Biostatistische Studienplanung II. Dr. Matthias Kohl SIRS-Lab GmbH
|
|
|
- Ella Schulz
- vor 8 Jahren
- Abrufe
Transkript
1 Biostatistische Studienplanung II Dr. Matthias Kohl SIRS-Lab GmbH

2 Inhalt Lineare Modelle: Definition und Beispiele KQ- und robuste Schätzer Diagnostik Ausblick: Mixed-Effects

3 Definition des linearen Modells y = 0 + x x m x m + y: Beobachtungen (abhängige Variable) x 1,..., x m : Regressoren (unabh. Variablen),..., m : unbekannte Parameter : zufälliger Fehler
,.")
4 Beispiele für lineare Modelle y = x + 2 x2 + y = log(x) + y = sin(2x) + 2 cos(x2 ) + Linear bedeutet linear in den Parametern!

5 Kleinste-Quadrate Schätzer I y i = 0 + x 1i + 2 x 2i m x mi + i Voraussetzungen an i : Erwartungswert E( i ) = 0 Homoskedastizität: Var( i ) = Unkorreliertheit: Cov( i, j ) = 0 (i j) Dann: KQ-Schätzer BLUE!
 = Unkorreliertheit: Cov( i, j ) = 0 (i j) Dann:")
6 Kleinste-Quadrate Schätzer II Zusätzlich: i stochastische unabhängig i normalverteilt Dann: KQ-Schätzer auch ML-Schätzer! Außerdem: Umfangreiche Testtheorie steht zur Verfügung!

7 Vorteile Linearer Modelle Einfache, klare Struktur Nichtlineare Zusammenhänge sind lokal durch lineare Funktionen approximierbar Optimale Schätzer für große Klasse von Schätzern Theorie (nahezu) vollständig bekannt
 vollständig")
8 Nachteile Linearer Modelle Schlechte Extrapolationseigenschaften (nur lokale Gültigkeit bzw. innerhalb der Daten) Große Anfälligkeit gegen Abweichungen von den Modellannahmen bzw. Ausreißern Wichtig: Validierung des Modells!

9 Beispiel 1 * * D.G. Altman (1991), Practical Statistics for Medical Research, Table 11.6, Chapman & Hall.

10 Beispiel 1 KQ-Schätzer I Coefficients: Estimate Std. Error t value Pr(> t ) (Intercept) e-09 *** blood.glucose * --- Signif. codes: 0 '***' '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1 Residual standard error: on 21 degrees of freedom (1 observation deleted due to missingness) Multiple R-Squared: , Adjusted R-squared: F-statistic: on 1 and 21 DF, p-value:
 Multiple R-Squared: 0.")
11 Einschub: R 2 und Korrelation Pearson's product-moment correlation data: blood.glucose and short.velocity t = 2.101, df = 21, p-value = alternative hypothesis: true correlation is not equal to 0 95 percent confidence interval: sample estimates: cor

12 Beispiel 1 KQ-Schätzer II

13 Beispiel 1 Residuen

14 Beispiel 1 Linearität und Homoskedastizität
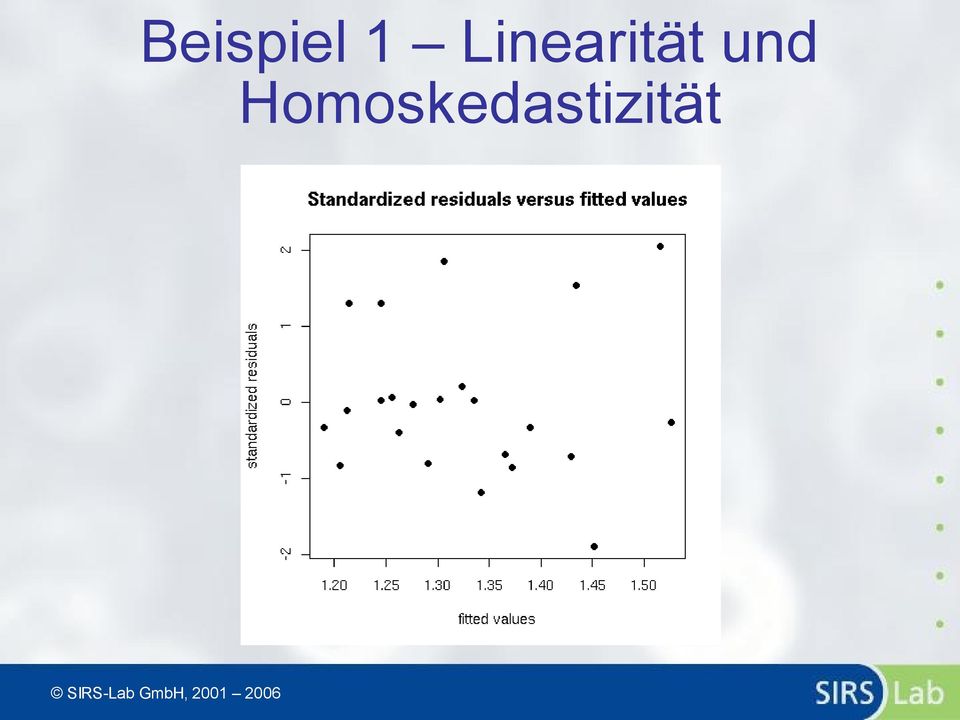
15 Beispiel 1 Heteroskedastizität studentized Breusch-Pagan test BP = , df = 1, p-value = Goldfeld-Quandt test GQ = , df1 = 10, df2 = 9, p-value = Harrison-McCabe test HMC = , p-value = 0.092

16 Beispiel 1 Linearität Harvey-Collier test HC = , df = 20, p-value = Rainbow test Rain = , df1 = 12, df2 = 9, p-value =

