Basisfunktionen. und Neuronale Netze. Volker Tresp
|
|
|
- Bella Raske
- vor 7 Jahren
- Abrufe
Transkript
1 Basisfunktionen und Neuronale Netze Volker Tresp 1
2 I am an AI optimist. We ve got a lot of work in machine learning, which is sort of the polite term for AI nowadays because it got so broad that it s not that well defined. Bill Gates (Scientific American Interview, 2004) If you invent a breakthrough in artificial intelligence, so machines can learn, Mr. Gates responded, that is worth 10 Microsofts. (Quoted in NY Times, Monday March 3, 2004) 2
3 Nichtlineare Abbildungen und Klassifikatoren Regression: Es ist eher unwahrscheinlich, dass die wahre Funktion f(x) linear ist, obwohl dies bei Problemstellungen in hohen Eingangsdimensionen durchaus eine praktische Annahme ist. (Oder in der Physik: F = ma) Wir wollen die Mächtigkeit unseres Modelles erhöhen, so dass auch beliebige nichtlineare funktionelle Abhängigkeiten gelernt werden können Klassifikation: Ebenso kann man annehmen, dass lineare Trennflächen für die Mehrzahl der Anwendungen nicht optimal sind Wir wollen die Mächtigkeit unseres Modelles erhöhen, so dass auch beliebige nichtlineare Trennflächen modelliert werden können 3
4 XOR ist nicht linear separierbar Wie kann man es dennoch schaffen, unter Zuhilfenahme eines linearen Klassifikators, eine nichtlineare Trennfläche zu realisieren? 4
5 Hinzunahme weiterer Basisfunktionen Lineares Modell: Eingangsvektor: 1, x 1, x 2 Lineares Modell mit zusätzlicher Basisfunktion: 1, x 1, x 2, x 1 x 2 Der Wechselwirkungsterm (Interaktionsterm) x 1 x 2 koppelt die Eingänge in einer nichtlinearen Weise 5
6 Mit z 3 = x 1 x 2 wird das XOR linear separierbar f(x) = 1 2x 1 2x 2 + 4x 1 x 2 z = (1, x 1, x 2, x 1 x 2 ) with w = (1, 2, 2, 4) 6

7 f(x) = 1 2x 1 2x 2 + 4x 1 x 2 7
8 Trennebenen 8
9 Eine Nichtlineare Abbildung Wie kann man es schaffen, unter Zuhilfenahme einer linearen Regression, eine nichtlineare Abbildung zu realisieren? 9
10 f(x) = x 0.3x 3 Basisfunktionen z = (1, x, x 2, x 3 ) mit w = (0, 1, 0, 0.3) 10
11 Lineare Regression (Ridge Regression) Mehrdimensionales lineares Modell: f(x i, w) = w 0 + M 1 j=1 w j x i,j = x T i w Regularisierte Kostenfunktion J pen N N (w) = (y i f(x i, w)) 2 + λ i=1 M i=0 w 2 i Lösung ŵ P en = ( X T X + λi) 1 X T y mit X = x 1,0... x 1,M x N,0... x N,M 1 11
12 Lineare Regression mit dem Formalismus der Basisfunktionen Neu: φ j (x) = x j : Basisfunktion φ j (x) ist identisch zur j-ten Eingangsdimension Mehrdimensionales lineares Modell: f(x i, w) = w 0 + M 1 j=1 w j φ j (x i ) Regularisierte Kostenfunktion J pen N N (w) = (y i f(x i, w)) 2 + λ i=1 M i=0 w 2 i Lösung ŵ P en = ( Φ T Φ + λi) 1 Φ T y mit Φ = φ 0(x 1 )... φ M 1 (x 1 ) φ 0 (x N )... φ M 1 (x N ) 12
13 Grundidee Die Grundidee ist denkbar einfach: Neben den Eingangsvariablen x i, formen wir zusätzliche Variablen, die sich als deterministische Funktionen der Eingangsvariablen berechnen lassen Beispiel: polynomiale Basisfunktionen {1, x 1, x 2, x 3, x 1 x 2, x 1 x 3, x 2 x 3, x 2 1, x2 2, x2 3 } Die neuen Variablen z 0,... z Mφ 1 werden durch Basisfunktionen {φ h (x)} M φ 1 h=0 berechnet Im Beispiel: z 0 = φ 0 (x) = 1 z 1 = φ 1 (x) = x 1 z 5 = φ 5 (x) = x 1 x 3... Unabhängig von der Wahl der Basisfunktionen, wird die Regression mit den obigen Gleichungen (der linearen Regression) berechnet 13
14 Lineare Regression mit der Schreibweise der Transformierten Variablen Z Mehrdimensionales lineares Modell: f(z i, w) = w 0 + M 1 j=1 w j z i,j = z T i w Regularisierte Kostenfunktion J pen N N (w) = (y i f(z i, w)) 2 + λ i=1 M i=0 w 2 i Lösung ŵ P en = ( Z T Z + λi) 1 Z T y mit Z = z 1,0... z 1,M z N,0... z N,M 1 14
15 Konstruktion nichtlinearer Systeme für Regression und Klassifikation Im neuen Raum z 0,..., z Mφ 1 können wir nun alle bereits behandelten linearen Ansätze zur Klassifikation und Regression verwenden und erhalten Systeme zur nichtlinearen Klassifikation und Regression! Regression: f(x) = M φ 1 h=0 w h φ h (x) Klassifikation mit Diskriminantenfunktion: f(x) = M φ 1 h=0 w h φ h (x) 15
16 Radiale Basisfunktionen (RBF) Wir hatten schon polynomiale Basisfunktionen kennengelernt Eine weitere beliebte Klasse von Basisfunktionen sind Radiale Basisfunktionen (RBF). Typische Vertreter sind Gauss-Glocken φ h (x) = exp ( ) 1 2s 2 x c h 2 h 16
17 Drei RBFs (blau) formen f(x) (pink) 17
18 Optimale Basisfunktionen Soweit schien alles etwas zu gut um wahr zu sein Hier ist der Pferdefuß: die Anzahl sinnvoller Basisfunktionen steigt exponentiell an mit der Anzahl der Eingangsvariablen Will ich z.b. K RBF s pro Dimension spendieren, benötige ich für M Dimensionen K M RBFs Ähnlich schnell steigt die Anzahl sinnvoller Polynome mit der Dimensionalität Die zentrale Frage zur Lösung nichtlinearer Probleme: wie erhalte ich eine kleine Anzahl problemangepasster Basisfunktionen 18
19
20 Modellselektion: Polynomiale Basisfunktionen Zunächst wird ein lineares Modell mit den Eingangsvariablen geformt Es werden polynomiale Basifunktionen hinzugenommen und es wird geprüft, welche signifikant das Modell verbessern Besonders geeignet für Klassifikationsaufgaben (Polynomklassifikatoren: Siemens-Dematic OCR, J. Schürmann): Dimensionsreduktion durch PCA Begrenzte Dimensionserhöhung durch Einführung signifikanter Polynome Lineare Klassifikation 19
21 Modellselektion: RBFs Es kann sinnvoll sein, die Daten im Eingangsraum zu Gruppieren (Clustern) und die Clusterzentren als Zentren der Gaussglocken zu übernehmen Die Weiten der Gaussglocken ergeben sich z. B. dann aus der Varianz der Verteilung der Daten in den jeweiligen Clustern Ein weiteres sinnvolles Vorgehen besteht darin, soviele Gaussglocken zu definieren, wie es Datenpunkte gibt M φ = N. Die Zentren der Gaussglocken werden durch die Datenpunkte bestimmt, die Weiten der Gaussglocken werden über Kreuzvalidierung bestimmt (siehe Gauss Prozess Regression) 20
22 RBFs durch Clustern 21
23 RBFs für jeden Datenpunkt 22
24 Applikationsspezifische Merkmale Die Transformation der Rohdaten in eine applikationsspezifische Repräsentation stellt anwendungsspezifische Basisfunktionen dar; besonders wenn die Repräsentation hochdimensional ist Wir haben bereits die Vektorraumrepräsentation von Dokumenten kennengelernt Die Ableitung von oft einer großen Anzahl von Merkmalen für Dokumente, Bilder, Genesequenzen,... ist ein sehr aktives Forschungsgebiet Mit anderen Worten: wenn die Vorverarbeitung schon eine hohe Zahl von Merkmalenliefert, dann ist die Wahrscheinlichkeit hoch, dass eine lineares System das Problem bereits lösen kann. Dies ist absolut bemerkenswert: Probleme können in hohen Dimensionen einfacherer werden; vergleiche: Curse of Dimensionality (Bellman) 23
25 Flexiblere Modelle: Neuronale Netze Soweit wurden die Basisfunktionen (mehr oder weniger) als bekannt vorausgesetzt Auch bei einem Neuronalen Netz besteht der Ausgang aus der linear-gewichteten Summation von Basisfunktionen f(x) = M φ 1 h=0 w h φ h (x, v h ) 24
26 Neuronale Netze: wesentliche Vorteile Neuronale Netze sind universelle Approximatoren: jede stetige Funktion kann beliebig genau approximiert werden (mit genügend vielen sigmoiden Basisfunktionen) Entscheidender Vorteil Neuronaler Netze: mit wenigen Basisfunktionen einen sehr guten Fit zu erreichen bei gleichzeitiger hervorragender Generalisierungseigenschaften Besondere Approximationseigenschaften Neuronaler Netze in hohen Dimensionenen Basisfunktionen werden problemangepasst optimiert 25
27 Neuronale Netze: wesentliche Vorteile (2) Spezielle Form der Basisfunktionen φ h (x, v h ) = z h = sig M j=0 v h,j x j mit sig(in) = exp( in) Adaption der inneren Parameter v h,j der Basisfunktionen! 26
