Folien und Supplementals auf
|
|
|
- Karlheinz Albrecht
- vor 7 Jahren
- Abrufe
Transkript



1 Folien und Supplementals auf
2 Folien und Supplementals auf
3 Motivation Die Link-Liste auf ExPASy bietet eine gute Übersicht man verliert sich aber leicht. Es gibt viele spezifische Datenbanken, aber mit einer geringen Auswahl an Datenbanken von allgemeiner Bedeutung kommt man schon sehr weit. Diese sollen hier besprochen werden. Zielsetzung Für verschiedene Datenbanken von allgemeiner Bedeutung soll angerissen werden: Übersicht über Datenbestand: Ursprung, Relevanz, Vollständigkeit? Wie stelle ich eine korrekte Suchanfrage? Welche zusätzlichen Funktionen bietet die Datenbank? Allgemeine Konzepte und Probleme der angewandten Bioinformatik in Zusammenhang mit Datenbanken: Einblick in die Sortierung und Klassifizierung von Daten. Einblick in das Daten-Sharing zwischen Datenbanken. Weitere Probleme der Bioinformatik: Redundanz, Kontrolle/Überprüfung der Daten
4 Überblick behalten INFORMATIONEN UND ERLÄUTERUNGEN UniProtKB: Swiss-Prot/TrEMBL und UniParc, UniRef SEKUNDÄRE DATENBANKEN: PROTEIN-DOMÄNEN UND -FAMILIEN Sequenz-basiert: PROSITE, PRINTS, Pfam Struktur-basiert: SCOP, CATH Gene Ontology (GO) InterPro auf EBI PROTEIN-SEQUENZEN UND STRUKTUREN RCSB & PDBe Entrez Structure Group auf NCBI Molecular Modeling Database (MMDB) Conserved Domain Database (CDD) BioSystems, PubChem, IBIS, Cn3D, CDTree Entrez Protein STOFFWECHSELWEGE UND ENZYME IntEnz auf EBI UniPathway KEGG SPEZIFISCHE DATENBANKEN HPRD ViralZone
 und PIR (Protein Information Resource; Erbe der ältesten Protein-Sequenz-DB).")
5 UniProt Universal Protein Resource UniProt enthält Protein-Sequenzen und erläuternde funktionelle Informationen. Es handelt sich um die größte und bekannteste bioinformatische Datenbank für Proteine. Das UniProt Consortium besteht aus der Kollaboration zwischen EBI, SIB (Entwickler von ExPASy) und PIR (Protein Information Resource; Erbe der ältesten Protein-Sequenz-DB). Der relevante Teil von UniProt ist die UniProt Knowledgebase (UniProtKB). Sie gliedert sich in UniProtKB/SwissProt und UniProtKB/TrEMBL. UniRef (UniProt Reference Clusters) verbindet automatisch Sequenzen innerhalb einer Spezies und basiert auf den UniProtKB-Einträgen. UniRef100 verbindet alle Einträge mit Sequenz- Identität (UniRef90 verbindet Einträge mit über 90% Sequenz-Identität). Folgende Folien Keine redundanten Verknüpfungen von Sequenzen. Kombinierung zu einem Dateneintrag (erleichterte Suche).
6 UniProt Universal Protein Resource UniProtKB/Swiss-Prot Enthält Daten mit sehr hoher Qualität: keine Redundanz, manuelle Kommentierung. UniProt-Kuratoren beziehen ihre Informationen aus der Literatur. Ziel ist es alle bekannten Informationen zu einem Protein zentral zugänglich zu machen. Ein Eintrag beinhaltet u.a. alle Protein- Produkte desselben Gens (alternatives Spleißen, Polymorphismen, post-translationale Modifikationen) sowie alle Gene, die zum selben Genprodukt führen; jeweils von einem spezifischen Organismus. Die Klassifizierung in Proteinfamilien wird regelmäßig überprüft (Aktualität).
7 UniProt Universal Protein Resource UniProtKB/TrEMBL Enthält automatisch kommentierte und klassifizierte Daten. Die Einträge werden nach und nach in die UniProtKB/Swiss-Prot integriert und für die manuelle Kommentierung ausgewählt. Die Rohdaten Die Sequenz-Informationen erhält UniProtKB letztlich u.a. aus Übersetzungen von codierenden Nukleotid-Sequenzen aus DDBJ/EMBL- Bank/GenBank. Sequenzen aus den PDB-Strukturen. FlyBase & WormBase. Direkt aus der Literatur.

8 UniProt Universal Protein Resource UniParc Die Rohdaten landen zuerst in UniParc. Einige Sequenzen (kleine Fragmente, synthetische Sequenzen etc.) gelangen nicht in die UniProtKB. UniParc beinhaltet alle öffentlich verfügbaren Protein-Sequenz-Daten! Jeder Eintrag hat eine UniParc ID. Es wird regelmäßig überprüft, sodass wichtige Daten in UniProtKB aufgenommen werden.
9 UniProt Universal Protein Resource Swiss-Prot These days, Swiss-Prot has troubles coping with the present rate of new (nucleotide) sequence determination and is falling behind in terms of Completeness Bioinformatics for Dummies, p. 106 TrEMBL Datenflut ist nicht aufzuhalten! Manuelle Annotierung nahezu unmöglich
10 UniProt Universal Protein Resource Wie weit sind wir von einem vollständigen Datensatz entfernt?






11 UniProt Universal Protein Resource Start-Seite von UniProt Suche über Felder möglich. Suche lässt sich stetig erweitern. Es folgt eine Beispiel-Suchanfrage: Hexokinase
12 UniProt Universal Protein Resource Ergebnis-Übersicht: Tabelle Sortierung nach einzelnen Spalten-Infos möglich (klicke auf Pfeile in oberster Zeile) Goldener Stern = Swiss-Prot Eintrag Silberner Stern = TrEMBL Eintrag


13 UniProt Universal Protein Resource Tabellen-Ansicht anpassen: Infos, die in Spalten angezeigt werden, lassen sich ändern:
 Pathway")
14 UniProt Universal Protein Resource Ansicht anpassen: Statt Tabelle Kategorien-Baum. Ergebnisse lassen sich kategorisieren nach Taxonomie Keyword Gene Ontology (GO) Pathway EC-Nummer
15 UniProt Universal Protein Resource Ansicht anpassen: Zusammenfassen der Ergebnisse mittels UniRef. UniRef kann alle Ergebnisse mit 50%, 90% oder 100% Homologie in Cluster zusammenfassen.

: unten Retrieve klicken.")
16 UniProt Universal Protein Resource Speichern: direkt aus der Tabellenansicht Einzelne Einträge aus UniRef oder UniProtKB speichern: Häkchen setzen Direktes Alignment möglich: unten Align klicken. Speichern in verschiedenen Formaten (z.b. FASTA): unten Retrieve klicken. Alle Einträge der Tabelle speichern: klicke rechts oben auf Download.

17 UniProt Universal Protein Resource Wie sieht nun ein UniProt-Eintrag aus?
.")
 werden auf der Ergebnis-Seite verlinkt.")

18 UniProt Universal Protein Resource Ergebnis-Seite: am Beispiel der Hexokinase-1 Ausführliche Querverweise zu zahlreichen Datenbanken (Cross References). Minimale Redundanz der Einträge: Ein Eintrag je Protein. Verschiedene Produkte (Isoformen) werden auf der Ergebnis-Seite verlinkt. Jeder Eintrag hat eine eindeutige UniProtKB ID. häufige Aktualisierung der Einträge bei Proteinen, an denen geforscht wird. Immer AN, nicht Entry Name notieren! Veraltete accession numbers bleiben mit dem Eintrag assoziiert!

19 ATTRIBUTES UniProt Universal Protein Resource Hier ist notiert, ob es sich um das reife Protein oder um ein Proprotein handelt COMMENTS Alle Informationen wurden aus der Literatur entnommen und dem Eintrag zugeordnet.
20 ONTOLOGIES UniProt Universal Protein Resource ALTERNATIVE PRODUCTS UniProtKB-Einträge, die mit diesem Protein wechselwirken. BINARY INTERACTIONS Separat werden die vollständigen Sequenzen der Isoformen angezeigt. SEQUENCES
21 FEATURES UniProt Universal Protein Resource
22 FEATURES UniProt Universal Protein Resource Molecule Processing: Signal peptide, chain Regions: topological domain, domain, transmembrane, repeat, nucleotide binding, region Sites: active site, binding site, site Aminoacid Modification: modified residue, glycosylation, disulfide bond, cross-link natural variation: alternative sequence, natural variant experimental info: mutagenesis, sequence conflict secondary structure: helix, strand, turn Die entsprechenden Feature-Keys der einzelnen Features werden in der Spalte Description in Bezug auf den vorliegenden Fall genauer definiert. Für jedes Feature kann die Sequenz analysiert werden: Setze Haken und wähle retrieve oder blast; wähle zwei Sequenzen und wähle retrieve oder align. Domain hat hier eine breitere Definition nicht vergleichbar mit den Definitionen sekundärer Datenbanken (hier existieren verschiedene Domänen!)
23 CROSS-REFERENCES UniProt Universal Protein Resource PubMed-Verweise sind separat angezeigt REFERENCES

24 UniProt Universal Protein Resource ID-Mapping bekannte ID s können über UniProt beliebig übersetzt werden. Bekannte ID wird unter Identifiers eingegeben. Eingabefeld From enthält die Art der bekannten ID. Eingabefeld To enthält die Art der gesuchten ID. Links führen zu den entsprechenden Datenbanken Cross-Referencing zwischen Datenbank-Einträgen. wichtig: IDs am Besten immer irgendwie mit speichern

25 UniProt Universal Protein Resource Das Flat-File Format hinter den hübsch präsentierten Informations-Seiten Orange hinterlegter Link TEXT Verwandt mit dem EMBL-Format: identischer 2-Buchstaben Code Gliederung in 5 Hauptbereiche: general information bibliographic information functional information feature table sequence part Alles Andere: graphische Aufbereitung der Daten! Hier ist auch direkt die FASTA-Sequenz erreichbar
26 UniProt Universal Protein Resource Viele sekundäre Datenbanken nutzen die UniProtKB Daten und katalogisieren sie nach eigenen Kriterien. Im Vordergrund stehen dabei unterschiedliche Repräsentationen (das Protein wird in einem spezifischen Kontext dargestellt). Beispiel-Datenbanken, welche die UniProtKB-Einträge nutzen: UniPathway (Kontext: Stoffwechselwege) InterPro (Kontext: Protein-Signaturen, d.h. Domänen, Familien und konservierte Stellen) ViralZone (Kontext: virale Proteine)
27 Überblick behalten INFORMATIONEN UND ERLÄUTERUNGEN UniProtKB: Swiss-Prot/TrEMBL und UniParc, UniRef SEKUNDÄRE DATENBANKEN: PROTEIN-DOMÄNEN UND -FAMILIEN Sequenz-basiert: PROSITE, PRINTS, Pfam Struktur-basiert: SCOP, CATH Gene Ontology (GO) InterPro auf EBI PROTEIN-SEQUENZEN UND STRUKTUREN RCSB & PDBe Entrez Structure Group auf NCBI Molecular Modeling Database (MMDB) Conserved Domain Database (CDD) BioSystems, PubChem, IBIS, Cn3D, CDTree Entrez Protein STOFFWECHSELWEGE UND ENZYME IntEnz auf EBI UniPathway KEGG SPEZIFISCHE DATENBANKEN HPRD ViralZone
28 Sekundäre Datenbanken Die primäre Datenbank ist Urheber des Datenbestandes (z.b. UniProtKB). Mehrere sekundäre Datenbanken interpretieren und kategorisieren den Datenbestand aus einer primären Datenbank auf unterschiedliche Weise. Die hier gelisteten DBs verwenden die Datenbestände aus UniProtKB. Prinzipiell zwei Möglichkeiten der Klassifizierung: nach struktureller Verwandtschaft. nach Sequenz-Homologien. Suche über Schlüsselwörter oder über Sequenz möglich. Zuordnung neuer Sequenzen ist erleichtert!
29 PROSITE protein functional sites beheimatet auf ExPASy. Abfrage über ExPASy Prosite-WWW-Server. Klassifizierung der Proteine über Bestimmung einzelner konservierter Motive (Patterns). Motiv = kurzer Sequenzabschnitt (10-20 AS), die in verwandten Proteinen konserviert sind und meist eine Schlüsselfunktion in der Proteinfunktion einnehmen. Suche nach solchen Motiven kann in unbekannten Proteinen ein Hinweis auf die Zugehörigkeit zu einer Proteinfamilie bzw. die Funktion des Proteins liefern. Motiv wird aus multiplen Alignments abgeleitet und als regulärer Ausdruck (formalisiertes Muster zur Beschreibung einer Zeichenfolge) in der DB gespeichert. In PROSITE entspricht der reguläre Ausdruck folgendem Muster: Einzelne Aminosäure-Positionen im Ein-Buchstaben-Code, getrennt durch Bindestriche Position durch verschiedene AS besetzt: mögliche AS in eckigen Klammern angegeben. Positionen durch beliebige AS besetzt: mit x gekennzeichnet. Positionen durch beliebige AS mit Ausnahme definierter AS besetzt: nicht-mögliche AS in geschweiften Klammern angegeben. aufeinanderfolgende Wiederholungen mit der Zahl der Wiederholungen in runden Klammern angegeben: z.b. x(2) = x-x oder x(2,4) = x-x oder x-x-x oder x-x-x-x

30 PROSITE protein functional sites Standardmäßig sorgt ein Häkchen bei exclude patterns with a high probability of occurence dafür, dass häufige Motive nicht angezeigt werden. Suche über ID oder Sequenz möglich. Scan Prosite ermöglicht mehrere Optionen bei der Durchführung des Prosite- Scans. Eingabe der UniProtKB ID oder Sequenz
 Beschreibungsseite enthält Infos zur biologischen Bedeutung und Funktion")
 ID beginnt mit PS Außerdem: Rule-Einträge (Annotierung) ID beginnt mit PRU Eingabe der UniProt")
31 PROSITE protein functional sites Beispiel der functional site N-myristoylation site Ergebnisseite enthält zu jedem gefundenem Motiv einen Accession-Number-Link zur Beschreibungsseite (ID beginnt mit PDOC) Beschreibungsseite enthält Infos zur biologischen Bedeutung und Funktion der functional site sowie das genaue Muster! Beachte: Warnung, das es sich um ein häufiges Muster handelt! Prosite enthält auch Profil-Einträge (Matrix) ID beginnt mit PS Außerdem: Rule-Einträge (Annotierung) ID beginnt mit PRU Eingabe der UniProt ID oder Sequenz Motiv der functional site
32 PRINTS fingerprints Verwendet Fingerprints zur Klassifizierung von Sequenzen. Fingerprints bestehen aus mehreren Sequenzmotiven, die in der PRINTS DB durch kurze, lokale ungapped Alignments repräsentiert werden. Mehrere funktionelle Bereiche im Protein = Proteinsequenz hat mehrere Sequenzmotive. Dadurch steigt die Sensitivität der Analyse an, weil die Zugehörigkeit eines Proteins zu einer Proteinfamilie auch bewertet werden kann, wenn eines der Motive nicht vorliegt. Die Verwandtschaft der Proteine anhand der verschiedenen Fingerprints wird über E-Values bestimmt. E-Value ist Maß dafür, mit einer zufälligen Aminosäure-Sequenz einen Treffer der gleichen Güte zu produzieren. Je kleiner dieser Wert, desto besser!

