Analytische Statistik I. Statistische Methoden in der Korpuslinguistik Heike Zinsmeister WS 2009/10
|
|
|
- Herbert Karlheinz Winter
- vor 8 Jahren
- Abrufe
Transkript
1 Analytische Statistik I Statistische Methoden in der Korpuslinguistik Heike Zinsmeister WS 2009/10

2 Testen Anpassungstests (goodness of fit) Weicht eine gegebene Verteilung signifikant von einer bekannten Verteilung ab? Weicht der Mittelwert oder die Standardabweichung einer gegebenen Stichprobe signifikant von einem anderweitig gegebenen Mittelwert oder Standardabweichung ab? Unterschiedstests Weicht eine gegebene Verteilung signifikant von einer anderen ebenfalls gegebenen Verteilung ab?

3 Vorüberlegungen Testen über das Bilden einer Nullhypothese H 0, die widerlegt werden soll der statistische Test erzeugt eine Test- Statistik mit bekannter Verteilung Idee H 0 nimmt an, dass die Teststatistik keinen extremen Wert annimmt Hypothese H1 nimmt an, dass die Teststatistik einen extremen Wert annimmt extrem = weit außen in den Rändern/Flügeln der Distribution

4 Vorüberlegungen "weit draußen" p-wert: Wahrscheinlichkeit aller summierten Teststatistik-Werte vom statistischen Prüfwert q bis zum Ende der Kurve (bzw. Fläche unter der Kurve) Irrtumswahrscheinlichkeit, dass fälschlicherweise H 1 angenommen wird Festlegung: Signifikanzniveau α p=0.05 (95%) p=0.01 (99%) p=0.001 (99,9%)
 p=0.01 (99%) p=0.")
5 Normalverteilung library(languager) shadenormal.fnc(qnts= c(0.025,0.975))

6 Schätzen des Mittelwerts Problem: die Varianz eines Merkmals in der Grundgesamtheit ist unbekannt Vorgehen: Schätzen aufgrund von einer Stichprobenvarianz Beobachtung: der standardisierte Mittelwert normalverteilter Daten ist bei dieser Schätzung nicht mehr normalverteilt, sondern weist für kleine Werte des Parameters n eine größere Breite und Flankenbetonung der Mittelwert ist t-verteilt ( Students t-verteilung ) Hypothesentests, bei denen die t-verteilung Verwendung wird: verschiedene t-tests
 Hypothesentests, bei denen die t-verteilung Verwendung wird: verschiedene t-tests 20. 01.")
7 t-verteilung Code: siehe ab Folie 9. df = degrees of freedom. Anzahl der frei veränderbaren Parameter. Hier: n

8 t-verteilung
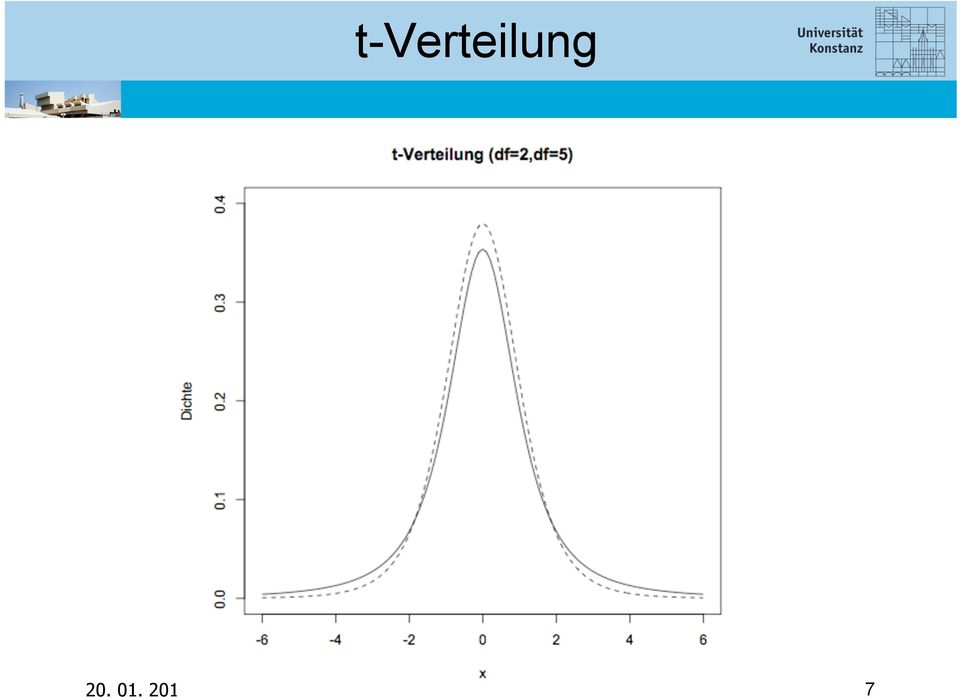
9 t-verteilung
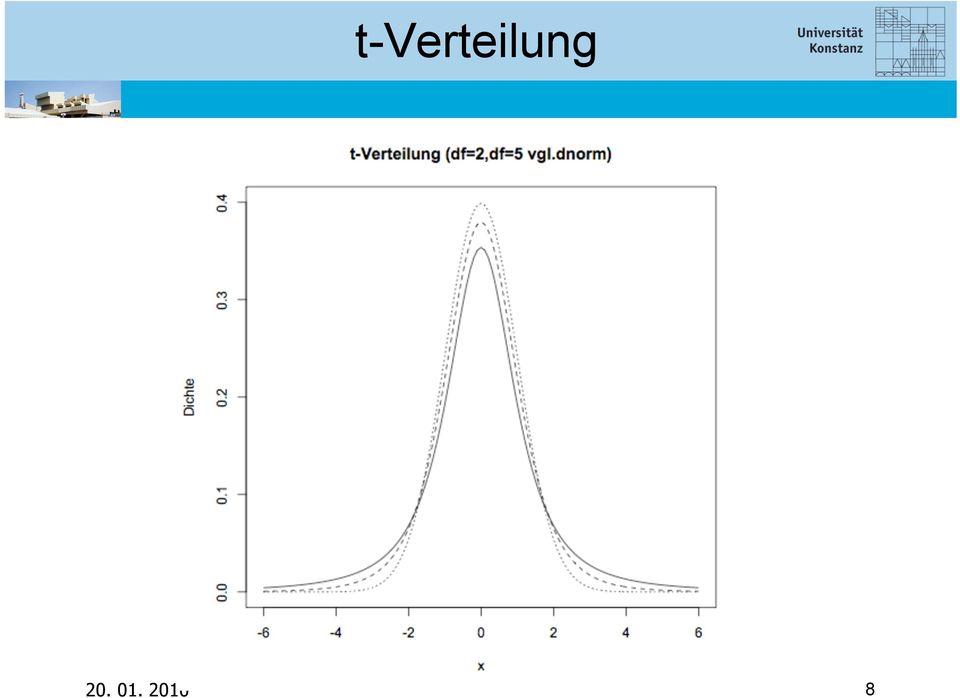
10 t-verteilung mit zunehmender Anzahl an Freiheitsgraden df (d.h. veränderbaren Parametern), nähert sich die t-verteilung der Normalverteilung an ab df>30 ist der Unterschied redundant das heißt, ab einer Datengrundlage von mehr als 30 Dateneinheiten können selbst bei unbekannter Varianz Tests verwendet werden, die auf der Normalverteilung basieren

11 Code für die t-verteilungsfolien x=seq(-6,6,0.1) # Intitialisierung # par(mfrow=c(2,2)) # mehrere Diagramme y1=dt(x,2) # df=2 # 1. Diagramm plot(x,y1, xlab="x", ylab="dichte", ylim=c(0,0.4), type="l", main="t-verteilung (df=2)") # 2. Diagramm plot(x,y1, xlab="x", ylab="dichte", ylim=c(0,0.4), type="l", main="t-verteilung (df=2,df=5)") y2=dt(x,5) # df=5 lines(x,y2, type="l", lty= 2) # lty: line type # 3. Diagramm plot(x,y1, xlab="x", ylab="dichte", ylim=c(0,0.4), type="l", main="t-verteilung (df=2,df=5 vgl.dnorm)") lines(x,y2, type="l", lty= 2) y3=dnorm(x) # vgl. Normalverteilung lines(x,y3, type="l", lty= 3)
, type=\"l\", main=\"t-verteilung (df=2,df=5)\") y2=dt(x,5) # df=5 lines(x,y2, type=\"l\", lty= 2) # lty: line type # 3.")
12 Anpassungstest Fall 1 eine abhängige Variable auf Verhältnisniveau Test: sind die Daten normalverteilt? Methode Shapiro-Wilk-Test, shapiro.test() Ablaufschema 1. Formulieren der Hypothesen 2. Graphische Betrachtung 3. Ermittlung der Prüfstatistik W und der Irrtumswahrscheinlichkeit p

13 Beispiel: Anpassungstest: Fall 1 Spracherwerbsdaten des Russischen zur Aspekthypothese (vgl. Stoll und Gries, Ms.) anfänglich starke Korrelation von Präsens und imperfektivem Aspekt sowie Präteritum und perfektivem Aspekt Frage: wie entwickelt sich das Korrelationsmaß über die Zeit? Test: sind die Korrelationsmaße von 117 Aufnahmen normalverteilt? eine abhängige Variable auf Verhältnisniveau Normalverteilung?

