Korpusbasierte Analyse internetbasierter Kommunikation: Herausforderungen und Perspektiven
|
|
|
- Frieder Gerhardt
- vor 5 Jahren
- Abrufe
Transkript
1 Korpusbasierte Analyse internetbasierter Kommunikation: Herausforderungen und Perspektiven Neue Wege in der Nutzung von Korpora: Data-Mining für die textorientierten Geisteswissenschaften Fachtagung, 30. Oktober 2015 Michael Beißwenger KobRA Korpus-basierte linguistische Recherche und Analyse mit Hilfe von Data-Mining Harald Lüngen Christian Pölitz
2 Herausforderungen bei der korpusbasierten Analyse [1] Werkzeuge für die automatische linguistische Annotation können mit der Schriftlichkeit in Genres internetbasierter Kommunikation nicht umgehen ( Nonstandard-Phänomene : Abweichungen von den Normen der geschriebenen Standardsprache; fehlende Standards für die Verarbeitung netztypischer Stlelemente) Handannotation: kostet viel Zeit (und Geld) Volltextsuche: Hohe Zahl an unerwünschten Treffern; Trefferlisten müssen vor der Analyse intellektuell bereinigt werden (auch teuer) [2] Zwar können IBK-Daten prinzipiell in großen Mengen aus dem Web erhoben werden (s. web as corpus ) die Datensets, die man bei der Analyse tatsächlich bewältigen kann, sind aber i.d.r. eher klein. Fragestellung: Können Machine-Learning-Verfahren für eine Bereinigung von Trefferlisten zu Fragestellungen im Bereich IBK adaptiert werden?
3 Beispiel für eine Lernaufgabe: Aktionswort-Finder Aktionswörter basieren auf einem Wort im Deutschen häufig einem Inflektiv, das entweder alleine steht (lach, schüttel) oder um weitere Einheiten erweitert sein kann (lautlach, kopfschüttel). Ich Ich frage frage mich, mich, ob's ob's wohl wohl nen nen Fachbegriff für für genau diese diese Art Art von von Klangerzeugern gibt? gibt? *grübel* *Augenroll* Das Das ist ist genau meine Argumentation. Deinen Kommentar finde finde ich ich *räusper* problematisch. Sie dienen zur (häufig spielerischen) Beschreibung von Emotionen, mentalen oder körperlichen Zuständen oder Aktivitäten sowie als Illokutions- und Ironiemarker. Sie sind typischerweise nicht syntaktisch integriert. Sie werden häufig (nicht immer) durch Asterisken markiert (*lach*, *freu*).
4 Beispiel für eine Lernaufgabe: Aktionswort-Finder Daten: z.b. (1): z.b. (2): Trefferliste für die häufigsten Aktionswort-Formen (lol, lach, freu, grins, wink, seufz) (Storrer 2013) Trefferliste Beliebige Ausdrücke zwischen Asterisken Aufgabe: Lerne, ausgehend von einem Sample mit manuell klassifizierten Daten, ein Modell, das es erlaubt, die Treffer automatisch in zwei Klassen zu teilen! Beispiele für unerwünschte Treffer: (1) Ich freu mich auf die Diskussion :) (1) hahahahaha ich lach mich tot xd (2) hehe, hast mich erwischt. Nein, das mit dem Zitat hatte ich im Eifer des Gefechts eingefügt und *natürlich* ist es von Watson. (2) Go(s) = (1,8s+1)*(0,9s+1)*(0,54s+1). Die Überschwingung wird auf ca. 3 % reduziert.

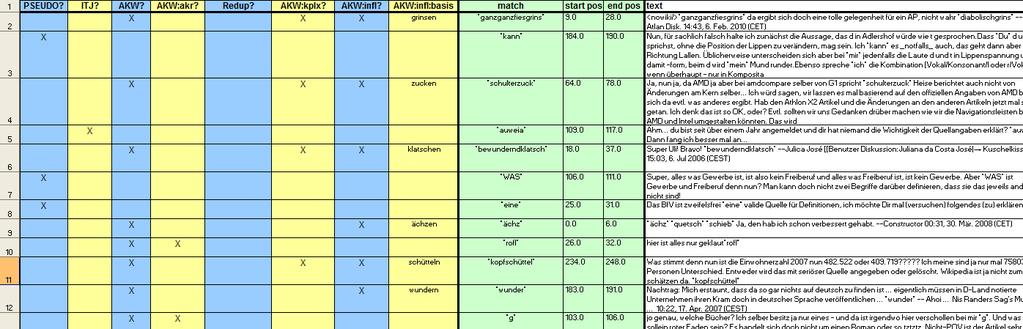




5 KobRA-Seminar / TU-Dortmund, SS Interdisziplinäres Hauptseminar (Germanistik / Informatik): Korpusgestützte Analyse internetbasierter Kommunikation mit Hilfe von Data-Mining
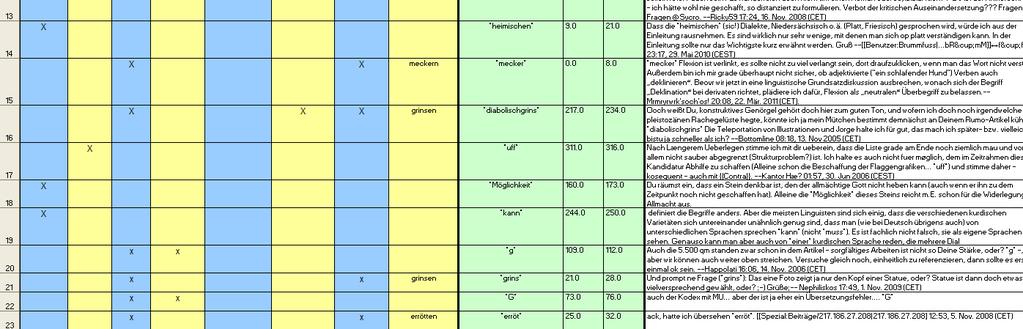
6 KobRA-Seminar / TU-Dortmund, SS Seminarprojekt: Automatische Eliminierung von Pseudotreffern und Finden von Nadeln im Heuhaufen für große Trefferlisten zu ausgewählten sprachlichen Phänomenen internetbasierter Kommunikation zum Beispiel: Aktionswörter: freu, lach, schmunzel, ganzfiesgrins, nicht-kanonische Verwendungen von weil und obwohl (V2 anstelle von V-L): ja toll aber so richtig steht es nicht drin weil damals sollten wir nämlich eine arbeit in informatik machen über das dualsystem

7 KobRA-Seminar / TU-Dortmund, SS Germanistik-Studierende Informatik-Studierende
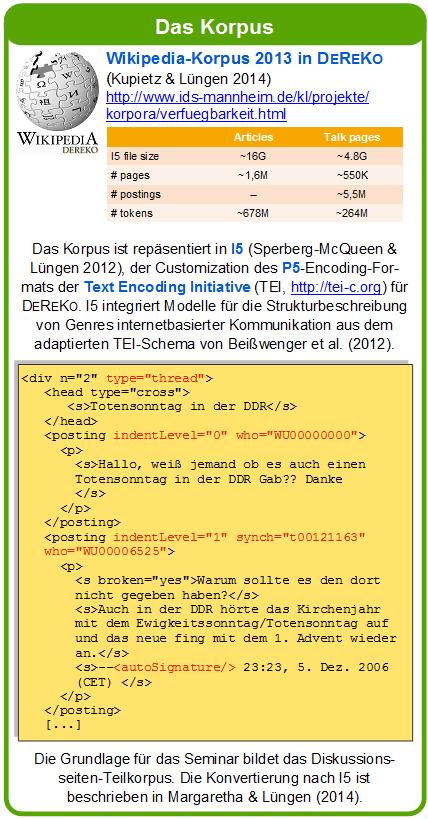
8 WIKIPEDIA IN DEREKO (2013) Artikel Diskussionen # WP-Seiten (Texte) # Postings # Tokens I5-Dateigröße 16G 4,8G Encoding in I5 + CMC (Sperberg-McQueen/Lüngen 2012, Beißwenger et al. 2015) Threads, Heuristiken für Posting-Segmentierung in Diskussionen POS-Annotationen mit TreeTagger/ STTS 1.0 (standoff) COSMAS II oder Download v. Referenz: Eliza Margaretha / Harald Lüngen (2014): Building Linguistic Corpora from Wikipedia Articles and Discussions. In: Journal of Language Technology and Computational Linguistics (JLCL) 29 (2), S , Harald Lüngen, Eliza Margaretha: Wikipedia-Korpora in DEREKO 2013 und
9 CMC DOKUMENTSTRUKTUR IN I5 IBK-ELEMENTE ADAPTIERT VON BEIßWENGER ET AL <div n="2" type="thread"> <head type="cross"> <s>totensonntag in der DDR</s> </head> <posting indentlevel="0" who="wu "> <p> <s>hallo, weiß jemand ob es auch einen Totensonntag in der DDR Gab?? Danke</s> </p> </posting> <posting indentlevel="1" synch="t " who="wu "> <p> <s broken="yes">warum sollte es den dort nicht gegeben haben?</s> <s>auch in der DDR hörte das Kirchenjahr mit dem Ewigkeitssonntag/ Totensonntag auf und das neue fing mit dem 1. Advent wieder an.</s> <s>--<autosignature/> 23:23, 5. Dez (CET) </s> </p> </posting> [ ] Harald Lüngen, Eliza Margaretha: Wikipedia-Korpora in DEREKO 2013 und 2015
 796.638.747 309.897.027 271.441.322 Englisch (en) 2.403.943.177 1.270.217.981 2.698.338.998 Französisch (fr) 764.459.026 137.107.729 372.")