17 Zufällige Residuen

18 Heteroskedastische Residuen I

19 Heteroskedastische Residuen II

20 Residuen: Nicht-Linearität

21 Beispiel 1 Korrelation I
22 Beispiel 1 Korrelation II Breusch-Godfrey test for serial correlation of order 1 LM test = , df = 1, p-value = Breusch-Godfrey test for serial correlation of order 3 LM test = , df = 3, p-value = Durbin-Watson test DW = , p-value = (alternative hypothesis: true autocorrelation is greater than 0)
23 Beispiel 1 Normalität I
24 Beispiel 1 Normalität II Auswahl wichtiger Tests Anderson-Darling test: A = , p-value = Cramer-von Mises test: W = , p-value = Lilliefors (Kolmogorov-Smirnov) test: D = , p-value = Pearson chi-square test: P = , p-value = Shapiro-Francia test: W = , p-value =
25 Transformationen Hilfreich, falls Voraussetzungen verletzt: Box-Cox Potenztransformation Varianzstabilisierende Transformation (falls Verteilung der y i bekannt) Generalisierte kleinste Quadrate Methode (falls Fehler i nicht homoskedastisch bzw. nicht unkorreliert)
26 Beispiel 1 Ausreißer I
27 Beispiel 1 Ausreißer II Dixon test for outliers: Q.13 = , p-value = (alternative hypothesis: highest value is an outlier) Grubbs test for one outlier: G.13 = , U = , p-value = (alternative hypothesis: highest value is an outlier) Grubbs test for two opposite outliers: G.13 = , U = , p-value = (alternative hypothesis: and are outliers)
28 Robuste Schätzer Huber (1981): M-Schätzer Hampel et al (1986): M-Schätzer Yohai (1987): MM-Schätzer Rousseeuw and Leroy (1987): LMS- und LTS-Schätzer Rieder (1994): AL-Schätzer
29 Vorteile Robuster Schätzer Robust gegen Modellabweichungen verschiedener Art (d.h. Ideales Modell + Umgebung) M- bzw. AL-Schätzer asymptotisch optimal innerhalb großer Klasse von Schätzern
30 Nachteile Robuster Schätzer Komplizierte Theorie I.d.R. nur asymptotische Aussagen; d.h., asymptotisch optimaler Schätzer, asymptotische Tests, usw. Höherer Rechenaufwand
31 Beispiel 1 Robuste Schätzer
32 Beispiel 2 * * P.J. Rousseeuw and A.M. Leroy (1987), Robust Regression and Outlier Detection, Wiley.
33 Variablenselektion - Methoden forward selection: Füge Variablen hinzu bis eine gewisse Vorgabe erreicht ist. backward elimination: Entferne Variablen bis eine gewisse Vorgabe erreicht ist. all subsets: Betrachte alle möglichen Teilmodelle und wähle das beste.
34 Variablenselektion - Kriterien p-werte: t- oder F-Test adjusted R 2 : Wähle Modell mit größtem angepasstem R 2 Mallows' C p : Wähle Modell mit C p p Akaike information criterion (AIC): proportional zu C p
35 Ausblick: Linear Mixed-Effect Models y ij = β 1 x 1ij + + β p x pij + b i1 z 1ij + + b iq z qij + ε ij b ik ~ N(0, ψ k2 ), Cov(b k, b k' ) = ψ kk' ε ij ~ N(0, σ 2 λ ijj ), Cov(ε ij, ε ij' ) = σ 2 λ ijj'
36 Einsatzbereiche von Linear Mixed-Effect Models generell: abhängige Daten (z.b. repeated measures oder longitudinal data) Blockdesigns (auch unbalanziert!) verschachtelte Designs Split-Plot Experimente
37 Beispiel 3* * Potthoff, R. F. and Roy, S. N. (1964), A generalized multivariate analysis of variance model useful especially for growth curve problems', Biometrika, *51*,
38 Beispiel 3 Getrennte Analyse
39 Beispiel 3 Linear Mixed-Effect Model I Betrachte das Modell: y ij = β 0 + β 1 x 1ij + b i + ε ij b i ~ N(0, ψ 2 ), ε ij ~ N(0, σ 2 )
40 Beispiel 3 Linear Mixed-Effect Model II Random effects: Formula: ~1 Subject (Intercept) Residual StdDev: Fixed effects: distance ~ I(age - 11) Value Std.Error DF t-value p-value (Intercept) I(age - 11)
41 Software I P. Dalgaard (2005). ISwR: Introductory Statistics with R. R package version J. Fox (2006). car: Companion to Applied Regression. R package version J. Gross (2006). nortest: Tests for Normality. R package version 1.0. M. Kohl (2006). RobRex: Optimally robust influence curves for regression and scale. R package version L. Komsta (2006). outliers: Tests for outliers. R package version J. Pinheiro, D. Bates, S. DebRoy and and D. Sarkar (2006). nlme: Linear and nonlinear mixed effects models. R package version
42 Software II R Development Core Team (2006). R: A Language and Environment for Statistical Computing. R Foundation for Statistical Computing. Vienna, Austria. ISBN , URL V. Todorov, A. Ruckstuhl, M. Salibian-Barrera and M. Maechler (2006). robustbase: Basic Robust Statistics. R package version W.N. Venables and B.D. Ripley (2002). Modern Applied Statistics with S. Fourth Edition. Springer, New York. ISBN D. Wuertz, many others and see the SOURCE file (2006). fmultivar: Rmetrics - Multivariate Market Analysis. R package version
43 Literatur I R. Christensen (2002). Plane Answers to Complex Questions. The Theory of Linear Models. Third Edition. Springer. New York. P. Dalgaard (2002). Introductory Statistics with R. Springer. New York. J. Faraway (2002). Practical Regression and ANOVA in R. R. Heiberger and B. Holland (2004). Statistical Analysis and Data Display. An Intermediate Course with Examples in S-Plus, R and SAS. Springer. New York. J. Pinheiro and D. Bates (2000). Mixed-Effects Models in S and S-Plus. Springer. New York.
44 Literatur II H. J. Trampisch und J. Windeler (Hrsg.) (2000): Medizinische Statistik. Springer Verlag. 2. Auflage. W. Venables and B. Ripley (2002). Modern Applied Statistics with S. Fourth Edition. Springer. New York.
Versuchsplanung SoSe 2015 R - Lösung zu Übung 1 am 24.04.2015 Autor: Ludwig Bothmann
 Versuchsplanung SoSe 2015 R - Lösung zu Übung 1 am 24.04.2015 Autor: Ludwig Bothmann Contents Aufgabe 1 1 b) Schätzer................................................. 3 c) Residuenquadratsummen........................................
Versuchsplanung SoSe 2015 R - Lösung zu Übung 1 am 24.04.2015 Autor: Ludwig Bothmann Contents Aufgabe 1 1 b) Schätzer................................................. 3 c) Residuenquadratsummen........................................
Lösung zu Kapitel 11: Beispiel 1
 Lösung zu Kapitel 11: Beispiel 1 Eine Untersuchung bei 253 Personen zur Kundenzufriedenheit mit einer Einzelhandelskette im Südosten der USA enthält Variablen mit sozialstatistischen Daten der befragten
Lösung zu Kapitel 11: Beispiel 1 Eine Untersuchung bei 253 Personen zur Kundenzufriedenheit mit einer Einzelhandelskette im Südosten der USA enthält Variablen mit sozialstatistischen Daten der befragten
Lineare Modelle in R: Einweg-Varianzanalyse
 Lineare Modelle in R: Einweg-Varianzanalyse Achim Zeileis 2009-02-20 1 Datenaufbereitung Wie schon in der Vorlesung wollen wir hier zur Illustration der Einweg-Analyse die logarithmierten Ausgaben der
Lineare Modelle in R: Einweg-Varianzanalyse Achim Zeileis 2009-02-20 1 Datenaufbereitung Wie schon in der Vorlesung wollen wir hier zur Illustration der Einweg-Analyse die logarithmierten Ausgaben der
Kovarianzanalyse. Truthahngewicht. Truthahngewicht. Methoden empirischer Sozialforschung. 1 metrische und mehrere metrische und kategoriale Variablen
 Kovarianzanalyse 1 metrische und mehrere metrische und kategoriale Variablen Methoden empirischer Sozialforschung Lineare Modelle (2. Teil) Wie läßt sich die Abhängigkeit einer metrischen Variablen von
Kovarianzanalyse 1 metrische und mehrere metrische und kategoriale Variablen Methoden empirischer Sozialforschung Lineare Modelle (2. Teil) Wie läßt sich die Abhängigkeit einer metrischen Variablen von
Biostatistik 101 Korrelation - Regressionsanalysen
 Good Data don't need statistics Biostatistik 101 Korrelation - Regressionsanalysen Carl Herrmann IPMB Uni Heidelberg & DKFZ B080 carl.herrmann@uni-heidelberg.de Korrelation Sind Alter und Blutdruck miteinander
