Anwendung von Vektormodell und boolschem Modell in Kombination
|
|
|
- Elke Mann
- vor 6 Jahren
- Abrufe
Transkript
1 Anwendung von Vektormodell und boolschem Modell in Kombination Julia Kreutzer Seminar Information Retrieval Institut für Computerlinguistik Universität Heidelberg

2 Motivation Welche Filme sind empfehlenswert? rry-potter-7-harry-potter-unddie-heiligtümer-des-todes-2 [9.1.15] [9.1.15]
3 Motivation Welche Filme sind empfehlenswert? kollaboratives Filtering: Filmbewertung durch Nutzende inhaltsbasiert: Ähnlichkeiten von Filmen allgemeine Problematik im IR: Definition der Relevanz Lösung: diese Definition den Nutzenden überlassen durch Realisierung einer Kombination von Modellen
4 Überblick 1. Motivation 2. Ziel 3. Umsetzung A. Konzept B. Daten C. Implementierung 4. Demo 5. Weitere Ideen
5 Ziel Implementierung eines Filmempfehlungssystem, das viele Filme kennt ohne Nutzerbewertungen auskommt die Relevanz der Empfehlungen erläutert individuelle Anfragen erlaubt Anfragen effizient bearbeitet
6 Umsetzung: Konzept IR Modell: Analyse Filme F Anfrage A F Analyse Repräsentation Matching & Ranking empfohlene Filme E F \{A}
7 Umsetzung: Konzept Film xy finde ich gut, welche Filme sind ähnlich bezüglich Kriterien a und b? Filme F Anfrage A F Analyse Analyse Repräsentation Matching & Ranking empfohlene Filme E F \{A}
8 Umsetzung: Konzept Datenbasis: Informationen zu Filmen: ID, Titel, Plot, Schauspieler, Input: Anfrage=FilmID, Gewichtung von Ähnlichkeitskriterien, k Output: k ähnlichste Filme aus der Datenbasis bezüglich der Ähnlichkeitskriterien, Details zur Empfehlung
9 Umsetzung: Konzept Matching: gewichtete Kombination von mehreren Ähnlichkeitsscores Kriterium Titel Plot Genre(s) Schauspieler Regisseur(e) Ähnlichkeitsmaß Edit Distance Cosinus semantischer Vektoren Jaccard (Menge) Jaccard (Menge) Jaccard (Menge) Beispiel: w = [1, 5, 3, 9, 0] nw = [1/18, 5/18, 1/6, 1/2, 0] totalsimscore = 1/18*titleSim + 5/18*PlotSim + 1/6*GenreSim + 1/2*CastSim
10 Umsetzung: Daten Filmsammlung: Beschränkung auf Kino- und TV-Filme Informationen zu Filmen: eindeutige ID, User-Ratings, Kritiken, Titel (in verschiedenen Sprachen), Genre, Länge, Regisseur, Drehbuchautor, Schauspieler, Zusammenfassung, Zitate, Produktionsdetails, uvm
11 Umsetzung: Implementierung Vorgehen bei der Implementierung (python): 1. Erstellung der Filmsammlung 2. Interne Repräsentation der Filme 3. Erstellung eines semantischen Vektorraums für Plots 4. Erstellung einer Ähnlichkeitsmatrix, bzw. Index 5. Anfrage- und Empfehlungsroutinen, Demo
12 Umsetzung: Implementierung 1. Erstellung der Filmsammlung imdbpy: Python API für IMDb Zugriff auf IMDb-Daten für Filme und deren Attribute auch: Titelsuche, Abspeichern im XML-Format i = IMDb() id = m = i.get_movie(id)
13 Umsetzung: Implementierung 2. Interne Repräsentation der Filme Film-Daten zu top 250 Filmen (XML): 13,4 MB Filtern ausgewählter Attribute mit xml.dom: FilmID Titel (englisch) Plot und Plot-Zusammenfassung Genre Schauspieler Regisseur Movie- Instanzen pickle dump: 1,2 MB
14 Umsetzung: Implementierung 3. Erstellung eines semantischen Vektorraums für Plots Dimensionen: Titel, Plots (NLTK Stoppwörter gefiltert) Aufbau des Vektormodells: gensim (python library) Dictionary für Dimensionen: Wort ID Repräsentation der Filme als Bag of Words = Korpus LogEntModel für Korpus Index für dieses Modell erzeugen und abspeichern
15 Umsetzung: Implementierung 3. Erstellung eines semantischen Vektorraums für Plots LogEntropy-Gewicht für Term i in Dokument j: localweight i, j =log(frequency i, j +1) P i, j = frequency i, j j frequency i, j globalweight i =1+ j P i, j log(p i, j ) log(numberofdocuments+1) finalweight i, j =localweight i, j globalweight i
16 Umsetzung: Implementierung 3. Erstellung eines semantischen Vektorraums für Plots movies = loadmovies( top250movies.pkl ) d = loaddict( top250movies.dict ) corpus = movies2corpus(movies) corpusbow = corpus2bow(corpus) model = models.logentropymodel(corpusbow) index = similarities.docsim.similarity("index/", model[corpusbow], len(d), len(movies)) movies index.save("logent_top250movies.index") index
17 Umsetzung: Implementierung 4. Erstellung einer Ähnlichkeitsmatrix, bzw. Index Option 1: Ähnlichkeit zur Laufzeit berechnen Option 2: Ähnlichkeitsmatrix zuvor berechnen
18 Umsetzung: Implementierung 4. Erstellung einer Ähnlichkeitsmatrix, bzw. Index Option 2: Ähnlichkeitsmatrix zuvor berechnen 1) für jedes Film-Paar 5 Ähnlichkeiten 5 Matrizen 2) Sparse Matrix: scipy.sparse.coo_matrix 3) gensim.matutils.sparse2corpus MmCorpus 4) Serialisierung des MmCorpus Zugriff in O(1)
19 Demo Demo 1: top250 Filme, Stand Demo 2, Erweiterung: top1000 Filme mit > Bewertungen, Stand
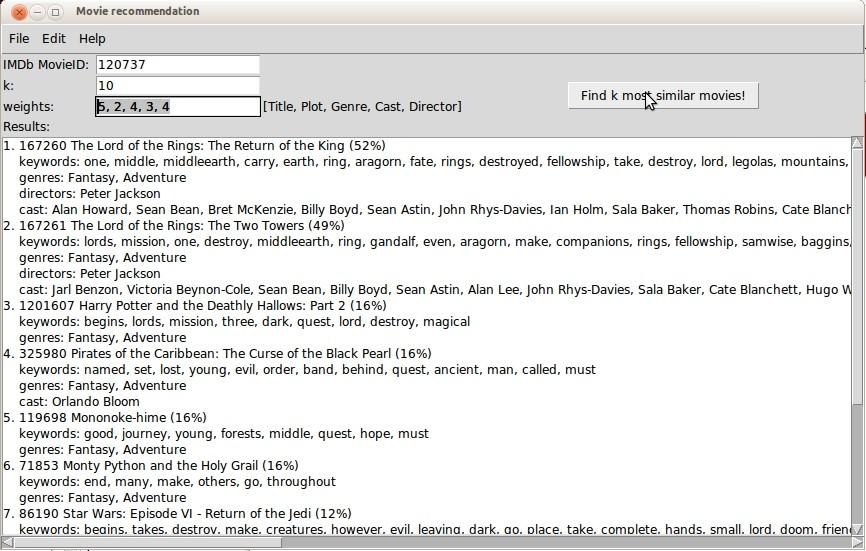
20 Demo 1

21 Demo 2
22 Weitere Ideen Datensatz: vergrößern ad-hoc Online-Abfrage (ohne Ähnlichkeitsmatrix) Funktionalität: Titelsuche einbauen Anfrageoption mit dummy movie verfeinerte Ähnlichkeitsmaße
23 Referenzen Quellen des Bildmaterials für Folie 2: (alle: Stand ) Internet Movie Database Filmlisten: [ ] [9.1.15]
24 Referenzen Karin Haenelt, Information Retrieval. Einführung. Kursfolien gensim: Řehůřek, Radim, and Petr Sojka. "Software framework for topic modelling with large corpora." In Proceedings of the LREC 2010 Workshop on New Challenges for NLP Frameworks, pp 45-50, May NLTK: Bird, Steven, Edward Loper and Ewan Klein (2009), Natural Language Processing with Python. O'Reilly Media Inc. IMDbPY: [ ]
Part-Of-Speech-Tagging mit Viterbi Algorithmus
 Part-Of-Speech-Tagging mit Viterbi Algorithmus HS Endliche Automaten Inna Nickel, Julia Konstantinova 19.07.2010 1 / 21 Gliederung 1 Motivation 2 Theoretische Grundlagen Hidden Markov Model Viterbi Algorithmus
Part-Of-Speech-Tagging mit Viterbi Algorithmus HS Endliche Automaten Inna Nickel, Julia Konstantinova 19.07.2010 1 / 21 Gliederung 1 Motivation 2 Theoretische Grundlagen Hidden Markov Model Viterbi Algorithmus
Personalisierung. Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung. Data Mining.
