Welche Textklassifikationen gibt es und was sind ihre spezifischen Merkmale?
|
|
|
- Reinhold Otto
- vor 8 Jahren
- Abrufe
Transkript
1 Text

2 Welche Textklassifikationen gibt es und was sind ihre spezifischen Merkmale?

3 Textklassifikationen Natürliche bzw. unstrukturierte Texte Normale Texte ohne besondere Merkmale und Struktur Semistrukturierte Texte HTML-Dokumente, die aus natürlichen Text bestehen und durch HTML-Tags strukturiert werden. Strukturierte Texte Datenbanken, Tabellen und XML

4 Was ist XML? Woraus besteht sie und wonach richtet sie sich?

5 XML XML (Extensible Markup Language) gehört zu den sogenannten Markup Languages Dient zur Darstellung hierarchisch strukturierter Daten in Form von Textdateien Besteht aus Tags ; Atributen und den entsprechenden Atributwerten Richtet sich nach der Wohlgeformtheit Einhaltung von allen XML Regelungen Richtet sich nach der Validität also nach der Gültigkeit der Grammatik

6 Was ist TEI?

7 Die Text Encoding Initiative: Geschichte 1987 entstanden als internationale Initiative von Philologinnen und Philologen Dokumentenformat zur Repräsentation von Texten in digitaler Form Es ist Vielseitig und Praxisnah

8 Wie lässt sich TEI differenzieren?

9 Die Text Encoding Initiative: Differenzierung das Konsortium (TEI-C), 2000 gegründet Und Richtlinien und Empfehlungen zur Kodierung+ Austausch von Textdokumenten Intention: Geisteswissenschaftler sollen über größtmögliche Freiheit verfügen, textuell vorliegende Information nach eigenem Textbegriff in XML zu codieren.

10 An welche Richtlinien und Standards hält sich TEI?

11 Die Text Encoding Initiative: Standards und Guidelines Standards der TEI schränken die schier unendlichen Auszeichnungsmöglichkeiten von XML ein. Dabei stellen sich die folgenden Grundfragen: Welche Tags und welche Attribute lassen sich verwenden, um eigene Texte auszuzeichnen? Wie lassen sich die Tags miteinander kombinieren / verschachteln?

12 Die Text Encoding Initiative: Modularisierung Flexible Auswahl von TEI-Elementen aufgrund des modularen Charakters der TEI. So muss ein eigenes Schema nicht alle Elemente und Attribute der TEI enthalten. Module, u.a.: core für Basiselemente header für Metadaten textstructure für grundlegende Textstrukturen drama für Dramen prose, poetry, etc.

13 Methodenverortung Data Mining: Einsatz auf stark strukturierten Daten Text Mining: Informationsextraktion aus (u.a. semistrukturierten) Texten; Verwendung von Verfahren / Algorithmen des Data Minings Automatisierte Strukturierung von Texten (insbes. sehr großen Mengen von Texten) Information Retrieval: Suchanfragen an einen Textcorpus Wie finde ich die von mir gesuchte Information?

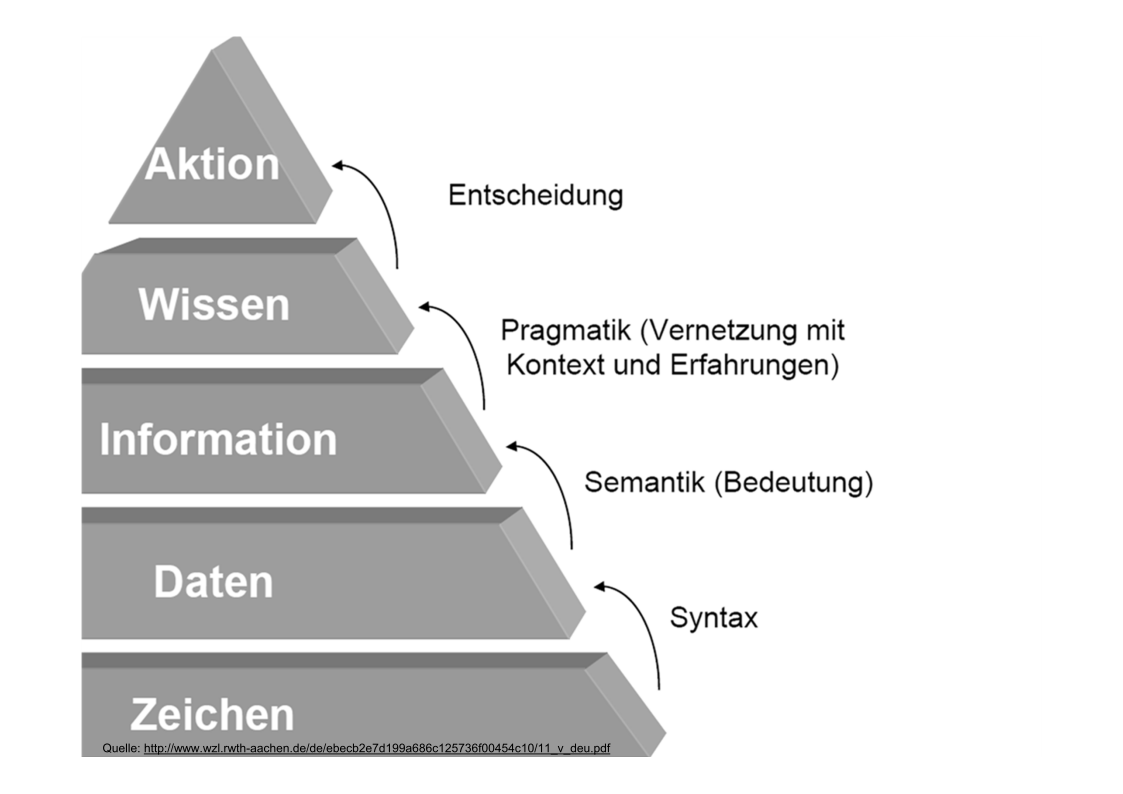
14 Bedeutung

15 Tf-idf-Maß Termfrequenz,: Wie häufig findet sich die Wortform / der Term im Dokument? Inverse Dokumentfrequenz : Wie häufig findet sich die Wortform / der Term im Gesamtkorpus? Annahme: Eine Wortform, die nur in wenigen Titelaufnahmen des Gesamtbestandes anzutreffen ist, verfügt über eine höhere Trennschärfe als eine Wortform, die sich in zahlreichen Titelaufnahmen findet.

16 IDF : Text Mining Tool Termfrequenz: Häufigkeit des (Such)Terms / der Wortform im jeweiligen Dokument Bestimmung der Trennschärfe einer Wortform: Inverse Document Frequency (IDF), Inverse Dokumenthäufigkeit Annahme: Eine Wortform, die nur in wenigen Titelaufnahmen des Gesamtbestandes anzutreffen ist, verfügt über eine höhere Trennschärfe als eine Wortform, die sich in zahlreichen Titelaufnahmen findet.

17 IDF : Text Mining Tool Weitere Schritte 1) Gewichtung: Gewichtung der Suchphrase bestimmen, sprich relevante Suchterme charakterisieren

18 IDF : Text Mining Tool Weitere Schritte 2) Vektorraum Verbindungen zu verschiedenen Termen erstellen und mögliche Vergleiche aufbauen Komplexität verringern und Verbindungen aufzeigen.

