Signalverarbeitung 2. Volker Stahl - 1 -
|
|
|
- Arwed Rosenberg
- vor 5 Jahren
- Abrufe
Transkript
1 - 1 -
2 Spracherkennung gestern und morgen - 2 -

3 Ziel Klassifikation von Signalen, Mustererkennung z.b. Sprache, Gestik, Handschrift, EKG, Verkehrssituationen, Sensor Signal Klasse 1 Klasse 2 Klasse n Vorverarbeitung: Berechnung von Merkmalvektoren Klassifikation: Vergleich mit Referenzmustern - 3 -
4 Inhalt Abstandsmaß für Vektorfolgen unterschiedlicher Länge Dynamische Zeitverzerrung, Dynamische Programmierung Berechnung eines Referenzmusters aus mehreren Beispielen Mittelwert, Varianz, Mahalanobis Abstand Zufallsvariablen Modellieren von Unsicherheit, Normalverteilung Hidden Markov Modelle, Lernen aus Beispielen Viterbi Training, Expectation Maximization (EM), k-means Algorithmus, Mischverteilungen Statistische Abhängigkeit, Kovarianz Vermeiden von Fehlklassifikationen, n-dimensionale Normalverteilung - 4 -
5 Inhalt (optional) Dekorrelation, Hauptachsentransformation Vereinfachung des Klassifikationsproblems durch Vorverarbeitung Maximum Likelihood Schätzung Theoretischer Hintergrund statistischer Lernverfahren - 5 -
6 Vorlesungsunterlagen Ilias bzw. Folien der Vorlesung Übungsaufgaben Daten für Experimente Literaturhinweise - 6 -
7 Leistungsnachweis Vorlesungsbegleitendes Programmierprojekt Entwicklung eines zuverlässigen Klassifikators Sukzessive Verbesserung, Hausaufgaben Programmiersprache C oder Matlab Abgabe in letzter Vorlesungswoche (Ausarbeitung und Software) - 7 -
8 Literatur Mathematical Methods and Algorithms for Signal Processing Todd K. Moon, Wynn C. Stirling Elementare Einführung in die Wahrscheinlichkeitsrechnung Karl Bosch (E-Book, 519.Bosch) Elementare Einführung in die angewandte Statistik Karl Bosch (519.Bosch) Mustererkennung mit Markov-Modellen Theorie, Praxis, Anwendungsgebiete Gernot A. Fink ( Fin) Pattern Classification and Scene Analysis Richard O. Duda, Peter E. Hart (519.Dud) The Elements of Statistical Learning Trevor Hastie, Robert Tibshirani, Jerome Friedman (519.Has) - 8 -
")
, ARPA (1993-1996), DARPA (1996- ) Aktuelles")
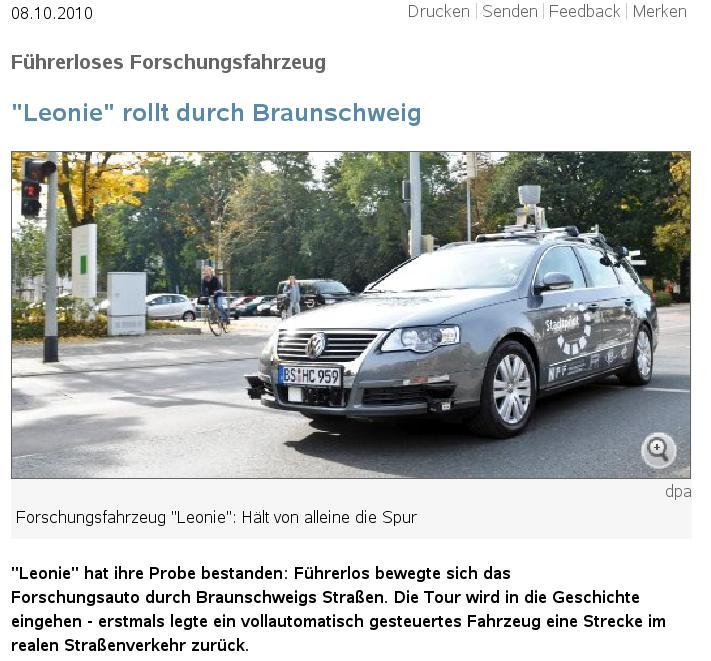
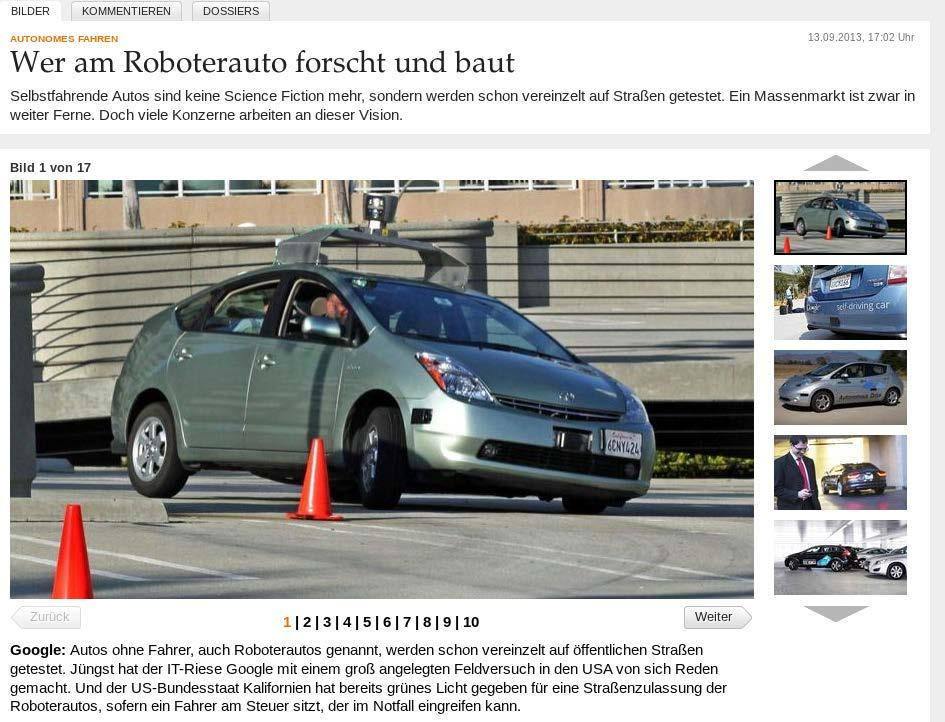
9 Beispiel: DARPA Grand Challenge 1957 Sputnik Schock Gründung der ARPA 1958 (Advanced Research Projects Agency) als Behörde des US Verteidigungsministeriums DARPA ( ), ARPA ( ), DARPA (1996- ) Aktuelles Budget 3 Mrd. $ - 9 -


10 Beispiel: DARPA Grand Challenge 1969 Arpanet Weitere Projekte: Tarnkappentechnologie, GPS, Grand Challenge 2004, Mohave Wüste Nevada, 241km. Grand Challenge 2005 Urban Challenge

11 - 11 -
12 - 12 -
13 - 13 -
14 Aktuelle DARPA Projekte (Quelle: Download ) Military Bioengineering & Human Enhancing Das Ziel heißt Human Enhancing, Soldaten sollen mit Hilfe von Drogen, Genen und Mikrochips schneller, härter und kampffähiger werden ein Motto, dem sich die Darpa mit viel Geld und Know-How widmet. Continuous Assisted Performance mit biotechnologischen Mitteln (Implantaten, Manipulation des Stoffwechsels, etc.) erreichen, dass Soldaten bis zu sieben Tage lang wach bleiben können, ohne dabei den Verstand zu verlieren. Brain Machine Interfaces ein Programm, für das der Darpa zurzeit 24 Millionen Dollar zur Verfügung stehen. Ziel von Brain Machine Interfaces (Hirn-Maschine-Schnittstellen) ist es, aus menschlichen Gehirnen Informationen zu gewinnen, die für Computer verwertbar sind Chips im Kopf sollen Panzer oder Hubschrauber oder auch den Soldaten steuern, dem sie implantiert wurden. Stellen Sie sich eine Zeit vor, in der Soldaten allein mittels Gedanken kommunizieren, stellen sie sich eine Zeit vor, in der menschliche Gehirne ihre eigenen drahtlosen Modems besitzen statt auf der Basis von Gedanken zu handeln, haben Kampfflugzeuge dann Gedanken, die handeln

15 (Quelle: Zeit Online, Download )
16 Mustererkennung Beispiel Schriftzeichenerkennung A
17 Erkennen heißt Klassifizieren Gegeben: Gesucht: Signal (bzw. daraus berechnete Merkmale): Muster Endlich viele Klassen Klasse, zu der das Signal gehört. Beispiele: Buchstabenerkennung Spracherkennung (Phonemerkennung, Worterkennung) Visuelle Qualitätskontrolle (ok, Ausschuss) Medizinische Diagnostik (Röntgenbilder, EKG, )
18 Klassifizieren heißt Vergleichen mit Bekanntem Gegeben: Gesucht: Zu klassifizierendes Muster Ein Referenzmuster zu jeder Klasse Die Klasse, deren Referenzmuster am ähnlichsten zu dem zu klassifizierenden Muster ist. Problem: Geeignetes Ähnlichkeitsmaß zwischen Mustern?