 Personalisierung Personalisierung Thomas Mandl Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung Klassifikation Die Nutzer werden in vorab bestimmte Klassen/Nutzerprofilen
Personalisierung Personalisierung Thomas Mandl Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung Klassifikation Die Nutzer werden in vorab bestimmte Klassen/Nutzerprofilen
Korpora in NLTK Vortrag im Seminar Computerlinguis6sche Textanalyse WS 2014/15 (B- GSW- 12, M- GSW- 09)
") Korpora in NLTK Vortrag im Seminar Computerlinguis6sche Textanalyse WS 2014/15 (B- GSW- 12, M- GSW- 09) Johannes Hellrich Lehrstuhl für Computerlinguis6k Ins6tut für Germanis6sche SprachwissenschaQ Friedrich-
Korpora in NLTK Vortrag im Seminar Computerlinguis6sche Textanalyse WS 2014/15 (B- GSW- 12, M- GSW- 09) Johannes Hellrich Lehrstuhl für Computerlinguis6k Ins6tut für Germanis6sche SprachwissenschaQ Friedrich-
Textdokument-Suche auf dem Rechner Implementierungsprojekt
 Textdokument-Suche auf dem Rechner Implementierungsprojekt Referent: Oliver Petra Seminar: Information Retrieval Institut für Computerlinguistik Ruprecht-Karls-Universität Heidelberg 19.01.2015 Überblick
Textdokument-Suche auf dem Rechner Implementierungsprojekt Referent: Oliver Petra Seminar: Information Retrieval Institut für Computerlinguistik Ruprecht-Karls-Universität Heidelberg 19.01.2015 Überblick
Welche Textklassifikationen gibt es und was sind ihre spezifischen Merkmale?
 Text Welche Textklassifikationen gibt es und was sind ihre spezifischen Merkmale? Textklassifikationen Natürliche bzw. unstrukturierte Texte Normale Texte ohne besondere Merkmale und Struktur Semistrukturierte
Text Welche Textklassifikationen gibt es und was sind ihre spezifischen Merkmale? Textklassifikationen Natürliche bzw. unstrukturierte Texte Normale Texte ohne besondere Merkmale und Struktur Semistrukturierte
Web Information Retrieval. Zwischendiskussion. Überblick. Meta-Suchmaschinen und Fusion (auch Rank Aggregation) Fusion
 Fusion") Web Information Retrieval Hauptseminar Sommersemester 2003 Thomas Mandl Überblick Mehrsprachigkeit Multimedialität Heterogenität Qualität, semantisch, technisch Struktur Links HTML Struktur Technologische
Web Information Retrieval Hauptseminar Sommersemester 2003 Thomas Mandl Überblick Mehrsprachigkeit Multimedialität Heterogenität Qualität, semantisch, technisch Struktur Links HTML Struktur Technologische
INEX. INitiative for the Evaluation of XML Retrieval. Sebastian Rassmann, Christian Michele
 INEX INitiative for the Evaluation of XML Retrieval Was ist INEX? 2002 gestartete Evaluierungsinitiative Evaluierung von Retrievalmethoden für XML Dokumente Berücksichtigt die hierarchische Dokumentstruktur
INEX INitiative for the Evaluation of XML Retrieval Was ist INEX? 2002 gestartete Evaluierungsinitiative Evaluierung von Retrievalmethoden für XML Dokumente Berücksichtigt die hierarchische Dokumentstruktur
Suchmaschinen. Anwendung RN Semester 7. Christian Koczur
 Suchmaschinen Anwendung RN Semester 7 Christian Koczur Inhaltsverzeichnis 1. Historischer Hintergrund 2. Information Retrieval 3. Architektur einer Suchmaschine 4. Ranking von Webseiten 5. Quellenangabe
Suchmaschinen Anwendung RN Semester 7 Christian Koczur Inhaltsverzeichnis 1. Historischer Hintergrund 2. Information Retrieval 3. Architektur einer Suchmaschine 4. Ranking von Webseiten 5. Quellenangabe
Vorlesung Information Retrieval Wintersemester 04/05
 Vorlesung Information Retrieval Wintersemester 04/05 14. Oktober 2004 Institut für Informatik III Universität Bonn Tel. 02 28 / 73-45 31 Fax 02 28 / 73-43 82 jw@informatik.uni-bonn.de 1 Themenübersicht
Vorlesung Information Retrieval Wintersemester 04/05 14. Oktober 2004 Institut für Informatik III Universität Bonn Tel. 02 28 / 73-45 31 Fax 02 28 / 73-43 82 jw@informatik.uni-bonn.de 1 Themenübersicht
GDI-Forum Nordrhein-Westfalen Technischer Workshop 2 - Geodienste - 2.3 INSPIRE-konforme Download-Dienste. Inhalt
 GDI-Forum Nordrhein-Westfalen Technischer Workshop 2 - Geodienste - 2.3 INSPIRE-konforme Download-Dienste Inhalt Inspire Downloaddienste -Grundlagen- Varianten Direkter Zugriff via WFS Vordefinierte Datensätze
GDI-Forum Nordrhein-Westfalen Technischer Workshop 2 - Geodienste - 2.3 INSPIRE-konforme Download-Dienste Inhalt Inspire Downloaddienste -Grundlagen- Varianten Direkter Zugriff via WFS Vordefinierte Datensätze
GATE General Architecture for Text Engineering. Alexander Hein & Erik Dießler (VL Text Analytics - 08.05.2008)
") GATE General Architecture for Text Engineering Alexander Hein & Erik Dießler (VL Text Analytics - 08.05.2008) Überblick GATE Die Idee Die Architektur Was noch - JAPE / DIFF / GUK ANNIE Einige Beispiele
GATE General Architecture for Text Engineering Alexander Hein & Erik Dießler (VL Text Analytics - 08.05.2008) Überblick GATE Die Idee Die Architektur Was noch - JAPE / DIFF / GUK ANNIE Einige Beispiele
Clustering mit dem K-Means-Algorithmus (Ein Experiment)
") Clustering mit dem K-Means- (Ein Experiment) Andreas Runk 7. März 2013 Index 1 2 3 4 5 Andreas Runk Clustering mit dem K-Means- 2/40 Ziele: des K-Means Finde/erstelle geeignetes Testcorpus möglichst gute
Clustering mit dem K-Means- (Ein Experiment) Andreas Runk 7. März 2013 Index 1 2 3 4 5 Andreas Runk Clustering mit dem K-Means- 2/40 Ziele: des K-Means Finde/erstelle geeignetes Testcorpus möglichst gute
Recommender Systems. Stefan Beckers Praxisprojekt ASDL SS 2006 Universität Duisburg-Essen April 2006
 Recommender Systems Stefan Beckers Praxisprojekt ASDL SS 2006 Universität Duisburg-Essen April 2006 Inhalt 1 - Einführung 2 Arten von Recommender-Systemen 3 Beispiele für RCs 4 - Recommender-Systeme und
Recommender Systems Stefan Beckers Praxisprojekt ASDL SS 2006 Universität Duisburg-Essen April 2006 Inhalt 1 - Einführung 2 Arten von Recommender-Systemen 3 Beispiele für RCs 4 - Recommender-Systeme und
Seminar Datenbanksysteme
 Seminar Datenbanksysteme Recommender System mit Text Analysis für verbesserte Geo Discovery Eine Präsentation von Fabian Senn Inhaltsverzeichnis Geodaten Geometadaten Geo Discovery Recommendation System
Seminar Datenbanksysteme Recommender System mit Text Analysis für verbesserte Geo Discovery Eine Präsentation von Fabian Senn Inhaltsverzeichnis Geodaten Geometadaten Geo Discovery Recommendation System
Übung Medienretrieval WS 07/08 Thomas Wilhelm, Medieninformatik, TU Chemnitz
 02_Grundlagen Lucene Übung Medienretrieval WS 07/08 Thomas Wilhelm, Medieninformatik, TU Chemnitz Was ist Lucene? (1) Apache Lucene is a high-performance, full-featured text search engine library written
02_Grundlagen Lucene Übung Medienretrieval WS 07/08 Thomas Wilhelm, Medieninformatik, TU Chemnitz Was ist Lucene? (1) Apache Lucene is a high-performance, full-featured text search engine library written
Full Text Search in Databases
 Full Text Search in Databases Verfasser: Stefan Kainrath (0651066) h0651066@wu-wien.ac.at 0664/1327136 Betreuer: Dipl.-Ing. Mag. Dr. Albert Weichselbraun Inhaltsverzeichnis 1 Motivation... 3 2 Anforderungen...
