PROBABILISTIC PARSING FOR GERMAN USING SISTER-HEAD DEPENDENCIES
|
|
|
- Minna Bayer
- vor 5 Jahren
- Abrufe
Transkript
1 Ausgangsfrage PROBABILISTIC PARSING FOR GERMAN USING SISTER-HEAD DEPENDENCIES Irina Gossmann Carine Dombou 9. Juli 2007
2 INHALT Ausgangsfrage 1 AUSGANGSFRAGE 2 SYNTAX DES DEUTSCHEN + NEGRA 3 PROBABILISTISCHE PARSER 4 EXPERIMENT 1 5 EXPERIMENT 2 6 SCHLUSSFOLGERUNG 7 LITERATUR
3 INHALT Ausgangsfrage 1 AUSGANGSFRAGE 2 SYNTAX DES DEUTSCHEN + NEGRA 3 PROBABILISTISCHE PARSER 4 EXPERIMENT 1 5 EXPERIMENT 2 6 SCHLUSSFOLGERUNG 7 LITERATUR
4 Ausgangsfrage AUSGANGSFRAGE Lexikalisierte Parser sind um etwa 10% besser, als unlexikalisierte Parser Aber: die meisten lexikalisierten Parser wurden für Englisch/Penn Treebank entwickelt Frage: was wären die Ergebnisse bei anderen Sprachen/Annotationsstilen?

5 Ausgangsfrage LEXIKALISIERTES PARSING BEI ANDEREN SPRACHEN
6 INHALT Ausgangsfrage 1 AUSGANGSFRAGE 2 SYNTAX DES DEUTSCHEN + NEGRA 3 PROBABILISTISCHE PARSER 4 EXPERIMENT 1 5 EXPERIMENT 2 6 SCHLUSSFOLGERUNG 7 LITERATUR
7 INHALT Ausgangsfrage 1 AUSGANGSFRAGE 2 SYNTAX DES DEUTSCHEN + NEGRA 3 PROBABILISTISCHE PARSER 4 EXPERIMENT 1 5 EXPERIMENT 2 6 SCHLUSSFOLGERUNG 7 LITERATUR
8 Ausgangsfrage PROBABILISTISCHE PARSER 1. Unlexikalisierte PCFG (Charniak 1993) Die lexikalisierten Parser werden gegen einen einfachen PCFG-Parser geprüft (Baseline). p(lhs RHS) = p(rhs LHS) = alle Vorkommen von rule Regeln mit gleicher linken Seite Die Summe der W keiten aller Regeln mit derselben LHS ist 1. p(baum T) = Produkt der W keiten aller in T angewandten Regeln.
9 Ausgangsfrage PROBABILISTISCHE PARSER 2. Carrol und Rooth s lexikalisiertes Modell (1998) Entspricht Charniaks Modell (1997). p(rule) = p(rhs LHS) = p rule (C 1...C n P, l(p)) n p choice (l(c i ) C i, P, l(p)) i=1 für eine Regel der Form P > C 1...Cn. l(p) ist Kopf der Eltern-Kategorie, l(c i ) ist Kopf einer der Tochter-Kategorien
10 Ausgangsfrage PROBABILISTISCHE PARSER Regel: 3. Collins lexikalisiertes Modell Regelw keit:
11 Ausgangsfrage PROBABILISTISCHE PARSER Regel: 3. Collins lexikalisiertes Modell Regelw keit:
12 Ausgangsfrage PROBABILISTISCHE PARSER Regel: 3. Collins lexikalisiertes Modell Regelw keit:
13 Ausgangsfrage w ist der Kopf der Konstituente, t ist Tag des Kopfs der Konstituente, d misst die Entfernung vom Kopf

14 Ausgangsfrage HEAD-HEAD VS. SISTER-HEAD W keit einer Konstituente
15 INHALT Ausgangsfrage 1 AUSGANGSFRAGE 2 SYNTAX DES DEUTSCHEN + NEGRA 3 PROBABILISTISCHE PARSER 4 EXPERIMENT 1 5 EXPERIMENT 2 6 SCHLUSSFOLGERUNG 7 LITERATUR
16 Ausgangsfrage VERGLEICH DER 3 PARSER Hypothese: Lexikalisierung verbessert die Ergebnisse. weitere Verbesserungen der Ergebnisse durch Berürcksichtigung der zusätzlichen Informationen in Negra (grammatical function labels, coordinate categories, flache PPs).
17 Ausgangsfrage VORBEREITUNG DES KORPUS Es wurde der Treebank-Format von Negra genommen. Das Korpus wurde aufgeteilt: Training (18602 Bäume), Development (1000 Bäume), Testing (1000 Bäume). In Development- und Test-Abschnitte wurden nur Sätze unter 40 Wörtern aufgenommen.
18 Ausgangsfrage GRAMMAR INDUCTION Baseline: Grammatik + Lexikon: wurden aus dem Korpus ausgelesen, nachdem alle grammatical function labels und Spuren entfernt wurden (nicht lexikalisiert). Parser: probabilistischer left-corner-parser Lopar (unlexicalized mode).
19 Ausgangsfrage GRAMMAR INDUCTION Carrol und Rooth: Grammatik + Lexikon: wurden aus dem Korpus ausgelesen; die Köpfe der Kategorien S, VP, AP und AVP sind in Negra bereits markiert, für alle anderen Kategorien mussten die Köpfe manuell annotiert werden. Parser: Lopar (lexicalized mode).
20 Ausgangsfrage GRAMMAR INDUCTION Collins: Grammatik + Lexikon: wie bei CARROL UND ROOTH. Abweichungen vom Original-Modell von Collins: alle leeren Kategoien (Spuren) wurden entfernt (das Modell der Autoren kann damit nicht umgehen), für nicht-rekursive NPs wurden head-head-w keiten genommen. Parser: implementiert von einem der Autoren.
21 Ausgangsfrage TRAINING + TESTING (1) Bei den lexikalisierten Modellen hat man mit Smoothing nachgeholfen. Variationen: Baseline und Carrol und Rooth: ± grammatical function labels Carrol und Rooth: ± PARAMETER POOLING (Berücksichtigung von coordinate categories und flachen PPs in Negra)
22 Ausgangsfrage TRAINING + TESTING (1) - PARAMETER POOLING Pooling: Zusammenlegen von Kategorien (dabei wächst die W keit der einzelnen Regeln).
23 Ausgangsfrage TRAINING + TESTING (1) - PARAMETER POOLING Pooling: Zusammenlegen von Kategorien (dabei wächst die W keit der einzelnen Regeln).
24 Ausgangsfrage TRAINING + TESTING (2) Verschiedene Part-of-Speech Tags: Der test-set wurde für alle Parser mit dem POS-Tagger TnT getaggt, der zuvor an dem training-set trainiert wurde. Die Genauigkeit, gemessen am development-set, war 97,12%. Perfect tagging mode: Es wurden auch Tests mit korrekten POS-Tags (gold standard) durchgeführt, um die obere Performance-Grenze der Parser zu bestimmen.
25 Ausgangsfrage AUSWERTUNG MIT PARSEVAL SCORES LR: LP: korrekte Klamern im Parse alle Klammern im Baum korrekte Klammern im Parse alle Klammern im Parse CBs: Durchschnitt der sich kreuzenden Klammern pro Baum. 0CB: Prozentsatz der Bäume ohne sich kreuzende Klammern. 2CB : Prozentsatz der Bäume mit zwei oder weniger sich kreuzenden Klammern. Cov.: Prozentsatz der Sätze, die geparst werden konnten.
26 ERGEBNISSE Ausgangsfrage
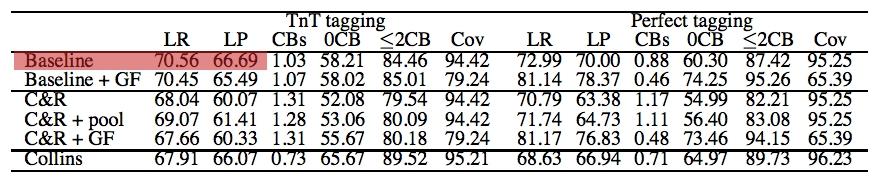
27 ERGEBNISSE Ausgangsfrage
28 ERGEBNISSE Ausgangsfrage
29 ERGEBNISSE Ausgangsfrage
30 ERGEBNISSE Ausgangsfrage
31 ERGEBNISSE Ausgangsfrage
32 ERGEBNISSE Ausgangsfrage

33 ERGEBNISSE Ausgangsfrage
34 Ausgangsfrage ERGEBNISSE 1. Berücksichtigung von grammatical functions hat die Ergebnisse sogar verschlechtert. 2. Parameter pooling verbesserte die Ergebnisse etwas. 3. Lexikalisierung hat die Ergebnisse verschlechtert (wie die Lernkurven zeigen, ist der kleine Korpusumfang nicht die Ursache dafür).
