Textklassifikation, Informationsextraktion
|
|
|
- Hajo Auttenberg
- vor 6 Jahren
- Abrufe
Transkript

1 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Textklassifikation, Informationsextraktion Tobias Scheffer Thomas Vanck
2 Textklassifikation, Informationsextraktion 2
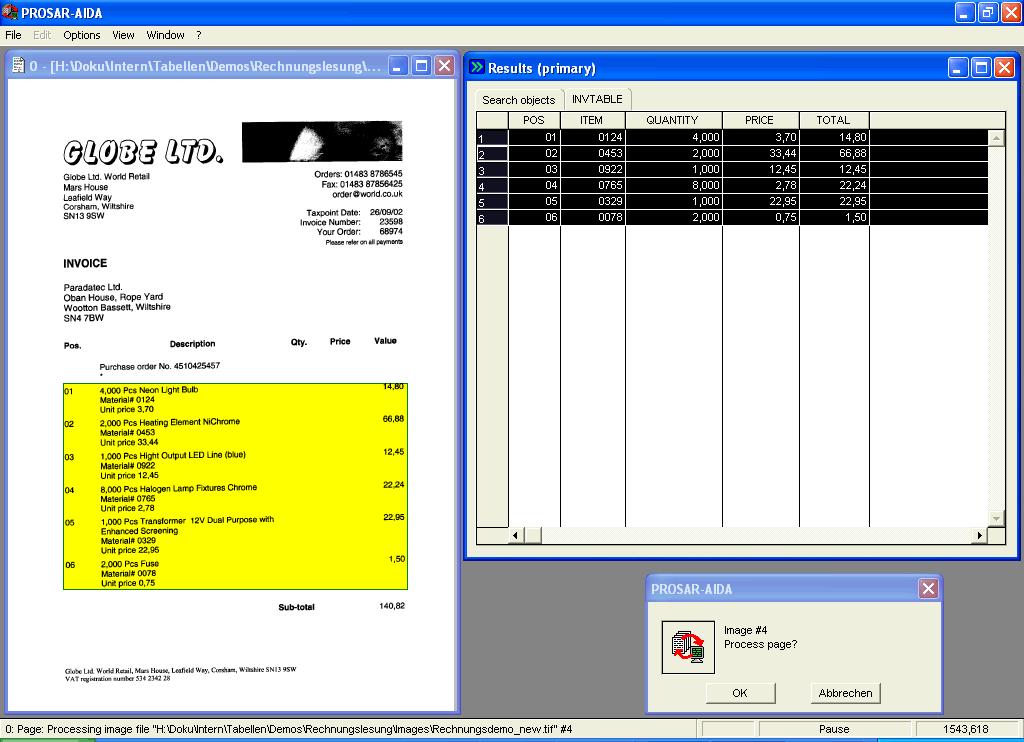
3 Textklassifikation, Informationsextraktion Textklassifikator: Ordnet einen Text einer Menge von inhaltlichen Kategorien zu. Wird häufig aus Prozessdaten gelernt. Anwendungsbeispiel: Posteingangsverarbeitung. Informationsextraktion: Identifikation definierter Felder in Dokument. Wird häufig aus Prozessdaten gelernt. Anwendungsbeispiel: Automatisierung von Dokumentenverarbeitungsprozessen. 3
4 Textklassifikation: Repräsentation Nach Tokenisierung wird Text durch Vektor repräsentiert. Vektorraummodell: Vektor der Worthäufigkeiten für probabilistische Modelle. TFIDFRepräsentation für lineare Verfahren. Wortreihenfolge bleibt unberücksichtigt. Vektorraummodell mit NGrammen: Wird für Spamerkennung verwendet. Jedes NGramm durch Dimension repräsentiert, oder Sparse Binary Polynomial Hashing oder Orthogonal Sparse NGrams. 4
5 Repräsentation Jedes NGramm durch Dimension repräsentiert, Nur NGramme, die auch tatsächlich auftreten. Sparse Binary Polynomial Hashing Fenster der Breite N wird über Text geschoben, Jede Teilmenge von bis zu N Tokens, die in dieser Reihenfolge auftauchen und das am weitesten rechts stehende Token beinhalten, ist eine Dimension, Orthogonal Sparse Bigrams. Fenster der Breite N wird über Text geschoben, Jedes Paar aus einem beliebigen Token im Fenster und dem am rechten Fensterrand stehenden Token ist ein Merkmal. SBPH und OSB: NGramme mit Platzhaltern. 5
6 Klassifikator / Entscheidungsfunktion Für eine binäre Klassifikation (y= 1 oder 1) wird eine Entscheidungsfunktion f(x) gelernt. Je größer f(x), desto wahrscheinlicher ist, dass x zur Klasse gehört. Wenn f(x) θ, dann entscheide h(x) = 1, sonst h(x) = 1. Klassifikator h(x), Entscheidungsfunktion f(x). Der Wert für θ verschiebt false positives zu false negatives. Optimaler Wert hängt von Kosten einer positiven oder negativen Fehlklassifikation ab. 6
7 Evaluation von Textklassifikatoren Fehlklassifikationswahrscheinlichkeit Häufig nicht aussagekräftig, weil P(1) sehr klein. Wie gut sind 5% Fehler, wenn P(1)=3%? Idee: Nicht Klassifikator bewerten, sondern Entscheidungsfunktion. Precision / Recall PrecisionRecallKurve bewertet Entscheidungsfunktion, Jeder Wert für θ entspricht Punkt auf PRKurve. FMeasure: Durchschnitt aus Precision und Recall. Receiver Operating Characteristic (ROCKurve) Bewertet Entscheidungsfunktion, Fläche unter ROCKurve = P(positives Beispiel hat höheren fwert als negatives Beispiel) 7
8 ROCAnalyse Entscheidungsfunktion Schwellwert = Klassifikator. Großer Schwellwert: Mehr positive Bsp falsch. Kleiner Schwellwert: Mehr negative Bsp falsch. Bewertung der Entscheidungsfunktion unabhängig vom konkreten Schwellwert. ReceiverOperatingCharacteristicAnalyse Kommt aus der Radartechnik, im 2. Weltkrieg entwickelt. Bewertung der Qualität von Entscheidungsfunktionen. 8
9 ROCKurven Charakterisieren das Verhalten des Klassifikators für alle möglichen Schwellwerte. XAchse: False Positives : Anzahl negativer Beispiele, die als positiv klassifiziert werden. YAchse: True Positives : Anzahl positiver Beispiele, die als positiv klassifiziert werden. 9
10 Bestimmen der ROCKurve von f Für alle positiven Beispiele xp in Testmenge Füge f(xp) in sortierte Liste Lp ein. Für alle negativen Beispiele xn in Testmenge Füge f(xn) in sortierte Liste Ln ein. tp = fp = 0 Wiederhole solange Lp und Ln nicht leer sind. Wenn Lp Element Ln Element dann increment(tp) und Lp = LP Next. Wenn Ln Element Lp Element dann increment(fp) und Ln = Ln Next. Zeichne neuen Punkt (fp, tp) 10
11 Flächeninhalt der ROCKurve Flächeninhalt AUC kann durch Integrieren (Summieren der TrapezFlächeninhalte) bestimmt werden. p = zufällig gezogenes Positivbeispiel n = zufällig gezogenes Negativbeispiel Theorem: AUC = P(f(p) > f(n)). Beweisidee: ROCKurve mit nur einem Positiv und einem Negativbeispiel (Flächeninhalt 0 oder 1); Durchschnitt vieler solcher Kurven = AUC. 11
12 Precision / Recall Alternative zur ROCAnalyse. Stammt aus dem Information Retrieval. Precision: P(richtig als positiv erkannt) Recall: P(als positiv erkannt ist positiv) 12
13 Precision / Recall Zusammenfassungen der Kurve in einer Zahl: FMeasure: Maximum über alls (p,r)paare auf der Kurve: PrecisionRecallBreakevenPoint: Derjenige Wert PRBEP für den gilt: Precision(θ) = Recall(θ) = PRBEP. 13
14 Precision / Recall TradeOff recall precision Precision/RecallKurven Welcher Klassifikator ist der Beste / Schlechteste 14
15 Fehlerschätzung Wir haben Klassifikator h gelernt, und wollen nun wissen wie gut er ist. Echter Fehler ist unbekannt. Verwende Fehlerschätzer Bias = 15
16 Fehlerschätzung Problem: Fehlerschätzung nur auf den Trainingsdaten Empirischen Fehler: Messe wie viele Datenpunkte falsch klassifiziert werden. Es kann sein, dass (Overfitting) Dann gilt für den Bias = D.h. wir sind sehr optimistisch, was unseren Fehler angeht, da wir ihn geringer schätzen als den tatsächlichen echten Fehler. Deshalb: Fehlerschätzung auf Trainingsdaten schlecht! 16
17 HoldoutTesting Besser: Verwende Testdaten, die nicht zum Trainieren den Klassifikators benutzt wurden. TrainingundTest: Verwende 80% der Daten zum Trainieren Verwende 20% der Daten zum Testen Auf 20% der Daten wird dann, ROCKurve, PRKurve ermittelt. 17
18 HoldoutTesting Algorithmus TrainingandTest Aufteilen der Datenbank in Trainingsmenge und Testmenge. h1 = Lernalgorithmus (Trainingsmenge) Bestimme Ê anhand der Testmenge. h = Lernalgorithmus (alle Beispiele) Liefere Hypothese h zusammen mit Fehlerschätzer TrainingandTest ist für große Datenbanken gut anwendbar. Problematisch für kleine Datenbanken 18
19 NFold CrossValidation Idee: Teile Daten D in N gleichgroße Teilstücke Trainiere auf D\Di und teste dann auf Di Iteriere wie folgt: Training examples 19
20 NFold CrossValidation Algorithmus NCV (Beispiele D) Bilde N etwa gleich große Blöcke D1,...,Dn von Beispielen, die zusammen D ergeben. Ê=0. For i = 1... N h = Lernalgorithmus (D \ Di) Ê = Ê empirischer Fehler von h auf Di Ê = Ê/N h = Lernalgorithmus (D) Liefere Hypothese h mit Fehlerschätzer S Ê ± z δ 2 N N Wenn D = N, heisst das Verfahren LeaveoneOut. Nur leicht pessimistischer Schätzer. 20
21 Was man über Hyperebenen wissen sollte Wir beschreiben eine Hyperebene durch, wobei 1. Was ist? 2. Wann gilt bzw. Die Ebene ist ein Model, mit dem klassifiziert werden kann 1. Wie bestimmt man eine derartige Ebene für eine Menge 2. Wie viele gibt es? 3. Welche ist die beste (für ungesehene Daten)? 21
22 Lineare Klassifikatoren 22
23 Lineare Klassifikatoren Umformulierung mit zusätzlichem, konstanten Eingabeattribut x 0 =1: T f (x) = w (1..n ) x (1..n ) w 0 x x 1 0 = (w 1... w n )... w x 1 0 = (w 0 w 1... w n )... x n T = w (0..n ) x (0..n) x n 23
24 Rocchio : Mittelpunkt der neg. Beispiele : Mittelpunkt der pos. Beispiele Trennebene: Normalenvektor = (x 1 x 1 ) x 1 Bestimmung von w 0 : Mittelpunkt (x 1 x 1 )/2 muss auf der Ebene liegen. w x 1 f ((x 1 x 1 ) /2) = (x 1 x 1 )(x 1 x 1 ) /2 w 0 = 0 w 0 = 24