Full Text Search in Databases Verfasser: Stefan Kainrath (0651066) h0651066@wu-wien.ac.at 0664/1327136 Betreuer: Dipl.-Ing. Mag. Dr. Albert Weichselbraun Inhaltsverzeichnis 1 Motivation... 3 2 Anforderungen...
Vorlesung Suchmaschinen Semesterklausur Wintersemester 2013/14
 Universität Augsburg, Institut für Informatik Wintersemester 2013/14 Prof. Dr. W. Kießling 10. Oktober 2013 F. Wenzel, D. Köppl Suchmaschinen Vorlesung Suchmaschinen Semesterklausur Wintersemester 2013/14
Universität Augsburg, Institut für Informatik Wintersemester 2013/14 Prof. Dr. W. Kießling 10. Oktober 2013 F. Wenzel, D. Köppl Suchmaschinen Vorlesung Suchmaschinen Semesterklausur Wintersemester 2013/14
Integration, Migration und Evolution
 14. Mai 2013 Programm für heute 1 2 Quelle Das Material zu diesem Kapitel stammt aus der Vorlesung Datenintegration & Datenherkunft der Universität Tübingen gehalten von Melanie Herschel im WS 2010/11.
14. Mai 2013 Programm für heute 1 2 Quelle Das Material zu diesem Kapitel stammt aus der Vorlesung Datenintegration & Datenherkunft der Universität Tübingen gehalten von Melanie Herschel im WS 2010/11.
XML und seine Anwendungsmöglichkeiten bei der Archivierung im Gesundheitswesen
 Institut für Terminologie und angewandte Wissensforschung XML und seine Anwendungsmöglichkeiten bei der Archivierung im Gesundheitswesen Johannes Palme (itaw), Lukas Faulstich (ID) Karlsruher Archivtage
Institut für Terminologie und angewandte Wissensforschung XML und seine Anwendungsmöglichkeiten bei der Archivierung im Gesundheitswesen Johannes Palme (itaw), Lukas Faulstich (ID) Karlsruher Archivtage
Web Data Mining. Albert Weichselbraun
 Web Data Mining Albert Weichselbraun Vienna University of Economics and Business Department of Information Systems and Operations Augasse 2-6, 1090 Vienna albert.weichselbraun@wu.ac.at May 2011 Agenda
Web Data Mining Albert Weichselbraun Vienna University of Economics and Business Department of Information Systems and Operations Augasse 2-6, 1090 Vienna albert.weichselbraun@wu.ac.at May 2011 Agenda
Tagging von Online-Blogs
 Tagging von Online-Blogs Gertrud Faaß (vertreten durch Josef Ruppenhofer) STTS tagset and tagging: special corpora 24. September 2012 Faaß MODEBLOGS 1 Korpuslinguistische studentische Projekte am IwiSt
Tagging von Online-Blogs Gertrud Faaß (vertreten durch Josef Ruppenhofer) STTS tagset and tagging: special corpora 24. September 2012 Faaß MODEBLOGS 1 Korpuslinguistische studentische Projekte am IwiSt
Sentiment Analysis (SA) Robert Bärhold & Mario Sänger Text Analytics WS 2012/13 Prof. Leser
 Robert Bärhold & Mario Sänger Text Analytics WS 2012/13 Prof. Leser") Sentiment Analysis (SA) Robert Bärhold & Mario Sänger Text Analytics WS 2012/13 Prof. Leser Gliederung Einleitung Problemstellungen Ansätze & Herangehensweisen Anwendungsbeispiele Zusammenfassung 2 Gliederung
Sentiment Analysis (SA) Robert Bärhold & Mario Sänger Text Analytics WS 2012/13 Prof. Leser Gliederung Einleitung Problemstellungen Ansätze & Herangehensweisen Anwendungsbeispiele Zusammenfassung 2 Gliederung
Seminar Text- und Datamining Textmining-Grundlagen Erste Schritte mit NLTK
 Seminar Text- und Datamining Textmining-Grundlagen Erste Schritte mit NLTK Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 16.05.2013 Gliederung 1 Vorverarbeitung
Seminar Text- und Datamining Textmining-Grundlagen Erste Schritte mit NLTK Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 16.05.2013 Gliederung 1 Vorverarbeitung
Ähnlichkeitssuche auf XML-Daten
 Ähnlichkeitssuche auf XML-Daten Christine Lehmacher Gabriele Schlipköther Übersicht Information Retrieval Vektorraummodell Gewichtung Ähnlichkeitsfunktionen Ähnlichkeitssuche Definition, Anforderungen
Ähnlichkeitssuche auf XML-Daten Christine Lehmacher Gabriele Schlipköther Übersicht Information Retrieval Vektorraummodell Gewichtung Ähnlichkeitsfunktionen Ähnlichkeitssuche Definition, Anforderungen
Text Mining mit LingPipe
 Text Mining mit LingPipe Hauptseminar Information Retrieval PD Dr. Karin Haenelt Universität Heidelberg Vortrag von Alexander Kappe im Wintersemester 2008/2009 Übersicht Text Mining Definition & Abgrenzung
Text Mining mit LingPipe Hauptseminar Information Retrieval PD Dr. Karin Haenelt Universität Heidelberg Vortrag von Alexander Kappe im Wintersemester 2008/2009 Übersicht Text Mining Definition & Abgrenzung
Datenmanagement und einfache Automatisierungen in Ingenieursanwendungen mit dem DataFinder Eike Hoffmann 5. April 2006 Frankfurt a.m.
 Datenmanagement und einfache Automatisierungen in Ingenieursanwendungen mit dem DataFinder Eike Hoffmann 5. April 2006 Frankfurt a.m. Folie 1 > DataFinder Organize your data > Eike Hoffmann Datenmanagement
Datenmanagement und einfache Automatisierungen in Ingenieursanwendungen mit dem DataFinder Eike Hoffmann 5. April 2006 Frankfurt a.m. Folie 1 > DataFinder Organize your data > Eike Hoffmann Datenmanagement
Wissensrepräsentation
 Wissensrepräsentation Vorlesung Sommersemester 2008 9. Sitzung Dozent Nino Simunic M.A. Computerlinguistik, Campus DU Statistische Verfahren der KI (II) Klassifizieren von Dokumenten Informationsbeschaffung
Wissensrepräsentation Vorlesung Sommersemester 2008 9. Sitzung Dozent Nino Simunic M.A. Computerlinguistik, Campus DU Statistische Verfahren der KI (II) Klassifizieren von Dokumenten Informationsbeschaffung
Web Scraping. Seminar Aktuelle Software-Engineering Praktiken für das World Wide Web JK 19.05.2010
 Web Scraping Seminar Aktuelle Software-Engineering Praktiken für das World Wide Web JK 19.05.2010 Inhalt Einführung Motivation Dokumente herunterladen Scraping Document Object Model Regular Expressions
Web Scraping Seminar Aktuelle Software-Engineering Praktiken für das World Wide Web JK 19.05.2010 Inhalt Einführung Motivation Dokumente herunterladen Scraping Document Object Model Regular Expressions
Einführung in die Java- Programmierung
 Einführung in die Java- Programmierung Dr. Volker Riediger Tassilo Horn riediger horn@uni-koblenz.de WiSe 2012/13 1 Wichtig... Mittags Pommes... Praktikum A 230 C 207 (Madeleine) F 112 F 113 (Kevin) E
Einführung in die Java- Programmierung Dr. Volker Riediger Tassilo Horn riediger horn@uni-koblenz.de WiSe 2012/13 1 Wichtig... Mittags Pommes... Praktikum A 230 C 207 (Madeleine) F 112 F 113 (Kevin) E
SCHNITTSTELLEN ZUR NUTZUNG DER KORPUSANALYSEPLATTFORM KORAP
 Marc Kupietz und Nils Diewald SCHNITTSTELLEN ZUR NUTZUNG DER KORPUSANALYSEPLATTFORM KORAP KobRA-Abschlusstagung, 30.10.2015 ÜBERBLICK 1. 2. 3. 4. 5. IDS im KobRA-Projekt KorAP Schnittstellen Protokoll
Marc Kupietz und Nils Diewald SCHNITTSTELLEN ZUR NUTZUNG DER KORPUSANALYSEPLATTFORM KORAP KobRA-Abschlusstagung, 30.10.2015 ÜBERBLICK 1. 2. 3. 4. 5. IDS im KobRA-Projekt KorAP Schnittstellen Protokoll
Datenbank- Recherche. SS 2015 8. Veranstaltung 18. Juni 2015. Philipp Schaer - philipp.schaer@gesis.org Philipp Mayr - philipp.mayr@gesis.