35 LERNKURVEN Ausgangsfrage
36 Ausgangsfrage Also: Die Hypothese ist falsch!
37 INHALT Ausgangsfrage 1 AUSGANGSFRAGE 2 SYNTAX DES DEUTSCHEN + NEGRA 3 PROBABILISTISCHE PARSER 4 EXPERIMENT 1 5 EXPERIMENT 2 6 SCHLUSSFOLGERUNG 7 LITERATUR
38 INHALT Ausgangsfrage 1 AUSGANGSFRAGE 2 SYNTAX DES DEUTSCHEN + NEGRA 3 PROBABILISTISCHE PARSER 4 EXPERIMENT 1 5 EXPERIMENT 2 6 SCHLUSSFOLGERUNG 7 LITERATUR
39 Ausgangsfrage SCHLUSSFOLGERUNG Flache Regeln in Negra entsprechen der syntaktischen Struktur des Deutschen, insbesondere der semi-freien Wortstellung. Für flache Strukturen ist das sister-head-modell besser geeignet als die head-head-modelle. Weiterführend: wird dieses Modell für andere Sprachen ebenfalls gute Ergebnisse liefern?
40 INHALT Ausgangsfrage 1 AUSGANGSFRAGE 2 SYNTAX DES DEUTSCHEN + NEGRA 3 PROBABILISTISCHE PARSER 4 EXPERIMENT 1 5 EXPERIMENT 2 6 SCHLUSSFOLGERUNG 7 LITERATUR
41 Ausgangsfrage LITERATUR Amit Dubey and Frank Keller, Using Sister-Head Dependencies, ACL 2003 Amit Dubey, Statistical Parsing for German, 2004
42 !"#$%&'()*+%",
43 -.,$*/$0%&'",(102",%&'*3$", 4567"880"+#,2 90$ :083" ;<=(0%$ %&'>0" ,280%&'", 4-$"88#,2 7"+ C69)8"9",$" D-#EF"/$"G( HEF"/$"G(I7F#,/$"J(09!"#$%&'", 0%$ 3+"0 4K"+E)6%0$06, L>*+ 30BG(*E"+ -*$L$.)N
44
45 O"2+* I,,6$*$06,%%&'"9* D-/#$ "$(*8AGPQQRJ S S O1=TI(U*#9E*,/ 4 VWWAXQY(Z6/",%(D[XAYX[('*,7*,,6$0"+$" -M$L"J 4!"#$%&'"(\"0$#,2%*+$0/"8 38*&'" %.,$*/$0%&'" T")+M%",$*$06,", S /66+70,0"+",7" C*$"26+0", D;-G(;O]J S U"%&'+03$#,2", 3^+ 2+*99*$0%&'" <#,/$06,", LAUN(5HD567030"+JG:!D'"*7JG-UD%#EF"&$JG H;D&8*#%*8(6EF"&$J
46
47 1B)"+09",$([
48 <"'8"+*,*8.%"( S ;'#,/0,2(<"'8"+(*#%( ;6880,%(567"88 *J_]](,"E",(7",( 50$$"8,_O](7"%((( Z'"*$"+%`` EJ_]](,"E",(7",( 50$$"8,`_O](7"%( Z'"*$"+%`
49 <"'8"+*,*8.%"DE0%PJ S <*8%&'"(=+",L",(E"0(]]%G-%G(#,7(K]% S =+^,7"(@6,(70"%",(<"'8"+,N 4:"*74:"*7(IE'M,202/"0$(09(;6880,%( 567"88 4<8*&''"0$(@6,(T"2"8,(0,(O"2+*

50 <"'8"+*,*8.%"DE0%[J S O"2+*(0%$(38*&'"+(*8%(]",, S a,$"+%&'0"780&'"(i,l*'8(*,(zb&'$"+,
51 O"#"+(I,%*$L S :.)6$'"%"N 4-&'8"&'$"(]"+36+9*,L(E"0( 8"B0/*80%0"+$"9(567"88(>"2",(<8*&''"0$(7"%( ;6+)#%
52 ?0"(/*,,(9*,(70"%"(<8*&''"0$( 86%>"+7",c S d7""n( PJ ]]%(E"*+E"0$",N(I826+0$'9#%
53
54 S *,2">",7"$
55 [J(d7""([N ;6880,%(567"88(3^+(,6,4 *88"(*,7"+"(C*$"26+0",(90$(-0%$"+4:"*74 IE'M,202/"0$",($"%$",!d9)80/*$06,(E0,M+"+(\>"02"(0,(7"+( =+*99*$0/)+67#/$06,

56 -0%$"+4'"*7(!")",7",70"%
57 5"$'67", PJH+020,*8(;6880,%(567"88(90$(967030L0"+$"9( Z+*0,0,2(Z"%$(D]]%(-)*8$#,2J$+*0,0"+", C*$"2+6+0",($"%$", 4%0%$"+4'"*7(3^+(O]% 4%0%$"+4'"*7(3^+(]]% 4%0%$"+4'"*7(3^+(*88"(C*$"26+0",
58 5"$'67", VJ567"88(90$(%0%$"+4'"*74IE'M,202/"0$",(3^+( *88"(C*$"26+0",((*#e"+("0,"+A!U"%$099#,2(7"+(-0%$"+4:"*74 IE'M,202/"0$(3^+(70"(E"%$"(]"+36+9*,LA

59 1+2"E,0%%"
60 1+2"E,0%%"(7"+(5"$'67"P S f-)80$(]]g(0,($+*0,0,2(*,7($"%$0,2($"%$%!-$"02"+#,2(0,(htdy4rij(#,7(h]djkij S U.(f;688*)%"7(]]gN("0,"(8"0&'$"(-",/#,2( 0,(hT(*,7(h](09(K"+28"0&'(L#( #,967030L0"+$"9(;6880,%l 567"88
61 1+2"E,0%%"(7"+(5"$'67"[ S <^+(Z,Z($*2%N S!O]%(3M88$(L#(YRAkmihT(#,7(YkAmW(h] S!#,967030L0"+$"%(;6880,%(567"88(E"%%"+ S!]]%("+'b'$(#9(RXA[RhT(#,7(YkAmWh] S U"%$"(]"+36+9*,L(E"0(-0%$"+4:"*7( IE'M,202/"0$(3^+(*88"(C*$"26+0",DRPAV[hT( #,7(RXAQViJ S <^+()"+3"&$($*2%N(K"+E"%%"+#,2(@6,(*88",( C*$"26+0",(90$(-0%$"+4:"*74IE'M202/"0$",
62 1+2"E,0%%"(7"+(5"$'67"V
63 4<^+(-(#,7(&66+70,0"+",7"(C*$"26+0"!10,"(-",/#,2(#9(Pi 4 <*%$(/"0,(133"/$(E"0(I]GIK]G#,7(O](3^+( )"+3"/$(Z*220,2
64 !0%&#%%06, S ]+6E8"9(7"+(<8*&''"0$(2"8b%$c! C"0,"(K"+E"%%"+#,2(90$(]]%(-)80$$0,2(*#3( f&688*)%"7(&*$"26+0"%ga S IE"+n(=+#,7(L#+(U"%$",(]"+36+9*,L(E"0(-0%$"+4 :"*74IE'M,202/"0$",(<8*&''"0$(@6,(O"2+*(09( ="2",%*$L(L#+(<"'8"+*,*8.%" S -0%$"+4:"*7(567"88 ^E"+$+033$ %6>6' ,*8( ;6880,%(567"88 *8% *#&' #,8"B0/*80%0"+$" U*%"80,"( 90$ Pih](#,7(mihT
65 K"+28"0&'(90$(3+^'"+",(I+E"0$", S C"0,"+()+6E*E080%$0%&'"+(Z+""E*,/4 $+*0,0"+$"+()*+%"+(3^+(!"#$%&' S :"*748"B0/*80%0"+$"%(567"88(@6,(;*++688 #,7(T66$'(*,2">*,7$(3^+(!"#$%&'(@6,(( U"08("$(*8ADPQQQG[XX[J 4:*,7*,,6$0"+$"(=+*99*$0/ 4a,*,,6$0"+$"+(;6+)#% 4O#+(*#3(O"E",%M$L"((#,7(+"8*$0@"((( -M$L"
66 S #,7(U0/"8D[XXXJ(3^+(Z&'"%&'",(#,7( ;'0,"%0%&'(
Probabilistic Context Free Grammars, Part II
 Probabilistic Context Free Grammars, Part II Prof Dr. Matthew Crocker Universität des Saarlandes 16. Juli 2015 Matthew Crocker (UdS) PCFG II 16. Juli 2015 1 / 25 Themen heute: 1 Wiederholung: PCFG 2 Formeln
Probabilistic Context Free Grammars, Part II Prof Dr. Matthew Crocker Universität des Saarlandes 16. Juli 2015 Matthew Crocker (UdS) PCFG II 16. Juli 2015 1 / 25 Themen heute: 1 Wiederholung: PCFG 2 Formeln
Probabilistische kontextfreie Grammatiken
 Probabilistische kontextfreie Grammatiken Vorlesung Computerlinguistische Techniken Alexander Koller 08. Dezember 2015 Let s play a game Ich gebe Ihnen ein Nichtterminalsymbol. S, NP, VP, PP, oder POS-Tag
Probabilistische kontextfreie Grammatiken Vorlesung Computerlinguistische Techniken Alexander Koller 08. Dezember 2015 Let s play a game Ich gebe Ihnen ein Nichtterminalsymbol. S, NP, VP, PP, oder POS-Tag
Probabilistische kontextfreie Grammatiken
 Mathematische Grundlagen III Probabilistische kontextfreie Grammatiken 14 Juni 2011 1/26 Ambiguität beim Parsing Wörter können verschiedene Bedeutungen haben und mehr als einer Wortkategorien angehören
Mathematische Grundlagen III Probabilistische kontextfreie Grammatiken 14 Juni 2011 1/26 Ambiguität beim Parsing Wörter können verschiedene Bedeutungen haben und mehr als einer Wortkategorien angehören
Satz Umstrukturierung für statistisch. Anna Schiffarth Dozentin: Miriam Kaeshammer Fortgeschrittene Methoden der statistisch maschinellen Übersetzung
 Satz Umstrukturierung für statistisch maschinelle Übersetzung Anna Schiffarth Dozentin: Miriam Kaeshammer Fortgeschrittene Methoden der statistisch maschinellen Übersetzung Einführung Beschreibung einer
Satz Umstrukturierung für statistisch maschinelle Übersetzung Anna Schiffarth Dozentin: Miriam Kaeshammer Fortgeschrittene Methoden der statistisch maschinellen Übersetzung Einführung Beschreibung einer
Probabilistisches Parsing Teil II
 Ruprecht-Karls-Universität Heidelberg Computerlinguistisches Seminar SS 2002 HS: Parsing Dozentin: Dr. Karin Haenelt Referentin: Anna Björk Nikulásdóttir 10.06.02 1. Parsingmodelle Probabilistisches Parsing