Good Data don't need statistics Biostatistik 101 Korrelation - Regressionsanalysen Carl Herrmann IPMB Uni Heidelberg & DKFZ B080 carl.herrmann@uni-heidelberg.de Korrelation Sind Alter und Blutdruck miteinander
1 Interaktion von zwei Dummyvariablen. 2 Interaktion einer Dummyvariablen mit einer kardinalskalierten Variablen
 Modelle mit Interationsvariablen I Modelle mit Interationsvariablen II In der beim White-Test verwendeten Regressionsfuntion y = β 0 + β 1 x 1 + β 2 x 2 + β 3 x 2 1 + β 4 x 2 2 + β 5 x 1 x 2, ist anders
Modelle mit Interationsvariablen I Modelle mit Interationsvariablen II In der beim White-Test verwendeten Regressionsfuntion y = β 0 + β 1 x 1 + β 2 x 2 + β 3 x 2 1 + β 4 x 2 2 + β 5 x 1 x 2, ist anders
Musterlösung zu Serie 14
 Dr. Lukas Meier Statistik und Wahrscheinlichkeitsrechnung FS 21 Musterlösung zu Serie 14 1. Der Datensatz von Forbes zeigt Messungen von Siedepunkt (in F) und Luftdruck (in inches of mercury) an verschiedenen
Dr. Lukas Meier Statistik und Wahrscheinlichkeitsrechnung FS 21 Musterlösung zu Serie 14 1. Der Datensatz von Forbes zeigt Messungen von Siedepunkt (in F) und Luftdruck (in inches of mercury) an verschiedenen
Korrelation - Regression. Berghold, IMI
 Korrelation - Regression Zusammenhang zwischen Variablen Bivariate Datenanalyse - Zusammenhang zwischen 2 stetigen Variablen Korrelation Einfaches lineares Regressionsmodell 1. Schritt: Erstellung eines
Korrelation - Regression Zusammenhang zwischen Variablen Bivariate Datenanalyse - Zusammenhang zwischen 2 stetigen Variablen Korrelation Einfaches lineares Regressionsmodell 1. Schritt: Erstellung eines
Biostatistik 101 Korrelation - Regressionsanalysen
 Good Data don't need statistics Biostatistik 101 Korrelation - Regressionsanalysen Carl Herrmann IPMB Uni Heidelberg & DKFZ B080 carl.herrmann@uni-heidelberg.de Korrelation Sind Alter und Blutdruck miteinander
Good Data don't need statistics Biostatistik 101 Korrelation - Regressionsanalysen Carl Herrmann IPMB Uni Heidelberg & DKFZ B080 carl.herrmann@uni-heidelberg.de Korrelation Sind Alter und Blutdruck miteinander
Statistik Einführung // Lineare Regression 9 p.2/72
 Statistik Einführung Lineare Regression Kapitel 9 Statistik WU Wien Gerhard Derflinger Michael Hauser Jörg Lenneis Josef Ledold Günter Tirler Rosmarie Wakolbinger Statistik Einführung // Lineare Regression
Statistik Einführung Lineare Regression Kapitel 9 Statistik WU Wien Gerhard Derflinger Michael Hauser Jörg Lenneis Josef Ledold Günter Tirler Rosmarie Wakolbinger Statistik Einführung // Lineare Regression
Geometrische Brownsche Bewegung und Brownsche Brücke
 Geometrische Brownsche Bewegung und Brownsche Brücke Korinna Griesing Dozentin: Prof. Dr. Christine Müller 17. April 2012 Korinna Griesing 1 (26) Inhalt Motivation Statistische Methoden Geometrische Brownsche
Geometrische Brownsche Bewegung und Brownsche Brücke Korinna Griesing Dozentin: Prof. Dr. Christine Müller 17. April 2012 Korinna Griesing 1 (26) Inhalt Motivation Statistische Methoden Geometrische Brownsche
Statistische Auswertung der Daten von Blatt 13
 Statistische Auswertung der Daten von Blatt 13 Problemstellung 1 Graphische Darstellung der Daten 1 Diskussion der Normalverteilung 3 Mittelwerte und deren Konfidenzbereiche 3 Signifikanz der Behandlung
Statistische Auswertung der Daten von Blatt 13 Problemstellung 1 Graphische Darstellung der Daten 1 Diskussion der Normalverteilung 3 Mittelwerte und deren Konfidenzbereiche 3 Signifikanz der Behandlung
Nichtparametrische Analyse longitudinaler Daten in faktoriellen Experimenten. Frank Konietschke
 Nichtparametrische Analyse longitudinaler Daten in faktoriellen Experimenten Frank Konietschke Abteilung für Medizinische Statistik Universität Göttingen 1 Übersicht Beispiele CGI (repeated measures) γ-gt
Nichtparametrische Analyse longitudinaler Daten in faktoriellen Experimenten Frank Konietschke Abteilung für Medizinische Statistik Universität Göttingen 1 Übersicht Beispiele CGI (repeated measures) γ-gt
Kapitel 4: Binäre Regression
 Kapitel 4: Binäre Regression Steffen Unkel (basierend auf Folien von Nora Fenske) Statistik III für Nebenfachstudierende WS 2013/2014 4.1 Motivation Ausgangssituation Gegeben sind Daten (y i, x i1,...,
Kapitel 4: Binäre Regression Steffen Unkel (basierend auf Folien von Nora Fenske) Statistik III für Nebenfachstudierende WS 2013/2014 4.1 Motivation Ausgangssituation Gegeben sind Daten (y i, x i1,...,
Lineare Strukturgleichungsmodelle (LISREL) Konfirmatorische Faktorenanalyse (CFA)
 Konfirmatorische Faktorenanalyse (CFA)") Interdisziplinäres Seminar Lineare Strukturgleichungsmodelle (LISREL) Konfirmatorische Faktorenanalyse (CFA) WS 2008/09 19.11.2008 Julia Schiele und Lucie Wink Dozenten: Prof. Dr. Bühner, Prof. Dr. Küchenhoff
Interdisziplinäres Seminar Lineare Strukturgleichungsmodelle (LISREL) Konfirmatorische Faktorenanalyse (CFA) WS 2008/09 19.11.2008 Julia Schiele und Lucie Wink Dozenten: Prof. Dr. Bühner, Prof. Dr. Küchenhoff
Klausur zur Vorlesung Statistik III für Studenten mit dem Wahlfach Statistik
 Ludwig Fahrmeir, Nora Fenske Institut für Statistik Bitte für die Korrektur freilassen! Aufgabe 1 2 3 4 Punkte Klausur zur Vorlesung Statistik III für Studenten mit dem Wahlfach Statistik 29. März 21 Hinweise:
Ludwig Fahrmeir, Nora Fenske Institut für Statistik Bitte für die Korrektur freilassen! Aufgabe 1 2 3 4 Punkte Klausur zur Vorlesung Statistik III für Studenten mit dem Wahlfach Statistik 29. März 21 Hinweise:
Empirische Wirtschaftsforschung in R
 Empirische Wirtschaftsforschung in R Schätzung der keynesianischen Geldnachfragefunktion auf Basis von Daten der dänischen Volkswirtschaft Jonas Richter-Dumke Universität Rostock, Institut für Volkswirtschaftslehre
Empirische Wirtschaftsforschung in R Schätzung der keynesianischen Geldnachfragefunktion auf Basis von Daten der dänischen Volkswirtschaft Jonas Richter-Dumke Universität Rostock, Institut für Volkswirtschaftslehre
Biostatistik, WS 2015/2016 Der zwei-stichproben-t-test
 1/29 Biostatistik, WS 2015/2016 Der zwei-stichproben-t-test (t-test für ungepaarte Stichproben) Matthias Birkner http://www.staff.uni-mainz.de/birkner/biostatistik1516/ 11.12.2015 2/29 Inhalt 1 t-test
1/29 Biostatistik, WS 2015/2016 Der zwei-stichproben-t-test (t-test für ungepaarte Stichproben) Matthias Birkner http://www.staff.uni-mainz.de/birkner/biostatistik1516/ 11.12.2015 2/29 Inhalt 1 t-test
Multiple Regression III
 Multiple Regression III Werner Brannath VO Biostatistik im WS 2006/2007 Inhalt Überprüfung der Modellannahmen Residuen-Plot Normal-Q-Q-Plot Cook s Distanz-Plot Maßnahmen bei Abweichungen von Modellannahmen
Multiple Regression III Werner Brannath VO Biostatistik im WS 2006/2007 Inhalt Überprüfung der Modellannahmen Residuen-Plot Normal-Q-Q-Plot Cook s Distanz-Plot Maßnahmen bei Abweichungen von Modellannahmen
Log-lineare Analyse I
 1 Log-lineare Analyse I Einleitung Die log-lineare Analysemethode wurde von L.A. Goodman in den 60er und 70er Jahren entwickelt. Sie dient zur Analyse von Zusammenhängen in mehrdimensionalen Kontingenztafeln
1 Log-lineare Analyse I Einleitung Die log-lineare Analysemethode wurde von L.A. Goodman in den 60er und 70er Jahren entwickelt. Sie dient zur Analyse von Zusammenhängen in mehrdimensionalen Kontingenztafeln
Darstellung eines VAR(p)-Prozesses als VAR(1)-Prozess
-Prozesses als VAR(1)-Prozess") Darstellung eines VAR(p)-Prozesses als VAR(1)-Prozess Definiere x t = Y t Y t 1. Y t p+1 Sylvia Frühwirth-Schnatter Econometrics III WS 2012/13 1-84 Darstellung eines VAR(p)-Prozesses als VAR(1)-Prozess
