High Performance Computing
|
|
|
- Guido Baumhauer
- vor 8 Jahren
- Abrufe
Transkript
1 High Performance Computing SS 2004 PD Dr. A. Strey Abteilung Neuroinformatik, Universität Ulm Inhalt Einführung hohe Leistung durch Parallelität! kurze Historie des High Performance Computing (C) Top 500 Architekturen für C Exkurs: SIMD-Parallelrechner und Vektorrechner Hochleistungsprozessoren (z.b. UltraSparc, Pentium 4, Itanium, Opteron) Parallelrechner mit gemeinsamem Speicher (SMP = Symmetric Multiprocessor ) Parallelrechner mit verteiltem Speicher (DMC = Distributed Memory Computer ) Parallelrechner mit virtuellem gemeinsamem Speicher (ccnuma = cache-coherent Non-Uniform Memory Access ) Cluster aus PCs/Workstations/SMPs 2
 Parallelrechner mit gemeinsamem Speicher (SMP = Symmetric Multiprocessor ) Parallelrechner mit verteiltem Speicher (DMC =")
2 Inhalt (Forts.) Programmierumgebungen für C High Performance Fortran PVM ( Parallel Virtual Machine ) MPI ( Message Passing Interface ) Threads OpenMP automatische Vektorisierung / Parallelisierung Leistungsbewertung von C-Systemen Typische C Anwendungen, z.b.: Lösen großer Gleichungssysteme Simulation neuronaler Netze Sequenzanalyse in Bioinformatik Ausblick: Trends und Perspektiven 3 Lernziele Verständnis der wichtigsten Architekturkonzepte moderner C-Systeme Grundlagen der prozessparallelen Programmierung von C- Systemen Entwicklung eigener prozessparalleler Programme mit MPI Grundlagen der threadparallelen Programmierung von C- Systemen Entwicklung eigener threadparalleler Programme mit OpenMP Leistungsbewertung von C-Systemen 4

3 Aufbau Vorlesung: Di., 16-18, Raum O27/121 Übung: Fr., , Raum O27/121 voraussichtliche Übungstermine: 1) Rechnerarchitekturen für C ) MPI, Teil ) MPI, Teil ) OpenMP, Teil ) OpenMP, Teil ) Leistungsbewertung Literatur V. Kumar, A. Grama, A. Gupta, Introduction to Parallel Computing, Addison-Wesley, 2003 D.E. Culler, J.P. Singh, Parallel Computer Architecture: A Hardware/Software Approach, Morgan Kaufmann, 1999 K. Dowd, Ch. Severance, High Performance Computing, O Reilly, 1998 T. Rauber, G. Rünger, Parallele und Verteilte Programmierung, Springer, 2000 I. Foster, Designing and Building Parallel Programs, Addison- Wesley, 1995 (Online-Version unter www-unix.mcs.anl.gov/dbpp) G.C. Fox, R.D. Williams, Parallel Computing Works, Morgan Kaufmann, 1994 (Online-Version unter 6
 G.C. Fox, R.D. Williams, Parallel Computing Works, Morgan Kaufmann, 1994 (Online-Version unter www.")
4 Warum C? zur Reduktion der Rechenzeit bei der Lösung eines Problems zur Berechnung größerer Probleme bei gleicher Rechenzeit (Problemgröße wächst permanent, weil Wunsch nach Realitätsnähe bei Modellierung ständig zunimmt) zur Ermöglichung von Simulationen in Echtzeit typische heutige C Anwendungen: Wettervorhersage, Simulation von Autos und Flugzeugen, Data Mining, Simulation neuronaler Netze, Analyse von DNA- oder Proteinsequenzen zur Lösung von zukünftigen noch bedeutend komplexeren Aufgaben (Grand Challenge Problems) mit ggf. neuen Algorithmen : Globale Klima-Simulation, Erdbebenvorhersage, Simulation der Ozeanströmungen, Evolution von Galaxien, Analyse des menschlichen Genoms 7 Parallelität hohe Leistung überwiegend durch hohe Taktraten und durch Ausnutzung von Parallelität in der Rechnerarchitektur Verteilung von Arbeit und Daten auf viele gleichzeitig arbeitende Rechenknoten Arten der Organisation von Parallelität (Flynn s Taxonomie) SISD (Single Instruction, Single Data, keine Parallelität!) SIMD (Single Instruction, Multiple Data) MIMD (Multiple Instruction, Multiple Data) SPMD (Same Program, Multiple Data) Arten der Organisation des Speichers Gemeinsamer Speicher (Shared Memory) Verteilter Speicher (Distributeted Memory) 8
 mit ggf.")
5 Parallelität (Forts.) Vor-/Nachteile paralleler Verarbeitung: + kürzere Ausführungszeit aufwendige Programmierung ( hohe Kosten für Entwicklung und Pflege) effiziente Parallelisierung oft nicht trivial Schlüsselprobleme: Partitionierung eines Problems und ggf. Lastverteilung (Ziele: hohe Lokalität, maximale Auslastung, minimale Kommunikation) Skalierbarkeit (d.h. Erhöhung der Leistung bei Erhöhung der Prozessoranzahl) Portabilität der Anwendungen (d.h. rechnerunabhängige parallele Programmierung) Koordination und Synchronisation bei der parallelen Verarbeitung Kopplung sehr vieler Prozessoren 9 SIMD-Parallelrechner Kontrolleinheit broadcastet Instruktionen an viele einfache Prozessorelemente (PEs) alle PEs führen taktsynchron die gleiche Instruktion auf unterschiedlichen Daten aus datenparallele Programmierung einzige Ausnahme: Maskierung durch paralleles if-konstrukt gut für Operationen auf Vektoren und Matrizen Beispiele: Connection Machine, ILLIAC IV, ICL DAP, MasPar MP1 und MP2 Prinzip heute auch zu finden in SIMD-Einheiten moderner Ps 10
 Koordination und Synchronisation bei der parallelen Verarbeitung Kopplung sehr vieler Prozessoren 9 SIMD-Parallelrechner Kontrolleinheit broadcastet")
6 MIMD-Parallelrechner mehrere komplexe und unabhängig arbeitende Prozessoren prozeßparallele Programmierung gemeinsamer Speicher (mit globalem Adreßraum) oder verteilter Speicher größere Flexibilität als bei SIMD preiswerter dank Standardkomponenten weites Spektrum an Architekturen, z.b.: Symmetrische Multiprozessoren (SMP) Parallelrechner mit verteiltem Speicher (DMC = Distributed Memory Computer ) Cluster aus PCs/Workstations Beispiele: Intel ipsc und Paragon, Cray T3D und T3E, SP2, Sun C 11 Historie C : Meilensteine 1972: Slotnick entwickelt Illiac IV (erster SIMD-Computer mit Bit PEs in Gitter-Topologie) 1976: Cray Research installiert ersten Vektorrechner Cray-1 mit einer Leistung von 100 MFlop/s 1982: Fujitsu installiertvp-200 Vektorrechner mit 500 MFlop/s 1985: Thinking Machines stellt Connection Machine CM1 vor (SIMD-Computer mit 64k 1-Bit PEs) 1986: erster SMP: Sequent Balance 8000, 8 CPUs 1988: Intel stellt ipsc/2 vor (MIMD-Rechner mit bis zu 128 in einem Hyperkubus angeordneten 386-Prozessoren) 1992: MasPar liefert MP2 aus (SIMD-Computer mit 16k 32-Bit Prozessorelementen) 12
 Parallelrechner mit verteiltem Speicher (DMC = Distributed Memory Computer ) Cluster aus PCs/Workstations Beispiele: Intel ipsc und Paragon, Cray T3D und T3E,")
7 Historie C : Meilensteine (Forts.) 1993: Cray baut MIMD-Rechner Cray T3D (bis zu 2048 DEC Alpha-Prozessoren verbunden in 3DTorus-Topologie) 1994: SP2: Kopplung vieler RISCSystem/6000 Workstations über ein schnelles, skalierbares Netzwerk 1995: DEC Alpha Prozessor mit 4-facher Superskalarität 1996: SGI Origin 2000 (erster Parallelrechner mit virtuellem gemeinsamem Speicher) 1997: System Deep Blue schlägt Weltschachmeister Kasparov 1997: ASCI Red mit 4536 Pentium Pro CPUs erreicht eine Leistung von mehr als 1 TFlop/s 2003: ASCI Q aus 4096 Alpha CPUs erreicht mehr als 10 TFlop/s (Details: 13 Leistung von C Systemen 14
 1997: System Deep Blue schlägt Weltschachmeister Kasparov 1997: ASCI Red mit 4536 Pentium Pro CPUs erreicht eine Leistung")
8 Leistung von Prozessoren 15 Technologie für Prozessoren Taktrate bei Mikroprozessoren erhöhte sich von 1 MHz (1980) auf 1 GHz (2000) Mooresches Gesetz: Verdopplung von Geschwindigkeit des Prozessors und Kapazität der Speicherbausteine alle 1,5 Jahre! gibt es physikalische Grenzen? Lichtgeschwindigkeit: 30 cm/ns Geschwindigkeit der Signalausbreitung in Kupfer: 9 cm/ns (1 GHz entspricht einer Taktbreite von 1ns) Energieverbrauch (und somit Wärmeentwicklung) wachsen linear mit Taktfrequenz (Reduktion der Betriebsspannung, kann nicht beliebig klein werden!) weitere Leistungssteigerungen langfristig hauptsächlich nur durch Ausnutzung von Parallelität! 16
 wachsen linear mit Taktfrequenz (Reduktion der Betriebsspannung, kann nicht beliebig klein werden!")