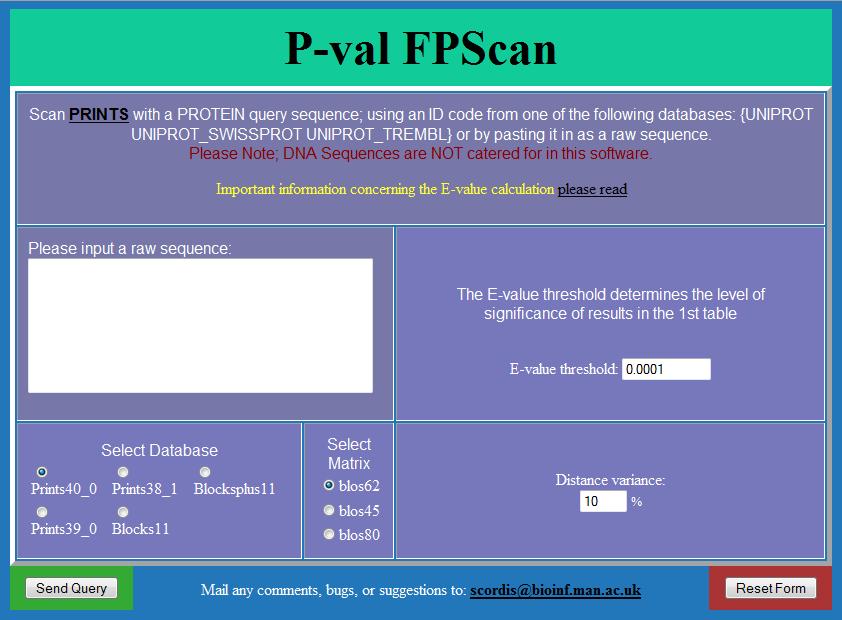
33 PRINTS fingerprints Sequenz im RAW-Format eingeben.

34 PRINTS fingerprints Ergebnis: zuerst werden die Highest Scoring Fingerprints angezeigt Beschreibung der Signatur auf PRINTS Zeigt verwandte Fingerprints auf PRINTS Es folgen die Top 10 Scoring Fingerprints und eine Übersicht über alle Fingerprints der einzelnen gefundenen Proteine.
35 Pfam Protein families Klassifizierung von Proteinfamilien über Profile. Profil = Schema, das für jede Position in der Sequenz die Wahrscheinlichkeit für das Auftreten einer bestimmten AS bzw. einer bestimmten Insertion oder Deletion bewertet. konservierte Positionen werden im Bewertungsschema stärker berücksichtigt als nichtkonservierte (gewichtetes Bewertungsschema) Basis der Profile sind multiple Sequenz-Alignments und Hidden Markov Modelle (HMMs). Anschließend werden weitere Sequenzen aus Swiss-Prot automatisch zu den einzelnen Alignments hinzugefügt. Die resultierenden Alignments repräsentieren funktionelle Einheiten und beinhalten evolutiv verwandte Sequenzen. Aufgrund automatisierter Alignments ist es möglich, dass die Sequenzen keine evolutiv determinierte Beziehung besitzen. Daher müssen Ergebnisse weiter abgesichert werden.

36 Pfam Protein families Jedes Pfam-Profil repräsentiert eine Protein-Familie oder Domäne. Pfam-Familien werden in Clans gruppiert, wenn sie denselben evolutiven Ursprung haben. Indizien hierfür sind Sequenz-Homologien, Struktur-Homologien und Ähnlichkeiten im HMM-Profil. Pfam-A Einträge haben die höchste Qualität (manuell annotierte Familien) Pfam-B Einträge werden über die ADDA-DB automatisch generiert. Verwendung, um funktionell konservierte Regionen zu identifizieren, wenn kein Pfam-A Eintrag existiert. Pfam ermöglicht auch die Analyse von Proteomen und Proteinen mit komplexer Domänen-Architektur. Zahlreiche Eingabe-Möglichkeiten: Input kann z.b. auch eine PDB-Datei sein
37 Überblick behalten INFORMATIONEN UND ERLÄUTERUNGEN UniProtKB: Swiss-Prot/TrEMBL und UniParc, UniRef SEKUNDÄRE DATENBANKEN: PROTEIN-DOMÄNEN UND -FAMILIEN Sequenz-basiert: PROSITE, PRINTS, Pfam Struktur-basiert: SCOP, CATH Gene Ontology (GO) InterPro auf EBI PROTEIN-SEQUENZEN UND STRUKTUREN RCSB & PDBe Entrez Structure Group auf NCBI Molecular Modeling Database (MMDB) Conserved Domain Database (CDD) BioSystems, PubChem, IBIS, Cn3D, CDTree Entrez Protein STOFFWECHSELWEGE UND ENZYME IntEnz auf EBI UniPathway KEGG SPEZIFISCHE DATENBANKEN HPRD ViralZone
.")
38 SCOP Structural Classification of Proteins Evolutiv verwandte Proteine mit ähnlicher biologischer Funktion müssen einen ähnlichen strukturellen Aufbau haben. Daher: Funktion eines unbekannten Proteins über Vergleich des strukturellen Aufbaus mit dem Aufbau bekannter Proteine vorhersagbar! (Grundgedanke von SCOP und CATH). SCOP klassifiziert Proteine mit bekannter Struktur hierarchisch in drei Hauptklassen. Familien Beschreiben Proteine mit eindeutiger evolutiver Beziehung zueinander. Proteine einer Familie haben mindesten 30% Sequenzidentität über die Gesamtlänge des Proteins. Ausnahme: aufgrund ähnlicher Struktur und Funktion ist Verwandtschaft nachgewiesen. Superfamilien Proteine mit geringer Sequenzidentität. strukturelle und funktionale Eigenschaften legen aber verwandtschaftliche Beziehung nahe. Faltungen Proteine mit gleicher Abfolge von Sekundärstrukturelementen in gleicher Topologie verwandtschaftliche Beziehung ist nicht notwendig.
39 CATH Class, Architecture, Topology, Homologous Superfamily CATH klassifiziert Proteine mit bekannter Struktur hierarchisch in vier Hauptklassen. Class-Kategorie Automatische Klassifizierung, bei Bedarf manuelle Ergänzung. Berücksichtigung der Sekundärstruktur-Element-Anteile ohne Rücksicht auf ihre Anordnung und Verbindung untereinander. Kategorisierung in: mainly-α, mainly-β, α-β, wenige Sekundärstrukturelemente. Architecture-Kategorie Manuelle Bearbeitung. Anordnung der Sekundärstruktur-Elemente zueinander. Kategorisierung über Beschreibungen wie barrel, sandwich, β-propeller. Topology-Kategorie Form der Proteine und Verbindungen der Sekundärstruktur-Elemente untereinander. Kategorisierung basiert auf Algorithmus, der empirisch abgeleitete Parameter zur Domänen-Klassifizierung einsetzt. Homologues Superfamily Homologe Proteindomänen (Domänen mit gemeinsamer Abstammung). Ähnlichkeit der Sequenzen wird durch Sequenzvergleich mit anschließendem Strukturvergleich bestimmt, entsprechend der Kategorisierung in der Topology-Kategorie.
 Protein-Domänen, die eine hohe Sequenz-Identität aufweisen (mindestens xx% über 80% der Länge der größeren Domäne).")
40 CATH Class, Architecture, Topology, Homologous Superfamily Domänen innerhalb einer H-Kategorie werden nochmals zusammengefasst. Hierzu ist eine fünfte Kategorie definiert: Die Sequenz-Familie (4 Level: S.O.L.I.) Protein-Domänen, die eine hohe Sequenz-Identität aufweisen (mindestens xx% über 80% der Länge der größeren Domäne). Ähnliche Funktionen sind dadurch wahrscheinlich. Das fünfte Level (D) wird genutzt, um verschiedene Proteine mit 100% Sequenz-Identität voneinander unterscheiden zu können (neue Einträge im selben L-Level bekommen fortlaufende Nummer) Letztlich hat jede Domäne in CATH eine einzigartige CATHSOLID-Klassifikation. Beispiel bei einem Vergleich der Klassen zwischen drei Einträgen:
41 Überblick behalten INFORMATIONEN UND ERLÄUTERUNGEN UniProtKB: Swiss-Prot/TrEMBL und UniParc, UniRef SEKUNDÄRE DATENBANKEN: PROTEIN-DOMÄNEN UND -FAMILIEN Sequenz-basiert: PROSITE, PRINTS, Pfam Struktur-basiert: SCOP, CATH Gene Ontology (GO) InterPro auf EBI PROTEIN-SEQUENZEN UND STRUKTUREN RCSB & PDBe Entrez Structure Group auf NCBI Molecular Modeling Database (MMDB) Conserved Domain Database (CDD) BioSystems, PubChem, IBIS, Cn3D, CDTree Entrez Protein STOFFWECHSELWEGE UND ENZYME IntEnz auf EBI UniPathway KEGG SPEZIFISCHE DATENBANKEN HPRD ViralZone
42 Keine sekundäre Datenbank hat aber hier irgendwie ganz gut hingepasst :) Initiative von Bioinformatikern mit dem Ziel die Repräsentation von Gen- und Genprodukt- Attributen zu standardisieren, Datenbank- und Organismus-übergreifend. 1998, zunächst entwickelt in Zusammenarbeit zwischen drei MODs (Model organism databases). GO Consortium heute umfasst wesentlich mehr Datenbanken, darunter EBI. GO enthält ein definiertes, hierarchisch aufgebautes Vokabular, um Charakteristiken von Genprodukten zu beschreiben. Es gibt drei Ontologie-Ebenen (Cytochrom c): Molekülfunktion biologischer Prozess zelluläre Komponente GO Gene Ontology (oxidoreductase activity) (oxidative phosphorylation, induction of cell death) (mitochondrial matrix, mitochondrial inner membrane) GO-Terms ermöglichen eine bessere Suche zwischen Genprodukten derselben Ontologie. GO-Terms ermöglichen standartisierte Sortierung von Proteinen Wozu das Ganze? MeSH-Terms (siehe Literatur-Seminar) machen dasselbe für Literatur! Datenbank A: Protein X ist in Protein-Synthese invovliert. Datenbank B: Protein X ist in Translation invovliert. Metasuche nach allen Proteinen, die an Translation beteiligt sind. Ergebnis?? Computer kann die Phrasen nicht übersetzen!
 Die assoziierten")
43 GO Gene Ontology Mapping GO ist nicht das einzige Vokabular-System zur Beschreibung von Genprodukt- Charakteristika. Es gibt unzählige Vokabular-Versionen einzelner Datenbanken: Keywords von UniProt EC-Nummern Domänen-Bezeichnung aus Pfam, PRINTS, ProSite COG (Clusters of Orthologous Groups) Die assoziierten Vokabeln in anderen Datenbanken können jedoch in das GO-Vokabular übersetzt werden (Mapping). Diese Vorgehensweise ist jedoch nur ein Anhaltspunkt oft ist die Übersetzung nicht eindeutig und korrekte Ergebnisse könnten dadurch ausgeschlossen werden.
44 Überblick behalten INFORMATIONEN UND ERLÄUTERUNGEN UniProtKB: Swiss-Prot/TrEMBL und UniParc, UniRef SEKUNDÄRE DATENBANKEN: PROTEIN-DOMÄNEN UND -FAMILIEN Sequenz-basiert: PROSITE, PRINTS, Pfam Struktur-basiert: SCOP, CATH Gene Ontology (GO) InterPro auf EBI PROTEIN-SEQUENZEN UND STRUKTUREN RCSB & PDBe Entrez Structure Group auf NCBI Molecular Modeling Database (MMDB) Conserved Domain Database (CDD) BioSystems, PubChem, IBIS, Cn3D, CDTree Entrez Protein STOFFWECHSELWEGE UND ENZYME IntEnz auf EBI UniPathway KEGG SPEZIFISCHE DATENBANKEN HPRD ViralZone

45 InterPro Integrated Resources of Proteins Domains and Functional Sites InterPro kombiniert die Ergebnisse mehrerer sekundärer Datenbanken, die verschiedene Methoden verwenden, um Protein-Signaturen zu definieren. Die Modelle sind aus den AS-Sequenzen bekannter Protein-Familien abgeleitet. Sie werden dazu verwendet Sequenzen unbekannter Funktion nach Signaturen zu durchsuchen, damit sie schneller klassifiziert werden können. Dies ist im Zeitalter der Hochdurchsatz-Genom-Sequenzierung extrem wichtig. Problem dabei: unterschiedliche Datenbank = unterschiedliches Modell = unterschiedliche Klassifizierung Member Databases von InterPro Das Ziel von InterPro ist die Erstellung einer Internet-Präsenz, die Informationen über alle Typen von Protein-Klassifikationen für ein gegebenes Protein listet.

46 InterPro Integrated Resources of Proteins Domains and Functional Sites Woher kommen die Protein-Signaturen? Was sind Protein-Signaturen? Signatur-Arten in InterPro Die Signaturen sind mit GO-Klassifizierungen verknüpft (funktionelle Klassifizierung)
47 InterPro Integrated Resources of Proteins Domains and Functional Sites InterPro besteht aus drei Haupt-Datensätzen: Proteine, Signaturen und Einträge. Proteine Die Protein-Datensätze in InterPro stammen aus der UniProtKB sowie UniParc und UniMES. Signaturen Die Protein-Daten gelangen zu den Member-DBs und dienen der Berechnung der Signaturen anhand der verschiedenen Modelle. Alle produzierte Signaturen, welche dieselben Protein-Familien oder Domänen beschreiben, erhalten dieselbe InterPro ID und werden als ein Ergebnis zusammengefasst. Verwandte Signaturen sind jeweils miteinander verlinkt. Einträge InterPro hält für die einzelnen Ergebnisse weitere Informationen bereit, die im InterPro- Eintrag zusammengefasst werden, darunter: Beschreibendes Abstract über die Funktionen der Proteine und Signaturen, die mit dem Ergebnis assoziiert sind. Links zu den sekundären Datenbanken (Quell-Datenbanken für die Signaturen). Links zu PubMed (Literatur), PDB und weiteren Datenbanken.

48 InterPro Integrated Resources of Proteins Domains and Functional Sites Was bringt mir diese Datenbank eigentlich? Tool für die Erkennung von Protein- Verwandtschaften unbekannter Sequenzen. Eingabe einer beliebigen FASTA-Sequenz in InterProScan => Suche nach ähnlichen Signaturen anhand der Methoden der Unter-Datenbanken => Klassifizierung des Proteins => Phylogenetische Analyse. BLAST in sekundären Datenbanken mit den entsprechenden Modellen Besonders wichtig für die Menge an Daten in Genom-Sequenzierungs-Projekten. Erster Ansatz, wenn neues Protein oder Gen entdeckt wurde, um es einzuordnen.

 InterProScan 2)")
49 InterPro Integrated Resources of Proteins Domains and Functional Sites InterProScan ist jedoch nicht ausreichend! The only way to make complete analyses of the domains contained in your sequence is to use the three major domain servers: 1) InterProScan 2) CD-Search 3) Motif-Scan - Bioinformatics for Dummies, S. 182
50 InterPro Integrated Resources of Proteins Domains and Functional Sites Proteine im InterPro-Eintrag InterPro-ID des Eintrags Art des Eintrags (Family, Domain, Site) Die Ergebnisse enthalten unter anderem folgende Daten: Hier geht s zu den 5 verschiedenen Listen-Ansichten der zu diesem InterPro-Eintrag gehörenden Proteine. Signaturen im InterPro Eintrag Verwandte InterPro Einträge Funktion der Proteine/Signaturen Hier geht s zu den Signatur-Einträgen in den sekundären Datenbanken. Hier geht s zu den GO-Einträgen (Funktions-Hierarchien). Suchanfragen können auch über PDB ID, PubMed ID, InterPro ID oder FASTA-Sequenz (Eindeutigkeit) bekannter Proteine gestellt werden. Alternativ über Phrasen wie Hexokinase oder SH3 (Problem: viele Suchergebnisse, schlechte Übersicht).


51 InterPro Integrated Resources of Proteins Domains and Functional Sites Die Ergebnisse enthalten unter anderem folgende Daten: Abstract, geschrieben von Kuratoren Taxonomischer Überblick Schlüssel für die Sequenz- Annotierung. Beispiel-Proteine mit ihren Signaturen (mit Links)
52 InterPro Integrated Resources of Proteins Domains and Functional Sites Die Ergebnisse enthalten Balken unter stehen anderem für folgende Daten: A) InterPro-Einträge. 1) rot: gewählter Eintrag, hier: Hexokinase. 2) andere Farben: Einträge, deren Sequenzen sich mit dem aktuellen Eintrag überschneiden. Z.B. konservierte Stellen in Hexokinase-Domäne. B) Bereiche mit Infos zur Struktur. Die Struktur-Informationen werden aus sekundären Datenbanken geholt. 1) Wenn Struktur aufgeklärt: Link zur PDB-Datei + Links zur Klassifizierung von Signaturen innerhalb der Struktur nach SCOP und CATH. 2) Wenn Struktur nicht aufgeklärt: automatisiertes Homologie- Modelling über sekundäre Datenbanken (MODBASE und Swiss- Model) liefern theoretisch Beispiel-Proteine mit ihren Signaturen (mit Links) berechnete Strukturen!
53 InterPro Integrated Resources of Proteins Domains and Functional Sites

54 InterPro Integrated Resources of Proteins Domains and Functional Sites Rot = Signatur (hier: Hexokinase-Domäne) des InterPro-Eintrags. Jede Farbe repräsentiert einen anderen InterPro-Eintrag. Liste aller zum InterPro-Eintrag gehörenden Proteine = alle Proteine mit Hexokinase- Domäne. Anzeige der Domänen- Architektur der Proteine.