14 Anpassungstest: Fall 1 Hypothesen H 0 : Die Datenpunkte weisen eine Normalverteilung auf; W = 1. H 1 : Die Datenpunkte weisen keine Normalverteilung auf; W 1. eine abhängige Variable auf Verhältnisniveau Normalverteilung?

15 Anpassungstest: Fall 1 Graphische Betrachtung: eine abhängige Variable auf Verhältnisniveau Normalverteilung? # Datei: /Users/cluser/Korpuslinguistik/_sflwr/_inputfiles/g_data_chapters_1-5/ _tempus-aspekt.txt Russisch=read.table(file=file.choose(), header=t) attach(russisch) hist(tempus_aspekt, xlim=c(0, 1), freq=f, xlab="tempus-aspekt-korrelation", ylab="dichte", main="") 20. lines(density(tempus_aspekt))

16 Anpassungstest: Fall 1 Prüfstatistik shapiro.test(tempus_aspekt) eine abhängige Variable auf Verhältnisniveau Normalverteilung? Shapiro-Wilk normality test data: TEMPUS_ASPEKT W = , p-value = p>0.05 H 0 gilt: Daten sind normalverteilt H 1 darf nicht angenommen werden

17 Anpassungstest: Fall 1 eine abhängige Variable auf Verhältnisniveau Normalverteilung? Schriftliche Zusammenfassung der Ergebnisse "Die Verteilung der Cramers V-Werte [des Korrelationsmaßes] für die Tempus-Aspekt- Korrelation bei diesem Kind weicht gemäß einem Shapiro-Wilk-Test nicht signifikant von der Normalverteilung ab: W= 0,9942; p = 0,9132." (nach Gries 2008: 156)
![Korrelationsmaßes] für die Tempus-Aspekt- Korrelation bei diesem Kind weicht gemäß einem](/docs-images/45/11432016/images/page_17.jpg "Shapiro-Wilk-Test nicht signifikant von der Normalverteilung ab: W= 0,9942; p = 0,9132.")
18 Weiterer Test auf Normalverteilung Quantile-quantile Plot Quantilen der Standardnormalverteilung auf der x- Achse Quantilen der beobachteten Verteilung auf der y- Achse Bei Normalverteilung bildet Plot eine diagonale Linie (unabhängige von Mittelwert und Standardabweichung) ermöglicht eine intuitive "positive" Überprüfung von Normalverteilung, ersetzt aber nicht einen statistischen Test

19 Weiterer Test auf Normalverteilung Unsere Beispieldaten: qqnorm(tempus_aspekt) qqline(tempus_aspekt)
")
20 Anpassungstest: Fall 2 Fall 2 eine abhängige Variable auf Nominal- oder Kategorialniveau Frage: sind zwei Ausprägungen einer Variable gleich häufig? Test: sind die Daten so verteilt, dass sie einer bekannten Verteilung entsprechen? Methode: Chi-Quadrat-Test; chisq.test()

21 Anpassungstest: Fall 2 Methode: Chi-Quadrat-Test; chisq.test() Voraussetzungen Alle Beobachtungen sind von einander unabhängig 80% der erwarteten Häufigkeiten sind größer oder gleich 5 Alle erwarteten Häufigkeiten sind größer als
22 Anpassungstest: Fall 2 Methode: Chi-Quadrat-Test; chisq.test() Ablaufschema 1. Formulierung der Hypothesen 2. Tabellierung der beobachteten Häufigkeiten; graphische Betrachtung 3. Ermitteln der Häufigkeiten, die gemäß H 0 zu erwarten wären. 4. Testen der Voraussetzungen 5. Berechnen der Abweichungsmaße für alle beobachteten Häufigkeiten 6. Summierung der Abweichungsmaße zur Ermittlung der Prüfstatistik χ 2 7. Ermittlung der Freiheitsgrade df und der Irrtumswahrscheinlichkeit p
23 Anpassungstest: Fall 2 Beispiel Worstellungsalternation a. He picked up the book Verb-Partikel-direktes_Objekt b. He picked the book up Verb-direktes_Objekt-Partikel Frage Beide Konstruktionen werden von vielen für bedeutungsgleich gehalten. Sind sie gleich häufig?
24 Hypothesen Anpassungstest: Fall 2 H 0 : Die Häufigkeit der Variablenausprägungen der Variable Konstruktion sind identisch; die Variation in der gezogenen Stichprobe ist zufällig. H 1 : Die Häufigkeiten der Variablenausprägungen der Variable Konstruktion sind nicht identisch; die Variation in der Stichprobe ist nicht zufällig. In statistischer Form: H 0 : n V PART DO = n V DO PART H 1 : n V PART DO n V DO PART eine abhängige Variable auf Nominal-/Kategorialniveau Chi-Quadrat-Verteilung?
25 Anpassungstest: Fall 2 eine abhängige Variable auf Nominal-/Kategorialniveau Tabellierung der beobachteten Häufigkeiten Experiment Beschreibungen von Bildern (Peters 2001) Chi-Quadrat-Verteilung? Verb-Partikel-direktes_Objekt 247 Verb-direktes_Objekt-Partikel 150 pie(vpcs, labels=c("verb- Partikel-Direktes Objekt", "Verb-Direktes Objekt- Partikel"))
26 Anpassungstest: Fall 2 eine abhängige Variable auf Nominal-/Kategorialniveau Chi-Quadrat-Verteilung? Ermitteln der Häufigkeiten, die gemäß H 0 zu erwarten wären. Verb-Partikel-direktes_Objekt 198,5 Verb-direktes_Objekt-Partikel 198,5 In R: VPCs.erw<-rep(sum(VPCs)/length(VPCs), length(vpcs)) Testen der Voraussetzungen: OK
27 Anpassungstest: Fall 2 Berechnen der Abweichungsmaße für alle beobachteten Häufigkeiten und Summierung der Abweichungsmaße zur Ermittlung der Prüfstatistik χ 2 Chi " Quadrat = # 2 = In R: eine abhängige Variable auf Nominal-/Kategorialniveau Chi-Quadrat-Verteilung? ( beobachtet " erwartet) 2 $ n i=1 erwartet! sum(((vpcs-vpcs.erw)^2)/vpcs.erw) ca. 23,
28 Einschub: Werte von χ 2 Große Abweichung höherer Chi-Quadrat-Wert Keine Abweichung Chi-Quadrat-Wert = 0 Statistische Hypothesen - reformuliert H 0 : χ 2 = 0. H 1 : χ 2 >
29 Anpassungstest: Fall 2 Interpretation des Chi-Quadrat-Werts Ermittlung der Freiheitsgrade df und der Irrtumswahrscheinlichkeit p df =1 Kritische χ 2 -Werte für p zweiseitig eine abhängige Variable auf Nominal-/Kategorialniveau Chi-Quadrat-Verteilung? p=0,05 p=0,01 p=0,001 df=1 3,841 6,635 10,827 df=2 5,991 9,21 13,815 df=3 7,815 11,345 16,
30 Kritische Werte in R erstellen # ermittle den kritischen Chi-Quadrat-Wert fuer p=0,05, 0,01 und 0,001 (bei df=1) qchisq(c(0.05, 0.01, 0.001), 1, lower.tail=f) [1] # ermittle die kritischen Chi-Quadrat-Wert fuer p=0,05, 0,01 und 0,001 (bei df=1, df=2 und df=3) p.werte<-matrix(rep(c(0.05, 0.01, 0.001), 3), byrow=t, ncol=3) df.werte<-matrix(rep(1:3, 3), byrow=f, ncol=3) qchisq(p.werte, df.werte, lower.tail=f) [,1] [,2] [,3] [1,] [2,] [3,] (Gries 2008: 160)
31 Anpassungstest: Fall 2 Interpretation des Ergebnisses 23,7 > 10,827 Ablehnung der Nullhypothese "Die Verteilung der beiden Konstruktionen weicht gemäß einem Chi-Quadrat-Anpassungstest hoch signifikant von der erwarteten Gleichverteilung ab (χ 2 =23,7; df= 1; p zweiseitig < 0,001): Die Konstruktion V-PTK-DO wurde 247 Mal beobachtet, obwohl sie nur 199 Mal erwartet wurde. Die Konstruktion V-DO-PTK wurde nur 150 Mal beobachtet, obwohl sie 199 Mal erwartet wurde." (nach Gries 2008: 161)
32 Der Chi-Quadrat-Test in R Ermittlung des genauen p-werts in R pchisq(23.7, 1, lower.tail=f) [1] e-06 Der eigentliche Test chisq.test(vpcs, p=c(0.5, 0.5)) Chi-squared test for given probabilities data: VPCs X-squared = , df = 1, p-value = 1.126e
33 Der Chi-Quadrat-Test in R Ermittlung der gesamten Information von chisq.test() test<-chisq.test(vpcs, p=c(0.5, 0.5)) str(test) Daraus abgeleitet: die erwarteten Häufigkeiten test$expected [1]
34 Schlusskommentar Der Chi-Quadrat-Test ist ein zweiseitiger Test Bei df=1 ist auch ein einseitiger Test möglich durch Halbierung des pchisq()-werts Analoger Test für relative Häufigkeiten: prop.test() Test auf signifikante Abweichungen einer relativen Häufigkeit zu einer erwarteten relativen Häufigkeit
9. Schätzen und Testen bei unbekannter Varianz
 9. Schätzen und Testen bei unbekannter Varianz Dr. Antje Kiesel Institut für Angewandte Mathematik WS 2011/2012 Schätzen und Testen bei unbekannter Varianz Wenn wir die Standardabweichung σ nicht kennen,
9. Schätzen und Testen bei unbekannter Varianz Dr. Antje Kiesel Institut für Angewandte Mathematik WS 2011/2012 Schätzen und Testen bei unbekannter Varianz Wenn wir die Standardabweichung σ nicht kennen,
Analytische Statistik: Varianzanpassungstest, Varianzhomogenitätstest. Statistische Methoden in der Korpuslinguistik Heike Zinsmeister WS 2008/09
 Analytische Statistik: Varianzanpassungstest, Varianzhomogenitätstest Statistische Methoden in der Korpuslinguistik Heike Zinsmeister WS 2008/09 Varianzanpassungstest Untersuchung der Streuung einer bzw.
