Big Learning. Datenmanagement und Datenanalyse: Energiemanagement mit lokaler Wetterinformation. Michael Zwick. Dr. Holger Schöner
|
|
|
- Heidi Schenck
- vor 8 Jahren
- Abrufe
Transkript

1 Big Learning Datenmanagement und Datenanalyse: Energiemanagement mit lokaler Wetterinformation Michael Zwick Dr. Holger Schöner Das SCCH ist eine Initiative der Das SCCH befindet sich im

2 Big Data Trend 2

3 Datenquellen, Datenmanagement Prognose und Steuerung Analyse und Optimierung Datenmanagement Sensor Netzwerke 3

4 Agenda Datenmanagement Warum NoSQL? NoSQL!= NoSQL Hadoop/HBase Use Case Energie-Container Datenanalyse Use Cases Datenanalyse Herausforderungen Techniken zur Parallelisierung Ausblick 4

5 Kurze Geschichte eines Internet-Startups Standard-Installation einer Open-Source Datenbank MySQL, Firebird, PostgreSQL 1 Server Immer mehr Benutzer Datenmenge steigt dramatisch IT-Abteilung muss reagieren Mehr Disks, mehr RAM, schnellere/mehr CPUs Optimierung SQL, Indizes Voraggregation/Materialized Views Partitionierung der Datenbanktabellen Replikation der Daten auf mehrere DB-Knoten (Load Balancing) Schließlich wurde die gehisst Teuer (HW, Lizenzen) und schwer zu administrieren Denormalisierung, vermeiden aufwendiger Join-Operationen MySQL: DB-Backend ohne Transaktionen (MyISAM) 5
 und schwer zu administrieren Denormalisierung, vermeiden aufwendiger Join-Operationen MySQL: DB-Backend ohne")
6 Big Data bei MySpace 1 Mio. User Messaging Images ~ 450 Server Profiles 6

7 Anforderungen/ Einschränkungen Transaktionen Joins Sekundär-Indizes Normalisierung Query Optimizer Consistency Availability Partition Tolerance Commodity Hardware Skalierbarkeit Verfügbarkeit Performanz Flexibleres Schema Spares tables Semi-structured unstructured 7

8 Tabular Key-Value Stores Google File System 2003 Bigtable 2006 Dynamo


9 NoS...? Dokument Tabelle NoSQL Key-Value Graph 9

10 Hadoop Open source Google File System Java SDK (mittels RPC auch andere Frameworks) Verteilte Verarbeitung von großen Datenmengen Skalierbar und zuverlässig Commodity Hardware Redundante Speicherung von Datenblöcken (default: 3) Storage+Analyseframework HDFS (Hadoop Distributed Filesystem) Hadoop MapReduce Weitverbreitet Amazon/A9, Facebook, Google, IBM, Joost, Last.fm, New York Times, PowerSet, Veoh, Yahoo!... 10

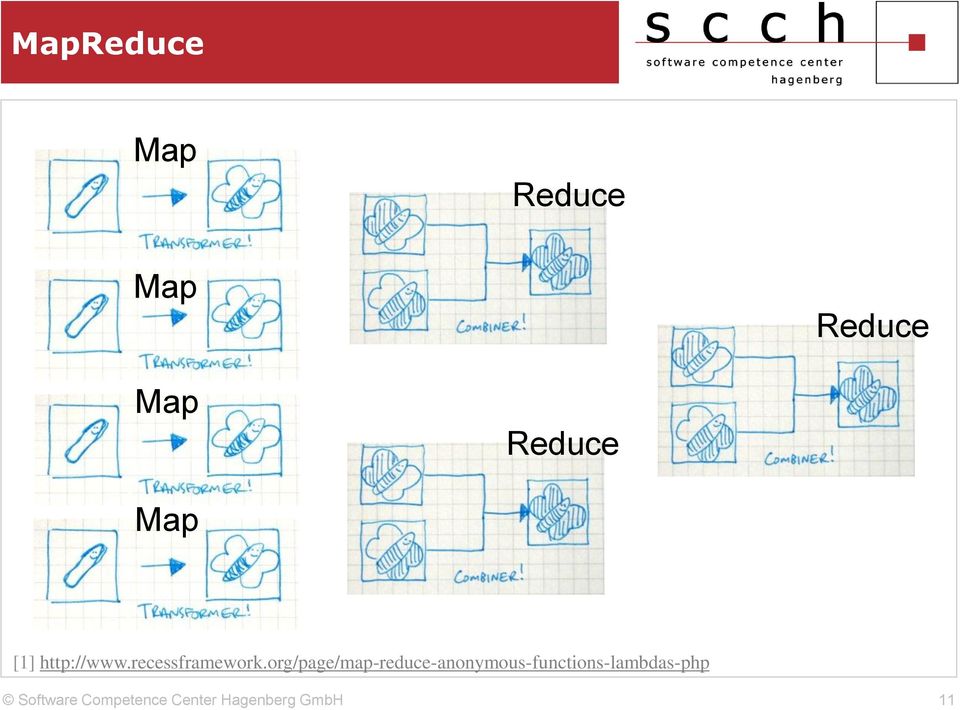
11 MapReduce Map Reduce Map Reduce Map Reduce Map [1] 11
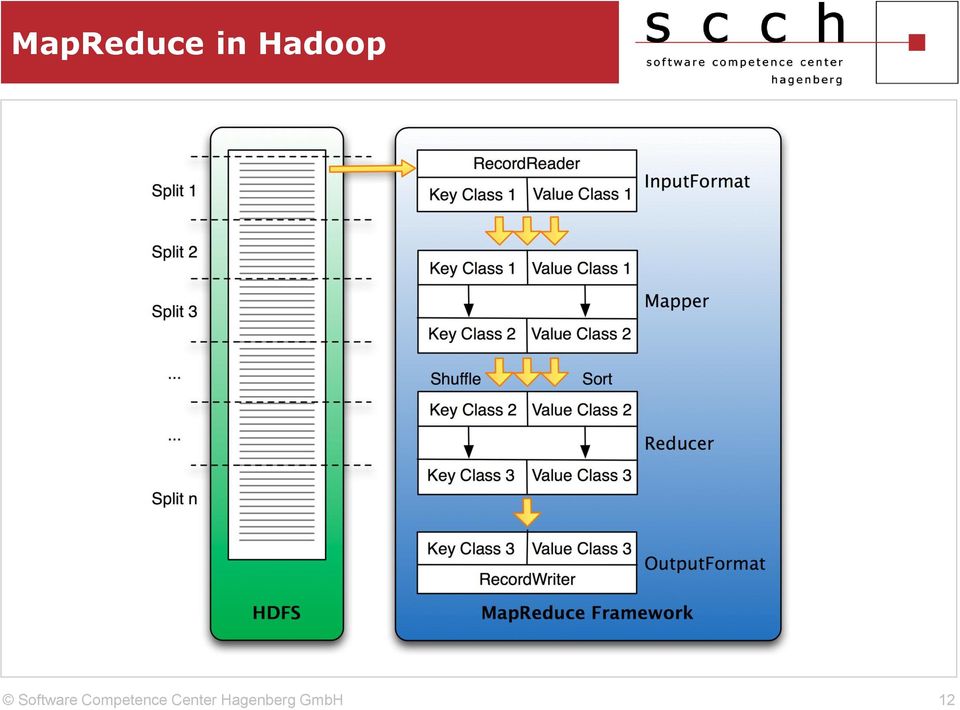
12 MapReduce in Hadoop 12
13 Apache Projekte Apache Hive Pig Zu SQL ähnliche Abfragesprache und Metadaten-Repository High-level Sprache alternativ zu Hive Mahout Machine-Learning Algorithmen für Hadoop Flume Sammeln/Verarbeiten von Log- und Eventdaten Sqoop Integration mit RDBMS Oozie Workflow-Engine für Hadoop-Jobs 13

14 HBase Open source Google Bigtable Hadoop als Datenspeicher Schneller wahlfreier Zugriff als Ergänzung zu MapReduce Nicht relationale, verteilte Datenbank Dünnbesetzte Tabellen/Spaltenorientierte Speicherung Ausfallsicher Ziele Milliarden Zeilen Millionen Spalten Tausende Versionen Daten im Petabyte-Bereich auf tausenden von Knoten 14

15 HBase Datenmodell ColumnFamily1 (CF2) Timestamp qualifier1 qualifier2 qualifier3 qualifier4... rowkey1 ts3 value value ts2 value value ts1 value value rowkey2 ts5 value ts4 value ts3 value value ts2 value (rowkey, column, timestamp) -> cell column := <column_family>:<qualifier> 15
")
16 HBase Architektur Master Metadaten Koordination Regionserver Regions Queries Clients Master Metadaten Clients Regionserver Daten 16

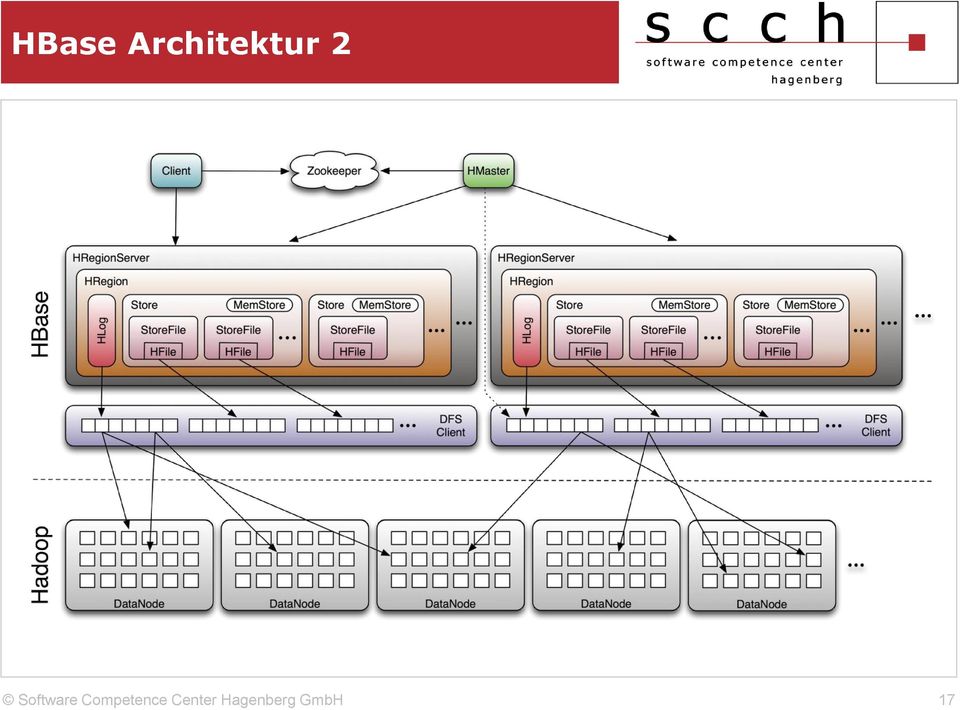
17 HBase Architektur 2 17
18 Anwendungsfall Energieversorgung sicherstellen (an jedem Punkt der Erde) Energiemix Sonne/Wind Backup Diesel Batterien als Puffer Individuell konfigurierbar Intelligente Steuerung Wartungsarm Weitere Energiequellen zuschaltbar 18