28 Harte und weiche (sigmoide) Übertragungsfunktion Zunächst wird die Aktivierungsfunktion als gewichtete Summe der Eingangsgrössen x i berechnet zu h = M 1 j=0 w j x j (beachte: x 0 = 1 ist ein konstanter Eingang, so dass w 0 dem Bias entspricht) Das sigmoide Neuron unterscheidet sich vom Perceptron durch die Übertragungsfunktion Perceptron : ŷ = sign(h) SigmoidesNeuron : ŷ = sig(h) 27

29 28
30 Transferfunktion Definiere die Hyperebene Teppich über einer Stufe z h = sig M j=0 M j=0 v h,j x j = 0.5 v h,j x j = 0 29
31 30
32 Lernen der Gewichte des Neuronalen Netzes In der Regression gibt es ein lineares Ausgangsneuron und Ziel ist, ebenso wir bei der linearen Regression, die Minimierung des quadratischen Fehlers J N (w, v) = N (y i f(x i, w, v)) 2 i=1 Obwohl die logistische Regression auch populär ist, benutzt man für die Klassifikation ebenso die Minimierung des quadratischen Fehlers; für C-Klassen Klassifikation gibt es entsprechend C Ausgangsneuronen; Im folgenden beschäftigen wir uns mit der Minimierung des quadratischen Fehlers bezogen auf ein Ausgangsneuron 31
33 Gradientenbasiertes Lernen der Ausgangsgewichte des Neuronalen Netzes Fast alle in Frage kommenden Optimierungsverfahren benötigen den Gradienten der Kostenfunktion nach den Parametern. Für die Ausgangsgewichte ergibt sich: J N (w, v) w h N = 2 z h (x i )(y i f(x i, w, v)) i=1 Die Optimierung der Ausgangsparameter w ist einfach (vergeleiche: ADALINE Lernregel) Musterbasierter Gradientenabstieg: w h w h + η z h (x i ) (y i f(x i, w)) 32
34 Lernen der Eingangsgewichte des Neuronalen Netzes Die Optimierung der Eingangsparameter v = (v 1,1, v 1,2,... v Mφ 1,M) T Die Kostenfunktion ist: nichtkonvex, nicht-quadratisch, nichtlinear und besitzt eine grosse Anzahl lokaler Minima Der Gradient berechnet sich zu (Kettenregel, Backpropagation Regel) J N (w, v) v h,j N = 2 w h z h (x i) x i,j (y i f(x i, w, v)) i=1 z h = exp( z h ) (1 + exp( z h )) 2 = z h(1 z h ) 33
35 Backprop Lernregel Batch Mode v h,j (t + 1) = v h,j (t) η J N(w, v) v h,j Musterbasierter Gradientenabstieg mit Trainingsmuster (x i, y i ) v h,j v h,j + η w h z h (x i )(1 z h (x i )) x i,j [y i f(x i, w, v)] Quasi Newton, Konjugiertes Gradientenverfahren,... 34
36 Neuronale Netze: Variationen Mehrere Ausgänge (z. B. Klassifikation) Sigmoide Transformation auch am Ausgangsneuron Mehrere versteckte Schichten 35
37 Neuronale Netze: Regularisierung Einfügen und Optimierung eines Regularisierungssterms J pen N (w, v) = N i=1 M φ 1 (y i f(x i, w, v) 2 + λ 1 h=0 w 2 h + λ 2 M φ 1 h=0 M j=0 v 2 h,j J pen N (w, v) = J N(w, v) w h w h + 2λ 1 w h J pen N (w, v) = J N(w, v) v h,j v h,j + 2λ 1 v h,j Stopped Training 36
38 Musterbasiertes Lernen mit Regularisierung (Weight Decay) Trainingsmuster (x i, y i ) w h w h + η 1 z h (x i ) (y i f(x i, w)) η 2 w h v h,j v h,j + η 1 w h z h (x i )(1 z h (x i )) x i,j [y i f(x i, w, v)] η 2 v h,j 37
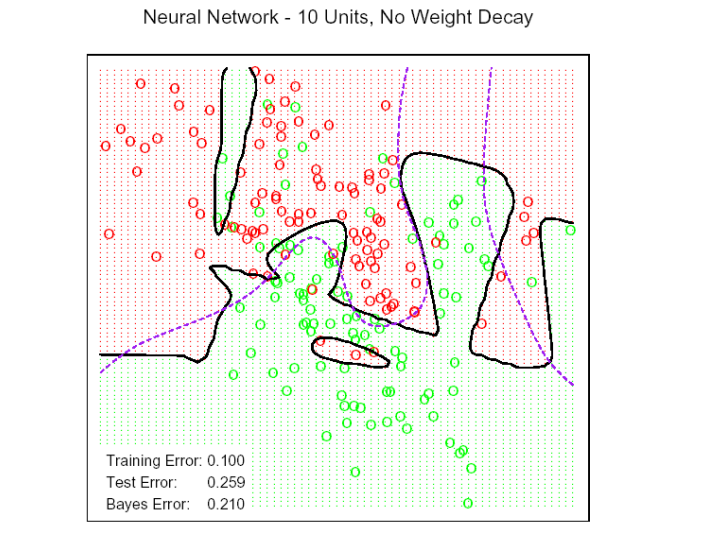
39 38

40

41
42

43 OCR Application 39
44 OCR (Bell Labs) Im Beispiel hier: grauwertige Bilder; 320 Ziffern im Trainingssatz, 160 Ziffern im Testsatz Net-1: Keine versteckte Schicht: entspricht in etwa logistischer Regression (10 Perzeptrons) Net-2: Eine versteckte Schicht mit 12 Knoten; vollvernetzt (normales Neuronales Netz mit einer versteckten Schicht) Net-3: Zwei versteckte Schichten mit lokaler Verbindungsstruktur (ohne weight-sharing!) Jede der 8 8 Neuronen in der ersten versteckten Schicht sind nur mit 3 3 Eingangsneuronen verbunden aus einem rezeptivem Feld verbunden In der zweiten versteckten Schicht ist jedes der 4 4 Neuronen mit 5 5 Neuronen der ersten versteckten Schicht verbunden Net-3 hat weniger als 50% der Gewichte als Net-2 aber mehr Neuronen 40
45 41
46 Weitere LeNets Net-4: Zwei versteckte Schichten mit lokaler Verbindungsstruktur und weight-sharing Net-5: Zwei versteckte Schichten mit lokaler Verbindungsstruktur und zwei Ebenen von weight-sharing Trainingsfehler für alle Netze gleich 0 (da sehr viele freie Parameter) 42
47 43
48
49
50 OCR: Kommentare Der reale Datensatz ist entsprechend größer Hier haben standard Neuronale Netze eine Fehlerrate von 4.5 % erreicht (vanilla backprop) LeNet-5 ist eine komplexere Version von Net-5 und erreicht eine Fehlerrate von nur 0.8 % 44
51
52

53
54 Zusammenfassung Neuronale Netze sind sehr leistungsfähig mit hoher Performanz Das Training ist aufwendig aber man kann mit einiger Berechtigung sagen, dass das Neuronale Netz tatsächlich etwas lernt, nämlich die optimale Repräsentation der Eingangsdaten in der versteckten Schicht Die Vorhersage ist schnell berechenbar Neuronale Netze sind universelle Approximatoren Neuronale Netze besitzen sehr gute Approximationseigenschaften Nachteil: das Training hat etwas von einer Kunst; eine Reihe von Größen müssen bestimmmt werden (Anzahl der versteckten Knoten...) Nachteil: Ein trainiertes Netz stellt ein lokales Optimum dar; Nichteindeutigkeit der Lösung Aber: In einem neuen Benchmarktest hat ein (Bayes sches) Neuronales Netz alle konkurrierenden Ansätze geschlagen! 45
55 Neuronale Netze in der Zeitreihenmodellierung Sei x t, t = 1, 2,... die zeitdiskrete Zeitreihe von Interesse (Beispiel: Aktienkurs von Siemens) Sei u t, t = 1, 2,... eine weitere Zeitreihe, die Informationen über x t liefert (Beispiel: Dow Jones) Der Einfachheit halber nehmen wir an, dass x t und u t skalar sind; Ziel ist die Vorhersage des nächsten Werts der Zeitreihe Wir nehmen ein System an der Form x t = f(x t 1,..., x t Mx, u t 1,..., u t Mu ) + ɛ t mit i.i.d. Zufallszahlen ɛ t, t = 1, 2,.... Diese modellieren unbekannte Störgrößen 46
56 Neuronale Netze in der Zeitreihenmodellierung (2) Wir modellieren durch ein Neuronales Netz f(x t 1,..., x t Mx, u t 1,..., u t Mu ) f NN (x t 1,..., x t Mx, u t 1,..., u t Mu, w, v) und erhalten als Kostenfunktion J N (w, v) = N (x t f NN (x t 1,..., x t Mx, u t 1,..., u t Mu, w, v)) 2 t=1 Das Neuronale Netz kann nun wie zuvor mit Backpropagation trainiert werden Das beschriebene Modell ist ein NARX Modell: Nonlinear Auto Regressive Model with external inputs. Andere Bezeichnung: TDNN (time-delay neural network) 47
57 Rekurrente Neuronale Netze Wenn x t nicht direkt gemessen werden kann, sondern nur verrauschte Messungen zur Verfügung stehen (Verallgemeinerung des linearen Kalman Filters), reicht einfaches Backpropagation nicht mehr aus, sondern man muss komplexere Lernverahren verwenden: Backpropagation through time (BPTT) Real-Time Recurrent Learning (RTRL) Dynamic Backpropagation 48
58
59 APPENDIX 49
60 Appendix: Approximationsgenauigkeit Neuronaler Netze Dies ist der entscheidende Punkt: wieviele innere Knoten sind notwendig, um eine vorgegebene Approximationsgenauigkeit zu erreichen? Die Anzahle der inneren Knoten, die benötigt werden, um eine vorgegebene Approximationsgenauigkeit zu erreichen, hängt von der Komplexität der zu approximierenden Funktion ab. Barron führt für das Maß der Komplexität der zu approximierenden Funktion f(x) die Größe C f ein, welche definiert ist als R d w f(w) dw = C f, wobei f(w) die Fouriertransformation von f(x) ist. C f bestraft im Besonderen hohe Frequenzanteile. Die Aufgabe des Neuronalen Netzes ist es, eine Funktion f(x) mit Komplexitätsmaß C f zu approximieren. 50
61 Der Eingangsvektors x ist aus R d, das Neuronale Netz besitzt n innere Knoten und die Netzapproximation bezeichnen wir mit f n (x) Wir definieren als Approximationsfehler AF den mittleren quadratischen Fehler zwischen f(x) und f n (x) AF = (f(x) f n (x)) 2 µ(dx). B r (1) µ ist ein beliebiges Wahrscheinlichkeitsmaß auf der Kugel B r = {x : x r} mit Radius r > 0 Barron hat nun gezeigt, daß für jede Funktion, für welche C f endlich ist und für jedes n 1 ein Neuronales Netz mit einer inneren Schicht existiert, so daß für den nach letzten Gleichung definierten Approximationsfehler AF Neur gilt AF Neur (2rC f) 2. (2) n Dieses überraschende Resultat zeigt, daß die Anzahl der inneren Knoten unabhängig von der Dimension d des Eingangsraumes ist.
