Klasse neuer Blumenpunkt 3 (4) Modelling Phase petal width (in cm) ? Iris-setosa Iris-virginica 1 (N = 100 samples) 0.5 (Entscheidungsgrenze) petal length (in cm) [4] Image sources: Species Iris Group of North America Database, 35 / 59
36 Was bedeutet Lernen eigentlich hier? Die Nutzung von Beobachtungen um einen zugrundeliegenden Prozess zu entdecken Drei Arten der Lernansätze heissen überwachtes, unüberwachtes, und reinforcement Lernen Überwachtes Lernen Die Mehrheit der Methoden in diesem Kurs folgt diesem Ansatz Beispiel: Kreditzusage basierend auf vorherigen Kundenanträgen Unüberwachtes Lernen Oft vor anderem Lernen angewandt höherwertige Datenrepräsentation Beispiel: Münzenerkennung in Automaten basierend auf Gewicht/Größe Reinforcement Learning Typischer eher menschliche Weg des Lernens Beispiel: Baby versucht eine heisse Kaffeetasse zu berühren (wiederholt) 36 / 59
37 Lernansatz Überwachtes Lernen Jeder Prädiktor hat einen Response Der Output überwacht den Lernfortschritt Input Output Daten Ziel: Ein Modell trainieren das Response mit Prediktor verbindet Prädiktiv: Versucht so akkurat wie möglich Vorhersagen über die Reponse von zukünftigen Beobachtungen zu machen Inferenz: Versucht besser die Beziehungen zwischen Response und Prädiktor zu verstehen Überwachte Lernansätze trainieren ein Modell das Reponse mit Prädiktor verbindet Überwachte Lernansätze werden in Klassifikationsalgorithmen wie SVMs benutzt Überwachte Lernansätze arbeiten mit Daten = [input, korrekter output] [13] An Introduction to Statistical Learning 37 / 59
38 Beispiel Lernansatz Überwachtes Lernen petal width (in cm) ? Die labels lenken den Lernfortschritt wie ein Supervisor uns hilft Iris-setosa Iris-virginica 1 (N = 100 samples) 0.5 (Entscheidungsgrenze) petal length (in cm) Tutorial Teil 2 gibt mehr Details in das überwachte Lernen mit Klassifikationsalgorithmen 38 / 59
39 Lernmodell Support Vector Machines SVMs SVMs sind häufig benutzt & flexible Klassifikationsmethode Idee: Linear model funktionieren, geht besser Beispiel: was ist die beste Entscheidungsgrenze hier für Zukünftige Daten (lineares Beispiel) ( maximal margin classifier example) Support Vector Machines (SVM) & Kernelmethoden sind 2-3 Vorlesungen, hier nur oberflächlich 39 / 59




40 Übung Jupyther auf SDIL Platform Jupyther Notebook Datei unter /gpfs/sdic16/tutorials/pisvm-scripts-examples/ 40 / 59
41 Übungen Iris SVM 41 / 59

42 SVMs und Iris Datensatz Was passiert bei SVMs da nun eigentlich? [15] scikit-learn SVM 42 / 59
43 Lernansatz Unüberwachtes Lernen Jeder Prädiktor hat keinen Response Trotzdem können interessante Dinge gelernt werden Input No output Daten Ziel: Untersuchung der Beziehungen zwischen den Daten Cluster analysis: Prüfen ob Daten in gewissen Gruppen fallen Herausforderungen Keine response/output das uns bei der Datenanalyse hilft Clustern von Gruppen die sich überschneiden hart zu differenzieren Unüberwachte Lernansätze untersuchen die Beziehungen zwischen den Daten Unüberwachte Lernansätze werden in Cluster Algorithmen benutzt wie K-Means oder DBSCAN Unüberwachte Lernansätze arbeiten mit Daten = [input, ---] [13] An Introduction to Statistical Learning 43 / 59


44 Beispiel Lernansatz Unüberwachtes Lernen Praxis: Die Anzahl von Cluster wird oft nicht genau erkannt # [13] An Introduction to Statistical Learning Forschungsaktivitäten mit Timo Dickscheid et al. (Juelich Institute of Neuroscience & Medicine) 44 / 59
45 Lernansatz Reinforcement Lernen Jeder Prädiktor hat einen Grad der Response Mit Grad ist hier die Güte gemeint Input Etwas an output & Grad der Güte des Outputs Daten Ziel: Lernen durch Iterationen Geleitet durch Grad des Outputs: prüfe gelerntes uns vergleiche mit Grad Herausforderung: Iterationen brauchen oft sehr viel CPUs (e.g. backgammon Spielrunden) Reinforcement Lernansätze lernen durch Iterationen und Nutzen den Grad des Outputs Reinforcement Lernansätze werden oft in Spielalgorithmen benutzt (bspw. Backgammon) Reinforcement Lernansätze arbeiten mit Daten = [input, etwas output, Grad des Output] [13] An Introduction to Statistical Learning 45 / 59
46 Zusammenfassung Terminologien & Datensätze Target Funktion Idealle Funktion die die Daten erklärt die wir lernen wollen Labelled Dataset (samples) in-sample Daten geben uns: Lernen vs. Auswendiglernen Das Ziel ist es ein System zu erzeugen das gut out of sample funktioniert Wir wollen zukünftige Daten (ouf of sample) korrekt klassifizieren Datensatz Teil Eins: Training set Benutzt um maschinelle Lernalgorithmus zu trainieren Resultat nach dem Training: ein trainiertes System Datensatz Teil Zwei: Test set (4) Modelling Phase (5) Evaluation Phase Benutzt um zu testen ob trainiertes System wohl gut funktionieren wird Resultat nach dem Testen: Genauigkeit des trainierten Systems 46 / 59
47 Modell Evaluation Unterschiedliche Phasen Unterschiedliche Phasen im Lernen Trainingsphase ist ein Suche nach Hypothesis Testingphase prüft ob wir richtig lernen (wenn die Hypothesis klar ist) Arbeit an Training Samples (4) Modelling Phase (5) Evaluation Phase (bspw. Student Klausurtraining anhand von Beispielen um Error in zu reduzieren, dann test via Klausur sein wird) Erzeuge zwei Datensätze training set test set Einer nur für Training Training Examples (aka training set) Ein anderer exklusiv für Testen (Historische Daten, groundtruth Daten, Beispiele) (aka test set) Aufteilung nach Fausregeln & Anwendung (bspw. 10 % training, 90% test) Praxis: Wenn man einen Datensatz bekommt sofort Testdaten sichern ( diese in eine Ecke schmeissen und in Modellierungsphase vergessen ) Argumentation: Nach Lernen haben Trainingsdaten optimistische Neigung 47 / 59
48 Modell Evaluation Testing Phase & Confusion Matrix Modell ist klar Modell wird dann mit dem Testdatensatz genutzt Parameter w i sind gesetzt und wir haben eine Entscheidungsgrenze bereits Evaluation der Performance des Modells Zählung der Test samples die falsch vorhergesagt sind Zählung der Test samples die korrekt vorhergesagt sind Bspw. Erzeuge confusion matrix für ein zwei Klassen Problem (5) Evaluation Phase Zählung per sample Vorhergesagte Klasse Class = 1 Class = 0 Tatsächliche Class Class = 1 f 11 f 10 Class = 0 f 01 f 00 (wird oft als Basis für weitere Performance Metriken genutzt) 48 / 59
49 Modell Evaluation Testing Phase & Performance Metrics Zählung per sample Vorhergesagte Klasse (5) Evaluation Phase Tatsächliche Class Class = 1 Class = 0 Class = 1 f 11 f 10 Class = 0 f 01 f 00 Genauigkeit, engl. Accurary (in %) (100% Genauigkeit beim Lernen ist oft ein Anzeichen von Problemen bei der Nutzung von maschinellen Lernen) Error rate Wenn Evaluation des Modells ist gut: (6) Deployment Phase 49 / 59