10 WIKIPEDIA-KORPORA AM IDS (2015) KONVERTIERUNG: ELIZA MARGARETHA Neue Features 2015: Nutzerdiskussionen (User Talk Pages ) Verbesserung der Posting-Segmentierung Language-Links in Metadaten Artikel #tok Diskussionen #tok Nutzerdiskussionen #tok Deutsch (de) Englisch (en) Französisch (fr) Ungarisch (hu) Norwegisch (no) Spanisch (es) Kroatisch (hr) Italienisch (it) Polnisch (pl) Harald Lüngen, Eliza Margaretha: Wikipedia-Korpora in DEREKO 2013 und
11 Ergebnisse der Seminarprojekte und Desiderate Lernaufgaben zu Aktionswörtern: (1) Precision: 87% Recall: 92% (2) Precision: 74% Recall: 71% Identifizierung nicht-kanonischer Verwendungen von weil: Precision: 13% Recall: 55% Wenn man zum reinen Bag-of-words-Ansatz Part-of-speechund Parse-Tree-Kernels zuschaltet, werden die Ergebnisse sogar schlechter. Eine Verbesserung der Lernverfahren setzt eine Anpassung der genutzten Sprachverarbeitungswerkzeuge voraus.
12 Desiderat 1: NLP für CMC Die Probleme betreffen verschiedene Ebenen des Verarbeitungsprozesses: Tokenisierungsprobleme: Der Tokenisierungsprozess erzeugt Tokens, die keine sinnvollen linguistischen Einheiten darstellen (z.b. aufgrund von speedwriting phenomena) Kategorisierungsprobleme: Es gibt eine passende Kategorie im verwendeten Tagset, der Tagger kann das entsprechende Tag aber nicht zuweisen (z.b. aufgrund von umgangssprachlichen Schreibungen) Kategorienprobleme: Der Tagger kann kein sinnvolles Tag zuweisen, da für die betreffende Kategorie im Tagset kein Tag existiert (z.b. im Falle von Emoticons, Emojis, Hsshtags, Aktionswörtern, konzeptionell mündlichen Verschmelzungsformen) Cf. Bartz et al. (2014) Korpusbasierte Analyse internetbasierter Kommunikation

13 STTS 2.0 : Erweitertes Part-of-speech-Tagset für IBK Korpusbasierte Analyse internetbasierter Kommunikation
14 STTS 2.0 : Erweitertes Part-of-speech-Tagset für IBK PoS tag Category Examples I. Tags for phenomena which are specific for CMC / social media discourse: EMO ASC ASCII emoticon :-) :-( ^^ O.O EMO IMG Graphic emoticon AKW Interaction word *lach*, freu, grübel, *lol* HST Hash tag Kreta war super! #urlaub ADR Addressing Wie isset so? URL Uniform resource locator EML address peterklein@web.de II. Tags for phenomena which are typical for spontaneous spoken language in colloquial registers: VV PPER APPR ART VM PPER VA PPER KOUS PPER PPER PPER ADV ART Tags for types of colloquial contractions which are frequent in CMC (APPRART is already existing in STTS 1999) schreibste, machste vorm, überm, fürn willste, darfste, musste haste, biste, isses wenns, weils, obse ichs, dus, ers son, sone PTK IFG Intensitätspartikeln, Fokuspartikeln, Gradpartikeln sehr schön, höchst eigenartig, nur sie, voll geil PTK MA Modal particles Das ist ja / vielleicht doof. Ist das denn richtig so? Das war halt echt nicht einfach. PTK MWL Particle as part of a multi-word lexeme keine mehr, noch mal, schon wieder DM Discourse markers weil, obwohl, nur, also,... with V2 clauses ONO Onomatopoeia boing, miau, zisch Abgestimmt auf die STTS- Erweiterungen für das Tagging gesprochener Sprache (FOLK-Korpus, IDS)

15 GSCL Shared Task zum PoS-Tagging für IBK
16 Desiderat 2: Standards für die Annotation von IBK-Korpora Es müssen Annotationsstandards entwickelt werden, die es erlauben, 1) die Ergebnisse von Sprachverarbeitungsverfahren sinnvoll und abfragbar in Korpora zu annotieren; 2) diese Annotationen in Formaten zu repräsentieren, die interoperabel sind mit Standards, die für die Annotation von Text- und Gesprächskorpora eingesetzt werden ( vergleichende korpusbasierte Analyse von IBK mit Text- und Gesprächsdaten); 3) die linguistische Annotation mit einer sinnvollen Annotation der strukturellen Besonderheiten von IBK-Genres (z.b. Threadstrukturen) und zugehörigen Metadaten zu verbinden; 4) Ergebnisse von Korpusanalysen, die diese Annotationen nutzen, wiederum als neue Annotationen (in standardisierten Formaten) den Korpora hinzuzufügen.
: http://wiki.")
17 TEI Special Interest Group (SIG) zu IBK Dokumentation des aktuellen TEI-Schemaentwurfs für IBK (Stand Oktober 2015): Mediated_Communication
18 Ausblick: Anwendung in Projekten CLARIN-D-Kurationsprojekt ChatCorpus2CLARIN WhatsApp-Datensammlung (Projekt What's up, Deutschland? ) Wikipedia-Korpus in DEREKO DWDS Blog-Korpus News-Korpus in DEREKO Projekt Deutsches Referenzkorpus zur internetbasierten Kommunikation (DeRiK)
Deutsches Referenzkorpus zur internetbasierten Kommunikation:
 Deutsches Referenzkorpus zur internetbasierten Kommunikation: Fragen der Standardisierung und Datenerhebung Michael Beißwenger (Dortmund) Lothar Lemnitzer (Berlin) Internetbasierte Kommunikation Internetbasierte
Deutsches Referenzkorpus zur internetbasierten Kommunikation: Fragen der Standardisierung und Datenerhebung Michael Beißwenger (Dortmund) Lothar Lemnitzer (Berlin) Internetbasierte Kommunikation Internetbasierte
Experiments with Tokenization and Part-of-speech Tagging for German CMC Discourse. Thomas Bartz, Michael Beißwenger, Angelika Storrer
 Experiments with Tokenization and Part-of-speech Tagging for German CMC Discourse Thomas Bartz, Michael Beißwenger, Angelika Storrer Processing and Annotating CMC discourse Desiderata from the perspective
Experiments with Tokenization and Part-of-speech Tagging for German CMC Discourse Thomas Bartz, Michael Beißwenger, Angelika Storrer Processing and Annotating CMC discourse Desiderata from the perspective
Korpusbasierte Analyse internetbasierter Kommunikation
 35. Jahrestagung der DGfS, 12.-15. März 2013, Potsdam Arbeitsgruppe 10: Modellierung nicht-standardisierter Schriftlichkeit Thomas Bartz, Angelika Storrer Korpusbasierte Analyse internetbasierter Kommunikation
35. Jahrestagung der DGfS, 12.-15. März 2013, Potsdam Arbeitsgruppe 10: Modellierung nicht-standardisierter Schriftlichkeit Thomas Bartz, Angelika Storrer Korpusbasierte Analyse internetbasierter Kommunikation
POS FÜR(S) FOLK UND FÜR KORPORA INTERNETBASIERTER KOMMUNIKATION
 FOLK UND FÜR KORPORA INTERNETBASIERTER KOMMUNIKATION") Thomas Bartz & Swantje Westpfahl POS FÜR(S) FOLK UND FÜR KORPORA INTERNETBASIERTER KOMMUNIKATION Workshop»Internetlinguistik und Korpusanalyse«Hannover, den 2. Mai VORTRAG Einführung Aufbau von Korpora
Thomas Bartz & Swantje Westpfahl POS FÜR(S) FOLK UND FÜR KORPORA INTERNETBASIERTER KOMMUNIKATION Workshop»Internetlinguistik und Korpusanalyse«Hannover, den 2. Mai VORTRAG Einführung Aufbau von Korpora
Corpus-based language analysis in research and teaching:
 Corpus-based language analysis in research and teaching: Experiences, requirements and perspectives Angelika Storrer Corpus-based research projects Bericht zur Lage der deutschen Sprache [report on the
Corpus-based language analysis in research and teaching: Experiences, requirements and perspectives Angelika Storrer Corpus-based research projects Bericht zur Lage der deutschen Sprache [report on the
Repräsentation und linguistische Annotation von Korpora internetbasierter Kommunikation: Herausforderungen und Perspektiven
 Repräsentation und linguistische Annotation von internetbasierter Kommunikation: Herausforderungen und Perspektiven Michael Beißwenger 26. 11. 2014 Internetbasierte Kommunikation Internetbasierte Kommunikation