55 InterPro Integrated Resources of Proteins Domains and Functional Sites InterPro Relationships ermöglicht Querverlinkung zwischen InterPro-Einträgen. CHILD/PARENT: >75% der Proteine im Protein-Set des CHILD-Eintrags müssen auch im PARENT Protein-Set vorkommen. Die Signaturen der CHILD/PARENT Einträge müssen mindestens 50% überlappen. Der Child-Eintrag ist immer spezifischer als der PARENT-Eintrag. Passt eine Sequenz zum CHILD-Eintrag, passt sie immer auch zum PARENT-Eintrag. CONATINS/FOUND IN Es werden strukturelle und funktionelle Features definiert, die nicht über CHILD/PARENT Beziehungen definiert sind. Darunter: Regions, Domains, Repeats, Sites. >40% der Proteine im InterPro-Eintrag müssen dieses Feature enthalten. Verlinkung von InterPro-Einträgen, die in ihrer Zusammensetzung ähnlich sind, aber keine evolutionäre Verwandtschaft aufweisen müssen.
56 So which database is better? As with everything, it depends on your problem: we would certainly suggest using more than one method. Pfam DB, FAQ
57 Überblick behalten INFORMATIONEN UND ERLÄUTERUNGEN UniProtKB: Swiss-Prot/TrEMBL und UniParc, UniRef SEKUNDÄRE DATENBANKEN: PROTEIN-DOMÄNEN UND -FAMILIEN Sequenz-basiert: PROSITE, PRINTS, Pfam Struktur-basiert: SCOP, CATH Gene Ontology (GO) InterPro auf EBI PROTEIN-SEQUENZEN UND STRUKTUREN RCSB & PDBe Entrez Structure Group auf NCBI Molecular Modeling Database (MMDB) Conserved Domain Database (CDD) BioSystems, PubChem, IBIS, Cn3D, CDTree Entrez Protein STOFFWECHSELWEGE UND ENZYME IntEnz auf EBI UniPathway KEGG SPEZIFISCHE DATENBANKEN HPRD ViralZone Mehr dazu im BCDS-Seminar: PDB & PyMol
58 Die PDB (Protein-Databank) Die PDB ist ein Archiv mit experimentell bestimmten Strukturen von Proteinen, Nukleinsäuren und höheren Assemblierungen. 4 Datenbanken bilden zusammen die wwpdb (world wide). Sie können eigenständig Daten anlegen, prozessieren und zur Verfügung stellen, während wwpdb die Aktionen überwacht und die Daten verteilt. Der Upload erfolgt direkt durch die Wissenschaftler, welche die Struktur experimentell bestimmt haben. RCSB PDB wird durch die Research Collaboratory for Structural Bioinformatics, USA verwaltet. PDBe (auch: MSD, macromolecular structure database) auf EBI, UK. PDBj, Japan. BMRB (Biological Magnetic Resonance Databank) enthält NMR Daten biologischer Makromoleküle, Universität Wisconsin-Madison, USA. Die Suche in diesen Datenbanken und die Such-Ausgabe erfolgt sehr komfortabel unter: RCSB PDB PDBsum auf EBI Mehr dazu im BCDS-Seminar: PDB & PyMol

59

60
61 Überblick behalten INFORMATIONEN UND ERLÄUTERUNGEN UniProtKB: Swiss-Prot/TrEMBL und UniParc, UniRef SEKUNDÄRE DATENBANKEN: PROTEIN-DOMÄNEN UND -FAMILIEN Sequenz-basiert: PROSITE, PRINTS, Pfam Struktur-basiert: SCOP, CATH Gene Ontology (GO) InterPro auf EBI PROTEIN-SEQUENZEN UND STRUKTUREN RCSB & PDBe Entrez Structure Group auf NCBI Molecular Modeling Database (MMDB) Conserved Domain Database (CDD) BioSystems, PubChem, IBIS, Cn3D, CDTree Entrez Protein STOFFWECHSELWEGE UND ENZYME IntEnz auf EBI UniPathway KEGG SPEZIFISCHE DATENBANKEN HPRD ViralZone
62 NCBI Structure Group Die NCBI Structure Group bietet mehrere Ressourcen, um Strukturen zu finden: BioSystems Database Pathways Molecular Modeling Database (MMDB) 3D-Strukturen Conserved Domain Database (CDD) Domänen PubChem Databases (PC) Liganden Vergleichbar mit den 3 Ebenen der KEGG-Datenbanken. Sie sind untereinander und mit den anderen NCBI Datenbanken querverlinkt. Die Daten stammen meist aus anderen, primären Datenbanken. Der Vorteil an diesen Datenbanken sind die teilweise sehr interessanten Tools, die in NCBI integriert sind: VAST Struktur-Homologie-Suche Cn3D Struktur-Vergleiche IBIS Protein/Protein-Interaktionen CDTree Phylogenetische Bäume
63 Überblick behalten INFORMATIONEN UND ERLÄUTERUNGEN UniProtKB: Swiss-Prot/TrEMBL und UniParc, UniRef SEKUNDÄRE DATENBANKEN: PROTEIN-DOMÄNEN UND -FAMILIEN Sequenz-basiert: PROSITE, PRINTS, Pfam Struktur-basiert: SCOP, CATH Gene Ontology (GO) InterPro auf EBI PROTEIN-SEQUENZEN UND STRUKTUREN RCSB & PDBe Entrez Structure Group auf NCBI Molecular Modeling Database (MMDB) Conserved Domain Database (CDD) BioSystems, PubChem, IBIS, Cn3D, CDTree Entrez Protein STOFFWECHSELWEGE UND ENZYME IntEnz auf EBI UniPathway KEGG SPEZIFISCHE DATENBANKEN HPRD ViralZone
64 NCBI Structure Group Suche in der MMDB text term search: Suche über Felder in den PDB-flat-file Daten. protein BLAST: Eingabe-Sequenz wird mit Sequenzen aus der PDB-Datenbank verglichen. Wenn die Eingabe-Sequenz bereits existiert, sind über den Entrez-Protein-Eintrag unter Links/Related Structures bereits die berechneten BLAST-Ergebnisse gespeichert. VAST search: Nach Upload von 3D-Koordinaten im PDB-Format werden diese mit den 3D- Koordinaten von Strukturen in der PDB-Datenbank verglichen. Mithilfe des Programms Cn3D kann die Struktur-Homologie visualisiert werden. siehe Protein-Tools, nachmittags
65 NCBI Structure Group text term search Kuriosität: Aufgrund unterschiedlicher Definitionen in Quelldatenbanken kann ein und das selbe Protein mehrere MGs haben! Je nach Suchmaschine existieren unterschiedliche Suchfelder! Sie sind auf den Hilfe-Seiten einsehbar. Intervall-Anfragen: FromValue:ToValue[Field] [PDBACC] = PDB ID (wird auch ohne Feld erkannt). [EC] = EC-Nummer (Wildcards verwenden). [RES] = Auflösung der PDB-Struktur (in Angstrom). [EXP] = experimentelle Methode (X-Ray, NMR). [PDDAT] = Datum der Veröffentlichung der Struktur in der PDB. [ORGN] = Organismus, in dem die Struktur vorkommt. [CHN] = 1-Letter Code der Kette in der PDB-Struktur (ASCII Format). Format von Daten: [LIGD] = Bezeichnung des Liganden in der PDB Struktur. YYYY/MM/DD, [MWT] = Molekulargewicht (in Dalten). YYYY/MM, YYYY [PCC] = Anzahl an Polypeptidketten in der Struktur (oligomerer Zustand). [MPRC] = Anzahl modifizierter AS in der Struktur. Die Literatur betreffend, welche die Struktur publizierte: [TITLE], [AUTH], [JOURNAL]
, Taxonomie-Informationen (NCBI Taxonomy), ähnliche Protein-Sequenzen (Entrez Protein),")
66 NCBI Structure Group Die MMDB beinhaltet ausschließlich Strukturen aus der wwpdb. Die Ergebnis-Seiten verknüpfen die PDB-Daten mit weiteren Informationen aus NCBI: Literatur-Verweise (PubMed), Taxonomie-Informationen (NCBI Taxonomy), ähnliche Protein-Sequenzen (Entrez Protein), verwandte 3D-Strukturen (CCD, 3D Domains), Informationen zu gebundenen Liganden (PubChem). Display: Summary Format (MMDB Suche) Zeigt alle bekannten Liganden an. Zeigt alle enthaltenen Domänen an.
 Der erste Eintrag entspricht der Kombination beider Domänen.")
67 NCBI Structure Group Die Suche nach 3D-Domänen kann auch direkt über Search 3D Domains erfolgen. Datenquelle: MMDB (Sortierung der Strukturen in einzelne Domänen). Basis für Struktur-Verwandtschafts-Analysen von Domänen über das NCBI-Tool VAST. Display: Summary Format (3D Domains Suche) Der erste Eintrag entspricht der Kombination beider Domänen. Bei Klick auf ID oder Abbildung der drei Ergebnisse gelangt man immer zum selben MMDB-Eintrag. Link zu VAST-Eintrag für ausgewählte Domäne.
68 NCBI Structure Group Wie sieht nun ein MMDB-Eintrag aus? sehr übersichtlich (vergleiche Registerkarten in PDBsum oder RCSB) Link VAST führt zu einer Tabelle, welche die Domänen des Proteins listet. Auswahl einer Domäne führt ebenso zum VAST-Eintrag. Link zum CDD-Eintrag des gesamten Proteins Link zum VAST-Eintrag des gesamten Proteins Link zum VAST-Eintrag der 3D-Domäne 1. Beachte: 3D-Domäne ist nicht durch Sequenz begrenzt! Link zum CDD-Eintrag der konservierten Sequenz 2. Beachte: hier geht es um Sequenz-Vergleiche!

69 NCBI Structure Group Wie sieht nun ein VAST-Eintrag aus? Vector Alignment Search Tool VAST ist ein Vektor-basierender Algorithmus, mit dem 3D Strukturen verglichen werden. Diese Seite listet verwandte Proteine in Bezug auf ihre strukturelle Verwandtschaft. Von hier aus lassen sich gezielt Struktur-Überlagerungen in Zusammenhang mit Sequenz- Alignments anzeigen. Die zu vergleichenden Strukturen einfach markieren und View 3D Alignment anklicken


70 NCBI Structure Group Visualisierung erfolgt über Cn3D! 2 Fenster: Sequenz-Alignment + Struktur Überlagerung. Rot = identisch Blau = konserviert Grau = nicht konserviert Mehr dazu später bei Protein- Analyse-Tools
71 Überblick behalten INFORMATIONEN UND ERLÄUTERUNGEN UniProtKB: Swiss-Prot/TrEMBL und UniParc, UniRef SEKUNDÄRE DATENBANKEN: PROTEIN-DOMÄNEN UND -FAMILIEN Sequenz-basiert: PROSITE, PRINTS, Pfam Struktur-basiert: SCOP, CATH Gene Ontology (GO) InterPro auf EBI PROTEIN-SEQUENZEN UND STRUKTUREN RCSB & PDBe Entrez Structure Group auf NCBI Molecular Modeling Database (MMDB) Conserved Domain Database (CDD) BioSystems, PubChem, IBIS, Cn3D, CDTree Entrez Protein STOFFWECHSELWEGE UND ENZYME IntEnz auf EBI UniPathway KEGG SPEZIFISCHE DATENBANKEN HPRD ViralZone
72 NCBI Structure Group Konservierte Domäne = in der Evolution mehrmals auftauchende, strukturell und/oder funktional vom Gesamt-Protein entkoppelte Einheit. Die CDD nutzt u.a. den Input verschiedener Datenbanken, welche Domänen klassifizieren (vergleichbar mit InterPro). Der Unterschied zwischen CDD und 3D Domains Die 3D Domains Database speichert Strukturen (x,y,z-koordinaten der einzelnen Atome). Die CDD speichert lediglich die Sequenz einer konservierten Region im Protein. CD-Modelle basieren auf multiplen Sequenz-Alignments verwandter Proteine aus zahlreichen Organismen. So werden Sequenz-Regionen mit ähnlichen AS-Muster identifiziert. CDD-Eintrag = Summe aller Sequenzen, die zur selben konservierten Domäne gehören.
73 NCBI Structure Group Erst in Verbindung mit der MMDB kann die Domänen-Struktur in Zusammenhang mit den konservierten Sequenzen betrachtet und analysiert werden. Ziel der CDD: stimmen die Daten aus den multiplen Sequenz-Alignments mit den Informationen aus der Überlagerung der 3D-Strukturen überein? Logisch: gleiche Sequenz = gleiche Struktur! Frage: ähnliche Sequenz = ähnliche Struktur? Ziel: Rückschlüsse auf Ursache der Funktion (Sequenz/Struktur/Funktion Beziehung) Hierzu gibt es das Programm Cn3D auf NCBI Es zeigt gleichzeitig Sequenz-Alignment und Struktur-Überlagerung an.

74 NCBI Structure Group Das CD-Search Tool Suche von konservierten Domänen anhand der FASTA-Sequenz möglich Alternativ normale Suche über Entrez
75 NCBI Structure Group Selbes Beispiel: Hexokinase (PDBID: 3H1V) Link zum CDD-Eintrag des gesamten Proteins Link zum CDD-Eintrag der konservierten Sequenz 2. Beachte: hier geht es um Sequenz-Vergleiche!
76 NCBI Structure Group Wie sieht nun ein CDD-Eintrag aus? Sequenzen derselben Domäne aus Proteinen verschiedener Organismen (nur eine Auswahl wird dargestellt). Bedeutung von dieselbe Domäne wird von den Quell-Datenbanken (verschiedene Modelle) definiert. Hier ist die Quell-Datenbank Pfam. Zum Superfamilien- Eintrag Info-Text über die CD Das Alignment kann im mfasta Format gespeichert werden. Farben stehen für den Grad der Konservativität. Die Sensitivität kann über Color Bit eingestellt werden: rot: am besten konserviert blau: mittelmäßig konserviert grau: am schlechtesten konserviert


.")
77 NCBI Structure Group Die Häufigkeit, mit der eine bestimmte Aminosäure in einer bestimmten Position der Sequenz vorliegt, lässt sich über die PSSM (position-specific scoring matrix) visualisieren. Struktur-Überlagerung in Cn3D betrachten Representatives: Link zu den einzelnen Protein-Sequenzen des Alignments. Related Protein: alle Protein- Sequenzen mit dieser Domäne (RPS- BLAST). Related Structure: Alle Protein- Sequenzen mit bekannter 3D-Struktur, die eine ähnliche PSSM aufweisen (auch RPS-BLAST).