Darstellung eines VAR(p)-Prozesses als VAR(1)-Prozess Definiere x t = Y t Y t 1. Y t p+1 Sylvia Frühwirth-Schnatter Econometrics III WS 2012/13 1-84 Darstellung eines VAR(p)-Prozesses als VAR(1)-Prozess
Statistische Datenanalyse mit R, Korrelation und Regression. Dr. Andrea Denecke Leibniz Universität IT-Services
 Statistische Datenanalyse mit R, Korrelation und Regression Dr. Andrea Denecke Leibniz Universität IT-Services Korrelationsanalyse Eine Korrelationsanalyse soll herausfinden Ob ein linearer Zusammenhang
Statistische Datenanalyse mit R, Korrelation und Regression Dr. Andrea Denecke Leibniz Universität IT-Services Korrelationsanalyse Eine Korrelationsanalyse soll herausfinden Ob ein linearer Zusammenhang
Verallgemeinerte lineare Modelle. Promotion. Promotion. Methoden empirischer Sozialforschung. 1 binäre und mehrere metrische und kategoriale Variablen
 Verallgemeinerte lineare Modelle 1 binäre und mehrere metrische und kategoriale Variablen Methoden empirischer Sozialforschung Verallgemeinerte lineare Modelle () Wie läßt sich die Abhängigkeit der Erfolgswahrscheinlichkeit
Verallgemeinerte lineare Modelle 1 binäre und mehrere metrische und kategoriale Variablen Methoden empirischer Sozialforschung Verallgemeinerte lineare Modelle () Wie läßt sich die Abhängigkeit der Erfolgswahrscheinlichkeit
Übungen zur Veranstaltung Statistik 2 mit SPSS
 Raum 22, Tel. 39 4 Aufgabe 5. Wird der neue Film MatchPoint von Woody Allen von weiblichen und männlichen Zuschauern gleich bewertet? Eine Umfrage unter 00 Kinobesuchern ergab folgende Daten: Altersgruppe
Raum 22, Tel. 39 4 Aufgabe 5. Wird der neue Film MatchPoint von Woody Allen von weiblichen und männlichen Zuschauern gleich bewertet? Eine Umfrage unter 00 Kinobesuchern ergab folgende Daten: Altersgruppe
Einführung in die formale Demographie Übung
 Einführung in die formale Demographie Übung Roland Rau mailto:roland.rau@uni-rostock.de 27. Oktober 2014 Inhaltsverzeichnis 1 Eigene Funktionen schreiben 2 2 Regression in R 3 3 Aufgaben 8 3.1 Schreiben
Einführung in die formale Demographie Übung Roland Rau mailto:roland.rau@uni-rostock.de 27. Oktober 2014 Inhaltsverzeichnis 1 Eigene Funktionen schreiben 2 2 Regression in R 3 3 Aufgaben 8 3.1 Schreiben
(Repeated-measures ANOVA) path = "Verzeichnis wo Sie anova1 gespeichert haben" attach(paste(path, "anova1", sep="/"))
 path = Verzeichnis wo Sie anova1 gespeichert haben attach(paste(path, anova1, sep=/))") Varianzanalyse mit Messwiederholungen (Repeated-measures ANOVA) Jonathan Harrington Befehle: anova2.txt path = "Verzeichnis wo Sie anova1 gespeichert haben" attach(paste(path, "anova1", sep="/")) Messwiederholungen:
Varianzanalyse mit Messwiederholungen (Repeated-measures ANOVA) Jonathan Harrington Befehle: anova2.txt path = "Verzeichnis wo Sie anova1 gespeichert haben" attach(paste(path, "anova1", sep="/")) Messwiederholungen:
Weitere (wählbare) Kontraste in der SPSS Prozedur Allgemeines Lineares Modell
 Kontraste in der SPSS Prozedur Allgemeines Lineares Modell") Einfaktorielle Versuchspläne 27/40 Weitere (wählbare) Kontraste in der SPSS Prozedur Allgemeines Lineares Modell Abweichung Einfach Differenz Helmert Wiederholt Vergleich Jede Gruppe mit Gesamtmittelwert
Einfaktorielle Versuchspläne 27/40 Weitere (wählbare) Kontraste in der SPSS Prozedur Allgemeines Lineares Modell Abweichung Einfach Differenz Helmert Wiederholt Vergleich Jede Gruppe mit Gesamtmittelwert
Motivation. Wilcoxon-Rangsummentest oder Mann-Whitney U-Test. Wilcoxon Rangsummen-Test Voraussetzungen. Bemerkungen
 Universität Karlsruhe (TH) Forschungsuniversität gegründet 825 Wilcoxon-Rangsummentest oder Mann-Whitney U-Test Motivation In Experimenten ist die Datenmenge oft klein Daten sind nicht normalverteilt Dann
Universität Karlsruhe (TH) Forschungsuniversität gegründet 825 Wilcoxon-Rangsummentest oder Mann-Whitney U-Test Motivation In Experimenten ist die Datenmenge oft klein Daten sind nicht normalverteilt Dann
Umgang mit und Ersetzen von fehlenden Werten bei multivariaten Analysen
 Umgang mit und Ersetzen von fehlenden Werten bei multivariaten Analysen Warum überhaupt Gedanken machen? Was fehlt, ist doch weg, oder? Allgegenwärtiges Problem in psychologischer Forschung Bringt Fehlerquellen
Umgang mit und Ersetzen von fehlenden Werten bei multivariaten Analysen Warum überhaupt Gedanken machen? Was fehlt, ist doch weg, oder? Allgegenwärtiges Problem in psychologischer Forschung Bringt Fehlerquellen
Häufigkeitstabellen. Balken- oder Kreisdiagramme. kritischer Wert für χ2-test. Kontingenztafeln
 Häufigkeitstabellen Menüpunkt Data PivotTable Report (bzw. entsprechendes Icon): wähle Data Range (Zellen, die die Daten enthalten + Zelle mit Variablenname) wähle kategoriale Variable für Spalten- oder
Häufigkeitstabellen Menüpunkt Data PivotTable Report (bzw. entsprechendes Icon): wähle Data Range (Zellen, die die Daten enthalten + Zelle mit Variablenname) wähle kategoriale Variable für Spalten- oder
iid N(0, σ 2 ), b i, ε ij unabhängig i, j
, b i, ε ij unabhängig i, j") Aufgabe 2 Betrachten Sie erneut den Datensatz zum Blutdruck. Als Signifikanzniveau wird in dieser Aufgabe α = 5% verwendet. (a) Fitten Sie folgendes Modell in R, wobei gender i = 0, falls Person i weiblich
Aufgabe 2 Betrachten Sie erneut den Datensatz zum Blutdruck. Als Signifikanzniveau wird in dieser Aufgabe α = 5% verwendet. (a) Fitten Sie folgendes Modell in R, wobei gender i = 0, falls Person i weiblich
Lean Body Mass [kg] Estimate Std. Error t value Pr(> t ) (Intercept) ??? lbm <2e-16 ***
![Lean Body Mass [kg] Estimate Std. Error t value Pr(> t ) (Intercept) ??? lbm <2e-16 ***](/thumbs/76/73817896.jpg "Lean Body Mass [kg] Estimate Std. Error t value Pr(> t ) (Intercept) ??? lbm <2e-16 ***") Körperkraft [Nm] 0 50 100 150 200 250 0 20 40 60 80 Lean Body Mass [kg] Dieses Quiz soll Ihnen helfen, den R Output einer einfachen linearen Regression besser zu verstehen (s. Kapitel 5.4.1) Es wurden
Körperkraft [Nm] 0 50 100 150 200 250 0 20 40 60 80 Lean Body Mass [kg] Dieses Quiz soll Ihnen helfen, den R Output einer einfachen linearen Regression besser zu verstehen (s. Kapitel 5.4.1) Es wurden
Interne und externe Modellvalidität
 Interne und externe Modellvalidität Interne Modellvalidität ist gegeben, o wenn statistische Inferenz bzgl. der untersuchten Grundgesamtheit zulässig ist o KQ-Schätzer der Modellparameter u. Varianzschätzer
Interne und externe Modellvalidität Interne Modellvalidität ist gegeben, o wenn statistische Inferenz bzgl. der untersuchten Grundgesamtheit zulässig ist o KQ-Schätzer der Modellparameter u. Varianzschätzer
Gefährdet die ungleiche Verteilung unseres Vermögens den gesellschaftlichen Zusammenhalt?
 Gefährdet die ungleiche Verteilung unseres Vermögens den gesellschaftlichen Zusammenhalt? Prof. Dr. K.-W. Hansmann Rotary-Vortrag am 22. September 2014 (Die farbigen Graphiken habe ich mit der Progrmmiersprache
Gefährdet die ungleiche Verteilung unseres Vermögens den gesellschaftlichen Zusammenhalt? Prof. Dr. K.-W. Hansmann Rotary-Vortrag am 22. September 2014 (Die farbigen Graphiken habe ich mit der Progrmmiersprache
Statistik II Wahrscheinlichkeitsrechnung und induktive Statistik Erste Klausur zum Sommersemester 2005 26. Juli 2005
 Statistik II Wahrscheinlichkeitsrechnung und induktive Statistik Erste Klausur zum Sommersemester 2005 26. Juli 2005 Aufgabe 1: Grundzüge der Wahrscheinlichkeitsrechnung 19 P. Als Manager eines großen