9 TOP 500 seit 1993 wird halbjährlich eine Liste der weltweit 500 schnellsten C-Systeme erstellt Bewertungsmaßstab ist der LINPACK Benchmark (Lösung eines großen linearen Gleichungssystems der Form A x = b) R max gibt die Leistung eines Systems in GigaFlop/s bei einer individuell gewählten optimalen Problemgröße N max an R peak gibt die theoretisch erreichbare Spitzenleistung an Details unter 17 Top 500 Auszug (Top 20, international, Teil 1) Rank Site Country/Year Computer / Processors Manufacturer R max R peak 1 Earth Simulator Center Japan/2002 Earth-Simulator / 5120 NEC Los Alamos National Laboratory United States/2002 ASCI Q - AlphaServer SC45, 1.25 GHz / Virginia Tech 1100 Dual 2.0 GHz Apple G5/Infiniband 4X/Cisco GigE / 2200 Self-made NCSA PowerEdge 1750, P4 Xeon 3.06 GHz, Myrinet / 2500 Dell Pacific Northwest National Laboratory Integrity rx2600 Itanium2 1.5 GHz, Quadrics / Los Alamos National Laboratory Opteron 2 GHz, Myrinet / 2816 Linux Networx Lawrence Livermore National Lab United States/2002 MCR Linux Cluster Xeon 2.4 GHz - Quadrics / 2304 Linux Networx/Quadrics Lawrence Livermore National Lab United States/2000 ASCI White, SP Power3 375 MHz / NERSC/LBNL United States/2002 SP Power3 375 MHz 16 way / Lawrence Livermore National Lab xseries Cluster Xeon 2.4 GHz - Quadrics / 1920 /Quadrics
 Rank Site Country/Year Computer / Processors Manufacturer R max R peak 1 Earth Simulator Center Japan/2002 Earth-Simulator / 5120 NEC 35860 40960")
10 Top 500 Auszug (Top 20, international, Teil 2) 11 National Aerospace Laboratory of Japan Japan/2002 PRIMEPOWER C2500 (1.3 GHz) / 2304 Fujitsu Pittsburgh Supercomputing Center United States/2001 AlphaServer SC45, 1 GHz / NCAR (National Center for Atmospheric Research) pseries 690 Turbo 1.3 GHz / Chinese Academy of Science China/2003 DeepComp 6800, Itanium2 1.3 GHz, QsNet / 1024 Legend Commissariat a l'energie Atomique (CEA) France/2001 AlphaServer SC45, 1 GHz / Cx United Kingdom/2002 pseries 690 Turbo 1.3GHz / Forecast Systems Laboratory United States/2002 Aspen Systems, Dual Xeon 2.2 GHz, Myrinet2000 / 1536 Ti Naval Oceanographic Office United States/2002 pseries 690 Turbo 1.3GHz / Government Cray X1 / 252 Cray Inc Oak Ridge National Laboratory Cray X1 / 252 Cray Inc Top 500 Auszug (Top 20, Deutschland, Teil 1) Rank Site Country/Year Computer / Processors Manufacturer R max R peak 31 Max-Planck-Gesellschaft MPI/IPP pseries 690 Turbo 1.3 GHz / Deutscher Wetterdienst SP Power3 375 MHz 16 way / Leibniz Rechenzentrum Germany/2002 SR8000-F1/168 / 168 Hitachi DKRZ - Deutsches Klimarechenzentrum SX-6/192M24 / 192 NEC HLRN at Universitaet Hannover / RRZN Germany/2002 pseries 690 Turbo 1.3GHz / HLRN at ZIB/Konrad Zuse-Zentrum fuer Informationstechnik Germany/2002 pseries 690 Turbo 1.3GHz / Universitaet Aachen/RWTH Fire 15k/6800 Cluster / 672 Sun Universitaet Heidelberg - IWR Germany/2002 HELICS AMD 1.4 GHz - Myrinet / 512 Megware EDS/ Adam Opel AG pseries 690 Turbo 1.3GHz / Fraunhofer Institut, Ernst-Mach Institute xseries Cluster Xeon 2.0 GHz - Myrinet /
 France/2001 AlphaServer SC45, 1 GHz / 2560 3980 5120 16 Cx United Kingdom/2002 pseries 690 Turbo 1.")
11 Top 500 Auszug (Top 20, Deutschland, Teil 2) 226 BMW AG Integrity Superdome, 1.5 GHz, lex / Consumer Industry xseries Xeon 2.8 GHz, GigEthernet / W. Karmann GmbH xseries Xeon 2.8 GHz, GigEthernet / Postbank Germany/2002 pseries 690 Turbo 1.3 GHz, GigEth / Hewlett Packard Integrity rx2600 Itanium2 1.5 GHz, Myrinet / PIK pseries GHz / Deutsche Telekom AG Germany/2000 SP Power3 375 MHz / Government AlphaServer SC45, 1.25 GHz / Pharmaceutical Company Germany/2001 SP Power3 375 MHz / OverWrite SuperDome 875 MHz/HyperPlex / TOP 500, Trend bei C-Architekturen 22

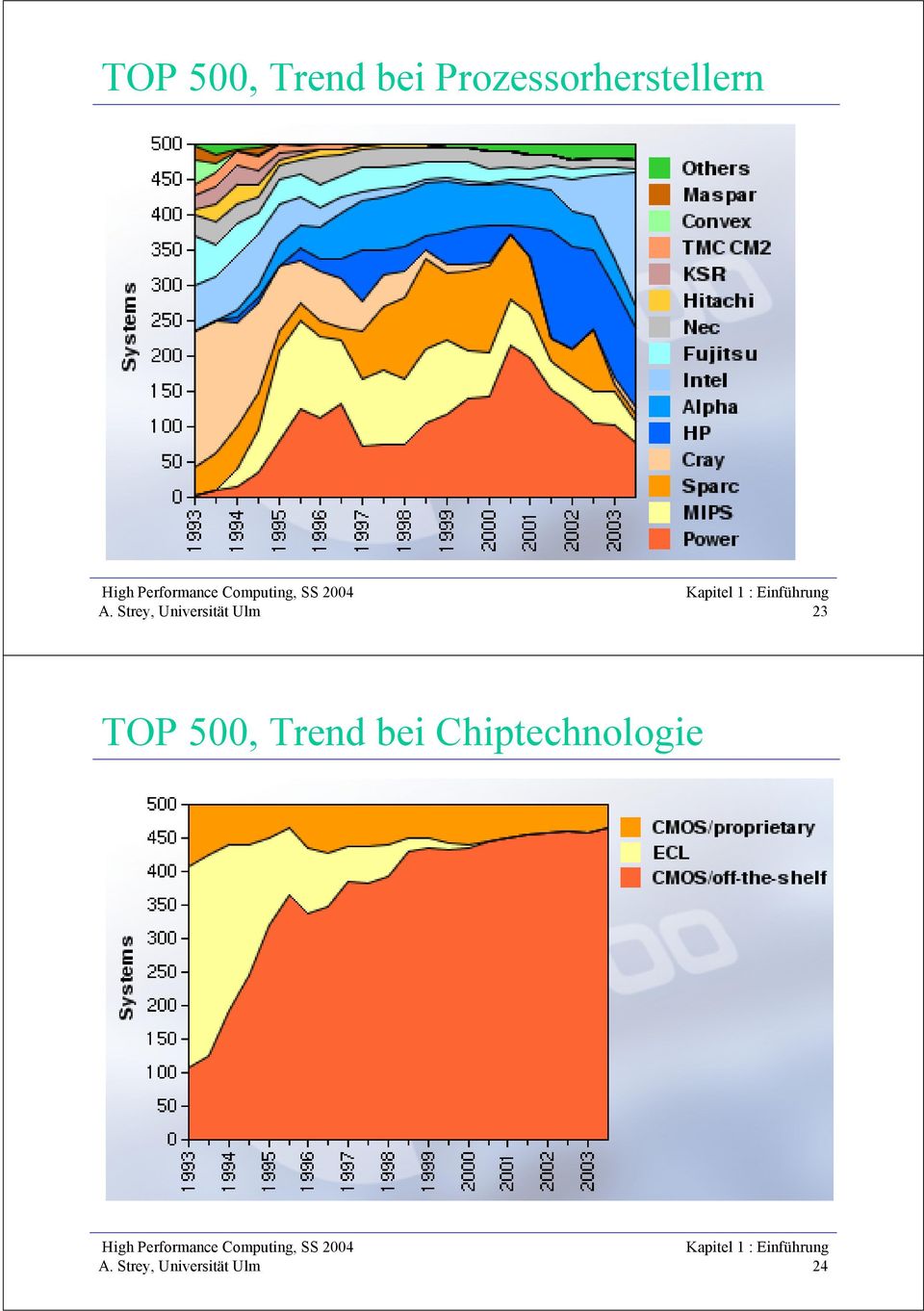
12 TOP 500, Trend bei Prozessorherstellern 23 TOP 500, Trend bei Chiptechnologie 24
13 TOP 500, Trend bei C-Nutzung 25

High Performance Computing
 High Performance Computing SS 2002 PD Dr. A. Strey Abteilung Neuroinformatik, Universität Ulm Email: strey@informatik.uni-ulm.de Inhalt Einführung hohe Leistung durch Parallelität! kurze Historie des High
High Performance Computing SS 2002 PD Dr. A. Strey Abteilung Neuroinformatik, Universität Ulm Email: strey@informatik.uni-ulm.de Inhalt Einführung hohe Leistung durch Parallelität! kurze Historie des High
Ein kleiner Einblick in die Welt der Supercomputer. Christian Krohn 07.12.2010 1
 Ein kleiner Einblick in die Welt der Supercomputer Christian Krohn 07.12.2010 1 Vorschub: FLOPS Entwicklung der Supercomputer Funktionsweisen von Supercomputern Zukunftsvisionen 2 Ein Top10 Supercomputer
Ein kleiner Einblick in die Welt der Supercomputer Christian Krohn 07.12.2010 1 Vorschub: FLOPS Entwicklung der Supercomputer Funktionsweisen von Supercomputern Zukunftsvisionen 2 Ein Top10 Supercomputer
Projektseminar Parallele Programmierung
 HTW Dresden WS 2014/2015 Organisatorisches Praktikum, 4 SWS Do. 15:00-18:20 Uhr, Z136c, 2 Doppelstunden o.g. Termin ist als Treffpunkt zu verstehen Labore Z 136c / Z 355 sind Montag und Donnerstag 15:00-18:20
HTW Dresden WS 2014/2015 Organisatorisches Praktikum, 4 SWS Do. 15:00-18:20 Uhr, Z136c, 2 Doppelstunden o.g. Termin ist als Treffpunkt zu verstehen Labore Z 136c / Z 355 sind Montag und Donnerstag 15:00-18:20
XSC. Reimar Bauer, Rebecca Breu. Dezember 2008. Forschungszentrum Jülich. Weihnachtsfeier, 10. Dezember 2008 1
 XSC Reimar Bauer, Rebecca Breu Forschungszentrum Jülich Dezember 2008 Weihnachtsfeier, 10. Dezember 2008 1 Supercomputing I I Forschungszentrum Ju lich mischt da mit Zweimal im Jahr gibt es eine Top 500-Liste
XSC Reimar Bauer, Rebecca Breu Forschungszentrum Jülich Dezember 2008 Weihnachtsfeier, 10. Dezember 2008 1 Supercomputing I I Forschungszentrum Ju lich mischt da mit Zweimal im Jahr gibt es eine Top 500-Liste
Proseminar Rechnerarchitekturen. Parallelcomputer: Multiprozessorsysteme
 wwwnet-texde Proseminar Rechnerarchitekturen Parallelcomputer: Multiprozessorsysteme Stefan Schumacher, , PGP Key http://wwwnet-texde/uni Id: mps-folientex,v
wwwnet-texde Proseminar Rechnerarchitekturen Parallelcomputer: Multiprozessorsysteme Stefan Schumacher, , PGP Key http://wwwnet-texde/uni Id: mps-folientex,v
Intel 80x86 symmetrische Multiprozessorsysteme. Eine Präsentation im Rahmen des Seminars Parallele Rechnerarchitekturen von Bernhard Witte
