Übersicht. 20. Verstärkungslernen
|
|
|
- Hansi Auttenberg
- vor 8 Jahren
- Abrufe
Transkript
1 Übersicht I Künstliche Intelligenz II Problemlösen III Wissen und Schlußfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen VI Lernen 18. Lernen aus Beobachtungen 19. Lernen in neuronalen & Bayes schen Netzen 20. Verstärkungslernen 21. Wissen beim Lernen VII Kommunizieren, Wahrnehmen und Handeln

2 Reinforcement Learning Problem: Agent bekommt irgendwann ein Feedback und muss herausfinden, welche seiner letzten Aktionen dafür verantwortlich war. Typisch für alle Lebewesen (Positives Feedback ist z.b. Freude, negatives Feedback Schmerz). Verschiedene Lernsituationen: Umgebung kann zugänglich oder unzugänglich sein. Agent kann Wissen über Umgebung und die Effekte seiner Aktionen haben oder er muß außer den Nützlichkeiten auch das Modell lernen. Feedback kann nur in End- oder in allen Zuständen möglich sein. Feedback kann ein Teil der zu maximierenden Nützlichkeit (z.b. im Tischtennis) oder es können Hinweise sein ( Guter Zug ). Agent kann ein passiver oder aktiver Lerner sein. Zwei Haupttypen von Lernverfahren der Nützlichkeitsfunktion: Agent lernt über Zustände, die er zur Aktionsselektion nutzt Q-Lernen: Agent lernt direkt von Aktionen in Zuständen.
 oder es können Hinweise sein ( Guter Zug ). Agent kann ein passiver oder aktiver Lerner sein.")
3 Beispiel: Reinforcement Learning

4 Passives Lernen in bekannten Umgebungen Annahmen: Der Agent beobachtet Zustandsübergänge mit bekanntem Zustandsübergangswahrscheinlichkeiten und versucht die Nützlichkeiten der Zustände zu lernen (z.b. die Nützlichkeit einer vorgegebenen Politik für sein Verhalten). Die Nützlichkeit einer Sequenz ist gleich der Summe der Belohnungen der Zustände in der Sequenz. Zukünftige Belohnung eines Zustandes (reward-to-go) = Belohnung bis zum Erreichen des Zielzustandes = Erwartete Nützlichkeit
 = Belohnung bis zum Erreichen des Zielzustandes = Erwartete")
5 Passives Lernen in bekannten Umgebungen: Algorithmen und Datenstrukturen Basisalgorithmus: Der Agent aktualisiert mit jeder Trainingssequenz die erwarteten Nützlichkeiten der betroffenen Zustände. Dabei gibt es verschiedene Möglichkeiten: Naiver Ansatz (LMS) Adaptives dynamisches Programmieren Zeitliches Differenzlernen Datenstrukturen: U: Tabelle der aktuellen Nützlichkeitswerte aller Zustände N: Tabelle der Häufigkeiten aller Zustände M: Tabelle der Übergangswahrscheinlichkeiten zwischen den Zuständen

6 Naives Aktualisieren der Nützlichkeiten (LMS = Least Mean Square Approach) In einer Trainingssequenz werden für alle Zustände der Sequenz ihre beobachteten Nützlichkeiten rückwärts berechnet. Diese werden entsprechend der Häufigkeit der Zustände über alle Trainingssequenzen gewichtet und daraus die Gesamtnützlichkeit des Zustandes berechnet. Rückführung auf induktives Problem: Es gibt eine Menge von Beispielen [Zustand, beobachtete Nützlichkeit], die mit bekannten induktiven Lerntechniken oder Neuronalen Netzen verallgemeinert werden (insbesondere falls Nützlichkeit nicht als Tabelle, sondern als Funktion repräsentiert wird) Problem: Der Algorithmus berücksichtigt nicht das Wissen über Übergangswahrscheinlichkeiten zwischen den Zuständen und konvergiert deswegen extrem langsam.
![Rückführung auf induktives Problem: Es gibt eine Menge von Beispielen [Zustand, beobachtete Nützlichkeit], die mit bekannten induktiven Lerntechniken oder Neuronalen Netzen verallgemeinert werden](/docs-images/47/9394811/images/page_6.jpg "(insbesondere falls Nützlichkeit nicht als Tabelle, sondern als Funktion repräsentiert wird) Problem: Der Algorithmus berücksichtigt nicht das Wissen über Übergangswahrscheinlichkeiten zwischen")
7 Generelle Agentenstruktur & naives Aktualisieren (LMS)

8 Beispiel-Ergebnisse: Naives Aktualisieren (LMS)

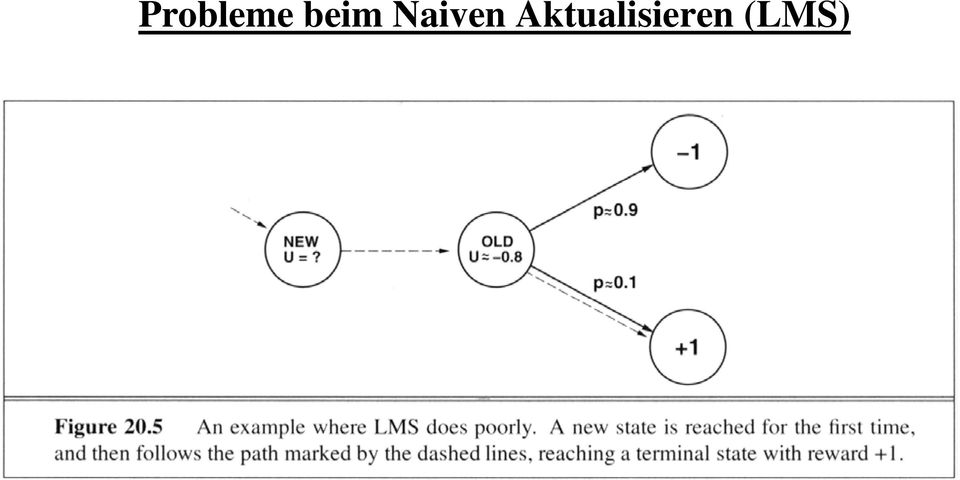
9 Probleme beim Naiven Aktualisieren (LMS)
10 Adaptives Dynamisches Programmieren Tatsächlich ist die Nützlichkeit eines Zustandes der entsprechend der Übergangswahrscheinlickeiten gewichtete Durchschnitt der Nützlichkeiten der Nachbarzustände, d.h. U(i) = R(i) + j M ij U(j) U = Nützlichkeit (Utility) R = Belohnung (Reward) M ij = Übergangswahrscheinlichkeit von Zustand i nach Zustand j Wenn der Agent genügend Pfade beobachtet hat, kann er das Gleichungssystem von n Gleichungen mit n Unbekannten lösen. Wenn dafür dynamische Programmierverfahren benutzt werden, heißt die Reinforcement-Lernmethode adaptives dynamisches Programmieren. Allerdings können die Gleichungssysteme extrem groß und damit nicht mehr handhabbar werden, z.b. bei Backgammon Gleichungen mit Unbekannten.

11 Beispiel-Ergebnisse: Adaptives Dynamisches Programmieren

12 Zeitliches Differenzlernen Kombination der Vorteile vom LMS- und ADP-Ansatz (Einfachheit bei Berücksichtigung von Übergangswahrscheinlichkeiten) Das naive Aktualisieren der Nützlichkeiten berücksichtigt nicht die Übergangswahrscheinlichkeiten. Wenn man von einem Zustand i nach j kommt und derzeit galt: U(i) = -0,5 und U(j) = +0,5 dann sollte U(i) besser an seinen Nachfolger angepaßt werden. Das lässt sich durch folgende Aktualisierungsregel korrigieren: U(i) U(i) + α (R(i) + U(j) - U(i)) Wobei α ein Parameter Lernrate ist, der mit zunehmender Zeit verkleinert wird (ähnlich wie bei simulated annealing).
 U(i) + α (R(i) + U(j) - U(i)) Wobei α ein Parameter Lernrate ist, der mit")
13 Algorithmus Zeitliches Differenzlernen

14 Beispiel-Ergebnisse: Zeitliches Differenzlernen

15 Passives Lernen in einer unbekannten Umgebung In einer unbekannte Umgebung sind die Übergangswahrscheinlichkeiten zwischen Zuständen nicht bekannt. Da sie vom naiven Aktualisieren und vom Zeitlichen Differenzlernen nicht benutzt werden, ändern sich die Algorithmen nicht. Für das adaptive dynamische Programmieren können die Übergangswahrscheinlichkeiten aus den beobachteten Übergängen in den Trainingssequenzen approximiert werden. Da von einer Trainingssequenz zur nächsten sich die Übergangswahrscheinlichkeiten nur geringfügig ändern, kann für das Gesamtproblem das Verfahren der Value Iteration (Kap. 17) benutzt werden.

