Einführung in Data Mining mit Weka. Philippe Thomas Ulf Leser
|
|
|
- Gitta Beck
- vor 8 Jahren
- Abrufe
Transkript
1 Einführung in Data Mining mit Weka Philippe Thomas Ulf Leser

2 Data Mining Drowning in Data yet Starving for Knowledge Computers have promised us a fountain of wisdom but delivered a flood of data The non trivial extraction of implicit, previously unknown, and potentially useful information from data Practical Machine Learning 2

3 Beispiele Banken Kreditwürdigkeit / Schufa Wertbapierhandel Bildklassifikation Synthetic Aperture Radar Ölausbreitung im Golf von Mexiko Porträtfinder Intrusion detection Kaufgewohnheiten (Payback) 3

4 Beispiele Männlich / Weibliche Authoren: Männlich: Bestimmte/Unbestimmte Artikel Eigennamen Weiblich: Pronomen S. Argamon, M. Koppel, J. Fine, A. R. Shimoni, Gender, Genre, and Writing Style in Formal Written Texts, Text, volume 23, number 3, pp

5 Erfolge Netflix Start: Oktober 2006 Daten: 100 Millionen (personenbezogene) ratings Ziel: 10% Verbesserung über das Netflix eigene Empfehlungssystem 21 September 2009: Filme Postleitzahlen Datum BellKor s Pragmatic Chaos How to Break Anonymity of the Netflix Prize Dataset? (Arvind Narayanan, Vitaly Shmatikov) 5

6 Erfolge Erkrankungen von Soya Bohnen Raynaud-Syndrom (Swanson 1986) Regeln waren besser als die der Experten Fish-Öl Blut Viskosität, Gefäßaktivität verbessert Blutzirkulation Wikipedia Raynaud-Syndrom Verkauf von Bier und Windeln 6

7 Konkretes Beispiel 7
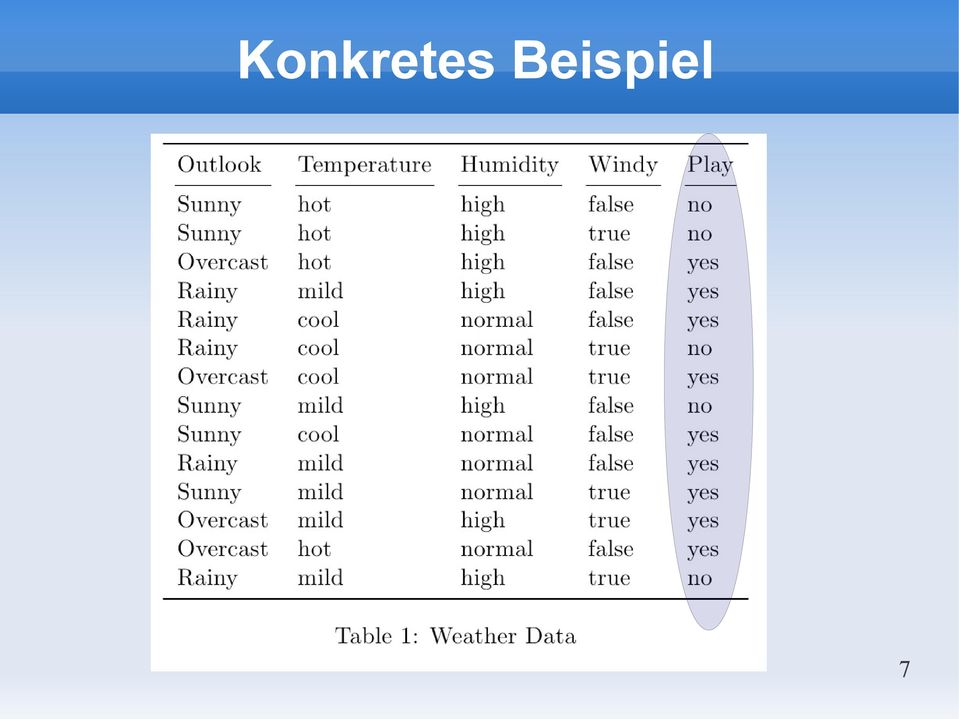
8 Aufgabe Vorhersage von play anhand der vier Attribute Outlook Temperature Humidity Windy 8

9 Erster Versuch 9
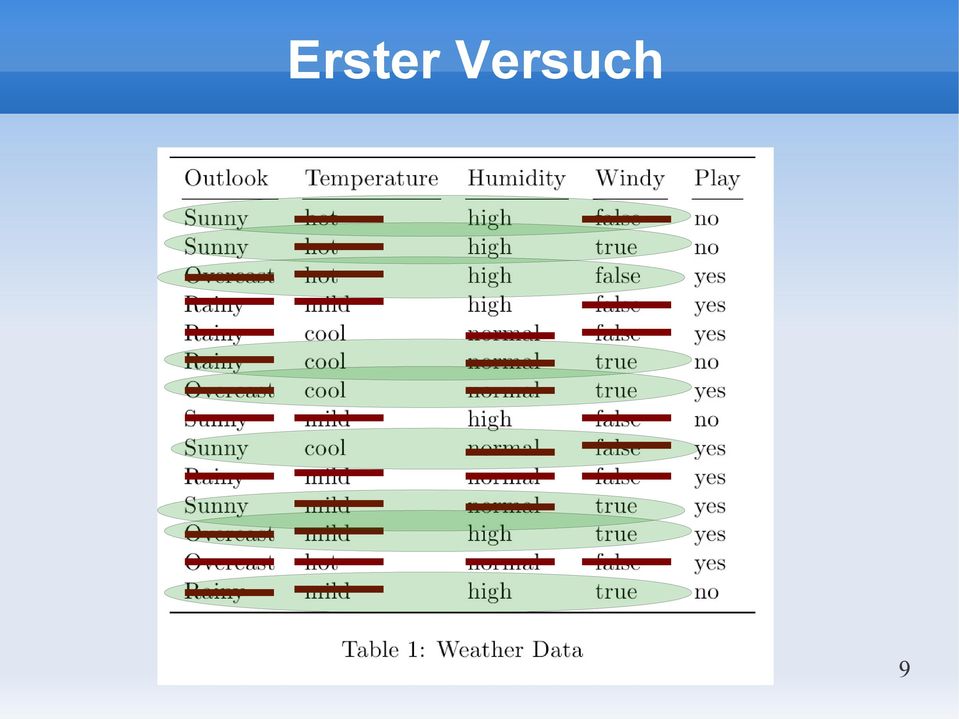
10 K-Nearest Neighbors Instanz basierter Algorithmus Kein Training Langsame Vorhersage (Clevere Datenstruktur) Benötigt eine Distanzfunktion Hintergrundwissen (Sunny Overcast Rainy) Attribute gleich wichtig Welcher k-wert ist am besten? Empfindlich für Rauschen Ungeeignet für Hochdimensionale Daten 10

11 Data Representation Feature vector / Merkmalsvektor Reduktion des Problems auf Eigenschaften Bildverarbeitung Fourierkoeffizienten Spamklassifikation Rich, Viagra, million $ Häufig sparse features Nur bedingt großer Überlap zwischen Training/Test Example Weather Temperature Play 1 Sunny Cold Yes 2 Rain Worm No 11

12 Statistical Modeling Play = 2/9 * 3/9 * 3/9 * 3/9 *9/14 = = 20.5% Play = 3/5 * 1/5 * 4/5 * 3/5 *5/14 = = 79.5% 12

13 Naïve Bayes P [ E H ] P [ H ] P [ H E ]= P[E] P [ yes E ]= P [ E1 yes ] P [ E2 yes ] P [ E3 yes ]... P [ yes ] P[E] P [ yes X ]= P[E] Konstant 13
![] P [ E3 yes ].](/docs-images/40/8151817/images/page_13.jpg ".. P [ yes ] P[E] 2 3 3 3 9 9 9 9 9 14 P")
14 Naïve Bayes Benutzt alle verfügbaren Attribute Attribute sind gleich wichtig und unabhängig Annahme oft verletzt (Temperatur) Feature Selektion kann hilfreich sein Kann mit fehlenden Attributen umgehen Wahrscheinlichkeiten können 0 werden Pseudocounts Kann in der Grundvariante nur mit Nominalen Daten umgehen There is nothing naïve in using Naïve Bayes 14


15 Evaluation Kreuzvalidierung Daten sind nur begrenzt verfügbar Training und Test müssen getrennt sein Quelle: 15

16 Evaluation Kreuzvalidierung 10 fold CV ist üblich Verteilung der Klassen sollte gleich sein Straitifiziertes Sampling Leave one out CV ist ein Spezialfall LOOCV liefert immer das selbe Ergebnis Per se nicht stratifiziert Rechenintensiv Intrinsische Evaluation Quelle:


17 Evaluation Vierfeldertrafel Quelle: Wikipedia Binäre Klassifikation hat vier mögliche Ergebnisse Rp, Fp, Fn, Rn Accuracy/Vertrauenswahrscheinlichkeit RMS für numerische Variablen 17

18 Weka Sourceforge Projekt (GPL v2) Java GUI und API Sammlung an Algorithmen für pre-processing, maschinelles lernen und Visualisierung Gefördert seit