78 NCBI Structure Group Position-specific Scoring Matrix Konsensus-Sequenz = wahrscheinlichste Sequenz Daten-Tabelle für eine Aminosäure-Position
79 NCBI Structure Group Wo kamen nochmal die Daten her? (1) Verschiedene NCBI-externe Datenbanken (unterschiedliche Modelle zur Klassifizierung der Domänen). (2) Von NCBI-Kuratoren aus 3D-Struktur-Informationen abgeleitete Domänen. Problem: Redundanz Lösung von InterPro: Ein Eintrag für eine Sequenz und Gegenüberstellung der Modelle. Lösung von NCBI: Einzelne Einträge für die Modelle. Die CDD fasst ähnliche Domänen- Modelle verschiedener Quellen in Superfamilien zusammen. Wie gelange ich zum Superfamilien-Eintrag? (1) Der Link zur Superfamilie ist auf der CDD-Ergebnis-Seite (2) Direkte Suche in CDD nach einer Domänen-Bezeichnung (Beispiel: SH3)

 NCBI-interner Eintrag für SH3 ID beginnt mit cd NCBI-externe")
80 NCBI Structure Group So sieht ein Superfamilien-Eintrag aus ID beginnt mit ci Links zu den Einzel-Einträgen : ID beginnt mit DB- Name der Quell- Datenbank (hier: pfam bzw. smart) NCBI-interner Eintrag für SH3 ID beginnt mit cd NCBI-externe Einträge: SH3 aus Pfam, SH3 Variante aus Pfam SH3 aus Smart
81 NCBI Structure Group Vorteile von NCBI-internen Superfamilien-Einträgen Erstellung mit dem Ziel der Aufklärung von Sequenz/Struktur/Funktions-Beziehungen Kuratoren haben die Alignments aus anderen Datenbanken überprüft und mit der Struktur-Überlagerung verglichen. In den Sequenz-Alignments wurden auf Basis dieser Analyse strukturell konservierte Abschnitte hervorgehoben. Es wurden konservierte Stellen (z.b. Bindestellen, katalytische Reste etc.) markiert (mit Verlinkung zur Literatur). Phylogenetischer Baum wird angezeigt (Nutze NCBI-Tool CDTree)


82 NCBI Structure Group Wie sieht ein NCBI-interner Eintrag aus? Obere Box enthält Kommentare zu einzelnen konservierten Bereichen. Beispiel zeigt Superfamilien- Eintrag mit Unterfamilien, für die eigene Superfamilien- Einträge existieren. Einzelne Zweige des phylogenetischen Baums können über die Unterfamilien-Einträge betrachtet werden. bekannt aus pfam-eintrag: Boxen mit Verlinkungen und Sequenz-Alignment (nicht gezeigt).
83 Überblick behalten INFORMATIONEN UND ERLÄUTERUNGEN UniProtKB: Swiss-Prot/TrEMBL und UniParc, UniRef SEKUNDÄRE DATENBANKEN: PROTEIN-DOMÄNEN UND -FAMILIEN Sequenz-basiert: PROSITE, PRINTS, Pfam Struktur-basiert: SCOP, CATH Gene Ontology (GO) InterPro auf EBI PROTEIN-SEQUENZEN UND STRUKTUREN RCSB & PDBe Entrez Structure Group auf NCBI Molecular Modeling Database (MMDB) Conserved Domain Database (CDD) BioSystems, PubChem, IBIS, Cn3D, CDTree Entrez Protein STOFFWECHSELWEGE UND ENZYME IntEnz auf EBI UniPathway KEGG SPEZIFISCHE DATENBANKEN HPRD ViralZone
84 NCBI Structure Group PubChem Databases PubChem enthält Informationen über biologische Aktivität kleiner Moleküle. Es besteht aus drei Datenbanken: PCSubstances und PCBioAssay enthalten Informationen aus der wissenschaftlichen Community. PCCompound enthält aus diesen Datenbanken abgeleitete, nicht-redundante Informationen. Was bringt mir das in Zusammenhang mit 3D-Strukturen? 3D Strukturen mit Ligand findet man einfacher über Ligand-Suche bei PubChem. Querverlinkungen führen zur 3D Struktur des Ligand-gebundenen Makromoleküls.



85 NCBI Structure Group Protein-Strukturen mit allen Ergebnis- Verbindungen als Ligand. Protein-Strukturen mit dieser Verbindung als Ligand
86 NCBI Structure Group BioSystems Database Suche in verschiedenen Pathway- und Interaktions-Datenbanken: KEGG wird später noch eingeführt. Reactome biologische Pathways. BIOCYC Sammlung von >500 Organismus-spezifischen Pathway/Genom- Datenbanken. PID, Pathway Interaction Database human molecular signaling, regulatory events, cellular processes). Sie ermöglicht den Zugang zu Signalwegen von verschiedenen Quell-Datenbanken und verknüpft diese mit Informationen zu Literatur, molekularen und chemischen Daten über Entrez. Suche nach Glycolysis liefert über 3000 Ergebnisse Für Pathways besser direkt KEGG ansteuern!

87 NCBI Structure Group Inferred Biomolecular Interactions Server (IBIS) Suche nach Interaktionspartnern. oben: Sequenz mit Interaktionsstellen markiert. unten: Liste der Interaktionspartner mit Interaktionsstellen Ähnliche Funktion auf EBI: IntAct.

88 Cn3D & CDTree Eigenständige Programme, Installation notwendig! Verwurzelt mit der CD-Database der Entrez-Structure Group (Verlinkung startet das Programm automatisch, wenn installiert).



89 Cn3D Gleichzeitige Darstellung von Sequenz- und Struktur-Alignment Manuell Annotierte Signaturen zugänglich. Beschreibung der Domänen-Funktion Einzelne konservierte Stellen lassen sich hervorheben



90 CDTree Darstellung von evolutionären Verwandtschaften, Hilfestellung bei der Klassifizierung von Proteinen, verschiedene grafische Darstellungen lassen sich exportieren.
91 Überblick behalten INFORMATIONEN UND ERLÄUTERUNGEN UniProtKB: Swiss-Prot/TrEMBL und UniParc, UniRef SEKUNDÄRE DATENBANKEN: PROTEIN-DOMÄNEN UND -FAMILIEN Sequenz-basiert: PROSITE, PRINTS, Pfam Struktur-basiert: SCOP, CATH Gene Ontology (GO) InterPro auf EBI PROTEIN-SEQUENZEN UND STRUKTUREN RCSB & PDBe Entrez Structure Group auf NCBI Molecular Modeling Database (MMDB) Conserved Domain Database (CDD) BioSystems, PubChem, IBIS, Cn3D, CDTree Entrez Protein STOFFWECHSELWEGE UND ENZYME IntEnz auf EBI UniPathway KEGG SPEZIFISCHE DATENBANKEN HPRD ViralZone
92 Entrez Protein Entkoppelt von der NCBI Structure Group - Hier geht es um Protein-Sequenzen! keine einzelne DB, sondern Zusammenstellung von Einträgen unterschiedlicher Protein- Sequenz-Datenbanken. DB-Format ist äquivalent zum GenBank-Format. Datenquellen: übersetzte codierende Sequenzen (CDS) aus DNA-Sequenzen in GenBank/EMBL/DDBJ Protein-Sequenzen aus PIR, UniProtKB/Swiss-Prot und PRF Protein-Sequenzen aus gelösten Strukturen in der PDB Isoformen, unvollständige Sequenzen, Proproteine haben unterschiedliche Einträge. => Hohe Redundanz der Daten => sehr spezifische Suchanfragen notwendig! Protein-Sequenz über andere Datenbanken: Wenn Gen bekannt, ist eine genauere Suche über Entrez Gene möglich. Wenn Protein-Struktur aufgeklärt ist, Verlinkung über die PDB-Einträge. Besser: UniProtKB-Suche, da hier die Redundanz minimiert ist (UniRef). Suche direkt in Entrez Protein daher eher selten bis gar nicht notwendig.
93 Überblick behalten INFORMATIONEN UND ERLÄUTERUNGEN UniProtKB: Swiss-Prot/TrEMBL und UniParc, UniRef SEKUNDÄRE DATENBANKEN: PROTEIN-DOMÄNEN UND -FAMILIEN Sequenz-basiert: PROSITE, PRINTS, Pfam Struktur-basiert: SCOP, CATH Gene Ontology (GO) InterPro auf EBI PROTEIN-SEQUENZEN UND STRUKTUREN RCSB & PDBe Entrez Structure Group auf NCBI Molecular Modeling Database (MMDB) Conserved Domain Database (CDD) BioSystems, PubChem, IBIS, Cn3D, CDTree Entrez Protein STOFFWECHSELWEGE UND ENZYME IntEnz auf EBI UniPathway KEGG SPEZIFISCHE DATENBANKEN HPRD ViralZone


")
94 IntEnz Integrated relational Enzyme database Enzymdatenbank auf EBI mit dem Fokus auf Enzym-Nomenklatur. Entwickelt in Zusammenarbeit mit SIB (ExPASy) Hier befindet sich die äquivalente ENZYME-Database. Enthält die offizielle Version des Enzym-Nomenklatur Systems (EC-System), das durch die NC-UIBMB (International Union of Biochemistry and Molecular Biology) festgelegt wird. Zusätzlich ist die offizielle Klassifizierung erweitert (Hinweis: preliminary EC Number). Suche oder EC-Browsing möglich.
95 Überblick behalten INFORMATIONEN UND ERLÄUTERUNGEN UniProtKB: Swiss-Prot/TrEMBL und UniParc, UniRef SEKUNDÄRE DATENBANKEN: PROTEIN-DOMÄNEN UND -FAMILIEN Sequenz-basiert: PROSITE, PRINTS, Pfam Struktur-basiert: SCOP, CATH Gene Ontology (GO) InterPro auf EBI PROTEIN-SEQUENZEN UND STRUKTUREN RCSB & PDBe Entrez Structure Group auf NCBI Molecular Modeling Database (MMDB) Conserved Domain Database (CDD) BioSystems, PubChem, IBIS, Cn3D, CDTree Entrez Protein STOFFWECHSELWEGE UND ENZYME IntEnz auf EBI UniPathway KEGG SPEZIFISCHE DATENBANKEN HPRD ViralZone
96 UniPathway Die metabolische Tür zu UniProtKB/Swiss-Prot Nutzt die UniProtKB Einträge und kategorisiert sie nach den Stoffwechselwegen, an denen sie beteiligt sind. Die Datenbank ist in 5 Ebenen aufgebaut. Ebene 0: Super-Pathway Klassifizierung der Stoffwechselwege in größere Kategorien, Super-Pathways: Glykolyse Kohlenhydratstoffwechsel Ebene 1: UPA (Pathway) Die Stoffwechselwege sind unabhängig vom Organismus definiert (z.b. Glykolyse). Hier können jedoch unterschiedliche Zwischenprodukte vorkommen (Verzweigungen im Pathway). definiert als Satz von linearen Sub-Pathways, verbunden durch die terminalen Produkte und Edukte. Ebene 2: ULS (Linear Sub-Pathway) ULS können Teil von mehreren Pathways sein. keine Verzweigungen; definierte Folge enzymatischer Reaktionen. Nummerierung der enzymatischen Reaktionen in step 1 bis step n.
97 UniPathway Die metabolische Tür zu UniProtKB/Swiss-Prot Ebene 3: UER (Enzymreaktion) UERs gehören zu einem definierten Sub-Pathway. besteht aus zwei Datensätzen: biochemische Reaktion und Enzym. eine enzymatische Reaktion kann auf unterschiedliche Arten erfolgen, sodass verschiedene Sequenz-Reaktionen stattfinden können (z.b. NADH oder NADPH als Co-Substrat). Ebene 4: USR (Sequenz-Reaktion) USRs gehören zu einer definierten Enzymreaktion. Folge elementarer chemischer Reaktionen. Eine Sequenz-Reaktion kann in mehrere elementare chemische Reaktionen aufgeteilt werden (A B C wird zu A B und B C). definiert durch eine EC-Nummer sowie Edukte und Produkte. Ebene 5: UCR (Chemische Reaktion) UCRs können zu verschiedenen Enzymreaktionen gehören. Ein-Schritt-Reaktion Ebene 6 : UPC (chemische Verbindung) UPCs können zu verschiedenen chemischen Reaktionen gehören. Datenquelle: KEGG LIGAND Database

98 Beispiel: Glykolyse UniPathway Die metabolische Tür zu UniProtKB/Swiss-Prot Es lassen sich Organismus-spezifische Pathways tabellarisch anzeigen. Pathways sind direkt mit UniProtKB verlinkt. Browse Pathway zeigt eine Tabelle aller Stoffwechselwege an (über 700).





99 UniPathway: Glykolyse Links zum Sub-Pathway-Eintrag Ontology View: Einordnung des Prozesses in den Gesamt- Zusammenhang; Links zu Sub-Pathways, Enzymreaktion und Enzyme Beteiligte Proteine auf Pathwayund Enzymreaktions-Ebene Chemical View Protein View: Tabellarische Übersicht beteiligter Proteine, Links zur ENZYM-Datenbank und UniProtKB-Liste für bestimmtes Reich (Archaea, Bacteria, Eukaryota)
100 Überblick behalten INFORMATIONEN UND ERLÄUTERUNGEN UniProtKB: Swiss-Prot/TrEMBL und UniParc, UniRef SEKUNDÄRE DATENBANKEN: PROTEIN-DOMÄNEN UND -FAMILIEN Sequenz-basiert: PROSITE, PRINTS, Pfam Struktur-basiert: SCOP, CATH Gene Ontology (GO) InterPro auf EBI PROTEIN-SEQUENZEN UND STRUKTUREN RCSB & PDBe Entrez Structure Group auf NCBI Molecular Modeling Database (MMDB) Conserved Domain Database (CDD) BioSystems, PubChem, IBIS, Cn3D, CDTree Entrez Protein STOFFWECHSELWEGE UND ENZYME IntEnz auf EBI UniPathway KEGG SPEZIFISCHE DATENBANKEN HPRD ViralZone

101 KEGG Kyoto Encyclopedia of Genes and Genomes A grand challenge in the post-genomic era is a complete computer representation of the cell, the organism, and the biosphere, which will enable computational prediction of higher-level complexity of cellular processes and organism behaviors from genomic and molecular information. KEGG ist eine Repräsentation biologischer Systeme am Computer. KEGG besteht aus 16 Datenbanken. Sie repräsentieren zusammen drei Informations-Ebenen. Startpunkt: KEGG PATHWAY Informationen anderer Datenbanken durch Verlinkung: KEGG ENZYME KEGG REACTION KEGG COMPOUND
102 KEGG Kyoto Encyclopedia of Genes and Genomes PATHWAY vs. BRITE KEGG Pathway enthält Stoffwechsel- und Signalweg-Karten, basierend auf molekulare Interaktionen und Reaktionen. KEGG Brite ermöglicht eine hierarchische Klassifikationen, die das Wissen über biologische Systeme repräsentiert. Klassifikation von KEGG PATHWAY ist auf molekulare Interaktionen und Reaktionen beschränkt. KEGG BRITE nutzt viele weitere funktionale Beziehungen zur Definition verschiedener Hierarchien! Mapping aller Datensätze (Genomics, Transcriptomics, Proteomics, Metabolomics) zu den BRITE-Hierarchien.
103 KEGG-PATHWAY Sammlung manuell gezeichneter Pathway-Karten, basierend auf dem Wissen über molekulare Interaktions- und Reaktions-Netzwerke. Metabolism (Kohlenhydrate, Energie, Lipid, Nukleotid, Aminosäure, Cofaktor/Vitamin) Genetic Information Processing (Transkription, Translation, Faltung, Sortierung, Degradation, Replikation, DNA-Reparatur) Environmental Information Processing (Membran-Transport, Signal-Transduktionswege, Signalmolekül-Interaktion) Cellular Processes (Autophagie, Endozytose, Zellzyklus, Zelltot, Immunsystem, Nervensystem) Human Diseases Drug Developement

104 KEGG PATHWAY globale Metabolismus-Karte

105 KEGG PATHWAY Punkte repräsentieren Stoffwechsel-Intermediate (pop-up Info). Link zu KEGG Compound. Schriftzüge repräsentieren einzelne Pathways. Link zu den Pathway-Karten.

106 KEGG COMPOUND Über die Datentabelle des Stoffwechsel-Intermediats gelangt man zu allen Pathways, bei denen es beteiligt ist!
107 KEGG PATHWAY Sammlung manuell gezeichneter Pathway- Karten, basierend auf das Wissen über molekulare Interaktionsund Reaktions- Netzwerke. Links zu angrenzenden Stoffwechselwegen EC-Nummern führen zu einer großen Daten- Tabelle mit Infos aus: KEGG Enzyme KEGG Orthology KEGG Reaction


108 KEGG ENZYME Daten-Tabelle enthält viele Informationen: Alternative Bezeichnungen des Enzyms. Substrate, Produkte, Cofaktoren, Enzymklasse. katalysierte Reaktionen (Verweis zu KEGG Reactions). Manuell geschriebene Kommentare. Pathways, in die das Enzym involviert ist. Links zu PubMed und weiteren Enzym-DBs.