19 Sensordaten Einstrahlung Windgeschwindigkeit Windrichtung Temperatur Umgebung Module Panelstellung Wechselrichter Strom Spannung Batterieladezustand 19

20 Erfahrungen mit HBase Messwerte sind WORM-Daten Skalierung mit der Anzahl der Energie-Container Messwerte sind nicht für jedes Gerät bzw. zu jeder Zeit verfügbar MapReduce geeignet zur Vorverarbeitung der Sensordaten Fehlerfrüherkennung Vorhersage Energieertrag Row-Key beeinflusst Skalierbarkeit des Gesamtsystems Komprimierung Datenmengen Snapshot alle 5 Minuten (~ 80 Messwerte) 1 Container 8,4 Mio. Messwerte/Jahr 170 Mio. Messwerte in 20 Jahren 170 Mrd. Messwerte bei 1000 Anlagen 20

21 Agenda Datenanalyse Analyse und Prognose Use Cases Vorhersage lokales Wetter Vorhersage Energiebedarf Optimierung Energieerzeugung Herausforderungen Datenanalyse, Vorhersagemodelle Techniken zur Parallelisierung MapReduce, GraphLab, GPGPU Ausblick SCCH 21
22 Analyse, Optimierung, Prognose Prognose und Steuerung Analyse und Optimierung Datenmanagement Sensor Netzwerke 22
23 Daten - Analyse Vorhersage, Soft Sensors Regression/Klassifikation: Vorhersage Resultat / Zustand / Eigenschaften eines Prozesses oder Teiles Wissens-Generierung Interpretation eines gelernter Modelle, um vorhandene Zusammenhänge explizit zu machen Diagnose Aufdecken und Erklären von Problemen, Ausreißern BigData Parallelisierung 23

24 Use Case: Vorhersage lokales Wetter mb, , Salzburg Linz St. Pölten Wien Eisenstadt 48 Daten Sammlung Bregenz 47 Innsbruck Graz 47 Klagenfurt Analyse Datenquellen Globale Wettermodelle: GFS,... Lokale Sensoren: Wettermeldungen, (Klein-)Kraftwerke,... Topographie, Expertenwissen Erkenntnisse / Expertenwissen 4 6 Vorhersage Modelle Alcohol Ziele Eventplanung, Planung von Außenarbeiten Optimierung von Energieverbrauch/-produktion 24

25 Use Case: Vorhersage Gebäude-Energieverbrauch Umgebung Globalstrahlung, Temperatur, Wind, Luftfeuchtigkeit Intelligente Sensoren Wettermodelle Gewohnheiten Tages-, Wochenzyklus,... Sensoren Steuerung Jalousien, Nachtlüftung, Sollwerte Ziele Vorausschauende Anpassung Identifikation von Problemen/ Abweichungen durch Vergleich Verbrauch/Prognose 25
 Rainfall-Runoff-Model (Hebenstreit 2000) HYSIM: Wellenablauf / Niederschlagsabflussmode ll (Drabek et al.")

26 Use Case: Optimierung Energieerzeugung Aktuelle Durchflusswerte, Niederschläge / Temperaturen & Prognosen Schneeschmelze- und Bodenfeuchtemodell (Holzmann & Nachtnebel 2002) Datenbasierte Modelle (z.b. Ridge Regression, Neuronale Netze) Rainfall-Runoff-Model (Hebenstreit 2000) HYSIM: Wellenablauf / Niederschlagsabflussmode ll (Drabek et al. 2002) CH Legende: Laufkraftwerke der AHP Speicherkraftwerke der AHP Gemeinschaftskraftwerke der AHP Beteiligungen des Verbund INN Oberaufdorf-Ebbs Gerlos Mayrhofen Bösdornau Roßhag Braunau-Simbach Nußdorf D Passau-Ingling Schärding-Neuhaus Egglfing-Obernberg Ering-Frauenstein SALZACH INN Kreuzbergmaut Bischofshofen Urreiting Funsingau Schwarzach St. Veit Wallnerau Kaprun- Hauptstufe Häusling Kaprun-Oberstufe Reißeck-Kreuzeck Malta-Oberstufe Paternion DRAU Kellerberg Jochenstein Rosegg-St. Jakob Mühlrading Staning Garsten-St. Ulrich Rosenau Mandling Ternberg Klaus Salza Sölk Bodendorf-Paal Malta-Hauptstufe Malta-Unterstufe Villach Feistritz-Ludmannsdorf Aschach Ferlach-Maria Rain Ottensheim-Wilhering ENNS Triebenbach St. Georgen Abwinden-Asten St. Pantaleon Krippau Fisching MUR Bodendorf-Mur Wallsee-Mitterk. Leoben Friesach Graz DONAU Melk Losenstein Ybbs-Persenbeug Großraming Weyer Schönau Edling Annabrücke Altenmarkt Landl Hieflau St.Martin Lebring Lavamünd Schwabeck Altenwörth Dionysen Pernegg Laufnitzdorf Arnstein Rabenstein Peggau Weinzödl Spielfeld Greifenstein Mellach Gralla Gabersdorf Obervogau SLO CZ Freudenau SK H SAMBA: Optimierungsfunktion Optimale Gewichtung von Modellen Ziele Kurzfristig: Einbeziehung Verfügbarkeit natürlicher Ressourcen in Energieproduktionsplanung (Wasser, Wind, Sonne) Langfristig: Planung von Standorten, Auslegung von Systemen 26
27 Herausforderungen Datenanalyse Große Datenmengen, flexibler Zugriff nötig Lange Zeiträume für Hintergrundwissen notwendig Lokal: Viele Orte mit Messwerten Große Modellanzahl, komplexe Modellstrukturen Für jeden Ort ein Modell (mit Koppelung zwischen Modellen) Modelle für unterschiedliche Vorhersagegrößen, gemeinsame Vorverarbeitung Unterschiedliche Hardwarearchitekturen verfügbar Client-Server, Multicore, Cluster, GPGPU, heterogene Systeme Vielzahl Algorithmen Paralleles Vorverarbeiten Lineare Algebra Graphalgorithmen Pipelines 27
28 Techniken zur Parallelisierung MapReduce Verteilen unabhängiger ähnlicher Aufgaben auf mehrere Cores/GPGPUs Gute Integration mit Hadoop vorhanden Probleme mit iterativen Prozessen, komplexen Abhängigkeiten GraphLab Effiziente Implementation für Berechnungen mit komplexen Abhängigkeiten Datenhandling selber zu implementieren GPGPU Sehr wichtig für High Performance Anwendungen Aufwendiger Lowlevel-Code Oder Nutzung von Highlevel-Bibliotheken/-Sprachen (z.b. SaC), wobei noch kein Standard etabliert ist 28
29 Ausblick ParaPhrase EU-gefördertes Projekt Entwicklung von Parallel Patterns Refactoring für Parallelisierung Unterstützung unterschiedlicher Hardware 29

 5,7 Mio. Euro Umsatz im GJ 10/11 Angesiedelt im Softwarepark Hagenberg Seit 01.")
30 SCCH Anwendungsorientierte Forschung Gegründet im Juli 1999 von Instituten der Johannes Kepler Universität Linz im K plus-programm Kooperation Wissenschaft Wirtschaft Johannes Kepler Universität als starker Partner Unternehmensform: Non-Profit GmbH ~ 70 Mitarbeiter (inkl. Partnern ca. 80) 5,7 Mio. Euro Umsatz im GJ 10/11 Angesiedelt im Softwarepark Hagenberg Seit COMET-Kompetenzzentrum 30
31 Forschungsschwerpunkte Process and Quality Engineering Software Engineering Software-Qualität Softwareentwicklungs-prozess Models, Architectures and Tools Software Architektur modelbasierte Entwicklung Integration von Architektur und Entwicklung Data Analysis Systems automatisierte und intelligente Datenanalyse Vorhersage Wissensgewinnung Knowledge-Based Vision Systems maschinelles Sehen Objekterkennung Objektverfolgung 31

