Folien und Supplementals auf
|
|
|
- Julius Ursler
- vor 7 Jahren
- Abrufe
Transkript



1 Folien und Supplementals auf

2 Folien und Supplementals auf
3 Motivation Es gibt viele spezifische Datenbanken, aber mit einer geringen Auswahl an Datenbanken von allgemeiner Bedeutung kommt man schon sehr weit. Diese sollen hier besprochen werden. Zielsetzung Für verschiedene Datenbanken von allgemeiner Bedeutung soll angerissen werden: Übersicht über Datenbestand: Ursprung, Relevanz, Vollständigkeit? Wie stelle ich eine korrekte Suchanfrage? Welche zusätzlichen Funktionen bietet die Datenbank? Allgemeine Konzepte und Probleme der angewandten Bioinformatik in Zusammenhang mit Datenbanken: Einblick in die Sortierung und Klassifizierung von Daten. Einblick in das Daten-Sharing zwischen Datenbanken. Weitere Probleme der Bioinformatik: Redundanz, Kontrolle/Überprüfung der Daten

")
4 Zuerst: Überblick behalten Übersicht über DNA-Datenbanken Entrez Nucleotide Entrez Gene HomoloGene und UniGene Entrez Genome und Genome Project Map-Viewer und Sequence Viewer HGNC und Gene Ontology Ensembl MODs (model organism databases) Biomart und SRS
5 3 Generationen: Nukleotidsequenz-Datenbanken Erste Generation: Sequenz-spezifische Datenbanken (GenBank) Alle über Sequenzierung produzierten Nukleotid-Sequenzen, mit Verweis zur Literatur. Grund: Anfangs wenig Sequenzen, Referenz bei gegebener Sequenz zu finden stand im Zentrum. Zweite Generation: Gen-spezifische Datenbanken (Entrez Gene) Gründe: (1) Ausschluss von nicht-gen-sequenzen & Zusammensetzen einzelner Sequenz- Einträge zum Gen-Eintrag für bessere Übersicht; (2) Molekularbiologen arbeiten mit Genen; (3) Beseitigung der Redundanz; gezielte Vergleiche zwischen Genen verschiedener Organismen möglich. Dritte Generation: Genom-basierende Datenbanken (Entrez Genome) Gründe: hohe Anzahl an Genom-Projekten, Gene im genomischen Kontext verstehen (Regulation). Viele verschiedene Organismus-spezifische DBs. Vergleiche zwischen Genomen möglich (comparative genomics).
6 Welche Datenbanken werden für die Suchen verwendet? GenBank ist die genetische Sequenz-Datenbank der US-Regierung Hohe Redundanz: Sammlung aller öffentlich verfügbaren DNA-Sequenzen (über 100 Millionen aus 250k Arten), auch verschiedene Sequenzierungen desselben Gens. Keine Überwachung: Wikipedia, in der jeder seine Sequenzen veröffentlichen kann (Formular im www oder per Mail). GenBank auf NCBI ist Teil der INSDC (International Nucleotide Sequence Database Collaboration). Sie beinhaltet weiter: DNA DataBank of Japan (DDBJ) am CIB (Center for Information Biology) European Molecular Biology Laboratory (EMBL) am EBI (European Bioinformatics Institute). Die Daten dieser drei Datenbanken werden alle 24h abgeglichen (selber Datenbestand). Primärdatenbank
7 Welche Datenbanken werden für die Suchen verwendet? RefSeq (Reference Sequence) ist eine nicht redundante Sammlung von DNA, RNA und Protein-Sequenzen verschiedener Taxa. Nur für das Labor relevante Arten (ca. 8000). Von jeder Art wird nur die am häufigsten vorkommende Gen-Variante gespeichert (keine Mutanten, keine verschiedenen Sequenzierprojekte ). Überwachung: Daten werden von NCBI ausgewählt und überwacht. RefSeq Eintrag = einzelnes, natürlich vorkommendes Molekül eines Organismus. Ziel: Erstellung eines Standard-Datensatzes mit Sequenz-Informationen für eine Spezies. RefSeq nutzt ausschließlich Daten anderer öffentlicher Datenbank-Archive. Sekundärdatenbank



8 GenBank/RefSeq vs. TrEMBL/Swiss-Prot GenBank/RefSeq und UniProt haben eine ähnliche Bedeutung unter den biologischen Datenbanken für den gemeinen Biologen. GenBank ist eine Quell-Datenbank (repository DB) Daten werden von Wissenschaftlern hochgeladen. Der Informationsgehalt ist abhängig von diesen Wissenschaftlern! GenBank-Einträge können durch Überprüfung von NBCI in RefSeq landen Der GenBank- Eintrag bleibt aber erhalten! Swiss-Prot ist keine Quell-Datenbank, beinhaltet aber aus der Literatur abgeleitete Informationen. Eine Gruppe von Experten überprüfen und annotieren die Daten Sie benötigen dafür keinerlei Erlaubnis von den Urhebern. TrEMBL ist ein Puffer für automatisch annotierte Nukleotid-Sequenzen aus GenBank (Kriterium: Sequenz-Ähnlichkeiten). Nach Überprüfung werden TrEMBL-Einträge in Swiss-Prot-Einträge konvertiert (TrEMBL- Eintrag wird entfernt).
 und komplizierter Umgang (Segmented Sequences). Gene: findet Gene aller Organismen, für die ein RefSeq- Genom existiert.")
9 Gegenüberstellung der NCBI-DNA/RNA-Datenbanken Nucleotide: findet alle DNA/RNA Nukleotid-Sequenzen (gdna, cdna, mrna, rrna ), die in der INSDC gespeichert sind sowie RefSeq-Einträge und Sequenzen aus der PDB. Hohe Redundanz (SNPs, verschiedene Sequenzierprojekte) und komplizierter Umgang (Segmented Sequences). Gene: findet Gene aller Organismen, für die ein RefSeq- Genom existiert. Genome: findet nur vollständige Genom-Sequenzen. Einteilung in sechs Organismus-Gruppen: Archeen, Bakterien, Eukaryoten, Viren, Viroide und Plasmide ( Einträge). Genome-Project: findet vollständige und unvollständige Genom-Sequenzen. Einteilung in Organismus-spezifische Portale, über welche die einzelnen Projekte erreicht werden können. Manchmal ist es sinnvoll, verschiedene Suchen zu verwenden und zu vergleichen.
10 Überblick behalten Entrez Nucleotide Entrez Gene HomoloGene und UniGene Entrez Genome und Genome Project Map-Viewer und Sequence Viewer HGNC und Gene Ontology Ensembl MODs (model organism databases) Biomart und SRS
11 Entrez Nucleotide Datenquellen: GenBank & RefSeq übersetzte Sequenzen aus PDB-Strukturen in der PDB. TPA (Third Party Annotation) Database. TPA Database Records TPA-Sequenz (genomisch oder mrna) ist direkt abgeleitet oder assembliert aus Primär- Sequenz-Daten (GenBank). Enthalten zusätzliche aus der Literatur abgeleitete Informationen, die aus neuen Experimenten gewonnen wurden. Die Primär-Daten aus GenBank beinhalten nur Kommentare von den Laboren, welche die Sequenzierung durchgeführt haben! Bei Entrez Nucleotide stehen die Sequenz-Rohdaten im Mittelpunkt (GenBank-Format, FASTA-Format). The number of bases in these databases continues to grow at an exponential rate. NCBI, Manual
![Entrez Nucleotide Suchanfrage: Hexokinase AND "Mus musculus"[organism], Display-Format: Summary Registerkarten ermöglichen Filterung der Ergebnisse.](/docs-images/61/46128077/images/12-0.png "Automatisch Cross- Search in Entrez Gene Link zum Ergebnis, Standard: GenBank-Format Entrez Nucleotide findet meist mrnas oder Genome-Shotgun Sequenzen, die das Hk-Gen oder Teile davon enthalten")
12 Entrez Nucleotide Suchanfrage: Hexokinase AND "Mus musculus"[organism], Display-Format: Summary Registerkarten ermöglichen Filterung der Ergebnisse. Automatisch Cross- Search in Entrez Gene Link zum Ergebnis, Standard: GenBank-Format Entrez Nucleotide findet meist mrnas oder Genome-Shotgun Sequenzen, die das Hk-Gen oder Teile davon enthalten können. Warum? (1) Teile von Genom- Sequenzen entstehen im Zuge der Sequenzier-Projekte. (2) Es existieren mehrere mrna-varianten von einem Gen. (3) Es werden selten vollständige Gene sequenziert!
13 Entrez Nucleotide GenBank-Format verschiedene Formate wählbar flat file Format, Gegliedert in 4 Bereiche locus section reference section Records definieren die Informationen innerhalb der entsprechenden Zeile. Records ermöglichen spezifische Suchanfragen.

14 Entrez Nucleotide GenBank-Format LOCUS ist eindeutig für jeden GenBank-Eintrag, kann sich aber im Gegensatz zur AN bei Überarbeitung der DB ändern. locus section reference section Ein GenBank-Eintrag darf nur Informationen zum selben Molekültyp enthalten! Dieser ist ebenso unter LOCUS angezeigt. Die letzte Spalte unter LOCUS gibt das Datum der letzten Modifizieurng des Eintrags an.
, bei Klick auf CDS.")
15 Entrez Nucleotide GenBank-Format features section Die Links führen zu Entrez Protein bzw. zur ENZYME Datenbank auf ExPASy; Allgemein: Links zu externen DBs Die Links zeigen nur den entsprechenden Ausschnitt der Sequenz: z.b. nur die codierende Sequenz ( ), bei Klick auf CDS.
16 Entrez Nucleotide features section: GenBank-Eintrag eines prokaryotischen Gens (1) source: einzelne Bereiche der Sequenz können andere Quellen haben (Unterscheidung von z.b. Klonierungsvektor und Host-Sequenz). (2) promotor: exakte Koordinaten des Promotor-Elements; getrennte Promotor-Zeilen für jedes Promotor-Element (z.b. -35 Region und -10 Region). (3) misc feature: putativer Bereich des Transkriptionsstarts. (4) RBS: Position der ribosomalen Bindestelle. (5) CDS: Bereich der codierenden Sequenz (offener Leserahmen). (1) Erste Zeile enthält exakte Koordinaten des ORF von ATG bis zum ersten Stopp-Codon (2) Jede folgende Zeile enthält den Namen eines Protein-Produkts, den entsprechenden genetischen Code und IDs für die Protein-Sequenz (3) Der letzte Bereich enthält die gesamte AS-Sequenz des codierenden Segments (6) misc feature: putative Stamm-Loop-Strukturen und Repeats als regulatorische Elemente. Achtung! GenBank Einträge beinhalten oft mehr als ein Gen! Kennzeichen: mehrere RBS und CDS-Bereiche Sie lassen sich aber über die Verlinkung einzeln anzeigen ;)
17 Entrez Nucleotide GenBank-Einträge eukaryotischer mrna und Gene features section: mrna (reife mrna; Beispiel: U90223) (1) sig peptide: Bereich einer Targeting-Sequenz (sig=signal) (2) mat peptide: Bereich des reifen Peptids (mat=mature) locus line: Gen (wie es im Genom vorliegt; Beispiel: AF018430) Neues Feld: SEGMENT bezieht sich auf die Intron/Exon-Struktur eukaryotischer Gene. 2 of 4 = zweites Segment von vier Es werden alle Segmente zur Rekonstruktion der mrna benötigt! Ein Segment kann mehrere Exons enthalten! Tipp: Klicke auf 4 um alle Segmente in einer Ansicht anzuzeigen!
18 Entrez Nucleotide GenBank-Einträge eukaryotischer mrna und Gene features section: Gen (1) source/map: gibt die Chromosomen-Lokalisation an. (2) gene: Rezept für Rekonstruktion der mrna (Exon-Spleiß-Rezept) GenBank-Eintrag ID von Nukleotid bis Nukleotid Nukleotid-Intervall aus aktuellem GenBank-Eintrag (3) mrna: verschiedene mrna-felder repräsentieren unterschiedliche alternative Spleißvarianten; Rekonstruktion nach identischem Schema wie bei gene-feld. (4) exon: verschiedene exon-felder zeigen Exon-Positionen in diesem GenBank-Eintrag.
19 Entrez Nucleotide GenBank-Einträge eukaryotischer mrna und Gene Antwort: Exon 1 wurde oben übersprungen Exon 2 beginnt unten an einer späteren Position BCII-Vorlesung: Exon-Skipping alternative Akzeptor-Stelle

20 Entrez Nucleotide GenBank-Format ORF: (siehe features section) jede Zeile enthält 60 Basen, beginnend mit der laufenden Nummerierung. ungeeignet für die meisten Sequenz- Tools. Konvertierung in FASTA notwendig! Anhand der features section lässt sich die Sequenz leicht, z.b. in dem Programm Serial Cloner annotieren und damit arbeiten. Und die zwei anderen Datenbanken der INSDC? DDBJ-Format: identisch EMBL-Format: ähnlich, Verwendung eines 2-Buchstaben-Codes anstelle ausgeschriebener Felder sequence section
21 Entrez Nucleotide GenBank-Format GenBank Format in 4 Bereiche gegliedert: locus name: Kopf mit Identifier und kurzer definition line; Die Felder SOURCE und ORGANISM definieren den biologischen Ursprung der DNA-Sequenz. reference section: Verweise zur Literatur, die für die Sequenz-Bestimmung relevant ist. features section: mittlerer Teil enthält Informationen zu den einzelnen Bereichen der Sequenz, im Falle von Genomen z.b. die Sequenzen der Proteine einzelner Gene und Promotor-Regionen. sequence section: Zuletzt folgt die eigentlich gesuchte Nukleotid-Sequenz. Achtung: unvollständige Annotierung sehr häufig! Konsequenz: auf Keywords basierende DB-Suchen ergeben nicht alle relevanten Daten! PubMed-Suchen bringen dich nicht immer zum entsprechenden Gen. Erwarte nie, dass Daten in Primärdatenbanken vollständig annotiert sind!

22 Entrez Nucleotide FASTA- und RAW-Format für Proteine und Nukleinsäuren. FASTA-Format: Erste Zeile (definition line) beginnt mit > und enthält eine ID mit einer optionalen kurzen Definition. Es folgt die Sequenz in Großbuchstaben. Mehrere Sequenzen werden über die definition lines getrennt. Standard Input-Format für Sequenz-Analyse- Tools RAW-Format: FASTA-Sequenz ohne erste Zeile. Von einigen Tools gefordert, die mit nur einer Sequenz arbeiten. Graphics-Format Öffnet den Sequence-Viewer, näheres später

.")
23 Entrez Nucleotide Rechte Seite nicht übersehen GenBank/FASTA-Format Transkriptionsvarianten in Entrez Nucleotide Eintrag in Entrez Gene Eintrag in HomoloGene Hier kann ein bestimmter Abschnitt der Sequenz angezeigt werden (oder Klick auf die Links). Querverlinkungen zu anderen Datenbanken!