109 KEGG ORTHOLOGY KEGG REACTION Sehr übersichtliche Navigation Schlichtes und einheitliches Layouts der Daten-Tabellen aller Unter-Datenbanken. Gut sichtbare Querverlinkungen zwischen allen Einträgen.

110 KEGG PATHWAY Such-Feld: Eingabe von z.b. Stoffwechsel-Intermediaten Klicke auf Suchergebnis und Karte vergrößert entsprechenden Ausschnitt Navigation durch KEGG-PATHWAY über KEGG Atlas Browser (optional). Funktionen: Zoomen, Konfigurierbare Verlinkung, Übersicht über alle Maps, History-Funktion
111 Überblick behalten INFORMATIONEN UND ERLÄUTERUNGEN UniProtKB: Swiss-Prot/TrEMBL und UniParc, UniRef SEKUNDÄRE DATENBANKEN: PROTEIN-DOMÄNEN UND -FAMILIEN Sequenz-basiert: PROSITE, PRINTS, Pfam Struktur-basiert: SCOP, CATH Gene Ontology (GO) InterPro auf EBI PROTEIN-SEQUENZEN UND STRUKTUREN RCSB & PDBe Entrez Structure Group auf NCBI Molecular Modeling Database (MMDB) Conserved Domain Database (CDD) BioSystems, PubChem, IBIS, Cn3D, CDTree Entrez Protein STOFFWECHSELWEGE UND ENZYME IntEnz auf EBI UniPathway KEGG SPEZIFISCHE DATENBANKEN HPRD ViralZone
112 HPRD Human Protein Reference Database Eigenständige Datenbank, keine Verwendung anderer Datenbestände wie UniProtKB. Die Daten werden 100% manuell über Kuratoren auf der Basis von Literatur in die Datenbank eingegeben. Manuelle und eindeutige Klassifizierung. Jedes Protein bekommt eine spezifische Kategorie, welche die häufigste/wichtigste Funktion beschreibt (demokratische Abstimmung). Besondere Features oder Kollaborationen Human Proteinpedia: Community-Portal, in dem Arbeitskreise Informationen über Proteine austauschen. Ist neben der publizierten Literatur einer der Quellen für HPRD. Pathways: Datenbank NetPath (Entwicklung durch HPRD) hat bisher 20 Signalwege. PhosphoMotif Finder: Sucht anhand der FASTA-Sequenz Phosphorylierungsstellen.

113 HPRD Human Protein Reference Database Browser: Molekülklasse, Domäne, Motive, posttranslationale Modifikation, subzelluläre Lokalisation. Suchanfrage: u.a. über verschiedene IDs oder Protein-Bezeichnung.
114 HPRD Human Protein Reference Database Protein-Liste nach Suchanfrage oder Browsen. Domänen-Architektur wird graphisch hübsch dargestellt

.")

115 HPRD Human Protein Reference Database Links zu Hierarchie auf GO-Datenbank Sehr gute Informationen: assoziierte Erkrankungen (Link zu OMIM). Protein-Protein Interaktionen mit experimenteller Methode. DNA- und Protein- Sequenz (ORF bzw. Domänen sind markiert). Kotakt zum ersten Kommentator Kommentar anhängen
116 Überblick behalten INFORMATIONEN UND ERLÄUTERUNGEN UniProtKB: Swiss-Prot/TrEMBL und UniParc, UniRef SEKUNDÄRE DATENBANKEN: PROTEIN-DOMÄNEN UND -FAMILIEN Sequenz-basiert: PROSITE, PRINTS, Pfam Struktur-basiert: SCOP, CATH Gene Ontology (GO) InterPro auf EBI PROTEIN-SEQUENZEN UND STRUKTUREN RCSB & PDBe Entrez Structure Group auf NCBI Molecular Modeling Database (MMDB) Conserved Domain Database (CDD) BioSystems, PubChem, IBIS, Cn3D, CDTree Entrez Protein STOFFWECHSELWEGE UND ENZYME IntEnz auf EBI UniPathway KEGG SPEZIFISCHE DATENBANKEN HPRD ViralZone

117 ViralZone ViralZone ist auf ExPASy lokalisisert und verwendet die UniProtKB-Einträge. Es müssen zunächst einzelne Viren ausgewählt werden. Ein Sammel-Eintrag zeigt dann alle codierten Proteine sowie Infos über Capsid-Struktur und Lebenszyklus. Suche oder Browsing über Baltimore-Klassifizierung Host Virion-Struktur
118 ViralZone Sehr gute Übersicht: zu sehen sind Baltimore-Klassifizierung, Virion-Struktur und Host-Klassifizierung.




119 ViralZone Informationen sind auf 3 Ebenen vorhanden. Viele Viren wurden Betreff Genom, Genexpression und Replikation manuell annotiert.