Analytische Statistik: Varianzanpassungstest, Varianzhomogenitätstest Statistische Methoden in der Korpuslinguistik Heike Zinsmeister WS 2008/09 Varianzanpassungstest Untersuchung der Streuung einer bzw.
Melanie Kaspar, Prof. Dr. B. Grabowski 1
 7. Hypothesentests Ausgangssituation: Man muss sich zwischen 2 Möglichkeiten (=Hypothesen) entscheiden. Diese Entscheidung soll mit Hilfe von Beobachtungen ( Stichprobe ) getroffen werden. Die Hypothesen
7. Hypothesentests Ausgangssituation: Man muss sich zwischen 2 Möglichkeiten (=Hypothesen) entscheiden. Diese Entscheidung soll mit Hilfe von Beobachtungen ( Stichprobe ) getroffen werden. Die Hypothesen
Statistik II für Betriebswirte Vorlesung 2
 PD Dr. Frank Heyde TU Bergakademie Freiberg Institut für Stochastik Statistik II für Betriebswirte Vorlesung 2 21. Oktober 2014 Verbundene Stichproben Liegen zwei Stichproben vor, deren Werte einander
PD Dr. Frank Heyde TU Bergakademie Freiberg Institut für Stochastik Statistik II für Betriebswirte Vorlesung 2 21. Oktober 2014 Verbundene Stichproben Liegen zwei Stichproben vor, deren Werte einander
Bachelorabschlussseminar Dipl.-Kfm. Daniel Cracau
 1 Einführung in die statistische Datenanalyse Bachelorabschlussseminar Dipl.-Kfm. Daniel Cracau 2 Gliederung 1.Grundlagen 2.Nicht-parametrische Tests a. Mann-Whitney-Wilcoxon-U Test b. Wilcoxon-Signed-Rank
1 Einführung in die statistische Datenanalyse Bachelorabschlussseminar Dipl.-Kfm. Daniel Cracau 2 Gliederung 1.Grundlagen 2.Nicht-parametrische Tests a. Mann-Whitney-Wilcoxon-U Test b. Wilcoxon-Signed-Rank
Quantitative Auswertung. Korpuslinguistik Dr. Heike Zinsmeister
 Quantitative Auswertung Korpuslinguistik Dr. Heike Zinsmeister 02.12.2011 Analysetypen Deskriptive Statistik Beschreibung der 'Gestalt' von Datenverteilungen Grafische Darstellungen Zentrale Maße (Mittelwert
Quantitative Auswertung Korpuslinguistik Dr. Heike Zinsmeister 02.12.2011 Analysetypen Deskriptive Statistik Beschreibung der 'Gestalt' von Datenverteilungen Grafische Darstellungen Zentrale Maße (Mittelwert
Tutorial: Homogenitätstest
 Tutorial: Homogenitätstest Eine Bank möchte die Kreditwürdigkeit potenzieller Kreditnehmer abschätzen. Einerseits lebt die Bank ja von der Vergabe von Krediten, andererseits verursachen Problemkredite
Tutorial: Homogenitätstest Eine Bank möchte die Kreditwürdigkeit potenzieller Kreditnehmer abschätzen. Einerseits lebt die Bank ja von der Vergabe von Krediten, andererseits verursachen Problemkredite
Eine Einführung in R: Statistische Tests
 Eine Einführung in R: Statistische Tests Bernd Klaus, Verena Zuber Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.uni-leipzig.de/ zuber/teaching/ws12/r-kurs/
Eine Einführung in R: Statistische Tests Bernd Klaus, Verena Zuber Institut für Medizinische Informatik, Statistik und Epidemiologie (IMISE), Universität Leipzig http://www.uni-leipzig.de/ zuber/teaching/ws12/r-kurs/
Grundlagen der Inferenzstatistik
 Grundlagen der Inferenzstatistik (Induktive Statistik oder schließende Statistik) Dr. Winfried Zinn 1 Deskriptive Statistik versus Inferenzstatistik Die Deskriptive Statistik stellt Kenngrößen zur Verfügung,
Grundlagen der Inferenzstatistik (Induktive Statistik oder schließende Statistik) Dr. Winfried Zinn 1 Deskriptive Statistik versus Inferenzstatistik Die Deskriptive Statistik stellt Kenngrößen zur Verfügung,
Güte von Tests. die Wahrscheinlichkeit für den Fehler 2. Art bei der Testentscheidung, nämlich. falsch ist. Darauf haben wir bereits im Kapitel über
 Güte von s Grundlegendes zum Konzept der Güte Ableitung der Gütefunktion des Gauss im Einstichprobenproblem Grafische Darstellung der Gütefunktionen des Gauss im Einstichprobenproblem Ableitung der Gütefunktion
Güte von s Grundlegendes zum Konzept der Güte Ableitung der Gütefunktion des Gauss im Einstichprobenproblem Grafische Darstellung der Gütefunktionen des Gauss im Einstichprobenproblem Ableitung der Gütefunktion
Motivation. Wilcoxon-Rangsummentest oder Mann-Whitney U-Test. Wilcoxon Rangsummen-Test Voraussetzungen. Bemerkungen
 Universität Karlsruhe (TH) Forschungsuniversität gegründet 825 Wilcoxon-Rangsummentest oder Mann-Whitney U-Test Motivation In Experimenten ist die Datenmenge oft klein Daten sind nicht normalverteilt Dann
Universität Karlsruhe (TH) Forschungsuniversität gegründet 825 Wilcoxon-Rangsummentest oder Mann-Whitney U-Test Motivation In Experimenten ist die Datenmenge oft klein Daten sind nicht normalverteilt Dann
Biostatistik, WS 2015/2016 Der zwei-stichproben-t-test
 1/29 Biostatistik, WS 2015/2016 Der zwei-stichproben-t-test (t-test für ungepaarte Stichproben) Matthias Birkner http://www.staff.uni-mainz.de/birkner/biostatistik1516/ 11.12.2015 2/29 Inhalt 1 t-test
1/29 Biostatistik, WS 2015/2016 Der zwei-stichproben-t-test (t-test für ungepaarte Stichproben) Matthias Birkner http://www.staff.uni-mainz.de/birkner/biostatistik1516/ 11.12.2015 2/29 Inhalt 1 t-test
Analog zu Aufgabe 16.1 werden die Daten durch folgenden Befehl eingelesen: > kredit<-read.table("c:\\compaufg\\kredit.