62 Man beachte, daß für konventionelle Approximatoren mit festen Basisfunktionen der Approximationsfehler AF kon exponentiell mit der Dimension ansteigt : AF kon (1/n) 2/d. Für gewisse Funktionenklassen kann C f exponentiell schnell mit der Dimension anwachsen, und es wäre somit nicht viel gewonnen. Barron zeigt jedoch, daß C f für große Klassen von Funktionen nur recht langsam mit der Dimension (z.b. proportional) wächst. Quellen: Tresp, V. (1995). Die besonderen Eigenschaften Neuronaler Netze bei der Approximation von Funktionen. Künstliche Intelligenz, Nr. 4. A. Barron. Universal Approximation Bounds for Superpositions of a Sigmoidal Function. IEEE Trans. Information Theory, Vol. 39, Nr. 3, Seite , Mai 1993.
Neuronale Netze. Volker Tresp
 Neuronale Netze Volker Tresp 1 Einführung Der Entwurf eines guten Klassifikators/Regressionsmodells hängt entscheidend von geeigneten Basisfunktion en ab Manchmal sind geeignete Basisfunktionen (Merkmalsextraktoren)
Neuronale Netze Volker Tresp 1 Einführung Der Entwurf eines guten Klassifikators/Regressionsmodells hängt entscheidend von geeigneten Basisfunktion en ab Manchmal sind geeignete Basisfunktionen (Merkmalsextraktoren)
Neuronale Netze. Volker Tresp
 Neuronale Netze Volker Tresp 1 Einführung Der Entwurf eines guten Klassifikators/Regressionsmodells hängt entscheidend von geeigneten Basisfunktion en ab Manchmal sind geeignete Basisfunktionen (Merkmalsextraktoren)
Neuronale Netze Volker Tresp 1 Einführung Der Entwurf eines guten Klassifikators/Regressionsmodells hängt entscheidend von geeigneten Basisfunktion en ab Manchmal sind geeignete Basisfunktionen (Merkmalsextraktoren)
Die Datenmatrix für Überwachtes Lernen
 Die Datenmatrix für Überwachtes Lernen X j j-te Eingangsvariable X = (X 0,..., X M 1 ) T Vektor von Eingangsvariablen M Anzahl der Eingangsvariablen N Anzahl der Datenpunkte Y Ausgangsvariable x i = (x
Die Datenmatrix für Überwachtes Lernen X j j-te Eingangsvariable X = (X 0,..., X M 1 ) T Vektor von Eingangsvariablen M Anzahl der Eingangsvariablen N Anzahl der Datenpunkte Y Ausgangsvariable x i = (x
Lineare Klassifikatoren. Volker Tresp
 Lineare Klassifikatoren Volker Tresp 1 Einführung Lineare Klassifikatoren trennen Klassen durch eine lineare Hyperebene (genauer: affine Menge) In hochdimensionalen Problemen trennt schon eine lineare
Lineare Klassifikatoren Volker Tresp 1 Einführung Lineare Klassifikatoren trennen Klassen durch eine lineare Hyperebene (genauer: affine Menge) In hochdimensionalen Problemen trennt schon eine lineare
Lineare Regression. Volker Tresp
 Lineare Regression Volker Tresp 1 Die Lernmaschine: Das lineare Modell / ADALINE Wie beim Perzeptron wird zunächst die Aktivierungsfunktion gewichtete Summe der Eingangsgrößen x i berechnet zu h i = M
Lineare Regression Volker Tresp 1 Die Lernmaschine: Das lineare Modell / ADALINE Wie beim Perzeptron wird zunächst die Aktivierungsfunktion gewichtete Summe der Eingangsgrößen x i berechnet zu h i = M
Optimal-trennende Hyperebenen und die Support Vector Machine. Volker Tresp
 Optimal-trennende Hyperebenen und die Support Vector Machine Volker Tresp 1 (Vapnik s) Optimal-trennende Hyperebenen (Optimal Separating Hyperplanes) Wir betrachten wieder einen linearen Klassifikator
Optimal-trennende Hyperebenen und die Support Vector Machine Volker Tresp 1 (Vapnik s) Optimal-trennende Hyperebenen (Optimal Separating Hyperplanes) Wir betrachten wieder einen linearen Klassifikator
Nichtlineare Klassifikatoren
 Nichtlineare Klassifikatoren Mustererkennung und Klassifikation, Vorlesung No. 11 1 M. O. Franz 12.01.2008 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht
Nichtlineare Klassifikatoren Mustererkennung und Klassifikation, Vorlesung No. 11 1 M. O. Franz 12.01.2008 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht
Mustererkennung: Neuronale Netze. D. Schlesinger ()Mustererkennung: Neuronale Netze 1 / 12
Mustererkennung: Neuronale Netze 1 / 12") Mustererkennung: Neuronale Netze D. Schlesinger ()Mustererkennung: Neuronale Netze 1 / 12 Feed-Forward Netze y 1 y 2 y m...... x 1 x 2 x n Output Schicht i max... Zwischenschicht i... Zwischenschicht 1
Mustererkennung: Neuronale Netze D. Schlesinger ()Mustererkennung: Neuronale Netze 1 / 12 Feed-Forward Netze y 1 y 2 y m...... x 1 x 2 x n Output Schicht i max... Zwischenschicht i... Zwischenschicht 1
Das Perzeptron. Volker Tresp
 Das Perzeptron Volker Tresp 1 Einführung Das Perzeptron war eines der ersten ernstzunehmenden Lernmaschinen Die wichtigsten Elemente Sammlung und Vorverarbeitung der Trainingsdaten Wahl einer Klasse von
Das Perzeptron Volker Tresp 1 Einführung Das Perzeptron war eines der ersten ernstzunehmenden Lernmaschinen Die wichtigsten Elemente Sammlung und Vorverarbeitung der Trainingsdaten Wahl einer Klasse von
Hannah Wester Juan Jose Gonzalez
 Neuronale Netze Supervised Learning Proseminar Kognitive Robotik (SS12) Hannah Wester Juan Jose Gonzalez Kurze Einführung Warum braucht man Neuronale Netze und insbesondere Supervised Learning? Das Perzeptron
Neuronale Netze Supervised Learning Proseminar Kognitive Robotik (SS12) Hannah Wester Juan Jose Gonzalez Kurze Einführung Warum braucht man Neuronale Netze und insbesondere Supervised Learning? Das Perzeptron
6.4 Neuronale Netze zur Verarbeitung von Zeitreihen
 6.4 Neuronale Netze zur Verarbeitung von Zeitreihen Aufgabe: Erlernen einer Zeitreihe x(t + 1) = f(x(t), x(t 1), x(t 2),...) Idee: Verzögerungskette am Eingang eines neuronalen Netzwerks, z.b. eines m-h-1
6.4 Neuronale Netze zur Verarbeitung von Zeitreihen Aufgabe: Erlernen einer Zeitreihe x(t + 1) = f(x(t), x(t 1), x(t 2),...) Idee: Verzögerungskette am Eingang eines neuronalen Netzwerks, z.b. eines m-h-1
Grundlagen zu neuronalen Netzen. Kristina Tesch
 Grundlagen zu neuronalen Netzen Kristina Tesch 03.05.2018 Gliederung 1. Funktionsprinzip von neuronalen Netzen 2. Das XOR-Beispiel 3. Training des neuronalen Netzes 4. Weitere Aspekte Kristina Tesch Grundlagen
Grundlagen zu neuronalen Netzen Kristina Tesch 03.05.2018 Gliederung 1. Funktionsprinzip von neuronalen Netzen 2. Das XOR-Beispiel 3. Training des neuronalen Netzes 4. Weitere Aspekte Kristina Tesch Grundlagen
Thema 3: Radiale Basisfunktionen und RBF- Netze
 Proseminar: Machine Learning 10 Juli 2006 Thema 3: Radiale Basisfunktionen und RBF- Netze Barbara Rakitsch Zusammenfassung: Aufgabe dieses Vortrags war es, die Grundlagen der RBF-Netze darzustellen 1 Einführung
Proseminar: Machine Learning 10 Juli 2006 Thema 3: Radiale Basisfunktionen und RBF- Netze Barbara Rakitsch Zusammenfassung: Aufgabe dieses Vortrags war es, die Grundlagen der RBF-Netze darzustellen 1 Einführung
Wissensentdeckung in Datenbanken
 Wissensentdeckung in Datenbanken Deep Learning (II) Nico Piatkowski und Uwe Ligges Informatik Künstliche Intelligenz 25.07.2017 1 von 14 Überblick Faltungsnetze Dropout Autoencoder Generative Adversarial
Wissensentdeckung in Datenbanken Deep Learning (II) Nico Piatkowski und Uwe Ligges Informatik Künstliche Intelligenz 25.07.2017 1 von 14 Überblick Faltungsnetze Dropout Autoencoder Generative Adversarial
Lineare Klassifikatoren. Volker Tresp
 Lineare Klassifikatoren Volker Tresp 1 Klassifikatoren Klassifikation ist die zentrale Aufgabe in der Mustererkennung Sensoren liefern mir Informationen über ein Objekt Zu welcher Klasse gehört das Objekt:
Lineare Klassifikatoren Volker Tresp 1 Klassifikatoren Klassifikation ist die zentrale Aufgabe in der Mustererkennung Sensoren liefern mir Informationen über ein Objekt Zu welcher Klasse gehört das Objekt:
Neuronale Netze. Anna Wallner. 15. Mai 2007
 5. Mai 2007 Inhalt : Motivation Grundlagen Beispiel: XOR Netze mit einer verdeckten Schicht Anpassung des Netzes mit Backpropagation Probleme Beispiel: Klassifikation handgeschriebener Ziffern Rekurrente
5. Mai 2007 Inhalt : Motivation Grundlagen Beispiel: XOR Netze mit einer verdeckten Schicht Anpassung des Netzes mit Backpropagation Probleme Beispiel: Klassifikation handgeschriebener Ziffern Rekurrente
Weitere Untersuchungen hinsichtlich der Anwendung von KNN für Solvency 2. Tom Schelthoff