24 Entrez Nucleotide Suche Accession-Numbers sind in Publikation genannt, welche mit den entsprechenden Sequenzen arbeiten. Verwandte Sequenzen können über Links/Related sequences angezeigt werden. Über den Top Organism Tree rechts können die Ergebnisse auf Homo Sapiens eingeschränkt werden.
25 Entrez Nucleotide Suche Eingabe human [organism] AND dutpase [Protein name] Resultat: 4 GenBank-Einträge, die den einzelnen Exons zugeordnet werden können + 1 Eintrag, der alle Exons enthält. Über Links/Related Sequences und über den Top Organism Tree/Homo Sapiens werden zusätzliche Treffer erhalten. Suchen liefern unterschiedliche Ergebnisse. Problem: unterschiedliche Annotierung. human [organism] AND dutpase [protein name] 5 Ergebnisse human [organism] AND dutp pyrophosphatase [protein name] 14 Ergebnisse (0 der 5 von oben) human [organism] AND dutp pyrophosphatase [Title] 11 Ergebnisse
26 Entrez Nucleotide Suche Die meisten Ergebnisse dieser Suche enthalten EST (Expressed Sequence Tags). Diese werden automatisch ausgeblendet. ESTs resultieren aus Sequenzierung einer cdna- Bibliothek (schnelle Methode, schlechte Sequenzqualität, geringe Sequenzlängen) Für ESTs gibt es eine eigene Datenbank (dbest), die ein Teil der GenBank-Datenbank repräsentiert. Wie auch dbest ist dbgss (Genome Survey Sequence) ein Teil der GenBank-Datenbank. Hier sind die meisten Sequenzen jedoch genomischen Ursprungs und keine cdna (mrna-ursprung).

27 Entrez Nucleotide Über Limits sind Sucheinschränkungen möglich Suche: Limits z.b. show only master of set : zeigt nur das Ergebnis segmentierter Sequenzen an, das alle Sequenzen in einem GenBank-Eintrag zusammenfasst. Aber: Keyword-based search ist bei Entrez Nucleotide generell nicht zu empfehlen. Automatische Cross-Search in Entrez-Gene
28 Überblick behalten Entrez Nucleotide Entrez Gene HomoloGene und UniGene Entrez Genome und Genome Project Map-Viewer und Sequence Viewer HGNC und Gene Ontology Ensembl MODs (model organism databases) Biomart und SRS
29 Entrez Gene Datenquellen: Daten aller Organismen mit vollständigen Genom-Daten in RefSeq. Viele verschiedene Quell-Datenbanken liefern weitere Informationen zu den Genen. Daten: Jeder Eintrag repräsentiert ein einzelnes Gen eines gegebenen Organismus. Jedes Gen hat eine eindeutige GeneID. Standard-Datensatz: Gen-Symbol, sowie Gen-Sequenz oder Position im Genom. Zusätzliche Daten (optional): Informationen über homologe Gene, Literaturverweise sowie Informationen über Expression, Struktur und Funktion von Transkripten. Zielsetzung: Ansicht von Genom-Daten auf der Gen-Ebene. Gen-bezogene Daten machen mehr Sinn als eine lange Liste von GenBank- Einträgen, die erst im Geiste zusammengesetzt werden müssen.
![Entrez Gene Suchanfrage: Hexokinase[Protein] AND "Mus musculus"[organism] Display-Format: Summary (über Drop-Down Menü andere Anzeige einstellbar). Registerkarten ermöglichen Filterung der Ergebnisse.](/docs-images/61/46128077/images/30-0.png "Current Only zeigt nur aktuelle Gene an. In einigen Fällen werden Sequenzen überarbeitet, die alten Versionen bleiben aber in der DB gespeichert.")
30 Entrez Gene Suchanfrage: Hexokinase[Protein] AND "Mus musculus"[organism] Display-Format: Summary (über Drop-Down Menü andere Anzeige einstellbar). Registerkarten ermöglichen Filterung der Ergebnisse. Current Only zeigt nur aktuelle Gene an. In einigen Fällen werden Sequenzen überarbeitet, die alten Versionen bleiben aber in der DB gespeichert. Genes Genomes zeigt nur Gene mit bekanntem genomischen Kontext an. SNP Gene View zeigt nur Gene an, für die SNPs beschrieben sind (SNP = Single Nucleotide Polymorphism -> Mutation).

31 Entrez Gene Format: Summary Offizielle Gen-Abkürzung Quell-Organismus Voller Name des Gens Alternative Gen- Bezeichnungen Eindeutige Referenznummer in Entrez Gene Exakte Lokalisation des Gens im Genom

32 Entrez Gene Format: Full Report Link zur Quell-Datenbank Link zum Taxonomie-Browser Link zum RefSeq-Eintrag Link zum Sequence-Viewer Gen & Transkript Kontext genomischer Kontext Link zum Map-Viewer

33 Entrez Gene Format: Full Report Graphische Ansicht zeigt alternative Spleißprodukte (mrnas) untereinander. Dicke Linien in der mrna sind Exons, Dünne Linien Introns. Verlinkung zu mrnaund Protein-Sequenzen genomischer Kontext Gen & Transkript Kontext Sequenzen anzeigen oder Gen im Sequence Viewer betrachten Verlinkung zu benachbarten Genen in Entrez Gene
34 Entrez Gene Format: Full Report Table of Contents: Verlinkungen innerhalb des Gene- Eintrags. Links: Eintrag in anderer Datenbank oder Listen mehrerer Einträge, die mit diesem Gen-Eintrag verwandt sind. SNP: Liste aller Punktmutationen des Gens Protein: Liste aller Protein-Sequenzen, die mit diesem Gen assoziiert sind (Entrez Protein). Nucleotide: Liste aller Nukleotid-Sequenzen, die mit diesem Gen assoziiert sind (Entrez Nucleotide). HomoloGene: fasst homologe Gene-Einträge in einen HomoloGene-Eintrag zusammen KEGG: Eintrag in KEGG Enzyme mit Verlinkung zu Stoffwechsel-Karten.
35 Entrez Gene Die Ergebnis-Seite enthält viele Informationen und Verlinkungen: Informationen über Gen-Transkripte: Pathways, Funktion, Lokalisation, Interaktion. Homologe Gene und verwandte Sequenzen. Viele LinkOut-Ressourcen, Literaturverweise. Unter Related Sequences sind die einzelnen assoziierten GenBank-Einträge abrufbar. Entrez Gene verbindet Entrez Nucleotide, Entrez Genome, Entrez Protein und PubMed. Alle Verlinkungen direkt vorhanden. Ist das Gen bekannt, kommt man über diese Suche zu all diesen Informationen. Entrez Gene ist in diesem Fall der beste Startpunkt einer Suche.
36 Überblick behalten Entrez Nucleotide Entrez Gene HomoloGene und UniGene Entrez Genome und Genome Project Map-Viewer und Sequence Viewer HGNC und Gene Ontology Ensembl MODs (model organism databases) Biomart und SRS
37 HomoloGene System zur automatischen Detektion von homologen Genen zwischen verschiedenen Organismen. Zum automatisierten Vergleich der Protein-Sequenzen dient BlastP. Grundlage sind annotierte Gene von vollständig sequenzierten eukaryotischen Genomen. Jeder Eintrag enthält einen Satz homologer Gene sowie ihrer Genprodukte mit Links zu den konservierten Domänen (CDD). Zusätzlich sind die passenden UniGene-Einträge verlinkt (Informationen über Transkription). Suche über Limits wichtig! z.b. Look only for / Human disease genes.
38 HomoloGene Informationen zum Phänotyp werden aus vielen Organismus-spezifischen Datenbanken entnommen. Verlinkung zu OMIM (Online Mendelian Inheritance in Man) OMIM enthält Artikel (eher Bücher) über humane Gene, die mit Erkrankungen assoziiert sind.
39 UniGene Eine Datenbank für das Transkriptom von Organismen nicht nur für Gene. Jeder Eintrag entspricht einem Satz von Transkripten aus dem selben Transkriptions- Lokus (Bsp. Gen oder Pseudogen). Daran gekoppelte Informationen sind: mrna-sequenzen, EST-Sequenzen und cdna Klone. Berechnete Protein-Ähnlichkeiten (PROTSIM). Informationen zur Gen-Expression: Muster (EST-Profiles): Zelltypen, Krankheiten, Entwicklungszustand. Experimentelle Daten (GEO-Profiles). Genomische Lokalisation (Mapping-position). UniGene gruppiert die Einträge in UniGene Cluster nach ihrer Ähnlichkeit (Abstufungen: >90%, 70-90%, <70%). Ähnliche Zielsetzung wie UniProt: Sammlung nicht-redundanter Sequenzen.


40 UniGene EST-Profile wurden nur grob berechnet. Grundlage sind EST-Zählungen und cdna-quellen (Berichte von Wissenschaftlern, welche die Sequenzen hochgeladen haben). Nur zur Abschätzung! Indiz für Genaktivität kein Beweis! GEO-Profile enthalten experimentelle Daten zur Genexpression und sind wesentlich aussagekräftiger! Datensatz (GDSxxx) enthält mehrere, vergleichbare Einträge. Serie (GSExxxx) ist ein Original-Eintrag durch einen Wissenschaftler.
41 Überblick behalten Entrez Nucleotide Entrez Gene HomoloGene und UniGene Entrez Genome und Genome Project Map-Viewer und Sequence Viewer HGNC und Gene Ontology Ensembl MODs (model organism databases) Biomart und SRS
42 Kurzer Einschub: Genom-Sequenzierung Primärdaten: Aus Genom-Sequenzierung resultieren hochfragmentierte Nukleotid-Sequenzen (einzelne GenBank-Einträge für ein Genom). Außerdem fehlt die Zuordnung funktionaler Einheiten (z.b. Gene) zu den Genom-Sequenz- Abschnitten. Whole Genome Shot-Gun Methode Gesamtes Genom wird zu 1-10kb langen Sequenzen fragmentiert. Es folgt Klonierung und Sequenzierung der Fragmente. Die flankierenden Vektor-Sequenzen müssen entfernt werden. Die Sequenzen können dann aufgrund Überlappung mithilfe eines Computerprogramms assembliert werden. Ausgangspunkt für Mapping-Regionen sind STS (sequence tagged sites). Dies sind kurze ( bp) Sequenzen, die einmalig im Genom vorkommen und damit eine spezifische Position in der physikalische Genom-Karte definieren.
43 Kurzer Einschub: Genom-Sequenzierung Nach der Assemblierung resultieren so genannte Contigs Sätze von überlappenden Genom-Sequenzabschnitten. Die Contigs müssen nun zum Genom assembliert werden. Aufgrund von Lücken (Gaps) ist dies oft nicht möglich. Die Gaps werden allmählich durch verschiedene Sequenzierprojekte geschlossen der aktuelle Stand der Genom- Assemblierung wird in Assembly-Versionen festgehalten, die in Genom- Datenbanken hinterlegt sind. Das Assembly dient zur Identifizierung von codierenden Regionen: Mapping von EST zum Genom: Aus mrna eines Organismus entsteht cdna-bibliothek. Diese wird über Alignment einzelnen Genom-Regionen zugeordnet. Dies sind dann eindeutig ORFs. Vorhersage von ORFs: z.b. anhand Codon-Usage Muster (nicht in Introns!) Finden von ORFs über Homologie-Datenbank-Suchen: potentieller ORF wird übersetzt. Es folgen BLAST-Suchen in Datenbanken, welche orthologe Gene in Cluster sortieren (z.b. COG, UniGene)
44 Kurzer Einschub: Genom-Sequenzierung Es folgt die Annotierung der Sequenzen mit Funktionen und Eigenschaften, die ebenso stetig in verschiedenen Laboren neu beschrieben werden. Übernehmen der Annotierung aus den Protein-/mRNA-Metadaten anderer Datenbanken. Annotierung bezüglich Genomik: funktionelle Regionen wie Promotoren, Operatoren, Enhancer-Elemente müssen gefunden und annotiert werden. AAA-Prozess: Zusammenfassung: Assembly Alignment Annotation


45 Genome Reference Consortium (GRC) In den AAA-Prozess eines Genoms ist quasi die Wissenschaft der gesamten Welt involviert. Jemand muss jedoch für die Veröffentlichung einer offiziellen, aktuellen Version sorge tragen: Das Referenzgenom. GRC ist für die Referenzgenome für Mensch und Maus verantwortlich. Es besteht aus NCBI, EBI, dem Wellcome Trust Sanger Institute und dem Genome Center at Washington University. Auf der Homepage wird dargestellt, woran gerade gearbeitet wird. Es werden falsch repräsentierte Gen-Loki korrigiert und Lücken im Genom geschlossen.

46 Entrez Genome Entrez Genome ermöglicht eine Betrachtung der Genome mithilfe verschiedener physikalischer und genetischer Karten. Die Datenbank ist in sechs Organismen-Gruppen organisiert: Archeen, Bakterien, Eukaryoten, Viren, Viroide und Plasmide.
.")
47 Entrez Genome Tabellarische Übersichten für die sechs Hauptkategorien in der Navi-Leiste auswählbar. Links direkt zum Genom oder Proteom sowie allen codierten RNAs. Unterschiedliche Sortierung möglich (Klicke auf proteins um nach Protein-Anzahl zu sortieren). Links zu Entrez Taxonomy Verlinkung zum MAP- Viewer oder zur Ansicht Übersicht über das Proteom Overview (Tabellenin Entrez Genome. Format)., abhängig Übersicht vom über das RNAom Von dort aus Verlinkung Link zu Entrez zu Gene Entrez Protein, Entrez Gene Von dort aus und MMDB-Eintrag Verlinkung zu DNA- Sequenzen im FASTA-Format
48 Entrez Genome einfache Suchanfrage, statt Auswahl über Tabelle: Homo Sapiens [Organism] liefert 75 Ergebnisse: 1 Chromosom = 1 Ergebnis 3 beendete Sequenzier-Projekte (2002, 2006, 2007) 1x DNA aus Mitochondrium 1x Mitochondriales Genom aus Homo Sapiens Neanderthalensis Chromosom 7 als alternative Assemblierung vorhanden 22+X+Y * =75 Escherichia Coli [Organism] liefert 167 Ergebnisse: nur 1 chromosomales Genom, aber viele E.coli Stämme sehr viele Plasmide
. DNA-Typ (linear, zirkulär). Anzahl der Nukleotide.")
49 Entrez Genome Summary-Format nach Suchanfrage Informationen: Name und Datum des Sequenzier-Projekts. Bezeichnung des Replikons (Chromosomale Einheit). DNA-Typ (linear, zirkulär). Anzahl der Nukleotide.

50 Entrez Genome Overview-Format Links zu Entrez Gene und Entrez Protein Links zu Genome Project E.Coli Stamm GenBank Format betrachten Ergebnis in Sequence Viewer betrachten

51 Entrez Genome Protein Table-Format Über Display/Protein FASTA lassen sich alle Proteine des Genoms im FASTA-Format herunterladen
52 Entrez Genome-Project Genome Projekt Wozu noch eine Genom-Datenbank? Sammlung vollständiger und unvollständiger (in Sequenzierung befindlicher) Genome von zellulären Organismen (keine Genome von Organellen, Viren oder Plasmiden (sind über Entrez Nucleotide und Entrez Genome erreichbar). Genome-Project beinhaltet Daten verschiedener Projekte, welche Sequenzierung, Assemblierung, Kartierung und Kommentierung von Genomen betreiben. Organismus-spezifische Portale enthalten Liste aller Projekte. Genome-Project Portale von Bakterien enthalten: Beschreibung und Abbildung des Bakteriums. Details über den Lebensraum. Informationen über die Pathogenität und assoziierte Erkrankungen. Anwendung und Bedeutung des Bakterienstammes (wissenschaftlich).

