TD-Gammon. Michael Zilske
|
|
|
- Alfred Fiedler
- vor 6 Jahren
- Abrufe
Transkript
1 TD-Gammon Michael Zilske


2 TD-Gammon Ein Backgammon-Spieler von Gerald Tesauro (Erste Version: 1991)
3 TD-Gammon Ein Neuronales Netz, das immer wieder gegen sich selbst spielt und dadurch lernt, eine gute Bewertungsfunktion für Backgammon-Positionen zu sein Eine Erfolgsgeschichte für Reinforcement Learning Der damals stärkste Computerspieler Weltklassespieler haben von TD-Gammon Eröffnungszüge übernommen.

4 Backgammon Ein uraltes Spiel für zwei Spieler Wahrscheinlich 1000 Jahre älter als Schach
5 Backgammon Es wird gewürfelt. Beide Spieler müssen ihre Steine nach Hause bringen. Denkt an Mensch, ärgere Dich nicht. Die Strecke ist eindimensional und kein Kreis. Die Spieler kommen einander entgegen. Einzelne Steine können herausgeworfen werden. Zusammen stehende Steine blockieren. Es wird um Geld gespielt, oder um Punkte in Matches aus vielen Runden.
6 Backgammon
7 Das Problem Komplexe Spiele haben riesige Zustandsmengen. Für Backgammon: ca Spiel nach Wertetabelle ist daher unmöglich. Hoher Verzweigungsfaktor Für Backgammon: etwa verschiedene Würfe durchschnittlich 20 mögliche Züge pro Wurf zu viel, um tief im Spielbaum zu suchen zum Vergleich: Schach Dame 8-10
8 Die Lösung Heuristische Bewertung von Spielpositionen Approximation der theoretischen Value-Function Bisherige Ansätze: Design einer Bewertungsheuristik mit menschlichen Experten Überwachtes Lernen eines neuronalen Netzes anhand einer Spieldatenbank (Neurogammon, 1989) Neuheiten bei TD-Gammon: keinerlei Vorwissen über das Spiel keinerlei Beeinflussung durch die Auffassung menschlicher Spieler
9 Das neuronale Netz approximiert beliebige stetige Funktionen lernt durch Änderung der Kantengewichte
10 Das neuronale Netz in TD-Gammon Eingabe: Einfache Repräsentation des Spielfeldinhalts durch 198 Werte Ausgabe: Geschätzte Wahrscheinlichkeit für einfachen Sieg doppelten Sieg einfachen Sieg des Gegners doppelten Sieg des Gegners Innere Knoten (hidden units)
11 Repräsentation einer Spielposition 4 Eingänge stehen für die Anzahl der weißen Steine auf einem Feld 4 Eingänge stehen für die Anzahl der schwarzen Steine auf einem Feld 2 Eingänge stehen für die weißen bzw. schwarzen Steine, die gerade herausgeworfen sind 4 Eingänge stehen für die weißen bzw. schwarzen Steine, die bereits zu Hause sind 2 Eingänge stehen dafür, ob weiß bzw. schwarz am Zuge ist
12 Ein Spielzug Würfle Bewerte für jeden möglichen Zug die resultierende Spielposition (after state) optional: schaue für einige der am besten bewerteten Positionen zwei oder drei Halbzüge in die Zukunft Wähle den besten Zug Lerne
13 Lernen Das Netz wird mit kleinen, zufälligen Gewichten initialisiert. Es bewertet zunächst völlig zufällig. Nach jedem Zug wird der TD(λ)-Algorithmus angewendet, um die Gewichte zu verbessern. w w = Y Y t t 1 t t 1 t k=1 t k w Y k
14 Lernen w: Kantengewichte des Netzes α: Lernparameter Y t+1 : Bewertung der Spielposition S t+1 durch das Netz mit den Gewichten w t λ: Verfallsparameter w w = Y Y t t 1 t t 1 t k=1 t k w Y k
15 Gradientenabstiegsverfahren Bilde den Gradienten des TD-Fehlers bezüglich der Kantengewichte. Interpretiere ihn als Maß dafür, wie stark das jeweilige Gewicht am Fehler beteiligt ist. Je größer der Gradient in einer gewissen Koordinate, desto stärker verändere das entsprechende Gewicht. w Y t 1 Y t 2
16 TD(λ) Auch Gewichte, die für länger zurückliegende Züge ausschlaggebend waren, sollen in Erwägung der aktuelle Position verbessert werden. Und zwar nicht bis zu einer festen Anzahl n vergangener Schritte, sondern durchgängig in geringerem Maße, je länger der Zug her ist. λ heißt Verfalls-Parameter und gibt an, wie stark die Relevanz einer zurückliegenden Entscheidung nach jedem Zug abnimmt. [0,1]
17 Eligibility Traces Konsequenz: Es wird ein Vektor aus sogenannten eligibility traces geführt. Sie geben an, in welchem Maße jedes Gewicht es gerade verdient (eligible), verändert zu werden, basierend auf aktueller und vergangener Relevanz.
18 Eligibility Traces Die eligibility traces werden nach jedem Zug mit dem Verfalls-Parameter multipliziert und verblassen etwas. Sodann kommen die Relevanzen für den aktuellen Fehler hinzu: e e w Y t
19 Nocheinmal: Die Lernformel Zusammengefasst: w w = Y Y e t 1 t t 1 t t e t = k=1 t t k w Y k e t 1 = e t Y w t
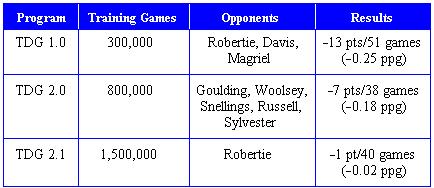
20 Erfolge
21 Splittest du oder slottest du? Seit einer Analyse durch TD-Gammon wird ein Eröffnungszug, der bis dahin als selbstverständlich galt, praktisch nicht mehr gespielt. Wurf: 4/1 weiß ist am Zug
22 Absolute und relative Genauigkeit TD-Gammons Einschätzungen liegen oft um mehr als einen zehntel Punkt daneben. Das macht aber nichts. Offenbar liegen die Einschätzungen benachbarter Züge hinreichend gleich daneben, so dass trotzdem sehr gute Entscheidungen getroffen werden.
23 Würfeln fördert den Lernprozess Weil gewürfelt wird, kommen automatisch sehr verschiedene Spielsituationen zustande. Das ist wichtig bei selbst lernenden Systemen. Sonst könnte es sein, dass bei schlechter Initialisierung große Teile des Positionsraums gar nicht besucht werden. Bei selbst lernenden Dame- und Go-Spielern ist das ein Problem. TD-Gammon hat und braucht keinen weiteren Mechanismus für erforschende Züge.
24 Würfeln fördert den Lernprozess Auch bei zwei dümmstmöglichen Spielern geht das Spiel immer auf sein Ende zu. Die theoretische Value-Funktion ist einigermaßen stetig und glatt. Kleine Veränderungen der Position bewirken kleine Veränderungen der Gewinnchancen. Bei deterministischen Spielen ist die theoretische Value-Funktion diskret. (Gewinne ich, verliere ich, unentschieden)
25 Lineare Eigenschaften TD-Gammon geht ohne den blassesten Dunst einer Ahnung von Backgammon an den Start...und findet sehr schnell heraus, dass es Erfolg versprechend ist, andere Steine zu schlagen eigene Steine zu schützen starke Positionen aufzubauen Diese Dinge nennt man linear features des Backgammon-Spiels, weil man sie durch lineare Funktionen der Position beschreiben kann.
26 Lineare Eigenschaften Man folgert: Neuronale Netze kombiniert mit TD-Learning entdecken sehr schnell den linearen Anteil einer Funktion Trotzdem werden in späteren Versionen von TD- Gammon wieder bestimmte Features per Hand kodiert und als zusätzliche Eingaben an das neuronale Netz gelegt.