 Intel 80x86 symmetrische Multiprozessorsysteme Eine Präsentation im Rahmen des Seminars Parallele Rechnerarchitekturen von Bernhard Witte Gliederung I. Parallel Computing Einführung II.SMP Grundlagen III.Speicherzugriff
Intel 80x86 symmetrische Multiprozessorsysteme Eine Präsentation im Rahmen des Seminars Parallele Rechnerarchitekturen von Bernhard Witte Gliederung I. Parallel Computing Einführung II.SMP Grundlagen III.Speicherzugriff
Distributed Memory Computer (DMC)
") Distributed Memory Computer (DMC) verteilter Speicher: jeder Prozessor kann nur auf seinen lokalen Speicher zugreifen Kopplung mehrerer Prozessoren über E/A-Schnittstellen und Verbindungsnetzwerk, nicht
Distributed Memory Computer (DMC) verteilter Speicher: jeder Prozessor kann nur auf seinen lokalen Speicher zugreifen Kopplung mehrerer Prozessoren über E/A-Schnittstellen und Verbindungsnetzwerk, nicht
moderne Prozessoren Jan Krüger jkrueger@techfak.uni-bielefeld.de
 moderne Prozessoren Jan Krüger jkrueger@techfak.uni-bielefeld.de Übersicht FachChinesisch SPARC - UltraSparc III/IV PowerPC - PowerPC 970(G5) X86 - Pentium4(Xeon), Itanium, (Pentium M) X86 - AthlonXP/MP,
moderne Prozessoren Jan Krüger jkrueger@techfak.uni-bielefeld.de Übersicht FachChinesisch SPARC - UltraSparc III/IV PowerPC - PowerPC 970(G5) X86 - Pentium4(Xeon), Itanium, (Pentium M) X86 - AthlonXP/MP,
Kapitel 5. Parallelverarbeitung. Formen der Parallelität
 Kapitel 5 Parallelverarbeitung é Formen der Parallelität é Klassifikation von parallelen Rechnerarchitekturen é Exkurs über Verbindungsstrukturen Bernd Becker Technische Informatik I Formen der Parallelität
Kapitel 5 Parallelverarbeitung é Formen der Parallelität é Klassifikation von parallelen Rechnerarchitekturen é Exkurs über Verbindungsstrukturen Bernd Becker Technische Informatik I Formen der Parallelität
Grundlagen der Parallelisierung
 Grundlagen der Parallelisierung Philipp Kegel, Sergei Gorlatch AG Parallele und Verteilte Systeme Institut für Informatik Westfälische Wilhelms-Universität Münster 3. Juli 2009 Inhaltsverzeichnis 1 Einführung
Grundlagen der Parallelisierung Philipp Kegel, Sergei Gorlatch AG Parallele und Verteilte Systeme Institut für Informatik Westfälische Wilhelms-Universität Münster 3. Juli 2009 Inhaltsverzeichnis 1 Einführung
Orientierungsveranstaltungen 2009 Informatikstudien der Universität Wien
 Orientierungsveranstaltungen 2009 Informatikstudien der Universität Wien Scientific Computing 07. Oktober 2009 Siegfried Benkner Wilfried Gansterer Fakultät für Informatik Universität Wien www.cs.univie.ac.at
Orientierungsveranstaltungen 2009 Informatikstudien der Universität Wien Scientific Computing 07. Oktober 2009 Siegfried Benkner Wilfried Gansterer Fakultät für Informatik Universität Wien www.cs.univie.ac.at
Centre of Excellence for High Performance Computing Erlangen Kompetenzgruppe für Supercomputer und Technisch-Wissenschaftliche Simulation
 1 Centre of Excellence for High Performance Computing Erlangen Kompetenzgruppe für Supercomputer und Technisch-Wissenschaftliche Simulation Dr. G. Wellein, Regionales Rechenzentrum Erlangen Supercomputer
1 Centre of Excellence for High Performance Computing Erlangen Kompetenzgruppe für Supercomputer und Technisch-Wissenschaftliche Simulation Dr. G. Wellein, Regionales Rechenzentrum Erlangen Supercomputer
Computeranwendung in der Chemie Informatik für Chemiker(innen)
") Computeranwendung in der Chemie Informatik für Chemiker(innen) Dr. Jens Döbler Arbeitsgruppe Quantenchemie jd@chemie.hu-berlin.de Jens Döbler 2003 "Computer in der Chemie", WS 2003-04, Humboldt-Universität
Computeranwendung in der Chemie Informatik für Chemiker(innen) Dr. Jens Döbler Arbeitsgruppe Quantenchemie jd@chemie.hu-berlin.de Jens Döbler 2003 "Computer in der Chemie", WS 2003-04, Humboldt-Universität
Parallelrechner (1) Anwendungen: Simulation von komplexen physikalischen oder biochemischen Vorgängen Entwurfsunterstützung virtuelle Realität
 Anwendungen: Simulation von komplexen physikalischen oder biochemischen Vorgängen Entwurfsunterstützung virtuelle Realität") Parallelrechner (1) Motivation: Bedarf für immer leistungsfähigere Rechner Leistungssteigerung eines einzelnen Rechners hat physikalische Grenzen: Geschwindigkeit von Materie Wärmeableitung Transistorgröße
Parallelrechner (1) Motivation: Bedarf für immer leistungsfähigere Rechner Leistungssteigerung eines einzelnen Rechners hat physikalische Grenzen: Geschwindigkeit von Materie Wärmeableitung Transistorgröße
Codesigned Virtual Machines
 Codesigned Virtual Machines Seminar Virtualisierung Philipp Kirchhofer philipp.kirchhofer@student.kit.edu Institut für Technische Informatik Lehrstuhl für Rechnerarchitektur Universität Karlsruhe (TH)
Codesigned Virtual Machines Seminar Virtualisierung Philipp Kirchhofer philipp.kirchhofer@student.kit.edu Institut für Technische Informatik Lehrstuhl für Rechnerarchitektur Universität Karlsruhe (TH)
Dienstleistungen Abteilung Systemdienste
 Dienstleistungen Abteilung Systemdienste Betrieb zentraler Rechenanlagen Speicherdienste Systembetreuung im Auftrag (SLA) 2 HP Superdome Systeme Shared Memory Itanium2 (1.5 GHz) - 64 CPUs, 128 GB RAM -
Dienstleistungen Abteilung Systemdienste Betrieb zentraler Rechenanlagen Speicherdienste Systembetreuung im Auftrag (SLA) 2 HP Superdome Systeme Shared Memory Itanium2 (1.5 GHz) - 64 CPUs, 128 GB RAM -
Mikrocontroller Grundlagen. Markus Koch April 2011
 Mikrocontroller Grundlagen Markus Koch April 2011 Übersicht Was ist ein Mikrocontroller Aufbau (CPU/RAM/ROM/Takt/Peripherie) Unterschied zum Mikroprozessor Unterschiede der Controllerarten Unterschiede
Mikrocontroller Grundlagen Markus Koch April 2011 Übersicht Was ist ein Mikrocontroller Aufbau (CPU/RAM/ROM/Takt/Peripherie) Unterschied zum Mikroprozessor Unterschiede der Controllerarten Unterschiede
Excel beschleunigen mit dem mit Windows HPC Server 2008 R2
 Excel beschleunigen mit dem mit Windows HPC Server 2008 R2 Steffen Krause Technical Evangelist Microsoft Deutschland GmbH http://blogs.technet.com/steffenk Haftungsausschluss Microsoft kann für die Richtigkeit
Excel beschleunigen mit dem mit Windows HPC Server 2008 R2 Steffen Krause Technical Evangelist Microsoft Deutschland GmbH http://blogs.technet.com/steffenk Haftungsausschluss Microsoft kann für die Richtigkeit
Johann Wolfgang Goethe-Universität
 Flynn sche Klassifikation SISD (single instruction, single data stream): IS IS CU PU DS MM Mono (Mikro-)prozessoren CU: Control Unit SM: Shared Memory PU: Processor Unit IS: Instruction Stream MM: Memory
