Lösungen zu den Kontrollfragen und Vernetzungsaufgaben
|
|
|
- Sven Becke
- vor 5 Jahren
- Abrufe
Transkript
1 Lösungen zu den Kontrollfragen und Vernetzungsaufgaben Kapitel 1: Ablauf einer Studie Kontrollfragen 1. Bitte ergänzen Sie die Lückentexte. Das Gütekriterium der..validität. prüft, inwiefern ein Konstrukt tatsächlich das misst, was es zu messen vorgibt. Die..Reliabilität.. ist ein Maß für die Zuverlässigkeit eines Messinstrumentes. Objektivität.. liegt bei einer Messung dann vor, wenn mehrere Forscher unabhängig voneinander zum selben Ergebnis kommen. 2. Wie würden Sie "Kausalität" definieren? Welche Bedingungen müssen erfüllt sein, damit man Kausalität annehmen kann? Definition: Mit Kausalität bezeichnet man Ursache-Wirkungs-Zusammenhänge. Bedingungen, damit man Kausalität annehmen kann: Die vermutete Ursache (UV) und angenommene Wirkung (AV) sollten korrelieren. Es darf keine Störgrößen geben, die die abhängige Variable beeinflussen, d.h. die Wirkung darf nur auf die AV zurückzuführen sein. Die Ursache (UV) muss zeitlich vor der Wirkung (AV) liegen. 3. Grenzen Sie den qualitativen und den quantitativen Forschungsansatz voneinander ab. Was ist ein Mixed-Methods-Ansatz? Warum kann es sinnvoll sein, einen Mixed-Methods-Ansatz zu verfolgen? Abgrenzung qualitativ vs. quantitativ: Mit qualitativen Studien wird explorativ und anhand von kleinen Stichproben versucht, einen Sachverhalt besser zu verstehen und aufzuhellen. Die Repräsentativität der eher weichen Daten, die z. B. in Gruppendiskussionen gewonnen werden, ist gering. Quantitative Studien wollen Zusammenhänge entdecken und prüfen, sie haben deskriptiven und/oder explikativen Charakter. Es werden harte, quantitative Daten gewonnen. Diese werden mithilfe von statistischen Analyseverfahren ausgewertet. Die Fallzahl ist meist groß und bei einer geeigneten Auswahl der Stichprobe kann diese auch repräsentativ für die Grundgesamtheit sein. Definition Mixed-Methods-Ansatz: Forschungsansatz, bei dem qualitative und quantitative Studien kombiniert eingesetzt werden Zweck von Mixed-Methods-Ansätzen: Beide Ansätze bringen Vorteile mit sich, die sich bei Mixed-Methods-Ansätzen verbinden lassen. Z. B. können mit einer qualitativen Vorstudie Problemfelder identifiziert werden, die dann in eine quantitative Studie einfließen und mit einer größeren Stichprobe näher analysiert werden. Manchmal bleiben auch bei quantitativen Studien Fragen offen, denen im Nachgang mit einer qualitativen Studie noch mal nachgegangen werden kann.


2 4. Welche der im Folgenden aufgeführten Antworten sind richtig? Ob eine Variable normalverteilt ist, lässt sich per Augenschein in einem Histogramm erkennen. Der Kolmogorov-Smirnov-Anpassungstest prüft die Nullhypothese, dass die Beobachtungswerte einer Variablen in der Grundgesamtheit nicht der Normalverteilung folgen. Eine Verteilung ist rechtssteil und linksschief, wenn sich die Beobachtungswerte oberhalb des arithmetischen Mittels häufen. Vernetzungsaufgaben 1. Berechnen Sie für die Variable mix 1 ( Ich mag es, Mixgetränke zu trinken. ) folgende deskriptive Statistiken: Häufigkeiten, arithmetisches Mittel, Median, Varianz, Standardabweichung.


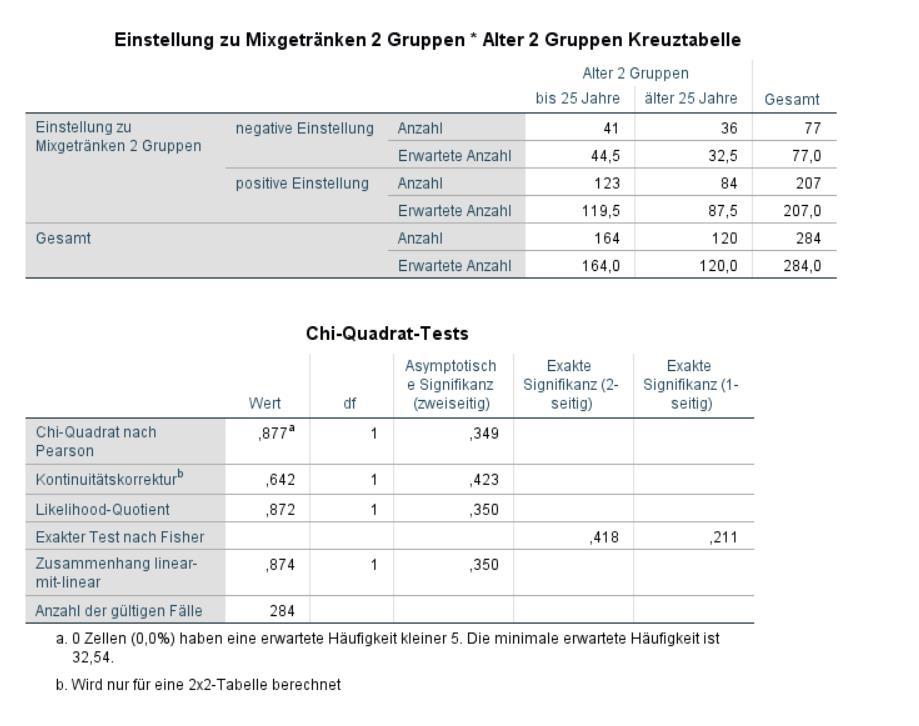
3 2. Das Alter ist im Datensatz als metrisch skalierte Variable gespeichert. Transformieren Sie die Variable Alter in eine nominal skalierte Variable um. Nutzen Sie zur Bildung von zwei Gruppen den Median-Split, d.h. verwenden Sie den Median, um den Datensatz für die Variable Alter in zwei etwa gleich große Gruppen aufzuteilen. Der Median beträgt 25. Es werden deshalb die folgenden zwei Gruppen gebildet: Gruppe 1 = bis 25 Jahre alt, Gruppe 2 = älter als 25 Die Gruppe der bis 25-Jährigen umfasst 165 Befragte, 123 Probanden sind älter als 25 Jahre alt. 3. Berechnen Sie, ob ein statistisch signifikanter Unterschied zwischen dem Alter (bis 25 Jahre; > 25 Jahre) und der Einstellung zu Mixgetränken (Variable mix 1: Ich mag es, Mixgetränke zu trinken. ) besteht. Nutzen Sie hierfür die Kreuztabellierung und den Chi-Quadrat-Test. Beachten Sie, dass für diese Analyse beide Variablen nominal skaliert sein müssen. Sie müssen deshalb zunächst die intervallskalierte Variable mix1 in eine nominal skalierte Variable umwandeln. Transformieren Sie dazu die Variable wie folgt: 1 = negative Einstellung zu Mixgetränken (Ausgangswerte -3, -2, -1, 0), 2 = positive Einstellung zu Mixgetränken (Ausgangswerte 1, 2, 3). 77 Befragte (27,1%) haben eine eher negative Einstellung zu Mixgetränken, 207 Befragte (72,9%) haben hingegen auf dem positiven Teil der Skala geantwortet und damit eine eher positive Einstellung zu Mixgetränken. Die Kreuztabelle zeigt, dass beobachtete und erwartete Häufigkeiten nur wenig voneinander abweichen. Dies deutet darauf hin, dass sich die Altersgruppen nicht in ihrer Einstellung zu Mixgetränken unterscheiden. Der Chi-Quadrat-Test liefert ein nicht-signifikantes Ergebnis (p =,349). Das heißt, die beiden Altersgruppen unterscheiden sich nicht in ihrer Einstellung zu Mixgetränken.
4
5 Kapitel 2: Varianzanalyse Kontrollfragen 1. Ergänzen Sie die Lückentexte. Je nach Anzahl der abhängigen und unabhängigen Variablen lassen sich verschiedene Formen der Varianzanalyse einsetzen. Möchte man den Einfluss mehrerer unabhängiger Variablen auf eine abhängige Variable untersuchen, verwendet man die.. mehrfaktorielle ANOVA... Im Falle mehrerer abhängiger Variablen greift man auf die..manova... zurück. 2. Zu welchem Zweck wird der F-Test im Rahmen der Varianzanalyse eingesetzt? Erläutern Sie die Logik des F-Tests. Zweck: Der F-Test lässt sich für jede unabhängige Variable berechnen. Er prüft, ob der Einfluss der unabhängigen Variablen auf die abhängige Variable statistisch signifikant ist, d.h. ob der Unterschied zwischen den Gruppen nicht nur zufälliger Natur ist. Logik: Es wird ein empirischer F-Wert berechnet, der mit einem theoretischen F-Wert verglichen wird. Wenn der empirische F-Wert größer ist als der theoretische F-Wert, kann die Nullhypothese verworfen werden. Den theoretischen F-Wert entnimmt man aus Tabellen der F-Verteilung, die in einschlägigen Statistik-Lehrbüchern enthalten sind. Um den theoretischen F-Wert ablesen zu können, müssen zunächst noch das Signifikanzniveau (= -Fehler) festgelegt und die Zahl der Freiheitsgrade bestimmt werden. 3. Erklären Sie, unter welchen Voraussetzungen sich die einfaktorielle ANOVA als Testverfahren eignet. Metrisch skalierte AV, nominal skalierte UV Normalverteilung der Werte der abhängigen Variablen in allen Grundgesamtheiten Homogene Varianzen innerhalb der Gruppen 4. Welche der im Folgenden aufgeführten Aussagen sind richtig? Wenn der Levene-Test zu einem nicht-signifikanten Ergebnis führt, liegt keine Varianzhomogenität vor. Aus einer Variablen werden Gruppen gebildet und deren Einfluss auf eine abhängige Variable untersucht. Der F-Test führt zu einem signifikanten Ergebnis. Dies lässt den Schluss zu, dass die Mittelwerte in den Gruppen gleich groß sind. Der t-test (für unabhängige Stichproben) lässt sich nur für Designs mit einer abhängigen und einer unabhängigen Variablen mit 2 Fallgruppen anwenden. Ein Interaktionseffekt liegt dann vor, wenn die Wirkung einer unabhängigen Variablen auf die abhängige Variable von der Ausprägung einer anderen unabhängigen Variablen abhängt. Vernetzungsaufgaben Untersuchen Sie anhand der Varianzanalyse, inwiefern das Geschlecht die Einstellung zu Mixgetränken beeinflusst.
 ist p <,050, d.h. die Nullhypothese, wonach die Varianzen in den Gruppen homogen sind, kann verworfen werden.")