27 Das wars!
Learning To Play Chess Using Temporal Differences
 Learning To Play Chess Using Temporal Differences Der Vortrag wird von Pham Thi Thu Trang gehalten 17.06.2004 1 Einleitung TD- learning ist zuerst von Samuel (1959) entwickelt und später von Sutton (1988)
Learning To Play Chess Using Temporal Differences Der Vortrag wird von Pham Thi Thu Trang gehalten 17.06.2004 1 Einleitung TD- learning ist zuerst von Samuel (1959) entwickelt und später von Sutton (1988)
Intelligente Systeme
 Intelligente Systeme Spiele Prof. Dr. R. Kruse C. Braune {rudolf.kruse,christian,braune}@ovgu.de Institut für Intelligente Kooperierende Systeme Fakultät für Informatik Otto-von-Guericke Universität Magdeburg
Intelligente Systeme Spiele Prof. Dr. R. Kruse C. Braune {rudolf.kruse,christian,braune}@ovgu.de Institut für Intelligente Kooperierende Systeme Fakultät für Informatik Otto-von-Guericke Universität Magdeburg
Backgammon. Tobias Krönke. Technische Universität Darmstadt Fachbereich Informatik Fachgebiet Knowledge Engineering
 Technische Universität Darmstadt Fachbereich Informatik Fachgebiet Knowledge Engineering Seminar zu Knowledge Engineering und Lernen in Spielen, 2010 Gliederung Gliederung Startaufstellung Abbildung: GNU
Technische Universität Darmstadt Fachbereich Informatik Fachgebiet Knowledge Engineering Seminar zu Knowledge Engineering und Lernen in Spielen, 2010 Gliederung Gliederung Startaufstellung Abbildung: GNU
Der Bestimmtheitssatz
 2. Spielbäume und Intelligente Spiele Der Minimax-Algorithmus Der Bestimmtheitssatz Satz 2.1. Gegeben sei ein Spiel, das die folgenden Eigenschaften hat: 1. Das Spiel wird von zwei Personen gespielt. 2.
2. Spielbäume und Intelligente Spiele Der Minimax-Algorithmus Der Bestimmtheitssatz Satz 2.1. Gegeben sei ein Spiel, das die folgenden Eigenschaften hat: 1. Das Spiel wird von zwei Personen gespielt. 2.
Reinforcement Learning
 Reinforcement Learning Viktor Seifert Seminar: Knowledge Engineering und Lernen in Spielen SS06 Prof. Johannes Fürnkranz Übersicht 1. Definition 2. Allgemeiner Lösungsansatz 3. Temporal Difference Learning
Reinforcement Learning Viktor Seifert Seminar: Knowledge Engineering und Lernen in Spielen SS06 Prof. Johannes Fürnkranz Übersicht 1. Definition 2. Allgemeiner Lösungsansatz 3. Temporal Difference Learning
der Künstlichen Intelligenz
 Einführung in die Methoden der Künstlichen --- Vorlesung vom 30.4.2009 --- Sommersemester 2009 Ingo J. Timm, René Schumann Professur für Wirtschaftsinformatik und Simulation (IS) Spiele spielen Prof. Timm
Einführung in die Methoden der Künstlichen --- Vorlesung vom 30.4.2009 --- Sommersemester 2009 Ingo J. Timm, René Schumann Professur für Wirtschaftsinformatik und Simulation (IS) Spiele spielen Prof. Timm
Übersicht. Künstliche Intelligenz: 6. Spiele Frank Puppe 1
 Übersicht I Künstliche Intelligenz II Problemlösen 3. Problemlösen durch Suche 4. Informierte Suchmethoden 5. Constraint-Probleme 6. Spiele III Wissen und Schlußfolgern IV Logisch Handeln V Unsicheres
Übersicht I Künstliche Intelligenz II Problemlösen 3. Problemlösen durch Suche 4. Informierte Suchmethoden 5. Constraint-Probleme 6. Spiele III Wissen und Schlußfolgern IV Logisch Handeln V Unsicheres
Übersicht. Künstliche Intelligenz: 21. Verstärkungslernen Frank Puppe 1
 Übersicht I Künstliche Intelligenz II Problemlösen III Wissen und Schlussfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen VI Lernen 18. Lernen aus Beobachtungen 19. Wissen beim Lernen 20. Statistische
Übersicht I Künstliche Intelligenz II Problemlösen III Wissen und Schlussfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen VI Lernen 18. Lernen aus Beobachtungen 19. Wissen beim Lernen 20. Statistische
Übersicht. 5. Spiele. I Künstliche Intelligenz II Problemlösen 3. Problemlösen durch Suche 4. Informierte Suchmethoden
 Übersicht I Künstliche Intelligenz II Problemlösen 3. Problemlösen durch Suche 4. Informierte Suchmethoden 5. Spiele III Wissen und Schlußfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen VI
Übersicht I Künstliche Intelligenz II Problemlösen 3. Problemlösen durch Suche 4. Informierte Suchmethoden 5. Spiele III Wissen und Schlußfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen VI
Einführung in die Methoden der Künstlichen Intelligenz. Suche bei Spielen
 Einführung in die Methoden der Künstlichen Intelligenz Suche bei Spielen Dr. David Sabel WS 2012/13 Stand der Folien: 5. November 2012 Zwei-Spieler-Spiele Ziel dieses Abschnitts Intelligenter Agent für
Einführung in die Methoden der Künstlichen Intelligenz Suche bei Spielen Dr. David Sabel WS 2012/13 Stand der Folien: 5. November 2012 Zwei-Spieler-Spiele Ziel dieses Abschnitts Intelligenter Agent für
RL und Funktionsapproximation
 RL und Funktionsapproximation Bisher sind haben wir die Funktionen V oder Q als Tabellen gespeichert. Im Allgemeinen sind die Zustandsräume und die Zahl der möglichen Aktionen sehr groß. Deshalb besteht
RL und Funktionsapproximation Bisher sind haben wir die Funktionen V oder Q als Tabellen gespeichert. Im Allgemeinen sind die Zustandsräume und die Zahl der möglichen Aktionen sehr groß. Deshalb besteht
Neuronale Netze in der Phonetik: Feed-Forward Netze. Pfitzinger, Reichel IPSK, LMU München {hpt 14.