 Lösung 16.3 Analog zu Aufgabe 16.1 werden die Daten durch folgenden Befehl eingelesen: > kredit
Lösung 16.3 Analog zu Aufgabe 16.1 werden die Daten durch folgenden Befehl eingelesen: > kredit
Franz Kronthaler. Statistik angewandt. Datenanalyse ist (k)eine Kunst. Excel Edition. ^ Springer Spektrum
eine Kunst. Excel Edition. ^ Springer Spektrum") Franz Kronthaler Statistik angewandt Datenanalyse ist (k)eine Kunst Excel Edition ^ Springer Spektrum Inhaltsverzeichnis Teil I Basiswissen und Werkzeuge, um Statistik anzuwenden 1 Statistik ist Spaß 3
Franz Kronthaler Statistik angewandt Datenanalyse ist (k)eine Kunst Excel Edition ^ Springer Spektrum Inhaltsverzeichnis Teil I Basiswissen und Werkzeuge, um Statistik anzuwenden 1 Statistik ist Spaß 3
Willkommen zur Vorlesung Statistik (Master)
") Willkommen zur Vorlesung Statistik (Master) Thema dieser Vorlesung: Verteilungsfreie Verfahren Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften
Willkommen zur Vorlesung Statistik (Master) Thema dieser Vorlesung: Verteilungsfreie Verfahren Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften
Ein möglicher Unterrichtsgang
 Ein möglicher Unterrichtsgang. Wiederholung: Bernoulli Experiment und Binomialverteilung Da der sichere Umgang mit der Binomialverteilung, auch der Umgang mit dem GTR und den Diagrammen, eine notwendige
Ein möglicher Unterrichtsgang. Wiederholung: Bernoulli Experiment und Binomialverteilung Da der sichere Umgang mit der Binomialverteilung, auch der Umgang mit dem GTR und den Diagrammen, eine notwendige
Prüfung eines Datenbestandes
 Prüfung eines Datenbestandes auf Abweichungen einzelner Zahlen vom erwarteten mathematisch-statistischen Verhalten, die nicht mit einem Zufall erklärbar sind (Prüfung auf Manipulationen des Datenbestandes)
Prüfung eines Datenbestandes auf Abweichungen einzelner Zahlen vom erwarteten mathematisch-statistischen Verhalten, die nicht mit einem Zufall erklärbar sind (Prüfung auf Manipulationen des Datenbestandes)
Willkommen zur Vorlesung Statistik
 Willkommen zur Vorlesung Statistik Thema dieser Vorlesung: Varianzanalyse Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften Prof. Dr. Wolfgang
Willkommen zur Vorlesung Statistik Thema dieser Vorlesung: Varianzanalyse Prof. Dr. Wolfgang Ludwig-Mayerhofer Universität Siegen Philosophische Fakultät, Seminar für Sozialwissenschaften Prof. Dr. Wolfgang
Überblick über die Tests
 Anhang A Überblick über die Tests A.1 Ein-Stichproben-Tests A.1.1 Tests auf Verteilungsannahmen ˆ Shapiro-Wilk-Test Situation: Test auf Normalverteilung H 0 : X N(µ, σ 2 ) H 1 : X nicht normalverteilt
Anhang A Überblick über die Tests A.1 Ein-Stichproben-Tests A.1.1 Tests auf Verteilungsannahmen ˆ Shapiro-Wilk-Test Situation: Test auf Normalverteilung H 0 : X N(µ, σ 2 ) H 1 : X nicht normalverteilt
METHODENLEHRE I WS 2013/14 THOMAS SCHÄFER
 METHODENLEHRE I WS 2013/14 THOMAS SCHÄFER DAS THEMA: INFERENZSTATISTIK IV INFERENZSTATISTISCHE AUSSAGEN FÜR ZUSAMMENHÄNGE UND UNTERSCHIEDE Inferenzstatistik für Zusammenhänge Inferenzstatistik für Unterschiede
METHODENLEHRE I WS 2013/14 THOMAS SCHÄFER DAS THEMA: INFERENZSTATISTIK IV INFERENZSTATISTISCHE AUSSAGEN FÜR ZUSAMMENHÄNGE UND UNTERSCHIEDE Inferenzstatistik für Zusammenhänge Inferenzstatistik für Unterschiede
Lösungen zu Janssen/Laatz, Statistische Datenanalyse mit SPSS 1
 LÖSUNG 3A Lösungen zu Janssen/Laatz, Statistische Datenanalyse mit SPSS 1 Mit den Berechnungsfunktionen LG10(?) und SQRT(?) in "Transformieren", "Berechnen" können logarithmierte Werte sowie die Quadratwurzel
LÖSUNG 3A Lösungen zu Janssen/Laatz, Statistische Datenanalyse mit SPSS 1 Mit den Berechnungsfunktionen LG10(?) und SQRT(?) in "Transformieren", "Berechnen" können logarithmierte Werte sowie die Quadratwurzel
Profil A 49,3 48,2 50,7 50,9 49,8 48,7 49,6 50,1 Profil B 51,8 49,6 53,2 51,1 51,1 53,4 50,7 50 51,5 51,7 48,8
 1. Aufgabe: Eine Reifenfirma hat für Winterreifen unterschiedliche Profile entwickelt. Bei jeweils gleicher Geschwindigkeit und auch sonst gleichen Bedingungen wurden die Bremswirkungen gemessen. Die gemessenen
1. Aufgabe: Eine Reifenfirma hat für Winterreifen unterschiedliche Profile entwickelt. Bei jeweils gleicher Geschwindigkeit und auch sonst gleichen Bedingungen wurden die Bremswirkungen gemessen. Die gemessenen
B 2. " Zeigen Sie, dass die Wahrscheinlichkeit, dass eine Leiterplatte akzeptiert wird, 0,93 beträgt. (genauerer Wert: 0,933).!:!!
.!:!!") Das folgende System besteht aus 4 Schraubenfedern. Die Federn A ; B funktionieren unabhängig von einander. Die Ausfallzeit T (in Monaten) der Federn sei eine weibullverteilte Zufallsvariable mit den folgenden
Das folgende System besteht aus 4 Schraubenfedern. Die Federn A ; B funktionieren unabhängig von einander. Die Ausfallzeit T (in Monaten) der Federn sei eine weibullverteilte Zufallsvariable mit den folgenden
Stichprobenauslegung. für stetige und binäre Datentypen
 Stichprobenauslegung für stetige und binäre Datentypen Roadmap zu Stichproben Hypothese über das interessierende Merkmal aufstellen Stichprobe entnehmen Beobachtete Messwerte abbilden Schluss von der Beobachtung
Stichprobenauslegung für stetige und binäre Datentypen Roadmap zu Stichproben Hypothese über das interessierende Merkmal aufstellen Stichprobe entnehmen Beobachtete Messwerte abbilden Schluss von der Beobachtung
9. StatistischeTests. 9.1 Konzeption
 9. StatistischeTests 9.1 Konzeption Statistische Tests dienen zur Überprüfung von Hypothesen über einen Parameter der Grundgesamtheit (bei einem Ein-Stichproben-Test) oder über die Verteilung einer Zufallsvariablen
9. StatistischeTests 9.1 Konzeption Statistische Tests dienen zur Überprüfung von Hypothesen über einen Parameter der Grundgesamtheit (bei einem Ein-Stichproben-Test) oder über die Verteilung einer Zufallsvariablen
Überblick über die Verfahren für Ordinaldaten
 Verfahren zur Analyse ordinalskalierten Daten 1 Überblick über die Verfahren für Ordinaldaten Unterschiede bei unabhängigen Stichproben Test U Test nach Mann & Whitney H Test nach Kruskal & Wallis parametrische
Verfahren zur Analyse ordinalskalierten Daten 1 Überblick über die Verfahren für Ordinaldaten Unterschiede bei unabhängigen Stichproben Test U Test nach Mann & Whitney H Test nach Kruskal & Wallis parametrische
Statistik mit Excel. für Praktiker: Statistiken aufbereiten und präsentieren HORST-DIETER RADKE
 Statistik mit Excel für Praktiker: Statistiken aufbereiten und präsentieren HORST-DIETER RADKE INHALTS- VERZEICHNIS Vorwort 13 Schreiben Sie uns! 15 1 Statistische Untersuchungen 17 Wozu Statistik? 18
Statistik mit Excel für Praktiker: Statistiken aufbereiten und präsentieren HORST-DIETER RADKE INHALTS- VERZEICHNIS Vorwort 13 Schreiben Sie uns! 15 1 Statistische Untersuchungen 17 Wozu Statistik? 18
Monte-Carlo-Simulationen mit Copulas. Kevin Schellkes und Christian Hendricks 29.08.2011
 Kevin Schellkes und Christian Hendricks 29.08.2011 Inhalt Der herkömmliche Ansatz zur Simulation logarithmischer Renditen Ansatz zur Simulation mit Copulas Test und Vergleich der beiden Verfahren Fazit
Kevin Schellkes und Christian Hendricks 29.08.2011 Inhalt Der herkömmliche Ansatz zur Simulation logarithmischer Renditen Ansatz zur Simulation mit Copulas Test und Vergleich der beiden Verfahren Fazit
90-minütige Klausur Statistik für Studierende der Kommunikationswissenschaft
 Prof. Dr. Helmut Küchenhoff SS08 90-minütige Klausur Statistik für Studierende der Kommunikationswissenschaft am 22.7.2008 Anmerkungen Überprüfen Sie bitte sofort, ob Ihre Angabe vollständig ist. Sie sollte
Prof. Dr. Helmut Küchenhoff SS08 90-minütige Klausur Statistik für Studierende der Kommunikationswissenschaft am 22.7.2008 Anmerkungen Überprüfen Sie bitte sofort, ob Ihre Angabe vollständig ist. Sie sollte
Einige Statistische Tests für den Ein- Zwei- und k-stichprobenfall (Nach Sachs, Stat. Meth.)
") ue biostatistik: nichtparametrische testverfahren / ergänzung 1/6 h. Lettner / physik Statistische Testverfahren Einige Statistische Tests für den Ein- Zwei- und k-stichprobenfall (Nach Sachs, Stat. Meth.)
ue biostatistik: nichtparametrische testverfahren / ergänzung 1/6 h. Lettner / physik Statistische Testverfahren Einige Statistische Tests für den Ein- Zwei- und k-stichprobenfall (Nach Sachs, Stat. Meth.)
Statistik II für Betriebswirte Vorlesung 3
 PD Dr. Frank Heyde TU Bergakademie Freiberg Institut für Stochastik Statistik II für Betriebswirte Vorlesung 3 5. November 2013 Beispiel: Aktiensplit (Aczel & Sounderpandan, Aufg. 14-28) Ein Börsenanalyst
PD Dr. Frank Heyde TU Bergakademie Freiberg Institut für Stochastik Statistik II für Betriebswirte Vorlesung 3 5. November 2013 Beispiel: Aktiensplit (Aczel & Sounderpandan, Aufg. 14-28) Ein Börsenanalyst
Statistik mit Excel. für Praktiker: Statistiken aufbereiten und präsentieren HORST-DIETER RADKE. Markt+Technik
 Statistik mit Excel für Praktiker: Statistiken aufbereiten und präsentieren HORST-DIETER RADKE Markt+Technik Vorwort Schreiben Sie uns! 13 15 Statistische Untersuchungen 17 Wozu Statistik? 18 Wirtschaftliche
Statistik mit Excel für Praktiker: Statistiken aufbereiten und präsentieren HORST-DIETER RADKE Markt+Technik Vorwort Schreiben Sie uns! 13 15 Statistische Untersuchungen 17 Wozu Statistik? 18 Wirtschaftliche
Forschungsstatistik I
 Prof. Dr. G. Meinhardt. Stock, Nordflügel R. 0-49 (Persike) R. 0- (Meinhardt) Sprechstunde jederzeit nach Vereinbarung Forschungsstatistik I Dr. Malte Persike persike@uni-mainz.de WS 008/009 Fachbereich
Prof. Dr. G. Meinhardt. Stock, Nordflügel R. 0-49 (Persike) R. 0- (Meinhardt) Sprechstunde jederzeit nach Vereinbarung Forschungsstatistik I Dr. Malte Persike persike@uni-mainz.de WS 008/009 Fachbereich
Korrelation - Regression. Berghold, IMI
 Korrelation - Regression Zusammenhang zwischen Variablen Bivariate Datenanalyse - Zusammenhang zwischen 2 stetigen Variablen Korrelation Einfaches lineares Regressionsmodell 1. Schritt: Erstellung eines
Korrelation - Regression Zusammenhang zwischen Variablen Bivariate Datenanalyse - Zusammenhang zwischen 2 stetigen Variablen Korrelation Einfaches lineares Regressionsmodell 1. Schritt: Erstellung eines
Einfache Varianzanalyse für abhängige
 Einfache Varianzanalyse für abhängige Stichproben Wie beim t-test gibt es auch bei der VA eine Alternative für abhängige Stichproben. Anmerkung: Was man unter abhängigen Stichproben versteht und wie diese
Einfache Varianzanalyse für abhängige Stichproben Wie beim t-test gibt es auch bei der VA eine Alternative für abhängige Stichproben. Anmerkung: Was man unter abhängigen Stichproben versteht und wie diese
Varianzanalyse (ANOVA: analysis of variance)
") Varianzanalyse (AOVA: analysis of variance) Einfaktorielle VA Auf der Basis von zwei Stichproben wird bezüglich der Gleichheit der Mittelwerte getestet. Variablen müssen Variablen nur nominalskaliert sein.
