BigTable Else
|
|
|
- Karin Kramer
- vor 8 Jahren
- Abrufe
Transkript
1 BigTable Else

2 Einführung Distributed Storage System im Einsatz bei Google (2006) speichert strukturierte Daten petabyte-scale, > 1000 Nodes nicht relational, NoSQL setzt auf GFS auf RaumZeitLabor e.v. 2

3 Die BigTable dünnbesetzte, sortierte, multidimensionale Map bt[row: str; column: str; time: int] value Row: bis zu 64kb, lexikographisch sortiert Value: uninterpretiertes Byte-Array RaumZeitLabor e.v. 3
![int] value Row: bis zu 64kb, lexikographisch sortiert](/docs-images/46/2165632/images/page_3.jpg "Value: uninterpretiertes Byte-Array 11.12.")
4 Columns bestehen aus Column Family und Qualifier column := family:qualifier Family muss vorher angelegt werden Daten in Column Family vom selben Typ werden zusammen komprimiert wenige Column Families, unbegrenzt viele Qualifier Grundlage für ACL RaumZeitLabor e.v. 4

5 Timestamps jede Zelle kann beliebig viele Versionen haben Versionen: 64-bit Integer frei wählbar oder vom System vergeben in umgekehrter Reihenfolge gespeichert Garbage Collection: letzte n Versionen (Anzahl) neueste Versionen (Alter) RaumZeitLabor e.v. 5
 neueste Versionen (Alter) 11.12.")
6 Beispiel: Webtable com.cnn.www Row Key contents Column Family anchor Column Family cnnsi.com Column Qualifier t n Versionen RaumZeitLabor e.v. 6

7 API: Schreiben Table *T = OpenOrDie( /bigtable/web/webtable ); RowMutation r1(t, com.cnn.www ); R1.Set( anchor: CNN ); R1.Delete( anchor: ); Operation op; Apply(&op, &r1); RaumZeitLabor e.v. 7

8 API: Lesen Scanner scanner(t); ScanStream *stream; Stream = scanner.fetchcolumnfamily( anchor ); stream->setreturnallversions(); Scanner.Lookup( com.cnn.www ); for (;!stream->done(); stream->next()) { printf( %s %s %11d %s\n, scanner.rowname(), stream->columnname(), stream->microtimestamp(), stream->value()); } RaumZeitLabor e.v. 8
, stream->columnname(), stream->microtimestamp(), stream->value()); } 11.12.")
9 SSTables Sorted String Table interne Datenstruktur für Tablets persistente, geordnete, immutable Map: sstable[key: byte] value: byte enthält Datenblöcke (typischerweise 64k) Blockindex am Ende der Tabelle (im Speicher) RaumZeitLabor e.v. 9
 11.12.")
10 Tablets Tablet: Row-Range, verteilt auf Nodes (vertikale Fragmentierung) zu Beginn: nur ein Tablet Tablet Server können dynamisch hinzugefügt bzw. entfernt werden (vom Master) jeder Tablet Server hat bis zu tausend Tablets Clients lesen und schreiben auf Tablet Servern RaumZeitLabor e.v. 10

11 Tablet Location Root Tablet: enthält alle Tablet Locations wird nie fragmentiert (nie mehr als drei Level) Metadata wird vom Client gecached, Prefetching RaumZeitLabor e.v. 11

12 Tablet Assignment jedes Tablet genau einem Server zugeordnet Tablet Server registrieren sich in Lock Service wenn ein Tablet nicht zugeordnet ist, sucht der Master einen passenden Server heraus wenn Master abstürzt, sucht neuer Master alle Tablet Server heraus, und scannt METADATA Splits werden von Tablet Server erledigt RaumZeitLabor e.v. 12

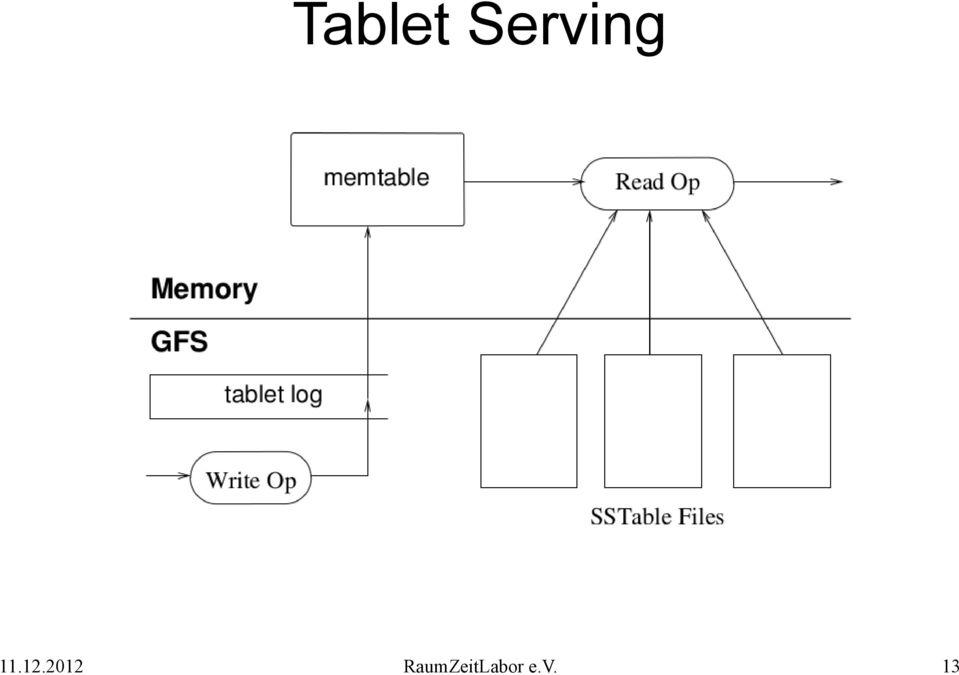
13 Tablet Serving RaumZeitLabor e.v. 13
14 Leckerbissen (1) Locality Groups Column Families bilden jeweils eine Locality Group können als in-memory markiert werden Compression Locality Groups können komprimiert werden Komprimierung erfolgt blockweise wird von Entwickler festgelegt Kompressionsrate: ~10: RaumZeitLabor e.v. 14

15 Leckerbissen (2) Caching Scan Cache: serverseitiger key-value Cache Block Cache: SSTable Block Cache Bloom Filter... ermöglich Vorhersage, ob Key/Column vorhanden Wenn nein: mit Sicherheit nicht; wenn ja: vielleicht kann von Anwendung aktiviert werden RaumZeitLabor e.v. 15

16 Open Source Hadoop: Framework für verteilte, skalierbare Anwendungen HDFS: Hadoop Filesystem HBase: freie BigTable Implementierung Disclaimer: alles Java ;-) HyperTable RaumZeitLabor e.v. 16
 HyperTable 11.12.")
17 Quelle Illustrationen und Infos aus: Chang, F., Dean, J., & Ghemawat, S. (2008). Bigtable: A distributed storage system for structured data. ACM Transactions on Database Systems. Retrieved from RaumZeitLabor e.v. 17

18 Nicht weiter erwähnt Locking Transaktionen (Commit-Logs) Performance Evaluation RaumZeitLabor e.v. 18


19 KTHXBYE RaumZeitLabor e.v. 19

Apache HBase. A BigTable Column Store on top of Hadoop
 Apache HBase A BigTable Column Store on top of Hadoop Ich bin... Mitch Köhler Selbstständig seit 2010 Tätig als Softwareentwickler Softwarearchitekt Student an der OVGU seit Oktober 2011 Schwerpunkte Client/Server,
Apache HBase A BigTable Column Store on top of Hadoop Ich bin... Mitch Köhler Selbstständig seit 2010 Tätig als Softwareentwickler Softwarearchitekt Student an der OVGU seit Oktober 2011 Schwerpunkte Client/Server,
Google's BigTable: Ein verteiltes Speichersystem für strukturierte Daten. von Florian Eiteljörge
 Google's BigTable: Ein verteiltes Speichersystem für strukturierte Daten von Florian Eiteljörge 1. Was ist Bigtable? 2. Datenmodell Übersicht 3. Implementierung/Architektur von Bigtable 4. Vergleich mit
Google's BigTable: Ein verteiltes Speichersystem für strukturierte Daten von Florian Eiteljörge 1. Was ist Bigtable? 2. Datenmodell Übersicht 3. Implementierung/Architektur von Bigtable 4. Vergleich mit
Stefan de Lorenzo Sommer Semester 2015
 Notizen zur Diskussion des Papers: Bigtable: A Distributed Storage System for Structured Data von F. Chang, J. Dean, S Ghemawat, W. C. Hsieh, D. A. Wallach, M. Burrows, T. Chandra, A. Fikes, und R. E.