16 Unterschiede zwischen Adaptivem Dynamischem Programmieren (ADP) und Zeitlichem Differenzlernen (ZD) ZD adaptiert einen Zustand nur an seinen beobachteten Vorgänger, ADP an alle Nachbarn. Unterschied wird bei vielen Trainingssequenzen unbedeutend. ZD macht nur eine Anpassung pro beobachtete Transition ADP für alle Nachbarn und propagiert diese weiter ZD grobe Approximation von ADP Unterschied kann verringert werden, wenn für ZD Pseudo-Erfahrungen auf der Basis des bisherigen Wissen über Zustandsübergänge generiert werden. Entsprechend kann ADP angepasst werden, indem nur große Wertänderungen an wahrscheinliche Nachbarn propagiert werden approximatives ADP

17 Aktives Lernen in unbekannten Umgebungen Ein aktiver Agent hat die Möglichkeit, in jedem Zustand die jeweils beste Aktion zu wählen. Im Vergleich zum passiven Lernen ändert sich: die Zustandsübergangsfunktion, da sie jetzt auch von der gewählten Aktion abhängt. Die Berechung der Nützlichkeit eines Zustandes, bei der immer die beste Aktion zugrundegelegt wird. Die Verhaltenskomponente fragt die gelernten Funktionen ständig ab. Die Lernalgorithmen ändern sich nicht wesentlich, beim adaptiven dynamischen Programmieren müssen nur die aktionsabhängigen statt der einfachen Zustandsübergangswahrscheinlichkeiten aktualisiert und benutzt werden. Die Zustandsaktualisierungsfunktion beim zeitlichen Differenzlernen ändert sich gar nicht.

18 Algorithmus: Aktives Dynamisches Adaptives Programmieren

19 Erkunden der Umgebung Die Hauptschwierigkeit beim aktiven Lernen ergibt sich daraus, dass Aktionen nicht nur die Belohnung maximieren sollen, sondern auch zur Erkundung der Umgebung nützlich sind. Wie soll kurzfristiger und langfristiger Gewinn gegeneinander abgewogen werden? Grad des Konservativismus sollte proportional zum Wissensstand sein. Umsetzung: Wenig erkundete Pfade bekommen eine belohnungsunabhängige Verstärkung, die mit häufigerem Durchlaufen abnimmt.

20 Beispiel-Ergebnisse mit total konservativem (greedy) und total explorativem (wacky) Extrem(1)
")
21 Beispiel-Ergebnisse mit gemischter Strategie R + = optimistisch geschätzte Belohnung, N e = Anzahl Versuche Erkundungsfunktion f (u,n) = R + falls n < N e, sonst u (bekannte Utility)
22 Direktes Lernen von Aktionen: Q-Lernen (1) Q(a, i) = Wert der Aktion a im Zustand i Zusammenhang zwischen Nützlichkeit und Q-Werten: U(i) = max a Q(a,i) Der Q-Wert einer Aktion in einem Zustand ergibt sich aus der Belohnung in diesem Zustand + den wahrscheinlichkeitsgewichteten Q- Werten der besten Aktionen in den Nachbarzustände, die durch die Aktion erreicht werden.
23 Direktes Lernen von Aktionen: Q-Lernen (2) Während sich das dynamische adaptive Programmieren nicht übertragen lässt, da es Nützlichkeiten der Zustände benötigt, kann das zeitliche Differenzenlernen leicht angepasst werden: Q(a, i) Q(a, i) + α (R(i) + max a Q(a,j) Q(a,i)) das nach jedem Übergang von Zustand i nach Zustand j berechnet wird. Beim aktiven Lernen werden wiederum seltene Aktionen in Zuständen belohnt. Q-Lernen benötigt kein Modell der Welt und kann daher kein deklaratives Wissen repräsentieren: Eignung eher für einfache Umgebungen.
24 Algorithmus Q-Lernen
25 Beispiel-Ergebnisse: Q-Lernen
26 Generalisierung beim Reinforcement-Lernen Im allgemeinen ist es unmöglich, alle Zustände explizit zu bewerten (z.b. Schach mit ca Stellungen). Stattdessen werden implizite Repräsentationen der Nützlichkeiten benötigt, die häufig als lineare Funktionen von Zustandsvariablen dargestellt werden: U(i) = w 1 f 1 (i) + w 2 f 2 (i) w n f n (i) wobei die Nützlichkeitsfunktion durch n Gewichte repräsentiert wird. Das ist nicht nur eine enorme Speicherreduktion, sondern auch eine Verallgemeinerung, so dass der Agent nicht mehr alle Zustände kennen muss. In den Lernfunktionen muss (außer beim adaptiven dynamischen Programmieren) nur die Nützlichkeit eines Zustandes durch die Nützlichkeit der Zustandsfunktion ersetzt werden, z.b. für Zeitliches Differenzlernen mit einem Gewichtsvektor w = w 1,w 2,... w n : w w +α [r + U w (j) U w (i)] (w) U w (i) was einem Gradienten-Abstiegs-Verfahren wie bei neuralen Netzen entspricht, die sich gut für diese Lernverfahren eignen.
27 Anwendungen in Spielen: Anwendungen Checker-Programm (Samuel 59, 67): Unterschiede zu obiger Formel: - Es wird die aktuelle Stellungsbewertungsbewertung mit der durch Vorausberechnung im Suchbaum entstandenen Stellungsbewertung verglichen. - Es werden nicht die Endzustände im Spiel bewertet, sondern die oben berechneten. Allerdings wird Materialvorteil immer positiv bewertet. Backgamman-Programm (Tesauro 89, 92): 1. Version: Neuronales Netz auf der Basis vom Q-Lernen mit Bewertungen von menschlichen Experten. 2. Version: Neuronales Netz auf der Basis vom TD-Lernen ohne menschliche Bewertungen: bessere Ergebnisse. Anwendungen für Roboter-Steuerung: Inverses Pendel
28 Stab-Balancieren-Problem
29 Genetische Algorithmen und evolutionäre Programmierung Grundidee: Ausgangspunkt ist eine Population von Individuen, die sich entsprechend ihrer Fitness reproduzieren. Dabei ändern sich die Individuen, entweder durch Mutationen und/oder durch Vermischung ihrer Eigenschaften, die als Informationsstring kodiert werden. Kritische Fragen: - Fitness Funktion - Repräsentation von Individuen - Auswahl von Individuen zur Vermehrung Reproduktion von Individuen
30 Genetischer Basisalgorithmus
31 Restaurant-Beispiel für Genetischen Algorithmus
Übersicht. Künstliche Intelligenz: 21. Verstärkungslernen Frank Puppe 1
 Übersicht I Künstliche Intelligenz II Problemlösen III Wissen und Schlussfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen VI Lernen 18. Lernen aus Beobachtungen 19. Wissen beim Lernen 20. Statistische
Übersicht I Künstliche Intelligenz II Problemlösen III Wissen und Schlussfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen VI Lernen 18. Lernen aus Beobachtungen 19. Wissen beim Lernen 20. Statistische
Reinforcement Learning
 Effiziente Darstellung von Daten Reinforcement Learning 02. Juli 2004 Jan Schlößin Einordnung Was ist Reinforcement Learning? Einführung - Prinzip der Agent Eigenschaften das Ziel Q-Learning warum Q-Learning
Effiziente Darstellung von Daten Reinforcement Learning 02. Juli 2004 Jan Schlößin Einordnung Was ist Reinforcement Learning? Einführung - Prinzip der Agent Eigenschaften das Ziel Q-Learning warum Q-Learning
Aufabe 7: Baum-Welch Algorithmus
 Effiziente Algorithmen VU Ausarbeitung Aufabe 7: Baum-Welch Algorithmus Florian Fest, Matr. Nr.0125496 baskit@generationfun.at Claudia Hermann, Matr. Nr.0125532 e0125532@stud4.tuwien.ac.at Matteo Savio,
Effiziente Algorithmen VU Ausarbeitung Aufabe 7: Baum-Welch Algorithmus Florian Fest, Matr. Nr.0125496 baskit@generationfun.at Claudia Hermann, Matr. Nr.0125532 e0125532@stud4.tuwien.ac.at Matteo Savio,
Die Invaliden-Versicherung ändert sich
 Die Invaliden-Versicherung ändert sich 1 Erklärung Die Invaliden-Versicherung ist für invalide Personen. Invalid bedeutet: Eine Person kann einige Sachen nicht machen. Wegen einer Krankheit. Wegen einem
Die Invaliden-Versicherung ändert sich 1 Erklärung Die Invaliden-Versicherung ist für invalide Personen. Invalid bedeutet: Eine Person kann einige Sachen nicht machen. Wegen einer Krankheit. Wegen einem
AGROPLUS Buchhaltung. Daten-Server und Sicherheitskopie. Version vom 21.10.2013b
 AGROPLUS Buchhaltung Daten-Server und Sicherheitskopie Version vom 21.10.2013b 3a) Der Daten-Server Modus und der Tresor Der Daten-Server ist eine Betriebsart welche dem Nutzer eine grosse Flexibilität
AGROPLUS Buchhaltung Daten-Server und Sicherheitskopie Version vom 21.10.2013b 3a) Der Daten-Server Modus und der Tresor Der Daten-Server ist eine Betriebsart welche dem Nutzer eine grosse Flexibilität
Lineargleichungssysteme: Additions-/ Subtraktionsverfahren
 Lineargleichungssysteme: Additions-/ Subtraktionsverfahren W. Kippels 22. Februar 2014 Inhaltsverzeichnis 1 Einleitung 2 2 Lineargleichungssysteme zweiten Grades 2 3 Lineargleichungssysteme höheren als
Lineargleichungssysteme: Additions-/ Subtraktionsverfahren W. Kippels 22. Februar 2014 Inhaltsverzeichnis 1 Einleitung 2 2 Lineargleichungssysteme zweiten Grades 2 3 Lineargleichungssysteme höheren als
Professionelle Seminare im Bereich MS-Office
 Der Name BEREICH.VERSCHIEBEN() ist etwas unglücklich gewählt. Man kann mit der Funktion Bereiche zwar verschieben, man kann Bereiche aber auch verkleinern oder vergrößern. Besser wäre es, die Funktion
Der Name BEREICH.VERSCHIEBEN() ist etwas unglücklich gewählt. Man kann mit der Funktion Bereiche zwar verschieben, man kann Bereiche aber auch verkleinern oder vergrößern. Besser wäre es, die Funktion
Eva Douma: Die Vorteile und Nachteile der Ökonomisierung in der Sozialen Arbeit