Statistik II Wahrscheinlichkeitsrechnung und induktive Statistik Erste Klausur zum Sommersemester 2005 26. Juli 2005 Aufgabe 1: Grundzüge der Wahrscheinlichkeitsrechnung 19 P. Als Manager eines großen
Breusch-Pagan-Test I auf Heteroskedastie in den Störgrößen
 Breusch-Pagan-Test I Ein weiterer Test ist der Breusch-Pagan-Test. Im Gegensatz zum Goldfeld-Quandt-Test ist es nicht erforderlich, eine (einzelne) Quelle der Heteroskedastizität anzugeben bzw. zu vermuten.
Breusch-Pagan-Test I Ein weiterer Test ist der Breusch-Pagan-Test. Im Gegensatz zum Goldfeld-Quandt-Test ist es nicht erforderlich, eine (einzelne) Quelle der Heteroskedastizität anzugeben bzw. zu vermuten.
MEHR ALS LINEAR ODER LOGISTISCH?
 MEHR ALS LINEAR ODER LOGISTISCH? QUANTILS EN UND ADAPTIVE SPLINES IN SAS MIHAI PAUNESCU QUANTILE proc univariate data=dat; ods select moments quantiles; var sales; Basic Statistical Measures Location Variability
MEHR ALS LINEAR ODER LOGISTISCH? QUANTILS EN UND ADAPTIVE SPLINES IN SAS MIHAI PAUNESCU QUANTILE proc univariate data=dat; ods select moments quantiles; var sales; Basic Statistical Measures Location Variability
Technische Universität München Zentrum Mathematik Sommersemester Juli 2005 Arbeitszeit 60 Minuten
 Name: Frau Herr (nichtzutreffendes bitte streichen) Fachrichtung geb. am (Tag/Mon/Jahr) Semestralklausur aus Praktikum BWL-Statistik Technische Universität München Zentrum Mathematik Sommersemester 2005
Name: Frau Herr (nichtzutreffendes bitte streichen) Fachrichtung geb. am (Tag/Mon/Jahr) Semestralklausur aus Praktikum BWL-Statistik Technische Universität München Zentrum Mathematik Sommersemester 2005
Name (in Druckbuchstaben): Matrikelnummer: Unterschrift:
: Matrikelnummer: Unterschrift:") 20-minütige Klausur zur Vorlesung Lineare Modelle im Sommersemester 20 PD Dr. Christian Heumann Ludwig-Maximilians-Universität München, Institut für Statistik 2. Oktober 20, 4:5 6:5 Uhr Überprüfen Sie
20-minütige Klausur zur Vorlesung Lineare Modelle im Sommersemester 20 PD Dr. Christian Heumann Ludwig-Maximilians-Universität München, Institut für Statistik 2. Oktober 20, 4:5 6:5 Uhr Überprüfen Sie
Aufgabe 35 mit R (Ökonometrie SS 2014 an der UdS)
") Vorbereitungen Aufgabe 35 mit R (Ökonometrie SS 2014 an der UdS) Falls das R - Paket car noch nicht installiert wurde, kann dies mit der Funktion install.packages() erledigt werden. install.packages("car")
Vorbereitungen Aufgabe 35 mit R (Ökonometrie SS 2014 an der UdS) Falls das R - Paket car noch nicht installiert wurde, kann dies mit der Funktion install.packages() erledigt werden. install.packages("car")
Analytische Statistik I. Statistische Methoden in der Korpuslinguistik Heike Zinsmeister WS 2009/10
 Analytische Statistik I Statistische Methoden in der Korpuslinguistik Heike Zinsmeister WS 2009/10 Testen Anpassungstests (goodness of fit) Weicht eine gegebene Verteilung signifikant von einer bekannten
Analytische Statistik I Statistische Methoden in der Korpuslinguistik Heike Zinsmeister WS 2009/10 Testen Anpassungstests (goodness of fit) Weicht eine gegebene Verteilung signifikant von einer bekannten
Die Varianzanalyse ohne Messwiederholung. Jonathan Harrington. Bi8e noch einmal datasets.zip laden
 Die Varianzanalyse ohne Messwiederholung Jonathan Harrington Bi8e noch einmal datasets.zip laden Variablen, Faktoren, Stufen Eine Varianzanalyse ist die Erweiterung von einem t- test t- test oder ANOVA
Die Varianzanalyse ohne Messwiederholung Jonathan Harrington Bi8e noch einmal datasets.zip laden Variablen, Faktoren, Stufen Eine Varianzanalyse ist die Erweiterung von einem t- test t- test oder ANOVA
Tutorial: Regression Output von R
 Tutorial: Regression Output von R Eine Firma erzeugt Autositze. Ihr Chef ist besorgt über die Anzahl und die Kosten von Maschinenausfällen. Das Problem ist, dass die Maschinen schon alt sind und deswegen
Tutorial: Regression Output von R Eine Firma erzeugt Autositze. Ihr Chef ist besorgt über die Anzahl und die Kosten von Maschinenausfällen. Das Problem ist, dass die Maschinen schon alt sind und deswegen
Eine Einführung in R: Varianzanalyse
 Eine Einführung in R: Varianzanalyse Bernd Klaus, Verena Zuber Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig 6. Januar 2011 Bernd Klaus, Verena Zuber Das
Eine Einführung in R: Varianzanalyse Bernd Klaus, Verena Zuber Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig 6. Januar 2011 Bernd Klaus, Verena Zuber Das
Ein Vergleich von 2-Stichproben-Verfahren mit Berücksichtigung von Baselinewerten bei ordinalen Zielvariablen
 Ein Vergleich von 2-Stichproben-Verfahren mit Berücksichtigung von Baselinewerten bei ordinalen Zielvariablen Alexander Siemer Abteilung Medizinische Statistik Universität Göttingen 47. Biometrisches Kolloquium
Ein Vergleich von 2-Stichproben-Verfahren mit Berücksichtigung von Baselinewerten bei ordinalen Zielvariablen Alexander Siemer Abteilung Medizinische Statistik Universität Göttingen 47. Biometrisches Kolloquium
Auswertung und Lösung
 Körperkraft [Nm] 0 50 100 150 200 250 0 20 40 60 80 Lean Body Mass [kg] Dieses Quiz soll Ihnen helfen, den R Output einer einfachen linearen Regression besser zu verstehen (s. Kapitel 5.4.1) Es wurden
Körperkraft [Nm] 0 50 100 150 200 250 0 20 40 60 80 Lean Body Mass [kg] Dieses Quiz soll Ihnen helfen, den R Output einer einfachen linearen Regression besser zu verstehen (s. Kapitel 5.4.1) Es wurden
Allgemeine Regressionsanalyse. Kovariablen / Prädiktoren / unabhängige Variablen X j R d, evtl. deterministisch
 Prof. Dr. J. Franke Statistik II für Wirtschaftswissenschaftler 9.1 Allgemeine Regressionsanalyse Daten (X j, Y j ), j = 1,..., N unabhängig Kovariablen / Prädiktoren / unabhängige Variablen X j R d, evtl.
Prof. Dr. J. Franke Statistik II für Wirtschaftswissenschaftler 9.1 Allgemeine Regressionsanalyse Daten (X j, Y j ), j = 1,..., N unabhängig Kovariablen / Prädiktoren / unabhängige Variablen X j R d, evtl.
CIM2004 Übung 7: Permutationstest, Bootstrap & Jackknife
 CIM2004 Übung 7: Permutationstest, Bootstrap & Jackknife Michael Höhle hoehle@stat.uni-muenchen.de Lösung 24. Juni 2004 1 Permutationstest Bilirubin ist ein Zerlegungsprodukt von Haemoglobin. Falls die
CIM2004 Übung 7: Permutationstest, Bootstrap & Jackknife Michael Höhle hoehle@stat.uni-muenchen.de Lösung 24. Juni 2004 1 Permutationstest Bilirubin ist ein Zerlegungsprodukt von Haemoglobin. Falls die
Tutorial: Homogenitätstest
 Tutorial: Homogenitätstest Eine Bank möchte die Kreditwürdigkeit potenzieller Kreditnehmer abschätzen. Einerseits lebt die Bank ja von der Vergabe von Krediten, andererseits verursachen Problemkredite
Tutorial: Homogenitätstest Eine Bank möchte die Kreditwürdigkeit potenzieller Kreditnehmer abschätzen. Einerseits lebt die Bank ja von der Vergabe von Krediten, andererseits verursachen Problemkredite
Konfidenz-, Prognoseintervalle und Hypothesentests IV im multiplen linearen Regressionsmodell mit heteroskedastischen Störgrößen
 4 Multiple lineare Regression Heteroskedastische Störgrößen 4.10 Konfidenz-, Prognoseintervalle und Hypothesentests IV im multiplen linearen Regressionsmodell mit heteroskedastischen Störgrößen Ein approximatives
4 Multiple lineare Regression Heteroskedastische Störgrößen 4.10 Konfidenz-, Prognoseintervalle und Hypothesentests IV im multiplen linearen Regressionsmodell mit heteroskedastischen Störgrößen Ein approximatives
Prognoseintervalle für y 0 gegeben x 0
 10 Lineare Regression Punkt- und Intervallprognosen 10.5 Prognoseintervalle für y 0 gegeben x 0 Intervallprognosen für y 0 zur Vertrauenswahrscheinlichkeit 1 α erhält man also analog zu den Intervallprognosen