Varianzanalyse (AOVA: analysis of variance) Einfaktorielle VA Auf der Basis von zwei Stichproben wird bezüglich der Gleichheit der Mittelwerte getestet. Variablen müssen Variablen nur nominalskaliert sein.
Auswerten mit Excel. Viele Video-Tutorials auf Youtube z.b. http://www.youtube.com/watch?v=vuuky6xxjro
 Auswerten mit Excel Viele Video-Tutorials auf Youtube z.b. http://www.youtube.com/watch?v=vuuky6xxjro 1. Pivot-Tabellen erstellen: In der Datenmaske in eine beliebige Zelle klicken Registerkarte Einfügen
Auswerten mit Excel Viele Video-Tutorials auf Youtube z.b. http://www.youtube.com/watch?v=vuuky6xxjro 1. Pivot-Tabellen erstellen: In der Datenmaske in eine beliebige Zelle klicken Registerkarte Einfügen
Auswertung mit dem Statistikprogramm SPSS: 30.11.05
 Auswertung mit dem Statistikprogramm SPSS: 30.11.05 Seite 1 Einführung SPSS Was ist eine Fragestellung? Beispiel Welche statistische Prozedur gehört zu welcher Hypothese? Statistische Berechnungen mit
Auswertung mit dem Statistikprogramm SPSS: 30.11.05 Seite 1 Einführung SPSS Was ist eine Fragestellung? Beispiel Welche statistische Prozedur gehört zu welcher Hypothese? Statistische Berechnungen mit
Einfache statistische Auswertungen mit dem Programm SPSS
 Einfache statistische Auswertungen mit dem Programm SPSS Datensatz: fiktive_daten.sav Dipl. Päd. Anne Haßelkus Dr. Dorothea Dette-Hagenmeyer 11/2011 Überblick 1 Deskriptive Statistiken; Mittelwert berechnen...
Einfache statistische Auswertungen mit dem Programm SPSS Datensatz: fiktive_daten.sav Dipl. Päd. Anne Haßelkus Dr. Dorothea Dette-Hagenmeyer 11/2011 Überblick 1 Deskriptive Statistiken; Mittelwert berechnen...
5. Schließende Statistik. 5.1. Einführung
 5. Schließende Statistik 5.1. Einführung Sollen auf der Basis von empirischen Untersuchungen (Daten) Erkenntnisse gewonnen und Entscheidungen gefällt werden, sind die Methoden der Statistik einzusetzen.
5. Schließende Statistik 5.1. Einführung Sollen auf der Basis von empirischen Untersuchungen (Daten) Erkenntnisse gewonnen und Entscheidungen gefällt werden, sind die Methoden der Statistik einzusetzen.
i x k k=1 i u i x i v i 1 0,2 24 24 0,08 2 0,4 30 54 0,18 3 0,6 54 108 0,36 4 0,8 72 180 0,60 5 1,0 120 300 1,00 2,22 G = 1 + 1 n 2 n i=1
 1. Aufgabe: Der E-Commerce-Umsatz (in Millionen Euro) der fünf größten Online- Shopping-Clubs liegt wie folgt vor: Club Nr. Umsatz 1 120 2 72 3 54 4 30 5 24 a) Bestimmen Sie den Ginikoeffizienten. b) Zeichnen
1. Aufgabe: Der E-Commerce-Umsatz (in Millionen Euro) der fünf größten Online- Shopping-Clubs liegt wie folgt vor: Club Nr. Umsatz 1 120 2 72 3 54 4 30 5 24 a) Bestimmen Sie den Ginikoeffizienten. b) Zeichnen
Business Value Launch 2006
 Quantitative Methoden Inferenzstatistik alea iacta est 11.04.2008 Prof. Dr. Walter Hussy und David Tobinski UDE.EDUcation College im Rahmen des dokforums Universität Duisburg-Essen Inferenzstatistik Erläuterung
Quantitative Methoden Inferenzstatistik alea iacta est 11.04.2008 Prof. Dr. Walter Hussy und David Tobinski UDE.EDUcation College im Rahmen des dokforums Universität Duisburg-Essen Inferenzstatistik Erläuterung
Statistik für Studenten der Sportwissenschaften SS 2008
 Statistik für Studenten der Sportwissenschaften SS 008 Aufgabe 1 Man weiß von Rehabilitanden, die sich einer bestimmten Gymnastik unterziehen, dass sie im Mittel µ=54 Jahre (σ=3 Jahre) alt sind. a) Welcher
Statistik für Studenten der Sportwissenschaften SS 008 Aufgabe 1 Man weiß von Rehabilitanden, die sich einer bestimmten Gymnastik unterziehen, dass sie im Mittel µ=54 Jahre (σ=3 Jahre) alt sind. a) Welcher
Gemischte Modelle. Fabian Scheipl, Sonja Greven. SoSe 2011. Institut für Statistik Ludwig-Maximilians-Universität München
 Gemischte Modelle Fabian Scheipl, Sonja Greven Institut für Statistik Ludwig-Maximilians-Universität München SoSe 2011 Inhalt Amsterdam-Daten: LMM Amsterdam-Daten: GLMM Blutdruck-Daten Amsterdam-Daten:
Gemischte Modelle Fabian Scheipl, Sonja Greven Institut für Statistik Ludwig-Maximilians-Universität München SoSe 2011 Inhalt Amsterdam-Daten: LMM Amsterdam-Daten: GLMM Blutdruck-Daten Amsterdam-Daten:
Prüfen von Mittelwertsunterschieden: t-test
 Prüfen von Mittelwertsunterschieden: t-test Sven Garbade Fakultät für Angewandte Psychologie SRH Hochschule Heidelberg sven.garbade@hochschule-heidelberg.de Statistik 1 S. Garbade (SRH Heidelberg) t-test
Prüfen von Mittelwertsunterschieden: t-test Sven Garbade Fakultät für Angewandte Psychologie SRH Hochschule Heidelberg sven.garbade@hochschule-heidelberg.de Statistik 1 S. Garbade (SRH Heidelberg) t-test
Box-and-Whisker Plot -0,2 0,8 1,8 2,8 3,8 4,8
 . Aufgabe: Für zwei verschiedene Aktien wurde der relative Kurszuwachs (in % beobachtet. Aus den jeweils 20 Quartaldaten ergaben sich die folgenden Box-Plots. Box-and-Whisker Plot Aktie Aktie 2-0,2 0,8,8
. Aufgabe: Für zwei verschiedene Aktien wurde der relative Kurszuwachs (in % beobachtet. Aus den jeweils 20 Quartaldaten ergaben sich die folgenden Box-Plots. Box-and-Whisker Plot Aktie Aktie 2-0,2 0,8,8
Klausur zur Vorlesung Multivariate Verfahren, SS 2006 6 Kreditpunkte, 90 min
 Klausur, Multivariate Verfahren, SS 2006, 6 Kreditpunkte, 90 min 1 Prof. Dr. Fred Böker 08.08.2006 Klausur zur Vorlesung Multivariate Verfahren, SS 2006 6 Kreditpunkte, 90 min Gesamtpunkte: 39 Aufgabe
Klausur, Multivariate Verfahren, SS 2006, 6 Kreditpunkte, 90 min 1 Prof. Dr. Fred Böker 08.08.2006 Klausur zur Vorlesung Multivariate Verfahren, SS 2006 6 Kreditpunkte, 90 min Gesamtpunkte: 39 Aufgabe
Analytische Statistik II. Statistische Methoden in der Korpuslinguistik Heike Zinsmeister WS 2008/09
 Analytische Statistik II Statistische Methoden in der Korpuslinguistik Heike Zinsmeister WS 2008/09 Testen Anpassungstests (goodness of fit) Weicht eine gegebene Verteilung signifikant von einer bekannten
Analytische Statistik II Statistische Methoden in der Korpuslinguistik Heike Zinsmeister WS 2008/09 Testen Anpassungstests (goodness of fit) Weicht eine gegebene Verteilung signifikant von einer bekannten
QM: Prüfen -1- KN16.08.2010
 QM: Prüfen -1- KN16.08.2010 2.4 Prüfen 2.4.1 Begriffe, Definitionen Ein wesentlicher Bestandteil der Qualitätssicherung ist das Prüfen. Sie wird aber nicht wie früher nach der Fertigung durch einen Prüfer,
QM: Prüfen -1- KN16.08.2010 2.4 Prüfen 2.4.1 Begriffe, Definitionen Ein wesentlicher Bestandteil der Qualitätssicherung ist das Prüfen. Sie wird aber nicht wie früher nach der Fertigung durch einen Prüfer,
Korrelation (II) Korrelation und Kausalität
 Korrelation und Kausalität") Korrelation (II) Korrelation und Kausalität Situation: Seien X, Y zwei metrisch skalierte Merkmale mit Ausprägungen (x 1, x 2,..., x n ) bzw. (y 1, y 2,..., y n ). D.h. für jede i = 1, 2,..., n bezeichnen
Korrelation (II) Korrelation und Kausalität Situation: Seien X, Y zwei metrisch skalierte Merkmale mit Ausprägungen (x 1, x 2,..., x n ) bzw. (y 1, y 2,..., y n ). D.h. für jede i = 1, 2,..., n bezeichnen
Würfelt man dabei je genau 10 - mal eine 1, 2, 3, 4, 5 und 6, so beträgt die Anzahl. der verschiedenen Reihenfolgen, in denen man dies tun kann, 60!.
