Unüberwachtes Lernen
|
|
|
- Calvin Langenberg
- vor 5 Jahren
- Abrufe
Transkript
1 Unüberwachtes Lernen Mustererkennung und Klassifikation, Vorlesung No. 12 M. O. Franz
2 Übersicht 1 Hauptkomponentenanalyse 2 Nichtlineare Hauptkomponentenanalyse 3 K-Means-Clustering
3 Übersicht 1 Hauptkomponentenanalyse 2 Nichtlineare Hauptkomponentenanalyse 3 K-Means-Clustering
4 Unüberwachtes Lernen Bei unüberwachten Lernproblemen ist die Klassenzugehörigkeit der Trainingsbeispiele unbekannt. Anwendungsfälle: Clusteranalyse: Die Daten werden aufgrund bestimmter Kriterien (z.b. räumliche Nähe) in Klassen zusammengefaßt. Dimensionsreduktion: Suche nach niedrigdimensionalen Repräsentationen der Daten zur Interpretation oder für Lernaufgaben.
5 Hauptkomponentenanalyse In der Hauptkomponentenanalyse wird nach Richtungen in den Daten gesucht, entlang derer die Daten extremale (d.h. maximale oder minimale) Varianz haben. Anwendung: Dimensionsreduktion durch Weglassen der Richtungen mit der kleinsten Varianz. Annahme: die Daten seien zentriert, d.h. der Schwerpunkt m = 1 n liegt am Ursprung. i x i
6 Varianz entlang einer Raumrichtung Gesucht sind Richtungen mit extremaler Varianz. Eine beliebige Richtung im R d wird durch einen Einheitsvektor q dargestellt, auf die Datenpunkte x projiziert werden: A = x q = q x mit q = q q = 1 Wir nehmen an, daß die Datenpunkte durch eine vektorwertige Zufallsvariable mit Erwartungswert E[x] = 0 erzeugt werden. Damit ist auch die Projektion A auf q eine Zufallsvariable mit Varianz in Richtung q: σ 2 (q) = E[A 2 ] E[A] 2 E[A] = q E[x] = 0 = E[(q x)(x q)] 0 = q E[xx ]q = q Rq mit Korrelationsmatrix R = E[xx ]
7 Raumrichtungen extremaler Varianz als Eigenwertproblem An Richtungen extremaler Varianz ist die Ableitung von σ 2 (q) = 0, d.h. bei einer infinitesimalen Richtungsänderung δq gilt Mit Hilfe von σ 2 = q Rq ergibt sich σ 2 (q + δq) = σ 2 (q) + O(δq 2 ) σ 2 (q + δq) = (q + δq) R(q + δq) = q Rq + 2(δq) Rq + O(δq 2 ) und σ 2 (q + δq) = σ 2 (q) + 2(δq) Rq Damit beide Gleichungen gültig sind, muß (δq) Rq = 0 sein. Weiterhin gilt q + δq = 1, d.h. (q + δq) (q + δq) = 1 damit muß auch hier (δq) q = 0 sein. Zusammen ergibt sich (δq) Rq + λ(δq) q = 0 bzw. (δq) (Rq λq) = 0 und damit die Eigenwertgleichung Rq = λq mit λ = σ 2 (q)
8 Hauptkomponenten Die Lösungen der Eigenwertgleichung der Korrelationsmatrix R Rq = λq sind also die Richtungen extremaler Varianz, die Eigenwerte geben die Varianz der Daten entlang dieser Richtungen an. Die Eigenwertgleichung hat i.a. d verschiedene, zueinander orthogonale Richtungen q i als Lösung. Diese Richtungsvektoren werden als neue Basis im R d gewählt. Die Projektionen eines Datenpunktes auf die q i a i = q i x = x q i heißen die Hauptkomponenten von x. Die Darstellung eines Datenpunktes in diesem neuen Koordinatensystem entspricht also einer Rotation, nach der die Koordinatenachsen entlang der Richtungen extremaler Varianz zeigen.
9 Dimensionsreduktion Prinzip: es werden nur die l Basisvektoren mit der größten Varianz beibehalten, Richtungen kleinerer Varianz werden verworfen. Der resultierende Vektor in R l ist ˆx = l a i q i mit a i = q i x. i=1 Man kann zeigen, daß die so gewählte Basis den kleinsten Rekonstruktionsfehler unter allen Basen von R l hat (s. Haykin, 99). [Haykin 99]
10 2D-Beispiel [Haykin 99]

11 Beispiel: Eigengesichter
12 Übersicht 1 Hauptkomponentenanalyse 2 Nichtlineare Hauptkomponentenanalyse 3 K-Means-Clustering
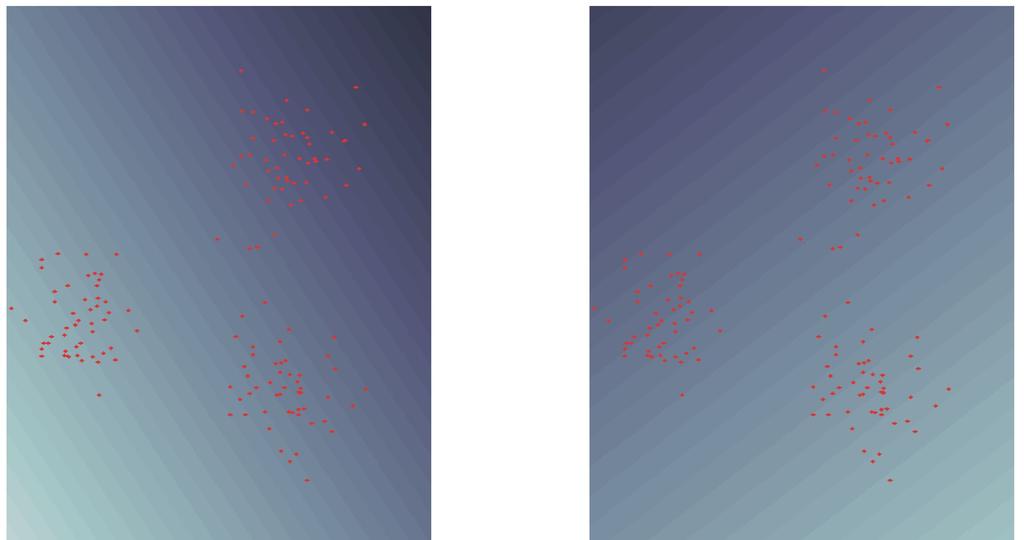
13 Hauptkomponentenanalyse auf 3 Clustern
14 Dimensionsreduktion mit linearen Methoden Die Hauptkomponentenanalyse ist eine lineare Methode. Sie beschreibt Unterräume mit besonders hoher bzw. niedriger Varianz. Die Basisvektoren q i dieser Unterräume sind Linearkombinationen der Trainingsdatenpunkte, d.h. lineare Superpositionen dieser Daten (s. z.b. Eigengesichter). Für Bilder führen solche Repräsentationen oft zu unerwünschten Artefakten (Geisterbilder). Oft befinden sich die Daten auf niedrigdimensionalen Untermannigfaltigkeiten, die keinem Unterraum entsprechen, sondern gekrümmten Hyperflächen. Die Hauptkomponentenanalyse fängt nur paarweise Korrelationen ein, keine komplexeren statistischen Abhängigkeiten. Für solche Probleme müssen nichtlineare Methoden zur Dimensionsreduktion eingesetzt werden.
 definieren eine Basis aus m nichtlinearen Funktionen ϕ(x), (2) bilden darüber die Daten nichtlinear in einen erweiterten Merkmalsraum R m ab und machen (3) dort eine")
15 Nichtlineare Hauptkomponentenanalyse (1) Grundidee: Nichtlineare Transformation der Daten in einen (oft höherdimensionalen) Merkmalsraum. Hier: gleicher Ansatz wie bei nichtlinearer Klassifikation, d.h. wir (1) definieren eine Basis aus m nichtlinearen Funktionen ϕ(x), (2) bilden darüber die Daten nichtlinear in einen erweiterten Merkmalsraum R m ab und machen (3) dort eine Hauptkomponentenanalyse.
16 Nichtlineare Hauptkomponentenanalyse (2) Analog zur Klassifikation werden die Basisfunktionen in einen erweiterten Merkmalsvektor geschrieben, z.b für eine Basis aus RBFs ϕ i (x) = e x x i 2 2 y = Φ(x) = e x x e x x e x xn 2 2 R n ergibt sich dann eine Korrelationsmatrix R = E[Φ(x)Φ(x) ] = 1 n n Φ(x i )Φ(x i ), i=1 deren Eigenwertzerlegung eine nichtlineare Hauptkomponentenanalyse im R n darstellt.