6 1. Prüfen Sie zunächst, ob die Variable mix1 ( Ich mag es, Mixgetränke zu trinken. ) die Voraussetzung der Varianzhomogenität erfüllt. Mit dem Levene-Test wird geprüft, ob die Variable die Anforderung der Varianzhomogenität erfüllt. In unserem Fall (basiert auf Mittelwert) ist p <,050, d.h. die Nullhypothese, wonach die Varianzen in den Gruppen homogen sind, kann verworfen werden. Die Voraussetzung der Varianzhomogenität ist damit nicht erfüllt. 2. Berechnen Sie nun zunächst die Mittelwerte, die Männer und Frauen für die Variable mix1 aufweisen. Der Mittelwert der männlichen Probanden liegt bei,89 und damit etwas unter dem Gesamtmittelwert von 1,02. Die weiblichen Probanden haben einen Mittelwert, der leicht über dem Mittelwert der Gesamtstichprobe liegt (1,14). Frauen scheinen etwas lieber Mixgetränke zu trinken als Männer. 3. Rechnen Sie nun eine einfache Varianzanalyse und prüfen Sie die Güte der Analyse mit dem F-Test. Der F-Test liefert für die Variable sex einen Signifikanzwert von p =,215. Der Unterschied zwischen Männern und Frauen ist nicht signifikant.


7 4. Zusätzlich zum Geschlecht soll nun noch das Alter als weitere unabhängige Variable in die Analyse einfließen. Da die unabhängigen Variablen nominal skaliert sein müssen, muss die metrisch skalierte Variable Alter zunächst umkodiert werden. Transformieren Sie die Variable Alter anhand des Medians (25 Jahre) in zwei Gruppen: 1 = bis 25 Jahre, 2 = älter als 25 Jahre. Berechnen Sie den Mittelwert für den Fall, dass das Geschlecht und das Alter gleichzeitig als unabhängige Variablen und die Variable mix1 als abhängige Variable betrachtet werden. Die deskriptiven Statistiken zeigen, dass Männer über 25 Jahre die negativste Einstellung gegenüber Mix-Getränken haben (,48). Die positivste Einstellung haben Frauen, die älter als 25 Jahre alt sind (1,28). Es ist kein deutlicher Effekt des Alters oder des Geschlechts zu erkennen. Die Mittelwerte lassen aber einen Interaktionseffekt von Alter und Geschlecht vermuten.
.")
8 Die Ergebnisse der F-Tests bestätigen die Vermutung. Der Einfluss des Alters ist nicht signifikant (p =,631). Auch die Variable Geschlecht übt keinen signifikanten Einfluss aus (p =,711). Der Interaktionseffekt von Geschlecht und Alter ist signifikant (p =,016).
9 Kapitel 3: Faktorenanalyse Kontrollfragen 1. Bitte ergänzen Sie die Lückentexte. Die..Faktorladung.. gibt an, wie hoch eine einzelne Variable auf einen Faktor lädt. Der..Eigenwert.. wird pro Faktor berechnet und entspricht der Summe der quadrierten Faktorladungen eines Faktors über alle Variablen hinweg. Der..Faktorwert... ergibt sich als Produkt von Faktorladungs-Matrix und Ausgangsdatenmatrix. Er gibt an, wie ein Proband einen Faktor bewertet hätte. 2. Warum wird die explorative Faktorenanalyse als "explorativ" bezeichnet? Die Faktorenanalyse ist eine Interdependenzanalyse, d.h. es werden Zusammenhänge zwischen einer Vielzahl von Variablen aufgedeckt. Die Variablen werden dabei nicht in unabhängige und abhängige Variablen unterteilt. Es bestehen häufig auch keine theoretischen Vorannahmen dazu, wie die Variablen zusammenhängen. Der Forscher geht bei explorativen Faktorenanalysen empiriegeleitet vor, d.h. er trifft keine theoretischen Vorannahmen zur Faktorstruktur. 3. Anhand welcher Kriterien kann man entscheiden, wie viele Faktoren extrahiert werden sollten? Nennen Sie die Kriterien und erläutern Sie diese näher. Scree-Test: Der Scree-Test ist eine grafische Darstellungsform, bei der die Eigenwerte aller gebildeten Faktoren absteigend geordnet dargestellt werden. Es ergibt sich eine degressiv abfallende Kurve. Zu wählen ist die Anzahl an Faktoren, nach der die Eigenwertkurve noch einmal merklich abfällt (= Elbow ). Kaiser-Kriterium: Es sollen so viele Faktoren bestimmt werden, wie es Faktoren mit einem Eigenwert > 1 gibt. 4. Welche der folgenden Aussagen sind richtig? Von der Einfachstruktur der Faktorladungsmatrix spricht man, wenn möglichst viele Variablen jeweils auf mehrere Faktoren hoch laden. Cronbachs Alpha ist ein Maß für die interne Konsistenz eines Faktors. Es handelt sich dabei um ein lokales Gütekriterium. Der Bartlett-Test kann zum Prüfen der Voraussetzungen für eine Faktorenanalyse nur dann eingesetzt werden, wenn die Variablen normalverteilt sind. Faktoren mit einer Kommunalität von 0,5 sollten von der Analyse ausgeschlossen werden. Vernetzungsaufgaben Ihre Aufgabe ist es nun, eine Faktorenanalyse anhand der folgenden Variablen zur Messung der Einstellung gegenüber Marken zu rechnen: qb1, qb2, mt1, mt2, mb1, mb2, prb1, prb2. 1. Prüfen Sie zunächst, ob die Variablen für eine Faktorenanalyse geeignet sind. Betrachten Sie hierzu die Kommunalitäten der Ausgangsvariablen und berechnen Sie das KMO-Kriterium.


10 Das KMO-Kriterium beträgt,588. Da es größer als,500 ist, sind die Daten für eine Faktorenanalyse geeignet. Die Kommunalitäten sind für alle Variablen größer als der geforderte Wert von,500. Die Analyse kann daher mit allen Variablen fortgeführt werden. 2. Berechnen Sie nun die rotierte Faktorladungsmatrix. Verwenden Sie dabei die Hauptkomponenten-Analyse und das Varimax-Verfahren. Wie viele Faktoren sollten gebildet werden? Wie lassen sich die Faktoren inhaltlich interpretieren?
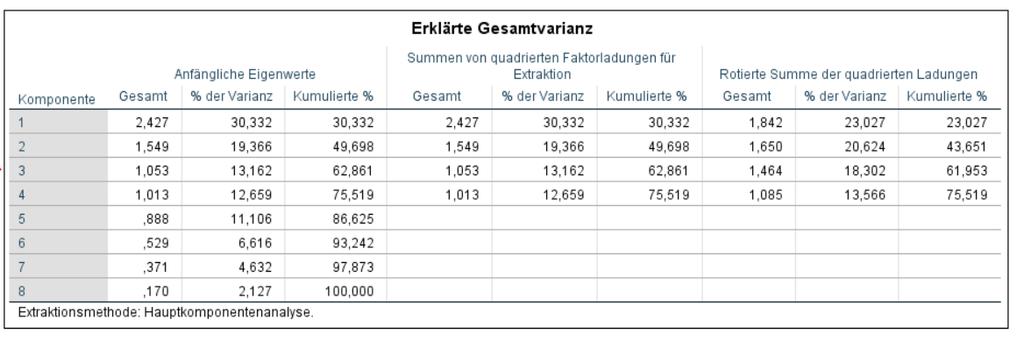
11 Faktor 1 = Markenbewusstsein Faktor 2 = Qualitätsbewusstsein Faktor 3 = Markentreue Faktor 4 = Prestigebewusstsein Qualitätsbewusstsein: Für besondere Qualität gebe ich gern etwas mehr aus. Qualitätsbewusstsein: Manchmal leiste ich mir ganz bewußt die beste Qualität. Markentreue: Bei vielen Produkten kaufe ich immer nur eine bestimmte Marke. Markentreue: Wenn ich mit einer Marke zufrieden bin, bleibe ich auch dabei. Markenbewusstsein: Markenprodukte sind qualitativ besser als markenlose Ware. Markenbewusstsein: Markenprodukte sind zwar teurer als andere Produkte, dafür aber auch besser. Prestigebewusstsein: Ich finde es wichtig, bei Freunden, Bekannten und Kollegen anerkannt zu sein. Prestigebewusstsein: Einige Produkte kaufe ich bewusst deshalb, weil mich meine Freunde darum beneiden werden. Rotierte Komponentenmatrix a Extraktionsmethode: Hauptkomponentenanalyse. Komponente Rotationsmethode: Varimax mit Kaiser-Normalisierung.,068,838,179,058,064,854,201 -,009,170,195,780 -,024 -,022,143,855,073,951,058,050,044,944,081,092,035 -,004 -,163,154,844,094,352 -,131,600 a. Die Rotation ist in 4 Iterationen konvergiert. 3. Prüfen Sie die globale Güte der Faktorenanalyse anhand der erklärten Varianz. Die erklärte Varianz beträgt 75,52%. Die vier Faktoren zusammen erklären damit mehr als 50% der Varianz der Variablen, was für die globale Güte der Faktorenanalyse spricht.
12
13 Kapitel 4: Regressionsanalyse Kontrollfragen 1. Ergänzen Sie die Lückentexte. Mit Hilfe von.. standardisierten Regressionskoeffizienten... lässt sich die Stärke des Einflusses zweier oder mehrerer unabhängiger Variablen überprüfen. Hohe absolute Beta-Werte sprechen für einen..starken.. Einfluss eines Prädiktors auf die abhängige Variable. Ob eine weitere aufgenommene unabhängige Variable auch einen zusätzlichen Erklärungsbeitrag leistet, kann man weiterhin aus dem Anstieg des..korrigierten Bestimmtheitsmaßes.. ablesen. 2. Nach welcher Maßgabe wird die Regressionsanalyse geschätzt? Welches Minimierungsproblem soll dabei gelöst werden? Die Regressionsanalyse wird nach Maßgabe der Methode der kleinsten Quadrate geschätzt. Demnach soll die Regressionsgerade so geschätzt werden, dass die Summe der quadrierten Abweichungen zwischen tatsächlichen und vorhergesagten Werten minimal ausfällt. 3. Was versteht man unter Autokorrelation? Bei welchen Daten ist es wichtig, auf Autokorrelation zu prüfen? Autokorrelation bedeutet, dass die Residuen miteinander korrelieren. Autokorrelation ist besonders bei Zeitreihenanalysen anzutreffen, da in diesem Fall die aufeinander folgenden Residuen miteinander korrelieren können. 4. Welche der folgenden Aussagen sind richtig? Der Regressionskoeffizient (b) entspricht bei der einfachen linearen Regressionsanalyse dem Wert der Steigung der linearen Regressionsgeraden. Der t-test prüft die lokale Güte einer Regressionsanalyse. Er testet für alle unabhängigen Variablen gemeinsam, ob sich die Regressionskoeffizienten von Null unterscheiden. Damit der F- und der t-test interpretiert werden dürfen, müssen die Residuen bei einer multiplen Regressionsanalyse der Normalverteilung folgen. Vernetzungsaufgaben Sie sollen nun eine multiple Regressionsanalyse rechnen. Die abhängige Variable ist mix1 ( Ich mag es, Mixgetränke zu trinken. ). Als unabhängige Variablen fließen die folgenden Variablen ein: fak1_reg_hedo: Spaß am Einkauf/Hedonismus, fak2_reg_mb: Markenbewusstsein, fak3_reg_qb: Qualitätsbewusstsein, fak4_reg_inno: Innovationsakzeptanz, fak5_reg_mt: Markentreue, fak6_reg_kf: Kontaktfreudigkeit. 1. Berechnen Sie die Regressionskoeffizienten und stellen Sie die Regressionsgleichung auf. Verwenden Sie dabei die Schrittweise Methode. Wie beurteilen Sie Richtung und Stärke des Einflusses, den die einzelnen UV auf die AV ausüben? Einstellung zu Mixgetränken = 1,026 +,342 * Innovationsakzeptanz +,268 * Kontaktfreudigkeit
 als die Kontaktfreudigkeit (,152). 2. Betrachten Sie nun das Bestimmtheitsmaß und das korrigierte Bestimmtheitsmaß.")

