Reinforcement learning
|
|
|
- Silke Raske
- vor 6 Jahren
- Abrufe
Transkript

1 Reinforcement learning Erfolgsgeschichten... Quelle: twitter.com/ai memes
2 Q-Learning als Art von Reinforcement learning Paul Kahlmeyer February 5, 2019
3 1 Einführung 2 Q-Learning Begriffe Algorithmus 3 Tic-Tac-Toe Regeln Q-Table learning deep Q-learning 4 Experiment Q-Table Q-NN 5 Quellen 6 Vorführung
4 Szenario: Klausurlernen Gegeben: viele Altklausuren ihrer Kommilitonen Gesucht: richtige Antworten auf Fragen in aktueller Klausur
5 Szenario: Klausurlernen Szenario 1: gute Kommilitonen Antworten Richtigkeit Note supervised learning
6 Szenario: Klausurlernen Szenario 2: schlechte Kommilitonen Antworten unsupervised learning
7 Szenario: Klausurlernen Szenario 3: normale Kommilitonen Antworten Note reinforcement learning
8 Kategorien von Lernverfahren Welche Lernverfahren können unterscheiden werden? Überwachtes Lernen Trennfunktionen lernen Unüberwachtes Lernen Struktur lernen Reinforcement Learning optimales Verhalten lernen

9 Kategorien von Lernverfahren Warum können wir nicht nur überwacht Lernen? Labeln teuer Labeln nicht möglich Quelle: assetstore.unity.com
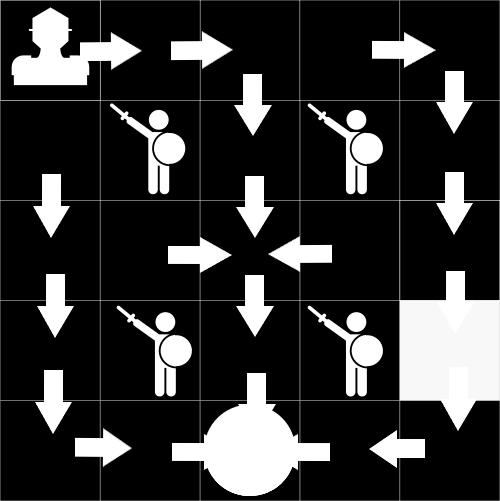
10 Reinforcement learning generelles Interaktionskonzept Quelle: kdnuggets.com


11 Begriffe Beispiel: Ritter Prinzessin Quelle: medium.freecodecamp.org
12 Begriffe Agent

13 Begriffe Environment
14 Begriffe Action

15 Begriffe State
16 Begriffe Reward
17 Begriffe mathematische Modellierung State: s S Action: a A Reward: R(s) : S R Policy: π t : S A

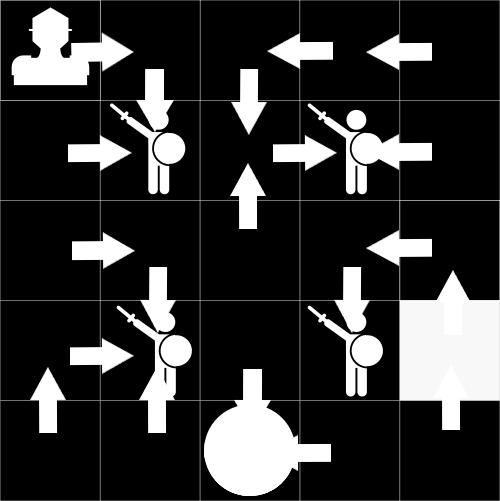
18 Begriffe Policy

19 Begriffe optimal Policy
20 Begriffe mathematische Modellierung State: s S Action: a A Reward: R(s) : S R Policy: π t : S A [optimal: π ] Übergangswkt.: p(s s, a)
21 Begriffe Beispiel Übergangswahrscheinlichkeiten
22 Begriffe mathematische Modellierung State: s S Action: a A Reward: R(s) : S R Policy: π t : S A [optimal: π ] Übergangswkt.: p(s s, a) Q-Value: Q (s, a) = p(s s, a) s S [ ] R(s ) + max a A Q (s, a )
23 Begriffe Q-Value
24 Begriffe mathematische Modellierung State: s S Action: a A Reward: R(s) : S R Policy: π t : S A [optimal: π ] Übergangswkt.: p(s s, a) Q-Value: Q (s, a) = p(s s, a) s S V-Value: V (s) = max a A Q (s, a) [ ] R(s ) + max a A Q (s, a )
25 Begriffe Discount-Faktor γ Q (s, a) = s S [ ] p(s s, a) R(s ) + max a A Q (s, a ) zukünftige Belohnungen vs. unmittelbare Belohnungen Q (s, a) = [ ] p(s s, a) R(s ) + γ max a A Q (s, a ) γ [0, 1] s S
26 Begriffe Discount-Faktor γ = 0.7
27 Q-learning Algorithmus Grober Ablauf Initialisiere Q(s, a) mit geeigneten Startwerten; while Fitness des Agenten zu schlecht do Agiere in Umwelt; Beobachte s, R(s), a, s ; Update Q(s, a); end
28 Q-learning Algorithmus Updateschritt R(s ), falls s ([ Endzustand ] Q t+1 (s, a) = Q t (s, a) + α R(s) + γ max Q t(s, a ) a A ) Q t (s, a), sonst
29 Q-learning Algorithmus Konvergenz Lemma Für t konvergiert Q t (s, a) gegen Q (s, a), falls α t = und t=0 αt 2 < t=0
30 Exkurs: Reinforcement learning Verschiedene Konzepte Model based vs. Model free
31 Exkurs: Reinforcement learning generelles Interaktionskonzept
32 Exkurs: Reinforcement learning Verschiedene Konzepte Model based vs. Model free off-policy vs. on-policy
33 Exkurs: Reinforcement learning Updateschritt Q-learning R(s ), falls s ([ Endzustand ] Q t+1 (s, a) = Q t (s, a) + α R(s) + γ max Q t(s, a ) a A ) Q t (s, a), sonst
34 Exkurs: Reinforcement learning Verschiedene Arten-Wo steht Q-learning? Model based vs. Model free Kenntniss von p(s s, a) off-policy vs. on-policy Updateschritt ohne/mit policy
35 Regeln sollte eigentlich klar sein... zwei Spieler (X,O) X beginnt 3x3 Feld erster Spieler mit 3 Symbolen in einer Reihe (horizontal/vertikal/diagonal) gewinnt sonst unentschieden Quelle: eddyerburgh.me
36 Lernen mit Tabelle begrenzt anwendbar Q-Values für alle möglichen State-Action Paare durch Tabelle modellieren < 3 9 States 9 mögliche Aktionen < Einträge r1c r1c2-5 0 r1c r3c
37 Lernen mit Tabelle Konkreter Ablauf Lege α, γ fest; Lege R(s) fest; Initialisiere Q(s, a) mit geeigneten Startwerten; while Fitness des Agenten zu schlecht do Spiele Spiel gegen Gegner; Speichere (s, R(s), a, s ); for erlebte (s,r(s),a,s ) do R(s ), falls s ([ Endzustand end end Q t+1 (s, a) = Q t (s, a) + α R(s) + γ max a Q t (s, a ) A ] Q t (s, a) ), sonst