17 Nichtlineare Hauptkomponentenanalyse auf 3 Clustern
18 Übersicht 1 Hauptkomponentenanalyse 2 Nichtlineare Hauptkomponentenanalyse 3 K-Means-Clustering
19 Clustering Situation: Eine Menge von Objekten und ein Ähnlichkeitsmaß zwischen diesen Objekten. Die Objekte seien als Punkte in einem Raum darstellbar, ihre Ähnlichkeiten als Distanzen. Clustern: geg. eine Punktmenge, partitioniere sie so in Cluster, daß sich Punkte im selben Cluster nahe sind, Punkte in verschiedenen Clustern weit auseinanderliegen. Hierarchisches Clustern Zentroidbasiertes Clustern Single-Linkage Clustering Probabilistische generative Modelle...
20 K-Means-Clustering 1 Initialisierung: geg. Datenpunkte x n, n = 1... N, setze K Prototypen auf Zufallswerte m (0) k 2 Zuweisungsschritt: weise jedem Datenpunkt x n den nächsten Prototyp ˆk n zu, d.h. ˆk n = argmin k x n m k 2 3 Anpassungsschritt: Setze m k auf den Mittelwert der ihm zugewiesenen Datenpunkte m k = n r knx n n r kn mit dem Indikator r kn = 1 wenn k = ˆk n, sonst r kn = 0. 4 Wiederhole Zuweisungs- und Anpassungsschritt, bis sich die Zuordnung nicht mehr ändert.
21 Beispiel: K-means auf 2D-Daten [McKay 2003]
22 Problematische Fälle [McKay 2003]
23 Probleme bei K-Means Ad-hoc-Merkmale Anzahl der Prototypen steht von vornherein fest. Wie soll im Falle von mehreren möglichen Clusterzuteilungen entschieden werden? Warum ist gerade der Mittelwert ein guter Repräsentant für den Cluster? Gibt es bessere Distanzfunktionen? Algorithmische Probleme Nur die Distanz zählt, nicht die Clustergröße. Keine Repräsentation der Clusterform Sog. harte Zuweisung: jeder Punkt trägt nur zu einem Cluster bei und hat dort dasselbe Gewicht.
24 Soft K-Means 1 Initialisierung: geg. Datenpunkte x n, n = 1... N, setze K Prototypen auf Zufallswerte m (0) k 2 Zuweisungsschritt: Jeder Datenpunkt x n erhält eine weiche Zuweisung zu allen Prototypen über die Indikatorfunktion r kn = exp( β m k x n ) i exp( β m mit r kn = 1 i x n ) β beschreibt die Reichweite der Prototypen. 3 Anpassungsschritt: Setze m k auf den Mittelwert der ihm zugewiesenen Datenpunkte m k = n r knx n n r kn 4 Wiederhole Zuweisungs- und Anpassungsschritt, bis sich die Zuordnung nicht mehr ändert. k
25 Beispiel: Soft K-Means example auf 2D-Daten [McKay 2003]
Principal Component Analysis (PCA)
") Principal Component Analysis (PCA) Motivation: Klassifikation mit der PCA Berechnung der Hauptkomponenten Theoretische Hintergründe Anwendungsbeispiel: Klassifikation von Gesichtern Weiterführende Bemerkungen
Principal Component Analysis (PCA) Motivation: Klassifikation mit der PCA Berechnung der Hauptkomponenten Theoretische Hintergründe Anwendungsbeispiel: Klassifikation von Gesichtern Weiterführende Bemerkungen
Nichtlineare Klassifikatoren
 Nichtlineare Klassifikatoren Mustererkennung und Klassifikation, Vorlesung No. 11 1 M. O. Franz 12.01.2008 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht
Nichtlineare Klassifikatoren Mustererkennung und Klassifikation, Vorlesung No. 11 1 M. O. Franz 12.01.2008 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht
Überblick. Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung
 Grundlagen Überblick Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes-Klassifikator
Grundlagen Überblick Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes-Klassifikator
Mustererkennung. Übersicht. Unüberwachtes Lernen. (Un-) Überwachtes Lernen Clustering im Allgemeinen k-means-verfahren Gaussian-Mixture Modelle
 Überwachtes Lernen Clustering im Allgemeinen k-means-verfahren Gaussian-Mixture Modelle") Mustererkennung Unüberwachtes Lernen R. Neubecker, WS 01 / 01 Übersicht (Un-) Überwachtes Lernen Clustering im Allgemeinen k-means-verfahren 1 Lernen Überwachtes Lernen Zum Training des Klassifikators
Mustererkennung Unüberwachtes Lernen R. Neubecker, WS 01 / 01 Übersicht (Un-) Überwachtes Lernen Clustering im Allgemeinen k-means-verfahren 1 Lernen Überwachtes Lernen Zum Training des Klassifikators
1. Referenzpunkt Transformation
 2.3 Featurereduktion Idee: Anstatt Features einfach wegzulassen, generiere einen neuen niedrigdimensionalen Featureraum aus allen Features: Redundante Features können zusammengefasst werden Irrelevantere
2.3 Featurereduktion Idee: Anstatt Features einfach wegzulassen, generiere einen neuen niedrigdimensionalen Featureraum aus allen Features: Redundante Features können zusammengefasst werden Irrelevantere
Einführung in die Hauptkomponentenanalyse
 Einführung in die Hauptkomponentenanalyse Florian Steinke 6. Juni 009 Vorbereitung: Einige Aspekte der multivariaten Gaußverteilung Definition.. Die -D Gaußverteilung für x R ist ( p(x exp (x µ σ. ( Notation:
Einführung in die Hauptkomponentenanalyse Florian Steinke 6. Juni 009 Vorbereitung: Einige Aspekte der multivariaten Gaußverteilung Definition.. Die -D Gaußverteilung für x R ist ( p(x exp (x µ σ. ( Notation:
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Clusteranalyse. Niels Landwehr
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Niels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer Ansatz:
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Niels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer Ansatz:
Mustererkennung. Merkmalsreduktion. R. Neubecker, WS 2016 / Übersicht
 Mustererkennung Merkmalsreduktion R. Neubecker, WS 2016 / 2017 Übersicht 2 Merkmale Principal Component Analysis: Konzept Mathematische Formulierung Anwendung Eigengesichter 1 Merkmale 3 (Zu) Viele Merkmale
Mustererkennung Merkmalsreduktion R. Neubecker, WS 2016 / 2017 Übersicht 2 Merkmale Principal Component Analysis: Konzept Mathematische Formulierung Anwendung Eigengesichter 1 Merkmale 3 (Zu) Viele Merkmale
Clusteranalyse: Gauß sche Mischmodelle
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse: Gauß sche Mischmodelle iels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse: Gauß sche Mischmodelle iels Landwehr Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Klausur zur Vorlesung Analyse mehrdimensionaler Daten, Lösungen WS 2010/2011; 6 Kreditpunkte, 90 min
 Klausur, Analyse mehrdimensionaler Daten, WS 2010/2011, 6 Kreditpunkte, 90 min 1 Prof. Dr. Fred Böker 21.02.2011 Klausur zur Vorlesung Analyse mehrdimensionaler Daten, Lösungen WS 2010/2011; 6 Kreditpunkte,
Klausur, Analyse mehrdimensionaler Daten, WS 2010/2011, 6 Kreditpunkte, 90 min 1 Prof. Dr. Fred Böker 21.02.2011 Klausur zur Vorlesung Analyse mehrdimensionaler Daten, Lösungen WS 2010/2011; 6 Kreditpunkte,
Klassifikation und Ähnlichkeitssuche
 Klassifikation und Ähnlichkeitssuche Vorlesung XIII Allgemeines Ziel Rationale Zusammenfassung von Molekülen in Gruppen auf der Basis bestimmter Eigenschaften Auswahl von repräsentativen Molekülen Strukturell
Klassifikation und Ähnlichkeitssuche Vorlesung XIII Allgemeines Ziel Rationale Zusammenfassung von Molekülen in Gruppen auf der Basis bestimmter Eigenschaften Auswahl von repräsentativen Molekülen Strukturell
5.Tutorium Multivariate Verfahren
 5.Tutorium Multivariate Verfahren - Hauptkomponentenanalyse - Nicole Schüller: 27.06.2016 und 04.07.2016 Hannah Busen: 28.06.2016 und 05.07.2016 Institut für Statistik, LMU München 1 / 18 Gliederung 1
5.Tutorium Multivariate Verfahren - Hauptkomponentenanalyse - Nicole Schüller: 27.06.2016 und 04.07.2016 Hannah Busen: 28.06.2016 und 05.07.2016 Institut für Statistik, LMU München 1 / 18 Gliederung 1
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen. Clusteranalyse. Tobias Scheffer Thomas Vanck
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Thomas Vanck Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Clusteranalyse Tobias Scheffer Thomas Vanck Überblick Problemstellung/Motivation Deterministischer Ansatz: K-Means Probabilistischer
k-nächste-nachbarn-schätzung