19 Weka 19

20 Explorer 20
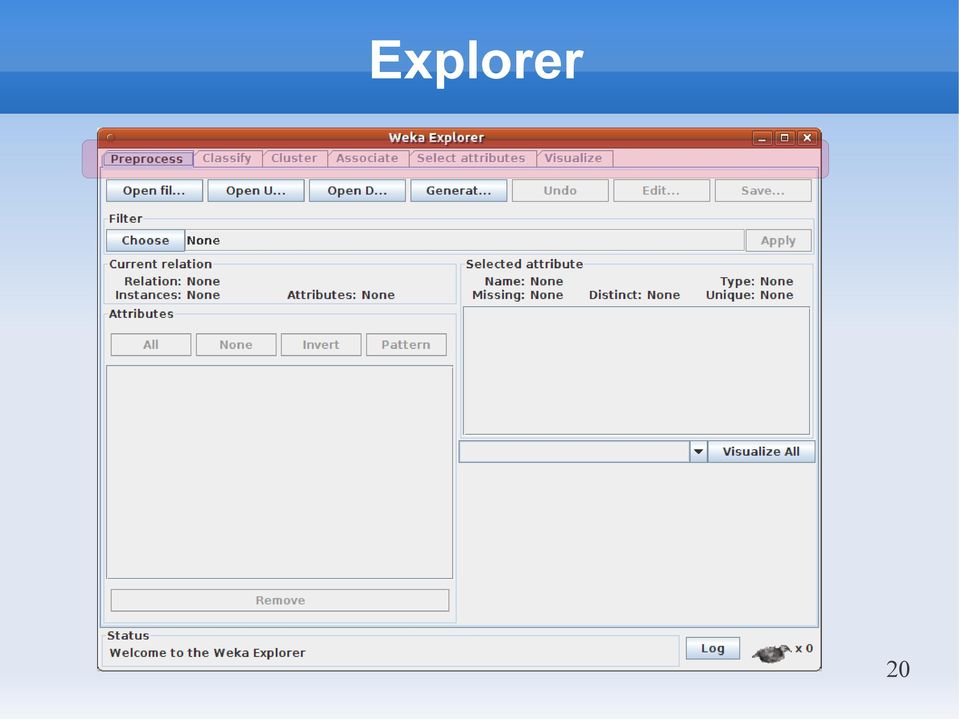
21 Attribute-Relation File Format Andrew's Ridiculous File Format 21

22 Explorer 22
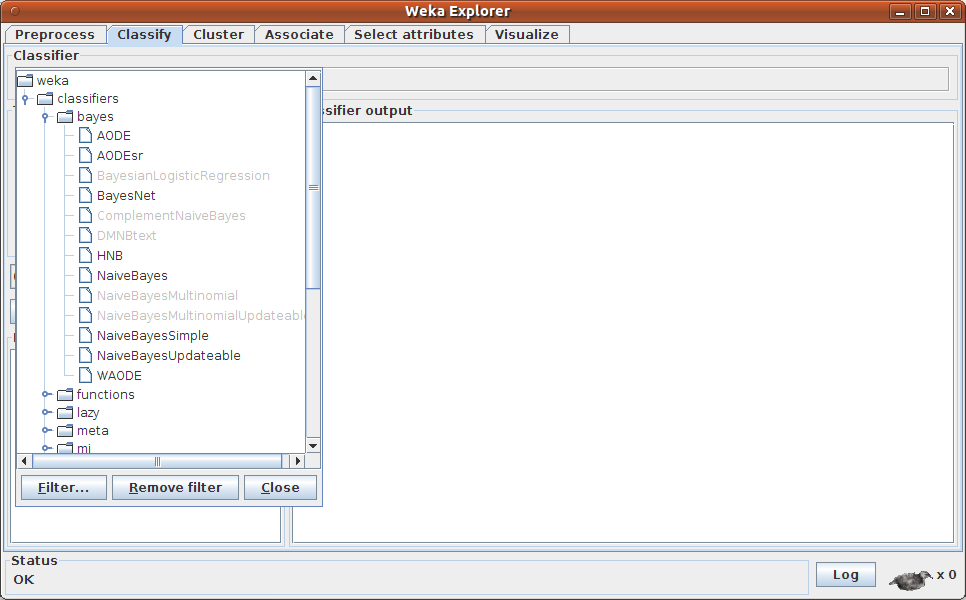
23 Klassifizierung 10 x CV 23

24 Naïve Bayes 24

25 Entscheidungsbaum 25
26 Feature Selection Attribute können irrelevant (Haarfarbe) oder redundant (Kelvin, Celcius, Fahrenheit) sein Entscheidungsbaum hat Probleme mit irrelevanten features Naive Bayes vor allem mit redundanten Deshalb Feature Selection Aber, das Ergebnis muss nicht zwingend besser sein! 26

27 Feature Selection 27
28 Clustering Unsupervised Suche nach natürlichen Gruppen Beispiel: Outlier detection Unbekannte Subtypen von Krebs Social Networks (Personencluster) 28

29 Clustering 29
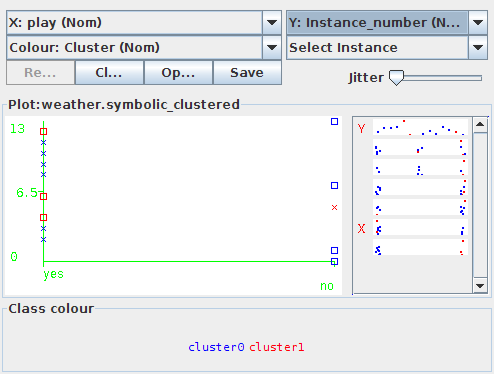
30 Clustering 30
31 Clustering Clustering liefert 50% Fehler! 31

32 Visualisierung 32
33 Probleme Weka Speicherverbrauch und Rechenzeit Lernverfahren Hochdimensionale Daten Kein Inkrementelles Lernen im Experimenter möglich Java Doc nur oberflächlich vorhanden Große Auswahl an verschiedenen Algorithmen, aber weniger Möglichkeiten 33
34 Probleme Data Mining Wenig Beispiele, viele Features Overfitting Semantischer Drift Wahl des passenden Algorithmus Attribute Selection? Meta-Classifier? Evaluierung allgemein schwer 34
35 Probleme Concept drift Daten ändern sich über Zeit (sehr häufig) Regelmäßige Erneuerung der Daten Spam detection Maschine bekommt neue Parameter Erderwärmung Amazonkunden ändern verhalten mit Alter Teuer (Rechenzeit, Kosten, Arbeitszeit) So gut wie nie als Problem behandelt 35
36 Welche Methode? Scaling to Very Very Large Corpora for Natural Language Disambiguation (Banko and Brill 2001) 36
37 Weitere Informationen Weka Wiki Weka Manual (325 Seiten) Mailing Liste Youtube 37
38 Alternativen RapidMiner (Weka mit hübscherer GUI) SPSS R Oracle Darwin MS-SQL 38

