Proseminar. GPU-Computing Cuda vs. OpenCL. SS 2013 Alexander Stepanov
|
|
|
- Jörg Dressler
- vor 5 Jahren
- Abrufe
Transkript
1 Proseminar GPU-Computing Cuda vs. OpenCL SS 2013 Alexander Stepanov
2 Inhaltsverzeichnis 1. Einführung: Warum GPU Computing? CPU vs. GPU GPU Architektur 2. CUDA Architektur Beispiel Matrix Multiplikation 3. OpenCL Architektur Beispiel Matrix Multiplikation 4. CUDA vs. OpenCL 5. Fazit
3 CPU vs. GPU Top CPUs: AMD FX-8350 Opteron 6386 SE i7-3970x Xeon E Takt 4,2 GHz 3,2 GHz 4,0 GHz 3,8 GHz Kerne Threads GFLOPs (SP DP) Top GPUs: HD 7870 GHz HD 7990 GTX Titan GTX 690 Takt MHz MHz 876 MHz MHz Shader GFLOPs (SP DP) Speicher (GDDR5) 3 GB 2 3 GB 6 GB 2 2 GB

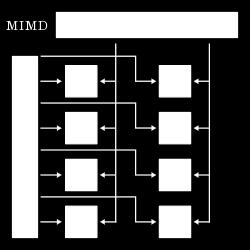

4 CPU vs. GPU
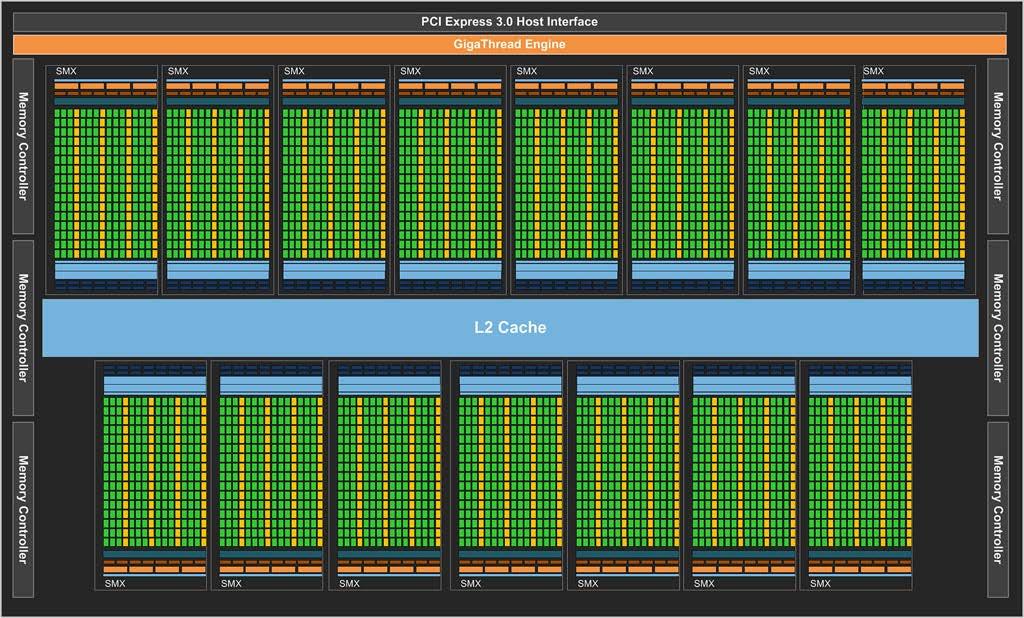
5 GPU Architektur (GK110 GTX Titan)

6 GPU Architektur (GK110 GTX Titan) L1-Cache: 64 KB / SMX Data-Cache: 48 KB /SMX L2-Cache: KB 196 SP Cores / SMX 64 DPU / SMX 32 SFU / SMX 16 Texture Units / SMX 4 Warp Scheduler / SMX
7 CPU vs. GPU GPU Massiv Parallelisiert Wenig Cache Langsam bei Verzweigungen CPU Großer Befehlssatz Branch Prediction
8 CUDA (Compute Unified Device Architecture) 2007 von NVIDIA released Wird nur von NVIDIA gepflegt und läuft nur auf deren Hardware Aktuellste Version: 5.0 Sprache: CUDA-C und PTX Assembler Läuft auf Windows, Linux und Mac OS X
 aus und überträgt das Ergebnis zurück zum Host Warp-Scheduler: Partitioniert mehrere Blöcke zu Warps Ein Warp führt eine")
9 CUDA Ablauf: CPU kopiert kompilierten Kernel-Code und Daten auf die GPU. GPU führt den Code in Warps (32 Threads) aus und überträgt das Ergebnis zurück zum Host Warp-Scheduler: Partitioniert mehrere Blöcke zu Warps Ein Warp führt eine Instruktion gleichzeitig aus (SIMD)
10 CUDA // Kernel Code global void mmult ( const float *A, const float *B, float *C, int width) { int i = blockidx.x * blockdim.x + threadidx.x; int j = blockidx.y * blockdim.y + threadidx.y; global zeichnet Kernelcode aus. Wird zur Laufzeit vom Nvcc (NVIDIA CUDA Compiler) kompiliert. device (global), constant (constant), share (shared) sind Schlüsselwörter für die Speicherhierarchie in CUDA Nachteil: Matrixgröße beschränkt auf Blockgröße => Kernel mehrere Zellen berechnen lassen => Mehr Blöcke zur Problemlösung beauftragen } float val = 0; for( int k = 0; k < width; k++ ) val += A[width *j+k] * B[width *k+i]; C[width *j+i] = val ;
11 CUDA // Host Code host int main (int argc, char ** argv ) { // Matrizengrößen A (1024 x 512), B (512 x 2048) => C (512 x 512) size_t sizea = 1024 * 512 * sizeof(float); size_t sizeb = 512 * 2048 * sizeof(float); size_t sizec = 512 * 512 * sizeof(float); // Matrizen im Host anlegen float *h_a = (float *) malloc(sizea); float *h_b = (float *) malloc(sizeb); float *h_c = (float *) malloc(sizec); // Matrizenspeicher auf der GPU (Device) reservieren float* d_a, d_b, d_c; cudamalloc (( void **) &d_a, sizea ); cudamalloc (( void **) &d_b, sizeb ); cudamalloc (( void **) &d_c, sizec ); // Matrizen vom Host zur GPU kopieren cudamemcpy(d_a, h_a, sizea, cudamemcpyhosttodevice); cudamemcpy(d_b, h_b, sizeb, cudamemcpyhosttodevice); // Kernel vorbereiten und ausführen dim3 threads(16, 16) ; //Blockgröße dim3 grid(512 / threads.x, 512 / threads.y ); //Gridgröße mmult<<<grid, threads>>>(d_a, d_b, d_c, 512); } // Ergebnis Matrix d_c von der GPU zum Host h_c kopieren cudamemcpy (h_c, d_c, sizec, cudamemcpydevicetohost );
12 OpenCL (Open Computing Language) Spezifikation Ende 2008 veröffentlich Aktuelle Version: 1.2 Wurde ursprünglich von Apple entwickelt, jetzt in den Händen der Kronos Group Offener Standard (wie OpenGL) Sprache: Kernel in OpenCL C und Host in C/C++ Plattform- und Geräteunabhängige Gerätehersteller kümmern sich selbst um den OpenCL-Support in ihren Chips

13 OpenCL Ablauf (Ähnlich wie bei CUDA): CPU kopiert kompilierten Kernel-Code und Daten auf die GPU. GPU führt den Code in den Compute Units aus und überträgt das Ergebnis zurück zum Host
14 OpenCL const char kernel_src [] = " kernel void mmult ( global const float *A, " " global const float *B, " " global float *C, " " int wa, int wb) " "{ " " int i = get_global_id (0); " " int j = get_global_id (1); " " " " float val = 0; " " for( int k = 0; k < wa; k++ ) " " val += A[wA*j+k] * B[wB*k+i]; " " C[wA*j+i] = val; " "} "; Kernelcode wird als String übergeben und dann zur Laufzeit kompiliert. Schlüsselwörter für Speicherhierarchie: global (global), constant (constant), local (share) und private (privat)
15 OpenCL int main (int argc, const char * argv []) { // Matrizengrößen A (1024 x 512), B (512 x 2048) => C (512 x 512) size_t sizea = 1024 * 512 * sizeof(float); size_t sizeb = 512 * 2048 * sizeof(float); size_t sizec = 512 * 512 * sizeof(float); // Matrizen im Host anlegen float *h_a = (float *) malloc(sizea); float *h_b = (float *) malloc(sizeb); float *h_c = (float *) malloc(sizec); // Auf welcher Platform soll das laufen cl_uint num_platforms ; cl_platform_id platform ; cl_int err = clgetplatformids (1, & platform, & num_platforms ); // Auf welchem Gerät soll das laufen cl_device_id device ; clgetdeviceids(platform, CL_DEVICE_TYPE_GPU, 1, &device, 0); // Erstelle context, command queue, program und kernel cl_context context = clcreatecontext(0, 1, &device, 0, 0, &err); cl_command_queue cmd_queue = clcreatecommandqueue(context, device, 0, 0); cl_program program = clcreateprogramwithsource(context, 1, &kernel_src, 0, &err); clbuildprogram(program, 0, 0, 0, 0, 0); cl_kernel kernel = clcreatekernel (program, " mmult ", &err); } // Matrizen erstellen float * h_a = new float[sizea]; float * h_b = new float[sizeb]; float * h_c = new float[sizec]; cl_mem