38 Problem Erkundung Exploration vs. Exploitation Agent kann beim Spielen wählen zwischen: Strategie verfolgen (Exploitation) andere Möglichkeiten ausprobieren (Exploration) Üblicherweise: Training: Trade-off zwischen Exploration und Exploitation Testen: Nur Exploitation Trade-off ist Teil von π t
39 Problem Erkundung Exploration vs. Exploitation ε-greedy Strategie: neuer Hyperparameter ε [0, 1] vor neuem Zug: ziehe x als Realisierung von X Unif[0, 1] x < ε: Exploration x ε: Exploitation zu Beginn: ε groß zu Ende: ε klein
40 Problem Größe Lösungsraum quasi-unendliche Tabellen sind unhandlich Tic-Tac-Toe übersichtlich Tabelle möglich Go, Schach, stetiger Zustandsraum (Roboter),... (vollständige) Tabelle unmöglich A endlich Ansatz: Tabelle durch Neuronales Netz ersetzen Input: State s Output: Q(s, a 1 ),..., Q(s, a n )
41 Problem Input Wie codiert man ein Spielfeld? Naiver Ansatz: X 1 O 1 leer 0 Besserer Ansatz: Indikatoren für X,O,leer X-Indikator+O-Indikator+leer-Indikator 3 9 Werte
42 Problem Input Wie codiert man ein Spielfeld? X 0 O 1 leer
43 Problem Update Was wird eigentlich geupdated? Updateschritt Tabelle: Q t+1 (s, a) Q t (s, a) + α Updateschritt Neuronales Netz: Agent erfährt (s, R(s), a, s ) Error Backpropagation ([ R(s) + γ max ] Q t(s, a ) a A ) Q t (s, a)
44 Problem Update Was wird eigentlich geupdated? Bisheriger Output erfahrener Output Fehlerterm Q t (s, a 1 )... Q t (s, a k )... Q t (s, a n) Q t (s, a 1 )... R(s) + γ max a A Q t (s, a )... Q t (s, a n) 0... ([ R(s) + γ max a A Q t (s, a ) ] Q t(s, a) )
45 Weitere Ideen Konvergenz ist schwer max Q t(s, a ) aus seperatem NN a A batch learning α t 0...
46 Lernen mit Tabelle Aufbau Spiel gegen sich selbst nur valide Züge Nach jedem Spiel Q-Values updaten Danach Fitnessbestimmung: 30 Spiele gegen naiven Spieler mit seed=0, greedy 15-mal X, 15-mal O Prozent der nicht-verlorenen Spiele Nach Spielen ENDE
47 Lernen mit Tabelle Hyperparameter α = 0.01 γ = 0.8 ε = max( t, 0.2) R victory = 100 R draw = 0 R nothing = 0
48 Lernen mit Tabelle Ergebnisse 5491 Spiele bis Fitness 1.0 Aufwand im Tabellen-Handling
49 Lernen mit NN Aufbau Spiel gegen sich selbst nur valide Züge Nach jedem Spiel Q-Values updaten Nach Update Target NN überschreiben Danach Fitnessbestimmung: 30 Spiele gegen naiven Spieler mit seed=0, greedy 15-mal X, 15-mal O Prozent der nicht-verlorenen Spiele Nach Spielen ENDE
50 Lernen mit NN Hyperparameter α = 0.01 γ = 0.8 ε = max( t, 0.2) R victory = 1.0 R draw = 0.5 R nothing = 0.5 Input = 3 9 Hidden = Output = 9
51 Lernen mit NN Ergebnisse 2443 Spiele bis Fitness 1.0 Aufwand in Wahl der Hyperparameter
52 Lernen mit NN Ergebnisse 2443 Spiele bis Fitness 1.0 Aufwand in Wahl der Hyperparameter
53 Reinforcement learning Grenzen? DeepMind Deep Q-learning Atari video games (Stand 2015) Montezumas Revenge 0% Quelle: deepmind.com

54 Reinforcement learning Was ist so schwer an Montezumas Revenge? Quelle: deepmind.com komplexe Abfolge von Aktionen spärliche Belohnungen!!! (sparse rewards) generell: Design von R(s)
55 Simonini, Thomas: Diving deeper into Reinforcement Learning with Q-Learning Dammann, Patrick: Einführung in das Reinforcement Learning Mnih/Kavukcuoglu/... : Human level control trough deep reinforcement learning Melo, Francisco S.:Convergence of Q-learning: a simple proof Sutton/Barto: Reinforcement learning-an Introduction Juliani, Arthur: On solving Montezumas Revenge-Looking beyond the hype of recent Deep RL successes
56 LETS PLAY
Reinforcement Learning
 Reinforcement Learning 1. Allgemein Reinforcement Learning 2. Neuronales Netz als Bewertungsfunktion 3. Neuronales Netz als Reinforcement Learning Nils-Olaf Bösch 1 Allgemein Reinforcement Learning Unterschied
Reinforcement Learning 1. Allgemein Reinforcement Learning 2. Neuronales Netz als Bewertungsfunktion 3. Neuronales Netz als Reinforcement Learning Nils-Olaf Bösch 1 Allgemein Reinforcement Learning Unterschied
Reinforcement-Learning
 Reinforcement-Learning Vortrag von: Fabien Lapok Betreuer: Prof. Dr. Meisel 1 Agenda Motivation Überblick und Probleme von RL Aktuelle Forschung Mein Vorgehen Konferenzen und Quellen 2 Reinforcement Learning
Reinforcement-Learning Vortrag von: Fabien Lapok Betreuer: Prof. Dr. Meisel 1 Agenda Motivation Überblick und Probleme von RL Aktuelle Forschung Mein Vorgehen Konferenzen und Quellen 2 Reinforcement Learning
Dynamic Programming. To compute optimal policies in a perfect model of the environment as a Markov decision process.