 k-nächste-nachbarn-schätzung Mustererkennung und Klassifikation, Vorlesung No. 7 1 M. O. Franz 29.11.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht
k-nächste-nachbarn-schätzung Mustererkennung und Klassifikation, Vorlesung No. 7 1 M. O. Franz 29.11.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht
Multivariate Verfahren
 Multivariate Verfahren Oliver Muthmann 31. Mai 2007 Gliederung 1 Einführung 2 Varianzanalyse (MANOVA) 3 Regressionsanalyse 4 Faktorenanalyse Hauptkomponentenanalyse 5 Clusteranalyse 6 Zusammenfassung Komplexe
Multivariate Verfahren Oliver Muthmann 31. Mai 2007 Gliederung 1 Einführung 2 Varianzanalyse (MANOVA) 3 Regressionsanalyse 4 Faktorenanalyse Hauptkomponentenanalyse 5 Clusteranalyse 6 Zusammenfassung Komplexe
10.2 Linearkombinationen
 147 Vektorräume in R 3 Die Vektorräume in R 3 sind { } Geraden durch den Ursprung Ebenen durch den Ursprung R 3 Analog zu reellen Vektorräumen kann man komplexe Vektorräume definieren. In der Definition
147 Vektorräume in R 3 Die Vektorräume in R 3 sind { } Geraden durch den Ursprung Ebenen durch den Ursprung R 3 Analog zu reellen Vektorräumen kann man komplexe Vektorräume definieren. In der Definition
H. Stichtenoth WS 2005/06
 H. Stichtenoth WS 25/6 Lösungsvorschlag für das. Übungsblatt Aufgabe : Der gesuchte Unterraum U ist die lineare Hülle von v und v 2 (siehe Def. 5. und Bsp. 5.5b), d. h. U : Spanv,v 2 } v R : v λ v + λ
H. Stichtenoth WS 25/6 Lösungsvorschlag für das. Übungsblatt Aufgabe : Der gesuchte Unterraum U ist die lineare Hülle von v und v 2 (siehe Def. 5. und Bsp. 5.5b), d. h. U : Spanv,v 2 } v R : v λ v + λ
Projektgruppe. Clustering und Fingerprinting zur Erkennung von Ähnlichkeiten
 Projektgruppe Jennifer Post Clustering und Fingerprinting zur Erkennung von Ähnlichkeiten 2. Juni 2010 Motivation Immer mehr Internet-Seiten Immer mehr digitale Texte Viele Inhalte ähnlich oder gleich
Projektgruppe Jennifer Post Clustering und Fingerprinting zur Erkennung von Ähnlichkeiten 2. Juni 2010 Motivation Immer mehr Internet-Seiten Immer mehr digitale Texte Viele Inhalte ähnlich oder gleich
VII Unüberwachte Data-Mining-Verfahren
 VII Unüberwachte Data-Mining-Verfahren Clusteranalyse Assoziationsregeln Generalisierte Assoziationsregeln mit Taxonomien Formale Begriffsanalyse Self Organizing Maps Institut AIFB, 00. Alle Rechte vorbehalten.
VII Unüberwachte Data-Mining-Verfahren Clusteranalyse Assoziationsregeln Generalisierte Assoziationsregeln mit Taxonomien Formale Begriffsanalyse Self Organizing Maps Institut AIFB, 00. Alle Rechte vorbehalten.
Übungsblatt
 Übungsblatt 3 3.5.27 ) Die folgenden vier Matrizen bilden eine Darstellung der Gruppe C 4 : E =, A =, B =, C = Zeigen Sie einige Gruppeneigenschaften: a) Abgeschlossenheit: Berechnen Sie alle möglichen
Übungsblatt 3 3.5.27 ) Die folgenden vier Matrizen bilden eine Darstellung der Gruppe C 4 : E =, A =, B =, C = Zeigen Sie einige Gruppeneigenschaften: a) Abgeschlossenheit: Berechnen Sie alle möglichen
, v 3 = und v 4 =, v 2 = V 1 = { c v 1 c R }.
 154 e Gegeben sind die Vektoren v 1 = ( 10 1, v = ( 10 1. Sei V 1 = v 1 der von v 1 aufgespannte Vektorraum in R 3. 1 Dann besteht V 1 aus allen Vielfachen von v 1, V 1 = { c v 1 c R }. ( 0 ( 01, v 3 =
154 e Gegeben sind die Vektoren v 1 = ( 10 1, v = ( 10 1. Sei V 1 = v 1 der von v 1 aufgespannte Vektorraum in R 3. 1 Dann besteht V 1 aus allen Vielfachen von v 1, V 1 = { c v 1 c R }. ( 0 ( 01, v 3 =
Multivariate Verteilungen und Copulas
 Multivariate Verteilungen und Copulas Zufallsvektoren und Modellierung der Abhängigkeiten Ziel: Modellierung der Veränderungen der Risikofaktoren X n = (X n,1, X n,2,..., X n,d ) Annahme: X n,i und X n,j
Multivariate Verteilungen und Copulas Zufallsvektoren und Modellierung der Abhängigkeiten Ziel: Modellierung der Veränderungen der Risikofaktoren X n = (X n,1, X n,2,..., X n,d ) Annahme: X n,i und X n,j
Überblick. Überblick. Bayessche Entscheidungsregel. A-posteriori-Wahrscheinlichkeit (Beispiel) Wiederholung: Bayes-Klassifikator
 Wiederholung: Bayes-Klassifikator") Überblick Grundlagen Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes-Klassifikator
Überblick Grundlagen Einführung in die automatische Mustererkennung Grundlagen der Wahrscheinlichkeitsrechnung Klassifikation bei bekannter Wahrscheinlichkeitsverteilung Entscheidungstheorie Bayes-Klassifikator
Lineare Algebra und Datenwissenschaften in Ingenieur- und Informatikstudiengängen
 Lineare Algebra und Datenwissenschaften in Ingenieur- und Informatikstudiengängen Heiko Knospe Technische Hochschule Köln heiko.knospe@th-koeln.de 6. September 26 / 2 Einleitung Das Management und die
Lineare Algebra und Datenwissenschaften in Ingenieur- und Informatikstudiengängen Heiko Knospe Technische Hochschule Köln heiko.knospe@th-koeln.de 6. September 26 / 2 Einleitung Das Management und die
Quantenmechanik-Grundlagen Klassisch: Quantenmechanisch:
 Quantenmechanik-Grundlagen HWS DPI 4/08 Klassisch: Größen haben i. Allg. kontinuierliche Messwerte; im Prinzip beliebig genau messbar, auch mehrere gemeinsam. Streuung nur durch im Detail unbekannte Störungen
Quantenmechanik-Grundlagen HWS DPI 4/08 Klassisch: Größen haben i. Allg. kontinuierliche Messwerte; im Prinzip beliebig genau messbar, auch mehrere gemeinsam. Streuung nur durch im Detail unbekannte Störungen
Lineare Algebra. Mathematik II für Chemiker. Daniel Gerth
 Lineare Algebra Mathematik II für Chemiker Daniel Gerth Überblick Lineare Algebra Dieses Kapitel erklärt: Was man unter Vektoren versteht Wie man einfache geometrische Sachverhalte beschreibt Was man unter
Lineare Algebra Mathematik II für Chemiker Daniel Gerth Überblick Lineare Algebra Dieses Kapitel erklärt: Was man unter Vektoren versteht Wie man einfache geometrische Sachverhalte beschreibt Was man unter
Übungen zur Linearen Algebra 1
 Übungen zur Linearen Algebra 1 Wintersemester 014/015 Universität Heidelberg - IWR Prof. Dr. Guido Kanschat Dr. Dörte Beigel Philipp Siehr Blatt 7 Abgabetermin: Freitag, 05.1.014, 11 Uhr Aufgabe 7.1 (Vektorräume
Übungen zur Linearen Algebra 1 Wintersemester 014/015 Universität Heidelberg - IWR Prof. Dr. Guido Kanschat Dr. Dörte Beigel Philipp Siehr Blatt 7 Abgabetermin: Freitag, 05.1.014, 11 Uhr Aufgabe 7.1 (Vektorräume
Inhaltsverzeichnis 1. EINLEITUNG...1
 VII Inhaltsverzeichnis Vorwort...V Verzeichnis der Abbildungen...XII Verzeichnis der Tabellen... XVI Verzeichnis der Übersichten...XXII Symbolverzeichnis... XXIII 1. EINLEITUNG...1 2. FAKTORENANALYSE...5
VII Inhaltsverzeichnis Vorwort...V Verzeichnis der Abbildungen...XII Verzeichnis der Tabellen... XVI Verzeichnis der Übersichten...XXII Symbolverzeichnis... XXIII 1. EINLEITUNG...1 2. FAKTORENANALYSE...5
Multivariate Verteilungen
 Multivariate Verteilungen Zufallsvektoren und Modellierung der Abhängigkeiten Ziel: Modellierung der Veränderungen der Risikofaktoren X n = (X n,1, X n,2,..., X n,d ) Annahme: X n,i und X n,j sind abhängig
Multivariate Verteilungen Zufallsvektoren und Modellierung der Abhängigkeiten Ziel: Modellierung der Veränderungen der Risikofaktoren X n = (X n,1, X n,2,..., X n,d ) Annahme: X n,i und X n,j sind abhängig
Mathematik für Naturwissenschaftler II SS 2010
 Mathematik für Naturwissenschaftler II SS 2010 Lektion 8 18. Mai 2010 Kapitel 8. Vektoren (Fortsetzung) Lineare Unabhängigkeit (Fortsetzung) Basis und Dimension Definition 80. (Lineare (Un-)Abhängigkeit)
Mathematik für Naturwissenschaftler II SS 2010 Lektion 8 18. Mai 2010 Kapitel 8. Vektoren (Fortsetzung) Lineare Unabhängigkeit (Fortsetzung) Basis und Dimension Definition 80. (Lineare (Un-)Abhängigkeit)
Vektoren und Matrizen
 Vektoren und Matrizen Die multivariate Statistik behandelt statistische Eigenschaften und Zusammenhänge mehrerer Variablen, im Gegensatz zu univariaten Statistik, die in der Regel nur eine Variable untersucht.