53 Entrez Genome-Project Homo Sapiens Projekt-Seite Link zum Map- Viewer für das jeweilige Chromosom
54 Überblick behalten Entrez Nucleotide Entrez Gene HomoloGene und UniGene Entrez Genome und Genome Project Map-Viewer und Sequence Viewer HGNC und Gene Ontology Ensembl MODs (model organism databases) Biomart und SRS
55 Suche in Entrez Genome nach Homo Sapiens [Organism] und Wähle eine AC-ID, um zur NCBI Map-Viewer-Ansicht zu gelangen. Oder vom entsprechenden Eintrag in Entrez Gene über Verlinkung:

56 Weitere Möglichkeit: Suche über Map-Viewer Homepage Wähle hier den Organismus Eingabe des Suchbegriffs Suchbegriffe können sein: Gen-Bezeichnung GenBank AN Proteine, Transkripte chromosomale bp-abschnitte Alle Objekte, die in irgendeiner weise mit dem Genom assoziiert sind! Willst du z.b. eine Region des Genoms zwischen zwei Loci anzeigen, benutze als Operator OR.


57 Der Map-Viewer Schneller Wechsel zu anderem Chromosom Gen am Anfang und am Ende des markierten Genom-Abschnitts Map schließen oder als Master-Map wählen Hilfe-Seite über diese Map Links-Klick Menü 4 verschiedene Maps Rechts: Master-Map Transkriptions-Richtung des vorangehenden Gens Links zur Darstellung des entsprechenden Gens Es folgen nacheinander je 16x Vergrößerungen, um die Gen-Ebene erkennen zu können


58 Der Map-Viewer
59 Der Map-Viewer
60 Der Map-Viewer Map-Viewer ist nicht sinnvoll zur Navigation auf Gen-Ebene Hierfür dient der Sequence Viewer (mehr dazu gleich)


61 Der Map-Viewer Map-Viewer ermöglicht Gegenüberstellung verschiedener Maps. Für jeden Datenbankeintrag sind unterschiedliche Maps, basierend auf den Gen- und Genom-Daten hinterlegt. Maps können über Maps & Options beliebig angeordnet, hinzugefügt oder entfernt werden. Es lassen sich für Vergleiche Maps anderer Organismen anzeigen. Zur Verfügung stehende Maps für das Genom von Homo Sapiens

62 Der Map-Viewer Was ist eine Master-Map? Wird im Map-Viewer auf der rechten Seite angezeigt. Rechts neben der Master-Map werden die Mapspezifischen Funktionen eingeblendet. Zur Master-Map machen oder Map vom Map-Viewer entfernen Gene-Map als Master-Map: Gene werden angezeigt viele Links zu den Genen OMIM: Online Mendelian Inheritance in Man sv: Sequence Viewer pr: Entrez Protein hm: HomoloGene Aktuelle Master-Map
63 Der Map-Viewer Hintergründe: 2 Maps der Standard-Darstellung Die Contig Map Contig = Satz überlappender DNA-Stücke derselben genetischen Quelle. ein Contig entsteht durch mehrfache teilweise Sequenzierung eines DNA- Moleküls (Chromosom) und anschließende Überlappung aneinander grenzender DNA-Bereiche. zwischen mehreren Contigs befinden sich Lücken, die nicht sequenziert wurden. Die Contig Map zeigt die sequenzierten und nicht sequenzierten Bereiche des Genoms bzw. die Contigs und die Lücken. Gene-Sequence Map Entspricht einem Alignment von mrnas zu den Contigs und Gen-Prognosen. Es werden daher nur putative Gene angezeigt. Qualität des Alignments wird durch Farbe angedeutet (hellblau ist die beste). User sieht Gene aus den RefSeq- und GenBank-Daten im genomischen Kontext. Gene auf der rechten Seite werden in (+)-Richtung, Gene auf der linken Seite in ( )- Richtung transkribiert.
 Assembly = Genom- Version Element-Typ (Gen, Transkript ) Art der hinterlegten Map")
64 Suchausgabe über Map-Viewer Homepage Loki der gefundenen Elemente Filterung der Ergebnisse nach Chromosom Filterung der Ergebnisse nach Element-Typ (z.b. nur Gene) Assembly = Genom- Version Element-Typ (Gen, Transkript ) Art der hinterlegten Map

65 Vom MAP-Viewer geht s direkt zum Sequence-Viewer: Oder vom entsprechenden Eintrag in Entrez Gene über Verlinkung:
66 Der Sequence-Viewer Benutzeroberfläche Übersichts -Element Graphisches Element
67 Der Sequence-Viewer Optionen zur Navigation der angezeigte Ausschnitt im graphischen Element kann beliebig gewählt werden (Drag&Drop) Suchfeld ermöglicht direktes Springen zu einzelnen Genen. Sucheingabe wie in Entrez Gene (z.b. auch Protein-Name) Gehe zu bestimmter Sequenz-Position Zoom und Position der Darstellung auch im graphischen Element direkt wählbar
 Öffnet ein zweites Fenster")
68 Der Sequence-Viewer Optionen zur Anzeige Vollständige FASTA oder GenBank-Sequenz anzeigen (Achtung: Dateigröße ) Öffnet ein zweites Fenster mit der Sequenz


")
69 Der Sequence-Viewer Optionen zur Anzeige Pop-up Anzeige mit Infos Rechts-Klick: Menü Zoom auf Sequenz-Ebene (DNA und Protein) Wahl verschiedener Formate (FASTA, GenBank) BLAST-Anfrage
70 Überblick behalten Entrez Nucleotide Entrez Gene HomoloGene und UniGene Entrez Genome und Genome Project Map-Viewer und Sequence Viewer HGNC und Gene Ontology Ensembl MODs (model organism databases) Biomart und SRS
71 Suche die richtigen Suchbegriffe, um deine Suchanfrage zu verbessern! Kennst du die offizielle Gen-Bezeichnung nicht, dann schaue bei HGNC nach! Kennst du die wissenschaftliche Bezeichnung des gesuchten Organismus nicht, NCBI Taxonomy hilft! Suchst du Gene, die mit einer bestimmten Funktion assoziiert sind, nutze GO-Terms!
72 HGNC Human Genome Organisation (HUGO) Gene Nomenclature Committee Das Gen-Symbol besteht ausschließlich aus lateinischen Großbuchstaben und arabischen Ziffern. Als Richtlinie werden sechs-stellige Symbole angestrebt. Der erste Charakter des Symbols muss ein Buchstabe sein. Ziffern sollten generell nur in Ausnahmefällen verwendet werden. IUPAC International Union of Pure and Applied Chemistry Nomenklatur für organische und biochemische Substanzen (Symbole und Terminologie). IUBMB International Union of Biochemistry and Molecular Biology Nomenklatur und Klassifizierung von Enzym-Reaktionen (EC-Nummern).

73 NCBI Taxonomy Suche der wissenschaftlichen Bezeichnung eines Organismus. Exakter Taxonomie-Pfad lässt sich schnell nachschlagen. Es lassen sich für jeden Taxonomie-Pfad die Anzahl der Datenbank-Einträge in verschiedenen Datenbanken (Protein, DNA etc.) anzeigen.
. GO Consortium heute umfasst wesentlich mehr Datenbanken, darunter EBI.")
74 Initiative von Bioinformatikern mit dem Ziel die Repräsentation von Gen- und Genprodukt- Attributen zu standardisieren, Datenbank- und Organismus-übergreifend. 1998, zunächst entwickelt in Zusammenarbeit zwischen drei MODs (Model organism databases). GO Consortium heute umfasst wesentlich mehr Datenbanken, darunter EBI. GO enthält ein definiertes, hierarchisch aufgebautes Vokabular, um Charakteristiken von Genprodukten zu beschreiben. Es gibt drei Ontologie-Ebenen (Cytochrom c): Molekülfunktion biologischer Prozess zelluläre Komponente GO Gene Ontology (oxidoreductase activity) (oxidative phosphorylation, induction of cell death) (mitochondrial matrix, mitochondrial inner membrane) GO-Terms ermöglichen eine bessere Suche zwischen Genprodukten derselben Ontologie.
75 Überblick behalten Entrez Nucleotide Entrez Gene HomoloGene und UniGene Entrez Genome und Genome Project Map-Viewer und Sequence Viewer HGNC und Gene Ontology Ensembl MODs (model organism databases) Biomart und SRS
76 Ensembl Gründung 1999 als Antwort auf die bevorstehende Fertigstellung des Human Genom-Projekts. Gemeinschaftsprojekt von EBI und dem Wellcome Trust Sanger Institute (annotiert Genome). Ziel ist es eine zentrale Informationsquelle rund um das Human-Genom und Genome weiterer Vertebraten (Modellorganismen) bereit zu stellen startete das Projekt Ensembl Genomes, das mit Genomen mehrerer Organismen aufwartet. Computer-gestütztes, automatisches Alignment von Protein-Sequenzen und mrna-sequenzen aus UniProtKB und RefSeq zu Genom-Abschnitten. Automatische Generierung graphischer Ansichten auf Basis von Gen- Alignments und genomischen Daten anhand eines Referenz-Genoms. Annotation-Updates ca. alle 2 Monate (aktuelle Ensembl Version 52). Gen/Genom-Updates einmal im Jahr.

77
78 Übersicht aller Organismen mit Genom- Daten auf Ensembl (nur Vertebraten!) Verlinkung zu Ensembl- Projekten, die Genome von anderen Organismen bereit stellen.

79 Die einzelnen Organismus-Portale lassen sich dann z.b. nach Gene oder Erkrankungen durchsuchen. Es wird der Status des Assembly und der Annotierung beschrieben. Klicke auf Karyotype Betrachtungsebenen in Ensembl Karyotype: Übersicht über alle Chromosomen Location: bestimmter Bereich eines Chromosoms Gene: Gen im genomischen Kontext Transcript: z.b. mrna Variation: Mutation eines Gens Regulation: z.b. Promotor-Elemente

80 Karyotype/Whole Genome Informationen zum Genom und zum Assembly Klicke auf ein Chromosom 2 Optionen: Chromosome Summary Jump to location view


81 Karyotype/Chromosome Summary

82 Karyotype/Region Overview und /Region in Detail Genom-Browser wie MAP-Viewer auf NCBI. Beliebiges Herein- und Herauszoomen. Ansicht ist nützlich, um Gen-Modelle aus Ensembl mit Protein- und mrna- Sequenzen anderer Datenbanken wie NCBI RefSeq, EMBL-Bank oder UniProt zu vergleichen.


83 Suche nach einem Gen Zurück auf die Homo Sapiens Startseite!? Hier klicken! Hier lassen sich einzelne Gene global über das Human-Genom finden! Bei Suche auf Starseite sind 3 Felder notwendig: Spezies: Human oder Homo Sapiens Ansicht: Gene oder SNP oder family oder domain oder chromosome Beschreibung: Gen-Bezeichnung, Symbol, Beschreibung oder Basenpaar-Position Beispiel: Human IL2 Ergebnisse aus drei Ansichten
84 Suche nach einem Gen Ergebnis-Tabelle: Achte auf drei Bereiche! Description Gen-Symbol Art des Eintrags: protein-coding pseudogene snorna/rrna protein-family interpro-domain SNP (Single nucleotide polymorphism) Ergebnis enthält Verlinkung zu zwei Ebenen: GeneView Region in detail Zunächst: GeneView VEGA Vertebrate Genome Annotation VEGA besteht aus einem Consortium von Kuratoren. manuelle Annotierung für jeden individuellen Fall. Das HAVANA set ist ein Teil des VEGA-Consortiums und zwecks Vergleich mit der automatischen Annotierung durch Ensembl in die Ensembl Gene Datenbank integriert. Unterscheidung über die ID Ensembl-Einträge beginnen mit ENS

85 GeneView Page Gen-Bezeichnung stammt von der HGNC (HUGO Gene Nomenclature Committee), die Beschreibung aus dem Eintrag in UniProtKB-Swiss-Prot. Ein Gen-Eintrag besteht immer aus einem oder mehreren Transkripten, die in einer Tabelle direkt ausgewählt werden können. CCDS = consensus coding sequences in Übereinstimmung von Ensembl, Havana, NCBI, UCSC Ensembl-ID-Nomenklatur: ENSMUSG = Ensembl-Eintrag eines Gens aus mus musculus OTT = Vega Havana Eintrag Für Homo Sapiens fehlt die Spezifikation des Organismus! G = Gen, T = Transkript, E = Exon, P = Protein, F =Family


86 GeneView Page Weiter unten: grafische Darstellung der Gen-Struktur für jedes Transkript. Transkripte mit überlappender CDS werden unter derselben Gene-ID gruppiert. Die blaue dicke Säule repräsentiert die Contigs oberhalb dargestellte Transkripte sind auf dem Vorwärtsstrang codiert unterhalb dargestellte sind auf dem Rückwärtsstrang transkribiert. Über die Transkript-Tabelle oder direkt über die Grafische Darstellung gelangt man zum Transcript-Eintrag. Transcript summary Page



87 GeneView Page Sequence: Genom-Sequenz im FASTA-Format im Bereich des entsprechenden Gens. Exons sind farbig hinterlegt. Chromosomen-Nummer Häufigste Humangenom-Sequenz vom HGP Basenpaar-Intervall Vorwärtsstrang (-1 = Rückwärtsstrang) Die Ansicht ist hoch-konfigurierbar:
88 GeneView Page Supporting Evidence: Übersicht über alle mrnas und Proteine, die dem Ensembl-Transkript zugrunde liegen (Verlinkung zu NCBI RefSeq, NCBI CCDS, UniProtKB etc.). External Data: Für jeden Eintrag zuerst auf Configure this Page, Auswahl der externen Datenbanken wie Reactome oder UniProt, Speichern, dann lassen sich die gewählten Datenbanken unter External Data auswählen. Außerdem: Splice variants: Liste aller alternativen Spleißprodukte. Regulation: Liste aller regulatorischen genetischen Elemente. Genetic Variation: Liste aller bekannten Mutationen.
")
89 GeneView Page Supporting Evidence: Übersicht über alle mrnas und Proteine, die dem Ensembl-Transkript zugrunde liegen (Verlinkung zu NCBI RefSeq, NCBI CCDS, UniProtKB etc.). Abschnitt: comparative Genomics Hierüber sind Alignments möglich genomic alignements: Vergleich der Gen-Sequenzen verschiedener Organismen (meist paarweise Alignments, einige multiple Alignments) gene tree: phylogentische Verwandtschaftsbeziehungen der Gene zur Einschätzung des Homologie-Grades (Ergebnis des multiplen Sequenz-Alignments aller Ensembl-Spezies) Orthologues: Homologe Proteine durch Artbildung entstanden; Sie behalten dieselbe Funktion bei. Paralogues: Homologe Proteine durch Duplikation innerhalb des Genoms entstanden; Sie entwickeln neue Funktionen.