 Dynamic Programming To compute optimal policies in a perfect model of the environment as a Markov decision process. 1. Dynamic Programming Algorithmen die Teilergebnisse speichern und zur Lösung des Problems
Dynamic Programming To compute optimal policies in a perfect model of the environment as a Markov decision process. 1. Dynamic Programming Algorithmen die Teilergebnisse speichern und zur Lösung des Problems
Reinforcement Learning
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning Uwe Dick Inhalt Problemstellungen Beispiele Markov Decision Processes Planen vollständige MDPs Lernen unbekannte
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning Uwe Dick Inhalt Problemstellungen Beispiele Markov Decision Processes Planen vollständige MDPs Lernen unbekannte
Einsatz von Reinforcement Learning in der Modellfahrzeugnavigation
 Einsatz von Reinforcement Learning in der Modellfahrzeugnavigation von Manuel Trittel Informatik HAW Hamburg Vortrag im Rahmen der Veranstaltung AW1 im Masterstudiengang, 02.12.2008 der Anwendung Themeneinordnung
Einsatz von Reinforcement Learning in der Modellfahrzeugnavigation von Manuel Trittel Informatik HAW Hamburg Vortrag im Rahmen der Veranstaltung AW1 im Masterstudiengang, 02.12.2008 der Anwendung Themeneinordnung
Reinforcement Learning
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning Uwe Dick Inhalt Problemstellungen Beispiele Markov Decision Processes Planen vollständige MDPs Lernen unbekannte
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning Uwe Dick Inhalt Problemstellungen Beispiele Markov Decision Processes Planen vollständige MDPs Lernen unbekannte
3. Das Reinforcement Lernproblem
 3. Das Reinforcement Lernproblem 1. Agierender Agent in der Umgebung 2. Discounted Rewards 3. Markov Eigenschaft des Zustandssignals 4. Markov sche Entscheidung 5. Werte-Funktionen und Bellman sche Optimalität
3. Das Reinforcement Lernproblem 1. Agierender Agent in der Umgebung 2. Discounted Rewards 3. Markov Eigenschaft des Zustandssignals 4. Markov sche Entscheidung 5. Werte-Funktionen und Bellman sche Optimalität
Reinforcement Learning
 Effiziente Darstellung von Daten Reinforcement Learning 02. Juli 2004 Jan Schlößin Einordnung Was ist Reinforcement Learning? Einführung - Prinzip der Agent Eigenschaften das Ziel Q-Learning warum Q-Learning
Effiziente Darstellung von Daten Reinforcement Learning 02. Juli 2004 Jan Schlößin Einordnung Was ist Reinforcement Learning? Einführung - Prinzip der Agent Eigenschaften das Ziel Q-Learning warum Q-Learning
Reinforcement Learning. Volker Tresp
 Reinforcement Learning Volker Tresp 1 Überwachtes und unüberwachtes Lernen Überwachtes Lernen: Zielgrößen sind im Trainingsdatensatz bekannt; Ziel ist die Verallgemeinerung auf neue Daten Unüberwachtes
Reinforcement Learning Volker Tresp 1 Überwachtes und unüberwachtes Lernen Überwachtes Lernen: Zielgrößen sind im Trainingsdatensatz bekannt; Ziel ist die Verallgemeinerung auf neue Daten Unüberwachtes
2. Beispiel: n-armiger Bandit
 2. Beispiel: n-armiger Bandit 1. Das Problem des n-armigen Banditen 2. Methoden zur Berechung von Wert-Funktionen 3. Softmax-Auswahl von Aktionen 4. Inkrementelle Schätzverfahren 5. Nichtstationärer n-armiger
2. Beispiel: n-armiger Bandit 1. Das Problem des n-armigen Banditen 2. Methoden zur Berechung von Wert-Funktionen 3. Softmax-Auswahl von Aktionen 4. Inkrementelle Schätzverfahren 5. Nichtstationärer n-armiger
8. Reinforcement Learning
 8. Reinforcement Learning Einführung 8. Reinforcement Learning Wie können Agenten ohne Trainingsbeispiele lernen? Auch kennt der Agent zu Beginn nicht die Auswirkungen seiner Handlungen. Stattdessen erhält
8. Reinforcement Learning Einführung 8. Reinforcement Learning Wie können Agenten ohne Trainingsbeispiele lernen? Auch kennt der Agent zu Beginn nicht die Auswirkungen seiner Handlungen. Stattdessen erhält
Reinforcement Learning
 Reinforcement Learning Viktor Seifert Seminar: Knowledge Engineering und Lernen in Spielen SS06 Prof. Johannes Fürnkranz Übersicht 1. Definition 2. Allgemeiner Lösungsansatz 3. Temporal Difference Learning
Reinforcement Learning Viktor Seifert Seminar: Knowledge Engineering und Lernen in Spielen SS06 Prof. Johannes Fürnkranz Übersicht 1. Definition 2. Allgemeiner Lösungsansatz 3. Temporal Difference Learning
Seminar. Knowledge Engineering und Lernen in Spielen. Reinforcement Learning to Play Tetris. TU - Darmstadt Mustafa Gökhan Sögüt, Harald Matussek 1
 Seminar Knowledge Engineering und Lernen in Spielen Reinforcement Learning to Play Tetris 1 Überblick Allgemeines zu Tetris Tetris ist NP-vollständig Reinforcement Learning Anwendung auf Tetris Repräsentationen
Seminar Knowledge Engineering und Lernen in Spielen Reinforcement Learning to Play Tetris 1 Überblick Allgemeines zu Tetris Tetris ist NP-vollständig Reinforcement Learning Anwendung auf Tetris Repräsentationen
Temporal Difference Learning
 Temporal Difference Learning Das Temporal Difference (TD) Lernen ist eine bedeutende Entwicklung im Reinforcement Lernen. Im TD Lernen werden Ideen der Monte Carlo (MC) und dynamische Programmierung (DP)
Temporal Difference Learning Das Temporal Difference (TD) Lernen ist eine bedeutende Entwicklung im Reinforcement Lernen. Im TD Lernen werden Ideen der Monte Carlo (MC) und dynamische Programmierung (DP)
Monte Carlo Methoden
 Monte Carlo Methoden Lernverfahren zur Berechnung von Wertefunktionen und Policies werden vorgestellt. Vollständige Kenntnis der Dynamik wird nicht vorausgesetzt (im Gegensatz zu den Verfahren der DP).
Monte Carlo Methoden Lernverfahren zur Berechnung von Wertefunktionen und Policies werden vorgestellt. Vollständige Kenntnis der Dynamik wird nicht vorausgesetzt (im Gegensatz zu den Verfahren der DP).