120 ViralZone Protein-Einträge in Swiss-Prot, sortiert nach den einzelnen Virus-Stämmen z.b. HIV-1 Gruppe M, Subtyp H.





121 Fragen? Folien und Supplementals auf
Einführung in die Angewandte Bioinformatik: Proteinsequenz-Datenbanken
 Einführung in die Angewandte Bioinformatik: Proteinsequenz-Datenbanken 14.05.2009 Prof. Dr. Sven Rahmann 1 3 Proteinsequenz-Datenbanksysteme NCBI Entrez Proteins EBI SRS Proteins UniProt (empfohlen) 2
Einführung in die Angewandte Bioinformatik: Proteinsequenz-Datenbanken 14.05.2009 Prof. Dr. Sven Rahmann 1 3 Proteinsequenz-Datenbanksysteme NCBI Entrez Proteins EBI SRS Proteins UniProt (empfohlen) 2
MOL.504 Analyse von DNA- und Proteinsequenzen. Datenbanken & Informationssysteme
 MOL.504 Analyse von DNA- und Proteinsequenzen Datenbanken & Informationssysteme Inhaltsübersicht Informationsysteme National Center for Biotechnology Information (NCBI) The European Bioinformatics Institute
MOL.504 Analyse von DNA- und Proteinsequenzen Datenbanken & Informationssysteme Inhaltsübersicht Informationsysteme National Center for Biotechnology Information (NCBI) The European Bioinformatics Institute
Softwarewerkzeuge der. Bioinformatik
 Bioinformatik Wintersemester 2006/2007 Tutorial 1: Biologische Datenbanken SRS Tutorial 1: Datenbanken 1/22 Sequenzquellen DNA- Sequenzierung Protein- Sequenzierung Translation Proteinsequenzen Tutorial
Bioinformatik Wintersemester 2006/2007 Tutorial 1: Biologische Datenbanken SRS Tutorial 1: Datenbanken 1/22 Sequenzquellen DNA- Sequenzierung Protein- Sequenzierung Translation Proteinsequenzen Tutorial
Multiple Alignments. Vorlesung Einführung in die Angewandte Bioinformatik Prof. Dr. Sven Rahmann. Webseite zur Vorlesung
 Multiple Alignments Vorlesung Einführung in die Angewandte Bioinformatik Prof. Dr. Sven Rahmann Webseite zur Vorlesung http://bioinfo.wikidot.com/ Sprechstunde Mo 16-17 in OH14, R214 Sven.Rahmann -at-
Multiple Alignments Vorlesung Einführung in die Angewandte Bioinformatik Prof. Dr. Sven Rahmann Webseite zur Vorlesung http://bioinfo.wikidot.com/ Sprechstunde Mo 16-17 in OH14, R214 Sven.Rahmann -at-
Protein-Datenbanken. Protein- Datenbanken. Christian Fink
 Protein- Datenbanken Christian Fink 1 » Übersicht «PDB PDB_TM OPM HIC-UP Klotho 2 » PDB «PDB = Protein Data Bank 3D-Strukturen von Proteinen & Nukleinsäuren Gegründet 1971 als freies Archiv für biologische
Protein- Datenbanken Christian Fink 1 » Übersicht «PDB PDB_TM OPM HIC-UP Klotho 2 » PDB «PDB = Protein Data Bank 3D-Strukturen von Proteinen & Nukleinsäuren Gegründet 1971 als freies Archiv für biologische
Molekularbiologische Datenbanken
 Molekularbiologische Datenbanken Übungen Sommersemester 2004 Silke Trißl Prof. Ulf Leser Wissensmanagement in der Bioinformatik Organisatorisches Mittwoch 11 13 Uhr, RUD26 0'313 Mi, 05. Mai 2004 entfällt
Molekularbiologische Datenbanken Übungen Sommersemester 2004 Silke Trißl Prof. Ulf Leser Wissensmanagement in der Bioinformatik Organisatorisches Mittwoch 11 13 Uhr, RUD26 0'313 Mi, 05. Mai 2004 entfällt
Biowissenschaftlich recherchieren
 Biowissenschaftlich recherchieren Uber den Einsatz von Datenbanken und anderen Ressourcen der Bioinformatik Nicola Gaedeke Birkhauser Basel Boston Berlin Inhaltsverzeichnis Vorwort xi 1 Die Informationssucheim
Biowissenschaftlich recherchieren Uber den Einsatz von Datenbanken und anderen Ressourcen der Bioinformatik Nicola Gaedeke Birkhauser Basel Boston Berlin Inhaltsverzeichnis Vorwort xi 1 Die Informationssucheim
InterPro & SP-ML. Syntax und Verwendung der Beschreibungssprache XML Ausarbeitung im Seminar XML in der Bioinformatik.
 InterPro & SP-ML Syntax und Verwendung der Beschreibungssprache XML Ausarbeitung im Seminar XML in der Bioinformatik Stefan Albaum 18. Dezember 2002 Inhaltsverzeichnis 1 SPTr-XML 2 1.1 SWISS-PROT...........................
InterPro & SP-ML Syntax und Verwendung der Beschreibungssprache XML Ausarbeitung im Seminar XML in der Bioinformatik Stefan Albaum 18. Dezember 2002 Inhaltsverzeichnis 1 SPTr-XML 2 1.1 SWISS-PROT...........................
Gleichheit, Ähnlichkeit, Homologie
 Gleichheit, Ähnlichkeit, Homologie Identität (identity) Verhältnis der Anzahl identischer Aminosäuren zur Gesamtzahl der Aminosäuren; objektiv Ähnlichkeit (similarity) Verhältnis ähnlicher Aminosäuren
Gleichheit, Ähnlichkeit, Homologie Identität (identity) Verhältnis der Anzahl identischer Aminosäuren zur Gesamtzahl der Aminosäuren; objektiv Ähnlichkeit (similarity) Verhältnis ähnlicher Aminosäuren
Die wichtigsten Bioinformatikdatenbanken. SwissProt, PDB, Scop, CATH, FSSP, PROSITE, Pfam
 Die wichtigsten Bioinformatikdatenbanken SwissProt, PDB, Scop, CATH, FSSP, PROSITE, Pfam Übersicht Nucleotidsequenzen: GenBank, EMBL Proteindatenbank SwissProt Proteinstrukturen: Brookhavens PDB Proteinklassifizierung:
Die wichtigsten Bioinformatikdatenbanken SwissProt, PDB, Scop, CATH, FSSP, PROSITE, Pfam Übersicht Nucleotidsequenzen: GenBank, EMBL Proteindatenbank SwissProt Proteinstrukturen: Brookhavens PDB Proteinklassifizierung:
BCDS Seminar. Protein Tools
 BCDS Seminar Protein Tools Gliederung Nützliche Tools Three-/one-letter Amino Acids' Сodes RandSeq Random Protein Sequence Generator Protein Colourer ProtParam PeptideCutter ProtScale TMHMM Server 2.0
BCDS Seminar Protein Tools Gliederung Nützliche Tools Three-/one-letter Amino Acids' Сodes RandSeq Random Protein Sequence Generator Protein Colourer ProtParam PeptideCutter ProtScale TMHMM Server 2.0
Comperative Protein Structure Modelling of Genes and Genomes
 Comperative Protein Structure Modelling of Genes and Genomes Satisfaction of Spatial Restraints / Loop Modelling Nikolas Gross und Maximilian Miller Ludwig-Maximilians-Universität 29.11.2007 1 von 31 Table
Comperative Protein Structure Modelling of Genes and Genomes Satisfaction of Spatial Restraints / Loop Modelling Nikolas Gross und Maximilian Miller Ludwig-Maximilians-Universität 29.11.2007 1 von 31 Table
Übung II. Einführung, Teil 1. Arbeiten mit Ensembl
 Übung II Einführung, Teil 1 Arbeiten mit Ensembl Ensembl Genome Browser (Bereitstellung von Vielzeller Genomen) Projekt wurde 1999 initiiert Projektpartner EMBL European Bioinformatics Institute (EBI)
Übung II Einführung, Teil 1 Arbeiten mit Ensembl Ensembl Genome Browser (Bereitstellung von Vielzeller Genomen) Projekt wurde 1999 initiiert Projektpartner EMBL European Bioinformatics Institute (EBI)
Kleiner Führerschein für Datenbanken und ein Programm zur 3D-Visualisierung
 Information (Lehrer): Kleiner Führerschein für Datenbanken und ein Programm zur 3D-Visualisierung Mit der Bioinformatik hat sich ein eigener interdisziplinärer Wissenschaftszweig entwickelt, der Sequenzdaten
Information (Lehrer): Kleiner Führerschein für Datenbanken und ein Programm zur 3D-Visualisierung Mit der Bioinformatik hat sich ein eigener interdisziplinärer Wissenschaftszweig entwickelt, der Sequenzdaten
Primärstruktur. Wintersemester 2011/12. Peter Güntert
 Primärstruktur Wintersemester 2011/12 Peter Güntert Primärstruktur Beziehung Sequenz Struktur Proteinsequenzen, Sequenzdatenbanken Sequenzvergleich (sequence alignment) Sequenzidentität, Sequenzhomologie
Primärstruktur Wintersemester 2011/12 Peter Güntert Primärstruktur Beziehung Sequenz Struktur Proteinsequenzen, Sequenzdatenbanken Sequenzvergleich (sequence alignment) Sequenzidentität, Sequenzhomologie
MOL.504 Analyse von DNA- und Proteinsequenzen. Übungsaufgaben Datenbanken und Informationssysteme
 MOL.504 Analyse von DNA- und Proteinsequenzen Übungsaufgaben Datenbanken und Informationssysteme Ü1 Tutorial für NCBI NCBI Nucleotide: Suche nach cellobiose dehydrogenase fungi Ü1 Tutorial für NCBI NCBI
MOL.504 Analyse von DNA- und Proteinsequenzen Übungsaufgaben Datenbanken und Informationssysteme Ü1 Tutorial für NCBI NCBI Nucleotide: Suche nach cellobiose dehydrogenase fungi Ü1 Tutorial für NCBI NCBI
Vertiefendes Seminar zur Vorlesung Biochemie
 Vertiefendes Seminar zur Vorlesung Biochemie 31.10.2014 Proteine: Struktur Gerhild van Echten-Deckert Fon. +49-228-732703 Homepage: http://www.limes-institut-bonn.de/forschung/arbeitsgruppen/unit-3/abteilung-van-echten-deckert/abt-van-echten-deckert-startseite/
Vertiefendes Seminar zur Vorlesung Biochemie 31.10.2014 Proteine: Struktur Gerhild van Echten-Deckert Fon. +49-228-732703 Homepage: http://www.limes-institut-bonn.de/forschung/arbeitsgruppen/unit-3/abteilung-van-echten-deckert/abt-van-echten-deckert-startseite/
Klausur Bioinformatik für Biotechnologen
 Name, Vorname: 1 Klausur Bioinformatik für Biotechnologen Studiengang Molekulare Biotechnologie TU Dresden WS 2011/2012 Prof. Michael Schroeder 15.02.2012 Die Dauer der Klausur beträgt 90 Minuten. Bitte
Name, Vorname: 1 Klausur Bioinformatik für Biotechnologen Studiengang Molekulare Biotechnologie TU Dresden WS 2011/2012 Prof. Michael Schroeder 15.02.2012 Die Dauer der Klausur beträgt 90 Minuten. Bitte
Attached! Proseminar Netzwerkanalyse SS 2004 Thema: Biologie
 Rheinisch-Westfälischen Technischen Hochschule Aachen Lehr- und Forschungsgebiet Theoretische Informatik Prof. Rossmanith Attached! Proseminar Netzwerkanalyse SS 2004 Thema: Biologie Deniz Özmen Emmanuel
Rheinisch-Westfälischen Technischen Hochschule Aachen Lehr- und Forschungsgebiet Theoretische Informatik Prof. Rossmanith Attached! Proseminar Netzwerkanalyse SS 2004 Thema: Biologie Deniz Özmen Emmanuel
Bioinformatik II: Phylogenetik
 Bioinformatik II: Phylogenetik phylogenetisch Phylai: griechische Klans phylum: der Stamm phylogenetisch: die Stammesgeschichte von Lebewesen betreffend Hierarchien der Klassifikation: Domäne: Eukaryonten
Bioinformatik II: Phylogenetik phylogenetisch Phylai: griechische Klans phylum: der Stamm phylogenetisch: die Stammesgeschichte von Lebewesen betreffend Hierarchien der Klassifikation: Domäne: Eukaryonten
Vertiefendes Seminar zur Vorlesung Biochemie I Bearbeitung Übungsblatt 4
 Vertiefendes Seminar zur Vorlesung Biochemie I 20.11.2015 Bearbeitung Übungsblatt 4 Gerhild van Echten-Deckert Fon. +49-228-732703 Homepage: http://www.limes-institut-bonn.de/forschung/arbeitsgruppen/unit-3/
Vertiefendes Seminar zur Vorlesung Biochemie I 20.11.2015 Bearbeitung Übungsblatt 4 Gerhild van Echten-Deckert Fon. +49-228-732703 Homepage: http://www.limes-institut-bonn.de/forschung/arbeitsgruppen/unit-3/
Threading - Algorithmen
 Threading - Algorithmen Florian Lindemann 22.11.2007 Florian Lindemann () Threading - Algorithmen 22.11.2007 1 / 25 Gliederung 1 Prospect Scoring Function Algorithmus Weitere Eigenschaften Komplexität
Threading - Algorithmen Florian Lindemann 22.11.2007 Florian Lindemann () Threading - Algorithmen 22.11.2007 1 / 25 Gliederung 1 Prospect Scoring Function Algorithmus Weitere Eigenschaften Komplexität
Zentrum für Bioinformatik. Übung 4: Revision. Beispielfragen zur Klausur im Modul Angewandte Bioinformatik (erste Semesterhälfte)
") Andrew Torda Björn Hansen Iryna Bondarenko Zentrum für Bioinformatik Übung zur Vorlesung Angewandte Bioinformatik Sommersemester 2014 20./23.06.2014 Übung 4: Revision Beispielfragen zur Klausur im Modul
Andrew Torda Björn Hansen Iryna Bondarenko Zentrum für Bioinformatik Übung zur Vorlesung Angewandte Bioinformatik Sommersemester 2014 20./23.06.2014 Übung 4: Revision Beispielfragen zur Klausur im Modul
Datenbanken in der Molekularbiologie
 WS2017/2018 F1-Praktikum Genomforschung und Sequenzanalyse - Einführung in Methoden der Bioinformatik- Datenbanken in der Molekularbiologie Folie: Tal Dagan, D dorf Datenbanken in der Molekularbiologie
WS2017/2018 F1-Praktikum Genomforschung und Sequenzanalyse - Einführung in Methoden der Bioinformatik- Datenbanken in der Molekularbiologie Folie: Tal Dagan, D dorf Datenbanken in der Molekularbiologie
1/10. Ihre Namen: Gruppe: Evolutionsbiologie 2, WS2015/2016: Bioinformatik - Übung 1
 Ihre Namen: Gruppe: Evolutionsbiologie 2, WS2015/2016: Bioinformatik - Übung 1 Erstellen Sie bitte vor Beginn der Übung einen Ordner auf dem Desktop, in dem Sie alle benötigten Dateien speichern können
Ihre Namen: Gruppe: Evolutionsbiologie 2, WS2015/2016: Bioinformatik - Übung 1 Erstellen Sie bitte vor Beginn der Übung einen Ordner auf dem Desktop, in dem Sie alle benötigten Dateien speichern können
Ihre Namen: Gruppe: Öffnen Sie die Fasta-Dateien nur mit einem Texteditor, z.b. Wordpad oder Notepad, nicht mit Microsoft Word oder Libre Office.
 Ihre Namen: Gruppe: Evolutionsbiologie 2, WS2016/2017: Bioinformatik - Übung 1 Erstellen Sie vor Beginn der Übung einen Ordner auf dem Desktop, in dem Sie alle benötigten Dateien speichern kö nnen (z.b.
Ihre Namen: Gruppe: Evolutionsbiologie 2, WS2016/2017: Bioinformatik - Übung 1 Erstellen Sie vor Beginn der Übung einen Ordner auf dem Desktop, in dem Sie alle benötigten Dateien speichern kö nnen (z.b.
Datenbanken in der Molekularbiologie
 WS2015/2016 F1-Praktikum Genomforschung und Sequenzanalyse - Einführung in Methoden der Bioinformatik- Datenbanken in der Molekularbiologie Folie: Tal Dagan, D dorf Datenbanken in der Molekularbiologie
WS2015/2016 F1-Praktikum Genomforschung und Sequenzanalyse - Einführung in Methoden der Bioinformatik- Datenbanken in der Molekularbiologie Folie: Tal Dagan, D dorf Datenbanken in der Molekularbiologie
Modell Bahn Verwaltung. Tutorial. Links. Min. Programm Version 0.65, März w w w. r f n e t. c h 1 / 11
 Modell Bahn Verwaltung Tutorial Links Min. Programm Version 0.65, März 2015 Tutorial Version 04.01.2017 rfnet Software w w w. r f n e t. c h 1 / 11 Vorwort... 3 1 Links... 4 1.1 Einführung... 4 1.2 Link
Modell Bahn Verwaltung Tutorial Links Min. Programm Version 0.65, März 2015 Tutorial Version 04.01.2017 rfnet Software w w w. r f n e t. c h 1 / 11 Vorwort... 3 1 Links... 4 1.1 Einführung... 4 1.2 Link
Eine Detailsuche in der Cochrane Library
 Eine Detailsuche in der Cochrane Library Suche in allen Texten nach den Begriffen schizo*, drugs, atypical und antipsychotic Suche in allen Datenbanken der Cochrane Library Folgende Suchfunktionen stehen
Eine Detailsuche in der Cochrane Library Suche in allen Texten nach den Begriffen schizo*, drugs, atypical und antipsychotic Suche in allen Datenbanken der Cochrane Library Folgende Suchfunktionen stehen
Übungen zur Vorlesung Molekularbiologische Datenbanken. Lösungsblatt 1: Datenbanksuche
 Wissensmanagement in der Bioinformatik Prof. Dr. Ulf Leser, Silke Trißl Übungen zur Vorlesung Molekularbiologische Datenbanken Lösungsblatt 1: Datenbanksuche Symptome 1.Ein Kind kommt in die Praxis und
Wissensmanagement in der Bioinformatik Prof. Dr. Ulf Leser, Silke Trißl Übungen zur Vorlesung Molekularbiologische Datenbanken Lösungsblatt 1: Datenbanksuche Symptome 1.Ein Kind kommt in die Praxis und
RIS-ABFRAGEHANDBUCH AMTLICHE VETERINÄRNACHRICHTEN DES BM FÜR GESUNDHEIT UND FRAUEN
 RIS-ABFRAGEHANDBUCH AMTLICHE VETERINÄRNACHRICHTEN DES BM FÜR GESUNDHEIT UND FRAUEN 1 Überblick Seit 15. September 2004 werden die Amtliche Veterinärnachrichten (AVN) des Bundesministeriums für Gesundheit
RIS-ABFRAGEHANDBUCH AMTLICHE VETERINÄRNACHRICHTEN DES BM FÜR GESUNDHEIT UND FRAUEN 1 Überblick Seit 15. September 2004 werden die Amtliche Veterinärnachrichten (AVN) des Bundesministeriums für Gesundheit
DATENQUALITÄT IN GENOMDATENBANKEN
 DATENQUALITÄT IN GENOMDATENBANKEN Alexander Fehr 28. Januar 2004 Gliederung Motivation Biologische Grundkonzepte Genomdaten Datenproduktion und Fehler Data Cleansing 2 Motivation (1) Genomdatenbanken enthalten
DATENQUALITÄT IN GENOMDATENBANKEN Alexander Fehr 28. Januar 2004 Gliederung Motivation Biologische Grundkonzepte Genomdaten Datenproduktion und Fehler Data Cleansing 2 Motivation (1) Genomdatenbanken enthalten
Grundlagen der Bioinformatik Assignment 3: Hierarchical Clustering SS Yvonne Lichtblau/Johannes Starlinger