19 Beispiel Schriftzeichenerkennung Referenzmuster Klasse A: Referenzmuster Klasse B: A B Zu klassifizierendes Muster: A Ähnlichkeits- / Abstandsmaß?
20 Vorverarbeitung Berechnung trennscharfer Merkmale eines Musters: Merkmalvektoren. Zeitsignal (Sprache, Gesten, EKG ) Folge von Merkmalvektoren Vorverarbeitung ist anwendungsabhängig! Unterschiedliche Merkmale für Sprache, Gesten, Handschrift, Bilder,
21 Abstandsmaß zwischen Folgen von Merkmalvektoren Referenzmuster Klasse A: Referenzmuster Klasse B: Zu klassifizierendes Muster:
22 Euklidischer Abstand
23 Abstandsmaß für unterschiedlich lange Folgen? Referenzmuster Klasse A: Referenzmuster Klasse B: Zu klassifizierendes Muster:
24 Matching Referenz Test
25 Referenz Test Darstellung als Pfad in einem Suchgitter Referenz Test
26 Einschränkungen beim Matching Jedem Testvektor muss genau ein Referenzvektor zugeordnet werden! (Zuordnungsfunktion) Verboten! zweihundertdrei Zeitliche Reihenfolge muss beibehalten werden! (Monotone Zuordnungsfunktion) Verboten! dreihundertzwei
27 Einschränkungen beim Matching Die ersten und letzten Vektoren müssen einander zugeordnet werden! Fachhochschule hoch Erzwungen! Keine zwei aufeinanderfolgenden Referenzvektoren dürfen übersprungen werden! Siebenhundertfünfundzwanzig Verboten! Siebenundzwanzig
28 Gesucht: Pfad durch Gitter mit minimalen Kosten von links unten nach rechts oben monoton steigend maximale Steigung 2 (einen Referenzvektor überspringen) Referenz Test
29 Konsequenz: Nur 3 Arten von Übergängen im Gitter Next Übergang Loop Übergang Skip Übergang
30 Viterbi Algorithmus: Berechnung des optimalen Pfades
31 - 31 -
32 - 32 -
33 - 33 -
34 - 34 -
35 - 35 -
36 - 36 -
37 - 37 -
38 Verbesserung: Mehrere Referenzmuster pro Klasse Referenzmuster einer Klasse: Mittelwert für die Klasse: Modell Zustände
39 Problem: Referenzfolgen einer Klasse unterschiedlich lang Referenzmuster einer Klasse: Lösung: Alle Referenzvektorfolgen einer Klasse auf ein gemeinsames Modell fester Länge matchen!
40 Viterbi Training eines Modells Überblick: Bestimme Modell Länge Matching (Annahme lineare Zeitverzerrung) Initiale Schätzung der Modellvektoren Iteriere Matching (dynamische Zeitverzerrung, Viterbi) Neuberechnung der Modellvektoren
41 Wahl der Modell Länge Modell zu lang! Wahl der Modell Länge z.b. ½ Median der Längen der Referenzvektorfolgen
42 Lineare Segmentierung Modell Referenzmuster Lineare Zuordnung der Merkmalvektoren einer Referenzaufnahme zu den Modellzuständen
43 Beispiel Referenzmuster einer Klasse (gegeben) Länge 6 Länge 7 Modell für die Klasse (gesucht) Länge
44 Lineare Segmentierung
45 Initiale Schätzung der Modellvektoren Modellvektor = Mittelwert über alle Referenzvektoren, die dem Modellzustand zugeordnet wurden
46 Matchen der Referenzfolgen gegen das Modell mit Viterbi Algorithmus (Segmentierung)
47 Neuschätzung der Modellvektoren Modellvektor = Mittelwert über alle Referenzvektoren, die dem Modellzustand zugeordnet wurden Iteration: Matching mit neuem Modell, Modell neu schätzen aus neuer Zuordnung

48 Zahlenbeispiel
Signalverarbeitung 2. Volker Stahl - 1 -
 - 1 - Überblick Bessere Modelle, die nicht nur den Mittelwert von Referenzvektoren sondern auch deren Varianz berücksichtigen Weniger Fehlklassifikationen Mahalanobis Abstand Besseres Abstandsmaß basierend
- 1 - Überblick Bessere Modelle, die nicht nur den Mittelwert von Referenzvektoren sondern auch deren Varianz berücksichtigen Weniger Fehlklassifikationen Mahalanobis Abstand Besseres Abstandsmaß basierend
Mustererkennung. Termine: Montag 9:45-11:15, F138 Mittwoch 11:30-13:00, D108 Freitag 11:30-13:00, A210. Skript, Literatur, Anmeldung im Netz
 Mustererkennung Termine: Montag 9:45-11:15, F138 Mittwoch 11:30-13:00, D108 Freitag 11:30-13:00, A210 Skript, Literatur, Anmeldung im Netz Mustererkennung Anwendungsbeispiele für Mustererkennung? Mustererkennung
Mustererkennung Termine: Montag 9:45-11:15, F138 Mittwoch 11:30-13:00, D108 Freitag 11:30-13:00, A210 Skript, Literatur, Anmeldung im Netz Mustererkennung Anwendungsbeispiele für Mustererkennung? Mustererkennung
Signalverarbeitung 2. Volker Stahl - 1 -
 - 1 - Hidden Markov Modelle - 2 - Idee Zu klassifizierende Merkmalvektorfolge wurde von einem (unbekannten) System erzeugt. Nutze Referenzmerkmalvektorfolgen um ein Modell Des erzeugenden Systems zu bauen
- 1 - Hidden Markov Modelle - 2 - Idee Zu klassifizierende Merkmalvektorfolge wurde von einem (unbekannten) System erzeugt. Nutze Referenzmerkmalvektorfolgen um ein Modell Des erzeugenden Systems zu bauen
Methoden zur Cluster - Analyse
 Kapitel 4 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität Leipzig Machine learning in bioinformatics
Kapitel 4 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität Leipzig Machine learning in bioinformatics
Hidden-Markov-Modelle
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hidden-Markov-Modelle Tobias Scheffer Thomas Vanck Hidden-Markov-Modelle: Wozu? Spracherkennung: Akustisches Modell. Geschriebene
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hidden-Markov-Modelle Tobias Scheffer Thomas Vanck Hidden-Markov-Modelle: Wozu? Spracherkennung: Akustisches Modell. Geschriebene
Sprachsynthese und Spracherkennung
 90 Sprachsynthese und Spracherkennung von John N. Holmes Mit 51 Bildern und 69 Übungen mit Lösungshinweisen R. Oldenbourg Verlag München Wien 1991 INHALT Vorwort 11 1 Lautsprachliche Kommunikation 15 1.1
90 Sprachsynthese und Spracherkennung von John N. Holmes Mit 51 Bildern und 69 Übungen mit Lösungshinweisen R. Oldenbourg Verlag München Wien 1991 INHALT Vorwort 11 1 Lautsprachliche Kommunikation 15 1.1
:21 Uhr Modulbeschreibung #1290/1 Seite 1 von 5
 04.12.2015 16:21 Uhr Modulbeschreibung #1290/1 Seite 1 von 5 Modulbeschreibung Maschinelles Lernen 1 Modultitel: Maschinelles Lernen 1 Machine Learning 1 URL: Leistungspunkte: 9 Sekretariat: Modulsprache:
04.12.2015 16:21 Uhr Modulbeschreibung #1290/1 Seite 1 von 5 Modulbeschreibung Maschinelles Lernen 1 Modultitel: Maschinelles Lernen 1 Machine Learning 1 URL: Leistungspunkte: 9 Sekretariat: Modulsprache:
Mustererkennung. Übersicht. Unüberwachtes Lernen. (Un-) Überwachtes Lernen Clustering im Allgemeinen k-means-verfahren Gaussian-Mixture Modelle
 Überwachtes Lernen Clustering im Allgemeinen k-means-verfahren Gaussian-Mixture Modelle") Mustererkennung Unüberwachtes Lernen R. Neubecker, WS 01 / 01 Übersicht (Un-) Überwachtes Lernen Clustering im Allgemeinen k-means-verfahren 1 Lernen Überwachtes Lernen Zum Training des Klassifikators
Mustererkennung Unüberwachtes Lernen R. Neubecker, WS 01 / 01 Übersicht (Un-) Überwachtes Lernen Clustering im Allgemeinen k-means-verfahren 1 Lernen Überwachtes Lernen Zum Training des Klassifikators
Statistik, Datenanalyse und Simulation
 Dr. Michael O. Distler distler@kph.uni-mainz.de Mainz, 13. Juli 2011 Ziel der Vorlesung Vermittlung von Grundkenntnissen der Statistik, Simulationstechnik und numerischen Methoden (Algorithmen) Aufgabe:
Dr. Michael O. Distler distler@kph.uni-mainz.de Mainz, 13. Juli 2011 Ziel der Vorlesung Vermittlung von Grundkenntnissen der Statistik, Simulationstechnik und numerischen Methoden (Algorithmen) Aufgabe:
Vorlesung Digitale Bildverarbeitung Sommersemester 2013
 Vorlesung Digitale Bildverarbeitung Sommersemester 2013 Sebastian Houben (Marc Schlipsing) Institut für Neuroinformatik Inhalt Crash-Course in Machine Learning Klassifikationsverfahren Grundsätzliches
Vorlesung Digitale Bildverarbeitung Sommersemester 2013 Sebastian Houben (Marc Schlipsing) Institut für Neuroinformatik Inhalt Crash-Course in Machine Learning Klassifikationsverfahren Grundsätzliches
INTELLIGENTE DATENANALYSE IN MATLAB
 INTELLIGENTE DATENANALYSE IN MATLAB Einführungsveranstaltung Überblick Organisation Literatur Inhalt und Ziele der Vorlesung Beispiele aus der Praxis 2 Organisation Vorlesung/Übung + Projektarbeit. 4 Semesterwochenstunden.