 Eva Douma: Die Vorteile und Nachteile der Ökonomisierung in der Sozialen Arbeit Frau Dr. Eva Douma ist Organisations-Beraterin in Frankfurt am Main Das ist eine Zusammen-Fassung des Vortrages: Busines
Eva Douma: Die Vorteile und Nachteile der Ökonomisierung in der Sozialen Arbeit Frau Dr. Eva Douma ist Organisations-Beraterin in Frankfurt am Main Das ist eine Zusammen-Fassung des Vortrages: Busines
Theoretische Grundlagen der Informatik WS 09/10
 Theoretische Grundlagen der Informatik WS 09/10 - Tutorium 6 - Michael Kirsten und Kai Wallisch Sitzung 13 02.02.2010 Inhaltsverzeichnis 1 Formeln zur Berechnung Aufgabe 1 2 Hamming-Distanz Aufgabe 2 3
Theoretische Grundlagen der Informatik WS 09/10 - Tutorium 6 - Michael Kirsten und Kai Wallisch Sitzung 13 02.02.2010 Inhaltsverzeichnis 1 Formeln zur Berechnung Aufgabe 1 2 Hamming-Distanz Aufgabe 2 3
Kapitel 5: Dynamisches Programmieren Gliederung
 Gliederung 1. Grundlagen 2. Zahlentheoretische Algorithmen 3. Sortierverfahren 4. Ausgewählte Datenstrukturen 5. Dynamisches Programmieren 6. Graphalgorithmen 7. String-Matching 8. Kombinatorische Algorithmen
Gliederung 1. Grundlagen 2. Zahlentheoretische Algorithmen 3. Sortierverfahren 4. Ausgewählte Datenstrukturen 5. Dynamisches Programmieren 6. Graphalgorithmen 7. String-Matching 8. Kombinatorische Algorithmen
Lineare Gleichungssysteme
 Lineare Gleichungssysteme 1 Zwei Gleichungen mit zwei Unbekannten Es kommt häufig vor, dass man nicht mit einer Variablen alleine auskommt, um ein Problem zu lösen. Das folgende Beispiel soll dies verdeutlichen
Lineare Gleichungssysteme 1 Zwei Gleichungen mit zwei Unbekannten Es kommt häufig vor, dass man nicht mit einer Variablen alleine auskommt, um ein Problem zu lösen. Das folgende Beispiel soll dies verdeutlichen
Informationsblatt Induktionsbeweis
 Sommer 015 Informationsblatt Induktionsbeweis 31. März 015 Motivation Die vollständige Induktion ist ein wichtiges Beweisverfahren in der Informatik. Sie wird häufig dazu gebraucht, um mathematische Formeln
Sommer 015 Informationsblatt Induktionsbeweis 31. März 015 Motivation Die vollständige Induktion ist ein wichtiges Beweisverfahren in der Informatik. Sie wird häufig dazu gebraucht, um mathematische Formeln
Abituraufgabe zur Stochastik, Hessen 2009, Grundkurs (TR)
") Abituraufgabe zur Stochastik, Hessen 2009, Grundkurs (TR) Eine Firma stellt USB-Sticks her. Sie werden in der Fabrik ungeprüft in Packungen zu je 20 Stück verpackt und an Händler ausgeliefert. 1 Ein Händler
Abituraufgabe zur Stochastik, Hessen 2009, Grundkurs (TR) Eine Firma stellt USB-Sticks her. Sie werden in der Fabrik ungeprüft in Packungen zu je 20 Stück verpackt und an Händler ausgeliefert. 1 Ein Händler
50 Fragen, um Dir das Rauchen abzugewöhnen 1/6
 50 Fragen, um Dir das Rauchen abzugewöhnen 1/6 Name:....................................... Datum:............... Dieser Fragebogen kann und wird Dir dabei helfen, in Zukunft ohne Zigaretten auszukommen
50 Fragen, um Dir das Rauchen abzugewöhnen 1/6 Name:....................................... Datum:............... Dieser Fragebogen kann und wird Dir dabei helfen, in Zukunft ohne Zigaretten auszukommen
6. Bayes-Klassifikation. (Schukat-Talamazzini 2002)
") 6. Bayes-Klassifikation (Schukat-Talamazzini 2002) (Böhm 2003) (Klawonn 2004) Der Satz von Bayes: Beweis: Klassifikation mittels des Satzes von Bayes (Klawonn 2004) Allgemeine Definition: Davon zu unterscheiden
6. Bayes-Klassifikation (Schukat-Talamazzini 2002) (Böhm 2003) (Klawonn 2004) Der Satz von Bayes: Beweis: Klassifikation mittels des Satzes von Bayes (Klawonn 2004) Allgemeine Definition: Davon zu unterscheiden
Das große ElterngeldPlus 1x1. Alles über das ElterngeldPlus. Wer kann ElterngeldPlus beantragen? ElterngeldPlus verstehen ein paar einleitende Fakten
 Das große x -4 Alles über das Wer kann beantragen? Generell kann jeder beantragen! Eltern (Mütter UND Väter), die schon während ihrer Elternzeit wieder in Teilzeit arbeiten möchten. Eltern, die während
Das große x -4 Alles über das Wer kann beantragen? Generell kann jeder beantragen! Eltern (Mütter UND Väter), die schon während ihrer Elternzeit wieder in Teilzeit arbeiten möchten. Eltern, die während
Anmerkungen zur Übergangsprüfung
 DM11 Slide 1 Anmerkungen zur Übergangsprüfung Aufgabeneingrenzung Aufgaben des folgenden Typs werden wegen ihres Schwierigkeitsgrads oder wegen eines ungeeigneten fachlichen Schwerpunkts in der Übergangsprüfung
DM11 Slide 1 Anmerkungen zur Übergangsprüfung Aufgabeneingrenzung Aufgaben des folgenden Typs werden wegen ihres Schwierigkeitsgrads oder wegen eines ungeeigneten fachlichen Schwerpunkts in der Übergangsprüfung
Was meinen die Leute eigentlich mit: Grexit?
 Was meinen die Leute eigentlich mit: Grexit? Grexit sind eigentlich 2 Wörter. 1. Griechenland 2. Exit Exit ist ein englisches Wort. Es bedeutet: Ausgang. Aber was haben diese 2 Sachen mit-einander zu tun?
Was meinen die Leute eigentlich mit: Grexit? Grexit sind eigentlich 2 Wörter. 1. Griechenland 2. Exit Exit ist ein englisches Wort. Es bedeutet: Ausgang. Aber was haben diese 2 Sachen mit-einander zu tun?
Vermeiden Sie es sich bei einer deutlich erfahreneren Person "dranzuhängen", Sie sind persönlich verantwortlich für Ihren Lernerfolg.
 1 2 3 4 Vermeiden Sie es sich bei einer deutlich erfahreneren Person "dranzuhängen", Sie sind persönlich verantwortlich für Ihren Lernerfolg. Gerade beim Einstig in der Programmierung muss kontinuierlich
1 2 3 4 Vermeiden Sie es sich bei einer deutlich erfahreneren Person "dranzuhängen", Sie sind persönlich verantwortlich für Ihren Lernerfolg. Gerade beim Einstig in der Programmierung muss kontinuierlich
Leichte-Sprache-Bilder
 Leichte-Sprache-Bilder Reinhild Kassing Information - So geht es 1. Bilder gucken 2. anmelden für Probe-Bilder 3. Bilder bestellen 4. Rechnung bezahlen 5. Bilder runterladen 6. neue Bilder vorschlagen
Leichte-Sprache-Bilder Reinhild Kassing Information - So geht es 1. Bilder gucken 2. anmelden für Probe-Bilder 3. Bilder bestellen 4. Rechnung bezahlen 5. Bilder runterladen 6. neue Bilder vorschlagen
Korrelation (II) Korrelation und Kausalität
 Korrelation und Kausalität") Korrelation (II) Korrelation und Kausalität Situation: Seien X, Y zwei metrisch skalierte Merkmale mit Ausprägungen (x 1, x 2,..., x n ) bzw. (y 1, y 2,..., y n ). D.h. für jede i = 1, 2,..., n bezeichnen
Korrelation (II) Korrelation und Kausalität Situation: Seien X, Y zwei metrisch skalierte Merkmale mit Ausprägungen (x 1, x 2,..., x n ) bzw. (y 1, y 2,..., y n ). D.h. für jede i = 1, 2,..., n bezeichnen
6.2 Scan-Konvertierung (Scan Conversion)
") 6.2 Scan-Konvertierung (Scan Conversion) Scan-Konvertierung ist die Rasterung von einfachen Objekten (Geraden, Kreisen, Kurven). Als Ausgabemedium dient meist der Bildschirm, der aus einem Pixelraster
6.2 Scan-Konvertierung (Scan Conversion) Scan-Konvertierung ist die Rasterung von einfachen Objekten (Geraden, Kreisen, Kurven). Als Ausgabemedium dient meist der Bildschirm, der aus einem Pixelraster
Markovketten. Bsp. Page Ranking für Suchmaschinen. Wahlfach Entscheidung unter Risiko und stat. Datenanalyse 07.01.2015
 Markovketten Markovketten sind ein häufig verwendetes Modell zur Beschreibung von Systemen, deren Verhalten durch einen zufälligen Übergang von einem Systemzustand zu einem anderen Systemzustand gekennzeichnet
Markovketten Markovketten sind ein häufig verwendetes Modell zur Beschreibung von Systemen, deren Verhalten durch einen zufälligen Übergang von einem Systemzustand zu einem anderen Systemzustand gekennzeichnet
Rekursionen. Georg Anegg 25. November 2009. Methoden und Techniken an Beispielen erklärt
 Methoden und Techniken an Beispielen erklärt Georg Anegg 5. November 009 Beispiel. Die Folge {a n } sei wie folgt definiert (a, d, q R, q ): a 0 a, a n+ a n q + d (n 0) Man bestimme eine explizite Darstellung
Methoden und Techniken an Beispielen erklärt Georg Anegg 5. November 009 Beispiel. Die Folge {a n } sei wie folgt definiert (a, d, q R, q ): a 0 a, a n+ a n q + d (n 0) Man bestimme eine explizite Darstellung
50. Mathematik-Olympiade 2. Stufe (Regionalrunde) Klasse 11 13. 501322 Lösung 10 Punkte
 Klasse 11 13. 501322 Lösung 10 Punkte") 50. Mathematik-Olympiade. Stufe (Regionalrunde) Klasse 3 Lösungen c 00 Aufgabenausschuss des Mathematik-Olympiaden e.v. www.mathematik-olympiaden.de. Alle Rechte vorbehalten. 503 Lösung 0 Punkte Es seien
50. Mathematik-Olympiade. Stufe (Regionalrunde) Klasse 3 Lösungen c 00 Aufgabenausschuss des Mathematik-Olympiaden e.v. www.mathematik-olympiaden.de. Alle Rechte vorbehalten. 503 Lösung 0 Punkte Es seien
Behörde für Bildung und Sport Abitur 2008 Lehrermaterialien zum Leistungskurs Mathematik
 Abitur 8 II. Insektenpopulation LA/AG In den Tropen legen die Weibchen einer in Deutschland unbekannten Insektenpopulation jedes Jahr kurz vor Beginn der Regenzeit jeweils 9 Eier und sterben bald darauf.