 040304 Übung 9a Analysis, Abschnitt 4, Folie 8 Die Wahrscheinlichkeit, dass bei n - maliger Durchführung eines Zufallexperiments ein Ereignis A ( mit Wahrscheinlichkeit p p ( A ) ) für eine beliebige Anzahl
040304 Übung 9a Analysis, Abschnitt 4, Folie 8 Die Wahrscheinlichkeit, dass bei n - maliger Durchführung eines Zufallexperiments ein Ereignis A ( mit Wahrscheinlichkeit p p ( A ) ) für eine beliebige Anzahl
Inhaltsverzeichnis. Regressionsanalyse. http://mesosworld.ch - Stand vom: 20.1.2010 1
 Inhaltsverzeichnis Regressionsanalyse... 2 Lernhinweise... 2 Einführung... 2 Theorie (1-8)... 2 1. Allgemeine Beziehungen... 3 2. 'Best Fit'... 3 3. 'Ordinary Least Squares'... 4 4. Formel der Regressionskoeffizienten...
Inhaltsverzeichnis Regressionsanalyse... 2 Lernhinweise... 2 Einführung... 2 Theorie (1-8)... 2 1. Allgemeine Beziehungen... 3 2. 'Best Fit'... 3 3. 'Ordinary Least Squares'... 4 4. Formel der Regressionskoeffizienten...
Das Dialogfeld für die Regressionsanalyse ("Lineare Regression") findet sich im Statistik- Menu unter "Regression"-"Linear":
 findet sich im Statistik- Menu unter Regression-Linear:") Lineare Regression Das Dialogfeld für die Regressionsanalyse ("Lineare Regression") findet sich im Statistik- Menu unter "Regression"-"Linear": Im einfachsten Fall werden mehrere Prädiktoren (oder nur
Lineare Regression Das Dialogfeld für die Regressionsanalyse ("Lineare Regression") findet sich im Statistik- Menu unter "Regression"-"Linear": Im einfachsten Fall werden mehrere Prädiktoren (oder nur
Kontingenzkoeffizient (nach Pearson)
") Assoziationsmaß für zwei nominale Merkmale misst die Unabhängigkeit zweier Merkmale gibt keine Richtung eines Zusammenhanges an 46 o jl beobachtete Häufigkeiten der Kombination von Merkmalsausprägungen
Assoziationsmaß für zwei nominale Merkmale misst die Unabhängigkeit zweier Merkmale gibt keine Richtung eines Zusammenhanges an 46 o jl beobachtete Häufigkeiten der Kombination von Merkmalsausprägungen
Einführung in SPSS. 1. Die Datei Seegräser
 Einführung in SPSS 1. Die Datei Seegräser An 25 verschiedenen Probestellen wurde jeweils die Anzahl der Seegräser pro m 2 gezählt und das Vorhandensein von Seeigeln vermerkt. 2. Programmaufbau Die wichtigsten
Einführung in SPSS 1. Die Datei Seegräser An 25 verschiedenen Probestellen wurde jeweils die Anzahl der Seegräser pro m 2 gezählt und das Vorhandensein von Seeigeln vermerkt. 2. Programmaufbau Die wichtigsten
Füllmenge. Füllmenge. Füllmenge. Füllmenge. Mean = 500,0029 Std. Dev. = 3,96016 N = 10.000. 485,00 490,00 495,00 500,00 505,00 510,00 515,00 Füllmenge
 2.4 Stetige Zufallsvariable Beispiel. Abfüllung von 500 Gramm Packungen einer bestimmten Ware auf einer automatischen Abfüllanlage. Die Zufallsvariable X beschreibe die Füllmenge einer zufällig ausgewählten
2.4 Stetige Zufallsvariable Beispiel. Abfüllung von 500 Gramm Packungen einer bestimmten Ware auf einer automatischen Abfüllanlage. Die Zufallsvariable X beschreibe die Füllmenge einer zufällig ausgewählten
Felix-Nicolai Müller. Seminar Fragebogenmethodik - WS2009/2010 - Universität Trier Dr. Dirk Kranz 24.11.2009
 Cohen s Kappa Felix-Nicolai Müller Seminar Fragebogenmethodik - WS2009/2010 - Universität Trier Dr. Dirk Kranz 24.11.2009 Felix-Nicolai Müller Cohen s Kappa 24.11.2009 1 / 21 Inhaltsverzeichnis 1 2 3 4
Cohen s Kappa Felix-Nicolai Müller Seminar Fragebogenmethodik - WS2009/2010 - Universität Trier Dr. Dirk Kranz 24.11.2009 Felix-Nicolai Müller Cohen s Kappa 24.11.2009 1 / 21 Inhaltsverzeichnis 1 2 3 4
Fortgeschrittene Statistik Logistische Regression
 Fortgeschrittene Statistik Logistische Regression O D D S, O D D S - R A T I O, L O G I T T R A N S F O R M A T I O N, I N T E R P R E T A T I O N V O N K O E F F I Z I E N T E N, L O G I S T I S C H E
Fortgeschrittene Statistik Logistische Regression O D D S, O D D S - R A T I O, L O G I T T R A N S F O R M A T I O N, I N T E R P R E T A T I O N V O N K O E F F I Z I E N T E N, L O G I S T I S C H E
Multiple Regression. Ziel: Vorhersage der Werte einer Variable (Kriterium) bei Kenntnis der Werte von zwei oder mehr anderen Variablen (Prädiktoren)
 bei Kenntnis der Werte von zwei oder mehr anderen Variablen (Prädiktoren)") Multiple Regression 1 Was ist multiple lineare Regression? Ziel: Vorhersage der Werte einer Variable (Kriterium) bei Kenntnis der Werte von zwei oder mehr anderen Variablen (Prädiktoren) Annahme: Der Zusammenhang
Multiple Regression 1 Was ist multiple lineare Regression? Ziel: Vorhersage der Werte einer Variable (Kriterium) bei Kenntnis der Werte von zwei oder mehr anderen Variablen (Prädiktoren) Annahme: Der Zusammenhang
Beurteilung der biometrischen Verhältnisse in einem Bestand. Dr. Richard Herrmann, Köln
 Beurteilung der biometrischen Verhältnisse in einem Bestand Dr. Richard Herrmann, Köln Beurteilung der biometrischen Verhältnisse in einem Bestand 1 Fragestellung Methoden.1 Vergleich der Anzahlen. Vergleich
Beurteilung der biometrischen Verhältnisse in einem Bestand Dr. Richard Herrmann, Köln Beurteilung der biometrischen Verhältnisse in einem Bestand 1 Fragestellung Methoden.1 Vergleich der Anzahlen. Vergleich
Quantilsschätzung als Werkzeug zur VaR-Berechnung
 Quantilsschätzung als Werkzeug zur VaR-Berechnung Ralf Lister, Aktuar, lister@actuarial-files.com Zusammenfassung: Zwei Fälle werden betrachtet und die jeweiligen VaR-Werte errechnet. Im ersten Fall wird
Quantilsschätzung als Werkzeug zur VaR-Berechnung Ralf Lister, Aktuar, lister@actuarial-files.com Zusammenfassung: Zwei Fälle werden betrachtet und die jeweiligen VaR-Werte errechnet. Im ersten Fall wird
Statistische Auswertung der Daten von Blatt 13
 Statistische Auswertung der Daten von Blatt 13 Problemstellung 1 Graphische Darstellung der Daten 1 Diskussion der Normalverteilung 3 Mittelwerte und deren Konfidenzbereiche 3 Signifikanz der Behandlung
Statistische Auswertung der Daten von Blatt 13 Problemstellung 1 Graphische Darstellung der Daten 1 Diskussion der Normalverteilung 3 Mittelwerte und deren Konfidenzbereiche 3 Signifikanz der Behandlung
Academic Skills - Befragung und Auswertung
 Otto-von-Guericke University Magdeburg Allgemein Befragung Eine Befragung ist eine wissenschaftliche Maßnahme zur Erforschung von Verhalten, Einstellung oder Wissen Des Weiteren können auch demographische
Otto-von-Guericke University Magdeburg Allgemein Befragung Eine Befragung ist eine wissenschaftliche Maßnahme zur Erforschung von Verhalten, Einstellung oder Wissen Des Weiteren können auch demographische
Standardab er des. Testwert = 145.5 95% Konfidenzintervall. T df Sig. (2-seitig) Differenz Untere Obere -2.011 698.045-5.82-11.50 -.14.