19 IDF : Text Mining Tool Weitere Schritte 3) Ahnlichkeitsmaß Ähnlichkeit von Such- und Vergleichstitel bzw. der korrespondierenden Vektoren ermitteln 4) Cluster Cluster ähnlicher Titel generieren: Cluster I: Titel mit Gewichtung = Cluster II: Titel mit Gewichtung = MAB Einträge (Author Name, Place of Printing, etc.) unscharf (fuzzy) vergleichen

20 Was versteht man unter den Begriffen recall und precision und wozu dient dieses System?

21 IDF : Text Mining Tool Bewertung Trefferquote (recall) und Genauigkeit (precision) bewerten Suchergebnisse. Recall: Liefert die Suchanfrage ein relevantes Ergebnis? Precision: Ist der gefundene / zurückgelieferte Treffer für die Suchanfrage relevant?
22 Was ist das VD 18-Projekt?
23 VD 18 Projekt Ein Projekt zur Digitalisierung von historischen Werken Als Pilotprojekt gefördert Umfasst an der Universität zu Köln mehr als eine Million Titel
HTML5. Wie funktioniert HTML5? Tags: Attribute:
 HTML5 HTML bedeutet Hypertext Markup Language und liegt aktuell in der fünften Fassung, also HTML5 vor. HTML5 ist eine Auszeichnungssprache mit der Webseiten geschrieben werden. In HTML5 wird festgelegt,
HTML5 HTML bedeutet Hypertext Markup Language und liegt aktuell in der fünften Fassung, also HTML5 vor. HTML5 ist eine Auszeichnungssprache mit der Webseiten geschrieben werden. In HTML5 wird festgelegt,
2 Evaluierung von Retrievalsystemen
 2. Evaluierung von Retrievalsystemen Relevanz 2 Evaluierung von Retrievalsystemen Die Evaluierung von Verfahren und Systemen spielt im IR eine wichtige Rolle. Gemäß der Richtlinien für IR der GI gilt es,...
2. Evaluierung von Retrievalsystemen Relevanz 2 Evaluierung von Retrievalsystemen Die Evaluierung von Verfahren und Systemen spielt im IR eine wichtige Rolle. Gemäß der Richtlinien für IR der GI gilt es,...
Semestralklausur zur Vorlesung. Web Mining. Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7.
 Semestralklausur zur Vorlesung Web Mining Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7. 2004 Name: Vorname: Matrikelnummer: Fachrichtung: Punkte: (1).... (2)....
Semestralklausur zur Vorlesung Web Mining Prof. J. Fürnkranz Technische Universität Darmstadt Sommersemester 2004 Termin: 22. 7. 2004 Name: Vorname: Matrikelnummer: Fachrichtung: Punkte: (1).... (2)....
Containerformat Spezifikation
 Containerformat Spezifikation Version 1.0-09.05.2011 Inhaltsverzeichnis 0 Einführung... 4 0.1 Referenzierte Dokumente... 4 0.2 Abkürzungen... 4 1 Containerformat... 5 1.1 Aufbau des Container-Headers...
Containerformat Spezifikation Version 1.0-09.05.2011 Inhaltsverzeichnis 0 Einführung... 4 0.1 Referenzierte Dokumente... 4 0.2 Abkürzungen... 4 1 Containerformat... 5 1.1 Aufbau des Container-Headers...
Würfelt man dabei je genau 10 - mal eine 1, 2, 3, 4, 5 und 6, so beträgt die Anzahl. der verschiedenen Reihenfolgen, in denen man dies tun kann, 60!.
 040304 Übung 9a Analysis, Abschnitt 4, Folie 8 Die Wahrscheinlichkeit, dass bei n - maliger Durchführung eines Zufallexperiments ein Ereignis A ( mit Wahrscheinlichkeit p p ( A ) ) für eine beliebige Anzahl
040304 Übung 9a Analysis, Abschnitt 4, Folie 8 Die Wahrscheinlichkeit, dass bei n - maliger Durchführung eines Zufallexperiments ein Ereignis A ( mit Wahrscheinlichkeit p p ( A ) ) für eine beliebige Anzahl
... MathML XHTML RDF
 RDF in wissenschaftlichen Bibliotheken (LQI KUXQJLQ;0/ Die extensible Markup Language [XML] ist eine Metasprache für die Definition von Markup Sprachen. Sie unterscheidet sich durch ihre Fähigkeit, Markup
RDF in wissenschaftlichen Bibliotheken (LQI KUXQJLQ;0/ Die extensible Markup Language [XML] ist eine Metasprache für die Definition von Markup Sprachen. Sie unterscheidet sich durch ihre Fähigkeit, Markup
Professionelle Seminare im Bereich MS-Office
 Der Name BEREICH.VERSCHIEBEN() ist etwas unglücklich gewählt. Man kann mit der Funktion Bereiche zwar verschieben, man kann Bereiche aber auch verkleinern oder vergrößern. Besser wäre es, die Funktion
Der Name BEREICH.VERSCHIEBEN() ist etwas unglücklich gewählt. Man kann mit der Funktion Bereiche zwar verschieben, man kann Bereiche aber auch verkleinern oder vergrößern. Besser wäre es, die Funktion
Blumen-bienen-Bären Academy. Kurzanleitung für Google Keyword Planer + Google Trends
 Kurzanleitung für Google Keyword Planer + Google Trends Der Google Keyword Planer Mit dem Keyword Planer kann man sehen, wieviele Leute, in welchen Regionen und Orten nach welchen Begriffen bei Google
Kurzanleitung für Google Keyword Planer + Google Trends Der Google Keyword Planer Mit dem Keyword Planer kann man sehen, wieviele Leute, in welchen Regionen und Orten nach welchen Begriffen bei Google
OKB-000091 Die MS SQL-Volltextsuche für organice SQL einrichten
 OKB-000091 Die MS SQL-Volltextsuche für organice SQL einrichten Dienstag, 16. August 2005 16:55 FAQ-Nr: OKB-000091 Betrifft: organice SQL Frage: Wie richte ich die Volltextindizierung des MS SQL-Servers
OKB-000091 Die MS SQL-Volltextsuche für organice SQL einrichten Dienstag, 16. August 2005 16:55 FAQ-Nr: OKB-000091 Betrifft: organice SQL Frage: Wie richte ich die Volltextindizierung des MS SQL-Servers
Containerformat Spezifikation
 Containerformat Spezifikation Version 1.1-21.02.2014 Inhaltsverzeichnis 0 Einführung... 4 0.1 Referenzierte Dokumente... 4 0.2 Abkürzungen... 4 1 Containerformat... 5 1.1 Aufbau des Container-Headers...
Containerformat Spezifikation Version 1.1-21.02.2014 Inhaltsverzeichnis 0 Einführung... 4 0.1 Referenzierte Dokumente... 4 0.2 Abkürzungen... 4 1 Containerformat... 5 1.1 Aufbau des Container-Headers...
SWOT Analyse zur Unterstützung des Projektmonitorings
 SWOT Analyse zur Unterstützung des Projektmonitorings Alle QaS-Dokumente können auf der QaS-Webseite heruntergeladen werden, http://qas.programkontoret.se Seite 1 Was ist SWOT? SWOT steht für Stärken (Strengths),
SWOT Analyse zur Unterstützung des Projektmonitorings Alle QaS-Dokumente können auf der QaS-Webseite heruntergeladen werden, http://qas.programkontoret.se Seite 1 Was ist SWOT? SWOT steht für Stärken (Strengths),
Kill Keyword Density. Weshalb die Keyword Density blanker Unsinn ist.
 Kill Keyword Density Weshalb die Keyword Density blanker Unsinn ist. Kill Keyword Density» & Karl Kratz Das ist. Jana ist Diplom- Mathematikerin und Controlling-Leiterin bei der Innovation Group AG. Ihr
Kill Keyword Density Weshalb die Keyword Density blanker Unsinn ist. Kill Keyword Density» & Karl Kratz Das ist. Jana ist Diplom- Mathematikerin und Controlling-Leiterin bei der Innovation Group AG. Ihr
Predictive Modeling Markup Language. Thomas Morandell
 Predictive Modeling Markup Language Thomas Morandell Index Einführung PMML als Standard für den Austausch von Data Mining Ergebnissen/Prozessen Allgemeine Struktur eines PMML Dokuments Beispiel von PMML