 Neuronale Netze in der Phonetik: Feed-Forward Netze Pfitzinger, Reichel IPSK, LMU München {hpt reichelu}@phonetik.uni-muenchen.de 14. Juli 2006 Inhalt Typisierung nach Aktivierungsfunktion Lernen in einschichtigen
Neuronale Netze in der Phonetik: Feed-Forward Netze Pfitzinger, Reichel IPSK, LMU München {hpt reichelu}@phonetik.uni-muenchen.de 14. Juli 2006 Inhalt Typisierung nach Aktivierungsfunktion Lernen in einschichtigen
TUD Computer Poker Challenge
 TUD Computer Poker Challenge The Challenge of Poker Björn Heidenreich 31. März 2008 The Challenge of Poker Björn Heidenreich 1 Anforderungen an einen guten Poker-Spieler Hand Strength Hand Potential Bluffing
TUD Computer Poker Challenge The Challenge of Poker Björn Heidenreich 31. März 2008 The Challenge of Poker Björn Heidenreich 1 Anforderungen an einen guten Poker-Spieler Hand Strength Hand Potential Bluffing
Einführung in die Methoden der Künstlichen Intelligenz. Suche bei Spielen
 Einführung in die Methoden der Künstlichen Intelligenz Suche bei Spielen Prof. Dr. Manfred Schmidt-Schauß SoSe 2016 Stand der Folien: 12. Mai 2016 Zwei-Spieler-Spiele Ziel dieses Abschnitts Intelligenter
Einführung in die Methoden der Künstlichen Intelligenz Suche bei Spielen Prof. Dr. Manfred Schmidt-Schauß SoSe 2016 Stand der Folien: 12. Mai 2016 Zwei-Spieler-Spiele Ziel dieses Abschnitts Intelligenter
Spielregeln Backgammon
 Das Ziel von Backgammon Spielregeln Backgammon Ziel diese Spieles besteht darin, seine Steine (schwarz oder weiß) in das eigene Heimfeld zu bringen und sie dann von dort abzuwürfeln (rauszunehmen). Dabei
Das Ziel von Backgammon Spielregeln Backgammon Ziel diese Spieles besteht darin, seine Steine (schwarz oder weiß) in das eigene Heimfeld zu bringen und sie dann von dort abzuwürfeln (rauszunehmen). Dabei
Kombinatorische Spiele mit Zufallselementen
 Kombinatorische Spiele mit Zufallselementen Die Realität ist nicht so streng determiniert wie rein kombinatorische Spiele. In vielen Situationen spielt der Zufall (Risko) eine nicht zu vernachlässigende
Kombinatorische Spiele mit Zufallselementen Die Realität ist nicht so streng determiniert wie rein kombinatorische Spiele. In vielen Situationen spielt der Zufall (Risko) eine nicht zu vernachlässigende
6. Spiele Arten von Spielen. 6. Spiele. Effizienzverbesserung durch Beschneidung des Suchraums
 6. Spiele Arten von Spielen 6. Spiele Kombinatorische Spiele als Suchproblem Wie berechnet man eine gute Entscheidung? Effizienzverbesserung durch Beschneidung des Suchraums Spiele mit Zufallselement Maschinelles
6. Spiele Arten von Spielen 6. Spiele Kombinatorische Spiele als Suchproblem Wie berechnet man eine gute Entscheidung? Effizienzverbesserung durch Beschneidung des Suchraums Spiele mit Zufallselement Maschinelles
Reinforcement Learning
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning Uwe Dick Inhalt Problemstellungen Beispiele Markov Decision Processes Planen vollständige MDPs Lernen unbekannte
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Reinforcement Learning Uwe Dick Inhalt Problemstellungen Beispiele Markov Decision Processes Planen vollständige MDPs Lernen unbekannte
Reinforcement Learning
 Reinforcement Learning Valentin Hermann 25. Juli 2014 Inhaltsverzeichnis 1 Einführung 3 2 Wie funktioniert Reinforcement Learning? 3 2.1 Das Modell................................... 3 2.2 Exploration
Reinforcement Learning Valentin Hermann 25. Juli 2014 Inhaltsverzeichnis 1 Einführung 3 2 Wie funktioniert Reinforcement Learning? 3 2.1 Das Modell................................... 3 2.2 Exploration
Bachelorarbeit. Miriam Tödten. Einsatz eines maschinellen Lernverfahrens in einem Othello-Spielprogramm
 Hochschule für Angewandte Wissenschaften Hamburg Hamburg University of Applied Sciences Bachelorarbeit Miriam Tödten Einsatz eines maschinellen Lernverfahrens in einem Othello-Spielprogramm Fakultät Technik
Hochschule für Angewandte Wissenschaften Hamburg Hamburg University of Applied Sciences Bachelorarbeit Miriam Tödten Einsatz eines maschinellen Lernverfahrens in einem Othello-Spielprogramm Fakultät Technik
Einführung in die Methoden der Künstlichen Intelligenz
 Einführung in die Methoden der Künstlichen --- Vorlesung vom 8.5.2007 --- Sommersemester 2007 Prof. Dr. Ingo J. Timm, Andreas D. Lattner Professur für Wirtschaftsinformatik und Simulation (IS) Ein kleiner
Einführung in die Methoden der Künstlichen --- Vorlesung vom 8.5.2007 --- Sommersemester 2007 Prof. Dr. Ingo J. Timm, Andreas D. Lattner Professur für Wirtschaftsinformatik und Simulation (IS) Ein kleiner
Reinforcement Learning
 Reinforcement Learning 1. Allgemein Reinforcement Learning 2. Neuronales Netz als Bewertungsfunktion 3. Neuronales Netz als Reinforcement Learning Nils-Olaf Bösch 1 Allgemein Reinforcement Learning Unterschied
Reinforcement Learning 1. Allgemein Reinforcement Learning 2. Neuronales Netz als Bewertungsfunktion 3. Neuronales Netz als Reinforcement Learning Nils-Olaf Bösch 1 Allgemein Reinforcement Learning Unterschied
Wissensbasierte Systeme. Kombinatorische Explosion und die Notwendigkeit Heuristischer Suche. Heuristiken und ihre Eigenschaften
 1 Michael Beetz Technische Universität München Wintersemester 2004/05 Kombinatorische Explosion und die Notwendigkeit Heuristischer Suche 2 3 der Eigenschaften der 4 : 8-Puzzle 5 Heuristiken und ihre Eigenschaften
1 Michael Beetz Technische Universität München Wintersemester 2004/05 Kombinatorische Explosion und die Notwendigkeit Heuristischer Suche 2 3 der Eigenschaften der 4 : 8-Puzzle 5 Heuristiken und ihre Eigenschaften
Zwei-Spieler-Spiele. Einführung in die Methoden der Künstlichen Intelligenz. Suche bei Spielen. Schach. Schach (2)
") Einführung in die Methoden der Künstlichen Intelligenz Suche bei Spielen Prof. Dr. Manfred Schmidt-Schauß Ziel dieses Abschnitts Intelligenter Agent für Zweipersonenspiele Beispiele: Schach, Dame, Mühle,...
Einführung in die Methoden der Künstlichen Intelligenz Suche bei Spielen Prof. Dr. Manfred Schmidt-Schauß Ziel dieses Abschnitts Intelligenter Agent für Zweipersonenspiele Beispiele: Schach, Dame, Mühle,...
Einführung in die Künstliche Intelligenz. 6. Spiele
 Einführung in die Künstliche Intelligenz 6. Spiele Prof. Dr. Susanne Biundo-Stephan Institut für Künstliche Intelligenz, Universität Ulm WS 2012/2013 S. Biundo-Stephan (Universität Ulm) 6. Spiele WS 2012/2013
Einführung in die Künstliche Intelligenz 6. Spiele Prof. Dr. Susanne Biundo-Stephan Institut für Künstliche Intelligenz, Universität Ulm WS 2012/2013 S. Biundo-Stephan (Universität Ulm) 6. Spiele WS 2012/2013
Reinforcement Learning für Brettspiele: Der Temporal Difference Algorithmus
 e-print http://www.gm.fh-koeln.de/ciopwebpub/kone15a.d/tr-tdgame.pdf, Februar 2015 Reinforcement Learning für Brettspiele: Der Temporal Difference Algorithmus Wolfgang Konen Institut für Informatik, Fakultät
e-print http://www.gm.fh-koeln.de/ciopwebpub/kone15a.d/tr-tdgame.pdf, Februar 2015 Reinforcement Learning für Brettspiele: Der Temporal Difference Algorithmus Wolfgang Konen Institut für Informatik, Fakultät
6in1 Deluxe Spiele-Koffer. Spielanleitung
 6in1 Deluxe Spiele-Koffer Spielanleitung 1 ihr neuer spielekoffer Sehr gehrte Kunden, wir danken Ihnen für den Kauf dieses Spiele- Koffers. Mit diesem eleganten Koffer sind Sie für Spiele-Abende und lange
6in1 Deluxe Spiele-Koffer Spielanleitung 1 ihr neuer spielekoffer Sehr gehrte Kunden, wir danken Ihnen für den Kauf dieses Spiele- Koffers. Mit diesem eleganten Koffer sind Sie für Spiele-Abende und lange
Suche in Spielbäumen Spielbäume Minimax Algorithmus Alpha-Beta Suche. Suche in Spielbäumen. KI SS2011: Suche in Spielbäumen 1/20
 Suche in Spielbäumen Suche in Spielbäumen KI SS2011: Suche in Spielbäumen 1/20 Spiele in der KI Suche in Spielbäumen Spielbäume Minimax Algorithmus Alpha-Beta Suche Einschränkung von Spielen auf: 2 Spieler:
Suche in Spielbäumen Suche in Spielbäumen KI SS2011: Suche in Spielbäumen 1/20 Spiele in der KI Suche in Spielbäumen Spielbäume Minimax Algorithmus Alpha-Beta Suche Einschränkung von Spielen auf: 2 Spieler:
Arbeit: Page, Brin, Motwani, Winograd (1998). Ziel: Maß für absolute
. Ziel: Maß für absolute") 3.4 PageRank Arbeit: Page, Brin, Motwani, Winograd (1998). Ziel: Maß für absolute Wichtigkeit von Webseiten; nicht Relevanz bezüglich Benutzeranfrage. Anfrageunabhängiges Ranking. Ausgangspunkt: Eingangsgrad.
3.4 PageRank Arbeit: Page, Brin, Motwani, Winograd (1998). Ziel: Maß für absolute Wichtigkeit von Webseiten; nicht Relevanz bezüglich Benutzeranfrage. Anfrageunabhängiges Ranking. Ausgangspunkt: Eingangsgrad.