INTELLIGENTE DATENANALYSE IN MATLAB Einführungsveranstaltung Überblick Organisation Literatur Inhalt und Ziele der Vorlesung Beispiele aus der Praxis 2 Organisation Vorlesung/Übung + Projektarbeit. 4 Semesterwochenstunden.
Hidden Markov Modelle
 Hidden Markov Modelle in der Sprachverarbeitung Paul Gabriel paul@pogo.franken.de Seminar Sprachdialogsysteme: Hidden Markov Modelle p.1/3 Überblick Merkmalsvektoren Stochastischer Prozess Markov-Ketten
Hidden Markov Modelle in der Sprachverarbeitung Paul Gabriel paul@pogo.franken.de Seminar Sprachdialogsysteme: Hidden Markov Modelle p.1/3 Überblick Merkmalsvektoren Stochastischer Prozess Markov-Ketten
Bielefeld Graphics & Geometry Group. Brain Machine Interfaces Reaching and Grasping by Primates
 Reaching and Grasping by Primates + 1 Reaching and Grasping by Primates Inhalt Einführung Theoretischer Hintergrund Design Grundlagen Experiment Ausblick Diskussion 2 Reaching and Grasping by Primates
Reaching and Grasping by Primates + 1 Reaching and Grasping by Primates Inhalt Einführung Theoretischer Hintergrund Design Grundlagen Experiment Ausblick Diskussion 2 Reaching and Grasping by Primates
EFME Aufsätze ( Wörter) Der Aufbau von Entscheidungsbäumen...1
 Der Aufbau von Entscheidungsbäumen...1") EFME Aufsätze (150 200 Wörter) Der Aufbau von Entscheidungsbäumen...1 PCA in der Gesichtserkennung... 2 Bias, Varianz und Generalisierungsfähigkeit... 3 Parametrische und nicht-parametrische Lernverfahren:
EFME Aufsätze (150 200 Wörter) Der Aufbau von Entscheidungsbäumen...1 PCA in der Gesichtserkennung... 2 Bias, Varianz und Generalisierungsfähigkeit... 3 Parametrische und nicht-parametrische Lernverfahren:
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Clusteranalyse. Tobias Scheffer Thomas Vanck
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Thomas Vanck Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Thomas Vanck Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Bildverarbeitung Herbstsemester. Mustererkennung
 Bildverarbeitung Herbstsemester Herbstsemester 2009 2012 Mustererkennung 1 Inhalt Einführung Mustererkennung in Grauwertbildern Ähnlichkeitsmasse Normalisierte Korrelation Korrelationskoeffizient Mustererkennung
Bildverarbeitung Herbstsemester Herbstsemester 2009 2012 Mustererkennung 1 Inhalt Einführung Mustererkennung in Grauwertbildern Ähnlichkeitsmasse Normalisierte Korrelation Korrelationskoeffizient Mustererkennung
Algorithmen für Geographische Informationssysteme
 Algorithmen für Geographische Informationssysteme 2. Vorlesung: 16. April 2014 Thomas van Dijk basiert auf Folien von Jan-Henrik Haunert Map Matching? Map Matching! Map Matching...als Teil von Fahrzeugnavigationssystemen
Algorithmen für Geographische Informationssysteme 2. Vorlesung: 16. April 2014 Thomas van Dijk basiert auf Folien von Jan-Henrik Haunert Map Matching? Map Matching! Map Matching...als Teil von Fahrzeugnavigationssystemen
Mustererkennung und Klassifikation
 Mustererkennung und Klassifikation WS 2007/2008 Fakultät Informatik Technische Informatik Prof. Dr. Matthias Franz mfranz@htwg-konstanz.de www-home.htwg-konstanz.de/~mfranz/heim.html Grundlagen Überblick
Mustererkennung und Klassifikation WS 2007/2008 Fakultät Informatik Technische Informatik Prof. Dr. Matthias Franz mfranz@htwg-konstanz.de www-home.htwg-konstanz.de/~mfranz/heim.html Grundlagen Überblick
INTELLIGENTE DATENANALYSE IN MATLAB. Einführungsveranstaltung
 INTELLIGENTE DATENANALYSE IN MATLAB Einführungsveranstaltung Überblick Organisation. Literatur. Inhalt und Ziele der Vorlesung. Beispiele aus der Praxis. 2 Organisation Vorlesung/Übung + Projektarbeit.
INTELLIGENTE DATENANALYSE IN MATLAB Einführungsveranstaltung Überblick Organisation. Literatur. Inhalt und Ziele der Vorlesung. Beispiele aus der Praxis. 2 Organisation Vorlesung/Übung + Projektarbeit.