 Differenz Untere Obere -2.011 698.045-5.82-11.50 -.14.") Aufgabe : einfacher T-Test Statistik bei einer Stichprobe Standardfehl Standardab er des Mittelwert weichung Mittelwertes 699 39.68 76.59 2.894 Test bei einer Sichprobe Testwert = 45.5 95% Konfidenzintervall
Aufgabe : einfacher T-Test Statistik bei einer Stichprobe Standardfehl Standardab er des Mittelwert weichung Mittelwertes 699 39.68 76.59 2.894 Test bei einer Sichprobe Testwert = 45.5 95% Konfidenzintervall
Evaluation der Normalverteilungsannahme
 Evaluation der Normalverteilungsannahme. Überprüfung der Normalverteilungsannahme im SPSS P. Wilhelm; HS SPSS bietet verschiedene Möglichkeiten, um Verteilungsannahmen zu überprüfen. Angefordert werden
Evaluation der Normalverteilungsannahme. Überprüfung der Normalverteilungsannahme im SPSS P. Wilhelm; HS SPSS bietet verschiedene Möglichkeiten, um Verteilungsannahmen zu überprüfen. Angefordert werden
Statistische Thermodynamik I Lösungen zur Serie 1
 Statistische Thermodynamik I Lösungen zur Serie Zufallsvariablen, Wahrscheinlichkeitsverteilungen 4. März 2. Zwei Lektoren lesen ein Buch. Lektor A findet 2 Druckfehler, Lektor B nur 5. Von den gefundenen
Statistische Thermodynamik I Lösungen zur Serie Zufallsvariablen, Wahrscheinlichkeitsverteilungen 4. März 2. Zwei Lektoren lesen ein Buch. Lektor A findet 2 Druckfehler, Lektor B nur 5. Von den gefundenen
Einführung in die statistische Datenanalyse I
 Einführung in die statistische Datenanalyse I Inhaltsverzeichnis 1. EINFÜHRUNG IN THEORIEGELEITETES WISSENSCHAFTLICHES ARBEITEN 2 2. KRITIERIEN ZUR AUSWAHL STATISTISCH METHODISCHER VERFAHREN 2 3. UNIVARIATE
Einführung in die statistische Datenanalyse I Inhaltsverzeichnis 1. EINFÜHRUNG IN THEORIEGELEITETES WISSENSCHAFTLICHES ARBEITEN 2 2. KRITIERIEN ZUR AUSWAHL STATISTISCH METHODISCHER VERFAHREN 2 3. UNIVARIATE
Häufigkeitstabellen. Balken- oder Kreisdiagramme. kritischer Wert für χ2-test. Kontingenztafeln
 Häufigkeitstabellen Menüpunkt Data PivotTable Report (bzw. entsprechendes Icon): wähle Data Range (Zellen, die die Daten enthalten + Zelle mit Variablenname) wähle kategoriale Variable für Spalten- oder
Häufigkeitstabellen Menüpunkt Data PivotTable Report (bzw. entsprechendes Icon): wähle Data Range (Zellen, die die Daten enthalten + Zelle mit Variablenname) wähle kategoriale Variable für Spalten- oder
Webergänzung zu Kapitel 10
 Webergänzung zu Kapitel 10 10.1.4 Varianzanalyse (ANOVA: analysis of variance) Im Kapitel 10 haben wir uns hauptsächlich mit Forschungsbeispielen beschäftigt, die nur zwei Ergebnissätze hatten (entweder
Webergänzung zu Kapitel 10 10.1.4 Varianzanalyse (ANOVA: analysis of variance) Im Kapitel 10 haben wir uns hauptsächlich mit Forschungsbeispielen beschäftigt, die nur zwei Ergebnissätze hatten (entweder
Vorgaben der DIN ISO 13528 Statistische Verfahren für Eignungsprüfungen durch Ringversuche
 Konsens- oder Referenzwerte in Ringversuchen Möglichkeiten und Grenzen Dr.-Ing. Michael Koch Institut für Siedlungswasserbau, Wassergüte und Abfallwirtschaft der Universität Stuttgart Arbeitsbereich Hydrochemie
Konsens- oder Referenzwerte in Ringversuchen Möglichkeiten und Grenzen Dr.-Ing. Michael Koch Institut für Siedlungswasserbau, Wassergüte und Abfallwirtschaft der Universität Stuttgart Arbeitsbereich Hydrochemie
Die Optimalität von Randomisationstests
 Die Optimalität von Randomisationstests Diplomarbeit Elena Regourd Mathematisches Institut der Heinrich-Heine-Universität Düsseldorf Düsseldorf im Dezember 2001 Betreuung: Prof. Dr. A. Janssen Inhaltsverzeichnis
Die Optimalität von Randomisationstests Diplomarbeit Elena Regourd Mathematisches Institut der Heinrich-Heine-Universität Düsseldorf Düsseldorf im Dezember 2001 Betreuung: Prof. Dr. A. Janssen Inhaltsverzeichnis
2. Deskriptive Statistik 2.1. Häufigkeitstabellen, Histogramme, empirische Verteilungsfunktionen
 4. Datenanalyse und Modellbildung Deskriptive Statistik 2-1 2. Deskriptive Statistik 2.1. Häufigkeitstabellen, Histogramme, empirische Verteilungsfunktionen Für die Auswertung einer Messreihe, die in Form
4. Datenanalyse und Modellbildung Deskriptive Statistik 2-1 2. Deskriptive Statistik 2.1. Häufigkeitstabellen, Histogramme, empirische Verteilungsfunktionen Für die Auswertung einer Messreihe, die in Form
Grundlagen von Versuchsmethodik und Datenanalyse
 Grundlagen von Versuchsmethodik und Datenanalyse Der Anfang: Hypothesen über Ursache-Wirkungs-Zusammenhänge Ursache Wirkung Koffein verbessert Kurzzeitgedächtnis Gewaltfilme führen zu aggressivem Verhalten
Grundlagen von Versuchsmethodik und Datenanalyse Der Anfang: Hypothesen über Ursache-Wirkungs-Zusammenhänge Ursache Wirkung Koffein verbessert Kurzzeitgedächtnis Gewaltfilme führen zu aggressivem Verhalten
Weitere (wählbare) Kontraste in der SPSS Prozedur Allgemeines Lineares Modell
 Kontraste in der SPSS Prozedur Allgemeines Lineares Modell") Einfaktorielle Versuchspläne 27/40 Weitere (wählbare) Kontraste in der SPSS Prozedur Allgemeines Lineares Modell Abweichung Einfach Differenz Helmert Wiederholt Vergleich Jede Gruppe mit Gesamtmittelwert
Einfaktorielle Versuchspläne 27/40 Weitere (wählbare) Kontraste in der SPSS Prozedur Allgemeines Lineares Modell Abweichung Einfach Differenz Helmert Wiederholt Vergleich Jede Gruppe mit Gesamtmittelwert
Übungen zur Veranstaltung Statistik 2 mit SPSS
 Raum 22, Tel. 39 4 Aufgabe 5. Wird der neue Film MatchPoint von Woody Allen von weiblichen und männlichen Zuschauern gleich bewertet? Eine Umfrage unter 00 Kinobesuchern ergab folgende Daten: Altersgruppe
Raum 22, Tel. 39 4 Aufgabe 5. Wird der neue Film MatchPoint von Woody Allen von weiblichen und männlichen Zuschauern gleich bewertet? Eine Umfrage unter 00 Kinobesuchern ergab folgende Daten: Altersgruppe
Klausur Nr. 1. Wahrscheinlichkeitsrechnung. Keine Hilfsmittel gestattet, bitte alle Lösungen auf dieses Blatt.
 Klausur Nr. 1 2014-02-06 Wahrscheinlichkeitsrechnung Pflichtteil Keine Hilfsmittel gestattet, bitte alle Lösungen auf dieses Blatt. Name: 0. Für Pflicht- und Wahlteil gilt: saubere und übersichtliche Darstellung,
Klausur Nr. 1 2014-02-06 Wahrscheinlichkeitsrechnung Pflichtteil Keine Hilfsmittel gestattet, bitte alle Lösungen auf dieses Blatt. Name: 0. Für Pflicht- und Wahlteil gilt: saubere und übersichtliche Darstellung,
Gibt es einen Geschmacksunterschied zwischen Coca Cola und Cola Zero?