50 Datensatz Rome 50 / 59



51 Übung Jupyther auf SDIL Platform Jupyther Notebook Datei unter /gpfs/sdic16/tutorials 51 / 59
52 Übungen Rome 52 / 59
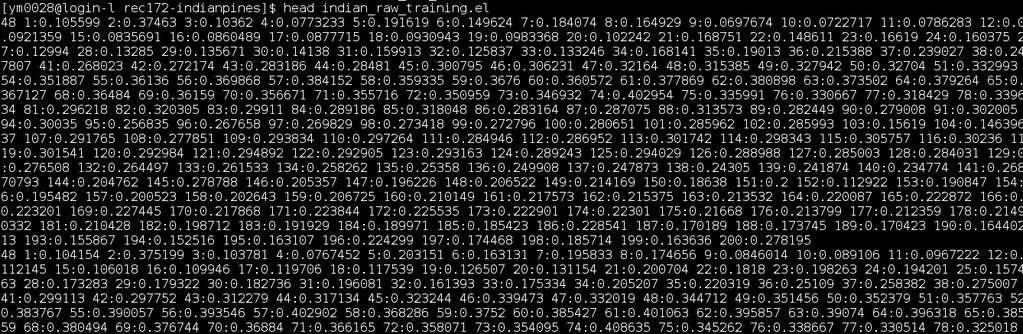
53 Datensatz Indianpines 53 / 59

54 Übungen Indianpines 54 / 59
55 [Video] European Plate Observing System [14] EPOS Data Community Services, YouTube 55 / 59
56 Referenzen 56 / 59
57 Referenzen (1) [1] Introduction to Data Mining, Pang-Ning Tan, Michael Steinbach, Vipin Kumar, Addison Wesley, ISBN , English, ~769 pages, 2005 [2] PANGAEA Data Collection, Data Publisher for Earth & Environmental Science, Online: [3] UCI Machine Learning Repository, Online: [4] Species Iris Group of North America Database, Online: [5] UCI Machine Learning Repository Iris Dataset, Online: [6] Wikipedia Sepal, Online: [7] Rattle Library for R, Online: [8] F. Rosenblatt, The Perceptron--a perceiving and recognizing automaton, Report , Cornell Aeronautical Laboratory, 1957 [9] Rosenblatt, The Perceptron: A probabilistic model for information storage and orgainzation in the brain, Psychological Review 65(6), pp , 1958 [10] PLA Algorithm, YouTube Video, Online: [11] C. Shearer, CRISP-DM model, Journal Data Warehousing, 5:13 [12] Pete Chapman, CRISP-DM User Guide, 1999, Online: 57 / 59
58 Referenzen (2) [13] An Introduction to Statistical Learning with Applications in R, Online: [14] EPOS - European Plate Observing System -- Community Services, YouTube Video, Online: [15] scikit-learn SVM, Online: 58 / 59

59 Danke für Ihre Aufmerksamkeit Folien sind in Kürze erhältlich auf: 59 / 59
Einführung in Maschinelles Lernen zur Datenanalyse
 Einführung in Maschinelles Lernen zur Datenanalyse Prof. Dr. Ing. Morris Riedel School of Engineering and Natural Sciences, University of Iceland Research Group Leader, Juelich Supercomputing Centre, Germany
Einführung in Maschinelles Lernen zur Datenanalyse Prof. Dr. Ing. Morris Riedel School of Engineering and Natural Sciences, University of Iceland Research Group Leader, Juelich Supercomputing Centre, Germany
Logistische Regression
 Logistische Regression Christian Herta August, 2013 1 von 45 Christian Herta Logistische Regression Lernziele Logistische Regression Konzepte des maschinellen Lernens (insb. der Klassikation) Entscheidungsgrenze,
Logistische Regression Christian Herta August, 2013 1 von 45 Christian Herta Logistische Regression Lernziele Logistische Regression Konzepte des maschinellen Lernens (insb. der Klassikation) Entscheidungsgrenze,
Mathematische Grundlagen III
 Mathematische Grundlagen III Maschinelles Lernen III: Clustering Vera Demberg Universität des Saarlandes 7. Juli 202 Vera Demberg (UdS) Mathe III 7. Juli 202 / 35 Clustering vs. Klassifikation In den letzten
Mathematische Grundlagen III Maschinelles Lernen III: Clustering Vera Demberg Universität des Saarlandes 7. Juli 202 Vera Demberg (UdS) Mathe III 7. Juli 202 / 35 Clustering vs. Klassifikation In den letzten
Approximate Maximum Margin Algorithms with Rules Controlled by the Number of Mistakes
 Approximate Maximum Margin Algorithms with Rules Controlled by the Number of Mistakes Seminar Maschinelles Lernen VORTRAGENDER: SEBASTIAN STEINMETZ BETREUT VON: ENELDO LOZA MENCÍA Inhalt Vorbedingungen
Approximate Maximum Margin Algorithms with Rules Controlled by the Number of Mistakes Seminar Maschinelles Lernen VORTRAGENDER: SEBASTIAN STEINMETZ BETREUT VON: ENELDO LOZA MENCÍA Inhalt Vorbedingungen
Nutzung maschinellen Lernens zur Extraktion von Paragraphen aus PDF-Dokumenten
 Nutzung maschinellen Lernens zur Extraktion von Paragraphen aus PDF-Dokumenten Albert-Ludwigs-Universität zu Freiburg 13.09.2016 Maximilian Dippel max.dippel@tf.uni-freiburg.de Überblick I Einführung Problemstellung
Nutzung maschinellen Lernens zur Extraktion von Paragraphen aus PDF-Dokumenten Albert-Ludwigs-Universität zu Freiburg 13.09.2016 Maximilian Dippel max.dippel@tf.uni-freiburg.de Überblick I Einführung Problemstellung
Machine Learning Tutorial
 Machine Learning Tutorial a very fast WEKA Introduction busche@ismll.uni-hildesheim.de 05.01.09 1 Hauptbestandteile von WEKA: Instances Instance Attribute FastVector Classifier Evaluation (Filter) http://weka.wiki.sourceforge.net/
Machine Learning Tutorial a very fast WEKA Introduction busche@ismll.uni-hildesheim.de 05.01.09 1 Hauptbestandteile von WEKA: Instances Instance Attribute FastVector Classifier Evaluation (Filter) http://weka.wiki.sourceforge.net/
Einführung in Support Vector Machines (SVMs)
") Einführung in (SVM) Januar 31, 2011 Einführung in (SVMs) Table of contents Motivation Einführung in (SVMs) Outline Motivation Vektorrepräsentation Klassifikation Motivation Einführung in (SVMs) Vektorrepräsentation
Einführung in (SVM) Januar 31, 2011 Einführung in (SVMs) Table of contents Motivation Einführung in (SVMs) Outline Motivation Vektorrepräsentation Klassifikation Motivation Einführung in (SVMs) Vektorrepräsentation
Machine Learning. 1. Grundlagen des Machine Learning
 Machine Learning 1. Grundlagen des Machine Learning Grundlagen des Machine Learning Begriff Machine Learning Definitionen Machine Learning Formale Definition Machine Learning Aufgaben im Machine Learning
Machine Learning 1. Grundlagen des Machine Learning Grundlagen des Machine Learning Begriff Machine Learning Definitionen Machine Learning Formale Definition Machine Learning Aufgaben im Machine Learning
Pareto optimale lineare Klassifikation
 Seminar aus Maschinellem Lernen Pareto optimale lineare Klassifikation Vesselina Poulkova Betreuer: Eneldo Loza Mencía Gliederung 1. Einleitung 2. Pareto optimale lineare Klassifizierer 3. Generelle Voraussetzung
Seminar aus Maschinellem Lernen Pareto optimale lineare Klassifikation Vesselina Poulkova Betreuer: Eneldo Loza Mencía Gliederung 1. Einleitung 2. Pareto optimale lineare Klassifizierer 3. Generelle Voraussetzung
Modell Komplexität und Generalisierung
 Modell Komplexität und Generalisierung Christian Herta November, 2013 1 von 41 Christian Herta Bias-Variance Lernziele Konzepte des maschinellen Lernens Targetfunktion Overtting, Undertting Generalisierung
Modell Komplexität und Generalisierung Christian Herta November, 2013 1 von 41 Christian Herta Bias-Variance Lernziele Konzepte des maschinellen Lernens Targetfunktion Overtting, Undertting Generalisierung
Analytics Entscheidungsbäume