Abitur 8 II. Insektenpopulation LA/AG In den Tropen legen die Weibchen einer in Deutschland unbekannten Insektenpopulation jedes Jahr kurz vor Beginn der Regenzeit jeweils 9 Eier und sterben bald darauf.
Tangentengleichung. Wie lautet die Geradengleichung für die Tangente, y T =? Antwort:
 Tangentengleichung Wie Sie wissen, gibt die erste Ableitung einer Funktion deren Steigung an. Betrachtet man eine fest vorgegebene Stelle, gibt f ( ) also die Steigung der Kurve und somit auch die Steigung
Tangentengleichung Wie Sie wissen, gibt die erste Ableitung einer Funktion deren Steigung an. Betrachtet man eine fest vorgegebene Stelle, gibt f ( ) also die Steigung der Kurve und somit auch die Steigung
Kapitalerhöhung - Verbuchung
 Kapitalerhöhung - Verbuchung Beschreibung Eine Kapitalerhöhung ist eine Erhöhung des Aktienkapitals einer Aktiengesellschaft durch Emission von en Aktien. Es gibt unterschiedliche Formen von Kapitalerhöhung.
Kapitalerhöhung - Verbuchung Beschreibung Eine Kapitalerhöhung ist eine Erhöhung des Aktienkapitals einer Aktiengesellschaft durch Emission von en Aktien. Es gibt unterschiedliche Formen von Kapitalerhöhung.
Statuten in leichter Sprache
 Statuten in leichter Sprache Zweck vom Verein Artikel 1: Zivil-Gesetz-Buch Es gibt einen Verein der selbstbestimmung.ch heisst. Der Verein ist so aufgebaut, wie es im Zivil-Gesetz-Buch steht. Im Zivil-Gesetz-Buch
Statuten in leichter Sprache Zweck vom Verein Artikel 1: Zivil-Gesetz-Buch Es gibt einen Verein der selbstbestimmung.ch heisst. Der Verein ist so aufgebaut, wie es im Zivil-Gesetz-Buch steht. Im Zivil-Gesetz-Buch
Nicht über uns ohne uns
 Nicht über uns ohne uns Das bedeutet: Es soll nichts über Menschen mit Behinderung entschieden werden, wenn sie nicht mit dabei sind. Dieser Text ist in leicht verständlicher Sprache geschrieben. Die Parteien
Nicht über uns ohne uns Das bedeutet: Es soll nichts über Menschen mit Behinderung entschieden werden, wenn sie nicht mit dabei sind. Dieser Text ist in leicht verständlicher Sprache geschrieben. Die Parteien
Abschlussprüfung Realschule Bayern II / III: 2009 Haupttermin B 1.0 B 1.1
 B 1.0 B 1.1 L: Wir wissen von, dass sie den Scheitel hat und durch den Punkt läuft. Was nichts bringt, ist beide Punkte in die allgemeine Parabelgleichung einzusetzen und das Gleichungssystem zu lösen,
B 1.0 B 1.1 L: Wir wissen von, dass sie den Scheitel hat und durch den Punkt läuft. Was nichts bringt, ist beide Punkte in die allgemeine Parabelgleichung einzusetzen und das Gleichungssystem zu lösen,
1 C H R I S T O P H D R Ö S S E R D E R M A T H E M A T I K V E R F Ü H R E R
 C H R I S T O P H D R Ö S S E R D E R M A T H E M A T I K V E R F Ü H R E R L Ö S U N G E N Seite 7 n Wenn vier Menschen auf einem Quadratmeter stehen, dann hat jeder eine Fläche von 50 mal 50 Zentimeter
C H R I S T O P H D R Ö S S E R D E R M A T H E M A T I K V E R F Ü H R E R L Ö S U N G E N Seite 7 n Wenn vier Menschen auf einem Quadratmeter stehen, dann hat jeder eine Fläche von 50 mal 50 Zentimeter
Würfelt man dabei je genau 10 - mal eine 1, 2, 3, 4, 5 und 6, so beträgt die Anzahl. der verschiedenen Reihenfolgen, in denen man dies tun kann, 60!.
 040304 Übung 9a Analysis, Abschnitt 4, Folie 8 Die Wahrscheinlichkeit, dass bei n - maliger Durchführung eines Zufallexperiments ein Ereignis A ( mit Wahrscheinlichkeit p p ( A ) ) für eine beliebige Anzahl
040304 Übung 9a Analysis, Abschnitt 4, Folie 8 Die Wahrscheinlichkeit, dass bei n - maliger Durchführung eines Zufallexperiments ein Ereignis A ( mit Wahrscheinlichkeit p p ( A ) ) für eine beliebige Anzahl
Lösung. Prüfungsteil 1: Aufgabe 1
 Zentrale Prüfung 01 Lösung Diese Lösung wurde erstellt von Cornelia Sanzenbacher. Sie ist keine offizielle Lösung des Ministeriums für Schule und Weiterbildung des Landes. Prüfungsteil 1: Aufgabe 1 a)
Zentrale Prüfung 01 Lösung Diese Lösung wurde erstellt von Cornelia Sanzenbacher. Sie ist keine offizielle Lösung des Ministeriums für Schule und Weiterbildung des Landes. Prüfungsteil 1: Aufgabe 1 a)
Stellen Sie bitte den Cursor in die Spalte B2 und rufen die Funktion Sverweis auf. Es öffnet sich folgendes Dialogfenster
 Es gibt in Excel unter anderem die so genannten Suchfunktionen / Matrixfunktionen Damit können Sie Werte innerhalb eines bestimmten Bereichs suchen. Als Beispiel möchte ich die Funktion Sverweis zeigen.
Es gibt in Excel unter anderem die so genannten Suchfunktionen / Matrixfunktionen Damit können Sie Werte innerhalb eines bestimmten Bereichs suchen. Als Beispiel möchte ich die Funktion Sverweis zeigen.
Betriebskalender & Kalenderfunktionen
 Betriebskalender & Kalenderfunktionen Der Betriebskalender ist in OpenZ für 2 Dinge verantwortlich: 1. Berechnung der Produktionszeiten im Modul Herstellung 2. Schaffung der Rahmenbedingungen, für die
Betriebskalender & Kalenderfunktionen Der Betriebskalender ist in OpenZ für 2 Dinge verantwortlich: 1. Berechnung der Produktionszeiten im Modul Herstellung 2. Schaffung der Rahmenbedingungen, für die
11.3 Komplexe Potenzreihen und weitere komplexe Funktionen
 .3 Komplexe Potenzreihen und weitere komplexe Funktionen Definition.) komplexe Folgen: z n = x n + j. y n mit zwei reellen Folgen x n und y n.) Konvergenz: Eine komplexe Folge z n = x n + j. y n heißt
.3 Komplexe Potenzreihen und weitere komplexe Funktionen Definition.) komplexe Folgen: z n = x n + j. y n mit zwei reellen Folgen x n und y n.) Konvergenz: Eine komplexe Folge z n = x n + j. y n heißt
Landes-Arbeits-Gemeinschaft Gemeinsam Leben Gemeinsam Lernen Rheinland-Pfalz e.v.