25 Rocchio Trennebenen hat maximalen Abstand von den Mittelpunkten der Klassen. Trainingsbeispiele können falsch klassifiziert werden. Differenz der Mittelwerte kann schlechter Normalenvektor für Diskrimination sein. 25
26 Perzeptron Lineares Modell: Ziel: Für alle Beispiele (x i, 1): Für alle Beispiele (x i, 1): 26
27 Perzeptron Lineares Modell: Ziel: Für alle Beispiele (x i, 1): Für alle Beispiele (x i, 1): Ziel: Für alle Beispiele: = Beispiel liegt auf der richtigen Seite der Ebene. 27
28 Perzeptron Lineares Modell: Ziel: Für alle Beispiele: PerzeptronOptimierungskriterium: 28
29 Perzeptron Lineares Modell: Ziel: Für alle Beispiele: PerzeptronOptimierungskriterium: Subgradient für Beispiel (x i, y i ): 29
30 Perzeptron Lineares Modell: PerzeptronOptimierungskriterium: Subgradient für Beispiel (x i, y i ): Gradientenaufstieg: Wiederhole, für alle Beispiele mit 30
31 31
32 PerzeptronAlgorithmus Lineares Modell: PerzeptronTrainingsalgorithmus: Solange noch Beispiele (x i, y i ) mit der Hypothese inkonsistent sind, iteriere über alle Beispiele Wenn dann 32
33 PerzeptronAlgorithmus Perzeptron findet immer eine Trennebene, wenn eine existiert (Optimierungskriterium ist konvex). Existiert immer eine Trennebene? Wenn keine Trennebene existiert, dann konvergiert der PerzeptronAlgorithmus auch nicht. 33
34 Probleme 1. Wenn linearseparierbar, dann mehre Modelle: Welches ist das beste? Lösung: MaximalMarginAnsatz 34
35 Probleme 1. Wenn linearseparierbar, dann mehre Modelle: Welches ist das beste? Lösung: MaximalMarginAnsatz 35
36 MarginPerzeptron PerzeptronKlassifikation: Perzeptron: für alle Beispiele muss gelten = Beispiel liegt auf der richtigen Seite der Ebene. MarginPerzeptron: = Beispiel mindestens δ von Trennebene entfernt. 36
37 MarginPerzeptronAlgorithmus Lineares Modell: PerzeptronTrainingsalgorithmus: Solange noch Beispiele (x i, y i ) mit der Hypothese inkonsistent sind, iteriere über alle Beispiele Wenn dann 37
38 MarginMaximierung Perzeptron: für alle Beispiele muss gelten MarginPerzeptron: Finde Ebene, die alle Beispiele mindestens δ von Ebene entfernt. Fester, voreingestellter Wert δ. MarginMaximierung: Finde Ebene, die alle Beispiele mindestens δ von Ebene entfernt. Für den größtmöglichen Wert δ. 38
39 MarginMaximierung MarginMaximierung: Finde Ebene, die alle Beispiele mindestens δ von Ebene entfernt. Für den größtmöglichen Wert δ. Maximiere δ unter der Nebenbedingungen: für alle w Beispiele (x i, y i ) gelte T = Minimiere w unter der Nebenbedingung: für alle Beispiele (x i, y i ): y i y i w T w x i δ w x i δ y i w T x i 1 39
40 Probleme 1. Wenn linearseparierbar, dann mehre Modelle: Welches ist das beste? Lösung: MaximalMarginAnsatz 2. Daten verrauscht / falsch gelabelte Daten Lösung: Slack zulassen 40
41 SoftMarginMaximierung HardMarginMaximierung: Minimiere w unter der Nebenbedingungen: für alle Beispiele (x i, y i ): y i w T x i 1 SoftMarginMaximierung: Minimiere unter den Nebenbedingungen: für alle Beispiele (x i, y i ): y i w T x i 1 ξ i Alle ξ i 0. SoftMarginEbene existiert immer, HardMarginEbene nicht! Slack ξ i Margin 1/ w 41
42 SoftMarginMaximierung SoftMarginMaximierung: Minimiere unter den Nebenbedingungen: für alle Beispiele (x i, y i ): y i w T x i 1 ξ i Alle ξ i 0. Einsetzen von ξ i in Optimierungskriterium ergibt Minimiere: Slack ξ i Margin 1/ w 42
43 SoftMarginMaximierung SoftMarginMaximierung: Minimiere: Minimierung mit Gradientenverfahren. Annäherung durch differenzierbare Variante (Huber statt HingeLoss), dann NewtonVerfahren. Kriterium ist konvex, es gibt genau ein Minimum. Primale Support Vector Machine. O(n 2 ), unter Beispiele, unter Attribute. Slack ξ i Margin 1/ w 43
44 SoftMarginMaximierung SoftMarginMaximierung: Minimiere: Minimierung mit Gradientenverfahren. Wiederhole: Enthält Summe über alle Beispiele 44
45 Probleme 1. Wenn linearseparierbar, dann mehre Modelle: Welches ist das beste? Lösung: MaximalMarginAnsatz 2. Daten verrauscht / falsch gelabelte Daten Lösung: Slack zulassen 3. Keine Fehlerwahrscheinlichkeit der Klassifikation Lösung: Logistic Regression 45
46 Logistische Regression SVM: großer Entscheidungsfunktionswert ~ hohe Sicherheit der Vorhersage. Aber: beim Lernen nicht auf korrekte Kalibrierung der Klassenwahrscheinlichkeiten optimiert. f(x)=18.3 Risiko eines Fehlers? Logistische Regression: Vorhersage der Klassenwahrscheinlichkeit. 46
47 Logistische Regression Bayes Regel: Logodd ratio: 1 1 exp( a) nennt man auch SigmoidFunktion 47
48 Logistische Regression Likelihood jeder Klasse normalverteilt, gemeinsame Kovarianzmatrix für beide Klassen. Loggodds ratio: 48
49 Logistische Regression Likelihood jeder Klasse normalverteilt, gemeinsame Kovarianzmatrix für beide Klassen. Loggodds ratio: 49
50 Logistische Regression Wenn zwei Klassen jeweils normalverteilte Likelihood mit derselben Kovarianzmatrix haben, dann nimmt P(y x) diese Form an: P(y x) ywxw 0 50
51 Logistische Regression Bisher: Motivation der Form des logistischen Klassifikationsmodells. Falls Klassenverteilungen bekannt wären, könnten wir w und w 0 aus µ 1, µ 1 und Σ herleiten. Sind aber nicht bekannt. Verteilungsannahme muss auch nicht stimmen. Jetzt: Wir finden wir tatsächlich Parameter w und w 0? 51
52 Logistische Regression Prior über Parameter: Normalverteilung, w~ N(0,νI) Posterior: E(w,L) = log p(w L) Verlustfunktion: N = [[y i = 1]]log(σ(w T x i )) [[y i = 1]]log(1 σ(w T x i )) log( i=1 1 (2π) d νi ) w T Iw 2ν 2 52
53 Logistische Regression Verlustfunktion ist konvex und differenzierbar. Gradientenabstieg führt zum Minimum. 53
INTELLIGENTE DATENANALYSE IN MATLAB. Evaluation & Exploitation von Modellen
 INTELLIGENTE DATENANALYSE IN MATLAB Evaluation & Exploitation von Modellen Überblick Schritte der Datenanalyse: Datenvorverarbeitung Problemanalyse Problemlösung Anwendung der Lösung Aggregation und Selektion
INTELLIGENTE DATENANALYSE IN MATLAB Evaluation & Exploitation von Modellen Überblick Schritte der Datenanalyse: Datenvorverarbeitung Problemanalyse Problemlösung Anwendung der Lösung Aggregation und Selektion
INTELLIGENTE DATENANALYSE IN MATLAB. Evaluation & Exploitation von Modellen
 INTELLIGENTE DATENANALYSE IN MATLAB Evaluation & Exploitation von Modellen Überblick Schritte der Datenanalyse: Datenvorverarbeitung Problemanalyse Problemlösung Anwendung der Lösung Aggregation und Selektion
INTELLIGENTE DATENANALYSE IN MATLAB Evaluation & Exploitation von Modellen Überblick Schritte der Datenanalyse: Datenvorverarbeitung Problemanalyse Problemlösung Anwendung der Lösung Aggregation und Selektion
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Hypothesenbewertung
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hypothesenbewertung Christoph Sawade/Niels Landwehr Dominik Lahmann Tobias Scheffer Überblick Hypothesenbewertung, Risikoschätzung
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hypothesenbewertung Christoph Sawade/Niels Landwehr Dominik Lahmann Tobias Scheffer Überblick Hypothesenbewertung, Risikoschätzung
Funktionslernen. 5. Klassifikation. 5.6 Support Vector Maschines (SVM) Reale Beispiele. Beispiel: Funktionenlernen
 Reale Beispiele. Beispiel: Funktionenlernen") 5. Klassifikation 5.6 Support Vector Maschines (SVM) übernommen von Stefan Rüping, Katharina Morik, Universität Dortmund Vorlesung Maschinelles Lernen und Data Mining, WS 2002/03 und Katharina Morik, Claus