 Weitere Untersuchungen hinsichtlich der Anwendung von KNN für Solvency 2 Tom Schelthoff 30.11.2018 Inhaltsverzeichnis Deep Learning Seed-Stabilität Regularisierung Early Stopping Dropout Batch Normalization
Weitere Untersuchungen hinsichtlich der Anwendung von KNN für Solvency 2 Tom Schelthoff 30.11.2018 Inhaltsverzeichnis Deep Learning Seed-Stabilität Regularisierung Early Stopping Dropout Batch Normalization
Wir haben in den vorherigen Kapiteln verschiedene Verfahren zur Regression und Klassifikation kennengelernt (z.b. lineare Regression, SVMs)
") 6. Neuronale Netze Motivation Wir haben in den vorherigen Kapiteln verschiedene Verfahren zur Regression und Klassifikation kennengelernt (z.b. lineare Regression, SVMs) Abstrakt betrachtet sind alle diese
6. Neuronale Netze Motivation Wir haben in den vorherigen Kapiteln verschiedene Verfahren zur Regression und Klassifikation kennengelernt (z.b. lineare Regression, SVMs) Abstrakt betrachtet sind alle diese
Neuronale Netze in der Phonetik: Feed-Forward Netze. Pfitzinger, Reichel IPSK, LMU München {hpt 14.
 Neuronale Netze in der Phonetik: Feed-Forward Netze Pfitzinger, Reichel IPSK, LMU München {hpt reichelu}@phonetik.uni-muenchen.de 14. Juli 2006 Inhalt Typisierung nach Aktivierungsfunktion Lernen in einschichtigen
Neuronale Netze in der Phonetik: Feed-Forward Netze Pfitzinger, Reichel IPSK, LMU München {hpt reichelu}@phonetik.uni-muenchen.de 14. Juli 2006 Inhalt Typisierung nach Aktivierungsfunktion Lernen in einschichtigen
Künstliche Neuronale Netze
 Inhalt (Biologische) Neuronale Netze Schwellenwertelemente Allgemein Neuronale Netze Mehrschichtiges Perzeptron Weitere Arten Neuronaler Netze 2 Neuronale Netze Bestehend aus vielen Neuronen(menschliches
Inhalt (Biologische) Neuronale Netze Schwellenwertelemente Allgemein Neuronale Netze Mehrschichtiges Perzeptron Weitere Arten Neuronaler Netze 2 Neuronale Netze Bestehend aus vielen Neuronen(menschliches
Maschinelles Lernen Vorlesung
 Maschinelles Lernen Vorlesung SVM Kernfunktionen, Regularisierung Katharina Morik 15.11.2011 1 von 39 Gliederung 1 Weich trennende SVM 2 Kernfunktionen 3 Bias und Varianz bei SVM 2 von 39 SVM mit Ausnahmen
Maschinelles Lernen Vorlesung SVM Kernfunktionen, Regularisierung Katharina Morik 15.11.2011 1 von 39 Gliederung 1 Weich trennende SVM 2 Kernfunktionen 3 Bias und Varianz bei SVM 2 von 39 SVM mit Ausnahmen
Praktische Optimierung
 Wintersemester 27/8 Praktische Optimierung (Vorlesung) Prof. Dr. Günter Rudolph Fakultät für Informatik Lehrstuhl für Algorithm Engineering Metamodellierung Inhalt Multilayer-Perceptron (MLP) Radiale Basisfunktionsnetze
Wintersemester 27/8 Praktische Optimierung (Vorlesung) Prof. Dr. Günter Rudolph Fakultät für Informatik Lehrstuhl für Algorithm Engineering Metamodellierung Inhalt Multilayer-Perceptron (MLP) Radiale Basisfunktionsnetze
Lineare Klassifikatoren
 Lineare Klassifikatoren Mustererkennung und Klassifikation, Vorlesung No. 8 1 M. O. Franz 06.12.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht 1 Nächste-Nachbarn-
Lineare Klassifikatoren Mustererkennung und Klassifikation, Vorlesung No. 8 1 M. O. Franz 06.12.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht 1 Nächste-Nachbarn-
Neural Networks: Architectures and Applications for NLP
 Neural Networks: Architectures and Applications for NLP Session 02 Julia Kreutzer 8. November 2016 Institut für Computerlinguistik, Heidelberg 1 Overview 1. Recap 2. Backpropagation 3. Ausblick 2 Recap
Neural Networks: Architectures and Applications for NLP Session 02 Julia Kreutzer 8. November 2016 Institut für Computerlinguistik, Heidelberg 1 Overview 1. Recap 2. Backpropagation 3. Ausblick 2 Recap
Wissensentdeckung in Datenbanken
 Wissensentdeckung in Datenbanken Deep Learning Nico Piatkowski und Uwe Ligges Informatik Künstliche Intelligenz 20.07.2017 1 von 11 Überblick Künstliche Neuronale Netze Motivation Formales Modell Aktivierungsfunktionen
Wissensentdeckung in Datenbanken Deep Learning Nico Piatkowski und Uwe Ligges Informatik Künstliche Intelligenz 20.07.2017 1 von 11 Überblick Künstliche Neuronale Netze Motivation Formales Modell Aktivierungsfunktionen
Rekurrente / rückgekoppelte neuronale Netzwerke
 Rekurrente / rückgekoppelte neuronale Netzwerke Forschungsseminar Deep Learning 2018 Universität Leipzig 12.01.2018 Vortragender: Andreas Haselhuhn Neuronale Netzwerke Neuron besteht aus: Eingängen Summenfunktion
Rekurrente / rückgekoppelte neuronale Netzwerke Forschungsseminar Deep Learning 2018 Universität Leipzig 12.01.2018 Vortragender: Andreas Haselhuhn Neuronale Netzwerke Neuron besteht aus: Eingängen Summenfunktion
Was bisher geschah Künstliche Neuronen: Mathematisches Modell und Funktionen: Eingabe-, Aktivierungs- Ausgabefunktion Boolesche oder reelle Ein-und
 Was bisher geschah Künstliche Neuronen: Mathematisches Modell und Funktionen: Eingabe-, Aktivierungs- Ausgabefunktion Boolesche oder reelle Ein-und Ausgaben Aktivierungsfunktionen: Schwellwertfunktion
Was bisher geschah Künstliche Neuronen: Mathematisches Modell und Funktionen: Eingabe-, Aktivierungs- Ausgabefunktion Boolesche oder reelle Ein-und Ausgaben Aktivierungsfunktionen: Schwellwertfunktion
Technische Universität Berlin Fakultät IV Elektrotechnik und Informatik. 8. Aufgabenblatt
 Technische Universität Berlin Fakultät IV Elektrotechnik und Informatik Künstliche Intelligenz: Grundlagen und Anwendungen Albayrak, Fricke (AOT) Oer, Thiel (KI) Wintersemester 2014 / 2015 8. Aufgabenblatt
Technische Universität Berlin Fakultät IV Elektrotechnik und Informatik Künstliche Intelligenz: Grundlagen und Anwendungen Albayrak, Fricke (AOT) Oer, Thiel (KI) Wintersemester 2014 / 2015 8. Aufgabenblatt
Martin Stetter WS 03/04, 2 SWS. VL: Dienstags 8:30-10 Uhr
 Statistische und neuronale Lernverfahren Martin Stetter WS 03/04, 2 SWS VL: Dienstags 8:30-0 Uhr PD Dr. Martin Stetter, Siemens AG Statistische und neuronale Lernverfahren Behandelte Themen 0. Motivation
Statistische und neuronale Lernverfahren Martin Stetter WS 03/04, 2 SWS VL: Dienstags 8:30-0 Uhr PD Dr. Martin Stetter, Siemens AG Statistische und neuronale Lernverfahren Behandelte Themen 0. Motivation
RL und Funktionsapproximation
 RL und Funktionsapproximation Bisher sind haben wir die Funktionen V oder Q als Tabellen gespeichert. Im Allgemeinen sind die Zustandsräume und die Zahl der möglichen Aktionen sehr groß. Deshalb besteht
RL und Funktionsapproximation Bisher sind haben wir die Funktionen V oder Q als Tabellen gespeichert. Im Allgemeinen sind die Zustandsräume und die Zahl der möglichen Aktionen sehr groß. Deshalb besteht
Konzepte der AI Neuronale Netze
 Konzepte der AI Neuronale Netze Franz Wotawa Institut für Informationssysteme, Database and Artificial Intelligence Group, Technische Universität Wien Email: wotawa@dbai.tuwien.ac.at Was sind Neuronale
Konzepte der AI Neuronale Netze Franz Wotawa Institut für Informationssysteme, Database and Artificial Intelligence Group, Technische Universität Wien Email: wotawa@dbai.tuwien.ac.at Was sind Neuronale
Frequentisten und Bayesianer. Volker Tresp
 Frequentisten und Bayesianer Volker Tresp 1 Frequentisten 2 Die W-Verteilung eines Datenmusters Nehmen wir an, dass die wahre Abhängigkeit linear ist, wir jedoch nur verrauschte Daten zur Verfügung haben
Frequentisten und Bayesianer Volker Tresp 1 Frequentisten 2 Die W-Verteilung eines Datenmusters Nehmen wir an, dass die wahre Abhängigkeit linear ist, wir jedoch nur verrauschte Daten zur Verfügung haben
Das Modell: Nichtlineare Merkmalsextraktion (Preprozessing) + Lineare Klassifikation
 + Lineare Klassifikation") Das Modell: Nichtlineare Merkmalsextraktion (Preprozessing) + Lineare Klassifikation Hochdimensionaler Eingaberaum {0,1} Z S quadratisch aufgemalt (zwecks besserer Visualisierung) als Retina bestehend
Das Modell: Nichtlineare Merkmalsextraktion (Preprozessing) + Lineare Klassifikation Hochdimensionaler Eingaberaum {0,1} Z S quadratisch aufgemalt (zwecks besserer Visualisierung) als Retina bestehend
Neuronale Netze. Christian Böhm.
