Physische Datenorganisation
|
|
|
- Moritz Kaufer
- vor 7 Jahren
- Abrufe
Transkript
1 Vorlesung Datenbanksysteme vom Physische Datenorganisation Architektur eines DBMS Speicherhierarchie Index-Verfahren Ballung (Clustering) beste Zugriffsmethode
2 Architektur eines DBMS Wichtigste SW-Komponenten eines DBMS SW-Komponenten der physischen Speicherorganisation
3 Architektur eines DBMS 3
4 Disk Space Manager: Verwaltet die Daten auf der Platte Die höheren Schichten des DBMS sehen keine HW-Details sondern nur noch eine Sammlung von Seiten Disk Space Manager stellt Routinen bereit für Allokieren / Deallokieren von Seiten Lesen / Schreiben einer Seite Bemerkung: 1 Seite entspricht einem oder mehreren Blöcken auf der Platte Lesen/Schreiben einer Seite in einem I/O-Vorgang Die meisten DB-Systeme haben eigenes Disk Management (und erweitern nicht bloß die File System Funktionen des OS) flexibler, größere OS-Unabhängigkeit 4
5 Buffer Manager: Verwaltet den Datenbankpuffer (buffer pool) im Hauptspeicher Bearbeitung von Daten kann immer nur im Hauptspeicher (und nicht direkt auf der Platte) geschehen. Seiten müssen von der Platte in den Datenbankpuffer gelesen und später wieder auf Platte zurückgeschrieben werden. Buffer Manager ist für das Einlesen und Auslagern von Seiten zw. Datenbankpuffer und Platte verantwortlich. Die anderen Schichten des DBMS fordern einfach eine Seite an. Buffer Manager speichert zu jeder Seite im Puffer Information: ob die Seite noch verwendet wird: in diesem Fall darf die Seite nicht durch andere Seiten überschrieben werden. ob die Seite geändert wurde: nur in diesem Fall ist Zurückschreiben auf Platte nötig 5
6 Files and Access Methods Layer: Die Zeilen einer DB-Tabelle (= Tupeln einer Relation) haben im Allgemeinen nicht auf einer einzelnen Seite Platz. Logisch zusammengehörige Seiten werden als File verwaltet. Zwei Hauptaufgaben dieses Software Layers: 1. Verwaltung der Seiten eines Files (entspricht üblicherweise einer Tabelle): Heap file : Zufällige Verteilung der Tupeln auf die Seiten Index file : Spezielle Verteilung der Tupeln auf die Seiten zwecks Optimierung bestimmter Zugriffe. 2. Verwaltung der Tupeln innerhalb einer einzelnen Seite: Seitenformat: Tupeln mit fixer oder variabler Länge Zugriff der anderen SW-Schichten auf die einzelnen Tupeln: mit TID (Tupelidentifikator) (engl.: RID: record ID), d.h. Seiten-ID + Speicherplatz innerhalb der Seite 6
7 Speicherhierarchie Primärer / sekundärer / tertiärer Speicher Zugriffszeiten Puffer-Verwaltung Adressierung von Tupeln
8 Überblick: Speicherhierarchie Register Cache Hauptspeicher Plattenspeicher Primärspeicher Sekundärspeicher Archivspeicher Tertiärspeicher 8
9 Überblick: Speicherhierarchie Register kleine Kapazität, hohe Geschwindigkeit Cache Hauptspeicher Plattenspeicher unbegrenzte Kapazität, niedrige Geschwindigkeit Archivspeicher 9
10 Überblick: Speicherhierarchie < 1ns Register > 1ns Cache 100ns Hauptspeicher 10 ms Plattenspeicher sec Archivspeicher Zugriffslücke
11 Lesen von Daten von der Platte Seek Time: Arm auf gewünschte Spur positionieren: ca. 4ms Latenzzeit (= rotational delay ): Warten, bis sich der gesuchte Block am Kopf vorbeibewegt (durchschnittlich ½ Plattenumdrehung; Umdrehungen / min) ca. 3ms Transfer von der Platte zum Hauptspeicher: (1000 Mb/s) ca. 150 MB/s Bemerkung: Sektor: physikalische Größe der Platte, meist 512B Block: kleinste Lese/Schreib- Einheit (= mehrere Sektoren), z.b.: 4kB, 8kB 11
12 Random versus Chained IO Beispiel: 1000 Blöcke à 4KB sind zu lesen Random I/O Jedes Mal Arm positionieren Jedes Mal Latenzzeit 1000 * (4 ms + 3 ms) + Transferzeit von 4 MB ca ms + 30ms ca. 7s Chained I/O Ein Mal positionieren, dann von der Platte kratzen 4 ms + 3ms + Transferzeit von 4 MB ca. 7ms + 30 ms ca. 40ms Also ist chained IO ein bis zwei Größenordnungen schneller als random IO in Datenbank-Algorithmen unbedingt beachten! 12
13 Up to date latency times Interessante Webseite: Latency Numbers Every Programmer Should Know Beispiele: L1 cache reference: 1ns Main memory reference: 100 ns Reading 1MByte sequentially from memory: 150 µs SSD random read: 17 µs Reading 1MByte sequentially from SSD: 2ms Disk seek time: 8ms Reading 1MByte sequentially from disk: 9ms Packet round trip in same data center: 500 µs Packet round trip Europe/USA: 150 ms 13
14 Datenbankpuffer-Verwaltung Hauptspeicher Bemerkung: DBMS greift nie direkt auf eine Seite (= Block) des Hintergrundspeichers zu Seite muss zuerst in den Hauptspeicher (Datenbankpuffer) gelesen werden. einlagern verdrängen Platte ~ persistente DB 14
15 Ein- und Auslagern von Seiten DB-Puffer ist in Seitenrahmen gleicher Größe aufgeteilt. Ein Rahmen kann eine Seite aufnehmen. Überzählige Seiten werden auf die Platte ausgelagert. Hauptspeicher 0 4K 8K 12K Platte 16K 20K 24K 28K P123 32K 36K 40K 44K P480 48K 52K 56K 60K Seitenrahmen Seite 15
16 Adressierung von Tupeln auf dem Hintergrundspeicher 16
17 Verschiebung innerhalb einer Seite 17
18 Verschiebung von einer Seite auf eine andere Forward 18
19 Verschiebung von einer Seite auf eine andere Bei der nächsten Verschiebung wird der Forward auf Seite 4711 geändert (kein Forward auf Seite 4812) 19
20 Index-Verfahren B-Bäume B + -Bäume Hashing R-Bäume
21 B-Bäume Problemstellung: Normale Binär-Bäume (wie AVL-Bäume, Rot/Schwarz- Bäume) sind gut geeignet für den Hauptspeicher. Bei Datenbanken benötigt man ein Verfahren, das auf die Seitengröße des Hintergrundspeichers abgestimmt ist. Lösung: B-Bäume (oder B + -Bäume) Idee von B-Bäumen (und B + -Bäumen): Die Knotengröße entspricht der Seitengröße. Der Verzweigungsgrad des Baums hängt davon ab, wie viele Einträge auf einer Seite Platz haben. Durch entsprechende Algorithmen für das Einfügen und Löschen von Daten wird garantiert, dass der Baum immer ausbalanciert ist logarithmische Zugriffszeiten. 21
22 D.. Weitere Daten S.. Suchschlüssel V.. Verweise (SeitenNr) 22
23 23
24 24
25 Einfügen eines neuen Objekts (Datensatz) in einen B-Baum 25
26 Beispiel 1 B-Baum vom Grad k = 2 Ausgangssituation: 1 Knoten mit Schlüssel-Werten 10, 13, 19 Sukzessiver Aufbau des Baums durch das Einfügen neuer Schlüssel-Werte: 7, 3, 1, 2, 4 26
27 Beispiel
28 Beispiel
29 Beispiel 1?
30 Beispiel 1?
31 Beispiel 1 10?
32 Beispiel 1 10?
33 Beispiel ?
34 Beispiel ?
35 Beispiel 1 10?
36 Beispiel 1 10?
37 Beispiel ?
38 Beispiel ?
39 Beispiel ?
40 Beispiel ?
41 Beispiel ?
42 Beispiel ?
43 Beispiel ?
44 Beispiel 1 4 4?
45 Beispiel 1?
46 Beispiel 2 B-Baum vom Grad k = 2 Ausgangssituation: Baum der Tiefe 2 Die Wurzel hat bereits den maximalen Füllstand erreicht Einfügen eines weiteren Knotens führt zur Teilung eines Blattknotens Teilung des Blattknotens führt nun zur Teilung der Wurzel Resultat: Baum der Tiefe 3 46
47 Beispiel 2 8?
48 Beispiel 2 8?
49 Beispiel 2 8?
50 Beispiel 2 8?
51 Beispiel 2 8?
52 Beispiel 2 6?
53 Beispiel 2 6?
54 Beispiel 2 6?
55 Beispiel 2 6?
56 Beispiel ?
57 Beispiel ?
58 Beispiel ?
59 Beispiel ?
60 Beispiel 2 10 B-Baum mit Minimaler Speicherplatzausnutzung ?
61 Beispiel 3 B-Baum vom Grad k = 2 Ausgangssituation: Einige Knoten haben minimalen Füllstand Löschen von Schlüsselwerten führt zu Unterlauf. Ausgleich mit einem Nachbarknoten erforderlich. 61
62 Beispiel ?
63 Beispiel ?

64 Beispiel ? 19 Unterlauf
65 Beispiel ? 19 Unterlauf
66 Beispiel ?
67 Beispiel 4 B-Baum vom Grad k = 2 Ausgangssituation: Baum der Tiefe 3 Einige Knoten haben minimalen Füllstand Löschen von Schlüsselwerten führt zu Unterlauf Da die Nachbarknoten ebenfalls minimalen Füllstand haben, müssen 2 Knoten verschmolzen werden. Durch das Verschmelzen kann es zu einem Unterlauf des Vaterknotens kommen. Vorgang wird wiederholt. Resultat: Baum der Tiefe 2 67
68 Beispiel ?