5. Klassifikation 5.6 Support Vector Maschines (SVM) übernommen von Stefan Rüping, Katharina Morik, Universität Dortmund Vorlesung Maschinelles Lernen und Data Mining, WS 2002/03 und Katharina Morik, Claus
INTELLIGENTE DATENANALYSE IN MATLAB
 INTELLIGENTE DATENANALYSE IN MATLAB Evaluation & Exploitation von Modellen Überblick Sh Schritte der Datenanalyse: Datenvorverarbeitung Problemanalyse Problemlösung Anwendung der Lösung Aggregation und
INTELLIGENTE DATENANALYSE IN MATLAB Evaluation & Exploitation von Modellen Überblick Sh Schritte der Datenanalyse: Datenvorverarbeitung Problemanalyse Problemlösung Anwendung der Lösung Aggregation und
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Modellevaluierung. Niels Landwehr
 Universität Potsdam Institut für Informatik ehrstuhl Maschinelles ernen Modellevaluierung Niels andwehr ernen und Vorhersage Klassifikation, Regression: ernproblem Eingabe: Trainingsdaten Ausgabe: Modell
Universität Potsdam Institut für Informatik ehrstuhl Maschinelles ernen Modellevaluierung Niels andwehr ernen und Vorhersage Klassifikation, Regression: ernproblem Eingabe: Trainingsdaten Ausgabe: Modell
Lineare Klassifikatoren. Volker Tresp
 Lineare Klassifikatoren Volker Tresp 1 Klassifikatoren Klassifikation ist die zentrale Aufgabe in der Mustererkennung Sensoren liefern mir Informationen über ein Objekt Zu welcher Klasse gehört das Objekt:
Lineare Klassifikatoren Volker Tresp 1 Klassifikatoren Klassifikation ist die zentrale Aufgabe in der Mustererkennung Sensoren liefern mir Informationen über ein Objekt Zu welcher Klasse gehört das Objekt:
Inhalt. 4.1 Motivation. 4.2 Evaluation. 4.3 Logistische Regression. 4.4 k-nächste Nachbarn. 4.5 Naïve Bayes. 4.6 Entscheidungsbäume
 4. Klassifikation Inhalt 4.1 Motivation 4.2 Evaluation 4.3 Logistische Regression 4.4 k-nächste Nachbarn 4.5 Naïve Bayes 4.6 Entscheidungsbäume 4.7 Support Vector Machines 4.8 Neuronale Netze 4.9 Ensemble-Methoden
4. Klassifikation Inhalt 4.1 Motivation 4.2 Evaluation 4.3 Logistische Regression 4.4 k-nächste Nachbarn 4.5 Naïve Bayes 4.6 Entscheidungsbäume 4.7 Support Vector Machines 4.8 Neuronale Netze 4.9 Ensemble-Methoden
Einführung in das Maschinelle Lernen I
 Einführung in das Maschinelle Lernen I Vorlesung Computerlinguistische Techniken Alexander Koller 26. Januar 2015 Maschinelles Lernen Maschinelles Lernen (Machine Learning): äußerst aktiver und für CL
Einführung in das Maschinelle Lernen I Vorlesung Computerlinguistische Techniken Alexander Koller 26. Januar 2015 Maschinelles Lernen Maschinelles Lernen (Machine Learning): äußerst aktiver und für CL
Decision Tree Learning
 Decision Tree Learning Computational Linguistics Universität des Saarlandes Sommersemester 2011 28.04.2011 Entscheidungsbäume Repräsentation von Regeln als Entscheidungsbaum (1) Wann spielt Max Tennis?
Decision Tree Learning Computational Linguistics Universität des Saarlandes Sommersemester 2011 28.04.2011 Entscheidungsbäume Repräsentation von Regeln als Entscheidungsbaum (1) Wann spielt Max Tennis?
Vorlesung Wissensentdeckung
 Vorlesung Wissensentdeckung Klassifikation und Regression: nächste Nachbarn Katharina Morik, Uwe Ligges 14.05.2013 1 von 24 Gliederung Funktionsapproximation 1 Funktionsapproximation Likelihood 2 Kreuzvalidierung
Vorlesung Wissensentdeckung Klassifikation und Regression: nächste Nachbarn Katharina Morik, Uwe Ligges 14.05.2013 1 von 24 Gliederung Funktionsapproximation 1 Funktionsapproximation Likelihood 2 Kreuzvalidierung
Textmining Klassifikation von Texten Teil 2: Im Vektorraummodell
 Textmining Klassifikation von Texten Teil 2: Im Vektorraummodell Dept. Informatik 8 (Künstliche Intelligenz) Friedrich-Alexander-Universität Erlangen-Nürnberg (Informatik 8) Klassifikation von Texten Teil
Textmining Klassifikation von Texten Teil 2: Im Vektorraummodell Dept. Informatik 8 (Künstliche Intelligenz) Friedrich-Alexander-Universität Erlangen-Nürnberg (Informatik 8) Klassifikation von Texten Teil
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Clusteranalyse. Tobias Scheffer Thomas Vanck
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Thomas Vanck Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Thomas Vanck Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Bayes sches Lernen: Übersicht
 Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 10: Naive Bayes (V. 1.0)
Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 10: Naive Bayes (V. 1.0)
Support Vector Machines (SVM)
") Universität Ulm 12. Juni 2007 Inhalt 1 2 3 Grundlegende Idee Der Kern-Trick 4 5 Multi-Klassen-Einteilung Vor- und Nachteile der SVM 1 2 3 Grundlegende Idee Der Kern-Trick 4 5 Multi-Klassen-Einteilung Vor-
Universität Ulm 12. Juni 2007 Inhalt 1 2 3 Grundlegende Idee Der Kern-Trick 4 5 Multi-Klassen-Einteilung Vor- und Nachteile der SVM 1 2 3 Grundlegende Idee Der Kern-Trick 4 5 Multi-Klassen-Einteilung Vor-
Wissensentdeckung in Datenbanken
 Wissensentdeckung in Datenbanken Strukturelle Modelle SVMstruct Katharina Morik, Claus Weihs LS 8 Informatik 16.6.2009 1 von 37 Gliederung LS 8 Informatik 1 Überblick Lernaufgaben 2 Primales Problem 3
Wissensentdeckung in Datenbanken Strukturelle Modelle SVMstruct Katharina Morik, Claus Weihs LS 8 Informatik 16.6.2009 1 von 37 Gliederung LS 8 Informatik 1 Überblick Lernaufgaben 2 Primales Problem 3
Überblick. Grundkonzepte des Bayes schen Lernens. Wahrscheinlichstes Modell gegeben Daten Münzwürfe Lineare Regression Logistische Regression
 Überblick Grundkonzepte des Baes schen Lernens Wahrscheinlichstes Modell gegeben Daten Münzwürfe Lineare Regression Logistische Regression Baes sche Vorhersage Münzwürfe Lineare Regression 57 Erinnerung:
Überblick Grundkonzepte des Baes schen Lernens Wahrscheinlichstes Modell gegeben Daten Münzwürfe Lineare Regression Logistische Regression Baes sche Vorhersage Münzwürfe Lineare Regression 57 Erinnerung:
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Zusammenfassung. Tobias Scheffer Paul Prasse Michael Großhans Uwe Dick
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Zusammenfassung Tobias Scheffer Paul Prasse Michael Großhans Uwe Dick Statistische Sprachmodelle Wie wahrscheinlich ist ein bestimmter
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Zusammenfassung Tobias Scheffer Paul Prasse Michael Großhans Uwe Dick Statistische Sprachmodelle Wie wahrscheinlich ist ein bestimmter
Vorlesung Wissensentdeckung
 Gliederung Vorlesung Wissensentdeckung Additive Modelle Katharina Morik, Weihs 1 Merkmalsauswahl Gütemaße und Fehlerabschätzung.6.015 1 von 33 von 33 Ausgangspunkt: Funktionsapproximation Aufteilen der
Gliederung Vorlesung Wissensentdeckung Additive Modelle Katharina Morik, Weihs 1 Merkmalsauswahl Gütemaße und Fehlerabschätzung.6.015 1 von 33 von 33 Ausgangspunkt: Funktionsapproximation Aufteilen der
Pareto optimale lineare Klassifikation
 Seminar aus Maschinellem Lernen Pareto optimale lineare Klassifikation Vesselina Poulkova Betreuer: Eneldo Loza Mencía Gliederung 1. Einleitung 2. Pareto optimale lineare Klassifizierer 3. Generelle Voraussetzung
Seminar aus Maschinellem Lernen Pareto optimale lineare Klassifikation Vesselina Poulkova Betreuer: Eneldo Loza Mencía Gliederung 1. Einleitung 2. Pareto optimale lineare Klassifizierer 3. Generelle Voraussetzung
Bayes sches Lernen: Übersicht
 Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 5: Naive Bayes + IBL (V.