 Landes-Arbeits-Gemeinschaft Gemeinsam Leben Gemeinsam Lernen Rheinland-Pfalz e.v. Wer sind wir? Wir sind ein Verein. Wir setzen uns für Menschen mit Behinderung ein. Menschen mit Behinderung sollen überall
Landes-Arbeits-Gemeinschaft Gemeinsam Leben Gemeinsam Lernen Rheinland-Pfalz e.v. Wer sind wir? Wir sind ein Verein. Wir setzen uns für Menschen mit Behinderung ein. Menschen mit Behinderung sollen überall
Bewertung des Blattes
 Bewertung des Blattes Es besteht immer die Schwierigkeit, sein Blatt richtig einzuschätzen. Im folgenden werden einige Anhaltspunkte gegeben. Man unterscheidet: Figurenpunkte Verteilungspunkte Längenpunkte
Bewertung des Blattes Es besteht immer die Schwierigkeit, sein Blatt richtig einzuschätzen. Im folgenden werden einige Anhaltspunkte gegeben. Man unterscheidet: Figurenpunkte Verteilungspunkte Längenpunkte
Zahlenwinkel: Forscherkarte 1. alleine. Zahlenwinkel: Forschertipp 1
 Zahlenwinkel: Forscherkarte 1 alleine Tipp 1 Lege die Ziffern von 1 bis 9 so in den Zahlenwinkel, dass jeder Arm des Zahlenwinkels zusammengezählt das gleiche Ergebnis ergibt! Finde möglichst viele verschiedene
Zahlenwinkel: Forscherkarte 1 alleine Tipp 1 Lege die Ziffern von 1 bis 9 so in den Zahlenwinkel, dass jeder Arm des Zahlenwinkels zusammengezählt das gleiche Ergebnis ergibt! Finde möglichst viele verschiedene
W-Rechnung und Statistik für Ingenieure Übung 11
 W-Rechnung und Statistik für Ingenieure Übung 11 Christoph Kustosz (kustosz@statistik.tu-dortmund.de) Mathematikgebäude Raum 715 Christoph Kustosz (kustosz@statistik.tu-dortmund.de) W-Rechnung und Statistik
W-Rechnung und Statistik für Ingenieure Übung 11 Christoph Kustosz (kustosz@statistik.tu-dortmund.de) Mathematikgebäude Raum 715 Christoph Kustosz (kustosz@statistik.tu-dortmund.de) W-Rechnung und Statistik
Fotos verkleinern mit Paint
 Fotos verkleinern mit Paint Warum Paint? Sicher, es gibt eine Menge kostenloser guter Programme und Möglichkeiten im Netz zum Verkleinern von Fotos. Letztendlich ist es Geschmackssache, aber meine Erfahrungen
Fotos verkleinern mit Paint Warum Paint? Sicher, es gibt eine Menge kostenloser guter Programme und Möglichkeiten im Netz zum Verkleinern von Fotos. Letztendlich ist es Geschmackssache, aber meine Erfahrungen
Vergleichsklausur 12.1 Mathematik vom 20.12.2005
 Vergleichsklausur 12.1 Mathematik vom 20.12.2005 Mit CAS S./5 Aufgabe Alternative: Ganzrationale Funktionen Berliner Bogen Das Gebäude in den Abbildungen heißt Berliner Bogen und steht in Hamburg. Ein
Vergleichsklausur 12.1 Mathematik vom 20.12.2005 Mit CAS S./5 Aufgabe Alternative: Ganzrationale Funktionen Berliner Bogen Das Gebäude in den Abbildungen heißt Berliner Bogen und steht in Hamburg. Ein
Welche Lagen können zwei Geraden (im Raum) zueinander haben? Welche Lagen kann eine Gerade bezüglich einer Ebene im Raum einnehmen?
 zueinander haben? Welche Lagen kann eine Gerade bezüglich einer Ebene im Raum einnehmen?") Welche Lagen können zwei Geraden (im Raum) zueinander haben? Welche Lagen können zwei Ebenen (im Raum) zueinander haben? Welche Lagen kann eine Gerade bezüglich einer Ebene im Raum einnehmen? Wie heiÿt
Welche Lagen können zwei Geraden (im Raum) zueinander haben? Welche Lagen können zwei Ebenen (im Raum) zueinander haben? Welche Lagen kann eine Gerade bezüglich einer Ebene im Raum einnehmen? Wie heiÿt
Derivate und Bewertung
 . Dr. Daniel Sommer Marie-Curie-Str. 30 60439 Franfurt am Main Klausur Derivate und Bewertung.......... Wintersemester 2008/09 Klausur Derivate und Bewertung Wintersemester 2008/09 Aufgabe 1: Zinsurven,
. Dr. Daniel Sommer Marie-Curie-Str. 30 60439 Franfurt am Main Klausur Derivate und Bewertung.......... Wintersemester 2008/09 Klausur Derivate und Bewertung Wintersemester 2008/09 Aufgabe 1: Zinsurven,
geben. Die Wahrscheinlichkeit von 100% ist hier demnach nur der Gehen wir einmal davon aus, dass die von uns angenommenen
 geben. Die Wahrscheinlichkeit von 100% ist hier demnach nur der Vollständigkeit halber aufgeführt. Gehen wir einmal davon aus, dass die von uns angenommenen 70% im Beispiel exakt berechnet sind. Was würde
geben. Die Wahrscheinlichkeit von 100% ist hier demnach nur der Vollständigkeit halber aufgeführt. Gehen wir einmal davon aus, dass die von uns angenommenen 70% im Beispiel exakt berechnet sind. Was würde
Programmierkurs Java
 Programmierkurs Java Dr. Dietrich Boles Aufgaben zu UE16-Rekursion (Stand 09.12.2011) Aufgabe 1: Implementieren Sie in Java ein Programm, das solange einzelne Zeichen vom Terminal einliest, bis ein #-Zeichen
Programmierkurs Java Dr. Dietrich Boles Aufgaben zu UE16-Rekursion (Stand 09.12.2011) Aufgabe 1: Implementieren Sie in Java ein Programm, das solange einzelne Zeichen vom Terminal einliest, bis ein #-Zeichen
Primzahlen und RSA-Verschlüsselung
 Primzahlen und RSA-Verschlüsselung Michael Fütterer und Jonathan Zachhuber 1 Einiges zu Primzahlen Ein paar Definitionen: Wir bezeichnen mit Z die Menge der positiven und negativen ganzen Zahlen, also
Primzahlen und RSA-Verschlüsselung Michael Fütterer und Jonathan Zachhuber 1 Einiges zu Primzahlen Ein paar Definitionen: Wir bezeichnen mit Z die Menge der positiven und negativen ganzen Zahlen, also
Unterrichtsmaterialien in digitaler und in gedruckter Form. Auszug aus: Übungsbuch für den Grundkurs mit Tipps und Lösungen: Analysis
 Unterrichtsmaterialien in digitaler und in gedruckter Form Auszug aus: Übungsbuch für den Grundkurs mit Tipps und Lösungen: Analysis Das komplette Material finden Sie hier: Download bei School-Scout.de
Unterrichtsmaterialien in digitaler und in gedruckter Form Auszug aus: Übungsbuch für den Grundkurs mit Tipps und Lösungen: Analysis Das komplette Material finden Sie hier: Download bei School-Scout.de
Kapiteltests zum Leitprogramm Binäre Suchbäume
 Kapiteltests zum Leitprogramm Binäre Suchbäume Björn Steffen Timur Erdag überarbeitet von Christina Class Binäre Suchbäume Kapiteltests für das ETH-Leitprogramm Adressaten und Institutionen Das Leitprogramm
Kapiteltests zum Leitprogramm Binäre Suchbäume Björn Steffen Timur Erdag überarbeitet von Christina Class Binäre Suchbäume Kapiteltests für das ETH-Leitprogramm Adressaten und Institutionen Das Leitprogramm
1 topologisches Sortieren
 Wolfgang Hönig / Andreas Ecke WS 09/0 topologisches Sortieren. Überblick. Solange noch Knoten vorhanden: a) Suche Knoten v, zu dem keine Kante führt (Falls nicht vorhanden keine topologische Sortierung
Wolfgang Hönig / Andreas Ecke WS 09/0 topologisches Sortieren. Überblick. Solange noch Knoten vorhanden: a) Suche Knoten v, zu dem keine Kante führt (Falls nicht vorhanden keine topologische Sortierung
How to do? Projekte - Zeiterfassung
 How to do? Projekte - Zeiterfassung Stand: Version 4.0.1, 18.03.2009 1. EINLEITUNG...3 2. PROJEKTE UND STAMMDATEN...4 2.1 Projekte... 4 2.2 Projektmitarbeiter... 5 2.3 Tätigkeiten... 6 2.4 Unterprojekte...
How to do? Projekte - Zeiterfassung Stand: Version 4.0.1, 18.03.2009 1. EINLEITUNG...3 2. PROJEKTE UND STAMMDATEN...4 2.1 Projekte... 4 2.2 Projektmitarbeiter... 5 2.3 Tätigkeiten... 6 2.4 Unterprojekte...
Berufsunfähigkeit? Da bin ich finanziell im Trockenen.