14 Es werden zwei Prädiktoren in das Modell aufgenommen. Beide üben einen positiven Einfluss auf die abhängige Variable aus. Die Innovationsakzeptanz übt einen etwas stärkeren Einfluss aus (,203) als die Kontaktfreudigkeit (,152). 2. Betrachten Sie nun das Bestimmtheitsmaß und das korrigierte Bestimmtheitsmaß. Welche Aussagen lassen sich aus beiden Werten ableiten? Das Bestimmtheitsmaß für das Modell 2 beträgt,064. Das korrigierte Bestimmtheitsmaß liegt bei,057. Insgesamt erklären die Faktoren Innovationsakzeptanz und Kontaktfreudigkeit damit 6,4% der abhängigen Variablen mix 1 : Ich mag es, Mixgetränke zu trinken. Anhand des korrigierten Bestimmtheitsmaßes lässt sich erkennen, ob durch die Aufnahme einer weiteren unabhängigen Variablen in das Modell der Anteil der erklärten Varianz der abhängigen Variablen steigt. Dies ist hier der Fall (von 3,6% auf 5,7%). 3. Prüfen Sie die globale und die lokale Güte des berechneten Regressionsmodells. Die globale Güte wird mit dem F-Test beurteilt, der die Nullhypothese testet, dass alle Regressionskoeffizienten in der Grundgesamtheit Null sind. In Modell 2 ist der F-Test hoch signifikant (p,001). Die Nullhypothese kann abgelehnt werden. D.h. der Einfluss von mindestens einer der unabhängigen Variablen Innovationsakzeptanz und Kontaktfreudigkeit auf die Variable Einstellung zu Mixgetränken ist nicht zufällig.


15 Die lokale Güte des Modells wird mit dem t-test geprüft. Der t-test prüft für jeden Regressionskoeffizienten einzeln, ob der Einfluss der jeweiligen UV auf die AV signifikant ist. In unserem Beispiel erreichen alle zwei unabhängigen Variablen ein p,010. Es besteht also jeweils ein statistisch hoch signifikanter Einfluss der UV auf die AV.
16 Kapitel 5: Clusteranalyse Kontrollfragen 1. Ergänzen Sie die folgenden Lückentexte. Bei..agglomerativen hierarchischen.. Fusionierungsalgorithmen werden pro Analyseschritt diejenigen Objekte zusammengefasst, welche die geringste Distanz zueinander aufweisen. Die..Single Linkage.. Methode eignet sich besonders dazu, um Ausreißer zu identifizieren. Der Vorteil der..ward.. Methode besteht darin, dass in etwa gleich große Gruppen gebildet werden. 2. Wie kann die Proximität (Ähnlichkeit) bzw. Distanz zwischen Objekten bestimmt werden? Was versteht man unter der Minkowski-Metrik? Es können je nach Fragestellung und Skalenniveau der Variablen unterschiedliche Distanz- bzw. Ähnlichkeitsmaße berechnet werden. Die Minkowski-Metrik bildet die Grundlage für die Berechnung von Distanzen. Sie enthält als entscheidende Größen die Minkowski- Konstanten c und r, mit denen die Art der Minkowski-Metrik festgelegt wird. 3. Wie bestimmt man die Anzahl der Cluster und wie können die Cluster inhaltlich interpretiert werden? Zur Bestimmung der Anzahl der Cluster können u.a. das Dendrogramm und das Elbow- Kriterium herangezogen werden. Es sollten zudem nur so viele Cluster bestimmt werden, wie inhaltlich sinnvoll interpretiert werden können. Um die Cluster zu interpretieren, werden die Mittelwerte der beschreibenden Variablen pro Cluster berechnet (Clusterlösung = UV, beschreibende Variablen = AV). Indem man die Eigenschaften der Cluster vergleicht, lassen sich die Gruppen interpretieren und passende Bezeichnungen finden. 4. Welche der im Folgenden aufgeführten Aussagen sind richtig? Die Clusteranalyse verfolgt das Ziel, Variablen so zu Gruppen zusammenzufassen, dass die Gruppen in sich möglichst homogen und untereinander möglichst heterogen sind. Bei der Clusteranalyse handelt es sich im Gegensatz zur Faktorenanalyse um eine Interdependenzanalyse. Inferenzstatistische Verfahren können deshalb nicht zur Güteprüfung herangezogen werden. Nach dem inversen Scree-Test liegt die optimale Zahl der zu bildenden Cluster da, wo in der Grafik ein Knick zu erkennen ist, d.h. die Fehlerquadratsumme fällt sprunghaft ab. Die Streuung innerhalb eines Clusters wird analog zur Bestimmung der Streuung bei der Varianzanalyse ermittelt. Vernetzungsaufgaben Rechnen Sie nun eine Clusteranalyse, um Kundentypen zu identifizieren. Verwenden Sie die folgenden Variablen: fak1_mb: Markenbewusstsein, fak2_qb: Qualitätsbewusstsein, fak3_mt: Markentreue, fak4_pb: Preisbewusstsein.
17 1. Verwenden Sie als Fusionierungsalgorithmus die Ward-Methode und als Distanzmaß die quadrierte euklidische Distanz. Speichern Sie die gebildete Clusterlösung als Variable. Lassen Sie sich eine 5-Cluster-Lösung ausgeben. 2. Wie lassen sich die Cluster inhaltlich interpretieren? Cluster 1: Qualitätsbewusste ohne Markenpräferenz Dieses Cluster achtet gleichzeitig auf Qualität und Preis und ist nicht markenbewusst. Cluster 2: Qualitätsbewusste Markenkäufer Dieses Cluster ist sowohl markenbewusst wie auch markentreu. Cluster 3: Preisbewusste Das Preisbewusstsein ist stark ausgeprägt. Das Cluster ist nicht markenbewusst und nicht markentreu. Cluster 4: Smart Shopper Das Cluster ist markentreu und hat gleichzeitig ein hohes Preisbewusstsein (d.h. sie warten darauf, dass ihre Marken günstig angeboten werden. Cluster 5: Experimentierfreudige Die Preissensibilität ist gering. Die Käufer achten auf Qualität, sind aber nicht sehr markenbewusst.

18
Hypothesentests mit SPSS
 Beispiel für eine einfache Regressionsanalyse (mit Überprüfung der Voraussetzungen) Daten: bedrohfb_v07.sav Hypothese: Die Skalenwerte auf der ATB-Skala (Skala zur Erfassung der Angst vor terroristischen
Beispiel für eine einfache Regressionsanalyse (mit Überprüfung der Voraussetzungen) Daten: bedrohfb_v07.sav Hypothese: Die Skalenwerte auf der ATB-Skala (Skala zur Erfassung der Angst vor terroristischen
1 Übungsaufgaben zur Regressionsanalyse
 1 Übungsaufgaben zur Regressionsanalyse 1 1 Übungsaufgaben zur Regressionsanalyse 1.1 Übungsaufgaben zu Seite 1 und 2 1. Wie lautet die Regressionsfunktion? 2. Welche Absatzmenge ist im Durchschnitt bei
1 Übungsaufgaben zur Regressionsanalyse 1 1 Übungsaufgaben zur Regressionsanalyse 1.1 Übungsaufgaben zu Seite 1 und 2 1. Wie lautet die Regressionsfunktion? 2. Welche Absatzmenge ist im Durchschnitt bei
Einführung in die Statistik für Politikwissenschaftler Sommersemester 2011
 Einführung in die Statistik für Politikwissenschaftler Sommersemester 2011 Es können von den Antworten alle, mehrere oder keine Antwort(en) richtig sein. Nur bei einer korrekten Antwort (ohne Auslassungen
Einführung in die Statistik für Politikwissenschaftler Sommersemester 2011 Es können von den Antworten alle, mehrere oder keine Antwort(en) richtig sein. Nur bei einer korrekten Antwort (ohne Auslassungen
6-Variablen-Fall. Dipl.-Ök. John Yun Bergische Universität Wuppertal Gaußstraße Wuppertal
 Dipl.-Ök. John Yun Bergische Universität Wuppertal Gaußstraße 20 42097 Wuppertal Allgemein 6 Konstrukte: - Preisorientierung (6 Items) - Werbeakzeptanz (6 Items) - Qualitätsbewusstsein (6 Items) - Trendbewusstsein
Dipl.-Ök. John Yun Bergische Universität Wuppertal Gaußstraße 20 42097 Wuppertal Allgemein 6 Konstrukte: - Preisorientierung (6 Items) - Werbeakzeptanz (6 Items) - Qualitätsbewusstsein (6 Items) - Trendbewusstsein
Statistik II Übung 3: Hypothesentests
 Statistik II Übung 3: Hypothesentests Diese Übung beschäftigt sich mit der Anwendung diverser Hypothesentests (zum Beispiel zum Vergleich der Mittelwerte und Verteilungen zweier Stichproben). Verwenden
Statistik II Übung 3: Hypothesentests Diese Übung beschäftigt sich mit der Anwendung diverser Hypothesentests (zum Beispiel zum Vergleich der Mittelwerte und Verteilungen zweier Stichproben). Verwenden
SozialwissenschaftlerInnen II
 Statistik für SozialwissenschaftlerInnen II Henning Best best@wiso.uni-koeln.de Universität zu Köln Forschungsinstitut für Soziologie Statistik für SozialwissenschaftlerInnen II p.1 Varianzanalyse Statistik
Statistik für SozialwissenschaftlerInnen II Henning Best best@wiso.uni-koeln.de Universität zu Köln Forschungsinstitut für Soziologie Statistik für SozialwissenschaftlerInnen II p.1 Varianzanalyse Statistik
Teil: lineare Regression
 Teil: lineare Regression 1 Einführung 2 Prüfung der Regressionsfunktion 3 Die Modellannahmen zur Durchführung einer linearen Regression 4 Dummyvariablen 1 Einführung o Eine statistische Methode um Zusammenhänge
Teil: lineare Regression 1 Einführung 2 Prüfung der Regressionsfunktion 3 Die Modellannahmen zur Durchführung einer linearen Regression 4 Dummyvariablen 1 Einführung o Eine statistische Methode um Zusammenhänge
fh management, communication & it Constantin von Craushaar fh-management, communication & it Statistik Angewandte Statistik
 fh management, communication & it Folie 1 Überblick Grundlagen (Testvoraussetzungen) Mittelwertvergleiche (t-test,..) Nichtparametrische Tests Korrelationen Regressionsanalyse... Folie 2 Überblick... Varianzanalyse
fh management, communication & it Folie 1 Überblick Grundlagen (Testvoraussetzungen) Mittelwertvergleiche (t-test,..) Nichtparametrische Tests Korrelationen Regressionsanalyse... Folie 2 Überblick... Varianzanalyse
6-Variablen-Fall. Dipl.-Ök. John Yun Bergische Universität Wuppertal Gaußstraße Wuppertal
 Dipl.-Ök. John Yun Bergische Universität Wuppertal Gaußstraße 20 42097 Wuppertal Allgemein 6 Konstrukte: - soziale Kontakte (6 Items) - Markenbewusstsein (6 Items) - Werbeakzeptanz (6 Items) - materielle
Dipl.-Ök. John Yun Bergische Universität Wuppertal Gaußstraße 20 42097 Wuppertal Allgemein 6 Konstrukte: - soziale Kontakte (6 Items) - Markenbewusstsein (6 Items) - Werbeakzeptanz (6 Items) - materielle
Faktorenanalysen mit SPSS. Explorative Faktorenanalyse als Instrument der Dimensionsreduktion. Interpretation des SPSS-Output s
 Explorative Faktorenanalyse als Instrument der Dimensionsreduktion Beispiel: Welche Dimensionen charakterisieren die Beurteilung des sozialen Klimas in der Nachbarschaft? Variablen: q27a bis q27g im Datensatz
Explorative Faktorenanalyse als Instrument der Dimensionsreduktion Beispiel: Welche Dimensionen charakterisieren die Beurteilung des sozialen Klimas in der Nachbarschaft? Variablen: q27a bis q27g im Datensatz
Lösungen zu Janssen/Laatz, Statistische Datenanalyse mit SPSS 1. LÖSUNG 13 a.