32 Kontakt Michael Zwick Dr. Holger Schöner
Apache HBase. A BigTable Column Store on top of Hadoop
 Apache HBase A BigTable Column Store on top of Hadoop Ich bin... Mitch Köhler Selbstständig seit 2010 Tätig als Softwareentwickler Softwarearchitekt Student an der OVGU seit Oktober 2011 Schwerpunkte Client/Server,
Apache HBase A BigTable Column Store on top of Hadoop Ich bin... Mitch Köhler Selbstständig seit 2010 Tätig als Softwareentwickler Softwarearchitekt Student an der OVGU seit Oktober 2011 Schwerpunkte Client/Server,
Softwarearchitektur als Mittel für Qualitätssicherung und SOA Governance
 Softwarearchitektur als Mittel für Qualitätssicherung und SOA Governance Mag. Georg Buchgeher +43 7236 3343 855 georg.buchgeher@scch.at www.scch.at Das SCCH ist eine Initiative der Das SCCH befindet sich
Softwarearchitektur als Mittel für Qualitätssicherung und SOA Governance Mag. Georg Buchgeher +43 7236 3343 855 georg.buchgeher@scch.at www.scch.at Das SCCH ist eine Initiative der Das SCCH befindet sich
Hadoop. Eine Open-Source-Implementierung von MapReduce und BigTable. von Philipp Kemkes
 Hadoop Eine Open-Source-Implementierung von MapReduce und BigTable von Philipp Kemkes Hadoop Framework für skalierbare, verteilt arbeitende Software Zur Verarbeitung großer Datenmengen (Terra- bis Petabyte)
Hadoop Eine Open-Source-Implementierung von MapReduce und BigTable von Philipp Kemkes Hadoop Framework für skalierbare, verteilt arbeitende Software Zur Verarbeitung großer Datenmengen (Terra- bis Petabyte)
Big Data Mythen und Fakten
 Big Data Mythen und Fakten Mario Meir-Huber Research Analyst, IDC Copyright IDC. Reproduction is forbidden unless authorized. All rights reserved. About me Research Analyst @ IDC Author verschiedener IT-Fachbücher
Big Data Mythen und Fakten Mario Meir-Huber Research Analyst, IDC Copyright IDC. Reproduction is forbidden unless authorized. All rights reserved. About me Research Analyst @ IDC Author verschiedener IT-Fachbücher
Big Data Informationen neu gelebt
 Seminarunterlage Version: 1.01 Copyright Version 1.01 vom 21. Mai 2015 Dieses Dokument wird durch die veröffentlicht. Copyright. Alle Rechte vorbehalten. Alle Produkt- und Dienstleistungs-Bezeichnungen
Seminarunterlage Version: 1.01 Copyright Version 1.01 vom 21. Mai 2015 Dieses Dokument wird durch die veröffentlicht. Copyright. Alle Rechte vorbehalten. Alle Produkt- und Dienstleistungs-Bezeichnungen
Möglichkeiten für bestehende Systeme
 Möglichkeiten für bestehende Systeme Marko Filler Bitterfeld, 27.08.2015 2015 GISA GmbH Leipziger Chaussee 191 a 06112 Halle (Saale) www.gisa.de Agenda Gegenüberstellung Data Warehouse Big Data Einsatz-
Möglichkeiten für bestehende Systeme Marko Filler Bitterfeld, 27.08.2015 2015 GISA GmbH Leipziger Chaussee 191 a 06112 Halle (Saale) www.gisa.de Agenda Gegenüberstellung Data Warehouse Big Data Einsatz-
ANALYTICS, RISK MANAGEMENT & FINANCE ARCHITECTURE. NoSQL Datenbanksysteme Übersicht, Abgrenzung & Charakteristik
 ARFA ANALYTICS, RISK MANAGEMENT & FINANCE ARCHITECTURE NoSQL Datenbanksysteme Übersicht, Abgrenzung & Charakteristik Ralf Leipner Domain Architect Analytics, Risk Management & Finance 33. Berner Architekten
ARFA ANALYTICS, RISK MANAGEMENT & FINANCE ARCHITECTURE NoSQL Datenbanksysteme Übersicht, Abgrenzung & Charakteristik Ralf Leipner Domain Architect Analytics, Risk Management & Finance 33. Berner Architekten
Überblick und Vergleich von NoSQL. Datenbanksystemen
 Fakultät Informatik Hauptseminar Technische Informationssysteme Überblick und Vergleich von NoSQL Christian Oelsner Dresden, 20. Mai 2011 1 1. Einführung 2. Historisches & Definition 3. Kategorien von
Fakultät Informatik Hauptseminar Technische Informationssysteme Überblick und Vergleich von NoSQL Christian Oelsner Dresden, 20. Mai 2011 1 1. Einführung 2. Historisches & Definition 3. Kategorien von
Beratung. Results, no Excuses. Consulting. Lösungen. Grown from Experience. Ventum Consulting. SQL auf Hadoop Oliver Gehlert. 2014 Ventum Consulting
 Beratung Results, no Excuses. Consulting Lösungen Grown from Experience. Ventum Consulting SQL auf Hadoop Oliver Gehlert 1 Ventum Consulting Daten und Fakten Results, no excuses Fachwissen Branchenkenntnis
Beratung Results, no Excuses. Consulting Lösungen Grown from Experience. Ventum Consulting SQL auf Hadoop Oliver Gehlert 1 Ventum Consulting Daten und Fakten Results, no excuses Fachwissen Branchenkenntnis
June 2015. Automic Hadoop Agent. Data Automation - Hadoop Integration
 June 2015 Automic Hadoop Agent Data Automation - Hadoop Integration + Aufbau der Hadoop Anbindung + Was ist eigentlich ist MapReduce? + Welches sind die Stärken von Hadoop + Welches sind die Schwächen
June 2015 Automic Hadoop Agent Data Automation - Hadoop Integration + Aufbau der Hadoop Anbindung + Was ist eigentlich ist MapReduce? + Welches sind die Stärken von Hadoop + Welches sind die Schwächen
Apache Lucene. Mach s wie Google! Bernd Fondermann freier Software Architekt bernd.fondermann@brainlounge.de berndf@apache.org
 Apache Lucene Mach s wie Google! Bernd Fondermann freier Software Architekt bernd.fondermann@brainlounge.de berndf@apache.org 1 Apache Apache Software Foundation Software free of charge Apache Software
Apache Lucene Mach s wie Google! Bernd Fondermann freier Software Architekt bernd.fondermann@brainlounge.de berndf@apache.org 1 Apache Apache Software Foundation Software free of charge Apache Software
Generalisierung von großen Datenbeständen am Beispiel der Gebäudegeneralisierung mit CHANGE
 Institut für Kartographie und Geoinformatik Leibniz Universität Hannover Generalisierung von großen Datenbeständen am Beispiel der Gebäudegeneralisierung mit CHANGE Frank Thiemann, Thomas Globig Frank.Thiemann@ikg.uni-hannover.de
Institut für Kartographie und Geoinformatik Leibniz Universität Hannover Generalisierung von großen Datenbeständen am Beispiel der Gebäudegeneralisierung mit CHANGE Frank Thiemann, Thomas Globig Frank.Thiemann@ikg.uni-hannover.de
ETL in den Zeiten von Big Data
 ETL in den Zeiten von Big Data Dr Oliver Adamczak, IBM Analytics 1 1 Review ETL im Datawarehouse 2 Aktuelle Herausforderungen 3 Future of ETL 4 Zusammenfassung 2 2015 IBM Corporation ETL im Datawarehouse
ETL in den Zeiten von Big Data Dr Oliver Adamczak, IBM Analytics 1 1 Review ETL im Datawarehouse 2 Aktuelle Herausforderungen 3 Future of ETL 4 Zusammenfassung 2 2015 IBM Corporation ETL im Datawarehouse
25.09.2014. Zeit bedeutet eine Abwägung von Skalierbarkeit und Konsistenz
 1 2 Dies ist ein Vortrag über Zeit in verteilten Anwendungen Wir betrachten die diskrete "Anwendungszeit" in der nebenläufige Aktivitäten auftreten Aktivitäten in einer hochgradig skalierbaren (verteilten)
1 2 Dies ist ein Vortrag über Zeit in verteilten Anwendungen Wir betrachten die diskrete "Anwendungszeit" in der nebenläufige Aktivitäten auftreten Aktivitäten in einer hochgradig skalierbaren (verteilten)
Oracle Big Data Technologien Ein Überblick
 Oracle Big Data Technologien Ein Überblick Ralf Lange Global ISV & OEM Sales NoSQL: Eine kurze Geschichte Internet-Boom: Erste Ansätze selbstgebauter "Datenbanken" Google stellt "MapReduce"
Oracle Big Data Technologien Ein Überblick Ralf Lange Global ISV & OEM Sales NoSQL: Eine kurze Geschichte Internet-Boom: Erste Ansätze selbstgebauter "Datenbanken" Google stellt "MapReduce"
MapReduce und Datenbanken Thema 15: Strom bzw. Onlineverarbeitung mit MapReduce
 MapReduce Jan Kristof Nidzwetzki MapReduce 1 / 17 Übersicht 1 Begriffe 2 Verschiedene Arbeiten 3 Ziele 4 DEDUCE: at the intersection of MapReduce and stream processing Beispiel 5 Beyond online aggregation:
MapReduce Jan Kristof Nidzwetzki MapReduce 1 / 17 Übersicht 1 Begriffe 2 Verschiedene Arbeiten 3 Ziele 4 DEDUCE: at the intersection of MapReduce and stream processing Beispiel 5 Beyond online aggregation:
Ein Beispiel. Ein Unternehmen will Internettechnologien im Rahmen des E- Business nutzen Welche Geschäftsprozesse?
 Ein Beispiel Ein Unternehmen will Internettechnologien im Rahmen des E- Business nutzen Welche Geschäftsprozesse? Dipl.-Kfm. Claus Häberle WS 2015 /16 # 42 XML (vereinfacht) visa