90 Transcript summary Page Type: known protein coding = Transkript passt zu einer bekannten ID in UniProtKB oder NCBI RefSeq. Type: novel protein coding = Transkript lässt sich nicht auf so eine ID zurückführen. Ensemble/Havana match = Transkripte mit höchster Qualität, da zwei Projekte auf Basis von Protein und mrna unabhängig voneinander exakt dasselbe Alignment erzielten. Zurück zur Gene-Summary!? Hier klicken!


.")
91 Transcript summary Page Sequenz-Informationsseiten zu Exons, cdna und Protein Protein Information/Domains & Features enthält eine Liste von Domänen innerhalb des Transkripts mit Verweisen zu den sekundären Datenbanken. Protein Information/Variations enthält eine Liste von Mutationen. General Identifier: Liste aller IDs von externen Datenbanken, die zum entsprechenden Transkript passen (Update alle 2 Monate). Gene Ontology (GO) Terms: definieren die Funktion des Gens (hierarchische Klassifizierung, siehe Evidence Codes der GO-Terms zeigen den Indikator für die Zuordnung.
 Großer Genom-Ausschnitt.")
92 Region in Detail Betrachtung von Genen im genomischen Kontext Genomischer Kontext!? Hier klicken! Location-Link vom Gene oder Transcript-Eintrag [Region in detail]-link nach einer Suche Region in Detail -Ansicht enthält 2 Regionen: (1) Großer Genom-Ausschnitt. Die rote Box ist der Bereich des Chromosoms, dass in (2) vergrößert dargestellt ist. Alle Gene sind mit ihrer GeneView Page verlinkt. (2) Vergrößerte Darstellung des Zielgens. Neben den Genen in dieser Chromosomen- Position ist auch die Konservierung der einzelnen Nukleotide über 29 Spezies dargestellt (constrained elements). Beliebiges herein- und heraus-zoomen möglich. Für größere Übersichtsseiten wähle Region Overview
 Links-Klick Menü (3) über")


93 Region in Detail Zoomen: (1) Panel in der Mitte (2) Links-Klick Menü (3) über Maus-click&drag Über Links-Klick auf Grafik-Elemente sind Verlinkung und weitere Infos zugänglich Chromosom Contigs Gene im genomischen Kontext Konservierung Gene

94 Region in Detail Einstellungen und Ansichten über Configure this Page frei wählbar

95 Region in Detail Zoom eines hochkonservierten Exons. Über Configure this page wurden alle Sequenzen eingeblendet.
96 Überblick behalten Entrez Nucleotide Entrez Gene HomoloGene und UniGene Entrez Genome und Genome Project Map-Viewer und Sequence Viewer HGNC und Gene Ontology Ensembl MODs (model organism databases) Biomart und SRS




97 Übersicht: Model Organism Databases MODs sind Datenbanken, die spezifisch für einen bestimmten Organismus sind. Sie existieren für alle wichtigen Modellorganismen. colibase Wormbase Flybase MGI Escherichia coli Caenorhabditis elegans Drosophila melanogaster Mus musculus Enthalten sind meist alle denkbaren Informationen über den entsprechenden Organismus. Im Mittelpunkt steht jedoch meist das Genom, oft auch Phänotyp-Beschreibungen. Teilweise stammen die Daten aus anderen primären Datenbanken. Teilweise sind es Quelldatenbanken für andere sekundäre Datenbanken.
98 GMOD Projekt Gegründet, um Software-Tools zu entwickeln, die beim Daten-Management in verschiedenen MODs hilfreich sein können. Früher hat jedes MOD-Projekt seine eigene Suchmaschine und sein eigenes DBMS entwickelt.
99 Überblick behalten Entrez Nucleotide Entrez Gene HomoloGene und UniGene Entrez Genome und Genome Project Map-Viewer und Sequence Viewer HGNC und Gene Ontology Ensembl MODs (model organism databases) Biomart und SRS
100 Biomart und SRS search and retrieval systems for biological information Metasuchmaschine auf NCBI: Entrez - Metasuchmaschine auf EBI: EB-Eye Es wurden weitere Web-Services entwickelt, um als Metasuchmaschinen in verschiedenen biologischen Datenbanken suchen zu können. Biomart und SRS sind die zwei bekanntesten Systeme. Ziel ist die Datenintegration, d.h. die Kombination verschiedener Daten aus verschiedenen Quellen, um dem Benutzer eine einheitliche Sicht auf diese Daten zu geben. Große Herausforderung, die immer wichtiger wird (exponentielles Datenwachstum). Weiteres Problem in der Bioinformatik ist die Daten-Integrität, d.h. alle Daten sollen Widerspruchsfrei (konsistent) sein. Dies ist eine wichtige Bedingung, die ein DBMS ständig überwachen muss. Da Daten meist nicht überwacht werden (INSDC) und ohne Kontrolle als Grundlage für weitere Datenbanken (verschiedene DBMS) dienen, verbreiten sich Fehler schnell (z.b. unvollständige Annotierung). Die Web-Services ermöglichen Datenintegration. Die Daten-Integrität muss aber vom Benutzer selbst durch vergleichende Analyse überprüft werden sicher ist sicher.
.")

101 Biomart Biomart ist ein System zur gezielten, themenbasierten Datensuche und wird zum Teil von EBI entwickelt. Das System ist u.a. in Ensembl und EBI integriert, kann aber auch eigenständig auf der Homepage von Biomart verwendet werden. Es dient der Suche Informationen innerhalb großen Datensätzen (z.b. Genomen). Es ermöglicht die Suche von bestimmten Features wie SNPs innerhalb eines Genoms oder Genom-Abschnitts. In Biomart sind verschiedene Datensätze implementiert, die zuvor ausgewählt werden müssen Ensembl ist nur einer dieser Datensätze. Ensembl: Direkt auf der Startseite EBI: Unter InterPro in der Navigationsleiste
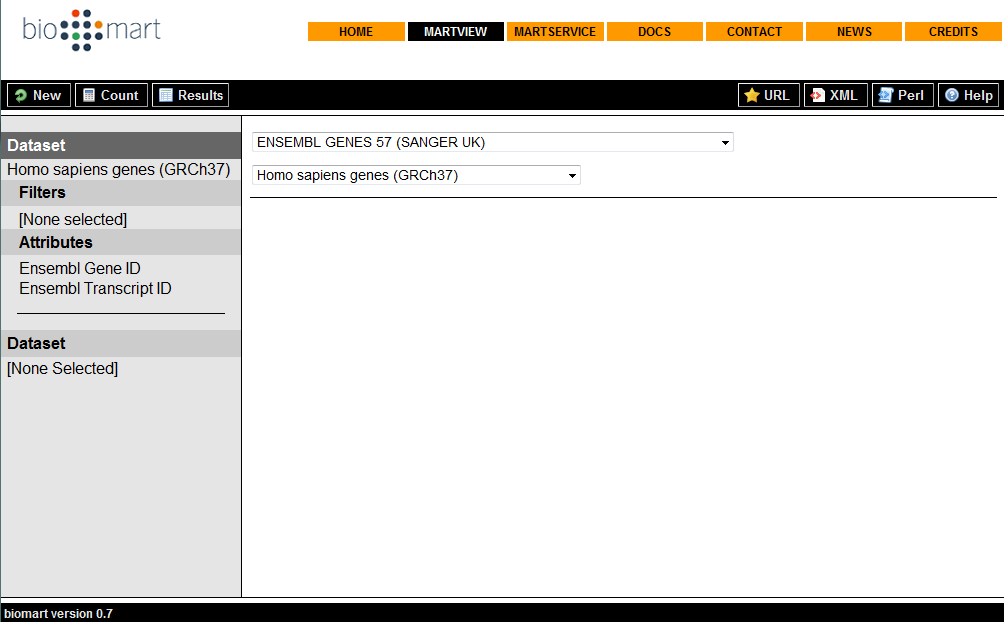
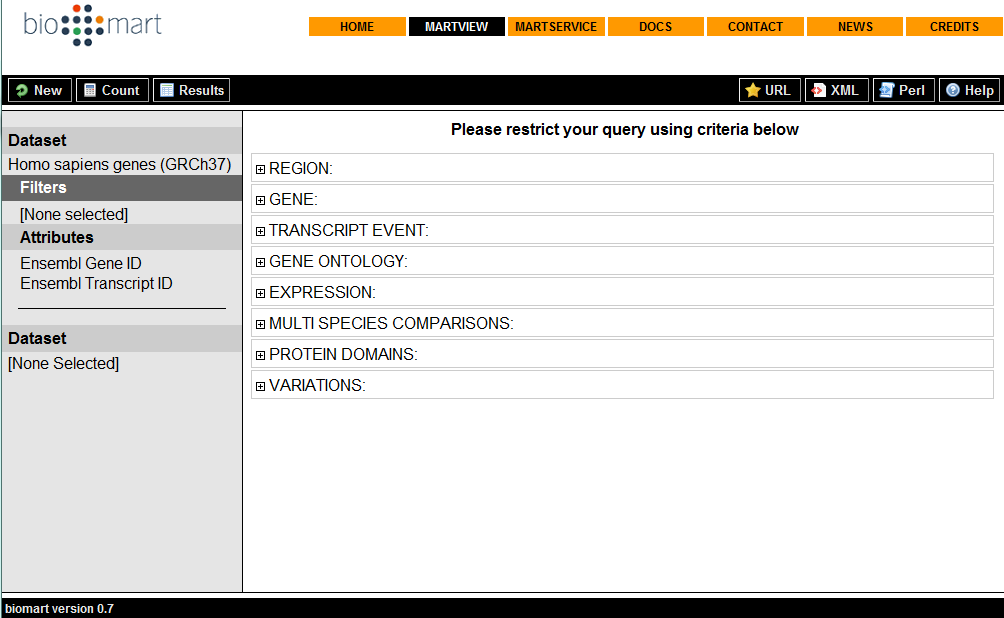

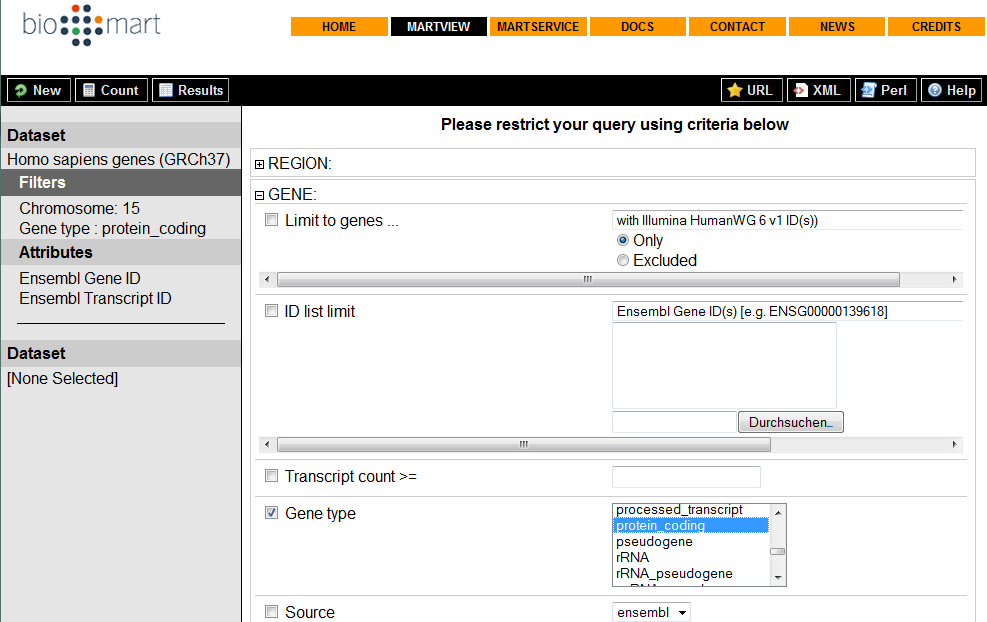
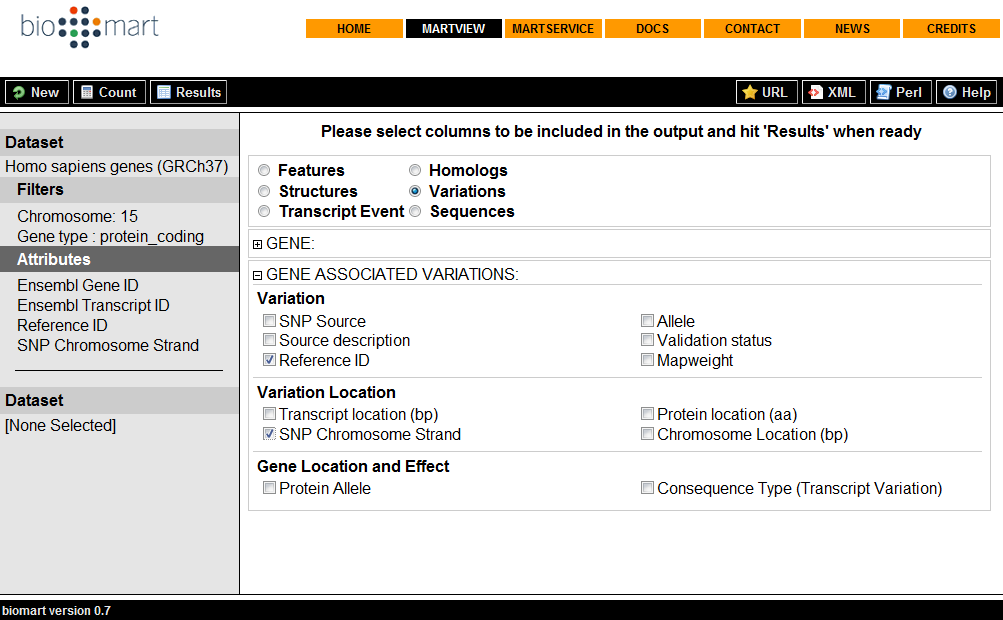

102 Biomart

103 SRS Sequence Retrieval System Verschiedene Registerkarten oben auswählbar. Unter Quick-Search kann ohne Datenbank- Auswahl direkt gestartet werden. Alternative: Unter Library Page können verschiedene Datenbanken ausgewählt werden, die zur Suche verwendet werden sollen.
")
104 SRS Sequence Retrieval System Unter Query Form kann dann eine typische Suchanfrage gestellt werden: Nutzung von Feldern für einzelne Suchbegriffe, die über Operatoren (AND, OR, NOT) verknüpft sind.