Thinking Machine. Idee. Die Thinking Machine Visualisierung versucht, die Denkprozesse eines Schachcomputers sichtbar zu machen
 Thinking Machine (http://www.turbulence.org/spotlight/thinking/) Idee Die Thinking Machine Visualisierung versucht, die Denkprozesse eines Schachcomputers sichtbar zu machen Sie wurde von Martin Wattenberg
Thinking Machine (http://www.turbulence.org/spotlight/thinking/) Idee Die Thinking Machine Visualisierung versucht, die Denkprozesse eines Schachcomputers sichtbar zu machen Sie wurde von Martin Wattenberg
Samuel's Checkers Program
 Samuel's Checkers Program Seminar: Knowledge Engineering und Lernen in Spielen 29.06.2004 Ge Hyun Nam Überblick Einleitung Basis Dame-Programm Maschinelles Lernen Auswendiglernen Verallgemeinerndes Lernen
Samuel's Checkers Program Seminar: Knowledge Engineering und Lernen in Spielen 29.06.2004 Ge Hyun Nam Überblick Einleitung Basis Dame-Programm Maschinelles Lernen Auswendiglernen Verallgemeinerndes Lernen
8. Reinforcement Learning
 8. Reinforcement Learning Einführung 8. Reinforcement Learning Wie können Agenten ohne Trainingsbeispiele lernen? Auch kennt der Agent zu Beginn nicht die Auswirkungen seiner Handlungen. Stattdessen erhält
8. Reinforcement Learning Einführung 8. Reinforcement Learning Wie können Agenten ohne Trainingsbeispiele lernen? Auch kennt der Agent zu Beginn nicht die Auswirkungen seiner Handlungen. Stattdessen erhält
Hannah Wester Juan Jose Gonzalez
 Neuronale Netze Supervised Learning Proseminar Kognitive Robotik (SS12) Hannah Wester Juan Jose Gonzalez Kurze Einführung Warum braucht man Neuronale Netze und insbesondere Supervised Learning? Das Perzeptron
Neuronale Netze Supervised Learning Proseminar Kognitive Robotik (SS12) Hannah Wester Juan Jose Gonzalez Kurze Einführung Warum braucht man Neuronale Netze und insbesondere Supervised Learning? Das Perzeptron
Spielanleitung für das Backgammon-Spiel mit freundlicher Genehmigung von
 Spielanleitung für das Backgammon-Spiel mit freundlicher Genehmigung von http://www.bkgm.com/rules/german/rules.html Obwohl Backgammon ein Würfelspiel ist, ist es ein Spiel, bei dem geistige Geschicklichkeit
Spielanleitung für das Backgammon-Spiel mit freundlicher Genehmigung von http://www.bkgm.com/rules/german/rules.html Obwohl Backgammon ein Würfelspiel ist, ist es ein Spiel, bei dem geistige Geschicklichkeit
Übersicht. 20. Verstärkungslernen
 Übersicht I Künstliche Intelligenz II Problemlösen III Wissen und Schlußfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen VI Lernen 18. Lernen aus Beobachtungen 19. Lernen in neuronalen & Bayes
Übersicht I Künstliche Intelligenz II Problemlösen III Wissen und Schlußfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen VI Lernen 18. Lernen aus Beobachtungen 19. Lernen in neuronalen & Bayes
Axel Reichert. Der Backgammon-Begleiter
 Reichert Backgammon Axel Reichert Der Backgammon-Begleiter München 2011 Inhaltsverzeichnis 1 Rennspiel............................. 4 2 Blockadespiel.......................... 4 3 Haltespiel.............................
Reichert Backgammon Axel Reichert Der Backgammon-Begleiter München 2011 Inhaltsverzeichnis 1 Rennspiel............................. 4 2 Blockadespiel.......................... 4 3 Haltespiel.............................
Praktikum Algorithmen-Entwurf (Teil 7)
") Praktikum Algorithmen-Entwurf (Teil 7) 28.11.2005 1 1 Vier gewinnt Die Spielregeln von Vier Gewinnt sind sehr einfach: Das Spielfeld besteht aus 7 Spalten und 6 Reihen. Jeder Spieler erhält zu Beginn des
Praktikum Algorithmen-Entwurf (Teil 7) 28.11.2005 1 1 Vier gewinnt Die Spielregeln von Vier Gewinnt sind sehr einfach: Das Spielfeld besteht aus 7 Spalten und 6 Reihen. Jeder Spieler erhält zu Beginn des
Selbstlernende Agenten für das skalierbare Spiel Hex: Untersuchung verschiedener KI-Verfahren im GBG-Framework. Bachelorarbeit.
 Gummersbach, im Juli 2017 Selbstlernende Agenten für das skalierbare Spiel Hex: Untersuchung verschiedener KI-Verfahren im GBG-Framework Bachelorarbeit ausgearbeitet von Kevin D. Galitzki zur Erlangung
Gummersbach, im Juli 2017 Selbstlernende Agenten für das skalierbare Spiel Hex: Untersuchung verschiedener KI-Verfahren im GBG-Framework Bachelorarbeit ausgearbeitet von Kevin D. Galitzki zur Erlangung
Wahlpflichtfach Informatik
 Wahlpflichtfach Informatik Dipl.-Ing. Michael NIEDERLE Klassen: 6C, 7AB 3-jährig (1 Doppelstunde pro Jahr); maturabel Was vor wenigen Jahren noch Sciene Fiction war, ist heute Realität. So entwickelt z.b.
Wahlpflichtfach Informatik Dipl.-Ing. Michael NIEDERLE Klassen: 6C, 7AB 3-jährig (1 Doppelstunde pro Jahr); maturabel Was vor wenigen Jahren noch Sciene Fiction war, ist heute Realität. So entwickelt z.b.