Ein Beispiel Ein Unternehmen will Internettechnologien im Rahmen des E- Business nutzen Welche Geschäftsprozesse? Dipl.-Kfm. Claus Häberle WS 2015 /16 # 42 XML (vereinfacht) visa
BigTable. 11.12.2012 Else
 BigTable 11.12.2012 Else Einführung Distributed Storage System im Einsatz bei Google (2006) speichert strukturierte Daten petabyte-scale, > 1000 Nodes nicht relational, NoSQL setzt auf GFS auf 11.12.2012
BigTable 11.12.2012 Else Einführung Distributed Storage System im Einsatz bei Google (2006) speichert strukturierte Daten petabyte-scale, > 1000 Nodes nicht relational, NoSQL setzt auf GFS auf 11.12.2012
SQL on Hadoop für praktikables BI auf Big Data.! Hans-Peter Zorn und Dr. Dominik Benz, Inovex Gmbh
 SQL on Hadoop für praktikables BI auf Big Data! Hans-Peter Zorn und Dr. Dominik Benz, Inovex Gmbh War nicht BigData das gleiche NoSQL? 2 Wie viele SQL Lösungen für Hadoop gibt es mittlerweile? 3 ! No SQL!?
SQL on Hadoop für praktikables BI auf Big Data! Hans-Peter Zorn und Dr. Dominik Benz, Inovex Gmbh War nicht BigData das gleiche NoSQL? 2 Wie viele SQL Lösungen für Hadoop gibt es mittlerweile? 3 ! No SQL!?
Big Data in der Forschung
 Big Data in der Forschung Dominik Friedrich RWTH Aachen Rechen- und Kommunikationszentrum (RZ) Gartner Hype Cycle July 2011 Folie 2 Was ist Big Data? Was wird unter Big Data verstanden Datensätze, die
Big Data in der Forschung Dominik Friedrich RWTH Aachen Rechen- und Kommunikationszentrum (RZ) Gartner Hype Cycle July 2011 Folie 2 Was ist Big Data? Was wird unter Big Data verstanden Datensätze, die
EXASOL Anwendertreffen 2012
 EXASOL Anwendertreffen 2012 EXAPowerlytics Feature-Architektur EXAPowerlytics In-Database Analytics Map / Reduce Algorithmen Skalare Fkt. Aggregats Fkt. Analytische Fkt. Hadoop Anbindung R LUA Python 2
EXASOL Anwendertreffen 2012 EXAPowerlytics Feature-Architektur EXAPowerlytics In-Database Analytics Map / Reduce Algorithmen Skalare Fkt. Aggregats Fkt. Analytische Fkt. Hadoop Anbindung R LUA Python 2
Einführung in Hadoop
 Einführung in Hadoop Inhalt / Lern-Ziele Übersicht: Basis-Architektur von Hadoop Einführung in HDFS Einführung in MapReduce Ausblick: Hadoop Ökosystem Optimierungen Versionen 10.02.2012 Prof. Dr. Christian
Einführung in Hadoop Inhalt / Lern-Ziele Übersicht: Basis-Architektur von Hadoop Einführung in HDFS Einführung in MapReduce Ausblick: Hadoop Ökosystem Optimierungen Versionen 10.02.2012 Prof. Dr. Christian
Peter Dikant mgm technology partners GmbH. Echtzeitsuche mit Hadoop und Solr
 Peter Dikant mgm technology partners GmbH Echtzeitsuche mit Hadoop und Solr ECHTZEITSUCHE MIT HADOOP UND SOLR PETER DIKANT MGM TECHNOLOGY PARTNERS GMBH WHOAMI peter.dikant@mgm-tp.com Java Entwickler seit
Peter Dikant mgm technology partners GmbH Echtzeitsuche mit Hadoop und Solr ECHTZEITSUCHE MIT HADOOP UND SOLR PETER DIKANT MGM TECHNOLOGY PARTNERS GMBH WHOAMI peter.dikant@mgm-tp.com Java Entwickler seit
Seminar Cloud Data Management WS09/10. Tabelle1 Tabelle2
 Seminar Cloud Data Management WS09/10 Tabelle1 Tabelle2 1 Einführung DBMS in der Cloud Vergleich verschiedener DBMS Beispiele Microsoft Azure Amazon RDS Amazon EC2 Relational Databases AMIs Was gibt es
Seminar Cloud Data Management WS09/10 Tabelle1 Tabelle2 1 Einführung DBMS in der Cloud Vergleich verschiedener DBMS Beispiele Microsoft Azure Amazon RDS Amazon EC2 Relational Databases AMIs Was gibt es
Seminar Informationsintegration und Informationsqualität. Dragan Sunjka. 30. Juni 2006
 Seminar Informationsintegration und Informationsqualität TU Kaiserslautern 30. Juni 2006 Gliederung Autonomie Verteilung führt zu Autonomie... Intra-Organisation: historisch Inter-Organisation: Internet
Seminar Informationsintegration und Informationsqualität TU Kaiserslautern 30. Juni 2006 Gliederung Autonomie Verteilung führt zu Autonomie... Intra-Organisation: historisch Inter-Organisation: Internet
Wide Column Stores. Felix Bruckner Mannheim, 15.06.2012
 Wide Column Stores Felix Bruckner Mannheim, 15.06.2012 Agenda Einführung Motivation Grundlagen NoSQL Grundlagen Wide Column Stores Anwendungsfälle Datenmodell Technik Wide Column Stores & Cloud Computing
Wide Column Stores Felix Bruckner Mannheim, 15.06.2012 Agenda Einführung Motivation Grundlagen NoSQL Grundlagen Wide Column Stores Anwendungsfälle Datenmodell Technik Wide Column Stores & Cloud Computing
Neue Ansätze der Softwarequalitätssicherung
 Neue Ansätze der Softwarequalitätssicherung Googles MapReduce-Framework für verteilte Berechnungen am Beispiel von Apache Hadoop Universität Paderborn Fakultät für Elektrotechnik, Informatik und Mathematik
Neue Ansätze der Softwarequalitätssicherung Googles MapReduce-Framework für verteilte Berechnungen am Beispiel von Apache Hadoop Universität Paderborn Fakultät für Elektrotechnik, Informatik und Mathematik
Analyse von unstrukturierten Daten. Peter Jeitschko, Nikolaus Schemel Oracle Austria
 Analyse von unstrukturierten Daten Peter Jeitschko, Nikolaus Schemel Oracle Austria Evolution von Business Intelligence Manuelle Analyse Berichte Datenbanken (strukturiert) Manuelle Analyse Dashboards
Analyse von unstrukturierten Daten Peter Jeitschko, Nikolaus Schemel Oracle Austria Evolution von Business Intelligence Manuelle Analyse Berichte Datenbanken (strukturiert) Manuelle Analyse Dashboards
Fragenkatalog zum Kurs 1666 (Datenbanken in Rechnernetzen) Kurstext von SS 96
 Kurstext von SS 96") Fragenkatalog zum Kurs 1666 (Datenbanken in Rechnernetzen) Kurstext von SS 96 Dieser Fragenkatalog wurde aufgrund das Basistextes und zum Teil aus den Prüfungsprotokollen erstellt, um sich auf mögliche
Fragenkatalog zum Kurs 1666 (Datenbanken in Rechnernetzen) Kurstext von SS 96 Dieser Fragenkatalog wurde aufgrund das Basistextes und zum Teil aus den Prüfungsprotokollen erstellt, um sich auf mögliche
Prototypenentwicklung zur Identifikation gleichartiger Nachrichtenticker am Beispiel des Gashandels
 Prototypenentwicklung zur Identifikation gleichartiger Nachrichtenticker am Beispiel des Gashandels TDWI Konferenz München, 24.06.2014 M.Sc.Susann Dreikorn Institut für Wirtschaftsinformatik, 2014 Agenda
Prototypenentwicklung zur Identifikation gleichartiger Nachrichtenticker am Beispiel des Gashandels TDWI Konferenz München, 24.06.2014 M.Sc.Susann Dreikorn Institut für Wirtschaftsinformatik, 2014 Agenda
AS/point, Ihr Partner die nächsten 10 und mehr Jahre -
 AS/point, Ihr Partner die nächsten 10 und mehr Jahre - technologisch betrachtet http://www.aspoint.de 1 Unsere vier Säulen heute e-waw modulare Warenwirtschaft für iseries evo-one Organisation und CRM
AS/point, Ihr Partner die nächsten 10 und mehr Jahre - technologisch betrachtet http://www.aspoint.de 1 Unsere vier Säulen heute e-waw modulare Warenwirtschaft für iseries evo-one Organisation und CRM
Apache Hadoop. Distribute your data and your application. Bernd Fondermann freier Software Architekt bernd.fondermann@brainlounge.de berndf@apache.
 Apache Hadoop Distribute your data and your application Bernd Fondermann freier Software Architekt bernd.fondermann@brainlounge.de berndf@apache.org Apache The Apache Software Foundation Community und
Apache Hadoop Distribute your data and your application Bernd Fondermann freier Software Architekt bernd.fondermann@brainlounge.de berndf@apache.org Apache The Apache Software Foundation Community und
Definition Informationssystem
 Definition Informationssystem Informationssysteme (IS) sind soziotechnische Systeme, die menschliche und maschinelle Komponenten umfassen. Sie unterstützen die Sammlung, Verarbeitung, Bereitstellung, Kommunikation
Definition Informationssystem Informationssysteme (IS) sind soziotechnische Systeme, die menschliche und maschinelle Komponenten umfassen. Sie unterstützen die Sammlung, Verarbeitung, Bereitstellung, Kommunikation
Clustering mit Shared Storage. Ing. Peter-Paul Witta paul.witta@cubit.at
 Clustering mit Shared Storage Ing. Peter-Paul Witta paul.witta@cubit.at Clustering mehrere kleine Rechner leisten gemeinsam Grosses günstige dual intel/amd Server load sharing High Availability combined