Flynn sche Klassifikation SISD (single instruction, single data stream): IS IS CU PU DS MM Mono (Mikro-)prozessoren CU: Control Unit SM: Shared Memory PU: Processor Unit IS: Instruction Stream MM: Memory
MOGON. Markus Tacke HPC ZDV. HPC - AHRP Markus Tacke, ZDV, Universität Mainz
 MOGON Markus Tacke HPC ZDV HPC - AHRP Was ist Mogon allgemein? Das neue High Performance Cluster der JGU Ein neues wichtiges Werkzeug für Auswertung von Messdaten und Simulationen Beispiele Kondensierte
MOGON Markus Tacke HPC ZDV HPC - AHRP Was ist Mogon allgemein? Das neue High Performance Cluster der JGU Ein neues wichtiges Werkzeug für Auswertung von Messdaten und Simulationen Beispiele Kondensierte
Verkürzung von Entwurfszeiten
 Verkürzung von Entwurfszeiten durch Matlab-basiertes HPC R. Fink, S. Pawletta Übersicht aktuelle Situation im ingenieurtechnischen Bereich Multi-SCEs als Konzept zur Verkürzung von Entwurfszeiten Realisierung
Verkürzung von Entwurfszeiten durch Matlab-basiertes HPC R. Fink, S. Pawletta Übersicht aktuelle Situation im ingenieurtechnischen Bereich Multi-SCEs als Konzept zur Verkürzung von Entwurfszeiten Realisierung
Big Data in der Forschung
 Big Data in der Forschung Dominik Friedrich RWTH Aachen Rechen- und Kommunikationszentrum (RZ) Gartner Hype Cycle July 2011 Folie 2 Was ist Big Data? Was wird unter Big Data verstanden Datensätze, die
Big Data in der Forschung Dominik Friedrich RWTH Aachen Rechen- und Kommunikationszentrum (RZ) Gartner Hype Cycle July 2011 Folie 2 Was ist Big Data? Was wird unter Big Data verstanden Datensätze, die
The world we live in and Supercomputing in general
 The world we live in and Supercomputing in general Achim Streit aktuelle Prozessoren Desktop Intel Pentium 4 mit 3.2 GHz AMD Athlon XP 3200+ mit 2.2 GHz IBM PowerPC G5 mit 2.0 GHz (64-bit) Server & Workstation
The world we live in and Supercomputing in general Achim Streit aktuelle Prozessoren Desktop Intel Pentium 4 mit 3.2 GHz AMD Athlon XP 3200+ mit 2.2 GHz IBM PowerPC G5 mit 2.0 GHz (64-bit) Server & Workstation
2 Rechnerarchitekturen
 2 Rechnerarchitekturen Rechnerarchitekturen Flynns Klassifikation Flynnsche Klassifikation (Flynn sche Taxonomie) 1966 entwickelt, einfaches Modell, bis heute genutzt Beschränkung der Beschreibung auf
2 Rechnerarchitekturen Rechnerarchitekturen Flynns Klassifikation Flynnsche Klassifikation (Flynn sche Taxonomie) 1966 entwickelt, einfaches Modell, bis heute genutzt Beschränkung der Beschreibung auf
Einleitung. Dr.-Ing. Volkmar Sieh WS 2005/2006. Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg
 Technologische Trends Historischer Rückblick Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2005/2006 Technologische Trends Historischer Rückblick Übersicht
Technologische Trends Historischer Rückblick Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2005/2006 Technologische Trends Historischer Rückblick Übersicht
Enterprise Computing
 Enterprise Computing Prof. Dr.-Ing. Wilhelm G. Spruth Teil 6 Partitionierung NUMA Sharing Disk Storage HP Superdome Cell Board 4 Itanium 2 CPU Chips 32 128 Gbyte I/O Bus mit Kühlern Hauptspeicher Anschlüsse
Enterprise Computing Prof. Dr.-Ing. Wilhelm G. Spruth Teil 6 Partitionierung NUMA Sharing Disk Storage HP Superdome Cell Board 4 Itanium 2 CPU Chips 32 128 Gbyte I/O Bus mit Kühlern Hauptspeicher Anschlüsse
Super rechnen ohne Superrechner Oder: Was hat das Grid mit Monte Carlo zu tun?
 Super rechnen ohne Superrechner Oder: Was hat das Grid mit Monte Carlo zu tun? Marius Mertens 20.02.2015 Super rechnen ohne Superrechner? Warum? Algorithmik und Parallelisierung Wie? Alternative Architekturen
Super rechnen ohne Superrechner Oder: Was hat das Grid mit Monte Carlo zu tun? Marius Mertens 20.02.2015 Super rechnen ohne Superrechner? Warum? Algorithmik und Parallelisierung Wie? Alternative Architekturen
Einführung in die Informatik
 Einführung in die Informatik Einleitung Organisatorisches, Motivation, Herangehensweise Wolfram Burgard Cyrill Stachniss 0.1 Vorlesung Zeit und Ort: Mo 16.00 18.00 Uhr Gebäude 101, HS 00-026 Informationen
Einführung in die Informatik Einleitung Organisatorisches, Motivation, Herangehensweise Wolfram Burgard Cyrill Stachniss 0.1 Vorlesung Zeit und Ort: Mo 16.00 18.00 Uhr Gebäude 101, HS 00-026 Informationen
2.5. VERBINDUNGSNETZWERKE GESTALTUNGSKRITERIEN DER NETZWERKE TOPOLOGIE ALS GRAPH. Vorlesung 5 TOPOLOGIE: DEFINITIONEN : Sei G = (V, E) ein Graph mit:
 ein Graph mit:") Vorlesung 5.5. VERBINDUNGSNETZWERKE Kommunikation zwischen den einzelnen Komponenten eines arallelrechners wird i.d.r. über ein Netzwerk organisiert. Dabei unterscheidet man zwei Klassen der Rechner: TOOLOGIE:
Vorlesung 5.5. VERBINDUNGSNETZWERKE Kommunikation zwischen den einzelnen Komponenten eines arallelrechners wird i.d.r. über ein Netzwerk organisiert. Dabei unterscheidet man zwei Klassen der Rechner: TOOLOGIE:
Einführung in die Systemprogrammierung
 Einführung in die Systemprogrammierung Speedup: Grundlagen der Performanz Prof. Dr. Christoph Reichenbach Fachbereich 12 / Institut für Informatik 30. April 2015 Eine Aufgabe aus der Praxis Gegeben ein
Einführung in die Systemprogrammierung Speedup: Grundlagen der Performanz Prof. Dr. Christoph Reichenbach Fachbereich 12 / Institut für Informatik 30. April 2015 Eine Aufgabe aus der Praxis Gegeben ein
Programmierung von Multicore-Rechnern
 Programmierung von Multicore-Rechnern Prof. Dr.-Ing. habil. Peter Sobe HTW Dresden, Fakultät Informatik/Mathematik www.informatik.htw-dresden.de Gliederung: Ein Blick auf Multicore-Prozessoren/ und -Rechner
Programmierung von Multicore-Rechnern Prof. Dr.-Ing. habil. Peter Sobe HTW Dresden, Fakultät Informatik/Mathematik www.informatik.htw-dresden.de Gliederung: Ein Blick auf Multicore-Prozessoren/ und -Rechner
Einleitung. Dr.-Ing. Volkmar Sieh. Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2006/2007
 Einleitung Dr.-Ing. Volkmar Sieh Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2006/2007 Einleitung 1/50 2006/10/09 Übersicht 1 Einleitung 2 Technologische
Einleitung Dr.-Ing. Volkmar Sieh Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2006/2007 Einleitung 1/50 2006/10/09 Übersicht 1 Einleitung 2 Technologische
C C. Hochleistungsrechnen (HPC) auf dem Windows Compute Cluster des RZ der RWTH Aachen. 1 WinHPC 2006 - Einführung Center. 31.