Bayes sches Lernen: Übersicht Bayes sches Theorem MAP, ML Hypothesen MAP Lernen Minimum Description Length Principle Bayes sche Klassifikation Naive Bayes Lernalgorithmus Teil 5: Naive Bayes + IBL (V.
Vorlesung Wissensentdeckung
 Vorlesung Wissensentdeckung Additive Modelle Katharina Morik, Weihs 2.6.2015 1 von 33 Gliederung 1 Merkmalsauswahl Gütemaße und Fehlerabschätzung 2 von 33 Ausgangspunkt: Funktionsapproximation Die bisher
Vorlesung Wissensentdeckung Additive Modelle Katharina Morik, Weihs 2.6.2015 1 von 33 Gliederung 1 Merkmalsauswahl Gütemaße und Fehlerabschätzung 2 von 33 Ausgangspunkt: Funktionsapproximation Die bisher
Klassifikation von Daten Einleitung
 Klassifikation von Daten Einleitung Lehrstuhl für Künstliche Intelligenz Institut für Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg (Lehrstuhl Informatik 8) Klassifikation von Daten Einleitung
Klassifikation von Daten Einleitung Lehrstuhl für Künstliche Intelligenz Institut für Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg (Lehrstuhl Informatik 8) Klassifikation von Daten Einleitung
Information Retrieval,
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Information Retrieval, Vektorraummodell Tobias Scheffer Uwe Dick Peter Haider Paul Prasse Information Retrieval Konstruktion von
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Information Retrieval, Vektorraummodell Tobias Scheffer Uwe Dick Peter Haider Paul Prasse Information Retrieval Konstruktion von
Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 2016
 Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 1 M. Sperber (matthias.sperber@kit.edu) S. Nguyen (thai.nguyen@kit.edu) Übungsblatt 3 Maschinelles Lernen und Klassifikation Abgabe online
Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester 1 M. Sperber (matthias.sperber@kit.edu) S. Nguyen (thai.nguyen@kit.edu) Übungsblatt 3 Maschinelles Lernen und Klassifikation Abgabe online
Clusteranalyse: Gauß sche Mischmodelle
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse: Gauß sche Mischmodelle iels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse: Gauß sche Mischmodelle iels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Vorlesung Maschinelles Lernen
 Gliederung Vorlesung Maschinelles Lernen Strukturelle Modelle SVMstruct Katharina Morik, Claus Weihs 24520 Überblick Lernaufgaben 2 Primales Problem 3 Duales Problem 4 Optimierung der SVMstruct 5 Anwendungen
Gliederung Vorlesung Maschinelles Lernen Strukturelle Modelle SVMstruct Katharina Morik, Claus Weihs 24520 Überblick Lernaufgaben 2 Primales Problem 3 Duales Problem 4 Optimierung der SVMstruct 5 Anwendungen
Information Retrieval, Vektorraummodell
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Information Retrieval, Vektorraummodell Tobias Scheffer Paul Prasse Michael Großhans Uwe Dick Information Retrieval Konstruktion
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Information Retrieval, Vektorraummodell Tobias Scheffer Paul Prasse Michael Großhans Uwe Dick Information Retrieval Konstruktion
Entscheidungsbäume aus großen Datenbanken: SLIQ
 Entscheidungsbäume aus großen Datenbanken: SLIQ C4.5 iteriert häufig über die Trainingsmenge Wie häufig? Wenn die Trainingsmenge nicht in den Hauptspeicher passt, wird das Swapping unpraktikabel! SLIQ:
Entscheidungsbäume aus großen Datenbanken: SLIQ C4.5 iteriert häufig über die Trainingsmenge Wie häufig? Wenn die Trainingsmenge nicht in den Hauptspeicher passt, wird das Swapping unpraktikabel! SLIQ:
Hidden-Markov-Modelle
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hidden-Markov-Modelle Tobias Scheffer Thomas Vanck Hidden-Markov-Modelle: Wozu? Spracherkennung: Akustisches Modell. Geschriebene
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Hidden-Markov-Modelle Tobias Scheffer Thomas Vanck Hidden-Markov-Modelle: Wozu? Spracherkennung: Akustisches Modell. Geschriebene
Einführung in Support Vector Machines (SVMs)
") Einführung in (SVM) Januar 31, 2011 Einführung in (SVMs) Table of contents Motivation Einführung in (SVMs) Outline Motivation Vektorrepräsentation Klassifikation Motivation Einführung in (SVMs) Vektorrepräsentation
Einführung in (SVM) Januar 31, 2011 Einführung in (SVMs) Table of contents Motivation Einführung in (SVMs) Outline Motivation Vektorrepräsentation Klassifikation Motivation Einführung in (SVMs) Vektorrepräsentation
Lineare Regression. Volker Tresp
 Lineare Regression Volker Tresp 1 Die Lernmaschine: Das lineare Modell / ADALINE Wie beim Perzeptron wird zunächst die Aktivierungsfunktion gewichtete Summe der Eingangsgrößen x i berechnet zu h i = M
Lineare Regression Volker Tresp 1 Die Lernmaschine: Das lineare Modell / ADALINE Wie beim Perzeptron wird zunächst die Aktivierungsfunktion gewichtete Summe der Eingangsgrößen x i berechnet zu h i = M
6.4 Neuronale Netze zur Verarbeitung von Zeitreihen
 6.4 Neuronale Netze zur Verarbeitung von Zeitreihen Aufgabe: Erlernen einer Zeitreihe x(t + 1) = f(x(t), x(t 1), x(t 2),...) Idee: Verzögerungskette am Eingang eines neuronalen Netzwerks, z.b. eines m-h-1
6.4 Neuronale Netze zur Verarbeitung von Zeitreihen Aufgabe: Erlernen einer Zeitreihe x(t + 1) = f(x(t), x(t 1), x(t 2),...) Idee: Verzögerungskette am Eingang eines neuronalen Netzwerks, z.b. eines m-h-1
Nutzung maschinellen Lernens zur Extraktion von Paragraphen aus PDF-Dokumenten
 Nutzung maschinellen Lernens zur Extraktion von Paragraphen aus PDF-Dokumenten Albert-Ludwigs-Universität zu Freiburg 13.09.2016 Maximilian Dippel max.dippel@tf.uni-freiburg.de Überblick I Einführung Problemstellung
Nutzung maschinellen Lernens zur Extraktion von Paragraphen aus PDF-Dokumenten Albert-Ludwigs-Universität zu Freiburg 13.09.2016 Maximilian Dippel max.dippel@tf.uni-freiburg.de Überblick I Einführung Problemstellung
Vorlesung Maschinelles Lernen
 Vorlesung Maschinelles Lernen Strukturelle Modelle SVMstruct Katharina Morik LS 8 Künstliche Intelligenz Fakultät für Informatik 16.12.2008 1 von 35 Gliederung LS 8 Künstliche Intelligenz Fakultät für
Vorlesung Maschinelles Lernen Strukturelle Modelle SVMstruct Katharina Morik LS 8 Künstliche Intelligenz Fakultät für Informatik 16.12.2008 1 von 35 Gliederung LS 8 Künstliche Intelligenz Fakultät für
Vorlesung Maschinelles Lernen
 Gliederung Vorlesung Maschinelles Lernen Strukturelle Modelle SVMstruct Katharina Morik 6.2.2008 Überblick Lernaufgaben 2 Primales Problem 3 Duales Problem 4 Optimierung der SVMstruct 5 Anwendungen von
Gliederung Vorlesung Maschinelles Lernen Strukturelle Modelle SVMstruct Katharina Morik 6.2.2008 Überblick Lernaufgaben 2 Primales Problem 3 Duales Problem 4 Optimierung der SVMstruct 5 Anwendungen von
Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester Lösungsblatt 3 Maschinelles Lernen und Klassifikation
 Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester M. Sperber (matthias.sperber@kit.edu) S. Nguyen (thai.nguyen@kit.edu) Lösungsblatt 3 Maschinelles Lernen und Klassifikation Aufgabe : Zufallsexperiment