 Lösungen zu Janssen/Laatz, Statistische Datenanalyse mit SPSS 1 LÖSUNG 13 a. Die Variablen sollten hoch miteinander korrelieren. Deshalb sollten die einfachen Korrelationskoeffizienten hoch ausfallen.
Lösungen zu Janssen/Laatz, Statistische Datenanalyse mit SPSS 1 LÖSUNG 13 a. Die Variablen sollten hoch miteinander korrelieren. Deshalb sollten die einfachen Korrelationskoeffizienten hoch ausfallen.
Faktorenanalysen mit SPSS. Explorative Faktorenanalyse als Instrument der Dimensionsreduzierung. Interpretation des SPSS-Output s
 Explorative Faktorenanalyse als Instrument der Dimensionsreduzierung Beispiel: Welche Dimensionen charakterisieren die Beurteilung des sozialen Klimas in der Nachbarschaft? Variablen: q27a bis q27g im
Explorative Faktorenanalyse als Instrument der Dimensionsreduzierung Beispiel: Welche Dimensionen charakterisieren die Beurteilung des sozialen Klimas in der Nachbarschaft? Variablen: q27a bis q27g im
Name Vorname Matrikelnummer Unterschrift
 Dr. Hans-Otfried Müller Institut für Mathematische Stochastik Fachrichtung Mathematik Technische Universität Dresden Klausur Statistik II (Sozialwissenschaft, Nach- und Wiederholer) am 26.10.2007 Gruppe
Dr. Hans-Otfried Müller Institut für Mathematische Stochastik Fachrichtung Mathematik Technische Universität Dresden Klausur Statistik II (Sozialwissenschaft, Nach- und Wiederholer) am 26.10.2007 Gruppe
FH- Management & IT. Constantin von Craushaar FH-Management & IT Statistik Angewandte Statistik (Übungen)
") FH- Management & IT Folie 1 Rückblick Häufigkeiten berechnen Mittelwerte berechnen Grafiken ausgeben Grafiken anpassen und als Vorlage abspeichern Variablenoperationen Fälle vergleichen Fälle auswählen
FH- Management & IT Folie 1 Rückblick Häufigkeiten berechnen Mittelwerte berechnen Grafiken ausgeben Grafiken anpassen und als Vorlage abspeichern Variablenoperationen Fälle vergleichen Fälle auswählen
VS PLUS
 VS PLUS Zusatzinformationen zu Medien des VS Verlags Statistik II Inferenzstatistik 2010 Übungsaufgaben und Lösungen Inferenzstatistik 2 [Übungsaufgaben und Lösungenn - Inferenzstatistik 2] ÜBUNGSAUFGABEN
VS PLUS Zusatzinformationen zu Medien des VS Verlags Statistik II Inferenzstatistik 2010 Übungsaufgaben und Lösungen Inferenzstatistik 2 [Übungsaufgaben und Lösungenn - Inferenzstatistik 2] ÜBUNGSAUFGABEN
Exploratorische Faktorenanalyse. Exploratorische Faktorenanalyse. Exploratorische Faktorenanalyse
 Exploratorische Faktorenanalyse Der Begriff Faktorenanalyse umfasst eine Gruppe multivariater Analyseverfahren, mit denen zugrundeliegende gemeinsame Dimensionen von Variablenmengen (z.b. Fragebogenitems)
Exploratorische Faktorenanalyse Der Begriff Faktorenanalyse umfasst eine Gruppe multivariater Analyseverfahren, mit denen zugrundeliegende gemeinsame Dimensionen von Variablenmengen (z.b. Fragebogenitems)
Lösungen zu Janssen/Laatz, Statistische Datenanalyse mit SPSS 1
 LÖSUNG 13 a) Lösungen zu Janssen/Laatz, Statistische Datenanalyse mit SPSS 1 Die Variablen sollten hoch miteinander korrelieren. Deshalb sollten die einfachen Korrelationskoeffizienten hoch ausfallen.
LÖSUNG 13 a) Lösungen zu Janssen/Laatz, Statistische Datenanalyse mit SPSS 1 Die Variablen sollten hoch miteinander korrelieren. Deshalb sollten die einfachen Korrelationskoeffizienten hoch ausfallen.
Statistik II Übung 3: Hypothesentests Aktualisiert am
 Statistik II Übung 3: Hypothesentests Aktualisiert am 12.04.2017 Diese Übung beschäftigt sich mit der Anwendung diverser Hypothesentests (zum Beispiel zum Vergleich der Mittelwerte und Verteilungen zweier
Statistik II Übung 3: Hypothesentests Aktualisiert am 12.04.2017 Diese Übung beschäftigt sich mit der Anwendung diverser Hypothesentests (zum Beispiel zum Vergleich der Mittelwerte und Verteilungen zweier
Parametrische vs. Non-Parametrische Testverfahren
 Parametrische vs. Non-Parametrische Testverfahren Parametrische Verfahren haben die Besonderheit, dass sie auf Annahmen zur Verteilung der Messwerte in der Population beruhen: die Messwerte sollten einer
Parametrische vs. Non-Parametrische Testverfahren Parametrische Verfahren haben die Besonderheit, dass sie auf Annahmen zur Verteilung der Messwerte in der Population beruhen: die Messwerte sollten einer
Diagnostik von Regressionsmodellen (1)
") Diagnostik von Regressionsmodellen (1) Bei Regressionsanalysen sollte immer geprüft werden, ob das Modell angemessen ist und ob die Voraussetzungen eines Regressionsmodells erfüllt sind. Das Modell einer
Diagnostik von Regressionsmodellen (1) Bei Regressionsanalysen sollte immer geprüft werden, ob das Modell angemessen ist und ob die Voraussetzungen eines Regressionsmodells erfüllt sind. Das Modell einer
4.1. Verteilungsannahmen des Fehlers. 4. Statistik im multiplen Regressionsmodell Verteilungsannahmen des Fehlers
 4. Statistik im multiplen Regressionsmodell In diesem Kapitel wird im Abschnitt 4.1 zusätzlich zu den schon bekannten Standardannahmen noch die Annahme von normalverteilten Residuen hinzugefügt. Auf Basis
4. Statistik im multiplen Regressionsmodell In diesem Kapitel wird im Abschnitt 4.1 zusätzlich zu den schon bekannten Standardannahmen noch die Annahme von normalverteilten Residuen hinzugefügt. Auf Basis
Angewandte Statistik 3. Semester
 Angewandte Statistik 3. Semester Übung 5 Grundlagen der Statistik Übersicht Semester 1 Einführung ins SPSS Auswertung im SPSS anhand eines Beispieles Häufigkeitsauswertungen Grafiken Statistische Grundlagen
Angewandte Statistik 3. Semester Übung 5 Grundlagen der Statistik Übersicht Semester 1 Einführung ins SPSS Auswertung im SPSS anhand eines Beispieles Häufigkeitsauswertungen Grafiken Statistische Grundlagen
Statistik II: Klassifikation und Segmentierung
 Medien Institut : Klassifikation und Segmentierung Dr. Andreas Vlašić Medien Institut (0621) 52 67 44 vlasic@medien-institut.de Gliederung 1. Faktorenanalyse 2. Clusteranalyse 3. Key Facts 2 I 14 Ziel
Medien Institut : Klassifikation und Segmentierung Dr. Andreas Vlašić Medien Institut (0621) 52 67 44 vlasic@medien-institut.de Gliederung 1. Faktorenanalyse 2. Clusteranalyse 3. Key Facts 2 I 14 Ziel
Statistik. Jan Müller
 Statistik Jan Müller Skalenniveau Nominalskala: Diese Skala basiert auf einem Satz von qualitativen Attributen. Es existiert kein Kriterium, nach dem die Punkte einer nominal skalierten Variablen anzuordnen
Statistik Jan Müller Skalenniveau Nominalskala: Diese Skala basiert auf einem Satz von qualitativen Attributen. Es existiert kein Kriterium, nach dem die Punkte einer nominal skalierten Variablen anzuordnen
Statistik II Übung 4: Skalierung und asymptotische Eigenschaften
 Statistik II Übung 4: Skalierung und asymptotische Eigenschaften Diese Übung beschäftigt sich mit der Skalierung von Variablen in Regressionsanalysen und mit asymptotischen Eigenschaften von OLS. Verwenden
Statistik II Übung 4: Skalierung und asymptotische Eigenschaften Diese Übung beschäftigt sich mit der Skalierung von Variablen in Regressionsanalysen und mit asymptotischen Eigenschaften von OLS. Verwenden
SPSS-Ausgabe 1: Univariate Varianzanalyse. Profildiagramm. [DatenSet1] D:\Sozialwiss2006_7\STAT2\Daten\mathsalaries.sav. Seite 1
![SPSS-Ausgabe 1: Univariate Varianzanalyse. Profildiagramm. [DatenSet1] D:\Sozialwiss2006_7\STAT2\Daten\mathsalaries.sav. Seite 1](/thumbs/70/63991775.jpg "SPSS-Ausgabe 1: Univariate Varianzanalyse. Profildiagramm. [DatenSet1] D:\Sozialwiss2006_7\STAT2\Daten\mathsalaries.sav. Seite 1") SPSS-Ausgabe : Univariate Varianzanalyse [DatenSet] D:\Sozialwiss2006_7\STAT2\Daten\mathsalaries.sav Tests der Zwischensubjekteffekte Abhängige Variable: Einkommen Quelle Korrigiertes Modell Konstanter
SPSS-Ausgabe : Univariate Varianzanalyse [DatenSet] D:\Sozialwiss2006_7\STAT2\Daten\mathsalaries.sav Tests der Zwischensubjekteffekte Abhängige Variable: Einkommen Quelle Korrigiertes Modell Konstanter