Notizen zur Diskussion des Papers: Bigtable: A Distributed Storage System for Structured Data von F. Chang, J. Dean, S Ghemawat, W. C. Hsieh, D. A. Wallach, M. Burrows, T. Chandra, A. Fikes, und R. E.
Hadoop. Eine Open-Source-Implementierung von MapReduce und BigTable. von Philipp Kemkes
 Hadoop Eine Open-Source-Implementierung von MapReduce und BigTable von Philipp Kemkes Hadoop Framework für skalierbare, verteilt arbeitende Software Zur Verarbeitung großer Datenmengen (Terra- bis Petabyte)
Hadoop Eine Open-Source-Implementierung von MapReduce und BigTable von Philipp Kemkes Hadoop Framework für skalierbare, verteilt arbeitende Software Zur Verarbeitung großer Datenmengen (Terra- bis Petabyte)
BigTable vs. HBase. Iman Gharib. Schriftliche Ausarbeitung angefertigt im Rahmen des Seminars NOSQL
 BigTable vs. HBase Iman Gharib Schriftliche Ausarbeitung angefertigt im Rahmen des Seminars NOSQL Universität Leipzig Fakultät für Mathematik und Informatik Wintersemester 2012 Betreuerin: Diplom-Bioinformatikerin
BigTable vs. HBase Iman Gharib Schriftliche Ausarbeitung angefertigt im Rahmen des Seminars NOSQL Universität Leipzig Fakultät für Mathematik und Informatik Wintersemester 2012 Betreuerin: Diplom-Bioinformatikerin
Beratung. Results, no Excuses. Consulting. Lösungen. Grown from Experience. Ventum Consulting. SQL auf Hadoop Oliver Gehlert. 2014 Ventum Consulting
 Beratung Results, no Excuses. Consulting Lösungen Grown from Experience. Ventum Consulting SQL auf Hadoop Oliver Gehlert 1 Ventum Consulting Daten und Fakten Results, no excuses Fachwissen Branchenkenntnis
Beratung Results, no Excuses. Consulting Lösungen Grown from Experience. Ventum Consulting SQL auf Hadoop Oliver Gehlert 1 Ventum Consulting Daten und Fakten Results, no excuses Fachwissen Branchenkenntnis
Wide-Column Datenmodell nach BigTable
 Wide-Column Datenmodell nach BigTable Cassandra Gliederung Wide-Column Datenmodell nach BigTable Einführung Datenmodell nach BigTable Rows Columns Timestamps Thrift RPC API Fazit Einführung Wichtigsten
Wide-Column Datenmodell nach BigTable Cassandra Gliederung Wide-Column Datenmodell nach BigTable Einführung Datenmodell nach BigTable Rows Columns Timestamps Thrift RPC API Fazit Einführung Wichtigsten
mywms Vorlage Seite 1/5 mywms Datenhaltung von Haug Bürger
 mywms Vorlage Seite 1/5 mywms Datenhaltung von Haug Bürger Grundlegendes Oracle9i PostgreSQL Prevayler Memory mywms bietet umfangreiche Konfigurationsmöglichkeiten um die Daten dauerhaft zu speichern.
mywms Vorlage Seite 1/5 mywms Datenhaltung von Haug Bürger Grundlegendes Oracle9i PostgreSQL Prevayler Memory mywms bietet umfangreiche Konfigurationsmöglichkeiten um die Daten dauerhaft zu speichern.
NoSQL Datenbanken am Beispiel von HBase. Daniel Georg
 NoSQL Datenbanken am Beispiel von HBase Daniel Georg No to SQL at all sondern Not only SQL Open- Source Community Erst im Jahr 2009 gestartet Community bietet verschiede Lösungen: Casandra, CouchDD, HBase,
NoSQL Datenbanken am Beispiel von HBase Daniel Georg No to SQL at all sondern Not only SQL Open- Source Community Erst im Jahr 2009 gestartet Community bietet verschiede Lösungen: Casandra, CouchDD, HBase,
Hochverfügbare Virtualisierung mit Open Source
 Hochverfügbare Virtualisierung mit Open Source Gliederung DRBD Ganeti Libvirt Virtualisierung und Hochverfügbarkeit Hochverfügbarkeit von besonderer Bedeutung Defekt an einem Server => Ausfall vieler VMs
Hochverfügbare Virtualisierung mit Open Source Gliederung DRBD Ganeti Libvirt Virtualisierung und Hochverfügbarkeit Hochverfügbarkeit von besonderer Bedeutung Defekt an einem Server => Ausfall vieler VMs
Konsistenzproblematik bei der Cloud-Datenspeicherung
 Konsistenzproblematik bei der Cloud-Datenspeicherung ISE Seminar 2012 Adrian Zylla 1 Cloud Bereitstellung von Speicher- und Rechenkapazität Die Cloud ist für den Anwender eine Blackbox Besitzt drei Servicemodelle
Konsistenzproblematik bei der Cloud-Datenspeicherung ISE Seminar 2012 Adrian Zylla 1 Cloud Bereitstellung von Speicher- und Rechenkapazität Die Cloud ist für den Anwender eine Blackbox Besitzt drei Servicemodelle
Trackaufzeichnungen können als Active-Logs oder mit eigenen Namen versehene und auf max. 500 Punkte begrenzte Saved-Tracks gespeichert werden.
 60CSx USB Massenspeicher_V1.2.doc Seite 1 von 5 Garmin 60CSx MicroSD-Card als Trackspeicher nutzen. Trackaufzeichnungen können als Active-Logs oder mit eigenen Namen versehene und auf max. 500 Punkte begrenzte
60CSx USB Massenspeicher_V1.2.doc Seite 1 von 5 Garmin 60CSx MicroSD-Card als Trackspeicher nutzen. Trackaufzeichnungen können als Active-Logs oder mit eigenen Namen versehene und auf max. 500 Punkte begrenzte
Umbenennen eines NetWorker 7.x Servers (UNIX/ Linux)
") NetWorker - Allgemein Tip #293, Seite 1/6 Umbenennen eines NetWorker 7.x Servers (UNIX/ Linux) Dies wird offiziell nicht von unterstützt!!! Sie werden also hierfür keinerlei Support erhalten. Wenn man
NetWorker - Allgemein Tip #293, Seite 1/6 Umbenennen eines NetWorker 7.x Servers (UNIX/ Linux) Dies wird offiziell nicht von unterstützt!!! Sie werden also hierfür keinerlei Support erhalten. Wenn man
NoSQL. Einblick in die Welt nicht-relationaler Datenbanken. Christoph Föhrdes. UnFUG, SS10 17.06.2010
 NoSQL Einblick in die Welt nicht-relationaler Datenbanken Christoph Föhrdes UnFUG, SS10 17.06.2010 About me Christoph Föhrdes AIB Semester 7 IRC: cfo #unfug@irc.ghb.fh-furtwangen.de netblox GbR (http://netblox.de)
NoSQL Einblick in die Welt nicht-relationaler Datenbanken Christoph Föhrdes UnFUG, SS10 17.06.2010 About me Christoph Föhrdes AIB Semester 7 IRC: cfo #unfug@irc.ghb.fh-furtwangen.de netblox GbR (http://netblox.de)
Kampagnen. mit Scopevisio und CleverReach
 Kampagnen mit Scopevisio und CleverReach 1. Erstellen Sie eine Kampagne... 3 1.1 Filtern Sie Ihre Scopevisio-Kontakte...3 2. Verknüpfen Sie CleverReach und Scopevisio... 5 3. Export zu CleverReach... 6
Kampagnen mit Scopevisio und CleverReach 1. Erstellen Sie eine Kampagne... 3 1.1 Filtern Sie Ihre Scopevisio-Kontakte...3 2. Verknüpfen Sie CleverReach und Scopevisio... 5 3. Export zu CleverReach... 6