 Ludwig Maximilians Universität München Institut für Informatik Forschungsgruppe Data Mining in der Medizin Neuronale Netze Christian Böhm http://dmm.dbs.ifi.lmu.de/dbs 1 Lehrbuch zur Vorlesung Lehrbuch
Ludwig Maximilians Universität München Institut für Informatik Forschungsgruppe Data Mining in der Medizin Neuronale Netze Christian Böhm http://dmm.dbs.ifi.lmu.de/dbs 1 Lehrbuch zur Vorlesung Lehrbuch
Computational Intelligence 1 / 20. Computational Intelligence Künstliche Neuronale Netze Perzeptron 3 / 20
 Gliederung / Künstliche Neuronale Netze Perzeptron Einschränkungen Netze von Perzeptonen Perzeptron-Lernen Perzeptron Künstliche Neuronale Netze Perzeptron 3 / Der Psychologe und Informatiker Frank Rosenblatt
Gliederung / Künstliche Neuronale Netze Perzeptron Einschränkungen Netze von Perzeptonen Perzeptron-Lernen Perzeptron Künstliche Neuronale Netze Perzeptron 3 / Der Psychologe und Informatiker Frank Rosenblatt
Wenn PCA in der Gesichtserkennung eingesetzt wird heißen die Eigenvektoren oft: Eigenfaces
 EFME-Zusammenfassusng WS11 Kurze Fragen: Wenn PCA in der Gesichtserkennung eingesetzt wird heißen die Eigenvektoren oft: Eigenfaces Unter welcher Bedingung konvergiert der Online Perceptron Algorithmus?
EFME-Zusammenfassusng WS11 Kurze Fragen: Wenn PCA in der Gesichtserkennung eingesetzt wird heißen die Eigenvektoren oft: Eigenfaces Unter welcher Bedingung konvergiert der Online Perceptron Algorithmus?
Linear nichtseparable Probleme
 Linear nichtseparable Probleme Mustererkennung und Klassifikation, Vorlesung No. 10 1 M. O. Franz 20.12.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht
Linear nichtseparable Probleme Mustererkennung und Klassifikation, Vorlesung No. 10 1 M. O. Franz 20.12.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht
Rekurrente Neuronale Netze
 Rekurrente Neuronale Netze Gregor Mitscha-Baude May 9, 2016 Motivation Standard neuronales Netz: Fixe Dimensionen von Input und Output! Motivation In viele Anwendungen variable Input/Output-Länge. Spracherkennung
Rekurrente Neuronale Netze Gregor Mitscha-Baude May 9, 2016 Motivation Standard neuronales Netz: Fixe Dimensionen von Input und Output! Motivation In viele Anwendungen variable Input/Output-Länge. Spracherkennung
Mustererkennung. Support Vector Machines. R. Neubecker, WS 2018 / Support Vector Machines
 Mustererkennung R. Neubecker, WS 018 / 019 (SVM) kommen aus der statistischen Lerntheorie gehören zu den optimalen Klassifikatoren = SVMs minimieren nicht nur den Trainingsfehler, sondern auch den (voraussichtlichen)
Mustererkennung R. Neubecker, WS 018 / 019 (SVM) kommen aus der statistischen Lerntheorie gehören zu den optimalen Klassifikatoren = SVMs minimieren nicht nur den Trainingsfehler, sondern auch den (voraussichtlichen)
So lösen Sie das multivariate lineare Regressionsproblem von Christian Herta
 Multivariate Lineare Regression Christian Herta Oktober, 2013 1 von 34 Christian Herta Multivariate Lineare Regression Lernziele Multivariate Lineare Regression Konzepte des Maschinellen Lernens: Kostenfunktion
Multivariate Lineare Regression Christian Herta Oktober, 2013 1 von 34 Christian Herta Multivariate Lineare Regression Lernziele Multivariate Lineare Regression Konzepte des Maschinellen Lernens: Kostenfunktion
Optimierung. Optimierung. Vorlesung 2 Optimierung ohne Nebenbedingungen Gradientenverfahren. 2013 Thomas Brox, Fabian Kuhn
 Optimierung Vorlesung 2 Optimierung ohne Nebenbedingungen Gradientenverfahren 1 Minimierung ohne Nebenbedingung Ein Optimierungsproblem besteht aus einer zulässigen Menge und einer Zielfunktion Minimum
Optimierung Vorlesung 2 Optimierung ohne Nebenbedingungen Gradientenverfahren 1 Minimierung ohne Nebenbedingung Ein Optimierungsproblem besteht aus einer zulässigen Menge und einer Zielfunktion Minimum
5 Interpolation und Approximation
 5 Interpolation und Approximation Problemstellung: Es soll eine Funktion f(x) approximiert werden, von der die Funktionswerte nur an diskreten Stellen bekannt sind. 5. Das Interpolationspolynom y y = P(x)
5 Interpolation und Approximation Problemstellung: Es soll eine Funktion f(x) approximiert werden, von der die Funktionswerte nur an diskreten Stellen bekannt sind. 5. Das Interpolationspolynom y y = P(x)
Vorlesung Digitale Bildverarbeitung Sommersemester 2013
 Vorlesung Digitale Bildverarbeitung Sommersemester 2013 Sebastian Houben (Marc Schlipsing) Institut für Neuroinformatik Inhalt Crash-Course in Machine Learning Klassifikationsverfahren Grundsätzliches
Vorlesung Digitale Bildverarbeitung Sommersemester 2013 Sebastian Houben (Marc Schlipsing) Institut für Neuroinformatik Inhalt Crash-Course in Machine Learning Klassifikationsverfahren Grundsätzliches
Überblick. Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung
 Grundlagen Überblick Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes-Klassifikator
Grundlagen Überblick Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes-Klassifikator
Neuronale. Netze. Henrik Voigt. Neuronale. Netze in der Biologie Aufbau Funktion. Neuronale. Aufbau Netzarten und Topologien
 in der Seminar Literaturarbeit und Präsentation 17.01.2019 in der Was können leisten und was nicht? Entschlüsseln von Texten??? Bilderkennung??? in der in der Quelle: justetf.com Quelle: zeit.de Spracherkennung???
in der Seminar Literaturarbeit und Präsentation 17.01.2019 in der Was können leisten und was nicht? Entschlüsseln von Texten??? Bilderkennung??? in der in der Quelle: justetf.com Quelle: zeit.de Spracherkennung???