Deskription, Statistische Testverfahren und Regression. Seminar: Planung und Auswertung klinischer und experimenteller Studien
 Deskription, Statistische Testverfahren und Regression Seminar: Planung und Auswertung klinischer und experimenteller Studien Deskriptive Statistik Deskriptive Statistik: beschreibende Statistik, empirische
Deskription, Statistische Testverfahren und Regression Seminar: Planung und Auswertung klinischer und experimenteller Studien Deskriptive Statistik Deskriptive Statistik: beschreibende Statistik, empirische
Aufgaben zur Multivariaten Statistik
 Prof. Dr. Reinhold Kosfeld Fachbereich Wirtschaftswissenschaften Universität Kassel Aufgaben zur Multivariaten Statistik Teil : Aufgaben zur Einleitung. Was versteht man unter einer univariaten, bivariaten
Prof. Dr. Reinhold Kosfeld Fachbereich Wirtschaftswissenschaften Universität Kassel Aufgaben zur Multivariaten Statistik Teil : Aufgaben zur Einleitung. Was versteht man unter einer univariaten, bivariaten
Statistik II (Sozialwissenschaften)
") Dr. Hans-Otfried Müller Institut für Mathematische Stochastik Fachrichtung Mathematik Technische Universität Dresden http://www.math.tu-dresden.de/sto/mueller/ Statistik II (Sozialwissenschaften) 2. Konsultationsübung,
Dr. Hans-Otfried Müller Institut für Mathematische Stochastik Fachrichtung Mathematik Technische Universität Dresden http://www.math.tu-dresden.de/sto/mueller/ Statistik II (Sozialwissenschaften) 2. Konsultationsübung,
Statistik II: Signifikanztests /2
 Medien Institut : Signifikanztests /2 Dr. Andreas Vlašić Medien Institut (0621) 52 67 44 vlasic@medien-institut.de Gliederung 1. Korrelation 2. Exkurs: Kausalität 3. Regressionsanalyse 4. Key Facts 2 I
Medien Institut : Signifikanztests /2 Dr. Andreas Vlašić Medien Institut (0621) 52 67 44 vlasic@medien-institut.de Gliederung 1. Korrelation 2. Exkurs: Kausalität 3. Regressionsanalyse 4. Key Facts 2 I
Hypothesentests mit SPSS
 Beispiel für eine zweifaktorielle Varianzanalyse mit Messwiederholung auf einem Faktor (univariate Lösung) Daten: POKIII_AG4_V06.SAV Hypothese: Die physische Attraktivität der Bildperson und das Geschlecht
Beispiel für eine zweifaktorielle Varianzanalyse mit Messwiederholung auf einem Faktor (univariate Lösung) Daten: POKIII_AG4_V06.SAV Hypothese: Die physische Attraktivität der Bildperson und das Geschlecht
Statistik II. IV. Hypothesentests. Martin Huber
 Statistik II IV. Hypothesentests Martin Huber 1 / 22 Übersicht Weitere Hypothesentests in der Statistik 1-Stichproben-Mittelwert-Tests 1-Stichproben-Varianz-Tests 2-Stichproben-Tests Kolmogorov-Smirnov-Test
Statistik II IV. Hypothesentests Martin Huber 1 / 22 Übersicht Weitere Hypothesentests in der Statistik 1-Stichproben-Mittelwert-Tests 1-Stichproben-Varianz-Tests 2-Stichproben-Tests Kolmogorov-Smirnov-Test
Statistische Messdatenauswertung
 Roland Looser Statistische Messdatenauswertung Praktische Einführung in die Auswertung von Messdaten mit Excel und spezifischer Statistik-Software für naturwissenschaftlich und technisch orientierte Anwender
Roland Looser Statistische Messdatenauswertung Praktische Einführung in die Auswertung von Messdaten mit Excel und spezifischer Statistik-Software für naturwissenschaftlich und technisch orientierte Anwender
Chi-Quadrat Verfahren
 Chi-Quadrat Verfahren Chi-Quadrat Verfahren werden bei nominalskalierten Daten verwendet. Die einzige Information, die wir bei Nominalskalenniveau zur Verfügung haben, sind Häufigkeiten. Die Quintessenz
Chi-Quadrat Verfahren Chi-Quadrat Verfahren werden bei nominalskalierten Daten verwendet. Die einzige Information, die wir bei Nominalskalenniveau zur Verfügung haben, sind Häufigkeiten. Die Quintessenz
Musterklausur im Fach Käuferverhalten und Marketingforschung. Prof. Dr. M. Kirchgeorg
 Lehrstuhl Marketingmanagement Musterklausur im Fach Käuferverhalten und Marketingforschung Prof. Dr. M. Kirchgeorg Punkteverteilung: Aufgabe max. Punktzahl erreichte Punktzahl I-1 12 I-2 10 I-3 8 Gesamt
Lehrstuhl Marketingmanagement Musterklausur im Fach Käuferverhalten und Marketingforschung Prof. Dr. M. Kirchgeorg Punkteverteilung: Aufgabe max. Punktzahl erreichte Punktzahl I-1 12 I-2 10 I-3 8 Gesamt
Prüfung aus Statistik 2 für SoziologInnen
 Prüfung aus Statistik 2 für SoziologInnen 11. Oktober 2013 Gesamtpunktezahl =80 Name in Blockbuchstaben: Matrikelnummer: Wissenstest (maximal 16 Punkte) Kreuzen ( ) Sie die jeweils richtige Antwort an.
Prüfung aus Statistik 2 für SoziologInnen 11. Oktober 2013 Gesamtpunktezahl =80 Name in Blockbuchstaben: Matrikelnummer: Wissenstest (maximal 16 Punkte) Kreuzen ( ) Sie die jeweils richtige Antwort an.
Vorlesung: Multivariate Statistik für Psychologen
 Vorlesung: Multivariate Statistik für Psychologen 7. Vorlesung: 05.05.2003 Agenda 2. Multiple Regression i. Grundlagen ii. iii. iv. Statistisches Modell Verallgemeinerung des Stichprobenmodells auf Populationsebene
Vorlesung: Multivariate Statistik für Psychologen 7. Vorlesung: 05.05.2003 Agenda 2. Multiple Regression i. Grundlagen ii. iii. iv. Statistisches Modell Verallgemeinerung des Stichprobenmodells auf Populationsebene
Die Funktion f wird als Regressionsfunktion bezeichnet.
 Regressionsanalyse Mit Hilfe der Techniken der klassischen Regressionsanalyse kann die Abhängigkeit metrischer (intervallskalierter) Zielgrößen von metrischen (intervallskalierten) Einflussgrößen untersucht
Regressionsanalyse Mit Hilfe der Techniken der klassischen Regressionsanalyse kann die Abhängigkeit metrischer (intervallskalierter) Zielgrößen von metrischen (intervallskalierten) Einflussgrößen untersucht
Standardisierte Vorgehensweisen und Regeln zur Gewährleistung von: Eindeutigkeit Schlussfolgerungen aus empirischen Befunden sind nur dann zwingend
 Standardisierte Vorgehensweisen und Regeln zur Gewährleistung von: Eindeutigkeit Schlussfolgerungen aus empirischen Befunden sind nur dann zwingend oder eindeutig, wenn keine alternativen Interpretationsmöglichkeiten
Standardisierte Vorgehensweisen und Regeln zur Gewährleistung von: Eindeutigkeit Schlussfolgerungen aus empirischen Befunden sind nur dann zwingend oder eindeutig, wenn keine alternativen Interpretationsmöglichkeiten
Vahlen kompakt. Marketing-Forschung. Mit Fallbeispiel
 Vahlen kompakt Marketing-Forschung Mit Fallbeispiel Bearbeitet von Von Prof. Dr. Stefan Hoffmann, Dr. Anja Franck, Dr. Uta Schwarz, Prof. Dr. Katja Soyez, und Dr. Stefan Wünschmann 1. Auflage 2018. Buch.
Vahlen kompakt Marketing-Forschung Mit Fallbeispiel Bearbeitet von Von Prof. Dr. Stefan Hoffmann, Dr. Anja Franck, Dr. Uta Schwarz, Prof. Dr. Katja Soyez, und Dr. Stefan Wünschmann 1. Auflage 2018. Buch.
Explorative Faktorenanalyse
 Explorative Faktorenanalyse 1 Einsatz der Faktorenanalyse Verfahren zur Datenreduktion Analyse von Datenstrukturen 2 -Ich finde es langweilig, mich immer mit den selben Leuten zu treffen -In der Beziehung
Explorative Faktorenanalyse 1 Einsatz der Faktorenanalyse Verfahren zur Datenreduktion Analyse von Datenstrukturen 2 -Ich finde es langweilig, mich immer mit den selben Leuten zu treffen -In der Beziehung
Statistische Methoden in den Umweltwissenschaften
 Statistische Methoden in den Umweltwissenschaften Korrelationsanalysen Kreuztabellen und χ²-test Themen Korrelation oder Lineare Regression? Korrelationsanalysen - Pearson, Spearman-Rang, Kendall s Tau
Statistische Methoden in den Umweltwissenschaften Korrelationsanalysen Kreuztabellen und χ²-test Themen Korrelation oder Lineare Regression? Korrelationsanalysen - Pearson, Spearman-Rang, Kendall s Tau
Es können keine oder mehrere Antworten richtig sein. Eine Frage ist NUR dann richtig beantwortet, wenn ALLE richtigen Antworten angekreuzt wurden.