Predictive Modeling Markup Language Thomas Morandell Index Einführung PMML als Standard für den Austausch von Data Mining Ergebnissen/Prozessen Allgemeine Struktur eines PMML Dokuments Beispiel von PMML
Personalisierte Email versenden
 1. Starten Sie Excel und Word und klicken in der Word-Menüleiste auf Extras (WICHTIG: personalisierte Emails werden aus Word versendet) 2. wählen Sie nun Briefe und Sendungen 3. und starten den Seriendruck-Assistent.
1. Starten Sie Excel und Word und klicken in der Word-Menüleiste auf Extras (WICHTIG: personalisierte Emails werden aus Word versendet) 2. wählen Sie nun Briefe und Sendungen 3. und starten den Seriendruck-Assistent.
XINDICE. The Apache XML Project 3.12.09. Name: J acqueline Langhorst E-Mail: blackyuriko@hotmail.de
 Name: J acqueline Langhorst E-Mail: blackyuriko@hotmail.de 3.12.09 HKInformationsverarbeitung Kurs: Datenbanken vs. MarkUp WS 09/10 Dozent: Prof. Dr. M. Thaller XINDICE The Apache XML Project Inhalt Native
Name: J acqueline Langhorst E-Mail: blackyuriko@hotmail.de 3.12.09 HKInformationsverarbeitung Kurs: Datenbanken vs. MarkUp WS 09/10 Dozent: Prof. Dr. M. Thaller XINDICE The Apache XML Project Inhalt Native
FRAGEBOGEN ANWENDUNG DES ECOPROWINE SELBSTBEWERTUNG-TOOLS
 Dieser Fragebogen bildet eine wichtige Rückmeldung der Pilotweingüter über Verständnis, Akzeptanz und Effektivität des ECOPROWINE Selbstbewertung-tools für alle daran Beteiligten. Dieser Fragebogen besteht
Dieser Fragebogen bildet eine wichtige Rückmeldung der Pilotweingüter über Verständnis, Akzeptanz und Effektivität des ECOPROWINE Selbstbewertung-tools für alle daran Beteiligten. Dieser Fragebogen besteht
Ökonomik der Agrar und Ernährungswirtschaft in ILIAS
 ILIAS Open Source elearning Die ersten Schritte in ILIAS & Der Zugriff auf das Modul Ökonomik der Agrar und Ernährungswirtschaft in ILIAS Gliederung Login Einführung Was versteht man unter ILIAS? Hauptansichten
ILIAS Open Source elearning Die ersten Schritte in ILIAS & Der Zugriff auf das Modul Ökonomik der Agrar und Ernährungswirtschaft in ILIAS Gliederung Login Einführung Was versteht man unter ILIAS? Hauptansichten
SDD System Design Document
 SDD Software Konstruktion WS01/02 Gruppe 4 1. Einleitung Das vorliegende Dokument richtet sich vor allem an die Entwickler, aber auch an den Kunden, der das enstehende System verwenden wird. Es soll einen
SDD Software Konstruktion WS01/02 Gruppe 4 1. Einleitung Das vorliegende Dokument richtet sich vor allem an die Entwickler, aber auch an den Kunden, der das enstehende System verwenden wird. Es soll einen
Schritt 1. Anmelden. Klicken Sie auf die Schaltfläche Anmelden
 Schritt 1 Anmelden Klicken Sie auf die Schaltfläche Anmelden Schritt 1 Anmelden Tippen Sie Ihren Benutzernamen und Ihr Passwort ein Tipp: Nutzen Sie die Hilfe Passwort vergessen? wenn Sie sich nicht mehr
Schritt 1 Anmelden Klicken Sie auf die Schaltfläche Anmelden Schritt 1 Anmelden Tippen Sie Ihren Benutzernamen und Ihr Passwort ein Tipp: Nutzen Sie die Hilfe Passwort vergessen? wenn Sie sich nicht mehr
Dr. Kraus & Partner Ihr Angebot zu Konfliktmanagement
 Dr. Kraus & Partner Ihr Angebot zu Konfliktmanagement Sämtliche Zeichnungen und Karikaturen dieser Präsentation sind urheberrechtlich geschützt und dürfen nur mit schriftlicher Genehmigung seitens Dr.
Dr. Kraus & Partner Ihr Angebot zu Konfliktmanagement Sämtliche Zeichnungen und Karikaturen dieser Präsentation sind urheberrechtlich geschützt und dürfen nur mit schriftlicher Genehmigung seitens Dr.
Wie lässt sich die Multiplikation von Bruchzahlen im Operatorenmodell und wie im Größenmodell einführen?
 Modulabschlussprüfung ALGEBRA / GEOMETRIE Lösungsvorschläge zu den Klausuraufgaben Aufgabe 1: Wie lässt sich die Multiplikation von Bruchzahlen im Operatorenmodell und wie im Größenmodell einführen? Im
Modulabschlussprüfung ALGEBRA / GEOMETRIE Lösungsvorschläge zu den Klausuraufgaben Aufgabe 1: Wie lässt sich die Multiplikation von Bruchzahlen im Operatorenmodell und wie im Größenmodell einführen? Im
Fachdidaktik der Informatik 18.12.08 Jörg Depner, Kathrin Gaißer
 Fachdidaktik der Informatik 18.12.08 Jörg Depner, Kathrin Gaißer Klassendiagramme Ein Klassendiagramm dient in der objektorientierten Softwareentwicklung zur Darstellung von Klassen und den Beziehungen,
Fachdidaktik der Informatik 18.12.08 Jörg Depner, Kathrin Gaißer Klassendiagramme Ein Klassendiagramm dient in der objektorientierten Softwareentwicklung zur Darstellung von Klassen und den Beziehungen,
Übungen zur Softwaretechnik
 Technische Universität München Fakultät für Informatik Lehrstuhl IV: Software & Systems Engineering Markus Pister, Dr. Bernhard Rumpe WS 2002/2003 Lösungsblatt 9 17. Dezember 2002 www4.in.tum.de/~rumpe/se
Technische Universität München Fakultät für Informatik Lehrstuhl IV: Software & Systems Engineering Markus Pister, Dr. Bernhard Rumpe WS 2002/2003 Lösungsblatt 9 17. Dezember 2002 www4.in.tum.de/~rumpe/se
Projektsteuerung Projekte effizient steuern. Welche Steuerungsinstrumente werden eingesetzt?
 1.0 Projektmanagement Mitarbeiter, die Projekte leiten oder zukünftig übernehmen sollen Vermittlung von Grundwissen zur erfolgreichen Durchführung von Projekten. Die Teilnehmer erarbeiten anhand ihrer
1.0 Projektmanagement Mitarbeiter, die Projekte leiten oder zukünftig übernehmen sollen Vermittlung von Grundwissen zur erfolgreichen Durchführung von Projekten. Die Teilnehmer erarbeiten anhand ihrer
esearch one-single-point-of-information Federated Search Modul
 Produktbroschüre esearch one-single-point-of-information Federated Search Modul WIR HABEN DIE LÖSUNG FÜR IHREN VORSPRUNG www.mira-glomas.net esearch ermöglicht es, Ihren benötigten internen Informationsbedarf
Produktbroschüre esearch one-single-point-of-information Federated Search Modul WIR HABEN DIE LÖSUNG FÜR IHREN VORSPRUNG www.mira-glomas.net esearch ermöglicht es, Ihren benötigten internen Informationsbedarf
Michaela Knirsch-Wagner
 Michaela Knirsch-Wagner Wie schätzen Sie die aktuelle Lage auf den Finanzmärkten ein? Herr Lacina, Sie legen Ihr Geld tatsächlich nur in Sparbüchern an? Haben Sie so schlechte Erfahrungen gemacht? Herr
Michaela Knirsch-Wagner Wie schätzen Sie die aktuelle Lage auf den Finanzmärkten ein? Herr Lacina, Sie legen Ihr Geld tatsächlich nur in Sparbüchern an? Haben Sie so schlechte Erfahrungen gemacht? Herr
- Google als Suchmaschine richtig nutzen -
 - Google als Suchmaschine richtig nutzen - Google ist die wohl weltweit bekannteste und genutzte Suchmaschine der Welt. Google indexiert und aktualisiert eingetragene Seiten in bestimmten Intervallen um
- Google als Suchmaschine richtig nutzen - Google ist die wohl weltweit bekannteste und genutzte Suchmaschine der Welt. Google indexiert und aktualisiert eingetragene Seiten in bestimmten Intervallen um
Fragebogen ISONORM 9241/110-S
 Fragebogen ISONORM 9241/110-S Beurteilung von Software auf Grundlage der Internationalen Ergonomie-Norm DIN EN ISO 9241-110 von Prof. Dr. Jochen Prümper www.seikumu.de Fragebogen ISONORM 9241/110-S Seite