Erste Schritte um Schach zu lernen
 Erste Schritte um Schach zu lernen Erstellt durch wikihow Übersetzungen: Schach ist ein sehr beliebtes Spiel und weithin als eines der ältesten noch gespielten Spiele anerkannt. Obwohl die Regeln von Schach
Erste Schritte um Schach zu lernen Erstellt durch wikihow Übersetzungen: Schach ist ein sehr beliebtes Spiel und weithin als eines der ältesten noch gespielten Spiele anerkannt. Obwohl die Regeln von Schach
Künstliche Intelligenz - Optimierungsprobleme - Suche in Spielbäumen
 Künstliche Intelligenz - Optimierungsprobleme - Suche in Spielbäumen Stephan Schwiebert WS 2009/2010 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Optimierungsprobleme
Künstliche Intelligenz - Optimierungsprobleme - Suche in Spielbäumen Stephan Schwiebert WS 2009/2010 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Optimierungsprobleme
f h c 7 a 1 b 1 g 2 2 d
 ) Man bestimme mit Hilfe des Dijkstra-Algorithmus einen kürzesten Weg von a nach h: c 7 a b f 5 h 3 4 5 i e 6 g 2 2 d Beim Dijkstra-Algorithmus wird in jedem Schritt von den noch unmarkierten Knoten jener
) Man bestimme mit Hilfe des Dijkstra-Algorithmus einen kürzesten Weg von a nach h: c 7 a b f 5 h 3 4 5 i e 6 g 2 2 d Beim Dijkstra-Algorithmus wird in jedem Schritt von den noch unmarkierten Knoten jener
Der Alpha-Beta-Algorithmus
 Der Alpha-Beta-Algorithmus Maria Hartmann 19. Mai 2017 1 Einführung Wir wollen für bestimmte Spiele algorithmisch die optimale Spielstrategie finden, also die Strategie, die für den betrachteten Spieler
Der Alpha-Beta-Algorithmus Maria Hartmann 19. Mai 2017 1 Einführung Wir wollen für bestimmte Spiele algorithmisch die optimale Spielstrategie finden, also die Strategie, die für den betrachteten Spieler
Vierte Schularbeit Mathematik Klasse 7A G am xx
 Vierte Schularbeit Mathematik Klasse 7A G am xx.05.2016 SCHÜLERNAME: Punkte im ersten Teil: Punkte im zweiten Teil: Davon Kompensationspunkte: Note: Notenschlüssel: Falls die Summe der erzielten Kompensationspunkte
Vierte Schularbeit Mathematik Klasse 7A G am xx.05.2016 SCHÜLERNAME: Punkte im ersten Teil: Punkte im zweiten Teil: Davon Kompensationspunkte: Note: Notenschlüssel: Falls die Summe der erzielten Kompensationspunkte
Intelligenz in Datenbanken. Dr. Stefan Freundt Star512 Datenbank GmbH. star512 datenbank gmbh
 Intelligenz in Datenbanken Dr. Stefan Freundt Star512 Datenbank GmbH Einleitung Definition von Business! Definition von Intelligenz? Künstliche Intelligenz: Motivation Schach erfordert Intelligenz ==>
Intelligenz in Datenbanken Dr. Stefan Freundt Star512 Datenbank GmbH Einleitung Definition von Business! Definition von Intelligenz? Künstliche Intelligenz: Motivation Schach erfordert Intelligenz ==>
5. Spiele. offensichtlich eine Form von Intelligenz. Realisierung des Spielens als Suchproblem
 5. Spiele Spiele, insbesondere Brettspiele, stellen eines der ältesten Teil- und Anwendungsgebiete der KI dar (Shannon und Turing: 1950 erstes Schachprogramm). Brettspiele stellen eine sehr abstrakte und
5. Spiele Spiele, insbesondere Brettspiele, stellen eines der ältesten Teil- und Anwendungsgebiete der KI dar (Shannon und Turing: 1950 erstes Schachprogramm). Brettspiele stellen eine sehr abstrakte und
Konzepte der AI Neuronale Netze
 Konzepte der AI Neuronale Netze Franz Wotawa Institut für Informationssysteme, Database and Artificial Intelligence Group, Technische Universität Wien Email: wotawa@dbai.tuwien.ac.at Was sind Neuronale
Konzepte der AI Neuronale Netze Franz Wotawa Institut für Informationssysteme, Database and Artificial Intelligence Group, Technische Universität Wien Email: wotawa@dbai.tuwien.ac.at Was sind Neuronale
Schriftlicher Test Teilklausur 2
 Technische Universität Berlin Fakultät IV Elektrotechnik und Informatik Künstliche Intelligenz: Grundlagen und Anwendungen Wintersemester 2012 / 2013 Albayrak, Fricke (AOT) Opper, Ruttor (KI) Schriftlicher
Technische Universität Berlin Fakultät IV Elektrotechnik und Informatik Künstliche Intelligenz: Grundlagen und Anwendungen Wintersemester 2012 / 2013 Albayrak, Fricke (AOT) Opper, Ruttor (KI) Schriftlicher
Design Studio (ab 1.4) Add-On Hierarchiekomponente
 Add-On Hierarchiekomponente") Design Studio (ab 1.4) Add-On Hierarchiekomponente Entwickelt durch JOIN(+) GmbH Sommerhalde 12 78351 Bodman-Ludwigshafen Germany CONTENT 1 Hierarchie Komponente Beschreibung... 3 2 Features... 4 2.1 Kennzahlenauswahl...
Design Studio (ab 1.4) Add-On Hierarchiekomponente Entwickelt durch JOIN(+) GmbH Sommerhalde 12 78351 Bodman-Ludwigshafen Germany CONTENT 1 Hierarchie Komponente Beschreibung... 3 2 Features... 4 2.1 Kennzahlenauswahl...
GP-Music: An Interactive Genetic Programming System for Music Generation with Automated Fitness
 GP-Music: An Interactive Genetic Programming System for Music Generation with Automated Fitness Raters Brad Johanson, Riccardo Poli Seminarvortrag von Thomas Arnold G ˇ ˇ ˇ ˇ WS 2012/13 TU Darmstadt Seminar
GP-Music: An Interactive Genetic Programming System for Music Generation with Automated Fitness Raters Brad Johanson, Riccardo Poli Seminarvortrag von Thomas Arnold G ˇ ˇ ˇ ˇ WS 2012/13 TU Darmstadt Seminar
Maschinelle Sprachverarbeitung: N-Gramm-Modelle
 HUMBOLD-UNIVERSIÄ ZU BERLIN Institut für Informatik Lehrstuhl Wissensmanagement Maschinelle Sprachverarbeitung: N-Gramm-Modelle obias Scheffer, Ulf Brefeld Statistische Sprachmodelle Welche Sätze sind
HUMBOLD-UNIVERSIÄ ZU BERLIN Institut für Informatik Lehrstuhl Wissensmanagement Maschinelle Sprachverarbeitung: N-Gramm-Modelle obias Scheffer, Ulf Brefeld Statistische Sprachmodelle Welche Sätze sind
Igel Ärgern Spielanleitung/Spielregeln. Brettspielnetz.de Team Copyright 2017 Spiele von Doris und Frank
 Igel Ärgern Spielanleitung/Spielregeln Brettspielnetz.de Team Copyright 2017 Spiele von Doris und Frank Inhalt Igel Ärgern Spielregeln...1 Einleitung und Spielidee...2 Spielablauf...3 Blockierte Igel...4
Igel Ärgern Spielanleitung/Spielregeln Brettspielnetz.de Team Copyright 2017 Spiele von Doris und Frank Inhalt Igel Ärgern Spielregeln...1 Einleitung und Spielidee...2 Spielablauf...3 Blockierte Igel...4
Wissensbasierte Systeme 5. Brettspiele
 Wissensbasierte Systeme 5. Brettspiele Suchstrategien für Spiele, Spiele mit Zufall, Stand der Kunst Michael Beetz Plan-based Robot Control 1 Inhalt 5.1 Brettspiele 5.2 Minimax-Suche 5.3 Alpha-Beta-Suche
Wissensbasierte Systeme 5. Brettspiele Suchstrategien für Spiele, Spiele mit Zufall, Stand der Kunst Michael Beetz Plan-based Robot Control 1 Inhalt 5.1 Brettspiele 5.2 Minimax-Suche 5.3 Alpha-Beta-Suche
3. Das Reinforcement Lernproblem
 3. Das Reinforcement Lernproblem 1. Agierender Agent in der Umgebung 2. Discounted Rewards 3. Markov Eigenschaft des Zustandssignals 4. Markov sche Entscheidung 5. Werte-Funktionen und Bellman sche Optimalität
3. Das Reinforcement Lernproblem 1. Agierender Agent in der Umgebung 2. Discounted Rewards 3. Markov Eigenschaft des Zustandssignals 4. Markov sche Entscheidung 5. Werte-Funktionen und Bellman sche Optimalität
Temporal Difference Learning
 Temporal Difference Learning Das Temporal Difference (TD) Lernen ist eine bedeutende Entwicklung im Reinforcement Lernen. Im TD Lernen werden Ideen der Monte Carlo (MC) und dynamische Programmierung (DP)
Temporal Difference Learning Das Temporal Difference (TD) Lernen ist eine bedeutende Entwicklung im Reinforcement Lernen. Im TD Lernen werden Ideen der Monte Carlo (MC) und dynamische Programmierung (DP)
Wahrscheinlichkeitsverteilungen
 Universität Bielefeld 3. Mai 2005 Wahrscheinlichkeitsrechnung Wahrscheinlichkeitsrechnung Das Ziehen einer Stichprobe ist die Realisierung eines Zufallsexperimentes. Die Wahrscheinlichkeitsrechnung betrachtet
Universität Bielefeld 3. Mai 2005 Wahrscheinlichkeitsrechnung Wahrscheinlichkeitsrechnung Das Ziehen einer Stichprobe ist die Realisierung eines Zufallsexperimentes. Die Wahrscheinlichkeitsrechnung betrachtet
Spiele. Programmierpraktikum WS04/05 Lange/Matthes 106
 Spiele Programmierpraktikum WS04/05 Lange/Matthes 106 Theorie eines Spiels mathematisch: k-spieler Spiel ist Graph G = (V, E) wobei V partitioniert in V 1,..., V k Knoten v V heissen Konfigurationen oft
Spiele Programmierpraktikum WS04/05 Lange/Matthes 106 Theorie eines Spiels mathematisch: k-spieler Spiel ist Graph G = (V, E) wobei V partitioniert in V 1,..., V k Knoten v V heissen Konfigurationen oft
Intelligente Agenten
 Intelligente Agenten Einige einfache Überlegungen zu Agenten und deren Interaktionsmöglichkeiten mit ihrer Umgebung. Agent benutzt: Sensoren Aktuatoren (Aktoren; Effektoren) zum Beobachten/Mess seiner
Intelligente Agenten Einige einfache Überlegungen zu Agenten und deren Interaktionsmöglichkeiten mit ihrer Umgebung. Agent benutzt: Sensoren Aktuatoren (Aktoren; Effektoren) zum Beobachten/Mess seiner
Neuronale Netze. Christian Böhm.