 Datenbank- Recherche SS 2015 8. Veranstaltung 18. Juni 2015 Philipp Schaer - philipp.schaer@gesis.org Philipp Mayr - philipp.mayr@gesis.org GESIS Leibniz- InsFtut für SozialwissenschaJen 2 Themen der heu2gen
Datenbank- Recherche SS 2015 8. Veranstaltung 18. Juni 2015 Philipp Schaer - philipp.schaer@gesis.org Philipp Mayr - philipp.mayr@gesis.org GESIS Leibniz- InsFtut für SozialwissenschaJen 2 Themen der heu2gen
Ruhr.pm XML-Daten verarbeiten mit XML::LibXML Autor: EMail: Datum: http://ruhr.pm.org/
 XML-Daten verarbeiten mit XML::LibXML Autor: EMail: Datum: Simon Wilper simon AT ruhr.pm.org http://ruhr.pm.org/ Template Version 0.1 The use of a camel image in association with Perl is a trademark of
XML-Daten verarbeiten mit XML::LibXML Autor: EMail: Datum: Simon Wilper simon AT ruhr.pm.org http://ruhr.pm.org/ Template Version 0.1 The use of a camel image in association with Perl is a trademark of
neofonie DER SPEZIALIST FÜR IHRE INFORMATIONSARCHITEKTUR
 neofonie DER SPEZIALIST FÜR IHRE INFORMATIONSARCHITEKTUR Suchportale der nächsten Generation Dr. Thomas Schwotzer Leiter Forschung, neofonie Suche eine Folien Geschichte 1993: Beginn der HTML-Ära 1993
neofonie DER SPEZIALIST FÜR IHRE INFORMATIONSARCHITEKTUR Suchportale der nächsten Generation Dr. Thomas Schwotzer Leiter Forschung, neofonie Suche eine Folien Geschichte 1993: Beginn der HTML-Ära 1993
design kommunikation development
 http://www.dkd.de dkd design kommunikation development Apache Solr - A deeper look Stefan Sprenger, Developer dkd Olivier Dobberkau, Geschäftsführer dkd Agenda Einführung Boosting Empfehlungen Ausblick
http://www.dkd.de dkd design kommunikation development Apache Solr - A deeper look Stefan Sprenger, Developer dkd Olivier Dobberkau, Geschäftsführer dkd Agenda Einführung Boosting Empfehlungen Ausblick
Web Service Discovery mit dem Gnutella Peer-to-Peer Netzwerk
 Seminar E-Services WS 02/03 Web Service Discovery mit dem Gnutella Peer-to-Peer Netzwerk WS 02/03 Web Service Discovery mit dem Gnutella Peer-to-Peer Netzwerk Inhalt Einführung Discovery Problematik Standard
Seminar E-Services WS 02/03 Web Service Discovery mit dem Gnutella Peer-to-Peer Netzwerk WS 02/03 Web Service Discovery mit dem Gnutella Peer-to-Peer Netzwerk Inhalt Einführung Discovery Problematik Standard
VisVerdi goes VSIM. VisVerdi Import/Export und VisVerdi light
 VisVerdi goes VSIM VisVerdi Import/Export und VisVerdi light Was ist VSIM? Vehicle Safety Information Model Digital Image Library Image Analysis Film Analysis Dummy Sensor Test Information System Vehicle
VisVerdi goes VSIM VisVerdi Import/Export und VisVerdi light Was ist VSIM? Vehicle Safety Information Model Digital Image Library Image Analysis Film Analysis Dummy Sensor Test Information System Vehicle
MCP Managing Conference Proceedings
 Projekt Workshop zur Global Info SFM WEP, 19-20. Juli 2000, Braunschweig MCP Managing Conference Proceedings Paper Submission und Review bei der EUROGRAPHICS 2000 Resultate und Ausblick bmb+f Global Info
Projekt Workshop zur Global Info SFM WEP, 19-20. Juli 2000, Braunschweig MCP Managing Conference Proceedings Paper Submission und Review bei der EUROGRAPHICS 2000 Resultate und Ausblick bmb+f Global Info
5. Suchmaschinen Herausforderungen beim Web Information Retrieval. Herausforderungen beim Web Information Retrieval. Architektur von Suchmaschinen
 5. Suchmaschinen Herausforderungen beim Web Information Retrieval 5. Suchmaschinen 5. Suchmaschinen Herausforderungen beim Web Information Retrieval Verweisstrukturen haben eine wichtige Bedeutung Spamming
5. Suchmaschinen Herausforderungen beim Web Information Retrieval 5. Suchmaschinen 5. Suchmaschinen Herausforderungen beim Web Information Retrieval Verweisstrukturen haben eine wichtige Bedeutung Spamming
XML-Frameworks in verschiedenen Programmiersprachen Proseminar Textkodierung und Auszeichnung
 XML-Frameworks in verschiedenen Programmiersprachen Proseminar Textkodierung und Auszeichnung Matthias Bethke bethke@linguistik.uni-erlangen.de Linguistische Informatik Universität Erlangen-Nürnberg Sommersemester
XML-Frameworks in verschiedenen Programmiersprachen Proseminar Textkodierung und Auszeichnung Matthias Bethke bethke@linguistik.uni-erlangen.de Linguistische Informatik Universität Erlangen-Nürnberg Sommersemester
SharePoint 2013 als Wissensplattform
 SharePoint 2013 als Wissensplattform Daniel Dobrich & Darius Kaczmarczyk 29.11.2012 7. SharePoint UserGroup Hamburg Treffen 1 Themen Verwaltete Metadaten in SharePoint 2013 Was sind verwaltete Metadaten
SharePoint 2013 als Wissensplattform Daniel Dobrich & Darius Kaczmarczyk 29.11.2012 7. SharePoint UserGroup Hamburg Treffen 1 Themen Verwaltete Metadaten in SharePoint 2013 Was sind verwaltete Metadaten
Semantik Visualisierung
 Semantik Visualisierung Seminar im Wintersemester 2010/2011 GRIS Technische Universität Darmstadt Kawa Nazemi Fraunhofer IGD Fraunhoferstraße 5 64283 Darmstadt kawa.nazemi@igd.fraunhofer.de kawa.nazemi@gris.informatik@tu-darmstadt.de
Semantik Visualisierung Seminar im Wintersemester 2010/2011 GRIS Technische Universität Darmstadt Kawa Nazemi Fraunhofer IGD Fraunhoferstraße 5 64283 Darmstadt kawa.nazemi@igd.fraunhofer.de kawa.nazemi@gris.informatik@tu-darmstadt.de
Benutzermodelle, Information Retrieval und Visualisierung
 Benutzermodelle, Information Retrieval und Visualisierung Swantje Willms University of Pittsburgh, Pennsylvania, USA swillms@mail.sis.pitt.edu Abstract: Wir stellen eine zweischichtige Visualisierung vor,
Benutzermodelle, Information Retrieval und Visualisierung Swantje Willms University of Pittsburgh, Pennsylvania, USA swillms@mail.sis.pitt.edu Abstract: Wir stellen eine zweischichtige Visualisierung vor,
Vorlesung Information Retrieval Wintersemester 04/05
 Vorlesung Information Retrieval Wintersemester 04/05 20. Januar 2005 Institut für Informatik III Universität Bonn Tel. 02 28 / 73-45 31 Fax 02 28 / 73-43 82 jw@informatik.uni-bonn.de 0 Themenübersicht
Vorlesung Information Retrieval Wintersemester 04/05 20. Januar 2005 Institut für Informatik III Universität Bonn Tel. 02 28 / 73-45 31 Fax 02 28 / 73-43 82 jw@informatik.uni-bonn.de 0 Themenübersicht
Lernende Suchmaschinen
 Lernende Suchmaschinen Qingchui Zhu PG 520 - Intelligence Service (WiSe 07 / SoSe 08) Verzeichnis 1 Einleitung Problemstellung und Zielsetzung 2 Was ist eine lernende Suchmaschine? Begriffsdefinition 3
Lernende Suchmaschinen Qingchui Zhu PG 520 - Intelligence Service (WiSe 07 / SoSe 08) Verzeichnis 1 Einleitung Problemstellung und Zielsetzung 2 Was ist eine lernende Suchmaschine? Begriffsdefinition 3
Die treffende Auswahl anbieten: Im Internet (Referat 3a)
") www.zeix.com Die treffende Auswahl anbieten: Im Internet (Referat 3a) Fachtagung: Suchfunktionen im Web Zürich, 26. Oktober 2006 Jürg Stuker, namics Gregor Urech, Zeix Bern, Frankfurt, Hamburg, München,