Clustering mit Shared Storage Ing. Peter-Paul Witta paul.witta@cubit.at Clustering mehrere kleine Rechner leisten gemeinsam Grosses günstige dual intel/amd Server load sharing High Availability combined
Markus Feichtinger. Power Systems. Der Weg zu POWER! 2009 IBM Corporation
 Markus Feichtinger Power Systems Der Weg zu POWER! Agenda Motivation Lösung Beispiel Export / Import - Überblick - Migration Beispiel XenoBridge - Überblick - Migration Benefits 2 Motivation Strategisch
Markus Feichtinger Power Systems Der Weg zu POWER! Agenda Motivation Lösung Beispiel Export / Import - Überblick - Migration Beispiel XenoBridge - Überblick - Migration Benefits 2 Motivation Strategisch
Oracle Data Warehouse Mit Big Data neue Horizonte für das Data Warehouse ermöglichen
 DATA WAREHOUSE Oracle Data Warehouse Mit Big Data neue Horizonte für das Data Warehouse ermöglichen Alfred Schlaucher, Detlef Schroeder DATA WAREHOUSE Themen Big Data Buzz Word oder eine neue Dimension
DATA WAREHOUSE Oracle Data Warehouse Mit Big Data neue Horizonte für das Data Warehouse ermöglichen Alfred Schlaucher, Detlef Schroeder DATA WAREHOUSE Themen Big Data Buzz Word oder eine neue Dimension
Persönlichkeiten bei bluehands
 Persönlichkeiten bei Technologien bei Skalierbare Anwendungen mit Windows Azure GmbH & co.mmunication KG am@.de; posts..de/am 1 2 3 4 5 6 7 8 9 Immer mehr Mehr Performance Mehr Menge Mehr Verfügbarkeit
Persönlichkeiten bei Technologien bei Skalierbare Anwendungen mit Windows Azure GmbH & co.mmunication KG am@.de; posts..de/am 1 2 3 4 5 6 7 8 9 Immer mehr Mehr Performance Mehr Menge Mehr Verfügbarkeit
Hadoop aus IT-Operations Sicht Teil 1 Hadoop-Grundlagen
 Hadoop aus IT-Operations Sicht Teil 1 Hadoop-Grundlagen Brownbag am Freitag, den 26.07.2013 Daniel Bäurer inovex GmbH Systems Engineer Wir nutzen Technologien, um unsere Kunden glücklich zu machen. Und
Hadoop aus IT-Operations Sicht Teil 1 Hadoop-Grundlagen Brownbag am Freitag, den 26.07.2013 Daniel Bäurer inovex GmbH Systems Engineer Wir nutzen Technologien, um unsere Kunden glücklich zu machen. Und
PostgreSQL in großen Installationen
 PostgreSQL in großen Installationen Cybertec Schönig & Schönig GmbH Hans-Jürgen Schönig Wieso PostgreSQL? - Die fortschrittlichste Open Source Database - Lizenzpolitik: wirkliche Freiheit - Stabilität,
PostgreSQL in großen Installationen Cybertec Schönig & Schönig GmbH Hans-Jürgen Schönig Wieso PostgreSQL? - Die fortschrittlichste Open Source Database - Lizenzpolitik: wirkliche Freiheit - Stabilität,
Prof. Dr.-Ing. Rainer Schmidt 1
 Prof. Dr.-Ing. Rainer Schmidt 1 Business Analytics und Big Data sind Thema vieler Veröffentlichungen. Big Data wird immer häufiger bei Google als Suchbegriff verwendet. Prof. Dr.-Ing. Rainer Schmidt 2
Prof. Dr.-Ing. Rainer Schmidt 1 Business Analytics und Big Data sind Thema vieler Veröffentlichungen. Big Data wird immer häufiger bei Google als Suchbegriff verwendet. Prof. Dr.-Ing. Rainer Schmidt 2
Storage-Trends am LRZ. Dr. Christoph Biardzki
 Storage-Trends am LRZ Dr. Christoph Biardzki 1 Über das Leibniz-Rechenzentrum (LRZ) Seit 50 Jahren Rechenzentrum der Bayerischen Akademie der Wissenschaften IT-Dienstleister für Münchner Universitäten
Storage-Trends am LRZ Dr. Christoph Biardzki 1 Über das Leibniz-Rechenzentrum (LRZ) Seit 50 Jahren Rechenzentrum der Bayerischen Akademie der Wissenschaften IT-Dienstleister für Münchner Universitäten
Excel beschleunigen mit dem mit Windows HPC Server 2008 R2
 Excel beschleunigen mit dem mit Windows HPC Server 2008 R2 Steffen Krause Technical Evangelist Microsoft Deutschland GmbH http://blogs.technet.com/steffenk Haftungsausschluss Microsoft kann für die Richtigkeit
Excel beschleunigen mit dem mit Windows HPC Server 2008 R2 Steffen Krause Technical Evangelist Microsoft Deutschland GmbH http://blogs.technet.com/steffenk Haftungsausschluss Microsoft kann für die Richtigkeit
RavenDB, schnell und skalierbar
 RavenDB, schnell und skalierbar Big Data & NoSQL, Aydin Mir Mohammadi bluehands GmbH & Co.mmunication KG am@bluehands.de Immer mehr Mehr Performance Mehr Menge Mehr Verfügbarkeit Skalierung http://www.flickr.com/photos/39901968@n04/4864698533/
RavenDB, schnell und skalierbar Big Data & NoSQL, Aydin Mir Mohammadi bluehands GmbH & Co.mmunication KG am@bluehands.de Immer mehr Mehr Performance Mehr Menge Mehr Verfügbarkeit Skalierung http://www.flickr.com/photos/39901968@n04/4864698533/
peer-to-peer Dateisystem Synchronisation
 Ziel Realisierungen Coda Ideen Fazit Literatur peer-to-peer Dateisystem Synchronisation Studiendepartment Informatik Hochschule für Angewandte Wissenschaften Hamburg 30. November 2007 Ziel Realisierungen
Ziel Realisierungen Coda Ideen Fazit Literatur peer-to-peer Dateisystem Synchronisation Studiendepartment Informatik Hochschule für Angewandte Wissenschaften Hamburg 30. November 2007 Ziel Realisierungen
Projektpraktikum: Verteilte Datenverarbeitung mit MapReduce
 Projektpraktikum: Verteilte Datenverarbeitung mit MapReduce Timo Bingmann, Peter Sanders und Sebastian Schlag 21. Oktober 2014 @ PdF Vorstellung INSTITUTE OF THEORETICAL INFORMATICS ALGORITHMICS KIT Universität
Projektpraktikum: Verteilte Datenverarbeitung mit MapReduce Timo Bingmann, Peter Sanders und Sebastian Schlag 21. Oktober 2014 @ PdF Vorstellung INSTITUTE OF THEORETICAL INFORMATICS ALGORITHMICS KIT Universität
MySQL High Availability. DOAG 2013 Datenbank. 14. Mai 2013, Düsseldorf. Oli Sennhauser
 MySQL High Availability DOAG 2013 Datenbank 14. Mai 2013, Düsseldorf Oli Sennhauser Senior MySQL Berater, FromDual GmbH oli.sennhauser@fromdual.com 1 / 23 Über FromDual GmbH FromDual bietet neutral und
MySQL High Availability DOAG 2013 Datenbank 14. Mai 2013, Düsseldorf Oli Sennhauser Senior MySQL Berater, FromDual GmbH oli.sennhauser@fromdual.com 1 / 23 Über FromDual GmbH FromDual bietet neutral und
Was ist Windows Azure? (Stand Juni 2012)
") Was ist Windows Azure? (Stand Juni 2012) Windows Azure Microsofts Cloud Plattform zu Erstellung, Betrieb und Skalierung eigener Cloud-basierter Anwendungen Cloud Services Laufzeitumgebung, Speicher, Datenbank,
Was ist Windows Azure? (Stand Juni 2012) Windows Azure Microsofts Cloud Plattform zu Erstellung, Betrieb und Skalierung eigener Cloud-basierter Anwendungen Cloud Services Laufzeitumgebung, Speicher, Datenbank,
Allgemeines zu Datenbanken
 Allgemeines zu Datenbanken Was ist eine Datenbank? Datensatz Zusammenfassung von Datenelementen mit fester Struktur Z.B.: Kunde Alois Müller, Hegenheimerstr. 28, Basel Datenbank Sammlung von strukturierten,
Allgemeines zu Datenbanken Was ist eine Datenbank? Datensatz Zusammenfassung von Datenelementen mit fester Struktur Z.B.: Kunde Alois Müller, Hegenheimerstr. 28, Basel Datenbank Sammlung von strukturierten,
Dateisysteme und Datenverwaltung in der Cloud
 Dateisysteme und Datenverwaltung in der Cloud Sebastian Fischer Master-Seminar Cloud Computing - WS 2013/14 Institut für Telematik, Universität zu Lübeck Dateisysteme und Datenverwaltung in der Cloud 1
Dateisysteme und Datenverwaltung in der Cloud Sebastian Fischer Master-Seminar Cloud Computing - WS 2013/14 Institut für Telematik, Universität zu Lübeck Dateisysteme und Datenverwaltung in der Cloud 1
ISBN: 978-3-8428-0679-5 Herstellung: Diplomica Verlag GmbH, Hamburg, 2011
 Nils Petersohn Vergleich und Evaluation zwischen modernen und traditionellen Datenbankkonzepten unter den Gesichtspunkten Skalierung, Abfragemöglichkeit und Konsistenz Diplomica Verlag Nils Petersohn Vergleich
Nils Petersohn Vergleich und Evaluation zwischen modernen und traditionellen Datenbankkonzepten unter den Gesichtspunkten Skalierung, Abfragemöglichkeit und Konsistenz Diplomica Verlag Nils Petersohn Vergleich
Datenverzeichnis backupen MySQLdump Replication. MySQL 4, 5. Kapitel 12: Backup. Marcel Noe
 MySQL 4, 5 Kapitel 12: Backup Gliederung 1 2 3 Gliederung 1 2 3 Eine sehr einfache Form des Backup stellt das backupen des Datenverzeichnisses mittels konventioneller Backup Tools dar. Syntax cp -ar /var/lib/mysql
MySQL 4, 5 Kapitel 12: Backup Gliederung 1 2 3 Gliederung 1 2 3 Eine sehr einfache Form des Backup stellt das backupen des Datenverzeichnisses mittels konventioneller Backup Tools dar. Syntax cp -ar /var/lib/mysql