39 Java 39
 40")

40 Java (cont) 40
41 Machine Learning 41
42 The End 42 Quele: flickr CMU G20 protests
43 Assoziationsregeln Beschreiben Korrelationen zwischen auftretenden Ereignissen Warenkorbanalyse Zahnbürste Zahpasta 43
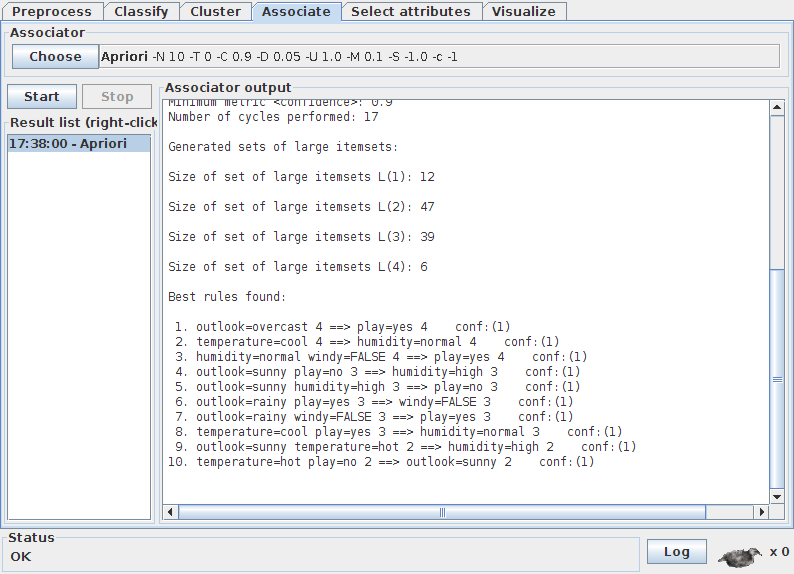
44 Assoziationsregeln 44
Vorlesungsplan. Von Naïve Bayes zu Bayesischen Netzwerk- Klassifikatoren. Naïve Bayes. Bayesische Netzwerke
 Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Data Mining und maschinelles Lernen
 Data Mining und maschinelles Lernen Einführung und Anwendung mit WEKA Caren Brinckmann 16. August 2000 http://www.coli.uni-sb.de/~cabr/vortraege/ml.pdf http://www.cs.waikato.ac.nz/ml/weka/ Inhalt Einführung:
Data Mining und maschinelles Lernen Einführung und Anwendung mit WEKA Caren Brinckmann 16. August 2000 http://www.coli.uni-sb.de/~cabr/vortraege/ml.pdf http://www.cs.waikato.ac.nz/ml/weka/ Inhalt Einführung:
WEKA A Machine Learning Interface for Data Mining
 WEKA A Machine Learning Interface for Data Mining Frank Eibe, Mark Hall, Geoffrey Holmes, Richard Kirkby, Bernhard Pfahringer, Ian H. Witten Reinhard Klaus Losse Künstliche Intelligenz II WS 2009/2010
WEKA A Machine Learning Interface for Data Mining Frank Eibe, Mark Hall, Geoffrey Holmes, Richard Kirkby, Bernhard Pfahringer, Ian H. Witten Reinhard Klaus Losse Künstliche Intelligenz II WS 2009/2010
Seminar Textmining SS 2015 Grundlagen des Maschinellen Lernens
 Seminar Textmining SS 2015 Grundlagen des Maschinellen Lernens Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 17.04.2015 Entscheidungsprobleme beim Textmining
Seminar Textmining SS 2015 Grundlagen des Maschinellen Lernens Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 17.04.2015 Entscheidungsprobleme beim Textmining
Künstliche Intelligenz Maschinelles Lernen
 Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert Sommersemester 2009 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen
Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert Sommersemester 2009 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen
Insulin Dependent Diabetes Mellitus Rats and Autoimmune Diabetes
 1 Insulin Dependent Diabetes Mellitus Rats and Autoimmune Diabetes, Georg Füllen Institut für Biostatistik und Informatik in Medizin und Alternsforschung Universität Rostock 2 Einführung: Diabetes Diabetes
1 Insulin Dependent Diabetes Mellitus Rats and Autoimmune Diabetes, Georg Füllen Institut für Biostatistik und Informatik in Medizin und Alternsforschung Universität Rostock 2 Einführung: Diabetes Diabetes
Mining High-Speed Data Streams
 Mining High-Speed Data Streams Pedro Domingos & Geoff Hulten Departement of Computer Science & Engineering University of Washington Datum : 212006 Seminar: Maschinelles Lernen und symbolische Ansätze Vortragender:
Mining High-Speed Data Streams Pedro Domingos & Geoff Hulten Departement of Computer Science & Engineering University of Washington Datum : 212006 Seminar: Maschinelles Lernen und symbolische Ansätze Vortragender:
Data Mining-Modelle und -Algorithmen
 Data Mining-Modelle und -Algorithmen Data Mining-Modelle und -Algorithmen Data Mining ist ein Prozess, bei dem mehrere Komponenten i n- teragieren. Sie greifen auf Datenquellen, um diese zum Training,
Data Mining-Modelle und -Algorithmen Data Mining-Modelle und -Algorithmen Data Mining ist ein Prozess, bei dem mehrere Komponenten i n- teragieren. Sie greifen auf Datenquellen, um diese zum Training,
6. Bayes-Klassifikation. (Schukat-Talamazzini 2002)
") 6. Bayes-Klassifikation (Schukat-Talamazzini 2002) (Böhm 2003) (Klawonn 2004) Der Satz von Bayes: Beweis: Klassifikation mittels des Satzes von Bayes (Klawonn 2004) Allgemeine Definition: Davon zu unterscheiden
6. Bayes-Klassifikation (Schukat-Talamazzini 2002) (Böhm 2003) (Klawonn 2004) Der Satz von Bayes: Beweis: Klassifikation mittels des Satzes von Bayes (Klawonn 2004) Allgemeine Definition: Davon zu unterscheiden
Proseminar - Data Mining
 Proseminar - Data Mining SCCS, Fakultät für Informatik Technische Universität München SS 2012, SS 2012 1 Data Mining Pipeline Planung Aufbereitung Modellbildung Auswertung Wir wollen nützliches Wissen
Proseminar - Data Mining SCCS, Fakultät für Informatik Technische Universität München SS 2012, SS 2012 1 Data Mining Pipeline Planung Aufbereitung Modellbildung Auswertung Wir wollen nützliches Wissen
RapidMiner als Werkzeug für die textorientierten Geisteswissenschaften Katharina Morik
 technische universität RapidMiner als Werkzeug für die textorientierten Geisteswissenschaften Katharina Morik Name Autor Ort und Datum Informatik: Linguistik: Methoden + Verfahren Forschungsfragen, Anforderungen
technische universität RapidMiner als Werkzeug für die textorientierten Geisteswissenschaften Katharina Morik Name Autor Ort und Datum Informatik: Linguistik: Methoden + Verfahren Forschungsfragen, Anforderungen
Grundbegriffe der Informatik
 Grundbegriffe der Informatik Einheit 15: Reguläre Ausdrücke und rechtslineare Grammatiken Thomas Worsch Universität Karlsruhe, Fakultät für Informatik Wintersemester 2008/2009 1/25 Was kann man mit endlichen
Grundbegriffe der Informatik Einheit 15: Reguläre Ausdrücke und rechtslineare Grammatiken Thomas Worsch Universität Karlsruhe, Fakultät für Informatik Wintersemester 2008/2009 1/25 Was kann man mit endlichen
Grundlagen der Datenanalyse am Beispiel von SPSS
 Grundlagen der Datenanalyse am Beispiel von SPSS Einführung Dipl. - Psych. Fabian Hölzenbein hoelzenbein@psychologie.uni-freiburg.de Einführung Organisatorisches Was ist Empirie? Was ist Statistik? Dateneingabe
Grundlagen der Datenanalyse am Beispiel von SPSS Einführung Dipl. - Psych. Fabian Hölzenbein hoelzenbein@psychologie.uni-freiburg.de Einführung Organisatorisches Was ist Empirie? Was ist Statistik? Dateneingabe
ML-Werkzeuge und ihre Anwendung
 Kleine Einführung: und ihre Anwendung martin.loesch@kit.edu (0721) 608 45944 Motivation Einsatz von maschinellem Lernen erfordert durchdachtes Vorgehen Programmieren grundlegender Verfahren aufwändig fehlerträchtig
Kleine Einführung: und ihre Anwendung martin.loesch@kit.edu (0721) 608 45944 Motivation Einsatz von maschinellem Lernen erfordert durchdachtes Vorgehen Programmieren grundlegender Verfahren aufwändig fehlerträchtig
SYN Grundlagen Algorithmen Anwendung FIN. Anomalieerkennung. UnFUG WS2011/2012. Alexander Passfall <alex@passfall.de> Hochschule Furtwangen
 1/23 UnFUG WS2011/2012 Alexander Passfall Hochschule Furtwangen 3. November 2011 2/23 Inhalt 1 Grundlagen Typen Funktionsweise 2 Algorithmen Outlier Detection Machine Learning 3 Anwendung
1/23 UnFUG WS2011/2012 Alexander Passfall Hochschule Furtwangen 3. November 2011 2/23 Inhalt 1 Grundlagen Typen Funktionsweise 2 Algorithmen Outlier Detection Machine Learning 3 Anwendung
Business-Rule-Management als Instrument des Software-Reengineering
 Business-Rule-Management als Instrument des Software-Reengineering Olaf Resch Olaf Resch am 4. Mai 2005 in Bad Honnef 1 Agenda Software und Wissen. Verschmelzung als Evolutionshindernis. Business-Rule-Technologie.
Business-Rule-Management als Instrument des Software-Reengineering Olaf Resch Olaf Resch am 4. Mai 2005 in Bad Honnef 1 Agenda Software und Wissen. Verschmelzung als Evolutionshindernis. Business-Rule-Technologie.
Studierende, die diese Vorlesung hören, haben sich auch für folgende Lehrveranstaltungen interessiert:
 Studierende, die diese Vorlesung hören, haben sich auch für folgende Lehrveranstaltungen interessiert: 1 des FG Informationssysteme Datenbanken Internet-Suchmaschinen Information Retrieval Information
Studierende, die diese Vorlesung hören, haben sich auch für folgende Lehrveranstaltungen interessiert: 1 des FG Informationssysteme Datenbanken Internet-Suchmaschinen Information Retrieval Information