Ruprecht-Karls-Universität Heidelberg Computerlinguistisches Seminar SS 2002 HS: Parsing Dozentin: Dr. Karin Haenelt Referentin: Anna Björk Nikulásdóttir 10.06.02 1. Parsingmodelle Probabilistisches Parsing
Programmierkurs Python II
 Programmierkurs Python II Michaela Regneri & tefan Thater FR 4.7 Allgemeine Linguistik (Computerlinguistik) Universität des aarlandes ommersemester 2010 (Charniak, 1997) the dog biscuits N V N V the dog
Programmierkurs Python II Michaela Regneri & tefan Thater FR 4.7 Allgemeine Linguistik (Computerlinguistik) Universität des aarlandes ommersemester 2010 (Charniak, 1997) the dog biscuits N V N V the dog
Das Trainings-Regime Ergebnisse Fehlerdiskussion Zusammenfassung. Baumbank-Training. Mateusz Jozef Dworaczek
 04.06.2007 Inhalt 1 Definition Anno 1996 Überwachtes Training 2 Ablesen der Baumbankgrammatik Berechnen der Regelwahrscheinlichkeiten PCFG 3 Parameter zur Messung der Güte des Parsens 4 Fehlerquellen 1.Fehler
04.06.2007 Inhalt 1 Definition Anno 1996 Überwachtes Training 2 Ablesen der Baumbankgrammatik Berechnen der Regelwahrscheinlichkeiten PCFG 3 Parameter zur Messung der Güte des Parsens 4 Fehlerquellen 1.Fehler
Syntax und Parsing. OS Einblicke in die Computerlinguistik. Philipp Rabe, 13IN-M
 OS Einblicke in die Computerlinguistik basierend auf Computerlinguistik und Sprachtechnologie, 3. Auflage, Spektrum, Heidelberg 2010 22. Mai 2014 Ausgangssituation Tokenisierung und Wortarten-Tagging vollendet
OS Einblicke in die Computerlinguistik basierend auf Computerlinguistik und Sprachtechnologie, 3. Auflage, Spektrum, Heidelberg 2010 22. Mai 2014 Ausgangssituation Tokenisierung und Wortarten-Tagging vollendet
Charts. Motivation. Grundfrage. Chart als Graph
 Charts Motivation Übersicht Chart bzw. Well-Formed Substring Table (WFST) Als azyklischer Graph, Tabelle und Relation Kantenbeschriftungen Kategorien: WFST Regeln: Passive Charts Regelhyposen: Aktive Charts
Charts Motivation Übersicht Chart bzw. Well-Formed Substring Table (WFST) Als azyklischer Graph, Tabelle und Relation Kantenbeschriftungen Kategorien: WFST Regeln: Passive Charts Regelhyposen: Aktive Charts
Diskriminatives syntaktisches Reranking für SMT
 Diskriminatives syntaktisches Reranking für SMT Fortgeschrittene Themen der statistischen maschinellen Übersetzung Janina Nikolic 2 Agenda Problem: Ranking des SMT Systems Lösung: Reranking-Modell Nutzung
Diskriminatives syntaktisches Reranking für SMT Fortgeschrittene Themen der statistischen maschinellen Übersetzung Janina Nikolic 2 Agenda Problem: Ranking des SMT Systems Lösung: Reranking-Modell Nutzung
Dependenzgrammatik-Parsing
 Dependenzgrammatik-Parsing LMT-/Watson-Parser, MaltParser, Stanford Parser Kurt Eberle k.eberle@lingenio.de 03. August 2018 1 / 45 Übersicht Dependenzgrammatik Regelbasiertes Dependenz-Parsing Statistisches
Dependenzgrammatik-Parsing LMT-/Watson-Parser, MaltParser, Stanford Parser Kurt Eberle k.eberle@lingenio.de 03. August 2018 1 / 45 Übersicht Dependenzgrammatik Regelbasiertes Dependenz-Parsing Statistisches
Probabilistische kontextfreie Grammatiken und Parsing. Sebastian Pado
 Probabilistische kontextfreie Grammatiken und Parsing Sebastian Pado 18.01.2005 1 Robustes Parsing Ziel: Syntaktische Analyse von freiem Text Anwendungen: Freier Dialog Große Textmengen (Internet) Herausforderungen
Probabilistische kontextfreie Grammatiken und Parsing Sebastian Pado 18.01.2005 1 Robustes Parsing Ziel: Syntaktische Analyse von freiem Text Anwendungen: Freier Dialog Große Textmengen (Internet) Herausforderungen
Lösungsvorschlag für das Übungsblatt 8. Aufgabe1.
 Lösungsvorschlag für das Übungsblatt 8. Aufgabe1. 3 Det A N VP R6 4 Any A N VP L3 5 Any intelligent N VP L4 6 Any intelligent cat VP L2 Nach den Regeln kann der Satz weiter nicht erzeugt warden, deswegen
Lösungsvorschlag für das Übungsblatt 8. Aufgabe1. 3 Det A N VP R6 4 Any A N VP L3 5 Any intelligent N VP L4 6 Any intelligent cat VP L2 Nach den Regeln kann der Satz weiter nicht erzeugt warden, deswegen
Kontextfreie Grammatiken
 Kontextfreie Grammatiken Vorlesung Computerlinguistische Techniken Alexander Koller 16. Oktober 2015 Übersicht Worum geht es in dieser Vorlesung? Übungen und Abschlussprojekt Kontextfreie Grammatiken Computerlinguistische
Kontextfreie Grammatiken Vorlesung Computerlinguistische Techniken Alexander Koller 16. Oktober 2015 Übersicht Worum geht es in dieser Vorlesung? Übungen und Abschlussprojekt Kontextfreie Grammatiken Computerlinguistische
MODIFIKATIONEN DES TOMITA-PARSERS FÜR ID/LP UND FEATURE GRAMMARS Jens Woch
 Fachbeiträge MODIFIKATIONEN DES TOMITA-PARSERS FÜR ID/LP UND FEATURE GRAMMARS Jens Woch Abstract: Die Verwendung von ID/LP-Grammatiken und komplexen Symbolen ist bei Flektionsreichen und in der Wortstellung
Fachbeiträge MODIFIKATIONEN DES TOMITA-PARSERS FÜR ID/LP UND FEATURE GRAMMARS Jens Woch Abstract: Die Verwendung von ID/LP-Grammatiken und komplexen Symbolen ist bei Flektionsreichen und in der Wortstellung
Syntax natürlicher Sprachen
 Syntax natürlicher Sprachen 03: Phrasen und Konstituenten Martin Schmitt Ludwig-Maximilians-Universität München 08.11.2017 Martin Schmitt (LMU) Syntax natürlicher Sprachen 08.11.2017 1 Themen der heutigen
Syntax natürlicher Sprachen 03: Phrasen und Konstituenten Martin Schmitt Ludwig-Maximilians-Universität München 08.11.2017 Martin Schmitt (LMU) Syntax natürlicher Sprachen 08.11.2017 1 Themen der heutigen
A Topical/Local Classifier for Word Sense Idendification (TLC) Anne Schwartz
 Anne Schwartz") A Topical/Local Classifier for Word Sense Idendification (TLC) Anne Schwartz anne@coli.uni-sb.de A Topical/Local Classifier for Word Sense Idendification (TLC) entwickelt von: - Martin Chodorow (Dep. of
A Topical/Local Classifier for Word Sense Idendification (TLC) Anne Schwartz anne@coli.uni-sb.de A Topical/Local Classifier for Word Sense Idendification (TLC) entwickelt von: - Martin Chodorow (Dep. of
Sharon Goldwater & David McClosky. Sarah Hartmann Advanced Topics in Statistical Machine Translation
 Sharon Goldwater & David McClosky Sarah Hartmann 13.01.2015 Advanced Topics in Statistical Machine Translation Einführung Modelle Experimente Diskussion 2 Einführung Das Problem Der Lösungsvorschlag Modelle
Sharon Goldwater & David McClosky Sarah Hartmann 13.01.2015 Advanced Topics in Statistical Machine Translation Einführung Modelle Experimente Diskussion 2 Einführung Das Problem Der Lösungsvorschlag Modelle
Korpus. Was ist ein Korpus?