Konzepte der AI Neuronale Netze
 Konzepte der AI Neuronale Netze Franz Wotawa Institut für Informationssysteme, Database and Artificial Intelligence Group, Technische Universität Wien Email: [email protected] Was sind Neuronale
Konzepte der AI Neuronale Netze Franz Wotawa Institut für Informationssysteme, Database and Artificial Intelligence Group, Technische Universität Wien Email: [email protected] Was sind Neuronale
Intelligente Systeme
 Intelligente Systeme Spiele Prof. Dr. R. Kruse C. Braune {rudolf.kruse,christian,braune}@ovgu.de Institut für Intelligente Kooperierende Systeme Fakultät für Informatik Otto-von-Guericke Universität Magdeburg
Intelligente Systeme Spiele Prof. Dr. R. Kruse C. Braune {rudolf.kruse,christian,braune}@ovgu.de Institut für Intelligente Kooperierende Systeme Fakultät für Informatik Otto-von-Guericke Universität Magdeburg
EVOLUTION STRATEGIES DANIELA SCHACHERER SEMINAR: IST KÜNSTLICHE INTELLIGENZ GEFÄHRLICH? SOMMERSEMESTER 2017
 EVOLUTION STRATEGIES DANIELA SCHACHERER SEMINAR: IST KÜNSTLICHE INTELLIGENZ GEFÄHRLICH? SOMMERSEMESTER 2017 Inhalt Einleitung und Überblick Evolutionsstrategien Grundkonzept Evolutionsstrategien als Alternative
EVOLUTION STRATEGIES DANIELA SCHACHERER SEMINAR: IST KÜNSTLICHE INTELLIGENZ GEFÄHRLICH? SOMMERSEMESTER 2017 Inhalt Einleitung und Überblick Evolutionsstrategien Grundkonzept Evolutionsstrategien als Alternative
Reinforcement Learning
 Ziel: Lernen von Bewertungsfunktionen durch Feedback (Reinforcement) der Umwelt (z.b. Spiel gewonnen/verloren). Anwendungen: Spiele: Tic-Tac-Toe: MENACE (Michie 1963) Backgammon: TD-Gammon (Tesauro 1995)
Ziel: Lernen von Bewertungsfunktionen durch Feedback (Reinforcement) der Umwelt (z.b. Spiel gewonnen/verloren). Anwendungen: Spiele: Tic-Tac-Toe: MENACE (Michie 1963) Backgammon: TD-Gammon (Tesauro 1995)
Überblick. Mathematik und Spiel. Ohne Glück zum Sieg. Bedeutung der Strategie. Zwei Hauptaspekte
 Überblick Ohne Glück zum Sieg R. Verfürth Fakultät für Mathematik Ruhr-Universität Bochum Bochum / 8. Oktober 2009 Kategorisierung Strategische Spiele Bewertung einer Stellung Aufwand Epilog Literatur
Überblick Ohne Glück zum Sieg R. Verfürth Fakultät für Mathematik Ruhr-Universität Bochum Bochum / 8. Oktober 2009 Kategorisierung Strategische Spiele Bewertung einer Stellung Aufwand Epilog Literatur
TD-Gammon. Michael Zilske
 TD-Gammon Michael Zilske [email protected] TD-Gammon Ein Backgammon-Spieler von Gerald Tesauro (Erste Version: 1991) TD-Gammon Ein Neuronales Netz, das immer wieder gegen sich selbst spielt und dadurch
TD-Gammon Michael Zilske [email protected] TD-Gammon Ein Backgammon-Spieler von Gerald Tesauro (Erste Version: 1991) TD-Gammon Ein Neuronales Netz, das immer wieder gegen sich selbst spielt und dadurch
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Uwe Dick
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning Uwe Dick Inhalt Problemstellungen Beispiele Markov Decision Processes Planen vollständige MDPs Lernen unbekannte
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning Uwe Dick Inhalt Problemstellungen Beispiele Markov Decision Processes Planen vollständige MDPs Lernen unbekannte
Entwicklung einer KI für Skat. Hauptseminar Erwin Lang
 Entwicklung einer KI für Skat Hauptseminar Erwin Lang Inhalt Skat Forschung Eigene Arbeit Risikoanalyse Skat Entwickelte sich Anfang des 19. Jahrhunderts Kartenspiel mit Blatt aus 32 Karten 3 Spieler Trick-taking
Entwicklung einer KI für Skat Hauptseminar Erwin Lang Inhalt Skat Forschung Eigene Arbeit Risikoanalyse Skat Entwickelte sich Anfang des 19. Jahrhunderts Kartenspiel mit Blatt aus 32 Karten 3 Spieler Trick-taking
Monte Carlo Methoden
 Monte Carlo Methoden im Verstärkungslernen [Spink] Bryan Spink 2003 Ketill Gunnarsson [ [email protected] ], Seminar zum Verstärkungslernen, Freie Universität Berlin [ www.inf.fu-berlin.de ] Einleitung
Monte Carlo Methoden im Verstärkungslernen [Spink] Bryan Spink 2003 Ketill Gunnarsson [ [email protected] ], Seminar zum Verstärkungslernen, Freie Universität Berlin [ www.inf.fu-berlin.de ] Einleitung
Kapitel LF: I. Beispiele für Lernaufgaben. Beispiele für Lernaufgaben. LF: I Introduction c STEIN
 Kapitel LF: I I. Einführung in das Maschinelle Lernen Bemerkungen: Dieses Kapitel orientiert sich an dem Buch Machine Learning von Tom Mitchell. http://www.cs.cmu.edu/ tom/mlbook.html 1 Autoeinkaufsberater?
Kapitel LF: I I. Einführung in das Maschinelle Lernen Bemerkungen: Dieses Kapitel orientiert sich an dem Buch Machine Learning von Tom Mitchell. http://www.cs.cmu.edu/ tom/mlbook.html 1 Autoeinkaufsberater?