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Maschinelles Lernen
 Universität Potsdam Institut für Informatik Lehrstuhl Niels Landwehr, Silvia Makowski, Christoph Sawade, Tobias Scheffer Organisation Vorlesung/Übung, praktische Informatik. 4 SWS. Übung: Di 10:00-11:30
Universität Potsdam Institut für Informatik Lehrstuhl Niels Landwehr, Silvia Makowski, Christoph Sawade, Tobias Scheffer Organisation Vorlesung/Übung, praktische Informatik. 4 SWS. Übung: Di 10:00-11:30
Wissensentdeckung in Datenbanken
 Wissensentdeckung in Datenbanken Modellklassen, Verlustfunktionen Nico Piatkowski und Uwe Ligges 02.05.2017 1 von 15 Literatur Trevor Hastie, Robert Tibshirani, Jerome Friedman. The Elements of Statistical
Wissensentdeckung in Datenbanken Modellklassen, Verlustfunktionen Nico Piatkowski und Uwe Ligges 02.05.2017 1 von 15 Literatur Trevor Hastie, Robert Tibshirani, Jerome Friedman. The Elements of Statistical
Clustering 2010/06/11 Sebastian Koch 1
 Clustering 2010/06/11 1 Motivation Quelle: http://www.ha-w.de/media/schulung01.jpg 2010/06/11 2 Was ist Clustering Idee: Gruppierung von Objekten so, dass: Innerhalb einer Gruppe sollen die Objekte möglichst
Clustering 2010/06/11 1 Motivation Quelle: http://www.ha-w.de/media/schulung01.jpg 2010/06/11 2 Was ist Clustering Idee: Gruppierung von Objekten so, dass: Innerhalb einer Gruppe sollen die Objekte möglichst
10.5 Maximum-Likelihood Klassifikation (I)
") Klassifikation (I) Idee Für die Klassifikation sind wir interessiert an den bedingten Wahrscheinlichkeiten p(c i (x,y) D(x,y)). y Wenn man diese bedingten Wahrscheinlichkeiten kennt, dann ordnet man einem
Klassifikation (I) Idee Für die Klassifikation sind wir interessiert an den bedingten Wahrscheinlichkeiten p(c i (x,y) D(x,y)). y Wenn man diese bedingten Wahrscheinlichkeiten kennt, dann ordnet man einem
Überblick. Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung
 Grundlagen Überblick Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes-Klassifikator
Grundlagen Überblick Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes-Klassifikator
Segmentierung von Gesten
 Segmentierung von Gesten Anwendungen 1 Johann Heitsch 1 Motivation Maus & Tastatur 2 Motivation Single- / Multitouch 3 Motivation Interaktion mit großen Displays 4 Hochschule für Angewandte Wissenschaften
Segmentierung von Gesten Anwendungen 1 Johann Heitsch 1 Motivation Maus & Tastatur 2 Motivation Single- / Multitouch 3 Motivation Interaktion mit großen Displays 4 Hochschule für Angewandte Wissenschaften
Principal Component Analysis (PCA)
") Principal Component Analysis (PCA) Motivation: Klassifikation mit der PCA Berechnung der Hauptkomponenten Theoretische Hintergründe Anwendungsbeispiel: Klassifikation von Gesichtern Weiterführende Bemerkungen
Principal Component Analysis (PCA) Motivation: Klassifikation mit der PCA Berechnung der Hauptkomponenten Theoretische Hintergründe Anwendungsbeispiel: Klassifikation von Gesichtern Weiterführende Bemerkungen
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Tobias Scheffer, Tom Vanck, Paul Prasse
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Sprachtechnologie Tobias Scheffer, Tom Vanck, Paul Prasse Organisation Vorlesung/Übung, praktische Informatik. 4 SWS. Termin: Montags,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Sprachtechnologie Tobias Scheffer, Tom Vanck, Paul Prasse Organisation Vorlesung/Übung, praktische Informatik. 4 SWS. Termin: Montags,
Uwe Hassler. Statistik im. Bachelor-Studium. Eine Einführung. für Wirtschaftswissenschaftler. ^ Springer Gabler
 Uwe Hassler Statistik im Bachelor-Studium Eine Einführung für Wirtschaftswissenschaftler ^ Springer Gabler 1 Einführung 1 2 Beschreibende Methoden univariater Datenanalyse 5 2.1 Grundbegriffe 5 2.2 Häufigkeitsverteilungen
Uwe Hassler Statistik im Bachelor-Studium Eine Einführung für Wirtschaftswissenschaftler ^ Springer Gabler 1 Einführung 1 2 Beschreibende Methoden univariater Datenanalyse 5 2.1 Grundbegriffe 5 2.2 Häufigkeitsverteilungen
Überblick. Überblick. Bayessche Entscheidungsregel. A-posteriori-Wahrscheinlichkeit (Beispiel) Wiederholung: Bayes-Klassifikator
 Wiederholung: Bayes-Klassifikator") Überblick Grundlagen Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes-Klassifikator
Überblick Grundlagen Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes-Klassifikator
Inhalt. I. Deskriptive Statistik Einführung Die Grundgesamtheit Merkmale und Verteilungen Tabellen und Grafiken...
 I. Deskriptive Statistik 1 1. Einführung 3 1.1. Die Grundgesamtheit......................... 5 1.2. Merkmale und Verteilungen..................... 6 1.3. Tabellen und Grafiken........................ 10
I. Deskriptive Statistik 1 1. Einführung 3 1.1. Die Grundgesamtheit......................... 5 1.2. Merkmale und Verteilungen..................... 6 1.3. Tabellen und Grafiken........................ 10
Sprachdialogsystem mit robuster automatischer Spracherkennung
 Sprachdialogsystem mit robuster automatischer Spracherkennung Hans-Günter Hirsch Hochschule Niederrhein Fachbereich Elektrotechnik und Informatik Digitale Nachrichtentechnik http://dnt.kr.hs-niederrhein.de
Sprachdialogsystem mit robuster automatischer Spracherkennung Hans-Günter Hirsch Hochschule Niederrhein Fachbereich Elektrotechnik und Informatik Digitale Nachrichtentechnik http://dnt.kr.hs-niederrhein.de
Wahrscheinlichkeitsrechnung und Statistik für Biologen Diskriminanzanalyse
 Wahrscheinlichkeitsrechnung und Statistik für Biologen Diskriminanzanalyse Martin Hutzenthaler & Dirk Metzler http://evol.bio.lmu.de/_statgen 6. Juli 2010 Übersicht 1 Ruf des Kleinspechts 2 Modell Vorgehen
Wahrscheinlichkeitsrechnung und Statistik für Biologen Diskriminanzanalyse Martin Hutzenthaler & Dirk Metzler http://evol.bio.lmu.de/_statgen 6. Juli 2010 Übersicht 1 Ruf des Kleinspechts 2 Modell Vorgehen
Mustererkennung. Bayes-Klassifikator. R. Neubecker, WS 2016 / Bayes-Klassifikator
 Mustererkennung Bayes-Klassifikator R. Neubecker, WS 2016 / 2017 Bayes-Klassifikator 2 Kontext Ziel: Optimaler Klassifikator ( = minimaler Klassifikationsfehler), basierend auf Wahrscheinlichkeitsverteilungen
Mustererkennung Bayes-Klassifikator R. Neubecker, WS 2016 / 2017 Bayes-Klassifikator 2 Kontext Ziel: Optimaler Klassifikator ( = minimaler Klassifikationsfehler), basierend auf Wahrscheinlichkeitsverteilungen
Bayes Klassifikatoren M E T H O D E N D E S D A T A M I N I N G F A B I A N G R E U E L
 Bayes Klassifikatoren M E T H O D E N D E S D A T A M I N I N G F A B I A N G R E U E L Inhalt Grundlagen aus der Wahrscheinlichkeitsrechnung Hypothesenwahl Optimale Bayes Klassifikator Naiver Bayes Klassifikator
Bayes Klassifikatoren M E T H O D E N D E S D A T A M I N I N G F A B I A N G R E U E L Inhalt Grundlagen aus der Wahrscheinlichkeitsrechnung Hypothesenwahl Optimale Bayes Klassifikator Naiver Bayes Klassifikator
1. Referenzpunkt Transformation
 2.3 Featurereduktion Idee: Anstatt Features einfach wegzulassen, generiere einen neuen niedrigdimensionalen Featureraum aus allen Features: Redundante Features können zusammengefasst werden Irrelevantere
2.3 Featurereduktion Idee: Anstatt Features einfach wegzulassen, generiere einen neuen niedrigdimensionalen Featureraum aus allen Features: Redundante Features können zusammengefasst werden Irrelevantere
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Clusteranalyse. Niels Landwehr
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Niels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer Ansatz:
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Niels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer Ansatz:
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Christoph Sawade/Niels Landwehr/Tobias Scheffer
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Christoph Sawade/Niels Landwehr/Tobias Scheffer Überblick Problemstellung/Motivation Deterministischer i ti Ansatz:
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Christoph Sawade/Niels Landwehr/Tobias Scheffer Überblick Problemstellung/Motivation Deterministischer i ti Ansatz:
Klassifikation von Daten Einleitung
 Klassifikation von Daten Einleitung Lehrstuhl für Künstliche Intelligenz Institut für Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg (Lehrstuhl Informatik 8) Klassifikation von Daten Einleitung
Klassifikation von Daten Einleitung Lehrstuhl für Künstliche Intelligenz Institut für Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg (Lehrstuhl Informatik 8) Klassifikation von Daten Einleitung
Der Viterbi-Algorithmus im Part-of-Speech Tagging
 Der Viterbi-Algorithmus im Part-of-Speech Tagging Kursfolien Karin Haenelt 1 Themen Zweck des Viterbi-Algorithmus Hidden Markov Model Formale Spezifikation Beispiel Arc Emission Model State Emission Model
Der Viterbi-Algorithmus im Part-of-Speech Tagging Kursfolien Karin Haenelt 1 Themen Zweck des Viterbi-Algorithmus Hidden Markov Model Formale Spezifikation Beispiel Arc Emission Model State Emission Model
Map Matching. Problem: GPS-Punkte der Trajektorie weisen einen relativ großen Abstand zueinander auf.