 auf dem Windows Compute Cluster des RZ der RWTH Aachen. 1 WinHPC 2006 - Einführung Center. 31.") Hochleistungsrechnen (HP) auf dem Windows ompute luster des RZ der RWTH Aachen 31. Mai 2006 hristian Terboven Dieter an Mey {terboven anmey}@rz.rwth-aachen.de 1 WinHP 2006 - Einführung enter SunFire V40z
Hochleistungsrechnen (HP) auf dem Windows ompute luster des RZ der RWTH Aachen 31. Mai 2006 hristian Terboven Dieter an Mey {terboven anmey}@rz.rwth-aachen.de 1 WinHP 2006 - Einführung enter SunFire V40z
Select & Preprocessing Cluster. SPP Server #1. SPP Server #2. Cluster InterConnection. SPP Server #n
 C5000 High Performance Acquisition System Das C5000 System wurde für Messerfassungs- und Auswertungssystem mit sehr hohem Datenaufkommen konzipiert. Typische Applikationen für das C5000 sind große Prüfstände,
C5000 High Performance Acquisition System Das C5000 System wurde für Messerfassungs- und Auswertungssystem mit sehr hohem Datenaufkommen konzipiert. Typische Applikationen für das C5000 sind große Prüfstände,
MATCHING VON PRODUKTDATEN IN DER CLOUD
 MATCHING VON PRODUKTDATEN IN DER CLOUD Dr. Andreas Thor Universität Leipzig 15.12.2011 Web Data Integration Workshop 2011 Cloud Computing 2 Cloud computing is using the internet to access someone else's
MATCHING VON PRODUKTDATEN IN DER CLOUD Dr. Andreas Thor Universität Leipzig 15.12.2011 Web Data Integration Workshop 2011 Cloud Computing 2 Cloud computing is using the internet to access someone else's
Computational Biology: Bioelektromagnetismus und Biomechanik
 Computational Biology: Bioelektromagnetismus und Biomechanik Implementierung Gliederung Wiederholung: Biomechanik III Statische Elastomechanik Finite Elemente Diskretisierung Finite Differenzen Diskretisierung
Computational Biology: Bioelektromagnetismus und Biomechanik Implementierung Gliederung Wiederholung: Biomechanik III Statische Elastomechanik Finite Elemente Diskretisierung Finite Differenzen Diskretisierung
Die deutsche Windows HPC Benutzergruppe
 Christian Terboven, Dieter an Mey {terboven, anmey}@rz.rwth aachen.de Rechen und Kommunikationszentrum RWTH Aachen Windows HPC Server Launch 16. Oktober, Frankfurt am Main Agenda o Hochleistungsrechnen
Christian Terboven, Dieter an Mey {terboven, anmey}@rz.rwth aachen.de Rechen und Kommunikationszentrum RWTH Aachen Windows HPC Server Launch 16. Oktober, Frankfurt am Main Agenda o Hochleistungsrechnen
Inhaltsangabe zu den Systemvoraussetzungen:
 Inhaltsangabe zu den Systemvoraussetzungen: Seite 2 bis 1.500 Wohneinheiten und bis 2 Seite 3 bis 1.500 Wohneinheiten und bis 5 Seite 4 bis 5.000 Wohneinheiten und mehr als 10 Seite 5 bis 15.000 Wohneinheiten
Inhaltsangabe zu den Systemvoraussetzungen: Seite 2 bis 1.500 Wohneinheiten und bis 2 Seite 3 bis 1.500 Wohneinheiten und bis 5 Seite 4 bis 5.000 Wohneinheiten und mehr als 10 Seite 5 bis 15.000 Wohneinheiten
Architektur von Parallelrechnern 50
 Architektur von Parallelrechnern 50 Rechenintensive parallele Anwendungen können nicht sinnvoll ohne Kenntnis der zugrundeliegenden Architektur erstellt werden. Deswegen ist die Wahl einer geeigneten Architektur
Architektur von Parallelrechnern 50 Rechenintensive parallele Anwendungen können nicht sinnvoll ohne Kenntnis der zugrundeliegenden Architektur erstellt werden. Deswegen ist die Wahl einer geeigneten Architektur
PROLAG WORLD 2.0 PRODUKTBESCHREIBUNG SERVERSYSTEM, CLUSTERSYSTEME FÜR PROLAG WORLD
 PROLAG WORLD 2.0 PRODUKTBESCHREIBUNG SERVERSYSTEM, CLUSTERSYSTEME FÜR PROLAG WORLD Inhaltsverzeichnis 1. ZUSAMMENSTELLUNG VON SERVERN...3 1.1. ANFORDERUNGSPROFIL...3 1.2. 1.3. SERVER MODELLE...3 TECHNISCHE
PROLAG WORLD 2.0 PRODUKTBESCHREIBUNG SERVERSYSTEM, CLUSTERSYSTEME FÜR PROLAG WORLD Inhaltsverzeichnis 1. ZUSAMMENSTELLUNG VON SERVERN...3 1.1. ANFORDERUNGSPROFIL...3 1.2. 1.3. SERVER MODELLE...3 TECHNISCHE
Übersicht. Einleitung. Übersicht. Architektur. Dr.-Ing. Volkmar Sieh WS 2008/2009
 Übersicht Einleitung 1 Einleitung Dr.-Ing. Volkmar Sieh 2 Technologische Trends Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2008/2009 3 Historischer
Übersicht Einleitung 1 Einleitung Dr.-Ing. Volkmar Sieh 2 Technologische Trends Institut für Informatik 3: Rechnerarchitektur Friedrich-Alexander-Universität Erlangen-Nürnberg WS 2008/2009 3 Historischer
CHARON-AXP Alpha Hardwarevirtualisierung
 Alpha virtualisierung Nutzung von Softwareinvestitionen auf neuer plattform Jörg Streit, Reinhard Galler Inhalt: Alpha überblick Wozu Alpha? Prinzip der Produkte Performance Cluster Support Zusammenfassung
Alpha virtualisierung Nutzung von Softwareinvestitionen auf neuer plattform Jörg Streit, Reinhard Galler Inhalt: Alpha überblick Wozu Alpha? Prinzip der Produkte Performance Cluster Support Zusammenfassung
Fragestellung: Wie viele CPU Kerne sollte eine VM unter Virtualbox zugewiesen bekommen?
 Fragestellung: Wie viele CPU Kerne sollte eine VM unter Virtualbox zugewiesen bekommen? Umgebung Getestet wurde auf einem Linux-System mit voller invis-server Installation, auf dem eine virtuelle Maschine
Fragestellung: Wie viele CPU Kerne sollte eine VM unter Virtualbox zugewiesen bekommen? Umgebung Getestet wurde auf einem Linux-System mit voller invis-server Installation, auf dem eine virtuelle Maschine
Hardware-Architekturen
 Kapitel 3 Hardware-Architekturen Hardware-Architekturen Architekturkategorien Mehrprozessorsysteme Begriffsbildungen g Verbindungsnetze Cluster, Constellation, Grid Abgrenzungen Beispiele 1 Fragestellungen
Kapitel 3 Hardware-Architekturen Hardware-Architekturen Architekturkategorien Mehrprozessorsysteme Begriffsbildungen g Verbindungsnetze Cluster, Constellation, Grid Abgrenzungen Beispiele 1 Fragestellungen
Virtual System Cluster: Freie Wahl mit Open Source
 Virtual System Cluster: Freie Wahl mit Open Source LPI Partnertagung 2012 Sprecher: Uwe Grawert http://www.b1-systems.de 24. April 2012 c B1 Systems GmbH 2004 2012 Chapter -1, Slide 1 Freie Wahl beim Virtual
Virtual System Cluster: Freie Wahl mit Open Source LPI Partnertagung 2012 Sprecher: Uwe Grawert http://www.b1-systems.de 24. April 2012 c B1 Systems GmbH 2004 2012 Chapter -1, Slide 1 Freie Wahl beim Virtual
Das HLRN-System. Peter Endebrock, RRZN Hannover
 Das HLRN-System Peter Endebrock, RRZN Hannover vorweg (1) Heute Vorträge im Dreierpack: Peter Endebrock: Das HLRN-System Gerd Brand: MPI Simone Knief: OpenMP Peter Endebrock, RRZN Hannover, Kolloquium,
Das HLRN-System Peter Endebrock, RRZN Hannover vorweg (1) Heute Vorträge im Dreierpack: Peter Endebrock: Das HLRN-System Gerd Brand: MPI Simone Knief: OpenMP Peter Endebrock, RRZN Hannover, Kolloquium,
Übersicht. Nebenläufige Programmierung. Praxis und Semantik. Einleitung. Sequentielle und nebenläufige Programmierung. Warum ist. interessant?