Vektoren und Matrizen Die multivariate Statistik behandelt statistische Eigenschaften und Zusammenhänge mehrerer Variablen, im Gegensatz zu univariaten Statistik, die in der Regel nur eine Variable untersucht.
5. Geraden und Ebenen im Raum 5.1. Lineare Abhängigkeit und Unabhängigkeit von Vektoren
 5 Geraden und Ebenen im Raum 5 Lineare Abhängigkeit und Unabhängigkeit von Vektoren Definition: Die Vektoren a,a,,a n heißen linear abhängig, wenn mindestens einer dieser Vektoren als Linearkombination
5 Geraden und Ebenen im Raum 5 Lineare Abhängigkeit und Unabhängigkeit von Vektoren Definition: Die Vektoren a,a,,a n heißen linear abhängig, wenn mindestens einer dieser Vektoren als Linearkombination
Training von RBF-Netzen. Rudolf Kruse Neuronale Netze 134
 Training von RBF-Netzen Rudolf Kruse Neuronale Netze 34 Radiale-Basisfunktionen-Netze: Initialisierung SeiL fixed ={l,...,l m } eine feste Lernaufgabe, bestehend ausmtrainingsbeispielenl=ı l,o l. Einfaches
Training von RBF-Netzen Rudolf Kruse Neuronale Netze 34 Radiale-Basisfunktionen-Netze: Initialisierung SeiL fixed ={l,...,l m } eine feste Lernaufgabe, bestehend ausmtrainingsbeispielenl=ı l,o l. Einfaches
Klausurenkurs zum Staatsexamen (SS 2015): Lineare Algebra und analytische Geometrie 6
: Lineare Algebra und analytische Geometrie 6") Dr. Erwin Schörner Klausurenkurs zum Staatsexamen (SS 5): Lineare Algebra und analytische Geometrie 6 6. (Herbst, Thema, Aufgabe 4) Der Vektorraum R 4 sei mit dem Standard Skalarprodukt versehen. Der Unterraum
Dr. Erwin Schörner Klausurenkurs zum Staatsexamen (SS 5): Lineare Algebra und analytische Geometrie 6 6. (Herbst, Thema, Aufgabe 4) Der Vektorraum R 4 sei mit dem Standard Skalarprodukt versehen. Der Unterraum
Lineare Algebra II 8. Übungsblatt
 Lineare Algebra II 8. Übungsblatt Fachbereich Mathematik SS 11 Prof. Dr. Kollross 1./9. Juni 11 Susanne Kürsten Tristan Alex Gruppenübung Aufgabe G1 (Minitest) Sei V ein euklidischer oder unitärer Vektorraum.
Lineare Algebra II 8. Übungsblatt Fachbereich Mathematik SS 11 Prof. Dr. Kollross 1./9. Juni 11 Susanne Kürsten Tristan Alex Gruppenübung Aufgabe G1 (Minitest) Sei V ein euklidischer oder unitärer Vektorraum.
Lineare Klassifikatoren
 Lineare Klassifikatoren Mustererkennung und Klassifikation, Vorlesung No. 8 1 M. O. Franz 06.12.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht 1 Nächste-Nachbarn-
Lineare Klassifikatoren Mustererkennung und Klassifikation, Vorlesung No. 8 1 M. O. Franz 06.12.2007 1 falls nicht anders vermerkt, sind die Abbildungen entnommen aus Duda et al., 2001. Übersicht 1 Nächste-Nachbarn-
Basen von Schnitt und Summe berechnen
 Basen von Schnitt und Summe berechnen 1 / 8 Voraussetzung Es seien U 1, U 2 Untervektorräume von K n. Wir wollen Basen des Schnittes U 1 U 2 und der Summe bestimmen. U 1 + U 2 2 / 8 Bezeichnung Der Einfachheit
Basen von Schnitt und Summe berechnen 1 / 8 Voraussetzung Es seien U 1, U 2 Untervektorräume von K n. Wir wollen Basen des Schnittes U 1 U 2 und der Summe bestimmen. U 1 + U 2 2 / 8 Bezeichnung Der Einfachheit
5. Aufgabe Seien s, t beliebige Parameter. Unter welcher Bedingung sind die Vektoren s t
 Studiengang: PT/LOT/PVHT Algebra Serie Semester: WS 0/ Thema: Vektoralgebra. Aufgabe Seien a, b und c Vektoren der Ebene. Veranschaulichen Sie durch eine Skizze das: ( Assoziativgesetz: a + ) ( ) b + c
Studiengang: PT/LOT/PVHT Algebra Serie Semester: WS 0/ Thema: Vektoralgebra. Aufgabe Seien a, b und c Vektoren der Ebene. Veranschaulichen Sie durch eine Skizze das: ( Assoziativgesetz: a + ) ( ) b + c
Einleitung 2. 1 Koordinatensysteme 2. 2 Lineare Abbildungen 4. 3 Literaturverzeichnis 7
 Sonja Hunscha - Koordinatensysteme 1 Inhalt Einleitung 2 1 Koordinatensysteme 2 1.1 Kartesisches Koordinatensystem 2 1.2 Polarkoordinaten 3 1.3 Zusammenhang zwischen kartesischen und Polarkoordinaten 3
Sonja Hunscha - Koordinatensysteme 1 Inhalt Einleitung 2 1 Koordinatensysteme 2 1.1 Kartesisches Koordinatensystem 2 1.2 Polarkoordinaten 3 1.3 Zusammenhang zwischen kartesischen und Polarkoordinaten 3
Inhalt. Mathematik für Chemiker II Lineare Algebra. Vorlesung im Sommersemester Kurt Frischmuth. Rostock, April Juli 2015
 Inhalt Mathematik für Chemiker II Lineare Algebra Vorlesung im Sommersemester 5 Rostock, April Juli 5 Vektoren und Matrizen Abbildungen 3 Gleichungssysteme 4 Eigenwerte 5 Funktionen mehrerer Variabler
Inhalt Mathematik für Chemiker II Lineare Algebra Vorlesung im Sommersemester 5 Rostock, April Juli 5 Vektoren und Matrizen Abbildungen 3 Gleichungssysteme 4 Eigenwerte 5 Funktionen mehrerer Variabler
Mustererkennung. Support Vector Machines. R. Neubecker, WS 2018 / Support Vector Machines
 Mustererkennung R. Neubecker, WS 018 / 019 (SVM) kommen aus der statistischen Lerntheorie gehören zu den optimalen Klassifikatoren = SVMs minimieren nicht nur den Trainingsfehler, sondern auch den (voraussichtlichen)
Mustererkennung R. Neubecker, WS 018 / 019 (SVM) kommen aus der statistischen Lerntheorie gehören zu den optimalen Klassifikatoren = SVMs minimieren nicht nur den Trainingsfehler, sondern auch den (voraussichtlichen)
Bayessche Lineare Regression
 Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Baessche Lineare Regression Niels Landwehr Überblick Baessche Lernproblemstellung. Einführendes Beispiel: Münzwurfexperimente.
Universität Potsdam Institut für Informatik Lehrstuhl Maschinelles Lernen Baessche Lineare Regression Niels Landwehr Überblick Baessche Lernproblemstellung. Einführendes Beispiel: Münzwurfexperimente.