69 Beispiel ? Unterlauf
70 Beispiel ? merge
71 Beispiel ? merge
72 Beispiel 4 Unterlauf ?
73 Beispiel 4 merge ?
74 Beispiel 4 merge ?
75 Beispiel ?
76 Beispiel 4 Schrumpfung, Freie Knoten ?
77 Beispiel
78 Speicherstruktur eines B-Baums auf dem Hintergrundspeicher 4 Seite Nr 4 78
79 Speicherstruktur eines B-Baums auf dem Hintergrundspeicher 0*8KB 1*8KB 2*8KB 3*8KB 4*8KB 8 KB-Blöcke 3 0 Seitennummer Datei 79
80 Speicherstruktur eines B-Baums auf dem Hintergrundspeicher 0*8KB 1*8KB 2*8KB 3*8KB 4*8KB 8 KB-Blöcke 3 0 Seitennummer Datei 80
81 Speicherstruktur eines B-Baums auf dem Hintergrundspeicher 0*8KB 1*8KB 2*8KB 3*8KB 4*8KB Block- Nummer 0 8 KB-Blöcke Datei
82 Zusammenspiel: Hintergrundspeicher -- Hauptspeicher Hintergrundspeicher Datenbank- Puffer 4 4 Zugriffslücke
83 B + -Bäume Ziel bei B-Bäumen: geringe Tiefe. Dafür benötigt man hohen Verzweigungsgrad (d.h.: viele Kinder pro Knoten) Verzweigungsgrad wird bestimmt durch die Anzahl der Datensätze in einem Knoten Idee von B + -Bäumen: Daten werden ausschließlich in den Blättern gespeichert Die inneren Knoten dienen nur noch der Navigation, d.h.: Sie enthalten Referenzschlüssel und Verweise (aber keine weiteren Daten). Da Referenzschlüssel im Allgemeinen weniger Platz brauchen als vollst. Datensätze, erhöht sich der Verzweigungsgrad. Zusätzlicher Vorteil: Durch Verkettung der Blattknoten lassen sich Bereichsanfragen effizient beantworten. 83
84 B + -Baum Referenzschlüssel Suchschlüssel 84
85 Präfix B + -Bäume Idee: An den inneren Knoten werden nur Referenzschlüssel benötigt. Die Werte der Referenzschlüssel dienen nur der Navigation und müssen nicht unbedingt in den Daten existieren. Beispiel: P Curie Kant Popper Russel Anforderung an Referenzschlüssel P : Kant < P Popper 85
86 Idee von Hashing Direkte Abbildung von Werten eines Such-Schlüssels auf einen bestimmten Speicherbereich. Aufteilung des Speichers in Buckets. Jedes Bucket besteht aus einer primären Seite sowie möglicherweise 1 oder mehreren Überlaufseiten. Mittels Hashfunktion h: S B wird jedem Schlüsselwert eindeutig eine Bucket-Nummer zugeordnet. Gebräuchlichste Hashfunktionen: h(x) = x mod N (N = Anzahl der Buckets) oder: h(x) = (a*x + b) mod N (für geeignete Wahl von Konstanten a und b) Gute Hashfunktion : möglichst gleichmäßige Verteilung der möglichen Schlüsselwerte auf die Buckets. 86
87 Statisches Hashing A priori Allokation des Speichers, d.h.: jedes Bucket besteht exakt aus 1 Seite (= primäre Seite). Bei Überlauf einer Seite wird eine weitere Seite zum Bucket hinzugefügt (= Überlaufseite). Mit der Zeit können sehr viele Überlaufseiten entstehen Suchen innerhalb eines Buckets wird teuer. Lösung 1: Nachträgliche Vergrößerung der Hashtabelle Rehashing der Einträge Hashfunktion h(...) =... mod N wird ersetzt durch h(...) =... mod M (mit M > N) In Datenbankanwendungen: viele GB sehr teuer Lösung 2: Erweiterbares Hashing 87
88 Statisches Hashing 88
89 Erweiterbares Hashing zusätzliche Indirektion über ein Directory Directory enthält einen Zeiger (Seiten-Nr) des Hash-Bucket Dynamisches Wachsen und Schrumpfen ist möglich (ohne Überlaufseiten). Der Zugriff auf das Directory erfolgt über einen binären Hashcode (d.h.: Strings aus 0 und 1). Der Zugriff auf die Buckets erfolgt im Stil eines (i.a. nicht ausbalancierten) binären Entscheidungsbaums (= Trie ). Jeder Pfad im Trie entspricht einem String aus 0 und 1. 89
90 binärer Trie, Entscheidungsbaum Directory Bucket Bucket Bucket Bucket Bucket Bucket 90
91 91
92 Hashfunktion für erweiterbares Hashing h: Schlüsselmenge {0,1}* Der Bitstring muss lang genug sein, um alle Objekte auf ihre Buckets abbilden zu können Anfangs wird nur ein (kurzes) Präfix des Hash-Wertes (Bitstrings) benötigt. Wenn die Hashtabelle wächst, wird aber sukzessive ein längeres Präfix benötigt. Das Directory wird jeweils verdoppelt. Globale Tiefe (des Directory): Momentan verwendete Anzahl der Bits in den Hashwerten des Directory (= max. Länge der Pfade des binären Trie). Lokale Tiefe (jedes einzelnen Buckets): Länge des Pfades (im binären Trie), der auf dieses Bucket zeigt. 92

93 Beispiel- Hashfunktion: gespiegelte PersNr 93
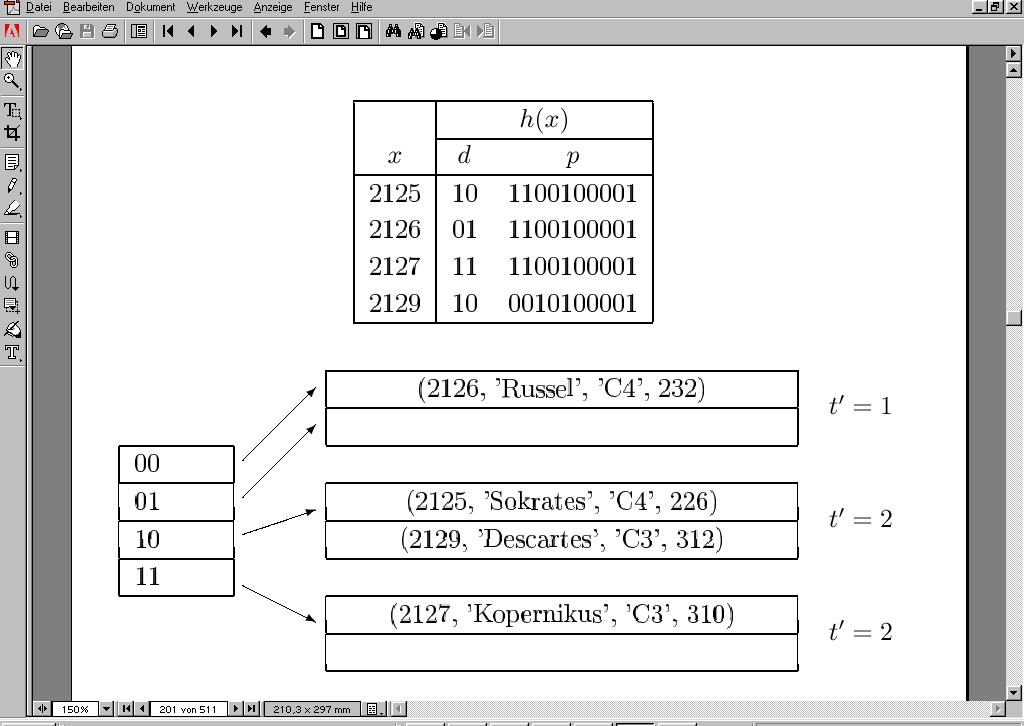
94 94
95 R-Bäume Ursprüngliche Motivation: Indexe für geometrische Daten Allgemeine Verwendungsmöglichkeit: Indexierung von mehreren Attributen (= Dimensionen) R-Baum = balancierter Baum. Die inneren Knoten dienen nur der Navigation; Daten nur an den Blättern (wie B + -Baum). Einträge eines inneren Knoten: Anstelle eines Referenzschlüssels enthält jeder Eintrag die Beschreibung einer n-dimensionalen Box. Verweis auf einen Nachfolger-Knoten. Alle Datenpunkte bzw. alle Boxes der Nachfolger müssen innerhalb der Box des Vorgängers liegen. 95
96 R-Baum: Urvater der baum-strukturierten mehrdimensionalen Zugriffsstrukturen [18,60] [60,120] K 80K 70K 60K Bond Mini Mickey Duck 60 Bond 40 Mickey Alter 20 Duck Mini 40K 60K 80K 100K 120K Gehalt 96
97 Gute vs. schlechte Partitionierung gute Partitionierung schlechte Partitionierung Mickey Bond Mickey Bond Alter Duck Mini Speedy Alter Duck Mini Speedy Gehalt Gehalt 97
98 Nächste Phase in der Entstehungsgeschichte des R-Baums [18,43] [60,80] [40,60] [100,120] 20 80K Mini 43 70K Mickey 18 60K Duck K K Bert (noch nicht eingefügt) Bond Bond Speedy Mickey Alter Duck Mini Speedy Gehalt 98
99 Bereichsanfragen auf dem R-Baum Anfragefenster [18,50] [25,65] [45,80] [95,120] Lucie Bond Sepp [18,20] [41,45] [41,50] Bert Mickey [60,80] [45,55] [60,70] [25,60] [110,120] [40,65] [95,100] Alter Ernie Duck Jan Speedy Mini Urmel Bill K Mickey 60K Jan 65K Sepp K Speedy 65 95K Lucie Beispiel: Gehaltfinde alle Tupel mit Alter in [47,67] und Gehalt in [55K,115K]. 99
100 100 [60,80] [18,20] [45,55] [41,45] [60,70] [41,50] [110,120] [25,60] [95,100] [40,65] [45,80] [18,50] [95,120] [25,65] Jan 60K 41 Sepp 65K 50 Mickey 70K 43 Speedy 100K 40 Lucie 95K 65 Mini 80K 20 Duck 60K 18 Bond 120K 60 Urmel 112K 35 Bert 55K 45 Ernie 45K 41 Bill 110K 25
101 Ballung Logisch verwandte Daten liegen am Hintergrundspeicher nahe beieinander
102 Objektballung / Clustering logisch verwandter Daten 102
103 103
104 104
105 Indexe und Ballung Geballter Index = Index, bei dem die Anordnung der Daten-Tupel der Ordnung der Einträge im Index entspricht. Beispiel: Angenommen, die Zeilen der Tabelle Student sind auf der Platte nach MatrNr sortiert. Index für Attribut MatrNr: geballt Index für Attribut Semester: nicht geballt Nutzen der Ballung bei unterschiedlichen Anfragen: Punktanfrage (exact match): Ballung irrelevant Bereichsanfrage (range selection): Ballung entscheidend Beispiel: Select * From Studenten Where Semester > 6; bei geballtem Index: Suche ersten Treffer (mittels Index) und durchlaufe ab hier alle Datensätze, solange die Bedingung erfüllt ist. 105
106 Index-Einträge und Daten Zwei Alternativen: 1. Der Index enthält (neben der Steuerinformation des Index) die Daten selbst, z.b.: B + -Index: Zeilen der Tabelle stehen in den Blattknoten Hash-Index: Zeilen der Tabelle stehen in den Buckets 2. Der Index enthält nur Verweise auf die Daten, d.h.: TIDs Auswirkung auf Ballung: Index mit Alternative 1 ist immer geballt. Index mit Alternative 2 kann geballt sein (falls die Zeilen der Tabelle entsprechend dem Suchschlüssel sortiert sind) 106