10 Lineare Regression Punkt- und Intervallprognosen 10.5 Prognoseintervalle für y 0 gegeben x 0 Intervallprognosen für y 0 zur Vertrauenswahrscheinlichkeit 1 α erhält man also analog zu den Intervallprognosen
ε heteroskedastisch BINARY CHOICE MODELS Beispiele: Wahlentscheidung Kauf langlebiger Konsumgüter Arbeitslosigkeit Schätzung mit OLS?
 BINARY CHOICE MODELS 1 mit Pr( Y = 1) = P Y = 0 mit Pr( Y = 0) = 1 P Beispiele: Wahlentscheidung Kauf langlebiger Konsumgüter Arbeitslosigkeit Schätzung mit OLS? Y i = X i β + ε i Probleme: Nonsense Predictions
BINARY CHOICE MODELS 1 mit Pr( Y = 1) = P Y = 0 mit Pr( Y = 0) = 1 P Beispiele: Wahlentscheidung Kauf langlebiger Konsumgüter Arbeitslosigkeit Schätzung mit OLS? Y i = X i β + ε i Probleme: Nonsense Predictions
Mehrfache und polynomiale Regression
 Mehrfache und polynomiale Regression Kriteria für die Durchführung einer Regression Jonathan Harrington Bitte datasets.zip (unter 5.5, Tabellarische Daten) neu herunterladen und in pfad auspacken Einfache
Mehrfache und polynomiale Regression Kriteria für die Durchführung einer Regression Jonathan Harrington Bitte datasets.zip (unter 5.5, Tabellarische Daten) neu herunterladen und in pfad auspacken Einfache
Einführung in die formale Demographie Übung
 Einführung in die formale Demographie Übung Roland Rau mailto:roland.rau@uni-rostock.de 03. November 2014 Inhaltsverzeichnis 1 Aufgaben vom 27. Oktober 2014 2 1.1 Schreiben von Funktionen............................
Einführung in die formale Demographie Übung Roland Rau mailto:roland.rau@uni-rostock.de 03. November 2014 Inhaltsverzeichnis 1 Aufgaben vom 27. Oktober 2014 2 1.1 Schreiben von Funktionen............................
Statistische Verfahren für das Data Mining in einem Industrieprojekt
 Statistische Verfahren für das Data Mining in einem Industrieprojekt Thorsten Dickhaus Forschungszentrum Jülich GmbH Zentralinstitut für Angewandte Mathematik Telefon: 02461/61-4193 E-Mail: th.dickhaus@fz-juelich.de
Statistische Verfahren für das Data Mining in einem Industrieprojekt Thorsten Dickhaus Forschungszentrum Jülich GmbH Zentralinstitut für Angewandte Mathematik Telefon: 02461/61-4193 E-Mail: th.dickhaus@fz-juelich.de
Eine Einführung in R: Statistische Tests
 Eine Einführung in R: Statistische Tests Bernd Klaus, Verena Zuber Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.uni-leipzig.de/ zuber/teaching/ws12/r-kurs/
Eine Einführung in R: Statistische Tests Bernd Klaus, Verena Zuber Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.uni-leipzig.de/ zuber/teaching/ws12/r-kurs/
Christian FG Schendera. Regressionsanalyse. mit SPSS. 2. korrigierte und aktualisierte Auflage DE GRUYTER OLDENBOURG
 Christian FG Schendera Regressionsanalyse mit SPSS 2. korrigierte und aktualisierte Auflage DE GRUYTER OLDENBOURG Inhalt Vorworte V 1 Korrelation 1 1.1 Einführung 1 1.2 Erste Voraussetzung: Das Skalenniveau
Christian FG Schendera Regressionsanalyse mit SPSS 2. korrigierte und aktualisierte Auflage DE GRUYTER OLDENBOURG Inhalt Vorworte V 1 Korrelation 1 1.1 Einführung 1 1.2 Erste Voraussetzung: Das Skalenniveau
Prof. Dr. Karl-Werner Hansmann
 Die Gelddruck-Maschine der Notenbanken ist für die Bekämpfung der Arbeitslosigkeit ungeeignet. von Prof. Dr. Karl-Werner Hansmann Universität Hamburg Vortrag beim Academic Network der Roland Berger School
Die Gelddruck-Maschine der Notenbanken ist für die Bekämpfung der Arbeitslosigkeit ungeeignet. von Prof. Dr. Karl-Werner Hansmann Universität Hamburg Vortrag beim Academic Network der Roland Berger School
Introduction to Modern Time Series Analysis
 Springer Texts in Business and Economics Introduction to Modern Time Series Analysis Bearbeitet von Gebhard Kirchgässner, Jürgen Wolters, Uwe Hassler 1. Auflage 2012. Buch. XII, 319 S. Hardcover ISBN 978
Springer Texts in Business and Economics Introduction to Modern Time Series Analysis Bearbeitet von Gebhard Kirchgässner, Jürgen Wolters, Uwe Hassler 1. Auflage 2012. Buch. XII, 319 S. Hardcover ISBN 978
> r.lm < lm(log10(ersch) log10(dist), > summary(r.lm) > r.lms < summary(r.lm) R-Funktionen zur linearen Regression. data = d.
 log10(dist), > summary(r.lm) > r.lms < summary(r.lm) R-Funktionen zur linearen Regression. data = d.") 3.4 S-Funktionen 75 R-Funktionen zur linearen Regression a Im package stat (immer vorhanden): lm > r.lm < lm(log10(ersch) log10(dist), data = d.spreng) b Funktion summary produziert Resultate, die man
3.4 S-Funktionen 75 R-Funktionen zur linearen Regression a Im package stat (immer vorhanden): lm > r.lm < lm(log10(ersch) log10(dist), data = d.spreng) b Funktion summary produziert Resultate, die man
Bachelorabschlussseminar Dipl.-Kfm. Daniel Cracau
 1 Einführung in die statistische Datenanalyse Bachelorabschlussseminar Dipl.-Kfm. Daniel Cracau 2 Gliederung 1.Grundlagen 2.Nicht-parametrische Tests a. Mann-Whitney-Wilcoxon-U Test b. Wilcoxon-Signed-Rank
1 Einführung in die statistische Datenanalyse Bachelorabschlussseminar Dipl.-Kfm. Daniel Cracau 2 Gliederung 1.Grundlagen 2.Nicht-parametrische Tests a. Mann-Whitney-Wilcoxon-U Test b. Wilcoxon-Signed-Rank
Lineare Regression in R, Teil 1
 Lineare Regression in R, Teil 1 Christian Kleiber Abt. Quantitative Methoden, WWZ, Universität Basel October 6, 2009 1 Vorbereitungen Zur Illustration betrachten wir wieder den Datensatz CASchools aus
Lineare Regression in R, Teil 1 Christian Kleiber Abt. Quantitative Methoden, WWZ, Universität Basel October 6, 2009 1 Vorbereitungen Zur Illustration betrachten wir wieder den Datensatz CASchools aus
3.1 Modell und Statistik Zusammenhang zwischen einer Zielgrösse Y und mehreren Eingangsgrössen X (1), X (2),..., X (m)
, X (2),..., X (m)") 3.1. MODELL UND STATISTIK 32 3 Multiple lineare Regression a 3.1 Modell und Statistik Zusammenhang zwischen einer Zielgrösse Y und mehreren Eingangsgrössen X (1), X (2),..., X (m) Y i = β 0 + β 1 x (1)
3.1. MODELL UND STATISTIK 32 3 Multiple lineare Regression a 3.1 Modell und Statistik Zusammenhang zwischen einer Zielgrösse Y und mehreren Eingangsgrössen X (1), X (2),..., X (m) Y i = β 0 + β 1 x (1)
Risikomanagement für Fahrzeugrestwerte von Leasingrückläufern. Masterarbeit
 Risikomanagement für Fahrzeugrestwerte von Leasingrückläufern Masterarbeit zur Erlangung des akademischen Grades Master of Science (M.Sc.) im Studiengang Wirtschaftswissenschaft der Wirtschaftswissenschaftlichen
Risikomanagement für Fahrzeugrestwerte von Leasingrückläufern Masterarbeit zur Erlangung des akademischen Grades Master of Science (M.Sc.) im Studiengang Wirtschaftswissenschaft der Wirtschaftswissenschaftlichen
Parametrische Statistik
 Statistik und ihre Anwendungen Parametrische Statistik Verteilungen, maximum likelihood und GLM in R Bearbeitet von Carsten F. Dormann 1. Auflage 2013. Taschenbuch. xxii, 350 S. Paperback ISBN 978 3 642
Statistik und ihre Anwendungen Parametrische Statistik Verteilungen, maximum likelihood und GLM in R Bearbeitet von Carsten F. Dormann 1. Auflage 2013. Taschenbuch. xxii, 350 S. Paperback ISBN 978 3 642
Syntax. Ausgabe *Ü12. *1. corr it25 with alter li_re kontakt.
 Syntax *Ü2. *. corr it25 with alter li_re kontakt. *2. regression var=it25 alter li_re kontakt/statistics /dependent=it25 /enter. regression var=it25 li_re kontakt/statistics /dependent=it25 /enter. *3.
Syntax *Ü2. *. corr it25 with alter li_re kontakt. *2. regression var=it25 alter li_re kontakt/statistics /dependent=it25 /enter. regression var=it25 li_re kontakt/statistics /dependent=it25 /enter. *3.