4 Lineare Abbildungen
 17. November 2008 34 4 Lineare Abbildungen 4.1 Lineare Abbildung: Eine Funktion f : R n R m heißt lineare Abbildung von R n nach R m, wenn für alle x 1, x 2 und alle α R gilt f(αx 1 ) = αf(x 1 ) f(x 1
17. November 2008 34 4 Lineare Abbildungen 4.1 Lineare Abbildung: Eine Funktion f : R n R m heißt lineare Abbildung von R n nach R m, wenn für alle x 1, x 2 und alle α R gilt f(αx 1 ) = αf(x 1 ) f(x 1
Wenn PCA in der Gesichtserkennung eingesetzt wird heißen die Eigenvektoren oft: Eigenfaces
 EFME-Zusammenfassusng WS11 Kurze Fragen: Wenn PCA in der Gesichtserkennung eingesetzt wird heißen die Eigenvektoren oft: Eigenfaces Unter welcher Bedingung konvergiert der Online Perceptron Algorithmus?
EFME-Zusammenfassusng WS11 Kurze Fragen: Wenn PCA in der Gesichtserkennung eingesetzt wird heißen die Eigenvektoren oft: Eigenfaces Unter welcher Bedingung konvergiert der Online Perceptron Algorithmus?
BZQ II: Stochastikpraktikum
 BZQ II: Stochastikpraktikum Block 3: Lineares Modell, Klassifikation, PCA Randolf Altmeyer January 9, 2017 Überblick 1 Monte-Carlo-Methoden, Zufallszahlen, statistische Tests 2 Nichtparametrische Methoden
BZQ II: Stochastikpraktikum Block 3: Lineares Modell, Klassifikation, PCA Randolf Altmeyer January 9, 2017 Überblick 1 Monte-Carlo-Methoden, Zufallszahlen, statistische Tests 2 Nichtparametrische Methoden
12. R n als EUKLIDISCHER VEKTORRAUM
 12. R n als EUKLIDISCHER VEKTORRAUM 1 Orthogonalität in der Ebene. Die Vektoren in der Ebene, die (im üblichen Sinne) senkrecht zu einem Vektor x = (x 1, x 2 ) T stehen, lassen sich leicht angeben. Sie
12. R n als EUKLIDISCHER VEKTORRAUM 1 Orthogonalität in der Ebene. Die Vektoren in der Ebene, die (im üblichen Sinne) senkrecht zu einem Vektor x = (x 1, x 2 ) T stehen, lassen sich leicht angeben. Sie
9 Eigenwerte und Eigenvektoren
 92 9 Eigenwerte und Eigenvektoren Wir haben im vorhergehenden Kapitel gesehen, dass eine lineare Abbildung von R n nach R n durch verschiedene Darstellungsmatrizen beschrieben werden kann (je nach Wahl
92 9 Eigenwerte und Eigenvektoren Wir haben im vorhergehenden Kapitel gesehen, dass eine lineare Abbildung von R n nach R n durch verschiedene Darstellungsmatrizen beschrieben werden kann (je nach Wahl
9 Eigenwerte und Eigenvektoren
 92 9 Eigenwerte und Eigenvektoren Wir haben im vorhergehenden Kapitel gesehen, dass eine lineare Abbildung von R n nach R n durch verschiedene Darstellungsmatrizen beschrieben werden kann (je nach Wahl
92 9 Eigenwerte und Eigenvektoren Wir haben im vorhergehenden Kapitel gesehen, dass eine lineare Abbildung von R n nach R n durch verschiedene Darstellungsmatrizen beschrieben werden kann (je nach Wahl
Elemente der Analysis II
 Elemente der Analysis II Informationen zur Vorlesung: http://www.mathematik.uni-trier.de/ wengenroth/ J. Wengenroth () 8. Mai 2009 1 / 29 Bemerkung In der Vorlesung Elemente der Analysis I wurden Funktionen
Elemente der Analysis II Informationen zur Vorlesung: http://www.mathematik.uni-trier.de/ wengenroth/ J. Wengenroth () 8. Mai 2009 1 / 29 Bemerkung In der Vorlesung Elemente der Analysis I wurden Funktionen
Klausurenkurs zum Staatsexamen (SS 2016): Lineare Algebra und analytische Geometrie 6
: Lineare Algebra und analytische Geometrie 6") Dr. Erwin Schörner Klausurenkurs zum Staatsexamen (SS 6): Lineare Algebra und analytische Geometrie 6 6. (Herbst, Thema, Aufgabe 4) Der Vektorraum R 4 sei mit dem Standard Skalarprodukt versehen. Der Unterraum
Dr. Erwin Schörner Klausurenkurs zum Staatsexamen (SS 6): Lineare Algebra und analytische Geometrie 6 6. (Herbst, Thema, Aufgabe 4) Der Vektorraum R 4 sei mit dem Standard Skalarprodukt versehen. Der Unterraum
Charakterisierung von 1D Daten
 Charakterisierung von D Daten Mittelwert: µ, Schätzung m x = x i / n Varianz σ2, Schätzung: s2 = (s: Standardabweichung) Höhere Momente s 2 = ( x i m x ) 2 n ( ) Eine Normalverteilung ist mit Mittelwert
Charakterisierung von D Daten Mittelwert: µ, Schätzung m x = x i / n Varianz σ2, Schätzung: s2 = (s: Standardabweichung) Höhere Momente s 2 = ( x i m x ) 2 n ( ) Eine Normalverteilung ist mit Mittelwert
Vektorräume. 1. v + w = w + v (Kommutativität der Vektoraddition)
") Vektorräume In vielen physikalischen Betrachtungen treten Größen auf, die nicht nur durch ihren Zahlenwert charakterisiert werden, sondern auch durch ihre Richtung Man nennt sie vektorielle Größen im Gegensatz
Vektorräume In vielen physikalischen Betrachtungen treten Größen auf, die nicht nur durch ihren Zahlenwert charakterisiert werden, sondern auch durch ihre Richtung Man nennt sie vektorielle Größen im Gegensatz
Hauptkomponentenanalyse. Volker Tresp
 Hauptkomponentenanalyse Volker Tresp 1 Mathematische Vorbereitung: Singulärwertzerlegung 2 Singulärwertzerlegung Singulärwertzerlegung, auch SVD von Singular Value Decomposition Eine beliebige (rechteckige,
Hauptkomponentenanalyse Volker Tresp 1 Mathematische Vorbereitung: Singulärwertzerlegung 2 Singulärwertzerlegung Singulärwertzerlegung, auch SVD von Singular Value Decomposition Eine beliebige (rechteckige,
1 Multivariate Zufallsvariablen
 1 Multivariate Zufallsvariablen 1.1 Multivariate Verteilungen Definition 1.1. Zufallsvariable, Zufallsvektor (ZV) Sei Ω die Ergebnismenge eines Zufallsexperiments. Eine (univariate oder eindimensionale)
1 Multivariate Zufallsvariablen 1.1 Multivariate Verteilungen Definition 1.1. Zufallsvariable, Zufallsvektor (ZV) Sei Ω die Ergebnismenge eines Zufallsexperiments. Eine (univariate oder eindimensionale)
Mustererkennung und Klassifikation
 Mustererkennung und Klassifikation WS 2007/2008 Fakultät Informatik Technische Informatik Prof. Dr. Matthias Franz mfranz@htwg-konstanz.de www-home.htwg-konstanz.de/~mfranz/heim.html Grundlagen Überblick
Mustererkennung und Klassifikation WS 2007/2008 Fakultät Informatik Technische Informatik Prof. Dr. Matthias Franz mfranz@htwg-konstanz.de www-home.htwg-konstanz.de/~mfranz/heim.html Grundlagen Überblick
Hans Delfs. Übungen zu Mathematik III für Medieninformatik
 Hans Delfs Übungen zu Mathematik III für Medieninformatik 1 RÄUMLICHE DARSTELLUNGEN VON OBJEKTEN 1 1 Räumliche Darstellungen von Objekten Der Einheitswürfel ist der achsenparallele Würfel in A 3, der von
Hans Delfs Übungen zu Mathematik III für Medieninformatik 1 RÄUMLICHE DARSTELLUNGEN VON OBJEKTEN 1 1 Räumliche Darstellungen von Objekten Der Einheitswürfel ist der achsenparallele Würfel in A 3, der von
7. Wie lautet die Inverse der Verkettung zweier linearer Abbildungen? 9. Wie kann die Matrixdarstellung einer linearen Abbildung aufgestellt werden?