 Was ist ein Korpus? Korpus Endliche Menge von konkreten sprachlichen Äußerungen, die als empirische Grundlage für sprachwiss. Untersuchungen dienen. Stellenwert und Beschaffenheit des Korpus hängen weitgehend
Was ist ein Korpus? Korpus Endliche Menge von konkreten sprachlichen Äußerungen, die als empirische Grundlage für sprachwiss. Untersuchungen dienen. Stellenwert und Beschaffenheit des Korpus hängen weitgehend
Formale Methoden III - Tutorium
 Formale Methoden III - Tutorium Daniel Jettka 08.05.06 Anmeldung im ekvv Inhaltsverzeichnis 1. Aufgaben vom 27.04.06 1.1 Aufgabe 1 1.2 Aufgabe 2 1.3 Aufgabe 3 1.4 Aufgabe 4 1.5 Aufgabe 5 1.6 Aufgabe 6
Formale Methoden III - Tutorium Daniel Jettka 08.05.06 Anmeldung im ekvv Inhaltsverzeichnis 1. Aufgaben vom 27.04.06 1.1 Aufgabe 1 1.2 Aufgabe 2 1.3 Aufgabe 3 1.4 Aufgabe 4 1.5 Aufgabe 5 1.6 Aufgabe 6
Linux I II III Res WN/TT NLTK XML XLE I II Weka E. Freitag. 9 XLE Transfer. 10 Weka. Ressourcen-Vorkurs
 Linux I II III Res WN/TT NLTK XML XLE I II Weka E Freitag 9 XLE Transfer 10 Weka Linux I II III Res WN/TT NLTK XML XLE I II Weka E XLE Transfer I Auf ella gibt es nicht nur XLE (den Parser) sondern auch
Linux I II III Res WN/TT NLTK XML XLE I II Weka E Freitag 9 XLE Transfer 10 Weka Linux I II III Res WN/TT NLTK XML XLE I II Weka E XLE Transfer I Auf ella gibt es nicht nur XLE (den Parser) sondern auch
Elektronische Korpora in der Lehre Anwendungsbeispiele aus der theoretischen 2 und / 27der. und der Computerlinguistik
 Elektronische Korpora in der Lehre Anwendungsbeispiele aus der theoretischen und der Linguistics Department Ruhr-University Bochum 18.1.2011 DSPIN-Workshop Sprachressourcen in der Lehre Erfahrungen, Einsatzszenarien,
Elektronische Korpora in der Lehre Anwendungsbeispiele aus der theoretischen und der Linguistics Department Ruhr-University Bochum 18.1.2011 DSPIN-Workshop Sprachressourcen in der Lehre Erfahrungen, Einsatzszenarien,
Part-of-Speech- Tagging
 Part-of-Speech- Tagging In: Einführung in die Computerlinguistik Institut für Computerlinguistik Heinrich-Heine-Universität Düsseldorf WS 2004/05 Dozentin: Wiebke Petersen Tagging Was ist das? Tag (engl.):
Part-of-Speech- Tagging In: Einführung in die Computerlinguistik Institut für Computerlinguistik Heinrich-Heine-Universität Düsseldorf WS 2004/05 Dozentin: Wiebke Petersen Tagging Was ist das? Tag (engl.):
Proseminar Linguistische Annotation
 Proseminar Linguistische Annotation Ines Rehbein und Josef Ruppenhofer SS 2010 Ines Rehbein und Josef Ruppenhofer (SS10) Linguistische Annotation April 2010 1 / 22 Seminarplan I. Linguistische Annotation
Proseminar Linguistische Annotation Ines Rehbein und Josef Ruppenhofer SS 2010 Ines Rehbein und Josef Ruppenhofer (SS10) Linguistische Annotation April 2010 1 / 22 Seminarplan I. Linguistische Annotation
Textmining Wissensrohstoff Text
 Textmining Wissensrohstoff Text Wintersemester 2008/09 Teil 5 Chunking und Parsing Uwe Quasthoff Universität Leipzig Institut für Informatik quasthoff@informatik.uni-leipzig.de Zerlegung von Sätzen 1.
Textmining Wissensrohstoff Text Wintersemester 2008/09 Teil 5 Chunking und Parsing Uwe Quasthoff Universität Leipzig Institut für Informatik quasthoff@informatik.uni-leipzig.de Zerlegung von Sätzen 1.
TnT - Statistischer Part-of- Speech Tagger
 TnT - Statistischer Part-of- Speech Tagger 2. Teil der Präsentation des TnT Taggers von Thorsten Brants Präsentation von Berenike Loos Gliederung 1. Installation und Beschreibung des Programms 2. Erläuterungen
TnT - Statistischer Part-of- Speech Tagger 2. Teil der Präsentation des TnT Taggers von Thorsten Brants Präsentation von Berenike Loos Gliederung 1. Installation und Beschreibung des Programms 2. Erläuterungen
Combinatory Categorial Grammar. Teil 2: Semantik in der CCG
 Combinatory Categorial Grammar Teil 2: Semantik in der CCG Referat Referentin: Éva Mújdricza Semantikkonstruktion SS 08 Dozenten: Anette Frank, Matthias Hartung Ruprecht-Karls-Universität HD 29.04.2008
Combinatory Categorial Grammar Teil 2: Semantik in der CCG Referat Referentin: Éva Mújdricza Semantikkonstruktion SS 08 Dozenten: Anette Frank, Matthias Hartung Ruprecht-Karls-Universität HD 29.04.2008
Effiziente [Analyse] N. unbeschränkter Texte
![Effiziente [Analyse] N. unbeschränkter Texte](/thumbs/95/126382159.jpg "Effiziente [Analyse] N. unbeschränkter Texte") Effiziente [Analyse] N Leistung Geschwindigkeit unbeschränkter Texte Grösse Genre Komplexität CL Vorlesung Universität Zürich, WS 2003/4 2. Sitzung, 27.11.03 Gerold Schneider Mo, 16-18, Hauptgebäude 321
Effiziente [Analyse] N Leistung Geschwindigkeit unbeschränkter Texte Grösse Genre Komplexität CL Vorlesung Universität Zürich, WS 2003/4 2. Sitzung, 27.11.03 Gerold Schneider Mo, 16-18, Hauptgebäude 321
Automatische Extraktion von Prädikat-Argument-Strukturen
 Automatische Extraktion von Prädikat-Argument-Strukturen Manfred Klenner Automatische ExtraktionvonPrädikat-Argument-Strukturen p.1/?? Übersicht Zielsetzung und Lernaufgabe Ressourcen und Tools Semantische
Automatische Extraktion von Prädikat-Argument-Strukturen Manfred Klenner Automatische ExtraktionvonPrädikat-Argument-Strukturen p.1/?? Übersicht Zielsetzung und Lernaufgabe Ressourcen und Tools Semantische
Mathematische Grundlagen III
 Mathematische Grundlagen III Maschinelles Lernen III: Clustering Vera Demberg Universität des Saarlandes 7. Juli 202 Vera Demberg (UdS) Mathe III 7. Juli 202 / 35 Clustering vs. Klassifikation In den letzten
Mathematische Grundlagen III Maschinelles Lernen III: Clustering Vera Demberg Universität des Saarlandes 7. Juli 202 Vera Demberg (UdS) Mathe III 7. Juli 202 / 35 Clustering vs. Klassifikation In den letzten
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. NLP-Pipeline. Tobias Scheffer Paul Prasse Michael Großhans
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen NLP-Pipeline Tobias Scheffer Paul Prasse Michael Großhans NLP- (Natural Language Processing-) Pipeline Folge von Verarbeitungsschritten
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen NLP-Pipeline Tobias Scheffer Paul Prasse Michael Großhans NLP- (Natural Language Processing-) Pipeline Folge von Verarbeitungsschritten
Implementierung eines LR-Parser-Generators mit syntaktischen Prädikaten
 Implementierung eines LR-Parser-Generators mit syntaktischen Prädikaten Aufgabenbeschreibung 29. Juli 2011 1 Einleitung und Motivation Der Parser-Generator Antlr [Par07] bietet die Möglichkeit, die Auswahl
Implementierung eines LR-Parser-Generators mit syntaktischen Prädikaten Aufgabenbeschreibung 29. Juli 2011 1 Einleitung und Motivation Der Parser-Generator Antlr [Par07] bietet die Möglichkeit, die Auswahl
Gliederung. Das TIGER-Korpus: Annotation und Exploration. TIGER-Korpus. 1. TIGER-Korpus. entstanden im Projekt TIGER (1999 heute) beteiligte Institute
 beteiligte Institute") Das TIGER-Korpus: Annotation und Exploration Stefanie Dipper Forschungskolloquium Korpuslinguistik, 11.11.03 Gliederung 1. TIGER-Korpus 2. Annotation 3. Visualisierung 4. Suche, Retrieval 5. Demo 6. Repräsentation
Das TIGER-Korpus: Annotation und Exploration Stefanie Dipper Forschungskolloquium Korpuslinguistik, 11.11.03 Gliederung 1. TIGER-Korpus 2. Annotation 3. Visualisierung 4. Suche, Retrieval 5. Demo 6. Repräsentation
Der eigentliche Inhalt (z.b. arithmetisch, algebraisch) wird ignoriert:
 wird ignoriert:") Überprüfung von Klammerausdrücken Der eigentliche Inhalt z.b. arithmetisch, algebraisch) wird ignoriert: a/b+c)-a c-b))) )))) Hier: nichtleere Klammerausdrücke, also nicht b+c ε. Geht aber auch ähnlich
Überprüfung von Klammerausdrücken Der eigentliche Inhalt z.b. arithmetisch, algebraisch) wird ignoriert: a/b+c)-a c-b))) )))) Hier: nichtleere Klammerausdrücke, also nicht b+c ε. Geht aber auch ähnlich
Inhalt. Einführung Formale Sprachen und Grammatiken Übergangsnetze Merkmalsstrukturen Unifikationsgrammatiken
 4 Syntax Inhalt Einführung Formale Sprachen und Grammatiken Übergangsnetze Merkmalsstrukturen Unifikationsgrammatiken 4.1 Einführung Einführung Oberflächenstruktur (OF) äußere Erscheinungsform eines Satzes
4 Syntax Inhalt Einführung Formale Sprachen und Grammatiken Übergangsnetze Merkmalsstrukturen Unifikationsgrammatiken 4.1 Einführung Einführung Oberflächenstruktur (OF) äußere Erscheinungsform eines Satzes