 Map Matching Problem: GPS-Punkte der Trajektorie weisen einen relativ großen Abstand zueinander auf. Ergebnis mit minimaler Fréchet-Distanz Annahme: Fahrer wählen bevorzugt kürzeste Wege im Straßennetz.
Map Matching Problem: GPS-Punkte der Trajektorie weisen einen relativ großen Abstand zueinander auf. Ergebnis mit minimaler Fréchet-Distanz Annahme: Fahrer wählen bevorzugt kürzeste Wege im Straßennetz.
1 Grundlagen der Wahrscheinlichkeitsrechnung Wahrscheinlichkeitsräume. Ein erster mathematischer Blick auf Zufallsexperimente...
 Inhaltsverzeichnis 1 Grundlagen der Wahrscheinlichkeitsrechnung 1 1.1 Wahrscheinlichkeitsräume Ein erster mathematischer Blick auf Zufallsexperimente.......... 1 1.1.1 Wahrscheinlichkeit, Ergebnisraum,
Inhaltsverzeichnis 1 Grundlagen der Wahrscheinlichkeitsrechnung 1 1.1 Wahrscheinlichkeitsräume Ein erster mathematischer Blick auf Zufallsexperimente.......... 1 1.1.1 Wahrscheinlichkeit, Ergebnisraum,
Unüberwachtes Lernen
 Unüberwachtes Lernen Mustererkennung und Klassifikation, Vorlesung No. 12 M. O. Franz 17.01.2008 Übersicht 1 Hauptkomponentenanalyse 2 Nichtlineare Hauptkomponentenanalyse 3 K-Means-Clustering Übersicht
Unüberwachtes Lernen Mustererkennung und Klassifikation, Vorlesung No. 12 M. O. Franz 17.01.2008 Übersicht 1 Hauptkomponentenanalyse 2 Nichtlineare Hauptkomponentenanalyse 3 K-Means-Clustering Übersicht
Informatik II, SS 2018
 Informatik II - SS 2018 (Algorithmen & Datenstrukturen) Vorlesung 21 (11.7.2018) String Matching (Textsuche) II Greedy Algorithmen I Algorithmen und Komplexität Textsuche / String Matching Gegeben: Zwei
Informatik II - SS 2018 (Algorithmen & Datenstrukturen) Vorlesung 21 (11.7.2018) String Matching (Textsuche) II Greedy Algorithmen I Algorithmen und Komplexität Textsuche / String Matching Gegeben: Zwei
Maschinelles Lernen II
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen II Niels Landwehr Organisation Vorlesung/Übung 4 SWS. Ort: 3.01.2.31. Termin: Vorlesung: Dienstag, 10:00-11:30.
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen II Niels Landwehr Organisation Vorlesung/Übung 4 SWS. Ort: 3.01.2.31. Termin: Vorlesung: Dienstag, 10:00-11:30.
VII Unüberwachte Data-Mining-Verfahren
 VII Unüberwachte Data-Mining-Verfahren Clusteranalyse Assoziationsregeln Generalisierte Assoziationsregeln mit Taxonomien Formale Begriffsanalyse Self Organizing Maps Institut AIFB, 00. Alle Rechte vorbehalten.
VII Unüberwachte Data-Mining-Verfahren Clusteranalyse Assoziationsregeln Generalisierte Assoziationsregeln mit Taxonomien Formale Begriffsanalyse Self Organizing Maps Institut AIFB, 00. Alle Rechte vorbehalten.
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Tobias Scheffer Christoph Sawade
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Christoph Sawade Heute: Niels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz:
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Christoph Sawade Heute: Niels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz:
Übungen zur Vorlesung Grundlagen der Bilderzeugung und Bildanalyse (Mustererkennung) WS 05/06. Musterlösung 11
 WS 05/06. Musterlösung 11") ALBERT-LUDWIGS-UNIVERSITÄT FREIBURG INSTITUT FÜR INFORMATIK Lehrstuhl für Mustererkennung und Bildverarbeitung Prof. Dr.-Ing. Hans Burkhardt Georges-Köhler-Allee Geb. 05, Zi 0-09 D-790 Freiburg Tel. 076-03
ALBERT-LUDWIGS-UNIVERSITÄT FREIBURG INSTITUT FÜR INFORMATIK Lehrstuhl für Mustererkennung und Bildverarbeitung Prof. Dr.-Ing. Hans Burkhardt Georges-Köhler-Allee Geb. 05, Zi 0-09 D-790 Freiburg Tel. 076-03
Projektgruppe. Text Labeling mit Sequenzmodellen
 Projektgruppe Enes Yigitbas Text Labeling mit Sequenzmodellen 4. Juni 2010 Motivation Möglichkeit der effizienten Verarbeitung von riesigen Datenmengen In vielen Bereichen erwünschte automatisierte Aufgabe:
Projektgruppe Enes Yigitbas Text Labeling mit Sequenzmodellen 4. Juni 2010 Motivation Möglichkeit der effizienten Verarbeitung von riesigen Datenmengen In vielen Bereichen erwünschte automatisierte Aufgabe:
Multivariate Verfahren
 Multivariate Verfahren Oliver Muthmann 31. Mai 2007 Gliederung 1 Einführung 2 Varianzanalyse (MANOVA) 3 Regressionsanalyse 4 Faktorenanalyse Hauptkomponentenanalyse 5 Clusteranalyse 6 Zusammenfassung Komplexe
Multivariate Verfahren Oliver Muthmann 31. Mai 2007 Gliederung 1 Einführung 2 Varianzanalyse (MANOVA) 3 Regressionsanalyse 4 Faktorenanalyse Hauptkomponentenanalyse 5 Clusteranalyse 6 Zusammenfassung Komplexe
Vorlesung: Statistik II für Wirtschaftswissenschaft
 Vorlesung: Statistik II für Wirtschaftswissenschaft Prof. Dr. Helmut Küchenhoff Institut für Statistik, LMU München Sommersemester 2017 6 Genzwertsätze Einführung 1 Wahrscheinlichkeit: Definition und Interpretation
Vorlesung: Statistik II für Wirtschaftswissenschaft Prof. Dr. Helmut Küchenhoff Institut für Statistik, LMU München Sommersemester 2017 6 Genzwertsätze Einführung 1 Wahrscheinlichkeit: Definition und Interpretation
Einführung R. Neubecker, WS 2018 / 2019
 Mustererkennung Einführung R. Neubecker, WS 2018 / 2019 1 Übersicht Hyperebenen-Mathematik Anmerkungen Zusammenfassung Mustererkennung (Pattern recognition) Mustererkennung ist die Fähigkeit, in einer
Mustererkennung Einführung R. Neubecker, WS 2018 / 2019 1 Übersicht Hyperebenen-Mathematik Anmerkungen Zusammenfassung Mustererkennung (Pattern recognition) Mustererkennung ist die Fähigkeit, in einer
Pareto optimale lineare Klassifikation
 Seminar aus Maschinellem Lernen Pareto optimale lineare Klassifikation Vesselina Poulkova Betreuer: Eneldo Loza Mencía Gliederung 1. Einleitung 2. Pareto optimale lineare Klassifizierer 3. Generelle Voraussetzung
Seminar aus Maschinellem Lernen Pareto optimale lineare Klassifikation Vesselina Poulkova Betreuer: Eneldo Loza Mencía Gliederung 1. Einleitung 2. Pareto optimale lineare Klassifizierer 3. Generelle Voraussetzung
Hypothesenbewertungen: Übersicht
 Hypothesenbewertungen: Übersicht Wie kann man Fehler einer Hypothese abschätzen? Wie kann man einschätzen, ob ein Algorithmus besser ist als ein anderer? Trainingsfehler, wirklicher Fehler Kreuzvalidierung