 Teil III: Statistik Alle Fragen sind zu beantworten. Es können keine oder mehrere Antworten richtig sein. Eine Frage ist NUR dann richtig beantwortet, wenn ALLE richtigen Antworten angekreuzt wurden. Wird
Teil III: Statistik Alle Fragen sind zu beantworten. Es können keine oder mehrere Antworten richtig sein. Eine Frage ist NUR dann richtig beantwortet, wenn ALLE richtigen Antworten angekreuzt wurden. Wird
Mehrfache Lineare Regression 1/9
 Mehrfache Lineare Regression 1/9 Ziel: In diesem Fallbeispiel soll die Durchführung einer mehrfachen linearen Regressionsanalyse auf der Basis vorhandener Prozessdaten (Felddaten) beschrieben werden. Nach
Mehrfache Lineare Regression 1/9 Ziel: In diesem Fallbeispiel soll die Durchführung einer mehrfachen linearen Regressionsanalyse auf der Basis vorhandener Prozessdaten (Felddaten) beschrieben werden. Nach
Sommersemester Marktforschung
 Dipl.-Kfm. Sascha Steinmann Universität Siegen Lehrstuhl für Marketing steinmann@marketing.uni-siegen.de Sommersemester 2010 Marktforschung Übungsaufgaben zu den Themen 3-6 mit Lösungsskizzen Aufgabe 1:
Dipl.-Kfm. Sascha Steinmann Universität Siegen Lehrstuhl für Marketing steinmann@marketing.uni-siegen.de Sommersemester 2010 Marktforschung Übungsaufgaben zu den Themen 3-6 mit Lösungsskizzen Aufgabe 1:
Statistik II Übung 1: Einfache lineare Regression
 Statistik II Übung 1: Einfache lineare Regression Diese Übung beschäftigt sich mit dem Zusammenhang zwischen dem Lohneinkommen von sozial benachteiligten Individuen (16-24 Jahre alt) und der Anzahl der
Statistik II Übung 1: Einfache lineare Regression Diese Übung beschäftigt sich mit dem Zusammenhang zwischen dem Lohneinkommen von sozial benachteiligten Individuen (16-24 Jahre alt) und der Anzahl der
B. Regressionsanalyse [progdat.sav]
![B. Regressionsanalyse [progdat.sav]](/thumbs/71/64345557.jpg "B. Regressionsanalyse [progdat.sav]") SPSS-PC-ÜBUNG Seite 9 B. Regressionsanalyse [progdat.sav] Ein Unternehmen möchte den zukünftigen Absatz in Abhängigkeit von den Werbeausgaben und der Anzahl der Filialen prognostizieren. Dazu wurden über
SPSS-PC-ÜBUNG Seite 9 B. Regressionsanalyse [progdat.sav] Ein Unternehmen möchte den zukünftigen Absatz in Abhängigkeit von den Werbeausgaben und der Anzahl der Filialen prognostizieren. Dazu wurden über
PRAXISORIENTIERTE EINFÜHRUNG
 GRUNDLAGEN DER STATISTIK PRAXISORIENTIERTE EINFÜHRUNG Rainer Gaupp Leiter Qualität & Prozesse 1 INHALTE DER EINFÜHRUNG Theoretische Grundlagen: Natur vs. Sozialwissenschaft. Skalentypen. Streu- und Lagemasse.
GRUNDLAGEN DER STATISTIK PRAXISORIENTIERTE EINFÜHRUNG Rainer Gaupp Leiter Qualität & Prozesse 1 INHALTE DER EINFÜHRUNG Theoretische Grundlagen: Natur vs. Sozialwissenschaft. Skalentypen. Streu- und Lagemasse.
Einführung in die Statistik für Politikwissenschaftler Wintersemester 2011/2012
 Einführung in die Statistik für Politikwissenschaftler Wintersemester 2011/2012 Es können von den Antwortmöglichkeiten alle, mehrere, eine oder keine Antwort(en) richtig sein. Nur bei einer korrekten Antwort
Einführung in die Statistik für Politikwissenschaftler Wintersemester 2011/2012 Es können von den Antwortmöglichkeiten alle, mehrere, eine oder keine Antwort(en) richtig sein. Nur bei einer korrekten Antwort
Ziel der linearen Regression
 Regression 1 Ziel der linearen Regression Bei der linearen Regression wird untersucht, in welcher Weise eine abhängige metrische Variable durch eine oder mehrere unabhängige metrische Variablen durch eine
Regression 1 Ziel der linearen Regression Bei der linearen Regression wird untersucht, in welcher Weise eine abhängige metrische Variable durch eine oder mehrere unabhängige metrische Variablen durch eine
Grundlagen sportwissenschaftlicher Forschung Inferenzstatistik 2
 Grundlagen sportwissenschaftlicher Forschung Inferenzstatistik 2 Dr. Jan-Peter Brückner jpbrueckner@email.uni-kiel.de R.216 Tel. 880 4717 Statistischer Schluss Voraussetzungen z.b. bzgl. Skalenniveau und
Grundlagen sportwissenschaftlicher Forschung Inferenzstatistik 2 Dr. Jan-Peter Brückner jpbrueckner@email.uni-kiel.de R.216 Tel. 880 4717 Statistischer Schluss Voraussetzungen z.b. bzgl. Skalenniveau und
Eigene MC-Fragen SPSS. 1. Zutreffend auf die Datenerfassung und Datenaufbereitung in SPSS ist
 Eigene MC-Fragen SPSS 1. Zutreffend auf die Datenerfassung und Datenaufbereitung in SPSS ist [a] In der Variablenansicht werden für die betrachteten Merkmale SPSS Variablen definiert. [b] Das Daten-Editor-Fenster
Eigene MC-Fragen SPSS 1. Zutreffend auf die Datenerfassung und Datenaufbereitung in SPSS ist [a] In der Variablenansicht werden für die betrachteten Merkmale SPSS Variablen definiert. [b] Das Daten-Editor-Fenster
Brückenkurs Statistik für Wirtschaftswissenschaften
 Peter von der Lippe Brückenkurs Statistik für Wirtschaftswissenschaften Weitere Übungsfragen UVK Verlagsgesellschaft mbh Konstanz Mit UVK/Lucius München UVK Verlagsgesellschaft mbh Konstanz und München
Peter von der Lippe Brückenkurs Statistik für Wirtschaftswissenschaften Weitere Übungsfragen UVK Verlagsgesellschaft mbh Konstanz Mit UVK/Lucius München UVK Verlagsgesellschaft mbh Konstanz und München
2. Generieren Sie deskriptive Statistiken (Mittelwert, Standardabweichung) für earny3 und kidsunder6yr3 und kommentieren Sie diese kurz.
 für earny3 und kidsunder6yr3 und kommentieren Sie diese kurz.") Statistik II Übung : Einfache lineare Regression Diese Übung beschäftigt sich mit dem Zusammenhang zwischen dem Lohneinkommen von sozial benachteiligten Individuen (6-24 Jahre alt) und der Anzahl der unter
Statistik II Übung : Einfache lineare Regression Diese Übung beschäftigt sich mit dem Zusammenhang zwischen dem Lohneinkommen von sozial benachteiligten Individuen (6-24 Jahre alt) und der Anzahl der unter
Statistik II Übung 2: Multivariate lineare Regression
 Statistik II Übung 2: Multivariate lineare Regression Diese Übung beschäftigt sich mit dem Zusammenhang zwischen Flugpreisen und der Flugdistanz, dem Passagieraufkommen und der Marktkonzentration. Verwenden
Statistik II Übung 2: Multivariate lineare Regression Diese Übung beschäftigt sich mit dem Zusammenhang zwischen Flugpreisen und der Flugdistanz, dem Passagieraufkommen und der Marktkonzentration. Verwenden
Bonus-Lektion: Prüfung der Voraussetzungen und Transformationen
 Seite 1 von 8 Bonus-Lektion: Prüfung der Voraussetzungen und Transformationen Ziel dieser Lektion: Du weißt, wie Du die einzelnen Voraussetzungen für die Signifikanztests und komplexeren Modelle prüfen
Seite 1 von 8 Bonus-Lektion: Prüfung der Voraussetzungen und Transformationen Ziel dieser Lektion: Du weißt, wie Du die einzelnen Voraussetzungen für die Signifikanztests und komplexeren Modelle prüfen
Übungsblätter zu Methoden der Empirischen Sozialforschung IV: Regressionsanalyse. Lösungsblatt zu Nr. 2
 Martin-Luther-Universität Halle-Wittenberg Institut für Soziologie Dr. Wolfgang Langer 1 Übungsblätter zu Methoden der Empirischen Sozialforschung IV: Regressionsanalyse Lösungsblatt zu Nr. 2 1. a) Je
Martin-Luther-Universität Halle-Wittenberg Institut für Soziologie Dr. Wolfgang Langer 1 Übungsblätter zu Methoden der Empirischen Sozialforschung IV: Regressionsanalyse Lösungsblatt zu Nr. 2 1. a) Je
Statistik II. Regressionsanalyse. Statistik II
 Statistik II Regressionsanalyse Statistik II - 23.06.2006 1 Einfachregression Annahmen an die Störterme : 1. sind unabhängige Realisationen der Zufallsvariable, d.h. i.i.d. (unabh.-identisch verteilt)
Statistik II Regressionsanalyse Statistik II - 23.06.2006 1 Einfachregression Annahmen an die Störterme : 1. sind unabhängige Realisationen der Zufallsvariable, d.h. i.i.d. (unabh.-identisch verteilt)
9 Faktorenanalyse. Wir gehen zunächst von dem folgenden Modell aus (Modell der Hauptkomponentenanalyse): Z = F L T
: Z = F L T") 9 Faktorenanalyse Ziel der Faktorenanalyse ist es, die Anzahl der Variablen auf wenige voneinander unabhängige Faktoren zu reduzieren und dabei möglichst viel an Information zu erhalten. Hier wird davon
9 Faktorenanalyse Ziel der Faktorenanalyse ist es, die Anzahl der Variablen auf wenige voneinander unabhängige Faktoren zu reduzieren und dabei möglichst viel an Information zu erhalten. Hier wird davon
Modulklausur Multivariate Verfahren
 Name, Vorname Matrikelnummer Modulklausur 31821 Multivariate Verfahren Datum Punkte Note Termin: 28. März 2014, 9.00-11.00 Uhr Erstprüfer: Univ.-Prof. Dr. H. Singer Hinweise zur Bearbeitung der Modulklausur
Name, Vorname Matrikelnummer Modulklausur 31821 Multivariate Verfahren Datum Punkte Note Termin: 28. März 2014, 9.00-11.00 Uhr Erstprüfer: Univ.-Prof. Dr. H. Singer Hinweise zur Bearbeitung der Modulklausur
Die Faktorenanalyse. Anwendung dann, wenn zwischen beobachtbaren und nicht direkt beobachtbaren Variablen ein kausales Verhältnis vermutet wird
 Die Faktorenanalyse Zielsetzung Datenreduktion: eine größere Anzahl von Variablen auf eine kleinere Anzahl unabhängiger Einflussgrößen zurückführen Grundlegende Idee Direkt beobachtbare Variablen spiegeln
Die Faktorenanalyse Zielsetzung Datenreduktion: eine größere Anzahl von Variablen auf eine kleinere Anzahl unabhängiger Einflussgrößen zurückführen Grundlegende Idee Direkt beobachtbare Variablen spiegeln
5. Lektion: Einfache Signifikanztests
 Seite 1 von 7 5. Lektion: Einfache Signifikanztests Ziel dieser Lektion: Du ordnest Deinen Fragestellungen und Hypothesen die passenden einfachen Signifikanztests zu. Inhalt: 5.1 Zwei kategoriale Variablen