www.zeix.com Die treffende Auswahl anbieten: Im Internet (Referat 3a) Fachtagung: Suchfunktionen im Web Zürich, 26. Oktober 2006 Jürg Stuker, namics Gregor Urech, Zeix Bern, Frankfurt, Hamburg, München,
Endliche Automaten zur Erkennung von Stoppwörtern
 Endliche Automaten zur Erkennung von Stoppwörtern Vortrag von Christian Schwarz & Andreas Beyer im Seminar FSM zur Spracherkennung 06.07.2009 DFA zur Spracherkennung 2009 - Uni Heidelberg - Vortrag Stoppwörter
Endliche Automaten zur Erkennung von Stoppwörtern Vortrag von Christian Schwarz & Andreas Beyer im Seminar FSM zur Spracherkennung 06.07.2009 DFA zur Spracherkennung 2009 - Uni Heidelberg - Vortrag Stoppwörter
Configuration Management mit Verbosy 17.04.2013 OSDC 2013. Eric Lippmann www.netways.de
 Configuration Management mit Verbosy 17.04.2013 OSDC 2013 Eric Lippmann Kurzvorstellung NETWAYS Expertise OPEN SOURCE SYSTEMS MANAGEMENT OPEN SOURCE DATA CENTER Monitoring & Reporting Configuration Management
Configuration Management mit Verbosy 17.04.2013 OSDC 2013 Eric Lippmann Kurzvorstellung NETWAYS Expertise OPEN SOURCE SYSTEMS MANAGEMENT OPEN SOURCE DATA CENTER Monitoring & Reporting Configuration Management
Dr. Thomas Meinike Hochschule Merseburg
 XSLT Programmierung effektiv und schmerzfrei! Dr. Thomas Meinike Hochschule Merseburg thomas.meinike@hs merseburg.de http://www.iks.hs merseburg.de/~meinike/ @XMLArbyter Zusatzmaterial Februar
XSLT Programmierung effektiv und schmerzfrei! Dr. Thomas Meinike Hochschule Merseburg thomas.meinike@hs merseburg.de http://www.iks.hs merseburg.de/~meinike/ @XMLArbyter Zusatzmaterial Februar
Modellierung von Geodaten
 Modellierung von Geodaten Universität Augsburg Fachbereich Informatik Seminar: Datenbankunterstützung für mobile GIS Sommersemester 2011 Zeev Turevsky Betreuer: Dipl.-Informatiker Florian Wenzel Gliederung
Modellierung von Geodaten Universität Augsburg Fachbereich Informatik Seminar: Datenbankunterstützung für mobile GIS Sommersemester 2011 Zeev Turevsky Betreuer: Dipl.-Informatiker Florian Wenzel Gliederung
HEALTH Institut für Biomedizin und Gesundheitswissenschaften
 HEALTH Institut für Biomedizin und Gesundheitswissenschaften Konzept zur Verbesserung eines klinischen Information Retrieval Systems unter Verwendung von Apache UIMA und medizinischen Ontologien Georg
HEALTH Institut für Biomedizin und Gesundheitswissenschaften Konzept zur Verbesserung eines klinischen Information Retrieval Systems unter Verwendung von Apache UIMA und medizinischen Ontologien Georg
Wie Google Webseiten bewertet. François Bry
 Wie Google Webseiten bewertet François Bry Heu6ge Vorlesung 1. Einleitung 2. Graphen und Matrizen 3. Erste Idee: Ranking als Eigenvektor 4. Fragen: Exisi6ert der Eigenvektor? Usw. 5. Zweite Idee: Die Google
Wie Google Webseiten bewertet François Bry Heu6ge Vorlesung 1. Einleitung 2. Graphen und Matrizen 3. Erste Idee: Ranking als Eigenvektor 4. Fragen: Exisi6ert der Eigenvektor? Usw. 5. Zweite Idee: Die Google
Bioinformatik I (Einführung)
") Kay Diederichs, Sommersemester 2015 Bioinformatik I (Einführung) Algorithmen Sequenzen Strukturen PDFs unter http://strucbio.biologie.unikonstanz.de/~dikay/bioinformatik/ Klausur: Fr 17.7. 10:00-11:00
Kay Diederichs, Sommersemester 2015 Bioinformatik I (Einführung) Algorithmen Sequenzen Strukturen PDFs unter http://strucbio.biologie.unikonstanz.de/~dikay/bioinformatik/ Klausur: Fr 17.7. 10:00-11:00
Semantische Suche auf einem Web-Korpus
 Semantische Suche auf einem Web-Korpus Philipp Bausch April 25, 2014 Philipp Bausch () Semantische Suche auf einem Web-Korpus April 25, 2014 1 / 18 Übersicht 1 Einleitung 2 Die Daten 3 Verarbeitung 4 Fazit
Semantische Suche auf einem Web-Korpus Philipp Bausch April 25, 2014 Philipp Bausch () Semantische Suche auf einem Web-Korpus April 25, 2014 1 / 18 Übersicht 1 Einleitung 2 Die Daten 3 Verarbeitung 4 Fazit
5. Vorlesung. Das Ranking Problem PageRank HITS (Hubs & Authorities) Markov Ketten und Random Walks PageRank und HITS Berechnung
 Markov Ketten und Random Walks PageRank und HITS Berechnung") 5. Vorlesung Das Ranking Problem PageRank HITS (Hubs & Authorities) Markov Ketten und Random Walks PageRank und HITS Berechnung Seite 120 The Ranking Problem Eingabe: D: Dokumentkollektion Q: Anfrageraum
5. Vorlesung Das Ranking Problem PageRank HITS (Hubs & Authorities) Markov Ketten und Random Walks PageRank und HITS Berechnung Seite 120 The Ranking Problem Eingabe: D: Dokumentkollektion Q: Anfrageraum
Objektorientierte Datenmodelle und - verwaltung
 Schlagworte der 90er: Objektorientiertes GIS OpenGIS Case-Tool Geoökologe Legt Problemstellung fest (Art, Anzahl, Dimension, Skalierung) Wählt Koordinatensystem Wählt Fachattribute OOUI (object-oriented
Schlagworte der 90er: Objektorientiertes GIS OpenGIS Case-Tool Geoökologe Legt Problemstellung fest (Art, Anzahl, Dimension, Skalierung) Wählt Koordinatensystem Wählt Fachattribute OOUI (object-oriented
Semantische Bildsuche mittels kollaborativer Filterung und visueller Navigation
 Semantische Bildsuche mittels kollaborativer Filterung und visueller Navigation Prof. Dr. Kai Uwe Barthel HTW Berlin / pixolution GmbH Übersicht Probleme der gegenwärtigen Bildsuchsysteme Schlagwortbasierte
Semantische Bildsuche mittels kollaborativer Filterung und visueller Navigation Prof. Dr. Kai Uwe Barthel HTW Berlin / pixolution GmbH Übersicht Probleme der gegenwärtigen Bildsuchsysteme Schlagwortbasierte
Seminar. NoSQL Datenbank Technologien. Michaela Rindt - Christopher Pietsch. Richtlinien Ausarbeitung (15. November 2015)
") Seminar Datenbank Technologien Richtlinien Ausarbeitung (15. November 2015) Michaela Rindt - Christopher Pietsch Agenda 1 2 3 1 / 12 Richtlinien Ausarbeitung (15. November 2015) Teil 1 2 / 12 Richtlinien
Seminar Datenbank Technologien Richtlinien Ausarbeitung (15. November 2015) Michaela Rindt - Christopher Pietsch Agenda 1 2 3 1 / 12 Richtlinien Ausarbeitung (15. November 2015) Teil 1 2 / 12 Richtlinien
Expose zur Studienarbeit Indizierung von XML-Daten mittels GRIPP
 Expose zur Studienarbeit Indizierung von XML-Daten mittels GRIPP Betreuer: Silke Trissl Autor: email: Florian Zipser zipser@informatik.hu-berlin.de 1 1 Motivation Auf dem Gebiet der relationalen Datenbanken
Expose zur Studienarbeit Indizierung von XML-Daten mittels GRIPP Betreuer: Silke Trissl Autor: email: Florian Zipser zipser@informatik.hu-berlin.de 1 1 Motivation Auf dem Gebiet der relationalen Datenbanken
SINT Rest App Documentation
 SINT Rest App Documentation Release 1.0 Florian Sachs September 04, 2015 Contents 1 Applikation 3 2 Rest Service 5 3 SOAP Service 7 4 Technologiestack 9 5 Deployment 11 6 Aufgabe 1: Google Webservice
SINT Rest App Documentation Release 1.0 Florian Sachs September 04, 2015 Contents 1 Applikation 3 2 Rest Service 5 3 SOAP Service 7 4 Technologiestack 9 5 Deployment 11 6 Aufgabe 1: Google Webservice