4. Lernen von Entscheidungsbäumen. Klassifikation mit Entscheidungsbäumen. Entscheidungsbaum
 4. Lernen von Entscheidungsbäumen Klassifikation mit Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch /Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse zugeordnet werden.
4. Lernen von Entscheidungsbäumen Klassifikation mit Entscheidungsbäumen Gegeben sei eine Menge von Objekten, die durch /Wert- Paare beschrieben sind. Jedes Objekt kann einer Klasse zugeordnet werden.
Naive Bayes. 5. Dezember 2014. Naive Bayes 5. Dezember 2014 1 / 18
 Naive Bayes 5. Dezember 2014 Naive Bayes 5. Dezember 2014 1 / 18 Inhaltsverzeichnis 1 Thomas Bayes 2 Anwendungsgebiete 3 Der Satz von Bayes 4 Ausführliche Form 5 Beispiel 6 Naive Bayes Einführung 7 Naive
Naive Bayes 5. Dezember 2014 Naive Bayes 5. Dezember 2014 1 / 18 Inhaltsverzeichnis 1 Thomas Bayes 2 Anwendungsgebiete 3 Der Satz von Bayes 4 Ausführliche Form 5 Beispiel 6 Naive Bayes Einführung 7 Naive
Exploration und Klassifikation von BigData
 Exploration und Klassifikation von BigData Inhalt Einführung Daten Data Mining: Vorbereitungen Clustering Konvexe Hülle Fragen Google: Riesige Datenmengen (2009: Prozessieren von 24 Petabytes pro Tag)
Exploration und Klassifikation von BigData Inhalt Einführung Daten Data Mining: Vorbereitungen Clustering Konvexe Hülle Fragen Google: Riesige Datenmengen (2009: Prozessieren von 24 Petabytes pro Tag)
Textmining Klassifikation von Texten Teil 1: Naive Bayes
 Textmining Klassifikation von Texten Teil 1: Naive Bayes Dept. Informatik 8 (Künstliche Intelligenz) Friedrich-Alexander-Universität Erlangen-Nürnberg (Informatik 8) Klassifikation von Texten 1: Naive
Textmining Klassifikation von Texten Teil 1: Naive Bayes Dept. Informatik 8 (Künstliche Intelligenz) Friedrich-Alexander-Universität Erlangen-Nürnberg (Informatik 8) Klassifikation von Texten 1: Naive
Predictive Modeling Markup Language. Thomas Morandell
 Predictive Modeling Markup Language Thomas Morandell Index Einführung PMML als Standard für den Austausch von Data Mining Ergebnissen/Prozessen Allgemeine Struktur eines PMML Dokuments Beispiel von PMML
Predictive Modeling Markup Language Thomas Morandell Index Einführung PMML als Standard für den Austausch von Data Mining Ergebnissen/Prozessen Allgemeine Struktur eines PMML Dokuments Beispiel von PMML
Seminar Text- und Datamining Datamining-Grundlagen
 Seminar Text- und Datamining Datamining-Grundlagen Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 23.05.2013 Gliederung 1 Klassifikationsprobleme 2 Evaluation
Seminar Text- und Datamining Datamining-Grundlagen Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 23.05.2013 Gliederung 1 Klassifikationsprobleme 2 Evaluation
Motivation. Themenblock: Klassifikation. Binäre Entscheidungsbäume. Ansätze. Praktikum: Data Warehousing und Data Mining.
 Motivation Themenblock: Klassifikation Praktikum: Data Warehousing und Data Mining Ziel Item hat mehrere Attribute Anhand von n Attributen wird (n+)-tes vorhergesagt. Zusätzliches Attribut erst später
Motivation Themenblock: Klassifikation Praktikum: Data Warehousing und Data Mining Ziel Item hat mehrere Attribute Anhand von n Attributen wird (n+)-tes vorhergesagt. Zusätzliches Attribut erst später
Verborgene Schätze heben
 Verborgene Schätze heben Data Mining mit dem Microsoft SQL Server Martin Oesterer Leiter Vertrieb HMS Analytical Software GmbH Data Mining. Was ist eigentlich wichtig? Data Mining ist: die Extraktion von
Verborgene Schätze heben Data Mining mit dem Microsoft SQL Server Martin Oesterer Leiter Vertrieb HMS Analytical Software GmbH Data Mining. Was ist eigentlich wichtig? Data Mining ist: die Extraktion von
Data Mining und Text Mining Einführung. S2 Einfache Regellerner
 Data Mining und Text Mining Einführung S2 Einfache Regellerner Hans Hermann Weber Univ. Erlangen, Informatik 8 Wintersemester 2003 hans.hermann.weber@gmx.de Inhalt Einiges über Regeln und Bäume R1 ein
Data Mining und Text Mining Einführung S2 Einfache Regellerner Hans Hermann Weber Univ. Erlangen, Informatik 8 Wintersemester 2003 hans.hermann.weber@gmx.de Inhalt Einiges über Regeln und Bäume R1 ein
Häufige Item-Mengen: die Schlüssel-Idee. Vorlesungsplan. Apriori Algorithmus. Methoden zur Verbessung der Effizienz von Apriori
 Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Semestralklausur zur Vorlesung. Web Mining. Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7.
 Semestralklausur zur Vorlesung Web Mining Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7. 2004 Name: Vorname: Matrikelnummer: Fachrichtung: Punkte: (1).... (2)....
Semestralklausur zur Vorlesung Web Mining Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7. 2004 Name: Vorname: Matrikelnummer: Fachrichtung: Punkte: (1).... (2)....
Computerlinguistische Textanalyse
 Computerlinguistische Textanalyse 10. Sitzung 06.01.2014 Einführung in die Textklassifikation Franz Matthies Lehrstuhl für Computerlinguistik Institut für Germanistische Sprachwissenschaft Friedrich-Schiller
Computerlinguistische Textanalyse 10. Sitzung 06.01.2014 Einführung in die Textklassifikation Franz Matthies Lehrstuhl für Computerlinguistik Institut für Germanistische Sprachwissenschaft Friedrich-Schiller
Beweisbar sichere Verschlüsselung
 Beweisbar sichere Verschlüsselung ITS-Wahlpflichtvorlesung Dr. Bodo Möller Ruhr-Universität Bochum Horst-Görtz-Institut für IT-Sicherheit Lehrstuhl für Kommunikationssicherheit bmoeller@crypto.rub.de 6
Beweisbar sichere Verschlüsselung ITS-Wahlpflichtvorlesung Dr. Bodo Möller Ruhr-Universität Bochum Horst-Görtz-Institut für IT-Sicherheit Lehrstuhl für Kommunikationssicherheit bmoeller@crypto.rub.de 6
Vortrag zum Paper Results of the Active Learning Challenge von Guyon, et. al. Sören Schmidt Fachgebiet Knowledge Engineering
 Vortrag zum Paper Results of the Active Learning Challenge von Guyon, et. al. Sören Schmidt Fachgebiet Knowledge Engineering 11.12.2012 Vortrag zum Paper Results of the Active Learning Challenge von Isabelle
Vortrag zum Paper Results of the Active Learning Challenge von Guyon, et. al. Sören Schmidt Fachgebiet Knowledge Engineering 11.12.2012 Vortrag zum Paper Results of the Active Learning Challenge von Isabelle
Proseminar: Geschichte des Computers Schachprogrammierung Die Digitale Revolution
 Die Digitale Revolution Internet 3D-Drucker Quants Singularität 27.02.14 Johannes Polster Das Spiel der Könige Sehr altes Spiel: Entstehung vor 1500 Jahren Weltberühmt Strategisches Spiel Kein Glück, Intelligenz,
Die Digitale Revolution Internet 3D-Drucker Quants Singularität 27.02.14 Johannes Polster Das Spiel der Könige Sehr altes Spiel: Entstehung vor 1500 Jahren Weltberühmt Strategisches Spiel Kein Glück, Intelligenz,
Data Mining mit RapidMiner
 Motivation Data Mining mit RapidMiner CRISP: DM-Prozess besteht aus unterschiedlichen Teilaufgaben Datenvorverarbeitung spielt wichtige Rolle im DM-Prozess Systematische Evaluationen erfordern flexible
Motivation Data Mining mit RapidMiner CRISP: DM-Prozess besteht aus unterschiedlichen Teilaufgaben Datenvorverarbeitung spielt wichtige Rolle im DM-Prozess Systematische Evaluationen erfordern flexible
Text Mining Praktikum. Durchführung: Andreas Niekler Email: aniekler@informatik.uni-leipzig.de Zimmer: Paulinum (P) 818
 818") Text Mining Praktikum Durchführung: Andreas Niekler Email: aniekler@informatik.uni-leipzig.de Zimmer: Paulinum (P) 818 Rahmenbedingungen Gruppen von 2- (max)4 Personen Jede Gruppe erhält eine Aufgabe Die
Text Mining Praktikum Durchführung: Andreas Niekler Email: aniekler@informatik.uni-leipzig.de Zimmer: Paulinum (P) 818 Rahmenbedingungen Gruppen von 2- (max)4 Personen Jede Gruppe erhält eine Aufgabe Die
Data Mining mit der SEMMA Methodik. Reinhard Strüby, SAS Institute Stephanie Freese, Herlitz PBS AG