d_a = clcreatebuffer ( context, CL_MEM_READ_ONLY, sizea, 0, 0); cl_mem d_b = clcreatebuffer ( context, CL_MEM_READ_ONLY, sizeb, 0, 0); cl_mem d_c = clcreatebuffer ( context, CL_MEM_WRITE_ONLY, sizec, 0, 0); // Speicher reservieren clsetkernelarg(kernel, 0, sizeof(cl_mem), &d_a); clsetkernelarg(kernel, 1, sizeof(cl_mem), &d_b); clsetkernelarg(kernel, 2, sizeof(cl_mem), &d_c); // work size berechnen size_t ws_global [] = {512, 512}; size_t ws_local [] = {16, 8}; // 128 items per group // Eingabematrizen zur GPU kopieren, Kernel starten und Ergebnis zurückkopieren clenqueuewritebuffer(cmd_queue, d_a, CL_FALSE, 0, sizea, h_a, 0, 0, 0); clenqueuewritebuffer(cmd_queue, d_b, CL_FALSE, 0, sizeb, h_b, 0, 0, 0); clenqueuendrangekernel(cmd_queue, kernel, 2, 0, ws_global, ws_local, 0, 0, 0); clenqueuereadbuffer(cmd_queue, d_c, CL_FALSE, 0, sizec, h_c, 0, 0, 0); clfinish(cmd_queue);

16 CUDA vs. OpenCL Wegen CUDA nur auf NVIDIA GPUs vergleichbar OpenCL ist von vornerein benachteiligt -> Wird mit CUDA umgesetzt Vergleich ist somit wegen dem Performanceverlust von Interesse CUDA Global Memory Constant Memory Shared Memory Local Memory Thread Thread-block OpenCL Global Memory Constant Memory Local Memory Private Memory Work-item Work-group
17 CUDA vs. OpenCL Test aus A Performance Comparison of CUDA and OpenCL 2010 von Kamran Karimi, Neil G. Dickson und Firas Hamze von D-Wave Systems Inc. in Canada Quanten-Spin-System Simulation mit AQUA (Adiabatic QUantum Algorthms) GPU: GTX 260 mit 192 Kernen Chiptakt: 576 MHz CUDA-Version: 2.3 OpenCL: 1.0
18 CUDA vs. OpenCL CUDA -> OpenCL: Syntaktische Anpassung (siehe Terminologie) keine Referenzen in OpenCL Qubits Kernel Laufzeit Datentransfer Gesamtlaufzeit 8 1,12 0,94 649,05 Kb 1, ,23 1, ,32 Kb 1, ,19 1, ,44 Kb 1, ,45 1, ,22 Kb 1,5 72 1,63 1, ,77 Kb 1, ,17 1, ,49 Kb 1, ,12 1, ,04 Kb 1,16
19 CUDA vs. OpenCL CUDA unterstützt spezifische Hardware-Features (z.b. Textur-Speicher) CUDA-Compiler besser optimiert => Selbst Kernel optimieren z.b. Schleifen entrollen A Comprehensive Performance Comparison of CUDA and OpenCL International Conference on Parallel Processing - Jianbin Fang, Ana Lucia Varbanescu and Henk Sips
20 Fazit Cuda: Hardwarenäher (PTX Assembler) => Performanter Von nur einem Hersteller betreut: schnellere Updates Großer Umfang an Tools OpenCL: Universeller
CUDA. Moritz Wild, Jan-Hugo Lupp. Seminar Multi-Core Architectures and Programming. Friedrich-Alexander-Universität Erlangen-Nürnberg
 CUDA Seminar Multi-Core Architectures and Programming 1 Übersicht Einleitung Architektur Programmierung 2 Einleitung Computations on GPU 2003 Probleme Hohe Kenntnisse der Grafikprogrammierung nötig Unterschiedliche
CUDA Seminar Multi-Core Architectures and Programming 1 Übersicht Einleitung Architektur Programmierung 2 Einleitung Computations on GPU 2003 Probleme Hohe Kenntnisse der Grafikprogrammierung nötig Unterschiedliche
GPGPU-Programmierung
 12 GPGPU-Programmierung 2013/04/25 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken ist im Allgemeinen nicht erlaubt. Motivation (1) General Purpose Computing on
12 GPGPU-Programmierung 2013/04/25 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken ist im Allgemeinen nicht erlaubt. Motivation (1) General Purpose Computing on
GPGPU-Programmierung
 12 GPGPU-Programmierung 2014/04/29 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken ist im Allgemeinen nicht erlaubt. Motivation (1) General Purpose Computing on
12 GPGPU-Programmierung 2014/04/29 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken ist im Allgemeinen nicht erlaubt. Motivation (1) General Purpose Computing on
OpenCL. Programmiersprachen im Multicore-Zeitalter. Tim Wiersdörfer
 OpenCL Programmiersprachen im Multicore-Zeitalter Tim Wiersdörfer Inhaltsverzeichnis 1. Was ist OpenCL 2. Entwicklung von OpenCL 3. OpenCL Modelle 1. Plattform-Modell 2. Ausführungs-Modell 3. Speicher-Modell
OpenCL Programmiersprachen im Multicore-Zeitalter Tim Wiersdörfer Inhaltsverzeichnis 1. Was ist OpenCL 2. Entwicklung von OpenCL 3. OpenCL Modelle 1. Plattform-Modell 2. Ausführungs-Modell 3. Speicher-Modell
Compute Unified Device Architecture CUDA
 Compute Unified Device Architecture 06. Februar 2012 1 / 13 Gliederung 2 / 13 : Compute Unified Device Architecture entwickelt von Nvidia Corporation spezifiziert Software- und Hardwareeigenschaften Ziel:
Compute Unified Device Architecture 06. Februar 2012 1 / 13 Gliederung 2 / 13 : Compute Unified Device Architecture entwickelt von Nvidia Corporation spezifiziert Software- und Hardwareeigenschaften Ziel:
OpenCL. Multi-Core Architectures and Programming (Seminar) Apelt, Nicolas / Zöllner, Christian
 Apelt, Nicolas / Zöllner, Christian") OpenCL Multi-Core Architectures and Programming (Seminar) Apelt, Nicolas / Zöllner, Christian Hardware-Software-Co-Design Universität Erlangen-Nürnberg Apelt, Nicolas / Zöllner, Christian 1 Was ist OpenCL?
OpenCL Multi-Core Architectures and Programming (Seminar) Apelt, Nicolas / Zöllner, Christian Hardware-Software-Co-Design Universität Erlangen-Nürnberg Apelt, Nicolas / Zöllner, Christian 1 Was ist OpenCL?
Praxiseinheit: Realisierung einer hardwarebeschleunigten Disparitätenberechnung zur automatischen Auswertung von Stereobildern
 Praxiseinheit: Realisierung einer hardwarebeschleunigten Disparitätenberechnung zur automatischen Auswertung von Stereobildern Institut für Betriebssysteme und Rechnerverbund TU Braunschweig 25.10., 26.10.
Praxiseinheit: Realisierung einer hardwarebeschleunigten Disparitätenberechnung zur automatischen Auswertung von Stereobildern Institut für Betriebssysteme und Rechnerverbund TU Braunschweig 25.10., 26.10.