Ralf Simon, DV-Orga - Kreisverwaltung Birkenfeld
 Ralf Simon, DV-Orga - Kreisverwaltung Birkenfeld Inhalt: Ausgangssituation vor Virtualisierung Wünsche an eine neue Lösung Migration mit CITRIX-Xen-Server-Technologie Management-Konsole Was hat uns die
Ralf Simon, DV-Orga - Kreisverwaltung Birkenfeld Inhalt: Ausgangssituation vor Virtualisierung Wünsche an eine neue Lösung Migration mit CITRIX-Xen-Server-Technologie Management-Konsole Was hat uns die
Infografik Business Intelligence
 Infografik Business Intelligence Top 5 Ziele 1 Top 5 Probleme 3 Im Geschäft bleiben 77% Komplexität 28,6% Vertrauen in Zahlen sicherstellen 76% Anforderungsdefinitionen 24,9% Wirtschaflicher Ressourceneinsatz
Infografik Business Intelligence Top 5 Ziele 1 Top 5 Probleme 3 Im Geschäft bleiben 77% Komplexität 28,6% Vertrauen in Zahlen sicherstellen 76% Anforderungsdefinitionen 24,9% Wirtschaflicher Ressourceneinsatz
Hadoop-as-a-Service (HDaaS)
") Hadoop-as-a-Service (HDaaS) Flexible und skalierbare Referenzarchitektur Arnold Müller freier IT Mitarbeiter und Geschäftsführer Lena Frank Systems Engineer @ EMC Marius Lohr Systems Engineer @ EMC Fallbeispiel:
Hadoop-as-a-Service (HDaaS) Flexible und skalierbare Referenzarchitektur Arnold Müller freier IT Mitarbeiter und Geschäftsführer Lena Frank Systems Engineer @ EMC Marius Lohr Systems Engineer @ EMC Fallbeispiel:
Big Data im Call Center: Kundenbindung verbessern, Antwortzeiten verkürzen, Kosten reduzieren! 25.02.2016 Sascha Bäcker Dr.
 Big Data im Call Center: Kundenbindung verbessern, Antwortzeiten verkürzen, Kosten reduzieren! 25.02.2016 Sascha Bäcker Dr. Florian Johannsen AGENDA 1. Big Data Projekt der freenet Group Dr. Florian Johannsen
Big Data im Call Center: Kundenbindung verbessern, Antwortzeiten verkürzen, Kosten reduzieren! 25.02.2016 Sascha Bäcker Dr. Florian Johannsen AGENDA 1. Big Data Projekt der freenet Group Dr. Florian Johannsen
Big Data: Nutzen und Anwendungsszenarien. CeBIT 2014 Dr. Carsten Bange, Gründer und Geschäftsführer BARC
 Big Data: Nutzen und Anwendungsszenarien CeBIT 2014 Dr. Carsten Bange, Gründer und Geschäftsführer BARC Big Data steht für den unaufhaltsamen Trend, dass immer mehr Daten in Unternehmen anfallen und von
Big Data: Nutzen und Anwendungsszenarien CeBIT 2014 Dr. Carsten Bange, Gründer und Geschäftsführer BARC Big Data steht für den unaufhaltsamen Trend, dass immer mehr Daten in Unternehmen anfallen und von
HANDBUCH LSM GRUNDLAGEN LSM
 Seite 1 1.0 GRUNDLAGEN LSM 1.1. SYSTEMVORAUSSETZUNGEN AB LSM 3.1 SP1 (ÄNDERUNGEN VORBEHALTEN) ALLGEMEIN Lokale Administratorrechte zur Installation Kommunikation: TCP/IP (NetBios aktiv), LAN (Empfehlung:
Seite 1 1.0 GRUNDLAGEN LSM 1.1. SYSTEMVORAUSSETZUNGEN AB LSM 3.1 SP1 (ÄNDERUNGEN VORBEHALTEN) ALLGEMEIN Lokale Administratorrechte zur Installation Kommunikation: TCP/IP (NetBios aktiv), LAN (Empfehlung:
Systemanforderungen für MuseumPlus und emuseumplus
 Systemanforderungen für MuseumPlus und emuseumplus Systemanforderungen für MuseumPlus und emuseumplus Gültig ab: 01.03.2015 Neben den aufgeführten Systemvoraussetzungen gelten zusätzlich die Anforderungen,
Systemanforderungen für MuseumPlus und emuseumplus Systemanforderungen für MuseumPlus und emuseumplus Gültig ab: 01.03.2015 Neben den aufgeführten Systemvoraussetzungen gelten zusätzlich die Anforderungen,
Teamprojekt & Projekt
 2. November 2010 Teamprojekt & Projekt Veranstalter: Betreuer: Prof. Dr. Georg Lausen Alexander Schätzle, Martin Przjyaciel-Zablocki, Thomas Hornung dbis Studienordnung Master: 16 ECTS 480 Semesterstunden
2. November 2010 Teamprojekt & Projekt Veranstalter: Betreuer: Prof. Dr. Georg Lausen Alexander Schätzle, Martin Przjyaciel-Zablocki, Thomas Hornung dbis Studienordnung Master: 16 ECTS 480 Semesterstunden
Systemvoraussetzungen winvs office winvs advisor
 Systemvoraussetzungen winvs office winvs advisor Stand Januar 2014 Software für die Versicherungsund Finanzverwaltung Handbuch-Version 1.8 Copyright 1995-2014 by winvs software AG, alle Rechte vorbehalten
Systemvoraussetzungen winvs office winvs advisor Stand Januar 2014 Software für die Versicherungsund Finanzverwaltung Handbuch-Version 1.8 Copyright 1995-2014 by winvs software AG, alle Rechte vorbehalten
Infrastruktur fit machen für Hochverfügbarkeit, Workload Management und Skalierbarkeit
 make connections share ideas be inspired Infrastruktur fit machen für Hochverfügbarkeit, Workload Management und Skalierbarkeit Artur Eigenseher, SAS Deutschland Herausforderungen SAS Umgebungen sind in
make connections share ideas be inspired Infrastruktur fit machen für Hochverfügbarkeit, Workload Management und Skalierbarkeit Artur Eigenseher, SAS Deutschland Herausforderungen SAS Umgebungen sind in
OSEK-OS. Oliver Botschkowski. oliver.botschkowski@udo.edu. PG AutoLab Seminarwochenende 21.-23. Oktober 2007. AutoLab
 OSEK-OS Oliver Botschkowski oliver.botschkowski@udo.edu PG Seminarwochenende 21.-23. Oktober 2007 1 Überblick Einleitung Motivation Ziele Vorteile Einführung in OSEK-OS Architektur Task Management Interrupt
OSEK-OS Oliver Botschkowski oliver.botschkowski@udo.edu PG Seminarwochenende 21.-23. Oktober 2007 1 Überblick Einleitung Motivation Ziele Vorteile Einführung in OSEK-OS Architektur Task Management Interrupt
NoSQL. Einblick in die Welt nicht-relationaler Datenbanken. Christoph Föhrdes. UnFUG, SS10 17.06.2010
 NoSQL Einblick in die Welt nicht-relationaler Datenbanken Christoph Föhrdes UnFUG, SS10 17.06.2010 About me Christoph Föhrdes AIB Semester 7 IRC: cfo #unfug@irc.ghb.fh-furtwangen.de netblox GbR (http://netblox.de)
NoSQL Einblick in die Welt nicht-relationaler Datenbanken Christoph Föhrdes UnFUG, SS10 17.06.2010 About me Christoph Föhrdes AIB Semester 7 IRC: cfo #unfug@irc.ghb.fh-furtwangen.de netblox GbR (http://netblox.de)
Datenbank-Service. RZ-Angebot zur Sicherstellung von Datenpersistenz. Thomas Eifert. Rechen- und Kommunikationszentrum (RZ)
") RZ-Angebot zur Sicherstellung von Datenpersistenz Thomas Eifert Rechen- und Kommunikationszentrum (RZ) Ausgangspunkt Beobachtungen: Für Datenhaltung /-Auswertung: Verschiebung weg von eigenen Schnittstellen
RZ-Angebot zur Sicherstellung von Datenpersistenz Thomas Eifert Rechen- und Kommunikationszentrum (RZ) Ausgangspunkt Beobachtungen: Für Datenhaltung /-Auswertung: Verschiebung weg von eigenen Schnittstellen
Prozessoptimierung in der Markt- und Medienforschung bei der Deutschen Welle (DW) mit Big Data Technologien. Berlin, Mai 2013
 mit Big Data Technologien. Berlin, Mai 2013") Prozessoptimierung in der Markt- und Medienforschung bei der Deutschen Welle (DW) mit Big Data Technologien Berlin, Mai 2013 The unbelievable Machine Company? 06.05.13 The unbelievable Machine Company
Prozessoptimierung in der Markt- und Medienforschung bei der Deutschen Welle (DW) mit Big Data Technologien Berlin, Mai 2013 The unbelievable Machine Company? 06.05.13 The unbelievable Machine Company
Copyr i g ht 2014, SAS Ins titut e Inc. All rights res er ve d. HERZLICH WILLKOMMEN ZUR VERANSTALTUNG VISUAL ANALYTICS
 HERZLICH WILLKOMMEN ZUR VERANSTALTUNG VISUAL ANALYTICS AGENDA VISUAL ANALYTICS 9:00 09:30 Das datengetriebene Unternehmen: Big Data Analytics mit SAS die digitale Transformation: Handlungsfelder für IT
HERZLICH WILLKOMMEN ZUR VERANSTALTUNG VISUAL ANALYTICS AGENDA VISUAL ANALYTICS 9:00 09:30 Das datengetriebene Unternehmen: Big Data Analytics mit SAS die digitale Transformation: Handlungsfelder für IT
Big-Data-Technologien - Überblick - Prof. Dr. Jens Albrecht
 Big-Data-Technologien - Überblick - Quelle: http://www.ingenieur.de/panorama/fussball-wm-in-brasilien/elektronischer-fussball-smartphone-app-helfen-training Big-Data-Anwendungen im Unternehmen Logistik
Big-Data-Technologien - Überblick - Quelle: http://www.ingenieur.de/panorama/fussball-wm-in-brasilien/elektronischer-fussball-smartphone-app-helfen-training Big-Data-Anwendungen im Unternehmen Logistik
FORGE2015 HDC Session 4. Nachhaltige Infrastruktur als technologische Herausforderung. Tibor Kálmán Tim Hasler Sven Bingert