 Kapitel Lineare Abbildungen Verständnisfragen Sachfragen Was ist eine lineare Abbildung? Erläutern Sie den Zusammenhang zwischen Unterräumen, linearer Unabhängigkeit und linearen Abbildungen! 3 Was ist
Kapitel Lineare Abbildungen Verständnisfragen Sachfragen Was ist eine lineare Abbildung? Erläutern Sie den Zusammenhang zwischen Unterräumen, linearer Unabhängigkeit und linearen Abbildungen! 3 Was ist
Studiengang: Semester: WS 09/10. Algebra Serie: 1. Thema: Vektoralgebra
 Studiengang: PT/LOT/PVHT Semester: WS 9/ Algebra Serie: Thema: Vektoralgebra. Aufgabe Seien a, b und c Vektoren der Ebene. Veranschaulichen Sie durch eine Skizze das: Assoziativgesetz: a + b + c = a +
Studiengang: PT/LOT/PVHT Semester: WS 9/ Algebra Serie: Thema: Vektoralgebra. Aufgabe Seien a, b und c Vektoren der Ebene. Veranschaulichen Sie durch eine Skizze das: Assoziativgesetz: a + b + c = a +
1 Beispiele multivariater Datensätze... 3
 Inhaltsverzeichnis Teil I Grundlagen 1 Beispiele multivariater Datensätze... 3 2 Elementare Behandlung der Daten... 15 2.1 Beschreibung und Darstellung univariater Datensätze... 15 2.1.1 Beschreibung und
Inhaltsverzeichnis Teil I Grundlagen 1 Beispiele multivariater Datensätze... 3 2 Elementare Behandlung der Daten... 15 2.1 Beschreibung und Darstellung univariater Datensätze... 15 2.1.1 Beschreibung und
Probabilistische Analyse regionaler Klimasimulationen
 Probabilistische Analyse regionaler Klimasimulationen Christian Schölzel und Andreas Hense Meteorologisches Institut der Universität Bonn Fachgespräch Ableitung von regionalen Klimaszenarien aus Multi-Modell-Ensembles,
Probabilistische Analyse regionaler Klimasimulationen Christian Schölzel und Andreas Hense Meteorologisches Institut der Universität Bonn Fachgespräch Ableitung von regionalen Klimaszenarien aus Multi-Modell-Ensembles,
3. Übungsblatt Aufgaben mit Lösungen
 . Übungsblatt Aufgaben mit Lösungen Aufgabe : Gegeben sind zwei Teilmengen von R : E := {x R : x x = }, und F ist eine Ebene durch die Punkte A = ( ), B = ( ) und C = ( ). (a) Stellen Sie diese Mengen
. Übungsblatt Aufgaben mit Lösungen Aufgabe : Gegeben sind zwei Teilmengen von R : E := {x R : x x = }, und F ist eine Ebene durch die Punkte A = ( ), B = ( ) und C = ( ). (a) Stellen Sie diese Mengen
Klassifikation durch direkten Vergleich (Matching)
") Klassifikation durch direkten Vergleich (Matching) Eine triviale Lösung für die Klassifikation ergibt sich durch direkten Vergleich des unbekannten Musters in allen Erscheinungsformen der Äquivalenzklasse
Klassifikation durch direkten Vergleich (Matching) Eine triviale Lösung für die Klassifikation ergibt sich durch direkten Vergleich des unbekannten Musters in allen Erscheinungsformen der Äquivalenzklasse
Geometrie. Bei der Addition von Vektoren erhält man einen Repräsentanten des Summenvektors +, indem man die Repräsentanten von aneinanderfügt:
 Geometrie 1. Vektoren Die Menge aller zueinander parallelen, gleich langen und gleich gerichteten Pfeile werden als Vektor bezeichnet. Jeder einzelne Pfeil heißt Repräsentant des Vektors. Bei Ortsvektoren:
Geometrie 1. Vektoren Die Menge aller zueinander parallelen, gleich langen und gleich gerichteten Pfeile werden als Vektor bezeichnet. Jeder einzelne Pfeil heißt Repräsentant des Vektors. Bei Ortsvektoren:
Abhängigkeitsmaße Seien X 1 und X 2 zwei Zufallsvariablen. Es gibt einige skalare Maße für die Abhängigkeit zwischen X 1 und X 2.
 Abhängigkeitsmaße Seien X 1 und X 2 zwei Zufallsvariablen. Es gibt einige skalare Maße für die Abhängigkeit zwischen X 1 und X 2. Lineare Korrelation Annahme: var(x 1 ),var(x 2 ) (0, ). Der Koeffizient
Abhängigkeitsmaße Seien X 1 und X 2 zwei Zufallsvariablen. Es gibt einige skalare Maße für die Abhängigkeit zwischen X 1 und X 2. Lineare Korrelation Annahme: var(x 1 ),var(x 2 ) (0, ). Der Koeffizient
2.3.4 Drehungen in drei Dimensionen
 2.3.4 Drehungen in drei Dimensionen Wir verallgemeinern die bisherigen Betrachtungen nun auf den dreidimensionalen Fall. Für Drehungen des Koordinatensystems um die Koordinatenachsen ergibt sich 1 x 1
2.3.4 Drehungen in drei Dimensionen Wir verallgemeinern die bisherigen Betrachtungen nun auf den dreidimensionalen Fall. Für Drehungen des Koordinatensystems um die Koordinatenachsen ergibt sich 1 x 1
Reelle Zufallsvariablen
 Kapitel 3 eelle Zufallsvariablen 3. Verteilungsfunktionen esultat aus der Maßtheorie: Zwischen der Menge aller W-Maße auf B, nennen wir sie W B ), und der Menge aller Verteilungsfunktionen auf, nennen
Kapitel 3 eelle Zufallsvariablen 3. Verteilungsfunktionen esultat aus der Maßtheorie: Zwischen der Menge aller W-Maße auf B, nennen wir sie W B ), und der Menge aller Verteilungsfunktionen auf, nennen
DWT 1.4 Rechnen mit kontinuierlichen Zufallsvariablen 234/467 Ernst W. Mayr
 1.4.2 Kontinuierliche Zufallsvariablen als Grenzwerte diskreter Zufallsvariablen Sei X eine kontinuierliche Zufallsvariable. Wir können aus X leicht eine diskrete Zufallsvariable konstruieren, indem wir
1.4.2 Kontinuierliche Zufallsvariablen als Grenzwerte diskreter Zufallsvariablen Sei X eine kontinuierliche Zufallsvariable. Wir können aus X leicht eine diskrete Zufallsvariable konstruieren, indem wir
Demokurs. Modul Vertiefung der Wirtschaftsmathematik Vertiefung der Statistik
 Demokurs Modul 3741 Vertiefung der Wirtschaftsmathematik und Statistik Kurs 41 Vertiefung der Statistik 15. Juli 010 Seite: 14 KAPITEL 4. ZUSAMMENHANGSANALYSE gegeben, wobei die Stichproben(ko)varianzen
Demokurs Modul 3741 Vertiefung der Wirtschaftsmathematik und Statistik Kurs 41 Vertiefung der Statistik 15. Juli 010 Seite: 14 KAPITEL 4. ZUSAMMENHANGSANALYSE gegeben, wobei die Stichproben(ko)varianzen
1 Lineare Unabhängigkeit Äquivalente Definition Geometrische Interpretation Vektorräume und Basen 6
 Wirtschaftswissenschaftliches Zentrum Universität Basel Mathematik Dr. Thomas Zehrt Vektorräume und Rang einer Matrix Inhaltsverzeichnis Lineare Unabhängigkeit. Äquivalente Definition.............................
Wirtschaftswissenschaftliches Zentrum Universität Basel Mathematik Dr. Thomas Zehrt Vektorräume und Rang einer Matrix Inhaltsverzeichnis Lineare Unabhängigkeit. Äquivalente Definition.............................