105 SRS Sequence Retrieval System Unter Tools können direkt zahlreiche Tools gestartet werden.





106 Fragen? Folien und Supplementals auf
Folien und Supplementals auf.
 Folien und Supplementals auf www.biokemika.de 1 Folien und Supplementals auf www.biokemika.de 2 National Center for Biotechnology Information http://www.ncbi.nlm.nih.gov/ NCBI European Bioinformatic Institute
Folien und Supplementals auf www.biokemika.de 1 Folien und Supplementals auf www.biokemika.de 2 National Center for Biotechnology Information http://www.ncbi.nlm.nih.gov/ NCBI European Bioinformatic Institute
MOL.504 Analyse von DNA- und Proteinsequenzen. Datenbanken & Informationssysteme
 MOL.504 Analyse von DNA- und Proteinsequenzen Datenbanken & Informationssysteme Inhaltsübersicht Informationsysteme National Center for Biotechnology Information (NCBI) The European Bioinformatics Institute
MOL.504 Analyse von DNA- und Proteinsequenzen Datenbanken & Informationssysteme Inhaltsübersicht Informationsysteme National Center for Biotechnology Information (NCBI) The European Bioinformatics Institute
Übung II. Einführung, Teil 1. Arbeiten mit Ensembl
 Übung II Einführung, Teil 1 Arbeiten mit Ensembl Ensembl Genome Browser (Bereitstellung von Vielzeller Genomen) Projekt wurde 1999 initiiert Projektpartner EMBL European Bioinformatics Institute (EBI)
Übung II Einführung, Teil 1 Arbeiten mit Ensembl Ensembl Genome Browser (Bereitstellung von Vielzeller Genomen) Projekt wurde 1999 initiiert Projektpartner EMBL European Bioinformatics Institute (EBI)
Biowissenschaftlich recherchieren
 Biowissenschaftlich recherchieren Uber den Einsatz von Datenbanken und anderen Ressourcen der Bioinformatik Nicola Gaedeke Birkhauser Basel Boston Berlin Inhaltsverzeichnis Vorwort xi 1 Die Informationssucheim
Biowissenschaftlich recherchieren Uber den Einsatz von Datenbanken und anderen Ressourcen der Bioinformatik Nicola Gaedeke Birkhauser Basel Boston Berlin Inhaltsverzeichnis Vorwort xi 1 Die Informationssucheim
BCDS - Biochemische Datenbanken und Software
 BCDS - Biochemische Datenbanken und Software Seminarinhalte Bioinformatische Genom- und Proteomanalyse Literaturrecherche und Zitation Naturwissenschaftliche Software Termine 25. Mai, 1. Juni, 8. Juni,
BCDS - Biochemische Datenbanken und Software Seminarinhalte Bioinformatische Genom- und Proteomanalyse Literaturrecherche und Zitation Naturwissenschaftliche Software Termine 25. Mai, 1. Juni, 8. Juni,
Einführung in die Angewandte Bioinformatik: Proteinsequenz-Datenbanken
 Einführung in die Angewandte Bioinformatik: Proteinsequenz-Datenbanken 14.05.2009 Prof. Dr. Sven Rahmann 1 3 Proteinsequenz-Datenbanksysteme NCBI Entrez Proteins EBI SRS Proteins UniProt (empfohlen) 2
Einführung in die Angewandte Bioinformatik: Proteinsequenz-Datenbanken 14.05.2009 Prof. Dr. Sven Rahmann 1 3 Proteinsequenz-Datenbanksysteme NCBI Entrez Proteins EBI SRS Proteins UniProt (empfohlen) 2
Molekularbiologische Datenbanken
 Molekularbiologische Datenbanken Übungen Sommersemester 2004 Silke Trißl Prof. Ulf Leser Wissensmanagement in der Bioinformatik Organisatorisches Mittwoch 11 13 Uhr, RUD26 0'313 Mi, 05. Mai 2004 entfällt
Molekularbiologische Datenbanken Übungen Sommersemester 2004 Silke Trißl Prof. Ulf Leser Wissensmanagement in der Bioinformatik Organisatorisches Mittwoch 11 13 Uhr, RUD26 0'313 Mi, 05. Mai 2004 entfällt
Applied Bioinformatics. maria.fischer@i-med.ac.at http://icbi.at/courses/bioinformatics_ex
 Applied Bioinformatics SS 2013 maria.fischer@i-med.ac.at http://icbi.at/courses/bioinformatics_ex Organisatorisches Termine Mo 18.03.2013 RR19 9:00 Di 19.03.2013 RR19 9:00 Mi 20.03.2013 RR19 9:00 Übungsziele
Applied Bioinformatics SS 2013 maria.fischer@i-med.ac.at http://icbi.at/courses/bioinformatics_ex Organisatorisches Termine Mo 18.03.2013 RR19 9:00 Di 19.03.2013 RR19 9:00 Mi 20.03.2013 RR19 9:00 Übungsziele
Übungen zur Vorlesung Molekularbiologische Datenbanken. Lösungsblatt 1: Datenbanksuche
 Wissensmanagement in der Bioinformatik Prof. Dr. Ulf Leser, Silke Trißl Übungen zur Vorlesung Molekularbiologische Datenbanken Lösungsblatt 1: Datenbanksuche Symptome 1.Ein Kind kommt in die Praxis und
Wissensmanagement in der Bioinformatik Prof. Dr. Ulf Leser, Silke Trißl Übungen zur Vorlesung Molekularbiologische Datenbanken Lösungsblatt 1: Datenbanksuche Symptome 1.Ein Kind kommt in die Praxis und
Übung II. Einführung. Teil 1 Arbeiten mit Sequenzen recombinante DNA
 Übung II Einführung Teil 1 Arbeiten mit Sequenzen recombinante DNA Recombinante DNA Technologie Protein Synthese In vitro Expression Libraries Gene Transfer in Tieren und Pflanzen Recombinante DNA Technologie
Übung II Einführung Teil 1 Arbeiten mit Sequenzen recombinante DNA Recombinante DNA Technologie Protein Synthese In vitro Expression Libraries Gene Transfer in Tieren und Pflanzen Recombinante DNA Technologie
Einführung in die Angewandte Bioinformatik: Nukleotidsequenz-Datenbanken
 Einführung in die Angewandte Bioinformatik: Nukleotidsequenz-Datenbanken 07.05.2009 Prof. Dr. Sven Rahmann 1 Datenbanken am NCBI über Entrez http://www.ncbi.nlm.nih.gov/entrez NIH = National Institute
Einführung in die Angewandte Bioinformatik: Nukleotidsequenz-Datenbanken 07.05.2009 Prof. Dr. Sven Rahmann 1 Datenbanken am NCBI über Entrez http://www.ncbi.nlm.nih.gov/entrez NIH = National Institute
BIOINFORMATIK I ÜBUNGEN.
 BIOINFORMATIK I ÜBUNGEN http://icbi.at/bioinf Organisation 3 Übungen Kurze Einführung anschließend Labor Protokoll (je 2 Studierende, elektronisch doc, pdf..) Abgabe der Übungen bis spätestens 29. 05.
BIOINFORMATIK I ÜBUNGEN http://icbi.at/bioinf Organisation 3 Übungen Kurze Einführung anschließend Labor Protokoll (je 2 Studierende, elektronisch doc, pdf..) Abgabe der Übungen bis spätestens 29. 05.
Datenbanken in der Molekularbiologie
 WS2015/2016 F1-Praktikum Genomforschung und Sequenzanalyse - Einführung in Methoden der Bioinformatik- Datenbanken in der Molekularbiologie Folie: Tal Dagan, D dorf Datenbanken in der Molekularbiologie
WS2015/2016 F1-Praktikum Genomforschung und Sequenzanalyse - Einführung in Methoden der Bioinformatik- Datenbanken in der Molekularbiologie Folie: Tal Dagan, D dorf Datenbanken in der Molekularbiologie
Datenbanken in der Molekularbiologie
 WS2017/2018 F1-Praktikum Genomforschung und Sequenzanalyse - Einführung in Methoden der Bioinformatik- Datenbanken in der Molekularbiologie Folie: Tal Dagan, D dorf Datenbanken in der Molekularbiologie
WS2017/2018 F1-Praktikum Genomforschung und Sequenzanalyse - Einführung in Methoden der Bioinformatik- Datenbanken in der Molekularbiologie Folie: Tal Dagan, D dorf Datenbanken in der Molekularbiologie
Genomics. Ernst W. Mayr Fakultät für Informatik TU München
 Genomics Ernst W. Mayr Fakultät für Informatik TU München http://wwwmayr.in.tum.de/ A. Biologische Hintergründe nde 1. Gene und Phänotypisches 1.1. Beobachtungen nach Mendel 1.2. Eukaryotische Zelle 1.3.
Genomics Ernst W. Mayr Fakultät für Informatik TU München http://wwwmayr.in.tum.de/ A. Biologische Hintergründe nde 1. Gene und Phänotypisches 1.1. Beobachtungen nach Mendel 1.2. Eukaryotische Zelle 1.3.
Gleichheit, Ähnlichkeit, Homologie
 Gleichheit, Ähnlichkeit, Homologie Identität (identity) Verhältnis der Anzahl identischer Aminosäuren zur Gesamtzahl der Aminosäuren; objektiv Ähnlichkeit (similarity) Verhältnis ähnlicher Aminosäuren
Gleichheit, Ähnlichkeit, Homologie Identität (identity) Verhältnis der Anzahl identischer Aminosäuren zur Gesamtzahl der Aminosäuren; objektiv Ähnlichkeit (similarity) Verhältnis ähnlicher Aminosäuren
DATENQUALITÄT IN GENOMDATENBANKEN
 DATENQUALITÄT IN GENOMDATENBANKEN Alexander Fehr 28. Januar 2004 Gliederung Motivation Biologische Grundkonzepte Genomdaten Datenproduktion und Fehler Data Cleansing 2 Motivation (1) Genomdatenbanken enthalten
DATENQUALITÄT IN GENOMDATENBANKEN Alexander Fehr 28. Januar 2004 Gliederung Motivation Biologische Grundkonzepte Genomdaten Datenproduktion und Fehler Data Cleansing 2 Motivation (1) Genomdatenbanken enthalten
Organisation und Evolution des Genoms
 Organisation und Evolution des Genoms Organisation und Evolution des Genoms Definition Genom: vollständige DNA-Sequenz eines Organismus I. Einfachstes Genom: Prokaryoten Zwei Gruppen, evolutionär unterschiedlicher
Organisation und Evolution des Genoms Organisation und Evolution des Genoms Definition Genom: vollständige DNA-Sequenz eines Organismus I. Einfachstes Genom: Prokaryoten Zwei Gruppen, evolutionär unterschiedlicher
BIOINFORMATIK UEBUNGEN UMIT SS2014
 BIOINFORMATIK UEBUNGEN UMIT SS2014 Dietmar Rieder http://icbi.at/courses/abi.html Organisatorisches Termine Übungsziele Arbeiten biologischer Datenbanken (NCBI, ) Arbeiten mit Protein und DNA/RNA Sequenzen
BIOINFORMATIK UEBUNGEN UMIT SS2014 Dietmar Rieder http://icbi.at/courses/abi.html Organisatorisches Termine Übungsziele Arbeiten biologischer Datenbanken (NCBI, ) Arbeiten mit Protein und DNA/RNA Sequenzen
Informationsgehalt von DNA
 Informationsgehalt von DNA Topics Genes code, gene organisation, signals, gene detection Genomes genome organisation, nucleotide patterns, junk DNA DNA als Informationsträger DNA Building Blocks Desoxyribose
Informationsgehalt von DNA Topics Genes code, gene organisation, signals, gene detection Genomes genome organisation, nucleotide patterns, junk DNA DNA als Informationsträger DNA Building Blocks Desoxyribose
BIOINFORMATIK UEBUNGEN MOLZEB SS2014
 BIOINFORMATIK UEBUNGEN MOLZEB SS2014 Dietmar Rieder icbi.at/courses/bioinformatics_lfu.html Organisatorisches Termine Übungsziele Kennlernen biologischer Datenbanken (NCBI, ) Arbeiten mit Protein und DNA/RNA
BIOINFORMATIK UEBUNGEN MOLZEB SS2014 Dietmar Rieder icbi.at/courses/bioinformatics_lfu.html Organisatorisches Termine Übungsziele Kennlernen biologischer Datenbanken (NCBI, ) Arbeiten mit Protein und DNA/RNA
MOL.504 Analyse von DNA- und Proteinsequenzen. Übungsaufgaben Datenbanken und Informationssysteme
 MOL.504 Analyse von DNA- und Proteinsequenzen Übungsaufgaben Datenbanken und Informationssysteme Ü1 Tutorial für NCBI NCBI Nucleotide: Suche nach cellobiose dehydrogenase fungi Ü1 Tutorial für NCBI NCBI
MOL.504 Analyse von DNA- und Proteinsequenzen Übungsaufgaben Datenbanken und Informationssysteme Ü1 Tutorial für NCBI NCBI Nucleotide: Suche nach cellobiose dehydrogenase fungi Ü1 Tutorial für NCBI NCBI
Einblicke in das menschliche Erbgut (Genom) am Computer
 am Computer") Einblicke in das menschliche Erbgut (Genom) am Computer Prof. Dr. Antje Krause FH Bingen 06721 / 409 253 akrause@fh-bingen.de Binger Nacht der Wissenschaft - 16.04.2010 Das menschliche Genom ist entschlüsselt
Einblicke in das menschliche Erbgut (Genom) am Computer Prof. Dr. Antje Krause FH Bingen 06721 / 409 253 akrause@fh-bingen.de Binger Nacht der Wissenschaft - 16.04.2010 Das menschliche Genom ist entschlüsselt
Bioinformatik Übungen SS 2010 ABI
 Bioinformatik Übungen SS 2010 ABI stephan.pabinger@i-med.ac.at http://genome.tugraz.at/umit/ 1 Übung I Rückblick 2 3 Übung I - Rückblick Unterschied: CDS - mrna 4 Übung I - Rückblick Unterschied: CDS mrna
Bioinformatik Übungen SS 2010 ABI stephan.pabinger@i-med.ac.at http://genome.tugraz.at/umit/ 1 Übung I Rückblick 2 3 Übung I - Rückblick Unterschied: CDS - mrna 4 Übung I - Rückblick Unterschied: CDS mrna
1/10. Ihre Namen: Gruppe: Evolutionsbiologie 2, WS2015/2016: Bioinformatik - Übung 1
 Ihre Namen: Gruppe: Evolutionsbiologie 2, WS2015/2016: Bioinformatik - Übung 1 Erstellen Sie bitte vor Beginn der Übung einen Ordner auf dem Desktop, in dem Sie alle benötigten Dateien speichern können
Ihre Namen: Gruppe: Evolutionsbiologie 2, WS2015/2016: Bioinformatik - Übung 1 Erstellen Sie bitte vor Beginn der Übung einen Ordner auf dem Desktop, in dem Sie alle benötigten Dateien speichern können
Bioinformatik an der FH Bingen
 Bioinformatik an der FH Bingen Prof. Dr. Antje Krause 05.11.2010 Wie alles begann... 1955 erste Proteinsequenz (nach 12 Jahren Arbeit) veröffentlicht (Insulin vom Rind) Frederick Sanger MALWTRLRPLLALLALWPPPPA