 Analytics Entscheidungsbäume Professional IT Master Prof. Dr. Ingo Claßen Hochschule für Technik und Wirtschaft Berlin Regression Klassifikation Quellen Regression Beispiel Baseball-Gehälter Gehalt: gering
Analytics Entscheidungsbäume Professional IT Master Prof. Dr. Ingo Claßen Hochschule für Technik und Wirtschaft Berlin Regression Klassifikation Quellen Regression Beispiel Baseball-Gehälter Gehalt: gering
, Data Mining, 2 VO Sommersemester 2008
 Evaluation 188.646, Data Mining, 2 VO Sommersemester 2008 Dieter Merkl e-commerce Arbeitsgruppe Institut für Softwaretechnik und Interaktive Systeme Technische Universität Wien www.ec.tuwien.ac.at/~dieter/
Evaluation 188.646, Data Mining, 2 VO Sommersemester 2008 Dieter Merkl e-commerce Arbeitsgruppe Institut für Softwaretechnik und Interaktive Systeme Technische Universität Wien www.ec.tuwien.ac.at/~dieter/
DOKUMENTENKLASSIFIKATION MIT MACHINE LEARNING
 DOKUMENTENKLASSIFIKATION MIT MACHINE LEARNING Andreas Nadolski Softwareentwickler andreas.nadolski@enpit.de Twitter: @enpit Blogs: enpit.de/blog medium.com/enpit-developer-blog 05.10.2018, DOAG Big Data
DOKUMENTENKLASSIFIKATION MIT MACHINE LEARNING Andreas Nadolski Softwareentwickler andreas.nadolski@enpit.de Twitter: @enpit Blogs: enpit.de/blog medium.com/enpit-developer-blog 05.10.2018, DOAG Big Data
Motivation. Klassifikationsverfahren sagen ein abhängiges nominales Merkmal anhand einem oder mehrerer unabhängiger metrischer Merkmale voraus
 3. Klassifikation Motivation Klassifikationsverfahren sagen ein abhängiges nominales Merkmal anhand einem oder mehrerer unabhängiger metrischer Merkmale voraus Beispiel: Bestimme die Herkunft eines Autos
3. Klassifikation Motivation Klassifikationsverfahren sagen ein abhängiges nominales Merkmal anhand einem oder mehrerer unabhängiger metrischer Merkmale voraus Beispiel: Bestimme die Herkunft eines Autos
Vorlesung Digitale Bildverarbeitung Sommersemester 2013
 Vorlesung Digitale Bildverarbeitung Sommersemester 2013 Sebastian Houben (Marc Schlipsing) Institut für Neuroinformatik Inhalt Crash-Course in Machine Learning Klassifikationsverfahren Grundsätzliches
Vorlesung Digitale Bildverarbeitung Sommersemester 2013 Sebastian Houben (Marc Schlipsing) Institut für Neuroinformatik Inhalt Crash-Course in Machine Learning Klassifikationsverfahren Grundsätzliches
Ridge Regression und Kernalized Support Vector Machines : Einführung und Vergleich an einem Anwendungsbeispiel
 Ridge Regression und Kernalized Support Vector Machines : Einführung und Vergleich an einem Anwendungsbeispiel Dr. Dominik Grimm Probelehrveranstaltung Fakultät für Informatik und Mathematik Hochschule
Ridge Regression und Kernalized Support Vector Machines : Einführung und Vergleich an einem Anwendungsbeispiel Dr. Dominik Grimm Probelehrveranstaltung Fakultät für Informatik und Mathematik Hochschule
Übersicht. Definition Daten Problemklassen Fehlerfunktionen
 Übersicht 1 Maschinelle Lernverfahren Definition Daten Problemklassen Fehlerfunktionen 2 Entwickeln von maschinellen Lernverfahren Aufteilung der Daten Underfitting und Overfitting Erkennen Regularisierung
Übersicht 1 Maschinelle Lernverfahren Definition Daten Problemklassen Fehlerfunktionen 2 Entwickeln von maschinellen Lernverfahren Aufteilung der Daten Underfitting und Overfitting Erkennen Regularisierung
SKOPOS Webinar 22. Mai 2018
 SKOPOS Webinar 22. Mai 2018 Marktforschung 2020: Künstliche Intelligenz und automatische Text Analysen? Christopher Harms, Consultant Research & Development 2 So? Terminator Exhibition: T-800 by Dick Thomas
SKOPOS Webinar 22. Mai 2018 Marktforschung 2020: Künstliche Intelligenz und automatische Text Analysen? Christopher Harms, Consultant Research & Development 2 So? Terminator Exhibition: T-800 by Dick Thomas
Semiüberwachte Paarweise Klassifikation
 Semiüberwachte Paarweise Klassifikation Andriy Nadolskyy Bachelor-Thesis Betreuer: Prof. Dr. Johannes Fürnkranz Dr. Eneldo Loza Mencía 1 Überblick Motivation Grundbegriffe Einleitung Übersicht der Verfahren
Semiüberwachte Paarweise Klassifikation Andriy Nadolskyy Bachelor-Thesis Betreuer: Prof. Dr. Johannes Fürnkranz Dr. Eneldo Loza Mencía 1 Überblick Motivation Grundbegriffe Einleitung Übersicht der Verfahren
Künstliche Intelligenz im Maschinen- und Anlagenbau Heilsbringer oder Hypebringer?
 ASQF Automation Day 2018 - Predictive Analytics Künstliche Intelligenz im Maschinen- und Anlagenbau Heilsbringer oder Hypebringer? Vasilij Baumann Co-Founder/Co-CEO vasilij.baumann@instrunext.com +49 931
ASQF Automation Day 2018 - Predictive Analytics Künstliche Intelligenz im Maschinen- und Anlagenbau Heilsbringer oder Hypebringer? Vasilij Baumann Co-Founder/Co-CEO vasilij.baumann@instrunext.com +49 931
Data Science Anwendungen bei innogy Netz & Infrastruktur (G&I)
") Data Science Anwendungen bei innogy Netz & Infrastruktur (G&I) - Grid Research and Insights Platform (GRIP) - Essener Energiegespräche 25. Oktober 2018 Philipp Clasen, Freier Mitarbeiter innogy SE 1 Einleitung
Data Science Anwendungen bei innogy Netz & Infrastruktur (G&I) - Grid Research and Insights Platform (GRIP) - Essener Energiegespräche 25. Oktober 2018 Philipp Clasen, Freier Mitarbeiter innogy SE 1 Einleitung
Wissensentdeckung in Datenbanken
 Wissensentdeckung in Datenbanken Deep Learning (II) Nico Piatkowski und Uwe Ligges Informatik Künstliche Intelligenz 25.07.2017 1 von 14 Überblick Faltungsnetze Dropout Autoencoder Generative Adversarial
Wissensentdeckung in Datenbanken Deep Learning (II) Nico Piatkowski und Uwe Ligges Informatik Künstliche Intelligenz 25.07.2017 1 von 14 Überblick Faltungsnetze Dropout Autoencoder Generative Adversarial
Vergleich von SVM und Regel- und Entscheidungsbaum-Lernern
 Vergleich von SVM und Regel- und Entscheidungsbaum-Lernern Chahine Abid Bachelor Arbeit Betreuer: Prof. Johannes Fürnkranz Frederik Janssen 28. November 2013 Fachbereich Informatik Fachgebiet Knowledge
Vergleich von SVM und Regel- und Entscheidungsbaum-Lernern Chahine Abid Bachelor Arbeit Betreuer: Prof. Johannes Fürnkranz Frederik Janssen 28. November 2013 Fachbereich Informatik Fachgebiet Knowledge
Vorlesung Wissensentdeckung
 Vorlesung Wissensentdeckung Einführung 5.4.2011 Gliederung 1 Modellbildung und Evaluation 2 Verlaufsmodell der Wissensentdeckung 3 Einführung in das Werkzeug RapidMiner Problem Wir haben nur eine endliche
Vorlesung Wissensentdeckung Einführung 5.4.2011 Gliederung 1 Modellbildung und Evaluation 2 Verlaufsmodell der Wissensentdeckung 3 Einführung in das Werkzeug RapidMiner Problem Wir haben nur eine endliche
kurze Wiederholung der letzten Stunde: Neuronale Netze Dipl.-Inform. Martin Lösch (0721) Dipl.-Inform.