 Data Mining mit der SEMMA Methodik Reinhard Strüby, SAS Institute Stephanie Freese, Herlitz PBS AG Data Mining Data Mining: Prozeß der Selektion, Exploration und Modellierung großer Datenmengen, um Information
Data Mining mit der SEMMA Methodik Reinhard Strüby, SAS Institute Stephanie Freese, Herlitz PBS AG Data Mining Data Mining: Prozeß der Selektion, Exploration und Modellierung großer Datenmengen, um Information
Lehrangebot. Fachgebiet Informationssysteme Prof. Dr. Norbert Fuhr. N. Fuhr, U. Duisburg-Essen. Lehrangebot
 Lehrangebot Fachgebiet Informationssysteme Prof. Dr. Norbert Fuhr N. Fuhr, U. Duisburg-Essen Lehrangebot 1 Lehrangebot des FG Informationssysteme Datenbanken Internet-Suchmaschinen Information Retrieval
Lehrangebot Fachgebiet Informationssysteme Prof. Dr. Norbert Fuhr N. Fuhr, U. Duisburg-Essen Lehrangebot 1 Lehrangebot des FG Informationssysteme Datenbanken Internet-Suchmaschinen Information Retrieval
Methodenkurs Text Mining 01: Know Your Data
 Methodenkurs Text Mining 01: Know Your Data Eva Enderichs SoSe2015 Eva EnderichsSoSe2015 01: Know Your Data 1 Eva EnderichsSoSe2015 01: Know Your Data 2 Typen von Korpora annotiert VS naturbelassen wenige
Methodenkurs Text Mining 01: Know Your Data Eva Enderichs SoSe2015 Eva EnderichsSoSe2015 01: Know Your Data 1 Eva EnderichsSoSe2015 01: Know Your Data 2 Typen von Korpora annotiert VS naturbelassen wenige
SharePoint Demonstration
 SharePoint Demonstration Was zeigt die Demonstration? Diese Demonstration soll den modernen Zugriff auf Daten und Informationen veranschaulichen und zeigen welche Vorteile sich dadurch in der Zusammenarbeit
SharePoint Demonstration Was zeigt die Demonstration? Diese Demonstration soll den modernen Zugriff auf Daten und Informationen veranschaulichen und zeigen welche Vorteile sich dadurch in der Zusammenarbeit
Risiken bei der Analyse sehr großer Datenmengen. Dr. Thomas Hoppe
 Risiken bei der Analyse sehr großer Datenmengen Dr. Thomas Hoppe Datenaufbereitung Datenanalyse Data Mining Data Science Big Data Risiken der Analyse Sammlung Integration Transformation Fehlerbereinigung
Risiken bei der Analyse sehr großer Datenmengen Dr. Thomas Hoppe Datenaufbereitung Datenanalyse Data Mining Data Science Big Data Risiken der Analyse Sammlung Integration Transformation Fehlerbereinigung
Tutorial: Homogenitätstest
 Tutorial: Homogenitätstest Eine Bank möchte die Kreditwürdigkeit potenzieller Kreditnehmer abschätzen. Einerseits lebt die Bank ja von der Vergabe von Krediten, andererseits verursachen Problemkredite
Tutorial: Homogenitätstest Eine Bank möchte die Kreditwürdigkeit potenzieller Kreditnehmer abschätzen. Einerseits lebt die Bank ja von der Vergabe von Krediten, andererseits verursachen Problemkredite
Marketing-Leitfaden zum. Evoko Room Manager. Touch. Schedule. Meet.
 Marketing-Leitfaden zum Evoko Room Manager. Touch. Schedule. Meet. Vorher Viele kennen die Frustration, die man bei dem Versuch eine Konferenz zu buchen, erleben kann. Unterbrechung. Plötzlich klopft
Marketing-Leitfaden zum Evoko Room Manager. Touch. Schedule. Meet. Vorher Viele kennen die Frustration, die man bei dem Versuch eine Konferenz zu buchen, erleben kann. Unterbrechung. Plötzlich klopft
arlanis Software AG SOA Architektonische und technische Grundlagen Andreas Holubek
 arlanis Software AG SOA Architektonische und technische Grundlagen Andreas Holubek Speaker Andreas Holubek VP Engineering andreas.holubek@arlanis.com arlanis Software AG, D-14467 Potsdam 2009, arlanis
arlanis Software AG SOA Architektonische und technische Grundlagen Andreas Holubek Speaker Andreas Holubek VP Engineering andreas.holubek@arlanis.com arlanis Software AG, D-14467 Potsdam 2009, arlanis
Social Media Guidelines. Miriam Nanzka, Hohenzollern SIEBEN
 Social Media Guidelines 1 Social Media Guidelines: KULTURWANDEL Social Media heißt: many-to-many-kommunikation! Für Organisationen ist das eine ganz neue Herausforderung, denn Kommunikation wird nur noch
Social Media Guidelines 1 Social Media Guidelines: KULTURWANDEL Social Media heißt: many-to-many-kommunikation! Für Organisationen ist das eine ganz neue Herausforderung, denn Kommunikation wird nur noch
Leichte-Sprache-Bilder
 Leichte-Sprache-Bilder Reinhild Kassing Information - So geht es 1. Bilder gucken 2. anmelden für Probe-Bilder 3. Bilder bestellen 4. Rechnung bezahlen 5. Bilder runterladen 6. neue Bilder vorschlagen
Leichte-Sprache-Bilder Reinhild Kassing Information - So geht es 1. Bilder gucken 2. anmelden für Probe-Bilder 3. Bilder bestellen 4. Rechnung bezahlen 5. Bilder runterladen 6. neue Bilder vorschlagen
e LEARNING Kurz-Anleitung zum Erstellen eines Wikis 1. Wiki erstellen
 Kurz-Anleitung zum Erstellen eines Wikis Die Aktivität Wiki verschafft Ihnen die Möglichkeit, Wissen zu sammeln und zu strukturieren. Dabei können Sie die Teilnehmer Ihres Kurses an der Erstellung des
Kurz-Anleitung zum Erstellen eines Wikis Die Aktivität Wiki verschafft Ihnen die Möglichkeit, Wissen zu sammeln und zu strukturieren. Dabei können Sie die Teilnehmer Ihres Kurses an der Erstellung des
Eva Douma: Die Vorteile und Nachteile der Ökonomisierung in der Sozialen Arbeit
 Eva Douma: Die Vorteile und Nachteile der Ökonomisierung in der Sozialen Arbeit Frau Dr. Eva Douma ist Organisations-Beraterin in Frankfurt am Main Das ist eine Zusammen-Fassung des Vortrages: Busines
Eva Douma: Die Vorteile und Nachteile der Ökonomisierung in der Sozialen Arbeit Frau Dr. Eva Douma ist Organisations-Beraterin in Frankfurt am Main Das ist eine Zusammen-Fassung des Vortrages: Busines
Übungen zur Vorlesung Induktive Statistik Bedingte Wahrscheinlichkeiten
 Fachhochschule Köln Fakultät für Wirtschaftswissenschaften Prof. Dr. Arrenberg Raum 221, Tel. 39 14 jutta.arrenberg@dvz.fh-koeln.de Aufgabe 3.1 Übungen zur Vorlesung Induktive Statistik Bedingte Wahrscheinlichkeiten
Fachhochschule Köln Fakultät für Wirtschaftswissenschaften Prof. Dr. Arrenberg Raum 221, Tel. 39 14 jutta.arrenberg@dvz.fh-koeln.de Aufgabe 3.1 Übungen zur Vorlesung Induktive Statistik Bedingte Wahrscheinlichkeiten
Was meinen die Leute eigentlich mit: Grexit?
 Was meinen die Leute eigentlich mit: Grexit? Grexit sind eigentlich 2 Wörter. 1. Griechenland 2. Exit Exit ist ein englisches Wort. Es bedeutet: Ausgang. Aber was haben diese 2 Sachen mit-einander zu tun?
Was meinen die Leute eigentlich mit: Grexit? Grexit sind eigentlich 2 Wörter. 1. Griechenland 2. Exit Exit ist ein englisches Wort. Es bedeutet: Ausgang. Aber was haben diese 2 Sachen mit-einander zu tun?
Educase. Release Notes 1.7: Neue Funktionen und Verbesserungen. Base-Net Informatik AG Wassergrabe 14 CH-6210 Sursee
 Educase Release Notes 1.7: Neue Funktionen und Verbesserungen Version: 1.0 Datum: 01.12.2015 08:34 Ersteller: Andreas Renggli Status: Abgeschlossen Base-Net Informatik AG Wassergrabe 14 CH-6210 Sursee
Educase Release Notes 1.7: Neue Funktionen und Verbesserungen Version: 1.0 Datum: 01.12.2015 08:34 Ersteller: Andreas Renggli Status: Abgeschlossen Base-Net Informatik AG Wassergrabe 14 CH-6210 Sursee
Würfelt man dabei je genau 10 - mal eine 1, 2, 3, 4, 5 und 6, so beträgt die Anzahl. der verschiedenen Reihenfolgen, in denen man dies tun kann, 60!.
 040304 Übung 9a Analysis, Abschnitt 4, Folie 8 Die Wahrscheinlichkeit, dass bei n - maliger Durchführung eines Zufallexperiments ein Ereignis A ( mit Wahrscheinlichkeit p p ( A ) ) für eine beliebige Anzahl
040304 Übung 9a Analysis, Abschnitt 4, Folie 8 Die Wahrscheinlichkeit, dass bei n - maliger Durchführung eines Zufallexperiments ein Ereignis A ( mit Wahrscheinlichkeit p p ( A ) ) für eine beliebige Anzahl
Use Cases. Die Sicht des Nutzers. Fortgeschrittenenpraktikum SS 2004