Bioinformatik an der FH Bingen Prof. Dr. Antje Krause 05.11.2010 Wie alles begann... 1955 erste Proteinsequenz (nach 12 Jahren Arbeit) veröffentlicht (Insulin vom Rind) Frederick Sanger MALWTRLRPLLALLALWPPPPA
Strategien der Gensuche. Datenbanken in der Molekularbiologie. Genomforschung und Sequenzanalyse - Einführung in Methoden der Bioinformatik-
 WS2016/2017 Genomforschung und Sequenzanalyse - Einführung in Methoden der Bioinformatik- Thomas Hankeln Human %GC 80 60 40 CEPG1 C11orf14 C11orf18 C11orf15 C11orf16 C11orf17 ASCL3 Strategien der Gensuche
WS2016/2017 Genomforschung und Sequenzanalyse - Einführung in Methoden der Bioinformatik- Thomas Hankeln Human %GC 80 60 40 CEPG1 C11orf14 C11orf18 C11orf15 C11orf16 C11orf17 ASCL3 Strategien der Gensuche
Attached! Proseminar Netzwerkanalyse SS 2004 Thema: Biologie
 Rheinisch-Westfälischen Technischen Hochschule Aachen Lehr- und Forschungsgebiet Theoretische Informatik Prof. Rossmanith Attached! Proseminar Netzwerkanalyse SS 2004 Thema: Biologie Deniz Özmen Emmanuel
Rheinisch-Westfälischen Technischen Hochschule Aachen Lehr- und Forschungsgebiet Theoretische Informatik Prof. Rossmanith Attached! Proseminar Netzwerkanalyse SS 2004 Thema: Biologie Deniz Özmen Emmanuel
Einführung in die Angewandte Bioinformatik: Nukleotidsequenz-Datenbanken
 Einführung in die Angewandte Bioinformatik: Nukleotidsequenz-Datenbanken 06.05.2010 Prof. Dr. Sven Rahmann 1 Datenbanken am NCBI über Entrez http://www.ncbi.nlm.nih.gov/entrez NIH = National Institute
Einführung in die Angewandte Bioinformatik: Nukleotidsequenz-Datenbanken 06.05.2010 Prof. Dr. Sven Rahmann 1 Datenbanken am NCBI über Entrez http://www.ncbi.nlm.nih.gov/entrez NIH = National Institute
Zentrales Dogma der Biologie
 Zentrales Dogma der Biologie Transkription: von der DNA zur RNA Biochemie 01/1 Transkription Biochemie 01/2 Transkription DNA: RNA: Biochemie 01/3 Transkription DNA: RNA: Biochemie 01/4 Transkription RNA:
Zentrales Dogma der Biologie Transkription: von der DNA zur RNA Biochemie 01/1 Transkription Biochemie 01/2 Transkription DNA: RNA: Biochemie 01/3 Transkription DNA: RNA: Biochemie 01/4 Transkription RNA:
Klausur zum Modul Molekularbiologie ILS, SS 2010 Freitag 6. August 10:00 Uhr
 Klausur zum Modul Molekularbiologie ILS, SS 2010 Freitag 6. August 10:00 Uhr Name: Matrikel-Nr.: Code Nummer: Bitte geben Sie Ihre Matrikel-Nr. und Ihren Namen an. Die Code-Nummer erhalten Sie zu Beginn
Klausur zum Modul Molekularbiologie ILS, SS 2010 Freitag 6. August 10:00 Uhr Name: Matrikel-Nr.: Code Nummer: Bitte geben Sie Ihre Matrikel-Nr. und Ihren Namen an. Die Code-Nummer erhalten Sie zu Beginn
Eikon Crashkurs Eikon ist eine Software von Thomson Reuters um Finanzinformationen abzurufen und zu analysieren.
 Eikon Crashkurs Eikon ist eine Software von Thomson Reuters um Finanzinformationen abzurufen und zu analysieren. Erste Schritte - Navigation Toolbar Nach dem Starten von Eikon öffnet sich die Toolbar am
Eikon Crashkurs Eikon ist eine Software von Thomson Reuters um Finanzinformationen abzurufen und zu analysieren. Erste Schritte - Navigation Toolbar Nach dem Starten von Eikon öffnet sich die Toolbar am
Primärstruktur. Wintersemester 2011/12. Peter Güntert
 Primärstruktur Wintersemester 2011/12 Peter Güntert Primärstruktur Beziehung Sequenz Struktur Proteinsequenzen, Sequenzdatenbanken Sequenzvergleich (sequence alignment) Sequenzidentität, Sequenzhomologie
Primärstruktur Wintersemester 2011/12 Peter Güntert Primärstruktur Beziehung Sequenz Struktur Proteinsequenzen, Sequenzdatenbanken Sequenzvergleich (sequence alignment) Sequenzidentität, Sequenzhomologie
Transkription Teil 2. - Transkription bei Eukaryoten -
 Transkription Teil 2 - Transkription bei Eukaryoten - Inhalte: Unterschiede in der Transkription von Pro- und Eukaryoten Die RNA-Polymerasen der Eukaryoten Cis- und trans-aktive Elemente Promotoren Transkriptionsfaktoren
Transkription Teil 2 - Transkription bei Eukaryoten - Inhalte: Unterschiede in der Transkription von Pro- und Eukaryoten Die RNA-Polymerasen der Eukaryoten Cis- und trans-aktive Elemente Promotoren Transkriptionsfaktoren
C SB. Genomics Herausforderungen und Chancen. Genomics. Genomic data. Prinzipien dominieren über Detail-Fluten. in 10 Minuten!
 Genomics Herausforderungen und Chancen Prinzipien dominieren über Detail-Fluten Genomics in 10 Minuten! biol. Prin cip les Genomic data Dr.Thomas WERNER Scientific & Business Consulting +49 89 81889252
Genomics Herausforderungen und Chancen Prinzipien dominieren über Detail-Fluten Genomics in 10 Minuten! biol. Prin cip les Genomic data Dr.Thomas WERNER Scientific & Business Consulting +49 89 81889252
Eine Detailsuche in der Cochrane Library
 Eine Detailsuche in der Cochrane Library Suche in allen Texten nach den Begriffen schizo*, drugs, atypical und antipsychotic Suche in allen Datenbanken der Cochrane Library Folgende Suchfunktionen stehen
Eine Detailsuche in der Cochrane Library Suche in allen Texten nach den Begriffen schizo*, drugs, atypical und antipsychotic Suche in allen Datenbanken der Cochrane Library Folgende Suchfunktionen stehen
Evolution & Genetik (Beispiel Hämoglobin) Prof. Dr. Antje Krause FH Bingen 06721 / 409 253 akrause@fh-bingen.de
 Prof. Dr. Antje Krause FH Bingen 06721 / 409 253 akrause@fh-bingen.de") Evolution & Genetik (Beispiel Hämoglobin) Prof. Dr. Antje Krause FH Bingen 06721 / 409 253 akrause@fh-bingen.de DNA (Desoxyribonukleinsäure) 5 3 CGATGTACATCG GCTACATGTAGC 3 5 Doppelhelix Basen: Adenin,
Evolution & Genetik (Beispiel Hämoglobin) Prof. Dr. Antje Krause FH Bingen 06721 / 409 253 akrause@fh-bingen.de DNA (Desoxyribonukleinsäure) 5 3 CGATGTACATCG GCTACATGTAGC 3 5 Doppelhelix Basen: Adenin,
Projekt. Java-Anwendung für die Sequenzanalyse (Metagenomik und Transkriptomik)
") Projekt Java-Anwendung für die Sequenzanalyse (Metagenomik und Transkriptomik) MHH Prof. Tümmler, Dr. Davenport FH Prof. Sprengel, Prof. Ahlers C. Davenport colindavengmail.com Version 27.09.2010 Spezifikation
Projekt Java-Anwendung für die Sequenzanalyse (Metagenomik und Transkriptomik) MHH Prof. Tümmler, Dr. Davenport FH Prof. Sprengel, Prof. Ahlers C. Davenport colindavengmail.com Version 27.09.2010 Spezifikation
Ihre Namen: Gruppe: Öffnen Sie die Fasta-Dateien nur mit einem Texteditor, z.b. Wordpad oder Notepad, nicht mit Microsoft Word oder Libre Office.
 Ihre Namen: Gruppe: Evolutionsbiologie 2, WS2016/2017: Bioinformatik - Übung 1 Erstellen Sie vor Beginn der Übung einen Ordner auf dem Desktop, in dem Sie alle benötigten Dateien speichern kö nnen (z.b.
Ihre Namen: Gruppe: Evolutionsbiologie 2, WS2016/2017: Bioinformatik - Übung 1 Erstellen Sie vor Beginn der Übung einen Ordner auf dem Desktop, in dem Sie alle benötigten Dateien speichern kö nnen (z.b.
Swissmem ebooks ebook Funktionen Software Version 4.x (PC)
") Swissmem ebooks ebook Funktionen Software Version 4.x (PC) 25.08.2017 Inhalt 6.0.0 ebook Funktionen 2 6.1.0 Übersicht...2 6.2.0 Notizen...3 6.2.1 Einfaches Notizfeld...3 6.2.2 Handschriftliches Notizfeld...6
Swissmem ebooks ebook Funktionen Software Version 4.x (PC) 25.08.2017 Inhalt 6.0.0 ebook Funktionen 2 6.1.0 Übersicht...2 6.2.0 Notizen...3 6.2.1 Einfaches Notizfeld...3 6.2.2 Handschriftliches Notizfeld...6
Swissmem ebooks ebook Funktionen Software Version 4.x (PC)
") Swissmem ebooks ebook Funktionen Software Version 4.x (PC) 29.05.2017 Inhalt 6.0.0 ebook Funktionen 2 6.1.0 Übersicht...2 6.2.0 Notizen...3 6.2.1 Einfaches Notizfeld...3 6.2.2 Handschriftliches Notizfeld...6
Swissmem ebooks ebook Funktionen Software Version 4.x (PC) 29.05.2017 Inhalt 6.0.0 ebook Funktionen 2 6.1.0 Übersicht...2 6.2.0 Notizen...3 6.2.1 Einfaches Notizfeld...3 6.2.2 Handschriftliches Notizfeld...6
Pharmazeutische Biologie WS2011/2012. Das neue Paradigma: Personalisierte Medizin
 3. Vorlesung Pharmazeutische Biologie WS2011/2012 Das neue Paradigma: Personalisierte Medizin Prof. Theo Dingermann Institut für Pharmazeutische Biologie Biozentrum Max-von Laue-Str. 9 60438 Frankfurt
3. Vorlesung Pharmazeutische Biologie WS2011/2012 Das neue Paradigma: Personalisierte Medizin Prof. Theo Dingermann Institut für Pharmazeutische Biologie Biozentrum Max-von Laue-Str. 9 60438 Frankfurt
Multiple Alignments. Vorlesung Einführung in die Angewandte Bioinformatik Prof. Dr. Sven Rahmann. Webseite zur Vorlesung
 Multiple Alignments Vorlesung Einführung in die Angewandte Bioinformatik Prof. Dr. Sven Rahmann Webseite zur Vorlesung http://bioinfo.wikidot.com/ Sprechstunde Mo 16-17 in OH14, R214 Sven.Rahmann -at-
Multiple Alignments Vorlesung Einführung in die Angewandte Bioinformatik Prof. Dr. Sven Rahmann Webseite zur Vorlesung http://bioinfo.wikidot.com/ Sprechstunde Mo 16-17 in OH14, R214 Sven.Rahmann -at-
Grundlagen der Bioinformatik Assignment 3: Hierarchical Clustering SS Yvonne Lichtblau/Johannes Starlinger
 Grundlagen der Bioinformatik Assignment 3: Hierarchical Clustering SS 2017 Yvonne Lichtblau/Johannes Starlinger Presentations Assignment 2 Yvonne Lichtblau Übungen Grundlagen der Bioinformatik SS 2017
Grundlagen der Bioinformatik Assignment 3: Hierarchical Clustering SS 2017 Yvonne Lichtblau/Johannes Starlinger Presentations Assignment 2 Yvonne Lichtblau Übungen Grundlagen der Bioinformatik SS 2017
Folien und Supplementals auf
 Folien und Supplementals auf www.biokemika.de Folien und Supplementals auf www.biokemika.de Motivation Die Link-Liste auf ExPASy bietet eine gute Übersicht man verliert sich aber leicht. Es gibt viele
Folien und Supplementals auf www.biokemika.de Folien und Supplementals auf www.biokemika.de Motivation Die Link-Liste auf ExPASy bietet eine gute Übersicht man verliert sich aber leicht. Es gibt viele
Exercises to Introduction to Bioinformatics Assignment 5: Protein interaction networks. Samira Jaeger
 Exercises to Introduction to Bioinformatics Assignment 5: Protein interaction networks Samira Jaeger Aufgabe 1 Netzwerkzentralität (6P) In der Vorlesung haben Degree Centrality besprochen. Finde drei weitere
Exercises to Introduction to Bioinformatics Assignment 5: Protein interaction networks Samira Jaeger Aufgabe 1 Netzwerkzentralität (6P) In der Vorlesung haben Degree Centrality besprochen. Finde drei weitere
Arbeiten mit Suchergebnissen
 Arbeiten mit Suchergebnissen Inhalt 1. Gruppieren... 2 2. Filter... 5 3. Sortieren... 7 4. Feldauswahl... 8 4.1. neue Felder hinzufügen... 8 4.2. bestehende Felder entfernen... 9 5. Summen bilden... 10
Arbeiten mit Suchergebnissen Inhalt 1. Gruppieren... 2 2. Filter... 5 3. Sortieren... 7 4. Feldauswahl... 8 4.1. neue Felder hinzufügen... 8 4.2. bestehende Felder entfernen... 9 5. Summen bilden... 10
Vorlesung Molekulare Humangenetik
 Vorlesung Molekulare Humangenetik WS 2013/2014 Dr. Shamsadin DNA-RNA-Protein Allgemeines Prüfungen o. Klausuren als indiv. Ergänzung 3LP benotet o. unbenotet Seminar Block 2LP Vorlesung Donnerstags 14-16
Vorlesung Molekulare Humangenetik WS 2013/2014 Dr. Shamsadin DNA-RNA-Protein Allgemeines Prüfungen o. Klausuren als indiv. Ergänzung 3LP benotet o. unbenotet Seminar Block 2LP Vorlesung Donnerstags 14-16
Kartenansicht mit GPS- Koordinaten
 Kartenansicht Koordinaten mit GPS- Es gibt Kameras und spezielle GPS Aufzeichnungsgeräte, die zum Zeitpunkt der Aufnahme eines Bildes die exakten GEOKoordinaten in die Bilddateien schreiben. Daminion ist
Kartenansicht Koordinaten mit GPS- Es gibt Kameras und spezielle GPS Aufzeichnungsgeräte, die zum Zeitpunkt der Aufnahme eines Bildes die exakten GEOKoordinaten in die Bilddateien schreiben. Daminion ist
Klausur Bioinformatik für Biotechnologen
 Name, Vorname: 1 Klausur Bioinformatik für Biotechnologen Studiengang Molekulare Biotechnologie TU Dresden WS 2011/2012 Prof. Michael Schroeder 15.02.2012 Die Dauer der Klausur beträgt 90 Minuten. Bitte
Name, Vorname: 1 Klausur Bioinformatik für Biotechnologen Studiengang Molekulare Biotechnologie TU Dresden WS 2011/2012 Prof. Michael Schroeder 15.02.2012 Die Dauer der Klausur beträgt 90 Minuten. Bitte
Wie nutzt man die Jobsuche am effektivsten?
 Wie nutzt man die Jobsuche am effektivsten? Inhaltsverzeichnis Das Suchformular Seite 2... Die Funktion Jobs durchsuchen Seite 4... Optimieren der Suchergebnis-Seite Seite 5... Optimieren der Suchergebnisse