Machinelles Lernen. «Eine kleine Einführung» BSI Business Systems Integration AG
 Machinelles Lernen «Eine kleine Einführung» @ZimMatthias Matthias Zimmermann BSI Business Systems Integration AG «Welcher Unterschied besteht zum Deep Blue Schachcomputer vor 20 Jahren?» AlphaGo Hardware
Machinelles Lernen «Eine kleine Einführung» @ZimMatthias Matthias Zimmermann BSI Business Systems Integration AG «Welcher Unterschied besteht zum Deep Blue Schachcomputer vor 20 Jahren?» AlphaGo Hardware
Kniffel-Agenten. Von Alexander Holtkamp
 Kniffel-Agenten Von Alexander Holtkamp Übersicht Grundregeln Vorteil der Monte Carlo -Methode Gliederung des Projekts Aufbau State - Action Kodierung von State - Action Optimierung Aussicht Grundregeln
Kniffel-Agenten Von Alexander Holtkamp Übersicht Grundregeln Vorteil der Monte Carlo -Methode Gliederung des Projekts Aufbau State - Action Kodierung von State - Action Optimierung Aussicht Grundregeln
Softwareprojektpraktikum Maschinelle Übersetzung
 Softwareprojektpraktikum Maschinelle Übersetzung Jan-Thorsten Peter, Andreas Guta, Jan Rosendahl [email protected] Vorbesprechung 5. Aufgabe 22. Juni 2017 Human Language Technology
Softwareprojektpraktikum Maschinelle Übersetzung Jan-Thorsten Peter, Andreas Guta, Jan Rosendahl [email protected] Vorbesprechung 5. Aufgabe 22. Juni 2017 Human Language Technology
Übersicht. Künstliche Intelligenz: 21. Verstärkungslernen Frank Puppe 1
 Übersicht I Künstliche Intelligenz II Problemlösen III Wissen und Schlussfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen VI Lernen 18. Lernen aus Beobachtungen 19. Wissen beim Lernen 20. Statistische
Übersicht I Künstliche Intelligenz II Problemlösen III Wissen und Schlussfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen VI Lernen 18. Lernen aus Beobachtungen 19. Wissen beim Lernen 20. Statistische
Kapitel 10. Lernen durch Verstärkung (Reinforcement Learning) Einführung. Robotik. Aufgaben sind oft sehr komplex. nicht programmierbar
 Einführung. Robotik. Aufgaben sind oft sehr komplex. nicht programmierbar") Vielleicht sollte ich beim nächsten mal den Schwung etwas früher einleiten oder langsamer fahren? Lernen durch negative Verstärkung. Kapitel Lernen durch Verstärkung (Reinforcement Learning) Copyright
Vielleicht sollte ich beim nächsten mal den Schwung etwas früher einleiten oder langsamer fahren? Lernen durch negative Verstärkung. Kapitel Lernen durch Verstärkung (Reinforcement Learning) Copyright
Seminar Künstliche Intelligenz WS 2013/14 Grundlagen des Maschinellen Lernens
 Seminar Künstliche Intelligenz WS 2013/14 Grundlagen des Maschinellen Lernens Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 19.12.2013 Allgemeine Problemstellung
Seminar Künstliche Intelligenz WS 2013/14 Grundlagen des Maschinellen Lernens Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 19.12.2013 Allgemeine Problemstellung
Rekurrente Neuronale Netze
 Rekurrente Neuronale Netze Gregor Mitscha-Baude May 9, 2016 Motivation Standard neuronales Netz: Fixe Dimensionen von Input und Output! Motivation In viele Anwendungen variable Input/Output-Länge. Spracherkennung
Rekurrente Neuronale Netze Gregor Mitscha-Baude May 9, 2016 Motivation Standard neuronales Netz: Fixe Dimensionen von Input und Output! Motivation In viele Anwendungen variable Input/Output-Länge. Spracherkennung
Bachelorarbeit. Jerom Schult. Deep Q Learning mit Künstlichen Neuronalen Netzen für Markov-Entscheidungsspiele
 Bachelorarbeit Jerom Schult Deep Q Learning mit Künstlichen Neuronalen Netzen für Markov-Entscheidungsspiele Fakultät Technik und Informatik Studiendepartment Informatik Faculty of Engineering and Computer
Bachelorarbeit Jerom Schult Deep Q Learning mit Künstlichen Neuronalen Netzen für Markov-Entscheidungsspiele Fakultät Technik und Informatik Studiendepartment Informatik Faculty of Engineering and Computer
Einführung in Heuristische Suche
 Einführung in Heuristische Suche Beispiele 2 Überblick Intelligente Suche Rundenbasierte Spiele 3 Grundlagen Es muss ein Rätsel / Puzzle / Problem gelöst werden Wie kann ein Computer diese Aufgabe lösen?
Einführung in Heuristische Suche Beispiele 2 Überblick Intelligente Suche Rundenbasierte Spiele 3 Grundlagen Es muss ein Rätsel / Puzzle / Problem gelöst werden Wie kann ein Computer diese Aufgabe lösen?
Künstliche Neuronale Netze
 Fakultät Informatik, Institut für Technische Informatik, Professur für VLSI-Entwurfssysteme, Diagnostik und Architektur Künstliche Neuronale Netze Hauptseminar Martin Knöfel Dresden, 16.11.2017 Gliederung
Fakultät Informatik, Institut für Technische Informatik, Professur für VLSI-Entwurfssysteme, Diagnostik und Architektur Künstliche Neuronale Netze Hauptseminar Martin Knöfel Dresden, 16.11.2017 Gliederung
Algorithmenalltag. Prof. Dr.-Ing. Johannes Konert Fachgebiet Web Engineering
 Algorithmenalltag Prof. Dr.-Ing. Johannes Konert Fachgebiet Web Engineering Start reden (Begrüßung) vortragen Aufmerk-samkeit erlangt? kurze Pause machen Ende Algorithmen Was machen sie mit uns? Was sind
Algorithmenalltag Prof. Dr.-Ing. Johannes Konert Fachgebiet Web Engineering Start reden (Begrüßung) vortragen Aufmerk-samkeit erlangt? kurze Pause machen Ende Algorithmen Was machen sie mit uns? Was sind
Universität Ulm CS5900 Hauptseminar Neuroinformatik Dozenten: Palm, Schwenker, Oubatti
 Verfasst von Nenad Marjanovic Betreut von Dr. Friedhelm Schwenker Universität Ulm - CS5900 Hauptseminar Neuroinformatik 1. Einleitung Dieses Arbeit befasst sich mit dem Maschinellen Lernen eines Agenten
Verfasst von Nenad Marjanovic Betreut von Dr. Friedhelm Schwenker Universität Ulm - CS5900 Hauptseminar Neuroinformatik 1. Einleitung Dieses Arbeit befasst sich mit dem Maschinellen Lernen eines Agenten
Reinforcement Learning 2
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning 2 Uwe Dick Inhalt Erinnerung: Bellman-Gleichungen, Bellman-Operatoren Policy Iteration Sehr große oder kontinuierliche
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning 2 Uwe Dick Inhalt Erinnerung: Bellman-Gleichungen, Bellman-Operatoren Policy Iteration Sehr große oder kontinuierliche