Fakultät für Informatik Übung zu Kognitive Systeme Sommersemester M. Sperber (matthias.sperber@kit.edu) S. Nguyen (thai.nguyen@kit.edu) Lösungsblatt 3 Maschinelles Lernen und Klassifikation Aufgabe : Zufallsexperiment
Überblick. Überblick. Bayessche Entscheidungsregel. A-posteriori-Wahrscheinlichkeit (Beispiel) Wiederholung: Bayes-Klassifikator
 Wiederholung: Bayes-Klassifikator") Überblick Grundlagen Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes-Klassifikator
Überblick Grundlagen Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes-Klassifikator
Klassifikation linear separierbarer Probleme
 Klassifikation linear separierbarer Probleme Lehrstuhl für Künstliche Intelligenz Institut für Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg (Lehrstuhl Informatik 8) Klassifikation linear
Klassifikation linear separierbarer Probleme Lehrstuhl für Künstliche Intelligenz Institut für Informatik Friedrich-Alexander-Universität Erlangen-Nürnberg (Lehrstuhl Informatik 8) Klassifikation linear
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Tobias Scheffer, Tom Vanck, Paul Prasse
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Sprachtechnologie Tobias Scheffer, Tom Vanck, Paul Prasse Organisation Vorlesung/Übung, praktische Informatik. 4 SWS. Termin: Montags,
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Sprachtechnologie Tobias Scheffer, Tom Vanck, Paul Prasse Organisation Vorlesung/Übung, praktische Informatik. 4 SWS. Termin: Montags,
Überwachtes Lernen / Support Vector Machines. Rudolf Kruse Neuronale Netze 246
 Überwachtes Lernen / Support Vector Machines Rudolf Kruse Neuronale Netze 246 Überwachtes Lernen, Diagnosesystem für Krankheiten Trainingsdaten: Expressionsprofile von Patienten mit bekannter Diagnose
Überwachtes Lernen / Support Vector Machines Rudolf Kruse Neuronale Netze 246 Überwachtes Lernen, Diagnosesystem für Krankheiten Trainingsdaten: Expressionsprofile von Patienten mit bekannter Diagnose
Computational Intelligence 1 / 20. Computational Intelligence Künstliche Neuronale Netze Perzeptron 3 / 20
 Gliederung / Künstliche Neuronale Netze Perzeptron Einschränkungen Netze von Perzeptonen Perzeptron-Lernen Perzeptron Künstliche Neuronale Netze Perzeptron 3 / Der Psychologe und Informatiker Frank Rosenblatt
Gliederung / Künstliche Neuronale Netze Perzeptron Einschränkungen Netze von Perzeptonen Perzeptron-Lernen Perzeptron Künstliche Neuronale Netze Perzeptron 3 / Der Psychologe und Informatiker Frank Rosenblatt
Wissensentdeckung in Datenbanken
 Wissensentdeckung in Datenbanken Deep Learning (II) Nico Piatkowski und Uwe Ligges Informatik Künstliche Intelligenz 25.07.2017 1 von 14 Überblick Faltungsnetze Dropout Autoencoder Generative Adversarial
Wissensentdeckung in Datenbanken Deep Learning (II) Nico Piatkowski und Uwe Ligges Informatik Künstliche Intelligenz 25.07.2017 1 von 14 Überblick Faltungsnetze Dropout Autoencoder Generative Adversarial
Support Vector Machines, Kernels
 Support Vector Machines, Kernels Katja Kunze 13.01.04 19.03.2004 1 Inhalt: Grundlagen/Allgemeines Lineare Trennung/Separation - Maximum Margin Hyperplane - Soft Margin SVM Kernels Praktische Anwendungen
Support Vector Machines, Kernels Katja Kunze 13.01.04 19.03.2004 1 Inhalt: Grundlagen/Allgemeines Lineare Trennung/Separation - Maximum Margin Hyperplane - Soft Margin SVM Kernels Praktische Anwendungen
Vorlesungsplan. Von Naïve Bayes zu Bayesischen Netzwerk- Klassifikatoren. Naïve Bayes. Bayesische Netzwerke
 Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Vorlesungsplan 17.10. Einleitung 24.10. Ein- und Ausgabe 31.10. Reformationstag, Einfache Regeln 7.11. Naïve Bayes, Entscheidungsbäume 14.11. Entscheidungsregeln, Assoziationsregeln 21.11. Lineare Modelle,
Vorlesung Wissensentdeckung
 Vorlesung Wissensentdeckung Stützvektormethode Katharina Morik, Uwe Ligges 23.5.2013 1 von 48 Gliederung 1 Geometrie linearer Modelle: Hyperebenen Einführung von Schölkopf/Smola 2 Lagrange-Optimierung
Vorlesung Wissensentdeckung Stützvektormethode Katharina Morik, Uwe Ligges 23.5.2013 1 von 48 Gliederung 1 Geometrie linearer Modelle: Hyperebenen Einführung von Schölkopf/Smola 2 Lagrange-Optimierung
Vorlesung Maschinelles Lernen
 Vorlesung Maschinelles Lernen Additive Modelle Katharina Morik Informatik LS 8 Technische Universität Dortmund 7.1.2014 1 von 34 Gliederung 1 Merkmalsauswahl Gütemaße und Fehlerabschätzung 2 von 34 Ausgangspunkt:
Vorlesung Maschinelles Lernen Additive Modelle Katharina Morik Informatik LS 8 Technische Universität Dortmund 7.1.2014 1 von 34 Gliederung 1 Merkmalsauswahl Gütemaße und Fehlerabschätzung 2 von 34 Ausgangspunkt:
1 Diskriminanzanalyse
 Multivariate Lineare Modelle SS 2008 1 Diskriminanzanalyse 1. Entscheidungstheorie 2. DA für normalverteilte Merkmale 3. DA nach Fisher 1 Problemstellungen Jedes Subjekt kann einer von g Gruppen angehören
Multivariate Lineare Modelle SS 2008 1 Diskriminanzanalyse 1. Entscheidungstheorie 2. DA für normalverteilte Merkmale 3. DA nach Fisher 1 Problemstellungen Jedes Subjekt kann einer von g Gruppen angehören
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Bayes sches Lernen. Niels Landwehr
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayes sches Lernen Niels Landwehr Überblick Grundkonzepte des Bayes schen Lernens Wahrscheinlichstes Modell gegeben Daten Münzwürfe
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Bayes sches Lernen Niels Landwehr Überblick Grundkonzepte des Bayes schen Lernens Wahrscheinlichstes Modell gegeben Daten Münzwürfe
Lineare Regression. Christian Herta. Oktober, Problemstellung Kostenfunktion Gradientenabstiegsverfahren
 Lineare Regression Christian Herta Oktober, 2013 1 von 33 Christian Herta Lineare Regression Lernziele Lineare Regression Konzepte des Maschinellen Lernens: Lernen mittels Trainingsmenge Kostenfunktion
Lineare Regression Christian Herta Oktober, 2013 1 von 33 Christian Herta Lineare Regression Lernziele Lineare Regression Konzepte des Maschinellen Lernens: Lernen mittels Trainingsmenge Kostenfunktion
Validation Model Selection Kreuz-Validierung Handlungsanweisungen. Validation. Oktober, von 20 Validation
 Validation Oktober, 2013 1 von 20 Validation Lernziele Konzepte des maschinellen Lernens Validierungsdaten Model Selection Kreuz-Validierung (Cross Validation) 2 von 20 Validation Outline 1 Validation
Validation Oktober, 2013 1 von 20 Validation Lernziele Konzepte des maschinellen Lernens Validierungsdaten Model Selection Kreuz-Validierung (Cross Validation) 2 von 20 Validation Outline 1 Validation
Seminar Textmining SS 2015 Grundlagen des Maschinellen Lernens
 Seminar Textmining SS 2015 Grundlagen des Maschinellen Lernens Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 17.04.2015 Entscheidungsprobleme beim Textmining
Seminar Textmining SS 2015 Grundlagen des Maschinellen Lernens Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 17.04.2015 Entscheidungsprobleme beim Textmining
INTELLIGENTE DATENANALYSE IN MATLAB. Überwachtes Lernen: Entscheidungsbäume