Das Perceptron. Volker Tresp
 Das Perceptron Volker Tresp 1 Ein biologisch motiviertes Lernmodell 2 Input-Output Modelle Ein biologisches System muss basierende auf Sensordaten eine Entscheidung treffen Ein OCR System klassifiziert
Das Perceptron Volker Tresp 1 Ein biologisch motiviertes Lernmodell 2 Input-Output Modelle Ein biologisches System muss basierende auf Sensordaten eine Entscheidung treffen Ein OCR System klassifiziert
Reinforcement Learning
 Reinforcement Learning 1. Allgemein Reinforcement Learning 2. Neuronales Netz als Bewertungsfunktion 3. Neuronales Netz als Reinforcement Learning Nils-Olaf Bösch 1 Allgemein Reinforcement Learning Unterschied
Reinforcement Learning 1. Allgemein Reinforcement Learning 2. Neuronales Netz als Bewertungsfunktion 3. Neuronales Netz als Reinforcement Learning Nils-Olaf Bösch 1 Allgemein Reinforcement Learning Unterschied
Interpolation und Approximation von Funktionen
 Kapitel 6 Interpolation und Approximation von Funktionen Bei ökonomischen Anwendungen tritt oft das Problem auf, dass eine analytisch nicht verwendbare (oder auch unbekannte) Funktion f durch eine numerisch
Kapitel 6 Interpolation und Approximation von Funktionen Bei ökonomischen Anwendungen tritt oft das Problem auf, dass eine analytisch nicht verwendbare (oder auch unbekannte) Funktion f durch eine numerisch
Perzeptronen. Katrin Dust, Felix Oppermann Universität Oldenburg, FK II - Department für Informatik Vortrag im Rahmen des Proseminars 2004
 Perzeptronen Katrin Dust, Felix Oppermann Universität Oldenburg, FK II - Department für Informatik Vortrag im Rahmen des Proseminars 2004 1/25 Gliederung Vorbilder Neuron McCulloch-Pitts-Netze Perzeptron
Perzeptronen Katrin Dust, Felix Oppermann Universität Oldenburg, FK II - Department für Informatik Vortrag im Rahmen des Proseminars 2004 1/25 Gliederung Vorbilder Neuron McCulloch-Pitts-Netze Perzeptron
Andreas Scherer. Neuronale Netze. Grundlagen und Anwendungen. vieweg
 Andreas Scherer Neuronale Netze Grundlagen und Anwendungen vieweg Inhaltsverzeichnis Vorwort 1 1 Einführung 3 1.1 Was ist ein neuronales Netz? 3 1.2 Eigenschaften neuronaler Netze 5 1.2.1 Allgemeine Merkmale
Andreas Scherer Neuronale Netze Grundlagen und Anwendungen vieweg Inhaltsverzeichnis Vorwort 1 1 Einführung 3 1.1 Was ist ein neuronales Netz? 3 1.2 Eigenschaften neuronaler Netze 5 1.2.1 Allgemeine Merkmale
Automatische Spracherkennung
 Automatische Spracherkennung 3 Vertiefung: Drei wichtige Algorithmen Teil 3 Soweit vorhanden ist der jeweils englische Fachbegriff, so wie er in der Fachliteratur verwendet wird, in Klammern angegeben.
Automatische Spracherkennung 3 Vertiefung: Drei wichtige Algorithmen Teil 3 Soweit vorhanden ist der jeweils englische Fachbegriff, so wie er in der Fachliteratur verwendet wird, in Klammern angegeben.
6.2 Feed-Forward Netze
 6.2 Feed-Forward Netze Wir haben gesehen, dass wir mit neuronalen Netzen bestehend aus einer oder mehreren Schichten von Perzeptren beispielsweise logische Funktionen darstellen können Nun betrachten wir
6.2 Feed-Forward Netze Wir haben gesehen, dass wir mit neuronalen Netzen bestehend aus einer oder mehreren Schichten von Perzeptren beispielsweise logische Funktionen darstellen können Nun betrachten wir
Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 2016
 Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 1 M. Sperber (matthias.sperber@kit.edu) S. Nguyen (thai.nguyen@kit.edu) Übungsblatt 3 Maschinelles Lernen und Klassifikation Abgabe online
Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 1 M. Sperber (matthias.sperber@kit.edu) S. Nguyen (thai.nguyen@kit.edu) Übungsblatt 3 Maschinelles Lernen und Klassifikation Abgabe online
Symbolumwandlung der Kernfunktionen
 91 Symbolumwandlung der Kernfunktionen Positiv definierte, konvexe Kernfunktionen können als Fuzzy-Mengen betrachtet werden. z.b.: µ B (x) = 1 1 + ( x 50 10 ) 2 92 ZF-Funktionen 1 1 0-5 0 5 (a) 1 0-5 0
91 Symbolumwandlung der Kernfunktionen Positiv definierte, konvexe Kernfunktionen können als Fuzzy-Mengen betrachtet werden. z.b.: µ B (x) = 1 1 + ( x 50 10 ) 2 92 ZF-Funktionen 1 1 0-5 0 5 (a) 1 0-5 0
Wir haben in den vorherigen Kapiteln verschiedene Verfahren zur Regression und Klassifikation kennengelernt (z.b. lineare Regression, SVMs)
") 6. Neuronale Netze Motivation Wir haben in den vorherigen Kapiteln verschiedene Verfahren zur Regression und Klassifikation kennengelernt (z.b. lineare Regression, SVMs) Abstrakt betrachtet sind alle diese
6. Neuronale Netze Motivation Wir haben in den vorherigen Kapiteln verschiedene Verfahren zur Regression und Klassifikation kennengelernt (z.b. lineare Regression, SVMs) Abstrakt betrachtet sind alle diese
Adaptive Systeme. Mehrere Neuronen, Assoziative Speicher und Mustererkennung. Prof. Dr. rer. nat. Nikolaus Wulff
 Adaptive Systeme Mehrere Neuronen, Assoziative Speicher und Mustererkennung Prof. Dr. rer. nat. Nikolaus Wulff Modell eines Neuron x x 2 x 3. y y= k = n w k x k x n Die n binären Eingangssignale x k {,}
Adaptive Systeme Mehrere Neuronen, Assoziative Speicher und Mustererkennung Prof. Dr. rer. nat. Nikolaus Wulff Modell eines Neuron x x 2 x 3. y y= k = n w k x k x n Die n binären Eingangssignale x k {,}
Neuronale Netze. Gehirn: ca Neuronen. stark vernetzt. Schaltzeit ca. 1 ms (relativ langsam, vgl. Prozessor)
") 29 Neuronale Netze Gehirn: ca. 10 11 Neuronen stark vernetzt Schaltzeit ca. 1 ms (relativ langsam, vgl. Prozessor) Mustererkennung in 0.1s 100 Schritte Regel 30 Was ist ein künstl. neuronales Netz? Ein
29 Neuronale Netze Gehirn: ca. 10 11 Neuronen stark vernetzt Schaltzeit ca. 1 ms (relativ langsam, vgl. Prozessor) Mustererkennung in 0.1s 100 Schritte Regel 30 Was ist ein künstl. neuronales Netz? Ein
Ridge Regression und Kernalized Support Vector Machines : Einführung und Vergleich an einem Anwendungsbeispiel
 Ridge Regression und Kernalized Support Vector Machines : Einführung und Vergleich an einem Anwendungsbeispiel Dr. Dominik Grimm Probelehrveranstaltung Fakultät für Informatik und Mathematik Hochschule
Ridge Regression und Kernalized Support Vector Machines : Einführung und Vergleich an einem Anwendungsbeispiel Dr. Dominik Grimm Probelehrveranstaltung Fakultät für Informatik und Mathematik Hochschule
Principal Component Analysis (PCA)
") Principal Component Analysis (PCA) Motivation: Klassifikation mit der PCA Berechnung der Hauptkomponenten Theoretische Hintergründe Anwendungsbeispiel: Klassifikation von Gesichtern Weiterführende Bemerkungen
Principal Component Analysis (PCA) Motivation: Klassifikation mit der PCA Berechnung der Hauptkomponenten Theoretische Hintergründe Anwendungsbeispiel: Klassifikation von Gesichtern Weiterführende Bemerkungen
Studiengang Simulation Technology
 1. Institut für Theoretische Physik Studiengang Simulation Technology Bachelorarbeit Selbstoptimierende Neuronale Netze zur Klassifizierung von Reaktanden und Produkten in der Reaktionsdynamik Erstprüfer
1. Institut für Theoretische Physik Studiengang Simulation Technology Bachelorarbeit Selbstoptimierende Neuronale Netze zur Klassifizierung von Reaktanden und Produkten in der Reaktionsdynamik Erstprüfer
Lineare Klassifikatoren
 Universität Potsdam Institut für Informatik Lehrstuhl Lineare Klassifikatoren Christoph Sawade, Blaine Nelson, Tobias Scheffer Inhalt Klassifikationsproblem Bayes sche Klassenentscheidung Lineare Klassifikator,
Universität Potsdam Institut für Informatik Lehrstuhl Lineare Klassifikatoren Christoph Sawade, Blaine Nelson, Tobias Scheffer Inhalt Klassifikationsproblem Bayes sche Klassenentscheidung Lineare Klassifikator,
Anwendung von neuronalen Netzen, Projection Pursuits und CARTs für die Schätzerkonstruktion unter R
 Anwendung von neuronalen Netzen, Projection Pursuits und CARTs für die Schätzerkonstruktion unter R Markus-Hermann Koch 18. Oktober 2009 Übersicht Regression im Allgemeinen Regressionsproblem Risiko Schematischer
Anwendung von neuronalen Netzen, Projection Pursuits und CARTs für die Schätzerkonstruktion unter R Markus-Hermann Koch 18. Oktober 2009 Übersicht Regression im Allgemeinen Regressionsproblem Risiko Schematischer
Ausgleichsproblem. Definition (1.0.3)
") Ausgleichsproblem Definition (1.0.3) Gegeben sind n Wertepaare (x i, y i ), i = 1,..., n mit x i x j für i j. Gesucht ist eine stetige Funktion f, die die Wertepaare bestmöglich annähert, d.h. dass möglichst
Ausgleichsproblem Definition (1.0.3) Gegeben sind n Wertepaare (x i, y i ), i = 1,..., n mit x i x j für i j. Gesucht ist eine stetige Funktion f, die die Wertepaare bestmöglich annähert, d.h. dass möglichst
Einführung in Support Vector Machines (SVMs)
") Einführung in (SVM) Januar 31, 2011 Einführung in (SVMs) Table of contents Motivation Einführung in (SVMs) Outline Motivation Vektorrepräsentation Klassifikation Motivation Einführung in (SVMs) Vektorrepräsentation
Einführung in (SVM) Januar 31, 2011 Einführung in (SVMs) Table of contents Motivation Einführung in (SVMs) Outline Motivation Vektorrepräsentation Klassifikation Motivation Einführung in (SVMs) Vektorrepräsentation
Computational Intelligence I Künstliche Neuronale Netze
 Computational Intelligence I Künstliche Neuronale Nete Universität Dortmund, Informatik I Otto-Hahn-Str. 6, 44227 Dortmund lars.hildebrand@uni-dortmund.de Inhalt der Vorlesung 0. Organisatorisches & Vorbemerkungen.