 Grundlagen der Bioinformatik Assignment 3: Hierarchical Clustering SS 2017 Yvonne Lichtblau/Johannes Starlinger Presentations Assignment 2 Yvonne Lichtblau Übungen Grundlagen der Bioinformatik SS 2017
Grundlagen der Bioinformatik Assignment 3: Hierarchical Clustering SS 2017 Yvonne Lichtblau/Johannes Starlinger Presentations Assignment 2 Yvonne Lichtblau Übungen Grundlagen der Bioinformatik SS 2017
 i ? @8A8= B? @8C8D? EGFHB,IKL)M N'D =?PO Q*R ST U,VGW X Y8Z[U \^]8T R _a` b8ced,wt f,ghw$c'_r TPh Die Quell-Literatur- Datenbank (a) System-Voraussetzungen Auf dem Rechner muss Access 97 installiert
i ? @8A8= B? @8C8D? EGFHB,IKL)M N'D =?PO Q*R ST U,VGW X Y8Z[U \^]8T R _a` b8ced,wt f,ghw$c'_r TPh Die Quell-Literatur- Datenbank (a) System-Voraussetzungen Auf dem Rechner muss Access 97 installiert
BIOINFORMATIK I ÜBUNGEN.
 BIOINFORMATIK I ÜBUNGEN http://icbi.at/bioinf Organisation 3 Übungen Kurze Einführung anschließend Labor Protokoll (je 2 Studierende, elektronisch doc, pdf..) Abgabe der Übungen bis spätestens 29. 05.
BIOINFORMATIK I ÜBUNGEN http://icbi.at/bioinf Organisation 3 Übungen Kurze Einführung anschließend Labor Protokoll (je 2 Studierende, elektronisch doc, pdf..) Abgabe der Übungen bis spätestens 29. 05.
Einführung in die Bioinformatik
 Einführung in die Bioinformatik Kay Nieselt Integrative Transkriptomik Zentrum für Bioinformatik Tübingen Kay.Nieselt@uni-tuebingen.de SS 2011 8. Biologische Netzwerke - Gut vernetzt hält besser Überblick
Einführung in die Bioinformatik Kay Nieselt Integrative Transkriptomik Zentrum für Bioinformatik Tübingen Kay.Nieselt@uni-tuebingen.de SS 2011 8. Biologische Netzwerke - Gut vernetzt hält besser Überblick
Seiten und Navigationspunkte
 Seiten und Navigationspunkte Legen Sie neue Seiten und Navigationspunkte an. Um Sie mit dem Anlegen von Seiten und Navigationspunkten vertraut zu machen, legen wir zunächst einen neuen Navigationspunkt
Seiten und Navigationspunkte Legen Sie neue Seiten und Navigationspunkte an. Um Sie mit dem Anlegen von Seiten und Navigationspunkten vertraut zu machen, legen wir zunächst einen neuen Navigationspunkt
GPilotS Dokumentation Version 5
 GPilotS Dokumentation Version 5 Hinweis: Text in eckigen Klammern [GPS] bezeichnet die Auswahl eines Menüpunktes, Text in runden Klammern (Ok) bezeichnet eine Eingabe in einem Auswahlbildschirm. ACHTUNG:
GPilotS Dokumentation Version 5 Hinweis: Text in eckigen Klammern [GPS] bezeichnet die Auswahl eines Menüpunktes, Text in runden Klammern (Ok) bezeichnet eine Eingabe in einem Auswahlbildschirm. ACHTUNG:
Bioinformatik I (Einführung)
") Kay Diederichs, Sommersemester 2015 Bioinformatik I (Einführung) Algorithmen Sequenzen Strukturen PDFs unter http://strucbio.biologie.unikonstanz.de/~dikay/bioinformatik/ Klausur: Fr 17.7. 10:00-11:00
Kay Diederichs, Sommersemester 2015 Bioinformatik I (Einführung) Algorithmen Sequenzen Strukturen PDFs unter http://strucbio.biologie.unikonstanz.de/~dikay/bioinformatik/ Klausur: Fr 17.7. 10:00-11:00
Tiscover CMS 7. Neuerungen im Vergleich zu Tiscover CMS 6
 Tiscover CMS 7 Neuerungen im Vergleich zu Tiscover CMS 6 Inhaltsverzeichnis An- und Abmeldung im Tiscover CMS 7... 3 1. Anmeldung... 3 2. Abmeldung... 3 Bereiche der Arbeitsoberfläche von Tiscover CMS
Tiscover CMS 7 Neuerungen im Vergleich zu Tiscover CMS 6 Inhaltsverzeichnis An- und Abmeldung im Tiscover CMS 7... 3 1. Anmeldung... 3 2. Abmeldung... 3 Bereiche der Arbeitsoberfläche von Tiscover CMS
Erste Schritte in etab
 Erste Schritte in etab Wegleitung für die interaktive Tabellenabfrage im etab-portal Im Folgenden werden anhand konkreter Aufgabenstellungen die grundlegenden Operationen von etab erläutert. 1. Auswahl
Erste Schritte in etab Wegleitung für die interaktive Tabellenabfrage im etab-portal Im Folgenden werden anhand konkreter Aufgabenstellungen die grundlegenden Operationen von etab erläutert. 1. Auswahl
Algorithmische Anwendungen WS 2005/2006
 Algorithmische Anwendungen WS 2005/2006 Sequenzalignment Gruppe F_lila_Ala0506 Allal Kharaz Yassine ELassad Inhaltsverzeichnis 1 Problemstellungen...................................... 3 1.1 Rechtschreibkorrektur...............................
Algorithmische Anwendungen WS 2005/2006 Sequenzalignment Gruppe F_lila_Ala0506 Allal Kharaz Yassine ELassad Inhaltsverzeichnis 1 Problemstellungen...................................... 3 1.1 Rechtschreibkorrektur...............................
Exercises to Introduction to Bioinformatics Assignment 5: Protein interaction networks. Samira Jaeger
 Exercises to Introduction to Bioinformatics Assignment 5: Protein interaction networks Samira Jaeger Aufgabe 1 Netzwerkzentralität (6P) In der Vorlesung haben Degree Centrality besprochen. Finde drei weitere
Exercises to Introduction to Bioinformatics Assignment 5: Protein interaction networks Samira Jaeger Aufgabe 1 Netzwerkzentralität (6P) In der Vorlesung haben Degree Centrality besprochen. Finde drei weitere
Kontakte. Inhaltsverzeichnis
 Kontakte Inhaltsverzeichnis 1 Einleitung... 3 2 Kontakt anlegen... 3 3 Kontakt (Firma / Person)... 3 3.1 Menü: Kontakt, Löschen, Aktivität, Kalender öffnen... 3 3.1.1 Kontakt - zusammenführen... 3 3.1.2
Kontakte Inhaltsverzeichnis 1 Einleitung... 3 2 Kontakt anlegen... 3 3 Kontakt (Firma / Person)... 3 3.1 Menü: Kontakt, Löschen, Aktivität, Kalender öffnen... 3 3.1.1 Kontakt - zusammenführen... 3 3.1.2
SVG Maut Exact. SVG Wir bewegen Logistik
 SVG Wir bewegen Logistik Inhaltsverzeichnis Registrierung und Login... 2 Meldung über Programänderungen und administrative Mitteilungen... 4 Menüleiste und Aufteilung des Programms... 4 1. Imports... 4
SVG Wir bewegen Logistik Inhaltsverzeichnis Registrierung und Login... 2 Meldung über Programänderungen und administrative Mitteilungen... 4 Menüleiste und Aufteilung des Programms... 4 1. Imports... 4
RIS-ABFRAGEHANDBUCH REGIERUNGSVORLAGEN
 RIS-ABFRAGEHANDBUCH REGIERUNGSVORLAGEN 1 Überblick Die Dokumentation der Regierungsvorlagen ist eine Teilapplikation des Rechtsinformationssystems der Republik Österreich (RIS) und wird vom Bundesministerium
RIS-ABFRAGEHANDBUCH REGIERUNGSVORLAGEN 1 Überblick Die Dokumentation der Regierungsvorlagen ist eine Teilapplikation des Rechtsinformationssystems der Republik Österreich (RIS) und wird vom Bundesministerium
Microsoft Access Arbeiten mit Tabellen. Anja Aue
 Microsoft Access Arbeiten mit Tabellen Anja Aue 10.11.16 Tabellen in der Datenblattansicht Ansicht des Anwenders. Eingabe von neuen Daten. Bearbeiten von vorhandenen Informationen. Microsoft Access Einführung
Microsoft Access Arbeiten mit Tabellen Anja Aue 10.11.16 Tabellen in der Datenblattansicht Ansicht des Anwenders. Eingabe von neuen Daten. Bearbeiten von vorhandenen Informationen. Microsoft Access Einführung
Folien und Supplementals auf
 Folien und Supplementals auf www.biokemika.de Folien und Supplementals auf www.biokemika.de Motivation Es gibt viele spezifische Datenbanken, aber mit einer geringen Auswahl an Datenbanken von allgemeiner
Folien und Supplementals auf www.biokemika.de Folien und Supplementals auf www.biokemika.de Motivation Es gibt viele spezifische Datenbanken, aber mit einer geringen Auswahl an Datenbanken von allgemeiner
XML-Translation Engine
 XML-Translation Engine Über die XML-Translation Engine Die XML-Translation Engine ist ein eigenständiges Tool (Add-On), das auf Visual Localize basiert. Die XML-Engine ermöglicht Ihnen die schnelle und
XML-Translation Engine Über die XML-Translation Engine Die XML-Translation Engine ist ein eigenständiges Tool (Add-On), das auf Visual Localize basiert. Die XML-Engine ermöglicht Ihnen die schnelle und
Kapitel 5: Protein-Datendanken
 Kapitel 5: Protein-Datendanken Vom Gen zum Protein n Motivation und historische Entwicklung n Proteomics Datengewinnung PEDRo-Projekt n Protein-Datenbanken Anforderungen Sequenz-Datenbanken Domain/Familien-Datenbanken
Kapitel 5: Protein-Datendanken Vom Gen zum Protein n Motivation und historische Entwicklung n Proteomics Datengewinnung PEDRo-Projekt n Protein-Datenbanken Anforderungen Sequenz-Datenbanken Domain/Familien-Datenbanken
Einführung in die Bioinformatik
 Einführung in die Bioinformatik Ringvorlesung Biologie Sommer 07 Burkhard Morgenstern Institut für Mikrobiologie und Genetik Abteilung für Bioinformatik Goldschmidtstr. 1 Online Materialien zur Ringvorlesung:
Einführung in die Bioinformatik Ringvorlesung Biologie Sommer 07 Burkhard Morgenstern Institut für Mikrobiologie und Genetik Abteilung für Bioinformatik Goldschmidtstr. 1 Online Materialien zur Ringvorlesung:
T:\Dokumentationen\Asseco_BERIT\Schulung\BERIT_LIDS7_Basiskurs\Impo rt_export\beritde_lt_do_20120918_lids7.basisschulung_import_export.
 LIDS 7 Import/Export Mannheim, 11.02.2013 Autor: Anschrift: Version: Status: Modifiziert von: Ablage: Christine Sickenberger - Asseco BERIT GmbH Asseco BERIT GmbH Mundenheimer Straße 55 68219 Mannheim
LIDS 7 Import/Export Mannheim, 11.02.2013 Autor: Anschrift: Version: Status: Modifiziert von: Ablage: Christine Sickenberger - Asseco BERIT GmbH Asseco BERIT GmbH Mundenheimer Straße 55 68219 Mannheim
Bioinformatik für Lebenswissenschaftler
 Bioinformatik für Lebenswissenschaftler Oliver Kohlbacher, Steffen Schmidt SS 2010 11. Hiden Markov Models & Phylogenien Abt. Simulation biologischer Systeme WSI/ZBIT, Eberhard Karls Universität Tübingen
Bioinformatik für Lebenswissenschaftler Oliver Kohlbacher, Steffen Schmidt SS 2010 11. Hiden Markov Models & Phylogenien Abt. Simulation biologischer Systeme WSI/ZBIT, Eberhard Karls Universität Tübingen
Inhalt. Seite 2 von 10
 Inhalt 1. Was ist TeD und was nicht... 1.1. Versionen... 2. Systemübersicht im Startmenü anlegen... 2.1. Eingabe der Kriterien... 2.2. Auswahl der Systeme... 3. Eingabe neuer Posten... 3.1. Daten eingeben...
Inhalt 1. Was ist TeD und was nicht... 1.1. Versionen... 2. Systemübersicht im Startmenü anlegen... 2.1. Eingabe der Kriterien... 2.2. Auswahl der Systeme... 3. Eingabe neuer Posten... 3.1. Daten eingeben...
Optimalcodierung. Thema: Optimalcodierung. Ziele
 Optimalcodierung Ziele Diese rechnerischen und experimentellen Übungen dienen der Vertiefung der Kenntnisse im Bereich der Optimalcodierung, mit der die Zeichen diskreter Quellen codiert werden können.
Optimalcodierung Ziele Diese rechnerischen und experimentellen Übungen dienen der Vertiefung der Kenntnisse im Bereich der Optimalcodierung, mit der die Zeichen diskreter Quellen codiert werden können.
Excel 2010. Grundlagen. Sabine Spieß, Peter Wies. 1. Ausgabe, 7. Aktualisierung, Juli 2013. Trainermedienpaket EX2010_TMP
 Sabine Spieß, Peter Wies Excel 2010 Grundlagen 1. Ausgabe, 7. Aktualisierung, Juli 2013 Trainermedienpaket EX2010_TMP 12 Excel 2010 - Grundlagen 12 Spezielle Gestaltungsmöglichkeiten nutzen Trainerhinweise
Sabine Spieß, Peter Wies Excel 2010 Grundlagen 1. Ausgabe, 7. Aktualisierung, Juli 2013 Trainermedienpaket EX2010_TMP 12 Excel 2010 - Grundlagen 12 Spezielle Gestaltungsmöglichkeiten nutzen Trainerhinweise
Inhalt. Seite 2 von 11
 Inhalt 1. Was ist TeD und was nicht... 3 1.1. Versionen... 3 2. Systemübersicht im Startmenü anlegen... 3 2.1. Eingabe der Kriterien... 3 2.2. Auswahl der Systeme... 4 3. Eingabe neuer Posten... 5 3.1.
Inhalt 1. Was ist TeD und was nicht... 3 1.1. Versionen... 3 2. Systemübersicht im Startmenü anlegen... 3 2.1. Eingabe der Kriterien... 3 2.2. Auswahl der Systeme... 4 3. Eingabe neuer Posten... 5 3.1.
Microsoft Access Abfragen: Informationen anzeigen und sortieren
 Microsoft Access Abfragen: Informationen anzeigen und sortieren Alle Kunden Die Namen der Mitarbeiter und deren E-Mail-Adresse Bestellungen, nach dem Datum sortiert Anja Aue 16.11.16 Abfragen Zusammenstellung
Microsoft Access Abfragen: Informationen anzeigen und sortieren Alle Kunden Die Namen der Mitarbeiter und deren E-Mail-Adresse Bestellungen, nach dem Datum sortiert Anja Aue 16.11.16 Abfragen Zusammenstellung
Excel 2016 Pivot Tabellen und Filter Daten professionell auswerten
 Schnellübersichten Excel 2016 Pivot Tabellen und Filter Daten professionell auswerten 1 Daten filtern 2 2 Pivot Tabellen aus Excel Daten erstellen 3 3 Pivot Tabellen auswerten und anpassen 4 4 Darstellung
Schnellübersichten Excel 2016 Pivot Tabellen und Filter Daten professionell auswerten 1 Daten filtern 2 2 Pivot Tabellen aus Excel Daten erstellen 3 3 Pivot Tabellen auswerten und anpassen 4 4 Darstellung
Einführung in die Bioinformatik: Lernen mit Kernen
 Einführung in die Bioinformatik: Lernen mit Kernen Dr. Karsten Borgwardt Forschungsgruppe für Maschinelles Lernen und Bioinformatik Max-Planck-Institut für Intelligente Systeme & Max-Planck-Institut für
Einführung in die Bioinformatik: Lernen mit Kernen Dr. Karsten Borgwardt Forschungsgruppe für Maschinelles Lernen und Bioinformatik Max-Planck-Institut für Intelligente Systeme & Max-Planck-Institut für
[wird Ihnen von Administrator/in oder Moderator/in zugewiesen]
![[wird Ihnen von Administrator/in oder Moderator/in zugewiesen]](/thumbs/69/61701968.jpg "[wird Ihnen von Administrator/in oder Moderator/in zugewiesen]") Allgemeines Adresse Benutzername Passwort Bildformat Bildgrösse IHREDOMAIN/galerie [wird Ihnen von Administrator/in oder Moderator/in zugewiesen] [wird Ihnen von Administrator/in oder Moderator/in zugewiesen]
Allgemeines Adresse Benutzername Passwort Bildformat Bildgrösse IHREDOMAIN/galerie [wird Ihnen von Administrator/in oder Moderator/in zugewiesen] [wird Ihnen von Administrator/in oder Moderator/in zugewiesen]
BreakerVisu External Profiles Assistant
 Handbuch 03/2016 BV External Profiles Assistant BreakerVisu External Profiles Assistant Wichtigste Steuerungen BreakerVisu External Profiles Assistant Wichtigste Steuerungen Steuerung Profile directory
Handbuch 03/2016 BV External Profiles Assistant BreakerVisu External Profiles Assistant Wichtigste Steuerungen BreakerVisu External Profiles Assistant Wichtigste Steuerungen Steuerung Profile directory
Excel 2013. Grundlagen. Sabine Spieß, Peter Wies. 1. Ausgabe, September 2013. Trainermedienpaket EX2013_TMP
 Excel 2013 Sabine Spieß, Peter Wies Grundlagen 1. Ausgabe, September 2013 Trainermedienpaket EX2013_TMP 12 Excel 2013 - Grundlagen 12 Spezielle Gestaltungsmöglichkeiten nutzen Trainerhinweise Unterrichtsdauer
Excel 2013 Sabine Spieß, Peter Wies Grundlagen 1. Ausgabe, September 2013 Trainermedienpaket EX2013_TMP 12 Excel 2013 - Grundlagen 12 Spezielle Gestaltungsmöglichkeiten nutzen Trainerhinweise Unterrichtsdauer
Übungsaufgaben zur Einführung in die Bioinformatik - Lösungen
 18.01.2013 Prof. P. Güntert 1 Vorlesung BPC I: Aspekte der Thermodynamik in der Strukturbiologie Übungsaufgaben zur Einführung in die Bioinformatik - Lösungen 1. Hamming und Levenshtein Distanzen a) Was
18.01.2013 Prof. P. Güntert 1 Vorlesung BPC I: Aspekte der Thermodynamik in der Strukturbiologie Übungsaufgaben zur Einführung in die Bioinformatik - Lösungen 1. Hamming und Levenshtein Distanzen a) Was
Übung II. Einführung. Teil 1 Arbeiten mit Sequenzen recombinante DNA
 Übung II Einführung Teil 1 Arbeiten mit Sequenzen recombinante DNA Recombinante DNA Technologie Protein Synthese In vitro Expression Libraries Gene Transfer in Tieren und Pflanzen Recombinante DNA Technologie
Übung II Einführung Teil 1 Arbeiten mit Sequenzen recombinante DNA Recombinante DNA Technologie Protein Synthese In vitro Expression Libraries Gene Transfer in Tieren und Pflanzen Recombinante DNA Technologie
Datenbanken für Online Untersuchungen
 Datenbanken für Online Untersuchungen Im vorliegenden Text wird die Verwendung einer MySQL Datenbank für Online Untersuchungen beschrieben. Es wird davon ausgegangen, dass die Untersuchung aus mehreren