Repräsentation und linguistische Annotation von internetbasierter Kommunikation: Herausforderungen und Perspektiven Michael Beißwenger 26. 11. 2014 Internetbasierte Kommunikation Internetbasierte Kommunikation
Überlegungen zur Modifikation und Erweiterung von STTS für das Tagging von Korpora zur internetbasierten Kommunikation
 Überlegungen zur Modifikation und Erweiterung von STTS für das Tagging von Korpora zur internetbasierten Kommunikation Thomas Bartz Michael Beißwenger Angelika Storrer CLARIN-D-Workshop: Das STTS-Tagset
Überlegungen zur Modifikation und Erweiterung von STTS für das Tagging von Korpora zur internetbasierten Kommunikation Thomas Bartz Michael Beißwenger Angelika Storrer CLARIN-D-Workshop: Das STTS-Tagset
Tagset and guidelines for the PoS tagging of language data from genres of computermediated communication / social media
 EmpiriST 2015 Shared Task of the Empirikom-Network for the automatic linguistic annotation of computer-mediated communication / social media Tagset and guidelines for the PoS tagging of language data from
EmpiriST 2015 Shared Task of the Empirikom-Network for the automatic linguistic annotation of computer-mediated communication / social media Tagset and guidelines for the PoS tagging of language data from
Textkorpora als Ressourcen für die Digital Humanities: Chancen, Herausforderungen, Perspektiven
 Textkorpora als Ressourcen für die Digital Humanities: Chancen, Herausforderungen, Perspektiven : Das BMBF-Projekt Ringvorlesung Digital Humanities: Die digitale Transformation der Geisteswissenschaften
Textkorpora als Ressourcen für die Digital Humanities: Chancen, Herausforderungen, Perspektiven : Das BMBF-Projekt Ringvorlesung Digital Humanities: Die digitale Transformation der Geisteswissenschaften
Blockseminar Einführung in die Korpuslinguistik Seminarleitung: Yvonne Krämer, M.A. Das Korpus. und seine Aufbereitung
 Blockseminar Einführung in die Korpuslinguistik Seminarleitung: Yvonne Krämer, M.A. Das Korpus und seine Aufbereitung Bestandteile eines Korpus sind i.d.r.: Primärdaten Metadaten Annotationen Annotationen
Blockseminar Einführung in die Korpuslinguistik Seminarleitung: Yvonne Krämer, M.A. Das Korpus und seine Aufbereitung Bestandteile eines Korpus sind i.d.r.: Primärdaten Metadaten Annotationen Annotationen
Stefan Engelberg (IDS Mannheim), Workshop Corpora in Lexical Research, Bucharest, Nov. 2008 [Folie 1] DWDS-Kernkorpus / DWDS corpus analysis
![Stefan Engelberg (IDS Mannheim), Workshop Corpora in Lexical Research, Bucharest, Nov. 2008 [Folie 1] DWDS-Kernkorpus / DWDS corpus analysis](/thumbs/25/6525885.jpg "Stefan Engelberg (IDS Mannheim), Workshop Corpora in Lexical Research, Bucharest, Nov. 2008 [Folie 1] DWDS-Kernkorpus / DWDS corpus analysis") Content 1. Empirical linguistics 2. Text corpora and corpus linguistics 3. Concordances 4. Application I: The German progressive 5. Part-of-speech tagging 6. Fequency analysis 7. Application II: Compounds
Content 1. Empirical linguistics 2. Text corpora and corpus linguistics 3. Concordances 4. Application I: The German progressive 5. Part-of-speech tagging 6. Fequency analysis 7. Application II: Compounds
Modellierung von linguistischen Forschungsdaten. Kolloquium Korpuslinguistik Carolin Odebrecht Humboldt-Universität zu Berlin
 Modellierung von linguistischen Forschungsdaten Kolloquium Korpuslinguistik 13.11.2013 Carolin Odebrecht Humboldt-Universität zu Berlin Überblick 1. Forschungskontext 2. Forschungsfrage 3. Anwendungsbereich
Modellierung von linguistischen Forschungsdaten Kolloquium Korpuslinguistik 13.11.2013 Carolin Odebrecht Humboldt-Universität zu Berlin Überblick 1. Forschungskontext 2. Forschungsfrage 3. Anwendungsbereich
Routineaufgaben bei der Nutzung von Korpora: Disambiguieren, Klassifizieren, Annotieren mit KobRA-Verfahren
 Neue Wege in der Nutzung von Korpora: Data-Mining für die textorientierten Geisteswissenschaften Thomas Bartz, Christian Pölitz Routineaufgaben bei der Nutzung von Korpora: Disambiguieren, Klassifizieren,
Neue Wege in der Nutzung von Korpora: Data-Mining für die textorientierten Geisteswissenschaften Thomas Bartz, Christian Pölitz Routineaufgaben bei der Nutzung von Korpora: Disambiguieren, Klassifizieren,
Korpus-basierte Recherche und Analyse mit Hilfe von Data Mining: Das Projekt KobRA
 Korpus-basierte Recherche und Analyse mit Hilfe von Data Mining: Das Projekt KobRA : Das BMBF-Projekt Fachtagung: Neue Wege in der Nutzung von Korpora: Data-Mining für die textorientierten Geisteswissenschaften
Korpus-basierte Recherche und Analyse mit Hilfe von Data Mining: Das Projekt KobRA : Das BMBF-Projekt Fachtagung: Neue Wege in der Nutzung von Korpora: Data-Mining für die textorientierten Geisteswissenschaften
Elektronische Korpora in der Lehre Anwendungsbeispiele aus der theoretischen 2 und / 27der. und der Computerlinguistik
 Elektronische Korpora in der Lehre Anwendungsbeispiele aus der theoretischen und der Linguistics Department Ruhr-University Bochum 18.1.2011 DSPIN-Workshop Sprachressourcen in der Lehre Erfahrungen, Einsatzszenarien,
Elektronische Korpora in der Lehre Anwendungsbeispiele aus der theoretischen und der Linguistics Department Ruhr-University Bochum 18.1.2011 DSPIN-Workshop Sprachressourcen in der Lehre Erfahrungen, Einsatzszenarien,
Tagging von Online-Blogs
 Tagging von Online-Blogs Gertrud Faaß (vertreten durch Josef Ruppenhofer) STTS tagset and tagging: special corpora 24. September 2012 Faaß MODEBLOGS 1 Korpuslinguistische studentische Projekte am IwiSt
Tagging von Online-Blogs Gertrud Faaß (vertreten durch Josef Ruppenhofer) STTS tagset and tagging: special corpora 24. September 2012 Faaß MODEBLOGS 1 Korpuslinguistische studentische Projekte am IwiSt
Digitale Sprachressourcen in der Lehrerbildung
 Digitale Sprachressourcen in der Lehrerbildung Forum CA 3 2016 Universität Hamburg Prof. Dr. Angelika Storrer 7.Juni.2016 Digitale Sprachressourcen in der Lehrerbildung Bereiche Bildungsstandards: Sprache
Digitale Sprachressourcen in der Lehrerbildung Forum CA 3 2016 Universität Hamburg Prof. Dr. Angelika Storrer 7.Juni.2016 Digitale Sprachressourcen in der Lehrerbildung Bereiche Bildungsstandards: Sprache
Automatisiertes Annotieren in CATMA
 Automatisiertes Annotieren in CATMA Thomas Bögel 1, Evelyn Gius 2, Marco Petris 2, Jannik Strötgen 3 1 Universität Heidelberg 2 Universität Hamburg 3 Max-Planck-Institut für Informatik jannik.stroetgen@mpi-inf.mpg.de
Automatisiertes Annotieren in CATMA Thomas Bögel 1, Evelyn Gius 2, Marco Petris 2, Jannik Strötgen 3 1 Universität Heidelberg 2 Universität Hamburg 3 Max-Planck-Institut für Informatik jannik.stroetgen@mpi-inf.mpg.de
Projektseminar "Texttechnologische Informationsmodellierung"
 Projektseminar "Texttechnologische Informationsmodellierung" Ziel dieser Sitzung Nach dieser Sitzung sollten Sie: Einige standards und projekte vom Namen her kennen Einen Überblick über und einen Eindruck
Projektseminar "Texttechnologische Informationsmodellierung" Ziel dieser Sitzung Nach dieser Sitzung sollten Sie: Einige standards und projekte vom Namen her kennen Einen Überblick über und einen Eindruck
DEREKO Das Deutsche Referenzkorpus