 Übersicht Aktuelle Themen zu Informatik der Systeme: Nebenläufige Programmierung: Praxis und Semantik Einleitung 1 2 der nebenläufigen Programmierung WS 2011/12 Stand der Folien: 18. Oktober 2011 1 TIDS
Übersicht Aktuelle Themen zu Informatik der Systeme: Nebenläufige Programmierung: Praxis und Semantik Einleitung 1 2 der nebenläufigen Programmierung WS 2011/12 Stand der Folien: 18. Oktober 2011 1 TIDS
The Modular Structure of Complex Systems. 30.06.2004 Seminar SoftwareArchitektur Fabian Schultz
 The Modular Structure of Complex Systems 1 Modularisierung Vorteile Organisation Mehrere unabhängig Teams können gleichzeitig arbeiten Flexibilität Änderung einzelner Module Verständlichkeit Nachteile
The Modular Structure of Complex Systems 1 Modularisierung Vorteile Organisation Mehrere unabhängig Teams können gleichzeitig arbeiten Flexibilität Änderung einzelner Module Verständlichkeit Nachteile
Brückenkurs / Computer
 Brückenkurs / Computer Sebastian Stabinger IIS 22 September 2014 1 / 24 Content 1 Allgemeines zum Studium 2 Was ist ein Computer? 3 Geschichte des Computers 4 Komponenten eines Computers 5 Aufbau eines
Brückenkurs / Computer Sebastian Stabinger IIS 22 September 2014 1 / 24 Content 1 Allgemeines zum Studium 2 Was ist ein Computer? 3 Geschichte des Computers 4 Komponenten eines Computers 5 Aufbau eines
Grundlagen der Programmierung 2. Parallele Verarbeitung
 Grundlagen der Programmierung 2 Parallele Verarbeitung Prof. Dr. Manfred Schmidt-Schauÿ Künstliche Intelligenz und Softwaretechnologie 27. Mai 2009 Parallele Algorithmen und Ressourcenbedarf Themen: Nebenläufigkeit,
Grundlagen der Programmierung 2 Parallele Verarbeitung Prof. Dr. Manfred Schmidt-Schauÿ Künstliche Intelligenz und Softwaretechnologie 27. Mai 2009 Parallele Algorithmen und Ressourcenbedarf Themen: Nebenläufigkeit,
Adaptive und fehlertolerante MPI-Varianten. Heiko Waldschmidt 05.02.2007
 Adaptive und fehlertolerante MPI-Varianten Heiko Waldschmidt 05.02.2007 Übersicht Einleitung Fehlertolerante MPI-Varianten Adaptives MPI Fazit Heiko Waldschmidt Adaptive und fehlertolerante MPI-Varianten
Adaptive und fehlertolerante MPI-Varianten Heiko Waldschmidt 05.02.2007 Übersicht Einleitung Fehlertolerante MPI-Varianten Adaptives MPI Fazit Heiko Waldschmidt Adaptive und fehlertolerante MPI-Varianten
Überblick über das Institut für Telematik
 Überblick über das Institut für Telematik Professoren Prof. Dr. Sebastian Abeck (seit 16) Prof. Dr. Michael Beigl (seit 2010) Prof. Dr. Hannes Hartenstein (seit 2003) Prof. Dr. Wilfried Juling (seit 18)
Überblick über das Institut für Telematik Professoren Prof. Dr. Sebastian Abeck (seit 16) Prof. Dr. Michael Beigl (seit 2010) Prof. Dr. Hannes Hartenstein (seit 2003) Prof. Dr. Wilfried Juling (seit 18)
Systemaspekte Verteilter Systeme Wintersemester 2004/05
 Systemaspekte Verteilter Systeme Wintersemester 2004/05 Odej Kao Institut für Informatik Universität Paderborn Prof. Dr. Odej Kao Dozent AG Betriebssysteme und Verteilte Systeme Fürstenallee 11, F2.101
Systemaspekte Verteilter Systeme Wintersemester 2004/05 Odej Kao Institut für Informatik Universität Paderborn Prof. Dr. Odej Kao Dozent AG Betriebssysteme und Verteilte Systeme Fürstenallee 11, F2.101
Symmetric Multiprocessing mit einer FPGA basierten. Marco Kirschke INF-M3 Seminar Wintersemester 2010/2011 25. November 2010
 Symmetric Multiprocessing mit einer FPGA basierten MPSoC Plattform Marco Kirschke INF-M3 Seminar Wintersemester 2010/2011 25. November 2010 Inhalt Motivation Vorarbeiten Ziele für die Masterarbeit Vorgehensweise
Symmetric Multiprocessing mit einer FPGA basierten MPSoC Plattform Marco Kirschke INF-M3 Seminar Wintersemester 2010/2011 25. November 2010 Inhalt Motivation Vorarbeiten Ziele für die Masterarbeit Vorgehensweise
Georg Hager Regionales Rechenzentrum Erlangen (RRZE)
") Erfahrungen und Benchmarks mit Dual- -Prozessoren Georg Hager Regionales Rechenzentrum Erlangen (RRZE) ZKI AK Supercomputing Karlsruhe, 22./23.09.2005 Dual : Anbieter heute IBM Power4/Power5 (Power5 mit
Erfahrungen und Benchmarks mit Dual- -Prozessoren Georg Hager Regionales Rechenzentrum Erlangen (RRZE) ZKI AK Supercomputing Karlsruhe, 22./23.09.2005 Dual : Anbieter heute IBM Power4/Power5 (Power5 mit
Übergang vom Diplom zum Bachelor
 Übergang vom Diplom zum Bachelor Da die Fächer des Bachelorstudienganges größtenteils aus Fächern des Diplomstudiengangs hervorgegangen sind, können sich die Studierenden diese Fächer aus dem Diplom für
Übergang vom Diplom zum Bachelor Da die Fächer des Bachelorstudienganges größtenteils aus Fächern des Diplomstudiengangs hervorgegangen sind, können sich die Studierenden diese Fächer aus dem Diplom für
Multicore Herausforderungen an das Software-Engineering. Prof. Dr.-Ing. Michael Uelschen Hochschule Osnabrück 15.09.2010
 Multicore Herausforderungen an das Software-Engineering Prof. Dr.-Ing. Michael Uelschen Hochschule Osnabrück 15.09.2010 Inhalt _ Motivation _ Herausforderung 1: Hardware _ Herausforderung 2: Software-Partitionierung
Multicore Herausforderungen an das Software-Engineering Prof. Dr.-Ing. Michael Uelschen Hochschule Osnabrück 15.09.2010 Inhalt _ Motivation _ Herausforderung 1: Hardware _ Herausforderung 2: Software-Partitionierung
Studiengang Angewandte Informatik Master-AI. Institut für Neuroinformatik
 Master-AI Willkommen in der AI! PO '13 Master Prüfungsordnung vom 30.09.2013 (PO '13) + Änderungssatzung Bitte lesen! Die Masterprüfung bildet den wissenschaftlich berufsqualifizierenden Abschluss des
Master-AI Willkommen in der AI! PO '13 Master Prüfungsordnung vom 30.09.2013 (PO '13) + Änderungssatzung Bitte lesen! Die Masterprüfung bildet den wissenschaftlich berufsqualifizierenden Abschluss des
1 Konzepte der Parallelverarbeitung
 Parallelverarbeitung Folie 1-1 1 Konzepte der Parallelverarbeitung Erhöhung der Rechenleistung verbesserte Prozessorarchitekturen mit immer höheren Taktraten Vektorrechner Multiprozessorsysteme (Rechner
Parallelverarbeitung Folie 1-1 1 Konzepte der Parallelverarbeitung Erhöhung der Rechenleistung verbesserte Prozessorarchitekturen mit immer höheren Taktraten Vektorrechner Multiprozessorsysteme (Rechner
Technische Informatik I
 Technische Informatik I SS 2001 PD Dr. A. Strey Abteilung Neuroinformatik Universität Ulm Inhalt Einführung: Überblick über die historische Entwicklung der Rechnerhardware Teil 1: Digitale Logik kurzer
Technische Informatik I SS 2001 PD Dr. A. Strey Abteilung Neuroinformatik Universität Ulm Inhalt Einführung: Überblick über die historische Entwicklung der Rechnerhardware Teil 1: Digitale Logik kurzer
Mehrprozessorarchitekturen (SMP, Cluster, UMA/NUMA)
") Proseminar KVBK Mehrprozessorarchitekturen (SMP, Cluster, UMA/NUMA) Arian Bär 12.07.2004 1. Einleitung 2. Symmetrische Multiprozessoren (SMP) 2.1. Allgemeines 2.2. Architektur 3. Speicherarchitekturen
Proseminar KVBK Mehrprozessorarchitekturen (SMP, Cluster, UMA/NUMA) Arian Bär 12.07.2004 1. Einleitung 2. Symmetrische Multiprozessoren (SMP) 2.1. Allgemeines 2.2. Architektur 3. Speicherarchitekturen
Hardware-Empfehlungen PrefSuite V2008
 Hardware-Empfehlungen PrefSuite V2008 Für Versionsstand PrefGest 2008.1.0.1142 Im Folgenden die von PrefSuite vorgeschlagenen Voraussetzungen: Systemvoraussetzungen für den SQL-Server Systemvoraussetzungen
Hardware-Empfehlungen PrefSuite V2008 Für Versionsstand PrefGest 2008.1.0.1142 Im Folgenden die von PrefSuite vorgeschlagenen Voraussetzungen: Systemvoraussetzungen für den SQL-Server Systemvoraussetzungen
IT für Führungskräfte. Zentraleinheiten. 11.04.2002 Gruppe 2 - CPU 1
 IT für Führungskräfte Zentraleinheiten 11.04.2002 Gruppe 2 - CPU 1 CPU DAS TEAM CPU heißt Central Processing Unit! Björn Heppner (Folien 1-4, 15-20, Rollenspielpräsentation 1-4) Harald Grabner (Folien
IT für Führungskräfte Zentraleinheiten 11.04.2002 Gruppe 2 - CPU 1 CPU DAS TEAM CPU heißt Central Processing Unit! Björn Heppner (Folien 1-4, 15-20, Rollenspielpräsentation 1-4) Harald Grabner (Folien
Hochleistungsrechnen für Wissenschaft und Wirtschaft im internationalen Verbund
 Hochleistungsrechnen für Wissenschaft und Wirtschaft im internationalen Verbund Prof. Dr. rer. nat. Christian Schröder Dipl.-Ing. Thomas Hilbig, Dipl.-Ing. Gerhard Hartmann Fachbereich Elektrotechnik und
Hochleistungsrechnen für Wissenschaft und Wirtschaft im internationalen Verbund Prof. Dr. rer. nat. Christian Schröder Dipl.-Ing. Thomas Hilbig, Dipl.-Ing. Gerhard Hartmann Fachbereich Elektrotechnik und
Processors for mobile devices
 Christopher Titel, Vorname, Pockrandt Name Fachbereich Abteilung, Fachbereich für Mathematik oder und Institut Informatik Processors for mobile devices DailyTech Vergleich von aktuellen Prozessoren Unterschiede
Christopher Titel, Vorname, Pockrandt Name Fachbereich Abteilung, Fachbereich für Mathematik oder und Institut Informatik Processors for mobile devices DailyTech Vergleich von aktuellen Prozessoren Unterschiede
Aktuelle Trends und Herausforderungen in der Finite-Elemente-Simulation
 Aktuelle Trends und Herausforderungen in der Finite-Elemente-Simulation Kai Diethelm GNS Gesellschaft für numerische Simulation mbh Braunschweig engineering software development Folie 1 Überblick Vorstellung
Aktuelle Trends und Herausforderungen in der Finite-Elemente-Simulation Kai Diethelm GNS Gesellschaft für numerische Simulation mbh Braunschweig engineering software development Folie 1 Überblick Vorstellung
Einführung in die Informatik II
 Einführung in die Informatik II Vorlesung Sommersemester 2013 Prof. Dr. Nikolaus Wulff Ziele der Vorlesung Sie vertiefen die Kenntnisse aus Informatik I und runden diese in weiteren Anwendungsgebieten
Einführung in die Informatik II Vorlesung Sommersemester 2013 Prof. Dr. Nikolaus Wulff Ziele der Vorlesung Sie vertiefen die Kenntnisse aus Informatik I und runden diese in weiteren Anwendungsgebieten
Systeme 1. Kapitel 10. Virtualisierung