Einfache lineare Modelle mit Statistik-Software R Beispiel (Ausgaben in Abhängigkeit vom Einkommen)
") 3 Einfache lineare Regression Einfache lineare Modelle mit R 36 Einfache lineare Modelle mit Statistik-Software R Beispiel (Ausgaben in Abhängigkeit vom Einkommen) > summary(lm(y~x)) Call: lm(formula =
3 Einfache lineare Regression Einfache lineare Modelle mit R 36 Einfache lineare Modelle mit Statistik-Software R Beispiel (Ausgaben in Abhängigkeit vom Einkommen) > summary(lm(y~x)) Call: lm(formula =
Einfache lineare Modelle mit Statistik-Software R Beispiel (Ausgaben in Abhängigkeit vom Einkommen)
") 3 Einfache lineare Regression Einfache lineare Modelle mit R 3.6 Einfache lineare Modelle mit Statistik-Software R Beispiel (Ausgaben in Abhängigkeit vom Einkommen) > summary(lm(y~x)) Call: lm(formula
3 Einfache lineare Regression Einfache lineare Modelle mit R 3.6 Einfache lineare Modelle mit Statistik-Software R Beispiel (Ausgaben in Abhängigkeit vom Einkommen) > summary(lm(y~x)) Call: lm(formula
E-Learning und E-Klausuren am Lehrstuhl für Wirtschafts- und Sozialstatistik, Universität Trier
 E-Learning und E-Klausuren am Lehrstuhl für Wirtschafts- und Sozialstatistik, Universität Trier Dr. Jan Pablo Burgard 13.11.2014 Göttingen, 13.11.2014 Burgard 1 (17) E-Learning und E-Klausuren WiSoStat
E-Learning und E-Klausuren am Lehrstuhl für Wirtschafts- und Sozialstatistik, Universität Trier Dr. Jan Pablo Burgard 13.11.2014 Göttingen, 13.11.2014 Burgard 1 (17) E-Learning und E-Klausuren WiSoStat
Standardab er des. Testwert = 145.5 95% Konfidenzintervall. T df Sig. (2-seitig) Differenz Untere Obere -2.011 698.045-5.82-11.50 -.14.
 Differenz Untere Obere -2.011 698.045-5.82-11.50 -.14.") Aufgabe : einfacher T-Test Statistik bei einer Stichprobe Standardfehl Standardab er des Mittelwert weichung Mittelwertes 699 39.68 76.59 2.894 Test bei einer Sichprobe Testwert = 45.5 95% Konfidenzintervall
Aufgabe : einfacher T-Test Statistik bei einer Stichprobe Standardfehl Standardab er des Mittelwert weichung Mittelwertes 699 39.68 76.59 2.894 Test bei einer Sichprobe Testwert = 45.5 95% Konfidenzintervall
Einige Grundbegriffe der Statistik
 Einige Grundbegriffe der Statistik Philipp Mitteröcker Basic terms Statistik (statistics) stammt vom lateinischen statisticum ( den Staat betreffend ) und dem italienischen statista ( Staatsmann" oder
Einige Grundbegriffe der Statistik Philipp Mitteröcker Basic terms Statistik (statistics) stammt vom lateinischen statisticum ( den Staat betreffend ) und dem italienischen statista ( Staatsmann" oder
1 Gliederung Zeitreihenökonometrie. Angewandte Ökonometrie (Folien) Zeitreihenökonometrie Universität Basel, FS 09. Dr. Sylvia Kaufmann.
 Zeitreihenökonometrie Universität Basel, FS 09. Dr. Sylvia Kaufmann.") Angewandte Ökonometrie (Folien) Zeitreihenökonometrie Universität Basel, FS 09 Dr Sylvia Kaufmann Februar 2009 Angewandte Ökonometrie, Sylvia Kaufmann, FS09 1 1 Gliederung Zeitreihenökonometrie Einführung
Angewandte Ökonometrie (Folien) Zeitreihenökonometrie Universität Basel, FS 09 Dr Sylvia Kaufmann Februar 2009 Angewandte Ökonometrie, Sylvia Kaufmann, FS09 1 1 Gliederung Zeitreihenökonometrie Einführung
Erste Schritte mit R. 2.1 Herunterladen der freien Software R
 Erste Schritte mit R 2 BevorwirunsmitdeninKap.1 eingeführten Fragestellungen beschäftigen, brauchen wir noch ein Werkzeug, um die Datensätze später wirklich auswerten zu können. Sicher lässt sich das in
Erste Schritte mit R 2 BevorwirunsmitdeninKap.1 eingeführten Fragestellungen beschäftigen, brauchen wir noch ein Werkzeug, um die Datensätze später wirklich auswerten zu können. Sicher lässt sich das in
Thema: Bootstrap-Methoden für die Regressionsanalyse. Bachelorarbeit. im Fachgebiet Wirtschaftsinformatik am Lehrstuhl für Quantitative Methoden
 Westfälische Wilhelms-Universität Münster Thema: Bootstrap-Methoden für die Regressionsanalyse Bachelorarbeit im Fachgebiet Wirtschaftsinformatik am Lehrstuhl für Quantitative Methoden Themensteller: Prof.
Westfälische Wilhelms-Universität Münster Thema: Bootstrap-Methoden für die Regressionsanalyse Bachelorarbeit im Fachgebiet Wirtschaftsinformatik am Lehrstuhl für Quantitative Methoden Themensteller: Prof.
Beispiel: Multiples Modell/Omitted Variable Bias I
 4 Multiple lineare Regression Konfidenzintervalle und Tests 4.3 Beispiel: Multiples Modell/Omitted Variable Bias I Beispieldatensatz mit Daten zur Lohnhöhe (y i ), zu den Ausbildungsjahren über den Hauptschulabschluss
4 Multiple lineare Regression Konfidenzintervalle und Tests 4.3 Beispiel: Multiples Modell/Omitted Variable Bias I Beispieldatensatz mit Daten zur Lohnhöhe (y i ), zu den Ausbildungsjahren über den Hauptschulabschluss
Regressionsanalysen. Zusammenhänge von Variablen. Ziel der Regression. ( Idealfall )
") Zusammenhänge von Variablen Regressionsanalysen linearer Zusammenhang ( Idealfall ) kein Zusammenhang nichtlinearer monotoner Zusammenhang (i.d.regel berechenbar über Variablentransformationen mittels
Zusammenhänge von Variablen Regressionsanalysen linearer Zusammenhang ( Idealfall ) kein Zusammenhang nichtlinearer monotoner Zusammenhang (i.d.regel berechenbar über Variablentransformationen mittels
> library(nlme) > fit <- lme(y ~ 1, random = ~1 id, data = sim.y.long) > summary(fit)
 > fit <- lme(y ~ 1, random = ~1 id, data = sim.y.long) > summary(fit)") Übungsblatt Analyse longitudinaler Daten und Zeitreihen SoSe 007 Donna Pauler Ankerst, Ulrich Mansmann, Volkmar Henschel, Michael Höhle Übung: Montag 0..007 Aufgabe 1 (Mixed Model Simulation) In dieser
Übungsblatt Analyse longitudinaler Daten und Zeitreihen SoSe 007 Donna Pauler Ankerst, Ulrich Mansmann, Volkmar Henschel, Michael Höhle Übung: Montag 0..007 Aufgabe 1 (Mixed Model Simulation) In dieser
Statistik. Sommersemester Prof. Dr. Stefan Etschberger Hochschule Augsburg
 für Betriebswirtschaft, Internationales Management, Wirtschaftsinformatik und Informatik Sommersemester 2016 Prof. Dr. Stefan Etschberger Hochschule Augsburg Einstichproben-t-Test und approximativer Gaußtest
für Betriebswirtschaft, Internationales Management, Wirtschaftsinformatik und Informatik Sommersemester 2016 Prof. Dr. Stefan Etschberger Hochschule Augsburg Einstichproben-t-Test und approximativer Gaußtest
QUALITY APP Messsystemanalyse komplett
 QUALITY APP Messsystemanalyse komplett Hinweise zur Validierung der Programme MSA1, MSA2, MSA3, MSA4, MSA5, MSA6 Dr. Konrad Reuter TQU VERLAG Inhalt Validierung Messtechnischer Software mit Microsoft EXCEL...
QUALITY APP Messsystemanalyse komplett Hinweise zur Validierung der Programme MSA1, MSA2, MSA3, MSA4, MSA5, MSA6 Dr. Konrad Reuter TQU VERLAG Inhalt Validierung Messtechnischer Software mit Microsoft EXCEL...
Komplexe Analyse von Wahldaten am Beispiel der Wahlen in Deutschland zwischen 1924 und 1933
 Komplexe Analyse von Wahldaten am Beispiel der Wahlen in Deutschland zwischen 1924 und 1933 André Klima1, Helmut Küchenhoff1, Paul W. Thurner2 1 Statistisches Beratungslabor, Institut für Statistik 2 Geschwister-Scholl-Institut
Komplexe Analyse von Wahldaten am Beispiel der Wahlen in Deutschland zwischen 1924 und 1933 André Klima1, Helmut Küchenhoff1, Paul W. Thurner2 1 Statistisches Beratungslabor, Institut für Statistik 2 Geschwister-Scholl-Institut
Empirische Softwaretechnik
 Empirische Softwaretechnik Prof. Dr. Walter F. Tichy Dr. Matthias Müller Sommersemester 2006 1 Einführung in das Statistikpaket 2 R?! nicht vergleichbar mit den üblichen Statistikprogrammen wie SAS oder