INFORMATIONSEXTRAKTION Computerlinguistik Referenten: Alice Holka, Sandra Pyka
 INFORMATIONSEXTRAKTION 1 22.12.09 Computerlinguistik Referenten: Alice Holka, Sandra Pyka INFORMATIONSEXTRAKTION(IE) 1. Einleitung 2. Ziel der IE 3. Funktionalität eines IE-Systems 4. Beispiel 5. Übung
INFORMATIONSEXTRAKTION 1 22.12.09 Computerlinguistik Referenten: Alice Holka, Sandra Pyka INFORMATIONSEXTRAKTION(IE) 1. Einleitung 2. Ziel der IE 3. Funktionalität eines IE-Systems 4. Beispiel 5. Übung
Übersicht. 11 Statistische Syntaxmodelle
 Übersicht 11 Statistische Syntaxmodelle 11.1 Induzierte PCFG-Modelle 11.1.1 grammar induction aus Treebank 11.1.2 Normalisierung und Evaluation 11.1.3 PCFGs mit abgeschwächten Unabhängigkeitsannahmen 11.2
Übersicht 11 Statistische Syntaxmodelle 11.1 Induzierte PCFG-Modelle 11.1.1 grammar induction aus Treebank 11.1.2 Normalisierung und Evaluation 11.1.3 PCFGs mit abgeschwächten Unabhängigkeitsannahmen 11.2
Teil 111. Chart-Parsing
 Teil 111 Chart-Parsing 102 Die im ersten Teil des Buches behandelten einfachen Parsingalgorithmen sind, anders als die meisten vor allem im Compilerbau verwendeten Algorithmen (z.b. die LLoder LR-Parsingalgorithmen),
Teil 111 Chart-Parsing 102 Die im ersten Teil des Buches behandelten einfachen Parsingalgorithmen sind, anders als die meisten vor allem im Compilerbau verwendeten Algorithmen (z.b. die LLoder LR-Parsingalgorithmen),
Maschinelle Sprachverarbeitung: Probabilistische, kontextfreie Grammatiken
 HUMBOLDT-UNIVERSITÄT ZU BERLIN Institut für Informatik Lehrstuhl Wissensmanagement Maschinelle Sprachverarbeitung: Probabilistische, kontextfreie Grammatiken Tobias Scheffer Ulf Brefeld Sprachmodelle N-Gramm-Modell:
HUMBOLDT-UNIVERSITÄT ZU BERLIN Institut für Informatik Lehrstuhl Wissensmanagement Maschinelle Sprachverarbeitung: Probabilistische, kontextfreie Grammatiken Tobias Scheffer Ulf Brefeld Sprachmodelle N-Gramm-Modell:
Erkennung von Teilsatzgrenzen
 Erkennung von Teilsatzgrenzen Maryia Fedzechkina Universität zu Köln Institut für Linguistik Sprachliche Informationsverarbeitung SoSe 2007 Hauptseminar Maschinelle Sprachverarbeitung Agenda Definitionen
Erkennung von Teilsatzgrenzen Maryia Fedzechkina Universität zu Köln Institut für Linguistik Sprachliche Informationsverarbeitung SoSe 2007 Hauptseminar Maschinelle Sprachverarbeitung Agenda Definitionen
Blockseminar Einführung in die Korpuslinguistik Seminarleitung: Yvonne Krämer, M.A. Das Korpus. und seine Aufbereitung
 Blockseminar Einführung in die Korpuslinguistik Seminarleitung: Yvonne Krämer, M.A. Das Korpus und seine Aufbereitung Bestandteile eines Korpus sind i.d.r.: Primärdaten Metadaten Annotationen Annotationen
Blockseminar Einführung in die Korpuslinguistik Seminarleitung: Yvonne Krämer, M.A. Das Korpus und seine Aufbereitung Bestandteile eines Korpus sind i.d.r.: Primärdaten Metadaten Annotationen Annotationen
Geplanter Sonderforschungsbereich 732. Incremental Specification in Context
 Geplanter Sonderforschungsbereich 732 Incremental Specification in Context Universität Stuttgart Finanzierungsantrag 2006/2 2010/1 Inhaltsverzeichnis D4, LexPar, Schmid.................................
Geplanter Sonderforschungsbereich 732 Incremental Specification in Context Universität Stuttgart Finanzierungsantrag 2006/2 2010/1 Inhaltsverzeichnis D4, LexPar, Schmid.................................
Eine nebenläufige Syntax-Semantik-Schnittstelle für Dependenzgrammatik 1
 Eine nebenläufige Syntax-Semantik-Schnittstelle für Dependenzgrammatik Ralph Debusmann 1. Diplomarbeit: TDG - ein deklarativer Grammatikformalismus für Dependenzgrammatik 2. Forschungsvorhaben: eine nebenläufige
Eine nebenläufige Syntax-Semantik-Schnittstelle für Dependenzgrammatik Ralph Debusmann 1. Diplomarbeit: TDG - ein deklarativer Grammatikformalismus für Dependenzgrammatik 2. Forschungsvorhaben: eine nebenläufige
Der VITERBI-Algorithmus
 Der VITERBI-Algorithmus Hauptseminar Parsing Sommersemester 2002 Lehrstuhl für Computerlinguistik Universität Heidelberg Thorsten Beinhorn http://janus.cl.uni-heidelberg.de/~beinhorn 2 Inhalt Ziel des
Der VITERBI-Algorithmus Hauptseminar Parsing Sommersemester 2002 Lehrstuhl für Computerlinguistik Universität Heidelberg Thorsten Beinhorn http://janus.cl.uni-heidelberg.de/~beinhorn 2 Inhalt Ziel des
Kombiniertes transformations-basiertes Lernen erweiterter Chunks
 Kombiniertes transformations-basiertes Lernen erweiterter Chunks Markus Dreyer Institut für Computerlinguistik Ruprecht-Karls-Universität Heidelberg dreyer@cl.uni-heidelberg.de Abstract Chunking beschränkt
Kombiniertes transformations-basiertes Lernen erweiterter Chunks Markus Dreyer Institut für Computerlinguistik Ruprecht-Karls-Universität Heidelberg dreyer@cl.uni-heidelberg.de Abstract Chunking beschränkt
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. NLP-Pipeline. Tobias Scheffer Peter Haider Uwe Dick Paul Prasse
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen NLP-Pipeline Tobias Scheffer Peter Haider Uwe Dick Paul Prasse NLP-Pipeline Folge von Verarbeitungsschritten für Informationsextraktion,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen NLP-Pipeline Tobias Scheffer Peter Haider Uwe Dick Paul Prasse NLP-Pipeline Folge von Verarbeitungsschritten für Informationsextraktion,
Stratego/XT und ASF+SDF Meta-Environment. Paul Weder Seminar Transformationen Datum:
 Stratego/XT und ASF+SDF Meta-Environment Paul Weder Seminar Transformationen Datum: 20.01.2006 Gliederung Allgemeines ASF+SDF Meta-Environment Stratego/XT Zusammenfassung/Vergleich SDF (Syntax Definition
Stratego/XT und ASF+SDF Meta-Environment Paul Weder Seminar Transformationen Datum: 20.01.2006 Gliederung Allgemeines ASF+SDF Meta-Environment Stratego/XT Zusammenfassung/Vergleich SDF (Syntax Definition
Automatisches Verstehen gesprochener Sprache
 Automatisches Verstehen gesprochener Sprache 6. Syntaxanalyse Martin Hacker Bernd Ludwig Günther Görz Professur für Künstliche Intelligenz Department Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg
Automatisches Verstehen gesprochener Sprache 6. Syntaxanalyse Martin Hacker Bernd Ludwig Günther Görz Professur für Künstliche Intelligenz Department Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg
Practical Grammar Engineering Using HPSG 2.Tag. Frederik Fouvry, Petter Haugereid, Valia Kordoni, Melanie Siegel
 Practical Grammar Engineering Using HPSG 2.Tag Frederik Fouvry, Petter Haugereid, Valia Kordoni, Melanie Siegel Inhalt Matrix Differenzlisten Debugging (Demo, Frederik) Die LinGO Grammar Matrix Ein Nachteil
Practical Grammar Engineering Using HPSG 2.Tag Frederik Fouvry, Petter Haugereid, Valia Kordoni, Melanie Siegel Inhalt Matrix Differenzlisten Debugging (Demo, Frederik) Die LinGO Grammar Matrix Ein Nachteil
Improving Part-Of-Speech Tagging for Social Media via Automatic Spelling Error Correction
 Improving Part-Of-Speech Tagging for Social Media via Automatic Spelling Error Correction Vorstellung AI-Studienprojekt für das SoSe 2019 Benedikt Tobias Bönninghoff 17.01.2019 Cognitive Signal Processing
Improving Part-Of-Speech Tagging for Social Media via Automatic Spelling Error Correction Vorstellung AI-Studienprojekt für das SoSe 2019 Benedikt Tobias Bönninghoff 17.01.2019 Cognitive Signal Processing
Einführung Computerlinguistik. Konstituentensyntax II
 Einführung Computerlinguistik Konstituentensyntax II Hinrich Schütze & Robert Zangenfeind Centrum für Informations- und Sprachverarbeitung, LMU München 2013-11-18 1 / 31 Take-away Phrasenstrukturgrammatik:
Einführung Computerlinguistik Konstituentensyntax II Hinrich Schütze & Robert Zangenfeind Centrum für Informations- und Sprachverarbeitung, LMU München 2013-11-18 1 / 31 Take-away Phrasenstrukturgrammatik:
Institut für Informatik Lehrstuhl Maschinelles Lernen
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen NLP-PipelinePipeline Tobias Scheffer Peter Haider Uwe Dick Paul Prasse NLP-Pipeline Folge von Verarbeitungsschritten für Informationsextraktion,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen NLP-PipelinePipeline Tobias Scheffer Peter Haider Uwe Dick Paul Prasse NLP-Pipeline Folge von Verarbeitungsschritten für Informationsextraktion,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. NLP-Pipeline. Tobias Scheffer Peter Haider Paul Prasse