10%, 7,57 kb 20%, 5,3 kb 30%, 4,33 kb 40%, 3,71 kb 50%, 3,34 kb. 60%, 2,97 kb 70%, 2,59 kb 80%, 2,15 kb 90%, 1,62 kb 99%, 1,09 kb
 Die Komprimierung: Die Abkürzung JPG (oder auch JPEG) steht für "Joint Photographic Experts Group". Dieses Bildformat ist nach der Expertengruppe, die es erfunden hat, benannt. Die Komprimierung empfiehlt
Die Komprimierung: Die Abkürzung JPG (oder auch JPEG) steht für "Joint Photographic Experts Group". Dieses Bildformat ist nach der Expertengruppe, die es erfunden hat, benannt. Die Komprimierung empfiehlt
Was ist Windows Azure? (Stand Juni 2012)
") Was ist Windows Azure? (Stand Juni 2012) Windows Azure Microsofts Cloud Plattform zu Erstellung, Betrieb und Skalierung eigener Cloud-basierter Anwendungen Cloud Services Laufzeitumgebung, Speicher, Datenbank,
Was ist Windows Azure? (Stand Juni 2012) Windows Azure Microsofts Cloud Plattform zu Erstellung, Betrieb und Skalierung eigener Cloud-basierter Anwendungen Cloud Services Laufzeitumgebung, Speicher, Datenbank,
Dateisysteme und Datenverwaltung in der Cloud
 Dateisysteme und Datenverwaltung in der Cloud Sebastian Fischer Master-Seminar Cloud Computing - WS 2013/14 Institut für Telematik, Universität zu Lübeck Dateisysteme und Datenverwaltung in der Cloud 1
Dateisysteme und Datenverwaltung in der Cloud Sebastian Fischer Master-Seminar Cloud Computing - WS 2013/14 Institut für Telematik, Universität zu Lübeck Dateisysteme und Datenverwaltung in der Cloud 1
FileMaker Konferenz 2011 Hamburg www.filemaker-konferenz.com. Speed. Performance Optimierung für Ihre Lösung / Entwickler
 Speed Performance Optimierung für Ihre Lösung / Entwickler [x] cross solution Armin Egginger - Zertifizierter FileMaker Entwickler Urheber von CrossCheck Netzwerk von Datenbankprogrammierern Kunden in
Speed Performance Optimierung für Ihre Lösung / Entwickler [x] cross solution Armin Egginger - Zertifizierter FileMaker Entwickler Urheber von CrossCheck Netzwerk von Datenbankprogrammierern Kunden in
4D Server v12 64-bit Version BETA VERSION
 4D Server v12 64-bit Version BETA VERSION 4D Server v12 unterstützt jetzt das Windows 64-bit Betriebssystem. Hauptvorteil der 64-bit Technologie ist die rundum verbesserte Performance der Anwendungen und
4D Server v12 64-bit Version BETA VERSION 4D Server v12 unterstützt jetzt das Windows 64-bit Betriebssystem. Hauptvorteil der 64-bit Technologie ist die rundum verbesserte Performance der Anwendungen und
3. Stored Procedures und PL/SQL
 3. Stored Procedures und PL/SQL Wenn eine Anwendung auf einer Client-Maschine läuft, wird normalerweise jede SQL-Anweisung einzeln vom Client an den Server gesandt, und jedes Ergebnistupel wird einzeln
3. Stored Procedures und PL/SQL Wenn eine Anwendung auf einer Client-Maschine läuft, wird normalerweise jede SQL-Anweisung einzeln vom Client an den Server gesandt, und jedes Ergebnistupel wird einzeln
Anleitung zur Einrichtung einer ODBC Verbindung zu den Übungsdatenbanken
 Betriebliche Datenverarbeitung Wirtschaftswissenschaften AnleitungzurEinrichtungeinerODBC VerbindungzudenÜbungsdatenbanken 0.Voraussetzung Diese Anleitung beschreibt das Vorgehen für alle gängigen Windows
Betriebliche Datenverarbeitung Wirtschaftswissenschaften AnleitungzurEinrichtungeinerODBC VerbindungzudenÜbungsdatenbanken 0.Voraussetzung Diese Anleitung beschreibt das Vorgehen für alle gängigen Windows
ANALYTICS, RISK MANAGEMENT & FINANCE ARCHITECTURE. NoSQL Datenbanksysteme Übersicht, Abgrenzung & Charakteristik
 ARFA ANALYTICS, RISK MANAGEMENT & FINANCE ARCHITECTURE NoSQL Datenbanksysteme Übersicht, Abgrenzung & Charakteristik Ralf Leipner Domain Architect Analytics, Risk Management & Finance 33. Berner Architekten
ARFA ANALYTICS, RISK MANAGEMENT & FINANCE ARCHITECTURE NoSQL Datenbanksysteme Übersicht, Abgrenzung & Charakteristik Ralf Leipner Domain Architect Analytics, Risk Management & Finance 33. Berner Architekten
Überblick und Vergleich von NoSQL. Datenbanksystemen
 Fakultät Informatik Hauptseminar Technische Informationssysteme Überblick und Vergleich von NoSQL Christian Oelsner Dresden, 20. Mai 2011 1 1. Einführung 2. Historisches & Definition 3. Kategorien von
Fakultät Informatik Hauptseminar Technische Informationssysteme Überblick und Vergleich von NoSQL Christian Oelsner Dresden, 20. Mai 2011 1 1. Einführung 2. Historisches & Definition 3. Kategorien von
PostgreSQL in großen Installationen
 PostgreSQL in großen Installationen Cybertec Schönig & Schönig GmbH Hans-Jürgen Schönig Wieso PostgreSQL? - Die fortschrittlichste Open Source Database - Lizenzpolitik: wirkliche Freiheit - Stabilität,
PostgreSQL in großen Installationen Cybertec Schönig & Schönig GmbH Hans-Jürgen Schönig Wieso PostgreSQL? - Die fortschrittlichste Open Source Database - Lizenzpolitik: wirkliche Freiheit - Stabilität,
Personen. Anlegen einer neuen Person
 Personen Der Menüpunkt Personen erlaubt die Wartung von bereits bestehenden Personen sowie das Neuanlegen von neuen Mitarbeitern. Durch Anklicken des Menüpunktes Personen erhält man die Auswahl aller Personen
Personen Der Menüpunkt Personen erlaubt die Wartung von bereits bestehenden Personen sowie das Neuanlegen von neuen Mitarbeitern. Durch Anklicken des Menüpunktes Personen erhält man die Auswahl aller Personen
Big Data Mythen und Fakten
 Big Data Mythen und Fakten Mario Meir-Huber Research Analyst, IDC Copyright IDC. Reproduction is forbidden unless authorized. All rights reserved. About me Research Analyst @ IDC Author verschiedener IT-Fachbücher
Big Data Mythen und Fakten Mario Meir-Huber Research Analyst, IDC Copyright IDC. Reproduction is forbidden unless authorized. All rights reserved. About me Research Analyst @ IDC Author verschiedener IT-Fachbücher
Binäre Bäume. 1. Allgemeines. 2. Funktionsweise. 2.1 Eintragen
 Binäre Bäume 1. Allgemeines Binäre Bäume werden grundsätzlich verwendet, um Zahlen der Größe nach, oder Wörter dem Alphabet nach zu sortieren. Dem einfacheren Verständnis zu Liebe werde ich mich hier besonders
Binäre Bäume 1. Allgemeines Binäre Bäume werden grundsätzlich verwendet, um Zahlen der Größe nach, oder Wörter dem Alphabet nach zu sortieren. Dem einfacheren Verständnis zu Liebe werde ich mich hier besonders
Wide Column Stores. Felix Bruckner Mannheim, 15.06.2012
 Wide Column Stores Felix Bruckner Mannheim, 15.06.2012 Agenda Einführung Motivation Grundlagen NoSQL Grundlagen Wide Column Stores Anwendungsfälle Datenmodell Technik Wide Column Stores & Cloud Computing
Wide Column Stores Felix Bruckner Mannheim, 15.06.2012 Agenda Einführung Motivation Grundlagen NoSQL Grundlagen Wide Column Stores Anwendungsfälle Datenmodell Technik Wide Column Stores & Cloud Computing
1. In den Admin-Bereich einlogen wie bei Bedienungsanleitung 11F Ziffer 1 bis 11
 Bilder und Dateien auf den Internet-Server hochladen Seite 1 von 7 Inhalt Anmelden bei DynPG ab Ziffer 1 Dateiverwaltung öffnen ab Ziffer 2 Datei-Gruppe auswählen ab Ziffer 3 Datei hochladen ab Ziffer
Bilder und Dateien auf den Internet-Server hochladen Seite 1 von 7 Inhalt Anmelden bei DynPG ab Ziffer 1 Dateiverwaltung öffnen ab Ziffer 2 Datei-Gruppe auswählen ab Ziffer 3 Datei hochladen ab Ziffer
Speichernetze (Storage Area Networks, SANs)
") Speichernetze (Storage Area Networks, SANs) Hochschule für Zürich MAS Informatik, Verteilte Systeme 22.9.2010 Outline 1 2 I/O en Prinzipschema serverzentrierte Architektur Disk Disk Disk Disk Disk Disk
Speichernetze (Storage Area Networks, SANs) Hochschule für Zürich MAS Informatik, Verteilte Systeme 22.9.2010 Outline 1 2 I/O en Prinzipschema serverzentrierte Architektur Disk Disk Disk Disk Disk Disk
peer-to-peer Dateisystem Synchronisation
 Ziel Realisierungen Coda Ideen Fazit Literatur peer-to-peer Dateisystem Synchronisation Studiendepartment Informatik Hochschule für Angewandte Wissenschaften Hamburg 30. November 2007 Ziel Realisierungen
Ziel Realisierungen Coda Ideen Fazit Literatur peer-to-peer Dateisystem Synchronisation Studiendepartment Informatik Hochschule für Angewandte Wissenschaften Hamburg 30. November 2007 Ziel Realisierungen
Big Data Informationen neu gelebt
 Seminarunterlage Version: 1.01 Copyright Version 1.01 vom 21. Mai 2015 Dieses Dokument wird durch die veröffentlicht. Copyright. Alle Rechte vorbehalten. Alle Produkt- und Dienstleistungs-Bezeichnungen
Seminarunterlage Version: 1.01 Copyright Version 1.01 vom 21. Mai 2015 Dieses Dokument wird durch die veröffentlicht. Copyright. Alle Rechte vorbehalten. Alle Produkt- und Dienstleistungs-Bezeichnungen
Synchronisierung. Kommunikationstechnik, SS 08, Prof. Dr. Stefan Brunthaler 73
 Synchronisierung Kommunikationstechnik, SS 08, Prof. Dr. Stefan Brunthaler 73 Übertragungsprozeduren Die Übertragung einer Nachricht zwischen Sender und Empfänger erfordert die Übertragung des Nutzsignals
Synchronisierung Kommunikationstechnik, SS 08, Prof. Dr. Stefan Brunthaler 73 Übertragungsprozeduren Die Übertragung einer Nachricht zwischen Sender und Empfänger erfordert die Übertragung des Nutzsignals
Algorithmen und Datenstrukturen Suchbaum
 Algorithmen und Datenstrukturen Suchbaum Matthias Teschner Graphische Datenverarbeitung Institut für Informatik Universität Freiburg SS 12 Motivation Datenstruktur zur Repräsentation dynamischer Mengen
Algorithmen und Datenstrukturen Suchbaum Matthias Teschner Graphische Datenverarbeitung Institut für Informatik Universität Freiburg SS 12 Motivation Datenstruktur zur Repräsentation dynamischer Mengen
MS SQL Server: Index Management. Stephan Arenswald 10. Juli 2008
 MS SQL Server: Index Management Stephan Arenswald 10. Juli 2008 Agenda 1. Einführung 2. Grundlagen Tabellen 3. Grundlagen Indexe 4. Indextypen 5. Index-Erstellung 6. Indexe und Constraints 7. Und Weiter...?
MS SQL Server: Index Management Stephan Arenswald 10. Juli 2008 Agenda 1. Einführung 2. Grundlagen Tabellen 3. Grundlagen Indexe 4. Indextypen 5. Index-Erstellung 6. Indexe und Constraints 7. Und Weiter...?
MapReduce. www.kit.edu. Johann Volz. IPD Snelting, Lehrstuhl Programmierparadigmen
 MapReduce Johann Volz IPD Snelting, Lehrstuhl Programmierparadigmen KIT Universität des Landes Baden-Württemberg und nationales Großforschungszentrum in der Helmholtz-Gemeinschaft www.kit.edu Wozu MapReduce?
MapReduce Johann Volz IPD Snelting, Lehrstuhl Programmierparadigmen KIT Universität des Landes Baden-Württemberg und nationales Großforschungszentrum in der Helmholtz-Gemeinschaft www.kit.edu Wozu MapReduce?
1 Einleitung. 1.1 Caching von Webanwendungen. 1.1.1 Clientseites Caching
 1.1 Caching von Webanwendungen In den vergangenen Jahren hat sich das Webumfeld sehr verändert. Nicht nur eine zunehmend größere Zahl an Benutzern sondern auch die Anforderungen in Bezug auf dynamischere
1.1 Caching von Webanwendungen In den vergangenen Jahren hat sich das Webumfeld sehr verändert. Nicht nur eine zunehmend größere Zahl an Benutzern sondern auch die Anforderungen in Bezug auf dynamischere
Verwaltung der Projekte
 ACS Data Systems AG Verwaltung der Projekte (Version 10.08.2009) Buchhaltung für Schulen ACS Data Systems AG Bozen / Brixen / Trient Tel +39 0472 27 27 27 obu@acs.it 2 Inhaltsverzeichnis 1. PROJEKTVERWALTUNG...
ACS Data Systems AG Verwaltung der Projekte (Version 10.08.2009) Buchhaltung für Schulen ACS Data Systems AG Bozen / Brixen / Trient Tel +39 0472 27 27 27 obu@acs.it 2 Inhaltsverzeichnis 1. PROJEKTVERWALTUNG...
DB2 Codepage Umstellung
 DB2 Codepage Umstellung Was bei einer Umstellung auf Unicode zu beachten ist Torsten Röber, SW Support Specialist DB2 April 2015 Agenda Warum Unicode? Unicode Implementierung in DB2/LUW Umstellung einer
DB2 Codepage Umstellung Was bei einer Umstellung auf Unicode zu beachten ist Torsten Röber, SW Support Specialist DB2 April 2015 Agenda Warum Unicode? Unicode Implementierung in DB2/LUW Umstellung einer
Ablaufbeschreibung für das neu Aufsetzen von Firebird und Interbase Datenbanken mit der IBOConsole
 Lavid-F.I.S. Ablaufbeschreibung für das neu Aufsetzen von Firebird und Interbase Datenbanken mit der Lavid Software GmbH Dauner Straße 12, D-41236 Mönchengladbach http://www.lavid-software.net Support:
Lavid-F.I.S. Ablaufbeschreibung für das neu Aufsetzen von Firebird und Interbase Datenbanken mit der Lavid Software GmbH Dauner Straße 12, D-41236 Mönchengladbach http://www.lavid-software.net Support:
Outlook Express. Einrichten des Zugangs per Outlook Express (IMAP ) Klicken Sie auf "E Mail Konto erstellen" um ein neues E Mail Konto einzurichten.
 Klicken Sie auf E Mail Konto erstellen um ein neues E Mail Konto einzurichten.") Outlook Express Einrichten des Zugangs per Outlook Express (IMAP ) Klicken Sie auf "E Mail Konto erstellen" um ein neues E Mail Konto einzurichten. Unter "Angezeigter Name" tragen Sie bitte den Namen ein,
Outlook Express Einrichten des Zugangs per Outlook Express (IMAP ) Klicken Sie auf "E Mail Konto erstellen" um ein neues E Mail Konto einzurichten. Unter "Angezeigter Name" tragen Sie bitte den Namen ein,
Algorithmen & Datenstrukturen 1. Klausur
 Algorithmen & Datenstrukturen 1. Klausur 7. Juli 2010 Name Matrikelnummer Aufgabe mögliche Punkte erreichte Punkte 1 35 2 30 3 30 4 15 5 40 6 30 Gesamt 180 1 Seite 2 von 14 Aufgabe 1) Programm Analyse
Algorithmen & Datenstrukturen 1. Klausur 7. Juli 2010 Name Matrikelnummer Aufgabe mögliche Punkte erreichte Punkte 1 35 2 30 3 30 4 15 5 40 6 30 Gesamt 180 1 Seite 2 von 14 Aufgabe 1) Programm Analyse
Java Einführung Operatoren Kapitel 2 und 3
 Java Einführung Operatoren Kapitel 2 und 3 Inhalt dieser Einheit Operatoren (unär, binär, ternär) Rangfolge der Operatoren Zuweisungsoperatoren Vergleichsoperatoren Logische Operatoren 2 Operatoren Abhängig
Java Einführung Operatoren Kapitel 2 und 3 Inhalt dieser Einheit Operatoren (unär, binär, ternär) Rangfolge der Operatoren Zuweisungsoperatoren Vergleichsoperatoren Logische Operatoren 2 Operatoren Abhängig
Kapitel 8: Physischer Datenbankentwurf
 8. Physischer Datenbankentwurf Seite 1 Kapitel 8: Physischer Datenbankentwurf Speicherung und Verwaltung der Relationen einer relationalen Datenbank so, dass eine möglichst große Effizienz der einzelnen
8. Physischer Datenbankentwurf Seite 1 Kapitel 8: Physischer Datenbankentwurf Speicherung und Verwaltung der Relationen einer relationalen Datenbank so, dass eine möglichst große Effizienz der einzelnen
Grundlagen von Python
 Einführung in Python Grundlagen von Python Felix Döring, Felix Wittwer November 17, 2015 Scriptcharakter Programmierparadigmen Imperatives Programmieren Das Scoping Problem Objektorientiertes Programmieren
Einführung in Python Grundlagen von Python Felix Döring, Felix Wittwer November 17, 2015 Scriptcharakter Programmierparadigmen Imperatives Programmieren Das Scoping Problem Objektorientiertes Programmieren
Grundlagen der Informatik. Prof. Dr. Stefan Enderle NTA Isny
 Grundlagen der Informatik Prof. Dr. Stefan Enderle NTA Isny 2 Datenstrukturen 2.1 Einführung Syntax: Definition einer formalen Grammatik, um Regeln einer formalen Sprache (Programmiersprache) festzulegen.
Grundlagen der Informatik Prof. Dr. Stefan Enderle NTA Isny 2 Datenstrukturen 2.1 Einführung Syntax: Definition einer formalen Grammatik, um Regeln einer formalen Sprache (Programmiersprache) festzulegen.
Einrichtung des Cisco VPN Clients (IPSEC) in Windows7
 in Windows7") Einrichtung des Cisco VPN Clients (IPSEC) in Windows7 Diese Verbindung muss einmalig eingerichtet werden und wird benötigt, um den Zugriff vom privaten Rechner oder der Workstation im Home Office über
Einrichtung des Cisco VPN Clients (IPSEC) in Windows7 Diese Verbindung muss einmalig eingerichtet werden und wird benötigt, um den Zugriff vom privaten Rechner oder der Workstation im Home Office über
Möglichkeiten für bestehende Systeme
 Möglichkeiten für bestehende Systeme Marko Filler Bitterfeld, 27.08.2015 2015 GISA GmbH Leipziger Chaussee 191 a 06112 Halle (Saale) www.gisa.de Agenda Gegenüberstellung Data Warehouse Big Data Einsatz-
Möglichkeiten für bestehende Systeme Marko Filler Bitterfeld, 27.08.2015 2015 GISA GmbH Leipziger Chaussee 191 a 06112 Halle (Saale) www.gisa.de Agenda Gegenüberstellung Data Warehouse Big Data Einsatz-
Anleitung zur Konfiguration eines NO-IP DynDNS-Accounts mit der TOOLBOXflex-3.2
 Anleitung zur Konfiguration eines NO-IP DynDNS-Accounts mit der TOOLBOXflex-3.2 DynDNS-Accounts sollten in regelmäßigen Abständen mit der vom Internet-Provider vergebenen IP- Adresse (z.b. 215.613.123.456)
Anleitung zur Konfiguration eines NO-IP DynDNS-Accounts mit der TOOLBOXflex-3.2 DynDNS-Accounts sollten in regelmäßigen Abständen mit der vom Internet-Provider vergebenen IP- Adresse (z.b. 215.613.123.456)
Erstellung eines Frameworks für Shop Systeme im Internet auf Basis von Java
 Erstellung eines Frameworks für Shop Systeme im Internet auf Basis von Java Präsentation zur Diplomarbeit von Übersicht Java 2 Enterprise Edition Java Servlets JavaServer Pages Enterprise JavaBeans Framework
Erstellung eines Frameworks für Shop Systeme im Internet auf Basis von Java Präsentation zur Diplomarbeit von Übersicht Java 2 Enterprise Edition Java Servlets JavaServer Pages Enterprise JavaBeans Framework
Technische Beschreibung: EPOD Server
 EPOD Encrypted Private Online Disc Technische Beschreibung: EPOD Server Fördergeber Förderprogramm Fördernehmer Projektleitung Projekt Metadaten Internet Foundation Austria netidee JKU Linz Institut für
EPOD Encrypted Private Online Disc Technische Beschreibung: EPOD Server Fördergeber Förderprogramm Fördernehmer Projektleitung Projekt Metadaten Internet Foundation Austria netidee JKU Linz Institut für
Internet Explorer Version 6
 Internet Explorer Version 6 Java Runtime Ist Java Runtime nicht installiert, öffnet sich ein PopUp-Fenster, welches auf das benötigte Plugin aufmerksam macht. Nach Klicken auf die OK-Taste im PopUp-Fenster
Internet Explorer Version 6 Java Runtime Ist Java Runtime nicht installiert, öffnet sich ein PopUp-Fenster, welches auf das benötigte Plugin aufmerksam macht. Nach Klicken auf die OK-Taste im PopUp-Fenster
Performance Tuning mit @enterprise
 @enterprise Kunden-Forum 2005 Performance Tuning mit @enterprise Herbert Groiss Groiss Informatics GmbH, 2005 Inhalt Datenbank RMI JAVA API HTTP Konfiguration Analyse Groiss Informatics GmbH, 2005 2 Datenbank
@enterprise Kunden-Forum 2005 Performance Tuning mit @enterprise Herbert Groiss Groiss Informatics GmbH, 2005 Inhalt Datenbank RMI JAVA API HTTP Konfiguration Analyse Groiss Informatics GmbH, 2005 2 Datenbank
Einführung in Hadoop
 Einführung in Hadoop Inhalt / Lern-Ziele Übersicht: Basis-Architektur von Hadoop Einführung in HDFS Einführung in MapReduce Ausblick: Hadoop Ökosystem Optimierungen Versionen 10.02.2012 Prof. Dr. Christian
Einführung in Hadoop Inhalt / Lern-Ziele Übersicht: Basis-Architektur von Hadoop Einführung in HDFS Einführung in MapReduce Ausblick: Hadoop Ökosystem Optimierungen Versionen 10.02.2012 Prof. Dr. Christian
Handbuch SyCOM Administration
 Handbuch SyCOM Administration Hotline: +9 (0) 89 970 - SEITHE & PARTNER GMBH & CO.KG Hafenweg a 99 Bergkamen INHALT SyCom.0.0.6 Administration von SyCom Bereich Allgemein Registerkarte Allgemein Registerkarte
Handbuch SyCOM Administration Hotline: +9 (0) 89 970 - SEITHE & PARTNER GMBH & CO.KG Hafenweg a 99 Bergkamen INHALT SyCom.0.0.6 Administration von SyCom Bereich Allgemein Registerkarte Allgemein Registerkarte
Installation von Office 365 auf einem privaten PC
 Installation von Office 365 auf einem privaten PC Schülerinnen und Schüler des Stiftsgymnasiums haben die Möglichkeit, auf Ihren privaten PCs kostenlos Microsoft Office 365 zu installieren. Dieser Anleitung
Installation von Office 365 auf einem privaten PC Schülerinnen und Schüler des Stiftsgymnasiums haben die Möglichkeit, auf Ihren privaten PCs kostenlos Microsoft Office 365 zu installieren. Dieser Anleitung
Java Einführung Collections
 Java Einführung Collections Inhalt dieser Einheit Behälterklassen, die in der Java API bereitgestellt werden Wiederholung Array Collections (Vector, List, Set) Map 2 Wiederholung Array a[0] a[1] a[2] a[3]...
Java Einführung Collections Inhalt dieser Einheit Behälterklassen, die in der Java API bereitgestellt werden Wiederholung Array Collections (Vector, List, Set) Map 2 Wiederholung Array a[0] a[1] a[2] a[3]...
Heimverwaltungsprogramm HVP Version 6.0
 Heimverwaltungsprogramm HVP Version 6.0 Dokumentenmanagement Version 1.0 des Handbuchs HeimTec GmbH Heimverwaltung HVP Internet: www.heimtec.com E-Mail: info@heimtec.com Inhalt 1. Einleitung...3 1.1. Speicherung
Heimverwaltungsprogramm HVP Version 6.0 Dokumentenmanagement Version 1.0 des Handbuchs HeimTec GmbH Heimverwaltung HVP Internet: www.heimtec.com E-Mail: info@heimtec.com Inhalt 1. Einleitung...3 1.1. Speicherung
Entwicklungen bei der Linux Clustersoftware
 Quo vadis Linux-HA? Entwicklungen bei der Linux Clustersoftware Michael Schwartzkopff misch@schwartzkopff.org (c) Michael Schwartzkopff, 2010 1 / 19 Linux Clustersoftware Linux Virtual Server Bietet Skalierbarkeit...
Quo vadis Linux-HA? Entwicklungen bei der Linux Clustersoftware Michael Schwartzkopff misch@schwartzkopff.org (c) Michael Schwartzkopff, 2010 1 / 19 Linux Clustersoftware Linux Virtual Server Bietet Skalierbarkeit...
SSDs und Flash Memory. Matthias Müller 16.Juni 2010 Institut für Verteilte Systeme
 SSDs und Flash Memory Matthias Müller 16.Juni 2010 Institut für Verteilte Systeme Seite 2 Inhalt Motivation Aufbau und Funktionsweise NAND vs NOR SLC vs MLC Speicherorganisation Vergleich mit konventionellen
SSDs und Flash Memory Matthias Müller 16.Juni 2010 Institut für Verteilte Systeme Seite 2 Inhalt Motivation Aufbau und Funktionsweise NAND vs NOR SLC vs MLC Speicherorganisation Vergleich mit konventionellen
Kommunikationsübersicht XIMA FORMCYCLE Inhaltsverzeichnis
 Kommunikationsübersicht Inhaltsverzeichnis Kommunikation bei Einsatz eines MasterServer... 2 Installation im... 2 Installation in der... 3 Kommunikation bei Einsatz eines MasterServer und FrontendServer...
Kommunikationsübersicht Inhaltsverzeichnis Kommunikation bei Einsatz eines MasterServer... 2 Installation im... 2 Installation in der... 3 Kommunikation bei Einsatz eines MasterServer und FrontendServer...
Konfigurationsanleitung Access Control Lists (ACL) Funkwerk. Copyright Stefan Dahler - www.neo-one.de 13. Oktober 2008 Version 1.0.
 Funkwerk. Copyright Stefan Dahler - www.neo-one.de 13. Oktober 2008 Version 1.0.") Konfigurationsanleitung Access Control Lists (ACL) Funkwerk Copyright Stefan Dahler - www.neo-one.de 13. Oktober 2008 Version 1.0 Seite - 1 - 1. Konfiguration der Access Listen 1.1 Einleitung Im Folgenden
Konfigurationsanleitung Access Control Lists (ACL) Funkwerk Copyright Stefan Dahler - www.neo-one.de 13. Oktober 2008 Version 1.0 Seite - 1 - 1. Konfiguration der Access Listen 1.1 Einleitung Im Folgenden
QR-FUNKTION. Informationen über zu erledigende Aufgaben an das Reinigungspersonal senden.
 QR-FUNKTION Informationen über zu erledigende Aufgaben an das Reinigungspersonal senden. Informationen über erledigte Aufgaben vom Reinigungspersonal erhalten. Verwaltung regelmäßiger Aufgaben Der Hauptzweck
QR-FUNKTION Informationen über zu erledigende Aufgaben an das Reinigungspersonal senden. Informationen über erledigte Aufgaben vom Reinigungspersonal erhalten. Verwaltung regelmäßiger Aufgaben Der Hauptzweck
17.1.2014 Einführung in die Programmierung Laborübung bei Korcan Y. Kirkici. 12.Übung 13.1. bis 17.1.2014
 17.1.2014 Einführung in die Programmierung Laborübung bei Korcan Y. Kirkici 12.Übung 13.1. bis 17.1.2014 1 BEFRAGUNG http://1.bp.blogspot.com/- waaowrew9gc/tuhgqro4u_i/aaaaaaaaaey/3xhl 4Va2SOQ/s1600/crying%2Bmeme.png
17.1.2014 Einführung in die Programmierung Laborübung bei Korcan Y. Kirkici 12.Übung 13.1. bis 17.1.2014 1 BEFRAGUNG http://1.bp.blogspot.com/- waaowrew9gc/tuhgqro4u_i/aaaaaaaaaey/3xhl 4Va2SOQ/s1600/crying%2Bmeme.png
Professionelle Seminare im Bereich MS-Office
 Der Name BEREICH.VERSCHIEBEN() ist etwas unglücklich gewählt. Man kann mit der Funktion Bereiche zwar verschieben, man kann Bereiche aber auch verkleinern oder vergrößern. Besser wäre es, die Funktion
Der Name BEREICH.VERSCHIEBEN() ist etwas unglücklich gewählt. Man kann mit der Funktion Bereiche zwar verschieben, man kann Bereiche aber auch verkleinern oder vergrößern. Besser wäre es, die Funktion
Handbuch. timecard Connector 1.0.0. Version: 1.0.0. REINER SCT Kartengeräte GmbH & Co. KG Goethestr. 14 78120 Furtwangen
 Handbuch timecard Connector 1.0.0 Version: 1.0.0 REINER SCT Kartengeräte GmbH & Co. KG Goethestr. 14 78120 Furtwangen Furtwangen, den 18.11.2011 Inhaltsverzeichnis Seite 1 Einführung... 3 2 Systemvoraussetzungen...
Handbuch timecard Connector 1.0.0 Version: 1.0.0 REINER SCT Kartengeräte GmbH & Co. KG Goethestr. 14 78120 Furtwangen Furtwangen, den 18.11.2011 Inhaltsverzeichnis Seite 1 Einführung... 3 2 Systemvoraussetzungen...
Fehlermonitor. Software zur seriellen Verbindung PC-Airdos Visualdatensignale und Fehlermeldungen-Ausagabe per SMS / Drucker
 Fehlermonitor Software zur seriellen Verbindung PC-Airdos Visualdatensignale und Fehlermeldungen-Ausagabe per SMS / Drucker Das Programm ist problemlos zu installieren auf jedem Windows-PC (XP) mit.net
Fehlermonitor Software zur seriellen Verbindung PC-Airdos Visualdatensignale und Fehlermeldungen-Ausagabe per SMS / Drucker Das Programm ist problemlos zu installieren auf jedem Windows-PC (XP) mit.net
Network Controller TCP/IP
 Intelligente Lösungen für elektronische Schließsysteme und Zugangskontrolle KOMPONENTENDATENBLATT Network Controller TCP/IP Funktioniert als Zwischenglied zwischen dem Metra NET (CAN) Netzwerk und dem
Intelligente Lösungen für elektronische Schließsysteme und Zugangskontrolle KOMPONENTENDATENBLATT Network Controller TCP/IP Funktioniert als Zwischenglied zwischen dem Metra NET (CAN) Netzwerk und dem
Synchronisations- Assistent
 TimePunch Synchronisations- Assistent Benutzerhandbuch Gerhard Stephan Softwareentwicklung -und Vertrieb 25.08.2011 Dokumenten Information: Dokumenten-Name Benutzerhandbuch, Synchronisations-Assistent
TimePunch Synchronisations- Assistent Benutzerhandbuch Gerhard Stephan Softwareentwicklung -und Vertrieb 25.08.2011 Dokumenten Information: Dokumenten-Name Benutzerhandbuch, Synchronisations-Assistent
Einführung in die technische Informatik
 Einführung in die technische Informatik Christopher Kruegel chris@auto.tuwien.ac.at http://www.auto.tuwien.ac.at/~chris Betriebssysteme Aufgaben Management von Ressourcen Präsentation einer einheitlichen
Einführung in die technische Informatik Christopher Kruegel chris@auto.tuwien.ac.at http://www.auto.tuwien.ac.at/~chris Betriebssysteme Aufgaben Management von Ressourcen Präsentation einer einheitlichen
Grundlagen der Programmierung 2. Bäume
 Grundlagen der Programmierung 2 Bäume Prof. Dr. Manfred Schmidt-Schauÿ Künstliche Intelligenz und Softwaretechnologie 24. Mai 2006 Graphen Graph: Menge von Knoten undzugehörige (gerichtete oder ungerichtete)
Grundlagen der Programmierung 2 Bäume Prof. Dr. Manfred Schmidt-Schauÿ Künstliche Intelligenz und Softwaretechnologie 24. Mai 2006 Graphen Graph: Menge von Knoten undzugehörige (gerichtete oder ungerichtete)
Zählen von Objekten einer bestimmten Klasse
 Zählen von Objekten einer bestimmten Klasse Ziel, Inhalt Zur Übung versuchen wir eine Klasse zu schreiben, mit der es möglich ist Objekte einer bestimmten Klasse zu zählen. Wir werden den ++ und den --
Zählen von Objekten einer bestimmten Klasse Ziel, Inhalt Zur Übung versuchen wir eine Klasse zu schreiben, mit der es möglich ist Objekte einer bestimmten Klasse zu zählen. Wir werden den ++ und den --
ALG-Seminar Sensornetze
 ALG-Seminar Sensornetze Benutzung der Testbedsoftware in den Fluren Tobias Baumgartner TU Braunschweig 27. April 2011 Tobias Baumgartner (TUBS) ALG-Seminar Sensornetze 27. April 2011 1 / 27 Testbedsoftware
ALG-Seminar Sensornetze Benutzung der Testbedsoftware in den Fluren Tobias Baumgartner TU Braunschweig 27. April 2011 Tobias Baumgartner (TUBS) ALG-Seminar Sensornetze 27. April 2011 1 / 27 Testbedsoftware
TREND SEARCH VISUALISIERUNG. von Ricardo Gantschew btk Berlin Dozent / Till Nagel
 von Ricardo Gantschew btk Berlin Dozent / Till Nagel 01 IDEE Einige kennen vielleicht GoogleTrends. Hierbei handelt es sich um eine Anwendung, bei der man verschiedenste Begriffe auf die Häufigkeit ihrer
von Ricardo Gantschew btk Berlin Dozent / Till Nagel 01 IDEE Einige kennen vielleicht GoogleTrends. Hierbei handelt es sich um eine Anwendung, bei der man verschiedenste Begriffe auf die Häufigkeit ihrer
Android VHS - Weiterbildungskurs Ort: Sulingen
 Kontakte Neuen Kontakt anlegen Um einen neuen Kontakt anzulegen, wird zuerst (Kontakte) aufgerufen. Unten Rechts befindet sich die Schaltfläche um einen neuen Kontakt zu erstellen. Beim Kontakt anlegen
Kontakte Neuen Kontakt anlegen Um einen neuen Kontakt anzulegen, wird zuerst (Kontakte) aufgerufen. Unten Rechts befindet sich die Schaltfläche um einen neuen Kontakt zu erstellen. Beim Kontakt anlegen
Programmierkurs Java
 Programmierkurs Java Dr. Dietrich Boles Aufgaben zu UE16-Rekursion (Stand 09.12.2011) Aufgabe 1: Implementieren Sie in Java ein Programm, das solange einzelne Zeichen vom Terminal einliest, bis ein #-Zeichen
Programmierkurs Java Dr. Dietrich Boles Aufgaben zu UE16-Rekursion (Stand 09.12.2011) Aufgabe 1: Implementieren Sie in Java ein Programm, das solange einzelne Zeichen vom Terminal einliest, bis ein #-Zeichen
Hadoop I/O. Datenintegrität Kompression Serialisierung Datei-basierte Datenstrukturen. 14.02.2012 Prof. Dr. Christian Herta 1/29
 Hadoop I/O Datenintegrität Kompression Serialisierung Datei-basierte Datenstrukturen 14.02.2012 Prof. Dr. Christian Herta 1/29 Data I/O und Hadoop Allgemeine Techniken Data I/O Datenintegrität Kompression
Hadoop I/O Datenintegrität Kompression Serialisierung Datei-basierte Datenstrukturen 14.02.2012 Prof. Dr. Christian Herta 1/29 Data I/O und Hadoop Allgemeine Techniken Data I/O Datenintegrität Kompression
Folgende Voraussetzungen für die Konfiguration müssen erfüllt sein: - Ein Bootimage ab Version 7.4.4. - Optional einen DHCP Server.
 1. Dynamic Host Configuration Protocol 1.1 Einleitung Im Folgenden wird die Konfiguration von DHCP beschrieben. Sie setzen den Bintec Router entweder als DHCP Server, DHCP Client oder als DHCP Relay Agent
1. Dynamic Host Configuration Protocol 1.1 Einleitung Im Folgenden wird die Konfiguration von DHCP beschrieben. Sie setzen den Bintec Router entweder als DHCP Server, DHCP Client oder als DHCP Relay Agent
Datenstrukturen & Algorithmen
 Datenstrukturen & Algorithmen Matthias Zwicker Universität Bern Frühling 2010 Übersicht Binäre Suchbäume Einführung und Begriffe Binäre Suchbäume 2 Binäre Suchbäume Datenstruktur für dynamische Mengen
Datenstrukturen & Algorithmen Matthias Zwicker Universität Bern Frühling 2010 Übersicht Binäre Suchbäume Einführung und Begriffe Binäre Suchbäume 2 Binäre Suchbäume Datenstruktur für dynamische Mengen
Mit einem PDA über VPN in s Internet der Uni Stuttgart
 Mit einem PDA über VPN in s Internet der Uni Stuttgart Version 4.0 Rechenzentrum Universität Stuttgart Abteilung NKS Andreas Greinert 06.10.2006 Mit einem PDA über VPN in s Internet der Uni Stuttgart...
Mit einem PDA über VPN in s Internet der Uni Stuttgart Version 4.0 Rechenzentrum Universität Stuttgart Abteilung NKS Andreas Greinert 06.10.2006 Mit einem PDA über VPN in s Internet der Uni Stuttgart...
SGI 1200-Serverfamilie - Bekannte Probleme
 SGI 1200-Serverfamilie - Bekannte Probleme In diesem Dokument werden Probleme und nicht standardmäßiges Funktionsverhalten behandelt, auf die Sie möglicherweise beim Installieren des SGI 1200-Servers bzw.
SGI 1200-Serverfamilie - Bekannte Probleme In diesem Dokument werden Probleme und nicht standardmäßiges Funktionsverhalten behandelt, auf die Sie möglicherweise beim Installieren des SGI 1200-Servers bzw.
Konfiguration des eigenen TUphone-Profils über TISS
 Konfiguration des eigenen TUphone-Profils über TISS Mit Hilfe von TISS können Sie einige Merkmale Ihres TUphone-Profils selbstständig ändern. Steigen Sie über https://tiss.tuwien.ac.at/ ein. Validieren
Konfiguration des eigenen TUphone-Profils über TISS Mit Hilfe von TISS können Sie einige Merkmale Ihres TUphone-Profils selbstständig ändern. Steigen Sie über https://tiss.tuwien.ac.at/ ein. Validieren
Architektur von Cassandra
 Seminar: NoSQL Wintersemester 201/2014 Cassandra Zwischenpräsentation 1 Ablauf Replica Partitioners Snitches Besteht aus mehrere Knoten Jeder Knoten kann (Lesen, Schreib. oder Löschen) Verwendet Hash Algorithm
Seminar: NoSQL Wintersemester 201/2014 Cassandra Zwischenpräsentation 1 Ablauf Replica Partitioners Snitches Besteht aus mehrere Knoten Jeder Knoten kann (Lesen, Schreib. oder Löschen) Verwendet Hash Algorithm
Howto. Einrichten des TREX Monitoring mit SAP Solution Manager Diagnostics
 Howto Einrichten des TREX Monitoring mit SAP Solution Manager Diagnostics Inhaltsverzeichnis: 1 GRUNDEINSTELLUNGEN IM SAP SOLUTION MANAGER... 3 1.1 ANLEGEN EINES SERVERS... 3 1.2 ANLEGEN EINES TECHNISCHEN
Howto Einrichten des TREX Monitoring mit SAP Solution Manager Diagnostics Inhaltsverzeichnis: 1 GRUNDEINSTELLUNGEN IM SAP SOLUTION MANAGER... 3 1.1 ANLEGEN EINES SERVERS... 3 1.2 ANLEGEN EINES TECHNISCHEN
Erstellen von x-y-diagrammen in OpenOffice.calc
 Erstellen von x-y-diagrammen in OpenOffice.calc In dieser kleinen Anleitung geht es nur darum, aus einer bestehenden Tabelle ein x-y-diagramm zu erzeugen. D.h. es müssen in der Tabelle mindestens zwei
Erstellen von x-y-diagrammen in OpenOffice.calc In dieser kleinen Anleitung geht es nur darum, aus einer bestehenden Tabelle ein x-y-diagramm zu erzeugen. D.h. es müssen in der Tabelle mindestens zwei
Anleitung fürs Webmail
 Anleitung fürs Webmail 29. Apr. 2010 V 1.0.0 Seite 1 / 19 Inhaltsverzeichnis Das neue Webmail...3 Anmeldung...4 E-Mail-Kontrolle...7 Generelle E-Mail-Weiterleitung/ Umleitung...7 Abwesenheits-Benachrichtigung...8
Anleitung fürs Webmail 29. Apr. 2010 V 1.0.0 Seite 1 / 19 Inhaltsverzeichnis Das neue Webmail...3 Anmeldung...4 E-Mail-Kontrolle...7 Generelle E-Mail-Weiterleitung/ Umleitung...7 Abwesenheits-Benachrichtigung...8
Einrichtung einer Weiterleitung auf eine private E-Mail Adresse in der Hochschule
 Einrichtung einer Weiterleitung auf eine private E-Mail Adresse in der Hochschule Dokumententitel: E-Mail Weiterleitung FH Dokumentennummer: its-00009 Version: 1.0 Bearbeitungsstatus: In Bearbeitung Letztes
Einrichtung einer Weiterleitung auf eine private E-Mail Adresse in der Hochschule Dokumententitel: E-Mail Weiterleitung FH Dokumentennummer: its-00009 Version: 1.0 Bearbeitungsstatus: In Bearbeitung Letztes
Mobile Anwendungen Google Cloud Messaging
 Mobile Anwendungen Google Cloud Messaging 1. Allgemeines zu Google Cloud Messaging (GCM): - 60% der Top 100 Apps nutzen Google Cloud Messagging - 200.000 Messages pro Sekunde = 17 Milliarden Messages pro
Mobile Anwendungen Google Cloud Messaging 1. Allgemeines zu Google Cloud Messaging (GCM): - 60% der Top 100 Apps nutzen Google Cloud Messagging - 200.000 Messages pro Sekunde = 17 Milliarden Messages pro
INSTALLATION ABACUS ABAWEBCLIENT
 INSTALLATION ABACUS ABAWEBCLIENT Mai 2005 / EMO v.2005.1 Diese Unterlagen sind urheberrechtlich geschützt. Alle Rechte, auch die der Übersetzung, des Nachdrucks und der Vervielfältigung der Unterlagen,
INSTALLATION ABACUS ABAWEBCLIENT Mai 2005 / EMO v.2005.1 Diese Unterlagen sind urheberrechtlich geschützt. Alle Rechte, auch die der Übersetzung, des Nachdrucks und der Vervielfältigung der Unterlagen,
Abacus Formula Compiler (AFC)
") Abacus Formula Compiler (AFC) Alle kennen Excel - jetzt sogar Ihre Java- Applikation! Bringt Tabellenkalkulationen auf die JVM http://formulacompiler.org/ Peter Arrenbrecht für Abacus Research AG http://abacus.ch/
Abacus Formula Compiler (AFC) Alle kennen Excel - jetzt sogar Ihre Java- Applikation! Bringt Tabellenkalkulationen auf die JVM http://formulacompiler.org/ Peter Arrenbrecht für Abacus Research AG http://abacus.ch/
OSF Integrator für Btracking und Salesforce Anleitung für die Nutzer
 OSF Integrator für Btracking und Salesforce Anleitung für die Nutzer Inhalt Beschreibung... 2 Beginn der Nutzung... 2 OSF Integrator für Btracking und Salesforce... 3 1. Fügen Sie Rechnungs- und Versandadressen
OSF Integrator für Btracking und Salesforce Anleitung für die Nutzer Inhalt Beschreibung... 2 Beginn der Nutzung... 2 OSF Integrator für Btracking und Salesforce... 3 1. Fügen Sie Rechnungs- und Versandadressen
Neue Ansätze der Softwarequalitätssicherung
 Neue Ansätze der Softwarequalitätssicherung Googles MapReduce-Framework für verteilte Berechnungen am Beispiel von Apache Hadoop Universität Paderborn Fakultät für Elektrotechnik, Informatik und Mathematik
Neue Ansätze der Softwarequalitätssicherung Googles MapReduce-Framework für verteilte Berechnungen am Beispiel von Apache Hadoop Universität Paderborn Fakultät für Elektrotechnik, Informatik und Mathematik
Architektur und Implementierung von Apache Derby
 Architektur und Implementierung von Apache Derby Das Zugriffssystem Carsten Kleinmann, Michael Schmidt TH Mittelhessen, MNI, Informatik 16. Januar 2012 Carsten Kleinmann, Michael Schmidt Architektur und
Architektur und Implementierung von Apache Derby Das Zugriffssystem Carsten Kleinmann, Michael Schmidt TH Mittelhessen, MNI, Informatik 16. Januar 2012 Carsten Kleinmann, Michael Schmidt Architektur und
Hilfe zur ekim. Inhalt:
 Hilfe zur ekim 1 Hilfe zur ekim Inhalt: 1 Benutzerkonten und rechte... 2 1.1 Hauptkonto (Unternehmer bzw. Lehrer)... 2 1.2 Benutzer (Mitarbeiter bzw. Schüler)... 3 2 Präsentationsmodus... 4 3 Warenkorb...
Hilfe zur ekim 1 Hilfe zur ekim Inhalt: 1 Benutzerkonten und rechte... 2 1.1 Hauptkonto (Unternehmer bzw. Lehrer)... 2 1.2 Benutzer (Mitarbeiter bzw. Schüler)... 3 2 Präsentationsmodus... 4 3 Warenkorb...
HERZLICH WILLKOMMEN SHAREPOINT 2013 - DEEP DIVE FOR ADMINS 11.09.2012 IOZ AG 2
 11.09.2012 IOZ AG 1 HERZLICH WILLKOMMEN SHAREPOINT 2013 - DEEP DIVE FOR ADMINS 11.09.2012 IOZ AG 2 AGENDA Über mich Architekturänderungen Systemvoraussetzungen Migration Fragen 11.09.2012 IOZ AG 3 ÜBER
11.09.2012 IOZ AG 1 HERZLICH WILLKOMMEN SHAREPOINT 2013 - DEEP DIVE FOR ADMINS 11.09.2012 IOZ AG 2 AGENDA Über mich Architekturänderungen Systemvoraussetzungen Migration Fragen 11.09.2012 IOZ AG 3 ÜBER
Einrichtung von VPN für Mac Clients bei Nortel VPN Router
 Einrichtung von VPN für Mac Clients bei Nortel VPN Router 2009 DeTeWe Communications GmbH! Seite 1 von 13 Einrichtung des Nortel VPN Routers (Contivity)! 3 Konfigurieren der globalen IPSec Einstellungen!
Einrichtung von VPN für Mac Clients bei Nortel VPN Router 2009 DeTeWe Communications GmbH! Seite 1 von 13 Einrichtung des Nortel VPN Routers (Contivity)! 3 Konfigurieren der globalen IPSec Einstellungen!
Bedienungsanleitung. Matthias Haasler. Version 0.4. für die Arbeit mit der Gemeinde-Homepage der Paulus-Kirchengemeinde Tempelhof
 Bedienungsanleitung für die Arbeit mit der Gemeinde-Homepage der Paulus-Kirchengemeinde Tempelhof Matthias Haasler Version 0.4 Webadministrator, email: webadmin@rundkirche.de Inhaltsverzeichnis 1 Einführung
Bedienungsanleitung für die Arbeit mit der Gemeinde-Homepage der Paulus-Kirchengemeinde Tempelhof Matthias Haasler Version 0.4 Webadministrator, email: webadmin@rundkirche.de Inhaltsverzeichnis 1 Einführung
Anleitung zur Erstellung und Bearbeitung von Seiten in Typo3. Typo3. Anleitung. Wenpas Informatik
 Anleitung zur Erstellung und Bearbeitung von Seiten in Typo3. Typo3 Anleitung Wenpas Informatik 1.0 Anmeldung im Backend Zum Backend einer Typo3 Seite gelangt man wenn man nichts anderes konfiguriert hat
Anleitung zur Erstellung und Bearbeitung von Seiten in Typo3. Typo3 Anleitung Wenpas Informatik 1.0 Anmeldung im Backend Zum Backend einer Typo3 Seite gelangt man wenn man nichts anderes konfiguriert hat