Empirische Softwaretechnik Prof. Dr. Walter F. Tichy Dr. Matthias Müller Sommersemester 2006 1 Einführung in das Statistikpaket 2 R?! nicht vergleichbar mit den üblichen Statistikprogrammen wie SAS oder
Zusammenhänge zwischen metrischen Merkmalen
 Zusammenhänge zwischen metrischen Merkmalen Darstellung des Zusammenhangs, Korrelation und Regression Daten liegen zu zwei metrischen Merkmalen vor: Datenpaare (x i, y i ), i = 1,..., n Beispiel: x: Anzahl
Zusammenhänge zwischen metrischen Merkmalen Darstellung des Zusammenhangs, Korrelation und Regression Daten liegen zu zwei metrischen Merkmalen vor: Datenpaare (x i, y i ), i = 1,..., n Beispiel: x: Anzahl
Lösungen zur Prüfung Angewandte Statistische Methoden in den Nutzierwissenschaften FS 2016
 ETH Zürich D-USYS Institut für Agrarwissenschaften Lösungen zur Prüfung Angewandte Statistische Methoden in den Nutzierwissenschaften FS 2016 Peter von Rohr Datum 30. Mai 2016 Beginn 08:00 Uhr Ende 08:45
ETH Zürich D-USYS Institut für Agrarwissenschaften Lösungen zur Prüfung Angewandte Statistische Methoden in den Nutzierwissenschaften FS 2016 Peter von Rohr Datum 30. Mai 2016 Beginn 08:00 Uhr Ende 08:45
Schweizer Statistiktage, Aarau, 18. Nov. 2004
 Schweizer Statistiktage, Aarau, 18. Nov. 2004 Qualitative Überprüfung der Modellannahmen in der linearen Regressionsrechnung am Beispiel der Untersuchung der Alterssterblichkeit bei Hitzeperioden in der
Schweizer Statistiktage, Aarau, 18. Nov. 2004 Qualitative Überprüfung der Modellannahmen in der linearen Regressionsrechnung am Beispiel der Untersuchung der Alterssterblichkeit bei Hitzeperioden in der
# Befehl für den Lilliefors-Test
 1/5 Matthias Rudolf & Diana Vogel R-Kurs Graduiertenakademie September 2017 Loesungsskript: Tests 1a library(nortest) 1b lillie.test Befehl für den Lilliefors-Test 2a, Datensatz "Schachbeispiel einlesen"
1/5 Matthias Rudolf & Diana Vogel R-Kurs Graduiertenakademie September 2017 Loesungsskript: Tests 1a library(nortest) 1b lillie.test Befehl für den Lilliefors-Test 2a, Datensatz "Schachbeispiel einlesen"
Beispiel 48. 4.3.2 Zusammengesetzte Zufallsvariablen
 4.3.2 Zusammengesetzte Zufallsvariablen Beispiel 48 Ein Würfel werde zweimal geworfen. X bzw. Y bezeichne die Augenzahl im ersten bzw. zweiten Wurf. Sei Z := X + Y die Summe der gewürfelten Augenzahlen.
4.3.2 Zusammengesetzte Zufallsvariablen Beispiel 48 Ein Würfel werde zweimal geworfen. X bzw. Y bezeichne die Augenzahl im ersten bzw. zweiten Wurf. Sei Z := X + Y die Summe der gewürfelten Augenzahlen.
Angewandte Ökonometrie, WS 2012/13, 1. Teilprüfung am 6.12.2012 - Lösungen. Das folgende Modell ist ein GARCH(1,1)-Modell:
-Modell:") Angewandte Ökonometrie, WS 2012/13, 1. Teilprüfung am 6.12.2012 - Lösungen LV-Leiterin: Univ.Prof.Dr. Sylvia Frühwirth-Schnatter 1 Wahr oder falsch? 1. Das folgende Modell ist ein GARCH(1,1)-Modell: Y
Angewandte Ökonometrie, WS 2012/13, 1. Teilprüfung am 6.12.2012 - Lösungen LV-Leiterin: Univ.Prof.Dr. Sylvia Frühwirth-Schnatter 1 Wahr oder falsch? 1. Das folgende Modell ist ein GARCH(1,1)-Modell: Y
1 Einfachregression 1.1In 10 Haushalten wurden Einkommen und Ausgaben für Luxusgüter erfragt:
 Beispiele zum Üben und Wiederholen zu Wirtschaftsstatistik 2 (Kurs 3) 1 Einfachregression 1.1In 10 Haushalten wurden Einkommen und Ausgaben für Luxusgüter erfragt: Haushaltseinkommen 12 24 30 40 80 60
Beispiele zum Üben und Wiederholen zu Wirtschaftsstatistik 2 (Kurs 3) 1 Einfachregression 1.1In 10 Haushalten wurden Einkommen und Ausgaben für Luxusgüter erfragt: Haushaltseinkommen 12 24 30 40 80 60
Statistik für Ingenieure Vorlesung 13
 Statistik für Ingenieure Vorlesung 13 Prof. Dr. Hans-Jörg Starkloff TU Bergakademie Freiberg Institut für Stochastik 6. Februar 2018 5.1.4. Weitere ausgewählte statistische Tests a) Binomialtest Der Binomialtest
Statistik für Ingenieure Vorlesung 13 Prof. Dr. Hans-Jörg Starkloff TU Bergakademie Freiberg Institut für Stochastik 6. Februar 2018 5.1.4. Weitere ausgewählte statistische Tests a) Binomialtest Der Binomialtest
Statistische Datenanalyse mit SPSS
 Aus dem Kursangebot des Rechenzentrums: Statistische Datenanalyse mit SPSS Dozent: Termine: Raum: Johannes Hain, Lehrstuhl für Mathematik VIII Statistik 24. bis 27.08.2015 jeweils von 13:00 bis 16:00 Uhr
Aus dem Kursangebot des Rechenzentrums: Statistische Datenanalyse mit SPSS Dozent: Termine: Raum: Johannes Hain, Lehrstuhl für Mathematik VIII Statistik 24. bis 27.08.2015 jeweils von 13:00 bis 16:00 Uhr
Peter M. Schneider. Zum Stand der Entwicklung und Anwendung probabilistischer Software für f r die Interpretation von komplexen DNA-Mischspuren
 Zum Stand der Entwicklung und Anwendung probabilistischer Software für f r die Interpretation von komplexen DNA-Mischspuren Peter M. Schneider 35. Spurenworkshop Complex Mixtures Komplexe Mischungen Mixture
Zum Stand der Entwicklung und Anwendung probabilistischer Software für f r die Interpretation von komplexen DNA-Mischspuren Peter M. Schneider 35. Spurenworkshop Complex Mixtures Komplexe Mischungen Mixture
Profil A 49,3 48,2 50,7 50,9 49,8 48,7 49,6 50,1 Profil B 51,8 49,6 53,2 51,1 51,1 53,4 50,7 50 51,5 51,7 48,8
 1. Aufgabe: Eine Reifenfirma hat für Winterreifen unterschiedliche Profile entwickelt. Bei jeweils gleicher Geschwindigkeit und auch sonst gleichen Bedingungen wurden die Bremswirkungen gemessen. Die gemessenen
1. Aufgabe: Eine Reifenfirma hat für Winterreifen unterschiedliche Profile entwickelt. Bei jeweils gleicher Geschwindigkeit und auch sonst gleichen Bedingungen wurden die Bremswirkungen gemessen. Die gemessenen
Inhaltsverzeichnis. Regressionsanalyse. http://mesosworld.ch - Stand vom: 20.1.2010 1
 Inhaltsverzeichnis Regressionsanalyse... 2 Lernhinweise... 2 Einführung... 2 Theorie (1-8)... 2 1. Allgemeine Beziehungen... 3 2. 'Best Fit'... 3 3. 'Ordinary Least Squares'... 4 4. Formel der Regressionskoeffizienten...
Inhaltsverzeichnis Regressionsanalyse... 2 Lernhinweise... 2 Einführung... 2 Theorie (1-8)... 2 1. Allgemeine Beziehungen... 3 2. 'Best Fit'... 3 3. 'Ordinary Least Squares'... 4 4. Formel der Regressionskoeffizienten...
Eine Einführung in R: Varianzanalyse
 Eine Einführung in R: Varianzanalyse Bernd Klaus, Verena Zuber Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig 13. Dezember 2012 Bernd Klaus, Verena Zuber,
Eine Einführung in R: Varianzanalyse Bernd Klaus, Verena Zuber Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig 13. Dezember 2012 Bernd Klaus, Verena Zuber,
Aufgabensammlung (Nicht-MC-Aufgaben) Klausur Ökonometrie WS 2014/15. ( = 57 Punkte)
 Klausur Ökonometrie WS 2014/15. ( = 57 Punkte)") Aufgabe 3 (6 + 4 + 8 + 4 + 10 + 4 + 9 + 4 + 8 = 57 Punkte) Hinweis: Beachten Sie die Tabellen mit Quantilen am Ende der Aufgabenstellung! Mit Hilfe eines multiplen linearen Regressionsmodells soll auf
Aufgabe 3 (6 + 4 + 8 + 4 + 10 + 4 + 9 + 4 + 8 = 57 Punkte) Hinweis: Beachten Sie die Tabellen mit Quantilen am Ende der Aufgabenstellung! Mit Hilfe eines multiplen linearen Regressionsmodells soll auf
Prognosen. Prognosen sind schwierig, besonders wenn sie die Zukunft betreffen. Auch ein Weiser hat nicht immer recht Prognosefehler sind hoch
 Universität Ulm 8969 Ulm Germany Dipl.-WiWi Sabrina Böck Institut für Wirtschaftspolitik Fakultät für Mathematik und Wirtschaftswissenschaften Ludwig-Erhard-Stiftungsprofessur Wintersemester 8/9 Prognosen
Universität Ulm 8969 Ulm Germany Dipl.-WiWi Sabrina Böck Institut für Wirtschaftspolitik Fakultät für Mathematik und Wirtschaftswissenschaften Ludwig-Erhard-Stiftungsprofessur Wintersemester 8/9 Prognosen