 DEREKO Das Deutsche Referenzkorpus INSTITUT FÜR DEUTSCHE SPRACHE KobRA-Kickoff-Treffen, Dortmund 16.11.2012 1/23 : DEREKO Das Deutsche Referenzkorpus, KobRA-Kickoff, Dortmund 16.11.12 Überblick 1 Allgemeines
DEREKO Das Deutsche Referenzkorpus INSTITUT FÜR DEUTSCHE SPRACHE KobRA-Kickoff-Treffen, Dortmund 16.11.2012 1/23 : DEREKO Das Deutsche Referenzkorpus, KobRA-Kickoff, Dortmund 16.11.12 Überblick 1 Allgemeines
Proseminar Linguistische Annotation
 Proseminar Linguistische Annotation Ines Rehbein und Josef Ruppenhofer SS 2010 Ines Rehbein und Josef Ruppenhofer (SS10) Linguistische Annotation April 2010 1 / 22 Seminarplan I. Linguistische Annotation
Proseminar Linguistische Annotation Ines Rehbein und Josef Ruppenhofer SS 2010 Ines Rehbein und Josef Ruppenhofer (SS10) Linguistische Annotation April 2010 1 / 22 Seminarplan I. Linguistische Annotation
Aufbau und Annotation eines Referenzkorpus zur deutschsprachigen. Kommunikation (DeRiK-Projekt)
") Aufbau und Annotation eines Referenzkorpus zur deutschsprachigen internetbasierten Kommunikation (DeRiK-Projekt) Michael Beißwenger Lothar Lemnitzer Workshop: Webkorpora in Computerlinguistik und Sprachforschung
Aufbau und Annotation eines Referenzkorpus zur deutschsprachigen internetbasierten Kommunikation (DeRiK-Projekt) Michael Beißwenger Lothar Lemnitzer Workshop: Webkorpora in Computerlinguistik und Sprachforschung
Digitale Sprachressourcen in der Lehrerbildung
 Digitale Sprachressourcen in der Lehrerbildung Forum CA 3 2016 Universität Hamburg Prof. Dr. Angelika Storrer 7.Juni.2016 1 2 Digitale Sprachressourcen in der Lehrerbildung Bereiche Bildungsstandards:
Digitale Sprachressourcen in der Lehrerbildung Forum CA 3 2016 Universität Hamburg Prof. Dr. Angelika Storrer 7.Juni.2016 1 2 Digitale Sprachressourcen in der Lehrerbildung Bereiche Bildungsstandards:
Strukturelle und linguistische Annotation in historischen Textkorpora am Beispiel des Deutschen Textarchivs
 Strukturelle und linguistische Annotation in historischen Textkorpora am Beispiel des Deutschen Textarchivs Susanne Haaf, Alexander Geyken, Bryan Jurish, Matthias Schulz, Christian Thomas, Frank Wiegand
Strukturelle und linguistische Annotation in historischen Textkorpora am Beispiel des Deutschen Textarchivs Susanne Haaf, Alexander Geyken, Bryan Jurish, Matthias Schulz, Christian Thomas, Frank Wiegand
Tagset und Richtlinie für das PoS- Tagging von Sprachdaten aus Genres internetbasierter Kommunikation
 EmpiriST 2015 Shared Task des Empirikom-Netzwerks zur automatischen linguistischen Annotation deutschsprachiger internetbasierter Kommunikation Tagset und Richtlinie für das PoS- Tagging von Sprachdaten
EmpiriST 2015 Shared Task des Empirikom-Netzwerks zur automatischen linguistischen Annotation deutschsprachiger internetbasierter Kommunikation Tagset und Richtlinie für das PoS- Tagging von Sprachdaten
DeR ek o - Das Deutsche Referenzkorpus
 Erschienen in: Zeitschrift für germanistische Linguistik, Bd. 45, Heft 1, S. 161-170 ZGL 2017; 45(1): 161-170 Linguistik im Internet Harald Lüngen* DeR ek o - Das Deutsche Referenzkorpus D er e K o - the
Erschienen in: Zeitschrift für germanistische Linguistik, Bd. 45, Heft 1, S. 161-170 ZGL 2017; 45(1): 161-170 Linguistik im Internet Harald Lüngen* DeR ek o - Das Deutsche Referenzkorpus D er e K o - the
Einführung. Stefanie Dipper Stefan Evert Heike Zinsmeister
 Einführung Stefanie Dipper Stefan Evert Heike Zinsmeister München, 28.1.2011 Korpus eine Sammlung gesprochener oder geschriebener Äußerungen typischerweise digitalisiert und maschinenlesbar Ebenen eines
Einführung Stefanie Dipper Stefan Evert Heike Zinsmeister München, 28.1.2011 Korpus eine Sammlung gesprochener oder geschriebener Äußerungen typischerweise digitalisiert und maschinenlesbar Ebenen eines
Centrum für Informations- und Sprachverarbeitung. Dr. M. Hadersbeck, Digitale Editionen, BAdW München
 # 1 Digitale Editionen und Auszeichnungssprachen Computerlinguistische FinderApps mit Facsimile-Reader Wittgenstein s Nachlass: WiTTFind Goethe s Faust: GoetheFind Hadersbeck M. et. al. Centrum für Informations-
# 1 Digitale Editionen und Auszeichnungssprachen Computerlinguistische FinderApps mit Facsimile-Reader Wittgenstein s Nachlass: WiTTFind Goethe s Faust: GoetheFind Hadersbeck M. et. al. Centrum für Informations-
CLARIN-D. Überblick, Metadaten, Demo. Christoph Kuras. Abt. Automatische Sprachverarbeitung Institut für Informatik, Universität Leipzig
 CLARIN-D Überblick, Metadaten, Demo Christoph Kuras Abt. Automatische Sprachverarbeitung Institut für Informatik, Universität Leipzig Institut für Informatik 1 CLARIN: Common Language Resource and Technology
CLARIN-D Überblick, Metadaten, Demo Christoph Kuras Abt. Automatische Sprachverarbeitung Institut für Informatik, Universität Leipzig Institut für Informatik 1 CLARIN: Common Language Resource and Technology
Swantje Westpfahl & Thomas Schmidt POS für(s) FOLK
 FOLK") Swantje Westpfahl & Thomas Schmidt POS für(s) FOLK Problemanalyse des POS- Taggings für spontansprachliche Daten anhand des Forschungsund Lehrkorpus Gesprochenes Deutsch 2 FOLK Forschungs- und Lehrkorpus
Swantje Westpfahl & Thomas Schmidt POS für(s) FOLK Problemanalyse des POS- Taggings für spontansprachliche Daten anhand des Forschungsund Lehrkorpus Gesprochenes Deutsch 2 FOLK Forschungs- und Lehrkorpus
Technischer Bericht. Integration der KobRA-Verfahren in WebLicht
 Universität Tübingen Seminar für Sprachwissenschaft (SfS) Lehrstuhl Allgemeine Sprachwissenschaft und Computerlinguistik Technische Universität Dortmund Fakultät Informatik Lehrstuhl für Künstliche Intelligenz
Universität Tübingen Seminar für Sprachwissenschaft (SfS) Lehrstuhl Allgemeine Sprachwissenschaft und Computerlinguistik Technische Universität Dortmund Fakultät Informatik Lehrstuhl für Künstliche Intelligenz
Erweiterung des STTS für gesprochene Sprache
 Erweiterung des STTS für gesprochene Sprache Ines Rehbein, Sören Schalowski und Heike Wiese Institut für Deutsche Sprache SFB 632 Informationsstruktur Universität Potsdam STTS Workshop am IMS Stuttgart
Erweiterung des STTS für gesprochene Sprache Ines Rehbein, Sören Schalowski und Heike Wiese Institut für Deutsche Sprache SFB 632 Informationsstruktur Universität Potsdam STTS Workshop am IMS Stuttgart
Ich baue ein eigenes Korpus
 Blockseminar Einführung in die Korpuslinguistik Seminarleitung: Yvonne Krämer, M.A. Ich baue ein eigenes Korpus Datengewinnung und aufbereitung Datengewinnung Das Untersuchungsinteresse bestimmt die benötigte
Blockseminar Einführung in die Korpuslinguistik Seminarleitung: Yvonne Krämer, M.A. Ich baue ein eigenes Korpus Datengewinnung und aufbereitung Datengewinnung Das Untersuchungsinteresse bestimmt die benötigte
Aux Flip in German: A Walk in the Woods
 Aux Flip in German: A Walk in the Woods Erhard Hinrichs 1, Kathrin Beck 1, and Tsuneko Nakazawa 2 1 Seminar für Sprachwissenschaft Eberhard Karls Universität Tübingen 2 University of Tokyo Aux Flip in
Aux Flip in German: A Walk in the Woods Erhard Hinrichs 1, Kathrin Beck 1, and Tsuneko Nakazawa 2 1 Seminar für Sprachwissenschaft Eberhard Karls Universität Tübingen 2 University of Tokyo Aux Flip in
Korpus. Was ist ein Korpus?