 Berufsunfähigkeit? Da bin ich finanziell im Trockenen. Unsere EinkommensSicherung schützt während des gesamten Berufslebens und passt sich an neue Lebenssituationen an. Meine Arbeitskraft für ein finanziell
Berufsunfähigkeit? Da bin ich finanziell im Trockenen. Unsere EinkommensSicherung schützt während des gesamten Berufslebens und passt sich an neue Lebenssituationen an. Meine Arbeitskraft für ein finanziell
Zeichen bei Zahlen entschlüsseln
 Zeichen bei Zahlen entschlüsseln In diesem Kapitel... Verwendung des Zahlenstrahls Absolut richtige Bestimmung von absoluten Werten Operationen bei Zahlen mit Vorzeichen: Addieren, Subtrahieren, Multiplizieren
Zeichen bei Zahlen entschlüsseln In diesem Kapitel... Verwendung des Zahlenstrahls Absolut richtige Bestimmung von absoluten Werten Operationen bei Zahlen mit Vorzeichen: Addieren, Subtrahieren, Multiplizieren
Grundlagen der Theoretischen Informatik, SoSe 2008
 1. Aufgabenblatt zur Vorlesung Grundlagen der Theoretischen Informatik, SoSe 2008 (Dr. Frank Hoffmann) Lösung von Manuel Jain und Benjamin Bortfeldt Aufgabe 2 Zustandsdiagramme (6 Punkte, wird korrigiert)
1. Aufgabenblatt zur Vorlesung Grundlagen der Theoretischen Informatik, SoSe 2008 (Dr. Frank Hoffmann) Lösung von Manuel Jain und Benjamin Bortfeldt Aufgabe 2 Zustandsdiagramme (6 Punkte, wird korrigiert)
infach Geld FBV Ihr Weg zum finanzellen Erfolg Florian Mock
 infach Ihr Weg zum finanzellen Erfolg Geld Florian Mock FBV Die Grundlagen für finanziellen Erfolg Denn Sie müssten anschließend wieder vom Gehaltskonto Rückzahlungen in Höhe der Entnahmen vornehmen, um
infach Ihr Weg zum finanzellen Erfolg Geld Florian Mock FBV Die Grundlagen für finanziellen Erfolg Denn Sie müssten anschließend wieder vom Gehaltskonto Rückzahlungen in Höhe der Entnahmen vornehmen, um
Die Post hat eine Umfrage gemacht
 Die Post hat eine Umfrage gemacht Bei der Umfrage ging es um das Thema: Inklusion Die Post hat Menschen mit Behinderung und Menschen ohne Behinderung gefragt: Wie zufrieden sie in dieser Gesellschaft sind.
Die Post hat eine Umfrage gemacht Bei der Umfrage ging es um das Thema: Inklusion Die Post hat Menschen mit Behinderung und Menschen ohne Behinderung gefragt: Wie zufrieden sie in dieser Gesellschaft sind.
Angewandte Ökonometrie, WS 2012/13, 1. Teilprüfung am 6.12.2012 - Lösungen. Das folgende Modell ist ein GARCH(1,1)-Modell:
-Modell:") Angewandte Ökonometrie, WS 2012/13, 1. Teilprüfung am 6.12.2012 - Lösungen LV-Leiterin: Univ.Prof.Dr. Sylvia Frühwirth-Schnatter 1 Wahr oder falsch? 1. Das folgende Modell ist ein GARCH(1,1)-Modell: Y
Angewandte Ökonometrie, WS 2012/13, 1. Teilprüfung am 6.12.2012 - Lösungen LV-Leiterin: Univ.Prof.Dr. Sylvia Frühwirth-Schnatter 1 Wahr oder falsch? 1. Das folgende Modell ist ein GARCH(1,1)-Modell: Y
Grundfunktionen und Bedienung
 Kapitel 13 Mit der App Health ist eine neue Anwendung in ios 8 enthalten, die von vorangegangenen Betriebssystemen bislang nicht geboten wurde. Health fungiert dabei als Aggregator für die Daten von Fitness-
Kapitel 13 Mit der App Health ist eine neue Anwendung in ios 8 enthalten, die von vorangegangenen Betriebssystemen bislang nicht geboten wurde. Health fungiert dabei als Aggregator für die Daten von Fitness-
1. Man schreibe die folgenden Aussagen jeweils in einen normalen Satz um. Zum Beispiel kann man die Aussage:
 Zählen und Zahlbereiche Übungsblatt 1 1. Man schreibe die folgenden Aussagen jeweils in einen normalen Satz um. Zum Beispiel kann man die Aussage: Für alle m, n N gilt m + n = n + m. in den Satz umschreiben:
Zählen und Zahlbereiche Übungsblatt 1 1. Man schreibe die folgenden Aussagen jeweils in einen normalen Satz um. Zum Beispiel kann man die Aussage: Für alle m, n N gilt m + n = n + m. in den Satz umschreiben:
Musterlösungen zur Linearen Algebra II Blatt 5
 Musterlösungen zur Linearen Algebra II Blatt 5 Aufgabe. Man betrachte die Matrix A := über dem Körper R und über dem Körper F und bestimme jeweils die Jordan- Normalform. Beweis. Das charakteristische
Musterlösungen zur Linearen Algebra II Blatt 5 Aufgabe. Man betrachte die Matrix A := über dem Körper R und über dem Körper F und bestimme jeweils die Jordan- Normalform. Beweis. Das charakteristische
Welche Unterschiede gibt es zwischen einem CAPAund einem Audiometrie- Test?
 Welche Unterschiede gibt es zwischen einem CAPAund einem Audiometrie- Test? Auch wenn die Messungsmethoden ähnlich sind, ist das Ziel beider Systeme jedoch ein anderes. Gwenolé NEXER g.nexer@hearin gp
Welche Unterschiede gibt es zwischen einem CAPAund einem Audiometrie- Test? Auch wenn die Messungsmethoden ähnlich sind, ist das Ziel beider Systeme jedoch ein anderes. Gwenolé NEXER g.nexer@hearin gp
Informatik-Sommercamp 2012. Mastermind mit dem Android SDK
 Mastermind mit dem Android SDK Übersicht Einführungen Mastermind und Strategien (Stefan) Eclipse und das ADT Plugin (Jan) GUI-Programmierung (Dominik) Mastermind und Strategien - Übersicht Mastermind Spielregeln
Mastermind mit dem Android SDK Übersicht Einführungen Mastermind und Strategien (Stefan) Eclipse und das ADT Plugin (Jan) GUI-Programmierung (Dominik) Mastermind und Strategien - Übersicht Mastermind Spielregeln
Vorgestellt von Hans-Dieter Stubben
 Neue Lösungen in der GGf-Versorgung Vorgestellt von Hans-Dieter Stubben Geschäftsführer der Bundes-Versorgungs-Werk BVW GmbH Verbesserungen in der bav In 2007 ist eine wichtige Entscheidung für die betriebliche
Neue Lösungen in der GGf-Versorgung Vorgestellt von Hans-Dieter Stubben Geschäftsführer der Bundes-Versorgungs-Werk BVW GmbH Verbesserungen in der bav In 2007 ist eine wichtige Entscheidung für die betriebliche
FRAGEBOGEN ANWENDUNG DES ECOPROWINE SELBSTBEWERTUNG-TOOLS
 Dieser Fragebogen bildet eine wichtige Rückmeldung der Pilotweingüter über Verständnis, Akzeptanz und Effektivität des ECOPROWINE Selbstbewertung-tools für alle daran Beteiligten. Dieser Fragebogen besteht
Dieser Fragebogen bildet eine wichtige Rückmeldung der Pilotweingüter über Verständnis, Akzeptanz und Effektivität des ECOPROWINE Selbstbewertung-tools für alle daran Beteiligten. Dieser Fragebogen besteht
Die Industrie- und Handelskammer arbeitet dafür, dass Menschen überall mit machen können
 Die Industrie- und Handelskammer arbeitet dafür, dass Menschen überall mit machen können In Europa gibt es einen Vertrag. In dem Vertrag steht: Alle Menschen sollen die gleichen Rechte haben. Alle Menschen
Die Industrie- und Handelskammer arbeitet dafür, dass Menschen überall mit machen können In Europa gibt es einen Vertrag. In dem Vertrag steht: Alle Menschen sollen die gleichen Rechte haben. Alle Menschen
OECD Programme for International Student Assessment PISA 2000. Lösungen der Beispielaufgaben aus dem Mathematiktest. Deutschland
 OECD Programme for International Student Assessment Deutschland PISA 2000 Lösungen der Beispielaufgaben aus dem Mathematiktest Beispielaufgaben PISA-Hauptstudie 2000 Seite 3 UNIT ÄPFEL Beispielaufgaben
OECD Programme for International Student Assessment Deutschland PISA 2000 Lösungen der Beispielaufgaben aus dem Mathematiktest Beispielaufgaben PISA-Hauptstudie 2000 Seite 3 UNIT ÄPFEL Beispielaufgaben
Herzlich Willkommen beim Webinar: Was verkaufen wir eigentlich?
 Herzlich Willkommen beim Webinar: Was verkaufen wir eigentlich? Was verkaufen wir eigentlich? Provokativ gefragt! Ein Hotel Marketing Konzept Was ist das? Keine Webseite, kein SEO, kein Paket,. Was verkaufen
Herzlich Willkommen beim Webinar: Was verkaufen wir eigentlich? Was verkaufen wir eigentlich? Provokativ gefragt! Ein Hotel Marketing Konzept Was ist das? Keine Webseite, kein SEO, kein Paket,. Was verkaufen
Livermore-Dow Jones-Analyse von 1959 bis 2004 Dow Jones 01.11.1959 bis 01.11.2004 blau: L5 rot: L1
 Livermore-Dow Jones-Analyse von 1959 bis 2004 Dow Jones 01.11.1959 bis 01.11.2004 blau: L5 rot: L1 Dow Jones 01.11.1959 bis 01.11.1964 blau: L5 rot: L1 1 Dow Jones 01.11.1964 bis 01.11.1969 blau: L5 rot:
Livermore-Dow Jones-Analyse von 1959 bis 2004 Dow Jones 01.11.1959 bis 01.11.2004 blau: L5 rot: L1 Dow Jones 01.11.1959 bis 01.11.1964 blau: L5 rot: L1 1 Dow Jones 01.11.1964 bis 01.11.1969 blau: L5 rot:
Unsere Ideen für Bremen!