AI in Computer Games. Übersicht. Motivation. Vorteile der Spielumgebung. Techniken. Anforderungen
 Übersicht AI in Computer Games Motivation Vorteile der Spielumgebung Techniken Anwendungen Zusammenfassung Motivation Vorteile der Spielumgebung Modellierung glaubwürdiger Agenten Implementierung menschlicher
Übersicht AI in Computer Games Motivation Vorteile der Spielumgebung Techniken Anwendungen Zusammenfassung Motivation Vorteile der Spielumgebung Modellierung glaubwürdiger Agenten Implementierung menschlicher
Neural Networks: Architectures and Applications for NLP
 Neural Networks: Architectures and Applications for NLP Session 02 Julia Kreutzer 8. November 2016 Institut für Computerlinguistik, Heidelberg 1 Overview 1. Recap 2. Backpropagation 3. Ausblick 2 Recap
Neural Networks: Architectures and Applications for NLP Session 02 Julia Kreutzer 8. November 2016 Institut für Computerlinguistik, Heidelberg 1 Overview 1. Recap 2. Backpropagation 3. Ausblick 2 Recap
TUD Computer Poker Challenge
 TUD Computer Poker Challenge The Challenge of Poker Björn Heidenreich 31. März 2008 The Challenge of Poker Björn Heidenreich 1 Anforderungen an einen guten Poker-Spieler Hand Strength Hand Potential Bluffing
TUD Computer Poker Challenge The Challenge of Poker Björn Heidenreich 31. März 2008 The Challenge of Poker Björn Heidenreich 1 Anforderungen an einen guten Poker-Spieler Hand Strength Hand Potential Bluffing
Einführung in das Maschinelle Lernen I
 Einführung in das Maschinelle Lernen I Vorlesung Computerlinguistische Techniken Alexander Koller 26. Januar 2015 Maschinelles Lernen Maschinelles Lernen (Machine Learning): äußerst aktiver und für CL
Einführung in das Maschinelle Lernen I Vorlesung Computerlinguistische Techniken Alexander Koller 26. Januar 2015 Maschinelles Lernen Maschinelles Lernen (Machine Learning): äußerst aktiver und für CL
Backgammon. Tobias Krönke. Technische Universität Darmstadt Fachbereich Informatik Fachgebiet Knowledge Engineering
 Technische Universität Darmstadt Fachbereich Informatik Fachgebiet Knowledge Engineering Seminar zu Knowledge Engineering und Lernen in Spielen, 2010 Gliederung Gliederung Startaufstellung Abbildung: GNU
Technische Universität Darmstadt Fachbereich Informatik Fachgebiet Knowledge Engineering Seminar zu Knowledge Engineering und Lernen in Spielen, 2010 Gliederung Gliederung Startaufstellung Abbildung: GNU
DOKUMENTENKLASSIFIKATION MIT MACHINE LEARNING
 DOKUMENTENKLASSIFIKATION MIT MACHINE LEARNING Andreas Nadolski Softwareentwickler [email protected] Twitter: @enpit Blogs: enpit.de/blog medium.com/enpit-developer-blog 05.10.2018, DOAG Big Data
DOKUMENTENKLASSIFIKATION MIT MACHINE LEARNING Andreas Nadolski Softwareentwickler [email protected] Twitter: @enpit Blogs: enpit.de/blog medium.com/enpit-developer-blog 05.10.2018, DOAG Big Data
Learning Phrase Representations using RNN Encoder Decoder for Statistical Machine Translation. Yupeng Guo
 Learning Phrase Representations using RNN Encoder Decoder for Statistical Machine Translation Yupeng Guo 1 Agenda Introduction RNN Encoder-Decoder - Recurrent Neural Networks - RNN Encoder Decoder - Hidden
Learning Phrase Representations using RNN Encoder Decoder for Statistical Machine Translation Yupeng Guo 1 Agenda Introduction RNN Encoder-Decoder - Recurrent Neural Networks - RNN Encoder Decoder - Hidden
Deep Learning im gesellschaftlichen Kontext. Grundseminar WS18 Jerom Schult
 Deep Learning im gesellschaftlichen Kontext Grndseminar WS18 Jerom Schlt Gliederng Motivation Reinforcement Learning mit KNN Deep Learning in der Gesellschaft Asblick Masterstdim Konferenzen Motivation
Deep Learning im gesellschaftlichen Kontext Grndseminar WS18 Jerom Schlt Gliederng Motivation Reinforcement Learning mit KNN Deep Learning in der Gesellschaft Asblick Masterstdim Konferenzen Motivation
Reinforcement Learning
 Reinforcement Learning Valentin Hermann 25. Juli 2014 Inhaltsverzeichnis 1 Einführung 3 2 Wie funktioniert Reinforcement Learning? 3 2.1 Das Modell................................... 3 2.2 Exploration
Reinforcement Learning Valentin Hermann 25. Juli 2014 Inhaltsverzeichnis 1 Einführung 3 2 Wie funktioniert Reinforcement Learning? 3 2.1 Das Modell................................... 3 2.2 Exploration
Bachelorarbeit. Konstantin Böhm
 Bachelorarbeit Konstantin Böhm Maschinelles Lernen: Vergleich von Monte Carlo Tree Search und Reinforcement Learning am Beispiel eines Perfect Information Game Fakultät Technik und Informatik Studiendepartment
Bachelorarbeit Konstantin Böhm Maschinelles Lernen: Vergleich von Monte Carlo Tree Search und Reinforcement Learning am Beispiel eines Perfect Information Game Fakultät Technik und Informatik Studiendepartment
Hannah Wester Juan Jose Gonzalez
 Neuronale Netze Supervised Learning Proseminar Kognitive Robotik (SS12) Hannah Wester Juan Jose Gonzalez Kurze Einführung Warum braucht man Neuronale Netze und insbesondere Supervised Learning? Das Perzeptron
Neuronale Netze Supervised Learning Proseminar Kognitive Robotik (SS12) Hannah Wester Juan Jose Gonzalez Kurze Einführung Warum braucht man Neuronale Netze und insbesondere Supervised Learning? Das Perzeptron
Artificial Intelligence. Was ist das? Was kann das?
 Artificial Intelligence Was ist das? Was kann das? Olaf Erichsen Tech-Day Hamburg 13. Juni 2017 Sehen wir hier bereits Künstliche Intelligenz (AI)? Quelle: www.irobot.com 2017 Hierarchie der Buzzwords
Artificial Intelligence Was ist das? Was kann das? Olaf Erichsen Tech-Day Hamburg 13. Juni 2017 Sehen wir hier bereits Künstliche Intelligenz (AI)? Quelle: www.irobot.com 2017 Hierarchie der Buzzwords
Seminar A - Spieltheorie und Multiagent Reinforcement Learning in Team Spielen
 Seminar A - Spieltheorie und Multiagent Reinforcement Learning in Team Spielen Michael Groß [email protected] 20. Januar 2003 0-0 Matrixspiel Matrix Game, Strategic Game, Spiel in strategischer Form.
Seminar A - Spieltheorie und Multiagent Reinforcement Learning in Team Spielen Michael Groß [email protected] 20. Januar 2003 0-0 Matrixspiel Matrix Game, Strategic Game, Spiel in strategischer Form.