Computational Intelligence I Künstliche Neuronale Nete Universität Dortmund, Informatik I Otto-Hahn-Str. 6, 44227 Dortmund lars.hildebrand@uni-dortmund.de Inhalt der Vorlesung 0. Organisatorisches & Vorbemerkungen.
Das Trust-Region-Verfahren
 Das Trust-Region-Verfahren Nadine Erath 13. Mai 2013... ist eine Methode der Nichtlinearen Optimierung Ziel ist es, das Minimum der Funktion f : R n R zu bestimmen. 1 Prinzip 1. Ersetzen f(x) durch ein
Das Trust-Region-Verfahren Nadine Erath 13. Mai 2013... ist eine Methode der Nichtlinearen Optimierung Ziel ist es, das Minimum der Funktion f : R n R zu bestimmen. 1 Prinzip 1. Ersetzen f(x) durch ein
Kapitel 10. Maschinelles Lernen Lineare Regression. Welche Gerade? Problemstellung. Th. Jahn. Sommersemester 2017
 10.1 Sommersemester 2017 Problemstellung Welche Gerade? Gegeben sind folgende Messungen: Masse (kg) 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 Kraft (N) 1.6 2.2 3.2 3.0 4.9 5.7 7.1 7.3 8.1 Annahme: Es gibt eine Funktion
10.1 Sommersemester 2017 Problemstellung Welche Gerade? Gegeben sind folgende Messungen: Masse (kg) 1.5 2.0 2.5 3.0 3.5 4.0 4.5 5.0 Kraft (N) 1.6 2.2 3.2 3.0 4.9 5.7 7.1 7.3 8.1 Annahme: Es gibt eine Funktion
Logistische Regression
 Logistische Regression Christian Herta August, 2013 1 von 45 Christian Herta Logistische Regression Lernziele Logistische Regression Konzepte des maschinellen Lernens (insb. der Klassikation) Entscheidungsgrenze,
Logistische Regression Christian Herta August, 2013 1 von 45 Christian Herta Logistische Regression Lernziele Logistische Regression Konzepte des maschinellen Lernens (insb. der Klassikation) Entscheidungsgrenze,
Vorlesung Wissensentdeckung
 Vorlesung Wissensentdeckung Klassifikation und Regression: nächste Nachbarn Katharina Morik, Uwe Ligges 14.05.2013 1 von 24 Gliederung Funktionsapproximation 1 Funktionsapproximation Likelihood 2 Kreuzvalidierung
Vorlesung Wissensentdeckung Klassifikation und Regression: nächste Nachbarn Katharina Morik, Uwe Ligges 14.05.2013 1 von 24 Gliederung Funktionsapproximation 1 Funktionsapproximation Likelihood 2 Kreuzvalidierung
Maschinelles Lernen: Neuronale Netze. Ideen der Informatik
 Maschinelles Lernen: Neuronale Netze Ideen der Informatik Kurt Mehlhorn Adrian Neumann 16. Januar 2014 Übersicht Biologische Inspiration Stand der Kunst in Objekterkennung auf Bildern Künstliche Neuronale
Maschinelles Lernen: Neuronale Netze Ideen der Informatik Kurt Mehlhorn Adrian Neumann 16. Januar 2014 Übersicht Biologische Inspiration Stand der Kunst in Objekterkennung auf Bildern Künstliche Neuronale
KNN für XOR-Funktion. 6. April 2009
 KNN für XOR-Funktion G.Döben-Henisch Fachbereich Informatik und Ingenieurswissenschaften FH Frankfurt am Main University of Applied Sciences D-60318 Frankfurt am Main Germany Email: doeben at fb2.fh-frankfurt.de
KNN für XOR-Funktion G.Döben-Henisch Fachbereich Informatik und Ingenieurswissenschaften FH Frankfurt am Main University of Applied Sciences D-60318 Frankfurt am Main Germany Email: doeben at fb2.fh-frankfurt.de
Neuronale Netze. Einführung i.d. Wissensverarbeitung 2 VO UE SS Institut für Signalverarbeitung und Sprachkommunikation
 Neuronale Netze Einführung in die Wissensverarbeitung 2 VO 708.560+ 1 UE 442.072 SS 2013 Institut für Signalverarbeitung und Sprachkommunikation TU Graz Inffeldgasse 12/1 www.spsc.tugraz.at Institut für
Neuronale Netze Einführung in die Wissensverarbeitung 2 VO 708.560+ 1 UE 442.072 SS 2013 Institut für Signalverarbeitung und Sprachkommunikation TU Graz Inffeldgasse 12/1 www.spsc.tugraz.at Institut für
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Clusteranalyse. Tobias Scheffer Thomas Vanck
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Thomas Vanck Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Thomas Vanck Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Künstliche neuronale Netze
 Künstliche neuronale Netze Eigenschaften neuronaler Netze: hohe Arbeitsgeschwindigkeit durch Parallelität, Funktionsfähigkeit auch nach Ausfall von Teilen des Netzes, Lernfähigkeit, Möglichkeit zur Generalisierung
Künstliche neuronale Netze Eigenschaften neuronaler Netze: hohe Arbeitsgeschwindigkeit durch Parallelität, Funktionsfähigkeit auch nach Ausfall von Teilen des Netzes, Lernfähigkeit, Möglichkeit zur Generalisierung
Einfaches Framework für Neuronale Netze
 Einfaches Framework für Neuronale Netze Christian Silberbauer, IW7, 2007-01-23 Inhaltsverzeichnis 1. Einführung...1 2. Funktionsumfang...1 3. Implementierung...2 4. Erweiterbarkeit des Frameworks...2 5.
Einfaches Framework für Neuronale Netze Christian Silberbauer, IW7, 2007-01-23 Inhaltsverzeichnis 1. Einführung...1 2. Funktionsumfang...1 3. Implementierung...2 4. Erweiterbarkeit des Frameworks...2 5.
kurze Wiederholung der letzten Stunde: Neuronale Netze Dipl.-Inform. Martin Lösch (0721) Dipl.-Inform.
 Dipl.-Inform.") kurze Wiederholung der letzten Stunde: Neuronale Netze martin.loesch@kit.edu (0721) 608 45944 Labor Wissensrepräsentation Aufgaben der letzten Stunde Übersicht Neuronale Netze Motivation Perzeptron Multilayer
kurze Wiederholung der letzten Stunde: Neuronale Netze martin.loesch@kit.edu (0721) 608 45944 Labor Wissensrepräsentation Aufgaben der letzten Stunde Übersicht Neuronale Netze Motivation Perzeptron Multilayer
Überblick. Überblick. Bayessche Entscheidungsregel. A-posteriori-Wahrscheinlichkeit (Beispiel) Wiederholung: Bayes-Klassifikator
 Wiederholung: Bayes-Klassifikator") Überblick Grundlagen Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes-Klassifikator
Überblick Grundlagen Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes-Klassifikator
Reinforcement Learning. Volker Tresp
 Reinforcement Learning Volker Tresp 1 Überwachtes und unüberwachtes Lernen Überwachtes Lernen: Zielgrößen sind im Trainingsdatensatz bekannt; Ziel ist die Verallgemeinerung auf neue Daten Unüberwachtes
Reinforcement Learning Volker Tresp 1 Überwachtes und unüberwachtes Lernen Überwachtes Lernen: Zielgrößen sind im Trainingsdatensatz bekannt; Ziel ist die Verallgemeinerung auf neue Daten Unüberwachtes
Modell Komplexität und Generalisierung
 Modell Komplexität und Generalisierung Christian Herta November, 2013 1 von 41 Christian Herta Bias-Variance Lernziele Konzepte des maschinellen Lernens Targetfunktion Overtting, Undertting Generalisierung
Modell Komplexität und Generalisierung Christian Herta November, 2013 1 von 41 Christian Herta Bias-Variance Lernziele Konzepte des maschinellen Lernens Targetfunktion Overtting, Undertting Generalisierung
Modellierung mit künstlicher Intelligenz
 Samuel Kost kosts@mailbox.tu-freiberg.de Institut für Numerische Mathematik und Optimierung Modellierung mit künstlicher Intelligenz Ein Überblick über existierende Methoden des maschinellen Lernens 13.
Samuel Kost kosts@mailbox.tu-freiberg.de Institut für Numerische Mathematik und Optimierung Modellierung mit künstlicher Intelligenz Ein Überblick über existierende Methoden des maschinellen Lernens 13.
Adaptive Systeme. Neuronale Netze: Neuronen, Perzeptron und Adaline. Prof. Dr. rer. nat. Nikolaus Wulff
 Adaptive Systeme Neuronale Netze: Neuronen, Perzeptron und Adaline Prof. Dr. rer. nat. Nikolaus Wulff Neuronale Netze Das (menschliche) Gehirn ist ein Musterbeispiel für ein adaptives System, dass sich
Adaptive Systeme Neuronale Netze: Neuronen, Perzeptron und Adaline Prof. Dr. rer. nat. Nikolaus Wulff Neuronale Netze Das (menschliche) Gehirn ist ein Musterbeispiel für ein adaptives System, dass sich
Polynomiale Regression lässt sich mittels einer Transformation der Merkmale auf multiple lineare Regression zurückführen
 Rückblick Polynomiale Regression lässt sich mittels einer Transformation der Merkmale auf multiple lineare Regression zurückführen Ridge Regression vermeidet Überanpassung, indem einfachere Modelle mit
Rückblick Polynomiale Regression lässt sich mittels einer Transformation der Merkmale auf multiple lineare Regression zurückführen Ridge Regression vermeidet Überanpassung, indem einfachere Modelle mit
Neuro-Info Notizen. Markus Klemm.net WS 2016/2017. Inhaltsverzeichnis. 1 Hebbsche Lernregel. 1 Hebbsche Lernregel Fälle Lernrate...