Programmierbeispiele und Implementierung. Name: Michel Steuwer E-Mail: michel.steuwer@wwu.de
 > Programmierbeispiele und Implementierung Name: Michel Steuwer E-Mail: michel.steuwer@wwu.de 2 > Übersicht > Matrix Vektor Multiplikation > Mandelbrotmenge / Apfelmännchen berechnen > Kantendetektion
> Programmierbeispiele und Implementierung Name: Michel Steuwer E-Mail: michel.steuwer@wwu.de 2 > Übersicht > Matrix Vektor Multiplikation > Mandelbrotmenge / Apfelmännchen berechnen > Kantendetektion
Masterpraktikum Scientific Computing
 Masterpraktikum Scientific Computing High-Performance Computing Thomas Auckenthaler Wolfgang Eckhardt Prof. Dr. Michael Bader Technische Universität München, Germany Outline Organisatorisches Entwicklung
Masterpraktikum Scientific Computing High-Performance Computing Thomas Auckenthaler Wolfgang Eckhardt Prof. Dr. Michael Bader Technische Universität München, Germany Outline Organisatorisches Entwicklung
Eine kurze Geschichte der Grafikkarten
 3.1 Einführung Eine kurze Geschichte der Grafikkarten ursprünglich: Graphics Card steuert Monitor an Mitte 80er: Grafikkarten mit 2D-Beschleunigung angelehnt an Arcade- und Home-Computer frühe 90er: erste
3.1 Einführung Eine kurze Geschichte der Grafikkarten ursprünglich: Graphics Card steuert Monitor an Mitte 80er: Grafikkarten mit 2D-Beschleunigung angelehnt an Arcade- und Home-Computer frühe 90er: erste
Masterpraktikum Scientific Computing
 Masterpraktikum Scientific Computing High-Performance Computing Thomas Auckenthaler Wolfgang Eckhardt Technische Universität München, Germany Outline Entwicklung General Purpose GPU Programming (GPGPU)
Masterpraktikum Scientific Computing High-Performance Computing Thomas Auckenthaler Wolfgang Eckhardt Technische Universität München, Germany Outline Entwicklung General Purpose GPU Programming (GPGPU)
Grundlagen von CUDA, Sprachtypische Elemente
 Grundlagen von CUDA, Sprachtypische Elemente Stefan Maskanitz 03.07.2009 CUDA Grundlagen 1 Übersicht 1. Einleitung 2. Spracheigenschaften a. s, Blocks und Grids b. Speicherorganistion c. Fehlerbehandlung
Grundlagen von CUDA, Sprachtypische Elemente Stefan Maskanitz 03.07.2009 CUDA Grundlagen 1 Übersicht 1. Einleitung 2. Spracheigenschaften a. s, Blocks und Grids b. Speicherorganistion c. Fehlerbehandlung
Parallele Algorithmen mit OpenCL. Universität Osnabrück, Henning Wenke,
 Parallele Algorithmen mit OpenCL Universität Osnabrück, Henning Wenke, 2013-04-17 Kapitel I OpenCL Einführung Allgemeines Open Compute Language: API für einheitliche parallele Programmierung heterogener
Parallele Algorithmen mit OpenCL Universität Osnabrück, Henning Wenke, 2013-04-17 Kapitel I OpenCL Einführung Allgemeines Open Compute Language: API für einheitliche parallele Programmierung heterogener
Einführung. GPU-Versuch. Andreas Schäfer Friedrich-Alexander-Universität Erlangen-Nürnberg
 GPU-Versuch andreas.schaefer@cs.fau.de Friedrich-Alexander-Universität Erlangen-Nürnberg Praktikum Parallele Rechnerarchitekturen SS2014 Outline 1 Einführung 2 Outlook 1 Einführung 2 Eine kurze Geschichte
GPU-Versuch andreas.schaefer@cs.fau.de Friedrich-Alexander-Universität Erlangen-Nürnberg Praktikum Parallele Rechnerarchitekturen SS2014 Outline 1 Einführung 2 Outlook 1 Einführung 2 Eine kurze Geschichte
GPU Architektur CUDA - OpenCL
 GPU Architektur und Programmiermöglichkeiten für GPGPU-Anwendungen kernel void matsq( global const float *mat, global float *out ) { int dim = get_global_size(0); //Matrix dimension int i = get_global_id(0);
GPU Architektur und Programmiermöglichkeiten für GPGPU-Anwendungen kernel void matsq( global const float *mat, global float *out ) { int dim = get_global_size(0); //Matrix dimension int i = get_global_id(0);
Yilmaz, Tolga MatNr: Mesaud, Elias MatNr:
 Yilmaz, Tolga MatNr: 157317 Mesaud, Elias MatNr: 151386 1. Aufbau und Funktionsweise einer Grafikkarte 2. CPU vs. GPU 3. Software 4. Beispielprogramme Kompilierung und Vorführung 5. Wo wird Cuda heutzutage
Yilmaz, Tolga MatNr: 157317 Mesaud, Elias MatNr: 151386 1. Aufbau und Funktionsweise einer Grafikkarte 2. CPU vs. GPU 3. Software 4. Beispielprogramme Kompilierung und Vorführung 5. Wo wird Cuda heutzutage
GPGPU-Architekturen CUDA Programmiermodell Beispielprogramm. Einführung CUDA. Ralf Seidler. Friedrich-Alexander-Universität Erlangen-Nürnberg
 Einführung CUDA Friedrich-Alexander-Universität Erlangen-Nürnberg PrakParRA, 18.11.2010 Outline 1 GPGPU-Architekturen 2 CUDA Programmiermodell 3 Beispielprogramm Outlook 1 GPGPU-Architekturen 2 CUDA Programmiermodell
Einführung CUDA Friedrich-Alexander-Universität Erlangen-Nürnberg PrakParRA, 18.11.2010 Outline 1 GPGPU-Architekturen 2 CUDA Programmiermodell 3 Beispielprogramm Outlook 1 GPGPU-Architekturen 2 CUDA Programmiermodell
GPGPU-Programming. Constantin Timm Informatik 12 TU Dortmund 2012/04/09. technische universität dortmund. fakultät für informatik informatik 12
 12 GPGPU-Programming Constantin Timm Informatik 12 TU Dortmund 2012/04/09 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken ist im Allgemeinen nicht erlaubt. Motivation
12 GPGPU-Programming Constantin Timm Informatik 12 TU Dortmund 2012/04/09 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken ist im Allgemeinen nicht erlaubt. Motivation
GPGPU WITH OPENCL. Praktikum Parallele Rechnerarchitekturen, 2015w Franz Richter-Gottfried
 GPGPU WITH OPENCL Praktikum Parallele Rechnerarchitekturen, 2015w Franz Richter-Gottfried INFRASTRUCTURE Enqueue interactive job srun --gres --pty bash Graphics cards available for tesla_k20,
GPGPU WITH OPENCL Praktikum Parallele Rechnerarchitekturen, 2015w Franz Richter-Gottfried INFRASTRUCTURE Enqueue interactive job srun --gres --pty bash Graphics cards available for tesla_k20,
Rheinisch-Westfälische Technische Hochschule Aachen. Seminararbeit
 Rheinisch-Westfälische Technische Hochschule Aachen Seminararbeit Analyse von General Purpose Computation on Graphics Processing Units Bibliotheken in Bezug auf GPU-Hersteller. Gregori Kerber Matrikelnummer
Rheinisch-Westfälische Technische Hochschule Aachen Seminararbeit Analyse von General Purpose Computation on Graphics Processing Units Bibliotheken in Bezug auf GPU-Hersteller. Gregori Kerber Matrikelnummer
GPGPU Architectures - Compiler Techniques and Applications SS 2012
 Seminar on GPGPU Architectures - Compiler Techniques and Applications SS 2012 Embedded Systems Group Department of Computer Science University of Kaiserslautern Preface The widespread use of so-called
Seminar on GPGPU Architectures - Compiler Techniques and Applications SS 2012 Embedded Systems Group Department of Computer Science University of Kaiserslautern Preface The widespread use of so-called
Cuda Speicherhierarchie
 Cuda Speicherhierarchie Threads eines Blocks können über Shared Memory kommunizieren Der Shared Memory ist klein aber sehr schnell Alle Threads können nur über Global Memory kommunizieren Der Global Memory
Cuda Speicherhierarchie Threads eines Blocks können über Shared Memory kommunizieren Der Shared Memory ist klein aber sehr schnell Alle Threads können nur über Global Memory kommunizieren Der Global Memory
General Purpose Computation on GPUs