 Was ist ein Korpus? Korpus Endliche Menge von konkreten sprachlichen Äußerungen, die als empirische Grundlage für sprachwiss. Untersuchungen dienen. Stellenwert und Beschaffenheit des Korpus hängen weitgehend
Was ist ein Korpus? Korpus Endliche Menge von konkreten sprachlichen Äußerungen, die als empirische Grundlage für sprachwiss. Untersuchungen dienen. Stellenwert und Beschaffenheit des Korpus hängen weitgehend
Tagger for German. Online BRILL-Tagger für das Deutsche
 Tagger for German Online BRILL-Tagger für das Deutsche Morphologie V/Ü, Anke Holler Uni Heidelberg, SS2007 Nataliya Mytyay Éva Mújdricza 19.07.2007 Designed by: Dóra Dobos Tagger for German Eric Brill
Tagger for German Online BRILL-Tagger für das Deutsche Morphologie V/Ü, Anke Holler Uni Heidelberg, SS2007 Nataliya Mytyay Éva Mújdricza 19.07.2007 Designed by: Dóra Dobos Tagger for German Eric Brill
Technischer Bericht. Integration der KobRA-Verfahren in die IDS-Infrastrukturen
 Technischer Bericht Nr. 2016/3 (Meilenstein 4c) Integration der KobRA-Verfahren in die IDS-Infrastrukturen BMBF-Verbundprojekt: Korpus-basierte linguistische Recherche und Analyse mithilfe von Data-Mining
Technischer Bericht Nr. 2016/3 (Meilenstein 4c) Integration der KobRA-Verfahren in die IDS-Infrastrukturen BMBF-Verbundprojekt: Korpus-basierte linguistische Recherche und Analyse mithilfe von Data-Mining
Vortrag im Rahmen der Vorlesung Data Warehouse Dozentin: Prof. Dr. Frey-Luxemburger WS 2011/2012. Referent: Florian Kalisch (GR09)
") Vortrag im Rahmen der Vorlesung Data Warehouse Dozentin: Prof. Dr. Frey-Luxemburger WS 2011/2012 Referent: Florian Kalisch (GR09) Rückblick Aktueller Status Einführung in Text-Mining Der Text-Mining Prozess
Vortrag im Rahmen der Vorlesung Data Warehouse Dozentin: Prof. Dr. Frey-Luxemburger WS 2011/2012 Referent: Florian Kalisch (GR09) Rückblick Aktueller Status Einführung in Text-Mining Der Text-Mining Prozess
Computerlinguistische Grundlagen. Jürgen Hermes Sommersemester 17 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln
 Computerlinguistische Grundlagen Jürgen Hermes Sommersemester 17 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Computerlinguistik: Schnittstellen Computerlinguistik aus
Computerlinguistische Grundlagen Jürgen Hermes Sommersemester 17 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Computerlinguistik: Schnittstellen Computerlinguistik aus
Syntaktische Tendenzen der Gegenwartssprache
 Syntaktische Tendenzen der Gegenwartssprache Anforderungen: Regelmäßige Teilnahme: max. 2 Fehlzeiten Vorbereitung auf die Sitzung: Text lesen, Fragen notieren, mitdiskutieren (!) Leitung einer Sitzung
Syntaktische Tendenzen der Gegenwartssprache Anforderungen: Regelmäßige Teilnahme: max. 2 Fehlzeiten Vorbereitung auf die Sitzung: Text lesen, Fragen notieren, mitdiskutieren (!) Leitung einer Sitzung
Gleiche Daten, unterschiedliche Erkenntnisziele?
 Gleiche Daten, unterschiedliche Erkenntnisziele? Zum Potential vermeintlich widersprüchlicher Zugänge zur Textanalyse Universität Hamburg Evelyn Gius Jan Christoph Meister Janina Jacke Marco Petris Universität
Gleiche Daten, unterschiedliche Erkenntnisziele? Zum Potential vermeintlich widersprüchlicher Zugänge zur Textanalyse Universität Hamburg Evelyn Gius Jan Christoph Meister Janina Jacke Marco Petris Universität
Annotation Guidelines for German Non-standard Varieties
 Annotation Guidelines for German Non-standard Varieties Marc Reznicek 4. Arbeitstagung 8.11.2012, Aachen Overview Motivation & Goals existing resources Data & Annotation test corpus annotation Chat DCC-Chat-Protocols
Annotation Guidelines for German Non-standard Varieties Marc Reznicek 4. Arbeitstagung 8.11.2012, Aachen Overview Motivation & Goals existing resources Data & Annotation test corpus annotation Chat DCC-Chat-Protocols
Quellen des Neuen Die Integration von Ressourcen zur schulischen und universitären Bildung in die CLARIN-D-Infrastruktur
 Quellen des Neuen Die Integration von Ressourcen zur schulischen und universitären Bildung in die CLARIN-D-Infrastruktur - Ein CLARIN-D Kurationsprojekt der F-AG Neuere Geschichte - Maret Keller, Christian
Quellen des Neuen Die Integration von Ressourcen zur schulischen und universitären Bildung in die CLARIN-D-Infrastruktur - Ein CLARIN-D Kurationsprojekt der F-AG Neuere Geschichte - Maret Keller, Christian
Listening Comprehension: Talking about language learning
 Talking about language learning Two Swiss teenagers, Ralf and Bettina, are both studying English at a language school in Bristo and are talking about language learning. Remember that Swiss German is quite
Talking about language learning Two Swiss teenagers, Ralf and Bettina, are both studying English at a language school in Bristo and are talking about language learning. Remember that Swiss German is quite
Forschungsdaten in den Geisteswissenschaften die germanistische Sprachwissenschaft
 Forschungsdaten in den Geisteswissenschaften die germanistische Sprachwissenschaft Andreas Witt Institut für Deutsche Sprache, Mannheim Workshop Forschungsdaten WGL Geschäftsstelle Berlin 2012-05-10 Institut
Forschungsdaten in den Geisteswissenschaften die germanistische Sprachwissenschaft Andreas Witt Institut für Deutsche Sprache, Mannheim Workshop Forschungsdaten WGL Geschäftsstelle Berlin 2012-05-10 Institut
Offener Diskurs: Sprachdaten in Deutschland. Prof. Andreas Witt (Institut für Deutsche Sprache)
") Offener Diskurs: Sprachdaten in Deutschland Prof. Andreas Witt (Institut für Deutsche Sprache) 1 Institut für Deutsche Sprache (IDS) Das Institut für Deutsche Sprache ist die zentrale außeruniversitäre
Offener Diskurs: Sprachdaten in Deutschland Prof. Andreas Witt (Institut für Deutsche Sprache) 1 Institut für Deutsche Sprache (IDS) Das Institut für Deutsche Sprache ist die zentrale außeruniversitäre
Modifikationsvorschläge zu STTS Stand der bisherigen Diskussion
 Stand und Perspektiven des Wortarttagsets STTS: Einführung in den Workshop Ulrich Heid Als Einführung in die Thematik des Workshops gehen wir von den Zielen und Aufgaben der CLARIN-D - Standorte Tübingen
Stand und Perspektiven des Wortarttagsets STTS: Einführung in den Workshop Ulrich Heid Als Einführung in die Thematik des Workshops gehen wir von den Zielen und Aufgaben der CLARIN-D - Standorte Tübingen
Part-of-Speech- Tagging
 Part-of-Speech- Tagging In: Einführung in die Computerlinguistik Institut für Computerlinguistik Heinrich-Heine-Universität Düsseldorf WS 2004/05 Dozentin: Wiebke Petersen Tagging Was ist das? Tag (engl.):
Part-of-Speech- Tagging In: Einführung in die Computerlinguistik Institut für Computerlinguistik Heinrich-Heine-Universität Düsseldorf WS 2004/05 Dozentin: Wiebke Petersen Tagging Was ist das? Tag (engl.):
Lösungsvorschlag für das Übungsblatt 8. Aufgabe1.
 Lösungsvorschlag für das Übungsblatt 8. Aufgabe1. 3 Det A N VP R6 4 Any A N VP L3 5 Any intelligent N VP L4 6 Any intelligent cat VP L2 Nach den Regeln kann der Satz weiter nicht erzeugt warden, deswegen
Lösungsvorschlag für das Übungsblatt 8. Aufgabe1. 3 Det A N VP R6 4 Any A N VP L3 5 Any intelligent N VP L4 6 Any intelligent cat VP L2 Nach den Regeln kann der Satz weiter nicht erzeugt warden, deswegen
Das Zusammenspiel interpretativer und automatisierbarer Verfahren bei der Aufbereitung und Auswertung mündlicher Daten
 Das Zusammenspiel interpretativer und automatisierbarer Verfahren bei der Aufbereitung und Auswertung mündlicher Daten Ein Fallbeispiel aus der angewandten Wissenschaftssprachforschung Cordula Meißner
Das Zusammenspiel interpretativer und automatisierbarer Verfahren bei der Aufbereitung und Auswertung mündlicher Daten Ein Fallbeispiel aus der angewandten Wissenschaftssprachforschung Cordula Meißner
Sprachtechnologien und maschinelle Übersetzung heute und morgen eine Einführung Martin Kappus (ZHAW)
") Martin Kappus (ZHAW) Ablauf: Warum sprechen wir heute über maschinelle Übersetzung? Geschichte und Ansätze Eingabe-/Ausgabemodi und Anwendungen 2 WARUM SPRECHEN WIR HEUTE ÜBER MASCHINELLE ÜBERSETZUNG?
Martin Kappus (ZHAW) Ablauf: Warum sprechen wir heute über maschinelle Übersetzung? Geschichte und Ansätze Eingabe-/Ausgabemodi und Anwendungen 2 WARUM SPRECHEN WIR HEUTE ÜBER MASCHINELLE ÜBERSETZUNG?