 Dipl.-Inform.") kurze Wiederholung der letzten Stunde: Neuronale Netze martin.loesch@kit.edu (0721) 608 45944 Labor Wissensrepräsentation Übersicht Neuronale Netze Motivation Perzeptron Grundlagen für praktische Übungen
kurze Wiederholung der letzten Stunde: Neuronale Netze martin.loesch@kit.edu (0721) 608 45944 Labor Wissensrepräsentation Übersicht Neuronale Netze Motivation Perzeptron Grundlagen für praktische Übungen
Inhalt. 4.1 Motivation. 4.2 Evaluation. 4.3 Logistische Regression. 4.4 k-nächste Nachbarn. 4.5 Naïve Bayes. 4.6 Entscheidungsbäume
 4. Klassifikation Inhalt 4.1 Motivation 4.2 Evaluation 4.3 Logistische Regression 4.4 k-nächste Nachbarn 4.5 Naïve Bayes 4.6 Entscheidungsbäume 4.7 Support Vector Machines 4.8 Neuronale Netze 4.9 Ensemble-Methoden
4. Klassifikation Inhalt 4.1 Motivation 4.2 Evaluation 4.3 Logistische Regression 4.4 k-nächste Nachbarn 4.5 Naïve Bayes 4.6 Entscheidungsbäume 4.7 Support Vector Machines 4.8 Neuronale Netze 4.9 Ensemble-Methoden
INTELLIGENTE DATENANALYSE IN MATLAB
 INTELLIGENTE DATENANALYSE IN MATLAB Einführungsveranstaltung Überblick Organisation Literatur Inhalt und Ziele der Vorlesung Beispiele aus der Praxis 2 Organisation Vorlesung/Übung + Projektarbeit. 4 Semesterwochenstunden.
INTELLIGENTE DATENANALYSE IN MATLAB Einführungsveranstaltung Überblick Organisation Literatur Inhalt und Ziele der Vorlesung Beispiele aus der Praxis 2 Organisation Vorlesung/Übung + Projektarbeit. 4 Semesterwochenstunden.
Maschinelles Lernen und Data Mining
 Semestralklausur zur Vorlesung Maschinelles Lernen und Data Mining Prof. J. Fürnkranz / Dr. G. Grieser Technische Universität Darmstadt Wintersemester 2004/05 Termin: 14. 2. 2005 Name: Vorname: Matrikelnummer:
Semestralklausur zur Vorlesung Maschinelles Lernen und Data Mining Prof. J. Fürnkranz / Dr. G. Grieser Technische Universität Darmstadt Wintersemester 2004/05 Termin: 14. 2. 2005 Name: Vorname: Matrikelnummer:
Efficient Learning of Label Ranking by Soft Projections onto Polyhedra
 Efficient Learning of Label Ranking by Soft Projections onto Polyhedra Technische Universität Darmstadt 18. Januar 2008 Szenario Notation duales Problem Weitere Schritte Voraussetzungen Tests Szenario
Efficient Learning of Label Ranking by Soft Projections onto Polyhedra Technische Universität Darmstadt 18. Januar 2008 Szenario Notation duales Problem Weitere Schritte Voraussetzungen Tests Szenario
Projekt Maschinelles Lernen WS 06/07
 Projekt Maschinelles Lernen WS 06/07 1. Auswahl der Daten 2. Evaluierung 3. Noise und Pruning 4. Regel-Lernen 5. ROC-Kurven 6. Pre-Processing 7. Entdecken von Assoziationsregeln 8. Ensemble-Lernen 9. Wettbewerb
Projekt Maschinelles Lernen WS 06/07 1. Auswahl der Daten 2. Evaluierung 3. Noise und Pruning 4. Regel-Lernen 5. ROC-Kurven 6. Pre-Processing 7. Entdecken von Assoziationsregeln 8. Ensemble-Lernen 9. Wettbewerb
INTELLIGENTE DATENANALYSE IN MATLAB. Einführungsveranstaltung
 INTELLIGENTE DATENANALYSE IN MATLAB Einführungsveranstaltung Überblick Organisation. Literatur. Inhalt und Ziele der Vorlesung. Beispiele aus der Praxis. 2 Organisation Vorlesung/Übung + Projektarbeit.
INTELLIGENTE DATENANALYSE IN MATLAB Einführungsveranstaltung Überblick Organisation. Literatur. Inhalt und Ziele der Vorlesung. Beispiele aus der Praxis. 2 Organisation Vorlesung/Übung + Projektarbeit.
Wir haben in den vorherigen Kapiteln verschiedene Verfahren zur Regression und Klassifikation kennengelernt (z.b. lineare Regression, SVMs)
") 6. Neuronale Netze Motivation Wir haben in den vorherigen Kapiteln verschiedene Verfahren zur Regression und Klassifikation kennengelernt (z.b. lineare Regression, SVMs) Abstrakt betrachtet sind alle diese
6. Neuronale Netze Motivation Wir haben in den vorherigen Kapiteln verschiedene Verfahren zur Regression und Klassifikation kennengelernt (z.b. lineare Regression, SVMs) Abstrakt betrachtet sind alle diese
Kapitel 5: Ensemble Techniken
 Ludwig Maximilians Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Skript zur Vorlesung Knowledge Discovery in Databases II im Sommersemester 2009 Kapitel 5:
Ludwig Maximilians Universität München Institut für Informatik Lehr- und Forschungseinheit für Datenbanksysteme Skript zur Vorlesung Knowledge Discovery in Databases II im Sommersemester 2009 Kapitel 5:
Das Perzeptron. Volker Tresp
 Das Perzeptron Volker Tresp 1 Einführung Das Perzeptron war eines der ersten ernstzunehmenden Lernmaschinen Die wichtigsten Elemente Sammlung und Vorverarbeitung der Trainingsdaten Wahl einer Klasse von
Das Perzeptron Volker Tresp 1 Einführung Das Perzeptron war eines der ersten ernstzunehmenden Lernmaschinen Die wichtigsten Elemente Sammlung und Vorverarbeitung der Trainingsdaten Wahl einer Klasse von
IMPULSVORTRAG KÜNSTLICHE INTELLIGENZ & HELMHOLTZ
 IMPULSVORTRAG KÜNSTLICHE INTELLIGENZ & HELMHOLTZ PROF. DR. ING. MORRIS RIEDEL, JUELICH SUPERCOMPUTING CENTRE (JSC) / UNIVERSITY OF ICELAND GRUPPENLEITER HIGH PRODUCTIVITY DATA PROCESSING & CROSS-SECTIONAL
IMPULSVORTRAG KÜNSTLICHE INTELLIGENZ & HELMHOLTZ PROF. DR. ING. MORRIS RIEDEL, JUELICH SUPERCOMPUTING CENTRE (JSC) / UNIVERSITY OF ICELAND GRUPPENLEITER HIGH PRODUCTIVITY DATA PROCESSING & CROSS-SECTIONAL
Methoden zur Cluster - Analyse
 Kapitel 4 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität Leipzig Machine learning in bioinformatics
Kapitel 4 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität Leipzig Machine learning in bioinformatics
Modell Training in Transkribus
 Modell Training in Transkribus Version v1.4.0 Letztes Update dieses Guides: 08.06.2017 Dieser Guide erklärt, wie Sie Transkribus verwenden können um ein Handschriftenerkennungsmodell (HTR Modell) zu trainieren.
Modell Training in Transkribus Version v1.4.0 Letztes Update dieses Guides: 08.06.2017 Dieser Guide erklärt, wie Sie Transkribus verwenden können um ein Handschriftenerkennungsmodell (HTR Modell) zu trainieren.
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Hypothesenbewertung
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hypothesenbewertung Christoph Sawade/Niels Landwehr Dominik Lahmann Tobias Scheffer Überblick Hypothesenbewertung, Risikoschätzung
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hypothesenbewertung Christoph Sawade/Niels Landwehr Dominik Lahmann Tobias Scheffer Überblick Hypothesenbewertung, Risikoschätzung
Clustering 2010/06/11 Sebastian Koch 1
 Clustering 2010/06/11 1 Motivation Quelle: http://www.ha-w.de/media/schulung01.jpg 2010/06/11 2 Was ist Clustering Idee: Gruppierung von Objekten so, dass: Innerhalb einer Gruppe sollen die Objekte möglichst
Clustering 2010/06/11 1 Motivation Quelle: http://www.ha-w.de/media/schulung01.jpg 2010/06/11 2 Was ist Clustering Idee: Gruppierung von Objekten so, dass: Innerhalb einer Gruppe sollen die Objekte möglichst
<Insert Picture Here> Grid Control 11g und My Oracle Support Ulrike Schwinn
 Grid Control 11g und My Oracle Support Ulrike Schwinn Herausforderungen 2 verschiedene Welten IT Operationen Support Performance Management Configuration Management Provisioning,
Grid Control 11g und My Oracle Support Ulrike Schwinn Herausforderungen 2 verschiedene Welten IT Operationen Support Performance Management Configuration Management Provisioning,
Artificial Intelligence. Was ist das? Was kann das?