Tag 9: Datenstrukturen
 Tag 9: Datenstrukturen A) Datenstrukturen B) Cell Arrays C) Anwendungsbeispiel: Stimulation in einem psychophysikalischen Experiment A) Datenstrukturen Wenn man komplizierte Datenmengen verwalten möchte,
Tag 9: Datenstrukturen A) Datenstrukturen B) Cell Arrays C) Anwendungsbeispiel: Stimulation in einem psychophysikalischen Experiment A) Datenstrukturen Wenn man komplizierte Datenmengen verwalten möchte,
SemTalk Services. SemTalk UserMeeting 29.10.2010
 SemTalk Services SemTalk UserMeeting 29.10.2010 Problemstellung Immer mehr Anwender nutzen SemTalk in Verbindung mit SharePoint Mehr Visio Dokumente Viele Dokumente mit jeweils wenigen Seiten, aber starker
SemTalk Services SemTalk UserMeeting 29.10.2010 Problemstellung Immer mehr Anwender nutzen SemTalk in Verbindung mit SharePoint Mehr Visio Dokumente Viele Dokumente mit jeweils wenigen Seiten, aber starker
Online-Recherche: Web-Recherche WS 2015/2016 7. Veranstaltung 3. Dezember 2015
 Online-Recherche: Web-Recherche WS 2015/2016 7. Veranstaltung 3. Dezember 2015 Philipp Schaer - philipp.schaer@gesis.org Philipp Mayr - philipp.mayr@gesis.org GESIS Leibniz-InsJtut für SozialwissenschaNen
Online-Recherche: Web-Recherche WS 2015/2016 7. Veranstaltung 3. Dezember 2015 Philipp Schaer - philipp.schaer@gesis.org Philipp Mayr - philipp.mayr@gesis.org GESIS Leibniz-InsJtut für SozialwissenschaNen
Methodik zur Qualitätsbeurteilung von IT Managementprozessen auf Basis von ITIL
 Methodik zur Qualitätsbeurteilung von IT Managementprozessen auf Basis von ITIL Michael Brenner Institut für Informatik, Ludwig Maximilians Universität München Motivation Fragestellung: Bestimmung der
Methodik zur Qualitätsbeurteilung von IT Managementprozessen auf Basis von ITIL Michael Brenner Institut für Informatik, Ludwig Maximilians Universität München Motivation Fragestellung: Bestimmung der
Zusatzfeatures für herkömmliche OPACs
 Zusatzfeatures für herkömmliche OPACs Herbsttagung der GSHS, Hamburg 17. November 2008 Silvia Munding, MPDL Inhalt GoogleBooks Einbinden des E-Book-Katalogs Social Bookmark Services Systematikbrowsing
Zusatzfeatures für herkömmliche OPACs Herbsttagung der GSHS, Hamburg 17. November 2008 Silvia Munding, MPDL Inhalt GoogleBooks Einbinden des E-Book-Katalogs Social Bookmark Services Systematikbrowsing
SDK zur CRM-Word-Schnittstelle
 SDK zur CRM-Word-Schnittstelle SDK zur CRM Wordinterface für Microsoft Dynamics CRM2011 zur Version 5.2.0 Inhalt 1. Vorwort... 3 2. Voraussetzungen... 4 3. Funktionsbeschreibung... 4 4. Technische Funktionsbeschreibung...
SDK zur CRM-Word-Schnittstelle SDK zur CRM Wordinterface für Microsoft Dynamics CRM2011 zur Version 5.2.0 Inhalt 1. Vorwort... 3 2. Voraussetzungen... 4 3. Funktionsbeschreibung... 4 4. Technische Funktionsbeschreibung...
SAS Metadatenmanagement Reporting und Analyse
 SAS Metadatenmanagement Reporting und Analyse Melanie Hinz mayato GmbH Am Borsigturm 9 Berlin melanie.hinz@mayato.com Zusammenfassung Metadaten sind seit Version 9 ein wichtiger Bestandteil von SAS. Neben
SAS Metadatenmanagement Reporting und Analyse Melanie Hinz mayato GmbH Am Borsigturm 9 Berlin melanie.hinz@mayato.com Zusammenfassung Metadaten sind seit Version 9 ein wichtiger Bestandteil von SAS. Neben
Fallbasierte automatische Klassifikation nach der RVK - k-nearest neighbour auf bibliografischen Metadaten
 Fallbasierte automatische Klassifikation nach der RVK - k-nearest neighbour auf bibliografischen Metadaten Magnus Pfeffer (Dipl.-Inform., M.A. LIS) Universität Mannheim, Universitätsbibliothek magnus.pfeffer@bib.uni-mannheim.de
Fallbasierte automatische Klassifikation nach der RVK - k-nearest neighbour auf bibliografischen Metadaten Magnus Pfeffer (Dipl.-Inform., M.A. LIS) Universität Mannheim, Universitätsbibliothek magnus.pfeffer@bib.uni-mannheim.de
DPF Dynamic Partial distance Function
 DPF Dynamic Partial distance Function Vorgelegt von Sebastian Loose (MatrikelNR.: 169172), Computervisualistikstudent im 4. Semester. Hausarbeit zum Papier DPF A Perceptual Distance Function for Image
DPF Dynamic Partial distance Function Vorgelegt von Sebastian Loose (MatrikelNR.: 169172), Computervisualistikstudent im 4. Semester. Hausarbeit zum Papier DPF A Perceptual Distance Function for Image
Proseminar - Data Mining
 Vorbesprechung Proseminar - Data Mining SCCS, Fakultät für Informatik Technische Universität München SS 2015 Vorbesprechung, SS 2015 1 Data Mining: Beispiele (1) Hausnummererkennung (Klassifikation) Source:
Vorbesprechung Proseminar - Data Mining SCCS, Fakultät für Informatik Technische Universität München SS 2015 Vorbesprechung, SS 2015 1 Data Mining: Beispiele (1) Hausnummererkennung (Klassifikation) Source:
Lazar (Lazy-Structure-Activity Relationships)
") Lazar (Lazy-Structure-Activity Relationships) Martin Gütlein, Albert-Ludwigs-Universität Freiburg Dr. Christoph Helma, in silico toxicology gmbh, Basel Halle, 4.3.2013 Advanced Course des AK Regulatorische
Lazar (Lazy-Structure-Activity Relationships) Martin Gütlein, Albert-Ludwigs-Universität Freiburg Dr. Christoph Helma, in silico toxicology gmbh, Basel Halle, 4.3.2013 Advanced Course des AK Regulatorische
Zabbix 2.4. What's new? What's new in Zabbix 2.4. 1 of
 Zabbix 2.4 What's new? 1 of What's new in Zabbix 2.4 About me Name: Pascal Schmiel Email: Schmiel@dv-loesungen.de WEB: www.dv-loesungen.de Senior Consultant Zabbix Certified Professional 2 of What's new
Zabbix 2.4 What's new? 1 of What's new in Zabbix 2.4 About me Name: Pascal Schmiel Email: Schmiel@dv-loesungen.de WEB: www.dv-loesungen.de Senior Consultant Zabbix Certified Professional 2 of What's new
Inhalt. TEIL I Grundlagen. 1 SAP HANA im Überblick... 31. 2 Einführung in die Entwicklungsumgebung... 75
 Geleitwort... 15 Vorwort... 17 Einleitung... 19 TEIL I Grundlagen 1 SAP HANA im Überblick... 31 1.1 Softwarekomponenten von SAP HANA... 32 1.1.1 SAP HANA Database... 32 1.1.2 SAP HANA Studio... 34 1.1.3
Geleitwort... 15 Vorwort... 17 Einleitung... 19 TEIL I Grundlagen 1 SAP HANA im Überblick... 31 1.1 Softwarekomponenten von SAP HANA... 32 1.1.1 SAP HANA Database... 32 1.1.2 SAP HANA Studio... 34 1.1.3
Kontextbasiertes Information Retrieval
 Kontextbasiertes Information Retrieval Modell, Konzeption und Realisierung kontextbasierter Information Retrieval Systeme Karlheinz Morgenroth Lehrstuhl für Medieninformatik Fakultät Wirtschaftsinformatik
Kontextbasiertes Information Retrieval Modell, Konzeption und Realisierung kontextbasierter Information Retrieval Systeme Karlheinz Morgenroth Lehrstuhl für Medieninformatik Fakultät Wirtschaftsinformatik
Institut for Geodäsie and Geoinformationstechnik. Kopplung von 3D Stadtmodellen mit Cloud-Diensten
 Donnerstag, 10. November 2011 Technische Universität Berlin Institut for Geodäsie and Geoinformationstechnik Methodik der Geoinformationstechnik Kopplung 3D Stadtmodelle von 3D-Stadtmodellen und Cloud