Deep Blue. Hendrik Baier
 Deep Blue Hendrik Baier Themen Matches Deep Blue Kasparov 1996/97 Faktoren von Deep Blues Erfolg Systemarchitektur Search Extensions Evaluationsfunktion Extended Book Vergleichstraining der Evaluationsfunktion
Deep Blue Hendrik Baier Themen Matches Deep Blue Kasparov 1996/97 Faktoren von Deep Blues Erfolg Systemarchitektur Search Extensions Evaluationsfunktion Extended Book Vergleichstraining der Evaluationsfunktion
Konstruieren der SLR Parsing Tabelle
 Konstruieren der SLR Parsing Tabelle Kontextfreie Grammatik (CFG) Notation 1. Diese Symbole sind Terminals: (a) Kleinbuchstaben vom Anfang des Alphabets wie a, b, c. (b) Operator Symbole wie +,, usw. (c)
Konstruieren der SLR Parsing Tabelle Kontextfreie Grammatik (CFG) Notation 1. Diese Symbole sind Terminals: (a) Kleinbuchstaben vom Anfang des Alphabets wie a, b, c. (b) Operator Symbole wie +,, usw. (c)
Zeitreihenanalyse mit Hidden Markov Modellen
 Elektrotechnik und Informationstechnik Institut für Automatisierungstechnik, Professur Prozessleittechnik Zeitreihenanalyse mit Hidden Markov Modellen (nach http://www.cs.cmu.edu/~awm/tutorials VL PLT2
Elektrotechnik und Informationstechnik Institut für Automatisierungstechnik, Professur Prozessleittechnik Zeitreihenanalyse mit Hidden Markov Modellen (nach http://www.cs.cmu.edu/~awm/tutorials VL PLT2
Sequentielle Entscheidungsprobleme. Übersicht. MDP (Markov Decision Process) MDP und POMDP. Beispiel für sequentielles Planungsproblem
 MDP und POMDP. Beispiel für sequentielles Planungsproblem") Übersicht I Künstliche Intelligenz II Problemlösen III Wissen und Schlußfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen 13. Unsicherheiten 14. Probabilistisches Schließen 15. Probabilistisches
Übersicht I Künstliche Intelligenz II Problemlösen III Wissen und Schlußfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen 13. Unsicherheiten 14. Probabilistisches Schließen 15. Probabilistisches
Herzlich Willkommen. Spielstrategien. gehalten von Nils Böckmann
 Herzlich Willkommen Spielstrategien gehalten von Nils Böckmann Agenda 1. Einführung 2. Problemstellung 3. Abgrenzung 4. Zielstellung / grober Überblick 5. Vorstellen der Konzepte 1. Umgebungslogik 2. Spielbäume
Herzlich Willkommen Spielstrategien gehalten von Nils Böckmann Agenda 1. Einführung 2. Problemstellung 3. Abgrenzung 4. Zielstellung / grober Überblick 5. Vorstellen der Konzepte 1. Umgebungslogik 2. Spielbäume
Neuronale Netze. Christian Böhm.
 Ludwig Maximilians Universität München Institut für Informatik Forschungsgruppe Data Mining in der Medizin Neuronale Netze Christian Böhm http://dmm.dbs.ifi.lmu.de/dbs 1 Lehrbuch zur Vorlesung Lehrbuch
Ludwig Maximilians Universität München Institut für Informatik Forschungsgruppe Data Mining in der Medizin Neuronale Netze Christian Böhm http://dmm.dbs.ifi.lmu.de/dbs 1 Lehrbuch zur Vorlesung Lehrbuch
Grundlagen der KI. 15. Handeln unter Unsicherheit
 Grundlagen der KI 15. Handeln unter Unsicherheit Maximieren des erwarteten Nutzens Michael Beetz 427 Viele Abbildungen sind dem Buch Artificial Intelligence: A Modern Approach entnommen. Viele Folien beruhen
Grundlagen der KI 15. Handeln unter Unsicherheit Maximieren des erwarteten Nutzens Michael Beetz 427 Viele Abbildungen sind dem Buch Artificial Intelligence: A Modern Approach entnommen. Viele Folien beruhen
Lineare Regression. Christian Herta. Oktober, Problemstellung Kostenfunktion Gradientenabstiegsverfahren
 Lineare Regression Christian Herta Oktober, 2013 1 von 33 Christian Herta Lineare Regression Lernziele Lineare Regression Konzepte des Maschinellen Lernens: Lernen mittels Trainingsmenge Kostenfunktion
Lineare Regression Christian Herta Oktober, 2013 1 von 33 Christian Herta Lineare Regression Lernziele Lineare Regression Konzepte des Maschinellen Lernens: Lernen mittels Trainingsmenge Kostenfunktion
Maschinelles Lernen auf FPGAs
 Folie 1 Gliederung 1. Motivation 2. Konzepte 3. Multilayer perceptrons (MLP) 4. Random Forest 5. Q-Learning 6. 7. Fazit & Ausblick Folie 2 Motivation Folie 3 Motivation Problem: Herkömmliche Algorithmen
Folie 1 Gliederung 1. Motivation 2. Konzepte 3. Multilayer perceptrons (MLP) 4. Random Forest 5. Q-Learning 6. 7. Fazit & Ausblick Folie 2 Motivation Folie 3 Motivation Problem: Herkömmliche Algorithmen
Einführung. Künstliche Intelligenz. Steuerungs- und Regelungstechnik. Psychologie. Reinforcement Learning (RL)
") Einführung Künstliche Intelligenz Psychlgie Reinfrcement Learning (RL) Steuerungs- und Regelungstechnik Neurwissenschaft Künstliche Neurnale Netze W19, 10.5.2006, J. Zhang 1 +148 Was ist Reinfrcement Learning?
Einführung Künstliche Intelligenz Psychlgie Reinfrcement Learning (RL) Steuerungs- und Regelungstechnik Neurwissenschaft Künstliche Neurnale Netze W19, 10.5.2006, J. Zhang 1 +148 Was ist Reinfrcement Learning?