Linguistische Grundlagen. Warum Tagging? Klassische Wortartenlehre Tagsets Annotation höherer Ebenen Design von Tagsets
 Linguistische Grundlagen Warum Tagging? Klassische Wortartenlehre Tagsets Annotation höherer Ebenen Design von Tagsets Warum Tagging? Abfragbarkeit linguistischer Information Generalisierbarkeit von Abfragen
Linguistische Grundlagen Warum Tagging? Klassische Wortartenlehre Tagsets Annotation höherer Ebenen Design von Tagsets Warum Tagging? Abfragbarkeit linguistischer Information Generalisierbarkeit von Abfragen
Korpuslinguistik IDS-Korpora und COSMAS II
 Korpuslinguistik IDS-Korpora und COSMAS II Heike Zinsmeister Korpuslinguistik 11. 11. 2011 Gliederung 1 Einleitung 2 Korpusbestand am IDS 3 Korpusrecherche mit COSMAS II 4 Referenzen Das Institut für Deutsche
Korpuslinguistik IDS-Korpora und COSMAS II Heike Zinsmeister Korpuslinguistik 11. 11. 2011 Gliederung 1 Einleitung 2 Korpusbestand am IDS 3 Korpusrecherche mit COSMAS II 4 Referenzen Das Institut für Deutsche
LAUDATIO - Eine Infrastruktur zur linguistischen Analyse historischer Korpora
 LAUDATIO - Eine Infrastruktur zur linguistischen Analyse historischer Korpora Carolin Odebrecht, Humboldt-Universität zu Berlin Florian Zipser, Humboldt-Universität zu Berlin, INRIA Historische Textkorpora
LAUDATIO - Eine Infrastruktur zur linguistischen Analyse historischer Korpora Carolin Odebrecht, Humboldt-Universität zu Berlin Florian Zipser, Humboldt-Universität zu Berlin, INRIA Historische Textkorpora
Modeling CMC genres in TEI:
 Modeling CMC genres in TEI: Suggestions and workshop reports from the TEI SIG Computer-Mediated Communication Special Topic Panel 7th Empirikom Workshop, Dortmund, Feb 20, 2014 Michael Beißwenger 1, Thierry
Modeling CMC genres in TEI: Suggestions and workshop reports from the TEI SIG Computer-Mediated Communication Special Topic Panel 7th Empirikom Workshop, Dortmund, Feb 20, 2014 Michael Beißwenger 1, Thierry
Vernetzung von Daten im Deutschen Textarchiv
 Vernetzung von Daten im Deutschen Textarchiv Susanne Haaf, Matthias Boenig, Christian Thomas, Alexander Geyken, Bryan Jurish, Frank Wiegand Berlin-Brandenburgische Akademie der Wissenschaften/Deutsches
Vernetzung von Daten im Deutschen Textarchiv Susanne Haaf, Matthias Boenig, Christian Thomas, Alexander Geyken, Bryan Jurish, Frank Wiegand Berlin-Brandenburgische Akademie der Wissenschaften/Deutsches
Korpusbasierte Sprachreflexion mit Online-Ressourcen. Heike Zinsmeister Institut für Maschinelle Sprachverarbeitung Universität Stuttgart
 Korpusbasierte Sprachreflexion mit Online-Ressourcen Heike Zinsmeister Institut für Maschinelle Sprachverarbeitung Universität Stuttgart CLARIN-D Common Language Resources and Technology Infrastructure
Korpusbasierte Sprachreflexion mit Online-Ressourcen Heike Zinsmeister Institut für Maschinelle Sprachverarbeitung Universität Stuttgart CLARIN-D Common Language Resources and Technology Infrastructure
Was ist ein Korpus. Zitat aus: Carstensen et al. Computerlinguistik und Sprachtechnologie: Eine Einführung. Kap. 4.2, Textkorpora
 Was ist ein Korpus Korpora sind Sammlungen linguistisch aufbereitete(r) Texte in geschriebener oder gesprochener Sprache, die elektronisch gespeichert vorliegen. Zitat aus: Carstensen et al. Computerlinguistik
Was ist ein Korpus Korpora sind Sammlungen linguistisch aufbereitete(r) Texte in geschriebener oder gesprochener Sprache, die elektronisch gespeichert vorliegen. Zitat aus: Carstensen et al. Computerlinguistik
Korpus-basierte Fallstudien der Dortmunder Linguistik I: Stützverbgefüge. Thomas Bartz, Michael Beißwenger, Nadja Radtke, Angelika Storrer
 Korpus-basierte Fallstudien der Dortmunder Linguistik I: Stützverbgefüge Thomas Bartz, Michael Beißwenger, Nadja Radtke, Angelika Storrer Fallstudie: Stützverbgefüge Projektkontext: Bericht zur Lage der
Korpus-basierte Fallstudien der Dortmunder Linguistik I: Stützverbgefüge Thomas Bartz, Michael Beißwenger, Nadja Radtke, Angelika Storrer Fallstudie: Stützverbgefüge Projektkontext: Bericht zur Lage der
Thomas Schmidt, Dolores Batinić DAS FORSCHUNGS- UND LEHRKORPUS GESPROCHENES DEUTSCH (FOLK) ALS QUELLE FÜR LEXIKOGRAPHISCHE ARBEIT
 ALS QUELLE FÜR LEXIKOGRAPHISCHE ARBEIT") Thomas Schmidt, Dolores Batinić DAS FORSCHUNGS- UND LEHRKORPUS GESPROCHENES DEUTSCH (FOLK) ALS QUELLE FÜR LEXIKOGRAPHISCHE ARBEIT GLIEDERUNG (1) FOLK ein Gesprächskorpus Daten, Annotationen, Design / Stratifikation
Thomas Schmidt, Dolores Batinić DAS FORSCHUNGS- UND LEHRKORPUS GESPROCHENES DEUTSCH (FOLK) ALS QUELLE FÜR LEXIKOGRAPHISCHE ARBEIT GLIEDERUNG (1) FOLK ein Gesprächskorpus Daten, Annotationen, Design / Stratifikation
Wortfinales Schwa in BeMaTaC: L1 vs. L2. Simon Sauer Korpuslinguistisches Kolloquium Humboldt-Universität zu Berlin
 Wortfinales Schwa in BeMaTaC: L1 vs. L2 Simon Sauer Korpuslinguistisches Kolloquium Humboldt-Universität zu Berlin 27.01.2016 Phänomen In gesprochenem Deutsch wird wortfinales Schwa oft weggelassen ich
Wortfinales Schwa in BeMaTaC: L1 vs. L2 Simon Sauer Korpuslinguistisches Kolloquium Humboldt-Universität zu Berlin 27.01.2016 Phänomen In gesprochenem Deutsch wird wortfinales Schwa oft weggelassen ich
Extraktion guter Belege aus Textkorpora durch Kombination eines regelbasierten Verfahrens mit maschinellem Lernen
 Extraktion guter Belege aus Textkorpora durch Kombination eines regelbasierten Verfahrens mit maschinellem Lernen Lothar Lemnitzer, Alexander Geyken Berlin-Brandenburgische Akademie der Wissenschaften
Extraktion guter Belege aus Textkorpora durch Kombination eines regelbasierten Verfahrens mit maschinellem Lernen Lothar Lemnitzer, Alexander Geyken Berlin-Brandenburgische Akademie der Wissenschaften
Der Data Science-Studiengang an der Hochschule Darmstadt
 Der Data Science-Studiengang an der Hochschule Darmstadt Sebastian Döhler Hochschule Darmstadt Fachtagung Data Science in Studium und Lehre 2018 Institut für Hochschulentwicklung September 19, 2018 Döhler
Der Data Science-Studiengang an der Hochschule Darmstadt Sebastian Döhler Hochschule Darmstadt Fachtagung Data Science in Studium und Lehre 2018 Institut für Hochschulentwicklung September 19, 2018 Döhler
Technik und Arbeitsablauf für FALKO
 Peter Adolphs Emil Kroymann Technik und Arbeitsablauf für FALKO 1 Software 1.1 EXMARaLDA Partitur-Editor EXMARaLDA ist ein Annotationswerkzeug für linguistische Korpora. Es wurde von der Universität Hamburg
Peter Adolphs Emil Kroymann Technik und Arbeitsablauf für FALKO 1 Software 1.1 EXMARaLDA Partitur-Editor EXMARaLDA ist ein Annotationswerkzeug für linguistische Korpora. Es wurde von der Universität Hamburg
Äußerungen + Segmentierung
 Äußerungen + Segmentierung Seminar: Dialoge auf Twitter Universität Potsdam Tatjana Scheffler tatjana.scheffler@uni-potsdam.de 21.10.2015 Organisatorisches Referatsvergabe Referate: - Termin zur Vorbesprechung
Äußerungen + Segmentierung Seminar: Dialoge auf Twitter Universität Potsdam Tatjana Scheffler tatjana.scheffler@uni-potsdam.de 21.10.2015 Organisatorisches Referatsvergabe Referate: - Termin zur Vorbesprechung
Digitale Sprachressourcen in den Lehramtsstudiengängen:
 Digitale Sprachressourcen in den Lehramtsstudiengängen: Kompetenzen Erfahrungen Desiderate Michael Beißwenger Angelika Storrer Dortmund Institut für deutsche Sprache und Literatur angelika.storrer@udo.edu
Digitale Sprachressourcen in den Lehramtsstudiengängen: Kompetenzen Erfahrungen Desiderate Michael Beißwenger Angelika Storrer Dortmund Institut für deutsche Sprache und Literatur angelika.storrer@udo.edu
Korpora. Referenten Duyen Tao-Pham Nedyalko Georgiev
 Korpora Referenten Duyen Tao-Pham Nedyalko Georgiev Hauptseminar: Angewandte Linguistische Datenverarbeitung (WS 11/12) Dozent: Prof. Dr. Jürgen Rolshoven Sprachliche Informationsverarbeitung Universität
Korpora Referenten Duyen Tao-Pham Nedyalko Georgiev Hauptseminar: Angewandte Linguistische Datenverarbeitung (WS 11/12) Dozent: Prof. Dr. Jürgen Rolshoven Sprachliche Informationsverarbeitung Universität
Seman&sche Daten für den Webau4ri6 einer Bibliothek
 Seman&sche Daten für den Webau4ri6 einer Bibliothek AGMB- Tagung GöBngen 26.09.2016 bis 28.09.2016 h#ps://pixabay.com/de/bin%c3%a4r- zuf%c3%a4llige- zahlen- digital- 1282366/ EDV / Bibliothek Andreas Bohne-Lang