 Ludwig Maximilians Universität München Institut für Informatik Forschungsgruppe Data Mining in der Medizin Neuronale Netze Christian Böhm http://dmm.dbs.ifi.lmu.de/dbs 1 Lehrbuch zur Vorlesung Lehrbuch
Ludwig Maximilians Universität München Institut für Informatik Forschungsgruppe Data Mining in der Medizin Neuronale Netze Christian Böhm http://dmm.dbs.ifi.lmu.de/dbs 1 Lehrbuch zur Vorlesung Lehrbuch
Lineare Regression. Christian Herta. Oktober, Problemstellung Kostenfunktion Gradientenabstiegsverfahren
 Lineare Regression Christian Herta Oktober, 2013 1 von 33 Christian Herta Lineare Regression Lernziele Lineare Regression Konzepte des Maschinellen Lernens: Lernen mittels Trainingsmenge Kostenfunktion
Lineare Regression Christian Herta Oktober, 2013 1 von 33 Christian Herta Lineare Regression Lernziele Lineare Regression Konzepte des Maschinellen Lernens: Lernen mittels Trainingsmenge Kostenfunktion
6.4 Neuronale Netze zur Verarbeitung von Zeitreihen
 6.4 Neuronale Netze zur Verarbeitung von Zeitreihen Aufgabe: Erlernen einer Zeitreihe x(t + 1) = f(x(t), x(t 1), x(t 2),...) Idee: Verzögerungskette am Eingang eines neuronalen Netzwerks, z.b. eines m-h-1
6.4 Neuronale Netze zur Verarbeitung von Zeitreihen Aufgabe: Erlernen einer Zeitreihe x(t + 1) = f(x(t), x(t 1), x(t 2),...) Idee: Verzögerungskette am Eingang eines neuronalen Netzwerks, z.b. eines m-h-1
Durch Zufall zum Dan? Die Monte-Carlo-Baumsuche
 Durch Zufall zum Dan? Die Monte-Carlo-Baumsuche Johannes Waldmann HTWK Leipzig Potsdamer Panda, April 2011 Wer hätte das gedacht... (Zen, Programmierer: Ojima Yoji) Spielbäume zu jedem Spiel gehört ein
Durch Zufall zum Dan? Die Monte-Carlo-Baumsuche Johannes Waldmann HTWK Leipzig Potsdamer Panda, April 2011 Wer hätte das gedacht... (Zen, Programmierer: Ojima Yoji) Spielbäume zu jedem Spiel gehört ein
Uninformierte Suche in Java Informierte Suchverfahren
 Uninformierte Suche in Java Informierte Suchverfahren Stephan Schwiebert WS 2008/2009 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln 8-Damen-Problem Gegeben: Schachbrett
Uninformierte Suche in Java Informierte Suchverfahren Stephan Schwiebert WS 2008/2009 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln 8-Damen-Problem Gegeben: Schachbrett
Twister. Für das Spiel Twister benötigt ihr folgende Drehscheibe:
 Twister Für das Spiel Twister benötigt ihr folgende Drehscheibe: Es können auf beiden Spielfelder bis zu drei Spieler spielen. Ein weiterer Mitspieler dreht die Scheibe und liest vor: z.b. Rechte Hand
Twister Für das Spiel Twister benötigt ihr folgende Drehscheibe: Es können auf beiden Spielfelder bis zu drei Spieler spielen. Ein weiterer Mitspieler dreht die Scheibe und liest vor: z.b. Rechte Hand
Grundlagen der Künstlichen Intelligenz Einführung Minimax-Suche Bewertungsfunktionen Zusammenfassung. Brettspiele: Überblick
 Grundlagen der Künstlichen Intelligenz 22. Mai 2015 41. Brettspiele: Einführung und Minimax-Suche Grundlagen der Künstlichen Intelligenz 41. Brettspiele: Einführung und Minimax-Suche Malte Helmert Universität
Grundlagen der Künstlichen Intelligenz 22. Mai 2015 41. Brettspiele: Einführung und Minimax-Suche Grundlagen der Künstlichen Intelligenz 41. Brettspiele: Einführung und Minimax-Suche Malte Helmert Universität
Vier Gewinnt Nicolas Schmidt Matthias Dietsche Bernhard Weiß Benjamin Ruile Datum: 17.2.2009 Tutor: Prof. Schottenloher Spieltheorie
 Vier Gewinnt Nicolas Schmidt Matthias Dietsche Bernhard Weiß Benjamin Ruile Datum: 17.2.2009 Tutor: Prof. Schottenloher Spieltheorie Präsentation Agenda I. Einführung 1. Motivation 2. Das Spiel Vier Gewinnt
Vier Gewinnt Nicolas Schmidt Matthias Dietsche Bernhard Weiß Benjamin Ruile Datum: 17.2.2009 Tutor: Prof. Schottenloher Spieltheorie Präsentation Agenda I. Einführung 1. Motivation 2. Das Spiel Vier Gewinnt
Schwellenwertelemente. Rudolf Kruse Neuronale Netze 8
 Schwellenwertelemente Rudolf Kruse Neuronale Netze 8 Schwellenwertelemente Ein Schwellenwertelement (Threshold Logic Unit, TLU) ist eine Verarbeitungseinheit für Zahlen mitneingängenx,...,x n und einem
Schwellenwertelemente Rudolf Kruse Neuronale Netze 8 Schwellenwertelemente Ein Schwellenwertelement (Threshold Logic Unit, TLU) ist eine Verarbeitungseinheit für Zahlen mitneingängenx,...,x n und einem
Spiele (antagonistische Suche) Übersicht. Typen von Spielen. Spielbaum. Spiele mit vollständiger Information
 Übersicht. Typen von Spielen. Spielbaum. Spiele mit vollständiger Information") Übersicht I Künstliche Intelligenz II Problemlösen 3. Problemlösen durch Suche 4. Informierte Suchmethoden 5. Constraint-Probleme 6. Spiele III Wissen und Schlußfolgern IV Logisch Handeln V Unsicheres
Übersicht I Künstliche Intelligenz II Problemlösen 3. Problemlösen durch Suche 4. Informierte Suchmethoden 5. Constraint-Probleme 6. Spiele III Wissen und Schlußfolgern IV Logisch Handeln V Unsicheres
Wir haben in den vorherigen Kapiteln verschiedene Verfahren zur Regression und Klassifikation kennengelernt (z.b. lineare Regression, SVMs)
") 6. Neuronale Netze Motivation Wir haben in den vorherigen Kapiteln verschiedene Verfahren zur Regression und Klassifikation kennengelernt (z.b. lineare Regression, SVMs) Abstrakt betrachtet sind alle diese
6. Neuronale Netze Motivation Wir haben in den vorherigen Kapiteln verschiedene Verfahren zur Regression und Klassifikation kennengelernt (z.b. lineare Regression, SVMs) Abstrakt betrachtet sind alle diese
V π (s) ist der Erwartungswert, der bei Start in s und Arbeit gemäß π insgesamt erreicht wird:
 ist der Erwartungswert, der bei Start in s und Arbeit gemäß π insgesamt erreicht wird:") Moderne Methoden der KI: Maschinelles Lernen Prof. Dr. sc. Hans-Dieter Burkhard Vorlesung Sommer-Semester 2007 Verstärkungs-Lernen (Reinforcement Learning) Literatur: R.S.Sutton, A.G.Barto Reinforcement
Moderne Methoden der KI: Maschinelles Lernen Prof. Dr. sc. Hans-Dieter Burkhard Vorlesung Sommer-Semester 2007 Verstärkungs-Lernen (Reinforcement Learning) Literatur: R.S.Sutton, A.G.Barto Reinforcement
Symbolisches Lernen in Go
 Symbolisches Lernen in Go Seminar Knowledge Engineering und Lernen in Spielen, SS 04 Frank Steinmann Motivation (1) Was kann gelernt werden? Globaler Ansatz: eine Funktion f: f: Stellungen x Züge -> ->