107 Verweis auf Datensatz mittels Tupelidentifikator (TID) 107
108 108
109 Beste Zugriffsmethode Beobachtung: Beste Methode hängt vom Anwendungsfall ab.
110 Anwendungsfall Select Name From Professoren Where PersNr = 2136 Select Name From Professoren Where Gehalt >= and Gehalt <=
111 Beste Methode Die wichtigsten Zugriffsmethoden: Heap File (ungeordnet bzw. kein passender Index) sortierte Datei geballter Index nicht geballter Index Die wichtigsten Anwendungsfälle: Durchlaufen des gesamten File (scan) Punktanfrage (exact match) Bereichsanfrage (range selection) Einfügen (insert) Löschen (delete) 111
112 Beste Methode Beste Methode hängt vom Anwendungsfall ab, d.h.: Es gibt keine Methode, die immer besser ist als die anderen, z.b.: Bei Punktanfragen ist Hash-Index im Allgemeinen etwas schneller als ein B + -Baum. Bei Bereichsanfragen ist Hash-Index wesentlich schlechter als ein B + -Baum. Bei einer Bereichsanfrage mit vielen Treffern wird auch ein nicht geballter B + -Baum schlechter (wegen Random I/O). Beim Einfügen ist ein ungeordnetes File am schnellsten. Gutes Verhalten in allen Lebenslagen : B + -Baum 112
113 Indexe in SQL Create index SemsterInd on Studenten (Semester) default Methode: B+-tree oder: Create index SemsterInd using hash on Studenten (Semester) drop index SemsterInd 113
Kapitel 7 Physische Datenorganisation. Speicherhierarchie Hintergrundspeicher / RAID Speicherstrukturen B-Bäume Hashing R-Bäume
 Kapitel 7 Physische Datenorganisation Speicherhierarchie Hintergrundspeicher / RAID Speicherstrukturen B-Bäume Hashing R-Bäume Überblick: Speicherhierarchie Register (L1/L2/L3) Cache Hauptspeicher Plattenspeicher
Kapitel 7 Physische Datenorganisation Speicherhierarchie Hintergrundspeicher / RAID Speicherstrukturen B-Bäume Hashing R-Bäume Überblick: Speicherhierarchie Register (L1/L2/L3) Cache Hauptspeicher Plattenspeicher
Kapitel 7 Physische Datenorganisation. Speicherhierarchie Hintergrundspeicher / RAID B-Bäume Hashing R-Bäume
 Kapitel 7 Physische Datenorganisation Speicherhierarchie Hintergrundspeicher / RAID B-Bäume Hashing R-Bäume Überblick: Speicherhierarchie Register (L1/L2/L3) Cache Hauptspeicher Plattenspeicher Archivspeicher
Kapitel 7 Physische Datenorganisation Speicherhierarchie Hintergrundspeicher / RAID B-Bäume Hashing R-Bäume Überblick: Speicherhierarchie Register (L1/L2/L3) Cache Hauptspeicher Plattenspeicher Archivspeicher
Physische Datenorganisation
 Physische Datenorganisation Physische Datenorganisation 2002 Prof. Dr. Rainer Manthey Informationssysteme 1 Übersicht Datenbanken, Relationen und Tupel werden auf der untersten Ebene der bereits vorgestellten
Physische Datenorganisation Physische Datenorganisation 2002 Prof. Dr. Rainer Manthey Informationssysteme 1 Übersicht Datenbanken, Relationen und Tupel werden auf der untersten Ebene der bereits vorgestellten
Kapitel 8: Physischer Datenbankentwurf
 8. Physischer Datenbankentwurf Seite 1 Kapitel 8: Physischer Datenbankentwurf Speicherung und Verwaltung der Relationen einer relationalen Datenbank so, dass eine möglichst große Effizienz der einzelnen
8. Physischer Datenbankentwurf Seite 1 Kapitel 8: Physischer Datenbankentwurf Speicherung und Verwaltung der Relationen einer relationalen Datenbank so, dass eine möglichst große Effizienz der einzelnen
Physischer Datenbankentwurf: Datenspeicherung
 Datenspeicherung.1 Physischer Datenbankentwurf: Datenspeicherung Beim Entwurf des konzeptuellen Schemas wird definiert, welche Daten benötigt werden und wie sie zusammenhängen (logische Datenbank). Beim
Datenspeicherung.1 Physischer Datenbankentwurf: Datenspeicherung Beim Entwurf des konzeptuellen Schemas wird definiert, welche Daten benötigt werden und wie sie zusammenhängen (logische Datenbank). Beim
Physische Datenorganisation
 Web Science & Technologies University of Koblenz Landau, Germany Grundlagen der Datenbanken Dr. Jérôme Kunegis Wintersemester 2013/14 Zugriffshierarchie 2 Eigenschaften der Datenträger 8 32 Mb CPU Cache
Web Science & Technologies University of Koblenz Landau, Germany Grundlagen der Datenbanken Dr. Jérôme Kunegis Wintersemester 2013/14 Zugriffshierarchie 2 Eigenschaften der Datenträger 8 32 Mb CPU Cache
! DBMS organisiert die Daten so, dass minimal viele Plattenzugriffe nötig sind.
 Unterschiede von DBMS und files Speichern von Daten! DBMS unterstützt viele Benutzer, die gleichzeitig auf dieselben Daten zugreifen concurrency control.! DBMS speichert mehr Daten als in den Hauptspeicher
Unterschiede von DBMS und files Speichern von Daten! DBMS unterstützt viele Benutzer, die gleichzeitig auf dieselben Daten zugreifen concurrency control.! DBMS speichert mehr Daten als in den Hauptspeicher
6. Formaler Datenbankentwurf 6.1. Rückblick. Datenbanken und Informationssysteme, WS 2012/13 22. Januar 2013 Seite 1
 6. Formaler Datenbankentwurf 6.1. Rückblick 3. Normalform Ein Relationsschema R = (V, F) ist in 3. Normalform (3NF) genau dann, wenn jedes NSA A V die folgende Bedingung erfüllt. Wenn X A F, A X, dann
6. Formaler Datenbankentwurf 6.1. Rückblick 3. Normalform Ein Relationsschema R = (V, F) ist in 3. Normalform (3NF) genau dann, wenn jedes NSA A V die folgende Bedingung erfüllt. Wenn X A F, A X, dann
Physische Datenorganisation
 Physische atenorganisation Speicherhierarchie Hintergrundspeicher / RI ( -äume Hashing R-äume ) Überblick: Speicherhierarchie Register ache 1 8 yte ompiler 8 128 yte ache-ontroller Plattenspeicher rchivspeicher
Physische atenorganisation Speicherhierarchie Hintergrundspeicher / RI ( -äume Hashing R-äume ) Überblick: Speicherhierarchie Register ache 1 8 yte ompiler 8 128 yte ache-ontroller Plattenspeicher rchivspeicher
Dateiorganisation und Zugriffsstrukturen
 Dateiorganisation und Zugriffsstrukturen Prof. Dr. T. Kudraß 1 Mögliche Dateiorganisationen Viele Alternativen existieren, jede geeignet für bestimmte Situation (oder auch nicht) Heap-Dateien: Geeignet
Dateiorganisation und Zugriffsstrukturen Prof. Dr. T. Kudraß 1 Mögliche Dateiorganisationen Viele Alternativen existieren, jede geeignet für bestimmte Situation (oder auch nicht) Heap-Dateien: Geeignet
Übung Datenbanksysteme II Physische Speicherstrukturen. Thorsten Papenbrock
 Übung Datenbanksysteme II Physische Speicherstrukturen Thorsten Papenbrock Organisatorisches: Übung Datenbanksysteme II 2 Übung Thorsten Papenbrock (thorsten.papenbrock@hpi.uni-potsdam.de) Tutoren Alexander
Übung Datenbanksysteme II Physische Speicherstrukturen Thorsten Papenbrock Organisatorisches: Übung Datenbanksysteme II 2 Übung Thorsten Papenbrock (thorsten.papenbrock@hpi.uni-potsdam.de) Tutoren Alexander
Aufbau Datenbanksysteme
 Aufbau Datenbanksysteme Lehrveranstaltung Datenbanktechnologien Prof. Dr. Ingo Claßen Prof. Dr. Martin Kempa Hochschule für Technik und Wirtschaft Berlin Speichersystem c Ingo Claßen, Martin Kempa Softwarearchitektur
Aufbau Datenbanksysteme Lehrveranstaltung Datenbanktechnologien Prof. Dr. Ingo Claßen Prof. Dr. Martin Kempa Hochschule für Technik und Wirtschaft Berlin Speichersystem c Ingo Claßen, Martin Kempa Softwarearchitektur
Baum-Indexverfahren. Einführung
 Baum-Indexverfahren Prof. Dr. T. Kudraß 1 Einführung Drei Alternativen, wie Dateneinträge k* im Index aussehen können: 1. Datensatz mit Schlüsselwert k 2.
Baum-Indexverfahren Prof. Dr. T. Kudraß 1 Einführung Drei Alternativen, wie Dateneinträge k* im Index aussehen können: 1. Datensatz mit Schlüsselwert k 2.
Baum-Indexverfahren. Prof. Dr. T. Kudraß 1
 Baum-Indexverfahren Prof. Dr. T. Kudraß 1 Einführung Drei Alternativen, wie Dateneinträge k* im Index aussehen können: 1. Datensatz mit Schlüsselwert k 2.
Baum-Indexverfahren Prof. Dr. T. Kudraß 1 Einführung Drei Alternativen, wie Dateneinträge k* im Index aussehen können: 1. Datensatz mit Schlüsselwert k 2.
Aufgabe 1 Indexstrukturen
 8. Übung zur Vorlesung Datenbanken im Sommersemester 2006 mit Musterlösungen Prof. Dr. Gerd Stumme, Dr. Andreas Hotho, Dipl.-Inform. Christoph Schmitz 25. Juni 2006 Aufgabe 1 Indexstrukturen Zeichnen Sie
8. Übung zur Vorlesung Datenbanken im Sommersemester 2006 mit Musterlösungen Prof. Dr. Gerd Stumme, Dr. Andreas Hotho, Dipl.-Inform. Christoph Schmitz 25. Juni 2006 Aufgabe 1 Indexstrukturen Zeichnen Sie
Cluster-Bildung. VL Datenbanken II 4 107
 Cluster-Bildung gemeinsame Speicherung von Datensätzen auf Seiten wichtige Spezialfälle: Ballung nach Schlüsselattributen. Bereichsanfragen und Gruppierungen unterstützen: Datensätze in der Sortierreihenfolge
Cluster-Bildung gemeinsame Speicherung von Datensätzen auf Seiten wichtige Spezialfälle: Ballung nach Schlüsselattributen. Bereichsanfragen und Gruppierungen unterstützen: Datensätze in der Sortierreihenfolge
Anfragebearbeitung 2. Vorlesung Datenbanksysteme vom
 Vorlesung Datenbanksysteme vom 21.11.2016 Anfragebearbeitung 2 Architektur eines DBMS Logische Optimierung Physische Optimierung Kostenmodelle + Tuning Physische Optimierung Iterator: einheitliche Schnittstelle
Vorlesung Datenbanksysteme vom 21.11.2016 Anfragebearbeitung 2 Architektur eines DBMS Logische Optimierung Physische Optimierung Kostenmodelle + Tuning Physische Optimierung Iterator: einheitliche Schnittstelle
Gleichheitsanfrage vs. Bereichsanfrage
 Datenbank Indexe Gleichheitsanfrage vs. Bereichsanfrage Gleichheitsanfrage (single key-value) : Abfragen, die eine Bedingung mit = haben Finde den Namen des Studenten mit Alter = 20 Bereichsanfrage (range
Datenbank Indexe Gleichheitsanfrage vs. Bereichsanfrage Gleichheitsanfrage (single key-value) : Abfragen, die eine Bedingung mit = haben Finde den Namen des Studenten mit Alter = 20 Bereichsanfrage (range
OPERATIONEN AUF EINER DATENBANK
 Einführung 1 OPERATIONEN AUF EINER DATENBANK Ein Benutzer stellt eine Anfrage: Die Benutzer einer Datenbank können meist sowohl interaktiv als auch über Anwendungen Anfragen an eine Datenbank stellen:
Einführung 1 OPERATIONEN AUF EINER DATENBANK Ein Benutzer stellt eine Anfrage: Die Benutzer einer Datenbank können meist sowohl interaktiv als auch über Anwendungen Anfragen an eine Datenbank stellen:
Speicherstrukturen und Zugriffssystem
 Speicherhierarchie Speicherhierarchie CPU Register Kapazität Bytes Zugriffszeit 1-5 ns Cache First-Level-Cache Second-Level-Cache Kilo-/Megabytes 2 10-2 20 2-20 ns Hauptspeicher Gigabytes 2 30 10-100 ns
Speicherhierarchie Speicherhierarchie CPU Register Kapazität Bytes Zugriffszeit 1-5 ns Cache First-Level-Cache Second-Level-Cache Kilo-/Megabytes 2 10-2 20 2-20 ns Hauptspeicher Gigabytes 2 30 10-100 ns
Bäume, Suchbäume und Hash-Tabellen
 Im folgenden Fokus auf Datenstrukturen, welche den assoziativen Zugriff (über einen bestimmten Wert als Suchkriterium) optimieren Bäume: Abbildung bzw. Vorberechnung von Entscheidungen während der Suche
Im folgenden Fokus auf Datenstrukturen, welche den assoziativen Zugriff (über einen bestimmten Wert als Suchkriterium) optimieren Bäume: Abbildung bzw. Vorberechnung von Entscheidungen während der Suche
Physische Datenorganisation. Kapitel 6 245 / 520
 Kapitel 6 Physische Datenorganisation 245 / 520 Speicherhierarchie Speicherhierarchie Verschiedene Schichten der Speicherung Je höher in der Hierarchie, desto schneller, teurer und kleiner Unterschiede
Kapitel 6 Physische Datenorganisation 245 / 520 Speicherhierarchie Speicherhierarchie Verschiedene Schichten der Speicherung Je höher in der Hierarchie, desto schneller, teurer und kleiner Unterschiede
B-Bäume I. Algorithmen und Datenstrukturen 220 DATABASE SYSTEMS GROUP
 B-Bäume I Annahme: Sei die Anzahl der Objekte und damit der Datensätze. Das Datenvolumen ist zu groß, um im Hauptspeicher gehalten zu werden, z.b. 10. Datensätze auf externen Speicher auslagern, z.b. Festplatte
B-Bäume I Annahme: Sei die Anzahl der Objekte und damit der Datensätze. Das Datenvolumen ist zu groß, um im Hauptspeicher gehalten zu werden, z.b. 10. Datensätze auf externen Speicher auslagern, z.b. Festplatte
1. Einfach verkettete Liste unsortiert 2. Einfach verkettete Liste sortiert 3. Doppelt verkettete Liste sortiert
 Inhalt Einführung 1. Arrays 1. Array unsortiert 2. Array sortiert 3. Heap 2. Listen 1. Einfach verkettete Liste unsortiert 2. Einfach verkettete Liste sortiert 3. Doppelt verkettete Liste sortiert 3. Bäume
Inhalt Einführung 1. Arrays 1. Array unsortiert 2. Array sortiert 3. Heap 2. Listen 1. Einfach verkettete Liste unsortiert 2. Einfach verkettete Liste sortiert 3. Doppelt verkettete Liste sortiert 3. Bäume
Datenbanksysteme II Indexstrukturen Felix Naumann
 Datenbanksysteme II Indexstrukturen (Kapitel 13) 5.5.2008 Felix Naumann Klausur 2 Mittwoch, 23.7. 9 13 Uhr 4 Stunden Umfang auf 1,5 Stunden ausgelegt Keine Hilfsmittel Motivation 3 Platzierung der Tupel
Datenbanksysteme II Indexstrukturen (Kapitel 13) 5.5.2008 Felix Naumann Klausur 2 Mittwoch, 23.7. 9 13 Uhr 4 Stunden Umfang auf 1,5 Stunden ausgelegt Keine Hilfsmittel Motivation 3 Platzierung der Tupel
4.3 Hintergrundspeicher
 4.3 Hintergrundspeicher Registers Instr./Operands Cache Blocks Memory Pages program 1-8 bytes cache cntl 8-128 bytes OS 512-4K bytes Upper Level faster Disk Tape Files user/operator Mbytes Larger Lower
4.3 Hintergrundspeicher Registers Instr./Operands Cache Blocks Memory Pages program 1-8 bytes cache cntl 8-128 bytes OS 512-4K bytes Upper Level faster Disk Tape Files user/operator Mbytes Larger Lower
SQL. SQL: Structured Query Language. Früherer Name: SEQUEL. Standardisierte Anfragesprache für relationale DBMS: SQL-89, SQL-92, SQL-99
 SQL Früherer Name: SEQUEL SQL: Structured Query Language Standardisierte Anfragesprache für relationale DBMS: SQL-89, SQL-92, SQL-99 SQL ist eine deklarative Anfragesprache Teile von SQL Vier große Teile:
SQL Früherer Name: SEQUEL SQL: Structured Query Language Standardisierte Anfragesprache für relationale DBMS: SQL-89, SQL-92, SQL-99 SQL ist eine deklarative Anfragesprache Teile von SQL Vier große Teile:
Datenbanken: Architektur & Komponenten 3-Ebenen-Architektur
 Datenbanken: Architektur & Komponenten 3-Ebenen-Architektur Moderne Datenbanksysteme sind nach der 3-Ebenen-Architektur gebaut: Anwendung 1 Web-Anwendung Anwendung 2 Java-Programm... Anwendung n Applikation
Datenbanken: Architektur & Komponenten 3-Ebenen-Architektur Moderne Datenbanksysteme sind nach der 3-Ebenen-Architektur gebaut: Anwendung 1 Web-Anwendung Anwendung 2 Java-Programm... Anwendung n Applikation
B-Bäume, Hashtabellen, Cloning/Shadowing, Copy-on-Write
 B-Bäume, Hashtabellen, Cloning/Shadowing, Copy-on-Write Thomas Maier Proseminar: Ein- / Ausgabe Stand der Wissenschaft Seite 1 von 13 Gliederung 1. Hashtabelle 3 2.B-Baum 3 2.1 Begriffserklärung 3 2.2
B-Bäume, Hashtabellen, Cloning/Shadowing, Copy-on-Write Thomas Maier Proseminar: Ein- / Ausgabe Stand der Wissenschaft Seite 1 von 13 Gliederung 1. Hashtabelle 3 2.B-Baum 3 2.1 Begriffserklärung 3 2.2
Datenbanken. Datenintegrität + Datenschutz. Tobias Galliat. Sommersemester 2012
 Datenbanken Datenintegrität + Datenschutz Tobias Galliat Sommersemester 2012 Professoren PersNr Name Rang Raum 2125 Sokrates C4 226 Russel C4 232 2127 Kopernikus C3 310 2133 Popper C3 52 2134 Augustinus
Datenbanken Datenintegrität + Datenschutz Tobias Galliat Sommersemester 2012 Professoren PersNr Name Rang Raum 2125 Sokrates C4 226 Russel C4 232 2127 Kopernikus C3 310 2133 Popper C3 52 2134 Augustinus
Kapitel 5 Dr. Jérôme Kunegis. SQL: Grundlagen. WeST Institut für Web Science & Technologien
 Kapitel 5 Dr. Jérôme Kunegis SQL: Grundlagen WeST Institut für Web Science & Technologien Lernziele Kenntnis der Grundkonzepte von SQL Fähigkeit zur praktischen Anwendung von einfachen SQL-Anweisungen
Kapitel 5 Dr. Jérôme Kunegis SQL: Grundlagen WeST Institut für Web Science & Technologien Lernziele Kenntnis der Grundkonzepte von SQL Fähigkeit zur praktischen Anwendung von einfachen SQL-Anweisungen
Datenbanksysteme I WS 2012/13 - Übung 0 - Bernhard Pietsch Friedrich-Schiller-Universität Jena Lehrstuhl für Datenbanken und Informationssysteme
 Datenbanksysteme I WS 2012/13 - Übung 0 - Bernhard Pietsch Friedrich-Schiller-Universität Jena Lehrstuhl für Datenbanken und Informationssysteme Organisatorisches (I) http://www.informatik.unijena.de/dbis/lehre/ws2012/dbs1/index.html
Datenbanksysteme I WS 2012/13 - Übung 0 - Bernhard Pietsch Friedrich-Schiller-Universität Jena Lehrstuhl für Datenbanken und Informationssysteme Organisatorisches (I) http://www.informatik.unijena.de/dbis/lehre/ws2012/dbs1/index.html
Grundlagen der Informatik. Prof. Dr. Stefan Enderle NTA Isny
 Grundlagen der Informatik Prof. Dr. Stefan Enderle NTA Isny 2 Datenstrukturen 2.1 Einführung Syntax: Definition einer formalen Grammatik, um Regeln einer formalen Sprache (Programmiersprache) festzulegen.
Grundlagen der Informatik Prof. Dr. Stefan Enderle NTA Isny 2 Datenstrukturen 2.1 Einführung Syntax: Definition einer formalen Grammatik, um Regeln einer formalen Sprache (Programmiersprache) festzulegen.
Kapitel 12: Schnelles Bestimmen der Frequent Itemsets
 Einleitung In welchen Situationen ist Apriori teuer, und warum? Kapitel 12: Schnelles Bestimmen der Frequent Itemsets Data Warehousing und Mining 1 Data Warehousing und Mining 2 Schnelles Identifizieren
Einleitung In welchen Situationen ist Apriori teuer, und warum? Kapitel 12: Schnelles Bestimmen der Frequent Itemsets Data Warehousing und Mining 1 Data Warehousing und Mining 2 Schnelles Identifizieren
Technische Informatik II Wintersemester 2002/03 Sommersemester 2001. Heiko Holtkamp Heiko@rvs.uni-bielefeld.de
 Technische Informatik II Wintersemester 2002/03 Sommersemester 2001 Heiko Holtkamp Heiko@rvs.uni-bielefeld.de Speicher ist eine wichtige Ressource, die sorgfältig verwaltet werden muss. In der Vorlesung
Technische Informatik II Wintersemester 2002/03 Sommersemester 2001 Heiko Holtkamp Heiko@rvs.uni-bielefeld.de Speicher ist eine wichtige Ressource, die sorgfältig verwaltet werden muss. In der Vorlesung
Grundlagen des relationalen l Modells
 Grundlagen des relationalen l Modells Seien D 1, D 2,..., D n Domänen (~Wertebereiche) Relation: R D 1 x... x D n Bsp.: Telefonbuch string x string x integer Tupel: t R Bsp.: t = ( Mickey Mouse, Main Street,
Grundlagen des relationalen l Modells Seien D 1, D 2,..., D n Domänen (~Wertebereiche) Relation: R D 1 x... x D n Bsp.: Telefonbuch string x string x integer Tupel: t R Bsp.: t = ( Mickey Mouse, Main Street,
Datenintegrität. Einschränkung der möglichen Datenbankzustände und -übergänge auf die in der Realität möglichen
 Datenintegrität Einschränkung der möglichen Datenbankzustände und -übergänge auf die in der Realität möglichen Formulierung von Integritätsbedingungen ist die wichtigste Aufgabe des DB-Administrators!
Datenintegrität Einschränkung der möglichen Datenbankzustände und -übergänge auf die in der Realität möglichen Formulierung von Integritätsbedingungen ist die wichtigste Aufgabe des DB-Administrators!
KAPITEL 2 VERWALTUNG DES HINTERGRUNDSPEICHERS
 KAPITEL 2 VERWALTUNG DES HINTERGRUNDSPEICHERS h_da Prof. Dr. Uta Störl Architektur von DBMS WS 2015/16 Kapitel 2: Verwaltung des Hintergrundspeichers 1 Verwaltung des Hintergrundspeichers Inhalte des Kapitels
KAPITEL 2 VERWALTUNG DES HINTERGRUNDSPEICHERS h_da Prof. Dr. Uta Störl Architektur von DBMS WS 2015/16 Kapitel 2: Verwaltung des Hintergrundspeichers 1 Verwaltung des Hintergrundspeichers Inhalte des Kapitels
Datenintegrität. Arten von Integritätsbedingungen. Statische Integritätsbedingungen. Referentielle Integrität. Integritätsbedingungen in SQL.
 Datenintegrität Arten von Integritätsbedingungen Statische Integritätsbedingungen Referentielle Integrität Integritätsbedingungen in SQL Trigger 1 Datenintegrität Einschränkung der möglichen Datenbankzustände
Datenintegrität Arten von Integritätsbedingungen Statische Integritätsbedingungen Referentielle Integrität Integritätsbedingungen in SQL Trigger 1 Datenintegrität Einschränkung der möglichen Datenbankzustände
Datenintegrität. Einschränkung der möglichen Datenbankzustände und -übergänge auf die in der Realität möglichen
 Datenintegrität Einschränkung der möglichen Datenbankzustände und -übergänge auf die in der Realität möglichen Formulierung von Integritätsbedingungen ist die wichtigste Aufgabe des DB-Administrators!
Datenintegrität Einschränkung der möglichen Datenbankzustände und -übergänge auf die in der Realität möglichen Formulierung von Integritätsbedingungen ist die wichtigste Aufgabe des DB-Administrators!
Architektur und Implementierung von Apache Derby
 Architektur und Implementierung von Apache Derby Das Zugriffssystem Carsten Kleinmann, Michael Schmidt TH Mittelhessen, MNI, Informatik 16. Januar 2012 Carsten Kleinmann, Michael Schmidt Architektur und
Architektur und Implementierung von Apache Derby Das Zugriffssystem Carsten Kleinmann, Michael Schmidt TH Mittelhessen, MNI, Informatik 16. Januar 2012 Carsten Kleinmann, Michael Schmidt Architektur und
1. Motivation / Grundlagen 2. Sortierverfahren 3. Elementare Datenstrukturen / Anwendungen 4. Bäume / Graphen 5. Hashing 6. Algorithmische Geometrie
 Gliederung 1. Motivation / Grundlagen 2. Sortierverfahren 3. Elementare Datenstrukturen / Anwendungen 4. Bäume / Graphen 5. Hashing 6. Algorithmische Geometrie 4/2, Folie 1 2014 Prof. Steffen Lange - HDa/FbI
Gliederung 1. Motivation / Grundlagen 2. Sortierverfahren 3. Elementare Datenstrukturen / Anwendungen 4. Bäume / Graphen 5. Hashing 6. Algorithmische Geometrie 4/2, Folie 1 2014 Prof. Steffen Lange - HDa/FbI
Physische Datenorganisation
 Herbstsemester 2011 CS241 Datenbanken mit Übungen Kapitel 9: Speicher- und Zugriffssystem H. Schuldt Physische Datenorganisation Im Zentrum des konzeptuellen Datenbankentwurfs steht die Frage, welche Daten
Herbstsemester 2011 CS241 Datenbanken mit Übungen Kapitel 9: Speicher- und Zugriffssystem H. Schuldt Physische Datenorganisation Im Zentrum des konzeptuellen Datenbankentwurfs steht die Frage, welche Daten
Kapitel VI. Speicherverwaltung. Speicherverwaltung
 Kapitel VI Speicherverwaltung 1 Speicherverwaltung Computer exekutiert Programme (mit Daten) im Hauptspeicher. Hauptspeicher: Großes Array von Wörtern (1 oder mehrere Bytes) Jedes Wort hat eine eigene
Kapitel VI Speicherverwaltung 1 Speicherverwaltung Computer exekutiert Programme (mit Daten) im Hauptspeicher. Hauptspeicher: Großes Array von Wörtern (1 oder mehrere Bytes) Jedes Wort hat eine eigene
Grundlagen der Rechnerarchitektur
 Grundlagen der Rechnerarchitektur Speicher Übersicht Speicherhierarchie Cache Grundlagen Verbessern der Cache Performance Virtueller Speicher SS 2012 Grundlagen der Rechnerarchitektur Speicher 2 Speicherhierarchie
Grundlagen der Rechnerarchitektur Speicher Übersicht Speicherhierarchie Cache Grundlagen Verbessern der Cache Performance Virtueller Speicher SS 2012 Grundlagen der Rechnerarchitektur Speicher 2 Speicherhierarchie
Informatik für Ökonomen II: Datenintegrität. Prof. Dr. Carl-Christian Kanne
 Informatik für Ökonomen II: Datenintegrität Prof. Dr. Carl-Christian Kanne 1 Konsistenzbedingungen DBMS soll logische Datenintegrität gewährleisten Beispiele für Integritätsbedingungen Schlüssel Beziehungskardinalitäten
Informatik für Ökonomen II: Datenintegrität Prof. Dr. Carl-Christian Kanne 1 Konsistenzbedingungen DBMS soll logische Datenintegrität gewährleisten Beispiele für Integritätsbedingungen Schlüssel Beziehungskardinalitäten
Hauptspeicherindexstrukturen. Stefan Sprenger Semesterprojekt Verteilte Echtzeitrecherche in Genomdaten 10. November 2015
 Hauptspeicherindexstrukturen Stefan Sprenger Semesterprojekt Verteilte Echtzeitrecherche in Genomdaten 10. November 2015 Agenda Einführung in Hauptspeichertechnologien Indexstrukturen in relationalen Datenbanken
Hauptspeicherindexstrukturen Stefan Sprenger Semesterprojekt Verteilte Echtzeitrecherche in Genomdaten 10. November 2015 Agenda Einführung in Hauptspeichertechnologien Indexstrukturen in relationalen Datenbanken
One of the few resources increasing faster than the speed of computer hardware is the amount of data to be processed. Bin Hu
 Bin Hu Algorithmen und Datenstrukturen 2 Arbeitsbereich fr Algorithmen und Datenstrukturen Institut fr Computergraphik und Algorithmen Technische Universität Wien One of the few resources increasing faster
Bin Hu Algorithmen und Datenstrukturen 2 Arbeitsbereich fr Algorithmen und Datenstrukturen Institut fr Computergraphik und Algorithmen Technische Universität Wien One of the few resources increasing faster
wichtigstes Betriebsmittel - neben dem Prozessor: Speicher
 Speicherverwaltung Aufgaben der Speicherverwaltung wichtigstes Betriebsmittel - neben dem Prozessor: Speicher Sowohl die ausführbaren Programme selbst als auch deren Daten werden in verschiedenen Speicherbereichen
Speicherverwaltung Aufgaben der Speicherverwaltung wichtigstes Betriebsmittel - neben dem Prozessor: Speicher Sowohl die ausführbaren Programme selbst als auch deren Daten werden in verschiedenen Speicherbereichen
Es sei a 2 und b 2a 1. Definition Ein (a, b)-baum ist ein Baum mit folgenden Eigenschaften:
-baum ist ein Baum mit folgenden Eigenschaften:") Binäre Suchbäume (a, b)-bäume (Folie 173, Seite 56 im Skript) Es sei a 2 und b 2a 1. Definition Ein (a, b)-baum ist ein Baum mit folgenden Eigenschaften: 1 Jeder Knoten hat höchstens b Kinder. 2 Jeder
Binäre Suchbäume (a, b)-bäume (Folie 173, Seite 56 im Skript) Es sei a 2 und b 2a 1. Definition Ein (a, b)-baum ist ein Baum mit folgenden Eigenschaften: 1 Jeder Knoten hat höchstens b Kinder. 2 Jeder
Datenbanksystem. System Global Area. Hintergrundprozesse. Dr. Frank Haney 1
 Datenbanksystem System Global Area Hintergrundprozesse Dr. Frank Haney 1 Komponenten des Datenbanksystems System Global Area Program Global Area Hintergrundprozesse Dr. Frank Haney 2 System Global Area
Datenbanksystem System Global Area Hintergrundprozesse Dr. Frank Haney 1 Komponenten des Datenbanksystems System Global Area Program Global Area Hintergrundprozesse Dr. Frank Haney 2 System Global Area
DATENSTRUKTUREN UND ALGORITHMEN
 DATENSTRUKTUREN UND ALGORITHMEN 2 Ist die Datenstruktur so wichtig??? Wahl der Datenstruktur wichtiger Schritt beim Entwurf und der Implementierung von Algorithmen Dünn besetzte Graphen und Matrizen bilden
DATENSTRUKTUREN UND ALGORITHMEN 2 Ist die Datenstruktur so wichtig??? Wahl der Datenstruktur wichtiger Schritt beim Entwurf und der Implementierung von Algorithmen Dünn besetzte Graphen und Matrizen bilden
Referentielle Integrität
 Datenintegrität Integitätsbedingungen Schlüssel Beziehungskardinalitäten Attributdomänen Inklusion bei Generalisierung statische Integritätsbedingungen Bedingungen an den Zustand der Datenbasis dynamische
Datenintegrität Integitätsbedingungen Schlüssel Beziehungskardinalitäten Attributdomänen Inklusion bei Generalisierung statische Integritätsbedingungen Bedingungen an den Zustand der Datenbasis dynamische
Anfragebearbeitung 3
 Anfragebearbeitung 3 VL Datenbanksysteme, WS 2014/5 Reinhard Pichler Arbeitsbereich Datenbanken und Artificial Intelligence Institut für Informationssysteme Technische Universität Wien Kostenmodelle und
Anfragebearbeitung 3 VL Datenbanksysteme, WS 2014/5 Reinhard Pichler Arbeitsbereich Datenbanken und Artificial Intelligence Institut für Informationssysteme Technische Universität Wien Kostenmodelle und
Informatik II Datenorganisation Datenbanken
 Informatik II Datenorganisation Datenbanken Studiengang Wirtschaftsingenieurwesen (2. Semester) Prof. Dr. Sabine Kühn Tel. (0351) 462 2490 Fachbereich Informatik/Mathematik skuehn@informatik.htw-dresden.de
Informatik II Datenorganisation Datenbanken Studiengang Wirtschaftsingenieurwesen (2. Semester) Prof. Dr. Sabine Kühn Tel. (0351) 462 2490 Fachbereich Informatik/Mathematik skuehn@informatik.htw-dresden.de
Die Sicht eines Sysadmins auf DB systeme
 Die Sicht eines Sysadmins auf DB systeme Robert Meyer 21. Oktober 2016 Robert Meyer Die Sicht eines Sysadmins auf DB systeme 21. Oktober 2016 1 / 20 Inhaltsverzeichnis 1 Einleitung 2 IO unter Linux typische
Die Sicht eines Sysadmins auf DB systeme Robert Meyer 21. Oktober 2016 Robert Meyer Die Sicht eines Sysadmins auf DB systeme 21. Oktober 2016 1 / 20 Inhaltsverzeichnis 1 Einleitung 2 IO unter Linux typische
Referentielle Integrität
 Datenintegrität Integitätsbedingungen Schlüssel Beziehungskardinalitäten Attributdomänen Inklusion bei Generalisierung statische Integritätsbedingungen Bedingungen an den Zustand der Datenbasis dynamische
Datenintegrität Integitätsbedingungen Schlüssel Beziehungskardinalitäten Attributdomänen Inklusion bei Generalisierung statische Integritätsbedingungen Bedingungen an den Zustand der Datenbasis dynamische
Konzepte von Betriebssystemkomponenten Disk-Caches und Dateizugriff
 Konzepte von Betriebssystemkomponenten Disk-Caches und Dateizugriff von Athanasia Kaisa Grundzüge eines Zwischenspeichers Verschiedene Arten von Zwischenspeicher Plattenzwischenspeicher in LINUX Dateizugriff
Konzepte von Betriebssystemkomponenten Disk-Caches und Dateizugriff von Athanasia Kaisa Grundzüge eines Zwischenspeichers Verschiedene Arten von Zwischenspeicher Plattenzwischenspeicher in LINUX Dateizugriff
Technische Informatik I. Übung 3 Speicherhierarchie. v t d 0 d 1 d 2 d 3 0 1 2 3. Technische Informatik I Übung 3. Technische Informatik I Übung 3
 Institut für Kommunikationsnetze und Rechnersysteme Technische Informatik I Paul J. Kühn, Matthias Meyer Übung 3 Speicherhierarchie Inhaltsübersicht Aufgabe 3.1 Daten-Cache Aufgabe 3.2 Virtueller Speicher
Institut für Kommunikationsnetze und Rechnersysteme Technische Informatik I Paul J. Kühn, Matthias Meyer Übung 3 Speicherhierarchie Inhaltsübersicht Aufgabe 3.1 Daten-Cache Aufgabe 3.2 Virtueller Speicher
Proseminar Kodierverfahren bei Dr. Ulrich Tamm Sommersemester 2003 Thema: Codierung von Bäumen (Prüfer Codes...)
") Proseminar Kodierverfahren bei Dr. Ulrich Tamm Sommersemester 2003 Thema: Codierung von Bäumen (Prüfer Codes...) Inhalt: Einleitung, Begriffe Baumtypen und deren Kodierung Binäre Bäume Mehrwegbäume Prüfer
Proseminar Kodierverfahren bei Dr. Ulrich Tamm Sommersemester 2003 Thema: Codierung von Bäumen (Prüfer Codes...) Inhalt: Einleitung, Begriffe Baumtypen und deren Kodierung Binäre Bäume Mehrwegbäume Prüfer
Paging. Einfaches Paging. Paging mit virtuellem Speicher
 Paging Einfaches Paging Paging mit virtuellem Speicher Einfaches Paging Wie bisher (im Gegensatz zu virtuellem Speicherkonzept): Prozesse sind entweder ganz im Speicher oder komplett ausgelagert. Im Gegensatz
Paging Einfaches Paging Paging mit virtuellem Speicher Einfaches Paging Wie bisher (im Gegensatz zu virtuellem Speicherkonzept): Prozesse sind entweder ganz im Speicher oder komplett ausgelagert. Im Gegensatz
Matthias Schubert. Datenbanken. Theorie, Entwurf und Programmierung relationaler Datenbanken. 2., überarbeitete Auflage. Teubner
 Matthias Schubert Datenbanken Theorie, Entwurf und Programmierung relationaler Datenbanken 2., überarbeitete Auflage m Teubner Inhalt Wichtiger Hinweis 12 Vorwort 13 Wer sollte dieses Buch lesen? 13 Noch
Matthias Schubert Datenbanken Theorie, Entwurf und Programmierung relationaler Datenbanken 2., überarbeitete Auflage m Teubner Inhalt Wichtiger Hinweis 12 Vorwort 13 Wer sollte dieses Buch lesen? 13 Noch
Einführung in Hauptspeicherdatenbanken
 Einführung in Hauptspeicherdatenbanken Harald Zankl Probevorlesung 13. 01., 13:15 14:00, HS C Inhaltsverzeichnis Organisation Überblick Konklusion Harald Zankl (LFU) Hauptspeicherdatenbanken 2/16 Organisation
Einführung in Hauptspeicherdatenbanken Harald Zankl Probevorlesung 13. 01., 13:15 14:00, HS C Inhaltsverzeichnis Organisation Überblick Konklusion Harald Zankl (LFU) Hauptspeicherdatenbanken 2/16 Organisation
Binäre Suchbäume. Mengen, Funktionalität, Binäre Suchbäume, Heaps, Treaps
 Binäre Suchbäume Mengen, Funktionalität, Binäre Suchbäume, Heaps, Treaps Mengen n Ziel: Aufrechterhalten einer Menge (hier: ganzer Zahlen) unter folgenden Operationen: Mengen n Ziel: Aufrechterhalten einer
Binäre Suchbäume Mengen, Funktionalität, Binäre Suchbäume, Heaps, Treaps Mengen n Ziel: Aufrechterhalten einer Menge (hier: ganzer Zahlen) unter folgenden Operationen: Mengen n Ziel: Aufrechterhalten einer
Datenbanksysteme SS 2007
 Datenbanksysteme SS 2007 Frank Köster (Oliver Vornberger) Institut für Informatik Universität Osnabrück Kapitel 6b: Das relationale Modell Das Relationale Modell (vgl. Lerneinheit 6a) Wertebereiche (Domänen):
Datenbanksysteme SS 2007 Frank Köster (Oliver Vornberger) Institut für Informatik Universität Osnabrück Kapitel 6b: Das relationale Modell Das Relationale Modell (vgl. Lerneinheit 6a) Wertebereiche (Domänen):
DATENBANKEN SQL UND SQLITE VON MELANIE SCHLIEBENER
 DATENBANKEN SQL UND SQLITE VON MELANIE SCHLIEBENER INHALTSVERZEICHNIS 1. Datenbanken 2. SQL 1.1 Sinn und Zweck 1.2 Definition 1.3 Modelle 1.4 Relationales Datenbankmodell 2.1 Definition 2.2 Befehle 3.
DATENBANKEN SQL UND SQLITE VON MELANIE SCHLIEBENER INHALTSVERZEICHNIS 1. Datenbanken 2. SQL 1.1 Sinn und Zweck 1.2 Definition 1.3 Modelle 1.4 Relationales Datenbankmodell 2.1 Definition 2.2 Befehle 3.