 FORGE2015 HDC Session 4 Nachhaltige Infrastruktur als technologische Herausforderung Tibor Kálmán Tim Hasler Sven Bingert Diskussionsgrundlage: Liste der Infrastrukturprobleme Wir unterscheiden gute (leicht
FORGE2015 HDC Session 4 Nachhaltige Infrastruktur als technologische Herausforderung Tibor Kálmán Tim Hasler Sven Bingert Diskussionsgrundlage: Liste der Infrastrukturprobleme Wir unterscheiden gute (leicht
Oracle GridControl Tuning Pack. best Open Systems Day April 2010. Unterföhring. Marco Kühn best Systeme GmbH marco.kuehn@best.de
 Oracle GridControl Tuning Pack best Open Systems Day April 2010 Unterföhring Marco Kühn best Systeme GmbH marco.kuehn@best.de Agenda GridControl Overview Tuning Pack 4/26/10 Seite 2 Overview Grid Control
Oracle GridControl Tuning Pack best Open Systems Day April 2010 Unterföhring Marco Kühn best Systeme GmbH marco.kuehn@best.de Agenda GridControl Overview Tuning Pack 4/26/10 Seite 2 Overview Grid Control
vinsight BIG DATA Solution
 vinsight BIG DATA Solution München, November 2014 BIG DATA LÖSUNG VINSIGHT Datensilos erschweren eine einheitliche Sicht auf die Daten...... und machen diese teilweise unmöglich einzelne individuelle Konnektoren,
vinsight BIG DATA Solution München, November 2014 BIG DATA LÖSUNG VINSIGHT Datensilos erschweren eine einheitliche Sicht auf die Daten...... und machen diese teilweise unmöglich einzelne individuelle Konnektoren,
Big Data Anwendungen Chancen und Risiken
 Big Data Anwendungen Chancen und Risiken Dr. Kurt Stockinger Studienleiter Data Science, Dozent für Informatik Zürcher Hochschule für Angewandte Wissenschaften Big Data Workshop Squeezing more out of Data
Big Data Anwendungen Chancen und Risiken Dr. Kurt Stockinger Studienleiter Data Science, Dozent für Informatik Zürcher Hochschule für Angewandte Wissenschaften Big Data Workshop Squeezing more out of Data
TELEMETRIE EINER ANWENDUNG
 TELEMETRIE EINER ANWENDUNG VISUAL STUDIO APPLICATION INSIGHTS BORIS WEHRLE TELEMETRIE 2 TELEMETRIE WELCHE ZIELE WERDEN VERFOLGT? Erkennen von Zusammenhängen Vorausschauendes Erkennen von Problemen um rechtzeitig
TELEMETRIE EINER ANWENDUNG VISUAL STUDIO APPLICATION INSIGHTS BORIS WEHRLE TELEMETRIE 2 TELEMETRIE WELCHE ZIELE WERDEN VERFOLGT? Erkennen von Zusammenhängen Vorausschauendes Erkennen von Problemen um rechtzeitig
BI in der Cloud eine valide Alternative Überblick zum Leistungsspektrum und erste Erfahrungen 11.15 11.45
 9.30 10.15 Kaffee & Registrierung 10.15 10.45 Begrüßung & aktuelle Entwicklungen bei QUNIS 10.45 11.15 11.15 11.45 Von Big Data zu Executive Decision BI für den Fachanwender bis hin zu Advanced Analytics
9.30 10.15 Kaffee & Registrierung 10.15 10.45 Begrüßung & aktuelle Entwicklungen bei QUNIS 10.45 11.15 11.15 11.45 Von Big Data zu Executive Decision BI für den Fachanwender bis hin zu Advanced Analytics
IT im Wandel Kommunale Anforderungen - zentrales Clientmanagement versus Standardtechnologie!?
 IT im Wandel Kommunale Anforderungen - zentrales Clientmanagement versus Standardtechnologie!? Visitenkarte Name: email: Telefon: Funktion: Jürgen Siemon Juergen.Siemon@ekom21.de 0561.204-1246 Fachbereichsleiter
IT im Wandel Kommunale Anforderungen - zentrales Clientmanagement versus Standardtechnologie!? Visitenkarte Name: email: Telefon: Funktion: Jürgen Siemon Juergen.Siemon@ekom21.de 0561.204-1246 Fachbereichsleiter
Open Source BI 2009 Flexibilität und volle Excel-Integration von Palo machen OLAP für Endanwender beherrschbar. 24. September 2009
 Open Source BI 2009 Flexibilität und volle Excel-Integration von Palo machen OLAP für Endanwender beherrschbar 24. September 2009 Unternehmensdarstellung Burda Digital Systems ist eine eigenständige und
Open Source BI 2009 Flexibilität und volle Excel-Integration von Palo machen OLAP für Endanwender beherrschbar 24. September 2009 Unternehmensdarstellung Burda Digital Systems ist eine eigenständige und
Cloud-Provider im Vergleich. Markus Knittig @mknittig
 Cloud-Provider im Vergleich Markus Knittig @mknittig As Amazon accumulated more and more services, the productivity levels in producing innovation and value were dropping primarily because the engineers
Cloud-Provider im Vergleich Markus Knittig @mknittig As Amazon accumulated more and more services, the productivity levels in producing innovation and value were dropping primarily because the engineers
Business Analytics Die Finanzfunktion auf dem Weg zur Strategieberatung? IBM Finance Forum, 20. März 2013 Prof. Dr.
 v Business Analytics Die Finanzfunktion auf dem Weg zur Strategieberatung? IBM Finance Forum, 20. März 2013 Prof. Dr. Gerhard Satzger Agenda 1. Wie sieht die erfolgreiche Finanzfunktion von morgen aus?
v Business Analytics Die Finanzfunktion auf dem Weg zur Strategieberatung? IBM Finance Forum, 20. März 2013 Prof. Dr. Gerhard Satzger Agenda 1. Wie sieht die erfolgreiche Finanzfunktion von morgen aus?
Windows HPC Server 2008 aus der Betreiberperspektive
 Windows HPC Server 2008 aus der Betreiberperspektive Michael Wirtz wirtz@rz.rwth aachen.de Rechen und Kommunikationszentrum RWTH Aachen WinHPC User Group Meeting 2009 30./31. März 09, Dresden Agenda o
Windows HPC Server 2008 aus der Betreiberperspektive Michael Wirtz wirtz@rz.rwth aachen.de Rechen und Kommunikationszentrum RWTH Aachen WinHPC User Group Meeting 2009 30./31. März 09, Dresden Agenda o
Citrix XenDesktopHDX 3D Pro
 Citrix XenDesktopHDX 3D Pro Johannes Steinemann Teamleiter IT-Solutions/Virtualisierung Geschäftsmodell der encadconsulting Die encadconsultingversteht CAD-Installationsumgebungen nicht als abgegrenzte
Citrix XenDesktopHDX 3D Pro Johannes Steinemann Teamleiter IT-Solutions/Virtualisierung Geschäftsmodell der encadconsulting Die encadconsultingversteht CAD-Installationsumgebungen nicht als abgegrenzte
Diplomarbeit: GOMMA: Eine Plattform zur flexiblen Verwaltung und Analyse von Ontologie Mappings in der Bio-/Medizininformatik
 Diplomarbeit: GOMMA: Eine Plattform zur flexiblen Verwaltung und Analyse von Ontologie Mappings in der Bio-/Medizininformatik Bearbeiter: Shuangqing He Betreuer: Toralf Kirsten, Michael Hartung Universität
Diplomarbeit: GOMMA: Eine Plattform zur flexiblen Verwaltung und Analyse von Ontologie Mappings in der Bio-/Medizininformatik Bearbeiter: Shuangqing He Betreuer: Toralf Kirsten, Michael Hartung Universität
20.01.2015 Fabian Grimme und Tino Krüger 1 INDREX. Evaluierung von H2O. Enterprise Data Management Beuth Hochschule für Technik
 20.01.2015 Fabian Grimme und Tino Krüger 1 INDREX Evaluierung von H2O Enterprise Data Management Beuth Hochschule für Technik 20.01.2015 Fabian Grimme und Tino Krüger 2 INDREX im Überblick In-Database
20.01.2015 Fabian Grimme und Tino Krüger 1 INDREX Evaluierung von H2O Enterprise Data Management Beuth Hochschule für Technik 20.01.2015 Fabian Grimme und Tino Krüger 2 INDREX im Überblick In-Database
Unternehmen und IT im Wandel: Mit datengetriebenen Innovationen zum Digital Enterprise
 Unternehmen und IT im Wandel: Mit datengetriebenen Innovationen zum Digital Enterprise Software AG Innovation Day 2014 Bonn, 2.7.2014 Dr. Carsten Bange, Geschäftsführer Business Application Research Center
Unternehmen und IT im Wandel: Mit datengetriebenen Innovationen zum Digital Enterprise Software AG Innovation Day 2014 Bonn, 2.7.2014 Dr. Carsten Bange, Geschäftsführer Business Application Research Center
REGIONALES RECHENZENTRUM ERLANGEN [ RRZE] Datenbanken. RRZE-Campustreffen, 11.06.2015 Stefan Roas und Ali Güclü Ercin, RRZE
![REGIONALES RECHENZENTRUM ERLANGEN [ RRZE] Datenbanken. RRZE-Campustreffen, 11.06.2015 Stefan Roas und Ali Güclü Ercin, RRZE](/thumbs/21/1205465.jpg "REGIONALES RECHENZENTRUM ERLANGEN [ RRZE] Datenbanken. RRZE-Campustreffen, 11.06.2015 Stefan Roas und Ali Güclü Ercin, RRZE") REGIONALES RECHENZENTRUM ERLANGEN [ RRZE] Datenbanken RRZE-Campustreffen, 11.06.2015 Stefan Roas und Ali Güclü Ercin, RRZE Agenda 1. Datenbankdienstleistungen des RRZE Überblick über die aktuell vorhandenen
REGIONALES RECHENZENTRUM ERLANGEN [ RRZE] Datenbanken RRZE-Campustreffen, 11.06.2015 Stefan Roas und Ali Güclü Ercin, RRZE Agenda 1. Datenbankdienstleistungen des RRZE Überblick über die aktuell vorhandenen