Fragebogen ISONORM 9241/110-S Beurteilung von Software auf Grundlage der Internationalen Ergonomie-Norm DIN EN ISO 9241-110 von Prof. Dr. Jochen Prümper www.seikumu.de Fragebogen ISONORM 9241/110-S Seite
Anleitung OpenCms 8 Webformular Auswertung
 Anleitung OpenCms 8 Webformular Auswertung 1 Erzbistum Köln Webformular Auswertung 15. August 2014 Inhalt 1. Allgemeines zum Webformular Auswertung... 3 2. Verwendung des Webformulars... 4 2.1. Reiter
Anleitung OpenCms 8 Webformular Auswertung 1 Erzbistum Köln Webformular Auswertung 15. August 2014 Inhalt 1. Allgemeines zum Webformular Auswertung... 3 2. Verwendung des Webformulars... 4 2.1. Reiter
Entwicklung mit Arbortext Editor 6.1
 Entwicklung mit Arbortext Editor 6.1 Überblick Kurscode Kurslänge TRN-4410-T 3 Tag In diesem Kurs lernen Sie die grundlegenden und erweiterten Bearbeitungsfunktionen von Arbortext Editor kennen. Der Schwerpunkt
Entwicklung mit Arbortext Editor 6.1 Überblick Kurscode Kurslänge TRN-4410-T 3 Tag In diesem Kurs lernen Sie die grundlegenden und erweiterten Bearbeitungsfunktionen von Arbortext Editor kennen. Der Schwerpunkt
Glaube an die Existenz von Regeln für Vergleiche und Kenntnis der Regeln
 Glaube an die Existenz von Regeln für Vergleiche und Kenntnis der Regeln Regeln ja Regeln nein Kenntnis Regeln ja Kenntnis Regeln nein 0 % 10 % 20 % 30 % 40 % 50 % 60 % 70 % 80 % 90 % Glauben Sie, dass
Glaube an die Existenz von Regeln für Vergleiche und Kenntnis der Regeln Regeln ja Regeln nein Kenntnis Regeln ja Kenntnis Regeln nein 0 % 10 % 20 % 30 % 40 % 50 % 60 % 70 % 80 % 90 % Glauben Sie, dass
GDPdU Export. Modulbeschreibung. GDPdU Export. Software-Lösungen. Stand: 21.02.2012. Seite 1
 Seite 1 Inhalt... 3 Allgemeines... 3 Vorteile... 3 Handhabung... 3 Seite 2 Allgemeines Mit der so genannten GDPdU-Schnittstelle (GDPdU steht für Grundsätze zum Datenzugriff und zur Prüfbarkeit digitaler
Seite 1 Inhalt... 3 Allgemeines... 3 Vorteile... 3 Handhabung... 3 Seite 2 Allgemeines Mit der so genannten GDPdU-Schnittstelle (GDPdU steht für Grundsätze zum Datenzugriff und zur Prüfbarkeit digitaler
Was muss ich über den Zulassungstest wissen?
 Was muss ich über den Zulassungstest wissen? Informationen zum freiwilligen Test zur Zulassung im Masterstudiengang Psychologie der Universität Ulm Stand: 11.6.2014 Generelle Info zum Zulassungsverfahren
Was muss ich über den Zulassungstest wissen? Informationen zum freiwilligen Test zur Zulassung im Masterstudiengang Psychologie der Universität Ulm Stand: 11.6.2014 Generelle Info zum Zulassungsverfahren
Google - Wie komme ich nach oben?
 Vortrag 17.03.2015 IHK Bonn /Rhein -Sieg Google - Wie komme ich nach oben? Internetagentur und Wirtschaftsdienst Bonn 1 Das sagt Google Bieten Sie auf Ihren Webseiten qualitativ hochwertigen Content, besonders
Vortrag 17.03.2015 IHK Bonn /Rhein -Sieg Google - Wie komme ich nach oben? Internetagentur und Wirtschaftsdienst Bonn 1 Das sagt Google Bieten Sie auf Ihren Webseiten qualitativ hochwertigen Content, besonders
Stellvertretenden Genehmiger verwalten. Tipps & Tricks
 Tipps & Tricks INHALT SEITE 1. Grundlegende Informationen 3 2.1 Aktivieren eines Stellvertretenden Genehmigers 4 2.2 Deaktivieren eines Stellvertretenden Genehmigers 11 2 1. Grundlegende Informationen
Tipps & Tricks INHALT SEITE 1. Grundlegende Informationen 3 2.1 Aktivieren eines Stellvertretenden Genehmigers 4 2.2 Deaktivieren eines Stellvertretenden Genehmigers 11 2 1. Grundlegende Informationen
Multicheck Schülerumfrage 2013
 Multicheck Schülerumfrage 2013 Die gemeinsame Studie von Multicheck und Forschungsinstitut gfs-zürich Sonderauswertung ICT Berufsbildung Schweiz Auswertung der Fragen der ICT Berufsbildung Schweiz Wir
Multicheck Schülerumfrage 2013 Die gemeinsame Studie von Multicheck und Forschungsinstitut gfs-zürich Sonderauswertung ICT Berufsbildung Schweiz Auswertung der Fragen der ICT Berufsbildung Schweiz Wir
Abitur 2007 Mathematik GK Stochastik Aufgabe C1
 Seite 1 Abiturloesung.de - Abituraufgaben Abitur 2007 Mathematik GK Stochastik Aufgabe C1 Eine Werbeagentur ermittelte durch eine Umfrage im Auftrag eines Kosmetikunternehmens vor Beginn einer Werbekampagne
Seite 1 Abiturloesung.de - Abituraufgaben Abitur 2007 Mathematik GK Stochastik Aufgabe C1 Eine Werbeagentur ermittelte durch eine Umfrage im Auftrag eines Kosmetikunternehmens vor Beginn einer Werbekampagne
Neuerungen in ReviPS Version 12g
 Neuerungen in ReviPS Version 12g Review-Aufgaben... 2 Offene Reviews... 4 Offene Arbeiten... 7 AuditCockpit... 8 Bilanz, Erfolgsrechung, Kennzahlen und sonstige Auswertungen... 9 Pendenzen, Risikofälle,
Neuerungen in ReviPS Version 12g Review-Aufgaben... 2 Offene Reviews... 4 Offene Arbeiten... 7 AuditCockpit... 8 Bilanz, Erfolgsrechung, Kennzahlen und sonstige Auswertungen... 9 Pendenzen, Risikofälle,
Unterrichtseinheiten zur Thematik Ökobilanz. Übersicht. Motivation und Lernziele. Einführung. Ablauf einer Ökobilanz. Beispiel.
 en Übersicht Motivation und Motivation Sorge zur Umwelt tragen Herausfinden, welches Produkt weniger umweltschädlich ist als andere Wissen wie man en erstellt nach der anerkannten Norm ISO14040 Verstehen,
en Übersicht Motivation und Motivation Sorge zur Umwelt tragen Herausfinden, welches Produkt weniger umweltschädlich ist als andere Wissen wie man en erstellt nach der anerkannten Norm ISO14040 Verstehen,
Erklären Sie die Innenfinanzierung und die Formen derselben!
 1. Aufgabe: Erklären Sie die Innenfinanzierung und die Formen derselben! Stellen Sie die verschiedenen Formen der Innenfinanzierung gegenüber und arbeiten die Vor- und Nachteile heraus! Erklären Sie die
1. Aufgabe: Erklären Sie die Innenfinanzierung und die Formen derselben! Stellen Sie die verschiedenen Formen der Innenfinanzierung gegenüber und arbeiten die Vor- und Nachteile heraus! Erklären Sie die
Basis (=100%) zusätzlichen Schulabschluss an. Befragungszeitraum: 29.11.-10.12.2011
 zusätzlichen Schulabschluss an. Befragungszeitraum: 29.11.-10.12.2011") Tabelle 1: Interesse an höherem Schulabschluss Streben Sie nach Beendigung der Schule, die Sie momentan besuchen, noch einen weiteren oder höheren Schulabschluss an? Seite 1 Selektion: Schüler die nicht
Tabelle 1: Interesse an höherem Schulabschluss Streben Sie nach Beendigung der Schule, die Sie momentan besuchen, noch einen weiteren oder höheren Schulabschluss an? Seite 1 Selektion: Schüler die nicht
Die Entwicklung eines Glossars (oder eines kontrollierten Vokabulars) für ein Unternehmen geht üblicherweise in 3 Schritten vor sich:
 für ein Unternehmen geht üblicherweise in 3 Schritten vor sich:") Glossare 1 Inhalt 1 Inhalt... 1 2 Prozesse... 1 3 Eine kleine Zeittabelle...... 1 4 Die ersten Schritte... 2 5 Die nächsten Schritte...... 2 6 Die letzten Schritte... 3 7 Das Tool...... 4 8 Beispiele...