Hypothesenbewertungen: Übersicht Wie kann man Fehler einer Hypothese abschätzen? Wie kann man einschätzen, ob ein Algorithmus besser ist als ein anderer? Trainingsfehler, wirklicher Fehler Kreuzvalidierung
Eine zweidimensionale Stichprobe
 Eine zweidimensionale Stichprobe liegt vor, wenn zwei qualitative Merkmale gleichzeitig betrachtet werden. Eine Urliste besteht dann aus Wertepaaren (x i, y i ) R 2 und hat die Form (x 1, y 1 ), (x 2,
Eine zweidimensionale Stichprobe liegt vor, wenn zwei qualitative Merkmale gleichzeitig betrachtet werden. Eine Urliste besteht dann aus Wertepaaren (x i, y i ) R 2 und hat die Form (x 1, y 1 ), (x 2,
Hidden Markov Modelle
 Hidden Markov Modelle (Vorabversion begleitend zur Vorlesung Spracherkennung und integrierte Dialogsysteme am Lehrstuhl Medieninformatik am Inst. f. Informatik der LMU München, Sommer 2005) Prof. Marcus
Hidden Markov Modelle (Vorabversion begleitend zur Vorlesung Spracherkennung und integrierte Dialogsysteme am Lehrstuhl Medieninformatik am Inst. f. Informatik der LMU München, Sommer 2005) Prof. Marcus
Ridge Regression und Kernalized Support Vector Machines : Einführung und Vergleich an einem Anwendungsbeispiel
 Ridge Regression und Kernalized Support Vector Machines : Einführung und Vergleich an einem Anwendungsbeispiel Dr. Dominik Grimm Probelehrveranstaltung Fakultät für Informatik und Mathematik Hochschule
Ridge Regression und Kernalized Support Vector Machines : Einführung und Vergleich an einem Anwendungsbeispiel Dr. Dominik Grimm Probelehrveranstaltung Fakultät für Informatik und Mathematik Hochschule
Lineare Methoden zur Klassifizierung
 Lineare Methoden zur Klassifizierung Kapitel 3 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität
Lineare Methoden zur Klassifizierung Kapitel 3 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität
Clusteranalyse: Gauß sche Mischmodelle
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse: Gauß sche Mischmodelle iels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse: Gauß sche Mischmodelle iels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Prof. Dr. Walter F. Tichy Dr. Matthias Müller Sommersemester 2006
 Empirische Softwaretechnik Prof. Dr. Walter F. Tichy Dr. Matthias Müller Sommersemester 2006 1 Experiment zur Vererbungstiefe Softwaretechnik: die Vererbungstiefe ist kein guter Schätzer für den Wartungsaufwand
Empirische Softwaretechnik Prof. Dr. Walter F. Tichy Dr. Matthias Müller Sommersemester 2006 1 Experiment zur Vererbungstiefe Softwaretechnik: die Vererbungstiefe ist kein guter Schätzer für den Wartungsaufwand
Stochastik für Informatiker
 Statistik und ihre Anwendungen Stochastik für Informatiker Bearbeitet von Lutz Dumbgen 1. Auflage 2003. Taschenbuch. XII, 267 S. Paperback ISBN 978 3 540 00061 7 Format (B x L): 15,5 x 23,5 cm Gewicht:
Statistik und ihre Anwendungen Stochastik für Informatiker Bearbeitet von Lutz Dumbgen 1. Auflage 2003. Taschenbuch. XII, 267 S. Paperback ISBN 978 3 540 00061 7 Format (B x L): 15,5 x 23,5 cm Gewicht:
Basiswissen Mathematik, Statistik und Operations Research für Wirtschaftswissenschaftler
 Basiswissen Mathematik, Statistik und Operations Research für Wirtschaftswissenschaftler Bearbeitet von Gert Heinrich 5., korr. Aufl. 2013. Taschenbuch. XV, 399 S. Paperback ISBN 978 3 486 75491 9 Format
Basiswissen Mathematik, Statistik und Operations Research für Wirtschaftswissenschaftler Bearbeitet von Gert Heinrich 5., korr. Aufl. 2013. Taschenbuch. XV, 399 S. Paperback ISBN 978 3 486 75491 9 Format
Inhalt. I Einführung. Kapitel 1 Konzept des Buches Kapitel 2 Messen in der Psychologie... 27
 Inhalt I Einführung Kapitel 1 Konzept des Buches........................................ 15 Kapitel 2 Messen in der Psychologie.................................. 27 2.1 Arten von psychologischen Messungen....................
Inhalt I Einführung Kapitel 1 Konzept des Buches........................................ 15 Kapitel 2 Messen in der Psychologie.................................. 27 2.1 Arten von psychologischen Messungen....................
Über dieses Buch Die Anfänge Wichtige Begriffe... 21
 Inhalt Über dieses Buch... 12 TEIL I Deskriptive Statistik 1.1 Die Anfänge... 17 1.2 Wichtige Begriffe... 21 1.2.1 Das Linda-Problem... 22 1.2.2 Merkmale und Merkmalsausprägungen... 23 1.2.3 Klassifikation
Inhalt Über dieses Buch... 12 TEIL I Deskriptive Statistik 1.1 Die Anfänge... 17 1.2 Wichtige Begriffe... 21 1.2.1 Das Linda-Problem... 22 1.2.2 Merkmale und Merkmalsausprägungen... 23 1.2.3 Klassifikation
1 Einleitung Definitionen, Begriffe Grundsätzliche Vorgehensweise... 3
 Inhaltsverzeichnis 1 Einleitung 1 1.1 Definitionen, Begriffe........................... 1 1.2 Grundsätzliche Vorgehensweise.................... 3 2 Intuitive Klassifikation 6 2.1 Abstandsmessung zur Klassifikation..................
Inhaltsverzeichnis 1 Einleitung 1 1.1 Definitionen, Begriffe........................... 1 1.2 Grundsätzliche Vorgehensweise.................... 3 2 Intuitive Klassifikation 6 2.1 Abstandsmessung zur Klassifikation..................
Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 2016
 Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 1 M. Sperber (matthias.sperber@kit.edu) S. Nguyen (thai.nguyen@kit.edu) Übungsblatt 3 Maschinelles Lernen und Klassifikation Abgabe online
Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 1 M. Sperber (matthias.sperber@kit.edu) S. Nguyen (thai.nguyen@kit.edu) Übungsblatt 3 Maschinelles Lernen und Klassifikation Abgabe online
Inhaltsverzeichnis 1 Einleitung Mensch-Maschine-Kommunikation in der Informations- und Kommunikationstechnik Grundbegriffe der Mensch-M
 1 Einleitung 1 1.1 Mensch-Maschine-Kommunikation in der Informations- und Kommunikationstechnik... 1 1.2 Grundbegriffe der Mensch-Maschine-Kommunikation... 2 1.3 Disziplinen der Mensch-Maschine-Kommunikation...
1 Einleitung 1 1.1 Mensch-Maschine-Kommunikation in der Informations- und Kommunikationstechnik... 1 1.2 Grundbegriffe der Mensch-Maschine-Kommunikation... 2 1.3 Disziplinen der Mensch-Maschine-Kommunikation...