Lineare Algebra und Numerische Mathematik für D-BAUG
 P Grohs T Welti F Weber Herbstsemester 25 Lineare Algebra und Numerische Mathematik für D-BAUG ETH Zürich D-MATH Beispiellösung für Serie 8 Aufgabe 8 Basen für Bild und Kern Gegeben sind die beiden 2 Matrizen:
P Grohs T Welti F Weber Herbstsemester 25 Lineare Algebra und Numerische Mathematik für D-BAUG ETH Zürich D-MATH Beispiellösung für Serie 8 Aufgabe 8 Basen für Bild und Kern Gegeben sind die beiden 2 Matrizen:
Anwendung v. symmetrischen Matrizen: Hauptachsentransformation
 Anwendung v. symmetrischen Matrizen: Hauptachsentransformation Einleitende Bemerkungen: Gl. für Kreis: Gl. für Elllipse: (gestauchter Kreis) Gl. für Kugel: Gl. für Elllipsoid: (gestauchter Kugel) Diese
Anwendung v. symmetrischen Matrizen: Hauptachsentransformation Einleitende Bemerkungen: Gl. für Kreis: Gl. für Elllipse: (gestauchter Kreis) Gl. für Kugel: Gl. für Elllipsoid: (gestauchter Kugel) Diese
Statistik II: Klassifikation und Segmentierung
 Medien Institut : Klassifikation und Segmentierung Dr. Andreas Vlašić Medien Institut (0621) 52 67 44 vlasic@medien-institut.de Gliederung 1. Faktorenanalyse 2. Clusteranalyse 3. Key Facts 2 I 14 Ziel
Medien Institut : Klassifikation und Segmentierung Dr. Andreas Vlašić Medien Institut (0621) 52 67 44 vlasic@medien-institut.de Gliederung 1. Faktorenanalyse 2. Clusteranalyse 3. Key Facts 2 I 14 Ziel
Clusteranalyse. Anwendungsorientierte Einführung. R. Oldenbourg Verlag München Wien. Von Dr. Johann Bacher
 Clusteranalyse Anwendungsorientierte Einführung Von Dr. Johann Bacher R. Oldenbourg Verlag München Wien INHALTSVERZEICHNIS Vorwort XI 1 Einleitung 1 1.1 Primäre Zielsetzung clusteranalytischer Verfahren
Clusteranalyse Anwendungsorientierte Einführung Von Dr. Johann Bacher R. Oldenbourg Verlag München Wien INHALTSVERZEICHNIS Vorwort XI 1 Einleitung 1 1.1 Primäre Zielsetzung clusteranalytischer Verfahren
42 Orthogonalität Motivation Definition: Orthogonalität Beispiel
 4 Orthogonalität 4. Motivation Im euklidischen Raum ist das euklidische Produkt zweier Vektoren u, v IR n gleich, wenn die Vektoren orthogonal zueinander sind. Für beliebige Vektoren lässt sich sogar der
4 Orthogonalität 4. Motivation Im euklidischen Raum ist das euklidische Produkt zweier Vektoren u, v IR n gleich, wenn die Vektoren orthogonal zueinander sind. Für beliebige Vektoren lässt sich sogar der
Kapitel 2: Mathematische Grundlagen
 [ Computeranimation ] Kapitel 2: Mathematische Grundlagen Prof. Dr. Stefan M. Grünvogel stefan.gruenvogel@fh-koeln.de Institut für Medien- und Phototechnik Fachhochschule Köln 2. Mathematische Grundlagen
[ Computeranimation ] Kapitel 2: Mathematische Grundlagen Prof. Dr. Stefan M. Grünvogel stefan.gruenvogel@fh-koeln.de Institut für Medien- und Phototechnik Fachhochschule Köln 2. Mathematische Grundlagen
Mathematische Werkzeuge R. Neubecker, WS 2016 / 2017
 Mustererkennung Mathematische Werkzeuge R. Neubecker, WS 2016 / 2017 Optimierung: Lagrange-Funktionen, Karush-Kuhn-Tucker-Bedingungen Optimierungsprobleme Optimierung Suche nach dem Maximum oder Minimum
Mustererkennung Mathematische Werkzeuge R. Neubecker, WS 2016 / 2017 Optimierung: Lagrange-Funktionen, Karush-Kuhn-Tucker-Bedingungen Optimierungsprobleme Optimierung Suche nach dem Maximum oder Minimum
3 Bedingte Erwartungswerte
 3 Bedingte Erwartungswerte 3.3 Existenz und Eindeutigkeit des bedingten Erwartungswertes E A 0(X) 3.6 Konvexitätsungleichung für bedingte Erwartungswerte 3.9 Konvergenzsätze von Levi, Fatou und Lebesgue
3 Bedingte Erwartungswerte 3.3 Existenz und Eindeutigkeit des bedingten Erwartungswertes E A 0(X) 3.6 Konvexitätsungleichung für bedingte Erwartungswerte 3.9 Konvergenzsätze von Levi, Fatou und Lebesgue
Mathematische Werkzeuge R. Neubecker, WS 2018 / 2019 Optimierung Lagrange-Funktionen, Karush-Kuhn-Tucker-Bedingungen
 Mustererkennung Mathematische Werkzeuge R. Neubecker, WS 018 / 019 Optimierung Lagrange-Funktionen, Karush-Kuhn-Tucker-Bedingungen 1 Optimierung Optimierungsprobleme Suche nach dem Maximum oder Minimum
Mustererkennung Mathematische Werkzeuge R. Neubecker, WS 018 / 019 Optimierung Lagrange-Funktionen, Karush-Kuhn-Tucker-Bedingungen 1 Optimierung Optimierungsprobleme Suche nach dem Maximum oder Minimum
Inhalt. 1 Unvollständige Clusteranalyseverfahren 35
 Inhalt i Einleitung 15 1.1 Zielsetzung clusteranalytischer Verfahren 15 1.2 Homogenität als Grundprinzip der Bildung von Clustern 16 1.3 Clusteranalyseverfahren 18 1.4 Grundlage der Clusterbildung 20 1.5
Inhalt i Einleitung 15 1.1 Zielsetzung clusteranalytischer Verfahren 15 1.2 Homogenität als Grundprinzip der Bildung von Clustern 16 1.3 Clusteranalyseverfahren 18 1.4 Grundlage der Clusterbildung 20 1.5
Lösungsskizzen zur Klausur Mathematik II
 sskizzen zur Klausur Mathematik II vom..7 Aufgabe Es sei die Ebene im R 3 gegeben. E = +λ 3 + µ λ,µ R (a) Geben Sie die Hesse-Normalform der Ebene E an. (b) Berechnen Sie die orthogonale Projektion Π E
sskizzen zur Klausur Mathematik II vom..7 Aufgabe Es sei die Ebene im R 3 gegeben. E = +λ 3 + µ λ,µ R (a) Geben Sie die Hesse-Normalform der Ebene E an. (b) Berechnen Sie die orthogonale Projektion Π E
Kapitel 5. Eigenwerte. Josef Leydold Mathematik für VW WS 2017/18 5 Eigenwerte 1 / 42
 Kapitel 5 Eigenwerte Josef Leydold Mathematik für VW WS 2017/18 5 Eigenwerte 1 / 42 Geschlossenes Leontief-Modell Ein Leontief-Modell für eine Volkswirtschaft heißt geschlossen, wenn der Konsum gleich
Kapitel 5 Eigenwerte Josef Leydold Mathematik für VW WS 2017/18 5 Eigenwerte 1 / 42 Geschlossenes Leontief-Modell Ein Leontief-Modell für eine Volkswirtschaft heißt geschlossen, wenn der Konsum gleich
Skalarprodukt. Das gewöhnliche Skalarprodukt ist für reelle n-tupel folgendermaßen erklärt: Sind. und v := reelle n-tupel, dann ist
 Orthogonalität p. 1 Skalarprodukt Das gewöhnliche Skalarprodukt ist für reelle n-tupel folgendermaßen erklärt: Sind u := u 1 u 2. u n reelle n-tupel, dann ist und v := v 1 v 2. v n u v := u 1 v 1 + u 2
Orthogonalität p. 1 Skalarprodukt Das gewöhnliche Skalarprodukt ist für reelle n-tupel folgendermaßen erklärt: Sind u := u 1 u 2. u n reelle n-tupel, dann ist und v := v 1 v 2. v n u v := u 1 v 1 + u 2
Statistik. Sommersemester Prof. Dr. Stefan Etschberger Hochschule Augsburg. für Betriebswirtschaft und internationales Management
 für Betriebswirtschaft und internationales Management Sommersemester 2015 Prof. Dr. Stefan Etschberger Hochschule Augsburg Testverteilungen Chi-Quadrat-Verteilung Sind X 1,..., X n iid N(0; 1)-verteilte
für Betriebswirtschaft und internationales Management Sommersemester 2015 Prof. Dr. Stefan Etschberger Hochschule Augsburg Testverteilungen Chi-Quadrat-Verteilung Sind X 1,..., X n iid N(0; 1)-verteilte
Multivariate Verteilungen. Gerhard Tutz LMU München
 Multivariate Verteilungen Gerhard Tutz LMU München INHALTSVERZEICHNIS 1 Inhaltsverzeichnis 1 Multivariate Normalverteilung 3 Wishart Verteilung 7 3 Hotellings T Verteilung 11 4 Wilks Λ 14 INHALTSVERZEICHNIS