Anfragebearbeitung. Vorlesung: Dr. Matthias Schubert
 Kapitel l5 Anfragebearbeitung Vorlesung: Dr. Matthias Schubert Skript 2009 Matthias Schubert Dieses Skript basiert auf dem Skript zur Vorlesung Datenbanksysteme II von Prof. Dr. Christian Böhm gehalten
Kapitel l5 Anfragebearbeitung Vorlesung: Dr. Matthias Schubert Skript 2009 Matthias Schubert Dieses Skript basiert auf dem Skript zur Vorlesung Datenbanksysteme II von Prof. Dr. Christian Böhm gehalten
DBS: Administration und Implementierung Klausur
 Prof. Dr. Stefan Brass 12.06.2001 Institut für Informatik Universität Gießen Hinweise DBS: Administration und Implementierung Klausur Die Bearbeitungszeit ist 1 Stunde, 30 Minuten (von 8 30 bis 10 00 ).
Prof. Dr. Stefan Brass 12.06.2001 Institut für Informatik Universität Gießen Hinweise DBS: Administration und Implementierung Klausur Die Bearbeitungszeit ist 1 Stunde, 30 Minuten (von 8 30 bis 10 00 ).
Suchen in Listen und Hashtabellen
 Kapitel 12: Suchen in Listen und Hashtabellen Einführung in die Informatik Wintersemester 2007/08 Prof. Bernhard Jung Übersicht Einleitung Lineare Suche Binäre Suche (in sortierten Listen) Hashverfahren
Kapitel 12: Suchen in Listen und Hashtabellen Einführung in die Informatik Wintersemester 2007/08 Prof. Bernhard Jung Übersicht Einleitung Lineare Suche Binäre Suche (in sortierten Listen) Hashverfahren
Abschluss Einblick und Ausblick
 Abschluss Einblick und Ausblick Prof. Dr. T. Kudraß 1 Benutzer Komponenten eines DBMS (Überblick) I/O-Prozessor Output-Generierung Parser für selbst. oder eingebettete Kommandos Precompiler Autorisierungs-Kontrolle
Abschluss Einblick und Ausblick Prof. Dr. T. Kudraß 1 Benutzer Komponenten eines DBMS (Überblick) I/O-Prozessor Output-Generierung Parser für selbst. oder eingebettete Kommandos Precompiler Autorisierungs-Kontrolle
Hauptspeicher- Datenbanksysteme. Hardware-Entwicklungen Column- versus Row-Store...
 Hauptspeicher- Datenbanksysteme Hardware-Entwicklungen Column- versus Row-Store... Hauptspeicher-Datenbanksysteme Disk is Tape, Tape is dead Jim Gray Die Zeit ist reif für ein Re-engineering der Datenbanksysteme
Hauptspeicher- Datenbanksysteme Hardware-Entwicklungen Column- versus Row-Store... Hauptspeicher-Datenbanksysteme Disk is Tape, Tape is dead Jim Gray Die Zeit ist reif für ein Re-engineering der Datenbanksysteme
IO Performance - Planung Messung, Optimierung. Ulrich Gräf Principal Sales Consultant Oracle Deutschland B.V. und Co. KG
 IO Performance - Planung Messung, Optimierung Ulrich Gräf Principal Sales Consultant Oracle Deutschland B.V. und Co. KG The following is intended to outline our general product direction. It is intended
IO Performance - Planung Messung, Optimierung Ulrich Gräf Principal Sales Consultant Oracle Deutschland B.V. und Co. KG The following is intended to outline our general product direction. It is intended
Informatik II, SS 2014
 Informatik II SS 2014 (Algorithmen & Datenstrukturen) Vorlesung 10 (3.6.2014) Binäre Suchbäume I Algorithmen und Komplexität Zusätzliche Dictionary Operationen Dictionary: Zusätzliche mögliche Operationen:
Informatik II SS 2014 (Algorithmen & Datenstrukturen) Vorlesung 10 (3.6.2014) Binäre Suchbäume I Algorithmen und Komplexität Zusätzliche Dictionary Operationen Dictionary: Zusätzliche mögliche Operationen:
Speicherverwaltung (Swapping und Paging)
") Speicherverwaltung (Swapping und Paging) Rückblick: Segmentierung Feste Einteilung des Speichers in einzelne Segmente 750k 0 Rückblick: Segmentierung Feste Einteilung des Speichers in einzelne Segmente
Speicherverwaltung (Swapping und Paging) Rückblick: Segmentierung Feste Einteilung des Speichers in einzelne Segmente 750k 0 Rückblick: Segmentierung Feste Einteilung des Speichers in einzelne Segmente
stattdessen: geräteunabhängiges, abstraktes Format für Speicherung und Transfer von Daten Datei
 Dateiverwaltung Dateiverwaltung 2002 Prof. Dr. Rainer Manthey Informatik II 1 Dateien weitere zentrale Aufgabe des Betriebssystems: "Verbergen" der Details der Struktur von und der Zugriffe auf Sekundärspeicher-Medien
Dateiverwaltung Dateiverwaltung 2002 Prof. Dr. Rainer Manthey Informatik II 1 Dateien weitere zentrale Aufgabe des Betriebssystems: "Verbergen" der Details der Struktur von und der Zugriffe auf Sekundärspeicher-Medien
Kapitel 3. Speicherhierachie. Beispiel für Cache Effekte. Motivation Externspeicheralgorithmen. Motivation Für Beachtung von Cache Effekten
 Kapitel 3 Algorithmen für große Datenmengen Motivation Externspeicheralgorithmen Es werden immer größere Datenmengen gesammelt (WWW, Medizin, Gentechnik ) Daten müssen auf großen externen Massenspeichern
Kapitel 3 Algorithmen für große Datenmengen Motivation Externspeicheralgorithmen Es werden immer größere Datenmengen gesammelt (WWW, Medizin, Gentechnik ) Daten müssen auf großen externen Massenspeichern
Kap. 4.4: B-Bäume Kap. 4.5: Dictionaries in der Praxis
 Kap. 4.4: B-Bäume Kap. 4.5: Dictionaries in der Praxis Professor Dr. Lehrstuhl für Algorithm Engineering, LS11 Fakultät für Informatik, TU Dortmund 13./14. VO DAP2 SS 2009 2./4. Juni 2009 1 2. Übungstest
Kap. 4.4: B-Bäume Kap. 4.5: Dictionaries in der Praxis Professor Dr. Lehrstuhl für Algorithm Engineering, LS11 Fakultät für Informatik, TU Dortmund 13./14. VO DAP2 SS 2009 2./4. Juni 2009 1 2. Übungstest
Inhalt. Datenbanken Vertiefung. Literatur und Quellen. Inhalt. Physische Datenorganisation I. Nikolaus Augsten. Wintersemester 2013/14
 Inhalt Datenbanken Vertiefung Physische Datenorganisation I Nikolaus Augsten nikolaus.augsten@sbg.ac.at FB Computerwissenschaften Universität Salzburg 1 Wintersemester 2013/14 Augsten (Univ. Salzburg)
Inhalt Datenbanken Vertiefung Physische Datenorganisation I Nikolaus Augsten nikolaus.augsten@sbg.ac.at FB Computerwissenschaften Universität Salzburg 1 Wintersemester 2013/14 Augsten (Univ. Salzburg)
TU München, Fakultät für Informatik Lehrstuhl III: Datenbanksysteme Prof. Alfons Kemper, Ph.D.
 TU München, Fakultät für Inforatik Lehrstuhl III: Datenbanksystee Prof. Alfons Keper, Ph.D. Blatt Nr. 11 Übung zur Vorlesung Grundlagen: Datenbanken i WS15/16 Harald Lang, Linnea Passing (gdb@in.tu.de)
TU München, Fakultät für Inforatik Lehrstuhl III: Datenbanksystee Prof. Alfons Keper, Ph.D. Blatt Nr. 11 Übung zur Vorlesung Grundlagen: Datenbanken i WS15/16 Harald Lang, Linnea Passing (gdb@in.tu.de)
Mengenvergleiche: Alle Konten außer das, mit dem größten Saldo.