 Use Cases Die Sicht des Nutzers Fortgeschrittenenpraktikum SS 2004 Gunar Fiedler Lehrstuhl für Technologie der Informationssysteme Kontakt: fiedler@is.informatik.uni-kiel.de Use Cases 2 Was ist ein Use
Use Cases Die Sicht des Nutzers Fortgeschrittenenpraktikum SS 2004 Gunar Fiedler Lehrstuhl für Technologie der Informationssysteme Kontakt: fiedler@is.informatik.uni-kiel.de Use Cases 2 Was ist ein Use
Begeisterung und Leidenschaft im Vertrieb machen erfolgreich. Kurzdarstellung des Dienstleistungsangebots
 Begeisterung und Leidenschaft im Vertrieb machen erfolgreich Kurzdarstellung des Dienstleistungsangebots Überzeugung Ulrich Vieweg Verkaufs- & Erfolgstraining hat sich seit Jahren am Markt etabliert und
Begeisterung und Leidenschaft im Vertrieb machen erfolgreich Kurzdarstellung des Dienstleistungsangebots Überzeugung Ulrich Vieweg Verkaufs- & Erfolgstraining hat sich seit Jahren am Markt etabliert und
Lernende Suchmaschinen
 Lernende Suchmaschinen Qingchui Zhu PG 520 - Intelligence Service (WiSe 07 / SoSe 08) Verzeichnis 1 Einleitung Problemstellung und Zielsetzung 2 Was ist eine lernende Suchmaschine? Begriffsdefinition 3
Lernende Suchmaschinen Qingchui Zhu PG 520 - Intelligence Service (WiSe 07 / SoSe 08) Verzeichnis 1 Einleitung Problemstellung und Zielsetzung 2 Was ist eine lernende Suchmaschine? Begriffsdefinition 3
Universität Zürich Informatikdienste. SpamAssassin. Spam Assassin. 25.04.06 Go Koordinatorenmeeting 27. April 2006 1
 Spam Assassin 25.04.06 Go Koordinatorenmeeting 27. April 2006 1 Ausgangslage Pro Tag empfangen die zentralen Mail-Gateways der Universität ca. 200 000 E-Mails Davon werden über 70% als SPAM erkannt 25.04.06
Spam Assassin 25.04.06 Go Koordinatorenmeeting 27. April 2006 1 Ausgangslage Pro Tag empfangen die zentralen Mail-Gateways der Universität ca. 200 000 E-Mails Davon werden über 70% als SPAM erkannt 25.04.06
3. Entscheidungsbäume. Verfahren zum Begriffslernen (Klassifikation) Beispiel: weiteres Beispiel: (aus Böhm 2003) (aus Morik 2002)
 Beispiel: weiteres Beispiel: (aus Böhm 2003) (aus Morik 2002)") 3. Entscheidungsbäume Verfahren zum Begriffslernen (Klassifikation) Beispiel: weiteres Beispiel: (aus Böhm 2003) (aus Morik 2002) (aus Wilhelm 2001) Beispiel: (aus Böhm 2003) Wann sind Entscheidungsbäume
3. Entscheidungsbäume Verfahren zum Begriffslernen (Klassifikation) Beispiel: weiteres Beispiel: (aus Böhm 2003) (aus Morik 2002) (aus Wilhelm 2001) Beispiel: (aus Böhm 2003) Wann sind Entscheidungsbäume
Tipps und Tricks zu Netop Vision und Vision Pro
 Tipps und Tricks zu Netop Vision und Vision Pro Anwendungen auf Schülercomputer freigeben und starten Netop Vision ermöglicht Ihnen, Anwendungen und Dateien auf allen Schülercomputern gleichzeitig zu starten.
Tipps und Tricks zu Netop Vision und Vision Pro Anwendungen auf Schülercomputer freigeben und starten Netop Vision ermöglicht Ihnen, Anwendungen und Dateien auf allen Schülercomputern gleichzeitig zu starten.
Für AX 4.0, den letzten Hotfix rollup einspielen. Der Hotfix wurde das erste Mal im Hotfix rollup 975357 eingeschlossen:
 I. DOCTYPE-Deklaration Die INDEX.XML-Datei, die beim GDPdU-Export erstellt wird, beinhaltet eine DOCTYPE-Deklaration, die inkorrekterweise als Kommentar herausgegeben wird:
I. DOCTYPE-Deklaration Die INDEX.XML-Datei, die beim GDPdU-Export erstellt wird, beinhaltet eine DOCTYPE-Deklaration, die inkorrekterweise als Kommentar herausgegeben wird:
Die Bundes-Zentrale für politische Bildung stellt sich vor
 Die Bundes-Zentrale für politische Bildung stellt sich vor Die Bundes-Zentrale für politische Bildung stellt sich vor Deutschland ist ein demokratisches Land. Das heißt: Die Menschen in Deutschland können
Die Bundes-Zentrale für politische Bildung stellt sich vor Die Bundes-Zentrale für politische Bildung stellt sich vor Deutschland ist ein demokratisches Land. Das heißt: Die Menschen in Deutschland können
Big & Smart Data. bernard.bekavac@htwchur.ch
 Big & Smart Data Prof. Dr. Bernard Bekavac Schweizerisches Institut für Informationswissenschaft SII Studienleiter Bachelor of Science in Information Science bernard.bekavac@htwchur.ch Quiz An welchem
Big & Smart Data Prof. Dr. Bernard Bekavac Schweizerisches Institut für Informationswissenschaft SII Studienleiter Bachelor of Science in Information Science bernard.bekavac@htwchur.ch Quiz An welchem
ε heteroskedastisch BINARY CHOICE MODELS Beispiele: Wahlentscheidung Kauf langlebiger Konsumgüter Arbeitslosigkeit Schätzung mit OLS?
 BINARY CHOICE MODELS 1 mit Pr( Y = 1) = P Y = 0 mit Pr( Y = 0) = 1 P Beispiele: Wahlentscheidung Kauf langlebiger Konsumgüter Arbeitslosigkeit Schätzung mit OLS? Y i = X i β + ε i Probleme: Nonsense Predictions
BINARY CHOICE MODELS 1 mit Pr( Y = 1) = P Y = 0 mit Pr( Y = 0) = 1 P Beispiele: Wahlentscheidung Kauf langlebiger Konsumgüter Arbeitslosigkeit Schätzung mit OLS? Y i = X i β + ε i Probleme: Nonsense Predictions
Fragebogen zur Evaluation der Vorlesung und Übungen Computer Grafik, CS231, SS05
 Fragebogen zur Evaluation der Vorlesung und Übungen Computer Grafik, CS231, SS05 Dozent: Thomas Vetter Bitte Name des Tutors angeben: Liebe Studierende, Ihre Angaben in diesem Fragebogen helfen uns, die
Fragebogen zur Evaluation der Vorlesung und Übungen Computer Grafik, CS231, SS05 Dozent: Thomas Vetter Bitte Name des Tutors angeben: Liebe Studierende, Ihre Angaben in diesem Fragebogen helfen uns, die
Installationshinweise für Serverbetrieb von Medio- Programmen
 Installationshinweise für betrieb von Medio- Programmen Prinzip Medio--Programme sind für den Betrieb in einem FileMaker Pro Netzwerk vorgesehen. Das Netzwerk umfasst mindestens einen (Host) und einen
Installationshinweise für betrieb von Medio- Programmen Prinzip Medio--Programme sind für den Betrieb in einem FileMaker Pro Netzwerk vorgesehen. Das Netzwerk umfasst mindestens einen (Host) und einen
Der Jazz Veranstaltungskalender für Deutschland, Österreich und die Schweiz
 Veranstaltung erstellen mit vorheriger Registrierung Wenn Sie sich bei Treffpunkt Jazz registrieren, genießen Sie folgende Vorteile: Sie können bereits eingestellte Veranstaltungen auch noch später ändern
Veranstaltung erstellen mit vorheriger Registrierung Wenn Sie sich bei Treffpunkt Jazz registrieren, genießen Sie folgende Vorteile: Sie können bereits eingestellte Veranstaltungen auch noch später ändern
Maschinelles Lernen und Data Mining: Methoden und Anwendungen
 Maschinelles Lernen und Data Mining: Methoden und Anwendungen Eyke Hüllermeier Knowledge Engineering & Bioinformatics Fachbereich Mathematik und Informatik GFFT-Jahrestagung, Wesel, 17. Januar 2008 Knowledge
Maschinelles Lernen und Data Mining: Methoden und Anwendungen Eyke Hüllermeier Knowledge Engineering & Bioinformatics Fachbereich Mathematik und Informatik GFFT-Jahrestagung, Wesel, 17. Januar 2008 Knowledge
Wissensmanagement. in KMU. Beratung und Produkte GmbH
 Wissensmanagement in KMU Warum Wissen in KMU managen? Motive von Unternehmern (KPMG 2001) Produktqualität erhöhen Kosten senken Produktivität erhöhen Kreativität fördern Wachstum steigern Innovationsfähigkeit
Wissensmanagement in KMU Warum Wissen in KMU managen? Motive von Unternehmern (KPMG 2001) Produktqualität erhöhen Kosten senken Produktivität erhöhen Kreativität fördern Wachstum steigern Innovationsfähigkeit
Das Social Semantic Web
 Das Social Semantic Web Treffpunkt für soziale und künstliche Intelligenz IT Businesstalk Vom Breitband zum Web 3.0 Salzburg, 14. Juni 2007 Dr. Sebastian Schaffert Salzburg Research Forschungsgesellschaft
Das Social Semantic Web Treffpunkt für soziale und künstliche Intelligenz IT Businesstalk Vom Breitband zum Web 3.0 Salzburg, 14. Juni 2007 Dr. Sebastian Schaffert Salzburg Research Forschungsgesellschaft
Die Invaliden-Versicherung ändert sich