 Neuro-Info Notizen Marus Klemm.net WS 6/7 Inhaltsverzeichnis Hebbsche Lernregel. Fälle........................................ Lernrate..................................... Neural Gas. Algorithmus.....................................
Neuro-Info Notizen Marus Klemm.net WS 6/7 Inhaltsverzeichnis Hebbsche Lernregel. Fälle........................................ Lernrate..................................... Neural Gas. Algorithmus.....................................
Datenmodelle, Regression
 Achte Vorlesung, 15. Mai 2008, Inhalt Datenmodelle, Regression Anpassen einer Ausgleichsebene Polynomiale Regression rationale Approximation, Minimax-Näherung MATLAB: polyfit, basic fitting tool Regression
Achte Vorlesung, 15. Mai 2008, Inhalt Datenmodelle, Regression Anpassen einer Ausgleichsebene Polynomiale Regression rationale Approximation, Minimax-Näherung MATLAB: polyfit, basic fitting tool Regression
H.J. Oberle Analysis III WS 2012/ Differentiation
 H.J. Oberle Analysis III WS 2012/13 13. Differentiation 13.1 Das Differential einer Abbildung Gegeben: f : R n D R m, also eine vektorwertige Funktion von n Variablen x = (x 1,..., x n ) T, wobei D wiederum
H.J. Oberle Analysis III WS 2012/13 13. Differentiation 13.1 Das Differential einer Abbildung Gegeben: f : R n D R m, also eine vektorwertige Funktion von n Variablen x = (x 1,..., x n ) T, wobei D wiederum
B-Spline-Kurve und -Basisfunktionen
 48 B-Spline-Kurve und -Basisfunktionen Eine B-Spline-Kurve der Ordnung k ist ein stückweise aus B-Splines (Basisfunktion) zusammengesetztes Polynom vom Grad (k 1), das an den Segmentübergängen im allgemeinen
48 B-Spline-Kurve und -Basisfunktionen Eine B-Spline-Kurve der Ordnung k ist ein stückweise aus B-Splines (Basisfunktion) zusammengesetztes Polynom vom Grad (k 1), das an den Segmentübergängen im allgemeinen
Beziehungen zwischen Verteilungen
 Kapitel 5 Beziehungen zwischen Verteilungen In diesem Kapitel wollen wir Beziehungen zwischen Verteilungen betrachten, die wir z.t. schon bei den einzelnen Verteilungen betrachtet haben. So wissen Sie
Kapitel 5 Beziehungen zwischen Verteilungen In diesem Kapitel wollen wir Beziehungen zwischen Verteilungen betrachten, die wir z.t. schon bei den einzelnen Verteilungen betrachtet haben. So wissen Sie
Neuronale Netze. Einführung i.d. Wissensverarbeitung 2 VO UE SS Institut für Signalverarbeitung und Sprachkommunikation
 Neuronale Netze Einführung in die Wissensverarbeitung 2 VO 708.560+ 1 UE 442.072 SS 2012 Institut für Signalverarbeitung und Sprachkommunikation TU Graz Inffeldgasse 12/1 www.spsc.tugraz.at Institut für
Neuronale Netze Einführung in die Wissensverarbeitung 2 VO 708.560+ 1 UE 442.072 SS 2012 Institut für Signalverarbeitung und Sprachkommunikation TU Graz Inffeldgasse 12/1 www.spsc.tugraz.at Institut für
(hoffentlich kurze) Einführung: Neuronale Netze. Dipl.-Inform. Martin Lösch. (0721) Dipl.-Inform.
 Einführung: Neuronale Netze. Dipl.-Inform. Martin Lösch. (0721) Dipl.-Inform.") (hoffentlich kurze) Einführung: martin.loesch@kit.edu (0721) 608 45944 Überblick Einführung Perzeptron Multi-layer Feedforward Neural Network MLNN in der Anwendung 2 EINFÜHRUNG 3 Gehirn des Menschen Vorbild
(hoffentlich kurze) Einführung: martin.loesch@kit.edu (0721) 608 45944 Überblick Einführung Perzeptron Multi-layer Feedforward Neural Network MLNN in der Anwendung 2 EINFÜHRUNG 3 Gehirn des Menschen Vorbild
Klassifikationsverfahren und Neuronale Netze
 Klassifikationsverfahren und Neuronale Netze Hauptseminar - Methoden der experimentellen Teilchenphysik Thomas Keck 9.12.2011 KIT Universität des Landes Baden-Württemberg und nationales Forschungszentrum
Klassifikationsverfahren und Neuronale Netze Hauptseminar - Methoden der experimentellen Teilchenphysik Thomas Keck 9.12.2011 KIT Universität des Landes Baden-Württemberg und nationales Forschungszentrum
kurze Wiederholung der letzten Stunde: Neuronale Netze Dipl.-Inform. Martin Lösch (0721) Dipl.-Inform.
 Dipl.-Inform.") kurze Wiederholung der letzten Stunde: Neuronale Netze martin.loesch@kit.edu (0721) 608 45944 Labor Wissensrepräsentation Neuronale Netze Motivation Perzeptron Übersicht Multilayer Neural Networks Grundlagen
kurze Wiederholung der letzten Stunde: Neuronale Netze martin.loesch@kit.edu (0721) 608 45944 Labor Wissensrepräsentation Neuronale Netze Motivation Perzeptron Übersicht Multilayer Neural Networks Grundlagen
Von schwachen zu starken Lernern
 Von schwachen zu starken Lernern Wir nehmen an, dass ein schwacher Lernalgorithmus L mit vielen Beispielen, aber großem Fehler ε = 1 2 θ gegeben ist. - Wie lässt sich der Verallgemeinerungsfehler ε von
Von schwachen zu starken Lernern Wir nehmen an, dass ein schwacher Lernalgorithmus L mit vielen Beispielen, aber großem Fehler ε = 1 2 θ gegeben ist. - Wie lässt sich der Verallgemeinerungsfehler ε von
Klassifikation und Ähnlichkeitssuche
 Klassifikation und Ähnlichkeitssuche Vorlesung XIII Allgemeines Ziel Rationale Zusammenfassung von Molekülen in Gruppen auf der Basis bestimmter Eigenschaften Auswahl von repräsentativen Molekülen Strukturell
Klassifikation und Ähnlichkeitssuche Vorlesung XIII Allgemeines Ziel Rationale Zusammenfassung von Molekülen in Gruppen auf der Basis bestimmter Eigenschaften Auswahl von repräsentativen Molekülen Strukturell
Analyse komplexer Szenen mit Hilfe von Convolutional Neural Networks
 Analyse komplexer Szenen mit Hilfe von Convolutional Anwendungen 1 Vitalij Stepanov HAW-Hamburg 24 November 2011 2 Inhalt Motivation Alternativen Problemstellung Anforderungen Lösungsansätze Zielsetzung
Analyse komplexer Szenen mit Hilfe von Convolutional Anwendungen 1 Vitalij Stepanov HAW-Hamburg 24 November 2011 2 Inhalt Motivation Alternativen Problemstellung Anforderungen Lösungsansätze Zielsetzung
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Modellevaluierung. Niels Landwehr
 Universität Potsdam Institut für Informatik ehrstuhl Maschinelles ernen Modellevaluierung Niels andwehr ernen und Vorhersage Klassifikation, Regression: ernproblem Eingabe: Trainingsdaten Ausgabe: Modell
Universität Potsdam Institut für Informatik ehrstuhl Maschinelles ernen Modellevaluierung Niels andwehr ernen und Vorhersage Klassifikation, Regression: ernproblem Eingabe: Trainingsdaten Ausgabe: Modell
Wenn man den Kreis mit Radius 1 um (0, 0) beschreiben möchte, dann ist. (x, y) ; x 2 + y 2 = 1 }
 beschreiben möchte, dann ist. (x, y) ; x 2 + y 2 = 1 }") A Analsis, Woche Implizite Funktionen A Implizite Funktionen in D A3 Wenn man den Kreis mit Radius um, beschreiben möchte, dann ist { x, ; x + = } eine Möglichkeit Oft ist es bequemer, so eine Figur oder
A Analsis, Woche Implizite Funktionen A Implizite Funktionen in D A3 Wenn man den Kreis mit Radius um, beschreiben möchte, dann ist { x, ; x + = } eine Möglichkeit Oft ist es bequemer, so eine Figur oder
Support Vector Machines, Kernels
 Support Vector Machines, Kernels Katja Kunze 13.01.04 19.03.2004 1 Inhalt: Grundlagen/Allgemeines Lineare Trennung/Separation - Maximum Margin Hyperplane - Soft Margin SVM Kernels Praktische Anwendungen
Support Vector Machines, Kernels Katja Kunze 13.01.04 19.03.2004 1 Inhalt: Grundlagen/Allgemeines Lineare Trennung/Separation - Maximum Margin Hyperplane - Soft Margin SVM Kernels Praktische Anwendungen
Inhalt. 4.1 Motivation. 4.2 Evaluation. 4.3 Logistische Regression. 4.4 k-nächste Nachbarn. 4.5 Naïve Bayes. 4.6 Entscheidungsbäume
 4. Klassifikation Inhalt 4.1 Motivation 4.2 Evaluation 4.3 Logistische Regression 4.4 k-nächste Nachbarn 4.5 Naïve Bayes 4.6 Entscheidungsbäume 4.7 Support Vector Machines 4.8 Neuronale Netze 4.9 Ensemble-Methoden
4. Klassifikation Inhalt 4.1 Motivation 4.2 Evaluation 4.3 Logistische Regression 4.4 k-nächste Nachbarn 4.5 Naïve Bayes 4.6 Entscheidungsbäume 4.7 Support Vector Machines 4.8 Neuronale Netze 4.9 Ensemble-Methoden