 Systeme 1 Kapitel 10 Virtualisierung Virtualisierung Virtualisierung: Definition: Der Begriff Virtualisierung beschreibt eine Abstraktion von Computerhardware hin zu einer virtuellen Maschine. Tatsächlich
Systeme 1 Kapitel 10 Virtualisierung Virtualisierung Virtualisierung: Definition: Der Begriff Virtualisierung beschreibt eine Abstraktion von Computerhardware hin zu einer virtuellen Maschine. Tatsächlich
INDEX. Netzwerk Überblick. Benötigte Komponenten für: Windows Server 2008. Windows Server 2008 R2. Windows Server 2012
 INDEX Netzwerk Überblick Benötigte Komponenten für: Windows Server 2008 Windows Server 2008 R2 Windows Server 2012 Windows SQL Server 2008 (32 Bit & 64 Bit) Windows SQL Server 2012 Client Voraussetzungen
INDEX Netzwerk Überblick Benötigte Komponenten für: Windows Server 2008 Windows Server 2008 R2 Windows Server 2012 Windows SQL Server 2008 (32 Bit & 64 Bit) Windows SQL Server 2012 Client Voraussetzungen
WIE ERHÖHT MAN DIE EFFIZIENZ DES BESTEHENDEN RECHENZENTRUMS UM 75% AK Data Center - eco e.v. 1. Dezember 2009
 WIE ERHÖHT MAN DIE EFFIZIENZ DES BESTEHENDEN RECHENZENTRUMS UM 75% AK Data Center - eco e.v. 1. Dezember 2009 HOST EUROPE GROUP Größter Anbieter von standardisierten Managed Hosting Lösungen in Deutschland
WIE ERHÖHT MAN DIE EFFIZIENZ DES BESTEHENDEN RECHENZENTRUMS UM 75% AK Data Center - eco e.v. 1. Dezember 2009 HOST EUROPE GROUP Größter Anbieter von standardisierten Managed Hosting Lösungen in Deutschland
GPGPU mit NVIDIA CUDA
 01.07.12 GPGPU mit NVIDIA CUDA General-Purpose on Formatvorlagecomputing des Graphics Processing durch Units Untertitelmasters mit KlickenCompute bearbeiten NVIDIA Unified Device Architecture Gliederung
01.07.12 GPGPU mit NVIDIA CUDA General-Purpose on Formatvorlagecomputing des Graphics Processing durch Units Untertitelmasters mit KlickenCompute bearbeiten NVIDIA Unified Device Architecture Gliederung
Systemanforderungen für MSI-Reifen Release 7
 Systemvoraussetzung [Server] Microsoft Windows Server 2000/2003/2008* 32/64 Bit (*nicht Windows Web Server 2008) oder Microsoft Windows Small Business Server 2003/2008 Standard od. Premium (bis 75 User/Geräte)
Systemvoraussetzung [Server] Microsoft Windows Server 2000/2003/2008* 32/64 Bit (*nicht Windows Web Server 2008) oder Microsoft Windows Small Business Server 2003/2008 Standard od. Premium (bis 75 User/Geräte)
SAP Systeme. Windows-Basierend. Heinrich Gschwandner SAP Competence Center. November 2004
 SAP Systeme Windows-Basierend Heinrich Gschwandner SAP Competence Center November 2004 Zertifizierte Intel/Itanium Server für SAP 32 bit Server ProLiant BL20pG2/BL40p Blade ProLiant ML370/G2;G3 ProLiant
SAP Systeme Windows-Basierend Heinrich Gschwandner SAP Competence Center November 2004 Zertifizierte Intel/Itanium Server für SAP 32 bit Server ProLiant BL20pG2/BL40p Blade ProLiant ML370/G2;G3 ProLiant
OSL Storage Cluster und RSIO unter Linux Storage-Attachment und Hochverfügbarkeit in 5 Minuten
 OSL Storage Cluster und RSIO unter Linux Storage-Attachment und Hochverfügbarkeit in 5 Minuten OSL Technologietage Berlin 12./13. September 2012 Christian Schmidt OSL Gesellschaft für offene Systemlösungen
OSL Storage Cluster und RSIO unter Linux Storage-Attachment und Hochverfügbarkeit in 5 Minuten OSL Technologietage Berlin 12./13. September 2012 Christian Schmidt OSL Gesellschaft für offene Systemlösungen
Parallel Computing. Einsatzmöglichkeiten und Grenzen. Prof. Dr. Nikolaus Wulff
 Parallel Computing Einsatzmöglichkeiten und Grenzen Prof. Dr. Nikolaus Wulff Parallel Architekturen Flynn'sche Klassifizierung: SISD: single Instruction, single Data Klassisches von-neumann sequentielles
Parallel Computing Einsatzmöglichkeiten und Grenzen Prof. Dr. Nikolaus Wulff Parallel Architekturen Flynn'sche Klassifizierung: SISD: single Instruction, single Data Klassisches von-neumann sequentielles
Moderne parallele Rechnerarchitekturen
 Seminar im WS0708 Moderne parallele Rechnerarchitekturen Prof. Sergei Gorlatch Dipl.-Inf. Maraike Schellmann schellmann@uni-muenster.de Einsteinstr. 62, Raum 710, Tel. 83-32744 Dipl.-Inf. Philipp Kegel
Seminar im WS0708 Moderne parallele Rechnerarchitekturen Prof. Sergei Gorlatch Dipl.-Inf. Maraike Schellmann schellmann@uni-muenster.de Einsteinstr. 62, Raum 710, Tel. 83-32744 Dipl.-Inf. Philipp Kegel
Proseminar Technische Informatik A survey of virtualization technologies
 Proseminar Technische Informatik A survey of virtualization technologies Referent: Martin Weigelt Proseminar Technische Informatik - A survey of virtualization technologies 1 Übersicht 1. Definition 2.
Proseminar Technische Informatik A survey of virtualization technologies Referent: Martin Weigelt Proseminar Technische Informatik - A survey of virtualization technologies 1 Übersicht 1. Definition 2.
Parallele Programmierung mit OpenMP
 Parallele Programmierung mit OpenMP - Eine kurze Einführung - 11.06.2003 RRZN Kolloquium SS 2003 1 Gliederung 1. Grundlagen 2. Programmiermodell 3. Sprachkonstrukte 4. Vergleich MPI und OpenMP 11.06.2003
Parallele Programmierung mit OpenMP - Eine kurze Einführung - 11.06.2003 RRZN Kolloquium SS 2003 1 Gliederung 1. Grundlagen 2. Programmiermodell 3. Sprachkonstrukte 4. Vergleich MPI und OpenMP 11.06.2003
Strukturelemente von Parallelrechnern
 Strukturelemente von Parallelrechnern Parallelrechner besteht aus einer Menge von Verarbeitungselementen, die in einer koordinierten Weise, teilweise zeitgleich, zusammenarbeiten, um eine Aufgabe zu lösen
Strukturelemente von Parallelrechnern Parallelrechner besteht aus einer Menge von Verarbeitungselementen, die in einer koordinierten Weise, teilweise zeitgleich, zusammenarbeiten, um eine Aufgabe zu lösen
PERI Softwarefinder Leitfaden
 Leitfaden Dieser Leitfaden hilft Ihnen, die richtige PERI Software für Ihre Schalungs- oder Gerüstplanung zu finden. Er bietet ausführliche Erläuterungen zu den verschiedenen Programmen. In der Übersicht
Leitfaden Dieser Leitfaden hilft Ihnen, die richtige PERI Software für Ihre Schalungs- oder Gerüstplanung zu finden. Er bietet ausführliche Erläuterungen zu den verschiedenen Programmen. In der Übersicht
Energiesparmechanismen des
 Energiesparmechanismen des Prozessors (x64) 2 Gliederung Motivation Einleitung Advanced Configuration and Power Interface (ACPI) P-States C-States Implementierung Intel AMD 3 Motivation von Marius Eschen
Energiesparmechanismen des Prozessors (x64) 2 Gliederung Motivation Einleitung Advanced Configuration and Power Interface (ACPI) P-States C-States Implementierung Intel AMD 3 Motivation von Marius Eschen
Systemvoraussetzungen
 Systemvoraussetzungen INDEX Netzwerk Überblick Benötigte n für: Windows Server 2008 Windows Server 2008 R2 Windows Server 2012 Windows SQL Server 2008 (32 Bit & 64 Bit) Windows SQL Server 2012 Client Voraussetzungen
Systemvoraussetzungen INDEX Netzwerk Überblick Benötigte n für: Windows Server 2008 Windows Server 2008 R2 Windows Server 2012 Windows SQL Server 2008 (32 Bit & 64 Bit) Windows SQL Server 2012 Client Voraussetzungen
NEC SX-ACE HPC-System
 Erste Erfahrungen mit dem neuen System Dr. Simone Knief; ZKI-Arbeitskreis Supercomputing, Kiel 17.03.2015 1 Überblick Rechnerkonfiguration Veränderungen SX-9 zu SX-ACE Benutzergruppen Erste Performanceergebnisse
Erste Erfahrungen mit dem neuen System Dr. Simone Knief; ZKI-Arbeitskreis Supercomputing, Kiel 17.03.2015 1 Überblick Rechnerkonfiguration Veränderungen SX-9 zu SX-ACE Benutzergruppen Erste Performanceergebnisse
Windows 7 ist da! Der Nachfolger von Vista kommt noch vor dem Sommer
 Windows 7 ist da! Der Nachfolger von Vista kommt noch vor dem Sommer 1. Vorwort Warum an Windows 7, dem Nachfolger von Windows Vista, kein Weg vorbeiführt, ist rasch erklärt: Es ist schneller, sicherer,
Windows 7 ist da! Der Nachfolger von Vista kommt noch vor dem Sommer 1. Vorwort Warum an Windows 7, dem Nachfolger von Windows Vista, kein Weg vorbeiführt, ist rasch erklärt: Es ist schneller, sicherer,
Systemvoraussetzungen für Autodesk Revit 2015 - Produkte (gemäß Angaben von Autodesk)
") Systemvoraussetzungen für Autodesk Revit 2015 - Produkte (gemäß Angaben von Autodesk) Mindestanforderung: Einstiegskonfiguration Betriebssystem ¹ Windows 8.1 Enterprise, Pro oder Windows 8.1 CPU-Typ Single-
Systemvoraussetzungen für Autodesk Revit 2015 - Produkte (gemäß Angaben von Autodesk) Mindestanforderung: Einstiegskonfiguration Betriebssystem ¹ Windows 8.1 Enterprise, Pro oder Windows 8.1 CPU-Typ Single-
Systeme 1: Architektur
 slide 1 Vorlesung Systeme 1: Architektur Prof. Dr. Ulrich Ultes-Nitsche Forschungsgruppe Departement für Informatik Universität Freiburg slide 2 Prüfung 18. Februar 2004 8h00-11h40 13h00-18h20 20 Minuten
slide 1 Vorlesung Systeme 1: Architektur Prof. Dr. Ulrich Ultes-Nitsche Forschungsgruppe Departement für Informatik Universität Freiburg slide 2 Prüfung 18. Februar 2004 8h00-11h40 13h00-18h20 20 Minuten
Projektpraktikum: Verteilte Datenverarbeitung mit MapReduce
 Projektpraktikum: Verteilte Datenverarbeitung mit MapReduce Timo Bingmann, Peter Sanders und Sebastian Schlag 21. Oktober 2014 @ PdF Vorstellung INSTITUTE OF THEORETICAL INFORMATICS ALGORITHMICS KIT Universität
Projektpraktikum: Verteilte Datenverarbeitung mit MapReduce Timo Bingmann, Peter Sanders und Sebastian Schlag 21. Oktober 2014 @ PdF Vorstellung INSTITUTE OF THEORETICAL INFORMATICS ALGORITHMICS KIT Universität
Ressourceneffiziente IT- Lösungen
 - Lösungen Vom Mikrodesktop bis zum Supercomputer Wolfgang Christmann Geschäftsführer christmann informationstechnik + medien GmbH & Co. KG cim_präsentation.ppt 1/14 Stromverbrauch IT»1 Klick bei Google
- Lösungen Vom Mikrodesktop bis zum Supercomputer Wolfgang Christmann Geschäftsführer christmann informationstechnik + medien GmbH & Co. KG cim_präsentation.ppt 1/14 Stromverbrauch IT»1 Klick bei Google
Über uns. HostByYou Unternehmergesellschaft (haftungsbeschränkt), Ostrastasse 1, 40667 Meerbusch, Tel. 02132 979 2506-0, Fax.