Mathematische Grundlagen III
 Mathematische Grundlagen III Maschinelles Lernen III: Clustering Vera Demberg Universität des Saarlandes 7. Juli 202 Vera Demberg (UdS) Mathe III 7. Juli 202 / 35 Clustering vs. Klassifikation In den letzten
Mathematische Grundlagen III Maschinelles Lernen III: Clustering Vera Demberg Universität des Saarlandes 7. Juli 202 Vera Demberg (UdS) Mathe III 7. Juli 202 / 35 Clustering vs. Klassifikation In den letzten
Automatische Spracherkennung
 Automatische Spracherkennung 2 Grundlagen: Mustererkennung Soweit vorhanden ist der jeweils englische Fachbegriff, so wie er in der Fachliteratur verwendet wird, in Klammern angegeben. Beispiele von Computerkommandos
Automatische Spracherkennung 2 Grundlagen: Mustererkennung Soweit vorhanden ist der jeweils englische Fachbegriff, so wie er in der Fachliteratur verwendet wird, in Klammern angegeben. Beispiele von Computerkommandos
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Sprachtechnologie. Tobias Scheffer Paul Prasse Michael Großhans
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Sprachtechnologie Tobias Scheffer Paul Prasse Michael Großhans Organisation Vorlesung/Übung, praktische Informatik. 4 SWS. 6 Leistungspunkte
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Sprachtechnologie Tobias Scheffer Paul Prasse Michael Großhans Organisation Vorlesung/Übung, praktische Informatik. 4 SWS. 6 Leistungspunkte
Modell Komplexität und Generalisierung
 Modell Komplexität und Generalisierung Christian Herta November, 2013 1 von 41 Christian Herta Bias-Variance Lernziele Konzepte des maschinellen Lernens Targetfunktion Overtting, Undertting Generalisierung
Modell Komplexität und Generalisierung Christian Herta November, 2013 1 von 41 Christian Herta Bias-Variance Lernziele Konzepte des maschinellen Lernens Targetfunktion Overtting, Undertting Generalisierung
ELEMENTARE EINFÜHRUNG IN DIE MATHEMATISCHE STATISTIK
 DIETER RASCH ELEMENTARE EINFÜHRUNG IN DIE MATHEMATISCHE STATISTIK MIT 53 ABBILDUNGEN UND 111 TABELLEN ZWEITE, BERICHTIGTE UND ERWEITERTE AUFLAGE s-~v VEB DEUTSCHER VERLAG DER WISSENSCHAFTEN BERLIN 1970
DIETER RASCH ELEMENTARE EINFÜHRUNG IN DIE MATHEMATISCHE STATISTIK MIT 53 ABBILDUNGEN UND 111 TABELLEN ZWEITE, BERICHTIGTE UND ERWEITERTE AUFLAGE s-~v VEB DEUTSCHER VERLAG DER WISSENSCHAFTEN BERLIN 1970
Wahrscheinlichkeitsrechnung und Statistik für Biologen Diskriminanzanalyse
 Wahrscheinlichkeitsrechnung und Statistik für Biologen Diskriminanzanalyse Noémie Becker & Dirk Metzler http://evol.bio.lmu.de/_statgen 3. Juli 2013 Übersicht 1 Ruf des Kleinspechts 2 Modell Vorgehen der
Wahrscheinlichkeitsrechnung und Statistik für Biologen Diskriminanzanalyse Noémie Becker & Dirk Metzler http://evol.bio.lmu.de/_statgen 3. Juli 2013 Übersicht 1 Ruf des Kleinspechts 2 Modell Vorgehen der
Stochastik in den Ingenieu rwissenschaften
 ---_..,.'"--.---------- Christine Müller Liesa Denecke Stochastik in den Ingenieu rwissenschaften Eine Einführung mit R ~ Springer Vieweg 1 Fragestellungen........................................... Teil
---_..,.'"--.---------- Christine Müller Liesa Denecke Stochastik in den Ingenieu rwissenschaften Eine Einführung mit R ~ Springer Vieweg 1 Fragestellungen........................................... Teil
Kapitel 2: Spracherkennung Automatisches Verstehen gesprochener Sprache
 Automatisches Verstehen gesprochener Sprache. Spracherkennung Martin Hacker Bernd Ludwig Günther Görz Professur für Künstliche Intelligenz Department Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg
Automatisches Verstehen gesprochener Sprache. Spracherkennung Martin Hacker Bernd Ludwig Günther Görz Professur für Künstliche Intelligenz Department Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg
Elementare Stochastik
 Mathematik Primarstufe und Sekundarstufe I + II Elementare Stochastik Mathematische Grundlagen und didaktische Konzepte Bearbeitet von Herbert Kütting, Martin J. Sauer, Friedhelm Padberg 3. Aufl. 2011.
Mathematik Primarstufe und Sekundarstufe I + II Elementare Stochastik Mathematische Grundlagen und didaktische Konzepte Bearbeitet von Herbert Kütting, Martin J. Sauer, Friedhelm Padberg 3. Aufl. 2011.
Website. Vorlesung Statistisches Lernen. Dozenten. Termine. Einheit 1: Einführung
 Website Vorlesung Statistisches Lernen Einheit 1: Einführung Dr. rer. nat. Christine Pausch Institut für Medizinische Informatik, Statistik und Epidemiologie Universität Leipzig (Aktuelle) Informationen
Website Vorlesung Statistisches Lernen Einheit 1: Einführung Dr. rer. nat. Christine Pausch Institut für Medizinische Informatik, Statistik und Epidemiologie Universität Leipzig (Aktuelle) Informationen
Elementare Begriffe der Wahrscheinlichkeitstheorie für die Sprachverarbeitung
 Elementare Begriffe der Wahrscheinlichkeitstheorie für die Sprachverarbeitung Kursfolien Karin Haenelt 1 Übersicht Wahrscheinlichkeitsfunktion P Wahrscheinlichkeit und bedingte Wahrscheinlichkeit Bayes-Formeln
Elementare Begriffe der Wahrscheinlichkeitstheorie für die Sprachverarbeitung Kursfolien Karin Haenelt 1 Übersicht Wahrscheinlichkeitsfunktion P Wahrscheinlichkeit und bedingte Wahrscheinlichkeit Bayes-Formeln
Inhaltliche Planung für die Vorlesung
 Vorlesung: Künstliche Intelligenz - Mustererkennung - P LS ES S ST ME Künstliche Intelligenz Miao Wang 1 Inhaltliche Planung für die Vorlesung 1) Definition und Geschichte der KI, PROLOG 2) Expertensysteme
Vorlesung: Künstliche Intelligenz - Mustererkennung - P LS ES S ST ME Künstliche Intelligenz Miao Wang 1 Inhaltliche Planung für die Vorlesung 1) Definition und Geschichte der KI, PROLOG 2) Expertensysteme
Vorlesung Statistisches Lernen
 Vorlesung Statistisches Lernen Einheit 1: Einführung Dr. rer. nat. Christine Pausch Institut für Medizinische Informatik, Statistik und Epidemiologie Universität Leipzig WS 2014/2015 1 / 20 Organisatorisches
Vorlesung Statistisches Lernen Einheit 1: Einführung Dr. rer. nat. Christine Pausch Institut für Medizinische Informatik, Statistik und Epidemiologie Universität Leipzig WS 2014/2015 1 / 20 Organisatorisches
Korrektur des Bias Feldes in MR Aufnahmen
 Sebastian Brandt Korrektur des Bias Feldes in MR Aufnahmen Folie 1 Korrektur des Bias Feldes in MR Aufnahmen Seminar Medizinische Bildverarbeitung Sebastian Brandt sbrandt@uni-koblenz.de Universität Koblenz-Landau
Sebastian Brandt Korrektur des Bias Feldes in MR Aufnahmen Folie 1 Korrektur des Bias Feldes in MR Aufnahmen Seminar Medizinische Bildverarbeitung Sebastian Brandt sbrandt@uni-koblenz.de Universität Koblenz-Landau
Crashkurs Mathematik für Ökonomen
 Crashkurs Mathematik für Ökonomen Thomas Zörner in Kooperation mit dem VW-Zentrum Wien, Oktober 2014 1 / 12 Outline Über diesen Kurs Einführung Lineare Algebra Analysis Optimierungen Statistik Hausübung
Crashkurs Mathematik für Ökonomen Thomas Zörner in Kooperation mit dem VW-Zentrum Wien, Oktober 2014 1 / 12 Outline Über diesen Kurs Einführung Lineare Algebra Analysis Optimierungen Statistik Hausübung
Dr. Maike M. Burda. Welchen Einfluss hat die Körperhöhe auf das Körpergewicht? Eine Regressionsanalyse. HU Berlin, Econ Bootcamp 7.-9.
 Dr. Maike M. Burda Welchen Einfluss hat die Körperhöhe auf das Körpergewicht? Eine Regressionsanalyse. HU Berlin, Econ Bootcamp 7.-9. Januar 2011 BOOTDATA11.GDT: 250 Beobachtungen für die Variablen...
Dr. Maike M. Burda Welchen Einfluss hat die Körperhöhe auf das Körpergewicht? Eine Regressionsanalyse. HU Berlin, Econ Bootcamp 7.-9. Januar 2011 BOOTDATA11.GDT: 250 Beobachtungen für die Variablen...