Symbolisches Lernen in Go Seminar Knowledge Engineering und Lernen in Spielen, SS 04 Frank Steinmann Motivation (1) Was kann gelernt werden? Globaler Ansatz: eine Funktion f: f: Stellungen x Züge -> ->
Wissensbasierte Suche
 Wissensbasierte Suche Jürgen Dorn Inhalt uninformierte Suche wissensbasierte Suche A* und IDA* Algorithmus Suche in Und/Oder-Graphen Jürgen Dorn 2003 Wissensbasierte Suche 1 Suche Suche in (expliziten
Wissensbasierte Suche Jürgen Dorn Inhalt uninformierte Suche wissensbasierte Suche A* und IDA* Algorithmus Suche in Und/Oder-Graphen Jürgen Dorn 2003 Wissensbasierte Suche 1 Suche Suche in (expliziten
Herzlich Willkommen. Spielstrategien. gehalten von Nils Böckmann
 Herzlich Willkommen Spielstrategien gehalten von Nils Böckmann Agenda 1. Einführung 2. Problemstellung 3. Abgrenzung 4. Zielstellung / grober Überblick 5. Vorstellen der Konzepte 1. Umgebungslogik 2. Spielbäume
Herzlich Willkommen Spielstrategien gehalten von Nils Böckmann Agenda 1. Einführung 2. Problemstellung 3. Abgrenzung 4. Zielstellung / grober Überblick 5. Vorstellen der Konzepte 1. Umgebungslogik 2. Spielbäume
Reranking. Parse Reranking. Helmut Schmid. Institut für maschinelle Sprachverarbeitung Universität Stuttgart
 Institut für maschinelle Sprachverarbeitung Universität Stuttgart schmid@ims.uni-stuttgart.de Die Folien basieren teilweise auf Folien von Mark Johnson. Koordinationen Problem: PCFGs können nicht alle
Institut für maschinelle Sprachverarbeitung Universität Stuttgart schmid@ims.uni-stuttgart.de Die Folien basieren teilweise auf Folien von Mark Johnson. Koordinationen Problem: PCFGs können nicht alle
Optimale Steuerung 1
 Optimale Steuerung 1 Kapitel 6: Nichtlineare Optimierung unbeschränkter Probleme Prof. Dr.-Ing. Pu Li Fachgebiet Simulation und Optimale Prozesse (SOP) Beispiel: Parameteranpassung für Phasengleichgewicht
Optimale Steuerung 1 Kapitel 6: Nichtlineare Optimierung unbeschränkter Probleme Prof. Dr.-Ing. Pu Li Fachgebiet Simulation und Optimale Prozesse (SOP) Beispiel: Parameteranpassung für Phasengleichgewicht
Bäume und Wälder. Bäume und Wälder 1 / 37
 Bäume und Wälder Bäume und Wälder 1 / 37 Bäume Ein (ungerichteter) Baum ist ein ungerichteter Graph G = (V, E), der zusammenhängend ist und keine einfachen Kreise enthält. Bäume und Wälder 2 / 37 Bäume
Bäume und Wälder Bäume und Wälder 1 / 37 Bäume Ein (ungerichteter) Baum ist ein ungerichteter Graph G = (V, E), der zusammenhängend ist und keine einfachen Kreise enthält. Bäume und Wälder 2 / 37 Bäume
Intelligente Algorithmen Einführung in die Technologie
 Intelligente Algorithmen Einführung in die Technologie Dr. KIT Universität des Landes Baden-Württemberg und nationales Forschungszentrum in der Helmholtz-Gemeinschaft www.kit.edu Natürlich sprachliche
Intelligente Algorithmen Einführung in die Technologie Dr. KIT Universität des Landes Baden-Württemberg und nationales Forschungszentrum in der Helmholtz-Gemeinschaft www.kit.edu Natürlich sprachliche
Backgammon Spielmaterial: als
 Backgammon Würfelspiel für 2 Spieler ab 10 Jahren Spielmaterial: Backgammon-Plan je 15 Steine in 2 Farben 2 Würfel l Dopplerwürfel Dieses Spiel gehört zu den ältesten und meistgespielten zugleich. Reste
Backgammon Würfelspiel für 2 Spieler ab 10 Jahren Spielmaterial: Backgammon-Plan je 15 Steine in 2 Farben 2 Würfel l Dopplerwürfel Dieses Spiel gehört zu den ältesten und meistgespielten zugleich. Reste
Einführung in Heuristische Suche
 Einführung in Heuristische Suche Beispiele 2 Überblick Intelligente Suche Rundenbasierte Spiele 3 Grundlagen Es muss ein Rätsel / Puzzle / Problem gelöst werden Wie kann ein Computer diese Aufgabe lösen?
Einführung in Heuristische Suche Beispiele 2 Überblick Intelligente Suche Rundenbasierte Spiele 3 Grundlagen Es muss ein Rätsel / Puzzle / Problem gelöst werden Wie kann ein Computer diese Aufgabe lösen?
Artificial Intelligence. Deep Learning Neuronale Netze
 Artificial Intelligence Deep Learning Neuronale Netze REVOLUTION Lernende Maschinen Mit lernenden Maschinen/Deep Learning erleben wir aktuell eine Revolution in der Informationsverarbeitung. Neue Methoden
Artificial Intelligence Deep Learning Neuronale Netze REVOLUTION Lernende Maschinen Mit lernenden Maschinen/Deep Learning erleben wir aktuell eine Revolution in der Informationsverarbeitung. Neue Methoden
Reinforcment learning
 Author: Alexander Camek Betreuer: Prof. Kramer 03.02.2004 Learning Inhalt Einführung in den Bereich Learning Learning Einführung in Generalisierung in Militärische Anwendungen Roboterkontrolle Schach Backgammon
Author: Alexander Camek Betreuer: Prof. Kramer 03.02.2004 Learning Inhalt Einführung in den Bereich Learning Learning Einführung in Generalisierung in Militärische Anwendungen Roboterkontrolle Schach Backgammon
Spielanleitung Backgammon
 Spielaufbau Das Spielbrett besteht aus 24 Dreiecken, Points oder Zungen genannt, von denen sich jeweils 12 auf einer Seite befinden. Zwischen dem 6. und 7. Point auf jeder Seite werden die Points durch
Spielaufbau Das Spielbrett besteht aus 24 Dreiecken, Points oder Zungen genannt, von denen sich jeweils 12 auf einer Seite befinden. Zwischen dem 6. und 7. Point auf jeder Seite werden die Points durch
SEMINAR REINFORCEMENT LEARNING OBERSEMINAR ADAPTIVE ROBOTERSTEUERUNG
 SEMINAR REINFORCEMENT LEARNING OBERSEMINAR ADAPTIVE ROBOTERSTEUERUNG Organisation, Überblick, Themen Überblick heutige Veranstaltung Organisatorisches Einführung in Reinforcement Learning Vorstellung der
SEMINAR REINFORCEMENT LEARNING OBERSEMINAR ADAPTIVE ROBOTERSTEUERUNG Organisation, Überblick, Themen Überblick heutige Veranstaltung Organisatorisches Einführung in Reinforcement Learning Vorstellung der
BACKGAMMON-STRATEGIEN und mehr...
 BACKGAMMON-STRATEGIEN und mehr... Herausgegeben von www.backgammon-spielen.info Kommentare und Fragen können Sie gerne an mail@backgammon-spielen.info schicken. Dieses Buch ist urheberrechtlich geschützt.
BACKGAMMON-STRATEGIEN und mehr... Herausgegeben von www.backgammon-spielen.info Kommentare und Fragen können Sie gerne an mail@backgammon-spielen.info schicken. Dieses Buch ist urheberrechtlich geschützt.