 Wahlprogramm Ganz klar Grün Unsere Ideen für Bremen! In leichter Sprache. Die Partei BÜNDNIS 90/DIE GRÜNEN hat diesen Text geschrieben. BÜNDNIS 90/DIE GRÜNEN Adresse: Schlachte 19/20 28195 Bremen Telefon:
Wahlprogramm Ganz klar Grün Unsere Ideen für Bremen! In leichter Sprache. Die Partei BÜNDNIS 90/DIE GRÜNEN hat diesen Text geschrieben. BÜNDNIS 90/DIE GRÜNEN Adresse: Schlachte 19/20 28195 Bremen Telefon:
3. LINEARE GLEICHUNGSSYSTEME
 176 3. LINEARE GLEICHUNGSSYSTEME 90 Vitamin-C-Gehalt verschiedener Säfte 18,0 mg 35,0 mg 12,5 mg 1. a) 100 ml + 50 ml + 50 ml = 41,75 mg 100 ml 100 ml 100 ml b) : Menge an Kirschsaft in ml y: Menge an
176 3. LINEARE GLEICHUNGSSYSTEME 90 Vitamin-C-Gehalt verschiedener Säfte 18,0 mg 35,0 mg 12,5 mg 1. a) 100 ml + 50 ml + 50 ml = 41,75 mg 100 ml 100 ml 100 ml b) : Menge an Kirschsaft in ml y: Menge an
LU-Zerlegung. Zusätze zum Gelben Rechenbuch. Peter Furlan. Verlag Martina Furlan. Inhaltsverzeichnis. 1 Definitionen.
 Zusätze zum Gelben Rechenbuch LU-Zerlegung Peter Furlan Verlag Martina Furlan Inhaltsverzeichnis Definitionen 2 (Allgemeine) LU-Zerlegung 2 3 Vereinfachte LU-Zerlegung 3 4 Lösung eines linearen Gleichungssystems
Zusätze zum Gelben Rechenbuch LU-Zerlegung Peter Furlan Verlag Martina Furlan Inhaltsverzeichnis Definitionen 2 (Allgemeine) LU-Zerlegung 2 3 Vereinfachte LU-Zerlegung 3 4 Lösung eines linearen Gleichungssystems
Ist Excel das richtige Tool für FMEA? Steve Murphy, Marc Schaeffers
 Ist Excel das richtige Tool für FMEA? Steve Murphy, Marc Schaeffers Ist Excel das richtige Tool für FMEA? Einleitung Wenn in einem Unternehmen FMEA eingeführt wird, fangen die meisten sofort damit an,
Ist Excel das richtige Tool für FMEA? Steve Murphy, Marc Schaeffers Ist Excel das richtige Tool für FMEA? Einleitung Wenn in einem Unternehmen FMEA eingeführt wird, fangen die meisten sofort damit an,
40-Tage-Wunder- Kurs. Umarme, was Du nicht ändern kannst.
 40-Tage-Wunder- Kurs Umarme, was Du nicht ändern kannst. Das sagt Wikipedia: Als Wunder (griechisch thauma) gilt umgangssprachlich ein Ereignis, dessen Zustandekommen man sich nicht erklären kann, so dass
40-Tage-Wunder- Kurs Umarme, was Du nicht ändern kannst. Das sagt Wikipedia: Als Wunder (griechisch thauma) gilt umgangssprachlich ein Ereignis, dessen Zustandekommen man sich nicht erklären kann, so dass
Was ich als Bürgermeister für Lübbecke tun möchte
 Wahlprogramm in leichter Sprache Was ich als Bürgermeister für Lübbecke tun möchte Hallo, ich bin Dirk Raddy! Ich bin 47 Jahre alt. Ich wohne in Hüllhorst. Ich mache gerne Sport. Ich fahre gerne Ski. Ich
Wahlprogramm in leichter Sprache Was ich als Bürgermeister für Lübbecke tun möchte Hallo, ich bin Dirk Raddy! Ich bin 47 Jahre alt. Ich wohne in Hüllhorst. Ich mache gerne Sport. Ich fahre gerne Ski. Ich
Linearen Gleichungssysteme Anwendungsaufgaben
 Linearen Gleichungssysteme Anwendungsaufgaben Lb S. 166 Nr.9 Im Jugendherbergsverzeichnis ist angegeben, dass in der Jugendherberge in Eulenburg 145 Jugendliche in 35 Zimmern übernachten können. Es gibt
Linearen Gleichungssysteme Anwendungsaufgaben Lb S. 166 Nr.9 Im Jugendherbergsverzeichnis ist angegeben, dass in der Jugendherberge in Eulenburg 145 Jugendliche in 35 Zimmern übernachten können. Es gibt
Das Leitbild vom Verein WIR
 Das Leitbild vom Verein WIR Dieses Zeichen ist ein Gütesiegel. Texte mit diesem Gütesiegel sind leicht verständlich. Leicht Lesen gibt es in drei Stufen. B1: leicht verständlich A2: noch leichter verständlich
Das Leitbild vom Verein WIR Dieses Zeichen ist ein Gütesiegel. Texte mit diesem Gütesiegel sind leicht verständlich. Leicht Lesen gibt es in drei Stufen. B1: leicht verständlich A2: noch leichter verständlich
mysql - Clients MySQL - Abfragen eine serverbasierenden Datenbank
 mysql - Clients MySQL - Abfragen eine serverbasierenden Datenbank In den ersten beiden Abschnitten (rbanken1.pdf und rbanken2.pdf) haben wir uns mit am Ende mysql beschäftigt und kennengelernt, wie man
mysql - Clients MySQL - Abfragen eine serverbasierenden Datenbank In den ersten beiden Abschnitten (rbanken1.pdf und rbanken2.pdf) haben wir uns mit am Ende mysql beschäftigt und kennengelernt, wie man
Semestralklausur zur Vorlesung. Web Mining. Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7.
 Semestralklausur zur Vorlesung Web Mining Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7. 2004 Name: Vorname: Matrikelnummer: Fachrichtung: Punkte: (1).... (2)....
Semestralklausur zur Vorlesung Web Mining Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7. 2004 Name: Vorname: Matrikelnummer: Fachrichtung: Punkte: (1).... (2)....
Wir unterscheiden folgende drei Schritte im Design paralleler Algorithmen:
 1 Parallele Algorithmen Grundlagen Parallele Algorithmen Grundlagen Wir unterscheiden folgende drei Schritte im Design paralleler Algorithmen: Dekomposition eines Problems in unabhängige Teilaufgaben.
1 Parallele Algorithmen Grundlagen Parallele Algorithmen Grundlagen Wir unterscheiden folgende drei Schritte im Design paralleler Algorithmen: Dekomposition eines Problems in unabhängige Teilaufgaben.
AZK 1- Freistil. Der Dialog "Arbeitszeitkonten" Grundsätzliches zum Dialog "Arbeitszeitkonten"
 AZK 1- Freistil Nur bei Bedarf werden dafür gekennzeichnete Lohnbestandteile (Stundenzahl und Stundensatz) zwischen dem aktuellen Bruttolohnjournal und dem AZK ausgetauscht. Das Ansparen und das Auszahlen
AZK 1- Freistil Nur bei Bedarf werden dafür gekennzeichnete Lohnbestandteile (Stundenzahl und Stundensatz) zwischen dem aktuellen Bruttolohnjournal und dem AZK ausgetauscht. Das Ansparen und das Auszahlen
Anleitung über den Umgang mit Schildern
 Anleitung über den Umgang mit Schildern -Vorwort -Wo bekommt man Schilder? -Wo und wie speichert man die Schilder? -Wie füge ich die Schilder in meinen Track ein? -Welche Bauteile kann man noch für Schilder
Anleitung über den Umgang mit Schildern -Vorwort -Wo bekommt man Schilder? -Wo und wie speichert man die Schilder? -Wie füge ich die Schilder in meinen Track ein? -Welche Bauteile kann man noch für Schilder
Prüfung: Vorlesung Finanzierungstheorie und Wertpapiermanagement
 Prüfung: Vorlesung Finanzierungstheorie und Wertpapiermanagement Die Prüfung zur Vorlesung Finanzierungstheorie und Wertpapiermanagement umfasst 20 Multiple Choice Fragen, wofür insgesamt 90 Minuten zur
Prüfung: Vorlesung Finanzierungstheorie und Wertpapiermanagement Die Prüfung zur Vorlesung Finanzierungstheorie und Wertpapiermanagement umfasst 20 Multiple Choice Fragen, wofür insgesamt 90 Minuten zur
Skript und Aufgabensammlung Terme und Gleichungen Mathefritz Verlag Jörg Christmann Nur zum Privaten Gebrauch! Alle Rechte vorbehalten!
 Mathefritz 5 Terme und Gleichungen Meine Mathe-Seite im Internet kostenlose Matheaufgaben, Skripte, Mathebücher Lernspiele, Lerntipps, Quiz und noch viel mehr http:// www.mathefritz.de Seite 1 Copyright
Mathefritz 5 Terme und Gleichungen Meine Mathe-Seite im Internet kostenlose Matheaufgaben, Skripte, Mathebücher Lernspiele, Lerntipps, Quiz und noch viel mehr http:// www.mathefritz.de Seite 1 Copyright
Der monatliche Tarif für ein Handy wurde als lineare Funktion der Form f(x) = k x + d modelliert (siehe Grafik).
 = k x + d modelliert (siehe Grafik).") 1) Handytarif Der monatliche Tarif für ein Handy wurde als lineare Funktion der Form f(x) = k x + d modelliert (siehe Grafik). Euro Gesprächsminuten Tragen Sie in der folgenden Tabelle ein, welche Bedeutung
1) Handytarif Der monatliche Tarif für ein Handy wurde als lineare Funktion der Form f(x) = k x + d modelliert (siehe Grafik). Euro Gesprächsminuten Tragen Sie in der folgenden Tabelle ein, welche Bedeutung
Wie optimiert man die Werbungserkennung von Ad- Detective?