 Artificial Intelligence Was ist das? Was kann das? Olaf Erichsen Tech-Day Hamburg 13. Juni 2017 Sehen wir hier bereits Künstliche Intelligenz (AI)? Quelle: www.irobot.com 2017 Hierarchie der Buzzwords
Artificial Intelligence Was ist das? Was kann das? Olaf Erichsen Tech-Day Hamburg 13. Juni 2017 Sehen wir hier bereits Künstliche Intelligenz (AI)? Quelle: www.irobot.com 2017 Hierarchie der Buzzwords
Computational Intelligence 1 / 20. Computational Intelligence Künstliche Neuronale Netze Perzeptron 3 / 20
 Gliederung / Künstliche Neuronale Netze Perzeptron Einschränkungen Netze von Perzeptonen Perzeptron-Lernen Perzeptron Künstliche Neuronale Netze Perzeptron 3 / Der Psychologe und Informatiker Frank Rosenblatt
Gliederung / Künstliche Neuronale Netze Perzeptron Einschränkungen Netze von Perzeptonen Perzeptron-Lernen Perzeptron Künstliche Neuronale Netze Perzeptron 3 / Der Psychologe und Informatiker Frank Rosenblatt
Weitere Untersuchungen hinsichtlich der Anwendung von KNN für Solvency 2. Tom Schelthoff
 Weitere Untersuchungen hinsichtlich der Anwendung von KNN für Solvency 2 Tom Schelthoff 30.11.2018 Inhaltsverzeichnis Deep Learning Seed-Stabilität Regularisierung Early Stopping Dropout Batch Normalization
Weitere Untersuchungen hinsichtlich der Anwendung von KNN für Solvency 2 Tom Schelthoff 30.11.2018 Inhaltsverzeichnis Deep Learning Seed-Stabilität Regularisierung Early Stopping Dropout Batch Normalization
Kapitel LF: I. Beispiele für Lernaufgaben. Beispiele für Lernaufgaben. LF: I Introduction c STEIN
 Kapitel LF: I I. Einführung in das Maschinelle Lernen Bemerkungen: Dieses Kapitel orientiert sich an dem Buch Machine Learning von Tom Mitchell. http://www.cs.cmu.edu/ tom/mlbook.html 1 Autoeinkaufsberater?
Kapitel LF: I I. Einführung in das Maschinelle Lernen Bemerkungen: Dieses Kapitel orientiert sich an dem Buch Machine Learning von Tom Mitchell. http://www.cs.cmu.edu/ tom/mlbook.html 1 Autoeinkaufsberater?
Die Datenmatrix für Überwachtes Lernen
 Die Datenmatrix für Überwachtes Lernen X j j-te Eingangsvariable X = (X 0,..., X M 1 ) T Vektor von Eingangsvariablen M Anzahl der Eingangsvariablen N Anzahl der Datenpunkte Y Ausgangsvariable x i = (x
Die Datenmatrix für Überwachtes Lernen X j j-te Eingangsvariable X = (X 0,..., X M 1 ) T Vektor von Eingangsvariablen M Anzahl der Eingangsvariablen N Anzahl der Datenpunkte Y Ausgangsvariable x i = (x
Combining Manual Feedback with Subsequent MDP Reward Signals for Reinforcement Learning W. Bradley Knox und Peter Stone
 Combining Manual Feedback with Subsequent MDP Reward Signals for Reinforcement Learning W. Bradley Knox und Peter Stone 14.12.2012 Informatik FB 20 Knowlegde Engineering Yasmin Krahofer 1 Inhalt Problemstellung
Combining Manual Feedback with Subsequent MDP Reward Signals for Reinforcement Learning W. Bradley Knox und Peter Stone 14.12.2012 Informatik FB 20 Knowlegde Engineering Yasmin Krahofer 1 Inhalt Problemstellung
kurze Wiederholung der letzten Stunde: Neuronale Netze Dipl.-Inform. Martin Lösch (0721) Dipl.-Inform.
 Dipl.-Inform.") kurze Wiederholung der letzten Stunde: Neuronale Netze martin.loesch@kit.edu (0721) 608 45944 Labor Wissensrepräsentation Aufgaben der letzten Stunde Übersicht Neuronale Netze Motivation Perzeptron Multilayer
kurze Wiederholung der letzten Stunde: Neuronale Netze martin.loesch@kit.edu (0721) 608 45944 Labor Wissensrepräsentation Aufgaben der letzten Stunde Übersicht Neuronale Netze Motivation Perzeptron Multilayer
Einführung in das Maschinelle Lernen I
 Einführung in das Maschinelle Lernen I Vorlesung Computerlinguistische Techniken Alexander Koller 26. Januar 2015 Maschinelles Lernen Maschinelles Lernen (Machine Learning): äußerst aktiver und für CL
Einführung in das Maschinelle Lernen I Vorlesung Computerlinguistische Techniken Alexander Koller 26. Januar 2015 Maschinelles Lernen Maschinelles Lernen (Machine Learning): äußerst aktiver und für CL
Kapitel ML: I. I. Einführung. Beispiele für Lernaufgaben Spezifikation von Lernproblemen
 Kapitel ML: I I. Einführung Beispiele für Lernaufgaben Spezifikation von Lernproblemen ML: I-8 Introduction c STEIN/LETTMANN 2005-2010 Beispiele für Lernaufgaben Autoeinkaufsberater Welche Kriterien liegen
Kapitel ML: I I. Einführung Beispiele für Lernaufgaben Spezifikation von Lernproblemen ML: I-8 Introduction c STEIN/LETTMANN 2005-2010 Beispiele für Lernaufgaben Autoeinkaufsberater Welche Kriterien liegen
Business Analytics Day Predictive Sales in CRM
 Business Analytics Day Predictive Sales in CRM Business Analytics Day 07.03.2019 Artur Felic, CAS Software AG in Zahlen CAS Software AG eine Netzwerkorganisation Jedem Kunden seine CAS CAS Mittelstand:
Business Analytics Day Predictive Sales in CRM Business Analytics Day 07.03.2019 Artur Felic, CAS Software AG in Zahlen CAS Software AG eine Netzwerkorganisation Jedem Kunden seine CAS CAS Mittelstand:
Maschinelles Lernen: Neuronale Netze. Ideen der Informatik
 Maschinelles Lernen: Neuronale Netze Ideen der Informatik Kurt Mehlhorn Adrian Neumann 16. Januar 2014 Übersicht Biologische Inspiration Stand der Kunst in Objekterkennung auf Bildern Künstliche Neuronale
Maschinelles Lernen: Neuronale Netze Ideen der Informatik Kurt Mehlhorn Adrian Neumann 16. Januar 2014 Übersicht Biologische Inspiration Stand der Kunst in Objekterkennung auf Bildern Künstliche Neuronale
Maschinelles Lernen II
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen II Niels Landwehr Organisation Vorlesung/Übung 4 SWS. Ort: 3.01.2.31. Termin: Vorlesung: Dienstag, 10:00-11:30.
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen II Niels Landwehr Organisation Vorlesung/Übung 4 SWS. Ort: 3.01.2.31. Termin: Vorlesung: Dienstag, 10:00-11:30.