Datenbanken für Online Untersuchungen Im vorliegenden Text wird die Verwendung einer MySQL Datenbank für Online Untersuchungen beschrieben. Es wird davon ausgegangen, dass die Untersuchung aus mehreren
ER-Modell, Normalisierung
 ER-Modell Mit dem Entity-Relationship-Modell kann die grundlegende Tabellen- und Beziehungsstruktur einer Datenbank strukturiert entworfen und visualisiert werden. Das fertige ER-Modell kann dann ganz
ER-Modell Mit dem Entity-Relationship-Modell kann die grundlegende Tabellen- und Beziehungsstruktur einer Datenbank strukturiert entworfen und visualisiert werden. Das fertige ER-Modell kann dann ganz
Anleitung online Findsystem des Staatsarchivs Graubünden
 Anleitung online Findsystem des Staatsarchivs Graubünden Inhalt 1 Was ist ein online Findsystem?... 2 2 Recherchemöglichkeiten... 2 2.1 Navigation... 2 2.2 Allgemeine Suche... 2 2.3 Suche nach Urkunden...
Anleitung online Findsystem des Staatsarchivs Graubünden Inhalt 1 Was ist ein online Findsystem?... 2 2 Recherchemöglichkeiten... 2 2.1 Navigation... 2 2.2 Allgemeine Suche... 2 2.3 Suche nach Urkunden...
Handy-Synchronisation Inhalt
 Handy-Synchronisation Inhalt 1. allgemeine Einstellungen... 2 1.1. Anlegen eines SyncAccounts... 2 1.1.1. Synchronisation über eigenen Exchange-Server... 3 1.1.2. gehostete Synchronisation... 5 1.2. Synchronisations-Einstellungen...
Handy-Synchronisation Inhalt 1. allgemeine Einstellungen... 2 1.1. Anlegen eines SyncAccounts... 2 1.1.1. Synchronisation über eigenen Exchange-Server... 3 1.1.2. gehostete Synchronisation... 5 1.2. Synchronisations-Einstellungen...
Einführung in die Bioinformatik
 Einführung in die Bioinformatik Kay Nieselt Integrative Transkriptomik Zentrum für Bioinformatik Tübingen Kay.Nieselt@uni-tuebingen.de SS 2012 5. Biologische Netzwerke - Gut vernetzt hält besser Überblick
Einführung in die Bioinformatik Kay Nieselt Integrative Transkriptomik Zentrum für Bioinformatik Tübingen Kay.Nieselt@uni-tuebingen.de SS 2012 5. Biologische Netzwerke - Gut vernetzt hält besser Überblick
Inhaltsverzeichnis WORTKOMBINATIONEN... 1
 Wortkombinationen Inhaltsverzeichnis WORTKOMBINATIONEN... 1 Wortkombinationen Was leistet die Funktion Wortkombinationen? Die Funktion Wortkombinationen liefert eine Übersicht, welche Kombinationen von
Wortkombinationen Inhaltsverzeichnis WORTKOMBINATIONEN... 1 Wortkombinationen Was leistet die Funktion Wortkombinationen? Die Funktion Wortkombinationen liefert eine Übersicht, welche Kombinationen von
JLR EPC. Kurzanleitung. Inhalt. German Version 2.0. Schritt-für-Schritt-Anleitung Erläuterung der Menüfunktionen
 JLR EPC Kurzanleitung Inhalt Schritt-für-Schritt-Anleitung........2-7 Erläuterung der Menüfunktionen.....8-11 German Version 2.0 JLR EPC Kurzanleitung 1. Anwendung öffnen Öffnen Sie Ihren Internet-Browser
JLR EPC Kurzanleitung Inhalt Schritt-für-Schritt-Anleitung........2-7 Erläuterung der Menüfunktionen.....8-11 German Version 2.0 JLR EPC Kurzanleitung 1. Anwendung öffnen Öffnen Sie Ihren Internet-Browser
Folien und Supplementals auf.
 Folien und Supplementals auf www.biokemika.de 1 Folien und Supplementals auf www.biokemika.de 2 National Center for Biotechnology Information http://www.ncbi.nlm.nih.gov/ NCBI European Bioinformatic Institute
Folien und Supplementals auf www.biokemika.de 1 Folien und Supplementals auf www.biokemika.de 2 National Center for Biotechnology Information http://www.ncbi.nlm.nih.gov/ NCBI European Bioinformatic Institute
Handhabung der tabellarischen Übersichten in MAXQDA
 Handhabung der tabellarischen Übersichten in MAXQDA Inhaltsverzeichnis HANDHABUNG DER TABELLARISCHEN ÜBERSICHTEN IN MAXQDA... 1 DIE SYMBOLLEISTE IN TABELLARISCHEN ÜBERSICHTEN... 1 HANDHABUNG VON TABELLARISCHEN
Handhabung der tabellarischen Übersichten in MAXQDA Inhaltsverzeichnis HANDHABUNG DER TABELLARISCHEN ÜBERSICHTEN IN MAXQDA... 1 DIE SYMBOLLEISTE IN TABELLARISCHEN ÜBERSICHTEN... 1 HANDHABUNG VON TABELLARISCHEN
Online Suchsystem Guide
 Liebe Kreative, auf den folgenden Seiten möchten wir Euch einige Hinweise geben, die den Umgang mit der Suchmaschine erleichtern und Euch dabei helfen sollen, schnell und zielsicher zur passenden Musik
Liebe Kreative, auf den folgenden Seiten möchten wir Euch einige Hinweise geben, die den Umgang mit der Suchmaschine erleichtern und Euch dabei helfen sollen, schnell und zielsicher zur passenden Musik
Bioinformatik: Schnittstelle zwischen Informatik und Life-Science
 Bioinformatik: Schnittstelle zwischen Informatik und Life-Science Andreas Zendler (PD Dr.rer.nat.Dr.phil.) GI / GChACM 12. ovember 2001 Inhaltsübersicht I. Einführung II. Bioinformatik III. Industrial
Bioinformatik: Schnittstelle zwischen Informatik und Life-Science Andreas Zendler (PD Dr.rer.nat.Dr.phil.) GI / GChACM 12. ovember 2001 Inhaltsübersicht I. Einführung II. Bioinformatik III. Industrial
Vorhersage von Protein-Funktionen. Patrick Pfeffer
 Vorhersage von Protein-Funktionen Patrick Pfeffer Überblick Motivation Einleitung Methode Markov Random Fields Der Gibbs Sampler Parameter-Schätzung Bayes sche Analyse Resultate Pfeffer 2 Motivation Es
Vorhersage von Protein-Funktionen Patrick Pfeffer Überblick Motivation Einleitung Methode Markov Random Fields Der Gibbs Sampler Parameter-Schätzung Bayes sche Analyse Resultate Pfeffer 2 Motivation Es
In diesem Abschnitt wollen wir uns mit der Architektur von Datenbank Managements Systemen beschäftigen.
 1 In diesem Abschnitt wollen wir uns mit der Architektur von Datenbank Managements Systemen beschäftigen. Zunächst stellt sich die Frage: Warum soll ich mich mit der Architektur eines DBMS beschäftigen?
1 In diesem Abschnitt wollen wir uns mit der Architektur von Datenbank Managements Systemen beschäftigen. Zunächst stellt sich die Frage: Warum soll ich mich mit der Architektur eines DBMS beschäftigen?
Wie nutzt man die Jobsuche am effektivsten?
 Wie nutzt man die Jobsuche am effektivsten? Inhaltsverzeichnis Das Suchformular Seite 2... Die Funktion Jobs durchsuchen Seite 4... Optimieren der Suchergebnis-Seite Seite 5... Optimieren der Suchergebnisse
Wie nutzt man die Jobsuche am effektivsten? Inhaltsverzeichnis Das Suchformular Seite 2... Die Funktion Jobs durchsuchen Seite 4... Optimieren der Suchergebnis-Seite Seite 5... Optimieren der Suchergebnisse
RIS-ABFRAGEHANDBUCH ERLÄSSE DER BUNDESMINISTERIEN
 RIS-ABFRAGEHANDBUCH ERLÄSSE DER BUNDESMINISTERIEN 1 Überblick Die Dokumentation von Erlässen (Rundschreiben, Mitteilungen, etc.) österreichischer Bundesministerien (mit Ausnahme des BM für Finanzen) ist
RIS-ABFRAGEHANDBUCH ERLÄSSE DER BUNDESMINISTERIEN 1 Überblick Die Dokumentation von Erlässen (Rundschreiben, Mitteilungen, etc.) österreichischer Bundesministerien (mit Ausnahme des BM für Finanzen) ist
Access 2010. für Windows. Andrea Weikert 1. Ausgabe, 4. Aktualisierung, Juni 2012. Grundlagen für Anwender
 Andrea Weikert 1. Ausgabe, 4. Aktualisierung, Juni 2012 Access 2010 für Windows Grundlagen für Anwender ACC2010 2 Access 2010 - Grundlagen für Anwender 2 Mit Datenbanken arbeiten In diesem Kapitel erfahren
Andrea Weikert 1. Ausgabe, 4. Aktualisierung, Juni 2012 Access 2010 für Windows Grundlagen für Anwender ACC2010 2 Access 2010 - Grundlagen für Anwender 2 Mit Datenbanken arbeiten In diesem Kapitel erfahren
RIS-ABFRAGEHANDBUCH LANDESGESETZBLATT NICHT AUTHENTISCH (OHNE NÖ UND WIEN)
") RIS-ABFRAGEHANDBUCH LANDESGESETZBLATT NICHT AUTHENTISCH (OHNE NÖ UND WIEN) 1 Überblick Die Dokumentation der Landesgesetzblätter ist eine Teilapplikation des Rechtsinformationssystems der Republik Österreich
RIS-ABFRAGEHANDBUCH LANDESGESETZBLATT NICHT AUTHENTISCH (OHNE NÖ UND WIEN) 1 Überblick Die Dokumentation der Landesgesetzblätter ist eine Teilapplikation des Rechtsinformationssystems der Republik Österreich
Protein Data Bank Tutorial
 Protein Data Bank Tutorial 1 INHALT 1. Einleitung... 3 2. Systemvoraussetzungen... 4 3. Suchtfunktionen... 4 3.1. Top Bar Search... 4 3.1.1. PDB ID or Text... 4 3.1.2. Author... 5 3.1.3. Structural Genomis
Protein Data Bank Tutorial 1 INHALT 1. Einleitung... 3 2. Systemvoraussetzungen... 4 3. Suchtfunktionen... 4 3.1. Top Bar Search... 4 3.1.1. PDB ID or Text... 4 3.1.2. Author... 5 3.1.3. Structural Genomis
JIRA für CoDeSys - Erste Schritte
 Dokument Version 1.0 3S-Smart Software Solutions GmbH Seite 1 von 7 INHALT 1 STARTBILDSCHIRM 3 2 TYPISCHE ANWENDUNGSBEISPIELE 3 2.1 Eigene Issues suchen 3 2.2 Geplante Versionen und deren Inhalt 3 2.3
Dokument Version 1.0 3S-Smart Software Solutions GmbH Seite 1 von 7 INHALT 1 STARTBILDSCHIRM 3 2 TYPISCHE ANWENDUNGSBEISPIELE 3 2.1 Eigene Issues suchen 3 2.2 Geplante Versionen und deren Inhalt 3 2.3
Bioinformatik I (Einführung)
") Kay Diederichs, Sommersemester 2017 Bioinformatik I (Einführung) Algorithmen Sequenzen Strukturen PDFs unter http://strucbio.biologie.unikonstanz.de/~dikay/bioinformatik/ Klausur: Fr 28.7. 10:00-11:00
Kay Diederichs, Sommersemester 2017 Bioinformatik I (Einführung) Algorithmen Sequenzen Strukturen PDFs unter http://strucbio.biologie.unikonstanz.de/~dikay/bioinformatik/ Klausur: Fr 28.7. 10:00-11:00
C SB. Genomics Herausforderungen und Chancen. Genomics. Genomic data. Prinzipien dominieren über Detail-Fluten. in 10 Minuten!
 Genomics Herausforderungen und Chancen Prinzipien dominieren über Detail-Fluten Genomics in 10 Minuten! biol. Prin cip les Genomic data Dr.Thomas WERNER Scientific & Business Consulting +49 89 81889252
Genomics Herausforderungen und Chancen Prinzipien dominieren über Detail-Fluten Genomics in 10 Minuten! biol. Prin cip les Genomic data Dr.Thomas WERNER Scientific & Business Consulting +49 89 81889252
Im Programm navigieren Daten bearbeiten Daten erfassen Fließtext erfassen Daten ändern Daten ansehen...
 INHALTSVERZEICHNIS Im Programm navigieren... 2 Daten bearbeiten... 2 Daten erfassen... 2 Fließtext erfassen... 3 Daten ändern... 3 Daten ansehen... 4 Sortierung... 4 Spaltenanordnung... 4 Spaltenauswahl...
INHALTSVERZEICHNIS Im Programm navigieren... 2 Daten bearbeiten... 2 Daten erfassen... 2 Fließtext erfassen... 3 Daten ändern... 3 Daten ansehen... 4 Sortierung... 4 Spaltenanordnung... 4 Spaltenauswahl...
Hornetsecurity Outlook-Add-In
 Hornetsecurity Outlook-Add-In für Spamfilter Service, Aeternum und Verschlüsselungsservice Blanko (Dokumenteneigenschaften) 1 Inhaltsverzeichnis 1. Das Outlook Add-In... 3 1.1 Feature-Beschreibung... 3
Hornetsecurity Outlook-Add-In für Spamfilter Service, Aeternum und Verschlüsselungsservice Blanko (Dokumenteneigenschaften) 1 Inhaltsverzeichnis 1. Das Outlook Add-In... 3 1.1 Feature-Beschreibung... 3
Bioinformatik Für Biophysiker
 Bioinformatik Für Biophysiker Sommersemester 2009 Silke Trißl / Ulf Leser Wissensmanagement in der Bioinformatik Wissensmanagement in der Bioinformatik Schwerpunkte Algorithmen der Bioinformatik Management
Bioinformatik Für Biophysiker Sommersemester 2009 Silke Trißl / Ulf Leser Wissensmanagement in der Bioinformatik Wissensmanagement in der Bioinformatik Schwerpunkte Algorithmen der Bioinformatik Management
Advertizor Version 1.1 Formatbeschreibung der Import-Schnittstellen
 Advertizor Version 1.1 Formatbeschreibung der Import-Schnittstellen Advertizor - Kunden-Schnittstelle Stand 27. Mai 2008 Seite 1 von 7 Inhaltsverzeichnis 1 STAMMDATE-IMPORT SCHITTSTELLE...3 1.1 Definition
Advertizor Version 1.1 Formatbeschreibung der Import-Schnittstellen Advertizor - Kunden-Schnittstelle Stand 27. Mai 2008 Seite 1 von 7 Inhaltsverzeichnis 1 STAMMDATE-IMPORT SCHITTSTELLE...3 1.1 Definition
Tags filtern im Eigenschaften-Panel
 Tags filtern im Eigenschaften-Panel Im Eigenschaften-Panel werden Ihnen alle Informationen zu dem jeweils im Browser selektierten Element angezeigt. Sie können dort weitere Tags wie z.b. Stichwörter hinzufügen
Tags filtern im Eigenschaften-Panel Im Eigenschaften-Panel werden Ihnen alle Informationen zu dem jeweils im Browser selektierten Element angezeigt. Sie können dort weitere Tags wie z.b. Stichwörter hinzufügen
Applied Bioinformatics. maria.fischer@i-med.ac.at http://icbi.at/courses/bioinformatics_ex
 Applied Bioinformatics SS 2013 maria.fischer@i-med.ac.at http://icbi.at/courses/bioinformatics_ex Organisatorisches Termine Mo 18.03.2013 RR19 9:00 Di 19.03.2013 RR19 9:00 Mi 20.03.2013 RR19 9:00 Übungsziele
Applied Bioinformatics SS 2013 maria.fischer@i-med.ac.at http://icbi.at/courses/bioinformatics_ex Organisatorisches Termine Mo 18.03.2013 RR19 9:00 Di 19.03.2013 RR19 9:00 Mi 20.03.2013 RR19 9:00 Übungsziele
Im Original veränderbare Word-Dateien
 Die Eingabe der Feldnamen der beiden Tabellen in unsere Datenbank Bücherei geht recht zügig, weil wir uns bereits im Vorfeld Gedanken gemacht haben, welche Informationen über Bücher uns wichtig sind und
Die Eingabe der Feldnamen der beiden Tabellen in unsere Datenbank Bücherei geht recht zügig, weil wir uns bereits im Vorfeld Gedanken gemacht haben, welche Informationen über Bücher uns wichtig sind und
B enutzergruppenverwaltung (K unden des Automobil-P ortals )
") B enutzergruppenverwaltung (K unden des Automobil-P ortals ) Inhaltsverzeichnis B as is funktionen... 1 Zugang zum Benutzerverzeichnis... 1 Person oder Gruppe suchen... 3 Gruppe durch Suche/Auswahl von
B enutzergruppenverwaltung (K unden des Automobil-P ortals ) Inhaltsverzeichnis B as is funktionen... 1 Zugang zum Benutzerverzeichnis... 1 Person oder Gruppe suchen... 3 Gruppe durch Suche/Auswahl von
Schnellstartanleitung
 Schnellstartanleitung Inhalt: Ein Projekt erstellen Ein Projekt verwalten und bearbeiten Projekt/Assessment-Ergebnisse anzeigen Dieses Dokument soll Ihnen dabei helfen, Assessments auf der Plattform CEB
Schnellstartanleitung Inhalt: Ein Projekt erstellen Ein Projekt verwalten und bearbeiten Projekt/Assessment-Ergebnisse anzeigen Dieses Dokument soll Ihnen dabei helfen, Assessments auf der Plattform CEB
E-Mail- Nachrichten organisieren
 5 E-Mail- Nachrichten organisieren kkkk In den beiden vorangegangenen Kapiteln haben Sie grundlegende und fortgeschrittene Verfahren beim Erstellen, Versenden und Empfangen von E-Mail- Nachrichten kennengelernt.
5 E-Mail- Nachrichten organisieren kkkk In den beiden vorangegangenen Kapiteln haben Sie grundlegende und fortgeschrittene Verfahren beim Erstellen, Versenden und Empfangen von E-Mail- Nachrichten kennengelernt.
Bezeichnung bestimmen, mit der Domänen in Google erscheinen
 Bezeichnung bestimmen, mit der Domänen in Google erscheinen Jürgen Eckert - Domplatz 2-96049 Bamberg Tel (09 51) 5 02 2 75, Fax (09 51) 5 02 2 71 Mobil (01 79) 3 22 09 33, privat (09 51) 9 68 58 34 E-Mail:
Bezeichnung bestimmen, mit der Domänen in Google erscheinen Jürgen Eckert - Domplatz 2-96049 Bamberg Tel (09 51) 5 02 2 75, Fax (09 51) 5 02 2 71 Mobil (01 79) 3 22 09 33, privat (09 51) 9 68 58 34 E-Mail:
KURZANLEITUNG FÜR DAS BIOMASSELOGISTIK-WIKI BIO:LOGIC
 KURZANLEITUNG FÜR DAS BIOMASSELOGISTIK-WIKI BIO:LOGIC Anleitung für Nutzer des Wikis Stand November 2013 INHALT Aufbau des Wikis (Nutzeroberfläche) Einfach Bearbeitungsfunktionen Erweiterte Funktionen
KURZANLEITUNG FÜR DAS BIOMASSELOGISTIK-WIKI BIO:LOGIC Anleitung für Nutzer des Wikis Stand November 2013 INHALT Aufbau des Wikis (Nutzeroberfläche) Einfach Bearbeitungsfunktionen Erweiterte Funktionen
Algorithmen für paarweise Sequenz-Alignments. Katharina Hembach
 Proseminar Bioinformatik WS 2010/11 Algorithmen für paarweise Sequenz-Alignments Katharina Hembach 06.12.2010 1 Einleitung Paarweise Sequenz-Alignments spielen in der Bioinformatik eine wichtige Rolle.
Proseminar Bioinformatik WS 2010/11 Algorithmen für paarweise Sequenz-Alignments Katharina Hembach 06.12.2010 1 Einleitung Paarweise Sequenz-Alignments spielen in der Bioinformatik eine wichtige Rolle.