Grundlagen zu neuronalen Netzen. Kristina Tesch
 Grundlagen zu neuronalen Netzen Kristina Tesch 03.05.2018 Gliederung 1. Funktionsprinzip von neuronalen Netzen 2. Das XOR-Beispiel 3. Training des neuronalen Netzes 4. Weitere Aspekte Kristina Tesch Grundlagen
Grundlagen zu neuronalen Netzen Kristina Tesch 03.05.2018 Gliederung 1. Funktionsprinzip von neuronalen Netzen 2. Das XOR-Beispiel 3. Training des neuronalen Netzes 4. Weitere Aspekte Kristina Tesch Grundlagen
Active Hidden Markov Models for Information Extraction
 HMMs in der IE p.1/28 Active Hidden Markov Models for Information Extraction Seminar Informationsextraktion im WiSe 2002/2003 Madeleine Theile HMMs in der IE p.2/28 Inhaltsübersicht Ziel formalere Aufgabenbeschreibung
HMMs in der IE p.1/28 Active Hidden Markov Models for Information Extraction Seminar Informationsextraktion im WiSe 2002/2003 Madeleine Theile HMMs in der IE p.2/28 Inhaltsübersicht Ziel formalere Aufgabenbeschreibung
Algorithmen für Geographische Informationssysteme
 Algorithmen für Geographische Informationssysteme 8. Vorlesung: 10. Dezember 2012 Jan-Henrik Haunert Map Matching Problemformulierung Gegeben: Das Straßennetz als planar eingebetteter Graph G = V, E Die
Algorithmen für Geographische Informationssysteme 8. Vorlesung: 10. Dezember 2012 Jan-Henrik Haunert Map Matching Problemformulierung Gegeben: Das Straßennetz als planar eingebetteter Graph G = V, E Die
Lehrinhalte Statistik (Sozialwissenschaften)
") Lehrinhalte Technische Universität Dresden Institut für Mathematische Stochastik Dresden, 13. November 2007 Seit 2004 Vorlesungen durch Klaus Th. Hess und Hans Otfried Müller. Statistik I: Beschreibende
Lehrinhalte Technische Universität Dresden Institut für Mathematische Stochastik Dresden, 13. November 2007 Seit 2004 Vorlesungen durch Klaus Th. Hess und Hans Otfried Müller. Statistik I: Beschreibende
Statistik II SoSe 2006 immer von 8:00-9:30 Uhr
 Statistik II SoSe 2006 immer von 8:00-9:30 Uhr Was machen wir in der Vorlesung? Testen und Lineares Modell Was machen wir zu Beginn: Wir wiederholen und vertiefen einige Teile aus der Statistik I: Konvergenzarten
Statistik II SoSe 2006 immer von 8:00-9:30 Uhr Was machen wir in der Vorlesung? Testen und Lineares Modell Was machen wir zu Beginn: Wir wiederholen und vertiefen einige Teile aus der Statistik I: Konvergenzarten
Deskriptive Beschreibung linearer Zusammenhänge
 9 Mittelwert- und Varianzvergleiche Mittelwertvergleiche bei k > 2 unabhängigen Stichproben 9.4 Beispiel: p-wert bei Varianzanalyse (Grafik) Bedienungszeiten-Beispiel, realisierte Teststatistik F = 3.89,
9 Mittelwert- und Varianzvergleiche Mittelwertvergleiche bei k > 2 unabhängigen Stichproben 9.4 Beispiel: p-wert bei Varianzanalyse (Grafik) Bedienungszeiten-Beispiel, realisierte Teststatistik F = 3.89,
Statistische Methoden der Datenanalyse
 Statistische Methoden der Datenanalyse Professor Markus Schumacher Freiburg / Sommersemester 2009 Motivation Syllabus Informationen zur Vorlesung Literatur Organisation der Übungen und Scheinkriterium
Statistische Methoden der Datenanalyse Professor Markus Schumacher Freiburg / Sommersemester 2009 Motivation Syllabus Informationen zur Vorlesung Literatur Organisation der Übungen und Scheinkriterium
Projekt-INF Folie 1
 Folie 1 Projekt-INF Entwicklung eines Testbed für den empirischen Vergleich verschiedener Methoden des maschinellen Lernens im Bezug auf die Erlernung von Produktentwicklungswissen Folie 2 Inhalt Ziel
Folie 1 Projekt-INF Entwicklung eines Testbed für den empirischen Vergleich verschiedener Methoden des maschinellen Lernens im Bezug auf die Erlernung von Produktentwicklungswissen Folie 2 Inhalt Ziel
Vorwort Abbildungsverzeichnis Teil I Mathematik 1
 Inhaltsverzeichnis Vorwort Abbildungsverzeichnis V XIII Teil I Mathematik 1 1 Elementare Grundlagen 3 1.1 Grundzüge der Mengenlehre... 3 1.1.1 Darstellungsmöglichkeiten von Mengen... 4 1.1.2 Mengenverknüpfungen...
Inhaltsverzeichnis Vorwort Abbildungsverzeichnis V XIII Teil I Mathematik 1 1 Elementare Grundlagen 3 1.1 Grundzüge der Mengenlehre... 3 1.1.1 Darstellungsmöglichkeiten von Mengen... 4 1.1.2 Mengenverknüpfungen...
Was ist Statistik? CASE Center for Applied Statistics and Econometrics Institut für Statistik and Ökonometrie Humboldt-Universität zu Berlin
 CASE Center for Applied Statistics and Econometrics Institut für Statistik and Ökonometrie Humboldt-Universität zu Berlin http://ise.wiwi.hu-berlin.de http://www.xplore-stat.de http://www.md-stat.com Grundlagen
CASE Center for Applied Statistics and Econometrics Institut für Statistik and Ökonometrie Humboldt-Universität zu Berlin http://ise.wiwi.hu-berlin.de http://www.xplore-stat.de http://www.md-stat.com Grundlagen
Quantitative Methoden der Agrarmarktanalyse und des Agribusiness
 Quantitative Methoden der Agrarmarktanalyse und des Agribusiness Teil Quantitative Methoden der Agrarmarktanalyse Vorlesung: Montag und Mittwoch 8:30-10:00 Dr. Bernhard Brümmer Tel.: 0431-880-4449, Fax:
Quantitative Methoden der Agrarmarktanalyse und des Agribusiness Teil Quantitative Methoden der Agrarmarktanalyse Vorlesung: Montag und Mittwoch 8:30-10:00 Dr. Bernhard Brümmer Tel.: 0431-880-4449, Fax:
McCallum et al Vorgestellte Techniken. Reinforcement Learning Naive Bayes Classification Hidden Markov Models. Viterbi
 Einstieg Building Domain Specific Search Engines with Machine Learning Techniques McCallum et al. 1999 Vorgestellte Techniken Reinforcement Learning Naive Bayes Classification Hidden Markov Models Viterbi
Einstieg Building Domain Specific Search Engines with Machine Learning Techniques McCallum et al. 1999 Vorgestellte Techniken Reinforcement Learning Naive Bayes Classification Hidden Markov Models Viterbi
Informatik II, SS 2014
 Informatik II SS 2014 (Algorithmen & Datenstrukturen) Vorlesung 20 (23.7.2014) All Pairs Shortest Paths, String Matching (Textsuche) Algorithmen und Komplexität Vorlesungsevaluation Sie sollten alle eine
Informatik II SS 2014 (Algorithmen & Datenstrukturen) Vorlesung 20 (23.7.2014) All Pairs Shortest Paths, String Matching (Textsuche) Algorithmen und Komplexität Vorlesungsevaluation Sie sollten alle eine
Prozedurales Programmieren und Problemlösungsstrategien
 Prozedurales Programmieren und Problemlösungsstrategien Bachelorstudiengänge Umwelttechnik und Maschinenbau Prof. Dr. Thomas Hoch Problemlösungsstrategien Prozedurales Programmieren und Problemlösungsstrategien
Prozedurales Programmieren und Problemlösungsstrategien Bachelorstudiengänge Umwelttechnik und Maschinenbau Prof. Dr. Thomas Hoch Problemlösungsstrategien Prozedurales Programmieren und Problemlösungsstrategien
Reranking. Parse Reranking. Helmut Schmid. Institut für maschinelle Sprachverarbeitung Universität Stuttgart
 Institut für maschinelle Sprachverarbeitung Universität Stuttgart schmid@ims.uni-stuttgart.de Die Folien basieren teilweise auf Folien von Mark Johnson. Koordinationen Problem: PCFGs können nicht alle
Institut für maschinelle Sprachverarbeitung Universität Stuttgart schmid@ims.uni-stuttgart.de Die Folien basieren teilweise auf Folien von Mark Johnson. Koordinationen Problem: PCFGs können nicht alle
Kapitel 1. Einleitung
 Kapitel 1 Einleitung Gegenstand dieser Arbeit ist die Anwendung und Evaluierung von statistischen Verfahren für die rechnergestützte Erkennung von Mustern in Bildern und Bildsequenzen. Die verwendeten
Kapitel 1 Einleitung Gegenstand dieser Arbeit ist die Anwendung und Evaluierung von statistischen Verfahren für die rechnergestützte Erkennung von Mustern in Bildern und Bildsequenzen. Die verwendeten