Donnerstag, 10. November 2011 Technische Universität Berlin Institut for Geodäsie and Geoinformationstechnik Methodik der Geoinformationstechnik Kopplung 3D Stadtmodelle von 3D-Stadtmodellen und Cloud
Information Retrieval in XML- Dokumenten
 Inhalt Information Retrieval in XML- Dokumenten Norbert Fuhr Universität Dortmund fuhr@cs.uni-dortmund.de I. Einführung II. III. IV. IR-Konzepte für XML XIRQL HyREX-Retrievalengine V. Zusammenfassung und
Inhalt Information Retrieval in XML- Dokumenten Norbert Fuhr Universität Dortmund fuhr@cs.uni-dortmund.de I. Einführung II. III. IV. IR-Konzepte für XML XIRQL HyREX-Retrievalengine V. Zusammenfassung und
GIS und raumbezogene Datenbanken
 GIS und raumbezogene Datenbanken Eine raumbezogene Datenbank (spatial database) dient der effizienten Speicherung, Verwaltung und Anfrage von raumbezogenen Daten. datenbankorientiert Ein geographisches
GIS und raumbezogene Datenbanken Eine raumbezogene Datenbank (spatial database) dient der effizienten Speicherung, Verwaltung und Anfrage von raumbezogenen Daten. datenbankorientiert Ein geographisches
Freebase Eine Datenbank mit RDF-Tripeln zu Personen, Orten, Dingen(2005-2012)
") Freebase Eine Datenbank mit RDF-Tripeln zu Personen, Orten, Dingen(2005-2012) Karin Haenelt 1.5.2015 Inhalt Historie Datenbank 2 Historie 2005-2012 Freebase 7.2005, Metaweb Technologies Inc. entwickelt
Freebase Eine Datenbank mit RDF-Tripeln zu Personen, Orten, Dingen(2005-2012) Karin Haenelt 1.5.2015 Inhalt Historie Datenbank 2 Historie 2005-2012 Freebase 7.2005, Metaweb Technologies Inc. entwickelt
Microsoft SQL Server 2005 Konfigurierung, Administration,
 Ruprecht Droge, Markus Raatz 2008 AGI-Information Management Consultants May be used for personal purporses only or by libraries associated to dandelon.com network. Microsoft SQL Server 2005 Konfigurierung,
Ruprecht Droge, Markus Raatz 2008 AGI-Information Management Consultants May be used for personal purporses only or by libraries associated to dandelon.com network. Microsoft SQL Server 2005 Konfigurierung,
Proseminar - Data Mining
 Proseminar - Data Mining SCCS, Fakultät für Informatik Technische Universität München SS 2012, SS 2012 1 Data Mining Pipeline Planung Aufbereitung Modellbildung Auswertung Wir wollen nützliches Wissen
Proseminar - Data Mining SCCS, Fakultät für Informatik Technische Universität München SS 2012, SS 2012 1 Data Mining Pipeline Planung Aufbereitung Modellbildung Auswertung Wir wollen nützliches Wissen
Ruby on Rails. Thomas Baustert Ralf Wirdemann www.b-simple.de. Alternative zur Web-Entwicklung mit Java? 27.06.2005 www.b-simple.
 Ruby on Rails Alternative zur Web-Entwicklung mit Java? Thomas Baustert Ralf Wirdemann www.b-simple.de 27.06.2005 www.b-simple.de 1 Überblick Was ist Ruby on Rails? Weblog Demo Rails Komponenten Controller,
Ruby on Rails Alternative zur Web-Entwicklung mit Java? Thomas Baustert Ralf Wirdemann www.b-simple.de 27.06.2005 www.b-simple.de 1 Überblick Was ist Ruby on Rails? Weblog Demo Rails Komponenten Controller,
Abstrakt zum Vortrag im Oberseminar. Graphdatenbanken. Gero Kraus HTWK Leipzig 14. Juli 2015
 Abstrakt zum Vortrag im Oberseminar Graphdatenbanken Gero Kraus HTWK Leipzig 14. Juli 2015 1 Motivation Zur Darstellung komplexer Beziehungen bzw. Graphen sind sowohl relationale als auch NoSQL-Datenbanken
Abstrakt zum Vortrag im Oberseminar Graphdatenbanken Gero Kraus HTWK Leipzig 14. Juli 2015 1 Motivation Zur Darstellung komplexer Beziehungen bzw. Graphen sind sowohl relationale als auch NoSQL-Datenbanken
Modellierung eines Epidemie- Frühwarnsystems mit. Nicolas With Master Seminar WS 2012/13
 Modellierung eines Epidemie- Frühwarnsystems mit SocialMedia Mining Nicolas With Master Seminar WS 2012/13 Agenda Einstieg Motivation Abgrenzung Ziel Status Projekt 1 Projekt 2 Ausblick Chancen Risiken
Modellierung eines Epidemie- Frühwarnsystems mit SocialMedia Mining Nicolas With Master Seminar WS 2012/13 Agenda Einstieg Motivation Abgrenzung Ziel Status Projekt 1 Projekt 2 Ausblick Chancen Risiken
SAP NetWeaver Gateway. Connectivity@SNAP 2013
 SAP NetWeaver Gateway Connectivity@SNAP 2013 Neue Wege im Unternehmen Neue Geräte und Usererfahrungen Technische Innovationen in Unternehmen Wachsende Gemeinschaft an Entwicklern Ausdehnung der Geschäftsdaten
SAP NetWeaver Gateway Connectivity@SNAP 2013 Neue Wege im Unternehmen Neue Geräte und Usererfahrungen Technische Innovationen in Unternehmen Wachsende Gemeinschaft an Entwicklern Ausdehnung der Geschäftsdaten
Auch der eigene Katalog als Quelle: Zusammenführung von elektronischer und gedruckter Fassung; verschiedenen Auflagen usw.: Fließender Übergang zu
 1 2 3 4 Auch der eigene Katalog als Quelle: Zusammenführung von elektronischer und gedruckter Fassung; verschiedenen Auflagen usw.: Fließender Übergang zu FRBR 5 Begriff stammt aus: Coffmann, Steve: The
1 2 3 4 Auch der eigene Katalog als Quelle: Zusammenführung von elektronischer und gedruckter Fassung; verschiedenen Auflagen usw.: Fließender Übergang zu FRBR 5 Begriff stammt aus: Coffmann, Steve: The
Analyse von Student-Studentund Student-Tutor-Interaktionen
 Analyse von Student-Studentund Student-Tutor-Interaktionen Nils Montenegro Humboldt-Universität zu Berlin 1 / 25 Einleitung Wozu Interaktionen analysieren? Wie kann ein System eingreifen? Wie kann man
Analyse von Student-Studentund Student-Tutor-Interaktionen Nils Montenegro Humboldt-Universität zu Berlin 1 / 25 Einleitung Wozu Interaktionen analysieren? Wie kann ein System eingreifen? Wie kann man
Apache Lucene. Mach s wie Google! Bernd Fondermann freier Software Architekt bernd.fondermann@brainlounge.de berndf@apache.org
 Apache Lucene Mach s wie Google! Bernd Fondermann freier Software Architekt bernd.fondermann@brainlounge.de berndf@apache.org 1 Apache Apache Software Foundation Software free of charge Apache Software
Apache Lucene Mach s wie Google! Bernd Fondermann freier Software Architekt bernd.fondermann@brainlounge.de berndf@apache.org 1 Apache Apache Software Foundation Software free of charge Apache Software
PHILIPP-SCHAFFNER.CH. Teil der Blooniverse Media Group. 28. November 2009 DrupalCamp Vienna
 PHILIPP-SCHAFFNER.CH Teil der Blooniverse Media Group 28. November 2009 DrupalCamp Vienna Was bezweckt.mobi die mobile TLD? Die Top Level Domain.mobi weist eindeutig auf eine mobile Website hin Es gibt
PHILIPP-SCHAFFNER.CH Teil der Blooniverse Media Group 28. November 2009 DrupalCamp Vienna Was bezweckt.mobi die mobile TLD? Die Top Level Domain.mobi weist eindeutig auf eine mobile Website hin Es gibt
DATENBANKEN SQL UND SQLITE VON MELANIE SCHLIEBENER
 DATENBANKEN SQL UND SQLITE VON MELANIE SCHLIEBENER INHALTSVERZEICHNIS 1. Datenbanken 2. SQL 1.1 Sinn und Zweck 1.2 Definition 1.3 Modelle 1.4 Relationales Datenbankmodell 2.1 Definition 2.2 Befehle 3.