Schneller als Hadoop?
 Schneller als Hadoop? Einführung in Spark Cluster Computing 19.11.2013 Dirk Reinemann 1 Agenda 1. Einführung 2. Motivation 3. Infrastruktur 4. Performance 5. Ausblick 19.11.2013 Dirk Reinemann 2 EINFÜHRUNG
Schneller als Hadoop? Einführung in Spark Cluster Computing 19.11.2013 Dirk Reinemann 1 Agenda 1. Einführung 2. Motivation 3. Infrastruktur 4. Performance 5. Ausblick 19.11.2013 Dirk Reinemann 2 EINFÜHRUNG
Wide column-stores für Architekten
 Wide column-stores für Architekten Andreas Buckenhofer Daimler TSS GmbH Ulm Schlüsselworte Big Data, Hadoop, HBase, Cassandra, Use Cases, Row Key, Hash Table NoSQL Datenbanken In den letzten Jahren wurden
Wide column-stores für Architekten Andreas Buckenhofer Daimler TSS GmbH Ulm Schlüsselworte Big Data, Hadoop, HBase, Cassandra, Use Cases, Row Key, Hash Table NoSQL Datenbanken In den letzten Jahren wurden
BIG UNIVERSITÄTSRECHENZENTRUM
 UNIVERSITÄTS RECHENZENTRUM LEIPZIG BIG DATA @ UNIVERSITÄTSRECHENZENTRUM Forschung und Entwicklung Entwicklung eines E-Science-Angebots für die Forschenden an der Universität Leipzig Stefan Kühne Axel Ngonga
UNIVERSITÄTS RECHENZENTRUM LEIPZIG BIG DATA @ UNIVERSITÄTSRECHENZENTRUM Forschung und Entwicklung Entwicklung eines E-Science-Angebots für die Forschenden an der Universität Leipzig Stefan Kühne Axel Ngonga
SAP HANA als In-Memory-Datenbank-Technologie für ein Enterprise Data Warehouse
 www.osram-os.com SAP HANA als In-Memory-Datenbank-Technologie für ein Enterprise Data Warehouse Oliver Neumann 08. September 2014 AKWI-Tagung 2014 Light is OSRAM Agenda 1. Warum In-Memory? 2. SAP HANA
www.osram-os.com SAP HANA als In-Memory-Datenbank-Technologie für ein Enterprise Data Warehouse Oliver Neumann 08. September 2014 AKWI-Tagung 2014 Light is OSRAM Agenda 1. Warum In-Memory? 2. SAP HANA
Solaris Cluster. Dipl. Inform. Torsten Kasch <tk@cebitec.uni Bielefeld.DE> 8. Januar 2008
 Dipl. Inform. Torsten Kasch 8. Januar 2008 Agenda Übersicht Cluster Hardware Cluster Software Konzepte: Data Services, Resources, Quorum Solaris Cluster am CeBiTec: HA Datenbank
Dipl. Inform. Torsten Kasch 8. Januar 2008 Agenda Übersicht Cluster Hardware Cluster Software Konzepte: Data Services, Resources, Quorum Solaris Cluster am CeBiTec: HA Datenbank
EXCHANGE 2013. Neuerungen und Praxis
 EXCHANGE 2013 Neuerungen und Praxis EXCHANGE 2013 EXCHANGE 2013 NEUERUNGEN UND PRAXIS Kevin Momber-Zemanek seit September 2011 bei der PROFI Engineering Systems AG Cisco Spezialisierung Cisco Data Center
EXCHANGE 2013 Neuerungen und Praxis EXCHANGE 2013 EXCHANGE 2013 NEUERUNGEN UND PRAXIS Kevin Momber-Zemanek seit September 2011 bei der PROFI Engineering Systems AG Cisco Spezialisierung Cisco Data Center
NoSQL. Was Architekten beachten sollten. Dr. Halil-Cem Gürsoy adesso AG. Architekturtag @ SEACON 2012 Hamburg
 NoSQL Was Architekten beachten sollten Dr. Halil-Cem Gürsoy adesso AG Architekturtag @ SEACON 2012 Hamburg 06.06.2012 Agenda Ein Blick in die Welt der RDBMS Klassifizierung von NoSQL-Datenbanken Gemeinsamkeiten
NoSQL Was Architekten beachten sollten Dr. Halil-Cem Gürsoy adesso AG Architekturtag @ SEACON 2012 Hamburg 06.06.2012 Agenda Ein Blick in die Welt der RDBMS Klassifizierung von NoSQL-Datenbanken Gemeinsamkeiten
XAMPP-Systeme. Teil 3: My SQL. PGP II/05 MySQL
 XAMPP-Systeme Teil 3: My SQL Daten Eine Wesenseigenschaft von Menschen ist es, Informationen, in welcher Form sie auch immer auftreten, zu ordnen, zu klassifizieren und in strukturierter Form abzulegen.
XAMPP-Systeme Teil 3: My SQL Daten Eine Wesenseigenschaft von Menschen ist es, Informationen, in welcher Form sie auch immer auftreten, zu ordnen, zu klassifizieren und in strukturierter Form abzulegen.
Dell Data Protection Solutions Datensicherungslösungen von Dell
 Dell Data Protection Solutions Datensicherungslösungen von Dell André Plagemann SME DACH Region SME Data Protection DACH Region Dell Softwarelösungen Vereinfachung der IT. Minimierung von Risiken. Schnellere
Dell Data Protection Solutions Datensicherungslösungen von Dell André Plagemann SME DACH Region SME Data Protection DACH Region Dell Softwarelösungen Vereinfachung der IT. Minimierung von Risiken. Schnellere
Abschlussarbeiten für StudentInnen
 Camunda bietet StudentInnen die Möglichkeit, ihre Abschlussarbeit zu einem praxisnahen und wirtschaftlich relevanten Thema zu schreiben. Alle Themen im Überblick Elasticsearch (Backend) Java Client (Backend)
Camunda bietet StudentInnen die Möglichkeit, ihre Abschlussarbeit zu einem praxisnahen und wirtschaftlich relevanten Thema zu schreiben. Alle Themen im Überblick Elasticsearch (Backend) Java Client (Backend)
Mission. TARGIT macht es einfach und bezahlbar für Organisationen datengetrieben zu werden
 Mission TARGIT macht es einfach und bezahlbar für Organisationen datengetrieben zu werden Der Weg zu einem datengesteuerten Unternehmen # Datenquellen x Größe der Daten Basic BI & Analytics Aufbau eines
Mission TARGIT macht es einfach und bezahlbar für Organisationen datengetrieben zu werden Der Weg zu einem datengesteuerten Unternehmen # Datenquellen x Größe der Daten Basic BI & Analytics Aufbau eines
Unsere Kassenlösung Cashtex im Netzwerk
 Unsere nlösung im Netzwerk www.profitex-software.eu 1 V7 - Die kaufmännische nlösung Einplatzversion Beispiel: 1 nplatz nsystem: 1 nplatz (einfache Variante) Vorteil: kostengünstige Variante (erweiterungsfähig)
Unsere nlösung im Netzwerk www.profitex-software.eu 1 V7 - Die kaufmännische nlösung Einplatzversion Beispiel: 1 nplatz nsystem: 1 nplatz (einfache Variante) Vorteil: kostengünstige Variante (erweiterungsfähig)
Albert HAYR Linux, IT and Open Source Expert and Solution Architect. Open Source professionell einsetzen
 Open Source professionell einsetzen 1 Mein Background Ich bin überzeugt von Open Source. Ich verwende fast nur Open Source privat und beruflich. Ich arbeite seit mehr als 10 Jahren mit Linux und Open Source.
Open Source professionell einsetzen 1 Mein Background Ich bin überzeugt von Open Source. Ich verwende fast nur Open Source privat und beruflich. Ich arbeite seit mehr als 10 Jahren mit Linux und Open Source.
NoSQL Datenbanken am Beispiel von HBase. Daniel Georg
 NoSQL Datenbanken am Beispiel von HBase Daniel Georg No to SQL at all sondern Not only SQL Open- Source Community Erst im Jahr 2009 gestartet Community bietet verschiede Lösungen: Casandra, CouchDD, HBase,
NoSQL Datenbanken am Beispiel von HBase Daniel Georg No to SQL at all sondern Not only SQL Open- Source Community Erst im Jahr 2009 gestartet Community bietet verschiede Lösungen: Casandra, CouchDD, HBase,
Explosionsartige Zunahme an Informationen. 200 Mrd. Mehr als 200 Mrd. E-Mails werden jeden Tag versendet. 30 Mrd.
 Warum viele Daten für ein smartes Unternehmen wichtig sind Gerald AUFMUTH IBM Client Technical Specialst Data Warehouse Professional Explosionsartige Zunahme an Informationen Volumen. 15 Petabyte Menge
Warum viele Daten für ein smartes Unternehmen wichtig sind Gerald AUFMUTH IBM Client Technical Specialst Data Warehouse Professional Explosionsartige Zunahme an Informationen Volumen. 15 Petabyte Menge
Festpreisprojekte in Time und in Budget
 Festpreisprojekte in Time und in Budget Wie effizient kann J2EE Softwareentwicklung sein? Copyright 2006 GEBIT Solutions Agenda Positionierung der GEBIT Solutions Herausforderung Antwort Überblick Beispielprojekt
Festpreisprojekte in Time und in Budget Wie effizient kann J2EE Softwareentwicklung sein? Copyright 2006 GEBIT Solutions Agenda Positionierung der GEBIT Solutions Herausforderung Antwort Überblick Beispielprojekt
Projektarbeit POS II zum Thema Branchensoftware in der Druckindustrie. Ben Polter, Holger Räbiger, Kilian Mayer, Jochen Wied
 Projektarbeit POS II zum Thema Branchensoftware in der Druckindustrie Ben Polter, Holger Räbiger, Kilian Mayer, Jochen Wied Die SAP AG ist der größte europäische und weltweit drittgrößte Softwarehersteller.
Projektarbeit POS II zum Thema Branchensoftware in der Druckindustrie Ben Polter, Holger Räbiger, Kilian Mayer, Jochen Wied Die SAP AG ist der größte europäische und weltweit drittgrößte Softwarehersteller.