Wie nutzt man die Jobsuche am effektivsten? Inhaltsverzeichnis Das Suchformular Seite 2... Die Funktion Jobs durchsuchen Seite 4... Optimieren der Suchergebnis-Seite Seite 5... Optimieren der Suchergebnisse
MOL.504 Analyse von DNA- und Proteinsequenzen
 MOL.504 Analyse von DNA- und Proteinsequenzen Kurs 1 Monika Oberer, Karl Gruber MOL.504 Modul-Übersicht Einführung, Datenbanken BLAST-Suche, Sequenzalignment Proteinstrukturen Virtuelles Klonieren Abschlusstest
MOL.504 Analyse von DNA- und Proteinsequenzen Kurs 1 Monika Oberer, Karl Gruber MOL.504 Modul-Übersicht Einführung, Datenbanken BLAST-Suche, Sequenzalignment Proteinstrukturen Virtuelles Klonieren Abschlusstest
Ausprägungsfach Bioinformatik im Rahmen des Bachelor-Studiengangs Informatik. CIBIV Center for Integrative Bioinformatics Vienna
 Ausprägungsfach Bioinformatik im Rahmen des Bachelor-Studiengangs Informatik Center for Integrative Bioinformatics Vienna (CIBIV) Max F. Perutz Laboratories (MFPL) Vienna, Austria http://www.cibiv.at CIBIV
Ausprägungsfach Bioinformatik im Rahmen des Bachelor-Studiengangs Informatik Center for Integrative Bioinformatics Vienna (CIBIV) Max F. Perutz Laboratories (MFPL) Vienna, Austria http://www.cibiv.at CIBIV
Trio-Analyse (Exome-Seq)
") WS2017/2018 MSc Modul 7A Genomforschung und Sequenzanalyse - Einführung in Methoden der Bioinformatik- AG Hankeln Trio-Analyse (Exome-Seq) Mutationen mit Krankheitsrelevanz im Humangenom More than 3800
WS2017/2018 MSc Modul 7A Genomforschung und Sequenzanalyse - Einführung in Methoden der Bioinformatik- AG Hankeln Trio-Analyse (Exome-Seq) Mutationen mit Krankheitsrelevanz im Humangenom More than 3800
Bioinformatik: The Next Generation
 Bioinformatik: The Next Generation Prof. Dr. Caroline Friedel Lehr- und Forschungseinheit Bioinformatik Was ist Bioinformatik? Theoretische und Praktische Informatik Statistik, Mathematik Molekularbiologie,
Bioinformatik: The Next Generation Prof. Dr. Caroline Friedel Lehr- und Forschungseinheit Bioinformatik Was ist Bioinformatik? Theoretische und Praktische Informatik Statistik, Mathematik Molekularbiologie,
Im Programm navigieren Daten bearbeiten Daten erfassen Fließtext erfassen Daten ändern Daten ansehen...
 INHALTSVERZEICHNIS Im Programm navigieren... 2 Daten bearbeiten... 2 Daten erfassen... 2 Fließtext erfassen... 3 Daten ändern... 3 Daten ansehen... 4 Sortierung... 4 Spaltenanordnung... 4 Spaltenauswahl...
INHALTSVERZEICHNIS Im Programm navigieren... 2 Daten bearbeiten... 2 Daten erfassen... 2 Fließtext erfassen... 3 Daten ändern... 3 Daten ansehen... 4 Sortierung... 4 Spaltenanordnung... 4 Spaltenauswahl...
Willkommen. Benutzerhandbuch für die OECD Online-Bibliothek
 Willkommen Benutzerhandbuch für die OECD Online-Bibliothek Startseite Sie haben drei Möglichkeiten, zu den Studien und Statistiken der OECD zu gelangen: Klicken Sie oben auf die Kategorie, für die Sie
Willkommen Benutzerhandbuch für die OECD Online-Bibliothek Startseite Sie haben drei Möglichkeiten, zu den Studien und Statistiken der OECD zu gelangen: Klicken Sie oben auf die Kategorie, für die Sie
Schreibe ein Programm, das den AT Gehalt diese DNA Sequenz berechnet. Hinweis: A-Gehalt plus T-Gehalt bezogen auf die gesamte Sequenz.
 1 Einführung Keine Übungen 2 Python - Zeichenketten - "Strings" (1. Tag) 2.1 AT Gehalt berechnen Berechne aus der folgenden DNA Sequenz den AT-Gehalt. GAGATTTCTTTATTACAATCACTGTGTTTGTTAAAATACCTGCNTCACTTGGTTGTTCTTCAATAACACCAACTTA
1 Einführung Keine Übungen 2 Python - Zeichenketten - "Strings" (1. Tag) 2.1 AT Gehalt berechnen Berechne aus der folgenden DNA Sequenz den AT-Gehalt. GAGATTTCTTTATTACAATCACTGTGTTTGTTAAAATACCTGCNTCACTTGGTTGTTCTTCAATAACACCAACTTA
Preanalytical Benchmark Database
 Manual Preanalytical Benchmark Database Januar 2017 Zielsetzung Ziel dieses Projektes ist, dass Laboratorien in einem ersten Schritt die Hämolysedaten ihrer verschiedenen Einsenderbereiche (allgemeinstationär,
Manual Preanalytical Benchmark Database Januar 2017 Zielsetzung Ziel dieses Projektes ist, dass Laboratorien in einem ersten Schritt die Hämolysedaten ihrer verschiedenen Einsenderbereiche (allgemeinstationär,
Klonierung von S2P Rolle der M19-Zellen. POL-Seminar der Biochemie II 13.02.2007 Sebastian Gabriel
 Klonierung von S2P Rolle der M19-Zellen POL-Seminar der Biochemie II 13.02.2007 Sebastian Gabriel Inhalt 1. Was ist eine humane genomische DNA-Bank? 2. Unterschied zwischen cdna-bank und genomischer DNA-Bank?
Klonierung von S2P Rolle der M19-Zellen POL-Seminar der Biochemie II 13.02.2007 Sebastian Gabriel Inhalt 1. Was ist eine humane genomische DNA-Bank? 2. Unterschied zwischen cdna-bank und genomischer DNA-Bank?
Softwarewerkzeuge der. Bioinformatik
 Bioinformatik Wintersemester 2006/2007 Tutorial 1: Biologische Datenbanken SRS Tutorial 1: Datenbanken 1/22 Sequenzquellen DNA- Sequenzierung Protein- Sequenzierung Translation Proteinsequenzen Tutorial
Bioinformatik Wintersemester 2006/2007 Tutorial 1: Biologische Datenbanken SRS Tutorial 1: Datenbanken 1/22 Sequenzquellen DNA- Sequenzierung Protein- Sequenzierung Translation Proteinsequenzen Tutorial
2.1 Installation der Root-Zertifkate Installation des Client Zertifikat Überprüfung der installierten Zertifikate...
 Benutzerhandbuch Inhaltsangabe 1. Systemvoraussetzungen... 1 2. Installation der Zertifikate... 1 2.1 Installation der Root-Zertifkate... 1 2.1 Installation des Client Zertifikat... 2 2.3 Überprüfung der
Benutzerhandbuch Inhaltsangabe 1. Systemvoraussetzungen... 1 2. Installation der Zertifikate... 1 2.1 Installation der Root-Zertifkate... 1 2.1 Installation des Client Zertifikat... 2 2.3 Überprüfung der
AlgoBio WS 16/17 Protein-DNA Interaktionen ChiP-Seq Datenanalyse. Annalisa Marsico
 AlgoBio WS 16/17 Protein-DNA Interaktionen ChiP-Seq Datenanalyse Annalisa Marsico 6.02.2017 Protein-DNA Interaktionen Häufig binden sich Proteine an DNA, um ihre biologische Funktion zu regulieren. Transkriptionsfaktoren
AlgoBio WS 16/17 Protein-DNA Interaktionen ChiP-Seq Datenanalyse Annalisa Marsico 6.02.2017 Protein-DNA Interaktionen Häufig binden sich Proteine an DNA, um ihre biologische Funktion zu regulieren. Transkriptionsfaktoren
real.de Lister Lite Afterbuy Team (bs) 2017/03/01 16:56
 2017/03/01 16:56") real.de Lister Lite Afterbuy Team (bs) 2017/03/01 16:56 Inhaltsverzeichnis Page 2 of 10 - zuletzt bearbeitet von Afterbuy Team (bs) am 2017/03/01 16:56 real.de Schnittstelle einrichten Die Suchmaske und
real.de Lister Lite Afterbuy Team (bs) 2017/03/01 16:56 Inhaltsverzeichnis Page 2 of 10 - zuletzt bearbeitet von Afterbuy Team (bs) am 2017/03/01 16:56 real.de Schnittstelle einrichten Die Suchmaske und
Bioinformatik: The Next Generation
 Bioinformatik: The Next Generation Prof. Dr. Caroline Friedel Lehr- und Forschungseinheit Bioinformatik Was ist Bioinformatik? Prof. Dr. Caroline Friedel, Tag der offenen Tür der LMU 2 Was ist Bioinformatik?
Bioinformatik: The Next Generation Prof. Dr. Caroline Friedel Lehr- und Forschungseinheit Bioinformatik Was ist Bioinformatik? Prof. Dr. Caroline Friedel, Tag der offenen Tür der LMU 2 Was ist Bioinformatik?
Aufgabe 7: Distanzbasierte Phylogenie: Neighbor Joining. Stefan Kröger, Philippe Thomas Wissensmanagement in der Bioinformatik
 Aufgabe 7: Distanzbasierte Phylogenie: Neighbor Joining Stefan Kröger, Philippe Thomas Wissensmanagement in der Bioinformatik Daten Wir verwenden neue Daten Die müssen sie ausnahmsweise selber suchen DNA-Sequenzen
Aufgabe 7: Distanzbasierte Phylogenie: Neighbor Joining Stefan Kröger, Philippe Thomas Wissensmanagement in der Bioinformatik Daten Wir verwenden neue Daten Die müssen sie ausnahmsweise selber suchen DNA-Sequenzen
InterPro & SP-ML. Syntax und Verwendung der Beschreibungssprache XML Ausarbeitung im Seminar XML in der Bioinformatik.
 InterPro & SP-ML Syntax und Verwendung der Beschreibungssprache XML Ausarbeitung im Seminar XML in der Bioinformatik Stefan Albaum 18. Dezember 2002 Inhaltsverzeichnis 1 SPTr-XML 2 1.1 SWISS-PROT...........................
InterPro & SP-ML Syntax und Verwendung der Beschreibungssprache XML Ausarbeitung im Seminar XML in der Bioinformatik Stefan Albaum 18. Dezember 2002 Inhaltsverzeichnis 1 SPTr-XML 2 1.1 SWISS-PROT...........................
MBI: Sequenz-Vergleich mit Alignment
 MBI: Sequenz-Vergleich mit Alignment Bernhard Haubold 28. Oktober 2014 Wiederholung: Was ist Bioinformatik? Historische Übersicht; CABIOS Bioinformatics Gemeinsames Thema: Information in vivo DNA Epigenetik
MBI: Sequenz-Vergleich mit Alignment Bernhard Haubold 28. Oktober 2014 Wiederholung: Was ist Bioinformatik? Historische Übersicht; CABIOS Bioinformatics Gemeinsames Thema: Information in vivo DNA Epigenetik
Informationstechnologie in der Pflanzenzüchtung. Biocomputing in einem Züchtungsunternehmen. Andreas Menze KWS SAAT AG, Einbeck
 Informationstechnologie in der Pflanzenzüchtung Biocomputing in einem Züchtungsunternehmen Andreas Menze KWS SAAT AG, Einbeck Biocomputing in einem Züchtungsunternehmen Biocomputing Was ist das? Wozu wird
Informationstechnologie in der Pflanzenzüchtung Biocomputing in einem Züchtungsunternehmen Andreas Menze KWS SAAT AG, Einbeck Biocomputing in einem Züchtungsunternehmen Biocomputing Was ist das? Wozu wird
Tags filtern im Eigenschaften-Panel
 Tags filtern im Eigenschaften-Panel Im Eigenschaften-Panel werden Ihnen alle Informationen zu dem jeweils im Browser selektierten Element angezeigt. Sie können dort weitere Tags wie z.b. Stichwörter hinzufügen
Tags filtern im Eigenschaften-Panel Im Eigenschaften-Panel werden Ihnen alle Informationen zu dem jeweils im Browser selektierten Element angezeigt. Sie können dort weitere Tags wie z.b. Stichwörter hinzufügen
Vorlesungsthemen Mikrobiologie
 Vorlesungsthemen Mikrobiologie 1. Einführung in die Mikrobiologie B. Bukau 2. Zellaufbau von Prokaryoten B. Bukau 3. Bakterielles Wachstum und Differenzierung B. Bukau 4. Bakterielle Genetik und Evolution
Vorlesungsthemen Mikrobiologie 1. Einführung in die Mikrobiologie B. Bukau 2. Zellaufbau von Prokaryoten B. Bukau 3. Bakterielles Wachstum und Differenzierung B. Bukau 4. Bakterielle Genetik und Evolution
Arten der Intronen. Spliceosome Struktur des snrnp U1. Spliceosome. Vorlesung 3: Evolution des eukaryotischen Genoms 4/20/11
 Vorlesung 3: Evolution des eukaryotischen Genoms Struktur des eukaryotischen Gens Intronen und Exonen Genduplikation--Familien des Gens Eiweißdomänen (Protein domains) Domänen und Exonen: sind sie verwandt?
Vorlesung 3: Evolution des eukaryotischen Genoms Struktur des eukaryotischen Gens Intronen und Exonen Genduplikation--Familien des Gens Eiweißdomänen (Protein domains) Domänen und Exonen: sind sie verwandt?
Was ist Bioinformatik?
 9. Kurstag: Bioinformatik Der Begriff "Bioinformatik" wurde 1989 erstmals von D.R. Masys im JOURNAL OF RESEARCH OF THE NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY erwähnt. Was ist Bioinformatik? Die
9. Kurstag: Bioinformatik Der Begriff "Bioinformatik" wurde 1989 erstmals von D.R. Masys im JOURNAL OF RESEARCH OF THE NATIONAL INSTITUTE OF STANDARDS AND TECHNOLOGY erwähnt. Was ist Bioinformatik? Die
Einführung Molekulare Bioinformatik
 Einführung Molekulare Bioinformatik Bernhard Haubold 21. Oktober 2014 Übersicht Was ist Bioinformatik? Kursstruktur Was ist Bioinformatik? Geschichtliche Entwicklung Information: Speicherung & Übertragung
Einführung Molekulare Bioinformatik Bernhard Haubold 21. Oktober 2014 Übersicht Was ist Bioinformatik? Kursstruktur Was ist Bioinformatik? Geschichtliche Entwicklung Information: Speicherung & Übertragung
Beschreiben Sie in Stichworten zwei der drei Suppressormutationen, die man in Hefe charakterisiert hat. Starzinski-Powitz, 6 Fragen, 53 Punkte Name
 Starzinski-Powitz, 6 Fragen, 53 Punkte Name Frage 1 8 Punkte Nennen Sie 2 Möglichkeiten, wie der Verlust von Heterozygotie bei Tumorsuppressorgenen (Z.B. dem Retinoblastomgen) zum klompletten Funktionsverlust
Starzinski-Powitz, 6 Fragen, 53 Punkte Name Frage 1 8 Punkte Nennen Sie 2 Möglichkeiten, wie der Verlust von Heterozygotie bei Tumorsuppressorgenen (Z.B. dem Retinoblastomgen) zum klompletten Funktionsverlust