Glossare 1 Inhalt 1 Inhalt... 1 2 Prozesse... 1 3 Eine kleine Zeittabelle...... 1 4 Die ersten Schritte... 2 5 Die nächsten Schritte...... 2 6 Die letzten Schritte... 3 7 Das Tool...... 4 8 Beispiele...
Über die Internetseite www.cadwork.de Hier werden unter Download/aktuelle Versionen die verschiedenen Module als zip-dateien bereitgestellt.
 Internet, Codes und Update ab Version 13 Um Ihnen einen möglichst schnellen Zugang zu den aktuellsten Programmversionen zu ermöglichen liegen Update-Dateien für Sie im Internet bereit. Es gibt drei Möglichkeiten
Internet, Codes und Update ab Version 13 Um Ihnen einen möglichst schnellen Zugang zu den aktuellsten Programmversionen zu ermöglichen liegen Update-Dateien für Sie im Internet bereit. Es gibt drei Möglichkeiten
Je früher, desto klüger: Vorsorgen mit der SV Rentenversicherung.
 S V R e n t e n v e r s i c h e ru n g Je früher, desto klüger: Vorsorgen mit der SV Rentenversicherung. Was auch passiert: Sparkassen-Finanzgruppe www.sparkassenversicherung.de Wie Sie die magere gesetzliche
S V R e n t e n v e r s i c h e ru n g Je früher, desto klüger: Vorsorgen mit der SV Rentenversicherung. Was auch passiert: Sparkassen-Finanzgruppe www.sparkassenversicherung.de Wie Sie die magere gesetzliche
Angaben zu einem Kontakt...1 So können Sie einen Kontakt erfassen...4 Was Sie mit einem Kontakt tun können...7
 Tutorial: Wie kann ich Kontakte erfassen In myfactory können Sie Kontakte erfassen. Unter einem Kontakt versteht man einen Datensatz, der sich auf eine Tätigkeit im Zusammenhang mit einer Adresse bezieht.
Tutorial: Wie kann ich Kontakte erfassen In myfactory können Sie Kontakte erfassen. Unter einem Kontakt versteht man einen Datensatz, der sich auf eine Tätigkeit im Zusammenhang mit einer Adresse bezieht.
Management Summary. Was macht Führung zukunftsfähig? Stuttgart, den 21. April 2016
 Management Summary Stuttgart, den 21. April 2016 Was macht Führung zukunftsfähig? Ergebnisse einer repräsentativen Befragung von Führungs- und Nachwuchskräften in Privatwirtschaft und öffentlichem Dienst
Management Summary Stuttgart, den 21. April 2016 Was macht Führung zukunftsfähig? Ergebnisse einer repräsentativen Befragung von Führungs- und Nachwuchskräften in Privatwirtschaft und öffentlichem Dienst
News & RSS. Einleitung: Nachrichten er-(veröffentlichen) und bereitstellen Nachrichten erstellen und bereitstellen
 und bereitstellen Nachrichten erstellen und bereitstellen") News & RSS Nachrichten er-(veröffentlichen) und bereitstellen Nachrichten erstellen und bereitstellen Einleitung: Sie wollen Ihre Nutzer immer mit den neuesten Informationen versorgen bzw. auf dem laufendem
News & RSS Nachrichten er-(veröffentlichen) und bereitstellen Nachrichten erstellen und bereitstellen Einleitung: Sie wollen Ihre Nutzer immer mit den neuesten Informationen versorgen bzw. auf dem laufendem
http://www.therealgang.de/
 http://www.therealgang.de/ Titel : Author : Kategorie : Vorlesung HTML und XML (Einführung) Dr. Pascal Rheinert Sonstige-Programmierung Vorlesung HTML / XML: Grundlegende Informationen zu HTML a.) Allgemeines:
http://www.therealgang.de/ Titel : Author : Kategorie : Vorlesung HTML und XML (Einführung) Dr. Pascal Rheinert Sonstige-Programmierung Vorlesung HTML / XML: Grundlegende Informationen zu HTML a.) Allgemeines:
Wie Google Webseiten bewertet. François Bry
 Wie Google Webseiten bewertet François Bry Heu6ge Vorlesung 1. Einleitung 2. Graphen und Matrizen 3. Erste Idee: Ranking als Eigenvektor 4. Fragen: Exisi6ert der Eigenvektor? Usw. 5. Zweite Idee: Die Google
Wie Google Webseiten bewertet François Bry Heu6ge Vorlesung 1. Einleitung 2. Graphen und Matrizen 3. Erste Idee: Ranking als Eigenvektor 4. Fragen: Exisi6ert der Eigenvektor? Usw. 5. Zweite Idee: Die Google
Suchmaschinenalgorithmen. Vortrag von: Thomas Müller
 Suchmaschinenalgorithmen Vortrag von: Thomas Müller Kurze Geschichte Erste Suchmaschine für Hypertexte am CERN Erste www-suchmaschine World Wide Web Wanderer 1993 Bis 1996: 2 mal jährlich Durchlauf 1994:
Suchmaschinenalgorithmen Vortrag von: Thomas Müller Kurze Geschichte Erste Suchmaschine für Hypertexte am CERN Erste www-suchmaschine World Wide Web Wanderer 1993 Bis 1996: 2 mal jährlich Durchlauf 1994:
Social Customer Service. Wie machen Sie Ihre Mitarbeiter fit für den Kundenservice 2.0?
 Social Customer Service Wie machen Sie Ihre Mitarbeiter fit für den Kundenservice 2.0? 1 Warum ein Training - am Beispiel: 2 Social Media verstehen - am Beispiel 3 SMT + E 3 = SCS Social Emphatie Social
Social Customer Service Wie machen Sie Ihre Mitarbeiter fit für den Kundenservice 2.0? 1 Warum ein Training - am Beispiel: 2 Social Media verstehen - am Beispiel 3 SMT + E 3 = SCS Social Emphatie Social
Installation von horizont 4 bei Verwendung mehrerer Datenbanken
 horizont 4 Installation von horizont 4 bei Verwendung mehrerer Datenbanken Erstellt von der buchner documentation gmbh 1 Inhaltsverzeichnis Inhalt...3 Einleitung...3 Vorgehensweise der Installation bei
horizont 4 Installation von horizont 4 bei Verwendung mehrerer Datenbanken Erstellt von der buchner documentation gmbh 1 Inhaltsverzeichnis Inhalt...3 Einleitung...3 Vorgehensweise der Installation bei
MORE Profile. Pass- und Lizenzverwaltungssystem. Stand: 19.02.2014 MORE Projects GmbH
 MORE Profile Pass- und Lizenzverwaltungssystem erstellt von: Thorsten Schumann erreichbar unter: thorsten.schumann@more-projects.de Stand: MORE Projects GmbH Einführung Die in More Profile integrierte
MORE Profile Pass- und Lizenzverwaltungssystem erstellt von: Thorsten Schumann erreichbar unter: thorsten.schumann@more-projects.de Stand: MORE Projects GmbH Einführung Die in More Profile integrierte
Einbindung einer ACT!12-16 Datenbank als Datenquelle für den Bulkmailer 2012
 Einbindung einer ACT!12-16 Datenbank als Datenquelle für den Bulkmailer 2012 Eine langvermisste Funktion ist mit den neuesten Versionen von ACT! und Bulkmailer wieder verfügbar. Mit dem Erscheinen der
Einbindung einer ACT!12-16 Datenbank als Datenquelle für den Bulkmailer 2012 Eine langvermisste Funktion ist mit den neuesten Versionen von ACT! und Bulkmailer wieder verfügbar. Mit dem Erscheinen der
esearch one-single-point-of-information Federated Search Modul
 Produktbroschüre esearch one-single-point-of-information Federated Search Modul WIR HABEN DIE LÖSUNG FÜR IHREN VORSPRUNG www.mira-glomas.net esearch ermöglicht es, Ihren benötigten internen Informationsbedarf
Produktbroschüre esearch one-single-point-of-information Federated Search Modul WIR HABEN DIE LÖSUNG FÜR IHREN VORSPRUNG www.mira-glomas.net esearch ermöglicht es, Ihren benötigten internen Informationsbedarf
Erstellen einer digitalen Signatur für Adobe-Formulare
 Erstellen einer digitalen Signatur für Adobe-Formulare (Hubert Straub 24.07.13) Die beiden Probleme beim Versenden digitaler Dokumente sind einmal die Prüfung der Authentizität des Absenders (was meist