Seman&sche Daten für den Webau4ri6 einer Bibliothek AGMB- Tagung GöBngen 26.09.2016 bis 28.09.2016 h#ps://pixabay.com/de/bin%c3%a4r- zuf%c3%a4llige- zahlen- digital- 1282366/ EDV / Bibliothek Andreas Bohne-Lang
NLP Eigenschaften von Text
 NLP Eigenschaften von Text Dr. Andreas Hotho Dominik Benz Beate Krause Sommersemester 2008 Folie: 1 Übersicht Einführung Eigenschaften von Text Words I: Satzgrenzenerkennung, Tokenization, Kollokationen
NLP Eigenschaften von Text Dr. Andreas Hotho Dominik Benz Beate Krause Sommersemester 2008 Folie: 1 Übersicht Einführung Eigenschaften von Text Words I: Satzgrenzenerkennung, Tokenization, Kollokationen
Gewinnung, Aufbereitung und Analyse von Korpora zu Genres internetbasierter Kommunikation: Herausforderungen und Perspektiven
 Wissenschaftliches Netzwerk Empirische Erforschung internetbasierter Kommunikation Gewinnung, Aufbereitung und Analyse von Korpora zu Genres internetbasierter Kommunikation: Herausforderungen und Perspektiven
Wissenschaftliches Netzwerk Empirische Erforschung internetbasierter Kommunikation Gewinnung, Aufbereitung und Analyse von Korpora zu Genres internetbasierter Kommunikation: Herausforderungen und Perspektiven
Sprachtechnologie als Grundlage für die maschinelle Auswertung von Texten
 Sprachtechnologie als Grundlage für die maschinelle Auswertung von Texten Dr-Ing Michael Piotrowski Leibniz-Institut für Europäische Geschichte @true_mxp Bamberg, 20 November 2015
Sprachtechnologie als Grundlage für die maschinelle Auswertung von Texten Dr-Ing Michael Piotrowski Leibniz-Institut für Europäische Geschichte @true_mxp Bamberg, 20 November 2015
Optionally, an is sent : Erfahrungen mit automatisierter Erkennung schlechter Anforderungen
 Richtig testen Hier soll das der Richtige Titel rein testen Optionally, an e-mail is sent : Erfahrungen mit automatisierter Erkennung schlechter Anforderungen www.qs-tag.de Maximilian Junker Qualicen GmbH
Richtig testen Hier soll das der Richtige Titel rein testen Optionally, an e-mail is sent : Erfahrungen mit automatisierter Erkennung schlechter Anforderungen www.qs-tag.de Maximilian Junker Qualicen GmbH
Aufgabe. Erstellen eines kleinen Lernerkorpus exemplarisches Aufzeigen, wie Fehler sinnvoll klassifiziert und annotiert werden könnten
 Aufgabe Erstellen eines kleinen Lernerkorpus exemplarisches Aufzeigen, wie Fehler sinnvoll klassifiziert und annotiert werden könnten Mitstreiterinnen: Elena Briskina, Julia Hantschel, Jenny Krüger, Stéphanie
Aufgabe Erstellen eines kleinen Lernerkorpus exemplarisches Aufzeigen, wie Fehler sinnvoll klassifiziert und annotiert werden könnten Mitstreiterinnen: Elena Briskina, Julia Hantschel, Jenny Krüger, Stéphanie
"What's in the news? - or: why Angela Merkel is not significant
 "What's in the news? - or: why Angela Merkel is not significant Andrej Rosenheinrich, Dr. Bernd Eickmann Forschung und Entwicklung, Unister GmbH, Leipzig UNISTER Seite 1 Unister Holding UNISTER Seite 2
"What's in the news? - or: why Angela Merkel is not significant Andrej Rosenheinrich, Dr. Bernd Eickmann Forschung und Entwicklung, Unister GmbH, Leipzig UNISTER Seite 1 Unister Holding UNISTER Seite 2
Extraktion von Preordering-Regeln für Maschinelle Übersetzung
 Extraktion von Preordering-Regeln für Maschinelle Übersetzung Gruppe4 -Otedama- Julian Hitschler, Benjamin Körner, Mayumi Ohta Computerlinguistik Universität Heidelberg Softwareprojekt SS13 Übersicht 1.
Extraktion von Preordering-Regeln für Maschinelle Übersetzung Gruppe4 -Otedama- Julian Hitschler, Benjamin Körner, Mayumi Ohta Computerlinguistik Universität Heidelberg Softwareprojekt SS13 Übersicht 1.
Identifizierung von Adressangaben in Texten ohne Verwendung von Wörterbüchern
 Expose zur Diplomarbeit Identifizierung von Adressangaben in Texten ohne Verwendung von Wörterbüchern Nora Popp Juli 2009 Betreuer: Professor Ulf Leser HU Berlin, Institut für Informatik Ziel In dieser
Expose zur Diplomarbeit Identifizierung von Adressangaben in Texten ohne Verwendung von Wörterbüchern Nora Popp Juli 2009 Betreuer: Professor Ulf Leser HU Berlin, Institut für Informatik Ziel In dieser
Inhalt. Vorwort vii. Einleitung 1
 Inhalt Vorwort vii Einleitung 1 1 Linguistic politeness und facework 9 1.1 Face 10 1.1.1 Face, Selbst und Identität 15 1.1.1.1 Selbst 17 1.1.1.2 Identität 19 1.1.2 Identität und Selbst in Relation zu face
Inhalt Vorwort vii Einleitung 1 1 Linguistic politeness und facework 9 1.1 Face 10 1.1.1 Face, Selbst und Identität 15 1.1.1.1 Selbst 17 1.1.1.2 Identität 19 1.1.2 Identität und Selbst in Relation zu face
Whitepaper Bio-Mode. Quelle: http://freshideen.com/trends/bio-kleidung.html
 Whitepaper Bio-Mode Quelle: http://freshideen.com/trends/bio-kleidung.html Seite 1 von 11 Wo wird über Bio-Mode diskutiert? 0,79% 0,76% 0,00% 0,56% 5,26% 9,81% 9,93% 0,15% 72,73% News Soziale Netzwerke
Whitepaper Bio-Mode Quelle: http://freshideen.com/trends/bio-kleidung.html Seite 1 von 11 Wo wird über Bio-Mode diskutiert? 0,79% 0,76% 0,00% 0,56% 5,26% 9,81% 9,93% 0,15% 72,73% News Soziale Netzwerke
A Topical/Local Classifier for Word Sense Idendification (TLC) Anne Schwartz
 Anne Schwartz") A Topical/Local Classifier for Word Sense Idendification (TLC) Anne Schwartz anne@coli.uni-sb.de A Topical/Local Classifier for Word Sense Idendification (TLC) entwickelt von: - Martin Chodorow (Dep. of
A Topical/Local Classifier for Word Sense Idendification (TLC) Anne Schwartz anne@coli.uni-sb.de A Topical/Local Classifier for Word Sense Idendification (TLC) entwickelt von: - Martin Chodorow (Dep. of
Korpusannotation: Vom nachhaltigen Aufbereiten einer Ressource
 Korpusannotation: Vom nachhaltigen Aufbereiten einer Ressource Kerstin Eckart 18. Februar 2013 Kerstin Eckart 1 / 45 Übersicht Konzepte und Beispiele Vorgehen beim Aufbereiten einer Ressource Entscheidungen
Korpusannotation: Vom nachhaltigen Aufbereiten einer Ressource Kerstin Eckart 18. Februar 2013 Kerstin Eckart 1 / 45 Übersicht Konzepte und Beispiele Vorgehen beim Aufbereiten einer Ressource Entscheidungen
Twitter als interaktive Erweiterung des Mediums Fernsehen: Inhaltliche Analyse von Tatort- Tweets
 Twitter als interaktive Erweiterung des Mediums Fernsehen: Inhaltliche Analyse von Tatort- Tweets Manuel Burghardt 1, Heike Karsten 2, Melanie Pflamminger 2 und Christian Wolff 1 Lehrstuhl für Medieninformatik
Twitter als interaktive Erweiterung des Mediums Fernsehen: Inhaltliche Analyse von Tatort- Tweets Manuel Burghardt 1, Heike Karsten 2, Melanie Pflamminger 2 und Christian Wolff 1 Lehrstuhl für Medieninformatik
Corpus based Identification of Text Segments. Thomas Ebert Betreuer: MSc. Martin Schmitt
 Corpus based Identification of Text Segments Thomas Ebert Betreuer: MSc. Martin Schmitt Übersicht 1. Motivation 2. Ziel der Arbeit 3. Vorgehen 4. Probleme 5. Evaluierung 6. Erkenntnisse und offene Fragen
Corpus based Identification of Text Segments Thomas Ebert Betreuer: MSc. Martin Schmitt Übersicht 1. Motivation 2. Ziel der Arbeit 3. Vorgehen 4. Probleme 5. Evaluierung 6. Erkenntnisse und offene Fragen
LAUDATIO-Repository für Anwender. Carolin Odebrecht Humboldt-Universität zu Berlin LAUDATIO-repository.org
 LAUDATIO-Repository für Anwender Carolin Odebrecht Humboldt-Universität zu Berlin LAUDATIO-repository.org Arbeiten mit (historischen) Fragen, die oft gestellt werden: Korpora Wo finde ich Korpora aus dem
LAUDATIO-Repository für Anwender Carolin Odebrecht Humboldt-Universität zu Berlin LAUDATIO-repository.org Arbeiten mit (historischen) Fragen, die oft gestellt werden: Korpora Wo finde ich Korpora aus dem
Korpus-basierte Recherche und Analyse mit Hilfe von Data Mining:
 KobRA: Korpus-basierte Recherche und Analyse mit Hilfe von Data Mining: Motivation und Zielsetzungen Angelika Storrer Überblick o o o o o o Leitziel und Zusammenspiel der Projektpartner Ausgangslage: Welche
KobRA: Korpus-basierte Recherche und Analyse mit Hilfe von Data Mining: Motivation und Zielsetzungen Angelika Storrer Überblick o o o o o o Leitziel und Zusammenspiel der Projektpartner Ausgangslage: Welche
Technischer Bericht. Nr. 2014/1 (Meilenstein 2)
") Technische Universität Dortmund Fakultät Informatik Lehrstuhl für Künstliche Intelligenz Universität Mannheim Seminar für deutsche Philologie Lehrstuhl Germanistische Linguistik Technischer Bericht Nr.