 Gibt es einen Geschmacksunterschied zwischen Coca Cola und Cola Zero? Manche sagen: Ja, manche sagen: Nein Wie soll man das objektiv feststellen? Kann man Geschmack objektiv messen? - Geschmack ist subjektiv
Gibt es einen Geschmacksunterschied zwischen Coca Cola und Cola Zero? Manche sagen: Ja, manche sagen: Nein Wie soll man das objektiv feststellen? Kann man Geschmack objektiv messen? - Geschmack ist subjektiv
R ist freie Software und kann von der Website. www.r-project.org
 R R ist freie Software und kann von der Website heruntergeladen werden. www.r-project.org Nach dem Herunterladen und der Installation von R kann man R durch Doppelklicken auf das R-Symbol starten. R wird
R R ist freie Software und kann von der Website heruntergeladen werden. www.r-project.org Nach dem Herunterladen und der Installation von R kann man R durch Doppelklicken auf das R-Symbol starten. R wird
14.01.14 DAS THEMA: INFERENZSTATISTIK II. Standardfehler Konfidenzintervalle Signifikanztests. Standardfehler
 DAS THEMA: INFERENZSTATISTIK II INFERENZSTATISTISCHE AUSSAGEN Standardfehler Konfidenzintervalle Signifikanztests Standardfehler der Standardfehler Interpretation Verwendung 1 ZUR WIEDERHOLUNG... Ausgangspunkt:
DAS THEMA: INFERENZSTATISTIK II INFERENZSTATISTISCHE AUSSAGEN Standardfehler Konfidenzintervalle Signifikanztests Standardfehler der Standardfehler Interpretation Verwendung 1 ZUR WIEDERHOLUNG... Ausgangspunkt:
Statistik II Wahrscheinlichkeitsrechnung und induktive Statistik Erste Klausur zum Sommersemester 2005 26. Juli 2005
 Statistik II Wahrscheinlichkeitsrechnung und induktive Statistik Erste Klausur zum Sommersemester 2005 26. Juli 2005 Aufgabe 1: Grundzüge der Wahrscheinlichkeitsrechnung 19 P. Als Manager eines großen
Statistik II Wahrscheinlichkeitsrechnung und induktive Statistik Erste Klausur zum Sommersemester 2005 26. Juli 2005 Aufgabe 1: Grundzüge der Wahrscheinlichkeitsrechnung 19 P. Als Manager eines großen
Studiendesign/ Evaluierungsdesign
 Jennifer Ziegert Studiendesign/ Evaluierungsdesign Praxisprojekt: Nutzerorientierte Evaluierung von Visualisierungen in Daffodil mittels Eyetracker Warum Studien /Evaluierungsdesign Das Design einer Untersuchung
Jennifer Ziegert Studiendesign/ Evaluierungsdesign Praxisprojekt: Nutzerorientierte Evaluierung von Visualisierungen in Daffodil mittels Eyetracker Warum Studien /Evaluierungsdesign Das Design einer Untersuchung
Varianzanalyse ANOVA
 Varianzanalyse ANOVA Johannes Hain Lehrstuhl für Mathematik VIII Statistik 1/23 Einfaktorielle Varianzanalyse (ANOVA) Bisher war man lediglich in der Lage, mit dem t-test einen Mittelwertsvergleich für
Varianzanalyse ANOVA Johannes Hain Lehrstuhl für Mathematik VIII Statistik 1/23 Einfaktorielle Varianzanalyse (ANOVA) Bisher war man lediglich in der Lage, mit dem t-test einen Mittelwertsvergleich für
Grundlagen der Inferenzstatistik: Was Ihnen nicht erspart bleibt!
 Grundlagen der Inferenzstatistik: Was Ihnen nicht erspart bleibt! 1 Einführung 2 Wahrscheinlichkeiten kurz gefasst 3 Zufallsvariablen und Verteilungen 4 Theoretische Verteilungen (Wahrscheinlichkeitsfunktion)
Grundlagen der Inferenzstatistik: Was Ihnen nicht erspart bleibt! 1 Einführung 2 Wahrscheinlichkeiten kurz gefasst 3 Zufallsvariablen und Verteilungen 4 Theoretische Verteilungen (Wahrscheinlichkeitsfunktion)
Statistische Auswertung:
 Statistische Auswertung: Die erhobenen Daten mittels der selbst erstellten Tests (Surfaufgaben) Statistics Punkte aus dem Punkte aus Surftheorietest Punkte aus dem dem und dem Surftheorietest max.14p.
Statistische Auswertung: Die erhobenen Daten mittels der selbst erstellten Tests (Surfaufgaben) Statistics Punkte aus dem Punkte aus Surftheorietest Punkte aus dem dem und dem Surftheorietest max.14p.
Bearbeiten elektronische Rechnungen (Invoices)
") Bearbeiten elektronische Rechnungen (Invoices) 1. Zweck des Programms: Die elektronischen Rechnungen können zur Zeit für folgenden Bereiche genutzt werden:.. Anzeige der Rechnungen mit den relevanten Werten..
Bearbeiten elektronische Rechnungen (Invoices) 1. Zweck des Programms: Die elektronischen Rechnungen können zur Zeit für folgenden Bereiche genutzt werden:.. Anzeige der Rechnungen mit den relevanten Werten..
Statistik im Versicherungs- und Finanzwesen
 Springer Gabler PLUS Zusatzinformationen zu Medien von Springer Gabler Grimmer Statistik im Versicherungs- und Finanzwesen Eine anwendungsorientierte Einführung 2014 1. Auflage Übungsaufgaben zu Kapitel
Springer Gabler PLUS Zusatzinformationen zu Medien von Springer Gabler Grimmer Statistik im Versicherungs- und Finanzwesen Eine anwendungsorientierte Einführung 2014 1. Auflage Übungsaufgaben zu Kapitel
Kurzeinführung LABTALK
 Kurzeinführung LABTALK Mit der Interpreter-Sprache LabTalk, die von ORIGIN zur Verfügung gestellt wird, können bequem Datenmanipulationen sowie Zugriffe direkt auf das Programm (Veränderungen der Oberfläche,
Kurzeinführung LABTALK Mit der Interpreter-Sprache LabTalk, die von ORIGIN zur Verfügung gestellt wird, können bequem Datenmanipulationen sowie Zugriffe direkt auf das Programm (Veränderungen der Oberfläche,
Statistik I für Betriebswirte Vorlesung 5
 Statistik I für Betriebswirte Vorlesung 5 PD Dr. Frank Heyde TU Bergakademie Freiberg Institut für Stochastik 07. Mai 2015 PD Dr. Frank Heyde Statistik I für Betriebswirte Vorlesung 5 1 Klassische Wahrscheinlichkeitsdefinition
Statistik I für Betriebswirte Vorlesung 5 PD Dr. Frank Heyde TU Bergakademie Freiberg Institut für Stochastik 07. Mai 2015 PD Dr. Frank Heyde Statistik I für Betriebswirte Vorlesung 5 1 Klassische Wahrscheinlichkeitsdefinition
Data Mining: Einige Grundlagen aus der Stochastik
 Data Mining: Einige Grundlagen aus der Stochastik Hagen Knaf Studiengang Angewandte Mathematik Hochschule RheinMain 21. Oktober 2015 Vorwort Das vorliegende Skript enthält eine Zusammenfassung verschiedener
Data Mining: Einige Grundlagen aus der Stochastik Hagen Knaf Studiengang Angewandte Mathematik Hochschule RheinMain 21. Oktober 2015 Vorwort Das vorliegende Skript enthält eine Zusammenfassung verschiedener
Anhand des bereits hergeleiteten Models erstellen wir nun mit der Formel
 Ausarbeitung zum Proseminar Finanzmathematische Modelle und Simulationen bei Raphael Kruse und Prof. Dr. Wolf-Jürgen Beyn zum Thema Simulation des Anlagenpreismodels von Simon Uphus im WS 09/10 Zusammenfassung
Ausarbeitung zum Proseminar Finanzmathematische Modelle und Simulationen bei Raphael Kruse und Prof. Dr. Wolf-Jürgen Beyn zum Thema Simulation des Anlagenpreismodels von Simon Uphus im WS 09/10 Zusammenfassung
Professionelle Seminare im Bereich MS-Office
 Der Name BEREICH.VERSCHIEBEN() ist etwas unglücklich gewählt. Man kann mit der Funktion Bereiche zwar verschieben, man kann Bereiche aber auch verkleinern oder vergrößern. Besser wäre es, die Funktion
Der Name BEREICH.VERSCHIEBEN() ist etwas unglücklich gewählt. Man kann mit der Funktion Bereiche zwar verschieben, man kann Bereiche aber auch verkleinern oder vergrößern. Besser wäre es, die Funktion
Binäre abhängige Variablen
 Binäre abhängige Variablen Thushyanthan Baskaran thushyanthan.baskaran@awi.uni-heidelberg.de Alfred Weber Institut Ruprecht Karls Universität Heidelberg Einführung Oft wollen wir qualitative Variablen
Binäre abhängige Variablen Thushyanthan Baskaran thushyanthan.baskaran@awi.uni-heidelberg.de Alfred Weber Institut Ruprecht Karls Universität Heidelberg Einführung Oft wollen wir qualitative Variablen
Statistische Analyse von Ereigniszeiten
 Statistische Analyse von Survival Analysis VO Biostatistik im WS 2006/2007 1 2 3 : Leukemiedaten (unzensiert) 33 Patienten mit Leukemie; Zielvariable Überlebenszeit. Alle Patienten verstorben und Überlebenszeit
Statistische Analyse von Survival Analysis VO Biostatistik im WS 2006/2007 1 2 3 : Leukemiedaten (unzensiert) 33 Patienten mit Leukemie; Zielvariable Überlebenszeit. Alle Patienten verstorben und Überlebenszeit
Statistik II. Statistik II, SS 2001, Seite 1 von 5
 Statistik II, SS 2001, Seite 1 von 5 Statistik II Hinweise zur Bearbeitung Hilfsmittel: - Taschenrechner (ohne Datenbank oder die Möglichkeit diesen zu programmieren) - Formelsammlung im Umfang von einer
Statistik II, SS 2001, Seite 1 von 5 Statistik II Hinweise zur Bearbeitung Hilfsmittel: - Taschenrechner (ohne Datenbank oder die Möglichkeit diesen zu programmieren) - Formelsammlung im Umfang von einer