, Ostrastasse 1, 40667 Meerbusch, Tel. 02132 979 2506-0, Fax.") Ostrastasse 1, 40667 Meerbusch, Tel. 02132 979 2506-0, Fax. 02132 979 2506-9 Über uns Mit innovativen Technologien und exzellenten Leistungen bietet das Unternehmen HostByYou seit Jahren weltweit professionelle
Ostrastasse 1, 40667 Meerbusch, Tel. 02132 979 2506-0, Fax. 02132 979 2506-9 Über uns Mit innovativen Technologien und exzellenten Leistungen bietet das Unternehmen HostByYou seit Jahren weltweit professionelle
Kingston Technology WHD. November 30, 2012. Andreas Scholz, BDM Integration und Server D-A
 Kingston Technology WHD Andreas Scholz, BDM Integration und Server D-A November 30, 2012 Agenda Trends Speicher Konfigurationen Warum KingstonConsult? KingstonConsult Speicher Bandbreite: balanced vs.
Kingston Technology WHD Andreas Scholz, BDM Integration und Server D-A November 30, 2012 Agenda Trends Speicher Konfigurationen Warum KingstonConsult? KingstonConsult Speicher Bandbreite: balanced vs.
Modulbeschreibung. The course is principally designed to impart: technical skills 50%, method skills 40%, system skills 10%, social skills 0%.
 Titel des Moduls: Parallel Systems Dt.: Parallele Systeme Verantwortlich für das Modul: Heiß, Hans-Ulrich E-Mail: lehre@kbs.tu-berlin.de URL: http://www.kbs.tu-berlin.de/ Modulnr.: 866 (Version 2) - Status:
Titel des Moduls: Parallel Systems Dt.: Parallele Systeme Verantwortlich für das Modul: Heiß, Hans-Ulrich E-Mail: lehre@kbs.tu-berlin.de URL: http://www.kbs.tu-berlin.de/ Modulnr.: 866 (Version 2) - Status:
Systemanforderungen Verlage & Akzidenzdruck
 OneVision Software AG Inhalt Asura 9.5, Asura Pro 9.5, Garda 5.0...2 PlugBALANCEin 6.5, PlugCROPin 6.5, PlugFITin 6.5, PlugRECOMPOSEin 6.5, PlugSPOTin 6.5,...2 PlugTEXTin 6.5, PlugINKSAVEin 6.5, PlugWEBin
OneVision Software AG Inhalt Asura 9.5, Asura Pro 9.5, Garda 5.0...2 PlugBALANCEin 6.5, PlugCROPin 6.5, PlugFITin 6.5, PlugRECOMPOSEin 6.5, PlugSPOTin 6.5,...2 PlugTEXTin 6.5, PlugINKSAVEin 6.5, PlugWEBin
High Performance Computing Cluster-Lösung mit MOSIX im Einsatz bei VA-TECH HYDRO
 High Performance Computing Cluster-Lösung mit MOSIX im Einsatz bei VA-TECH HYDRO Anastasios Stomas SFI Technology Services AG 12. März 2003 anastasios.stomas@sfi.ch Seite 1 Hintergrund INHALT Cluster-
High Performance Computing Cluster-Lösung mit MOSIX im Einsatz bei VA-TECH HYDRO Anastasios Stomas SFI Technology Services AG 12. März 2003 anastasios.stomas@sfi.ch Seite 1 Hintergrund INHALT Cluster-
Aktuelle Themen der Informatik: Virtualisierung
 Aktuelle Themen der Informatik: Virtualisierung Sebastian Siewior 15 Mai 2006 1 / 22 1 Überblick 2 Techniken 3 Paravirtualisierung 4 Ende 2 / 22 Wieso Virtualisieren Wieso mehrere Betriebsysteme auf einer
Aktuelle Themen der Informatik: Virtualisierung Sebastian Siewior 15 Mai 2006 1 / 22 1 Überblick 2 Techniken 3 Paravirtualisierung 4 Ende 2 / 22 Wieso Virtualisieren Wieso mehrere Betriebsysteme auf einer
Preisvergleich ProfitBricks - Amazon Web Services M3 Instanz
 Preisvergleich - Amazon Web Services M3 Instanz Stand Preisliste : 10.04.2014 www.profitbricks.de Stand Preisliste : 10.04.2014 Hotline: 0800 22 44 66 8 product@profitbricks.com Vorwort Preisvergleiche
Preisvergleich - Amazon Web Services M3 Instanz Stand Preisliste : 10.04.2014 www.profitbricks.de Stand Preisliste : 10.04.2014 Hotline: 0800 22 44 66 8 product@profitbricks.com Vorwort Preisvergleiche
Systemanforderungen (Mai 2014)
") Systemanforderungen (Mai 2014) Inhaltsverzeichnis Einführung... 2 Einzelplatzinstallation... 2 Peer-to-Peer Installation... 3 Client/Server Installation... 4 Terminal-,Citrix-Installation... 5 Virtualisierung...
Systemanforderungen (Mai 2014) Inhaltsverzeichnis Einführung... 2 Einzelplatzinstallation... 2 Peer-to-Peer Installation... 3 Client/Server Installation... 4 Terminal-,Citrix-Installation... 5 Virtualisierung...
Manycores: Hardware und Low-Level Programmierung
 Manycores: Hardware und Low-Level Programmierung Florian Sattler Universität Passau 18. Juni 2014 Übersicht Einführung Neue Architekturen Programmierung Supercomputing Fazit 2 / 29 Top 500 3 / 29 Motivation
Manycores: Hardware und Low-Level Programmierung Florian Sattler Universität Passau 18. Juni 2014 Übersicht Einführung Neue Architekturen Programmierung Supercomputing Fazit 2 / 29 Top 500 3 / 29 Motivation
Vorstellung des Fachgebietes Technische Informatik
 Fakultät Informatik, Institut für Technische Informatik, Professur Rechnerarchitektur Vorstellung des Fachgebietes Technische Informatik Professur Rechnerarchitektur Zellescher Weg 12 Nöthnitzer Strasse
Fakultät Informatik, Institut für Technische Informatik, Professur Rechnerarchitektur Vorstellung des Fachgebietes Technische Informatik Professur Rechnerarchitektur Zellescher Weg 12 Nöthnitzer Strasse
Institut für Informatik
 Institut für Informatik Peter Forbrig Institutsdirektor 22. 5. 2013 UNIVERSITÄT ROSTOCK INSTITUTE FÜR INFORMATIK FACHTAGUNG-DATENSCHUTZ 2013 1 Herzlich willkommen zur Datenschutz-Fachtagung 2013 Professuren
Institut für Informatik Peter Forbrig Institutsdirektor 22. 5. 2013 UNIVERSITÄT ROSTOCK INSTITUTE FÜR INFORMATIK FACHTAGUNG-DATENSCHUTZ 2013 1 Herzlich willkommen zur Datenschutz-Fachtagung 2013 Professuren