 Wie optimiert man die Werbungserkennung von Ad- Detective? Die Ad-Detective-Werbe-Erkennung von VideiReDo basiert auf der Erkennung von Schwarzwerten / scharzen Bildern, die die Werbeblöcke abgrenzen.
Wie optimiert man die Werbungserkennung von Ad- Detective? Die Ad-Detective-Werbe-Erkennung von VideiReDo basiert auf der Erkennung von Schwarzwerten / scharzen Bildern, die die Werbeblöcke abgrenzen.
Kurzanleitung MAN E-Learning (WBT)
") Kurzanleitung MAN E-Learning (WBT) Um Ihr gebuchtes E-Learning zu bearbeiten, starten Sie bitte das MAN Online- Buchungssystem (ICPM / Seminaris) unter dem Link www.man-academy.eu Klicken Sie dann auf
Kurzanleitung MAN E-Learning (WBT) Um Ihr gebuchtes E-Learning zu bearbeiten, starten Sie bitte das MAN Online- Buchungssystem (ICPM / Seminaris) unter dem Link www.man-academy.eu Klicken Sie dann auf
Maximizing the Spread of Influence through a Social Network
 1 / 26 Maximizing the Spread of Influence through a Social Network 19.06.2007 / Thomas Wener TU-Darmstadt Seminar aus Data und Web Mining bei Prof. Fürnkranz 2 / 26 Gliederung Einleitung 1 Einleitung 2
1 / 26 Maximizing the Spread of Influence through a Social Network 19.06.2007 / Thomas Wener TU-Darmstadt Seminar aus Data und Web Mining bei Prof. Fürnkranz 2 / 26 Gliederung Einleitung 1 Einleitung 2
Abituraufgabe zur Analysis, Hessen 2009, Grundkurs (TR)
") Abituraufgabe zur Analysis, Hessen 2009, Grundkurs (TR) Gegeben ist die trigonometrische Funktion f mit f(x) = 2 sin(2x) 1 (vgl. Material 1). 1.) Geben Sie für die Funktion f den Schnittpunkt mit der y
Abituraufgabe zur Analysis, Hessen 2009, Grundkurs (TR) Gegeben ist die trigonometrische Funktion f mit f(x) = 2 sin(2x) 1 (vgl. Material 1). 1.) Geben Sie für die Funktion f den Schnittpunkt mit der y
Impulse Inklusion 2014 Beteiligungskulturen - Netzwerke - Kooperationen (Leichte Sprache Version)
") Impulse Inklusion 2014 Beteiligungskulturen - Netzwerke - Kooperationen (Leichte Sprache Version) Das heißt: Beteiligungskultur: Wie können Menschen mit Behinderungen überall mitmachen und mitsprechen.
Impulse Inklusion 2014 Beteiligungskulturen - Netzwerke - Kooperationen (Leichte Sprache Version) Das heißt: Beteiligungskultur: Wie können Menschen mit Behinderungen überall mitmachen und mitsprechen.
Leitfaden zur Durchführung eines Jahreswechsels in BüroWARE 5.x
 Leitfaden zur Durchführung eines Jahreswechsels in BüroWARE 5.x Zentrale: T: 07121/69509-0 F: 07121/69509-50 Technik: T: 07121/69509-30 ecommerce: T: 07121/69509-20 Software: T: 07121/69509-10 E-Mail Web
Leitfaden zur Durchführung eines Jahreswechsels in BüroWARE 5.x Zentrale: T: 07121/69509-0 F: 07121/69509-50 Technik: T: 07121/69509-30 ecommerce: T: 07121/69509-20 Software: T: 07121/69509-10 E-Mail Web
BITte ein BIT. Vom Bit zum Binärsystem. A Bit Of Magic. 1. Welche Werte kann ein Bit annehmen? 2. Wie viele Zustände können Sie mit 2 Bit darstellen?
 BITte ein BIT Vom Bit zum Binärsystem A Bit Of Magic 1. Welche Werte kann ein Bit annehmen? 2. Wie viele Zustände können Sie mit 2 Bit darstellen? 3. Gegeben ist der Bitstrom: 10010110 Was repräsentiert
BITte ein BIT Vom Bit zum Binärsystem A Bit Of Magic 1. Welche Werte kann ein Bit annehmen? 2. Wie viele Zustände können Sie mit 2 Bit darstellen? 3. Gegeben ist der Bitstrom: 10010110 Was repräsentiert
Universität Bonn 28. Juli 2010 Fachbereich Rechts- und Wirtschaftswissenschaften Statistische Abteilung Prof. Dr. A. Kneip. KLAUSUR Statistik B
 Universität Bonn 28. Juli 2010 Fachbereich Rechts- und Wirtschaftswissenschaften Statistische Abteilung Prof. Dr. A. Kneip Sommersemester 2010 KLAUSUR Statistik B Hinweise zur Bearbeitung: Bei allen Teilaufgaben
Universität Bonn 28. Juli 2010 Fachbereich Rechts- und Wirtschaftswissenschaften Statistische Abteilung Prof. Dr. A. Kneip Sommersemester 2010 KLAUSUR Statistik B Hinweise zur Bearbeitung: Bei allen Teilaufgaben
Catherina Lange, Heimbeiräte und Werkstatträte-Tagung, November 2013 1
 Catherina Lange, Heimbeiräte und Werkstatträte-Tagung, November 2013 1 Darum geht es heute: Was ist das Persönliche Geld? Was kann man damit alles machen? Wie hoch ist es? Wo kann man das Persönliche Geld
Catherina Lange, Heimbeiräte und Werkstatträte-Tagung, November 2013 1 Darum geht es heute: Was ist das Persönliche Geld? Was kann man damit alles machen? Wie hoch ist es? Wo kann man das Persönliche Geld
Wichtige Forderungen für ein Bundes-Teilhabe-Gesetz
 Wichtige Forderungen für ein Bundes-Teilhabe-Gesetz Die Parteien CDU, die SPD und die CSU haben versprochen: Es wird ein Bundes-Teilhabe-Gesetz geben. Bis jetzt gibt es das Gesetz noch nicht. Das dauert
Wichtige Forderungen für ein Bundes-Teilhabe-Gesetz Die Parteien CDU, die SPD und die CSU haben versprochen: Es wird ein Bundes-Teilhabe-Gesetz geben. Bis jetzt gibt es das Gesetz noch nicht. Das dauert
Erstellen von x-y-diagrammen in OpenOffice.calc
 Erstellen von x-y-diagrammen in OpenOffice.calc In dieser kleinen Anleitung geht es nur darum, aus einer bestehenden Tabelle ein x-y-diagramm zu erzeugen. D.h. es müssen in der Tabelle mindestens zwei
Erstellen von x-y-diagrammen in OpenOffice.calc In dieser kleinen Anleitung geht es nur darum, aus einer bestehenden Tabelle ein x-y-diagramm zu erzeugen. D.h. es müssen in der Tabelle mindestens zwei
Bevölkerung mit Migrationshintergrund an der Gesamtbevölkerung 2012
 Statistische Übersicht inkl. dem Vergleich zwischen und zur (Aus-)Bildungssituation von jungen Menschen mit und ohne Migrationshintergrund 1 in den Bundesländern nach dem Mikrozensus Erstellt im Rahmen
Statistische Übersicht inkl. dem Vergleich zwischen und zur (Aus-)Bildungssituation von jungen Menschen mit und ohne Migrationshintergrund 1 in den Bundesländern nach dem Mikrozensus Erstellt im Rahmen
AUTOMATISIERTE HANDELSSYSTEME
 UweGresser Stefan Listing AUTOMATISIERTE HANDELSSYSTEME Erfolgreich investieren mit Gresser K9 FinanzBuch Verlag 1 Einsatz des automatisierten Handelssystems Gresser K9 im Portfoliomanagement Portfoliotheorie
UweGresser Stefan Listing AUTOMATISIERTE HANDELSSYSTEME Erfolgreich investieren mit Gresser K9 FinanzBuch Verlag 1 Einsatz des automatisierten Handelssystems Gresser K9 im Portfoliomanagement Portfoliotheorie
Was ist Sozial-Raum-Orientierung?
 Was ist Sozial-Raum-Orientierung? Dr. Wolfgang Hinte Universität Duisburg-Essen Institut für Stadt-Entwicklung und Sozial-Raum-Orientierte Arbeit Das ist eine Zusammen-Fassung des Vortrages: Sozialräume
Was ist Sozial-Raum-Orientierung? Dr. Wolfgang Hinte Universität Duisburg-Essen Institut für Stadt-Entwicklung und Sozial-Raum-Orientierte Arbeit Das ist eine Zusammen-Fassung des Vortrages: Sozialräume
4. AUSSAGENLOGIK: SYNTAX. Der Unterschied zwischen Objektsprache und Metasprache lässt sich folgendermaßen charakterisieren:
 4. AUSSAGENLOGIK: SYNTAX 4.1 Objektsprache und Metasprache 4.2 Gebrauch und Erwähnung 4.3 Metavariablen: Verallgemeinerndes Sprechen über Ausdrücke von AL 4.4 Die Sprache der Aussagenlogik 4.5 Terminologie
4. AUSSAGENLOGIK: SYNTAX 4.1 Objektsprache und Metasprache 4.2 Gebrauch und Erwähnung 4.3 Metavariablen: Verallgemeinerndes Sprechen über Ausdrücke von AL 4.4 Die Sprache der Aussagenlogik 4.5 Terminologie