GPilotS Dokumentation Version 5
 GPilotS Dokumentation Version 5 Hinweis: Text in eckigen Klammern [GPS] bezeichnet die Auswahl eines Menüpunktes, Text in runden Klammern (Ok) bezeichnet eine Eingabe in einem Auswahlbildschirm. ACHTUNG:
GPilotS Dokumentation Version 5 Hinweis: Text in eckigen Klammern [GPS] bezeichnet die Auswahl eines Menüpunktes, Text in runden Klammern (Ok) bezeichnet eine Eingabe in einem Auswahlbildschirm. ACHTUNG:
Das Schönste am Computer ist doch die Nutzung des Internets, speziell des World Wide Web, in dem Sie Webseiten zu allen denkbaren Themen sowie
 Im Web surfen mit dem 6 Das Schönste am Computer ist doch die Nutzung des Internets, speziell des World Wide Web, in dem Sie Webseiten zu allen denkbaren Themen sowie weitere Inhalte finden. Zum Durchforsten
Im Web surfen mit dem 6 Das Schönste am Computer ist doch die Nutzung des Internets, speziell des World Wide Web, in dem Sie Webseiten zu allen denkbaren Themen sowie weitere Inhalte finden. Zum Durchforsten
1. Benennen Sie die Elemente der Access-Benutzeroberfläche: Wann müssen Sie einer Datenbank einen Namen geben?
 Fragenkatalog Access 2007 501 Benutzeroberfläche 1. Benennen Sie die Elemente der Access-Benutzeroberfläche: 2. Wann müssen Sie einer Datenbank einen Namen geben? o Beim Erstellen o Spätestens beim Schließen
Fragenkatalog Access 2007 501 Benutzeroberfläche 1. Benennen Sie die Elemente der Access-Benutzeroberfläche: 2. Wann müssen Sie einer Datenbank einen Namen geben? o Beim Erstellen o Spätestens beim Schließen
Seiten und Navigationspunkte
 Seiten und Navigationspunkte Legen Sie neue Seiten und Navigationspunkte an. Um Sie mit dem Anlegen von Seiten und Navigationspunkten vertraut zu machen, legen wir zunächst einen neuen Navigationspunkt
Seiten und Navigationspunkte Legen Sie neue Seiten und Navigationspunkte an. Um Sie mit dem Anlegen von Seiten und Navigationspunkten vertraut zu machen, legen wir zunächst einen neuen Navigationspunkt
GTL Global Technical Library
 GTL Global Technical Library Bedienungsanleitung Technical Publication Tower V4 09.2016 1 Vorwort Betriebssystem Kompatibler Browser Windows Internet Explorer 8*, 9, 10, 11 Firefox 24+ Chrome 37+ Opera
GTL Global Technical Library Bedienungsanleitung Technical Publication Tower V4 09.2016 1 Vorwort Betriebssystem Kompatibler Browser Windows Internet Explorer 8*, 9, 10, 11 Firefox 24+ Chrome 37+ Opera
Online Suchsystem Guide
 Liebe Kreative, auf den folgenden Seiten möchten wir Euch einige Hinweise geben, die den Umgang mit der Suchmaschine erleichtern und Euch dabei helfen sollen, schnell und zielsicher zur passenden Musik
Liebe Kreative, auf den folgenden Seiten möchten wir Euch einige Hinweise geben, die den Umgang mit der Suchmaschine erleichtern und Euch dabei helfen sollen, schnell und zielsicher zur passenden Musik
Bioinformatik Für Biophysiker
 Bioinformatik Für Biophysiker Sommersemester 2009 Silke Trißl / Ulf Leser Wissensmanagement in der Bioinformatik Wissensmanagement in der Bioinformatik Schwerpunkte Algorithmen der Bioinformatik Management
Bioinformatik Für Biophysiker Sommersemester 2009 Silke Trißl / Ulf Leser Wissensmanagement in der Bioinformatik Wissensmanagement in der Bioinformatik Schwerpunkte Algorithmen der Bioinformatik Management
1. Benennen Sie die Elemente der Access-Benutzeroberfläche: Wann müssen Sie einer Datenbank einen Namen geben?
 Fragenkatalog Access 2003 Daniela Wagner 501 Benutzeroberfläche 1. Benennen Sie die Elemente der Access-Benutzeroberfläche: 2. Wann müssen Sie einer Datenbank einen Namen geben? o Beim Erstellen o Spätestens
Fragenkatalog Access 2003 Daniela Wagner 501 Benutzeroberfläche 1. Benennen Sie die Elemente der Access-Benutzeroberfläche: 2. Wann müssen Sie einer Datenbank einen Namen geben? o Beim Erstellen o Spätestens
Gentechnologie für Einsteiger
 T. A. Brown Gentechnologie für Einsteiger 3. Auflage Aus dem Englischen übersetzt von Sebastian Vogel Spektrum Akademischer Verlag Heidelberg Berlin Vorwort Vorwort zur dritten englischen Auflage Vorwort
T. A. Brown Gentechnologie für Einsteiger 3. Auflage Aus dem Englischen übersetzt von Sebastian Vogel Spektrum Akademischer Verlag Heidelberg Berlin Vorwort Vorwort zur dritten englischen Auflage Vorwort
Playlistmanager für den D2-Director
 Playlistmanager für den D2-Director Ein Programm zum bearbeiten, organisieren und auswerten der Datenbanken der Numark -Produkte: D2-Director, DDS, DDS-80, IDJ2 und HD-Mix Die Software läuft unter Windows
Playlistmanager für den D2-Director Ein Programm zum bearbeiten, organisieren und auswerten der Datenbanken der Numark -Produkte: D2-Director, DDS, DDS-80, IDJ2 und HD-Mix Die Software läuft unter Windows
Principles of heredity Mutations, substitutions and polymorphisms
 Bioinformatics 1 Principles of heredity Mutations, substitutions and polymorphisms Claudia Acquisti Evolutionary Functional Genomics Institute for Evolution and Biodiversity, WWU Münster claudia.acquisti@uni-muenster.de
Bioinformatics 1 Principles of heredity Mutations, substitutions and polymorphisms Claudia Acquisti Evolutionary Functional Genomics Institute for Evolution and Biodiversity, WWU Münster claudia.acquisti@uni-muenster.de
DNA mrna Protein. Initiation Elongation Termination. RNA Prozessierung. Unterschiede Pro /Eukaryoten
 7. Transkription Konzepte: DNA mrna Protein Initiation Elongation Termination RNA Prozessierung Unterschiede Pro /Eukaryoten 1. Aus welchen vier Nukleotiden ist RNA aufgebaut? 2. RNA unterscheidet sich
7. Transkription Konzepte: DNA mrna Protein Initiation Elongation Termination RNA Prozessierung Unterschiede Pro /Eukaryoten 1. Aus welchen vier Nukleotiden ist RNA aufgebaut? 2. RNA unterscheidet sich
In den Proteinen der Lebewesen treten in der Regel 20 verschiedene Aminosäuren auf. Deren Reihenfolge muss in der Nucleotidsequenz der mrna und damit
 In den Proteinen der Lebewesen treten in der Regel 20 verschiedene Aminosäuren auf. Deren Reihenfolge muss in der Nucleotidsequenz der mrna und damit in der Nucleotidsequenz der DNA verschlüsselt (codiert)
In den Proteinen der Lebewesen treten in der Regel 20 verschiedene Aminosäuren auf. Deren Reihenfolge muss in der Nucleotidsequenz der mrna und damit in der Nucleotidsequenz der DNA verschlüsselt (codiert)
Datenformat zum Import von CSV-Dateien
 Datenformat zum Import von CSV-Dateien (Eingabe für das BJ 2015; Stand Dez. 2015) Allgemeines Zur Vereinfachung der Dateneingabe für die Deutsche Bibliotheksstatistik (DBS) haben die Fachstellen die Möglichkeit,
Datenformat zum Import von CSV-Dateien (Eingabe für das BJ 2015; Stand Dez. 2015) Allgemeines Zur Vereinfachung der Dateneingabe für die Deutsche Bibliotheksstatistik (DBS) haben die Fachstellen die Möglichkeit,
Strukturierte Extraktion von Text aus PDF. Präsentation der Masterarbeit von Fabian Schillinger
 Strukturierte Extraktion von Text aus PDF Präsentation der Masterarbeit von Fabian Schillinger Übersicht Motivation Probleme bei der Textextraktion Ablauf des entwickelten Systems Ergebnisse Präsentation
Strukturierte Extraktion von Text aus PDF Präsentation der Masterarbeit von Fabian Schillinger Übersicht Motivation Probleme bei der Textextraktion Ablauf des entwickelten Systems Ergebnisse Präsentation
In diesem ersten Kapitel erhalten Sie einen Überblick über das Programm Microsoft PowerPoint 2003.
 In diesem ersten Kapitel erhalten Sie einen Überblick über das Programm Microsoft PowerPoint 2003. Was erfahren Sie in diesem Kapitel? Wozu man PowerPoint verwenden kann Wie man PowerPoint startet und
In diesem ersten Kapitel erhalten Sie einen Überblick über das Programm Microsoft PowerPoint 2003. Was erfahren Sie in diesem Kapitel? Wozu man PowerPoint verwenden kann Wie man PowerPoint startet und
Ab sofort ist es möglich, mehrere Formulare gleichzeitig zu bearbeiten, um Änderungen oder neue Eingaben gleichzeitig vornehmen zu können.
 ProjectNetWorld 6.4 In der Version ProjectNetWorld 6.4 erwarten Sie neue Funktionen und Weiterentwicklungen, die wir Ihnen im Folgenden kurz beschreiben. Alle Informationen erhalten Sie zudem in den Handbüchern
ProjectNetWorld 6.4 In der Version ProjectNetWorld 6.4 erwarten Sie neue Funktionen und Weiterentwicklungen, die wir Ihnen im Folgenden kurz beschreiben. Alle Informationen erhalten Sie zudem in den Handbüchern
Handbuch. Herzlich Willkommen im neuen ExpertenPortal der top itservices AG. Sie haben Fragen zu der Registrierung oder Bedienung?
 Handbuch Herzlich Willkommen im neuen ExpertenPortal der top itservices AG. Sie haben Fragen zu der Registrierung oder Bedienung? Schauen Sie in unserem Handbuch nach oder kontaktieren Sie unser Support
Handbuch Herzlich Willkommen im neuen ExpertenPortal der top itservices AG. Sie haben Fragen zu der Registrierung oder Bedienung? Schauen Sie in unserem Handbuch nach oder kontaktieren Sie unser Support
27 Funktionelle Genomanalysen Sachverzeichnis
 Inhaltsverzeichnis 27 Funktionelle Genomanalysen... 543 27.1 Einleitung... 543 27.2 RNA-Interferenz: sirna/shrna-screens 543 Gunter Meister 27.3 Knock-out-Technologie: homologe Rekombination im Genom der
Inhaltsverzeichnis 27 Funktionelle Genomanalysen... 543 27.1 Einleitung... 543 27.2 RNA-Interferenz: sirna/shrna-screens 543 Gunter Meister 27.3 Knock-out-Technologie: homologe Rekombination im Genom der
1. Skizzieren Sie schematisch ein Gen mit flankierender Region. Bezeichnen und beschriften Sie:
 1. Skizzieren Sie schematisch ein Gen mit flankierender Region. Bezeichnen und beschriften Sie: - 5 UTR (leader) - 3 UTR (trailer) - Terminator - Stopp-Kodon - Initiationskodon - Transkriptionsstartstelle
1. Skizzieren Sie schematisch ein Gen mit flankierender Region. Bezeichnen und beschriften Sie: - 5 UTR (leader) - 3 UTR (trailer) - Terminator - Stopp-Kodon - Initiationskodon - Transkriptionsstartstelle
DAS EINSTEIGERSEMINAR
 DAS EINSTEIGERSEMINAR Microsoft Office Excel 2010 Gudrun Rehn-Göstenmeier LERNEN ÜBEN ANWENDEN Teil I: Lernen L1 Dateiorganisation Bevor wir uns mit den Excel-spezifischen Befehlen und Funktionen befassen
DAS EINSTEIGERSEMINAR Microsoft Office Excel 2010 Gudrun Rehn-Göstenmeier LERNEN ÜBEN ANWENDEN Teil I: Lernen L1 Dateiorganisation Bevor wir uns mit den Excel-spezifischen Befehlen und Funktionen befassen
Online-Feldbuch User Manual Version
 Version 22.07.2015 Seite 1 von 16 Inhaltsverzeichnis 1 Zugang zum Online-Feldbuch 2 Login 3 Die Übersichtsseite des Online-Feldbuchs 4 Das Fundmeldeformular 5 Arbeiten mit dem Kartierfenster 6 Fundmeldungen
Version 22.07.2015 Seite 1 von 16 Inhaltsverzeichnis 1 Zugang zum Online-Feldbuch 2 Login 3 Die Übersichtsseite des Online-Feldbuchs 4 Das Fundmeldeformular 5 Arbeiten mit dem Kartierfenster 6 Fundmeldungen
Modell Bahn Verwaltung. Tutorial. Links. Min. Programm Version 0.65, März w w w. r f n e t. c h 1 / 11
 Modell Bahn Verwaltung Tutorial Links Min. Programm Version 0.65, März 2015 Tutorial Version 04.01.2017 rfnet Software w w w. r f n e t. c h 1 / 11 Vorwort... 3 1 Links... 4 1.1 Einführung... 4 1.2 Link
Modell Bahn Verwaltung Tutorial Links Min. Programm Version 0.65, März 2015 Tutorial Version 04.01.2017 rfnet Software w w w. r f n e t. c h 1 / 11 Vorwort... 3 1 Links... 4 1.1 Einführung... 4 1.2 Link
RÖK Typo3 Dokumentation
 2016 RÖK Typo3 Dokumentation Redakteur Sparten Eine Hilfe für den Einstieg in Typo3. Innpuls Werbeagentur GmbH 01.01.2016 2 RÖK Typo3 Dokumentation 1) Was ist Typo3?... 3 2) Typo3 aufrufen und Anmelden...
2016 RÖK Typo3 Dokumentation Redakteur Sparten Eine Hilfe für den Einstieg in Typo3. Innpuls Werbeagentur GmbH 01.01.2016 2 RÖK Typo3 Dokumentation 1) Was ist Typo3?... 3 2) Typo3 aufrufen und Anmelden...
Übungsaufgaben zur Einführung in die Bioinformatik - Lösungen
 18.01.2013 Prof. P. Güntert 1 Vorlesung BPC I: Aspekte der Thermodynamik in der Strukturbiologie Übungsaufgaben zur Einführung in die Bioinformatik - Lösungen 1. Hamming und Levenshtein Distanzen a) Was
18.01.2013 Prof. P. Güntert 1 Vorlesung BPC I: Aspekte der Thermodynamik in der Strukturbiologie Übungsaufgaben zur Einführung in die Bioinformatik - Lösungen 1. Hamming und Levenshtein Distanzen a) Was