 Mengenvergleiche: Mehr Möglichkeiten als der in-operator bietet der θany und der θall-operator, also der Vergleich mit irgendeinem oder jedem Tupel der Unteranfrage. Alle Konten außer das, mit dem größten
Mengenvergleiche: Mehr Möglichkeiten als der in-operator bietet der θany und der θall-operator, also der Vergleich mit irgendeinem oder jedem Tupel der Unteranfrage. Alle Konten außer das, mit dem größten
Abstraktionsschichten. Das Relationale Datenmodell
 Abstraktionsschichten. Das Relationale Datenmodell Verschiedene Abstraktionsebene Data in Beziehung zur Application Data in Beziehung zur Datenmodell Data in Beziehung zur physischen Darstellung Datenunabhängigkeit
Abstraktionsschichten. Das Relationale Datenmodell Verschiedene Abstraktionsebene Data in Beziehung zur Application Data in Beziehung zur Datenmodell Data in Beziehung zur physischen Darstellung Datenunabhängigkeit
Systeme 1. Kapitel 3 Dateisysteme WS 2009/10 1
 Systeme 1 Kapitel 3 Dateisysteme WS 2009/10 1 Letzte Vorlesung Dateisysteme Hauptaufgaben Persistente Dateisysteme (FAT, NTFS, ext3, ext4) Dateien Kleinste logische Einheit eines Dateisystems Dateitypen
Systeme 1 Kapitel 3 Dateisysteme WS 2009/10 1 Letzte Vorlesung Dateisysteme Hauptaufgaben Persistente Dateisysteme (FAT, NTFS, ext3, ext4) Dateien Kleinste logische Einheit eines Dateisystems Dateitypen
Bäume. 2006 Jiri Spale, Algorithmen und Datenstrukturen - Bäume 1
 Bäume 2006 Jiri Spale, Algorithmen und Datenstrukturen - Bäume 1 Inhalt Grundbegriffe: Baum, Binärbaum Binäre Suchbäume (Definition) Typische Aufgaben Suchaufwand Löschen allgemein, Methode Schlüsseltransfer
Bäume 2006 Jiri Spale, Algorithmen und Datenstrukturen - Bäume 1 Inhalt Grundbegriffe: Baum, Binärbaum Binäre Suchbäume (Definition) Typische Aufgaben Suchaufwand Löschen allgemein, Methode Schlüsseltransfer
Kapitel 7 Datenbank-Tuning
 Kapitel 7 Datenbank-Tuning Flien zum Datenbankpraktikum Wintersemester 2012/13 LMU München 2008 Thmas Bernecker, Tbias Emrich 2010 Tbias Emrich, Erich Schubert unter Verwendung der Flien des Datenbankpraktikums
Kapitel 7 Datenbank-Tuning Flien zum Datenbankpraktikum Wintersemester 2012/13 LMU München 2008 Thmas Bernecker, Tbias Emrich 2010 Tbias Emrich, Erich Schubert unter Verwendung der Flien des Datenbankpraktikums
Geometrische Algorithmen
 Geometrische Algorithmen Bin Hu Algorithmen und Datenstrukturen 2 Arbeitsbereich für Algorithmen und Datenstrukturen Institut für Computergraphik und Algorithmen Technische Universität Wien Einführung
Geometrische Algorithmen Bin Hu Algorithmen und Datenstrukturen 2 Arbeitsbereich für Algorithmen und Datenstrukturen Institut für Computergraphik und Algorithmen Technische Universität Wien Einführung
Semantische Integrität (auch: Konsistenz) der in einer Datenbank gespeicherten Daten als wichtige Anforderung
 der in einer Datenbank gespeicherten Daten als wichtige Anforderung") 6. Datenintegrität Motivation Semantische Integrität (auch: Konsistenz) der in einer Datenbank gespeicherten Daten als wichtige Anforderung nur sinnvolle Attributwerte (z.b. keine negativen Semester) Abhängigkeiten
6. Datenintegrität Motivation Semantische Integrität (auch: Konsistenz) der in einer Datenbank gespeicherten Daten als wichtige Anforderung nur sinnvolle Attributwerte (z.b. keine negativen Semester) Abhängigkeiten
Verteilte Systeme. Verteilte Systeme. 5 Prozeß-Management SS 2016
 Verteilte Systeme SS 2016 Universität Siegen rolanda.dwismuellera@duni-siegena.de Tel.: 0271/740-4050, Büro: H-B 8404 Stand: 31. Mai 2016 Betriebssysteme / verteilte Systeme Verteilte Systeme (1/14) i
Verteilte Systeme SS 2016 Universität Siegen rolanda.dwismuellera@duni-siegena.de Tel.: 0271/740-4050, Büro: H-B 8404 Stand: 31. Mai 2016 Betriebssysteme / verteilte Systeme Verteilte Systeme (1/14) i
TU München, Fakultät für Informatik Lehrstuhl III: Datenbanksysteme Prof. Dr. Thomas Neumann
 TU München, Fakultät für Informatik Lehrstuhl III: Datenbanksysteme Prof. Dr. Thomas Neumann Blatt Nr. 8 Übung zur Vorlesung Grundlagen: Datenbanken im WS14/15 Harald Lang (harald.lang@in.tum.de) http://www-db.in.tum.de/teaching/ws1415/grundlagen/
TU München, Fakultät für Informatik Lehrstuhl III: Datenbanksysteme Prof. Dr. Thomas Neumann Blatt Nr. 8 Übung zur Vorlesung Grundlagen: Datenbanken im WS14/15 Harald Lang (harald.lang@in.tum.de) http://www-db.in.tum.de/teaching/ws1415/grundlagen/
Dynamische Mengen. Realisierungen durch Bäume
 Dynamische Mengen Eine dynamische Menge ist eine Datenstruktur, die eine Menge von Objekten verwaltet. Jedes Objekt x trägt einen eindeutigen Schlüssel key[x]. Die Datenstruktur soll mindestens die folgenden
Dynamische Mengen Eine dynamische Menge ist eine Datenstruktur, die eine Menge von Objekten verwaltet. Jedes Objekt x trägt einen eindeutigen Schlüssel key[x]. Die Datenstruktur soll mindestens die folgenden
Kapitel 6 Anfragebearbeitung
 LUDWIG- MAXIMILIANS- UNIVERSITY MUNICH DEPARTMENT INSTITUTE FOR INFORMATICS DATABASE Skript zur Vorlesung: Datenbanksysteme II Sommersemester 2014 Kapitel 6 Anfragebearbeitung Vorlesung: PD Dr. Peer Kröger
LUDWIG- MAXIMILIANS- UNIVERSITY MUNICH DEPARTMENT INSTITUTE FOR INFORMATICS DATABASE Skript zur Vorlesung: Datenbanksysteme II Sommersemester 2014 Kapitel 6 Anfragebearbeitung Vorlesung: PD Dr. Peer Kröger
Datenbanken II Speicherung und Verarbeitung großer Objekte (Large Objects [LOBs])
![Datenbanken II Speicherung und Verarbeitung großer Objekte (Large Objects [LOBs])](/thumbs/26/8144922.jpg "Datenbanken II Speicherung und Verarbeitung großer Objekte (Large Objects [LOBs])") Datenbanken II Speicherung und Verarbeitung großer Objekte (Large Objects [LOBs]) Hochschule für Technik, Wirtschaft und Kultur Leipzig 06.06.2008 Datenbanken II,Speicherung und Verarbeitung großer Objekte
Datenbanken II Speicherung und Verarbeitung großer Objekte (Large Objects [LOBs]) Hochschule für Technik, Wirtschaft und Kultur Leipzig 06.06.2008 Datenbanken II,Speicherung und Verarbeitung großer Objekte
Theoretische Informatik 1 WS 2007/2008. Prof. Dr. Rainer Lütticke
 Theoretische Informatik 1 WS 2007/2008 Prof. Dr. Rainer Lütticke Inhalt der Vorlesung Grundlagen - Mengen, Relationen, Abbildungen/Funktionen - Datenstrukturen - Aussagenlogik Automatentheorie Formale
Theoretische Informatik 1 WS 2007/2008 Prof. Dr. Rainer Lütticke Inhalt der Vorlesung Grundlagen - Mengen, Relationen, Abbildungen/Funktionen - Datenstrukturen - Aussagenlogik Automatentheorie Formale
TU München, Fakultät für Informatik Lehrstuhl III: Datenbanksysteme Prof. Dr. Thomas Neumann
 TU München, Fakultät für Informatik Lehrstuhl III: Datenbanksysteme Prof. Dr. Thomas Neumann Blatt Nr. 11 Übung zur Vorlesung Einsatz und Realisierung von Datenbanksystemen im SoSe15 Moritz Kaufmann (moritz.kaufmann@tum.de)
TU München, Fakultät für Informatik Lehrstuhl III: Datenbanksysteme Prof. Dr. Thomas Neumann Blatt Nr. 11 Übung zur Vorlesung Einsatz und Realisierung von Datenbanksystemen im SoSe15 Moritz Kaufmann (moritz.kaufmann@tum.de)
10. Datenbank Design 1
 1 Die Hauptaufgabe einer Datenbank besteht darin, Daten so lange zu speichern bis diese explizit überschrieben oder gelöscht werden. Also auch über das Ende (ev. sogar der Lebenszeit) einer Applikation
1 Die Hauptaufgabe einer Datenbank besteht darin, Daten so lange zu speichern bis diese explizit überschrieben oder gelöscht werden. Also auch über das Ende (ev. sogar der Lebenszeit) einer Applikation
Betriebssysteme WS 2012/13 Peter Klingebiel, DVZ. Zusammenfassung Kapitel 4 - Datenträger/Dateiverwaltung
 Betriebssysteme WS 2012/13 Peter Klingebiel, DVZ Zusammenfassung Kapitel 4 - Datenträger/Dateiverwaltung Zusammenfassung Kapitel 4 Dateiverwaltung 1 Datei logisch zusammengehörende Daten i.d.r. permanent
Betriebssysteme WS 2012/13 Peter Klingebiel, DVZ Zusammenfassung Kapitel 4 - Datenträger/Dateiverwaltung Zusammenfassung Kapitel 4 Dateiverwaltung 1 Datei logisch zusammengehörende Daten i.d.r. permanent
Datenstrukturen und Algorithmen
 Datenstrukturen und Algorithmen VO 708.031 Bäume robert.legenstein@igi.tugraz.at 1 Inhalt der Vorlesung 1. Motivation, Einführung, Grundlagen 2. Algorithmische Grundprinzipien 3. Sortierverfahren 4. Halden
Datenstrukturen und Algorithmen VO 708.031 Bäume robert.legenstein@igi.tugraz.at 1 Inhalt der Vorlesung 1. Motivation, Einführung, Grundlagen 2. Algorithmische Grundprinzipien 3. Sortierverfahren 4. Halden
Nachtrag zu binären Suchbäumen
 Nachtrag zu binären Suchbäumen (nicht notwendigerweise zu AVL Bäumen) Löschen 1 3 2 10 4 12 1. Fall: Der zu löschende Knoten ist ein Blatt: einfach löschen 2. Fall: Der zu löschende Knoten hat ein Nachfolgeelement
Nachtrag zu binären Suchbäumen (nicht notwendigerweise zu AVL Bäumen) Löschen 1 3 2 10 4 12 1. Fall: Der zu löschende Knoten ist ein Blatt: einfach löschen 2. Fall: Der zu löschende Knoten hat ein Nachfolgeelement
Teil VIII Von Neumann Rechner 1
 Teil VIII Von Neumann Rechner 1 Grundlegende Architektur Zentraleinheit: Central Processing Unit (CPU) Ausführen von Befehlen und Ablaufsteuerung Speicher: Memory Ablage von Daten und Programmen Read Only
Teil VIII Von Neumann Rechner 1 Grundlegende Architektur Zentraleinheit: Central Processing Unit (CPU) Ausführen von Befehlen und Ablaufsteuerung Speicher: Memory Ablage von Daten und Programmen Read Only
Microsoft Access 2010 SQL nutzen
 Microsoft Access 2010 SQL nutzen Welche Bestellungen hat Kunde x aufgegeben? Welche Kunden haben noch nie bestellt? Wer hat welche Bestellungen von welchen Kunden aufgenommen? S(tructured)Q(uery)L(anguage)
Microsoft Access 2010 SQL nutzen Welche Bestellungen hat Kunde x aufgegeben? Welche Kunden haben noch nie bestellt? Wer hat welche Bestellungen von welchen Kunden aufgenommen? S(tructured)Q(uery)L(anguage)
Tuning von PostGIS mit Read- Only-Daten von OpenStreetMap
 Tuning von PostGIS mit Read- Only-Daten von OpenStreetMap Prof. Stefan Keller (Fach-)Hochschule für Technik Rapperswil (bei Zürich) 11.11.2011 PGConf.DE - Stefan Keller 1 Was ist OpenStreetMap? Wikipedia
Tuning von PostGIS mit Read- Only-Daten von OpenStreetMap Prof. Stefan Keller (Fach-)Hochschule für Technik Rapperswil (bei Zürich) 11.11.2011 PGConf.DE - Stefan Keller 1 Was ist OpenStreetMap? Wikipedia