 General Purpose Computation on GPUs Matthias Schneider, Robert Grimm Universität Erlangen-Nürnberg {matthias.schneider, robert.grimm}@informatik.stud.uni-erlangen.de M. Schneider, R. Grimm 1 Übersicht
General Purpose Computation on GPUs Matthias Schneider, Robert Grimm Universität Erlangen-Nürnberg {matthias.schneider, robert.grimm}@informatik.stud.uni-erlangen.de M. Schneider, R. Grimm 1 Übersicht
OpenCL. OpenCL. Boris Totev, Cornelius Knap
 OpenCL OpenCL 1 OpenCL Gliederung Entstehungsgeschichte von OpenCL Was, warum und überhaupt wieso OpenCL CUDA, OpenGL und OpenCL GPUs OpenCL Objekte Work-Units OpenCL Adressbereiche OpenCL API Codebeispiel
OpenCL OpenCL 1 OpenCL Gliederung Entstehungsgeschichte von OpenCL Was, warum und überhaupt wieso OpenCL CUDA, OpenGL und OpenCL GPUs OpenCL Objekte Work-Units OpenCL Adressbereiche OpenCL API Codebeispiel
Parallele Algorithmen mit OpenCL. Universität Osnabrück, Henning Wenke,
 Parallele Algorithmen mit OpenCL Universität Osnabrück, Henning Wenke, 203-04-24 Was bisher geschah Host Device Platform Führt aus Führt aus Device Context Applikation Java, C++, Kernel (OpenCL C) Memory
Parallele Algorithmen mit OpenCL Universität Osnabrück, Henning Wenke, 203-04-24 Was bisher geschah Host Device Platform Führt aus Führt aus Device Context Applikation Java, C++, Kernel (OpenCL C) Memory
Software Engineering für moderne parallele Plattformen 9. GPGPUs: Grafikkarten als Parallelrechner
 Software Engineering für moderne parallele Plattformen 9. GPGPUs: Grafikkarten als Parallelrechner Dipl.-Inform. Korbinian Molitorisz M. Sc. Luis Manuel Carril Rodriguez KIT Universität des Landes Baden-Württemberg
Software Engineering für moderne parallele Plattformen 9. GPGPUs: Grafikkarten als Parallelrechner Dipl.-Inform. Korbinian Molitorisz M. Sc. Luis Manuel Carril Rodriguez KIT Universität des Landes Baden-Württemberg
GPUs. Arbeitsbereich Wissenschaftliches Rechnen Fachbereich Informatik Fakultät für Mathematik, Informatik und Naturwissenschaften Universität Hamburg
 GPUs Arbeitsbereich Wissenschaftliches Rechnen Fachbereich Informatik Fakultät für Mathematik, Informatik und Naturwissenschaften Universität Hamburg Vorgelegt von: Johannes Coym E-Mail-Adresse: 4coym@informatik.uni-hamburg.de
GPUs Arbeitsbereich Wissenschaftliches Rechnen Fachbereich Informatik Fakultät für Mathematik, Informatik und Naturwissenschaften Universität Hamburg Vorgelegt von: Johannes Coym E-Mail-Adresse: 4coym@informatik.uni-hamburg.de
GPGPU mit NVIDIA CUDA
 01.07.12 GPGPU mit NVIDIA CUDA General-Purpose on Formatvorlagecomputing des Graphics Processing durch Units Untertitelmasters mit KlickenCompute bearbeiten NVIDIA Unified Device Architecture Gliederung
01.07.12 GPGPU mit NVIDIA CUDA General-Purpose on Formatvorlagecomputing des Graphics Processing durch Units Untertitelmasters mit KlickenCompute bearbeiten NVIDIA Unified Device Architecture Gliederung
GPGPU-Architekturen CUDA Programmiermodell Beispielprogramm Organiosatorisches. Tutorial CUDA. Ralf Seidler
 Friedrich-Alexander-Universität Erlangen-Nürnberg 05.10.2010 Outline 1 GPGPU-Architekturen 2 CUDA Programmiermodell 3 Beispielprogramm 4 Organiosatorisches Outlook 1 GPGPU-Architekturen 2 CUDA Programmiermodell
Friedrich-Alexander-Universität Erlangen-Nürnberg 05.10.2010 Outline 1 GPGPU-Architekturen 2 CUDA Programmiermodell 3 Beispielprogramm 4 Organiosatorisches Outlook 1 GPGPU-Architekturen 2 CUDA Programmiermodell
Physikalische Berechnungen mit General Purpose Graphics Processing Units (GPGPUs)
") Fakultätsname XYZ Fachrichtung XYZ Institutsname XYZ, Professur XYZ Physikalische Berechnungen mit General Purpose Graphics Processing Units (GPGPUs) im Rahmen des Proseminars Technische Informatik Juni
Fakultätsname XYZ Fachrichtung XYZ Institutsname XYZ, Professur XYZ Physikalische Berechnungen mit General Purpose Graphics Processing Units (GPGPUs) im Rahmen des Proseminars Technische Informatik Juni
GPU-Programmierung: OpenCL
 Seminar: Multicore Programmierung Sommerstemester 2009 04.06.2009 Inhaltsverzeichnis 1 GPU-Programmierung von Grafikkarten von GPU-Computing 2 Architektur Spracheigenschaften Vergleich mit CUDA Beispiel
Seminar: Multicore Programmierung Sommerstemester 2009 04.06.2009 Inhaltsverzeichnis 1 GPU-Programmierung von Grafikkarten von GPU-Computing 2 Architektur Spracheigenschaften Vergleich mit CUDA Beispiel
Seminararbeit GPU Architektur und Programmiermöglichkeiten für GPGPU-Anwendungen
 Seminararbeit GPU Architektur und Programmiermöglichkeiten für GPGPU-Anwendungen Marius Gräfe University of Kaiserslautern, Embedded Systems Group m graefe10@cs.uni-kl.de 25. Oktober 2012 Alone we can
Seminararbeit GPU Architektur und Programmiermöglichkeiten für GPGPU-Anwendungen Marius Gräfe University of Kaiserslautern, Embedded Systems Group m graefe10@cs.uni-kl.de 25. Oktober 2012 Alone we can
GPU-Computing. Michael Vetter
 GPU-Computing Universität Hamburg Scientific Visualization and Parallel Processing @ Informatik Climate Visualization Laboratory @ Clisap/CEN Übersicht Hintergrund und Entwicklung von GPGPU Programmierumgebungen
GPU-Computing Universität Hamburg Scientific Visualization and Parallel Processing @ Informatik Climate Visualization Laboratory @ Clisap/CEN Übersicht Hintergrund und Entwicklung von GPGPU Programmierumgebungen
CUDA. Axel Jena, Jürgen Pröll. Multi-Core Architectures and Programming. Friedrich-Alexander-Universität Erlangen-Nürnberg Axel Jena, Jürgen Pröll 1
 CUDA Axel Jena, Jürgen Pröll Multi-Core Architectures and Programming Axel Jena, Jürgen Pröll 1 Warum Tesla? Traditionelle Graphikkarten Getrennte Prozessoren für Vertex- / Pixelberechnungen - Nachteil:
CUDA Axel Jena, Jürgen Pröll Multi-Core Architectures and Programming Axel Jena, Jürgen Pröll 1 Warum Tesla? Traditionelle Graphikkarten Getrennte Prozessoren für Vertex- / Pixelberechnungen - Nachteil:
Computergrafik Universität Osnabrück, Henning Wenke,
 Computergrafik Universität Osnabrück, Henning Wenke, 2012-06-25 Kapitel XV: Parallele Algorithmen mit OpenCL 15.1 Parallele Programmierung Quellen: V.a. Wikipedia. Leistungsdaten unter Vorbehalt. Bitte
Computergrafik Universität Osnabrück, Henning Wenke, 2012-06-25 Kapitel XV: Parallele Algorithmen mit OpenCL 15.1 Parallele Programmierung Quellen: V.a. Wikipedia. Leistungsdaten unter Vorbehalt. Bitte
Programmierung von Graphikkarten
 Programmierung von Graphikkarten Stefan Lang Interdisziplinäres Zentrum für Wissenschaftliches Rechnen Universität Heidelberg INF 368, Raum 532 D-69120 Heidelberg phone: 06221/54-8264 email: Stefan.Lang@iwr.uni-heidelberg.de
Programmierung von Graphikkarten Stefan Lang Interdisziplinäres Zentrum für Wissenschaftliches Rechnen Universität Heidelberg INF 368, Raum 532 D-69120 Heidelberg phone: 06221/54-8264 email: Stefan.Lang@iwr.uni-heidelberg.de
GPU-Computing im Rahmen der Vorlesung Hochleistungsrechnen
 GPU-Computing im Rahmen der Vorlesung Hochleistungsrechnen Universität Hamburg Scientific Visualization and Parallel Processing Übersicht Hintergrund und Entwicklung von GPGPU Programmierumgebungen & Werkzeuge
GPU-Computing im Rahmen der Vorlesung Hochleistungsrechnen Universität Hamburg Scientific Visualization and Parallel Processing Übersicht Hintergrund und Entwicklung von GPGPU Programmierumgebungen & Werkzeuge
CUDA by Example. Paralleles Rechnen auf der Grafikkarte. Leipzig, Paul Jähne SethosII
 CUDA by Example Paralleles Rechnen auf der Grafikkarte Leipzig, 31.03.2017 Paul Jähne SethosII 1 Warum? 2 Aufbau CPU geringe Latenz große Zwischenspeicher besser für serielle Ausführung GPU hohe Rechenleistung
CUDA by Example Paralleles Rechnen auf der Grafikkarte Leipzig, 31.03.2017 Paul Jähne SethosII 1 Warum? 2 Aufbau CPU geringe Latenz große Zwischenspeicher besser für serielle Ausführung GPU hohe Rechenleistung
Ferienakademie Erik Muttersbach
 Ferienakademie 2009 - Erik Muttersbach 1. Einführung 2. Kernels, Threads, Blocks 3. CUDA Execution Model 4. Software Stack 5. Die CUDA Runtime API 6. Speichertypen/ Zugriff 7. Profiling und Optimierung
Ferienakademie 2009 - Erik Muttersbach 1. Einführung 2. Kernels, Threads, Blocks 3. CUDA Execution Model 4. Software Stack 5. Die CUDA Runtime API 6. Speichertypen/ Zugriff 7. Profiling und Optimierung
Interaktive Globale Beleuchtung nach dem Antiradiance-Verfahren mittels der Open Computing Language (OpenCL)
") Interaktive Globale Beleuchtung nach dem Antiradiance-Verfahren mittels der Open Computing Language (OpenCL) Verteidigung der Belegarbeit Andreas Stahl Zielstellung Globales Beleuchtungsverfahren für die
Interaktive Globale Beleuchtung nach dem Antiradiance-Verfahren mittels der Open Computing Language (OpenCL) Verteidigung der Belegarbeit Andreas Stahl Zielstellung Globales Beleuchtungsverfahren für die
Refactoring the UrQMD Model for Many- Core Architectures
 Refactoring the UrQMD Model for Many- Core Architectures Mathias Radtke Semiar: Softwaretechnologie (WS 2013/2014 Goethe-Universität Frankfurt Agenda: 1. UrQMD 2. CPU Vs. GPU 3. Von FORTRAN zu C++/OpenCL
Refactoring the UrQMD Model for Many- Core Architectures Mathias Radtke Semiar: Softwaretechnologie (WS 2013/2014 Goethe-Universität Frankfurt Agenda: 1. UrQMD 2. CPU Vs. GPU 3. Von FORTRAN zu C++/OpenCL
Gliederung. Was ist CUDA? CPU GPU/GPGPU CUDA Anwendungsbereiche Wirtschaftlichkeit Beispielvideo
 Gliederung Was ist CUDA? CPU GPU/GPGPU CUDA Anwendungsbereiche Wirtschaftlichkeit Beispielvideo Was ist CUDA? Nvidia CUDA ist eine von NvidiaGPGPU-Technologie, die es Programmierern erlaubt, Programmteile
Gliederung Was ist CUDA? CPU GPU/GPGPU CUDA Anwendungsbereiche Wirtschaftlichkeit Beispielvideo Was ist CUDA? Nvidia CUDA ist eine von NvidiaGPGPU-Technologie, die es Programmierern erlaubt, Programmteile
Raytracing in GA mittels OpenACC. Michael Burger, M.Sc. FG Scientific Computing TU Darmstadt
 Raytracing in GA mittels OpenACC Michael Burger, M.Sc. FG Scientific Computing TU Darmstadt michael.burger@sc.tu-darmstadt.de 05.11.12 FB Computer Science Scientific Computing Michael Burger 1 / 33 Agenda
Raytracing in GA mittels OpenACC Michael Burger, M.Sc. FG Scientific Computing TU Darmstadt michael.burger@sc.tu-darmstadt.de 05.11.12 FB Computer Science Scientific Computing Michael Burger 1 / 33 Agenda
OpenCL Implementierung von OpenCV Funktionen
 Multi-Core Architectures and Programming OpenCL Implementierung von OpenCV Funktionen julian.mueller@e-technik.stud.uni-erlangen.de Hardware/Software Co-Design August 18, 2011 1 Table of content 1 OpenCL
Multi-Core Architectures and Programming OpenCL Implementierung von OpenCV Funktionen julian.mueller@e-technik.stud.uni-erlangen.de Hardware/Software Co-Design August 18, 2011 1 Table of content 1 OpenCL
Paralleler Cuckoo-Filter. Seminar: Implementierungstechniken für Hauptspeicherdatenbanksysteme Jeremias Neth München, 21.
 Paralleler Cuckoo-Filter Seminar: Implementierungstechniken für Hauptspeicherdatenbanksysteme Jeremias Neth München, 21. November 2017 1 Paralleler Cuckoo-Filter Cuckoo-Hashtabelle Serieller Cuckoo-Filter
Paralleler Cuckoo-Filter Seminar: Implementierungstechniken für Hauptspeicherdatenbanksysteme Jeremias Neth München, 21. November 2017 1 Paralleler Cuckoo-Filter Cuckoo-Hashtabelle Serieller Cuckoo-Filter
Parallele Programmierung mit GPUs
 Parallele Programmierung mit GPUs Jutta Fitzek Vortrag im Rahmen des Moduls Parallele Programmierung, WS12/13, h_da Agenda GPUs: Historie GPU Programmierung Konzepte Codebeispiel Generelle Tipps & Tricks
Parallele Programmierung mit GPUs Jutta Fitzek Vortrag im Rahmen des Moduls Parallele Programmierung, WS12/13, h_da Agenda GPUs: Historie GPU Programmierung Konzepte Codebeispiel Generelle Tipps & Tricks
Grafikkarten-Architektur
 > Grafikkarten-Architektur Parallele Strukturen in der GPU Name: Sebastian Albers E-Mail: s.albers@wwu.de 2 > Inhalt > CPU und GPU im Vergleich > Rendering-Pipeline > Shader > GPGPU > Nvidia Tesla-Architektur
> Grafikkarten-Architektur Parallele Strukturen in der GPU Name: Sebastian Albers E-Mail: s.albers@wwu.de 2 > Inhalt > CPU und GPU im Vergleich > Rendering-Pipeline > Shader > GPGPU > Nvidia Tesla-Architektur
Heterogeneous Computing
 Heterogeneous Computing with OpenCL Advanced GPU Course, 05.05.2014 Wolfram Schenck SimLab Neuroscience, JSC Overview of the Lecture 1 OpenCL Basics 2 Multi Device: Data Partitioning 3 Multi Device: Load
Heterogeneous Computing with OpenCL Advanced GPU Course, 05.05.2014 Wolfram Schenck SimLab Neuroscience, JSC Overview of the Lecture 1 OpenCL Basics 2 Multi Device: Data Partitioning 3 Multi Device: Load
Parallel Computing in der industriellen Bildverarbeitung
 SOLUTIONS FOR MACHINE VISION Parallel Computing in der industriellen Bildverarbeitung Dipl.-Inform. Alexander Piaseczki Research and Development Sirius Advanced Cybernetics GmbH Tools & Solutions für die
SOLUTIONS FOR MACHINE VISION Parallel Computing in der industriellen Bildverarbeitung Dipl.-Inform. Alexander Piaseczki Research and Development Sirius Advanced Cybernetics GmbH Tools & Solutions für die
Digital Image Interpolation with CUDA
 Digital Image Interpolation with CUDA Matthias Schwarz & Martin Rustler Hardware-Software-Co-Design Universität Erlangen-Nürnberg matthias.schwarz@e-technik.stud.uni-erlangen.de martin.rustler@e-technik.stud.uni-erlangen.de
Digital Image Interpolation with CUDA Matthias Schwarz & Martin Rustler Hardware-Software-Co-Design Universität Erlangen-Nürnberg matthias.schwarz@e-technik.stud.uni-erlangen.de martin.rustler@e-technik.stud.uni-erlangen.de
Multicore-Architekturen
 Universität Erlangen- Nürnberg Technische Universität München Universität Stuttgart Multicore-Architekturen Vortrag im Rahmen der Ferienakademie 2009 Kurs 1: Programmierkonzepte für Multi-Core Rechner
Universität Erlangen- Nürnberg Technische Universität München Universität Stuttgart Multicore-Architekturen Vortrag im Rahmen der Ferienakademie 2009 Kurs 1: Programmierkonzepte für Multi-Core Rechner
RST-Labor WS06/07 GPGPU. General Purpose Computation On Graphics Processing Units. (Grafikkarten-Programmierung) Von: Marc Blunck
 Von: Marc Blunck") RST-Labor WS06/07 GPGPU General Purpose Computation On Graphics Processing Units (Grafikkarten-Programmierung) Von: Marc Blunck Ablauf Einführung GPGPU Die GPU GPU Architektur Die Programmierung Programme
RST-Labor WS06/07 GPGPU General Purpose Computation On Graphics Processing Units (Grafikkarten-Programmierung) Von: Marc Blunck Ablauf Einführung GPGPU Die GPU GPU Architektur Die Programmierung Programme
Software Engineering für moderne, parallele Plattformen. 9. GPGPUs: Grafikkarten als Parallelrechner. Dr. Victor Pankratius
 Software Engineering für moderne, parallele Plattformen 9. GPGPUs: Grafikkarten als Parallelrechner Dr. Victor Pankratius Dr. Victor Pankratius, Dipl.Inform. Frank Otto IPD Tichy Lehrstuhl für Programmiersysteme
Software Engineering für moderne, parallele Plattformen 9. GPGPUs: Grafikkarten als Parallelrechner Dr. Victor Pankratius Dr. Victor Pankratius, Dipl.Inform. Frank Otto IPD Tichy Lehrstuhl für Programmiersysteme
Hochleistungsrechnen Grafikkartenprogrammierung. Prof. Dr. Thomas Ludwig Universität Hamburg Informatik Wissenschaftliches Rechnen
 Hochleistungsrechnen Grafikkartenprogrammierung Prof. Dr. Thomas Ludwig Universität Hamburg Informatik Wissenschaftliches Rechnen Übersicht Hintergrund und Entwicklung von GPGPU Programmierumgebungen &
Hochleistungsrechnen Grafikkartenprogrammierung Prof. Dr. Thomas Ludwig Universität Hamburg Informatik Wissenschaftliches Rechnen Übersicht Hintergrund und Entwicklung von GPGPU Programmierumgebungen &
Rechnerarchitektur (RA)
") 12 Rechnerarchitektur (RA) Sommersemester 2015 Foliensatz 6: Grafikprozessoren und GPGPU-Programmierung Michael Engel Informatik 12 michael.engel@tu-.. http://ls12-www.cs.tu-.de/daes/ Tel.: 0231 755 6121
12 Rechnerarchitektur (RA) Sommersemester 2015 Foliensatz 6: Grafikprozessoren und GPGPU-Programmierung Michael Engel Informatik 12 michael.engel@tu-.. http://ls12-www.cs.tu-.de/daes/ Tel.: 0231 755 6121
Parallele Algorithmen mit OpenCL. Universität Osnabrück, Henning Wenke, 2013-05-08
 Parallele Algorithmen mit OpenCL Universität Osnabrück, Henning Wenke, 2013-05-08 Aufräumen Ressourcen in umgekehrter Abhängigkeitsreihenfolge freigeben Objekte haben Reference-Count (RC), initial 1 clrelease
Parallele Algorithmen mit OpenCL Universität Osnabrück, Henning Wenke, 2013-05-08 Aufräumen Ressourcen in umgekehrter Abhängigkeitsreihenfolge freigeben Objekte haben Reference-Count (RC), initial 1 clrelease
MESIF- (links) vs. MESI-Protokoll (rechts)
 vs. MESI-Protokoll (rechts)") 2.3 Beispiele für Multikern-Architekturen 2.3.1 Intel-Nehalem-Architektur MESIF- (links) vs. MESI-Protokoll (rechts) Annahme: Prozessor links unten und rechts oben haben Kopie MESIF : Nur Prozessor, dessen
2.3 Beispiele für Multikern-Architekturen 2.3.1 Intel-Nehalem-Architektur MESIF- (links) vs. MESI-Protokoll (rechts) Annahme: Prozessor links unten und rechts oben haben Kopie MESIF : Nur Prozessor, dessen
GPGPU-Architekturen CUDA CUDA Beispiel OpenCL OpenCL Beispiel. CUDA & OpenCL. Ralf Seidler. Friedrich-Alexander-Universität Erlangen-Nürnberg
 CUDA und OpenCL Friedrich-Alexander-Universität Erlangen-Nürnberg 24. April 2012 Outline 1 GPGPU-Architekturen 2 CUDA 3 CUDA Beispiel 4 OpenCL 5 OpenCL Beispiel Outlook 1 GPGPU-Architekturen 2 CUDA 3 CUDA
CUDA und OpenCL Friedrich-Alexander-Universität Erlangen-Nürnberg 24. April 2012 Outline 1 GPGPU-Architekturen 2 CUDA 3 CUDA Beispiel 4 OpenCL 5 OpenCL Beispiel Outlook 1 GPGPU-Architekturen 2 CUDA 3 CUDA
Volumenrendering mit CUDA
 Volumenrendering mit CUDA Arbeitsgruppe Visualisierung und Computergrafik http://viscg.uni-muenster.de Überblick Volumenrendering allgemein Raycasting-Algorithmus Volumen-Raycasting mit CUDA Optimierung
Volumenrendering mit CUDA Arbeitsgruppe Visualisierung und Computergrafik http://viscg.uni-muenster.de Überblick Volumenrendering allgemein Raycasting-Algorithmus Volumen-Raycasting mit CUDA Optimierung
OPENCL. Praktikum Parallele Rechnerarchitekturen, 2015w Franz Richter-Gottfried
 OPENCL Praktikum Parallele Rechnerarchitekturen, 2015w Franz Richter-Gottfried INFRASTRUCTURE Overview, Manuals https://faui36a.informatik.uni-erlangen.de/trac/puppet/wiki/systemlist https://faui36a.informatik.uni-erlangen.de/trac/puppet/wiki/slurmintroduction
OPENCL Praktikum Parallele Rechnerarchitekturen, 2015w Franz Richter-Gottfried INFRASTRUCTURE Overview, Manuals https://faui36a.informatik.uni-erlangen.de/trac/puppet/wiki/systemlist https://faui36a.informatik.uni-erlangen.de/trac/puppet/wiki/slurmintroduction
CUDA Workshop. Ausblick. Daniel Tenbrinck
 CUDA Workshop Ausblick Daniel Tenbrinck Computer Vision and Pattern Recognition Group Institut für Informatik Westfälische Wilhelms-Universität Münster 03.Juli 2009 Folie: 1 / 10 Daniel Tenbrinck CUDA
CUDA Workshop Ausblick Daniel Tenbrinck Computer Vision and Pattern Recognition Group Institut für Informatik Westfälische Wilhelms-Universität Münster 03.Juli 2009 Folie: 1 / 10 Daniel Tenbrinck CUDA
Automatische OpenCL-Code-Analyse zur Bestimmung von Speicherzugriffsmustern
 Automatische OpenCL-Code-Analyse zur Bestimmung von Speicherzugriffsmustern Bachelorarbeit Moritz Lüdecke 8. Juli 2014 INSTITUT FÜR TECHNISCHE INFORMATIK - LEHRSTUHL FÜR RECHNERARCHITEKTUR UND PARALLELVERARBEITUNG
Automatische OpenCL-Code-Analyse zur Bestimmung von Speicherzugriffsmustern Bachelorarbeit Moritz Lüdecke 8. Juli 2014 INSTITUT FÜR TECHNISCHE INFORMATIK - LEHRSTUHL FÜR RECHNERARCHITEKTUR UND PARALLELVERARBEITUNG
Der Goopax Compiler GPU-Programmierung in C++ ZKI AK-Supercomputing, Münster, 27.03.2014, Ingo Josopait
 Der Goopax Compiler GPU-Programmierung in C++ AMD R9 290X: 5.6 TFLOPS (SP MulAdd) Programmierung ~10000 Threads Entwicklungsumgebungen Entwicklungsumgebungen CUDA, OpenCL Compiler: kernel GPU Maschinencode
Der Goopax Compiler GPU-Programmierung in C++ AMD R9 290X: 5.6 TFLOPS (SP MulAdd) Programmierung ~10000 Threads Entwicklungsumgebungen Entwicklungsumgebungen CUDA, OpenCL Compiler: kernel GPU Maschinencode
> High-Level Programmierung heterogener paralleler Systeme
 > High-Level Programmierung heterogener paralleler Systeme Projektseminar im SoSe 2012 Prof. Sergei Gorlatch, Michel Steuwer, Tim Humernbrum AG Parallele und Verteilte Systeme, Westfälische Wilhelms-Universität
> High-Level Programmierung heterogener paralleler Systeme Projektseminar im SoSe 2012 Prof. Sergei Gorlatch, Michel Steuwer, Tim Humernbrum AG Parallele und Verteilte Systeme, Westfälische Wilhelms-Universität
FPGA Beschleuniger. Your Name. Armin Jeyrani Mamegani Your Organization (Line #2)
") FPGA Beschleuniger 15.12.2008 Armin Jeyrani Mamegani Your Name HAW Hamburg Your Title Department Your Organization Informatik (Line #1) Your Organization (Line #2) Einleitung Wiederholung aus AW1: Handy
FPGA Beschleuniger 15.12.2008 Armin Jeyrani Mamegani Your Name HAW Hamburg Your Title Department Your Organization Informatik (Line #1) Your Organization (Line #2) Einleitung Wiederholung aus AW1: Handy
Parallelisierung mit Hilfe grafischer Prozessoren 318
 Parallelisierung mit Hilfe grafischer Prozessoren 318 Schon sehr früh gab es diverse Grafik-Beschleuniger, die der normalen CPU Arbeit abnahmen. Die im März 2001 von Nvidia eingeführte GeForce 3 Series
Parallelisierung mit Hilfe grafischer Prozessoren 318 Schon sehr früh gab es diverse Grafik-Beschleuniger, die der normalen CPU Arbeit abnahmen. Die im März 2001 von Nvidia eingeführte GeForce 3 Series
OpenCL. Seminar Programmiersprachen im Multicore-Zeitalter Universität Siegen Tim Wiersdörfer tim.wiersdoerfer@student.uni-siegen.
 OpenCL Seminar Programmiersprachen im Multicore-Zeitalter Universität Siegen Tim Wiersdörfer tim.wiersdoerfer@student.uni-siegen.de Abstract: In diesem Dokument wird ein grundlegender Einblick in das relativ
OpenCL Seminar Programmiersprachen im Multicore-Zeitalter Universität Siegen Tim Wiersdörfer tim.wiersdoerfer@student.uni-siegen.de Abstract: In diesem Dokument wird ein grundlegender Einblick in das relativ
Optimierungen der Lattice Boltzmann Methode auf x86-64 basierten Architekturen
 Optimierungen der Lattice Boltzmann Methode auf x86-64 basierten Architekturen J. Treibig, S. Hausmann, U. Ruede 15.09.05 / ASIM 2005 - Erlangen Gliederung 1 Einleitung Motivation Grundlagen 2 Optimierungen
Optimierungen der Lattice Boltzmann Methode auf x86-64 basierten Architekturen J. Treibig, S. Hausmann, U. Ruede 15.09.05 / ASIM 2005 - Erlangen Gliederung 1 Einleitung Motivation Grundlagen 2 Optimierungen
Praktikumsanleitung GPU-Computing. Manuel Hohmann
 Praktikumsanleitung GPU-Computing Manuel Hohmann 20. Juni 2012 Inhaltsverzeichnis 1 Grundlagen 4 1.1 GPU-Computing.................................. 4 1.1.1 GPUs, Kernels und Arbeitsgruppen...................
Praktikumsanleitung GPU-Computing Manuel Hohmann 20. Juni 2012 Inhaltsverzeichnis 1 Grundlagen 4 1.1 GPU-Computing.................................. 4 1.1.1 GPUs, Kernels und Arbeitsgruppen...................
Motivation (GP)GPU CUDA Zusammenfassung. CUDA und Python. Christian Wilms. Integriertes Seminar Projekt Bildverarbeitung
GPU CUDA Zusammenfassung. CUDA und Python. Christian Wilms. Integriertes Seminar Projekt Bildverarbeitung") CUDA und Python Christian Wilms Integriertes Seminar Projekt Bildverarbeitung Universität Hamburg WiSe 2013/14 12. Dezember 2013 Christian CUDA und Python 1 Gliederung 1 Motivation 2 (GP)GPU 3 CUDA 4 Zusammenfassung
CUDA und Python Christian Wilms Integriertes Seminar Projekt Bildverarbeitung Universität Hamburg WiSe 2013/14 12. Dezember 2013 Christian CUDA und Python 1 Gliederung 1 Motivation 2 (GP)GPU 3 CUDA 4 Zusammenfassung
Parallelisierung der Matrixmultiplikation
 Ein Beispiel für parallele Algorithmen Ivo Hedtke hedtke@math.uni-jena.de www.minet.uni-jena.de/~hedtke/ ehem. Hiwi am Lehrstuhl für Wissenschaftliches Rechnen (Prof. Dr. Zumbusch) Institut für Angewandte
Ein Beispiel für parallele Algorithmen Ivo Hedtke hedtke@math.uni-jena.de www.minet.uni-jena.de/~hedtke/ ehem. Hiwi am Lehrstuhl für Wissenschaftliches Rechnen (Prof. Dr. Zumbusch) Institut für Angewandte
Implementierung eines GPU-beschleunigten Kalman-Filters mittels OpenCL
 Implementierung eines GPU-beschleunigten Kalman-Filters Track Fitting für das ATLAS-Experiment am CERN Masterarbeit vorgelegt von: Maik Dankel, B.Sc. Matrikelnummer: 58 28 28 Erstgutachter: Zweitgutachter:
Implementierung eines GPU-beschleunigten Kalman-Filters Track Fitting für das ATLAS-Experiment am CERN Masterarbeit vorgelegt von: Maik Dankel, B.Sc. Matrikelnummer: 58 28 28 Erstgutachter: Zweitgutachter:
Gliederung. Problemstellung Motivation Multi-Agenten Simulation GPU Programmierung Stand der Technik Abgrenzung
 Philipp Kayser Gliederung Problemstellung Motivation Multi-Agenten Simulation GPU Programmierung Stand der Technik Abgrenzung Multi-Agenten Simulation (MAS) simuliert durch eine Vielzahl von Agenten Die
Philipp Kayser Gliederung Problemstellung Motivation Multi-Agenten Simulation GPU Programmierung Stand der Technik Abgrenzung Multi-Agenten Simulation (MAS) simuliert durch eine Vielzahl von Agenten Die
LEISTUNGSVERGLEICH VON FPGA, GPU UND CPU FÜR ALGORITHMEN ZUR BILDBEARBEITUNG PROSEMINAR INF-B-610
 LEISTUNGSVERGLEICH VON FPGA, GPU UND CPU FÜR ALGORITHMEN ZUR BILDBEARBEITUNG PROSEMINAR INF-B-610 Dominik Weinrich dominik.weinrich@tu-dresden.de Dresden, 30.11.2017 Gliederung Motivation Aufbau und Hardware
LEISTUNGSVERGLEICH VON FPGA, GPU UND CPU FÜR ALGORITHMEN ZUR BILDBEARBEITUNG PROSEMINAR INF-B-610 Dominik Weinrich dominik.weinrich@tu-dresden.de Dresden, 30.11.2017 Gliederung Motivation Aufbau und Hardware
Parallelisierung mit Hilfe grafischer Prozessoren 323
 Parallelisierung mit Hilfe grafischer Prozessoren 323 Schon sehr früh gab es diverse Grafik-Beschleuniger, die der normalen CPU Arbeit abnahmen. Die im März 2001 von Nvidia eingeführte GeForce 3 Series
Parallelisierung mit Hilfe grafischer Prozessoren 323 Schon sehr früh gab es diverse Grafik-Beschleuniger, die der normalen CPU Arbeit abnahmen. Die im März 2001 von Nvidia eingeführte GeForce 3 Series
Prinzipieller Aufbau der Architektur eines Multikern- Prozessors. Programmierung Standard-Mulitkern-Prozessoren mit OpenMP
 3.1 Einführung Multi-Core-Architekturen Motivation Multikern-Prozessoren Prinzipieller Aufbau der Architektur eines Multikern- Prozessors Programmierung Standard-Mulitkern-Prozessoren mit OpenMP Programmierung
3.1 Einführung Multi-Core-Architekturen Motivation Multikern-Prozessoren Prinzipieller Aufbau der Architektur eines Multikern- Prozessors Programmierung Standard-Mulitkern-Prozessoren mit OpenMP Programmierung
GPGPU Programming nvidia CUDA vs. AMD/ATI Stream Computing. Seminar HWS 08/09 by Erich Marth
 Computing 1 Inhalt Einführung nvidia CUDA AMD Stream Computing CUDA vs. Stream Computing - Warum, Vorteile, Motivation - Überblick, API - Details, Beispiele - Überblick, API - Details, Beispiele - wesentliche
Computing 1 Inhalt Einführung nvidia CUDA AMD Stream Computing CUDA vs. Stream Computing - Warum, Vorteile, Motivation - Überblick, API - Details, Beispiele - Überblick, API - Details, Beispiele - wesentliche
Enblend - Portierung auf die GPU
 Multi-Core Architectures and Programming Enblend - Portierung auf die GPU Hardware/Software Co-Design September 25, 2009 1 Inhalt 1 Motivation 2 Enblend-Algorithmus 3 Beschleunigung mittels Cuda 4 Benchmark
Multi-Core Architectures and Programming Enblend - Portierung auf die GPU Hardware/Software Co-Design September 25, 2009 1 Inhalt 1 Motivation 2 Enblend-Algorithmus 3 Beschleunigung mittels Cuda 4 Benchmark
Das Software-Loch im Hochleistungsrechnen
 Das Software-Loch im Hochleistungsrechnen Christian Bischof FG Scientific Computing Hochschulrechenzentrum TU Darmstadt 05.07.2012 FB. Computer Science Scientific Computing Christian Bischof 1 WORUM GEHT
Das Software-Loch im Hochleistungsrechnen Christian Bischof FG Scientific Computing Hochschulrechenzentrum TU Darmstadt 05.07.2012 FB. Computer Science Scientific Computing Christian Bischof 1 WORUM GEHT
1 Einleitung. 2 Parallelisierbarkeit von. Architektur
 Beschleunigung von Aufgaben der parallelen Bildverarbeitung durch Benutzung von NVIDIA-Grafikkarten mit der Compute Unified Device Architecture (CUDA) Roman Glebov roman@glebov.de Abstract Diese Arbeit
Beschleunigung von Aufgaben der parallelen Bildverarbeitung durch Benutzung von NVIDIA-Grafikkarten mit der Compute Unified Device Architecture (CUDA) Roman Glebov roman@glebov.de Abstract Diese Arbeit
CUDA. 7. Vorlesung GPU Programmierung. Danke an Hendrik Lensch
 CUDA 7. Vorlesung Thorsten Grosch Danke an Hendrik Lensch Parallele l Programmierung mit der GPU Bisher: GPU = OpenGL Pipeline mit Shadern Alles orientiert sich am Rendering Programme für Eckpunkte und
CUDA 7. Vorlesung Thorsten Grosch Danke an Hendrik Lensch Parallele l Programmierung mit der GPU Bisher: GPU = OpenGL Pipeline mit Shadern Alles orientiert sich am Rendering Programme für Eckpunkte und
CUDA. (Compute Unified Device Architecture) Thomas Trost. May 31 th 2016
 Thomas Trost. May 31 th 2016") CUDA (Compute Unified Device Architecture) Thomas Trost May 31 th 2016 Introduction and Overview platform and API for parallel computing on GPUs by NVIDIA relatively straightforward general purpose use
CUDA (Compute Unified Device Architecture) Thomas Trost May 31 th 2016 Introduction and Overview platform and API for parallel computing on GPUs by NVIDIA relatively straightforward general purpose use
Neue Dual-CPU Server mit Intel Xeon Scalable Performance (Codename Purley/Skylake-SP)
") Neue Dual-CPU Server mit Intel Xeon Scalable Performance (Codename Purley/Skylake-SP) @wefinet Werner Fischer, Thomas-Krenn.AG Webinar, 17. Oktober 2017 Intel Xeon Scalable Performance _ Das ist NEU: Neue
Neue Dual-CPU Server mit Intel Xeon Scalable Performance (Codename Purley/Skylake-SP) @wefinet Werner Fischer, Thomas-Krenn.AG Webinar, 17. Oktober 2017 Intel Xeon Scalable Performance _ Das ist NEU: Neue
CUDA. Jürgen Pröll. Multi-Core Architectures and Programming. Friedrich-Alexander-Universität Erlangen-Nürnberg Jürgen Pröll 1
 CUDA Jürgen Pröll Multi-Core Architectures and Programming Jürgen Pröll 1 Image-Resize: sequentiell resize() mit bilinearer Interpolation leicht zu parallelisieren, da einzelne Punkte voneinander unabhängig
CUDA Jürgen Pröll Multi-Core Architectures and Programming Jürgen Pröll 1 Image-Resize: sequentiell resize() mit bilinearer Interpolation leicht zu parallelisieren, da einzelne Punkte voneinander unabhängig
Compute Unified Device Architecture (CUDA)
") Compute Unified Device Architecture (CUDA) Thomas Koller 12. Februar 2012 Zusammenfassung Diese Ausarbeitung beschäftigt sich mit der Programmierung von Grafikkarten mittels CUDA. Bei bestimmten Berechnungen
Compute Unified Device Architecture (CUDA) Thomas Koller 12. Februar 2012 Zusammenfassung Diese Ausarbeitung beschäftigt sich mit der Programmierung von Grafikkarten mittels CUDA. Bei bestimmten Berechnungen
Multi- und Many-Core
 Multi- und Many-Core Benjamin Warnke Arbeitsbereich Wissenschaftliches Rechnen Fachbereich Informatik Fakultät für Mathematik, Informatik und Naturwissenschaften Universität Hamburg 2016-12-15 Benjamin
Multi- und Many-Core Benjamin Warnke Arbeitsbereich Wissenschaftliches Rechnen Fachbereich Informatik Fakultät für Mathematik, Informatik und Naturwissenschaften Universität Hamburg 2016-12-15 Benjamin
PGI Accelerator Model
 PGI Accelerator Model Philip Höhlein, Nils Werner Supervision: R. Membarth, P. Kutzer, F. Hannig Hardware-Software-Co-Design Universität Erlangen-Nürnberg Philip Höhlein, Nils Werner 1 Übersicht Motivation
PGI Accelerator Model Philip Höhlein, Nils Werner Supervision: R. Membarth, P. Kutzer, F. Hannig Hardware-Software-Co-Design Universität Erlangen-Nürnberg Philip Höhlein, Nils Werner 1 Übersicht Motivation
 Übersicht 1. Anzeigegeräte 2. Framebuffer 3. Grundlagen 3D Computergrafik 4. Polygongrafik, Z-Buffer 5. Texture-Mapping/Shading 6. GPU 7. Programmierbare Shader 1 LCD/TFT Technik Rotation der Licht-Polarisationsebene
Übersicht 1. Anzeigegeräte 2. Framebuffer 3. Grundlagen 3D Computergrafik 4. Polygongrafik, Z-Buffer 5. Texture-Mapping/Shading 6. GPU 7. Programmierbare Shader 1 LCD/TFT Technik Rotation der Licht-Polarisationsebene
Multi-Core Architectures and Programming. Bilateral Grid Filter
 Multi-Core Architectures and Programming Bilateral Grid Filter - Parallelisierung mit CUDA - C. Kugler und E. Sert Inhalt Motivation Bilateral Filter (Exkurs) Bilateral Grid Filter Portierung auf Grafikkarte
Multi-Core Architectures and Programming Bilateral Grid Filter - Parallelisierung mit CUDA - C. Kugler und E. Sert Inhalt Motivation Bilateral Filter (Exkurs) Bilateral Grid Filter Portierung auf Grafikkarte
Objekterkennung mit künstlichen neuronalen Netzen
 Objekterkennung mit künstlichen neuronalen Netzen Frank Hallas und Alexander Butiu Universität Erlangen Nürnberg, Lehrstuhl für Hardware/Software CoDesign Multicorearchitectures and Programming Seminar,
Objekterkennung mit künstlichen neuronalen Netzen Frank Hallas und Alexander Butiu Universität Erlangen Nürnberg, Lehrstuhl für Hardware/Software CoDesign Multicorearchitectures and Programming Seminar,
Untersuchung und Vorstellung moderner Grafikchiparchitekturen
 Fakultät Informatik, Institut für Technische Informatik, Professur für VLSI-Entwurfssysteme, Diagnostik und Architektur Untersuchung und Vorstellung moderner Grafikchiparchitekturen Hauptseminar Technische
Fakultät Informatik, Institut für Technische Informatik, Professur für VLSI-Entwurfssysteme, Diagnostik und Architektur Untersuchung und Vorstellung moderner Grafikchiparchitekturen Hauptseminar Technische
Introduction Workshop 11th 12th November 2013
 Introduction Workshop 11th 12th November 2013 Lecture I: Hardware and Applications Dr. Andreas Wolf Gruppenleiter Hochleistungsrechnen Hochschulrechenzentrum Overview Current and next System Hardware Sections
Introduction Workshop 11th 12th November 2013 Lecture I: Hardware and Applications Dr. Andreas Wolf Gruppenleiter Hochleistungsrechnen Hochschulrechenzentrum Overview Current and next System Hardware Sections
2.6 Graphikprozessoren
 12 2.6 Graphikprozessoren Peter Marwedel Informatik 12 TU Dortmund 2012/04/16 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken ist im Allgemeinen nicht erlaubt.
12 2.6 Graphikprozessoren Peter Marwedel Informatik 12 TU Dortmund 2012/04/16 Diese Folien enthalten Graphiken mit Nutzungseinschränkungen. Das Kopieren der Graphiken ist im Allgemeinen nicht erlaubt.
Parallelisierung auf CUDA
 Parallelisierung auf CUDA Seminar Multi-Core Architectures and Programming 1 Übersicht RSA-Faktorisierung Image Flooding 2 RSA-Faktorisierung Erster Ansatz Implementierung des Pollard-Rho Algorithmus (sequentiell)
Parallelisierung auf CUDA Seminar Multi-Core Architectures and Programming 1 Übersicht RSA-Faktorisierung Image Flooding 2 RSA-Faktorisierung Erster Ansatz Implementierung des Pollard-Rho Algorithmus (sequentiell)
Verteidigung der Bachelorarbeit, Willi Mentzel
 Verteidigung der Bachelorarbeit, Willi Mentzel Motivation U.S. Energy Consumption Breakdown 3x Durchschnittliche Leistungsaufnahme 114 Millionen kw Hohes Optimierungspotential 2 Ziele für Energieoptimierung
Verteidigung der Bachelorarbeit, Willi Mentzel Motivation U.S. Energy Consumption Breakdown 3x Durchschnittliche Leistungsaufnahme 114 Millionen kw Hohes Optimierungspotential 2 Ziele für Energieoptimierung