Seite 1 von 7 5. Lektion: Einfache Signifikanztests Ziel dieser Lektion: Du ordnest Deinen Fragestellungen und Hypothesen die passenden einfachen Signifikanztests zu. Inhalt: 5.1 Zwei kategoriale Variablen
Ergebnisse VitA und VitVM
 Ergebnisse VitA und VitVM 1 Basisparameter... 2 1.1 n... 2 1.2 Alter... 2 1.3 Geschlecht... 5 1.4 Beobachtungszeitraum (von 1. Datum bis letzte in situ)... 9 2 Extraktion... 11 3 Extraktionsgründe... 15
Ergebnisse VitA und VitVM 1 Basisparameter... 2 1.1 n... 2 1.2 Alter... 2 1.3 Geschlecht... 5 1.4 Beobachtungszeitraum (von 1. Datum bis letzte in situ)... 9 2 Extraktion... 11 3 Extraktionsgründe... 15
Hypothesentests mit SPSS. Beispiel für eine einfaktorielle Varianzanalyse Daten: museum_m_v05.sav
 Beispiel für eine einfaktorielle Varianzanalyse Daten: museum_m_v05.sav Hypothese: Die Beschäftigung mit Kunst ist vom Bildungsgrad abhängig. 1. Annahmen Messniveau: Modell: Die Skala zur Erfassung der
Beispiel für eine einfaktorielle Varianzanalyse Daten: museum_m_v05.sav Hypothese: Die Beschäftigung mit Kunst ist vom Bildungsgrad abhängig. 1. Annahmen Messniveau: Modell: Die Skala zur Erfassung der
Statistisches Testen
 Statistisches Testen Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Differenzen Anteilswert Chi-Quadrat Tests Gleichheit von Varianzen Prinzip des Statistischen Tests Konfidenzintervall
Statistisches Testen Grundlegendes Prinzip Erwartungswert Bekannte Varianz Unbekannte Varianz Differenzen Anteilswert Chi-Quadrat Tests Gleichheit von Varianzen Prinzip des Statistischen Tests Konfidenzintervall
Statistik Prüfung 24. Jänner 2008
 Statistik Prüfung 24. Jänner 2008 February 10, 2008 Es ist immer nur EINE Antwort richtig, bei falsch beantworteten Fragen gibt es KEINEN Punktabzug. Werden mehrere Antworten bei einer Frage angekreuzt,
Statistik Prüfung 24. Jänner 2008 February 10, 2008 Es ist immer nur EINE Antwort richtig, bei falsch beantworteten Fragen gibt es KEINEN Punktabzug. Werden mehrere Antworten bei einer Frage angekreuzt,
Teilklausur des Moduls Kurs 42221: Vertiefung der Statistik
 Name, Vorname Matrikelnummer Teilklausur des Moduls 32741 Kurs 42221: Vertiefung der Statistik Datum Termin: 21. März 2014, 14.00-16.00 Uhr Prüfer: Univ.-Prof. Dr. H. Singer Vertiefung der Statistik 21.3.2014
Name, Vorname Matrikelnummer Teilklausur des Moduls 32741 Kurs 42221: Vertiefung der Statistik Datum Termin: 21. März 2014, 14.00-16.00 Uhr Prüfer: Univ.-Prof. Dr. H. Singer Vertiefung der Statistik 21.3.2014
Inhaltsverzeichnis. Über die Autoren Einleitung... 21
 Inhaltsverzeichnis Über die Autoren.... 7 Einleitung... 21 Über dieses Buch... 21 Was Sie nicht lesen müssen... 22 Törichte Annahmen über den Leser... 22 Wie dieses Buch aufgebaut ist... 23 Symbole, die
Inhaltsverzeichnis Über die Autoren.... 7 Einleitung... 21 Über dieses Buch... 21 Was Sie nicht lesen müssen... 22 Törichte Annahmen über den Leser... 22 Wie dieses Buch aufgebaut ist... 23 Symbole, die
» S C H R I T T - F Ü R - S C H R I T T - A N L E I T U N G «M U L T I P L E L I N E A R E R E G R E S S I O N M I T S P S S / I B M Daniela Keller
 » SCHRITT-FÜR-SCHRITTANLEITUNG«MULTIPLE LINEARE REGRESSION MIT SPSS/IBM Daniela Keller Daniela Keller - MULTIPLE LINEARE REGRESSION MIT SPSS/IBM Impressum 2016 Statistik und Beratung Dipl.-Math. Daniela
» SCHRITT-FÜR-SCHRITTANLEITUNG«MULTIPLE LINEARE REGRESSION MIT SPSS/IBM Daniela Keller Daniela Keller - MULTIPLE LINEARE REGRESSION MIT SPSS/IBM Impressum 2016 Statistik und Beratung Dipl.-Math. Daniela
Sitzung 4: Übungsaufgaben für Statistik 1
 1 Sitzung 4: Übungsaufgaben für Statistik 1 Aufgabe 1: In einem Leistungstest werden von den Teilnehmern folgende Werte erzielt: 42.3; 28.2; 30.5, 32.0, 33.0, 38.8. Geben Sie den Median, die Spannweite
1 Sitzung 4: Übungsaufgaben für Statistik 1 Aufgabe 1: In einem Leistungstest werden von den Teilnehmern folgende Werte erzielt: 42.3; 28.2; 30.5, 32.0, 33.0, 38.8. Geben Sie den Median, die Spannweite
UE Angewandte Statistik Termin 4 Gruppenvergleichstests
 UE Angewandte Statistik Termin 4 Gruppenvergleichstests Martina Koller Institut für Pflegewissenschaft SoSe 2015 INHALT 1 Allgemeiner Überblick... 1 2 Normalverteilung... 2 2.1 Explorative Datenanalyse...
UE Angewandte Statistik Termin 4 Gruppenvergleichstests Martina Koller Institut für Pflegewissenschaft SoSe 2015 INHALT 1 Allgemeiner Überblick... 1 2 Normalverteilung... 2 2.1 Explorative Datenanalyse...
Multivariate Verfahren
 Multivariate Verfahren Lineare Regression Zweck: Vorhersage x Dimensionsreduktion x x Klassifizierung x x Hauptkomponentenanalyse Korrespondenzanalyse Clusteranalyse Diskriminanzanalyse Eigenschaften:
Multivariate Verfahren Lineare Regression Zweck: Vorhersage x Dimensionsreduktion x x Klassifizierung x x Hauptkomponentenanalyse Korrespondenzanalyse Clusteranalyse Diskriminanzanalyse Eigenschaften:
Ermitteln Sie auf 2 Dezimalstellen genau die folgenden Kenngrößen der bivariaten Verteilung der Merkmale Weite und Zeit:
 1. Welche der folgenden Kenngrößen, Statistiken bzw. Grafiken sind zur Beschreibung der Werteverteilung des Merkmals Konfessionszugehörigkeit sinnvoll einsetzbar? A. Der Modalwert. B. Der Median. C. Das
1. Welche der folgenden Kenngrößen, Statistiken bzw. Grafiken sind zur Beschreibung der Werteverteilung des Merkmals Konfessionszugehörigkeit sinnvoll einsetzbar? A. Der Modalwert. B. Der Median. C. Das
Inhaltsverzeichnis. Vorwort
 V Vorwort XI 1 Zum Gebrauch dieses Buches 1 1.1 Einführung 1 1.2 Der Text in den Kapiteln 1 1.3 Was Sie bei auftretenden Problemen tun sollten 2 1.4 Wichtig zu wissen 3 1.5 Zahlenbeispiele im Text 3 1.6
V Vorwort XI 1 Zum Gebrauch dieses Buches 1 1.1 Einführung 1 1.2 Der Text in den Kapiteln 1 1.3 Was Sie bei auftretenden Problemen tun sollten 2 1.4 Wichtig zu wissen 3 1.5 Zahlenbeispiele im Text 3 1.6
3. Lektion: Deskriptive Statistik
 Seite 1 von 5 3. Lektion: Deskriptive Statistik Ziel dieser Lektion: Du kennst die verschiedenen Methoden der deskriptiven Statistik und weißt, welche davon für Deine Daten passen. Inhalt: 3.1 Deskriptive
Seite 1 von 5 3. Lektion: Deskriptive Statistik Ziel dieser Lektion: Du kennst die verschiedenen Methoden der deskriptiven Statistik und weißt, welche davon für Deine Daten passen. Inhalt: 3.1 Deskriptive
5. Seminar Statistik
 Sandra Schlick Seite 1 5. Seminar 5. Seminar Statistik 30 Kurztest 4 45 Testen von Hypothesen inkl. Übungen 45 Test- und Prüfverfahren inkl. Übungen 45 Repetitorium und Prüfungsvorbereitung 15 Kursevaluation
Sandra Schlick Seite 1 5. Seminar 5. Seminar Statistik 30 Kurztest 4 45 Testen von Hypothesen inkl. Übungen 45 Test- und Prüfverfahren inkl. Übungen 45 Repetitorium und Prüfungsvorbereitung 15 Kursevaluation
Aufgaben zu Kapitel 5:
 Aufgaben zu Kapitel 5: Aufgabe 1: Ein Wissenschaftler untersucht, in wie weit die Reaktionszeit auf bestimmte Stimuli durch finanzielle Belohnung zu steigern ist. Er möchte vier Bedingungen vergleichen:
Aufgaben zu Kapitel 5: Aufgabe 1: Ein Wissenschaftler untersucht, in wie weit die Reaktionszeit auf bestimmte Stimuli durch finanzielle Belohnung zu steigern ist. Er möchte vier Bedingungen vergleichen:
Welche der folgenden Aussagen sind richtig? (x aus 5) A Ein metrisches Merkmal, das überabzählbar viele Ausprägungen besitzt heißt diskret.
 A Ein metrisches Merkmal, das überabzählbar viele Ausprägungen besitzt heißt diskret.") Grundlagen der Statistik 25.9.2014 7 Aufgabe 7 Welche der folgenden Aussagen sind richtig? (x aus 5) A Ein metrisches Merkmal, das überabzählbar viele Ausprägungen besitzt heißt diskret. B Ein Merkmal
Grundlagen der Statistik 25.9.2014 7 Aufgabe 7 Welche der folgenden Aussagen sind richtig? (x aus 5) A Ein metrisches Merkmal, das überabzählbar viele Ausprägungen besitzt heißt diskret. B Ein Merkmal
Franz Kronthaler. Statistik angewandt. Datenanalyse ist (k)eine Kunst. mit dem R Commander. A Springer Spektrum
eine Kunst. mit dem R Commander. A Springer Spektrum") Franz Kronthaler Statistik angewandt Datenanalyse ist (k)eine Kunst mit dem R Commander A Springer Spektrum Inhaltsverzeichnis Teil I Basiswissen und Werkzeuge, um Statistik anzuwenden 1 Statistik ist
Franz Kronthaler Statistik angewandt Datenanalyse ist (k)eine Kunst mit dem R Commander A Springer Spektrum Inhaltsverzeichnis Teil I Basiswissen und Werkzeuge, um Statistik anzuwenden 1 Statistik ist
Statistik K urs SS 2004
 Statistik K urs SS 2004 3.Tag Grundlegende statistische Maße Mittelwert (mean) Durchschnitt aller Werte Varianz (variance) s 2 Durchschnittliche quadrierte Abweichung aller Werte vom Mittelwert >> Die
Statistik K urs SS 2004 3.Tag Grundlegende statistische Maße Mittelwert (mean) Durchschnitt aller Werte Varianz (variance) s 2 Durchschnittliche quadrierte Abweichung aller Werte vom Mittelwert >> Die
Wahrscheinlichkeit 1-α: richtige Entscheidung - wahrer Sachverhalt stimmt mit Testergebnis überein. Wahrscheinlichkeit α: falsche Entscheidung -
 wahrer Sachverhalt: Palette ist gut Palette ist schlecht Entscheidung des Tests: T K; Annehmen von H0 ("gute Palette") positive T > K; Ablehnen von H0 ("schlechte Palette") negative Wahrscheinlichkeit
wahrer Sachverhalt: Palette ist gut Palette ist schlecht Entscheidung des Tests: T K; Annehmen von H0 ("gute Palette") positive T > K; Ablehnen von H0 ("schlechte Palette") negative Wahrscheinlichkeit
Instrument zur Untersuchung eines linearen Zusammenhangs zwischen zwei (oder mehr) Merkmalen.