Multivariate Verteilungen Gerhard Tutz LMU München INHALTSVERZEICHNIS 1 Inhaltsverzeichnis 1 Multivariate Normalverteilung 3 Wishart Verteilung 7 3 Hotellings T Verteilung 11 4 Wilks Λ 14 INHALTSVERZEICHNIS
T2 Quantenmechanik Lösungen 7
 T2 Quantenmechanik Lösungen 7 LMU München, WS 7/8 7.. Lineare Algebra Prof. D. Lüst / Dr. A. Schmidt-May version: 28.. Gegeben sei ein komplexer Hilbert-Raum H der Dimension d. Sei { n } mit n,..., d eine
T2 Quantenmechanik Lösungen 7 LMU München, WS 7/8 7.. Lineare Algebra Prof. D. Lüst / Dr. A. Schmidt-May version: 28.. Gegeben sei ein komplexer Hilbert-Raum H der Dimension d. Sei { n } mit n,..., d eine
Maschinelles Lernen in der Bioinformatik
 Maschinelles Lernen in der Bioinformatik Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) VL 5/6 Selbständiges Lernen Jana Hertel Professur für Bioinformatik Institut
Maschinelles Lernen in der Bioinformatik Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) VL 5/6 Selbständiges Lernen Jana Hertel Professur für Bioinformatik Institut
Deskriptive Beschreibung linearer Zusammenhänge
 9 Mittelwert- und Varianzvergleiche Mittelwertvergleiche bei k > 2 unabhängigen Stichproben 9.4 Beispiel: p-wert bei Varianzanalyse (Grafik) Bedienungszeiten-Beispiel, realisierte Teststatistik F = 3.89,
9 Mittelwert- und Varianzvergleiche Mittelwertvergleiche bei k > 2 unabhängigen Stichproben 9.4 Beispiel: p-wert bei Varianzanalyse (Grafik) Bedienungszeiten-Beispiel, realisierte Teststatistik F = 3.89,
Selbstständiges Lernen
 Kapitel 5 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität Leipzig Machine learning in bioinformatics
Kapitel 5 Spezialvorlesung Modul 10-202-2206 (Fortgeschrittene Methoden in der Bioinformatik) Jana Hertel Professur für Bioinformatik Institut für Informatik Universität Leipzig Machine learning in bioinformatics
Lösungen Serie 5. D-MAVT Lineare Algebra II FS 2018 Prof. Dr. N. Hungerbühler
 D-MAVT Lineare Algebra II S 8 Prof. Dr. N. Hungerbühler Lösungen Serie 5. Die Abbildung V n R n, v [v] B, die jedem Vektor seinen Koordinatenvektor bezüglich einer Basis B zuordnet, ist linear. Sei B =
D-MAVT Lineare Algebra II S 8 Prof. Dr. N. Hungerbühler Lösungen Serie 5. Die Abbildung V n R n, v [v] B, die jedem Vektor seinen Koordinatenvektor bezüglich einer Basis B zuordnet, ist linear. Sei B =
Fallstudien der mathematischen Modellbildung Teil 3: Quanten-Operationen. 0 i = i 0
 Übungsblatt 1 Aufgabe 1: Pauli-Matrizen Die folgenden Matrizen sind die Pauli-Matrizen, gegeben in der Basis 0, 1. [ [ [ 0 1 0 i 1 0 σ 1 = σ 1 0 = σ i 0 3 = 0 1 1. Zeigen Sie, dass die Pauli-Matrizen hermitesch
Übungsblatt 1 Aufgabe 1: Pauli-Matrizen Die folgenden Matrizen sind die Pauli-Matrizen, gegeben in der Basis 0, 1. [ [ [ 0 1 0 i 1 0 σ 1 = σ 1 0 = σ i 0 3 = 0 1 1. Zeigen Sie, dass die Pauli-Matrizen hermitesch
5. Clusteranalyse Vorbemerkungen. 5. Clusteranalyse. Grundlegende Algorithmen der Clusteranalyse kennen, ihre Eigenschaften
 5. Clusteranalyse Vorbemerkungen 5. Clusteranalyse Lernziele: Grundlegende Algorithmen der Clusteranalyse kennen, ihre Eigenschaften benennen und anwenden können, einen Test auf das Vorhandensein einer
5. Clusteranalyse Vorbemerkungen 5. Clusteranalyse Lernziele: Grundlegende Algorithmen der Clusteranalyse kennen, ihre Eigenschaften benennen und anwenden können, einen Test auf das Vorhandensein einer
Ferienkurs Quantenmechanik 2009
 Ferienkurs Quantenmechanik 2009 Grundlagen der Quantenmechanik Vorlesungsskript für den 3. August 2009 Christoph Schnarr Inhaltsverzeichnis 1 Axiome der Quantenmechanik 2 2 Mathematische Struktur 2 2.1
Ferienkurs Quantenmechanik 2009 Grundlagen der Quantenmechanik Vorlesungsskript für den 3. August 2009 Christoph Schnarr Inhaltsverzeichnis 1 Axiome der Quantenmechanik 2 2 Mathematische Struktur 2 2.1
9 Lineare Gleichungssysteme
 9 Lineare Gleichungssysteme Eine der häufigsten mathematischen Aufgaben ist die Lösung linearer Gleichungssysteme In diesem Abschnitt beschäftigen wir uns zunächst mit Lösbarkeitsbedingungen und mit der
9 Lineare Gleichungssysteme Eine der häufigsten mathematischen Aufgaben ist die Lösung linearer Gleichungssysteme In diesem Abschnitt beschäftigen wir uns zunächst mit Lösbarkeitsbedingungen und mit der
Mathematische Grundlagen für die Vorlesung. Differentialgeometrie
 Mathematische Grundlagen für die Vorlesung Differentialgeometrie Dr. Gabriele Link 13.10.2010 In diesem Text sammeln wir die nötigen mathematischen Grundlagen, die wir in der Vorlesung Differentialgeometrie
Mathematische Grundlagen für die Vorlesung Differentialgeometrie Dr. Gabriele Link 13.10.2010 In diesem Text sammeln wir die nötigen mathematischen Grundlagen, die wir in der Vorlesung Differentialgeometrie
Kapitel 3. Vektorräume. Josef Leydold Mathematik für VW WS 2017/18 3 Vektorräume 1 / 41. : x i R, 1 i n x n
 Kapitel Vektorräume Josef Leydold Mathematik für VW WS 07/8 Vektorräume / 4 Reeller Vektorraum Die Menge aller Vektoren x mit n Komponenten bezeichnen wir mit x R n =. : x i R, i n x n und wird als n-dimensionaler
Kapitel Vektorräume Josef Leydold Mathematik für VW WS 07/8 Vektorräume / 4 Reeller Vektorraum Die Menge aller Vektoren x mit n Komponenten bezeichnen wir mit x R n =. : x i R, i n x n und wird als n-dimensionaler
Kapitel 3. Vektorräume. Josef Leydold Mathematik für VW WS 2017/18 3 Vektorräume 1 / 41
 Kapitel 3 Vektorräume Josef Leydold Mathematik für VW WS 2017/18 3 Vektorräume 1 / 41 Reeller Vektorraum Die Menge aller Vektoren x mit n Komponenten bezeichnen wir mit R n = x 1. x n : x i R, 1 i n und
Kapitel 3 Vektorräume Josef Leydold Mathematik für VW WS 2017/18 3 Vektorräume 1 / 41 Reeller Vektorraum Die Menge aller Vektoren x mit n Komponenten bezeichnen wir mit R n = x 1. x n : x i R, 1 i n und
Übungen zu Multimedia-Datenbanken Aufgabenblatt 4 - Musterlösungen
 Übungen zu Multimedia-Datenbanken Aufgabenblatt 4 - Musterlösungen Übung: Dipl.-Inf. Tina Walber Vorlesung: Dr.-Ing. Marcin Grzegorzek Fachbereich Informatik, Universität Koblenz Landau Ausgabe: 31.0.2010
Übungen zu Multimedia-Datenbanken Aufgabenblatt 4 - Musterlösungen Übung: Dipl.-Inf. Tina Walber Vorlesung: Dr.-Ing. Marcin Grzegorzek Fachbereich Informatik, Universität Koblenz Landau Ausgabe: 31.0.2010
5.1 Affine Räume und affine Abbildungen
 402 LinAlg II Version 1.2 21. Juli 2006 c Rudolf Scharlau 5.1 Affine Räume und affine Abbildungen Ein affiner Raum besteht aus zwei Mengen P und G zusammen mit einer Relation der Inzidenz zwischen ihnen.
402 LinAlg II Version 1.2 21. Juli 2006 c Rudolf Scharlau 5.1 Affine Räume und affine Abbildungen Ein affiner Raum besteht aus zwei Mengen P und G zusammen mit einer Relation der Inzidenz zwischen ihnen.
Lösungen zur Prüfung Lineare Algebra I/II für D-MAVT
 Prof. N. Hungerbühler ETH Zürich, Winter 6 Lösungen zur Prüfung Lineare Algebra I/II für D-MAVT. Hinweise zur Bewertung: Jede Aussage ist entweder wahr oder falsch; machen Sie ein Kreuzchen in das entsprechende
Prof. N. Hungerbühler ETH Zürich, Winter 6 Lösungen zur Prüfung Lineare Algebra I/II für D-MAVT. Hinweise zur Bewertung: Jede Aussage ist entweder wahr oder falsch; machen Sie ein Kreuzchen in das entsprechende