Validation Model Selection Kreuz-Validierung Handlungsanweisungen. Validation. Oktober, von 20 Validation
 Validation Oktober, 2013 1 von 20 Validation Lernziele Konzepte des maschinellen Lernens Validierungsdaten Model Selection Kreuz-Validierung (Cross Validation) 2 von 20 Validation Outline 1 Validation
Validation Oktober, 2013 1 von 20 Validation Lernziele Konzepte des maschinellen Lernens Validierungsdaten Model Selection Kreuz-Validierung (Cross Validation) 2 von 20 Validation Outline 1 Validation
Der CRISP-DM Prozess für Data Mining
 technische universität Der CRISP-DM Prozess für Data Mining Prof. Dr. Katharina Morik Wozu einen standardisierten Prozess? Der Prozess der Wissensentdeckung muss verlässlich und reproduzierbar sein auch
technische universität Der CRISP-DM Prozess für Data Mining Prof. Dr. Katharina Morik Wozu einen standardisierten Prozess? Der Prozess der Wissensentdeckung muss verlässlich und reproduzierbar sein auch
Data Mining mit RapidMiner. Fakultät Informatik Lehrstuhl für Künstliche Intelligenz
 Data Mining mit RapidMiner Fakultät Informatik Motivation CRISP: DM-Prozess besteht aus unterschiedlichen Teilaufgaben Datenvorverarbeitung spielt wichtige Rolle im DM-Prozess Systematische Evaluationen
Data Mining mit RapidMiner Fakultät Informatik Motivation CRISP: DM-Prozess besteht aus unterschiedlichen Teilaufgaben Datenvorverarbeitung spielt wichtige Rolle im DM-Prozess Systematische Evaluationen
Data Mining und Maschinelles Lernen Lösungsvorschlag für das 1. Übungsblatt
 Data Mining und Maschinelles Lernen Lösungsvorschlag für das 1. Übungsblatt Knowledge Engineering Group Data Mining und Maschinelles Lernen Lösungsvorschlag 1. Übungsblatt 1 1. Anwendungsszenario Überlegen
Data Mining und Maschinelles Lernen Lösungsvorschlag für das 1. Übungsblatt Knowledge Engineering Group Data Mining und Maschinelles Lernen Lösungsvorschlag 1. Übungsblatt 1 1. Anwendungsszenario Überlegen
Vorlesungsplan. Von Naïve Bayes zu Bayesischen Netzwerk- Klassifikatoren. Naïve Bayes. Bayesische Netzwerke
 Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Multivariate Pattern Analysis. Jan Mehnert, Christoph Korn
 Multivariate Pattern Analysis Jan Mehnert, Christoph Korn Übersicht 1. Motivation 2. Features 3. Klassifizierung 4. Statistik 5. Annahmen & Design 6. Similarity 7. Beispiel Grenzen & Probleme der klassischen
Multivariate Pattern Analysis Jan Mehnert, Christoph Korn Übersicht 1. Motivation 2. Features 3. Klassifizierung 4. Statistik 5. Annahmen & Design 6. Similarity 7. Beispiel Grenzen & Probleme der klassischen
Big Data - und nun? Was kann die Bioinformatik?
 Big Data - und nun? Was kann die Bioinformatik? Jochen Kruppa Institut für Biometrie und Klinische Epidemiologie jochenkruppa@charitede 1 59 Vorstellung Wer spricht heute zu Ihnen? Studium der Pflanzenbiotechnologie
Big Data - und nun? Was kann die Bioinformatik? Jochen Kruppa Institut für Biometrie und Klinische Epidemiologie jochenkruppa@charitede 1 59 Vorstellung Wer spricht heute zu Ihnen? Studium der Pflanzenbiotechnologie
Data Mining und Maschinelles Lernen
 Data Mining und Maschinelles Lernen Wintersemester 2015/16 Musterlösung für das 7. Übungsblatt Aufgabe 1 Evaluierungsmethoden Ein Datenset enthält 2 n Beispiele, wobei genau n Beispiele positiv sind und
Data Mining und Maschinelles Lernen Wintersemester 2015/16 Musterlösung für das 7. Übungsblatt Aufgabe 1 Evaluierungsmethoden Ein Datenset enthält 2 n Beispiele, wobei genau n Beispiele positiv sind und
Nachweis von Feature Freezes durch Clustering
 Ste en Herbold nstitut für nformatik Universität Göttingen 18.11.2008 - Metrikon 2008 Ste en Herbold - (1/21) Überblick Einführung Grundlagen Metriken Maschinelles Lernen Sammeln von Metrikdaten Anwendung
Ste en Herbold nstitut für nformatik Universität Göttingen 18.11.2008 - Metrikon 2008 Ste en Herbold - (1/21) Überblick Einführung Grundlagen Metriken Maschinelles Lernen Sammeln von Metrikdaten Anwendung
Kapitel 4: Data Mining DATABASE SYSTEMS GROUP. Überblick. 4.1 Einleitung. 4.2 Clustering. 4.3 Klassifikation
 Überblick 4.1 Einleitung 4.2 Clustering 4.3 Klassifikation 1 Klassifikationsproblem Gegeben: eine Menge O D von Objekten o = (o 1,..., o d ) O mit Attributen A i, 1 i d eine Menge von Klassen C = {c 1,...,c
Überblick 4.1 Einleitung 4.2 Clustering 4.3 Klassifikation 1 Klassifikationsproblem Gegeben: eine Menge O D von Objekten o = (o 1,..., o d ) O mit Attributen A i, 1 i d eine Menge von Klassen C = {c 1,...,c
Einführung in Data Mining anhand des Modells CRISP-DM
 Einführung in Data Mining anhand des Modells CRISP-DM Seminarvortrag Linnea Passing Seminar, Scientific Programming, FH Aachen Stand: 11.01.2011 Rechen- und Kommunikationszentrum (RZ) Agenda Motivation
Einführung in Data Mining anhand des Modells CRISP-DM Seminarvortrag Linnea Passing Seminar, Scientific Programming, FH Aachen Stand: 11.01.2011 Rechen- und Kommunikationszentrum (RZ) Agenda Motivation
Skript Lineare Algebra
 Skript Lineare Algebra sehr einfach Erstellt: 2018/19 Von: www.mathe-in-smarties.de Inhaltsverzeichnis Vorwort... 2 1. Vektoren... 3 2. Geraden... 6 3. Ebenen... 8 4. Lagebeziehungen... 10 a) Punkt - Gerade...
Skript Lineare Algebra sehr einfach Erstellt: 2018/19 Von: www.mathe-in-smarties.de Inhaltsverzeichnis Vorwort... 2 1. Vektoren... 3 2. Geraden... 6 3. Ebenen... 8 4. Lagebeziehungen... 10 a) Punkt - Gerade...
So lösen Sie das multivariate lineare Regressionsproblem von Christian Herta
 Multivariate Lineare Regression Christian Herta Oktober, 2013 1 von 34 Christian Herta Multivariate Lineare Regression Lernziele Multivariate Lineare Regression Konzepte des Maschinellen Lernens: Kostenfunktion
Multivariate Lineare Regression Christian Herta Oktober, 2013 1 von 34 Christian Herta Multivariate Lineare Regression Lernziele Multivariate Lineare Regression Konzepte des Maschinellen Lernens: Kostenfunktion
Rekurrente Neuronale Netze
 Rekurrente Neuronale Netze Gregor Mitscha-Baude May 9, 2016 Motivation Standard neuronales Netz: Fixe Dimensionen von Input und Output! Motivation In viele Anwendungen variable Input/Output-Länge. Spracherkennung
Rekurrente Neuronale Netze Gregor Mitscha-Baude May 9, 2016 Motivation Standard neuronales Netz: Fixe Dimensionen von Input und Output! Motivation In viele Anwendungen variable Input/Output-Länge. Spracherkennung
Klassifikation und Ähnlichkeitssuche
 Klassifikation und Ähnlichkeitssuche Vorlesung XIII Allgemeines Ziel Rationale Zusammenfassung von Molekülen in Gruppen auf der Basis bestimmter Eigenschaften Auswahl von repräsentativen Molekülen Strukturell
Klassifikation und Ähnlichkeitssuche Vorlesung XIII Allgemeines Ziel Rationale Zusammenfassung von Molekülen in Gruppen auf der Basis bestimmter Eigenschaften Auswahl von repräsentativen Molekülen Strukturell
Analyse von Transaktionsdaten im Online-Ticketing mit Data-Mining-Methoden
 1 Analyse von Transaktionsdaten im Online-Ticketing mit Data-Mining-Methoden Marten Pfannenschmidt, Freie Universität Berlin Prof. Dr. Jan Fabian Ehmke, Europa-Universität Viadrina Frank Schreier, Berliner
1 Analyse von Transaktionsdaten im Online-Ticketing mit Data-Mining-Methoden Marten Pfannenschmidt, Freie Universität Berlin Prof. Dr. Jan Fabian Ehmke, Europa-Universität Viadrina Frank Schreier, Berliner
Bielefeld Graphics & Geometry Group. Brain Machine Interfaces Reaching and Grasping by Primates
 Reaching and Grasping by Primates + 1 Reaching and Grasping by Primates Inhalt Einführung Theoretischer Hintergrund Design Grundlagen Experiment Ausblick Diskussion 2 Reaching and Grasping by Primates
Reaching and Grasping by Primates + 1 Reaching and Grasping by Primates Inhalt Einführung Theoretischer Hintergrund Design Grundlagen Experiment Ausblick Diskussion 2 Reaching and Grasping by Primates
Accountability in Algorithmic. Decision Making.