DATENBANKEN SQL UND SQLITE VON MELANIE SCHLIEBENER INHALTSVERZEICHNIS 1. Datenbanken 2. SQL 1.1 Sinn und Zweck 1.2 Definition 1.3 Modelle 1.4 Relationales Datenbankmodell 2.1 Definition 2.2 Befehle 3.
Proseminar - Data Mining
 Proseminar - Data Mining SCCS, Fakultät für Informatik Technische Universität München SS 2014, SS 2014 1 Data Mining: Beispiele (1) Hausnummererkennung (Klassifikation) Source: http://arxiv.org/abs/1312.6082,
Proseminar - Data Mining SCCS, Fakultät für Informatik Technische Universität München SS 2014, SS 2014 1 Data Mining: Beispiele (1) Hausnummererkennung (Klassifikation) Source: http://arxiv.org/abs/1312.6082,
SQL für Trolle. mag.e. Dienstag, 10.2.2009. Qt-Seminar
 Qt-Seminar Dienstag, 10.2.2009 SQL ist......die Abkürzung für Structured Query Language (früher sequel für Structured English Query Language )...ein ISO und ANSI Standard (aktuell SQL:2008)...eine Befehls-
Qt-Seminar Dienstag, 10.2.2009 SQL ist......die Abkürzung für Structured Query Language (früher sequel für Structured English Query Language )...ein ISO und ANSI Standard (aktuell SQL:2008)...eine Befehls-
Sharing Digital Knowledge and Expertise
 Sharing Digital Knowledge and Expertise Die Spring und Summer Schools des GCDH Veranstaltungen 2012 2015 Summer und Spring Schools Workshop: Soziale Netzwerkanalyse Grundlagen und Interpretation Strickmuster
Sharing Digital Knowledge and Expertise Die Spring und Summer Schools des GCDH Veranstaltungen 2012 2015 Summer und Spring Schools Workshop: Soziale Netzwerkanalyse Grundlagen und Interpretation Strickmuster
Semantische Reputationsinteroperabilität
 Semantische sinteroperabilität Adrian Paschke (CSW) und Rehab Alnemr (HPI) Corporate Semantic Web Workshop, Xinnovations 2010, 14. September 2010, Berlin Agenda Motivation Unternehmensreputation Probleme
Semantische sinteroperabilität Adrian Paschke (CSW) und Rehab Alnemr (HPI) Corporate Semantic Web Workshop, Xinnovations 2010, 14. September 2010, Berlin Agenda Motivation Unternehmensreputation Probleme
Konferenzbericht EKAW 2012
 Konferenzbericht EKAW 2012 Johannes Hellrich 9.-12. Oktober 2012 Johannes Hellrich EKAW 1 / 20 IESD Parallel Faceted Browsing - Idee Faceted Browsing ist weit verbreitet, aber limitiert - der Nutzer sieht
Konferenzbericht EKAW 2012 Johannes Hellrich 9.-12. Oktober 2012 Johannes Hellrich EKAW 1 / 20 IESD Parallel Faceted Browsing - Idee Faceted Browsing ist weit verbreitet, aber limitiert - der Nutzer sieht
Big Data bei unstrukturierten Daten. AW1 Vortrag Sebastian Krome
 Big Data bei unstrukturierten Daten AW1 Vortrag Sebastian Krome Agenda Wiederholung Aspekte von Big Data Datenverarbeitungsprozess TextMining Aktuelle Paper Identification of Live News Events Using Twitter
Big Data bei unstrukturierten Daten AW1 Vortrag Sebastian Krome Agenda Wiederholung Aspekte von Big Data Datenverarbeitungsprozess TextMining Aktuelle Paper Identification of Live News Events Using Twitter
Toleranzschema. ArtemiS SUITE
 Anzeige von Referenz- und Grenzwertkurven Überprüfung von Analyseergebnissen auf Über- bzw. Unterschreitungen der definierten Grenzwertkurven HEARING IS A FASCINATING SENSATION ArtemiS SUITE Motivation
Anzeige von Referenz- und Grenzwertkurven Überprüfung von Analyseergebnissen auf Über- bzw. Unterschreitungen der definierten Grenzwertkurven HEARING IS A FASCINATING SENSATION ArtemiS SUITE Motivation
CARL HANSER VERLAG. Dirk Ammelburger XML. Grundlagen der Sprache und Anwendungen in der Praxis 3-446-22562-5. www.hanser.de
 CARL HANSER VERLAG Dirk Ammelburger XML Grundlagen der Sprache und Anwendungen in der Praxis 3-446-22562-5 www.hanser.de 1 1.1 Einleitung... 2 Über dieses Buch... 3 1.2 Für wen ist das Buch gedacht?...
CARL HANSER VERLAG Dirk Ammelburger XML Grundlagen der Sprache und Anwendungen in der Praxis 3-446-22562-5 www.hanser.de 1 1.1 Einleitung... 2 Über dieses Buch... 3 1.2 Für wen ist das Buch gedacht?...
10 Tipps, mit denen Ihr Google-Analytics-Account doppelt so effektiv wird (Teil I -Tipp1-5)
") 10 Tipps, mit denen Ihr Google-Analytics-Account doppelt so effektiv wird (Teil I -Tipp1-5) SMX München, 09.04.2013, Panel 4 Analyse & Conversion Dr. Christoph Gummersbach Inhaber Webfield Consulting,
10 Tipps, mit denen Ihr Google-Analytics-Account doppelt so effektiv wird (Teil I -Tipp1-5) SMX München, 09.04.2013, Panel 4 Analyse & Conversion Dr. Christoph Gummersbach Inhaber Webfield Consulting,
BillSAFE Payment Layer Integration Guide
 BillSAFE Payment Layer Integration Guide letzte Aktualisierung: 10.06.2013 Inhaltsverzeichnis 1 Vorwort...2 1.1 Inhalt...2 1.2 Zielgruppe...2 1.3 Voraussetzungen...2 1.4 Feedback...2 1.5 Versionshistorie...3
BillSAFE Payment Layer Integration Guide letzte Aktualisierung: 10.06.2013 Inhaltsverzeichnis 1 Vorwort...2 1.1 Inhalt...2 1.2 Zielgruppe...2 1.3 Voraussetzungen...2 1.4 Feedback...2 1.5 Versionshistorie...3
Ersetzt die Suchmaschine den Verbund-OPAC? Erfahrungen, Perspektiven und mögliche Kooperationsfelder aus Sicht der Verbünde
 Ersetzt die Suchmaschine den Verbund-OPAC? Erfahrungen, Perspektiven und mögliche Kooperationsfelder aus Sicht der Verbünde Hermann Kronenberg 94. DBT Düsseldorf, 16. März 2005 Inhalt Katalog oder Suchmaschine?
Ersetzt die Suchmaschine den Verbund-OPAC? Erfahrungen, Perspektiven und mögliche Kooperationsfelder aus Sicht der Verbünde Hermann Kronenberg 94. DBT Düsseldorf, 16. März 2005 Inhalt Katalog oder Suchmaschine?
Konzeption und Entwicklung eines intelligenten Software-Agenten zum Web-Content-Mining
 und Entwicklung eines intelligenten Software- zum Web-Content-Mining Was sind Software-? Programme, die Arbeiten im Auftrag von Benutzern selbstständig ausführen. Eigenschaften Autonomie Soziale Fähigkeiten
und Entwicklung eines intelligenten Software- zum Web-Content-Mining Was sind Software-? Programme, die Arbeiten im Auftrag von Benutzern selbstständig ausführen. Eigenschaften Autonomie Soziale Fähigkeiten