 INTELLIGENTE DATENANALYSE IN MATLAB Überwachtes Lernen: Entscheidungsbäume Literatur Stuart Russell und Peter Norvig: Artificial Intelligence. Andrew W. Moore: http://www.autonlab.org/tutorials. 2 Überblick
INTELLIGENTE DATENANALYSE IN MATLAB Überwachtes Lernen: Entscheidungsbäume Literatur Stuart Russell und Peter Norvig: Artificial Intelligence. Andrew W. Moore: http://www.autonlab.org/tutorials. 2 Überblick
Dynamische Systeme und Zeitreihenanalyse // Multivariate Normalverteilung und ML Schätzung 11 p.2/38
 Dynamische Systeme und Zeitreihenanalyse Multivariate Normalverteilung und ML Schätzung Kapitel 11 Statistik und Mathematik WU Wien Michael Hauser Dynamische Systeme und Zeitreihenanalyse // Multivariate
Dynamische Systeme und Zeitreihenanalyse Multivariate Normalverteilung und ML Schätzung Kapitel 11 Statistik und Mathematik WU Wien Michael Hauser Dynamische Systeme und Zeitreihenanalyse // Multivariate
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Entscheidungsbäume
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Entscheidungsbäume Christoph Sawade/Niels Landwehr Jules Rasetaharison, Tobias Scheffer Entscheidungsbäume Eine von vielen Anwendungen:
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Entscheidungsbäume Christoph Sawade/Niels Landwehr Jules Rasetaharison, Tobias Scheffer Entscheidungsbäume Eine von vielen Anwendungen:
Von schwachen zu starken Lernern
 Von schwachen zu starken Lernern Wir nehmen an, dass ein schwacher Lernalgorithmus L mit vielen Beispielen, aber großem Fehler ε = 1 2 θ gegeben ist. - Wie lässt sich der Verallgemeinerungsfehler ε von
Von schwachen zu starken Lernern Wir nehmen an, dass ein schwacher Lernalgorithmus L mit vielen Beispielen, aber großem Fehler ε = 1 2 θ gegeben ist. - Wie lässt sich der Verallgemeinerungsfehler ε von
Theoretische Informatik 1
 Theoretische Informatik 1 Teil 12 Bernhard Nessler Institut für Grundlagen der Informationsverabeitung TU Graz SS 2007 Übersicht 1 Maschinelles Lernen Definition Lernen 2 agnostic -learning Definition
Theoretische Informatik 1 Teil 12 Bernhard Nessler Institut für Grundlagen der Informationsverabeitung TU Graz SS 2007 Übersicht 1 Maschinelles Lernen Definition Lernen 2 agnostic -learning Definition
Softwareprojektpraktikum Maschinelle Übersetzung
 Softwareprojektpraktikum Maschinelle Übersetzung Jan-Thorsten Peter, Andreas Guta, Jan Rosendahl max.bleu@i6.informatik.rwth-aachen.de Vorbesprechung 5. Aufgabe 22. Juni 2017 Human Language Technology
Softwareprojektpraktikum Maschinelle Übersetzung Jan-Thorsten Peter, Andreas Guta, Jan Rosendahl max.bleu@i6.informatik.rwth-aachen.de Vorbesprechung 5. Aufgabe 22. Juni 2017 Human Language Technology
, Data Mining, 2 VO Sommersemester 2008
 Evaluation 188.646, Data Mining, 2 VO Sommersemester 2008 Dieter Merkl e-commerce Arbeitsgruppe Institut für Softwaretechnik und Interaktive Systeme Technische Universität Wien www.ec.tuwien.ac.at/~dieter/
Evaluation 188.646, Data Mining, 2 VO Sommersemester 2008 Dieter Merkl e-commerce Arbeitsgruppe Institut für Softwaretechnik und Interaktive Systeme Technische Universität Wien www.ec.tuwien.ac.at/~dieter/
Polynomiale Regression lässt sich mittels einer Transformation der Merkmale auf multiple lineare Regression zurückführen
 Rückblick Polynomiale Regression lässt sich mittels einer Transformation der Merkmale auf multiple lineare Regression zurückführen Ridge Regression vermeidet Überanpassung, indem einfachere Modelle mit
Rückblick Polynomiale Regression lässt sich mittels einer Transformation der Merkmale auf multiple lineare Regression zurückführen Ridge Regression vermeidet Überanpassung, indem einfachere Modelle mit
INTELLIGENTE DATENANALYSE IN MATLAB
 INTELLIGENTE DATENANALYSE IN MATLAB Überwachtes Lernen: Entscheidungsbäume Literatur Stuart Russell und Peter Norvig: Artificial i Intelligence. Andrew W. Moore: http://www.autonlab.org/tutorials. 2 Überblick
INTELLIGENTE DATENANALYSE IN MATLAB Überwachtes Lernen: Entscheidungsbäume Literatur Stuart Russell und Peter Norvig: Artificial i Intelligence. Andrew W. Moore: http://www.autonlab.org/tutorials. 2 Überblick
Maschinelle Sprachverarbeitung: N-Gramm-Modelle
 HUMBOLD-UNIVERSIÄ ZU BERLIN Institut für Informatik Lehrstuhl Wissensmanagement Maschinelle Sprachverarbeitung: N-Gramm-Modelle obias Scheffer, Ulf Brefeld Statistische Sprachmodelle Welche Sätze sind
HUMBOLD-UNIVERSIÄ ZU BERLIN Institut für Informatik Lehrstuhl Wissensmanagement Maschinelle Sprachverarbeitung: N-Gramm-Modelle obias Scheffer, Ulf Brefeld Statistische Sprachmodelle Welche Sätze sind
Bildverarbeitung: RANSAC. D. Schlesinger () Bildverarbeitung: RANSAC 1 / 11
 Bildverarbeitung: RANSAC 1 / 11") Bildverarbeitung: RANSAC D. Schlesinger () Bildverarbeitung: RANSAC 1 / 11 Beispielaufgaben Man suche eine Gerade ax + by = 1 d.h. die unbekannten Parameter a und b anhand einer Lernstichprobe der Punkte
Bildverarbeitung: RANSAC D. Schlesinger () Bildverarbeitung: RANSAC 1 / 11 Beispielaufgaben Man suche eine Gerade ax + by = 1 d.h. die unbekannten Parameter a und b anhand einer Lernstichprobe der Punkte
Mathe III. Garance PARIS. Mathematische Grundlagen III. Evaluation. 16. Juli /25
 Mathematische Grundlagen III Evaluation 16 Juli 2011 1/25 Training Set und Test Set Ein fairer Test gibt an, wie gut das Modell im Einsatz ist Resubstitution: Evaluation auf den Trainingsdaten Resubstitution
Mathematische Grundlagen III Evaluation 16 Juli 2011 1/25 Training Set und Test Set Ein fairer Test gibt an, wie gut das Modell im Einsatz ist Resubstitution: Evaluation auf den Trainingsdaten Resubstitution
Klausur zu Methoden der Statistik II (mit Kurzlösung) Sommersemester Aufgabe 1
 Sommersemester Aufgabe 1") Lehrstuhl für Statistik und Ökonometrie der Otto-Friedrich-Universität Bamberg Prof. Dr. Susanne Rässler Klausur zu Methoden der Statistik II (mit Kurzlösung) Sommersemester 2013 Aufgabe 1 In einer Urne
Lehrstuhl für Statistik und Ökonometrie der Otto-Friedrich-Universität Bamberg Prof. Dr. Susanne Rässler Klausur zu Methoden der Statistik II (mit Kurzlösung) Sommersemester 2013 Aufgabe 1 In einer Urne
Mustererkennung. Bayes-Klassifikator. R. Neubecker, WS 2016 / Bayes-Klassifikator
 Mustererkennung Bayes-Klassifikator R. Neubecker, WS 2016 / 2017 Bayes-Klassifikator 2 Kontext Ziel: Optimaler Klassifikator ( = minimaler Klassifikationsfehler), basierend auf Wahrscheinlichkeitsverteilungen
Mustererkennung Bayes-Klassifikator R. Neubecker, WS 2016 / 2017 Bayes-Klassifikator 2 Kontext Ziel: Optimaler Klassifikator ( = minimaler Klassifikationsfehler), basierend auf Wahrscheinlichkeitsverteilungen
Moderne Methoden der KI: Maschinelles Lernen
 Moderne Methoden der KI: Maschinelles Lernen Prof. Dr.Hans-Dieter Burkhard Vorlesung Sommer-Semester 2008 Konzept-Lernen Konzept-Lernen Lernen als Suche Inductive Bias Konzept-Lernen: Problemstellung Ausgangspunkt:
Moderne Methoden der KI: Maschinelles Lernen Prof. Dr.Hans-Dieter Burkhard Vorlesung Sommer-Semester 2008 Konzept-Lernen Konzept-Lernen Lernen als Suche Inductive Bias Konzept-Lernen: Problemstellung Ausgangspunkt:
Seminar Text- und Datamining Datamining-Grundlagen
 Seminar Text- und Datamining Datamining-Grundlagen Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 23.05.2013 Gliederung 1 Klassifikationsprobleme 2 Evaluation
Seminar Text- und Datamining Datamining-Grundlagen Martin Hacker Richard Schaller Künstliche Intelligenz Department Informatik FAU Erlangen-Nürnberg 23.05.2013 Gliederung 1 Klassifikationsprobleme 2 Evaluation
Support Vector Machines (SVM)
") Seminar Statistische Lerntheorie und ihre Anwendungen Support Vector Machines (SVM) Jasmin Fischer 12. Juni 2007 Inhaltsverzeichnis Seite 1 Inhaltsverzeichnis 1 Grundlagen 2 2 Lineare Trennung 3 2.1 Aufstellung
Seminar Statistische Lerntheorie und ihre Anwendungen Support Vector Machines (SVM) Jasmin Fischer 12. Juni 2007 Inhaltsverzeichnis Seite 1 Inhaltsverzeichnis 1 Grundlagen 2 2 Lineare Trennung 3 2.1 Aufstellung
Computer Vision: AdaBoost. D. Schlesinger () Computer Vision: AdaBoost 1 / 10
 Computer Vision: AdaBoost 1 / 10") Computer Vision: AdaBoost D. Schlesinger () Computer Vision: AdaBoost 1 / 10 Idee Gegeben sei eine Menge schwacher (einfacher, schlechter) Klassifikatoren Man bilde einen guten durch eine geschickte Kombination
Computer Vision: AdaBoost D. Schlesinger () Computer Vision: AdaBoost 1 / 10 Idee Gegeben sei eine Menge schwacher (einfacher, schlechter) Klassifikatoren Man bilde einen guten durch eine geschickte Kombination
Syntaktische und Statistische Mustererkennung. Bernhard Jung
 Syntaktische und Statistische Mustererkennung VO 1.0 840.040 (UE 1.0 840.041) Bernhard Jung bernhard@jung.name http://bernhard.jung.name/vussme/ 1 Rückblick Entscheidungstheorie Bayes'sche Klassifikation
Syntaktische und Statistische Mustererkennung VO 1.0 840.040 (UE 1.0 840.041) Bernhard Jung bernhard@jung.name http://bernhard.jung.name/vussme/ 1 Rückblick Entscheidungstheorie Bayes'sche Klassifikation
Neuronale Netze. Anna Wallner. 15. Mai 2007
 5. Mai 2007 Inhalt : Motivation Grundlagen Beispiel: XOR Netze mit einer verdeckten Schicht Anpassung des Netzes mit Backpropagation Probleme Beispiel: Klassifikation handgeschriebener Ziffern Rekurrente
5. Mai 2007 Inhalt : Motivation Grundlagen Beispiel: XOR Netze mit einer verdeckten Schicht Anpassung des Netzes mit Backpropagation Probleme Beispiel: Klassifikation handgeschriebener Ziffern Rekurrente
Bachelorarbeit Erkennung von Fließtext in PDF-Dokumenten
 Bachelorarbeit Erkennung von Fließtext in PDF-Dokumenten 16.08.2016 David Spisla Albert Ludwigs Universität Freiburg Technische Fakultät Institut für Informatik Gliederung Motivation Schwierigkeiten bei
Bachelorarbeit Erkennung von Fließtext in PDF-Dokumenten 16.08.2016 David Spisla Albert Ludwigs Universität Freiburg Technische Fakultät Institut für Informatik Gliederung Motivation Schwierigkeiten bei
Maschinelles Lernen Entscheidungsbäume
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen Entscheidungsbäume Paul Prasse Entscheidungsbäume Eine von vielen Anwendungen: Kreditrisiken Kredit - Sicherheiten
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Maschinelles Lernen Entscheidungsbäume Paul Prasse Entscheidungsbäume Eine von vielen Anwendungen: Kreditrisiken Kredit - Sicherheiten
x 2 x 1 x 3 5.1 Lernen mit Entscheidungsbäumen
 5.1 Lernen mit Entscheidungsbäumen Falls zum Beispiel A = {gelb, rot, blau} R 2 und B = {0, 1}, so definiert der folgende Entscheidungsbaum eine Hypothese H : A B (wobei der Attributvektor aus A mit x
5.1 Lernen mit Entscheidungsbäumen Falls zum Beispiel A = {gelb, rot, blau} R 2 und B = {0, 1}, so definiert der folgende Entscheidungsbaum eine Hypothese H : A B (wobei der Attributvektor aus A mit x
Maschinelles Lernen: Symbolische Ansätze
 Semestralklausur zur Vorlesung Maschinelles Lernen: Symbolische Ansätze Prof. J. Fürnkranz / Dr. G. Grieser Technische Universität Darmstadt Wintersemester 2005/06 Termin: 23. 2. 2006 Name: Vorname: Matrikelnummer:
Semestralklausur zur Vorlesung Maschinelles Lernen: Symbolische Ansätze Prof. J. Fürnkranz / Dr. G. Grieser Technische Universität Darmstadt Wintersemester 2005/06 Termin: 23. 2. 2006 Name: Vorname: Matrikelnummer:
Wenn man den Kreis mit Radius 1 um (0, 0) beschreiben möchte, dann ist. (x, y) ; x 2 + y 2 = 1 }
 beschreiben möchte, dann ist. (x, y) ; x 2 + y 2 = 1 }") A Analsis, Woche Implizite Funktionen A Implizite Funktionen in D A3 Wenn man den Kreis mit Radius um, beschreiben möchte, dann ist { x, ; x + = } eine Möglichkeit Oft ist es bequemer, so eine Figur oder
A Analsis, Woche Implizite Funktionen A Implizite Funktionen in D A3 Wenn man den Kreis mit Radius um, beschreiben möchte, dann ist { x, ; x + = } eine Möglichkeit Oft ist es bequemer, so eine Figur oder
Vorlesung: Lineare Modelle
 Vorlesung: Lineare Modelle Prof Dr Helmut Küchenhoff Institut für Statistik, LMU München SoSe 2014 5 Metrische Einflußgrößen: Polynomiale Regression, Trigonometrische Polynome, Regressionssplines, Transformationen
Vorlesung: Lineare Modelle Prof Dr Helmut Küchenhoff Institut für Statistik, LMU München SoSe 2014 5 Metrische Einflußgrößen: Polynomiale Regression, Trigonometrische Polynome, Regressionssplines, Transformationen
Künstliche Intelligenz Maschinelles Lernen
 Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert Sommersemester 2009 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen
Künstliche Intelligenz Maschinelles Lernen Stephan Schwiebert Sommersemester 2009 Sprachliche Informationsverarbeitung Institut für Linguistik Universität zu Köln Maschinelles Lernen Überwachtes Lernen
Mathematische Grundlagen III
 Mathematische Grundlagen III Maschinelles Lernen III: Clustering Vera Demberg Universität des Saarlandes 7. Juli 202 Vera Demberg (UdS) Mathe III 7. Juli 202 / 35 Clustering vs. Klassifikation In den letzten
Mathematische Grundlagen III Maschinelles Lernen III: Clustering Vera Demberg Universität des Saarlandes 7. Juli 202 Vera Demberg (UdS) Mathe III 7. Juli 202 / 35 Clustering vs. Klassifikation In den letzten
Learning to Rank Sven Münnich
 Learning to Rank Sven Münnich 06.12.12 Fachbereich 20 Seminar Recommendersysteme Sven Münnich 1 Übersicht 1. Einführung 2. Methoden 3. Anwendungen 4. Zusammenfassung & Fazit 06.12.12 Fachbereich 20 Seminar
Learning to Rank Sven Münnich 06.12.12 Fachbereich 20 Seminar Recommendersysteme Sven Münnich 1 Übersicht 1. Einführung 2. Methoden 3. Anwendungen 4. Zusammenfassung & Fazit 06.12.12 Fachbereich 20 Seminar
Syntaktische und Statistische Mustererkennung. Bernhard Jung
 Syntaktische und Statistische Mustererkennung VO 1.0 840.040 (UE 1.0 840.041) Bernhard Jung bernhard@jung.name http://bernhard.jung.name/vussme/ 1 Rückblick Distanzmaße, Metriken, Pattern Matching Entscheidungstabellen,
Syntaktische und Statistische Mustererkennung VO 1.0 840.040 (UE 1.0 840.041) Bernhard Jung bernhard@jung.name http://bernhard.jung.name/vussme/ 1 Rückblick Distanzmaße, Metriken, Pattern Matching Entscheidungstabellen,
Personalisierung. Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung. Data Mining.