 Die Invaliden-Versicherung ändert sich 1 Erklärung Die Invaliden-Versicherung ist für invalide Personen. Invalid bedeutet: Eine Person kann einige Sachen nicht machen. Wegen einer Krankheit. Wegen einem
Die Invaliden-Versicherung ändert sich 1 Erklärung Die Invaliden-Versicherung ist für invalide Personen. Invalid bedeutet: Eine Person kann einige Sachen nicht machen. Wegen einer Krankheit. Wegen einem
Kapitel 6. Komplexität von Algorithmen. Xiaoyi Jiang Informatik I Grundlagen der Programmierung
 Kapitel 6 Komplexität von Algorithmen 1 6.1 Beurteilung von Algorithmen I.d.R. existieren viele Algorithmen, um dieselbe Funktion zu realisieren. Welche Algorithmen sind die besseren? Betrachtung nicht-funktionaler
Kapitel 6 Komplexität von Algorithmen 1 6.1 Beurteilung von Algorithmen I.d.R. existieren viele Algorithmen, um dieselbe Funktion zu realisieren. Welche Algorithmen sind die besseren? Betrachtung nicht-funktionaler
Ein Vergleich von Methoden für Multi-klassen Support Vector Maschinen
 Ein Vergleich von Methoden für Multi-klassen Support Vector Maschinen Einführung Auf binären Klassifikatoren beruhende Methoden One-Against-All One-Against-One DAGSVM Methoden die alle Daten zugleich betrachten
Ein Vergleich von Methoden für Multi-klassen Support Vector Maschinen Einführung Auf binären Klassifikatoren beruhende Methoden One-Against-All One-Against-One DAGSVM Methoden die alle Daten zugleich betrachten
Data Mining Anwendungen und Techniken
 Data Mining Anwendungen und Techniken Knut Hinkelmann DFKI GmbH Entdecken von Wissen in banken Wissen Unternehmen sammeln ungeheure mengen enthalten wettbewerbsrelevantes Wissen Ziel: Entdecken dieses
Data Mining Anwendungen und Techniken Knut Hinkelmann DFKI GmbH Entdecken von Wissen in banken Wissen Unternehmen sammeln ungeheure mengen enthalten wettbewerbsrelevantes Wissen Ziel: Entdecken dieses
» Export von Stud.IP-Daten auf eigene Web-Seiten» Workshop Donnerstag, 18.09.2014
 Elmar Ludwig, Peter Thienel» Export von Stud.IP-Daten auf eigene Web-Seiten» Workshop Donnerstag, 18.09.2014» Stud.IP-Tagung 2014 (Göttingen) A Struktur des Workshops Allgemeine Einführung Was sind externe
Elmar Ludwig, Peter Thienel» Export von Stud.IP-Daten auf eigene Web-Seiten» Workshop Donnerstag, 18.09.2014» Stud.IP-Tagung 2014 (Göttingen) A Struktur des Workshops Allgemeine Einführung Was sind externe
WAS finde ich WO im Beipackzettel
 WAS finde ich WO im Beipackzettel Sie haben eine Frage zu Ihrem? Meist finden Sie die Antwort im Beipackzettel (offiziell "Gebrauchsinformation" genannt). Der Aufbau der Beipackzettel ist von den Behörden
WAS finde ich WO im Beipackzettel Sie haben eine Frage zu Ihrem? Meist finden Sie die Antwort im Beipackzettel (offiziell "Gebrauchsinformation" genannt). Der Aufbau der Beipackzettel ist von den Behörden
Instruktionsheft für neue Webshop Hamifleurs
 Instruktionsheft für neue Webshop Hamifleurs Instruktionen für neue Webshop Hamifleurs Gehen Sie zu www.hamifleurs.nl. Klicken Sie auf Login Kunden und es erscheint der Bildschirm auf der nächsten Seite.
Instruktionsheft für neue Webshop Hamifleurs Instruktionen für neue Webshop Hamifleurs Gehen Sie zu www.hamifleurs.nl. Klicken Sie auf Login Kunden und es erscheint der Bildschirm auf der nächsten Seite.
Preisvergleich ProfitBricks - Amazon Web Services M3 Instanz
 Preisvergleich - Amazon Web Services M3 Instanz Stand Preisliste : 10.04.2014 www.profitbricks.de Stand Preisliste : 10.04.2014 Hotline: 0800 22 44 66 8 product@profitbricks.com Vorwort Preisvergleiche
Preisvergleich - Amazon Web Services M3 Instanz Stand Preisliste : 10.04.2014 www.profitbricks.de Stand Preisliste : 10.04.2014 Hotline: 0800 22 44 66 8 product@profitbricks.com Vorwort Preisvergleiche
trivum Multiroom System Konfigurations- Anleitung Erstellen eines RS232 Protokolls am Bespiel eines Marantz SR7005
 trivum Multiroom System Konfigurations- Anleitung Erstellen eines RS232 Protokolls am Bespiel eines Marantz SR7005 2 Inhalt 1. Anleitung zum Einbinden eines über RS232 zu steuernden Devices...3 1.2 Konfiguration
trivum Multiroom System Konfigurations- Anleitung Erstellen eines RS232 Protokolls am Bespiel eines Marantz SR7005 2 Inhalt 1. Anleitung zum Einbinden eines über RS232 zu steuernden Devices...3 1.2 Konfiguration
4. AuD Tafelübung T-C3
 4. AuD Tafelübung T-C3 Simon Ruderich 17. November 2010 Arrays Unregelmäßige Arrays i n t [ ] [ ] x = new i n t [ 3 ] [ 4 ] ; x [ 2 ] = new i n t [ 2 ] ; for ( i n t i = 0; i < x. l e n g t h ; i ++) {
4. AuD Tafelübung T-C3 Simon Ruderich 17. November 2010 Arrays Unregelmäßige Arrays i n t [ ] [ ] x = new i n t [ 3 ] [ 4 ] ; x [ 2 ] = new i n t [ 2 ] ; for ( i n t i = 0; i < x. l e n g t h ; i ++) {
Sentiment Analysis (SA) Robert Bärhold & Mario Sänger Text Analytics WS 2012/13 Prof. Leser
 Robert Bärhold & Mario Sänger Text Analytics WS 2012/13 Prof. Leser") Sentiment Analysis (SA) Robert Bärhold & Mario Sänger Text Analytics WS 2012/13 Prof. Leser Gliederung Einleitung Problemstellungen Ansätze & Herangehensweisen Anwendungsbeispiele Zusammenfassung 2 Gliederung
Sentiment Analysis (SA) Robert Bärhold & Mario Sänger Text Analytics WS 2012/13 Prof. Leser Gliederung Einleitung Problemstellungen Ansätze & Herangehensweisen Anwendungsbeispiele Zusammenfassung 2 Gliederung
Motivation. Themenblock: Data Preprocessing. Einsatzgebiete für Data Mining I. Modell von Gianotti und Pedreschi
 Motivation Themenblock: Data Preprocessing We are drowning in information, but starving for knowledge! (John Naisbett) Was genau ist Datenanalyse? Praktikum: Data Warehousing und Data Mining Was ist Data
Motivation Themenblock: Data Preprocessing We are drowning in information, but starving for knowledge! (John Naisbett) Was genau ist Datenanalyse? Praktikum: Data Warehousing und Data Mining Was ist Data
Die neue Aufgabe von der Monitoring-Stelle. Das ist die Monitoring-Stelle:
 Die neue Aufgabe von der Monitoring-Stelle Das ist die Monitoring-Stelle: Am Deutschen Institut für Menschen-Rechte in Berlin gibt es ein besonderes Büro. Dieses Büro heißt Monitoring-Stelle. Mo-ni-to-ring
Die neue Aufgabe von der Monitoring-Stelle Das ist die Monitoring-Stelle: Am Deutschen Institut für Menschen-Rechte in Berlin gibt es ein besonderes Büro. Dieses Büro heißt Monitoring-Stelle. Mo-ni-to-ring
HTML5. Wie funktioniert HTML5? Tags: Attribute:
 HTML5 HTML bedeutet Hypertext Markup Language und liegt aktuell in der fünften Fassung, also HTML5 vor. HTML5 ist eine Auszeichnungssprache mit der Webseiten geschrieben werden. In HTML5 wird festgelegt,
HTML5 HTML bedeutet Hypertext Markup Language und liegt aktuell in der fünften Fassung, also HTML5 vor. HTML5 ist eine Auszeichnungssprache mit der Webseiten geschrieben werden. In HTML5 wird festgelegt,
In diesem Tutorial lernen Sie, wie Sie einen Termin erfassen und verschiedene Einstellungen zu einem Termin vornehmen können.
 Tutorial: Wie erfasse ich einen Termin? In diesem Tutorial lernen Sie, wie Sie einen Termin erfassen und verschiedene Einstellungen zu einem Termin vornehmen können. Neben den allgemeinen Angaben zu einem
Tutorial: Wie erfasse ich einen Termin? In diesem Tutorial lernen Sie, wie Sie einen Termin erfassen und verschiedene Einstellungen zu einem Termin vornehmen können. Neben den allgemeinen Angaben zu einem
Grundlagen der Künstlichen Intelligenz
 Grundlagen der Künstlichen Intelligenz 22. Constraint-Satisfaction-Probleme: Kantenkonsistenz Malte Helmert Universität Basel 14. April 2014 Constraint-Satisfaction-Probleme: Überblick Kapitelüberblick
Grundlagen der Künstlichen Intelligenz 22. Constraint-Satisfaction-Probleme: Kantenkonsistenz Malte Helmert Universität Basel 14. April 2014 Constraint-Satisfaction-Probleme: Überblick Kapitelüberblick
ebay Mode Fokus ebay Partner Network