Algorithmen und Datenstrukturen (für ET/IT)
") Algorithmen und Datenstrukturen (für ET/IT) Sommersemester 05 Dr. Tobias Lasser Computer Aided Medical Procedures Technische Universität München Programm heute Einführung Grundlagen von Algorithmen Grundlagen
Algorithmen und Datenstrukturen (für ET/IT) Sommersemester 05 Dr. Tobias Lasser Computer Aided Medical Procedures Technische Universität München Programm heute Einführung Grundlagen von Algorithmen Grundlagen
KALAHA. Erfahrungen bei der Implementation von neuronalen Netzen in APL. Dipl.Math. Ralf Herminghaus, April 2018
 KALAHA Erfahrungen bei der Implementation von neuronalen Netzen in APL Dipl.Math. Ralf Herminghaus, April 2018 1. Die Schlagzeile 2. Die Idee APL ist eine Super-Sprache! Also: So schwierig kann das ja
KALAHA Erfahrungen bei der Implementation von neuronalen Netzen in APL Dipl.Math. Ralf Herminghaus, April 2018 1. Die Schlagzeile 2. Die Idee APL ist eine Super-Sprache! Also: So schwierig kann das ja
Klausur zur Vorlesung Stochastik II
 Institut für Mathematische Stochastik WS 003/004 Universität Karlsruhe 05. 04. 004 Prof. Dr. G. Last Klausur zur Vorlesung Stochastik II Dauer: 90 Minuten Name: Vorname: Matrikelnummer: Diese Klausur hat
Institut für Mathematische Stochastik WS 003/004 Universität Karlsruhe 05. 04. 004 Prof. Dr. G. Last Klausur zur Vorlesung Stochastik II Dauer: 90 Minuten Name: Vorname: Matrikelnummer: Diese Klausur hat
Einführung in die Methoden der Künstlichen Intelligenz. Suche bei Spielen
 Einführung in die Methoden der Künstlichen Intelligenz Suche bei Spielen Dr. David Sabel WS 2012/13 Stand der Folien: 5. November 2012 Zwei-Spieler-Spiele Ziel dieses Abschnitts Intelligenter Agent für
Einführung in die Methoden der Künstlichen Intelligenz Suche bei Spielen Dr. David Sabel WS 2012/13 Stand der Folien: 5. November 2012 Zwei-Spieler-Spiele Ziel dieses Abschnitts Intelligenter Agent für
Grundlagen zu neuronalen Netzen. Kristina Tesch
 Grundlagen zu neuronalen Netzen Kristina Tesch 03.05.2018 Gliederung 1. Funktionsprinzip von neuronalen Netzen 2. Das XOR-Beispiel 3. Training des neuronalen Netzes 4. Weitere Aspekte Kristina Tesch Grundlagen
Grundlagen zu neuronalen Netzen Kristina Tesch 03.05.2018 Gliederung 1. Funktionsprinzip von neuronalen Netzen 2. Das XOR-Beispiel 3. Training des neuronalen Netzes 4. Weitere Aspekte Kristina Tesch Grundlagen
Übungsblatt 6 Lösungen
 Grundlagen der Künstlichen Intelligenz Prof. Dr. J. Boedecker, Prof. Dr. W. Burgard, Prof. Dr. F. Hutter, Prof. Dr. B. Nebel M. Krawez, T. Schulte Sommersemester 2018 Universität Freiburg Institut für
Grundlagen der Künstlichen Intelligenz Prof. Dr. J. Boedecker, Prof. Dr. W. Burgard, Prof. Dr. F. Hutter, Prof. Dr. B. Nebel M. Krawez, T. Schulte Sommersemester 2018 Universität Freiburg Institut für
Intelligente Algorithmen Einführung in die Technologie
 Intelligente Algorithmen Einführung in die Technologie Dr. KIT Universität des Landes Baden-Württemberg und nationales Forschungszentrum in der Helmholtz-Gemeinschaft www.kit.edu Natürlich sprachliche
Intelligente Algorithmen Einführung in die Technologie Dr. KIT Universität des Landes Baden-Württemberg und nationales Forschungszentrum in der Helmholtz-Gemeinschaft www.kit.edu Natürlich sprachliche
Softwareprojektpraktikum Maschinelle Übersetzung Verbesserungen für Neuronale Übersetzungssysteme
 Softwareprojektpraktikum Maschinelle Übersetzung Verbesserungen für Neuronale Übersetzungssysteme Julian Schamper, Jan Rosendahl [email protected] 04. Juli 2018 Human Language Technology
Softwareprojektpraktikum Maschinelle Übersetzung Verbesserungen für Neuronale Übersetzungssysteme Julian Schamper, Jan Rosendahl [email protected] 04. Juli 2018 Human Language Technology
Institut für Informatik Lehrstuhl Maschinelles Lernen. Uwe Dick
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning 2 Uwe Dick Funktionsapproximation Modellierung Value Iteration Least-Squares-Methoden Gradienten-Methoden
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning 2 Uwe Dick Funktionsapproximation Modellierung Value Iteration Least-Squares-Methoden Gradienten-Methoden
Institut für Angewandte Mikroelektronik und Datentechnik Fachbereich Elektrotechnik und Informationstechnik Universität Rostock.
 Seite 1 Optimierung der Verbindungsstrukturen in Digitalen Neuronalen Netzwerken Workshop on Biologically Inspired Methods on Modelling and Design of Circuits and Systems 5.10.2001 in Ilmenau, Germany
Seite 1 Optimierung der Verbindungsstrukturen in Digitalen Neuronalen Netzwerken Workshop on Biologically Inspired Methods on Modelling and Design of Circuits and Systems 5.10.2001 in Ilmenau, Germany
Weitere Untersuchungen hinsichtlich der Anwendung von KNN für Solvency 2. Tom Schelthoff
 Weitere Untersuchungen hinsichtlich der Anwendung von KNN für Solvency 2 Tom Schelthoff 30.11.2018 Inhaltsverzeichnis Deep Learning Seed-Stabilität Regularisierung Early Stopping Dropout Batch Normalization
Weitere Untersuchungen hinsichtlich der Anwendung von KNN für Solvency 2 Tom Schelthoff 30.11.2018 Inhaltsverzeichnis Deep Learning Seed-Stabilität Regularisierung Early Stopping Dropout Batch Normalization
Der Metropolis-Hastings Algorithmus
 Der Algorithmus Michael Höhle Department of Statistics University of Munich Numerical Methods for Bayesian Inference WiSe2006/07 Course 30 October 2006 Markov-Chain Monte-Carlo Verfahren Übersicht 1 Einführung
Der Algorithmus Michael Höhle Department of Statistics University of Munich Numerical Methods for Bayesian Inference WiSe2006/07 Course 30 October 2006 Markov-Chain Monte-Carlo Verfahren Übersicht 1 Einführung
Übersicht. 1 Einführung in Markov-Chain Monte-Carlo Verfahren. 2 Kurze Wiederholung von Markov-Ketten
 Markov-Chain Monte-Carlo Verfahren Der Algorithmus Michael Höhle Department of Statistics University of Munich Numerical Methods for Bayesian Inference WiSe2006/07 Course 30 October 2006 Übersicht 1 Einführung
Markov-Chain Monte-Carlo Verfahren Der Algorithmus Michael Höhle Department of Statistics University of Munich Numerical Methods for Bayesian Inference WiSe2006/07 Course 30 October 2006 Übersicht 1 Einführung