Temporal Difference Learning for Game Playing
 Temporal Difference Learning for Game Playing Wenchao Li Hauptseminar Neuroinformatik Universität Ulm, Abteilung Neuroinformatik, Sommersemester 2007 Zusammenfassung Heutige Schachprogramme sind in der
Temporal Difference Learning for Game Playing Wenchao Li Hauptseminar Neuroinformatik Universität Ulm, Abteilung Neuroinformatik, Sommersemester 2007 Zusammenfassung Heutige Schachprogramme sind in der
Wahrscheinlichkeitsrechnung und Statistik
 8. Vorlesung Pseudozufallszahlen sind, wie der Name schon sagt, keine echten Zufallszahlen, sondern werden durch Generatoren erzeugt. Als Pseudozufallszahlen bezeichnet man Zahlenfolgen die durch einen
8. Vorlesung Pseudozufallszahlen sind, wie der Name schon sagt, keine echten Zufallszahlen, sondern werden durch Generatoren erzeugt. Als Pseudozufallszahlen bezeichnet man Zahlenfolgen die durch einen
Knowledge Engineering und Lernen in Spielen. Thema: Opening Book Learning von: Thomas Widjaja
 Knowledge Engineering und Lernen in Spielen Thema: Opening Book Learning von: Thomas Widjaja Gliederung Allgemeines Drei Beispielverfahren zum Anpassen eines Opening Books Deep Blue Logistello (Michael
Knowledge Engineering und Lernen in Spielen Thema: Opening Book Learning von: Thomas Widjaja Gliederung Allgemeines Drei Beispielverfahren zum Anpassen eines Opening Books Deep Blue Logistello (Michael
Berechnung approximierter Voronoi-Zellen auf geometrischen Datenströmen
 Definition Berechnung approximierter Voronoi-Zellen auf geometrischen Datenströmen Seminar über Algorithmen WS 2005/2006 Vorgetragen von Oliver Rieger und Patrick-Thomas Chmielewski basierend auf der Arbeit
Definition Berechnung approximierter Voronoi-Zellen auf geometrischen Datenströmen Seminar über Algorithmen WS 2005/2006 Vorgetragen von Oliver Rieger und Patrick-Thomas Chmielewski basierend auf der Arbeit
Hamiltonsche Graphen
 Hamiltonsche Graphen Definition 3.2. Es sei G = (V, E) ein Graph. Ein Weg, der jeden Knoten von G genau einmal enthält, heißt hamiltonscher Weg. Ein Kreis, der jeden Knoten von G genau einmal enthält,
Hamiltonsche Graphen Definition 3.2. Es sei G = (V, E) ein Graph. Ein Weg, der jeden Knoten von G genau einmal enthält, heißt hamiltonscher Weg. Ein Kreis, der jeden Knoten von G genau einmal enthält,
Was ist Reinforcement Learning? Einführung. Überwachtes Lernen. Reinforcement Learning. Ziel: erreiche soviel Reward wie möglich
 Fachbereich Infrmatik Fachbereich Infrmatik Psychlgie Einführung Künstliche Intelligenz Reinfrcement Learning (RL) Steuerungs- und Regelungstechnik Was ist Reinfrcement Learning? Lernen aus Interaktin
Fachbereich Infrmatik Fachbereich Infrmatik Psychlgie Einführung Künstliche Intelligenz Reinfrcement Learning (RL) Steuerungs- und Regelungstechnik Was ist Reinfrcement Learning? Lernen aus Interaktin
Datenorientierte SA. Aufbau und Grundlagen. Aufbau und Grundlagen. Aufbau und Grundlagen. Was sind neuronale Netze?
 Datenorientierte SA Was sind neuronale Netze? Neuronale Netze: Grundlagen und Anwendungen Neuronale Netze bilden die Struktur eines Gehirns oder eines Nervensystems ab Andreas Rauscher 0651993 Damir Dudakovic
Datenorientierte SA Was sind neuronale Netze? Neuronale Netze: Grundlagen und Anwendungen Neuronale Netze bilden die Struktur eines Gehirns oder eines Nervensystems ab Andreas Rauscher 0651993 Damir Dudakovic
Hauptklausur zur Vorlesung Theoretische Grundlagen der Informatik Wintersemester 2011/2012
 Institut für Theoretische Informatik Lehrstuhl Prof. Dr. D. Wagner Hauptklausur zur Vorlesung Theoretische Grundlagen der Informatik Wintersemester 2011/2012 Hier Aufkleber mit Name und Matrikelnr. anbringen
Institut für Theoretische Informatik Lehrstuhl Prof. Dr. D. Wagner Hauptklausur zur Vorlesung Theoretische Grundlagen der Informatik Wintersemester 2011/2012 Hier Aufkleber mit Name und Matrikelnr. anbringen
6. Vorlesung. Rechnen mit Matrizen.
 6. Vorlesung. Rechnen mit Matrizen. In dieser Vorlesung betrachten wir lineare Gleichungs System. Wir betrachten lineare Gleichungs Systeme wieder von zwei Gesichtspunkten her: dem angewandten Gesichtspunkt
6. Vorlesung. Rechnen mit Matrizen. In dieser Vorlesung betrachten wir lineare Gleichungs System. Wir betrachten lineare Gleichungs Systeme wieder von zwei Gesichtspunkten her: dem angewandten Gesichtspunkt
EVOLUTION STRATEGIES DANIELA SCHACHERER SEMINAR: IST KÜNSTLICHE INTELLIGENZ GEFÄHRLICH? SOMMERSEMESTER 2017
 EVOLUTION STRATEGIES DANIELA SCHACHERER SEMINAR: IST KÜNSTLICHE INTELLIGENZ GEFÄHRLICH? SOMMERSEMESTER 2017 Inhalt Einleitung und Überblick Evolutionsstrategien Grundkonzept Evolutionsstrategien als Alternative
EVOLUTION STRATEGIES DANIELA SCHACHERER SEMINAR: IST KÜNSTLICHE INTELLIGENZ GEFÄHRLICH? SOMMERSEMESTER 2017 Inhalt Einleitung und Überblick Evolutionsstrategien Grundkonzept Evolutionsstrategien als Alternative
Taktische Motive 1: Die Gabel
 Taktische Motive 1: Die Gabel Charakteristisch für eine Gabel ist, dass eine Figur zwei Figuren gleichzeitig angreift. In greift der Springer gleichzeitig den König und den Turm an, nun muss der König
Taktische Motive 1: Die Gabel Charakteristisch für eine Gabel ist, dass eine Figur zwei Figuren gleichzeitig angreift. In greift der Springer gleichzeitig den König und den Turm an, nun muss der König
Aufnahmeprüfung 2016 für die Berufsmaturitätsschulen des Kantons Zürich
 Aufnahmeprüfung 2016 für die Berufsmaturitätsschulen des Kantons Zürich Mathematik Basierend auf Lehrmittel «Mathematik Sekundarstufe I» Serie: A1 Dauer: 90 Minuten Name: Vorname: Adresse: Prüfungsnummer:
Aufnahmeprüfung 2016 für die Berufsmaturitätsschulen des Kantons Zürich Mathematik Basierend auf Lehrmittel «Mathematik Sekundarstufe I» Serie: A1 Dauer: 90 Minuten Name: Vorname: Adresse: Prüfungsnummer:
Aufnahmeprüfung 2016 für die Berufsmaturitätsschulen des Kantons Zürich
 Aufnahmeprüfung 2016 für die Berufsmaturitätsschulen des Kantons Zürich Mathematik Basierend auf Lehrmittel «Mathematik Sekundarstufe I» Serie: A2 Dauer: 90 Minuten Name: Vorname: Adresse: Prüfungsnummer:
Aufnahmeprüfung 2016 für die Berufsmaturitätsschulen des Kantons Zürich Mathematik Basierend auf Lehrmittel «Mathematik Sekundarstufe I» Serie: A2 Dauer: 90 Minuten Name: Vorname: Adresse: Prüfungsnummer:
Theoretische Informatik 1
 Theoretische Informatik 1 Teil 12 Bernhard Nessler Institut für Grundlagen der Informationsverabeitung TU Graz SS 2007 Übersicht 1 Maschinelles Lernen Definition Lernen 2 agnostic -learning Definition
Theoretische Informatik 1 Teil 12 Bernhard Nessler Institut für Grundlagen der Informationsverabeitung TU Graz SS 2007 Übersicht 1 Maschinelles Lernen Definition Lernen 2 agnostic -learning Definition