 Accountability in Algorithmic Decision Making Vural Mert, Larcher Daniel 1. Juni 2016 Zusammenfassung Diese Seminararbeit gibt einen kurzen Überblick über die Algorithmische Entscheidungsfindung, deren
Accountability in Algorithmic Decision Making Vural Mert, Larcher Daniel 1. Juni 2016 Zusammenfassung Diese Seminararbeit gibt einen kurzen Überblick über die Algorithmische Entscheidungsfindung, deren
Intelligente Algorithmen Einführung in die Technologie
 Intelligente Algorithmen Einführung in die Technologie Dr. KIT Universität des Landes Baden-Württemberg und nationales Forschungszentrum in der Helmholtz-Gemeinschaft www.kit.edu Natürlich sprachliche
Intelligente Algorithmen Einführung in die Technologie Dr. KIT Universität des Landes Baden-Württemberg und nationales Forschungszentrum in der Helmholtz-Gemeinschaft www.kit.edu Natürlich sprachliche
Adaptive Resonance Theory
 Adaptive Resonance Theory Jonas Jacobi, Felix J. Oppermann C.v.O. Universität Oldenburg Adaptive Resonance Theory p.1/27 Gliederung 1. Neuronale Netze 2. Stabilität - Plastizität 3. ART-1 4. ART-2 5. ARTMAP
Adaptive Resonance Theory Jonas Jacobi, Felix J. Oppermann C.v.O. Universität Oldenburg Adaptive Resonance Theory p.1/27 Gliederung 1. Neuronale Netze 2. Stabilität - Plastizität 3. ART-1 4. ART-2 5. ARTMAP
A linear-regression analysis resulted in the following coefficients for the available training data
 Machine Learning Name: Vorname: Prof. Dr.-Ing. Klaus Berberich Matrikel: Aufgabe 1 2 3 4 Punkte % % (Bonus) % (Gesamt) Problem 1 (5 Points) A linear-regression analysis resulted in the following coefficients
Machine Learning Name: Vorname: Prof. Dr.-Ing. Klaus Berberich Matrikel: Aufgabe 1 2 3 4 Punkte % % (Bonus) % (Gesamt) Problem 1 (5 Points) A linear-regression analysis resulted in the following coefficients
Ideen und Konzepte der Informatik. Maschinelles Lernen. Kurt Mehlhorn
 Ideen und Konzepte der Informatik Maschinelles Lernen Kurt Mehlhorn Übersicht Lernen: Begriff Beispiele für den Stand der Kunst Spamerkennung Handschriftenerkennung mit und ohne Trainingsdaten Gesichts-
Ideen und Konzepte der Informatik Maschinelles Lernen Kurt Mehlhorn Übersicht Lernen: Begriff Beispiele für den Stand der Kunst Spamerkennung Handschriftenerkennung mit und ohne Trainingsdaten Gesichts-
Projekt-INF Folie 1
 Folie 1 Projekt-INF Entwicklung eines Testbed für den empirischen Vergleich verschiedener Methoden des maschinellen Lernens im Bezug auf die Erlernung von Produktentwicklungswissen Folie 2 Inhalt Ziel
Folie 1 Projekt-INF Entwicklung eines Testbed für den empirischen Vergleich verschiedener Methoden des maschinellen Lernens im Bezug auf die Erlernung von Produktentwicklungswissen Folie 2 Inhalt Ziel
Wie können Computer lernen?
 Wie können Computer lernen? Ringvorlesung Perspektiven der Informatik, 18.2.2008 Prof. Jun. Matthias Hein Department of Computer Science, Saarland University, Saarbrücken, Germany Inferenz I Wie lernen
Wie können Computer lernen? Ringvorlesung Perspektiven der Informatik, 18.2.2008 Prof. Jun. Matthias Hein Department of Computer Science, Saarland University, Saarbrücken, Germany Inferenz I Wie lernen
Seminar Textmining SS 2015 Grundlagen des Maschinellen Lernens
 Seminar Textmining SS 2015 Grundlagen des Maschinellen Lernens Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 17.04.2015 Entscheidungsprobleme beim Textmining
Seminar Textmining SS 2015 Grundlagen des Maschinellen Lernens Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 17.04.2015 Entscheidungsprobleme beim Textmining
Microsoft Azure Deutschland ist jetzt verfügbar -
 Einordnung und Überblick Data Scientist Operationalisierung IT-Abteilung Anwendungsentwickler Der Data Scientist agil Tool seiner Wahl möglichst wenig Zeit Skalierung Code für die Operationalisierung Der
Einordnung und Überblick Data Scientist Operationalisierung IT-Abteilung Anwendungsentwickler Der Data Scientist agil Tool seiner Wahl möglichst wenig Zeit Skalierung Code für die Operationalisierung Der
Maschinelles Lernen: Symbolische Ansätze
 Maschinelles Lernen: Symbolische Ansätze Wintersemester 2009/2010 Musterlösung für das 1. Übungsblatt Aufgabe 1: Anwendungsszenario Überlegen Sie sich ein neues Szenario des klassifizierenden Lernens (kein
Maschinelles Lernen: Symbolische Ansätze Wintersemester 2009/2010 Musterlösung für das 1. Übungsblatt Aufgabe 1: Anwendungsszenario Überlegen Sie sich ein neues Szenario des klassifizierenden Lernens (kein
Modellierung mit künstlicher Intelligenz
 Samuel Kost kosts@mailbox.tu-freiberg.de Institut für Numerische Mathematik und Optimierung Modellierung mit künstlicher Intelligenz Ein Überblick über existierende Methoden des maschinellen Lernens 13.
Samuel Kost kosts@mailbox.tu-freiberg.de Institut für Numerische Mathematik und Optimierung Modellierung mit künstlicher Intelligenz Ein Überblick über existierende Methoden des maschinellen Lernens 13.
Ein Vergleich von Methoden für Multi-klassen Support Vector Maschinen
 Ein Vergleich von Methoden für Multi-klassen Support Vector Maschinen Einführung Auf binären Klassifikatoren beruhende Methoden One-Against-All One-Against-One DAGSVM Methoden die alle Daten zugleich betrachten
Ein Vergleich von Methoden für Multi-klassen Support Vector Maschinen Einführung Auf binären Klassifikatoren beruhende Methoden One-Against-All One-Against-One DAGSVM Methoden die alle Daten zugleich betrachten
Neural Networks: Architectures and Applications for NLP
 Neural Networks: Architectures and Applications for NLP Session 02 Julia Kreutzer 8. November 2016 Institut für Computerlinguistik, Heidelberg 1 Overview 1. Recap 2. Backpropagation 3. Ausblick 2 Recap
Neural Networks: Architectures and Applications for NLP Session 02 Julia Kreutzer 8. November 2016 Institut für Computerlinguistik, Heidelberg 1 Overview 1. Recap 2. Backpropagation 3. Ausblick 2 Recap
Innovative Datenanalyse für die Medizin
 Innovative Datenanalyse für die Medizin IDEALearning Intelligent Data Evaluation and Analysis by Machine Learning Dr. Susanne Winter winter:science Technologiezentrum Ruhr Universitätsstr. 142 44799 Bochum
Innovative Datenanalyse für die Medizin IDEALearning Intelligent Data Evaluation and Analysis by Machine Learning Dr. Susanne Winter winter:science Technologiezentrum Ruhr Universitätsstr. 142 44799 Bochum
Einführung i.d. Wissensverarbeitung
 Einführung in die Wissensverarbeitung 2 VO 708.560 + 1 UE 442.072 SS 2012 Institut für Signalverarbeitung und Sprachkommunikation TU Graz Inffeldgasse 12/1 www.spsc.tugraz.at Institut für Grundlagen der
Einführung in die Wissensverarbeitung 2 VO 708.560 + 1 UE 442.072 SS 2012 Institut für Signalverarbeitung und Sprachkommunikation TU Graz Inffeldgasse 12/1 www.spsc.tugraz.at Institut für Grundlagen der
Kapitel 12: Schnelles Bestimmen der Frequent Itemsets
 Einleitung In welchen Situationen ist Apriori teuer, und warum? Kapitel 12: Schnelles Bestimmen der Frequent Itemsets Data Warehousing und Mining 1 Data Warehousing und Mining 2 Schnelles Identifizieren
Einleitung In welchen Situationen ist Apriori teuer, und warum? Kapitel 12: Schnelles Bestimmen der Frequent Itemsets Data Warehousing und Mining 1 Data Warehousing und Mining 2 Schnelles Identifizieren
Neuronale Netze. Christian Böhm.