Erstellen einer digitalen Signatur für Adobe-Formulare (Hubert Straub 24.07.13) Die beiden Probleme beim Versenden digitaler Dokumente sind einmal die Prüfung der Authentizität des Absenders (was meist
Barrierefreie Webseiten erstellen mit TYPO3
 Barrierefreie Webseiten erstellen mit TYPO3 Alternativtexte Für jedes Nicht-Text-Element ist ein äquivalenter Text bereitzustellen. Dies gilt insbesondere für Bilder. In der Liste der HTML 4-Attribute
Barrierefreie Webseiten erstellen mit TYPO3 Alternativtexte Für jedes Nicht-Text-Element ist ein äquivalenter Text bereitzustellen. Dies gilt insbesondere für Bilder. In der Liste der HTML 4-Attribute
Workshops. Gewinnen Sie mehr Zeit und Qualität im Umgang mit Ihrem Wissen
 Wissens-Workshops Workshops Gewinnen Sie mehr Zeit und Qualität im Umgang mit Ihrem Wissen Sie haben viel weniger Zeit für die inhaltliche Arbeit, als Sie sich wünschen. Die Informationsflut verstellt
Wissens-Workshops Workshops Gewinnen Sie mehr Zeit und Qualität im Umgang mit Ihrem Wissen Sie haben viel weniger Zeit für die inhaltliche Arbeit, als Sie sich wünschen. Die Informationsflut verstellt
Ebenenmasken Grundlagen
 Ebenenmasken Grundlagen Was sind Ebenmasken? Was machen sie? Wofür braucht man sie? Wie funktionieren sie? Ebenmasken sind eines der sinnvollsten Tools in anspruchvollen EBV Programmen (EBV = elektronische
Ebenenmasken Grundlagen Was sind Ebenmasken? Was machen sie? Wofür braucht man sie? Wie funktionieren sie? Ebenmasken sind eines der sinnvollsten Tools in anspruchvollen EBV Programmen (EBV = elektronische
Objektorientierte Programmierung für Anfänger am Beispiel PHP
 Objektorientierte Programmierung für Anfänger am Beispiel PHP Johannes Mittendorfer http://jmittendorfer.hostingsociety.com 19. August 2012 Abstract Dieses Dokument soll die Vorteile der objektorientierten
Objektorientierte Programmierung für Anfänger am Beispiel PHP Johannes Mittendorfer http://jmittendorfer.hostingsociety.com 19. August 2012 Abstract Dieses Dokument soll die Vorteile der objektorientierten
Kollaborative Konstruktionsglossare im Fachfremdsprachenlernen Deutsch, Estnisch, Lettisch, Litauisch AntConc Arbeit mit digitalen Textsammlungen
 Ko[Gloss] Kollaborative Konstruktionsglossare im Fachfremdsprachenlernen Deutsch, Estnisch, Lettisch, Litauisch AntConc Arbeit mit digitalen Textsammlungen Ko[Gloss] Digitale Analyse: Sprachliche Muster
Ko[Gloss] Kollaborative Konstruktionsglossare im Fachfremdsprachenlernen Deutsch, Estnisch, Lettisch, Litauisch AntConc Arbeit mit digitalen Textsammlungen Ko[Gloss] Digitale Analyse: Sprachliche Muster
Wien = Menschlich. freigeist.photography
 Wien = Menschlich freigeist.photography Idee zu diesem Projekt Wovon lebt eine Stadt wie WIEN? Von seiner Geschichte, seiner Architektur, seinen Sehenswürdigkeiten und kulinarischen heimischen Köstlichkeiten.
Wien = Menschlich freigeist.photography Idee zu diesem Projekt Wovon lebt eine Stadt wie WIEN? Von seiner Geschichte, seiner Architektur, seinen Sehenswürdigkeiten und kulinarischen heimischen Köstlichkeiten.
FIS: Projektdaten auf den Internetseiten ausgeben
 Rechenzentrum FIS: Projektdaten auf den Internetseiten ausgeben Ist ein Forschungsprojekt im Forschungsinformationssystem (FIS) erfasst und für die Veröffentlichung freigegeben, können Sie einige Daten
Rechenzentrum FIS: Projektdaten auf den Internetseiten ausgeben Ist ein Forschungsprojekt im Forschungsinformationssystem (FIS) erfasst und für die Veröffentlichung freigegeben, können Sie einige Daten
Kapiteltests zum Leitprogramm Binäre Suchbäume
 Kapiteltests zum Leitprogramm Binäre Suchbäume Björn Steffen Timur Erdag überarbeitet von Christina Class Binäre Suchbäume Kapiteltests für das ETH-Leitprogramm Adressaten und Institutionen Das Leitprogramm
Kapiteltests zum Leitprogramm Binäre Suchbäume Björn Steffen Timur Erdag überarbeitet von Christina Class Binäre Suchbäume Kapiteltests für das ETH-Leitprogramm Adressaten und Institutionen Das Leitprogramm
Bundesverband Flachglas Großhandel Isolierglasherstellung Veredlung e.v. U g -Werte-Tabellen nach DIN EN 673. Flachglasbranche.
 Bundesverband Flachglas Großhandel Isolierglasherstellung Veredlung e.v. U g -Werte-Tabellen nach DIN EN 673 Ug-Werte für die Flachglasbranche Einleitung Die vorliegende Broschüre enthält die Werte für
Bundesverband Flachglas Großhandel Isolierglasherstellung Veredlung e.v. U g -Werte-Tabellen nach DIN EN 673 Ug-Werte für die Flachglasbranche Einleitung Die vorliegende Broschüre enthält die Werte für
Anleitung zur Erstellung von Serienbriefen (Word 2003) unter Berücksichtigung von Titeln (wie Dr., Dr. med. usw.)
 unter Berücksichtigung von Titeln (wie Dr., Dr. med. usw.)") Seite 1/7 Anleitung zur Erstellung von Serienbriefen (Word 2003) unter Berücksichtigung von Titeln (wie Dr., Dr. med. usw.) Hier sehen Sie eine Anleitung wie man einen Serienbrief erstellt. Die Anleitung
Seite 1/7 Anleitung zur Erstellung von Serienbriefen (Word 2003) unter Berücksichtigung von Titeln (wie Dr., Dr. med. usw.) Hier sehen Sie eine Anleitung wie man einen Serienbrief erstellt. Die Anleitung
S TAND N OVEMBE R 2012 HANDBUCH DUDLE.ELK-WUE.DE T E R M I N A B S P R A C H E N I N D E R L A N D E S K I R C H E
 S TAND N OVEMBE R 2012 HANDBUCH T E R M I N A B S P R A C H E N I N D E R L A N D E S K I R C H E Herausgeber Referat Informationstechnologie in der Landeskirche und im Oberkirchenrat Evangelischer Oberkirchenrat
S TAND N OVEMBE R 2012 HANDBUCH T E R M I N A B S P R A C H E N I N D E R L A N D E S K I R C H E Herausgeber Referat Informationstechnologie in der Landeskirche und im Oberkirchenrat Evangelischer Oberkirchenrat
Fragebogen. zur Erschließung und Sicherung von Online-Dokumenten. Auswahl von elektronischen Publikationen
 Fragebogen zur Erschließung und Sicherung von Online-Dokumenten I. Angaben zum Ansprechpartner Nachname Vorname Institution E-Mail-Adresse II. Auswahl von elektronischen Publikationen 1a) Wertet Ihre Institution
Fragebogen zur Erschließung und Sicherung von Online-Dokumenten I. Angaben zum Ansprechpartner Nachname Vorname Institution E-Mail-Adresse II. Auswahl von elektronischen Publikationen 1a) Wertet Ihre Institution
Ihr Weg in die Suchmaschinen
 Ihr Weg in die Suchmaschinen Suchmaschinenoptimierung Durch Suchmaschinenoptimierung kann man eine höhere Platzierung von Homepages in den Ergebnislisten von Suchmaschinen erreichen und somit mehr Besucher
Ihr Weg in die Suchmaschinen Suchmaschinenoptimierung Durch Suchmaschinenoptimierung kann man eine höhere Platzierung von Homepages in den Ergebnislisten von Suchmaschinen erreichen und somit mehr Besucher
Info-Veranstaltung zur Erstellung von Zertifikaten
 Info-Veranstaltung zur Erstellung von Zertifikaten Prof. Dr. Till Tantau Studiengangsleiter MINT Universität zu Lübeck 29. Juni 2011 Gliederung Zertifikate Wer, Wann, Was Ablauf der Zertifikaterstellung