Technische Universität Dortmund Fakultät Informatik Lehrstuhl für Künstliche Intelligenz Universität Mannheim Seminar für deutsche Philologie Lehrstuhl Germanistische Linguistik Technischer Bericht Nr.
Named Entity Recognition auf Basis von Wortlisten
 Named Entity Recognition auf Basis von Wortlisten EDM SS 2017 Lukas Abegg & Tom Schilling Named Entity Recognition auf Basis von Wortlisten Lukas Abegg - Humboldt Universität zu Berlin Tom Schilling -
Named Entity Recognition auf Basis von Wortlisten EDM SS 2017 Lukas Abegg & Tom Schilling Named Entity Recognition auf Basis von Wortlisten Lukas Abegg - Humboldt Universität zu Berlin Tom Schilling -
Automatische Rekonstruktion und Spezifizierung von Attributnamen in Webtabellen
 Automatische Rekonstruktion und Spezifizierung von Attributnamen in Webtabellen Mark Reinke Bachelorarbeit TU Dresden 17. Februar 2014 Webtabellen Warum sind Webtabellen von Bedeutung? Sie können relationale
Automatische Rekonstruktion und Spezifizierung von Attributnamen in Webtabellen Mark Reinke Bachelorarbeit TU Dresden 17. Februar 2014 Webtabellen Warum sind Webtabellen von Bedeutung? Sie können relationale
Herausforderungen in der Nutzung vorhandener Tools für arabische Daten
 Herausforderungen in der Nutzung vorhandener Tools für arabische Daten Tillmann Feige und Alicia González Vorgehen 1 Hintergründe & Workflow 2 Die Annotation 2.1 Anforderungen 3 Visualisierung 3.1 Anforderungen
Herausforderungen in der Nutzung vorhandener Tools für arabische Daten Tillmann Feige und Alicia González Vorgehen 1 Hintergründe & Workflow 2 Die Annotation 2.1 Anforderungen 3 Visualisierung 3.1 Anforderungen
Hintergrund: Morphologische Produktivität
 Hintergrund: Morphologische Produktivität Anke Lüdeling anke.luedeling@rz.hu-berlin.de einige Folien sind in Zusammenarbeit mit Stefan Evert (Osnabrück) entstanden Exkurs: Korpus & Korpuszählungen viele
Hintergrund: Morphologische Produktivität Anke Lüdeling anke.luedeling@rz.hu-berlin.de einige Folien sind in Zusammenarbeit mit Stefan Evert (Osnabrück) entstanden Exkurs: Korpus & Korpuszählungen viele
Speech Recognition Grammar Compilation in Grammatikal Framework. von Michael Heber
 Speech Recognition Grammar Compilation in Grammatikal Framework von Michael Heber Agenda 1. Einführung 2. Grammatical Framework (GF) 3. Kontextfreie Grammatiken und Finite-State Modelle 4. Quellen 2 1.
Speech Recognition Grammar Compilation in Grammatikal Framework von Michael Heber Agenda 1. Einführung 2. Grammatical Framework (GF) 3. Kontextfreie Grammatiken und Finite-State Modelle 4. Quellen 2 1.
Harry gefangen in der Zeit Begleitmaterialien
 Episode 091 Grammar 1. Indirect speech Indirect speech is used to report what someone has said without directly quoting that person. Direct speech Indirect speech Anna: "Ich fahre zu meiner Mutter." Anna
Episode 091 Grammar 1. Indirect speech Indirect speech is used to report what someone has said without directly quoting that person. Direct speech Indirect speech Anna: "Ich fahre zu meiner Mutter." Anna
Bachelorarbeit Erkennung von Fließtext in PDF-Dokumenten
 Bachelorarbeit Erkennung von Fließtext in PDF-Dokumenten 16.08.2016 David Spisla Albert Ludwigs Universität Freiburg Technische Fakultät Institut für Informatik Gliederung Motivation Schwierigkeiten bei
Bachelorarbeit Erkennung von Fließtext in PDF-Dokumenten 16.08.2016 David Spisla Albert Ludwigs Universität Freiburg Technische Fakultät Institut für Informatik Gliederung Motivation Schwierigkeiten bei
Korpuslinguistik mit PostgreSQL
 Korpuslinguistik mit PostgreSQL Johannes Graën Institut für Computerlinguistik Universität Zürich graen@cluzhch 2016-06-24 Übersicht Korpuslinguistik Abgetrennte Verbpräfixe Übersetzungsvarianten von Mehrwortausdrücken
Korpuslinguistik mit PostgreSQL Johannes Graën Institut für Computerlinguistik Universität Zürich graen@cluzhch 2016-06-24 Übersicht Korpuslinguistik Abgetrennte Verbpräfixe Übersetzungsvarianten von Mehrwortausdrücken
Wissenschaftliche Editionen: TEI, Perspektiven und Werkzeuge. Laurent Pugin
 Wissenschaftliche Editionen: TEI, Perspektiven und Werkzeuge Laurent Pugin laurent.pugin@rism-ch.org Überblick Die Text Encoding Initiative (TEI) Editionen: gestern heute morgen (incl. Werkzeuge) L. Pugin
Wissenschaftliche Editionen: TEI, Perspektiven und Werkzeuge Laurent Pugin laurent.pugin@rism-ch.org Überblick Die Text Encoding Initiative (TEI) Editionen: gestern heute morgen (incl. Werkzeuge) L. Pugin
ordnet.dk Vernetzung zwischen Wörterbuch und Korpus
 ordnet.dk Vernetzung zwischen Wörterbuch und Korpus Jörg Asmussen Det Danske Sprog- og Litteraturselskab, DSL Gesellschaft für dänische Sprache und Literatur ordnet.dk Vernetzung 1. Das Projekt ordnet.dk
ordnet.dk Vernetzung zwischen Wörterbuch und Korpus Jörg Asmussen Det Danske Sprog- og Litteraturselskab, DSL Gesellschaft für dänische Sprache und Literatur ordnet.dk Vernetzung 1. Das Projekt ordnet.dk
Deutsche Lernerwortarten im Falko Lernerkorpus Was Mehrebenen-POS-tags leisten können
 Deutsche Lernerwortarten im Falko Lernerkorpus Was Mehrebenen-POS-tags leisten können Marc Reznicek Humboldt-Universität zu Berlin STTS- Workshop 24.9.2012 Überblick STTS in Lernerkorpora Lernerfehler
Deutsche Lernerwortarten im Falko Lernerkorpus Was Mehrebenen-POS-tags leisten können Marc Reznicek Humboldt-Universität zu Berlin STTS- Workshop 24.9.2012 Überblick STTS in Lernerkorpora Lernerfehler
Verbal Morphosyntactic Disambiguation through Topological Field Recognition in German-Language Law Texts
 Institut für Computerlinguistik Verbal Morphosyntactic Disambiguation through Topological Field Recognition in German-Language Law Texts SFCM 2013 Kyoko Sugisaki and Stefan Höfler 06.09.2013 Seite 1 Background
Institut für Computerlinguistik Verbal Morphosyntactic Disambiguation through Topological Field Recognition in German-Language Law Texts SFCM 2013 Kyoko Sugisaki and Stefan Höfler 06.09.2013 Seite 1 Background