 Merkmalen.") Gliederung Grundidee Einfaches lineares Modell KQ-Methode (Suche nach der besten Geraden) Einfluss von Ausreißern Güte des Modells (Bestimmtheitsmaß R²) Multiple Regression Noch Fragen? Lineare Regression
Gliederung Grundidee Einfaches lineares Modell KQ-Methode (Suche nach der besten Geraden) Einfluss von Ausreißern Güte des Modells (Bestimmtheitsmaß R²) Multiple Regression Noch Fragen? Lineare Regression
x erhielt die Rücklauf/Responsequote. Im Vergleich auch zu anderen Kennzahlen ist bei der Responsequote die Standardabweichung am geringsten (1,95).
.") höchsten Zustimmungswert ( = 5,7) x erhielt die Rücklauf/Responsequote. Im Vergleich auch zu anderen Kennzahlen ist bei der Responsequote die Standardabweichung am geringsten (1,95). 3. Kennzahl entscheidet
höchsten Zustimmungswert ( = 5,7) x erhielt die Rücklauf/Responsequote. Im Vergleich auch zu anderen Kennzahlen ist bei der Responsequote die Standardabweichung am geringsten (1,95). 3. Kennzahl entscheidet
Statistik II: Signifikanztests /1
 Medien Institut : Signifikanztests /1 Dr. Andreas Vlašić Medien Institut (0621) 52 67 44 vlasic@medien-institut.de Gliederung 1. Noch einmal: Grundlagen des Signifikanztests 2. Der chi 2 -Test 3. Der t-test
Medien Institut : Signifikanztests /1 Dr. Andreas Vlašić Medien Institut (0621) 52 67 44 vlasic@medien-institut.de Gliederung 1. Noch einmal: Grundlagen des Signifikanztests 2. Der chi 2 -Test 3. Der t-test
Statistik II Übung 2: Multivariate lineare Regression
 Statistik II Übung 2: Multivariate lineare Regression Diese Übung beschäftigt sich mit dem Zusammenhang zwischen Flugpreisen und der Flugdistanz, dem Passagieraufkommen und der Marktkonzentration. Verwenden
Statistik II Übung 2: Multivariate lineare Regression Diese Übung beschäftigt sich mit dem Zusammenhang zwischen Flugpreisen und der Flugdistanz, dem Passagieraufkommen und der Marktkonzentration. Verwenden
Eigene MC-Fragen Kap. 4 Faktorenanalyse, Aggregation, Normierung. 1. Welche Aussage zu den Prinzipien der Faktorenanalyse ist zutreffend?
 Eigene MC-Fragen Kap. 4 Faktorenanalyse, Aggregation, Normierung 1. Welche Aussage zu den Prinzipien der Faktorenanalyse ist zutreffend? a) Die Faktorenanalyse hat ihren Ursprung in der theoretischen Intelligenzforschung.
Eigene MC-Fragen Kap. 4 Faktorenanalyse, Aggregation, Normierung 1. Welche Aussage zu den Prinzipien der Faktorenanalyse ist zutreffend? a) Die Faktorenanalyse hat ihren Ursprung in der theoretischen Intelligenzforschung.
Trim Size: 176mm x 240mm Lipow ftoc.tex V1 - March 9, :34 P.M. Page 11. Über die Übersetzerin 9. Einleitung 19
 Trim Size: 176mm x 240mm Lipow ftoc.tex V1 - March 9, 2016 6:34 P.M. Page 11 Inhaltsverzeichnis Über die Übersetzerin 9 Einleitung 19 Was Sie hier finden werden 19 Wie dieses Arbeitsbuch aufgebaut ist
Trim Size: 176mm x 240mm Lipow ftoc.tex V1 - March 9, 2016 6:34 P.M. Page 11 Inhaltsverzeichnis Über die Übersetzerin 9 Einleitung 19 Was Sie hier finden werden 19 Wie dieses Arbeitsbuch aufgebaut ist
Analyse von Kontingenztafeln
 Analyse von Kontingenztafeln Mit Hilfe von Kontingenztafeln (Kreuztabellen) kann die Abhängigkeit bzw. die Inhomogenität der Verteilungen kategorialer Merkmale beschrieben, analysiert und getestet werden.
Analyse von Kontingenztafeln Mit Hilfe von Kontingenztafeln (Kreuztabellen) kann die Abhängigkeit bzw. die Inhomogenität der Verteilungen kategorialer Merkmale beschrieben, analysiert und getestet werden.
Statistik II. Weitere Statistische Tests. Statistik II
 Statistik II Weitere Statistische Tests Statistik II - 19.5.2006 1 Überblick Bisher wurden die Test immer anhand einer Stichprobe durchgeführt Jetzt wollen wir die statistischen Eigenschaften von zwei
Statistik II Weitere Statistische Tests Statistik II - 19.5.2006 1 Überblick Bisher wurden die Test immer anhand einer Stichprobe durchgeführt Jetzt wollen wir die statistischen Eigenschaften von zwei
Einer Reihe von Merkmalen zugrunde liegende, gemeinsame Faktoren ermitteln.
 Faktoranalysen Aufbau 1. Sinn und Zweck 2. Eigenschaften der Merkmale 3. Extraktion der Faktoren 4. Anzahl der Faktoren 5. Rotation der Faktoren 6. Interpretation der Faktoren Sinn und Zweck Einer Reihe
Faktoranalysen Aufbau 1. Sinn und Zweck 2. Eigenschaften der Merkmale 3. Extraktion der Faktoren 4. Anzahl der Faktoren 5. Rotation der Faktoren 6. Interpretation der Faktoren Sinn und Zweck Einer Reihe
1 Wahrscheinlichkeitsrechnung. 2 Zufallsvariablen und ihre Verteilung. 3 Statistische Inferenz. 4 Intervallschätzung. 5 Hypothesentests.
 0 Einführung 1 Wahrscheinlichkeitsrechnung 2 Zufallsvariablen und ihre Verteilung 3 Statistische Inferenz 4 Intervallschätzung 5 Hypothesentests 6 Regression Lineare Regressionsmodelle Deskriptive Statistik:
0 Einführung 1 Wahrscheinlichkeitsrechnung 2 Zufallsvariablen und ihre Verteilung 3 Statistische Inferenz 4 Intervallschätzung 5 Hypothesentests 6 Regression Lineare Regressionsmodelle Deskriptive Statistik:
Statistik II Übung 1: Einfache lineare Regression
 Statistik II Übung 1: Einfache lineare Regression Diese Übung beschäftigt sich mit dem Zusammenhang zwischen dem Lohneinkommen von sozial benachteiligten Individuen (16-24 Jahre alt) und der Anzahl der
Statistik II Übung 1: Einfache lineare Regression Diese Übung beschäftigt sich mit dem Zusammenhang zwischen dem Lohneinkommen von sozial benachteiligten Individuen (16-24 Jahre alt) und der Anzahl der
Statistik III Regressionsanalyse, Varianzanalyse und Verfahren bei Messwiederholung mit SPSS
 Statistik III Regressionsanalyse, Varianzanalyse und Verfahren bei Messwiederholung mit SPSS Verena Hofmann Dr. phil. des. Departement für Sonderpädagogik Universität Freiburg Petrus-Kanisius-Gasse 21
Statistik III Regressionsanalyse, Varianzanalyse und Verfahren bei Messwiederholung mit SPSS Verena Hofmann Dr. phil. des. Departement für Sonderpädagogik Universität Freiburg Petrus-Kanisius-Gasse 21
Dr. Maike M. Burda. Welchen Einfluss hat die Körperhöhe auf das Körpergewicht? Eine Regressionsanalyse. HU Berlin, Econ Bootcamp
 Dr. Maike M. Burda Welchen Einfluss hat die Körperhöhe auf das Körpergewicht? Eine Regressionsanalyse. HU Berlin, Econ Bootcamp 8.-10. Januar 2010 BOOTDATA.GDT: 250 Beobachtungen für die Variablen... cm:
Dr. Maike M. Burda Welchen Einfluss hat die Körperhöhe auf das Körpergewicht? Eine Regressionsanalyse. HU Berlin, Econ Bootcamp 8.-10. Januar 2010 BOOTDATA.GDT: 250 Beobachtungen für die Variablen... cm:
Kapitel 3 Schließende lineare Regression Einführung. induktiv. Fragestellungen. Modell. Matrixschreibweise. Annahmen.
 Kapitel 3 Schließende lineare Regression 3.1. Einführung induktiv Fragestellungen Modell Statistisch bewerten, der vorher beschriebenen Zusammenhänge auf der Basis vorliegender Daten, ob die ermittelte
Kapitel 3 Schließende lineare Regression 3.1. Einführung induktiv Fragestellungen Modell Statistisch bewerten, der vorher beschriebenen Zusammenhänge auf der Basis vorliegender Daten, ob die ermittelte
Webergänzung zu Kapitel 10
 10.1.5 Varianzanalyse (ANOVA: analysis of variance ) Im Kapitel 10 haben wir uns hauptsächlich mit Forschungsbeispielen beschäftigt, die nur zwei Ergebnissätze hatten (entweder werden zwei unterschiedliche
10.1.5 Varianzanalyse (ANOVA: analysis of variance ) Im Kapitel 10 haben wir uns hauptsächlich mit Forschungsbeispielen beschäftigt, die nur zwei Ergebnissätze hatten (entweder werden zwei unterschiedliche
Es sei x 1. Zeigen Sie mittles vollständiger Induktion, dass dann für jede natürliche Zahl n 0 gilt: n x k = 1 xn+1 1 x.
 Aufgabe 1. (5 Punkte) Es sei x 1. Zeigen Sie mittles vollständiger Induktion, dass dann für jede natürliche Zahl n 0 gilt: n x k = 1 xn+1 k=0 1 x. Aufgabe 2. (7 Punkte) Bestimmen Sie das folgende Integral
Aufgabe 1. (5 Punkte) Es sei x 1. Zeigen Sie mittles vollständiger Induktion, dass dann für jede natürliche Zahl n 0 gilt: n x k = 1 xn+1 k=0 1 x. Aufgabe 2. (7 Punkte) Bestimmen Sie das folgende Integral
Klausurvorbereitung - Statistik
 Aufgabe 1 Klausurvorbereitung - Statistik Studenten der Politikwissenschaft der Johannes Gutenberg-Universität wurden befragt, seit wie vielen Semestern sie eingeschrieben sind. Berechnen Sie für die folgenden
Aufgabe 1 Klausurvorbereitung - Statistik Studenten der Politikwissenschaft der Johannes Gutenberg-Universität wurden befragt, seit wie vielen Semestern sie eingeschrieben sind. Berechnen Sie für die folgenden