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen NLP-Pipeline Tobias Scheffer Peter Haider Paul Prasse NLP-Pipeline Folge von Verarbeitungsschritten für Informationsextraktion,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen NLP-Pipeline Tobias Scheffer Peter Haider Paul Prasse NLP-Pipeline Folge von Verarbeitungsschritten für Informationsextraktion,
Hidden Markov Models in Anwendungen
 Hidden Markov Models in Anwendungen Prof Dr. Matthew Crocker Universität des Saarlandes 18. Juni 2015 Matthew Crocker (UdS) HMM Anwendungen 18. Juni 2015 1 / 26 Hidden Markov Modelle in der Computerlinguistik
Hidden Markov Models in Anwendungen Prof Dr. Matthew Crocker Universität des Saarlandes 18. Juni 2015 Matthew Crocker (UdS) HMM Anwendungen 18. Juni 2015 1 / 26 Hidden Markov Modelle in der Computerlinguistik
Combinatory Categorial Grammar. Teil 1: Syntax in der CCG
 Combinatory Categorial Grammar Teil 1: Syntax in der CCG Referat Referentin: Éva Mújdricza Semantikkonstruktion SS 08 Dozenten: Anette Frank, Matthias Hartung Ruprecht-Karls-Universität HD 22.04.2008 Übersicht
Combinatory Categorial Grammar Teil 1: Syntax in der CCG Referat Referentin: Éva Mújdricza Semantikkonstruktion SS 08 Dozenten: Anette Frank, Matthias Hartung Ruprecht-Karls-Universität HD 22.04.2008 Übersicht
Adventure-Problem. Vorlesung Automaten und Formale Sprachen Sommersemester Adventure-Problem
 -Problem Vorlesung Automaten und Formale Sprachen Sommersemester 2018 Prof. Barbara König Übungsleitung: Christina Mika-Michalski Zum Aufwärmen: wir betrachten das sogenannte -Problem, bei dem ein Abenteurer/eine
-Problem Vorlesung Automaten und Formale Sprachen Sommersemester 2018 Prof. Barbara König Übungsleitung: Christina Mika-Michalski Zum Aufwärmen: wir betrachten das sogenannte -Problem, bei dem ein Abenteurer/eine
Dependency-Based Construction of Semantic Space Models ( Padó, Lapata 2007) Distributionelle Semantik WS 11/
 Distributionelle Semantik WS 11/") Dependency-Based Construction of Semantic Space Models ( Padó, Lapata 2007) Distributionelle Semantik WS 11/12 21.11.2011 Lena Enzweiler 1 Was ist das Problem? Wortbasierte Vektormodelle betrachten nur
Dependency-Based Construction of Semantic Space Models ( Padó, Lapata 2007) Distributionelle Semantik WS 11/12 21.11.2011 Lena Enzweiler 1 Was ist das Problem? Wortbasierte Vektormodelle betrachten nur
Evaluation und Training von HMMs
 Evaluation und Training von MMs Vorlesung omputerlinguistische Techniken Alexander Koller. Dezember 04 MMs: Beispiel initial p. a 0 0.8 0.7 0. Eisner 0. transition p. 0. 0.6 a 0.5 0. emission p. b () States
Evaluation und Training von MMs Vorlesung omputerlinguistische Techniken Alexander Koller. Dezember 04 MMs: Beispiel initial p. a 0 0.8 0.7 0. Eisner 0. transition p. 0. 0.6 a 0.5 0. emission p. b () States
Speech Recognition Grammar Compilation in Grammatikal Framework. von Michael Heber
 Speech Recognition Grammar Compilation in Grammatikal Framework von Michael Heber Agenda 1. Einführung 2. Grammatical Framework (GF) 3. Kontextfreie Grammatiken und Finite-State Modelle 4. Quellen 2 1.
Speech Recognition Grammar Compilation in Grammatikal Framework von Michael Heber Agenda 1. Einführung 2. Grammatical Framework (GF) 3. Kontextfreie Grammatiken und Finite-State Modelle 4. Quellen 2 1.
Semi-automatische Ontologieerstellung mittels TextToOnto
 Semi-automatische Ontologieerstellung mittels TextToOnto Mark Hall SE Computational Linguistics 14. Juni 2004 Zusammenfassung Das Erstellen von Ontologien ist ein komplexer und langwieriger Prozess. Um
Semi-automatische Ontologieerstellung mittels TextToOnto Mark Hall SE Computational Linguistics 14. Juni 2004 Zusammenfassung Das Erstellen von Ontologien ist ein komplexer und langwieriger Prozess. Um
Software Entwicklung 1. Fallstudie: Arithmetische Ausdrücke. Rekursive Klassen. Überblick. Annette Bieniusa / Arnd Poetzsch-Heffter
 Software Entwicklung 1 Annette Bieniusa / Arnd Poetzsch-Heffter Fallstudie: Arithmetische Ausdrücke AG Softech FB Informatik TU Kaiserslautern Bieniusa/Poetzsch-Heffter Software Entwicklung 1 2/ 33 Überblick
Software Entwicklung 1 Annette Bieniusa / Arnd Poetzsch-Heffter Fallstudie: Arithmetische Ausdrücke AG Softech FB Informatik TU Kaiserslautern Bieniusa/Poetzsch-Heffter Software Entwicklung 1 2/ 33 Überblick
Kontextsensitive Sprachen
 Kontextsensitive Sprachen Standardbeispiel: {anbncn} S a b c S a A b B c c B A B b c B b b A A b a A a a Im Bereich der natürlichen Sprachen gibt es zahlreiche kontextsensitive Phänomene in der Semantik
Kontextsensitive Sprachen Standardbeispiel: {anbncn} S a b c S a A b B c c B A B b c B b b A A b a A a a Im Bereich der natürlichen Sprachen gibt es zahlreiche kontextsensitive Phänomene in der Semantik
Latent Vector Weighting. Word Meaning in Context
 Latent Vector Weighting for Word Meaning in Context Tim Van de Cruys, Thierry Poibeau, Anna Korhonen (2011) Präsentation von Jörn Giesen Distributionelle Semantik 16.01.2012 1 Distributational Hypothesis
Latent Vector Weighting for Word Meaning in Context Tim Van de Cruys, Thierry Poibeau, Anna Korhonen (2011) Präsentation von Jörn Giesen Distributionelle Semantik 16.01.2012 1 Distributational Hypothesis
Automaten und formale Sprachen Klausurvorbereitung
 Automaten und formale Sprachen Klausurvorbereitung Rami Swailem Mathematik Naturwissenschaften und Informatik FH-Gießen-Friedberg Inhaltsverzeichnis 1 Definitionen 2 2 Altklausur Jäger 2006 8 1 1 Definitionen
Automaten und formale Sprachen Klausurvorbereitung Rami Swailem Mathematik Naturwissenschaften und Informatik FH-Gießen-Friedberg Inhaltsverzeichnis 1 Definitionen 2 2 Altklausur Jäger 2006 8 1 1 Definitionen
Baumadjunktionsgrammatiken
 Baumadjunktionsgrammatiken Vorlesung Grammatikformalismen Alexander Koller 22. April 2016 Grammatikformalismen Grammatik- formalismus Grammatik- theorie abstrakt Grammatik prache konkret formal linguistisch
Baumadjunktionsgrammatiken Vorlesung Grammatikformalismen Alexander Koller 22. April 2016 Grammatikformalismen Grammatik- formalismus Grammatik- theorie abstrakt Grammatik prache konkret formal linguistisch
Topologische Dependenzgrammatik
 Topologische Dependenzgrammatik Ralph Debusmann Universität des Saarlandes rade@coli.uni-sb.de Zusammenfassung In diesem Artikel erläutern wir eine neue Grammatiktheorie namens topologische Dependenzgrammatik
Topologische Dependenzgrammatik Ralph Debusmann Universität des Saarlandes rade@coli.uni-sb.de Zusammenfassung In diesem Artikel erläutern wir eine neue Grammatiktheorie namens topologische Dependenzgrammatik
Typengetriebene Interpretation. Arnim von Stechow Einführung in die Semantik
 Typengetriebene Interpretation Arnim von Stechow Einführung in die Semantik arnim.stechow@uni-tuebingen.de Programm Logische Typen Typengesteuerte Interpretation λ-schreibweise Prädikatsmodifikation (PM)
Typengetriebene Interpretation Arnim von Stechow Einführung in die Semantik arnim.stechow@uni-tuebingen.de Programm Logische Typen Typengesteuerte Interpretation λ-schreibweise Prädikatsmodifikation (PM)
Software Entwicklung 1
 Software Entwicklung 1 Annette Bieniusa / Arnd Poetzsch-Heffter AG Softech FB Informatik TU Kaiserslautern Fallstudie: Arithmetische Ausdrücke Bieniusa/Poetzsch-Heffter Software Entwicklung 1 2/ 33 Überblick
Software Entwicklung 1 Annette Bieniusa / Arnd Poetzsch-Heffter AG Softech FB Informatik TU Kaiserslautern Fallstudie: Arithmetische Ausdrücke Bieniusa/Poetzsch-Heffter Software Entwicklung 1 2/ 33 Überblick
Interdisziplinäre fachdidaktische Übung: Modelle für Sprachen in der Informatik. SS 2016: Grossmann, Jenko
 Interdisziplinäre fachdidaktische Übung: Modelle für Sprachen in der SS 2016: Grossmann, Jenko Die Beschreibung orientiert sich am Begriffssystem der Beschreibung natürlicher Sprachen Sprache in der steht
Interdisziplinäre fachdidaktische Übung: Modelle für Sprachen in der SS 2016: Grossmann, Jenko Die Beschreibung orientiert sich am Begriffssystem der Beschreibung natürlicher Sprachen Sprache in der steht
Lemmatisierung. Einführung in die Korpuslinguistik. Lemmatisierung und Wortarttagging. Lemmatisierung. zum Erinnern... zum Erinnern...
 Lemmatisierung Einführung in die Korpuslinguistik Anke Lüdeling anke.luedeling@rz.hu-berlin.de Sommersemester 2007 zum Lemmatisieren braucht man also ein Lexikon, in dem die Lemmata mit ihrer Flexionsklasse
Lemmatisierung Einführung in die Korpuslinguistik Anke Lüdeling anke.luedeling@rz.hu-berlin.de Sommersemester 2007 zum Lemmatisieren braucht man also ein Lexikon, in dem die Lemmata mit ihrer Flexionsklasse
Overview. Motivation Learner text and target hypoteses correction of POS-tags parsing the target hypothesis TH1
 Overview Motivation Learner text and target hypoteses correction of POS-tags parsing the target hypothesis TH1 Motivation up -to -date learner corpora allow us to investigate surface structure features
Overview Motivation Learner text and target hypoteses correction of POS-tags parsing the target hypothesis TH1 Motivation up -to -date learner corpora allow us to investigate surface structure features
Syntaktische Annotationen. Korpuslinguistik Dr. Heike Zinsmeister
 Syntaktische Annotationen Korpuslinguistik Dr. Heike Zinsmeister 18.11.2011 Syntax Gestern war mir, wie vielen europäischen Abgeordneten, die Teilnahme unmöglich, da der Flug von Air France, mit dem wir
Syntaktische Annotationen Korpuslinguistik Dr. Heike Zinsmeister 18.11.2011 Syntax Gestern war mir, wie vielen europäischen Abgeordneten, die Teilnahme unmöglich, da der Flug von Air France, mit dem wir
Wortfinales Schwa in BeMaTaC: L1 vs. L2. Simon Sauer Korpuslinguistisches Kolloquium Humboldt-Universität zu Berlin
 Wortfinales Schwa in BeMaTaC: L1 vs. L2 Simon Sauer Korpuslinguistisches Kolloquium Humboldt-Universität zu Berlin 27.01.2016 Phänomen In gesprochenem Deutsch wird wortfinales Schwa oft weggelassen ich
Wortfinales Schwa in BeMaTaC: L1 vs. L2 Simon Sauer Korpuslinguistisches Kolloquium Humboldt-Universität zu Berlin 27.01.2016 Phänomen In gesprochenem Deutsch wird wortfinales Schwa oft weggelassen ich
Inhalt Kapitel 11: Formale Syntax und Semantik
 Inhalt Kapitel 11: Formale Syntax und Semantik 1 Abstrakte und konkrete Syntax 2 Lexikalische Analyse 3 Formale Sprachen, Grammatiken, BNF 4 Syntaxanalyse konkret 266 Abstrakte und konkrete Syntax Abstrakte
Inhalt Kapitel 11: Formale Syntax und Semantik 1 Abstrakte und konkrete Syntax 2 Lexikalische Analyse 3 Formale Sprachen, Grammatiken, BNF 4 Syntaxanalyse konkret 266 Abstrakte und konkrete Syntax Abstrakte
Proseminar Syntax. Diana Schackow
 Proseminar Syntax Diana Schackow 1 Fahrplan Inhalt: Analyse syntaktischer Strukturen deskriptive Perspektive, typologische Vielfalt Vergleich verschiedener theoretischer Ansätze 2 Fahrplan Voraussetzungen:
Proseminar Syntax Diana Schackow 1 Fahrplan Inhalt: Analyse syntaktischer Strukturen deskriptive Perspektive, typologische Vielfalt Vergleich verschiedener theoretischer Ansätze 2 Fahrplan Voraussetzungen:
Ivana Daskalovska. Willkommen zur Übung Einführung in die Computerlinguistik. Morphologie. Sarah Bosch,
 Ivana Daskalovska Willkommen zur Übung Einführung in die Computerlinguistik Morphologie Wiederholung Aufgabe 1 Was ist Morphologie, Morphem? 3 Aufgabe 1 Was ist Morphologie, Morphem? Teildisziplin der
Ivana Daskalovska Willkommen zur Übung Einführung in die Computerlinguistik Morphologie Wiederholung Aufgabe 1 Was ist Morphologie, Morphem? 3 Aufgabe 1 Was ist Morphologie, Morphem? Teildisziplin der
Der Earley-Algorithmus
 Der Earley-Algorithmus Kursfolien Karin Haenelt 25.03.02 1 25.03.02 2 Inhalt Funktion des Earley-Algorithmus Begriffe Erkenner/Parser Kontextfreie Grammatik Ein Beispiel Funktionen des Algorithmus Funktionsweise
Der Earley-Algorithmus Kursfolien Karin Haenelt 25.03.02 1 25.03.02 2 Inhalt Funktion des Earley-Algorithmus Begriffe Erkenner/Parser Kontextfreie Grammatik Ein Beispiel Funktionen des Algorithmus Funktionsweise
Linux I II III Res WN/TT NLTK BNC/XML XLE I XLE. Nicolas Bellm. 3. April 2008
 Linux I II III Res WN/TT NLTK BNC/XML I 3. April 2008 Inhalt Linux I II III Res WN/TT NLTK BNC/XML I 8 I Vorbereitung Grammatik I Grammatik II Parsen Dateien Linux I II III Res WN/TT NLTK BNC/XML I Vorbereitung
Linux I II III Res WN/TT NLTK BNC/XML I 3. April 2008 Inhalt Linux I II III Res WN/TT NLTK BNC/XML I 8 I Vorbereitung Grammatik I Grammatik II Parsen Dateien Linux I II III Res WN/TT NLTK BNC/XML I Vorbereitung
Der Earley-Algorithmus
 Der Earley-Algorithmus Kursfolien Karin Haenelt 25.03.02 1 25.03.02 2 Inhalt Funktion des Earley-Algorithmus Begriffe Erkenner/Parser Kontextfreie Grammatik Ein Beispiel Funktionen des Algorithmus Funktionsweise
Der Earley-Algorithmus Kursfolien Karin Haenelt 25.03.02 1 25.03.02 2 Inhalt Funktion des Earley-Algorithmus Begriffe Erkenner/Parser Kontextfreie Grammatik Ein Beispiel Funktionen des Algorithmus Funktionsweise
Hidden Markov Models in Anwendungen
 Hidden Markov Models in Anwendungen Dr. Vera Demberg Universität des Saarlandes 31. Mai 2012 Vera Demberg (UdS) HMM Anwendungen 31. Mai 2012 1 / 26 Hidden Markov Modelle in der Computerlinguistik Table
Hidden Markov Models in Anwendungen Dr. Vera Demberg Universität des Saarlandes 31. Mai 2012 Vera Demberg (UdS) HMM Anwendungen 31. Mai 2012 1 / 26 Hidden Markov Modelle in der Computerlinguistik Table
Chart-Parsing. bersicht. Ziel. Motivation: Bisher vorgestellte Verfahren sind nicht effizient Grundidee des Chart-Parsing Datenstruktur
 Chart-Parsing bersicht Ziel Motivation: Bisher vorgestellte Verfahren sind nicht effizient Grundidee des Chart-Parsing Datenstruktur Knoten passive und aktive Kanten gepunktete Regeln (dotted rules) Fundamentalregel
Chart-Parsing bersicht Ziel Motivation: Bisher vorgestellte Verfahren sind nicht effizient Grundidee des Chart-Parsing Datenstruktur Knoten passive und aktive Kanten gepunktete Regeln (dotted rules) Fundamentalregel
Das Xerox Linguistics Environment (XLE) Ling 232 Maschinelle Übersetzung Dr. Heike Zinsmeister SS 2011
 Ling 232 Maschinelle Übersetzung Dr. Heike Zinsmeister SS 2011") Das Xerox Linguistics Environment (XLE) Ling 232 Maschinelle Übersetzung Dr. Heike Zinsmeister SS 2011 Hintergrund Übersicht Xerox Linguistics Environment (XLE) das Pargram-Projekt Lexical Functional Grammar
Das Xerox Linguistics Environment (XLE) Ling 232 Maschinelle Übersetzung Dr. Heike Zinsmeister SS 2011 Hintergrund Übersicht Xerox Linguistics Environment (XLE) das Pargram-Projekt Lexical Functional Grammar
Einführung in die Computerlinguistik
 Mehrdeutigkeit der Wortart Einführung in die Computerlinguistik Statistische Modellierung und Evaluation WS 2008/2009 Manfred Pinkal Sie haben in Moskau liebe genossen Sie haben in Moskau liebe Genossen
Mehrdeutigkeit der Wortart Einführung in die Computerlinguistik Statistische Modellierung und Evaluation WS 2008/2009 Manfred Pinkal Sie haben in Moskau liebe genossen Sie haben in Moskau liebe Genossen
Hidden-Markov-Modelle
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hidden-Markov-Modelle Tobias Scheffer Thomas Vanck Hidden-Markov-Modelle: Wozu? Spracherkennung: Akustisches Modell. Geschriebene
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hidden-Markov-Modelle Tobias Scheffer Thomas Vanck Hidden-Markov-Modelle: Wozu? Spracherkennung: Akustisches Modell. Geschriebene
Syntax natürlicher Sprachen
 Syntax natürlicher Sprachen 02: Grammatik und Bäume Martin Schmitt Ludwig-Maximilians-Universität München 25.10.2017 Martin Schmitt (LMU) Syntax natürlicher Sprachen 25.10.2017 1 1 Syntax im NLTK 2 Grammatik
Syntax natürlicher Sprachen 02: Grammatik und Bäume Martin Schmitt Ludwig-Maximilians-Universität München 25.10.2017 Martin Schmitt (LMU) Syntax natürlicher Sprachen 25.10.2017 1 1 Syntax im NLTK 2 Grammatik
, Data Mining, 2 VO Sommersemester 2008
 Evaluation 188.646, Data Mining, 2 VO Sommersemester 2008 Dieter Merkl e-commerce Arbeitsgruppe Institut für Softwaretechnik und Interaktive Systeme Technische Universität Wien www.ec.tuwien.ac.at/~dieter/
Evaluation 188.646, Data Mining, 2 VO Sommersemester 2008 Dieter Merkl e-commerce Arbeitsgruppe Institut für Softwaretechnik und Interaktive Systeme Technische Universität Wien www.ec.tuwien.ac.at/~dieter/
Eine Erweiterung der kontextfreien Grammatiken: PATR-II
 Eine Erweiterung der kontextfreien Grammatiken: PATR-II Das ursprüngliche Problem war: Wie kann man strukturelle Information (Phrasenstruktur) von anderen grammatischen Informationen (wie Kongruenz, Rektion
Eine Erweiterung der kontextfreien Grammatiken: PATR-II Das ursprüngliche Problem war: Wie kann man strukturelle Information (Phrasenstruktur) von anderen grammatischen Informationen (wie Kongruenz, Rektion
Part-of-Speech Tagging. Stephanie Schuldes
 Part-of-Speech Tagging Stephanie Schuldes 05.06.2003 PS Erschließen von großen Textmengen Geißler/Holler SoSe 2003 Motivation Ziel: vollständiges Parsing und Verstehen natürlicher Sprache Herantasten durch
Part-of-Speech Tagging Stephanie Schuldes 05.06.2003 PS Erschließen von großen Textmengen Geißler/Holler SoSe 2003 Motivation Ziel: vollständiges Parsing und Verstehen natürlicher Sprache Herantasten durch
Inhalt. Was ist Dependenzgrammatik? Dependenzgrammatik und Phrasenstrukturgrammatik Maltparser Syntaxnet/Parsey McParseface Übung Quellen
 Dependenzparsing 1 Inhalt Was ist Dependenzgrammatik? Dependenzgrammatik und Phrasenstrukturgrammatik Maltparser Syntaxnet/Parsey McParseface Übung Quellen 2 Was ist Dependenzgrammatik? Theorie Entwickelt
Dependenzparsing 1 Inhalt Was ist Dependenzgrammatik? Dependenzgrammatik und Phrasenstrukturgrammatik Maltparser Syntaxnet/Parsey McParseface Übung Quellen 2 Was ist Dependenzgrammatik? Theorie Entwickelt
Projekt Maschinelles Lernen WS 06/07
 Projekt Maschinelles Lernen WS 06/07 1. Auswahl der Daten 2. Evaluierung 3. Noise und Pruning 4. Regel-Lernen 5. ROC-Kurven 6. Pre-Processing 7. Entdecken von Assoziationsregeln 8. Ensemble-Lernen 9. Wettbewerb
Projekt Maschinelles Lernen WS 06/07 1. Auswahl der Daten 2. Evaluierung 3. Noise und Pruning 4. Regel-Lernen 5. ROC-Kurven 6. Pre-Processing 7. Entdecken von Assoziationsregeln 8. Ensemble-Lernen 9. Wettbewerb
Slot Grammar Eine Einführung
 Slot Grammar Eine Einführung München, 4. Dez. 2002 Gerhard Rolletschek gerhard@cis.uni-muenchen.de 1 ! Entstehungskontext Übersicht! Elemente der Slot Grammar (Was ist ein Slot?)! Complement Slots vs.
Slot Grammar Eine Einführung München, 4. Dez. 2002 Gerhard Rolletschek gerhard@cis.uni-muenchen.de 1 ! Entstehungskontext Übersicht! Elemente der Slot Grammar (Was ist ein Slot?)! Complement Slots vs.
Conference Presentation
 Conference Presentation Maschinelle Übersetzung für Dialekte SCHERRER, Yves Reference SCHERRER, Yves. Maschinelle Übersetzung für Dialekte. In: 5. Tage der Schweizer Linguistik / 5èmes Journées Suisses
Conference Presentation Maschinelle Übersetzung für Dialekte SCHERRER, Yves Reference SCHERRER, Yves. Maschinelle Übersetzung für Dialekte. In: 5. Tage der Schweizer Linguistik / 5èmes Journées Suisses
Vortrag SWP Gruppe 3
 Translation Memories für automatische Patentübersetzung Institut für Computerlinguistik 22.07.2013 2 / 26 Inhaltsübersicht 1 2 3 4 5 6 3 / 26 Erinnerung Aus PatTR-Korpus SMT-System lernen Fuzzy Matches
Translation Memories für automatische Patentübersetzung Institut für Computerlinguistik 22.07.2013 2 / 26 Inhaltsübersicht 1 2 3 4 5 6 3 / 26 Erinnerung Aus PatTR-Korpus SMT-System lernen Fuzzy Matches
Parsing regulärer Ausdrücke. Karin Haenelt
 Karin Haenelt 25.4.2009 1 Inhalt kontextfreie Grammatik für reguläre Ausdrücke Grundlagen Parsebaum: konkrete Syntax Syntaxbaum: abstrakte Syntax Algorithmus: rkennung Konstruktion des Syntaxbaumes 2 Grammatik
Karin Haenelt 25.4.2009 1 Inhalt kontextfreie Grammatik für reguläre Ausdrücke Grundlagen Parsebaum: konkrete Syntax Syntaxbaum: abstrakte Syntax Algorithmus: rkennung Konstruktion des Syntaxbaumes 2 Grammatik
1 Part-of-Speech Tagging
 2. Übung zur Vorlesung NLP Analyse des Wissensrohstoes Text im Sommersemester 2008 Dr. Andreas Hotho, Dipl.-Inform. Dominik Benz, Wi.-Inf. Beate Krause 28. Mai 2008 1 Part-of-Speech Tagging 1.1 Grundlagen
2. Übung zur Vorlesung NLP Analyse des Wissensrohstoes Text im Sommersemester 2008 Dr. Andreas Hotho, Dipl.-Inform. Dominik Benz, Wi.-Inf. Beate Krause 28. Mai 2008 1 Part-of-Speech Tagging 1.1 Grundlagen
3 Exkurs: Der λ-kalkül
 3 Exkurs: Der λ-kalkül Alonso Churchs λ-kalkül (ca. 1940) ist der formale Kern jeder funktionalen Programmiersprache. Der λ-kalkül ist eine einfache Sprache, mit nur wenigen syntaktischen Konstrukten und
3 Exkurs: Der λ-kalkül Alonso Churchs λ-kalkül (ca. 1940) ist der formale Kern jeder funktionalen Programmiersprache. Der λ-kalkül ist eine einfache Sprache, mit nur wenigen syntaktischen Konstrukten und
Projektseminar "Texttechnologische Informationsmodellierung"
 Projektseminar "Texttechnologische Informationsmodellierung" Ziel dieser Sitzung Nach dieser Sitzung sollten Sie: Einige standards und projekte vom Namen her kennen Einen Überblick über und einen Eindruck
Projektseminar "Texttechnologische Informationsmodellierung" Ziel dieser Sitzung Nach dieser Sitzung sollten Sie: Einige standards und projekte vom Namen her kennen Einen Überblick über und einen Eindruck