 ebay Mode Fokus ebay Partner Network Einkaufen bei ebay.de Nummer 1 des deutschen ecommerce 22 Millionen Nutzer pro Monat Durchschnittlich mehr als 30 Millionen Artikel im Angebot Alle 12 Sekunden wird
ebay Mode Fokus ebay Partner Network Einkaufen bei ebay.de Nummer 1 des deutschen ecommerce 22 Millionen Nutzer pro Monat Durchschnittlich mehr als 30 Millionen Artikel im Angebot Alle 12 Sekunden wird
Unterschiedliche Verkehrsmittel Lehrerinformation
 Lehrerinformation 1/10 Arbeitsauftrag Verschiedene Verkehrsmittel werden verglichen und möglichen Nutzen und Nutzern zugeordnet. Die in Bezug auf Nachhaltigkeit vorbildlichen Ansätze werden diskutiert.
Lehrerinformation 1/10 Arbeitsauftrag Verschiedene Verkehrsmittel werden verglichen und möglichen Nutzen und Nutzern zugeordnet. Die in Bezug auf Nachhaltigkeit vorbildlichen Ansätze werden diskutiert.
Sollten während der Benutzung Probleme auftreten, können Sie die folgende Liste zur Problembehebung benutzen, um eine Lösung zu finden.
 12. Problembehebung Sollten während der Benutzung Probleme auftreten, können Sie die folgende Liste zur Problembehebung benutzen, um eine Lösung zu finden. Sollte Ihr Problem nicht mit Hilfe dieser Liste
12. Problembehebung Sollten während der Benutzung Probleme auftreten, können Sie die folgende Liste zur Problembehebung benutzen, um eine Lösung zu finden. Sollte Ihr Problem nicht mit Hilfe dieser Liste
Elementare Bildverarbeitungsoperationen
 1 Elementare Bildverarbeitungsoperationen - Kantenerkennung - 1 Einführung 2 Gradientenverfahren 3 Laplace-Verfahren 4 Canny-Verfahren 5 Literatur 1 Einführung 2 1 Einführung Kantenerkennung basiert auf
1 Elementare Bildverarbeitungsoperationen - Kantenerkennung - 1 Einführung 2 Gradientenverfahren 3 Laplace-Verfahren 4 Canny-Verfahren 5 Literatur 1 Einführung 2 1 Einführung Kantenerkennung basiert auf
GOST - NORMEN IN ÜBERSETZUNG RUSSIAN STANDARDS IN TRANSLATION
 GOST - NORMEN IN ÜBERSETZUNG RUSSIAN STANDARDS IN TRANSLATION Zusammengestellt und herausgegeben von Tatiana Czepurnyi in Zusammenarbeit mit Monika Lemke VORWORT In der vorliegenden Liste sind Übersetzungen
GOST - NORMEN IN ÜBERSETZUNG RUSSIAN STANDARDS IN TRANSLATION Zusammengestellt und herausgegeben von Tatiana Czepurnyi in Zusammenarbeit mit Monika Lemke VORWORT In der vorliegenden Liste sind Übersetzungen
Europäischer Fonds für Regionale Entwicklung: EFRE im Bundes-Land Brandenburg vom Jahr 2014 bis für das Jahr 2020 in Leichter Sprache
 Für Ihre Zukunft! Europäischer Fonds für Regionale Entwicklung: EFRE im Bundes-Land Brandenburg vom Jahr 2014 bis für das Jahr 2020 in Leichter Sprache 1 Europäischer Fonds für Regionale Entwicklung: EFRE
Für Ihre Zukunft! Europäischer Fonds für Regionale Entwicklung: EFRE im Bundes-Land Brandenburg vom Jahr 2014 bis für das Jahr 2020 in Leichter Sprache 1 Europäischer Fonds für Regionale Entwicklung: EFRE
Entscheidungsunterstützende Systeme
 Entscheidungsunterstützende Systeme (WS 015/016) Klaus Berberich (klaus.berberich@htwsaar.de) Rainer Lenz (rainer.lenz@htwsaar.de) 0. Organisatorisches Dozenten Klaus Berberich (klaus.berberich@htwsaar.de)
Entscheidungsunterstützende Systeme (WS 015/016) Klaus Berberich (klaus.berberich@htwsaar.de) Rainer Lenz (rainer.lenz@htwsaar.de) 0. Organisatorisches Dozenten Klaus Berberich (klaus.berberich@htwsaar.de)
Softwaretests in Visual Studio 2010 Ultimate Vergleich mit Java-Testwerkzeugen. Alexander Schunk Marcel Teuber Henry Trobisch
 Softwaretests in Visual Studio 2010 Ultimate Vergleich mit Java-Testwerkzeugen Alexander Schunk Henry Trobisch Inhalt 1. Vergleich der Unit-Tests... 2 2. Vergleich der Codeabdeckungs-Tests... 2 3. Vergleich
Softwaretests in Visual Studio 2010 Ultimate Vergleich mit Java-Testwerkzeugen Alexander Schunk Henry Trobisch Inhalt 1. Vergleich der Unit-Tests... 2 2. Vergleich der Codeabdeckungs-Tests... 2 3. Vergleich
So funktioniert die NetWorker 7.5 Eigenschaft zum Sichern umbenannter Verzeichnisse ( Backup renamed Directories )
") NetWorker 7.5.0 - Allgemein Tip 8, Seite 1/7 So funktioniert die NetWorker 7.5 Eigenschaft zum Sichern umbenannter Verzeichnisse ( Backup renamed Directories ) Bisher war es der NetWorker Client Software
NetWorker 7.5.0 - Allgemein Tip 8, Seite 1/7 So funktioniert die NetWorker 7.5 Eigenschaft zum Sichern umbenannter Verzeichnisse ( Backup renamed Directories ) Bisher war es der NetWorker Client Software
Sichere Netlog-Einstellungen
 Sichere Netlog-Einstellungen 1. Netlog Startseite... 2 2. Konto erstellen - registrieren... 2 3. Verwalten... 3 3.1 Übersicht / Profilfoto... 3 3.2 Profil / Hauptprofil... 3 4. Einstellungen - Privatsphäre...
Sichere Netlog-Einstellungen 1. Netlog Startseite... 2 2. Konto erstellen - registrieren... 2 3. Verwalten... 3 3.1 Übersicht / Profilfoto... 3 3.2 Profil / Hauptprofil... 3 4. Einstellungen - Privatsphäre...
2. Schönheitsoperationen. Beauty S.324. 322 Lifestyle Lifestyle
 2. Schönheitsoperationen 2. Schönheitsoperationen S.324 Beauty 322 Lifestyle Lifestyle 323 2. Schönheitsoperationen Eine Schönheitsoperation ist eine Operation, die medizinisch nicht nötig ist. Eine solche
2. Schönheitsoperationen 2. Schönheitsoperationen S.324 Beauty 322 Lifestyle Lifestyle 323 2. Schönheitsoperationen Eine Schönheitsoperation ist eine Operation, die medizinisch nicht nötig ist. Eine solche
Business Analytics im E-Commerce
 Business Analytics im E-Commerce Kunde, Kontext und sein Verhalten verstehen für personalisierte Kundenansprache Janusz Michalewicz CEO Über die Firma Crehler Erstellung von Onlineshops Analyse von Transaktionsdaten
Business Analytics im E-Commerce Kunde, Kontext und sein Verhalten verstehen für personalisierte Kundenansprache Janusz Michalewicz CEO Über die Firma Crehler Erstellung von Onlineshops Analyse von Transaktionsdaten
Frankfurt am Main. Dortmund. Stuttgart. Düsseldorf
 Aufgabenstellung Ein Handlungsreisender will seine Produkte in den zehn größten Städten Deutschlands verkaufen. Er startet in Berlin und will seine Reise dort beenden. Die zehn einwohnerreichsten Städte
Aufgabenstellung Ein Handlungsreisender will seine Produkte in den zehn größten Städten Deutschlands verkaufen. Er startet in Berlin und will seine Reise dort beenden. Die zehn einwohnerreichsten Städte
t r Lineare Codierung von Binärbbäumen (Wörter über dem Alphabet {, }) Beispiel code( ) = code(, t l, t r ) = code(t l ) code(t r )
 Beispiel code( ) = code(, t l, t r ) = code(t l ) code(t r )") Definition B : Menge der binären Bäume, rekursiv definiert durch die Regeln: ist ein binärer Baum sind t l, t r binäre Bäume, so ist auch t =, t l, t r ein binärer Baum nur das, was durch die beiden vorigen
Definition B : Menge der binären Bäume, rekursiv definiert durch die Regeln: ist ein binärer Baum sind t l, t r binäre Bäume, so ist auch t =, t l, t r ein binärer Baum nur das, was durch die beiden vorigen
9 Auto. Rund um das Auto. Welche Wörter zum Thema Auto kennst du? Welches Wort passt? Lies die Definitionen und ordne zu.
 1 Rund um das Auto Welche Wörter zum Thema Auto kennst du? Welches Wort passt? Lies die Definitionen und ordne zu. 1. Zu diesem Fahrzeug sagt man auch Pkw oder Wagen. 2. kein neues Auto, aber viel billiger
1 Rund um das Auto Welche Wörter zum Thema Auto kennst du? Welches Wort passt? Lies die Definitionen und ordne zu. 1. Zu diesem Fahrzeug sagt man auch Pkw oder Wagen. 2. kein neues Auto, aber viel billiger
Informatik 12 Datenbanken SQL-Einführung
 Informatik 12 Datenbanken SQL-Einführung Gierhardt Vorbemerkungen Bisher haben wir Datenbanken nur über einzelne Tabellen kennen gelernt. Stehen mehrere Tabellen in gewissen Beziehungen zur Beschreibung
Informatik 12 Datenbanken SQL-Einführung Gierhardt Vorbemerkungen Bisher haben wir Datenbanken nur über einzelne Tabellen kennen gelernt. Stehen mehrere Tabellen in gewissen Beziehungen zur Beschreibung