 Personalisierung Personalisierung Thomas Mandl Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung Klassifikation Die Nutzer werden in vorab bestimmte Klassen/Nutzerprofilen
Personalisierung Personalisierung Thomas Mandl Der Personalisierungsprozess Nutzerdaten erheben aufbereiten auswerten Personalisierung Klassifikation Die Nutzer werden in vorab bestimmte Klassen/Nutzerprofilen
Lösung Übungsblatt 5
 Lösung Übungsblatt 5 5. Januar 05 Aufgabe. Die sogenannte Halb-Normalverteilung spielt eine wichtige Rolle bei der statistischen Analyse von Ineffizienzen von Produktionseinheiten. In Abhängigkeit von
Lösung Übungsblatt 5 5. Januar 05 Aufgabe. Die sogenannte Halb-Normalverteilung spielt eine wichtige Rolle bei der statistischen Analyse von Ineffizienzen von Produktionseinheiten. In Abhängigkeit von
Statistik und Wahrscheinlichkeitsrechnung
 Statistik und Wahrscheinlichkeitsrechnung Dr. Jochen Köhler 1 Inhalt der heutigen Vorlesung Statistik und Wahrscheinlichkeitsrechnung Zusammenfassung der vorherigen Vorlesung Übersicht über Schätzung und
Statistik und Wahrscheinlichkeitsrechnung Dr. Jochen Köhler 1 Inhalt der heutigen Vorlesung Statistik und Wahrscheinlichkeitsrechnung Zusammenfassung der vorherigen Vorlesung Übersicht über Schätzung und
Mathematische Werkzeuge R. Neubecker, WS 2016 / 2017
 Mustererkennung Mathematische Werkzeuge R. Neubecker, WS 2016 / 2017 Optimierung: Lagrange-Funktionen, Karush-Kuhn-Tucker-Bedingungen Optimierungsprobleme Optimierung Suche nach dem Maximum oder Minimum
Mustererkennung Mathematische Werkzeuge R. Neubecker, WS 2016 / 2017 Optimierung: Lagrange-Funktionen, Karush-Kuhn-Tucker-Bedingungen Optimierungsprobleme Optimierung Suche nach dem Maximum oder Minimum
Mehrdimensionale Zufallsvariablen
 Mehrdimensionale Zufallsvariablen Im Folgenden Beschränkung auf den diskreten Fall und zweidimensionale Zufallsvariablen. Vorstellung: Auswerten eines mehrdimensionalen Merkmals ( ) X Ỹ also z.b. ω Ω,
Mehrdimensionale Zufallsvariablen Im Folgenden Beschränkung auf den diskreten Fall und zweidimensionale Zufallsvariablen. Vorstellung: Auswerten eines mehrdimensionalen Merkmals ( ) X Ỹ also z.b. ω Ω,
Numerische Methoden und Algorithmen in der Physik
 Numerische Methoden und Algorithmen in der Physik Hartmut Stadie, Christian Autermann 15.01.2009 Numerische Methoden und Algorithmen in der Physik Christian Autermann 1/ 47 Methode der kleinsten Quadrate
Numerische Methoden und Algorithmen in der Physik Hartmut Stadie, Christian Autermann 15.01.2009 Numerische Methoden und Algorithmen in der Physik Christian Autermann 1/ 47 Methode der kleinsten Quadrate
Latente Dirichlet-Allokation
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Latente Dirichlet-Allokation Tobias Scheffer Peter Haider Paul Prasse Themenmodellierung Themenmodellierung (Topic modeling) liefert
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Latente Dirichlet-Allokation Tobias Scheffer Peter Haider Paul Prasse Themenmodellierung Themenmodellierung (Topic modeling) liefert
Aufgabe 1 Probabilistische Inferenz
 Seite 1 von 8 Aufgabe 1 Probabilistische Inferenz (28 Punkte) Die BVG will besser auf Ausfälle im S-Bahn-Verkehr eingestellt sein. Sie geht dabei von folgenden Annahmen aus: An 20% der Tage ist es besonders
Seite 1 von 8 Aufgabe 1 Probabilistische Inferenz (28 Punkte) Die BVG will besser auf Ausfälle im S-Bahn-Verkehr eingestellt sein. Sie geht dabei von folgenden Annahmen aus: An 20% der Tage ist es besonders
Maschinelles Lernen: Symbolische Ansätze
 Maschinelles Lernen: Symbolische Ansätze Wintersemester 2008/2009 Musterlösung für das 5. Übungsblatt Aufgabe 1: Covering-Algorithmus und Coverage-Space Visualisieren Sie den Ablauf des Covering-Algorithmus
Maschinelles Lernen: Symbolische Ansätze Wintersemester 2008/2009 Musterlösung für das 5. Übungsblatt Aufgabe 1: Covering-Algorithmus und Coverage-Space Visualisieren Sie den Ablauf des Covering-Algorithmus
Wichtige Definitionen und Aussagen
 Wichtige Definitionen und Aussagen Zufallsexperiment, Ergebnis, Ereignis: Unter einem Zufallsexperiment verstehen wir einen Vorgang, dessen Ausgänge sich nicht vorhersagen lassen Die möglichen Ausgänge
Wichtige Definitionen und Aussagen Zufallsexperiment, Ergebnis, Ereignis: Unter einem Zufallsexperiment verstehen wir einen Vorgang, dessen Ausgänge sich nicht vorhersagen lassen Die möglichen Ausgänge
Statistische Tests für unbekannte Parameter
 Konfidenzintervall Intervall, das den unbekannten Parameter der Verteilung mit vorgegebener Sicherheit überdeckt ('Genauigkeitsaussage' bzw. Zuverlässigkeit einer Punktschätzung) Statistischer Test Ja-Nein-Entscheidung
Konfidenzintervall Intervall, das den unbekannten Parameter der Verteilung mit vorgegebener Sicherheit überdeckt ('Genauigkeitsaussage' bzw. Zuverlässigkeit einer Punktschätzung) Statistischer Test Ja-Nein-Entscheidung
Statistical Learning
 Statistical Learning M Gruber KW 45 Rev 1 1 Support Vector Machines Definition 1 (Lineare Trennbarkeit) Eine Menge Ü µ Ý µ Ü Æµ Ý Æµ R ist linear trennbar, wenn mindestens ein Wertepaar Û R µ existiert
Statistical Learning M Gruber KW 45 Rev 1 1 Support Vector Machines Definition 1 (Lineare Trennbarkeit) Eine Menge Ü µ Ý µ Ü Æµ Ý Æµ R ist linear trennbar, wenn mindestens ein Wertepaar Û R µ existiert
Principal Component Analysis (PCA)
") Principal Component Analysis (PCA) Motivation: Klassifikation mit der PCA Berechnung der Hauptkomponenten Theoretische Hintergründe Anwendungsbeispiel: Klassifikation von Gesichtern Weiterführende Bemerkungen
Principal Component Analysis (PCA) Motivation: Klassifikation mit der PCA Berechnung der Hauptkomponenten Theoretische Hintergründe Anwendungsbeispiel: Klassifikation von Gesichtern Weiterführende Bemerkungen
BZQ II: Stochastikpraktikum
 BZQ II: Stochastikpraktikum Block 5: Markov-Chain-Monte-Carlo-Verfahren Randolf Altmeyer February 1, 2017 Überblick 1 Monte-Carlo-Methoden, Zufallszahlen, statistische Tests 2 Nichtparametrische Methoden
BZQ II: Stochastikpraktikum Block 5: Markov-Chain-Monte-Carlo-Verfahren Randolf Altmeyer February 1, 2017 Überblick 1 Monte-Carlo-Methoden, Zufallszahlen, statistische Tests 2 Nichtparametrische Methoden
Die Datenmatrix für Überwachtes Lernen
 Die Datenmatrix für Überwachtes Lernen X j j-te Eingangsvariable X = (X 0,..., X M 1 ) T Vektor von Eingangsvariablen M Anzahl der Eingangsvariablen N Anzahl der Datenpunkte Y Ausgangsvariable x i = (x
Die Datenmatrix für Überwachtes Lernen X j j-te Eingangsvariable X = (X 0,..., X M 1 ) T Vektor von Eingangsvariablen M Anzahl der Eingangsvariablen N Anzahl der Datenpunkte Y Ausgangsvariable x i = (x
Klausur zur Mathematik für Biologen
 Mathematisches Institut der Heinrich-Heine-Universität DÜSSELDORF WS 2002/2003 12.02.2003 (1) Prof. Dr. A. Janssen / Dr. H. Weisshaupt Klausur zur Mathematik für Biologen Bitte füllen Sie das Deckblatt
Mathematisches Institut der Heinrich-Heine-Universität DÜSSELDORF WS 2002/2003 12.02.2003 (1) Prof. Dr. A. Janssen / Dr. H. Weisshaupt Klausur zur Mathematik für Biologen Bitte füllen Sie das Deckblatt
Übersicht. Künstliche Intelligenz: 18. Lernen aus Beobachtungen Frank Puppe 1
 Übersicht I Künstliche Intelligenz II Problemlösen III Wissen und Schlußfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen VI Lernen 18. Lernen aus Beobachtungen 19. Wissen beim Lernen 20. Statistische
Übersicht I Künstliche Intelligenz II Problemlösen III Wissen und Schlußfolgern IV Logisch Handeln V Unsicheres Wissen und Schließen VI Lernen 18. Lernen aus Beobachtungen 19. Wissen beim Lernen 20. Statistische
Lineare Klassifikationsmethoden
 Universität Ulm Fakultät für Mathematik und Wirtschaftswissenschaften Lineare Klassifikationsmethoden Statistische Lerntheorie und ihre Anwendungen Seminararbeit in dem Institut für Stochastik Prüfer:
Universität Ulm Fakultät für Mathematik und Wirtschaftswissenschaften Lineare Klassifikationsmethoden Statistische Lerntheorie und ihre Anwendungen Seminararbeit in dem Institut für Stochastik Prüfer: