Literatur: Jeffrey D. Ullman: Principles of Database Systems, 2 nd Edition 1982, Kapitel 2.2
|
|
|
- Ursula Winter
- vor 6 Jahren
- Abrufe
Transkript
1 Hashorganisation HASHORGANISATION Literatur: Jeffrey D. Ullman: Principles of Database Systems, 2 nd Edition 982, Kapitel 2.2 Die Sätze der Datei werden auf eine Menge von Buckets aufgeteilt. Jedes Bucket besteht aus einem oder mehreren Blöcken. Die Aufteilung geschieht über eine Hashfunktion h: ein Satz mit dem Schlüsselwert v wird im Bucket mit der Nummer h(v) eingetragen. Die Hashtabelle (Bucket directory) enthält die Adressen des ersten Blocks in jedem Bucket. Im Header jedes Blocks befindet sich ein Zeiger auf den nächsten Block des Buckets (sofern vorhanden).
2 Hashorganisation 2 b b3 b2 Blocks B- bucket directory b4 b5 b6
3 Hashorganisation 3 Die Hashfunktion: Eine wünschenswerte Eigenschaft der Hashfunktion ist, dass sie gut hasht. Das heißt, h(v) ist über alle möglichen Werte von v gleich gut verteilt. Für kleine B kann das Bucketdirectory im Hauptspeicher gehalten werden. Sonst wird es über mehrere Blöcke verteilt.
4 Hashorganisation 4 Beispiel : Gegeben sei eine Folge von Datensätzen mit dem Integerwert v als Schlüssel, sowie ein Bucketdirectory mit 5 Buckets. Wir verwenden die Hashfunktion h(v) = v mod 5, die alle Datensätze auf die 5 Buckets verteilt: v = 3 h(v ) = 3 mod 5 = 3 Datensatz kommt in Bucket 3 v 2 = 5 h(v 2 ) = 5 mod 5 = Datensatz kommt in Bucket v 3 = h(v 3 ) = mod 5 = Datensatz kommt in Bucket Bucket directory
5 Hashorganisation 5 Beispiel 2:. Wir nehmen an der Schlüssel v liegt in Form von n Bits vor. v Die Bits werden in Gruppen g i zu jeweils 6 Bit zusammengefasst. Die letzte Gruppe wird, falls nötig, mit -Bits aufgefüllt. v g g 2
6 Hashorganisation 6 3. Die Gruppen g i werden jetzt als Integer-Zahlen behandelt und addiert. S = g i S = g + g 2 = = Die Summe wird durch die Anzahl der Buckets dividiert und der Rest wird als Bucket-Nummer des Satzes genommen. r = S mod #Buckets Für eine Bucketzahl von wären das zum Beispiel: r = 7269 mod = 69
7 Hashorganisation 7 Full/Empty Bit: Um leere Subblöcke von gefüllten unterscheiden zu können, führt man im Header jedes Blocks, für jeden Subblock ein full/empty Bit ein. Deletion Bit: Falls pinned Records auftreten können, reicht die Unterscheidung zwischen gefüllten und leeren Subblöcken nicht aus. Es muss dann ein zusätzliches Bit eingeführt werden, dass verhindert das Subblöcke von gelöschten Records wiederverwendet werden. full / empty d Record d Record 2 Header Subblock
8 Hashorganisation 8 Lookup (Suchen): Um einen bestimmten Satz finden zu können muss man folgendermaßen vorgehen:. Zunächst benötigt man den Schlüssel v des gesuchten Satzes. 2. Mit der Hashfunktion h berechnet man die Position i = h(v) des entsprechenden Buckets in der Hashtabelle. 3. Sequentielles Durchsuchen der Blöcke nach dem gewünschten Satz. Beispiel: Gegeben sei die unten stehende Hashtabelle mit der Hashfunktion h(v) = v mod Bucket directory
9 Hashorganisation 9 Beispiel (Fortsetzung):. Gesucht werde der Datensatz mit dem Schlüssel. 2. Berechne den Hashwert h() = mod 5 = Der Datensatz befindet sich also im Bucket Bucket directory 3. Sequentielles Durchsuchen der Blöcke im Bucket nach dem Datensatz mit Schlüssel Bucket directory
10 Hashorganisation Insertion (Einfügen): Bei dem Einfügen eines Satzes mit dem Schlüssel v wird folgendes Verfahren angewandt:. Wende das Lookup-Verfahren an, um den Satz zu suchen. Wenn der Satz gefunden werden konnte, kann er nicht ein weiteres mal eingefügt werden Fehler! (Das Einfügen eines Datensatzes ist natürlich nur möglich, wenn noch kein Datensatz mit diesem Schlüssel existiert!) 2. Konnte der Satz nicht gefunden werden, suche einen freien Subblock in den Blöcken für Bucket h(v). Wenn kein freier Subblock verfügbar ist, dann fordere einen neuen Block vom Dateisystem an und setze einen Zeiger auf den neuen Block im Header des bisher letzen Blocks im Bucket. 3. Füge den Satz in den freien Subblock ein.
11 Hashorganisation Beispiel: Es soll ein Datensatz mit dem Schlüssel 3 eingefügt werden.. Wende das Lookup-Verfahren an, um den Satz mit dem Schlüssel 3 zu suchen. 2. Konnte der Satz nicht gefunden werden, suche einen freien Subblock in den Blöcken für Bucket h(3) = 3 mod 5 = Bucket directory 3. Füge den Satz in den freien Subblock ein Bucket directory
12 Hashorganisation 2 Deletion (Löschen): Um einen Satz zu löschen, geht man folgendermaßen vor:. Finden das Satzes nach dem Lookup-Verfahren. 2. Setzen des entsprechen full/empty-bits auf damit der Subblock wieder verwendet werden kann. Bemerkungen: Bei pinned Records muss man anders vorgehen: in Schritt 2 wird das full/empty-bit auf gelassen und statt dessen das deleted-bit des Subblocks auf gesetzt. Wenn jetzt ein Zeiger auf den gelöschten Satz zeigt, kann erkannt werden, dass dieser Satz bereits gelöscht ist, und der Zeiger wird ebenfalls gelöscht oder auf NULL gesetzt. Bei unpinned Records kann der Löschalgorithmus so konstruiert werden, dass der letzte Satz aus dem letzten Block des Buckets in den freigewordenen Subblock verlegt wird. Wenn dabei der letzte Block keinen weiteren Satz mehr beinhaltet, kann er dem Dateisystem wieder zurückgegeben werden.
13 Hashorganisation 3 Beispiel: Es soll der Datensatz mit dem Schlüssel gelöscht werden.. Finden den Satz mit dem Schlüssel nach dem Lookup- Verfahren Bucket directory Full/Empty- Bits 2. Setzen des entsprechen full/empty-bits auf damit der Subblock wieder verwendet werden kann. Außerdem kann man noch den entsprechenden Eintrag löschen oder ihn später einfach überschreiben lassen Bucket directory Full/Empty- Bits
14 Hashorganisation 4 Modification (Verändern): Wenn eines oder mehrere Felder eines Satzes verändert werden sollen, wird nach folgendem Algorithmus vorgegangen: wenn eines der Felder der Schlüssel ist dann sonst lösche den Satz; füge den Satz erneut (an der richtigen Stelle) ein. suche den Satz; verändere den Satz. Bemerkung: Im Falle von pinned Records kann der Schlüssel eines Satzes nicht verändert werden.
 LENGTH: INT /* in feet */ WEIGHT: INT /* in tons */ Annahmen: Integer haben eine Länge von 2 Byte. Ein Satz ist 44 Bytes groß. Blöcke haben eine Länge von Byte.")
15 Hashorganisation 5 Beispiel: Dinosaurierdatei (Ullman): Ein Satz, der Informationen über einen Dinosaurier enthält, hat folgende Struktur: NAME: CHAR(2) /* key */ PERIOD: CHAR() HABITAT: CHAR(5) DIET: CHAR(5) LENGTH: INT /* in feet */ WEIGHT: INT /* in tons */ Annahmen: Integer haben eine Länge von 2 Byte. Ein Satz ist 44 Bytes groß. Blöcke haben eine Länge von Byte. Jeder Block hat einen Header mit einem 4 Byte großem Zeiger auf den nächsten Block und einem Byte, das die full/empty Bits beinhaltet.
16 Hashorganisation 6 Ein Block in unserer Datei hat also folgenden Aufbau: Header Record Record Als Hashfunktion wird die Länge des Schlüssels v modulo 5 gewählt. Daher besteht die Hashtabelle aus fünf Einträgen. Aufgabe: Im Folgenden werden jetzt. Ein Satz für den Elasmosaurus eingefügt: (Elasmosaurus, Cretaceous, sea, carn., 4, 5). 2. Der Satz für den Brontosaurus wird modifiziert, denn der richtige Name für den Brontosaurus ist Apatosaurus: (Apatosaurus, Jurassic, lake, herb., 7, 25).

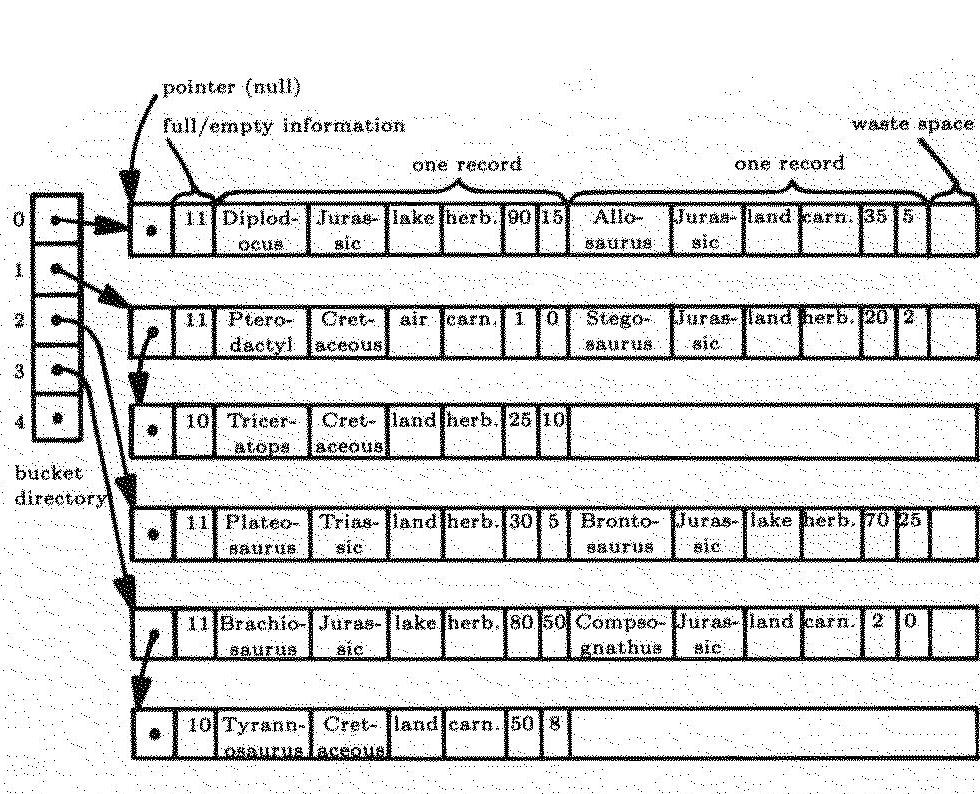
17 Hashorganisation 7 Die Dino-Datenbank vor den Transaktionen:

18 Hashorganisation 8. Einfügen des gewünschten Datensatzes (Elasmosaurus, Cretaceous, sea, carn., 4, 5) in die Dino-Datenbank: v(elsamosaurus) = 2 Bronto- Juras- lake herb saurus sic
 in (Apatosaurus, Jurassic, lake, herb.")
19 Hashorganisation 9 2. Modifikation des inkorrekten Datensatzes (Brontosaurus, Jurassic, lake, herb., 7, 25) in (Apatosaurus, Jurassic, lake, herb., 7, 25): Dazu wird der ursprüngliche Datensatz zwischengespeichert und gelöscht und anschließend der neue Datensatz eingefügt.
20 Hashorganisation 2 Laufzeitanalyse für Hashing: Jede der betrachteten Operationen Lookup, Modify, Insert und Delete benötigen einen Zugriff auf den Sekundärspeicher, falls die Hashtabelle nicht im Hauptspeicher gehalten wird, um den entsprechenden Block der Hashtabelle zu laden. Bei der sequentiellen Suche nach dem Satz werden im Schnitt die Hälfte der Blöcke eines Buckets durchsucht. Für jede Operation außer Lookup muss außerdem der modifizierte Block wieder zurückgeschrieben werden. Wenn also n die maximale Anzahl der Blöcke in einem Bucket ist, dann benötigt man für Lookup: + n/2 Zugriffe und für alle anderen Operationen + n/2 + Zugriffe auf den Sekundärspeicher. Best Case: Lookup: sonst + = 2 Zugriffe + + = 3 Zugriffe
21 Hashorganisation 2 Optimierung: Hashing kann daher optimiert werden, indem man die Anzahl der Blöcke pro Bucket möglichst reduziert. Anzahl der Buckets Anzahl der Sätze Sätze in einem Block Wenn die Datei dann größer wird, wird es notwendig, die Datei zu reorganisieren, indem die Hashfunktion geändert und die Hashtabelle vergrößert wird. Dies kann wie folgt geschehen:. Die Hashfunktion berechnet aus dem Schlüssel v eine große Integerzahl ( >> # Buckets) und dividiert diese modulo der Anzahl der Buckets. 2. Wenn die Datei reorganisiert wird, wird die Anzahl der Buckets um einen bestimmten Faktor c vergrößert (c=2). Wird die Anzahl der Buckets von n auf 2n vergrößert, werden alle Blöcke aus dem Bucket i ausschließlich auf die Buckets i und i + n verteilt.
22 Hashorganisation 22 Entartung einer Hashtabelle: Die Effizienz einer Hashtabelle beruht auf dem schnellen Finden des Buckets, das einen bestimmten Datensatz enthält. Innerhalb dieses Buckets wird dann sequentiell nach dem Datensatz gesucht. Sind in einem Bucket zu viele Datensätze (bzw. Blöcke), weil zum Beispiel die Hashfunktion schlecht gewählt wurde, ist die Suche ineffizient: 9 bucket directory... n In diesem Fall ist eine Umstrukturierung (Reorganisation) der Hashtabelle erforderlich.
23 Hashorganisation 23 Beispiel zum Reorganisieren: Ausgangssituation: Anzahl der Buckets: n = 2 Faktor c = 2 Daten:,, 2, 3, h(v) = v mod 2 i i und i + n h(v) = v mod 2 * c = v mod 4
24 Hashorganisation 24 Beispiele für häufige Anfragen in SQL (Bank): BANK-KONTO Kt.Nr Name Saldo... 5 Otto Müller 6 Karsten Tolle Otto Müller 8 97 Peter Werner 5 Eine Hash-Struktur ist vorteilhaft für alle Anfragen gegen den Schlüssel einer Relation: select * from BANK-KONTO where Kt.Nr =... jedoch problematisch bei Range-Queries oder Anfragen nach Nicht-Schlüssel-Attributen: select * from BANK-KONTO where Kt.Nr > select * from BANK-KONTO where Saldo = 5
25 Hashorganisation 25 Annahme: Es stehen 7 Buckets zur Verfügung: h(5) = 5 mod 7 = h() = 2 h() = 5 h(97) = 5 Otto Müller 6 97 Peter Werner 5 2 Karsten Tolle Otto Müller 8 6
INDEXDATEIEN ( INDEXED FILES )
") Indexdateien 1 INDEXDATEIEN ( INDEXED FILES ) ISAM (Indexed Sequential Access Method) Sätze werden nach ihren Schlüsselwerten sortiert. Schlüsselwerte sind immer vergleichbar und daher auch sortierbar.
Indexdateien 1 INDEXDATEIEN ( INDEXED FILES ) ISAM (Indexed Sequential Access Method) Sätze werden nach ihren Schlüsselwerten sortiert. Schlüsselwerte sind immer vergleichbar und daher auch sortierbar.
Datenbanksysteme SS 2013
 Datenbanksysteme SS 2013 Kapitel 4: Physikalische Datenorganisation Vorlesung vom 16.04.2013 Oliver Vornberger Institut für Informatik Universität Osnabrück Speicherhierarchie GB 10 GHertz TB 100 10 ms
Datenbanksysteme SS 2013 Kapitel 4: Physikalische Datenorganisation Vorlesung vom 16.04.2013 Oliver Vornberger Institut für Informatik Universität Osnabrück Speicherhierarchie GB 10 GHertz TB 100 10 ms
OPERATIONEN AUF EINER DATENBANK
 Einführung 1 OPERATIONEN AUF EINER DATENBANK Ein Benutzer stellt eine Anfrage: Die Benutzer einer Datenbank können meist sowohl interaktiv als auch über Anwendungen Anfragen an eine Datenbank stellen:
Einführung 1 OPERATIONEN AUF EINER DATENBANK Ein Benutzer stellt eine Anfrage: Die Benutzer einer Datenbank können meist sowohl interaktiv als auch über Anwendungen Anfragen an eine Datenbank stellen:
B*-BÄUME. Ein Index ist seinerseits wieder nichts anderes als eine Datei mit unpinned Records.
 B*-Bäume 1 B*-BÄUME Beobachtung: Ein Index ist seinerseits wieder nichts anderes als eine Datei mit unpinned Records. Es gibt keinen Grund, warum man nicht einen Index über einem Index haben sollte, und
B*-Bäume 1 B*-BÄUME Beobachtung: Ein Index ist seinerseits wieder nichts anderes als eine Datei mit unpinned Records. Es gibt keinen Grund, warum man nicht einen Index über einem Index haben sollte, und
SÄTZE MIT VARIABLER LÄNGE
 Sätze variabler Länge 1 SÄTZE MIT VARIABLER LÄNGE Generellere Struktur von Datensätzen: Ersetzen von Felder durch Gruppen von Feldern. Beispiel: n m E 1 E 2 e 1 e 2 e 11 e 12 e 21 e 22 e 23 e 24 variable
Sätze variabler Länge 1 SÄTZE MIT VARIABLER LÄNGE Generellere Struktur von Datensätzen: Ersetzen von Felder durch Gruppen von Feldern. Beispiel: n m E 1 E 2 e 1 e 2 e 11 e 12 e 21 e 22 e 23 e 24 variable
SÄTZE MIT VARIABLER LÄNGE
 Sätze variabler Länge 1 SÄTZE MIT VARIABLER LÄNGE Generellere Struktur von Datensätzen: Ersetzen von Felder durch Gruppen von Feldern. Beispiel: n m E 1 E 2 e 1 e 2 e 11 e 12 e 21 e 22 e 23 e 24 variable
Sätze variabler Länge 1 SÄTZE MIT VARIABLER LÄNGE Generellere Struktur von Datensätzen: Ersetzen von Felder durch Gruppen von Feldern. Beispiel: n m E 1 E 2 e 1 e 2 e 11 e 12 e 21 e 22 e 23 e 24 variable
13. Hashing. AVL-Bäume: Frage: Suche, Minimum, Maximum, Nachfolger in O(log n) Einfügen, Löschen in O(log n)
 Einfügen, Löschen in O(log n)") AVL-Bäume: Ausgabe aller Elemente in O(n) Suche, Minimum, Maximum, Nachfolger in O(log n) Einfügen, Löschen in O(log n) Frage: Kann man Einfügen, Löschen und Suchen in O(1) Zeit? 1 Hashing einfache Methode
AVL-Bäume: Ausgabe aller Elemente in O(n) Suche, Minimum, Maximum, Nachfolger in O(log n) Einfügen, Löschen in O(log n) Frage: Kann man Einfügen, Löschen und Suchen in O(1) Zeit? 1 Hashing einfache Methode
Mengenvergleiche: Alle Konten außer das, mit dem größten Saldo.
 Mengenvergleiche: Mehr Möglichkeiten als der in-operator bietet der θany und der θall-operator, also der Vergleich mit irgendeinem oder jedem Tupel der Unteranfrage. Alle Konten außer das, mit dem größten
Mengenvergleiche: Mehr Möglichkeiten als der in-operator bietet der θany und der θall-operator, also der Vergleich mit irgendeinem oder jedem Tupel der Unteranfrage. Alle Konten außer das, mit dem größten
Hash-Verfahren. Prof. Dr. T. Kudraß 1
 Hash-Verfahren Prof. Dr. T. Kudraß 1 Einführung Drei Alternativen, wie Dateneinträge k* im Index aussehen können: 1. Datensatz mit Schlüsselwert k.
Hash-Verfahren Prof. Dr. T. Kudraß 1 Einführung Drei Alternativen, wie Dateneinträge k* im Index aussehen können: 1. Datensatz mit Schlüsselwert k.
12. Hashing. Hashing einfache Methode um Wörtebücher zu implementieren, d.h. Hashing unterstützt die Operationen Search, Insert, Delete.
 Hashing einfache Methode um Wörtebücher zu implementieren, d.h. Hashing unterstützt die Operationen Search, Insert, Delete. Worst-case Zeit für Search: Θ(n). In der Praxis jedoch sehr gut. Unter gewissen
Hashing einfache Methode um Wörtebücher zu implementieren, d.h. Hashing unterstützt die Operationen Search, Insert, Delete. Worst-case Zeit für Search: Θ(n). In der Praxis jedoch sehr gut. Unter gewissen
! DBMS organisiert die Daten so, dass minimal viele Plattenzugriffe nötig sind.
 Unterschiede von DBMS und files Speichern von Daten! DBMS unterstützt viele Benutzer, die gleichzeitig auf dieselben Daten zugreifen concurrency control.! DBMS speichert mehr Daten als in den Hauptspeicher
Unterschiede von DBMS und files Speichern von Daten! DBMS unterstützt viele Benutzer, die gleichzeitig auf dieselben Daten zugreifen concurrency control.! DBMS speichert mehr Daten als in den Hauptspeicher
Algorithmen und Datenstrukturen
 Algorithmen und Datenstrukturen Prof. Martin Lercher Institut für Informatik Heinrich-Heine-Universität Düsseldorf Teil Hash-Verfahren Version vom: 18. November 2016 1 / 28 Vorlesung 9 18. November 2016
Algorithmen und Datenstrukturen Prof. Martin Lercher Institut für Informatik Heinrich-Heine-Universität Düsseldorf Teil Hash-Verfahren Version vom: 18. November 2016 1 / 28 Vorlesung 9 18. November 2016
Teil VII. Hashverfahren
 Teil VII Hashverfahren Überblick 1 Hashverfahren: Prinzip 2 Hashfunktionen 3 Kollisionsstrategien 4 Aufwand 5 Hashen in Java Prof. G. Stumme Algorithmen & Datenstrukturen Sommersemester 2009 7 1 Hashverfahren:
Teil VII Hashverfahren Überblick 1 Hashverfahren: Prinzip 2 Hashfunktionen 3 Kollisionsstrategien 4 Aufwand 5 Hashen in Java Prof. G. Stumme Algorithmen & Datenstrukturen Sommersemester 2009 7 1 Hashverfahren:
Untersuchen Sie, inwiefern sich die folgenden Funktionen für die Verwendung als Hashfunktion eignen. Begründen Sie Ihre Antwort.
 Prof. aa Dr. Ir. Joost-Pieter Katoen Christian Dehnert, Friedrich Gretz, Benjamin Kaminski, Thomas Ströder Tutoraufgabe 1 (Güte von Hashfunktionen): Untersuchen Sie, inwiefern sich die folgenden Funktionen
Prof. aa Dr. Ir. Joost-Pieter Katoen Christian Dehnert, Friedrich Gretz, Benjamin Kaminski, Thomas Ströder Tutoraufgabe 1 (Güte von Hashfunktionen): Untersuchen Sie, inwiefern sich die folgenden Funktionen
Programmiertechnik II
 Hash-Tabellen Überblick Hashfunktionen: Abbildung von Schlüsseln auf Zahlen Hashwert: Wert der Hashfunktion Hashtabelle: Symboltabelle, die mit Hashwerten indiziert ist Kollision: Paar von Schlüsseln mit
Hash-Tabellen Überblick Hashfunktionen: Abbildung von Schlüsseln auf Zahlen Hashwert: Wert der Hashfunktion Hashtabelle: Symboltabelle, die mit Hashwerten indiziert ist Kollision: Paar von Schlüsseln mit
Organisationsformen der Speicherstrukturen
 Organisationsformen der Speicherstrukturen Bäume und Hashing 1 Motivation Ablage von Daten soll einfachen, schnellen und inhaltsbezogenen Zugriff ermöglichen (z.b. Zeige alle Schüler des Lehrers X am heutigen
Organisationsformen der Speicherstrukturen Bäume und Hashing 1 Motivation Ablage von Daten soll einfachen, schnellen und inhaltsbezogenen Zugriff ermöglichen (z.b. Zeige alle Schüler des Lehrers X am heutigen
DATENBANKEN SQL UND SQLITE VON MELANIE SCHLIEBENER
 DATENBANKEN SQL UND SQLITE VON MELANIE SCHLIEBENER INHALTSVERZEICHNIS 1. Datenbanken 2. SQL 1.1 Sinn und Zweck 1.2 Definition 1.3 Modelle 1.4 Relationales Datenbankmodell 2.1 Definition 2.2 Befehle 3.
DATENBANKEN SQL UND SQLITE VON MELANIE SCHLIEBENER INHALTSVERZEICHNIS 1. Datenbanken 2. SQL 1.1 Sinn und Zweck 1.2 Definition 1.3 Modelle 1.4 Relationales Datenbankmodell 2.1 Definition 2.2 Befehle 3.
Vorlesung Informatik 2 Algorithmen und Datenstrukturen
 Vorlesung Informatik 2 Algorithmen und Datenstrukturen (11 Hashverfahren: Allgemeiner Rahmen) Prof. Dr. Susanne Albers Das Wörterbuch-Problem (1) Das Wörterbuch-Problem (WBP) kann wie folgt beschrieben
Vorlesung Informatik 2 Algorithmen und Datenstrukturen (11 Hashverfahren: Allgemeiner Rahmen) Prof. Dr. Susanne Albers Das Wörterbuch-Problem (1) Das Wörterbuch-Problem (WBP) kann wie folgt beschrieben
TU München, Fakultät für Informatik Lehrstuhl III: Datenbanksysteme Prof. Alfons Kemper, Ph.D.
 TU München, Fakultät für Informatik Lehrstuhl III: Datenbanksysteme Prof. Alfons Kemper, Ph.D. Blatt Nr. 2 Übung zur Vorlesung Grundlagen: Datenbanken im WS3/4 Henrik Mühe (muehe@in.tum.de) http://www-db.in.tum.de/teaching/ws34/dbsys/exercises/
TU München, Fakultät für Informatik Lehrstuhl III: Datenbanksysteme Prof. Alfons Kemper, Ph.D. Blatt Nr. 2 Übung zur Vorlesung Grundlagen: Datenbanken im WS3/4 Henrik Mühe (muehe@in.tum.de) http://www-db.in.tum.de/teaching/ws34/dbsys/exercises/
Physikalische Datenorganisation
 Kapitel 4 Physikalische Datenorganisation 4.1 Grundlagen Bedingt durch die unterschiedlichen Speichertechnologien weisen Hauptspeicher, Festplatte und Magnetband charakteristische Vor- und Nachteile auf.
Kapitel 4 Physikalische Datenorganisation 4.1 Grundlagen Bedingt durch die unterschiedlichen Speichertechnologien weisen Hauptspeicher, Festplatte und Magnetband charakteristische Vor- und Nachteile auf.
Vorlesung Informatik 2 Algorithmen und Datenstrukturen
 Vorlesung Informatik 2 Algorithmen und Datenstrukturen (12 Hashverfahren: Verkettung der Überläufer) Prof. Dr. Susanne Albers Möglichkeiten der Kollisionsbehandlung Kollisionsbehandlung: Die Behandlung
Vorlesung Informatik 2 Algorithmen und Datenstrukturen (12 Hashverfahren: Verkettung der Überläufer) Prof. Dr. Susanne Albers Möglichkeiten der Kollisionsbehandlung Kollisionsbehandlung: Die Behandlung
Die Anweisung create table
 SQL-Datendefinition Die Anweisung create table create table basisrelationenname ( spaltenname 1 wertebereich 1 [not null],... spaltenname k wertebereich k [not null]) Wirkung dieses Kommandos ist sowohl
SQL-Datendefinition Die Anweisung create table create table basisrelationenname ( spaltenname 1 wertebereich 1 [not null],... spaltenname k wertebereich k [not null]) Wirkung dieses Kommandos ist sowohl
Aufgabe 1 Indexstrukturen
 8. Übung zur Vorlesung Datenbanken im Sommersemester 2006 mit Musterlösungen Prof. Dr. Gerd Stumme, Dr. Andreas Hotho, Dipl.-Inform. Christoph Schmitz 25. Juni 2006 Aufgabe 1 Indexstrukturen Zeichnen Sie
8. Übung zur Vorlesung Datenbanken im Sommersemester 2006 mit Musterlösungen Prof. Dr. Gerd Stumme, Dr. Andreas Hotho, Dipl.-Inform. Christoph Schmitz 25. Juni 2006 Aufgabe 1 Indexstrukturen Zeichnen Sie
Beweis: Die obere Schranke ist klar, da ein Binärbaum der Höhe h höchstens
 Beweis: Die obere Schranke ist klar, da ein Binärbaum der Höhe h höchstens h 1 2 j = 2 h 1 j=0 interne Knoten enthalten kann. EADS 86/600 Beweis: Induktionsanfang: 1 ein AVL-Baum der Höhe h = 1 enthält
Beweis: Die obere Schranke ist klar, da ein Binärbaum der Höhe h höchstens h 1 2 j = 2 h 1 j=0 interne Knoten enthalten kann. EADS 86/600 Beweis: Induktionsanfang: 1 ein AVL-Baum der Höhe h = 1 enthält
Informatik II, SS 2014
 Informatik II SS 2014 (Algorithmen & Datenstrukturen) Vorlesung 7 (21.5.2014) Binäre Suche, Hashtabellen I Algorithmen und Komplexität Abstrakte Datentypen : Dictionary Dictionary: (auch: Maps, assoziative
Informatik II SS 2014 (Algorithmen & Datenstrukturen) Vorlesung 7 (21.5.2014) Binäre Suche, Hashtabellen I Algorithmen und Komplexität Abstrakte Datentypen : Dictionary Dictionary: (auch: Maps, assoziative
Überlaufbehandlung ohne Verkettung
 3.2 Statische Hash-Verfahren direkte Berechnung der Speicheradresse (Seitenadresse) eines Satzes über Schlüssel (Schlüsseltransformation) Hash-Funktion h: S {, 2,..., n} S = Schlüsselraum, n = Größe des
3.2 Statische Hash-Verfahren direkte Berechnung der Speicheradresse (Seitenadresse) eines Satzes über Schlüssel (Schlüsseltransformation) Hash-Funktion h: S {, 2,..., n} S = Schlüsselraum, n = Größe des
Datenbanken: Indexe. Motivation und Konzepte
 Datenbanken: Indexe Motivation und Konzepte Motivation Warum sind Indexstrukturen überhaupt wünschenswert? Bei Anfrageverarbeitung werden Tupel aller beteiligter Relationen nacheinander in den Hauptspeicher
Datenbanken: Indexe Motivation und Konzepte Motivation Warum sind Indexstrukturen überhaupt wünschenswert? Bei Anfrageverarbeitung werden Tupel aller beteiligter Relationen nacheinander in den Hauptspeicher
SQL. SQL: Structured Query Language. Früherer Name: SEQUEL. Standardisierte Anfragesprache für relationale DBMS: SQL-89, SQL-92, SQL-99
 SQL Früherer Name: SEQUEL SQL: Structured Query Language Standardisierte Anfragesprache für relationale DBMS: SQL-89, SQL-92, SQL-99 SQL ist eine deklarative Anfragesprache Teile von SQL Vier große Teile:
SQL Früherer Name: SEQUEL SQL: Structured Query Language Standardisierte Anfragesprache für relationale DBMS: SQL-89, SQL-92, SQL-99 SQL ist eine deklarative Anfragesprache Teile von SQL Vier große Teile:
Übersicht der wichtigsten MySQL-Befehle
 Übersicht der wichtigsten MySQL-Befehle 1. Arbeiten mit Datenbanken 1.1 Datenbank anlegen Eine Datenbank kann man wie folgt erstellen. CREATE DATABASE db_namen; 1.2 Existierende Datenbanken anzeigen Mit
Übersicht der wichtigsten MySQL-Befehle 1. Arbeiten mit Datenbanken 1.1 Datenbank anlegen Eine Datenbank kann man wie folgt erstellen. CREATE DATABASE db_namen; 1.2 Existierende Datenbanken anzeigen Mit
Themen. Hashverfahren. Stefan Szalowski Programmierung II Hashverfahren
 Themen Hashverfahren Einleitung Bisher: Suchen in logarithmischer Zeit --> Binärsuche Frage: Geht es eventuell noch schneller/effektiver? Finden von Schlüsseln in weniger als logarithmischer Zeit Wichtig
Themen Hashverfahren Einleitung Bisher: Suchen in logarithmischer Zeit --> Binärsuche Frage: Geht es eventuell noch schneller/effektiver? Finden von Schlüsseln in weniger als logarithmischer Zeit Wichtig
TU München, Fakultät für Informatik Lehrstuhl III: Datenbanksysteme Prof. Alfons Kemper, Ph.D.
 TU München, Fakultät für Informatik Lehrstuhl III: Datenbanksysteme Prof. Alfons Kemper, Ph.D. Blatt Nr. 10 Übung zur Vorlesung Grundlagen: Datenbanken im WS15/16 Harald Lang, Linnea Passing (gdb@in.tum.de)
TU München, Fakultät für Informatik Lehrstuhl III: Datenbanksysteme Prof. Alfons Kemper, Ph.D. Blatt Nr. 10 Übung zur Vorlesung Grundlagen: Datenbanken im WS15/16 Harald Lang, Linnea Passing (gdb@in.tum.de)
Datenbanken. Interne Datenorganisation:
 Interne Datenorganisation: Bisher: Konzeptionelle Betrachtungen einer Datenbank aus Sicht der Anwendung: Modellierung, Normalisieren, Sprache zum Einfügen, Ändern, Löschen, Lesen Jetzt: Betrachtung der
Interne Datenorganisation: Bisher: Konzeptionelle Betrachtungen einer Datenbank aus Sicht der Anwendung: Modellierung, Normalisieren, Sprache zum Einfügen, Ändern, Löschen, Lesen Jetzt: Betrachtung der
Oracle Database 12c Was Sie immer schon über Indexe wissen wollten
 Oracle Database 12c Was Sie immer schon über Indexe wissen wollten Marco Mischke, 08.09.2015 DOAG Regionaltreffen B* Indexe - Aufbau 0-Level Index A-F G-Z 1-Level Index A-F G-Z 2-Level Index A-F G-M N-Z
Oracle Database 12c Was Sie immer schon über Indexe wissen wollten Marco Mischke, 08.09.2015 DOAG Regionaltreffen B* Indexe - Aufbau 0-Level Index A-F G-Z 1-Level Index A-F G-Z 2-Level Index A-F G-M N-Z
Informatik II, SS 2014
 Informatik II SS 2014 (Algorithmen & Datenstrukturen) Vorlesung 9 (28.5.2014) Hashtabellen III Algorithmen und Komplexität Offene Adressierung : Zusammenfassung Offene Adressierung: Alle Schlüssel/Werte
Informatik II SS 2014 (Algorithmen & Datenstrukturen) Vorlesung 9 (28.5.2014) Hashtabellen III Algorithmen und Komplexität Offene Adressierung : Zusammenfassung Offene Adressierung: Alle Schlüssel/Werte
4. Hashverfahren. geg.: Wertebereich D, Schlüsselmenge S = {s 1,..., s n } D. Menge A von Speicheradressen; oft: A = {0,..., m 1}
 105 4. Hashverfahren geg.: Wertebereich D, Schlüsselmenge S = {s 1,..., s n } D Menge A von Speicheradressen; oft: A = {0,..., m 1} jedes Speicherverfahren realisiert h : D A mögliche Implementierungen
105 4. Hashverfahren geg.: Wertebereich D, Schlüsselmenge S = {s 1,..., s n } D Menge A von Speicheradressen; oft: A = {0,..., m 1} jedes Speicherverfahren realisiert h : D A mögliche Implementierungen
Seminar Datenbanken Martin Gerstmann
 Seminar Datenbanken Martin Gerstmann Gliederung 1. Ziele 2. Arten 2.1. erweiterbares Hashing 2.2. lineares Hashing 2.3. virtuelles Hashing 3. Bewertung 1. Ziele wachsende/schrumpfende Datenmengen verwalten
Seminar Datenbanken Martin Gerstmann Gliederung 1. Ziele 2. Arten 2.1. erweiterbares Hashing 2.2. lineares Hashing 2.3. virtuelles Hashing 3. Bewertung 1. Ziele wachsende/schrumpfende Datenmengen verwalten
Physischer Datenbankentwurf: Datenspeicherung
 Datenspeicherung.1 Physischer Datenbankentwurf: Datenspeicherung Beim Entwurf des konzeptuellen Schemas wird definiert, welche Daten benötigt werden und wie sie zusammenhängen (logische Datenbank). Beim
Datenspeicherung.1 Physischer Datenbankentwurf: Datenspeicherung Beim Entwurf des konzeptuellen Schemas wird definiert, welche Daten benötigt werden und wie sie zusammenhängen (logische Datenbank). Beim
Datenbank und Tabelle mit SQL erstellen
 Datenbank und Tabelle mit SQL erstellen 1) Übung stat Mit dem folgenden Befehlen legt man die Datenbank stat an und in dieser die Tabelle data1 : CREATE DATABASE stat; USE stat; CREATE TABLE data1 ( `id`
Datenbank und Tabelle mit SQL erstellen 1) Übung stat Mit dem folgenden Befehlen legt man die Datenbank stat an und in dieser die Tabelle data1 : CREATE DATABASE stat; USE stat; CREATE TABLE data1 ( `id`
Dateiorganisation und Zugriffsstrukturen
 Dateiorganisation und Zugriffsstrukturen Prof. Dr. T. Kudraß 1 Mögliche Dateiorganisationen Viele Alternativen existieren, jede geeignet für bestimmte Situation (oder auch nicht) Heap-Dateien: Geeignet
Dateiorganisation und Zugriffsstrukturen Prof. Dr. T. Kudraß 1 Mögliche Dateiorganisationen Viele Alternativen existieren, jede geeignet für bestimmte Situation (oder auch nicht) Heap-Dateien: Geeignet
Grundlagen der Programmierung
 Grundlagen der Programmierung Algorithmen und Datenstrukturen Die Inhalte der Vorlesung wurden primär auf Basis der angegebenen Literatur erstellt. Darüber hinaus sind viele Teile direkt aus der Vorlesung
Grundlagen der Programmierung Algorithmen und Datenstrukturen Die Inhalte der Vorlesung wurden primär auf Basis der angegebenen Literatur erstellt. Darüber hinaus sind viele Teile direkt aus der Vorlesung
Dateiorganisation und Zugriffsstrukturen. Prof. Dr. T. Kudraß 1
 Dateiorganisation und Zugriffsstrukturen Prof. Dr. T. Kudraß 1 Mögliche Dateiorganisationen Viele Alternativen existieren, jede geeignet für bestimmte Situation (oder auch nicht) Heap-Dateien: Geeignet
Dateiorganisation und Zugriffsstrukturen Prof. Dr. T. Kudraß 1 Mögliche Dateiorganisationen Viele Alternativen existieren, jede geeignet für bestimmte Situation (oder auch nicht) Heap-Dateien: Geeignet
TU München, Fakultät für Informatik Lehrstuhl III: Datenbanksysteme Prof. Dr. Thomas Neumann
 TU München, Fakultät für Informatik Lehrstuhl III: Datenbanksysteme Prof. Dr. Thomas Neumann Blatt Nr. 9 Übung zur Vorlesung Grundlagen: Datenbanken im WS4/5 Harald Lang (harald.lang@in.tum.de) http://www-db.in.tum.de/teaching/ws45/grundlagen/
TU München, Fakultät für Informatik Lehrstuhl III: Datenbanksysteme Prof. Dr. Thomas Neumann Blatt Nr. 9 Übung zur Vorlesung Grundlagen: Datenbanken im WS4/5 Harald Lang (harald.lang@in.tum.de) http://www-db.in.tum.de/teaching/ws45/grundlagen/
Kapitel DB:VI (Fortsetzung)
") Kapitel DB:VI (Fortsetzung) VI. Die relationale Datenbanksprache SQL Einführung SQL als Datenanfragesprache SQL als Datendefinitionssprache SQL als Datenmanipulationssprache Sichten SQL vom Programm aus
Kapitel DB:VI (Fortsetzung) VI. Die relationale Datenbanksprache SQL Einführung SQL als Datenanfragesprache SQL als Datendefinitionssprache SQL als Datenmanipulationssprache Sichten SQL vom Programm aus
Datenbanksysteme II Indexstrukturen Felix Naumann
 Datenbanksysteme II Indexstrukturen (Kapitel 13) 5.5.2008 Felix Naumann Klausur 2 Mittwoch, 23.7. 9 13 Uhr 4 Stunden Umfang auf 1,5 Stunden ausgelegt Keine Hilfsmittel Motivation 3 Platzierung der Tupel
Datenbanksysteme II Indexstrukturen (Kapitel 13) 5.5.2008 Felix Naumann Klausur 2 Mittwoch, 23.7. 9 13 Uhr 4 Stunden Umfang auf 1,5 Stunden ausgelegt Keine Hilfsmittel Motivation 3 Platzierung der Tupel
Datenbanksysteme II Multidimensionale Indizes Felix Naumann
 Datenbanksysteme II Multidimensionale Indizes (Kapitel 14) 26.5.2008 Felix Naumann Motivation 2 Annahme bisher: Eine Dimension Ein einziger Suchschlüssel Suchschlüssel hlü l kann auch Kombination von Attributen
Datenbanksysteme II Multidimensionale Indizes (Kapitel 14) 26.5.2008 Felix Naumann Motivation 2 Annahme bisher: Eine Dimension Ein einziger Suchschlüssel Suchschlüssel hlü l kann auch Kombination von Attributen
Datenstrukturen & Algorithmen Lösungen zu Blatt 5 FS 14
 Eidgenössische Technische Hochschule Zürich Ecole polytechnique fédérale de Zurich Politecnico federale di Zurigo Federal Institute of Technology at Zurich Institut für Theoretische Informatik 26. März
Eidgenössische Technische Hochschule Zürich Ecole polytechnique fédérale de Zurich Politecnico federale di Zurigo Federal Institute of Technology at Zurich Institut für Theoretische Informatik 26. März
MySQL-Befehle. In diesem Tutorial möchte ich eine kurze Übersicht der wichtigsten Befehle von MySQL geben.
 MySQL-Befehle 1. Einleitung In diesem Tutorial möchte ich eine kurze Übersicht der wichtigsten Befehle von MySQL geben. 2. Arbeiten mit Datenbanken 2.1 Datenbank anlegen Eine Datenbank kann man wie folgt
MySQL-Befehle 1. Einleitung In diesem Tutorial möchte ich eine kurze Übersicht der wichtigsten Befehle von MySQL geben. 2. Arbeiten mit Datenbanken 2.1 Datenbank anlegen Eine Datenbank kann man wie folgt
Kollision Hashfunktion Verkettung Offenes Hashing Perfektes Hashing Universelles Hashing Dynamisches Hashing. 4. Hashverfahren
 4. Hashverfahren geg.: Wertebereich D, Schlüsselmenge S = {s 1,..., s n } D Menge A von Speicheradressen; oft: A = {0,..., m 1} jedes Speicherverfahren realisiert h : D A mögliche Implementierungen von
4. Hashverfahren geg.: Wertebereich D, Schlüsselmenge S = {s 1,..., s n } D Menge A von Speicheradressen; oft: A = {0,..., m 1} jedes Speicherverfahren realisiert h : D A mögliche Implementierungen von
5.8.2 Erweiterungen Dynamische Hash-Funktionen (mit variabler Tabellengröße)?
?") 5.8.2 Erweiterungen Dynamische Hash-Funktionen (mit variabler Tabellengröße)? Ladefaktor: α, n aktuelle Anzahl gespeicherter Werte m Tabellengröße. Einfacher Ansatz: rehash() a z c h s r b s h a z Wenn
5.8.2 Erweiterungen Dynamische Hash-Funktionen (mit variabler Tabellengröße)? Ladefaktor: α, n aktuelle Anzahl gespeicherter Werte m Tabellengröße. Einfacher Ansatz: rehash() a z c h s r b s h a z Wenn
Grundlagen: Algorithmen und Datenstrukturen
 Grundlagen: Algorithmen und Datenstrukturen Prof. Dr. Hanjo Täubig Lehrstuhl für Effiziente Algorithmen (Prof. Dr. Ernst W. Mayr) Institut für Informatik Technische Universität München Sommersemester 2010
Grundlagen: Algorithmen und Datenstrukturen Prof. Dr. Hanjo Täubig Lehrstuhl für Effiziente Algorithmen (Prof. Dr. Ernst W. Mayr) Institut für Informatik Technische Universität München Sommersemester 2010
Übung Datenbanken in der Praxis. Datenmodifikation mit SQL
 Datenmodifikation mit SQL Folie 45 SQL - Datenmodifikation Einfügen INSERT INTO Relation [(Attribut, Attribut,...)] VALUES (Wert, Wert,...) INSERT INTO Relation [(Attribut, Attribut,...)] SFW-Anfrage Ändern
Datenmodifikation mit SQL Folie 45 SQL - Datenmodifikation Einfügen INSERT INTO Relation [(Attribut, Attribut,...)] VALUES (Wert, Wert,...) INSERT INTO Relation [(Attribut, Attribut,...)] SFW-Anfrage Ändern
Kapitel 9. Embedded SQL. Prof. Dr. Wolfgang Weber Vorlesung Datenbanken 1
 Kapitel 9 Embedded SQL Vorlesung Datenbanken 1 Embedded SQL (siehe auch [Date00]) Arbeitsweise ähnlich PL/SQL, allerdings: Normale Programmiersprache mit eingestreuten SQL-Befehlen und anderen Befehlen
Kapitel 9 Embedded SQL Vorlesung Datenbanken 1 Embedded SQL (siehe auch [Date00]) Arbeitsweise ähnlich PL/SQL, allerdings: Normale Programmiersprache mit eingestreuten SQL-Befehlen und anderen Befehlen
Vorlesung Datenstrukturen
 Vorlesung Datenstrukturen Hashing Maike Buchin 2. und 4.5.2017 Motivation häufig werden Daten anhand eines numerischen Schlüssel abgespeichert Beispiele: Studenten der RUB nach Matrikelnummer Kunden einer
Vorlesung Datenstrukturen Hashing Maike Buchin 2. und 4.5.2017 Motivation häufig werden Daten anhand eines numerischen Schlüssel abgespeichert Beispiele: Studenten der RUB nach Matrikelnummer Kunden einer
Datenbanken SQL Einführung Datenbank in MySQL einrichten mit PhpMyAdmin
 Datenbanken SQL Einführung Datenbank in MySQL einrichten mit PhpMyAdmin PhpMyAdmin = grafsches Tool zur Verwaltung von MySQL-Datenbanken Datenbanken erzeugen und löschen Tabellen und Spalten einfügen,
Datenbanken SQL Einführung Datenbank in MySQL einrichten mit PhpMyAdmin PhpMyAdmin = grafsches Tool zur Verwaltung von MySQL-Datenbanken Datenbanken erzeugen und löschen Tabellen und Spalten einfügen,
Muster. Informatik 3 (Februar 2004) Name: Matrikelnummer: Betrachten Sie den folgenden Suchbaum. A G H J K M N
 Name: Matrikelnummer: Betrachten Sie den folgenden Suchbaum. A G H J K M N") 2 von 15 Aufgabe 1: Suchbäume (14 ) Betrachten Sie den folgenden Suchbaum. A B C D E F G H I J K L M N O P R (a) (1 Punkt ) Geben Sie die Höhe des Knotens F an. (b) (1 Punkt ) Geben Sie die Tiefe des Knotens
2 von 15 Aufgabe 1: Suchbäume (14 ) Betrachten Sie den folgenden Suchbaum. A B C D E F G H I J K L M N O P R (a) (1 Punkt ) Geben Sie die Höhe des Knotens F an. (b) (1 Punkt ) Geben Sie die Tiefe des Knotens
Grundlagen: Algorithmen und Datenstrukturen
 Grundlagen: Algorithmen und Datenstrukturen Prof. Dr. Hanjo Täubig Lehrstuhl für Effiziente Algorithmen (Prof. Dr. Ernst W. Mayr) Institut für Informatik Technische Universität München Sommersemester 2010
Grundlagen: Algorithmen und Datenstrukturen Prof. Dr. Hanjo Täubig Lehrstuhl für Effiziente Algorithmen (Prof. Dr. Ernst W. Mayr) Institut für Informatik Technische Universität München Sommersemester 2010
Datensicherheit. 8. Datensicherheit
 8. Anforderungen an ein DBMS Identifikation und Authentisieren von Benutzern Autorisierung und Zugriffskontrolle Aufzeichnung von sicherheitsrelevanten Aktionen eines Benutzers typische Schwachstellen
8. Anforderungen an ein DBMS Identifikation und Authentisieren von Benutzern Autorisierung und Zugriffskontrolle Aufzeichnung von sicherheitsrelevanten Aktionen eines Benutzers typische Schwachstellen
Relationale Datenbanken in der Praxis
 Seite 1 Relationale Datenbanken in der Praxis Inhaltsverzeichnis 1 Datenbank-Design...2 1.1 Entwurf...2 1.2 Beschreibung der Realität...2 1.3 Enitiy-Relationship-Modell (ERM)...3 1.4 Schlüssel...4 1.5
Seite 1 Relationale Datenbanken in der Praxis Inhaltsverzeichnis 1 Datenbank-Design...2 1.1 Entwurf...2 1.2 Beschreibung der Realität...2 1.3 Enitiy-Relationship-Modell (ERM)...3 1.4 Schlüssel...4 1.5
Datenbanksysteme 2013
 Datenbanksysteme 2013 Kapitel 8: Datenintegrität Vorlesung vom 14.05.2013 Oliver Vornberger Institut für Informatik Universität Osnabrück Datenintegrität Statische Bedingung (jeder Zustand) Dynamische
Datenbanksysteme 2013 Kapitel 8: Datenintegrität Vorlesung vom 14.05.2013 Oliver Vornberger Institut für Informatik Universität Osnabrück Datenintegrität Statische Bedingung (jeder Zustand) Dynamische
Kapitel 8: Physischer Datenbankentwurf
 8. Physischer Datenbankentwurf Seite 1 Kapitel 8: Physischer Datenbankentwurf Speicherung und Verwaltung der Relationen einer relationalen Datenbank so, dass eine möglichst große Effizienz der einzelnen
8. Physischer Datenbankentwurf Seite 1 Kapitel 8: Physischer Datenbankentwurf Speicherung und Verwaltung der Relationen einer relationalen Datenbank so, dass eine möglichst große Effizienz der einzelnen
Algorithmen & Datenstrukturen Lösungen zu Blatt 9 HS 16
 Eidgenössische Technische Hochschule Zürich Ecole polytechnique fédérale de Zurich Politecnico federale di Zurigo Federal Institute of Technology at Zurich Departement Informatik 24. November 2016 Markus
Eidgenössische Technische Hochschule Zürich Ecole polytechnique fédérale de Zurich Politecnico federale di Zurigo Federal Institute of Technology at Zurich Departement Informatik 24. November 2016 Markus
Kapitel 12: Schnelles Bestimmen der Frequent Itemsets
 Einleitung In welchen Situationen ist Apriori teuer, und warum? Kapitel 12: Schnelles Bestimmen der Frequent Itemsets Data Warehousing und Mining 1 Data Warehousing und Mining 2 Schnelles Identifizieren
Einleitung In welchen Situationen ist Apriori teuer, und warum? Kapitel 12: Schnelles Bestimmen der Frequent Itemsets Data Warehousing und Mining 1 Data Warehousing und Mining 2 Schnelles Identifizieren
SQL. SQL SELECT Anweisung SQL-SELECT SQL-SELECT
 SQL SQL SELECT Anweisung Mit der SQL SELECT-Anweisung werden Datenwerte aus einer oder mehreren Tabellen einer Datenbank ausgewählt. Das Ergebnis der Auswahl ist erneut eine Tabelle, die sich dynamisch
SQL SQL SELECT Anweisung Mit der SQL SELECT-Anweisung werden Datenwerte aus einer oder mehreren Tabellen einer Datenbank ausgewählt. Das Ergebnis der Auswahl ist erneut eine Tabelle, die sich dynamisch
Garten - Daten Bank. - survival pack -
 Garten - Daten Bank - survival pack - Dr. Karsten Tolle PRG2 SS 2017 Inhalt heute Kurz: Motivation und Begriffe SQL (survival pack) create table (Tabelle erzeugen) insert into (Einfügen) select (Anfragen)
Garten - Daten Bank - survival pack - Dr. Karsten Tolle PRG2 SS 2017 Inhalt heute Kurz: Motivation und Begriffe SQL (survival pack) create table (Tabelle erzeugen) insert into (Einfügen) select (Anfragen)
Unterabfragen (Subqueries)
") Unterabfragen (Subqueries) Die kürzeste Formulierung ist folgende: SELECT Felderliste FROM Tabelle1 WHERE Tabelle1.Feldname Operator (SELECT Feldname FROM Tabelle2 WHERE Bedingung); wobei Tabelle1 und
Unterabfragen (Subqueries) Die kürzeste Formulierung ist folgende: SELECT Felderliste FROM Tabelle1 WHERE Tabelle1.Feldname Operator (SELECT Feldname FROM Tabelle2 WHERE Bedingung); wobei Tabelle1 und
Hash-Join Algorithmen
 Hash-Join lgorithmen dvanced Topics in Databases Ws08/09 atthias ichly Einleitung 2 Grundlage ist das Paper: Join Processing in Database Systems With Large ain emories Quelle: C Transactions on Database
Hash-Join lgorithmen dvanced Topics in Databases Ws08/09 atthias ichly Einleitung 2 Grundlage ist das Paper: Join Processing in Database Systems With Large ain emories Quelle: C Transactions on Database
Kapitel 6 HASHING. Algorithmen & Datenstrukturen Prof. Dr. Wolfgang Schramm
 Kapitel 6 HASHING Algorithmen & Datenstrukturen Prof. Dr. Wolfgang Schramm Übersicht 1 1. Einführung 2. Algorithmen 3. Eigenscha?en von Programmiersprachen 4. Algorithmenparadigmen 5. Suchen & SorGeren
Kapitel 6 HASHING Algorithmen & Datenstrukturen Prof. Dr. Wolfgang Schramm Übersicht 1 1. Einführung 2. Algorithmen 3. Eigenscha?en von Programmiersprachen 4. Algorithmenparadigmen 5. Suchen & SorGeren
1 Transaktionen in SQL. 2 Was ist eine Transaktion. 3 Eigenschaften einer Transaktion. PostgreSQL
 1 Transaktionen in SQL Um Daten in einer SQL-Datenbank konsistent zu halten, gibt es einerseits die Möglichkeit der Normalisierung, andererseits sog. Transaktionen. 2 Was ist eine Transaktion Eine Transaktion
1 Transaktionen in SQL Um Daten in einer SQL-Datenbank konsistent zu halten, gibt es einerseits die Möglichkeit der Normalisierung, andererseits sog. Transaktionen. 2 Was ist eine Transaktion Eine Transaktion
Algorithmen und Datenstrukturen 1 VL Übungstest WS Januar 2011
 Technische Universität Wien Institut für Computergraphik und Algorithmen Arbeitsbereich für Algorithmen und Datenstrukturen 186.172 Algorithmen und Datenstrukturen 1 VL 4.0 2. Übungstest WS 2010 14. Januar
Technische Universität Wien Institut für Computergraphik und Algorithmen Arbeitsbereich für Algorithmen und Datenstrukturen 186.172 Algorithmen und Datenstrukturen 1 VL 4.0 2. Übungstest WS 2010 14. Januar
SQL Tutorial. SQL - Tutorial SS 06. Hubert Baumgartner. INSO - Industrial Software
 SQL Tutorial SQL - Tutorial SS 06 Hubert Baumgartner INSO - Industrial Software Institut für Rechnergestützte Automation Fakultät für Informatik Technische Universität Wien Inhalt des Tutorials 1 2 3 4
SQL Tutorial SQL - Tutorial SS 06 Hubert Baumgartner INSO - Industrial Software Institut für Rechnergestützte Automation Fakultät für Informatik Technische Universität Wien Inhalt des Tutorials 1 2 3 4
5.3 Datenänderung/-zugriff mit SQL (DML)
") 5.3 Datenänderung/-zugriff mit SQL (DML) Hinweis: - DML-Anweisungen sind mengenorientiert - Mit einer Anweisungen kann mehr als ein Tupel eingefügt, geändert, gelöscht oder gelesen werden Benutzungs- und
5.3 Datenänderung/-zugriff mit SQL (DML) Hinweis: - DML-Anweisungen sind mengenorientiert - Mit einer Anweisungen kann mehr als ein Tupel eingefügt, geändert, gelöscht oder gelesen werden Benutzungs- und
6/23/06. Universelles Hashing. Nutzen des Universellen Hashing. Problem: h fest gewählt es gibt ein S U mit vielen Kollisionen
 Universelles Hashing Problem: h fest gewählt es gibt ein S U mit vielen Kollisionen wir können nicht annehmen, daß die Keys gleichverteilt im Universum liegen (z.b. Identifier im Programm) könnte also
Universelles Hashing Problem: h fest gewählt es gibt ein S U mit vielen Kollisionen wir können nicht annehmen, daß die Keys gleichverteilt im Universum liegen (z.b. Identifier im Programm) könnte also
Datenbanken. Seminararbeit. Einführung in das wissenschaftliche Arbeiten
 Seminararbeit vorgelegt von: Gutachter: Studienbereich: Christian Lechner Dr. Georg Moser Informatik Datum: 6. Juni 2013 Inhaltsverzeichnis Inhaltsverzeichnis 1 Einführung in Datenbanken 1 1.1 Motivation....................................
Seminararbeit vorgelegt von: Gutachter: Studienbereich: Christian Lechner Dr. Georg Moser Informatik Datum: 6. Juni 2013 Inhaltsverzeichnis Inhaltsverzeichnis 1 Einführung in Datenbanken 1 1.1 Motivation....................................
Welche Kunden haben die gleiche Ware bestellt? select distinct a1.name, a2.name from Auftrag a1, Auftrag a2 where a1.ware = a2.ware.
 *HVFKDFKWHOWH$QIUDJHQ In einer SQL-Anweisung können in der where-klausel, from-klausel, select-klausel wieder SQL-Anweisungen auftreten. Man spricht dann auch von einer geschachtelten Anfrage oder Unteranfrage.
*HVFKDFKWHOWH$QIUDJHQ In einer SQL-Anweisung können in der where-klausel, from-klausel, select-klausel wieder SQL-Anweisungen auftreten. Man spricht dann auch von einer geschachtelten Anfrage oder Unteranfrage.
Oracle 9i Einführung Performance Tuning
 Kurs Oracle 9i Einführung Performance Tuning Teil 3 Der Optimizer Timo Meyer Wintersemester 2005 / 2006 Seite 1 von 16 Seite 1 von 16 1. auf Tabellen 2. 3. Optimizer 4. Optimizer RBO 5. Optimizer CBO 6.
Kurs Oracle 9i Einführung Performance Tuning Teil 3 Der Optimizer Timo Meyer Wintersemester 2005 / 2006 Seite 1 von 16 Seite 1 von 16 1. auf Tabellen 2. 3. Optimizer 4. Optimizer RBO 5. Optimizer CBO 6.
8. Hashing Lernziele. 8. Hashing
 8. Hashing Lernziele 8. Hashing Lernziele: Hashverfahren verstehen und einsetzen können, Vor- und Nachteile von Hashing gegenüber Suchbäumen benennen können, verschiedene Verfahren zur Auflösung von Kollisionen
8. Hashing Lernziele 8. Hashing Lernziele: Hashverfahren verstehen und einsetzen können, Vor- und Nachteile von Hashing gegenüber Suchbäumen benennen können, verschiedene Verfahren zur Auflösung von Kollisionen
3 Query Language (QL) Einfachste Abfrage Ordnen Gruppieren... 7
 Einfachste Abfrage Ordnen Gruppieren... 7") 1 Data Definition Language (DDL)... 2 1.1 Tabellen erstellen... 2 1.1.1 Datentyp...... 2 1.1.2 Zusätze.... 2 1.2 Tabellen löschen... 2 1.3 Tabellen ändern (Spalten hinzufügen)... 2 1.4 Tabellen ändern
1 Data Definition Language (DDL)... 2 1.1 Tabellen erstellen... 2 1.1.1 Datentyp...... 2 1.1.2 Zusätze.... 2 1.2 Tabellen löschen... 2 1.3 Tabellen ändern (Spalten hinzufügen)... 2 1.4 Tabellen ändern
SQL. Datenmanipulation. Datenmanipulationssprache. Ein neues Tupel hinzufügen. Das INSERT Statement
 SQL Datenmanipulation Datenmanipulationssprache Ein DML Statement wird ausgeführt wenn: neue Tupel eingefügt werden existierende Tupel geändert werden existierende Tupel aus der Tabelle gelöscht werden
SQL Datenmanipulation Datenmanipulationssprache Ein DML Statement wird ausgeführt wenn: neue Tupel eingefügt werden existierende Tupel geändert werden existierende Tupel aus der Tabelle gelöscht werden
Übersicht. Volltextindex Boolesches Retrieval Termoperationen Indexieren mit Apache Lucene
 Übersicht Volltextindex Boolesches Retrieval Termoperationen Indexieren mit Apache Lucene 5.0.07 1 IR-System Peter Kolb 5.0.07 Volltextindex Dokumentenmenge durchsuchbar machen Suche nach Wörtern Volltextindex:
Übersicht Volltextindex Boolesches Retrieval Termoperationen Indexieren mit Apache Lucene 5.0.07 1 IR-System Peter Kolb 5.0.07 Volltextindex Dokumentenmenge durchsuchbar machen Suche nach Wörtern Volltextindex:
ids-system GmbH Tipp #3 Leer-Strings in SQL oder die Frage nach CHAR oder VARCHAR
 ids-system GmbH Tipp #3 Leer-Strings in SQL oder die Frage Zusammenfassung Dieses Dokument beschreibt die Unterschiede zwischen CHAR und VARCHAR Datentyp sowie die Behandlung im SQL Michael Tiefenbacher
ids-system GmbH Tipp #3 Leer-Strings in SQL oder die Frage Zusammenfassung Dieses Dokument beschreibt die Unterschiede zwischen CHAR und VARCHAR Datentyp sowie die Behandlung im SQL Michael Tiefenbacher
Aufbau und Bestandteile von Formularen. Oracle Forms. Erstellen eines neuen Blocks (1) Starten von Oracle Forms
 Starten von Oracle Forms") Oracle Forms Oracle Forms ist eine Applikation für den Entwurf und die Erstellung Forms-basierender Anwendungen. Diese Forms umfassen Dateneingabe-Formulare Datenabfrage-Formulare Browser-Formulare Oracle
Oracle Forms Oracle Forms ist eine Applikation für den Entwurf und die Erstellung Forms-basierender Anwendungen. Diese Forms umfassen Dateneingabe-Formulare Datenabfrage-Formulare Browser-Formulare Oracle
Physische Datenorganisat
 Physische Datenorganisat Speicherhierarchie Hintergrundspeicher / RAID B-Bäume Hashing (R-Bäume ) Objektballung Indexe in SQL Kapitel 7 1 Überblick: Speicherhierarchie Register Cache Hauptspeicher Plattenspeicher
Physische Datenorganisat Speicherhierarchie Hintergrundspeicher / RAID B-Bäume Hashing (R-Bäume ) Objektballung Indexe in SQL Kapitel 7 1 Überblick: Speicherhierarchie Register Cache Hauptspeicher Plattenspeicher
9. Dateisysteme. Betriebssysteme Harald Kosch Seite 164
 9. Dateisysteme Eine Datei ist eine Abstraktion für ein Aggregat von Informationen (muß nicht eine Plattendatei sein). Aufbau eines Dateisystems: Katalog (Directory) Einzelne Dateien (Files) Zwei Aspekte
9. Dateisysteme Eine Datei ist eine Abstraktion für ein Aggregat von Informationen (muß nicht eine Plattendatei sein). Aufbau eines Dateisystems: Katalog (Directory) Einzelne Dateien (Files) Zwei Aspekte
{0,1} rekursive Aufteilung des Datenraums in die Quadranten NW, NE, SW und SE feste Auflösung des Datenraums in 2 p 2 p Gitterzellen
 4.4 MX-Quadtrees (I) MatriX Quadtree Verwaltung 2-dimensionaler Punkte Punkte als 1-Elemente in einer quadratischen Matrix mit Wertebereich {0,1} rekursive Aufteilung des Datenraums in die Quadranten NW,
4.4 MX-Quadtrees (I) MatriX Quadtree Verwaltung 2-dimensionaler Punkte Punkte als 1-Elemente in einer quadratischen Matrix mit Wertebereich {0,1} rekursive Aufteilung des Datenraums in die Quadranten NW,
insert, update, delete Definition des Datenbankschemas select, from, where Rechteverwaltung, Transaktionskontrolle
 Einführung in SQL insert, update, delete Definition des Datenbankschemas select, from, where Rechteverwaltung, Transaktionskontrolle Quelle Wikipedia, 3.9.2015 SQL zur Kommunikation mit dem DBMS SQL ist
Einführung in SQL insert, update, delete Definition des Datenbankschemas select, from, where Rechteverwaltung, Transaktionskontrolle Quelle Wikipedia, 3.9.2015 SQL zur Kommunikation mit dem DBMS SQL ist
Anwendungsentwicklung Datenbanken SQL. Stefan Goebel
 Anwendungsentwicklung Datenbanken SQL Stefan Goebel SQL Structured Query Language strukturierte Abfragesprache von ANSI und ISO standardisiert deklarativ bedeutet was statt wie SQL beschreibt, welche Daten
Anwendungsentwicklung Datenbanken SQL Stefan Goebel SQL Structured Query Language strukturierte Abfragesprache von ANSI und ISO standardisiert deklarativ bedeutet was statt wie SQL beschreibt, welche Daten
Freispeicherverwaltung Martin Wahl,
 Freispeicherverwaltung Martin Wahl, 17.11.03 Allgemeines zur Speicherverwaltung Der physikalische Speicher wird in zwei Teile unterteilt: -Teil für den Kernel -Dynamischer Speicher Die Verwaltung des dynamischen
Freispeicherverwaltung Martin Wahl, 17.11.03 Allgemeines zur Speicherverwaltung Der physikalische Speicher wird in zwei Teile unterteilt: -Teil für den Kernel -Dynamischer Speicher Die Verwaltung des dynamischen
Algorithmen und Datenstrukturen VO 3.0 Vorlesungsprüfung 19. Oktober 2007
 Technische Universität Wien Institut für Computergraphik und Algorithmen Arbeitsbereich für Algorithmen und Datenstrukturen Algorithmen und Datenstrukturen 1 186.089 VO 3.0 Vorlesungsprüfung 19. Oktober
Technische Universität Wien Institut für Computergraphik und Algorithmen Arbeitsbereich für Algorithmen und Datenstrukturen Algorithmen und Datenstrukturen 1 186.089 VO 3.0 Vorlesungsprüfung 19. Oktober
Fachhochschule Kaiserslautern Labor Datenbanken mit MySQL SS2006 Versuch 1
 Fachhochschule Kaiserslautern Fachbereiche Elektrotechnik/Informationstechnik und Maschinenbau Labor Datenbanken Versuch 1 : Die Grundlagen von MySQL ------------------------------------------------------------------------------------------------------------
Fachhochschule Kaiserslautern Fachbereiche Elektrotechnik/Informationstechnik und Maschinenbau Labor Datenbanken Versuch 1 : Die Grundlagen von MySQL ------------------------------------------------------------------------------------------------------------
Übung Algorithmen und Datenstrukturen
 Übung Algorithmen und Datenstrukturen Sommersemester 2017 Patrick Schäfer, Humboldt-Universität zu Berlin Agenda: Kürzeste Wege, Heaps, Hashing Heute: Kürzeste Wege: Dijkstra Heaps: Binäre Min-Heaps Hashing:
Übung Algorithmen und Datenstrukturen Sommersemester 2017 Patrick Schäfer, Humboldt-Universität zu Berlin Agenda: Kürzeste Wege, Heaps, Hashing Heute: Kürzeste Wege: Dijkstra Heaps: Binäre Min-Heaps Hashing:
3. Übungsblatt zu Algorithmen I im SoSe 2017
 Karlsruher Institut für Technologie Prof. Dr. Jörn Müller-Quade Institut für Theoretische Informatik Björn Kaidel, Sebastian Schlag, Sascha Witt 3. Übungsblatt zu Algorithmen I im SoSe 2017 http://crypto.iti.kit.edu/index.php?id=799
Karlsruher Institut für Technologie Prof. Dr. Jörn Müller-Quade Institut für Theoretische Informatik Björn Kaidel, Sebastian Schlag, Sascha Witt 3. Übungsblatt zu Algorithmen I im SoSe 2017 http://crypto.iti.kit.edu/index.php?id=799
Seminar 2. SQL - DML(Data Manipulation Language) und. DDL(Data Definition Language) Befehle.
 und. DDL(Data Definition Language) Befehle.") Seminar 2 SQL - DML(Data Manipulation Language) und DDL(Data Definition Language) Befehle. DML Befehle Aggregatfunktionen - werden auf eine Menge von Tupeln angewendet - Verdichtung einzelner Tupeln yu
Seminar 2 SQL - DML(Data Manipulation Language) und DDL(Data Definition Language) Befehle. DML Befehle Aggregatfunktionen - werden auf eine Menge von Tupeln angewendet - Verdichtung einzelner Tupeln yu
GRUNDLAGEN VON INFORMATIONSSYSTEMEN INDEXSTRUKTUREN I: B-BÄUME UND IHRE VARIANTEN
 Informationssysteme - Indexstrukturen I: B-Bäume und ihre Varianten Seite 1 GRUNDLAGEN VON INFORMATIONSSYSTEMEN INDEXSTRUKTUREN I: B-BÄUME UND IHRE VARIANTEN Leiter des Proseminars: Dr.Thomas Bode Verfasser
Informationssysteme - Indexstrukturen I: B-Bäume und ihre Varianten Seite 1 GRUNDLAGEN VON INFORMATIONSSYSTEMEN INDEXSTRUKTUREN I: B-BÄUME UND IHRE VARIANTEN Leiter des Proseminars: Dr.Thomas Bode Verfasser
XAMPP-Systeme. Teil 3: My SQL. PGP II/05 MySQL
 XAMPP-Systeme Teil 3: My SQL Daten Eine Wesenseigenschaft von Menschen ist es, Informationen, in welcher Form sie auch immer auftreten, zu ordnen, zu klassifizieren und in strukturierter Form abzulegen.
XAMPP-Systeme Teil 3: My SQL Daten Eine Wesenseigenschaft von Menschen ist es, Informationen, in welcher Form sie auch immer auftreten, zu ordnen, zu klassifizieren und in strukturierter Form abzulegen.
Übungsklausur Algorithmen I
 Universität Karlsruhe, Institut für Theoretische Informatik Prof. Dr. P. Sanders 26.5.2010 svorschlag Übungsklausur Algorithmen I Hiermit bestätige ich, dass ich die Klausur selbständig bearbeitet habe:
Universität Karlsruhe, Institut für Theoretische Informatik Prof. Dr. P. Sanders 26.5.2010 svorschlag Übungsklausur Algorithmen I Hiermit bestätige ich, dass ich die Klausur selbständig bearbeitet habe:
Javakurs FSS Lehrstuhl Stuckenschmidt. Tag 4 ArrayList, PriorityQueue, HashSet und HashMap
 Javakurs FSS 2012 Lehrstuhl Stuckenschmidt Tag 4 ArrayList, PriorityQueue, HashSet und HashMap Array List Dynamisches Array ArrayList vertritt ein Array mit variabler Länge Kapazität passt sich automatisch
Javakurs FSS 2012 Lehrstuhl Stuckenschmidt Tag 4 ArrayList, PriorityQueue, HashSet und HashMap Array List Dynamisches Array ArrayList vertritt ein Array mit variabler Länge Kapazität passt sich automatisch
Kapitel 4. Streuen. (h K injektiv) k 1 k 2 K = h(k 1 ) h(k 2 )
 k 1 k 2 K = h(k 1 ) h(k 2 )") Kapitel 4 Streuen Wir behandeln nun Ipleentationen ungeordneter Wörterbücher, in denen die Schlüssel ohne Beachtung ihrer Sortierreihenfolge gespeichert werden dürfen, verlangen aber, dass es sich bei
Kapitel 4 Streuen Wir behandeln nun Ipleentationen ungeordneter Wörterbücher, in denen die Schlüssel ohne Beachtung ihrer Sortierreihenfolge gespeichert werden dürfen, verlangen aber, dass es sich bei
Universität Augsburg, Institut für Informatik WS 2007/2008 Prof. Dr. W. Kießling 18. Jan Dr. A. Huhn, M. Endres, T. Preisinger Übungsblatt 12
 Universität Augsburg, Institut für Informatik WS 2007/2008 Prof Dr W Kießling 18 Jan 2008 Dr A Huhn, M Endres, T Preisinger Übungsblatt 12 Datenbanksysteme I Hinweis: Das vorliegende Übungsblatt besteht
Universität Augsburg, Institut für Informatik WS 2007/2008 Prof Dr W Kießling 18 Jan 2008 Dr A Huhn, M Endres, T Preisinger Übungsblatt 12 Datenbanksysteme I Hinweis: Das vorliegende Übungsblatt besteht
Suchen in Listen und Hashtabellen
 Kapitel 12: Suchen in Listen und Hashtabellen Einführung in die Informatik Wintersemester 2007/08 Prof. Bernhard Jung Übersicht Einleitung Lineare Suche Binäre Suche (in sortierten Listen) Hashverfahren
Kapitel 12: Suchen in Listen und Hashtabellen Einführung in die Informatik Wintersemester 2007/08 Prof. Bernhard Jung Übersicht Einleitung Lineare Suche Binäre Suche (in sortierten Listen) Hashverfahren
PostgreSQL unter Debian Linux
 Einführung für PostgreSQL 7.4 unter Debian Linux (Stand 30.04.2008) von Moczon T. und Schönfeld A. Inhalt 1. Installation... 2 2. Anmelden als Benutzer postgres... 2 2.1 Anlegen eines neuen Benutzers...
Einführung für PostgreSQL 7.4 unter Debian Linux (Stand 30.04.2008) von Moczon T. und Schönfeld A. Inhalt 1. Installation... 2 2. Anmelden als Benutzer postgres... 2 2.1 Anlegen eines neuen Benutzers...