 Ludwig Maximilians Universität München Institut für Informatik Forschungsgruppe Data Mining in der Medizin Neuronale Netze Christian Böhm http://dmm.dbs.ifi.lmu.de/dbs 1 Lehrbuch zur Vorlesung Lehrbuch
Ludwig Maximilians Universität München Institut für Informatik Forschungsgruppe Data Mining in der Medizin Neuronale Netze Christian Böhm http://dmm.dbs.ifi.lmu.de/dbs 1 Lehrbuch zur Vorlesung Lehrbuch
Reranking. Parse Reranking. Helmut Schmid. Institut für maschinelle Sprachverarbeitung Universität Stuttgart
 Institut für maschinelle Sprachverarbeitung Universität Stuttgart schmid@ims.uni-stuttgart.de Die Folien basieren teilweise auf Folien von Mark Johnson. Koordinationen Problem: PCFGs können nicht alle
Institut für maschinelle Sprachverarbeitung Universität Stuttgart schmid@ims.uni-stuttgart.de Die Folien basieren teilweise auf Folien von Mark Johnson. Koordinationen Problem: PCFGs können nicht alle
Entscheidungsbäume aus großen Datenbanken: SLIQ
 Entscheidungsbäume aus großen Datenbanken: SLIQ C4.5 iteriert häufig über die Trainingsmenge Wie häufig? Wenn die Trainingsmenge nicht in den Hauptspeicher passt, wird das Swapping unpraktikabel! SLIQ:
Entscheidungsbäume aus großen Datenbanken: SLIQ C4.5 iteriert häufig über die Trainingsmenge Wie häufig? Wenn die Trainingsmenge nicht in den Hauptspeicher passt, wird das Swapping unpraktikabel! SLIQ:
Emotion Recognition of Call Center Conversations Robert Bosch Engineering and Business Solutions Private Limited
 Emotion Recognition of Call Center Conversations Robert Bosch Engineering and Business Solutions Private Limited 1 Agenda 1 Introduction 2 Problem Definition 3 Solution Overview 4 Why Consider Emotions
Emotion Recognition of Call Center Conversations Robert Bosch Engineering and Business Solutions Private Limited 1 Agenda 1 Introduction 2 Problem Definition 3 Solution Overview 4 Why Consider Emotions
Vorlesung Maschinelles Lernen
 Vorlesung Maschinelles Lernen Stützvektormethode Katharina Morik LS 8 Informatik 8.11.2011 1 von 38 Gliederung 1 2 Lagrange-Optimierung 2 von 38 Übersicht über die Stützvektormethode (SVM) Eigenschaften
Vorlesung Maschinelles Lernen Stützvektormethode Katharina Morik LS 8 Informatik 8.11.2011 1 von 38 Gliederung 1 2 Lagrange-Optimierung 2 von 38 Übersicht über die Stützvektormethode (SVM) Eigenschaften
Konzepte der AI Neuronale Netze
 Konzepte der AI Neuronale Netze Franz Wotawa Institut für Informationssysteme, Database and Artificial Intelligence Group, Technische Universität Wien Email: wotawa@dbai.tuwien.ac.at Was sind Neuronale
Konzepte der AI Neuronale Netze Franz Wotawa Institut für Informationssysteme, Database and Artificial Intelligence Group, Technische Universität Wien Email: wotawa@dbai.tuwien.ac.at Was sind Neuronale
Theoretische Informatik 1
 Theoretische Informatik 1 Teil 12 Bernhard Nessler Institut für Grundlagen der Informationsverabeitung TU Graz SS 2007 Übersicht 1 Maschinelles Lernen Definition Lernen 2 agnostic -learning Definition
Theoretische Informatik 1 Teil 12 Bernhard Nessler Institut für Grundlagen der Informationsverabeitung TU Graz SS 2007 Übersicht 1 Maschinelles Lernen Definition Lernen 2 agnostic -learning Definition
Data Mining und Maschinelles Lernen Wintersemester 2015/2016 Lösungsvorschlag für das 3. Übungsblatt
 Data Mining und Maschinelles Lernen Wintersemester 2015/2016 Lösungsvorschlag für das 3. Übungsblatt 18. November 2015 1 Aufgabe 1: Version Space, Generalisierung und Spezialisierung (1) Gegeben sei folgende
Data Mining und Maschinelles Lernen Wintersemester 2015/2016 Lösungsvorschlag für das 3. Übungsblatt 18. November 2015 1 Aufgabe 1: Version Space, Generalisierung und Spezialisierung (1) Gegeben sei folgende
Lineare Regression. Christian Herta. Oktober, Problemstellung Kostenfunktion Gradientenabstiegsverfahren
 Lineare Regression Christian Herta Oktober, 2013 1 von 33 Christian Herta Lineare Regression Lernziele Lineare Regression Konzepte des Maschinellen Lernens: Lernen mittels Trainingsmenge Kostenfunktion
Lineare Regression Christian Herta Oktober, 2013 1 von 33 Christian Herta Lineare Regression Lernziele Lineare Regression Konzepte des Maschinellen Lernens: Lernen mittels Trainingsmenge Kostenfunktion
Entwicklung einer Entscheidungssystematik für Data- Mining-Verfahren zur Erhöhung der Planungsgüte in der Produktion
 Entwicklung einer Entscheidungssystematik für Data- Mining-Verfahren zur Erhöhung der Planungsgüte in der Produktion Vortrag Seminararbeit David Pogorzelski Aachen, 22.01.2015 Agenda 1 2 3 4 5 Ziel der
Entwicklung einer Entscheidungssystematik für Data- Mining-Verfahren zur Erhöhung der Planungsgüte in der Produktion Vortrag Seminararbeit David Pogorzelski Aachen, 22.01.2015 Agenda 1 2 3 4 5 Ziel der
Focusing Search in Multiobjective Evolutionary Optimization through Preference Learning from User Feedback
 Focusing Search in Multiobjective Evolutionary Optimization through Preference Learning from User Feedback Thomas Fober Weiwei Cheng Eyke Hüllermeier AG Knowledge Engineering & Bioinformatics Fachbereich
Focusing Search in Multiobjective Evolutionary Optimization through Preference Learning from User Feedback Thomas Fober Weiwei Cheng Eyke Hüllermeier AG Knowledge Engineering & Bioinformatics Fachbereich
Von schwachen zu starken Lernern
 Von schwachen zu starken Lernern Wir nehmen an, dass ein schwacher Lernalgorithmus L mit vielen Beispielen, aber großem Fehler ε = 1 2 θ gegeben ist. - Wie lässt sich der Verallgemeinerungsfehler ε von
Von schwachen zu starken Lernern Wir nehmen an, dass ein schwacher Lernalgorithmus L mit vielen Beispielen, aber großem Fehler ε = 1 2 θ gegeben ist. - Wie lässt sich der Verallgemeinerungsfehler ε von
PPC und Data Mining. Seminar aus Informatik LV-911.039. Michael Brugger. Fachbereich der Angewandten Informatik Universität Salzburg. 28.
 PPC und Data Mining Seminar aus Informatik LV-911.039 Michael Brugger Fachbereich der Angewandten Informatik Universität Salzburg 28. Mai 2010 M. Brugger () PPC und Data Mining 28. Mai 2010 1 / 14 Inhalt
PPC und Data Mining Seminar aus Informatik LV-911.039 Michael Brugger Fachbereich der Angewandten Informatik Universität Salzburg 28. Mai 2010 M. Brugger () PPC und Data Mining 28. Mai 2010 1 / 14 Inhalt