Info-Veranstaltung zur Erstellung von Zertifikaten Prof. Dr. Till Tantau Studiengangsleiter MINT Universität zu Lübeck 29. Juni 2011 Gliederung Zertifikate Wer, Wann, Was Ablauf der Zertifikaterstellung
Mit Papier, Münzen und Streichhölzern rechnen kreative Aufgaben zum Umgang mit Größen. Von Florian Raith, Fürstenzell VORANSICHT
 Mit Papier, Münzen und Streichhölzern rechnen kreative Aufgaben zum Umgang mit Größen Von Florian Raith, Fürstenzell Alltagsgegenstände sind gut greifbar so werden beim Rechnen mit ihnen Größen begreifbar.
Mit Papier, Münzen und Streichhölzern rechnen kreative Aufgaben zum Umgang mit Größen Von Florian Raith, Fürstenzell Alltagsgegenstände sind gut greifbar so werden beim Rechnen mit ihnen Größen begreifbar.
Abituraufgabe zur Stochastik, Hessen 2009, Grundkurs (TR)
") Abituraufgabe zur Stochastik, Hessen 2009, Grundkurs (TR) Eine Firma stellt USB-Sticks her. Sie werden in der Fabrik ungeprüft in Packungen zu je 20 Stück verpackt und an Händler ausgeliefert. 1 Ein Händler
Abituraufgabe zur Stochastik, Hessen 2009, Grundkurs (TR) Eine Firma stellt USB-Sticks her. Sie werden in der Fabrik ungeprüft in Packungen zu je 20 Stück verpackt und an Händler ausgeliefert. 1 Ein Händler
Jede Zahl muss dabei einzeln umgerechnet werden. Beginnen wir also ganz am Anfang mit der Zahl,192.
 Binäres und dezimales Zahlensystem Ziel In diesem ersten Schritt geht es darum, die grundlegende Umrechnung aus dem Dezimalsystem in das Binärsystem zu verstehen. Zusätzlich wird auch die andere Richtung,
Binäres und dezimales Zahlensystem Ziel In diesem ersten Schritt geht es darum, die grundlegende Umrechnung aus dem Dezimalsystem in das Binärsystem zu verstehen. Zusätzlich wird auch die andere Richtung,
Erfolgreiche Maßnahmen für Ihr Reputationsmanagement
 Erfolgreiche Maßnahmen für Ihr Reputationsmanagement Roland Ballacchino Es dauert zwanzig Jahre, sich eine Reputation zu erwerben und fünf Minuten, sie zu verlieren. Wenn man das im Auge behält, handelt
Erfolgreiche Maßnahmen für Ihr Reputationsmanagement Roland Ballacchino Es dauert zwanzig Jahre, sich eine Reputation zu erwerben und fünf Minuten, sie zu verlieren. Wenn man das im Auge behält, handelt
Windows Explorer Das unbekannte Tool. Compi-Treff vom 19. September 2014 Thomas Sigg
 Windows Explorer Das unbekannte Tool Thomas Sigg Das Wort Explorer aus dem Englischen heisst eigentlich Auskundschafter, Sucher Der Windows Explorer darf nicht mit dem Internet Explorer verwechselt werden.
Windows Explorer Das unbekannte Tool Thomas Sigg Das Wort Explorer aus dem Englischen heisst eigentlich Auskundschafter, Sucher Der Windows Explorer darf nicht mit dem Internet Explorer verwechselt werden.
FAQ Verwendung. 1. Wie kann ich eine Verbindung zu meinem virtuellen SeeZam-Tresor herstellen?
 FAQ Verwendung FAQ Verwendung 1. Wie kann ich eine Verbindung zu meinem virtuellen SeeZam-Tresor herstellen? 2. Wie verbinde ich mein OPTIMUM-Konto und das Token, das SeeZam mir geschickt hat? 3. Ich möchte
FAQ Verwendung FAQ Verwendung 1. Wie kann ich eine Verbindung zu meinem virtuellen SeeZam-Tresor herstellen? 2. Wie verbinde ich mein OPTIMUM-Konto und das Token, das SeeZam mir geschickt hat? 3. Ich möchte
Anleitung zur Bearbeitung von Prüferkommentaren in der Nachreichung
 Anleitung zur Bearbeitung von Prüferkommentaren in der Nachreichung Inhalt 1. Schritt Prüferkommentare... 1 2. Schritt Prüferkommentar kommentieren... 4 3. Schritt Nachweisdokumente hochladen... 6 4. Schritt
Anleitung zur Bearbeitung von Prüferkommentaren in der Nachreichung Inhalt 1. Schritt Prüferkommentare... 1 2. Schritt Prüferkommentar kommentieren... 4 3. Schritt Nachweisdokumente hochladen... 6 4. Schritt
Konzepte der Informatik
 Konzepte der Informatik Vorkurs Informatik zum WS 2011/2012 26.09. - 30.09.2011 17.10. - 21.10.2011 Dr. Werner Struckmann / Christoph Peltz Stark angelehnt an Kapitel 1 aus "Abenteuer Informatik" von Jens
Konzepte der Informatik Vorkurs Informatik zum WS 2011/2012 26.09. - 30.09.2011 17.10. - 21.10.2011 Dr. Werner Struckmann / Christoph Peltz Stark angelehnt an Kapitel 1 aus "Abenteuer Informatik" von Jens
Meine Entscheidung zur Wiederaufnahme der Arbeit
 Meine Entscheidung zur Wiederaufnahme der Arbeit Die nachfolgende Übersicht soll Sie dabei unterstützen, Ihre Wünsche und Vorstellungen zur Wiederaufnahme der Arbeit für sich selbst einzuordnen. Sie soll
Meine Entscheidung zur Wiederaufnahme der Arbeit Die nachfolgende Übersicht soll Sie dabei unterstützen, Ihre Wünsche und Vorstellungen zur Wiederaufnahme der Arbeit für sich selbst einzuordnen. Sie soll
... hab ich gegoogelt. webfinder. Suchmaschinenmarketing !!!!!!
 ... hab ich gegoogelt. webfinder Suchmaschinenmarketing G egoogelt ist längst zu einem geflügelten Wort geworden. Wer googlet, der sucht und wer sucht, soll Sie finden. Und zwar an vorderster Position,
... hab ich gegoogelt. webfinder Suchmaschinenmarketing G egoogelt ist längst zu einem geflügelten Wort geworden. Wer googlet, der sucht und wer sucht, soll Sie finden. Und zwar an vorderster Position,
Vorlesung Text und Data Mining S9 Text Clustering. Hans Hermann Weber Univ. Erlangen, Informatik
 Vorlesung Text und Data Mining S9 Text Clustering Hans Hermann Weber Univ. Erlangen, Informatik Document Clustering Überblick 1 Es gibt (sehr viele) verschiedene Verfahren für das Bilden von Gruppen Bei
Vorlesung Text und Data Mining S9 Text Clustering Hans Hermann Weber Univ. Erlangen, Informatik Document Clustering Überblick 1 Es gibt (sehr viele) verschiedene Verfahren für das Bilden von Gruppen Bei
Mit dem Tool Stundenverwaltung von Hanno Kniebel erhalten Sie die Möglichkeit zur effizienten Verwaltung von Montagezeiten Ihrer Mitarbeiter.
 Stundenverwaltung Mit dem Tool Stundenverwaltung von Hanno Kniebel erhalten Sie die Möglichkeit zur effizienten Verwaltung von Montagezeiten Ihrer Mitarbeiter. Dieses Programm zeichnet sich aus durch einfachste
Stundenverwaltung Mit dem Tool Stundenverwaltung von Hanno Kniebel erhalten Sie die Möglichkeit zur effizienten Verwaltung von Montagezeiten Ihrer Mitarbeiter. Dieses Programm zeichnet sich aus durch einfachste
Stellen Sie bitte den Cursor in die Spalte B2 und rufen die Funktion Sverweis auf. Es öffnet sich folgendes Dialogfenster
 Es gibt in Excel unter anderem die so genannten Suchfunktionen / Matrixfunktionen Damit können Sie Werte innerhalb eines bestimmten Bereichs suchen. Als Beispiel möchte ich die Funktion Sverweis zeigen.
Es gibt in Excel unter anderem die so genannten Suchfunktionen / Matrixfunktionen Damit können Sie Werte innerhalb eines bestimmten Bereichs suchen. Als Beispiel möchte ich die Funktion Sverweis zeigen.
Klassenarbeit zu linearen Gleichungssystemen
 Klassenarbeit zu linearen Gleichungssystemen Aufgabe : Bestimme die Lösungsmenge der Gleichungssysteme mit Hilfe des Additionsverfahrens: x + 4y = 8 5x y = x y = x y = Aufgabe : Bestimme die Lösungsmenge
Klassenarbeit zu linearen Gleichungssystemen Aufgabe : Bestimme die Lösungsmenge der Gleichungssysteme mit Hilfe des Additionsverfahrens: x + 4y = 8 5x y = x y = x y = Aufgabe : Bestimme die Lösungsmenge
Contao Schulung. Martin Kozianka <martin@kozianka.de> Donnerstag, 20.11.2014
 Contao Schulung Martin Kozianka Donnerstag, 20.11.2014 Theorieteil 1 - Begriffe Frontend: Die eigentliche Webseite (Ansicht für die Besucher) Backend: Administrationsbereich bzw. Oberfläche
Contao Schulung Martin Kozianka Donnerstag, 20.11.2014 Theorieteil 1 - Begriffe Frontend: Die eigentliche Webseite (Ansicht für die Besucher) Backend: Administrationsbereich bzw. Oberfläche
Metadaten bei der Digitalisierung von analogen archivalischen Quellen. Kathrin Mileta, Dr. Martina Wiech
 Metadaten bei der Digitalisierung von analogen archivalischen Quellen Kathrin Mileta, Dr. Martina Wiech 2014 Metadaten Aufgabe des LAV NRW im DFG-Pilotprojekt zur Digitalisierung archivalischer Quellen:
Metadaten bei der Digitalisierung von analogen archivalischen Quellen Kathrin Mileta, Dr. Martina Wiech 2014 Metadaten Aufgabe des LAV NRW im DFG-Pilotprojekt zur Digitalisierung archivalischer Quellen:
Die Wirtschaftskrise aus Sicht der Kinder
 Die Wirtschaftskrise aus Sicht der Kinder Telefonische Befragung bei 151 Kindern im Alter von 8 bis 12 Jahren Präsentation der Ergebnisse Mai 2009 EYE research GmbH, Neuer Weg 14, 71111 Waldenbuch, Tel.
Die Wirtschaftskrise aus Sicht der Kinder Telefonische Befragung bei 151 Kindern im Alter von 8 bis 12 Jahren Präsentation der Ergebnisse Mai 2009 EYE research GmbH, Neuer Weg 14, 71111 Waldenbuch, Tel.
Webdesign-Multimedia HTML und CSS
 Webdesign-Multimedia HTML und CSS Thomas Mohr HTML Definition ˆ HTML (Hypertext Markup Language) ist eine textbasierte Auszeichnungssprache (engl. markup language) zur Strukturierung digitaler Dokumente
Webdesign-Multimedia HTML und CSS Thomas Mohr HTML Definition ˆ HTML (Hypertext Markup Language) ist eine textbasierte Auszeichnungssprache (engl. markup language) zur Strukturierung digitaler Dokumente
Ordner Berechtigung vergeben Zugriffsrechte unter Windows einrichten
 Ordner Berechtigung vergeben Zugriffsrechte unter Windows einrichten Was sind Berechtigungen? Unter Berechtigungen werden ganz allgemein die Zugriffsrechte auf Dateien und Verzeichnisse (Ordner) verstanden.
Ordner Berechtigung vergeben Zugriffsrechte unter Windows einrichten Was sind Berechtigungen? Unter Berechtigungen werden ganz allgemein die Zugriffsrechte auf Dateien und Verzeichnisse (Ordner) verstanden.
ClubWebMan Veranstaltungskalender
 ClubWebMan Veranstaltungskalender Terminverwaltung geeignet für TYPO3 Version 4. bis 4.7 Die Arbeitsschritte A. Kategorien anlegen B. Veranstaltungsort und Veranstalter anlegen B. Veranstaltungsort anlegen
ClubWebMan Veranstaltungskalender Terminverwaltung geeignet für TYPO3 Version 4. bis 4.7 Die Arbeitsschritte A. Kategorien anlegen B. Veranstaltungsort und Veranstalter anlegen B. Veranstaltungsort anlegen
Modellbildungssysteme: Pädagogische und didaktische Ziele
 Modellbildungssysteme: Pädagogische und didaktische Ziele Was hat Modellbildung mit der Schule zu tun? Der Bildungsplan 1994 formuliert: "Die schnelle Zunahme des Wissens, die hohe Differenzierung und
Modellbildungssysteme: Pädagogische und didaktische Ziele Was hat Modellbildung mit der Schule zu tun? Der Bildungsplan 1994 formuliert: "Die schnelle Zunahme des Wissens, die hohe Differenzierung und
Lineargleichungssysteme: Additions-/ Subtraktionsverfahren
 Lineargleichungssysteme: Additions-/ Subtraktionsverfahren W. Kippels 22. Februar 2014 Inhaltsverzeichnis 1 Einleitung 2 2 Lineargleichungssysteme zweiten Grades 2 3 Lineargleichungssysteme höheren als
Lineargleichungssysteme: Additions-/ Subtraktionsverfahren W. Kippels 22. Februar 2014 Inhaltsverzeichnis 1 Einleitung 2 2 Lineargleichungssysteme zweiten Grades 2 3 Lineargleichungssysteme höheren als
Saldo-Konto eines Mitarbeiters korrigieren
 Saldo-Konto eines Mitarbeiters korrigieren Das Korrigieren eines Kontos (in diesem Beispiel des Saldo Kontos) ist in der Personalwolke durch den Korrektur-Client möglich. Vorgehensweise Sie finden den
Saldo-Konto eines Mitarbeiters korrigieren Das Korrigieren eines Kontos (in diesem Beispiel des Saldo Kontos) ist in der Personalwolke durch den Korrektur-Client möglich. Vorgehensweise Sie finden den
Informationen zum Datenschutz im Maler- und Lackiererhandwerk
 Institut für Betriebsberatung des deutschen Maler- und Lackiererhandwerks Frankfurter Straße 14, 63500 Seligenstadt Telefon (06182) 2 52 08 * Fax 2 47 01 Maler-Lackierer-Institut@t-online.de www.malerinstitut.de
Institut für Betriebsberatung des deutschen Maler- und Lackiererhandwerks Frankfurter Straße 14, 63500 Seligenstadt Telefon (06182) 2 52 08 * Fax 2 47 01 Maler-Lackierer-Institut@t-online.de www.malerinstitut.de
Orientierungstest für angehende Industriemeister. Vorbereitungskurs Mathematik
 Orientierungstest für angehende Industriemeister Vorbereitungskurs Mathematik Weiterbildung Technologie Erlaubte Hilfsmittel: Formelsammlung Taschenrechner Maximale Bearbeitungszeit: 1 Stunde Provadis
Orientierungstest für angehende Industriemeister Vorbereitungskurs Mathematik Weiterbildung Technologie Erlaubte Hilfsmittel: Formelsammlung Taschenrechner Maximale Bearbeitungszeit: 1 Stunde Provadis
Anlegen eines Facebook-Profils (Privat-Profil) für BuchhändlerInnen und andere -- Stand Mai 2011
 für BuchhändlerInnen und andere -- Stand Mai 2011") Anlegen eines Facebook-Profils (Privat-Profil) für BuchhändlerInnen und andere -- Stand Mai 2011 Stefanie Leo www.buecherkinder.de 1 Schritt 1 Diese Seite erscheint wenn Sie www.facebook.com anklicken.
Anlegen eines Facebook-Profils (Privat-Profil) für BuchhändlerInnen und andere -- Stand Mai 2011 Stefanie Leo www.buecherkinder.de 1 Schritt 1 Diese Seite erscheint wenn Sie www.facebook.com anklicken.
4. Erstellung des eigenen Podcasts? Podcast Schülerheft
 4. Erstellung des eigenen Podcasts? 13 4. Erstellung eines Podcasts? Du möchtest sicher viele Leute mit Deinem Podcast ansprechen. Wenn Du einen eigenen Podcast erstellst, solltest Du Dir vorher überlegen
4. Erstellung des eigenen Podcasts? 13 4. Erstellung eines Podcasts? Du möchtest sicher viele Leute mit Deinem Podcast ansprechen. Wenn Du einen eigenen Podcast erstellst, solltest Du Dir vorher überlegen
Universal Gleismauer Set von SB4 mit Tauschtextur u. integrierten Gleismauerabschlüssen!
 Stefan Böttner (SB4) März 2013 Universal Gleismauer Set von SB4 mit Tauschtextur u. integrierten Gleismauerabschlüssen! Verwendbar ab EEP7.5(mitPlugin5) + EEP8 + EEP9 Abmessung: (B 12m x H 12m) Die Einsatzhöhe
Stefan Böttner (SB4) März 2013 Universal Gleismauer Set von SB4 mit Tauschtextur u. integrierten Gleismauerabschlüssen! Verwendbar ab EEP7.5(mitPlugin5) + EEP8 + EEP9 Abmessung: (B 12m x H 12m) Die Einsatzhöhe